- 语音处理工具
- 结束
语音处理工具
语音识别理论
详见站内专题: 语音识别理论
音频文件格式
格式总结
【2022-12-16】10大常见音频文件格式,你知道几个?
所有音频格式中
- (1)未压缩格式存储的文件。因为这些音频文件本质上是未被压缩的。只是将真实世界的声波转换成数字格式保存下来,而不需要进行任何处理。
- 未压缩音频格式最大的优点是真实,可以保留录制音频的详细信息,但需要占据较大的存储空间。
- 常见的未压缩音频文件格式有3种:wav、aiff、pcm
- (2)无损压缩的音频格式:保持原来的信息,同时降低存储开销
- (3)有损压缩的音频格式:允许损失部分信息,进一步降低存储开销
(1) 未压缩
未压缩音频文件格式有下面3种:wav、aiff、pcm
PCM、WAV与AIFF的差别
- AIFF与WAV之间的实际差异并不突出,二者只是版权归属不同。WAV归微软所有,而AIFF归苹果所有。但二者的相同点是非常显著的,即这两种格式都需要依赖PCM技术将模拟声音转换为数字格式。
- 也就是说,PCM是AIFF和WAV都包含的技术。而具体选择哪种格式主要取决于用户拥有的设备类型。
1. WAV文件格式
- WAV格式是音频文件中使用最广泛的未压缩格式之一。全称是Waveform Audio格式,在1991年由微软和IBM共同推出。音频容器使用未压缩技术,主要用于在CD中存储录音。
- 尽管这种格式在用户端不是很流行,但它仍然广泛运用于音频录制。因为WAV遵循标准的14位编码,并且采用未压缩技术,所以它的文件比较大。理想情况下,一分钟未压缩WAV文件的大小约为10 MB。不过,用户仍然可以选择使用无损压缩技术来压缩WAV文件。
Waveform Audio File Format(WAVE,又或者是因为WAV后缀而被大众所知的)是最常见的声音文件格式之一,是微软公司专门为Windows开发的一种标准数字音频文件,该文件能记录各种单声道或立体声的声音信息,并能保证声音不失真。
- 采用
RIFF(Resource Interchange File Format)文件格式结构。通常用来保存PCM格式的原始音频数据,所以通常被称为无损音频。但是严格意义上来讲,WAV也可以存储其它压缩格式的音频数据。
文件结构
- WAV文件遵循RIFF规则,其内容以
区块(chunk)为最小单位进行存储。 - WAV文件一般由3个区块组成:RIFF chunk、Format chunk和Data chunk。另外,文件中还可能包含一些可选的区块,如:Fact chunk、Cue points chunk、Playlist chunk、Associated data list chunk等。
- wav音频文件解析
wav文件编辑器, 该音频格式代表波形音频文件格式。 虽然 WAV文件 可能会占用很多存储空间,但是格式非常易于播放和编辑。
- Audacity 是免费和开源的 音频编辑程序
- WavePad 来自NCH Software,已被广泛使用。 如果要在计算机中编辑WAV文件,此音频编辑器可以是一种直观的解决方案。 通过将不同的曲目和通过录制及全部录制的专业音乐混合在一起,您可以使用该工具来创建音乐融合。 WavePad确实支持几乎所有流行的音频格式,例如MP3,WAV,VOX,GSM,WMA, OGG,AAC等
- Avid Pro Tools
- Reaper是一个DAW
- Abletion Live的一项重要功能是Ableton Live在制作音乐和编辑音频文件之间划清界限。
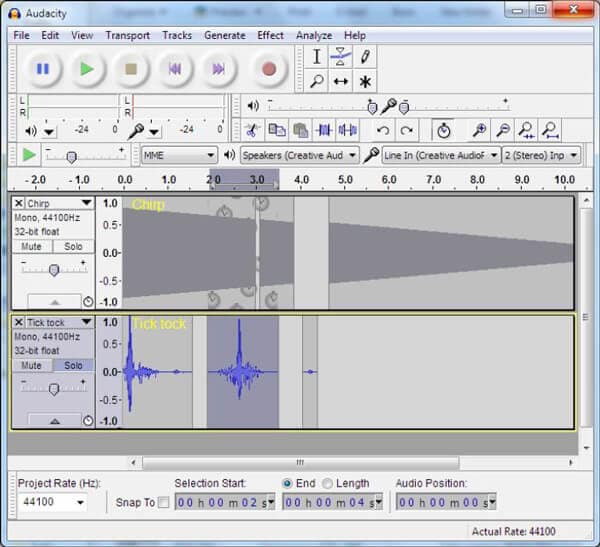
2. AIFF文件格式
- 和WAV一样,AIFF文件也是未压缩的。AIFF文件格式基于IFF(可互换文件格式),最初由苹果公司推出,这也是苹果公司制造的设备主要支持该格式音频的原因。AIFF格式是在存储CD录音的WAV格式之前3年推出的。目前,苹果用户主要使用的AIFF-C格式就是AIFF格式的压缩版本。
3. PCM音频文件
- PCM音频格式也是一种常用的未压缩格式,它主要用于把音频文件存储到CD和DVD中。PCM代表脉冲编码调制,是一种可以将模拟音频文件转换为数字格式的技术。为了达到理想情况,机器会以不同的间隔对音频文件进行采样,这就对应生成了文件的采样率。线性脉冲编码调制(LPCM)便是用于存储音频文件的PCM格式的子类型之一。
(2) 无损压缩
未压缩的原始音频文件会占用大量空间,因此建议先压缩这些音频文件再进行存储。通过使用拥有高级算法的无损压缩技术,用户可以在缩小文件体积的同时保留原始数据。理想情况下,无损压缩技术可以使文件大小减小2到5倍,同时仍保留原始数据。
常见的无损压缩音频格式有下面3种:FLAC、ALAC与WMA
FLAC、ALAC与WMA的差别
- 在所有无损压缩音频文件格式中,最广泛的是FLAC。
- 由于计算机设备的不同,苹果用户大都使用ALAC,而Windows用户更喜欢WMA。就文件自身而言,FLAC和ALAC都是免版税的压缩技术,而WMA则不是。
- 此外,WMA遵循严格的DRM限制,传播性比不上FLAC、ALAC。
1. FLAC音频文件
FLAC全称为Free Lossless Audio Codec,自2001年推出以来取得了巨大的发展进步。顾名思义,它是一种免费的开源压缩格式,适用于音频文件的日常存储。该格式可以将音频文件压缩到其原始大小的60%,而不会丢失任何位原始数据。目前,FLAC格式被认为是广为流行的MP3格式的最佳替代品,因为它能够最大程度上保留音频文件的原数据。
2. ALAC文件
ALAC代表Apple无损音频编解码器,是苹果公司开发的一项无损音频压缩技术,于2004年首次推出。为了推广ALAC格式,苹果公司在2011年公开了它的压缩算法,该文件格式因此流行。ALAC编码的两个主要文件扩展名是.m4a和.caf,它们分别代表iOS和Mac的本机压缩格式。由于iOS设备不支持FLAC压缩,因此苹果用户默认使用ALAC扩展。该压缩技术保留了音频的元内容,文件的大小通常只有WAV音频的一半。
3. WMA无损文件
WMA代全称为Windows Media Audio,由微软开发。WMA兼有无损和有损两种压缩模式可供用户选择。无损的WMA压缩技术仅支持DRM格式,不像FLAC和ALAC拥有良好的兼容性。此外,它主要由本机Windows用户使用。总之,WMA无损只是一种适用范围狭小的压缩技术,不建议用于数据传输或分发。
(3) 有损压缩
有损压缩的音频格式
日常生活中,大多数人并不希望音乐文件占用大量设备空间,因此人们常常使用有损压损的音频格式。它们采用有损压缩技术,可以大大减小文件体积,但音频的原始数据也会受到损害。有时,以此格式存储的音乐文件听起来甚至与原始音频毫不相像。
MP3、OGG、AAC和WMA的区别
- 这4种技术都采用有损压缩技术,但它们彼此之间完全不同。
- 由于其开源优势,MP3是使用最广泛的格式之一,而OGG是最不受欢迎的。
- AAC主要用于流媒体以及索尼和苹果的设备。
- WMA则多为微软用户使用。
- 虽然AAC和WMA提供的压缩文件质量比MP3更好,但不如MP3受欢迎。举一个最简单的例子,人们仍喜欢将音乐播放器称为“MP3播放器”而不是“AAC播放器”,这有力地证明了MP3格式无与伦比的普及度。
1. MP3文件格式
MP3无疑是各种领先平台和设备都能接受的最流行的音频格式。它代表MPEG-1音频第3层,于1993年由运动图像专家组首次推出。该压缩技术消除了人耳无法听到的所有声音以及噪声,专注于实际音频数据,这可以将音频文件的体积减小75%到90%。MP3也被称为通用音乐扩展,因为几乎每个媒体设备都支持此种开放格式。
2. OGG文件
OGG是一个免费的开源容器,主要与Vorbis文件相关联。由于Vorbis的发布,文件容器(和扩展)在21世纪初广为流行。虽然OGG的压缩技术非常复杂,但它并未取得成果,目前也没有在市场上被广泛使用。
3. AAC音频文件
AAC代表高级音频编码,可用作常见扩展的容器,如.3gp,.m4a,.aac等。它是iTunes,iOS,Sony Walkmans,Playstations,YouTube等设备的默认编码技术。此压缩格式是在MP3发布后不久开发的,于1997年正式发布。虽然它不像MP3那么受欢迎,但人们普遍认为AAC文件的音质更好。
4. WMA有损文件
自从1999年微软发布WMA格式以来,它经历了许多发展演变。WAM格式可以根据用户需求采用有损压缩技术或无损压缩技术。它可以在保留大部分数据的同时大幅减小音频文件的大小。虽然该格式的输出文件质量优于MP3,但它的版权独属微软并且使用受到DRM限制,因此没有受到广泛欢迎。
m4a
什么是M4A文件格式?
- M4A跟MP3一样,也是一种音频文件。它是以MP4格式所创建的纯音频文件, MP4有包含音频、视频数据的文件,也有只包含纯音频数据的文件。 为了区分这两种文件,Apple便在iTunes以及iPod中将只包含纯音频的MP4文件使用M4A格式来区别MP4的视频文件和纯音频文件。那M4A有哪些优点与缺点呢?
优点:
- M4A文件能在压缩的同时拥有无损的音质,可以在原始质量的前提下,以较小的文件保存。
- M4A音频文件不受保护,无需许可证或付款即可轻松传输。
- 直接将文件扩展名M4A改为M4R,就可将M4A音频设置为iPhone铃声。
缺点:
- M4A格式兼容性较差,无法广泛在所有的设备或播放器上播放。
M4A格式与MP3格式有何区别?
