- 向量化
- 结束
向量化
向量模型把人类世界里的语言转化为为计算机世界中的数字
人类语言是离散的, 所以需要通过 embedding 转化为连续数字
语言必须是离散的?【2026-5-13】何恺明推出ELF(Embedded Language Flows,嵌入式语言流),详见转内专题:扩散语言模型
向量化
距离度量方式
💡 核心差异与选择建议
- 余弦相似度 vs 欧氏距离
- 余弦相似度看的是「方向」,不关心向量的长度/大小,所以在文本语义匹配中更常用(比如两个不同长度的句子,只要语义相近,余弦相似度就会很高)。
- 欧氏距离看的是「绝对距离」,更适合关注向量大小差异的场景(比如图像特征、坐标点匹配)。
- 点积的特殊用法
- 点积其实等于「向量长度 × 余弦相似度」,如果向量已经做了归一化,点积就和余弦相似度等价。
- 它在推荐系统中很常用,因为能同时捕捉用户/物品向量的方向和强度差异。
| 方法 | 原理 | 结果含义 | 推荐场景 |
|---|---|---|---|
| 余弦相似度 | 计算两向量夹角的余弦值,关注方向,忽略大小 | 取值范围 [-1, 1],越接近 1 代表向量方向越一致、越相似 |
文本搜索、NLP 首选(比如语义向量匹配) |
| 欧氏距离 | 两点之间的直线距离,关注绝对位置差异 | 取值范围 [0, +∞),越接近 0 代表两点越近、越相似 |
图像检索、坐标系数据(比如特征点匹配) |
| 点积 | 向量各分量乘积之和,方向+长度综合考量 | 值越大越相似(无固定范围) | 推荐系统、归一化向量场景 |
import numpy as np
# 余弦相似度:衡量方向相似性
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 欧氏距离:衡量绝对位置差异
def euclidean_distance(a, b):
return np.linalg.norm(a - b)
# 点积:结合方向与长度
def dot_product(a, b):
return np.dot(a, b)
# 示例向量
v1 = np.array([0.12, -0.54, 0.87, 0.03])
v2 = np.array([0.10, -0.50, 0.90, 0.05])
v3 = np.array([-0.80, 0.20, -0.30, 0.70])
print(f"v1 vs v2 余弦相似度: {cosine_similarity(v1, v2):.4f}") # 约 0.9997(非常相似)
print(f"v1 vs v3 余弦相似度: {cosine_similarity(v1, v3):.4f}") # 约 -0.55(不相似)
多模态向量化
【2026-1-17】多模态Qwen3-VL-Embedding悄悄开源&技术剖析
互联网内容早已不只是文字——商品图、短视频、扫描件、直播切片…… 传统文本搜索引擎面对“以图搜文”“以视频搜商品”等跨模态需求时力不从心。 CLIP 之后,社区一直在寻找一个模型、一套向量空间、端到端搞定所有模态检索的终极方案。
核心挑战:如何构建一个统一、高精度的表示空间,使得来自不同模态(文本、图像、视频、文档图像)的数据能够被映射到同一语义平面上,从而实现跨模态的精准语义匹配与检索。
- 模态鸿沟(Modality Gap):不同模态的数据在原始特征空间中差异巨大,直接比较无意义。
- 语义对齐(Semantic Alignment):需要确保语义上相关的内容,无论其模态如何,在嵌入空间中距离相近,反之则远。
- 效率与精度的权衡:工业级应用要求模型在保持高检索精度的同时,还需具备低存储开销和高推理速度。
Qwen3-VL
【2026-1-8】Qwen3-VL 系列两大杀器
- Qwen3-VL-Embedding 与 Qwen3-VL-Reranker:迈向最先进的统一多模态检索与排序框架
- Qwen
- Qwen3-VL-Embedding
Embedding 负责“海选”,Reranker 负责“决赛”
两个核心组件构成:
- Qwen3-VL-Embedding:一个高效的双编码器(Bi-encoder)模型,负责将任意模态的输入快速编码为高维稠密向量。其核心目标是高召回率(Recall),即在海量候选集中快速筛选出与查询相关的Top-K结果。
- Qwen3-VL-Reranker:一个精细的交叉编码器(Cross-encoder)模型,负责对Embedding阶段召回的Top-K候选结果进行精排(Fine-grained Re-ranking),以提升最终排序的准确性。
双阶段架构
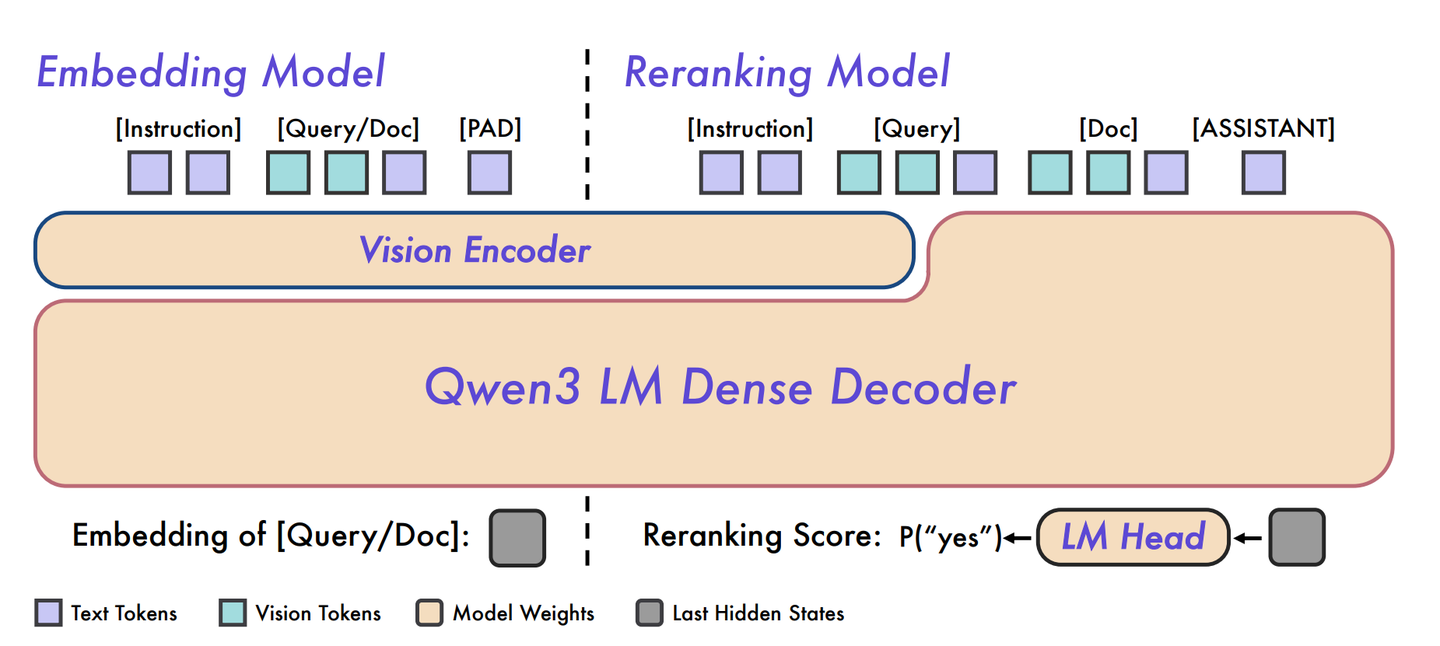
两者共同构成了一个经典的“检索-精排”(Retrieve-and-Rerank)工业级检索范式。
Qwen3-VL-Embedding/Reranker 用“大模型+大数据+大工程”把多模态检索推向了新 SOTA,同时兼顾了部署友好(维度/量化可调)与文本能力不衰减。
文本“urban architecture”与对应图像、视频、文档在同一流形中的位置示意
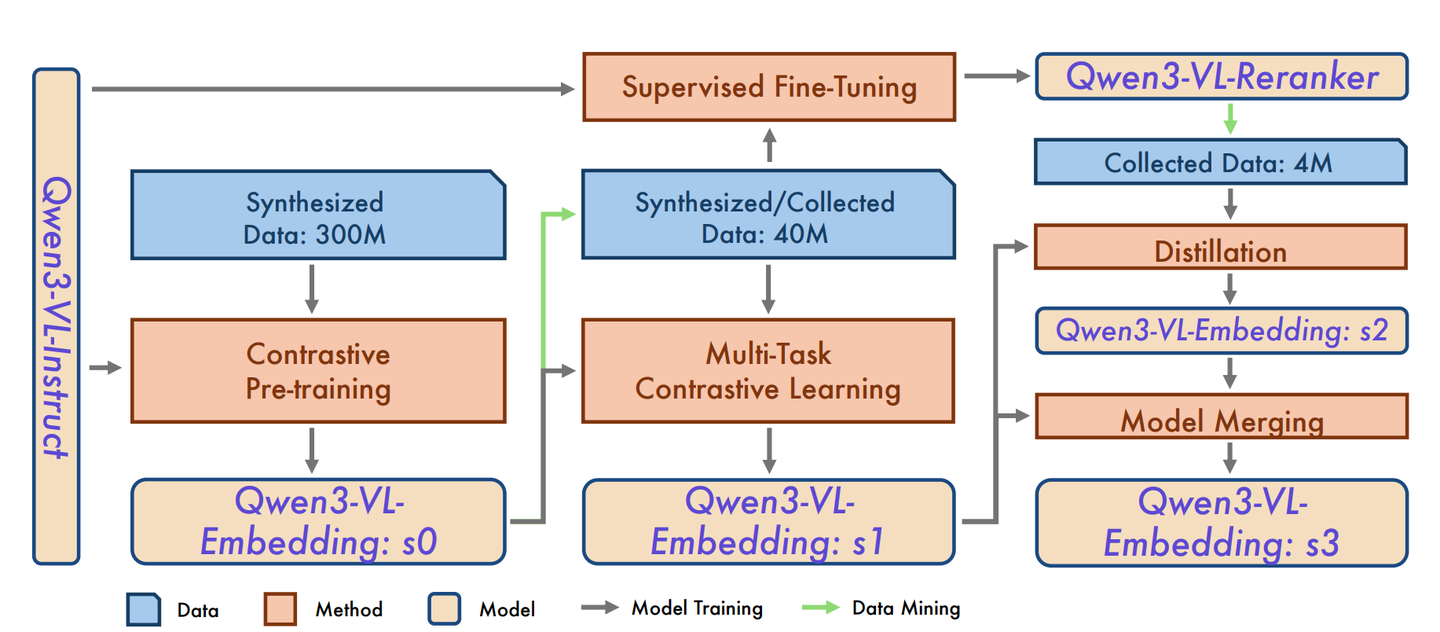
三阶段训练流程——对比预训练 → 多任务微调 → 蒸馏+模型融合
- Stage-0 对比预训练:20 亿级合成图文对,warm-up 出基座
- Stage-1 多任务微调:引入人工标注高质量数据,缓解任务失衡
- Stage-2 知识蒸馏:用 Reranker 的细粒度信号反哺 Embedding,最终再与 Stage-1 做加权合并,得到“不偏科”的 Stage-3 模型
文本向量化
嵌入(Embedding)是一种将文本或对象转换为向量表示的技术,将词语、句子或其他文本形式转换为固定长度的向量表示。
- 嵌入向量是由一系列浮点数构成的向量。
- 通过计算两个嵌入向量之间的距离,可以衡量它们之间的相关性。距离较小的嵌入向量表示文本之间具有较高的相关性,而距离较大的嵌入向量表示文本之间相关性较低。
以 Milvus 为代表的向量数据库利用语义搜索(Semantic Search)更快地检索到相关性更强的文档。
详见:
- sklearn专题里的文本向量化
文档向量化
自研框架选择
- 基于 OpenAIEmbeddings,官方给出了基于embeddings检索来解决GPT无法处理长文本和最新数据的问题的实现方案。参考
- 也可以使用 LangChain 框架。
参考
除了从文档中抓取数据,从指定网站URL抓取数据,实现智能客服外部知识库,可以借助ChatGPT写Python代码,PythonBeautiful Soup库的实现方式很成熟
大厂产品截图:智能客服知识库建设
- 企业资料库,关联大语言模型自动搜索
- 大模型文档知识抽取和“即搜即问”
都有ChatGPT了,为什么还要了解Embedding这种「低级货」技术?两个原因:
- 有些问题使用Embedding解决(或其他非ChatGPT的方式)会更加合理。通俗来说就是「杀鸡焉用牛刀」。
- ChatGPT性能方面不是特别友好,毕竟是逐字生成(一个Token一个Token吐出来的)。
文本切分
LangChain 切分工具
- Text Splitters文档: 选择对应的文本切分器,如果是通用文本的话,建议选择
RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入文本
loader = UnstructuredFileLoader("./data/news_test.txt")
# 将文本转成 Document 对象
data = loader.load()
print(f'documents:{len(data)}')
# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:",len(split_docs))
相似度
相似度索引
- 只用 embedding 来计算句子的相似度
# 初始化 prompt 对象
question = "2022年腾讯营收多少"
# 最多返回匹配的前4条相似度最高的句子
similarDocs = db.similarity_search(question, include_metadata=True,k=4)
# [print(x) for x in similarDocs]
接入ChatGLM来帮忙做总结和汇总
from langchain.chains import RetrievalQA
import IPython
# 更换 LLM
qa = RetrievalQA.from_chain_type(llm=ChatGLM(temperature=0.1), chain_type="stuff", retriever=retriever)
# 进行问答
query = "2022年腾讯营收多少"
print(qa.run(query))
用途
向量化用途广泛,LLM时代的作用大
LLM-Embedder, a unified embedding model to comprehensively support the retrieval augmentation needs of large language models, including knowledge retrieval, memory retrieval, examplar retrieval, and tool retrieval. It is fine-tuned over 6 tasks:
- 知识问答 Question Answering (qa)
- 对话检索 Conversational Search (convsearch)
- 聊天 Long Conversation (chat)
- 长程语言模型 Long-Range Language Modeling (lrlm)
- 情境学习 In-Context Learning (icl)
- 工具调用 Tool Learning (tool)

文本向量用途除了RAG检索,还有 信息检索、排序、分类、聚类、语义相似度中。IMG
- Embedding: Point wise, Pair wise, List wise
- Rerank: Cross-encoder, ColBERT, LLM
- RAG:
向量可视化
Project Golem
向量可视化开源工具:将768维向量降维可视化的3D诊断工具,可用于RAG系统分析。
向量化原理
基础模型大多基于 Transformer Encoder 预训练语言模型: BERT, RoBERTa,Ernie等
nn.Embedding
nn.Embedding 是 PyTorch中的一个常用模块
- 主要作用: 将输入整数序列转换为密集向量表示
- 值是
正态分布N(0,1)中随机取值
torch.nn.Embedding(num_embeddings, # 字典大小
embedding_dim, # 向量维数
padding_idx=None, # 将制定idx填充0
max_norm=None,
norm_type=2.0,
scale_grad_by_freq=False,
sparse=False,
_weight=None,
_freeze=False,
device=None,
dtype=None)
nn.Embedding 用来实现词与词向量的映射。
- nn.Embedding 有个权重(
.weight),形状是(num_words, embedding_dim)。 - 例如一共有100个词,每个词用16维向量表征,对应的权重就是一个100×16的矩阵。
- Embedding 输入形状
N×W,N是batch size,W是序列的长度,输出的形状是 N×W×embedding_dim。 - Embedding 输入必须是
