强化学习工具及应用
RL 理论
详见站内专题: 强化学习
工具
环境
模拟后端
- 如 gym (GymEnv)、Brax (BraxEnv) 或 DeepMind Control Suite (DMControlEnv))
gym
OpenAI开发了用于研发和比较强化学习算法的工具包 gym库。
gym 提供方便快捷的模拟器接口,一行代码构建能够于强化学习算法交互的模拟器
函数
step() 方法 非常核心,负责推进环境(模拟器或游戏)状态,并返回一些有用信息。
- 每一步,算法会传入一个动作到 step() 方法,然后返回新的状态、奖励等信息。
注:
- 新版
Env.step函数现在返回5个值,而不是之前的4个。 - 这5个返回值分别是:
观测(observation)、奖励(reward)、是否结束(done)、是否截断(truncated)和其他信息(info)。
step() 方法调用后返回四个主要元素:
- 观察(observation):这通常是一个数组或其他数据结构,表示环境的当前状态。
- 奖励(reward):一个数值,表示执行上一个动作后获得的即时奖励。
- 完成标记(done):一个布尔值,表示是否达到了环境的结束条件。
- 额外信息(info):一个字典,可能包含额外的调试信息或其他元数据。通常不应用于训练模型。
与其他技术比较,比如传统的监督学习,强化学习和 gym库的 step() 方法提供了更加动态和交互式的方式来训练模型。
- 监督学习中,一次性获取所有的输入和输出
- 而强化学习中,step() 方法让模型能够与环境进行连续的交互。
对于模拟复杂任务(比如游戏、机器人导航等)非常有用,因为允许模型在学习过程中不断地接收反馈,并据此调整行为。
示例
# !pip install gym
import gym
env = gym.make('CarDriving-v0')
observation = env.reset() # 初始的观察
action = choose_action(observation) # 算法选择的动作
observation, reward, done, info = env.step(action)
示例
月球车
代码
import gym
env_name = "LunarLander-v2"
env = gym.make(env_name) # 导入注册器中的环境
episodes = 10
for episode in range(1, episodes + 1):
state = env.reset() # gym风格的env开头都需要reset一下以获取起点的状态
done = False
score = 0
while not done:
env.render() # 将当前的状态化成一个frame,再将该frame渲染到小窗口上
action = env.action_space.sample() # 通过随机采样获取一个随即动作
n_state, reward, done, info = env.step(action) # 将动作扔进环境中,从而实现和模拟器的交互
score += reward
print("Episode : {}, Score : {}".format(episode, score))
env.close() # 关闭窗口
Gymnasium
Gymnasium 是 OpenAI Gym库后续维护版本,还提供了与旧版Gym环境兼容的封装层。
- 界面简洁、易于使用,能够表示一般的强化学习问题,是一个集成了多样化单智能体参考环境的强化学习的API标准。
- 参考
Gymnasium 是为所有单智能体环境提供API的项目,包括常见的环境
- 如 cartpole, pendulum, mountain-car, mujoco, atari 等等。
Gymnasium 核心是Env,高级Python类用来代表强化学习理论中的马尔科夫决策过程(MDP)。
Env提供了生成初始化状态、转移到新状态并执行动作、可视化等方法(类内的函数)。
每个环境都通过 action_space 和 observation_space 属性来指定有效的动作和观察值的格式
Env.action_space 和 Env.observation_space 都是类Space的实例, 两个重要的方法:
Space.contains()(检验一个元素是否在空间内)Space.sample()(生成空间的随机采样的一个元素)。
Env 类型
空间:
Box: 指定上下限(可以为无穷)的连续n维空间,如 小杆角度。Discrete: 由有限个元素组成的离散空间,如 小车动作{左,右}。MultiBinary: n维的二进制空间,即二进制数组。MultiDiscrete: 由一系列离散动作空间组成,每个元素中有不同数量的动作。Text: 具有最小和最大长度的字符串空间。Dict: 由简单空间组成的字典,如{"position": Box(-1,1, shape=(2,)), "color": Discrete(3)}。Tuple: 由简单空间组成的元组。Graph: 由相互连接的节点和边构成的数学图像(网络)。Sequence: 简单空间元素的可变长度的序列。
包装器,例如:
TimeLimit: 如果达到最大步数(或基础环境发出了截断信号),则发出截断信号。ClipAction: 将传递给step的任何动作“裁剪”,使其位于基础环境的动作空间内。RescaleAction: 对动作应用线性变换,将环境放缩到新的上下界内。TimeAwareObservation: 为观测值附加时间步长的信息。在某些情况下,这有助于确保状态转移是马尔可夫的。
wrapped_env # 包装后环境信息
wrapped_env.unwrapped # 原始信息
安装
安装 Gymnasium
pip install gymnasium
