- 汇总
- C语言
- C++
- 安装
- STL
- 工程实践
- C++开发库
- C++ Primer学习笔记
- 第II部分 C++ 标准库
- 第III 部分类设计者的工具
- 第IV部分高级主题
- 深度探索C++对象模型
- 第1章 关于对象(Object Lessons)
- 第2章 构造函数语意学(The Semantics of constructors)
- 2.1 构造函数
- 从概念来上来讲,每一个没有定义构造函数的类都会由编译器来合成一个默认构造函数,以使得可以定义一个该类的对象,但是默认构造函数是否真的会被合成,将视是否有需要而定。C++ standard 将合成的默认构造函数分为 trivial(不重要) 和 notrivial(重要) 两种,前文所述的四种情况对应于notrivial默认构造函数,其它情况都属于trivial。对于一个trivial默认构造函数,编译器的态度是,既然它全无用处,干脆就不合成它。在这儿要厘清的是概念与实现的差别,概念上追求缜密完善,在实现上则追求效率,可以不要的东西就不要。
- 2.2 拷贝构造函数(copy constuctor)
- 2.3 命名返回值优化
- 另外,有一点要注意的是,NRV优化,有可能带来程序员并不想要的结果,最明显的一个就是——当你的类依赖于构造函数或拷贝构造函数,甚至析构函数的调用次数的时候,想想那会发生什么。由此可见、Lippman的cfront对NRV优化抱有更谨慎的态度,而MS显然是更大胆。
- 2.4 成员初始化队列(Member Initialization List)
- 第3章 Data语意学(The Semantics of Data)
- 第4章 Function语意学(The Semantics of Function)
- 第5章 构造、解构、拷贝 语意学(Semantics of Construction,Destruction,and Copy)
- 第6章 执行期语意学(Runting Semantics)
- 面试题
- C++ 基础
- 1、引用和指针的区别?
- 2、从汇编层去解释一下引用
- 3、C++中的指针参数传递和引用参数传递
- 4、形参与实参的区别?
- 4-2 三种传递方式
- 5、
static的用法 - 6、静态变量什么时候初始化
- 7、const?
- 8、
const成员函数的理解和应用? - 9、指针和
const的用法 - 10、
mutable - 11、
extern用法? - 12、
int转字符串, 字符串转int - 13、深拷贝与浅拷贝?
- 14、
C++模板是什么,底层怎么实现的? - 15、
C语言struct和C++struct区别 - 16、虚函数可以声明为
inline吗? - 17、类成员初始化方式?构造函数的执行顺序?为什么用成员初始化列表会快一些?
- 18、成员列表初始化?
- 19、构造函数为什么不能为虚函数?析构函数为什么要虚函数?
- 20、析构函数的作用,如何起作用?
- 21、构造函数和析构函数可以调用虚函数吗,为什么
- 22、构造函数的执行顺序?析构函数的执行顺序?构造函数内部干了啥?拷贝构造干了啥?
- 23、虚析构函数的作用,父类的析构函数是否要设置为虚函数?
- 24、
构造函数析构函数可以调用虚函数吗? - 25、
构造函数,析构函数可否抛出异常 - 26、类如何实现
只能静态分配和只能动态分配 - 27、如果想将某个类用作基类,为什么该类必须定义而非声明?
- 28、什么情况会自动生成默认构造函数?
- 29、什么是类的继承?
- 30、什么是组合?
- 31、抽象基类为什么不能创建对象?
- 32、类什么时候会析构?
- 33、为什么友元函数必须在类内部声明?
- 34、介绍一下C++里面的多态?
- 35、用C 语言实现C++的继承
- 36、继承机制中对象之间如何转换?指针和引用之间如何转换?
- 37、组合与继承优缺点?
- 38、左值右值
- 39、移动构造函数
- 40、C 语言的编译链接过程?
