- 视频生成
- 视频生成工具
- 总结对比
- 提示词
- D-ID
- 【META】Make-A-Video
- 【谷歌】
- 【阿里】大模型
- 视频风格化
- 【Runway】
- 【微软】 NUWA-XL
- Invideo
- EasyPhoto 肖像动画
- Stable Video Diffusion
- ControlVideo
- pika
- animate anyone
- MagicAnimate
- WALT
- 【2024-2-16】OpenAI Sora
- Sora 复现
- 【2024-2-21】谷歌 Lumiere
- 【2024-2-23】谷歌 Genie
- SadTalker
- Gen 系列
- 字节
- OceanVideo
- Magi-1
- Apple
- Sora 2
- 提速
- 昆仑万维
- 应用
- 结束
视频生成
视频生成, Text2Video
文生视频总结
Text-to-Video: Phenaki 、 Soundify
Phenaki由谷歌打造,基于新的编解码器架构C-ViViT将视频压缩为离散嵌入,能够在时空两个维度上压缩视频,在时间上保持自回归的同时,还能自回归生成任意长度的视频Soundify是 Runway 开发的一个系统,目的是将声音效果与视频进行匹配,即制作音效。具体包括分类、同步和混合三个模块,首先模型通过对声音进行分类,将效果与视频匹配,随后将效果与每一帧进行比较,插入对应的音效。
AIGC 视频生成工具汇总
- artflow, 支持换人、背景、音色。 换脸,卡通,真人,图像,跟着内容自动变换表情
- synthesia
- invideo: Text to video maker, Convert Blog and Article to Videos
视频生成
- Deepfake
- VideoGPT
- GliaCloud
- ImageVideo
文生视频模型通常在非常短的视频片段上进行训练,需要使用计算量大且速度慢的滑动窗口方法来生成长视频。
因此,训得的模型难以部署和扩展,并且在保证上下文一致性和视频长度方面很受限。
文生视频面临挑战:
- 计算挑战:确保帧间空间和时间一致性会产生长期依赖性,从而带来高计算成本,使得大多数研究人员无法负担训练此类模型的费用。
- 缺乏高质量数据集: 文生视频的多模态数据集很少,而且标注更少,难以学习复杂的运动语义。
- 视频字幕的模糊性: “如何描述视频从而让模型学习更容易”这一问题至今悬而未决。
- 简短的文本提示不足以完整描述视频。
- 一系列文本提示或随时间推移的故事才能用于生成视频。
- 【2024-1-19】一文纵览文生图/文生视频技术发展路径与应用场景
VLM
视觉语言模型
Hugging Face 官方博客于2025年5月发布的技术文章《Vision Language Models (Better, faster, stronger)》,旨在对视觉语言模型(VLM)领域的最新进展进行系统性梳理和深度解析。自2024年初以来,VLM 领域经历了爆炸式的发展,不仅涌现出更小、更强的模型,还在模型架构、专业能力、多模态交互等方面取得了突破。本文将聚焦于这些核心变革,为技术从业者和初学者揭示 VLM 的前沿趋势,阐明其背后的技术原理,并展示其在机器人控制、文档理解、智能体交互等场景中的巨大应用价值。
视觉语言模型领域取得了令人瞩目的成就。模型正朝着更通用(Any-to-any)、更高效(MoE、小模型)、更智能(推理、智能体) 的方向发展。从简单的图文理解到复杂的机器人控制和文档分析,VLM 的应用边界不断拓宽。
文生视频技术发展
主流文生视频发展路径
- 1、早期发展(2016 年以前)
- 2、奠基任务:GAN/VAE/flow-based (2016-2019 年)
- 早期研究主要使用基于 GAN 和 VAE 方法在给定文本描述的情况下自回归地生成视频帧 (如 Text2Filter 及 TGANs-C)。
- 虽然这些工作为文生视频这一新计算机视觉任务奠定了基础,但应用范围有限,仅限于低分辨率、短距以及视频中目标的运动比较单一、孤立的情况。
- GAN: 模型参数量小,较轻便,所以更加擅长对单个或多个对象类进行建模。
- 但由于其训练过程的不稳定性,针对复杂数据集则极具挑战性,稳定性较差、生成图像缺乏多样性。
- GAN 代表作:VGAN、TGAN、VideoGPT、MoCoGAN、DVD-GAN、DIGAN
- 3、自回归模型及扩散模型生成阶段 (2019-2023)
- 与 GANs 相比,自回归模型具有明确的密度建模和稳定的训练优势,自回归模型可以通过帧与帧之间的联系,生成更为连贯且自然视频。
- 但是自回 归模型受制于计算资源、训练所需的数据、时间,模型本身参数数量通常比扩散模型大,对于计算资源要求及数据集的要求往往高于其他模型。
- 但因为 transformer 比 diffusion 更适合 scale up,且视频的时间序列结构很适合转化为预测下一帧的任务形态。
- 自回归模型发展三个阶段:
- 早期 逐像素 视觉合成:早期自回归模型,生成质量差、成本高,仅用于低分辨率图像视频,示例有 PixelCNN,PixelRNN,Image Transformer,Video Transformer,iGPT
- VQ-VAE 出现,预训练广泛应用: 离散视觉标记化方法使得高效大规模训练用于图像视频合成,示例有 GODIVA,VideoGPT
- 视频当做图像的时间序列,降低成本,但可能效果不佳;示例有 NUWA, CogVideo, Phenaki
- 4、未来发展趋势(2024-?)
- 5、视频生成模型 mapping
技术缘由
【2024-2-23】Sora前世今生:从文生图到文生视频, 已有介绍大多数分析都是从技术报告入手,对于普通读者难度较高。本文从文本生成图像到文本生成视频的技术演进角度解读从AE、VAE、DDPM、LDM到DiT和Sora的技术发展路线,旨在提供一条清晰简明的技术进化路径。
- (1)
自编码器(Autoencoder):压缩大于生成自编码器由编码器和解码器两个部分构成编码器负责学习输入到编码的映射 ,将高维输入(例如图片)转化为低维编码Z = e(x)解码器则学习编码到输出的映射 ,将这些低维编码还原为高维输出(例如重构的图片)x^ = d(z)- 目标:压缩前和还原后的向量尽可能相似(比如让平均平方误差MSE尽可能小),让神经网络学会使用低维编码表征原始的高维向量
- 生成:只要留下解码器,随便喂入一个低维编码,就得到一个高维向量(例如图片)
- 缺点: 对于未见过的低维编码,解码器重构的图片质量通常不佳,生成奇怪的样本。因为低维向量没有约束,导致过拟合
- 自编码器更多用于数据压缩。
- (2)
变分自编码器(Variational Autoencoders):迈向更鲁棒地生成- 自编码器不擅长图片生成, 因为过拟合
- 解决思路:既然自编码器将图片编码为确定性的数值编码会导致过拟合,变分自编码器就将图片编码为一个具有随机性的概率分布,比如标准正态分布。 这样当模型训练好后,只要给解码器喂入采样自标准正态分布的低维向量,就能够生成较为“真实”的图片了。
- 变分自编码器除了希望编码前解码后的样本尽可能相似(MSE尽可能小),还希望用于解码的数据服从标准正态分布,低维编码的分布和标准正态分布的KL散度尽可能小,损失函数加上这么一项约束。
- 变分自编码器减轻了自编码器过拟合问题,确实能用来做图片生成,但是生成图片通常会比较模糊。
- 变分自编码器的编码器和解码器都是一个神经网络,编码过程和解码过程一步就到位,一步到位可能带来的问题就是建模概率分布的能力有限/或者说能够对图片生成过程施加的约束是有限的/或者说“可控性”是比较低的。
- (3)
去噪扩散概率模型(DDPM):慢工出细活- 既然变分自编码器一步到位的编解码方式可能导致生成效果不太理想,DDPM就考虑拆成多步来做,将编码过程和解码过程分解为多步
- 扩散模型由两个阶段构成
- 前向扩散过程,比如给定一张照片,不断(也就是多步)往图片上添加噪声,直到最后这样图片看上去什么都不是(就是个纯噪声):
x = x1 -> x2 -> x3 -> ... -> x(t-1) -> xt = z - 反向去噪过程,给定噪声,不断执行去噪的这一操作,最终得到一张“真实好看”的照片: :
x = x1 <- x2 <- x3 <- ... <- x(t-1) <- xt = z
- 前向扩散过程,比如给定一张照片,不断(也就是多步)往图片上添加噪声,直到最后这样图片看上去什么都不是(就是个纯噪声):
- 从数据集中采样出一张图片,前向过程每步从高斯分布中采样出噪声叠加到时刻的图像上,当足够大时,最终会得到一个各向同性的高斯分布(球形高斯分布,各个方向方差都一样的多维高斯分布)。
- DDPM 通过多步迭代生成得到图片, 缓解了
变分自编码器生成图片模糊的问题,但是由于多步去噪过程需要对同一尺寸图片数据进行操作,导致了越大的图片需要计算资源越多(原来只要处理一次,现在有几步就要处理几次)。
- (4)
潜在扩散模型(LDM):借助VAE来降本增效- 问题:DDPM 在原始空间(像素级图片)进行扩散训练和采样比较费资源
- 解决:降维后在隐空间上进行,利用自编码降维,如将 512×512 的图片降成 64×64 图片, 执行ddpm流程得到64×64的图片,通过自编码器的解码器还原为 512×512 的图片
- 如何根据文本来生成图片? 既然要接收文本,就需要给模型安排上文本编码器(text encoder),把文本转化为模型能够理解的东西。
Stable Diffusion采用了CLIP文本编码器,输入一段文本,输出77个token的embeddings向量,每个向量的维度为768(可以理解为一段话最多保留77个字(或词),每个字(或词)用768维的向量表示)。 - 得到文本的表示后,在原来的U-net里叠加上文本信息, U-net的输入原由两部分组成(加噪后的图片+时间步长(t)), 扩展为三部分(增加文本token embedding)。Stable Diffusion 使用一种文本和图片之间的交叉注意力机制,计算图像和文本的相似度,然后根据这个相似度作为系数对文本进行加权
- (5)
Diffusion Transformers(DiT):当扩散模型遇到Transformer- LDM 扩散模型使用了
U-net这一网络结构,但这个结构是最佳吗? - 去年火了一整年的大语言模型、多模态大模型绝大部分用的都是Transformer结构,相比于U-net,Transformer结构的Scaling能力(模型参数量越大,性能越强)更受大家认可。
- 因此,
DiT其实就是把LDM中的U-net替换成了Transformer,并在Vision Transformer模块的基础上做了略微的修改使得在图片生成过程能够接受一些额外的信息,比如时间步,标签。 - Transformer如何处理图片数据?
