RAG 消失之路
问题
RAG 终会消失
相似≠相关
基本流程
200 页的文档 → 切块转换成嵌入向量 → 相似度检索 → LLM 作答
这种系统找到的是相似而非相关
- 看起来像(相似)而未必真正相关的片段。
场景:
- 适合简单问答。
- 金融财报、法律合同或技术手册等复杂的专业文档时,相似度与相关性之间的差距就是准确率走坏的开始。
RAG 工程暗伤
RAG 每个环节都藏着工程”暗伤”:
- 切片策略是玄学:按段落切?按 Token 数切?重叠多少?切片粒度直接影响检索质量,却没有银弹。
- Embedding 是黑盒:换个 Embedding 模型,检索效果可能天差地别。而且向量只是原文的一个”有损压缩”,信息必然丢失。
- 索引更新是噩梦:文档改一行,可能需要重新切片、重新 Embedding、重新写入。实时性?基本别想。
- 基础设施是成本:Milvus、Qdrant、Pinecone……光是向量数据库的选型、部署、运维就能消耗大量精力。
详见站内专题:大模型应用技术之RAG,检索增强生成
总结
方案总结
- 免嵌入 Embedding Free
- 树状推理:PageIndex
- 无检索:阿里 Sirchmunk(蒙特卡洛采样+自进化数据库)
- 文件检索:Google File Search、字节 OpenViking(依赖embedding)
新结构
【2026-4-3】M-FLOW 倒锥图路由-联想记忆
【2026-4-3】M-FLOW 由中国年轻团队开发,针对传统RAG仅做文本匹配、缺乏推理能力的短板。
19岁中国少年团队打造 M-Flow 记忆引擎,以“联想式记忆”颠覆传统AI搜索范式,在 LoCoMo、LongMemEval 等三大权威榜单全线登顶。其独创的Cone Graph锥形图谱结构,让AI像人一样从线索中激活上下文、重建情境,真正实现“会联想”的智能记忆。这不仅是技术突破,更是Agent迈向类人智能的关键一步
核心是”倒锥图路由架构”,通过 FacetPoint(原子断言)、Entity(命名事物)和Facet(截面维度)三层结构,实现多跳推理与跨文档关联。
详见站内专题:Agent 记忆设计
无嵌入 Embedding free
定义
无 Embedding RAG(RAG without embeddings)指任何不以向量嵌入作为主要检索手段的 RAG 架构。
- 省略经典步骤: “向量化查询和文档,然后进行向量近邻搜索”
论文
- 【2025-11-*】苏州 Embedding-Free RAG 提出 Embedding-Free RAG 方案,应道在文档问答中,实时、问题驱动
无 Embedding RAG 采用替代方案
- 基于关键字的搜索(如 BM25)
- LLM 驱动的迭代检索(如 ELITE)
- 基于知识图谱的方法(如 GraphRAG)
- 基于提示的检索(如 Prompt-RAG),以解决语义和操作上的限制。
无 Embedding RAG 优势
- 更好的可解释性、更低的延迟、更少的存储需求和更强的领域适应性。
这使其在医疗、法律、金融等专业领域以及需要透明度或跨文档推理的场景中极具价值。
总结
【2025-8-26】RAG 场景挑战与进阶方案对比表
| 场景 | 示例 | 传统向量 RAG 的挑战 | 无 Embedding/图/Agent 方案的优势 | 推荐策略 |
|---|---|---|---|---|
| 复杂的多跳问题 | X 和 Y 有什么联系? | 分别检索 X 和 Y 相关块,但不知道要连接起来;生成步骤可能会幻化出联系。 | 图可以明确地展示出路径 (X → … → Y)。以推理为中心的检索为 LLM 提供可遵循的事实链。 | GraphRAG(实体/关系遍历)或能够规划多跳查询的 Agentic 检索器。 |