- 41、
vector与list的区别与应用?怎么找某vector或者list的倒数第二个元素 - 42、
STL vector的实现,删除其中的元素,迭代器如何变化?为什么是两倍扩容?释放空间? - 43、容器内部删除一个元素
- 44、
STL迭代器如何实现 - 45、
set与hash_set的区别 - 46、
hashmap与map的区别 - 47、
map、set是怎么实现的,红黑树是怎么能够同时实现这两种容器? 为什么使用红黑树? - 48、如何在共享内存上使用STL标准库?
- 49、
map插入方式有几种? - 50、STL 中
unordered_map和map的区别,unordered_map如何解决冲突以及扩容 - 51、
vector越界访问下标,map越界访问下标?vector删除元素时会不会释放空间? - 52、
map[]与find的区别? - 53、STL 中
list,queue之间的区别 - 54、STL 中的allocator,deallocator
- 55、STL 中hash_map 扩容发生什么?
- 56、map 如何创建?
- 57、vector 的增加删除都是怎么做的?为什么是1.5 倍?
- 58、函数指针?
- 59、说说你对c 和c++的看法,c 和c++的区别?
- 60、c/c++的内存分配,详细说一下栈、堆、静态存储区?
- 61、堆与栈的区别?
- 62、野指针是什么?如何检测内存泄漏?
- 63、悬空指针和野指针有什么区别?
- 64、内存泄漏
- 65、
new和malloc的区别? - 66、
delete p;与delete[]p,allocator - 67、
new和delete的实现原理,delete是如何知道释放内存的大小的额? - 68、
malloc申请的存储空间能用delete释放吗 - 69、malloc 与free 的实现原理?
- 70、
malloc、realloc、calloc、alloca的区别 - 71、
__stdcall和__cdecl的区别? - 72、使用智能指针管理内存资源,
RAII - 73、手写实现智能指针类
- 74、内存对齐?位域?
- 75、结构体变量比较是否相等
- 76、位运算
- 77、为什么内存对齐
- 78、函数调用过程栈的变化,返回值和参数变量哪个先入栈?
- 79、怎样判断两个浮点数是否相等?
- 80、宏定义一个取两个数中较大值的功能
- 81、
define、const、typedef、inline使用方法? - 82、
printf实现原理? - 83、
#include的顺序以及尖叫括号和双引号的区别 - 84、lambda 函数
- 85、hello world 程序开始到打印到屏幕上的全过程?
- 86、模板类和模板函数的区别是什么?
- 87、为什么模板类一般都是放在一个h 文件中
- 88、C++中类成员的访问权限和继承权限问题。
- 89、cout 和printf 有什么区别?
- 90、重载运算符?
- 91、函数重载函数匹配原则
- 92、定义和声明的区别
- 93、
C++类型转换有四种 - 94、全局变量和static 变量的区别
static函数与普通函数有什么区别?- 95、静态成员与普通成员的区别
- 96、说一下理解
ifdefendif - 97、隐式转换,如何消除隐式转换?
- 98、虚函数的内存结构,那菱形继承的虚函数内存结构呢
- 99、多继承的优缺点,作为一个开发者怎么看待多继承
- 100、迭代器++it,it++哪个好,为什么
- 101、C++如何处理多个异常的?
- 102、模板和实现可不可以不写在一个文件里面?为什么?
- 104、智能指针的作用;
- 105、
auto_ptr作用 - 106、class、union、struct 的区别
- 107、
动态联编与静态联编 - 108、
动态编译与静态编译 - 109、
动态链接和静态链接区别 - 110、在不使用额外空间的情况下,交换两个数?
- 111、
strcpy和memcpy的区别 - 112、执行
int main(int argc,char *argv[])时的内存结构 - 113、
volatile关键字的作用? - 114、讲讲大端小端,如何检测(三种方法)
- 115、查看内存的方法
- 116、空类会默认添加哪些东西?怎么写?
- 117、标准库是什么?