Vision Transformer(ViT),主要思想就是将图片分割为固定大小的图像块(image patch/token),对每个图像块进行线性变换并添加位置信息,然后将得到的向量序列送入一个标准的Transformer编码器。
- LDM 扩散模型使用了
- (6) Sora:视频生成的新纪元
- Sora就是改进的
DiT。DiT本质上是VAE编码器 +ViT+DDPM+VAE解码器;OpenAI的技术报告体现出来的创新点:- 改进VAE -> 时空编码器
- 改进DiT -> 不限制分辨率和时长
- 至于图像分块、Scaling transformers、视频re-captioning、视频编辑(SDEdit)这些其实都是已知的一些做法了。
- 视频每一帧(frame)本质上就是一张图片。视频播放时,这些连续图片以一定速率(帧率,通常以每秒帧数FPS表示)快速播放,由于人眼的视觉暂留效应,这些连续静态图片在观众眼中形成了动态效果,从而产生了视频的流畅运动感。
- 视频生成可看作是多帧图片的生成,因此最low的做法就是把视频生成看作独立的图片生成,使用DiT生成多帧图片然后串起来就是视频了。
- 问题显然很大: 没有考虑视频不同帧图片之间的关联,可能会导致生成的多帧图像很不连贯,串起来看就不像是视频了。
- Sora就是改进的
- 改进VAE:融入时间关联
- 为了使视频生成连贯,VAE编解码过程自然需要考虑视频不同帧的关系,原来对图片进行处理相当于考虑的是图片空间上的关系,现在换到视频, 就是多了时间上的关系,即经典的时空联合建模问题。
- 时空联合建模方法:非常多,比如使用 3D CNN、时间空间单独处理再融合、设计精巧的注意力机制等等
- Sora技术报告中的Video compression network,没有提及具体做法,但是可看出是在VAE编码器上考虑了时空建模,对于解码器的设计没有相关介绍
- 其它做法:
- VideoLDM: 在解码器上插入额外的temporal layers来考虑视频帧之间的关系,而编码器是保持不变的。
- 几篇视频生成的相关论文: Make-A-Video、Emu Video、VideoLDM、AnimateDiff、VideoPoet、Lumiere
- 改进DiT:适配任意分辨率和时长
- 很多分享都在传Sora能适配任意分辨率和时长, 是参考了
NaViT这篇文章的做法,其实并非如此 - Vision Transformer (
ViT)本身就能够处理任意分辨率(不同分辨率就是相当于不同长度的图片块序列,不就类似给大语言模型提供不同长度的输入一个意思), NaViT只是提供了一种高效训练方法。 - DiT 如何处理不同分辨率、时长的视频数据? 假设 T×X×Y×C 的视频切成 T×(X/px)×(Y/py) 的图片块序列,由于T,X,Y 可变, 关键问题是改进DiT更好的识别不同图片块属于原始视频中哪个区域
- 一种做法是从位置编码的角度入手,比如对于输入Transformer的图片块,我们可以在patch embedding上叠加上时间、空间上的位置信息。
- 很多分享都在传Sora能适配任意分辨率和时长, 是参考了
扩散模型
扩散模型已成为 AI 视频生成领域的主流技术路径,由于扩散模型在图像生成方面的成功,其启发了基于扩散模型的视频生成的模型。
经典扩散模型
| 模型名称 | 发布时间 | 发布组织 | 介绍 |
|---|---|---|---|
| Video Diffusion Model | 2022.4 | 支持图像和视频数据的联合训练,减少小批量梯度的方差并加快优化,生主成长和更高分辨率的视频。 | |
| Make-A-Video | 2022.9 | Meta | 利用联合文本-图像先验,绕过对配对文本一视频数据的需求,潜在地扩展到更多的视频数据。 |
| Imagen Video | 2022.1 | 采用级联扩散视频模型,验证了在高清视频生成中的简洁性和有效性,文本生成图像设置中的冻结编码器文本调节和无分类器指导转移到视频生成仍然有效。 | |
| Tune-A-Video | 2022.12 | 新加坡国立,腾讯 | 使用预训练T2l模型生成T2V的框架,引入了用于T2V生成的一次性视频页调谐,消除了大规模视频数据集训练的负担,提出了有效的注意力调整和结构反转,可以显著提高时间一致性。 |
| Gen-1 | 2023.2 | Runway | 将潜在扩散模型扩展到视频生成,通过将时间层引入到预训练的图像模型中并对图像和视频进行联合训练,无需额外训练和预处理。 |
| Dreamix | 2023.2 | 提出了第一个基于文本的真实视频外观和运动编辑的方法,通过一种新颖的混合微调模型,可以显著提高运动编辑的质量。通过在简单的图像预处理操作之上应用视频编辑器方法,为文本引导的图像动画提供新的框架品。 | |
| NUWA-XL | 2023.3 | MRSA | “扩散超过扩散”的架构,”从粗到细”生成长视频,支持并行推理,这大大加快了长视频的生成速度。 |
| Text2Video-Zero | 2023.3 | UT Austin, U of Oregon | 提出零样本的文本生成视频的方法,仅使用预先训练的文本到图像扩散模型,而无需任何进一步的微调或优化,通过在潜在代码中编码运动动力学,并使用新的跨顿注意力重新编程每个侦的自我注意力,强制执行时间一致的生成。 |
| VideoLDM | 2023.4 | NVIDIA | 利用预先训练的图像DM并将其转换为视频生成器通过插入学习以时间一致的方式对齐图像的时间层,提出了一种有效的方法用于训练基于LDM的高高分辨率、长期一致的视频生成模型。 |
| PYoCo | 2023.5 | NVIDIA | 提出一种视频扩散噪声,用于微调文本到视频的文本到图像扩散模型,通过用噪声先验微调预训练的eDi-l模型来构建大规模的文本到视频扩散模型,并实现最先进的结果。 |
视频生成工具
总结对比
专题
- 【2024-9-3】8款国内外免费AI生成视频工具对比实测
- 国内:即梦AI、智谱清影、可灵AI、Vidu
- 国外:Runway、Pika、Stable Video、Luma Dream Machine
- 国内3款AI视频生成工具评分排列前三,即梦第一,而国外4款工具中只有Runway超越了国产vidu
- 知乎话题: 视频生成哪家好
- 飞书文档总结
【2024-12-16】 AI视频生成哪家强
(1)文生视频
免费工具文生视频效果总结:
- 整体效果:即梦>海螺>可灵>vidu>清影
- 即梦:侧重现实场景
- 海螺:电影风格,细腻
- 可灵:特写镜头,生成速度太慢,缺失一组样本
- Vidu:卡通动画风格,使用便利
- 清影:免费版效果就算了
(2)图生视频
免费工具图生视频效果总结:
- 整体效果:海螺>vidu>即梦>可灵>清影
- 海螺是唯一全部合格的工具,其余工具不达标(可灵缺失两组数据)
- 即梦:侧重现实场景
- 可灵:动作理解欠缺,生成速度太慢,缺失两组样本
- Vidu:人物识别、动作理解较好
- 清影:免费版还是算了
提示词
海螺AI 官方文档: 如何写视频提示词
基础公式
Prompt基础公式 = 要创建的主要表现物 + 场景空间 + 运动 / 变化
- 要创建的主要表现物:主要表现物是视频的核心信息,可以是人物、动物、其它物体亦或是不存在的想象之物。
- 场景空间:场景空间描述的是视频表现物的周围环境信息,可以是精确的标志性空间,如图书馆、咖啡厅,也可以是幻想性的虚构场景。
- 运动/变化:运动和变化是对于主要表现物在视频中的状态描述,例如物体的静止、运动;环境空间的转化等等。
例如:
- 一只小狗在公园中奔跑
- 一个女人打着伞在雨中的街头行走
- 山谷中的一条小溪静静流淌
精确公式
Prompt精确公式 = 要创建的主要表现物 + 场景空间 + 运动 / 变化 + 镜头运动 + 美感氛围
- 镜头运动:镜头运动可以限定视频画面的呈现方式,可以使用常见的镜头运动方式,例如 推、拉、摇、移、升、降等镜头运动方式,对画面呈现效果进行限定。
- 美感氛围感:可以对画面呈现的视觉风格、画面氛围感进行限定,可以得到更加符合预期的表现效果。
例如:
- 一对情侣坐在公园的长椅上交流,镜头维持固定拍摄情侣,画面色调偏暖,氛围温馨
- 一只小羊在一片草地里低头吃草,镜头缓缓推进小羊,画面色调自然写实
- 一个身穿西装的男人面色凝重地在面馆里吃面,镜头逐渐拉远展示面馆的吵闹环境,画面色调自然
D-ID
D-ID: Digital People Text-to-Video
- Create and interact with talking avatars at the touch of a button, to increase engagement and reduce costs.
- Studio
制作过程介绍:
复现故人
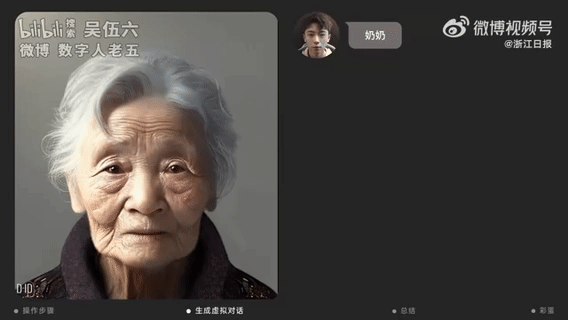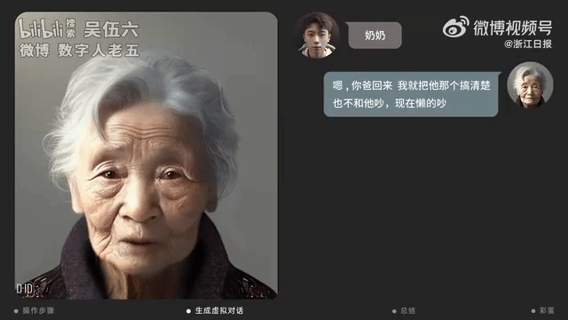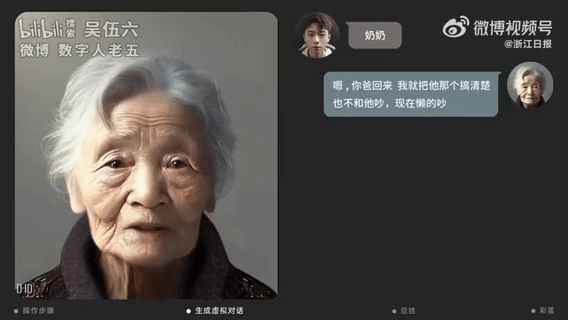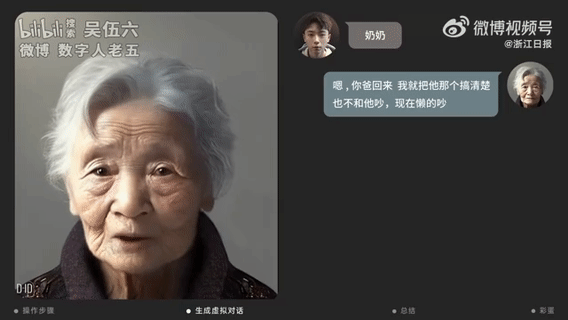
【2023-4-11】上海小伙用AI技术“复活”已故奶奶:讲着方言 像生前一样“唠叨”
- 上海一位24岁的00后视觉设计师,他用AI工具生成了奶奶的虚拟数字人,并和她用视频对话。
【META】Make-A-Video
【2022-10】Meta公布了一个能够生成高质量短视频的工具——Make-A-Video,利用这款工具生成的视频非常具有想象力。
【谷歌】
Imagen Video与Phenaki