初始化环境
- Gymnasium 初始化环境非常简单,只需要使用make()函数:
import gymnasium as gym
env = gym.make('CartPole-v1')
示例
import gymnasium as gym
# 初始化环境
env = gym.make("CartPole-v1", render_mode="human")
# 重置环境并获取第一次的观测
observation, info = env.reset(seed=42)
episode_over = False
while not episode_over:
# 在这里插入你自己的策略
action = env.action_space.sample()
# 执行动作使环境运行一个时间步(状态转移)
# 接收下一个观测,奖励,以及是否结束或者截断
observation, reward, terminated, truncated, info = env.step(action)
episode_over = terminated or truncated # 如果回合结束,跳出循环。多回合则注释掉。
# 如果回合结束,重置环境以开始新的回合
if terminated or truncated:
observation, info = env.reset()
env.close()
pygame
【2025-4-24】win 11 上调试pygame做的俄罗斯方块游戏,按 E/R/T 无反应
Pygame 可能遇到按键无响应问题
- 尤其是在中文输入法模式下
分析
- Pygame 默认将输入法模式设置为中文,导致按键事件无法正常捕获
解决:
- ① 按 shift: 切换输入法模式即可
- ② 代码中关闭中文输入模式
mport pygame
pygame.init()
screen = pygame.display.set_mode([640, 480])
pygame.key.stop_text_input() # 停止文本输入模式
running = True
while running:
for event in pygame.event.get():
if event.type == pygame.QUIT:
running = False
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_q:
print("你按下了q键")
pygame.quit()
TorchRL
Pytorch TorchRL 是一个用于 PyTorch 的开源强化学习 (RL) 库
- 中文文档 TorchRL
![]()
torchrl 输入和输出都是 tensordict 类
- torchrl直接强制要求输入是一个字典。
这个方法增加了灵活性,可以使得模块可以更好的重用。
安装
pip install torchrl
OpenAI Baseline
TensorFlow 1.* 实现的强化学习库
Stable Baselines
- 基于 OpenAI Baselines 改进版本,使用
TensorFlow 1.* - 实现了 100 多种 RL 算法: Baselines 重构,或 新增实现(如 Soft Actor-Critic (SAC) and Twin Delayed DDPG (TD3))
- A2C, Acer, ACKtr, DDPG, DQN, GAIL, HER, PPO1, PPO2, SAC, TD3, TRPO
安装
pip install stable-baselines[mpi]
问题
- 依赖 OpenAI Baselines
- 使用
TensorFlow 1.*, 新版TensorFlow 2.*出来后,之前不少代码废弃
Stable Baselines3
德国 German Aerospace Center (DLR) 研究员 Antonin Raffin 开发 Stable Baselines3 强化学习算法工具包
Stable Baselines3 用 PyTorch 重写,提供清晰、简单且高效的强化学习算法实现。
- 该库是 Stable Baselines 库的延续,采用更为现代和标准的编程实践
stable_baselines3 快速完成强化学习算法的搭建训练和评估,包括保存,录视频等
Stable Baselines3 为图像 (CnnPolicies)、其他类型的输入要素 (MlpPolicies) 和多个不同的输入 (MultiInputPolicies) 提供策略网络。
- MlpPolicies: MLP 结构, 适用于向量
- CnnPolicies: CNN 结构, 适用于图像输入
- MultiInputPolicies: 适用于 字典输入(多种类型)
安装
命令
pip install stable_baselines3 gym shimmy pygame
# 或源码
git clone https://github.com/DLR-RM/stable-baselines3.git
训练出来的RL算法(DQN+PPO)故障
- DQN 模型没有 masked 版本,每次 action 还是随机选择,导致训练速度太慢;
- PPO 虽然有 masked 版本,但还是和 DQN 一样:
- 预测时,action 卡住,选择的 action 不再更新,陷入死循环
- 详见一下日志、截图
代码架构
函数
BaseAlgorithm
A2C 和 PPO 继承自 BaseAlgorithm 类。
重要函数
__init__: 构造函数,初始化方法用于配置算法的参数和环境。_setup_model方法: 设置算法需要的模型,例如神经网络架构。learn方法: 主要训练循环,其中包含了数据收集、优化等步骤。collect_rollouts方法 (仅在 A2C 中): 收集经验数据,这些数据将用于训练。_update方法 (仅在 PPO 中): 核心更新步骤,包括执行多次优化迭代。
DQN
