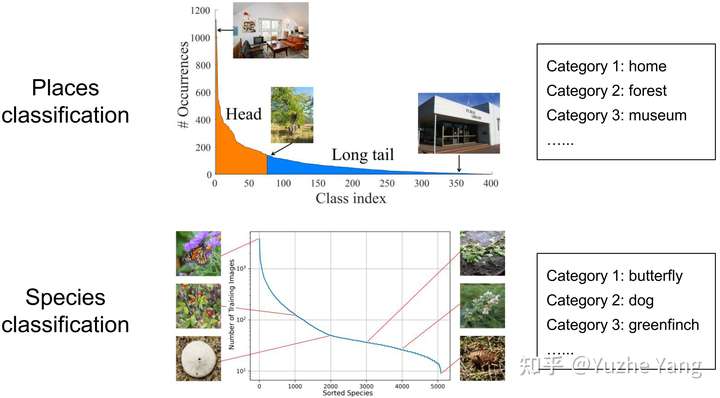
机器学习: 不平衡问题
不平衡数据集如何处理?
某些应用下
- 1∶35的比例就会使某些分类方法无效,甚至1∶10的比例也会使某些分类方法无效。
不平衡问题解法
以 Albert + TextCNN 为基础框架,将已有长尾问题损失函数解决方案集成进该基础框架进行多标签文本分类,数据的长尾问题是经常会遇见的一个棘手的问题,更为极端的情况甚至极个别的类的 trainning sample等于0。这对一个模型的性能影响是非常大的。
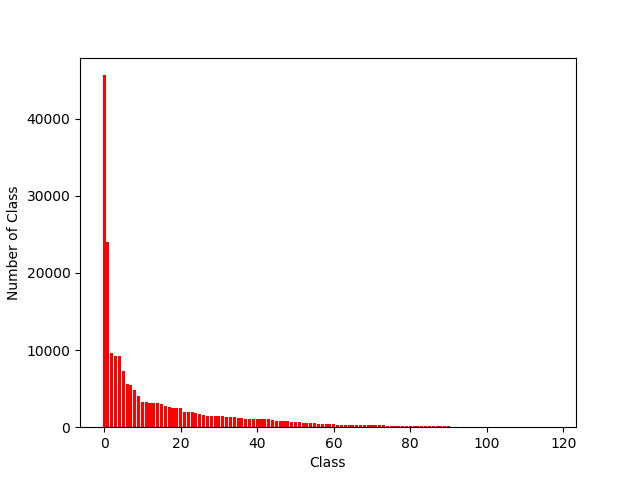
分类问题中不平衡数据集的解决方案,正负样本玄虚
- 1.
过抽样:简单赋值负样本——最常用,容易过拟合,SVM模型里用途不大 - 2.
欠抽样:随机减少正样本——造成信息丢失 - 3.算法层面:
- (1)重构训练集,按错分代价对训练集重构
- (2)代价敏感函数,大样本高代价,小样本低代价
- 4.特征选择:选取有区分度的特征
- 解决真实世界的问题:如何在不平衡数据集上使用机器学习,非平衡数据机器学习,【2019-04-25】如何处理机器学习中的不平衡类别问题-含代码实现
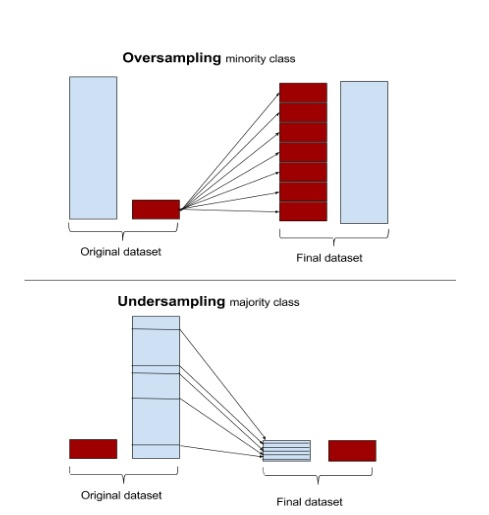
- 有道云笔记总结
- 【2021-5-30】样本不均衡的一顿操作:不平衡问题解法很多,最简单的就是重采样,包括过采样和欠采样,使各个类别数量大致相同;

- 更复杂的采样方式,如先对样本聚类,在需要降采样的样本上,按类别进行降采样,这样能丢失较少的信息。过采样不再是简单copy,可以加一点点”噪声”,生成更多的样本。
Tomek links:Tomek连接指的是在空间上”最近”的样本,但是是不同类别的样本。删除这些pair中,占大多数类别的样本。通过这种降采样方式,有利于分类模型的学习SMOTE给少数样本做扩充,SMOTE 在样本空间中少数样本随机挑选一个样本,计算k个邻近的样本,在这些样本之间插入一些样本做扩充,反复这个过程,知道样本均衡NearMiss降采样的方法,通过距离计算,删除掉一些无用的点。- NearMiss-1:在多数类样本中选择与最近的3个少数类样本的平均距离最小的样本。
- NearMiss-2:在多数类样本中选择与最远的3个少数类样本的平均距离最小的样本。
- NearMiss-3:对于每个少数类样本,选择离它最近的给定数量的多数类样本。
- NearMiss-1 考虑与最近的3个少数类样本的平均距离,是局部的;NearMiss-2考虑的是与最远的3个少数类样本的平均距离,是全局的。NearMiss-1方法得到的多数类样本分布也是“不均衡”的,它倾向于在比较集中的少数类附近找到更多的多数类样本,而在孤立的(或者说是离群的)少数类附近找到更少的多数类样本,原因是NearMiss-1方法考虑的局部性质和平均距离。NearMiss-3方法则会使得每一个少数类样本附近都有足够多的多数类样本,显然这会使得模型的精确度高、召回率低。
- 【2020-9-15】对于缓解类别不平衡,比较基本的方法就是调节样本权重,看起来“高端”一点的方法则是各种魔改 loss了(比如 Focal Loss、Dice Loss、Logits Adjustment 等),源自:再谈类别不平衡问题:调节权重与魔改Loss的综合分析
- (1)从光滑准确率到交叉熵
- (2)从光滑F1到加权交叉熵:对 loss 的各种魔改,本质上来说都只是在调整梯度,得到更合理的梯度
- (3)从扩大边界到Logits调整
- 长尾分布:少数类别的样本数目非常多,多数类别的样本数目非常少。

- 【2021-8-17】不要对不平衡的数据集使用准确度(accuracy)指标。这个指标常用于分类模型,不平衡数据集应采用kappa系数或马修斯相关系数(MCC)指标。


重采样
【2022-8-31】对”样本不均衡”一顿操作
使用频率最高的方式:对“多数”样本降采样,也可以对“少数”样本过采样
