- Function call 函数调用
- 结束
Function call 函数调用
GPT模型本身并不支持与外部系统、数据库或文件的实时交互。但可以使用函数来完成。
如何更可靠地从模型中获取结构化数据?
- Function Calling
模型微调后可以检测何时调用函数(取决于输入)并使用符合函数签名的 JSON 进行响应。
- 模型层面,识别出何时需要调用函数来对输出格式化
- 函数方面,设定具体格式化逻辑来更好使用
函数调用 (Function Calling) 提供了一种将 GPT 的能力与外部工具和 API 相连接的新方法
注意: API不会执行任何函数调用。
- 使用输出参数执行函数调用必须由开发人员完成。
- 比如,用户输入 #graphic_art(“a dragon”),API只会返回一个字符串”a dragon”,而不会真正生成一幅图像。要想真正执行函数,就需要开发人员自己编写代码来调用相应的服务或库。
参考
- Function Call: Chat 应用的插件基石与交互技术的变革黎明
- OpenAI的新能力——Function Calling
- 一文学会 OpenAI 的函数调用功能 Function Calling
- OpenAI开发系列(十一):Function calling功能的实际应用流程与案例解析
- OpenAI开发系列(十二):Function calling功能的流程优化与多轮对话实现
Function call 介绍
6月13日后,调用 OpenAI GPT 3.5 Turbo和GPT-4需要使用 Chat Completions API 。
这两个模型可以在chat completion的api中使用一个新的功能 —— Function Calling:可识别且格式化输出
Function Call 是 GPT API 中新功能。让开发者在调用 GPT-4 和 GPT-3.5-turbo 模型时,描述函数并让模型智能地输出一个包含调用这些函数所需参数的 JSON 对象。更可靠地将 GPT 能力与外部工具和 API 进行连接,从而实现以下应用:
- (1)创建聊天机器人:开发者可以调用外部工具(如 ChatGPT 插件)回答问题
- 将查询“北京的天气如何?”转换为调用
getCurrentWeather(location: string)的函数。
- 将查询“北京的天气如何?”转换为调用
- (2)将自然语言转换为 API 调用或数据库查询:
- “这个月我的前十个客户是谁?”转换为调用
get_customers_by_revenue(start_date, end_date, limit)的内部 API 调用, - 上个月 Acme 公司下了多少订单? 转换为使用
sql_query(query)的 SQL 查询。
- “这个月我的前十个客户是谁?”转换为调用
- (3)从文本中提取结构化数据:开发者可以定义一个名为
extract_people_data(people)的函数,以提取在维基百科文章中提到的所有人物。
Plugin vs Function vs Tool
【2023-10-19】Compare functions to plugins
- 插件
Plugin仅用于ChatGPT用户聊天页面内(OpenAI独有)- Plugins are solely for the ChatGPT User Interface.
- 函数
Function在 ChatGPT用户页面外(API调用)的本地/远程系统,用户自己负责其中的UI/api- Functions are for local or remote systems outside of ChatGPT.
- 但是也可以在插件开发中使用函数,而不能直接从API访问插件
- But you can use functions also in utilizing plugin development whereas you can not directly access plugins from the API.
Plugins work for chat, where OpenAI owns the UI. Functions for in the API, where you are responsible for the UI/api to an external app
Tool
- LangChain 中的 tools 概念
Function call 原理
从人机交互上来说, Function Call 本质上只做了一件事
- 准确识别用户语义,将其转为结构化指令。
机器无法理解「我叫小明,今年18岁,家在杭州市西湖边」这样非结构化输入。只有将其拆分为「姓名」、「年龄」这样的字段,机器才能识别相应的信息结构,并将这样结构化后的信息接入后续的流程。

Function Call 实现的最大的价值是:
让机器轻易地理解了用户模糊化输入,将其转换为机器可以理解的技术指令。这对于人机交互的范式完全是质的改变。
调用流程
Function call 完整调用流程
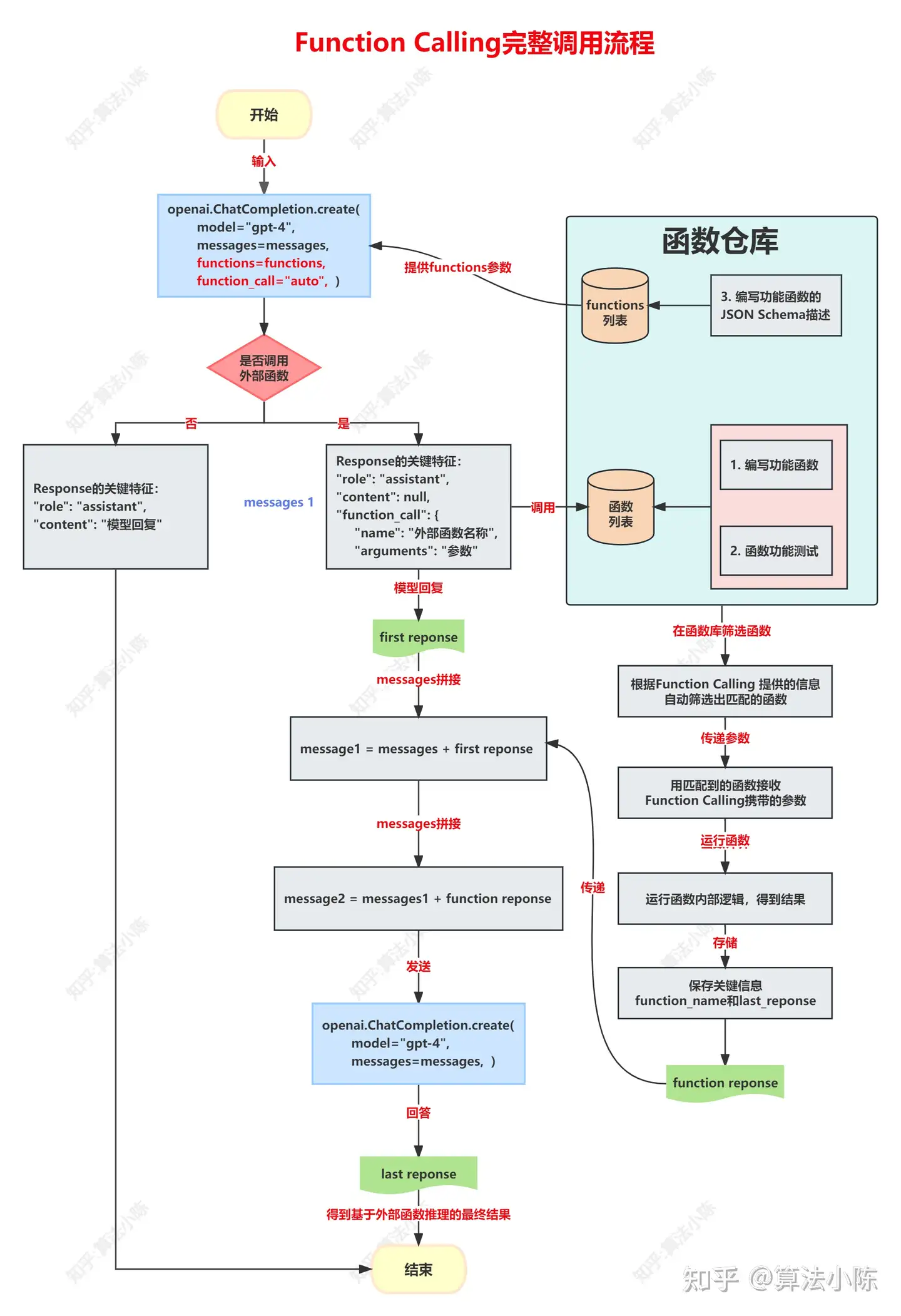
当大模型激活 Function Calling 功能时,其推理过程也会发生相应的改变:
- 根据大模型返回的函数和函数参数,在本地完成函数计算
- 然后再将计算过程和结果保存为message, 并追加到messages后面
- 并第2次调用 Chat Completion模型分析函数的计算结果,并最终根据函数计算结果输出用户问题的答案。
基本流程如下,形成一个循环:
- 1️⃣ User提供工具列表(function), 给LLM发指令P。
- 2️⃣ LLM返回要调用的工具名和参数信息。
- 3️⃣ User根据LLM返回信息在本地执行Tool工具,获取执行结果。
- 4️⃣ 将返回结果重新组织成指令P1,让LLM决定下次应该怎么执行和参数是什么
优化方向有两个:
- 提升functions参数的编写效率
- 优化不断拼接messages的过程。
请求参数
openai.createChatCompletion({
model: "gpt-3.5-turbo-0613",
messages: [
# ...
],
functions: [
{
name: 'function_name',
description: '该函数所具备能力的自然语言描述',
parameters: {
type: 'object',