DQN
- 【2013-12-19】DeepMind 论文 Playing Atari with Deep Reinforcement Learning
- sb3 官方文档 dqn
import gymnasium as gym
from stable_baselines3 import DQN
env = gym.make("CartPole-v1", render_mode="human")
model = DQN("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000, log_interval=4)
model.save("dqn_cartpole")
del model # remove to demonstrate saving and loading
model = DQN.load("dqn_cartpole")
obs, info = env.reset()
while True:
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
obs, info = env.reset()
PPO
PPO 版本
- 原版 ppo
- Maskable PPO: action 空间剔除无效部分,效率更高
功能
日志
stable_baselines3 封装了 tensorboard 前端服务, 可视化接口
tensorboard -logdir .\tensorboard\LunarLander-v2\
loss
loss 是当前策略网络查询得到的Q值和固定的目标网络查询的Q值的L1 loss
模型
模型参数
model = DQN(
"MlpPolicy",
env=env,
learning_rate=5e-4,
batch_size=128,
buffer_size=50000,
learning_starts=0,
target_update_interval=250,
policy_kwargs={"net_arch" : [256, 256]},
verbose=1,
tensorboard_log="./tensorboard/LunarLander-v2/"
)
应用
离线策略 Pendulum
同时用多个离线策略算法环境,更新 gradient_steps 参数
- 将其设置为
gradient_steps=-1,以执行所收集到的转换所需的所有梯度步骤
代码
import gym
from stable_baselines3 import SAC
from stable_baselines3.common.env_util import make_vec_env
env = make_vec_env("Pendulum-v0", n_envs=4, seed=0)
# We collect 4 transitions per call to `ènv.step()`
# and performs 2 gradient steps per call to `ènv.step()`
# if gradient_steps=-1, then we would do 4 gradients steps per call to `ènv.step()`
model = SAC('MlpPolicy', env, train_freq=1, gradient_steps=2, verbose=1)
model.learn(total_timesteps=10_000)
小车单摆 CartPole
PPO 训练 CartPole
import gym
from stable_baselines3 import PPO
def main():
env = gym.make('CartPole-v1') # 创建环境
model = PPO("MlpPolicy", env, verbose=1) # 创建模型
model.learn(total_timesteps=20000) # 训练模型
model.save("ppo_cartpole") # 保存模型
test_model(model) # 测试模型
def test_model(model):
env = gym.make('CartPole-v1', render_mode='human') # 可视化只能在初始化时指定
obs, _ = env.reset()
done1, done2 = False, False
total_reward = 0
while not done1 or done2:
action, _states = model.predict(obs, deterministic=True)
obs, reward, done1, done2, info = env.step(action)
total_reward += reward
print(f'Total Reward: {total_reward}')
env.close()
if __name__ == "__main__":
main()
另一个示例
import gym
import numpy as np
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv, SubprocVecEnv
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.utils import set_random_seed
def make_env(env_id, rank, seed=0):
"""
Utility function for multiprocessed env.