| 严格的事实/合规性需求 | 法律、金融、医疗 | 语义“差之毫厘”不可接受;如果措辞不同,权威条款/案例可能会被错过。 | 关键字/词法信号和领域知识图谱可以实现精确匹配和可审计的追溯;很容易展示为什么检索到了某个片段。 | 关键字/BM25 过滤 → 可选的 LLM 重排;或领域图谱(如引用、法规)。如果使用向量,也应先进行混合检索。 |
| 专业领域 / 小数据量文档 | 生物医学、法律、小众技术文档 | 通用 Embedding 难以处理专业术语/符号;可能会错误排序或遗漏关键段落。 | 利用文档结构(标题/目录)、本体和领域图谱;基于 Prompt 的章节选择性能可能优于向量。 | 基于 Prompt 的检索(感知目录/标题)、本体/图谱查询,或词法检索 → LLM 重排。 |
| 低查询量、海量语料库 | 档案馆、研究资料库 | 当查询稀少时,维护一个大型向量索引的成本很高;数据更新时的重新 Embedding 增加了运维开销。 | 按需的 Agentic 检索避免了闲置基础设施;成本仅在查询到达时产生。 | 基于 Agent 的检索,通过目录/元数据进行有针对性的阅读;可选择小型词法索引代替向量数据库。 |
💡 核心洞察总结
- 传统向量 RAG 的局限性:在多跳推理、精确合规、专业术语、冷启动/低流量场景下,单纯依赖语义相似度的检索会出现明显短板。
- 进阶方案的价值:图结构(GraphRAG)、词法/关键字检索、Agent 按需检索等方式,能更好地解决可解释性、精确匹配、成本控制等问题。
- 混合策略是趋势:多数场景下,推荐将向量检索与其他方案(如 BM25、图谱、Agent)结合,而非完全抛弃向量 RAG。
详见:超越向量数据库:探索无需 Embedding 的 RAG 新架构
文件检索
Claude Code
2025年5月,Anthropic 工程师 Boris 在 Latent Space 播客里提到
- Claude code 早期确实试过 RAG,标准方案–本地向量数据库加embedding检索,但效果不行,最终切换到叫“agentic search”的方式,让模型自己调用 grep、glob、find 这些 Linux 命令去实时搜索代码。
【2026-5-31】丁师兄讲大模型
Claude Code为什么放弃RAG?
- Embedding 对代码标识符的语义理解失效。
- getUserById 和 deleteUserById 两个函数名在向量空间里的距离非常近,因为共享了大量重复 token。但功能完全相反,查询vs删除。
- 代码不是自然语言,是结构化的精确标识符,函数名、类名、变量名本身就是最好的检索关键词。
- 这种场景下,精确匹配天然比语义匹配更可靠。grep 搜 processPayment 就是精确命中,不存在语义漂移的问题。
- RAG 管线准确率乘法效应。
- 整个链路: 文档切分、embedding生成、向量检索、重排序、最终生成,每个环节哪怕做到90%的准确率,五个环节乘下来就只剩不到 60%。
- 而且这些环节出错时,调试是噩梦级 – 不知道是 chunk切得不好、embedding质量问题、rerank 模型偏了。
- 但 grep 失败原因只有一个: 关键词没匹配上。这种确定性在工程上的价值是巨大的。
- 索引时效性。
- 代码仓库变化极快,上午建的索引下午可能就过时了。索引就跟实际代码漂移。
- 要么频繁重建索引付出巨大的计算开销,要么忍受过时索引带来的错误检索。
- 而 grep 每次都是实时搜索,拿到的永远是当前最新的代码状态,根本不存在同步问题。
更深一层: 架构哲学上的考量
- Claude Code 遵循经典原则
- 无状态设计。从 Unix 管道到 RESTAPI到 Serverless,在计算机科学里反复被验证过。
