- LangChain
- LangChain 演进
- LangChain 介绍
- 为什么有 LangChain
- LangChain 生态
- LangChain 观点
- LangChain 安装
- 功能
- LangChain 1.*
- LangChain 组件
- LangChain 实践
- 结束
LangChain
LangChain 演进
总结
LangChain / LangGraph / DeepAgents 演变
- 2022:只有 LangChain 独苗起步
- 2024:LangGraph 入局,逐步成为 LangChain 官方Agent底层
- 2025中:DeepAgents 诞生,做生态更高阶复杂智能体
- 2025年底:LangChain + LangGraph 同步 v1.0 正式定型
- 2026:只剩 DeepAgents 持续快速迭代更新
| 序号 | 时间 | LangChain | LangGraph | DeepAgents | 核心事件备注 |
|---|---|---|---|---|---|
| 1 | 2022-10-24 | v0.0.1初版,LLM抽象+Chains | — | — | LangChain 初始开源,基础Chain/LLM抽象 |
| 2 | 2024-01 | v0.1.0 稳定版,聚焦生产稳定性 | 初始开源版 | — | LangChain 进入生产可用;LangGraph 诞生 |
| 3 | 2024-01-22 | — | 初版,面向状态化、可循环 Agent 编排 | — | LangGraph 状态化循环Agent编排框架面世 |
| 4 | 2024-05 | v0.2.0 包分层、统一 invoke 接口、推荐 LangGraph 构建 Agent | — | — | LangChain 架构分层、统一invoke,主推LangGraph做Agent |
| 5 | 2024-06-27 | — | v0.1.0 稳定版,发布 LangGraph Cloud(托管) | — | LangGraph 首个正式稳定版,上线LangGraph Cloud |
| 6 | 2024-09 | v0.3.0 Pydantic 2 升级、类型强化、为 1.0 铺路 | — | — | LangChain 适配Pydantic2、强类型重构,为v1.0铺路 |
| 7 | 2025-07 | — | — | Alpha 初版,面向长周期复杂任务 | DeepAgents 首次发布,面向长周期复杂任务Agent |
| 8 | 2025-10-22 | v1.0.0 重大重构,统一 Agent API,基于 LangGraph | v1.0.0 正式版,持久化状态、人机交互、与 LangChain 1.0 同步发布 | — | 双框架同步毕业;LangChain 重大重构,深度绑定 LangGraph |
| 9 | 2025-10-28 | — | — | v0.2.0 可插拔后端、大结果自动落盘、会话摘要 | DeepAgents 可插拔后端、会话摘要、结果持久化 |
| 10 | 2026-04-07 | — | — | v0.5.0 里程碑:异步子 Agent、多模态(PDF / 音视频) | DeepAgents 异步子Agent、多模态PDF/音视频支持 |
| 11 | 2026-04-15 | — | — | v0.5.3 小版本更新 | DeepAgents 小版本修复优化 |
| 12 | 2026-04-29 | — | — | v0.5.4 支持模型专属配置(Harness Profiles) | DeepAgents 新增模型专属配置Harness Profiles |
| 13 | 2026-05-01 | — | — | v0.5.6 最新版 | DeepAgents 当前最新稳定版本 |
图解
背景介绍
【2025-12-26】LangChain 三年回顾:从框架演进看 Agent 开发的本质与未来
三年前,Harrison Chase 把 800 行代码推送到 GitHub。那只是个 side project,没有公司,没有宏大计划。
- 一个月后,ChatGPT 发布,一切都变了。
- 2022 年底,LangChain 发布,主打”易用”。核心理念:为 LLM 应用提供抽象层
- 2023 年夏天,LangChain 收到大量负面反馈。有些问题可以修:防止破坏性变更、让隐藏的 prompt 显式化、减少包体积、修复文档。但有个反馈最难解决:人们想要更多控制。LangChain 很容易上手,但很难定制和扩展。
- 2024 年1月,LangGraph 发布,主打”控制”。 LangChain 的 Chains 是 DAG(有向无环图),而 Agent 天然需要循环。Agent 调用搜索工具,发现结果不够好,想再搜一次
- LangGraph 的核心突破:支持循环图(Cyclical Graphs)
- LangGraph 只假设一件事:LLM 是慢的、不稳定的、开放式的。基于这个假设,LangGraph 聚焦两大支柱:1. 可控性(Controllability)2. 运行时(Runtime)
- 2024 年中,Harrison Chase 在 Sequoia AI Ascent 大会上提出了 Agent 的三大限制:Planning、UX、Memory。
- 2025 年7月,DeepAgents 发布,主打”深度”。
- 新术语开始流行:Context Engineering—— Agent 失败,通常不是模型问题,是上下文问题。
- Context Engineering 有四大策略:Write、Select、Compress和Isolate
- Deep Agents 有四大特征:1. 详细的系统提示词 2. 规划工具 3. 子智能体 4. 文件系统
- 2025 年10月,LangChain 1.0 发布,回归本质。
- LangChain 决定从头重写 LangChain,三个目标:让上手尽可能简单、允许比以前更多的定制、提供生产级运行时
如何实现?
- 聚焦核心:专注于工具调用循环——这已经成为”Agent”的代名词。
- 引入中间件:一个新概念,让开发者能在需要的地方精确控制”上下文工程”的生命周期。
- 基于 LangGraph:站在巨人的肩膀上,获得流式、持久执行、human-in-the-loop 等能力。
三层架构 — Framework、Runtime、Harness
2025 年 10 月,LangChain 明确了三个层次的定位:
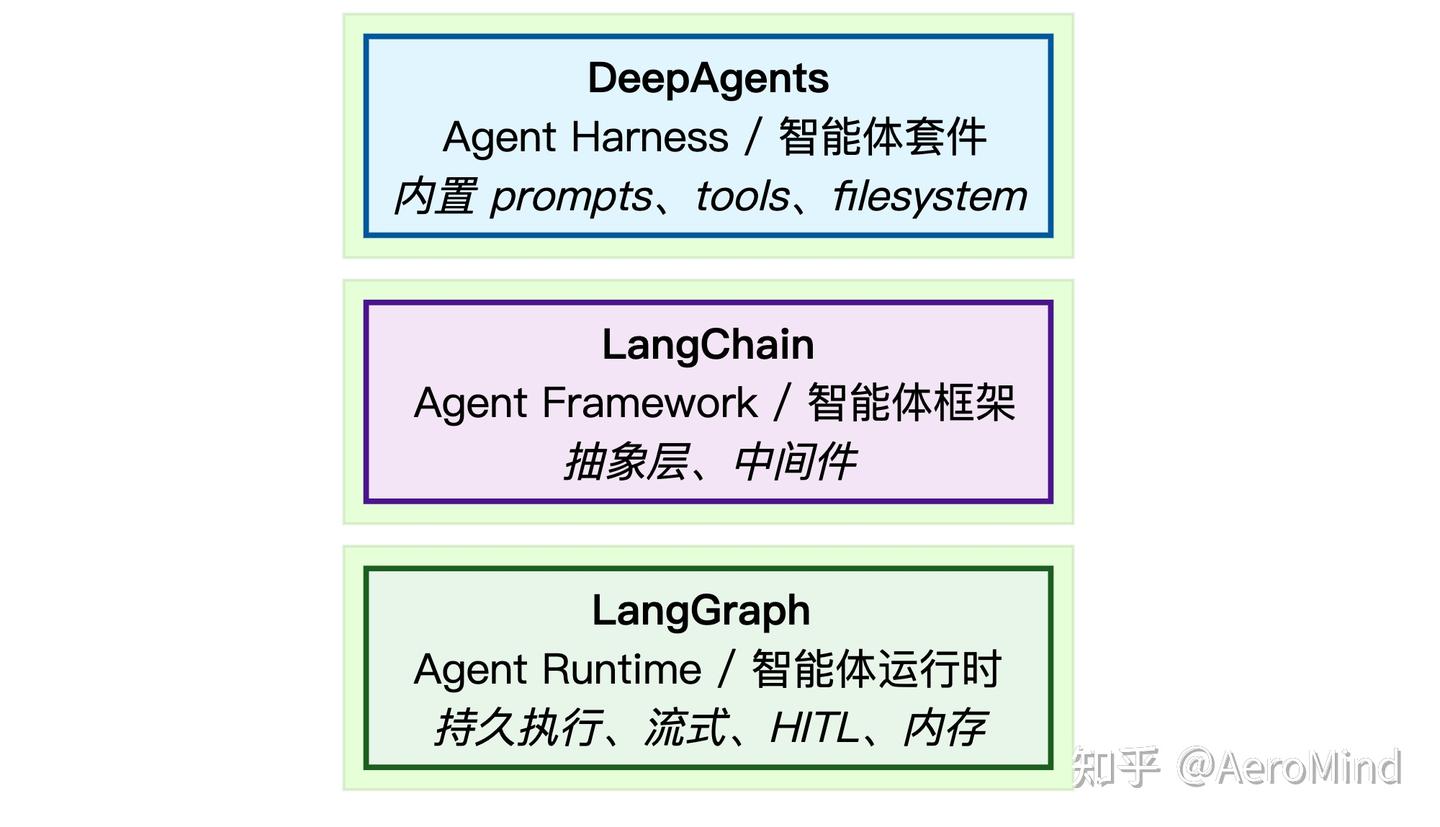
需要
- 完全控制 → LangGraph
- 快速上手 → LangChain
- 开箱即用 → DeepAgents
DeepAgents 建立在 LangChain 之上,LangChain 建立在 LangGraph 之上。
2025 年 12 月,LangChain 提出新概念:Agent Engineering——把非确定性的 LLM 系统打磨成可靠的生产体验。
三年,三次重写,四个版本。
这不是技术债务的堆积,而是整个行业对”什么是好的 Agent”认知的演进。
LangChain 介绍
LangChain, 语言链条,也称:兰链
2022年10月底,哈佛大学 Harrison Chase 开发, 基于开源大语言模型的AI工程开发框架
- LangChain 中的 “Lang” 指大语言模型,“Chain”即“链”,将大模型与其他组件连接成链,借此构建AI工程应用
- LangChain 多语言实现:Python、node.js 以及第三方提供的Go
- 几分钟内构建 GPT 驱动的应用程序。
Harrison Chase 于 2022 年 10 月底首次提交 LangChain。在被卷入 LLM 浪潮之前,只有短短几个月的开发时间
LangChain 帮助开发者将LLM与其他计算或知识源结合起来,创建更强大的应用程序。
论文《ReAct: Synergizing Reasoning and Acting in Language Models》的实现:
- 该论文展示了一种提示技术,允许模型「
推理」(通过思维链)和「行动」(通过能够使用预定义工具集中的工具,例如能够搜索互联网)。
LangChain 在没有任何收入/创收计划的情况下,获得了 1000 万美元的种子轮融资和 2000-2500 万美元的 A 轮融资,估值达到 2 亿美元左右。
【2024-3-15】从API到Agent:万字长文洞悉LangChain工程化设计
文本生成模型的实际输入和输出都是字符串
- 直接调用LLM的问题:输入格式化和输出结果解析上,要做大量重复文本处理工作。
- LangChain 提供
Prompt和OutputParser抽象,用户根据需求选择具体实现类型。
整体流程示例
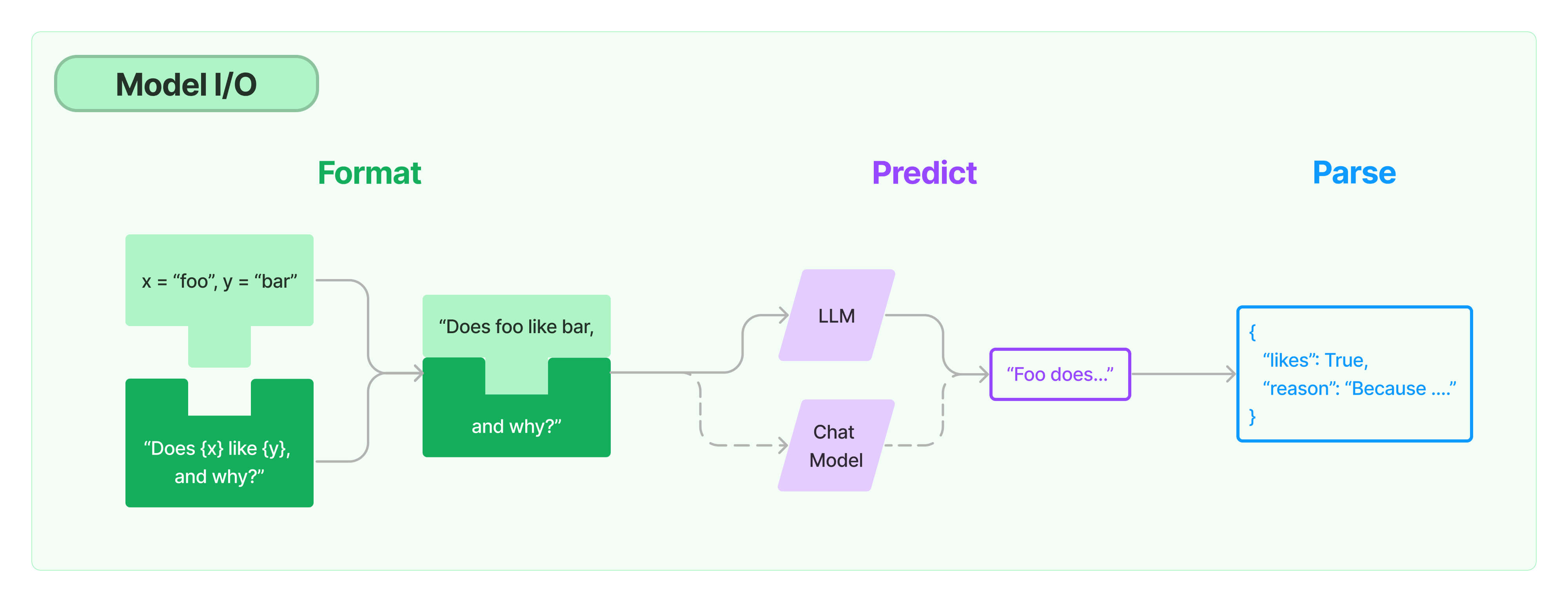
LangChain 以“工作流”形式将LLM与IO组件有序连接,从而具备构建复杂AI工程流程的能力
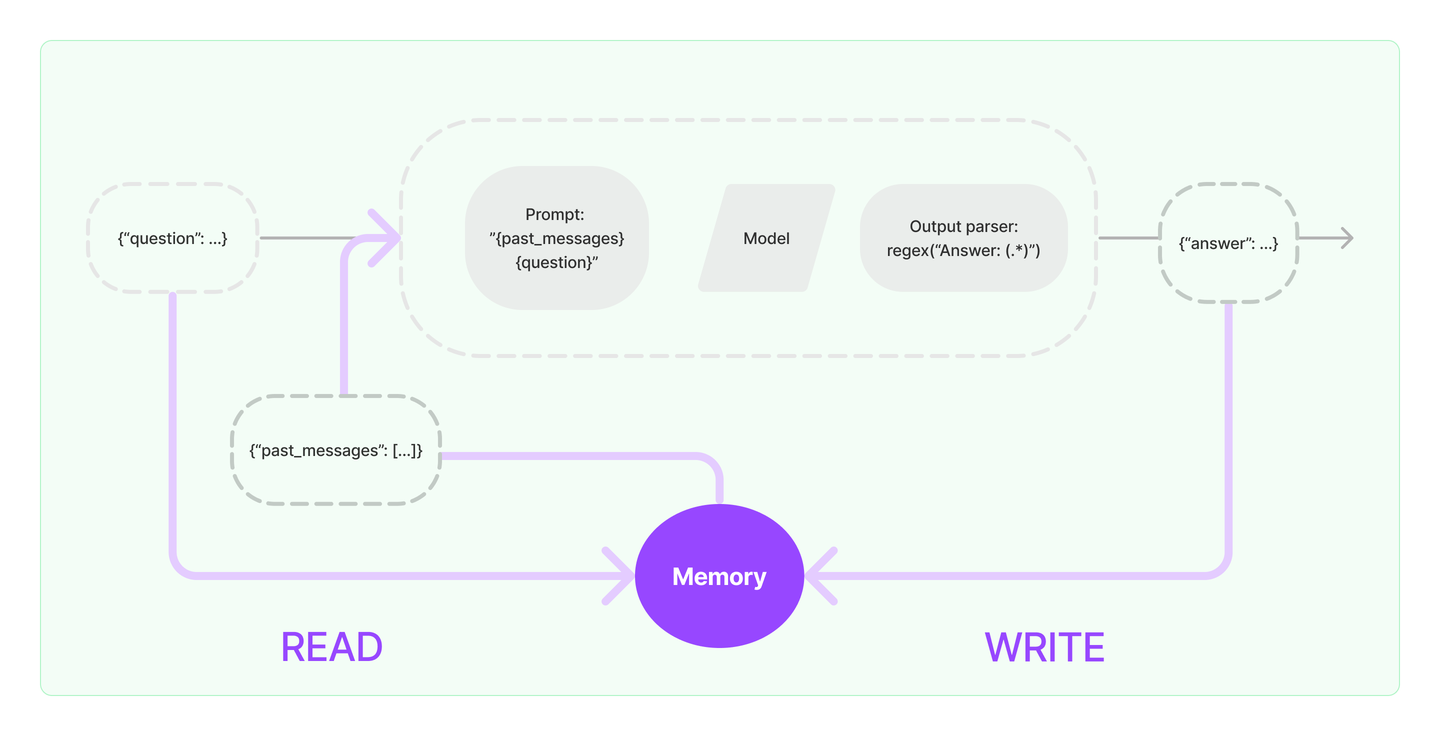
为什么有 LangChain
解决什么问题
构建大模型应用需要考虑这些问题:
- Prompt 管理:不同场景需要手写不同的
提示词(Prompt),还要维护多个 prompt 的版本和结构,很容易混乱。 - 调用逻辑的组织:如果你想让模型先问用户问题,然后再去查资料,再回答——你得自己写一整套逻辑流程。
- 多模型集成:假如不想用OpenAI的大模型,想尝试下HuggingFace其他大模型,就要自己封装和管理接口。
- 与外部工具对接:想要模型查数据库、搜索引擎、文件系统?自己写代码去连接、格式化、处理这些数据。
- 内存管理(聊天上下文):如让 AI 记住用户之前说过什么,你要自己存储这些对话记录,并加到 prompt 里。
- 调试 & 追踪:如果模型表现不对,很难知道是哪一步出了问题。没有自动化的 trace 系统。
例如,基于LLM开发一个问答系统,几行代码就可以完成最内核的功能:
from langchain_community.chat_models import ChatOllama
from langchain_core.messages import HumanMessage
# 初始化模型
model = ChatOllama(
model="qwen2.5:1.5b",
base_url="http://localhost:11434"# Ollama 服务地址
)
# 发送请求
response = model.invoke([
HumanMessage(content="用中文写一首关于秋天的短诗")
])
print(response.content)
总结
LangChain = 「Prompt + 模型 + 工具 + 记忆 + 检索」的组件化框架,用来构建多轮对话、文档问答、Agent 应用的乐高积木库。
| 传统方式 | LangChain 提供了什么? |
|---|---|
| 手工拼接 prompt | ✅ PromptTemplate,统一管理变量、格式 |
| 大模型 API 混乱 | ✅ LLM 模块封装 ChatGPT、通义、GLM |
| 多轮记忆难实现 | ✅ Memory 自动管理上下文 |
| 工具调用太繁琐 | ✅ Tool + Agent 模块自动调度工具 |
| RAG 链构建复杂 | ✅ Retriever + QAChain 一键搞定 |
| 多智能体交互难 | ✅ LangGraph、AgentType 支持多智能体流程 |
LangChain 生态
框架由几个部分组成。
LangChain库:Python 和 JavaScript 库。包含了各种组件的接口和集成,一个基本的运行时,用于将这些组件组合成链和代理,以及现成的链和代理的实现。- LangChain 模板:一系列易于部署的参考架构,用于各种任务。
LangServe: 一个用于将 LangChain 链部署为 REST API 的库。LangSmith: 一个开发者平台,让你可以调试、测试、评估和监控基于任何 LLM 框架构建的链,并且与 LangChain 无缝集成。- SmithDB: 转为 agent trace 数据设计的分布式数据库,解决海量嵌套span的存储查询问题
简化整个应用程序的生命周期:
- 开发:在
LangChain/LangChain.js中编写应用程序。使用模板作为参考,快速开始。 - 生产化:使用
LangSmith来检查、测试和监控链,这样可不断改进并有信心地部署。 - 部署:使用
LangServe将任何链转换为 API。
总结
安装
2025年9月,langchain 大升级,上个版本(0.3)升级到新版(1.0),代码结构大调整
安装指定版本
pip show langchain # 查看版本
pip install langchain==0.3.19 # 安装指定版本
pip install langchain>=0.3.0 # 向上兼容
pip install "langchain>=0.3.0,<0.4.0" # 指定区间
pip install langchain~=0.3.0 # 兼容小版本
pip install "langchain-core>=0.3.0,<0.4.0"
pip install "langchain-community~=0.3.0"
Python 版
