- Skills 技术专题
- Skill 基础知识
- 背景
- Skills 介绍
- Skills 结构
- Skill 质量
- Skill 改进
- 发展路线
- Skill 生成
- 内化到模型
- Skill 路由
- 进化
- 总结
- 【2025-12-*】SAGE:与RL融合
- SkillMaster
- Trace2Skill
- 【2026-2-2】新加坡南洋理工 MemSkill
- 【2026-2-9】芝加哥 SkillRL:与模型一起进化
- 【2026-3-1】华东师范 AutoSkill
- 【2026-3-19】Memento-Skills
- 【2026-3-30】中科院 D2Skill
- 【2026-4-9】DreamX:SkillClaw
- 【2026-4-9】阿里 SkillClaw
- 【2026-4-9】阿里云 SkillForge
- 【2026-5-7】谷歌 SkillOS
- 【2026-4-30】中科院 Skills-Coach
- 【2026-5-22】微软 SkillOpt:冻结模型
- 【2026-5-26】字节 MUSE-Autoskill
- 【2026-5-31】浙大+蚂蚁 SkillAdaptor
- Skill 膨胀
- 生态
- 实现
- 结束
Skills 技术专题
【2025-12-16】Claude Skills成为复杂工作流的最优解
Skill 基础知识
详见:飞书笔记 Agent Skill笔记
背景
Agent 为何需要“技能”?
通用大模型在执行专业任务时面临三大挑战:
- a, 上下文窗口限制: 无法将海量的专业知识(如公司内部的开发规范、品牌设计指南)一次性灌输给模型。
- b, 流程不确定性: 即使通过提示词进行指导,AI 在执行多步骤、复杂任务时,其输出结果和行为也常常不稳定、不一致。
- c, 高昂的 Token 成本: 每次请求都附带大量重复的背景信息和指令,导致成本高昂且效率低下。
Agent Skills 通过“程序化知识封装”解决了这些问题。 不是简单的提示词,而更像是一份标准作业程序(SOP)或一本给 AI 的“岗前培训手册”。
上下文工程问题
两个核心工程挑战,直接决定了agent的“天花板”:
- 上下文窗口的稀缺性: 如何让模型“知道”数百个工具的定义,而不耗尽昂贵且有限的上下文?
- 编排逻辑的复杂性: 面对多步骤、长周期的任务,如何保证模型遵循既定的业务流程,确保任务的鲁棒性?
核心矛盾:Context Window的有限性 vs 能力需求的无限性
传统做法是把所有工具、所有指令都塞进system prompt:
System Prompt = 基础指令 + 所有工具描述 + 所有专业知识 = 50K+ tokens = 高延迟 + 高成本 + 低效率
传统 API 函数调用 因其“急切加载”机制和对客户端的编排负担,已步履维艰。
解决连接性碎片化 确立了“通用连接器”的生态地位。
Skills 介绍
Anthropic’s implementation of skills for Claude: Agent Skills
然而,真正的架构质变来自 Anthropic 最新 Claude Skills 。
Claude Code Skills 设计灵感来自类比:
人类专家不是把所有知识都装在脑子里,而是在需要时查阅手册、调用专业知识。
Skills系统让AI Agent也具备这种能力:
用户请求 → Agent识别需要PDF技能 → 动态加载PDF处理指令 → 执行专业任务 → 返回结果
Claude Skills 不再将功能视为简单的工具集合,而是将其封装为“程序性知识”
- 一份专业的“员工入职手册”。
Skills + MCP 分层架构是构建下一代企业级高能效智能代理的最佳路径。
API 函数调用是不可或缺的底层执行原语,但其“急切加载”的上下文机制和脆弱的编排逻辑,使其不适合作为构建复杂、可扩展代理应用的核心架构 。模型上下文协议 成功地解决了连接性难题,为 AI 提供了标准化的“管道” 。
而 Claude Skills 代表了架构的质变。它通过渐进式披露”机制解决了上下文的扩展性瓶颈,无论是拥有 10 个还是 1000 个技能,启动成本都极低。更关键的是,它将复杂流程显式定义在 中,结合沙盒代码执行,极大地提升了复杂任务的流程鲁棒性和标准化。
三种设计范式:API Function Calling → MCP → Claude Skills
Skill 理解
skill 是 agent 从“会说话”到“能干活”的分水岭
- 以前:靠prompt工程、API拼接、demo级别agent
- 现在:skill可复用、调试、控成本、规模化
为什么要有 skill ?
- Skill = 被标准化的“可复用执行流程”
- Skill = 可复用 + 可测试 + 可监控 的最小执行单元
- 解决的问题:混乱、重复、不稳定、高成本
| 阶段 | 名称 | 核心特点 | 存在问题 | 本质总结 |
|---|---|---|---|---|
| 阶段1 | 只有 Prompt | 全靠大模型语言推理 | 多步骤任务极易混乱、运行不稳定 | 纸上谈兵,无外部能力支撑 |
| 阶段2 | Tool 调用 | 可查数据、调用API、执行计算 | 仅支持单步工具操作,不会多流程编排 | 有工具能力,但不会复杂流程使用 |
| 阶段3 | Agent 原生形态 | 具备规划Planning、记忆Memory、工具Tool三大能力 | 步骤一多逻辑混乱、重复调用浪费Token、执行不可控、逻辑无法复用 | 基础能力齐全,但缺少流程封装与约束 |
| 阶段4 | Skill 能力封装 | 将固定业务流程封装为独立Skill(如查天气、发消息、数据解析), 无需每次让LLM从零重新思考决策 | Skill 多了调用效果下降,同 工具 | 固化常用流程,实现能力复用、可控、稳定落地 |
合格的 Skill 本质是标准化执行单元,必须包含:
- 基础定义:名称(单一职责)、输入(明确参数)、输出(结构稳定)
- 执行逻辑:步骤(流程清晰)、Tool依赖(调用什么)
- 运行约束:前置条件(什么时候能用)、后置状态(是否写入Memory)
- 工程能力:异常处理(失败怎么兜底)、Token成本(是否轻量)
| 序号 | 核心原则 | 详细说明 |
|---|---|---|
| 1 | 单一职责(最重要) | 一个 Skill 仅负责一件事,不冗余、不跨界,降低维护成本,提升调用准确性 |
| 2 | 必须分类(核心优化点) | 推荐分为4类,分类是降低 Token 消耗的关键: • 查询类:负责数据、信息查询 • 操作类:负责执行具体操作(如发消息、调用API) • 计算类:负责数值计算、数据解析 • 记忆类:负责存储、提取上下文记忆 |
| 3 | 路由优先,不靠 LLM 猜 | 优先用规则匹配 Skill,LLM 仅作为兜底: • 规则匹配:关键词匹配、意图识别 • 避免 LLM 随机猜测,提升执行确定性 |
| 4 | 控制数量(经验值) | 合理控制 Skill 总数,避免失控: • 5~20个:最佳范围,易管理、易匹配 • 30个及以上:开始出现调用混乱、失控问题 |
| 5 | 可观测(必须做) | 需实时监控3个核心指标,避免浪费与异常: • 成功率:Skill 调用后的执行成功率 • Token 消耗:调用过程中 Token 用量 • 调用频次:各 Skill 的使用频率 |
| 6 | 复用优先 | 优先通过现有 Skill 组合实现新需求,而非新建 Skill,减少冗余开发与维护成本 |
误区
- skills 越多 ≠ Agent越强, skill/工具/能力堆多了,token消耗大、调用混乱、任务质量下滑
| 序号 | 错误做法 | 造成后果 |
|---|---|---|
| 1 | Skill 越多越好 | Agent 不会选择、匹配错乱 |
| 2 | 一个 Skill 承载过多功能 | 代码臃肿、逻辑耦合、不可维护 |
| 3 | 不对 Skill 做分类管理 | 调用混乱、上下文冗余、Token 爆炸 |
| 4 | 为炫技盲目开发 Skill | 无实际业务价值、徒增维护成本 |
| 5 | 没有设计 Skill 路由机制 | LLM 随机乱选 Skill、执行不可控 |
| 6 | 不做调用成本与用量监控 | 资源持续浪费、成本失控 |
Agent Skill 介绍
Agent Skill 本质上是结构化文件夹。
最简结构仅包含1个核心文件:SKILL.md。
my-skill/
├── SKILL.md # Required: metadata + instructions (必备)
├── scripts/ # Optional: executable code
├── references/ # Optional: documentation
├── assets/ # Optional: templates, resources
└── ... # Any additional files or directories
SKILL.md 文件通过 YAML frontmatter 定义元数据,通过 Markdown 正文提供详细指令。
name和description必备,其他字段可选name: 1-64个字符,小写阿拉伯字母、中线,不能以中线(-)开头、不能包含两个中线(--)、必须与父目录名匹配- 合法 name:
pdf-processing - 非法 name:
PDF-Processing,-pdf,pdf--processing
- 合法 name:
description: 1-1024个字符,解释skill做什么、什么时候触发,包含特定关键词,便于agent触发- 合格示例:
description: Extracts text and tables from PDF files, fills PDF forms, and merges multiple PDFs. Use when working with PDF documents or when the user mentions PDFs, forms, or document extraction. - 问题示例:
description: Helps with PDFs.
- 合格示例:
---
name: pdf-processing
description: Extract PDF text, fill forms, merge files. Use when handling PDFs.
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
allowed-tools: Bash(git:*) Bash(jq:*) Read
---
字段解释
元数据(Metadata): 告诉 Agent 这个 Skill 的“身份”和“用途”。- name: 技能的唯一标识,必须与文件夹名一致。
- description: 功能描述,是 Agent 决定是否激活此技能的关键依据。
- 指令 (Instructions): 告诉 Agent 在激活此技能后,应该“如何做”。这是分步的工作流指南。
关键机制:渐进式信息披露 (Progressive Disclosure)
Agent Skills 的设计精髓在于其高效的 Token 利用机制,它分三层按需加载信息:
- 第一层:元数据 (Metadata)Agent 启动时,仅加载所有可用 Skills 的 name 和 description。这消耗的 Token 极少,但足以让 Agent 对其能力库有一个全局认知。
- 第二层:核心指令 (Core Instructions)当用户的请求与某个 Skill 的 description 匹配时,Agent 才会完整加载该 Skill 的 SKILL .md 文件内容,获取详细的操作指南。
- 第三层:支持资源 (Supporting Resources)如果 SKILL .md 的指令中引用了外部脚本(位于 scripts/ 目录)或参考文档(位于 references/ 目录),Agent 仅在执行到该步骤时才会去访问这些文件。特别地,当执行脚本时,只有脚本的输出结果会进入上下文,代码本身不会,极大地节省了成本并保证了执行的确定性。
这种分层机制确保了 Agent 在具备强大扩展性的同时,运行成本极低且响应迅速。
Claude Code Skill
Anthropic’s implementation of skills for Claude: Agent Skills
【2026-4-23】手把手教你在Claude Code中熟练使用SKILL技能
视频大纲
| 时间 | 内容标题 |
|---|---|
| 00:27 | Skill简介 |
| 01:39 | Skill和Plugin区别 |
| 02:51 | 安装他人的Skill |
| 04:44 | 手动创建自己的Skill |
| 07:30 | 控制Skill的触发行为 |
| 08:01 | Skill的查看和管理 |
| 08:20 | Skill的停用和删除 |
| 08:55 | 找优质Skill的三种渠道 |
2025年10月,Anthropic 推出的扩展机制Claude Code Skill,Markdown文件形态,包含特定任务的提示词和工作流程。 三大特点:
- 可复用(写好一次多次使用)
- 可分享(直接安装他人Skill)
- 自动触发(根据需求匹配)。 与Plugin区别:
- Skill是单一能力模块
- Plugin是打包多个Skill的容器。 安装方式:
- 手动复制文件
- 第三方工具一键安装
- 通过插件管理。
使用时可自动触发或用斜杠命令手动调用。
获取渠道包括: 官方插件市场、第三方网站(skills.sh等)和GitHub。
Skills 结构
经典结构
SKILL.md文件的目录:
.minion/skills/
├── pdf/
│ ├── SKILL.md # 技能定义和指令
│ ├── references/ # 参考资料
│ ├── scripts/ # 辅助脚本
│ └── assets/ # 资源文件
├── xlsx/
│ └── SKILL.md
└── docx/
└── SKILL.md
SKILL.md 采用YAML frontmatter + Markdown body的格式
新结构
【2026-3-15】Skill Graph
【2026-3-15】Skill Graph > SKILL.md 渐进式披露典范
Claude Code 的 SKILL.md,给 Agent 注入一项技能。但想让 Agent 真正精通一个复杂领域——比如心理治疗、交易系统、法律知识库—— 一个文件根本装不下!
Skill Graph 很简单但很强的思路:把知识拆成多个 markdown 文件,用 wikilinks 连成网络。
- 每个文件是一个独立的概念或技能,文件之间通过正文中的双括号链接建立关联。Agent 不需要一次读完所有内容,而是像专家一样在知识网络中按需导航。
核心:
- wikilinks 嵌在正文里让 Agent 知道什么时候该深入
- YAML frontmatter 让 Agent 扫一眼描述就能判断要不要读全文
- MOC 在图谱变大时提供子话题导航。都是普通的 markdown 语法,不需要数据库也不需要向量索引
执行时,渐进式披露:
- Agent 先读 index 了解全局,再扫描 YAML 筛选相关文件,然后沿着 wikilinks 跳转到具体内容,最后只展开需要的章节。
- 一个 10 万字的知识库,Agent 可能只需要读 3000 字就能精准回答问题。
arscontexta 是这个理念的具体实现,一个 249 个文件的 Claude Code 插件。本身就是个 Skill Graph——教 Agent 怎么为你构建知识体系的知识体系。安装后用 /learn 指向任意话题就能自动搭建文件结构,用 /reduce 精炼和关联已有节点。
从单文件 skill 到 skill graph,本质上是 Agent 从”背课文”进化到”理解领域”。前者是静态注入,后者是动态导航。这个区别决定了 Agent 能处理多复杂的任务
【2026-5-10】Skill Wiki
SKILL.md 中, 每轮对话整块加载到 prompt 里,agent 看到的是一坨
为什么不能再用 SKILL.md 装一切?知识平铺、上下文爆炸、无法渐进式加载
| 问题 | 描述 |
|---|---|
| 上下文爆炸 | 知识一多,prompt 就跟着膨胀。坏知识、旧知识、无关知识,每轮都一起灌进上下文。 |
| 无法渐进加载 | Agent 要么全读,要么不读。长文档直接挤爆 context window,只读局部又容易丢失关联。 |
| 知识是平的 | 所有信息堆在一个文件里。没有类型、没有关系、没有导航,Agent 只能线性阅读。 |
skill wiki 解法对比
| 对比维度 | SKILL.md | Skill Wiki |
|---|---|---|
| token 成本 | 随 Prime 总量增长 | 只随实际加载量 |
| 坏知识污染 | 每轮都污染上下文 | 按需过滤 |
| 关系推理 | 很弱 / 几乎没有 | 有 14 个动词可推理 |
| 组合能力 | 不重新编译就难组合 | 可通过 contracts 组合 |
| 跨 corpus 引用 | 基本没有 | 支持 @scope/... 引用 |
Skill Wiki 把每条知识做成一个原子
- 原子有类型(比如 rule、pattern、value、fact、method、anti-pattern)
- 原子之间用 14 种关系连边(比如 requires、contradicts、refines、validates-with)。
- 网站:skill-wiki
- 开源仓库:prime-system
- 图解:小红书帖子
Skill Wiki 把领域知识(设计规则、安全检查、写作风格、分类法) 表达成有类型的原子 + 显式边图,按需加载。
- 把知识从长文档升级成类型化、可组合、可寻址的原子图
Agent 永远只看一份 ~3 KB 的索引;具体原子只在 brief 真正需要时才载入。
整个架构灵魂:存在 ≠ 内容。
- 先发现,再读取
- 先返回路径,不直接塞内容

一份 skill 先 装载一个小索引(大概 3KB,告诉 agent 有什么),原子正文按 brief 真需要时再加载,分粗、中、细三档。
- v 0.1.0 已成型的协议+实现
- 包含:28种源自kind、14个边动词、3级投影(summary→core→full)、组合契约、registry协议
rule DeglazeAfterSearing {
id: "@recipes/rule-deglaze-after-searing"
claim: "After searing, deglaze with stock or wine."
