Web前端服务
Web 3.0
【2022-8-9】目前web3.0还没到来。1.0是read,2.0是read&write这个大家基本赞同,但3.0增加了trust(或own)这个还有待验证。至少web3.0不是NFT和DApp能代表的。真正的Web3.0一定会伴随着设备和网络的升级一起来到,如果说1.0是PC+网线, 2.0是手机+4G,那3.0呢?目前的vr/ar/mr或者5g/6g都还早,需要进一步探索才能真的窥见web3.0全貌。
所以,目前的web3.0忽悠居多,大都是玩币那波人在炒作。web3.0是未来,但不是目前炒币人所定义的那个未来。
- 炒作web3.0概念的人还是17-18年炒币的那一波人,他们是玩金融的。利用区块链技术来回地玩金融,17-18年各种币层出不穷,被政府叫停后开始搞各种数字藏品和分布式APP。
浏览器
浏览器引擎
- Trident:IE浏览器引擎
- Gecko:Firefox浏览器引擎
- Presto:Opera浏览器引擎
- Webkit:Safari,Google Chrome浏览器引擎。
工作原理
【2026-4-16】
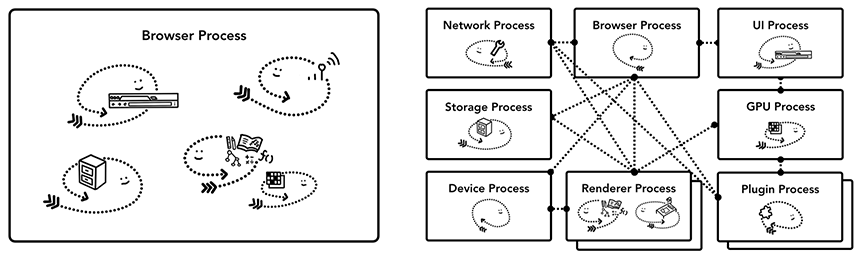
插件
tab-out 智能管理浏览器tab页
- 作者:哈佛毕业生 Zara
Tab Out 简化:
- Tab Out 现在是一个纯粹的 Chrome 扩展。没有服务器,没有 Node.js,没有 npm
- 保存的标签页存储在 http://chrome.storage .local;100%本地
git clone https://github.com/zarazhangrui/tab-out.git
前端、后端
前后端关系形象比喻: 前端是好看的皮囊,后端是复杂的肌肉骨骼,没有后者,前者啥也不是

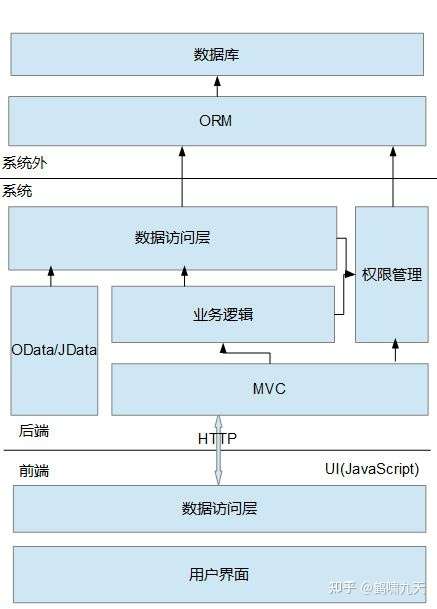
前端与后端的关系:近几年,前后端分离的思想主键深入,客户端+浏览器形成大前端,技术架构上逐渐的从传统的 后台MVC 向RESUFUI API+前端MV* 迁移,前端项目通过RESTful服务获取数据,RESTful API就是前后端的边界和桥梁。
前后端分离的好处是前端关注页面展现,后端关注业务逻辑,分工明确,职责清晰,前端工程师和后端工程师并行工作,提高开发效率。
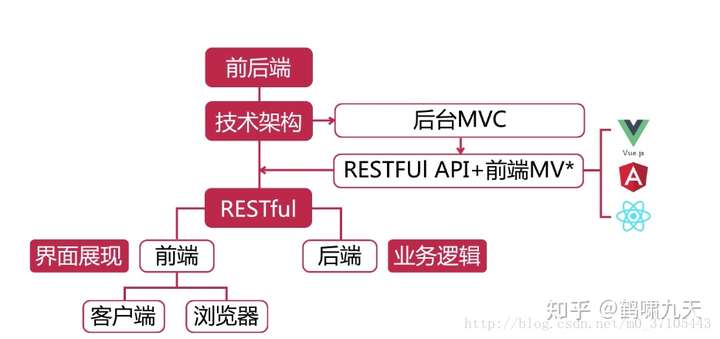
前后端演变历史
网站、应用等产品中,有三个很重要的东西 —— 浏览器、服务器、数据库。
以php(也可以是python、java等)项目常见的流程,其过程一般是类似于下面这张图。
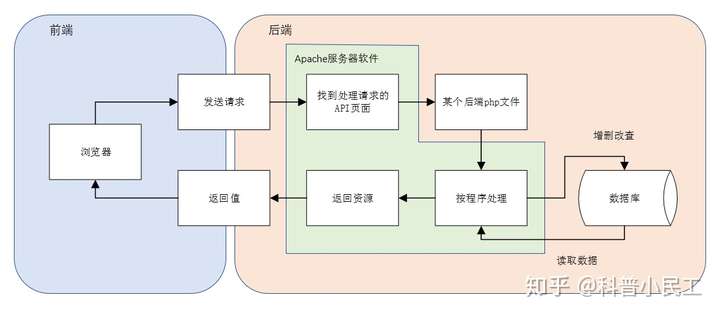
- 浏览器:“翻译”(即渲染)程序猿写的代码给用户看的,html文档主要会使用html、css、JavaScript三种语言
- 数据库:存放业务数据
- 服务器:自动操作(读写)数据库,如经常被提到的java、C++。
演变:
- 擅长html、css、JavaScript的程序猿,进化成了
前端工程狮,天天倒腾浏览器,他们对用户体验负责。 - 擅长java的程序猿,进化成了
后端攻城狮,天天倒腾数据库和服务器,他们对服务器性能及数据负责。 为了防止这两种不同的攻城狮工作内容混杂,双方约定一个发送请求的地址,和请求格式。 - 这种请求的地址和其相应的格式,又被称为
API(接口)。 至此,做好API文档后,前端和后端终于可以老死不相往来,各自调试各自的代码。
这一不相往来的概念,也被称为前后端分离。于是诞生了一种新的”变态”——Node.js,这个玩意虽然是用前端最爱的JavaScript语言,但是可以操作服务器。不过Node.js主要是被前端用来做中间件(可以理解为为了分离的更彻底一点)的,因此很多时候也被纳入前端范畴。
随着互联网的迅猛发展,逐步进化出了更多生物:
- 擅长美工的人成了
UI(美工) - 擅长沟通的人成了
产品经理PM,把客户和老板讲的东西理成结构化的文档,或是把用户的需求收集起来理成将来要做成软件的样子。 - 往网站上写文章,填内容实在是麻烦,而且要把网站流量做大,还得找个人出出主意,于是,
运营也诞生了。 - 上线后服务器怎么老是不稳定,后端大佬们都去做新项目了,得找个hold的住服务器和机房的专家,然后
运维出现了
前端
web前端分为网页设计师、网页美工、web前端开发工程师
网页设计师是对网页的架构、色彩以及网站的整体页面代码负责网页美工只针对UI这块的东西,比如网站是否做的漂亮web前端开发工程师是负责交互设计的,需要和程序员进行交互设计的配合。
前端工程师主要的工作职责分为三大部分
| 类型 | 设备端 | 备注 |
|---|---|---|
| 传统的Web前端开发 | PC | - |
| 移动端开发 | APP:Android/iOS/小程序开发 | 移动端的开发任务量是比较大 |
| 大数据呈现端开发 | PC | 基于已有的平台完可视化展现,如大屏 |
Web开发、APP开发以及小程序开发又统称为大前端
从应用范围来看,前端开发不仅被常人所知、且应用场景也要比后端广泛的太多太多。
- 一是
PC(Personal Computer) 即个人电脑。目前电脑端仍是前端一个主要的领域,主要分为面向大众的各类网站,如新闻媒体、社交、电商、论坛等和面向管理员的各种 CMS (内容管理系统)和其它的后台管理系统。 - 二 Web
App是指使用 Web 开发技术,实现的有较好用户体验的 Web 应用程序。它是运行在手机和桌面端浏览中,随着移动端网络速度的提升,Web App 为我们提供了很大的便利。此外近两年 Google 提出了一种新的 Web App 形态,即 PWA(渐进增强 Web APP) 。 - 三
WeChat(微信) 这个平台,拥有大量的用户群体,因此它也是我们前端开发另一个重要的领域。微信的公众号与订阅号为市场营销和自媒体从业者,打造了一个新的天地。 - 四
HybridApp (混合应用) 是指介于 Web App、原生 App (主要是 Android 或 iOS )之间的 App,它兼具原生 App 良好用户交互体验的优势和 Web App 跨平台开发的优势。 - 五
Game(游戏),HTML5 游戏从 2014 年 Egret 引擎开发的神经猫引爆朋友圈之后,就开始一发不可收拾。不过现在游戏开发变得越来越复杂,需要制作各种炫丽炫丽的效果,还要制作各炫丽于 2D 或者 3D 的场景。 - 六
Desktop桌面应用软件,就是我们日常生活中电脑中安装的各类软件。早期要开发桌面应用程序,就需要有专门的语言 UI (界面) 库支持,如 C++ 中的 Qt 库、MFC 库,Java 的 Swing、Python 的 PyQT 等,否则语言是没办法进行快速界面开发。 - 七
ServerNode.js 一发布,立刻在前端工程师中引起了轩然大波,前端工程师们几乎立刻对这一项技术表露出了相当大的热情和期待。看到 Node.js 这个名字,初学者可能会误以为这是一个 Java 应用,事实上,Node.js 采用 C++ 语言编写而成,是一个 Java 的运行环境。
前端开发涉及到的内容包括Html、CSS、JavaScript、Android开发(采用Java或者kotlin)、iOS开发(采用OC或者Swift)、各种小程序开发技术(类Html),随着前端开发任务的不断拓展,前端开发后端化也是一个较为明显的趋势,比如Nodejs的应用。
后端
后端工程师分三大部分
- 平台设计:搭建后端的支撑服务容器
- 接口设计:针对于不同行业进行相应的功能接口设计,通常一个平台有多套接口,就像卫星导航平台设有民用和军用两套接口一样
- 功能实现:完成具体的业务逻辑实现。
后端开发通常需要根据业务场景进行不同语言的选择,另外后端开发的重点在于算法设计、数据结构、性能优化等方面,在具体的功能实现部分可以采用Java、Python或者PHP等编程语言来实现。
Python Web 框架
详见站内专题: Web后端框架开发
前端与后端技术栈
- 前端开发技术:html5、css3、javascript、ajax、jquery、Bootstrap、Node.js 、Webpack,AngularJs,ReactJs,VueJs等技术。
- 后端开发技术: asp、php、jsp、.NET,以java为例,Struts spring springmvc Hibernate Http协议 Servlet Tomcat服务器等技术。
| 维度 | 前端 | 后端 |
|---|---|---|
| 编程语言 | HTML,CSS,JavaScript | PHP,Python,SQL,Java,Ruby,.NET,Perl |
| 框架 | Angular.JS,React.JS,Backbone.JS,Vue.JS,Sass,Ember.JS,NPM | Laravel,CakePHP,Express,CodeIgniter,Ruby on Rails,Pylon,ASP.NET |
| 数据库 | Local Storage, Core Data, SQLite, Cookies, Sessions | MySQL,Casandra,Postgre SQL,MongoDB,Oracle,Sybase,SQL Server |
| 服务器 | - | Ubuntu,Apache,Nginx,Linux,Windows |
| 其他 | AJAX,AMP,Atom,Babel,BEM,Blaze,Bourbon,Broccoli,Dojo,Flux,GraphQL,Gulp,Polymer,Socket.IO,Sublime Text | - |
前端
- 【2020-8-22】微信聊天窗口界面
- 【2020-8-28】EasyMock文档,Github地址,Easy Mock 是一个可视化,并且能快速生成 模拟数据 的持久化服务
- 【2021-5-13】机器学习建模与部署–以垃圾消息识别为例, 项目地址 kuhung/flask_vue_ML