- M4A与MP3相比,M4A可以在较小的文件大小中以相同的比特率来压缩音频。在质量方面,带有ALAC编解码器的M4A文件能拥有最原始的音质。也就是说,M4A文件能在压缩的同时拥有无损的音质,在原始质量的前提下,以较小的文件保存。
- M4A也能以相同的比特率提供比MP3更好的音质,比如您想获得相同的音质,使用MP3时需要256kbps的比特率,而使用M4A只需要192kbps的比特率。但是,在兼容性方面,MP3比M4A更广泛应用于不同类型的设备及播放器上
格式转换
工具
m4a → mp3:
- M4A转MP3 - 在线转换音频文件,格式多,但下载受阻
- m4a->mp3,可以下载
Python 处理音频
【2022-12-16】Python 多种音乐格式批量转换实战教程
- Pydub 是一个基于 ffmpeg 的 Python 音频处理模块,封装了许多 ffmpeg 底层接口,因此用它来做音乐歌曲文件格式转换会非常方便。
song = AudioSegment.from_wav("test_audio.wav") # wav 文件
song.export("test_audio_wav-mp3.mp3", format="mp3")
song = AudioSegment.from_ogg("test_audio.ogg") # ogg 文件
song.export("test_audio_ogg-mp3.mp3", format="mp3")
AudioSegment.from_file("test_audio.flac") # flac 文件
song.export("test_audio_flac-mp3.mp3", format="mp3")
mp3转其他
from pydub import AudioSegment
def trans_mp3_to_any_audio(filepath, audio_type):
"""
将mp3文件转化为任意音频文件格式
Args:
filepath (str): 文件路径
audio_type(str): 文件格式
"""
song = AudioSegment.from_mp3(filepath)
filename = filepath.split(".")[0]
song.export(f"{filename}.{audio_type}", format=f"{audio_type}")
# 调用
trans_mp3_to_any_audio("Alone.mp3", "ogg")
只要是ffmpeg支持的音乐音频格式,它都可以转换,支持的格式长达几十个,下面我简单列一些:
- wav,avi,mp4,flv,ogg,flac,ape,mp2,aiff,voc,au
任意格式间相互转换
from pydub import AudioSegment
def trans_any_audio_types(filepath, input_audio_type, output_audio_type):
"""
将任意音频文件格式转化为任意音频文件格式
Args:
filepath (str): 文件路径
input_audio_type(str): 输入音频文件格式
output_audio_type(str): 输出音频文件格式
"""
song = AudioSegment.from_file(filepath, input_audio_type)
filename = filepath.split(".")[0]
song.export(f"{filename}.{output_audio_type}", format=f"{output_audio_type}")
# 调用
trans_any_audio_types("Alone.ogg", "ogg", "flv")
批量转换
def trans_all_file(files_path, target="mp3"):
"""
批量转化音频音乐格式
Args:
files_path (str): 文件夹路径
target (str, optional): 目标音乐格式. Defaults to "mp3".
"""
for filepath in os.listdir(files_path):
# 路径处理
modpath = os.path.dirname(os.path.abspath(sys.argv[0]))
datapath = os.path.join(modpath, files_path + filepath)
# 分割为文件名字和后缀并载入文件
input_audio = os.path.splitext(datapath)
song = AudioSegment.from_file(datapath, input_audio[-1].split(".")[-1])
# 导出
song.export(f"{input_audio[0]}.{target}", format=target)
# 调用
trans_all_file("file/music/")
音频处理
声道分离
【2022-12-16】语音处理:Python实现立体声音频的声道分离批量处理
- 语音处理任务中,有时需要对立体声或多声道音频文件,批量处理成单声道文件,然后送入算法模型进行处理。
编码思路
- 用Python的 wavfile 包
- 先读取多声道音频到 data
- 将data中的左右声道分别提取到list中
- 将list数据写入新的单声道音频文件
from scipy.io import wavfile
def split_stereo(input_path, output_path):
# default stereo
samplerate, data = wavfile.read(input_path)
left = []
right = []
for item in data:
left.append(item[0])
right.append(item[1])
file_name = input_path.split('\\')[-1]
file_name = file_name.split('.')[0]
outfile_name = file_name + '_1ch_left.wav'
out_path_file = os.path.join(output_path, outfile_name)
wavfile.write(out_path_file, samplerate, np.array(left))
# wavfile.write('right.wav', samplerate, np.array(right))
注意
- 这个代码只适用于未压缩的WAV声音文件!压缩文件会报错
- 压缩文件使用soundfile
import soundfile as sf
musicFileName = "1016(37)_13733163362(4)_In_20190808140419.wav"
sig, sample_rate = sf.read(musicFileName)
print("采样率:%d" % sample_rate)
print("时长:", sig.shape[0]/sample_rate, '秒')
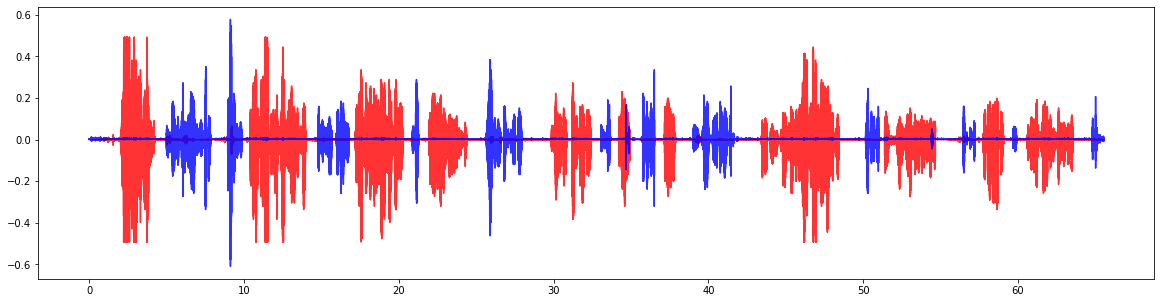
serviceData = sig.T[0]
clientData = sig.T[1]
print(serviceData)
print(clientData)
# -------- 可视化 ---------
import matplotlib.pyplot as plt
import numpy as np
plt.figure()
l=sig.shape[0]
x = [i/8000 for i in range(l)]
#plt.plot(x, clientData, c='r')
plt.plot(x, serviceData, c='r', alpha=0.8)
plt.plot(x, clientData, c='b', alpha=0.8)
plt.show()
音乐测试
【2022-12-17】各种格式、声道的音频测试文件集合
- Music files in this section are intended for testing of audio applications. The files are organized into different Formats and Sample Rates.
DeepSpeech
2014年12月18日,百度宣布吴恩达团队首个研究成果 —— 深度学习语音识别系统 Deep Speech。 一种更准确的语音识别技术。
Deep Speech 深度学习语音识别技术能够超越苹果和谷歌相关的语音识别技术
Deep Speech 的优势
- 在类似人群或是车内嘈杂的环境下能够实现将近81%的辨识准确率,优于谷歌的语音识别引擎(Google API)、Wit.AI、微软Bing语音搜索、苹果语音服务等。
美国卡内基梅隆大学的助理研究员Ian Lane对此表示,百度的该项成果有望打破语音识别的发展格局。
据悉,百度人工智能研发团队共收集了超过9600人、长达7000多小时的语音数据资料,大多数是安静环境中的语音,但百度公司还加入了15种嘈杂环境中的语音样本,如在饭馆、汽车、地铁等。
语音识别比赛
2022 科大讯飞的中文语义病句识别挑战赛
2022 科大讯飞的中文语义病句识别挑战赛, 赛题
任务
- 中文语义病句识别是一个二分类的问题,预测句子是否是语义病句。语义错误和拼写错误、语法错误不同,语义错误更加关注句子语义层面的合法性,语义病句例子如下表所示。
| 病句 | 解析 |
|---|---|
| 英法联军烧毁并洗劫了北京圆明园。 | 应该先“洗劫”,再“烧毁” |
| 山上的水宝贵,我们把它留给晚上来的人喝。 | 歧义,“晚上/来”“晚/上来” |
| 国内彩电市场严重滞销。 | “市场”不能“滞销” |
一个典型的二分类问题,文本字数较短(90字以下),评价指标为 F1,正负比大约是 3:1,从病句的定义和种类来看,不但有拼写错误、语义重复等语病,还有语义逻辑、歧义等目前 NLP 模型较难识别的病句。
视频语音内容提取
【2022-10-15】视频语音转文字工具:
MuAViC 唇语
【2023-8-30】Meta开源像语言识别系统,模型识别唇语翻译6种语言,本地部署人人可用
Meta利用TED/TEDx的视频语音素材,制作了MuAViC中的数据集。其中包含了1200小时,9种语言的文本语音视频素材,还有英语与6种语言之间的双向翻译。
音频转换
人与动物沟通
【2023-7-2】支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇, 将一个人的语音换成任何其他人的语音,也可以与动物之间的语音互换。
任意到任意(any-to-any)语音转换方法提高了自然度和说话者相似度,但复杂性却大大增加了。这意味着训练和推理的成本变得更高,使得改进效果难以评估和建立。
南非斯坦陵布什大学的一篇论文
引入了 K 最近邻语音转换(kNN-VC),一种简单而强大的任意到任意语音转换方法。在过程中不训练显式转换模型,而是简单地使用了 K 最近邻回归。
- kNN-VC 的架构 遵循了 编码器-转换器-声码器结构。首先编码器提取源语音和参照语音的自监督表示,然后转换器将每个源帧映射到参照中它们的最近邻,最后声码器根据转换后的特征生成音频波形。
狗语识别
【2024-6-10】 「汪汪」to Vector!密歇根博士生用AI解码狗的声音 LREC 2024
狗的语言也是「自然语言」,人的语言能word to vector,「汪汪」为什么不行?
来自密歇根大学的研究人员,开发了一款人工智能工具,可以区分不同含义的狗叫声,并识别狗的年龄、性别和品种。
- 论文地址:Towards Dog Bark Decoding: Leveraging Human Speech Processing for Automated Bark Classification
两种方式的实现效果:
- 完全用狗狗的声音数据从头训练模型;
- 在人类语音预训练模型的基础上,使用狗狗声音数据进行微调。
模型选择Wav2Vec2,是使用人类语音数据训练的SOTA语音表示模型。 通过这个模型,研究人员能够生成从狗身上收集的声学数据的表示,并解释这些表示。 实验表明,使用人类语音预训练的模型,居然表现更好。 看来通用基础大模型微调的套路,即使跨物种也能行得通。
理解动物的交流方式,要解决三个主要问题:
- (1)动物使用的语音和感知单位是什么?
- (2)组合这些单位的规则是什么?
- (3)这些单位是否有意义,如何将声音单位映射到具体含义?