LongTensor,FloatTensor需通过tensor.long()方法转成LongTensor。 - Embedding 权重可训练,既可以采用随机初始化,也可以预训练好的词向量初始化。
nn.Embedding 示例
两个句子:
- I want a plane
- I want to travel to Beijing
将两个句子转化为ID映射:
{I:1,want:2,a:3,plane:4,to:5,travel:6,Beijing:7}
转化成ID表示的两个句子如下:
- 1,2,3,4
- 1,2,5,6,5,7
import torch
from torch import nn
# 创建最大词个数为10,每个词用维度为4表示
embedding = nn.Embedding(10, 4)
# 将第一个句子填充0,与第二个句子长度对齐
in_vector = torch.LongTensor([
[1, 2, 3, 4, 0, 0],
[1, 2, 5, 6, 5, 7]
])
out_emb = embedding(in_vector)
print(in_vector.shape)
print((out_emb.shape))
print(out_emb)
print(embedding.weight)
注意:
- 句子中ID 不能大于最大词的index(上面例子中,不能大于词库总数)
- embeding 输入必须是维度对齐的,如果长度不够,需要预先做填充
静态嵌入-固定
示例
- 定义一个
词汇表大小(vocab_size)为 20 的嵌入层,每个词被嵌入到一个5维的向量空间(embedding_dim)。 - 用
nn.Embedding创建嵌入层。 - 创建一个输入张量,代表一系列词的索引。
- 通过嵌入层处理输入,得到每个词的嵌入向量
代码实现
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 设置参数
vocab_size = 20 # 词汇表大小
embedding_dim = 5 # 嵌入维度
# 创建嵌入层
embedding = nn.Embedding(vocab_size, embedding_dim)
# 创建输入张量(词索引)
input_tensor = torch.LongTensor([1, 3, 5, 7, 8, 12, 3])
# 获取嵌入结果
embedded = embedding(input_tensor)
print("Input shape:", input_tensor.shape) # torch.Size([7])
print("Embedded shape:", embedded.shape) # torch.Size([7, 5])
print("Embedding matrix shape:", embedding.weight.shape) # torch.Size([20, 5])
# 打印嵌入结果
print("\nEmbedded vectors:")
print(embedded)
# tensor([[-0.7115, 1.3720, 1.0951, -0.1077, 0.0682],
# [-1.3939, -0.2694, -0.7298, -1.5005, 1.5755],
# [-0.5595, -0.5638, 1.5433, 2.0986, -1.2377],
# [-0.2058, 1.0504, -0.3790, 0.1947, -1.3308],
# [ 0.1186, -0.1589, 0.4095, 0.6911, 0.7207],
# [-0.1059, 1.3301, 0.1568, -1.6441, -0.9790],
# [-1.3939, -0.2694, -0.7298, -1.5005, 1.5755]],
# grad_fn=<EmbeddingBackward0>)
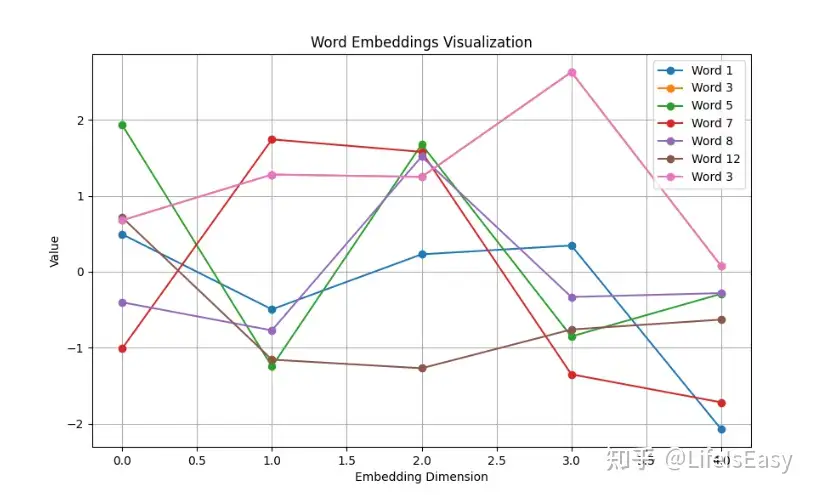
# ------- 可视化 ---------
plt.figure(figsize=(10, 6))
for i in range(len(input_tensor)):
word_embedding = embedded[i].detach().numpy()
plt.plot(range(embedding_dim), word_embedding, marker='o', label=f'Word {input_tensor[i].item()}')
plt.xlabel('Embedding Dimension')
plt.ylabel('Value')
plt.title('Word Embeddings Visualization')
plt.legend()
plt.grid(True)
plt.show()
动态嵌入-可训练
nn.Embedding 可学习性
- nn.Embedding 参数可以变化,参与梯度下降。
- 更新模型参数也会更新 nn.Embedding 参数, nn.Embedding 参数本身也是模型参数的一部分。
import torch
from torch import nn
# 创建最大词个数为10,每个词用维度为4表示
embedding = nn.Embedding(10, 4)
# 将第一个句子填充0,与第二个句子长度对齐
in_vector = torch.LongTensor([[1, 2, 3, 4, 0, 0], [1, 2, 5, 6, 5, 7]])
# embedding 权重参与梯度下降
optimizer = torch.optim.SGD(embedding.parameters(), lr=0.01)
criteria = nn.MSELoss()
for i in range(1000):
outputs = embedding(torch.LongTensor([1, 2, 3, 4]))
loss = criteria(outputs, torch.ones(4, 4))
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(embedding.weight)
new_output = embedding(in_vector)
print(new_output)
向量化方式
文本通过模型进行向量化的方式也有很多种不同的方式
cls: 取最后一层的第一个token(CLS)作为句子向量last_mean: 对最后一层的所有token取平均poolingfirst_last_mean: 第一层和最后一层分别平均池化,再取平均embedding_last_mean: embedding层和最后一层分别平均池化,再取平均last_weighted: 最后一层按token位置加权平均池化
损失函数
语义相似度损失函数
- PairInBatchNegCoSentLoss: 计算一个batch内每个句子与正例句子的余弦相似度,然后减去该句子与自身的相似度,再取log-sum-exp作为loss。
- TripletInBatchNegCoSentLoss: 在PairInBatchNegCoSentLoss的基础上,额外加入负例样本,计算句子与正负例的相似度差值。希望正例相似度–负例相似度的差值越大。
- PairInBatchNegSoftmaxContrastLoss: 将句子两两相似度矩阵进行softmax,并与句子本身的label计算交叉熵损失。
- TripletInBatchNegSoftmaxContrastLoss: 在3的基础上加入负例样本。
- PairInBatchNegSigmoidContrastLoss: 将句子两两相似度矩阵进行sigmoid,高于对角线的部分取负对数作为loss。
- TripletInBatchNegSigmoidContrastLoss: 在5的基础上加入负例样本。
- CoSentLoss: 输入预测相似度矩阵和真实相似度矩阵,计算两者差值进行log-sum-exp作为loss。这个损失是苏神提出来的,将排序的逻辑引入到了对比损失中。
语义相似的损失函数——主要思路是构建句子之间的相似度矩阵,然后通过比较正例和负例的相似度,采用交叉熵、log-sum-exp等方式计算loss,优化模型的句子表示,使得正例相似度更高。
训练策略
训练策略
- FullParametersTraining: 全参数微调,不进行任何修改,所有参数都参与训练。
- BitFitTraining: 只训练某些关键词参数,其他参数固定。通过keywords指定要训练的参数名。
- PrefixTraining: 只训练前缀tokens对应的embedding参数。通过additional_special_tokens指定前缀tokens,并只训练这些tokens的embedding。
这些策略可以平衡语料大小与模型大小,降低过拟合风险,帮助模型快速适应下游任务。通常先做全参数训练预热一下,再使用部分固定或前缀训练等策略微调到特定下游任务。
向量化类型
【2025-4-11】6 种嵌入类型及适用场景:
- • 稀疏嵌入:bm25
- • 密集嵌入:similarity
- • 量化嵌入:vector-quantization
- • 二进制嵌入:vector-quantization#binary-quantization
- • 可变尺寸:openais-matryoshka-embeddings-in-weaviate
- • 多向量嵌入:multi-vector-embeddings
向量化方案
可选
- 单独 embedding 服务
- LLM embedding
注意
- 语言模型很容易得到文本向量模型,但语言模型并不是为向量训练的,因此 直接pooling 不一定能取得满意效果
- 使用时需要针对任务微调, 把相似句子向量聚拢更近一些,把不相关的句子向量拉的更远一些。
榜单
Embedding 榜单 MTEB
- 英语:
NV-Embed-v2>bge-en-icl>stella-en_1.5b_v5>SFR-Embedding-2_R>gte-Qwen2-7b-instruct - 中文:
Conan-embedding-v1>xiaobu-embedding-v2>gte-Qwen2-7b-instruct 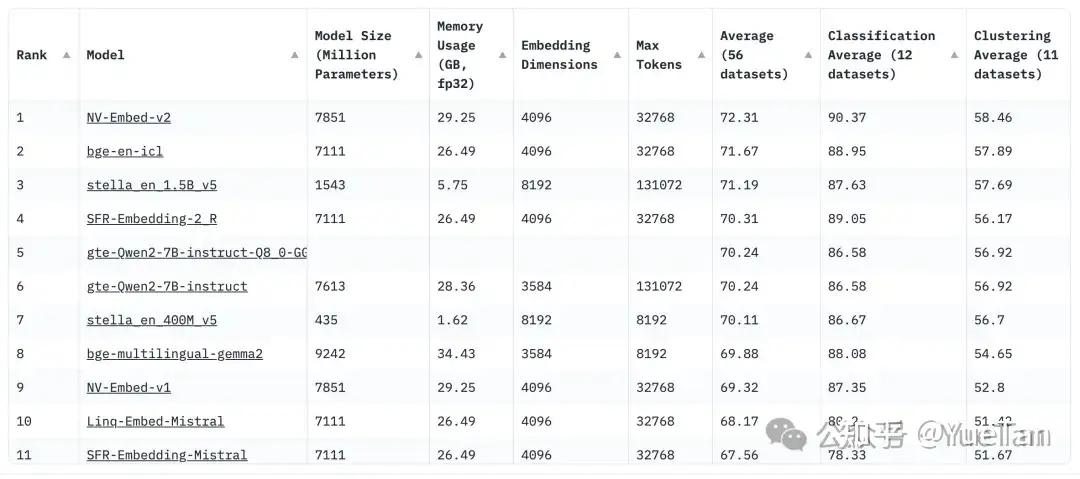
【2025-6-7】METB最新排名:
- Qwen3-Embedding全家挤占了2-4名
- 第一名还是Gemini,与自家测试结果有些差异
方案选型
一般默认使用 OpenAI 的 Embedding 接口来生成向量。
OpenAI通用型 Embedding 模型适合初学者,但一旦需求开始增加,最明智的选择:
- a) 使用自己的 Embedding 模型
- b) 使用不同的开源或闭源模型。
Embedding 模型的选择很大程度上受任务复杂程度影响。
- 简单任务(如情感分析或关键词匹配等)可能适合使用 MTEB 排行榜上任何一个通用模型。
- 但是,许多情况下需要采用特殊的 Embedding 模型。
示例
- 只差一个逗号, 意思大不相同
"Let's eat, Chris."
"Let's eat Chris."
大多数通用模型会认为这两个句子在高维 Embedding 空间中位置非常接近。但实际上,这两个句子应处于高维空间的两端,因为这两个句子含义的相似度较低。
许多 Embedding 模型是基于通用语言数据训练的,可能无法捕捉专业词汇或术语的微妙含义。
针对特定领域数据集训练或微调的模型能够为专业领域内的文本生成更精确的 Embeddings。在医疗诊断、法律文件分析或为特定产品提供技术支持等应用中,特定领域的模型能够更深入地理解相应领域使用的专业语言,显著优于通用模型。
Embedding 训练
【2024-9-7】动手学RAG:文本向量模型
如何从一个语言模型训练出一个向量模型呢?