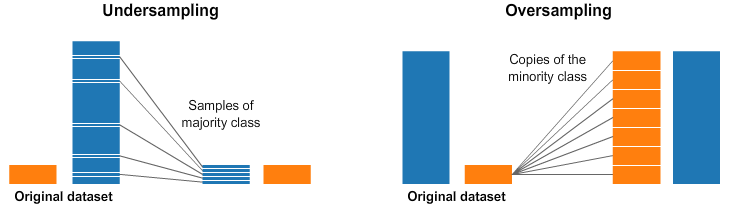
重采样缺点比较明显
- 过采样对少数样本”过度捕捞”
- 降采样会丢失大量信息
重采样方案
- 最简单: 随机过采样/降采样,使得各个类别的数量大致相同。
- 复杂: 先对样本聚类,在需要降采样的样本上,按类别进行降采样,这样能丢失较少的信息。
过采样时不用简单复制,可加一点”噪声”,生成更多样本。
降采样:Tomek links
Tomek 连接 在空间上”最近”的样本,但是是不同类别的样本。删除这些pair中,占大多数类别的样本。通过这种降采样方式,有利于分类模型的学习

降采样:NearMiss
通过距离计算,删除掉一些无用点。
- NearMiss-1:在多数类样本中选择与最近的3个少数类样本的平均距离最小的样本。
- NearMiss-2:在多数类样本中选择与最远的3个少数类样本的平均距离最小的样本。
- NearMiss-3:对于每个少数类样本,选择离它最近的给定数量的多数类样本。
对比
- NearMiss-1 考虑与最近的3个少数类样本的平均距离,是局部的;
- NearMiss-2 考虑与最远的3个少数类样本的平均距离,是全局的。
- NearMiss-1 得到的多数类样本分布也“不均衡”,它倾向于在比较集中的少数类附近找到更多的多数类样本,而在孤立的(或者说是离群的)少数类附近找到更少的多数类样本,原因是NearMiss-1方法考虑的局部性质和平均距离。
- NearMiss-3 会使得每一个少数类样本附近都有足够多的多数类样本,显然这会使得模型的精确度高、召回率低。
过采样:SMOTE
给少数样本做扩充,SMOTE 在样本空间中少数样本随机挑选一个样本,计算k个邻近的样本,在这些样本之间插入一些样本做扩充,反复这个过程,直到样本均衡

算法
回归
当前处理不平衡数据/长尾分布的方法绝大多数都是针对分类问题,,即目标值是不同类别的离散值(索引);
而回归问题中出现的数据不均衡问题确极少被研究。
如果涉及连续甚至是无限多目标值,如何解决回归问题中出现的数据不均衡问题呢?
什么是回归不均衡
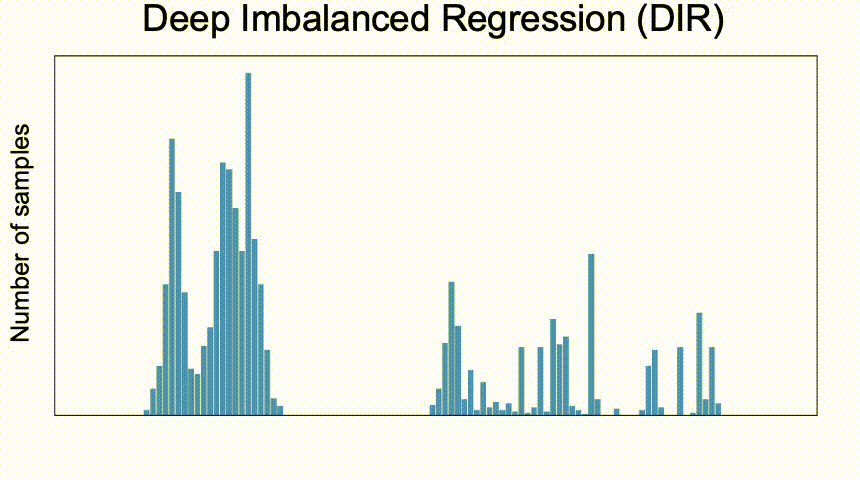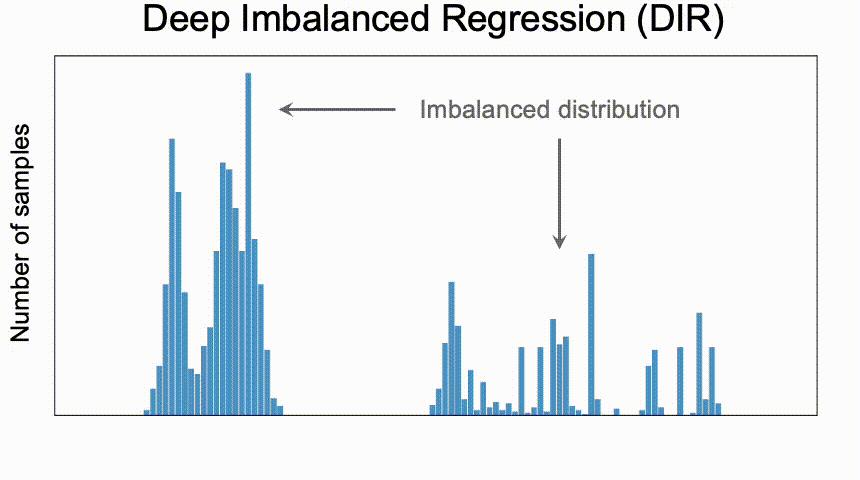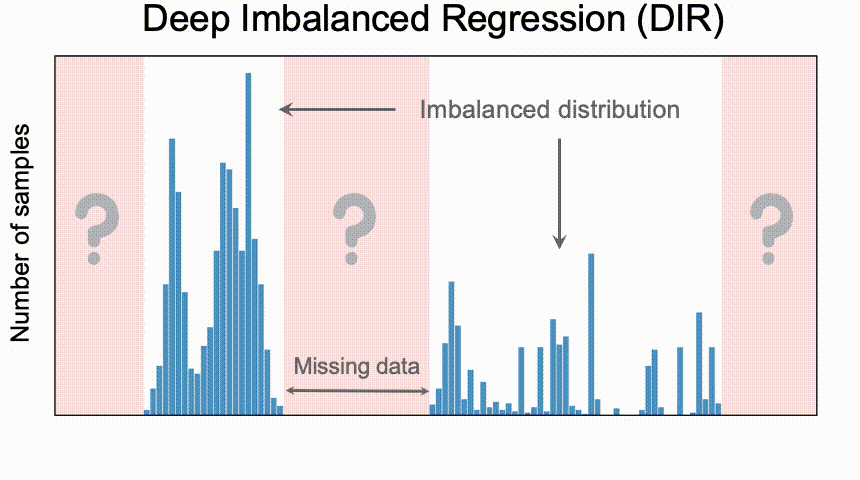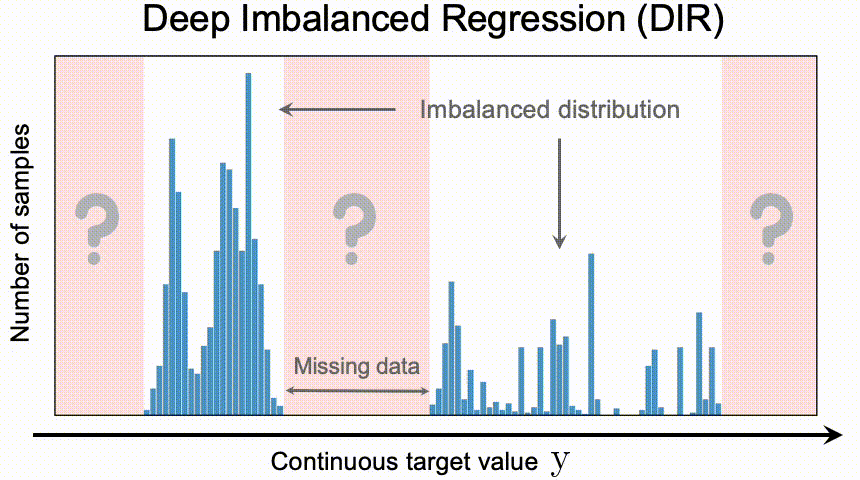
深度不平衡回归问题(DIR),从具有连续目标值的不平衡数据中学习,同时需要处理某些目标区域的潜在确实数据,并使最终模型能够泛化到整个支持所有目标值的范围上。
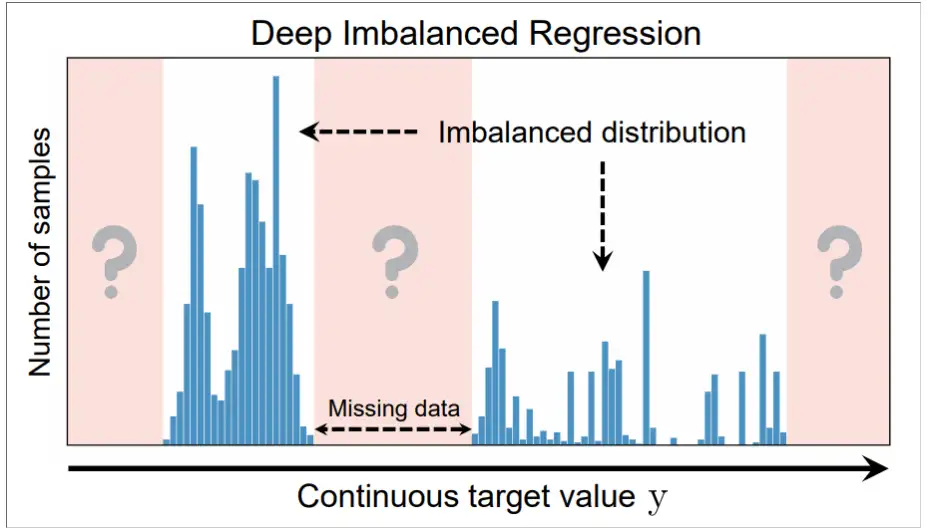
- 回归问题中 target value 分布(通过直方图可视化)存在不均衡,在
[t1− ∆, t1+ ∆]区间里存在大量样本,在[t2− ∆, t2+ ∆]则存在相对很稀少的样本,前者称为 highly represented neighborhood,后者为 weekly represented neighborhood; - 某些领域内
[t3− ∆, t3+ ∆],但是未来数据中存在[t3− ∆, t3+ ∆]内的数据;(注意第二点,如果未来也不存在[t3− ∆, t3+ ∆]区间的数据,这里其实就不存在missing data的问题了,例如商品的销量数据不存在负数,)
这类现象是普遍存在
- 爆款商品和冷门商品的销量就存在不均衡回归问题,爆款商品的销量数据很大,但是爆款商品的数量很少,普通商品的销量数据一般,但是普通商品的数量很大,这种情况下,如果不进行分组标准化处理(具体下文会有描述),会使得模型的拟合曲线(相对于分类问题的决策边界,没有找到关于回归问题的决策部分的专业术语,暂时称之为拟合曲线)偏向于处于highly represented neighborhood的样本;
这一点上和不均衡分类中的决策边界的移动方向是相反的
- 分类问题中,决策平面会随着类别权重的增加,逐渐远离高权重类别样本