简介
前端三要素
- HTML(结构层) : 超文本标记语言(Hyper Text Markup Language) ,决定网页的结构和内容
- CSS(表现层) : 层叠样式表(Cascading Style sheets) ,设定网页的表现样式。CSS预处理器:
- ①SASS:基于Ruby,通过服务端处理,功能强大。解析效率稿。需要学习 Ruby 语言,上手难度高于LESS。
- ②LESS:基于 NodeJS,通过客户端处理,使用简单。功能比 SASS 简单,解析效率也低于 SASS,但在实际开发中足够了,所以后台人员如果需要的话,建议使用 LESS。
- JavaScript(行为层) : 是一种弱类型脚本语言,其源代码不需经过编译,而是由浏览器解释运行,用于控制网页的行为
- ①原生JS开发,也就是让我们按照【ECMAScript】标准的开发方式,简称是ES,特点是所有浏览器都支持。
- ②TypeScript是一种由微软开发的自由和开源的编程语言。它是JavaScript的一个超集,而且本质上向这个语言添加了可选的静态类型和基于类的面向对象编程。由安德斯海尔斯伯格(C#、Delphi、TypeScript 之父; .NET 创立者)主导。该语言的特点就是除了具备 ES 的特性之外还纳入了许多不在标准范围内的新特性,所以会导致很多浏览器不能直接支持 TypeScript 语法,需要编译后(编译成 JS )才能被浏览器正确执行。
【2021-7-21】Vue快速入门学习笔记(更新ing)
HTML
文字效果
【2022-9-25】html文字效果
六个标题元素标签 —— < h1 >、< h2 >、< h3 >、< h4 >、< h5 >、< h6 >。每个元素代表文档中不同级别的内容;
- < h1 > 表示主标题(the main heading)
- < h2 > 表示二级子标题(subheadings)
- < h3 > 表示三级子标题(sub-subheadings),等等
- < span > 任一元素看起来像一个顶级标题, span元素没有语义。当想要对它用 CSS(或者 JS)时,可以用它包裹内容,且不需要附加任何额外的意义
斜体、加粗、下划线
- < i > 被用来传达传统上用斜体表达的意义:外国文字,分类名称,技术术语,一种思想……
- < b > 被用来传达传统上用粗体表达的意义:关键字,产品名称,引导句……
- < u > 被用来传达传统上用下划线表达的意义:专有名词,拼写错误……
大量的 HTML 元素可以来标记计算机代码:
- < code>: 用于标记计算机通用代码。
- < pre>: 用于保留空白字符(通常用于代码块)——如果您在文本中使用缩进或多余的空白,浏览器将忽略它,您将不会在呈现的页面上看到它。但是,如果您将文本包含在< pre> < /pre>标签中,那么空白将会以与你在文本编辑器中看到的相同的方式渲染出来。
- < var>: 用于标记具体变量名。
- < kbd>: 用于标记输入电脑的键盘(或其他类型)输入。
- < samp>: 用于标记计算机程序的输出。
HTML 还支持将时间和日期标记为可供机器识别的格式的 < time> 元素
<p>我是一个段落,千真万确。</p>
<h1>我是文章的标题</h1>
<h1>静夜思</h1>
<p>床前明月光 疑是地上霜</p>
<p>举头望明月 低头思故乡</p>
<span style="font-size: 32px; margin: 21px 0;">这是顶级标题吗?</span>
无序列表
<ul>
<li>豆浆</li>
<li>油条</li>
<li>豆汁</li>
<li>焦圈</li>
</ul>
有序列表,可以嵌套
<ol>
<li>沿着条路走到头</li>
<li>右转</li>
<li>直行穿过第一个十字路口</li>
<li>在第三个十字路口处左转</li>
<li>继续走 300 米,学校就在你的右手边</li>
<ul>
<li>豆浆</li>
<li>焦圈</li>
</ul>
</ol>
<p>This liquid is <strong>highly toxic(加粗)</strong> —
if you drink it, <strong>you may <em>die(斜体)</em></strong>.</p>
<p>
红喉北蜂鸟(学名:<i>Archilocus colubris(斜体)</i>)
菜单上有好多舶来词汇,比如 <i lang="uk-latn">vatrushka</i>(东欧乳酪面包),
<i lang="id">nasi goreng</i>(印尼炒饭)以及<i lang="fr">soupe à l'oignon</i>(法式洋葱汤)。
<b>加粗</b>,<u>下划线</u>
总有一天我会改掉写<u style="text-decoration-line: underline; text-decoration-style: wavy;">措字(下划线,波浪线)</u>的毛病。
</p>
缩略语:abbr用法
<p>第 33 届 <abbr title="夏季奥林匹克运动会">奥运会</abbr> 将于 2024 年 8 月在法国巴黎举行。</p>
上标、下标
<p> 上标:X<sup>2, 下标<sub>3 </p>
<pre><code>const para = document.querySelector('p');
para.onclick = function() {
alert('噢,噢,噢,别点我了。');
}</code></pre>
<p>请不要使用 <code><font></code> 、 <code><center></code> 等表象元素。</p>
<p>在上述的 JavaScript 示例中,<var>para</var> 表示一个段落元素。</p>
<p>按 <kbd>Ctrl</kbd>/<kbd>Cmd</kbd> + <kbd>A</kbd> 选择全部内容。</p>
<pre>$ <kbd>ping mozilla.org</kbd>
<samp>PING mozilla.org (63.245.215.20): 56 data bytes
64 bytes from 63.245.215.20: icmp_seq=0 ttl=40 time=158.233 ms</samp></pre>
<time datetime="2016-01-20">2016 年 1 月 20 日</time>
<!-- 标准简单日期 -->
<time datetime="2016-01-20">20 January 2016</time>
<!-- 只包含年份和月份-->
<time datetime="2016-01">January 2016</time>
<!-- 只包含月份和日期 -->
<time datetime="01-20">20 January</time>
<!-- 只包含时间,小时和分钟数 -->
<time datetime="19:30">19:30</time>
<!-- 还可包含秒和毫秒 -->
<time datetime="19:30:01.856">19:30:01.856</time>
<!-- 日期和时间 -->
<time datetime="2016-01-20T19:30">7.30pm, 20 January 2016</time>
<!-- 含有时区偏移值的日期时间 -->
<time datetime="2016-01-20T19:30+01:00">7.30pm, 20 January 2016 is 8.30pm in France</time>
<!-- 调用特定的周 -->
<time datetime="2016-W04">The fourth week of 2016</time>
分栏
【2020-8-24】Web页面分栏效果实现
- HTML中Frame实现左右分栏或上下分栏
- FrameSet中的Cols属性就控制了页面中的左右分篮,相应的rows则控制上下分栏
- 分栏的比例就有用逗号分开的10,*来确定
<frameset border=10 framespacing=10 cols=”10,*” frameborder="1" TOPMARGIN="0" LEFTMARGIN="0" MARGINHEIGHT="0" MARGINWIDTH="0">
<frame>
<frame>
</framset>
下拉框
- 【2021-6-8】下拉框提供选项,触发onchange时间,示例:
<html>
<head>
<script language="javascript" type="text/javascript">
function modify(osel){ // 下拉框动作变更通知
value = osel.options[osel.selectedIndex].text; //text
alert('你已选择:'+value);
//sessionStorage.setItem("product", value); // 本地session
//var product = window.sessionStorage.getItem('product');
//content.innerHTML += product;
}
function SetIndex(v){
var s=document.getElementById('selectSS');
s.selectedIndex=v;
if(s.onchange)s.onchange();
//sessionStorage.setItem("product", v);
}
</script>
</head>
<body>
<select id="selectSS" onChange="modify(this)">
<option value="1">第一项</option>
<option selected value="2">第二项(默认选中)</option>
<option value="3">第三项</option>
<option value="4">第四项</option>
</select>
<a href="#" onclick="SetIndex(0)">重置</a>
<div class=content>
获取的选项内容:
</div>
</body>
</html>
输入框提示
HTML5的datalist可以实现历史消息提示
<input id="country_name" name="country_name" type="text" list="city" />
<datalist id="city">
<option value="中国 北京">
<option value="中国 上海">
<option value="中国 广州">
<option value="中国 深圳">
<option value="中国 东莞">
</datalist>
JS
低代码平台
-
【2021-11-15】基于 magic-api 搭建自己的低代码平台,2021 开年“低代码”成了热门话题,各大云厂商都在加码。
- 阿里推出了易搭,通过简单的拖拽、配置,即可完成业务应用的搭建
- 腾讯则是推出了微搭,通过行业化模板、拖放式组件和可视化配置快速构建多端应用(小程序、H5 应用、Web 应用等),打通了小程序、云函数。
低代码项目
低代码开源项目:百度 amis、h5-Dooring 和 magic-api。
- 百度 amis(前端):百度 amis 是一套前端低代码框架,通过 JSON 配置就能生成各种后台页面,极大减少开发成本,甚至可以不需要了解前端。
- h5-Dooring(前端):h5-Dooring,让 H5 制作像搭积木一样简单, 轻松搭建 H5 页面, H5 网站, PC 端网站, 可视化设计。
- magic-api(后端):magic-api 是一个基于 Java 的接口快速开发框架,编写接口将通过 magic-api 提供的 UI 界面完成,自动映射为 HTTP 接口,无需定义 Controller、Service、Dao、Mapper、XML、VO 等 Java 对象即可完成常见的 HTTP API 接口开发。
【2022-3-9】GO语言实现的客户关系管理系统 YAO,开源低代码应用引擎:Yao,无需编写一行代码,即可快速创建 Web 服务和管理后台,大幅解放生产力。该工具内置了一套数据管理系统,通过编写 JSON,帮助开发者完成数据库模型、API 接口编写、管理后台界面搭建等工作,实现 90% 常见界面交互功能。内置管理系统与 Yao 并不耦合,开发者亦可采用 VUE、React 等任意前端技术实现管理界面。
- 项目示例 IoT管理平哪台:An example of cloud + edge IoT application, an unattended intelligent warehouse management system that supports face recognition and RFID.
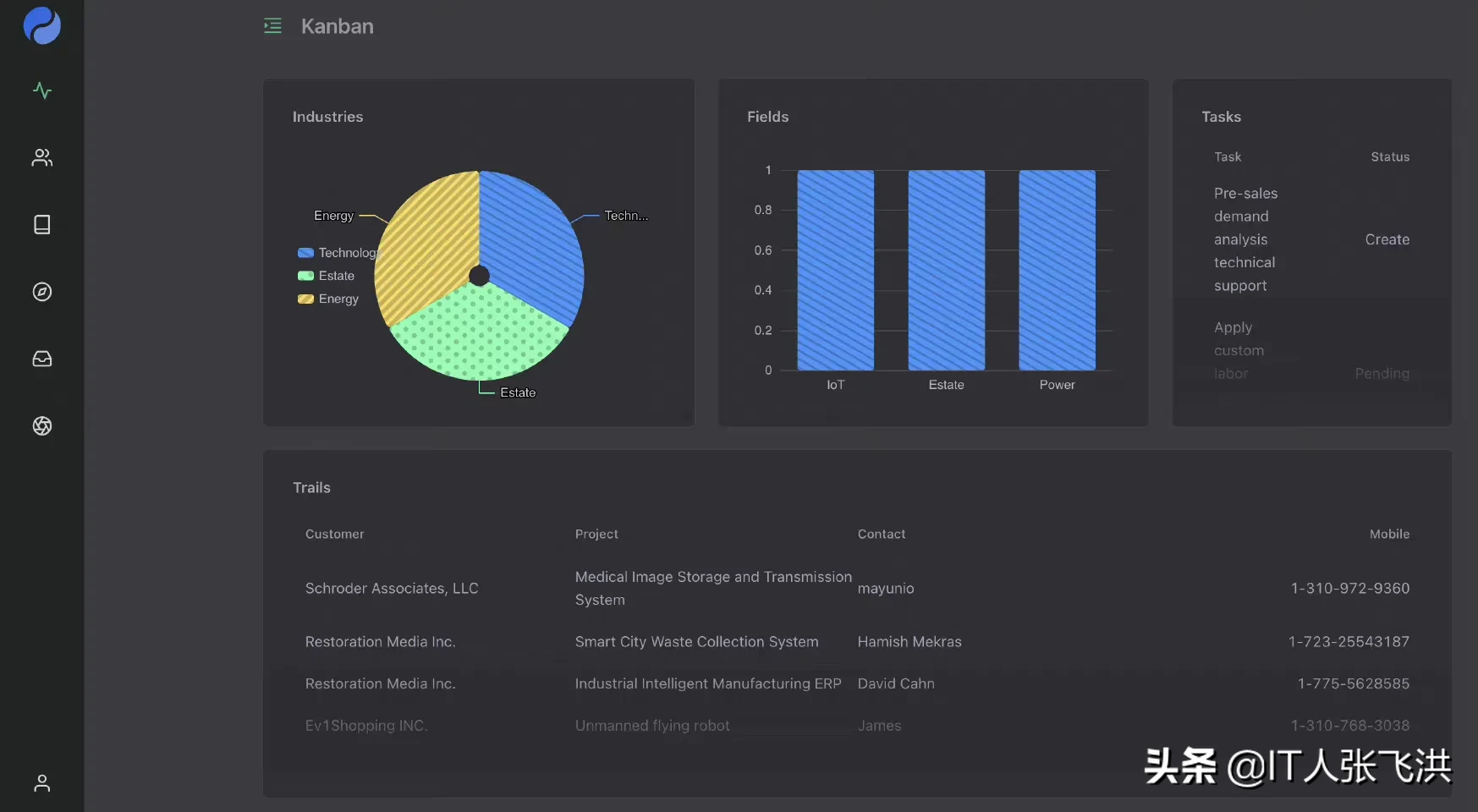
【2022-3-16】低代码平台 Variant Form,只用拖拖拽拽就生成vue页面代码,体验地址:vform表单设计器
python生成前端代码
详见:Python专题
Pynecone
【2022-12-15】GitHub 上的开源 Python 全栈开发框架:Pynecone
Gradio
Gradio web demo
- DEMO examples
pip install gradio # 安装
接 OpenAI 接口 实现 ChatGPT
import gradio as gr
import openai
openai.api_key = "sk-**"
def question_answer(role, question):
if not question:
return "输入为空..."
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{
"role": "user", # role (either “system”, “user”, or “assistant”)
"content": question}
]
)
# 返回信息
return (completion['choices'][0]['message']['role'], completion['choices'][0]['message']['content'])
gr.Interface(fn=question_answer,
# inputs=["text"], outputs=['text', "textbox"], # 简易用法
inputs=[gr.components.Dropdown(label="Role", placeholder="user", choices=['system', 'user', 'assistant']),
gr.inputs.Textbox(lines=5, label="Input Text", placeholder="问题/提示语(prompt)...")
],
outputs=[gr.outputs.Textbox(label="Role"), gr.outputs.Textbox(label="Generated Text")],
# ["highlight", "json", "html"], # 定制返回结果格式,3种输出分别用3种形式展示
examples=[['你是谁?'], ['帮我算个数,六乘5是多少']],
cache_examples=True, # 缓存历史案例
title="ChatGPT Demo",
description="A simplified version of DEMO [examples](https://gradio.app/demos/) "
).launch(share=True) # 启动 临时分享模式
#).launch() # 仅本地访问
通过request请求实现QA
import gradio as gr
import requests
def question_answer(question):
data = {"prompt": "默认: 北京朝阳区值得买吗?","max_new_tokens": 512}
if question:
data['prompt'] = question
url = 'http://10.135.177.134:9429/generation'
r = requests.post(url, json=data)
return json.loads(r.text)['text']
gr.Interface(fn=question_answer, inputs=["text"], outputs=["textbox"],
examples=[['小区一周之内发生两次跳楼事件,刚交了三个月房租我是租还是搬走呢?'],
['出租出去的房屋家电坏了,应该谁负责出维修费用?'],
['女方婚前父母出资买房,登记在女方名下,父母还贷,婚后怎么划分?'],
['退租房东不还押金怎么办?'],['小区环境太差,可以找物业吗'],
]
).launch(share=True)
#).launch()
streamlit
【2021-12-8】详解一个Python库,用于构建精美数据可视化web app. Python 库 Streamlit,它可以为机器学习和数据分析构建 web app。它的优势是入门容易、纯 Python 编码、开发效率高、UI精美。
- 对于交互式的数据可视化需求,完全可以考虑用 Streamlit 实现。特别是在学习、工作汇报的时候,用它的效果远好于 PPT。因为 Streamlit 提供了很多前端交互的组件,所以也可以用它来做一些简单的web 应用。
安装:
pip install streamlit # 安装
streamlit hello # 检查是否安装成功
主要功能:
- 文本组件:文本组件是用来在网页上展示各种类型的文本内容
- 数据组件:
- dataframe 和 table 组件可以展示表格。前者可动态展示。数据类型包括 pandas.DataFrame、pandas.Styler、pyarrow.Table、numpy.ndarray、Iterable、dict。
- json组件:显示json格式,展示地更美观,并且提供交互,可以展开、收起 json 的子节点。
- metric 组件用来展示指标的变化,数据分析中经常会用到。
- st.metric(label=”Temperature”, value=”70 °F”, delta=”1.2 °F”)
- 图标组件:包含两部分,一部分是原生组件,另一部分是渲染第三方库。
- 原生组件只包含 4 个图表,line_chart、area_chart 、bar_chart 和 map,分别展示折线图、面积图、柱状图和地图。
- 第三方库:matplotlib.pyplot、Altair、vega-lite、Plotly、Bokeh、PyDeck、Graphviz。
- 输入组件
- Streamlit 提供的输入组件都是基本的,都是我们在网站、移动APP上经常看到的。包括:
- button:按钮
- download_button:文件下载
- file_uploader:文件上传
- checkbox:复选框
- radio:单选框
- selectbox:下拉单选框
- multiselect:下拉多选框
- slider:滑动条
- select_slider:选择条
- text_input:文本输入框
- text_area:文本展示框
- number_input:数字输入框,支持加减按钮
- date_input:日期选择框
- time_input:时间选择框
- color_picker:颜色选择器
- 它们包含一些公共的参数:
- label:组件上展示的内容(如:按钮名称)
- key:当前页面唯一标识一个组件
- help:鼠标放在组件上展示说明信息
- on_click / on_change:组件发生交互(如:输入、点击)后的回调函数
- args:回调函数的参数
- kwargs:回调函数的参数

- Streamlit 提供的输入组件都是基本的,都是我们在网站、移动APP上经常看到的。包括:
- 多媒体组件
- Streamlit 定义了 image、audio 和 video 用于展示图片、音频和视频。可以展示本地多媒体,也通过 url 展示网络多媒体。

- 状态组件
- 状态组件用来向用户展示当前程序的运行状态,包括:
- progress:进度条,如游戏加载进度
- spinner:等待提示
- balloons:页面底部飘气球,表示祝贺
- error:显示错误信息
- warning:显示报警信息
- info:显示常规信息
- success:显示成功信息
- exception:显示异常信息(代码错误栈)
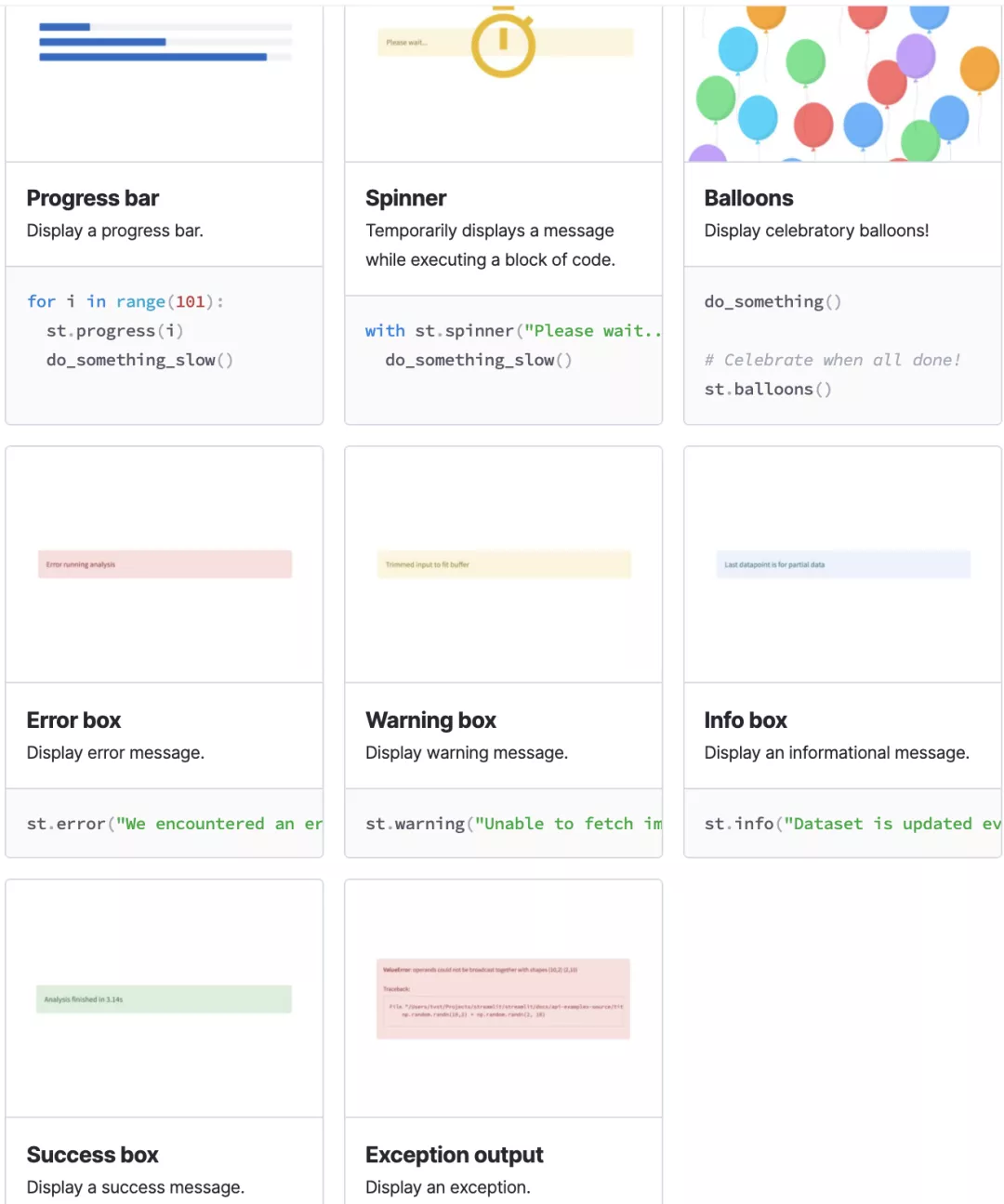
- 状态组件用来向用户展示当前程序的运行状态,包括:
Streamlit 可以展示纯文本、Markdown、标题、代码和LaTeX公式。
my_code.py
import streamlit as st
# markdown
st.markdown('Streamlit is **_really_ cool**.')
# 设置网页标题
st.title('This is a title')
# 展示一级标题
st.header('This is a header')
# 展示二级标题
st.subheader('This is a subheader')
# metric
st.metric(label="Temperature", value="70 °F", delta="1.2 °F")
# json组件
st.json({
'foo': 'bar',
'stuff': [
'stuff 1',
'stuff 2',
],
})
# 展示代码,有高亮效果
code = '''def hello():
print("Hello, Streamlit!")'''
st.code(code, language='python')
# 纯文本
st.text('This is some text.')
# LaTeX 公式
st.latex(r'''
a + ar + a r^2 + a r^3 + \cdots + a r^{n-1} =
\sum_{k=0}^{n-1} ar^k =
a \left(\frac{1-r^{n}}{1-r}\right)
''')
# 图表
chart_data = pd.DataFrame(np.random.randn(20, 3), columns=['a', 'b', 'c'])
st.line_chart(chart_data)
# 第三方图表
import matplotlib.pyplot as plt
arr = np.random.normal(1, 1, size=100)
fig, ax = plt.subplots()
ax.hist(arr, bins=20)
st.pyplot(fig)
# 交互输入框:下拉框
option = st.selectbox('下拉框', ('选项一', '选项二', '选项三'))
# 输出组件,可以输出字符串、DataFrame、普通对象等各种类型数据。
st.write('选择了:', option)
执行:streamlit run my_code.py ,streamlit 会启动 web 服务,加载指定的源文件。浏览器访问 http://localhost:8501/ 即可。
当源代码被修改,无需重启服务,在页面上点击刷新按钮就可加载最新的代码,运行和调试都非常方便。
- 页面布局。之前我们写的 Streamlit 都是按照代码执行顺序从上至下展示组件,Streamlit 提供了 5 种布局:
- sidebar:侧边栏,如:文章开头那张图,页面左侧模型参数选择
- columns:列容器,处在同一个 columns 内组件,按照从左至右顺序展示
- expander:隐藏信息,点击后可展开展示详细内容,如:展示更多
- container:包含多组件的容器
- empty:包含单组件的容器
- 控制流。控制 Streamlit 应用的执行,包括
- stop:可以让 Streamlit 应用停止而不向下执行,如:验证码通过后,再向下运行展示后续内容。
- form:表单,Streamlit 在某个组件有交互后就会重新执行页面程序,而有时候需要等一组组件都完成交互后再刷新(如:登录填用户名和密码),这时候就需要将这些组件添加到 form 中
- form_submit_button:在 form 中使用,提交表单。
- 缓存。这个比较关键,尤其是做机器学习的同学。刚刚说了, Streamlit 组件交互后页面代码会重新执行,如果程序中包含一些复杂的数据处理逻辑(如:读取外部数据、训练模型),就会导致每次交互都要重复执行相同数据处理逻辑,进而导致页面加载时间过长,影响体验。
- 加入缓存便可以将第一次处理的结果存到内存,当程序重新执行会从内存读,而不需要重新处理。
- 使用方法也简单,在需要缓存的函数加上 @st.cache 装饰器即可。前两天我们讲过 Python 装饰器。
DATE_COLUMN = 'date/time'
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
@st.cache
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
后端
HTTP
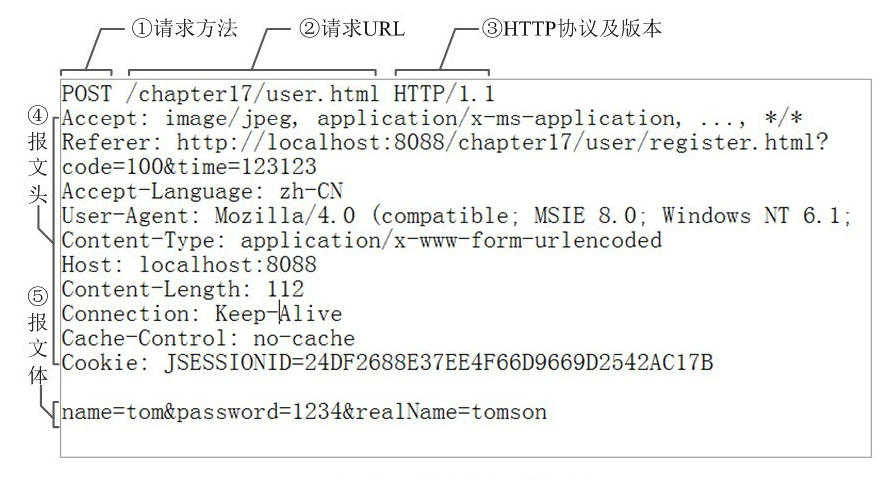
HTTP常见的方法:
GET:浏览器告知服务器:只 获取 页面上的信息并发给我。这是最常用的方法。POST:浏览器告诉服务器:想在 URL 上 发布 新信息。并且,服务器必须确保 数据已存储且仅存储一次。这是 HTML 表单通常发送数据到服务器的方法。PUT:类似 POST 但是服务器可能触发了存储过程多次,多次覆盖掉旧值。你可 能会问这有什么用,当然这是有原因的。考虑到传输中连接可能会丢失,在 这种 情况下浏览器和服务器之间的系统可能安全地第二次接收请求,而 不破坏其它东西。因为 POST 它只触发一次,所以用 POST 是不可能的。-
DELETE:删除给定位置的信息。 - 参考:HTTP请求时POST参数到底应该怎么传?,HTTP POST/GET 在线请求测试工具
HTTP请求头
- 请求三要素
- 根据应用场景的不同,HTTP请求的请求体有三种不同的形式, 通过header中的content-type指定, 这里只分析两个:
- 表单方式:APPlication/x-www-form-urlencoded(默认类型)
- 如果不指定其他类型的话, 默认是x-www-form-urlencoded, 此类型要求参数传递样式为key1=value1&key2=value2
- Flask代码:request.form得到字典

