- Web 开发框架
- 结束
Web 开发框架
新技术
- 【2026-3-*】pretext 实时文本排版,作者 chenglou,突破 DOM 树限制,实时渲染复杂页面版面
web框架
为什么要有web框架?(MVC)
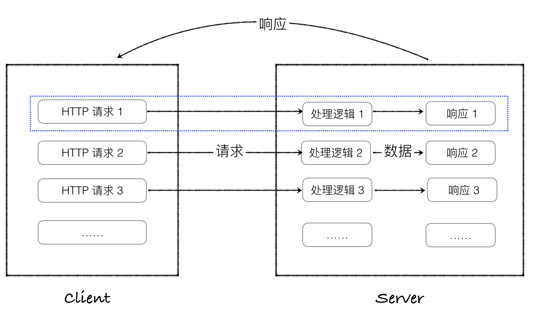
不用框架设计 Python 网页应用程序
- 最原始、直接的办法是使用CGI标准(1998年流行)。
- 从应用角度解释它是如何工作:
- 首先开发一个Python脚本,输出HTML代码
- 然后保存成.cgi扩展名的文件,latestbooks.cgi,上传至服务器
- 通过浏览器访问此文件。
代码示例:
#!/usr/bin/env python
import MySQLdb
# 输出html内容
print "Content-Type: text/html\n"
print "<html><head><title>Books</title></head>"
print "<body>"
print "<h1>Books</h1>"
print "<ul>"
# 连接数据库
connection = MySQLdb.connect(user='me', passwd='letmein', db='my_db')
cursor = connection.cursor()
cursor.execute("SELECT name FROM books ORDER BY pub_date DESC LIMIT 10")
# 取数,组装html元素
for row in cursor.fetchall():
print "<li>%s</li>" % row[0]
print "</ul>"
print "</body></html>"
# 关闭连接
connection.close()
简单、直接,易懂,但是带来的问题:
- 代码冗余:如果多处连接数据库,那每个独立的CGI脚本,不应该重复写数据库连接的代码。 比较实用的办法是写一个共享函数,可被多个代码调用。
- 开发效率低,容易出错:开发者不用关注如何输出Content-Type以及完成所有操作后去关闭数据库,初始化和释放 相关的工作应该交给一些通用的框架来完成。
- 不安全:每个页面都分别对应独立的数据库和密码
- 初学者容易出错:没有Python开发经验的web设计师,页面显示的逻辑与从数据库中读取书本记录分隔开,这样 Web设计师的重新设计不会影响到之前的业务逻辑。
Web框架为应用程序提供了一套程序框架, 这样可以专注于编写清晰、易维护的代码,而无需从头做起。如用django框架实现以上功能:
- 分成4个Python的文件,(models.py , views.py , urls.py ) 和html模板文件 (latest_books.html )
# ① models.py (the database tables)
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=50)
pub_date = models.DateField()
# ② views.py (the business logic)
from django.shortcuts import render_to_response
from models import Book
def latest_books(request):
book_list = Book.objects.order_by('-pub_date')[:10]
return render_to_response('latest_books.html', {'book_list': book_list})
# ③ urls.py (the URL configuration)
from django.conf.urls.defaults import *
import views
urlpatterns = patterns('',
(r'^latest/$', views.latest_books),
)
# ④ latest_books.html (the template)
<html><head><title>Books</title></head>
<body>
<h1>Books</h1>
<ul>
{ % for book in book_list % }
<li>{ { book.name } }</li>
{ % endfor % }
</ul>
</body></html>
不用关心语法细节;只要用心感觉整体的设计。 这里只关注分割后的几个文件:
- models.py 文件主要用一个 Python 类来描述数据表。 称为
模型(model) 。 运用这个类,可以通过简单的 Python 的代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。 - views.py文件包含了页面的业务逻辑。 latest_books()函数叫做
视图。 - urls.py 指出了什么样的 URL 调用什么的视图。 在这个例子中 /latest/ URL 将会调用 latest_books() 这个函数。 如果你的域名是example.com,任何人浏览网址 http://example.com/latest/ 将会调用latest_books()这个函数。
- latest_books.html 是 html
模板,描述了这个页面的设计是如何的。 使用带基本逻辑声明的模板语言,如{ % for book in book_list % }
这些部分松散遵循的模式称为模型-视图-控制器(MVC)。 简单的说, MVC 是一种软件开发的方法,它把代码的定义和数据访问的方法(模型)与请求逻辑 (控制器)还有用户接口(视图)分开来。
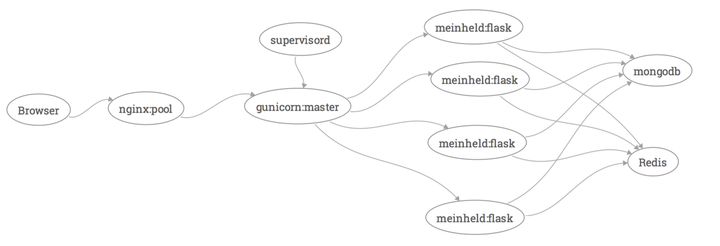
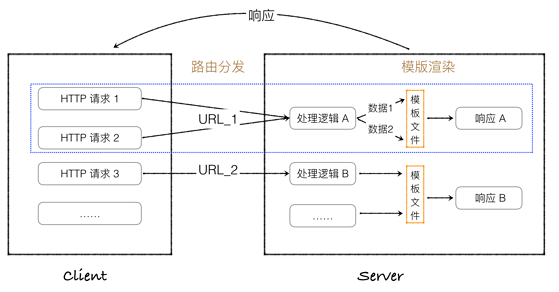
常见web框架
如图:
- 浏览器发起http请求,与服务器交互
- wsgi服务器接收到流量后,转由各个Python web框架处理
- 常规web框架包含三个部分:
- 框架控制逻辑:依次为 路由系统、业务逻辑、耦合适配(数据库+模板)
- 网页静态资源:html、js、css等,一般放static目录下
- 数据库:通过ORM交互
- 路由系统
- 业务处理逻辑
- 适配:模板、数据库
基于python的web框架,如tornado、flask、webpy都是在这个范围内进行增删裁剪的。例如tornado用的是自己的异步非阻塞“wsgi”,flask则只提供了最精简和基本的框架。Django则是直接使用了WSGI,并实现了大部分功能。
对比
- Python web框架的性能响应排行榜
- 从并发性上看Fastapi完全碾压了 Flask (实际上也领先了同为异步框架的tornado 不少)

- 【2020-11-26】Python Web 框架:Django、Flask 与 Tornado 的性能对比,结论
- Django:Python 界最全能的 web 开发框架,battery-include 各种功能完备,可维护性和开发速度一级棒。常有人说 Django 慢,其实主要慢在 Django ORM 与数据库的交互上,所以是否选用 Django,取决于项目对数据库交互的要求以及各种优化。而对于 Django 的同步特性导致吞吐量小的问题,其实可以通过 Celery 等解决,倒不是一个根本问题。Django 的项目代表:Instagram,Guardian。
- Tornado:天生异步,性能强悍是 Tornado 的名片,然而 Tornado 相比 Django 是较为原始的框架,诸多内容需要自己去处理。当然,随着项目越来越大,框架能够提供的功能占比越来越小,更多的内容需要团队自己去实现,而大项目往往需要性能的保证,这时候 Tornado 就是比较好的选择。Tornado项目代表:知乎。
- Flask:微框架的典范,号称 Python 代码写得最好的项目之一。Flask 的灵活性,也是双刃剑:能用好 Flask 的,可以做成 Pinterest,用不好就是灾难(显然对任何框架都是这样)。Flask 虽然是微框架,但是也可以做成规模化的 Flask。加上 Flask 可以自由选择自己的数据库交互组件(通常是 Flask-SQLAlchemy),而且加上 celery +redis 等异步特性以后,Flask 的性能相对 Tornado 也不逞多让,也许Flask 的灵活性可能是某些团队更需要的。
作者:Tim_Lee
Python Web 框架
参考:
Python 常见部署方法有 :
fcgi:用 spawn-fcgi 或者框架自带的工具对各个 project 分别生成监听进程,然后和 http 服务互动wsgi:利用 http 服务的 mod_wsgi 模块来跑各个 project(Web 应用程序或框架简单而通用的 Web 服务器 之间的接口)。uWSGI是一款像 php-cgi 一样监听同一端口,进行统一管理和负载平衡的工具,uWSGI,既不用 wsgi 协议也不用 fcgi 协议,而是自创了一个 uwsgi 的协议,据说该协议大约是 fcgi 协议的 10 倍那么快。
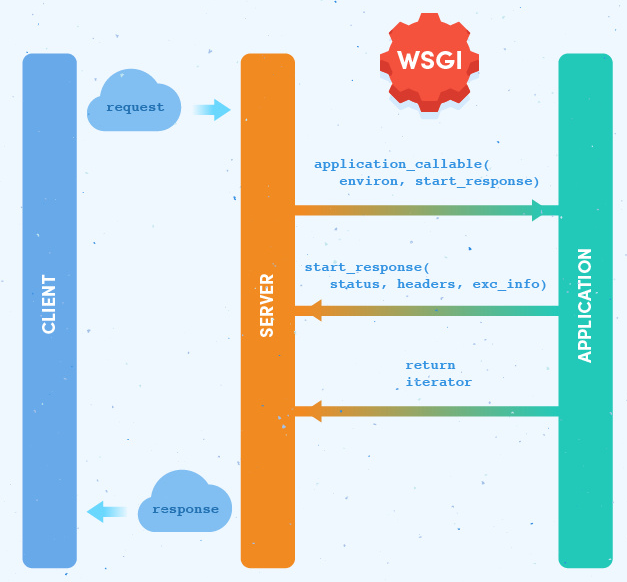
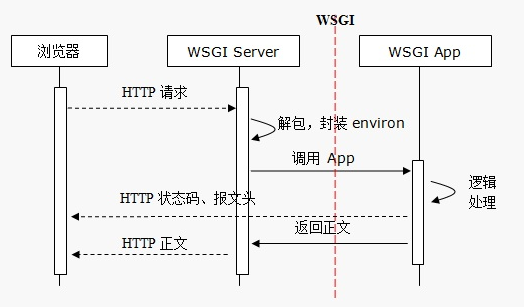
其实 WSGI 是分成 server 和 framework (即 application) 两部分 (当然还有 middleware 中间件)。
严格说 WSGI 只是一个协议, 规范 server 和 framework 之间连接的接口。
- 所有的 Python Web框架都要遵循 WSGI 协议
WSGI 中有一个非常重要的概念:每个Python Web应用都是一个可调用(callable)的对象。
- 在 flask 中,这个对象就是 app = Flask(name) 创建出来的 app,图中的绿色Application部分。
- 要运行web应用,必须有 web server,如熟悉的apache、nginx,或者python中的gunicorn,werkzeug提供的WSGIServer,是图的黄色Server部分
- Server和Application之间怎么通信,就是WSGI的功能,规定了 app(environ, start_response) 的接口,server会调用 application,并传给它两个参数:environ 包含了请求的所有信息,start_response 是 application 处理完之后需要调用的函数,参数是状态码、响应头部还有错误信息。
- WSGI application 非常重要的特点是可以嵌套。可以写个application,调用另外一个 application,然后再返回(类似一个 proxy)。一般来说,嵌套的最后一层是业务应用,中间就是 middleware。好处是可以解耦业务逻辑和其他功能,比如限流、认证、序列化等都实现成不同的中间层,不同的中间层和业务逻辑是不相关的,可以独立维护;而且用户也可以动态地组合不同的中间层来满足不同的需求。
- Flask基于Werkzeug WSGI工具箱和Jinja2 模板引擎。Flask也被称为“microframework”,因为它使用简单的核心,用extension增加其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这些功能:ORM、窗体验证工具、文件上传、各种开放式身份验证技术。Flask是一个核心,而其他功能则是一些插件
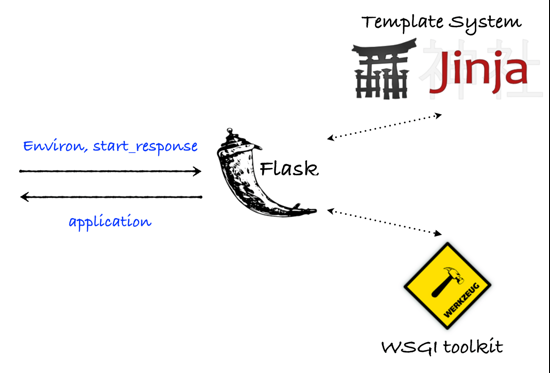
Flask是怎么将代码转换为可见的Web网页?
- 从Web程序的一般流程来看,当客户端想要获取动态资源时,(比如ASP和PHP这类语言写的网站),会发起一个HTTP请求(比如用浏览器访问一个URL),Web应用程序就会在服务器后台进行相应的业务处理(比如对数据库进行操作或是进行一些计算操作等),取出用户需要的数据,生成相应的HTTP响应(当然,如果访问的是 静态资源 ,服务器则会直接返回用户所需的资源,不会进行业务处理)
- 实际应用中,不同的请求可能会调用相同的处理逻辑,即Web开发中所谓的路由分发
- Flask中,使用werkzeug来做路由分发,werkzeug是Flask使用的底层WSGI库(WSGI,全称 Web Server Gateway interface,或者 Python Web Server Gateway Interface,是为 Python 语言定义的Web服务器和Web应用程序之间的一种简单而通用的接口)。
- WSGI将Web服务分成两个部分:服务器和应用程序。
- WGSI服务器只负责与网络相关的两件事:接收浏览器的HTTP请求、向浏览器发送HTTP应答;
- 而对HTTP请求的具体处理逻辑,则通过调用WSGI应用程序进行。
参考:
WSGI server 把服务器功能以 WSGI 接口暴露出来。比如 mod_wsgi 是一种 server, 把 apache 的功能以 WSGI 接口的形式提供出来。
- WSGI framework 就是我们经常提到的 Django 这种框架。不过需要注意的是, 很少有单纯的 WSGI framework , 基于 WSGI 的框架往往都自带 WSGI server。比如 Django、CherryPy 都自带 WSGI server 主要是测试用途, 发布时则使用生产环境的 WSGI server。而有些 WSGI 下的框架比如 pylons、bfg 等, 自己不实现 WSGI server。使用 paste 作为 WSGI server。
- Paste 是流行的 WSGI server, 带有很多中间件。还有 flup 也是一个提供中间件的库。 搞清楚 WSGI server 和 application, 中间件自然就清楚了。除了 session、cache 之类的应用, 前段时间看到一个 bfg 下的中间件专门用于给网站换肤的 (skin) 。中间件可以想到的用法还很多。
- 这里再补充一下, 像 django 这样的框架如何以 fastcgi 的方式跑在 apache 上的。这要用到 flup.fcgi 或者 fastcgi.py (eurasia 中也设计了一个 fastcgi.py 的实现) 这些工具, 它们就是把 fastcgi 协议转换成 WSGI 接口 (把 fastcgi 变成一个 WSGI server) 供框架接入。
- 整个架构是这样的: django -> fcgi2wsgiserver -> mod_fcgi -> apache 。
- 虽然我不是 WSGI 的粉丝, 但是不可否认 WSGI 对 python web 的意义重大。有意自己设计 web 框架, 又不想做 socket 层和 http 报文解析的同学, 可以从 WSGI 开始设计自己的框架。在 python 圈子里有个共识, 自己随手搞个 web 框架跟喝口水一样自然, 非常方便。或许每个 python 玩家都会经历一个倒腾框架的
uWSGI 的主要特点如下:
- 超快的性能。
- 低内存占用(实测为 apache2 的 mod_wsgi 的一半左右)。
- 多app管理。
- 详尽的日志功能(可以用来分析 app 性能和瓶颈)。
- 高度可定制(内存大小限制,服务一定次数后重启等)。
Django就没有用异步,通过线程来实现并发,这也是WSGI普遍的做法,跟tornado不是一个概念
作者:HylaruCoder
简单说下几种部署方式
- Flask 内置 WebServer + Flask App = 弱鸡版本的 Server, 单进程(单 worker) / 失败挂掉 / 不易 Scale
- Gunicorn + Flask App = 多进程(多 worker) / 多线程 / 失败自动帮你重启 Worker / 可简单Scale
- 多 Nginx + 多 Gunicorn + Flask App = 小型多实例 Web 应用,一般也会给 gunicorn 挂 supervisor
在生产环境中, 一般都是请求的走向都是 Nginx -> gunicorn -> flask/django app
第一个问题,Flask 作为一个 Web 框架,内置了一个 webserver, 但这自带的 Server 到底能不能用?
- 官网的介绍: While lightweight and easy to use, Flask’s built-in server is not suitable for production as it doesn’t scale well. Some of the options available for properly running Flask in production are documented here.
