- Python
- 高级语法
- python技能
- Python生态系统
- 空值判断
- 数学函数
- Numpy
- Arrow
- Pandas
- Python技巧
- 1. 重复元素判定
- 2. 字符元素组成判定
- 3. 内存占用
- 4. 字节占用
- 5. 打印 N 次字符串
- 6. 大写第一个字母
- 7. 分块
- 8. 压缩
- 9. 解包
- 10. 链式对比
- 11. 逗号连接
- 12. 元音统计
- 13. 首字母小写
- 14. 展开列表
- 15. 列表的差
- 16. 通过函数取差
- 17. 链式函数调用
- 18. 检查重复项
- 19. 合并两个字典
- 20. 将两个列表转化为字典
- 21. 使用枚举
- 22. 执行时间
- 23. Try else
- 24. 元素频率
- 25. 回文序列
- 26. 不使用 if-else 的计算子
- 27. Shuffle
- 28. 展开列表
- 29. 交换值
- 30. 字典默认值
- 结束
Python
Python简介
1989年,吉多·范罗苏姆(Guido van Rossum),外号龟叔,1956年出生,荷兰人,26岁在阿姆斯特丹大学获得数学和计算机科学硕士学位。1989年圣诞节,33岁的龟叔为打发时间,决定为当时正构思的一个新的脚本语言编写一个解释器。当时电视上非常流行一个电视剧蒙提·派森的飞行马戏团,作为这个马戏团的狂热粉丝,他以Python命名该项目,使用C进行开发,于是Python就诞生了。
Python(脚本语言)← C语言
- Python的底层是用C语言写的,很多标准库和第三方库也都是用C写的,运行速度非常快
- Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议 。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。
- 最初的Python用 C语言编写实现,又称为 CPython。一般所讨论的Python其实就是 CPython。
- 随着编程语言的不断发展,Python 的实现方式也发生了变化,除了用 C 语言实现外,Python 还有其他的实现方式。
- 用
Java语言实现的 Python 称为JPython - 用
.net实现的 Python 称为IronPython等等。 PyPy可能是最令人兴奋的 Python 实现,因为其目标就是将 Python 重写为 Python。在 PyPy 中,Python 解释器本身是用 Python 编写的。
更多编程语言介绍:
Python 2 vs Python 3
python2 不支持的 Python3语法,案例如下:
# ** 用法
outputs = model.generate(**inputs, max_new_tokens=20)
【2020-8-24】Python代码版本转换
2to3 -help # 帮助
2to3 -w . #将当前整个文件夹代码从python2转到python3
# python2文件会在.py后面再加上一个后缀.bak,而新生成的python3文件使用之前python2文件的命名
安装 python
软件源
【2026-3-9】官方地址速度慢(4k/s),可切换国内源(100k/s)
如 python 3.12 下载地址:
https://www.python.org/ftp/python/3.12.0/Python-3.12.0.tar.xz
wget https://mirrors.aliyun.com/python-release/source/Python-3.12.0.tgz
工具包安装
Mac
mac下安装命令
- 先安装 homebrew
# === brew 工具 ====
# 安装homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 搜索Python版本
brew search python3
# 安装
brew install python@3.8
Windows
windows下安装
- windows miniconda 下载地址
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe -o miniconda.exe
start /wait "" miniconda.exe /S
del miniconda.exe
编译安装
自动编译
- 【2020-7-3】脚本如下:
#-----自定义区------
# 下载python3
src_file='https://www.python.org/ftp/python/3.8.3/Python-3.8.3.tgz'
file_name="${src_file##*/}"
install_dir=~/bin
#-------------------
[ -e ${file_name} ]||{
wget ${src_file}
echo "下载完毕..."
}&& echo "文件已存在, $file_name"
# 解压
tar zxvf ${file_name}
echo "安装目录: $install_dir"
# 安装
new_dir=${file_name%.*}
cd $new_dir
./configure --prefix=${install_dir}/python38
# 如果不设置安装目录prefix, 就会提示sudo权限
make && make install
echo "安装完毕,请设置环境变量"
No module named _ssl
错误:No module named ‘_ssl’
- 原因:虽然 mac 系统已经装了openssl包及相关的头文件,但是默认python3.7的源码包中指定的ssl头文件目录不包含mac上openssl的路径
- 备注:macos 没有openssl-devel这个安装包,内容都已经在openssl中了
#./configure --with-ssl # 注明ssl
# [2023-8-5] Debian 10实践,pip install命令瘫痪,编译安装时没有纳入openssl
./configure --prefix=/home/wangqiwen.at/bin --with-ssl=/usr/bin/openssl
# 另一种配置
./configure --prefix=/web-soft/Python-3.11.4 --with-openssl-rpath=auto --with-openssl=/usr/local/openssl
make
sudo make install
【2023-8-5】Python3.8 SSL模块报错 No module named ‘_ssl’, 但Python3.6.9却没有报错。 解法
- 下载 Python 3.8.2
- 解压的文件中找到
Python-3.8.2/Modules/Setup文件 - 注释掉 5行,删掉原bin文件,重新编译
- 再次 import ssl,验证
# Socket module helper for socket(2)
_socket socketmodule.c timemodule.c
# Socket module helper for SSL support; you must comment out the other
# socket line above, and possibly edit the SSL variable:
SSL=/usr/local/ssl
_ssl _ssl.c \
-DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \
-L$(SSL)/lib -lssl -lcrypto
# -------- 再次编译 ------
./configure --prefix=/usr/local/python3.8/
make
make install
【2025-5-14】腾讯云服务器上,CentSO 编译安装 python 3.11,再次遇到 ssl 问题
- 以上解法都失效
解决方法
- SSL模块错误:如果出现 Could not build the ssl module!错误,确保安装了
openssl11
# 下载最新的软件安装包
# wget https://www.python.org/ftp/python/3.11.0/Python-3.11.0.tgz
# wget https://www.python.org/ftp/python/3.12.0/Python-3.12.0.tar.xz
# 解压缩安装包
tar -xzf Python-3.11.0.tgz
pip install openai # 此时报错 ssl 连接问题
# -------------------------------
# SSL模块错误:如果出现Could not build the ssl module!错误,确保安装了openssl11
# centos 里 ssl 自带, 路径 /usr/bin/openssl
# 重新安装依赖包
sudo yum -y install gcc zlib zlib-devel libffi libffi-devel readline-devel openssl-devel openssl11 openssl11-devel
# 设置环境变量
export CFLAGS=$(pkg-config --cflags openssl11)
export LDFLAGS=$(pkg-config --libs openssl11)
# 编译安装,指定 openssl 路径
./configure --prefix=/usr/local/python --with-ssl=/usr/bin/openssl
# 编译
make
sudo make install
环境变量
# 设置环境变量
#vim ~/.bash_profile
echo "
alias python3='${install_dir}/python38/bin/python3.8'
alias pip3='${install_dir}/python38/bin/pip3'
" >> ~/.bash_profile
echo '生效'
source ~/.bash_profile
echo '修改pip源'
mkdir ~/.pip
echo "
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
" > ~/.pip/pip.conf
# 或者一行命令设置
#pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
Python 编译器
Python解释器可用多种语言来实现,如
- CPython(用C编写)
- Jython(用Java编写)
- Iron Python(用.NET编写)
- PyPy(用Python编写)
CPython
CPython是Python解释器的最初实现,使用最广,最多维护
从Python官方网站下载并安装好Python 3.x后,就直接获得了一个官方版本的解释器:CPython
由于CPython是高级解释语言,因此有一定局限性,并且在速度方面没有任何优势
CPython 使用一种称为引用计数的技术。
- 每当引用对象时,Python对象的引用计数都会增加,而在取消引用该对象时则递减计数。
- 当引用计数为零时,CPython会自动为该对象调用内存释放函数。
陷阱
- 当大型对象树的引用计数变为零时,所有相关对象将被释放。因此,可能有很长的暂停时间,在此期间您的程序根本无法执行。
- 引用循环: 引用计数根本不起作用
class A(object):
pass
a = A()
a.some_property = a
del a
CPython 用循环垃圾回收器 解决
- 从已知根(如类型对象)开始遍历内存中的所有对象。
- 然后,标识所有可访问对象,并释放不可访问的对象,因为不再存在。
这样就解决了引用循环问题。
但是,当内存中存在大量对象时,可能会创建更明显的暂停。
PyPy 不用 引用计数,只使用第二种技术,即循环查找器。
- 定期从根开始遍历活动对象。
- 这使PyPy比CPython 优势,不需要考虑引用计数,从而使内存管理花费的总时间少于CPython。此方法只在每个次要集合之后添加几毫秒,而不像CPython那样一次添加数百毫秒
pypy
PyPy是CPython的一种快速且功能强大的替代方案, 不改代码的情况下大大提高速度。但它也不是万能,有一些局限性
Python 程序运行不快,要切换到另一种编程语言吗?
- 不一定。可以放弃 python.py 运行方式,转而使用 PyPy 即时编译器。
- Python 创建者 Guido von Rossum 都建议将
PyPy用于关键性能的 Python 程序。 - PyPy是不是真的比Python快?
PyPy 是 Python的JIT版本,如果存在大量高耗时且重复执行的代码, pypy运行速度比Python快很多.
PyPy 提升速度的秘诀: 「即时编译( just-in-time compilation)」,即 JIT 编译。
提前编译:- C、C ++、Swift、Haskell、Rust 等编程语言提前编译(AOT 编译)。
- 用这些语言编写代码之后,编译器会将源代码转换成特定计算机架构可读的机器码。
- 执行程序时,执行的并不是原始源代码,而是机器码。
解释语言:- Python、JavaScript、PHP 等。
- 与将源代码转换为机器码相比,解释过程中, 源代码是保持不变。
- 每次运行程序时,解释器都会逐行查看代码并运行。例如,每个 Web 浏览器都内置了 JavaScript 解释器。
PyPy 不同于解释器,并不会逐行运行代码,而是先将部分代码编译成机器码。
Pypy 安装
- 命令安装: 如下
- 源码安装:官网下载,然后添加路径到 PATH
brew install pypy3
效率对比
- 测试代码中, PyPy 速度大约是Python的94倍, 实测 45 倍
- 平均而言,速度是Python的4.3倍
- 参考
测试代码
import time
start_time = time.time()
total = 0
for i in range(1, 10000):
for j in range(1, 10000):
total += i + j
print(f"The result is {total}")
end_time = time.time()
print(f"It took {end_time-start_time:.2f} seconds to compute")
Mac OS 上实测
- 10.44/0.23=45.4
python
# Python 3.10.10 (main, Mar 21 2023, 13:41:39) [Clang 14.0.6 ] on darwin
# Type "help", "copyright", "credits" or "license" for more information.
brew install pypy3
# 安装后直接输入pypy3即可
pypy3
# Python 3.10.13 (fc59e61cfbff, Jan 15 2024, 14:27:53)
# [PyPy 7.3.15 with GCC Apple LLVM 15.0.0 (clang-1500.1.0.2.5)] on darwin
# Type "help", "copyright", "credits" or "license" for more information.
python test.py
# The result is 999800010000
# It took 10.44 seconds to compute
pypy3 test.py
# The result is 999800010000
# It took 0.23 seconds to compute
PyPy的局限性
- PyPy并非万能,并不适合所有任务。
- 甚至可能执行速度比CPython慢得多。
不适用于
- C扩展: C扩展模块运行速度都要比在CPython中慢得多。
- 原因: PyPy无法优化C扩展模块,因为不受完全支持。PyPy必须模拟代码中的引用计数,使其更慢。
- PyPy团队建议去掉CPython扩展并将其替换为纯Python版本。
- 如果不行的话,则必须使用CPython。
- 核心团队正在处理C扩展。有些软件包已被移植到PyPy,并且工作速度也同样快。
PyPy最适合纯Python应用程序, 长时间运行的程序
- PyPy运行时,执行许多操作以使代码运行得更快。
- 如果脚本本身很简单,则运行速度会低于CPython。
- 如果长时间运行,可能会带来显著的性能提升。
PyPy不是一个完全编译型的Python实现
pip
Python工具包查询网站 pypi: Find, install and publish Python packages with the Python Package Index
直接下载文件
注意
- 跟 Python版本匹配,不要错位。 如 Python 3.6就用pip
pip 安装
【2023-2-3】 阿里云服务器不管用,卡住了
# 下载安装脚本
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # [2023-2-3] 阿里云服务器不管用,卡住了
wget https://pip.pypa.io/en/stable/installation/#get-pip-py # 从pip官网直接下文件
wget https://bootstrap.pypa.io/get-pip.py # 安装
# 【2023-8-5】微云下载地址
https://share.weiyun.com/2Dr0n4G8
# 直接从whl包安装pip
python -m pip install --upgrade xxx # 注意:pip轮子的文件名.whl
python -m ensurepip --upgrade # 更新
# 【2023-8-5】debian系统,改用命令:
sudo apt install python3-pip
# =========
sudo python get-pip.py # python2
sudo python3 get-pip.py # python3
# mac 下安装
sudo easy_install pip
# 源码安装
wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=834b2904f92d46aaa333267fb1c922bb" --no-check-certificate
tar zxvf pip-1.5.4.tar.gz
python setup.py install
# 版本升级
python -m pip install --upgrade pip==20.0.2
【2024-12-12】直接安装 wheel 包
pip install pymupdf-1.25.1-cp39-abi3-win_amd64.whl
【2023-3-2】
- 错误: Defaulting to user installation because normal site-packages is not writeable
- 原因:
- 使用错误Python版本导致: python3 -m pip install $pkg_name
- 当前用户权限不足:
- pip install numpy –user
- sudo pip install numpy
配置pip源
pip源采用阿里云的pip源用于加速下载文件
- 阿里云:http://mirrors.aliyun.com/help/pypi
windows powershell
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
Linux/Mac
在 ~/.pip/pip.conf
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
# [install] trusted-host=mirrors.aliyun.com
【2023-8-5】由于pip.conf文件填写错误([install]未换行)导致:
目前收集的比较好的镜像地址有:
- http://pypi.v2ex.com/simple/
- http://pypi.douban.com/simple/
- http://mirrors.aliyun.com/pypi/simple/
pip安装时速度慢或者报超时?
解决办法:指定库地址,最好是国内
#(1)-i 指定源
sudo pip install face_recognition -i https://pypi.tuna.tsinghua.edu.cn/simple
# (2)设置超时时间
pip --default-timeout=100 install ....
#(3)新建文件pip.conf,内容:
mkdir ~/.pip
# [global]
# timeout = 6000
# index-url = http://pypi.tuna.tsinghua.edu.cn/simple/
# [install]
# use-mirrors = true
# mirrors = http://pypi.tuna.tsinghua.edu.cn/simple/
# trusted-host = pypi.tuna.tsinghua.edu.cn
pip install $p --trusted-host didiyum.sys.xiaojukeji.com -i http://didiyum.sys.xiaojukeji.com/didiyum/pip/simple/
pip 问题
pip 使用问题
ctypes
【2023-8-7】pip install 报错
ModuleNotFoundError: No module named '_ctypes'- 原因:Python3 有个内置模块 ctypes,外部函数库模块,兼容C语言的数据类型,并通过它调用Linux系统下的共享库(Shared library)
解决方法: 参考
- (1)、安装 libffi-devel
- centos下,可以使用命令 yum install libffi-devel -y
- ubuntu下,可以使用命令 sudo apt-get install libffi-dev
- (2)、重新安装python3版本即可
- python3源码安装包下执行命令:make install,重新进行安装
错误
ImportError: No module named bz2- 分析: debian 系统上没有安装bz2工具包
- 解法: 安装bz2后重新编译Python
sudo apt-get install libbz2-dev
ubuntu
【2025-1-8】ubuntu 新系统下实践
- 直接 pip install flask 报错
- 错误信息:
externally-managed-environment
原因
- “外部管理环境”错误背后的原因:Manjaro 22、Ubuntu 23.04、Fedora 38 以及其他的最新发行版中,正在使用 Python 包来实现此增强功能。
- 这个更新是为了避免「操作系统包管理器 (如pacman、yum、apt) 和 pip 等特定于 Python 的包管理工具之间的冲突」。
解法
- 修改变量
- sudo mv /usr/lib/python3.x/EXTERNALLY-MANAGED /usr/lib/python3.x/EXTERNALLY-MANAGED.bk
- 实践:无效,不存在对应文件
- 使用 pipx:
- sudo apt install pipx
- pipx ensurepath
- pipx install flask
- 开启虚拟环境后,再使用 pip —— 实践有效
windows site-package
【2025-3-12】python之修改pip默认install路径
- windows 环境下,Python pip 安装库,默认在C盘, 导致C盘空间满
- 比如
C:\Users\wqw\AppData\Roaming\Python\Python37\site-packages
- 比如
查看默认安装路径
- USER_BASE 和 USER_SITE 就是默认路径
python -m site
sys.path = [
'F:\\',
'D:\\Programs\\Python\\Python37\\python37.zip',
'D:\\Programs\\Python\\Python37\\DLLs',
'D:\\Programs\\Python\\Python37\\lib',
'D:\\Programs\\Python\\Python37',
'C:\\Users\\wqw\\AppData\\Roaming\\Python\\Python37\\site-packages',
'D:\\Programs\\Python\\Python37\\lib\\site-packages',
]
USER_BASE: 'C:\\Users\\wqw\\AppData\\Roaming\\Python' (exists)
USER_SITE: 'C:\\Users\\wqw\\AppData\\Roaming\\Python\\Python37\\site-packages' (exists)
ENABLE_USER_SITE: True
解法:
- 修改文件
D:\Programs\Python\Python37\lib\site.py
ENABLE_USER_SITE = True
USER_SITE = r"D:\Programs\Python\Python37\Lib\site-packages"
USER_BASE = r"D:\Programs\Python\Python37\Scripts"
pip 用法
pip命令:
- show:显示包详细信息
- list:list –outdate查看过期的包
- install :
pip install pyecharts==0.4.1(安装指定版本)pip install --upgrade pyecharts(升级)
- uninstall
- search
安装指定版本
pip show langchain # 查看版本
pip install langchain==0.3.19 # 安装指定版本
pip install langchain>=0.3.0 # 向上兼容
pip install "langchain>=0.3.0,<0.4.0" # 指定区间
pip install langchain~=0.3.0 # 兼容小版本
pip install "langchain-core>=0.3.0,<0.4.0"
pip install "langchain-community~=0.3.0"
详情
# pip版本
pip -v
# --- python ----
import sys
#sys模块提供了一系列有关Python运行环境的变量和函数。
print(sys.version)
#sys.version用来获取Python解释程序的版本信息
# ------------
pip -h
# 从备用索引安装
pip install --index-url http://my.package.repo/simple/ SomeProject
# 在安装期间搜索附加索引,PyPI
pip install --extra-index-url http://my.package.repo/simple SomeProject
# 指定源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package matplotlib
# 设为默认
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 指定版本
pip install 模块名==版本号
# 安装特定的源存档文件。
pip install ./downloads/SomeProject-1.0.4.tar.gz
# whl包
pip install test.whl
# 批量安装
pip install -r requirements.txt
# 升级
pip install --upgrade package_name
pip install -U transformers==4.38.2 # [2024-3-16]
# 查看信息
pip show -f package_name
# 查看已安装的库
pip list
# 已经安装的库中,看哪些需要版本升级
pip list -o
# 把已经安装的库信息保存到到本地txt文件中
pip freeze > requirements.txt
# 验证已安装的库是否有兼容依赖问题
pip check package-name
# 将库下载到本地指定文件,保存为whl格式
pip download package_name -d "要保存的文件路径"
# 卸载
pip uninstall package_name
特殊用法
- 工具包核心功能+扩展功能
- pip install
a[b]:安装包 a,并同时安装 b 这个可选依赖组里的所有依赖
# 只安装 requests 核心功能(默认)
pip install requests
# 安装 requests + security 可选依赖组(包含加密相关依赖,如 pyOpenSSL、cryptography 等)
pip install requests[security]
# 安装多个可选依赖组(用逗号分隔)
pip install requests[security,socks]
pip install "project[extra]"
pip install splinter django # 安装两个名为 splinter 和 django 的包。
pip install splinter[django] # 安装 splinter 包的变体,其中包含对 django 的 _支持_。请注意,与 django 包本身无关,而只是由 splinter 包定义的字符串,用于启用的特定功能集
installing 对 splinter 新增支持的软件包django。方括号([])不是特定的语法,只是约定。安装名为的软件包”splinter[django]“。
解释@chetner:
- 该命令
pip install splinter django将安装两个名为splinter和的软件包django。splinter[django] - 安装的一个变体splinter,其包含包支持对django。
注意,与django程序包本身无关,只是splinter程序包为启用的特定功能集定义的字符串。
pip search
【2023-5-30】pip search命令废弃
故障
(py310) TQV9MF4NXR:tree-of-thoughts bytedance$ pip install scikit-llm
# Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
# ERROR: Could not find a version that satisfies the requirement scikit-llm (from versions: none)
# ERROR: No matching distribution found for scikit-llm
(py310) TQV9MF4NXR:tree-of-thoughts bytedance$ pip search scikit-llm
# ERROR: XMLRPC request failed [code: -32500]
# RuntimeError: PyPI no longer supports 'pip search' (or XML-RPC search). Please use https://pypi.org/search (via a browser) instead. See https://warehouse.pypa.io/api-reference/xml-rpc.html#deprecated-methods for more information.
替代品
git clone https://github.com/shubhodeep9/pipsearch
cd pipsearch
python setup.py install
pip search your_pkg
Python依赖包
依赖包总结
【2020-8-23】python 项目依赖包管理
- 安装:
pip install -r requirements.txt
- 自动生成
requirements.txtpip install pipreqspipreqs /path/to/project
- 生成requirements.txt文件
pip freeze #显示所有依赖
pip freeze > requirement.txt #生成requirement.txt文件
pip install -r requirement.txt #根据requirement.txt生成相同的环境
- 对比分析
| 工具包 | 优点 | 缺点 |
|---|---|---|
pip freeze |
包含列表完全 | 不相关的依赖包也会包含进来 |
pipreqs |
只会包含项目 imports 的包 | 包含列表不是很完全 |
pip-compile |
精准控制项目依赖包 | 需要手动操作,不方便 |
pip requirements
python项目必须包含一个 requirements.txt 文件,用于记录所有依赖包及其精确的版本号,以便新环境部署。
语法格式
【2024-11-25】requirements.txt 中指定条件版本
omegaconf==2.3.0 // 指定某个版本
torch>=2.3.0 // 版本以上
// 条件分支,根据系统属性选择对应版本
onnxruntime-gpu==1.16.0; sys_platform == 'linux'
onnxruntime==1.16.0; sys_platform == 'darwin' or sys_platform == 'windows'
文件创建
① 生成 requirements 文件:
- 方法一:pip freeze
pip freeze > requirements.txtpip的freeze命令用于生成将当前项目的pip类库列表生成requirements.txt文件
- 方法二:使用 pipreqs
pipreqs用于生成requirements.txt文件可以根据需要导入的任何项目
为什么不用 pip Freeze 命令呢?
- pip 的 freeze 命令保存了保存当前Python环境下所有类库包,其它包括那些没有在当前项目中使用的类库。 (如果你没有的virtualenv)。
- pip 的 freeze 命令只保存与安装在环境python所有软件包。但有时只想将当前项目使用的类库导出生成为 requirements.txt;
生成 requirements.txt 文件的方法有很多,上面三种方法各有优劣
| 名称 | 优点 | 缺点 |
|---|---|---|
| pip freeze | 包含列表完全 | 不相关的依赖包也会包含进来 |
| pipreqs | 只会包含项目 imports 的包 | 包含列表不是很完全 |
| pip-compile | 精准控制项目依赖包 | 需要手动操作,不方便 |
注:requirements.txt 写法
# ==也可以换成>=, <=。
sed -i 's/==.*$//g' requirements.txt # 安装最新版本要去除后面的==再安装
spacy>=2.1.0,<2.2.0 # 版本范围
https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-2.1.0/en_core_web_lg-2.1.0.tar.gz#egg=en_core_web_lg # 直接从某地址下载
pymagnitude>=0.1.120 # 版本范围
# 【2023-4-12】直接使用git地址
git+https://github.com/microsoft/deepspeed.git
git+https://github.com/huggingface/transformers
更多实例见地址
② 创建环境副本,全新安装
pip install -r requirements.txt
# 安装远程机器上的requirements文件:
# 服务端搭建server:
python -m SimpleHTTPServer
# 获取:
pip install -i http://127.0.0.1:8000/ -r requirements.txt
使用方法:
pip install pipreqs # 安装
pipreqs /path/to/project # 按需导出requirements.txt
# 示例:
pipreqs mycode/recommond/ivr
# INFO: Successfully saved requirements file in mycode/recommond/ivr/requirements.txt
# 内容:只包含对应项目下用到的库
# xgboost==0.7.post4
# requests==2.18.4
# numpy==1.14.2
# pandas==0.22.0
# config_reader==0.8
# matplotlib==2.2.2
# scikit_learn==0.19.1
# tensorflow==1.8.0
参考:Python使用requirements.txt安装类库
虚拟环境
venv
注意:venv 只能使用当前系统已经安装好的python,无法使用其他版本的python环境。
优缺点分析:
- 1、venv 是 python3 自带,不需要额外安装库就能运行。
- 也可以单独安装: sudo apt install python3-venv
- 2、只能在3.3版本以后,2.x 用不了
- 3、venv 过于简单,没有额外api。
- 只能创建个虚拟环境,不能指定系统不存在的 python环境版本,不能查看环境列表。
pip install flask # 报错
python3 -m venv test_env # 生成 test_env 目录
# 激活虚拟环境
source test_env/bin/activate
pip install flask # 正常
virtualenv
virtualenv 是最流行的 python 虚拟环境配置工具。
- 不仅同时支持 python2 和 python3,而且可以为每个虚拟环境指定 python 解释器,并可以选择继承基础版本的包。
- 【2018-1-3】Python–Virtualenv简明教程,virtualenv官方文档
- python沙盒环境,virtualenv创建一个拥有自己安装目录的环境, 这个环境不与其他虚拟环境共享库, 能够方便的管理python版本和管理python库
优点
- 更快
- 扩展性更强
- 自动发现并可创建多版本的 Python 环境
- 可通过 pip 更新
- 丰富的编程接口
(1)安装:
pip install virtualenv
#或者由于权限问题使用sudo临时提升权限
sudo pip install virtualenv
virtualenv -h #获得帮助
(2)创建:
- 用virtualenv管理python环境
- 生成ENV目录,包含bin(解释器)、include 和 lib(python库)文件夹
- 运行, 会继承/usr/lib/python2.7/site-packages下的所有库, 最新版本virtualenv把把访问全局site-packages作为默认行为
virtualenv ENV # 创建一个名为ENV的目录, 并且安装了ENV/bin/python
virtualenv --system-site-packages ENV # 继承系统python环境
(3)激活虚拟环境:
- 当前目录下生成 ENV,进入,启动虚拟环境
virtualenv ENV # 创建一个名为ENV的目录, 并且安装了ENV/bin/python
#virtualenv --system-site-packages ENV # 继承已有环境
cd ENV
source ./bin/activate #激活当前virtualenv
# (ENV)➜ ENV git:(master) ✗ #注意终端发生了变化
【2020-5-14】注意:windows下没有bin目录,参考,执行方法:.\scripts\activate.bat
(4)关闭
# 关闭
deactivate
# 删除虚拟环境
rm -r venv
(5)指定python版本
- 可以使用-p PYTHON_EXE选项在创建虚拟环境的时候指定python版本
virtualenv venv --python=python3.5 # 指定python 3.5
#创建python2.7虚拟环境
virtualenv -p /usr/bin/python2.7 ENV2.7 # 指定本地python
virtualenv -p "C:\Program Files (x86)\Python\Python27" py2 # Windows下
添加 环境变量(env),并执行,便于启动
# vim ~/.bash_profile
alias env="source ${ENV}/bin/activate"
# 执行
source ~/.bash_profile
# 启动环境
env # 进入虚拟环境
anaconda 系列
anaconda 及 miniconda(小型版)
Conda 分为 Anaconda 和 Miniconda
Anaconda是一个包含了许多常用库的集合版本Miniconda是精简版本(只包含conda、pip、zlib、python 及所需的包),剩余的通过conda install command命令自行安装
anaconda
官方下载
# mac环境下安装
#brew cask install anaconda
brew install anaconda
export PATH="/usr/local/anaconda3/bin:$PATH"
# 官方地址,https://www.anaconda.com/products/individual,上面有最新版本地址
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
# 获取mincoda linux最新版
wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
# mincoda mac用户
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.sh
# 清华镜像地址: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/, 找最新下载地址
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh
bash Anaconda3-2019.03-Linux-x86_64.sh
# [2021-6-15]注意:直接使用以上命令会出错:from conda.cli import main ModuleNotFoundError: No module named 'conda'
# 解法:加-u
bash Anaconda3-2019.03-Linux-x86_64.sh -u
miniconda
【2023-2-27】miniconda安装过程
- 先后选择:enter(同意协议)→ yes(同意默认目录~/miniconda)→ yes(同意初始化)
- 执行环境变量: source ~/.bashrc
# 下载linux版本miniconda
wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 安装
sh Miniconda3-latest-Linux-x86_64.sh # enter(同意协议)→ yes(同意默认目录~/miniconda)→ yes(同意初始化)
# 环境变量配置
install_dir='/mnt/bn/flow-algo-intl/wangqiwen/bin'
export PATH=${PATH}:${install_dir}/miniconda3/bin # conda 命令路径
source ${install_dir}/miniconda3/etc/profile.d/conda.sh # 【2024-3-17】避免 Ubuntu上环境激活失效问题(conda init无效)
环境设置
conda config --set auto_activate_base true # 设置conda自动启动
# 自动在 ~/.bashrc 里添加环境变量
# 如果不执行,就报错, 且无法 activate 环境
conda activate base # 提示 CondaError: Run 'conda init' before 'conda activate'
# 添加bin路径, 并执行
source ~/.bashrc/ # 或 ~/.bash_profile
# 启动conda
conda
# 创建新的Python环境
conda create -n py310 python=3.10
conda activate py310 # 激活环境
conda deactivate
安装完成之后会多几个应用
- Anaconda Navigtor :用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在 Navigator 中手工实现。
- Jupyter notebook :基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程。
- qtconsole :一个可执行 IPython 的仿终端图形界面程序,相比 Python Shell 界面,qtconsole 可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
- spyder :一个使用Python语言、跨平台的、科学运算集成开发环境。
- 加入环境变量
- 安装器若提示“
Do you wish the installer to prepend the Anaconda install location to PATH in your /home/<user>/.bash_profile ?,建议输入“yes”。 - 如果输入“no”,则需要手动添加路径。添加 export PATH=”/
/bin:$PATH" 在 .bashrc 或者 .bash_profile 中。
- 安装器若提示“
- 注意:
- 不要擅自在bash_profile中添加alias别名!会导致虚拟环境切换后python、pip转换失效
# anaconda 环境
export PATH="~/anaconda3/bin:$PATH"
# 以下语句不要添加!
alias python='/home/wangqiwen004/anaconda3/bin/python'
alias pip='/home/wangqiwen004/anaconda3/bin/pip'
# 如果仍然失效,强制使用变量切换
sra(){
CONDA_ROOT="~/anaconda3"
env=$1
conda activate $env
export LD_LIBRARY_PATH="$CONDA_ROOT/envs/$env/lib:$LD_LIBRARY_PATH"
export PATH=$CONDA_ROOT/envs/$env/bin:$PATH
}
# 【2020-7-10】以上方法不支持默认环境base的切换,优化如下:
sra(){
CONDA_ROOT="~/anaconda3"
# 获取当前虚拟环境名称列表(不含base)
env_list=(`conda info -e | awk '{if($1!~/#|base/)printf $1" "}'`)
env=$1
conda activate $env
echo "env=$env, str=${env_list[@]}"
# 判断是否匹配已有环境名称
# echo "${env_list[@]}" | grep $env && echo "yes" || echo "no"
#[[ "$1" =~ "${env_str}" ]] && echo "yes" || echo "no"
#[[ ${env_list[@]/${env}/} != ${env_list[@]} ]] && {
res="no"
for i in ${env_list[@]}
do
[ "$i" == "$env" ] && res="yes"
done
[ $res == "yes" ] && {
echo "找到目标环境$env"
export LD_LIBRARY_PATH="$CONDA_ROOT/envs/$env/lib:$LD_LIBRARY_PATH"
export PATH=$CONDA_ROOT/envs/$env/bin:$PATH
}||{
echo "启用默认环境base"
env="base"
export LD_LIBRARY_PATH="$CONDA_ROOT/lib:$LD_LIBRARY_PATH"
export PATH=$CONDA_ROOT/bin:$PATH
}
echo "环境切换完毕: --> $env"
}
alias srd='conda deactivate'
# 激活的使用方法
sra learn
- 注意:不要这样加!
常用命令
汇总如下:
conda --version # 查看版本
# 创建新的Python环境
conda create -n py310 python=3.10
conda activate py310 # 激活环境
conda deactivate
activate # 切换到base环境
activate py3 # 切换到py3环境
conda create -n py3 python=3 # 创建一个名为py3的环境并指定python版本为3(的最新版本,也可以是2.7、3.6等))
conda create -n py3 numpy matplotlib python=2.7 # 创建环境同时安装必要的包
conda create -n py36_tf1 python=3.6 tensorflow==1.11 # [2020-7-21]
conda create -n myenv python=3.6 -y # 免交互提示
conda create --prefix="D:\\my_python\\envs\\my_py_env" python=3.6.3 # 自定义虚拟环境
conda create --name env_name --clone py3 # 克隆环境 py3 -> env_name
conda env list # 列出conda管理的所有环境, conda info -e
source activate py3 # linux下激活虚拟环境conda activate,windows下为:activate py3
source deactivate # linux下关闭虚拟环境conda deactivate,windows下为:deactivate
conda list # 列出当前环境的所有包
conda list -n py3 # 列出某环境下的所有包
conda install requests #安装requests包, 同pip install
# 【2023-2-27】
conda install -q pandas # 静默安装
conda install -y pandas # 默认yes,免交互提示
conda install --yes pandas # 默认yes,免交互提示
# 或者使用环境变量
# enable yes to all in current env
conda config --env --set always_yes true
# disable it in current env
conda config --env --remove always_yes
conda install -n your_env_name [package] # 即可安装package到your_env_name中
conda remove requests #卸载requets包
conda remove -n py3 --all # 删除py3环境及下属所有包
conda remove --name py3 package_name # 删除py3环境下某个包
# pip install openpyxl -U
# conda update openpyxl
conda update requests # 更新requests包
# conda update --all # 更新所有库
conda search pyqtgraph # 搜索包(模糊查找)
conda search --full-name pyqtgraph # 精确查找
conda env export > environment.yaml # 导出当前环境的包信息
conda env create -f environment.yaml # 用配置文件创建新的虚拟环境
下载源设置
# 添加Anaconda的TUNA镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
# TUNA的help中镜像地址加有引号,需要去掉
# -------- 清华镜像 ---------
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
#Conda Forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
#msys2(可略)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
#bioconda(可略)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
#menpo(可略)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
#pytorch
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
# for legacy win-64(可略)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/peterjc123/
conda config --set show_channel_urls yes
#-------- 中科大镜像 --------
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
conda config --set show_channel_urls yes
#-------- 北外镜像 ---------
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/main/
#Conda Forge
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/conda-forge/
#msys2(可略)
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/msys2/
#bioconda(可略)
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/bioconda/
#menpo(可略)
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/menpo/
#pytorch
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
# for legacy win-64(可略)
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/peterjc123/
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
# 【2021-6-15】直接修改文件
vim ~/.condarc
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
ssl_verify: true
问题解决
install 速度慢
- 使用
conda install安装各种包的时候速度很慢,参考:conda install速度慢
解决
- 修改conda镜像路径
- 执行如下命令,更换仓库径路为清华镜像路径
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- 在自己用户目录C:\Users<你的用户名>下生成一个文件,名字为:~/.condarc
conda config --set show_channel_urls yes
- 修改.condarc文件为如下:
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
show_channel_urls: true
ssl_verify: true
- 执行完上述三步,conda的镜像路径就更换完毕,如不放心可以
conda info查看 channel URLs 信息已经更改。
【2021-9-22】更换清华源后,依然很慢:出现卡顿/失败
- Collecting package metadata (repodata.json)
- 解决办法: 将.condarc中的清华源的https全部换成http,或者将代理软件(clash for windows)设置为全局代理
- conda清除国内源:conda config –remove-key channels
channel 问题
【2020-8-22】执行 conda install flask-restplus 时,pip没问题
- Solving environment: failed with initial frozen solve. Retrying with flexible solve
- 解决:执行
conda config --add channels conda-forgeconda config --set channel_priority flexible
【2021-7-15】问题:
- PackagesNotFoundError: The following packages are not available from current channels
- 解决:
conda config --add channels https://anaconda.org(缺失的源)
env 激活失败
【2023-7-21】conda activate 激活失败
- 错误提示:
- 【2024-3-8】 CondaError: Run ‘conda init’ before ‘conda activate’
- CommandNotFoundError: Your shell has not been properly configured to use ‘conda activate’
- 按照提示执行
conda init bash并重新打开窗口依然不行
解决方法: refer
- anaconda:
source ~/anaconda3/etc/profile.d/conda.sh - minconda:
source ~/miniconda3/etc/profile.d/conda.sh# 实践成功
# 环境变量配置
install_dir='/mnt/bn/flow-algo-intl/wangqiwen/bin'
export PATH=${PATH}:${install_dir}/miniconda3/bin # conda 命令路径
source ${install_dir}/miniconda3/etc/profile.d/conda.sh # 【2024-3-17】避免 Ubuntu上环境激活失效问题(conda init无效)
Python 3.12 问题
安装 wandb 时,出错
pip install -U byted-wandb -i https://bytedpypi.byted.org/simple
错误信息
ModuleNotFoundError: No module named ‘imp’
原因:
- Python 3.12版本问题, imp 丢弃
解法:
- (1) 替换 imp:
import imp->import importlib - (2) 使用 Python 3.11
conda 环境迁移
【2024-3-27】将conda安装目录复制到新目录后,修改路径后,用 pip install 安装软件时,依然调用旧目录
- 更新 ~/.bashrc 里的旧目录, source 后,
conda init # 安装conda后,自动通过 conda init 命令在 ~/.bashrc 尾部追加以下代码片段
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/condabin/conda
# no change /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/conda
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/conda-env
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/activate
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/deactivate
# no change /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/etc/profile.d/conda.sh
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/etc/fish/conf.d/conda.fish
# no change /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/shell/condabin/Conda.psm1
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/shell/condabin/conda-hook.ps1
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/lib/python3.12/site-packages/xontrib/# conda.xsh
# modified /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/etc/profile.d/conda.csh
# no change /root/.bashrc
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/etc/profile.d/conda.sh" ]; then
. "/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/etc/profile.d/conda.sh"
else
export PATH="/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
# 指向新路径
which conda pip python
# /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/conda
# /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/pip
# /mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/python
# 但 执行 conda 时,还是指向旧路径
conda env list
# bash: /mnt/bn/larkai-fr-gpt/wangqiwen/bin/miniconda3/bin/conda: No such file or directory
原因:
- 当前版本下的 conda 和 pip 文件是python代码, 且第一行就指定了Python旧路径
- 修改配置文件里的目录(
CONDA_EXE和CONDA_PYTHON_EXE),miniconda3/etc/profile.d/conda.sh - vim 修改命令:
%s/larkai-fr-gpt/flow-algo-cn/g
head ../../bin/miniconda3/etc/profile.d/conda.sh
# 显示内容
export CONDA_EXE='/mnt/bn/larkai-fr-gpt/wangqiwen/bin/miniconda3/bin/conda'
export _CE_M=''
export _CE_CONDA=''
export CONDA_PYTHON_EXE='/mnt/bn/larkai-fr-gpt/wangqiwen/bin/miniconda3/bin/python'
# 以上旧路径都改成新路径
#!/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/python
# Copyright (C) 2012 Anaconda, Inc
# SPDX-License-Identifier: BSD-3-Clause
__conda_exe() (
"$CONDA_EXE" $_CE_M $_CE_CONDA "$@"
)
这个配置文件会影响其他文件,如: conda, pip
- 单独修改 这两个文件没用
conda_dir="/mnt/bn/flow-algo-cn/wangqiwen/bin"
cat ${conda_dir}/miniconda3/bin/conda
cat ${conda_dir}/miniconda3/bin/pip
You will probably get the following:
# ----------------- 【conda 文件】 ----------------
#!/mnt/bn/larkai-fr-gpt/wangqiwen/bin/miniconda3/bin/python
# 改成新路径
#!/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/python
# -*- coding: utf-8 -*-
import sys
# Before any more imports, leave cwd out of sys.path for internal 'conda shell.*' commands.
# see https://github.com/conda/conda/issues/6549
if len(sys.argv) > 1 and sys.argv[1].startswith('shell.') and sys.path and sys.path[0] == '':
# The standard first entry in sys.path is an empty string,
# and os.path.abspath('') expands to os.getcwd().
del sys.path[0]
# ----------------- 【pip 文件】 ----------------
#!/mnt/bn/larkai-fr-gpt/wangqiwen/bin/miniconda3/bin/python
# 改成新路径
#!/mnt/bn/flow-algo-cn/wangqiwen/bin/miniconda3/bin/python
# -*- coding: utf-8 -*-
import re
import sys
from pip._internal.cli.main import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0])
UV
Rust 编写的极速 Python 包和项目管理工具
- 【2025-4-5】UV包管理工具全面指南:对比conda/pip与实战教程
- UV中文文档
包管理和虚拟环境工具演进
pip->virtualenv->conda->UV(Ultrafast Virtualenv)
UV 简介
UV(Ultrafast Virtualenv)是 Astral 团队2023年用Rust开发的新一代Python包管理工具。
设计目标
- 解决Python包管理中的速度和依赖解析问题,使Python开发更加流畅高效。
UV 由 Rust语言编写,性能上有显著优势。
可替代 pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv
UV 特点
传统 Python 需要多个工具配合:
- venv 创建环境
- pip 装包
- requirements.txt 管依赖
- 手动处理依赖冲突
- virtualenvwrapper 管多项目
- pip-tools 锁依赖
而 uv 整合这些功能,统一通过 pyproject.toml + uv.lock 管理。
这种集中式管理方式极大提升了开发专注度:不再分神在环境配置上,只专注写业务逻辑。
特点
- 极速安装:比pip和conda快5-10倍
- 可靠的依赖解析:使用先进的解析算法,能更好地处理复杂依赖关系
- 兼容性:与pip的大部分命令兼容,支持requirements.txt和pyproject.toml
- 高效缓存:智能缓存系统,减少重复下载
- 原子操作:安装过程更安全,失败时不会留下半完成状态
- 轻量级:专注于Python包管理,不像conda那样管理整个系统级依赖
另外
- UV 兼容 pip 大部分命令,但某些高级或不常用的选项可能不支持。使用
uv pip --help查看支持的选项。 - UV创建的是标准Python虚拟环境,可以被任何支持venv的工具识别。
对比分析
UV vs. conda vs. pip :深度对比
设计哲学与适用场景
| 工具 | 设计哲学 | 最适用场景 |
|---|---|---|
| UV | 极速、安全的Python包管理 | Python Web开发、一般Python项目 |
| conda | 全语言包管理系统 | 数据科学、跨语言项目、需要系统级依赖的项目 |
| pip | Python官方包安装工具 | 简单Python项目、作为其他工具的后端 |
总结:uv
- 快: rust编写,并行安装依赖,比 pip 和 conda 都快;
- 现代: 项目结构清晰,依赖写在 pyproject.toml ,最后锁定在 lock文件 中;
- 轻: 删除
.venv文件夹就等于删掉环境; - 干净: 不污染系统,不自动写配置,不乱改 .bashrc
venv、Conda (Miniconda) 、uv (推荐project模式)
具体特性对比内容如下:
| 特性 | venv | Conda (Miniconda) | uv (推荐project模式) |
|---|---|---|---|
| 是否内置 | ✅是 | ❌(需安装) | ❌(需安装) |
| 安装方式 | Python自带 | 官网下载安装(推荐Miniconda) | pip install uv |
| 环境创建速度 | ✅快 | ❌慢 | 超快(并行) |
| 占用空间 | ✅小 | ❌大 | ✅小 |
| 依赖管理 | 手动requirements.txt | conda + pip | ✅pyproject.toml + uv.lock |
| 项目初始化 | ❌无 | ❌无 | ✅uv init一键结构化 |
| 源支持 | 使用pip镜像 | 使用Conda自有源 | 使用pip镜像 |
| 非Python包支持 | ❌ | ✅(如cudatoolkit) | ❌ |
| 适合场景 | 脚本 / 嵌入式工具链 | 数据科学 / 科研项目 | 所有项目,特别是现代开发 |
虚拟环境管理对比
UV
- 创建标准兼容的Python虚拟环境
- 与venv模块兼容,但速度更快
- 环境激活方式与标准Python虚拟环境相同
conda
- 创建独立的环境,包含完整的Python解释器副本
- 环境之间完全隔离,包括系统库
- 需要特定的conda命令来激活环境
pip
- 本身不创建虚拟环境,通常与venv或virtualenv配合使用
- 只管理Python包,不处理环境
依赖解析方式
UV 使用先进的依赖解析器,能更快地解决冲突 在复杂依赖网络中表现更好 支持锁文件,确保环境可重现
conda 有自己的依赖解析系统,考虑非Python依赖 解析速度较慢,但能处理跨语言依赖 使用environment.yml管理环境
pip 简单的依赖解析,可能在复杂情况下出现问题 不支持原生锁文件(需要依赖pip-tools等工具) 在解决依赖冲突时可能不够智能
性能对比
在安装pandas包及其依赖时的性能对比(数据为示例):
| 工具 | 首次安装时间 | 重复安装时间(缓存后) |
|---|---|---|
| UV | 8秒 | 2秒 |
| conda | 45秒 | 12秒 |
| pip | 25秒 | 10秒 |
UV 安装
安装UV工具:
# 使用pipx安装(推荐)
pipx install uv
# 或使用pip安装
pip install uv
# 或在conda环境中安装
conda install uv -c conda-forge
#-------------
# Linux或者MacOS系统安装:
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows系统:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# 或直接 pip 安装(可能影响系统 Python):
pip install uv
# 检查是否安装成功
uv --help
uv --version # uv 0.9.20
uv -v
uv python list # 查看可用python版本
#--------- 更新 --------
uv self update # 仅独立安装模式
# [2026-3-24] macos 实测有效
# info: Checking for updates...
# success: Upgraded uv from v0.9.21 to v0.11.0! https://github.com/astral-sh/uv/releases/tag/0.11.0
pip install uv --upgrade
或
# 默认安装在 ~/.local/bin
# 如果设置了 XDG_BIN_HOME,则会使用该路径代替。
# 如果设置了 XDG_DATA_HOME,目标目录将推断为 XDG_DATA_HOME/../bin。
curl -LsSf https://astral.sh/uv/install.sh | sh
# 自定义安装路径,使用 UV_INSTALL_DIR
# powershell 实测无效,报错
$env:UV_INSTALL_DIR = "E:\program_file\uv" powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# powershell 实测有效
$env:XDG_BIN_HOME='E:\program_file\uv'
问题
win 11上,自定义安装目录到 e 盘,出现问题:
- uv 安装后,没有 uv.exe 文件
原因
- 默认将 uv.exe 编译到
Lib\site-packages\bin中,而此目录已存在(如提前安装了别的库 tensorboard),导致生成失败
按照提示,加 –upgrade 后,bin 目录被覆盖,别的bin文件没了
- E:\program_file\python\Lib\site-packages\bin
pip install uv
# Successfully installed uv-0.6.14
# WARNING: Target directory E:\program_file\python\Lib\site-packages\uv already exists. Specify --upgrade to force replacement.
# WARNING: Target directory E:\program_file\python\Lib\site-packages\uv-0.6.14.dist-info already exists. Specify --upgrade to force replacement.
# WARNING: Target directory E:\program_file\python\Lib\site-packages\bin already exists. Specify --upgrade to force replacement.
# 按照提示,
pip install uv --upgrade
改进:
- 手工将 bin 目录下 exe 文件复制到 E:\program_file\python\Scripts
使用
使用方式:
- (1) 传统方式: venv + pip 加速版,适合脚本或已有项目
- (2) project 模式: 类似nodejs 的 npm
- (3) Tool 模式
(1) 虚拟环境(传统)
传统方式(兼容 venv):
uv status # 显示当前环境信息
source myenv/bin/activate # 激活环境
# 工具包安装
uv pip list
uv pip install --upgrade numpy # 升级
uv pip install numpy
uv pip uninstall numpy
uv pip freeze > requirements.txt # 导出依赖包
uv pip install <path_to_wheel>.whl # 本地wheel文件
uv pip install -r requirements.txt
uv pip install -r requirements.txt --force-reinstall # 覆盖安装
(2) project 模式
推荐方式:project 模式
uv init # 初始化项目(生成 pyproject.toml)
uv add numpy # 安装依赖并自动写入配置文件
uv run main.py # 自动激活环境 + 运行代码
执行 uv run 时,uv 会自动创建 .venv 文件夹,读取 pyproject.toml 和 uv.lock,同步依赖并运行程序。
还可以
uv add -r requirements.txt # 从传统依赖列表迁移
模式(2)和现有工程融合, 从创建到build都包含。
uv 推荐模式以项目为中心,类似 npm 的体验:
uv init
uv add flask
uv run app.py
一切都写在 pyproject.toml,不需要手动维护 requirements.txt,也不需要关心激活哪个环境、有没有冲突
- 因为环境就是项目自己管理的
.venv文件夹。 - 只要把项目文件夹打包发给别人,对方很快就能100%同步
git clone ...
uv sync
就能 100% 还原运行环境。比 pip + venv 要靠谱
(3) Tool 模式
除了project,还有 tool 方式,安装和运行命令行程序时,做到较好的隔离。 比如
uv tool install --python 3.12 pdf2zh
一键安装pdf翻译工具。独立依赖,不会因电脑环境导致问题。
虚拟环境
创建新环境:
# 创建名为 "myproject" 新虚拟环境
uv venv myproject
# 指定 Python版本
uv venv myproject --python=3.10
激活环境:
source myproject/bin/activate # Unix/Linux/macOS:
myproject\\Scripts\\activate # Windows:
deactivate # 退出环境
注意:没有 list 命令!conda 采用中心注册机制,uv 放弃中心管理模式,采用“一个环境一个项目”的工作流,venv 相互隔离
- 暂无查看虚拟环境的命令!没有 list 命令(uv venv list), 有人提了建议,官方issue尚未采纳
- 替代方法:uv python list 查看python版本
uv venv myenv --python=3.10 # 创建虚拟环境
uv create myenv # 创建虚拟环境
uv create myenv --python=python3.8
# 切换虚拟环境
uv switch myenv --python=python3.9
uv status # 显示当前环境信息
source myenv/bin/activate # 激活环境
uv cache clean # 清理缓存
uv delete myenv # 删除虚拟环境
uv activate anotherenv # 切换到其他虚拟环境
uv venv list # 不存在! ls ~/.cache/uv/environments*
安装包
uv 安装Python
uv python list # 查看python
uv python install # 默认最新版,cpython
uv python install 3.12 # 指定版本
uv python install 3.11 3.12
uv python install pypy@3.10 # pypy
uv python install --reinstall # 重新安装
配置
设置环境变量
| 变量 | 功能 | 取值 | 分析 |
|---|---|---|---|
UV_DEFAULT_INDEX |
指定国内源,加速安装 | https://pypi.tuna.tsinghua.edu.cn/simple |
|
XDG_BIN_HOME |
自定义安装路径 | ‘E:\program_file\uv’ | |
直接安装
# 安装单个包
uv pip install numpy
# 安装特定版本
uv pip install pandas==2.0.0
# 从requirements.txt安装
uv pip install -r requirements.txt
# 从pyproject.toml安装
uv pip install -e .
性能优化功能
# 并行安装依赖
uv pip install -r requirements.txt --parallel
# 使用缓存安装
uv pip install numpy --cache-dir ~/.uv/cache
依赖解析失败时如何处理?
解决方案:
# 查看详细的依赖冲突信息
uv pip install package-name --verbose
# 尝试放宽版本限制
uv pip install "package-name>=1.0.0" --no-deps
UV缓存占用太多空间
解决方案:
# 清理UV缓存
uv cache clean
# 限制缓存大小
uv cache limit 2GB
uv tool
“tool”命令:独立工具安装
UV 提供类似于 pipx 的功能,隔离环境中安装Python工具,同时命令行接口全局可用。
这个功能通过 uv tool 命令实现。
c install vs 普通包安装:
简明对比
普通包安装 (例如 pip install black)
- 安装位置:安装到当前活跃的Python环境中
- 使用范围:只能在安装环境中使用
- 环境影响:可能会影响当前环境的其他包
- 使用方式:需要先激活环境才能使用
把工具放在一个特定的工具箱里,只有打开那个工具箱时才能用这工具。
# 在项目A环境中
pip install black
# 在项目B环境中也需要单独安装
pip install black
uv tool install black (类似于 pipx install black)
- 安装位置:创建专用隔离环境来安装这个工具
- 使用范围:全局可用,任何终端会话都能使用
- 环境影响:不会影响其他Python项目或环境
- 使用方式:直接在命令行调用,无需激活环境
给工具建了独立的小房间,但在房子的任何地方都能用到它。
uv tool安装:
# 只需安装一次
uv tool install black
# 在任何项目中都可以使用black命令,不需要激活环境
uv tool install 让工具全局可用,且不与项目环境冲突。适用于想在所有项目中使用的命令行工具。
uv tool安装的工具无法运行?
解决方案:
# 检查工具是否成功安装
uv tool list
# 检查PATH环境变量是否包含UV的bin目录
echo $PATH
# 重新安装工具
uv tool install --force tool-name
uv tool 安装的工具版本管理?
解决方案:
# 查看当前安装的版本
uv tool list
# 安装特定版本
uv tool install tool-name==1.2.3
# 升级到最新版本
uv tool upgrade tool-name
项目管理
项目依赖文件
uv tree # 查看依赖树
# 将当前环境导出到requirements.txt
uv pip freeze > requirements.txt
# 创建锁文件
uv pip compile pyproject.toml -o requirements.lock
工具集成
Poetry
与Poetry项目集成:
# 从Poetry项目安装依赖
uv pip install -e .
# 将Poetry依赖导出并安装
poetry export -f requirements.txt | uv pip install -r -
PDM
与PDM项目集成:
# 使用PDM生成的requirements.txt
uv pip install -r pdm.lock
conda
UV和conda可以协同工作
conda管理Python解释器和系统库
# 创建基础conda环境,只包含Python和系统依赖
conda create -n datascience python=3.10 numpy pandas -c conda-forge
# 激活环境
conda activate datascience
# 使用UV安装其余Python包
uv pip install scikit-learn matplotlib seaborn jupyterlab
现有conda项目中引入UV
对于已有的conda项目,可以逐步引入UV:
# 从conda环境导出Python包依赖
conda activate myenv
pip freeze > requirements.txt
# 使用UV安装新的Python包依赖
uv pip install -r requirements.txt
uv pip install new-package
使用UV的tool命令替代conda安装独立工具
# 替代conda安装独立工具
uv tool install --force --python python3.10 jupyter
uv tool install --force --python python3.11 black mypy ruff
UV 使用命令
python 版本
# 管理 Python 版本。
uv python install # 安装 Python 版本。
uv python list # 查看可用的 Python 版本。
uv python find # 查找已安装的 Python 版本。
uv python pin # 为当前项目指定使用的 Python 版本。
uv python uninstall # 卸载 Python 版本。
运行独立的 Python 脚本(如 example.py)。
uv run # 运行脚本。
uv add --script # 为脚本添加依赖。
uv remove --script # 从脚本中移除依赖。
tool 管理
# 安装Python工具
uv tool install black
# 指定版本安装
uv tool install flake8==6.0.0
# 安装最新版本
uv tool install mypy@latest
# 使用特定Python版本安装
uv tool install --python python3.11 pytest
# 强制重新安装
uv tool install --force django-admin
高级选项
# 安装带有额外依赖的工具
uv tool install "jupyter[notebook]"
# 从特定源安装
uv tool install --index-url <https://test.pypi.org/simple/> experimental-tool
# 安装开发版本
uv tool install git+https://github.com/user/project.git
# 列出已安装的工具
uv tool list
# 升级已安装的工具
uv tool upgrade aider-chat
# 卸载工具
uv tool uninstall black
uvx / uv tool run # 在临时环境中运行工具。
uv tool install # 全局安装工具。
uv tool uninstall # 卸载工具。
uv tool list # 列出已安装的工具。
uv tool update-shell # 更新 shell,使工具可执行文件生效。
uv tool 命令的优势:
- 比pipx更快的安装速度
- 更可靠的依赖解析
- 与UV的其他命令保持一致的体验
- 支持多种安装源和安装方式
项目管理
创建并管理包含 pyproject.toml 的 Python 项目。
uv init # 创建一个新项目。
uv add # 向项目添加依赖。
uv remove # 从项目中移除依赖。
uv sync # 同步项目依赖到环境。
uv lock # 为项目依赖创建锁文件。
uv run # 在项目环境中运行命令。
uv tree # 查看项目的依赖树。
uv build # 构建项目的分发包。
uv publish # 将项目发布到包索引。
包管理
uv venv # 创建新虚拟环境
uv pip install # 安装包到当前环境。
uv pip show # 显示已安装包的详细信息。
uv pip freeze # 列出已安装包及其版本。
uv pip check # 检查当前环境中的包是否兼容。
uv pip list # 列出已安装的包。
uv pip uninstall # 卸载包。
uv pip tree # 查看环境的依赖树。
# 锁定报
uv pip compile # 将需求文件编译为锁文件。
uv pip sync # 根据锁文件同步环境。
状态管理
uv 的状态,如缓存、存储目录,或执行自更新:
uv cache clean # 清理缓存条目。
uv cache prune # 清理过期的缓存条目。
uv cache dir # 显示 uv 缓存目录路径。
uv tool dir # 显示 uv 工具目录路径。
uv python dir # 显示 uv 安装的 Python 版本路径。
uv self update # 将 uv 更新到最新版本。
案例
Web开发项目步骤:
创建和设置项目:
# 创建项目目录
mkdir webproject && cd webproject
# 创建虚拟环境
uv venv .venv
source .venv/bin/activate # 或在Windows上使用 .venv\\Scripts\\activate
# 创建基本项目结构
mkdir -p src/webproject tests
touch pyproject.toml
配置项目依赖: pyproject.toml
[project]
name = "webproject"
version = "0.1.0"
description = "A web project example"
dependencies = [
"flask>=2.0.0",
"sqlalchemy>=2.0.0",
"pydantic>=2.0.0",
]
安装依赖:
# 安装项目依赖
uv pip install -e .
# 安装开发依赖
uv pip install pytest black mypy
创建锁文件:
# 生成锁文件确保环境可重现
uv pip compile pyproject.toml -o requirements.lock
安装开发工具:
# 使用uv tool安装常用开发工具
uv tool install black
uv tool install --python python3.10 aider-chat@latest
开发项目:
# 添加更多依赖时
# 1. 更新pyproject.toml
# 2. 运行:
uv pip install -e .