properties: {
argument_name: {
type: 'string',
description: '该参数的自然语言描述'
},
# ...
},
required: ['argument_name']
}
},
# ...
]
})
functions 参数支持以数组形式录入多组函数信息,其中:
name:函数名称。后续模型会在需要调用函数时返回此名称。description:函数功能描述。模型通过该描述理解函数能力,并判断是否需要调用该函数。parameters.properties:函数所需参数。以对象的形式描述函数所需的参数,其中对象的key即为参数名。type:参数类型。支持JSON Schema协议。description:参数描述。
required:必填参数的参数名列表。
控制模型应该如何响应函数调换。
支持几种输入:
- “
none“:模型不调用函数,直接返回内容。没有提供可调用函数时的默认值。 - “
auto“:模型根据用户输入自行决定是否调用函数以及调用哪个函数。提供可调用函数时的默认值。 {"name": "function_name"}:强制模型调用指定的函数。
添加对话角色,向消息列表中添加函数返回值
- 函数执行完成后,将函数的返回内容追加到消息列表中,并携带完整的消息列表再次请求聊天API,以获得GPT的后续响应。
- 消息列表中,角色的可选值除了原有的
系统(system)、用户(user)、助理(assistant)外,新增了函数(function)类型,用来标识该消息时函数调用的返回内容。
注意:
消息列表中追加函数调用响应消息前,还需要首先将上一步模型返回的消息追加到消息列表中,以保证消息列表中的上下文完整。
响应参数
可选项(choices)中提供了两个响应参数:
finish_reason响应内容结束的原因:stop:已返回完整消息。length:已达到令牌限制或由max_tokens参数设置的上限。function_call:模型决定需要调用一个函数。content_filter:内容触发了拦截策略,忽略返回内容。null:API响应仍在执行。- 其中,若返回function_call则表示模型需要调用函数。此时message参数会额外返回函数信息以及函数参数信息。
message.function_call- 若响应内容结束的原因是模型需要调用函数,则message参数中会增加一个用于描述函数信息的function_call参数,其格式如下:
name:函数名称。arguments:函数参数信息。JSON字符串格式。
两阶段代码
from dotenv import load_dotenv
import os
import openai
import json
load_dotenv()
openai.api_key = os.environ.get("OPENAI_API_KEY")
# 任务执行函数
def get_pizza_info(pizza_name: str):
pizza_info = {
"name": pizza_name,
"price": "10.99",
}
return json.dumps(pizza_info)
# 函数调用详情
functions = [
{
"name": "get_pizza_info",
# 描述非常重要:llm 用函数描述来识别函数 (Function Calling) 是否适合回答用户的请求。
"description": "Get name and price of a pizza of the restaurant",
"parameters": {
"type": "object",
"properties": { # 参数信息
"pizza_name": {
"type": "string",
"description": "The name of the pizza, e.g. Salami",
},
},
"required": ["pizza_name"], # 必备参数
},
}
]
def chat(query): # 调用
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[{"role": "user", "content": query}],
functions=functions, # 设置函数调用
#function_call="auto", # 开启function call
)
message = response["choices"][0]["message"]
return message
if message.get("function_call"):
# 解析第一次调用的时候返回的 pizza 信息
function_name = message["function_call"]["name"]
pizza_name = json.loads(message["function_call"] ["arguments"]).get("pizza_name")
print(pizza_name)
# 这里将 chat 小助手函数的响应结果提取后,传递 function_response
function_response = get_pizza_info(
pizza_name=pizza_name
)
second_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[
{"role": "user", "content": query},
message,
{
"role": "function",
"name": function_name,
"content": function_response, # function calling 的 content 是 get_pizza_info 函数
},
],
)
second_response
Function call 实例
用户问题:
帮我给小美发一封邮件,告诉她我晚上不回去吃了。
原始GPT:
亲爱的小美,我希望你一切都好。。。。
设置prompt:
// prompt 设计
将以下内容转换为json格式,包含两个字段:receiver(接收人)、content(邮件内容)
- 帮我给小美发一封邮件,告诉她我晚上不回去吃了。
// 返回
{
"reveiver":"小美", "content":"亲爱的小美..."