【2022-10-8】图像生成卷腻了,谷歌全面转向文字→视频生成,挑战分辨率和长度; 文本转图像上卷了大半年之后,Meta、谷歌等科技巨头又将目光投向了一个新的战场:文本转视频。
谷歌公司 CEO Sundar Pichai 亲自安利了这一领域的最新成果:两款文本转视频工具——Imagen Video 与 Phenaki。
Imagen Video主打视频品质-
Phenaki主要挑战视频长度,可以说各有千秋。
生成式建模在最近的文本到图像 AI 系统中取得了重大进展,比如 DALL-E 2、Imagen、Parti、CogView 和 Latent Diffusion。
- 扩散模型在密度估计、文本到语音、图像到图像、文本到图像和 3D 合成等多种生成式建模任务中取得了巨大成功。
谷歌要做的是从文本生成视频。
- 以往的视频生成工作集中于: 具有自回归模型的受限数据集、具有自回归先验的潜变量模型以及近来的非自回归潜变量方法。扩散模型也已经展示出了出色的中等分辨率视频生成能力。
谷歌推出了 Imagen Video,论文地址,它是一个基于级联视频扩散模型的文本条件视频生成系统。
- 给出文本提示,Imagen Video 就可以通过一个由 frozen T5 文本编码器、基础视频生成模型、级联时空视频超分辨率模型组成的系统来生成高清视频。
VideoPoet
【2023-12-22】VideoPoet, 谷歌推出的视频生成大模型 VideoPoet,蒋路是谷歌项目负责人,类似 OpenAI 刚刚发布的 Sora。
- A large language model for zero-shot video generation
- VideoPoet: A large language model for zero-shot video generation
- 资讯
零镜头视频生成大模型 VideoPoet。
- 执行各种视频生成任务,包括文本到视频、图像到视频、视频风格化、视频修复和修复,以及视频转音频。该工具被感叹是一个突破性文生视频工具。
VideoPoet 视频生成模型采用了单 Transformer 架构,将任何自回归语言模型或大型语言模型转换为高质量的视频生成器,支持生成方形或纵向视频,以针对短格式内容定制生成视频,并支持视频输入生成音频。
组件:
- 预训练的 MAGVIT V2 视频分词器和 SoundStream 音频分词器将可变长度的图像、视频和音频剪辑转换为统一词汇表中的离散代码序列。这些代码与基于文本的语言模型兼容,有助于与文本等其他模式的集成。
- 自回归语言模型跨视频、图像、音频和文本模态学习,以自回归预测序列中的下一个视频或音频 Token。
- 大模型训练框架引入了多模态生成学习目标的混合,包括文本到视频、文本到图像、图像到视频、视频帧延续、视频修复和修复、视频风格化和视频到视频-声音的。此外,这些任务可以组合在一起以获得额外的零样本功能(例如文本到音频)。
VideoPoet 采用了名为 Tokenizer 的数据处理技术,将视频和音频片段编码为离散标记序列(discrete tokens),这些标记也可以被转换回原始表示。其中,视频和图像数据使用名为 MAGVIT V2 的技术,音频数据使用 SoundStream 的技术。
VideoPoet 通过多个 Tokenizer 训练一个自回归语言模型,以学习跨视频、图像、音频和文本模态。一旦模型根据某些上下文生成了标记,这些标记就可以通过分词器解码器转换回可查看的表示。
【2024-2-21】谷歌视频大模型VideoPoet负责人蒋路加入TikTok
谷歌高级科学家、卡内基梅隆大学(CMU)计算机学院兼职教授蒋路,已经加入TikTok。
【阿里】大模型
【2023-3-22】阿里达摩院已在AI模型社区“魔搭”ModelScope上线了“文本生成视频大模型”。
- 整体模型参数约17亿,目前只支持英文输入。扩散模型采用Unet3D结构,通过从纯高斯噪声视频中,迭代去噪的过程,实现视频生成的功能。
- 模型还不支持中文输入,而且生成的视频长度多在2-4秒,等待时间从20多秒到1分多钟不等,画面的真实度、清晰度以及长度等方面还有待提升。
- 扩散模型采用 Unet3D 结构,通过从纯高斯噪声视频中,迭代去噪的过程,实现视频生成的功能
- 体验地址
视频风格化
【2022-9-7】通过将预训练的语言图像模型(pretrained language-image models)调整为视频识别,以此将对比语言图像预训练方法(contrastive language-image pretraining)扩展到视频领域;
【Runway】
Gen-2
【2023-4-11】视频领域的Midjourney,AI视频生成新秀Gen-2内测作品流出, 博主 Nick St. Pierre
- 论文:Structure and Content-Guided Video Synthesis with Diffusion Models
- Gen-2还处于婴儿期,后面一定会更好。
【2023-11-4】Gen-2颠覆AI生成视频!一句话秒出4K高清大片,网友:彻底改变游戏规则
Gen-2,迎来了“iPhone时刻”般的史诗级更新 —— 依旧是简单一句话输入,不过这一次,视频效果一口气拉到了4K超逼真的高度
跟 PIKA这位AI生成视频顶流相比,Gen-2 目前无论是在画质的清晰度,视频的流畅度等方面,都是更胜一筹。
视频生成的AI工具
- 2023年2月,诞生 Gen-1
- 2023年3月20日,发布(论文3月11号)Gen-2,带来了八大功能:
- 文生视频、文本+参考图像生视频、静态图片转视频、视频风格迁移、故事板(Storyboard)、Mask(比如把一只正在走路的小白狗变成斑点狗)、渲染和个性化(比如把甩头小哥秒变海龟人)。
提示:
Gen-1已经可以开始玩了(125次机会用完之后就只能按月付费了),Gen-2还没有正式对公开放。
背后的公司Runway成立于2018年,为《瞬息全宇宙》特效提供过技术支持,也参与了Stable Diffusion的开发(妥妥的潜力股)。
一句话拍大片, 只凭一句提示词就能完成,不需要借鉴其它图片和视频。
- 提示词: “一个身材匀称or对称(symmetrical)的男人在酒吧接受采访”
- 生成结果:只见一个身着深色衬衣的男人正望着对方侃侃而谈,眼神和表情透露着一股认真和坦率,对面的人则时不时点头以示附和。
- 视频
Gen-4
【2025-4-1】Runway 发布最新 AI 视频生成模型 Gen-4。
目前为止保真度最高的 AI 驱动视频生成工具之一。
- 最大亮点:「世界一致性」,保持角色、场景高度一致性
核心优势
- 在不同视频场景中,保持角色、地点和物体的高度一致性,维持“连贯的世界环境”,并从场景内不同视角和位置,重新生成元素。
官方指出
- Gen-4 有效利用视觉参考资料,并结合用户文本指令,创造出风格、主体、地点等要素保持一致的新图像和视频,整个过程无需进行模型微调或额外的专门训练。”
- Gen-4 在生成具有高度动态感和逼真运动效果的视频方面表现卓越,同时在主体、物体和风格的一致性、对用户指令的精准遵循度以及对现实世界规律的理解方面,均达到了同类顶尖水平。
Gen-4 通过对海量视频数据进行训练而成,数据源保密
Runway Gen-4 已向所有付费用户和企业客户开放。用于角色、位置和物体一致性的场景参考功能即将推出。
Gen-4 核心亮点包括:
- 世界一致性:多个场景中保持人物、场景和物体的一致性,无需额外精调。
- 参考图能力:仅凭一张参考图,即可在不同光线和场景中生成一致的角色或物体。
- 场景覆盖:从任意角度重建和捕捉场景,只需提供参考图和描述。
- 物理效果:模拟真实世界物理规律,呈现逼真的光照、阴影和动态效果。
- 视频质量:具备极强的提示理解能力和世界构建能力。
- 生成式视觉特效:提供快速、可控的视频特效,可与实拍和传统特效无缝融合。
传统视觉特效制作需要耗费大量时间进行建模、渲染和后期调整,Runway Gen-4 引入生成式视觉特效(GVFX)技术,能够通过 AI 驱动的生成能力,大幅缩短了这一过程。
使用
- 用户只需提供角色的参考图像,模型便能在不同的光照条件下生成外观持续一致的角色。
- 构建具体场景时,用户可以上传主体的图像,并辅以文字描述,明确说明希望生成的镜头构图要求。
【微软】 NUWA-XL
微软亚研院最新发布了一个可以根据文字生成超长视频的AI:NUWA-XL。
只用16句简单描述,它就能get一段长达11分钟的动画:
Invideo
Invideo 将任何内容或想法转换为视频
EasyPhoto 肖像动画
【2023-11-8】EasyPhoto : 让你的AIGC肖像动起来
EasyPhoto 一个基于SDWebUI生态的AIGC插件,专门用于生成真/像/美的AI写真
EasyPhoto 支持用户上传少量自己的图片,快速训练个性化的人像Lora模型,并进行多种肖像生成。
最近基于AnimateDiff提出的运动先验模型,拓展了EasyPhoto的肖像生成能力,使之能够生成动态的肖像。
-
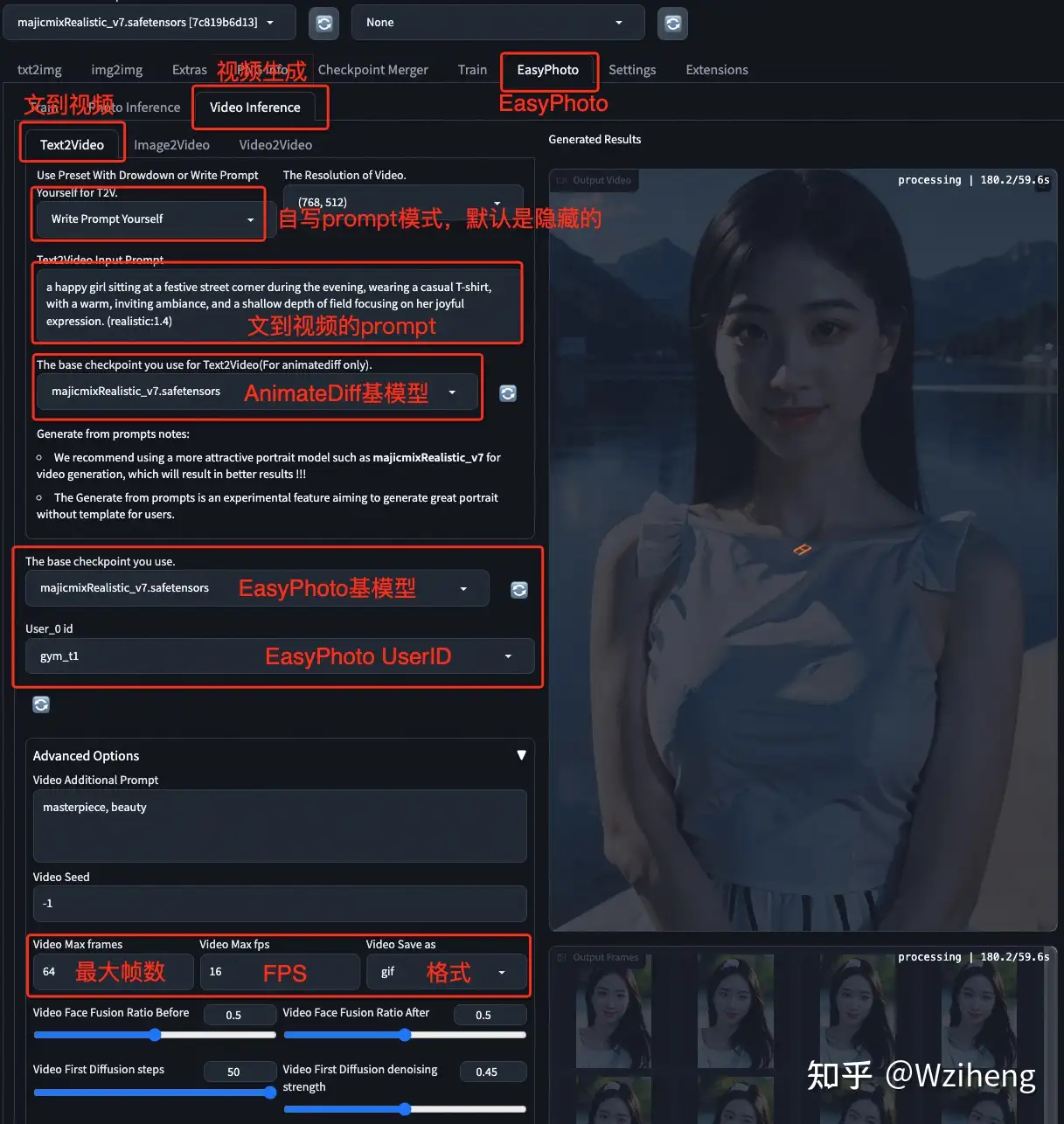
- 文到视频:
- 图到视频: 用户上传首图或首尾图,以完成指定人像的生成, 支持基于真人的风格转换、切换
- 视频到视频: 模板换脸功能也可以非常自然地应用于视频



Stable Video Diffusion
【2023-11-22】Stable Video Diffusion来了,代码权重已上线
AI 画图的著名公司 Stability AI,终于入局 AI 生成视频了。产品已经横跨图像、语言、音频、三维和代码等多种模态
