模型蒸馏
【2020-9-23】田渊栋团队新作:神经网络“彩票假设”可泛化,强化学习和NLP也适用
- MIT研究人员
Jonathan Frankle和Michael Carbin提出的彩票假设(lottery ticket hypothesis)表明,通过从“幸运”初始化(lucky initialization,通常被称为“中奖彩票”)开始训练深度神经网络,以最小的性能损失(甚至获得收益)将网络缩小10-100倍 - 这项工作不仅可用更少资源进行训练,还可以在更小的设备(例如智能手机和VR头盔)上更快地运行模型推理。
- 但
彩票假设尚未被AI社区完全理解。特别是尚不清楚中奖彩票是取决于特定因素,还是代表了DNN的一种固有特性。 - Facebook AI 最新研究发现了第一个确定的证据,证明
彩票假设在相关但截然不同的数据集中普遍存在,并可以扩展到强化学习(RL)和自然语言处理(NLP)。
| 模型类型 | 图解 |
|---|---|
| teacher | 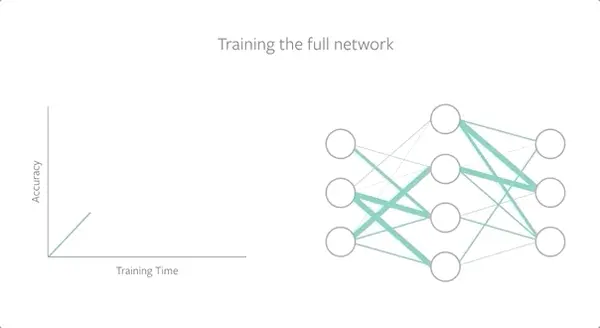 |
| student | 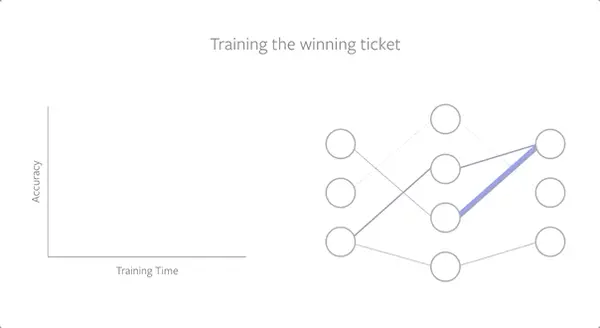 |
- 蒸馏模型采用
迁移学习 - 蒸馏目标: 让student学习到teacher的泛化能力
- 蒸馏本质: 压缩模型
模型蒸馏介绍
背景

- 很多基于 Transformer 的模型,模型参数数量单位是百万,这些模型变得越来越大。这些模型的体积也限制了其在现实世界中的使用,因为各方面因素:
- 这种模型训练花费高,使用昂贵的 GPU 服务器才能提供大规模服务。
- 模型太大导致推理时间也变长,不能用于一些实时性要求高的任务中。
- 现在有不少机器学习任务需要运行在终端上,例如智能手机,这种情况也必须使用轻量级的模型。
尽管大模型性能优越,但存在明显的局限性:
- 高计算成本:运行1次推理可能需要数十甚至上百个GPU,普通用户根本无法负担。
- 内存占用大:许多设备(如手机、嵌入式系统)根本没有足够的存储空间支持这些模型。
- 实时性差:由于计算量庞大,大模型往往无法满足实时响应的需求。
相比之下,经过蒸馏的小模型可轻松部署在各种场景中,无论是智能手机还是自动驾驶汽车,都能流畅运行。
这些小模型还保留了大部分原始模型的能力,真正实现了“鱼与熊掌兼得”。
不少研究开始针对 BERT 进行模型压缩,常见的模型压缩方法:
模型蒸馏Distillation,使用大模型学到的知识训练小模型,从而让小模型具有大模型的泛化能力。- 通过一些优化目标从大型、知识丰富、fixed的teacher模型学习一个小型的student模型。蒸馏机制主要分为3种类型:
- 从软标签蒸馏:DistilBERT、EnsembleBERT
- 从其他知识蒸馏:TinyBERT、BERT-PKD、MobileBERT、 MiniLM、DualTrain
- 蒸馏到其他结构:Distilled-BiLSTM
- 通过一些优化目标从大型、知识丰富、fixed的teacher模型学习一个小型的student模型。蒸馏机制主要分为3种类型:
量化Quantization,降低大模型精度,减小模型。- 将高精度模型用低精度来表示;如Q-BERT和Q8BERT,量化通常需要兼容的硬件。