- 很显然,内置的 webserver 是能用的。但不适合放在生产环境。这个 server 本来就是给开发者用的。框架本身并不提供生产环境的 web 服务器,SpringBoot 这种内置 Tomcat 生产级服务器 是例外。
- 查看 flask 代码的时候也可以看到这个 WebServer 的名称也叫做 run_simple , too simple 的东西往往不太适合生产。
from werkzeug.serving import run_simple
run_simple('localhost', 5000, application, use_reloader=True)
来看看为什么? 假设我们使用的是 Nginx + Flask Run 来当作生产环境,全部部署在一台机器上。
劣势如下:
- 『单 Worker』只有一个进程在跑所有的请求,而由于实现的简陋性,内置 webserver 很容易卡死。并且只有一个 Worker 在跑请求。在多核 CPU 下,仅仅占用一核。当然,其实也可以多起几个进程。
- 『缺乏 Worker 的管理』接上,加入负载量上来了,Gunicorn 可以调节 Worker 的数量。而这个东西,内置的 Webserver 是不适合做这种事情的。
一言以蔽之,太弱,几个请求就打满了。
第二个问题,Gunicorn 作为 Server 相对而言可以有什么提升。
gunicorn 的优点如下
- 帮忙 scale worker, 进程挂了自动重启
- 用 python 的框架 flask/django/webpy 配置起来都差不多。
- 还有信号机制。可以支持多种配置。
在管理 worker 上,使用了 pre-fork 模型,即一个 master 进程管理多个 worker 进程,所有请求和响应均由 Worker 处理。Master 进程是一个简单的 loop, 监听 worker 不同进程信号并且作出响应。比如接受到 TTIN 提升 worker 数量,TTOU 降低运行 Worker 数量。如果 worker 挂了,发出 CHLD, 则重启失败的 worker, 同步的 Worker 一次处理一个请求。
PS: 如果没有静态资源并且无需反向代理的话,抛弃 Nginx 直接使用 Gunicorn 和 Flask app 也能搞定。
并发与并行
并发与并行:
并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。
并发在同一时刻只有一条指令执行,只不过进程(线程)在CPU中快速切换,速度极快,给人看起来就是“同时运行”的印象,实际上同一时刻只有一条指令进行。但实际上如果我们在一个应用程序中使用了多线程,线程之间的轮换以及上下文切换是需要花费很多时间的。
当并发执行累加操作不超过百万次时,速度会比串行执行累加操作要慢。
- 原因:线程有创建和上下文切换的开销,导致并发执行的速度会比串行慢的情况出现。
多个线程可以执行在单核或多核CPU上,单核CPU也支持多线程执行代码,CPU通过给每个线程分配CPU时间片(机会)来实现这个机制。CPU为了执行多个线程,就需要不停的切换执行的线程,这样才能保证所有的线程在一段时间内都有被执行的机会。
此时,CPU分配给每个线程的执行时间段,称作它的时间片。CPU时间片一般为几十毫秒。CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后切换到下一个任务。
但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
根据多线程的运行状态来说明:多线程环境中,当一个线程的状态由Runnable转换为非Runnable(Blocked、Waiting、Timed_Waiting)时,相应线程的上下文信息(包括CPU的寄存器和程序计数器在某一时间点的内容等)需要被保存,以便相应线程稍后再次进入Runnable状态时能够在之前的执行进度的基础上继续前进。而一个线程从非Runnable状态进入Runnable状态可能涉及恢复之前保存的上下文信息。这个对线程的上下文进行保存和恢复的过程就被称为上下文切换。
摘自:redis为什么这么快
Gunicorn 多进程实现并发
问题
【2022-3-8】gunicorn是多进程,多个进程之间session不共享!详见地址
- Gunicorn中的worker实际上对应的是多进程,默认配置每个worker之间是独立存在的进程, worker会实例化一个新的Flask对象跑起来
解决方法:
- 使用固定的SECRET_KEY,app.config[‘SECRET_KEY’] = ‘XXXXX’ —— 【注】仅限单机有效,无法解决多机部署同步
- 将session数据存放到数据库中, 如使用redis —— 【注】多机有效,更靠谱 这样Gunicorn中使用worker实现的多进程之间就不会出现数据不同步的情况了.
介绍
Gunicorn(“绿色独角兽”)是一个被广泛使用的高性能的python WSGI UNIX HTTP服务器,移植自Ruby的独角兽(Unicorn)项目,使用pre-fork worker模式具有使用非常简单,轻量级的资源消耗,以及高性能等特点。
- pre-fork worker模式: 一个中央master进程来管理一系列的工作进程,master并不知道各个独立客户端。所有的请求和响应完全由工作进程去完成。master通过一个循环不断监听各个进程的信号并作出相应反应,这些信号包括TTIN、TTOU和CHLD。TTIN和TTOU告诉master增加或者减少正在运行的进程数,CHLD表明一个子进程被终止了,在这种情况下master进程会自动重启这个失败的进程。
Gunicorn是主流的WSGI容器之一,它易于配置,兼容性好,CPU消耗很少,它支持多种worker模式:
- 同步worker:默认模式,也就是一次只处理一个请求。最简单的同步工作模式
- 异步worker:通过Eventlet、Gevent实现的异步模式,gevent和eventlet都是基于greenlet库,利用python协程实现的
- 异步IOWorker:目前支持gthread和gaiohttp; gaiohttp利用aiohttp库实现异步IO,支持web socket; gthread采用的事线程工作模式,利用线程池管理连接
- Tronado worker:tornado框架,利用python Tornado框架实现
工作模式是通过work_class参数配置的值:缺省值:sync
- sync
- Gevent
- Eventlet
- tornado
- gaiohttp
- gthread
参考:

Gunicorn(Green Unicorn)是一个WSGI HTTP服务器,python自带的有个web服务器,叫做 wsgiref,Gunicorn的优势在于,它使用了pre-fork worker模式,gunicorn在启动时,会在主进程中预先fork出指定数量的worker进程来处理请求,gunicorn依靠操作系统来提供负载均衡,推荐的worker数量是(2*$num_cores)+1 python是单线程的语言,当进程阻塞时,后续请求将排队处理。所用pre-fork worker模式,极大提升了服务器请求负载。
安装
pip install gunicorn
使用, 编写wsgi接口, test.py代码
from flask import Flask
app = Flask(__name__)
def application(environ,start_response):
start_response('200 OK',[('Content-Type','text/html')])
return b'<h1>Hello,web!</h1>'
使用gunicorn监听请求,运行以下命令
- -w:指定fork的worker进程数
- -b:指定绑定的端口
- test:模块名,python文件名
- application:变量名,python文件中可调用的wsgi接口名称
# 启动并发进程, 注意:不是. 而是 :
gunicorn -w 2 -b 0.0.0.0:8000 test:application
# 查询配置信息
gunicorn -h
gunicorn相关参数
- 1) -c CONFIG,–config=CONFIG, 指定一个配置文件(py文件)
- 2) -b BIND,–bind=BIND 与指定socket进行板顶
- 3) -D,–daemon 后台进程方式运行gunicorn进程
- 4) -w WORKERS,–workers=WORKERS, 工作进程的数量
- 获取CPU个数: python -c ‘import multiprocessing;print(multiprocessing.cpu_count())’
- 5) -k WORKERCLASS,–worker-class=WORKERCLASS, 工作进程类型,包括sync(默认),eventlet,gevent,tornado,gthread,gaiohttp
- 6) –backlog INT 最大挂起的连接数
- 7)–log-level LEVEL 日志输出等级
- 8) –access-logfile FILE 访问日志输出文件
- 9)–error-logfile FILE 错误日志输出文件
gunicorn可以写在配置文件中,下面举列说明配置文件的写法,gunicorn.conf.py
bind = "0.0.0.0:8000"
workers = 2
常用项目配置
# config.py
import os
import gevent.monkey
gevent.monkey.patch_all()
import multiprocessing
# debug = True # 用于开发环境,非线上环境
# 开启debug项后,在启动gunicorn的时候可以看到所有可配置项的配置
loglevel = 'debug' # debug、info、warning、error、critical
bind = "0.0.0.0:7001"
# 日志文件。 注意:如果log不存在,启动会报错
pidfile = "log/gunicorn.pid"
accesslog = "log/access.log"
errorlog = "log/debug.log"
daemon = True # 开启后台运行
# 启动的进程数
workers = multiprocessing.cpu_count()
worker_class = 'gevent'
x_forwarded_for_header = 'X-FORWARDED-FOR'
运行以下命令:
# 使用配置文件启动服务
gunicorn -c gunicorn.conf.py test:application
【2021-11-30】项目中使用的gunicorn配置文件:gunicorn_config.py
# !/usr/bin/env python
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2021 ke.com, Inc. All Rights Reserved
# **************************************************************************
# * @file gunicorn并发配置
# * @author wangqiwen004@ke.com
# * @date 2021/11/30 12:17
# **************************************************************************
__author__ = "wangqiwen004@ke.com"
__copyright__ = "Copyright of beike (2021)."
import os
from numbers import Number
import psutil
core_number = psutil.cpu_count(logical=True)
if isinstance(core_number, Number):
workers_num = core_number
else:
workers_num = 5
port = os.getenv('PORT', '7399')
bind = '0.0.0.0:{}'.format(port) # 绑定地址
backlog = 128
workers = workers_num
print('Child process number: {} with port: {}'.format(workers, port))
graceful_timeout = 3
proc_name = 'bwbd_server'
preload_app = True
# */* vim: set expandtab ts=4 sw=4 sts=4 tw=400: */
启动脚本:服务入口脚本 start_all.py, 里面的app是flask初始化后的对象
- gunicorn –pid=run.pid –config gunicorn_config.py –daemon start_all:app
#! /bin/bash
export LANG='UTC-8'
export LC_ALL='en_US.UTF-8'
echo "MATRIX_CODE_DIR:" "$MATRIX_CODE_DIR"
if [ 0"$MATRIX_CODE_DIR" = "0" ];then
export MATRIX_CODE_DIR="`pwd`"
export MATRIX_APPLOGS_DIR="."
export MATRIX_PRIVDATA_DIR="."
fi
LOG_FILE=$MATRIX_APPLOGS_DIR/log
if [ ! -e $LOG_FILE ];then
mkdir $LOG_FILE
fi
export ENVTYPE=`cat "$MATRIX_CODE_DIR"/env_flag.in`
echo "condition is: "$ENVTYPE
case $1 in
start)
echo "run start ... "$MATRIX_PRIVDATA_DIR
source $MATRIX_PRIVDATA_DIR/venv/bin/activate
cd $MATRIX_CODE_DIR
#source install.sh
# gunicorn --pid=run.pid --config gunicorn_config.py --daemon start_all:app
$MATRIX_PRIVDATA_DIR/venv/bin/gunicorn \
--pid=$LOG_FILE/run.pid \
--config bin/gunicorn_config.py \
--daemon start_all:app \
deactivate
echo "start with nohup"
;;
run)
source $MATRIX_PRIVDATA_DIR/venv/bin/activate
cd $MATRIX_CODE_DIR
#source install.sh
$MATRIX_PRIVDATA_DIR/venv/bin/gunicorn \
--pid=$LOG_FILE/run.pid \
--config bin/gunicorn_config.py \
start_all:app
;;
*)
echo "Using option{start|run|stop}"
;;
esac
uvicorn
类似gunicorn
FastAPI 推荐使用 uvicorn 来运行服务,Uvicorn 是基于 uvloop 和 httptools 构建的闪电般快速的 ASGI 服务器
- uvloop 用于替换标准库 asyncio 中的事件循环,使用 Cython 实现,它非常快,可以使 asyncio 的速度提高 2-4 倍。asyncio 不用我介绍吧,写异步代码离不开它。
- httptools 是 nodejs HTTP 解析器的 Python 实现。
- ASGI 服务器是异步网关协议接口,一个介于网络协议服务和 Python 应用之间的标准接口,能够处理多种通用的协议类型,包括 HTTP,HTTP2 和 WebSocket。ASGI 帮助 Python 在 Web 框架上和 Node.JS 及 Golang 相竟争,目标是获得高性能的 IO 密集型任务,ASGI 支持 HTTP2 和 WebSockets,WSGI 是不支持的。
- Python 仍缺乏异步的网关协议接口,ASGI 的出现填补了这一空白.
安装:
- pip install uvicorn
服务启动
- 命令行方式
# main.py里的app应用
uvicorn main:app
# --reload: 热启动,方便代码的开发
uvicorn main:app --reload
# 指定host和port
uvicorn main:app --reload --host 192.XXX.XXX --port 8001
uvicorn main:app --host 10.200.24.101 --port 8094
- Python代码方式, demo.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def root():
return {"name":"wangqien", "value":23}
# 异步接口
@app.get("/index")
async def index():
return {"name":"wangqien", "value":23}
@app.get("/items/{item_id}")
async def read_item(item_id: str, q: str = None, short: bool = False):
item = {"item_id": item_id}
if q:
item.update({"q": q})
if not short:
item.update(
{"description": "This is an amazing item that has a long description"}
)
return item
if __name__ == '__main__':
import uvicorn
uvicorn.run(app=app)
# 自定义host、port
uvicorn.run(app, host="192.XXX.XXX", port=8001)
# 设置日志级别
uvicorn.run("demo:app", host="127.0.0.1", port=5000, log_level="info")
# 设置热更新
uvicorn.run(app="demo:app", host="127.0.0.1", port=8000, reload=True, debug=True)
supervisor
supervisor用作流程管理器,应该:
- 用其文件描述符将套接字移交给uvicorn,supervisor始终将其用作0,并且必须在本fcgi-program节中进行设置。或为每个uvicorn进程使用UNIX域套接字。
一个简单的主管配置可能看起来像这样: administratord.conf:
[supervisord]
[fcgi-program:uvicorn]
socket=tcp://localhost:8000
command=venv/bin/uvicorn --fd 0 example:App
numprocs=4
process_name=uvicorn-%(process_num)d
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
运行: supervisord -n
supervisor实现程序的后台守护运行, 也可以实现开机自动重启
# 下载安装supervisor, 请注意此时所在目录还是项目目录 /root/xubobo/project
pip install supervisor
# 初始化配置文件
echo_supervisord_conf > supervisor.conf
# 此时目录下多了一个配置文件, 修改此配置文件
vim supervisor.conf
# 在配置文件最底部加入如下配置
[program: githook]
command=/root/xubobo/githook/venv/bin/gunicorn -w 3 -b 0.0.0.0:5000 app:app ; 启动命令
directory=/root/xubobo/githook ; 项目的文件夹路径
startsecs=0 ; 启动时间
stopwaitsecs=0 ; 终止等待时间
autostart=true ; 是否自动启动
autorestart=true ; 是否自动重启
stdout_logfile=/data/python/SMT/log/gunicorn.log ; log 日志
stderr_logfile=/data/python/SMT/log/gunicorn.err ; 错误日志
# 指定配置文件来启动supervisord
supervisord -c supervisor.conf
# 检查状态
supervisorctl -c supervisor.conf status
# 可以看到 githook 应用已经是RUNNING状态了
supervisor的常用命令
# 通过配置文件启动supervisor
supervisord -c supervisor.conf
# 察看supervisor的状态
supervisorctl -c supervisor.conf status
# 重新载入 配置文件
supervisorctl -c supervisor.conf reload
# 启动指定/所有 supervisor管理的程序进程
supervisorctl -c supervisor.conf start [all]|[appname]
# 关闭指定/所有 supervisor管理的程序进程
supervisorctl -c supervisor.conf stop [all]|[appname]
gevent/grequests
用requests向某个url批量发起POST请求,交互的内容很简单,若开启多线程去访问占用太多资源不合理。 想到了使用协程gevent,grequests 模块相当于是封装了gevent的requests模块
安装
- 若是联网安装,直接 pip install grequests 完事
- 若是离线安装,需要先安装 greenlet模块 和 gevent模块 ,再安装 grequests模块
# coding:utf-8
adata = json.dumps({"key": "value"})
header = {"Content-type": "appliaction/json", "Accept":"application/json"}
url = "http://www.baidu.com"
task = []
req = grequests.request("POST", url=url, data=adata, headers=header)
task.append(req)
# 此处map的requests参数是装有实例化请求对象的列表,其返回值也是列表, size参数可以控制并发的数量
resp = grequests.map(task)
print resp
# 查看返回值的属性值,我们关注的一般就是text json links url headers 等了
print dir(resp[0])
#==============
urls = ["http://www.baidu.com", "http://www.baidu.com", "http://www.baidu.com"]
req = (grequests.get(u) for u in urls)
resp = grequests.map(req)
grequests和requests的对比
- grequests比单个的requests请求要快一点,当网络延迟较高时,grequests优势比较明显,修改 map的size参数进行尝试,合理的设置size值,不要太大,超过阀值再大也没有用
# coding:utf-8
import grequests
import time
import json
import requests
adata = json.dumps({"key": "value"})
header = {"Content-type": "appliaction/json", "Accept":"application/json"}
def use_grequests(num):
task = []
urls = ["http://hao.jobbole.com/python-docx/" for i in range(num)]
while urls:
url = urls.pop(0)
rs = grequests.request("POST", url, data=adata, headers=header)
task.append(rs)
resp = grequests.map(task, size=5)
return resp
def use_requests(num):
urls = ["http://hao.jobbole.com/python-docx/" for i in range(num)]
index = 0
while urls:
url = urls.pop(0)
resp = requests.post(url=url, headers=header, data=adata)
index += 1
if index % 10 == 0:
print u'目前是第{}个请求'.format(index)
def main(num):
time1 = time.time()
finall_res = use_requests(num)
print finall_res
time2 = time.time()
T = time2 - time1
print u'use_requests发起{}个请求花费了{}秒'.format(num, T)
print u'正在使用grequests模块发起请求...'