- 不建索引: 零配置,用户 clone 完代码就能直接用,不需要等几分钟构建 embedding。
- 不维护状态: 零运维负担,没有“索引卡住了”“缓存损坏了”这种问题。
- Anthropic内部原则 “everythingis the model” – 尽量让模型驱动决策,而不是在模型外面搭复杂的工程管线。模型每变强一分,整个系统就自动变好一分,这其实就是Rich Sutton 说的 Bitter Lesson 在工程上的体现。
- 无状态设计。从 Unix 管道到 RESTAPI到 Serverless,在计算机科学里反复被验证过。
- 安全性。
- RAG 方案把代码做embedding存到某个地方,不管是本地还是云端,存在信息泄露的风险–学术上证明可从embedding反推原始内容。
- 而 grep 完全在本地执行,从架构上就杜绝了这个问题。
辩证思考: 这种方案的不足
ClaudeCode 方案也有代价,最大的是 token 消耗。
- 每次搜索都是实时执行,模型要列目录、读文件、做多轮探索,token 用量远高于一次性的向量检索。
- Milvus 团队批评:这是“烧 token”。
- 而且对于超大型代码库,纯 grep 方式在概念级搜索上确实有短板:想找“所有跟权限校验相关的逻辑”,grep 不一定能覆盖所有变体写法。
业界共识:混合方案。
- 精确搜索处理标识符级别查找,语义检索处理概念级别的探索,两者互补。
Claude Code 选择极简方案,Cursor 选择 向量索引,未来大概率会在中间某个位置收敛。
核心就是三层:
- 技术事实层:embedding对代码的失效和管线复杂度
- 架构哲学层:无状态设计和“everythingis the model”的理念
- 辩证层:承认 token 成本和概念搜索的局限。
Google File Search
【2025-11-06】file-search-gemini-api
Google 在 Gemini 生态里直接宣判了 RAG 的死刑。
File Search 概括:Google 把 RAG 从工程领域直接删掉了。
- 以前做 RAG 是一整条流水线:切 chunk → embedding → 向量库 → 检索策略 → 引用链路 → 缓存优化 → prompt 拼装。
- 现在 Gemini 的 File Search 非常简单,把PDF/JSON/代码/Markdown 扔进一个 store,然后问问题。
- 剩下全部交给模型。不需要理解 RAG,也不需要设计 RAG,甚至不需要知道 RAG 曾经长什么样。
就这么简单,整个 RAG 技术链路的所有复杂度不可逆地被压到平台底层。AI 应用的门槛又被 Google 掐了一次脖子。我也没想到有一天模型厂商竟然用这种方式吞掉了技术。
【2026-2-6】字节 OpenViking
Agent 开发面临以下挑战:
- 上下文碎片化:记忆存储在代码中,资源在向量数据库中,技能分散在各处,难以统一管理。
- 上下文需求激增:智能体的长运行任务在每次执行时都会产生上下文。简单的截断或压缩会导致信息丢失。
- 检索效果不佳:传统 RAG 使用扁平化存储,缺乏全局视图,难以理解信息的完整上下文。
- 上下文不可观察:传统 RAG 的隐式检索链像黑盒,出错时难以调试。
- 记忆迭代有限:当前记忆只是用户交互的记录,缺乏智能体相关的任务记忆。
朴素 RAG 的数据切片是平铺式存储,缺乏全局视野,面对海量、多模态且有信息组织的数据越来越力不从心,可能会错失关键信息。同时,过于关注语义相关性,在需要兴趣泛化和探索的开放式场景中表现不佳。
OpenViking 专为 AI 智能体设计的开源上下文数据库。
- 目标:为智能体定义一个极简的上下文交互范式,让开发者完全告别上下文管理的烦恼
【2026-2-6】OpenViking 给 Agent 定义极简上下文交互范式,让开发者彻底告别上下文管理的烦恼。