:param env_id: (str) the environment ID
:param num_env: (int) the number of environments you wish to have in subprocesses
:param seed: (int) the inital seed for RNG
:param rank: (int) index of the subprocess
"""
def _init():
env = gym.make(env_id)
env.seed(seed + rank)
return env
set_random_seed(seed)
return _init
if __name__ == '__main__':
env_id = "CartPole-v1"
num_cpu = 4 # Number of processes to use
# Create the vectorized environment
env = SubprocVecEnv([make_env(env_id, i) for i in range(num_cpu)])
# Stable Baselines provides you with make_vec_env() helper
# which does exactly the previous steps for you.
# You can choose between `DummyVecEnv` (usually faster) and `SubprocVecEnv`
# env = make_vec_env(env_id, n_envs=num_cpu, seed=0, vec_env_cls=SubprocVecEnv)
model = PPO('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=25_000)
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
月球车 LunarLander
import gym
from stable_baselines3 import DQN
from stable_baselines3.common.vec_env.dummy_vec_env import DummyVecEnv
from stable_baselines3.common.evaluation import evaluate_policy
env_name = "LunarLander-v2"
env = gym.make(env_name) # 导入注册器中的环境
env = DummyVecEnv([lambda : env]) # env 包装,从而将环境向量化, 便于同时使用多个环境,提高采样和训练的效率
model = DQN(
"MlpPolicy", # DQN 策略, MLP 神经网络
env=env,
verbose=1
)
# 启动训练
# total_timesteps 总时间步, 模拟的 state,action,reward,next state 采样数量
model.learn(total_timesteps=1e5)
# 评估效果
mean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=10, render=False)
env.close()
mean_reward, std_reward # (-166.24617834256043, 50.530194648006685)
# 模型保存
model.save("./model/LunarLander3.pkl")
预测
env = gym.make(env_name)
model = DQN.load("./model/LunarLander3.pkl")
state = env.reset()
done = False
score = 0
while not done:
action, _ = model.predict(observation=state)
state, reward, done, info = env.step(action=action)
score += reward
env.render()
env.close()
score
另一个完整示例
import gym
from stable_baselines3 import DQN
from stable_baselines3.common.evaluation import evaluate_policy
# Create environment
env = gym.make('LunarLander-v2')
# Instantiate the agent
model = DQN('MlpPolicy', env, verbose=1)
# Train the agent
model.learn(total_timesteps=int(2e5))
# Save the agent
model.save("dqn_lunar")
del model # delete trained model to demonstrate loading
# Load the trained agent
# NOTE: if you have loading issue, you can pass `print_system_info=True`
# to compare the system on which the model was trained vs the current one
# model = DQN.load("dqn_lunar", env=env, print_system_info=True)
model = DQN.load("dqn_lunar", env=env)