applies-to: [braise, roast]
requires: [@recipes/term-deglazing,
@recipes/method-pan-sauce]
validates-with: [@recipes/source-mcgee-on-food]
}
目前完整实现了基于社区中所有前端和设计的skill组成的prime:@frontend-design
- 898 个原子,分在 9 个子领域里:色彩、版式、动效、间距、可访问性、voice、视觉层次、布局、组件。
实现效果和对比见最后 整套协议和@frontend-design现已开源。
【2026-6-24】Skill-MAS 元技能
【2026-6-24】蚂蚁集团、港科大 推出 Skill-MAS
LLM 自动生成多智能体系统(MAS)已成为解决复杂任务的核心前沿方向。但现有方案陷入模型能力与经验留存难以兼顾的两难困境:
- 推理阶段多智能体方案可以直接调用能力顶尖的冻结基座大模型,但会重复执行相同的搜索流程,无法从历史交互经验中学习沉淀;
- 与之相反,训练阶段多智能体依靠梯度更新内化历史经验,却受限于中小模型偏低的能力上限,很难扩展到前沿超大参数大模型。
多智能体系统的自动编排领域,分为两条技术路径:
- 推理时编排:使用前沿模型,结合复杂的提示词和迭代搜索算法进行编排;
- 训练时编排:设计编排数据集,对小模型进行训练微调;
而 Skill-MAS 开辟了第三条技术路径:将编排能力的知识抽象为结构化,可自适应进化的「元技能」,成功解耦「参数更新」与「经验保留」
- 将高层多智能体调度编排能力抽象为可迭代进化的元技能(Meta-Skill),从而把经验留存与模型参数更新完全解耦。
Skill-MAS 通过闭环优化循环持续打磨这套架构级知识,分为两步:
- 多轨迹推演(Multi-Trajectory Rollout):基于当前元技能,为每项任务采样多样化行为分布;
- 选择性反思(Selective Reflection):自适应筛选高优先级任务,通过分层对比分析,将系统级交互经验提炼为具备泛化性、策略层面的通用准则。
四类复杂基准数据集、四款不同大模型上开展的大量实验证明:Skill-MAS 不仅能带来显著性能提升,同时拥有优异的算力成本与效果平衡。
进一步分析表明,迭代进化后的元技能具备极强鲁棒性,在未见过的全新任务、不同大模型之间均表现出出色迁移能力
结构上分为三大模块:任务拆解,Agent 工程,工作流编排,让参数冻结的模型也能通过反思不断积累经验;
Skill 质量
Agent 时代”新代码资产”实战方案
【2026-6-8】Anthropic、阿里、顺丰的 Skill 方法论对比
- ① Anthropic 写作法:聚焦单点突破,只教模型易错陷阱(Gotchas最值钱),Description 作为模型触发器,提供开放式指令保障复用性
- ② 阿里管理法:把 Skill 当正式代码,强制 Git管理/Code Review/Benchmark,Bug 追责等同Java,纳入企业级DevOps流程
- ③ 顺丰进化法:Agent 本体冻结能力下沉 Skill层,用Skill替代固定Workflow,通过 Agent Studio 实现版本管理与自进化
工业级 skills
将好用的提示词进一步做成 可触发、可执行、可检查、可持续修改的工作流包。
工业级skills的标准:
- 触发准确:该用时再触发
- 权限收敛:只给必要权限
- 模型匹配:任务匹配模型
- 渐进披露:材料按需读取
- 可评测:能做验证测试
- 可迭代:能持续改进
开发流程
分析需求 → 写成可复用 prompt/workflow → 跑起来测试 → 看哪里不稳定 → 修改 → 再测试
【2026-5-29】如何从零开发一个工业级的 SKILL
OpenAI:如何系统评估skill
OpenAI:如何系统评估skill,证明它没被改坏?
核心: 从依赖主观体感维护,转变为依靠证据和测试用例进行维护 。
三步:
- 先定义“成功”:将评估标准细化为四类,分别是:
任务结果(Outcome)、执行过程(Process)、输出风格(Style)和成本效率(Efficiency)。 - 手动暴露盲区:识别 Skill可能失控的三个关键点,包括触发边界、运行环境和执行顺序。
- 小样本持续回归:建立包含四类样本的回归测试集,包括显式调用、隐式调用、带上下文的调用和负向控制样本,以持续监控Skill的稳定性。
Skill 改进
发展路线
【2026-5-31】2026 年, skill 方向的主线已经变化,详情
- 从“给 agent 塞一段提示词” 升级成 “把 skill 当作可训练、可检索、可验证、可优化、可内化的能力资产”
其中最值得优先看的 17 篇分别覆盖参数内化、skill repo 管理、文本空间优化、原子能力 RL、skill retrieval benchmark
- 🌱 1. 这批论文共同确认新问题:agent 经验越来越多,但如果只停留在对话历史、长 prompt、人工 skill 文件或一次性 badcase 数据里,会带来 token 成本、检索噪声、重复探索、隐私暴露和能力不可复用。
- 🌱 2. 早期 GRPO/RLVR 论文更关注 reward、advantage、KL、采样效率;2026 的 skill 论文把研究对象换成“能力单元生命周期”,重点变成 skill 从哪里来、如何表示、如何触发、如何训练、如何验证、如何更新、如何迁移到无 skill 推理。
- 🌱 3. 核心矛盾:外部 skill 能立刻提升 agent,但外部 skill 也让模型依赖上下文;参数内化能降低推理成本,但需要解决 credit assignment、训练崩塌、skill 遗忘和副作用。
- 🌱 4. 切入点分别:
- SKILL0/SkillC 逐步撤掉 skill;
- Skill-SD/HASP 把轨迹经验变成训练期监督;
- SkillMaster/SkillOS/SkillOpt/SkillGrad 让 skill 自身可优化;
- SkillRet/RubricRAG/SCRIBE 补齐检索和评估环节。
【2026-5-7】Skills 演进已分化出三条工程主线,还有一条探索性旁支。小红书帖子
- 主线一:Skills 内置编排
- Skills 底层由 subagent 支持,天然具备灵活性,可以在内部编排逻辑——设定路由、大 Skill 嵌套小 Skill,也可启动多个 subagent 并行。支持串联、嵌套与并行化。
- 主线二:大模型自行编排
- 主线一的成熟必然走向 Agentic Skills。由模型的推理能力自主决定 Skill 调用顺序,灵活但确定性低。
- 主线三:Workflow Skills
- 看似对 workflow agent 的回退,在系统化场景中仍有存在价值。前两种路径用于人工工作自动化没问题,但一旦系统化,确定性成为硬约束。Workflow Skills 是折中。
- 主线四:Skill Graphs
- 对 SKILL.md 的深度升维,目标是解决技能过载后的检索与调用效率。将技能改造为图谱结构,描述依赖关系和因果链路,在图上做语义拓扑搜索。目前只是概念阶段,图结构的维护成本大概率超过检索收益,生命力不会很强。
- 【2026-4-29】腾讯混元
SkillSynth:Toward Scalable Terminal Task Synthesis via Skill Graphs
Agent Skill 四大演进主线
| 主线 | 名称 | 成熟阶段 | 核心原理 | 能力特点 | 优缺点/定位 |
|---|---|---|---|---|---|
| 主线一 | Skills 内置编排 | 成熟 | 底层由 Subagent 支撑,可内部自定义路由、大Skill嵌套小Skill,支持多 Subagent 并行启动 | 支持串联、嵌套、并行编排 | 灵活性强,人工可控,逻辑规整可落地 |
| 主线二 | 大模型自行编排 | 萌芽 | 依托模型自身推理能力,自主决策 Skill 调用先后顺序 | 高度智能、灵活自适应 | 自由度高,但执行确定性低,容易跑偏 |
| 主线三 | Workflow Skills | 折中 | 偏结构化流程化编排,是系统化场景下的折中方案 | 强确定性、可约束,适合业务系统化落地 | 牺牲部分灵活性,换取稳定可控,适合标准化业务流程 |
| 主线四 | Skill Graphs | 探索 | 对 SKILL.md 深度升维,把技能组织成图谱结构,刻画依赖与因果链路,做语义拓扑检索 | 解决技能过载后的检索、调度效率问题 | 目前仅概念阶段;图结构维护成本高,大概率收益抵不上成本,生命力偏弱 |
总结
- 工程侧走混合驱动,学术侧的 Skill Graphs 值得观察但暂不看好。这些方向都还在萌芽期,远没到需要做技术选型的程度。
Skill 生成
【2026-3-5】华东师范 autoskill
【2026-3-5】华东师范+上海AI Lab 推出 autoskill,经验驱动的skill自进化
- 论文 AUTOSKILL: EXPERIENCE-DRIVEN LIFELONG LEARNING VIA SKILL SELF-EVOLUTION
- 代码 AutoSkill, 说明文档
- 解读 AutoSkill:让你的skills越用越聪明
在大语言模型的实际落地场景中,用户往往会持续提出固定偏好与需求:例如减少模型幻觉、遵循企业规范行文、避免过于专业晦涩的表述等。
但这类交互体验很少被沉淀为可复用的知识, 导致大模型智能体无法在多轮会话间持续积累个性化能力。
AutoSkill:一套基于交互经验的终身学习框架,能够让 LLM 智能体从对话、交互轨迹中自动提炼、维护、复用技能。
AutoSkill 是 Experience-driven Lifelong Learning(ELL,经验驱动终身学习) 的工程化实践。 从真实交互经验(对话 + agent)中学习,自动生成可复用技能,并通过合并与版本演进持续优化已有技能。
AutoSkill
- 从用户交互经验中抽象出标准化技能,支持技能持续自主迭代;
- 无需对底层大模型重训,即可在后续请求中动态注入匹配的技能。
本框架为模型无关的插件式分层设计,兼容各类现有大模型,并定义统一的技能表达格式,支持技能在不同智能体、用户、任务间共享与迁移。
借此,AutoSkill 将转瞬即逝的交互体验,转化为显性、可复用、可组合的模型能力。
AutoSkill 的设计动机、整体架构、技能完整生命周期与工程实现,并将其与过往记忆机制、检索增强、个性化优化、智能体系统相关研究做对比定位。AutoSkill 为构建可终身学习的个性化智能体、个人数字替身,提供了一套具备落地性与扩展性的可行方案