本周二,基于 Stable Diffusion 的视频生成模型 Stable Video Diffusion 来了,AI 社区马上开始了热议。
- 论文地址:stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasetss
- 项目地址:generative-models
现在,可以基于原有的静止图像来生成一段几秒钟的视频。
基于 Stability AI 原有的 Stable Diffusion 文生图模型,Stable Video Diffusion 成为了开源或已商业行列中为数不多的视频生成模型之一。
Stable Video Diffusion 以两种图像到视频模型的形式发布,能够以每秒 3 到 30 帧之间的可定制帧速率生成 14 和 25 帧的视频。
在外部评估中,Stability AI 证实这些模型超越了用户偏好研究中领先的闭源模型(runway、pika Labs)
ControlVideo
【2023-5-26】清华发布 ControlVideo
最新成果 ControlVideo,一种用于文本驱动视频编辑的新方法。
- 利用文本到图像扩散模型 和 ControlNet 的功能,ControlVideo 旨在增强与给定文本对齐的视频的保真度和时间一致性,同时保留源视频的结构。 这是通过结合额外的条件来实现的,例如边缘图,使用精心设计的策略对源视频文本对的关键帧和时间注意力进行微调。
- 对 ControlVideo 的设计进行了深入探索,以指导未来对一次性调整视频扩散模型的研究。
- 在数量上,ControlVideo 在忠实度和一致性方面优于一系列竞争基线,同时仍与文本提示保持一致。
- 此外,它还提供具有高视觉真实感和保真度的视频。 源内容,展示了使用包含不同程度源视频信息的控件的灵活性,以及多个控件组合的潜力
pika
Pika Labs (pika.art) 是一款创新的视频创建工具,可以将文本和图像转换为引人入胜的视频
- An idea-to-video platform that brings your creativity to motion
- elon musk video
Pika Labs 推出了创新的文本和图像转视频平台,只需打字即可激发你的创造力。这个平台让你能够将旅程中的图像转换为 Discord 上引人入胜的视频!测试阶段是免费
- 【2023-8-13】Pika Labs 新魔法:一键将图像转为视频
- 【2023-11-29】Pika Labs发布1.0版本AI视频生成器,满足多种风格视频需求,Pika 1.0采用了全新的AI模式,能够以3D动画、动漫、卡通和电影等多种风格生成和编辑视频。
体验方式
- 点击链接 加入 Pika
- 进入 Pika Labs Discord 服务器,请前往“#generate”频道
- 使用“/create”命令添加图像以及提示说明
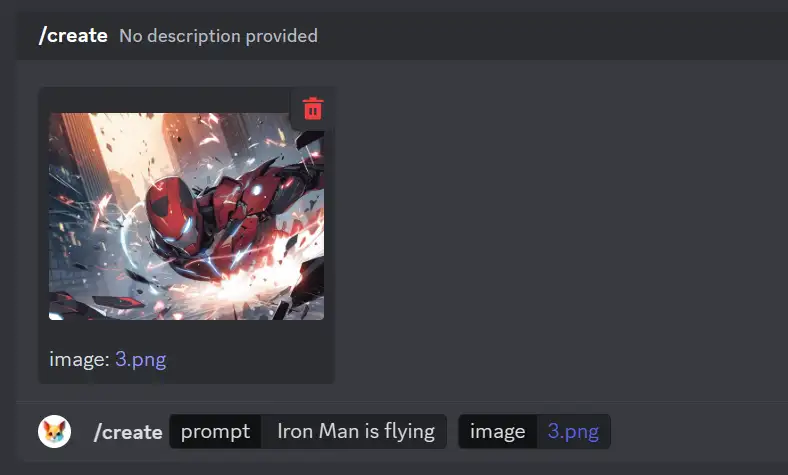
与 Gen-2 不同的是,文本将提供对视频创建的更大控制,PikaLabs 可以更好地结合文本以与图像完美配合

animate anyone
【2023-11-28】阿里发布animate anyone简直逆天,一张照片生成任意动作视频
- 论文:Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
- github: AnimateAnyone
- 演示视频
实现方法
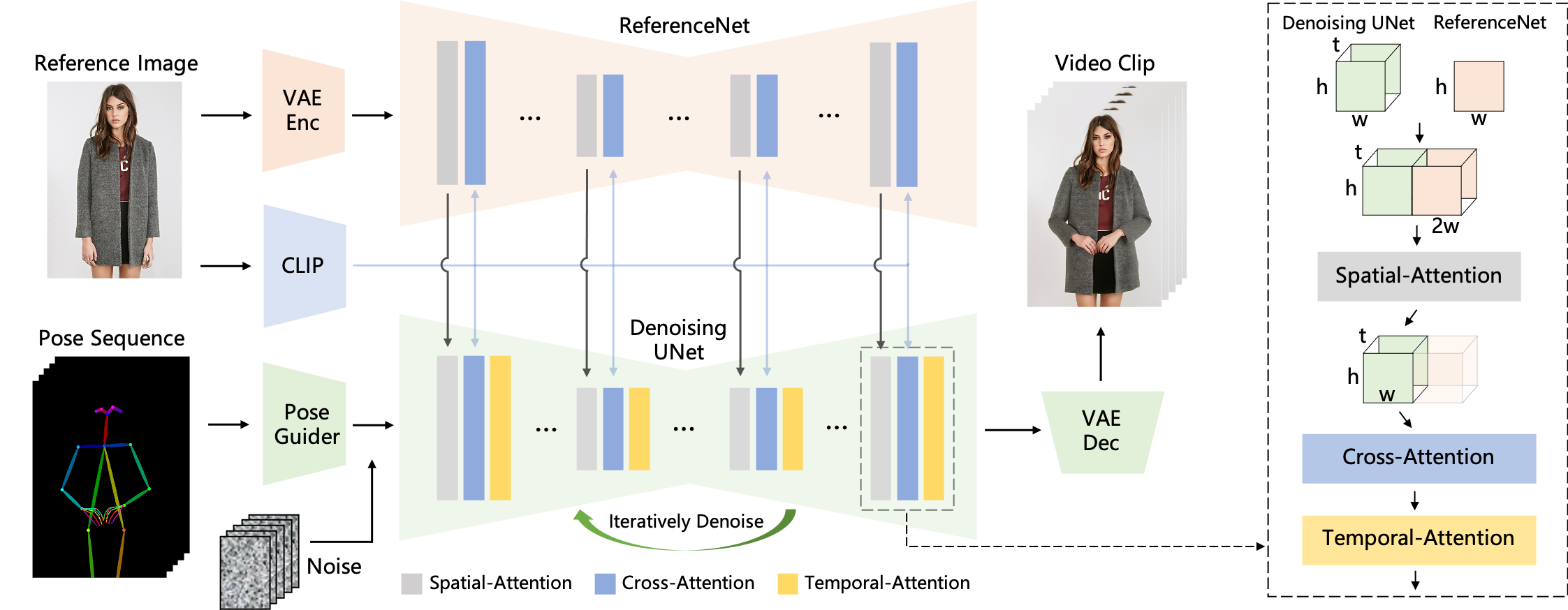
MagicAnimate
字节跳动新开源基于SD 1.5的 MagicAnimate,只需要一张照片和一组动作,就能生成近似真人的舞蹈视频。
开源地址:
- magicanimate
- github magic-animate
以后在社交平台上看到的小姐姐舞蹈短视频很可能就是AI生成的。
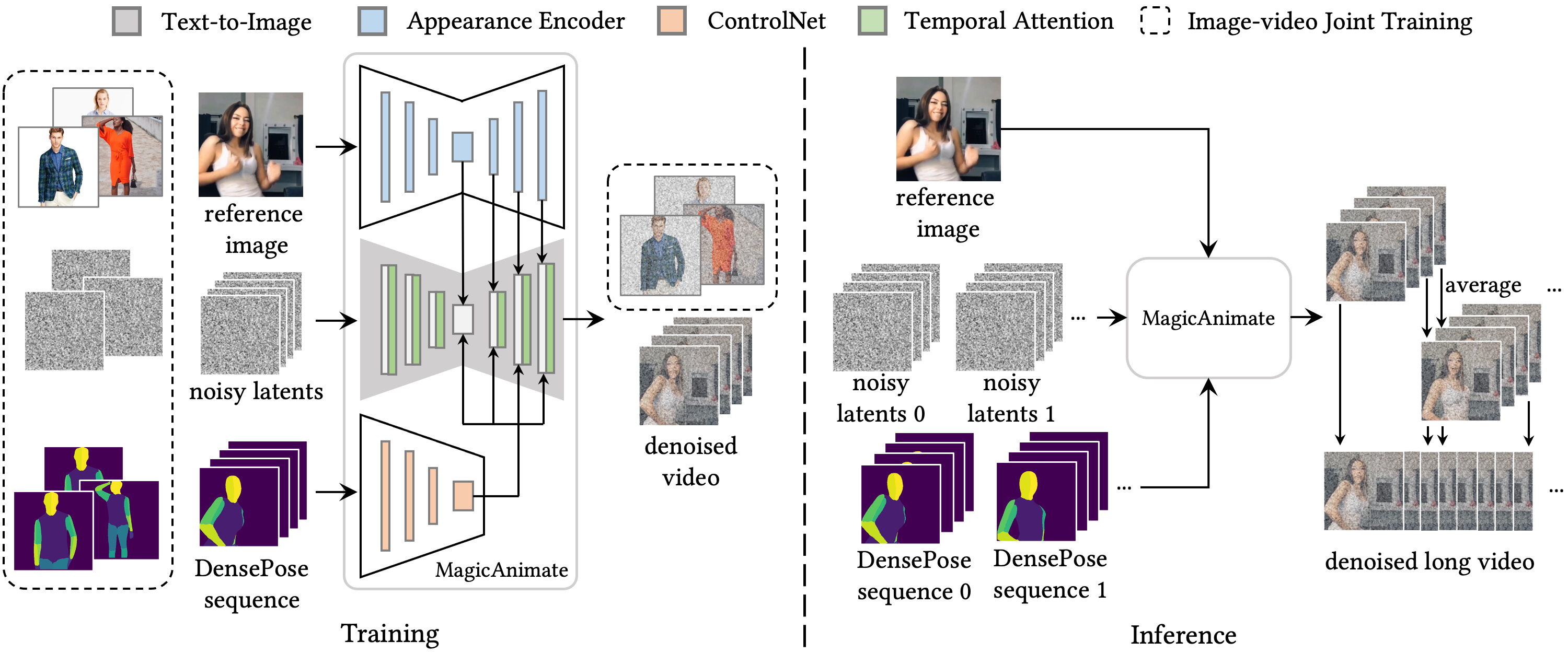
# sd-vae-ft-mse
git lfs clone https://huggingface.co/stabilityai/sd-vae-ft-mse
# stable-diffusion-v1-5
git lfs clone https://huggingface.co/runwayml/stable-diffusion-v1-5
# MagicAnimate 模型
git lfs clone https://huggingface.co/zcxu-eric/MagicAnimate
WALT
【2023-12-12】斯坦福 李飞飞谷歌破局之作!用Transformer生成逼真视频,下一个Pika来了?
- 论文:Photorealistic Video Generation with Diffusion Models
- Photorealistic Video Generation with Diffusion Models
支持
英伟达高级科学家Jim Fan转发评论道:
- 2022年是影像之年
- 2023是声波之年
-
而2024,是视频之年!
- 首先,研究人员使用因果编码器在共享潜在空间中压缩图像和视频。
- 其次,为了提高记忆和训练效率,研究人员使用基于窗口注意力的Transformer架构来进行潜在空间中的联合空间和时间生成建模。
- 研究人员的模型可以根据自然语言提示生成逼真的、时间一致的运动:
两个关键决策,组成三模型级联
W.A.L.T的方法有两个关键决策。
- 首先,研究者使用因果编码器在统一的潜在空间内联合压缩图像和视频,从而实现跨模态的训练和生成。
- 其次,为了提高记忆和训练效率,研究者使用了为空间和时空联合生成建模量身定制的窗口注意力架构。
- 通过这两个关键决策,团队在已建立的视频(UCF-101 和 Kinetics-600)和图像(ImageNet)生成基准测试上实现了SOTA,而无需使用无分类器指导。
- 最后,团队还训练了三个模型的级联,用于文本到视频的生成任务,包括一个基本的潜在视频扩散模型和两个视频超分辨率扩散模型,以每秒8帧的速度,生成512 x 896分辨率的视频。
W.A.L.T的关键是将图像和视频编码到一个共享的潜在空间中。
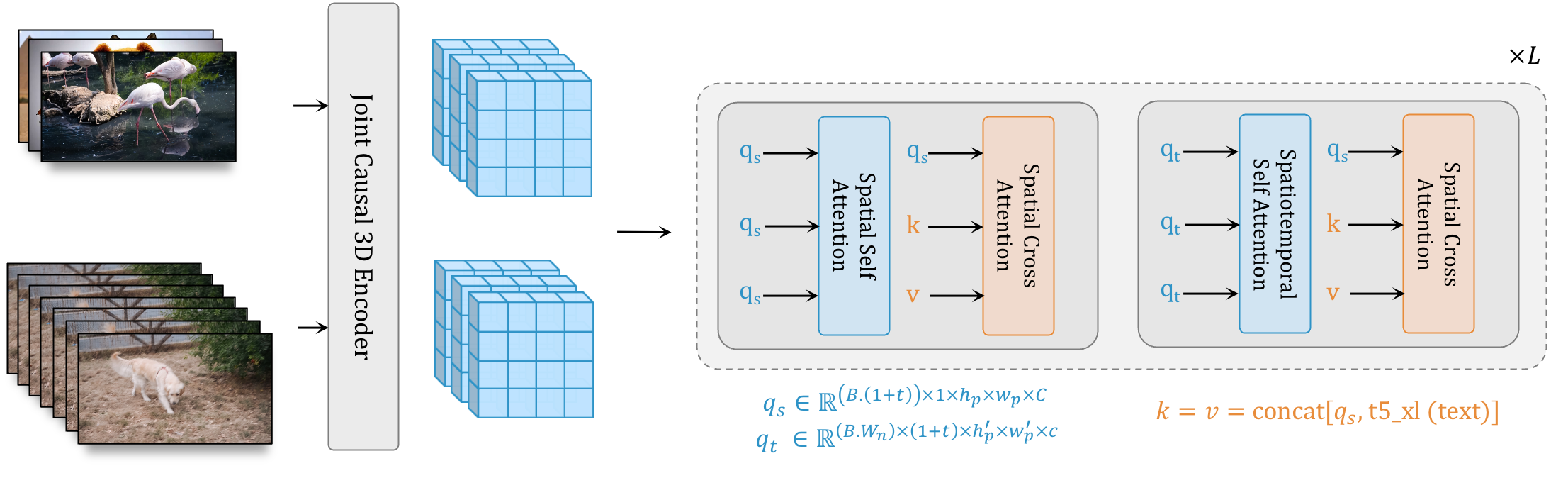
Transformer主干通过具有两层窗口限制注意力的块来处理这些潜在空间——空间层捕捉图像和视频中的空间关系,而时空层模拟视频中的时间动态,并通过身份注意力掩码传递图像。
【2024-2-16】OpenAI Sora
当大家还沉迷如何用文生文,文生图时,OpenAI掏出来了一个视频生成模型Sora。
- Sora 根据文本指令或静态图像生成长达1分钟视频的扩散模型
- 视频中还包含精细复杂的场景、生动的角色表情以及复杂的镜头运动 —— 目前市面上视频模型做不到
Sora 介绍
OpenAI全新发布文生视频模型Sora
- 经纬创投: 一石激起千层浪,揭秘Sora的技术报告
从皮肤纹理到瞳孔睫毛,Sora的还原度达到了「没有AI味」
循环网络、生成对抗网络、自回归Transformer和扩散模型等方法只关注于特定类型的视觉数据、较短的视频或者固定尺寸的视频。
而 Sora 不同,它是一种通用的视觉数据模型,能够生成各种持续时间、宽高比和分辨率的视频和图片,甚至长达一分钟的高清视频。
竞品对比

特点: “60s超长长度”、“单视频多角度镜头”和“世界模型”
- 60s超长视频:
- 其它AI视频还挣扎在4s连贯性的边缘,OpenAI直接60s
- 单视频多角度镜头:
- 当前AI工作流都是单镜头单生成,一个视频里面有多角度的镜头,主体还能保证完美的一致性,这无法想象
- OpenAI直接一句Prompt,在一分钟的镜头里,实现了多角度的镜头切换…而且…物体一致…
- 世界模型:
- 世界模型最难的是收集、清洗数据。
- Runway 世界模型,毫无动静。
- 但是OpenAI的Sora,直接来了一波大的,已经能懂物理规律了。
OpenAI Sora
目前Sora只面向邀请的制作者和安全专家开放测试,还没有公测时间表。
而堪称「世界模型」的技术报告仍然没有公开具体的训练细节。
- 技术报告: Video generation models as world simulators(视频生成模型作为世界模拟器)
Sora训练数据源未知,“ClosedAI”原则,并没有透露相关信息。
观点
英伟达高级研究科学家Jim Fan认为:
Sora是一款数据驱动的物理模拟引擎,通过一些去噪和梯度计算来学习复杂的渲染、「直觉」物理、长远规划推理和语义基础。它直接输入文本/图像并输出视频像素,通过大量视频、梯度下降,在神经参数中隐式地学习物理引擎,它不会在循环中显式调用虚拟引擎5,但虚拟引擎5生成的(文本、视频)对有可能会作为合成数据添加到训练集中。
LeCun表示:
「仅根据文字提示生成逼真的视频,并不代表模型理解了物理世界。生成视频的过程与基于世界模型的因果预测完全不同」。
Sora 原理
Sora是一种扩散模型,通过从一开始看似静态噪声的视频出发,经过多步的噪声去除过程,逐渐生成视频。Sora不仅能够一次性生成完整的视频,还能延长已生成的视频。通过让模型能够预见多帧内容,团队成功克服了确保视频中的主体即便暂时消失也能保持一致性的难题。
- Creating video from text
- 技术报告: Video generation models as world simulators(视频生成模型作为世界模拟器), 中文版
- 拆解OpenAI技术报告:Sora是怎么生成视频的?