ASR Demo
Gradio 实时语音识别
【2023-7-28】Real Time Speech Recognition
- load Wav2Vec2 from Hugging Face transformers
import gradio as gr
from transformers import pipeline
# pip install --upgrade transformers
p = pipeline("automatic-speech-recognition")
def transcribe(audio):
text = p(audio)["text"]
return text
gr.Interface(
fn=transcribe,
inputs=gr.Audio(source="microphone", type="filepath"),
# gr.Audio(source="microphone", type="filepath", streaming=True), # 流式
outputs="text").launch()
实时语音
Mesh、MCU和SFU是多人视频通讯中常用的三种架构。
- Mesh架构去中心化,但随着参与方数量的增加,系统资源需求会越来越高;
- MCU架构中心化,可以减轻参与方的负担,但中心服务器的压力会比较大,且存在延迟;
- SFU架构介于两者之间,既可以保证实时性和视频质量,又可以降低服务器的压力。
基于 WebRTC 的多对多实时通信的开源项目也有很多,多方通信架构三种方案。
Mesh方案,多个终端之间两两进行连接,形成一个网状结构。- 比如 A、B、C 三个终端进行多对多通信,当 A 想要共享媒体(比如音频、视频)时,它需要分别向 B 和 C 发送数据。同样的道理,B 想要共享媒体,就需要分别向 A、C 发送数据,依次类推。这种方案对各终端的带宽要求比较高。
MCU(Multipoint Conferencing Unit)方案,由一个服务器和多个终端组成一个星形结构。各终端将自己要共享的音视频流发送给服务器,服务器端会将在同一个房间中的所有终端的音视频流进行混合,最终生成一个混合后的音视频流再发给各个终端,这样各终端就可以看到 / 听到其他终端的音视频了。实际上服务器端就是一个音视频混合器,这种方案服务器的压力会非常大。SFU(Selective Forwarding Unit)方案,该方案也是由一个服务器和多个终端组成,但与 MCU 不同的是,SFU 不对音视频进行混流,收到某个终端共享的音视频流后,就直接将该音视频流转发给房间内的其他终端。它实际上就是一个音视频路由转发器。
在实时音视频通信领域,MCU(Multipoint Control Unit)和SFU(Selective Forwarding Unit)是两种主流的媒体服务器架构
ASR 工具
Vosk
Vosk是言语识别工具包。
特点 0 支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语, 印地语, 捷克语, 波兰语, 乌兹别克语, 韩国语, 塔吉克语, 吉尔吉斯语
- 移动设备上脱机工作-Raspberry Pi,Android,iOS
- 使用简单的 pip3 install vosk 安装
- 每种语言的手提式模型只有是50Mb, 但还有更大的服务器模型可用
- 提供流媒体API,以提供最佳用户体验(与流行的语音识别python包不同)
- 还有用于不同编程语言的包装器-java / csharp / javascript等
- 可以快速重新配置词汇以实现最佳准确性
- 支持说话人识别
openai whisper
whisper 介绍
【2022-11-15】whisper,Open AI Introducing Whisper 强调 Whisper 的语音识别能力已达到人类水准。
- Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
- Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的
多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。 - OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
相比目前市面上的其他现有方法通常使用较小的、更紧密配对的「音频 - 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
端侧部署
TF Lite
【2025-2-*】离线语音识别+翻译,TF Lite
- github 地址:whisper_android
- 演示视频 youtube
pip install tensorflow
pip install kivy # 跨平台python库,开发多触摸app
https://github.com/vilassn/whisper_android
llama.cpp
llama.cpp 主要目标是在本地和云中的各种硬件上,以最小的设置和最先进的性能实现LLM推理。
- 无任何依赖关系的纯C/C++实现
- 苹果硅是一流的公民-通过ARM NEON、Accelerate和Metal框架进行优化
- 支持x86架构的AVX、AVX2和AVX512
- 1.5位、2位、3位、4位、5位、6位和8位整数量化,用于更快的推理和减少内存使用
- 用于在NVIDIA GPU上运行LLM的自定义CUDA内核(通过HIP支持AMD GPU)
- Vulkan、SYCL和(部分)OpenCL后端支持
- CPU+GPU混合推理,部分加速大于VRAM总容量的模型
Distil-Whisper
【2023-12-6】Distil-Whisper 不仅继承了原始Whisper模型的优秀血统,更在性能和速度上进行了显著的提升。专为英语设计的Distil-Whisper,在减小模型体积的同时,实现了处理速度的大幅跳跃,这在现有的AI语音识别技术中堪称一次创新的突破。
论文详解:Distil-Whisper的原理和技术架构,请访问论文地址。
项目实践:若想实际操作Distil-Whisper,可以通过项目地址访问其GitHub页面。
国内资源:为了方便国内开发者,Whisper v2&v3模型的国内镜像可以通过AIFastHub进行下载。
【2024-3-29】【distil-large-v3:Whisper large-v3的蒸馏精简版】
Distil-Whisper的设计旨在加快推理速度,仅使用两个解码器层,实现了与原版Whisper相媲美的语音识别准确性,但速度却提升了惊人的6.3倍。此外,Distil-Whisper在降低幻听错误方面也取得了重大进展,使用分块长文本算法时,幻听错误率降低了约30%。
实时转写
Live ASR Engine
I have implemented (not from scratch) LiveASREngine using whisper using the following codebase
The only change I made was in the wav2vec2_inference.py: initialized whisper model with hugging face pipeline. my code
The problem I am facing now:
- If I do not say anything and the entire room is silent, the engine continuously prints “you” or “thank you”, I tested the system in a quiet room. still getting the same issue.
stream-translator
Command line utility to transcribe or translate audio from livestreams in real time. Uses streamlink to get livestream URLs from various services and OpenAI’s whisper for transcription/translation. This script is inspired by audioWhisper which transcribes/translates desktop audio.
Webui demo(加 VAD)
huggingface whisper-webui
- 源自:Whisper WebUI with a VAD for more accurate non-English transcripts (Japanese)
- For longer audio files (>10 minutes) not in English, it is recommended that you select Silero VAD (Voice Activity Detector) in the VAD option.
- Max audio file length: 600 s
Using a VAD is necessary, as unfortunately Whisper suffers from a number of minor and major issues that is particularly apparent when applied to transcribing non-English content - from producing incorrect text (wrong kanji), setting incorrect timings (lagging), to even getting into an infinite loop outputting the same sentence over and over again.
视频字幕
【2022-11-17】YouTube Video Transcription with Whisper ,将 youtube 视频实时提取文本、字幕文件
- 用 Streamlit 搭建
- github 代码:yt-whisper-demo

# text
Have you ever seen a polar bear playing bass? Or robot painted like a Picasso? Didn\'t think so. Dali2 is a new AI system from OpenAI that can take simple text descriptions like a quality-dunking a basketball and turn them into photo realistic images that have never existed before.
# 字幕文件
1
00:00:00,000 --> 00:00:03,400
Have you ever seen a polar bear playing bass?
2
00:00:03,400 --> 00:00:05,800
Or robot painted like a Picasso?
执行过程
Whisper 执行操作的大致过程:
- 输入的音频文件被分割成 30 秒的小段、转换为 log-Mel频谱图,然后传递到编码器。
- 解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。

安装
First, we need to install the depedencies we need. We will install FFmpeg - tool to record, convert and stream audio and video
- 详见站内 视频专题
apt install ffmpeg # 安装音频处理工具
pip install git+https://github.com/openai/whisper.git # 下载whisper
【2022-11-16】OpenAI 开源音频转文字模型 Whisper 尝鲜
已装 conda 和 ffmpeg 的话,简单的配置大概是:
# 创建虚拟环境
conda create -n whisper python=3.9
conda activate whisper
pip install git+https://github.com/openai/whisper.git
whisper audio.mp3 --model medium --language Chinese # ASR
【2023-3-2】Whisper 是OpenAI 在 2022 年 9 月开源的语音转文字模型。
- OpenAI 现在已经通过API提供了
V2 模型,它提供方便的按需访问,价格为0.006美元/分钟。 - 开发人员现在可以在 API 中使用开源的 Whisper large-v2 模型,而且速度更快,成本效益更高
- Introducing ChatGPT and Whisper APIs
- Whisper API is available through our transcriptions (transcribes in source language) or translations (transcribes into English) endpoints, and accepts a variety of formats (
m4a,mp3,mp4,mpeg,mpga,wav,webm)
import openai
file = open("/path/to/file/openai.mp3", "rb")
transcription = openai.Audio.transcribe("whisper-1", f)
print(transcription)
代码解读
whisper 代码结构
assets# 配置信息,gpt2,multilingual等normalizers# 特殊字符归一化处理__init__.py# 工具包导入时,加载依赖文件__main__.py# cli命令audio.py# 音频处理- load_audio : 用ffmpeg加载音频文件(wav/mp3…),重采样
- 如果是字符串(文件名),调用 load_audio 函数(ffmpeg工具)加载音频文件
- log_mel_spectrogram : 调用torch函数,计算梅尔倒谱系数
- pad_or_trim : 截断、填充
- load_audio : 用ffmpeg加载音频文件(wav/mp3…),重采样
decoding.py# 解码- detect_language 语种检测
- DecodingOptions 解码配置
- DecodingResult 解码结果
- Inference 推理
- PytorchInference
- SequenceRanker
- MaximumlikelihoodRanker
- TokenDecoder
- GreedyDecoder
- BeamSearchDecoder
- LogitFilter
- SuppressBlank
- SuppressTokens
- ApplyTimestampRules
- DecodingTask
- decode : 重载 torch的decode函数,调用 DecodingTask
model.py# 模型文件tokenizer.py# 分字、分词transcribe.py# 转写、翻译utils.py# 工具包,输出函数 write_text, write_srt
whisper 代码调用关系
_init_.py 内容
# 导入相关文件
from .audio import load_audio, log_mel_spectrogram, pad_or_trim
from .decoding import DecodingOptions, DecodingResult, decode, detect_language
from .model import Whisper, ModelDimensions
from .transcribe import transcribe
# 定义 load_model
def load_model(name: str, device: Optional[Union[str, torch.device]] = None, download_root: str = None, in_memory: bool = False) -> Whisper:
...