}
基本解决,但问题:
- 用户输入未知,难以识别用户意图是发邮件,还是其它操作
如何更可靠地从模型中获取结构化数据?Function Calling
微调后可检测:何时应该调用函数(取决于输入), 并使用符合函数签名的 JSON 进行响应。
- 模型层面,识别出何时需要调用函数来对输出格式化
- 函数方面,设定具体的格式化逻辑, 更好使用
index.py,完整代码
import json
from enum import Enum
import openai
openai.api_key = 'xxx'
def run_conversation():
MODEL = "gpt-3.5-turbo-0613"
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "user", "content": "给小美发个邮件,告诉她我晚饭不回家吃了"},
],
temperature=0
)
message = response["choices"][0]["message"]
print(message)
run_conversation()
发邮件的文件 EmailSkill.py , 文件就导出了两个函数
- 用来给Function Calling调用的函数:send_email
- 发邮件的操作函数:send_email_action
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
# 发送邮件操作
def send_email_action(receiver, content):
if (not receiver): return
# 邮件配置
smtp_server = "smtp.163.com"
smtp_port = 25
sender_email = "sender_email"
receiver_email = receiver
password = 'password'
# 构建邮件内容
message = MIMEMultipart()
message["From"] = Header('AI <%s>' % sender_email)
message["To"] = receiver_email
message["Subject"] = "我是您的AI助理,您有一封邮件请查看"
body = content
message.attach(MIMEText(body, "plain"))
# 连接到邮件服务器并发送邮件
with smtplib.SMTP(smtp_server, smtp_port) as server:
server.starttls()
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message.as_string())
# 供Function Calling使用的输出处理函数
def send_email(receiver, content = ''):
# 通讯录
Contact = {
"小美": "xx@example.com",
}
email_info = {
"receiver": Contact[receiver],
"content": content
}
return email_info
chat completion api 新增了两个参数:
function_call: 一个开关,控制模型是否要调用函数对输出进行处理,默认为”none”不开启, 设置为”auto”表示开启functions: 对输出结果进行处理的函数描述列表
functions 示例
两个必填的参数:
- receiver:邮件接收方,string类型
- content:邮件内容,string类型
{
"name": "send_email", // 函数名
"description": "send email assistant", // 函数描述:llm 用函数描述来识别函数 (Function Calling) 是否适合回答用户的请求。非常重要!
"parameters": { // 给LLM看的函数签名
"type": "object",
"properties": { // 必填参数信息
"receiver": {
"type": "string",
"description": "email receiver",
},
"content": {"type": "string", "description": "email content"},
},
"required": ["receiver", "content"], // 哪些参数必备
}
}
调用代码
import json
from enum import Enum
import openai
openai.api_key = 'xxx'
from EmailSkill import send_email, send_email_action
# 为什么要单独定义这个枚举类?
class SkillFunctions(Enum):
SendEmail = 'send_email'
def run_conversation():
MODEL = "gpt-3.5-turbo-0613"
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "user", "content": "给小美发个邮件,告诉她我晚饭不回家吃了"},
],
temperature=0,
functions=[ # 新增功能 function call
{
"name": SkillFunctions.SendEmail.value,
"description": "send email assistant",
"parameters": {
"type": "object",
"properties": {
"receiver": {
"type": "string",
"description": "收件人名字即可",
},
"content": {"type": "string", "description": "邮件的内容"},
},
"required": ["receiver", "content"],
},
}
],
function_call="auto", # 自动识别是否开启功能
)
message = response["choices"][0]["message"]
print(message)
# GPT 推理执行
run_conversation()
# ---------- 返回结果处理 ------------
if(message.get("function_call")):
# 函数调用处理区
function_name = message["function_call"]["name"] # 函数名
arguments = json.loads(message["function_call"]["arguments"]) # 参数信息
# 动作处理
if (function_name == SkillFunctions.SendEmail.value):
email_info = send_email( # 整理邮件信息
receiver=arguments.get('receiver'),
content=arguments.get('content')
)
print(email_info)
send_email_action(**email_info) # 执行任务:发送邮件
print('邮件已发送')
效果
Function Call 训练
【2025-5-6】大模型算法面经:Function Call、MCP、A2A
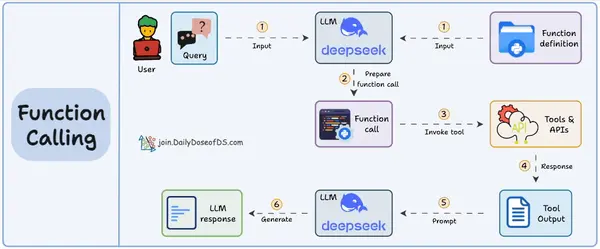