- 【2024-2-28】微软和理海大学解读Sora技术解读技术报告和逆向工程,首次全面回顾了 Sora 的背景、相关技术、新兴应用、当前局限和未来机遇。
- 【2024-3-20】张俊林 [技术神秘化的去魅:Sora关键技术逆向工程图解]https://zhuanlan.zhihu.com/p/687928845)
- Sora的Visual Encoder-Decoder很可能采用了TECO(Temporally Consistent Transformer )模型的思路,而不是广泛传闻的MAGVIT-v2
- Patch部分支持“可变分辨率及可变长宽比”视频,应该是采用了NaVIT的思路,而不是Padding方案
- Sora保持生成视频的“长时一致性”也许会采取暴力手段
- 袁粒课题组-北大信工 PKU-YuanGroup,推出开源复现 Open-Sora-Plan
- Sora学习手册-飞书文档
- 【2024-3-1】微软37页论文逆向工程Sora,得到了哪些结论, 人工智能生成内容(AIGC)技术的最新进展实现了内容创建的民主化,使用户能够通过简单的文本指令生成所需的内容
视觉类的生成模型经历了多样化的发展路线:(图见原文)
- 生成对抗网络(GAN)和变分自动编码器(VAE)的引入是重要转折点
- 流模型和扩散模型进一步增强了图像生成的细节和质量。
- BERT 和 GPT 成功将 Transformer 架构应用于 NLP 后,研究人员尝试迁移到 CV 领域,比如 Transformer 架构与视觉组件相结合,使其能够应用于下游 CV 任务,包括 Vision Transformer (
ViT) 和 Swin Transformer ,进一步发展了这一概念。在 Transformer 取得成功的同时,扩散模型也在图像和视频生成领域取得了长足进步。扩散模型为利用U-Nets将噪声转换成图像提供了一个数学上合理的框架,U-Nets 通过学习在每一步预测和减轻噪声来促进这一过程。
- BERT 和 GPT 成功将 Transformer 架构应用于 NLP 后,研究人员尝试迁移到 CV 领域,比如 Transformer 架构与视觉组件相结合,使其能够应用于下游 CV 任务,包括 Vision Transformer (
- 2021 年以来,能够解释人类指令的生成语言和视觉模型,即所谓的多模态模型,成为了人工智能领域的热门议题。
- CLIP 是一种开创性的视觉语言模型,它将 Transformer 架构与视觉元素相结合,便于在大量文本和图像数据集上进行训练。通过从一开始就整合视觉和语言知识,CLIP 可以在多模态生成框架内充当图像编码器。
- Stable Diffusion 是一种多用途文本到图像人工智能模型,以其适应性和易用性而著称。它采用 Transformer 架构和潜在扩散技术来解码文本输入并生成各种风格的图像,进一步说明了多模态人工智能的进步。
- 2022 年 11 月ChatGPT发布后,2023 年出现了大量文本到图像的商业化产品,如 Stable Diffusion、Midjourney、DALL-E 3。这些工具能让用户通过简单的文字提示生成高分辨率和高质量的新图像,展示了人工智能在创意图像生成方面的潜力。
- 由于视频的时间复杂性,从文本到图像到文本到视频的过渡具有挑战性。尽管工业界和学术界做出了许多努力,但大多数现有的视频生成工具,如 Pika 和 Gen-2 ,都仅限于生成几秒钟的短视频片段。
- Sora 是一项重大突破,类似于 ChatGPT 在 NLP 领域的影响。Sora 是第一个能够根据人类指令生成长达一分钟视频的模型,同时保持较高的视觉质量和引人注目的视觉连贯性,从第一帧到最后一帧都具有渐进感和视觉连贯性。
- Sora 在准确解读和执行复杂的人类指令方面表现突出,生成包含多个角色的详细场景
- 具有细微运动和交互描绘的扩展视频序列,克服了早期视频生成模型所特有的短片段和简单视觉渲染的限制
- Sora 作为世界模拟器的潜力,它可以提供对所描绘场景的物理和背景动态的细微洞察。
Sora 核心本质:一个具有灵活采样维度的扩散 Transformer。由三部分组成:
- (1)时空压缩器首先将原始视频映射到潜在空间。
- (2) 然后,ViT 处理 token 化的潜在表示,并输出去噪潜在表示。
- (3) 类似 CLIP 的调节机制接收 LLM 增强的用户指令和潜在的视觉提示,引导扩散模型生成风格化或主题化的视频。
经过许多去噪步骤后,生成视频的潜在表示被获取,然后通过相应的解码器映射回像素空间。
Sora 技术
Sora 背后的技术
OpenAI 技术报告,一些关于Sora的剖析:
- Sora建立在DiT模型上(Scalable Diffusion Models with Transformers, ICCV 2023)
- Sora有用于生成模型的视觉patches(ViT patches用于视频输入)
- “视频压缩网络”(可能是VAE的视觉编码器和解码器)
- Scaling transformers(Sora已证明diffusion transformers可以有效扩展)
- 用于训练的1920x1080p视频(无裁剪)
- 重新标注(OpenAI DALL·E 3)和文本扩展(OpenAI GPT)
从 OpenAI Sora 技术报告和 Saining Xie 的推特可以看出,Sora 基于 Diffusion Transformer 模型。它大量借鉴了DiT、ViT和扩散模型,没有太多花哨的东西。
在Sora之前,不清楚是否可以实现长篇幅一致性。通常,这类模型只能生成几秒钟的256*256视频。“我们从大型语言模型中获得灵感,这些模型通过在互联网规模的数据上训练获得了通用能力。” Sora已经展示了通过可能在互联网规模数据上进行端到端训练,可以实现这种长篇幅一致性。
Sora 建立在扩散Transformer(DiT)模型之上(发表于ICCV 2023), 可能的架构
- 一个带有Transformer骨架的扩散模型:
DiT= [VAE编码器 +ViT+DDPM+VAE解码器]。
Sora与DiT没有太大区别,但Sora通过扩大其模型和训练规模,证明了其长期时空一致性。
在变长持续时间、分辨率和宽高比的视频和图像上,联合训练文本条件扩散模型
对持续时间、分辨率和宽高比各不相同的视频和图片进行文本条件扩散模型的联合训练,采用Transformer架构处理视频和图片的时空块隐编码,最新模型 Sora 能生成一分钟高质量视频
沿着LLM方向,继续扩展模型规模,物理世界通用模拟器可以构建出世界模型
- We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
- Sora builds on past research in
DALL·EandGPTmodels. It uses the recaptioning technique fromDALL·E 3, which involves generating highly descriptive captions for the visual training data. As a result, the model is able to follow the user’s text instructions in the generated video more faithfully.
Sora模型逐渐拥有了一项新能力,叫做三维一致性。
- Sora能够生成动态视角的视频。同时随着视角的移动和旋转,人物及场景元素在三维空间中仍然保持一致的运动状态。
- AI理解三维物理世界跟人类方式不一样,它采用了一种拓扑结构上的理解。
- 视频的视角发生变化,那么相应的纹理映射也要改变。Sora 真实感非常强,纹理映射在拓扑结构上就得非常准确。
- 三维一致性能力使Sora能够模拟来自现实世界中人物、动物和环境的某些方面。
OpenAI为了训练出Sora,将各类视觉数据转化为统一表示。
块(patches), 类似于大语言模型中的token,块将图像或视频帧分割成的一系列小块区域。这些块是模型处理和理解原始数据的基本单元。- 对于视频生成模型而言,
块不仅包含了局部的空间信息,还包含了时间维度上的连续变化信息。模型可以通过学习patches之间的关系来捕捉运动、颜色变化等复杂视觉特征,并基于此重建出新的视频序列。
这样的处理方式有助于模型理解和生成视频中的连贯动作和场景变化,从而实现高质量的视频内容生成。
OpenAI 在块的基础上,将其压缩到低维度潜在空间,再将其分解为“时空块”(spacetime patches)。
- 潜在空间 是一个能够在复杂性降低和细节保留之间达到近乎最优的平衡点,极大地提升了视觉保真度
时空块从视频帧序列中提取出, 具有固定大小和形状的空间-时间区域。相较于块,时空块强调了连续性,模型通过时空块来观察视频内容随时间和空间的变化规律。
为了制造这些时空块,OpenAI训练了一个网络,降低视觉数据的维度,叫做视频压缩网络。这个网络接受原始视频作为输入,并输出一个在时间和空间上都进行了压缩的潜在表示。Sora在这个压缩后的潜在空间中进行训练和生成视频。同时,OpenAI也训练了一个相应的解码器模型,用于将生成的潜在向量映射回像素空间。
“块”非常接近token,作用和token差不多。
- 对于给定的压缩输入视频,OpenAI 直接提取一系列块作为Transformer token使用
- 然后这些时空块会被进一步编码并传递给Transformer网络进行全局自注意力学习。
- 最后利用Transformer的强大能力来处理并生成具有不同属性的视频内容。
这一方案同样适用于图像,因为图像可以看作是仅有一帧的视频。
基于块的表示方法使得Sora能够对不同分辨率、时长和宽高比的视频和图像进行训练。推理阶段,可在一个适当大小的网格中排列随机初始化的块来控制生成视频的尺寸。
数据处理
当前图像和视频生成技术常常将视频统一调整到一个标准尺寸,比如 4秒钟、分辨率256x256的视频。
而 Sora 直接在视频原始尺寸上进行训练,优点:
- 视频生成更加灵活:img
- Sora能够制作各种尺寸的视频,从宽屏的1920x1080到竖屏的1080x1920,应有尽有。
- Sora 可为各种设备制作适配屏幕比例的内容
- 更好的画质 img
- 直接在视频原始比例上训练(而不是裁剪成正方形),能够显著提升视频的画面表现和构图效果
- 更强的语言理解
- 用视频说明进行训练,不仅能提高文本的准确性,还能提升视频的整体质量。
- 提示语多样化(文本→图像/视频)
- 接受图像或视频等其他形式的输入。
- Sora 能执行一系列图像和视频编辑任务,比如 制作无缝循环视频、给静态图片添加动态、在时间线上扩展视频的长度等等。
Sora 支持其他类型的数据输入
- 比如:图像或视频,以达到图片生成视频、视频生成视频的效果。这一特性使得Sora能够执行广泛的图像和视频编辑任务——例如制作完美循环播放的视频、为静态图像添加动画效果、向前或向后延展视频时间轴等。
能力 —— 技术报告中文版
- 视频时间线扩展
- Sora不仅能生成视频,还能将视频沿时间线向前或向后扩展;将视频向两个方向延伸,创造出一个无缝的循环视频
- 图像生成
- Sora也拥有生成图像能力,分辨率最高可达2048x2048像素
- 视频风格、环境变换
- 将 SDEdit 技术应用于Sora,使其能够不需要任何先验样本,即可改变视频的风格和环境
- 视频无缝衔接
- 用Sora在两个不同视频间创建平滑的过渡效果,即使这两个视频的主题和场景完全不同。
- 模拟能力涌现
- 随着模型规模扩大,Sora 不需要专门针对3D空间、物体等设置特定规则,就模拟出人类、动物以及自然环境的某些特征。
- 3D空间真实感:视角动态变化的视频
- 场景/物体一致性:长视频中,保持场景和物体随时间的连续性,即便在物体被遮挡或离开画面时,也能保持其存在感
- 场景交互能力
- Sora能模拟出影响世界状态的简单行为,Sora的生成符合物理世界的规则
- 数字世界模拟
- Sora不仅能模拟现实世界,还能够模拟数字世界,比如视频游戏
数据仍然还是王道
数据层面上,OpenAI也给出了两点很有参考价值的方法
- 不对视频/图片进行裁剪等预处理,使用native size
- 数据质量很重要,比如(文本、视频)这样的成对数据,原始的文本可能并不能很好的描述视频,可以通过re-captioning的方式来优化文本描述,这一点在DALL·E 3的报告中也已经强调了,这里只是进一步从图片re-captioning扩展到视频re-captioning。
DALL·E 3 如何做re-captioning
- 基于图像这个条件(条件生成),用 CLIP 编码图像,把图像embedding放进去,生成文本描述
- 图像打标模型怎么训练?CoCa 方法,同时考虑对比损失和LM损失
模型推理策略
官方展示Sora的应用有很多,比如文生视频、图生视频、视频反推、视频编辑、视频融合等。
- 文生视频:喂入DiT的就是文本embedding+全噪声patch
- 视频编辑:类似SDEdit的做法,在视频上加点噪声(不要搞成全是噪声),然后拿去逐步去噪
- 图生视频、视频反推、视频融合:喂入DiT的就是文本embedding(可选)+特定帧用给定图片的embedding+其他帧用全噪声patch
Sora 除了文生视频,也支持文生图,这里其实透露出了一种统一的味道。未来发展肯定会出现更加强大的多模态统一
- 万物皆可“分词”,选择合适的编码器 + Transformer结构或其他 + 合适的解码器,就可能实现各种不同模态之前的互相转换、互相生成!