- 回归问题中,拟合曲线会逐渐靠近highly represented neighborhood 样本;
DIR 难点:
- 对于连续目标值(标签),不同目标值之间的硬边界不再存在,无法直接采用不平衡分类的处理方法。
- 连续标签本质上说明在不同目标值之间的距离是有意义的。这些目标值直接告诉了哪些数据之间相隔更近,指导如何理解这个连续区间上的数据不均衡的程度。
对于DIR,某些目标值可能根本没有数据,这为对目标值做 extrapolation 和 interpolation 提供了需求。
2021 DIR
【2021-7-14】ICML 2021 (Long Oral) 深入研究不平衡回归问题,经典数据不平衡问题下,探索了非常实际但极少被研究的问题:数据不平衡回归问题。
- 现有处理不平衡数据/长尾分布的方法绝大多数仅针对分类问题,即目标值是不同类别的离散值(索引);
- 许多实际的任务涉及连续的,甚至有时是无限多的目标值。
本文推广了传统不平衡分类问题的范式,将数据不平衡问题从离散值域推广到连续域。
不均衡回归问题适用于两种场景:
- 静态回归问题;
- 单序列的动态回归问题
三个方面:
- 1)提出一个深度不均衡回归(Deep Imbalanced Regression,
DIR)任务,定义为从具有连续目标的不平衡数据中学习,并能泛化到整个目标范围; - 2)提出两种解决DIR的新方法,标签分布平滑(label distribution smoothing,
LDS)和特征分布平滑(feature distribution smoothing,FDS),来解决具有连续目标的不平衡数据的学习问题; - 3)建立了5个新DIR数据集,包括了CV、NLP、healthcare上的不平衡回归任务,致力于帮助未来在不平衡数据上的研究。
基准DIR数据集
- IMDB-WIKI-DIR(vision, age):基于IMDB-WIKI数据集,从包含人面部的图像来推断估计相应的年龄。
- AgeDB-DIR(vision, age):基于AgeDB数据集,同样是根据输入图像进行年龄估计。
- NYUD2-DIR(vision, depth):基于NYU2数据集,用于构建depth estimation的DIR任务。
- STS-B-DIR(NLP, test similarity score):基于STS-B数据集,任务是推断两个输入句子之间的语义文本的相似度得分。
- SHHS-DIR(Healthcare, health condition score):基于SHHS数据集,该任务是推断一个人的总体健康评分。
方法一:标签分布平滑
- 统计学习领域中的核密度估计(LDS)方法,给定连续经验标签密度分布,LDS 使用了一个对称核函数k,用经验密度分布与之卷积,得到一个kernel-smoothed 有效标签密度分布,用来直观体现临近标签的数据样本具有的信息重叠问题,通过LDS计算出的有效标签密度分布结果与误差分布的相关性明显增强。
- 有了LDS估计出的有效标签密度,就可以用解决类别不平衡问题的方法,直接应用于解决DIR问题。比如,最简单地一种make sence方式是利用重加权的方法,通过将损失函数乘以每个目标值的LDS估计标签密度的倒数来对其进行加权。
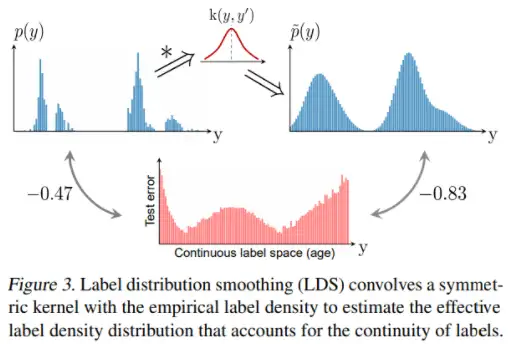
方法二:特征分布平滑(FDS)
如果模型预测正常且数据是均衡的,那么label相近的samples,它们对应的feature的统计信息应该也是彼此接近的。这里作者也举了一个实例验证了这个直觉。作者同样使用对IMDB-WIKI上训练的ResNet-50模型。主要focus在模型学习到的特征空间,不是标签空间。我们关注的最小年龄差是1岁,因此我们将标签空间分为了等间隔的区间,将具有相同目标区间的要素分到同一组。然后,针对每个区间中的数据计算其相应的特征统计量(均值、方差)
FDS 是对特征空间进行分布的平滑,本质上是在临近的区间之间传递特征的统计信息。此过程的主要作用是去校准特征分布的潜在的有偏差的估计,尤其是对那些样本很少的目标值而言。