将 Function Calling 能力赋予 LLM 主要通过监督微调 (Supervised Fine-tuning, SFT) 实现,而不是预训练阶段从零开始专门训练。
基础模型需要先具备良好的指令遵循和代码/结构化数据生成能力。
训练/微调核心思想
教会模型两件事:
- 识别意图 (Intent Recognition): 理解用户请求, 是否借助外部工具/函数来完成,而不是直接生成文本回答。
- 参数提取与格式化 (Argument Extraction & Formatting): 如果要调用函数,正确地从用户请求中抽取出所需参数,并按照预先定义的格式(通常是 JSON)生成函数调用的指令。
示意图
训练/微调过程
训练/微调过程:
- (1) 准备数据集: 最关键的一步。
- (2) 选择基础模型:
- (3) 格式化训练数据:
- (4) 进行微调:
根据 Llama 技术报告,大模型工具调用能力在 post training 时添加,包含多个 SFT 和 DPO 迭代过程。
Llama3 使用 tool 流程大致和 GPT4 tool call 差不多:
Llama3 对 SFT Tool 数据集的描述:
- 标注员只对 assistant 信息进行排名打分,通常模型对当前问题的推理能力越强,打分越高,而不对 tool 信息进行排名打分。
- 其次,不用 rejection sampling,因为 Llama 团队在后期的 tool 测评中,没有收益。
为了加快标注过程,Llama 团队首先通过在之前的 Llama 3 检查点生成的合成数据上进行微调,以此来引导基本的工具使用能力。因此标注员需要进行的改动较少。
同样地,随着 Llama 3 在训练过程中逐渐改进,逐步复杂化人类标注协议:
- 从标注单轮 tool use 的对话数据开始
- 逐步过渡到标注对话中包含了 tool use 的数据
- 最后到标注对话中包含了多步 tool use 以及数据分析的训练数据。
数据集
构建包含 Function Calling 场景的指令微调数据集。
每条数据样本通常包含:
- 用户输入 (Input/Query): 一个可能需要调用函数的用户请求。
- 例如:“查询北京今天的天气怎么样?” 或 “给我写一首关于春天的诗”。
- 可用函数/工具描述 (Available Functions/Tools Description): 一个结构化的描述,告知模型当前有哪些函数可用,每个函数的用途、所需参数及其类型和描述。这个描述本身就是文本,需要设计一种清晰的格式(见下一个问题)。
- 期望的输出 (Desired Output):
如果需要调用函数: 一个特定格式的字符串,包含函数名和提取出的参数的 JSON 对象。
例如:
{
"name": "get_weather",
"arguments": {
"city": "北京",
"date": "今天"
}
}
如果不需要调用函数: 模型应该生成的直接文本回答。
- 例如:“好的,这是一首关于春天的诗:…”
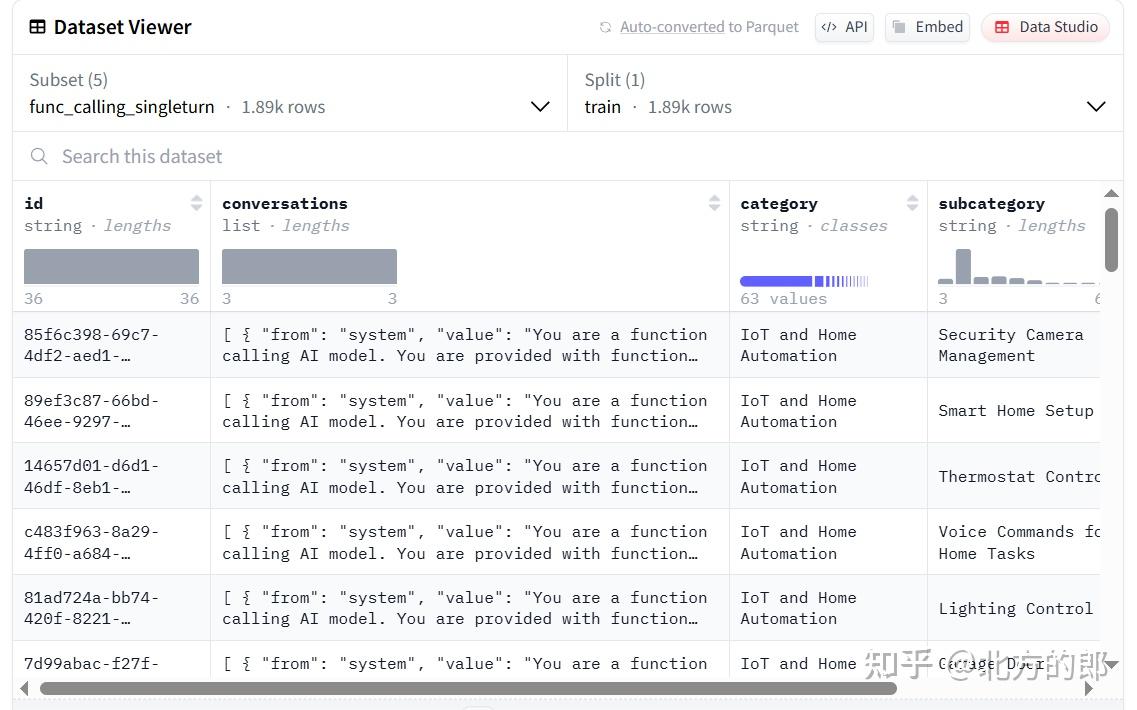
训练数据样例
数据集, huggingface 数据集
通常遵循以下结构,特殊提示词(Prompting)或模板来实现:
基本结构:
[系统提示/全局指令] (可选,设定角色、能力边界等)
[可用函数/工具描述区]
(这里详细列出每个可用函数的结构化描述)
[对话历史] (可选,对于多轮对话很重要)
User: ...
Assistant: ...
User: ... (当前用户请求)
[触发指令/分隔符] (提示模型开始思考或生成)
Assistant:
可用函数/工具描述区的格式: 这是核心部分,需要清晰地传达每个函数的信息。常见做法是使用 JSON 列表或类似的结构化文本:
Functions available:
[
{
"name": "get_weather",
"description": "查询指定城市和日期的天气信息。",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "需要查询天气的城市名称,例如:北京"
},
"date": {
"type": "string",
"description": "需要查询的日期,例如:今天、明天、2023-10-26"
}
},
"required": ["city", "date"] // 指明哪些参数是必须的
}
},
{
"name": "send_email",
"description": "发送邮件给指定的收件人。",
"parameters": {
"type": "object",
"properties": {
"recipient": {
"type": "string",
"description": "收件人的邮箱地址"
},
"subject": {
"type": "string",
"description": "邮件主题"
},
"body": {
"type": "string",
"description": "邮件正文内容"
}
},
"required": ["recipient", "subject", "body"]
}
}
// ... 可以有更多函数描述
]
关键要素:
- name: 函数的唯一标识符。
- description: 用自然语言清晰描述函数的功能和适用场景,这是模型理解何时调用该函数的关键。
- parameters: 定义函数接受的参数。
- type: 通常是 “object”。
- properties: 一个对象,列出每个参数的名称、类型 (string, integer, boolean, enum 等) 和描述 (解释参数的含义和格式)。
- required: 一个列表,包含必须提供的参数名称。
对话流程中的格式:
- 1 用户请求: 用户发出请求,例如 “帮我查一下明天上海的天气,然后给张三发邮件告诉他结果”。
- 2 模型首次响应 (Function Call): 模型识别到需要调用 get_weather,生成 JSON:
{
"name": "get_weather",
"arguments": {
"city": "上海",
"date": "明天"
}
}
知名 function call 数据集有 glaive-function-calling-v2-sharegpt,其输入格式为:
tools:
[
{
"name":"generate_password",
"description":"Generate a random password with specified criteria",
"parameters":{
"type":"object",
"properties":{
"length":{
"type":"integer",
"description":"The length of the password"
},
"include_numbers":{
"type":"boolean",
"description":"Include numbers in the password"
},
"include_special_characters":{
"type":"boolean",
"description":"Include special characters in the password"
}
},
"required":[
"length"
]
}
}
]
tools 会像 system prompt 一样,一起放到输入的 prompt 里。
组织好的对话数据:
[
{
"from":"human",
"value":"I need a new password. Can you generate one for me?"