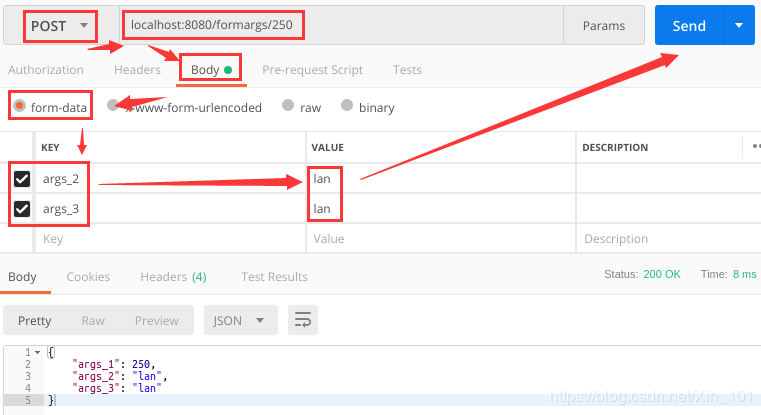
- 如果不指定其他类型的话, 默认是x-www-form-urlencoded, 此类型要求参数传递样式为key1=value1&key2=value2
- json方式:application/json
- 更适合传递大数据的形式, 参数样式就是json格式, 例如{"key1":"value1","key2":[1,2,3]}等.
- Flask代码:request.json得到字典


- 更适合传递大数据的形式, 参数样式就是json格式, 例如{"key1":"value1","key2":[1,2,3]}等.
- 表单方式:APPlication/x-www-form-urlencoded(默认类型)
- GET方式获取地址栏参数
- Flask代码:request.args得到字典

HTTP响应头
- 响应三要素

URL
【2022-3-15】图解浏览器URL构成
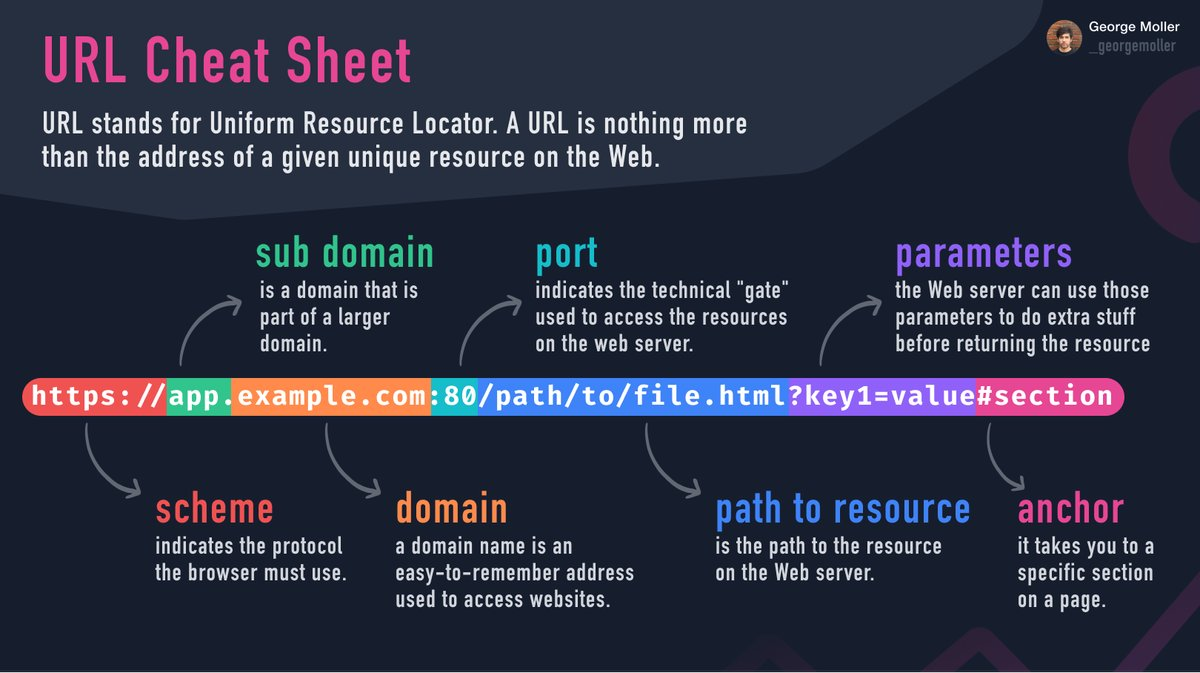
URL 转码
使用url进行跨页面(跨域)传值的时候,会出现某些带特殊字符的url,在浏览器上被处理了
后端传给前端的跳转路径:
- http://127.0.0.1:8088/harbor/sign-in?userName=admin&userPassword=1Qaz2wsx#
浏览器跳转时浏览器地址栏的url变成:
- http://127.0.0.1:8088/harbor/sign-in?userName=admin&userPassword=1Qaz2wsx
注意:
- 末尾处的#不见了
还有其他情况, 如url中的参数有 “/” “&” “@” 特殊字符时,url都会出现错误…
解决方案:
使用URL的编码和解码 对 特殊字符进行处理
原文链接:https://blog.csdn.net/lettuce_/article/details/104746263
浏览器对特殊字符转码
# 字符转码依次是
空格 -> %20
! -> %21
# -> %23
% -> %25
& -> %26
( -> %28
) -> %29
: -> %3A
/ -> %2F
= -> %3D
? -> %3F
, -> %2C
@ -> %40
完整转换关系:ASCII 编码参考手册
var password = decodeURIComponent("1Qazwsx%23");
console.log(password);
//显示结果 1Qazwsx#
post/get参数获取
- flask的post,get请求及获取不同格式的参数
-