分类
加权交叉熵损失函数
类别不均衡的情况下,需要通过损失函数中设置权重参数来调节各类之间的比重。一般不同类别的权重占比需要通过多次实验调整。如首先采用中值频率平衡的方法来结算每一个类的权重。然后在同时实验的效果对权重进行微调找到最合适的类别权重。
中值频率平衡的原理如下:
其中 表示
类别在训练集中的实例个数,
表示训练集的大小,
对所有类别的实例数目进行排序之后取到的中位数。
有了上述对于权重的计算,但是tensorflow中没有对应的多标签分类的加权二进制交叉熵损失函数的api封装,所以这个函数得我们自己自定义,核心代码如下:
epsilon = 1.e-8
logits = tf.nn.sigmoid(prediction)
# 做一个截断操作,防止后续log的计算中出现nan值
logits = tf.clip_by_value(logits, epsilon, 1. - epsilon)
#这里的weight_c就是用前面公式求出来得到的一个列表
weight = tf.constant(weight_c)
# 这里的label为真值
loss = -tf.reduce_mean(weight*label*tf.log(logits)+(1-label)*tf.log((1-logits)))
Focal loss
详见站内专题: 损失函数
Dice Loss
详见站内专题: 损失函数
Class-Balanced Loss
【2021-10-17】谷歌对CVPR 2019上发表的一篇文章的综述。它为最常用的损耗(softmax-cross-entropy、focal loss等)提出了一个针对每个类别的重新加权方案,能够快速提高精度,特别是在处理高度类不平衡的数据时。
- 论文: Class-Balanced Loss Based on Effective Number of Samples
- [PyTorch实现源码]https://github.com/vandit15/Class-balanced-loss-pytorch)
样本有效数量
在处理长尾数据集(其中大部分样本属于很少的类,而许多其他类的样本非常少)的时候,如何对不同类的损失进行加权可能比较棘手, 通常将权重设置为类样本的倒数或类样本的平方根的倒数。
问题:
- 随着样本数量的增加,新数据点的带来的好处会减少。新样本极有可能是现有样本的近似副本,特别是在训练神经网络时使用大量数据增强(如重新缩放、随机裁剪、翻转等)的时候,很多都是这样的样本。用有效样本数重新加权可以得到较好的结果。
有效样本数:近似n个样本所覆盖的实际体积,其中总体积N由总样本表示
每个样本的贡献:
- 第j个样本对有效样本数的贡献为β^(j-1), 如果β=0,则En=1。同样,当β→1的时候En→n。后者可以很容易地用洛必达法则证明。
- 这意味着当N很大时,有效样本数与样本数N相同。在这种情况下,唯一原型数N很大,每个样本都是唯一的。然而,如果N=1,这意味着所有数据都可以用一个原型表示。
类别均衡损失
如果没有额外的信息,不能为每个类设置单独的Beta值,因此,使用整个数据的时候,将把它设置为一个特定的值(通常设置为0.9、0.99、0.999、0.9999中的一个)。
类别均衡损失可表示为:
这里, L(p,y) 可以是任意的损失。
类别均衡 Focal Loss
使用一个特别设计的损失来处理类别不均衡的数据集 原始版本的 focal loss有一个α平衡变量。这里,我们将使用每个类的有效样本数对其重新加权。
类似地,这样一个重新加权的项也可以应用于其他著名的损失(sigmod -cross-entropy, softmax-cross-entropy等)。
实现
在开始实现之前,需要注意的一点是,在使用基于sigmoid的损失进行训练时,使用b=-log(C-1)初始化最后一层的偏差,其中C是类的数量,而不是0。这是因为设置b=0会在训练开始时造成巨大的损失,因为每个类的输出概率接近0.5。因此,我们可以假设先验类是1/C,并相应地设置b的值。