},
{
"from":"gpt",
"value":"Of course! How long would you like your password to be? And do you want it to include numbers and special characters?"
},
{
"from":"human",
"value":"I want it to be 12 characters long and yes, it should include both numbers and special characters."
},
{
"from":"function_call",
"value":"{\"name\": \"generate_password\", \"arguments\": {\"length\": 12, \"include_numbers\": true, \"include_special_characters\": true}}"
},
{
"from":"observation",
"value":"{\"password\": \"4#7gB6&9L1!0\"}"
},
{
"from":"gpt",
"value":"Here is your new password: 4#7gB6&9L1!0. Please make sure to save it in a secure place."
}
]
把 tool 的函数名,工具描述,变量名,变量类型打包成 prompt 的一部分。
然后再全局设计这样的指令模版
qwen-agent 里设置了这样的包含工具的对话模版:
# 工具
你拥有如下工具:
{tool_descs}
你可以在回复中插入零次、一次或多次以下命令以调用工具:
#FUNCTION#: 工具名称,必须是[{tool_names}]之一。
#ARGS#: 工具输入
#RESULT#: 工具结果
#RETURN#: 根据工具结果进行回复
然后通过 post-training 或者微调,可以让模型理解工具的含义。当然实际在定义所使用的工具时,前面提到的这些必要的工具信息需要含义清楚,定义清晰,否则实际使用的效果也会大打折扣。
推理数据
对话流程格式:
- 1 用户请求: 用户发出请求,例如 “帮我查一下明天上海的天气,然后给张三发邮件告诉他结果”。
- 2 模型首次响应 (Function Call): 模型识别到需要调用 get_weather,生成 JSON:
{
"name": "get_weather",
"arguments": {
"city": "上海",
"date": "明天"
}
}
- 3 外部执行: 应用程序捕获这个 JSON,调用实际的天气 API。
- 4 将结果喂回模型: 将 API 返回的天气结果格式化后,作为新的输入信息提供给模型。例如:
Function Result for get_weather:
{
"temperature": "25°C",
"condition": "晴朗"
}
- 5 模型再次响应 (可能再次 Function Call 或最终回答): 模型看到天气结果,现在需要执行邮件发送任务,生成 JSON:
{
"name": "send_email",
"arguments": {
"recipient": "张三", // 可能需要澄清张三的邮箱
"subject": "明天上海天气",
"body": "明天上海的天气是 25°C,天气晴朗。"
}
}
- 6 外部执行: 应用程序调用邮件发送服务。
- 7 将结果喂回模型: 告知邮件发送成功。
- 8 模型最终回答: 模型生成最终的自然语言回复给用户:“我已经查询到明天上海天气是25°C,晴朗,并且已经发邮件告诉张三了。”
基座模型
选择一个具备强大指令遵循能力的预训练 LLM
例如 Llama, GPT, ChatGLM 等
格式化
格式化训练数据:
- 将每条数据样本组合成模型可以理解的格式。
通常是将“用户输入”和“可用函数描述”拼接起来作为模型输入 (Prompt),将“期望的输出”(无论是 JSON 函数调用还是文本回答)作为目标输出 (Completion/Target)。
需要使用特定的分隔符或模板来区分不同部分。
微调
进行微调:
使用标准 SFT 方法(全参数微调或 PEFT 如 LoRA)在准备好的数据集上训练模型。
模型的优化目标: 最小化预测输出和期望输出之间的差异(例如,使用交叉熵损失)。
模型通过学习这些样本,学会根据用户输入和可用函数描述,决定是直接回答还是生成特定格式的函数调用 JSON。
关键挑战
- 数据集质量: 需要足够多、覆盖各种场景(需要/不需要调用、不同函数、参数变化、模糊表达)的高质量数据。
- 函数描述清晰度: 函数描述的质量直接影响模型能否正确理解和使用函数。
- 负样本: 需要包含足够多明确不需要调用函数的样本,防止模型“过度触发”函数调用。
Function Call 评测
【2023-12-14】评测结论
- 工具数量超过5个时,fc效果下降
- 工具数: 5, 10
- 工具识别准确率 96% -> 91%
- 参数识别准确率 57% -> 56%
- 参数识别准确率低
- 顺序影响:
- 放list前面效果最好,尾部次之,中间最差,与学术界结论一致
Function call 问题
注意事项
- 函数描述 计入token,所以何时使用、如何使用, 要自己抉择。
- 潜在风险(AI存在幻觉或分析不准确),官方强烈建议在代表用户采取行动(发送电子邮件、在线发布内容、进行购买等)之前增加用户确认流程。
Function Call 多返回
【2023-11-6】如何一次返回多个function?
需要一个小trick:定义一个复合函数 multi_Func,将候选functions 囊括进来
- 在function call的list里加一个选项:
"required": ["get_Weather", "get_Events"],这样每次gpt都返回这些functions,如果没命中,取值就是null - 详见:Emulated multi-function calls within one request
I want to share my insights in how to call multiple functions within one function API call. This is the function API schema I use:
{
"name": "multi_Func",
"description": "Call two functions in one call",
"parameters": {
"type": "object",
"properties": {
"get_Weather": {
"name": "get_Weather",
"description": "Get the weather for the location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"],
}
},
"get_Events": {
"name": "get_Events",
"description": "Get events for the location at specified date",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"date": {
"type": "string",
"description": "The date of the event, e.g. 2021-01-01."
}
},
"required": ["location", "date"],
}
}
}, "required": ["get_Weather", "get_Events"],
}
}
Scenario 1: User asks: “Get the events for San Francisco at 25th May 2023.” Response:
'function_call': {'name': 'multi_Func', 'arguments': '{\n "get_Weather": null,\n "get_Events": {\n "location": "San Francisco",\n "date": "2023-05-25"\n }\n}'}}, 'finish_reason': 'function_call'}
You see, that the function call to get_Weather is null. Scenario 2: User asks: “Get the weather for San Franciso.” Response:
'function_call': {'name': 'multi_Func', 'arguments': '{\n "get_Weather": {\n "location": "San Francisco"\n },\n "get_Events": null\n}'}}
Here the get_Events is null Scenario 3: User asks: “Get the weather for San Francisco and the events for May 25th 2023.” Response:
'function_call': {'name': 'multi_Func', 'arguments': '{\n "get_Weather": {\n "location": "San Francisco"\n },\n "get_Events": {\n "date": "2023-05-25",\n "location": "San Francisco"\n }\n}'}}
You get both functions called.