time3 = time.time()
finall_res2 = use_grequests(num)
print finall_res2
time4 = time.time()
T2 = time4 - time3
print u'use_grequests发起{}个请求花费了{}秒'.format(num, T2)
if __name__ == '__main__':
main(100)
手动使用gevent配合requests模块
# coding:utf-8
import gevent
import time
from gevent import monkey
import requests
monkey.patch_all()
datali = [x for x in range(100)]
task = []
def func(i):
print u'第{}个请求'.format(i)
url = "http://hao.jobbole.com/python-docx/"
resp = requests.get(url=url)
return resp
time1 = time.time()
for i in datali:
task.append(gevent.spawn(func, i))
res = gevent.joinall(task)
print len(res)
time2 = time.time()
T = time2 - time1
print u'消耗了{}秒'.format(T)
Flask
Flask Web框架用于快速开发Web应用程序。
flask 内核内置了两个最重要的组件,所有其它组件都通过易扩展的插件系统集成进来。
这两个内置的组件分别是 werkzeug 和 jinja2 。
werkzeug编写 Python WSGI 程序的工具包,它的结构设计和代码质量在开源社区广受褒扬,其源码被尊为Python技术领域最值得阅读的开源库之一。jinja2功能极为强大的模板系统,完美支持unicode中文,每个模板都运行在安全的沙箱环境中,使用jinja2编写的模板代码非常优美。
【2021-3-18】flask 1.0和1.1版本差异,api返回值类型不同,前者不能直接返回python的dict类型,要用json.dumps转换为string,后者可直接返回dict结构,自动转换

Web 原理
Web应用程序 (World Wide Web)诞生最初为了利用互联网交流工作文档

一切从客户端发起请求开始
- 所有Flask程序都必须创建一个程序实例。
- 当客户端想要获取资源时,一般会通过浏览器发起HTTP请求。
- 此时,Web服务器使用一种名为WEB服务器网关接口的
WSGI(Web Server Gateway Interface)协议,把来自客户端的请求都交给Flask程序实例。 - Flask使用
Werkzeug来做路由分发(URL请求和视图函数之间的对应关系)。根据每个URL请求,找到具体的视图函数。 - 在Flask程序中,路由一般是通过程序实例的
装饰器实现。- 通过调用视图函数,获取到数据后,把数据传入HTML模板文件中,模板引擎负责渲染HTTP响应数据,然后由Flask返回响应数据给浏览器,最后浏览器显示返回的结果。
- 安装:
pip install flask
werkzeug 用法
from werkzeug.wrappers import Request, Response
@Request.application
def application(request):
return Response('Hello World!')
if __name__ == '__main__':
from werkzeug.serving import run_simple
run_simple('localhost', 4000, application)
快速入门
【2022-3-2】Python Web 开发框架Flask快速入门
网站项目开发基本模式

一个Web应用程序包含了三个部分,前端,服务端,数据库。
- 数据库负责存储数据,作为数据存储和查询的引擎;
- 前端网站作为用户直接查看的页面,负责展示数据。
- Flask 负责对数据库进行操作,将数据库中的数据渲染至前端。
大致工作:
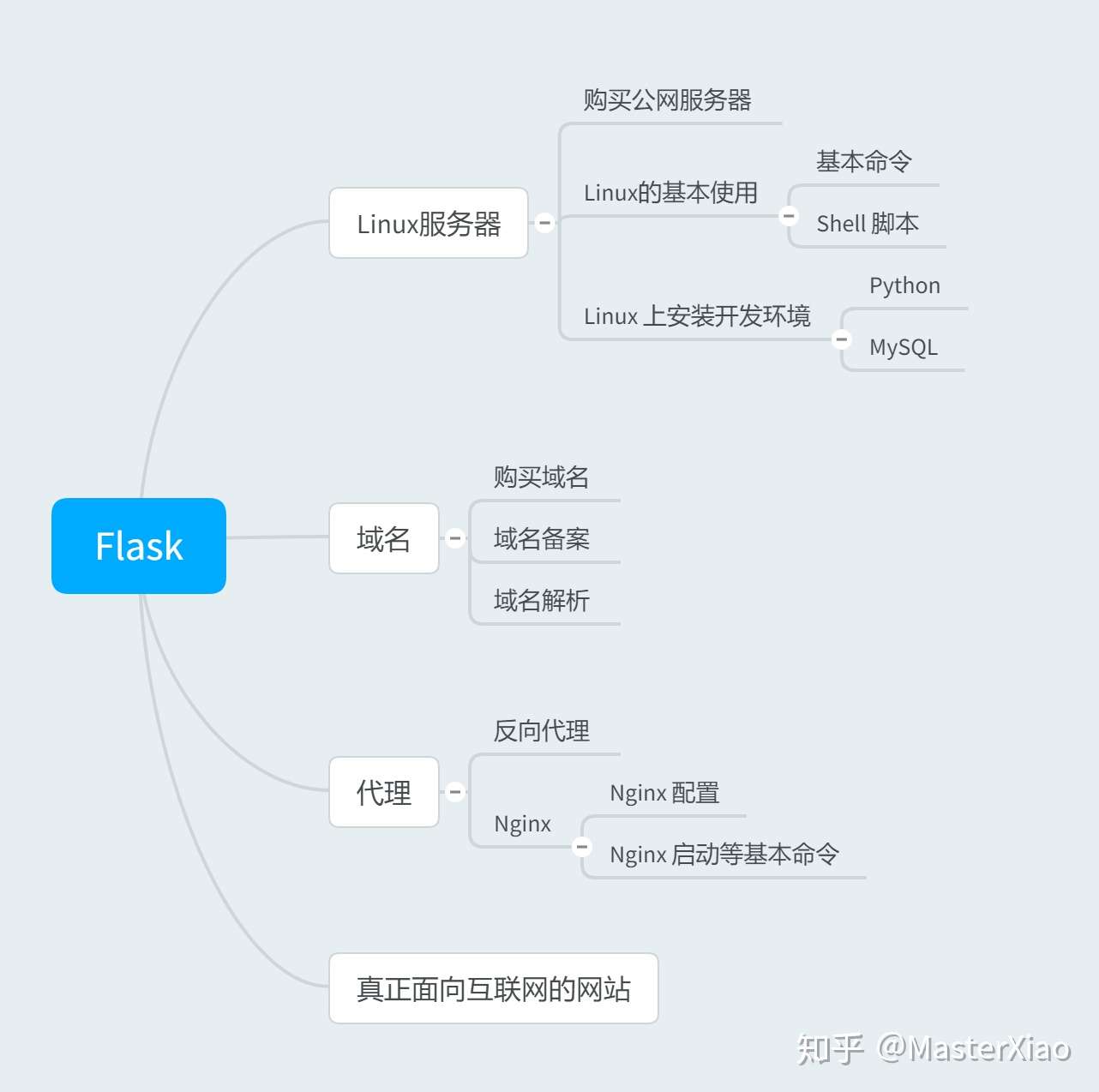
原始版本
新建Python文件,比如 helloFlask.py
from flask import Flask
app = Flask(__name__)
# 日志系统配置
handler = logging.FileHandler('app.log', encoding='UTF-8')
#设置日志文件,和字符编码
logging_format = logging.Formatter(
'%(asctime)s - %(levelname)s - %(filename)s - %(funcName)s - %(lineno)s - %(message)s')
handler.setFormatter(logging_format)
app.logger.addHandler(handler)
#设置日志存储格式,也可以自定义日志格式满足不同的业务需求
@app.route('/')
def hello_world():
app.logger.info('hi...')
# app.logger.info('message info is %s', message, exc_info=1)。
#app.logger.exception('%s', e) # 异常信息
return 'Hello World!'
if __name__ == '__main__':
#app.run() # 本地访问:只能从你自己的计算机上访问
app.run(host='0.0.0.0') # 外网可访问
- 运行:
python helloFlask.py - 浏览器上输入 http://127.0.0.1:5000/,便会看到 Hello World! 字样

改进:路由
不访问索引页,而是直接访问某个页面?
route()装饰器把一个函数绑定到对应的 URL 上
@app.route('/')
def index():
return 'Index Page'
# 路由到子页面
# 注:也可以在一个函数上附着多个规则
@app.route('/hello')
def hello():
return 'Hello World'
改进:模板
怎么给服务器的用户呈现一个漂亮的页面呢?
- 肯定需要用到 html、css ,如果想要更炫, 还要加入 js
- 问题:这么一大堆字段串全都写到视图中通过 return 返回,太麻烦了,因为定义字符串是不会出任何效果和错误的,如果有一个专门定义前端页面的地方就好了。
- Flask 配备了 Jinja2 模板引擎。
jinja2 是功能强大的模板系统,完美支持unicode中文,每个模板都运行在安全的沙箱环境中,使用jinja2编写的模板代码非常优美。
jinjia2示例:
- 使用时,去掉 % 与大括号中间的空格(规避jekyll语法)
{ % extends "layout.html" % }
{ % block body % }
<ul>
{ % for user in users % }
<li><a href="{ { user.url } }">{ { user.username } }</a></li>
{ % endfor % }
</ul>
{ % endblock % }
Flask 会在 templates 文件夹里寻找模板。
- 如在
templates下面创建模板index.html
from flask import render_template
# render_template() 方法来渲染模板
@app.route('/index/')
def hello(name=None):
name = "张三"
return render_template('index.html', name=name)
html 文件调用变量
<!doctype html>
<title>Hello from Flask</title>
<!-- 使用模板判断语句:if else endif -->
{ % if name % }
<h1>Hello { { name } }!</h1>
{ % else % }
<h1>Hello World!</h1>
{ % endif % }
<!-- 使用循环语句 -->
{ % for i in range(1,10) % }
{ % for j in range(1,i+1) % }
{ { j } } x { { i } } = { { i*j } }
{ % endfor % }
<br>
{ % endfor % }
输入 127.0.0.1:5000/index,即可看到:
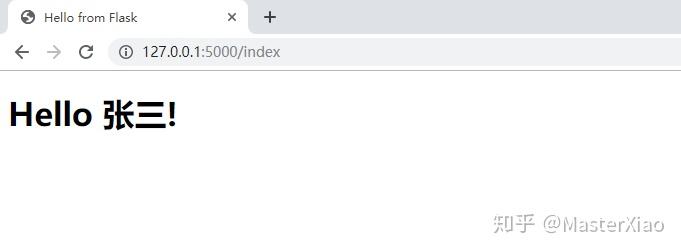
模板中使用变量:
- 在 html 中定义 {{ 变量名 } }
- 在 flask 中设定变量的key 和 value:
render_template('index.html', name="张三")
改进:缓存(全局变量)
【2022-3-2】Github上最受欢迎的Python轻量级框架Flask入门
为了避免重复计算,将已经计算的 pi(n)值缓存起来,下次直接查询。同时不再只返回一个单纯字符串,返回一个json串,里面有一个字段cached用来标识当前的结果是否从缓存中直接获取的。
- 为什么缓存类PiCache需要使用RLock呢?
- 因为考虑到多线程环境下, Python字典读写不是完全线程安全的,需要使用锁来保护一下数据结构。
import math
import threading
from flask import Flask, request
from flask.json import jsonify
app = Flask(__name__)
class PiCache(object):
""" 计算圆周率 """
def __init__(self):
self.pis = {}
self.lock = threading.RLock() # 使用进程锁
def set(self, n, pi):
with self.lock: # 开锁
self.pis[n] = pi
def get(self, n):
with self.lock: # 开锁
return self.pis.get(n)
# 全局变量用于缓存
cache = PiCache()
@app.route("/pi")
def pi():
n = int(request.args.get('n', '100'))
result = cache.get(n)
if result:
return jsonify({"cached": True, "result": result})
s = 0.0
for i in range(1, n):
s += 1.0/i/i
result = math.sqrt(6*s)
cache.set(n, result)
return jsonify({"cached": False, "result": result})
if __name__ == '__main__':
app.run()
运行 python flask_pi.py,打开浏览器访问 http://localhost:5000/pi?n=1000000,可以看到页面输出
{
"cached": false,
"result": 3.141591698659554
}
改进:分布式缓存(redis)
上面的缓存仅仅是内存缓存,有问题:
- 进程重启后,缓存结果消失,下次计算又得重新开始。
- 如果开启第二个端口5001来提供服务,那这第二个进程也无法享受第一个进程的内存缓存,而必须重新计算。 所以这里要引入分布式缓存Redis来共享计算缓存,避免跨进程重复计算,避免重启重新计算。
import math
import redis
from flask import Flask, request
from flask.json import jsonify
app = Flask(__name__)
class PiCache(object):
# 使用redis实现分布式缓存
def __init__(self, client):
self.client = client # redis连接
def set(self, n, result):
# 设置值
self.client.hset("pis", str(n), str(result))
def get(self, n):
# 获取值
result = self.client.hget("pis", str(n))
if not result:
return
return float(result)
client = redis.StrictRedis() # redis客户端
cache = PiCache(client) # 缓存值
@app.route("/pi")
def pi():
n = int(request.args.get('n', '100'))
result = cache.get(n)
if result:
return jsonify({"cached": True, "result": result})
s = 0.0
for i in range(1, n):
s += 1.0/i/i
result = math.sqrt(6*s)
cache.set(n, result)
return jsonify({"cached": False, "result": result})
if __name__ == '__main__':
app.run('127.0.0.1', 5000)
改进:数据库
sql语句操作数据库
ORM框架
O是object,也就类对象的意思R是relation,翻译成中文是关系,也就是关系数据库中数据表的意思M是mapping,是映射的意思。
ORM框架把类和数据表进行了一个映射,可以通过类和类对象就能操作所对应的表格数据。
- ORM框架还可以根据设计的类自动生成数据库中的表格,省去了自己建表的过程。
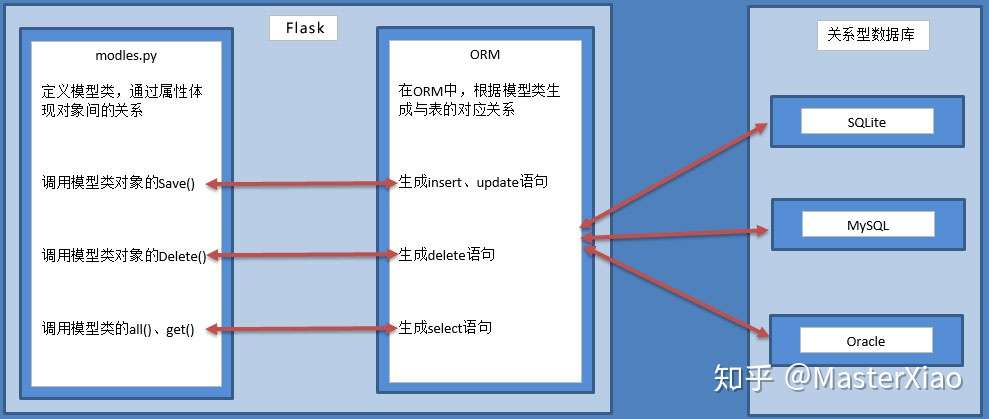
用Flask进行数据库开发的步骤如下:
- 配置连接数据库的选项
- 定义模型类
- 通过类和对象完成数据库增删改查操作
| 名字 | 备注 |
| SQLALCHEMY_DATABASE_URI | 用于连接的数据库 URI 。例如: sqlite:////tmp/test.dbmysql://username:password@server/db |
| SQLALCHEMY_BINDS | 一个映射 binds 到连接 URI 的字典。更多 binds 的信息见用 Binds 操作多个数据库。 |
| SQLALCHEMY_ECHO | 如果设置为Ture, SQLAlchemy 会记录所有 发给 stderr 的语句,这对调试有用。(打印sql语句) |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或启用查询记录。查询记录 在调试或测试模式自动启用。更多信息见get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式禁用原生 unicode 支持。当使用 不合适的指定无编码的数据库默认值时,这对于 一些数据库适配器是必须的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是引擎默认值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 设定连接池的连接超时时间。默认是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自动回收连接。这对 MySQL 是必要的, 它默认移除闲置多于 8 小时的连接。注意如果 使用了 MySQL , Flask-SQLALchemy 自动设定 这个值为 2 小时。 |
字段类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
字段属性:
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
from flask import Flask
# Flask中使用mysql数据库,需要安装一个flask-sqlalchemy的扩展
# pip install flask-sqlalchemy
# 要连接mysql数据库,还需要安装 flask-mysqldb
# pip install flask-mysqldb
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
#设置连接数据库的URL
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/Flask_test'
#设置每次请求结束后会自动提交数据库中的改动
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
class Role(db.Model):
# 定义表名
__tablename__ = 'roles'
# 定义列对象,字段属性
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
us = db.relationship('User', backref='role')
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True, index=True)
email = db.Column(db.String(64),unique=True)
pswd = db.Column(db.String(64))
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
if __name__ == '__main__':
db.drop_all() # 删表
db.create_all() # 建表
ro1 = Role(name='admin')
ro2 = Role(name='user')
#db.session.add(ro1) # 插入数据——单挑
db.session.add_all([ro1,ro2]) # 插入数据——多条
db.session.commit() # 修改已有表,需要额外commit才生效
us1 = User(name='wang',email='wang@163.com',pswd='123456',role_id=ro1.id)
us2 = User(name='zhang',email='zhang@189.com',pswd='201512',role_id=ro2.id)
us3 = User(name='chen',email='chen@126.com',pswd='987654',role_id=ro2.id)
us4 = User(name='zhou',email='zhou@163.com',pswd='456789',role_id=ro1.id)
db.session.add_all([us1,us2,us3,us4])
db.session.commit()
User.query.get(name='wang') # 查询主键
#查询roles表id为1的角色
ro1 = Role.query.get(1)
#查询该角色的所有用户
ro1.us
User.query.all() # 返回所有查询结果
User.query.first() # 返回查询结果第一个
User.query.filter_by(name='wang').all() # 查询:wang
User.query.filter(User.name!='wang').all() # 逻辑非,返回名字不等于wang的所有数据
User.query.filter(User.name.endswith('g')).all() # 模糊查询
# 逻辑与
from sqlalchemy import and_
User.query.filter(and_(User.name!='wang',User.email.endswith('163.com'))).all()
# 逻辑或
from sqlalchemy import or_
User.query.filter(or_(User.name!='wang',User.email.endswith('163.com'))).all()
user = User.query.first()
user.name = 'dong' # 更新数据
User.query.filter_by(name='zhang').update({'name':'li'}) # 更新数据:update
db.session.commit()
db.session.delete(user) # 删除数据
db.session.commit()
User.query.all()
app.run(debug=True)
表结构
| 列名 | 说明 | 类型 |
|---|---|---|
| id | 表id(自动递增,主键) | int |
| provincename | 省名 | varchar |
| cityname | 省会名 | varchar |
| usernumber | 用户数量 | int |
完整代码:
from flask import Flask,render_template,request,redirect
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
#设置数据库连接
host='127.0.0.1'
user='root'
passwd="wangqiwen"
port=3306
db='newhouse_database'
#设置连接数据库的URL
#app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:asd8283676@127.0.0.1:3306/web'