不足
Sora对涌现物理的理解脆弱,并不完美,仍会产生严重、不符合常识的幻觉,还不能很好掌握物体间的相互作用。
Sora作为一个模拟器存在着不少局限性。
- 模拟基本物理交互(如玻璃破碎)时的准确性不足
- 无法准确模拟许多基本交互的物理过程,以及其他类型的交互,比如吃食物。物体状态的变化并不总是能够得到正确的模拟,这说明很多现实世界的物理规则是没有办法通过现有的训练来推断的。
- 长视频中出现的逻辑不连贯或物体会无缘无故地出现。
- 比如,随着时间推移,有的人物、动物或物品会消失、变形或者生出分身;
- 或者出现一些违背物理常识的闹鬼画面,像穿过篮筐的篮球、悬浮移动的椅子。如果将这些镜头放到影视剧里或者作为精心制作的长视频的素材,需要做很多修补工作。
Case
Prompt:
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
# 一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信又随意。街道潮湿且反光,在彩色灯光的照射下形成镜面效果。许多行人走来走去。
# Prompt: 多镜头
A beautiful silhouette animation shows a wolf howling at the moon, feeling lonely, until it finds its pack.
# 一个美丽的剪影动画展示了一只狼对着月亮嚎叫,感到孤独,直到它找到狼群。
# Prompt: 世界模型
A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics and finally the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer.
# 提示:一只猫叫醒熟睡的主人,要求吃早餐。主人试图忽视这只猫,但猫尝试了新的策略,最后主人从枕头下拿出秘密藏匿的零食,让猫再呆一会儿。
# Prompt:
A Chinese Lunar New Year celebration video with Chinese Dragon.
# 提示:与中国龙一起庆祝中国农历新年的视频。
Sora 复现
Latte
【2024-1-5】澳大利亚莫纳什大学+上海AI实验室+南京邮电推出 Latte, 又叫 Latent Diffusion Transformer, 采用了前边提到的视频切片序列和Vision Transformer的方法
- 从视频里抠出来一堆时空token,通过一系列的Transformer模块,在潜在空间里模仿视频分布。
- 因为视频里的token实在是多,设计了四个高效的变种,这样更好地处理视频的空间和时间维度。
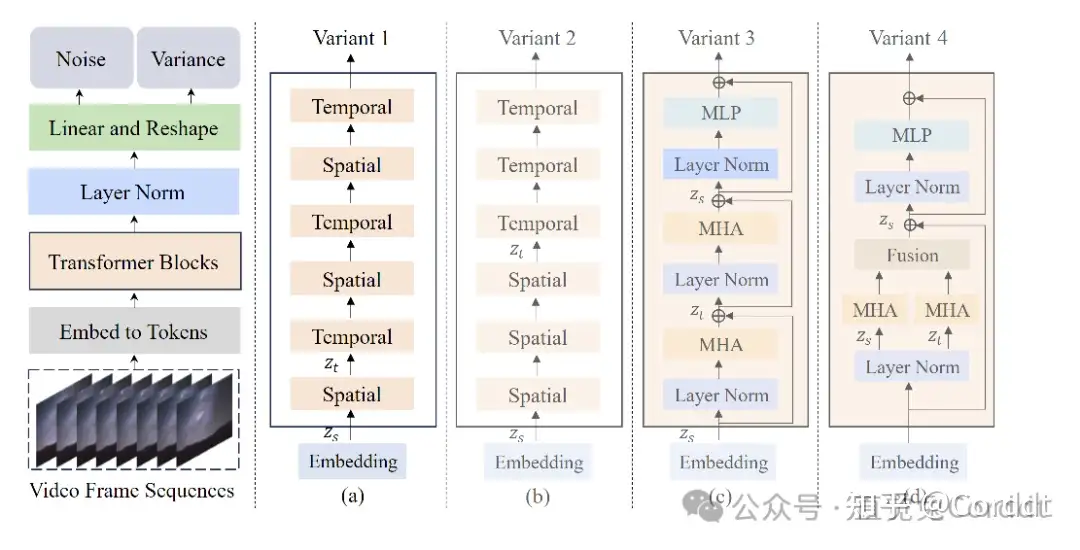
- 论文 Latte: Latent Diffusion Transformer for Video Generation
- 官方Latte
- 个人复现 train_your_own_sora
- Latte训练需要80GB显存的A100或者H100。
Open-Sora
【2024-3-18】没等来OpenAI,等来了Open-Sora全面开源
- 继 2 周前推出成本直降 46% 的 Sora 训练推理复现流程后
- Colossal-AI 团队全面开源全球首个类 Sora 架构视频生成模型 「Open-Sora 1.0」,涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球 AI 热爱者共同推进视频创作的新纪元。
- Open-Sora 开源地址
- 目前版本仅使用了 400K 的训练数据,模型的生成质量和遵循文本的能力都有待提升。例如, 在上面的乌龟视频中,生成的乌龟多了一只脚。Open-Sora 1.0 也并不擅长生成人像和复杂画面。
Vidu
【2024-4-27】中国首个Sora级视频大模型发布
4月27日上午,2024中关村论坛年会未来人工智能先锋论坛上,生数科技联合清华大学发布中国首个长时长、高一致性、高动态性视频大模型——Vidu。
Vidu不仅能够模拟真实物理世界,还拥有丰富想象力,具备多镜头生成、时空一致性高等特点,这也是自Sora发布之后全球率先取得重大突破的视频大模型,性能全面对标国际顶尖水平,并在加速迭代提升中。
该模型采用团队原创的Diffusion与Transformer融合的架构U-ViT,支持一键生成长达16秒、分辨率高达1080P的高清视频内容。
根据现场演示的效果,Vidu能够模拟真实的物理世界,能够生成细节复杂、并且符合真实物理规律的场景,例如合理的光影效果、细腻的人物表情等。它还具有丰富的想象力,能够生成真实世界不存在的虚构画面,创造出具有深度和复杂性的超现实主义内容,例如“画室里的一艘船正在海浪中驶向镜头”这样的场景。
此外,Vidu能够生成复杂的动态镜头,不再局限于简单的推、拉、移等固定镜头,而是能够围绕统一主体在一段画面里就实现远景、近景、中景、特写等不同 镜头的切换,包括能直接生成长镜头、追焦、转场等效果,给视频注入镜头语言。
Vidu的快速突破源自于团队在贝叶斯机器学习和多模态大模型的长期积累和多项原创性成果。其核心技术 U-ViT 架构由团队于2022年9月提出,早于Sora采用的DiT架构,是全球首个Diffusion与Transformer融合的架构,完全由团队自主研发。
【2024-2-21】谷歌 Lumiere
- 【2024-1-26】谷歌爆肝7个月做出的AI视频生成器,彻底改变游戏规则
- 【2024-2-21】Google重磅发布AI视频生成模型Lunia,效果超Pika和Runway
Google重磅发布了AI视频大模型Lumiere,效果秒杀AI视频王者Pika和Runway, AI视频生成的新王诞生
- 功能丰富:文生视频、图文生视频、风格化、视频编辑
- 5s时长
Lumia采用了全新的AI视频生成算法,带来了更强的性能和视觉效果。
- 亮点一:视频生成时长从过去的4秒升级到5秒,内容更加丰富。
- 亮点二:视频画面的质量和连贯性显著提升,之前AI生成的视频画面非常不可控,视频画面过度极易出现畸形和异常。
大规模视频扩散模型 Lumiere凭借最先进的时空U-Net架构,在一次一致的通道中生成整个视频。通过联合空间和“时间”下采样(downsampling)来实现生成,这样能显著增加生成视频的长度和生成的质量。
【2024-2-23】谷歌 Genie
【2024-2-23】继OpenAI Sora的世界模型,Google也发布了基础世界模型Genie,生成式交互环境(Generative Interactive Environments)。
Genie 是一个 110 亿参数的基础世界模型,可通过单张图像提示生成可玩的交互式环境。它生成的虚拟世界「自主可控」,一键能生成可玩的虚拟游戏!