It is not calling the function_call twice, but it emulates it.
Function Call 实现
开源模型 Function Calling 能力的相关信息,包括采用的 chat template,function call 训练方案等。
涉及模型: LlaMa 3.1, Mistral Large 2,glm-4-9b-chat,Qwen 2。
LangChain 实现
LangChain 中如何使用 Function call?
- message.additional_kwargs
- tools
- agent
注意:
- langchain的版本不低于0.0.200, 之前的版本尚不支持函数调用 (Function Calling);
print_version函数(Function Calling) 检查目前的langchain的版本是否大于0.0.200。
import pkg_resources
def print_version(package_name):
try:
version = pkg_resources.get_distribution(package_name).version
print(f"The version of the {package_name} library is {version}.")
except pkg_resources.DistributionNotFound:
print(f"The {package_name} library is not installed.")
print_version("langchain")
The version of the langchain library is 0.0.205.
LangChain additional_kwargs
如何与 LangChain 一起使用?
- 首先导入 ChatOpenAI 类和 HumanMessage、AIMessage,还有 ChatMessage 类,这些类可以帮助我们创建这种功能,包括用户角色等。
- 可以不必要像之前那样,定义角色等,只需要传递 content。其他的都交给了 Langchain.
- 然后在这里创建模型 LLM,通过实例化 ChatOpenAI
- message.additional_kwargs 中包括了函数调用 (Function Calling)字典
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, AIMessage, ChatMessage
# 创建模型 LLM
llm = ChatOpenAI(model="gpt-3.5-turbo-0613")
# 运行预测消息函数
message = llm.predict_messages( # 参数 functions
[HumanMessage(content="What is the capital of france?")], functions=functions
)
# 返回: message.additional_kwargs
# AIMessage(content='The capital of France is Paris.', additional_kwargs={}, example=False)
message_pizza = llm.predict_messages(
[HumanMessage(content="How much does pizza salami cost?")], functions=functions
)
message
# AIMessage(content='', additional_kwargs={'function_call': {'name': 'get_pizza_info', 'arguments': '{\n"pizza_name": "Salami"\n}'}}, example=False)
import json
# 打印结果是 'Salami'
pizza_name = json.loads(message_pizza.additional_kwargs["function_call"]["arguments"]).get("pizza_name")
# 将'Salami'传参给 get_pizza_info 函数
pizza_api_response = get_pizza_info(pizza_name=pizza_name)
# '{"name": "Salami", "price": "10.99"}'
second_response = llm.predict_messages(
[
HumanMessage(content=query), # query = "How much does pizza salami cost?"
AIMessage(content=str(message_pizza.additional_kwargs)),
ChatMessage(
role="function",
additional_kwargs={
"name": message_pizza.additional_kwargs["function_call"]["name"]
},
# pizza_api_response = get_pizza_info(pizza_name=pizza_name)
content=pizza_api_response
),
],
functions=functions,
)
# second_response
LangChain tools
LangChain 提供了与外部世界交互的另一种标准化方法,进行请求或其他操作,这些称为工具 tools
工具 tools 是由 Chain 提供的类,可以创建自己的工具。
from typing import Optional
from langchain.tools import BaseTool
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
# 继承基类工具来创建自定义类或自定义工具
class StupidJokeTool(BaseTool):
"""
function call 示例
"""
# 提供工具的名称和描述
name = "StupidJokeTool"
description = "Tool to explain jokes about chickens"
# 定义下划线开头的函数: _run 函数 和 _arun ,实现异步和同步支持。
def _run(
self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
return "It is funny, because AI..."
async def _arun(
self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None
) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("joke tool does not support async")
使用工具(format_tool_to_openai_function)将自定义类(StupidJokeTool)转成标准格式
from langchain.tools import format_tool_to_openai_function, MoveFileTool
tools = [StupidJokeTool(), MoveFileTool()]
# 将自己的 tools 转换为格式化的 function
functions = [format_tool_to_openai_function(t) for t in tools]
# functions 是之前定义的一个变量:一个函数列表
query = "Why does the chicken cross the road? To get to the other side"
output = llm.predict_messages([HumanMessage(content=query)], functions=functions)
# output
second_response = llm.predict_messages(
[
HumanMessage(content=query),
AIMessage(content=str(output.additional_kwargs)),
ChatMessage(
role="function",
additional_kwargs={
"name": output.additional_kwargs["function_call"]["name"]
},
content="""
{tool_response}
""",
),
],
functions=functions,
)
# second_response
output 运行结果:
AIMessage(content='', additional_kwargs={'function_call': {'name': 'StupidJokeTool', 'arguments': '{\n"__arg1": "To get to the other side"\n}'}}, example=False)
#-------------
AIMessage(content='', additional_kwargs={'function_call': {'name': 'StupidJokeTool', 'arguments': '{\n "__arg1": "To get to the other side"\n}'}}, example=False)
LangChain Agent
Langchain Agent 如何实现 Function Calling ?
- 导入一些链 Chain,例如 LLMMathChain,还有一个 chat_models,聊天模型在这里使用 ChatOpenAI 创建LLM。
from langchain import LLMMathChain
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
]
此代理能够回答普通问题并进行一些计算,因此用初始化代理函数 (Function Calling) ,现在用它与工具。
agent = initialize_agent(tools, llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=True)
现在有新的代理类型 OPENAI_FUNCTIONS ,属于 openai 函数类型,运行这个代理不需要传递任何关键字参数或额外的参数,只需要像这样使用它。
现在运行“法国的首都是什么”,得到的结果是法国的首都:巴黎。
agent.run("What is the capital of france?")
得到:
> Entering new chain...
The capital of France is Paris.
> Finished chain.
'The capital of France is Paris.'
100 除以 25 等于多少,这时候计算器被调用,得到最终答案 100 除以 25 等于 4。
agent.run("100 除以 25 等于多少?")