- 官方中文文档
OpenViking 摒弃了传统 RAG 的碎片化向量存储模式,创新性地采用“文件系统范式” , 将 Agent 所需的记忆、资源和技能进行统一的结构化组织。
不再将上下文视为扁平的文本切片,而是将其统一抽象并组织于一个虚拟文件系统中。无论是记忆、资源还是能力,都会被映射到 viking:// 协议下的虚拟目录,拥有唯一的 URI。这种范式赋予了 Agent 前所未有的上下文操控能力,使其能像开发者一样,通过 list、find 等标准指令来精确、确定性地定位、浏览和操作信息,让上下文的管理从模糊的语义匹配演变为直观、可追溯的“文件操作”。
OpenViking 借鉴业界前沿实践,在上下文写入时便自动将其处理为三个层级:
- L0 (摘要) :一句话概括,用于快速判断。
- L1 (概述) :包含核心信息和使用场景,供 Agent 在规划阶段进行决策。
- L2 (详情) :完整的原始数据,供 Agent 在确有必要时深入读取。
OpenViking 设计一套创新的目录递归检索策略,深度融合了多种检索方式的优点:
- 首先,通过意图分析生成多个检索条件;然后,利用向量检索快速定位初始切片所在的高分目录;
- 接着,在该目录下进行二次检索,并将高分结果更新至候选集合;若目录下仍存在子目录,则逐层递归重复上述二次检索步骤;
- 最终,拿到最相关上下文返回。这种 “先锁定高分目录、再精细探索内容” 的策略,不仅能找到语义最匹配的片段,更能理解信息所在的完整语境,从而提升检索的全局性与准确性。
作者:字节跳动开源
借助 OpenViking,上下文不再是散落一地的拼图,而是一个层次分明、井然有序的认知系统。
- 文件系统管理范式 → 解决碎片化问题: 基于文件系统范式,将记忆、资源、技能进行统一上下文管理
- 分层上下文按需加载 → 降低 Token 消耗: L0/L1/L2 三层结构,按需加载,大幅节省成本
- 目录递归检索 → 提升检索效果: 支持原生文件系统检索方式,融合目录定位与语义搜索,实现递归式精准上下文获取
- 可视化检索轨迹 → 上下文可观测: 支持可视化目录检索轨迹,让用户能够清晰观测问题根源并指导检索逻辑优化
- 会话自动管理 → 上下文自迭代: 自动压缩对话中的内容、资源引用、工具调用等信息,提取长期记忆,让 Agent 越用越聪明
安装
pip install openviking --upgrade --force-reinstall
OpenViking 需要以下模型能力:
- VLM 模型:用于图像和内容理解
- Embedding 模型:用于向量化和语义检索
启动服务
# 启动服务器
openviking-server
# 或者后台运行
nohup openviking-server > /data/log/openviking.log 2>&1 &
无向量 Vectorless RAG
传统 RAG 架构中,“Embeddings + 向量搜索”构成了“检索”环节的核心
基于 Embedding 的 RAG 问题:
- 基础设施复杂性和高昂成本。
- 生成 Embeddings、维护向量数据库以及数据更新后的重新索引都需要大量的计算和存储资源。
Vectorless RAG 介绍
【2026-6-13】分块时代结束,无向量RAG的核心拆解
基于推理的检索(Reasoning-based retrieval)正在取代大多数团队好几年才搭起来的技术栈……
- 固有认知:
RAG=向量
无向量 RAG(Vectorless RAG)是完全不同的检索架构
无向量 RAG 不再用文档切片和向量嵌入,直接读取文档组织结构,构建完美映射文档实际目录的分层树状索引(Hierarchical Tree Index), 大章节、小章节、子章节, 让LLM进行逻辑推理的结构化目录。