剪枝Pruning,去掉模型中作用比较小的连接。- 将模型中影响较小的部分舍弃。如Compressing BERT,还有结构化剪枝 LayerDrop,其在训练时进行Dropout,预测 再剪掉Layer,不像知识蒸馏需要提前固定student模型的尺寸大小。
参数共享,共享网络中部分参数,降低模型参数数量。- 相似模型单元间的参数共享;
- ALBERT主要通过矩阵分解和跨层参数共享来做到对参数量的减少。
模块替换:BERT-of-Theseus 根据伯努利分布进行采样,决定使用原始的大模型模块还是小模型,只使用task loss。- 【2021-3-14】精简总结
- 总结
- ALBERT 也是一种 BERT 压缩方法,主要是用了参数共享和矩阵分解的方法压缩 BERT,但是 ALBERT 只减少模型的参数,并不能减少其 inference 时间。
- 两种使用模型蒸馏压缩 BERT 的算法
- 第一种是
DistilBERT,将 12 层的 BERT-base 模型蒸馏到 6 层的 BERT 模型; - 第二种是将 BERT 模型蒸馏到
BiLSTM模型。
- 第一种是
- 更多内容:BERT 模型蒸馏 Distillation BERT
-
【2020-9-14】albert 用于中文Q/A,github代码
- 模型压缩和加速四个技术是设计高效小型网络、剪枝、量化和蒸馏
- 2015年,Hinton等人首次提出神经网络中的知识蒸馏(
Knowledge Distillation, KD)技术/概念。较前者的一些工作,这是一个通用而简单的、不同的模型压缩技术。 
蒸馏,就是知识蒸馏,将教师网络(teacher network)的知识迁移到学生网络(student network)上,使得学生网络的性能表现如教师网络一般,这样就可以愉快地将学生网络部署到移动手机和其它边缘设备上。- 第一,利用大规模数据训练一个教师网络;
- 第二,利用大规模数据训练一个学生网络,这时损失函数由两部分组成:
- 一部分是拿教师和学生网络的输出logits计算蒸馏损失/KL散度,见[2]中的(4)式
- 一部分是拿学生网络的输出和数据标签计算交叉熵损失。
- 通常会进行两种方向的蒸馏
- 一种是大模型瘦身:from deep and large to shallow and small network
- 另一种是集成模型单一化:from ensembles of classifiers to individual classifier。


过去一直 follow着transformer系列模型的进展,从BERT到GPT2再到XLNet。然而随着模型体积增大,线上性能也越来越差,所以决定开一条新线,开始follow模型压缩之模型蒸馏的故事线。
Hinton在NIPS2014[1]提出了知识蒸馏(Knowledge Distillation)的概念,旨在把一个大模型或者多个模型ensemble学到的知识迁移到另一个轻量级单模型上,方便部署。简单的说就是用新的小模型去学习大模型的预测结果,改变一下目标函数。听起来是不难,但在实践中小模型真的能拟合那么好吗?所以还是要多看看别人家的实验,掌握一些trick。
模型蒸馏定义
什么是模型蒸馏?