Genie 由三个部分组成:
- (1)一个潜在动作模型,用于推断每对帧之间的潜在动作;
- (2)一个视频 tokenizer,用于将原始视频帧转换为离散 token;
- (3)一个动态模型,用于在给定潜在动作和过去帧 token 的情况下,预测视频的下一帧。
有了Genie,可以:
- (1)用文本生成图像,再把图像输入到Genie,生成一个可玩的虚拟游戏;
- (2)画一张草图,输入给Genie,……
-
(3)Genie是一种通用方法,其训练视频的方法可以用于多个其他领域,比如机器人,智能体等
- 项目:genie-2024
- 论文:Genie: Generative Interactive Environments
Genie: Generative Interactive Environments(生成式交互环境)
论文摘要:
- 介绍 Genie,这是第一个通过无标签的互联网视频以无监督方式训练的生成交互环境。
该模型可以被提示生成无数种通过文本、合成图像、照片甚至草图描述的动作可控的虚拟世界。在 11B 参数下,Genie 可以被视为基础世界模型。它由时空视频分词器、自回归动力学模型和简单且可扩展的潜在动作模型组成。Genie 使用户能够在生成的环境中逐帧进行操作,尽管训练时没有任何真实动作标签或世界模型文献中常见的其他特定领域要求。
此外,由此产生的学习潜在动作空间有助于训练智能体模仿未见过的视频中的行为,为未来训练多面手智能体开辟道路。
SadTalker
【2024-5-16】SadTalker 是一款开源的AI工具,将静态图像转换成动态视频,并使图像中的人物根据音频内容进行讲话。
它使用了一种叫做 SadNet 的神经网络来实现,该神经网络可以捕捉音频中的情感和语音模式,并将其转化为逼真的面部表情和头部动作。
SadTalker 的工作原理可以简单概括为以下几个步骤:
- 输入: 用户提供一张图片和一段音频。音频可以是用户自己的录音,也可以是文本转语音生成的语音。
- 处理: SadTalker 分析音频以提取情感和语音模式。
- 输出: 然后,该工具会根据提取的语音特征,使图像中的人物进行相应的动画,包括嘴唇运动、面部表情甚至轻微的头部动作。
SadTalker 具有以下特点:
- 易于使用: SadTalker 提供了一个简单的界面,即使是没有任何技术背景的用户也可以轻松上手。
- 功能强大: 该工具可以生成逼真且自然的动画效果,并支持多种音频格式和图像类型。
- 开源: SadTalker 是开源的,这意味着任何人都可以对其进行修改和扩展。
SadTalker 的应用非常广泛,包括:
- 创建虚拟形象: 用户可以使用自己的照片或插图来创建逼真的虚拟形象,并使其根据自己的声音或其他语音进行讲话。
- 动画演示文稿: 在演示文稿中添加动画角色或讲解视频可以使其更加生动有趣,并提高观众的参与度。
- 娱乐目的: SadTalker 可以用于制作搞笑视频或表情包,为用户带来欢乐。
【2024-6-6】可灵
- 生成超120s视频,更懂物理,复杂运动也能精准建模
采用Sora相似的技术路线,结合多项自研技术创新,生成的视频不仅运动幅度大且合理,还能模拟物理世界特性,具备强大的概念组合能力和想象力。
数据上看,可灵支持生成长达2分钟的30fps的超长视频,分辨率高达1080p,且支持多种宽高比。
Gen 系列
Gen-3 Alpha
【2024-6-17】Gen-3 Alpha重磅发布,Sora最强竞争对手
6月17日晚,著名生成式AI平台 Runway 在官网发布了全新文生视频模型——Gen-3 Alpha。
与Gen-2相比,Gen-3在生成视频的质量、色彩、饱和度、光影、文本语义还原、运镜、动作一致性、场景切换等实现大幅度提升。
此外,Gen-3和Sora、可灵、Dream Machine一样是个世界模型,具备模拟物理世界的能力。其生成视频的物理效果,例如,下落、碰撞、触摸、风吹、生长、雨水等都非常逼真。
Gen-3 还没有正式全面公测,但邀请了影视、开发等人员进行了内测,流出来的视频效果非常棒, 一次可以生成11秒的视频。
字节
2024年5月,字节跳动旗下的文生视频产品 Dreamina(隶属于视频剪辑产品“剪映”)在改名为“即梦”,改名同时产品做了一次更新,普通用户即可使用AI文生视频工具生成3秒的短视频,VIP用户可以生成6秒的短视频。
【2024-9-24】字节跳动旗下火山引擎在深圳举办AI创新巡展,同时发布了豆包视频生成 PixelDance 和 Seaweed 两款大模型,目前已经面向企业市场开启邀测。
即梦的内测版已经在使用最新的豆包视频生成模型——Seaweed。
豆包视频生成模型也是基于DiT架构。不过,豆包视频生成模型通过高效的DiT融合计算单元,让视频在大动态与运镜中自由切换,拥有变焦、环绕、平摇、缩放、目标跟随等多镜头语言能力。全新设计的扩散模型训练方法攻克了多镜头切换的一致性难题,在镜头切换的同时保持主体、风格、氛围的一致性。
“豆包视频生成大模型能攻克指令遵循、运镜(多镜头下主体一致性)等难题,背后有技术上的突破和全栈能力的优势,还有抖音、剪映对视频理解的优势。”谭待说道。
【2024-2-20】字节 Boximator
视频界“神笔马良” —— 字节Boximator模型
产品信息:
- Boximator 是一款由字节跳动开发的文生视频模型,可通过文本精准控制生成视频中人物或物体的动作。
产品功能:
- 用户只需输入一句描述具体动作的文本,Boximator便可生成对应动作的视频片段,目前很多文生视频大模型其实做不到这一点。
同时在Pika 1.0、Gen-2、Boximator上输入文本“一位英俊的男人用右手从口袋中掏出一支玫瑰,并注视着这只玫瑰”,三个大模型最终生成的视频中,只有Boximator做到了男士掏花和看花的动作,其他两个均没有
2024年2月20日,字节跳动相关人士表示,Boximator是视频生成领域控制对象运动的技术方法研究项目,目前还无法作为完善的产品落地,距离国外领先的视频生成模型在画面质量、保真率、视频时长等方面还有很大差距。
【2024-9-24】PixelDance
PixelDance 一种基于扩散模型的新颖方法,它将第一帧和最后一帧的图像指令与视频生成的文本指令相结合。
综合实验结果表明,使用公共数据训练的 PixelDance 在合成复杂场景和复杂动作的视频方面表现出明显更好的熟练程度,为视频生成树立了新标准
【2024-9-24】Seaweed
待定
Veo 1
【2024-5】I / O大会上首次宣布Veo
Veo 2
Veo 发布7个月后,2024年12月17日,谷歌发布文生视频模型Veo的下一个版本 Veo 2。
- 项目官网: veo-2
但Veo仅在十几天前的12月3日才登上Axtrix,在这之前,用户只能利用VideoFX中的实验工具小规模试用这一视频生成软件。
核心升级。
- 首先,真实感和保真度大为增加,它支持对长度为8s、清晰度为4K视频的输出,并在细节、真实性和伪影减少方面提升巨大。
- 其次,Veo 以其对物理学的理解及遵循详细指令的能力,能够高度精确地捕捉运动。这正是前几日Sora 频频翻车的点。
- 第三,Veo 2还提供了更多的相机控制选项,你可以输入诸如“镜头缓慢推进她的面庞”、“摄像机在追逐车辆的过程中趋于稳定”、“极近的特写镜头”来去描述你需要的镜头模式。
Veo 2 主要功能
- 高分辨率视频生成: 生成高达4K分辨率的视频,提供更清晰的视觉效果。
- 理解镜头控制指令:理解并执行有关镜头运动和风格的指令,如广角、特写、无人机视角等。
- 模拟物理现象和人类表情:模型能更真实地模拟现实世界的物理效果和人类表情变化.
- 减少错误生成:显著减少如多余手指或意外物体等常见错误。
-
安全性:生成的视频嵌入不可见的 SynthID 水印,便于识别 A 生成的视频内容。
Veo 2 技术原理
- 深度学习模型:基于深度学习技术,特别是变换器(Transformers)架构,理解和处理输入的文本或图像提示。
- 文本到视频的合成:Veo2将文本描述转换为视频内容,涉及到自然语言处理(NLP)和计算机视觉技术的结合。
- 物理模拟:集成物理引擎,确保生成的视频内容在物理上是合理的。 面部和表情识别:用面部识别技术捕捉和模拟人类表情,提高视频的真实感。
测试中,Veo 达到 SOTA 水平。谷歌选取了其他包括Sora在内的顶尖模型,在 Meta 发布的基准数据集 MovieGenBench 上比拼了 1003 条提示及其对应视频。
Veo占优的情况都接近或超过了50%,不占劣势的情况则能达到70%左右。
Sora Turbo在谷歌测试的所有模型中居然是表现最差的,而表现最好的是可灵1.5。
短板
- 复杂场景或复杂运动中保持完全的一致性仍然没法被突破。范例中,依然会出现凭空出现的人物。在运动中,人也可能依然出现那种不自然的“AI扭曲”。
Veo 3
2025年5月21 日,I/O 开发者大会上,谷歌发布新一代视频生成模型 Veo3
首个可生成视频背景音效的模型。
- 不仅能合成画面,还能为鸟鸣或街头交通等场景配上相应的音效,甚至还可生成人物对话。
Veo 3,特别是通过影视制作工具Flow,旨在赋能电影制作人和内容创作者。Flow允许用户创建场景、管理素材、编辑故事情节并控制镜头运动。

Veo 3 还不免费开放,Google Gemini的AI Ultra订阅者(每月249.99美元)才能使用。
OceanVideo
Magi-1
【2025-4-21】 Sand.ai(三代科技)正式发布其首个视频生成大模型产品 Magi-1
全球首个自回归视频生成大模型
Swin Transformer 作者创业团队出品
Magi-1 在以下几个方面表现出色:
- 跨场景物理一致性:如人物动作、背景环境的自然衔接;
- 提示词理解能力:对细节、情绪、空间场景等关键词具备较强解析能力;
- 模型开源可控:全程开源,支持研究者与开发者深度参与模型迭代。
虽然 Magi-1 尚未与 Sora 等国际顶尖模型在质量与时长上完全对标,但其“产品可用性 + 开源策略”组合,为中国视频生成模型赛道注入新活力。特别是在跨帧物理一致性、场景构图稳定性方面,Magi-1 已达到全球领先水平。
Apple
FastVLM 介绍
FastVLM 是苹果发布的视觉语言模型,可以在iPhone和Mac上离线运行,能够理解图像内容并回答问题。所有预测都在设备本地处理,确保隐私和安全
- 【2024-12-17】CVPR 2025 FastVLM: Efficient Vision Encoding for Vision Language Models
- GitHub ml-fastvlm
实时理解
【2025-9-2】FastVLM:实时视频理解
苹果在 Hugging Face 平台上开源 FastVLM 视觉语言模型的浏览器试用版。资讯
- FastVLM 基于 LLaVA 和 qwen2
- 模型:FastVLM-0.5B
- 浏览器实时运行,速度↑85x,体积↓3.4x
FastVLM 以其“闪电般”的视频字幕生成速度著称,只要用户拥有搭载 Apple Silicon 芯片的 Mac 设备,即可轻松上手体验这一前沿技术。
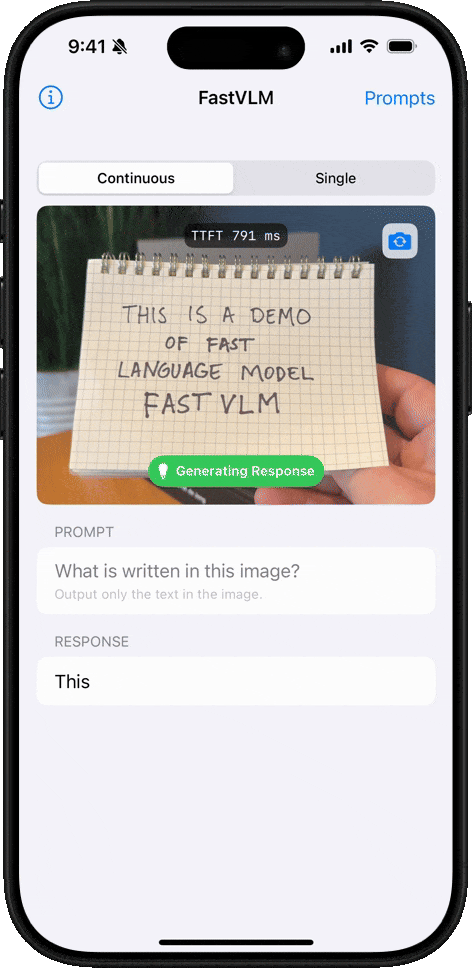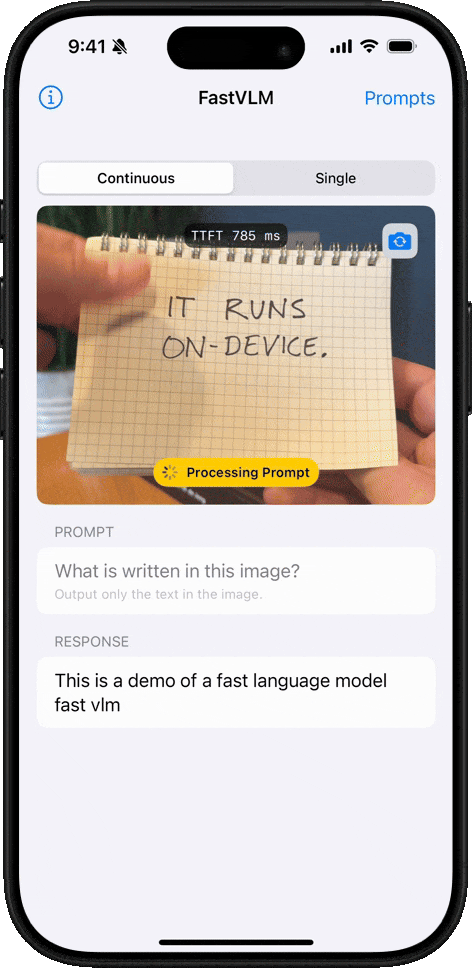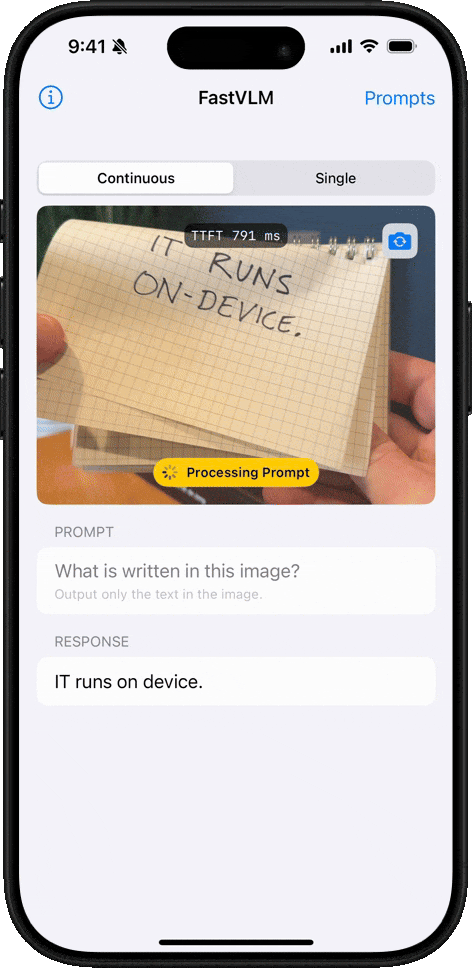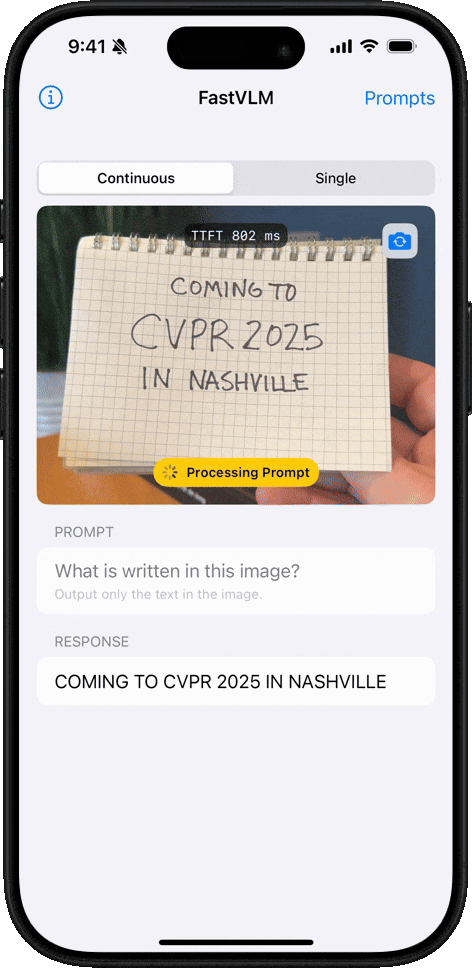
核心优势