几种范式总结:
- 训练方式: 合理设计的多阶段pipeline仍然能够提升性能
- 数据,数据大小、质量、多样性很重要: 甚至更长的文本在向量模型中也更受重视。合成数据开始展露头脚
- 模型: Decoder-only LLM 微调的向量模型效果越来越好。大模型也逐步统治向量模型榜单,带来的收益和增加的开销相比如何,咱也不知道,但是这些参数中蕴含的知识确实让人印象深刻
对比学习和难负样本挖掘仍然扮演关键角色。- 多任务: 用不同任务不同来源的数据进行训练,一个batch内如何组织数据也有优化空间。
- instruction-based fine-tuning 可以在训练时帮助模型拿到任务上的线索
总结
【2025-3-17】资料
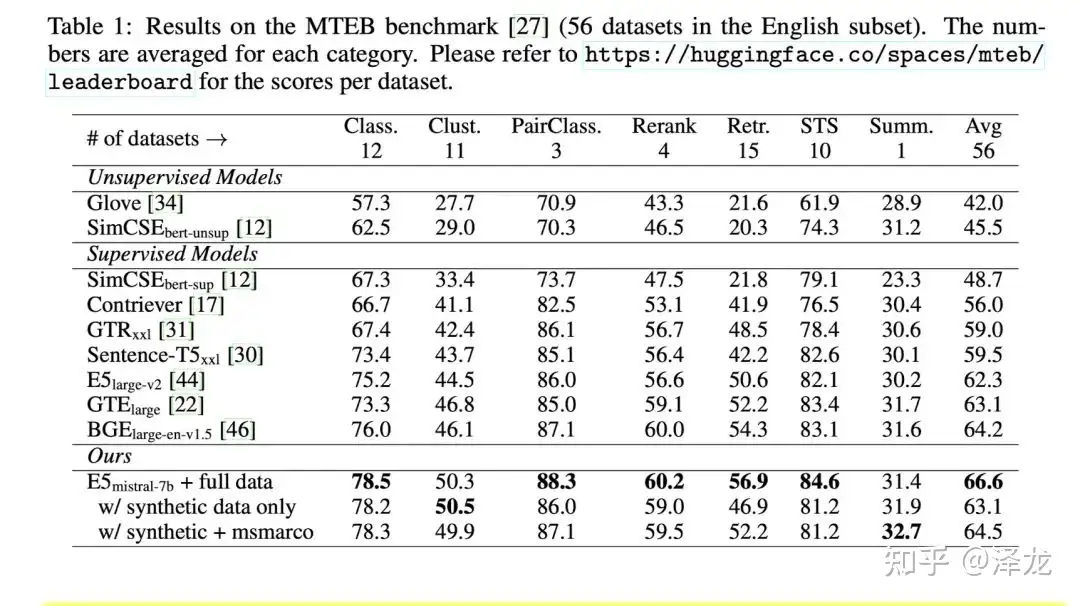
| 模型名称 | 开发团队 | 核心特点 | 适用场景 | 性能指标(MTEB/MIRACL) |
|---|---|---|---|---|
| BGE-M3 | 智源研究院 | 支持 100+ 语言,集成稠密/稀疏/多向量混合检索,8192 tokens 长文本处理能力 | 企业级多语言知识库、复杂格式文档检索(表格/图表解析) | MIRACL平均召回率89.2% |
| Gemini Embedding | Google AI | 基于动态稀疏注意力机制,支持 8K 上下文,Matryoshka 降维技术减少 83% 存储需求 | 多模态检索、金融/法律领域长文档分析、跨语言知识库 | MMTEB多语言Borda分数最高 |
| mxbai-embed-large | Mixed Bread AI | 1024 维高精度向量,短文本优化,模型体积仅为 OpenAI text-embedding-3-large 的 60% | 中小团队快速部署、实时语义搜索(电商/客服场景) | MTEB平均得分72.1 |
| nomic-embed-text | Nomic AI | 768 维平衡设计,短文本相似度计算效率领先,支持动态分块策略 | 社交媒体内容分析、竞品监控、短问答系统 | 短文本检索F1值78.5% |
| Jina Embedding | Jina AI | 基于 3.8 亿高质量句对训练,35M 参数量推理速度极快 | 移动端轻量化应用、边缘计算场景(如物联网设备日志分析) | 推理速度比同类快3倍 |
| GTE | 阿里巴巴达摩院 | 基于 BERT 框架优化,直接处理代码无需微调,适配技术文档检索 | 开发者文档检索(如 API 手册查询)、编程问答社区 | 代码检索准确率92.7% |
open-retrievals
Open-Retrievals 是一个统一文本向量、检索、重排的工具,使信息检索、RAG等更加便捷
- 全套向量微调,对比学习、大模型、point-wise、pairwise、listwise
- 全套重排微调,cross encoder、ColBERT、LLM
- 定制化、模块化RAG,支持在Transformers、Langchain、LlamaIndex中便捷使用微调后的模型
All-in-One: Text Embedding, Retrieval, Reranking and RAG
pip install open-retrievals
(1) BGE模型
- 普通文本语料进行 RetroMAE 预训练
- 大量文本对进行 batch内 负样本
对比学习 - 高质量文本进行困难负样本+batch内负样本根据任务对比学习微调
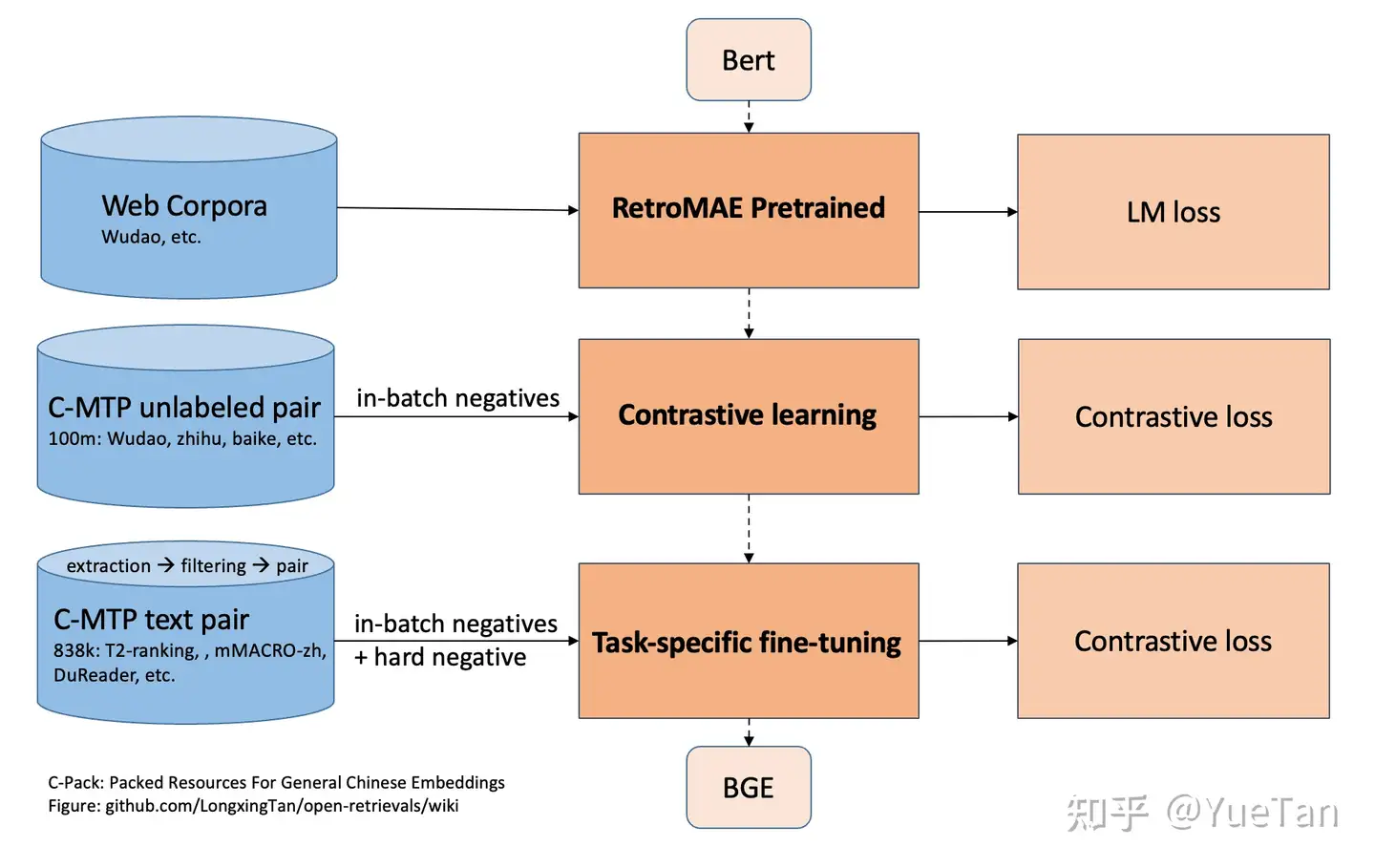
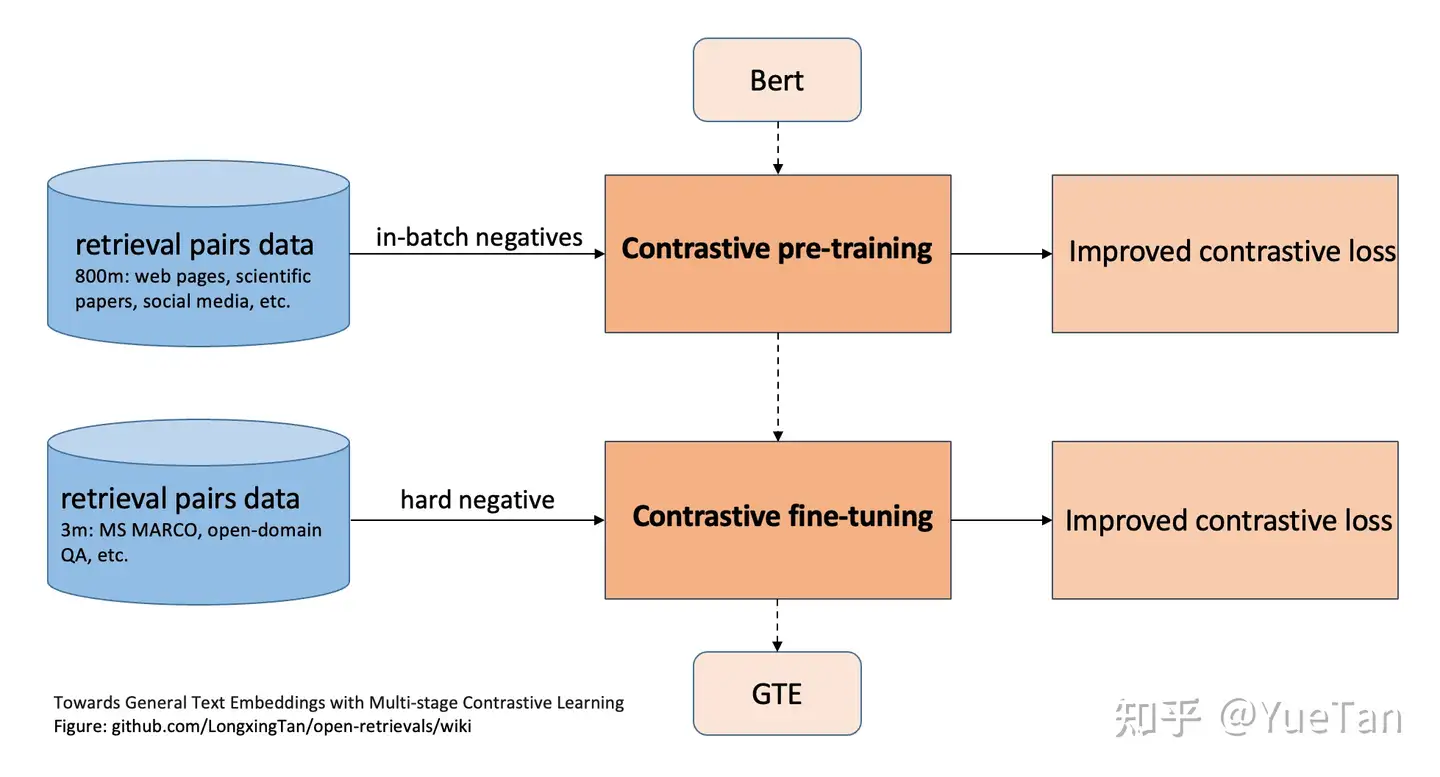
(2) GTE模型
- 大量文本对进行 batch内 负样本
对比学习 - 高质量文本进行困难负样本学习
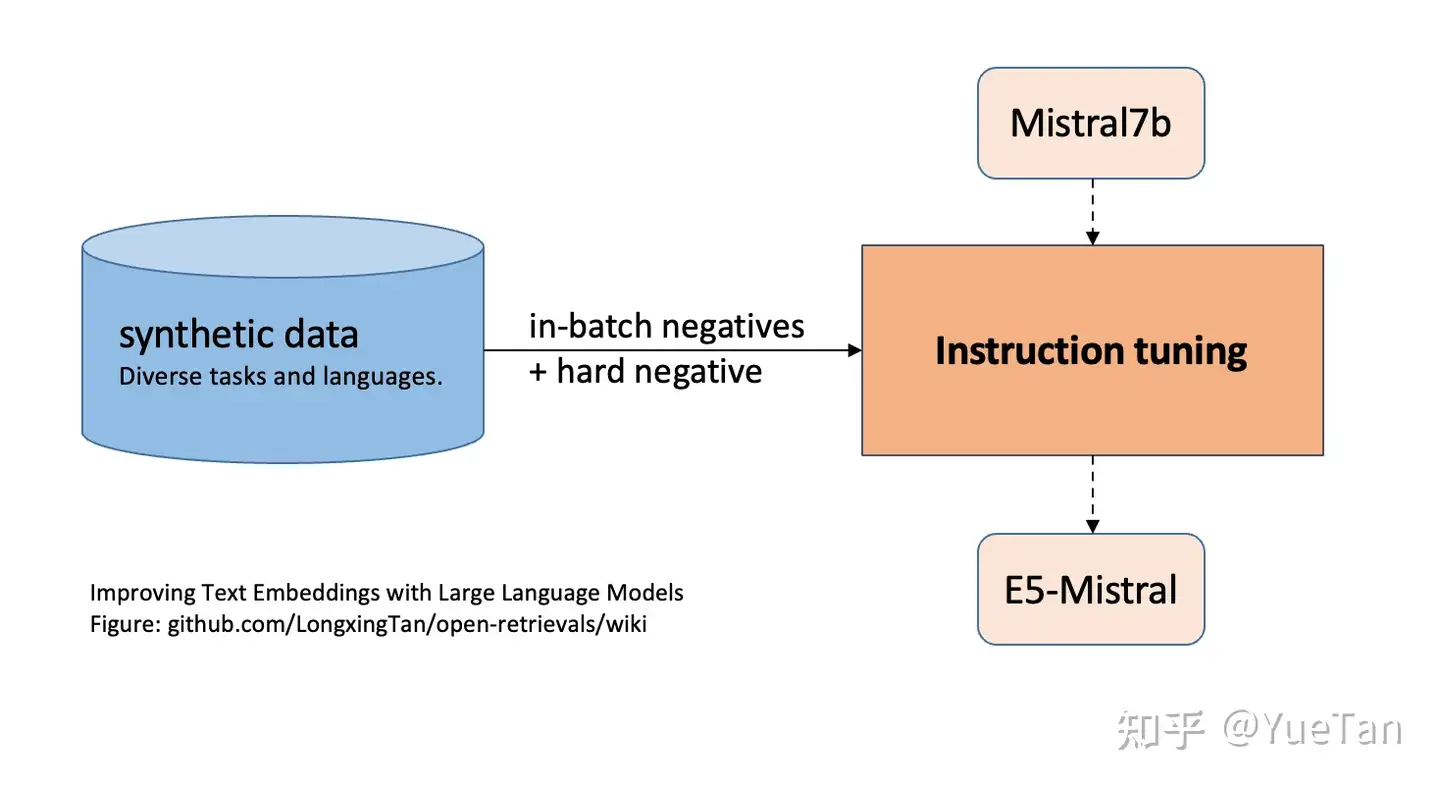
(3) E5-mistral模型
合成大量不同任务, 不同语言的检索数据,困难负样本与batch内负样本对比学习
(4) nv-embed模型
- 高质量检索数据进行困难负样本加batch内负样本对比学习
- 继续根据非检索数据,如一些分类等其他任务数据进行微调
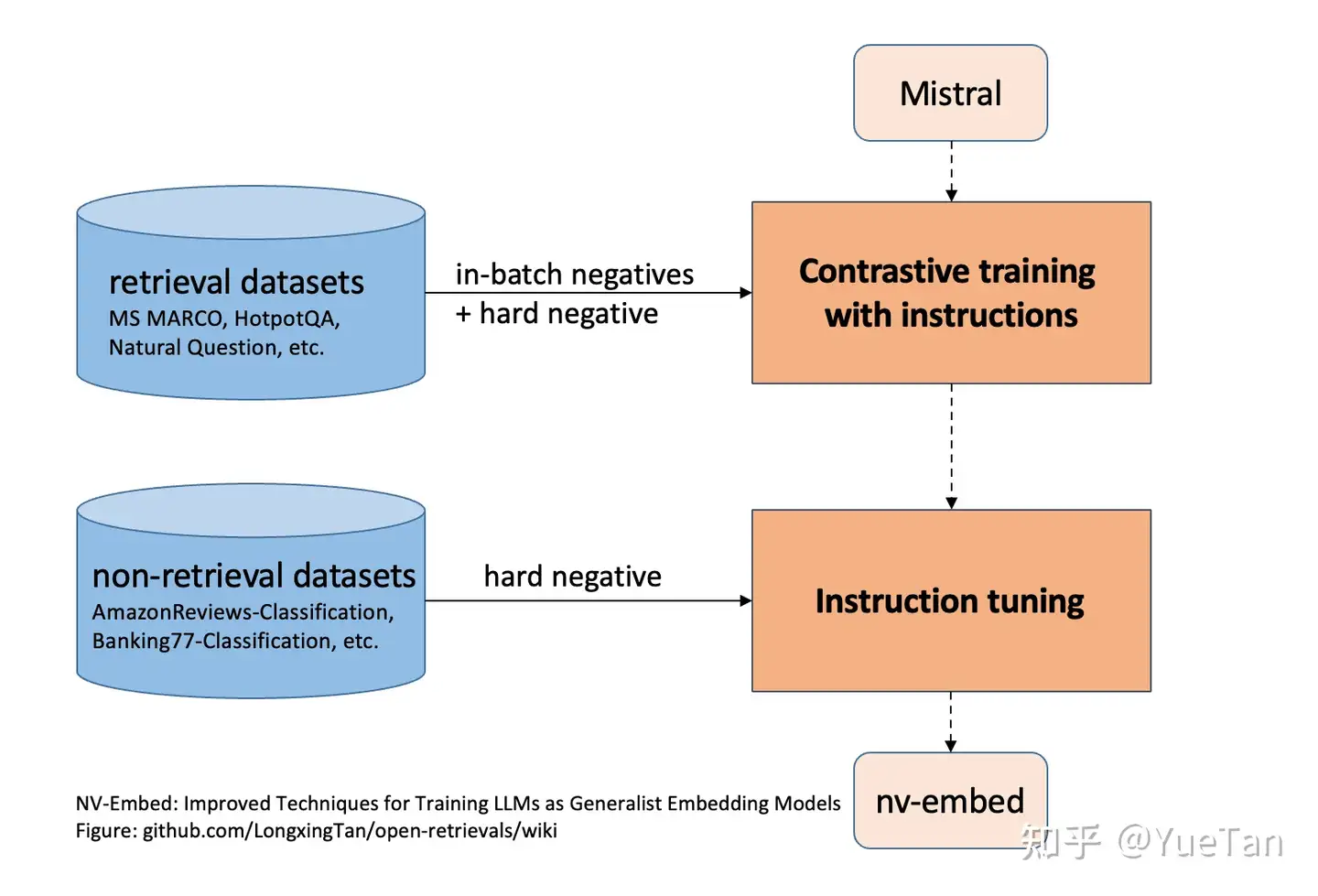
无论是transformer encoder还是decoder模型,都可以从以下统一结构中衍生而来,只不过有些步骤可以省略。
- 语言模型继续预训练
- 大量文本对的in-batch对比学习
- 高质量文本对的困难负样本对比学习
- 多任务进一步微调

Embedding 评测
衡量 word embedding 好坏,没有完美方案。
【2024-8-30】CTR 预测理论(八):Embedding 质量评估方法总结
实际上,评价其质量最好的方式: 以word embedding对于具体任务的实际收益(上线效果)为评价标准
评估方法主要分为 word2vec 和 item2vec 两个部分
- 前者有较多的比较成熟的度量方案
- 后者则基本上没有统一认可的方案。
【2024-9-5】如何评估 Embedding 模型
评估文本 Embedding 模型的两种主流方法。
Arize-Phoenix- Arize AI 的 Phoenix 库个非常实用的多功能工具,评估 LLM 和 Embedding 模型。Phoenix 提供了一种简单且灵活的方法来记录和查看高维 Embeddings,帮助用户了解模型可能出错的地方。
- 可视化展示空间距离
Ragas- 虽然 LlamaIndex 或 Haystack 等现有工具支持构建 RAG(检索增强生成)Pipeline,但如何测试性能是非常棘手。
- Ragas 能轻松完成这项任务。Ragas(检索增强生成评估)是一个开源库,提供评估 LLM 生成文本的工具,帮助了解 RAG Pipeline 的性能。
- 此外,Ragas 还与 CI/CD 流程集成,允许定期检查性能,从而维持并提升 RAG 生成的质量。
word2vec
- Relatedness
- Relatedness: task(相似度评价指标,看看空间距离近的词,跟人的直觉是否一致)目前大部分工作都是依赖wordsim353等词汇相似性数据集进行相关性度量,并以之作为评价word embedding质量的标准。这种评价方式对数据集的大小、领域等属性很敏感。
- wordsim353 相关内容
- Analogy
- Analogy: task也就是著名 A - B = C - D 词汇类比任务(所谓的 analogy task,如 king – queen = man – woman)
- Categorization
- Categorization分类 看词在每个分类中的概率
- 文本也可采用 document classification task:一种通过使用词向量来计算文本向量(可以被用来进行文本分类的工作)的方法,为了得到文本向量,task通常采用了一种很简单的方法:取文本中所有词的
- 聚类算法(可视化)
- 例如 kmeans 聚类,查看聚类分布效果 。若向量维度偏高,则对向量进行降维,并可视化。如使用pca,t-sne等降维可视化方法,包括google的tensorboard(http://projector.tensorflow.org/),python的matplotlib等工具,从而得到词向量分布。