- 检索从此变成推理过程,而不再是相似度匹配。
运作机制
- 文档索引
- 项目符号将完整文档解析为
分层树状结构。 - 无需分块、无需向量化、无需向量数据库。
- 项目符号将完整文档解析为
- 树状推理
- LLM 从根节点开始,一路向下遍历到相关叶节点。
- 在向更深层级推进之前,先评估当前层级的上下文。
- 上下文感知检索
- 将完整的对话历史无缝融入搜索中。
- 返回精确的页码和章节引用,全链路可追溯。
- 智能体化执行
- VectifyAI 基于 OpenAI Agents SDK 构建可运行 Demo。
- 实现端到端的智能体流水线,中间没有插入任何向量层。
效果
FinanceBench 中
- 行业领先的开源无向量RAG框架
PageIndex拿到 98.7%的高分。 - 带联网搜索功能的
ChatGPT-4o仅为31%。
PageIndex
【2026-1-22】相似度 ≠ 相关性:颠覆传统 RAG,PageIndex 让 AI 学会”推理式检索”
RAG 根本问题:相似度 ≠ 相关性。
寻找真正相关的信息,不是相似度匹配,而是推理能力。 PageIndex 试图解决的革命性挑战。
PageIndex 是开创性、无向量、基于推理 RAG 系统,从长文档中构建分层树索引,并使用大语言模型通过树搜索进行智能体化的、上下文感知的检索。
- 目标:针对长篇、专业级文档(例如财报、监管文件、技术手册)提供比传统向量检索更相关、更可解释的检索方法。
- 核心思想:先用 LLM 构建文档的层次化“目录/树”索引(自然语义的节点,而非机械的 chunk),再通过基于树的检索与 LLM 推理来找到最相关的段落或页,从而实现“人类专家式”的导航与抽取。
- GitHub PageIndex
特点
- 无向量化数据库(No Vector DB) — 不依赖向量数据库或相似度搜索,而是依靠文档结构 + LLM 推理来判断“相关性”,避免“vibe retrieval(感觉相似但不相关)”。
- 无需盲目切片(No Chunking) — 文档按自然章节/页面组织成树形结构,保留原始语义边界,避免人工分块导致的上下文破碎与检索误差。
- 类人检索(Human-like Retrieval) — 通过树搜索与链式推理模拟专家如何在长文档中导航(比如先查看目录/章节再逐步深入),因此检索结果包含可追溯的页码/章节引用,解释性强。
- 可解释性与可追溯性(Explainability & Traceability) — 每次检索都能返回“为什么选到这一节/页”的理由与路径,便于审计与人工验证(非常适合合规/财务/法务等领域)。
- 配套资源丰富 — 仓库提供:示例代码、cookbooks(Vectorless RAG、Vision -based RAG)、Colab 笔记本、API 文档与 chat 平台(chat.pageindex.ai),便于快速试验与集成。
PageIndex 代表了 RAG 技术的一次范式转移:从”相似度匹配”到”推理驱动检索”。
核心价值主张:
- ✅ 无需向量数据库:降低架构复杂度
- ✅ 保留文档结构:维护原始语义完整性
- ✅ 可解释检索:每一步推理都有迹可循
- ✅ 人类化导航:模拟专家阅读模式
受 AlphaGo 启发,PageIndex 模拟人类专家如何通过树搜索导航和提取复杂文档中的知识,使 LLM 能够”思考”和”推理”出最相关的文档部分。
模拟人类专家阅读长文档的方式:
- 扫描目录 → 快速定位相关章节
- 推理判断 → 分析哪个部分最相关
- 深入阅读 → 逐层深入获取细节
- 交叉验证 → 在多个相关部分间跳转
| 传统向量 RAG | 问题 | PageIndex |
|---|---|---|
| 语义相似度搜索 | 推理驱动检索 | |