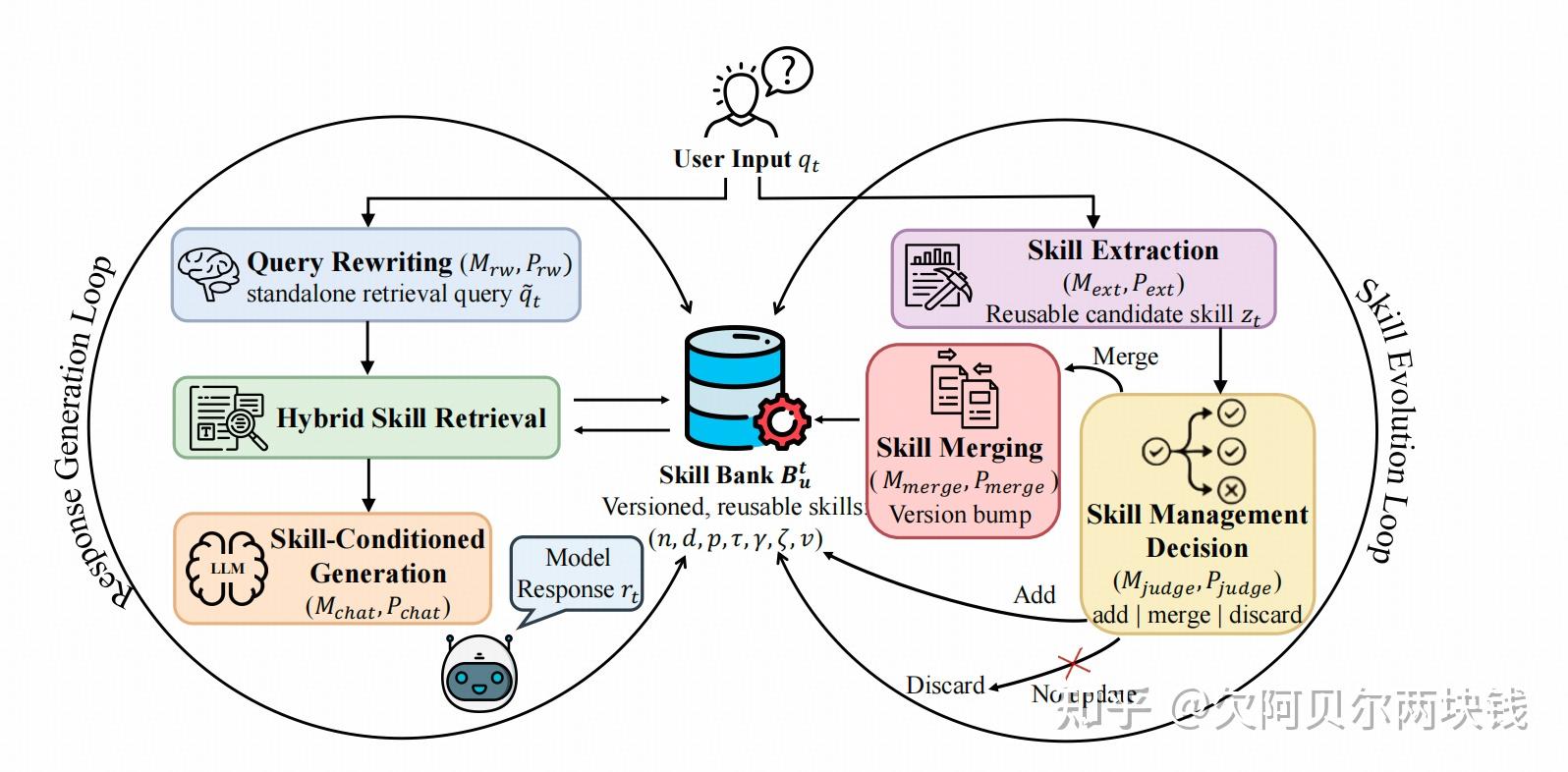
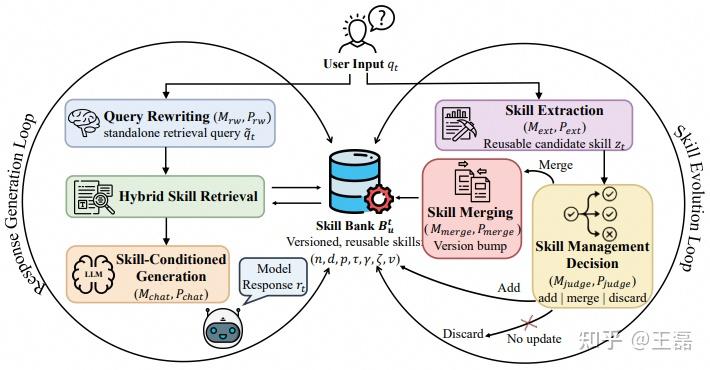
AutoSkill 框架,由两个紧密耦合的过程组成。
- 左侧循环,复用已有技能:技能增强响应生成,利用当前技能库通过查询重写、技能检索和上下文注入来支持响应生成。
- 右侧循环,技能演化:通过提取和维护将交互经验转化为显式技能。
- 通过这种方式,系统通过显式记忆增长而非模型微调来持续改进
AutoSkill 通过四阶段生命周期实现skill的闭环管理:
- 经验获取:收集对话消息、行为轨迹等原始交互数据;
- 技能提取:抽象生成技能候选,聚焦可复用能力而非实例化事实;
- 技能维护与版本化:通过add/merge/discard决策优化技能库,确保紧凑性与一致性;
- 技能复用:检索相关技能并注入生成过程,实现经验的跨会话应用。
【2026-4-30】清华 Ctx2Skill
【2026-5-7】从上下文中自动提取Skill !清华等提出 Ctx2Skill,上下文学习新方案
问题:
- 当大模型面对一份很长、很复杂、甚至完全超出参数记忆的文档时,自己从里面提炼出“可复用技能”,以后遇到同类问题直接按技能办事,而不是每次重新硬读一遍上下文。
【2026-4-30】清华大学、 DeepLang AI 、 UIUC 、复旦大学、香港中文大学等机构提出框架 Ctx2Skill
目标不是再做一个更花哨的 RAG ,也不是让模型多背一点知识,而是把“上下文学习”这件事往前推一步:
- 传统做法: 把上下文塞进提示词,让模型边读边答;
Ctx2Skill:
- 则先让模型把上下文里的规则、流程、约束、判断标准提炼成自然语言技能;
- 后续答题时,模型带着这份技能集再去处理任务。
不依赖人工标注,也不需要外部环境给出执行反馈。
整个技能发现过程靠多智能体自博弈完成:一个模型负责出题,一个模型负责解题,一个模型负责判题;失败会推动 Reasoner 补技能,成功会推动 Challenger 出更刁钻的题。
Ctx2Skill 的核心:用自博弈逼出技能
Ctx2Skill 核心设计: 面向技能优化的 self-play loop 。
- 不是简单让模型“总结一下文档”,而是让不同角色围绕同一份上下文不断对抗。
主要角色有三个:
- Challenger : 根据上下文生成任务和评分标准;
- Reasoner : 根据上下文和当前技能集尝试回答任务;
- Judge : 按评分标准判断答案是否通过。
另外还有两类辅助角色: Proposer 和 Generator 。
- Proposer 负责诊断问题
- Generator 负责把诊断转成具体技能修改。
六步。
- 第一步, Challenger 出题。 它拿到原始上下文和自己的 Challenger 技能集,生成若干任务,以及每个任务的评分标准。注意,评分标准很关键,因为后续反馈都来自这里。
- 第二步, Reasoner 解题。 Reasoner 拿到上下文、任务和自己的 Reasoner 技能集,生成答案。
- 第三步, Judge 判题。 Judge 逐条检查评分标准。论文采用的是“全或无”的任务求解定义:只要某个任务有一个评分标准没过,这个任务就不算解决。
- 第四步,结果分流。 没答好的任务进入失败集合,答好的任务进入成功集合。
- 第五步,失败推动 Reasoner 学技能。 Reasoner 侧的 Proposer 分析失败案例,判断当前技能集缺了什么知识、规则或流程; Generator 再把这个诊断转成新的自然语言技能。
- 第六步,成功推动 Challenger 变强。 如果 Reasoner 已经能解决某些任务, Challenger 侧也会总结成功案例,更新自己的出题策略,下次更精准地探测 Reasoner 的薄弱点。
自博弈很容易失控。
- 出题方越出越偏,解题方越学越窄,最后技能集看起来很厚,泛化反而变差。
为了解决这个问题,作者又加了 Cross-Time Replay (跨时间重放) 机制,从不同迭代阶段里挑出最平衡的技能集,而不是盲目相信最后一轮。
【2026-6-15】香港理工 OpenClaw-Skill
【2026-6-15】香港理工、南洋理工、清华提出 OpenClaw-Skill
研究引入基于树搜索的Skill构建框架,构建结构化,多样化且泛化性强的技能树;
其核心价值是将Skill构建从「单模型,单轨迹蒸馏」提升到了「多模型协作,树状搜索,强化学习优化」的新高度;
LLM Agent 配备高效技能 是支撑 OpenClaw 等真实系统完成复杂任务的关键。
如何自动构建可复用技能的框架,提升大模型在工具调用、多步骤推理、动态环境交互场景下的表现?
协同技能树搜索(Collective Skill Tree Search, CSTS),全新基于树搜索的技能构建框架,能够生成结构化、多样化、具备泛化能力的技能树。
CSTS 核心思路: 群体智能
通过两个迭代阶段协同完成高效技能的搜索、筛选与组合:
- 协同技能节点生成(CSN-Gen): 整合多模型的群体知识,为每一个子任务挖掘多元化候选技能,实现全面的技能探索。
- 协同技能节点评估(CSN-Assess): 以多模型作为评审器,通过两套打分机制完成技能节点的评测与筛选:
- (1)群体质量打分:聚合多份独立评估结果,稳健衡量技能的实际效果;
- (2)群体泛化打分:专门验证该技能能否在不同模型上通用。
依托 CSTS 构建完整技能树,并同步生成增强技能训练数据,让模型能够高效学习并调用各类技能。
协同技能强化学习:从技能树中主动选取多项相关技能,拓宽解空间搜索范围,避免模型单一依赖某一项技能,从而陷入同质化、次优的解决方案。
最终训练得到的模型 OpenClaw-Skill,在长时序规划、工具调用、跨场景泛化等多项高难度基准测试中,展现出顶尖的智能体执行能力。
【2026-6-18】MIT GUI Agent skill 生成调研
【2026-6-18】MIT + 哈佛 对 GUI Agent skill 自动生成
探索「如何从实际任务的运行轨迹中,挖掘出可用 Skill 库」,主要分为三个阶段:
- (1)分割任务轨迹:识别交互轨迹中的「Skill 边界」,将连续的底层操作序列切分为有意义的候选技能段;
- (2)构建 Skill 库:对分割出的片段进行聚类,生成一套技能词汇表;
- (3)策略训练:在挖掘出技能库后,训练模型学习如何组合这些Skill;
该方法能够产生了高精度且易读的 Skill 结构,但并没能有效转化为更强的代理策略;
原因:边界检测不精准,丢失动作的顺序信息,离线奖励模型的局限;
显式技能库能提升智能体的可观测性,但目前尚不明确:能否从交互数据中挖掘出这类技能库,并以此优化下游决策策略?
三阶段流水线来研究该问题:切分图形界面交互轨迹、将轨迹片段聚类生成候选技能、基于生成的标注数据训练具备技能感知能力的决策策略。
在基准测试数据集上,挖掘得到的聚类结果具备良好可读性:
- 8 个聚类分组中,有 5 个与 InteraSkill Workflows 人工标注的匹配纯度达到 0.95 以上。但可读性不代表跨域迁移效果。
- 采用 GRPO 优化后,InteraSkill Workflows 数据集的技能步骤准确率仅从 18.5% 小幅提升至 20.5%;
- BrowseComp + 数据集指标几乎无变化;且在源域核心指标上,其效果甚至不如简单的频次先验基线。
该方法定位为一项诊断性研究:轨迹挖掘确实可以提取出便于人工查看的技能结构,但当前的分段边界检测算法、无序片段表征方案以及离线奖励模型,都不足以稳定实现跨域决策策略性能提升
内化到模型
Skills 融入模型训练
【2026-4-2】美团 SKILL0
如果说 Agent 是 LLM 的双手,那 Skill 库就是 Agent 的肌肉记忆——但怎么让记忆真的好用、真的省力,一直是道没解开的题。
美团最近连出两篇论文,分别叫 Skill1 和 SKILL0
- SKILL0:训练时学,推理时甩掉, “外部技能库怎么进化”
- Skill1:用频率分解,让”选、用、造”一起进化. “技能怎么内化到模型参数里”。
两篇论文从两个方向把同一个问题往前推了一大步:让 Agent 的技能既强又轻。
- Skill1 解决了”外部技能库怎么自我进化”的问题——选、用、造三个环节不再各自为战
- SKILL0 解决了”技能能不能长进模型里”的问题——训练完就把技能库扔掉,推理极轻
Agent 技能管理可以从两个方向同时突破:对外,技能库可以越用越聪明;对内,技能可以变成模型本能。
【2026-4-2】美团LongCat:把Skill内化到模型: SKILL0:训练时学,推理时甩掉
从 Claude 到 OpenClaw,Skills已经成为增强LLM智能体的重要方法,Skills本质是结构化的过程知识和可执行资源的集合。在Agent运行时找到相关技能匹配到Prompt中。
所以最终还是作用于提示词,论文指出了三个缺点:
- 引入了检索噪声:引入无关或误导性指导,污染智能体上下文
- token开销大:skill到内容会注入prompt中,同时在多轮问答中不断累积
- 缺乏泛化:模型只根据技能描述输出,能力在上下文中,不在模型参数中
Skill0 是首个把Skill内化作为训练目标的强化学习框架,通过上下文学习(In-Context Reinforcement Learning,ICRL)来实现。
在ALFWorld和 Search-based QA两个基准上对Skill0进行评估,使用了多种方法。
从最终的数据上来看:
- SKill0(3B)在ALFWorld上比AgentOCR提高了9.7%,在Search-QA上提升了6.6%
- SKill0 达到了类似SkillRL的Skill增强方法的性能
- 在ALFWorld上仅0.38k tokens/步,SKillRL是2.21k,非常大的减少了token消耗
当然也有局限性:
- 性能依赖于SkillBank即初始技能库的质量和覆盖范围;
- 线下Skill分组需要针对新领域重新划分,不够灵活;
- 评估范围还很小,当前局限于特定任务类型。
原文总结:
“We believe SKILL0 establishes skill internalization as a new principled and scalable paradigm, paving the way from tool-augmented toward truly autonomous LLM agents and self-sufficient intelligence.”