- PostMan界面
状态码
【2021-4-26】HTTP状态码说明,HTTP定义了四十个标准状态代码,可用于传达客户端请求的结果。状态代码分为以下五个类别
| 类别 | 要点 | 描述 | 示例 |
|---|---|---|---|
| 1xx | 信息 | 通信传输协议级信息 | 100(客户端发送请求) |
| 2xx | 成功 | 表示客户端的请求已成功接受 | 200(OK),201(创建),202(已接受),204(无内容), |
| 3xx | 重定向 | 表示客户端必须执行一些其他操作才能完成其请求 | 301(永久移动),302(找到),303(见其他),304(未修改),307(临时重定向) |
| 4xx | 客户端错误 | 此类错误状态代码指向客户端 | 400(不良请求),401(未经授权),403(禁止),404(未找到),405(不允许的方法),406(不可接受),412(前提条件失败),415(不支持的媒体类型),499(超时) |
| 5xx | 服务器错误 | 服务器负责这些错误状态代码 | 500(内部服务器错误),501(未实施) |
API
API 介绍
- API(application programming interfaces),即应用程序编程接口。API由服务器(Server)提供(服务器有各种各样的类型,一般我们浏览网页用到的是web server,即网络服务器),通过API,计算机可以读取、编辑网站数据,就像人类可以加载网页、提交信息等。通俗地,API可以理解为家用电器的插头,用户只提供插座,并执行将插头插入插座的行为,不需要考虑电器内部如何运作。从另外一个角度上讲API是一套协议,规定了与外界的沟通方式:如何发送请求和接受响应。
【2021-11-24】阿里面试题:如何实现幂等
- 实现方式很多,使用过的有例如先放个token在内存或redis中,然后post的时候带上,还得考虑token过期时间,定时删除等。或者根据数据库里的某字段唯一性比如订单告唯一。或者按状态机,使用过spring statemachine来做。我们生产上真实出现过重复创建payment,原因没查出😓当时还做了前端不允许刷新,后退,禁用对应按键。
- 幂等号是指token吗,用的是redis里的key自增。
- 分布式事务常见有xa,tcc或者利用mq来通过中间状态实现最终一致性。xa和bytetcc用在强一致性的场景。原理其实二者差不多都是二阶段提交。xa来说分tm,xa,APP。tm是协调者,程序员通过tm.begin 会开启一个事务放到线程上下文里,当其它的参与者一般是数据库在开事务时候会检查线程上下文是否有事务,如果有就加入。这样一个分布式事务里就含有好多子事务。当调用tm.commit 就会分成二阶段提交。xa使用场景限制在数据库,mq都可以掌控的情况下。而tcc放在分布式情况下,只不过tm从线程上下文变成一个涉及远程通讯的协调者,可以看bytetcc源码。tcc还有局限就是太麻烦。
API架构
【2023-5-31】流行API架构系统
- 🔹SOAP
- 🔹RESTful
- 🔹GraphQL
- 🔹gRPC
- 🔹WebSocket
- 🔹Webhook
图解
理解RESTful API
- RESTful API即满足RESTful风格设计的API,RESTful表示的是一种互联网软件架构(以网络为基础的应用软件的架构设计),如果一个架构符合REST原则,就称它为RESTful架构。RESTful架构的特点:
- 每一个URI代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;把”资源”具体呈现出来的形式,叫做它的”表现层”(Representation)。比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
- 客户端通过四个HTTP动词,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
API设计规范
在移动互联网,分布式、微服务盛行的今天,现在项目绝大部分都采用的微服务框架,前后端分离方式,一般系统的大致整体架构图
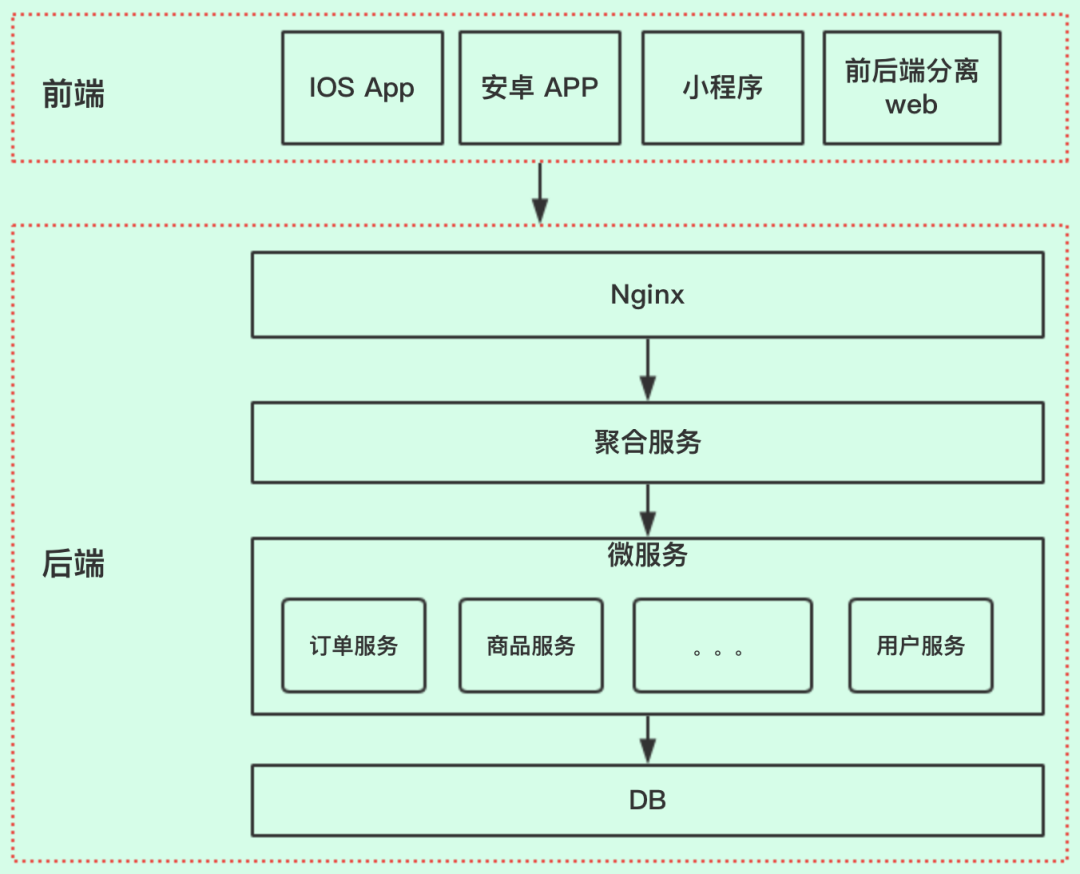
接口交互
- 前端和后端进行交互,前端按照约定请求URL路径,并传入相关参数,后端服务器接收请求,进行业务处理,返回数据给前端。
API与客户端用户的通信协议,总是使用HTTPS协议,以确保交互数据的传输安全。
其它要求:
- 限流设计、熔断设计、降级设计,大部分都用不到,当用上了基本上也都在网关中加这些功能。
资料:
path路径规范
域名设计:
- 应该尽量将API部署在专用域名之下:https://api.example.com
- 如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下:https://www.example.com/api
路径又称”终点”(end point),表示API的具体网址。
- 1、在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词。【所用的名词往往与数据库的表格名对应】
- 2、数据库中的表一般都是同种记录的”集合“(collection),所以API中的名词也应该使用复数。
例子:
- https://api.example.com/v1/products
- https://api.example.com/v1/users
- https://api.example.com/v1/employees
| 动作 | 前缀 | 备注 |
|---|---|---|
| 获取 | get | get{XXX} |
| 获取 | get | get{XXX}List |
| 新增 | add | add{XXX} |
| 修改 | update | update{XXX} |
| 保存 | save | save{XXX} |
| 删除 | delete | delete{XXX} |
| 上传 | upload | upload{XXX} |
| 发送 | send | send{XXX} |
版本控制
https://api.example.com/v{n}
- 1、应该将API的版本号放入URL。
- 2、采用多版本并存,增量发布的方式。
- 3、n代表版本号,分为整型和浮点型
- 整型: 大功能版本, 如v1、v2、v3 …
- 浮点型: 补充功能版本, 如v1.1、v1.2、v2.1、v2.2 …
- 4、对于一个 API 或服务,应在生产中最多保留 3 个最详细的版本
请求方式
- GET(SELECT): 从服务器取出资源(一项或多项)。
- POST(CREATE): 在服务器新建一个资源。
- PUT(UPDATE): 在服务器更新资源(客户端提供改变后的完整资源)。
- DELETE(DELETE): 从服务器删除资源。
例子:
- GET /v1/products 获取所有商品
- GET /v1/products/ID 获取某个指定商品的信息
- POST /v1/products 新建一个商品
- PUT /v1/products/ID 更新某个指定商品的信息
- DELETE /v1/products/ID 删除某个商品,更合理的设计详见【9、非RESTful API的需求】
- GET /v1/products/ID/purchases 列出某个指定商品的所有投资者
- GET /v1/products/ID/purchases/ID 获取某个指定商品的指定投资者信息
请求参数
传入参数分为4种类型:
- 1、cookie: 一般用于OAuth认证
- 2、request header: 一般用于OAuth认证
- 3、请求body数据:
- 4、地址栏参数:
- 1)restful 地址栏参数 /v1/products/ID ID为产品编号,获取产品编号为ID的信息
- 2)get方式的查询字段 详情:
- Query
- url?后面的参数,存放请求接口的参数数据。
- Header
- 请求头,存放公共参数、requestId、token、加密字段等。
- Body
- Body 体,存放请求接口的参数数据。
- 公共参数
- APP端请求:network(网络:wifi/4G)、operator(运营商:中国联通/移动)、platform(平台:iOS/Android)、system(系统:ios 13.3/android 9)、device(设备型号:iPhone XY/小米9)、udid(设备唯一标识)、apiVersion(API版本号:v1.1)
- Web端请求:appKey(授权key),调用方需向服务方申请 appKey(请求时使用) 和 secretKey(加密时使用)。
- 安全规范
- 敏感参数加密处理:登录密码、支付密码,需加密后传输,建议使用 非对称加密。
- 参数命名规范:建议使用驼峰命名,首字母小写。
- requestId 建议携带唯一标示追踪问题。
若记录数量很多,服务器不可能返回全部记录给用户。API应该提供分页参数及其它筛选参数,过滤返回结果。
- /v1/products?page=1&pageSize=20 指定第几页,以及每页的记录数。
- /v1/products?sortBy=name&order=asc 指定返回结果按照哪个属性排序,以及排序顺序。
返回格式
【2021-11-16】
整体格式
响应结构有两种:
- 方式一:包装响应格式,会在真正的响应数据外面包装一层,比如code、message等数据,如果接口报错,响应Status依然为200,更改响应数据里的code。
- 方式二:不包装响应数据,需要什么返回什么,如果接口报错,更改响应Status,同时换另一种响应格式,告知前端错误信息。
两种方式各有千秋,这里不谈孰优孰劣
第一种:
- code只是示例,实际项目中应为项目提前定义好的业务异常code,如10025,如果希望得到建议,可以参考另一篇文章异常及错误码定义。
- 这种方式接口响应的Status均为200,使用响应体中的code来区分状态。 无论如何,接口返回响应的数据结构都是一致的。实现提来也比较简单,每个接口都返回统一的一个类型即可,也可以各自返回各自的,再统一进行包装。
// 接口正常
{
code: 200,
msg: null,
data: {
"name": "张三",
"age": 108
}
}
// 接口异常
{
code: 500,
msg: "系统开小差了,稍后再试吧。"
}
第二种:不包装响应数据
- 这种方式,成功的时候只返回请求的数据,而失败时才会返回失败信息,两种情况数据结构是不同的,需要通过响应的status来区分。
- 这里的code指的是业务上的错误码,并不是简单的http status
// 正常
{
"name": "张三",
"age": 108
}
// 异常
{
code: 500,
msg: ""
}
典型数据字段
后端返回给前端数据, 一般用JSON体方式,定义如下:
{
#返回状态码
code:integer,
#返回信息描述
message:string,
#返回值
data:object
}
(1)code
- code表示返回状态码,一般开发时需要什么,就添加什么。如接口要返回用户权限异常,加一个状态码为101吧,下一次又要加一个数据参数异常,就加一个102的状态码。这样虽然能够照常满足业务,但状态码太凌乱了,可以参考HTTP请求返回的状态码
 常见的HTTP状态码:
常见的HTTP状态码:- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误 这样做的好处是就把错误类型归类到某个区间内,如果区间不够,可以设计成4位数。
- 1000~1999 区间表示参数错误
- 2000~2999 区间表示用户错误
- 3000~3999 区间表示接口异常 前端开发人员在得到返回值后,根据状态码就可以知道,大概什么错误,再根据message相关的信息描述,可以快速定位。
总结:
- 接口正常访问情况下,服务器返回2××的HTTP状态码;如200一切正常、201资源被创建、204资源被删除
- 当用户访问接口出错时,服务器会返回给一个合适的4××或者5××的HTTP状态码;以及一个application/json格式的消息体,消息体中包含错误码code和错误说明message。
- 5××错误(500 =< status code)为服务器或程序出错,客户端只需要提示“服务异常,请稍后重试”即可,该类错误不在每个接口中列出。
- 4××错误(400 =< status code<500)为客户端的请求错误,需要根据具体的code做相应的提示和逻辑处理,message仅供开发时参考,不建议作为用户提示。
(2)Message
- 这个字段相对理解比较简单,就是发生错误时,如何友好的进行提示。一般的设计是和code状态码一起设计
(3)data
- 需要返回给前端的数据。这个data内的数据一定要是JSON格式,方便前端的解析。
数据常见的有2个大类:
- 业务操作结果
- 业务操作的过程,能否封装、优化要看实际情况,但是业务操作的最终结果,即最终得到的要返回给前端的数据,可以使用AOP统一封装的前面提到的统一格式中,而不用每次手动封装。
- 参数校验结果
- 参数的校验如果不使用第三方库,会在代码中多出很多的冗余代码,所以,最好使用oval、hibernate validate或者Spring等参数校验方式,可以大幅度美观代码。
字段
- 数据脱敏
- 用户手机号、用户邮箱、身份证号、支付账号、邮寄地址等要进行脱敏,部分数据加 * 号处理。
- 属性名命名时,建议使用驼峰命名,首字母小写。
- 属性值为空时,严格按类型返回默认值。
- 金额类型/时间日期类型的属性值,如果仅用来显示,建议后端返回可以显示的字符串。
- 业务逻辑的状态码和对应的文案,建议后端两者都返回。
- 调用方不需要的属性,不要返回。
| 参数 | 类型 | 说明 | 备注 |
|---|---|---|---|
| code | Number | 结果码 | 成功=1失败=-1未登录=401无权限=403 |
| showMsg | String | 显示信息 | 系统繁忙,稍后重试 |
| errorMsg | String | 错误信息 | 便于研发定位问题 |
| data | Object | 数据 | JSON 格式 |
{
"code": 1,
"showMsg": "success",
"errorMsg": "",
"data": {
"list": [],
"pagination": {
"total": 100,
"currentPage": 1,
"prePageCount": 10
}
}
}
API接口:
# response:
#----------------------------------------
{
status: 200, // 详见【status】
data: {
code: 1, // 详见【code】
data: {} || [], // 数据
message: '成功', // 存放响应信息提示,显示给客户端用户【须语义化中文提示】
sysMsg: 'success' // 存放响应信息提示,调试使用,中英文都行
... // 其它参数,如 total【总记录数】等
},
message: '成功', // 存放响应信息提示,显示给客户端用户【须语义化中文提示】
sysMsg: 'success' // 存放响应信息提示,调试使用,中英文都行
}
#----------------------------------------
【status】:
200: OK 400: Bad Request 500:Internal Server Error
401:Unauthorized
403:Forbidden
404:Not Found
【code】:
1: 获取数据成功 | 操作成功 0:获取数据失败 | 操作失败
签名设计(权限)
权限分为
- none:无需任何授权;
- token:需要用户登录授权,可通过header Authorization和Cookie CoSID传递;
- admintoken:需要管理员登录授权,可通过header Authorization和Cookie CoCPSID传递;
- token或admintoken:用户登录授权或管理员登录授权都可以;
- sign:需要签名,一般用于服务端内部相互调用,详见 孩宝API HMAC-SHA1签名。
签名验证没有确定的规范,自己制定就行,可以选择使用 对称加密、 非对称加密、 单向散列加密 等,分享下原来写的签名验证,供参考。
日志平台设计
日志平台有利于故障定位和日志统计分析。
日志平台的搭建可以使用的是 ELK 组件,使用 Logstash 进行收集日志文件,使用 Elasticsearch 引擎进行搜索分析,最终在 Kibana 平台展示出来。
幂等性设计
我们无法保证接口的每一次调用都是有返回结果的,要考虑到出现网络异常的情况。
- 举个例子,订单创建时,我们需要去减库存,这时接口发生了超时,调用方进行了重试,这时是否会多扣一次库存?
解决这类问题有 2 种方案:
- 一、服务方提供相应的查询接口,调用方在请求超时后进行查询,如果查到了,表示请求处理成功了,没查到就走失败流程。
- 二、调用方只管重试,服务方保证一次和多次的请求结果是一样的。
对于第二种方案,就需要服务方的接口支持幂等性。
大致设计思路是这样的:
- 调用接口前,先获取一个全局唯一的令牌(Token)
- 调用接口时,将 Token 放到 Header 头中
- 解析 Header 头,验证是否为有效 Token,无效直接返回失败
- 完成业务逻辑后,将业务结果与 Token 进行关联存储,设置失效时间
- 重试时不要重新获取 Token,用要上次的 Token
非Restful API
- 1、实际业务开展过程中,可能会出现各种的api不是简单的restful 规范能实现的。