| 固定分块策略 | 固定大小分块会破坏语义完整性,分块边界难以确定, 跨分块信息丢失 | 自然文档结构: 保留自然章节划分,每个节点包含完整语义单元,层次结构维护上下文关系 |
| 黑盒向量匹配 | 可解释的检索路径 | |
| 要向量数据库 | 零向量依赖, 依赖文章结构、LLM推理、上下文感知 |
PageIndex 完全抛弃了向量数据库,依赖:
- 文档结构:章节、标题、段落层次
- LLM 推理:理解查询意图,导航文档树
- 上下文感知:考虑检索路径的可解释性
原理
- 树状索引结构
- PageIndex 先将长 PDF 文档转换为语义树结构,类似于”目录”,但针对 LLM 使用进行了优化
- 这种结构保留了原始文档的层次关系,而不是机械地切分成固定大小的块
- 两阶段检索流程
- 阶段一:生成目录树
- 阶段二:推理驱动的树搜索
分析
- Indexing(构建树索引):对长文档(通常以 PDF 为主)生成一个层次化的 TOC-like tree,每个节点记录标题、开始/结束页、摘要等元信息。
- Tree Search(基于树的检索):用户提问时,系统并不是直接检索向量相似度,而是让 LLM 在树上进行搜索与推理——先筛选高层节点,再逐层深入直到定位最相关的页面/段落。
- Reasoning-based RAG(推理式 RAG):定位到相关节点后,结合节点文本与模型进行生成式回答,回答中保留来源页码与节点路径以支持可验证性。
效果
- 金融问答测试集 FinanceBench 98.7% 准确率
FinanceBench 准确率对比表
| 系统 | FinanceBench 准确率 |
|---|---|
| 传统向量 RAG | ~60–70% |
| 混合检索系统 | ~75–85% |
| PageIndex (Mafin 2.5) | 98.7% |
示例
- “请分析 2023 年 Q3 报告中,供应链风险对营收的具体影响,并对比去年同期数据。”
传统向量 RAG 困境:
- 无法理解”对比去年同期”需要跨章节检索
- 相似度搜索会错过隐含在风险因素中的营收影响
- 无法执行多步骤推理
用户查询: “供应链风险对 Q3 营收的影响”
PageIndex 推理路径:
- 分析查询 → 需要风险因素 + 营收数据
- 搜索树结构 → 定位”风险因素”章节
- 推理导航 → 找到”供应链风险”子章节
- 跨章节关联 → 跳转到”财务业绩”章节
- 综合答案 → 结合两处信息生成回答
当前局限
- 依赖 LLM 推理能力:检索质量与模型推理能力直接相关
- 初始索引成本:构建树索引需要时间
- 动态文档支持:频繁更新的文档需要重建索引
适合场景
- 需要精确检索的专业文档
- 复杂的多步骤推理问题
- 高准确率要求的问答系统
不太适合的场景
- 新闻文章(结构简单,向量检索足够)
- 聊天记录(无明确层次结构)
- 短文档(不需要复杂索引)
使用方法
# 1. 克隆仓库
git clone https://github.com/VectifyAI/PageIndex.git
cd PageIndex
# 2. 安装依赖
pip3 install --upgrade -r requirements.txt
# 3. 配置 API Key
echo "CHATGPT_API_KEY=your_openai_key_here" > .env
# 使用
python3 run_pageindex.py --pdf_path /path/to/document.pdf # 处理 pdf 文档
python3 run_pageindex.py --md_path /path/to/document.md # 处理 Markdown 文档
注意
- 使用 Markdown 时,PageIndex 通过