pip install langchain # 工具包
pip install -e . # 源码安装
pip install langchain-community # 社区版
pip install langchain-core # 核心版
pip install langchain-experimental # 实验版
pip install "langserve[all]" # langserve
# 将LangChain可运行文件和链作为REST API部署
pip install langchain-cli # 包含 langserve
pip install langsmith
Go 版
【2025-3-5】LangChainGo 提示词工程(Prompt Engineering)
示例
解析
ollama.New:初始化 Ollama LLM,使用 WithModel 方法传入对应的llama模型名称。llm.Call(ctx, prompt):将提示词传递给LLM,获取AI生成的文本。
prompts.NewPromptTemplate():创建一个带有变量的提示词模板。
Format(map[string]string{"topic": "nim-lang这门语言"}):动态填充 topic 变量。
NewChatPromptTemplate 创建对话模板,包含多个 MessageFormatter。
NewSystemMessagePromptTemplate定义系统角色(如客服助手)。NewHumanMessagePromptTemplate定义用户输入模板,``等变量为占位符
package main
import (
"context"
"fmt"
"log"
"github.com/tmc/langchaingo/llms/ollama"
"github.com/tmc/langchaingo/prompts"
)
func main() {
llm, err := ollama.New( ollama.WithModel("qwen2:7b"), )
if err != nil {
log.Fatal(err)
}
// 定义prompt: ① template提示词模板
// promptTemplate := prompts.NewPromptTemplate(
// "请使用一句话描述 ",
// []string{"topic"},
// )
// // 输出模板
// fmt.Println(promptTemplate.Template)
// // 渲染模板
// prompt, err := promptTemplate.Format(map[string]any{
// "topic": "nim-lang这门语言",
// })
// 定义prompt: ② 创建一个新的聊天提示模板
prompt := prompts.NewChatPromptTemplate([]prompts.MessageFormatter{
prompts.NewSystemMessagePromptTemplate("你是一个智能翻译助手", []string{}),
prompts.NewHumanMessagePromptTemplate("将这段文本从翻译成:\n",
[]string{"input", "output", "question"}),
})
// 模版解析
val, err := prompt.FormatPrompt(map[string]any{
"input": "中文",
"output": "英文",
"question": "你好,世界",
})
if err != nil {
log.Fatal(err)
}
fmt.Println(prompt)
// 调用llm
ctx := context.Background()
res, err := llm.Call(ctx, prompt)
if err != nil {
log.Fatal(err)
}
fmt.Println(res)
}
可视化
LangFlow
【2023-7-4】LangFlow 是 LangChain 的一种图形用户界面(GUI),为大型语言模型(LLM)提供了易用的实验和原型设计工具。通过使用 LangFlow,用户可以利用 react-flow 轻松构建LLM应用。
无需编码/低代码的 LangChain 扩展
LangFlow 是 LangChain 可视化扩展。
- 将 LangChain 强大的后端与 直观的拖放界面 结合在一起。
- LangFlow 使不擅长编写代码的用户能利用语言模型的强大功能。
优势:
- 可视化工作流创建:与 LangGraph 类似,LangFlow 提供了一个可视化界面用于构建工作流。然而,它是基于 LangChain 构建,用户可利用 LangChain 的强大功能,而无需编写大量代码。
- 快速原型制作的理想选择:LangFlow 非常适合快速 原型化想法 或构建概念验证应用程序。
- 适合初学者:很好的入门点,适合那些对编码不太熟悉但想要创建语言模型工作流的用户。
【2025-3-17】Langflow 实现本地知识库 带对话记忆功能的知识库, 实现代码检查
- 文档向量化后,存入向量数据库中,然后用 deepseek-r1:1.5b 模型,整合 RAG 取回的内容后输出回答。
- 代码 langflow-rag-app
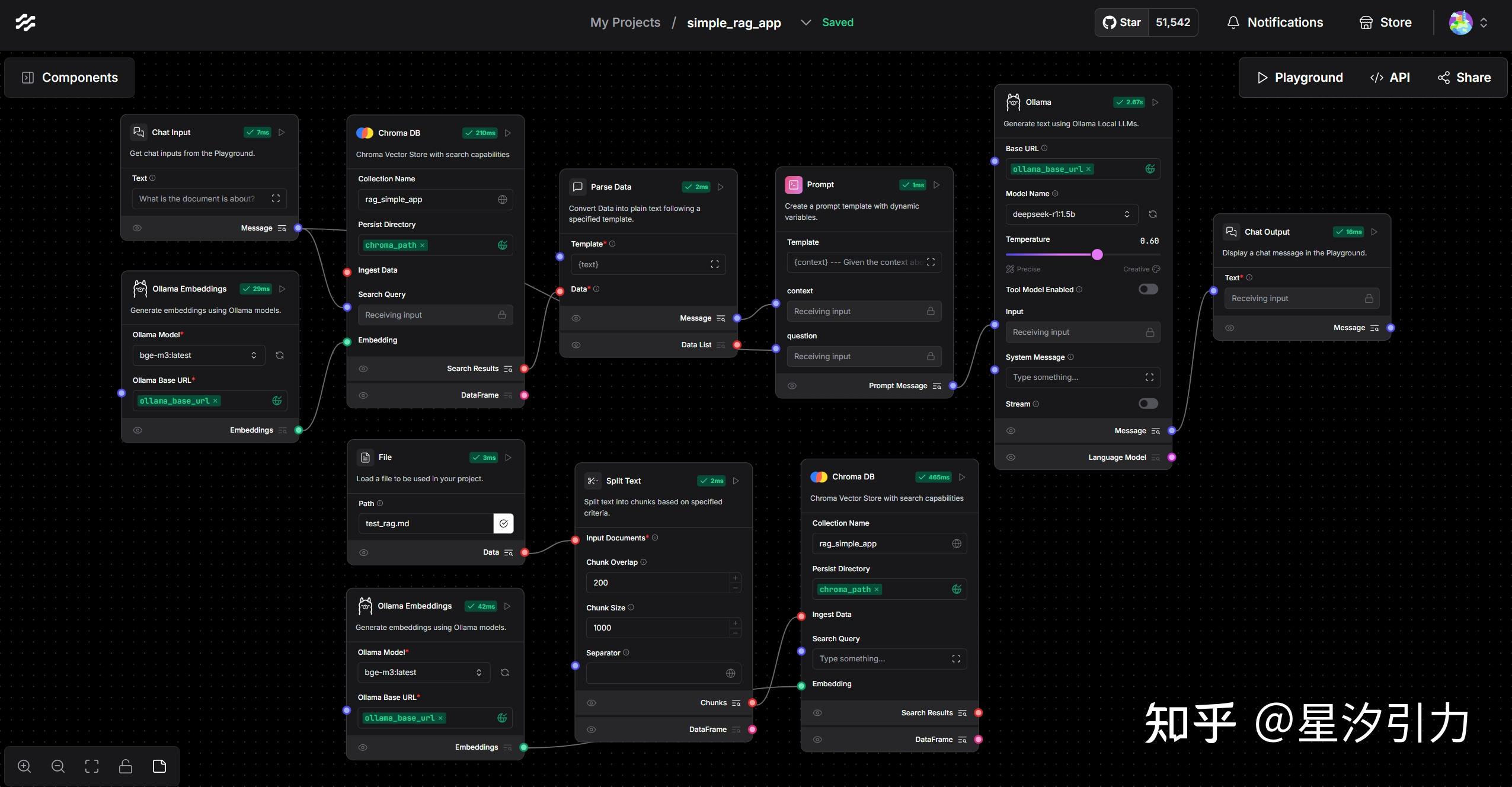
LogSpace 出品,LangFlow github 的主要功能包括:
- 提供多种 LangChain 组件以供选择,如语言模型、提示序列化器、代理和链等。
- 通过编辑提示参数、链接链和代理,以及跟踪代理的思考过程,用户可以探索这些组件的功能。
- 使用 LangFlow,用户可以将流程导出为 JSON 文件,然后在 LangChain 中使用。
- LangFlow 的图形用户界面(GUI)提供了一种直观的方式来进行流程实验和原型开发,包括拖放组件和聊天框

- 官方 UI 配置文件集合
pip install langflow # 安装
langflow # 启动
python -m langflow # 上面命令不管用时用这个
自动弹出本地web页面: http://127.0.0.1:7860/, 配置可导出为json格式
json格式导入 flow
from langflow import load_flow_from_json
flow = load_flow_from_json("path/to/flow.json")
# Now you can use it like any chain
flow("Hey, have you heard of LangFlow?")
LangGraph
基于LCEL确实能描述复杂 LangChain计算图结构,但依然有DAG天然的设计限制,即不能支持“循环”。
LangGraph 只假设一件事:LLM 是慢、不稳定、开放式。
基于这个假设,LangGraph 聚焦两大支柱:
- 可控性(Controllability)
- 没有隐藏的 prompt,没有隐藏的上下文工程。你完全控制你的系统——无论是 workflow、agent 还是介于两者之间的任何东西。
- 运行时(Runtime)
- 把生产环境需要的一切都内置进来:流式输出、状态管理、human-in-the-loop、持久执行。
这两大支柱带来了六个生产特性:
- 实际延迟高: 并行化
- 感知延迟高: 流式输出
- 重试次数多: 任务队列
- 重试代价大: 检查点
- 行为不可控: Human-in-the-loop
- 黑盒难调试: 追踪
LangGraph:可视化复杂工作流
LangGraph 为开发者设计的新框架,适合那些偏好 可视化方法 来构建语言模型管道的用户。
- 通过 基于图的可视化 构建复杂的工作流,从而更容易理解不同任务和组件之间的依赖关系。
- 这对于多个步骤(如文本生成、文档检索和分类)串联在一起的大型应用尤其有用。
优势:
- 可视化工作流表示:LangGraph 允许您可视化不同组件之间的数据和操作流。这种图形化的方法直观且有助于设计更复杂的管道。
- 调试简单:LangGraph 可视化特性使得识别工作流中的瓶颈或问题节点变得更加容易。
示例用例:
- 假设构建一个自动化系统,首先使用语言模型检索相关文档,然后将其传递给摘要生成器。
- LangGraph 中,直观地绘制出此工作流程,展示每个步骤之间的关系。如果链中的任何一点出现问题,视觉工具使您能够轻松定位问题所在。
何时使用 LangGraph:
- 管理 复杂的工作流程,并且重视 图形界面 来理解您的管道,LangGraph 是一个绝佳的选择。特别适合那些更喜欢直观的拖放式工作流程设计的开发人员或数据科学家。
关键点:
- 如果需要清晰的语言处理工作流程的可视化表示。
- 在创建需要分支或多路径依赖的更复杂的管道时。
【2026-5-8】langgraph cli 用法
安装
pip install langgraph-cli # 安装基础版本
pip install -U "langgraph-cli[inmem]" # 安装开发版本(支持 dev 命令)
langgraph --help
使用方法
| 配置 | 含义 | 其他 |
|---|---|---|
| -c | 指定配置文件 | –config, 默认 langgraph.json |
| -host | 绑定ip | 默认 127.0.0.1 |
| -port | 指定端口 | 绑定端口,默认 2024 |
| –no-reload | 关闭自动加载 | false |
| –n-jobs-per-worker | 启动worker数 | 默认 10 |
| –debug-port | 调试监听端口 | - |
| –wait-for-client | 是否等待监听客户端连接 | false |
| –no-browser | 不弹出浏览器地址 | - |
| –studio-url | langgraph studio 实例连接地址 | smith.langchain.com |
| –allow-blocking | 异步阻塞时不触发错误 | false |
| –tunnel | 暴露本地服务到外部渠道的前端页面,如 cloudflare | - |
| –help | 帮助 | - |
nohup langgraph dev --port 8011 --host 10.191.61.23 &>log.txt &
langgraph dev # 启动开发服务器(支持热重载)
langgraph dev -c langgraph.json # 指定配置文件
langgraph dev --port 8000 --host 0.0.0.0 # 指定端口和主机
langgraph dev --debug-port 5678 --wait-for-client # 启用调试
启动 langgraph api 服务
- 接口文档访问地址默认 docs,内嵌了 js, 需要挂梯子。
- 参考 api_ref.html
LangSmith 闭源
LLM 大模型应用可观测性工具最有名的是 Langsmith
LangSmith 是 LangChain 官方 生产级LLM应用程序构建平台。
- 调试、测试、评估和监控任何LLM框架上构建的链和智能代理
- 并与 LangChain 无缝集成,LangChain 是构建LLM的首选开源框架。
- langchain 执行过程中的数据可视化展示,用于观察 chain tool llm 之前的嵌套关系、执行耗时、token 消耗等指标
- 官方文档
LangChain无缝衔接的LangSmith平台,可以跟踪程序运行步骤,提供详细调试信息,同时支持数据集收集和自动化测试评估等功能,极大方便了AI大模型应用程序的开发过程。
【2026-5-19】SmithDB
LangSmith 是 LangChain的LLM应用DevOps平台,专注可观测性与调试;
【2026-5-19】SmithDB 则专为Agent Trace数据设计的分布式数据库,解决海量嵌套Span的存储查询问题。
目前 SmithDB 定价尚未公开,可能整合在 LangSmith 服务中,建议关注LangChain官方公告获取准确信息。
第三方
LangSmith 缺点: 云平台,不能本地部署,对国内不友好
总结
对比分析
LangFuse 开源
Langfuse 开源项目,而 LangSmith 闭源项目
开源生产级AI应用维护平台:LangFuse,LangSmith 平替,可集成 LangChain,也可直接对接 OpenAI API。
- 与 LangChain 没关系
Langfuse 支持
- 在线数据标注和收集
- 从本地导入数据集。
LangWatch
LangWatch 全面的LLM运维平台,帮助AI团队管理大语言模型(LLM)应用的全生命周期。
- GitHub LangWatch
要点
- 平台可无缝集成任意技术栈,提供监控、评估与优化工具,确保AI质量、安全与性能。
- 通过自动化质量检查、引入人工闭环评估和详尽分析,LangWatch帮助企业降低幻觉、数据泄露等AI风险,加速从概念验证到生产部署。
- 平台支持可视化实验追踪、定制化评估和告警系统,助力团队打造可靠合规的AI产品,实现持续优化。
LangChain 观点
【2023-7-23】我为什么放弃了 LangChain?