# 3. 更新锁文件:
uv pip compile pyproject.toml -o requirements.lock
可执行文件
Python 打包
- 将 可见的 Python 源码转成不可见可执行文件
- 好处: 不用安装依赖包、提升安全性
- 运行环境: win下的exe, linux下的bin文件
总结
【2025-2-25】Python 脚本打包工具
| 工具 | 打包输出 | 适用平台 | 分析 | 备注 |
|---|---|---|---|---|
Py2exe |
可执行文件 | windows | 已经停止维护 | |
py2app |
可执行文件 | Mac | ||
pyinstaller |
可执行文件 | win/linux/mac | 次之 | |
cx_Freeze |
可执行文件 | 跨平台 | ||
Nuitka |
可执行文件 | win/linux/mac | 推荐 | |
setuptools |
Python工具包 | - | 打包分发 |
setuptools
setuptools 是 python标准的打包分发工具,将python项目打包安装
- 其他人像调用标准库或python第三方库那样直接使用;
- 也可以将项目上传到Pypi供更多人的下载安装使用。
构建前的结构包含:demo、docs、setup.py , 其中主要的 demo文件夹和setup.py。
setup.py 内容示例
import os, shutil
from setuptools import setup, find_packages
#移除构建的build文件夹
CUR_PATH = os.path.dirname(os.path.abspath(__file__))
path = os.path.join(CUR_PATH, 'build')
if os.path.isdir(path):
print('INFO del dir ', path)
shutil.rmtree(path)
setup(
name = 'demo', #应用名
author = 'selfeasy',
version = '0.1', #版本号
packages = find_packages(), #包括在安装包内的Python包
include_package_data = True, #启用清单文件MANIFEST.in,包含数据文件
exclude_package_data = {'docs':['1.txt']}, #排除文件
install_requires = [#自动安装依赖
'Flask>=0.10',
],
)
打包
python setup.py bdist_egg
python setup.py --help #查看setup文件的配置信息可以包含哪些
python setup.py --help-commands # 查看程序打包和分发可以使用的命令有哪些
当前目录下的”dist”创建”egg”文件,名为”MyApp-1.0-py2.7.egg”。
- 文件名格式: ”应用名-版本号-Python版本.egg”
- 当前目录多了”build”和”MyApp.egg-info”子目录来存放打包的中间结果。
安装
python setup.py install
将当前的Python应用安装到当前Python环境的”site-packages”目录下,像导入标准库一样导入该应用的代码
py2exe
py2exe 是Python打包工具,将Python代码打包成Windows可执行文件。
使用 py2exe 打包Python代码也很简单,只需要在命令行中输入以下命令:
python setup.py py2exe
cx_Freeze
cx_Freeze 将 Python 脚本打包成可执行文件,并且支持跨平台。
使用 cx_Freeze 也可以将 Python 代码打包成独立的可执行文件。
安装 cx_Freeze
pip install cx-Freeze
使用 cx_Freeze 打包
cxfreeze your_script.py --target-dir dist
执行以上命令后,cx_Freeze 将会在指定目录下生成可执行文件。
py2app
py2app 将 Python代码打包成MacOS可执行文件。
使用
python setup.py py2app
pyinstaller
用 pyInstaller 打包的示例命令
安装
pip install pyinstaller
使用
# 打包单个文件
pyinstaller your_script.py
# 打包多个py文件
pyinstaller [主文件] -p [其他文件1] -p [其他文件2]
# 打包时去除cmd框
pyinstaller -F XXX.py --noconsole
# 打包加入exe图标 picturename.ico是图片
pyinstaller -F -i picturename.ico -w XXX.py
# 打包去除控制台
pyinstaller -w xxx.py
# 打包方便查看报错,可看到控制台
pyinstaller -c xxx.py
# 错误
# class RegexFlag(enum.IntFlag):
# AttributeError: module 'enum' has no attribute 'IntFlag'
# 查看是否安装enum34包
# 卸载enum34即可,python程序可正常运行
执行命令后,pyinstaller 将会在当前目录下生成多个文件,其中包含了打包好的可执行文件。
- 目录:
build(打包时临时文件)dist(打包好的应用) 包含 exe 和 依赖包
- 文件:
xxx.spec(打包参数)
Nuitka
新一代 Python打包+加速神器:Nuitka
可打包 Python代码,并提升执行效率,支持多平台
Nuitka 是Python编译器,将Python代码编译成C++代码,然后将其打包成可执行文件。
使用命令:
nuitka your_script.py
这将生成一个可执行文件,在Windows、Linux和MacOS上运行。
Nuitka 和 pyinstaller 可以结合使用
- 将 Python代码 编译成C++代码,然后 pyinstaller将其打包成可执行文件。
命令:
nuitka --standalone your_script.py
pyinstaller your_script.spec
Python 教程
python入门教程:
入门路线图
- 基本语法
- 变量
- 数据类型: 字符串、数值型、list、tuple、set、bool、dict
- 控制流: 条件判断、循环
- 函数: 迭代器、生成器
- 面向对象: 类、抽象、继承
- 装饰器、异常
- 模块
- 测试
变量
命名规则
变量的命名规则
- 1、需要见名知义,通过变量名,就知道它所指向的值是什么。
- 2、变量名可以由字母、下划线和数字组成。
- 3、但是不能以数字开头。
- 4、页不能以关键字重名。
- 5、建议不要与内置函数或者是类重名,不然会覆盖原始内置函数的功能。
- 6、被视为一种惯例,并无绝对性与强制性。
- 7、目的是为了增加代码的可读性。
注意
- Python中的标识符区分大小写
变量类型
数据类型可以分为数字型和非数字型
- 数字型:整型(int)、浮点数(float)、布尔(bool)、复数(complex)
- 非数字型:字符串、列表、元组、字典
提示:
- 在Python2.0中,整数根据保存数值的长度还分为:int(整数)、long(长整数)
类型判断
判断变量类型的几种方法
- type: type(a) == type([])
- isinstance(a, list)
prompt = 'fdsfd'
print(type(prompt))
# if type(prompt) != 'str':
if type(prompt) != type('test'):
print('不是str')
else:
print('是str')
if isinstance(prompt, str):
print('是str')
else:
print('不是str')
传值 or 传引用
在 C/C++ 中,传值和传引用是函数参数传递的两种方式,在Python中参数是如何传递的?
- python函数参数既不是传参,也不是传引用,而是传对象!
- Python 函数中,参数的传递本质上是一种赋值操作,而赋值操作是一种名字到对象的绑定过程
全局变量
注意
- 引用全局变量,不需要golbal声明
- 修改全局变量,需要使用global声明
- 特别地,列表、字典等如果只是修改其中元素的值,可以直接使用全局变量,不需要global声明
#!/usr/bin/python
# Filename: func_global.py
def func():
global x
print 'x is', x
x = 2
print 'Changed local x to', x
x = 50
func()
print 'Value of x is', x
类型提示 typing
Python 主要卖点之一是动态类型,这一点也不会改变。
- 2014年9月,Guido van Rossum (Python BDFL) 创建了一个Python增强提议(PEP-484),为Python添加类型提示(Type Hints)。并在一年后,于2015年9月作为Python3.5.0的一部分发布了。于是对于存在了二十五年的Python,有了一种标准方法向代码中添加类型信息
- 仅仅提示作用:输入函数的第一个参数 first_name,输入点号(.)然后敲下 Ctrl+Space 来触发代码补全
def test(a: str) -> str:
print(a)
return 3
def document_frequency(term: str, corpus: str) -> tuple[int, int]:
"""
Calculate the number of documents in a corpus that contain a
given term
@params : term, the term to search each document for, and corpus, a collection of
documents. Each document should be separated by a newline.
@returns : the number of documents in the corpus that contain the term you are
searching for and the number of documents in the corpus
@examples :
>>> document_frequency("first", "This is the first document in the corpus.\\nThIs\
is the second document in the corpus.\\nTHIS is \
the third document in the corpus.")
(1, 3)
"""
corpus_without_punctuation = corpus.lower().translate(
str.maketrans("", "", string.punctuation)
) # strip all punctuation and replace it with ''
docs = corpus_without_punctuation.split("\n")
term = term.lower()
return (len([doc for doc in docs if term in doc]), len(docs))
以上类型提示方式偏弱,对于复杂类型不管用, 即便已经声明为了对应的类型,但实际上并不能反映整个列表、元组的结构
names: list = ['Germey', 'Guido'] # 并不知道元素时string类型
version: tuple = (3, 7, 4) # 并不知道元素是 int
operations: dict = {'show': False, 'sort': True}
typing 模块提供了非常 “强 “的类型支持,比如 List[str]、Tuple[int, int, int] 则可以表示由 str 类型的元素组成的列表和由 int 类型的元素组成的长度为 3 的元组。
# 强类型提示
from typing import List, Tuple, Dict
# List(列表) 是 list 的泛型
names: List[str] = ['Germey', 'Guido']
var: List[int or float] = [2, 3.5] # 多种元素类型
var: List[List[int]] = [[1, 2], [2, 3]] # 嵌套
# Tuple(元组)是 tuple 的泛型
version: Tuple[int, int, int] = (3, 7, 4)
person: Tuple[str, int, float] = ('Mike', 22, 1.75) # 多种类型
# Sequence,是 collections.abc.Sequence 的泛型,不区分是列表还是元组
def square(elements: Sequence[float]) -> List[float]:
return [x ** 2 for x in elements]
# Dict(字典)是 dict 的泛型;Dict 用于注解返回类型
operations: Dict[str, bool] = {'show': False, 'sort': True}
# Mapping(映射)是 collections.abc.Mapping 的泛型。Mapping 用于注解参数
def size(rect: Mapping[str, int]) -> Dict[str, int]:
return {'width': rect['width'] + 100, 'height': rect['width'] + 100}
# Set(集合)是 set 的泛型;Set 用于注解返回类型
# AbstractSet 是 collections.abc.Set 的泛型,用于注解参数。
def describe(s: AbstractSet[int]) -> Set[int]:
return set(s)
# NoReturn,当一个方法没有返回结果时,注解它的返回类型
def hello() -> NoReturn:
print('hello')
# Any是一种特殊的类型,可以代表所有类型,静态类型检查器的所有类型都与 Any 类型兼容,所有的无参数类型注解和返回类型注解的都会默认使用 Any 类型
def add(a):
return a + 1
def add(a: Any) -> Any:
return a + 1
# TypeVar 自定义兼容特定类型的变量
height = 1.75
Height = TypeVar('Height', int, float, None)
def get_height() -> Height:
return height
# NewType 声明一些具有特殊含义的类型
Person = NewType('Person', Tuple[str, int, float])
person = Person(('Mike', 22, 1.75))
# Callable,可调用类型
print(Callable, type(add), isinstance(add, Callable)) # typing.Callable <class 'function'> True
# Union,联合类型,Union[X, Y] 代表要么是 X 类型,要么是 Y 类型。 联合类型的联合类型等价于展平后的类型
Union[Union[int, str], float] == Union[int, str, float]
Union[int] == int # 仅有一个参数的联合类型会坍缩成参数自身
Union[int, str, int] == Union[int, str] # 多余的参数会被跳过
Union[int, str] == Union[str, int] # 在比较联合类型的时候,参数顺序会被忽略
【2023-11-9】LLM 推理代码
from typing import Any, Dict, List, Union
prompts: List[str] = [
"user: 上海有什么好玩的地方 assistant: ",
"user: 请给我一些学习上的建议 assistant: ",
]
print(prompts)
数值型
bool
bool 类型来表示真(True)或假(False),
True 和 False 是 Python 中的关键字,当作为 Python 代码输入时,一定要注意字母的大小写,否则解释器会报错。
bool 类型用于代表某个事情的真(对)或假(错)
- 如果这个事情是正确的,用 True(或 1)代表;
- 如果这个事情是错误的,用 False(或 0)代表。
5>3 # True
4>20 # False
整型
【2025-4-25】Python 整型是整数,包括: 负整数、0、正整数,在程序中的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等。
Python 3.x 允许使用下划线_作为数字(包括整数和小数)分隔符。
- 通常每隔三个数字添加一个下划线,类似于英文数字中的逗号。
- 下划线不会影响数字本身的值。
click = 1301547
distance = 384_000_000
print("Python教程阅读量:", click) # Python教程阅读量:1301547
print("地球和月球的距离:", distance) # 地球和月球的距离:384000000
浮点型
浮点型就是小数
python中的两种形式:
- 例如 34.6、346.0、0.346。
- Python 小数的指数形式的写法为:
aEn或aen- a 为尾数部分,是一个十进制数;
- n 为指数部分,是一个十进制整数;
- E或e是固定的字符,用于分割尾数部分和指数部分。
- 整个表达式等价于 a×10^n。
字符串
格式化输出
格式化输出主要方法:Python 3’s f-Strings: An Improved String Formatting Syntax
%: 老方法, 不适宜多变量,容易混淆、错位format: 变量多,字符串长时,仍然不方便f'{x}': 最方便
a = 'I\'m like a {} chasing {}.'
# 按顺序格式化字符串,'I'm like a dog chasing cars.'
a.format('dog', 'cars')
b = 'I prefer {1} {0} to {2} {0}'# 在大括号中指定参数所在位置
b.format('food', 'Chinese', 'American')
a = 2000
name = "Eric"
age = 74
# (1) % 方式
"Hello, %s." % name # 老方法, 不适宜多变量,容易混淆、错位
# (2) format 方式
"Hello, {}. You are {}.".format(name, age) # 改进:format
"Hello, {1}. You are {0}.".format(age, name)
person = {'name': 'Eric', 'age': 74}
"Hello, {name}. You are {age}.".format(name=person['name'], age=person['age'])
"Hello, {name}. You are {age}.".format(**person) # format:变量多,字符串长时,仍然不方便
print(f"{a}.wav") # 直接引用变量
# (3) f string 方式
f"Hello, {name}. You are {age}."
# [2024-8-9] 输出变量的简洁方式, 后面加=
f"{name=}" # name=Eric
f"{2 * 37}" # 直接放表达式
特殊操作
常见特殊符号
- r 前缀表示原始字符串, 忽略转义符,如 换行符
\n、\t、\r、\"等 - b 前缀表示字节字符串
- u 前缀表示Unicode字符串
- f 前缀表示格式化字符串。
【2025-6-27】问题
- python 中
json.loads(x), 当x包含嵌套json字符串时,转义符号(")会触发json解析错误
解决方法
folder_name = r"C:\Users\username\Documents"
file_name = "example.txt"
file_path = fr"{folder_name}\{file_name}"
print(file_path) # 输出: C:\Users\username\Documents\example.txt
s = '{"a":1, "b":"{\"b1\":3}"}'
def fun(x):
return json.loads(fr'{x}')
# 嵌套方式通过函数传参后,特殊符号失效
fun(s) # 无效,照常 json load 失败
format – py26
Python 2.6 引入了 format 进行字符串格式化,相比在字符串中用 % 类似C的方式,更加强大方便
a = 3.1415
b = 'hello'
c = 'world'
print('%.1f' % a) # 取1位小数
print('{}'.format(a))
print('{:,}'.format(a)) # 千分位逗号区分
print('{0} {1} {0}'.format(b,c)) # 打乱顺序
print('{a} {tom} {a}'.format(tom='hello',a='world')) # 带关键字
print('%.3e' % 1.11) # 取3位小数,用科学计数法
print('{:.2f}'.format(a))
print(f'{a:.2f}') # format的隐含模式
# 对齐方式,分别使用<、>和^三个符号表示左对齐、右对齐和居中对齐
print('{:30}'.format(b)) # 宽度30
print('{:<30}'.format(b)) # 宽度30, 左对齐
print('{:30>}'.format(b)) # 宽度30, 右对齐
print('{:^30}'.format(b)) # 宽度30, 居中
print('{:*^30}'.format(b)) # 宽度30, 居中, *填充
填充常跟对齐一起使用
- ^、<、>分别是居中、左对齐、右对齐,后面带宽度
- :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
'{:0>8}'.format('189') #'00000189'
# >代表右对齐,>前是要填充的字符,依次输出:
# 000001
# 000019
# 000256
for i in [1, 19, 256]:
print('The index is {:0>6d}'.format(i))
# <代表左对齐,依次输出:
# *---------
# ****------
# *******---
for x in ['*', '****', '*******']:
progress_bar = '{:-<10}'.format(x)
print(progress_bar)
'{:.2f}'.format(321.33345)
for x in [0.0001, 1e17, 3e-18]:
print('{:.6f}'.format(x)) # 按照小数点后6位的浮点数格式
print('{:.1e}'.format(x)) # 按照小数点后1位的科学记数法格式
print ('{:g}'.format(x)) # 系统自动选择最合适的格式
其他类型:
- b、d、o、x分别是二进制、十进制、八进制、十六进制
'{:b}'.format(17) #10001
'{:,}'.format(1234567890) #'1,234,567,890',用,号还能用来做金额的千位分隔符
template = '{name} is {age} years old.' #按变量名引用
c = template.format(name='Tom', age=8)) # Tom is 8 years old.
d = template.format(age=7, name='Jerry')# Jerry is 7 years old.
字符串 format 函数可以接受不限个参数,位置可以不按顺序,可以不用或者用多次,不过2.6不能为空{},2.7才可以。
- list和tuple可以通过“打散”成普通参数给函数,而dict可以打散成关键字参数给函数(通过和*)。
- 可轻松的传个 list/tuple/dict 给 format函数,非常灵活。
#(1)通过关键字参数
'{name},{age}'.format(age=18,name='kzc') # 'kzc,18'
# (2)通过对象属性
class Person:
def __init__(self,name,age):
self.name,self.age = name,age
def __str__(self):
return 'This guy is {self.name},is {self.age} old'.format(self=self)
str(Person('kzc',18)) #'This guy is kzc,is 18 old'
# (3)通过下标
p=['kzc',18]
'{0[0]},{0[1]}'.format(p) #'kzc,18'
format 在生成字符串和文档时非常有用
f string – py36
f 字符串:
Python 3.6新特性,更方便、更快- As of Python 3.6, f-strings are a great new way to format strings. Not only are they more readable, more concise, and less prone to error than other ways of formatting, but they are also faster
a = 2000
name = "Eric"
age = 74
# [2024-8-9] 输出变量的简洁方式, 后面加=
f"{name=}" # name=Eric
def to_lowercase(input):
return input.lower()
name = "Eric Idle"
f"{to_lowercase(name)} is funny." # 调用函数
f"{name.lower()} is funny."
# 类中调用
class Comedian:
def __init__(self, first_name, last_name, age):
self.first_name = first_name
self.last_name = last_name
self.age = age
def __str__(self):
return f"{self.first_name} {self.last_name} is {self.age}."
def __repr__(self):
return f"{self.first_name} {self.last_name} is {self.age}. Surprise!"
new_comedian = Comedian("Eric", "Idle", "74")
f"{new_comedian}" # 'Eric Idle is 74.'
f"{new_comedian!r}" # 'Eric Idle is 74. Surprise!'
name = "Eric"
profession = "comedian"
affiliation = "Monty Python"
# 多行模式
# If you don't put an f in front of each individual line, then you'll just have regular, old, garden-variety strings and not shiny, new, fancy f-strings.
# 用tuple
message = ( # 多行模式
f"Hi {name}. "
f"You are a {profession}. "
f"You were in {affiliation}."
)
# 换行模式
message = f"Hi {name}. " \
f"You are a {profession}. " \
f"You were in {affiliation}."
message # 'Hi Eric. You are a comedian. You were in Monty Python.'
message = f"""
Hi {name}.
You are a {profession}.
You were in {affiliation}.
"""
message # 包含换行符:'\n Hi Eric.\n You are a comedian.\n You were in Monty Python.\n'
性能测试
import timeit
timeit.timeit("""name = "Eric"
age = 74
'%s is %s.' % (name, age)""", number = 10000) # 0.00332
timeit.timeit("""name = "Eric"
age = 74
'{} is {}.'.format(name, age)""", number = 10000) # 0.00424
timeit.timeit("""name = "Eric"
age = 74
f'{name} is {age}.'""", number = 10000) # 0.00248
字符串示例
Python中字符串相关的处理都非常方便,来看例子:
a = 'Life is short, you need Python'
a.lower() # 'life is short, you need Python'
a.upper() # 'LIFE IS SHORT, YOU NEED PYTHON'
a.count('i') # 2
a.find('e') # 从左向右查找'e',3
a.rfind('need') # 从右向左查找'need',19
a.replace('you', 'I') # 'Life is short, I need Python'
tokens = a.split() # ['Life', 'is', 'short,', 'you', 'need', 'Python']
b = ' '.join(tokens) # 用指定分隔符按顺序把字符串列表组合成新字符串
c = a + '\n' # 加了换行符,注意+用法是字符串作为序列的用法
c.rstrip() # 右侧去除换行符
[x for x in a] # 遍历每个字符并生成由所有字符按顺序构成的列表
'Python' in a # True
print(a.capitalize()) #将字符串首字母大写
print(a.center(20)) #将字符串a置于20个空格字符的中间
print(a.startswith('H')) #判断字符串是否以某个字母开始
print(a.startswith('h'))
print(a.endswith('n')) #判断字符串是否以某个字母结束
print(a.lower()) #将字符串统一小写
print(a.upper()) #将字符串统一大写
print(a.islower()) #判断字符串是否小写
print(a.isupper()) #判断字符串是否大写
print(a.find('l')) #查找字符串,返回第一个查找到的字符串的首字符的索引,找不到不报错返回-1
print(a.index('P')) #查找字串,返回索引,查不到报错
print(a.replace('l', 'W')) #替换所有
编码方式
常见编码介绍:
GB2312编码:适用于汉字处理、汉字通信等系统之间的信息交换GBK编码:是汉字编码标准之一,是在 GB2312-80 标准基础上的内码扩展规范,使用了双字节编码ASCII编码:是对英语字符和二进制之间的关系做的统一规定Unicode编码:这是一种世界上所有字符的编码。当然了它没有规定的存储方式。UTF-8编码:是 Unicode Transformation Format - 8 bit 的缩写, UTF-8 是 Unicode 的一种实现方式。它是可变长的编码方式,可以使用 1~4 个字节表示一个字符,可根据不同的符号而变化字节长度。
Python内部的字符串一般都是 Unicode编码。代码中字符串的默认编码与代码文件指定编码是一致。所以要做一些编码转换通常是要以Unicode作为中间编码进行转换的,即先将其他编码的字符串解码(decode)成 Unicode,再从 Unicode编码(encode)成另一种编码。
- decode: 将其他编码的字符串转换成 Unicode 编码
- name.decode(“GB2312”),表示将GB2312编码的字符串name转换成Unicode编码
- encode: 将Unicode编码转换成其他编码的字符串
- name.encode(”GB2312“),表示将Unicode编码的字符串name转换成GB2312编码 所以在进行编码转换的时候必须先知道 name 是那种编码,然后 decode 成 Unicode 编码,最后载 encode 成需要编码的编码。当然了,如果 name 已经就是 Unicode 编码了,那么就不需要进行 decode 进行解码转换了,直接用 encode 就可以编码成你所需要的编码。值得注意的是:对 Unicode 进行编码和对 str 进行编码都是错误的。
#-*- coding: UTF-8 -*-
# 指定编码方式
import sys
print sys.getdefaultencoding() # 获取系统默认编码
name = '你好'
name.decode(“GB2312”) # 将GB2312编码的字符串name转换成Unicode编码
name.encode(”GB2312“) # 将Unicode编码的字符串name转换成GB2312编码
bytes.decode(encoding="utf-8", errors="strict")
str.encode(encoding="utf-8", errors="strict")
errors 是 错误处理方案。
- 默认为 ‘strict’, 意为编码错误引起一个UnicodeError。
- 其他可能得值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
汉字识别
汉字的unicode编码范围 u4e00 到 u9fa5
- 汉字的判断
- 汉字的unicode编码范围 u4e00 到 u9fa5
- 数字0-9的判断
- 数字的unicode编码范围根据全角和半角,有两个不同区域,半角数字 u0030 到 u0039,全角数字 uff10 到 uff19。
- 字母的unicode编码根据字母大小写,以及全角和半角共有四个区域。
- 半角大写字母:u0041 - u005a ,半角小写字母:u0061 - u007a ;
- 全角大写字母:uff21 - uff3a , 全角小写字母:uff41 - uff5a 。
- 非汉字和数字字母的判断
- 判断除汉字、数字0-9、字母之外的字符
ord('。') # str -> int
chr(12290) # int -> str
def is_chinese(uchar):
"""判断一个unicode是否是汉字"""
if uchar >= u'\u4e00' and uchar<=u'\u9fa5':
return True
else:
return False
def is_number(uchar):
"""判断一个unicode是否是半角数字"""
if uchar >= u'\u0030' and uchar<=u'\u0039':
return True
else:
return False
def is_Qnumber(uchar):
"""判断一个unicode是否是全角数字"""
if uchar >= u'\uff10' and uchar <= u'\uff19':
return True
else:
return False
def is_other(uchar):
"""判断是否非汉字,数字和英文字符"""
if not (is_chinese(uchar) or is_number(uchar) or is_alphabet(uchar)):
return True
else:
return False
中文全角、半角
【2022-11-18】在自然语言处理过程中,全角、半角的的不一致会导致信息抽取不一致,因此需要统一。
全角半角转换说明
有规律(不含空格):
- 全角字符unicode编码从65281~65374 (十六进制 0xFF01 ~ 0xFF5E)
- 半角字符unicode编码从33~126 (十六进制 0x21~ 0x7E)
特例:
- 空格比较特殊,全角为 12288(0x3000),半角为 32(0x20)
- 除空格外,全角/半角按unicode编码排序在顺序上是对应的(半角 + 0x7e= 全角),所以可以直接通过用+-法来处理非空格数据,对空格单独处理。
注:
- 中文文字永远是全角,只有英文字母、数字键、符号键才有全角半角的概念,一个字母或数字占一个汉字的位置叫全角,占半个汉字的位置叫半角。
- 引号在中英文、全半角情况下是不同的

库函数说明
chr() 函数用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。unichr() 跟它一样,只不过返回的是Unicode字符。ord() 函数是chr()函数(对于8位的ASCII字符串)或 unichr()函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的ASCII数值,或者Unicode数值。
# -*- coding: cp936 -*-
def strQ2B(ustring):
"""全角转半角"""
rstring = ""
for uchar in ustring:
inside_code=ord(uchar)
if inside_code == 12288: #全角空格直接转换
inside_code = 32
elif inside_code == 12290: # 句号。【2022-11-18】补充
inside_code = 46
elif (inside_code >= 65281 and inside_code <= 65374): #全角字符(除空格)根据关系转化
inside_code -= 65248
#rstring += unichr(inside_code) # python 2
rstring += chr(inside_code) # python 3
return rstring
def strB2Q(ustring):
"""半角转全角"""
rstring = ""
for uchar in ustring:
inside_code=ord(uchar)
if inside_code == 32: #半角空格直接转化
inside_code = 12288
elif inside_code == 46: # 句号.【2022-11-18】补充
inside_code = 12290
elif inside_code >= 32 and inside_code <= 126: #半角字符(除空格)根据关系转化
inside_code += 65248
#rstring += unichr(inside_code) # python 2
rstring += chr(inside_code) # python 3
return rstring
b = strQ2B("mn123abc博客园")
print b
c = strB2Q("mn123abc博客园")
print c
注意
- Python2 使用 chr() 将 Ascii 值转换成对应字符,unichr() 将 Unicode 值转换成对应字符
- Python3中该内置函数消失了!实际上是Python3中的 chr() 不仅仅支持 Ascii 转换,直接支持了更为适用的 Unicode 转换。
中文编码
Python 2.x中,str和bytes的数据类型是Byte类型的对象,但在Python 3.x中,这一点现在已经改变。
Python b 字符串由字节数据组成,这意味着代表整数的字头在0 到255 之间**。
- ** b string 和 string的主要区别在于其数据类型。
- 普通字符串有一串Unicode字符,如UTF-16或UTF-32,而Python b字符串有字节数据类型,意味着代表0到255之间的整数的字头(也被称为八位数)。
- 通过在Python普通字符串前面添加前缀b,将其数据类型从 字符串修改 为字节。
app_string = 'Happiest Season'
print(type(app_string)) # <class 'str'>
app_string_b = b'Happiest Season'
print(type(app_string_b)) # <class 'bytes'>
print('ÑÞ') # ÑÞ
print('ÑÞ'.encode('UTF-8')) # b'\xc3\x91\xc3\x9e'
print(len('ÑÞ'.encode('UTF-8'))) # 4 --- utf8编码
print(b'\xc3\x91\xc3\x9e'.decode('UTF-8')) # ÑÞ --- 解码(字节转字符串)
print(len(b'\xc3\x91\xc3\x9e'.decode('UTF-8'))) # 2
基础数据结构
Python中的容器是异常好用且异常有用的结构, 主要有列表(list),元组(tuple),字典(dict)和集合(set)
Python中的内置数据结构(Built-in Data Structure): 列表list、元组tuple、字典dict、集合set
list- list的显著特征:
- 列表中的每个元素都可变的,意味着可以对每个元素进行修改和删除;
- 列表是有序的,每个元素的位置是确定的,可以用索引去访问每个元素;
- 列表中的元素可以是Python中的任何对象;
- 可以为任意对象就意味着元素可以是字符串、整数、元组、也可以是list等Python中的对象。
- Python中包含6中內建的序列:列表,元组,字符串、Unicode字符串、buffer对象和xrange对象
- list的显著特征:
tuple- 元组Tuple,用法与List类似,但Tuple一经初始化,就不能修改,没有List中的append(), insert(), pop()等修改的方法,只能对元素进行查询
dict- 字典dictionary全称这个概念就是基于现实生活中的字典原型,生活中的使用名称-内容对数据进行构建,Python中使用键(key)-值(value)存储,也就是java、C++中的map。
- 字典中的数据必须以键值对的形式出现,即k,v:
- key:必须是可哈希的值,比如intmstring,float,tuple,但是,list,set,dict不行 ; value:任何值
- 键不可重复,值可重复,键若重复字典中只会记该键对应的最后一个值
- 字典中键(key)是不可变的,何为不可变对象,不能进行修改;而值(value)是可以修改的,可以是任何对象。在dict中是根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。
set- 集合更接近数学上集合的概念。集合中每个元素都是无序的、不重复的任意对象。可以通过集合去判断数据的从属关系,也可以通过集合把数据结构中重复的元素减掉。集合可做集合运算,可添加和删除元素。
- 集合内数据无序,即无法使用索引和分片, 集合内部数据元素具有唯一性,可以用来排除重复数据, 集合内的数据:str,int,float,tuple,冰冻集合等,即内部只能放置可哈希数据
- frozen set:冰冻集合是不可以进行任何修改的集合
frozenset是一种特殊集合- 常用方法
- intersection:交集
- difference:差集
- union:并集
- issubset:检查一个集合是否为另一个子集
- issuperset:检查一个集合是否为另一个超集
- 常用方法
list 列表
list 遍历
遍历列表可使用 for循环、while循环 和 enumerate()函数等多种方法来实现。
for循环: 最常用,因为简单、易读且高效。enumerate: 同时获取元素索引和值。while循环: 虽然也可以遍历列表,但通常更加复杂且容易出错。
在处理嵌套列表时,可以使用嵌套的for循环来遍历所有元素。
经典示例
arr = ['马','蹄','哒','哒','哒']
idx = 1
# for 遍历
for item in arr: # 未复制, 原地操作
# print(f'{idx}: {item}')
if item == '哒':
arr.remove(item) # 修改原数组, 删除第一个出现元素
print(f'{idx}\t{arr}')
idx += 1
print(f'end\t{arr}')
# 3 ['马', '蹄', '哒', '哒']
# 4 ['马', '蹄', '哒']
# end ['马', '蹄', '哒']
# enumerate 遍历
for i, item in enumerate(arr):
# print(f'{i}: {item}')
if item == '哒':
arr.remove(item) # 修改原数组, 删除第一个出现元素
print(f'{i}\t{arr}')
print(f'end\t{arr}')
list 操作
列表的基本操作有访问,增加,删除,和拼接
a.append(5) # 末尾插入值,[1, 2, 3, 5]
a.extend([34, 37]) # 扩充列表
a.index(2) # 找到第一个2所在的位置,也就是1
a[2] # 取下标,也就是位置在2的值,也就是第三个值3
a += [4, 3, 2] # 拼接,[1, 2, 3, 5, 4, 3, 2]
a.insert(1, 0) # 在下标为1处插入元素0,[1, 0, 2, 3, 5, 4, 3, 2]
x.insert(6,6666)
# 删除元素
a.pop() # 删除最后一个元素,并返回值
a.pop(1) # 删除第2个元素,并返回值
a.remove(2) # 按值删除,移除第一个2,[1, 0, 3, 5, 4, 3, 2]
del(x[3]) #字符串删除操作,小心使用,不要在遍历时改变list结构
reverse(a)
a.reverse() # 倒序,a变为[2, 3, 4, 5, 3, 0, 1]
x.clear() # 清空列表
x.copy() # 复制
a[3] = 9 # 指定下标处赋值,[2, 3, 4, 9, 3, 0, 1]
b = a[2:5] # 取下标2开始到5之前的子序列,[4, 9, 3]
c = a[2:-2] # 下标也可以倒着数,方便算不过来的人,[4, 9, 3]
d = a[2:] # 取下标2开始到结尾的子序列,[4, 9, 3, 0, 1]
e = a[:5] # 取开始到下标5之前的子序列,[2, 3, 4, 9, 3]
f = a[:] # 取从开头到最后的整个子序列,相当于值拷贝,[2, 3, 4, 9, 3, 0, 1]
a[2:-2] = [1, 2, 3] # 赋值也可以按照一段来,[2, 3, 1, 2, 3, 0, 1]
g = a[::-1] # 也是倒序,通过slicing实现并赋值,效率略低于reverse()
a.sort()
print(a) # 列表内排序,a变为[0, 1, 1, 2, 2, 3, 3]
【2017-9-5】
c = [-10,-5,0,5,3,10,15,-20,25]
print(c.index(min(c))) # 返回最小值
print(c.index(max(c))) # 返回最大值
print(x.count(23)) #统计元素出现个数
# 排序
c = sorted(a, reverse=True)
tuple 元组
元组和列表有很多相似的地方,最大的区别在于不可变
- 还有如果初始化只包含一个元素的tuple和列表不一样,因为语法必须明确,所以必须在元素后加上逗号。
- 另外直接用逗号分隔多个元素赋值默认是个tuple,这在函数多返回值的时候很好用:
a = (1, 2)
b = tuple(['3', 4]) # 也可以从列表初始化
c = (5,)
print(c) # (5,)
d = (6)
print(d) # 6
e = 3, 4, 5
print(e) # (3, 4, 5)
dict 字典
字典是一种非常常见的“键-值”(key-value)映射结构
- 键无重复,一个键不能对应多个值,不过多个键可以指向一个值
重要方法
- keys():获取所有键
- values():获取所有值
- items():获取所有键值对
常见操作
a = {'Tom': 8, 'Jerry': 7}
print(a['Tom']) # 8
b = dict(Tom=8, Jerry=7) # 一种字符串作为键更方便的初始化方式
print(b['Tom']) # 8
if 'Jerry' in a: # 判断'Jerry'是否在keys里面
print(a['Jerry']) # 7
print(a.get('Spike')) # None,通过get获得值,即使键不存在也不会报异常
a['Spike'] = 10
a['Tyke'] = 3
a.update({'Tuffy': 2, 'Mammy Two Shoes': 42})
print(a.values()) # dict_values([8, 2, 3, 7, 10, 42])
print(a.pop('Mammy Two Shoes')) # 移除'Mammy Two Shoes'的键值对,并返回42
print(a.keys()) # dict_keys(['Tom', 'Tuffy', 'Tyke', 'Jerry', 'Spike'])
b = a.items()
print(b) # [('Tuffy', 2), ('Spike', 10), ('Tom', 8), ('Tyke', 3), ('Jerry', 7)]
from operator import itemgetter
c = sorted(a.items(), key=itemgetter(1))
print(c) # [('Tuffy', 2), ('Tyke', 3), ('Jerry', 7), ('Tom', 8), ('Spike', 10)]
d = sorted(a.iteritems(), key=itemgetter(1))
print(d) # [('Tuffy', 2), ('Tyke', 3), ('Jerry', 7), ('Tom', 8), ('Spike', 10)]
e = sorted(a)
print(e) # 只对键排序,['Jerry', 'Spike', 'Tom', 'Tuffy', 'Tyke']
dict 有序输出
dic = {'t':2, 'r':1, 'e':3}
# 用sorted函数的key= 参数排序:
# 按照key进行排序
print(sorted(dic.items(), key=lambda d: d[0])) # [('e', 3), ('r', 1), ('t', 2)]
# 按照value进行排序
print(sorted(dic.items(), key=lambda d: d[1])) # [('r', 1), ('t', 2), ('e', 3)]
经验:流式计算均值
【2023-7-27】读入元素过程中,同时计算均值
a = {'x':3, 'y':7, 'z':2}
score = 0
for i, k in enumerate(a):
score = (score * i + a[k])/(i+1)
print(f"第{i+1}轮: 当前元素: {k}, 当前均值: {score}")
# 第1轮: 当前元素: x, 当前均值: 3.0
# 第2轮: 当前元素: y, 当前均值: 5.0
# 第3轮: 当前元素: z, 当前均值: 4.0
set 集合
集合是一种很有用的数学操作,比如列表去重,或是理清两组数据之间的关系,集合的操作符和位操作符有交集
set是一个无序且不重复的元素集合。
- 集合对象是一组无序排列的可哈希的值,集合成员可以做字典中的键。
- 集合支持用 in 和 not in 操作符检查成员,由 len() 内建函数得到集合的基数(大小), 用 for 循环迭代集合的成员。
- 但是因为集合本身是无序的,不可以为集合创建索引或执行切片(slice)操作,也没有键(keys)可用来获取集合中元素的值。
set和dict一样,只是没有value,相当于dict的key集合,由于dict的key是不重复的,且key是不可变对象因此set也有如下特性:
- 不重复
- 元素为不可变对象
A = set([1, 2, 3, 4])
B = {3, 4, 5, 6}
C = set([1, 1, 2, 2, 2, 3, 3, 3, 3])
print(C) # 集合的去重效果,set([1, 2, 3])
print(A | B) # 求并集,set([1, 2, 3, 4, 5, 6])
print(A & B) # 求交集,set([3, 4])
print(A - B) # 求差集,属于A但不属于B的,set([1, 2])
print(B - A) # 求差集,属于B但不属于A的,set([5, 6])
print(A ^ B) # 求对称差集,相当于(A-B)|(B-A),set([1, 2, 5, 6])
# ===== 比较 ======
se = {11, 22, 33}
be = {22, 55}
temp1 = se.difference(be) # 找到se中存在,be中不存在的集合,返回新值
print(temp1) # {33, 11}
print(se) # {33, 11, 22}
temp2 = se.difference_update(be) # 找到se中存在,be中不存在的集合,覆盖掉se
print(temp2) # None
print(se) # {33, 11},
# ===== 删除 ======
discard()、remove()、pop()
se = {11, 22, 33}
se.discard(11)
se.discard(44) # 移除不存的元素不会报错
print(se)
se = {11, 22, 33}
se.remove(11)
se.remove(44) # 移除不存的元素会报错
print(se)
se = {11, 22, 33} # 移除末尾元素并把移除的元素赋给新值
temp = se.pop()
print(temp) # 33
print(se) # {11, 22}
# ===== 取交集 ======
se = {11, 22, 33}
be = {22, 55}
temp1 = se.intersection(be) #取交集,赋给新值
print(temp1) # 22
print(se) # {11, 22, 33}
temp2 = se.intersection_update(be) #取交集并更新自己
print(temp2) # None
print(se) # 22
# ===== 判断 ======
se = {11, 22, 33}
be = {22}
print(se.isdisjoint(be)) #False,判断是否不存在交集(有交集False,无交集True)
print(se.issubset(be)) #False,判断se是否是be的子集合
print(se.issuperset(be)) #True,判断se是否是be的父集合
# ===== 合并 ======
se = {11, 22, 33}
be = {22}
temp1 = se.symmetric_difference(be) # 合并不同项,并赋新值
print(temp1) #{33, 11}
print(se) #{33, 11, 22}
temp2 = se.symmetric_difference_update(be) # 合并不同项,并更新自己
print(temp2) #None
print(se) #{33, 11}
# ===== 取并集 ======
se = {11, 22, 33}
be = {22,44,55}
temp=se.union(be) #取并集,并赋新值
print(se) #{33, 11, 22}
print(temp) #{33, 22, 55, 11, 44}
# ===== 更新 ======
se = {11, 22, 33}
be = {22,44,55}
se.update(be) # 把se和be合并,得出的值覆盖se
print(se)
se.update([66, 77]) # 可增加迭代项
print(se)
# ===== 集合的转换 ======
se = set(range(4))
li = list(se)
tu = tuple(se)
st = str(se)
print(li,type(li)) # [0, 1, 2, 3] <class 'list'>
print(tu,type(tu)) # (0, 1, 2, 3) <class 'tuple'>
print(st,type(st)) # {0, 1, 2, 3} <class 'str'>
示例
mylist = ['Google', 'Yahoo', 'Baidu']
#变更索引位置1Yahoo的内容为Microsoft
mylist[1] = 'Microsoft'
#获取索引位置1到5的数据,注意这里只会取到索引位置4,这里叫做取头不取尾
mylist[1:5] # 'Tencent', 'Microsoft', 'Baidu', 'Alibaba'
#获取从最头到索引位置5的数据
mylist[ :5] #'Google', 'Tencent', 'Microsoft', 'Baidu', 'Alibaba'
#获取从索引位置2开到最后的数据
mylist[2:] #'Microsoft', 'Baidu', 'Alibaba','Sina'
mylist.append('Alibaba') #运行结果: ['Google', 'Microsoft', 'Baidu', 'Alibaba']
mylist.insert(1, 'Tencent') # ['Google', 'Tencent', 'Microsoft', 'Baidu', 'Alibaba']
# 删除尾部元素
mylist.pop() # 会返回被删除元素
# 删除指定位置的元素
mylist.pop(1) # 删除索引为1的元素,并返回删除的元素
mylist.remove('Microsoft') #删除列表中的Microsoft
del mylist[1:3] #删除列表中索引位置1到位置 3 的数据
mylist.sort() # 排序 [1, 2 ,4, 5]
# 【2021-10-22】list元素排序,非原地
table_data = sorted(table_data,key=lambda x:x[1], reverse=True)
print(len(mylist)) # 长度
a = [1,2,3,4,5,6]
#在a的数据基础上每个数据乘以10,再生成一个列表b,
b = [i*10 for i in a]
#生成一个从1到20的列表
a = [x for x in range(1,20)]
#把a中所有偶数生成一个新的列表b
b = [m for m in a if m % 2 == 0]
print(b)
# tuple
a = (1,2,3,4)
# dict
d = {}
d = dict() # 创建空字典2
d = {"one":1,"two":2,"three":3,"four":4} #直接赋值方式
d = dict.fromkeys(d.keys(), "222")
d = {k:v for k,v in d.items()} #常规字典生成式
d = {k:v for k,v in d.items() if v % 2 ==0} #加限制条件的字典生成方式
print(d.get("one333"))
del d["one"] #删除一个数据,使用del
d.clear() # 清空字典
print(d)
if "two" in d:
print("key")
#for k in d:
#for v in d.values():
for k in d.keys():
print(k,d[k])
for k,v in d.items():
print(k,'--->',v)
#for key, value in enumerate(words):
# 通用函数:len,max,min,dict
d = {"one":1,"two":2,"three":3,"four":4}
print(max(d), min(d), len(d))
#集合的定义
s = set()
s = frozenset() # 冰冻集合
s = set([1,2,3])
s.add(6)
s.remove(2)
s1 = {1,2,3,4,5,6,7}
s2 = {5,6,7,8,9}
#交集
s_1 = s1.intersection(s2)
#差集
s_2 = s1.difference(s2)
#并集
s_3 = s1.union(s2)
#检查一个集合是否为另一个子集
s_4 = s1.issubset(s2)
print("检查子集结果:",s_4)
#检查一个集合是否为另一个超集
s_5 = s1.issuperset(s2)
print("检查超集结果:",s_5)
高级数据结构
【2021-3-11】Python高级数据结构详解
- Collection、Array、Heapq、Bisect、Weakref、Copy以及Pprint这些数据结构的用法 Collections
- collections模块包含了内建类型之外的一些有用的工具,例如Counter、
defaultdict、OrderedDict、deque以及nametuple。 - 其中Counter、
deque以及defaultdict最常用。 - Counter:统计频次
Weakref- weakref模块能够帮助我们创建Python引用,却不会阻止对象的销毁操作。
- strong reference是一个对对象的引用次数、生命周期以及销毁时机产生影响的指针。
- Weak reference则是对对象的引用计数器不会产生影响。当一个对象存在weak reference时,并不会影响对象的撤销。这就说,如果一个对象仅剩下weak reference,那么它将会被销毁。
Copy()- 通过shallow或deep copy语法提供复制对象的函数操作。shallow和deep copying的不同之处在于对于混合型对象的操作(混合对象是包含了其他类型对象的对象,例如list或其他类实例)。
- 对于shallow copy而言,它创建一个新的混合对象,并且将原对象中其他对象的引用插入新对象。
- 对于deep copy而言,它创建一个新的对象,并且递归地复制源对象中的其他对象并插入新的对象中。
- 通过shallow或deep copy语法提供复制对象的函数操作。shallow和deep copying的不同之处在于对于混合型对象的操作(混合对象是包含了其他类型对象的对象,例如list或其他类实例)。
- Pprint()
- Pprint模块能够提供比较优雅的数据结构打印方式,如果你需要打印一个结构较为复杂,层次较深的字典或是JSON对象时,使用Pprint能够提供较好的打印结果。
Counter
词频统计
原生态
a = ['a','b','r','a','d','r']
b = {}
for i in a:
if i in b.keys():
b[i] += 1
else:
b[i] = 1
# 改进, get 方法
# b[i] = b.get(i, 0) + 1
print(b) # {'a': 2, 'b': 1, 'r': 2, 'd': 1}
每次都要判断key是否存在
优化:setdefault
a = ['a','b','r','a','d','r']
b = {}
for i in a:
b.setdefault(i,0) # setdefault 设置不存在时的默认值
b[i] += 1
print(b) # {'a': 2, 'b': 1, 'r': 2, 'd': 1}
虽然去除了if语句,但对于每一个key,我们都需要进行判断是否需要给一个默认值。
优化:defaultdict
defaultdict字典相当于是普通字段的强化版,继承原始dict的功能,并赋予了它新的特性。
from collections import defaultdict
a = ['a','b','r','a','d','r']
# 初始化defaultdict的参数是一个可调用对象,即函数名, int
# 除了int,也可以用:list对应[],str对应的是空字符串,set对应set(),int对应0
b = defaultdict(int)
# b = defaultdict(lambda :0) # 等效表达:匿名函数
for i in a:
b[i] += 1
print(b)
int函数相当于
def fun(): return 0
也可以使用匿名函数
b = defaultdict(lambda :0)
优化:Counter
Counter类的目的是用来跟踪值出现的次数。
- 它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。
- 计数值可以是任意的Interger(包括0和负数)
创建的方式有三种
- 第一种是空的Counter类
- 第二种传入一个可迭代对象,可以是str、list、tuple、dict
- 最后一种是以键值对的形式。
from collections import Counter
a = Counter() # 空的Counter类
b = Counter('afdasfdasd') # 传入一个可迭代对象
c = Counter({'a':4,'b':7}) # 以键值对的形式
d = Counter(a=4,b=7)
e = Counter('积极,中性,积极'.split(','))
# 计数结果是一个字典样式,故若查找的key不存在将会报错。
print(a,b,c,d,e)
# most_common([n]) 将计数结果以列表嵌套二元元组的形式返回。
# 参数n表示给最多n个元素计数,且计数量大的优先,默认返回所有计数。
print(b.most_common()) # Counter({'a': 3, 'd': 3, 'f': 2, 's': 2})
t = e.most_common(2) # [('积极', 2), ('中性', 1)]
print(e.most_common(2)[0]) # ('积极', 2)
print(b.most_common(2)) # [('a', 3), ('d', 3), ('f', 2), ('s', 2)][('a', 3), ('d', 3)]
namedtuple
namedtuple: 给 tuple 以及 tuple 中的每一个元素都取名字
如下的代码,account[0],account[1] 分别指的什么?不清楚
account = ('checking', 1850.90)
print(account[0]) # name
print(account[1]) # balance
使用namedtuple
from collections import namedtuple
account = ('checking', 1850.90) # 普通tuple定义方法
Account = namedtuple("Account", ['name', 'balance']) # namedtuple定义方法
# 第1个参数是 tuple 名称,和定义名称相同
# 第2个参数是 fields 名称
accountNamedTuple_1 = Account('checking', 1850.90) # 定义具体数值
print(accountNamedTuple_1.name, accountNamedTuple_1.balance) # checking 1850.9
accountNamedTuple_2 = Account._make(account) # 传入普通tuple值,_make方法
account_name_2, account_balance_2 = accountNamedTuple_2
print(account_name_2, account_balance_2) # checking 1850.9
accountNamedTuple_3 = Account(*account) # 传入普通tuple值,*方法
account_name_3, account_balance_3 = accountNamedTuple_3
print(account_name_3, account_balance_3) # checking 1850.9
print(accountNamedTuple_1._asdict()['balance']) # 1850.9
print(accountNamedTuple_2._asdict()['balance']) # 1850.9
print(accountNamedTuple_3._asdict()['balance']) # 1850.9
Deque 双端队列
Deque:双端队列
- Deque是一种由队列结构扩展而来的
双端队列(double-ended queue),队列元素能够在队列两端添加或删除。因此它还被称为头尾连接列表(head-tail linked list) - Deque 线程安全,经过优化的append和pop操作,在队列两端的相关操作都能够达到近乎O(1)的时间复杂度。虽然list也支持类似的操作,但是它是对定长列表的操作表现很不错,而当遇到pop(0)和insert(0, v)这样既改变了列表的长度又改变其元素位置的操作时,其复杂度就变为O(n)了
deque:double ended queue 双端队列,使用deque而非 list 的原因首先是deque效率高,其次它保证线程安全 (thread safe),deque 所有的操作都是线程安全的 ,因此在使用 thread 时可使用 deque
from collections import deque
friends = deque(('Rolf', 'Charlie', 'Jen', 'Anna'))
friends.append('Jose')
friends.appendleft('Anthony') # 左侧追加
print(friends) # deque(['Anthony', 'Rolf', 'Charlie', 'Jen', 'Anna', 'Jose'])
friends.pop()
print(friends) # deque(['Anthony', 'Rolf', 'Charlie', 'Jen', 'Anna'])
friends.popleft() # 左侧弹出
print(friends) # deque(['Rolf', 'Charlie', 'Jen', 'Anna'])
Array
Array 时间换空间
- array模块定义了一个很像list的新对象类型,不同之处在于只能装一种类型的元素。
- 省空间,但时间慢:如存储一千万个整数,用list至少需要160MB的存储空间,而使用array只需要40MB。但虽然说能够节省空间,array上基本操作比list慢。
列表推导式(list comprehension)时,会将array整个转换为list,使得存储空间膨胀。一个可行的替代方案是使用生成器表达式创建新的array
Heapq
heapq
- heapq模块使用一个用堆实现的优先级队列。
- 堆是一种简单的有序列表,并且置入了堆的相关规则。
- 堆是一种树形的数据结构,树上的子节点与父节点之间存在顺序关系。
函数:
heappush(heap, x) # 将x压入堆中
heappop(heap) # 从堆中弹出最小的元素
heapify(heap) # 让列表具备堆特征
heapreplace(heap, x) # 弹出最小的元素,并将x压入堆中
nlargest(n, iter) # 返回iter中n个最大的元素
nsmallest(n, iter) # 返回iter中n个最小的元素
Bisect
Bisect- bisect模块能够提供保持list元素序列的支持,使用了二分法完成大部分的工作。它在向一个list插入元素的同时维持list是有序的。
from collections import Counter
li = ["Dog", "Cat", "Mouse", 42, "Dog", 42, "Cat", "Dog"]
a = Counter(li)
print(a) # Counter({'Dog': 3, 42: 2, 'Cat': 2, 'Mouse': 1})
print(len(set(li))) # 4
print(a.most_common(3)) # [('Dog', 3), ('Cat', 2), ('Mouse', 1)]
from collections import deque
q = deque(range(5))
q.append(5)
q.appendleft(6)
print q
print q.pop()
print q.popleft()
print q.rotate(3) # 队列的旋转操作,Right rotate(正参数)是将右端的元素移动到左端,而Left rotate(负参数)则相反
from collections import defaultdict
location = defaultdict(['a', 'b']) # 有序
location = defaultdict(('a', 'b')) # 无序
# 对于较大的array,这种in-place修改能够比用生成器创建一个新的array至少提升15%的速度
import array
a = array.array("i", [1,2,3,4,5])
b = array.array(a.typecode, (2*x for x in a)) # 节省空间
for i, x in enumerate(a): # 提效
a[i] = 2*x
import heapq
heap = []
for value in [20, 10, 30, 50, 40]:
heapq.heappush(heap, value) # 入堆
while heap:
print heapq.heappop(heap) # 出堆
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
print(heapq.nlargest(3, nums)) # Prints [42, 37, 23]
print(heapq.nsmallest(3, nums)) # Prints [-4, 1, 2]
expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price']) # 针对字典的复杂操作
import bisect
a = [(0, 100), (150, 220), (500, 1000)]
bisect.insort_right(a, (250,400))
print bisect.bisect(a, (550, 1200)) # 5 寻找插入点
print a # [(0, 100), (150, 220), (250, 400), (500, 1000)]
import weakref
a = Foo() #created
b = a() # 强引用
b = weakref.ref(a) # 弱引用
b = weakref.proxy(a) # proxy更像是一个strong reference,但当对象不存在时会抛出异常
# 删除strong reference的时候,对象将立即被销毁
del a
import copy
a = [1,2,3]
b = [4,5]
c = [a,b]
d = c # 正常复制
print id(c) == id(d) # True - d is the same object as c
print id(c[0]) == id(d[0]) # True - d[0] is the same object as c[0]
d = copy.copy(c) # Shallow Copy 浅拷贝,创建一个新的容器,其包含的引用指向原对象中的对象
print id(c) == id(d) # False - d is now a new object
print id(c[0]) == id(d[0]) # True - d[0] is the same object as c[0]
d = copy.deepcopy(c) # Deep Copy 深拷贝,创建的对象包含的引用指向复制出来的新对象
print id(c) == id(d) # False - d is now a new object
print id(c[0]) == id(d[0]) # False - d[0] is now a new object
import pprint
matrix = [ [1,2,3], [4,5,6], [7,8,9] ]
a = pprint.PrettyPrinter(width=20)
a.pprint(matrix)
# [[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]]
dict 扩展
Defaultdict
Defaultdict: 默认字典
使用dict时
- 如果引用的Key不存在,就会抛出KeyError。
- 如果希望key不存在时,返回一个默认值呢?这就是 defaultdict
from collections import defaultdict
dd = defaultdict(lambda: 'NULL')
dd['key1'] = 'abc'
dd['key1'] # key1存在, 'abc'
dd['key2'] # key2不存在,返回默认值 'NULL'
注意
- 默认值是调用函数返回的,而函数在创建 defaultdict对象时传入。
- 除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的
一键多值
(1) setdefault 实现
d={}
d.setdefault('a',[]).append(1)
d.setdefault('a',[]).append(2)
d.setdefault('b',[]).append(3)
print(d) # {'a': [1, 2], 'b': [3]}
(2) defaultdict 实现
from collections import defaultdict
# {'a':[1,2,3]}
d=defaultdict(list)
d['a'].append(1)
d['a'].append(2)
d['a'].append(3)
print(d) # defaultdict(list, {'a': [1, 2, 3]})
s=defaultdict(set)
s['a'].add(1)
s['a'].add(4)
s['b'].add(2)
s['b'].add(3)
s['c'].add(3)
s['c'].add(6)
s['c'].add(6)
print(s) # defaultdict(set, {'a': {1, 4}, 'b': {2, 3}, 'c': {3, 6}})
defaultdict 和 setdefault 的比较
- 也可以用 setdefault 来实现以上操作,但是每次到用 setdefault 都会创建一个初始值的新实例
OrderedDict
dict里的Key无序,导致遍历dict时,无法确定Key的顺序。
- 如果要保持Key的顺序呢?用OrderedDict
from collections import OrderedDict
# ----- dict 无序 ------
d = dict([('a', 1), ('b', 2), ('c', 3)])
d # dict的Key是无序的
# {'a': 1, 'c': 3, 'b': 2}
# ----- dict 有序 ------
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
od # OrderedDict的Key是有序的
# OrderedDict([('a', 1), ('b', 2), ('c', 3)])
od = OrderedDict()
od['z'] = 1
od['y'] = 2
od['x'] = 3
od.keys() # 按照插入的Key的顺序返回, ['z', 'y', 'x']
注意
- OrderedDict 的 Key 会按照插入顺序排列,不是Key本身排序
OrderedDict 可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value)
ChainMap
如何查找多个字典?
- 逐个遍历:如果x没有,就遍历y…
x={'a':1,'c':2}
y={'b':3,'c':4}
x.update(y) # y 中的值覆盖 x
print(x) # {'a': 1, 'c': 4, 'b': 3}
有没有更好的办法?
- ChainMap只是维护了一个记录底层映射关系的列表,如果有重复的值,会采用第一个映射中对应的值,修改映射的操作总是会作用在第一个映射结构上。
ChainMap 和 update 的比较
- update方法,执行x.update(y), x会就地改变,如果y中有和x中一样的关键字,则y中关键字相应的值会覆盖x中相应关键字的值。
- ChainMap的修改只体现在第一个字典中
from collections importChainMap
z=ChainMap(x,y)
print(z) # ChainMap({'a': 1, 'c': 2}, {'b': 3, 'c': 4})
print(z['a']) # 1
print(z['b']) # 3
print(z['c']) # 2, 返回第一个找到的值
# 修改值
z['c']=10 # 只修改了第一个映射里的c
z['d']=20 # 只在第一个映射里添加了键值对:'d':20
print(z) # ChainMap({'a': 1, 'c': 10, 'd': 20}, {'b': 3, 'c': 4})
del z['a'] # 在z里删除关键字a,会在字典x中体现出来
print(x) # {'c': 10, 'd': 20}
del z['b'] # 通过z修改不了字典y, KeyError: "Key not found in the first mapping: 'b'"
# ChainMap后,对原始映射的修改会反映到合并后的结果中
x={'a':1,'c':2}
y={'b':3,'c':4}
z=ChainMap(x,y)
x['a']=10
print(z) # ChainMap({'a': 10, 'c': 2}, {'b': 3, 'c': 4})
aadict
- aadict包:在dict的基础上封装了一层,使其能够像操作属性一样使用字典。使得后续操作更加简便且易读,还可以预防不必要的异常出现。
- 代码示例
from addict import Dict
configs = Dict()
configs.platform.status = "on"
configs.platform.web.task.name = "测试-1204"
configs.platform.web.periods.start = "2020-10-01"
configs.platform.web.periods.end = "2020-10-31"
# 获取不存在的key时会返回一个空字典,不用担心报KeyError,对返回值做判空处理即可
app_configs = configs.platform.app
assert app_configs == {}
bidict
bidict,一个超酷的 Pythonicon 库,提供了一种双向字典的实现,即一种能够通过键或值来进行快速查找的数据结构icon。可以使用bidict库创建、访问和修改双向映射。bidict库提供了一些方法来处理安全的双向映射,可以在数据处理中使用双向映射来关联两个不同的数据集
dataclass
【2023-1-13】Dataclasses是一些适合于存储数据对象(data object)的Python类
对于那些熟悉对象关系映射(Object Relational Mapping,简称 ORM)的人来说,一个模型实例就是一个数据对象,表示了一种特定类型的实体,存储了用于定义或表示那种实体的属性。
Python3.7 提供了一个装饰器 dataclass,用以把一个类转化为 dataclass。
from dataclasses import dataclass
# 常规表示
class Number:
def __init__(self, val):
self.val = val
def __eq__(self, other):
return self.val == other.val
def __lt__(self, other):
return self.val < other.val
one = Number(1)
one.val
# dataclass表示
@dataclass
class Number:
val:int
test:int = 0 # 定义默认值
one = Number(1)
# dataclass会自动添加一个__repr__函数,不用手动实现
one.val # 1
dataclass装饰器带来的变化:
- 无需定义 __init__,然后将值赋给 self,dataclass 负责处理它(LCTT 译注:此处原文可能有误,提及一个不存在的d)
- 无需定义 数据比较类方法,如 eq 和 lt
- 更加易读, 预先定义了成员属性,以及类型提示。现在立即能知道 val是int类型, 这比一般定义类成员的方式更具可读性。
工具包导入
python导入相关,绝对导入可以在任何地方使用, 所有非 相对导入 都是绝对导入。
绝对导入根据 sys.path 来查找 包 或 模块. sys.path 是一个列表, 通常情况下会包含
- 内建模块 的索引路径
- 第三方库 的保存路径
- 环境变量 PYTHONPATH 列出的目录
- 脚本所在目录或当前目录 前三个路径一般不需要怎么管, 容易出现问题的地方是第四个 脚本所在目录或当前目录.