if name in _MODELS:
# 下载模型文件
checkpoint_file = _download(_MODELS[name], download_root, in_memory)
方法解读
李沐解读:OpenAI Whisper 精读【论文精读】
摘要
- 扩大语音识别弱监督数据的规模,达到 68 万小时,并在大规模数据上进行多语言(98种)、多任务的训练,得到了一个泛化性能很好的模型。该模型在常见语音识别数据集上,不需要微调,直接以
zero-shot的方式进行测试,结果与在这些数据集上训练过的语音识别模型性能相当。 - Weak Supervision 是指本文所用数据虽然是有标注的,但并不是为了训练模型专门进行的人工标注,所以是质量较低的标注,故称为 “弱监督”。
- 语音识别上最近进展是用无标签数据进行自监督预训练。
- Wav2Vec,收集了大量无标签的语音数据,通过
对比学习方式预训练语音编码器。在编码器预训练完成之后,再在标准语音识别数据集上微调,得到的结果优于只在语音识别训练集训练的模型。自监督预训练用到的无标签语音数据规模最多已经达到 100 万小时。 - Wav2Vec-U 在无监督语音识别训练方面取得了一些相关进展,不需要微调
- Wav2Vec,收集了大量无标签的语音数据,通过
数据集
数据集
- 68 万小时的语音识别数据,除了数据的规模大幅上升之外,数据的多样性也更加丰富。
- 68 万小时的语音数据中,有 11.7 万小时涵盖了除英语外的其他 96 种语言,有 12.5 万小时是其他语言到英语的翻译数据。
- 由于数据够多,模型够强,本文模型直接预测原始文本,而不经过任何
标准化(standardization), 输出就是最终识别结果,而无需经过反向的文本归一化(inverse text normalization)后处理。- 注:文本归一化包括如将所有单词变小写,所有简写展开,所有标点去掉等操作,而反向文本归一化就是上述操作的反过程
- 语音数据包含不同环境、不同语言、不同说话人等多样的数据,这有助于训练出文件的语音识别系统。然而,文本标签的多样性对模型的学习是一种阻碍。为了解决这个问题,本文使用了几种自动过滤方法,来提高文本标签的质量
- 首先,收集自互联网的语音识别数据,文本标签可能来自现有的语音识别系统的识别结果。之前有研究工作表明,在训练数据中混有机器生成的标签数据会损害模型的性能。为此,本文根据机器识别结果的一些特点,过滤掉了这些数据。
- 另外,对数据中语音所属语言和文本进行语种检测。如果文本是非英语的其他语言,则要求语音也必须是同种语言;如果文本是英语,则语音可以是任何语言(因为本文方法中有一个其他语言到英语的翻译任务)。
- 本文用一个语音识别模型在收集的数据上进行测试,发现在一些错误率极高的数据中,存在音频信息不完整、字幕声音不匹配等低质量数据,这些数据同样会被过滤掉。
- 另外,可能在收集的数据中含有标准语音识别数据集中的内容,为了避免对测试结果产生影响,这部分数据同样需要去掉。
最后,将音频切分为 30s 的片段,配上对应文本,得到训练数据。
模型结构
模型直接使用 Transformer 第一次提出时的 encoder-decoder 架构
- Whisper 的输出侧是声音信号,声音信号的预处理是将音频文件重采样到 16000 Hz,并计算出 80 通道的梅尔频谱,计算时窗口大小为 25ms,步长为 10ms。然后将数值归一化到 -1 到 1 之间,作为输入数据。
- 对于每一个时间点,提取了一个 80 维的特征。之前数据处理部分提到每个音频被切分为 30s 的片段,这里步长为 10,所以每 30 秒有 3000 个时间点。
- 综上,对于一个 30 秒的音频数据,提取到形状为 3000x80 的特征。对应到 NLP 中,可以理解为句子长度为 3000,每个词的词嵌入维度为 80。
- 3000x80 的输入数据首先通过两个 1D 卷积层,得到 1500x80 的特征。
- 后面的处理就是标准的 Transformer encoder-decoder结构了。
- 将这个特征送入到 Transformer encoder 中,提取处的特征作为交叉注意力输入送给 decoder。
- decoder 每次预测下一个 token,其输入是对应多任务学习的一些预设 token 和 prompt。
模型结构

There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and relative speed.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
For English-only applications, the .en models tend to perform better, especially for the tiny.en and base.en models. We observed that the difference becomes less significant for the small.en and medium.en models.
Whisper’s performance varies widely depending on the language. The figure below shows a WER breakdown by languages of Fleurs dataset, using the large model. More WER and BLEU scores corresponding to the other models and datasets can be found in Appendix D in the paper.
中文而言,Whisper各模型:
tiny是没有做断句的,或者说,直接根据停顿断句base已经开始根据逻辑断句,但会出语法错误small已经很少语法错误,但断句水平却直线下降,很奇怪medium不仅能够完美的断句,还能判断语气
多任务
语音识别系统除了识别出语音中的语言文本(转录)之外,还需要做一些其他的任务。比如是否有人在说话(voice activity detection, VAD)、谁在说话(speaker diarization),和反向文本归一化等。
- 在语音识别系统中,这些任务分别由不同的模型来处理,但本文由 Whisper 一个模型完成。多个语音任务由同一个模型完成,有利有弊。
- 好处是 all-in-one 的模型听起来比较 fancy,比较符合对于语音识别系统的期待。
- 坏处是多个任务中, 如果某几个性能相对较差,整个模型难以调试。而且,如果需求只是做某一个比较简单的任务(如 VAD),一般来说一个简单的模型就可以胜任,但是 Whisper 需要跑起整个大模型。
- Whisper 模型共处理4个任务,如图左上所示。
- (1) 转录英文:给定英文语音,转录成英文文本;
- (2) 转录+翻译:给定其他语言语音,转录并翻译成英文文本;
- (3) 转录源语言:给定其他语言语音,转录成该语言文本;
- (4) 静音检测:给定只有背景音乐的音频,识别出无人说话。
所有这些任务都由解码器预测的 token 序列表示,从而使得一个模型能够处理多个任务。这几个任务及模型输出 token 的关系可以下方的图示中的 token 序列看出:
- 在 START OF TRANSCRIPT token 之后,如果当前无人说话,则识别为 NO SPEECH 。
- 如果有人说话,则识别出当前语音所属的语言 LANGUAGE TAG 。
- 然后有两种可能的任务
TRANSCRIBE还是翻译任务TRANSLATE,这两种任务又分为两种形式:带时间戳的 和 不带时间戳的,分别穿插或不穿插时间戳 token ,预测出文本 token。最后到达 EOT token,整个流程结束。
使用方法
ASR shell 调用
whisper "audio.mp3" --task transcribe --model base # 执行转写任务
whisper audio.mp3 --model tiny --device cpu --fp16 False # 用 CPU、FP32跑
whisper --language Chinese --model large audio.wav # 指定模型 large
# [00:00.000 --> 00:08.000] 如果他们使用航空的方式运输货物在某些航线上可能要花几天的时间才能卸货和通关
whisper --language Chinese --model large audio.wav --initial_prompt "以下是普通話的句子。" # traditional 默认是繁体
# [00:00.000 --> 00:08.000] 如果他們使用航空的方式運輸貨物,在某些航線上可能要花幾天的時間才能卸貨和通關。
whisper --language Chinese --model large audio.wav --initial_prompt "以下是普通话的句子。" # simplified 指定简体中文
# [00:00.000 --> 00:08.000] 如果他们使用航空的方式运输货物,在某些航线上可能要花几天的时间才能卸货和通关。
注
- fp16是指采用2字节(16位)进行编码存储的一种数据类型;
- 同理,fp32是指采用4字节(32位)
- 使用简体中文,参考:Simplified Chinese rather than traditional?
fp16和fp32相比对训练的优化:
- 内存占用减少:很明显,应用fp16内存占用比原来更小,可以设置更大的batch_size
- 加速计算:加速计算只在最近的一些新gpu中,这一块我还没有体验到好处…有论文指出fp16训练速度可以是fp32的2-8倍
By default, terminal uses beam search which generally performs better than greedy search (python’s default).
- 默认情况下,终端模式使用 beam search,而python使用 greedy search
python脚本
import whisper
model = whisper.load_model("base")
voice_file = "audio.mp3"
# jupyter 中播放语音
import IPython
IPython.display.Audio(audioPath, autoplay=True)
# 执行 ASR
result = model.transcribe("audio.mp3")
# 方法①
# options = whisper.DecodingOptions(language= 'en', fp16=False)
# result = whisper.decode(model, mel, options)
# 方法②
# result = model.transcribe(audioPath, fp16=False, language='English')
# 语音翻译 task='translate'
# result = model.transcribe(audioPath, task='translate',language='zh',verbose=True,initial_prompt=prompt)
result = model.transcribe("audio.mp3", initial_prompt='vocabulary' )
print(result["text"])
# ------ 加时间 ------
start_asr = time.time()
result = model.transcribe(audioPath, task='translate',language='zh',verbose=True,initial_prompt=prompt)
end_asr = time.time()
time_load = start_asr - start_asr
time_asr = end_asr - start_asr
print("模型加载时间:{:.2f}\nasr时间:{:.2f}".format(time_load, time_asr))
print(result["text"])
【2022-11-21】提示, 参考: Where do I use –initial-prompt in python code?
- prompt可以是词库列表,如 prompt=”Tensorflow pytorch”,添加方式
- (1)一次性生效
- (2)批量生效
#(1)一次性生效,临时配置
result = model.transcribe(audioPath, language='zh', verbose=True, initial_prompt=prompt)
#(2)批量生效,使用全局配置
options = whisper.DecodingOptions(fp16=False)
result = whisper.decode(model, mel, options)
参数详解
DecodingOptions
DecodingOptions 类定义:
task: 任务类型,transcribe(转写任务) 或 translate(翻译任务)language: 语种,如果为空,自动启动语言检测任务fp16: 使用GPU,False时表示CPU- 采样参数
- temperature: 采样温度
- sample_len: 最大采样长度
- best_of: 独立样本数
- beam_size: beam search数
- patience: beam search里的耐心指数?
length_penalty: 生成(beam或n-best)候选句子排序中的长度惩罚- 提示、前缀、字符压缩
prompt: 上文提示prefix: 当前句子前缀- suppress_blank: 是否压缩空格
- suppress_tokens: 需要压缩的特殊字符,如 -1
- 时间采样
- without_timestamps: 是否省略时间信息?
- max_initial_timestamp: 最大初始时间
@dataclass(frozen=True)
class DecodingOptions:
task: str = "transcribe" # whether to perform X->X "transcribe" or X->English "translate"
language: Optional[str] = None # language that the audio is in; uses detected language if None
# sampling-related options
temperature: float = 0.0
sample_len: Optional[int] = None # maximum number of tokens to sample
best_of: Optional[int] = None # number of independent samples to collect, when t > 0
beam_size: Optional[int] = None # number of beams in beam search, when t == 0
patience: Optional[float] = None # patience in beam search (https://arxiv.org/abs/2204.05424)
# options for ranking generations (either beams or best-of-N samples)
length_penalty: Optional[float] = None # "alpha" in Google NMT, None defaults to length norm
# prompt, prefix, and token suppression
prompt: Optional[Union[str, List[int]]] = None # text or tokens for the previous context
prefix: Optional[Union[str, List[int]]] = None # text or tokens to prefix the current context
suppress_blank: bool = True # this will suppress blank outputs list of tokens ids (or comma-separated token ids) to suppress
# "-1" will suppress a set of symbols as defined in `tokenizer.non_speech_tokens()`
suppress_tokens: Optional[Union[str, Iterable[int]]] = "-1"
# timestamp sampling options
without_timestamps: bool = False # use <|notimestamps|> to sample text tokens only
max_initial_timestamp: Optional[float] = 1.0 # the initial timestamp cannot be later than this
# implementation details
fp16: bool = True # use fp16 for most of the calculation
prompt 和 prefix 的作用,官方作答
promptconditions the model on the text that appeared in the previous ~30 seconds of audio, and in long-form transcription it helps continuing the text in a consistent style- e.g. starting a sentence with a capital letter if the previous context ended with a period. You can also use this for “prompt engineering”, to inform the model to become more likely to output certain jargon (“ So we were just talking about DALL·E”) or do a crude form(原始格式) of speaker turn tracking (e.g. “ - Hey how are you doing? - I’m doing good. How are you?”, note that the token for “ -“ is suppressed by default and will need to be enabled manually.)
prefixaccepts a partial transcription (部分转录) for the current audio input, allowing for resuming the transcription after a certain point within the 30-second speech. I made this option to prototype semi-realtime transcription, where overlapping windows would be used to incrementally accept audio every second or so, and prefix could contain the text for the overlapping portion.