由 LangChain 推广的 ReAct 工作流在 InstructGPT/text-davinci-003 中特别有效,但成本很高,而且对于小型项目来说并不容易使用。
「LangChain 是 RAG 最受欢迎的工具,阅读 LangChain 的全面文档,以便更好地理解如何最好地利用它。」
经过一周的研究,运行 LangChain 的 demo 示例可以工作,但是任何调整以适应食谱聊天机器人约束的尝试都会失败。
- 解决了这些 bug 之后,聊天对话的整体质量很差,而且毫无趣味。经过紧张的调试之后,没有找到任何解决方案。
- 用回了低级别的 ReAct 流程,立即在对话质量和准确性上超过了 LangChain 实现
LangChain 问题: 让简单事情变得相对复杂,而这种不必要的复杂性造成了一种「部落主义」,损害了整个新兴的人工智能生态系统。
- LangChain 代码量与仅用官方 openai 库的代码量大致相同,估计 LangChain 合并了更多对象类,但代码优势并不明显。
- LangChain 吹嘘的提示工程只是
f-strings,还有额外步骤。为什么需要使用这些 PromptTemplates 来做同样的事情呢? - 真正要做的:
- 如何创建 Agent,结合迫切想要的
ReAct工作流。而 LangChain示例里每个思想/行动/观察中都使用了自己的 API 调用 OpenAI,所以链条比想象的要慢。
- 如何创建 Agent,结合迫切想要的
- LangChain 如何存储到目前为止的对话?
制作自己的 Python 软件包要比让 LangChain 来满足自己的需求容易得多
LangChain 确实也有很多实用功能,比如文本分割器和集成向量存储,这两种功能都是「用 PDF / 代码聊天」演示不可或缺的(在我看来这只是一个噱头)。
LangChain 安装
安装步骤
- python 3.8 以上才能安装
pip install langchain
pip install openai
# 环境变量
# ① 在终端中设置环境变量:
export OPENAI_API_KEY = "..."
# ② Jupyter notebook 或 Python 脚本中工作,这样设置环境变量:
import os
os.environ[ "OPENAI_API_KEY" ] = "..."
测试:构建LLM应用
- LangChain 目前支持 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 类型。
- 一般主要使用 HumanMessage、AIMessage 和 SystemMessage。
from langchain.llms import OpenAI
# -------【构建LLM应用】--------
llm = OpenAI(temperature=0.9) # 初始化包装器,temperature越高结果越随机
# 调用
text = "What would be a good company name for a company that makes colorful socks?"
print(llm(text)) # 生成结果,结果是随机的 例如: Glee Socks. Rainbow Cozy SocksKaleidoscope Socks.
# -------【构建Prompt】-------
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
print(prompt.format(product="colorful socks"))
# 输出结果 What is a good name for a company that makes colorful socks?
# -------【构建聊天应用】-------
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
# ------ 单条消息 --------
chat = ChatOpenAI(temperature=0)
chat([HumanMessage(content="Translate this sentence from English to French. I love programming.")])
#输出结果 AIMessage(content="J'aime programmer.", additional_kwargs={})
# ------ 多条消息:批处理 --------
batch_messages = [
[
SystemMessage(content="You are a helpful assistant that translates English to Chinese."),
HumanMessage(content="Translate this sentence from English to Chinese. I love programming.")
],
[
SystemMessage(content="You are a helpful assistant that translates English to Chinese."),
HumanMessage(content="Translate this sentence from English to Chinese. I love artificial intelligence.")
],
]
result = chat.generate(batch_messages)
print(result)
result.llm_output['token_usage']
# ------ 消息模板 ------
from langchain.chat_models import ChatOpenAI
# 加模板后,导入方式变化:增加 PromptTemplate后缀
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
chat = ChatOpenAI(temperature=0)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat(chat_prompt.format_prompt(input_language="English", output_language="Chinese", text="I love programming.").to_messages())
# -> AIMessage(content="我喜欢编程。(Wǒ xǐhuān biānchéng.)", additional_kwargs={})
将内存与聊天模型初始化的链和代理一起使用。
- 与 Memory for LLMs 的主要区别:将以前的消息保留为唯一的内存对象,而不是将压缩成一个字符串。
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder, # 消息占位符
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know."),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
llm = ChatOpenAI(temperature=0)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)
conversation.predict(input="Hi there!") # -> 'Hello! How can I assist you today?'
conversation.predict(input="I'm doing well! Just having a conversation with an AI.") # -> "That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?"
conversation.predict(input="Tell me about yourself.")
功能
LangChain 构建的有趣应用程序包括(但不限于):
- 聊天机器人
- 特定领域的总结和问答
- 查询数据库以获取信息然后处理它们的应用程序
- 解决特定问题的代理,例如数学和推理难题
垂直领域知识库问答架构变化
- 【2023-7-20】LangChain+LLM大模型问答能力搭建与思考
| 架构图 | BERT时代 | LLM时代 |
|---|---|---|
| 图解 | 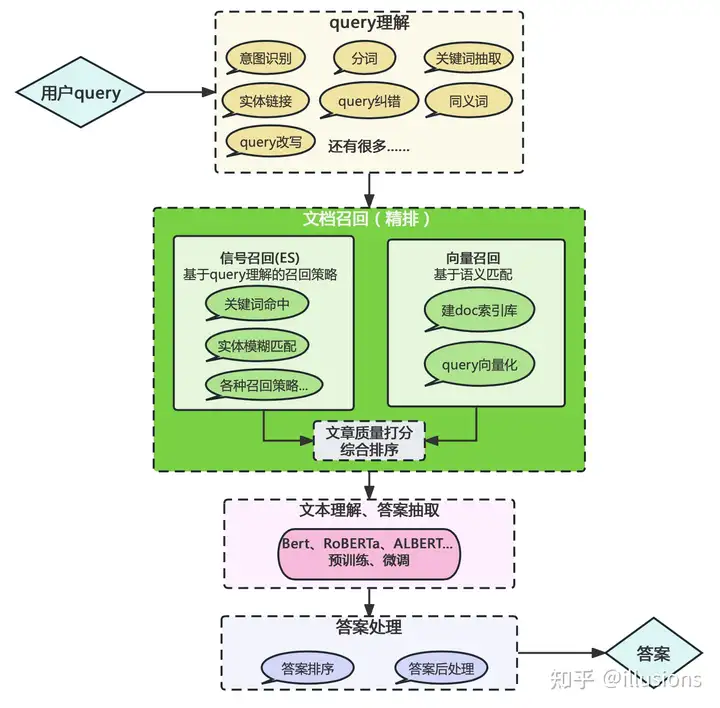 |
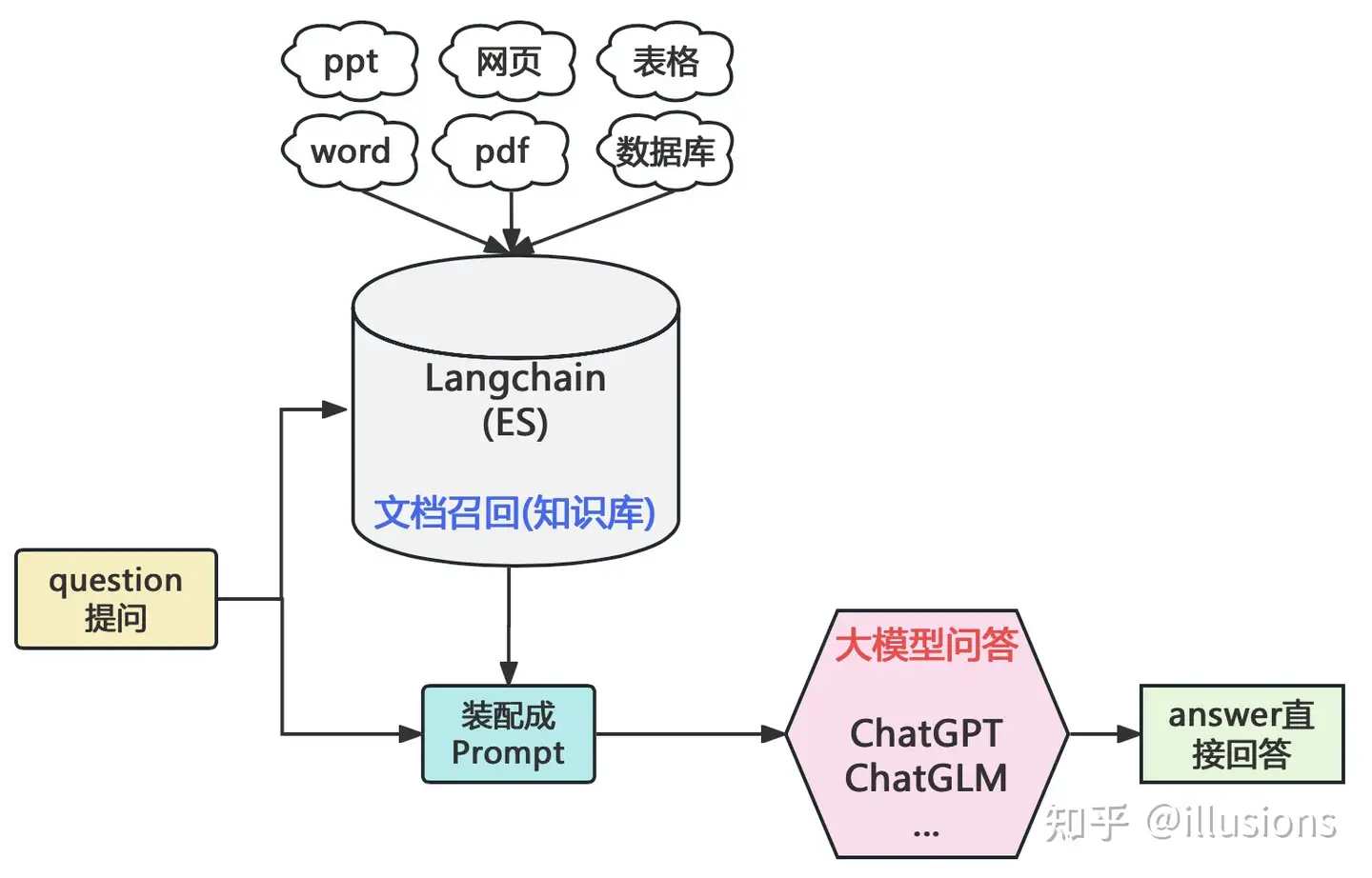 |
| 分析 | query理解异常重要 | LLMs直接把模块的工作包揽了下来,原本的query分词、分类、纠错、关键词等工作变成了制定合适的Prompt |
文档介绍
- 官方文档, 中文文档
- GPT开发利器LangChain指北
- Github: python版本(已经有4W多的star), go语言版
- 基于LangChain从零实现Auto-GPT完全指南
- 【2023-8-2】京东云LangChain简介
示例
LangChain组件:
- LLM:语言模型抽象层
- PromptTemplate:提示词模板
- LLMChain:将LLM和提示词模板串联起来
简易问答系统代码
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
# 初始化LLM
llm = OpenAI(temperature=0.7)
# 创建提示模板
prompt = PromptTemplate(
input_variables=["question"],
template="请回答下面的问题:{question}"
)
# 创建chain
chain = LLMChain(llm=llm, prompt=prompt)
# 测试运行
response = chain.run("什么是人工智能?")
print(response)
LangChain 1.*
模型接入
【2026-5-8】接入各种模型
from langchain.chat_models import init_chat_model
# 初始化本地 Ollama 模型
model = init_chat_model(
"qwen3-0.6b", # 本地模型名称
model_provider="ollama", # 指定提供商
api_key='note-needed', # 本地模型,不需要 api key
base_url="http://localhost:11434/v1" # Ollama API 地址
)
# 初始化本地 LM Studio 模型
# uv pip install langchain-openai
model = init_chat_model(
"qwen3-0.6b", # 本地模型名称
model_provider="openai", # 指定提供商
api_key='note-needed', # 本地模型,不需要 api key
base_url="http://localhost:1234/v1" # LM Studio API 地址
)
# 初始化远程 llm proxy 模型
model = init_chat_model(
"minimax-m2.5-external", # 本地模型名称
model_provider="openai", # 指定提供商
api_key='sk-YO9j--***', # api key
base_url="http://llm-***.intra.test.com" # remote API 地址
)
# 调用模型
print(model.invoke("你好,你是谁?"))
工具使用
【2026-5-9】LangChain Tools 入门:让 LLM 拥有”手”
LangChain 工具调用核心三环节
| 核心环节 | 作用说明 | 通俗类比 |
|---|---|---|
@tool 装饰器 |
把普通 Python 函数变成 LLM 可调用的工具 | 给函数办一张工具身份证 |
bind_tools() |
把一组工具注册给模型,告诉模型可以使用这些工具 | 给 LLM 发一个工具箱 |
tool_calls |
模型返回的调用意图,包含工具名和参数 | LLM 写的任务派遣单 |
关键认知:
LLM 并不真正”执行”工具
这是极其重要的认知:模型只负责”决定调用什么工具、传什么参数”,真正执行工具函数的,是代码或 Agent 框架的 runtime。
LLM 想象成一位指挥官,工具是前线士兵。指挥官下达命令(tool_calls),士兵执行动作(实际函数),然后把结果回报给指挥官。指挥官再根据结果决定下一步。
总结
- 工具描述(docstring)就是 prompt, 直接决定了模型是否知道在什么时候调用工具、该传什么参数。写 docstring 要像写 prompt 一样认真。
- 模型只”决定”,不”执行”: 模型输出的是 tool_calls(调用意图),真正执行 Python 函数的是你的代码。两者必须协作,才能完成”有手”的 Agent。
- bind_tools() 是”声明式”, 不改变原模型,而是返回一个新对象。这种不可变设计让你可以在同一份代码中,为同一个模型绑定不同的工具组合。
- temperature 对工具调用有影响: 工具调用需要精确匹配,建议把 temperature 设低(0 ~ 0.3),减少模型在”调不调工具”上的犹豫。
- 工具的数量和质量决定 Agent 的天花板: 好的 Agent 不在于模型有多强,而在于它的工具箱有多丰富、工具描述有多精准。
代码示例
import os
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
# ------------------------------
# 1. 定义工具
# ------------------------------
# @tool 装饰器会自动:
# - 将函数名作为工具名
# - 将 docstring 作为工具描述(这个描述极其重要!)
# 注意:docstring 就是 prompt 的一部分。描述越清晰、例子越具体,模型调用越准确。如果 docstring 写得太模糊,模型可能不知道该在什么时候调用这个工具,也不知道该传什么参数。
# - 从类型注解生成参数 schema
@tool
def get_weather(location: str) -> str:
"""获取指定城市的当前天气。参数 location 是城市名称,例如:北京、上海。"""
# 实际项目中这里应该调用真实天气 API
return f"{location} 当前天气:晴朗,25°C。"
@tool
def calculate(expr: str) -> str:
"""计算数学表达式。参数 expr 是数学表达式字符串,例如:2 + 2 * 3。"""
try:
result = eval(expr) # 仅作演示,生产环境请用更安全的方式
return f"计算结果:{result}"
except Exception as e:
return f"计算出错:{e}"
# ------------------------------
# 2. 将工具绑定到 LLM
# ------------------------------
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
temperature=0.1, # 工具调用时温度低一些更稳定
)
# bind_tools() 告诉模型:"你现在可以使用这些工具了"
llm_with_tools = llm.bind_tools([get_weather, calculate])
# ------------------------------
# 3. 观察模型如何决定是否调用工具
# ------------------------------
test_inputs = [
"北京天气怎么样?", # 应该触发 get_weather
"123 乘以 456 等于多少?", # 应该触发 calculate
"讲一个关于程序员的笑话", # 不应该触发任何工具
]
for user_input in test_inputs:
print(f"\n{'='*50}")
print(f"用户: {user_input}")
response = llm_with_tools.invoke([HumanMessage(user_input)])
# 检查 response.tool_calls —— 这就是模型决定调用工具的证据
if response.tool_calls:
print(f"AI 决定调用工具:")
for tc in response.tool_calls:
print(f" - 工具名: {tc['name']}")
print(f" - 参数: {tc['args']}")
else:
print(f"AI 直接回答:")
print(f" {response.content}")
运行结果
==================================================
用户: 北京天气怎么样?
AI 决定调用工具:
- 工具名: get_weather
- 参数: {'location': '北京'}
==================================================
用户: 123 乘以 456 等于多少?