- 2、需要有一些api突破restful规范原则。
-
3、特别是移动互联网的api设计,更需要有一些特定的api来优化数据请求的交互。
- 1)、删除单个,批量删除 : DELETE /v1/product body参数{ids:[]}
- 2)、页面级API : 把当前页面中需要用到的所有数据通过一个接口一次性返回全部数据
接口文档
- 1、尽量采用自动化接口文档,可以做到在线测试,同步更新。
- 生成的工具为apidoc,详细阅读官方文档:http://apidocjs.com
- 2、应包含:接口BASE地址、接口版本、接口模块分类等。
- 3、每个接口应包含:
- 接口地址:不包含接口BASE地址。
- 请求方式: get、post、put、delete等。
- 请求参数:数据格式【默认JSON、可选form data】、数据类型、是否必填、中文描述。
- 响应参数:类型、中文描述。
工具
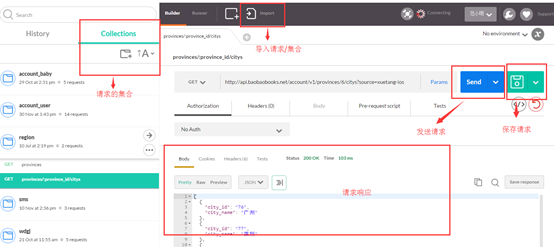
Postman 模拟请求
推荐Chrome浏览器插件Postman作为接口测试工具, Postman下载地址
Mod-Header 修改Header
【2023-11-2】Chrome 访问网页时,有时要构造/修改下网页请求的http请求头
- modheader 满足这样需求的插件工具,简单而实用。
- 参考
安装
- Chrome 打开 “扩展程序”
- 输入 ModHeader 后搜索出该插件安装下即可。
启动
- 点击
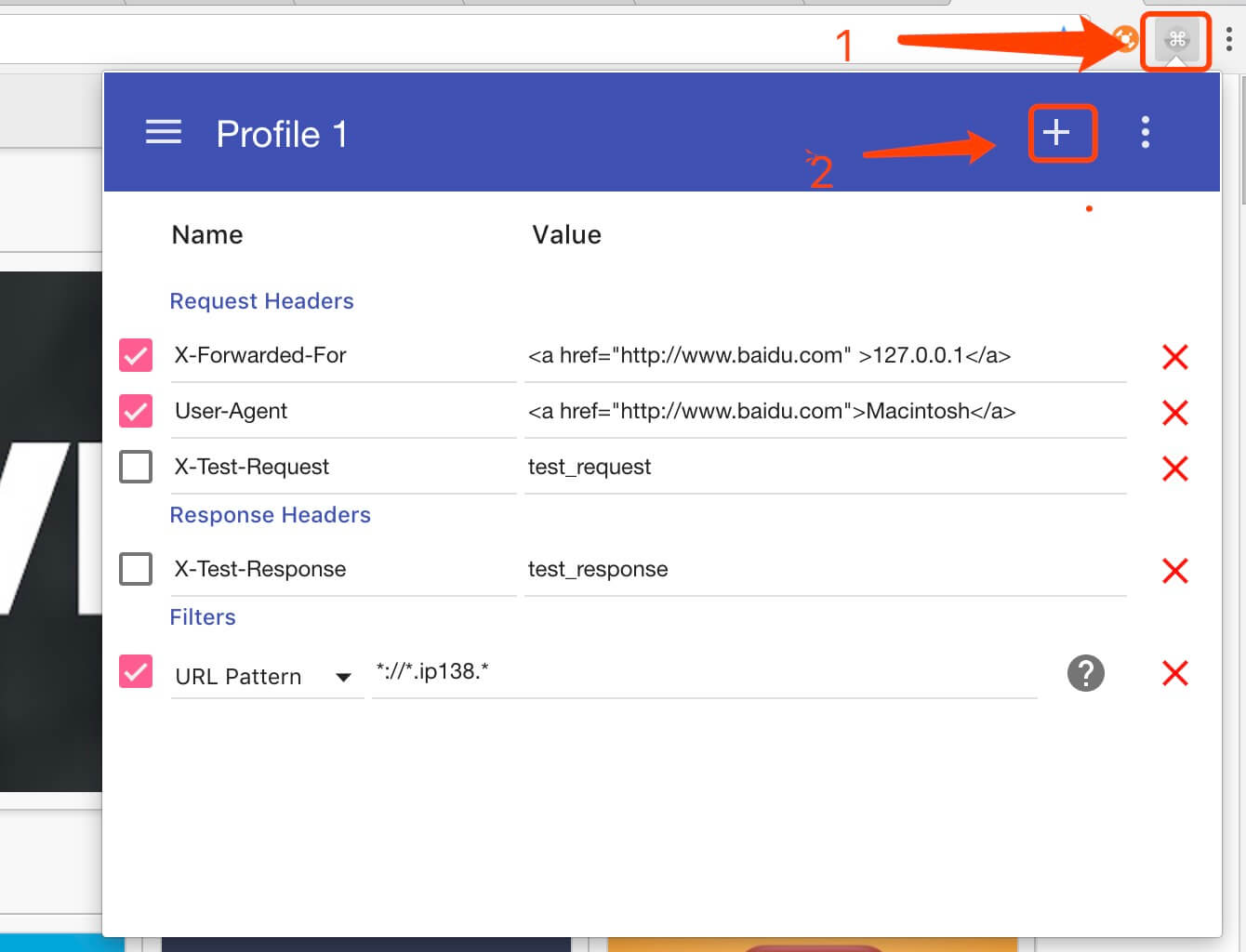
配置 Http请求头
- 点击+号后弹出菜单选择“Request header”,之后会在面板下的Request header分类多了一项,输入要增加(或者修改)的请求头的key 和value 即可。
x-use-ppe: 1
x-tt-env: ppe_dev_jiangyl
x-env-idc: lf
设置 Http 回应头
- 和设置请求头差不多,点击+号后弹出菜单选择“Response header”,之后会在面板下的Response heade分类多了一项,输入要增加的请求头的key 和value 即可。
设置Filter过滤
- 点击+号后弹出菜单选择“Filter”,在Filter分类会多一项规则,如图所示,增加了一项“://.ip138.*”,也就是说设定了该设置只对ip138网站起作用,设定规则格式比较灵活,如果不设定,则所有网站请求都会有效。
示例
# !/usr/bin/env python
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2021 *.com, Inc. All Rights Reserved
# **************************************************************************
# * @file main.py FAQ推荐服务
# * @author ****
# * @date 2021/11/06 10:44
# **************************************************************************
from flask import Flask, request, render_template, make_response, g
from flasgger import Swagger
from functools import wraps # 装饰器工具,用于时间统计
import logging # 日志模块
import os
import json
import time
# flask服务
app = Flask(__name__)
main_dir = '..'
log_path = '{}/logs/recommend/'.format(main_dir)
# -------- log -------------
if not os.path.exists(log_path):
# 目录不存在,进行创建操作
os.makedirs(log_path)
# logging.basicConfig函数对日志的输出格式及方式做相关配置
# 第一步,创建一个logger
logger = logging.getLogger()
logger.setLevel(logging.INFO) # Log等级总开关
# 第二步,创建一个handler,用于写入日志文件
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
log_name = log_path + rq + '.log'
logfile = log_name
fh = logging.FileHandler(logfile, mode='w')
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
# 第三步,定义handler的输出格式
formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
# 第四步,将logger添加到handler里面
logger.addHandler(fh)
# --------- 启动服务 ----------
project_name = 'aionsite_newhouse' # aionsite_newhouse,contract_center,isc_ssc,homespeech_smarthome
# 配置文件主目录
conf_dir = 'infrastructure/engines/legacy'
# swagger api
Swagger(app)
@app.route('/', methods=['GET', 'POST'])
def home():
# 服务主页
res = {"msg":"-", "status":0, "req":{} , "resp":{}}
req_data = {}
if request.method == 'GET':
req_data = request.values # 表单形式
elif request.method == 'POST':
req_data = request.json # json形式
else:
res['msg'] = '异常请求(非GET/POST)'
res['status'] = -1
res['req'] = req_data
res['msg'] = "服务主页"
return render_template("index.html")
@app.route('/recommend', methods=['GET', 'POST'])
def recommend():
"""
新房驻场客服问题推荐请求接口
2021-11-5
---
tags:
- NLU服务接口
parameters:
- name: product
in: path
type: string
required: true
description: newhouse (新房电子驻场客服)
- name: project_id
in: path
type: string
required: true
description: 楼盘id
- name: city_name
in: path
type: string
required: True
description: 城市名
- name: position
in: path
type: string
required: false
description: 展示位置, detail(盘源详情页)、pop(弹窗页)
- name: raw_text
in: path
type: string
required: false
description: 检索词(暂时不用)
responses:
500:
description: 自定义服务端错误
200:
description: 自定义状态描述
"""
# 各业务线接口, product字段区分,status >= 0合法,1截取topn,2补足topn
res = {"message":"-", "errno":0, "data":{}}
req_data = {}
if request.method == 'GET':
req_data = request.values # 表单形式
elif request.method == 'POST':
req_data = request.json # json形式
else:
res['message'] = '异常请求(非GET/POST)'
res['errno'] = -1
req_dict = {}
# 参数处理
for k in ['product', 'project_id', 'city_name', 'position']:
req_dict[k] = req_data.get(k, "-")
# 保存请求信息
#res['req'].update(req_data)
if req_dict['product'] != 'newhouse':
res.update({"errno": -2, "message":"product取值无效"})
return res
if req_dict['position'] not in ('detail', 'pop'):
res.update({"errno": -3, "message":"position缺失/取值无效"})
return res
# 处理请求信息
res['data'] = {
"project_id": 671289,
"project_name": "天朗·富春原颂",
"pv": 230, # 楼盘累计请求数(包含点击、文字、语音所有触发请求的行为)
"percent": 0.02, # 累计累计请求数占比
"question_num": 9, # 累计点击问题数
"click_num": 24, # 累计点击次数,含:更多问题
"question_list":
[ # 字段说明:问题id,点击次数,点击占比(分母限该楼盘),楼盘名
{"pos": 1, "question_id": 8, "click_num": 5, "click_percent": 26.316, "question_name": "项目基本信息"},
{"pos": 2, "question_id": 1, "click_num": 5, "click_percent": 26.316, "question_name": "售楼处地址及接待信息"},
{"pos": 3, "question_id": 2, "click_num": 3, "click_percent": 15.789, "question_name": "在售户型信息?"},
{"pos": 4, "question_id": 6, "click_num": 2, "click_percent": 10.526, "question_name": "此项目激励政策是什么?"},
{"pos": 5, "question_id": 13, "click_num": 1, "click_percent": 5.263, "question_name": "带看规则及注意事项是什么?"},
{"pos": 6, "question_id": 10, "click_num": 1, "click_percent": 5.263, "question_name": "物业信息"},
{"pos": 7, "question_id": 4, "click_num": 1, "click_percent": 5.263, "question_name": "当前有哪些开发商优惠?"},
{"pos": 8, "question_id": 3, "click_num": 1, "click_percent": 5.263, "question_name": "在售楼栋信息?"}
],
}
res['errno'] = 0
res['message'] = '请求正常'
# 后处理:①空值 ②不足5-6个 ③超纲
# 默认配置信息: detail页(详情页: 8,2,1,28,3,6),pop页(弹窗页: 8,2,1,3,6)
default_info = {}
# 弹窗页默认答案
default_info['pop'] = [
{"pos": 1, "question_id": 8, "click_num": 0, "click_percent": 0.0, "question_name": "项目基本信息"},
{"pos": 2, "question_id": 2, "click_num": 0, "click_percent": 0.0, "question_name": "在售户型信息?"},
{"pos": 3, "question_id": 1, "click_num": 0, "click_percent": 0.0, "question_name": "售楼处地址及接待信息"},
{"pos": 4, "question_id": 3, "click_num": 0, "click_percent": 0.0, "question_name": "在售楼栋信息?"},
{"pos": 5, "question_id": 6, "click_num": 0, "click_percent": 0.0, "question_name": "此项目激励政策是什么?"}
]
# 详情页默认答案
default_info['detail'] = [
{"pos": 1, "question_id": 8, "click_num": 0, "click_percent": 0.0, "question_name": "项目基本信息"},
{"pos": 2, "question_id": 2, "click_num": 0, "click_percent": 0.0, "question_name": "在售户型信息?"},
{"pos": 3, "question_id": 1, "click_num": 0, "click_percent": 0.0, "question_name": "售楼处地址及接待信息"},
{"pos": 4, "question_id": 28, "click_num": 0, "click_percent": 0.0, "question_name": "项目笔记"},
{"pos": 5, "question_id": 3, "click_num": 0, "click_percent": 0.0, "question_name": "在售楼栋信息?"},
{"pos": 6, "question_id": 6, "click_num": 0, "click_percent": 0.0, "question_name": "此项目激励政策是什么?"}
]
top_num = len(default_info[req_dict['position']])
diff_num = res['data']['question_num'] - top_num
diff_num = -2
if diff_num > 0:
res['data']['question_list'] = res['data']['question_list'][:top_num]
res['errno'] = 1
res['message'] = '截取TopN'
elif diff_num == 0:
pass
else: # 补默认值
id_list = [i["question_id"] for i in res['data']['question_list']]
cnt = 0
for i in default_info[req_dict['position']]:
if cnt + diff_num >= 0:
break
if i["question_id"] in id_list:
continue
i["pos"] = res['data']['question_list'][-1]['pos'] + 1
res['data']['question_list'].append(i)
cnt += 1
res['errno'] = 2
res['message'] = '补足topN'
logger.info(json.dumps(res, ensure_ascii=False))
return res
if __name__ == '__main__':
#app.run(host='0.0.0.0', port=8089)
app.run(host='10.200.24.101', port=8092)
#app.run(host='10.200.24.101', port=8092)
微服务
【2022-11-15】“微服务”真是言过其实,带给全社会巨量的人力物力财力的浪费!
- 马斯克也发话了:“今天的部分工作将是关闭 “微服务 “臃肿的软件。实际上,只有不到20%的人需要Twitter来工作。”
现在已是“后微服务”时代,已经全面进入对微服务反思的阶段。
- 知名的Spring框架也对微服务进行了反思,推出了“Spring Modulith”。它告诉我们一个良好的应用是从构建优秀的“模块化单体”应用开始的。 Spring Modulith地址:网页链接
自动生成APIs文档
- 【2022-1-26】国产apidoc, github, 创业公司,在沙河碧水庄园别墅办公,月薪高达10w
- 【2020-8-22】自动为Flask写的API生成帮助文档
- 使用swagger 生成 Flask RESTful API
- Flask 系列之 构建 Swagger UI 风格的 WebAPI, 基于 Flask 而创建 Swagger UI 风格的 WebAPI 包有很多,如
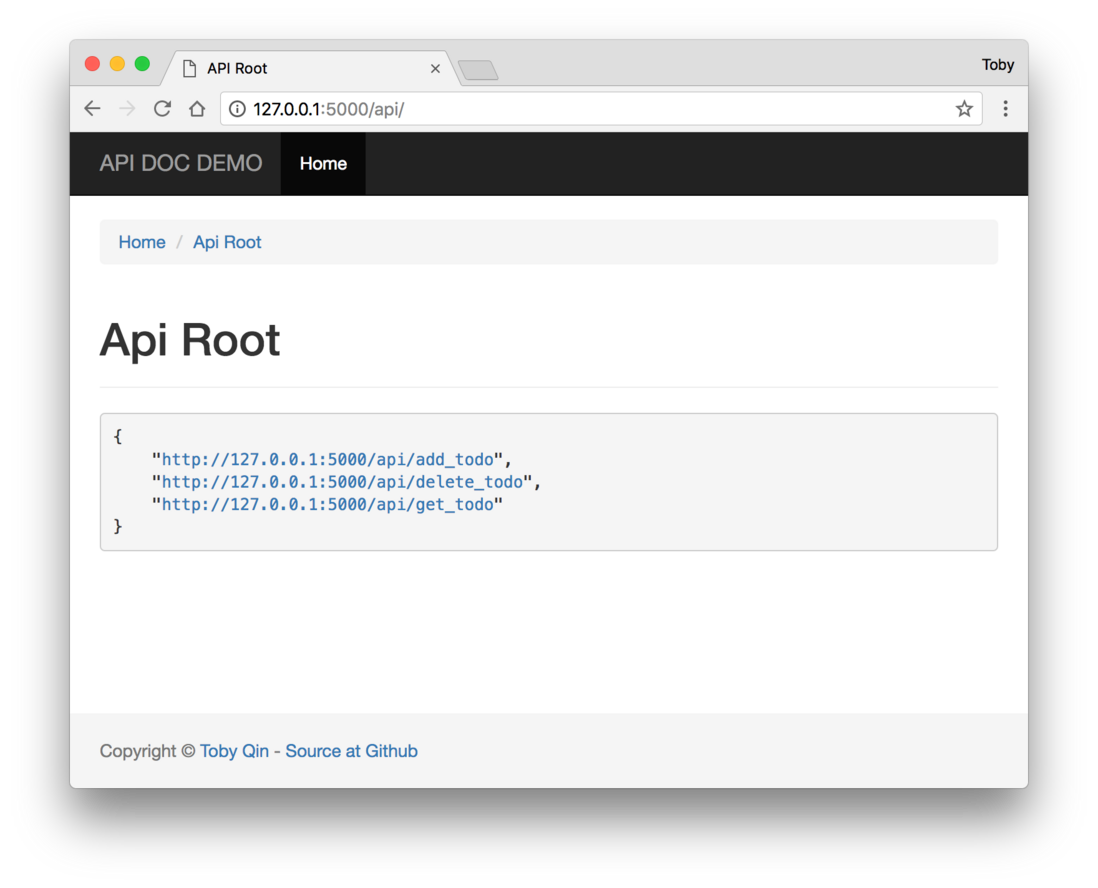