导入顺序
首先,这个路径会被添加到 sys.path 最前面, 所以如果该路径下存在和内建或第三方库同名的模块或包, 使用绝对导入会优先导入那个同名的模块。然后就是确定添加的这个目录到底是 脚本所在目录 还是 当前目录 了。
汇总:
- 直接执行脚本 时添加的路径是 脚本所在目录.
Python -m方式执行脚本时- Python2 添加 脚本所在目录
- 而 Python3 添加 当前目录
- 【2025-4-26】因此, 无需单独添加主路径
sys.path.insert(0, os.getcwd()) - 但是, 直接执行脚本
python a/b/test.py时, 仍然需要单独添加
- 同目录下, 同名的
包和模块,包的导入优先级比模块高。- 优先级排序为:当前目录或脚本所在
目录==>内建模块==>第三方库 包==>模块
- 优先级排序为:当前目录或脚本所在
- import 会生成
.pyc文件,.pyc文件执行速度不比.py快, 但是加载速度更快 - 重复 import 只会执行第一次 import
- 如果在 执行过程中 中 import 的模块发生改动,可以通过 reload 函数重新加载
from xxx import *会导入除了以 _ 开头的所有变量,但是如果定义了 all, 那么会导入 all 中列出的东西import xxx.object的方式不能直接使用 object, 仍然需要通过 xxx.object 的方式使用import xxx.object as obj的方式可以直接使用 obj
Python3.4 之后的版本中, 内置函数 reload 被移除了, 要使用可以通过 from importlib import reload 导入
模块、包与库
多种类型:模块 → 包 → 库
- (1) 模块 module
- (2) 包 package
- (3) 库
备注:
- 模块、包、库这三个概念实际上都是模块,只不过是个体和集合的区别
使用 import 导入的东西只有三种: 包, 模块, 其他对象.
包:__init__.py文件所在目录- 该文件用于组织包(package),方便管理各个模块之间的引用、控制着包的导入行为。
- 可以是空文件,表示导入所在目录的所有文件,也可以指定导入的包
__ALL__ = ['a.py','b.py'],但不建议写模块,以保证该文件简单。- 模糊导入时,形如 from package import ,是由
__all__定义的。 - 精确导入,形如 from package import *、import package.class。
- 模糊导入时,形如 from package import ,是由
__path__也是一个常用变量,是个列表,默认情况下只有一个元素,即当前包(package)的路径。修改 path 可改变包(package)内的搜索路径。
模块: 单个 .py 文件- 其他
对象: 除了 包 和 模块 以外的 Python Object
(1)模块 module
模块指一个文件,如 .py文件,里面定义了一些函数和变量,需要的时候就可以导入这些模块(问题:class算模块吗?)
可以作为module的文件类型有:”.py”、”.pyo”、”.pyc”、”.pyd”、”.so”、”.dll”。
导入方法:
import a
import a as b # 定义别名
(2)包 package
包指一个目录,在模块之上的概念,为了方便管理而将文件进行打包。
- 一个文件夹下必须要有 __init__.py 这个文件才会被识别为包。
- 除了 __init__.py,就是一些模块文件和子目录。
导入方法:
# 直接整体导入
import a
import a as b
from a import *
# 部分导入--from + import导入包中的部分模块
from a import a1
from a import a1 as b
from a import a1,a2
(3)库
库是具有相关功能模块的集合。
- 这也是Python的一大特色之一,即具有强大的
标准库、第三方库以及自定义模块。 标准库:就是下载安装的python里那些自带的模块- 注意:里面有一些模块是看不到的, 比如像sys模块,这与linux下的cd命令看不到是一样的情况
第三方库:就是由其他的第三方机构,发布的具有特定功能的模块自定义模块:用户自己可以自行编写模块,然后使用
导入方式
使用 import 的两种格式:
- import package/module
- from package/module import object
单独使用 import 的时候, 导入的只能是 包 或 模块.
- 而 from … import … 的形式则可以从
包或模块中导入任意对象。
Python在导入import包的时候,有绝对导入和相对导入方式。
- 绝对导入:import p1.m1 或者 from p1 import m1 等。
- 相对导入:from . import m1 或者 from .. import m1 或者 from ..p1 import m1 或者 from .m1 import f1等。
- 相对导入的方式只能用在
包内部, 语法格式为:from . import object, - . 代表当前目录, .. 代表父级目录, 之后每多一个点代表目录上升一层。
- 代表相对路径的符号 . 只能出现在 from 后面而不能出现在 import 后面, 即:
- 相对导入的方式只能用在
比较而言,绝对导入更为简便清晰,相对导入则可维护性强,但是容易出错。
- (1)标准导入:“标准”import,顶部导入
- (2)顺序导入
- 嵌套导入;各个模块的Local命名空间的独立的。即:
- test模块 import moduleA后,只能访问moduleA模块,不能访问moduleB模块。虽然moduleB已加载到内存中,如需访问,还得明确地在test模块 import moduleB。实际上打印locals(),字典中只有moduleA,没有moduleB。
- 循环导入/嵌套导入
- 嵌套导入;各个模块的Local命名空间的独立的。即:
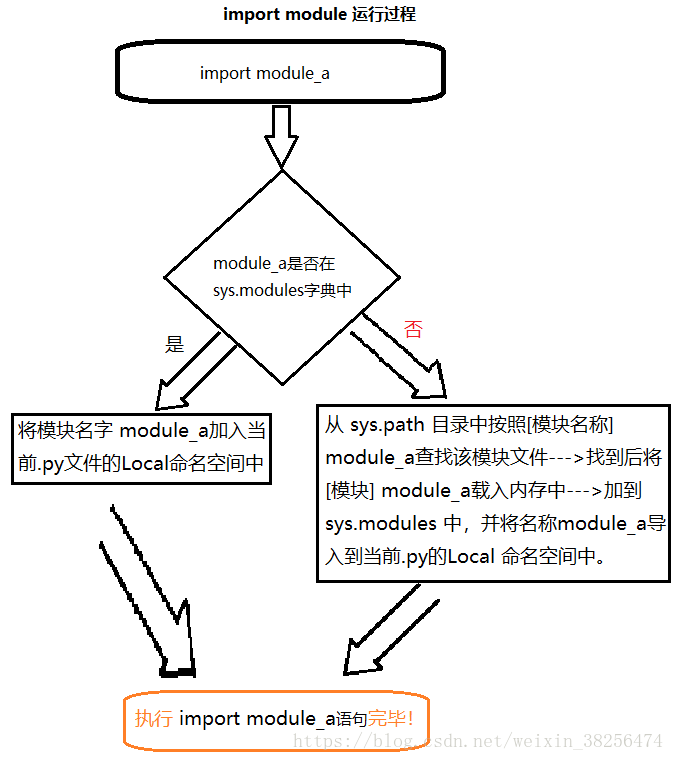
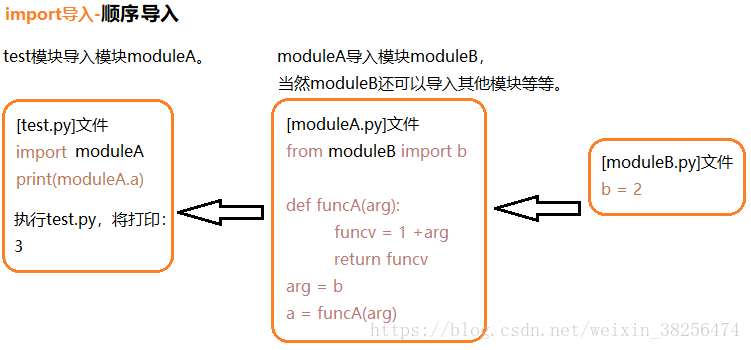
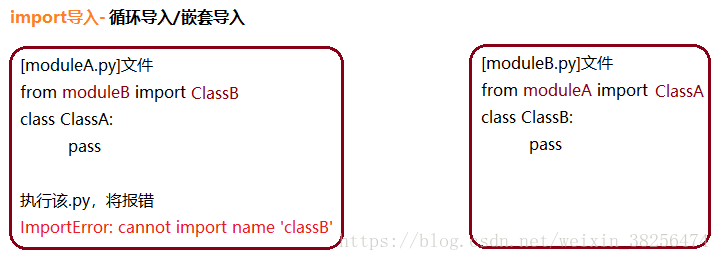
导入示例
# -*- coding: utf-8 -*-
# 绝对导入
import sys
print(sys.path[0:1])
# 相对导入
from . import utils # True
import .utils # False
from xxx import * # 会导入除了以 _ 开头的所有变量,但是如果定义了 __all__, 那么会导入 __all__ 中列出的东西
import xxx.object # 不能直接使用 object, 仍然需要通过 xxx.object 的方式使用
import xxx.object as obj # 直接使用 obj
# 批量导入
from click import (
argument,
command,
echo,
edit,
group,
Group,
option,
pass_context,
Option,
version_option,
BadParameter,
)
import sys, os
print(__file__) #当前.py文件的位置
print(os.path.abspath(__file__)) #返回当前.py文件的绝对路径
print(os.path.dirname(os.path.abspath(__file__))) #当前文件的绝对路径目录,不包括当前 *.py 部分,即只到该文件目录
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #返回文件本身目录的上层目录
print(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) #每多一层,即再上一层目录
print(os.path.realpath(__file__)) #当前文件的真实地址
print(os.path.dirname(os.path.realpath(__file__))) # 当前文件夹的路径
path = os.path.dirname(os.path.abspath(__file__))
sys.path.append(path) #将目录或路径加入搜索路径
print(__name__)
注意:
from prompt import *命令只能在模块层次使用, 不在在函数内执行
init 用法
【2023-2-21】python init 作用详解
__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件。
- 通常 __init__.py 文件为空,实际上还可以增加其他功能。
- 导入一个包时,实际上是导入了它的__init__.py文件。
- 所以在__init__.py文件中批量导入所需要的模块,而不再需要一个一个的导入。
访问 _init_.py文件中的引用文件,需要加上包名。
_init__.py中还有一个重要的变量,__all_, 它用来将模块全部导入。
不用包时:
# package
# __init__.py
import re
import urllib
import sys
import os
# a.py
import package
print(package.re, package.urllib, package.sys, package.os)
使用 __init__ 包时, 既可以导入系统包,也可以导入自定义包
# __init__.py
import subpackage1.a # 将模块subpackage.a导入全局命名空间,例如访问a中属性时用subpackage1.a.attr
from subpackage1 import a # 将模块a导入全局命名空间,例如访问a中属性时用a.attr_a
from subpackage.a import attr_a # 将模块a的属性直接导入到命名空间中,例如访问a中属性时直接用attr_a
__all__ = ['os', 'sys', 're', 'urllib']
# a.py
from package import *
Python 库目录
python -c "import sys; print(sys.path)" # 终端直接执行python代码
python -m http.server 8081 # 运行模块,如简易文件服务
python -m test.py # 相当于import,叫做当做模块来启动
python -u test.py # 按照指定用户权限执行脚本
函数
函数属性
函数名
获取函数名情况分为: 内部、外部
- 外部获取,使用指向函数的对象,然后用
__name__属性 - 内部获取, 借用 sys 模块
def a():
pass
a.__name__
getattr(a,'__name__')
除此之外还可以:getattr(a,'__name__')
从外部获取的方法是非常灵活
从函数内部获取函数本身的名字就需要用些技巧。
使用sys模块方法:
def a():
print(sys._getframe().f_code.co_name)
f_code和co_name可以参考python源码解析的pyc生成和命名空间章节。
使用修饰器方法:
- 用修饰器就可以对函数指向一个变量,然后取变量对象的
__name__方法。
def timeit(func):
def run(*argv):
print(func.__name__)
if argv:
ret = func(*argv)
else:
ret = func()
return ret
return run
@timeit
def t(a):
print a
t(1)
default
【2023-3-9】python 将默认参数存储在函数对象之中,__defaults__ 属性中,此后每次调用函数默认参数都是最开始计算的那一个,而由于这个默认参数是可变对象,内容变了,下一次调用当然就是最新的值。
def foo(x=[]):
x.append(1)
return x
# foo.__defaults__ 属性中
print(foo()) # [1]
print(foo()) # [1, 1]
函数传参
传参总结
【2018-6-28】Python 4种传值方式:
- (1) 必选传参
func(param)def func(a,b)调用时要严格一致(数量和顺序)
- (2) 默认传参
func(param=value)def func(a, b=3)- 默认参数要在必选参数后面 —— 频繁踩坑!
- 默认参数顺序不一致时, 需要指定参数名
- (3) 可选传参
func(*param)def func(a, b=3, *c)- 参数个数不确定时使用可选参数,以tuple元组形式调用(列表也可以)
func(2,b=2,*c)*号作用:- 定义函数时,将传入参数转成元组
- 调用时, 将元组解开成单个元素
- (4) 关键字传参
func(**param)def func(a,b=3, *c, **d)def func(*a, **b)接受任意类型参数- 多个参数,默认值,dict形式传递
func(1,10,11,**d)**号作用:参考:Python 函数定义以及参数传递- 定义函数时,将传入的参数转成字典
- 调用时将字典解开成单个元素
# (1) 必选参数
def func(a, b):
pass
# (2) 默认参数
def func(a, b=1):
pass
# (3) 可选传参:list形式
def func(a, b=3, *c):
pass
c=[ 2,5,1 ] # 或(2,5,1)
func(a=2, *c)
# (4) 关键字传参: 任意类型, dict 形式
def func(a, b=3, *c, **d):
pass
d = {"a":1,"b":2,"c":3}
func(1, 10, 11, **d)
问题总结
【2024-7-10】包含默认值参数的函数
代码
# 错误: non-default argument follows default argument
def func(b=1, a):
print(a, b)
return a+b
# 修复: 将默认参数放最后
def func(a, b=1):
print(a, b)
return a+b
if __name__ == '__main__':
res = func(2)
报错
SyntaxError: non-default argument follows default argument
特殊函数
map, reduce 和 filter
map 可以用于对可遍历结构的每个元素执行同样的操作,批量操作:
map(lambda x: x**2, [1, 2, 3, 4]) # [1, 4, 9, 16]
map(lambda x, y: x + y, [1, 2, 3], [5, 6, 7]) # [6, 8, 10]
reduce 则是对可遍历结构的元素按顺序进行两个输入参数的操作,并且每次的结果保存作为下次操作的第一个输入参数,还没有遍历的元素作为第二个输入参数。这样的结果就是把一串可遍历的值,减少(reduce)成一个对象:
reduce(lambda x, y: x + y, [1, 2, 3, 4]) # ((1+2)+3)+4=10
filter 根据条件对可遍历结构进行筛选:
filter(lambda x: x % 2, [1, 2, 3, 4, 5]) # 筛选奇数,[1, 3, 5]
注意
- 对于 filter 和 map ,在Python2中返回结果是列表,Python3中是生成器。
列表生成(list comprehension)
列表生成是Python2.0中加入的一种语法,可以非常方便地用来生成列表和迭代器,比如上节中map的两个例子和filter的一个例子可以用列表生成重写为:
[x**2 for x in [1, 2, 3, 4]] # [1, 4, 9 16]
[sum(x) for x in zip([1, 2, 3], [5, 6, 7])] # [6, 8, 10]
[x for x in [1, 2, 3, 4, 5] if x % 2] # [1, 3, 5]
callable
【2022-4-9】callable() 函数用于检查一个对象是否是可调用的。
- 如果返回 True,object 仍然可能调用失败;
- 但如果返回 False,调用对象 object 绝对不会成功。
对于函数、方法、lambda 函式、 类以及实现了 __call__ 方法的类实例, 它都返回 True。
- 简版:只要可以在一个对象的后面使用小括号来执行代码,那么这个对象就是callable对象
callable(0) # False
callable("runoob") # False
# ------ 函数 -------
def add(a, b):
return a + b
callable(add) # 函数返回 True
# ------- 类 --------
class A: # 类
def method(self):
return 0
callable(A) # 类返回 True,因为定义过方法
# ------- 实例 -------
a = A()
callable(a) # 没有实现 __call__, 返回 False
class B:
def __call__(self):
return 0
callable(B) # True
b = B()
callable(b) # 实现 __call__, 返回 True
absl库
absl 库全称是 Abseil Python Common Libraries。它原本是个C++库,后来被迁移到了Python上。
Abseil Python命令库
- 这个absl库是建立Python应用的代码集合。
- 从Google自己的Python代码基础上收集来的,被用于测试和工业中。
特点:
- 简单的应用创建
- 分布式命令行标志系统
- 用户自定义模块和附加特征
- 测试工具
安装方法:
- pip install absl-py
示例:输入参数,name 代表名字,num_times 代表语句重复次数。name是必填参数,num_times是可选参数,默认值为1.
from absl import app
from absl import flags
FLAGS = flags.FLAGS # 用法和TensorFlow的FLAGS类似,具有谷歌独特的风格。
flags.DEFINE_string("name", None, "Your name.")
flags.DEFINE_integer("num_times", 1,
"Number of times to print greeting.")
# 指定必须输入的参数
flags.mark_flag_as_required("name")
def main(argv):
del argv # 无用
for i in range(0, FLAGS.num_times):
print('Hello, %s!' % FLAGS.name)
if __name__ == '__main__':
app.run(main) # 和tf.app.run()类似
代码:test.py
"""Test helper fot smoke_test.sh"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import sys
from absl import app
from absl import flags
from absl import logging
FlAGS = flags.FLAGS
flags.DEFINE_string('echo', None, 'Test to echo')
flags.DEFINE_integer('times', 10, 'how many times to print the string')
def main(argv):
del argv # Unused
print("Running under Python {0[0]}.{0[1]}.{0[2]}".format(sys.version_info),
file = sys.stderr)
logging.info('echo is %s', FlAGS.echo)
for _ in range(FlAGS.times):
print('Hello Python!')
if __name__ == '__main__':
app.run(main)
终端命令:
- python test.py –name = ‘David’ –times = 6
高阶函数
高阶函数的定义
- 高阶函数其实就是参数为函数的函数
- 或把函数作为结果返回的函数是高阶函数(higher-order function)。
回调函数
【2022-10-8】自从搞懂了回调函数,我对Python的理解上了一个台阶
把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,这就是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
定义
- 回调函数就是被作为参数传递的函数
# 高阶函数
def calculator(v1,v2,fn):
result = fn(v1,v2)
return result
# calculator的回调函数
def add(v1,v2):
return v1 + v2
# 调用calculator,计算1+1
print(calculator(1,1,add))
- calculator是高阶函数,而add是回调函数
- add函数就被称为calculator的回调函数
回调函数和递归函数的区别
- 回调函数是在一个函数中“回调函数”以参数的形式传入,并在该函数内部被调用。
- 而递归函数是在一个函数中,调用了自己。
时间计算
time 和 datetime 两个模块,转换流程:时间格式转换图

ISO 8601
- 一种标准化的时间表示方法,表示格式为 :YYYY-MM-DDThh:mm:ss ± timezone,表示不同时区的时间,时区部分用Z 表示为 UTC 标准时区。两个例子:
1997-07-16T08:20:30Z # UTC 时间的 1997 年 7 月 16 号 8:20:30
1997-07-16T19:20:30+08:00 # 东八区时间的 1997 年 7 月 16 号 19:20:30
时间概念
- GMT 时间:格林威治时间,基准时间
- UTC 时间:Coordinated Universal Time,全球协调时间,更精准的基准时间,与 GMT 基本等同
- CST 中国基准时间:为 UTC 时间 + 8 小时,即 UTC 时间的 0 点对应于中国基准时间的 8 点,即为一般称为东八区的时间
整个地球分为24个时区,每个时区都有自己的本地时间。
- 国际无线电通信中,为统一而普遍使用一个标准时间,称为通用协调时(UTC, Universal Time Coordinated)。UTC与格林尼治平均时(GMT, Greenwich Mean Time)一样,都与英国伦敦的本地时相同。UTC与GMT含义完全相同。
- 北京时区是东八区,领先UTC 8个小时。所以将UTC装换成北京时间时,需要加上8小时。
时间戳
- 1970年1月1日 00:00:00 UTC+00:00时区的时刻称为
epoch time,记为0,当前的时间戳即为从 epoch time 到现在的秒数,一般叫做 timestamp,因此一个时间戳一定对应于一个特定的 UTC 时间,同时也对应于其他时区的一个确定的时间。因此时间戳可以认为是一个相对安全的时间表示方法。
获取当前时间
两种方法: time 和 datetime
time
import time
tm = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
print(tm) # 2024-07-01 15:19:56
datetime
import datetime
tm = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(tm) # '2024-07-01 15:12:23'
datetime
datetime 分成两种类型:
naive,本地类型时间,没有指定时区信息,此类型的时区是根据运行环境确定对应的时区。因此这种类型的时间会因为运行环境的不同而得到不同时间戳aware,带时区类型的时间,这种类型的时间对象由于时间和时区都是确定的,因此对应于确定的时间戳
举例如下:
from datetime import datetime, timezone
now = datetime.now() # native 类型
now.tzinfo # None
utc_now = datetime.now(timezone.utc) # aware类型, 指定时区
utc_now.tzinfo # UTC
now 没有指定时区,为 naive 类型的时间,其时区与运行环境相关。而 utc_now 指定了 UTC 时区,为 aware 类型的时间。
获取当前时间
- datetime.now() 获取当前时间,支持设置对应的时区,如果不设置时区默认获取的是本地的时间,根据是否指定时区可能穿件出 naive 类型的时间或者 aware 类型的时间,但是对应的时间戳都是符合预期的。
- datetime.utcnow() 谨慎使用 获取是当前 UTC 对应的时间,但是生成的 datetime 对象是没有指定时区的,因此使用的是本地时区,创建的是 naive 类型的时间。因此如果运行环境为东八区,得到的时间是 UTC 对应的时间,但是时区是东八区,最终得到的时间会比预期早 8 个小时,转化得到时间戳也是不符合预期的。
from datetime import datetime
now = datetime.now()
now.timestamp() # 1610035129.323702
unow = datetime.utcnow()
unow.timestamp() # 1610006329.323797
在 2021-01-07 23:58:49 在东八区环境下运行
- now.timestamp() 得到时间戳转化为对应的时间为东八区的 2021-01-07 23:58:49
- 但是 unow.timestamp() 得到的时间戳对应的时间为东八区的 2021-01-07 15:58:49,对应于 UTC 时间 2021-01-07 07:58:49,和 UTC 的当前时间完全对不上。
时间戳操作
- datetime.timestamp() 当前时间对应的时间戳
- datetime.fromtimestamp() 根据时间戳生成运行环境时区对应的时间
- datetime.utcfromtimestamp() 谨慎使用, 根据时间戳生成对应的 UTC 时间,由于生成的 datetime 是没有指定时区的,因此获取时间戳看起来得到的是 8 个小时之前时间的时间戳
from datetime import datetime
timestamp = 1610035129
d1 = datetime.fromtimestamp(timestamp) # 2021-01-07 23:58:49
d2 = datetime.utcfromtimestamp(timestamp) # 2021-01-07 15:58:49
时区转换
时区设置
- 默认 datetime 没有时区信息,通过 datetime.replace() 为时间设置上时区,但必须保证对应的时间与时区信息匹配,否则就会导致错误的时区的时间
一个简单例子就是:
from datetime import datetime, timedelta, timezone
tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00,即东八区对应的时区 now = datetime.now() # 默认构建的时间无时区 dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00
设置上对应的时区后,对应的日期与时间是不变的,但是由于设置了全新的时区,如果与之前的时区不同,那么对应的时间戳就会改变,使用此方法时要谨慎
时区转换
- 将带有时区信息的时间转换为另一个时区的时间,通过 datetime.astimezone() 可以实现
一个简单的例子是:
from datetime import datetime, timedelta, timezone
utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc) # 构建了 UTC 的当前时间
bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8))) # 将时区转化为东八区的时间
通过 astimezone() 进行转换后,虽然时间变化了,但是对应的是同样的基准时间,因此对应的时间戳是不变的,
import datetime
# ------方法①---------
t_str = '2023-08-16T08:20:30Z'
utc_now = datetime.datetime.strptime(t_str,'%Y-%m-%dT%H:%M:%SZ') # 从字符串里获取 UTC时间
#utc_now = datetime.datetime.utcnow() # 直接获取本地UTC时间
print('转换前:', utc_now, ', 时区:', utc_now.tzinfo)
tm_new = utc_now.replace(tzinfo=datetime.timezone.utc).astimezone(tz=None) # 转本地时间(即中国时间,东八区)
print('转换后:', tm_new.strftime('%Y-%m-%d %H:%M:%S'))
# -------方法②---------
import datetime
date_str = [ "2023-08-17T08:20:54Z", "2023-08-17T08:28:47.776Z" ]
for s in date_str:
if s.find('.') != -1:
UTC_FORMAT = "%Y-%m-%dT%H:%M:%S.%fZ"
else:
UTC_FORMAT = "%Y-%m-%dT%H:%M:%SZ"
utc_date = datetime.datetime.strptime(s, UTC_FORMAT)
local_date = utc_date + datetime.timedelta(hours=8)
local_date_str = datetime.datetime.strftime(local_date ,'%Y-%m-%d %H:%M:%S')
print(local_date_str ) # 2019-07-26 16:20:54
pytz 工具
from pytz import timezone
def datetime_as_timezone(date_time, time_zone):
tz = timezone(time_zone)
utc = timezone('UTC')
return date_time.replace(tzinfo=utc).astimezone(tz)
def datetime_to_str(date_time):
date_time_tzone = datetime_as_timezone(date_time, 'Asia/Shanghai')
return '{0:%Y-%m-%d %H:%M}'.format(date_time_tzone)
时间差函数
import time
import datetime
def diff_time(start, end, size='seconds'):
#start = '2017-10-04 09:01:04'
#end = '2017-10-05 10:02:50'
start_tm = datetime.datetime.strptime(start, "%Y-%m-%d %H:%M:%S")
end_tm = datetime.datetime.strptime(end, "%Y-%m-%d %H:%M:%S")
diff = end_tm - start_tm
print('{} -> {} = {}'.format(start, end, (end_tm - start_tm).seconds))
if size == 'second':
return diff.total_seconds()
elif size == 'minute':
return diff.total_seconds()//60
elif size == 'hour':
return diff.total_seconds()//3600
elif size == 'day':
return diff.days
else: # 格式未知
return diff.total_seconds()
return diff.total_seconds()
start = '2017-10-04 09:01:04'
end = '2017-10-04 10:02:50'
res = diff_time(start, end, 'minute')
res
时间转换
from datetime import datetime
def str2timestamp(s):
# 字符串 → 时间戳
# s = '2021-10-25 15:29:08' -> 1635146948
ts = datetime.strptime(str_p,'%Y-%m-%d %H:%M:%S').timestamp()
return ts
def timestamp2str(ts):
# 时间戳 → 字符串
# 1695212244 -> 2023-09-20 20:17:24
cur_date = datetime.fromtimestamp(ts)
cur_date_str = datetime.strftime(cur_date ,'%Y-%m-%d %H:%M:%S')
# cur_date_str = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
return cur_date_str
for item in openai.File.list()['data']:
#print(item)
pass
import pandas as pd
df_file = pd.DataFrame(openai.File.list()['data'])
df_file['time'] = df_file['created_at'].map(timestamp2str)
df_file
用法详解:
import time
import datetime
# 【2023-2-11】一步到位, 时间戳→字符串输出
ts = 1695212244
tm = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
print('time用法')
time_now = int(time.time()) # 获取当前时间的时间戳
print(int(datetime.datetime.now().timestamp())) # 获取当前时间的时间戳
print(int(time.time())) # 获取当前时间的时间戳
today = datetime.datetime.today().date() # 当前日期
weekday = today.weekday() # 当前星期几
# 时间增量
yestoday = today + datetime.timedelta(days=-1)
tomorrow = today + datetime.timedelta(days=1)
print(today) # 2019-01-30
print(yestoday)# 2019-01-29
print(tomorrow)# 2019-01-31
print('datetime用法')
dt_now = datetime.datetime.fromtimestamp(time_now)
print(type(dt_now), dt_now) # <class 'datetime.datetime'> 2020-12-16 10:40:34
print(int(datetime.datetime.now().timestamp())) # 获取当前时间的时间戳
print('字符串转datetime')
str_p = '2021-10-25 15:29:08'
d = datetime.datetime.strptime(str_p,'%Y-%m-%d %H:%M:%S')
print(str_p, d) # 2019-01-30 15:29:08
d = datetime.datetime.strptime(str_p,'%Y-%m-%d %H:%M:%S')
week = d.weekday() + 1
# 月、日、时、分、秒
d.month, d.day, d.hour, d.minute, d.second
d.weekday() # 星期
print('datetime转字符串')
print(d.strftime("%d/%b/%Y:%H:%M:%S")) # 16/Dec/2020:11:01:37
print(d.strftime('%Y-%m-%d %H:%M:%S')) # 2020-06-16 10:31:08
# 星期几
datetime.date(2022, 2, 22).isoweekday()
datetime.date(2022, 2, 22).weekday() # 1
datetime.date(2022, 2, 22).strftime("%A") # 'Tuesday'
datetime.date(2022, 2, 22).strftime("%a") # 'Tue'
import calendar
calendar.weekday(2022, 2, 22) # 1
print('时间差')
# 字符串时间差 【2022-9-17】亲测
print ((userEnd-userStart).days) # 0 天数
# print (end-start).total_seconds() # 30.029522 精确秒数
# print (end-start).seconds # 30 秒数
# print (end-start).microseconds # 29522 毫秒数
a1='2017-10-04 09:01:04'
a2='2017-10-05 10:02:50'
test1=datetime.datetime.strptime(a1, "%Y-%m-%d %H:%M:%S")
test2=datetime.datetime.strptime(a2, "%Y-%m-%d %H:%M:%S")
diff=test2-test1
print('{} -> {} = {}'.format(start, end, (userEnd-userStart).seconds))
print(diff.days)
print(diff.total_seconds())
print(diff.total_seconds()//60)
流程控制
遍历列表可使用 for循环、while循环 和 enumerate()函数等多种方法来实现。
for循环: 最常用,因为简单、易读且高效。enumerate: 同时获取元素索引和值。while循环: 虽然也可以遍历列表,但通常更加复杂且容易出错。
在处理嵌套列表时,可以使用嵌套的for循环来遍历所有元素。
Bad Case
经典示例
arr = ['马','蹄','哒','哒','哒']
idx = 1
# for 遍历
for item in arr: # 未复制, 原地操作
# print(f'{idx}: {item}')
if item == '哒':
arr.remove(item) # 修改原数组, 删除第一个出现元素
print(f'{idx}\t{arr}')
idx += 1
print(f'end\t{arr}')
# 3 ['马', '蹄', '哒', '哒']
# 4 ['马', '蹄', '哒']
# end ['马', '蹄', '哒']
# enumerate 遍历
for i, item in enumerate(arr):
# print(f'{i}: {item}')
if item == '哒':
arr.remove(item) # 修改原数组, 删除第一个出现元素
print(f'{i}\t{arr}')
print(f'end\t{arr}')
迭代器
迭代器 iterator 是一个特殊对象,用于遍历访问可迭代对象 iterable。
Python 通过迭代器 iterator 实现 for … in 循环语句
for item in iterable:
print(item)
for … in 代码被转化为
iterator = iter(iterable)
while True:
try:
item = next(iterator)
print(item)
except StopIteration:
break
for
循环遍历
a = ['Google', 'Baidu', 'Huawei', 'Taobao', 'QQ']
for i in range(len(a)):
print(i, a[i])
else 语句
for n in range(2, 100):
for x in range(2, n):
if n % x == 0:
print(n, '等于', x, '*', n//x)
break
# continue
else:
# 循环中没有找到元素
print(n, ' 是质数')
range
函数
range(start, stop[, step])
range(10) # 从 0 开始到 9, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
range(1, 11) # 从 1 开始到 10, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
range(0, 30, 5) # 步长为 5, [0, 5, 10, 15, 20, 25]
range(0, 10, 3) # 步长为 3, [0, 3, 6, 9]
range(0, -10, -1) # 负数
# [0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
# range(0) # []
range(1, 0) # []
while
number = 10
i = 0
while i < number:
print(i)
i += 1
if i == 7:
break
else:
print("执行完毕!")
switch 语句
switch
C++, Java里的switch语句,以C++为例:
#include
using namespace std;
int main() {
int day = 4;
switch (day) {
case 1:
cout << "Monday";
break;
case 2:
cout << "Tuesday";
break;
case 3:
cout << "Wednesday";
break;
case 4:
cout << "Thursday";
break;
case 5:
cout << "Friday";
break;
case 6:
cout << "Saturday";
break;
case 7:
cout << "Sunday";
break;
}
return 0;
}
Python解法
【2022-11-7】然而,Python 老版本没有 switch 语句,3.10版本后才有
def number_to_string(argument):
match argument:
case 0:
return "zero"
case 1:
return "one"
case 2:
return "two"
case default:
return "something"
if __name__ = "__main__":
argument = 0
number_to_string(argument)
3.10以前如何实现switch功能?3种方法
- dict
- if then
- class 面向对象
- 匿名函数
dict方式
dict 结构:
# Function to convert number into string
def monday():
return "monday"
# Switcher is dictionary data type here
def numbers_to_strings(argument):
switcher = {
0: "zero",
1: "one",
2: "two",
3: monday # 此处的value值也可以是函数名
}
# get() method of dictionary data type returns
# value of passed argument if it is present
# in dictionary otherwise second argument will
# be assigned as default value of passed argument
return switcher.get(argument, "nothing")
# Driver program
if __name__ == "__main__":
argument=0
print (numbers_to_strings(argument))
if-else方法
if-else 实现
bike = 'Yamaha'
if bike == 'Hero':
print("bike is Hero")
elif bike == "Suzuki":
print("bike is Suzuki")
elif bike == "Yamaha":
print("bike is Yamaha")
else:
print("Please choose correct answer")
类属性方式
类属性实现
class Python_Switch:
def day(self, month):
default = "Incorrect day"
# 拼装、提取、返回属性方法
return getattr(self, 'case_' + str(month), lambda: default)()
def case_1(self):
return "Jan"
def case_2(self):
return "Feb"
def case_3(self):
return "Mar"
my_switch = Python_Switch()
print(my_switch.day(1))
print(my_switch.day(3))
匿名函数
def zero():
return 'zero'
def one():
return 'one'
def indirect(i):
switcher={
0:zero,
1:one,
2:lambda:'two'
}
func=switcher.get(i,lambda :'Invalid')
return func()
indirect(4)
itertools 高效迭代
itertools模块
- 【2017-9-27】摘自:PYTHON-进阶-ITERTOOLS模块小结
- itertools用于高效循环的迭代函数集合
代码:
from itertools import *
i = 0
for item in cycle(['a', 'b', 'c']):#无限循环
#for i in repeat('over', 5): #重复5次
#for i in izip(count(1), ['a', 'b', 'c']):
#for i in chain([1, 2, 3], ['a', 'b', 'c']): #多个迭代器串联成一个
i += 1
if i == 10:
break
print (i, item)
无穷循环器
count(5, 2) #从5开始的整数循环器,每次增加2,即5, 7, 9, 11, 13, 15 ...
cycle('abc') #重复序列的元素,既a, b, c, a, b, c ...
repeat(1.2) #重复1.2,构成无穷循环器,即1.2, 1.2, 1.2, ...
repeat也可以有一个次数限制:
repeat(10, 5) #重复10,共重复5次
函数式工具
函数式编程是将函数本身作为处理对象的编程范式。在Python中,函数也是对象,因此可以轻松的进行一些函数式的处理,比如map(), filter(), reduce()函数。
itertools包含类似的工具。这些函数接收函数作为参数,并将结果返回为一个循环器
from itertools import *
rlt = imap(pow, [1, 2, 3], [1, 2, 3])
for num in rlt:
print(num)
此外,还可以用下面的函数:
starmap(pow, [(1, 1), (2, 2), (3, 3)])
# pow将依次作用于表的每个tuple。
# ifilter函数与filter()函数类似,只是返回的是一个循环器。
ifilter(lambda x: x > 5, [2, 3, 5, 6, 7]
# 将lambda函数依次作用于每个元素,如果函数返回True,则收集原来的元素。6, 7
ifilterfalse(lambda x: x > 5, [2, 3, 5, 6, 7]) # 与上面类似,但收集返回False的元素。2, 3, 5
takewhile(lambda x: x < 5, [1, 3, 6, 7, 1]) # 当函数返回True时,收集元素到循环器。一旦函数返回False,则停止。1, 3
dropwhile(lambda x: x < 5, [1, 3, 6, 7, 1]) # 当函数返回False时,跳过元素。一旦函数返回True,则开始收集剩下的所有元素到循环器。6, 7, 1
组合工具
可以通过组合原有循环器,来获得新的循环器。
chain([1, 2, 3], [4, 5, 7]) # 连接两个循环器成为一个。1, 2, 3, 4, 5, 7
product('abc', [1, 2]) # 多个循环器集合的笛卡尔积。相当于嵌套循环
for m, n in product('abc', [1, 2]):
print m, n
permutations('abc', 2) # 从'abcd'中挑选两个元素,比如ab, bc, ... 将所有结果排序,返回为新的循环器。
# 注意,上面的组合分顺序,即ab, ba都返回。
combinations('abc', 2) # 从'abcd'中挑选两个元素,比如ab, bc, ... 将所有结果排序,返回为新的循环器。
# 注意,上面的组合不分顺序,即ab, ba的话,只返回一个ab。
combinations_with_replacement('abc', 2) # 与上面类似,但允许两次选出的元素重复。即多了aa, bb, cc
groupby()
将key函数作用于原循环器的各个元素。
- 根据key函数结果,将拥有相同函数结果的元素分到一个新的循环器。
- 每个新的循环器以函数返回结果为标签。这就好像一群人的身高作为循环器。
可以使用这样一个key函数: 如果身高大于180,返回”tall”;如果身高底于160,返回”short”;中间的返回”middle”。最终,所有身高将分为三个循环器,即”tall”, “short”, “middle”。
def height_class(h):
if h > 180:
return "tall"
elif h < 160:
return "short"
else:
return "middle"
friends = [191, 158, 159, 165, 170, 177, 181, 182, 190]
friends = sorted(friends, key = height_class)
for m, n in groupby(friends, key = height_class):
print(m)
print(list(n))
注意,groupby的功能类似于UNIX中的uniq命令。分组之前需要使用sorted()对原循环器的元素,根据key函数进行排序,让同组元素先在位置上靠拢。
其它工具
compress('ABCD', [1, 1, 1, 0]) # 根据[1, 1, 1, 0]的真假值情况,选择第一个参数'ABCD'中的元素。A, B, C
islice() # 类似于slice()函数,只是返回的是一个循环器
izip() # 类似于zip()函数,只是返回的是一个循环器。
# (1)无限迭代器
迭代器 参数 结果 例子
count() start, [step] start, start+step, start+2*step, ... count(10) --> 10 11 12 13 14 ...
cycle() p p0, p1, ... plast, p0, p1, ... cycle('ABCD') --> A B C D A B C D ...
repeat() elem [,n] elem, elem, elem, ... endlessly or up to n times repeat(10, 3) --> 10 10 10
# (2)处理输入序列迭代器
迭代器 参数 结果 例子
chain() p, q, ... p0, p1, ... plast, q0, q1, ... chain('ABC', 'DEF') --> A B C D E F
compress() data, selectors (d[0] if s[0]), (d[1] if s[1]), ... compress('ABCDEF', [1,0,1,0,1,1]) --> A C E F
dropwhile() pred, seq seq[n], seq[n+1], starting when pred fails dropwhile(lambda x: x<5, [1,4,6,4,1]) --> 6 4 1
groupby() iterable[, keyfunc] sub-iterators grouped by value of keyfunc(v)
ifilter() pred, seq elements of seq where pred(elem) is True ifilter(lambda x: x%2, range(10)) --> 1 3 5 7 9
ifilterfalse() pred, seq elements of seq where pred(elem) is False ifilterfalse(lambda x: x%2, range(10)) --> 0 2 4 6 8
islice() seq, [start,] stop [, step] elements from seq[start:stop:step] islice('ABCDEFG', 2, None) --> C D E F G
imap() func, p, q, ... func(p0, q0), func(p1, q1), ... imap(pow, (2,3,10), (5,2,3)) --> 32 9 1000
starmap() func, seq func(*seq[0]), func(*seq[1]), ... starmap(pow, [(2,5), (3,2), (10,3)]) --> 32 9 1000
tee() it, n it1, it2 , ... itn splits one iterator into n
takewhile() pred, seq seq[0], seq[1], until pred fails takewhile(lambda x: x<5, [1,4,6,4,1]) --> 1 4
izip() p, q, ... (p[0], q[0]), (p[1], q[1]), ... izip('ABCD', 'xy') --> Ax By
izip_longest() p, q, ... (p[0], q[0]), (p[1], q[1]), ... izip_longest('ABCD', 'xy', fillvalue='-') --> Ax By C- D-
# (3)组合生成器
迭代器 参数 结果
product() p, q, ... [repeat=1] cartesian product, equivalent to a nested for-loop
permutations() p[, r] r-length tuples, all possible orderings, no repeated elements
combinations() p, r r-length tuples, in sorted order, no repeated elements
combinations_with_replacement() p, r r-length tuples, in sorted order, with repeated elements
product('ABCD', repeat=2) AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD
permutations('ABCD', 2) AB AC AD BA BC BD CA CB CD DA DB DC
combinations('ABCD', 2) AB AC AD BC BD CD
combinations_with_replacement('ABCD', 2) AA AB AC AD BB BC BD CC CD DD
第一部分
- itertools.count(start=0, step=1)
- itertools.cycle(iterable)
- itertools.repeat(object[, times])
第二部分
- itertools.chain(*iterables)
- itertools.compress(data, selectors)
- itertools.dropwhile(predicate, iterable)
- itertools.groupby(iterable[, key])
- itertools.ifilter(predicate, iterable)
- itertools.ifilterfalse(predicate, iterable)
- itertools.islice(iterable, stop)
- itertools.imap(function, *iterables)
- itertools.starmap(function, iterable)
- itertools.tee(iterable[, n=2])
- itertools.takewhile(predicate, iterable)
- itertools.izip(*iterables)
- itertools.izip_longest(*iterables[, fillvalue])
第三部分
- itertools.product(*iterables[, repeat])
- itertools.permutations(iterable[, r])
- itertools.combinations(iterable, r)
- itertools.combinations_with_replacement(iterable, r)
第四部分
- 扩展
- 自定义扩展
- 补充
路径文件
可用工具包 os 和 Path
| pathlib操作 | os及os.path操作 | 功能描述 |
|---|---|---|
| Path.resolve() | os.path.abspath() | 获得绝对路径 |
| Path.chmod() | os.chmod() | 修改文件权限和时间戳 |
| Path.mkdir() | os.mkdir() | 创建目录 |
| Path.rename() | os.rename() | 文件或文件夹重命名,如果路径不同,会移动并重新命名 |
| Path.replace() | os.replace() | 文件或文件夹重命名,如果路径不同,会移动并重新命名,如果存在,则破坏现有目标。 |
| Path.rmdir() | os.rmdir() | 删除目录 |
| Path.unlink() | os.remove() | 删除一个文件 |
| Path.unlink() | os.unlink() | 删除一个文件 |
| Path.cwd() | os.getcwd() | 获得当前工作目录 |
| Path.exists() | os.path.exists() | 判断是否存在文件或目录name |
| Path.home() | os.path.expanduser() | 返回电脑的用户目录 |
| Path.is_dir() | os.path.isdir() | 检验给出的路径是一个文件 |
| Path.is_file() | os.path.isfile() | 检验给出的路径是一个目录 |
| Path.is_symlink() | os.path.islink() | 检验给出的路径是一个符号链接 |
| Path.stat() | os.stat() | 获得文件属性 |
| PurePath.is_absolute() | os.path.isabs() | 判断是否为绝对路径 |
| PurePath.joinpath() | os.path.join() | 连接目录与文件名或目录 |
| PurePath.name | os.path.basename() | 返回文件名 |
| PurePath.parent | os.path.dirname() | 返回文件路径 |
| Path.samefile() | os.path.samefile() | 判断两个路径是否相同 |
| PurePath.suffix | os.path.splitext() | 分离文件名和扩展名 |
相对于传统 os及os.path,pathlib 具体优势:
- pathlib 统一管理,解决了传统操作导入模块不统一问题;
- pathlib 不同操作系统之间切换非常简单;
- pathlib 面向对象的,路径处理更灵活方便,解决了传统路径和字符串并不等价的问题;
- pathlib 简化了很多操作,简单易用。
详见 总结
系统识别
【2024-12-11】自动识别不同操作系统
多种方式实现,主要区别
sys.platform在构建配置时指定的编译器定义os.name用于检查特定模块是否可用(例如:POSIX,nt, …)platform.system()实际上运行uname和潜在的几个其他函数来确定运行时的系统类型
paddle 源码示例
sys.platform 名称映射
| 系统 | 返回值 |
|---|---|
| window | ‘win32’ |
| linux | ‘linux’ |
| Windows/Cygwin | ‘cygwin’ |
| Mac OS X | ‘darwin’ |
import sys
sys_name = sys.platform
if sys_name.startswith('win32') or sys_name.startwith('cygwin'):
print('windows 系统')
elif sys_name.startswith('linux'):
print('linux系统')
# elif sys_name.startwith('cygwin'):
# print('Windows/Cygwin 系统')
elif sys_name.startswith('darwin'):
print('Mac OS X 系统')
else:
print(f'未知系统: {sys_name}')
os.name
- 返回当前操作系统的类型
- 只注册了3个值:分别是 posix , nt , java
import os
print(os.name)
另一种方法 platform.system()
- 返回当前操作系统名字
- Linux , Windows , Java , … 如果不能确定会返回空字符串
这是在上层的脚本实现,需要在运行时执行。
platform.system() 名称映射
import platform
def avx_supported():
"""
Whether current system(Linux, MacOS, Windows) is supported with AVX.
"""
sysstr = platform.system().lower()
has_avx = False
if sysstr == 'linux':
try:
pipe = os.popen('cat /proc/cpuinfo | grep -i avx')
has_avx = pipe.read() != ''
pipe.close()
except Exception as e:
sys.stderr.write(
'Can not get the AVX flag from /proc/cpuinfo.\n'
'The original error is: %s\n' % str(e)
)
return has_avx
elif sysstr == 'darwin':
try:
pipe = os.popen('sysctl machdep.cpu.features | grep -i avx')
has_avx = pipe.read() != ''
pipe.close()
except Exception as e:
sys.stderr.write(
'Can not get the AVX flag from machdep.cpu.features.\n'
'The original error is: %s\n' % str(e)
)
if not has_avx:
import subprocess
pipe = subprocess.Popen(
'sysctl machdep.cpu.leaf7_features | grep -i avx',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
_ = pipe.communicate()
has_avx = True if pipe.returncode == 0 else False
return has_avx
elif sysstr == 'windows':
import ctypes
ONE_PAGE = ctypes.c_size_t(0x1000)
os 包
目录操作
import os
os.getcwd() # 当前目录
os.path.abspath(path) #返回绝对路径
os.path.basename(path) #返回文件名
os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径
os.path.dirname(path) #返回文件路径
os.path.exists(path) #路径存在则返回True,路径损坏返回False
# 判断是否已经存在该目录
if not os.path.exists(File_Path):
# 目录不存在,进行创建操作
os.mkdir(File_Path) # 创建一层目录
os.makedirs(File_Path) #使用os.makedirs()方法创建多层目录
print("目录新建成功:" + File_Path)
os.path.lexists #路径存在则返回True,路径损坏也返回True
os.path.expanduser(path) #把path中包含的"~"和"~user"转换成用户目录
os.path.expandvars(path) #根据环境变量的值替换path中包含的"$name"和"${name}"
os.path.getatime(path) #返回最近访问时间(浮点型秒数)
os.path.getmtime(path) #返回最近文件修改时间
os.path.getctime(path) #返回文件 path 创建时间
os.path.getsize(path) #返回文件大小,如果文件不存在就返回错误
os.path.isabs(path) #判断是否为绝对路径
os.path.isfile(path) #判断路径是否为文件
os.path.isdir(path) #判断路径是否为目录
os.path.islink(path) #判断路径是否为链接
os.path.ismount(path) #判断路径是否为挂载点
os.path.join(path1[, path2[, ...]]) #把目录和文件名合成一个路径
os.path.normcase(path) #转换path的大小写和斜杠
os.path.normpath(path) #规范path字符串形式
os.path.realpath(path) #返回path的真实路径
os.path.relpath(path[, start]) #从start开始计算相对路径
os.path.samefile(path1, path2) #判断目录或文件是否相同
os.path.sameopenfile(fp1, fp2) #判断fp1和fp2是否指向同一文件
os.path.samestat(stat1, stat2) #判断stat tuple stat1和stat2是否指向同一个文件
os.path.split(path) #把路径分割成 dirname 和 basename,返回一个元组
os.path.splitdrive(path) #一般用在 windows 下,返回驱动器名和路径组成的元组
os.path.splitext(path) #分割路径中的文件名与拓展名
os.path.splitunc(path) #把路径分割为加载点与文件
os.path.walk(path, visit, arg) #遍历path,进入每个目录都调用visit函数,visit函数必须有3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有文件名,args则为walk的第三个参数
os.path.supports_unicode_filenames #设置是否支持unicode路径名
Path 包
目录操作
from pathlib import Path
p.cwd() # 获取当前路径
p.stat() # 获取当前文件的信息
p.exists() # 判断当前路径是否是文件或者文件夹
p.glob(filename) # 获取路径下的所有符合filename的文件,返回一个generator
p.rglob(filename) # 与上面类似,只不过是返回路径中所有子文件夹的符合filename的文件
p.is_dir() # 判断该路径是否是文件夹
p.is_file() # 判断该路径是否是文件
p.iterdir() #当path为文件夹时,通过yield产生path文件夹下的所有文件、文件夹路径的迭代器
P.mkdir(parents=Fasle) # 根据路径创建文件夹,parents=True时,会依次创建路径中间缺少的文件夹
p_news = p/'new_dirs/new_dir'
p_news.mkdir(parents=True)
os.mkdir() # 创建路径中的最后一级目录,即:只创建path_03目录,而如果之前的目录不存在并且也需要创建的话,就会报错。os.makedirs() # 创建多层目录,即:Test,path_01,path_02,path_03如果都不存在的话,会自动创建,但是如果path_03也就是最后一级目录已存在的话就会抛出FileExistsError异常。
P.open(mode='r', buffering=-1, encoding=None, errors=None, newline=None) #类似于open()函数
p.rename(target) # 当target是string时,重命名文件或文件夹;当target是Path时,重命名并移动文件或文件夹
p.replace(target) # 重命名当前文件或文件夹,如果target所指示的文件或文件夹已存在,则覆盖原文件
p.parent(),p.parents() # parent获取path的上级路径,parents获取path的所有上级路径
p.is_absolute() # 判断path是否是绝对路径
p.match(pattern) # 判断path是否满足pattern
p.rmdir() # 当path为空文件夹的时候,删除该文件夹
p.name # 获取path文件名
p.suffix # 获取path文件后缀
遍历文件
分情形
- 只有文件时,用
os.listdir - 包含目录时,用
os.walk - 通配符查找, 用 glob
os.listdir/walk
分情形
- 只有文件时,用
os.listdir - 包含目录时,用
os.walk
import os
path = r'E:\test'
# os.listdir
filenames=os.listdir(path)
print(filenames)
# os.walk
for filepath,dirnames,filenames in os.walk(path):
for filename in filenames:
print(os.path.join(filepath,filename))
glob
glob 是 python 自带的操作文件模块。
- glob 查找符合规定的文件路径名
常用的方法有 glob.glob() 和 glob.iglob()
glob.glob()返回一个列表glob.iglob()返回生成器。
通配符与正则表达式(re 模块)不同。
*匹配0个或多个字符;**匹配所有文件,目录,子目录和子目录里面的文件 (3.5版本新增)?匹配单个字符;[]匹配指定范围内的字符,如:[0-9]匹配数字。[!]匹配不在指定范围内的字符
import glob
for name in glob.glob('dir/*'):
print(name)
# for file in glob.glob("*"): # 当前目录下所有文件
# for file in glob.glob("**", recursive=True): # 当前及子目录下所有文件
# for file in glob.glob("*.py"): # 当前目录下py文件
# for file in glob.glob("*/*.py", recursive=True): # 一级子目录下py文件
# for file in glob.glob("**/*.py", recursive=True): # 当前及子目录下py文件
for file in glob.glob("*.txt"):
print(file)
示例目录
- 当前目录只有两个文件, 其余都是目录
.
├── example
├── dir1
├── dir2
├── dir3
├── train
├── val
├── test
├── _config.yml
└── exp.py
遍历当前目录
print(glob.glob('./*'))
# out:
# ['.\\example', '.\\exp.py', '.\\test', '.\\train', '.\\val', '.\\_config.yml']
遍历上一级目录(example文件夹中)
print(glob.glob('../*'))
# out:
# ['.\\example', '.\\exp.py', '.\\test', '.\\train', '.\\val', '.\\_config.yml']
遍历本级下文件
print(glob.glob('./*.*')) #本级下所有文件
print(glob.glob("./*.yml")) #本级下所有yml文件
# out:
# ['.\\exp.py', '.\\_config.yml']
# ['.\\_config.yml']
匹配特定文件目录
print(glob.glob("./*[ca][nf]*")) # 匹配ca和nf字母组合但一定相邻的名字
print(glob.glob("./*[ca]*[nf]*")) # 匹配有ca和nf中任意字母组合的名字
print(glob.glob("./*e?p*")) # 匹配e和p中间只有一个字符的名字
# out:
# []
# ['.\\train', '.\\_config.yml']
# ['.\\exp.py']
匹配子目录及文件
print(glob.glob("./example/*")) # 遍历example文件夹中所有内容
print(glob.glob("./example/*/*")) # 遍历example文件夹中所有子文件夹及子文件夹中的文件
# out:
# ['./example\\dir1', './example\\dir2', './example\\dir3']
# ['./example\\dir1\\dir1.py', './example\\dir2\\dir2.py', './example\\dir3\\dir3.py']
正则表达式
【2010-7-4】Python正则表达式指南
正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。
正则解析
正则表达式进行匹配的流程
- 正则表达式文本 –引擎–> 正则表达式对象 –匹配–> 被匹配文本 –> 匹配结果
Python支持的正则表达式元字符和语法: 图
() # 分组,保存,编号逐个+1
(?P<name>) # 分组别名 name
\<num> # 引用编号num的分组匹配到字符串
(?:) # 不分组
(?iLmsux) # 匹配模式,每个字母一个
(?#) # 注释
# 前后查找的操作符:
(?=) # 正向前查找
(?!) # 负向前查找
(?<=) # 正向后查找
(?<!) # 负向后查找
(?(id/name)yes|no) # 条件匹配,如果编号id/别名name的组匹配成功,则匹配yes,否则no
正则解析,图 源自Python正则表达式
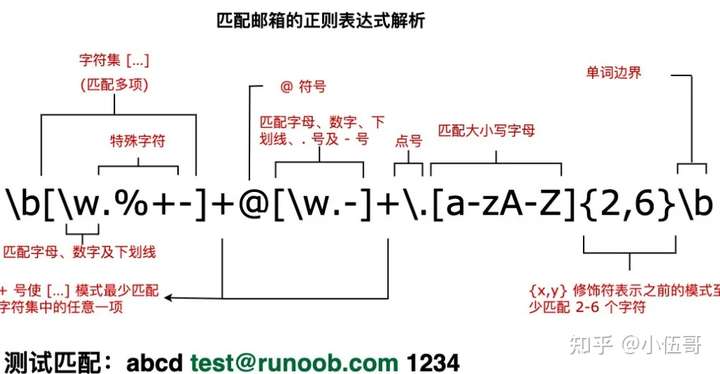
re模块
Python的re模块主要定义了9个常量、12个函数、1个异常 re.compile模式:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)M(MULTILINE): 多行模式,改变’^’和’$’的行为(参见上图)S(DOTALL): 点任意匹配模式,改变’.’的行为L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
正则表达re模块共有12个函数,概览:
- search、match、fullmatch:查找一个匹配项
search:查找任意位置的匹配项match:必须从字符串开头匹配fullmatch:整个字符串与正则完全匹配- 以上三种方法返回match对象,几个常用的方法如下:
- m.start() 返回匹配到的字符串的起使字符在原始字符串的索引
- m.end() 返回匹配到的字符串的结尾字符在原始字符串的索引
- m.group() 返回指定组的匹配结果
- m.groups() 返回所有组的匹配结果
- m.span() 以元组形式给出对应组的开始和结束位置
findall、finditer:查找多个匹配项- 1)findall: 从字符串任意位置查找,返回一个列表
- 2)finditer:从字符串任意位置查找,返回一个迭代器,适用大量匹配项
split: 分割- re.split(r”[;:]”,”var A;B;C:integer;”)
sub,subn:替换- re.sub(‘\d+’,’*’,’aaa34bvsa56s’,count=1)
- 与 re.sub函数 功能一致,只不过返回一个元组 (字符串, 替换次数)
- re.subn(‘\d’,’*’,’aaa34bvsa56s’)#每个数字都替换一次
- compile函数、template函数: 将正则表达式的样式编译为一个 正则表达式对象
正则语法总结:图

代码示例
import re
p = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)
pattern = r'\d+' # 定义正则表达式
text = "Hello 123 World 456" # 定义目标字符串
match = re.match(pattern, text)
match = re.search(pattern, text) # 使用search()方法搜索匹配的子串
# 判断是否命中
if match:
print("找到匹配的子串:", match.group()) # 输出:找到匹配的子串: 123
else:
print("未找到匹配的子串")
print ("正则表达式:", p.pattern) # (\w+) (\w+)(?P<sign>.*)
print ("匹配模式:", p.flags) # 48
print ("分组数目:", p.groups) # 3
print ("别名分组:", p.groupindex) # {'sign': 3}
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
print ("原始字符串:", m.string) # 要匹配的原始字符串
print ("原始正则表达式:", m.re) # 要匹配的原始正则
print ("索引范围: [{}, {}]".format(m.pos, m.endpos)) # [0, 12]
print ("捕获的最后一个分组索引:", m.lastindex) # 3
print ("捕获的最后一个分组别名:", m.lastgroup) # sign
print ("获取多个组:", m.group(1, 2)) # ('hello', 'world')
print ("获取全部组(元组):", m.groups()) # ('hello', 'world', '!')
print ("获取全部别名组(字典):", m.groupdict()) # {'sign': '!'}
print ("第2个字符串范围: [{},{}]".format(m.start(2), m.end(2))) # (6, 11)
print ("第2个字符串范围:", m.span(2)) # (6, 11)
print ("局部重排:", m.expand(r'\2 \1\3')) # world hello!