AI 决定调用工具:
- 工具名: calculate
- 参数: {'expr': '123 * 456'}
==================================================
用户: 讲一个关于程序员的笑话
AI 直接回答:
一个程序员去面试。
面试官问:"你有什么缺点?"
程序员说:"我比较固执。"
面试官说:"能举个例子吗?"
程序员说:"不能。"
DeepAgents
详见站内专题:Loop Engineering
LangChain 组件
LangChain 架构
- 【2024-3-15】从API到Agent:万字长文洞悉LangChain工程化设计
- 官方文档: Towards LangChain 0.1: LangChain-Core and LangChain-Community
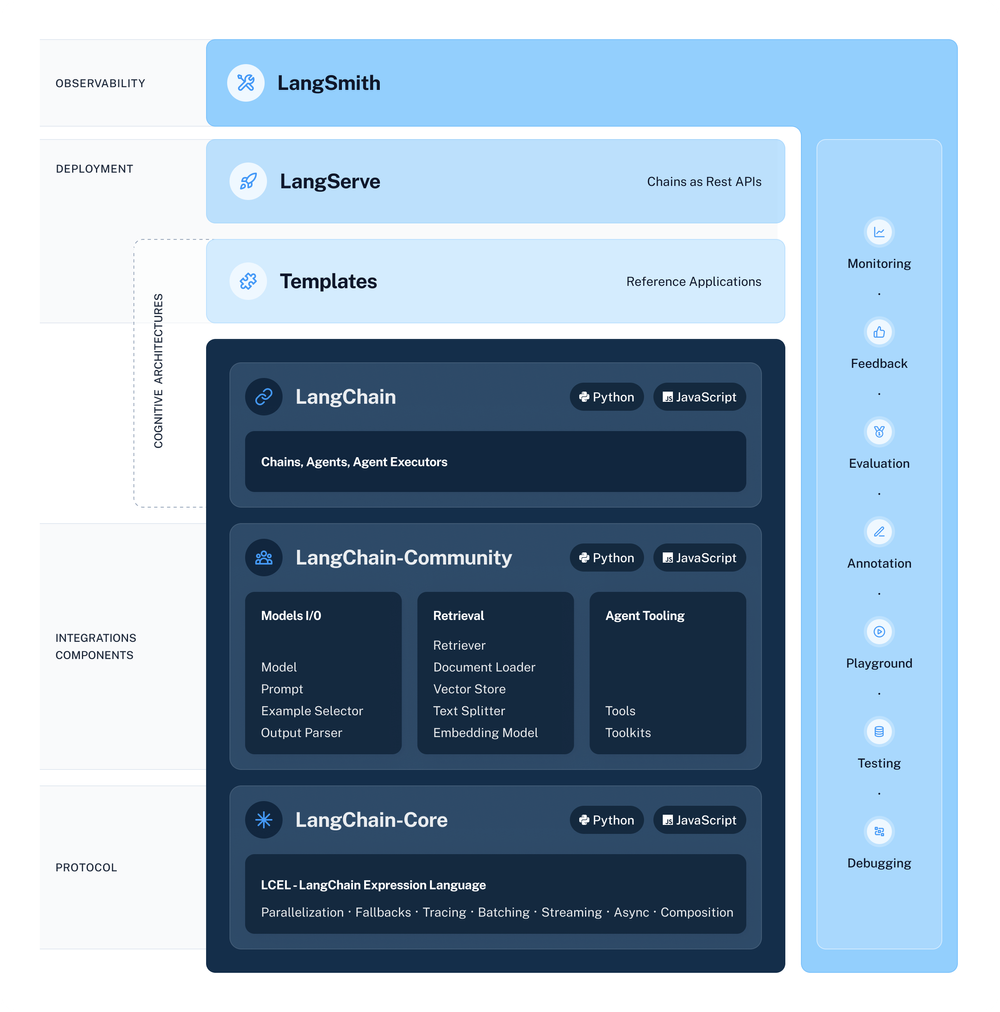
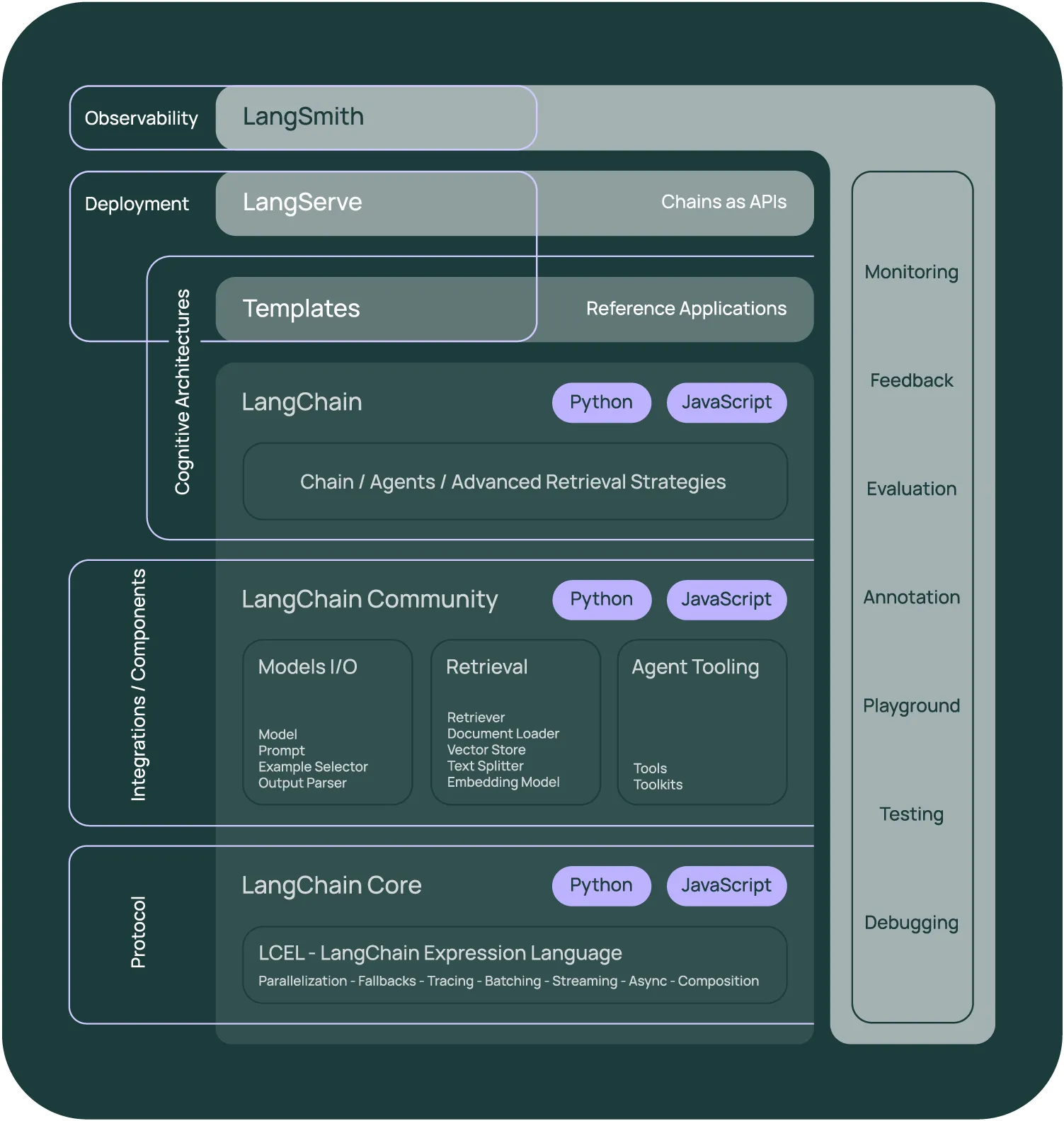
技术栈
LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。
LLM 技术栈主要由四个部分组成:
- 数据预处理(data preprocessing pipeline):主要包括数据源连接、数据转化、下游连接器(如向量数据库),特别是对于繁杂的数据源,如数千个PDF、PPTX、聊天记录、抓取的HTML等大量数据提取、清理、转换工作,跟大数据分析任务的前期步骤很类似,不同的是大模型的数据处理可能会用到OCR模型、Python脚本和正则表达式等方式,并以API方式向外部提供JSON数据,以便嵌入终端和存储在向量数据库中。
- 嵌入与向量存储(embeddings +vector store ):以往嵌入主要用于如文档聚类之类的特定任务,新架构中,直接将文档及其嵌入存储在向量数据库中,可以通过LLM端点实现关键的交互模式。直接存储原始嵌入,意味着数据可以以其自然格式存储,从而实现更快的处理时间和更高效的数据检索。
- LLM 终端(LLM endpoints):LLM终端负责管理模型的资源,包括内存和计算资源,并提供可扩展和容错的接口,用于向下游应用程序提供LLM输出。
- LLM 编程框架(LLM programming framework):LLM编程框架提供了一套工具和抽象,用于使用语言模型构建应用程序。在现代技术栈中出现了各种类型的组件,包括:LLM提供商、嵌入模型、向量存储、文档加载器、其他外部工具(谷歌搜索等),这些框架的一个重要功能是协调各种组件。
模块
LangChain 库本身由几个不同包组成。
langchain-core:聊天模型和其他组件的基础抽象,基础抽象和 LangChain 表达式语言(LCEL)。langchain-community:由社区维护的第三方集成工具, Model i/o, Retrieval, Agent Tooling。langchain:构成应用程序认知架构的链、代理和检索策略。Chain/Agent/Advanced RetrievalIntegration packages:负责维护不同厂家的大模型,由轻量级的包组成,例如 langchain-openai、langchain-anthropic 等。LangGraph:基于 LangChain 的扩展库,用于构建有状态、多角色的智能体(Agents)应用。通过将任务流程建模为状态图(StateGraph),实现对复杂任务的精细控制和管理。LangSmith:用于开发、调试、测试和监控基于大语言模型(LLM)应用的平台,它有点像你写 LLM 应用时的 “全能开发调试仪表盘”。
2 个核心功能为:
- 1)LLM 模型与外部数据源进行连接。
- 2)LLM 模型与环境交互,通过 Agent 使用工具。
LangChain包含六部分组件
- Models、Prompts、Indexes、Memory、Chains、Agents。
LangChain主要支持6种组件:
Models:模型,各种类型的模型和模型集成,比如GPT-4Prompts:提示,包括提示管理、提示优化和提示序列化Memory:记忆,用来保存和模型交互时的上下文状态Indexes:索引,用来结构化文档,以便和模型交互Chains:链,一系列对各种组件的调用Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止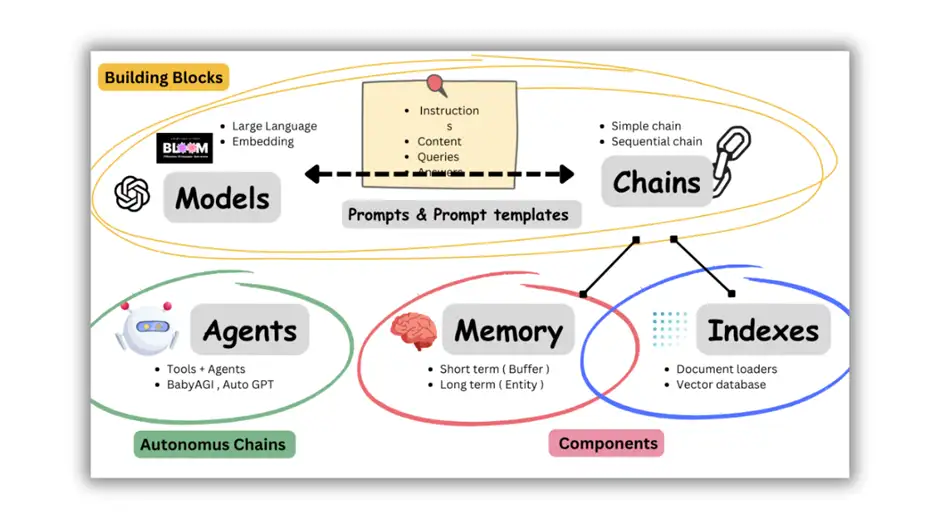
框架
LangChain 框架示意图
Document Loaders and Utils
LangChain 的 Document Loaders 和 Utils 模块分别用于连接到数据源和计算源。
当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
Document Loaders 的Unstructured 可以将这些原始数据源转换为可处理的文本。
The following document loaders are provided:
CSVLoader CSV文件DataFrameLoader 从 pandas 数据帧加载数据Diffbot从 URL 列表中提取 HTML 文档,并将其转换为我们可以在下游使用的文档格式DirectoryLoader 加载目录中的所有文档EverNote印象笔记Git从 Git 存储库加载文本文件Google DriveGoogle网盘HTMLHTML 文档MarkdownNotebook将 .ipynb 笔记本中的数据加载为适合 LangChain 的格式NotionPDFPowerPointUnstructured FileLoader 使用Unstructured加载多种类型的文件,目前支持加载文本文件、powerpoints、html、pdf、图像等URL加载 URL 列表中的 HTML 文档内容Word Documents
Text Spltters
文本分割用来分割文本。
为什么需要分割文本?
- 因为每次不管把文本当作 prompt 发给 openai api ,还是使用 embedding 功能, 都是有字符限制的。
将一份300页的 pdf 发给 openai api,进行总结,肯定会报超过最大 Token 错。所以需要用文本分割器去分割 loader 进来的 Document。
- 默认推荐的文本拆分器是
RecursiveCharacterTextSplitter - 默认情况以 [“\n\n”, “\n”, “ “, “”] 字符进行拆分。
- 其它参数说明:
length_function如何计算块的长度。默认只计算字符数,但在这里传递令牌计数器是很常见的。chunk_size:块的最大大小(由长度函数测量)。chunk_overlap:块之间的最大重叠。有一些重叠可以很好地保持块之间的一些连续性(例如,做一个滑动窗口)
CharacterTextSplitter默认情况下以 separator=”\n\n”进行拆分TiktokenText Splitter使用OpenAI 的开源分词器包来估计使用的令牌
# This is a long document we can split up.
with open('../../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=metadatas)
print(texts[0])
# This is a long document we can split up.
with open('../../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
LangChain Embedding
模型拉到本地使用的好处:
- 训练模型
- 可用本地的 GPU
- 有些模型无法在 HuggingFace 运行
LangChain Embedding示例
- HuggingFace
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
- llama-cpp
# !pip install llama-cpp-python
from langchain.embeddings import LlamaCppEmbeddings
llama = LlamaCppEmbeddings(model_path="/path/to/model/ggml-model-q4_0.bin")
text = "This is a test document."
query_result = llama.embed_query(text)
doc_result = llama.embed_documents([text])
- OpenAI
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
(1)Models(模型):LLM选择
LangChain 本身不提供 LLM,提供通用的接口访问 LLM,可以很方便的更换底层的 LLM 以及自定义自己的 LLM。
Models(模型): 可选择不同的LLM与Embedding模型。可以直接调用 API 工作,也可以运行本地模型。
LLMs(大语言模型): 接收文本字符作为输入,返回文本字符,类似 OpenAI 的text-davinci-003Chat Models聊天模型: 由语言模型支持但将聊天消息列表作为输入并返回聊天消息的模型。- 一般使用的 ChatGPT 以及 Claude 为 Chat Models。
- 聊天模型基于LLMs,不同: 接收聊天消息作为输入,返回聊天消息
- 聊天消息是一种特定格式数据,LangChain中支持四种消息:
AIMessage,HumanMessage,SystemMessage,ChatMessage,需要按照角色把数据传递给模型,这部分在后面文章里再详细解释。
Text Embedding:用于文本的向量化表示。文本嵌入模型接收文本作为输入,返回的是浮点数列表. 设计用于与嵌入交互的类- 用于实现基于知识库的问答和semantic search,相比 fine-tuning 最大的优势:不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
- 例如,可调用OpenAI、Cohere、HuggingFace等Embedding标准接口,对文本向量化。
- 两个方法:
embed_documents和embed_query。最大区别在于接口不同:一种处理多个文档,而另一种处理单个文档。 - 文本嵌入模型集成了如下的源:AzureOpenAI、Hugging Face Hub、InstructEmbeddings、Llama-cpp、OpenAI 等
- HuggingFace Models
总结:
OpenAI属于LLMs,其输入是字符串,输出也是字符串;ChatOpenAI属于聊天模型,其输入是消息列表,输出是消息列表。
怎么选择?