Below shows where prompt and prefix go in the tokens:

initial_prompt 源码解读
- 用 GPT2 TokenizerFast 分词器,将 prompt 参数导入的文本分字
# prompt 文本里的字符扩充到token集合中
initial_prompt = decode_options.pop("initial_prompt", None) or []
if initial_prompt:
initial_prompt = tokenizer.encode(" " + initial_prompt.strip())
all_tokens.extend(initial_prompt)
def encode(self, text, **kwargs):
return self.tokenizer.encode(text, **kwargs)
# https://github.com/openai/whisper/blob/eff383b27b783e280c089475852ba83f20f64998/whisper/tokenizer.py#L137
class Tokenizer:
"""A thin wrapper around `GPT2TokenizerFast` providing quick access to special tokens"""
tokenizer: "GPT2TokenizerFast"
def decode(self, token_ids: Union[int, List[int], np.ndarray, torch.Tensor], **kwargs):
return self.tokenizer.decode(token_ids, **kwargs)
transcribe
def transcribe(
model: "Whisper",
audio: Union[str, np.ndarray, torch.Tensor],
*,
verbose: Optional[bool] = None,
temperature: Union[float, Tuple[float, ...]] = (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
compression_ratio_threshold: Optional[float] = 2.4,
logprob_threshold: Optional[float] = -1.0,
no_speech_threshold: Optional[float] = 0.6,
condition_on_previous_text: bool = True,
**decode_options,
)
transcribe 参数说明
verbose: 是否输出调试信息到终端 Whether to display the text being decoded to the console.- True: 显示所有调试信息(segment片段),displays all the details
- False: 只显示解码进度, displays minimal details.
- None: 不显示。does not display anything
temperature: 采样温度- Temperature for sampling. It can be a tuple of temperatures, which will be successfully used upon failures according to either
compression_ratio_thresholdorlogprob_threshold.
- Temperature for sampling. It can be a tuple of temperatures, which will be successfully used upon failures according to either
compression_ratio_threshold: float 压缩率最低阈值- If the gzip compression ratio is above this value, treat as failed
logprob_threshold: float log似然最低阈值- If the average log probability over sampled tokens is below this value, treat as failed
no_speech_threshold: float 静音阈值,用来判断是否静音分片- If the no_speech probability is higher than this value AND the average log probability over sampled tokens is below
logprob_threshold, consider the segment as silent
- If the no_speech probability is higher than this value AND the average log probability over sampled tokens is below
condition_on_previous_text: bool 是否使用上一句结果作为提示语, 关闭后,不容易陷入循环、时间戳不一致,但同时前后分片可能不一致- if True, the previous output of the model is provided as a prompt for the next window;
- if false, disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop, such as repetition looping or timestamps going out of sync.
decode_options: dict 全局参数 DecodingOptions- Keyword arguments to construct
DecodingOptionsinstances
- Keyword arguments to construct
使用注意
- ① 指定
language为zh(简体中文),要不然默认出繁体字 - ②
verbose可以先开着,能看到分句片段信息 - ③
initial_prompt填入房产领域字典,分隔符随意(空格、逗号等) - ④ 模型
model使用medium以上,最好是large,其它版本中文断句效果差 - ⑤
fp16使用GPU转写,cpu慢,一般5min音频耗时1-2min - ⑥ 音频格式:mp3或wav都行,mp3是有损压缩,比wav小
输出结果
# verbose = True
[00:00.000 --> 00:16.000] 中央政务区的成立,东城区人口总量将会严格管控,坚决落实老城不再拆,保证单头的政委,使得二环内乃至东城区未来都将不再有新增土地。
# verbose = False
100%|██████████| 1767/1767 [00:04<00:00, 395.72frames/s]
【2022-12-15】whisper 批处理,model.transcribe() modified to perform batch inference on audio files #662
- 一次性推理多条语音信息,加速
- 用户改写版

import whisper
model = whisper.load_model("base")
# 批量撰写
results = model.transcribe(["audio1.mp3", "audio2.mp3"])
print(results[0]['text'])
print(results[1]['text'])
转写结果
返回字典结构
- text:最终输出的总文本
- segments:分段详情信息
- language:语言类型
{
"text": "项目的物业 富华行物业 管理长安俱乐部长安俱乐部是十大俱乐部之首 物业费是24块钱一瓶",
"segments": [
{"id": 0, "seek": 0, "start": 0.0, "end": 7.0, "text": "项目的物业 富华行物业 管理长安俱乐部", "tokens": [50364, 10178, 117, 11386, 1546, 23516, 940, 248, 220, 47564, 5322, 236, 8082, 23516, 940, 248, 220, 23131, 13876, 32271, 16206, 7792, 109, 44365, 13470, 50714, 50714, 32271, 16206, 7792, 109, 44365, 13470, 1541, 20145, 3582, 7792, 109, 44365, 13470, 9574, 25444, 220, 23516, 940, 248, 18464, 117, 1541, 7911, 47734, 39623, 2257, 163, 241, 114, 50964], "temperature": 0.0, "avg_logprob": -0.14029632765671302, "compression_ratio": 0.41346153846153844, "no_speech_prob": 0.14019320905208588},
{"id": 1, "seek": 700, "start": 7.0, "end": 36.0, "text": "长安俱乐部是十大俱乐部之首 物业费是24块钱一瓶", "tokens": [50364, 32271, 16206, 7792, 109, 44365, 13470, 1541, 20145, 3582, 7792, 109, 44365, 13470, 9574, 25444, 220, 23516, 940, 248, 18464, 117, 1541, 7911, 47734, 39623, 2257, 163, 241, 114, 51814], "temperature": 0.0, "avg_logprob": -0.10979152470827103, "compression_ratio": 0.3380281690140845, "no_speech_prob": 0.0005883726407773793}],
"language": "Chinese"
}
问题
- VAD 功能不足:当音频分片不足30s时,最后一个分片的截止时间错误, 详见issue, VAD讨论
- In the [“segment”] field of the dictionary returned by the function transcribe(), each item will have segment-level details, and there is
no_speech_probthat contains the probability of the token <|nospeech|>. This combined with the log probability threshold and the compression ratio threshold performs a crude VAD in transcribe(), but you might find a better result by combining with a separate VAD tool that’s more accurate. - 【2022-11-21】作者回复:需要加参数,just added
--condition_on_previous_textFalse option.
- In the [“segment”] field of the dictionary returned by the function transcribe(), each item will have segment-level details, and there is
评测
英文语音识别
- 不同语音识别模型在 LibriSpeech dev-clean 上的性能(横轴)和在多个数据集上的平均性能(纵轴)
- 虽然很多有监督方法在该数据集上训练之后能够得到很低的错误率(~1.6%),但这些模型在多个数据集上测试的平均错误率却非常高(>20%),很可能是这些有监督方法过拟合了 LibriSpeech 数据集。而 Whisper 虽然在 LibriSpeech 上错误率没有特别低,但是在多数据集测试中错误率也不错。这足以说明 Whisper 优秀的泛化性能。
多语言语音识别
- 在小数据集 MLS 上,Whisper 表现更好;而在更大的 VoxPopuli 上,在训练集上训练过的有监督方法性能更好。
- 整体上随着训练数据的增多,错误率是会下降的。
- 另外,在相同训练数据量的情况下, ZH、KO,即
中文、韩文等语言的错误率相对较高。这可能有两个原因- 一是东亚语言与世界主流的英语、法语等差别较大,无法从多语言联合训练中受益
- 二是 Whisper 的 tokenizer 对于这类语言也不太友好。
多语言/多任务联合训练与仅英语训练对比
- 蓝线表示全部使用英语数据进行训练,橙线表示多语言、多任务联合训练的结果。
- 随着训练数据量的增加,多语言、多任务联合训练对英语本身的语音识别性能也是有帮助的
Whisper 的意义
- 指明了只要有大规模数据,通过一个简单的 Transformer encoder–decoder 架构就能训练出可靠的语音识别模型。并且开源了他们的训练权重。
- 缺点也很明显,目前 Whisper 对推理基本无优化,Large 模型需要约 10 G 显存,速度也比较慢。不过在未来,肯定会有一系列工作从算法上或者从工程上来优化 Whisper 的推理部署。
音频采用的是:
节选开头一段
将飞书妙记和Whisper在各等级模型下跑的结果作对比:

Whisper 识别结果




飞书妙记给用户开放的转写能力大约在 tiny 到 base 之间(转写速度也在 tiny 左右,已经很快了)
- 对比目的并不是比较二者的技术,否则对于飞书妙计相当的不公平,作为一款消费级应用,它不可能给用户跑medium等级的模型来做转写
- 对比意义是,Whisper作为一个开源模型,和消费级产品比起来怎么样?
答案是,完全可以替代
- 用 small 模型足以实现当下的免费体验了。
- 用 medium 以上的模型,可以用「时间」换「好得多的使用体验」
从对比截图也能看到,Whisper在medium模型下的断句水平就已经让人欣喜了,不是说技术有多先进,而是,这是开源模型啊, 做到同样水平的转写,基本属于付费服务了
不足
- 在词汇上,Whisper偶尔不那么准确,但它是准确识别发音的,也就是说,这是词库的问题,相信开源社区很快就会有针对中文的优化模型出现
意义是什么呢?