模型蒸馏是一种知识提取过程。
核心思想
- 将一个复杂模型(通常称为“
教师模型”)中学到的知识转移到一个简单模型(称为“学生模型”)中。 - 通过这种方式,
学生模型能够在性能上接近教师模型,但其计算需求和存储空间大大减少。
论文
【2015-3-9】蒸馏诞生
2015年3月9日,Google Hinton、Jeff Dean 等人发表论文
提出知识蒸馏,Knowledge Distillation,简称 KD,一种基于“软目标”的知识蒸馏方法,即学生模型不仅学习教师模型的硬标签(one-hot labels),还要学习输出的概率分布。
让学生模型获得更丰富的表示能力,从而更好地理解数据的内在结构和特征。
【2022-7-12】解耦知识蒸馏
【2022-4-12】旷视、清华 CVPR 2022 解耦知识蒸馏,让Hinton在7年前提出的方法重回SOTA行列
- 【2022-7-12】论文链接:Decoupled Knowledge Distillation
- 代码链接:mdistiller
KD 用 Teacher 网络和 Student 网络的输出 logits 来计算 KL Loss,从而实现 dark knowledge 的传递,利用 Teacher 已经学到的知识帮助 Student 收敛得更好。在 KD 之后,更多的基于中间特征的蒸馏方法不断涌现,不断刷新知识蒸馏的 SOTA。但该研究认为,KD 这样的 logits 蒸馏方法具备两点好处:
- 基于 feature 的蒸馏方法需要更多复杂的结构来拉齐特征的尺度和网络的表示能力,而 logits 蒸馏方法更简单高效;
- 相比中间 feature,logits 的语义信息是更 high-level 且更明确的,基于 logits 信号的蒸馏方法也应该具备更高的性能上限,因此,对 logits 蒸馏进行更多的探索是有意义的。
该研究尝试一种拆解的方法来更深入地分析 KD:将 logits 分成两个部分(如图),蓝色部分代表目标类别(target class)的 score,绿色部分代表非目标类别(Non-target class)的 score。这样的拆解使得我们可以重新推导 KD 的 Loss 公式,得到一个新的等价表达式,进而做更多的实验和分析。
知识蒸馏(Knowledge Distillation, KD)
用原始未微调模型作为“教师”,指导微调中的“学生”模型,保留通用知识。
蒸馏形式
- Logits 蒸馏:最小化教师与学生输出分布的 KL 散度;
- 中间层蒸馏:约束 hidden states 或 attention map 的相似性
损失函数
L = α L_task + β⋅KL(p_teacher||p_student)
通常 β = 0.3-1.0,蒸馏数据可为通用语料或任务数据本身。
优势与挑战
- ✅ 有效保留“暗知识”;
- ❌ 增加训练开销(需教师前向);
- ❌ 需谨慎选择蒸馏数据,避免任务冲突。
代表性论文
- Continual Learning via KD: Sun et al., Continual Learning for Natural Language Generation via Knowledge Distillation, ACL 2020.
- DistillMCL: Wang et al., DistillMCL: Distillation-based Multi-task Continual Learning for Language Models, EMNLP 2023.
名词解释
概念
- teacher - 原始模型或模型 ensemble
- student - 新模型
- transfer set - 用来迁移teacher知识、训练student的数据集合
- soft target - teacher输出的预测结果(一般是softmax之后的概率)
- hard target - 样本原本标签
- temperature - 蒸馏目标函数中的超参数
- born-again network - 蒸馏的一种,指student和teacher的结构和尺寸完全一样
- teacher annealing - 防止student的表现被teacher限制,在蒸馏时逐渐减少soft targets的权重
基本思想
知识蒸馏是让一个小模型去学习大模型,所以首先会有一个预训练好的大模型,称之为Teacher模型,小模型被称为Student模型。知识蒸馏让Student模型去尽量拟合。
- 动机: 跟ground truth的one-hot编码相比,Teacher模型的输出概率分布包含着更多信息,从Teacher模型的概率分布中学习,能让Student模型充分去模拟Teacher模型的行为。
- 在具体的学习Teacher模型概率分布这个过程中,知识蒸馏还引入了温度概念
- Teacher和Student的logits都先除以一个参数T,然后再去做softmax,得到的概率值再去做交叉熵。
- 温度T控制着Student模型学习的程度
- 当T>1时,Student模型学习的是一个更加平滑的概率分布
- 当T<1时,则是更加陡峭的分布。
- 因此,学习过程中,T一般是一个逐渐变小的过程。
- Teacher 模型经过温度T之后的输出被称之为soft labels。
通俗理解
【2025-1-31】大白话告诉你什么是模型蒸馏技术?