【2026-5-7】美团 SKILL1
【2026-5-7】Skill1:用频率分解,让”选、用、造”一起进化
核心思路:
- 用一套强化学习信号同时驱动技能选择、技能使用和技能提炼三个模块。
怎么做到的?把任务最终的成功/失败信号做了频率分解:
- 低频分量(长期趋势)→ 归给”技能选择”——说明是选对了技能才赢了
- 高频分量(短期波动)→ 归给”技能提炼”——说明是执行过程中某个关键动作立了功
这样,一个 reward 信号同时教会了三件事,不需要分别设计三套奖励函数。
底座是 Qwen2.5-7B-Instruct,训练在 8 卡 H800 上跑约 30 小时。用 GRPO(Group Relative Policy Optimization),不走 SFT,直接 RL 端到端训练。
Skill 路由
【2026-4-1】阿里 SkillRouter 单技能路由
SkillRouter:破解大规模Skills选择难题的新范式
问题:
- 上下文容量瓶颈:现有Agent架构无法将数万条技能的完整信息全部注入模型上下文,否则会造成严重的上下文溢出、推理延迟飙升与成本失控;
- 技能匹配精度难题:社区贡献的技能普遍存在严重的功能重叠,大量技能拥有相似的名称与描述,但在实现细节、入参要求、适用场景上存在本质差异。仅依赖名称、描述这类元数据,根本无法完成精准的技能选择。
当Agent面对用户任务时,如何从海量技能库中精准匹配到最适配的那一个,已经成为制约Agent规模化落地的核心瓶颈。
技能路由:从大量候选技能池中筛选出与用户任务最相关的技能集合
但相关研究不足。当前智能体架构采用渐进式披露设计 —— 仅向智能体暴露技能名称和描述,而隐藏完整的实现主体 —— 这一设计隐含地认为元数据足以支撑技能选择。
对 约 8 万个技能和 75 个专家验证查询的基准数据集系统性实证研究,发现:
- 技能主体(完整的实现文本)是决定性信号 —— 移除技能主体会导致所有检索方法的性能下降 29-44 个百分点
- 交叉编码器注意力分析显示,91.7% 注意力集中在技能主体字段上,描述仅占 1.0%。Skills 池中功能高度重叠,进一步放大 body 的区分价值。
【2026-4-1】阿里推出 SkillRouter,两阶段 “检索 - 重排序” 流水线,总参数量仅为 12 亿(6 亿编码器 + 6 亿重排序器)。
- 【2026-3-23】《SkillRouter: Retrieve-and-Rerank Skill Selection for LLM Agents at Scale》
- 【2026-4-1】SkillRouter: Skill Routing for LLM Agents at Scale
针对这一行业痛点给出了系统性的实证研究与轻量化解决方案,为大规模Agent技能路由提供了全新的技术范式。
SkillRouter: 专为大规模Agent技能路由设计的两阶段检索-重排流水线,总参数量仅 1.2B(0.6B双编码器检索 + 0.6B交叉编码器重排),在保证顶尖匹配精度的同时,实现了极致的轻量化与部署友好性。
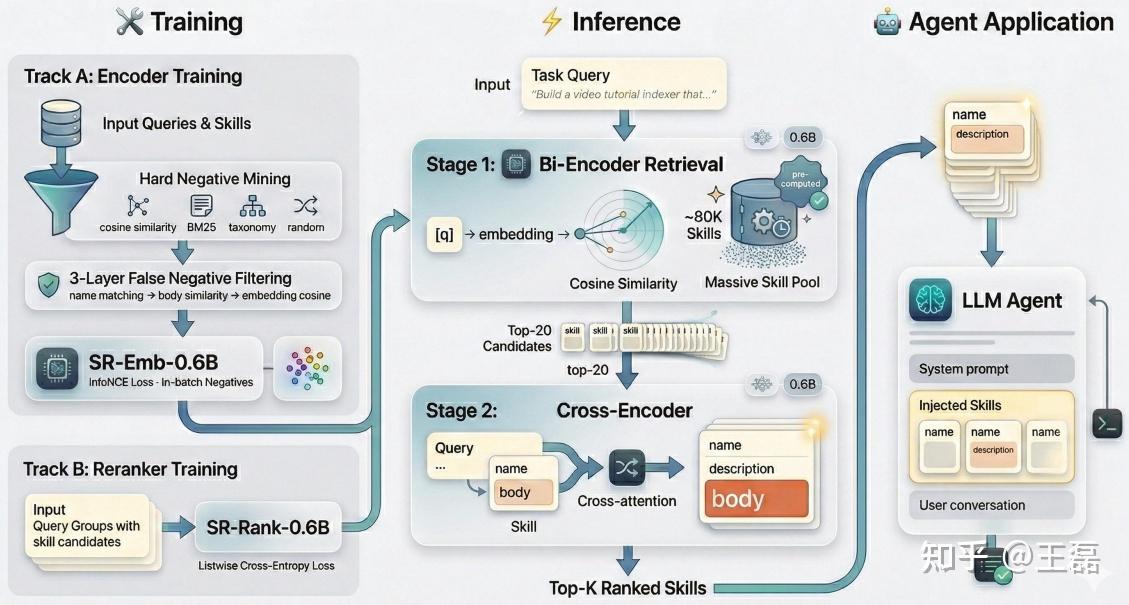
SkillRouter 两阶段 retrieve-and-rerank 流水线,总参数仅 1.2B(0.6B 编码器 + 0.6B 重排序器),专为消费级硬件设计。
- 第一阶段(SR-Emb-0.6B):双编码器,用完整 Skills 文本(name+desc+body)预编码 Skills 池,ANN 检索 Top-20 候选。采用精心负例挖掘 + 三层假阴性过滤 + In-batch InfoNCE 对比学习。
- 第二阶段(SR-Rank-0.6B):交叉编码器,逐对处理 query 与候选的完整文本,采用 listwise 交叉熵损失(LW),迫使模型在同质 Skills 间进行相对排序。 训练数据:37,979 对查询-Skills 样本(GPT-4o-mini 合成,训练/测试完全 disjoint)。
SkillRouter 实现了 74.0% top-1 路由准确率,在评估的紧凑型和零样本基准模型中取得了最优的平均结果,同时仍可部署在消费级硬件上。
实验结果
- 主要指标:Hit@1(Top-1 路由准确率,主指标)、MRR@10、nDCG@10、Recall@K、FC@10。
- 紧凑模型性能:SkillRouter-1.2B 在 Easy/Hard 难度上平均 Hit@1 达 74.0%(单 Skill 查询 72.9%,多 Skills 查询 74.5%)。
- 对比:显著优于最强零样本 8B 基线(Qwen3-Emb-8B × Qwen3-Rank-8B,68.0%),提升 +6.0pp;也优于 GPT-4o-mini/GPT-5.4-mini 等 LLM Judge 作为重排序器。
- 8B 扩展:相同配方下 Hit@1 升至 76.0%,验证方法可扩展。
- 关键消融:
- 假阴性过滤:+4.0pp Hit@1(Hard 难度更明显)。
- Listwise 损失 vs Pointwise BCE:+30.7pp(后者在高度同质池中失效)。
【2026-6-16】阿里云 SkillWeaver(技能编织器)多技能路由
【2026-6-16】阿里云提出 SkillWeaver
大部分技能路由的相关研究当作「单一Skill选择问题」,但在实际任务场景中,完成任务需要多种 Skill 的组合;
SkillWeaver 框架专门解决多个 Skill 复杂路由组合的问题:
- 任务分解:使用微调的模型分解复杂任务,每个子任务只对应一个 Skill;
- Skill检索:根据子任务的语义相似度,从技能库中识别候选技能;
- 组合规划:通过任务规划器,根据 Skill 间的兼容性,合理搭配选出最终技能; ⭐️ 研究通过迭代反馈机制决了复杂任务中「分解粒度不均匀」的难题。同时,研究还推出了针对 Skill 路由组合的测试集 CompSkillBench;
agent 愈发依赖外部技能(即可复用的工具描述规范),但真实业务任务往往需要组合多项技能,而非仅选用单一技能。
将该场景抽象定义为组合式技能路由问题:给定一条复杂用户指令与海量技能库,将指令拆解为原子子任务,为每个子任务匹配适配技能,并组装生成可执行规划流程。
SKILLWEAVER(技能编织器),一套「拆解 - 检索 - 组装」一体化框架,由三部分构成:
- LLM 任务拆解器
- 搭载 FAISS 索引的双编码器技能检索器
- 感知依赖关系的有向无环图(DAG)规划器。
为支撑算法评测,构建了 COMPSKILLBENCH 评测基准:数据集包含 300 条组合式查询、2209 条来自开源 MCP 生态的真实服务技能,覆盖 24 大功能分类。
实验结果表明,任务拆解质量是整体性能的核心瓶颈:采用常规大模型直接拆解方案,步骤级分类召回率仅 34.2%。
针对该痛点,提出迭代式技能感知拆解算法(SAD),一套检索增强反馈闭环机制,可循环对齐任务拆解结果与现有可用技能。
- 仅单次迭代下,SAD 即可将拆解准确率从 51.0% 提升至 67.7%,相对提升 32.7%,威尔科克森检验 p 值小于 10⁻⁶,提升效果显著。
- 基于拆解精度(DA)的条件分析证实:合理的任务粒度是高效检索的前提;当拆解精度达标(DA=1)时,Top1 分类召回率 CatR@1 从 34% 提升至 41%。
SKILLWEAVER 可将上下文窗口占用量降低 99% 以上;跨域迁移实验验证其具备优秀泛化能力 —— 即便检索库中不存在目标功能分类,拆解精度相对提升幅度仍可达 35.6%。
进化
skill 自进化:
- 经验驱动,把历史轨迹、反思、成功案例、失败教训提炼为经验(skills),后续任务中检索出来归纳、总结、塞进 Prompt,帮助 Agent 后续更好的决策
【2026-3-30】【Skills】06- 如何实现Skills的自进化
当前 Agent 虽积累了海量历史经验,却因孤立运行和记忆机制缺陷,无法将其转化为成长动力:既不能复用成败经验,也难以从噪声文本中提炼有效决策模式,反而造成上下文臃肿。
尤其在长期个性化场景中,用户稳定的核心诉求(如写作规范)与现有方案矛盾突出——参数更新成本高,简单记忆又无法将偏好转化为可执行策略。
唯有建立 Skills 自进化机制,将零散经验提炼为核心原则,封装为统一、可编辑、可迁移的Skills,才能使Agent摆脱“有经验无成长”的困境,真正实现持续、高效、可控的自我迭代。
技能自进化机制的本质是“将经验转化为可进化的技能”,通过技能提取、技能存储和检索、反馈进化、迭代闭环流程,实现技能或者智能体的持续能力提升。
自进化机制,包含以下流程:
- (1)技能库构建
- 技能提取:以用户查询作为提取依据,收集多样化交互轨迹(对比同一场景下的成功/失败轨迹),从交互中抽象出可复用、长期有效的候选技能。
- 技能存储:构建结构化的技能管理能力树,实现技能的层次化管理和高效检索。技能的编排和检索,可以参考之前发的文章。
- (2)递归式技能进化
- 维护失败模式:基于初始技能库,收集任务执行失败时的轨迹,分析并筛选高价值的失败模式。
- 递归式技能进化:基于分析结果,生成新技能或优化原有技能,更新SKILLBANK。
- (3)技能迭代管理
- 技能迭代:对新增的候选技能,先检索现有技能库中最相似的技能,在通过决策机制,实现技能的新增、合并或丢弃,从而避免冗余与库体膨胀。
- 合并迭代策略:若决策为合并,需要与现有技能做语义融合,保留原有技能的核心标识,整合新增的约束与细节,同时升级版本号,实现同一项能力的持续迭代优化,而非重复创建相似技能。
总结
【2026-4-16】小红书:5篇skills 自进化论文,从 Trace2Skill、SkillClaw、CoEvoSkills,读到SkillRL和Skill-SD。方法各异,但本质上都在回答同一个问题:怎么让Agent把”做过的事”变成”可复用的能力”。
- Trace2Skill 思路很直接——让LLM总结已跑出来的路径,从成功/失败轨迹里”挖”出补丁,打到一个初始技能上。
- SkillClaw 把视角拉大了,做多个用户、多个Agent的轨迹聚合,夜间自动分析、验证、部署,版本管理做得挺扎实。
- CoEvoSkills 更有意思,让生成器和验证器两个独立Agent互相”卷”着从零进化技能,一个写卷子一个出题,考不过就加难度。
- SkillRL 和 Skill-SD 则把战场拉回了RL。SkillRL把Skill当成”抽象动作”,建层次化SkillBank,和策略网络一起端到端训练。
- Skill-SD 最极致,完全在单模型内部做自蒸馏闭环,让student模型自己用Skill”教”自己,实现真正的self-improvement。
判断:Skill蒸馏值得长期关注,确实代表了Agent从”手动配置”走向”自我进化”的趋势
但现阶段更适合作为辅助工具嵌入已有工作流,别指望它全自动产出生产级技能。模型能帮你归纳经验、发现模式,但最终能不能用、敢不敢用,还是要人来拍板。
分类维度
- 经验驱动:直接经验驱动,rl 奖励驱动
- 是否冻结 agent
- skill 沉淀形态载体:模型参数?单一文档? 结构化技能包
- 经验沉淀到外部文档(SkillOpt、SkillForge等)
- 经验内化进权重(SkillRL、SAGE、Evolving-RL等)
| skill 进化方法 | 驱动信号(直接经验/间接经验) | 沉淀skill的形态 | 是否涉及模型权重更新 | 代表工作 |
|---|---|---|---|---|
| 文本空间优化 | 验证集分数(gate) | 单一.md 文档 | 否(冻结模型) | SkillOpt |
| 领域闭环改写 | 失败工单/执行失败 | 单一.md 文档 | 否 | SkillForge |
| RL 协同进化 | RL 奖励 | 分层技能库/包 | 是(训模型) | SkillIRL / SAGE / SkillIOS |
| 经验提取-利用联合优化 | RL(两路监督信号) | 经验内化进权重 | 是(训模型) | Evolving-RL |
| 多能力统一进化(信用分配为核心) | RL(共享或分路奖励) | 经验内化进权重 | 是(训模型) | Skill1 / SkillMaster |
| 协同验证 | 跨任务对比验证 | 多文件技能包 | 否 | EvoSkills/CoEvoSkills |
【2026-7-4】skill进化综述
| 路线 | 代表方法 | 主要输入 | 更新对象 | 最适合场景 |
|---|---|---|---|---|
| 在线闭环 | Hermes | 当前任务经验 | 本地 Skill 文件 | 个人 Agent、开发者工具 |
| 轨迹蒸馏 | Trace2Skill | 批量成功/失败 trace | 可迁移 Skill 目录 | 有评测集的垂直任务 |
| 共进化验证 | CoEvoSkills | 任务说明、环境、验证反馈 | 多文件 Skill 包 | 企业流程、复杂工具链 |
| 分层知识库 | SkillX | 强 Agent rollouts | 三层 SkillKB | 多工具、可迁移知识库 |
| 集体演化 | SkillClaw | 多用户 session | 共享 SkillHub | 平台型 Agent 产品 |
| 文本优化 | SkillOpt | rollout + validation | 单个 Skill 文档 | 有回归集/CI 的项目 |
| Repo 治理 | SkillOS | 相关任务流 | Curator 管理策略 | 长期运行 Agent |