- 很快互联网上的音频和视频资料中的对话台词,也可以搜索了吧,就像音乐可以搜歌词一样,音频不再是监管的法外之地了
- 对于播客爱好者来说,很快,拥有自动高质量转写的播客客户端不再是梦
kaggle上GPU测试(P100)
| 模型版本 | 模型加载时间 | asr时间 | asr效果 | asr样例 |
|---|---|---|---|---|
| small版 | 13.80 | 81.49 | 一般,70% | 操作的时候肯定是得去一点点弄这个都是早知道要费时间还是其他的一个环节早知道环节这段其实老海就有还有大概三个因为不会是说他那些其他东西都用不好了只用了这么大的你这三个表演好几个秒像那个色料然后然后吃点去你们弄的对我弄的不太好吃用色料跟挺好搭的会简单一些对一会讲大概两三个小时还要两个小时子龙的两个小时这么久吗 |
| medium版 | 19.20s | 136.82s | 较好,93% | 操作中肯定是得就是去一点点的弄这个都是找资料废食还是其他的一些环节就是整个环节资料其中脑海只有还有大概三个四个小时吧因为不会是说他那些提干的东西都运用好了只用录音的那一个塞表上好几个秒像资料然后操作对然后吃脸是你们弄的吗对吃脸也是你们弄的不弄是不点吗只弄资料跟提款达会简单一些吗对肯定会简单大概那怎么弄两三个小时还要两个小时只弄这两个部分有两个小时 |
| large版 | 56.84 | 214.82 | 较好,95% | 超的时候肯定是得去一点点的弄这个都是找资料废食还是其他的一些环节肯定是找个环节资料其实脑海中有还有没嘛大概三四个小时吧因为不会是说他那些体肝那些东西都已经弄好了只用录一个这么大的那个好几个资料一个资料表上好几个表相互资料然后套单对然后吃点是你们弄的吗对对如果不弄就不念了只用资料跟听到答案会简单一些吗对肯定会简单大概能够两三个小时两个小时还要两个小时只弄了两部分也要两个小时对这么久吗 |
import time
import whisper
start_load = time.time()
model_type = 'small' # tiny,base,small,medium,large
model = whisper.load_model(model_type)
start_asr = time.time()
# 测试数据:15min的录音,有环境噪音(音乐),文件占15m
audioPath = '../input/audio-test/output_m4atomp3.net.mp3'
#result = model.transcribe("audio.mp3")
#result = model.transcribe("audio.mp3",fp16=False) # CPU版
#result = model.transcribe(audioPath, fp16=False, language='English')
#result = model.transcribe(audioPath, fp16=False, language='Chinese')
result = model.transcribe(audioPath, language='Chinese')
end_asr = time.time()
time_load = start_asr - start_load
time_asr = end_asr - start_asr
print("模型加载时间:{:.2f}\nasr时间:{:.2f}".format(time_load, time_asr))
print(result["text"])
优化
ASR 纠错
ASR(自动语音识别)里“专有名词老认错”问题。
- “ChatGPT”“长江白鲟”这种领域特定的命名实体,ASR(比如Whisper)在通用场景里挺准,但遇到这些词常转错,后续用这些转录文本做任务就全乱了。
- 又叫 (NEC)
【2025-10-24】ASR纠错迎来新方法:华为提出SS+GL方案,大幅提升命名实体识别准确率
主流的NEC(命名实体纠正)方法分两类:
- 一类是“边生成边纠正”,得改ASR系统本身,第三方云服务(比如讯飞、亚马逊的ASR)根本用不了;
- 另一类是“生成后再纠正”,更通用,其中最常见的是 PED-NEC(基于语音编辑距离的方法)。
PED-NEC 有个大毛病——如果错的文本和真实实体“长得太不一样”,就彻底歇菜。比如:
- “大语言模型”被ASR转成“大原模型”,俩词字面差挺多;
- “Midjourney”转成“米德仲尼”(英文变中文音译);
- “灵耀X”转成“01X”(汉字变数字);
- “ChatGPT”转成“Check GPT”(拼写差一截)。
新方法叫“生成式标注NEC”,核心是两步:SS(语音特征检索候选实体)+ GL(生成式标注错误文本)。
不依赖文本长得像不像,而是靠语音特征找候选,再让模型“智能标出”错词,最后替换——完美解决“长得不一样”的问题。
方法
实时 ASR
Really Real Time Speech To Text #608
- the demo here
Real-time transcription with Whisper on a desktop app #246
For many who would rather use a desktop app than a CLI, I made a cross-platform app called Buzz.
移动设备
On-device Whisper inference on mobile (iPhone 13 Mini) #407
- 苹果手机上执行whisper
说话人识别
Speaker identification 说话人识别功能实现的几种思路
| 序号 | 思路 | 详情 | 优点 | 缺点 |
|---|---|---|---|---|
| 1 | 单独用说话人识别 | pyannote.audio识别说话人,逐个分片输入 whisper | 开销大 | |
| 2 | 分离左右声道 | 将原始语音按左右声道分割成两个文件,分别调研 whisper 再合并 | 简单 | 时间信息丢失,难以合并 |
| 3 | ||||
| 4 |
- 从声音中分离左右声道,再单独使用 whisper 识别,
(1)方法一:pyannote.audio
pyannote.audio is an open-source toolkit written in Python for speaker diarization.
Based on PyTorch machine learning framework, it provides a set of trainable end-to-end neural building blocks that can be combined and jointly optimized to build speaker diarization pipelines.
pyannote.audio also comes with pretrained models and pipelines covering a wide range of domains for voice activity detection, speaker segmentation, overlapped speech detection, speaker embedding reaching state-of-the-art performance for most of them.
(2)方法二:声道分割【有问题】
Speaker diarization using stereo channels #585:Speaker diarization 说话人识别(分类)。I’ve found a series of steps that may work for me:
- Using ffmpeg mute one channel (doesnt matter which one) and save the audio file
- Using ffmpeg use silencedetect on the newly created audio file from step 1
- silencedetect can provide you with a series of start and end times where you can assume the silenced portions of this new audio file represent the “other” speaker.
- Use whisper to transcribe the original unmodified audio file
- Use the start and end times from step 3 and the timestamps from Whisper to correctly match the transcription to the right speaker.
ffmpeg 分割音频文件为左声道、右声道,分别调用whisper转写,再拼接
问题:分割声道后,时间维度丢失
- The problem with splitting the channels is that you lose the time dimension. Each channel now has its own start and end times relative to its own audio file.
Steps 1 - 3 on a four hour long audio file completed in under 20 seconds for me.
(3)方法三
Transcription and diarization (speaker identification) #264
Speaker Prediction using Whisper - Lex Podcasts #624
- I performed speaker prediction on Lex Fridman Podcast captions using hidden states from Whisper, which lead to reasonable results (F1-score of 93%). I explore using the hidden states of various encoder blocks in the Whisper transformer and train a classifier. Using hidden states of some encoder blocks lead to better results than others. I summarized my findings in this repo and Blog Post
finetune
fine-tune 实践
- Check-out this blog for fine-tuning Whisper for multilingual ASR with Hugging Face Transformers
- It provides a step-by-step guide to fine-tuning, right from data preparation to evaluation 🤗 There’a Google Colab so you can also run it as a notebook
- run_speech_recognition_whisper
- Fine Tuning code in Japanese Kana: AudioWhisper_Train_v00001.ipynb
whisper + diffsion
- Thanks to recently published models, we have the ability to create images from the spoken words. This opens up a lot of possibilities for us.

【2025-11-10】Omnilingual ASR
语音识别长期集中于英语、中文、西班牙语等高资源语言,依赖大量人工标注数据,使得全球许多弱势语言在数字化过程中持续被排除。
Meta指出,此落差造成语音AI的全球普及性大幅受限,而Omnilingual ASR正是针对该根本问题所设计。
【2025-11-10】META FAIR 发布 Omnilingual ASR, 全语言自动语音识别系统 ,资讯
- META 官方博客
- Twitter 介绍
- huggingface 地址 omniasr-transcriptions
- github omnilingual-asr
要点
- 错误率别比 Whisper v3 更低
- 支持1600种语言(包括几种中国方言,粤语、闽南语等), 249种高资源语言(每语言至少50小时语料)、881种中资源语言(10至50小时),以及546种低资源语言(少于10小时)
- 模型包括300M、1B、3B、7B四个大小,7B大小为目前开源最佳,运行大约需要15G显存,同时开源了数据集。
Meta 将语音基础模型 wav2vec 2.0 扩展至70亿参数(7B),并提供CTC(Connectionist Temporal Classification)与基于Transformer架构的大型语言模形式解码器(LLM-ASR)等两种解码架构。后者特别强化长尾语言表现,使模型能在极少语料下依然保持可用准确度。
另一项关键突破: “Bring Your Own Language(自带语言)”能力。用户只需提供少量音频与文本配对样本,即可扩展至未支持语言,依靠的正是大型语言模型的场景式学习能力,让语音识别能以极低门槛覆盖更多语言社交媒体。
【2025-12-15】Fun-ASR-Nano
【2025-12-15】Fun-ASR-Nano 技术指南:端到端实时语音识别大模型
2025年12月15日,FunAudioLLM 团队推出 Fun-ASR-Nano-2512。
- 技术报告
- 模型地址 Fun-ASR-Nano-2512,含评测数据
Fun-ASR 是通义实验室推出的端到端语音识别大模型。
- 基于数千万小时的真实语音数据训练而成,具备强大的上下文理解能力和行业适应性。
- 支持低延迟实时转写,覆盖31种语言。
- 在教育、金融等垂直领域表现出色,能够精准识别专业术语和行业表达,有效解决“幻觉”生成和语言混淆等问题,实现“听得清、懂得意、写得准”。
经过千万小时级真实语音数据训练的端到端语音识别(ASR)大模型,专为高精度、低延迟场景设计。
亮点
- 极致性能:支持低延迟实时转写,具备强大的上下文理解能力。
- 全能覆盖:
- 31 种语言:重点优化东亚、东南亚语言,支持中英日韩等混合识别。
- 7 大方言:吴语、粤语、闽南语、客家话、赣语、湘语、晋语。
- 26 种口音:覆盖河南、陕西、四川、重庆、云贵广等 20+ 地区口音。