形象比喻
- 有个知识渊博的朋友(强大的
教师模型),什么问题都能轻松解答:上知天文下知地理 - 但这个大佬太「忙」(推理时间长),或者出场费太贵(GPU消耗大),不是随时都能找得到(无法满足便宜、实时的要求)。
有一天,好不容易请来了大佬,多问点问题,把能想到的、有价值的疑问一股脑儿抛出去,希望能给出详尽的答案。
- 如: 1+1=?, 鸡蛋和萝卜哪个圆?你是谁?。。。
问题:
- 即便他愿意回答,也不可能把每个回答都一字不差地记下来,毕竟信息量太大,容易混淆和遗忘。
解法:
- 把朋友回答的精华部分提炼出来,用自己的话重新组织,既保留了关键信息,又方便日后回顾和分享给其他人。
- 这个过程就是知识“蒸馏”。
深度学习和人工智能领域,这项技术被用来从大模型中提取核心知识或特征,然后以一种更高效、更精简的形式呈现出来,提高计算效率或降低资源消耗。
蒸馏步骤
模型蒸馏步骤
- 1:训练
教师模型- 模型蒸馏前,需要一个高性能教师模型。可以是任何类型的深度学习模型,比如卷积神经网络(CNN)用于图像处理,或者循环神经网络(RNN)用于处理序列数据。
- 教师模型的训练通常需要大量的数据和计算资源。比如,在图像分类任务中,可能需要使用数百万张图片来训练一个复杂的卷积神经网络。
- 示例: DeepSeek 671B大模型, 经过海量数据的训练,具备极高的准确率
- 2:生成软标签
教师模型训练完成,用来生成“软标签”。- 软标签是
教师模型对输入数据的输出结果。与传统的硬标签(例如,图像分类中的0和1)不同,软标签提供了每个类别的概率分布。 - 例如,在图像分类中,教师模型可能会给出一个图像属于“猫”的概率为0.7,属于“狗”的概率为0.2,属于“鸟”的概率为0.1。这种概率分布包含了更多的信息,能够帮助学生模型更好地学习。
- 示例: DeepSeek 1.5B 小模型, 结构简单、参数少,但潜力巨大。
- 3:训练
学生模型(知识传递)- 用
教师模型生成的软标签来训练学生模型。 学生模型通过模仿教师模型的输出或中间特征来学习,教师模型生成包含多个可能性的概率分布(称为“软标签”),而学生模型则尝试复制这个分布。学生模型是较小的神经网络,具有更少的参数。- 训练过程中,
学生模型不仅要学习输入数据的硬标签(真实标签),还要学习教师模型生成的软标签。 - 通过这种方式,学生模型能够从教师模型中获得更多的知识,从而提高其性能。
- 用
流程图
通用知识蒸馏方法
- 第一步是训练
Net-T; - 第二步是在高温
T下,蒸馏Net-T的知识到Net-S
流程图
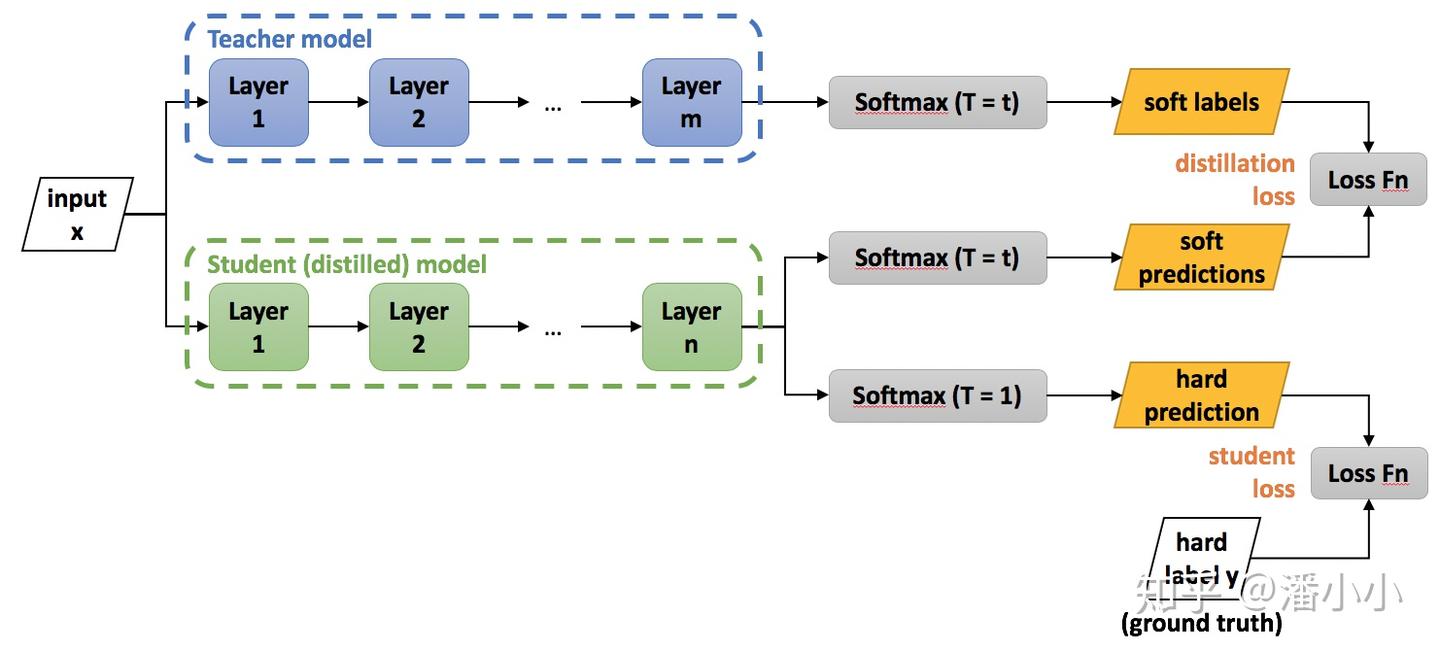
- 知识蒸馏示意图来自knowledge_distillation
目标函数
高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。
$ L = \alpha L_{soft} + \beta L_{hard} $
- $L$ 为总损失
- $L_{soft}$ 和 $L_{hard}$ 分别是两种不同类型的损失
- $L_{soft}$:
Net-T和Net-S同时输入 transfer set (可直接复用训练Net-T用到的training set), 用Net-T产生的softmax distribution (with high temperature) 来作为soft target,Net-S在相同温度T条件下的softmax输出和soft target的cross entropy - $L_{hard}$: Net-S在T=1的条件下的softmax输出和ground truth的cross entropy
- $L_{soft}$:
- $\alpha$ 和 $\beta$ 是权重系数,用于调整 $L_{soft}$ 和 $L_{hard}$ 在总损失 $L$ 中所占比重,且 $\alpha$、$\beta$ 为非负实数。
思考
(1) $L_{hard}$ 必要性