Item2vec
Item2vec 应用到推荐场景中,把 item 视为 word,将用户行为序列视为一个集合,item 间的共现为正样本,并按照item的频率分布进行负样本采样。
- 关于 Item2Vec 请参考论文:Item2Vec: Neural Item Embedding for Collaborative Filtering
目前绝大部分资料针对 word2vec,很多方案(上述方法 1, 2, 3)并不能迁移到 item2vec。
- 比如第 1 个方案,对于 word2vec,目前存在 wordsim353 作为评价 word embedding 质量的标准,但是 item2vec 并没有此类标准。
- 而对于2, 3来说,用户行为序列并不太容易用来 Analogy 和 Categorization。
解决方式如下:
- 从item2vec得到的词向量中随机抽出一部分进行人工判别可靠性。即人工判断各维度item与标签item的相关程度,判断是否合理,序列是否相关。
- 然后word2vec的方法4,5可以借鉴,对item2vec得到的词向量进行聚类或者可视化,查看其聚类效果如何。这样就从局部(抽样人工筛查)和整体(聚类效果)两方面进行了评估,虽然不够准确,但是也算是一种思路。
事实上,这种方式相对更容易操作一些,例如,对于用户商品 ID 特征,是否训练之后对应的 embedding 可以聚类到一起(可通过 TensorBoard 的 t-sne 进行可视化展现),从可视化结果中应该可以得到一个较好的展现。
还有一种方案,就是用大量数据训练出一个相对新的类似于 wordsim353 标准的 item 类型的标准,之后进行相似度度量。但是实现难度主要在训练数据的质量和时效性方面,对于商品类还好,但对于新闻类这种更新率极快的 item 类型,时效性是很大问题。
当然,也可通过观察实际效果来定,也可采用替换 embedding 对应值为初试值来看预测效果是否有显著下降;
评测实践
【2023-12-14】评测结论
Embedding向量化实验
- top1 召回 Accracy:
Ada v2(84%) >BGE(81%) >M3E(78%) >AngIE(67%) - top3 bge,m3e和ada002比差距不大了
- top5 基本就持平
| model | top1 | top3 | top5 | top10 | 维度 | 语言 |
|---|---|---|---|---|---|---|
| Openai AdaEmbedding V2 | 0.8415 | 0.9471 | 0.9660 | 0.9849 | 1536 | 中文 |
m3e |
0.7811 | 0.9132 | 0.9472 | 0.9811 | 768 | 中文 |
bge |
0.8113 | 0.9358 | 0.9660 | 0.9849 | 768 | 中文 |
angle |
0.6716 | 0.8604 | 0.9056 | 0.9283 | 768 | 中文 |
注意
- embedding 纬度不同,对 m3e/bge/angle 不公平
Embedding 榜单 MTEB
LLM Embedding
【2023-8-1】使用LLMs进行句子嵌入不如直接用BERT
上下文学习方法使LLMs生成高质量的句子嵌入,无需微调,其性能可与当前的对比学习方法相媲美。
模型参数超过十亿规模会对语义文本相似性(STS)任务的性能造成影响。然而,最大规模的模型超越了其他对比方法,取得了迁移任务上的最新最优结果。同时,还采用当前的对比学习方法对LLMs进行了微调,其中结合了本文提出的基于提示的方法的 2.7B OPT模型,在STS任务上的结果超过了4.8B ST5,达到了最新最优的性能。
问题探讨
- PromptEOL方法与之前的句子表示方法有何不同?PromptEOL 在句子嵌入方面有何优势?
- PromptEOL方法是一种显式单词限制,基于提示的方法,用于在LLMs中表示句子。
- 相比于之前的方法,PromptEOL方法在使用LLMs时更为兼容。通过将句子嵌入为提示 “
This sentence: “[text]” means” ,生成下一个token,并提取最终token的隐藏向量作为句子嵌入。PromptEOL表示能力更强。
- 比较PromptEOL方法与其他两种方法(平均和使用最后一个token)时,为什么PromptEOL方法能够表现得更好?
- PromptEOL方法在不同参数设置下的LLMs中都能显著提升句子表示性能。相较于平均和使用最后一个token的方法,在句子嵌入过程中,PromptEOL方法通过使用提示来引导LLMs生成下一个token,并提取最终token的隐藏向量。
- 这种提示-based的方法有助于在LLMs中更好地捕捉到句子的语义信息,从而提高句子表示的效果。
- 为什么即使LLMs的参数比BERT更多,但在句子表示任务上仍表现不如BERT?
- 尽管LLMs 参数数量比BERT更多,但在使用同样句子表示方法下,LLMs(例如OPT)在句子表示任务上仍然无法超越 BERT。
- 可能因为BERT具有双向注意力机制,可以隐含地将整个语义信息压缩到单个的
[MASK]token中。 - 而LLMs通过提示(PromptEOL方法)方式在句子表示中引入了单向生成的限制,可能无法充分地捕捉到句子的全局语义信息,导致在句子表示任务上的性能相对较低。
- In-Context Learning的概念是什么?如何与句子嵌入相关联?
- In-Context Learning是一种基于上下文学习的句子嵌入方法。上下文中学习提供更丰富的句子嵌入生成过程。文章提出了两种自动生成演示文本的方法,用于在上下文学习中的句子嵌入过程中提供文字输出。演示文本用于指导模型在上下文中生成想要的句子嵌入。通过使用这种带有演示的上下文学习方法,可以增强句子嵌入的质量和表现能力。
- 如何运用Fine-tuning方法来改善LLMs在句子表示任务中的性能?这种方法有哪些优势?
- 通过Fine-tuning方法结合对比学习框架,可改善LLMs在句子表示任务中的性能。为了解决Fine-tuning过程中内存需求大的问题,采用了高效调优的方法。
- 通过使用对比学习框架,以及结合高效调优方法,可以减少Fine-tuning过程中的内存需求,从而提高LLMs在句子表示任务中的性能。这种方法的优势在于可以在保证句子表示质量的同时,降低计算成本和内存消耗,提高了方法的实用性和可扩展性。
# (1) Loading base model
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-2.7b")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-2.7b")
tokenizer.pad_token_id = 0
tokenizer.padding_side = "left"
texts = [
"There's a kid on a skateboard.",
"A kid is skateboarding.",
"A kid is inside the house."