swagger
Swagger UI是一款Restful接口的文档在线自动生成+功能测试功能软件;通过swagger能够清晰、便捷地调试符合Restful规范的API;
flasgger
flasgger:Swagger Python工具包
flasgger 配置文件解析:
- 在flasgger的配置文件中,以yaml格式描述了flasgger页面的内容;
- tags标签中可以放置对这个api的描述和说明;
- parameters标签中可以放置这个api所需的参数
- 如果是GET方法,放置url中附带的请求参数
- 如果是POST方法,将参数放置在body参数 schema子标签下面;
- responses标签中可以放置返回的信息,以状态码的形式分别列出,每个状态码下可以用schema标签放置返回实体的格式;
【2020-8-26】页面测试功能(try it out)对GET/POST无效,传参失败
- 已提交issue:Failed to get parameters by POST method in “try it out” feature
- 【2021-7-19】参考帖子Parameter in body does not work in pydoc #461,正确的使用方法:parameter 针对url path里的参数,如果启用post需要新增body参数,里面注明post参数信息
安装:
- flask_restplus实践失败,个别依赖不满足,放弃
- pip install flasgger
示例
- 注意:yaml描述中需要加 response区(定义200),否则Web测试时无法正常显示
# coding:utf8
# **************************************************************************
# *
# * Copyright (c) 2020, Inc. All Rights Reserved
# *
# **************************************************************************
# * @file main.py
# * @author wangqiwen
# * @date 2020/08/22 08:32
# **************************************************************************
from flask import Flask, request, render_template, jsonify, request, redirect
#from flask_restplus import Api
from flasgger import Swagger, swag_from
app = Flask(__name__)
# 此处是为了让post 方法生效
app.config['SWAGGER'] = {
'title': 'api demo 展示',
'uiversion': 3,
'openapi': '3.0.3',
'persistAuthorization': True,
}
# swagger api封装,每个接口的注释文档中按照yaml格式排版
Swagger(app)
@app.route('/api/<arg>')
#@app.route("/index",methods=["GET","POST"])
#@app.route("/index/<int,>")
def hello_world():
"""
API说明
副标题(点击才能显示)
---
tags:
- 自动生成示例
parameters:
- name: arg # path参数区
in: path # (1)字段形式,输入框
type: string
enum: ['all', 'rgb', 'cmyk'] # 枚举类型
required: false
description: 变量含义(如取值 all/rgb/cmyk)
schema: # 设置默认值,如detail (可省略)
type: string
example: rgb
- name: body # post 参数区(与get冲突, GET方法下去掉body类型!)
in: body # (2)body形式,文本框格式
required: true
schema: # 以下参数不管用
id: 用户注册
required:
- username
- password
properties:
username:
type: string
description: 用户名.
password:
type: string
description: 密码.
inn_name:
type: string
description: 客栈名称.
requestBody: # POST 测试时,parameters 不管用,点击“try it out”后直接输入 json串即可
content:
application/json:
schema:
id: parameters
responses:
500:
description: 自定义服务端错误
200:
description: 自定义状态描述
schema:
id: awesome
properties:
language:
type: string
description: The language name
default: Lua
"""
res = {"code":0, "msg":'-', "data":{}}
if request.method == 'GET':
req_data = request.values # 表单形式
elif request.method == 'POST':
req_data = request.json # json形式
else:
res['msg'] = '异常请求(非GET/POST)'
res['status'] = -1
# return jsonify(result) # 方法①
# return json.dumps(res, ensure_ascii=False) # 方法②
return render_template('index.html')
@app.route('/', methods=['GET', 'POST'])
def home():
# 服务主页
res = {"msg":"-", "status":0, "request":{} , "response":{}}
req_data = {}
if request.method == 'GET':
req_data = request.values # 表单形式
elif request.method == 'POST':
req_data = request.json # json形式
else:
res['msg'] = '异常请求(非GET/POST)'
res['status'] = -1
res['request'] = req_data
res['msg'] = "服务主页"
return redirect("apidocs")
@app.route('/api', methods=['GET', 'POST'])
def api():
"""
OpenAI 请求接口
调用llm服务
---
tags:
- 大模型服务接口
parameters:
- name: system
in: path
type: string
required: false
description: 系统角色提示,用于设计LLM对应角色
- name: question
in: path
type: string
required: false
description: 用户问题
requestBody:
content:
application/json:
schema:
name: system
responses:
500:
description: 自定义服务端错误
200:
description: 自定义状态描述
"""
# 各业务线接口, product字段区分
res = {"msg":"-", "status":0, "request":{} , "response":{}}
req_data = {}
if request.method == 'GET':
req_data = request.values # 表单形式
elif request.method == 'POST':
req_data = request.json # json形式
else:
res['msg'] = '异常请求(非GET/POST)'
res['status'] = -1
# 字段解析,待补充
# 业务线接口
product = req_data.get("product", "-")
# 接口参数
raw_text = req_data.get("raw_text", "-")
session = req_data.get("session", "{}")
res['request'].update(req_data)
res["response"].update({"openai":"返回结果测试..."})
#return null # 【2022-1-27】swagger上回报错!返回非空才行,如json或字典格式
return res
if __name__ == '__main__':
#app.run()
#app.run(debug=True)
app.run(debug=True, host='10.26.15.30', port='8044')
# */* vim: set expandtab ts=4 sw=4 sts=4 tw=400: */
只要将yaml格式的flasgger描述性程序放置在两组双引号之间的位置,即可实现flasgger的基本功能
flasgger配置文件解析:
- 在flasgger的配置文件中,以yaml的格式描述了flasgger页面的内容;
- tags 标签中可以放置对这个api的描述和说明;
- parameters 标签中可以放置这个api所需的参数,如果是GET方法,可以放置url中附带的请求参数,如果是POST方法,可以将参数放置在 schema 子标签下面;
- responses 标签中可以放置返回的信息,以状态码的形式分别列出,每个状态码下可以用schema标签放置返回实体的格式;
注意
- 以上yaml描述文本可以单独放在文件中,api用@符号引入,示例:
import random
from flask import Flask, jsonify, request
from flasgger import Swagger
from flasgger.utils import swag_from
app = Flask(__name__)
Swagger(app)
@app.route('/api/<string:language>/', methods=['GET'])
@swag_from('index.yml') # 引用yaml描述文档
def index(language):
language = language.lower().strip()
features = [
"awesome", "great", "dynamic",
"simple", "powerful", "amazing",
"perfect", "beauty", "lovely"
]
size = int(request.args.get('size', 1))
if language in ['php', 'vb', 'visualbasic', 'actionscript']:
return "An error occurred, invalid language for awesomeness", 500
return jsonify(
language=language,
features=random.sample(features, size)
)
app.run(debug=True)
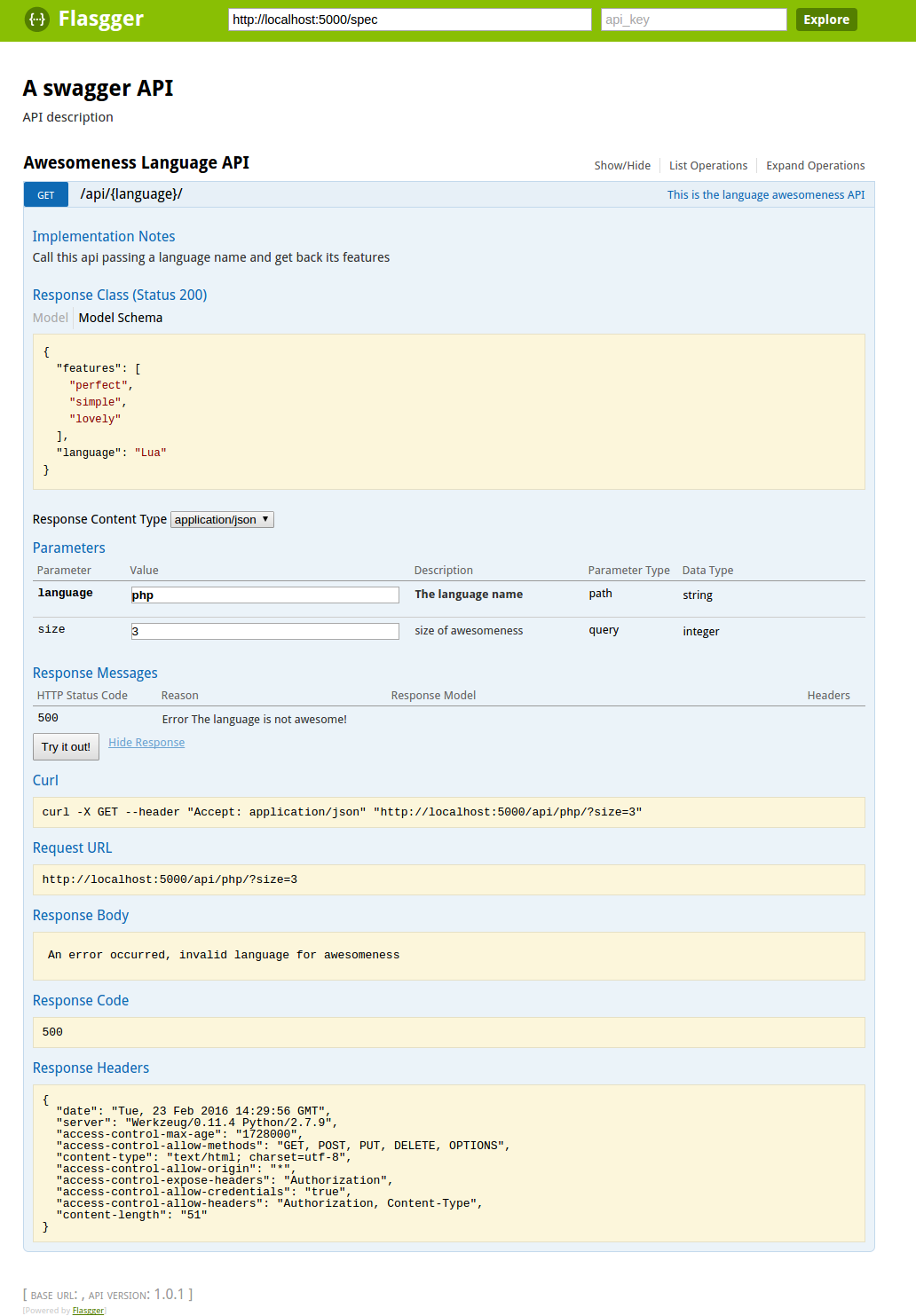
flasgger的不足
- flasgger的配置文件中,对于POST方法,在描述POST body的 schema 标签中,不支持以yaml格式描述的数组或嵌套的object,这使得页面上面无法显示这类POST body的example;
- 解决方案:将这类POST body的example放置在 description 部分(三横杠”—“上面的部分),由于 description 部分是用html格式解析的,所以可以以html的语法编写;
API 性能指标
【2022-7-25】一文详解吞吐量、QPS、TPS、并发数等高并发大流量指标
阿里双11高并发场景经常提到QPS、TPS、RT、吞吐量等指标,这些高并发高性能指标都是什么含义?如何来计算?
系统吞吐量
系统吞吐量指的是系统在单位时间内可处理的事务的数量,是用于衡量系统性能的重要指标。
例如在网络领域,某网络的系统吞吐量指的是单位时间内通过该网络成功传递的消息包数量。
举一个生活中的例子,一说就懂,比如:成都双流国际机场年旅客吞吐量达4011.7万人次,这里的系统单位时间就是年,完成的数量这里就是飞行人数。
上面谈到的是机场的吞吐量,而系统吞吐量指的是系统(比如服务器)在单位时间内可处理的事务的数量,是一个评估系统承受力的重要指标。
系统吞吐量有几个重要指标参数:
- QPS
- TPS
- 响应时间
- 并发数
QPS 每秒查询量
QPS(Queries Per Second):大家最熟知的就是QPS,这里我就不多说了,简要意思就是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS 每秒处理量
TPS(Transactions Per Second):意思是每秒钟系统能够处理的交易或事务的数量,它是衡量系统处理能力的重要指标。
具体事务的定义都是人为的,可以一个接口、多个接口、一个业务流程等等。
举一个例子,比如在web性能测试中,一个事务是指事务内第一个请求发送到接收到最后一个请求的响应的过程,以此来计算使用的时间和完成的事务个数。
以单接口定义为事务为例,每个事务包括了如下3个过程:
- a. 向服务器发请求
- b. 服务器自己的内部处理(包含应用服务器、数据库服务器等)
- c. 服务器返回结果给客户端。
总结,在web性能测试中一个事务表示“从用户发送请求->web server接受到请求,进行处理-> web server向DB获取数据->生成用户的object(页面),返回给用户”的过程。
怎么计算TPS的呢?
- 举一个最简单的例子,如果每秒能够完成100次上面这三个过程,那TPS就是100。
- 一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。
比如大家熟知的阿里双11,一秒峰值完成58.3万笔订单,这样就量化了系统处理高并发的重要指标。
QPS与TPS的区别
- 上面分别谈完了QPS与TPS,我们再来看看两者有什么区别呢?
- 假如对于一个页面的一次访问算一个TPS,但一次页面请求,可能产生N次对服务器的请求,服务器对这些请求,就可计入QPS之中,即QPS=N*TPS。
又假如对一个查询接口(单场景)压测,且这个接口内部不会再去请求其它接口,那么TPS=QPS。
RT响应时间
RT(Response-time)响应时间:执行一个请求从开始到最后收到响应数据所花费的总体时间,即从客户端发起请求到收到服务器响应结果的时间。
该请求可以是任何东西,从内存获取,磁盘IO,复杂的数据库查询或加载完整的网页。
暂时忽略传输时间,响应时间是处理时间和等待时间的总和,处理时间是完成请求要求的工作所需的时间,等待时间是请求在被处理之前必须在队列中等待的时间。
响应时间是一个系统最重要的指标之一,它的数值大小直接反应了系统的快慢。
并发数Concurrency 一文详解吞吐量、QPS、TPS、并发数等高并发大流量指标 并发数是指系统同时能处理的请求数量,这个也反应了系统的负载能力。
并发,指的是多个事情,在同一段时间段内发生了,大家都在争夺统一资源。
比如:当有多个线程在操作时,如果系统只有一个 CPU,则它根本不可能真正同时进行一个以上的线程,它只能把 CPU 运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状态,这种方式我们称之为并发(Concurrent)。
【2022-8-5】性能之巅-优化你的程序
- outline:关注&指标&度量,基础理论知识,工具&方法,最佳实践,参考资料
性能优化关注:CPU、内存、磁盘IO、网络IO等四个方面
- CPU:
- 处理器、核心
- 超线程、多线程
- 协程
- 调度、上下文切换
- 内存
- 虚拟内存、地址空间
- 分页、换页
- 总线
- 分配器、对象池
- 磁盘IO
- 缓存
- 控制器
- 交换分区
- 磁盘文件映射
- 网络IO
- 套接字、连接
- 网卡和中断、
- 协议、tcp/udp
- select/epoll
性能指标:经常关注的指标
- 吞吐率
- 吞吐量(throughtput):评价工作执行的速率,每秒操作量
- 响应时间(RT)、延迟(latency)
- 一次操作完成的时间,包括等待+服务时间,也包括返回结果,req-resp延时,延迟跟吞吐量相关联,吞吐量增大,延迟会升高
- QPS/IOPS
- 并发数:同时能处理的连接数
- QPS:每秒查询数
- IOPS:每秒i/o操作量
- TP99
- 响应时间的分布,通常关心的是top 90
- 资源使用率
- 资源使用比例,繁忙程度;CPU、存储和网络贷款 时间度量:从cpu cycle到网络IO,自上到下,时间量级越大。
- 网络i/o:内网(几ms),公网(几时ms)
- 磁盘i/o:1-10ms
- 固态硬盘i/o(山村):50-150us
- CPU访问主存DRAM:100ns
- L1-L3 Cache:1-20ns
- CPU cycle:0.2-0.3 ns
注:
- 1s = 10^3 ms(毫秒) = 10^6 us(微秒) = 10^9 ns(纳秒) = 10^10 ps(皮秒)
性能分析工具
p99
【2024-2-21】
- p50:数据集按升序排列,第50分位置大的数据(即升序排列后排在50%位置的数据)
- p90:数据集按升序排列,第90分位置大的数据(即升序排列后排在90%位置的数据)
- p99:数据集按升序排列,第99分位置大的数据(即升序排列后排在99%位置的数据
服务限流
四大限流算法的特点,优劣势对比,适用场景
-
【2023-11-1】资讯
- 一、固定窗口算法(Fixed Window Algorithm):
- 【特点】:固定窗口算法将时间划分为连续的固定窗口,每个窗口内维护一个请求计数器,如果当前窗口内的请求数量超过限制,则拒绝后续请求。
- 【优势】:简单,容易理解和实现。
- 【劣势】:无法应对突发流量,可能导致不均匀的流量分布。
- 【适用场景】:适用于对请求数量有严格限制的场景,特别是具有固定的时间要求,如每秒最多允许多少请求的场景。
- 【如何实现】:结合时间戳 + redis.incr 原子计算器
- 二、滑动窗口计数器(Sliding Window Counter):
- 【特点】:不同于固定窗口算法,滑动窗口算法维护一个可滑动的时间窗口,通常包含多个子窗口,以更灵活地适应不同的流量模式。每个子窗口内都维护一个 计- 数器,限制请求不仅受当前窗口,还受前几个窗口的总请求数量。
- 【优点】:能够应对不同的流量模式,适用于限制请求数量和处理突发流量。
- 【缺点】:需要更复杂的实现。
- 【适用场景】:适用于需要简单限流的场景,如短时间内的请求数限制。
- 三、令牌桶算法(Token Bucket Algorithm):
- 【特点】:该算法使用一个令牌桶,定期往桶中放入一定数量的令牌。请求需要消耗令牌,当桶中没有足够的令牌时,请求被拒绝。
- 【优点】:可以处理突发流量,令牌的速率可动态调整。
- 【缺点】:突发流量处理不足,不适合无法预测的流量,精确性受时间粒度限制,令牌桶维护成本
- 【适用场景】:适用于需要平滑限制请求速率的场景,例如网络请求限流。
- 四、漏桶算法(Leaky Bucket Algorithm):
- 【特点】:该算法使用一个固定容量的漏桶,请求进入漏桶,以固定速率从漏桶中流出。如果漏桶满了,请求将被拒绝。
- 【优点】:稳定的速率控制,平滑处理流量。
- 【缺点】:不精确度受容量和速率限制的影响,难以动态调整参数。
- 【适用场景】:适用于需要固定速率控制请求的场景,如请求日志写入。
区别:
1、固定窗口和滑动窗口的区别:
- 【时间窗口的定义】:
- a、固定窗口:时间被划分为连续的、固定大小的时间窗口,例如,每个窗口持续一秒或一分钟。每个时间窗口内有一个请求限制。
- b、滑动窗口:时间窗口可以滑动,通常包括多个子窗口,每个子窗口都有自己的请求限制。滑动窗口不要求时间窗口大小固定,可以更灵活地适应不同的流量模式。
【计数器维护】:
- a、固定窗口:在每个时间窗口内,维护一个计数器来记录请求的数量。请求数量限制仅在当前时间窗口内生效。
- b、滑动窗口:在每个子窗口内都维护一个计数器,每个子窗口都有独立的请求限制。请求数量限制受限于当前子窗口以及前几个子窗口的总请求数量。
【适应性】:
- a、固定窗口:固定窗口算法在限流时可能会导致不均匀的流量分布,因为请求被限制在每个时间窗口内,而在时间窗口之间可能会有不受限的流量。
- b、滑动窗口:滑动窗口算法更适应动态流量模式,可以根据历史请求情况来限制请求数量,更平滑地控制请求速率。
【复杂性】:
- a、固定窗口:算法相对简单,容易实现。
- b、滑动窗口:相对于固定窗口算法,实现滑动窗口算法通常更复杂,因为需要维护多个子窗口的状态。
2、令牌和漏桶的区别:
a、令牌桶算法关注的是维护一个固定速率的令牌产生和消耗,以平滑控制请求速率,确保请求以匀速处理。如果请求到达速率超过了令牌生成速率,请求将排队等待令牌。
b、漏桶算法关注的是按照恒定速率处理请求,即使请求到达速率不稳定,漏桶以固定速率处理请求,并将多余的请求丢弃。
SDK
SDK是什么
- SDK全称software development kit,软件开发工具包。第三方服务商提供的实现产品软件某项功能的工具包
-
一般都是一些软件工程师为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件时的开发工具的集合。
- API是一个函数,有其特定的功能;而SDK是一个很多功能函数的集合体,一个工具包。
- API是数据接口,SDK相当于开发集成工具环境,要在SDK的环境下来调用API。
- API接口对接过程中需要的环境需要自己提供,SDK不仅提供开发环境,还提供很多API。
- 简单功能调用,API调用方便快捷;复杂功能调用,SDK功能齐全。
RPC
资料
- 【2020-12-25】为啥需要RPC,而不是简单的HTTP?
- 【2021-11-24】1万行代码,单机50万QPS,今年最值得学习的开源RPC框架!
企业开发的模式一直定性为HTTP接口开发,即常说的 RESTful 风格的服务接口。对于接口不多、系统与系统交互较少的情况下,解决信息孤岛初期常使用的一种通信手段;
- 优点:简单、直接、开发方便。利用现成的http协议进行传输。要写一大份接口文档,严格地标明输入输出是什么,说清楚每一个接口的请求方法,以及请求参数需要注意的事项等。
- 但是对于大型企业来说,内部子系统较多、接口非常多的情况下,RPC框架的好处就显示出来了
- 首先,长链接,不必每次通信都要像http一样去3次握手什么的,减少了网络开销;
- 其次,RPC框架一般都有注册中心,有丰富的监控管理;
- 发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
什么是RPC
| 调用类型 | 过程 | 代码 | 示意图 | 备注 |
| — | — | — | –—— | — |
| 本地函数调用 | 传参→本地函数代码→执行→返回结果 | int result = Add(1, 2); |  |
所有动作发生同一个进程空间 |
| 远程过程调用 | 传参→远程调用→远程执行→返回结果 | int result = Add(1, 2);(socket通信) |  |
跨进程、跨服务器 |
RPC是什么
- 单机时代,一台电脑中跑多个进程,各个进程互不干扰,如果A进程需要实现一个功能,恰好B进程已经有了这个功能,于是A进程调B进程的该功能,于是出现了
IPC(Inter-process communication,进程间通信)。 - 互联网时代,多个电脑互联互通,一台电脑实现的功能,另一台电脑也需要就进行调用,相当于扩展了
IPC,成为RPC(remote process communication 远程过程调用)
RPC 是一台电脑进程调用另一台电脑进程的工具。
- 成熟的
RPC方案大多数会具备服务注册、服务发现、熔断降级和限流等机制。
RPC传输协议
- RPC 协议可以是 json、xml、http2,成熟的 RPC 框架一般都会定制自己的协议以满足各种需求,比如 thrift 的 TBinaryProtocal、TCompactProtocol
目前市面上的RPC已经有很多成熟的了
- Facebook家的
Thrift、Google家的gRPC、阿里家的Dubbo和蚂蚁家的SOFA。
RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务
- 本地过程调用:如果需要将本地student对象的age+1,可以实现一个addAge()方法,将student对象传入,对年龄进行更新之后返回即可,本地方法调用的函数体通过函数指针来指定。
- 远程过程调用:上述操作的过程中,如果addAge()这个方法在服务端,执行函数的函数体在远程机器上,如何告诉机器需要调用这个方法呢?
- 1.首先客户端需要告诉服务器,需要调用的函数,这里函数和进程ID存在一个映射,客户端远程调用时,需要查一下函数,找到对应的ID,然后执行函数的代码。
- 2.客户端需要把本地参数传给远程函数,本地调用的过程中,直接压栈即可,但是在远程调用过程中不再同一个内存里,无法直接传递函数的参数,因此需要客户端把参数转换成字节流,传给服务端,然后服务端将字节流转换成自身能读取的格式,是一个序列化和反序列化的过程。
- 3.数据准备好了之后,如何进行传输?网络传输层需要把调用的ID和序列化后的参数传给服务端,然后把计算好的结果序列化传给客户端,因此TCP层即可完成上述过程,gRPC中采用的是HTTP2协议。
总结
- Client端 :Student student = Call(ServerAddr, addAge, student)
-
- 将这个调用映射为Call ID。
-
- 将Call ID,student(params)序列化,以二进制形式打包
-
- 把2中得到的数据包发送给ServerAddr,这需要使用网络传输层
-
- 等待服务器返回结果
-
- 如果服务器调用成功,那么就将结果反序列化,并赋给student,年龄更新
-
- Server端
-
- 在本地维护一个Call ID到函数指针的映射call_id_map,可以用Map<String, Method> callIdMap
-
- 等待服务端请求
-
- 得到一个请求后,将其数据包反序列化,得到Call ID
-
- 通过在callIdMap中查找,得到相应的函数指针
-
- 将student(params)反序列化后,在本地调用addAge()函数,得到结果
-
- 将student结果序列化后通过网络返回给Client
-
- 图示
- 微服务的设计中,一个服务A如果访问另一个Module下的服务B,可以采用HTTP REST传输数据,并在两个服务之间进行序列化和反序列化操作,服务B把执行结果返回过来。
- 由于HTTP在应用层中完成,整个通信的代价较高,远程过程调用中直接基于TCP进行远程调用,数据传输在传输层TCP层完成,更适合对效率要求比较高的场景,RPC主要依赖于客户端和服务端之间建立Socket链接进行,底层实现比REST更复杂。