评估指标
为了避免对模型的误判,避免使用Accuracy,可以用confusion matrix,precision,recall,f1-score,AUC,ROC等指标
惩罚项
- 对少数样本预测错误增大惩罚,是一个比较直接的方式。
使用多种算法
- 模型融合不止能提升效果,也能解决样本不均的问题,经验上,树模型对样本不均的解决帮助很大,特别是随机森林,Random Forest,XGB,LGB等。因为树模型作用方式类似于if/else,所以迫使模型对少数样本也非常重视。
正确使用K-fold
- 当我们对样本过采样时,对过采样的样本使用k-fold,那么模型会过拟合我们过采样的样本,所以交叉验证要在过采样前做。在过采样过程中,应当增加些随机性,避免过拟合。
实验
实验结果
| 方法 | recall | precision | F1 |
|---|---|---|---|
| albert+textcnn | 83.7 | 96.0 | 89.4 |
| albert+textcnn(weight BCE) | 80.3 | 95.1 | 87.1 |
| albert+textcnn(Focal loss) | 85.6 | 94.8 | 90.2 |
| albert+textcnn(Dice loss) | 84.5 | 95.5 | 90.1 |
| albert+textcnn(DSC loss) | 84.9 | 96.2 | 90.5 |
Focal loss 模型还未 train 至收敛,收敛后的结果之后进行更新
此外,本表格会持续收录并验证一些最新的论文的从loss的角度来解决长尾问题的方案
结论
- 1)加权交叉熵:理论上完全能够取得精度的提升。但是实际操作起来却很难。需要很丰富的实际经验,尤其是对于我们这种类别很多的任务时。过于加大尾部类别的权重反而会起到反作用。所以,如何确定每个类别的权重成为该方法的瓶颈。
- 2) Focal loss: 在超参数设置得当的情况下能够提升召回率而精确度不会出现很大的下降。但是不同的数据集,超参数的设置需要进行多次实验才能得到最合适的设置。另外需要注意的是,focal loss最好与交叉熵loss一起使用,并且对两个loss需要设置合适的权重,不然单独使用focal loss容易将所有类的预测概率都推向1。此外加入了focal loss之后,模型需要更长的训练epoch才能收敛。
- 3)Dice loss/DSC loss: 与focal loss一样,与交叉熵loss一起使用效果更好。当然,两个loss的权重就需要实验寻找。
如何处理机器学习中的不平衡类别
不平衡类别使得“准确率”失去意义。这是机器学习 (特别是在分类)中一个令人惊讶的常见问题,出现于每个类别的观测样本不成比例的数据集中。
普通的准确率不再能够可靠地度量性能,这使得模型训练变得更加困难。
不平衡类别出现在多个领域,包括:
- 欺诈检测
- 垃圾邮件过滤
- 疾病筛查
- SaaS 客户流失
- 广告点击率
在本指南中,我们将探讨 5 种处理不平衡类别的有效方法。

例子:疾病筛查
一家研究医院要求你基于病人的生物输入来训练一个疾病检测模型。
- 机器学习新手小明,通过简单的特征工程后,划分数据集为训练集和测试集(4:1),开始兴冲冲的调试各种分类模型,LR、SVM、xgboost等,挨个实验,发现效果都不错,准确率高达99.9%了!
- 嗯,才不到一天时间呢,瞬间成就感爆棚,感觉可以整理成论文发表了,走上人生巅峰。
- 可是刚部署到线上时,发现所有病人都被判定为“没病”,几乎100%,大家都很开心,出了一个漏诊的病人埋怨没有即时发现病情而耽误治疗。
- 小明盯着绿色的99.9%,欣喜之余,不禁陷入了沉思:怎么会这么高?作为负责任的研发,小明仔细测试了模型,惊恐的发现:所有样本都被判为负例,都没病!
但这里有陷阱… 疾病非常罕见;筛查的病人中只有 8% 的患病率。
现在,在你开始之前,你觉得问题可能会怎样发展呢?想象一下,如果你根本没有去训练一个模型。相反,如果你只写一行代码,总是预测“没有疾病”,那会如何呢?