# Evaluate the agent
# NOTE: If you use wrappers with your environment that modify rewards,
# this will be reflected here. To evaluate with original rewards,
# wrap environment in a "Monitor" wrapper before other wrappers.
mean_reward, std_reward = evaluate_policy(model, model.get_env(), n_eval_episodes=10)
# Enjoy trained agent
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, rewards, dones, info = env.step(action)
env.render()
应用
量化交易
强化学习量化交易分类
- 【2022-3-14】【RL-Fintech】强化学习在金融量化领域的最新进展
- RL在量化交易里面的应用,大致分为4种:
- Portfolio Management(投资组合管理)—— 低频
- 通过灵活分配资产权重获得更高超额收益的问题。现实中的应用例子比如选股和指数增强基金。一般的解决方案是对股票的涨价潜力进行打分,买入具有上涨潜力的股票并增加权重,卖出可能跌或者相对弱势的股票。这是一个多时间序列(Multiple Time Series)上的权重再分配问题。
- 两篇baseline是 AlphaStock(2019) 和 DeepTrader(2021)
- Single-asset trading signal (单资产交易信号) —— 中高频
- 单资产的交易信号问题是指对单一资产进行买卖操作以获得比单纯持有更高利润的问题。监督学习在这类问题中取得了比较大的成功。
- 前面介绍的PM问题进来的研究热点在于时空关系的发掘方面,并没有很多RL算法设计上的独特创新。事实上RL独特的reward设计在2000-2006年左右研究得比较多,当时受制于算力,一般都还是单一资产的交易问题上进行应用。
- Execution(交易执行)—— 高频
- Option hedging(期权对冲和定价)。
- 其中PM一般是低频交易,单股交易信号一般是中高频,交易执行一般是高频tick级数据上的策略,至于期权定价则是理论和实践统一起来的工作。
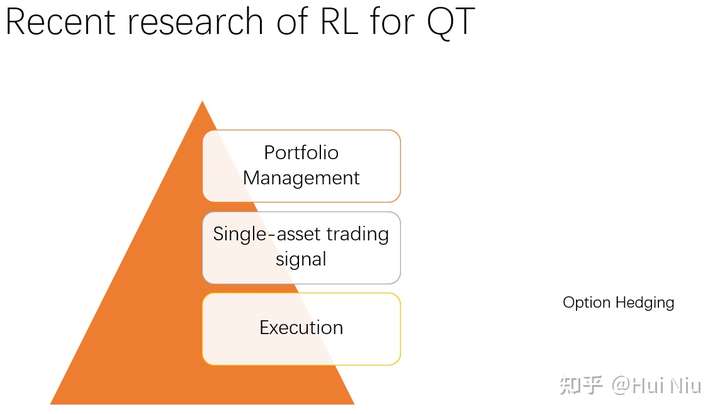
- Portfolio Management(投资组合管理)—— 低频
如何应用RL
- 【2021-4-6】强化学习(Reinforcement Learning)在量化交易领域如何应用
讲个大实话:这个问题的答案其实都不用看,肯定都不靠谱,靠谱的肯定不会告诉你