- 抗噪能力:针对远场、高噪环境(会议室、车载、工业现场)深度优化,识别率高达 93%。
- 音乐歌词识别:即使在背景音乐干扰下,也能准确识别歌词内容。
版本
- Fun-ASR 0.8B
- Fun-ASR-nano 0.2B
- 1-2GB
- 有4bit、8bit量化版
Fun-ASR 部署非常简洁,建议
- Python 3.8+ 环境
- GPU 进行推理,请确保安装了与 CUDA 版本匹配
# 1. 克隆代码或直接安装依赖
pip install -r requirements.txt
# 或者手动安装核心库 (FunASR)
pip install funasr modelscope
调用代码,省略
【2025-12-21】GLM-ASR
【2025-12-21】GLM-ASR开源,1.5B参数刷新端侧语音识别SOTA
智谱正式发布并开源GLM-ASR系列语音识别模型,并推出基于该系列模型打造的桌面端智谱AI输入法。
- GLM-ASR-2512:全球领先的云端语音识别模型;
- GLM-ASR-Nano-2512:参数量仅1.5B的开源SOTA端侧语音模型;
- 智谱AI输入法:将语音识别与大模型深度融合的桌面端效率工具。
GLM-ASR-Nano-2512 1.5B参数的端侧模型,取得了当前开源语音识别方向的SOTA表现,并在部分测试中优于若干闭源模型。该模型将识别能力压缩到本地运行,在保证高精度的同时,实现更强的隐私保护与更低的交互延迟。
传统输入法只负责打字,而智谱AI输入法直接调用底层GLM模型帮助用户翻译、扩写、精简屏幕上的任意一段文字,同时完成智能润色,让输出更加自然、通顺。整个过程在输入框内完成,实现“理解-执行-替换”一体化,无需在多个应用间反复切换。
TTS 工具
KittenTTS
【2025-8-5】超微型语音模型 KittenTTS:大小不到 25MB
Stellon Labs 专注于微型前沿模型(tiny frontier models)的 AI 研究实验室,由 YC 孵化。
首个模型是 KittenTTS,超小型的开源文本转语音(TTS)模型,其大小不到 25MB。
- github KittenTTS
该模型在发布后短短三周内便获得了巨大的关注,在 GitHub 上斩获 8000 多个星标,模型下载量超过 4.5 万次。
功能亮点:
- 超轻量级: 模型大小不到 25MB;
- CPU 优化: 无需 GPU,可在任何设备上运行;
- 高质量音色: 提供多种优质语音选项;
- 快速推理: 专为实时语音合成而优化。
Stellon Labs 的目标是构建覆盖语音、语言和视频智能领域的微型前沿模型,最终让 AI 技术能够在每一个设备上运行。
pip install https://github.com/KittenML/KittenTTS/releases/download/0.1/kittentts-0.1.0-py3-none-any.whl
使用
from kittentts import KittenTTS
m = KittenTTS("KittenML/kitten-tts-nano-0.2")
audio = m.generate("This high quality TTS model works without a GPU", voice='expr-voice-2-f' )
# available_voices : [ 'expr-voice-2-m', 'expr-voice-2-f', 'expr-voice-3-m', 'expr-voice-3-f', 'expr-voice-4-m', 'expr-voice-4-f', 'expr-voice-5-m', 'expr-voice-5-f' ]
# Save the audio
import soundfile as sf
sf.write('output.wav', audio, 24000)
各大tts平台总结
- 市场的TTS平台:讯飞语音,百度智能语音开放平台,阿里云,腾讯云,思必驰,捷通华声(灵云)等。
- 百度无人回复,没给报价,思必驰没找到任何公司人员
- 各平台均有使用,每天限次数,可以开发试听一下
- 总体效果
- 标贝 > 讯飞 > 阿里 > 百度 > 思必驰 > 灵云
- 详细代码参考:Python:TTS语音合成技术,市场各大平台对比以及实现
grdio demo
gradio demo
import tempfile
import gradio as gr
from neon_tts_plugin_coqui import CoquiTTS
LANGUAGES = list(CoquiTTS.langs.keys())
coquiTTS = CoquiTTS()
def tts(text: str, language: str):
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as fp:
coquiTTS.get_tts(text, fp, speaker = {"language" : language})
return fp.name
inputs = [gr.Textbox(label="Input", value=CoquiTTS.langs["en"]["sentence"], max_lines=3),
gr.Radio(label="Language", choices=LANGUAGES, value="en")]
outputs = gr.Audio(label="Output")
demo = gr.Interface(fn=tts, inputs=inputs, outputs=outputs)
demo.launch()
bark
【2023-4-23】GitHub 开源神器 Bark模型,让文本转语音更简单
- Bark 是由Suno创建的基于转换器的文本到音频模型。Bark 可以生成高度逼真的多语言语音以及其他音频 - 包括音乐、背景噪音和简单的音效。该模型还可以产生非语言交流,如大笑、叹息和哭泣。
项目地址:bark
功能如下:
- 非常真实自然的语音
- 英文效果最佳,其他语言还欠佳
- 支持通过文本生成歌曲
- 支持生成背景噪音、简单的音效
- 支持大笑、叹息、哭泣
硬件和推理速度
- Bark 经过测试,可在 CPU 和 GPU(pytorch 2.0+、CUDA 11.7 和 CUDA 12.0)上运行。运行 Bark 需要运行 >100M 的参数转换器模型。在现代 GPU 和 PyTorch nightly 上,Bark 可以大致实时地生成音频。在较旧的 GPU、默认 colab 或 CPU 上,推理时间可能会慢 10-100 倍。
# 安装
pip install git+https://github.com/suno-ai/bark.git
# 或者
git clone https://github.com/suno-ai/bark
cd bark && pip install .
代码
- Bark 支持开箱即用的各种语言,并自动根据输入文本确定语言。当出现代码转换文本提示时,Bark 将尝试使用相应语言的本地口音。英语质量目前是最好的。
- 默认识别电脑上有无GPU,如果没有GPU则会下载可用于CPU的训练模型,默认模型文件下载地址为当前用户目录.cache文件夹下,可以通过配置XDG_CACHE_HOME环境变量指定模型下载位置
【2023-7-14】Merlin 上分配GPU,测试效果
修改部分代码: bark/generation.py
- 新增自定义缓存目录:model_cache_dir
# model 缓存目录
model_cache_dir = '/mnt/bd/wangqiwen-hl/models' # 网盘地址
def _get_ckpt_path(model_type, use_small=False):
key = model_type
if use_small or USE_SMALL_MODELS:
key += "_small"
#return os.path.join(CACHE_DIR, REMOTE_MODEL_PATHS[key]["file_name"])
return os.path.join(model_cache_dir, REMOTE_MODEL_PATHS[key]["file_name"])
def _download(from_hf_path, file_name):
os.makedirs(CACHE_DIR, exist_ok=True)
#hf_hub_download(repo_id=from_hf_path, filename=file_name, local_dir=CACHE_DIR)
hf_hub_download(repo_id=from_hf_path, filename=file_name, local_dir=model_cache_dir)
测试代码
from bark import SAMPLE_RATE, generate_audio
from IPython.display import Audio
text_prompt = """
Hello, my name is Suno. And, uh — and I like pizza. [laughs]
But I also have other interests such as playing tic tac toe.
"""
audio_array = generate_audio(text_prompt) # 自动检测语种
Audio(audio_array, rate=SAMPLE_RATE)
# Bark 可以生成所有类型的音频,并且原则上看不出语音和音乐之间的区别。有时 Bark 选择将文本生成为音乐,可以通过在歌词周围添加音符来帮助它。
text_prompt = """
♪ In the jungle, the mighty jungle, the lion barks tonight ♪
"""
audio_array = generate_audio(text_prompt)
# 扬声器提示
# 提供特定的演讲者提示,例如旁白、男人、女人等。请注意,这些提示并不总是管用,尤其是在给出冲突的音频历史提示时。
text_prompt = """
WOMAN: I would like an oatmilk latte please.
MAN: Wow, that's expensive!
"""
audio_array = generate_audio(text_prompt)
语音风格化
音色转换:按照指定音色说话或歌唱
人生分离,人声分离:将音频(音乐)中的人声和其他声音分离
Supertone Shift
【2024-5-14】实时变声器 “Supertone Shift” 新维度, 可以实时自由地转换声音,使 Discord、VRChat 和 Twitch 上的流媒体更加有趣。
除了调整声音之外,还可以通过将自己的声音和角色的声音混合在一起来创造新的声音。
Supertone Shift 需要改变音频音高而又不希望其他音频特性发生变化的场合下非常有用。
无论是音乐制作、声音修正、音频后期制作还是DJ混音,Supertone Shift都能提供一个方便快捷的解决方案,帮助创作者实现他们的创意和需求。
语音克隆
【2024-4-27】
- 中文声音克隆在线体验
- 声音复刻:订制个人专属声音
MockingBird
【2023-4-9】实时中文语音克隆,声音模仿如此简单
- 开源项目
MockingBird,拟声鸟能够使用 5 秒的真实语音录音,即可通过机器学习的方式,对声音进行克隆,从而实现按相同声音说出任意的文本。 
- AI拟声: 5秒内克隆您的声音并生成任意语音内容 Clone a voice in 5 seconds to generate arbitrary speech in real-time
- DEMO 效果
通过借助 MockingBird 能够很轻松的克隆一个声音并应用到人工智能系统中,从而改善系统中机器人声音的效果。
- MockingBird 使用 PyTorch 开发,能够在 Windows 和 Linux 系统中运行,MockingBird 现在是可以开箱即用
- MockingBird 还提供了一个可供使用的 Web 页面,运行命令 python web.py 即可查看。
GPT-SoVITS 开源
【2024-1-16】GPT-SoVITS:适用于中文的语音克隆,据说目前中文最佳,支持通过5秒音频克隆、1分钟音频克隆,也支持通过完整训练来克隆。
A Powerful Few-shot Voice Conversion and Text-to-Speech WebUI
OpenAI: Voice Engine
【2024-3-31】OpenAI公司最近推出了一项革命性的声音克隆技术——“Voice Engine”
Voice Engine通过文本输入和15秒的音频样本,便能生成与原始说话者声音极为相似、情感丰富且自然逼真的语音。
Voice Engine 是一个少样本语音合成模型:
- 15s 克隆任意人声;
- ChatGPT 语音对话、朗读以及 Heygen 数字人背后的技术;
- Spotify使用它为不同的语言配音播客。
- 2022 年底开发完成,目前小范围邀测,还未公开发布使用;
- 配音演员可能会被革命;
- 定价据透露会是 15 美元 / 100 万字符。
安全措施。
- 使用水印技术追踪音频来源,以及对系统的使用方式进行主动监控。
- 产品推向市场时,将设立一个“禁止语音列表”,以检测并阻止与名人声音过于相似的人工智能生成声音,从而避免潜在的版权和隐私问题。
F5-TTS
F5-TTS 是上海交通大学、剑桥大学和吉利汽车研究院(宁波)有限公司于 2024 年共同开源的一款高性能文本到语音 (TTS) 系统,它基于流匹配的非自回归生成方法,结合了扩散变换器 (DiT) 技术。
F5-TTS 的主要功能: 零样本声音克隆、速度控制、情感表现控制、长文本合成以及多语言支持。
技术原理涉及到流匹配、扩散变换器 (DiT)、ConvNeXt V2 文本表示改进、Sway Sampling 策略以及端到端的系统设计。
E2 TTS,全称为「Embarrassingly Easy Text-to-Speech」,是一种先进的文本转语音 (TTS) 系统,通过简化的流程实现了人类水平的自然度和说话人相似性。
E2 TTS 核心在于它完全非自回归的特性,这意味着它可以一次性生成整个语音序列,而不需要逐步生成,从而显著提高了生成速度并保持了高质量的语音输出。
【2024-10-15】F5-TTS:5秒语音样本,精准克隆你的声音
- 代码:F5-TTS
- 项目主页:F5-TTS
- 论文 F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
- 在线体验 E2-F5-TTS
F5-TTS 有哪些亮点?