一个拙劣但准确的解决方案
def disease_screen(patient_data):
# 忽略 patient_data
return 'No Disease.'
很好,猜猜看?你的“解决方案”应该有 92% 的准确率!
不幸的是,以上准确率具有误导性。
- 对于未患该病的病人,你的准确率是 100% 。
- 对于已患该病的病人,你的准确率是 0%。
- 你的总体准确率非常高,因为大多数患者并没有患该病 (不是因为你的模型训练的好)。
这显然是一个问题,因为设计的许多机器学习算法是为了最大限度的提高整体准确率。本指南的其余部分将说明处理不平衡类别的不同策略。
重要提示:
- 首先,不会分离出一个独立的测试集,调整超参数或者实现交叉检验。
- 相反,只专注于解决不平衡类别问题。
- 并非每种技术都会适用于每个问题。
Balance Scale 数据集
用一个叫做 Balance Scale 数据的合成数据集
- 从这里 UCI 机器学习仓库下载。
数据集最初被生成用于模拟心理实验结果,规模便于处理并且包含不平衡类别
导入第三方依赖库并读取数据
import pandas as pd
import numpy as np
# 读取数据集
df = pd.read_csv('balance-scale.data', names=['balance', 'var1', 'var2', 'var3', 'var4'])
# 显示示例观测样本
df.head()
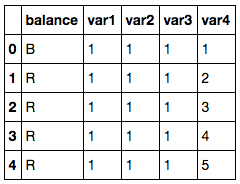
基于两臂的重量和距离,该数据集包含了天平是否平衡的信息。
- 包含 1 个目标变量 balance .
- 包含 4 个输入特征 var1 到 var4 .

目标变量有三个类别。
- R 表示右边重, 当 var3 * var4 > var1 * var2
- L 表示左边重, 当 var3 * var4 < var1 * var2
- B 表示平衡, 当 var3 * var4 = var1 * var2
每个类别数量
df['balance'].value_counts()
# R 288
# L 288
# B 49
# Name: balance, dtype: int64
然而,将把本问题转化为 二值分类 问题。
把天平平衡时的每个观测样本标记为 1 (正向类别),否则标记为 0 (负向类别):
转变成二值分类
# 转换为二值分类
df['balance'] = [1 if b=='B' else 0 for b in df.balance]
df['balance'].value_counts()
# 0 576
# 1 49
# Name: balance, dtype: int64
# About 8% were balanced
只有大约 8% 的观察样本平衡。 因此,如果预测结果总为 0,得到 92% 的准确率。
不平衡类别风险
一个数据集展示不平衡类别的风险。
首先,从 Scikit-Learn 导入逻辑回归算法和准确度度量模块。
导入算法和准确度度量模块
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
接着, 使用默认设置来生成一个简单模型。
在不平衡数据上训练一个模型
# 分离输入特征 (X) 和目标变量 (y)
y = df.balance
X = df.drop('balance', axis=1)
# 训练模型
clf_0 = LogisticRegression().fit(X, y)
# 在训练集上预测
pred_y_0 = clf_0.predict(X)
许多机器学习算法被设计为在默认情况下最大化总体准确率。
证实这一点:
# 准确率是怎样的?
print( accuracy_score(pred_y_0, y) )
# 0.9216
因此模型拥有 92% 的总体准确率,但是这是因为它只预测了一个类别吗?