app.config['SQLALCHEMY_DATABASE_URI'] = f'mysql://{user}:{passwd}@{host}:{port}/{db}'
app.logger.info(app.config['SQLALCHEMY_DATABASE_URI'])
#设置每次请求结束后会自动提交数据库中的改动
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app) # [2022-3-2]注意:先配置app再包sql!否则报错!https://blog.csdn.net/weixin_45455015/article/details/100059108
#设置数据库连接
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:asd8283676@127.0.0.1:3306/web'
#定义模型
class City(db.Model):
# 表模型
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
provincename = db.Column(db.String(255))
cityname = db.Column(db.String(255))
usernumber = db.Column(db.Integer)
#查询所有数据
@app.route("/select")
def selectAll():
cityList = City.query.order_by(City.id.desc()).all()
return render_template("index.html",city_list = cityList)
@app.route('/')
def index():
return selectAll()
#添加数据
@app.route('/insert',methods=['GET','POST'])
def insert():
#进行添加操作
province = request.form['province']
cityname = request.form['city']
number = request.form['number']
city = City(provincename=province,cityname=cityname,usernumber=number)
db.session.add(city)
db.session.commit()
#添加完成重定向至主页
return redirect('/')
@app.route("/insert_page")
def insert_page():
#跳转至添加信息页面
return render_template("insert.html")
#删除数据
@app.route("/delete",methods=['GET'])
def delete():
#操作数据库得到目标数据,before_number表示删除之前的数量,after_name表示删除之后的数量
id = request.args.get("id")
city = City.query.filter_by(id=id).first()
db.session.delete(city)
db.session.commit()
return redirect('/')
#修改操作
@app.route("/alter",methods=['GET','POST'])
def alter():
# 可以通过请求方式来改变处理该请求的具体操作
# 比如用户访问/alter页面 如果通过GET请求则返回修改页面 如果通过POST请求则使用修改操作
if request.method == 'GET':
id = request.args.get("id")
province = request.args.get("provincename")
cityname = request.args.get("cityname")
usernumber = request.args.get("usernumber")
city = City(id = id,provincename=province,cityname=cityname,usernumber = usernumber)
return render_template("alter.html",city = city)
else:
#接收参数,修改数据
id = request.form["id"]
province = request.form['province']
cityname = request.form['city']
number = request.form['number']
city = City.query.filter_by(id = id).first()
city.provincename = province
city.cityname = cityname
city.usernumber = number
db.session.commit()
return redirect('/')
if __name__ == "__main__":
db.create_all() # 必须有,自动建表
app.run(debug = True,host='0.0.0.0',port=8080)
定义模板:
- index.html
- alter.html
- insert.html
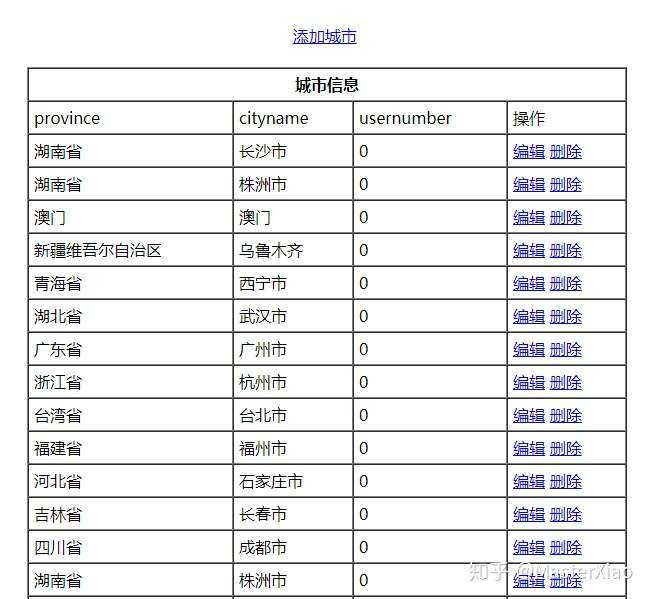
网页美化:
- 将Layui相关文件放入项目的static目录下(static目录用于存放静态文件如css,js文件可以让网站看起来更加美观)
- 添加到各个html页面:引入LayUI需要在HTML文件中导入LayUI的CSS文件和JS模块
效果:
改进:域名
购买域名
- 公网机器上部署好的服务器,还只能通过公网访问,要想通过域名能访问网站,还需要设置域名解析。
- 要给 web服务配置上域名,还需要到服务商网站购买域名,例如:阿里云、腾讯云等等。 域名备案
- 购买了域名之后无法直接使用,需要进行域名备案,同样在服务商那里备案即可。
改进:反向代理
反向代理
- 域名解析完成后,要做反向代理。
- 使用
nginx服务器可以作为域名代理服务。
通过这几个步骤就可以让web服务成为面向互联网的web服务啦。
可以参考最简单 nginx 配置文件配置如下:
- 这个代表将 http://flask.codejiaonang.com 域名,映射到本地web服务器的8848端口
server {
listen 80;
autoindex on;
server_name flask.codejiaonang.com;
access_log /usr/local/nginx/logs/access.log combined;
location / {
proxy_pass http://127.0.0.1:8848/;
}
}
扩展:类形式api,MethodView
【2022-3-2】Github上最受欢迎的Python轻量级框架Flask入门
类似Django,Flask也支持类形式的API编写方式。下面使用Flask原生支持的MethodView来改写一下上面的服务
import math
import redis
from flask import Flask, request
from flask.json import jsonify
from flask.views import MethodView
app = Flask(__name__)
class PiCache(object):
def __init__(self, client):
self.client = client
def set(self, n, result):
self.client.hset("pis", str(n), str(result))
def get(self, n):
result = self.client.hget("pis", str(n))
if not result:
return
return float(result)
client = redis.StrictRedis()
cache = PiCache(client)
class PiAPI(MethodView):
def __init__(self, cache):
self.cache = cache
def get(self, n):
result = self.cache.get(n)
if result:
return jsonify({"cached": True, "result": result})
s = 0.0
for i in range(1, n):
s += 1.0/i/i
result = math.sqrt(6*s)
self.cache.set(n, result)
return jsonify({"cached": False, "result": result})
# as_view提供了参数可以直接注入到MethodView的构造器中
# 我们不再使用request.args,而是将参数直接放进URL里面,这就是RESTFUL风格的URL
app.add_url_rule('/pi/<int:n>', view_func=PiAPI.as_view('pi', cache))
if __name__ == '__main__':
app.run('127.0.0.1', 5000)
flask默认的MethodView挺好用,但是也不够好用,它无法在一个类里提供多个不同URL名称的API服务。所以接下来引入flask的扩展flask-classy来解决这个问题。
import math
import redis
from flask import Flask
from flask.json import jsonify
from flask_classy import FlaskView, route # 扩展
app = Flask(__name__)
# pi的cache和fib的cache要分开
class PiCache(object):
def __init__(self, client):
self.client = client
def set_fib(self, n, result):
self.client.hset("fibs", str(n), str(result))
def get_fib(self, n):
result = self.client.hget("fibs", str(n))
if not result:
return
return int(result)
def set_pi(self, n, result):
self.client.hset("pis", str(n), str(result))
def get_pi(self, n):
result = self.client.hget("pis", str(n))
if not result:
return
return float(result)
client = redis.StrictRedis()
cache = PiCache(client)
class MathAPI(FlaskView):
@route("/pi/<int:n>")
def pi(self, n):
result = cache.get_pi(n)
if result:
return jsonify({"cached": True, "result": result})
s = 0.0
for i in range(1, n):
s += 1.0/i/i
result = math.sqrt(6*s)
cache.set_pi(n, result)
return jsonify({"cached": False, "result": result})
@route("/fib/<int:n>")
def fib(self, n):
result, cached = self.get_fib(n)
return jsonify({"cached": cached, "result": result})
def get_fib(self, n): # 递归,n不能过大,否则会堆栈过深溢出stackoverflow
if n == 0:
return 0, True
if n == 1:
return 1, True
result = cache.get_fib(n)
if result:
return result, True
result = self.get_fib(n-1)[0] + self.get_fib(n-2)[0]
cache.set_fib(n, result)
return result, False
MathAPI.register(app, route_base='/') # 注册到app
if __name__ == '__main__':
app.run('127.0.0.1', 5000)
app配置
app = Flask(__name__) # 这是实例化一个Flask对象,最基本的写法
app = Flask(__name__, template_folder='templates', static_url_path='/xxxxxx')
# Flask初始化
def __init__(self, import_name, static_path=None, static_url_path=None,
static_folder='static', template_folder='templates',
instance_path=None, instance_relative_config=False,
root_path=None):
app.run('127.0.0.1', 5000) # 设置ip、端口
app.run(debug=True) # debug = True 是指进入调试模式
其它参数:
- template_folder:模板所在文件夹的名字
- root_path:可以不用填,会自动找到,当前执行文件,所在目录地址,在return render_template时会将上面两个进行拼接,找到对应的模板地址
- static_folder:静态文件所在文件的名字,默认是static,可以不用填
- static_url_path:静态文件的地址前缀,写成什么,访问静态文件时,就要在前面加上这个
- 在根目录下创建目录,templates和static,则return render_template时,可以找到里面的模板页面;
- 如在static文件夹里存放11.png,在引用该图片时,静态文件地址为:/xxxxxx/11.png
- instance_relative_config:默认为False,当设置为True时,from_pyfile会从instance_path指定的地址下查找文件。
- instsnce_path:指定from_pyfile查询文件的路径,不设置时,默认寻找和app.run()的执行文件同级目录下的instance文件夹;如果配置了instance_path(注意需要是绝对路径),就会从指定的地址下里面的文件
- instance_path和instance_relative_config是配合来用的、这两个参数是用来找配置文件的,当用 app.config.from_pyfile(‘settings.py’)这种方式导入配置文件的时候会用到
路由
添加路由关系的本质:
- 将url和视图函数封装成一个Rule对象,添加到Flask的url_map字段中
绑定方式
路由绑定的两种方式
#方式一
@app.route('/index.html',methods=['GET','POST'],endpoint='index')
def index():
return 'Index'
#方式二
def index():
return "Index"
self.add_url_rule(rule='/index.html', endpoint="index", view_func=index, methods=["GET","POST"]) #endpoint是别名
# 或
app.add_url_rule(rule='/index.html', endpoint="index", view_func=index, methods=["GET","POST"])
app.view_functions['index'] = index
路由参数
可传入参数:
@app.route('/user/<username>') # 常用 不加参数的时候默认是字符串形式的
@app.route('/post/<int:post_id>') # 常用 #指定int,说明是整型的
@app.route('/post/<float:post_id>')
@app.route('/post/<path:path>')
@app.route('/login', methods=['GET', 'POST'])
# 类型说明
DEFAULT_CONVERTERS = {
'default': UnicodeConverter,
'string': UnicodeConverter,
'any': AnyConverter,
'path': PathConverter,
'int': IntegerConverter,
'float': FloatConverter,
'uuid': UUIDConverter,
}
反向生成URL: url_for
endpoint(“name”) # 别名,相当于django中的name
from flask import Flask, url_for
@app.route('/index',endpoint="xxx") #endpoint是别名
def index():
v = url_for("xxx")
print(v)
return "index"
@app.route('/zzz/<int:nid>',endpoint="aaa") #endpoint是别名
def zzz(nid):
v = url_for("aaa",nid=nid)
print(v)
return "index2"
# =============== 子域名访问============
@app.route("/static_index", subdomain="admin")
def static_index():
return "admin.bjg.com"
# ===========动态生成子域名===========
@app.route("/index",subdomain='<xxxxx>')
def index(xxxxx):
return "%s.bjg.com" %(xxxxx,)
传参
传递请求参数的方式有两种
- 一是打包成 JSON 之后再传递
- 一般用
POST请求来传递参数,然后用 FLASK 中 request 模块的 get_json() 方法获取参数。
- 一般用
- 二是直接放进 URL 进行传递 。
- 示例URL: http://127.0.0.1:5000/login?name=%27%E8%83%A1%E5%86%B2%27&nid=2
- 一般用
GET请求传递参数,然后从 request.args 中用 get() 方法获取参数 - 不过需要说明的是用 POST 请求也可以通过 URL 的方式传递参数,而且获取参数的方式与 GET 请求相同。
总结
获取请求数据,及相应
requestrequest.form# POST 请求数据request.args# GET 请求数据,不是完全意义上的字典,通过.to_dict可以转换成字典request.querystring# GET请求,bytes 形式的
responsereturn render_tempalte()return redirect()return ""v = make_response(返回值)# 把返回值包在函数里面,然后再通过.set_cookie绑定cookie等
- session
- 存在浏览器上,并且是加密的
- 依赖于:secret_key
request
from flask import request, jsonify
@app.route('/', methods = ["GET", "POST"])
def post_data():
# 假设有如下 JSON 数据
#{"obj": [{"name":"John","age":"20"}] }
# 可通过 request 的 args 属性来获取GET参数
name = request.args.get("name")
age = request.args.get("age")
# ----- POST -----
# 方法一
data = request.get_json() # 获取 JSON 数据,转为 dict
# data = pd.DataFrame(data["obj"]) # 获取参数并转变为 DataFrame 结构
# 方法二
# data = request.json # 获取 JOSN 数据
# data = data.get('obj') # 以字典形式获取参数
# ======= 统一 ======
if request.method == 'POST':
data = request.json # json 格式
data = request.form.to_dict() # form 格式
data = request.values # ?
elif request.method == 'GET':
data = request.args
# 经过处理之后得到要传回的数据
res = some_function(data)
# 将 DataFrame 数据再次打包为 JSON 并传回
# 方法一
res = '\{\{"obj": {} \} }'.format(res.to_json(orient = "records", force_ascii = False))
# 方法二
# res = jsonify({"obj":res.to_json(orient = "records", force_ascii = False)})
return res
response
返回内容
file
通过 form 表单 POST 上传文件,服务器端如何接收?