]
# (2) Use in-context learning to generate embeddings
# Directly using in-contex learning get embeddings
template = 'This_sentence_:_"A_jockey_riding_a_horse."_means_in_one_word:"Equestrian".This_sentence_:_"*sent_0*"_means_in_one_word:"'
inputs = tokenizer([template.replace('*sent_0*', i).replace('_', ' ') for i in texts], padding=True, return_tensors="pt")
with torch.no_grad():
embeddings = model(**inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
# (3) Use contrastive learning models to generate embeddings
# Using trained LoRA to get embeddings
from peft import PeftModel
peft_model = PeftModel.from_pretrained(model, "royokong/prompteol-opt-2.7b", torch_dtype=torch.float16)
template = 'This_sentence_:_"*sent_0*"_means_in_one_word:"'
inputs = tokenizer([template.replace('*sent_0*', i).replace('_', ' ') for i in texts], padding=True, return_tensors="pt")
with torch.no_grad():
embeddings = peft_model(**inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
Setup
OpenAIEmbeddings
OpenAI官方的embedding服务
OpenAIEmbeddings:
- 使用简单,并且效果比较好;
2022年12月发布的text-embedding-ada-002
Ada 几个版本
OpenAI的Embedding服务
直接使用openai的embedding服务
import os
import openai
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
# OPENAI_API_KEY = "填入专属的API key"
openai.api_key = OPENAI_API_KEY
text = "我喜欢你"
model = "text-embedding-ada-002"
emb_req = openai.Embedding.create(input=[text], model=model)
emb = emb_req.data[0].embedding
len(emb), type(emb)
# 相似度计算
from openai.embeddings_utils import get_embedding, cosine_similarity
# 注意它默认的模型是text-similarity-davinci-001,我们也可以换成text-embedding-ada-002
text1 = "我喜欢你"
text2 = "我钟意你"
text3 = "我不喜欢你"
emb1 = get_embedding(text1)
emb1 = get_embedding(text1, "text-embedding-ada-002") # 指定模型
emb2 = get_embedding(text2)
emb3 = get_embedding(text3)
cosine_similarity(emb1, emb2) # 0.9246855139297101
cosine_similarity(emb1, emb3) # 0.8578009661644189
问题
- 会消耗openai的token,特别是大段文本时,消耗的token还不少,如果知识库是比较固定的,可以考虑将每次生成的embedding做持久化,这样就不需要再调用openai了,可以大大节约token的消耗;
- 可能会有数据泄露的风险,如果是一些高度私密的数据,不建议直接调用。
LangChain调用OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import VectorDBQA
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.embeddings.openai import OpenAIEmbeddings
import IPython
import os
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_API_BASE"] = os.getenv("OPENAI_API_BASE")
embeddings = OpenAIEmbeddings()
# ---- 简洁版 -------
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
【2024-1-26】text-embedding-3-large
【2024-1-26】OpenAI发布新一代向量大模型,接口已经更新到text-embedding-3-large,embedding长度升级,价格最高下降5倍
决定向量检索准确性的核心是向量大模型的能力,即文本转成embedding向量是否准确。
OpenAI宣布了第三代向量大模型text-embedding
- 向量大模型包括2个版本,分别是:
text-embedding-3-small和text-embedding-3-large- 规模较小但是效率很高,后者是规模更大的版本,最高支持3072维度的向量
- 模型能力增强的同时价格下降
当前OpenAI不同向量大模型的对比:
| 模型名称 | 发布日期 | 输入维度 | 输出向量维度 | MIRACL 平均分 | MTEB平均分 | 价格 |
|---|---|---|---|---|---|---|
text-embedding-ada-002 |
2022年12月 | 8191 | 1536 | 31.4 | 61.0 | $0.0001 /1K tokens |
text-embedding-3-small |
2023年1月25日 | 8191 | 512和1536可选 | 44 | 512得分61.6 1536得分62.3 |
$0.00002 /1K tokens |
text-embedding-3-large |
2023年1月25日 | 8191 | 256/1024/3072可选 | 54.9 | 256得分62.0 1024得分64.1 3072得分64.6 |
$0.00013 / 1k tokens |
新向量大模型text-embedding-3支持dimensions参数,可选择生成不同长度的向量。而更长的向量效果更好,但是成本更高,速度更慢。从价格上来说,text-embedding-3-small和前一代的向量大模型维度一致,效果略强,不过价格下降5倍
MTEB评分结果
- 尽管text-embedding-3-large最高已经达到64.6分,但是MTEB排行榜上依然只能拍第四
| 排名 | 模型名称 | 模型大小(GB) | 输出向量维度 | 输入长度 | MTEB平均分 |
|---|---|---|---|---|---|
| 1 | voyage-lite-02-instruct |
/ | 1024 | 4000 | 67.13 |
| 2 | e5-mistral-7b-instruct |
14.22 | 4096 | 32768 | 66.63 |
| 3 | UAE-Large-V1 |
1.34 | 1024 | 512 | 64.64 |
HuggingFaceEmbeddings
HuggingFaceEmbeddings:
可以在HuggingFace上面选择各种sentence-similarity模型来进行实验,数据都是在本机上进行计算 需要一定的硬件支持,最好是有GPU支持,不然生成数据可能会非常慢 生成的向量效果可能不是很好,并且HuggingFace上的中文向量模型不是很多。
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import IPython
import sentence_transformers
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"text2vec2":"uer/sbert-base-chinese-nli",
"text2vec3":"shibing624/text2vec-base-chinese",
}
EMBEDDING_MODEL = "text2vec3"
# 初始化 hugginFace 的 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL], )
embeddings.client = sentence_transformers.SentenceTransformer(
embeddings.model_name, device='mps')
【2023-7-14】M3E
【2023-7-14】研究人员开源中文文本嵌入模型,填补中文向量文本检索领域的空白
由于 GPT 使用的 Transformer 模型的自身特性,导致模型只能从固定长度的上下文中生成文本。那么,当要模型感知更广阔的上下文时,该怎么做呢?
领域内通用的解决方案: 将历史对话或者领域语料中的相关知识通过向量检索,再补充到 GPT 模型的上下文中。
这样,GPT 模型就不需要感知全部文本,而是有重点、有目的地只关心那些相关的部分,这和 Transformer 内部的 Attention 机制原理相似,使得文本嵌入模型变成了 GPT 模型的记忆检索模块。
但是长期以来,领域内一直缺少开源、可用的中文文本嵌入模型作为文本检索。
- 中文开源文本嵌入模型中最被广泛使用的
text2vec主要是在中文自然语言推理数据集上进行训练的。 - OpenAI 出品的
text-embedding-ada-002模型被广泛使用 ,虽然该模型效果较好,但此模型不开源、也不免费,同时还有数据隐私和数据出境等问题。
MokaHR 开源 M3E
最近,MokaHR 团队开发了一种名为 M3E 的模型,这一模型弥补了中文向量文本检索领域的空白, M3E 模型在中文同质文本 S2S 任务上在 6 个数据集的平均表现好于 text2vec 和 text-embedding-ada-002 ,在中文检索任务上也优于二者。
-
huggingface: m3e-base
- 2023.06.08,添加检索任务的评测结果,在 T2Ranking 1W 中文数据集上,
m3e-base在 ndcg@10 上达到了 0.8004,超过了openai-ada-002的 0.7786 - 2023.06.07,添加文本分类任务的评测结果,在 6 种文本分类数据集上,m3e-base 在 accuracy 上达到了 0.6157,超过了 openai-ada-002 的 0.5956
M3E 是 Moka Massive Mixed Embedding 的缩写
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
- Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
- Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
Tips:
- 使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
- 多语言使用场景,并且不介意数据隐私的话,我建议使用 openai text-embedding-ada-002
- 代码检索场景,推荐使用 openai text-embedding-ada-002
- 文本检索场景,请使用具备文本检索能力的模型,只在 S2S 上训练的文本嵌入模型,没有办法完成文本检索任务
M3E 模型中使用的数据集、训练脚本、训练好的模型、评测数据集以及评测脚本都已开源,用户可以自由地访问和使用相关资源。该项目主要作者、MokaHR 自然语言处理工程师王宇昕表示:
“我相信 M3E 模型将成为中文文本向量检索中一个重要的里程碑,未来相关领域的工作,都可能从这些开源的资源中收益。”
M3E 使用 in-batch 负采样的对比学习的方式在句对数据集进行训练,为了保证 in-batch 负采样的效果,我们使用 A100 80G 来最大化 batch-size,并在共计 2200W+ 的句对数据集上训练了 1 epoch。训练脚本使用 uniem
直接使用
# pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
#Our sentences we like to encode
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
M3E 微调
M3E微调实战:uniem
- uniem 项目目标: 创建中文最好的通用文本嵌入模型。
uniem 提供了非常易用的 finetune 接口,几行代码,即刻适配!
from datasets import load_dataset
from uniem.finetuner import FineTuner
dataset = load_dataset('shibing624/nli_zh', 'STS-B')
# 指定训练的模型为 m3e-small
finetuner = FineTuner.from_pretrained('moka-ai/m3e-small', dataset=dataset)
finetuner.run(epochs=1)
详见 uniem 微调教程
MUSE 多语种
2019年 META 推出的MUSE, 包含很多小语种
A library for Multilingual Unsupervised or Supervised word Embeddings, whose goal is to provide the community with:
- state-of-the-art multilingual word embeddings (
fastTextembeddings aligned in a common space) - large-scale high-quality bilingual dictionaries for training and evaluation

S-BERT
【2023-9-5】s-bert
claude推荐用 s-bert embedding
【2023-9-21】C-Pack - FlagEmbedding
介绍
【2023-9-21】智源推出 语义模型:FlagEmbedding
数据集
- 由于embedding不是确定性任务,所以对数据的规模,多样性以及质量有很高的要求
- 包括但不限于Retrieval,Clustering,Pair classification,Reranking,STS,Summarization,Classification)
- 为了能达到Embedding的高区分度,至少需要上亿级别的训练实例。
- 同时,数据集的需要来源尽量广泛来提高模型的泛化性(generality)。
- 数据增强(Data Argumentation)对于原始数据的质量有很高的要求,所以需要进行数据清洗(Data clean),否则容易引入噪声。
原理
Training 训练一个 general-purpose 的text embeddings有两个重要因素:
- 1)一个好的编码器。
- 2)一个好的训练方案。
虽然说能够使用 unlabeled data 并基于 Bert 或者是T5能极大地提高预训练模型的性能,但是光这样还是不够的,需要通过复合的训练方案。
- 以面向嵌入(embedding)的预训练来准备文本编码器
- 对比学习需要从复杂的负采样中提高嵌入的可辨别性
- 基于指令微调来集成文本嵌入的不同表示能力
(1) Pre-training
- 使用为embedding任务量身定做的算法模型,wudao数据集,高质量,多样性的数据集来进行中文语言模型的预训练。
- 框架使用的是
RetroMAE中的MAE-style,简单但是高效。Masked的文本被编码到其嵌入中,然后在轻量级解码器上恢复干净的文本: 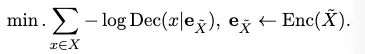
- 其中 Enc,Dec分别表示encoder和decoder,X, X’表示初始文本和masked 文本。
(2) General purpose fine-tuning
- 预训练模型用C-MTP的unlabeled data 进行对比学习,从negatives 来学习不同文本之间的差异
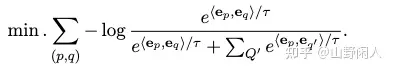
- p和q都是文本对,Q’ 是negatives q’的集合,t是温度。对比学习的关键因素是negatives,除了negatives mining之外,还使用了
in-batch negative samples技术,同时使用大batch size(19200),github上的代码还有cross device negatives跨设备负样本。
(3) Task-speific fine-tuning
- 针对特定任务的微调。使用 C-MTP(labeled data)进一步微调嵌入模型。带标签的数据集较小但质量较高。然而,所包含的任务类型不同,其影响可能相互矛盾。这里作者用了两个方式去解决这个问题:
- 1)指令微调来帮助模型来区分不同的任务。对于每一个文本对(p,q), 特定任务的指令 $I_t$ 会被附加到query这一端,改写之后的query: $q’ \leftarrow q + I_t$ . 这种指令是偏向于口语话的,例如“search relevant passages for the query”. 同时使用ANN-style策略进行negative sampling。
论文没有提出很新的训练方法、微调技巧,从基本内容上
- 先进行Bert类型的模型预训练,RetroMAE方法
- 然后进行无监督学习(对比学习)
- 最后是多任务的无监督学习(加入指令来区分不同的任务)。
效果评测
模型的效果表现出色,数据集的构建给之后的研究者提供了一个很好的Benchmark。
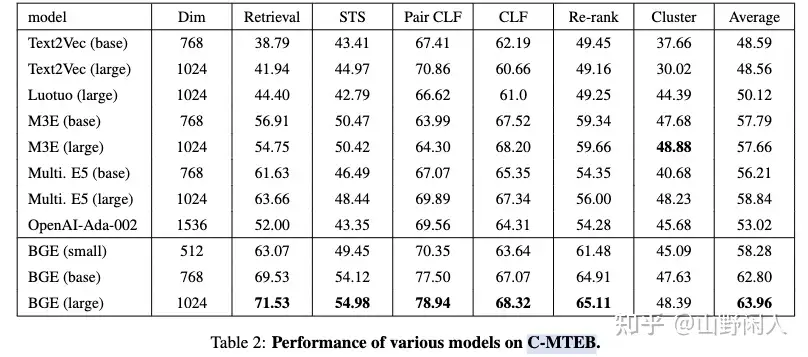
baai-general-embedding 模型在 MTEB 和 C-MTEB 排行榜上都实现了最先进的性能
- 超过 OpenAI
text-embedding-ada-002和m3e-large
BGE在语义理解问题上支持s2s(短文本匹配短文本),和s2p(短文本匹配长文本)
三组实验
- 短文本匹配长文本
- 短文本匹配长文本
- (instruction+)短文本匹配长文本
数据集: 下载了1w条训练数据
对比两个模型:BGE和M3E
结论
- 整体上BGE模型的分数要高一些
def semantic_retrieval(s1, s2, model):
s1_logit = model.encode(s1, show_progress_bar=True, normalize_embeddings=True)
s2_logit = model.encode(s2, show_progress_bar=True, normalize_embeddings=True)
score = np.dot(s1_logit, s2_logit.T)
print(score)
for i in range(len(s1)):
for j in range(len(s2)):
print(f"\n{s1[i]}\n{s2[j]}\n相似度为: {score[i][j]}")
from sentence_transformers import SentenceTransformer
import numpy as np
# 直接使用hugging face
# model = SentenceTransformer('moka-ai/m3e-base')
# 下载模型到本地,放在models目录下面
model = SentenceTransformer('models/bge')
# this is a s2s task
s1 = ["今天天气这么样", "今天中午吃什么"]
s2 = ["天气如何", "中午想吃什么"]
semantic_retrieval(s1, s2, model)
# this is a s2p task without instruction
s1 = ["酒精的危害", "如何戒烟", "学习的重要性"]
s2 = ["天气如何一次饮酒过量可引起急性酒精中毒。\n表现分三期:\n(1)早期(兴奋期)。血中酒精浓度达50mg/dl表现语无伦次,情感爆发,哭笑无常等。\n(2)中期(共济失调期)。血中酒精浓度150mg/dl。表现语言不清,意识模糊,步态蹒跚等。\n(3)后期(昏迷期)。血中酒精浓度250mg/dl以上。表现昏迷,瞳孔散大,大小便失禁,面色苍白。一般人的酒精致死量为5~8g/kg。",
"饮茶养生,当然,也能帮你摆脱吸烟的毛病。当你想要吸烟时,推荐给自己一杯浓茶,喝下去,会有很好的效果。",
"只有学习,才能让我们不断成长,当你体会到自己不断成长的时候,你就会发现,那种发自内心的快乐是其他物质无法带给我们的。 只有学习,才能获得新知,增长才干,才能实现我们的梦想。"
]
semantic_retrieval(s1, s2, model)
# this is a s2p task with instruction
instruction = "为这个句子生成表示以用于检索相关文章:"
s1 = ["酒精的危害", "如何戒烟", "学习的重要性"]
s1 = [instruction + s for s in s1]
s2 = ["饮酒过量可引起急性酒精中毒。\n表现分三期:\n(1)早期(兴奋期)。血中酒精浓度达50mg/dl表现语无伦次,情感爆发,哭笑无常等。\n(2)中期(共济失调期)。血中酒精浓度150mg/dl。表现语言不清,意识模糊,步态蹒跚等。\n(3)后期(昏迷期)。血中酒精浓度250mg/dl以上。表现昏迷,瞳孔散大,大小便失禁,面色苍白。一般人的酒精致死量为5~8g/kg。",
"饮茶养生,当然,也能帮你摆脱吸烟的毛病。当你想要吸烟时,推荐给自己一杯浓茶,喝下去,会有很好的效果。",
"只有学习,才能让我们不断成长,当你体会到自己不断成长的时候,你就会发现,那种发自内心的快乐是其他物质无法带给我们的。 只有学习,才能获得新知,增长才干,才能实现我们的梦想。"
]
semantic_retrieval(s1, s2, model)
安装
pip install -U FlagEmbedding
FlagEmbedding 使用
from FlagEmbedding import FlagModel
sentences = ["样例数据-1", "样例数据-2"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # 设置use_fp16为True可以加快计算,效果会稍有下降
embeddings_1 = model.encode(sentences)
embeddings_2 = model.encode(sentences)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# 对于短查询到长文档的检索任务,请对查询使用 encode_queries() 函数,其会自动为每个查询加上指令
# 由于候选文本不需要添加指令,检索中的候选集依然使用 encode() 或 encode_corpus() 函数
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
# ------ 计算相似度 --------
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) #设置 fp16 为True可以加快推理速度,效果会有可以忽略的下降
score = reranker.compute_score(['query', 'passage']) # 计算 query 和 passage的相似度
print(score)
scores = reranker.compute_score([['query 1', 'passage 1'], ['query 2', 'passage 2']])
print(scores)
Instruction参数 query_instruction_for_retrieval 请参照: Model List. 当加载微调后的模型时
- 如果没有在训练的json文件中为query添加指令,则将其设置为空字符串””;
- 如果训练数据中为query添加了指令,更改为新设置的指令。
FlagModel支持GPU也支持CPU推理。
- 如果GPU可用,其默认优先使用GPU。
- 如果想禁止其使用GPU,设置
os.environ["CUDA_VISIBLE_DEVICES"]="" - 为提高效率,FlagModel默认会使用所有的GPU进行推理。如果想要使用具体的GPU,请设置
os.environ["CUDA_VISIBLE_DEVICES"]。
Langchian 中使用
Langchian中使用bge模型:
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
transformers 中使用
transformers 中使用
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# 对于短查询到长文档的检索任务, 为查询加上指令
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
# ------ 计算相似度 --------
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
【2023-10-24】AnglE
AnglE 介绍
【2023-10-24】Embedding SOTA 是 AnglE, 在 STS13,STS14,STS15,STS16 以及 Sick-R 上都达到了 SOTA。
- Arxiv: 香港理工 AnglE-optimized Text Embeddings
- Github: AnglE
- Huggingface: SeanLee97/angle-llama-7b-nli-20231027
- Compare with M3E: 论文主要对比英语embedding效果,而m3e主要是中文embedding,所以暂未对比,11月发布中文预训练模型, 详见
AnglE 原理
高质量文本嵌入在提高语义文本相似度(STS)任务中起着至关重要的作用,这是大型语言模型(LLM)应用中的关键组成部分。然而,现有文本嵌入模型面临的一个普遍挑战是梯度消失问题,主要是优化目标中依赖余弦函数,而余弦函数具有饱和区域。
本文提出了一种新颖的角度优化文本嵌入模型——AnglE。 核心思想是在复杂空间中引入角度优化。这种方法有效地缓解了余弦函数饱和区域的不良影响,这可能会阻碍梯度并阻碍优化过程。
基于 AnglE 开箱即用的文本向量库,支持中英双语,可用于文本相似度计算、检索召回、匹配等场景。代码基于 🤗transformers 构建,提供易用的微调接口,可在 3090Ti、 4090 等消费级 GPU 上微调 LLaMA-7B 模型,支持多卡分布式训练。
AnglE 效果
在现有的短文本STS数据集和从GitHub Issues收集的新的长文本STS数据集上进行了实验。此外,还研究了具有有限标记数据的特定领域STS场景,并探讨了AnglE如何与LLM注释数据配合使用。
各种任务上进行了广泛的实验,包括短文本STS、长文本STS和特定领域的STS任务。
- AnglE优于忽略余弦饱和区域的最先进的STS模型。
- 证明了AnglE生成高质量文本嵌入的能力以及角度优化在STS中的有用性。
AnglE-roberta-wwm-ext 效果最佳
各数据集的微调及评估代码如下:
- ATEC: examples/Angle-ATEC.ipynb
- BQ: examples/Angle-BQ.ipynb
- LCQMC: examples/Angle-LCQMC.ipynb
- PAWSX: examples/Angle-PAWSX.ipynb
- SST-B:
AnglE 使用
# python -m pip install -U angle-emb
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel, PeftConfig
peft_model_id = 'SeanLee97/angle-llama-7b-nli-v2'
config = PeftConfig.from_pretrained(peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path).bfloat16().cuda()
model = PeftModel.from_pretrained(model, peft_model_id).cuda()
def decorate_text(text: str):
return f'Summarize sentence "{text}" in one word:"'
inputs = 'hello world!'
tok = tokenizer([decorate_text(inputs)], return_tensors='pt')
for k, v in tok.items():
tok[k] = v.cuda()
vec = model(output_hidden_states=True, **tok).hidden_states[-1][:, -1].float().detach().cpu().numpy()
print(vec)
微调模型
只需要准备好数据即可快速微调。数据格式必须要转成 datasets.Dataset (使用方式请参照官方文档 Datasets)且必须要提供 text1, text2, label 三列。
from datasets import load_dataset
from angle_emb import AnglE, AngleDataTokenizer
# 1. 加载模型
angle = AnglE.from_pretrained('hfl/chinese-roberta-wwm-ext', max_length=128, pooling_strategy='cls').cuda()
# 2. 加载数据并转换数据
ds = load_dataset('shibing624/nli_zh', 'STS-B')
ds = ds.rename_column('sentence1', 'text1')
ds = ds.rename_column('sentence2', 'text2')
ds = ds.select_columns(["text1", "text2", "label"])
train_ds = ds['train'].shuffle().map(AngleDataTokenizer(angle.tokenizer, angle.max_length), num_proc=8)
valid_ds = ds['validation'].map(AngleDataTokenizer(angle.tokenizer, angle.max_length), num_proc=8)
test_ds = ds['test'].map(AngleDataTokenizer(angle.tokenizer, angle.max_length), num_proc=8)
# 3. 训练
angle.fit(
train_ds=train_ds,
valid_ds=valid_ds,
output_dir='ckpts/sts-b',
batch_size=64,
epochs=5,
learning_rate=3e-5,
save_steps=100,
eval_steps=1000,
warmup_steps=0,
gradient_accumulation_steps=1,
loss_kwargs={
'w1': 1.0,
'w2': 1.0,
'w3': 1.0,
'cosine_tau': 20,
'ibn_tau': 20,
'angle_tau': 1.0
},
fp16=True,
logging_steps=100
)
# 4. 加载最优模型评估效果
angle = AnglE.from_pretrained('hfl/chinese-roberta-wwm-ext', pretrained_model_path='ckpts/sts-b/best-checkpoint').cuda()
corrcoef, accuracy = angle.evaluate(test_ds, device=angle.device)
print('corrcoef:', corrcoef)
【2024-1-7】E5-mistral-7b-instruct 新sota
【2024-1-7】微软E5-mistral-7b-instruct: 站在LLM肩膀上的text embedding
微软发布的text embedding模型E5-mistral-7b-instruct登顶MTEB,并且甩出了第二名一段明显距离。
- 首次采用LLM来做向量化模型
- 用LLM来生成向量化任务的人造数据,然后用
对比学习的loss,微调mistral-7b,仅仅使用人造数据,达到和其他模型可比的结果,当使用人造数据和开源的标注数据微调时,达到了MTEB的sota,比第二名高了2%。 - 生成式大语言模型和向量化任务是一枚硬币的正反面。都要求模型对自然语言有深刻的理解。(从而可以更好的表征句子)。而生成式大语言模型,采用自回归的预训练方式,在更多的数据上微调过,可以更好的表示句子。只需要少量的微调,就可以得到一个好的向量化模型。
向量化任务分为两种:不对称任务, 对称任务。
- 不对称任务:query和doc语义相关,但不是彼此另外的释义。(不仅仅是表达方式不同)
- 根据长度,又划分了四个细粒度:短-长;短-短;长-短;长-长匹配。
- 为每个细粒度,设计了两阶段的prompt模板。
- 提供几个候选,让大模头脑风暴一个类似候选任务的池子。(书籍搜索,科学文档搜索)
- 根据具体的任务定义,生成数据。 - 不对称任务,直接让LLM一个阶段生成数据的话,没有两个阶段做的多样性好。
- 对称任务:query和doc语义相关,不过表达方式不同。
- 单语匹配(STS)和多语匹配。
- 两个定义了不同的prompt模板,因为任务简单,直接一个阶段做的。
效果为什么好?参考
- E5-mistral-7b-instruct在query前面加一个细粒度的任务描述,利用LLM在训练阶段的能力,为句子得到更好的向量表示,之前确实模型做的没有这么细粒度。而且同一个query,任务不同,可以生成不同的向量。这个向量针对具体任务,有一定的辨识度。
- 针对不同的任务,给query侧加上任务定义的指令。doc侧不加。
- 不管是LLM生成的人造数据还是开源数据集,E5-mistral-7b-instruct都为正例挖掘了难负例。对于LLM生成的人造数据,让大模型自己生成难负例。对于开源数据集,用e5-base去挖掘了top100的难负例。这相当于让另外一个模型,去构造难负例,增加学习难度。相当于让encoder模型去为decoder构造了难负例。
- 模型扩大了10倍,比MTEB榜上的encoder模型,向量维度也是4096,如果encode模型这么大了,会不会有更好的效果呢?