# [2022-10-14] 正则替换,全部替换 等效于 repalce 函数
s="进入IM=>初始faq(te)=>点击faq(0:房源信息不真实,怎么举报?)"
out = re.sub(r'\(.*?\)', '', s, count=1) # 只替换一次
out = re.subn(r'\(.*?\)', '', s) # 返回tuple,(替换后的内容, 替换次数) ('进入IM=>初始faq=>点击faq', 2)
re.split9(r'=>', s) # 正则分割
# 槽位字典
pattern_city = re.compile('(?P<city>西安|武汉|青岛|广州|重庆)市?(?P<district>城六|咸阳|高陵|长安)区?',re.X)
pattern_loan = re.compile('(?P<loan>全款|公积金|商业|组合)贷款?')
pattern_info = re.compile('(?P<city>西安|武汉|青岛|广州|重庆)市?(?P<district>城六|咸阳|高陵|长安)区?(?P<loan>全款|公积金|商业|组合)贷款?',re.X)
slot_dict = {'city': '-', 'loan':'-'}
query = '西安长安区商业贷款'
res1 = pattern_info.match(query)
print(res1) # match对象
print(res1.groupdict()) # 返回字典(含别名)
res2 = pattern_info.findall(query) # 返回列表
print(res2)
regex模块
【2021-8-9】Python的regex模块——更强大的正则表达式引擎
内置的re模块不支持一些高级特性,比如下面这几个:
- 固化分组 Atomic grouping
- 占有优先量词 Possessive quantifiers
- 可变长度的逆序环视 Variable-length lookbehind
- 递归匹配 Recursive patterns
- (起始/继续)位置锚\G Search anchor 2009年,Matthew Barnett写了一个更强大正则表达式引擎——regex模块,这是一个Python的第三方模块。
- 安装:pip install regex 除了上面这几个高级特性,还有很多有趣、有用的东西,本文大致介绍一下,很多内容取自regex的文档。
regex基本兼容re模块,现有的程序可以很容易切换到regex模块:import regex as re;
regex有Version 0和Version 1两个工作模式,其中的Version 0基本兼容现有的re模块,以下是区别:
| Version 0 (基本兼容re模块) | Version 1 | |
|---|---|---|
| 启用方法 | 默认模式 | 设置regex.DEFAULT_VERSION = regex.V1,或者在表达式里写上(?V1) |
| 内联flag | 内联flag只能作用于整个表达式,不可关闭。 | 内联flag可以作用于局部表达式,可以关闭。 |
| 字符组 | 只支持简单的字符组。 | 字符组里可以有嵌套的集合,也可以做集合运算(并集、交集、差集、对称差集)。 |
| 大小写匹配 | 默认支持普通的Unicode字符大小写,如Й可匹配й。这与Python3里re模块的默认行为相同。 | 默认支持完整的Unicode字符大小写,如ss可匹配ß。可惜不支持Unicode组合字符与单一字符的大小写匹配,所以感觉这个特性不太实用。可以在表达式里写上(?-f)关闭此特性。 |
V1模式默认开启.FULLCASE(完整的忽略大小写匹配)。通常用不上这个,所以在忽略大小写匹配时用(?-f)关闭.FULLCASE即可,这样速度更快一点,例如:(?i-f)tag
Version 0模式和re模块不兼容之处
- \s的范围。
- 在re中,\s在这一带的范围是0x09 ~ 0x0D,0x1C ~ 0x1E。
- 在regex中,\s采用的是Unicode 6.3+标准的\p{Whitespace},在这一带的范围有所缩小,只有:0x09 ~ 0x0D。
- regex有模糊匹配(fuzzy matching)功能,能针对字符进行模糊匹配,提供了3种模糊匹配:
- i,模糊插入
- d,模糊删除
- s,模糊替换
- 以及e,包括以上三种模糊
import regex as re
# 两次匹配都是把捕获到的内容放到编号为1捕获组中,在某些情况很方便
regex.match(r"(?|(first)|(second))", "first").groups() # ('first',)
regex.match(r"(?|(first)|(second))", "second").groups() # ('second',)
# 局部范围的flag控制。在re模块,flag只能作用于整个表达式,现在可以作用于局部范围;全局范围的flag控制,如 (?si-f)<B>good</B>
# (?i:)是打开忽略大小写,(?-i:)则是关闭忽略大小写。
# 如果有多个flag挨着写既可,如(?is-f:),减号左边的是打开,减号右边的是关闭。
regex.search(r"<B>(?i:good)</B>", "<B>GOOD</B>") # <regex.Match object; span=(0, 11), match='<B>GOOD</B>'>
# 可重复使用的子句
regex.search(r'(?(DEFINE)(?P<quant>\d+)(?P<item>\w+))(?&quant) (?&item)', '5 elephants') # <regex.Match object; span=(0, 11), match='5 elephants'> , 此例中,定义之后,(?&quant)表示\d+,(?&item)表示\w+。如果子句很复杂,能省不少事。
# 模糊匹配:匹配hello,其中最多容许有两个字符的错误。
regex.findall('(?:hello){s<=2}', 'hallo')
# ['hallo']
# 部分匹配。可用于验证用户输入,当输入不合法字符时,立刻给出提示。
# 编译好的正则式用pickle存储到文件,直接pickle.load()就不必再次编译,节省时间
参数处理
用户参数
Python获取用户参数的几种方式:
- input()函数
- sys.argv模块
- argparse模块
- getopt模块
input函数
python2中input与python3的input不一样, python2中raw_input 与 python3 中的input 比较类似
- raw_input(): python2独有
- 小括号中放入的是提示信息,用来在获取数据之前给用户的一个简单提示
- 在从键盘获取了数据以后,会存放到等号右边的变量中
- 把用户输入的任何值都作为字符串来对待
- input()函数与raw_input()类似,但其接受的输入必须是表达式
# python 2
data = input() # 输入23、"hello"(字符串必须有引号,否则报错)
data = input('plase: ')
data = raw_input("hello, please input") # 不限类型
# Python 3
data = input("please enter the data: ")
# 无论输入的是什么,最终data的数据类型都是“str”
print(data)
sys.argv
sys标准库最常用的是sys.argv,用来调用命令行参数,这些命令行参数以链表形式存储于 sys 模块的 argv 变量。一律是字符串形式
- sys.argv[0]表示脚本本身
import sys
# python test.py one two three
print(sys.argv) # ['test.py', 'one', 'two', 'three']
print(sys.argv[0]) # 脚本名称
print(os.path.abspath(sys.argv[0])) # 脚本绝对路径
argparse
parser.add_argument 方法的type参数理论上可以是任何合法的类型
- 但有些参数传入格式比较麻烦,例如 list,所以一般用 bool, int, str, float 这些基本类型
- 更复杂的需求可以通过str传入,然后手动解析。
- bool类型的解析比较特殊,传入任何值都会被解析成True,传入空值时才为False
- 官方指南
import argparse
parser = argparse.ArgumentParser()
parser.description='please enter two parameters a and b ...'
# add_argument 指定命令行选项 help 设置提示语
parser.add_argument("-a", "--inputA", help="this is parameter a", dest="argA", type=int, default="0")
parser.add_argument("-b", "--inputB", help="this is parameter b", type=int, default="1")
parser.add_argument("-c", "--inputC", help="this is parameter c", action="store_true") # bull 变量,只要存在就是true
parser.add_argument("-v", "--verbosity", type=int, choices=[0, 1, 2], help="increase output verbosity") # 多种候选取值
parser.remove_argument('--autotuning') # 删除参数
# 解析参数
args = parser.parse_args()
print("parameter a is :",args.argA) # 使用自定义的别名, inputA --> argA
print("parameter b is :",args.inputB) # 使用系统默认变量名, inputB
if args.inputC:
print("inputC turned on")
# 类型转换
# vars() 函数返回对象object的属性和属性值的字典对象
my_dict = vars(args) # 转 dict
args = argparse.Namespace(**my_dict) # dict 转 对象
python test.py -h # 参数说明
python test.py -a 2 -b 3
tf.app.run
TensorFlow参数处理
tensorflow只提供以下几种方法:4种方法,分别对应str, int,bool,float类型的参数
- tf.app.flags.DEFINE_string
- tf.app.flags.DEFINE_integer
- tf.app.flags.DEFINE_boolean
- tf.app.flags.DEFINE_float 。 这里对bool的解析比较严格,传入1会被解析成True,其余任何值都会被解析成False。
脚本中需要定义一个接收一个参数的main方法:def main(_):,这个传入的参数是脚本名,一般用不到, 所以用下划线接收。
- 以batch_size参数为例,传入这个参数时使用的名称为–batch_size,也就是说,中划线不会像在argparse 中一样被解析成下划线。
tf.app.run()会寻找并执行入口脚本的main方法。也只有在执行了tf.app.run()之后才能从FLAGS中取出参数。
- 从它的签名来看,它也是可以自己指定需要执行的方法的,不一定非得叫main:
import tensorflow as tf
tf.app.flags.DEFINE_string('gpus', None, 'gpus to use')
tf.app.flags.DEFINE_integer('batch_size', 5, 'batch size')
FLAGS = tf.app.flags.FLAGS
def main(_):
print(FLAGS.gpus)
print(FLAGS.batch_size)
if __name__=="__main__":
tf.app.run()
getopt
getopt.getopt(args, shortopts, longopts=[])
- args指的是当前脚本接收的参数,它是一个列表,可以通过sys.argv获得
- shortopts 是短参数,类似-v,-h这样的参数。短参数后面有冒号 “:” 表示该参数有输入值。
- longopts 是长参数,类似–help,–version这样的参数。长参数后面带等号 “=” 表示参数有输入值
输入 -v 的时候打印脚本的版本信息,不执行脚本
通过getopt工具包实现
- Python实现文件上传下载,使用socket
import sys
import socket
import getopt
import time
upFileName = ""
#服务端涵数
def server_handle(port):
#创建服务端套接字
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#绑定IP和端口
server.bind(('0.0.0.0', port))
#监听
server.listen(10)
print("[*] Listening on 0.0.0.0:%d"%port)
while True:
client_socket, addr = server.accept()
download_file(client_socket)
#客户端涵数
def client_handle(target, port):
#创建socket连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((target, port))
#将字符串文件名转成字节发送,socket套接字是要用byte传输
client.send(upFileName.encode('utf-8'))
time.sleep(1)
upload_file(client)
#传输完文件后关闭文件流
client.close()
#文件下载涵数
def download_file(socket):
#读取socket传过来的文件名数据
fileName = socket.recv(1024)
#因为socket传过来的是字节码,所以这里需要转成字符串
fileName = fileName.decode()
print("[*]Receive the file:%s"%fileName)
#定义一个byte型的变量
fileBuffer = "".encode('utf-8')
#循环从socket中读取数据
while True:
#一次读取1024个字节
data = socket.recv(1024)
if data:
#读取的数据累加保存在变量中
fileBuffer += data
else:
#如果读到没有数据了就跳出结束
break;
#以写字节的形式打开一个文件
f = open("_"+fileName, 'wb')
#写文件
f.write(fileBuffer)
#关闭打开的文件
f.close()
#文件上传涵数
def upload_file(socket):
#以读byte字节的形式打开文件
f = open(upFileName, 'rb')
#读取文件
data = f.read()
#关闭打开文件
f.close()
#发送文件数据
socket.send(data)
#定义usage涵数(命令行提示信息)
def usage():
print("help info: python upload.py -h")
print("client: python upload.py -t [target] -p [port] -u [uploadfile]")
print("server: python filename.py -lp [port]")
sys.exit()
def main():
global upFileName #文件名
target = "" #目标IP
port = 0 #目标端口
help = False #显示帮助信息
listen = False #是否监听
#利用getopt模块获取命令行参数
opts, args = getopt.getopt(sys.argv[1:], "t:p:u:hl")
for o, a in opts:
if o == "-t":
target = a;
elif o == "-p":
port = int(a)
elif o == "-u":
upFileName = a
elif o == "-h":
help = True
elif o == "-l":
listen = True
else:
#断言,传入的参数有误
assert False, "Unhandled Option"
#打印帮助信息
if help:
usage()
#区分客户端和服务端
if listen:
server_handle(port)
else:
client_handle(target, port)
if __name__ == "__main__":
main()
环境变量
环境变量已经存在系统中,python脚本中直接通过 os.getenv(‘ENV_NAME’) 就能拿到指定的环境变量。
- os.environ模块获取有关系统的各种信息
- os.environ模块环境变量详解
# demo.py
import os
VAR1 = os.getenv('VAR1')
VAR2 = os.getenv('VAR2')
print(f"var1:{VAR1}")
print(f"var2:{VAR2}")
# os.environ 是环境变量的字典,但类型并不是 <class 'dict'>,不是所有字典的函数都能用
os.environ.keys() # 主目录下所有的 key
# 常见变量——win
os.environ['HOMEPATH']:当前用户主目录。
os.environ['TEMP']:临时目录路径。
os.environ["PATHEXT"]:可执行文件。
os.environ['SYSTEMROOT']:系统主目录。
os.environ['LOGONSERVER']:机器名。
os.environ['PROMPT']:设置提示符。
# 常见变量——linux
os.environ['USER']:当前使用用户。
os.environ['LC_COLLATE']:路径扩展的结果排序时的字母顺序。
os.environ['SHELL']:使用shell的类型。
os.environ['LAN']:使用的语言。
os.environ['SSH_AUTH_SOCK']:ssh的执行路径。
# 设置环境变量
os.environ['环境变量名称']='环境变量值' #其中key和value均为string类型
os.putenv('环境变量名称', '环境变量值')
os.environ.setdefault('环境变量名称', '环境变量值')
# 修改
os.environ['环境变量名称']='新环境变量值'
# 获取
os.environ['环境变量名称']
os.getenv('环境变量名称')
os.environ.get('环境变量名称', '默认值') #默认值可给可不给,环境变量不存在返回默认值
print(os.environ.get("HOME"))
print(os.environ.get("HOME", "default")) #环境变量HOME不存在,返回 default
# 删除
del os.environ['环境变量名称']
del(os.environ['环境变量名称'])
# 判断是否存在
'环境变量值' in os.environ # 存在返回 True,不存在返回 False
除此以外,还可以在 python 运行时指定环境变量。
# 临时环境变量
VAR1="test" VAR2=12 python demo.py
脚本可以拿到环境变量,但是在系统中用 env 命令是查不到的。export 是临时环境变量,只在当前 shell 有效。而上面这种设置环境变量的方式只对当前脚本有效。
Shell+Python 参数传递
【2024-3-16】变量传递
python -> shell
import os
var=123 # or var='123'
# (1) 环境变量
os.environ['var']=str(var) # environ的键值必须是字符串
os.system('echo $var')
# (2) 字符串连接
os.system('echo ' + path)
# (3) 管道
os.popen('wc -c', 'w').write(var)
# (4) 文件
output = open('/tmp/mytxt', 'w')
output.write(S) #把字符串S写入文件
output.writelines(L) #将列表L中所有的行字符串写到文件中
output.close()
# (5) 重定向
buf = open('/root/a.txt', 'w')
print >> buf, '123\n', 'abc'
shell → Python
- shell 中使用 export 关键词
- Python 中使用 os.getenv 或 os.popen
#www='wangqiwen' # 无法传递
export www='wangqiwen'
python t.py
echo "python 调用完毕"
t.py 内容
# coding:utf8
import os
# (1) 环境变量
a = os.getenv('www', '空')
print('python内读取环境变量:'+a)
# (2) 管道
b = os.popen('echo $www').read()
print('python内读取环境变量:'+b)
# (3) commands
import commands
var=commands.getoutput('echo $www') #输出结果
var=commands.getstatusoutput('echo $www') #退出状态和输出结果
# (4) 文件方式
input = open('/tmp/mytxt', 'r')
S = input.read( ) #把整个文件读到一个字符串中
S = input.readline( ) #读下一行(越过行结束标志)
L = input.readlines( ) #读取整个文件到一个行字符串的列表中
密码输入
getpass模块提供平台无关的在命令行下输入密码的方法;
该模块主要提供:
- 两个函数:
getuser,getpass - 一个报警:
GetPassWarning(当输入的密码可能会显示的时候抛出,该报警为UserWarning的一个子类)
import getpass
pwd = getpass.getpass() # 输入密码
pwd = getpass.getpass('请输入密码') # 输入密码
user = getpass.getuser() # 获取当前登录用户名
I/O 输入/输出
输出
【2018-6-13】不换行:
# Python2:加逗号
print x,
# Python3:加end
print(x,end="")
彩色显示:
print('This is a \033[1;35m test \033[0m!')
print('This is a \033[1;32;43m test \033[0m!')
print('\033[1;33;44mThis is a test !\033[0m')
显示颜色格式:\033[显示方式;字体色;背景色m……[\033[0m]
-------------------------------------------
字体色 | 背景色 | 颜色描述
-------------------------------------------
30 | 40 | 黑色
31 | 41 | 红色
32 | 42 | 绿色
33 | 43 | 黃色
34 | 44 | 蓝色
35 | 45 | 紫红色
36 | 46 | 青蓝色
37 | 47 | 白色
-------------------------------------------
-------------------------------
显示方式 | 效果
-------------------------------
0 | 终端默认设置
1 | 高亮显示
4 | 使用下划线
5 | 闪烁
7 | 反白显示
8 | 不可见
-------------------------------
文件读取
测试文件 test.txt
hello,my friends!
This is python big data analysis,
let's study.
open方法
mode常用的模式:
- r:表示文件只能读取
- w:表示文件只能写入
- a:表示打开文件,在原有内容的基础上追加内容,在末尾写入
- w+:表示可以对文件进行读写双重操作
如果是字节(二进制)形式读写文件,在mode参数中追加’b’即可
data_file = 'test.txt'
f = open(data_file,'w')
f = open(data_file,'a')
f = open(data_file,'w+')
f = open(data_file,'bw+')
f = open(data_file,'bw+', encoding='utf-8') # 指定编码方式
f.close() # 关闭文件
# 安全方式,不用单独close
with open(data_file, 'w') as f:
content = f.read() # 一次性读取所有内容
pass
# (1)readline 从文件中读取整行,包括换行符'\n'。
# readline方法会记住上一个readline函数读取的位置,接着读取下一行。
f.readline() # hello,my friends!
f.readline(size=5) # 指定读取大小: This (第二行的前5个字节)
# (2)readlines方法读取所有行,返回列表。
print(f.readlines()) # ['hello,my friends!', 'This is python big data analysis,', 'let's study.']
# (3) 读写位置重置 seek
# (0,0) 开头位置
# (0,1) 当前位置
# (0,2) 末尾位置
f.readline()
f.seek(0,0)
f.readline() # 文件开头, 不再是下一行
write 方法
with open(data_file, 'w') as f:
f.write('hello,my friends!\nthis is python big data analysis') # 不会换行
f.close()
# 清空文件
# f.truncate(0) # 0表示从开始位置清除,即整体清空
# 删除文件
import os
os.remove(data_file)
小文件
【2017-11-28】Python读取大文件(GB)
- read() 方法是一次性把文件的内容以字符串的方式读到内存, 放到一个字符串变量中
- 调用readline()可以每次读取一行内容
- readlines()的方法是一次性读取所有内容, 并按行生成一个list
因为read()和readlines()是一次性把文件加载到内存, 如果文件较大, 甚至比内存的大小还大, 内存就会爆掉。 所以,这两种方法只适合读取小文件。
f = open('/Users/michael/test.txt', 'r')
f = open('/Users/michael/test.jpg', 'rb') # 二进制文件
f = open('/Users/michael/gbk.txt', 'r', encoding='gbk') # 非utf8编码需要指定编码方式
f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore') # 忽略个别编码错误
f.read() # 'Hello, world!', 一次性读取所有内容
read(1000) # 如果文件有10G,内存就爆了,于是有了这种限额读取方法
for line in f.readlines(): # 一次读一行
print(line.strip()) # 把末尾的'\n'删掉
# 循序遍历
with open("text.txt","r") as f:
for line in f:
print(line)
#文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
f.close()
安全写法
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()
# 简化版
with open('/path/to/file', 'r') as f:
print(f.read())
大文件
实际工作中,会碰到读取10几G的大文件的需求, 比如说日志文件。 这时候就要用新的读取文件的方法。 这里提供两种方法, 有简单,有复杂,但基本原理都是一样的。 就是利用到生成器generator。
- 方法一:将文件切分成小段,每次处理完小段内容后,释放内存
- 这里会使用yield生成自定义可迭代对象,即generator, 每一个带有yield的函数就是一个generator
- 方法二:利用open(“”, “”)系统自带方法生成的迭代对象
- for line in f 这种用法是把文件对象f当作迭代对象, 系统将自动处理IO缓冲和内存管理, 更加pythonic
- 方法二:fileinput 处理, 用到了Python的fileinput模块
# 方法一
def read_in_block(file_path):
BLOCK_SIZE = 1024
with open(file_path, "r") as f:
while True:
block = f.read(BLOCK_SIZE) # 每次读取固定长度到内存缓冲区
if block:
yield block
else:
return # 如果读取到文件末尾,则退出
def test3():
file_path = "/tmp/test.log"
for block in read_in_block(file_path):
print block
# 方法二
def test4():
with open("/tmp/test.log") as f:
for line in f:
print line
# 方法三
import fileinput
for line in fileinput.input(['sum.log']):
print line
tqdm 包
【2024-3-6】tqdm 模块是python进度条库, 主要分为两种运行模式
- (1) 基于迭代对象运行: tqdm(iterator)
- (2) 手动进行更新
import time
from tqdm import tqdm, trange
#trange(i)是tqdm(range(i))的一种简单写法
for i in trange(100):
time.sleep(0.05)
for i in tqdm(range(100), desc='Processing'):
time.sleep(0.05)
dic = ['a', 'b', 'c', 'd', 'e']
pbar = tqdm(dic)
for i in pbar:
pbar.set_description('Processing '+i)
time.sleep(0.2)
# 100%|██████████| 100/100 [00:06<00:00, 16.04it/s]
# Processing: 100%|██████████| 100/100 [00:06<00:00, 16.05it/s]
# Processing e: 100%|██████████| 5/5 [00:01<00:00, 4.69it/s]
手动进行更新
import time
from tqdm import tqdm
with tqdm(total=200) as pbar:
pbar.set_description('Processing:')
# total表示总的项目, 循环的次数20*10(每次更新数目) = 200(total)
for i in range(20):
# 进行动作, 这里是过0.1s
time.sleep(0.1)
# 进行进度更新, 这里设置10个
pbar.update(10)
# 输出
# Processing:: 100%|██████████| 200/200 [00:02<00:00, 91.94it/s]
tqdm模块参数说明
class tqdm(object):
"""
Decorate an iterable object, returning an iterator which acts exactly
like the original iterable, but prints a dynamically updating
progressbar every time a value is requested.
"""
def __init__(self, iterable=None, desc=None, total=None, leave=False,
file=sys.stderr, ncols=None, mininterval=0.1,
maxinterval=10.0, miniters=None, ascii=None,
disable=False, unit='it', unit_scale=False,
dynamic_ncols=False, smoothing=0.3, nested=False,
bar_format=None, initial=0, gui=False):
参数说明
- iterable: 可迭代的对象, 在手动更新时不需要进行设置
- desc: 字符串, 左边进度条描述文字
- total: 总的项目数
- leave: bool值, 迭代完成后是否保留进度条
- file: 输出指向位置, 默认是终端, 一般不需要设置
- ncols: 调整进度条宽度, 默认是根据环境自动调节长度, 如果设置为0, 就没有进度条, 只有输出的信息
- unit: 描述处理项目的文字, 默认是’it’, 例如: 100 it/s, 处理照片的话设置为’img’ ,则为 100 img/s
- unit_scale: 自动根据国际标准进行项目处理速度单位的换算, 例如 100000 it/s » 100k it/s
示例
import time
from tqdm import tqdm
# 发呆0.5s
def action():
time.sleep(0.5)
with tqdm(total=100000, desc='Example', leave=True, ncols=100, unit='B', unit_scale=True) as pbar:
for i in range(10):
action() # 发呆0.5秒
pbar.update(10000) # 更新发呆进度
# Example: 100%|███████████████████████████████████████████████████| 100k/100k [00:05<00:00, 19.6kB/s]
写文件
shell
python -u test.py > a.log # 直接输出
python a_script.py 2>&1 | tee a.log # tee 重定向
python 写文件
f = open('/Users/michael/test.txt', 'w')
f.write('Hello, world!')
f.close()
# 安全便捷方式
with open('/Users/michael/test.txt', 'w') as f: # 覆盖模式
f.write('Hello, world!')
f.write("I am really enjoying it!\n") # 多行文本,注意加换行符
with open("text.txt","a") as file: # 追加模式
f.write("What I want to add on goes here")
# print >> f, 'print something' # python 2
print("hello", file=f) # 用print方法输出
#print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
文件权限管理
shutil 工具包
- shutil.
copymode(源文件路径,目标文件路径): 只复制权限 - shutil.
chown(文件路径,user=”“,group=””)
# 复制权限: shutil.copymode
# shutil.copymode("/usr/bin/ls", "/opt/myhosts")
# 修改权限: shutil.chown(文件路径,user="",group="")
shutil.chown("/opt/myhosts",user="cccc",group="hhh")
以指定用户来执行命令
- elasticsearch不能以root用户身份来启动,但如果登录了root用户,就要用另外的用户身份(例如例子中的es用户)来执行启动命令。
以es用户在当前目录新建一个文件 myfile
- -u 选项指定以哪个用户执行命令
- -H(HOME)选项请求安全策略将HOME环境变量设置为目标用户的主目录。
sudo -H -u es bash -c "touch myfile"
# 当前用户是root,以es用户来启动elasticsearch
sudo -H -u es bash -c "/opt/elasticsearch-7.9.1/bin/elasticsearch -d"
文档处理
参考
任意格式
组装各种格式文件函数,按照文件格式自动读取
- python eval 函数
support = {
'pdf': 'read_pdf_to_text',
'docx': 'read_docx_to_text',
'xlsx': 'read_excel_to_text',
'pptx': 'read_pptx_to_text',
'csv': 'read_txt_to_text',
'txt': 'read_txt_to_text',
}
def read_any_file_to_text(file_path):
file_suffix = file_path.split('.')[-1]
func = support.get(file_suffix)
if func is None:
return '暂不支持该文件格式'
text = eval(func)(file_path)
return text
read_any_file_to_text('xxx.pdf')
read_any_file_to_text('xxx.docx')
read_any_file_to_text('xxx.xlsx')
read_any_file_to_text('xxx.pptx')
read_any_file_to_text('xxx.csv')
read_any_file_to_text('xxx.txt')
word 文件
OnlyOffice
【2025-1-7】OnlyOffice
ONLYOFFICE 是一个免费开源的协作办公套件,适用于 Windows、Linux 和 macOS。
- 该套件包括 3 个主要微软 Office 的替代品(Word、Excel、PowerPoint)。也提供表单(Forms)生成器,PDF 查看器和文件转换器。
个人用户完全可以使用 ONLYOFFICE 代替 Microsoft Office,它与 Microsoft Office 高度兼容,并且免费无广告,可以在 ONLYOFFICE 官网上下载桌面版本或者手机版本。
- ONLYOFFICE 除了能够代替 Microsoft Office,还拥有云端存储,多人实时编辑共享的功能
- 云端的文档还可以协同编辑,我们只需要点击右上角的共享,添加一个链接,将这个链接发送给你的同事,你们就可以协同编辑。
实现原理
- 用户浏览器访问/打开文档, 进行查看或者编辑;
- 通过 url 上的 fileName 参数,使用 JavaScript API 将文档唯一标识符(key)以及文档发送到文档编辑器(editor)。
- 文档编辑器(editor)向文档编辑服务(server)发送一个打开文档的请求。
- 文档编辑服务从文档存储服务(document storage service)下载相对应的文档,并将文档转换为 Office Open XML 格式。
- 准备就绪后,文档编辑服务(server)会将转化后的文档传输到基于浏览器的文档编辑器(editor)。
- 文档编辑器提供编辑或者查看权限,对文档进行相应操作,执行保存。
python-docx
python-docx 库可创建、修改 Word(.docx)文件
docx库,可以执行各种任务
- 创建新文档:可以使用库从头开始或基于模板生成新的Word文档。这对于自动生成报告、信函和其他类型的文档非常有用。
- 修改现有文档:可以打开现有的Word文档,并使用库修改其内容、格式、样式等。这对于自动更新遵循特定结构的文档特别方便。
- 添加内容:可以使用库向文档添加段落、标题、表格、图像和其他元素。这有助于用数据动态填充文档。
- 格式化:该库允许将各种格式化选项应用于文档中的文本和元素,例如更改字体、颜色、对齐方式等。
- 提取信息:还可以从现有Word文档中提取文本、图像、表格和其他内容,以便进一步分析
函数用法
- 文档创建和保存
- Document(): 创建一个新的word文档
- Document.save(‘filename.docx’):保存一个document 称为文件(*.docx)
- Paragraphs and Text (段落和文本)
- add_paragraph(‘text’): 添加具有指定文本(text)的新段落(Paragraphs)。
- paragraph.text:获取或设置段落的文本内容。
- Headings (标题,可以设置几级标题)
- add_heading(‘text’, level=n): 添加具有指定文本和级别的标题 (1 to 9).
- Styles and Formatting (样式与格式)
- paragraph.style = ‘StyleName’: 应用特定的段落样式
- run = paragraph.add_run(‘text’): 添加一段具有特定格式的文本
- run.bold, run.italic, etc.: 对管路(run)应用格式设置
- Tables (表格操作)
- add_table(rows, cols): 添加具有指定行数和列数的表
- table.cell(row, col): 获取表中的特定单元格(cell)
- cell.text:获取或设置单元格的文本内容
- table.rows, table.columns:访问表的行和列
- Images(图片操作)
- document.add_picture(‘image_path’): 向文档中添加图像
- run.add_picture(‘image_path’): 将图像添加到特定管道(run)中, 比如简历照片位置固定的
- Document Properties (文档属性)
- document.core_properties.title: 设置文档的标题
- document.core_properties.author: 设置文档的作者
- document.core_properties.keywords: 设置文档的关键词
- Sections and Page Setup (分区和页面设置)
- section = document.sections[0]: 获取文档的第一部分( Get the first section of the document)
- section.page_width, section.page_height: 设置页面尺寸(Set page dimensions)
- Lists (列表): markdown中的list,比如下面的这两个就是无序的,大标题1,2,3…就是有序的
- add_paragraph(‘text’, style=’ListBullet’):创建无序列表( Create a bulleted list)
- add_paragraph(‘text’, style=’ListNumber’): 创建有序列表(Create a numbered list.)
- Hyperlinks (超链接)
- run.add_hyperlink(‘url’, ‘text’): 给当前管道(run)内的特定文本(text)添加超链接(Add a hyperlink to a run)
- Document Modification (文件修改)
- document.paragraphs: 访问文档中的所有段落(Access all paragraphs in the document)
- document.tables: 访问文档中的所有表格(Access all tables in the document)
- document.styles: 访问和操作文档样式(Access and manipulate document styles)
- Document Reading(文档读取)
- Document(‘filename.docx’): 读取一个存在的word文件
- document.paragraphs[0].text: 访问第一段(paragraphs)的文本(text)
安装
pip install python-docx
# 若安装超时或速度较慢,可更换安装源
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx
原文链接
测试数据
- docx 文档内容
摘要
二十一世纪,科技的不断发展,移动互联网行业的技术迭代不断深入。
电子商务已成为一项较为先进的商业模式在我国快速兴起与发展,网络购物这一行业发展日益成熟,网上购物已成当前购物订单评价方式的主流。
python-docx 三种类型:
Document对象(文档): 表示整个文档;Paragraph对象(段落): 标识段落(在输入文档,每一次回车产生新段落);Run对象(文字块): 标识相同样式的文本延续。- 属性不同,文字块也不同
- 属性:颜色、字体、斜体、加粗等
Document 对象 包含一个 Paragrapha 对象列表,Paragraph 对象包含一个 Run 对象的列表。
代码
import os
import re
import docx
work_path = 'E:\\pyspace\\wdocuments'
os.chdir(work_path)
doc = docx.Document('python演示文档.docx') # Document 对象
len(doc.paragraphs) # Paragraph 对象列表的长度
# 段落信息
for i, para in enumerate(doc.paragraphs):
print(f'No.{i+1}\n', para.text, sep='')
# 文字块信息
for i, para in enumerate(doc.paragraphs):
for j, run in enumerate(para.runs):
print(f'Para.{i+1} Run{j+i}: ', run.text, sep='')
Document
document 库提供函数来生成各种类型的文档,包括:PDF、Word、HTML和Markdown等
安装
pip install document
文本处理
文本处理功能,可以用于字符串的格式化、替换和截取等操作。
- format_string() 函数可以用于格式化字符串
- replace_string() 函数可以用于替换字符串中的指定部分
- substring() 函数可以用于截取字符串的指定部分
from document import format_string
name = "Alice"
age = 25
text = "My name is {name} and I am {age} years old."
formatted_text = format_string(text, name=name, age=age)
print(formatted_text)
# My name is Alice and I am 25 years old.
# 替换字符串
from document import replace_string
text = "Hello, World!"
new_text = replace_string(text, "World", "Alice")
print(new_text)
# 截取部分
from document import substring
text = "Hello, World!"
subtext = substring(text, start=7, end=12)
print(subtext)
(1) 文档读取
from docx import Document
path = '/media/bobo/自动化办公/wordOperation/wordDemo/test2.docx'
# 读取文档
doc = Document(path)
# (1)段落
print(doc.paragraphs) # 段落输出
# 输出列表,一共有4份内容
# [<docx.text.paragraph.Paragraph object at 0x7fca95f0aba8>,
# <docx.text.paragraph.Paragraph object at 0x7fca95f0abe0>,
# <docx.text.paragraph.Paragraph object at 0x7fca95f0ab70>,
#<docx.text.paragraph.Paragraph object at 0x7fca95f0ac50>,]
for paragraph in doc.paragraphs:
print(paragraph.text)
# 输出文件中的所有文字
# ......(省略)......
# (2)文字块
paragraph0 = doc.paragraphs[0]
runs0 = paragraph0.runs # 获取第一段的文字块
print(runs0)
for run0 in runs0:
print(run0.text)
# 输出结果:# 输出结果:该段落被分为1个文字块,文字块内容为“摘要”
# [<docx.text.run.Run object at 0x7f5ea3faec18>]
# 摘要
paragraph1 = doc.paragraphs[1]
runs1 = paragraph1.runs
print(runs1) # 空
paragraph2 = doc.paragraphs[2]
runs2 = paragraph2.runs
print(runs2) # 二十一世纪这段文本分块
for run2 in runs2:
print(run2.text)
# 输出结果:该段落被分为4个文字块
#[<docx.text.run.Run object at 0x7f3e6fe43c50>,
# <docx.text.run.Run object at 0x7f3e6fe43b38>,
# <docx.text.run.Run object at 0x7f3e6fe43dd8>,
# <docx.text.run.Run object at 0x7f3e6fe43cc0>]
# 二十一世纪
# ,科技的不断发展,
# 移动互联网行业的
# 技术迭代不断深入。
#(3)提取表格
t0 = doc.tables[1]
workbook = Workbook()
sheet = workbook.active
for i in range(len(t0.rows)):
list1 = []
for j in range(len(t0.columns)):
list1.append(t0.cell(i,j).text)
sheet.append(list1)
# 保存到 excel 文档
workbook.save(filename="/media/bobo/自动化办公/wordOperation/wordDemo/test.xlsx")
(2) 文档写入
代码
from docx import Document
path = './wordDemo/test2.docx'
# doc = Document(save_file) # 写入已有文件
doc = Document() # 写入新文件时,不需要提前创建
doc.add_heading("一级标题", level=1) # 添加一级标题
doc.add_heading('文档标题', 0)
# 添加段落时,赋值一个变量,方便后面格式调整
paragraph1 = doc.add_paragraph("物联网-万物互联成为新的趋势。")
paragraph2 = doc.add_paragraph("电商企业在不断丰富产品类,水果生鲜一类的电商产品,在网上购物商场中也占据一席之地,但目前却少有网站是单一为水果生鲜一类产品而设计。")
# 添加文字块(格式化)
paragraph3 = doc.add_paragraph() # 创建空段落,用于填充文字块
# 文字块格式化格式化
paragraph3.add_run("这句是被加粗了文字块").bold = True # 粗体
paragraph3.add_run(",这句是普通文字块,")
paragraph3.add_run("这句是斜体文字块").italic = True # 斜体
# 添加分页
doc.add_page_break() # 添加一个分页
# 在新分页中添加一句话
paragraph1 = doc.add_paragraph("这是新增的一页")
# 添加图片
# from docx import Document
from docx.shared import Cm # 设置图片大小格式,指定一个即可,自动计算另一个维度数值
# path = '/media/bobo/自动化办公/wordOperation/wordDemo/test2.docx'
picPath = '/media/bobo/自动化办公/wordOperation/openAndRead/pic.jpeg'
# doc = Document(path)
doc.add_picture(picPath, width=Cm(7), height=Cm(5))
# 添加表格
list1 = [
["姓名","性别","家庭地址"],
["唐僧","男","湖北省"],
["孙悟空","男","北京市"],
["猪八戒","男","广东省"],
["沙和尚","男","湖南省"]
]
table1 = doc.add_table(rows=5,cols=3)
for row in range(5):
cells = table1.rows[row].cells
for col in range(3):
cells[col].text = str(list1[row][col])
doc.add_paragraph("---------------------------------------------------------")
# 保存
doc.save(path)
# 注意,进行操作之后一定要进行保存操作,否则将对文件的修改会失效
文档保存
document库提供了一些函数来生成各种类型的文档,包括PDF、Word、HTML和Markdown等。
- 生成 pdf
- 生成 word
- 生成 markdown
- 生成 html
代码
from document import generate_pdf
title = "Sample Document"
content = "This is a sample document generated by Python document library."
output_path = "sample.pdf"
# 当前目录下生成一个名为”sample.pdf”的PDF文件。
generate_pdf(title, content, output_path)
# 生成 word 文档
from document import generate_word
output_path = "sample.docx"
generate_word(title, content, output_path)
# 生成 html 文档
from document import generate_html
output_path = "sample.html"
generate_html(title, content, output_path)
# 生成 markdown 文件
from document import generate_markdown
output_path = "sample.md"
generate_markdown(title, content, output_path)
使用模板生成
from document import generate_with_template
# 模板文件内容
template_path = "template.txt"
# Title:
# Content:
# <div class="page clearfix" post>
<!-- 左侧布局 -->
<div class="left">
<!-- 文章标题,page是全局变量 -->
<h1>计算机知识点汇总-脑图笔记</h1>
<div class="label">
<div class="label-card">
<i class="fa fa-calendar"></i>2019-06-29
</div>
<div class="label-card">
</div>
<div class="label-card">
</div>
<div class="label-card">
<!-- <span class="point">•</span> -->
<span class="categories">
<i class="fa fa-th-list"></i>
<a href="/category/#编程语言" title="Category: 编程语言" rel="category">编程语言</a>
<a href="/category/#计算机基础" title="Category: 计算机基础" rel="category">计算机基础</a>
<!-- <span class="point">•</span> -->
</span>
</div>
<div class="label-card">
<!-- <span class="point">•</span> -->
<span class="pageTag">
<i class="fa fa-tags"></i>
<!--a href="/tag/#%E8%AE%A1%E7%AE%97%E6%9C%BA" title="Tag: 计算机" rel="tag">计算机</a-->
<a href="/tag/#计算机" title="Tag: 计算机" rel="tag">计算机</a>
<!--a href="/tag/#Linux" title="Tag: Linux" rel="tag">Linux</a-->
<a href="/tag/#Linux" title="Tag: Linux" rel="tag">Linux</a>
<!--a href="/tag/#Shell" title="Tag: Shell" rel="tag">Shell</a-->
<a href="/tag/#Shell" title="Tag: Shell" rel="tag">Shell</a>
<!--a href="/tag/#Python" title="Tag: Python" rel="tag">Python</a-->
<a href="/tag/#Python" title="Tag: Python" rel="tag">Python</a>
<!--a href="/tag/#%E7%BC%96%E7%A8%8B" title="Tag: 编程" rel="tag">编程</a-->
<a href="/tag/#编程" title="Tag: 编程" rel="tag">编程</a>
<!--a href="/tag/#Numpy" title="Tag: Numpy" rel="tag">Numpy</a-->
<a href="/tag/#Numpy" title="Tag: Numpy" rel="tag">Numpy</a>
<!--a href="/tag/#Pandas" title="Tag: Pandas" rel="tag">Pandas</a-->
<a href="/tag/#Pandas" title="Tag: Pandas" rel="tag">Pandas</a>
<!--a href="/tag/#Matplotlib" title="Tag: Matplotlib" rel="tag">Matplotlib</a-->
<a href="/tag/#Matplotlib" title="Tag: Matplotlib" rel="tag">Matplotlib</a>
<!--a href="/tag/#SQL" title="Tag: SQL" rel="tag">SQL</a-->
<a href="/tag/#SQL" title="Tag: SQL" rel="tag">SQL</a>
<!--a href="/tag/#%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98" title="Tag: 数据挖掘" rel="tag">数据挖掘</a-->
<a href="/tag/#数据挖掘" title="Tag: 数据挖掘" rel="tag">数据挖掘</a>
<!--a href="/tag/#%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0" title="Tag: 机器学习" rel="tag">机器学习</a-->
<a href="/tag/#机器学习" title="Tag: 机器学习" rel="tag">机器学习</a>
<!--a href="/tag/#Web" title="Tag: Web" rel="tag">Web</a-->
<a href="/tag/#Web" title="Tag: Web" rel="tag">Web</a>
</span>
</div>
<!-- 【2022-9-26】站点访问统计 -->
<div align="right">阅读量<span id="busuanzi_value_page_pv"></span>次 </div>
</div>
<!-- 导读区 -->
<p style="color: #54489c; transition: all 0.5s ease 0s;"><i>Notes(温馨提示):</i></p>
<p>
<small>
<ol>
<li>★ 首次阅读建议浏览:<a href="/navi">导航指南</a>, 或划到本页末尾, 或直接<a href="/navi#可视化导航">点击跳转</a>, 查看全站导航图</li>
<li>★ <font color='green'>右上角工具条搜索文章,右下角二维码关注微信公众号(鹤啸九天),底栏分享、赞赏、评论</font>。</li>
<li>★ 转载请注明文章来源,知识点积累起来不容易,水滴石穿,绳锯木断,谢谢理解</li>
<li>★ 如有疑问,<a href="mailto:wqw547243068@163.com">邮件</a>讨论,欢迎贡献优质资料</li>
</ol>
</small>
</p>
<!-- 文章内容 -->
<hr>
<article itemscope itemtype="http://schema.org/BlogPosting">
<ul id="markdown-toc">
<li><a href="#it技能知识点汇总" id="markdown-toc-it技能知识点汇总">IT技能知识点汇总</a> <ul>
<li><a href="#导读" id="markdown-toc-导读">导读</a> <ul>
<li><a href="#mindmap" id="markdown-toc-mindmap">MindMap</a></li>
<li><a href="#导图一览" id="markdown-toc-导图一览">导图一览</a></li>
<li><a href="#如何阅读" id="markdown-toc-如何阅读">如何阅读</a></li>
</ul>
</li>
<li><a href="#linux知识点" id="markdown-toc-linux知识点">Linux知识点</a></li>
<li><a href="#shell知识点" id="markdown-toc-shell知识点">Shell知识点</a></li>
<li><a href="#python知识点" id="markdown-toc-python知识点">Python知识点</a> <ul>
<li><a href="#python技术点汇总" id="markdown-toc-python技术点汇总">Python技术点汇总</a></li>
<li><a href="#python基础" id="markdown-toc-python基础">Python基础</a></li>
<li><a href="#python-3" id="markdown-toc-python-3">Python 3</a></li>
<li><a href="#14-张思维导图" id="markdown-toc-14-张思维导图">14 张思维导图</a> <ul>
<li><a href="#基础知识" id="markdown-toc-基础知识">基础知识</a></li>
<li><a href="#数据类型" id="markdown-toc-数据类型">数据类型</a></li>
<li><a href="#序列" id="markdown-toc-序列">序列</a></li>
<li><a href="#字符串" id="markdown-toc-字符串">字符串</a></li>
<li><a href="#列表--元组" id="markdown-toc-列表--元组">列表 & 元组</a></li>
<li><a href="#字典--集合" id="markdown-toc-字典--集合">字典 & 集合</a></li>
<li><a href="#条件--循环" id="markdown-toc-条件--循环">条件 & 循环</a></li>
<li><a href="#文件对象" id="markdown-toc-文件对象">文件对象</a></li>
<li><a href="#错误--异常" id="markdown-toc-错误--异常">错误 & 异常</a></li>
<li><a href="#函数" id="markdown-toc-函数">函数</a></li>
<li><a href="#模块" id="markdown-toc-模块">模块</a></li>
<li><a href="#面向对象编程" id="markdown-toc-面向对象编程">面向对象编程</a></li>
</ul>
</li>
<li><a href="#python生态圈" id="markdown-toc-python生态圈">Python生态圈</a> <ul>
<li><a href="#numpy" id="markdown-toc-numpy">Numpy</a></li>
<li><a href="#pandas" id="markdown-toc-pandas">Pandas</a></li>
<li><a href="#matplotlib" id="markdown-toc-matplotlib">Matplotlib</a></li>
</ul>
</li>
</ul>
</li>
<li><a href="#数理统计" id="markdown-toc-数理统计">数理统计</a></li>
<li><a href="#sql--数据库" id="markdown-toc-sql--数据库">SQL & 数据库</a></li>
<li><a href="#数据挖掘" id="markdown-toc-数据挖掘">数据挖掘</a></li>
<li><a href="#机器学习" id="markdown-toc-机器学习">机器学习</a></li>
<li><a href="#web技术" id="markdown-toc-web技术">Web技术</a></li>
</ul>
</li>
<li><a href="#结束" id="markdown-toc-结束">结束</a></li>
</ul>
<blockquote>
<ul>
<li><a href="https://woaielf.github.io/">数林觅风</a></li>
</ul>
</blockquote>
<h1 id="it技能知识点汇总">IT技能知识点汇总</h1>
<h2 id="导读">导读</h2>
<h3 id="mindmap">MindMap</h3>
<ul>
<li>默认阅读顺序:从右→左,顺时针方向。</li>
<li>思维导图软件:XMind</li>
<li>如何下载?