- 118、
const char*与string之间的关系,传递参数问题? - 119、
new、delete、operator new、operator delete、placement new、placement delete - 120、为什么拷贝构造函数必须传
引用不能传值? - 121、空类的大小是多少?为什么?
- 122、你什么情况用指针当参数,什么时候用引用,为什么?
- 123、大内存申请时候选用哪种?
C++变量存在哪?变量的大小存在哪?符号表存在哪? - 124、为什么会有大端小端,
htol这一类函数的作用 - 125、静态函数能定义为虚函数吗?常函数?
- 126、
this指针调用成员变量时,堆栈会发生什么变化? - 127、静态绑定和动态绑定的介绍
- 128、设计一个类计算子类的个数
- 129、怎么快速定位错误出现的地方
- 130、虚函数的代价?
- 131、类对象的大小
- 132、移动构造函数
- 133、何时需要合成构造函数
- 134、何时需要合成复制构造函数
- 135、何时需要成员初始化列表?过程是什么?
- 136、程序员定义的析构函数被扩展的过程?
- 137、构造函数的执行算法?
- 138、构造函数的扩展过程?
- 139、哪些函数不能是虚函数
- 140.
sizeof和strlen的区别 - 141、简述
strcpy、sprintf与memcpy的区别 - 142、编码实现某一变量某位清
0或置1 - 143、将“引用”作为函数参数有哪些特点?
- 144、分别写出
BOOL,int,float, 指针类型的变量a与“零”的比较语句。 - 145、局部变量全局变量的问题?
- 146、数组和指针的区别?
- 147、C++如何阻止一个类被实例化?一般在什么时候将构造函数声明为private?
- 148、如何禁止自动生成拷贝构造函数?
- 149、
assert与NDEBUG - 150、
Debug和release的区别 - 151、
main函数有没有返回值 - 152、写一个比较大小的模板函数
- 153、
c++怎么实现一个函数先于main 函数运行 - 154、虚函数与纯虚函数的区别在于
- 155、智能指针怎么用?智能指针出现循环引用怎么解决?
- 156、
strcpy函数和strncpy函数的区别?哪个函数更安全? - 157、为什么要用
static_cast转换而不用c语言中的转换? - 158、成员函数里
memset(this,0,sizeof(*this))会发生什么 - 159、方法调用的原理(栈,汇编)