Net-T也有一定错误率,使用ground truth可有效降低错误被传播给Net-S的可能。- 老师虽然学识远远超过学生,但是他仍然可能出错,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
(2) hard为什么要小
经验
- hard权重较小时,效果更好
为什么
- soft target产生的 gradient 与 hard target 产生的 gradient之间有与 T 相关的比值。
同时使用soft target和hard target 时,要在soft target之前乘上 $T^2$ 系数,才能保证soft target和hard target贡献的梯度量基本一致。
【注意】
- Net-S 训练完毕后,做inference时其softmax的温度T要恢复到1.
公式推导见 知识蒸馏(Knowledge Distillation) 经典之作
思考
DeepSeek 抄袭 OpenAI ?
DeepSeek 是不是抄袭了OpenAI? 没有!
DeepSeek 用了多项技术,其中有一项是深度学习大模型训练中广泛使用的蒸馏技术
DeepSeek 在“蒸馏”的基础上,提出了创新的优化策略和应用方式,推动技术进步。
- 采用做监督微调(SFT)方法,用教师模型生成的80万个推理数据样本对学生模型进行微调。避免了传统强化学习阶段的冗长训练,显著提高了效率。
- 传统知识蒸馏关注模型层面的迁移,即学生模型模仿教师模型的输出。然而,DeepSeek 将数据蒸馏引入其中,形成了独特的“双轨制”蒸馏方法。
- 高效的知识迁移策略,包括基于特征的蒸馏和特定任务蒸馏。
- 前者通过提取教师模型中间层的特征信息,帮助学生模型更好地理解数据的本质;
- 后者则针对不同的应用场景(如文本生成、机器翻译等)进行针对性优化。
蒸馏分类
模型蒸馏
传统知识蒸馏主要关注模型层面的迁移,即学生模型模仿教师模型的输出。
数据蒸馏
数据蒸馏: 通过对训练数据进行增强、伪标签生成等操作,提升数据的质量和多样性。
例如,教师模型可以对原始图像进行旋转、裁剪等处理,从而生成更多样化的样本。这些高质量的数据为学生模型提供了更好的学习材料,使其能够更快速地成长。
双轨制蒸馏
DeepSeek 另辟蹊径,将数据蒸馏引入其中,形成了独特的“双轨制”蒸馏方法。
DeepSeek 在模型蒸馏方面进行了大量创新。
例如,采用监督微调(SFT)方法,用教师模型生成80万个推理数据样本, 对学生模型进行微调。
这种方法避免了传统强化学习阶段的冗长训练,显著提高了效率。
DeepSeek 开源了基于不同大小的 Qwen 和 Llama 架构的几个提炼模型。这些包括:
- DeepSeek-R1-Distill-Qwen-1.5B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Llama-70B
DeepSeek 还提出了一系列高效的知识迁移策略,包括基于特征的蒸馏和特定任务蒸馏。
- 特征的蒸馏: 通过提取教师模型中间层的特征信息,帮助学生模型更好地理解数据的本质;
- 特定任务蒸馏: 针对不同的应用场景(如文本生成、机器翻译等)进行针对性优化。
这些策略使得 DeepSeek 蒸馏模型在实际应用中表现出色。
- 例如,DeepSeek-R1-Distill-Qwen-7B 在AIME 2024上实现了55.5%的Pass@1,超越了QwQ-32B-Preview(最先进的开源模型)。这样的成绩证明了蒸馏技术的巨大潜力。
知识蒸馏方法
- 第一步,训练Net-T;
-
第二步,高温蒸馏:在高温T下,蒸馏Net-T的知识到Net-S
- 知识蒸馏示意图
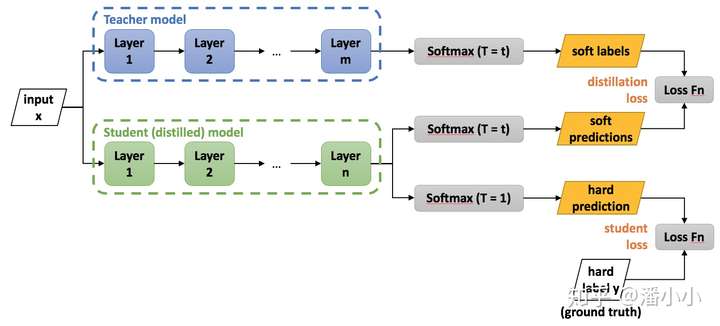

Teacher Model 和 Student Model
知识蒸馏使用 Teacher—Student 模型,其中teacher是“知识”的输出者,student是“知识”的接受者。