<ul>
<li>高清原图及 PDF 版下载链接(公众号「数林觅风」ID:zoemindmap):
<ul>
<li>❥ 公众号后台回复「python」</li>
<li>❥ 进入公众号目录「导图下载」</li>
</ul>
</li>
</ul>
</li>
</ul>
<h3 id="导图一览">导图一览</h3>
<p><strong>先看一下本文所有思维导图:</strong>
【小视频】</p>
<p>P.S.由于平台对图片有一定程度的压缩,<strong>建议下载高清原图,放大后阅读</strong>。</p>
<h3 id="如何阅读">如何阅读</h3>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/rules.png" alt="rules" /></p>
<p>对于基础较为薄弱的朋友,建议配合参考书目学习,更重要的是项目实战练习,<strong>把思维导图作为辅助梳理逻辑的工具</strong>。</p>
<h2 id="linux知识点">Linux知识点</h2>
<p>良好的 Linux 素养会让你在日常的工作中如鱼得水,在命令行里体会流水般的畅快感。</p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1709/170915-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1709/170915-2.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1709/170915-3.png" alt="" /></p>
<h2 id="shell知识点">Shell知识点</h2>
<p>在 Linux 的基础上再度深入学习 Shell,可以极大的减少重复工作的压力。毕竟批量处理才是工作的常态呢~</p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1709/170920-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1709/170920-2.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1709/170920-3.png" alt="" /></p>
<h2 id="python知识点">Python知识点</h2>
<p><strong>17 幅思维导图,主要就 Python 核心基础知识进行了细致梳理</strong>。无论你是编程初学者,还是经验丰富的程序员,都可以通过这些图<strong>快速了解或回忆 Python 编程中最重要的概念</strong>。</p>
<p><strong>1 计算机基础</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/1.png" alt="1" /></p>
<h3 id="python技术点汇总">Python技术点汇总</h3>
<ul>
<li><a href="https://woaielf.github.io/2017/06/13/python3-all/">【汇总】Python 编程核心知识体系</a></li>
<li><a href="https://woaielf.github.io/2016/12/03/python-basic-1/">【笔记】Python(一)基础篇之「基础&数据类型&控制流」</a></li>
<li><a href="https://woaielf.github.io/2016/12/05/python-basic-2/">【笔记】Python(二)基础篇之「函数&函数式编程」</a></li>
<li><a href="https://woaielf.github.io/2016/12/07/python-basic-3/">【笔记】Python(三)基础篇之「模块&面向对象编程」</a></li>
<li><a href="https://woaielf.github.io/2016/12/08/python-basic-4/">【笔记】Python(四)基础篇之「文件对象&错误处理」</a></li>
<li><a href="https://woaielf.github.io/2017/04/15/numpy/">【笔记】Python(五)数值计算库之「NumPy」</a></li>
<li><a href="https://woaielf.github.io/2017/04/22/Pandas/">【笔记】Python(六)数值计算库之「Pandas」</a></li>
<li><a href="https://woaielf.github.io/2017/04/27/matplotlib/">【笔记】Python(七)数据可视化之「Matplotlib」</a></li>
<li><a href="https://woaielf.github.io/2017/05/28/lib-1/">【笔记】Python(八)常用扩展库</a></li>
<li><a href="https://woaielf.github.io/2017/06/21/spider/">【笔记】Python(九)爬虫常用库</a></li>
</ul>
<h3 id="python基础">Python基础</h3>
<p><strong>2 Python 语言基础</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/2.png" alt="2" />
<strong>3 标准数据类型 (一) 数值 & 字典 & 集合</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/3.png" alt="3" />
<strong>4 标准类型补充</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/4.png" alt="4" />
<strong>5 标准数据类型 (二) 序列对象</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/5.png" alt="5" />
<strong>6 标准数据类型 (三) 字符串</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/6.png" alt="6" />
<strong>7 条件 & 循环</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/7.png" alt="7" />
<strong>8【进阶】条件 & 循环</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/8.png" alt="8" />
<strong>9 函数 & 模块</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/9.png" alt="9" />
<strong>10【进阶】函数</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/10.png" alt="10" />
<strong>11 模块</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/11.png" alt="11" />
<strong>12 面向对象编程</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/12.png" alt="12" />
<strong>13【进阶】面向对象编程</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/13.png" alt="13" />
<strong>14【进阶】补充知识</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/14.png" alt="14" />
<strong>15 文件对象</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/15.png" alt="15" />
<strong>16 异常处理</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/16.png" alt="16" />
<strong>17 测试 & 调试</strong>
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/media/15233609547427/17.png" alt="17" /></p>
<h3 id="python-3">Python 3</h3>
<p>本文主要涵盖了 Python 编程的核心知识(暂不包括标准库及第三方库,后续会发布相应专题的文章)。</p>
<ol>
<li>首先,按顺序依次展示了以下内容的一系列思维导图:<strong>基础知识,数据类型(数字,字符串,列表,元组,字典,集合),条件&循环,文件对象,错误&异常,函数,模块,面向对象编程</strong>;</li>
<li>接着,结合这些思维导图主要参考的资料,分享一下我的学习体验,一方面可供初学者参考,另一方面,也便于大家结合思维导图深入学习、理解、思考;</li>
<li>最后,提供几篇文章链接,方便希望从 Python 2.x 迁移到 3.x 的朋友理解。</li>
</ol>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-15.png" alt="" /></p>
<h3 id="14-张思维导图">14 张思维导图</h3>
<h4 id="基础知识">基础知识</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-1.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-2.png" alt="" /></p>
<h4 id="数据类型">数据类型</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-3.png" alt="" /></p>
<h4 id="序列">序列</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-4.png" alt="" /></p>
<h4 id="字符串">字符串</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-5.png" alt="" /></p>
<h4 id="列表--元组">列表 & 元组</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-6.png" alt="" /></p>
<h4 id="字典--集合">字典 & 集合</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-7.png" alt="" /></p>
<h4 id="条件--循环">条件 & 循环</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-8.png" alt="" /></p>
<h4 id="文件对象">文件对象</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-9.png" alt="" /></p>
<h4 id="错误--异常">错误 & 异常</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-10.png" alt="" /></p>
<h4 id="函数">函数</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-11.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-12.png" alt="" /></p>
<h4 id="模块">模块</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-13.png" alt="" /></p>
<h4 id="面向对象编程">面向对象编程</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1706/170613-14.png" alt="" /></p>
<p>参考资料</p>
<blockquote>
<p><a href="http://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html">Vamei 博客:Python 快速教程</a> <br /></p>
</blockquote>
<p>基于 Python 2.x,极佳的入门材料,非常推荐,即使希望学习 3.x 的朋友仍值得一看,毕竟版本之间的转移比编程思想本身要容易的多(版本转移可以看「推荐阅读」)。作者还基于 Python 3.x 写了一本书。</p>
<blockquote>
<p><a href="http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000">廖雪峰:Python 教程</a> <br /></p>
</blockquote>
<p>廖大大的经典教程,我是配合上面的教程一起看,从不同的角度加深理解。</p>
<blockquote>
<p>视频教程: Python语言程序设计</p>
</blockquote>
<p>基于 Python 3.x,中国大学 Mocc 平台,网址是:http://www.icourse163.org/learn/BIT-268001?tid=1002001005 ,老师还有另外一系列 Python 课程,也是适合入门。</p>
<blockquote>
<p>《Python 核心编程》第二版</p>
</blockquote>
<p>书籍有些偏老,中文印刷有明显的小错误,但内容较全面,从浅入深覆盖面较大,可以在有一定基础的情况下择需阅读。</p>
<p>推荐阅读</p>
<blockquote>
<p><a href="https://docs.python.org/3/whatsnew/3.0.html">What’s New In Python 3.0</a> <br />
<a href="http://sebastianraschka.com/Articles/2014_python_2_3_key_diff.html">The key differences between Python 2.7.x and Python 3.x with examples</a> <br />
相应中文版:<a href="http://chenqx.github.io/2014/11/10/Key-differences-between-Python-2-7-x-and-Python-3-x/">Python 2.7.x 与 Python 3.x 的主要差异</a> <br /></p>
</blockquote>
<h3 id="python生态圈">Python生态圈</h3>
<ul>
<li>numpy</li>
<li>pandas</li>
<li>matplotlib</li>
</ul>
<h4 id="numpy">Numpy</h4>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170415-1.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170415-2.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170415-3.png" alt="" /></p>
<p>Reference</p>
<blockquote>
<p>《Python for data analysis》 <br />
<a href="https://docs.scipy.org/doc/numpy/reference/?v=20170515184114">NumPy Reference — NumPy v1.12 Manual</a></p>
</blockquote>
<h4 id="pandas">Pandas</h4>
<p>Pandas 提供了数据结构——DataFrame,可以高效的处理一些数据分析任务。我们日常分析的数据,大多是存储在类似 excel 的数据表中,Pandas 可以灵活的按列或行处理数据,几乎是最常用的工具了。</p>
<ul>
<li><a href="https://blog.csdn.net/sinat_29675423/article/details/87972498">Pandas按行按列遍历Dataframe的几种方式</a>
<ul>
<li><img src="https://img-blog.csdnimg.cn/20190227142817847.png" alt="" /></li>
<li>简单对上面三种方法进行说明:
<ul>
<li>iterrows(): 按行遍历,将DataFrame的每一行迭代为(index, Series)对,可以通过row[name]对元素进行访问。</li>
<li>itertuples(): 按行遍历,将DataFrame的每一行迭代为元祖,可以通过row[name]对元素进行访问,比iterrows()效率高。</li>
<li>iteritems():按列遍历,将DataFrame的每一列迭代为(列名, Series)对,可以通过row[index]对元素进行访问。</li>
</ul>
</li>
</ul>
</li>
</ul>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-1.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-2.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-3.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-4.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-5.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-6.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170422-7.png" alt="" /></p>
<p>Reference</p>
<blockquote>
<p>《Python for data analysis》<br />
<a href="http://pandas.pydata.org/pandas-docs/stable/?v=20170515184114">pandas: powerful Python data analysis toolkit — pandas 0.20.1 documentation</a></p>
</blockquote>
<h4 id="matplotlib">Matplotlib</h4>
<p>Python 有非常丰富的第三方绘图库,matplotlib 使用起来也许并不是很便捷,因为图上每个元素都需要自己来定制。但仔细体会 matplotlib 背后的设计思想是很有趣的事情。seaborn 之类的绘图库是基于 matplotlib 封装的,因而后期需要自己灵活定制图形时就大大受用了。本文的两幅思维导图是基于两种不同的思路绘制的,偶有内容交叉,日常使用可以选择自己熟悉的方式(网上的教程大多是基于过程的函数式编程,即 pyplot 方法)。<strong>建议配合最后附上出的参考资料学习</strong>。</p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170427-1.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170427-2.png" alt="" /></p>
<p>Reference</p>
<blockquote>
<p>《Python for data analysis》<br />
<a href="http://matplotlib.org/index.html">Matplotlib: Python plotting — Matplotlib 2.0.2 documentation</a> <br />
<a href="http://www.cnblogs.com/vamei/archive/2013/01/30/2879700.html#commentform">绘图: matplotlib核心剖析</a> <br />
<a href="https://zhuanlan.zhihu.com/p/21443208?utm_medium=social&utm_source=qq?utm_medium=social&utm_source=qq">【数据可视化】 之 Matplotlib</a> <br />
<a href="http://python.jobbole.com/85106/">Python–matplotlib绘图可视化知识点整理</a> <br />
<a href="http://blog.csdn.net/u011497262/article/details/52325705">一份非常好的Matplotlib 教程</a></p>
</blockquote>
<h2 id="数理统计">数理统计</h2>
<ul>
<li><a href="https://woaielf.github.io/2017/03/20/sta-all/">【汇总】机器学习基础之「统计篇」</a></li>
<li><a href="https://woaielf.github.io/2016/12/21/sta-1/">【笔记】统计(一)描述性统计</a></li>
<li><a href="https://woaielf.github.io/2016/12/23/sta-2/">【笔记】统计(二)概率&概率分布</a></li>
<li><a href="https://woaielf.github.io/2016/12/25/sta-3/">【笔记】统计(三)抽样分布&区间估计</a></li>
<li><a href="https://woaielf.github.io/2016/12/26/sta-4/">【笔记】统计(四)假设检验</a></li>
<li><a href="https://woaielf.github.io/2016/12/27/sta-5/">【笔记】统计(五)两总体均值之差和比例之差的推断</a></li>
<li><a href="https://woaielf.github.io/2017/01/02/sta-6/">【笔记】统计(六)总体方差的统计推断</a></li>
<li><a href="https://woaielf.github.io/2017/01/03/sta-7/">【笔记】统计(七)多个比率的比较&独立性检验&拟合优度检验</a></li>
<li><a href="https://woaielf.github.io/2017/01/06/sta-8/">【笔记】统计(八)实验设计&方差分析</a></li>
<li><a href="https://woaielf.github.io/2017/02/14/sl-regression/">【笔记】统计(九)简单线性回归</a></li>
<li><a href="https://woaielf.github.io/2017/02/17/regression-2/">【笔记】统计(十)多元回归&回归分析</a></li>
<li><a href="https://woaielf.github.io/2017/02/20/none-para/">【笔记】统计(十一)时间序列及预测&非参数方法</a></li>
</ul>
<h2 id="sql--数据库">SQL & 数据库</h2>
<p>这篇笔记包括了<strong>基本的 SQL 语法</strong>,具体应用的 RDBMS 以 MySQL 为例,也会穿插一点点数据库的知识。最后讲了一下<strong>如何利用第三方库,结合 Python 使用 MySQL</strong>。</p>
<ul>
<li><a href="https://woaielf.github.io/2017/05/04/sql/">【笔记】SQL & MySQL</a></li>
<li><a href="https://woaielf.github.io/2017/05/25/jdata-mysql/">【实战】电商数据篇(二)MySQL 实战指南</a></li>
</ul>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-2.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-3.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-4.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-5.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-5.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-6.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1705/170504-7.png" alt="" /></p>
<p>Reference</p>
<blockquote>
<p>《SQL 必知必会》<br />
<a href="http://www.runoob.com/sql/sql-tutorial.html">SQL 教程-菜鸟教程</a> <br />
<a href="http://www.runoob.com/mysql/mysql-tutorial.html">MySQL 教程-菜鸟教程</a></p>
</blockquote>
<h2 id="数据挖掘">数据挖掘</h2>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170310-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170310-2.png" alt="" /></p>
<p>数据处理是第一步骤,对数据挖掘的成败至关重要。此方面的经验要通过实战逐渐积累,且有很强的领域针对性。「相似/异性度量」需要重点关注。</p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170317-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170317-2.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170325-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170325-2.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170325-3.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170330-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170330-2.png" alt="" /></p>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170331-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1703/170331-2.png" alt="" /></p>
<h2 id="机器学习">机器学习</h2>
<ul>
<li><a href="https://woaielf.github.io/2017/03/15/dm-1/">【笔记】机器学习(一)理论准备</a></li>
<li><a href="https://woaielf.github.io/2017/03/17/dm-2/">【笔记】机器学习(二)数据处理&相似/异性度量</a></li>
<li><a href="https://woaielf.github.io/2017/03/25/dm-3/">【笔记】机器学习(三)数学基础之「线性代数」</a></li>
<li><a href="https://woaielf.github.io/2017/03/30/dm-4/">【笔记】机器学习(四)特征工程&模型评估</a></li>
<li><a href="https://woaielf.github.io/2017/03/31/dm-5/">【笔记】机器学习(五)维归约</a></li>
<li><a href="https://woaielf.github.io/2017/04/06/dm-6/">【笔记】机器学习(六)分类方法-理论篇</a></li>
</ul>
<p>机器学习的这块知识体系非常庞大,部分知识可能深入不够,暂时仅供大家参考,我也还需要时间来更细致的学习。后续我会结合案例,单篇逐个进行讲解(可能需要的时间周期较长)。本文目前包括的理论包括<strong>决策树,规则分类器,最近邻方法,贝叶斯分类器,人工神经网络,支持向量机,集成学习以及不平衡类和多类问题</strong>。
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-1.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-2.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-3.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-4.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-5.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-6.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-7.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-8.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-9.png" alt="" />
<img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1704/170406-10.png" alt="" /></p>
<h2 id="web技术">Web技术</h2>
<p><img src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Pic/1611/161115-1.png" alt="" /></p>
<!-- ## PPT展示
<video width="800" height="450" controls="controls">
<source src="https://raw.githubusercontent.com/woaielf/woaielf.github.io/master/_posts/Video/161115.mp4" type="video/mp4" />
</video> -->
<h1 id="结束">结束</h1>
</article>
<hr>
<!-- 打赏 -->
<!-- 【2019-08-06】打赏功能, http://www.twistedwg.com/2018/05/06/jekyll-reward.html-->
<div class="reward">
<div class="reward-button">赏<span class="reward-code">
<span class="alipay-code"> <img class="alipay-img wdp-appear" src="/wqw/fig/alipay.png"><b>支付宝打赏</b> </span>
<span class="wechat-code"> <img class="wechat-img wdp-appear" src="/wqw/fig/wechatpay.png"><b>微信打赏</b> </span> </span>
</div>
<p class="reward-notice" style="color:chocolate">~ 海内存知已,天涯若比邻 ~</p>
</div>
<!-- 分享工具 -->
<h2 id="share">Share</h2>
<!-- https://github.com/overtrue/share.js -->
<div class="social-share"></div>
<!-- css & js -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/social-share.js/1.0.16/css/share.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/social-share.js/1.0.16/js/social-share.min.js"></script>
<!-- 相似文章 -->
<!-- 相关文章推荐 -->
<h2 id="comments">Related Posts</h2>
<!-- 翻页 -->
<head>
<!-- [2022-11-10]卡片样式 -->
<link href="/css/card.css " rel="stylesheet" type="text/css">
</head>
<div class="post-recent">
<div class="pre">
<p><strong>上一篇</strong> <a href="/partner">如何选择人生伴侣-How to choose life partner</a></p>
</div>
<div class="nex">
<p><strong>下一篇</strong> <a href="/python">Python技能</a></p>
</div>
</div>
<div class="kapian">
<div class="tu">
<img src="https://img.zcool.cn/community/01493a5cc98256a801214168b8995d.jpg">
</div>
<div class="wenben">
<p><a href="/partner">标题:如何选择人生伴侣-How to choose life partner</a></p>
<p style="padding-bottom: 20px;">摘要:如何过好这一生</p>
</div>
<div class="tu">
<img src="https://img.zcool.cn/community/01493a5cc98256a801214168b8995d.jpg">
</div>
<div class="wenben">
<p><a href="/python">标题:Python技能</a></p>
<p style="padding-bottom: 40px;">摘要:Python 开发相关技术知识点</p>
</div>
</div>
<h2> 站内可视化导航 </h2>
<!-- 文章导读区 -->
文章可视化导读:鼠标划过图形块时,如果出现蓝色光环, 点击即可跳转到对应主题
<!-- draw.io diagram -->
<div class="mxgraph" style="max-width:100%;border:1px solid transparent;" data-mxgraph="{"highlight":"#0000ff","nav":true,"resize":true,"dark-mode":"auto","toolbar":"zoom layers tags lightbox","edit":"_blank","xml":"<mxfile host=\"app.diagrams.net\" agent=\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36\" version=\"28.2.5\">\n <diagram id=\"4u5yHArNrn4fvDAkmxS5\" name=\"第 1 页\">\n <mxGraphModel dx=\"1297\" dy=\"714\" grid=\"1\" gridSize=\"10\" guides=\"1\" tooltips=\"1\" connect=\"1\" arrows=\"0\" fold=\"1\" page=\"1\" pageScale=\"1\" pageWidth=\"850\" pageHeight=\"1100\" math=\"0\" shadow=\"0\">\n <root>\n <mxCell id=\"0\" />\n <mxCell id=\"1\" parent=\"0\" />\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-600\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"786.25\" y=\"2013\" width=\"103.87\" height=\"57\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-598\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"589.12\" y=\"2013\" width=\"191\" height=\"57\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-613\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"161.87\" y=\"2037\" width=\"408.25\" height=\"183\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"379\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"210\" y=\"1120\" width=\"660\" height=\"400\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-522\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"117.13\" y=\"1060\" width=\"352.87\" height=\"130\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"378\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"896.12\" y=\"1780\" width=\"264\" height=\"340\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"380\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"896.75\" y=\"1190\" width=\"223.25\" height=\"130\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"381\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"734\" y=\"1060\" width=\"266.5\" height=\"103.37\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"382\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"640\" y=\"1223.25\" width=\"230\" height=\"96.75\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"383\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"863\" y=\"1370\" width=\"190\" height=\"126.25\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"384\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#E6D0DE;strokeColor=#ae4132;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"270\" y=\"1365\" width=\"441.25\" height=\"135\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"385\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"240.12\" y=\"1762.5\" width=\"270\" height=\"241\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"386\" value=\"\" style=\"ellipse;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"339.25\" y=\"1198.81\" width=\"280\" height=\"130\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"387\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#E6D0DE;strokeColor=#E6E6E6;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"277.62\" y=\"1530\" width=\"452.38\" height=\"160\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"388\" value=\"模型层\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=13;fontStyle=1;fontColor=#6666FF;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"296\" y=\"1397.5\" as=\"geometry\">\n <mxPoint x=\"-3\" y=\"-20\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"389\" value=\"模态层\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=13;fontStyle=1;fontColor=#6666FF;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"249.12\" y=\"1242\" as=\"geometry\">\n <mxPoint x=\"-8\" y=\"-5\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"文本生成\" link=\"text-generation\" id=\"391\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"425.75\" y=\"1213.69\" width=\"60\" height=\"18.81\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"图像生成\" link=\"image-generation\" id=\"392\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"496.5\" y=\"1215.75\" width=\"60\" height=\"23.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"393\" value=\"语音生成\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"360.74\" y=\"1240\" width=\"60\" height=\"17\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"视频生成\" link=\"video_gen\" id=\"394\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"532.62\" y=\"1248.81\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"395\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"451\" target=\"391\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"469\" y=\"1675\" as=\"sourcePoint\" />\n <mxPoint x=\"539\" y=\"1675\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"396\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"451\" target=\"392\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"465\" y=\"1350\" as=\"sourcePoint\" />\n <mxPoint x=\"439\" y=\"1285\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"397\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"451\" target=\"394\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"528\" y=\"1330\" as=\"sourcePoint\" />\n <mxPoint x=\"555\" y=\"1285\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"398\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"451\" target=\"393\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"558\" y=\"1360\" as=\"sourcePoint\" />\n <mxPoint x=\"585\" y=\"1315\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"扩散模型\" link=\"ddpm\" id=\"399\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#A680B8;strokeColor=none;shadow=1;fontColor=#FFFFFF;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"546.49\" y=\"1158.9999999999998\" width=\"60\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"401\" value=\"NLP任务\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d0cee2;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"753\" y=\"1470\" width=\"50\" height=\"30\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"402\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"404\" target=\"488\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"403\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"404\" target=\"490\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"对话系统\" link=\"dialogue-system\" id=\"404\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"309.5\" y=\"1160\" width=\"60\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"406\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"391\" target=\"404\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"425\" y=\"1260\" as=\"sourcePoint\" />\n <mxPoint x=\"565\" y=\"1220\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"407\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;dashed=1;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"401\" target=\"491\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"490\" y=\"1570\" as=\"sourcePoint\" />\n <mxPoint x=\"325\" y=\"1455\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"408\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;exitX=0.617;exitY=0.05;exitDx=0;exitDy=0;exitPerimeter=0;\" parent=\"1\" source=\"392\" target=\"399\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"685\" y=\"1433\" as=\"sourcePoint\" />\n <mxPoint x=\"735\" y=\"1455\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"409\" value=\"LLM大模型专题导航\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=19;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"593.118484809835\" y=\"1030.001125496954\" as=\"geometry\">\n <mxPoint x=\"1\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"LLM训练流程\" link=\"llm_train\" id=\"410\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d80073;strokeColor=#A50040;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"451.87\" y=\"1580\" width=\"80.75\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"分布式训练\" link=\"dist\" id=\"411\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d80073;strokeColor=#A50040;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"446.87\" y=\"1657.5\" width=\"90\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"GPU\" link=\"gpu\" id=\"412\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f5f5f5;strokeColor=#666666;shadow=1;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"425\" y=\"1620\" width=\"41.75\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"DeepSpeed\" link=\"deepspeed\" id=\"413\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f5f5f5;strokeColor=#666666;shadow=1;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"270.56\" y=\"1655\" width=\"70.12\" height=\"25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"414\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"411\" target=\"410\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"533\" y=\"1250\" as=\"sourcePoint\" />\n <mxPoint x=\"628\" y=\"1600\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"415\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"412\" target=\"410\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"523\" y=\"1660\" as=\"sourcePoint\" />\n <mxPoint x=\"523\" y=\"1620\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"416\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"410\" target=\"462\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"535.38\" y=\"1660\" as=\"sourcePoint\" />\n <mxPoint x=\"535.38\" y=\"1620\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"417\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"418\" target=\"422\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"RAG\" link=\"rag\" id=\"418\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"723\" y=\"1239\" width=\"37\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"FineTune\" link=\"finetune\" id=\"419\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"803\" y=\"1271\" width=\"60\" height=\"24\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"RLHF\" link=\"rlhf\" id=\"420\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffe6cc;strokeColor=#d79b00;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"616.87\" y=\"1646\" width=\"43.13\" height=\"24\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"421\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"422\" target=\"443\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"PEFT\" link=\"peft\" id=\"422\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"803\" y=\"1239\" width=\"37\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-544\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"423\" target=\"429\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-551\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"423\" target=\"o5D4xRg-JXB86p6HjegH-550\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"423\" value=\"数据准备\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d0cee2;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"285.75\" y=\"1585\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"模型评估\" link=\"llm_eva\" id=\"424\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d0cee2;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"628\" y=\"1580\" width=\"60\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"425\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;dashed=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;dashPattern=1 1;\" parent=\"1\" source=\"423\" target=\"410\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"532\" y=\"1320\" as=\"sourcePoint\" />\n <mxPoint x=\"628\" y=\"1360\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"426\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;dashed=1;dashPattern=1 1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"410\" target=\"424\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"558\" y=\"1595\" as=\"sourcePoint\" />\n <mxPoint x=\"478\" y=\"1605\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"PyTorch\" link=\"pytorch\" id=\"427\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f5f5f5;strokeColor=#666666;shadow=1;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"527.62\" y=\"1620\" width=\"55\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"428\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0;exitY=0.5;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"427\" target=\"410\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"523\" y=\"1660\" as=\"sourcePoint\" />\n <mxPoint x=\"523\" y=\"1620\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-543\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"429\" target=\"o5D4xRg-JXB86p6HjegH-542\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"数据标注\" link=\"label\" id=\"429\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d0cee2;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"285.75\" y=\"1540\" width=\"60\" height=\"25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"MoE\" link=\"moe\" id=\"430\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffe6cc;strokeColor=#d79b00;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"656.99\" y=\"1620\" width=\"37.38\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM应用方案\" link=\"llm_solution\" id=\"431\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f0a30a;strokeColor=#BD7000;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"595\" y=\"1370\" width=\"90\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Transformer\" link=\"transformer\" id=\"432\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"350.36\" y=\"1971.5\" width=\"80\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"GPT-1\" link=\"gpt\" id=\"433\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"251.01\" y=\"1923.5\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"BERT\" link=\"bert\" id=\"434\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"366.11000000000007\" y=\"1896\" width=\"50\" height=\"17.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"435\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"432\" target=\"433\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"439.11\" y=\"1868.5\" as=\"sourcePoint\" />\n <mxPoint x=\"525.11\" y=\"1828.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"436\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"432\" target=\"434\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"369.11000000000007\" y=\"1958.5\" as=\"sourcePoint\" />\n <mxPoint x=\"319.11\" y=\"1913.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"437\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"_A3We9M9UZmKuXBEy4Mw-527\" target=\"459\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"187.18\" y=\"1792.5\" as=\"sourcePoint\" />\n <mxPoint x=\"240.17000000000002\" y=\"1922.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"Scaline Law\" link=\"llm_law\" id=\"438\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"943\" y=\"1390\" width=\"73\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"复杂推理\" link=\"o1\" id=\"439\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"876.25\" y=\"1460\" width=\"50\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Function Call\" link=\"function\" id=\"440\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"873\" y=\"1425\" width=\"73\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Plugin 插件\" link=\"plugin\" id=\"441\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"952.13\" y=\"1425\" width=\"73\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"442\" value=\"小模型\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"321.74\" y=\"1370\" width=\"56\" height=\"20\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"Agent&lt;div&gt;智能体&lt;/div&gt;\" link=\"agent\" id=\"443\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"881\" y=\"1234.5\" width=\"60\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LangChain\" link=\"langchain\" id=\"444\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1052.75\" y=\"1273.81\" width=\"70\" height=\"21.19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AutoGen\" link=\"autogen\" id=\"445\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1052.75\" y=\"1240\" width=\"70\" height=\"15\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"CoT\" link=\"cot\" id=\"446\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffe6cc;strokeColor=#d79b00;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"616.87\" y=\"1620\" width=\"33.13\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"447\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;fillColor=#60a917;strokeColor=#2D7600;\" parent=\"1\" source=\"448\" target=\"449\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"Prompt Engineering&amp;nbsp;&lt;div&gt;提示工程&lt;/div&gt;\" link=\"pe\" id=\"448\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#60a917;strokeColor=#2D7600;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"740.5\" y=\"1113.37\" width=\"117\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"APE&amp;nbsp;&lt;div&gt;提示词自动化&lt;/div&gt;\" link=\"prompt_auto\" id=\"449\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#60a917;strokeColor=#2D7600;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"895.5\" y=\"1113.37\" width=\"80\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Prompt Attack&amp;nbsp;&lt;div&gt;提示词攻击&lt;/div&gt;\" link=\"prompt_attack\" id=\"450\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#60a917;strokeColor=#2D7600;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"890.5\" y=\"1063.37\" width=\"90\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"多模态\" link=\"modal\" id=\"451\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"463.99\" y=\"1306\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"452\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.25;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;fillColor=#60a917;strokeColor=#2D7600;\" parent=\"1\" source=\"448\" target=\"450\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"453\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;fillColor=#60a917;strokeColor=#2D7600;\" parent=\"1\" source=\"454\" target=\"448\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"Prompt Learning&amp;nbsp;&lt;div&gt;提示学习&lt;/div&gt;\" link=\"prompt\" id=\"454\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#60a917;strokeColor=#2D7600;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"740.5\" y=\"1063.37\" width=\"117\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Transformers 库\" link=\"huggingface\" id=\"455\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f5f5f5;strokeColor=#666666;shadow=1;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"350.75\" y=\"1535\" width=\"90\" height=\"25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Embedding\" link=\"emb\" id=\"456\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"459.37\" y=\"1913.5\" width=\"80\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"分词\" link=\"token\" id=\"457\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"459.37\" y=\"1945\" width=\"45\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"&lt;div&gt;&lt;span style=&quot;background-color: transparent; color: light-dark(rgb(0, 0, 0), rgb(255, 255, 255));&quot;&gt;预训练语言模型&lt;/span&gt;&lt;/div&gt;\" link=\"plm\" id=\"458\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"438.63\" y=\"1880\" width=\"87.83\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ChatGPT\" link=\"chatgpt\" id=\"459\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"246.56\" y=\"1760\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"460\" value=\"NLP模型\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=14;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"394.1184848098349\" y=\"1750.001125496954\" as=\"geometry\">\n <mxPoint x=\"1\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"461\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=5;strokeColor=#CCCCCC;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"385\" target=\"387\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"500\" y=\"1420\" as=\"sourcePoint\" />\n <mxPoint x=\"499\" y=\"1460\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"462\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#f8cecc;strokeColor=#b85450;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"310\" y=\"1425\" width=\"369.25\" height=\"70\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"ChatGLM\" link=\"chatglm\" id=\"463\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#e3c800;strokeColor=#B09500;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"523.99\" y=\"1460\" width=\"70\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Baichuan\" link=\"baichuan\" id=\"464\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#e3c800;strokeColor=#B09500;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"604.62\" y=\"1460\" width=\"70\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ChatGPT\" link=\"chatgpt\" id=\"465\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#e3c800;strokeColor=#B09500;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"446.87\" y=\"1460\" width=\"70\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"466\" value=\"大语言模型\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=13;fontStyle=1;fontColor=#333300;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"494.25\" y=\"1440\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"467\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"462\" target=\"451\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"504\" y=\"1580\" as=\"sourcePoint\" />\n <mxPoint x=\"504\" y=\"1520\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"468\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.25;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"462\" target=\"442\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"490\" y=\"1430\" as=\"sourcePoint\" />\n <mxPoint x=\"504\" y=\"1410\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"469\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.039;entryY=1;entryDx=0;entryDy=0;entryPerimeter=0;\" parent=\"1\" source=\"431\" target=\"382\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"504\" y=\"1440\" as=\"sourcePoint\" />\n <mxPoint x=\"650\" y=\"1310\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"470\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;dashed=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"485\" target=\"444\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"686.25\" y=\"1477.81\" as=\"sourcePoint\" />\n <mxPoint x=\"761.25\" y=\"1468.81\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"471\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;dashed=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"443\" target=\"485\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"613.5\" y=\"1338.81\" as=\"sourcePoint\" />\n <mxPoint x=\"1003.5\" y=\"1233.81\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"472\" value=\"垂类模型\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"270.56\" y=\"1397.5\" width=\"56\" height=\"20\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"473\" value=\"专题优化\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"751.5\" y=\"1421.88\" width=\"60\" height=\"22.5\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"474\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"384\" target=\"473\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"505\" y=\"1435\" as=\"sourcePoint\" />\n <mxPoint x=\"504\" y=\"1410\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"幻觉\" link=\"hallucination\" id=\"475\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"876.5\" y=\"1390\" width=\"50\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"476\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"473\" target=\"383\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"720.5\" y=\"1488\" as=\"sourcePoint\" />\n <mxPoint x=\"760.5\" y=\"1444\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"477\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"478\" target=\"418\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"753\" y=\"1289\" as=\"sourcePoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"PE\" link=\"pe\" id=\"478\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=#82b366;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"650\" y=\"1239\" width=\"30\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"479\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=1;exitY=0.25;exitDx=0;exitDy=0;\" parent=\"1\" source=\"384\" target=\"443\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"654\" y=\"1380\" as=\"sourcePoint\" />\n <mxPoint x=\"710\" y=\"1340\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"480\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.75;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"462\" target=\"431\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"640\" y=\"1375\" as=\"sourcePoint\" />\n <mxPoint x=\"655\" y=\"1333\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"481\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"418\" target=\"419\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"793\" y=\"1264\" as=\"sourcePoint\" />\n <mxPoint x=\"813\" y=\"1264\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-540\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"482\" target=\"o5D4xRg-JXB86p6HjegH-538\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"482\" value=\"推理性能\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"282.88\" y=\"1450\" width=\"56\" height=\"20\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"483\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.25;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"478\" target=\"381\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"635\" y=\"1380\" as=\"sourcePoint\" />\n <mxPoint x=\"662\" y=\"1330\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"484\" value=\"Prompt优化\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=-30;\" parent=\"483\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"-0.0199\" y=\"1\" relative=\"1\" as=\"geometry\">\n <mxPoint x=\"-13\" y=\"-5\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"485\" value=\"Agent框架\" style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"960.75\" y=\"1258.21\" width=\"70\" height=\"21.19\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"486\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;dashed=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"485\" target=\"445\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1047.25\" y=\"1278.81\" as=\"sourcePoint\" />\n <mxPoint x=\"1067.25\" y=\"1286.81\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"487\" value=\"模型训练\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=13;fontStyle=1;fontColor=#6666FF;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"528.75\" y=\"1560\" as=\"geometry\">\n <mxPoint x=\"-3\" y=\"-20\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"智能客服\" link=\"ics\" id=\"488\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"308.74\" y=\"1110.82\" width=\"60\" height=\"18.37\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"489\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"490\" target=\"513\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"对话管理\" link=\"dialogue-manager\" id=\"490\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"231.75\" y=\"1160\" width=\"60\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"491\" value=\"\" style=\"rounded=1;whiteSpace=wrap;html=1;dashed=1;fillColor=#fff2cc;strokeColor=#d6b656;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"810.5\" y=\"1535\" width=\"174.5\" height=\"170\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"文本生成\" link=\"text-generation\" id=\"492\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"826.93\" y=\"1615\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"文本分类\" link=\"cls\" id=\"493\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"901\" y=\"1585\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"文本匹配\" link=\"text-match\" id=\"494\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"825.5\" y=\"1585\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"NER\" link=\"ner\" id=\"495\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"826.93\" y=\"1645\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"阅读理解\" link=\"mrc\" id=\"496\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"906.43\" y=\"1645\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"497\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.995;exitY=0.874;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitPerimeter=0;\" parent=\"1\" source=\"384\" target=\"401\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"721\" y=\"1443\" as=\"sourcePoint\" />\n <mxPoint x=\"761\" y=\"1444\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"GPT-2\" link=\"gpt2\" id=\"498\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"251.01\" y=\"1883.5\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"499\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"433\" target=\"498\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"275.75\" y=\"1984\" as=\"sourcePoint\" />\n <mxPoint x=\"275.75\" y=\"1939\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"NLP基础知识\" link=\"nlp\" id=\"501\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"852.5\" y=\"1549\" width=\"90\" height=\"26\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"聚类\" link=\"cluster\" id=\"502\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"829.43\" y=\"1675\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"503\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"590.12\" y=\"1780\" width=\"300\" height=\"220\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"504\" value=\"深度学习\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=14;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"645.9284848098349\" y=\"1760.001125496954\" as=\"geometry\">\n <mxPoint x=\"-28\" y=\"12\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"机器学习\" link=\"ml\" id=\"505\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"733.12\" y=\"1809.5\" width=\"54.75\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"深度学习\" link=\"dl_note\" id=\"506\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"645.37\" y=\"1922\" width=\"54.5\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"神经网络\" link=\"ann\" id=\"507\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f0a30a;strokeColor=#BD7000;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"796.87\" y=\"1876.75\" width=\"64.5\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"神经网络调参\" link=\"ann_tune\" id=\"508\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"790.37\" y=\"1912.5\" width=\"81\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AutoML\" link=\"automl\" id=\"509\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"806.12\" y=\"1948.5\" width=\"48\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"强化学习\" link=\"rl\" id=\"510\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"592.75\" y=\"1979.5\" width=\"64.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"因果科学\" link=\"casual\" id=\"511\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"802.25\" y=\"1979.5\" width=\"64.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"多任务学习\" link=\"multi-task\" id=\"512\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"810.75\" y=\"1799.5\" width=\"62.5\" height=\"20.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"用户模拟器\" link=\"simulator\" id=\"513\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"139\" y=\"1160\" width=\"71\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"图神经网络\" link=\"gnn\" id=\"514\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"713.25\" y=\"1902\" width=\"64.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AGI\" link=\"agi\" id=\"515\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"930.12\" y=\"1840\" width=\"30\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"脑机接口\" link=\"bci\" id=\"516\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"997.12\" y=\"1836\" width=\"53\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AIGC行业\" link=\"aigc\" id=\"517\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"997.12\" y=\"1800\" width=\"63.5\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"518\" value=\"行业知识\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=14;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"1026.998484809835\" y=\"1770.001125496954\" as=\"geometry\">\n <mxPoint x=\"1\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"AI行业报告\" link=\"ai_report\" id=\"519\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"912.12\" y=\"1800\" width=\"64.5\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"具身智能\" link=\"embodied\" id=\"520\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1068.0000000000002\" y=\"1840.5\" width=\"53\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ML笔记\" link=\"ml_note\" id=\"522\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"675.62\" y=\"1770\" width=\"47.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-523\" value=\"应用层\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=13;fontStyle=1;fontColor=#6666FF;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"613.99\" y=\"1111.68\" as=\"geometry\">\n <mxPoint x=\"-7\" y=\"-2\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-527\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-524\" target=\"o5D4xRg-JXB86p6HjegH-526\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"人工智障\" link=\"dialogue\" id=\"o5D4xRg-JXB86p6HjegH-524\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f8cecc;strokeColor=#b85450;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"233.75\" y=\"1104.18\" width=\"58\" height=\"18.37\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-525\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=1;entryY=1;entryDx=0;entryDy=0;exitX=0;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"404\" target=\"o5D4xRg-JXB86p6HjegH-524\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"369\" y=\"1159\" as=\"sourcePoint\" />\n <mxPoint x=\"369\" y=\"1138\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"大模型时代对话系统\" link=\"llm_ds\" id=\"o5D4xRg-JXB86p6HjegH-526\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#008a00;strokeColor=#005700;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"139\" y=\"1098.37\" width=\"71\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM 开发模式\" link=\"llm_dev\" id=\"o5D4xRg-JXB86p6HjegH-528\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffe6cc;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"652.62\" y=\"1280\" width=\"77.38\" height=\"26\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"对比学习\" link=\"contrastive\" id=\"o5D4xRg-JXB86p6HjegH-529\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"725.75\" y=\"1977\" width=\"64.5\" height=\"20.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"计算机视觉\" link=\"cv\" id=\"o5D4xRg-JXB86p6HjegH-530\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"623.12\" y=\"2022\" width=\"64.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"视频理解\" link=\"video\" id=\"o5D4xRg-JXB86p6HjegH-531\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"613.99\" y=\"1195.75\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-532\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;exitX=0.75;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"394\" target=\"o5D4xRg-JXB86p6HjegH-531\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"528\" y=\"1232\" as=\"sourcePoint\" />\n <mxPoint x=\"537\" y=\"1189\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"推荐系统\" link=\"rp\" id=\"o5D4xRg-JXB86p6HjegH-533\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"486.6799999999999\" y=\"1780\" width=\"54.5\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"文档问答\" link=\"doc_chat\" id=\"o5D4xRg-JXB86p6HjegH-534\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"360.74\" y=\"1135.37\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-535\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" target=\"o5D4xRg-JXB86p6HjegH-534\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"390\" y=\"1170\" as=\"sourcePoint\" />\n <mxPoint x=\"369\" y=\"1138\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"开放域问答\" link=\"dialogue_qa\" id=\"o5D4xRg-JXB86p6HjegH-536\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"377.74\" y=\"1105.82\" width=\"65\" height=\"23.37\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM问题\" link=\"llm_think\" id=\"o5D4xRg-JXB86p6HjegH-537\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f8cecc;strokeColor=#b85450;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"752.5\" y=\"1379\" width=\"58\" height=\"30\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"推理优化\" link=\"llm_opt\" id=\"o5D4xRg-JXB86p6HjegH-538\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"169.5\" y=\"1450\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"服务部署实验\" link=\"exp\" id=\"o5D4xRg-JXB86p6HjegH-541\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"159.5\" y=\"1490\" width=\"80.5\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"自动标注\" link=\"label\" id=\"o5D4xRg-JXB86p6HjegH-542\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"200.5\" y=\"1540\" width=\"50\" height=\"25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ChatGPT应用\" link=\"chatgpt_application\" id=\"o5D4xRg-JXB86p6HjegH-545\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#dae8fc;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"222.62\" y=\"1200\" width=\"78.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"评估方法\" link=\"eva\" id=\"o5D4xRg-JXB86p6HjegH-546\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"708.87\" y=\"1550\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"目标检测\" link=\"loss\" id=\"o5D4xRg-JXB86p6HjegH-547\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"722.87\" y=\"2050\" width=\"51.25\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"大模型评测\" link=\"llm_eva\" id=\"o5D4xRg-JXB86p6HjegH-548\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"708.87\" y=\"1587.5\" width=\"62\" height=\"22.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ChatGPT复现\" link=\"chatgpt_mimic\" id=\"o5D4xRg-JXB86p6HjegH-549\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#dae8fc;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"236.88000000000005\" y=\"1710\" width=\"78.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AI生成\" link=\"llm_data\" id=\"o5D4xRg-JXB86p6HjegH-550\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"200\" y=\"1585\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM原理\" link=\"llm_arch\" id=\"o5D4xRg-JXB86p6HjegH-552\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d80073;strokeColor=#A50040;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"291.75\" y=\"1626\" width=\"62.87\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"音乐生成\" link=\"music_gen\" id=\"o5D4xRg-JXB86p6HjegH-553\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"260.87\" y=\"1242\" width=\"60\" height=\"15\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-554\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;dashed=1;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"393\" target=\"o5D4xRg-JXB86p6HjegH-553\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"528\" y=\"1232\" as=\"sourcePoint\" />\n <mxPoint x=\"537\" y=\"1189\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"推理加速\" link=\"infer\" id=\"o5D4xRg-JXB86p6HjegH-555\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"169.5\" y=\"1410\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM端侧部署\" link=\"llm_end_tool\" id=\"o5D4xRg-JXB86p6HjegH-556\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"240\" y=\"1337\" width=\"79.26\" height=\"21.19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"OpenAI\" link=\"openai\" id=\"o5D4xRg-JXB86p6HjegH-557\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#dae8fc;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"919.37\" y=\"1900\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AI公司\" link=\"ai_company\" id=\"o5D4xRg-JXB86p6HjegH-558\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#dae8fc;strokeColor=none;shadow=1;arcSize=50;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"976.62\" y=\"1900\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"AIGC 机会\" link=\"aigc_idea\" id=\"o5D4xRg-JXB86p6HjegH-559\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1084.93\" y=\"1800\" width=\"60.12\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-561\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-560\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"180\" y=\"1180\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"用户画像\" link=\"user\" id=\"o5D4xRg-JXB86p6HjegH-560\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"155\" y=\"1210\" width=\"51\" height=\"18.81\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"大脑原理\" link=\"brain\" id=\"o5D4xRg-JXB86p6HjegH-563\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"967.12\" y=\"1872.5\" width=\"53\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"回归分析\" link=\"regression\" id=\"o5D4xRg-JXB86p6HjegH-564\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#99CCFF;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"668.87\" y=\"1834\" width=\"58.75\" height=\"16\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"芯片\" link=\"chip\" id=\"o5D4xRg-JXB86p6HjegH-565\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;arcSize=50;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1027.0000000000002\" y=\"1907\" width=\"38\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"在线教育\" link=\"tutor\" id=\"o5D4xRg-JXB86p6HjegH-566\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"974.37\" y=\"2092.5\" width=\"53\" height=\"17\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"汽车原理\" link=\"car\" id=\"o5D4xRg-JXB86p6HjegH-567\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"964.62\" y=\"2011\" width=\"53\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"自动驾驶\" link=\"driving\" id=\"o5D4xRg-JXB86p6HjegH-568\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"926.7499999999999\" y=\"1978\" width=\"53\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"异常检测\" link=\"anomaly\" id=\"o5D4xRg-JXB86p6HjegH-569\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"734\" y=\"1856.75\" width=\"58.75\" height=\"17.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"聚类算法\" link=\"cluster\" id=\"o5D4xRg-JXB86p6HjegH-570\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#99CCFF;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"734\" y=\"1835\" width=\"58.75\" height=\"15\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-571\" value=\"\" style=\"rounded=0;whiteSpace=wrap;html=1;labelBackgroundColor=none;fontSize=10;fillColor=#f5f5f5;dashed=1;strokeColor=#666666;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"590.12\" y=\"2097\" width=\"260\" height=\"102\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"贝叶斯\" link=\"bayes\" id=\"o5D4xRg-JXB86p6HjegH-572\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"699.87\" y=\"2111\" width=\"47.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"元宇宙\" link=\"meta\" id=\"o5D4xRg-JXB86p6HjegH-573\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"911.62\" y=\"2040\" width=\"53\" height=\"15\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"新技术\" link=\"new_tech\" id=\"o5D4xRg-JXB86p6HjegH-574\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"929.2500000000001\" y=\"1947\" width=\"48\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"机器人\" link=\"robot\" id=\"o5D4xRg-JXB86p6HjegH-575\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1075.1200000000001\" y=\"1885\" width=\"40\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"搜索\" link=\"search\" id=\"o5D4xRg-JXB86p6HjegH-576\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"489.9099999999999\" y=\"1806.5\" width=\"40.75\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"可解释性\" link=\"explain\" id=\"o5D4xRg-JXB86p6HjegH-577\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#CCCCCC;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"595.75\" y=\"1854.25\" width=\"58.75\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"NAS\" link=\"nas\" id=\"o5D4xRg-JXB86p6HjegH-578\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"750.88\" y=\"1949\" width=\"34.5\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"元学习\" link=\"meta_learning\" id=\"o5D4xRg-JXB86p6HjegH-579\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"670.63\" y=\"1978.5\" width=\"47.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"情感计算\" link=\"emotion\" id=\"o5D4xRg-JXB86p6HjegH-580\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"902.43\" y=\"1615\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"知识追踪\" link=\"dkt\" id=\"o5D4xRg-JXB86p6HjegH-581\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1052.3700000000003\" y=\"2092.5\" width=\"53\" height=\"17\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"互联网金融\" link=\"finance\" id=\"o5D4xRg-JXB86p6HjegH-582\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"914.37\" y=\"2069.5\" width=\"62.25\" height=\"16\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"房产行业\" link=\"house\" id=\"o5D4xRg-JXB86p6HjegH-583\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1103.1200000000001\" y=\"2038.5\" width=\"53\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"量化交易\" link=\"quant\" id=\"o5D4xRg-JXB86p6HjegH-584\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"999.3700000000001\" y=\"2069.5\" width=\"53\" height=\"16\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"股票\" link=\"stock\" id=\"o5D4xRg-JXB86p6HjegH-585\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1079.6200000000001\" y=\"2069.5\" width=\"35.5\" height=\"16\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"物联网\" link=\"iot\" id=\"o5D4xRg-JXB86p6HjegH-586\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1040.6200000000001\" y=\"1971.5\" width=\"45\" height=\"17\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"移动设备\" link=\"phone\" id=\"o5D4xRg-JXB86p6HjegH-587\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1037.1200000000001\" y=\"2010\" width=\"53\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"语音生成\" link=\"voice\" id=\"o5D4xRg-JXB86p6HjegH-588\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"802.25\" y=\"2022\" width=\"56.25\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"模型部署\" link=\"model_deploy\" id=\"o5D4xRg-JXB86p6HjegH-589\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"255.5\" y=\"1490\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"最优化\" link=\"optimization\" id=\"o5D4xRg-JXB86p6HjegH-590\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#CCCCCC;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"599.68\" y=\"1807.5\" width=\"46.25\" height=\"17.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"排序学习\" link=\"ltr\" id=\"o5D4xRg-JXB86p6HjegH-591\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"487.23999999999984\" y=\"1833\" width=\"59.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"微积分\" link=\"calculus\" id=\"o5D4xRg-JXB86p6HjegH-592\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"751.12\" y=\"2111\" width=\"40.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"知识图谱\" link=\"kg\" id=\"o5D4xRg-JXB86p6HjegH-593\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"714.23\" y=\"1925\" width=\"54.74\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"博弈论\" link=\"game-thoery\" id=\"o5D4xRg-JXB86p6HjegH-594\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"781.13\" y=\"2137.5\" width=\"43.5\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"联邦学习\" link=\"faderation\" id=\"o5D4xRg-JXB86p6HjegH-595\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"588.99\" y=\"1923.5\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"密码学\" link=\"cryptography\" id=\"o5D4xRg-JXB86p6HjegH-596\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"676.73\" y=\"2165\" width=\"37.5\" height=\"24\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"流形学习\" link=\"manifold\" id=\"o5D4xRg-JXB86p6HjegH-597\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"654.12\" y=\"2137.5\" width=\"57.5\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Python\" link=\"python\" id=\"o5D4xRg-JXB86p6HjegH-598\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"335.99\" y=\"2050\" width=\"45.01\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"特征工程\" link=\"fe\" id=\"o5D4xRg-JXB86p6HjegH-599\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#CCCCCC;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"597.41\" y=\"1783.5\" width=\"59.12\" height=\"16.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"区块链\" link=\"block-chain\" id=\"o5D4xRg-JXB86p6HjegH-600\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"974.12\" y=\"2040\" width=\"53\" height=\"15\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"信息论\" link=\"information\" id=\"o5D4xRg-JXB86p6HjegH-601\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"795.62\" y=\"2111\" width=\"46\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"概率统计\" link=\"probability\" id=\"o5D4xRg-JXB86p6HjegH-602\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"597.37\" y=\"2137.5\" width=\"50.87\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"量子计算\" link=\"quantum\" id=\"o5D4xRg-JXB86p6HjegH-603\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1036.6200000000001\" y=\"2040\" width=\"53\" height=\"15\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Pandas\" link=\"pandas\" id=\"o5D4xRg-JXB86p6HjegH-604\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"390.25\" y=\"2050\" width=\"42.38\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Scikit-learn\" link=\"sklearn\" id=\"o5D4xRg-JXB86p6HjegH-605\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"441.75\" y=\"2051\" width=\"64.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"文本挖掘\" link=\"text-mining\" id=\"o5D4xRg-JXB86p6HjegH-606\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"907.06\" y=\"1675\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"神经网络可视化\" link=\"train_vis\" id=\"o5D4xRg-JXB86p6HjegH-607\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"650.12\" y=\"1879.5\" width=\"94\" height=\"17.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"不均衡问题\" link=\"imbalance\" id=\"o5D4xRg-JXB86p6HjegH-608\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#CCCCCC;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"591.97\" y=\"1830\" width=\"70\" height=\"20.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"精简笔记\" link=\"dl_sum\" id=\"o5D4xRg-JXB86p6HjegH-609\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"655.37\" y=\"1949\" width=\"54.75\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"文本分类\" link=\"cls\" id=\"o5D4xRg-JXB86p6HjegH-610\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#99CCFF;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"800.12\" y=\"1838\" width=\"61.5\" height=\"12\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ML军规\" link=\"ml_rule\" id=\"o5D4xRg-JXB86p6HjegH-611\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"738.13\" y=\"1770\" width=\"47.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"线性代数与矩阵\" link=\"bayes\" id=\"o5D4xRg-JXB86p6HjegH-612\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"594.99\" y=\"2111\" width=\"94.25\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Go\" link=\"go\" id=\"o5D4xRg-JXB86p6HjegH-614\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"235.12\" y=\"2048\" width=\"35.01\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"ML本质\" link=\"ml_essense\" id=\"o5D4xRg-JXB86p6HjegH-615\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"792.75\" y=\"1770\" width=\"47.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LBS\" link=\"lbs\" id=\"o5D4xRg-JXB86p6HjegH-616\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;arcSize=19;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1109.8700000000001\" y=\"1970\" width=\"30\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"傅里叶变换\" link=\"fourier\" id=\"o5D4xRg-JXB86p6HjegH-617\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"597.41\" y=\"2165\" width=\"70.44\" height=\"24\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Git\" link=\"git\" id=\"o5D4xRg-JXB86p6HjegH-618\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"164.10000000000002\" y=\"2079\" width=\"35.01\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Jupyter\" link=\"jupyter\" id=\"o5D4xRg-JXB86p6HjegH-619\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"204.47000000000003\" y=\"2079\" width=\"41.64\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Linux\" link=\"linux\" id=\"o5D4xRg-JXB86p6HjegH-620\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"296.36\" y=\"2079\" width=\"35.01\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Shell\" link=\"shell\" id=\"o5D4xRg-JXB86p6HjegH-621\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"283.62\" y=\"2050\" width=\"35.01\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Latex\" link=\"latex\" id=\"o5D4xRg-JXB86p6HjegH-622\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"252.35000000000002\" y=\"2079\" width=\"35.01\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Jekyll\" link=\"jekyll\" id=\"o5D4xRg-JXB86p6HjegH-623\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"518.85\" y=\"2115\" width=\"35.01\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"教育\" link=\"edu\" id=\"o5D4xRg-JXB86p6HjegH-624\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"918.5500000000001\" y=\"2092.5\" width=\"32.25\" height=\"17\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"分形几何\" link=\"fractal\" id=\"o5D4xRg-JXB86p6HjegH-625\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"718\" y=\"2137.5\" width=\"54.5\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"SQL\" link=\"data\" id=\"o5D4xRg-JXB86p6HjegH-626\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"180.12\" y=\"2145.5\" width=\"32.51\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"可视化\" link=\"vis\" id=\"o5D4xRg-JXB86p6HjegH-627\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"225.62\" y=\"2145.5\" width=\"47.01\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"数据挖掘\" link=\"dm\" id=\"o5D4xRg-JXB86p6HjegH-628\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"283.62\" y=\"2145.5\" width=\"50\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"vpn\" link=\"vpn\" id=\"o5D4xRg-JXB86p6HjegH-629\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"175.62\" y=\"2181.5\" width=\"32.51\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"计算机网络\" link=\"network\" id=\"o5D4xRg-JXB86p6HjegH-630\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"221.87\" y=\"2181.5\" width=\"65.01\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"计算机语言\" link=\"computer\" id=\"o5D4xRg-JXB86p6HjegH-631\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"292.26\" y=\"2181.5\" width=\"65.01\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"操作系统\" link=\"os\" id=\"o5D4xRg-JXB86p6HjegH-632\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"362.87\" y=\"2181.5\" width=\"54.01\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"图形学\" link=\"graphic\" id=\"o5D4xRg-JXB86p6HjegH-633\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"593.12\" y=\"2050\" width=\"46.87\" height=\"16.75\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"计算机知识脑图\" link=\"mindmap\" id=\"o5D4xRg-JXB86p6HjegH-634\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"341.12\" y=\"2145.5\" width=\"91.51\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"基础算法\" link=\"algorithm\" id=\"o5D4xRg-JXB86p6HjegH-635\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"180.86\" y=\"2113\" width=\"52.51\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"算法比赛\" link=\"kaggle\" id=\"o5D4xRg-JXB86p6HjegH-636\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"244.99\" y=\"2113\" width=\"52.51\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Web前端\" link=\"web\" id=\"o5D4xRg-JXB86p6HjegH-637\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"306.74\" y=\"2113\" width=\"52.51\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"架构设计\" link=\"arch\" id=\"o5D4xRg-JXB86p6HjegH-638\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"367.86\" y=\"2113\" width=\"52.51\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Docker\" link=\"docker\" id=\"o5D4xRg-JXB86p6HjegH-639\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"494.82\" y=\"2146.5\" width=\"41.64\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"小程序\" link=\"mini\" id=\"o5D4xRg-JXB86p6HjegH-640\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"427.11\" y=\"2114\" width=\"46.26\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"测试\" link=\"test\" id=\"o5D4xRg-JXB86p6HjegH-641\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"477.36\" y=\"2115\" width=\"36.01\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"面试指南\" link=\"interview\" id=\"o5D4xRg-JXB86p6HjegH-642\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"438.63\" y=\"2146.5\" width=\"50\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"数学历史\" link=\"math\" id=\"o5D4xRg-JXB86p6HjegH-643\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"720.35\" y=\"2165\" width=\"57.5\" height=\"24\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"makefile\" link=\"makefile\" id=\"o5D4xRg-JXB86p6HjegH-644\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"175.87\" y=\"2046.75\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Linux C\" link=\"linux-program\" id=\"o5D4xRg-JXB86p6HjegH-645\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"340.62\" y=\"2079\" width=\"51.5\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"C/C++\" link=\"c\" id=\"o5D4xRg-JXB86p6HjegH-647\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"402.61\" y=\"2080\" width=\"35.01\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"设计模式\" link=\"design\" id=\"o5D4xRg-JXB86p6HjegH-648\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"423.35\" y=\"2181.5\" width=\"54.01\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Tensorflow\" link=\"linux-program\" id=\"o5D4xRg-JXB86p6HjegH-649\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"445.87\" y=\"2077.5\" width=\"56.01\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Pytorch\" link=\"linux-program\" id=\"o5D4xRg-JXB86p6HjegH-651\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"512.11\" y=\"2050\" width=\"43.01\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Pytorch手册\" link=\"pytorch_simple\" id=\"o5D4xRg-JXB86p6HjegH-652\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"508.35999999999996\" y=\"2079\" width=\"73.01\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-653\" value=\"计算机基础\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=14;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"380.86848480983497\" y=\"2031.001125496954\" as=\"geometry\">\n <mxPoint x=\"-4\" y=\"-4\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-654\" value=\"数学知识\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=14;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"721.738484809835\" y=\"2088.001125496954\" as=\"geometry\">\n <mxPoint x=\"1\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"o5D4xRg-JXB86p6HjegH-655\" value=\"【2025-09-29】&lt;div&gt;wqw547243068@163.com&lt;/div&gt;\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;fontSize=14;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"759.998484809835\" y=\"1730.001125496954\" as=\"geometry\">\n <mxPoint x=\"-4\" y=\"-4\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"图像处理\" link=\"image\" id=\"ozFa4HHbGE1QGwIMumdl-522\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"644.37\" y=\"2050\" width=\"51.25\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"OCR\" link=\"ocr\" id=\"ozFa4HHbGE1QGwIMumdl-523\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"727.62\" y=\"2022\" width=\"39.25\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"智能硬件\" link=\"smart_device\" id=\"ozFa4HHbGE1QGwIMumdl-524\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1070.0600000000002\" y=\"1931\" width=\"50.12\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"传感器\" link=\"sensor\" id=\"ozFa4HHbGE1QGwIMumdl-525\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"1128.1200000000001\" y=\"1915.5\" width=\"40\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"GPT-3\" link=\"gpt\" id=\"ozFa4HHbGE1QGwIMumdl-526\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"251.01\" y=\"1843.5\" width=\"50\" height=\"15.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ozFa4HHbGE1QGwIMumdl-527\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"498\" target=\"ozFa4HHbGE1QGwIMumdl-526\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"250.76\" y=\"1924\" as=\"sourcePoint\" />\n <mxPoint x=\"211.76\" y=\"1924\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"Transformer&lt;span style=&quot;background-color: transparent; color: light-dark(rgb(0, 0, 0), rgb(255, 255, 255));&quot;&gt;改进&lt;/span&gt;\" link=\"transformer_update\" id=\"ozFa4HHbGE1QGwIMumdl-528\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"210.12\" y=\"1970.5\" width=\"97.74\" height=\"23\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ozFa4HHbGE1QGwIMumdl-529\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"432\" target=\"ozFa4HHbGE1QGwIMumdl-528\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"326.11\" y=\"1988.5\" as=\"sourcePoint\" />\n <mxPoint x=\"375.11000000000007\" y=\"1938.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"AIGC&lt;div&gt;内容检测&lt;/div&gt;\" link=\"aigc_detect\" id=\"ozFa4HHbGE1QGwIMumdl-530\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f8cecc;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"645.37\" y=\"1120\" width=\"65\" height=\"34\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"端到端对话\" link=\"end_voice\" id=\"ozFa4HHbGE1QGwIMumdl-531\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#008a00;strokeColor=#005700;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"139\" y=\"1060\" width=\"71\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM发展方向\" link=\"llm_direction\" id=\"ozFa4HHbGE1QGwIMumdl-532\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"919\" y=\"1358.19\" width=\"80\" height=\"25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ozFa4HHbGE1QGwIMumdl-534\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-526\" target=\"ozFa4HHbGE1QGwIMumdl-531\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"339\" y=\"1159\" as=\"sourcePoint\" />\n <mxPoint x=\"302\" y=\"1138\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"具身智能\" link=\"embodied\" id=\"_A3We9M9UZmKuXBEy4Mw-522\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"350.75\" y=\"1268\" width=\"60\" height=\"22\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-523\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"451\" target=\"_A3We9M9UZmKuXBEy4Mw-522\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"504\" y=\"1380\" as=\"sourcePoint\" />\n <mxPoint x=\"402\" y=\"1285\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"DeepSeek\" link=\"deepseek\" id=\"_A3We9M9UZmKuXBEy4Mw-524\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#e3c800;strokeColor=#B09500;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"371.75\" y=\"1460\" width=\"70\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-525\" value=\"Encoder模块&lt;div&gt;(NLU场景)&lt;/div&gt;\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"424.7484085634645\" y=\"1943.4975560958092\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-526\" value=\"Decoder模块&lt;div&gt;(NLG场景)&lt;/div&gt;\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"355.86840856346447\" y=\"1958.4975560958092\" as=\"geometry\">\n <mxPoint x=\"-7.585786437626904\" y=\"-7.65685424949238\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"GPT-3.5\" link=\"gpt\" id=\"_A3We9M9UZmKuXBEy4Mw-527\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"251.01\" y=\"1793.5\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-528\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"ozFa4HHbGE1QGwIMumdl-526\" target=\"_A3We9M9UZmKuXBEy4Mw-527\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"286.12\" y=\"1889.5\" as=\"sourcePoint\" />\n <mxPoint x=\"286.12\" y=\"1869.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"GPT-4\" link=\"gpt\" id=\"_A3We9M9UZmKuXBEy4Mw-529\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"322.13\" y=\"1763.5\" width=\"50\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-530\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"_A3We9M9UZmKuXBEy4Mw-527\" target=\"_A3We9M9UZmKuXBEy4Mw-529\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"286.12\" y=\"1793.5\" as=\"sourcePoint\" />\n <mxPoint x=\"299.12\" y=\"1763.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-531\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;dashPattern=1 1;\" parent=\"1\" source=\"433\" target=\"434\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"400.12\" y=\"1981.5\" as=\"sourcePoint\" />\n <mxPoint x=\"440.12\" y=\"1913.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-532\" value=\"2018年6月&lt;div&gt;&lt;br&gt;&lt;/div&gt;\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"207.73840856346453\" y=\"1938.4975560958092\" as=\"geometry\">\n <mxPoint x=\"2\" y=\"3\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-533\" value=\"2018年10月&lt;div&gt;Google&lt;/div&gt;\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"334.3684085634645\" y=\"1908.9975560958092\" as=\"geometry\">\n <mxPoint x=\"2\" y=\"3\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-534\" value=\"2019年2月\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"207.73840856346453\" y=\"1895.9975560958092\" as=\"geometry\">\n <mxPoint x=\"2\" y=\"3\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-535\" value=\"2020年5月\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"207.73840856346453\" y=\"1843.9975560958092\" as=\"geometry\">\n <mxPoint x=\"2\" y=\"3\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"Albert\" link=\"bert\" id=\"_A3We9M9UZmKuXBEy4Mw-536\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"365.36000000000007\" y=\"1863.5\" width=\"50\" height=\"15.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-537\" value=\"2019年10月&lt;div&gt;&lt;br&gt;&lt;/div&gt;\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"333.7484085634645\" y=\"1858.9975560958092\" as=\"geometry\">\n <mxPoint x=\"2\" y=\"3\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-538\" value=\"&lt;span style=&quot;font-family: Helvetica; font-size: 11px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: center; text-indent: 0px; text-transform: none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; white-space: nowrap; background-color: rgb(251, 251, 251); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial; float: none; display: inline !important;&quot;&gt;OpenAI&lt;/span&gt;\" style=\"text;whiteSpace=wrap;html=1;fontColor=#CC00CC;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"190.99\" y=\"1773.5\" width=\"40\" height=\"20\" as=\"geometry\" />\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-539\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;\" parent=\"1\" source=\"434\" target=\"_A3We9M9UZmKuXBEy4Mw-536\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"400.12\" y=\"1981.5\" as=\"sourcePoint\" />\n <mxPoint x=\"401.12\" y=\"1936.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"&lt;font style=&quot;&quot;&gt;Agent&lt;span style=&quot;background-color: transparent;&quot;&gt;应用&lt;/span&gt;&lt;/font&gt;\" link=\"agent_usecase\" id=\"_A3We9M9UZmKuXBEy4Mw-540\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b1ddf0;strokeColor=none;shadow=1;fontColor=#000000;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"960.75\" y=\"1219\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-541\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;dashed=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"443\" target=\"_A3We9M9UZmKuXBEy4Mw-540\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"952\" y=\"1264\" as=\"sourcePoint\" />\n <mxPoint x=\"983\" y=\"1264\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"端侧LLM\" link=\"llm_end\" id=\"_A3We9M9UZmKuXBEy4Mw-542\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"355.75\" y=\"1337\" width=\"50\" height=\"21.19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-543\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.25;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"462\" target=\"_A3We9M9UZmKuXBEy4Mw-542\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"400\" y=\"1420\" as=\"sourcePoint\" />\n <mxPoint x=\"380\" y=\"1410\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-544\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"_A3We9M9UZmKuXBEy4Mw-542\" target=\"o5D4xRg-JXB86p6HjegH-556\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"422\" y=\"1445\" as=\"sourcePoint\" />\n <mxPoint x=\"390\" y=\"1420\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-547\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"427\" target=\"427\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"训练框架\" link=\"dist_tool\" id=\"_A3We9M9UZmKuXBEy4Mw-548\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f5f5f5;strokeColor=#666666;shadow=1;fontColor=#333333;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"365\" y=\"1655\" width=\"55\" height=\"25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-549\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0;exitY=0.5;exitDx=0;exitDy=0;entryX=1;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"411\" target=\"_A3We9M9UZmKuXBEy4Mw-548\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"452\" y=\"1640\" as=\"sourcePoint\" />\n <mxPoint x=\"502\" y=\"1620\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-550\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0;exitY=0.5;exitDx=0;exitDy=0;entryX=1;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"_A3We9M9UZmKuXBEy4Mw-548\" target=\"413\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"462\" y=\"1650\" as=\"sourcePoint\" />\n <mxPoint x=\"512\" y=\"1630\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"ME\" link=\"rag\" id=\"_A3We9M9UZmKuXBEy4Mw-551\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;arcSize=37;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"742.62\" y=\"1275\" width=\"37\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-552\" value=\"模型编辑\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" parent=\"1\" vertex=\"1\" connectable=\"0\">\n <mxGeometry x=\"762.6200819079606\" y=\"1305.0020453684522\" as=\"geometry\" />\n </mxCell>\n <UserObject label=\"NL2SQL\" link=\"nl2sql\" id=\"_A3We9M9UZmKuXBEy4Mw-553\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"405.38\" y=\"1159\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-554\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"404\" target=\"_A3We9M9UZmKuXBEy4Mw-553\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"400\" y=\"1180\" as=\"sourcePoint\" />\n <mxPoint x=\"435\" y=\"1140\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"推荐系统\" link=\"RP\" id=\"_A3We9M9UZmKuXBEy4Mw-555\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"144.5\" y=\"1309.81\" width=\"60\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM推荐系统\" link=\"llm_rp\" id=\"_A3We9M9UZmKuXBEy4Mw-557\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"202.12\" y=\"1268.81\" width=\"75.5\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-558\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"_A3We9M9UZmKuXBEy4Mw-555\" target=\"_A3We9M9UZmKuXBEy4Mw-557\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"190\" y=\"1190\" as=\"targetPoint\" />\n <mxPoint x=\"191\" y=\"1220\" as=\"sourcePoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"机器人\" link=\"robot\" id=\"_A3We9M9UZmKuXBEy4Mw-560\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"425.75\" y=\"1337\" width=\"40\" height=\"17\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-561\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"_A3We9M9UZmKuXBEy4Mw-562\" target=\"_A3We9M9UZmKuXBEy4Mw-560\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"372\" y=\"1270\" as=\"sourcePoint\" />\n <mxPoint x=\"331\" y=\"1260\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"具身智能\" link=\"embodied\" id=\"_A3We9M9UZmKuXBEy4Mw-562\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"418.24\" y=\"1370\" width=\"56\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-563\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"482\" target=\"o5D4xRg-JXB86p6HjegH-555\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"293\" y=\"1470\" as=\"sourcePoint\" />\n <mxPoint x=\"230\" y=\"1470\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-564\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"459\" target=\"o5D4xRg-JXB86p6HjegH-549\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"356\" y=\"1780\" as=\"sourcePoint\" />\n <mxPoint x=\"356\" y=\"1740\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-566\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-563\" target=\"515\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1015.1200000000001\" y=\"1920.5\" as=\"sourcePoint\" />\n <mxPoint x=\"1068.1200000000001\" y=\"1885.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-567\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-563\" target=\"516\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1004.1200000000001\" y=\"1883\" as=\"sourcePoint\" />\n <mxPoint x=\"970.12\" y=\"1860\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-568\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-575\" target=\"520\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1004.1200000000001\" y=\"1883\" as=\"sourcePoint\" />\n <mxPoint x=\"1032.1200000000001\" y=\"1860\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-569\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-565\" target=\"o5D4xRg-JXB86p6HjegH-575\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1128.1200000000001\" y=\"1893\" as=\"sourcePoint\" />\n <mxPoint x=\"1127.1200000000001\" y=\"1871\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-570\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"ozFa4HHbGE1QGwIMumdl-525\" target=\"o5D4xRg-JXB86p6HjegH-575\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1138.1200000000001\" y=\"1903\" as=\"sourcePoint\" />\n <mxPoint x=\"1137.1200000000001\" y=\"1881\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-571\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;dashed=1;dashPattern=1 1;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-557\" target=\"515\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1148.1200000000001\" y=\"1913\" as=\"sourcePoint\" />\n <mxPoint x=\"1147.1200000000001\" y=\"1891\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-572\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"ozFa4HHbGE1QGwIMumdl-524\" target=\"o5D4xRg-JXB86p6HjegH-575\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1075.1200000000001\" y=\"1927\" as=\"sourcePoint\" />\n <mxPoint x=\"1114.1200000000001\" y=\"1915\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-573\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-624\" target=\"o5D4xRg-JXB86p6HjegH-566\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1077.3700000000001\" y=\"1917.5\" as=\"sourcePoint\" />\n <mxPoint x=\"1107.3700000000001\" y=\"1905.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-574\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-566\" target=\"o5D4xRg-JXB86p6HjegH-581\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1032.3700000000001\" y=\"2100.5\" as=\"sourcePoint\" />\n <mxPoint x=\"984.37\" y=\"2111.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-575\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-582\" target=\"o5D4xRg-JXB86p6HjegH-584\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"970.37\" y=\"2138.5\" as=\"sourcePoint\" />\n <mxPoint x=\"994.37\" y=\"2138.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-577\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-585\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1075.3700000000001\" y=\"2077.5\" as=\"sourcePoint\" />\n <mxPoint x=\"1052.3700000000001\" y=\"2077.5\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-578\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"515\" target=\"519\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1004.1200000000001\" y=\"1883\" as=\"sourcePoint\" />\n <mxPoint x=\"970.12\" y=\"1860\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-579\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"517\" target=\"519\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1014.1200000000001\" y=\"1893\" as=\"sourcePoint\" />\n <mxPoint x=\"980.12\" y=\"1870\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-580\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"517\" target=\"o5D4xRg-JXB86p6HjegH-559\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1025.99\" y=\"1913\" as=\"sourcePoint\" />\n <mxPoint x=\"991.9899999999999\" y=\"1890\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-581\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-574\" target=\"o5D4xRg-JXB86p6HjegH-568\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1034.1200000000001\" y=\"1913\" as=\"sourcePoint\" />\n <mxPoint x=\"1000.1200000000001\" y=\"1890\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-582\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-586\" target=\"o5D4xRg-JXB86p6HjegH-587\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1014.1200000000001\" y=\"1999\" as=\"sourcePoint\" />\n <mxPoint x=\"1014.1200000000001\" y=\"2020\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-583\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-616\" target=\"o5D4xRg-JXB86p6HjegH-586\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1024.1200000000001\" y=\"2009\" as=\"sourcePoint\" />\n <mxPoint x=\"1024.1200000000001\" y=\"2030\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-584\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-587\" target=\"o5D4xRg-JXB86p6HjegH-567\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1034.1200000000001\" y=\"2019\" as=\"sourcePoint\" />\n <mxPoint x=\"1034.1200000000001\" y=\"2040\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-585\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-567\" target=\"o5D4xRg-JXB86p6HjegH-568\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1044.1200000000001\" y=\"2029\" as=\"sourcePoint\" />\n <mxPoint x=\"1044.1200000000001\" y=\"2050\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-586\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-586\" target=\"o5D4xRg-JXB86p6HjegH-567\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1054.1200000000001\" y=\"2039\" as=\"sourcePoint\" />\n <mxPoint x=\"1054.1200000000001\" y=\"2060\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-587\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"ozFa4HHbGE1QGwIMumdl-524\" target=\"o5D4xRg-JXB86p6HjegH-586\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1064.1200000000001\" y=\"2049\" as=\"sourcePoint\" />\n <mxPoint x=\"1064.1200000000001\" y=\"2070\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-588\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;dashed=1;dashPattern=1 1;\" parent=\"1\" source=\"515\" target=\"507\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"954.12\" y=\"1910\" as=\"sourcePoint\" />\n <mxPoint x=\"955.12\" y=\"1870\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-590\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"507\" target=\"508\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"1004.1200000000001\" y=\"1883\" as=\"sourcePoint\" />\n <mxPoint x=\"970.12\" y=\"1860\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-591\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0.5;exitY=1;exitDx=0;exitDy=0;\" parent=\"1\" source=\"508\" target=\"509\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"839.12\" y=\"1903\" as=\"sourcePoint\" />\n <mxPoint x=\"772.12\" y=\"1923\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-592\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=0;exitY=0.5;exitDx=0;exitDy=0;entryX=1;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"509\" target=\"o5D4xRg-JXB86p6HjegH-578\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"800.12\" y=\"1960\" as=\"sourcePoint\" />\n <mxPoint x=\"790.12\" y=\"1960\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-593\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=0;entryDx=0;entryDy=0;exitX=0;exitY=0.75;exitDx=0;exitDy=0;\" parent=\"1\" source=\"507\" target=\"514\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"830.12\" y=\"1890\" as=\"sourcePoint\" />\n <mxPoint x=\"840.12\" y=\"1918\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-594\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" parent=\"1\" source=\"507\" target=\"o5D4xRg-JXB86p6HjegH-607\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"807.12\" y=\"1897\" as=\"sourcePoint\" />\n <mxPoint x=\"788.12\" y=\"1917\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-595\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=0.5;exitY=0;exitDx=0;exitDy=0;dashed=1;dashPattern=1 1;\" parent=\"1\" source=\"505\" target=\"522\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"807.12\" y=\"1897\" as=\"sourcePoint\" />\n <mxPoint x=\"755.12\" y=\"1912\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-596\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;dashPattern=1 1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"505\" target=\"o5D4xRg-JXB86p6HjegH-611\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"750.12\" y=\"1810\" as=\"sourcePoint\" />\n <mxPoint x=\"709.12\" y=\"1800\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-597\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;dashPattern=1 1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" parent=\"1\" source=\"505\" target=\"o5D4xRg-JXB86p6HjegH-615\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"729.12\" y=\"1818\" as=\"sourcePoint\" />\n <mxPoint x=\"772.12\" y=\"1800\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"模型蒸馏\" link=\"distill\" id=\"_A3We9M9UZmKuXBEy4Mw-599\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#dae8fc;strokeColor=#6c8ebf;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"592.12\" y=\"1885.5\" width=\"53.25\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"语音识别\" link=\"voice\" id=\"_A3We9M9UZmKuXBEy4Mw-601\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"805.12\" y=\"2050\" width=\"56.25\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-602\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-530\" target=\"ozFa4HHbGE1QGwIMumdl-523\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"816.12\" y=\"1970\" as=\"sourcePoint\" />\n <mxPoint x=\"795.12\" y=\"1971\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <mxCell id=\"_A3We9M9UZmKuXBEy4Mw-603\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-530\" target=\"o5D4xRg-JXB86p6HjegH-547\" edge=\"1\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"698.12\" y=\"2041\" as=\"sourcePoint\" />\n <mxPoint x=\"738.12\" y=\"2041\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"T5\" link=\"bert\" id=\"nBkZRaoQTL_ids0Wdmas-522\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"377.56\" y=\"1837.5\" width=\"33.12\" height=\"15.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"Geimini\" link=\"bert\" id=\"nBkZRaoQTL_ids0Wdmas-523\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" parent=\"1\" vertex=\"1\">\n <mxGeometry x=\"371.75\" y=\"1795.75\" width=\"50.49\" height=\"15.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM搜索\" link=\"llm_search\" id=\"ocm_PwVvUIHaqkUSxyUT-522\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"315.13\" y=\"1201\" width=\"58.01\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM游戏\" link=\"llm_game\" id=\"ocm_PwVvUIHaqkUSxyUT-523\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"569.99\" y=\"1128.37\" width=\"58.01\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM设施\" link=\"llm_infra\" id=\"ocm_PwVvUIHaqkUSxyUT-524\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"323.35\" y=\"1498.81\" width=\"56.65\" height=\"21.19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-525\" value=\"MCP/A2A\" style=\"edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];labelBackgroundColor=none;rotation=0;\" vertex=\"1\" connectable=\"0\" parent=\"1\">\n <mxGeometry x=\"406.75\" y=\"1506.4\" as=\"geometry\">\n <mxPoint x=\"2\" y=\"3\" as=\"offset\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"&lt;font style=&quot;&quot;&gt;Agent设计&lt;/font&gt;\" link=\"agent_design\" id=\"ocm_PwVvUIHaqkUSxyUT-526\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b1ddf0;strokeColor=none;shadow=1;fontColor=#000000;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"957.62\" y=\"1193.69\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"代码辅助\" link=\"llm_code\" id=\"ocm_PwVvUIHaqkUSxyUT-527\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"483.65999999999997\" y=\"1155.37\" width=\"58.01\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"长文本创作\" link=\"long_text\" id=\"ocm_PwVvUIHaqkUSxyUT-528\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"447.71000000000004\" y=\"1182.37\" width=\"71.14\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-529\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=0.5;entryY=1;entryDx=0;entryDy=0;dashed=1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;\" edge=\"1\" parent=\"1\" source=\"391\" target=\"ocm_PwVvUIHaqkUSxyUT-528\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"526\" y=\"1235\" as=\"sourcePoint\" />\n <mxPoint x=\"410\" y=\"1200\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"上下文工程\" link=\"context\" id=\"ocm_PwVvUIHaqkUSxyUT-530\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"730.6\" y=\"1211.5\" width=\"69.4\" height=\"21\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-531\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;\" edge=\"1\" parent=\"1\" source=\"478\" target=\"ocm_PwVvUIHaqkUSxyUT-530\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"710\" y=\"1260\" as=\"sourcePoint\" />\n <mxPoint x=\"753\" y=\"1260\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"LLM知识图谱\" link=\"llm_kg\" id=\"ocm_PwVvUIHaqkUSxyUT-532\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"236.88000000000002\" y=\"1315.81\" width=\"76.34\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"世界模型\" link=\"world_model\" id=\"ocm_PwVvUIHaqkUSxyUT-533\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"934\" y=\"1460\" width=\"50\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"&lt;font style=&quot;&quot;&gt;通用Agent&lt;/font&gt;\" link=\"general_agent\" id=\"ocm_PwVvUIHaqkUSxyUT-534\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b1ddf0;strokeColor=none;shadow=1;fontColor=#000000;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"909.3699999999999\" y=\"1292.5\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"&lt;font style=&quot;&quot;&gt;Agent记忆&lt;/font&gt;\" link=\"agent_memory\" id=\"ocm_PwVvUIHaqkUSxyUT-535\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b1ddf0;strokeColor=none;shadow=1;fontColor=#000000;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"1024.93\" y=\"1191.5\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"&lt;font style=&quot;&quot;&gt;GUI Agent&lt;/font&gt;\" link=\"agent_gui\" id=\"ocm_PwVvUIHaqkUSxyUT-536\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b1ddf0;strokeColor=none;shadow=1;fontColor=#000000;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"974.12\" y=\"1292.5\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"多模态案例\" link=\"multimodal_case\" id=\"ocm_PwVvUIHaqkUSxyUT-537\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"365\" y=\"1305\" width=\"65\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-538\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=1;strokeColor=#999999;entryX=1;entryY=0.5;entryDx=0;entryDy=0;dashed=1;exitX=0;exitY=0.5;exitDx=0;exitDy=0;\" edge=\"1\" parent=\"1\" source=\"451\" target=\"ocm_PwVvUIHaqkUSxyUT-537\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"380\" y=\"1240\" as=\"sourcePoint\" />\n <mxPoint x=\"340\" y=\"1241\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"扩散语言模型\" link=\"diffusion_lm\" id=\"ocm_PwVvUIHaqkUSxyUT-540\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"628\" y=\"1162.37\" width=\"79.88\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-541\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.75;exitDx=0;exitDy=0;\" edge=\"1\" parent=\"1\" source=\"399\" target=\"ocm_PwVvUIHaqkUSxyUT-540\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"540\" y=\"1317\" as=\"sourcePoint\" />\n <mxPoint x=\"609\" y=\"1280\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"强化学习发展史\" link=\"rl_history\" id=\"ocm_PwVvUIHaqkUSxyUT-542\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"553.86\" y=\"1952.5\" width=\"94.5\" height=\"18\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM因果推断\" link=\"llm_casual\" id=\"ocm_PwVvUIHaqkUSxyUT-543\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"236.88\" y=\"1292.5\" width=\"76.34\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"大模型自动评估\" link=\"llm_judge\" id=\"ocm_PwVvUIHaqkUSxyUT-544\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"707.88\" y=\"1613.75\" width=\"92.12\" height=\"22.5\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"全模态\" link=\"all_modality\" id=\"ocm_PwVvUIHaqkUSxyUT-545\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"544.62\" y=\"1306\" width=\"60\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-547\" value=\"\" style=\"rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=2;strokeColor=#999999;entryX=0;entryY=0.5;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" edge=\"1\" parent=\"1\" source=\"451\" target=\"ocm_PwVvUIHaqkUSxyUT-545\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"530\" y=\"1317\" as=\"sourcePoint\" />\n <mxPoint x=\"599\" y=\"1280\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n <UserObject label=\"LLM多轮对话\" link=\"multi-turn\" id=\"ocm_PwVvUIHaqkUSxyUT-548\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"210\" y=\"1135\" width=\"81.75\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"微调新方法\" link=\"llm_finetune_new\" id=\"ocm_PwVvUIHaqkUSxyUT-549\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#ffcd28;strokeColor=none;shadow=1;gradientColor=#FFB570;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"805.12\" y=\"1302\" width=\"64.88\" height=\"24\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"类脑计算\" link=\"brain_compute\" id=\"ocm_PwVvUIHaqkUSxyUT-551\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#a0522d;strokeColor=#6D1F00;shadow=1;fontColor=#ffffff;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"997.12\" y=\"1460\" width=\"50\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"LLM意图识别\" link=\"llm_intent\" id=\"ocm_PwVvUIHaqkUSxyUT-552\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#b0e3e6;strokeColor=none;shadow=1;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"124.25\" y=\"1135\" width=\"81.75\" height=\"19\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"GPU显存\" link=\"gpu_cost\" id=\"ocm_PwVvUIHaqkUSxyUT-553\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#f5f5f5;strokeColor=#666666;shadow=1;fontColor=#333333;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"366.11\" y=\"1620\" width=\"55\" height=\"20\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <UserObject label=\"通义千问\" link=\"qwen\" id=\"ocm_PwVvUIHaqkUSxyUT-554\">\n <mxCell style=\"rounded=1;whiteSpace=wrap;html=1;fillColor=#e3c800;strokeColor=#B09500;shadow=1;fontColor=#000000;\" vertex=\"1\" parent=\"1\">\n <mxGeometry x=\"369.5\" y=\"1430\" width=\"70\" height=\"21.25\" as=\"geometry\" />\n </mxCell>\n </UserObject>\n <mxCell id=\"ocm_PwVvUIHaqkUSxyUT-555\" value=\"\" style=\"edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;entryX=0.5;entryY=1;entryDx=0;entryDy=0;exitX=1;exitY=0.5;exitDx=0;exitDy=0;\" edge=\"1\" parent=\"1\" source=\"o5D4xRg-JXB86p6HjegH-563\" target=\"ocm_PwVvUIHaqkUSxyUT-551\">\n <mxGeometry relative=\"1\" as=\"geometry\">\n <mxPoint x=\"313\" y=\"1470\" as=\"sourcePoint\" />\n <mxPoint x=\"250\" y=\"1430\" as=\"targetPoint\" />\n </mxGeometry>\n </mxCell>\n </root>\n </mxGraphModel>\n </diagram>\n</mxfile>\n"}"></div>
<script type="text/javascript" src="https://viewer.diagrams.net/js/viewer-static.min.js"></script>
<!-- 评论区 -->
<h2 id="comments">Comments</h2>
<!-- 【2023-1-4】github新插件giscus, 暂未启用 -->
<script src="https://giscus.app/client.js"
data-repo="wqw547243068/wqw547243068.github.io"
data-repo-id="MDEwOlJlcG9zaXRvcnkxNDE3ODEwMzg="
data-category="Announcements"
data-category-id="DIC_kwDOCHNoLs4CRJjU"
data-mapping="title"
data-strict="0"
data-reactions-enabled="1"
data-emit-metadata="0"
data-input-position="bottom"
data-theme="light"
data-lang="en"
// data-lang="zh-CN"
crossorigin="anonymous"
async>
</script>
<!-- disqus插件 -->
<p> --disqus-- </p>
<div id="disqus_thread"></div>
<script>
/**
* RECOMMENDED CONFIGURATION VARIABLES: EDIT AND UNCOMMENT THE SECTION BELOW TO INSERT DYNAMIC VALUES FROM YOUR PLATFORM OR CMS.