- ChatOpenAI 侧重于模型被给与一组消息来构成会话,模型基于这组会话会进行后续的响应。
- 实时对话交流的聊天机器人,用于与用户进行自然语言交互和提供实时的响应。
- OpenAI 基于问与答,没有会话概念。
- 开发和训练各种类型的机器学习模型,如图像识别、自然语言处理、语音识别等
大语言模型(LLMs)是 Models 核心,也是 LangChain 基础组成部分,LLMs本质上是一个大型语言模型的包装器,通过该接口与各种大模型进行交互。
- 这些模型包括OpenAI的GPT-3.5/4、谷歌的LaMDA/PaLM,Meta AI的LLaMA等。
LLMs 类的功能如下:
- 支持多种模型接口,如 OpenAI、Hugging Face Hub、Anthropic、Azure OpenAI、GPT4All、Llama-cpp…
- Fake LLM,用于测试
- 缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
- 用量记录
- 支持流模式(就是一个字一个字的返回,类似打字效果)
LangChain 调用 OpenAI 的 gpt-3.5-turbo 大语言模型的简单示例
import os
from langchain.llms import OpenAI
openai_api_key = 'sk-******'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(model_name="gpt-3.5-turbo")
# llm = OpenAI(model_name="text-davinci-003", n=2, best_of=2)
print(llm("讲个笑话,很冷的笑话"))
# 为什么鸟儿会成为游泳高手?因为它们有一只脚比另一只脚更长,所以游起泳来不费力!(笑)
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"])
llm_result.llm_output # 返回 tokens 使用量
# ----- 使用模板 -----
from langchain import PromptTemplate
prompt_template = '''作为一个资深编辑,请针对 >>> 和 <<< 中间的文本写一段摘要。
>>> {text} <<<
'''
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
print(prompt.format_prompt(text="我爱北京天安门"))
流式输出
流式输出
- LangChain在支持代理封装ChatGPT接口的基础上,也同样地把ChatGPT API接口的流式数据返回集成了进来
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI, ChatAnthropic
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # 流式
from langchain.schema import HumanMessage
# streaming
llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0)
resp = llm("Write me a song about sparkling water.")
缓存
缓存LLM的结果
- 调用ChatGPT的API接口往往会存在网络延时的情况
- 为了更优雅的实现LLM语言生成模型,LangChain同时提供了数据缓存的接口如果用户问了同样的问题,LangChain支持直接将所缓存的数据直接响应
import langchain
from langchain.cache import InMemoryCache # 启动缓存
langchain.llm_cache = InMemoryCache()
# To make the caching really obvious, lets use a slower model.
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
GPTCache
LLM 缓存工具
- GPTCache : A Library for Creating Semantic Cache for LLM Queries
- 支持 LangChain、Llama_index和OpenAI

# [GPTCache : A Library for Creating Semantic Cache for LLM Queries](https://github.com/zilliztech/GPTCache)
from gptcache import cache
from gptcache.adapter import openai
cache.init()
cache.set_openai_key()
异步返回
异步返回
- 构建复杂的LLM模型调用链时,往往存在接口的多次调用,而且并不能保证接口的实时性返回
- 这时可以使用接口异步返回的模型来提升功能的服务质量,系统的性能
import time
import asyncio # 异步
from langchain.llms import OpenAI
def generate_serially():
llm = OpenAI(temperature=0.9)
for _ in range(10):
resp = llm.generate(["Hello, how are you?"])
print(resp.generations[0][0].text)
async def async_generate(llm):
resp = await llm.agenerate(["Hello, how are you?"])
print(resp.generations[0][0].text)
async def generate_concurrently():
llm = OpenAI(temperature=0.9)
tasks = [async_generate(llm) for _ in range(10)]
await asyncio.gather(*tasks)
s = time.perf_counter()
# If running this outside of Jupyter, use asyncio.run(generate_concurrently())
await generate_concurrently()
elapsed = time.perf_counter() - s
print('\033[1m' + f"Concurrent executed in {elapsed:0.2f} seconds." + '\033[0m')
s = time.perf_counter()
generate_serially()
elapsed = time.perf_counter() - s
print('\033[1m' + f"Serial executed in {elapsed:0.2f} seconds." + '\033[0m')
多模型融合
整合多个模型
- 作为LangChain中的核心模块,LangChain不止支持简单的LLM,从简单的文本生成功能、会话聊天功能以及文本向量化功能均集成,并且将其封装成一个一个的链条节点
- (1)大语言模型
- (2)聊天模型: OpenAI所提供的多角色聊天,允许用户设定信息归属不同的角色,从而丰富用户的聊天背景,构造出更加拟人化的聊天效果
- (3)语言向量化模型
OpenAI
import os
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
from langchain.llms import OpenAI
from langchain import PromptTemplate, LLMChain
# 模板解析
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = OpenAI()
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
llm_chain.run(question)
角色设置
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(temperature=0)
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="Translate this sentence from English to French. I love programming.")
]
chat(messages)
模板化编排
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
Azure OpenAI
import os
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2022-12-01"
os.environ["OPENAI_API_BASE"] = "..."
os.environ["OPENAI_API_KEY"] = "..."
# Import Azure OpenAI
from langchain.llms import AzureOpenAI
# Create an instance of Azure OpenAI
# Replace the deployment name with your own
llm = AzureOpenAI(
deployment_name="td2",
model_name="text-davinci-002",
)
# Run the LLM
llm("Tell me a joke")
Hugging Face Hub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
from langchain import HuggingFaceHub
repo_id = "google/flan-t5-xl" # See https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads for some other options
llm = HuggingFaceHub(repo_id=repo_id, model_kwargs={"temperature":0, "max_length":64})
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "Who won the FIFA World Cup in the year 1994? "
print(llm_chain.run(question))
(2)Prompts(提示语): 模板化
能力总结:
- 把
你是一个{角色}变成变量模板 - 搭配 RAG / 角色扮演 / 多轮对话,提示词更清晰
- LLMChain、Agent 等模块的基础组件
template = "你是{domain}专家,请回答问题:{question}"
prompt = PromptTemplate.from_template(template)
通常作为输入传递给模型的信息被称为提示
- 提示可以是文本字符,也可以是文件、图片甚至视频
- LangChain目前只支持字符形式的提示。
提示一般不是硬编码的形式写在代码里,而是由模板和用户输入来生成,LangChain提供多个类和方法来构建提示。
提示模板- 提示模板是一种生成提示的方式,包含一个带有可替换内容的模板,从用户那获取一组参数并生成提示
- 提示模板用来生成LLMs的提示,最简单的使用场景,比如“我希望你扮演一个代码专家的角色,告诉我这个方法的原理{code}”。
聊天提示模板- 聊天模型接收聊天消息作为输入,再次强调聊天消息和普通字符是不一样的,聊天提示模板的作用就是为聊天模型生成提示
示例选择器- 示例选择器是一个高级版的数据筛选器
输出解析器- 由于模型返回的是文本字符,输出解析器可以把文本转换成结构化数据
Prompts(提示语): 管理LLM输入
- PromptTemplate 负责构建此输入
- LangChain 提供了可用于格式化输入和许多其他实用程序的提示模板。
当用户与大语言模型对话时,用户内容即Prompt(提示语)。
- 如果用户每次输入的Prompt中包含大量的重复内容,生成一个Prompt模板,将通用部分提取出来,用户输入输入部分作为变量。
Prompt模板十分有用
- 利用langchain构建专属客服助理,并且明确告诉其只回答知识库(产品介绍、购买流程等)里面的知识,其他无关的询问,只回答“我还没有学习到相关知识”。
- 这时可利用Prompt模板对llm进行约束。
调用LangChain的PromptTemplate
from langchain import PromptTemplate
# 【无变量模板】An example prompt with no input variables
no_input_prompt = PromptTemplate(input_variables=[], template="Tell me a joke.")
no_input_prompt.format()
# -> "Tell me a joke."
# ① 【有变量模板】
name_template = """
我想让你成为一个起名字的专家。给我返回一个名字的名单. 名字寓意美好,简单易记,朗朗上口.
关于{name_description},好听的名字有哪些?
"""
# 创建一个prompt模板
prompt_template = PromptTemplate(input_variables=["name_description"], template=name_template)
description = "男孩名字"
print(prompt_template.format(name_description=description))
# 我想让你成为一个起名字的专家。给我返回一个名字的名单. 名字寓意美好,简单易记,朗朗上口.关于男孩名字,好听的名字有哪些?
# ②【多变量模板】
# An example prompt with multiple input variables
multiple_input_prompt = PromptTemplate(
input_variables=["adjective", "content"],
template="Tell me a {adjective} joke about {content}."
)
multiple_input_prompt.format(adjective="funny", content="chickens")
# -> "Tell me a funny joke about chickens."
提出多个问题,两种方法:
- 使用generate方法遍历所有问题,逐个回答。
- 将所有问题放入单个提示中,这仅适用于更高级的LLMs。
# ③ 【多输入】
qs = [ # Text only
{'question': "Which NFL team won the Super Bowl in the 2010 season?"},
{'question': "If I am 6 ft 4 inches, how tall am I in centimeters?"},
{'question': "Who was the 12th person on the moon?"},
{'question': "How many eyes does a blade of grass have?"}
]
res = llm_chain.generate(qs)
# res = LLMResult(generations = [[Generation(text ='green bay packers', generation_info = None)], [Generation(text ='184', generation_info = None)], [Generation(text ='john glenn', generation_info = None)], [Generation(text ='one', generation_info = None)]], llm_output = None)
FewShot PromptTemplate
- 模板可以根据语料库中的内容进行匹配,最终可按照特定的格式匹配出样例中的内容。
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""
},
{
"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""
}
]
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
=========================
Question: Who lived longer, Muhammad Ali or Alan Turing?
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
(3)Indexes(索引):文档结构化
Indexes(索引):文档结构化方式, 以便LLM更好的交互
- 索引是指对文档进行结构化的方法,以便LLM能够更好的与之交互。
最常见的使用场景是文档检索,接收用户查询,返回最相关的文档。
- 注意: 索引也能用在除了检索外的其他场景,同样检索除了索引外也有其他的实现方式。
索引一般和检索非结构化数据(比如文本文档)相关,LangChain支持的主要索引类型如下,都是围绕着向量数据库的。
该组件主要包括:Document Loaders(文档加载器)、Text Splitters(文本拆分器)、VectorStores(向量存储器)以及Retrievers(检索器)。
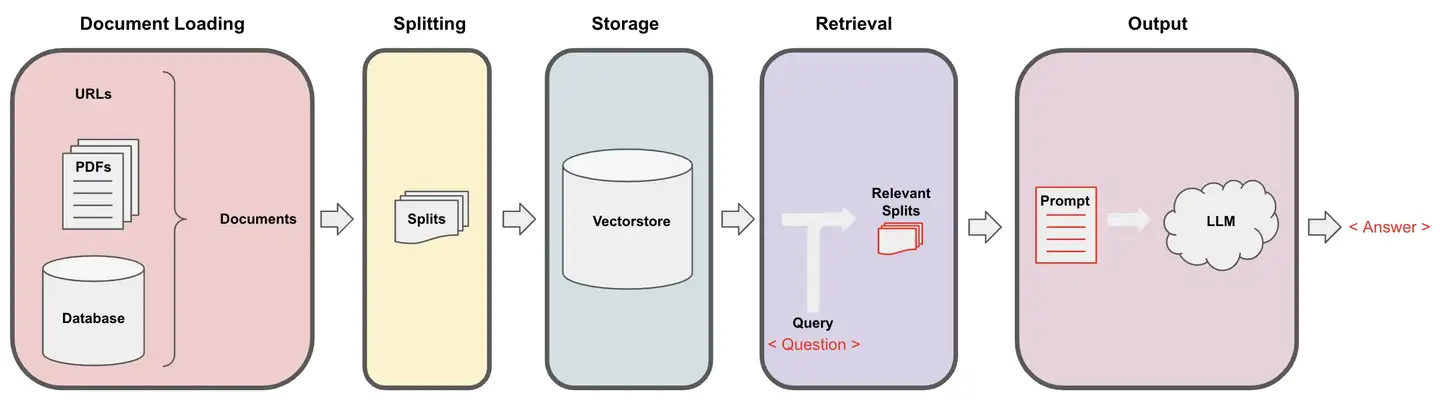
文本检索器:将特定格式数据转换为文本。输入可以是 pdf、word、csv、images 等。文本拆分器:将长文本拆分成小的文本块,便于LLM模型处理。- 由于模型处理数据时,对输入长度有限制,因此需要对长文本进行分块。
- 不同语言模型对块的大小定义不同,比如OpenAI的GPT对分块的长度通过token大小来限制,比如GPT-3.5是4096,即这个分块所包含的Token数量不能超过4096。
- 一般的分块方法:首先,对长文本进行断句,即分成一句一句话。然后,计算每句话包含的token数量,并从第一句话开始往后依次累加,直到达到指定数量,组成为1个分块。依次重复上述操作。比如按照字母切分的
Character,按照token切分的Tiktoken等。
向量存储器:存储提取的文本向量,包括Faiss、Milvus、Pinecone、Chroma等。向量检索器:通过用户输入的文本,检索器负责从底库中检索出特定相关度的文档。度量准则包括余弦距离、欧式距离等。
Document Loaders(文档加载器)
LangChain 通过 Loader 加载外部的文档,转化为标准的 Document 类型。
Document 类型主要包含两个属性:
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据,类似文档所在的路径等。
LangChain 目前支持结构化、非结构化以及公开以及私有的各种数据
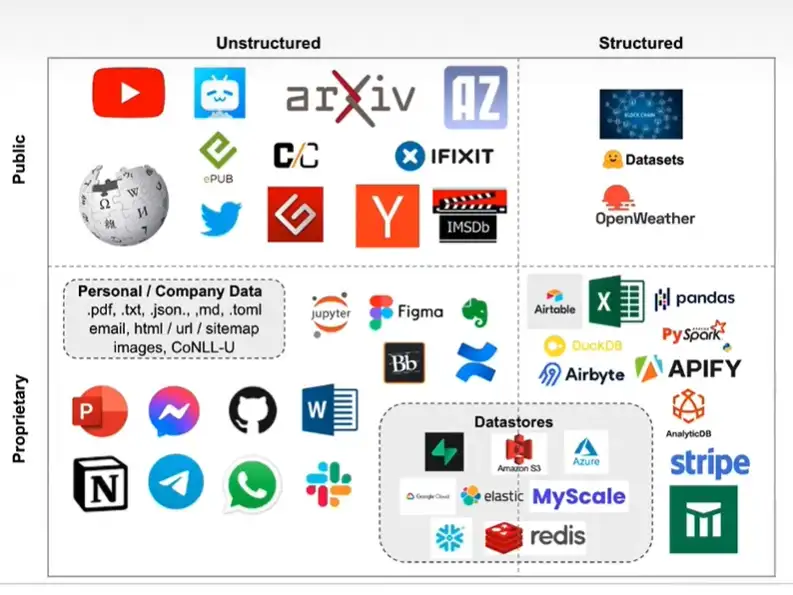
| 非结构化 unstructed | 结构化 structured | |
|---|---|---|
| 公开 public | Wikipedia, youtube, bilibili, arXiv, twitter, imdb… | Huggingface Datasets, OpenWeather |
| 私有 proprietary | ppt,word, Note, snapchat, github, jupyter.. | excel,pandas,spark… |
注
- 数据库介于私有区,既有结构化(mysql)又有非结构化(redis,es..)
数据源加载
# 🎨 加载B站(BiliBili)视频数据
#!pip install bilibili-api
from langchain.document_loaders.bilibili import BiliBiliLoader
loader = BiliBiliLoader(
["https://www.bilibili.com/video/BV1xt411o7Xu/"]
)
loader.load()
# 🎨 加载CSV数据
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv')
data = loader.load()
# 🎨 加载Email数据
#!pip install unstructured
from langchain.document_loaders import UnstructuredEmailLoader
loader = UnstructuredEmailLoader('example_data/fake-email.eml')
data = loader.load()
# 🎨 加载电子书Epub数据
#!pip install pandocs
from langchain.document_loaders import UnstructuredEPubLoader
loader = UnstructuredEPubLoader("winter-sports.epub", mode="elements")
data = loader.load()
# 🎨 加载Git数据
# !pip install GitPython
from git import Repo
repo = Repo.clone_from(
"https://github.com/hwchase17/langchain", to_path="./example_data/test_repo1"
)
branch = repo.head.reference
from langchain.document_loaders import GitLoader
loader = GitLoader(repo_path="./example_data/test_repo1/", branch=branch)
data = loader.load()
# 🎨 加载HTML数据
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader("example_data/fake-content.html")
data = loader.load()
# 🎨 加载Image图片数据
#!pip install pdfminer
from langchain.document_loaders.image import UnstructuredImageLoader
loader = UnstructuredImageLoader("layout-parser-paper-fast.jpg")
data = loader.load()
# 🎨 加载Word文档数据
from langchain.document_loaders import Docx2txtLoader
loader = Docx2txtLoader("example_data/fake.docx")
data = loader.load()
# [Document(page_content='Lorem ipsum dolor sit amet.', metadata={'source': 'example_data/fake.docx'})]
# 🎨 加载PDF文件数据
# !pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
pages[0]
Text Splitters(文本拆分器)
LLM 一般都会限制上下文窗口的大小,有 4k、16k、32k 等。针对大文本就需要进行文本分割,常用的文本分割器为 RecursiveCharacterTextSplitter,可以通过 separators 指定分隔符。其先通过第一个分隔符进行分割,不满足大小的情况下迭代分割。
文本分割主要有 2 个考虑:
- 1)将语义相关的句子放在一块形成一个 chunk。一般根据不同的文档类型定义不同的分隔符,或者可以选择通过模型进行分割。
- 2)chunk 控制在一定的大小,可以通过函数去计算。默认通过 len 函数计算,模型内部一般都是使用 token 进行计算。token 通常指的是将文本或序列数据划分成的小的单元或符号,便于机器理解和处理。使用 OpenAI 相关的大模型,可以通过 tiktoken 包去计算其 token 大小。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-3.5-turb
allowed_special="all",
separators=["\n\n", "\n", "。", ","],
chunk_size=7000,
chunk_overlap=0
)
docs = text_splitter.create_documents(["文本在这里"])
print(docs)
示例
# pip install chromadb
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 指定要使用的文档加载器
from langchain.document_loaders import TextLoader
documents = TextLoader('../state_of_the_union.txt', encoding='utf8')
# 接下来将文档拆分成块。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 然后我们将选择我们想要使用的嵌入。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# 我们现在创建 vectorstore 用作索引。
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# 这就是创建索引。然后,我们在检索器接口中公开该索引。
retriever = db.as_retriever()
# 创建一个链并用它来回答问题!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
VectorStores(向量存储器)
通过 Text Embedding models,将文本转为向量,可以进行语义搜索,在向量空间中找到最相似的文本片段。
- 目前支持常用的向量存储有 Faiss、Chroma 等。
- Embedding 模型支持 OpenAIEmbeddings、HuggingFaceEmbeddings 等。通过 HuggingFaceEmbeddings 加载本地模型可以节省 embedding 的调用费用。
#通过cache_folder加载本地模型
embeddings = HuggingFaceEmbeddings(model_name="text2vec-base-chinese", cache_folder="本地模型地址")
embeddings = embeddings_model.embed_documents(
[
"我爱北京天安门!",
"Hello world!"