知识蒸馏过程分为2个阶段:
- 原始模型训练:
- 训练”Teacher模型”, 简称为
Net-T,模型相对复杂,也可由多个分别训练的模型集成而成。 - 对”Teacher模型”不作任何关于模型架构、参数量、是否集成方面的限制,唯一要求对于输入X, 其都能输出Y,其中Y经过softmax 映射,输出值对应相应类别概率值。
- 训练”Teacher模型”, 简称为
- 精简模型训练:
- 训练”Student模型”, 简称为
Net-S,参数量较小、模型结构相对简单的单模型。 - 同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
- 训练”Student模型”, 简称为
知识蒸馏的关键点
- 如果回归机器学习最最基础的理论,可以很清楚地意识到一点(而这一点往往在我们深入研究机器学习之后被忽略): 机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。
- 泛化能力强: 在某问题的所有数据上都能很好地反应输入和输出之间的关系,无论是训练数据,还是测试数据,还是任何属于该问题的未知数据。
- 而现实中,由于我们不可能收集到某问题的所有数据来作为训练数据,并且新数据总是在源源不断的产生,因此我们只能退而求其次,训练目标变成在已有的训练数据集上建模输入和输出之间的关系。由于训练数据集是对真实数据分布情况的采样,训练数据集上的最优解往往会多少偏离真正的最优解(这里的讨论不考虑模型容量)。
-
而在知识蒸馏时,由于我们已经有了一个泛化能力较强的Net-T,我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。
- 一个很直白且高效的迁移泛化能力的方法就是使用softmax层输出的类别的概率来作为“soft target”。
- 传统training过程(hard targets): 对ground truth求极大似然
- KD的training过程(soft targets): 用large model的class probabilities作为soft targets
-
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。
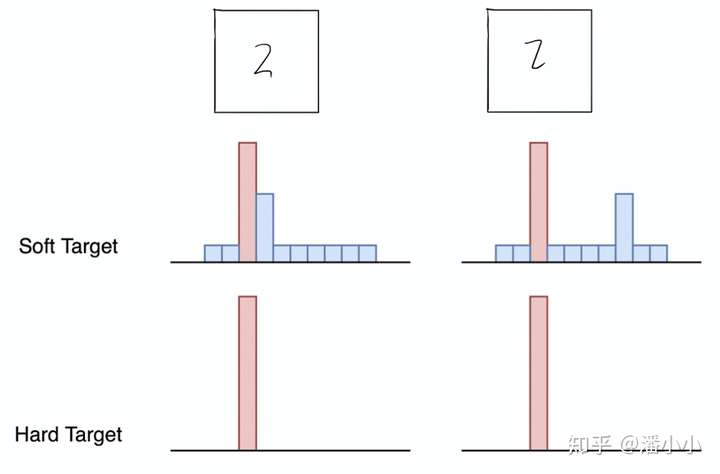
1 为什么蒸馏有用
好模型的目标不是拟合训练数据,而是学习如何泛化到新数据。
所以蒸馏目标是让student学习到teacher的泛化能力,理论上得到的结果会比单纯拟合训练数据的student要好。
另外,对于分类任务,如果soft targets的熵比hard targets高,那显然student会学习到更多的信息。
标签设置
标签
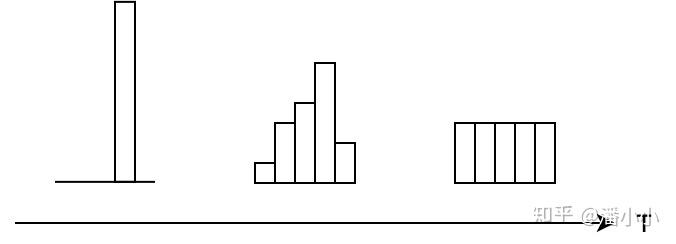
- 硬标签(hard targets): 多个类目只有1个是1,其他都是0
- 例如: 一个样本的标签是”猫”,那么 hard target 是
(0, 0, 1, 0, 0)
- 例如: 一个样本的标签是”猫”,那么 hard target 是
- 软标签(soft targets): 多个类目都有概率值,且和为1
- 例如: 一个样本的标签是”猫”,那么 soft target 是
(0.1, 0.1, 0.8, 0, 0)
- 例如: 一个样本的标签是”猫”,那么 soft target 是
示意图

- 这两个样本(2)的硬标签相同,但软标签不同
目标函数
- 传统训练过程(硬标签): 对 ground truth(硬标签) 求极大似然
- KD训练过程(软标签): 用 large model 的 class probabilities(类别概率) 作为 soft targets
KD 为什么更有效?
- softmax 层输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。