RPC框架
为什么需要RPC框架呢?
如果没有统一的RPC框架,各个团队的服务提供方就需要各自实现一套序列化、反序列化、网络框架、连接池、收发线程、超时处理、状态机等“业务之外”的重复技术劳动,造成整体的低效。
RPC框架的职责,就是要屏蔽各种复杂性:
- (1)调用方client感觉就像调用本地函数一样,来调用服务;
- (2)提供方server感觉就像实现一个本地函数一样,来实现服务;
什么时候需要RPC
- RPC通信方式,已经不仅仅是远程,这个远程就是指不在一个进程内,只能通过其他协议来完成,通常都是TCP或者是Http。
- 希望是和在同一个进程里,一致的体验
- http做不到,Http(TCP)本身的三次握手协议,就会带来大概1MS的延迟。每发送一次请求,都会有一次建立连接的过程,加上Http报文本身的庞大,以及Json的庞大,都需要作一些优化。
- 一般的场景下,没什么问题,但是对于Google这种级别的公司,他们接受不了。几MS的延迟可能就导致多出来几万台服务器,所以他们想尽办法去优化,优化从哪方面入手?
- 1.减少传输量。
- 2.简化协议。
- 3.用长连接,不再每一个请求都重新走三次握手流程
- Http的协议就注定了,在高性能要求的下,不适合用做线上分布式服务之间互相使用的通信协议。
- RPC服务主要是针对大型企业的,而HTTP服务主要是针对小企业的,因为RPC效率更高,而HTTP服务开发迭代会更快。
RPC基本组件
一个完整的RPC架构里面包含了四个核心的组件,分别是Client ,Server,Client Stub以及Server Stub,这个Stub大家可以理解为存根。分别说说这几个组件:
- 客户端(Client),服务的调用方。
- 服务端(Server),真正的服务提供者。
- 客户端存根,存放服务端的地址消息,再将客户端的请求参数打包成网络消息,然后通过网络远程发送给服务方。
- 服务端存根,接收客户端发送过来的消息,将消息解包,并调用本地的方法。
常见RPC框架
有哪些常见的,出圈的RPC框架呢?
- (1)gRPC,Google出品,支持多语言;
- (2)Thrift,Facebook出品,支持多语言;
- (3)Dubbo,阿里开源的,支持Java;
- (4)bRPC,百度开源的,支持C++,Java;
- (5)tRPC,腾讯RPC框架,支持多语言;
- (6)srpc,作者是搜狗的媛架构师liyingxin,基于WF,代码量1W左右:
- ① 非常适合用来学习RPC的架构设计;
- ② 又是一个工业级的产品,QPS可以到50W,应该是行业能目前性能最好的RPC框架了吧,有不少超高并发的线上应用都使用它。
- (7)。。。
Protobuf
protobuf 复杂场景使用,包含多层结构体嵌套,repeated等成员参数情况
定义实例
- (1)TKeyID结构体为TChargeYx结构体的必须的结构体成员。
- (2)TChangeYxPkg结构体包含一个必须成员TPkgHead结构体成员,一个重复的结构体成员TChargeYx。
- (3)相当于有三层结构体嵌套,且有重复结果体实现。
data_struct.pb.h
message TKeyID
{
required string sg_id = 1; //设备对象编码
required string sg_column_id = 2; //
};
message TPkgHead
{
required int32 package_type = 1; //消息类型:
required int32 data_num = 2; //数据个数
required int64 second = 3; //时间,1970开始秒
required int32 msecond = 4; //时间,毫秒部分
required int32 data_source = 5; //数据源标识
};
message TChangeYx
{
required TKeyID keyid = 1; //ID
required int64 yx_id = 2; //DID
required int32 value = 3; //值
required int32 status = 4; //质量码
required int64 second = 5; //数据时间,1970开始秒
required int32 msecond = 6; //数据时间,毫秒部分
};
message TChangeYxPkg //
{
required TPkgHead package_head = 1;
repeated TChangeYx yx_seq = 2;
};
c/c++ 引入 protobuf 文件
#include <iostream>
#include <fstream>
#include <string>
#include "data_struct.pb.h"
using namespace std;
int main(int argc, char* argv[]) {
while(true)
{
string tmp_str;
TKeyID *KeyId = new TKeyID();;//预留结构体,是yxyc的成员
TChangeYxPkg *Yxpkg = new TChangeYxPkg();
TPkgHead *PkgHead;//存放消息头
KeyId->set_sg_id("0");
KeyId->set_sg_column_id("1");
for (int i = 0; i < 6; i++)
{
TChangeYx* tmpchangeYx = Yxpkg->add_yx_seq();
tmpchangeYx->set_allocated_keyid(KeyId);
int64_t pnt_id = 11111+ i;
int fvalue = 10000+i*2;
int q= 1;
int64_t iCurrtSoc = time(NULL);
int iCurrtMs = 20 * i;
tmpchangeYx->set_yx_id(pnt_id);
tmpchangeYx->set_value(fvalue);
tmpchangeYx->set_status(q);
tmpchangeYx->set_second(iCurrtSoc);
tmpchangeYx->set_msecond(iCurrtMs);
}
PkgHead = new TPkgHead();
int64_t iCurrtSoc = time(NULL);
int iCurrtMs = 20 ;
PkgHead->set_package_type(1000);//变化
PkgHead->set_data_num(6);
PkgHead->set_second(iCurrtSoc);
PkgHead->set_msecond(iCurrtMs);
PkgHead->set_data_source(1);
Yxpkg->set_allocated_package_head(PkgHead);
// 调⽤序列化⽅法,将序列化后的⼆进制序列存⼊string
if (!Yxpkg->SerializeToString(&tmp_str))
cout << "序列化失败." << endl;
TChangeYxPkg YxpkgTwo;
// 调⽤反序列化⽅法,读取string中存放的⼆进制序列,并反序列化出对象
if (!YxpkgTwo.ParseFromString(tmp_str))
cout << "反序列化失败." << endl;
printf("%d-%d-%ld-%d-%d\n",YxpkgTwo.package_head().package_type(),YxpkgTwo.package_head().data_num(),YxpkgTwo.package_head().second(),YxpkgTwo.package_head().msecond(),YxpkgTwo.package_head().data_source());
int iCount = YxpkgTwo.yx_seq_size();
for (int i = 0; i < iCount; i++)
{
printf("%ld-",YxpkgTwo.yx_seq(i).yx_id());
printf("%d-%d-%ld-%d\n",YxpkgTwo.yx_seq(i).value(),YxpkgTwo.yx_seq(i).status(),YxpkgTwo.yx_seq(i).second(),YxpkgTwo.yx_seq(i).msecond());
}
printf("finish\n");
sleep(5);
}
return 0;
}
Thrift —— RPC框架
【2020-12-26】thrift是Facebook开源的一套rpc框架,目前被许多公司使用
- 使用IDL语言生成多语言的实现代码,程序员只需要实现自己的业务逻辑
- 支持序列化和反序列化操作,底层封装协议,传输模块
- 以同步rpc调用为主,使用libevent evhttp支持http形式的异步调用
- rpc服务端线程安全,客户端大多数非线程安全
- 相比protocol buffer效率差些,protocol buffer不支持rpc,需要自己实现rpc扩展,目前有grpc可以使用
- 由于thrift支持序列化和反序列化,并且支持rpc调用,其代码风格较好并且使用方便,对效率要求不算太高的业务,以及需要rpc的场景,可以选择thrift作为基础库
Thrift 介绍
Thrift最初由Facebook研发,用于各个服务之间的RPC通信。
Thrift是一个典型的CS(客户端/服务端)结构,客户端和服务端可以使用不同语言开发。
既然客户端和服务端能使用不同的语言开发,那么一定就要有一种中间语言来关联客户端和服务端的语言,这种语言就是IDL(Interface Description Language)
Thrift 是一个提供可扩展、跨语言的服务开发框架,通过其强大的代码生成器,可以和 C++、Java、Python、PHP、Erlang、Haskell、C#、Cocoa、Javascript、NodeJS、Smalltalk、OCaml、Golang等多种语言高效无缝的工作。
- thrift 使用二进制进行传输,速度更快。
Thrift IDL 介绍
Thrift IDL 接口定义语言
- 实现端对端之间可靠通讯的一套编码方案。
- 涉及传输数据的序列化和反序列化,常用的http的请求一般用json当做序列化工具,定制rpc协议的时候因为要求响应迅速等特点,所以大多数会定义一套序列化协议
Thrift IDL支持的数据类型包含:
Thrift 安装
Python 版
Python 安装 thrift
# ① 安装 Python 工具包
pip install thrift # python 工具包
# ② 本机工具命令
brew install thrit # mac
thrift -version # 如果打印出来:Thrift version x.x.x 表明 complier 安装成功
demo
项目示例: thrift_demo 参考
- 1 client 目录下的 client.py 实现客户端发送数据并打印接收到 server 端处理后的数据
- 2 server 目录下的 server.py 实现服务端接收客户端发送的数据,并对数据进行大写处理后返回给客户端
- 3 file 用于存放 thrift 的 IDL 文件: *.thrift
创建过程
mkdir thrift_demo && cd thrift_demo
mkdir server client file
cd file
# 填入 thrift 内容
echo "...." > example.thrift
# 生成项目文件
thrift -out .. --gen py example.thrift # 在 file 同级目录下生成 python 的包:example
example.thrift
namespace py example
struct Data {
1: string text
2: i32 id
}
service format_data {
Data do_format(1:Data data),
}
最后目录结构
tree
.
├── __init__.py
├── client
│ └── client.py
├── file
│ └── example.thrift
└── server
| ├── log.txt
| └── server.py
├── example
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-310.pyc
│ │ ├── format_data.cpython-310.pyc
│ │ └── ttypes.cpython-310.pyc
│ ├── constants.py
│ ├── format_data-remote
│ ├── format_data.py
│ └── ttypes.py
server.py 代码
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import os
import sys
cur_path =os.path.abspath(os.path.join(os.path.dirname('__file__'), os.path.pardir))
sys.path.append(cur_path)
from example import format_data
from example import ttypes
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from thrift.server import TServer
__HOST = 'localhost'
__PORT = 9000
class FormatDataHandler(object):
def do_format(self, data):
print(data.text, data.id)
# can do something
return ttypes.Data(data.text.upper(), data.id)
if __name__ == '__main__':
handler = FormatDataHandler()
processor = format_data.Processor(handler)
transport = TSocket.TServerSocket(__HOST, __PORT)
# 传输方式,使用buffer
tfactory = TTransport.TBufferedTransportFactory()
# 传输的数据类型:二进制
pfactory = TBinaryProtocol.TBinaryProtocolFactory()
# 创建一个thrift 服务
rpcServer = TServer.TSimpleServer(processor,transport, tfactory, pfactory)
print('Starting the rpc server at', __HOST,':', __PORT)
rpcServer.serve()
print('done')
client.py 代码
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import os
import sys
sys.path.append(os.path.abspath(os.path.join(os.path.dirname('__file__'), os.path.pardir)))
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from example.format_data import Client
from example.format_data import Data
__HOST = 'localhost'
__PORT = 9000
try:
tsocket = TSocket.TSocket(__HOST, __PORT)
transport = TTransport.TBufferedTransport(tsocket)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Client(protocol)
data = Data('hello,world!', 123)
transport.open()
print('client-requets')
res = client.do_format(data)
# print(client.do_format(data).text)
print('server-answer', res)
transport.close()
except Thrift.TException as ex:
print(ex.message)
启动thrift
- 启动 server: 进入server目录,执行
python server.py, 日志信息:- Starting the rpc server at localhost : 9000
- 新窗口执行 client: 进入client目前,执行
python client.py, 日志信息:- client-requets
- server-answer Data(text=’HELLO,WORLD!’, id=123)
- 此时, server 端输出: hello,world! 123
- Thrift 的 RPC 接口定义成功
数据类型
基本类型
thrift不支持无符号类型,因为很多编程语言不存在无符号类型,比如java
基本类型:
- bool:布尔值,true 或 false
- byte:8 位有符号整数
- i16:16 位有符号整数
- i32:32 位有符号整数
- i64:64 位有符号整数
- double:64 位浮点数
- string:未知编码文本或二进制字符串
结构体(struct)
结构体类型:
- struct:定义公共对象,类似于 C 语言中的结构体定义
thrift也支持struct类型,将一些数据聚合在一起,方便传输管理。
struct 定义形式:
- 序号表示存储时各元素的相对顺序, 类似 Protobuf 中的id, 不一定非得连续
- 如 255 与 3 间隔大一片空缺, 预留空间
struct People {
1: string name;
2: i32 age;
3: string sex;
255: string extra;
}
枚举(enum)
枚举的定义形式和Java的Enum定义差不多,例如:
enum Sex {
MALE,
FEMALE
}
容器类型
容器类型:
list<T>: 一系列由T类型的数据组成的有序列表,元素可以重复set<T>: 一系列由T类型的数据组成的无序集合,元素不可重复map<K, V>: 一个字典结构,key为K类型,value为V类型,相当于Java中HMap<K,V>
集合元素可以是除了service之外的任何类型,包括exception。
异常(exception)
异常类型: exception 异常在语法和功能上类似于结构体,它在语义上不同于结构体—当定义一个 RPC 服务时,开发者可能需要声明一个远程方法抛出一个异常。
thrift支持自定义exception,规则和struct一样,如下:
exception RequestException {
1: i32 code;
2: string reason;
}
服务(service)
服务类型:
- service:对应服务的类
thrift定义服务相当于Java中创建Interface,service经过代码生成命令之后就会生成客户端和服务端的框架代码。
定义形式如下:
service HelloWordService {
// service中定义的函数,相当于Java interface中定义的函数
string doAction(1: string name, 2: i32 age);
}
类型自定义
thrift支持类似C++一样的typedef定义,比如:
typedef i32 Integer
typedef i64 Long
注意,末尾没有逗号或者分号
常量(const)
thrift 也支持常量定义,使用const关键字,例如:
const i32 MAX_RETRIES_TIME = 10
const string MY_WEBSITE = "http://qifuguang.me";
末尾的分号是可选的,可有可无,并且支持16进制赋值
命名空间
thrift 命名空间相当于Java中的package,主要目的是组织代码。
命名空间定义
thrift使用关键字namespace定义命名空间,例如:
namespace java com.winwill.thrift
格式是:namespace 语言名 路径
注意:
- 末尾不能有分号。
文件包含
thrift也支持文件包含,相当于C/C++中的include,Java中的import。使用关键字include定义,例 如:
include "global.thrift"
注释
- thrift 注释方式支持shell, C/C++风格的注释,即: #和//开头的语句都单当做注释,/**/包裹的语句也是注释。
可选/必选
可选与必选
- thrift 提供两个关键字
required,optional,分别用于表示对应的字段时必填的还是可选的。
例如:
struct People {
1: required string name;
2: optional i32 age;
}
表示name是必填的,age是可选的。
生成代码
用定义好的thrift文件生成目标语言的源码
python
thrift -out .. --gen py example.thrift # 在 file 同级目录下生成 python 的包:example
java
假设现在定义了如下一个thrift文件:
namespace java com.winwill.thrift
enum RequestType {
SAY_HELLO, //问好
QUERY_TIME, //询问时间
}
struct Request {
1: required RequestType type; // 请求的类型,必选
2: required string name; // 发起请求的人的名字,必选
3: optional i32 age; // 发起请求的人的年龄,可选
}
exception RequestException {
1: required i32 code;
2: optional string reason;
}
// 服务名
service HelloWordService {
string doAction(1: Request request) throws (1:RequestException qe); // 可能抛出异常。
}
在终端运行如下命令(前提是已经安装thrift):
thrift --gen java Test.thrift
则在当前目录会生成一个gen-java目录,该目录下会按照namespace定义的路径名一次一层层生成文件夹,到gen-java/com/winwill/thrift/目录下可以看到生成的4个Java类:
- thrift文件中定义的enum,struct,exception,service都相应地生成了一个Java类,这就是能支持Java语言的基本的框架代码。
更多见:thrift入门教程
gRPC与REST
- REST通常以业务为导向,将业务对象上执行的操作映射到HTTP动词,格式非常简单,可以使用浏览器进行扩展和传输,通过JSON数据完成客户端和服务端之间的消息通信,直接支持请求/响应方式的通信。不需要中间的代理,简化了系统的架构,不同系统之间只需要对JSON进行解析和序列化即可完成数据的传递。
- 但是REST也存在一些弊端,比如只支持请求/响应这种单一的通信方式,对象和字符串之间的序列化操作也会影响消息传递速度,客户端需要通过服务发现的方式,知道服务实例的位置,在单个请求获取多个资源时存在着挑战,而且有时候很难将所有的动作都映射到HTTP动词。
- 正是因为REST面临一些问题,因此可以采用gRPC作为一种替代方案
- gRPC 是一种基于二进制流的消息协议,可以采用基于Protocol Buffer的IDL定义grpc API,这是Google公司用于序列化结构化数据提供的一套语言中立的序列化机制,客户端和服务端使用HTTP/2以Protocol Buffer格式交换二进制消息。
- gRPC的优势是,设计复杂更新操作的API非常简单,具有高效紧凑的进程通信机制,在交换大量消息时效率高,远程过程调用和消息传递时可以采用双向的流式消息方式,同时客户端和服务端支持多种语言编写,互操作性强;
- 不过gRPC的缺点是不方便与JavaScript集成,某些防火墙不支持该协议。
- 注册中心:当项目中有很多服务时,可以把所有的服务在启动的时候注册到一个注册中心里面,用于维护服务和服务器之间的列表,当注册中心接收到客户端请求时,去找到该服务是否远程可以调用,如果可以调用需要提供服务地址返回给客户端,客户端根据返回的地址和端口,去调用远程服务端的方法,执行完成之后将结果返回给客户端。这样在服务端加新功能的时候,客户端不需要直接感知服务端的方法,服务端将更新之后的结果在注册中心注册即可,而且当修改了服务端某些方法的时候,或者服务降级服务多机部署想实现负载均衡的时候,我们只需要更新注册中心的服务群即可。