- 160、
MFC消息处理如何封装的? - 161、回调函数的作用
- 162、随机数的生成
- 164、C++临时对象产生的时机
- 结束
汇总
- 【2022-11-13】美国国家安全局(NSA)正在敦促开发人员转向内存安全语言–如C#、Go、Java、Ruby、Rust和Swift–以保护他们的代码免受远程代码执行或其他黑客攻击。在上述语言中,Java是企业和Android应用开发中使用最广泛的语言,而Swift是排名前十的语言,部分归功于iOS应用开发。而在系统编程中,人们对
Rust作为C和C++的替代品的兴趣也越来越大。- Google和微软最近的研究,他们在Chrome和Windows中分别有70%的安全问题与内存有关,其中许多是使用C和C++的结果,这两种语言更容易出现基于内存的漏洞。
- “NSA在”软件内存安全”网络安全信息表中指出:”恶意的网络行为者可以利用这些漏洞进行远程代码执行或其他不利影响,这往往可以损害一个设备,成为大规模网络入侵的第一步。常用的语言,如C和C++,在内存管理方面提供了很大的自由度和灵活性,同时严重依赖程序员对内存引用进行必要的检查。”
- 【2020-7-30】C++中的机器学习库,两个最流行的机器学习库:
- SHARK库:Shark是一个快速的模块库,它对监督学习算法(如线性回归、神经网络、聚类、k-means等)提供了强大的支持。它还包括线性代数和数值优化的功能。这些是在执行机器学习任务时非常重要的关键数学函数。
- MLPACK库:mlpack是一个用c++编写的快速灵活的机器学习库。它的目标是提供快速和可扩展的机器学习算法的实现。mlpack可以将这些算法作为简单的命令行程序、或绑定Python、Julia和c++,然后可以将这些类集成到更大规模的机器学习解决方案中。
- 【2020-8-4】C/C++语法规范,摘自:一张图总结Google C++编程规范(Google C++ Style Guide)
- 【2020-9-14】C++并发编程,通俗易懂讲解模板演变过程
- 【2020-10-29】C++模板沉思录
- 【2020-12-28】超好C++ cheatsheet, hackingcpp
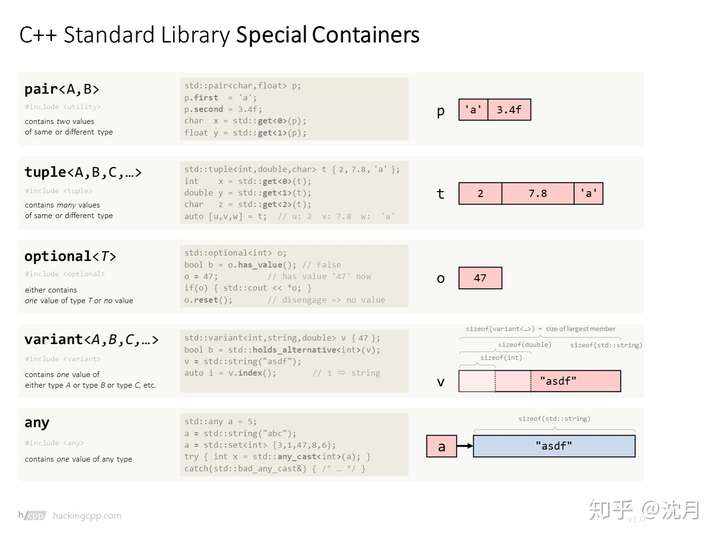
- c++ sequence containers, associative Containers, special Containers


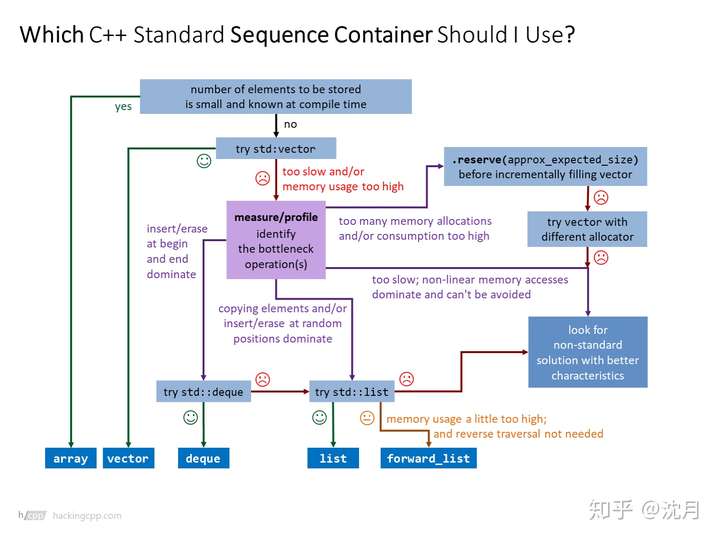
- 用哪个容器?