- 而传统训练过程(hard target)中,所有负标签都被统一对待。
- KD 训练方式使每个样本给
Net-S带来的信息量大于传统的训练方式。
通过蒸馏的方法训练出的Net-S相比使用完全相同的模型结构,和训练数据只使用hard target的训练方法得到的模型,拥有更好的泛化能力
2 蒸馏时 softmax
比之前的softmax多了一个参数T(temperature)
T越大产生的概率分布越平滑。
有两种蒸馏的目标函数:
-
- 只使用
soft targets:- 在蒸馏时teacher使用新的softmax产生soft targets;
- student使用新的softmax在transfer set上学习,和teacher使用相同的T。
- 只使用
-
- 同时使用
soft和hard targets:- student的目标函数是
hard target和soft target目标函数的加权平均,使用hard target时T=1,soft target时T和teacher的一样。 - Hinton的经验是给hard target的权重小一点。另外注意,因为在求梯度(导数)时,新目标函数会导致梯度是以前的
,所以要再乘上
,不然T变了的话hard target不减小(T=1),但soft target会变。
- student的目标函数是
- 同时使用
-
- 直接用logits的
MSE(是1的special case)
- 直接用logits的
3 如何选取合适的温度?
温度参数 T 很关键,用于调整教师模型输出的概率分布,使其更加平滑或陡峭。
$q_{i}=\frac{\exp(z_{i}/T)}{\sum_{j = 1}^{n}\exp(z_{j}/T)}$
( z_i ) 是教师模型的原始输出,( T ) 是温度参数。
- 当 ( T > 1 ) 时,分布会变得更加平滑;
- 当 ( T < 1 ) 时,分布会变得更加陡峭
直接用 softmax 层输出值作为 soft target, 有问题:
- 当 softmax 输出概率分布熵相对较小时,负标签值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。
- 因此,”温度”变量就派上了用场
T越高,softmax的概率分布越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
softmax 温度详解见站内专题 文本生成之解码
- 温度: T
- T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
- 温度的高低改变
Net-S训练过程中对负标签的关注程度:- 温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;
- 而温度较高时,负标签相关的值会相对增大,
Net-S会相对多地关注到负标签。
- 实际上,负标签中包含一定的信息,尤其是那些值显著高于平均值的负标签。但由于
Net-T的训练过程决定了负标签部分比较noisy,并且负标签的值越低,其信息就越不可靠。因此温度的选取比较empirical,本质上就是在下面两件事之中取舍:- 从有部分信息量的负标签中学习 –> 温度要高一些
- 防止受负标签中噪声的影响 –>温度要低一些
- 总的来说,T的选择和
Net-S的大小有关,Net-S参数量比较小的时候,相对比较低的温度就可以了(因为参数量小的模型不能capture all knowledge,所以可以适当忽略掉一些负标签的信息)
蒸馏经验
Transfer Set 和 Soft target
- 实验证实,Soft target 可以起到正则化作用(不用soft target的时候需要early stopping,用soft target后稳定收敛)
- 数据过少的话无法完整表达teacher学到的知识,需要增加无监督数据(用teacher的预测作为标签)或进行数据增强,可以使用的方法有:1.增加