# 我们应该兴奋吗?
print( np.unique( pred_y_0 ) )
# [0]
这个模型仅能预测 0,完全忽视了少数类别而偏爱多数类别。
第一个处理不平衡类别的技术:上采样少数类别。
1. 上采样少数类别
上采样是从少数类别中随机复制观测样本以增强其信号的过程。
达到这个目的有几种试探法,但是最常见的方法是使用简单的放回抽样的方式重采样。
首先,从 Scikit-Learn 中导入重采样模块:
重采样模块
from sklearn.utils import resample
接着,使用一个上采样过的少数类别创建一个新的 DataFrame。
- 首先,我们将每个类别的观测样本分离到不同的 DataFrame 中。
- 接着,我们将采用放回抽样的方式对少数类别重采样,让样本的数量与多数类别数量相当。
- 最后,我们将上采样后的少数类别 DataFrame 与原始的多数类别 DataFrame 合并。
上采样少数类别
# 分离多数和少数类别
df_majority = df[df.balance==0]
df_minority = df[df.balance==1]
# 上采样少数类别
df_minority_upsampled = resample(df_minority,
replace=True, # sample with replacement
n_samples=576, # to match majority class
random_state=123) # reproducible results
# 合并多数类别同上采样过的少数类别
df_upsampled = pd.concat([df_majority, df_minority_upsampled])
# 显示新的类别数量
df_upsampled.balance.value_counts()
# 1 576
# 0 576
# Name: balance, dtype: int64
新生成的 DataFrame 比原来拥有更多的观测样本,现在两个类别的比率为 1:1。
用逻辑回归训练另一个模型,这次在平衡数据集上进行:
在上采样后的数据集上训练模型
# 分离输入特征 (X) 和目标变量 (y)
y = df_upsampled.balance
X = df_upsampled.drop('balance', axis=1)
# 训练模型
clf_1 = LogisticRegression().fit(X, y)
# 在训练集上预测
pred_y_1 = clf_1.predict(X)
# 我们的模型仍旧预测仅仅一个类别吗?
print( np.unique( pred_y_1 ) )
# [0 1]
# 我们的准确率如何?
print( accuracy_score(y, pred_y_1) )
# 0.513888888889
现在这个模型不再只是预测一个类别了。虽然准确率急转直下,但现在的性能指标更有意义。
2. 下采样多数类别
下采样包括从多数类别中随机地移除观测样本,以防止它的信息主导学习算法。
其中最常见的试探法是不放回抽样式重采样。
这个过程同上采样极为相似
- 首先,我们将每个类别的观测样本分离到不同的 DataFrame 中。
- 接着,我们将采用不放回抽样来重采样多数类别,让样本的数量与少数类别数量相当。
- 最后,我们将下采样后的多数类别 DataFrame 与原始的少数类别 DataFrame 合并。
下采样多数类别
# 分离多数类别和少数类别
df_majority = df[df.balance==0]
df_minority = df[df.balance==1]
# 下采样多数类别
df_majority_downsampled = resample(df_majority,
replace=False, # sample without replacement
n_samples=49, # to match minority class
random_state=123) # reproducible results
# Combine minority class with downsampled majority class
df_downsampled = pd.concat([df_majority_downsampled, df_minority])
# Display new class counts
df_downsampled.balance.value_counts()
# 1 49
# 0 49
# Name: balance, dtype: int64
新生成的 DataFrame 比原始数据拥有更少的观察样本,现在两个类别的比率为 1:1。
再次使用逻辑回归训练一个模型:
在下采样后的数据集上训练模型
# Separate input features (X) and target variable (y)
y = df_downsampled.balance
X = df_downsampled.drop('balance', axis=1)
# Train model
clf_2 = LogisticRegression().fit(X, y)
# Predict on training set
pred_y_2 = clf_2.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_2 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_2) )
# 0.581632653061
模型不再仅预测一个类别,并且其准确率似乎有所提高。
还希望在一个未见过的测试数据集上验证模型时, 能看到更令人鼓舞的结果。
3. 改变你的性能指标
目前,通过重采样数据集来解决不平衡类别的问题的两种方法。接着,考虑使用其他性能指标来评估模型。
阿尔伯特•爱因斯坦
“如果你根据能不能爬树来判断一条鱼的能力,那你一生都会认为它是愚蠢的。”
这句话真正突出了选择正确评估指标的重要性。
对于分类的通用指标,推荐使用 ROC 曲线下面积 (AUROC)。
- AUROC 表示从中类别中区别观测样本的可能性。
- 如果从每个类别中随机选择一个观察样本,它将被正确的“分类”的概率是多大?
从 Scikit-Learn 中导入这个指标:
ROC 曲线下面积
from sklearn.metrics import roc_auc_score
为了计算 AUROC,你将需要预测类别的概率,而非仅预测类别。你可以使用如下代码获取这些结果 .predict_proba()
获取类别概率
# Predict class probabilities
prob_y_2 = clf_2.predict_proba(X)
# Keep only the positive class
prob_y_2 = [p[1] for p in prob_y_2]
prob_y_2[:5] # Example
# [0.45419197226479618,
# 0.48205962213283882,
# 0.46862327066392456,
# 0.47868378832689096,
# 0.58143856820159667]
那么在 AUROC 下 这个模型 (在下采样数据集上训练模型) 效果如何?