- 错误: 继续使用 request.form 获取文件 —— 失败!
- 解法:通过 request.files 获取文件
参考
发送文件
客户端发送文件
- requests.post 发起文件传输
- 注意: get 请求也可以!
import json
import os
import requests
# (1) 单个文件
cur_file = r'e:\a.txt'
# post 请求
resp = requests.post(URL, files={'file':open(cur_file, 'rb')}, headers=headers)
# get 请求
resp = requests.get(URL, files={'file':open(cur_file, 'rb')})
# (2) 批量传输文件
src_dir = 'E:\\a'
for root, dirs, files in os.walk(src_dir, topdown=True):
for name in files:
file = os.path.join(root, name)
files_t = {'file': ('new_' + name, open(file, 'rb'))}
headers = {'File-Name': 'new_' + name}
r = requests.post("http://192.123.123.123:1234/a", files=files_t, headers=headers)
print(r.text)
print(r)
接收文件
服务端接收文件
import json
from flask import Flask, request
app = Flask(__name__)
@app.route("/a", methods=["POST"])
def save_file():
data = request.files # 获取接收到的文件
print(type(data), data)
file = data['file']
print(file.filename) # 获取文件名
print(type(request.headers))
print(request.headers) # 获取 header
print(request.headers.get('File-Name'))
# 文件写入磁盘
file.save(file.filename)
return "已接收保存"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=1234)
示例: 服务器存储文件
完整示例
目录结构
__init__.py
start.py
save_file/
src_file/
主脚本 start.py
- 启动服务 python start.py
- 访问
127.0.0.1:7000/, 点击按钮上传文件 - 下载文件
127.0.0.1:7000/download?filename=2.gif
# coding:utf8
import os
from string import Template
from flask import Flask, request, send_file
from werkzeug.utils import secure_filename
app = Flask(__name__)
pwd = os.path.dirname(__file__)
#定义文件的保存路径和文件名尾缀
UPLOAD_FOLDER = os.path.join(pwd,'save_file')
ALLOWED_EXTENSIONS = {'txt', 'pdf', 'png', 'jpg', 'jpeg', 'gif'}
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
HOST = "127.0.0.1"
PORT = 7000
@app.route('/index')
def index():
"""
返回一个网页端提交的页面
:return:
"""
html = Template("""
<!DOCTYPE html>
<html>
<body>
<form action = "http://$HOST:$PORT/upload" method = "POST"
enctype = "multipart/form-data">
<input type = "file" name = "file" />
<input type = "submit"/>
</form>
</body>
</html>
""")
html = html.substitute({"HOST": HOST, "PORT": PORT})
return html
def allowed_file(filename):
"""
检验文件名尾缀是否满足格式要求
:param filename:
:return:
"""
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
"""
上传文件到save_file文件夹: 同名文件直接覆盖
以requests上传举例
wiht open('路径','rb') as file_obj:
rsp = requests.post('http://localhost:5000/upload,files={'file':file_obj})
print(rsp.text) --> file uploaded successfully
"""
if 'file' not in request.files:
return "No file part"
file = request.files['file']
if file.filename == '':
return 'No selected file'
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
return 'file uploaded successfully'
return "file uploaded Fail"
@app.route("/download")
def download_file():
"""
下载src_file目录下面的文件
eg:下载当前目录下面的文件,eg:http://localhost:7000/download?filename=123.tar
:return:
"""
file_name = request.args.get('filename')
print(f'文件名: {file_name=}')
# file_path = os.path.join(pwd,'src_file',file_name)
file_path = os.path.join(pwd,'save_file',file_name)
if os.path.isfile(file_path):
return send_file(file_path, as_attachment=True)
else:
return "The downloaded file does not exist"
import requests
def getFile(filename):
"""
下载文件
"""
URL=f"http://{HOST}:{PORT}/upload"
# f = open(r'D:\work\tools\file_server\templates\upload.html','rb')
f = open(filename)
rsp = requests.get(URL, files={'file':f})
print(rsp.text)
if __name__ == '__main__':
app.run(host=HOST, port=PORT)
问题
- 服务端直接判断文件存在性, 返回字符串,缺乏系统化方法 —— 数据库查询
- UI 简陋
示例: 数据库查询文件
参考
目录结构
app.py:包含Flask应用程序的后端代码file_mapping.db:SQLite 数据库文件,跟踪上传的文件uploads/:存储上传的文件
完整代码见 GitHub flask_learn
app模块化 blueprint
一个py文件中写入了很多路由, 维护代码非常麻烦,时长出现重名,错乱,然而并不能想普通py代码一样直接导入别的路由 → 路由模块化
Flask 提供特有的模块化处理方式blueprint
Blueprint 是存储操作方法的容器,这些操作在这个Blueprint 被注册到一个应用之后就可以被调用,Flask 可以通过Blueprint来组织URL以及处理请求。
Flask使用Blueprint让应用实现模块化,在Flask中,Blueprint具有如下属性:
- 一个应用app可以具有多个Blueprint
- 可以将一个Blueprint注册到任何一个未使用的URL下比如 “/”、“/sample”或者子域名
- 在一个应用中,一个模块可以注册多次
- Blueprint可以单独具有自己的模板、静态文件或者其它的通用操作方法,它并不是必须要实现应用的视图和函数的
- 在一个应用初始化时,就应该要注册需要使用的Blueprint 但是一个Blueprint并不是一个完整的应用,它不能独立于应用运行,而必须要注册到某一个应用中。
蓝图/Blueprint对象用起来和一个应用/Flask对象差不多,最大的区别在于蓝图对象没有办法独立运行,必须将它注册到一个应用对象上才能生效
使用蓝图可以分为三个步骤, 应用启动后,通过/admin/可以访问到蓝图中定义的视图函数
# 1,创建一个蓝图对象
admin=Blueprint('admin',__name__)
# 2,在这个蓝图对象上进行操作,注册路由,指定静态文件夹,注册模版过滤器
@admin.route('/')
def admin_home():
return 'admin_home'
# 3,在应用对象上注册这个蓝图对象
app.register_blueprint(admin,url_prefix='/admin')
运行机制
- 蓝图是保存了一组将来可以在应用对象上执行的操作,注册路由就是一种操作. 当在应用对象上调用 route 装饰器注册路由时,这个操作将修改对象的url_map路由表. 然而,蓝图对象根本没有路由表,当我们在蓝图对象上调用route装饰器注册路由时,它只是在内部的一个延迟操作记录列表defered_functions中添加了一个项
- 当执行应用对象的 register_blueprint() 方法时,应用对象将从蓝图对象的 defered_functions 列表中取出每一项,并以自身作为参数执行该匿名函数,即调用应用对象的 add_url_rule() 方法,这将真正的修改应用对象的路由表
蓝图的url前缀
- 当我们在应用对象上注册一个蓝图时,可以指定一个url_prefix关键字参数(这个参数默认是/)
- 在应用最终的路由表 url_map中,在蓝图上注册的路由URL自动被加上了这个前缀,这个可以保证在多个蓝图中使用相同的URL规则而不会最终引起冲突,只要在注册蓝图时将不同的蓝图挂接到不同的自路径即可
url_for
url_for('admin.index') # /admin/
全局变量
- 参考: Flask 上下文全局变量
- Flask 在分发请求之前激活(或推送)程序和请求上下文,请求处理完成后再将其删除。程 序上下文被推送后,就可以在线程中使用 current_app 和 g 变量。类似地,请求上下文被 推送后,就可以使用 request 和 session 变量。如果使用这些变量时我们没有激活程序上 下文或请求上下文,就会导致错误。
| 变量名 | 上下文 | 说明 |
|---|---|---|
| current_app | 程序上下文 | 当前激活程序的程序实例 |
| g | 程序上下文 | 处理请求时用作临时存储的对象,每次请求都会重设这个变量 |
| request | 请求上下文 | 请求对象,封装了客户端发出的HTTP请求中的内容 |
| session | 请求上下文 | 用户会话,用于存储请求之间需要记住的值的词典 |
- 代码示例:flask中4种全局变量
session
Session设置
- 代码
from flask import Flask,session
import os
from datetime import timedelta
app = Flask(__name__)
app.secret_key = "sdsfdsgdfgdfgfh" # 设置session时,必须要加盐,否则报错
app.config['SECRET_KEY'] = os.urandom(24)
app.config['PERMANENT_SESSION_LIFETIME'] = timedelta(days=7)
#SESSION_TYPE = "redis"
# 添加数据到session中
# 操作session的时候 跟操作字典是一样的。
# SECRET_KEY
@app.route('/')
def hello_world():
session['username'] = 'zhangsan'
# 如果没有指定session的过期时间,那么默认是浏览器关闭就自动结束
# 如果设置了session的permanent属性为True,那么过期时间是31天。
session.permanent = True
return 'Hello World!'
@app.route('/get/')
def get():
# session['username'] 如果username不存在则会抛出异常
# session.get('username') 如果username不存在会得到 none 不会报错 推荐使用
return session.get('username')
@app.route('/delete/')
def delete():
print(session.get('username'))
session.pop('username')
print(session.get('username'))
return 'success'
@app.route('/clear/')
def clear():
print(session.get('username'))
# 删除session中的所有数据
session.clear()
print(session.get('username'))
return 'success'
if __name__ == '__main__':
app.run(debug=True)
分布式session
- 【2020-9-11】以上代码仅适用单机版,如果部署在分布式环境,流量负载均衡,会出现session找不到的现象
- 分布式session一致性:
- 客户端发送一个请求,经过负载均衡后该请求会被分配到服务器中的其中一个,由于不同服务器含有不同的web服务器(例如Tomcat),不同的web服务器中并不能发现之前web服务器保存的session信息,就会再次生成一个JSESSIONID,之前的状态就会丢失
- 【2020-9-18】Flask Session共享的一种实现方式:使用出问题(待核实原因),改用redis直接存储session变量
import os
from flask import Flask, session, request
from flask_session import Session
from redis import Redis
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'redis' #session存储格式为redis
app.config['SESSION_REDIS'] = Redis( #redis的服务器参数
host='192.168.1.3', #服务器地址
port=6379) #服务器端口
app.config['SESSION_USE_SIGNER'] = True #是否强制加盐,混淆session
app.config['SECRET_KEY'] = os.urandom(24) #如果加盐,那么必须设置的安全码,盐
app.config['SESSION_PERMANENT'] = False #sessons是否长期有效,false,则关闭浏览器,session失效
app.config['PERMANENT_SESSION_LIFETIME'] = 3600 #session长期有效,则设定session生命周期,整数秒,默认大概不到3小时。
Session(app)
@app.route('/')
def default():
return session.get('key', 'not set')
@app.route('/test/')
def test():
session['key'] = 'test'
return 'ok'
@app.route('/set/')
def set():
arg = request.args.get('key')
print(arg)
session['key'] = arg
return 'ok'
@app.route('/get/')
def get():
return session.get('key', 'not set')
@app.route('/pop/')
def pop():
session.pop('key')
return session.get('key', 'not set')
@app.route('/clear/')
def clear():
session.clear()
return session.get('key', 'not set')
if __name__ == "__main__":
app.run(debug=True)
- 解决方法:
- 方案一:客户端存储
- 直接将信息存储在cookie中
- cookie是存储在客户端上的一小段数据,客户端通过http协议和服务器进行cookie交互,通常用来存储一些不敏感信息
- 缺点:
- 数据存储在客户端,存在安全隐患
- cookie存储大小、类型存在限制
- 数据存储在cookie中,如果一次请求cookie过大,会给网络增加更大的开销
- 方案二:session复制
- session复制是小型企业应用使用较多的一种服务器集群session管理机制,在真正的开发使用的并不是很多,通过对web服务器(例如Tomcat)进行搭建集群。
- 存在的问题:
- session同步的原理是在同一个局域网里面通过发送广播来异步同步session的,一旦服务器多了,并发上来了,session需要同步的数据量就大了,需要将其他服务器上的session全部同步到本服务器上,会带来一定的网路开销,在用户量特别大的时候,会出现内存不足的情况
- 优点:
- 服务器之间的session信息都是同步的,任何一台服务器宕机的时候不会影响另外服务器中session的状态,配置相对简单
- Tomcat内部已经支持分布式架构开发管理机制,可以对tomcat修改配置来支持session复制,在集群中的几台服务器之间同步session对象,使每台服务器上都保存了所有用户的session信息,这样任何一台本机宕机都不会导致session数据的丢失,而服务器使用session时,也只需要在本机获取即可
- 方案三:session绑定
- Nginx介绍:Nginx是一款自由的、开源的、高性能的http服务器和反向代理服务器
- Nginx能做什么:反向代理、负载均衡、http服务器(动静代理)、正向代理
- 如何使用nginx进行session绑定
- 利用nginx的反向代理和负载均衡,之前是客户端会被分配到其中一台服务器进行处理,具体分配到哪台服务器进行处理还得看服务器的负载均衡算法(轮询、随机、ip-hash、权重等),但是我们可以基于nginx的ip-hash策略,可以对客户端和服务器进行绑定,同一个客户端就只能访问该服务器,无论客户端发送多少次请求都被同一个服务器处理
- 缺点:
- 容易造成单点故障,如果有一台服务器宕机,那么该台服务器上的session信息将会丢失
- 前端不能有负载均衡,如果有,session绑定将会出问题
- 优点:
- 配置简单
- 方案四:session持久化到数据库
- 如:基于redis存储session方案
- 原理:就不用多说了吧,拿出一个数据库,专门用来存储session信息。保证session的持久化。
- 优点:服务器出现问题,session不会丢失
- 缺点:如果网站的访问量很大,把session存储到数据库中,会对数据库造成很大压力,还需要增加额外的开销维护数据库。
- 优点:
- 企业中使用的最多的一种方式
- spring为我们封装好了spring-session,直接引入依赖即可
- 数据保存在redis中,无缝接入,不存在任何安全隐患
- redis自身可做集群,搭建主从,同时方便管理
- 缺点:
- 多了一次网络调用,web容器需要向redis访问
- 基于redis存储session方案流程示意图

- 方案五:session复制
- terracotta实现session复制
- Terracotta的基本原理是对于集群间共享的数据,当在一个节点发生变化的时候,Terracotta只把变化的部分发送给Terracotta服务器,然后由服务器把它转发给真正需要这个数据的节点。对服务器session复制的优化。
SESSION_TYPE = "redis"
#在settings.py中写上这句话就能够让flask把session写在 redis中去
SESSION_REDIS = Redis(host='192.168.0.94', port='6379')
- 【2020-9-24】深夜,我偷听到程序员要对Session下手……,演变历史:
- 单机服务器(静态) → 单机服务器(动态) → 分布式服务器(Nginx) → Redis独立存储 → Token时代
- (1)单台Web服务器-静态:一个web服务器,每天处理的不过是一些静态资源文件,像HTML、CSS、JS、图片等等,按照HTTP协议的规范处理请求即可。
- (2)单台Web服务器-动态:
- 动态交互的网络应用开始如雨后春笋般涌现,像各种各样的论坛啊,购物网站啊之类
- Session诞生:记住每一个请求背后的用户是谁
- 浏览器登陆以后,服务器分配一个session id,表示一个会话,然后返回给浏览器保存着。后续再来请求的时候,带上,就能知道是谁
- (3)分布式Web服务器:
- 没几年,互联网的发展实在是太快,用户量蹭蹭上涨,session id数量也与日俱增,服务器不堪重负
- 增加nginx来进行负载均衡,单台服务器变成了3台web服务器组成的小集群
- 压力虽然减少,但session id的管理问题却变得复杂起来
- 请求如果发到某台机器,登记了session id,但下次请求说不定就发到第二胎,一会儿又发到第三台,这样各个服务器上的信息不一致,就会出现一些异常情况,用户估计要破口大骂:这什么辣鸡网站?