* LEARN WHY DEFINING THESE VARIABLES IS IMPORTANT: https://disqus.com/admin/universalcode/#configuration-variables
*/
var disqus_config = function() {
this.page.url = 'https://wqw547243068.github.io/mindmap'; // Replace PAGE_URL with your page's canonical URL variable
this.page.identifier = 'https://wqw547243068.github.io/mindmap'; // Replace PAGE_IDENTIFIER with your page's unique identifier variable
};
(function() { // DON'T EDIT BELOW THIS LINE
var d = document,
s = d.createElement('script');
s.src = '//wqw.disqus.com/embed.js';
s.setAttribute('data-timestamp', +new Date());
(d.head || d.body).appendChild(s);
})();
</script>
<noscript>Please enable JavaScript to view the <a href="https://disqus.com/?ref_noscript" rel="nofollow">comments powered by Disqus.</a></noscript>
</div>
<button class="anchor"><i class="fa fa-anchor"></i></button>
<!-- 右侧工具栏 -->
<div class="right">
<!-- 搜索框 -->
<div>
<!-- HTML elements for search -->
<input type="text" id="search-input" placeholder="搜索文章: Search blog posts..">
<ul id="results-container"></ul>
<!-- script pointing to jekyll-search.js -->
<script src="/js/simple-jekyll-search.min.js"></script>
<!-- <script src="https://cdn.rawgit.com/christian-fei/Simple-Jekyll-Search/master/dest/simple-jekyll-search.min.js"></script> -->
</div>
<!-- [2019-08-07]搜索框 -->
<script>
window.simpleJekyllSearch = new SimpleJekyllSearch({
searchInput: document.getElementById('search-input'),
resultsContainer: document.getElementById('results-container'),
json: '/search.json',
searchResultTemplate: '<li><a href="{url}?query={query}&date={date}" title="{date}">{title}</a></li>',
noResultsText: 'No results found <br> 暂无结果,请更换检索词...',
limit: 10,
fuzzy: false,
exclude: ['Welcome']
})
</script>
<!-- 访问可视化 -->
<!-- 访问统计可视化工具 -->
<div class="side">
<script type="text/javascript" src="//rf.revolvermaps.com/0/0/1.js?i=5q2837r7gjo&s=265&m=7&v=true&r=false&b=000000&n=false&c=ff0000" async="async"></script>
</div>
<script type='text/javascript' id='mapmyvisitors' src='https://mapmyvisitors.com/map.js?cl=ffffff&w=a&t=n&d=Jqz5ooTlHsfwaaqJF5LezHsg7HXvyf3s_N_TE_2u8xM'></script>
<div class="wrap">
<!-- Content目录区 -->
<div class="side content">
<div>
Content
</div>
<ul id="content-side" class="content-ul">
<li><a href="#comments">Comments</a></li>
</ul>
</div>
<!-- 公众号区 -->
<!-- 公众号区 -->
<div class="side content">
<div>My Moment ( 微信公众号 )</div>
<img src="https://wqw547243068.github.io/wqw/fig/wqw.png" alt="欢迎关注鹤啸九天" />
</div>
<!-- 其他div框放到这里 -->
<!-- <div class="side">bbbb</div> -->
</div>
</div>
</div>
<script>
/**
* target _blank
*/
(function() {
var aTags = document.querySelectorAll('article a:not([id])')
for (var i = 0; i < aTags.length; i++) {
aTags[i].setAttribute('target', '_blank')
}
}());
</script>
<script src="/js/pageContent.js " charset="utf-8"></script>
<!-- 【2022-9-1】 支持latex数学公式显示 -->
<script src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML" type="text/javascript"></script>
data = {
"title": "Sample Document",
"content": "This is a sample document generated by Python document library."
}
output_path = "sample.txt"
generate_with_template(template_path, data, output_path)
转 txt
格式转换
import docx2txt
def read_docx_to_text(file_path):
text = docx2txt.process(file_path)
return text
read_docx_to_text('xxx.docx')
MinerU
见下方
pdf 文件
【2022-11-25】python文档工具,参考
pdfplumber,可以方便地获取pdf的各种信息,包括文本、表格、图表、尺寸等。
- 1、它是一个纯python第三方库,适合python 3.x版本
- 2、它用来查看pdf各类信息,能有效提取文本、表格
- 3、它不支持修改或生成pdf,也不支持对pdf扫描件的处理
pdf 读取
PyMuPDF
【2025-1-13】PyMuPDF的安装与使用
MuPDF 是一个轻量级的 PDF、XPS和电子书查看器。MuPDF 由软件库、命令行工具和各种平台的查看器组成。
MuPDF 中的渲染器专为高质量抗锯齿图形量身定制。它以精确到像素的几分之一内的度量和间距呈现文本,以在屏幕上再现打印页面的外观时获得最高保真度。
PyMuPDF(当前1.18.17)是支持MuPDF(当前版本1.18.*)的Python绑定。
使用PyMuPDF,可访问扩展名为:
- 文档 “.pdf”、“.xps”、“.oxps”、“.cbz”、“.fb2”或“.epub”。
- 大约10种流行的图像格式:“.png”,“.jpg”,“.bmp”,“.tiff”等。
功能
- 解密文件
- 访问元信息、链接和书签
- 以栅格格式(PNG和其他格式)或矢量格式SVG呈现页面
- 搜索文本
- 提取文本和图像
- 转换为其他格式:PDF, (X)HTML, XML, JSON, text
- 对于PDF文档,存在大量的附加功能:它们可以创建、合并或拆分。页面可以通过多种方式插入、删除、重新排列或修改(包括注释和表单字段)。
- 可以提取或插入图像和字体
- 完全支持嵌入式文件
- pdf文件可以重新格式化,以支持双面打印,色调分离,应用标志或水印
- 完全支持密码保护:解密、加密、加密方法选择、权限级别和用户/所有者密码设置
- 支持图像、文本和绘图的 PDF 可选内容概念
- 可以访问和修改低级 PDF 结构
- 命令行模块”python -m fitz…”具有以下特性的多功能实用程序
安装命令:
pip install PyMuPDF
导入库:
import fitz
print(fitz.__doc__)
file_name = 'a.pdf'
doc = fitz.open(file_name)
doc.count_page # 页数
doc.metadata # 元数据
# 获取目标大纲
toc = doc.get_toc()
# 获取链接、标注
links = page.get_links()
for link in page.links():
# do something with 'link'
pass
# 加载指定页面 pno=2
page = doc.load_page(pno)
page = doc[pno]
for page in doc:
pass
# 提取文本
text = page.get_text(opt)
# 搜索文本
areas = page.search_for("mupdf")
# 保存
doc.save()
为什么不是 mupdf ?
历史原因:
- MuPDF 原始渲染库被称为 Libart。
- Artifex 软件获得 MuPDF 项目后,开发的重点转移到编写一种新的现代图形图书馆称为“Fitz”。
- Fitz最初是作为一个研发项目,以取代老化的Ghostscript图形库,但却成为了MuPDF的渲染引擎(引用自维基百科)。
MinerU
【2024-12-8】MinerU 是 opendatalab 开源的一站式数据提取工具,能够将pdf文档提取成对应的 markdown 和 json 格式,极大的简化和提高文档处理的效率
核心功能
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为
LaTeX格式 - 自动识别并转换文档中的表格为
HTML格式 - 自动检测扫描版PDF和乱码PDF,并启用
OCR功能 - OCR支持84种语言的检测与识别
- 支持多种输出格式,如多模态与NLP的 MarkdownMinerU 项目代码、按阅读顺序排序的JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检
- 支持CPU和GPU环境
- 兼容Windows、Linux和Mac平台
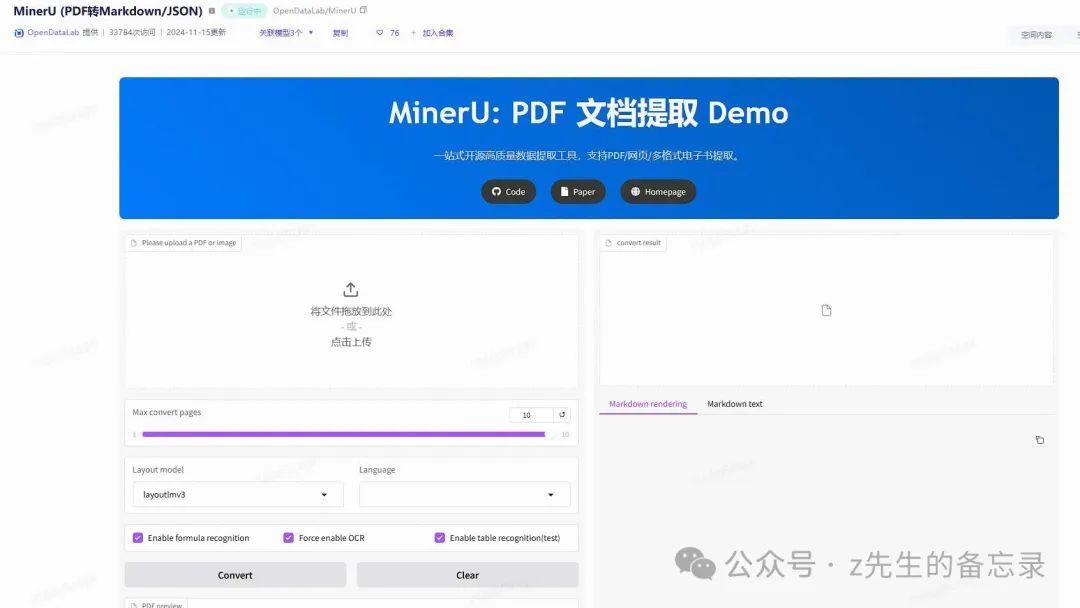
PyPDF2
(1) PyPDF2 工具
import PyPDF2
def read_pdf_to_text(file_path):
with open(file_path, 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfReader(pdf_file)
contents_list = []
for page in pdf_reader.pages:
content = page.extract_text()
contents_list.append(content)
return '\n'.join(contents_list)
read_pdf_to_text('xxx.pdf')
pdf -> 图片
【2024-12-12】
依赖包
pip install fitz
pip install PyMuPDF
转换代码
- 以PDF文件的页码为单位生成图片
参数说明:
- pdfPath:pdf文件的路径
- imgPath:图像要保存的文件夹
- zoom_x:x方向的缩放系数
- zoom_y:y方向的缩放系数
- rotation_angle:旋转角度
def pdf_image(pdfPath, imgPath, zoom_x, zoom_y, rotation_angle):
# 打开PDF文件
pdf = fitz.open(pdfPath)
# 逐页读取PDF
for pg in range(0, pdf.pageCount):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=False)
# 开始写图像
pm.writePNG(imgPath + str(pg) + ".png")
pdf.close()
pdf_image(r"01.pdf", r"images/", 10, 10, 0)
批量转换
步骤说明:
- 新建 pdf2image.py 文件并将以下代码复制并保存。
- 在与 pdf2image.py 文件同目录下创建pdfs和images文件夹。
- 将所有需要转换的PDF文件放入pdfs文件夹下。
- 运行 pdf2image.py,等待运行完成即可。
import fitz
import os
def mkdir(path):
folder = os.path.exists(path)
if not folder: # 判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) # makedirs 创建文件时如果路径不存在会创建这个路径
else:
pass
def pdf_image(pdfPath, imgPath, zoom_x, zoom_y, rotation_angle):
"""
:param pdfPath: pdf文件的路径
:param imgPath: 图像要保存的文件夹
:param zoom_x: x方向的缩放系数
:param zoom_y: y方向的缩放系数
:param rotation_angle: 旋转角度
:return: None
"""
# 打开PDF文件
pdf = fitz.open(pdfPath)
name = pdf.name
name = name.replace('pdfs/', '').replace('.pdf', '')
# 逐页读取PDF
for pg in range(0, pdf.pageCount):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=False)
# 开始写图像
mkdir(imgPath + name)
pm.writePNG(imgPath + name + '/' + str(pg + 1) + ".png")
pdf.close()
# pdf_image(r"pdfs/01.pdf", r"images/", 10, 10, 0)
file_dir = r'pdfs/'
file_list = []
for items in os.walk(file_dir, topdown=False):
file_list = items[2]
print(file_list)
for file in file_list:
head = 'pdfs/'
pdf_image(head + file, r"images/", 5, 5, 0)
pdfplumber
(2)pdfplumber 工具
查找关于每个文本字符、矩阵、和行的详细信息,也可以对表格进行提取并进行可视化调试。
pdfplumber.page 类中包含了几个主要的属性。
- page_number 页码
- width 页面宽度
- height 页面高度
常用方法
- extract_text() 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串
- extract_words() 返回的是所有的单词及其相关信息
- extract_tables() 提取页面的表格
- to_image() 用于可视化调试时,返回PageImage类的一个实例
#!pip install pdfplumber
# 导入pdfplumber
import pdfplumber
# 读取pdf文件,保存为pdf实例
pdf = pdfplumber.open("E:\\nba.pdf")
# 通过pdfplumber.PDF类的metadata属性获取pdf信息
pdf.metadata
# 通过pdfplumber.PDF类的metadata属性获取pdf页数
len(pdf.pages)
first_page = pdf.pages[0] # 第一页pdfplumber.Page实例
print('页码:', first_page.page_number) # 查看页码
print('页宽:', first_page.width) # 查看页宽
print('页高:', first_page.height) # 查看页高
# 访问第二页
first_page = pdf.pages[1]
# 读取文本
text = first_page.extract_text()
print(f'第{first_page.page_number}页文本内容: ', text)
# 自动读取表格信息,返回列表
table = first_page.extract_table()
table
# 将列表转为df
table_df = pd.DataFrame(table_2[1:],columns=table_2[0])
# 保存excel
table_df.to_excel('test.xlsx')
ppt 文件
工具 pptx
from pptx import Presentation
def read_pptx_to_text(file_path):
prs = Presentation(file_path)
text_list = []
for slide in prs.slides:
for shape in slide.shapes:
if shape.has_text_frame:
text_frame = shape.text_frame
text = text_frame.text
if text:
text_list.append(text)
return '\n'.join(text_list)
read_pptx_to_text('xxx.pptx')
excel 文件
直接使用 pandas 操作 excel、csv、json 文件
- 详见站内专题 pandas
飞书表格
【2023-10-19】python 飞书API调用——电子表格操作
输入的数据类型可以参考飞书官方的开发文档
#飞书文档的储存地址结构:https://企业地址/sheets/shtcnjGdHzBm7Qa85UXQYk9OPxh?sheet=402cb1 #一般来说sh开头为文档地址,sheet=后跟工作簿地址,这两块是代码需要引用的参数
import json
url = "https://open.feishu.cn/open-apis/sheets/v2/spreadsheets/shtcnxuRDo9QJDBCeowEAQqUIvd/values" #写入的sh开头的文档地址,其他不变
header = {"Content-Type": "application/json", "Authorization": "Bearer " + str(tat)} #请求头
post_data = {"valueRange": {"range": "402cb1!C3:N8" ,"values": [[ "Hello", 1],[ "World", 1]]}} #在402cb1这个工作簿内的单元格C3到N8写入内容为helloworld等内容
r2 = requests.put(url, data=json.dumps(post_data), headers=header) #请求写入
print( r2.json()["msg"]) #输出来判断写入是否成功
# 写入公式
post_data = {"valueRange": {"range": "PSGHlz!I2:I2" ,"values": [[{"type":"formula","text":"=IFERROR((E2-E9)/E9,0)"}]]}}
url = "https://open.feishu.cn/open- apis/sheets/v2/spreadsheets/shtcnl9XOiwOCVWEtjHuXKeT3zd/insert_dimension_range" #写入的sh开头的文档地址,其他不变
header = {"Content-Type": "application/json", "Authorization": "Bearer " + str(tat)} #请求头
post_data ={
"dimension":{
"sheetId":"PSGHlz",
"majorDimension":"ROWS",#可选COLUMNS
"startIndex":1,
"endIndex":2
},
"inheritStyle":"AFTER"#可选BEFORE
}
r2 = requests.post(url, data=json.dumps(post_data), headers=header) #请求写入
print( r2.json()["msg"]) #输出来判断写入是否成功
markdown
文件转markdown
【2024-12-16】 微软开源Python工具 MarkItDown,将各种文件转成 Markdown
- 文件: PDF、PowerPoint、Word、Excel、图片、音频和HTML等
- API简洁易用,支持多种文件类型,并包含OCR和语音转录功能,方便用户进行文本分析或索引。
支持的文件格式
- PDF (.pdf)
- PowerPoint (.pptx)
- Word (.docx)
- Excel (.xlsx)
- 图像(EXIF 元数据和 OCR)
- 音频(EXIF 元数据和语音转录)
- HTML(特殊处理 Wikipedia 等)
- 各种其他基于文本的格式(csv、json、xml 等)
安装
- 前置依赖 ffmpeg
API调用方法很简单
# pip install markitdown
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("test.xlsx")
print(result.text_content)
接入大模型
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(mlm_client=client, mlm_model="gpt-4o")
result = md.convert("example.jpg")
print(result.text_content)
文件 转 html
工具包 Mammoth
文件服务
Python 标准库 http.server
- Python 2: SimpleHttpServer
- Python 3: http.server
模块快速提供HTTP文件服务器
主要特点:
- 简单易用:一行命令即可启动服务器,无需编写复杂代码。
- 目录浏览:目录浏览功能,浏览器访问服务器上的文件和子目录。
- 静态文件服务:处理对静态文件的请求,如HTML、CSS、JavaScript、图片等。
- 跨平台支持:http.server模块在Windows、Linux和macOS等操作系统上均可运行。
使用
http.server 模块还提供命令行选项
-d(指定根目录)-b(指定绑定的IP地址)等。- 这些选项允许用户更加灵活地配置服务器的行为。
【2025-6-22】命令行
python -m http.server # 默认 8000 端口
# 指定端口
python -m http.server 8080
# 绑定 ip
python -m http.server -b 127.0.0.1 # 绑定 ip
python -m http.server --bind 127.0.0.1 # 绑定 ip
# 指定目录
python -m http.server -d /path/to/directory
python -m http.server --directory /path/to/directory
# CGI 处理请求
python -m http.server --cgi
启动后,服务器将自动将当前目录作为根目录,并提供该目录下的文件和子目录的HTTP访问。
除了命令行,还可以编写Python脚本来自定义服务器的行为。
脚本中,导入http.server模块中的SimpleHTTPRequestHandler类,并创建一个继承自该类的自定义处理器类。
然后,将这个自定义处理器类传递给HTTPServer类来启动服务器。
# server.py
import http.server
import socketserver
class MyHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b'Hello, World!')
if __name__ == '__main__':
PORT = 8000
with socketserver.TCPServer(("", PORT), MyHandler) as httpd:
print("Server started at http://localhost:{}/".format(PORT))
httpd.serve_forever()
内存管理
python不同于java和c,不用事先声明变量类型而直接对变量进行赋值
- 对象的类型和内存地址分配都是在运行时确定的——动态类型
Python的内存管理主要有三种机制:
引用计数机制- Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数
垃圾回收机制内存池机制
a. 引用计数
- 当给一个对象分配一个新名称或者将一个对象放入一个容器(列表、元组或字典)时,该对象的引用计数都会增加。
- 当使用del对对象显示销毁或者引用超出作用于或者被重新赋值时,该对象的引用计数就会减少。
可以使用sys.getrefcount()函数来获取对象的当前引用计数。
- 多数情况下,引用计数要比猜测的大的多。
- 对于不可变数据(数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
b. 垃圾回收
当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
- 当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。
- 然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。
- 为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
c. 内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
- 1)
Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。 - 2)Python中所有小于256个字节的对象都使用
pymalloc实现的分配器,而大的对象则使用系统的malloc。 - 3)对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
浅拷贝与深拷贝
【2018-5-25】Python中的对象之间赋值时是按引用传递的,如果需要拷贝对象,需要使用标准库中的copy模块。
- 1、赋值语句只是传引用,相当于贴一个标签
- 2、copy.copy
浅拷贝只拷贝父对象(仅顶层),不会拷贝对象的内部的子对象。 - 3、copy.deepcopy
深拷贝拷贝对象及其子对象
import copy
a = [1,2,3,4,['a','b']] #原始对象
b = a #赋值,传对象的引用,联动
c = copy.copy(a)#浅拷贝,顶层元素不变,深层的list变动
d = copy.deepcopy(a)#深拷贝,完全复制
a.append(5)
a[4].append('c')
print 'a=',a # a= [1, 2, 3, 4, ['a', 'b', 'c'], 5]
print 'b=',b # b= [1, 2, 3, 4, ['a', 'b', 'c'], 5]
print 'c=',c # c= [1, 2, 3, 4, ['a', 'b', 'c']]
print 'd=',d # d= [1, 2, 3, 4, ['a', 'b']]
python代码执行过程可视化,见pythontutor
拷贝特殊情况:
- 对于非容器类型(如数字、字符串、和其他’原子’类型的对象)没有拷贝这一说
- 对于这些类型,”obj is copy.copy(obj)” 、”obj is copy.deepcopy(obj)”
- 如果元组变量只包含原子类型对象,则不能深拷贝
网络请求
request工具包
get方法
# -*- coding:utf-8 -*-
import requests
import json
headers = {'user-agent': 'my-app/0.0.1'}
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
r = requests.get(url, headers=headers) # header
print(r.url) # 请求网址
print(r.text) # 返回内容
print(r.encoding) # 编码
# http://httpbin.org/get?key2=value2&key1=value1
post方法
多种用法
- 1、带数据的post
- 2、带header的post
- 3、带json的post
- 4、带参数的post
- 5、普通文件上传
- 6、定制化文件上传
- 7、多文件上传
- 超时设置
- 捕获异常
返回信息:

# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
data = {'key1':'value1','key2':'value2'}
# ① 带数据的post
r = requests.post(url, data=data)
# ② 带header的post
headers = {"User-Agent":"test request headers"}
r = requests.post(url, headers=headers)
#response = r.json()
print (r.text)
# ③ 带json的post
data = {
"sites": [
{ "name":"test" , "url":"www.test.com" },
{ "name":"google" , "url":"www.google.com" },
{ "name":"weibo" , "url":"www.weibo.com" }
]
}
r = requests.post(url, json=data)
# ④ 带参数的post
params = {'key1':'params1','key2':'params2'}
# r = requests.post(url)
r = requests.post(url, params=params)
# ⑤ 文件上传
files = {
'file':open('test.txt','rb')
}
r = requests.post(url,files=files)
# ⑥ 自定义文件名,文件类型、请求头
files = {
'file':('test.png',open('test.png','rb'),'image/png')
}
r = requests.post(url,files=files)
print (r.text)
# ⑦ 多文件上传
files = [
('file1',('test.txt',open('test.txt', 'rb'))),
('file2', ('test.png', open('test.png', 'rb')))
]
r = requests.post(url,files=files)
print (r.text)
# ⑧ 流式上传
with open( 'test.txt' ) as f:
r = requests.post(url,data = f)
# ⑨ 超时设置
# 设置总超时时间为 5 秒
response = requests.post(url, data=data, timeout=5)
# 连接超时设为 3 秒,读取超时设为 10 秒
# 为了更精细地控制,可以将 timeout 设置为一个包含两个浮点数的元组 (connect, read)
response = requests.post(url, data=data, timeout=(3.0, 10.0))
# ⑩ 捕获异常
from requests.exceptions import Timeout
try:
response = requests.post(url, data=data, timeout=5)
print(response.text)
except Timeout:
print("请求超时,请稍后重试!")
实际案例,调用情绪识别接口
import requests
import json
url = f'http://test.speech.analysis.ke.com/inspections/capability'
## headers中添加上content-type这个参数,指定为json格式
headers = {'Content-Type': 'application/json'}
text = "测!!"
data = {"biz_id":"utopia","app_id":"utopia","create_time":"2021-07-29 15:51:06",
"sentence":[
{"sentence_id":1,"text":"谢谢"},
{"sentence_id":2,"text":"你好"},
{"sentence_id":3,"text":"不好"},
{"sentence_id":4,"text":"怎么搞的"},
{"sentence_id":5,"text":"这也太慢了吧"},
{"sentence_id":6,"text":"妈的,到底管不管"},
#{"sentence_id"2,"text":f"{text}"}
],
"capability_id":"new_zhuangxiu_emotion_capability",
"audio_key":"","extend":{"context":[]}}
## post的时候,将data字典形式的参数用json包转换成json格式。
response = requests.post(url=url,data=json.dumps(data),headers=headers)
print(data)
# 接口说明:http://weapons.ke.com/project/6424/interface/api/632026
# 表扬>交流>中性>抱怨>不满>愤怒
# pos_appr 应该是 positive_appraisal
# pos_comm 应该是 positive_communication
# neu_neut 应该是neutral_neutral
# neg_comp 应该是 negative_complaint
# neg_dis 应该是negative_disappointed
# neg_angr 应该是negative_angry
type_info = {"pos_appr":"(正向)表扬型",
"pos_comm":"(正向)交流型",
"neu_neut":"中性型",
"neg_comp":"(负向)抱怨型",
"neg_dis":"(负向)不满型",
"neg_angr":"(负向)愤怒型"
}
res = eval(response.text)
print('-'*20)
print(res.keys())
print(res)
print('-'*20)
print('\n'.join(['%s\t%s\t%s\t%s'%(i['result'][0]['text'],i['result'][0]['type'], type_info.get(i['result'][0]['type'],'未知'), i['result'][0]['confidence']) for i in res['sentence']]))
配置文件
json
JSON 代表JavaScript对象符号。它是一种轻量级的数据交换格式,用于存储和交换数据。
- 一种独立于语言的格式,容易理解,因为本质上自描述。
python中有一个内置包 json ,支持JSON数据。 JSON中的数据表示为quoted-strings,由大括号{}之间的键值映射组成。json.load(s) & json.dump(s)
load/dump: 文件loads/dumps: 字符串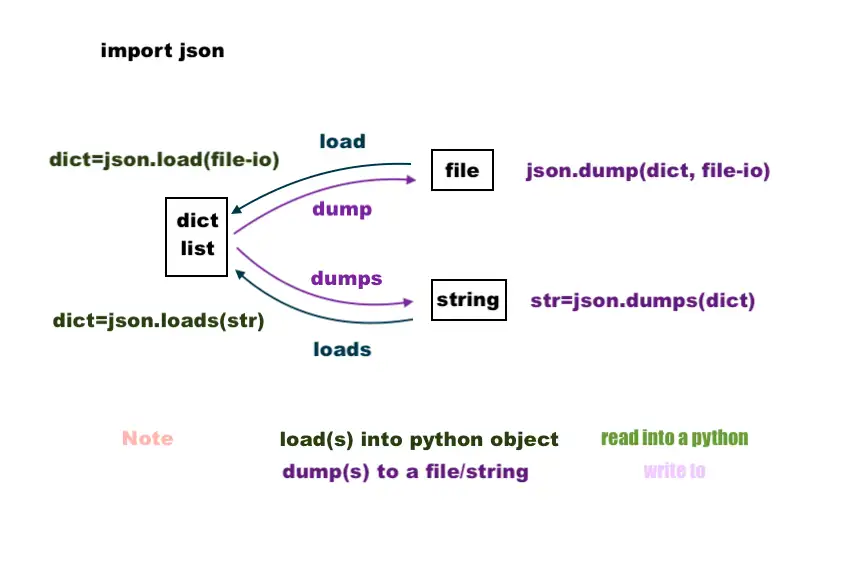
json 查看
json 可视化
- json handle 插件: Chrome 插件
- JSON Crack 一款免费开源数据可视化应用程序,能够将 JSON、YAML、XML、CSV 等数据格式可视化为交互式图表。
- 凭借其直观且用户友好的界面,JSON Crack 可以轻松探索、分析和理解最复杂的数据结构。
- online
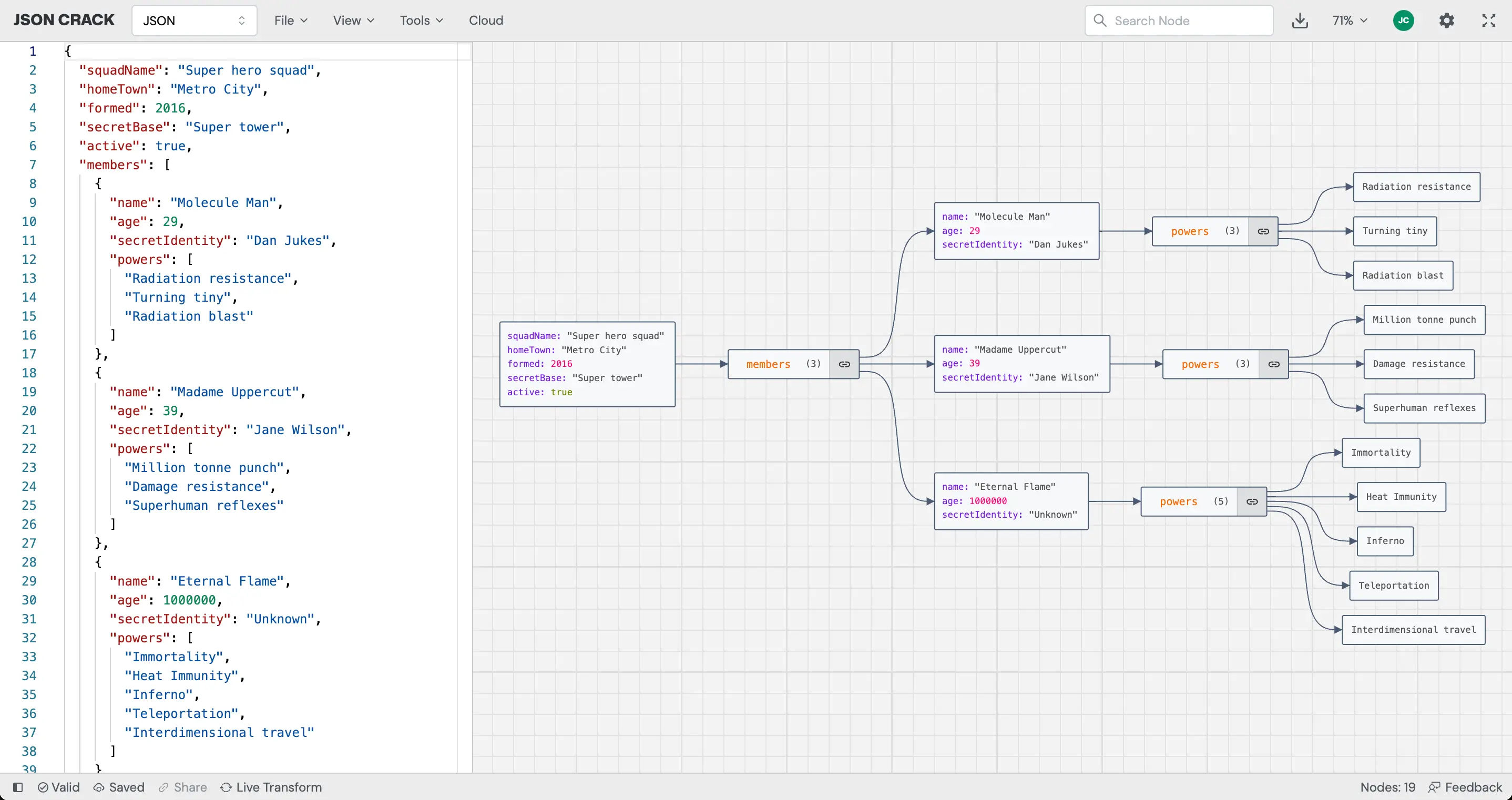
json 用法
import json
io = open("in.json","r") # 文件只有一个json串
string = io.read()
# json.loads(str)
dictionary = json.loads(string)
# or one-liner 或者 一步到位
# dictionary = json.loads(open("in.json","r").read())
print(dictionary)
# ----------------
dictionary = json.load(open("in.json","r"))
# 更规范写法
with open("temp.json",'r', encoding='UTF-8') as f:
load_dict = json.load(f)
# ------ dict -> str -------
d = {'alpha': 1, 'beta': 2}
s = json.dumps(d)
s = json.dumps(d, ensure_ascii=False, indent=2) # 中文显示,终端输出美化
print(s)
open("out.json","w").write(s) # 字典 → 字符串
json.dump(d, open("out.json","w")) # 字典 → 文件
特殊格式
【2023-9-19】采坑!
raw = '{"a":"this is a\" a."}' # 这种字符串, json解析时报错,转义符\"起作用
raw = r'{"a":"this is a\" a."}' # 字符串前面加 r,使用原生字符串,不转义
json.loads(raw) # {'a': 'this is a" a.'}
# 【2023-11-30】JSONDecodeError: Invalid control character at: line 1 column 175 (char 174)
import json
json_str = '{"name": "Bobby \nHadz"}'
# 👇️ set strict to False, 忽略特殊字符: \t, \n, \r, \0
result = json.loads(json_str) # 报错!JSONDecodeError: Invalid control character at: line 1 column 175 (char 174)
# ① raw字符串
json_str = r'{"name": "Bobby \nHadz"}'
result = json.loads(json_str)
# ② strict模式
result = json.loads(json_str, strict=False) # 字符串中允许使用控制字符
print(result) # 👉️ {'name': 'Bobby Hadz'}
非 json 格式字符串
# 【2024-3-18】 字符串中
# eval()将字符串转化为字典对象
s = "{'id': 'cc695906217', 'name': '种冲'}"
json.loads(s) # 出错,非json格式
eval(s) # 恢复成字典: {'id': 'cc695906217', 'name': '种冲'}
s = json.loads(json.dumps(eval(s))
jsonl
jsonl 格式
jsonl 格式的文件,每行是一个单独的json字符串
读取方法
- ① json.loads 逐个解析
- ② pandas的read_json方法
json.loads
【2023-5-2】jsonl 格式, JSON Lines,json数据集,常见于大模型数据集
- 每行都是json字符串,\n换行
- UTF-8编码
- 后缀是 .jsonl
{"prompt": "<提示文本>", "completion": "<理想的生成文本>"}
{"prompt": "<提示文本>", "completion": "<理想的生成文本>"}
{"prompt": "<提示文本>", "completion": "<理想的生成文本>"}
import json
test_file = 'in.json' # 一条json一行
def load_json(path):
return [json.loads(x) for x in open(path, encoding='utf-8')]
test_data = load_json(test_file)
pandas read_json
import pandas as pd
import json
# 不同格式的 json 读取
# ① 单行,columns和data分离
s = '{"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,5],[6,9]]}'
df = pd.read_json(s, orient='split')
# ② 单行,list形式
s = '[{"a":1,"b":2},{"a":3,"b":4}]'
df = pd.read_json(s, orient='records')
【2024-2-29】jsonl 文件读取
- Python2 执行报错,找不到文件
- Python3 执行正常
# ③ jsonl 文件格式
data_file = '/Users/bytedance/work/data/dataset.jsonl'
df = pd.read_json(open(data_file, 'r'), lines=True)
# [2024-1-31]
data_file = 'data/test_v1.json'
#df = pd.read_json(path_or_buf=data_file, lines=True)
df = pd.read_json(data_file, lines=True)
# 嵌套json结构经过pd解析后,可以直接按dict方式读取
# df['session'][0] 内容: cut_label, object_id, prompt(list)
df['object_id'] = df['session'].apply(lambda x: x['object_id'])
df['num'] = df['session'].apply(lambda x: len(x['prompt']))
df['prompt'] = df['session'].apply(lambda x: x['prompt'])
df['cut_label'] = df['session'].apply(lambda x: x['cut_label'])
json 修复
【2024-1-26】json_repair
- 修复损坏的JSON文件,尤其是LLM输出的病态JSON文件】
- A python module to repair broken JSON, very useful with LLMs
from json_repair import repair_json
try:
good_json_string = repair_json(bad_json_string)
except Exception:
# Not even this library could fix this JSON
You can use this library to completely replace json.loads():
import json_repair
try:
decoded_object = json_repair.loads(json_string)
except Exception:
# Not even this library could fix this JSON
or just
import json_repair
try:
decoded_object = json_repair.repair_json(json_string, return_objects=True)
except Exception:
# Not even this library could fix this JSON
【2024-1-26】实测代码
# coding:utf8
# git clone https://github.com/mangiucugna/json_repair.git
import os
os.sys.path.append('json_repair/src')
import json_repair
json_string = "{a:10, 'b':4, c:['x', y, 100]}"
print('校正前:', json_string)
try:
decoded_object = json_repair.loads(json_string)
print('校正后:', decoded_object)
except Exception as e:
# Not even this library could fix this JSON
print('撰写失败', e)
llama.cpp的grammars也提供json修复功能,只能在推理流程中控制
hjson
【2024-4-24】json 缺点: 不支持注释
HJSON 是 JSON 格式的扩展,增加了注释,并去掉多余的标识符。
- 注释支持 单行 和 多行,也支持Python脚本的#注释。
安装
pip install hjson
示例
{
// 注释
// 可以使用 #, // 或者 /**/,
// 数字
key: 1
// 字符串
contains: everything on this line
// 集合
cool: {
foo: 1
bar: 2
}
// 数组
list: [
1,
2,
]
// 多行字符串
realist:
'''
My half empty glass,
I will fill your empty half.
Now you are half full.
'''
}
使用
import hjson
text = """{
foo: a
bar: 1
}"""
# 解析文件
r = hjson.loads(text)
print(r)
# 结果返回一个字典
# OrderedDict([('foo', 'a'), ('bar', 1)])
# 解析文件
CONFIG_FILE = 'config.hjson'
with open(CONFIG_FILE) as f:
json_dic = hjson.load(f)
print json_dic
# dict -> hjson
hjson.dumps({'foo': 'text', 'bar': (1, 2)})
# dict -> json
hjson.dumpsJSON(['foo', {'bar': ('baz', None, 1.0, 2)}])
yaml
YAML是JSON(源)的超集。每个有效的JSON文件也是一个有效的YAML文件。这意味着您拥有所有期望的类型:整数,浮点数,字符串,布尔值,空值。以及序列和图。
yaml介绍
YAML是一种直观的能够被电脑识别的的数据序列化格式,容易被人类阅读,并且容易和脚本语言交互。YAML类似于XML,但是语法比XML简单得多,对于转化成数组或可以hash的数据时是很简单有效的。- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab,只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左对齐即可
- # 表示注释,从它开始到行尾都被忽略
- >- 表示换行
- 支持的数据类型
- 字符串,整型,浮点型,布尔型,null,时间,日期
- 主要特性,更多:Python YAML用法详解
- & 锚点 和 * 引用
- 强制转换,用!!实现
- 同一个yaml文件中,可以用 — 来分段
- 构造器(constructors)、表示器(representers)、解析器(resolvers )
- 包含子文件:!include
- 安装
- pip install pyyaml
yaml示例
- 【2021-4-6】大多数程序员都不知道的6个YAML功能
- config.yaml内容:
name: Tom Smith
name: 'Tom Smith' # str等效表达
# 长字符串(换行符非必须,仅为了好看) , >
disclaimer: >
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
In nec urna pellentesque, imperdiet urna vitae, hendrerit
odio. Donec porta aliquet laoreet. Sed viverra tempus fringilla.