E5-mistral-7b-instruct利用LLM产生了接近100种语言的高质量且多样化的训练数据,利用纯decoder的LLM在合成数据上进一步finetune。
仅依靠合成数据训练得到的text embedding可以媲美目前主流的sota模型,而混合合成数据跟真实标注数据训练完成的text embedding模型在BEIR跟MTEB上都达到新的sota效果。
给query加指令:
针对不同的任务,给query侧加上任务定义的指令。doc侧不加。(类似给每个任务细粒度的任务定义。)
- 生成的数据,就直接用大模型给的。
- 其他已有的数据集,就人工构造一个任务定义,加上。
模型训练:
- 对于query,输入指令+query+EOS;对于doc,输入doc+EOS。
- 输入到llm中,拿EOS token的向量,作为整个句子的表示。
- 然后用典型的对比学习,infoNCE loss。batch内随机负例+难负例。
数据集
- 借助GPT3.5-Turbo,GPT4去生成训练数据,构建多种语言跟任务类型的数据来增强训练数据的多样性。从大类来看可以将合成数据分为两大类,即非对称任务跟对称任务,最终构建得到超过15万个task definition的包括93种语言的50万个训练样本,每个样本的格式为(task definition, user query, positive document, hard negative document)。
模型训练
- mistral-7b-instruct的训练方式跟之前介绍的instructor相似,在query侧将task definition跟user query拼接到一起作为一个整体去生成query的向量表征,而document侧则不添加任何前缀。由于采用的纯decoder的语言模型Mistral-7b,会在query或者document后插入一个
[EOS],然后一同输入到语言模型中,将[EOS]位置上最后一层的隐层表示作为句向量。训练损失采用的是常规的对比损失,希望task definition+user query跟positive document足够靠近,同时跟hard negative document或者其他batch的负样本足够疏远。
实验结论
- 从MTEB上看,仅用LLM生成数据训练得到的text embedding效果就很不错了,混合了合成数据跟真实监督数据训练得到的text embedding更是取得了新的sota效果。在多语言能力上,也有不俗的表现,文中认为在低资源语言上的表现稍差一筹在于基底模型Mistral-7b预训练语料主要是英语。
- 弱监督对比学习预训练是主流text embedding模型成功的一个关键因素,研究人员对比弱监督对比学习预训练对于纯encoder的XLM跟纯decoder的Mistral-7b的影响,发现不做预训练对于Mistral-7b几乎没有影响,这可能是因为自回归预训练任务已经让纯decoder的Mistral-7b具备获取高质量文本表征的能力,所以只要经过finetune就可以称为强大的text embedding模型了。
E5-mistral-7b-instruct 代码
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-mistral-7b-instruct')
model = AutoModel.from_pretrained('intfloat/e5-mistral-7b-instruct')
max_length = 4096
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=max_length - 1, return_attention_mask=False, padding=False, truncation=True)
# append eos_token_id to every input_ids
batch_dict['input_ids'] = [input_ids + [tokenizer.eos_token_id] for input_ids in batch_dict['input_ids']]
batch_dict = tokenizer.pad(batch_dict, padding=True, return_attention_mask=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
Conan-Embedding - sota
【2024-9-30】通过负样本挖掘炼出更强Embedding模型
【2024-8-29】 北大推出 Conan-Embedding 模型,利用更多和更高质量的负样本来提升嵌入模型的能力。
起因
- embedding 效果对 RAG 效果至关重要
- 当前 embedding 优化主要通过
对比学习来改进, 即 在预处理阶段, 挖掘使用硬负样本
思路
- 训练过程中, 动态挖掘负样本, 充分利用负样本
- 跨GPU平衡损失
预训练阶段:
- 标准数据过滤方法(参考Internlm2)对数据进行预处理。
- bge-large-zh-v1.5 模型进行评分,丢弃评分低于 0.4 的数据。
- InfoNCE 损失函数 和 In-Batch Negative 方法进行训练
监督微调阶段:
- 将任务分为检索和语义文本相似性(STS)两类。
- 检索任务使用 InfoNCE 损失函数
- STS任务使用CoSENT损失函数
要点
- (1) 动态硬负样本挖掘:
- 记录每个数据点的当前平均负样本得分。
- 每100次迭代后,如果得分乘以1.15小于初始得分且绝对值小于0.8,则认为该负样本不再具有挑战性,并进行新一轮的硬负样本挖掘。
- (2) 跨GPU平衡损失:
- 在每个 前向-损失-反向-更新 周期内,以平衡方式引入每个任务,以获得稳定的搜索空间并最小化单次模型更新方向与全局最优解之间的差异。
- 对于检索任务,确保每个GPU有不同的负样本,同时共享相同的查询和正样本;
- 对于STS任务,增加批次大小以包含更多案例进行比较
数据集:
- 预训练阶段,收集了0.75亿对文本数据,分为标题-内容对、输入-输出对和问答对等类别。
- 微调阶段,选择了常见的检索、分类和STS任务的数据集。
实现细节:
- 使用BERT作为基础模型,并通过线性层将维度从1024扩展到1792。
- 使用AdamW优化器和学习率1e-5进行预训练,批量大小为8,使用64个Ascend 910B GPU进行训练,总时长为138小时。
- 微调阶段使用相同的优化器参数和学习率,批量大小为4(检索任务)和32(STS任务),使用16个Ascend 910B GPU进行训练,总时长为13小时。
结果与分析
CMTEB结果:
- Conan-Embedding 模型在CMTEB基准测试中的平均性能为72.62,超过了之前的最先进模型。
- 在检索和重排序任务中,Conan-Embedding 模型表现出显著的性能提升,表明增加的负样本数量和质量使模型能够看到更具挑战性的负样本,从而增强了其召回能力。
阿里 Qwen
Qwen-2
gte-Qwen2-7b-instruct
Qwen3-Embedding
【2025-6-6】阿里Qwen3 新模型 Embedding 及 Reranker霸榜(Top2)
2025年6月6日凌晨,阿里开源 Qwen3 新模型 Embedding 及 Reranker,支持多语言。
Qwen3-Embedding系列模型:
- 文本嵌入:Qwen3-Embedding,型号有 0.6B、4B和8B
- 文本排序:Qwen3-Reranker,型号有 0.6B、4B和8B
技术报告:
ModelScope:
Hugging Face:
GitHub:
多项基准测试中,Qwen3-Embedding 系列在文本表征和排序任务中,表现优异。
- Qwen3-Embedding 4B和8B效果超过Gemini Embedding(实验组最佳)
METB最新排名:
- Qwen3-Embedding全家挤占了2-4名
- 第一名还是Gemini,与自家测试结果有些差异
特点:
- ① 泛化性好:Qwen3-Embedding 系列在多个下游任务评估中领先。其中,8B 参数的 Embedding 模型在 MTEB 多语言 Leaderboard 榜单中位列第一(截至 2025 年 6 月 6 日,得分 70.58),超越众多商业 API 服务。此外,排序模型在各类文本检索场景中表现出色,显著提升了搜索结果的相关性。
- ② 模型架构灵活:Qwen3-Embedding 系列提供从 0.6B 到 8B 多种参数规模,以满足不同场景下的性能与效率需求。
此外,模型支持定制化:
- 表征维度自定义:允许用户根据实际需求调整表征维度,有效降低应用成本;
- 指令适配优化:支持用户自定义指令模板,以提升特定任务、语言或场景下的性能表现。
③ 多语言支持:Qwen3-Embedding 系列支持超过 100 种语言,涵盖主流自然语言及多种编程语言。具备强大的多语言、跨语言及代码检索能力,能够有效应对多语言场景下的数据处理需求。
原理
模型结构
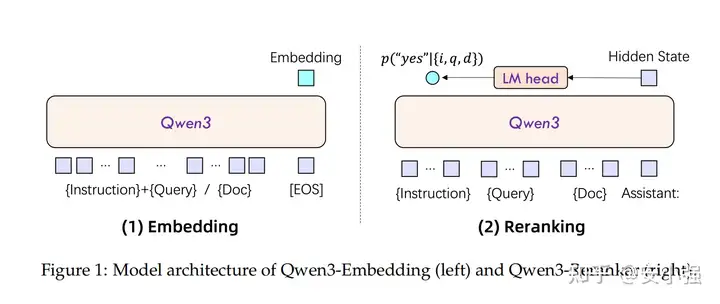
Qwen3-Embedding 直接用 Qwen3 dense 做骨干。
- 输入端把 Instruction+Query 拼成一条序列,保持Document不变,这样同一模型就能处理检索、STS、分类等场景,并保留32K上下文长度,长文档不会被截断。
- Embedding 向量取最后一层
[EOS]位置的隐藏状态,没有额外池化头,推理路径更短。 - 同一权重支持多分辨率向量(MRL):768、1024、4096 等维度可动态裁剪,方便在边缘或服务器侧按需部署。
- Reranker则把相关性判定写成“yes/no”二分类提示,只看下一token的两项概率即可得到打分,接口简单,延迟低。
【2025-6-21】Qwen3 Embedding模型架构、训练方法、数据策略
Qwen3 Embedding训练过程采用了多阶段训练pipline,结合了大规模无监督预训练和高质量数据集上的监督微调。
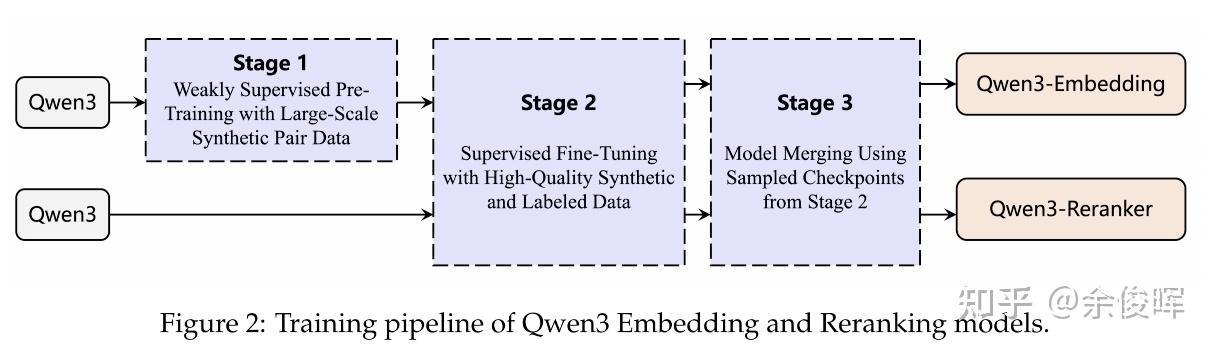
多阶段训练框架的基础上,Qwen3 Embedding系列引入了以下关键创新:
- 大规模合成数据驱动的弱监督训练:与之前的工作(如GTE、E5、BGE模型)不同,这些模型主要从开源社区(如问答论坛或学术论文)收集弱监督训练数据,提出利用基础模型的文本理解和生成能力直接合成配对数据。这种方法允许任意定义所需配对数据的各种维度,如任务、语言、长度和难度,并在合成提示中进行定义。与从开放域源收集数据相比,基础模型驱动的数据合成提供了更大的可控性,能够精确管理生成数据的质量和多样性,特别是在低资源场景和语言中。
- 高质量合成数据在监督微调中的利用:由于Qwen3基础模型的卓越性能,合成的数据质量非常高。因此,在监督训练的第二阶段,选择性地整合这些高质量合成数据进一步增强了整体模型性能和泛化能力。
- 模型合并:受到先前工作的启发,在完成监督微调后,应用了基于球面线性插值(slerp)的模型合并技术。该技术涉及合并微调过程中保存的多个模型检查点。目的是提高模型在各种数据分布上的鲁棒性和泛化性能。
huggingface embedding 使用方法
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
with torch.no_grad():
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7645568251609802, 0.14142508804798126], [0.13549736142158508, 0.5999549627304077]]
Embedding Gemma
【2025-9-5】Google 发布嵌入模型 Embedding Gemma, 闭源
基于 Gemma 3 架构的开源文本嵌入模型 EmbeddingGemma,拥有 308M 参数,支持超过 100 种语言,量化后可在 200 MB 以内的 RAM 上运行,在 MTEB 排行榜上位列 500 M 以下参数模型第一名
EmbeddingGemma 已在多个主流工具框架中获得支持,包括 sentence-transformers、llama.cpp、MLX、Ollama、LiteRT、transformers.js、LMStudio、Weaviate、Cloudflare Workers AI、LlamaIndex 和 LangChain 等。
Gemma-Embeddings-v1.0 核心任务:
- 将文本转化为768维或1024维的高精度向量,捕捉词汇、句法和语义的复杂关系。
技术优势:
- 长上下文建模:支持8K token的上下文窗口,通过动态稀疏注意力机制(Dynamic Sparse Attention)优化长文本处理。
- 该机制在序列长度超过2K时自动切换至块稀疏模式,将注意力计算复杂度从O(n²)降至O(n√n),同时保持98%的语义连贯性。
- 在技术文档理解测试中,对跨段落指代消解的准确率达89%(对比BERT的72%)。
- 多语言适配:
- 基于Unicode语义单元分词(Unicode-aware Tokenization),支持英语、中文、阿拉伯语等28种语言的混合输入。采用语言对抗训练(Language Adversarial Training),在跨语言检索任务中将Mean Reciprocal Rank(MRR)提升40%。
- 例如,中英跨语言检索在Tatoeba基准测试中达到92.3%的Top-1准确率。
- 轻量化推理:
- 2B/7B参数版本支持分组线性投影(Grouped Linear Projections),将矩阵乘法的计算量减少30%。结合FlashAttention-2优化,在NVIDIA T4 GPU上实现每秒2000 tokens的吞吐量。
- 通过动态量化(Dynamic Quantization)技术,7B模型在移动端(如iPhone 14 Pro)的推理延迟低于50ms。
模型参数量 308M, 上下文是 2K, 最亮眼的是这个新模型在 MTEB 榜单中 500M 以下的嵌入模型性能霸榜, 有需要将数据进行嵌入的同学可以试一试了
# 使用Hugging Face快速调用示例
from transformers import AutoModel, AutoTokenizer
import torch
model = AutoModel.from_pretrained("google/gemma-embeddings-v1", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-embeddings-v1")
text = "谷歌发布新一代文本嵌入模型"
inputs = tokenizer(text, return_tensors="pt", max_length=8192, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1) # 采用平均池化生成句向量
print(f"Embedding维度: {embeddings.shape[-1]}") # 输出: Embedding维度: 1024
向量评估
ChatGPT记忆模块搜索优化——文本语义向量相似M3E模型微调实战
语义相似度任务(Semantic Textual Similarity)是自然语言处理中的一个基础任务,目的是评估两个文本片段在语义上的相似程度。
主要思路:
- 将文本映射到语义向量空间,也就是将文本转化为固定长度的向量表示。
- 计算两个文本向量之间的相似度,例如使用余弦相似度。
- 相似度高则表示两个文本在语义上相似,相似度低则表示语义不同。
难点在于获得合适的文本向量表示,需要模型能够捕捉文本的语义信息,忽略词汇表面的差异,根据上下文判断语义是否相近。
文本相似度比较的主要三种类型。
s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等s2c, 即 sentence to code ,代表了自然语言和程序语言之间的嵌入能力,适用任务:代码检索
语义相似度模型几个关键问题,包括: 数据格式、基础模型选择、文本向量化表示、损失函数设计和训练策略等都有所不同。
评测数据集
语义相似度任务数据集包括STS-B, SICK 等。模型训练过程中需要大量语义相关的文本对构成监督数据,损失函数则常采用余弦相似度与标注相似度的差异作为优化目标。
语义相似度是NLP系统中重要模块,应用包括: 问答匹配、短文本聚类、语义搜索等等。提高语义相似度的准确性是自然语言理解的关键步骤。
数据格式
三种训练样本格式
示例如下:
Pair(句子对):每个样本包含一个正例句子对。用于学习区分正例和负例句子。
[{
'text': 'I love apples',
'positive_text': 'Apples are my favorite fruit'
},
{
'text': 'I play football',
'positive_text': 'Football is an exciting sport'
}]
Triplet(三元组) :每个样本包含一个正例句子和一个负例句子。可以更明确地学习区分正负样本。
[{
'text': 'I love apples',
'positive_text': 'Apples are my favorite fruit',
'negative_text': 'Bananas are too soft'
},
{
'text': 'I play football',
'positive_text': 'Football is an exciting sport',
'negative_text': 'Basketball is also great'
}]
Scored Pair(打分句子对):每个样本包含一对句子和它们的相似度分数。可以直接学习评估语义相似度。
[{
'text': 'I love apples',
'scored_text': 'Apples are my favorite fruit',
'score': 0.9
},
{
'text': 'I play football',
'scored_text': 'Football is an exciting sport',
'score': 0.8
}]
三者对比:
- Pair: 区分正负样本
- Triplet: 更明确的正负样本
- Scored Pair: 直接学习语义相似度
适用于不同的训练目标。
评测榜单
如何评估一个模型的好坏:MTEB Leaderboard - a Hugging Face Space by mteb 是针对大规模文本表示学习方法的一个评测排行榜。
-
将文本向量化模型在大量的评测数据集: 文本分类,聚类,文本排序,文本召回等大量数据集上进行评测,并给出一个平均的分数,来评估这个模型文本embeding的能力。
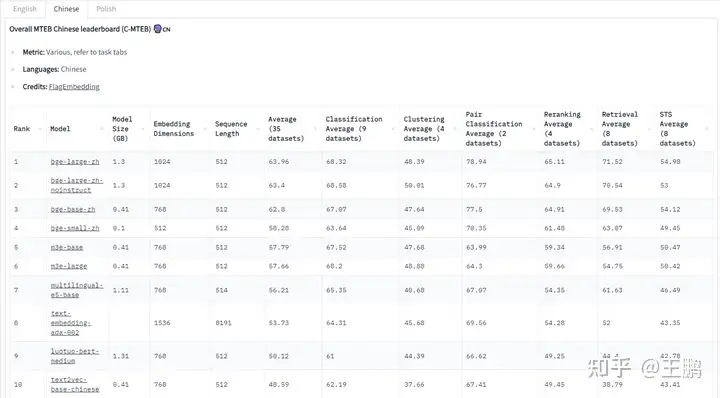
- BGE模型效果目前最强,而 M3E 紧随其后,不同模型采取了不同训练数据,训练模型和训练策略。large的模型效果更好
除了以上综合榜单,不同模型在不同类型任务下的表现有区别。
向量检索
大规模情况下,如何低延迟检索文档?