得到:
> Entering new chain...
Invoking: `Calculator` with `100 / 25`
> Entering new chain...
100 / 25```text
100 / 25
...numexpr.evaluate("100 / 25")...
Answer: 4.0
Finished chain. Answer: 4.0100 除以 25 等于 4。
所以对于代理 Langchain Agent 来说,工作非常流畅,会与其他的 llm 链一起工作。
ChatGLM3 Function Call
【2023-10-31】ChatGLM3 的工具调用(FunctionCalling)实现原理
tool信息
Tool 信息
- 放入请求参数里的 tools 里
tools = [
{
"name": "track",
"description": "追踪指定股票的实时价格",
"parameters": {
"type": "object",
"properties": {
"symbol": {
"description": "需要追踪的股票代码"
}
},
"required": ['symbol']
}
},
{
"name": "text-to-speech",
"description": "将文本转换为语音",
"parameters": {
"type": "object",
"properties": {
"text": {
"description": "需要转换成语音的文本"
},
"voice": {
"description": "要使用的语音类型(男声、女声等)"
},
"speed": {
"description": "语音的速度(快、中等、慢等)"
}
},
"required": ['text']
}
}
]
system_info = {"role": "system", "content": "Answer the following questions as best as you can. You have access to the following tools:", "tools": tools}
测试
提出问题
注意:
- 目前 ChatGLM3-6B 的工具调用只支持通过
chat方法,不支持stream_chat方法。
history = [system_info]
query = "帮我查询股票10111的价格"
response, history = model.chat(tokenizer, query, history=history)
print(response, history)
得到的输出
response: {'name': 'track', 'parameters': {'symbol': '10111'}}
history: [{'role': 'system', 'content': 'Answer the following questions as best as you can. You have access to the following tools:', 'tools': [{'name': 'track', 'description': '追踪指定股票的实时价格', 'parameters': {'type': 'object', 'properties': {'symbol': {'description': '需要追踪的股票代码'}}, 'required': ['symbol']}}, {'name': 'text-to-speech', 'description': '将文本转换为语音', 'parameters': {'type': 'object', 'properties': {'text': {'description': '需要转换成语音的文本'}, 'voice': {'description': '要使用的语音类型(男声、女声等)'}, 'speed': {'description': '语音的速度(快、中等、慢等)'}}, 'required': ['text']}}]}, {'role': 'user', 'content': '帮我查询股票10111的价格'}, {'role': 'assistant', 'metadata': 'track', 'content': " ```python\ntool_call(symbol='10111')\n```"}]
response 返回一个dict对象,这表示模型需要调用工具 track,并且需要传入参数 symbol。
注意 history 最后一个结果是:
{'role': 'assistant', 'metadata': 'track', 'content': " ```python\ntool_call(symbol='10111')\n```"}
奇怪,之前版本 ChatGLM 最后一个history的content都是跟response一样的结果,但是在这个回答结果中却不一样了,而且还多了一个字段:'metadata': 'track'。
调用工具,生成回复
- 自行实现调用工具的逻辑,定义了一个track方法来mock返回的结果。
假设已经得到了返回结果,将结果以 json 格式返回给模型并得到回复。
import json
def track(input):
return json.dumps({"price": 12412}, ensure_ascii=False)
result = track(response)
# 新增一个角色 observation
response, history = model.chat(tokenizer, result, history=history, role="observation")
print(response)
role="observation" 表示输入的是工具调用的返回值而不是用户输入,不能省略。
期望输出
根据您的查询,经过API的调用,股票10111的价格是12412。
工具调用已经结束,模型根据返回结果生成回复。对于比较复杂的问题,模型可能需要进行多次工具调用。这时可根据返回的 response 是 str 还是 dict 来判断返回的是生成的回复还是工具调用请求。
对于工具调用来说,response 是调用函数的参数,是经过特殊处理的。但是大模型只能生成文本,返回结果出现了dict 对象一定是有trick在里面的。
工具调用原理
ChatGLM3 训练工具调用的样本数据是如何构造的。
<|system|>
Answer the following questions as best as you can. You have access to the following tools:
[
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string"},
},
"required": ["location"],
},
}
]
<|user|>
今天北京的天气怎么样?
<|assistant|>
好的,让我们来查看今天的天气
<|assistant|>get_current_weather
\`\`\`python
tool_call(location="beijing", unit="celsius")
\`\`\`
<|observation|>
{"temperature": 22}
<|assistant|>
根据查询结果,今天北京的气温为 22 摄氏度。
工具调用的训练样本示例,原始的训练样本中,当需要调用工具的时候,返回的结果是
<|assistant|>get_current_weather
\`\`\`python
tool_call(location="beijing", unit="celsius")
\`\`\`
从工具调用的样本数据来看,ChatGLM3的工具调用规范分为两部分:
- 第一行是需要调用的函数,如上面例子中的 get_current_weather
- 第二行是代码,固定写死了调用 tool_call,参数部分 location=”beijing”, unit=”celsius” 是大模型可以自由发挥的地方。
例子跟官方例子格式一致,只不过变成了dict对象。metadata是函数名称,content是代码。这里大模型根据上下文推测出了参数是 symbol=’10111’。
{'role': 'assistant', 'metadata': 'track', 'content': " ```python\ntool_call(symbol='10111')\n```"}
正常来说,大模型返回什么,response的结果就应该是什么,但拿到的response为什么变成了:
{'name': 'track', 'parameters': {'symbol': '10111'}}
看ChatGLM3的推理源码:modeling_chatglm.py
def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, role: str = "user",
max_length: int = 8192, num_beams=1, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None,
**kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
gen_kwargs = {"max_length": max_length, "num_beams": num_beams, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
inputs = tokenizer.build_chat_input(query, history=history, role=role)
inputs = inputs.to(self.device)
eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>"),
tokenizer.get_command("<|observation|>")]
outputs = self.generate(**inputs, **gen_kwargs, eos_token_id=eos_token_id)
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):-1]
response = tokenizer.decode(outputs)
history.append({"role": role, "content": query})
response, history = self.process_response(response, history)
return response, history
首先看一下chat的实现,注意到response, history在返回之前是被处理过的。
response, history = self.process_response(response, history)
继续看process_response的代码实现:
def process_response(self, output, history):