sRPC
【2021-11-24】1万行代码,单机50万QPS,今年最值得学习的开源RPC框架!
什么是srpc?
- 基于WF的轻量级,超高性能,工业级RPC框架,兼容多协议,例如百度bRPC,腾讯tRPC,Google的gRPC,以及FB的thrift协议。
srpc特点
srpc有些什么特点?
- (1)支持多种IDL格式,包括
Protobuf,Thrift等,对于这类项目,可以一键迁移; - (2)支持多种序列化方式,包括
Protobuf,Thrift,json等; - (3)支持多压缩方法,对应用透明,包括gzip,zlib,lz4,snappy等;
- (4)支持多协议,对应用透明,包括http,https,ssl,tcp等;
- (5)高性能;不同客户端线程压力下的性能表现非常稳定,QPS在50W左右,优于同等压测配置的bRPC与thrift。
- (6)轻量级,低门槛,1W行左右代码,只需引入一个静态库;

设计思路
srpc的架构设计思路是怎样的?
作为一个RPC框架,srpc的架构是异常清晰的,用户需要关注这3个层次:
- (1)IDL接口描述文件层;
- (2)RPC序列化协议层;
- (3)网络通讯层;
同时,每一层次又提供了多种选择,用户可以任意的组合
- (1)IDL层,用户可以选择Protobuf或者Thrift;
- (2)协议层,可以选择Thrift,bRPC,tRPC等; 画外音:因此,才能和其他RPC框架无缝互通。
- (3)通信层,可以选择tcp或者http;

RPC的客户端要做什么工作,RPC的服务端要做什么工作,srpc框架又做了什么工作呢?
首先必须在IDL中要定义好:
- (1)逻辑请求包request;
- (2)逻辑响应包response;
- (3)服务接口函数method;

RPC-client的工作就异常简单了:
- (1)调用method;
- (2)绑定回调函数,处理回调; 对应上图中顶部方框的绿色部分。
RPC-server的工作也非常简单,像实现一个本地函数一样,提供远程的服务:
- (1)实现method;
- (2)接受request,逻辑处理,返回response; 对应上图中底部方框的黄色部分。
srpc框架完成了绝大部分的工作:
- (1)对request序列化,压缩,处理生成二进制报文;
- (2)连接池,超时,任务队列,异步等处理;
- (3)对request二进制报文处理,解压缩,反序列化; 对应上图中中间的方框的红色部分,以及大部分流程。
在这个过程中,srpc采用插件化设计,各种复杂性细节,对接口调用方与服务提供方,都是透明的,并且具备良好的扩展性。

另外,定义好IDL之后,服务端的代码可以利用框架提供的工具自动生成代码,业务服务提供方,只需要专注于业务接口的实现即可,你说帅气不帅气? 画外音:具体的生成工具,与生成方法,请参看git上的文档。
最后,我觉得这个srpc最帅气的地方之一,就是:开源版本即线上工程版本,更新快,issue响应快,并且文档真的很全! 画外音:不少大公司,公司内部的版本和开源的版本是两套代码,开源版本没有文档,KPI完成之后,开源就没人维护了,结果坑了一大票人。
如何快速上手
三个步骤
- 第一步:定义IDL描述文件。
- 第二步:生成代码,并实现ServiceIMPL,server端就搞定了。
- 第三步:自己定义一个请求客户端,向服务端发送echo请求。
代码:
// (1) 第一步:定义IDL描述文件
syntax = "proto3";// proto2 or proto3
message EchoRequest {
string message = 1;
string name = 2;
};
message EchoResponse {
string message = 1;
};
service Example {
rpc Echo(EchoRequest) returns (EchoResponse);
};
// (2) 第二步:生成代码,并实现ServiceIMPL,server端就搞定了
class ExampleServiceImpl : public Example::Service
{
public
void Echo(EchoRequest *request,
EchoResponse *response,
RPCContext *ctx) override
{
response->set_message("Hi, " + request->name());
}
};
// (3) 第三步:自己定义一个请求客户端,向服务端发送echo请求。
int main()
{
Example::SRPCClient client("127.0.0.1", 1412);
EchoRequest req;
req.set_message("Hello, srpc!");
req.set_name("zhangsan");
client.Echo(&req,
[](EchoResponse *response, RPCContext *ctx){});
return 0;
}
GraphQL
GraphQL简介
- GraphQL是一种新的API标准,它提供了一种比REST更有效、更强大和更灵活的替代方案。
- Facebook开发并开源的,现在由来自世界各地的公司和个人组成的大型社区维护。
- GraphQL本质上是一种基于api的查询语言,现在大多数应用程序都需要从服务器中获取数据,这些数据存储可能存储在数据库中,API的职责是提供与应用程序需求相匹配的存储数据的接口。
- 数据库无关的,而且可以在使用API的任何环境中有效使用,GraphQL是基于API之上的一层封装,目的是为了更好,更灵活的适用于业务的需求变化。
- 总结
- 强大的API查询语言
- 客户端服务器间通信中介
- 比Restful API更高效、灵活
GraphQL 对比 REST API
- 【2021-2-6】总结
| 维度 | Restful API | GraphQL |
|---|---|---|
| 接口 | 接口灵活性差、操作流程繁琐 | 声明式数据获取,接口数据精确返回,查询流程简洁,照顾了客户端的灵活性 |
| 扩展性 | 不断编写新接口(依赖于服务端) | 一个服务仅暴露一个 GraphQL 层,消除了服务器对数据格式的硬性规定,客户端按需请求数据,可进行单独维护和改进。 |
| 传输协议 | HTTP协议,不能灵活选择网络协议 | 传输层无关、数据库技术无关,技术栈选择更灵活 |
介绍
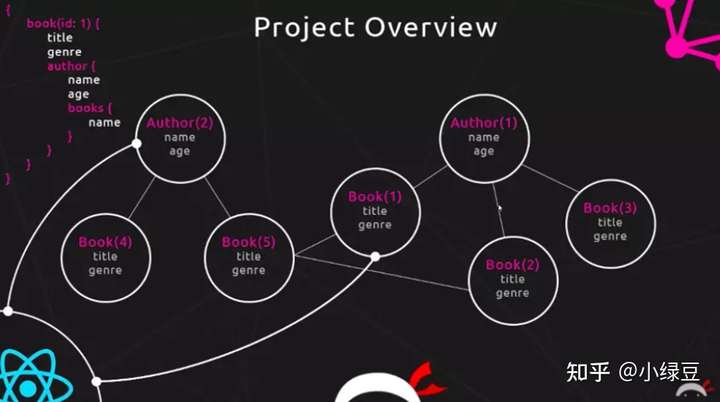
- 举例说明:前端向后端请求一个book对象的数据及其作者信息。
- REST API动图演示:
- GraphQL动图演示:
- 与REST多个endpoint不同,每一个的 GraphQL 服务其实对外只提供了一个用于调用内部接口的端点,所有的请求都访问这个暴露出来的唯一端点。
- GraphQL 实际上将多个 HTTP 请求聚合成了一个请求,将多个 restful 请求的资源变成了一个从根资源 POST 访问其他资源的 Comment 和 Author 的图,多个请求变成了一个请求的不同字段,从原有的分散式请求变成了集中式的请求,因此GraphQL又可以被看成是图数据库的形式。
- GraphQL的核心概念:图表模式(Schema)
- GraphQL设计了一套Schema模式(可以理解为语法),其中最重要的就是数据类型的定义和支持。类型(Type)就是模式(Schema)最核心的东西
- 什么是类型?
- 对于数据模型的抽象是通过类型(Type)来描述的,每一个类型有若干字段(Field)组成,每个字段又分别指向某个类型(Type)。这很像Java、C#中的类(Class)。
- GraphQL的Type简单可以分为两种,一种叫做Scalar Type(标量类型),另一种叫做Object Type(对象类型)。




GraphQL特点总结
- 声明式数据获取(可以对API进行查询): 声明式的数据查询带来了接口的精确返回,服务器会按数据查询的格式返回同样结构的 JSON 数据、真正照顾了客户端的灵活性。
- 一个微服务仅暴露一个 GraphQL 层:一个微服务只需暴露一个GraphQL endpoint,客户端请求相应数据只通过该端点按需获取,不需要再额外定义其他接口。
- 传输层无关、数据库技术无关:带来了更灵活的技术栈选择,比如我们可以选择对移动设备友好的协议,将网络传输数据量最小化,实现在网络协议层面优化应用。
GraphQL接口设计
- GraphQL获取数据三步骤
- 首先要设计数据模型,用来描述数据对象,它的作用可以看做是VO,用于告知GraphQL如何来描述定义的数据,为下一步查询返回做准备;
- 前端使用模式查询语言(Schema)来描述需要请求的数据对象类型和具体需要的字段(称之为声明式数据获取);
- 后端GraphQL通过前端传过来的请求,根据需要,自动组装数据字段,返回给前端。

- 设计思想:GraphQL 以图的形式将整个 Web 服务中的资源展示出来,客户端可以按照其需求自行调用,类似添加字段的需求其实就不再需要后端多次修改了。
- 创建GraphQL服务器的最终目标是:允许查询通过图和节点的形式去获取数据。
GraphQL支持的数据操作
- GraphQL对数据支持的操作有:
- 查询(Query):获取数据的基本查询。
- 变更(Mutation):支持对数据的增删改等操作。
- 订阅(Subscription):用于监听数据变动、并靠websocket等协议推送变动的消息给对方。
GraphQL执行逻辑
- 有人会问:
- 使用了GraphQL就要完全抛弃REST了吗?
- GraphQL需要直接对接数据库吗?
- 使用GraphQL需要对现有的后端服务进行大刀阔斧的修改吗?
- 答案是:NO!不需要!
- 它完全可以以一种不侵入的方式来部署,将它作为前后端的中间服务,也就是,现在开始逐渐流行的 前端 —— 中端 —— 后端 的三层结构模式来部署!
- 那就来看一下这样的部署模式图:
- 完全可以搭建一个GraphQL服务器,专门来处理前端请求,并处理后端服务获取的数据,重新进行组装、筛选、过滤,将完美符合前端需要的数据返回。
- 新的开发需求可以直接就使用GraphQL服务来获取数据了,以前已经上线的功能无需改动,还是使用原有请求调用REST接口的方式,最低程度的降低更换GraphQL带来的技术成本问题!
- 如果没有那么多成本来支撑改造,那么就不需要改造!
- 只有当原有需求发生变化,需要对原功能进行修改时,就可以换成GraphQL了。

GraphQL服务框架:
- 框架
- Apollo Engine:一个用于监视 GraphQL 后端的性能和使用的服务。
- Graphcool(github): 一个 BaaS(后端即服务),它为你的应用程序提供了一个 GraphQL 后端,且具有用于管理数据库和存储数据的强大的 web ui。
- Tipe (github): 一个 SaaS(软件即服务)内容管理系统,允许你使用强大的编辑工具创建你 的内容,并通过 GraphQL 或 REST API 从任何地方访问它。
- AWS AppSync:完全托管的 GraphQL 服务,包含实时订阅、离线编程和同步、企业级安全特性以及细粒度的授权控制。
- Hasura:一个 BaaS(后端即服务),允许你在 Postgres 上创建数据表、定义权限并使用 GraphQL 接口查询和操作。
- 工具
- graphiql (npm): 一个交互式的运行于浏览器中的 GraphQL IDE。
- Graphql Language Service: 一个用于构建 IDE 的 GraphQL 语言服务(诊断、自动完成等) 的接口。
- quicktype (github): 在 TypeScript、Swift、golang、C#、C++ 等语言中为 GraphQL 查 询生成类型。
- 想要获取更多关于Graphql的一些框架、工具,可以去awesome-graphql:一个神奇的社区,维护一系列库、资源等。更多Graphql的知识,可以去http://GraphQL.cn
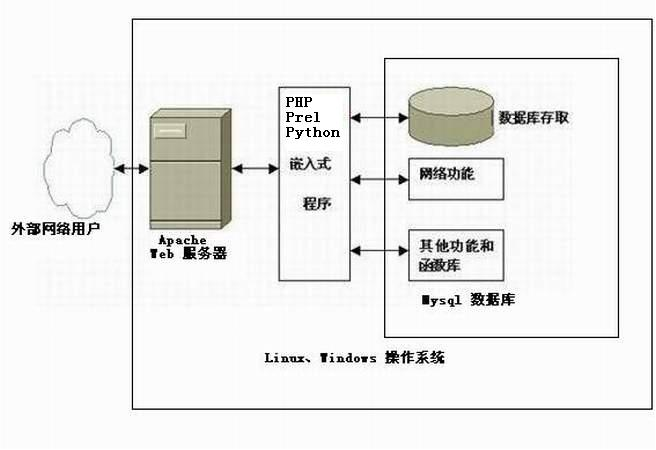
LAMP
LAMP 环境搭建指的是在 Linux 操作系统中分别安装 Apache 网页服务器、MySQL 数据库服务器和 PHP 开发服务器,以及一些对应的扩展软件。
 LAMP 环境是当前极为流行的搭建动态网站的开源软件系统,拥有良好的稳定性及兼容性。而且随着开源软件的蓬勃发展,越来越多的企业和个人选择在 LAMP 开发平台上搭建自己的网站。
LAMP 环境是当前极为流行的搭建动态网站的开源软件系统,拥有良好的稳定性及兼容性。而且随着开源软件的蓬勃发展,越来越多的企业和个人选择在 LAMP 开发平台上搭建自己的网站。- LAMP占全球网站总数的 52.19%(2013 年 7 月数据),其余的网站平台(如 Microsoft IIS 开发平台、Linux Nginx 开发平台、Google 开发平台等)占用了剩余的份额。
- LNMP环境中,使用 Nginx 网页服务器取代了 Apache 网页服务器。Nginx 是一款高性能的 HTTP 网页服务器和反向代理服务器,它的执行效率极高,配置相比 Apache 也较为简单,所以在短时间内被国内外很多大型公司所采用,大有取代 Apache 的势头(目前还是以 Apache 为主流的)。
- WAMP环境:Windows
- 参考:LAMP环境搭建和LNMP环境搭建
LAMP一键安装
LAMP一键安装包, github 是一个用 Linux Shell 编写的可以为 Amazon Linux/CentOS/Debian/Ubuntu 系统的 VPS 或服务器安装 LAMP(Linux + Apache + MySQL/MariaDB + PHP) 生产环境的 Shell 脚本。包含一些可选安装组件如:
- Zend OPcache, ionCube Loader, PDFlib, XCache, APCu, imagick, gmagick, libsodium, memcached, redis, mongodb, swoole, yaf, yar, msgpack, psr, phalcon, grpc, xdebug
- 其他诸如:OpenSSL, ImageMagick, GraphicsMagick, Memcached, phpMyAdmin, Adminer, Redis, re2c, KodExplorer
- 同时还有一些辅助脚本如:虚拟主机管理、Apache、MySQL/MariaDB、PHP 及 PhpMyAdmin、Adminer 的升级等。
程序目录
- MySQL 安装目录: /usr/local/mysql
- MySQL 数据库目录:/usr/local/mysql/data(默认路径,安装时可更改)
- MariaDB 安装目录: /usr/local/mariadb
- MariaDB 数据库目录:/usr/local/mariadb/data(默认路径,安装时可更改)
- PHP 安装目录: /usr/local/php
- Apache 安装目录: /usr/local/apache
默认的网站根目录: /data/www/default
# wget/git
yum -y install wget git # for Amazon Linux/CentOS
apt-get -y install wget git # for Debian/Ubuntu
# lamp包下载
git clone https://github.com/teddysun/lamp.git
cd lamp
chmod 755 *.sh
# 开始安装
./lamp.sh
# 使用方法
lamp add # 创建虚拟主机
lamp del # 删除虚拟主机
lamp list # 列出虚拟主机
lamp version # 显示当前版本
# 升级
cd ~/lamp
git reset --hard # Resets the index and working tree
git pull # Get latest version first
chmod 755 *.sh
./upgrade.sh # Select one to upgrade
./upgrade.sh apache # Upgrade Apache
./upgrade.sh db # Upgrade MySQL or MariaDB
./upgrade.sh php # Upgrade PHP
./upgrade.sh phpmyadmin # Upgrade phpMyAdmin
./upgrade.sh adminer # Upgrade Adminer
# 卸载
./uninstall.sh
# MySQL 或 MariaDB 命令
/etc/init.d/mysqld (start|stop|restart|status)
# Apache 命令
/etc/init.d/httpd (start|stop|restart|status)
# Memcached 命令(可选安装)
/etc/init.d/memcached (start|stop|restart|status)
# Redis 命令(可选安装)
/etc/init.d/redis-server (start|stop|restart|status)
Apache
Apache HTTP 服务器是世界上最广泛使用的 web 服务器。它是一个免费,开源,并且跨平台的 HTTP 服务器,包含强大的特性,并且可以使用很多模块进行扩展。
- Apache 在默认的 CentOS 源仓库中可用,并且安装非常直接。在基于 RHEL 的发行版中,Apache 软件包和服务被称为 httpd
# 安装Apache, 用 root 或者其他有 sudo 权限的用户身份
yum install httpd httpd-devel
# Apache 随系统启动:
chkconfig --levels 235 httpd on
# 启动apache服务
/bin/systemctl start httpd.service
Apache专用:
- 服务目录 /etc/httpd
- 主配置文件 /etc/httpd/conf/httpd.conf
- 网站数据目录 /var/www/html
- 访问日志 /var/log/httpd/access_log
- 错误日志 /var/log/httpd/error_log
PHP
php安装
- mac下安装php
- centos下安装php环境的方法:
- 首先安装并启动apache
- 然后安装mysql;
- “yum install php php-devel”命令安装php;
- 最后重启apache,访问服务器所在ip即可
- apache默认就是使用80端口
# 安装Apache
yum install httpd httpd-devel
# 启动apache服务
/bin/systemctl start httpd.service
# 如果访问失败,需要关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
# 安装mysql
yum install mysql mysql-server
# 启动mysql
systemctl start mysql.service
# 安装php
yum install php php-devel
# /var/www/html/下建立一个PHP文件index.php,加入代码:/var/www/html/下建立一个PHP文件index.php,加入代码:
# 注意:在centos7通过yum安装PHP7,首先在终端运行
rpm -ivh http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # 安装epel-release
rpm -Uvh htt[ps](http://www.111cn.net/fw/photo.html)://mirror.webtatic.com/yum/el7/webtatic-release.rpm
# 启动php
/bin/systemctl start httpd.service
php -v # 显示当前PHP版本
# 安装php扩展
yum install php-mysql php-gd php-imap php-ldap php-odbc php-pear php-xml php-xmlrpc
# 再次重启Apache
/bin/systemctl start httpd.service
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