下采样后数据集上训练的模型的 AUROC
print( roc_auc_score(y, prob_y_2) )
# 0.568096626406
这和在不平衡数据集上训练的原始模型相比,又如何呢?
不平衡数据集上训练的模型的 AUROC
prob_y_0 = clf_0.predict_proba(X)
prob_y_0 = [p[1] for p in prob_y_0]
print( roc_auc_score(y, prob_y_0) )
# 0.530718537415
在不平衡数据集上训练的原始模型拥有 92% 的准确率,它远高于下采样数据集上训练的模型的 58% 准确率。
然而,后者模型的 AUROC 为 57%,它稍高于 AUROC 为 53% 原始模型的 (并非远高于)。
注意:
- 如果 AUROC 的值为 0.47,要翻转预测,因为 Scikit-Learn 误解释了正向类别。
- AUROC 应该 >= 0.5
4. 惩罚算法 (代价敏感学习)
使用惩罚学习算法来增加对少数类别分类错误的代价。
一个流行的算法是惩罚性-SVM:
支持向量机
from sklearn.svm import SVC
训练时, 使用参数 class_weight='balanced' 来减少由于少数类别样本比例不足造成的预测错误。
也可以包含参数 probability=True ,如果想启用 SVM 算法的概率估计。
在原始的不平衡数据集上使用惩罚性的 SVM 训练模型:
SVM 在不平衡数据集上训练惩罚性-SVM
# 分离输入特征 (X) 和目标变量 (y)
y = df.balance
X = df.drop('balance', axis=1)
# 训练模型
clf_3 = SVC(kernel='linear',
class_weight='balanced', # penalize
probability=True)
clf_3.fit(X, y)
# 在训练集上预测
pred_y_3 = clf_3.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_3 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_3) )
# 0.688
# What about AUROC?
prob_y_3 = clf_3.predict_proba(X)
prob_y_3 = [p[1] for p in prob_y_3]
print( roc_auc_score(y, prob_y_3) )
# 0.5305236678
目的只是为了说明这种技术。真正决定哪种策略最适合这个问题,要在保留测试集上评估模型。
5. 使用基于树的算法
最后一个策略将考虑使用基于树的算法。决策树通常在不平衡数据集上表现良好,因为它们的层级结构允许它们从两个类别去学习。
在现代应用机器学习中,树集合(随机森林、梯度提升树等) 几乎总是优于单一决策树,所以我们将跳过单一决策树直接使用树集合模型:
随机森林
from sklearn.ensemble import RandomForestClassifier
现在,在原始的不平衡数据集上使用随机森林训练一个模型。
在不平衡数据集上训练随机森林
# 分离输入特征 (X) 和目标变量 (y)
y = df.balance
X = df.drop('balance', axis=1)
# 训练模型
clf_4 = RandomForestClassifier()
clf_4.fit(X, y)
# 在训练集上进行预测
pred_y_4 = clf_4.predict(X)
# 我们的模型仍然仅能预测一个类别吗?
print( np.unique( pred_y_4 ) )
# [0 1]
# 我们的准确率如何?
print( accuracy_score(y, pred_y_4) )
# 0.9744
# AUROC 怎么样?
prob_y_4 = clf_4.predict_proba(X)
prob_y_4 = [p[1] for p in prob_y_4]
print( roc_auc_score(y, prob_y_4) )
# 0.999078798186
97% 的准确率和接近 100% AUROC 是魔法吗?戏法?作弊?是真的吗?
嗯,树集合已经非常受欢迎,因为他们在许多现实世界的问题上表现的非常良好。
然而:
- 虽然这些结果令人激动,但是模型可能导致过拟合,因此做出最终决策之前, 仍要在未见过的测试集上评估模型。
注意:
- 由于算法的随机性,结果可能略有不同。为了能够复现试验结果,设置一个随机种子。
顺便提一下
有些策略没有写入本教程:
创建合成样本 (数据增强)
创建合成样本与上采样非常相似, 一些人将它们归为一类。例如, SMOTE 算法 是一种从少数类别中重采样的方法,会轻微的引入噪声,来创建”新“样本。
你可以在 imblearn 库 中 找到 SMOTE 的一种实现
注意:我们的读者之一,马可,提出了一个很好的观点:仅使用 SMOTE 而不适当的使用交叉验证所造成的风险。查看评论部分了解更多详情或阅读他的关于本主题的 博客文章 。
组合少数类别
组合少数类别的目标变量可能适用于某些多类别问题。
例如,假如你希望预测信用卡欺诈行为。在你的数据集中,每种欺诈方式可能会分别标注,但你可能并不关心区分他们。你可以将它们组合到单一类别“欺诈”中并把此问题归为二值分类问题。
重构欺诈检测
异常检测, 又称为离群点检测,是为了检测异常点(或离群点)和小概率事件。不是创建一个分类模型,你会有一个正常观测样本的 ”轮廓“。如果一个新观测样本偏离 “正常轮廓” 太远,那么它就会被标注为一个异常点。
总结 & 下一步
介绍了 5 种处理不平衡类别的有效方法:
- 上采样 少数类别
- 下采样 多数类别
- 改变性能指标
- 惩罚算法 (代价敏感学习)
- 使用基于树的算法
这些策略受没有免费的午餐定理支配,你应该尝试使用其中几种方法,并根据测试集的结果来决定你的问题的最佳解决方案。
【2019-04-25】Google colab上的代码实现
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