- 有道云C++学习笔记
- 【2021-3-24】超全面的后端开发C/C++面经整理分享含详细参考答案
【2024-1-24】Modern-CPP-Programming
Modern C++ Programming Course (C++11/14/17/20) ppt内容覆盖12章节
更多编程语言介绍:
【2024-2-3】C 语言手撸神经网络库:genann,一个轻量、无依赖、单文件的 C 语言神经网络库,内含丰富的示例和测试。代码简洁易读,适合作为初学者学习神经网络的入门项目。Github
#include "genann.h"
/* Not shown, loading your training and test data. */
double **training_data_input, **training_data_output, **test_data_input;
/* New network with 2 inputs,
* 1 hidden layer of 3 neurons each,
* and 2 outputs. */
genann *ann = genann_init(2, 1, 3, 2);
/* Learn on the training set. */
for (i = 0; i < 300; ++i) {
for (j = 0; j < 100; ++j)
genann_train(ann, training_data_input[j], training_data_output[j], 0.1);
}
/* Run the network and see what it predicts. */
double const *prediction = genann_run(ann, test_data_input[0]);
printf("Output for the first test data point is: %f, %f\n", prediction[0], prediction[1]);
genann_free(ann);
程序员
俄罗斯编程为什么厉害
案例
- 中国学校一个语音识别难题,识别普通长度需要10s,让俄罗斯团队帮忙优化,两个月后,降到了 1.2s。视频
怎么做到的?仔细检查了 C语言代码,发现代码里写了一堆指针引用语句,高达5层指针
【2023-12-23】俄罗斯人编程为什么这么厉害?
俄罗斯程序员在ACM国际大学生程序设计竞赛中对其他国家呈现碾压之势。
- 从2012年到2020年,俄罗斯连续9年获得冠军!国内著名院校却被远远甩在后面……
俄罗斯没诞生互联网巨无霸公司,但俄罗斯程序员却开发了一大批世界知名的软件:
- Web服务器Nginx
- 压缩软件7-zip
- 杀毒软件卡巴斯基
- 端到端加密语音和视频通话的IM软件Telegram:全世界活跃用户达到5亿
- 集成开发环境IDEA:(JetBrains总部在捷克,创始人是俄罗斯人)
- OLAP 列式数据库管理系统ClickHouse
- 交互式反汇编商用软件IDA Pro
- 俄罗斯方块
为什么厉害?
开玩笑
- 俄罗斯有着漫长的冬天,大部分时间都在下雪,困在家里没事干,只能思考,这正是写小说和代码所需要的,所以俄罗斯出现了很多伟大的文学家,也有很多伟大的程序员”。
- 不止俄罗斯,斯堪的纳维亚半岛上也出现了Linux和MySQL
- 《高频交易员》(Flash Boys)中提到:“高盛有一半程序员都是俄罗斯人,他们是在EC1030和EC 1040这些大型机上长大的,由于这些计算机的计算能力非常有限,这些程序员不得不编写极其高效的代码”。
俄罗斯程序员杰出的成就可以追溯到苏联时期留下的理科教育体系
- 苏联希望在核竞赛中超越美国及其盟友,需要优秀的技术专家,所以对数学、物理极其重视,投入大量精力打造了一套非常有效的人才培养机制。
- 苏联的大城市开设了专门研究数学和物理的学校,对有才华的孩子进行的精心培养。除了学校,还有俱乐部和专业杂志。
- 小学,信息学的基本内容掺杂在核心科目“数学”和“技术”中教授。
- 中学,信息学则是强制学科,内容包括:计算机功能原理、信息技术、网络技术、算法、语言和编程方法、建模等。结果十年间俄罗斯有60万中学生参加计算机科学考试,是美国的两倍多。
- 大学,信息学还是俄罗斯高中生进入大学的必考科目
编程最需要逻辑思维,而那些经过严格数学训练的人转到编程领域,基本上就是碾压。
虽然俄罗斯程序员非常厉害,但精英人群不能代表整个国家的IT水平。