- (3.1)nginx:同一个用户来的请求都发给同一台机器
- 好景不长,各服务器相继出现宕机情况,这时候nginx还得把请求交给还在工作的机器,原来的问题就又出现了
- (3.2)session同步:有新增、失效的情况都给其他机器招呼一下,大家都管理一份,这样就不会出现不一致的问题
- 搞了半天,又回到从前,一个人管理所有session id的情况了,不仅如此,还要抽出时间和几位兄弟同步,把session id搬来搬去,工作量不减反增了。
- (4)独立缓存——Redis
- session id都统一存在redis里面
- (5)Token时代
- Redis也不是万能的,也有崩溃的风险,一崩溃就全完了
- JWT(JSON Web Token) 技术,硬说让redis来管理保存session id负担太重了,以后不保存了
- 没有session id,但是换了一个token,用它来识别用户
- 第一部分是JWT的基本信息,然后把用户的身份信息放在第二部分,接着和第一部分合在一起做一个计算,计算的时候加入了一个只有我们才知道的密钥secretkey,计算结果作为第三部分。最后三部分拼在一起作为最终的token发送给客户端保存着···再收到这个token的时候,就可以通过同样的算法验证前面两部分的结果和第三部分是不是相同,就知道这个token是不是伪造的啦!因为密钥只有我们知道,别人没办法伪造出一个token的!最后确认有效之后,再取第二部分的用户身份信息,就知道这是谁了
- JWT:目前有两种实现方式
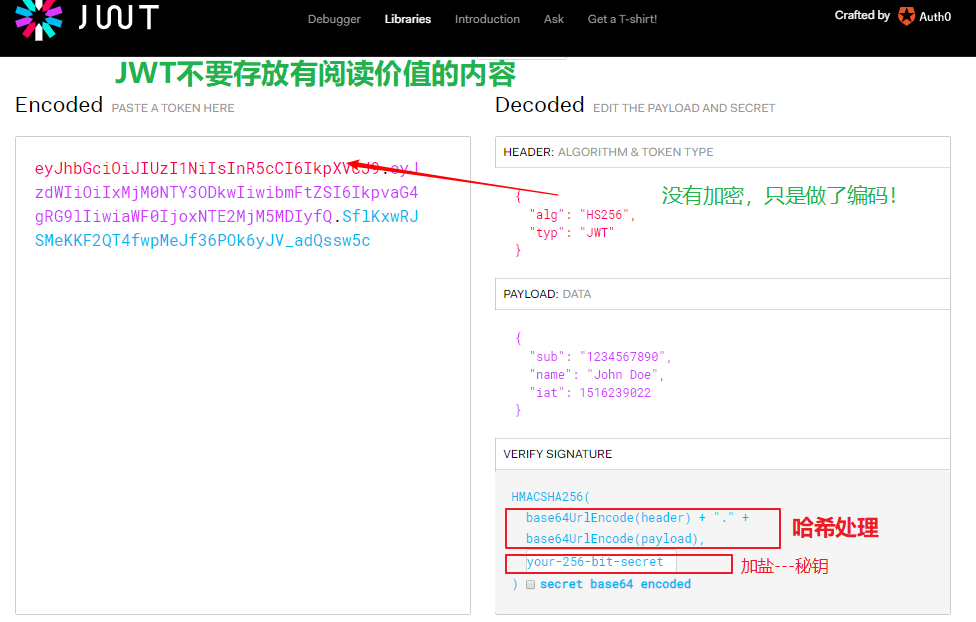
- JWS(JSON Web Signature)

- 分成三个部分:
- 头部(Header):用于描述关于该JWT的最基本的信息,例如:其类型、以及签名所用的算法等。JSON内容要经Base64 编码生成字符串成为Header。
- 载荷(PayLoad):payload的五个字段都是由JWT的标准所定义的。
- iss: 该JWT的签发者
- sub: 该JWT所面向的用户
- aud: 接收该JWT的一方
- exp(expires): 什么时候过期,这里是一个Unix时间戳
- iat(issued at): 在什么时候签发的
- 后面的信息可以按需补充。 JSON内容要经Base64 编码生成字符串成为PayLoad。
- 签名(signature):这个部分header与payload通过header中声明的加密方式,使用密钥secret进行加密,生成签名。JWS的主要目的是保证了数据在传输过程中不被修改,验证数据的完整性。但由于仅采用Base64对消息内容编码,因此不保证数据的不可泄露性。所以不适合用于传输敏感数据。
- JWE(JSON Web Encryption)
- 相对于JWS,JWE则同时保证了安全性与数据完整性。 JWE由五部分组成:

- JWE的计算过程相对繁琐,不够轻量级,因此适合与数据传输而非token认证,但该协议也足够安全可靠,用简短字符串描述了传输内容,兼顾数据的安全性与完整性
- 具体生成步骤为:
- JOSE含义与JWS头部相同。
- 生成一个随机的Content Encryption Key (CEK)。
- 使用RSAES-OAEP 加密算法,用公钥加密CEK,生成JWE Encrypted Key。
- 生成JWE初始化向量。
- 使用AES GCM加密算法对明文部分进行加密生成密文Ciphertext,算法会随之生成一个128位的认证标记Authentication Tag。 6.对五个部分分别进行base64编码。
- Python实现:PyJWT
- 详情:flask项目–认证方案Json Web Token(JWT)
import jwt
from jwt import PyJWTError
from datetime import datetime, timedelta
payload = { # jwt设置过期时间的本质 就是在payload中 设置exp字段, 值要求为格林尼治时间
"user_id": 1,
'exp': datetime.utcnow() + timedelta(seconds=30)
}
screct_key = "test"
# 生成token
token = jwt.encode(payload, key=screct_key, algorithm='HS256')
print(token)
# 验签token 返回payload pyjwt会自动校验过期时间
try:
data = jwt.decode(token, key=screct_key, algorithms='HS256')
print(data)
except PyJWTError as e:
print("jwt验证失败: %s" % e)
分布式唯一id
Twitter使用的分布式唯一id
Snowflake算法代码:
# Twitter's Snowflake algorithm implementation which is used to generate distributed IDs.
# https://github.com/twitter-archive/snowflake/blob/snowflake-2010/src/main/scala/com/twitter/service/snowflake/IdWorker.scala
import time
import logging
from src.utils.exceptions import InvalidSystemClock
# 64位ID的划分
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
# 最大取值计算
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5-1 0b11111
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
# 移位偏移计算
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
# 序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# Twitter元年时间戳
TWEPOCH = 1288834974657
logger = logging.getLogger('flask.app')
class IdWorker(object):
"""
用于生成IDs
"""
def __init__(self, datacenter_id, worker_id, sequence=0):
"""
初始化
:param datacenter_id: 数据中心(机器区域)ID
:param worker_id: 机器ID
:param sequence: 其实序号
"""
# sanity check
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id值越界')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id值越界')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1 # 上次计算的时间戳
def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000)
def get_id(self):
"""
获取新ID
:return:
"""
timestamp = self._gen_timestamp()
# 时钟回拨
if timestamp < self.last_timestamp:
logging.error('clock is moving backwards. Rejecting requests until {}'.format(self.last_timestamp))
raise InvalidSystemClock
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
if __name__ == '__main__':
worker = IdWorker(1, 2, 0)
print(worker.get_id())
进程、协程和线程
定义
进程:操作系统中资源分配/拥有的最小单位线程:操作系统中独立调度的最小单位- 线程是操作系统的内核对象,多线程编程时,如果线程数过多,就会导致频繁的上下文切换,这些 cpu时间是一个额外的耗费。
协程:非操作系统调度,而是程序猿代码控制- 协程在应用层模拟的线程,避免了上下文切换的额外耗费,兼顾了多线程的优点。简化了高并发程序的复杂度。
- goroutine 就是协程。 不同的是,Golang 在 runtime、系统调用等多方面对 goroutine 调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的CPU (P) 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。
区别
- 线程之间可以共享内存
flask高并发问题
- 【2021-6-18】Flask+Gunicorn(协程)高并发的解决方法探究, 直接使用flask的python code.py的方式运行,简单但不能解决高并发问题,不稳定,有一定概率遇到连接超时无返回的情况,不能用于生产环境。
- (1)通过设置app.run()的参数,来达到多进程的效果。但threaded与processes不能同时打开,如果同时设置的话,将会出错
- app.run(threaded=1, processes=2)
- (2)使用gevent做协程解决高并发问题
- (3)通过Gunicorn(with gevent)的形式对app进行包装,从而来启动服务【推荐】
- 指定进程和端口号: -w: 表示进程(worker) –bind:表示绑定ip地址和端口号(bind) —threads 多线程 -k 异步方案
- (1)通过设置app.run()的参数,来达到多进程的效果。但threaded与processes不能同时打开,如果同时设置的话,将会出错
flask异步调度
异步本质上并不比同步快。 在执行并发IO 绑定任务时, 异步是有益的。但是 对于 CPU密集型 任务,则未必有用,因此传统的 Flask 视图仍然适用于大多数用例。 Flask 异步支持的引入,带来本地化编写和使用异步代码的可能性。
由于 Flask本身的实现方式, Flask的异步支持性能不如异步优先框架。如果代码主要是基于异步的,那么可以考虑 Quart 。 Quart 是一个 Flask 的重新实现,但是基于 ASGI 标准而不是WSGI。这允许它处理大量并发请求、长时间运行 的请求和 websocket ,而不需要多个工作进程或线程。
同时,也可以用 Gevent 或 Eventlet 运行 Flask ,以获得异步请求处理的诸多好处。 这些库修补低级 Python 函数来实现这一点,而 async/ await 和 ASGI 则使用标准的现代 Python 功能。决定应该使用 Flask 还是 Quart 或其他东西 最终还是取决于项目的具体需求。
几种方案:
- flask async/await
- celery
- gevent
async/await
安装 Flask 时使用了额外的 async ( 即用 pip install flask[async] 命令安装),那么路由、出错处理器、请求前、请 求后和拆卸函数都可以是协程函数。这样,视图可以使用 async def 定义,并 使用 await 。 pip install flask[async] 命令会用到 contextvars.ContextVar , 因此需要 Python 3.7 以上版本。
@app.route("/get-data")
async def get_data():
data = await async_db_query(...)
return jsonify(data)
celery
【2021-12-1】celery + flask 异步调用任务
有一些非常耗时的任务,无法实现实时的RPC调用。因此计划使用celery + flask提供异步任务调度服务
一个请求的服务过程是这样:
- 1 服务器接到一个请求(一个几k到几百k的文本)
- 2 服务器计算摘要作为键值,将其加入异步任务。
- 3 服务器将摘要返回,状态为calculating。
- 4 异步任务执行耗时计算,结果有两个副本。一个存在本地(pkl),一个发往目标服务器。这样如果目标服务器没收到,服务就把本地的副本读取再发送,避免重新计算。
from flask import Flask
from celery import Celery # 消息队列中间件
from celery.result import AsyncResult
import time
app = Flask(__name__)
# 用以储存消息队列
app.config['CELERY_BROKER_URL'] = 'redis://127.0.0.1:6379/0'
# 用以储存处理结果
app.config['CELERY_RESULT_BACKEND'] = 'redis://127.0.0.1:6379/0'
celery_ = Celery(app.name, broker=app.config['CELERY_BROKER_URL'])
celery_.conf.update(app.config)
@celery_.task
def my_background_task(arg1, arg2):
# 两数相加
time.sleep(10)
return arg1+arg2
@app.route("/sum/<arg1>/<arg2>")
def sum_(arg1, arg2):
# 发送任务到celery,并返回任务ID,后续可以根据此任务ID获取任务结果
result = my_background_task.delay(int(arg1), int(arg2))
return result.id
@app.route("/get_result/<result_id>")
def get_result(result_id):
# 根据任务ID获取任务结果
result = AsyncResult(id=result_id)
return str(result.get())
启动方法
- 作用分别是: 启动flask服务(基本web服务),启动celery服务(异步任务),启动flower服务(监控任务)
# 运行flask服务
gunicorn entry_ner_cpu:app -b 0.0.0.0:5001
# 使用celery执行异步任务
celery -A entry_ner_cpu.celery_ worker
# 使用flower监督异步任务
flower --basic_auth=admin:admin --broker=redis://127.0.0.1:6379/0 --address=0.0.0.0 --port=5556
flower监控面板

模板使用
在jinja2中,存在三种语法:
- 1、控制结构 { % % }
- 2、变量取值 {{ } }
- 3、注释 {# #}
jinja2支持python中所有的Python数据类型比如列表、字段、对象等
if/for控制语句
前端的Jinja2语法中,if可以进行判断:存在的参数是否满足条件。
- 跟python很像,只是需要添加:大括号+百分号

Jinja2的for循环变量不需要{{ } }传入,不支持continue和break,但是和Python一样可以对Python的可迭代对象进行循环遍历。
- 每一次循环的对象是一个字段,使用.key直接拿到value值,如:{{ good.name } },或 {{ good[ “name” ] } }
- 问题:如果不知道字典中key呢?当做list遍历key即可
在一个循环代码块内部调用loop的属性可以获得循环中的状态数据
- loop.index: 当前迭代的索引(从1开始)
- loop.index0: 当前迭代的索引(从0开始)
- loop.first: 是否是第一次迭代,返回True,False
- loop.last: 是否是最后一次迭代,返回True,False
- loop.length: 返回序列长度
过滤器
-
过滤器的本质是一个转换函数,有时候不仅需要输出程序参数还要对参数进行修改转换才能输出,此时需要用到过滤器,过滤器写在变量后面,中间用 隔开, 左右没有空格
自定义过滤器
- 可以自己用Python语言实现一个自定义过滤器使用add_template_filter进行注册调用,或者使用修饰器template_filter注册
@app.template_filter('t_func')
def t_func(t):
t2 = time.time()
diff = t2 - t
if diff < 60:
return "刚刚"
elif 60 <= diff < 60 * 60:
return "%d分钟之前" % int(diff / 60)
elif 3600 <= diff < 3600 * 24:
return "%d小时之前" % int(diff / 3600)
else:
return "很久之前"
# 另一种注册方式
# app.add_template_filter(t_func, 't_func')
完整示例:
from flask import Flask #导入模块
from flask import render_template
app = Flask(__name__)
@app.route('/table') #定义第一页视图
def choice():
goods = [{'name':'包包', 'price':'500元'}, \
{'name':'口红', 'price':'300元'}, \
{'name':'冰淇淋', 'price':'20元'}]
# locals指定所有变量
return render_template('goods.html', **locals()) # 直接传入局部变量
@app.route('/user')
def user():
user = 'dongGe'
#user = ['dongGe'] # 列表
#user = {'name':'dongGe'} # 字典
return render_template('user.html',user=user)
@app.route('/loop')
def loop():
fruit = ['apple','orange','pear','grape']
return render_template('loop.html',fruit=fruit)
#return render_template('first.html', **locals()) # 直接把当前所有变量传下去
if __name__ == '__main__':
app.run(debug=True)
web页面代码
- 注意:为了避开jeklly语法冲突,{号、%号和{或}中间间用空格隔开,实际使用时去掉!