]
)
Retrievers(检索器)
Retriever 接口用于根据非结构化的查询获取文档,一般情况下是文档存储在向量数据库中。可以调用 get_relevant_documents 方法来检索与查询相关的文档。
Retrievers
检索器接口是一个通用接口,可以轻松地将文档与语言模型结合起来。
- 此接口公开了一个 get_relevant_documents 方法,该方法接受一个查询(一个字符串)并返回一个文档列表。
一般来说,用的都是 VectorStore Retriever。
- 此检索器由 VectorStore 大力支持。一旦你构造了一个 VectorStore,构造一个检索器就很容易了。
# # pip install faiss-cpu
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import DirectoryLoader
# 加载文件夹中的所有txt类型的文件,并转成 document 对象
loader = DirectoryLoader('./data/', glob='**/*.txt')
documents = loader.load()
# 接下来,我们将文档拆分成块。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 然后我们将选择我们想要使用的嵌入。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
from langchain.vectorstores import FAISS
db = FAISS.from_documents(texts, embeddings)
query = "未入职同事可以出差吗"
docs = db.similarity_search(query)
docs_and_scores = db.similarity_search_with_score(query)
print(docs)
retriever = db.as_retriever() # 最大边际相关性搜索 mmr
# retriever = db.as_retriever(search_kwargs={"k": 1}) # 搜索关键字
docs = retriever.get_relevant_documents("未入职同事可以出差吗")
print(len(docs))
# db.save_local("faiss_index")
# new_db = FAISS.load_local("faiss_index", embeddings)
# docs = new_db.similarity_search(query)
# docs[0]
(4)Chains(链条):组合链路
Langchain 通过 chain 将各个组件进行链接,以及 chain 之间进行链接,用于简化复杂应用程序的实现。
Chains(链条):将LLM与其他组件结合, 链允许将多个组件组合在一起以创建一个单一的、连贯的应用程序。
- 把一个个独立的组件链接在一起,LangChain名字的由来
- Chain 可理解为任务。一个 Chain 就是一个任务,也可以像链条一样,逐个执行多个链
Chain提供了一种将各种组件统一到应用程序中的方法。
- 例如,创建一个Chain,接受来自用户的输入,并通过PromptTemplate将其格式化,然后将格式化的输出传入到LLM模型中。
- 通过多个Chain与其他部件结合,可生成复杂的链,完成复杂的任务。
LangChain中,主要有下面几种链,LLMChain、Sequential Chain 以及 Route Chain,最常用 LLMChain。
LLMChain最基本的链- LLMChain由 PromptTemplate、模型和可选的输出解析器组成。
- 链接收多个输入变量,使用PromptTemplate生成提示,传递给模型,最后使用输出解析器把模型返回值转换成最终格式。

索引相关链- 和索引交互,把自己的数据和LLMs结合起来,最常见的例子是根据文档来回答问题。
提示选择器- 为不同模型生成不同的提示
LLM与其他组件结合,创建不同应用,一些例子:
- 将LLM与提示模板相结合
- 第一个 LLM 的输出作为第二个 LLM 的输入, 顺序组合多个 LLM
- LLM与外部数据结合,比如,通过langchain获取youtube视频链接,通过LLM视频问答
- LLM与长期记忆结合,比如聊天机器人
LLMChain
LangChain 核心构建模块是 LLMChain
LLMChain 由 PromptTemplate、LLM 和 OutputParser 组成。
三个方面:
LLM: 语言模型是核心推理引擎。用LangChain 需要了解不同类型的语言模型以及如何使用。Prompt Templates: 提供语言模型指令。这控制了语言模型的输出,因此了解如何构建提示和不同的提示策略至关重要。Output Parsers: 将LLM 原始响应转换为更易处理的格式,使得在下游使用输出变得容易。
LLM 的输出一般为文本,OutputParser 用于让 LLM 结构化输出并进行结果解析,方便后续的调用。
LLMChain = prompt + LLM + 一行 .run()。
🧠 能力总结:
- 把 prompt 和大模型绑定起来
- 自动格式化输入 → 请求模型 → 输出结果
- 可复用、可组合、可插入到 Agent 或流水线中
示例:
chain = LLMChain(prompt=prompt, llm=llm)
chain.run({"question": "LangChain 是什么?"})
LLM
LLMs 输入/输出简单易懂 - 字符串。
但 ChatModels
- 输入:
ChatMessage列表 - 输出: 单独
ChatMessage。
一个 ChatMessage 有两个必需的组件:
content: 消息内容。role:ChatMessage实体角色。
LangChain 提供了几个对象,用于方便地区分不同的角色:
HumanMessage: 人类/用户 ChatMessage。AIMessage: AI/助手 ChatMessage。SystemMessage: 系统 ChatMessage。FunctionMessage: 函数调用 ChatMessage。
如果这些角色都不合适,可用 ChatMessage类 手动指定角色
LangChain 提供标准接口:
predict: 接受一个字符串,返回一个字符串predict_messages: 接受一个消息列表,返回一个消息。
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
llm = OpenAI()
chat_model = ChatOpenAI()
text = "What would be a good company name for a company that makes colorful socks?"
llm.predict(text) # "Hi"
chat_model.predict(text) # "Hi"
from langchain import LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "Can Barack Obama have a conversation with George Washington?"
print(llm_chain.run(question))
LLMChain 是一个简单的链,它接受一个提示模板,用用户输入格式化它并返回来自 LLM 的响应。
from langchain.llms import OpenAI
from langchain.docstore.document import Document
import requests
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
import pathlib
import subprocess
import tempfile
"""
生成对以前撰写的博客文章有理解的博客文章,或者可以参考产品文档的产品教程
"""
source_chunks = ""
search_index = Chroma.from_documents(source_chunks, OpenAIEmbeddings())
from langchain.chains import LLMChain
prompt_template = """Use the context below to write a 400 word blog post about the topic below:
Context: {context}
Topic: {topic}
Blog post:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "topic"]
)
llm = OpenAI(temperature=0)
chain = LLMChain(llm=llm, prompt=PROMPT)
def generate_blog_post(topic):
docs = search_index.similarity_search(topic, k=4)
inputs = [{"context": doc.page_content, "topic": topic} for doc in docs]
print(chain.apply(inputs))
generate_blog_post("environment variables")
# 附加示例
llm_chain = LLMChain(prompt=prompt, llm=llm)
comment = "京东物流没的说,速度态度都是杠杠滴!这款路由器颜值贼高,怎么说呢,就是泰裤辣!这线条,这质感,这速度,嘎嘎快!以后妈妈再也不用担心家里的网速了!"
result = llm_chain.run(comment)
data = output_parser.parse(result)
print(f"type={type(data)}, keyword={data['keyword']}, emotion={data['emotion']}")
Sequential Chain (一串LLMChain)
SequentialChains 按预定义顺序执行的链。SimpleSequentialChain 为顺序链的最简单形式,其中每个步骤都有一个单一的输入 / 输出,一个步骤的输出是下一个步骤的输入。SequentialChain 为顺序链更通用的形式,允许多个输入 / 输出。
执行多个 LLMChain
- 顺序链是按预定义顺序执行其链接的链。
- 使用SimpleSequentialChain,其中每个步骤都有一个输入/输出,一个步骤的输出是下一个步骤的输入。
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
# location 链
llm = OpenAI(temperature=1)
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
location_chain = LLMChain(llm=llm, prompt=prompt_template)
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
meal_chain = LLMChain(llm=llm, prompt=prompt_template)
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("Rome")
Router Chain
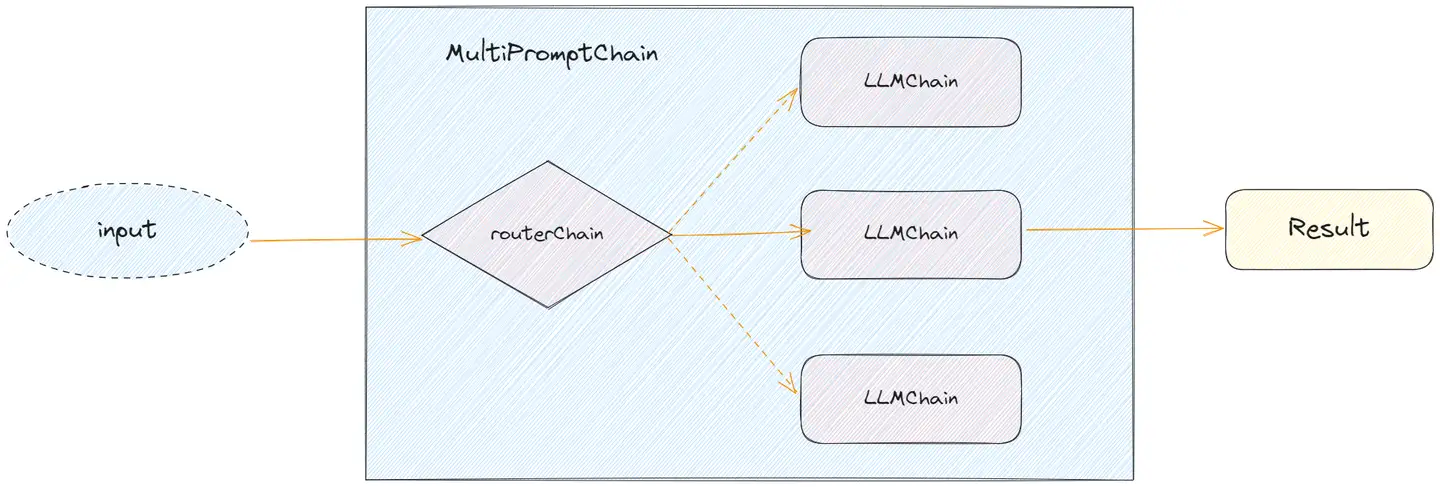
RouterChain 根据输入动态选择下一个链,每条链处理特定类型的输入。
RouterChain 由两个组件组成:
- 1)路由器链本身,负责选择要调用的下一个链,主要有 2 种 RouterChain,其中 LLMRouterChain 通过 LLM 进行路由决策,EmbeddingRouterChain 通过向量搜索的方式进行路由决策。
- 2)目标链列表,路由器链可以路由到的子链。
初始化 RouterChain 以及 destination_chains 完成后,通过 MultiPromptChain 将两者结合起来使用。
Documents Chain
下面 4 种 Chain 主要用于 Document 处理,基于文档生成摘要、问答等场景中经常会用到,在后续的落地实践里也会有所体现。
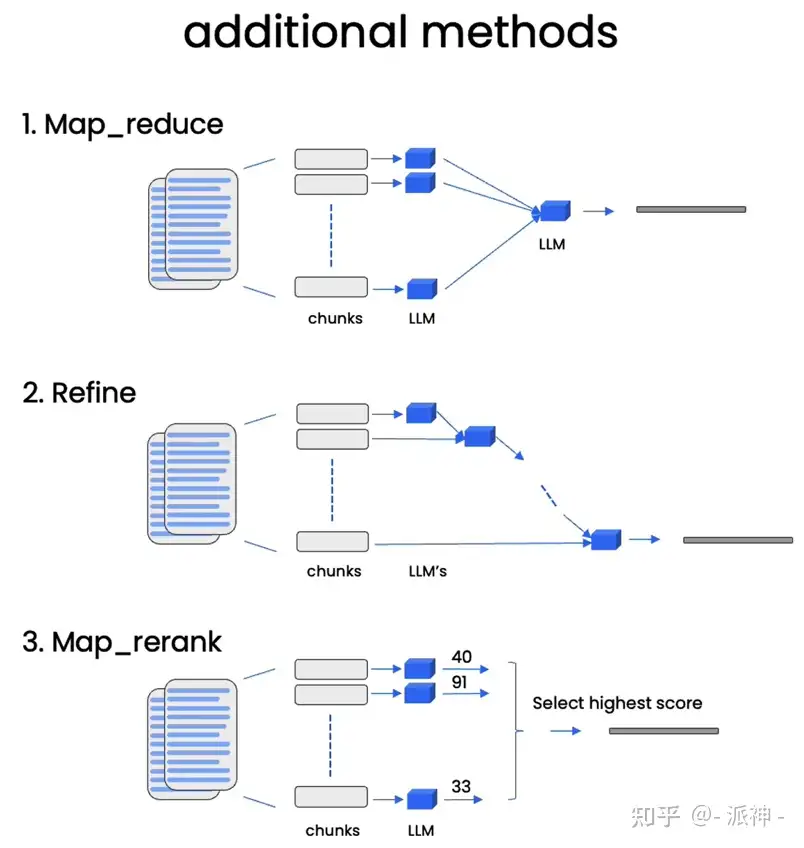
load_summarize_chain 三种不同的链式类型:stuff, map_reduce 和 refine
stuff: 文档内容直接送给 llmrefine: 文档串行传送给llm, 当前文档内容+上一步中间结果map_reduce: 每个文档单独并行处理, 再合并调用map_rerank: 每个文档单独并行处理, 再排序调用
数据准备
from langchain import OpenAI, PromptTemplate, LLMChain
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.mapreduce import MapReduceChain
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0)
text_splitter = CharacterTextSplitter()
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.read()
texts = text_splitter.split_text(state_of_the_union)
from langchain.docstore.document import Document
docs = [Document(page_content=t) for t in texts[:3]]
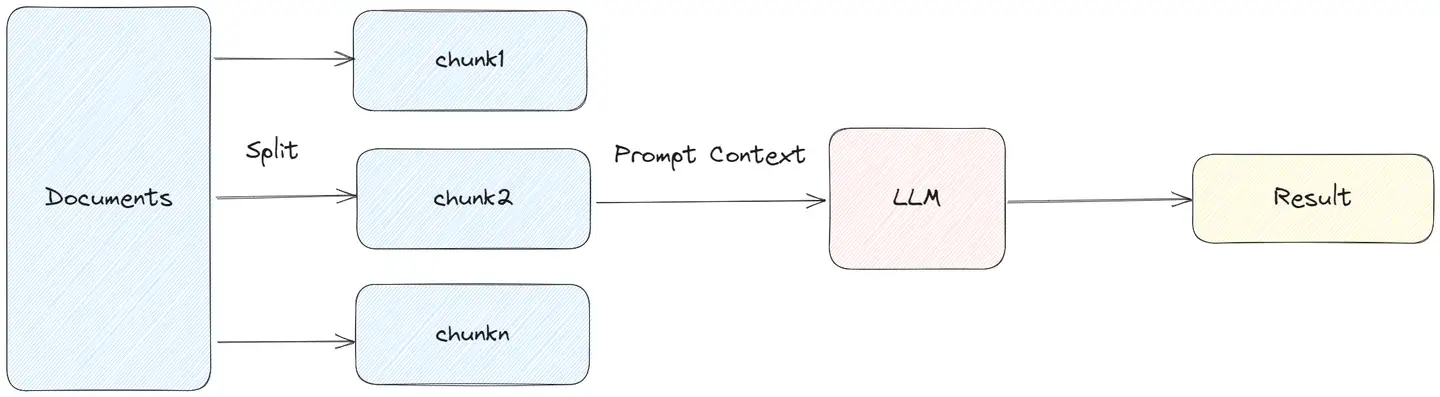
Stuff
StuffDocumentsChain 最直接,将所有获取到的文档作为 context 放入到 Prompt 中,传递到 LLM 获取答案。
这种方式完整保留上下文,调用 LLM 次数较少,建议能使用 stuff 的就使用这种方式。
- 其适合文档拆分的比较小,一次获取文档比较少的场景,不然容易超过 token 限制。
chain = load_summarize_chain(llm, chain_type="stuff")
chain.run(docs)
自定义 Prompt
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY IN ITALIAN:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="stuff", prompt=PROMPT)
chain.run(docs)
Refine
RefineDocumentsChain 通过迭代更新方式获取答案。
- 先处理第一个文档,作为 context 传递给 llm,获取中间结果 intermediate answer。
- 然后将第一个文档的中间结果以及第二个文档发给 llm 进行处理,后续的文档类似处理。
Refine 这种方式能部分保留上下文,以及 token 的使用能控制在一定范围。
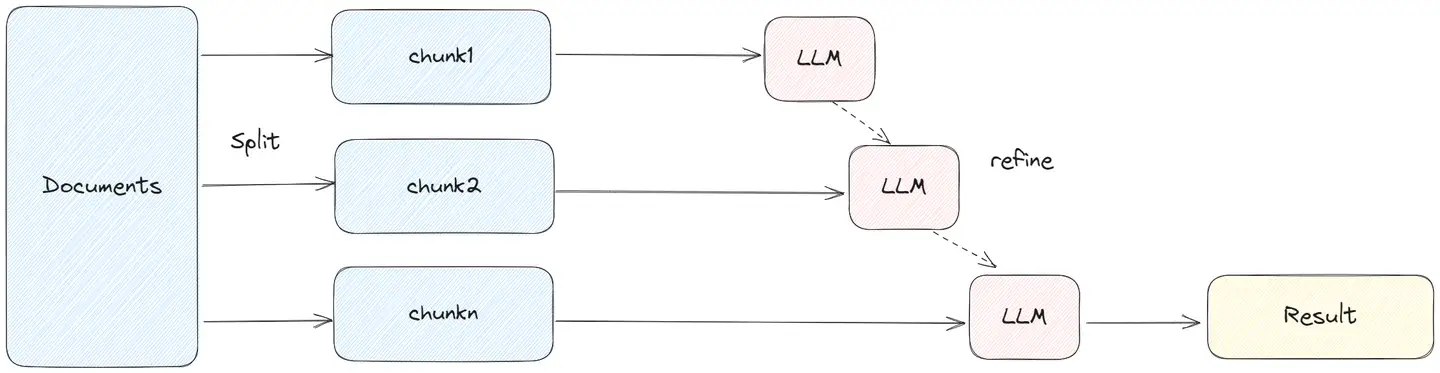
# 一步到位
chain = load_summarize_chain(llm, chain_type="refine")
chain.run(docs)
# 中间步骤
chain = load_summarize_chain(OpenAI(temperature=0), chain_type="refine", return_intermediate_steps=True)
chain({"input_documents": docs}, return_only_outputs=True)
自定义 prompt
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY IN ITALIAN:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
refine_template = (
"Your job is to produce a final summary\n"
"We have provided an existing summary up to a certain point: {existing_answer}\n"
"We have the opportunity to refine the existing summary"
"(only if needed) with some more context below.\n"
"------------\n"
"{text}\n"
"------------\n"
"Given the new context, refine the original summary in Italian"
"If the context isn't useful, return the original summary."