感兴趣的朋友可以在BigQuant AI平台上动手实践一下
1. 相比(无)监督学习,强化学习在量化领域应用时,首先需要建立一个环境,在环境中定义state,action,以及reward等。定义的方式有多种选择,比如:
- state: 可以将n天的价格,交易量数据组合成某一天的state,也可以用收益率或是其他因子组合作为某一天的state,如果想要定义有限个的state,可以定义为appreciated/ hold_value/ depreciated这样3类。
- action: 可以定义为buy/sell两种, 也可以定义为buy/sell/hold三种,或者定义为一个(-1,1)之间的一个连续的数,-1和1分别代表all out 和 holder两个极端。
- reward: 可以定义为新旧总资产价值之间的差,或是变化率,也可以将buy时的reward定义为0,sell时的定义为买卖价差。
2. 需要选择一个具体的强化学习方法:
- 1) Q-table (具体可参考:Reinforcement Learning Stock Trader)
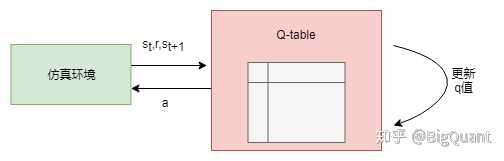
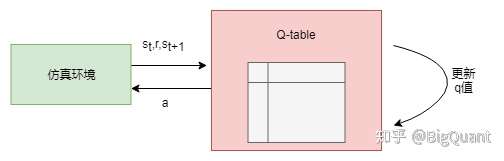
- Q-table里state是有限的,而我们定义的state里面的数据往往都是连续的,很难在有限个state里面去很好的表达。
- 2) Deep Q Network(参考:Reinforcement Learning for Stock Prediction )

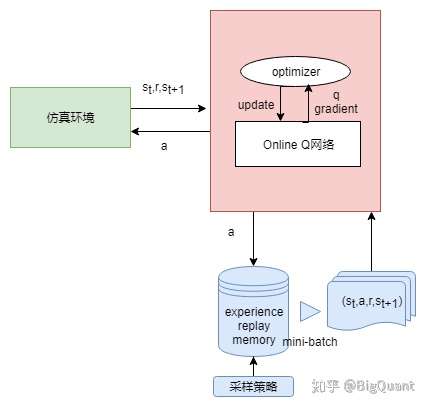
- 在1的基础上,将Q-table的功能用一个深度学习网络来实现,解决了有限个state的问题。
- 3) Actor Critic (参考:Deep-Reinforcement-Learning-in-Stock-Trading)

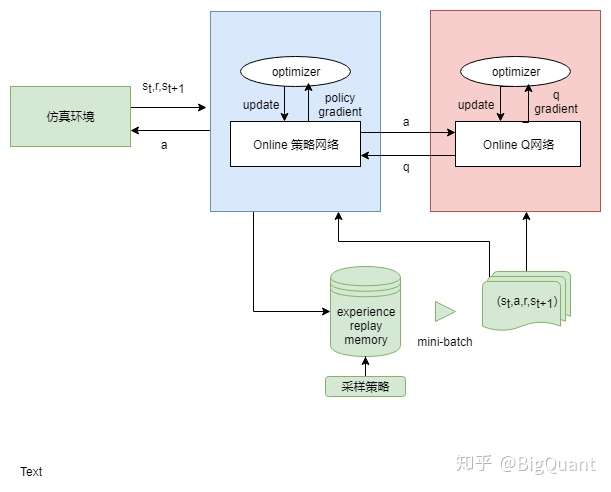
- 用两个模型,一个同DQN输出Q值,另一个直接输出行为。但由于两个模型参数更新相互影响,较难收敛。
- 4) DDPG(参考:ml-stock-prediction)
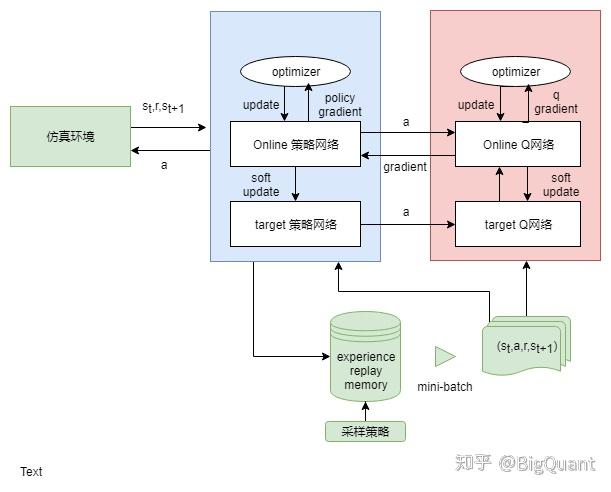
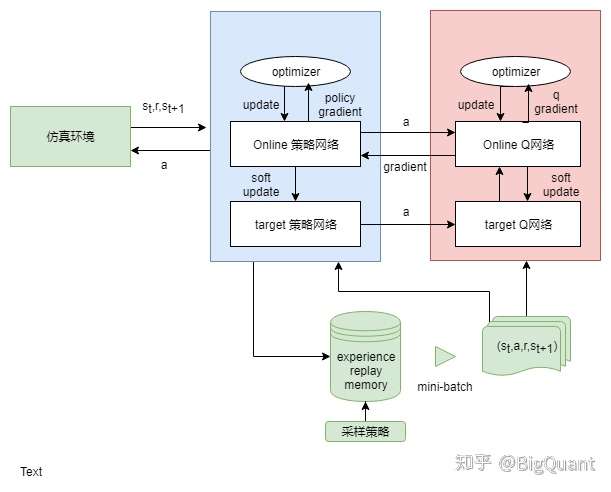
- 加入了不及时更新参数的模型,解决难收敛的问题
3. 由于多数方法中都用到了深度神经网络,我们还需要对神经网络的模型,深度,还有其他参数进行一个选择。
4. 比较简单的应用逻辑是对单个股票某一时间段进行择时,如果需要也可以在这个基础上进行一些调整,对某个股票池的股票进行分析,调整为一个选股策略。
游戏
详见站内专题: AI游戏策略
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