- 在 E2-TTS 的基础上改进:文本表示细化和推理采样策略。
- 在保持简单架构的同时,提供了更好的性能和更快的推理速度。
- 零样本能力更强,也就是语音克隆效果更加惊艳(文末有实测)
支持三种形式:
- TTS:标准的单音色语音克隆;
- Podcast:多音色克隆:有声读物制作者的福音;
- Multi-Style:多种说话情绪,例如 Shouting…
效果
- 只需 2 秒音频即可合成超拟人的语音,推理速度优于 FishSpeech 和 CosyVoice(阿里)
MMS(META)
【2023-5-23】规模性能双杀OpenAI,Meta语音达LLaMA级里程碑!开源MMS模型可识别1100+语言
- MMS支持1000多种语言,用圣经训练,错误率仅为Whisper数据集的一半
- 与OpenAI Whisper相比,多语言ASR模型支持11倍以上的语言,但在54种语言上的平均错误率还不到FLEURS的一半。
- 开源!覆盖 ASR 和 TTS
- 官方介绍,论文:scaling-speech-technology-to-1000-languages
TTSMaker
【2023-4-12】TTSMaker 是一款免费的文本转语音工具,提供语音合成服务,支持多种语言,包括英语、法语、德语、西班牙语、阿拉伯语、中文、日语、韩语、越南语等,以及多种语音风格。
可以用它大声朗读文本和电子书,或下载音频文件用于商业用途(完全免费),每周限制 20000 个字符(部分声音可支持无限制不限量使用)。
pyttsx
- 跨平台tts工具包
import pyttsx3
engine = pyttsx3.init()
voices = engine.getProperty('voices')
for voice in voices:
engine.setProperty('voice', voice.id)
engine.say('Here we go round the mulberry bush.')
engine.runAndWait()
案例:自动阅读网页新闻
【2022-1-25】自动化阅读网页新闻,从网页中抓取文本,然后自动化语音朗读
代码分为两大部分,第一通过爬虫抓取网页文本呢,第二通过阅读工具来朗读文本。
需要的第三方库:
- Beautiful Soup - 经典的HTML/XML文本解析器,用来提取爬下来的网页信息
- requests - 好用到逆天的HTTP工具,用来向网页发送请求获取数据
- Pyttsx3 - 将文本转换为语音,并控制速率、频率和语音
import pyttsx3
import requests
from bs4 import BeautifulSoup
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
newVoiceRate = 130 # Reduce The Speech Rate
engine.setProperty('rate',newVoiceRate)
engine.setProperty('voice', voices[1].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
text = str(input("Paste article\n"))
res = requests.get(text)
soup = BeautifulSoup(res.text,'html.parser')
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
text = " ".join(articles)
speak(text)
# engine.save_to_file(text, 'test.mp3') ## If you want to save the speech as a audio file
engine.runAndWait()
字节
【2022-11-21】火山引擎的工具 SAMI, SAMI团队 (Speech, Audio & Music Intelligence team) 致力于语音、音频、音乐等技术的研发和产品创新。我们的使命是通过多模态音频技术赋能内容创作和互动,让内容消费和创作变得更简单、愉悦和多元。 SAMI团队支持包括语音合成、音频处理和理解、音乐理解和生成等技术方向,并以中台形式服务于公司众多业务线
google tts
- 代码
from gtts import gTTS
import os
# define variables
s = "escape with plane"
file = "file.mp3"
# initialize tts, create mp3 and play
tts = gTTS(s, 'en')
tts.save(file)
os.system("mpg123 " + file)
阿里云tts
- 代码
def tts_ali(text):
# 获取存储的access_token, token_expireTime 两个同时更新
token_expireTime = 1551513046
access_token = "9fcdcd2a190f49cb926dc5c2e24043c8"
# 当前的时间戳 和 token有效期对比,如果过期则重新生成
local_time = int(time.time())
if local_time >= token_expireTime:
# 重新生成并存储
access_token, token_expireTime = get_token()
headers = {
"Content-Type": "application/json;charset=UTF-8",
"X-NLS-Token":access_token,
}
data_info = {
"appkey":"5dz4RRvAJufMAB6g",
"text":text,
"token":access_token,
"format":"wav",
"voice":"yina",
"sample_rate":"16000", # 音频采样率,默认是16000
"volume":"50", # 音量,范围是0~100,默认50
"speech_rate":"45", # 语速,范围是-500~500,默认是0
"pitch_rate":"0", # 语调,范围是-500~500,默认是0
# 试听发音人:https://ai.aliyun.com/nls/tts?spm=5176.8142029.388261.47.f8ed6d3e0NhBch
# 发音人参数:https://help.aliyun.com/document_detail/84435.html?spm=a2c4g.11186623.6.581.69a853d5E4c3vM
# 推荐:小梦 思悦 小美 伊娜
}
data = json.dumps(data_info)
ret = requests.post(ALI_URL, headers=headers, data=data, timeout=5)
save_wav(ret.content, "ali2.wav")
百度tts
【2020-11-28】Python百度AI语音识别——文字转语音
代码
# 百度
def tts_baidu(text):
baidu_url = "http://tsn.baidu.com/text2audio?lan=zh&ctp=1&cuid=abcdxxx&tok=24.ed4dfdxxxxxff0af259fc.2592000.1553756573.282335-15631432&tex={}&vol=9&per=0&spd=5&pit=5&aue=6".format(text)
ret = requests.get(baidu_url, timeout=5)
save_wav(ret.content, "siyue.wav")
讯飞语音
- 语音合成系统是一个基于语音合成的工具,但是这个东西由于很多厂家都提供了API的形式,因此开发难度大大降低,只需要调用几个API即可实现属于自己的语音合成工具;麻雀虽小,五脏俱全。
- 讯飞开放平台的WebAPI接口
申请账号,3个东西:
- APPID
- APISecret
- APIKey
安装:
pip install websocket-client
pip install playsound
带UI的代码见原文
微软 TTS
微软 Azure TTS
windows下tts
- 运行环境:Anaconda3(Python 3.7)+ windows 10
- 效果
- 代码:

import win32com.client
speaker = win32com.client.Dispatch("SAPI.SpVoice")
str1 = """
日照香炉生紫烟,
遥看瀑布挂前川。
飞流直下三千尺,
疑是银河落九天。
"""
speaker.Speak(str1)
for i in range(1, 6):
speaker.Speak("呵呵第" + str(i) + "次")
- 带GUI的版本
#pip install python-canalyzer
import win32com.client as wincl
from tkinter import *
def text2Speech():
text = e.get()
speak = wincl.Dispatch("SAPI.SpVoice")
speak.Speak(text)
#window configs
tts = Tk()
tts.wm_title("Text to Speech")
tts.geometry("600x400")
tts.config(background="#708090")
f=Frame(tts,height=600,width=800,bg="#bebebe")
f.grid(row=0,column=0,padx=10,pady=5)
lbl=Label(f,text="输入需要转换的文本 : ")
lbl.grid(row=1,column=0,padx=10,pady=2)
e=Entry(f,width=80)
e.grid(row=2,column=0,padx=10,pady=2)
btn=Button(f,text="语音输出",command=text2Speech)
btn.grid(row=3,column=0,padx=20,pady=10)
tts.mainloop()
ChatTTS
【】ChatTTS 对话场景的文本转语音
- 在线免费使用
ChatTTS 专为对话场景设计的语音生成模型,特别适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。它支持中文和英文,通过使用大约100,000小时的中文和英文数据进行训练,ChatTTS在语音合成中表现出高质量和自然度。
特点
ChatTTS特点
- 多语言支持: ChatTTS 的一个关键特性是支持多种语言,包括英语和中文。这使其能够为广泛用户群提供服务,并克服语言障碍
- 大规模数据训练: ChatTTS 使用了大量数据进行训练,大约有1000万小时的中文和英文数据。这样的大规模训练使其声音合成质量高,听起来自然
- 对话任务兼容性: ChatTTS 很适合处理通常分配给大型语言模型LLMs的对话任务。它可以为对话生成响应,并在集成到各种应用和服务时提供更自然流畅的互动体验
- 开源计划: 项目团队计划开源一个经过训练的基础模型。这将使学术研究人员和社区开发人员能够进一步研究和发展这项技术
- 控制和安全性: 团队致力于提高模型的可控性,添加水印,并将其与LLMs集成。这些努力确保了模型的安全性和可靠性
- 易用性: ChatTTS 为用户提供了易于使用的体验。它只需要文本信息作为输入,就可以生成相应的语音文件。这样的简单性使其方便有语音合成需求的用户
使用
安装
git clone https://github.com/2noise/ChatTTS
pip install torch ChatTTS
测试
import torch
import ChatTTS
from IPython.display import Audio
# 初始化ChatTTS
chat = ChatTTS.Chat()
chat.load_models()
# 定义要转换为语音的文本
texts = ["你好,欢迎使用ChatTTS!"]
# 生成语音
wavs = chat.infer(texts, use_decoder=True)
# 播放生成的音频
Audio(wavs[0], rate=24_000, autoplay=True)
SeedTTS
【2024-6-6】王炸级产品:字节跳动的Seed-TTS
无需经过长时间的训练,仅通过一段简短的语音样本,就能克隆出高度自然且富有表现力的语音。Seed-TTS在无需大量数据训练的情况下,就能生成与人类声音难以区分的语音。
Seed-TTS模型在实际应用中展现出了广泛的潜力和多样性,以下是一些具体的应用案例:
- 虚拟助手和聊天机器人 :可以生成自然流畅的语音,为虚拟助手和聊天机器人提供高质量的语音输出,提升用户的交互体验。
- 有声读物:能够生成多角色的有声读物,模仿不同的说话人和情感,为听众提供沉浸式的听书体验。
- 广告和影视配音 :可以生成带有特定情感和语气的语音,适用于广告和影视配音,使内容更加生动和富有感染力。
- 多语言内容创建:支持多语言环境,能够在不同语言之间生成自然的语音内容,适用于跨语言的语音合成和翻译场景。
- 情感语音生成:在广告、影视配音等场景中,Seed-TTS可以生成带有特定情感的语音,增强内容的表现力。
- 游戏和娱乐:可以为游戏中的角色配音,生成富有表现力的游戏语音,提升游戏的沉浸感和用户体验。
- 客户服务自动化 :在客户服务领域,Seed-TTS可以提供自动语音回复功能,处理常规咨询和信息查询。
- 电影和游戏配音:在电影制作和视频游戏开发中,Seed-TTS可以用于角色配音,提供多样化的声音选择。
- 新闻和播客制作 :可以自动将文本新闻或播客稿件转换成语音,快速制作音频内容。
- 辅助残障人士:可以为有语言障碍的人士提供语音合成服务,帮助他们更好地进行沟通。
Kokoro-82M
【2025-1-13】一个开源的TTS模型火了,参数只有82M,但榜单第一
- Kokoro-82M 参数量只有82M的TTS(Text-to-Speech)模型, 非大模型系列。虽然模型不大,但是Kokoro-82M在TTS Arena榜单上排行第一
- Kokoro-82M只在不到 100 小时音频上进行训练,开源协议为可商用的,Apache 2.0 许可,支持多语种:英、法、日、韩、中。
- 开源地址:Kokoro-82M
- 在线体验链接:Kokoro-TTS
安装
# 1️⃣ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/hexgrad/Kokoro-82M
%cd Kokoro-82M
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
接入代码
# 2️⃣ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3️⃣ Call generate, which returns 24khz audio and the phonemes used
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 🇺🇸 'a' => American English => en-us
# 🇬🇧 'b' => British English => en-gb
# 4️⃣ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)
LLM 语音交互
详见站内专题: 大模型语音交互
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