<html>
<head>
<!-- 过滤器 -->
<p>{ { name|default('小明', true)} }</p>
<p>{ { name or '小明'} }</p>
<p>{ { name|default('小明')|replace('小', '大')} }</p> <!-- 多个过滤器可以连续写 -->
<p>{ { ' 去除收尾空格 '|trim } }</p>
<p>{ { '我和'~name~'出去玩了'} }</p> <!-- 字符串连接,用~ -->
<!-- 可迭代对象过滤器 -->
{ % set items=[4,1,7,2] % }
<p>第一个元素{ { items|first } }</p> <!-- 第一个元素 -->
<p>最后一个元素{ { items|last } }</p> <!-- 最后一个元素 -->
<!-- 函数 -->
<p>列表长度{ { items|count } }</p>
<p>{ { 2.22|string + '你好'} }</p> <!-- 转string -->
<p>{ { 2.222|int } }</p>
<p>{ { -2.222|abs } }</p>
<p>{ { 2.222|round(2) } }</p> <!-- 保留小数,比如保留2为小数 -->
<p>{ { [3,6]|max } }</p>
<p>{ { [3,6]|min } }</p>
<p>{ { [1, 2, 3, 4, 5]|reverse|join(',')} }</p> <!-- 反转、连接 -->
<!-- with语句定义的变量只能够在 with语句块中使用, 一旦超过了代码块就不能使用; -->
<!-- set 语句作用域比with大 -->
{ % set items=[4,1,7,2] % }
<p>列表转字符串{ { [4,1,7,2]|join(',') } }</p> <!-- 元素连接 -->
<p>列表升序{ { [4,1,7,2]|sort } }</p>
<p>列表降序{ { [4,1,7,2]|sort(true) } }</p> <!-- 降序排列 -->
{ % set items = [{"name": "苹果", "price": 23}, {"name": "西瓜", "price": 33}, {"name": "西红柿", "price": 25}] % }
<!-- items = [{"name": "苹果", "price": 23}, {"name": "西瓜", "price": 33}, {"name": "西红柿", "price": 25}] -->
<p>根据某个属性排序 { { items|sort(attribute='price', reverse=true) } }</p>
{ % for item in items|sort(attribute='price', reverse=true) % }
<p> { { item.name } } </p>
{ % endfor % }
<p>文章发表于 { { t| t_func } }</p> <!-- 自定义过滤器 -->
<!-- 判断语句 -->
{ % if user % }
<title> hello { {user} } </title>
<!-- <title> hello </title> -->
<!-- <title> hello </title> -->
{ % else % }
<title> welcome to flask </title>
{ % endif % }
{ % with age=3 % }
<!-- 判断语句:算术运算 -->
{ % if age == 1 % }
<p>age为1</p>
{ % elif age == 2 % }
<p>age为2</p>
{ % else % }
<p>age不为1和2</p>
{ % endif % }
{ % endwith % }
</head>
<body>
<h1>hello world</h1>
<ul> <!-- 循环遍历语句:列表 -->
{ % for index in fruit % }
<li>{ { index } }</li>
{ % endfor % }
</ul>
<!-- good.html -->
<table>
<thead>
<th>商品名称</th>
<th>商品价格</th>
</thead>
<tbody> <!-- 循环遍历语句:字典 -->
{ % for good in goods % }
<tr>
<td> { {good.name} } </td>
<td> { {good.price} } </td>
</tr>
<!-- 使用loop关键词获取循环信息 -->
<p>循环长度{ { loop.length } }</p>
<p>当前索引{ { loop.index0 } }</p>
<p>是否结束{ { loop.last } }</p>
{ % endfor % }
<!-- 字典遍历,不用指定key -->
{ % for k in goods % }
{ { k } } -> { { goods[k] } }
{ % endfor % }
</tbody>
</table>
<!-- 变量赋值 -->
{ % set links = [
('home',url_for('.home')),
('service',url_for('.service')),
('about',url_for('.about')),
] % }
<p>set的值 { { a } }</p> <!-- 变量赋值:另一种 -->
{ % with b='321' % }
<p>with的值 { { b } } </p>
{ % endwith % }
<nav>
{ % for label,link in links % }
<!-- loop获取循环信息,loop.index表示下标, 从1开始 -->
{ % if not loop.first % }|{ % endif % }
<a href="{ % if link is current_link % }#
{ % else % }
{ { link } }
{ % endif % }
">{ { label } }</a>
{ % endfor % }
</nav>
<!-- 静态文件加载:url_for -->
<script src="{ { url_for('static', filename='js/tmp.js') } }"></script>
<script type="text/javascript" src="static/js/tmp.js"></script> <!-- 或更直接的方式 -->
<!-- 空白控制 -->
<div>
{ % if True % }
yay
{ % endif % }
</div>
</body>
</html>
文件上传下载
参考:
步骤
- 限制指定的后缀文件才可以上传
- 上传成功后, 跳转到成功页面
- 成功页面可以再返回上传页面
- 文件上传到指定的目录, 目录需要提前创建好
import os
from flask import Flask, request, redirect, url_for
from werkzeug import secure_filename
UPLOAD_FOLDER = '/tmp/uploads'
ALLOWED_EXTENSIONS = set(['txt', 'pdf', 'png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
@app.route('/upload/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
file = request.files['file']
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
return redirect(url_for('upload_success', filename=filename))
return '''
<!doctype html>
<title>Upload new File</title>
<h1>Upload new File</h1>
<form action="" method=post enctype=multipart/form-data>
<p><input type=file name=file>
<input type=submit value=Upload>
</form>
'''
@app.route('/upload_success')
def upload_success():
return '''
<!doctype html>
<title>上传成功</title>
<h1>上传成功</h1>
<a href="/upload/">继续上传</a>
'''
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080, debug=True)
另一个上传/下载完整示例
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os, sys
from flask import Flask, render_template, request, send_file, send_from_directory
app = Flask(__name__)
BASE_PATH = os.path.dirname(os.path.abspath(__file__))
@app.route("/")
def index():
# 文件上传页面
html="""<html>
<head>
<title>文件上传测试</title>
</head>
<body>
<form action="/upload" method="POST" enctype="multipart/form-data">
<input type="file" name="file" multiple="multiple" />
<input type="submit" value="提交" />
</form>
</body>
</html>"""
return html
@app.route("/upload", methods=["POST"])
def upload_file():
try:
# f = request.files["file"]
for f in request.files.getlist('file'):
filename = os.path.join(BASE_PATH, "upload", f.filename)
print(filename)
f.save(filename)
return "file upload successfully!"
except Exception as e:
return "failed!"
@app.route("/download/<filename>", methods=["GET"])
def download_file(filename):
# 下载方法:http://10.200.24.101:8093/download/log.txt
dir = os.path.join(BASE_PATH, 'download')
return send_from_directory(dir, filename, as_attachment=True)
def mkdir(dirname):
dir = os.path.join(BASE_PATH, dirname)
if not os.path.exists(dir):
os.makedirs(dir)
if __name__ == "__main__":
mkdir('download')
mkdir('upload')
app.run(host="10.200.24.101", port=8093, debug=False)
问题
错误
- ImportError: 无法从 ‘jinja2’ 导入名称 ‘escape’
- ImportError: cannot import name ‘escape’ from ‘jinja2’
原因
- Flask 版本问题: escape方法已在 3.1.0 版中删除Jinja2
解决
- 安装指定版本 Flask:
pip install Flask=3.0.3
Django
【2021-7-16】python为后端,vue为前端的web开发框架整合demo,拿来即用,django-vue-demo,安装详情:Django后端 + Vue前端 构建Web开发框架,覆盖node、mysql、vue等工具包
- Django在线教程:Django Book,中文
Django是什么?
Django是一个开放源代码的Web应用框架,由Python写成。采用了MVC的软件设计模式,即模型M,视图V和控制器C(注:实际上是MTV!)。它最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的网站的。并于2005年7月在BSD许可证下发布。这套框架是以比利时的吉普赛爵士吉他手Django Reinhardt来命名的。
- Django的主要目标是使得开发复杂的、数据库驱动的网站变得简单。
- Django注重组件的重用性和“可插拔性”,敏捷开发和DRY法则(Don’t Repeat Yourself)。 在Django中Python被普遍使用,甚至包括配置文件和数据模型。
MVC模式
MVC 由(试图View/控制器Controller/模型Model)组成,实际应用中
- 模型(Model)用来处理应用程序数据逻辑
- 视图(View)用来处理我们从M拿过来的数据(页面渲染,template)
- 控制器(Controller)定义程序行为选择相应的视图
大部分开发语言中都有MVC框架,MVC框架的核心思想是解耦,降低各功能模块之间的耦合性,方便变更,更容易重构代码,最大程度上实现代码的重用
MTV开发模式
Django是一个基于MVC构造的框架。但是在Django中,控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),称为MTV模式。它们各自的职责如下:
- (1) 模型(Model),即数据存取层——处理与数据相关的所有事务:如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等。
- (2) 视图(View),即表现层——处理与表现相关的决定:如何在页面或其他类型文档中进行显示。
- (3) 模板(Template),即业务逻辑层——存取模型及调取恰当模板的相关逻辑。模型与模板的桥梁。
MTV基于MVC,并在MVC的基础上做了更细的划分,区别主要在于C和T,C之前是控制器,现在变成了Template,把C融入到了View里。
MTV模式包含:视图(View)负责业务逻辑,并在适当时候调用Model和Template 模板(Template)负责如何把页面展示给用户 模型(Model)处理应用程序数据逻辑 Django的MTV模式
Django项目结构
每个django项目中可以包含多个APP(应用),相当于一个大型项目中的分系统、子模块、功能部件等等,相互之间比较独立,但也有联系。所有的APP共享项目资源。
Django文件结构:以新建应用test为例
manage.py: django管理主程序,一个项目一个- 创建数据库:python manage.py makemigrations,# 执行后,生成migrations目录,000*开头的文件里面包含sql语句
- python manage.py migrate
- 启动服务:python manage.py runserver 127.0.0.1:8000
- django默认有跨站请求保护机制,settings文件中将它关闭
wsgi.py: 网络通信主接口- 设置项目使用哪个settings.py
- os.environ.setdefault(‘DJANGO_SETTINGS_MODULE’, ‘test.settings’)
- application = get_wsgi_application()
urls.py:url路由文件,网址入口,关联到对应的views.py中的一个函数(或者generic类),访问网址就对应一个函数。- 新建应用路由导入:更改urls.py文件,新增 from test import urls
- url_patterns 中新增test应用的路由规则,如:path(r’api/’, include(test.urls))
settings.py:Django 的设置,配置文件,比如 DEBUG 的开关,静态文件的位置等- 变量 INSTALLED_APPS 引入新建的app
- 如果网页模板位置不在 templates,就需要修改:TEMPLATES 变量
- 如果静态资源位置不在 statics ,就需要修改:STATIC_URL 变量
- 配置数据库相关参数,如果用自带的sqlite,不需要修改。否则修改 DATABASE 变量,在mysql数据库创建mysite库
views.py处理用户发出的请求,调用 model.py- 从urls.py中对应过来, 通过渲染templates中的网页可以将显示内容,比如登陆后的用户名,用户请求的数据,输出到网页。
- test/views.py 文件中记录业务处理逻辑,函数必须继承自 request,且返回不能是字符串!
- def index(request)
- return render(request, ‘index.html’, {模板变量})
templates:文件夹 ,views.py 中的函数渲染templates中的Html模板,得到动态内容的网页,可用缓存来提高速度。- 引用 static 目录下静态资源
- 包含 jinja2 语法规则
models.py与数据库操作相关,定义数据库表格式,一张表一个类,存取数据时用到,不用数据库时可省略。- 必须继承自 model.Model,如:class UserInfo(model.Model)
- forms.py 表单,用户在浏览器上输入数据提交,对数据的验证工作以及输入框的生成等工作,可选。
- admin.py 后台,Django自带强大的后台功能和ORM框架,可以用很少量的代码就拥有一个强大的后台。
- manage.py统计目录下运行下列两个命令使数据库生效。
python manage.py syncdb # Django 1.6.x 及以下
# Django 1.7 及以上的版本需要用以下命令
python manage.py makemigrations [appname] #appname 即为此处的Blog
python manage.py migrate
# 创建超级用户
python manage.py createsuperuser # 密码以密文形式存储
# ------ 修改密码 -------
# 方法①
python manage.py changepassword username # 修改用户密码——这种方式会校验密码强度
# 方法②
python manage.py shell # 进入shell环境,执行以下代码:
# 此方法不会校验密码强度,可设置简单的密码
from django.contrib.auth.models import User
user = User.objects.get(username='用户名')
user.set_password('新的密码')
user.save()
可以通过 http://localhost:8000/admin/ 来访问后台
创建django项目
- (1)创建项目
- django-admin startproject mysite
- mysite下的文件: #整个项目的容器文件夹,这个名称可以随意起
- __init__.py # 这个文件告诉python这个目录是一个包
- settings.py # 该Django项目的配置/设置
- urls.py # Django项目的总路由管理文件
- wsgi.py #一个兼容的web服务器入口,在项目运行发布的时候用到
- manage.py #一个实用的命令行工具,可以让我们以各种方式和Django项目进行交互
- (2)启动服务:
- cd mysite
- python manage.py runserver
- python manage.py runserver 8000 # 指定端口
- python manage.py runserver 0.0.0.0:8000 # 监听机器所有ip(机器可能有多个ip)http://10.200.24.101:8080/
- python manage.py runserver 10.200.24.101:8080 # 监听指定ip(需要提前添加到settings里的ALLOW_HOST中)
- 访问:http://127.0.0.1:8000/
- (3)创建blog应用
- python manage.py startapp blog
- 目录结构
- blog/ __init__.py admin.py migrations/ __init__.py models.py tests.py views.py app.py
- (4)编辑settings.py文件
- 在文件尾部找到INSTALLED_APPS元组。把新建的app以模块的形式添加到元组里
- (5)Controller:
- 路由urls.py(有3种方式:函数、类和外部
- (6)建立数据模型
- (7)修改view
- (8)创建超级用户admin
- (9)启动服务器
view 视图
view
views.py文件:
from django.http import HttpResponse
# 视图函数 hello
def hello(request):
# 每个视图函数至少要有一个参数,通常叫request。
# 这是一个触发这个视图、包含当前Web请求信息的对象,是类django.http.HttpRequest的一个实例
return HttpResponse("Hello world") # 啥也不做,返回一个HttpResponse对象
# ----- 接收参数 ------
from django.http import Http404, HttpResponse
import datetime
# 从url正则里提取的参数offset
def hours_ahead(request, offset):
try:
offset = int(offset) # 字符串值转换为整数
except ValueError:
raise Http404() # 解析错误时,返回404页面
dt = datetime.datetime.now() + datetime.timedelta(hours=offset)
html = "<html><body>In %s hour(s), it will be %s.</body></html>" % (offset, dt)
return HttpResponse(html)
运行:python manage.py runserver,将看到Django的欢迎页面,而看不到Hello world显示页面。
- 因为mysite项目还对hello视图一无所知。需要通过一个详细描述的URL来显式的告诉并且激活这个视图。
viewset
针对同个资源的查询, 只是数量不同, 却需要定义两个不同的类视图, 太过冗余,于是, 视图集出现了, 它的作用就是将对同一资源的不同请求方式整合到一个视图当中.
路由
用 URLconf 绑定视图函数和URL
- RLconf 就像是 Django 所支撑网站目录。
- 本质是 URL 模式以及要为该 URL 模式调用的视图函数之间的映射表。
- 以这种方式告诉 Django,对于这个 URL 调用这段代码,对于那个 URL 调用那段代码。
URLconf(即 urls.py 文件)
from django.conf.urls.defaults import * # Django URLconf的基本构造。 包含了一个patterns函数。
# Uncomment the next two lines to enable the admin:
# from django.contrib import admin
# admin.autodiscover()
urlpatterns = patterns('',
# Example:
# (r'^mysite/', include('mysite.foo.urls')),
# Uncomment the admin/doc line below and add 'django.contrib.admindocs'
# to INSTALLED_APPS to enable admin documentation:
# (r'^admin/doc/', include('django.contrib.admindocs.urls')),
# Uncomment the next line to enable the admin:
# (r'^admin/', include(admin.site.urls)),
)
# Django 期望能从 ROOT_URLCONF 模块中找到它。 urlpatterns 变量定义了 URL 以及用于处理这些 URL 的代码之间的映射关系。
# -----------
from django.conf.urls.defaults import *
from mysite.views import hello # 引入了 hello 视图
# 所有指向 URL /hello/ 的请求都应由 hello 这个视图函数来处理
urlpatterns = patterns('',
('^hello/$', hello), # 把hello视图函数作为一个对象传递,而不是调用它
(r'^time/plus/(\d+)/$', hours_ahead), # 通配符,提取到offset变量中,如:def hours_ahead(request, offset)
)
# ------------ 流线型化(Streamlining)函数导入 -----------
from django.conf.urls.defaults import *
# 传入一个包含模块名和函数名的字符串,而不是函数对象本身
# 使用这个技术,就不必导入视图函数了;Django 会在第一次需要它时根据字符串所描述的视图函数的名字和路径,导入合适的视图函数。
urlpatterns = patterns('',
(r'^hello/$', **'mysite.views.hello'** ),
(r'^time/$', **'mysite.views.current_datetime'** ),
(r'^time/plus/(d{1,2})/$', **'mysite.views.hours_ahead'** ),
)
# 进一步简化:公共前缀提前
urlpatterns = patterns(**'mysite.views'** ,
(r'^hello/$', **'hello'** ),
(r'^time/$', **'current_datetime'** ),
(r'^time/plus/(d{1,2})/$', **'hours_ahead'** ),
)
# 多视图混合
urlpatterns = patterns('',
(r'^hello/$', 'mysite.views.hello'),
(r'^time/$', 'mysite.views.current_datetime'),
(r'^time/plus/(\d{1,2})/$', 'mysite.views.hours_ahead'),
(r'^tag/(\w+)/$', 'weblog.views.tag'),
)
# 改进:,分隔开
urlpatterns = patterns('mysite.views',
(r'^hello/$', 'hello'),
(r'^time/$', 'current_datetime'),
(r'^time/plus/(\d{1,2})/$', 'hours_ahead'),
)
urlpatterns += patterns('weblog.views',
(r'^tag/(\w+)/$', 'tag'),
)
# 改进:使用include
urlpatterns = patterns('',
(r'^(?P<username>\w+)/blog/', include('foo.urls.blog')),
)
templates 模板
将页面的设计和Python的代码分离开,会更干净简洁更容易维护。
- 使用 Django的 模板系统 (Template System)来实现这种模式
模板是一个文本,用于分离文档的表现形式和内容。 模板定义了占位符以及各种用于规范文档该如何显示的各部分基本逻辑(模板标签)。 模板通常用于产生HTML,但是Django的模板也能产生任何基于文本格式的文档。
<html>
<head><title>Ordering notice</title></head>
<body>
<h1>Ordering notice</h1>
<p>Dear { { person_name } },</p>
<p>Thanks for placing an order from { { company } }. It's scheduled to
ship on { { ship_date|date:"F j, Y" } }.</p>
<p>Here are the items you've ordered:</p>
<ul>
{ % for item in item_list % }
<li>{ { item } }</li>
{ % endfor % }
</ul>
{ % if ordered_warranty % }
<p>Your warranty information will be included in the packaging.</p>
{ % else % }
<p>You didn't order a warranty, so you're on your own when
the products inevitably stop working.</p>
{ % endif % }
<p>Sincerely,<br />{ { company } }</p>
</body>
</html>
Django 模板含有很多内置的tags和filters
- 用两个大括号括起来的文字(例如 { { person_name } } )称为
变量(variable) - 被大括号和百分号包围的文本(例如 { % if ordered_warranty % } )是
模板标签(template tag) - filter过滤器是一种最便捷的转换变量输出格式的方式, { {ship_date|date:”F j, Y” } }
使用Django模板的最基本方式如下:
- 用原始的模板代码字符串创建一个 Template 对象, Django同样支持用指定模板文件路径的方式来创建 Template 对象;
- 调用模板对象的render方法,并且传入一套变量context。它将返回一个基于模板的展现字符串,模板中的变量和标签会被context值替换。
from django import template
t = template.Template('My name is { { name } }.')
c = template.Context({'name': 'Adrian'}) # 环境变量
print t.render(c) # My name is Adrian. # 填充模板
c = template.Context({'name': 'Fred'})
print t.render(c) # My name is Fred.