)
refine_prompt = PromptTemplate(
input_variables=["existing_answer", "text"],
template=refine_template,
)
chain = load_summarize_chain(OpenAI(temperature=0), chain_type="refine", return_intermediate_steps=True, question_prompt=PROMPT, refine_prompt=refine_prompt)
chain({"input_documents": docs}, return_only_outputs=True)
MapReduce
MapReduceDocumentsChain 先通过 LLM 对每个 document 进行处理,然后将所有文档的答案在通过 LLM 进行合并处理,得到最终结果。
MapReduce 方式将每个 document 单独处理,可以并发进行调用。但是每个文档之间缺少上下文。
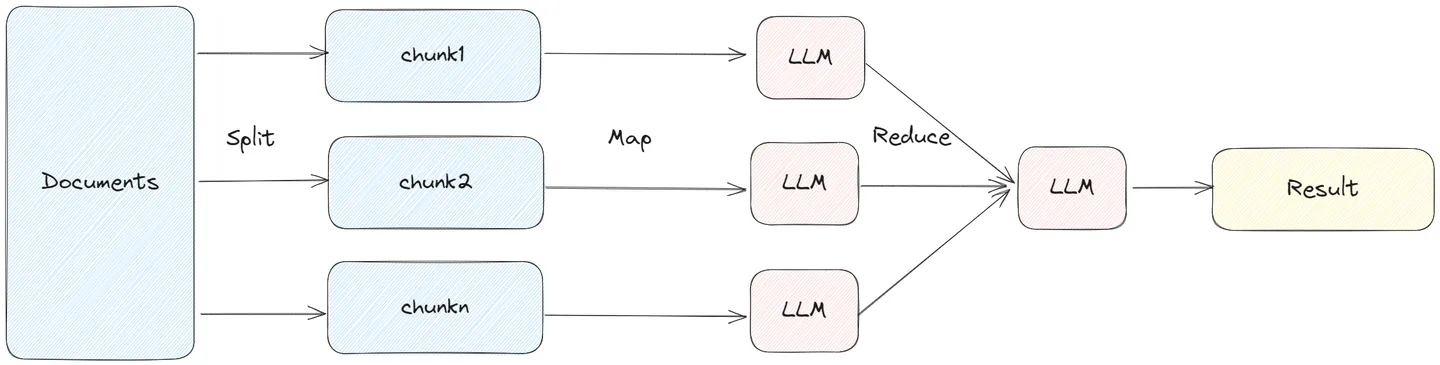
from langchain.chains.summarize import load_summarize_chain
# 一次到位
chain = load_summarize_chain(llm, chain_type="map_reduce")
chain.run(docs)
# 显示中间步骤 return_intermediate_steps 参数
chain = load_summarize_chain(OpenAI(temperature=0), chain_type="map_reduce", return_intermediate_steps=True)
chain({"input_documents": docs}, return_only_outputs=True) # {'map_steps':['a','b'], 'output_text':'...'}
自定义提示
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY IN ITALIAN:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(OpenAI(temperature=0), chain_type="map_reduce", return_intermediate_steps=True, map_prompt=PROMPT, combine_prompt=PROMPT)
chain({"input_documents": docs}, return_only_outputs=True)
map, reduce 阶段使用不同的 prompt
from langchain.chains.combine_documents.map_reduce import MapReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
# map 阶段
map_template_string = """Give the following python code information, generate a description that explains what the code does and also mention the time complexity.
Code:
{code}
Return the the description in the following format:
name of the function: description of the function
"""
# reduce 阶段
reduce_template_string = """Give the following following python fuctions name and their descritpion, answer the following question
{code_description}
Question: {question}
Answer:
"""
MAP_PROMPT = PromptTemplate(input_variables=["code"], template=map_template_string)
REDUCE_PROMPT = PromptTemplate(input_variables=["code_description", "question"], template=reduce_template_string)
llm = OpenAI()
# 分别初始化
map_llm_chain = LLMChain(llm=llm, prompt=MAP_PROMPT) # map chain
reduce_llm_chain = LLMChain(llm=llm, prompt=REDUCE_PROMPT) # reduce chain
generative_result_reduce_chain = StuffDocumentsChain(
llm_chain=reduce_llm_chain,
document_variable_name="code_description",
)
combine_documents = MapReduceDocumentsChain(
llm_chain=map_llm_chain, # map 阶段
combine_document_chain=generative_result_reduce_chain, # reduce 合并阶段, 用 stuff chain
document_variable_name="code",
)
# map_reduce chain 构建
map_reduce = MapReduceChain(
combine_documents_chain=combine_documents,
text_splitter=CharacterTextSplitter(separator="\n##\n", chunk_size=100, chunk_overlap=0),
)
code = """
shellSort():
...
"""
map_reduce.run(input_text=code, question="Which function has a better time complexity?")
MapRerank
MapRerankDocumentsChain 和 MapReduceDocumentsChain 类似
- 先通过 LLM 对每个 document 进行处理,每个答案都会返回一个 score,最后选择 score 最高的答案。
MapRerank 和 MapReduce 类似,会大批量的调用 LLM,每个 document 之间是独立处理。
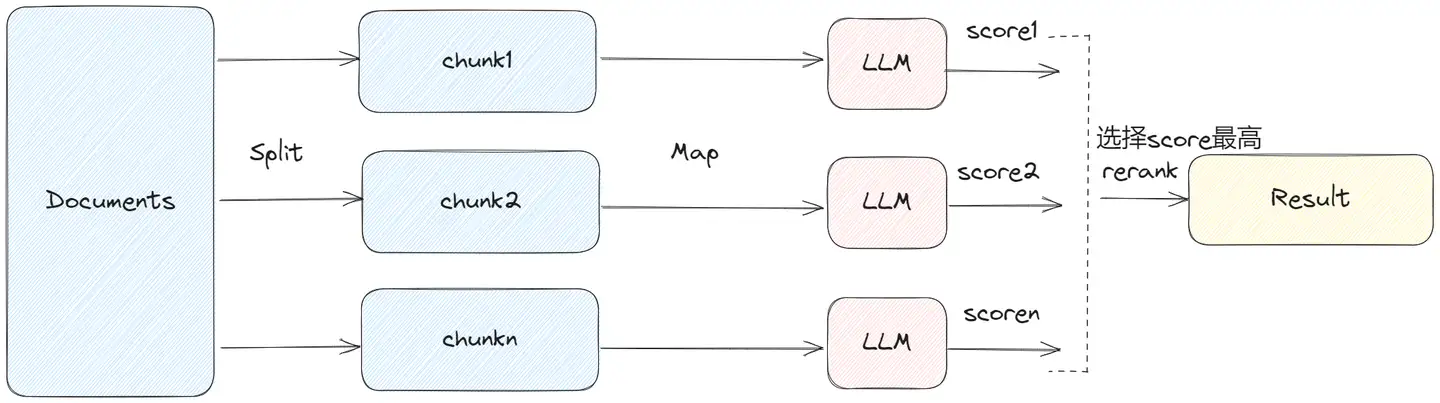
(5)Agents(智能体):其他工具
“链”可以帮助将一系列 LLM 调用链接在一起。然而,在某些任务中,调用顺序通常是不确定的。
- 有些应用并不是一开始就确定调用哪些模型,而是依赖于用户输入
LangChain 库提供了代理“Agents”,根据未知输入而不是硬编码来决定下一步采取的行动。
Agent 字面含义是代理,如果说 LLM 是大脑,Agent 就是代理大脑使用工具 Tools。
目前大模型一般都存在知识过时、逻辑计算能力低等问题,通过 Agent 访问工具,可以去解决这些问题。这个领域特别活跃,诞生了类似 AutoGPT、BabyAGI、AgentGPT 等一堆优秀的项目。传统使用 LLM,需要给定 Prompt 一步一步的达成目标,通过 Agent 是给定目标,其会自动规划并达到目标。
Agents通常由三个部分组成:Action、Observation和Decision。
Action是代理执行的操作Observation是代理接收到的信息Decision是代理基于Action和Observation做出的决策。
Agent 核心组件
Agent 核心组件
Agent:代理,负责调用 LLM 以及决定下一步的 Action。其中 LLM 的 prompt 必须包含 agent_scratchpad 变量,记录执行的中间过程Tools:工具,Agent 可以调用的方法。LangChain 已有很多内置的工具,也可以自定义工具。注意 Tools 的 description 属性,LLM 会通过描述决定是否使用该工具。ToolKits:工具集,为特定目的的工具集合。类似 Office365、Gmail 工具集等Agent Executor:Agent 执行器,负责进行实际的执行。
Agent 使用LLM来确定要采取哪些行动以及按什么顺序采取的行动。操作可以使用工具并观察其输出,也可以返回用户。
创建agent时的参数:
LLM:为代理提供动力的语言模型。工具:执行特定职责的功能, 方便模型和其他资源交互- 比如:Google搜索,数据库查找,Python Repl。工具的接口当前是一个函数,将字符串作为输入,字符串作为输出。
工具集- 解决特定问题的工具集合
代理:highest level API、custom agent. 要使用的代理。围绕模型的包装器,接收用户输入,决定模型的行为代理执行器- 代理和一组工具,调用代理
# Create RetrievalQA Chain
from langchain.chains import RetrievalQA
retrieval_qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())
# Create an Agent
from langchain.agents import initialize_agent, Tool
tools = [
Tool(
name="Example QA System",
func=retrieval_qa.run,
description="Example description of the tool."
),
]
# Agent 的初始化, 除了 llm、tools 等参数,还需要指定 AgentType。
# 通过 agent.agent.llm_chain.prompt.template 方法,获取其推理决策所使用的模板
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
# Use Agent
agent.run("Ask a question related to the documents")
Agent 类型
Agent Type
- zero-shot-react-description: 只考虑当前的操作,不会记录以及参考之前的操作。react 表明通过 ReAct 框架进行推理,description 表明通过工具的 description 进行是否使用的决策。
- chat-conversational-react-description:
- conversational-react-description:
- react-docstore:
- self-ask-with-search 等,类似 chat-conversational-react-description 通过 memory 记录之前的对话,应答会参考之前的操作。
自定义 Tool
Agents(智能体):访问其他工具
Agents是LLM与工具之间的接口,Agents用来确定任务与工具。
一般的Agents执行任务过程:
- a. 首先,接收用户输入,并转化为PromptTemplate
- b. 其次,Agents通过调用LLM输出action,并决定使用哪种工具执行action
- c. 最后,Agents调用工具完成action任务
Agents可以调用那些工具完成任务?
| 工具 | 描述 |
|---|---|
| 搜索 | 调用谷歌浏览器或其他浏览器搜索指定内容 |
| 终端 | 在终端中执行命令,输入应该是有效的命令,输出将是运行该命令的任何输出 |
| Wikipedia | 从维基百科生成结果 |
| Wolfram-Alpha | WA 搜索插件——可以回答复杂的数学、物理或任何查询,将搜索查询作为输入。 |
| Python REPL | 用于评估和执行 Python 命令的 Python shell。它以 python 代码作为输入并输出结果。输入的 python 代码可以从 LangChain 中的另一个工具生成 |
Agent 通过调用 wikipedia 工具,对用户提出的问题回答。尽管gpt-3.5功能强大,但是其知识库截止到2021年9月,因此,agent调用wikipedia外部知识库对用户问题回答。
回答过程如下:
- a. 分析用户输入问题,采取的 Action 为通过 Wikipedia 实现,并给出了Action的输入
- b. 根据分析得到了最相关的两页,并进行了总结
- c. 对最后的内容进一步提炼,得到最终答案
import os
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
# from langchain.agents import AgentType
openai_api_key = 'sk-F9xxxxxxx55q8YgXb6s5dJ1A4LjA'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0)
tools = load_tools(["wikipedia","llm-math",'serpapi'], llm=llm)
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
# agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, # 或
verbose=True
)
print(agent.run("列举spaceX星舰在2022年后的发射记录?"))
print(agent.run("今天的日期是多少?2024年有多少天?"))
多种方式可以自定义 Tool,最简单的方式是通过 @tool 装饰器,将一个函数转为 Tool。注意函数必须得有 docString,其为 Tool 的描述。
from azure_chat_llm import llm
from langchain.agents import load_tools, initialize_agent, tool
from langchain.agents.agent_types import AgentType
from datetime import date
@tool
def time(text: str) -> str:
"""
返回今天的日期。
"""
return str(date.today())
tools = load_tools(['llm-math'], llm=llm)
tools.append(time)
agent_math = initialize_agent(agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
tools=tools,
llm=llm,
verbose=True)
print(agent_math("计算45 * 54"))
print(agent_math("今天是哪天?"))