| RL 内化 | SKILL0 | 环境交互 + skill curriculum | 模型参数(内化) | 模型方、平台方 |
| RL 协同 | Skill1 | 环境交互 + reward decomposition | 统一 policy(选+用+蒸馏) | 可训练 Agent 系统 |
【2025-12-*】SAGE:与RL融合
2025 年 12 月
- 论文:Reinforcement Learning for Self-Improving Agent with Skill Library,arXiv:2512.17102
首次将skill进化与RL融合。
- 核心:提出 SAGE(Skill Augmented GRPO for self-Evolution),把技能系统性地纳入 RL 学习。
- 关键组件 Sequential Rollout:每次 rollout 让 Agent 在一连串相似任务上迭代部署,把skill学习和奖励信号串起来。
- 局限:产出的技能仍是单文件的skill,而不是结构化的多文件技能包。
SkillMaster
待定
Trace2Skill
待定
【2026-2-2】新加坡南洋理工 MemSkill
现有Agent记忆系统普遍存在三大核心局限:
- 强依赖人工先验:预设静态的记忆操作(增/删/改等),无法适配多样交互与动态任务;
- 长历史处理效率低:主流逐轮增量式更新在超长交互中调用成本高、性能衰减明显;
- 进化能力缺失:现有自进化记忆研究仅聚焦架构元优化或基准搭建,未实现记忆操作行为的自主迭代与进化。
【2026-2-2】新加坡南洋理工提出 MemSkill 将传统固定记忆操作,重构为可学习、可复用、可进化的记忆技能。一套结构化的、可组合的执行例程,用于从交互轨迹中完成信息提取、整合、修剪与更新。
面向Agent的MemSkill记忆框架 将Agent记忆操作重构为可进化的技能抽象,打破了传统人工固定记忆流程的刚性局限,为自进化Agent记忆系统提供了新的范式。
设计了“强化学习优化技能使用 + LLM引导技能进化” 的双阶段闭环自进化体系,实现了记忆技能库本身的持续自主迭代优化。
数据集:
- LoCoMo:用于评估从长对话式交互历史中构建记忆的能力。
- LongMemEval:用于评估从长对话式交互历史中构建记忆的能力。
- HotpotQA:用于研究技能泛化能力。
- ALFWorld:用于评估具身交互任务。
核心实验结果
4类典型基准上完成了全面验证,对比了8个SOTA基线方案
- 全场景性能领先:
- 对话长记忆场景(LoCoMo/LongMemEval):在LLaMA3.3-70B与Qwen3-Next80B双底座下,MemSkill的F1值、LLM裁判打分(L-J)均全面超越所有基线,其中LoCoMo的L-J得分达50.96,远超第二名MemoryOS的44.59。
- 具身交互场景(ALFWorld):在Seen/Unseen两个子集上,任务成功率(SR)均为全场最高,Unseen场景成功率达47.01,显著优于第二名的38.06,同时交互步数更少,决策效率更高。
- 极强的泛化迁移能力:
- 跨模型迁移:仅用LLaMA训练的技能库,可直接迁移至Qwen3底座,无需额外训练仍保持SOTA性能。
- 跨数据集迁移:LoCoMo训练的技能库,可零样本迁移至LongMemEval、HotpotQA,且在50/100/200篇文档的超长上下文场景下,优势随上下文长度增加进一步放大。
【2026-2-9】芝加哥 SkillRL:与模型一起进化
Agent在网页导航、深度研究等复杂任务中展现出强大的能力,但其发展仍受制于核心瓶颈——无法有效利用历史经验实现自我进化。具体问题三个方面:
- 经验复用能力缺失:当前任务执行多为孤立运行,Agent无法从过往的成功或失败中学习,导致系统难以实现持续进化。
- 现有记忆方案存在缺陷:直接存储原始轨迹存在冗余噪声、难以泛化高层模式,且易至上下文膨胀,随任务复杂度增加而性能下降。
- 经验与策略优化脱节:现有方案仅能模仿过往的解决方案,无法将经验提炼为核心决策原则,也无法驱动Agent内部策略的自适应优化。
【2026-2-9】芝加哥大学、伯克利等推出 SkillRL
为什么“存轨迹”不够
- 现有 LLM Agent “经验”常以外部记忆形式保存原始轨迹,但轨迹往往冗长、包含探索回退与噪声,导致相似检索时上下文开销高、关键信号稀释,甚至性能随任务复杂度上升而退化。
有效迁移需要“抽象”:类似人类不记每一步,而是形成可复用的技能规则。
SkillRL:
- 把交互轨迹“蒸馏”为可检索、可复用的技能(SkillBank),再在强化学习过程中按验证失败递归扩展技能库,实现“策略—技能库” 协同进化。
最大区别:
- skillrl 通过 RL 奖励驱动,在skill进化的同时也训练基础模型利用skill的能力(改权重)。
SKILLRL 通过自动技能发现和递归进化,让智能体能像人类一样从经验中高效学习,而非每次任务都从头开始
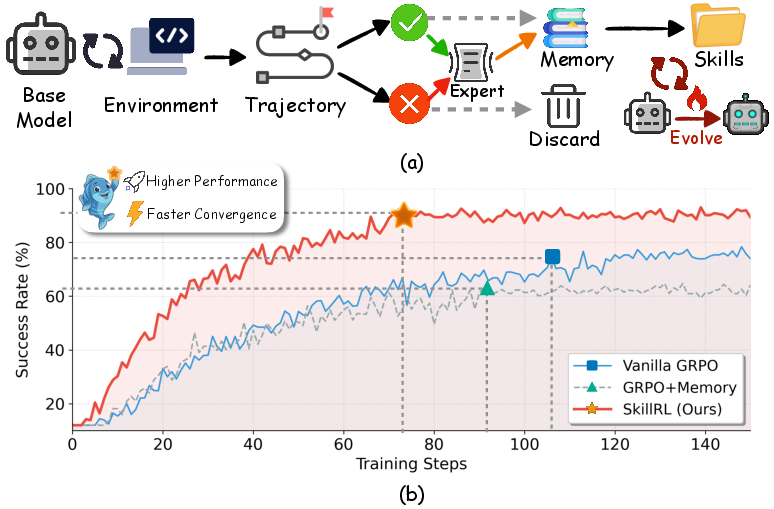
SkillRL 框架
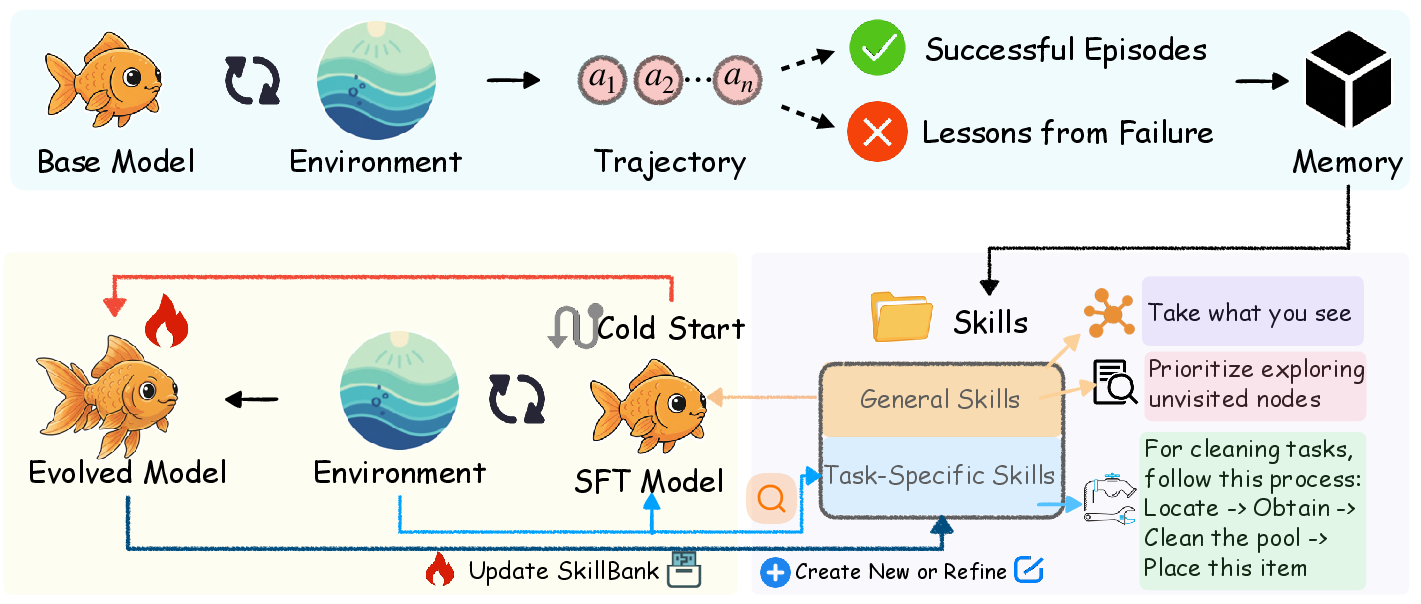
SkillBank 具体形态:
- 既有“系统化探索、动作前检查、循环逃逸”等通用规则
- 也有 WebShop 的“先核验约束、变体切换后复查价格、发现不匹配立即返回搜索”等细粒度流程技能;
- 同时配套错误分类(如“遗漏约束”“变体导致价格漂移未复查”“过早购买”),用于把失败轨迹转成可执行的防错原则。
相比存原始轨迹的记忆方法,技能抽象带来约 10–20× 的上下文压缩,同时提升决策可用性,缓解“冗余/噪声”与“信息密度”的矛盾。
关键方法:
- 1️⃣ 经验驱动技能蒸馏:成功轨迹提炼战略模式,失败轨迹生成失败教训,将冗余轨迹转化为高价值技能
- 2️⃣ 分层技能库 SKILL-BANK:
- 通用技能提供基础指导
- 任务特定技能提供针对性策略
- 3️⃣ 递归技能进化:在强化学习过程中动态更新技能库,与代理策略共同进化
关键模块:
- 经验式技能蒸馏:成功轨迹 → 提炼成成功模版(strategic patterns);失败轨迹 → 压缩成失败教训(lessons from failure)。
- 分层 SkillBank:分 General Skills(通用skill)和 Task-Specific Skills(任务级启发式),配自适应检索。
- 递归技能进化:skill库在 RL 过程中通过分析验证集失败,与 Agent 的 policy 协同进化(co-evolve)
💡 核心创新:
- 1️⃣ 从”死记硬背”到”理解精髓”:避免存储冗余轨迹,提取高价值技能
- 2️⃣ 技能库与策略的”共同进化”:形成”学习-进化-再学习”的良性循环
效果
- ALFWorld、WebShop 与 7 个检索增强 QA 任务上取得 SOTA;
- 消融显示:去掉冷启动 SFT 或用原始轨迹替代技能库会显著掉点。
SkillRL 由三部分构成:
- 经验驱动的技能蒸馏:用教师模型将成功/失败轨迹分别提炼为“成功策略技能”和“失败教训技能”。
- 层级技能库 SkillBank:区分通用技能与任务类型相关技能 ,并定义结构化字段(名称、原则、when_to_apply)以便检索与执行。
- 递归技能进化:在 RL 训练中周期性分析验证失败轨迹,生成新技能并更新 SkillBank,使其随策略提升而扩展。
【2026-3-1】华东师范 AutoSkill
AutoSkill:基于技能自进化的经验驱动型终身学习框架
随着Agent落地应用,用户会在多轮会话中反复表达稳定的需求(如减少幻觉、遵循特定写作规范等),但现有方案存在明显局限:
- 参数更新/自进化方案:通过自反思、反馈优化等方式调整模型参数,面对高频、细粒度个性化场景,成本高且可控性差;
- 长时记忆方案:仅存储对话片段、偏好文本,把历史交互当作待检索的文本,而非可落地执行的行为策略;
- 技能学习方案:技能多隐式存在于提示词、执行轨迹或策略中,缺乏统一的可编辑、可维护、可迁移机制。
【2026-3-1】华东师范+上海AI Lab 提出 AutoSkill,将交互经验从 “原始记忆文本” 升级为 “可执行的行为技能单元”,把用户的重复需求固化为结构化的技能制品,实现跨会话的能力持续积累。
- 《AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution》
- 【2026-2-4】代码 AutoSkill,中文解读
AutoSkill 是 Experience-driven Lifelong Learning(ELL,经验驱动终身学习) 的工程化实践。 它从真实交互经验(对话 + agent)中学习,自动生成可复用技能,并通过合并与版本演进持续优化已有技能。
核心贡献
- 形式化 “将LLM交互经验转化为显式可复用技能” 的个性化问题,提出了完整的AutoSkill框架;
- 设计了覆盖技能提取 — 迭代优化 — 检索 — 复用的全生命周期技能管理机制,无需修改基座模型即可实现终身能力进化。
AutoSkill 是无需训练的终身学习框架,通过技能自进化机制提升性能,其完全基于提示词驱动实现,全程无需训练/微调基座模型。
核心思想:
- 将可复用的任务求解模式封装为带版本控制的显式技能,在生成响应时检索相关技能,并根据新交互不断优化技能库。
框架由两个耦合的循环驱动:
- 技能增强的响应生成循环:负责检索相关技能辅助当前响应;
- 技能进化循环:负责从新对话中提取经验并持续更新技能库。
基于 WildChat-1M 真实用户交互语料开展实验,筛选出8轮以上的长对话,按中英语言、GPT-3.5/GPT-4模型分为四个子集,验证了框架的有效性。
【2026-3-19】Memento-Skills
【2026-3-19】Memento 推出 Memento-Skills:让Agent自主设计Skill,实现自我进化
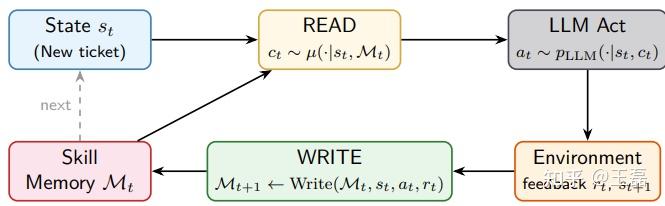
伦敦大学学院、香港科技大学(广州)、吉林大学等机构联合开发的Memento-Skills框架,可持续学习LLM Agent系统,能让Agent自主构建、适配和优化面向特定任务的技能,全程不需要修改底层LLM的任何参数,就能实现能力的持续进化,甚至能自己设计面向新场景的Agent。
Memento-Skills 核心运行逻辑是 Read-Write Reflective Learning(读写反思学习) 循环,这个闭环完美模拟了人类学习的过程:从经验中学习,犯错后总结教训,提炼成可复用的方法 —— 经验手册,下次遇到类似问题直接使用。
【2026-3-30】中科院 D2Skill
【2026-3-30】中国科学院自动化研究所等机构联合发布论文,提出了一种动态双粒度技能库框架,通过双粒度技能组织和动态管理,实现策略与技能库的协同进化。
智能体强化学习(Agentic RL)可从可复用经验中获得显著收益,但现有基于技能的方法主要提取轨迹级指导,且往往缺乏用于维护动态演化技能记忆的系统性机制。
D2Skill:面向智能体强化学习的动态双粒度技能库,将可复用经验组织为两种技能:用于高层级指导的任务技能,以及用于细粒度决策支持和错误修正的步骤技能。
D2Skill 通过在同一策略下进行配对的基线推演和技能注入推演,联合训练策略与技能库,并利用两者的性能差距,推导用于技能更新和策略优化的事后效用信号。该技能库完全基于训练时的经验构建,通过反思持续扩展,并借助效用感知的检索与剪枝机制进行维护。
双粒度技能设计包括任务技能和步骤技能,前者提供高层任务指导,后者提供细粒度的决策支持。动态技能管理机制确保技能库始终保持高效,通过反思驱动的技能生成、效用感知的检索与剪枝,持续维护高可用性的技能库。
ALFWORLD和WEBSHOP基准测试中,相比无技能基线提升了10-20个百分点的成功率,同时保持较低的训练开销。
在 ALFWorld 和 WebShop 数据集上,采用 Qwen2.5-7B-Instruct 和 Qwen3-4B-Instruct-2507 模型进行的实验表明,与无技能基线相比,D2Skill 可将成功率稳定提升 10 至 20 个百分点。进一步的消融实验和分析显示,双粒度技能建模和动态技能维护均是实现这些性能提升的关键,同时所学习的技能具有更高的效用、可跨评估场景迁移,且仅引入适度的训练开销。
【2026-4-9】DreamX:SkillClaw
【2026-4-9】SkillClaw:通过 Agentic Evolver 实现技能的集体进化
OpenClaw 这类 LLM agent 依赖于可重用的技能来执行复杂任务,然而部署后保持静态。
因此,不同用户处理任务时,重复发现相似的工作流、工具使用模式以及失败模式,这阻碍了系统通过经验进行自我演进的能力。
虽然来自不同用户的交互可以为技能在何时有效或失效提供互补的信号,但现有系统缺乏异构经验(heterogeneous experiences)转化为可靠技能更新的机制。
DreamX 团队提出 SkillClaw,用于多用户 agent 生态系统中集体技能演进(collective skill evolution)框架。将跨用户及跨时间的交互视为改进技能的核心信号。
SkillClaw 能够持续聚合使用过程中产生的轨迹(trajectories),并利用自主演进器(autonomous evolver)对其进行处理;
- 该演进器能够识别重复出现的行为模式,并通过优化现有技能或通过新增能力来扩展技能集,从而将这些模式转化为技能更新。
- 由此产生的技能会被维护在一个共享仓库中,并在用户之间进行同步,从而使在某一特定场景下发现的改进能够传播至整个系统,且无需用户投入额外精力。