句点查找可以多级深度嵌套
句点查找规则可概括为: 当模板系统在变量名中遇到点时,按照以下顺序尝试进行查找:
- 字典类型查找 (比如 foo[“bar”] )
- 属性查找 (比如 foo.bar )
- 方法调用 (比如 foo.bar() )
- 列表类型索引查找 (比如 foo[bar] )
- 不能使用负数列表索引!,如 item.-1
model 模型
1. 创建数据库
创建数据库 (注意设置 数据的字符编码)
- 由于Django自带的orm是data_first类型的ORM,使用前必须先创建数据库
create database day70 default character set utf8 collate utf8_general_ci;
2. 数据库设置
修改project中的settings.py文件中设置;
- 连接 MySQL数据库(Django默认使用的是sqllite数据库)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'day70',
'USER': 'eric',
'PASSWORD': '123123',
'HOST': '192.168.182.128',
'PORT': '3306',
}
}
# 增加以下语句,可以查看orm操作执行的原生SQL语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
3. 修改mysql默认方式
修改project 中的__init__py 文件设置 Django默认连接MySQL的方式
import pymysql
pymysql.install_as_MySQLdb()
4. 注册
setings文件注册APP
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
]
5. models.py创建表
# 新增字段可以为空(免得迁移时报错)
startdate = models.CharField(max_length=255, verbose_name="任务开始时间",null=True, blank=True)
# (1)字符串类
name=models.CharField(max_length=32)
# models.CharField 对应的是MySQL的varchar数据类型
# char 和 varchar的区别 :
# char和varchar的共同点是存储数据的长度,不能 超过max_length限制,
# 不同点是varchar根据数据实际长度存储,char按指定max_length()存储数据;所有前者更节省硬盘空间;
# 详情:
EmailField(CharField):
IPAddressField(Field)
URLField(CharField)
SlugField(CharField)
UUIDField(Field)
FilePathField(Field)
FileField(Field)
ImageField(FileField)
CommaSeparatedIntegerField(CharField)
# (2)时间字段
models.DateTimeField(null=True)
date=models.DateField()
# (3)数字字段
(max_digits=30,decimal_places=10)总长度30小数位 10位)
# 数字:
num = models.IntegerField()
num = models.FloatField() # 浮点
price=models.DecimalField(max_digits=8,decimal_places=3) # 精确浮点
# (4)枚举字段
choice=(
(1,'男人'),
(2,'女人'),
(3,'其他')
)
lover=models.IntegerField(choices=choice) #枚举类型
# (5)其它字段
db_index = True # 表示设置索引
unique(唯一的意思) = True # 设置唯一索引
# 联合唯一索引
class Meta:
unique_together = (
('email','ctime'),
)
# 联合索引(不做限制)
index_together = (
('email','ctime'),
)
ManyToManyField(RelatedField) #多对多操作
更多字段介绍见原文
6. 数据迁移
在winds cmd或者Linux shell的项目的manage.py目录下执行
python manage.py makemigrations # 把你写在models中的代码翻译成增、删、改的 SQL 语句
python manage.py migrate # 将上述翻译的SQL语句去数据库执行
python manage.py migrate --fake # 假设 migrate 把所有SQL语句执行成功
python manage.py inspectdb > models.py # 检查DB中已经创建完毕的表结构,生成model.py
表创建之时,新增字段既没有设置默认值,也没有设置新增字段可为空,去对应原有数据导致
ORM 对象关系映射
ORM:Object Relational Mapping(关系对象映射)
- 类名 –> 数据库中的表名
- 类属性对应 –> 数据库里的字段
- 类实例对应 –> 数据库表里的一行数据

obj.id obj.name…..类实例对象的属性
Django orm的优势:
- Django的orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句;用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite….,如果数据库迁移,只需要更换Django的数据库引擎即可;
python manage.py makemigrations #根据app下的migrations目录中的记录,检测当前model层代码是否发生变化?
python manage.py migrate #把orm代码转换成sql语句去数据库执行
python manage.py migrate --fake #只记录变化,不提交数据库操作
python manage.py inspectdb > models.py #检查DB中已经创建完毕的表结构,生成model.py
https://www.cnblogs.com/sss4/articles/7070942.html
示例
Web 应用中,主观逻辑经常牵涉到与数据库的交互。 数据库驱动网站 在后台连接数据库服务器,从中取出一些数据,然后在 Web 页面用漂亮的格式展示这些数据。
from django.shortcuts import render_to_response
from mysite.books.models import Book
def book_list(request):
books = Book.objects.order_by('name')
return render_to_response('book_list.html', {'books': books})
把数据存取逻辑、业务逻辑和表现逻辑组合在一起的概念有时被称为软件架构的 Model-View-Controller (MVC)模式。 在这个模式中, Model 代表数据存取层,View 代表的是系统中选择显示什么和怎么显示的部分,Controller 指的是系统中根据用户输入并视需要访问模型,以决定使用哪个视图的那部分。
# 创建应用books:python manage.py startapp books
#
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author) # 多对多字段 叫做 authors
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
Django 可以根据 model.py 自动生成这些 CREATE TABLE 语句
- 除非单独指明,否则Django会自动为每个模型生成一个自增长的整数主键字段每个Django模型都要求有单独的主键id
模型激活:在数据库中创建这些表
- 编辑 settings.py 文件, 找到 INSTALLED_APPS 设置
- 添加‘mysite.books’ 到 INSTALLED_APPS 的末尾
- 创建数据库表:
- python manage.py validate # 检查语法
- python manage.py sqlall books # 执行
- python manage.py syncdb # 提交到数据库
ORM连接
把一对多,多对多,分为正向和反向查找两种方式。
正向查找:ForeignKey在 UserInfo表中,如果从UserInfo表开始向其他的表进行查询,这个就是正向操作,反之如果从UserType表去查询其他的表这个就是反向操作。
- 一对多:models.ForeignKey(其他表)
- 多对多:models.ManyToManyField(其他表)
- 一对一:models.OneToOneField(其他表)
正向连表操作总结:
- 所谓正、反向连表操作的认定无非是Foreign_Key字段在哪张表决定的,
- Foreign_Key字段在哪张表就可以哪张表使用Foreign_Key字段连表,反之没有Foreign_Key字段就使用与其关联的 小写表名;
- 1对多:对象.外键.关联表字段,values(外键字段__关联表字段)
- 多对多:外键字段.all()
反向连表操作总结:
- 通过value、value_list、fifter 方式反向跨表:小写表名__关联表字段
- 通过对象的形式反向跨表:小写表面_set().all()
应用场景:
- 一对多:当一张表中创建一行数据时,有一个单选的下拉框(可以被重复选择)
- 例如:创建用户信息时候,需要选择一个用户类型【普通用户】【金牌用户】【铂金用户】等。
- 多对多:在某表中创建一行数据是,有一个可以多选的下拉框
- 例如:创建用户信息,需要为用户指定多个爱好
- 一对一:在某表中创建一行数据时,有一个单选的下拉框(下拉框中的内容被用过一次就消失了
- 例如:原有含10列数据的一张表保存相关信息,经过一段时间之后,10列无法满足需求,需要为原来的表再添加5列数据
form 表单
HttpRequest对象包含当前请求URL的一些信息:
| 属性/方法 | 说明 | 举例 |
| request.path | 除域名以外的请求路径,以正斜杠开头 | “/hello/” |
| request.get_host() | 主机名(比如,通常所说的域名) | “127.0.0.1:8000” or “www.example.com” |
| request.get_full_path() | 请求路径,可能包含查询字符串 | “/hello/?print=true” |
| request.is_secure() | 如果通过HTTPS访问,则此方法返回True, 否则返回False | True 或者 False |
还有:
- request.META 是一个Python字典,包含了所有本次HTTP请求的Header信息,比如用户IP地址和用户Agent(通常是浏览器的名称和版本号)。 注意,Header信息的完整列表取决于用户所发送的Header信息和服务器端设置的Header信息。
- HttpRequest对象还有两个属性包含了用户所提交的信息: request.GET 和 request.POST。二者都是类字典对象,可以通过它们来访问GET和POST数据。
- request.GET和request.POST都有get()、keys()和values()方法,你可以用用 for key in request.GET 获取所有的键。
- POST数据是来自HTML中的〈form〉标签提交的,而GET数据可能来自〈form〉提交也可能是URL中的查询字符串(the query string)。
view函数里,要始终用这个属性或方法来得到URL,而不要手动输入
# BAD!
def current_url_view_bad(request):
return HttpResponse("Welcome to the page at /current/")
# GOOD
def current_url_view_good(request):
return HttpResponse("Welcome to the page at %s" % request.path)
示例:
<html>
<head>
<title>Search</title>
</head>
<body>
<form action="/search/" method="get">
<input type="text" name="q">
<input type="submit" value="Search">
</form>
</body>
</html>
# urls.py
urlpatterns = patterns('',
# ...
(r'^search-form/$', views.search_form),
(r'^search/$', views.search), # 指向search方法
# ...
)
# views.py
def search(request):
if 'q' in request.GET:
message = 'You searched for: %r' % request.GET['q'] # q 对应html里的input内容
else:
message = 'You submitted an empty form.'
return HttpResponse(message)
Django REST Framework
前后端分离的架构设计越来越流行,业界甚至出现了API优先的趋势。显然API开发已经成为后端程序员的必备技能了,那作为Python程序员特别是把Django作为自己主要的开发框架的程序员,推荐使用Django REST framework(DRF)这个API框架。
Django REST framework(DRF)框架文档齐全,社区较稳定,而且由于它是基于Django这个十分全面的框架而设计开发的,能够让开发者根据自己的业务需要,使用极少的代码量快速的开发一套符合RESTful风格的API,并且还支持自动生成API文档。
# 创建项目目录mkdir tutorial
cd tutorial# 创建一个virtualenv来隔离我们本地的包依赖关系virtualenv env
source env/bin/activate # 在Windows下使用 `env\Scripts\activate`# 在创建的虚拟环境中安装 Django 和 Django REST frameworkpip install django
pip install djangorestframework# 创建一个新项目和一个单个应用django-admin.py startproject tutorial . # 注意结尾的'.'符号cd tutorial
django-admin.py startapp quickstart
cd ..
python manage.py migrate
python manage.py createsuperuser
(1)定义序列化程序
创建一个名为 tutorial/quickstart/serializers.py的文件,用于数据表示。
from django.contrib.auth.models import User, Group
from rest_framework import serializers
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ('url', 'username', 'email', 'groups')
class GroupSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Group
fields = ('url', 'name')
(2)编写视图
打开 tutorial/quickstart/views.py 文件开始写视图代码
from django.contrib.auth.models import User, Group
from rest_framework import viewsets
from tutorial.quickstart.serializers import UserSerializer, GroupSerializer
# 将所有常见行为分组写到叫 ViewSets 的类中
class UserViewSet(viewsets.ModelViewSet):
"""
允许用户查看或编辑的API路径。
"""
queryset = User.objects.all().order_by('-date_joined')
serializer_class = UserSerializer
class GroupViewSet(viewsets.ModelViewSet):
"""
允许组查看或编辑的API路径。
"""
queryset = Group.objects.all()
serializer_class = GroupSerializer
编写路由
在tutorial/urls.py中开始写连接API的URLs。
from django.conf.urls import url, include
from rest_framework import routers
from tutorial.quickstart import views
router = routers.DefaultRouter()
router.register(r'users', views.UserViewSet)
router.register(r'groups', views.GroupViewSet)
# 使用自动URL路由连接我们的API。
# 另外,我们还包括支持浏览器浏览API的登录URL。
urlpatterns = [
url(r'^', include(router.urls)),
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]
全局设置
想打开分页,希望API只能由管理员使用。设置模块都在 tutorial/settings.py 中。
INSTALLED_APPS = (
...
'rest_framework',
)
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.IsAdminUser',
],
'PAGE_SIZE': 10
}
测试api
命令行启动服务器。
- python manage.py runserver
现在可以从命令行访问我们的API,使用诸如 curl …
curl -H 'Accept: application/json; indent=4' -u admin:password123 http://127.0.0.1:8000/users/
# 或使用httpie
http -a admin:password123 http://127.0.0.1:8000/users/
# 返回结果
{
"count": 2,
"next": null,
"previous": null,
"results": [
{
"email": "admin@example.com",
"groups": [],
"url": "http://127.0.0.1:8000/users/1/",
"username": "admin"
},
{
"email": "tom@example.com",
"groups": [ ],
"url": "http://127.0.0.1:8000/users/2/",
"username": "tom"
}
]
}
或直接通过浏览器,转到URL http://127.0.0.1:8000/users/
Django+vue
【2022-2-22】Django+Vue前后端分离实战
Fastapi

- FastAPI使用小结
- 全面拥抱 FastApi — 多应用程序管理蓝图APIRouter
- (入门篇)Python框架之FastAPI——一个比Flask和Tornado更高性能的API 框架
- (进阶篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架
- (完结篇)Python框架之FastAPI——一个比Flask和Tornado更高性能的API 框架
简介
- FastAPI是一个现代、快速(高性能)的 Web 框架,基于标准 Python 类型提示,使用 Python 3.6+ 构建 API。
- 几点感受:
- 性能并发更强了,支持异步 async
- 基于 Pydantic 的类型声明,自动校验参数
- 自动生成交互式的 API 接口文档
- Django REST Framework 的主要功能是自动 API 文档。 API 文档有个标准叫 Swagger ,用 JSON 或 YAML 来描述。
- 上手简单,能快速编码
- 主要特征是:
- 高速:与NodeJS和Go相当,拥有高性能。 现有最快的Python框架之一。
- 并发性能可以和 NodeJS 以及 Go 相媲美。它是基于Starlette框架, 类似于Starlette 的一个子类。
- 快速编码:将功能开发速度提高约200%至300%。
- 更少的Bug:减少约40%的人为(开发人员)导致的错误。
- 直观:更好的编辑支持。补全任何地方。更少的调试时间。
- 简单:方便使用和学习。减少阅读文档的时间。
- 简介:最小化代码重复。每个参数声明的多个要素。更少的错误。
- 健壮:获取便于生产的代码。带自动交互式文档。
- 基于标准:基于(并完全兼容)API 的开放标准:OpenAPI(以前称为Swagger)和 JSON Schema。
- 高速:与NodeJS和Go相当,拥有高性能。 现有最快的Python框架之一。
- 【2021-5-8】问题:严格的参数验证、没有类似flask的全局变量
部署
# 安装
pip install fastapi
pip install uvicorn
pip install gunicorn # 或者
#使用uvicorn启动
uvicorn sql_app.main:app --reload
# 指定host和port
uvicorn main:app --host=0.0.0.0 --port=8800
访问
- http://127.0.0.1:8000
- 打开自动生成的文档:http://127.0.0.1:8000/docs,可以动态传入数据
使用
代码示例
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def index():
return "Hello world"
# 异步请求
@app.get("/index")
async def index():
return "Hello world"
@app.get("/items/{item_id}")
async def read_item(item_id: str, q: str = None, short: bool = False):
item = {"item_id": item_id}
if q:
item.update({"q": q})
if not short:
item.update(
{"description": "This is an amazing item that has a long description"}
)
return item
from typing import Optional
from fastapi import FastAPI, Path, Query
# 指定参数格式、合法范围
@app.get("/bar/{foo}")
# @app.post("/bar") # post请求
async def read_item(
foo: int = Path(1, title='描述'),
age: int = Query(..., le=120, title="年龄"),
name: Optional[str] = Query(None, min_length=3, max_length=50, regex="^xiao\d+$")
):
return {"foo": foo, "age": age, "name": name}
# Path方法获取请求路径里面的参数如 http://127.0.0.1:8000/bar/123
# Query方法获取请求路径后面的查询参数如 http://127.0.0.1:8000/bar?name=xiaoming&age=18
# Body方法获取请求体里面的参数,前提是请求头得用accept: application/json
跨域 —— CORS
【2022-2-25】
flask解法
安装CORS包:
pip install -U flask-cors
添加2行代码:
from flask import Flask
from flask_cors import CORS
app = Flask(__name__)
CORS(app)
@app.route("/")
def helloWorld():
return "Hello, cross-origin-world!"
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