(6)Memory(记忆):
模型是无状态的,不保存上一次交互时的数据
- OpenAI的API服务没有上下文概念,而chatGPT是额外实现了上下文功能。
正常情况下 Chain 无状态的,每次交互都是独立的,无法知道之前历史交互的信息。
对于像聊天机器人这样的应用程序,需要记住以前的对话内容。
- 但默认情况下,LLM对历史内容没有记忆功能。LLM的输出只针对用户当前的提问内容回答。
- 为解决这个问题,Langchain提供了记忆组件,用来管理与维护历史对话内容。
LangChain 使用 Memory 组件保存和管理历史消息,这样可以跨多轮进行对话,在当前会话中保留历史会话的上下文。Memory 组件支持多种存储介质,可以与 Monogo、Redis、SQLite 等进行集成,以及简单直接形式就是 Buffer Memory。常用的 Buffer Memory 有
- 1)
ConversationSummaryMemory:以摘要的信息保存记录 - 2)
ConversationBufferWindowMemory:以原始形式保存最新的 n 条记录 - 3)
ConversationBufferMemory:以原始形式保存所有记录通过查看 chain 的 prompt,可以发现 {history} 变量传递了从 memory 获取的会话上下文。下面的示例演示了 Memory 的使用方式,可以很明细看到,答案是从之前的问题里获取的。
| 类型 | 特点 |
|---|---|
BufferMemory |
存整段历史 |
SummaryMemory |
自动总结上下文 |
TokenMemory |
控制上下文 token 数量 |
WindowMemory |
只记 N 轮 |
langchain 提供不同的Memory组件完成内容记忆,下面列举四种:
ConversationBufferMemory:记住全部对话内容。这是最简单的内存记忆组件,它的功能是直接将用户和机器人之间的聊天内容记录在内存中。imgConversationBufferWindowMemory:记住最近k轮的聊天内容。与之前的ConversationBufferMemory组件的差别是它增加了一个窗口参数,它的作用是可以指定保存多轮对话的数量。img- 在该例子中设置了对话轮数k=2,即只能记住前两轮的内容,“我的名字”是在前3轮中的Answer中回答的,因此其没有对其进行记忆,所以无法回答出正确答案。
ConversationSummaryMemory:ConversationSummaryMemory它不会将用户和机器人之前的所有对话都存储在内存中。它只会存储一个用户和机器人之间的聊天内容的摘要,这样做的目的可能是为了节省内存开销和token的数量。VectorStored-Backed Memory: 将所有之前的对话通过向量的方式存储到VectorDB(向量数据库)中,在每一轮新的对话中,会根据用户的输入信息,匹配向量数据库中最相似的K组对话。
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from azure_chat_llm import llm
memory = ConversationBufferMemory()
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
print(conversation.prompt)
print(conversation.predict(input="我的姓名是tiger"))
print(conversation.predict(input="1+1=?"))
print(conversation.predict(input="我的姓名是什么"))
注
ConversationBufferMemory会存储所有对话历史,对于长对话可能会消耗较多token。ConversationBufferWindowMemory只保留最近几轮对话。实际项目中使用
国内不少LLm团队采用langChain,集成llm本地化知识库
- langChain,babyAGI 想做AGI生态,=力不从心。autoGPT好一点,相对简单。
- langChain,babyAGI 子模块,都是几百个。特别是langChain,模块库居然有600多张子模块map架构图
无需OpenAI API Key,构建个人化知识库的终极指南
构建知识库的主要流程:
- 加载文档
- 文本分割
- 构建矢量数据库
- 引入LLM
- 创建qa_chain,开始提问
LangChain 实践
文档生成总结
文档生成总结
- 1)通过 Loader 加载远程文档
- 2)通过 Splitter 基于 Token 进行文档拆分
- 3)加载 summarize 链,链类型为 refine,迭代进行总结
LangChain 落地实践
3.1 文档生成总结
- 1)通过 Loader 加载远程文档
- 2)通过 Splitter 基于 Token 进行文档拆分
- 3)加载 summarize 链,链类型为 refine,迭代进行总结
from langchain.prompts import PromptTemplate
from langchain.document_loaders import PlaywrightURLLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from azure_chat_llm import llm
loader = PlaywrightURLLoader(urls=["https://content.jr.jd.com/article/index.html?pageId=708258989"])
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-3.5-turbo",
allowed_special="all",
separators=["\n\n", "\n", "。", ","],
chunk_size=7000,
chunk_overlap=0
)
prompt_template = '''
作为一个资深编辑,请针对 >>> 和 <<< 中间的文本写一段摘要。
>>> {text} <<<
'''
refine_template = '''
作为一个资深编辑,基于已有的一段摘要:{existing_answer},针对 >>> 和 <<< 中间的文本完善现有的摘要。
>>> {text} <<<
'''
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
REFINE_PROMPT = PromptTemplate(
template=refine_template, input_variables=["existing_answer", "text"]
)
# 三种不同的链式类型:stuff, map_reduce 和 refine
chain = load_summarize_chain(llm, chain_type="refine", question_prompt=PROMPT, refine_prompt=REFINE_PROMPT, verbose=False)
# chain = load_summarize_chain(llm, chain_type="map_reduce")
docs = text_splitter.split_documents(data)
result = chain.run(docs)
print(result)
基于外部文档的问答
基于外部文档的问答
- 1)通过 Loader 加载远程文档
- 2)通过 Splitter 基于 Token 进行文档拆分
- 3)通过 FAISS 向量存储文档,embedding 加载 HuggingFace 的 text2vec-base-chinese 模型
- 4)自定义 QA 的 prompt,通过 RetrievalQA 回答相关的问题
作者:京东云
链接:https://www.zhihu.com/question/609483833/answer/3146379316
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
from langchain.chains import RetrievalQA
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from azure_chat_llm import llm
loader = WebBaseLoader("https://in.m.jd.com/help/app/register_info.html")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-3.5-turbo",
allowed_special="all",
separators=["\n\n", "\n", "。", ","],
chunk_size=800,
chunk_overlap=0
)
docs = text_splitter.split_documents(data)
#设置自己的模型路径
embeddings = HuggingFaceEmbeddings(model_name="text2vec-base-chinese", cache_folder="model")
vectorstore = FAISS.from_documents(docs, embeddings)
template = """请使用下面提供的背景信息来回答最后的问题。 如果你不知道答案,请直接说不知道,不要试图凭空编造答案。
回答时最多使用三个句子,保持回答尽可能简洁。 回答结束时,请一定要说"谢谢你的提问!"
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"], template=template)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
result = qa_chain({"query": "用户注册资格"})
print(result["result"])
print(len(result['source_documents']))
LangChain + Milvus
from langchain.embeddings.openai import OpenAIEmbeddings # openai
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI # openai
import os
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
# Question Answering Chain
# ① 加载文档
with open("../test.txt") as f:
state_of_the_union = f.read()
# ② 文本分割
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) # 指定分割器
texts = text_splitter.split_text(state_of_the_union) # 分割文本
embeddings = OpenAIEmbeddings() # 使用OpenAI的embedding服务
# ③ 构建适量数据库
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))]).as_retriever()
query = "What did the president say about Justice Breyer"
docs = docsearch.get_relevant_documents(query)
# ④ 引入LLM,创建qa_chain
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
# ⑤ 开始提问
answer = chain.run(input_documents=docs, question=query)
print(answer)
以上构建依赖OpenAI,有第三方免费服务吗?
Huggingface开源AI模型构建本地知识库
- 开源的google/flan-t5-xlAI模型
from langchain import HuggingFacePipeline
from langchain.chains import RetrievalQA
from langchain.chains.question_answering import load_qa_chain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms.base import LLM
import os
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
os.environ["HUGGINGFACEHUB_API_TOKEN"] = 'HUGGINGFACEHUB_API_TOKEN'
# Document Loaders
loader = TextLoader('../example_data/test.txt', encoding='utf8')
documents = loader.load()
# Text Splitters
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select embeddings
embeddings = HuggingFaceEmbeddings()
# create vectorstores
db = Chroma.from_documents(texts, embeddings)
# Retriever
retriever = db.as_retriever(search_kwargs={"k": 2})
query = "what is embeddings?"
docs = retriever.get_relevant_documents(query)
for item in docs:
print("page_content:")
print(item.page_content)
print("source:")
print(item.metadata['source'])
print("---------------------------")
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-xl")
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=512,
temperature=0,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
chain = load_qa_chain(llm, chain_type="stuff")
llm_response = chain.run(input_documents=docs, question=query)
print(llm_response)
print("done.")
集成了 Milvus 和 LangChain:参考
class VectorStore(ABC):
"""Interface for vector stores."""
@abstractmethod
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
kwargs:Any,
) ->List[str]:
"""
Run more texts through the embeddings and add to the vectorstore.
"""
@abstractmethod
def similarity_search(self, query:str, k:int =4,kwargs: Any) -> List[Document]:
"""Return docs most similar to query."""
def max_marginal_relevance_search(self, query: str, k: int = 4, fetch_k: int = 20) -> List[Document]:
"""Return docs selected using the maximal marginal relevance."""
raise NotImplementedError
@classmethod
@abstractmethod
def from_texts(
cls: Type[VST],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> VST:
"""Return VectorStore initialized from texts and embeddings."""
将 Milvus 集成到 LangChain 中,实现几个关键函数:add_texts()、similarity_search()、max_marginal_relevance_search()和 from_text()
将 Milvus 集成到 LangChain 中的确存在一些问题,最主要的是 Milvus 无法处理 JSON 文件。目前,只有两种解决方法:
- 现有的 Milvus collection 上创建一个 VectorStore。
- 基于上传至 Milvus 的第一个文档创建一个 VectorStore。
LangChain + Faiss + Ray 实践
【2023-5-29】Building an LLM open source search engine in 100 lines using LangChain and Ray
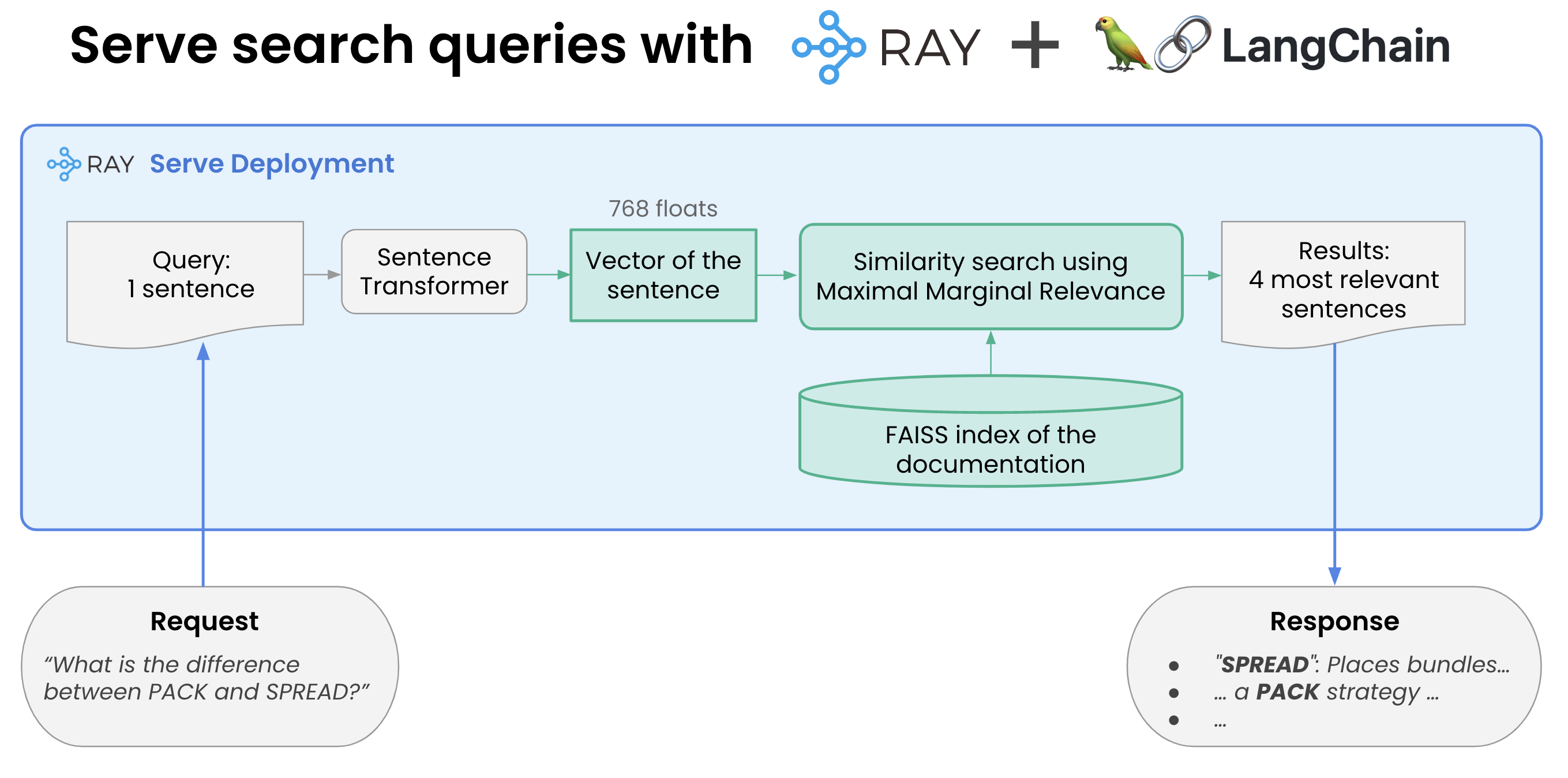
- Building the index: Build a document index easily with Ray and Langchain
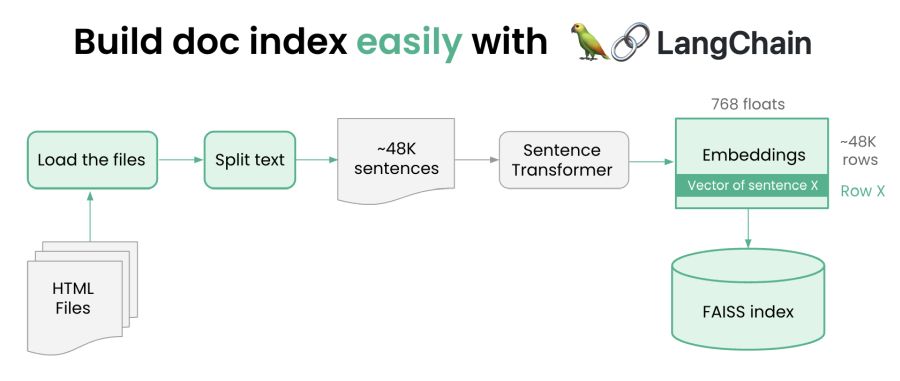
- Build a document index 4-8x faster with Ray
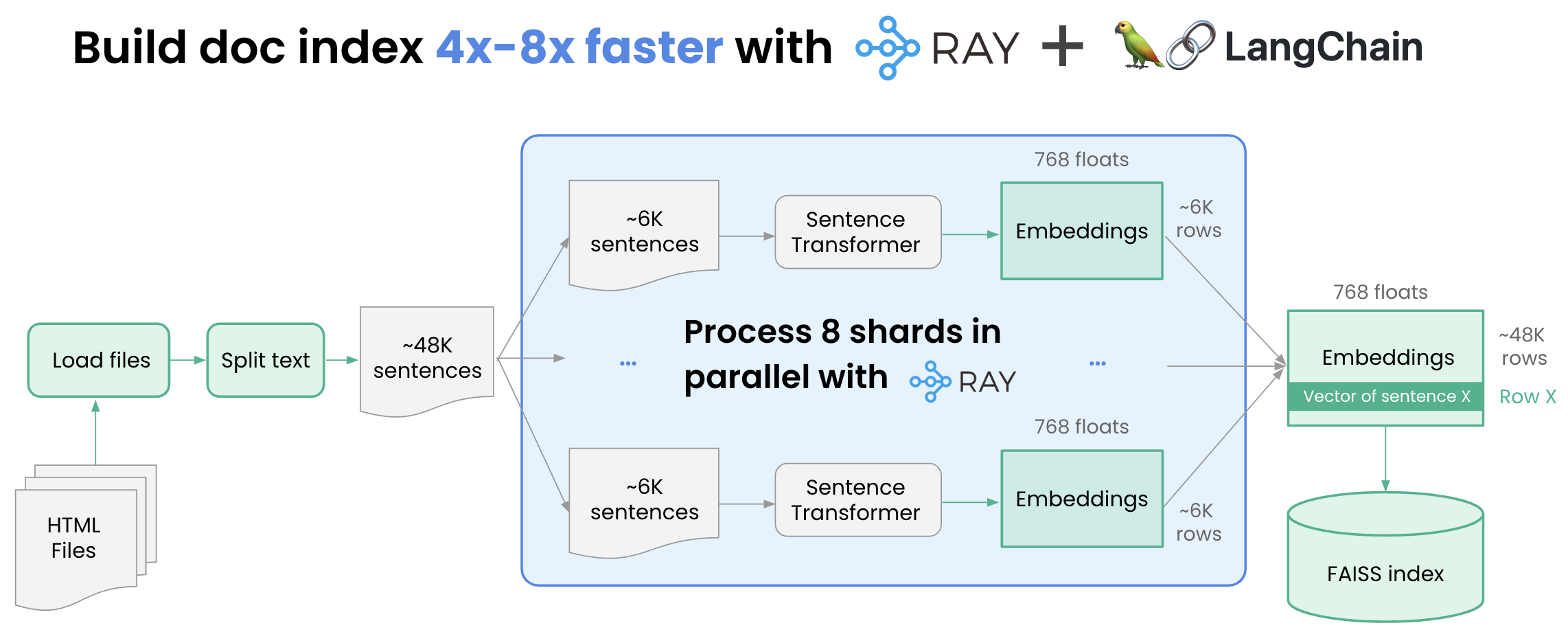
- Serving: Serve search queries with Ray and Langchain
LangChain+ChatGLM 本地问答
ChatGLM-6B api部署:ChatGLM 集成进LangChain工具
- api.py
- 默认本地的 8000 端口,通过 POST 方法进行调用
pip install fastapi uvicorn
python api.py
效果
curl -X POST "http://{your_host}:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
# 结果
{
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
"status":200,
"time":"2023-03-23 21:38:40"
}
封装 ChatGLM API到LangChain中
from langchain.llms.base import LLM
from langchain.llms.utils import enforce_stop_tokens
from typing import Dict, List, Optional, Tuple, Union
import requests
import json
class ChatGLM(LLM):
max_token: int = 10000
temperature: float = 0.1
top_p = 0.9
history = []
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "ChatGLM"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
# headers中添加上content-type这个参数,指定为json格式
headers = {'Content-Type': 'application/json'}
data=json.dumps({
'prompt':prompt,
'temperature':self.temperature,
'history':self.history,
'max_length':self.max_token
})
# print("ChatGLM prompt:",prompt)
# 调用api
response = requests.post("{your_host}/api",headers=headers,data=data)
# print("ChatGLM resp:",response)
if response.status_code!=200:
return "查询结果错误"
resp = response.json()
if stop is not None:
response = enforce_stop_tokens(response, stop)
self.history = self.history+[[None, resp['response']]]
return resp['response']
# 调用
llm = ChatGLM()
print(llm("你会做什么"))
# ChatGLM prompt: 你会做什么
# 我是一个大型语言模型,被训练来回答人类提出的问题。我不能做任何实际的事情,只能通过文字回答问题。如果你有任何问题,我会尽力回答。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}