- 近似最近邻(ANN)算法。
语义匹配会直接决定是否能够检索到正确的知识
向量检索技术
优化了检索速度,并返回近似(而非精确)的前 k 个最相似的邻居,以少许准确度损失换取大幅加速。
ANN嵌入索引是一种数据结构,高效地进行ANN搜索。在嵌入空间上构建分区,以便快速定位查询向量所在的特定空间。一些技术包括:
局部敏感哈希(LSH):核心思想是创建哈希函数,使得相似的项有可能落入同一个哈希桶中。通过只需要检查相关的桶,我们可以高效地执行最近邻查询。- Facebook AI相似性搜索(
FAISS):它使用量化和索引的组合来实现高效的检索,支持CPU和GPU,并且由于其对内存的高效利用,可以处理数十亿个向量。 - 分层可导航小世界(
HNSW):受到“六度分隔”的启发,它构建了一个体现小世界现象的分层图结构。在这里,大多数节点可以通过最少的跳数从任何其他节点到达。这种结构允许HNSW从更广泛、更粗糙的近似开始查询,并逐渐在较低层次上缩小搜索范围。 - 可扩展最近邻居(
ScaNN):ANN通过两个步骤完成。 - 首先,粗粒度量化减少了搜索空间。
- 然后,在减少的集合内进行细粒度搜索。这是我见过的最佳召回率/延迟权衡。
局部敏感散列(LSH)是一组方法,用于将数据向量转换成散列值,同时保留其相似性信息,从而缩小搜索范围。
传统方法包括三个步骤:
- 矢量化:将原始文本编码成矢量。
- K-gram 是由 k 个连续的标记词组成的词组。根据上下文,标记可以是单词或符号。切分的最终目的是使用收集到的 k-gram 对每个文档进行编码。
- 句子 “learning datascience is fascinating “收集长度为 k = 3 的唯一字符串
- MinHashing:将向量转换成一种称为签名的特殊表示,可用于比较它们之间的相似性。
- 向量的相似性可以通过
雅卡指数(两个集合的交集)进行比较。请记住,两个集合的雅卡指数定义为两个集合中共同元素的数量除以所有元素的长度。 - 编码向量的稀疏性: 计算两个单击编码向量之间的相似度得分将耗费大量时间。如果转换为密集格式会更有效率。是设计这样一个函数,将这些向量转换到一个较小的维度,并保留相似性信息。构建这种函数的方法叫做 MinHashing。
- MinHashing 是一个哈希函数,对输入向量的分量进行排列,然后返回排列后的向量分量等于 1 的第一个索引, img
- 向量的相似性可以通过
- LSH 功能:将签名块散列到不同的桶中。如果一对向量的签名至少有一次落在同一个桶中,它们就会被视为候选者。
- 原始文本转化为保留相似性信息的等长密集签名。然而,这种密集签名通常仍然具有很高的维度,直接比较,效率很低。建立一个哈希表来加速搜索性能,但即使两个签名非常相似,只有一个位置不同,哈希值仍有可能不同(因为向量余数可能不同)。不过通常希望它们归入同一个桶中。
- LSH 机制会建立一个由多个部分组成的哈希表,如果一对签名至少有一个相应的部分,就会被放入同一个桶中。
- 参考
在评估ANN指数时,需要考虑一些因素,包括:
- 回忆:它在与精确最近邻的比较中表现如何?
- 延迟/吞吐量:每秒可以处理多少个查询?
- 内存占用:为了提供索引需要多少RAM?
- 添加新项目的便利性:是否可以在不重新索引所有文档(LSH)或需要重建索引(ScaNN)的情况下添加新项目?
没有最好,只有更合适。进行基准测试之前,首先定义功能和非功能需求。
- ScaNN在召回率和延迟之间的权衡方面表现出色(请参见此处的基准测试图表)。
详见
索引结构划分
【2023-8-25】按索引结构划分
- 树结构索引:
- 图结构索引:
- 分层聚类索引:
- 向量量化索引:
| 索引结构类型 | 原理 | 适用场景 | 示例 |
|---|---|---|---|
| 树结构索引 | - | 低维空间相似性搜索 不适合高维空间,内存占用大,搜索慢 |
KD-Tree, BallTree |
| 图结构索引 | - | 高维空间实时相似性搜索,内存占用小,速度快 | HNSW |
| 分层聚类索引 | - | 高维空间相似性搜索,性能和内存平衡 | Annoy |
| 向量量化索引 | - | 大规模高维空间相似性搜索,api丰富 | Faiss (IVF,IVFPQ) |
相似性搜索
相似性搜索经常出现在 NLP 领域、搜索引擎或推荐系统中,在这些领域中,需要为查询检索最相关的文档或项目。
向量数据库
向量数据库(Vectorstores)用于存储文本、图像等编码后的特征向量,支持向量相似度查询与分析。
- 文本语义检索,通过比较输入文本的特征向量与底库文本特征向量的相似性,从而检索目标文本,即利用了向量数据库中的相似度查询(余弦距离、欧氏距离等)。
因为数据相关性搜索其实是向量运算。
所以,不管使用 openai api embedding 功能还是直接通过 向量数据库 直接查询,都需要将加载进来的数据 Document 进行向量化,才能进行向量运算搜索。
转换成向量也很简单,只需要把数据存储到对应的向量数据库中即可完成向量的转换。
向量数据库
官方也提供了很多的向量数据库供我们使用,包括:
- Annoy
- Chroma
- ElasticSearch
- FAISS
- Milvus
- PGVector
- Pinecone
- Redis
代表性数据库
- Chroma、Pinecone、Qdrand
更多支持的向量数据库使用方法,可转至链接。
【2023-12-7】主流数据库一览
几个主流的向量数据库中
- Milvus 在大规模、检索性能、社区影响力等方面都具备绝对优势,其分布式架构也更Match下一代存储的理念。
- Weaviate 在使用案例上,有很多现成的例子,跟当前GPT前沿热门项目贴合比较紧秘,但在大规模生产环境使用场景中,还需要接受考验。
- Chroma 是一个很轻量级的数据库,底层使用了clickhouse、duckdb等存储引擎
| 数据库名称 | 是否开源 | 社区影响力 | 编程语言 | 核心特性 | 适用场景 |
|---|---|---|---|---|---|
Pinecone |
否 | 未知 | 向量存储与检索、全托管 | Saas类业务场景 | |
weaviate |
是 | 5.3k star | Go | 同时支持向量与对象的存储、支持向量检索与结构化过滤、具备主流模式成熟的使用案例。高速、灵活,不仅仅具备向量检索,还会支持推荐、总结等能力 | |
qdrant |
是 | 6.3k star | Rust | 向量存储与检索、云原生、分布式、支持过滤、丰富的数据类型、WAL日志写入 | |
milvus |
是 | 17.7k star | Go | 极高的检索性能: 万亿矢量数据集的毫秒级搜索非结构化数据的极简管理丰富的API跨平台实时搜索和分析可靠:具有很高的容灾与故障转移能力高度可拓展与弹性支持混合检索统一的Lambda架构社区支持、行业认可 | |
Chroma |
是 | 4.1k star | python | 轻量、内存级 |
Redis
Redis 通过 RedisSearch 模块,也原生支持向量检索。
RedisSearch 是一个Redis模块,提供了查询、二级索引,全文检索以及向量检索等能力。
如果要使用RedisSearch,需要首先在Redis数据上声明索引
RedisVL
同时考虑 “高性能”、“实时性”、“生产环境可靠性”和“生态成熟度”这几个要求,Redis 往往会脱颖而出。
而 RedisVL (Redis Vector Library)正是为了更顺畅地在 Python 里驾驭Redis的向量搜索能力。
RedisVL 不是一个独立数据库,而是官方推出的、生产就绪的 Python客户端库
- 目标很明确:成为构建AI应用时,连接业务逻辑与Redis向量存储层的那座最稳固的桥梁。
当时用着某个纯向量数据库,单次检索虽然不慢,但一旦结合复杂的元数据过滤(比如按时间、按分类、按状态筛选),延迟就上来了,更别提想做实时缓存和会话管理还得额外引入组件,架构变得复杂。
RedisVL 直接把向量搜索、复杂过滤、语义缓存、LLM记忆管理这些AI应用的核心需求 用一套简洁的Python API封装了起来,背后是久经考验的Redis引擎。
- “闪电般的向量搜索遇上了企业级的可靠性”
RedisVL 架构:
- 基础索引与检索层 :基石,对应 SearchIndex 和各类 Query 对象。负责在Redis中创建和管理支持向量的搜索索引,并执行向量搜索、全文搜索、混合搜索以及复杂的多条件过滤。这部分功能直接对应Redis Search模块的能力,但 redisvl 通过Pythonic的API让其更易用。
- 开发工具链层 :提升开发效率,包括 Vectorizer (与OpenAI、Cohere等多家嵌入模型服务集成)、 Reranker (对搜索结果进行重排序以提升相关性)以及命令行工具 rvl 。特别是 Vectorizer ,它抽象了调用不同嵌入模型API的细节,让“文本变向量”这个过程变得标准化。
- AI扩展模式层 :这是 redisvl 的精华所在,封装了AI应用中的常见模式。 SemanticCache 用于缓存LLM的问答对以降低成本和延迟; EmbeddingsCache 专门缓存昂贵的嵌入向量; SemanticMessageHistory 为AI智能体(Agent)提供基于向量搜索的“记忆”能力; SemanticRouter 实现语义路由。这些不是简单的工具,而是经过验证的最佳实践设计模式,可以直接集成到你的AI应用架构中。
安装
pip install redisvl
pip install redisvl[mcp]
Faiss
from langchain.vectorstores import FAISS
db = FAISS.from_documents(split_docs, embeddings)
db.save_local("./faiss/news_test")
# 加载持久化向量
db = FAISS.load_local("./faiss/news_test",embeddings=embeddings)
# ====== 或 ========
vs_path = "./vector_store"
if vs_path and os.path.isdir(vs_path):
vector_store = FAISS.load_local(vs_path, embeddings)
vector_store.add_documents(docs)
else:
if not vs_path:
vs_path = f"""{VS_ROOT_PATH}{os.path.splitext(file)[0]}_FAISS_{datetime.datetime.now().strftime("%Y%m%d_%H%M%S")}"""
vector_store = FAISS.from_documents(docs, embeddings)
vector_store.save_local(vs_path)
docs = vector_store.similarity_search(query)
docs_and_scores = vector_store.similarity_search_with_score(query)
Milvus
Milvus: 面向下一代的生成式AI向量数据库,支持云原生
Zilliz, 构建在Milvus之上的数据基础设施
vector_db = Milvus.from_documents(
docs,
embeddings,
connection_args={"host": "127.0.0.1", "port": "19530"},
)
docs = vector_db.similarity_search(query)
docs[0]
Qdrant
Qdrant 是面向下一代的生成式AI向量数据库,同时也具备云原生的特性
Chroma
Chroma是一个很轻量级的数据库,底层使用了clickhouse、duckdb等存储引擎
Chroma: 一个开源的向量数据库。 可以快速基于Python和JavaScript构建内存级LLM应用
Chroma 比较轻量,直接安装库
from langchain.vectorstores import Chroma
# 初始化加载器
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/openai/news_test")
# 持久化
db.persist()
# 持久化后,可以直接选择从持久化文件中加载,不需要再重新就可使用了
db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)
# pip install chromadb
# 加载索引
from langchain.vectorstores import Chroma
vectordb = Chroma(persist_directory="./vector_store", embedding_function=embeddings)
# 向量相似度计算
query = "未入职同事可以出差吗"
docs = vectordb.similarity_search(query)
docs2 = vectordb.similarity_search_with_score(query)
print(docs[0].page_content)
# 在检索器接口中公开该索引
retriever = vectordb.as_retriever(search_type="mmr")
docs = retriever.get_relevant_documents(query)[0]
print(docs.page_content)
Pinecone
Pinecone是一个专门为工程师与开发者设计的向量数据库。
作为一个全托管的服务,它减轻了工程师以及运维人员的负担,使得客户可以聚焦于数据内在价值的抽取。
- 免费版可以支持500w的向量存储,其用法简单,价格低廉,可以快速支持向量检索业务的验证与尝试。
- 在特性上Pinecone也具有高速、准确以及可拓展等特性,此外也具备对单级元数据过滤和尖端稀疏-密集索引等高级功能。
使用案例
| 名称 | 描述 |
|---|---|
| GPT-4 Retrieval Augmentation | 如何通过检索增强来增强GPT4的能力 |
| Generative Question-Answering | 生成式问答 |
| Semantic Search | 语义搜索,构建一个简单的语义搜索 |
import pinecone
# Connecting to Pinecone
pinecone.deinit()
pinecone.init(
api_key="YOUR_API_KEY", # find at app.pinecone.io
environment="YOUR_ENV" # next to api key in console
)
# similarity_search
docsearch = Pinecone.from_documents(docs, embeddings, index_name="langchain-demo")
docs = docsearch.similarity_search(query)
print(docs[0].page_content)
# Create a Pinecone Service
pinecone_service = pinecone.Service()
# Create an Embedding Model
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# Create a Vectorstore
from langchain.vectorstores import Chroma
vectorstore = Chroma(embeddings, pinecone_service)
# Upload documents to Pinecone Vectorstore
from langchain.vectorstores import Chroma
docsearch = Chroma.from_documents(texts, embeddings, collection_name="collection_name")
PGVector
from langchain.vectorstores.pgvector import PGVector
import os
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "postgres"),
user=os.environ.get("PGVECTOR_USER", "postgres"),
password=os.environ.get("PGVECTOR_PASSWORD", "postgres"),
)
db = PGVector.from_documents(
embedding=embeddings,
documents=docs,
collection_name="state_of_the_union",
connection_string=CONNECTION_STRING,
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score: List[Tuple[Document, float]] = db.similarity_search_with_score(query)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
Weaviate
Weaviate 是一个开源的矢量数据库,具有健壮、可拓展、云原生以及快速等特性
Weaviate 是一个开源的向量数据库,可以存储对象、向量,支持将矢量搜索与结构化过滤与云原生数据库容错和可拓展性等能力相结合。
- 支持GraphQL、REST和各种语言的客户端访问。
- github地址
Weaviate在使用案例上,有很多现成的例子,跟当前GPT前沿热门项目贴合比较紧秘,但在大规模生产环境使用场景中,还需要接受考验。
谷歌 TurboVec
【2026-5-30】Google 开源 TurboVec(实际项目名 turbovec)
- 基于 TurboQuant 算法的高性能向量索引库
- 核心优势: 16倍内存压缩(如31GB→4GB)和搜索提速,支持零训练动态索引、纯本地部署,适用于隐私敏感型RAG场景。
- 项目地址:turbovec
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