#标记判断标题层级。建议从 PDF 转换时使用 PageIndex 的专用 OCR,以保持原始层次结构。
PageIndex 还支持纯视觉的 RAG 模式,直接处理 PDF 页面图像:避免 OCR 错误累积, 保留图表、表格等视觉信息, 适合扫描版文档
无检索
【2026-2-27】阿里 Sirchmunk
RAG 诸多问题有解吗?Sirchmunk
Sirchmunk 是阿里 ModelScope 团队开源的无索引智能搜索引擎,思路非常野:不做 Embedding,不建向量库,直接读原始文件就能搜。
总结:
- Sirchmunk 是开源、无需 Embedding 、具备 Agent 能力的搜索引擎,能把原始数据实时转化为自进化的智能知识体。
- 不做 Embedding,不建索引,直接在原始文件上搜索,用 LLM 理解内容,用知识簇沉淀结果。
Sirchmunk 代表新方向
- 从”预计算”到”按需计算”
- “Embedding 即理解”到”LLM 即理解”
- 从”静态索引”到”活的知识”
Sirchmunk 不是传统 RAG 的全面替代,而是在特定场景下(本地搜索、快速部署、数据频繁变化)提供了一个更轻、更快、更实时的选择
Sirchmunk 全名取自 “Search” + “Chipmunk”(花栗鼠),官方解释:花栗鼠会把找到的坚果藏起来备用,Sirchmunk 也一样,每次搜索的结果都会被结构化存储、持续进化,越用越聪明。
| 维度 | 传统 RAG | Sirchmunk |
|---|---|---|
| 搭建成本 | 高(向量库+embedding+ETL,如 VectorDB、GraphDB、文档解析器…) | ✅零基础设施,文件丢进去,直接对数据检索 |
| 数据时效性 | 滞后(批量重建索引) | ✅实时,即时 & 动态,变了立刻生效,自进化索引实时反映变化 |
| 准确度 | 有损,近似向量匹配 | ✅确定性 + 上下文感知,无损,直接操作原始文本 |
| 工作流 | 复杂 ETL 管线 | ✅扔文件就搜,零配置集成 |
| 基础设施 | 重(向量库+GPU) | 轻量(DuckDB+Parquet) |
| 可扩展性 | 成熟,线性成本增长 | ✅极低 RAM/CPU 消耗,但处于早期阶段 |
核心功能与特点:
- 🔍 Embedding-Free(无需向量化):不用建向量库,不用跑 ETL 管线,文件扔进去直接就能搜。支持 100+ 种文件格式,PDF、代码、Markdown 全都行
- 🧠 自进化知识簇(Self-Evolving Knowledge Clusters):每次搜索的结果不会被丢弃,而是形成结构化的”知识簇”,越搜越聪明,相似问题秒回
- 🎯 蒙特卡洛证据采样(Monte Carlo Evidence Sampling):用探索-利用策略从大文档中精准抽取证据,不用读完全文就能找到关键信息
- 🤖 ReAct Agent 兜底:标准检索搞不定?自动启动 ReAct Agent 迭代探索,直到找到答案
- 🔌 五种接入方式:MCP 协议(对接 Claude Desktop、Cursor IDE)、REST API、WebSocket 实时聊天、CLI 命令行、Web UI,全都内置
架构图
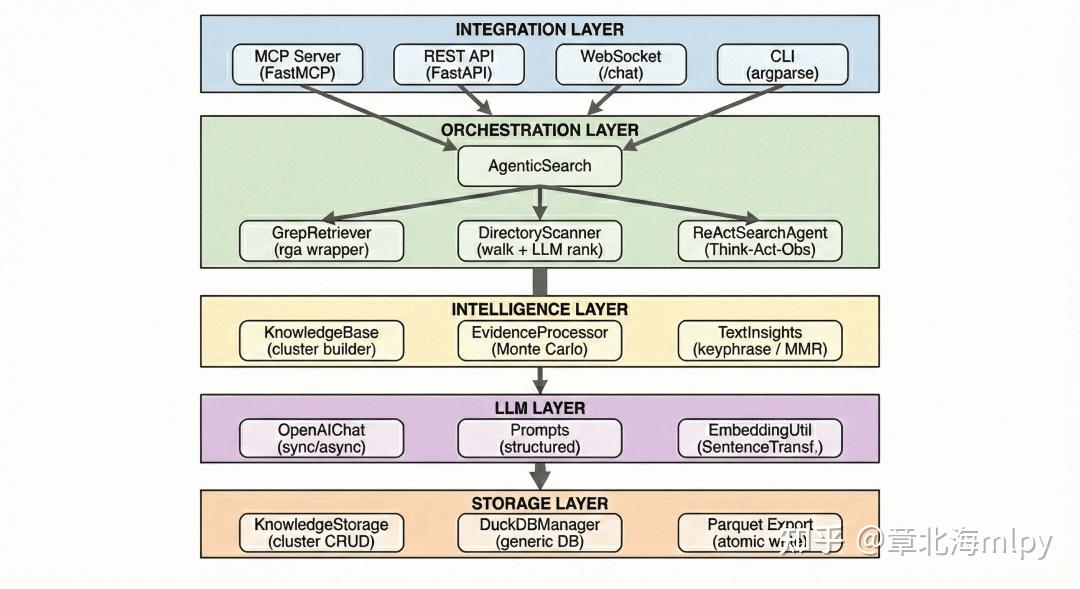
三大核心机制
- 底层引擎:ripgrep——极速文本搜索,速度快、零索引、格式友好
- 目前最快的命令行文本搜索工具,Rust编写,代码库搜索场景下性能远超grep,还能搜pdf/word/excel等二进制文件
- ripgrep 本质是关键词匹配,Sirchmunk 设计边界——需要 LLM 来弥补语义理解的缺口
- 证据提取:
蒙特卡洛重要性采样- 不同于RAG的确定性,Sirchmunk 把”从文档中找相关内容”这件事,建模成了一个采样问题,并借鉴了蒙特卡洛方法的思想