# 多行字符串, | 相当于行间换行符\n
mail_signature: |
Martin Thoma
Tel. +49 123 4567
age: 37
list_by_square_bracets_0:
- foo
- bar
list_by_square_bracets_1: [foo, bar] # list的等效表达
spouse:
name: Jane Smith
age: 25
map_by_curly_braces: {foo: bar, bar: baz} # dict的等效表达
children:
- name: Jimmy Smith
age: 15
- name1: Jenny Smith
age1: 12
# YAML支持11种写布尔值的方法
bool_a : yes # true/True
bool_b : no # false/False
# 三个-表示多文档,返回list,如 [{'foo': 'bar'}, {'fizz': 'buzz'}]
---
# 这个例子输出一个字典,其中value包括所有基本类型
str: "Hello World!"
int: 110
float: 3.141
boolean: true # or false
None: null # 也可以用 ~ 号来表示 null
time: 2016-09-22t11:43:30.20+08:00 # ISO8601,写法百度
date: 2016-09-22 # 同样ISO8601
name: &name 灰蓝 # 设置被引用字段别名
tester: *name # * 取引用内容(仅含值)
# 成对引用(锚)
localhost: &localhost1
host: 127.0.0.1
user:
<<: *localhost1 # <<表示按照K/V形式成对展开,合并键
db: 8
# [2023-7-20] 换行表达
test_str: >-
换行测试
新的一行
a: !!str 3.14 # 转字符串
b: !!int "123" # 转int
# 复杂类型
tuple_example: !!python/tuple
- 1337
- 42
set_example: !!set {1337, 42}
date_example: !!timestamp 2020-12-31
- 操作方法
import yaml
# 文件
f = open(r'config.yml')
# 字符串
f = '''
---
name: James
age: 20
---
name: Lily
age: 19
'''
y = yaml.load(f)
y = yaml.load_all(f) # 多个yaml区域
for data in y:
print(data)
# 转成yaml文档
obj1 = {'name': 'Silenthand Olleander',
'race': 'Human',
'traits': ['ONE_HAND', 'ONE_EYE']
}
obj2 = {"name": "James", "age": 20}
print(yaml.dump(obj1,))
# 中文输出
import json
print(json.dumps(obj1, ensure_ascii=False, indent=2))
print(yaml.dump(d,default_flow_style=False, indent=2, allow_unicode=True))
f = open(r'out_config.yml','w')
print(yaml.dump(obj2,f))
yaml.dump_all([obj1, obj2], f) # 一次输出多个片区
【2023-7-24】错误提示
load() missing 1 required positional argument: ‘Loader’
原因: 5.4 版本后, yaml 读文件方法升级
- Starting from pyyaml>=5.4, it doesn’t have any discovered critical vulnerabilities
- if your YAML file contains just simple YAML (str, int, lists), try to use yaml.safe_load() instead of yaml.load(). And If you need FullLoader, you can use yaml.full_load().
import yaml
f = open('test.yml')
# ----- old -----
info = yaml.load(f) # 报错
y = yaml.load_all(f) # 多个yaml区域
# 解法1
info = yaml.load(ymlfile, Loader=yaml.Loader)
# 解法2
# ---- new -----
info = yaml.safe_load(f)
info = yaml.full_load(f)
高级功能
- 【2021-3-16】文件包含,YAML不包括任何种类的“import”或“include”语句。不过可以通过重写构造器来实现
- 研究源码(yaml文件嵌套)发现:yaml嵌套还是基于在load中重载一个钩子类,对yaml的value进行解析处理
- 通过value前缀判定的!注意下面的a:后面要有一个空格。
- 参考:
# === 文件 bar.yaml ====
- 3.6
- [1, 2, 3]
# === 文件 foo.yaml ====
a: 1
b:
- 1.43
- 543.55
# 包含别的文件
c: !include bar.yaml
- python调用代码
import os
import yaml
class Loader(yaml.Loader):
def __init__(self, stream):
self._root = os.path.split(stream.name)[0]
super(Loader, self).__init__(stream)
def include(self, node):
filename = os.path.join(self._root, self.construct_scalar(node))
with open(filename, 'r') as f:
return yaml.load(f, Loader)
# 添加新的语法标记
Loader.add_constructor('!include', Loader.include)
def load_yaml(yaml_file):
"""
:param yaml_file:
:return:
"""
with open(yaml_file, 'r') as f:
config = yaml.load(f, Loader)
return config
y = load_yaml('foo.yaml')
print(yaml.dump(y))
- 简洁版
import yaml
import os
def yaml_include(loader, node):
# Get the path out of the yaml file
file_name = os.path.join(os.path.dirname(loader.name), node.value)
with open(file_name) as inputfile:
return yaml.load(inputfile)
yaml.add_constructor("!include", yaml_include)
stream = open('foo.yaml', 'r')
print(yaml.dump(yaml.load(stream)))
- 或者
#!/usr/bin/python
import os.path
import yaml
class IncludeLoader(yaml.Loader):
def __init__(self, *args, **kwargs):
super(IncludeLoader, self).__init__(*args, **kwargs)
self.add_constructor('!include', self._include)
if 'root' in kwargs:
self.root = kwargs['root']
elif isinstance(self.stream, file):
self.root = os.path.dirname(self.stream.name)
else:
self.root = os.path.curdir
def _include(self, loader, node):
oldRoot = self.root
filename = os.path.join(self.root, loader.construct_scalar(node))
self.root = os.path.dirname(filename)
data = yaml.load(open(filename, 'r'))
self.root = oldRoot
return data
class Config(object):
def __init__(self, path):
config_file = open(path, 'r')
self.config_content = yaml.load(config_file, IncludeLoader)
config_file.closed
def getConfigContent(self):
return self.config_content
dotenv
Dotenv 是一个零依赖模块,从 .env 文件中读取环境变量
- 以 k,v 方式读取环境变量
- 像访问系统环境变量一样使用
.env文件中的变量
安装
安装
pip install -U python-dotenv
参数
load_dotenv() 参数
dotenv_path: 指定.env文件路径- 默认为None, 自定调用
dotenv.find_dotenv()查找文件位置 - 文件名不是
.env那就必须传递该参数了
- 默认为None, 自定调用
override:.env与系统环境变量冲突- 默认使用系统变量,如果要用
.env变量覆盖系统变量,可以给load_dotenv()传递参数override=True。 - 临时使用了 .env 中变量值
- 默认使用系统变量,如果要用
encoding: encoding 参数指定文件的编码方式。
使用
.env 文件示例
API_KEY="sk-81c0********"
BASE_URL="https://api.deepseek.com"
MODEL_NAME="deepseek-chat"
简洁版
import os
from dotenv import load_dotenv, find_dotenv
# pip install python-dotenv
# load_dotenv() # 默认从当前目录或父目录查找 .env 文件
# load_dotenv('../') # 指定目录
load_dotenv(find_dotenv(), override=True)
api_key = os.getenv("OPENAI_API_KEY", '-')
base_url = os.getenv("BASE_URL", '-')
model_name = os.getenv("MODEL_NAME", '-')
print(f'{api_key=}\n{base_url=}\n{model_name=}')
加载 配置信息
from dotenv import load_dotenv, find_dotenv
from pathlib import Path # Python 3.6+ only
# 一、自动搜索 .env 文件
load_dotenv(verbose=True)
# 二、与上面方式等价
load_dotenv(find_dotenv(), verbose=True)
load_dotenv(find_dotenv(), override=True) # 开启自动更新功能
# 三、或者指定 .env 文件位置
env_path = Path('.') / '.env'
load_dotenv(dotenv_path=env_path, verbose=True)
# 从流对象中加载
from io import StringIO # Python2: from StringIO import StringIO
from dotenv import dotenv_values
filelike = StringIO('SPAM=EGGS\n')
filelike.seek(0)
# 显示加载结果 dotenv_values
parsed = dotenv_values(stream=filelike)
parsed['SPAM'] # 'EGGS'
使用配置信息
# --- 使用 -----
import os
SECRET_KEY = os.getenv("API_KEY")
DATABASE_PASSWORD = os.getenv("MODEL_NAME")
# -----或--------
import dotenv
# from dotenv import load_dotenv, find_dotenv
from getpass import getpass
# 从当前目录或其父目录中的.env文件或指定的路径加载环境变量
dotenv.load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
ipython 加载
%load_ext dotenv # 加载扩展
%dotenv # 加载 env文件
%dotenv relative/or/absolute/path/to/.env # 制定文件
%dotenv -o # 覆盖原有变量
%dotenv -v # 输出提示信息
问题
load_dotenv 函数默认不会更新配置项。
例子
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
隐藏大坑。.env 中更新配置项的值时,不会生效。
原因:
- load_dotenv 默认不会更新已经存在的配置项。
- 推荐使用 override 参数
推荐代码如下:
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv(), override=True)
env文件中 # 处理
.env 中 如下写法:
BASEURL=http://codehub.com/#/python
# 在 url 中表示锚点, 而 Python 中表示注释开始。
此时 BASEURL 值是 http://codehub.com/。
以下写法均符合预期。
# 问题配置
BASEURL=http://codehub.com/#/python
# 解决: 加引号
BASEURL="http://codehub.com/#/python"
BASEURL='http://codehub.com/#/python'
用双引号 / 单引号括起来。
xml
【2023-8-11】XML 指可扩展标记语言(eXtensible Markup Language)
Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree:
- SAX (simple API for XML )
- Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。
- DOM(Document Object Model)
- 将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。
- ElementTree(元素树)
- ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
注:
- 因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)。
python中用xml.dom.minidom来解析xml文件 refer
测试数据
- data 里 包含多个 country
- country 属性: name
- country 子节点: rank, year, gdppc, neighbor
<?xml version="1.0"?>
<data>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
解析代码
#!/usr/bin/python
#coding=utf-8
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开XML文档
DOMTree = xml.dom.minidom.parse("country.xml")
Data = DOMTree.documentElement
# 判断是否包属性 name
if Data.hasAttribute("name"):
print "name element : %s" % Data.getAttribute("name")
# 在集合中获取所有国家
Countrys = Data.getElementsByTagName("country")
# 打印每个国家的详细信息
for Country in Countrys:
print "*****Country*****"
# 获取属性
if Country.hasAttribute("name"):
print "name: %s" % Country.getAttribute("name")
# 获取 子节点, 及其元素取值
rank = Country.getElementsByTagName('rank')[0]
print "rank: %s" % rank.childNodes[0].data # 元素取值
year = Country.getElementsByTagName('year')[0]
print "year: %s" % year.childNodes[0].data
gdppc = Country.getElementsByTagName('gdppc')[0]
print "gdppc: %s" % gdppc.childNodes[0].data
# 获取 子节点属性
for neighbor in Country.getElementsByTagName("neighbor"):
print neighbor.tagName, ":", neighbor.getAttribute("name"), neighbor.getAttribute("direction")
打日志
日志级别等级
- CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET
logging
logging模块
#!coding:utf-8
import logging
import logging.handlers
import datetime, time
#logging 初始化工作
logger = logging.getLogger("zjlogger")
logger.setLevel(logging.DEBUG)
# 添加TimedRotatingFileHandler
# (1) 定义一个1秒换一次log文件的handler, 保留3个旧log文件
rf_handler = logging.handlers.TimedRotatingFileHandler(filename="all.log",when='S',interval=1, backupCount=3)
#handler = logging.handlers.RotatingFileHandler(LOG_FILE, maxBytes=1024 * 1024, backupCount=5, encoding='utf-8') # 实例化handler
# (2) 写入文件myapp.log,如果文件超过100个Bytes,仅保留5个文件。
handler = logging.handlers.RotatingFileHandler('myapp.log', maxBytes=100, backupCount=5)
rf_handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(filename)s[:%(lineno)d] - %(message)s"))
#在控制台打印日志
handler = logging.StreamHandler()
handler.setLevel(logging.DEBUG)
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.addHandler(rf_handler)
logger.addHandler(handler)
# logging格式化输出
d={"a":1, "c":[3,1,2]}
logger.info("this is %s, %s", d['a'], d)
while True:
# 不同日志等级
logger.debug('debug message')
logger.info('info message')
logger.warning('warning message')
logger.error('error message')
logger.critical('critical message')
time.sleep(1)
使用logging模块,参考:python logging模块详解
- 日志级别等级:
CRITICAL>ERROR>WARNING>INFO>DEBUG>NOTSET
# coding:utf8
import logging
if __name__ == '__main__':
#[2018-1-17]http://blog.csdn.net/zyz511919766/article/details/25136485/
# 设置日志格式,日志文件(默认打到标准输出),模式(追加还是覆盖)
# 日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET
#logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%a, %d %b %Y %H:%M:%S',filename='test.log',filemode='w')
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%Y-%M-%d %H:%M:%S',filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.critical('critical message')
# 创建一个logger,不用调logging包
log = logging.getLogger()
log.debug('debug')
# 日志等级大全
log.debug('logger debug message')
log.info('logger info message')
log.warning('logger warning message')
log.error('logger error message')
log.critical('logger critical message')
【2024-3-20】设置北京时间
import logging
import datetime
def beijing(sec, what):
beijing_time = datetime.datetime.now() + datetime.timedelta(hours=8)
return beijing_time.timetuple()
logging.Formatter.converter = beijing
logging.basicConfig(
format="%(asctime)s %(levelname)s: %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S",
)
logging.info('完成')
loguru模块
- 【2021-3-30】不想手动再配置logging?那可以试试loguru
- logging库采用模块化设计,虽然可以设置不同的 handler 来进行组合,但是在配置上通常较为繁琐;而且如果不是特别处理,在一些多线程或多进程的场景下使用 logging 还会导致日志记录会出现错乱或是丢失的情况。
- loguru库不仅能够减少繁琐的配置过程还能实现和logging类似的功能,同时还能保证日志记录的线程进程安全,又能够和 logging 相兼容,并进一步追踪异常也能进行代码回溯。一个专为像我这样懒人而生日志记录库
- logger 本身就是一个已经实例化好的对象,如果没有特殊的配置需求,那么自身就已经带有通用的配置参数;同时它的用法和 logging 库输出日志时的用法一致, 可配置部分相比于 logging 每次要导入特定的handler再设定一些formatter来说是更为「傻瓜化」了
- 日志文件留存、压缩,甚至自动清理。可以通过对 rotation 、compression 和 retention 三个参数进行设定来满足: rotation 参数能够帮助我们将日志记录以大小、时间等方式进行分割或划分
#!pip install loguru
from loguru import logger
logger.debug("debug message" )
logger.info("info level message 中文信息输出 ")
logger.warning("warning level message")
logger.critical("critical level message")
# 可配置
import os
logger.add(os.path.expanduser("~/Desktop/testlog.log"))
# 序列化配置:通过 serialize 参数将其转化成序列化的 json 格式,最后将导入类似于 MongoDB、ElasticSearch 这类数 NoSQL 数据库中用作后续的日志分析。
logger.add(os.path.expanduser("~/Desktop/testlog.log"), serialize=True)
# loguru 集成了一个名为 better_exceptions 的库,不仅能够将异常和错误记录,并且还能对异常进行追溯
logger.add(os.path.expanduser("~/Desktop/exception_log.log"), backtrace=True, diagnose=True)
# 与logging兼容
import logging.handlers
file_handler = logging.handlers.RotatingFileHandler(LOG_FILE, encoding="utf-8")
logger.add(file_handler)
# -------------
logger.info("hello, world!")
# 日志自动清理
LOG_DIR = os.path.expanduser("~/Desktop/logs")
LOG_FILE = os.path.join(LOG_DIR, "file_{time}.log")
if os.path.exits(LOG_DIR):
os.mkdir(LOG_DIR)
# ①自动切分日志,大小、时间等方式进行分割或划分
logger.add(LOG_FILE, rotation = "200KB")
# ②分割文件的数量越来越多,可以进行压缩对日志进行压缩、留存
logger.add(LOG_FILE, rotation = "200KB", compression="zip")
# ③只想保留一段时间内的日志并对超期的日志进行删除;
# 当然对 retention 传入整数时,该参数表示的是所有文件的索引,而非要保留的文件数;只有两个时间最近的日志文件会被保留下来,其他都被直接清理掉了
logger.add(LOG_FILE, rotation="200KB",retention=1)
for n in range(10000):
logger.info(f"test - {n}")
- loguru 还为输出的日志信息带上了不同的颜色样式(schema),使得结果更加美观
彩色日志
Python Colorama模块可跨多终端显示不同的颜色字体和背景,只需要导入colorama模块即可,不用再每次都像linux一样指定颜色。
Fore是针对字体颜色,Back是针对字体背景颜色,Style是针对字体格式
- Fore: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
- Back: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
- Style: DIM, NORMAL, BRIGHT, RESET_ALL
注意
- 颜色RED,GREEN都需要大写,先指定是颜色和样式是针对字体还是字体背景,然后再添加颜色,颜色就是英文单词指定的颜色
测试代码
!pip install colorama
from colorama import Fore, Back, Style
init(autoreset=True) # 初始化,并且设置颜色设置自动恢复, 不用单独reset
print(Fore.RED + 'some red text')
print(Back.GREEN + 'and with a green background')
print(Style.DIM + 'and in dim text')
print(Style.RESET_ALL)
print('back to normal now')
# 记得要及时关闭colorma的作用范围
# 如果不关闭的话,后面所有的输出都会是你指定的颜色
print(Style.RESET_ALL)
服务部署
python文件功能实现了,怎么交付?
两种方案:
- 直接给 python文件,让对方自行安装python。
- 把 python文件 和 python环境 一起给对方,直接点点点即可。
python工具往往涉及到很多依赖
- 在线状态下,可以通过pip requirements来管理安装
- 离线怎么办? 客户端处于内网、无网环境
服务打包
【2024-12-9】多种打包方式 参考
- 导出安装包为
requirements.txt: 目标电脑需要安装同版本python并且联网使用pip freeze > requirements.txt# 依赖包冗余, 改: pipreqs your_dir/pip install -r requirements.txt
- 导出安装包为
requirements.txt: 目标电脑需要安装同版本python无需联网使用- 有网电脑上准备 离线 wheel 包
pip download -d ./packs -r requirements.txt,复制文件到U盘 - 无网电脑上安装
pip install --no-index --find-links=./packs -r requirements.txt
- 有网电脑上准备 离线 wheel 包
- 虚拟环境: venv/virtualenv, 目标电脑需要安装同版本python
- 虚拟环境:
python -m venv pyvenv - 激活虚拟环境,安装依赖包,出现在 lib/site-package 目录下,复制到U盘
- 目标电脑上创建虚拟环境
- 替换无网电脑上 lib/site-package 文件
- 虚拟环境:
- python绿色版本: 目标电脑无需安装python
- 下载绿色版 Python, embeddable就是绿色版
- 下载 get-pip.py, 浏览器输入链接: https://bootstrap.pypa.io/get-pip.py 右键另存为 保存到解压文件夹中
- 安装 pip:
python get-pip.py
- 安装 pip:
- 其它操作
- pyinstaller : 生成exe可执行文件
- 安装 pyinstaller:
pip install pyinstaller - 打包: pyinstaller -F main.py
- 双击 dist 中的 main.exe 即可
- 安装 pyinstaller:
| 方式 | 优点 | 缺点 |
|---|---|---|
| 1 导出 requirements.txt + 联网 | 安装只需要requirements.txt文件即可、操作简单 | 联网、python环境、安装 |
| 2 导出 requirements.txt + 无网 | 无需联网、操作简单 | python环境、安装包占地方、需要安装 |
| 3 虚拟环境 + Python | 不会破坏原有python环境 | 同上 |
| 4 免安装版 | 目标电脑无需python环境、绿色免安装 | 制作步骤较多 |
| 5 可执行文件 | 目标电脑无需python环境、操作简单 | 打包容易失败、启动比较慢、打包后体积较大 |
虚拟环境部署
资料
- Python 安装包:
- 3.9.9, 包含
embed的是绿色版, 免安装
- 3.9.9, 包含
# (1) 在线机器
cd pkgs # 进入待打包程序目录
pip install jupyter .... # 当前程序依赖包
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple # 速度慢时加清华镜像
# 整理依赖包
# pip freeze > requirements.txt # 输出到文件
pip install pipreqs
pipreqs start.py > requirements.txt # 精简依赖包信息, 只保存实际使用的工具
pip download -r requirements.txt -d ./packages # 下载工具包到本地 ./packages
# 文件集合:
# 1 python安装包
# 2 requirements_full.txt
# 3 packages/ 文件夹
# 将 所有 wheel包、安装程序 复制到U盘
cp . /u # windows 下直接复制
# (2) 离线机器, 接U盘
# 安装Python、或绿色版
点击安装
直接复制文件: 绿色安装, 含 embed # 下载内容:python-3.7.9-embed-amd64.zip
# 安装本地依赖包
pip install --no-index --find-links /u/pkgs -r requirements.txt
pyinstaller
创建独立应用(包含依赖包)后,可用 PyInstaller 将 Python 程序生成可直接运行程序,分发到对应的 Windows 或 Mac OS X 平台上运行。
pyinstaller 生成相应的 spec 文件,大体流程如下:
- 1、在脚本目录生成 xxx.spec 文件 (取决于 -n 参数,没传,则与 xxx.py 同名为 xxx);
- 2、创建 build 目录;
- 3、写入一些日志文件和中间流程文件到 build 目录;
- 4、创建 dist 目录;
- 5、生成可执行文件或文件夹到 dist 目录;
【2021-11-23】 pyinstaller 可以把python文件直接打包成可执行文件,符合需求。
# pip安装
pip install pyinstaller
pip install pyinstaller --trusted-host https://pypi.org --trusted-host https://files.pythonhosted.org
# 或源码安装
git clone https://github.com/dkw72n/pyinstaller.git
python setup.py install
建议用 在线方式安装 PyInstaller 模块,不要使用离线包!
- 因为 PyInstaller 模块还依赖其他模块,pip 在安装 PyInstaller 模块时会先安装它的依赖模块。
pyinstaller用法:
- -F 指定打包文件, 生成一个exe文件
- -D –onedir 创建目录,包含exe文件,但会依赖很多文件(默认选项)
- -c –console, –nowindowed 使用控制台,无界面(默认)
- -w –windowed, –noconsole 使用窗口,无控制台
- -p 添加搜索路径,让其找到对应的库。
- -i 改变生成程序的icon图标
# 打包
pyinstaller -F demo.py
# 生成完成后,将会在此 app 目录下看到多 dist 目录,并在该目录下看到 app.exe 文件
pyinstaller.py -F -p C:\python27; ..\demo.py # 注意当前目录是下一级目录里
pyinstaller.py -F -p C:\python27; -i ..\a.ico ..\demo.py # icon图标
开机启动
Python服务开机启动 必须写成windows的服务程序Windows Service,要借助第三方模块 pywin32
- PythonService 定义见文章
#1.安装服务
python PythonService.py install
#2.让服务自动启动
python PythonService.py --startup auto install
#3.启动服务
python PythonService.py start
#4.重启服务
python PythonService.py restart
#5.停止服务
python PythonService.py stop
#6.删除/卸载服务
python PythonService.py remove
高级语法
Python三器:装饰器、迭代器和生成器
属性
【2022-3-22】python类属性介绍
使用类或实例直接操作类属性
- 缺点:对类的属性没有操作控制规则,容易被人修改。
属性的定义:python中的属性其实是普通方法的衍生。
操作类属性有三种方法:
- 使用 @property 装饰器操作类属性。
- 使用 类 或 实例 直接操作类属性(例如:obj.name,obj.age=18,del obj.age)
- 使用python内置函数操作属性。
属性存在的意义:
- 1、访问属性时可以制造出和访问字段完全相同的假象,属性由方法衍生而来,如果Python中没有属性,方法完全可以代替其功能。
- 2、定义属性可以动态获取某个属性值,属性值由属性对应的方式实现,应用更灵活。
- 3、可以制定自己的属性规则,用于防止他人随意修改属性值。
#coding=utf-8
class Employee(object):
#所有员工基类
empCount = 0
def __init__(self, name, salary) :
#类的构造函数
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self) :
#类方法
print ("total employee ",Employee.empCount)
def displayEmployee(self) :
print ("name :",self.name , ", salary :", self.salary)
#创建Employee类的实例对象
emp1 = Employee("丽丽", 10000)
emp1.displayCount()
emp1.displayEmployee()
emp1.salary = 20000 #修改属性 salary
print (emp1.salary)
emp1.age = 25 #添加属性 age
print (emp1.age)
del emp1.age #删除 age属性
emp1.empCount=100
Employee.empCount=1000
# 结果:total employee 1
# name : 丽丽 , salary : 10000
# 20000
# 25
python内置函数操作属性。
- 1)getattr(obj, name[, default]):访问对象的属性,如果存在返回对象属性的值,否则抛出AttributeError异常。
- 2)hasattr(obj,name):检查是否存在某个属性,存在返回True,否则返回False。
- 3)setattr(obj,name,value):设置一个属性。如果属性不存在,会创建一个新属性,该函数无返回值。若存在则更新这个值。
- 4)delattr(obj, name):删除属性,如果属性不存在则抛出AttributeError异常,该函数也无返回值。
#encoding=utf-8
class Employee(object):
#所有员工基类
empCount=0
def __init__(self,name,age,salary):
#类的构造函数
self.name=name
self.salary=salary
self.age=age
Employee.empCount+=1
def displayCount(self):
#类方法
print("total employee",Employee.empCount)
def displayEmployee(self):
print("name:",self.name,"age:",self.age,",salary:",self.salary)
#创建Employee类的实例对象
emp1=Employee("Rose",27,20000)
#判断实例对象是否存在某个属性,存在返回True,否则返回False
if hasattr(emp1,'name'):
name_value=getattr(emp1,'name') #获取name属性值
print( "name的属性值为:",name_value)
else:
print ("员工属性不存在")
#给实例添加一个属性
if hasattr(emp1,'tel'):
print ("员工属性已存在")
else:
setattr(emp1,'tel','17718533234')
t1=getattr(emp1,'tel')
print("tel的属性值为:",t1)
setattr(emp1,'tel','15042622134')
t2=getattr(emp1,'tel')
print("tel修改后的属性值为:",t2)
#给实例删除一个属性
if hasattr(emp1,'age'):
delattr(emp1,'age')
else:
print ("员工tel属性不存在")
#验证属性是否删除成功
if hasattr(emp1,'age'):
print( "属性age存在!")
else:
print ("属性age不存在!")
# 结果:
# name的属性值为: Rose
# tel的属性值为: 17718533234
# tel修改后的属性值为: 15042622134
# 属性age不存在!
Python内置类属性,这里做简单介绍:
- __dict__ : 类的属性(获取类所有信息):结果返回一个字典包含类属性及属性值,类方法等所有类信息
- __doc__ : 类的文档字符串,也就是类的帮助信息。
- __name__: 类名
- __module__: 类定义所在的模块
- 如果在当前模块返回’__main__’;
- 如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
- __bases__ : 类的所有父类(包含了所有父类组成的元组)
#coding=utf-8
class Employee (object):
"""所有员工的基类"""
empCount = 0
def __init__(self, name, salary) :
#类的构造函数
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self) :
#类方法
print ("total employee ",Employee.empCount )
def displayEmployee(self) :
print ("name :",self.name , ", salary :", self.salary)
print ("Employee.__doc__:", Employee.__doc__ )
print ("Employee.__name__:", Employee.__name__ )
print ("Employee.__module__:", Employee.__module__ )
print ("Employee.__bases__:", Employee.__bases__ )
print ("Employee.__dict__:", Employee.__dict__ )
装饰器
- 【2021-4-26】不懂Python装饰器,你敢说会Python?
- 场景:多个函数中添加计时代码
- 解法:装饰器
操作类属性方法之一:
- 使用 @property 装饰器操作类属性。
class Goods(object):
def __init__(self):
self.value=50
# 经典类只有property
@property
def price(self): # 查看属性
return self.value
# 新式类才有如下功能:setter、deleter
@price.setter # 添加/设置属性(属性名.setter)
def price(self, value):
if value >=50 and value<=100: #对属性的取值和赋值加以控制
self.value=value
print (self.value)
else:
print ("请输入一个50到100之间的数!")
@price.deleter # 删除属性(属性名.deleter) 注意:属性一旦删除,就无法设置和获取
def price(self):
del self.value
print ("price is deleted!")
obj = Goods()
print (obj.price) # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
obj.price=106 # 自动执行 @price.setter 修饰的 price 方法,并将106 赋值给方法
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
结果输出:
- 50
- 请输入一个50到100之间的数!
- price is deleted!
定义
把原来的函数给包了起来,在不改变原函数代码的情况下,在外面起到了装饰作用,这就是传说中的装饰器。它其实就是个普通的函数。
示例
import time
# (1)不带参数装饰器
def timer(func):
'''统计函数运行时间的装饰器'''
def wrapper():
start = time.time()
func()
end = time.time()
used = end - start
print(f'{func.__name__} used {used}')
return wrapper
# 先调用timer函数,生成一个包装了step1的新的函数timed_step1.
# 剩下的就是调用这个新的函数time_step1(),它会帮我们记录时间。
timed_step1 = timer(step1)
timed_step1()
# 简洁版
timer(step1)()
# (2)带参数的装饰器
# wrapper使用了通配符,*args代表所有的位置参数,**kwargs代表所有的关键词参数。这样就可以应对任何参数情况。
# wrapper调用被装饰的函数的时候,只要原封不动的把参数再传递进去就可以
def timer(func):
'''统计函数运行时间的装饰器'''
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
used = end - start
print(f'{func.__name__} used {used}')
return wrapper
# @符号,语法糖衣
@timer
def step1(num):
print(f'我走了#{num}步')
step1(5)
# (3)带返回值的装饰器
def timer(func):
'''统计函数运行时间的装饰器'''
def wrapper(*args, **kwargs):
start = time.time()
ret_value = func(*args, **kwargs)
end = time.time()
used = end - start
print(f'{func.__name__} used {used}')
return ret_value
return wrapper
@timer
def add(num1, num2):
return num1 + num2
sum = add(5, 8)
print(sum)
python技能
调试
code 比 print、pdb 要简单。
- 常用pycharm的debugger,感觉比code要好用一些。pycharm可以深入到method里去debug。code好像不能。只能在最上层看变量,执行方法。

pdb 调试
pdb 是 python 自带的一个包,为 python 程序提供了一种交互的源代码调试功能,主要特性包括: 设置断点、单步调试、进入函数调试、查看当前代码、查看栈片段、动态改变变量 的值等。
pdb 2种用法:
非侵入式方法(不用额外修改源代码,在命令行下直接运行就能调试)python3 -m pdb filename.py
侵入式方法(需要在被调试的代码中添加一行代码然后再正常运行代码)import pdb;pdb.set_trace()
# 非侵入式
python3 -m pdb filename.py
# 侵入式
import pdb
pdb.set_trace()
命令行看到下面这个提示符时,说明正确打开pdb
(Pdb)
命令:参考
- 查看
- l: 查看当前位置前后11行源代码(多次会翻页)
- ll: 查看当前函数或框架的所有源代码
- p 打印变量值
pa+b 执行表达式a: 打印函数参数及值whatisvar: 打印变量(var)类型w: 打印堆栈信息, 箭头表示当前栈
- 逐行调试
n: 执行下一行,不进函数体s: 执行下一行,可进入函数内部r: 执行下一行,函数中时,直接执行到函数返回处
- 连续执行
c: 连续执行, 直至下一个断点untlineno: 执行到指定行jlineno: 直接跳到指定行
- 栈操作: 跳到堆栈上一层 u;跳到堆栈下一层 d
u: 返回到上一个栈帧,初步尝试发现是可以回退执行d: 进入下一个栈帧
b: 条件断点,对for循环比较有用- b 查看断点设置
- b lineno 添加到行(lineno)
- b filename:lineno 添加到文件(filename)的某行(lineno)
- b functionname 函数第一行设置断点
- tbreak 临时断点(执行一次后自动删除), 用法同上
- cl 清除断点
- cl 清除所有断点
- cl filename:lineno
- cl bpnumber 清除指定序号的断点
- 交互
interact: 启动python交互解释器, ctrl+d 返回pdb
- 退出
- q: 退出pdb
code 模块
【2023-1-10】系统自带的code模块支持以交互方式调试代码, test.py
import code # python3 内置
bal_a = 2324
bal_b = 0
bal_c = 409
bal_d = -2
account_balances = [bal_a, bal_b, bal_c, bal_d]
def display_bal():
for balance in account_balances:
if balance < 0:
print("Account balance of {} is below 0; add funds now.".format(balance))
elif balance == 0:
print("Account balance of {} is equal to 0; add funds soon.".format(balance))
else:
print("Account balance of {} is above 0.".format(balance))
# Use interact() function to start the interpreter with local namespace
code.interact(local=locals()) # 启动交互调试,局部变量
code.interact(local=globals()) # 启动交互调试,全局变量
code.interact(local=dict(globals(), **locals())) # 局部变量+全局变量
# Use interact() function to start the interpreter
code.interact(banner="Start", local=locals(), exitmsg="End") # 启动交互调试,设置提示语(开始 Start、结束 End)
display_bal()
执行 python3 test.py
python3 test.py # 执行交互调试
# Python 3.5.2 (default, Nov 17 2016, 17:05:23)
# [GCC 5.4.0 20160609] on linux
# Type "help", "copyright", "credits" or "license" for more information.
# (InteractiveConsole)
print(bal_c) # 输出变量
print(account_balances)
print(display_bal()) # 调用函数
唯一id
uuid生成
- uuid是128位的全局唯一标识符(univeral unique identifier),通常用32位的一个字符串的形式来表现。有时也称guid(global unique identifier)。python中自带了uuid模块来进行uuid的生成和管理工作。(具体从哪个版本开始有的不清楚。。)
- python中的uuid模块基于信息如MAC地址、时间戳、命名空间、随机数、伪随机数来uuid。具体方法有如下几个:
- uuid.uuid1() 基于MAC地址,时间戳,随机数来生成唯一的uuid,可以保证全球范围内的唯一性。
- uuid.uuid2() 算法与uuid1相同,不同的是把时间戳的前4位置换为POSIX的UID。不过需要注意的是python中没有基于DCE的算法,所以python的uuid模块中没有uuid2这个方法。
- uuid.uuid3(namespace,name) 通过计算一个命名空间和名字的md5散列值来给出一个uuid,所以可以保证命名空间中的不同名字具有不同的uuid,但是相同的名字就是相同的uuid了。【感谢评论区大佬指出】namespace并不是一个自己手动指定的字符串或其他量,而是在uuid模块中本身给出的一些值。比如uuid.NAMESPACE_DNS,uuid.NAMESPACE_OID,uuid.NAMESPACE_OID这些值。这些值本身也是UUID对象,根据一定的规则计算得出。
- uuid.uuid4() 通过伪随机数得到uuid,是有一定概率重复的
- uuid.uuid5(namespace,name) 和uuid3基本相同,只不过采用的散列算法是sha1
一般而言,在对uuid的需求不是很复杂的时候,uuid1方法就已经够用了
import uuid
name = 'test_name'
# namespace = 'test_namespace'
namespace = uuid.NAMESPACE_URL
print uuid.uuid1()
print uuid.uuid3(namespace,name)
print uuid.uuid4()
print uuid.uuid5(namespace,name)
md5
代码
import hashlib
def calculate_md5(data):
md5_hash = hashlib.md5()
md5_hash.update(data.encode('utf-8'))
return md5_hash.hexdigest()
prompt_md5 = calculate_md5(prompt)
性能优化
- 【2020-9-10】Python语言优化
- 原生的python通常都是由cpython实现,而cpython的运行效率,确实让人不敢恭维,比较好的解决方案有cython、numba、pypy等等
cython
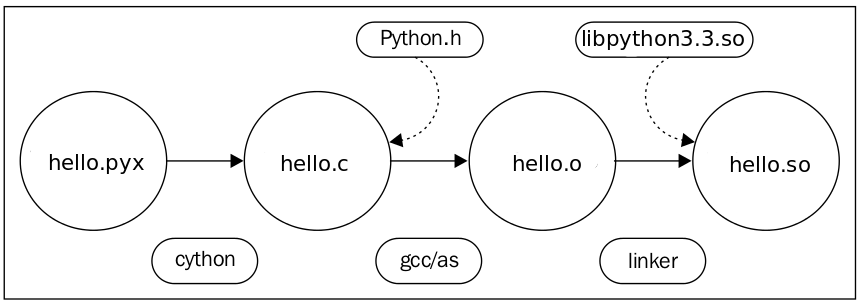
numba
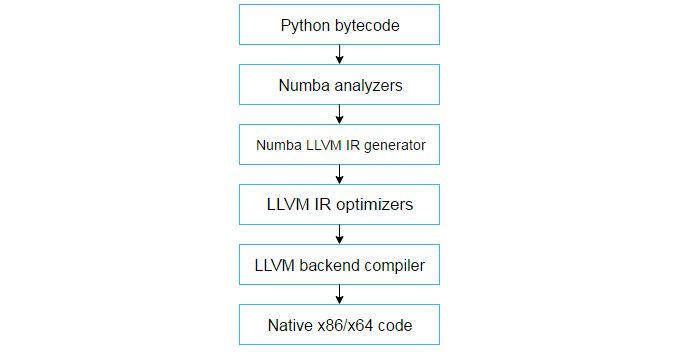
pypy
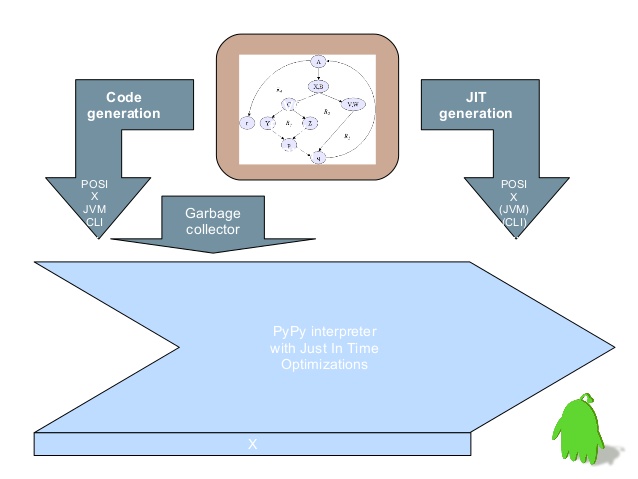
异步
- Python语言没有真正的进程,而是通过
协程来实现,多线程也受制于GIL- Python 因为有
GIL(全局解释锁),不可能有真正多线程,因此很多情况下都会用 multiprocessing 实现并发,而且在Python中应用多线程还要注意关键地方的同步,不太方便,用协程代替多线程和多进程是很好的选择,因为它吸引人的特性:主动调用/退出,状态保存,避免cpu上下文切换等…
- Python 因为有
- 参考
效率进阶之路
爬虫效率进阶之路:
- (1)urllib和urllib2包抓5个页面总共耗时7.6秒
- (2)requests包6.5秒!虽然比用urllib快了1秒多,但是总体来说,他们基本还是处于同一水平线的,程序并没有快很多,这一点的差距或许是requests对请求做了优化导致的。
- (3)lxml库→正则,继续提升1s
- (4)
多线程:threading库有效的解决了阻塞等待的问题,足足比之前的程序快了80%!只需要1.4秒就可完成电影列表的抓取。- 多线程受限于GIL,能否用多进程提速?
- (5)
多进程:ProcessPoolExecutor库实现多进程- ThreadPoolExecutor和ProcessPoolExecutor是Python3.2之后引入的分别对线程池和进程池的一个封装,如果使用Python2.x,需要安装futures这个库才能使用
- 多进程带来的优点(cpu处理)并没有得到体现,反而创建和调度进程带来的开销要远超出它的正面效应,拖了一把后腿。即便如此,多进程带来的效益相比于之前单进程单线程的模型要好得多。
- (6)基于协程的网络库,叫做
gevent,异步功能,只有1.2秒,果然很快- gevent给予了我们一种以同步逻辑来书写异步程序的能力,看monkey.patch_all()这段代码,它是整个程序实现异步的黑科技
- 但gevent的魔术给他带来了一定的困惑,并非Pythonic的清晰优雅
-
(7)
async/await:同步的requests库改成了支持asyncio的aiohttp库,使用3.5的async/await语法(3.5之前用@asyncio.coroutine和yield from代替)写出了协程版本,1.7s - 清晰优雅的协程可以说实现异步的最优方案之一
- 协程的机制使得我们可以用同步的方式写出异步运行的代码。
思考:
- 更换零件带来的优化小,而且扩展性有限
- 网络应用通常瓶颈都在IO层面,解决等待读写的问题比提高文本解析速度来的更有性价比!
GIL 锁
【2023-8-7】Python考虑去除GIL,真正的多线程要来了
GIL 的全称是 Global Interpreter Lock(全局解释器锁),不是 Python 独有,而是在实现 CPython(Python 解释器)引入的概念。
- GIL 理解为互斥锁,保护 Python 对象,防止同一时刻多个线程执行 Python 的字节码,从而确保线程安全。
- GIL 弊端,同一时刻只能有一个线程在CPU 上执行,无法将多个线程映射到多个 CPU 上,使得 Python 并不能实现真正的多线程并发,从而降低了执行效率。
GIL锁开启时,同个进程内的多个线程只能串行而不能并行。
GIL 释放有两种触发方式:遇到I/O操作、超出时间限制。
- 遇到I/O操作时,原线程运行结束,其余线程对CPU使用权进行「竞争」。
- 但如果是超时释放,原来运行的线程会重新加入这场「竞争」。
这种做法是出于安全性考虑,但已经不能适应时代的发展。
GIL诞生时,CPU 还只有一个核心,但发展过程中,GIL始终保持着全局锁定的特性,导致多核CPU早已普及的今天,多出的核心并没有被利用,大量算力被浪费,对于AI、ML等计算密集领域,效率会出现严重降低。
Python 团队已经正式接受了删除 GIL 的这个提议,并将其设置为可选模式
- Meta 软件工程师 Sam Gross 花费了四年多的时间才完成这一工程。
将 no-GIL 构建作为一种实验性构建模式,大概会在 3.13 版本(也有可能推迟到 3.14 版本)可用。希望 no-GIL 成为默认方式,并删除 GIL 的所有痕迹
【2025-10-7】Python 3.14 发布,资讯
最大突破:
- 移除 GIL(全局解释器锁),终于实现真正的多线程并行,尤其利好CPU密集型应用。配套的自由线程API和新解释器路径让并发编程更规范。
但关键争议:
- 实际性能提升幅度有限(官方预估3%-5%),且大量依赖C扩展的老库需要适配。
- 就像Python之父提醒的,别神话并发——它解决了根本性障碍,但不会自动让所有程序跑得更快,大规模项目迁移仍需时间验证稳定性。
多线程
参考
- 【2024-2-8】功能强大的python包(十一):threading
进程+线程
进程间通讯
进程、线程及其之间的关系与特点:
- 进程是资源分配的最小单元,一个程序至少包含一个进程
- 线程是程序执行的最小单元,一个进程至少包含一个线程
- 每个进程都有自己独占的地址空间、内存、数据栈等;由于进程间的资源独立,所以进程间通信(IPC)是多进程的关键问题
- 同一进程下的所有线程都共享该进程的独占资源,由于线程间的资源共享,所有数据同步与互斥是多线程的难点
此外,多进程多线程也必须考虑硬件资源的架构:
- 单核CPU中每个进程中同时刻只能运行一个线程,只在多核CPU中才能够实现线程并发
- 当线程需运行但运行空间不足时,先运行高优先级线程,后运行低优先级线程
- Windows系统新开进行会增加很大的开销,因此Windows系统下使用多线程更具优势,这时更应该考虑的问题是资源同步和互斥
- Linux系统新开进程的开销增加很小,因此Linux系统下使用多进程更具优势,这时更应该考虑的问题是进程间通信
总结
- IO密集型(不用CPU)→ 多线程
- 计算密集型(用CPU)→ 多进程
使用线程和进程的目的都是为了提升效率
- (1)单进程单线程,主进程/主线程
- (2)自定义线程:主进程 → 主线程/子线程
Python 有两种形式可以开启线程
threading.Thread()方式: 函数调用- 继承
thread.Thread类: 面向对象
GIL 全局解释器锁
Python 的设计上有 Global Interpreter Lock (GIL), 导致 Python 一次只能做一件事情.
- 尽管 Python 完全支持多线程编程, 但解释器的C语言实现部分在完全并行时并不是线程安全的。 实际上,解释器被一个全局解释器锁保护着,确保任何时候都只有一个Python线程执行。
- GIL最大的问题:Python 多线程程序并不能利用多核CPU 优势 (比如一个使用了多个线程的计算密集型程序只会在一个单CPU上面运行)。
Python 并非真正意义上的多线程

GIL只会影响到那些严重依赖CPU的程序(比如计算型的)。
- 如果程序大部分只会涉及到I/O,比如网络交互,那么使用多线程就很合适, 因为大部分时间都在等待。
-
实际上,完全可以放心的创建几千个Python线程, 现代操作系统运行这么多线程没有任何压力,没啥可担心的。
- python在运行计算密集型的多线程程序时,更倾向于让线程在整个时间片内始终占据GIL
- 而I/O密集型的多线程程序在I/O被调用前会释放GIL,允许其他线程在I/O执行时获得GIL
因此python 多线程更适用于I/O密集型的程序(网络爬虫)
threading.Thread()
threading.Thread()方式开启线程
- 创建
threading.Thread()对象 - 通过
target指定运行函数 - 通过
args指定需要的参数 - 通过
start运行线程
非必须:
- 通过
threading.Lock()保证线程同步 - 通过
join阻塞运行 - 通过
name指定线程名称 - 通过
daemon设置守护线程
threading 用法
主要方法


import threading
# 查看已激活线程数
threading.active_count() # 2
# 查看所有线程
threading.enumerate() # [<_MainThread(MainThread, started 140736011932608)>, <Thread(SockThread, started daemon 123145376751616)>]
# 查看正在运行的线程
threading.current_thread() # <_MainThread(MainThread, started 140736011932608)>
def T1_job():
print("T1 start\n")
for i in range(10):
time.sleep(0.1)
print("T1 finish\n")
def T2_job():
print("T2 start\n")
print("T2 finish\n")
if __name__ == '__main__':
thread = threading.Thread(target=thread_job,)
thread_1 = threading.Thread(target=T1_job, name='T1') # 定义线程
thread_2 = threading.Thread(target=T2_job, name='T2') # 定义线程
# 启动、阻塞顺序很重要,直接关系到 各个任务之间的依赖关系
thread_1.start() # 开启线程T1
thread_2.start() # 开启线程T2
thread_2.join() # 阻塞T2
thread_1.join() # 阻塞T1
print("all done\n")
并发
import datetime
import os
import threading
import time
def log(msg):
pid = os.getpid() # 获取进程编号
tid = threading.current_thread().ident # 获取当前线程编号
print(f"进程[{pid}]-线程[{tid}]: {msg}")
def add(x, y):
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log(f"现在的时间是:{now}")
log(f"执行加法:{x} + {y} = {x + y}")
time.sleep(3)
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log(f"现在的时间是:{now},结束加法运算")
return x + y
if __name__ == '__main__':
log("=== 主线程 ===")
t1 = threading.Thread(target=add, args=(1, 2))
t2 = threading.Thread(target=add, args=(3, 4))
t1.start()
t2.start()
log("=== 主线程完事 ===")
执行结果
- 异常: 各个代码块并没有一起执行,执行顺序混乱
- 原因: 不同步
进程[18365]-线程[139826158360128]: === 主线程 ===
进程[18365]-线程[139826148665088]: 现在的时间是:2024-02-08 17:46:15
进程[18365]-线程[139826140272384]: 现在的时间是:2024-02-08 17:46:15
进程[18365]-线程[139826158360128]: === 主线程完事 ===
进程[18365]-线程[139826140272384]: 执行加法:3 + 4 = 7
进程[18365]-线程[139826148665088]: 执行加法:1 + 2 = 3
进程[18365]-线程[139826140272384]: 现在的时间是:2024-02-08 17:46:18,结束加法运算
进程[18365]-线程[139826148665088]: 现在的时间是:2024-02-08 17:46:18,结束加法运算
加锁实现同步
不同线程使用同一共享内存时,lock确保线程之间互不影响
锁被用来实现对共享资源的同步访问
两种锁
- 锁对象:
threading.Lock - 递归锁对象:
threading.RLock- 解决死锁问题;RLock对象内部维护着一个Lock和counter变量,counter记录着acquire的次数,从而使得资源可以被多次acquire,直到一个线程的所有acquire都被release时,其他线程才能够acquire资源。
- 死锁是指两个或两个以上的线程在执行过程中,因争夺资源访问权而造成的互相等待的现象,从而一直僵持下去。
- 条件变量对象:threading.Condition
- 信息量对象:threading.Semaphore
- 一个信号量管理一个内部计数器,acquire( )方法会减少计数器,release( )方法则增加计算器,计数器的值永远不会小于零,当调用acquire( )时,如果发现该计数器为零,则阻塞线程,直到调用release( ) 方法使计数器增加。
- 事件对象:threading.Event
- 如果一个或多个线程需要知道另一个线程的某个状态才能进入下一步的操作,就可以使用线程的event事件对象来处理。
- 定时器对象:threading.Timer
- 一个操作需要在等待一段时间之后执行,相当于一个定时器。
- 栅栏对象:threading.Barrier

在应用锁对象时,会发生死锁;死锁是指两个或两个以上的线程在执行过程中,因争夺资源访问权而造成的互相等待的现象,从而一直僵持下去。
递归锁对象就是用来解决死锁问题的,RLock对象内部维护着一个Lock和一个counter变量,counter记录着acquire的次数,从而使得资源可以被多次acquire,直到一个线程的所有acquire都被release时,其他线程才能够acquire资源。
使用lock的方法
- 每个线程执行运算修改共享内存之前,执行
lock.acquire()将共享内存上锁,确保当前线程执行时,内存不会被其他线程访问 - 执行运算完毕后,使用
lock.release()将锁打开,保证其他的线程可以使用该共享内存。 - 通过
threading.Lock()保证线程同步 (所有任务都执行完才会进行下一步)
mutex = threading.Lock() # 创建锁
mutex.acquire([timeout]) # 锁定
# 锁定方法acquire可以有一个超时时间的可选参数timeout。如果设定了timeout,则在超时后通过返回值可以判断是否得到了锁,从而可以进行一些其他的处理。
mutex.release() #释放
示例
import datetime
import os
import threading
import time
def log(msg):
pid = os.getpid() # 获取进程编号
tid = threading.current_thread().ident # 获取当前线程编号
print(f"进程[{pid}]-线程[{tid}]: {msg}")
def add(lock, x, y):
# 同一时间内,只有lock区域内代码在执行
lock.acquire() # 锁定
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log(f"现在的时间是:{now},开始加法运算")
log(f"执行加法:{x} + {y} = {x + y}")
time.sleep(3)
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log(f"现在的时间是:{now},结束加法运算")
lock.release() # 解锁
return x + y
if __name__ == '__main__':
log("=== 主线程 ===")
thread_lock = threading.Lock()
t1 = threading.Thread(target=add, args=(thread_lock, 1, 2))
t2 = threading.Thread(target=add, args=(thread_lock, 3, 4))
t1.start()
t2.start()
log("=== 主线程完事 ===")
执行结果
- 相同代码块一起执行, 如2个子线程
- 问题: 主线程并没有等任意子线程执行完
- 原因: 没有阻塞等待机制
进程[18446]-线程[140361755809344]: === 主线程 ===
进程[18446]-线程[140361746114304]: 现在的时间是:2024-02-08 17:50:16,开始加法运算
进程[18446]-线程[140361746114304]: 执行加法:1 + 2 = 3
进程[18446]-线程[140361755809344]: === 主线程完事 ===
进程[18446]-线程[140361746114304]: 现在的时间是:2024-02-08 17:50:19,结束加法运算
进程[18446]-线程[140361737721600]: 现在的时间是:2024-02-08 17:50:19,开始加法运算
进程[18446]-线程[140361737721600]: 执行加法:3 + 4 = 7
进程[18446]-线程[140361737721600]: 现在的时间是:2024-02-08 17:50:22,结束加法运算
守护线程
守护线程指程序运行时在后台提供一种通用服务的线程,比如垃圾回收线程;
- 这种线程在程序中并非不可或缺。
- 默认创建的线程为非守护线程,等所有的非守护线程结束后,程序也就终止了,同时杀死进程中的所有守护线程。
- 只要非守护线程还在运行,程序就不会终止。
t1 = threading.Thread(target=add, args=(thread_lock, 1, 2), name="", daemon=False) # 默认, 非守护进程
t2 = threading.Thread(target=sub, args=(thread_lock, 8, 4), name='', daemon=False) # 守护进程
join 阻塞
没有阻塞时,主进程直接按顺序执行,不管子进程是否执行完毕
import datetime
import os
import threading
import time
def log(msg):
pid = os.getpid()
tid = threading.current_thread().ident
print(f"进程[{pid}]-线程[{tid}]: {msg}")
def add(lock, x, y):
lock.acquire()
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log(f"现在的时间是:{now},开始加法运算")
log(f"执行加法:{x} + {y} = {x + y}")
time.sleep(3)
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log(f"现在的时间是:{now},结束加法运算")
lock.release()
return x + y
if __name__ == '__main__':
log(f'=== 主线程开始 === {datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}')
thread_lock = threading.Lock()
t1 = threading.Thread(target=add, args=(thread_lock, 1, 2), name='t1')
t2 = threading.Thread(target=add, args=(thread_lock, 3, 4), name='t2')
# 子线程启停顺序直接影响任务依赖关系
t1.start() # 启动t1
t2.start() # 启动t2
t1.join() # 主线程要等待子线程1结束
t2.join() # 主线程要等待子线程2结束
log(f'=== 主线程结束 === {datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}')
执行结果
进程[18612]-线程[140486813877824]: === 主线程开始 === 2024-02-08 17:55:02
进程[18612]-线程[140486804182784]: 现在的时间是:2024-02-08 17:55:02,开始加法运算
进程[18612]-线程[140486804182784]: 执行加法:1 + 2 = 3
进程[18612]-线程[140486804182784]: 现在的时间是:2024-02-08 17:55:05,结束加法运算
进程[18612]-线程[140486795790080]: 现在的时间是:2024-02-08 17:55:05,开始加法运算
进程[18612]-线程[140486795790080]: 执行加法:3 + 4 = 7
进程[18612]-线程[140486795790080]: 现在的时间是:2024-02-08 17:55:08,结束加法运算
进程[18612]-线程[140486813877824]: === 主线程结束 === 2024-02-08 17:55:08
存储进程结果
如何记录各个进程执行结果?
- 多线程调用的函数不能用return返回值!
- 解法: 用 queue
import threading
import time
from queue import Queue
def job(l,q):
for i in range (len(l)):
l[i] = l[i]**2
# 多线程调用的函数不能用return返回值
q.put(l)
def multithreading():
# 定义一个Queue,用来保存返回值,代替return
q =Queue()
threads = []
data = [[1,2,3],[3,4,5],[4,4,4],[5,5,5]]
# 定义并启动4个线程
for i in range(4):
t = threading.Thread(target=job,args=(data[i],q)) #Thread首字母要大写,被调用的job函数没有括号,只是一个索引,参数在后面
t.start()#开始线程
threads.append(t) #把每个线程append到线程列表中
# 阻塞在主进程前面
for thread in threads:
thread.join()
# 定义空列表results,将4个线运行结果保存到列表results
results = []
for _ in range(4):
results.append(q.get())
print(results) # [[1, 4, 9], [9, 16, 25], [16, 16, 16], [25, 25, 25]]
if __name__=='__main__':
multithreading()
继承 thread.Thread类
完整示例
#!/usr/bin/env python
#coding=utf-8
import threading
import time
class MyThread(threading.Thread):
def run(self):
global num
time.sleep(1)
if mutex.acquire(1):
num = num+1
msg = self.name+' set num to '+str(num)
print(msg)
mutex.release()
num = 0
mutex = threading.Lock()
def test():
for i in range(5):
t = MyThread()
t.start()
if __name__ == '__main__':
test()
输出:
Thread-1 set num to 1
Thread-3 set num to 2
Thread-4 set num to 3
Thread-5 set num to 4
Thread-2 set num to 5
示例
import threading
import time
lock = threading.Lock() #创建锁
def fun(data):
try:
lock.acquire(True) #锁定
print("------> fun 1:",time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())),data)
time.sleep(5)
print("------> fun 2:", time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())),data)
finally:
lock.release()#释放
threading.Thread(target = fun, name='socket_tcp_server', kwargs={'data':100}).start()
threading.Thread(target = fun, name='socket_tcp_server', kwargs={'data':200}).start()
threading.Thread(target = fun, name='socket_tcp_server', kwargs={'data':300}).start()
threading.Thread(target = fun, name='socket_tcp_server', kwargs={'data':400}).start()
协程
协程,又称作Coroutine。从字面上来理解,即协同运行的例程,它是比是线程(thread)更细量级的用户态线程- 特点是允许用户的主动调用和主动退出,挂起当前的例程然后返回值或去执行其他任务,接着返回原来停下的点继续执行。
- 问题
- 函数都是线性执行的,怎么会说执行到一半返回,等会儿又跑到原来的地方继续执行
- 答案是用yield语句
- yield能把一个函数变成一个generator,与return不同,yield在函数中返回值时会保存函数的状态,使下一次调用函数时会从上一次的状态继续执行,即从yield的下一条语句开始执行
- 好处:数列较大时,可以一边循环一边计算的机制,节省了存储空间,提高了运行效率
- 操作系统具有getcontext和swapcontext这些特性,通过系统调用,我们可以把上下文和状态保存起来,切换到其他的上下文,这些特性为coroutine的实现提供了底层的基础。操作系统的Interrupts和Traps机制则为这种实现提供了可能性

代码
def fib(max):
n, a, b = 0, 0, 1
while n max:
# 每次调用函数时,都要耗费大量时间循环做重复的事情
# print b
# 用yield,则会生成一个generator,需要时,调用它的next方法获得下一个值
yield b
a, b = b, a + b
n = n + 1
用协程实现生产者-消费者模式
#-*- coding:utf-8
def consumer():
status = True
while True:
n = yield status
print("我拿到了{}!".format(n))
if n == 3:
status = False
def producer(consumer):
n = 5
while n > 0:
# yield给主程序返回消费者的状态
yield consumer.send(n)
n -= 1
if __name__ == '__main__':
# 由于yield,不同于一般函数执行,Python会当做一个generator对象
c = consumer()
# 将consumer(即变量c,它是一个generator)中的语句推进到第一个yield语句出现的位置
# 函数里的status = True和while True:都已经被执行了,程序停留在n = yield status的位置(未执行)
c.send(None) # 如果漏写这一句,那程序直接报错
# 定义了producer的生成器,注意的是这里我们传入了消费者的生成器,来让producer跟consumer通信。
p = producer(c)
# 循环地运行producer和获取它yield回来的状态
for status in p:
if status == False:
print("我只要3,4,5就行啦")
break
print("程序结束")
- 让生产者发送1,2,3,4,5给消费者,消费者接受数字,返回状态给生产者,而我们的消费者只需要3,4,5就行了,当数字等于3时,会返回一个错误的状态。最终我们需要由主程序来监控生产者-消费者的过程状态,调度结束程序。
- 生产者p调用了消费者c的send()方法,把n发送给consumer(即c),在consumer中的n = yield status,n拿到的是消费者发送的数字,同时,consumer用yield的方式把状态(status)返回给消费者,注意:这时producer(即消费者)的consumer.send()调用返回的就是consumer中yield的status!消费者马上将status返回给调度它的主程序,主程序获取状态,判断是否错误,若错误,则终止循环,结束程序。上面看起来有点绕,其实这里面generator.send(n)的作用是:把n发送generator(生成器)中yield的赋值语句中,同时返回generator中yield的变量(结果)。
- 结果
我拿到了5!
我拿到了4!
我拿到了3!
我只要3,4,5就行啦
程序结束
- Coroutine与Generator
- 相似:
- 都是不用return来实现重复调用的函数/对象,都用到了yield(中断/恢复)的方式来实现。
- 区别
- generator总是生成值,一般是迭代的序列
- coroutine关注的是消耗值,是数据(data)的消费者
- coroutine不会与迭代操作关联,而generator会
- coroutine强调协同控制程序流,generator强调保存状态和产生数据
- 协程相比于多进程和多线程的优点
- ①多进程和多线程创建开销大
- ②一个难以根治的缺陷,处理进程之间或线程之间的协作问题,因为是依赖多进程和多线程的程序在不加锁的情况下通常是不可控的,而协程则可以完美地解决协作问题,由用户来决定协程之间的调度。
asyncio
asyncio是python 3.4中新增的模块,它提供了一种机制,使得你可以用协程(coroutines)、IO复用(multiplexing I/O)在单线程环境中编写并发模型。
- 根据官方说明,asyncio模块主要包括了:
- 具有特定系统实现的事件循环(event loop);
- 数据通讯和协议抽象(类似Twisted中的部分);
- TCP,UDP,SSL,子进程管道,延迟调用和其他;
- Future类;
- yield from的支持;
- 同步的支持;
- 提供向线程池转移作业的接口;
下面来看下asyncio的一个例子:
import asyncio
async def compute(x, y):
print("Compute %s + %s ..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()
Python在3.5版本中引入了关于协程的语法糖async和await
- 用
async修饰将普通函数和生成器函数包装成异步函数和异步生成器 - 通过
await调用async修饰的异步函数 async用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件是sleep(5))消失后,也就是5秒到了再回来执行。await用来用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序。
参考
# 异步函数(协程)
async def async_function():
return 1
# 异步生成器
async def async_generator():
yield 1
# 通过类型判断可以验证函数的类型
import types
print(type(function) is types.FunctionType)
print(type(generator()) is types.GeneratorType)
print(type(async_function()) is types.CoroutineType)
print(type(async_generator()) is types.AsyncGeneratorType)
# 直接调用异步函数不会返回结果,而是返回一个coroutine对象:
print(async_function())
## <coroutine object async_function at 0x102ff67d8>
# 协程需要通过其他方式来驱动,因此可以使用这个协程对象的send方法给协程发送一个值:
print(async_function().send(None))
# 改进:捕获协程的真正返回值,新建run函数驱动协程
def run(coroutine):
try:
coroutine.send(None)
except StopIteration as e:
return e.value
# 在协程函数中,可以通过await语法来挂起自身的协程,并等待另一个协程完成直到返回结果:
async def async_function():
return 1
async def await_coroutine():
result = await async_function()
print(result)
run(await_coroutine())
# 1
任务调度
定期调度 —— Schedule
简单强大的Python库!Schedule—实用的周期任务调度工具
在Linux服务器上周期性地执行某个 Python 脚本
(1)最出名的选择应该是 Crontab 脚本,但是 Crontab 具有以下缺点:
- 不方便执行秒级的任务。
- 当需要执行的定时任务有上百个的时候,Crontab的管理就会特别不方便。 (2)Celery,但是 Celery 的配置比较麻烦,如果只是需要一个轻量级的调度工具,Celery 不会是一个好选择。
在你想要使用一个轻量级的任务调度工具,而且希望它尽量简单、容易使用、不需要外部依赖,最好能够容纳 Crontab 的所有基本功能,那么 Schedule 模块是你的不二之选。
# pip install schedule
import schedule
import time
def job():
print("I'm working...")