[MASK],2.用相同POS标签的词替换,2.随机n-gram采样,具体步骤参考文献2
超参数T
- T越大越能学到teacher模型的泛化信息。比如MNIST在对2的手写图片分类时,可能给2分配0.9的置信度,3是1e-6,7是1e-9,从这个分布可以看出2和3有一定的相似度,因此这种时候可以调大T,让概率分布更平滑,展示teacher更多的泛化能力
- T可以尝试1~20之间
BERT蒸馏
- 蒸馏单BERT[2]:模型架构:单层BiLSTM;目标函数:logits的MSE
- 蒸馏Ensemble BERT[3]:模型架构:BERT;目标函数:soft prob+hard prob;方法:MT-DNN。该论文用给每个任务训练多个MT-DNN,取soft target的平均,最后再训一个MT-DNN,效果比纯BERT好3.2%。但感觉该研究应该是刷榜的结晶,平常应该没人去训BERT ensemble吧。。
- BAM[4]:Born-aging Multi-task。用多个任务的Single BERT,蒸馏MT BERT;目标函数:多任务loss的和;方法:在mini-batch中打乱多个任务的数据,任务采样概率为
,防止某个任务数据过多dominate模型、teacher annealing、layerwise-learning-rate,LR由输出层到输出层递减,因为前面的层需要学习到general features。最终student在大部分任务上超过teacher,而且上面提到的tricks也提供了不少帮助。文献4还不错,推荐阅读一下。
- TinyBERT[5]:截止201910的SOTA。利用Two-stage方法,分别对预训练阶段和精调阶段的BERT进行蒸馏,并且不同层都设计了损失函数。与其他模型的对比如下:

总结
强调
- student学习的是teacher的泛化能力,而不是“过拟合训练数据”。
文献2中的BERT蒸馏任务,虽然比无蒸馏条件下有将近5个点的提升,但作者没有研究到底是因为数据增多还是蒸馏带来的提升。而且仍然距BERT有很大的距离,虽然速度提升了,但效果并不能上线。文献3中虽然有了比BERT更好的效果,但并没有用轻量的结构,性能还是不变。
资源:
- dkozlov/awesome-knowledge-distillation
- Distilling BERT Models with spaCy
- DistilBERT
- Multilingual MiniBERT: Tsai et al. (EMNLP 2019)
- 黑DeepSeek的模型蒸馏是什么?
模型蒸馏的优势
优势
- 降低计算需求
- 模型蒸馏能够显著降低计算需求。
教师模型通常非常庞大,需要大量计算资源进行推理。而经过蒸馏后的学生模型,虽然在性能上接近教师模型,但其结构更为简单,推理速度更快。- 以图像分类任务为例,复杂模型的推理时间可能需要几百毫秒,而经过蒸馏的学生模型可能只需几十毫秒。这对于需要实时响应的应用场景,如自动驾驶、智能监控等,具有重要意义。
- 减少存储空间
- 模型蒸馏能够有效减少存储空间。
教师模型参数量可能达到数亿,而学生模型经过蒸馏后,参数数量可以减少到几百万甚至更少。 - 这使得
学生模型能够在移动设备和边缘计算环境中运行,而不需要大量的存储空间。以智能手机为例,许多应用程序都希望在手机上运行深度学习模型,而模型蒸馏可以帮助实现这一目标。
- 模型蒸馏能够有效减少存储空间。
- 提高模型的泛化能力
- 模型蒸馏还能够提高
学生模型的泛化能力。由于学生模型在训练过程中不仅学习了硬标签,还学习了软标签,这使得它能更好地捕捉数据中的潜在模式。 - 这种学习方式可以帮助学生模型在面对未见过的数据时,表现得更加稳健。例如,在图像识别任务中,学生模型可能更能适应不同光照、角度和背景的变化,从而提高识别准确率。
- 模型蒸馏还能够提高
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