content = ""
history = deepcopy(history)
for response in output.split("<|assistant|>"):
metadata, content = response.split("\n", maxsplit=1)
if not metadata.strip():
content = content.strip()
history.append({"role": "assistant", "metadata": metadata, "content": content})
content = content.replace("[[训练时间]]", "2023年")
else:
history.append({"role": "assistant", "metadata": metadata, "content": content})
if history[0]["role"] == "system" and "tools" in history[0]:
content = "\n".join(content.split("\n")[1:-1])
def tool_call(**kwargs):
return kwargs
parameters = eval(content)
content = {"name": metadata.strip(), "parameters": parameters}
else:
content = {"name": metadata.strip(), "content": content}
return content, history
注意这段代码:
if history[0][“role”] == “system” and “tools” in history[0]:
还记得工具调用之前要声明一下system_info 和tools吗?这里就是判断了一下我们是不是用了工具调用。如果是就会进一步处理:
# 示例:此时content="" ```python\ntool_call(symbol='10111')\n```"
content = "\n".join(content.split("\n")[1:-1])
def tool_call(**kwargs):
return kwargs
parameters = eval(content)
content = {"name": metadata.strip(), "parameters": parameters}
上面的代码主要做了:
- 提取待执行的代码:将content=”
python\ntool_call(symbol='10111')\n” 转化为content=”tool_call(symbol=’10111’)” - 定义tool_call函数,其实就是返回dict格式的入参。
- eval()函数用于执行一个字符串表达式,并返回表达式的值。例如,eval(“1 + 2”)返回3 。在我们这个例子中其实就是执行tool_call(symbol=’10111’),返回结果就是:{‘symbol’: ‘10111’}
- 拼接最后的返回结果,即{‘name’: ‘track’, ‘parameters’: {‘symbol’: ‘10111’}} 注意这里的name是中metadata中获取的,其实就是tool的名称,由大模型预测的output中的第一行。
根据上面的分析,知道了为什么工具调用样本中要写死调用tool_call,因为要通过它将模型推理的入参转换为dict对象。
为了方便读者理解,我这里提供示例代码,有不理解的地方可以断点调试。
def process_response(output, history):
content = ""
for response in output.split("<|assistant|>"):
metadata, content = response.split("\n", maxsplit=1)
if not metadata.strip():
content = content.strip()
history.append({"role": "assistant", "metadata": metadata, "content": content})
content = content.replace("[[训练时间]]", "2023年")
else:
history.append({"role": "assistant", "metadata": metadata, "content": content})
if history[0]["role"] == "system" and "tools" in history[0]:
content = "\n".join(content.split("\n")[1:-1])
def tool_call(**kwargs):
return kwargs
parameters = eval(content)
content = {"name": metadata.strip(), "parameters": parameters}
else:
content = {"name": metadata.strip(), "content": content}
return content, history
#大模型预测的结果
output = """track
```python
tool_call(symbol='10111')
```"""
history = [{'role': 'system', 'content': 'Answer the following questions as best as you can. You have access to the following tools:', 'tools': [{'name': 'track', 'description': '追踪指定股票的实时价格', 'parameters': {'type': 'object', 'properties': {'symbol': {'description': '需要追踪的股票代码'}}, 'required': ['symbol']}}, {'name': 'text-to-speech', 'description': '将文本转换为语音', 'parameters': {'type': 'object', 'properties': {'text': {'description': '需要转换成语音的文本'}, 'voice': {'description': '要使用的语音类型(男声、女声等)'}, 'speed': {'description': '语音的速度(快、中等、慢等)'}}, 'required': ['text']}}]}, {'role': 'user', 'content': '帮我查询股票10111的价格'}]
process_response(output, history)
最后再解释一下为什么 ChatGLM3-6B 的工具调用只支持通过 chat 方法,不支持 stream_chat 方法。
- 从源码上面看,stream_chat 没有调用 process_response方法,自然就没法返回处理过的工具调用结果。
- 这只是表面原因,根本原因是 stream_chat 是一个个吐字的,没法中间做手脚将工具调用结果进行处理。
问题
GitHub上有人反馈了一堆 Function Call的问题
- function call 必填参数不输入,不会提示,有时还会自己输出无关内容
- tool_using中的cli_demo_tool.py,必填参数不输入,不会提示,有时还会自己编内容
- 正常能回答的问题也会去调用工具,不管有没有; 没有自动判断是否使用工具的能力,一直在各种问题上强制使用tools
- issue, 包含完整测试代码
llama 3.1
Tool Call Template 样式
- llama 3 工具调用能力在 post training 时加上去的。
- 大致的使用 tool 流程和 GPT 的 tool call 差不多

几种数据格式
- 样式1:Json based tool calling
- 样式2:Built in Python based tool calling
- 官方自带支持 brave_search, wolfram_alpha, 和 code interpreter 三种工具,使用这三种工具时,tokenizer 的处理方式与 json based tool calling 不太一样。具体是要在 system prompt
llama 3.1 tool call 格式,假设用户与agent有了以下对话:
tool_call = {"name": "get_current_temperature", "arguments": {"location": "Paris, France"}}
messages = [
{"role": "system", "content": "You are a bot that responds to weather queries."},
{"role": "user", "content": "Hey, what's the temperature in Paris right now?"},
{"role": "assistant", "tool_calls": [{"type": "function", "function": tool_call}]},
{"role": "tool", "name": "get_current_temperature", "content": "22.0"}
]
huggingface 提供的 function call 示例进行计算:
model_path = "/home/kevin/models/Meta-Llama-3.1-70B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
inputs = tokenizer.apply_chat_template(messages,
tools=[get_current_temperature],
add_generation_prompt=True,
tokenize=False,
tools_in_user_message=False)
LLM 工具优化
现有TIR RL工作多依赖SFT,与SimpleTIR的Zero RL范式不同:
- Search-R1/R1-Search(2025):用RL训练LLM调用搜索引擎,但仅支持单轮,且依赖SFT;
- ReTool(2025):先SFT学习工具调用格式,再RL优化,性能高但缺乏推理多样性;
- ToRL/Effective CIR(2025):针对数学TIR,但基于指令微调模型(如Qwen2.5-Math),非基础模型;
- ZeroTIR(2025):唯一的Zero TIR工作,但未解决梯度爆炸问题,性能低于SimpleTIR;
- SimpleTIR:首次实现多轮Zero TIR的稳定训练,且性能超越有SFT的基线。
详见站内专题:多轮对话效果改进-工具调用
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