# scedule.every(时间数).时间类型.do(job)
# 执行一次
schedule.every.day.at('22:30').do(job)
# 每10分钟执行一次 job 函数
schedule.every(10).minutes.do(job)
# 每十分钟执行任务
schedule.every(10).minutes.do(job)
# 每个小时执行任务
schedule.every.hour.do(job)
# 每天的10:30执行任务
schedule.every.day.at("10:30").do(job)
# 每个月执行任务
schedule.every.monday.do(job)
# 每个星期三的13:15分执行任务
schedule.every.wednesday.at("13:15").do(job)
# 每分钟的第17秒执行任务
schedule.every.minute.at(":17").do(job)
# do 将额外的参数传递给job函数
schedule.every(2).seconds.do(greet, name='Alice')
while True:
schedule.run_pending()
time.sleep(1)
多进程任务调度框架
- 【2021-1-21】多年前写的多任务调度框架,每天处理20T上网数据
# ***************************************************************************
# *
# * Copyright (c) 2012 Baidu.com, Inc. All Rights Reserved
# *
# **************************************************************************/
#/**
# * @file start.py
# * @author wangqiwen@baidu.com(zhanglun@baidu.com)
# * @date 2013/04/26 16:32
# * detect if data is ready
# * process data use codes defined in conf
# * output data to path in conf
# * multi thread , multi job commit
# * log is added
# **/
#import packages:
import ConfigParser
import string
import os
import sys
import threading
import time
import datetime
import logging
import urllib, re
import commands
import json
sys.path.append('.')
from optparse import OptionParser
#define class:
#job spec conf
class JobSpecConf:
def __init__(self):
self.job_name = None
self.input_ready = []
self.inputs = []
self.must_input = []
self.code_path = None
self.detect_start_time = 0
self.detect_end_time = 0
self.delay_before_start = 0
self.output_ready = None
self.map_con_num = 0
self.reduce_num = 0
#load jon conf
def loadJobConf(conf_file,date):
config = ConfigParser.ConfigParser()
config.read(conf_file)
global_conf.map_dict['$date'] = date
global_conf.map_dict['$date_pre'] = getPreDate(date=date)
# tranform job conf info
job_conf_list = []
try:
for section in config.sections():
# all job session name starts with 'job' in configre file
if not section.startswith('job'):
continue
# new job conf object
job_spec_conf = JobSpecConf()
job_spec_conf.job_name = config.get(section,"job_name")
# update job_name in map_dict
global_conf.map_dict['$job_name'] = job_spec_conf.job_name
# get input path & ready
item_list = config.options(section)
path_list = [multiReplace(config.get(section,i),global_conf.map_dict) for i in item_list if i.startswith('input_path_')]
ready_list = [multiReplace(config.get(section,i),global_conf.map_dict) for i in item_list if i.startswith('input_ready_')]
job_spec_conf.input_number = len(path_list)
if len(path_list) != len(ready_list):
logger.error("configure file(%s) error: input path & ready in section %s doesn't match !" %(conf_file,section))
return job_conf_list
job_spec_conf.inputs = path_list
job_spec_conf.input_ready = ready_list
if 'must_input' in item_list:
job_spec_conf.must_input = [multiReplace(config.get(section,'input_ready_%s'%(i)),global_conf.map_dict) for i in config.get(section,"must_input").split('&')]
logger.info('[%s] must_input = %s'%(job_spec_conf.job_name,repr(job_spec_conf.must_input)))
# get other info
job_spec_conf.output = multiReplace(config.get(section,"output"),global_conf.map_dict)
job_spec_conf.output_ready = multiReplace(config.get(section,"output_ready"),global_conf.map_dict)
job_spec_conf.code_path = multiReplace(config.get(section,"code_path"),global_conf.map_dict)
job_spec_conf.detect_start_time = config.get(section,"detect_start_time")
job_spec_conf.detect_end_time = config.get(section,"detect_end_time")
job_spec_conf.delay_before_start = config.getint(section,"delay_before_start")
job_spec_conf.map_con_num = config.get(section,"map_con_num")
job_spec_conf.reduce_num = config.get(section,"reduce_num")
job_conf_list.append(job_spec_conf)
logger.info("job conf info: %s" %(repr(job_conf_list)))
except Exception,err:
logger.error("error:(%s) when loading configure file(file:%s,section:%s)" %(err,conf_file,section))
return job_conf_list
def multiReplace(str,dict):
rx = re.compile('|'.join(map(re.escape,dict)))
def one_xlat(match):
return dict[match.group(0)]
return rx.sub(one_xlat,str)
#init logger
def initlog(date,job_type):
logger = logging.getLogger('%s.py' % job_type)
hdlr = logging.FileHandler('../log/%s/%s_%s.txt' % (now,job_type,date),mode="wb")
formatter = logging.Formatter('[%(levelname)s] [%(asctime)s]: %(message)s')
hdlr.setFormatter(formatter)
logger.addHandler(hdlr)
logger.setLevel(logging.DEBUG)
return logger
def send_mail(mail_alarm='on',title='mail title',content='mail content',receiver=None):
"""
usage: send_email(title,content,receiver)
shell: echo -e "hello" | mail -s "title" receivers
"""
if mail_alarm != 'on':
logger.info('alarm mail is off ...')
return 0
if receiver == None:
logger.info('Mail receiver address (%s) invalid !' %(receiver))
exit(-1)
code = os.system("echo -e \"%s\" | mail -s \"%s\" \"%s\"" %(content,title,receiver))
if 0 == code:
logger.info('Success to send mail (%s:%s) to %s' %(title,content,receiver))
return 0
else:
logger.error('Fail to send mail (%s:%s) to %s, error code (%s) ,program exit ...' %(title,content,receiver,code))
exit(-1)
def get_jobtracker_running_job_name_ids(url):
while True:
try:
lines = urllib.urlopen(url).readlines()
except:
raise
return False
if lines:
break
else:
logger.error("%s not reachable" % url)
found = False
jobs = {}
for line in lines:
line = line.strip()
if found == True:
if line.startswith('<h2'):
break
o = re.search('(job_[0-9]+_[0-9]+).+id="name_[0-9]+">([^<]+)<', line)
if o:
name, jid = o.groups()
jobs[name] = jid
if line == """<h2 id="running_jobs">Running Jobs</h2>""":
found = True
return jobs
#define class:
#global conf
class GlobalConf:
def __init__(self):
self.retry_interval = 0
self.output_path = ''
self.root_code_path = ''
self.hadoop_client = ''
self.re_run_number = 0
self.jobtracker = ''
self.map_dict = {'$output_path':'-','$date_pre':'-','$date':'-','$job_name':'-'}
self.mail_receiver_in = None
self.mail_alarm = 'on'
self.mail_receiver_out = None
#define functions:
#load global config
def globalConfLoad(config_file):
#load conf
config = ConfigParser.ConfigParser()
config.read(config_file)
#init conf
global_conf = GlobalConf()
global_conf.retry_interval = config.getint("global","retry_interval")
global_conf.output_path = config.get("global","output_path")
global_conf.map_dict['$output_path'] = global_conf.output_path
global_conf.root_code_path = config.get("global","root_code_path")
global_conf.hadoop_client = config.get("global","hadoop_client")
global_conf.re_run_number = config.getint("global","re_run_number")
global_conf.jobtracker = config.get("global", "jobtracker")
global_conf.mail_receiver_in = config.get("global","mail_receiver_in")
global_conf.mail_receiver_out = config.get("global","mail_receiver_out")
global_conf.mail_alarm = config.get("global","mail_alarm")
return global_conf
#test path exist
def checkHadoopFile(path,date,global_conf):
path_after_parse = multiReplace(path,global_conf.map_dict)
cmd = '%s fs -test -e %s' % (global_conf.hadoop_client,path_after_parse)
code, msg = commands.getstatusoutput(cmd)
if code == 0:
return True
elif msg:
logger.warning('hadoop file (%s) not found , error_id : %s' %(path_after_parse,msg))
return False
return False
def getPreDate(n = 1 , date = 'today'):
'''
get string of date before n days
'''
#date_pre = (datetime.datetime.strptime(date,'%Y%m%d')+datetime.timedelta(days=1)).strftime('%Y%m%d')
if date == 'today':
date_object = datetime.date.today()
else:
date_object = datetime.datetime.strptime(date,'%Y%m%d')
date_pre = (date_object + datetime.timedelta(days=-n)).strftime('%Y%m%d')
return date_pre
def stopTask(job_spec_conf, date):
task_prefix = "%s_%s_%s" % (options.pipeline, date, job_spec_conf.job_name)
found = True
while found:
found = False
running_jobs = get_jobtracker_running_job_name_ids(global_conf.jobtracker)
for job in running_jobs:
if job.startswith(task_prefix):
logger.info("%s: killing job %s " % (job_spec_conf, running_jobs[job]))
os.system('%s job -kill %s' % (global_conf.hadoop_client, running_jobs[job]))
found = True
def cleanData(job_spec_conf, date, stop = False):
if stop:
stopTask(job_spec_conf, date)
data_path = job_spec_conf.output
ready_path = job_spec_conf.output_ready
if 0 == os.system('%s fs -test -e %s' %(global_conf.hadoop_client,ready_path)):
os.system('%s fs -rmr %s && %s fs -rmr %s' %(global_conf.hadoop_client,ready_path,global_conf.hadoop_client,data_path))
logger.info("[%s] clean data (%s,%s)" %(job_spec_conf.job_name,data_path,ready_path))
def startMultiThead(date, tasks, options):
logger.info('Begin to run the whole job of day: %s' % date)
all_job_list = []
all_job_list = loadJobConf(options.config_file,date)
all_job_dict = {}
for job in all_job_list:
all_job_dict[job.job_name] = job
logger.info('all jobs in conf : %s' % json.dumps([i.job_name for i in all_job_list]))
# select some jobs
if tasks:
job_conf_list = []
for jobname in tasks:
if jobname in all_job_dict:
job_conf_list.append(all_job_dict[jobname])
else:
logger.error('job name (%s) error ! please check with configure file(%s),all job names:%s'%(jobname,options.config_file,repr(all_job_dict.keys())))
return False
else:
job_conf_list = all_job_list
# check whether each job need to run or not
job_conf_list = [c for c in job_conf_list if checkTask(c, date, options)]
logger.info('jobs need to run : %s' % repr([i.job_name for i in job_conf_list]))
if len(job_conf_list) <= 0:
logger.info('no job in list , exit ...')
return False
# clean old data
for c in job_conf_list:
cleanData(c, date, True)
if options.kill_task:
return True
# start multithread
if options.parallel:
# run all jobs at the same time
threads = [threading.Thread(target = tryRunTask, args = (c, date, options)) for c in job_conf_list]
for t in threads:
t.start()
for t in threads:
t.join()
else:
# run one by one
for c in job_conf_list:
tryRunTask(c, date, options)
logger.info('End of day: %s' % date)
def runOneTask(job_spec_conf, date, options):
start_time = datetime.datetime.strptime(getPreDate(n=0)+job_spec_conf.detect_start_time,'%Y%m%d%H:%M')
end_time = datetime.datetime.strptime(getPreDate(n=0)+job_spec_conf.detect_end_time,'%Y%m%d%H:%M')
# wait some time until start
if job_spec_conf.delay_before_start > 0:
logger.info('[%s] sleep %s mins before start to detect ...'%(job_spec_conf.job_name,job_spec_conf.delay_before_start))
time.sleep(job_spec_conf.delay_before_start*60)
# Initialize input path
input_ready_number = 0
detect_input_dict = {}
for i,v in enumerate(job_spec_conf.input_ready):
detect_input_dict[v] = job_spec_conf.inputs[i]
input_ready_list = []
input_path_list = []
# waiting
while True:
now_time = datetime.datetime.now()
time_info = '[now %s,start %s,end %s]' %(str(now_time),str(start_time),str(end_time))
#count ready input file
tmp_key_list = detect_input_dict.keys()
for tmp_input_ready in tmp_key_list:
if checkHadoopFile(tmp_input_ready,date,global_conf):
logger.info('[%s] detect input file (%s): ready ...' % (job_spec_conf.job_name,tmp_input_ready))
input_ready_list.append(tmp_input_ready)
input_path_list.append(detect_input_dict[tmp_input_ready])
del detect_input_dict[tmp_input_ready]
else:
logger.warning('[%s] detect input file (%s): not ready... %s' % (job_spec_conf.job_name,tmp_input_ready,time_info))
input_ready_number = len(input_ready_list)
logger.info('[%s] detect result : ready num => %d, must input num => %d, all input num => %d...' % (job_spec_conf.job_name,input_ready_number,len(job_spec_conf.must_input),job_spec_conf.input_number))
# check whether match min input
match = 0
if input_ready_number > 0:
match = 1
for i in job_spec_conf.must_input:
if i not in input_ready_list:
match = 0
break
if options.run_force and match :
logger.warning("[%s] run forcely... input data ready info : %s/%s " %(job_spec_conf.job_name,input_ready_number,job_spec_conf.input_number))
break
#too early
if now_time < start_time:
logger.info('[%s] time enough , wait until start time ... %s' %(job_spec_conf.job_name,time_info))
logger.info('[%s] sleep %d minutes (retry_interval)' % (job_spec_conf.job_name,global_conf.retry_interval))
time.sleep(global_conf.retry_interval*60)
continue
#all ready
if input_ready_number == job_spec_conf.input_number :
logger.info('[%s] detect_start_time %s , detect_end_time %s , all inputs are ready ...' %(job_spec_conf.job_name,job_spec_conf.detect_start_time,job_spec_conf.detect_end_time))
break
# too late
if options.enable_timeout and now_time >= end_time:
if match:
logger.warning('[%s] input ready before time over, ... input data ready info : %s/%s ' %(job_spec_conf.job_name,input_ready_number,job_spec_conf.input_number))
break
else:
logger.warning('[%s] time over , but input files not enough , exit now ... input data ready info : %s/%s ' %(job_spec_conf.job_name,input_ready_number,job_spec_conf.input_number))
exit(-1)
logger.info('[%s] sleep %d minutes (retry_interval)' % (job_spec_conf.job_name,global_conf.retry_interval))
time.sleep(global_conf.retry_interval*60)
# run
hadoop_job_cmd = 'sh %s%s %s %s %s %s %s %s %s %s %s &>../log/%s/%s_%s.txt' % (
global_conf.root_code_path,
job_spec_conf.code_path,
global_conf.hadoop_client,
'"%s"' % (';'.join(input_path_list)),
job_spec_conf.output,
job_spec_conf.job_name,
global_conf.root_code_path,
date,
"%s_%s_%s" % (options.pipeline, date, job_spec_conf.job_name),
job_spec_conf.map_con_num,
job_spec_conf.reduce_num,
now,
job_spec_conf.job_name,
date)
logger.info('[%s] hadoop job command: %s' % (job_spec_conf.job_name, hadoop_job_cmd))
code, msg = commands.getstatusoutput(hadoop_job_cmd)
if code != 0:
logger.error('[%s]: job Failled when running, error_code = %s(%s)' %(job_spec_conf.job_name,code,msg))
title = '[merge-wise][ERROR] [%s] Job failed when running !'%(job_spec_conf.job_name)
content = '[ERROR] [%s] Job failed when running , error_code = %s(%s)'%(job_spec_conf.job_name,code,msg)
logger.error('mail_receiver_in=%s'%(global_conf.mail_receiver_in))
send_mail(global_conf.mail_alarm,title,content,global_conf.mail_receiver_in)
return False
# result info : all input,ready input,miss input
result_dict = {'input_list':[],'input_num':0,'ready_list':[],'ready_num':0,'miss_list':[],'miss_num':0}
for i in job_spec_conf.input_ready:
if i in input_ready_list:
result_dict['ready_list'].append(i)
else:
result_dict['miss_list'].append(i)
result_dict['input_list'].append(i)
result_dict['ready_num'] = len(result_dict['ready_list'])
result_dict['miss_num'] = len(result_dict['miss_list'])
result_dict['input_num'] = len(result_dict['input_list'])
logger.info('[%s] result_dict : %s' %(job_spec_conf.job_name,repr(result_dict)))
# create ready file
output_ready = job_spec_conf.output_ready
hadoop_ready_cmd = 'echo %s | %s fs -put - %s' %(json.dumps(result_dict),global_conf.hadoop_client,output_ready)
logger.info('create ready file : %s' %(hadoop_ready_cmd))
code, msg = commands.getstatusoutput(hadoop_ready_cmd)
if code != 0:
logger.error('[%s] fail to create ready file (%s) , error_code = %s(%s)'%(job_spec_conf.job_name,output_ready,code,msg))
title = '[merge-wise][ERROR][%s] Failed to create ready file !'%(job_spec_conf.job_name)
content = '[ERROR] [%s] Failed to create ready file (%s),error_code = %s(%s)'%(job_spec_conf.job_name,output_ready,code,msg)
send_mail(global_conf.mail_alarm,title,content,global_conf.mail_receiver_in)
return False
if result_dict['miss_num'] > 0:
miss_source_info = ','.join([i.strip().split('/')[-3] for i in result_dict['miss_list']])
logger.info('[%s] job finished at the end without sources(%s)' %(job_spec_conf.job_name,miss_source_info))
title = '[merge-wise][WARNING][%s] Job finished at the end without sources(%s)' %(job_spec_conf.job_name,miss_source_info)
content = '[WARNING][%s] Job finished at the end without sources(%s)\n\nmiss_info = %s\n\nready_info = %s' %(job_spec_conf.job_name,miss_source_info,repr(result_dict['miss_list']),repr(result_dict['ready_list']))
send_mail(global_conf.mail_alarm,title,content,global_conf.mail_receiver_out)
if options.signal_zk:
cmd_out = os.system("%s cr -register %s -cronID %s" % (global_conf.hadoop_client, job_spec_conf.output, job_spec_conf.job_name))
if cmd_out != 0:
title = '[merge-wise][ERROR][%s] Failed to reigster zk data (%s)!'%(job_spec_conf.job_name,job_spec_conf.output)
content = '[ERROR][%s] Failed to reigster zk data (%s) ! error_code = %s '%(job_spec_conf.job_name, job_spec_conf.output ,str(cmd_out))
send_mail(global_conf.mail_alarm,title,content,global_conf.mail_receiver_in)
logger.error('[%s] job Failled, reigster zk data (%s) error, error_code = %s' %(job_spec_conf.job_name, job_spec_conf.output,str(cmd_out)))
return False
logger.info('[%s] job finish.' % (job_spec_conf.job_name))
return True
def checkTask(job_spec_conf, date, options):
# check whether job needs to run or not
output_ready = job_spec_conf.output_ready
if options.rerun or options.run_force:
return True
#if options.fix_data and checkMissTask(job_spec_conf, date):
# return True
if checkHadoopFile(output_ready, date, global_conf):
logger.info('check task %s : exist, %s' %(output_ready,job_spec_conf.job_name))
return False
else:
logger.info('check task %s : not exist, %s' %(output_ready,job_spec_conf.job_name))
return True
def tryRunTask(job_spec_conf, date, options):
logger.info('try to run task %s of %s' % (job_spec_conf.job_name, date))
for i in range(options.retry):
if runOneTask(job_spec_conf, date, options):
return
if i == (options.retry - 1):
break
logger.error('Task %s on %s failed, try again ...' % (job_spec_conf.job_name, date))
time.sleep(options.retry_sleep)
cleanData(job_spec_conf, date, False)
logger.error('Task %s on %s failed ...' % (job_spec_conf.job_name, date))
#main define here:
def main():
global options
global logger
global global_conf
usage = "usage: %start.py [options] [tasks]"
parser = OptionParser(usage=usage)
parser.add_option("-f", "--disable_timeout",
action = "store_false", dest = "enable_timeout", default = True,
help = "disable job timeout")
parser.add_option("-d", "--date", dest = "date", default = getPreDate(), help = "last day for job")
parser.add_option("-n", "--total_day", type = "int", dest = "total_day", default = 1, help = "total day for job")
parser.add_option("-s", "--sequence_run", action = "store_false", dest = "parallel", default = True, help = "run task one by one")
parser.add_option("-x", "--fix_data", action = "store_true", dest = "fix_data", default = False, help = "fix data")
parser.add_option("-p", "--pipeline", dest = "pipeline", default = "start", help = "pipeline name")
parser.add_option("-r", "--retry", type = "int", dest = "retry", default = 1, help = "job retry times")
parser.add_option("-R", "--rerun", action = "store_true", dest = "rerun", default = False, help = "rerun tasks")
parser.add_option("-w", "--retry_sleep", type = "int", dest = "retry_sleep", default = 300, help = "job retry sleep time, in seconds")
parser.add_option("-a", "--run_force", action = "store_true", dest = "run_force", default = False, help = "run job no matter the job has run already or data are not all ready")
parser.add_option("-c", "--config_file", dest = "config_file", default = "conf/job_conf.ini", help = "configure file path")
parser.add_option("-K", "--kill", action = "store_true", dest = "kill_task", default = False, help = "Kill tasks")
parser.add_option("-S", "--signal", action = "store_true", dest = "signal_zk", default = False, help = "Signal data reay in zk")
(options, tasks) = parser.parse_args()
logger = initlog(options.date, options.pipeline)
global_conf = globalConfLoad(options.config_file)
logger.info('=================================================')
logger.info('options=%s tasks=%s' %(repr(options),repr(tasks)))
#logger.info('options=%s tasks=%s' %(repr(options),repr(tasks)))
# get previous n days list before date, then start it
for i in xrange(options.total_day):
date_i = getPreDate(n=i,date=options.date)
startMultiThead(date_i, tasks, options)
logger.info('Finish. Time to quit soon ...')
#main start:
if __name__ == '__main__':
# call build.sh to update local directory
os.system('sh build.sh')
now = getPreDate( n = 0 )
main()
# */* vim: set expandtab ts=4 sw=4 sts=4 tw=400: */
- 【2021-1-26】其它调度框架,Python 实现并发Pipeline
- 对于Pipeline 根据侧重点的不同,有两种实现方式
- 用于加速多线程任务的pipeline
- 用于加速多线程任务的 Pipeline 主要强调 任务的顺序执行, 转移之间不涉及过于复杂的逻辑。所以 每个pipe 通过自身调用 next pipe。整体上强调 后向连续性。
- 用于控制流程的pipeline
- 用于流程控制的piepline, 强调任务的 逻辑性, 由外部 manager 来控制 pipeline 的执行方向。整体上强调前向的依赖性, 使用拓扑排序确定执行顺序。
终端文本可视化
rich
- 打印彩色字体,表单,进度条与状态动画,高级数据类型)
Rich是一个Python库,用于将丰富的文本(带有颜色和样式)写入终端,并用于显示高级内容,例如表格。 使用Rich使您的命令行应用程序更具视觉吸引力,并以更具可读性的方式呈现数据。Rich还可以通过漂亮的打印和语法突出显示数据结构来作为有用的调试辅助工具。
安装:pip install Rich
进度条
from rich.progress import track
from time import sleep
for step in track(range(100), description="Writing Medium Story..."):
sleep(0.1)
桌面提示
【2022-1-25】5个方便好用的Python自动化脚本
自动桌面提示
- 这个脚本会自动触发windows桌面通知,提示重要事项,比如说:您已工作两小时,该休息了, 可以设定固定时间提示,比如隔10分钟、1小时等
用到的第三方库:
- win10toast - 用于发送桌面通知的工具
from win10toast import ToastNotifier
import time
toaster = ToastNotifier()
header = input("What You Want Me To Remember\n")
text = input("Releated Message\n")
time_min=float(input("In how many minutes?\n"))
time_min = time_min * 60
print("Setting up reminder..")
time.sleep(2)
print("all set!")
time.sleep(time_min)
toaster.show_toast(f"{header}", f"{text}", duration=10, threaded=True)
while toaster.notification_active(): time.sleep(0.005)
ip地址
获取ip地址
【2023-7-31】Python获取本机IP地址的几种方式
Mac下获取ip地址
# 直接输出到终端 curl 命令
import requests
res = requests.get('http://myip.ipip.net', timeout=5).text
print(res)
# 使用 socket库
import socket
#client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#print(client_socket)
# res = socket.gethostbyname(socket.gethostname())
# print(res)
# (1) 获取ip —— 成功, 但获取的是局域网地址
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(("8.8.8.8", 80))
print(s.getsockname()[0])
# 适配ipv4、ipv6
addr = ("", 8080) # all interfaces, port 8080
if socket.has_dualstack_ipv6():
s = socket.create_server(addr, family=socket.AF_INET6, dualstack_ipv6=True)
else:
s = socket.create_server(addr)
print(s)
# (2) 直接使用socket --- Mac下失败!
# socket.gaierror: [Errno 8] nodename nor servname provided, or not known
hostname = socket.gethostname()
print('hostname: ', hostname)
IPAddr = socket.gethostbyname(hostname)
print("Your Computer Name is:"+hostname)
print("Your Computer IP Address is:"+IPAddr)
# (3) 适用于所有接口。它还适用于所有公共、私有、外部 IP。这种方法在 Linux、Windows 和 OSX 上很有效
def extract_ip():
st = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
st.connect(('10.255.255.255', 1))
IP = st.getsockname()[0]
except Exception:
IP = '127.0.0.1'
finally:
st.close()
return IP
print(extract_ip())
# (4) netifaces 模块用于提供有关网络接口及其状态的信息, 局域网IP。
from netifaces import interfaces, ifaddresses, AF_INET
for ifaceName in interfaces():
addresses = [i['addr'] for i in ifaddresses(ifaceName).setdefault(AF_INET, [{'addr':'No IP addr'}] )]
print(' '.join(addresses))
GUI 开发
开发 C/S, B/S 架构的交互页面
- tinkter
- pyGTK
- pyQT
- Gradio
- Streamlit
详见站内专题: Python GUI
面向对象
详见站内专题: 面向对象
Python生态系统
python模块:
- Numpy:多维数组容器,以矩阵为基础的数学计算模块,纯数学。
- Scipy:科学计算函数库,基于Numpy,科学计算库,有一些高阶抽象和物理模型。比方说做个傅立叶变换,这是纯数学的,用Numpy;做个滤波器,这属于信号处理模型了,在Scipy里找。
- Pandas:表格容器,提供了一套名为DataFrame的数据结构,比较契合统计分析中的表结构,并且提供了计算接口,可用Numpy或其它方式进行计算。金融行业
- Matplotlib:仿造MATLAB的画图工具
- Seaborn:画图工具
空值判断
python中的nan,即 Not A Number
计算结果为 nan 的情况
- 【2024-1-31】参考
a = -float('inf')
b = -float('inf')
c = float('inf')
d = float('inf')
# 取值为nan的情形
a-b
c-d
0*a
0*c
numpy中nan的表示为np.nan
- 不能使用
num==np.nan来判断
import numpy as np
x = np.nan
np.isnan(x)
方法
- numpy 判断
- Math 判断
- Pandas 判断
- 是否等于自身
import numpy as np
res = np.isnan(float('nan'))
import math
res = math.isnan(float('nan'))
import pandas as pd
res = pd.isna(float('nan'))
def is_nan(n):
return n != n
res = is_nan(float('nan'))
def is_nan(n):
return not float('-inf') < n < float('inf')
res = is_nan(nan)
数学函数
(1) 内置的数学函数
- min()和max()函数可用于查找可迭代的最小值或最大值
(2) Math模块
- Python还有一个名为math的内置模块,该模块扩展了数学函数的列表
常数
- math.e 欧拉数(2.7182 …)
- math.inf 浮点正无穷大
- math.nan 浮点NaN(非数字)值
- math.pi PI (3.1415…)
- math.tau tau(6.2831 …)
x = min(5, 10, 25)
y = max(5, 10, 25)
x = abs(-7.25) # 绝对值
# x的y次幂(x^y), pow(x,y)
x = pow(4, 3)
# ---------------
import math
x = math.sqrt(64) # 8
x = math.ceil(1.4) # 2
y = math.floor(1.4) # 1
x = math.pi # 常数 pi
函数
- math.acos() 数字的反余弦
- math.acosh() 反双曲余弦
- math.asin() 反正弦
- math.asinh() 反双曲正弦值
- math.atan() 弧度数的反正切
- math.atan2() 弧度的y / x的反正切
- math.atanh() 反双曲正切值
- math.ceil() 数字四舍五入到最接近的整数
- math.comb() 从n个项中选择k个项而无需重复和排序的方式数
- math.copysign() 由第一个参数的值和第二个参数的符号组成的浮点数
- math.cos() 数字的余弦值
- math.cosh() 数字的双曲余弦值
- math.degrees() 角度从弧度转换为度
- math.dist() 两个点(p和q)之间的欧几里得距离,其中p和q是该点的坐标
- math.erf() 数字的误差函数
- math.erfc() 数字的互补误差函数
- math.exp() E的x次方
- math.expm1() httpswwwcjavapycom
- math.fabs() 数字的绝对值
- math.factorial() 数字的阶乘
- math.floor() 数字四舍五入到最接近的整数
- math.fmod() x / y的余数
- math.frexp() 指定数字的尾数和指数
- math.fsum() 所有可迭代项(元组,数组,列表等)的总和。
- math.gamma() x处的伽玛函数
- math.gcd() 两个整数的最大公约数
- math.hypot() 欧几里得范数
- math.isclose() 检查两个值是否彼此接近
- math.isfinite() 检查一个数是否是有限的
- math.isinf() 检查数字是否为无穷大
- math.isnan() 检查值是否为NaN(不是数字)
- math.isqrt() 将平方根向下取整至最接近的整数
- math.ldexp() math.frexp()的逆,它是给定数字x和i的x * (2**i)
- math.lgamma() x的对数伽玛值
- math.log() 数字的自然对数,或数字以底为底的对数
- math.log10() x的以10为底的对数
- math.log1p() 1 + x的自然对数
- math.log2() x的以2为底的对数
- math.perm() 有序,无重复地从n个项中选择k个项的方式数
- math.pow() x的y次方的值
- math.prod() 可迭代的所有元素的乘积
- math.radians() 度值转换为弧度
- math.remainder() 可以使分子被分母完全整除的最接近的值
- math.sin() 一个数字的正弦值
- math.sinh() 数字的双曲正弦值
- math.sqrt() 数字的平方根
- math.tan() 数字的切线
- math.tanh() 数字的双曲正切
- math.trunc() 数字的截断整数部分
Numpy
- 【2020-12-28】NumPy初学教程,可视化指南
- Numpy知识点汇总
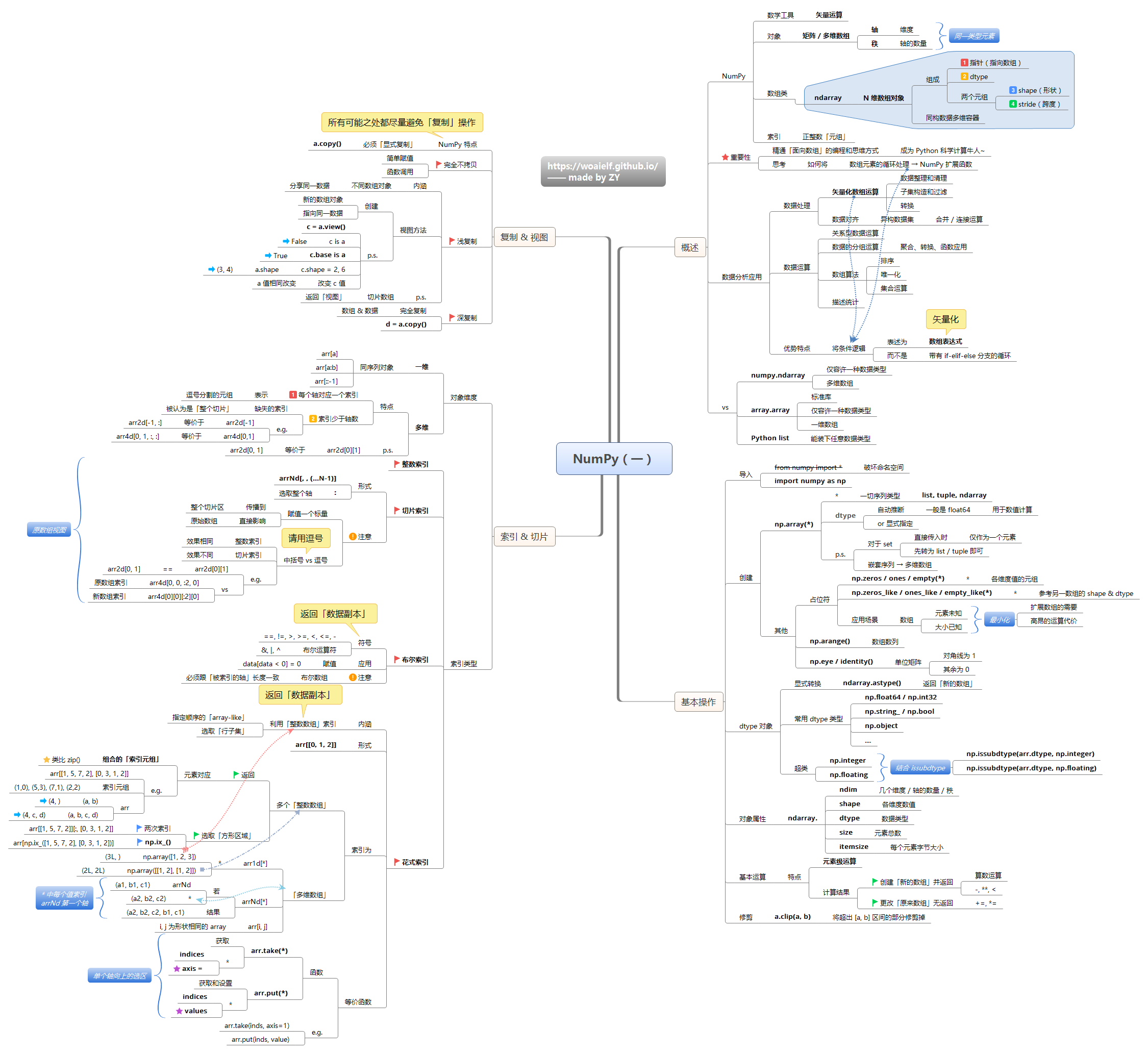
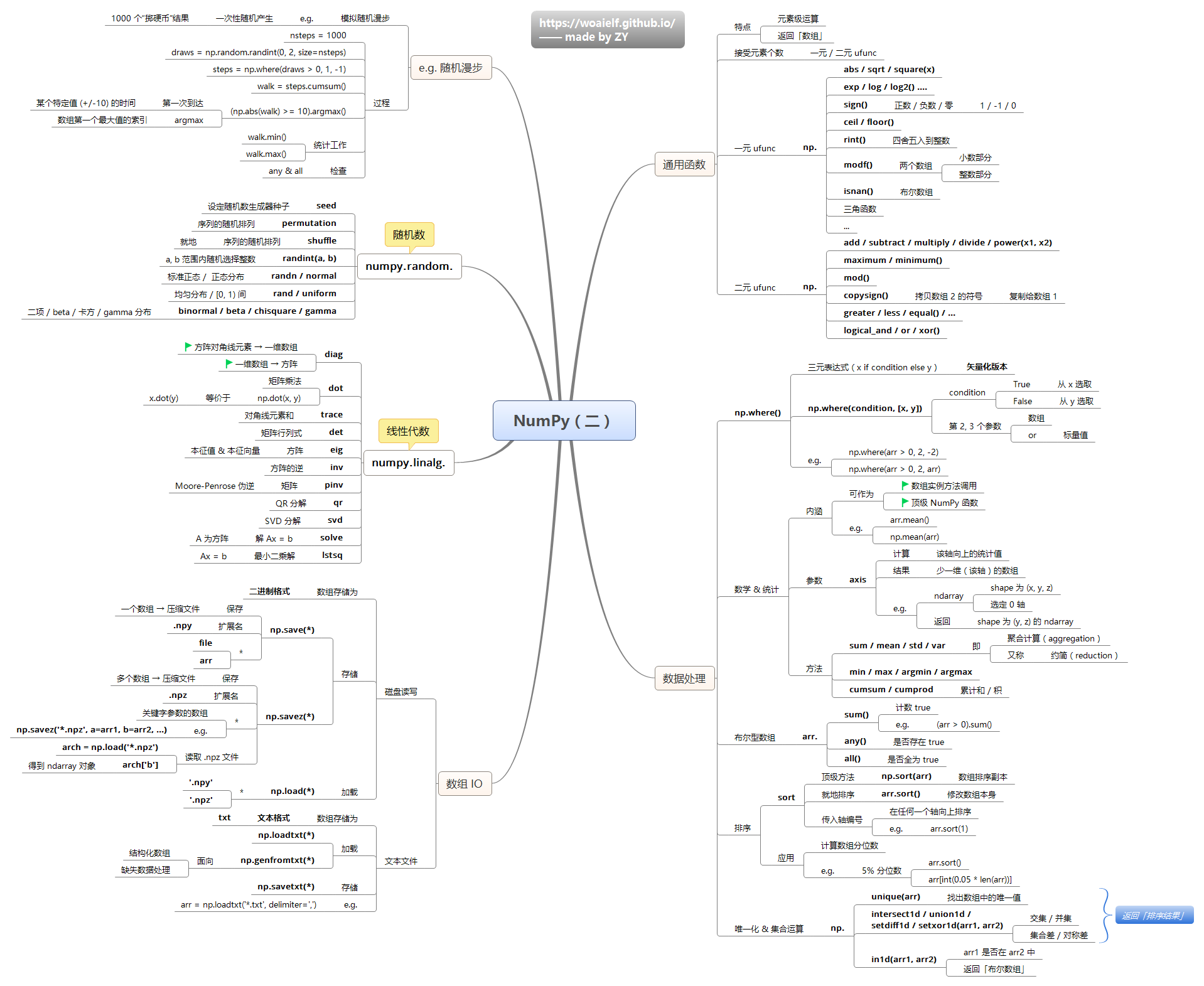
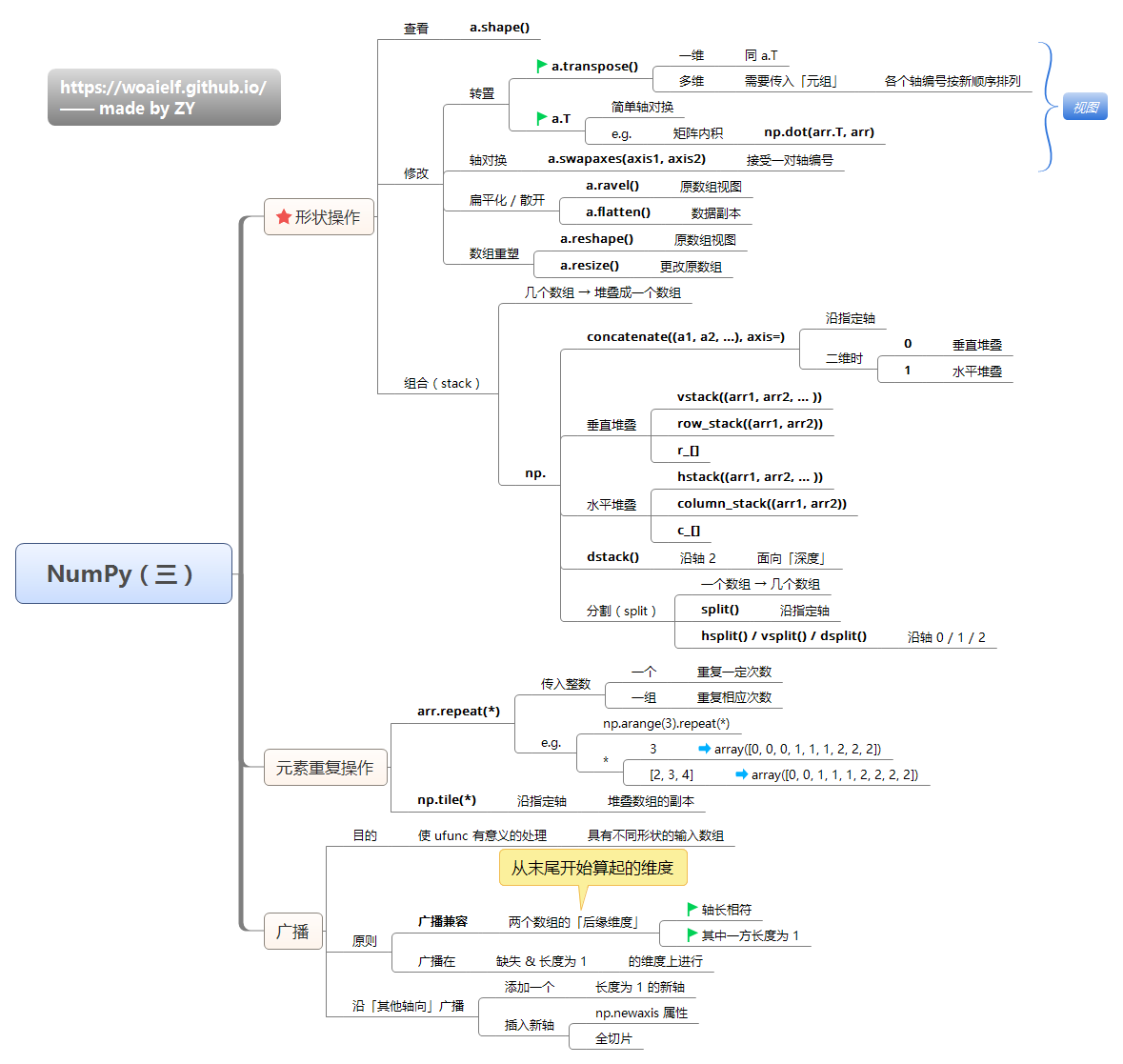
Reference
《Python for data analysis》
NumPy Reference — NumPy v1.12 Manual
基本操作
import numpy as np
a = np.arange(9).reshape(3,3)
b = a.view() # 视图方法创造一个新的数组对象指向同一数据
print 'a=\n', a
print '生成同型矩阵:\n', np.zeros_like(a)
np.empty_like(a), np.ones_like(a)
print 'a形状参数:', len(a), a.size, a.shape
b = [[2,4,1],[1,3,2]]
print np.reshape(b, (3,2))
c = (a==3) | (a==5)
print '数值筛选:下标\n{}\n取出的数值{}'.format(c, a[c])
a[2,1:] = 0
print '分块赋值后的a=\n{}'.format(a)
print 'np.all(a)={}, np.any(a)={}'.format(np.all(a), np.any(a))
a = np.arange(9) # 一维数组
a = a.reshape(3,3) # 一维变二维 (9,) -> (3,3)
print 'a=', a
print 'double:\n', a*2 # 逐个元素处理
a1 = np.repeat(a, 2) # 元素重复几遍(列向)
print 'repeat用法:(2)\n', a1
a1 = np.repeat(a, 2, axis=0) # 行向重复
print 'repeat用法:(2, axis=0)\n', a1
#print(np.repeat(a, (2, 1), axis=0))
a2 = np.tile(a, 2) # 以对象为单位重复
print 'tile用法:(2)\n', a2
a2 = np.tile(a, (2,2)) # 对a重复2*2
print 'tile用法:(2,2)\n', a2
a = np.squeeze(a) # 从数组的形状中删除单维条目,即把shape中为1的维度去掉
创建
创建 numpy 类型数据
import numpy as np
a = np.array([[1, 2], [3, 4]])
print(a)
str = """[[1 2]
[3 4]]"""
b = np.fromstring(str, dtype=int, sep=' ') # str -> array, 仅限一维数组
#b = np.array_str(str) # array -> str
#b = np.array_repr(np.array([1,2])) # array -> repr
b = np.matrix(str.replace('\n', ';')) # str -> matrix
print(b)
# 2,3,4,10,20,30,41,42,51,52,53
str = """[[1219 0 0 12 74 31 0 0 0 0]
[ 6 0 0 0 3 1 0 0 0 0]
[ 14 0 0 9 8 0 0 0 0 0]
[ 12 0 0 97 19 0 0 0 0 0]
[ 119 0 0 14 91 16 0 0 0 0]
[ 22 0 0 4 21 77 0 0 0 0]
[ 0 0 0 0 0 1 0 0 0 0]
[ 9 0 0 1 3 1 0 0 0 0]
[ 1 0 0 0 1 0 0 0 0 0]
[ 2 0 0 2 0 0 0 0 0 0]]"""
# print(str.replace('\n', ';'))
confusion = np.matrix(str.replace('\n', ';'))
print(confusion)
类型转换
numpy 数据类型
- numpy.float32 -> “python float”
- numpy.float64 -> “python float”
- numpy.uint32 -> “python int”
- numpy.int16 -> “python int”
【2024-7-23】用 val.item() 将 numpy 类型转为 Python 类型
import numpy as np
# for example, numpy.float32 -> python float
val = np.float32(0)
pyval = val.item()
print(type(pyval)) # <class 'float'>
# and similar...
type(np.float64(0).item()) # <class 'float'>
type(np.uint32(0).item()) # <class 'int'>
type(np.int16(0).item()) # <class 'int'>
type(np.cfloat(0).item()) # <class 'complex'>
type(np.datetime64(0, 'D').item()) # <class 'datetime.date'>
type(np.datetime64('2001-01-01 00:00:00').item()) # <class 'datetime.datetime'>
type(np.timedelta64(0, 'D').item()) # <class 'datetime.timedelta'>
拼接
Python中numpy数组的合并有很多方法,如
- list.append(): list方法,占用内存大
- np.concatenate():不会占用太多内存
- np.stack()
- np.hstack():水平拼接
- np.vstack():垂直拼接
- np.dstack() 其中最泛用的是第一个和第二个。第一个可读性好,比较灵活,但是占内存大。第二个则没有内存占用大的问题
复制操作:
- np.repeat:复制的是多维数组的每一个元素;axis来控制复制的行和列
- np.tile:复制的是多维数组本身;
import numpy as np
a = np.arange(9) # 一维数组
a = a.reshape(3,3) # 一维变二维 (9,) -> (3,3)
print 'a=', a
print 'double:', a*2 # 逐个元素处理
a1 = np.repeat(a, 2) # 元素重复几遍
print 'repeat用法:', a1
a2 = np.tile(a, 2) # 矩阵重复
print 'tile用法:', a2
a = np.squeeze(a) # 从数组的形状中删除单维条目,即把shape中为1的维度去掉
a = np.arange(9).reshape(3,3)
b = a * 2
print '水平拼接:', np.hstack((a,b)) # 水平拼接
print '水平拼接:', np.concatenate((a,b),axis=1) # 水平拼接
print '垂直拼接:', np.concatenate((a,b),axis=0) # 水平拼接
print '垂直拼接:', np.vstack((a,b))
print '纵轴拼接:', np.dstack((a,b))
#print '列组合:', column_stack(a) # 一维场景,二维同hstack
#print '行组合:', row_stack(a) # 一维场景,二维同vstack
代数&矩阵
import numpy as np
a=[[400,-201],[-800,401]]
rank = np.linalg.matrix_rank(a) # 秩
norm = np.linalg.norm(a) # 范数
det = np.linalg.det(a) # 特征值 -399.99999
inv = np.linalg.inv(a) # 求逆
pinv = np.linalg.pinv(a) # 求伪逆
value, vector = np.linalg.eig(a) # 特征值和特征向量
value = np.linalg.eigvals(a) # 特征值
cond = np.linalg.cond(a) # 条件数 2503,病态
qr = np.linalg.qr(a) # QR分解: 正交矩阵*上三角
svd = np.linalg.svd(a) # SVD分解
# one-hot
print(np.eye(5)) # 5*5单位矩阵
print(np.eye(5,4)) # 5*4矩阵,非方阵
print(np.eye(5,5,k=1)) # 单位阵,对角线上移k位
print(np.eye(5,5,k=-1)) # 单位阵,对角线下移k位
# ------ one-hot 编码-------
#设置类别的数量
num_classes = 10
#需要转换的整数
arr = [1,3,4,5,9]
#将整数转为一个10位的one hot编码
print(np.eye(num_classes)[arr])
# 由one-hot转换为普通np数组
data = [argmax(one_hot)for one_hot in one_hots]
逻辑运算
用 numpy 实现 与或非 运算
import numpy as np
v = np.linspace(1, 9, num=9).reshape([3, 3])
a = np.array([[True, False, False],
[True, True, False],
[False, False, False]])
b = np.array([[True, True, True],
[False, False, False],
[True, False, False]])
c = np.logical_and(a, b) # 与
d = np.logical_not(a) # 非
e = np.logical_or(a, b) # 或
cc = a & b
dd = ~a
ee = a | e
print(c, '\n', cc)
print(d, '\n', dd)
print(e, '\n', ee)
文件处理
Numpy提供了几种数据保存的方法
- 二进制:只能保存为二进制文件,且不能保存当前数据的行列信息
- tofile与fromfile
- save与load:Numpy专用的二进制格式保存数据,它们会自动处理元素类型和形状等信息。savez()提供了将多个数组存储至一个文件的能力,调用load()方法返回的对象,可以使用数组名对各个数组进行读取。这种方法,保存文件的后缀名字一定会被置为.npy
- 文本格式:
- savetxt与loadtxt
#------二进制-------
a.tofile("filename.bin")
b = numpy.fromfile("filename.bin",dtype = **)
np.save("a.npy", a.reshape(3,4))
c = np.load("a.npy")
# 存储多个数组到一个文件
a = np.array([[1,2,3],[4,5,6]])
b = np.arange(0,1.0,0.1)
c = np.sin(b)
np.savez("result.npz", a, b, sin_arr=c) #使用sin_arr命名数组c
r = np.load("result.npz") #加载一次即可
#------文本-------
numpy.savetxt("filename.txt",a)
b = numpy.loadtxt("filename.txt")
问题
汇总遇到过的问题
【2024-3-5】AttributeError: module ‘numpy’ has no attribute ‘object’
解决方法
- numpy版本倒退到支持使用 np.object 的最后一个版本
1.23.4
pip install numpy==1.23.4
# 1.24不行!
Arrow
Apache arrow 是用于内存计算的高性能列式数据存储格式。
PyArrow 是 apache arrow 的 python库,PyArrow 与 NumPy、pandas和内置的ython对象有很好的集成。基于Arrow的C++实现。
- 【2024-3-8】10分钟学会pyarrow
Pandas
详见站内专题: Pandas技术
Python技巧
Python 是机器学习最广泛采用的编程语言,它最重要的优势在于编程的易用性。如果读者对基本的 Python 语法已经有一些了解,那么这篇文章可能会给你一些启发。作者简单概览了 30 段代码,它们都是平常非常实用的技巧,我们只要花几分钟就能从头到尾浏览一遍。
1. 重复元素判定
以下方法可以检查给定列表是不是存在重复元素,它会使用 set() 函数来移除所有重复元素。
def all_unique(lst):
return len(lst) == len(set(lst))
x = [1,1,2,2,3,2,3,4,5,6]
y = [1,2,3,4,5]
all_unique(x) # False
all_unique(y) # True
2. 字符元素组成判定
检查两个字符串的组成元素是不是一样的。
from collections import Counter
def anagram(first, second):
return Counter(first) == Counter(second)
anagram("abcd3", "3acdb") # True
3. 内存占用
下面的代码块可以检查变量 variable 所占用的内存。
import sys
variable = 30
print(sys.getsizeof(variable)) # 24
4. 字节占用
下面的代码块可以检查字符串占用的字节数。
def byte_size(string):
return(len(string.encode('utf-8')))
byte_size(' ') # 4
byte_size('Hello World') # 11
5. 打印 N 次字符串
该代码块不需要循环语句就能打印 N 次字符串。
n = 2;
s ="Programming";
print(s * n);
# ProgrammingProgramming
6. 大写第一个字母
以下代码块会使用 title() 方法,从而大写字符串中每一个单词的首字母。
s = "programming is awesome"
print(s.title())
# Programming Is Awesome
7. 分块
给定具体的大小,定义一个函数以按照这个大小切割列表。
from math import ceil
def chunk(lst, size):
return list(
map(lambda x: lst[x * size:x * size + size],
list(range(0, ceil(len(lst) / size)))))
chunk([1,2,3,4,5],2)
# [[1,2],[3,4],5]
8. 压缩
这个方法可以将布尔型的值去掉,例如(False,None,0,“”),它使用 filter() 函数。
def compact(lst):
return list(filter(bool, lst))
compact([0, 1, False, 2, '', 3, 'a', 's', 34])
# [ 1, 2, 3, 'a', 's', 34 ]
9. 解包
如下代码段可以将打包好的成对列表解开成两组不同的元组。
array = [['a', 'b'], ['c', 'd'], ['e', 'f']]
transposed = zip(*array)
print(transposed)
# [('a', 'c', 'e'), ('b', 'd', 'f')]
10. 链式对比
我们可以在一行代码中使用不同的运算符对比多个不同的元素。
a = 3
print( 2 < a < 8) # True
print(1 == a < 2) # False
11. 逗号连接
下面的代码可以将列表连接成单个字符串,且每一个元素间的分隔方式设置为了逗号。
hobbies = ["basketball", "football", "swimming"]
print("My hobbies are: " + ", ".join(hobbies))
# My hobbies are: basketball, football, swimming
12. 元音统计
以下方法将统计字符串中的元音 (‘a’,’e’,’i’,’o’,’u’) 的个数,它是通过正则表达式做的。
import re
def count_vowels(str):
return len(len(re.findall(r'[aeiou]', str, re.IGNORECASE)))
count_vowels('foobar') # 3
count_vowels('gym') # 0
13. 首字母小写
如下方法将令给定字符串的第一个字符统一为小写。
def decapitalize(string):
return str[:1].lower() + str[1:]
decapitalize('FooBar') # 'fooBar'
decapitalize('FooBar') # 'fooBar'
14. 展开列表
该方法将通过递归的方式将列表的嵌套展开为单个列表。
def spread(arg):
ret = []
for i in arg:
if isinstance(i, list):
ret.extend(i)
else:
ret.append(i)
return ret
def deep_flatten(lst):
result = []
result.extend(
spread(list(map(lambda x: deep_flatten(x) if type(x) == list else x, lst))))
return result
deep_flatten([1, [2], [[3], 4], 5]) # [1,2,3,4,5]
15. 列表的差
该方法将返回第一个列表的元素,其不在第二个列表内。如果同时要反馈第二个列表独有的元素,还需要加一句 set_b.difference(set_a)。
def difference(a, b):
set_a = set(a)
set_b = set(b)
comparison = set_a.difference(set_b)
return list(comparison)
difference([1,2,3], [1,2,4]) # [3]
16. 通过函数取差
如下方法首先会应用一个给定的函数,然后再返回应用函数后结果有差别的列表元素。
def difference_by(a, b, fn):
b = set(map(fn, b))
return [item for item in a if fn(item) not in b]
from math import floor
difference_by([2.1, 1.2], [2.3, 3.4],floor) # [1.2]
difference_by([{ 'x': 2 }, { 'x': 1 }], [{ 'x': 1 }], lambda v : v['x'])
# [ { x: 2 } ]
17. 链式函数调用
你可以在一行代码内调用多个函数。
def add(a, b):
return a + b
def subtract(a, b):
return a - b
a, b = 4, 5
print((subtract if a > b else add)(a, b)) # 9
18. 检查重复项
如下代码将检查两个列表是不是有重复项。
def has_duplicates(lst):
return len(lst) != len(set(lst))
x = [1,2,3,4,5,5]
y = [1,2,3,4,5]
has_duplicates(x) # True
has_duplicates(y) # False
19. 合并两个字典
下面的方法将用于合并两个字典。
def merge_two_dicts(a, b):
c = a.copy() # make a copy of a
c.update(b) # modify keys and values of a with the ones from b
return c
a = { 'x': 1, 'y': 2}
b = { 'y': 3, 'z': 4}
print(merge_two_dicts(a, b))
# {'y': 3, 'x': 1, 'z': 4}
在 Python 3.5 或更高版本中,我们也可以用以下方式合并字典:
def merge_dictionaries(a, b)
return {**a, **b}
a = { 'x': 1, 'y': 2}
b = { 'y': 3, 'z': 4}
print(merge_dictionaries(a, b))
# {'y': 3, 'x': 1, 'z': 4}
20. 将两个列表转化为字典
如下方法将会把两个列表转化为单个字典。
def to_dictionary(keys, values):
return dict(zip(keys, values))
keys = ["a", "b", "c"]
values = [2, 3, 4]
print(to_dictionary(keys, values))
# {'a': 2, 'c': 4, 'b': 3}
21. 使用枚举
我们常用 For 循环来遍历某个列表,同样我们也能枚举列表的索引与值。
list = ["a", "b", "c", "d"]
for index, element in enumerate(list):
print("Value", element, "Index ", index, )
# ('Value', 'a', 'Index ', 0)
# ('Value', 'b', 'Index ', 1)
#('Value', 'c', 'Index ', 2)
# ('Value', 'd', 'Index ', 3)
22. 执行时间
如下代码块可以用来计算执行特定代码所花费的时间。
import time
start_time = time.time()
a = 1
b = 2
c = a + b
print(c) #3
end_time = time.time()
total_time = end_time - start_time
print("Time: ", total_time)
# ('Time: ', 1.1205673217773438e-05)
23. Try else
我们在使用 try/except 语句的时候也可以加一个 else 子句,如果没有触发错误的话,这个子句就会被运行。
try:
2*3
except TypeError:
print("An exception was raised")
else:
print("Thank God, no exceptions were raised.")
#Thank God, no exceptions were raised.
24. 元素频率
下面的方法会根据元素频率取列表中最常见的元素。
def most_frequent(list):
return max(set(list), key = list.count)
list = [1,2,1,2,3,2,1,4,2]
most_frequent(list)
25. 回文序列
以下方法会检查给定的字符串是不是回文序列,它首先会把所有字母转化为小写,并移除非英文字母符号。最后,它会对比字符串与反向字符串是否相等,相等则表示为回文序列。
def palindrome(string):
from re import sub
s = sub('[\W_]', '', string.lower())
return s == s[::-1]
palindrome('taco cat') # True
26. 不使用 if-else 的计算子
这一段代码可以不使用条件语句就实现加减乘除、求幂操作,它通过字典这一数据结构实现:
import operator
action = {
"+": operator.add,
"-": operator.sub,
"/": operator.truediv,
"*": operator.mul,
"**": pow
}
print(action['-'](50, 25)) # 25
27. Shuffle
该算法会打乱列表元素的顺序,它主要会通过 Fisher-Yates 算法对新列表进行排序:
from copy import deepcopy
from random import randint
def shuffle(lst):
temp_lst = deepcopy(lst)
m = len(temp_lst)
while (m):
m -= 1
i = randint(0, m)
temp_lst[m], temp_lst[i] = temp_lst[i], temp_lst[m]
return temp_lst
foo = [1,2,3]
shuffle(foo) # [2,3,1] , foo = [1,2,3]
28. 展开列表
将列表内的所有元素,包括子列表,都展开成一个列表。
def spread(arg):
ret = []
for i in arg:
if isinstance(i, list):
ret.extend(i)
else:
ret.append(i)
return ret
spread([1,2,3,[4,5,6],[7],8,9]) # [1,2,3,4,5,6,7,8,9]
29. 交换值
不需要额外的操作就能交换两个变量的值。
def swap(a, b):
return b, a
a, b = -1, 14
swap(a, b) # (14, -1)
spread([1,2,3,[4,5,6],[7],8,9]) # [1,2,3,4,5,6,7,8,9]
30. 字典默认值
通过 Key 取对应的 Value 值,可以通过以下方式设置默认值。如果 get() 方法没有设置默认值,那么如果遇到不存在的 Key,则会返回 None。
d = {'a': 1, 'b': 2}
print(d.get('c', 3)) # 3
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}