通过将多用户经验整合到持续的技能更新中,SkillClaw 实现了跨用户的知识迁移和能力的累积提升。
在 WildClawBench 上的实验表明,即使在交互和反馈有限的情况下,SkillClaw 也能显著提升 Qwen3-Max 在真实世界 agent 场景中的性能表现。
总结
- SkillClaw 是多用户 Agent 生态系统中集体技能进化的框架,利用自主的 evolver 将异构的交互轨迹转化为精炼或扩展的技能,从而实现全系统的知识迁移和能力的累积提升,显著增强了 Qwen3-Max 在 WildClawBench 上的表现。
【2026-4-9】阿里 SkillClaw
阿里 AMAP-ML 团队论文:SkillClaw,4月10日 登上HuggingFace当日论文榜第一,126个upvote。
- 📌 核心问题:AI Agent 靠 Skill库执行任务,但Skill一旦部署就是静态的,每个用户都在重复踩同样的坑、走同样的弯路,没有任何积累
- 🔄 SkillClaw 解法:持续收集所有用户交互轨迹 → 自动识别重复出现的行为模式 → 用一个”Evolver”把这些经验转成Skill更新 → 同步回共享Skill库,所有人受益
- 📊 在WildClawBench上测试,用有限的交互和反馈,就能显著提升Qwen3-Max在真实Agent场景中的表现
- 💻 代码已开源:
- 论文 SkillClaw: Let Skills Evolve Collectivelywith Agentic Evolver
以前Skill是人写人维护,现在是用户用、系统学、自动更新。
【2026-4-9】阿里云 SkillForge
针对 skill 编写的诸多问题(跟实际业务脱节+上线后效果迭代依赖人工+费时费力还容易出错)
【2026-4-9】阿里云智能客服(云产品技术领域)用另一种方案 SkillForge:Agent技能自动创建+自动进化框架
- (1)从真实历史工单中挖掘专家解决思路、常用工具和领域知识,再组装成结构化技能包(skill)。初始技能一致率提升4.3pp
- (2)上线后,技能如何自动进化?从知识/工具/澄清/风格4个维度分析bad case,追溯到skill文件具体段落,精准更改。
【实验验证】5个真实云服务场景、1883个工单
- 自进化3轮后,严格一致性率都提升了 9-12pp
- 从专家手写的技能出发,自动进化后效果也能反超人工
- 对比老系统(决策树+人工prompt),新方案高出13.76pp
【论文】SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support
SkillForge 作为首个端到端的垂直领域 Agent Skills自进化框架,很好地解决了企业Agent Skills 冷启动质量差和迭代效率低的两大核心痛点。
实验结果充分证明,通过领域情境化的Skills生成和自动化的自进化闭环,Skills质量可以持续提升,甚至可以超越人工整理的专家知识水平,给大模型Agent在企业场景的规模化落地提供了一条经过实际验证的可行技术路线。
背景
阿里云做智能客服用大模型Agent帮客户解决云产品的技术问题。
但很头疼的问题——给AI Agent写技能(Skill)太难了:
- 写出来的技能跟实际业务对不上,上线之后效果不好也不知道怎么改,只能靠人工一点点调,费时费力还容易漏。
SkillForge 让Agent技能自动创建+自动进化的框架, ACM SIGIR 2026 Industry Track 论文
- 【2026-4-9】SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support
- 解读 【Agent Skills洞察与实践】19-SkillForge:让企业级Agent Skills实现自主进化
SkillForge 设计思路很明确,围绕两个核心点展开:
- 完全扎根业务:所有Skills的知识和流程都从企业真实业务数据里挖,不依赖通用大模型的泛化能力,从根源上保证Skills和领域需求的匹配度。
- 全程不用人工管:整个迭代过程不需要人工介入,从失败分析、根因诊断到Skills重写全流程自动化,实现Skills质量的持续提升。
五阶段流水线设计,保证运行的稳定性和可追溯性:
- 初始化:领域情境化Skills生成器基于领域数据生成初始版本 SkillSkill_v0。
- 执行与监控:Agent加载Skills处理业务请求,把输出和专家参考回复的差异标记为不良案例。
- 一阶段:多维度故障分析,故障分析器从知识、工具、澄清、风格四个维度并行处理不良案例,生成结构化故障记录。
- 二阶段:聚合,按类别聚合单条故障记录,识别系统性问题并选取典型案例。
- 三阶段:诊断,
Skills诊断器分析聚合后的故障数据,把故障映射到Skills的具体缺陷位置,输出诊断报告和优化方案。 - 四阶段:优化,
Skills优化器通过安全虚拟文件系统执行优化方案,生成新版本 Skill Skill_v_n+1。
为了适配企业生产环境的安全要求,SkillForge特意做了约束型的Skills结构设计:剔除了可执行脚本目录,所有操作都只能通过预定义、已经过验证的系统工具完成,所有Agent都通过虚拟文件系统(VFS)和Skills资源交互,从设计上就避免了安全和稳定性风险。
SkillForge 核心思路:
- 1️⃣ 让技能初始版本就足够好
- 设计”领域上下文的技能创建器”,不是让大模型凭空生成技能,而是从真实的历史工单里挖掘专家的解决思路、常用工具和领域知识,再组装成结构化的技能包。
- 相比通用方法,初始技能一致性率直接提升了4.3个百分点。
- 2️⃣ 让技能自己越用越好. 技能上线后不是就不管了,而是搭了自进化闭环:
- 失败分析器:从知识/工具/澄清/风格四个维度拆解每个bad case
- 技能诊断器:把失败模式追溯到技能文件的具体段落
- 技能优化器:精准地改写技能,而不是推倒重来
每一轮部署反馈都会驱动技能自我迭代。
实验是在5个真实云服务场景、1883个工单上跑的,一些关键结果:
- 自进化3轮后,不管从什么起点出发,严格一致性率都提升了 9-12pp
- 甚至从专家手写的技能出发,自动进化后效果也能反超人工——说明自动化迭代确实能突破人工调优的天花板。
- 对比线上跑了很久的老系统(决策树+人工prompt),我们的方案高出13.76pp
| Skill 类型 | Strict一致性率 | Lenient一致性率 |
|---|---|---|
| 人工编写 | +10.99 pp | +12.21 pp |
| 领域生成 | +9.23 pp | +8 pp |
| 通用生成 | +11.6 pp | +4.9 pp |
使用价值很明显:
- 不用从零开始搭:不需要大量人工标注、专家花大量时间写Skills,从历史数据里就能自动生成质量不错的初始Skills。
- 节省维护成本:全自动化的自进化闭环,Skills质量会随着业务运行自己不断提高,不用人工花时间维护。
- 符合生产要求:无脚本的Skills设计加上沙箱运行环境,满足企业生产环境的安全合规要求。
在企业场景里,Agent能力上限很大程度上取决于技能的质量,而技能的质量又取决于能不能从实战反馈中持续学习。SkillForge 就是试图把这个循环自动化起来。
【2026-5-7】谷歌 SkillOS
【2026-5-7】谷歌发布 SkillOS
大多数AI智能体一次性问题解决者,用完就忘。
谷歌论文提出 SkillOS,让智能体学会自己管理可重用的技能库。
🧩 核心架构:执行器 + 技能策展人
- 执行器(冻结):负责实际任务执行,从技能库检索相关技能
- 技能策展人(可训练):学习哪些经验值得提炼、如何更新、何时删除
- 技能库(SkillRepo):Markdown格式存储,包含名称、工作流程、限制条件
🎯 三大策展操作
- insert_skill:从成功/失败经验中提炼新技能
- update_skill:根据新信息完善已有技能
- delete_skill:删除过时或有害的技能
🔮 用强化学习训练策展人
- 分组任务流:相关任务分组处理,密集学习信号
- 复合奖励:任务表现 + 函数调用有效性 + 内容质量 + 紧凑性
- 使用GRPO算法优化策展策略
📊 关键实验结果
- ALFWorld/WebShop/AIME三个领域全面超越基线
- 成功率更高的同时,使用的步骤更少
- 跨执行器泛化:用Qwen3-8B训练的策展人,给Gemini-2.5-Pro用也有效
- 元技能涌现:自动学会故障恢复、系统搜索、状态验证等高级策略
💡 核心洞察
- 技能管理应该是可学习的行为,而非手工规则
- 更新和删除能力是关键——防止知识污染
- 好的技能 = 提供清晰分支逻辑 + 绕过LLM常见陷阱
这个框架让智能体从一次性工具变成持续学习者,是迈向自演化AI的重要一步。
【2026-4-30】中科院 Skills-Coach
2026-5-1 skill coach
中国科学院大学、华东师范大学提出自动化框架 Skills-Coach,增强 LLM Agent 中 skills 的自我进化。
- Skills-Coach: A Self-Evolving Skill Optimizer via Training-Free GRPO
- Code: Skills-Coach
- Clawhub: skills-coach
当前 skills 生态系统的碎片化问题,Skills-Coach 探索 skills 能力的边界,从而促进智能应用所必需的全面能力覆盖。
该框架包含 4 个核心模块:
- 多样化任务生成模块,系统性地为各类 skills 创建综合测试套件;
- 轻量级优化模块,专注于优化 skills 提示词及其对应代码;
- 对比执行模块,促进原始 skills 与优化 skills 的执行与评估;
- 以及可追溯评估模块,依据指定标准对性能进行严格评估。
Skills-Coach 通过虚拟模式和真实模式提供灵活的执行选项。
为验证框架的有效性,研究团队构建了一个包含 48 项多种 skills 的综合 benchmark 数据集 Skill-X。
- Skills-Coach 在广泛类别 skills 能力上取得了性能提升,有潜力推动 LLM Agent 向更强鲁棒性和适应性发展。
【2026-5-22】微软 SkillOpt:冻结模型
资料
- 【2026-5-26】SkillOpt 让技能文档像模型参数一样自动进化
- 【2026-6-24】微软开源 SkillOpt:像训练神经网络一样训练智能体技能,零权重修改!
SkillOpt 优雅之处: 意识到前沿模型已被冻住,但文本技能可被求导。
SkillOpt 解决的问题:
- 怎么让技能文档自动进化,而且每次进化都保证比原来更强?
传统做法:费人、缺乏方向、昂贵且难迁移。
- 手工反复改 prompt
- 让 LLM 一口气生成一堆 prompt 然后挑最好的
- 微调模型。
SkillOpt 思路极其反直觉:
- 把技能文档当成神经网络的权重参数,用前向传播 + 反向传播的逻辑,在纯文本空间做梯度下降式的优化。
- 最终拿到
best_skill.md—— 人类可读、可审计、可版本管理、可跨模型迁移。部署时往 prompt 里一贴就完事,零额外推理开销。
把传统 ML 整套优化哲学完美平移到自然语言空间,产出的却是一个人人都能读懂的 .md 文件。
- 前向传播收集证据、反向传播更新参数、学习率控制步长、验证集早停
SkillOpt 最漂亮的地方: 把 DL训练核心概念一对一刻进了文本世界:
| 传统 ML 概念 | SkillOpt 中的对应 |
|---|---|
| 可训练参数 | 一个紧凑的 Markdown 技能文档(best_skill.md) |
| 前向传播 | 目标 LLM 用当前技能执行一批任务,记录完整轨迹和得分 |
| 反向传播 / 梯度估计 | 另一个优化器 LLM 分析成功/失败轨迹,提出结构化编辑建议 |
| 学习率 | 有界编辑预算(Bounded Edits),限制每次最多改几处 |
| 验证集 + 早停 | 验证门控(Validation Gate):只在验证集分数提升时才接受更新 |
| 动量 / 长期记忆 | Slow Update 和 Meta Skill,在 epoch 级别传递跨步经验 |
整个过程中,目标模型的权重一动不动,所有优化都发生在几百~一两千个 token 的文本文件上。
【2026-5-27】微软等提出 SkillOpt:把 Skill 当成模型一样训练,GPT-5.5 平均提升 23.5 分
【2026-5-22】微软研究院、上海交通大学、同济大学、复旦大学合作提出 SkillOpt ,把 Agent 的「技能文档」当作可训练状态,用轨迹反馈、受控文本编辑和验证集门控来优化技能,在不改模型权重、不增加部署期调用的前提下,让多个模型和执行环境稳定涨分。
- 📄 论文 SkillOpt: Executive Strategy for Self-Evolving Agent Skills
- 💻 代码仓库 SkillOpt
- 🌐 项目页面 SkillOpt
场景:
- 同一个表头识别错误,它今天犯一次,明天换个文件还会再犯;
- 同一个公式写入问题,换个 workbook 还会重复出现。
SkillOpt 解决这类反复出现的流程性失败。
可控性问题:
- 一次性生成很难覆盖真实任务里的失败模式;
- 人工技能容易停在经验层面;
- 无约束自我改写又可能把原本有用的规则删掉,或者把偶然样例里的细节写成通用规则。
SkillOpt 解决更工程化的问题:
- 如果 skill 是 Agent 适应某个领域的外部程序,那能不能像模型参数一样被训练?