- 极速响应:首 Token 输出速度惊人!FastVLM-0.5B 比 LLaVA-OneVision 快 85 倍。FastVLM-7B (结合 Qwen2) 比 Cambrian-1-8B 快 7.9 倍 (同等精度)。
- 小巧高效: 模型体积小,部署更轻松。FastVLM-0.5B 比 LLaVA-OneVision 小 3.4 倍。非常适合 iPhone、iPad、Mac 等端侧设备。
- 端侧智能: 无需依赖云端,直接在您的苹果设备上运行,保护隐私,响应更快。完美适配 iOS/Mac 生态,赋能边缘 AI 应用。
FastVLM 模型的核心优势在于其卓越的速度和效率。该模型利用苹果自研的开源机器学习框架 MLX 进行优化,专为 Apple Silicon 芯片设计。与同类模型相比,FastVLM 模型体积仅为三分之一左右,不过在视频字幕生成速度上却能提升 85 倍。
苹果此次发布的 FastVLM-0.5B 轻量版,可在浏览器内直接加载运行。
- 根据该媒体实测,在 16GB M2 Pro MacBook Pro 上,首次加载模型需数分钟,不过在启动后,便能精准描述画面中的人物、环境、表情及各种物体。
- 该模型支持本地运行,所有数据均在设备端处理,无需上传至云端,从而保障了用户的数据隐私。
FastVLM 的本地运行能力及其低延迟特性,让其在可穿戴设备和辅助技术领域展现出巨大潜力。例如,在虚拟摄像头应用中,该工具能即时详细描述多场景内容,FastVLM 未来有望成为这些设备的核心技术,为用户提供更智能、更便捷的交互体验。
Sora 2
【2025-10-01】Sora 2
2024年2月发布的初代Sora模型在许多方面可视为视频领域的“GPT-1时刻”,而Sora 2则直接迈入了视频领域的“GPT-3.5时刻”。
10月1日凌晨,OpenAI 新一代视频生成模型 Sora 2.0 与同名社交应用(Sora App)同步登场
不仅以物理准确性、多镜头连贯性和音画同步的技术突破,被定义为“视频领域的ChatGPT时刻”
Sora 2 技术突破(物理准确性、长视频连贯性、音画同步)大幅降低了高质量视频生成的门槛
Sora App
- 用户可以创建音视频生成内容、还能在可定制的信息流中“刷视频”,并通过“客串”功能将自己或朋友带入视频。
- 该App还自带防沉迷功能,默认对青少年每天在信息流中能看到的生成内容数量设置限制,并且对该群体的客串功能也设置了更严格的权限。
- OpenAI表示,除了自动化安全防护栈之外,还正在扩大人工审核团队规模,以便在出现欺凌情况时快速审查。此外,App还带有通过ChatGPT管理的家长控制功能。
同时,App在包括防止他人滥用肖像进行深度伪造、防范令人不安或非法内容的保障、定期检查Sora对用户情绪和幸福感的影响等方面都设置了缓解措施。
Sora 2 仅限受邀用户使用,iOS端应用可下载,安卓端可访问网页使用,将在美国和加拿大进行初步推广,并扩展至更多国家。
提速
【2025-12-23】清华 TurboDiffusion
【2025-12-23】清华系DeepSeek时刻来了,硅谷沸腾!单卡200倍加速,视频进入秒级时代
顶配GPU,如H100,在不加速的情况下生成短视频,仍需数分钟,这严重影响了落地应用的体验。更何况大多数创作者只有RTX 5090或4090这种消费级显卡。
清华大学TSAIL实验室携手生数科技,重磅发布视频生成加速框架 TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!
- Github: TurboDiffusion
- 技术报告: TurboDiffusion_Technical_Report
总结:在几乎不影响生成质量的前提下,让视频生成的速度直接飙升了100–200倍!
- RTX 5090显卡上,就能实现100-200倍的速度提升
黑科技加持:
- SageAttention:低比特量化注意力加速
- 传统Transformer注意力层在高分辨率视频场景中,计算开销巨大。TurboDiffusion采用清华自主研发的SageAttention技术,进行了低比特量化注意力加速,充分压榨了显卡性能,极致提速。
- GitHub链接:SageAttention
- Sparse-Linear Attention(SLA):稀疏注意力加速
- 在稀疏计算方面,TurboDiffusion引入了SLA(Sparse-Linear Attention)。
- 由于稀疏计算与低比特Tensor Core加速是正交的,SLA可以构建在SageAttention之上,显著减少了全连接矩阵乘法的冗余计算,在推理过程中进一步获得数倍的额外加速。
- GitHub链接:SLA
- rCM步数蒸馏加速:更少步生成
- NVIDIA开源实验室的rCM,是一种先进的步数蒸馏方法。它通过训练,让少量的采样步骤也能恢复与原模型一致的质量。这种方法能进行步数蒸馏加速,减少推理过程中的「扩散步数」,降低延迟而不损失画质。比如,原始Diffusion需要50–100步,rCM可压缩到4-8步。
- GitHub链接:RCM
- W8A8 INT8量化:线性层加速
- TurboDiffusion在线性层采用了W8A8的INT8量化策略,这样,就将模型权重和激活映射到8位整数空间,并在128×128的块粒度上进行分块量化,兼顾了速度与精度,而且还显著降低了推理功耗与内存占用。
这4项核心技术均由清华大学TSAIL团队联合生数科技自主研发,对AI多模态大模型的技术突破与产业落地具有里程碑式的价值与深远影响力。其中,SageAttention更是全球首个实现注意力计算量化加速的技术方案,已被工业界大规模部署应用。
例如,SageAttention已成功集成至NVIDIA推理引擎Tensor RT,同时完成在华为昇腾、摩尔线程S6000等主流GPU平台的部署与落地。此外,腾讯混元、字节豆包、阿里Tora、生数Vidu、智谱清影、百度飞桨、昆仑万维、Google Veo3、商汤、vLLM等国内外头部科技企业及团队,均已在核心产品中应用该技术,凭借其卓越性能创造了可观的经济效益。
昆仑万维
SkyReels-V1
【2025-2-18】 2月18日,昆仑万维开源中国首个面向AI短剧创作的视频生成模型SkyReels-V1、中国首个SOTA级别基于视频基座模型的表情动作可控算法SkyReels-A1。
- 开源地址(SkyReels-V1):https://taou.cn/a/gjWlQl
- 开源地址(SkyReels-A1):https://taou.cn/a/gjWlQR
昆仑万维 SkyReels 一次性开源 SkyReels-V1 和 SkyReels-A1 两个SOTA级别的模型和算法,将面向AI短剧创作的技术成果回馈开源社区和AIGC用户。
SkyReels-V1 可实现影视级人物微表情表演生成,支持33种细腻人物表情与400+种自然动作组合,高度还原真人情感表达。
SkyReels-V1 不仅支持文生视频、还能支持图生视频,是开源视频生成模型中参数最大的支持图生视频的模型,在同等分辨率下各项指标实现开源SOTA。
SkyReels-A1 能够基于任意人体比例(包括肖像、半身及全身构图)生成高度逼真的人物动态视频,其真实感源自对人物表情变化和情绪的精准模拟、皮肤肌理、身体动作跟随等多维度细节的深度还原。
【2026-1-29】SkyReel-V3
【2026-1-29】SkyReels-V3:登顶行业SOTA的开源多模态视频生成模型技术解析
昆仑天工(Skywork AI)开源最新多模态视频生成模型——SkyReels-V3。
- github SkyReels-V3
- 在线Demo
- 技术报告 SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers
不仅在多项核心指标上超越主流闭源系统(如Kling、Vidu等),更以全功能开源、模块化设计、分钟级长视频生成能力三大亮点,成为当前AI视频生成领域的标杆之作。
SkyReels-V3 的架构创新、核心技术突破及其三大核心能力:多参考图生视频(Reference-to-Video)、智能视频延长(Video Extension)与高保真虚拟人(Talking Avatar)。
原理
SkyReels-V3 并非三个独立模型的简单拼接,而是基于统一的多模态上下文学习(Multi-modal In-Context Learning, M-ICL)基座,通过任务特定微调衍生出三大功能分支:
- Reference-to-Video(R2V):支持1–4张参考图 + 文本提示生成5秒720P视频
- Video-to-Video(V2V):支持单镜头延长(5–30秒)与专业级镜头切换延长(5秒)
- Audio-to-Video(A2V):单图+音频驱动生成最长200秒的高清说话头像
“一核多支”设计极大提升了模型泛化能力与训练效率,同时保证各任务间共享底层视觉-语义理解能力。
核心技术突破:解决AI视频“不真、不连、不控”三大痛点
(1)痛点1:主体一致性差 → 精细化数据构建 + 多参考融合
传统图生视频模型常因训练数据粗糙导致角色变形、背景崩坏。SkyReels-V3 为此构建了一套端到端高质量视频-图像对齐数据流水线:
- 跨帧配对策略(Cross-frame Pairing):从连续视频中跨时间采样参考帧,增强时序逻辑建模
- 图像编辑辅助提取:利用分割与inpainting模型精准提取主体,并同步完成背景语义重写,避免“贴图感”
- 多参考条件编码:最多支持4张图(人物+服装+场景+道具),通过统一tokenization融入扩散过程
✅ 效果:
- 在200组混合测试集中,Reference Consistency达0.6698,超越Kling 1.6(0.6630)
(2)痛点2:视频不连贯 → 鲁棒时空建模 + 统一多段位置编码
传统模型仅做帧级插值,难以处理镜头切换或复杂运动。SkyReels-V3 引入:
- 统一多分段位置编码(Unified Multi-segment Positional Encoding):为不同镜头片段分配一致时空坐标,确保物体运动轨迹物理合理
- 分层混合训练:联合训练单镜头延续与多镜头切换任务,学习“何时切镜”“如何转场”
- 历史增强机制:在长视频延长中保留早期帧语义记忆,支持分钟级叙事连贯
✅ 支持5种专业转场:[ZOOM_IN_CUT]、[CUT_AWAY]、[REVERSE_SHOT]等,实现从“视觉延续”到“叙事延续”的跃迁
(3)痛点3:音画不同步 → 区域路由 + 关键帧约束生成
虚拟人唇形错位是行业难题。SkyReels-V3 提出:
- 区域路由机制(Region Routing):指定画面中某角色响应特定音频轨道,支持多人对话
- 语音单元-面部区域显式对齐:建模音素与嘴型肌肉运动的映射关系,适配中/英/韩及歌唱场景
- 关键帧约束生成框架:先生成等间隔关键帧确定动作骨架,再以音频为约束填充中间帧,避免长视频漂移
✅ 在内部评测中,Audio-Visual Sync得分8.18,接近OmniHuman 1.5(8.25),但Character Consistency更高(0.80 vs 0.81)
应用
营销
【2025-6-19】灵犀深智推出 ClipClap 营销短视频生成
AI驱动创作
- 依托多场景模型能力,自动从长视频中提取高光片段,通过AI智能剪辑,节省创作时间。
字幕生成
- 提供丰富的字幕模板,通过AI为您生成字幕,支持关键字高亮。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