- 三阶段采样流程:探索→聚焦→合成
- 好处:探索&利用平衡、文档无关、token高效
- 知识沉淀:自进化知识簇(Knowledge Cluster)
- 知识簇就是”记忆系统”,每次搜索完成后,结果不会被丢弃,而是被结构化为 KnowledgeCluster
- 自进化:语音覆盖面自动扩展、零成本加速、热度衰减
局限
- 语义检索能力有限:底层是关键词匹配,如果文档里写的是 “authentication”,你搜”鉴权”可能搜不到。LLM 生成的关键词能部分弥补,但不如向量检索的语义泛化能力。
- 大规模场景待验证:百万级文档下,ripgrep 的遍历式搜索是否仍然高效?官方尚未给出相关 benchmark。
- 项目成熟度:截至 2026 年 2 月,v0.0.3,88 Stars,2 位贡献者。适合尝鲜和特定场景,生产环境需谨慎评估。
- LLM 依赖:DEEP 模式下每次搜索都会调用 LLM(虽然知识簇复用可以降低频次),Token 消耗仍需关注。
安装:
# 推荐使用 conda 创建虚拟环境
conda create -n sirchmunk python=3.13 -y && conda activate sirchmunk
# 安装
pip install sirchmunk
# 如需 Web UI
pip install "sirchmunk[web]"
# 如需 MCP 支持(接入 Cursor / Claude Desktop)
pip install "sirchmunk[mcp]"
使用
import asyncio
from sirchmunk import AgenticSearch
from sirchmunk.llm import OpenAIChat
llm = OpenAIChat(
api_key="your-api-key",
base_url="https://api.openai.com/v1",
model="gpt-4o"
)
async def main():
searcher = AgenticSearch(llm=llm)
result = await searcher.search(
query="Transformer 的注意力机制是如何工作的?",
paths=["/path/to/your/documents"],
)
print(result)
asyncio.run(main())
【2026-5-3】德克萨斯 DCI
🌟 总结:
- 随着大模型推理能力的增强,与其强行把文本压缩成向量去比对,不如直接把文件系统的控制权(grep/bash)交给 Agent。DCI 打开了智能体搜索全新的设计空间
2026年5月3日,德克萨斯大学发布 DCI
- 论文:Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
- 得克萨斯A&M大学、滑铁卢大学、斯坦福大学、华盛顿大学等
💡 核心痛点:
- 如今的 RAG 和 Agent 检索几乎都离不开 Embedding 模型和向量数据库(Top-k 相似度检索)。
- 但这在复杂的 Agentic Search(智能体搜索)中成了瓶颈:难以处理精确的词汇约束、稀疏线索关联以及多步假设修正。
🚀 破局之法:直接语料库交互(DCI)
- 极简而强大的新方法——直接让 Agent 像程序员一样操作底层工具!
- 不需要任何 Embedding 模型!不需要向量索引!不需要离线预处理!
- Agent 直接使用通用终端工具(如 grep、find、bash shell 脚本等)在原始文本文件中搜索。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