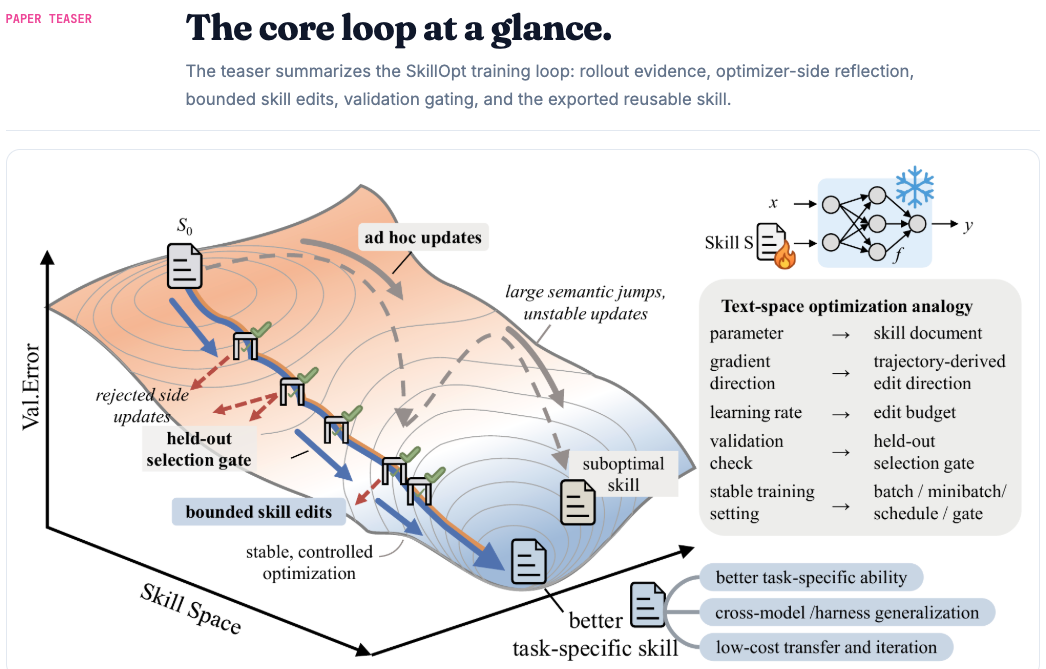
论文答案:把技能文档视为 frozen agent 的外部状态,用一个单独的优化器模型读取执行轨迹,然后只允许它对同一份 skill 做有预算的 add 、 delete 、 replace 编辑;每次编辑之后必须在 held-out selection split 上严格变好,才会被接受。
(1) 原理
调用链
scripts/train.py→skillopt/optimizer/→skillopt/gradient/
训练流程
Rollout(执行):目标模型用当前技能文档在训练任务上执行,记录完整的执行轨迹和得分Reflect(反思):优化器模型分析成功和失败的案例,找出可复用的流程和需要修正的错误Edit(编辑):生成结构化的添加、删除、替换操作,在文本学习率预算下合并和排序Gate(验证):候选技能只有在验证集上性能严格提升时才会被接受
这个架构好处:
- 目标模型可以是任何支持 API 调用的 LLM,不需要模型权重访问权限;
- 部署时零额外成本,只需要一个几百到几千 token 的 Markdown 文件;
- 技能文档还可以跨模型、跨执行环境迁移。
核心亮点
- 完全不碰模型权重:SkillOpt 完美避开了修改权重可能导致的问题,所有的优化都发生在外部文本上。
- 系统化的训练控制:把深度学习训练的整套方法论都搬过来了。
- 支持多种主流模型:支持:Azure OpenAI、OpenAI 直接调用、Anthropic Claude、通义千问(本地 vLLM 部署) 等。
- 自带可视化 WebUI:附带了一个基于 Gradio 的 Web 监控面板,可以直观地查看训练状态、技能快照、每步的改进效果等。
- 内置多种基准测试:项目已经内置了 6 个不同类型的基准测试,覆盖了问答、具身智能、文档理解、数学推理、代码生成等多个领域,可完成各种不同类型的任务。
详情
- (1)
Rollout——前向传播,收集证据- 从 train/ 里采样一个 batch(比如 40 条任务),把当前技能注入目标模型的 system prompt,然后逐一执行。每条任务都会记录完整的对话历史、工具调用、verifier 反馈和最终得分(0–1)。支持并行 worker,也支持 accumulation 模式(多次 rollout 后才触发一次更新,减少噪声)。这一块的成本是训练的主要开销。
- (2)
Reflection——文本空间的“反向传播” 整个系统的灵魂。- 拿到一批轨迹后,按成功/失败分组,切分成若干 reflection minibatch,然后:
- 对失败 mini-batch:优化器 LLM 分析失败原因,提出新增/修改指令
- 对成功 mini-batch:分析有效策略,提出值得保留的规则
- 之前被验证门拒掉的编辑,会作为负面样本喂给优化器
- 在 skillopt/prompts/ 下可以看到这些 reflection 的 prompt 模板,结构非常清晰:当前技能文档 + 几条成功/失败轨迹 + 可选的 rejected edits → 输出结构化的 ADD / DELETE / REPLACE 编辑指令。这一步本质上是让一个更强的模型,根据证据“说出”技能应该往哪个方向改——它就是文本空间的梯度估计。
- 拿到一批轨迹后,按成功/失败分组,切分成若干 reflection minibatch,然后:
- (3)
Bounded Edits——文本空间的学习率- 优化器 LLM 提出的编辑会被聚合、去重、按预期收益排序,然后用一个编辑预算 L 截断——只取 Top-L 个编辑应用到当前技能上。L 的值在配置中指定,支持余弦调度(训练早期 L 大,探索;后期 L 小,精细收敛)。
- 这个机制直接对应 DL 中的学习率:控制每次参数更新的步长,防止一步改残。
- (4)
Validation Gate——拒绝一切花架子- 候选新技能生成后,不是直接接受,而是先在 val/ 验证集上跑一遍。
- 只有当验证集平均得分严格超过当前最佳技能时,才接受这次更新。
- 被拒绝的候选会进入 rejected edit buffer,作为后续迭代的负面学习样本。
- (5)
Slow Update与Meta Skill——动量与长期记忆- 每个 epoch 结束时,SkillOpt 会做两件额外的事:
- Slow Update:在 epoch 前后的技能下重新执行部分训练样本,对比变化,生成一条纵向总结,写入技能文档的受保护区域。相当于给优化过程注入了动量。
- Meta Skill:优化器 LLM 自己的“元技能”,总结本 epoch 中哪种编辑模式有效、哪种无效。它会追加到下一个 epoch 的优化器 prompt 里,但不进入最终部署的 best_skill.md。
- 每个 epoch 结束时,SkillOpt 会做两件额外的事:
【2026-7-1】问题
- 初始prompt为空时,能用吗?
- edit动作有哪些?增删改?没有明确
- 多个编辑点冲突怎么办?缺乏单个编辑点质量评估
- 排序保留4个编辑点,为什么?
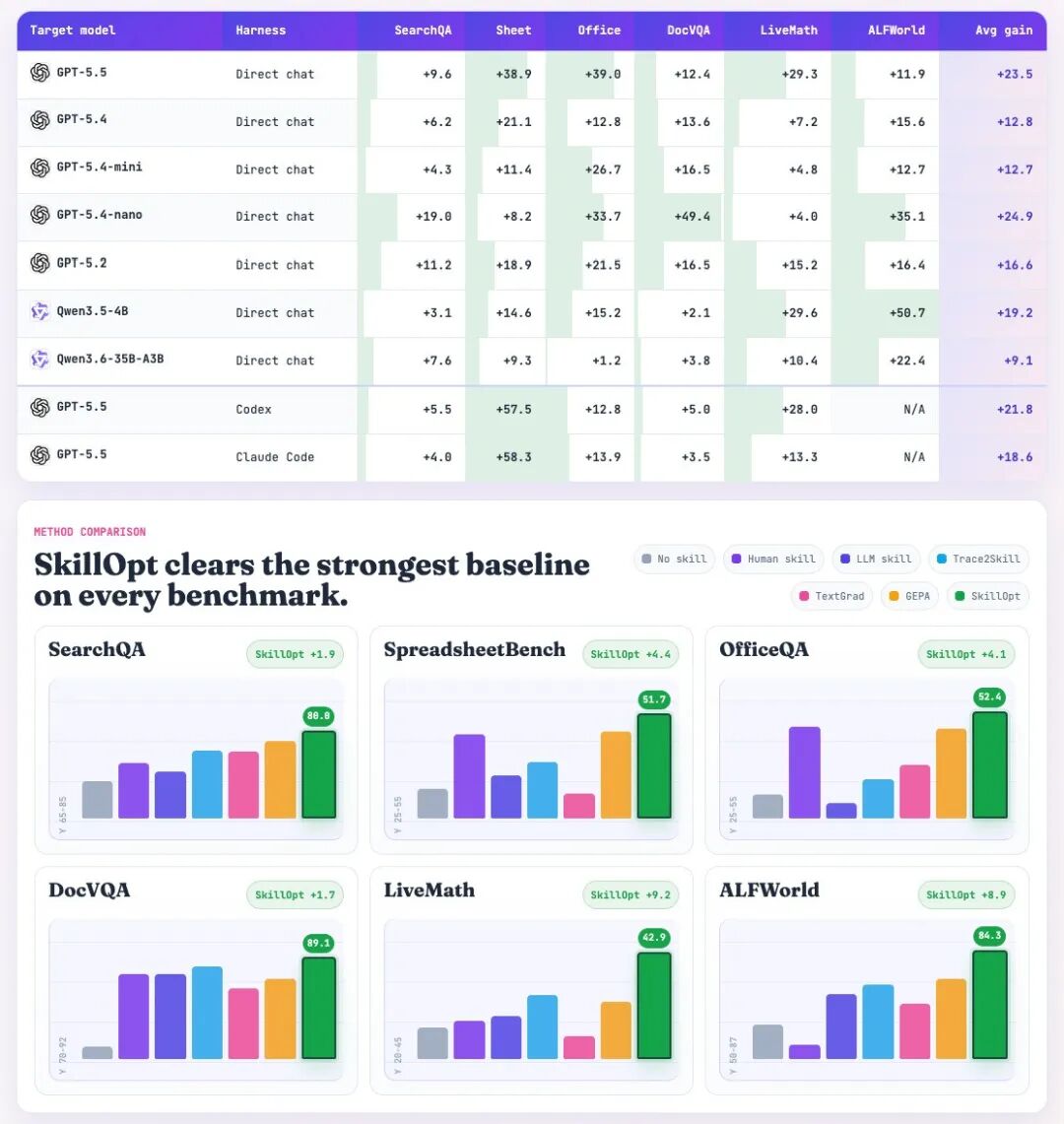
(2) 效果
SkiLlopt 最好
- No skill
- LLM skiLl
- Trace2skill
- TextGrad
- Human skill
- GEPA
测试了 7 个目标模型、6 个基准测试、3 个执行环境,总共 52 个(模型×基准×环境)组合,SkillOpt 在所有 52 个组合中都取得了最佳或并列最佳的成绩!
- 在 GPT-5.5 上,直接聊天模式的平均准确率提升了 +23.5 个百分点
- 在 Codex 智能体循环中,提升了 +24.8 个百分点
- 在 Claude Code 中,提升了 +19.1 个百分点
- 在 ALFWorld 任务上,GPT-5.4-mini 的准确率从 70.9% 提升到了 85.8%,只用了 4 步!
(3) 安装
git clone https://github.com/microsoft/SkillOpt.git
cd SkillOpt
pip install -e .
# 如果需要 ALFWorld 基准测试
pip install -e ".[alfworld]"
alfworld-download
(4) SkillOpt vs PE
让 GPT-5.5 自己写个 prompt,然后手动挑一挑,不也能用吗?
论文实验打了这种想法的脸。
- 相比“手写技能”、“LLM 一次性生成技能”、“GEPA 等 prompt 优化方法”,SkillOpt 在多任务上都有大幅领先,而且完全自动化。
- 本质原因: 传统 prompt engineering 无反馈或弱反馈,SkillOpt 利用了批量 rollout 的统计信号和验证集的严格筛选,每一轮更新都是数据驱动的。
如果过去曾熬夜改 prompt 改到想砸电脑,SkillOpt 可能会让你感动落泪。
(5) SkillOpt vs TextGrad
SkillOpt vs TextGrad:同为“文本梯度”,路线截然不同
总结:
TextGrad 更像一个通用文本微分框架 SkillOpt 是一个专为 Agent 技能优化设计的、面向生产的整合方案。
TextGrad 同样用 LLM 做文本反向传播。但两个项目的技术路线差异很大:
- 粒度不同:TextGrad 把对话中的每个变量都当作节点,分别计算“梯度”。SkillOpt 聚焦在一个整体技能文档上,所有经验都汇聚到同一个地方。
- 稳定性设计:SkillOpt 有 bounded edits + validation gate + negative buffer,整套机制像带了 SGD 动量、早停和拒绝采样的正规军;TextGrad 的反馈更自由,但也更容易发散。
- 最终产物:SkillOpt 输出一个可独立部署的 .md 文件;TextGrad 通常需要保留整个优化痕迹或动态构造 prompt。
- 迁移性:SkillOpt 的论文和代码都验证了技能可以跨模型、跨 harness 迁移,这是目前 TextGrad 没有明确展现的特性。
(6) SkillOpt 能上生产环境吗
能。目前我见过最“生产友好”的 Agent 优化方案之一,而且代码质量比我预期的更高。
生产级优势(代码层面已验证)
- 零额外推理成本:最终 skill 就是一个短文本,部署时不影响 token 消耗和延迟。
- 可审计、可回滚:人可以直接读 best_skill.md,可以 git 管理,可以 A/B 测试。
- 跨模型迁移:用强模型训出来的 skill,换到便宜的模型上依然有效。
- 离线训练,在线部署:训练时烧钱没关系,部署时白嫖。
- 代码质量高:调度器、prompt 缓存、智能截断等工程细节都已妥善处理,不是粗制滥造的研究原型。
- MIT 协议,支持 Azure/OpenAI/Anthropic/vLLM,开箱即用。
注意
- 编辑排序的静默回退:如第四节所述,建议在 clip.py 中加上警告日志,提升可观测性。
- 验证集的规模与噪声:如果验证集很小(<100 条),建议考虑引入 epsilon 容差或多次评估取均值,防止分数波动误导门控。
- 必须有可靠的自动评估:验证门需要自动打分,主观任务需要额外设计评分体系。
- 训练成本:rollout + reflection 的 API 调用量不小,但远低于微调,适合高价值、高频的重复性任务。
- v0.1.0 的成熟度:核心路径稳定,但边缘 case 和文档仍在完善中。“增强方向”可以作为 fork 后的贡献起点。
推荐的生产落地路径
- 选一个业务指标明确、有自动评估能力的场景(客服、数据分析、代码生成、文档处理)
- 准备好 train/val/test 数据,val 集不要太小(建议 ≥ 100 条)
- 用强优化器(GPT-5.5 或 Claude)搭配你的目标模型,跑 3–5 个 epoch
- 用 test 集和线上影子流量双重验证最终的 best_skill.md
- 把 skill 文件丢进生产环境,版本化管理,持续监控
- 定期用新收集的失败 case 重新训练,让技能持续进化
【2026-5-26】字节 MUSE-Autoskill
🧠 字节新作:Agent Skill也能自进化了? http://xhslink.com/o/5gjDXidznsq
Agent Skill 痛点
现在Agent虽然能写代码、调工具,但Skill大多是一次性,生成了就不会改。这次在数据分析上翻了车,下次换个任务还是犯同样的错。技能之间孤立、静态,缺乏长期的记忆和优化机制。
【2026-5-26】字节跳动提出:Skill不应只是几行脚本,而应变成有生命周期的自我进化闭环。推出 💡 MUSE-Autoskill:全生命周期管理
MUSE-Autoskill 自进化闭环分为五个阶段:
- 创建 (Creation):按需生成,自动编写 SKILL.md 文档和配套脚本;
- 记忆 (Memory):关键创新点是引入了skill-level的记忆,每个skill都有专属的 .memory.md,记录自己踩过的坑和适配建议。同时也保留短期和长期记忆架构;
- 管理 (Management):自动索引、合并同类项,甚至精简掉没用的废技能;
- 评估 (Evaluation):Skill必须通过单元测试才能进入库中,让Agent更可靠;
- 精化 (Refinement):根据运行报错自动 Patch 修复,越用越稳。
📊 评测结果
SkillsBench的51个任务上,MUSE总体准确率68.4%,比Codex(67.3%)和Hermes(61.2%)都高。with-skills 比 without-skills 提升15.2pp,说明Skill大幅提升了Agent的能力。
MUSE自己生成的skill在35个任务上伸直超过了人类手写的skill,这意味着好的skill生命周期管理,产出效果完全可以超越人工设计的经验。
【2026-5-31】浙大+蚂蚁 SkillAdaptor
【2026-6-2】Skill又进化了!蚂蚁SkillAdaptor竟然自适应
LLM Agent 技能迭代的真实困境:
- 反思越全面,修改越不稳定。
【2026-5-31】浙江大学和蚂蚁集团联合提出 SkillAdaptor
- 核心思路: 别急着全盘反思,先精准定位到第一步出错的地方,再只改对应的那条技能。
- 论文: SkillAdaptor: Self-Adapting Skills for LLM Agents from Trajectories
- GitHub: SkillAdaptor
SkillAdaptor 把技能适配从”轨迹级反思”切换到”步级归因”,分三步走:
- 第一步:定位(Localize)——给定一条失败轨迹,Localizer 预测第一个可操作的故障步骤t*,同时输出失败行为描述和改进建议。注意是”第一个”——因为后续的失败往往是前面某步出错的连锁反应,定位最早的故障点才能切断因果链。
- 第二步:追责(Link)——Linker 估计哪些被检索到的技能对失败负有最大责任,输出一个加权嫌疑集。更关键的是,它还要判断:失败是因为现有技能写错了(走修订路线),还是因为根本没有覆盖这种场景的技能(走新建路线)。
- 第三步:受控修改(Modify + Qualify)——Modifier 根据追责结果更新技能:修订则重写权重最高的技能并替换,新建则从故障步骤的上下文合成新技能。但更新不会直接生效——Qualifier 门控要求候选更新在重跑任务后指标 Δ ≥ 0 才被接受,否则丢弃。这个门控是整个框架稳定性的关键保险。
整个过程中,骨干模型参数始终冻结,所有改进都来自技能库的更新。
SkillAdaptor 的结论对做 Agent 工程的人有一个很直接的启发:技能迭代的效果,不取决于你反思得多全面,而取决于你归因得多精准。
Skill 膨胀
agent 把 Skill 直接塞 system prompt,越积越多,上下文窗口快被吃光,怎么办?
大部分人第一反应答错 —— 把 Skill 当 tool,两者机制完全不同。
【2026-5-31】
《MCP vs Skills》
- 每个skill元信息 100 token ,50个 skill 只占 5K token, 看着天衣无缝。
实践中,描述写详细,5-6个skill 就开始崩。三机制叠加。
渐进式披露 progressive disclosure 是起点,不是答案
三机制叠加,五六个就开始崩:
- ① Token 占用线性涨
- ② n^2 注意力被稀释
-
③ 检索精度断崖: char buget
- 瓶颈 1: char budget 截断
- 总预算 = context x1% 或 8000 字符 fallback
- 单 skill 上限 1536 字符
- 5-6 个长描述就撞穿 8000 字符
- 撞穿后自动截短,关键词流失,routing 断链
- 机制完全静默,没有任何报错
- 瓶颈 2: n^2 注意力稀释
- Transformer 数学约束, n token =n^2 对关系
- metadata 越多每个被注意到的概率越稀, 业界叫 context rot(Chroma 提出)
- 不是 lost-in-the-middle, 是 attention 摊薄
- window 再大也绕不过 - 架构级数学约束
- 瓶颈 3: 语义重叠
- 3 个 skill 都谈”PDF 处理” -> LLM 选不出
- BFCL v4 加 distractor 准确率掉 1-8 pp
- Anthropic: 人都选不出,AI也别指望
- 纯 LLM 推理 routing - 没有 embedding
- 3 个相似 skill, 比 100 个不相似的还坑
解决路径:
- ✅ 命名空间与打包
- ✅ 性能优化四件套
- ✅ 安全隐患(prompt injection)
- ✅ 当前市场主流方案
详见解读
分层workflow
【2026-5-10】关木 @ZeroZ_JQ 的章 从 Skills 到分层 Workflow:AI Agent 工程化的下一层抽象
问题:
skills 数量增加,并不能带来 Agent 行为的稳定性。
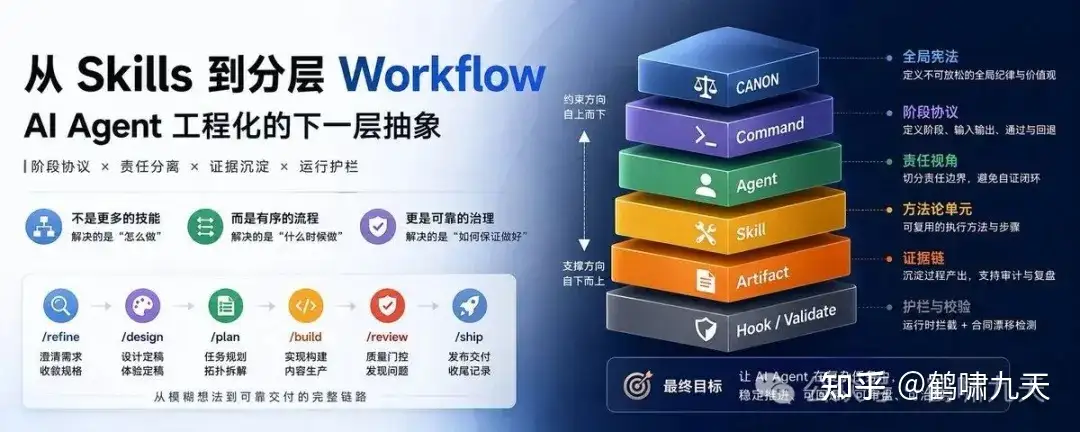
很多团队搭建 skills library时,把常见问题抽成一组可复用方法论,需要时调用。
- 测试时有 TDD skill
- 排查时有 debug skill
- 审查时有 review skill
- 写文档有 writing skill。
把零散经验变成复杂可用结构,让Agent在局部问题上不再临场发挥。
每个 skill 都在给 Agent 补某个局部能力:在某类任务上更稳定、更专业、更符合团队习惯。
但系统一旦继续生长,问题来了:skills 数量增加,Agent 行为未必稳定。

怎么办?
- 表面上是能力组织问题,但实际是工程控制问题。
- 小规模时,问题是“有没有合适的 skill”;
- 规模扩大后,变成:这些能力在什么阶段被调用,由什么责任视角调用,依据什么输入推进,留下什么产物,又由什么机制决定是否可以进入下一步。
skill 库方案存在瓶颈
Unified Skills 不再是做一组 skills,而是把 skills 组织成分层 workflow。
- skills 解决“怎么做”,而 workflow 解决“什么时候做、由谁做、做到什么程度、失败时退回哪里、过程证据留在哪里”。
当 Agent 开始承担连续工程任务时,真正要治理的就不再是能力本身,而是能力进入流程的方式。
Skills Library 的上限不是能力不足,而是工程失稳
工程交付需要状态机,而不是自由联想,因此,主路径不是“需要什么就调用什么”,而是:
/refine -> /design -> /plan -> /build -> /review -> /ship
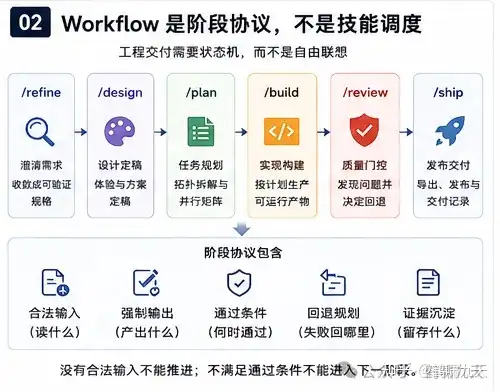
分层workflow
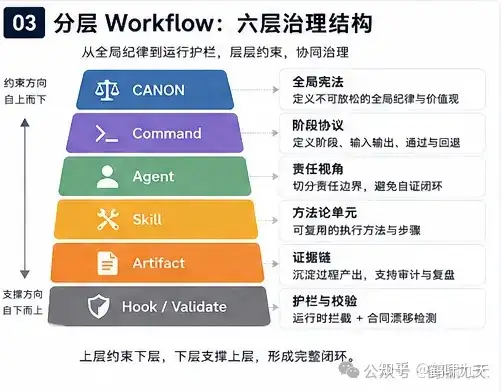
真正让 Unified Skills 变成工程系统的,不只是横向阶段,而是纵向分层。
- CANON -> Command -> Agent -> Skill -> Artifact -> Hook / validate
- CANON -> 命令 -> 代理 -> 技能 -> 产物 -> Hook / 验证
详见 解读 Skills爆炸?分层workflow
生态
浙大 SkillNet
【2026-3-8】Skill迎来大一统,浙大阿里腾讯等众多研究机构联合推出 SkillNet,拒绝「重复造轮子」
当前AI Agent面临核心困境:缺乏系统性的技能积累和迁移机制。
两个根本性缺陷:
- 缺乏统一的技能获取和整合机制:有价值的专业知识广泛存在于开源仓库、学术论文和Agent执行轨迹中,但它们仍然很大程度上是非结构化和孤立的。AI Agent无法自动将这些资源提炼为可复用、可执行的能力。
- 缺乏原则性的技能质量验证框架:没有内在和系统的评估,技能仓库容易”污染”,可执行性、安全性和鲁棒性只能通过下游任务成功间接评估。这种随机且不透明的验证引入了技术债务,破坏了长期能力增长。
【2026-2-26】浙江大学联合阿里巴巴、腾讯等19个机构提出 SkillNet ,构建了超过20万个AI技能的开放基础设施,通过统一本体论、五维度评估体系和技能关系图谱,让Agent从「重复造轮子」进化到「技能复用」,在三个基准测试中平均奖励提升40%、执行步骤减少30%。
- 📄 论文 SkillNet: Create, Evaluate, and Connect AI Skills
- 💻 GitHub SkillNet
- 🌐 官网 SkillNet
- 📦 PyPI包 skillnet-ai
- 🔌 API文档 api
SkillNet 将大规模Agent技能组织成结构化的技能网络,建模丰富的关系(如相似性、组合性和依赖性),支持多维度评估,并提供统一的接口用于技能发现、创建和分析。
SkillNet 三大核心贡献:
- 统一的技能框架:将碎片化的Agent经验转化为结构化的技能网络,支持丰富的关系建模,作为可操作知识工程的可扩展基础。
- 严谨的技能评估协议:建立了五维度评估体系(安全性、完整性、可执行性、可维护性、成本感知),确保大规模技能仓库的可靠性。
- 开源生态系统:发布了超过20万个技能、Python工具包和全面的基准测试,实证证明了在Agent规划和执行任务中的显著性能提升。
技能操作的三个步骤:
- 发现(Discovery):Agent最初只加载最小元数据(如名称和描述),识别可能与给定任务相关的技能。
- 激活(Activation):当任务与技能描述匹配时,Agent从SKILL.md读取完整指令并准备相关资源。
- 执行(Execution):Agent遵循指令,可选执行捆绑代码或利用引用资产完成任务。
安装
pip install skillnet-ai
实现
蒸馏人类
同事
【2026-4-3】colleague-skill 将冰冷的离别化为温暖的 Skill,欢迎加入数字生命1.0
reademe 文件“振聋发聩”、“发人深省”:
“你们搞大模型的就是码奸,你们已经害死前端兄弟了,还要害死后端兄弟,测试兄弟,运维兄弟,害死网安兄弟,害死ic兄弟,最后害死自己害死全人类”
女娲
【2026-4-8】GitHub 热门项目
效果
用户 ❯ 家里条件一般,孩子想学金融,去不了顶尖学校,该不该报?
张雪峰 ❯ 千万别报。我说过多少遍了,金融不是你学出来的,金融是
你爹妈给你带出来的。顶尖学校的金融,人家同学是行长的
儿子、基金经理的女儿,人脉就是资源。你普通家庭去个普通
学校学金融,毕业出来干什么?卖保险、跑银行柜台、做电销。
先谋生再谋爱,家里没矿就选技术类专业,学个硬本事,靠
自己吃饭。金融这碗饭,不是谁都端得起的。
女娲提取六层:
- 层次 说明
- 怎么说话 表达DNA——语气、节奏、用词偏好
- 怎么想 心智模型、认知框架
- 怎么判断 决策启发式
- 什么不做 反模式、价值观底线
- 知道局限 诚实边界
输入一个名字后,女娲做四件事:
- 六路并行采集 —— 著作、播客/访谈、社交媒体、批评者视角、决策记录、人生时间线,6个Agent同时跑,各自存档。
- 三重验证提炼 —— 一个观点要被收录为心智模型,必须:
- 跨2+个领域出现过(不是随口一说)、能推断对新问题的立场(有预测力)、不是所有聪明人都会这么想(有排他性)。
- 三个都过才收录。
- 构建Skill —— 3-7个心智模型 + 5-10条决策启发式 + 表达DNA + 价值观与反模式 + 诚实边界,写入SKILL.md。
- 质量验证 —— 拿3个此人公开回答过的问题测试,方向一致才通过。再用1个他没讨论过的问题测试,Skill应该表现出适度不确定而非斩钉截铁。
完整方法论在 references/extraction-framework.md。
原理
- 收集蒸馏人物的信息,包括:个人作品、访谈纪要、表达方式、外部观点、相关决策、人物时间线
- 整理成 skill 文件:张雪峰思维操作系统,覆盖:
- 角色扮演原则(最重要)
- 回答工作流:问题分类 → 按类型选择不同回答策略, 搜索多方面数据 → 作答(基于前面获取的数据,运用心智模型和表达DNA)
- 身份卡:我是谁、我的起点、最后在做什么
- 心智模型:社会筛子论、选择>努力、就业倒推法、阶层现实主义、争议即传播
- 决策启发式:灵魂追问法、中位数原则、不可替代性检验、500强测试、家庭背景分流、城市优先原则、10年后压迫测试、认态度不认事实
- 表达DNA:表述风格,包含句式、词汇、节奏、幽默、确定性、引用习惯、辩论策略
- 人物时间线
- 价值观与反模式:我追求的、我拒绝的、我没想清楚的
- 知识谱系
- 诚实边界
- 附调研来源
安装
npx skills add alchaincyf/nuwa-skill
Claude Code 里蒸馏:
蒸馏一个保罗·格雷厄姆 造一个张小龙的视角Skill 帮我做一个段永平的Skill 造完之后直接调用:
使用
用芒格的视角帮我分析这个投资决策 费曼会怎么解释量子计算? 切换到Naval,我在纠结三件事
Minion Skills
【2025-12-22】Minion Skills:Claude Skills的开源实现
LangChain Skills
LangChain Skills 支持
LangChain Skills 通过 skills 调用 langchain 工具
- LangChain
- LangGraph
- Deep Agents
# Local (current project):
npx skills add langchain-ai/langchain-skills --skill '*' --yes
# Global (all projects):
npx skills add langchain-ai/langchain-skills --skill '*' --yes --global
# To link skills to a specific agent (e.g. Claude Code):
npx skills add langchain-ai/langchain-skills --agent claude-code --skill '*' --yes --global
示例
from langchain.tools import tool
from langchain.agents import create_agent
@tool
def load_skill(skill_name: str) -> str:
"""Load a specialized skill prompt.
Available skills:
- write_sql: SQL query writing expert
- review_legal_doc: Legal document reviewer
Returns the skill's prompt and context.
"""
# Load skill content from file/database
...
agent = create_agent(
model="gpt-4o",
tools=[load_skill],
system_prompt=(
"You are a helpful assistant. "
"You have access to two skills: "
"write_sql and review_legal_doc. "
"Use load_skill to access them."
),
)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