现在的俄罗斯是个非常依赖能源的国家,石油和天然气的出口是主要收入来源,缺乏扶持的IT产业发展不起来。
俄罗斯知名的互联网公司很少
- 一个是Mail.ru,俄罗斯最大的门户网站,月活跃用户数达到1.2亿,这已经占到了俄罗斯总人口的80%多了。
- 另一个是本土搜索引擎Yandex。Yandex的市值是160亿美元,Mail.ru只有18亿美元,别说和美国的互联网巨无霸比了,放到中国也只是中小型互联网公司的水平。
俄罗斯对互联网企业监管比较严格,偏保守,导致多位互联网大佬跑到海外。
但相比俄罗斯,中国的顶级程序员太少了,产出的、有世界影响力的软件更少。
- 中国的互联网和软件公司都是在应用层激烈竞争,程序员整天被需求压得喘不过气来,业余时间被996榨干,回到家中,累得根本没有时间和精力去折腾自己的兴趣和爱好了。
C语言
- 【2020-12-16】万字长文详述C语言发展历史
- C语言有多伟大?多伟大我不知道,但是我知道很伟大。
- 如今这世界上,凡是带电的地方,可能都会有她(C语言)或者她的子孙的影子。
- 任何比C低级的语言,都不足以完整地抽象一个计算机系统;
- 任何比C高级的语言,都可以用C来实现。
- C语言之父:Ritchie 贝尔实验室的个人主页地址
- 丹尼斯·麦卡利斯泰尔·里奇(英语:Dennis MacAlistair Ritchie,1941年9月9日-2011年10月12日),美国计算机科学家。黑客圈子通常称他为“dmr”。他是C语言的创造者、Unix操作系统的关键开发者,对计算机领域产生了深远影响,并与肯·汤普逊同为1983年图灵奖得主。
- 履历
- C语言之父丹尼斯.M.里奇写的一篇关于《C语言发展史》的文章,明确指出
- C语言源自于B、BCPL两种语言。可以把C语言看做是站在巨人的肩上,顺应时代潮流的后浪。
- BCPL语言之父——Martin Richards
- 马丁·理查德(英语:Martin Richards,1940年7月21日-),生于英国,计算机科学家,为BCPL编程语言的发明者,发展了TRIPOS操作系统。
- 1966年,马丁·理查德在剑桥大学,以CPL编程语言为基础,发明了BCPL编程语言。
- B语言之父——Kenneth Lane Thompson
- 肯尼斯·兰·汤普逊(英语:Kenneth Lane Thompson,1943年2月4日-)小名肯·汤普逊(英语:Ken Thompson),美国计算机科学学者和工程师。黑客文化圈子通常称他为“ken”。在贝尔实验室工作期间,汤普逊设计和实现了Unix操作系统。他创造了B语言(基于BCPL) — C语言的前身,而且他是Plan 9操作系统的创造者和开发者之一。与丹尼斯·里奇同为1983年图灵奖得主。
- 2006年,汤普逊进入Google公司工作,与他人共同设计了Go语言。
- C语言时间线 Computer Languages History
- unix时间线
- Unix的诞生与C语言被广泛的传播、使用,有着密切的联系。
- 上图时间线只显示前几个与C语言在相同时间段内诞生的Unix版本(当然,感兴趣的话,可以查询Unix相关发展史,绝对会让你大吃一惊。其中最著名的几个分支:BSD、minix、Linux…)。
- 经历过几十年的风雨洗礼,C语言可谓风光无数,这世界上随处可见它的身影。但是,同时在一些人眼里,可能觉得C语言已是暮年(将近50岁)、老矣
- TIOBE 2020-09 编程语言排行榜告诉你,C语言宝刀未老
- C语言总结
C语言版本更迭
| 年份 | C标准 | 通用名 | 别名 | 标准编译选项 | GNU扩展选项 | |
|---|---|---|---|---|---|---|
| 1972 | Birth | C | - | - | - | - |
| 1978 | K&R | C | - | - | - | - |
| 1989-1990 | X3.159-1989, ISO/IEC 9899:1990 | C89 | C90, ANSI C, ISO C | -ansi, -std=c90, -std=iso9899:1990 | -std=gnu90 | |
| 1995 | ISO/IEC 9899/AMD1:1995 | AMD1 | C94, C95 | -std=iso9899:199409 | - | |
| 1999 | ISO/IEC 9899:1999 | C99 | - | -std=c99, -std=iso9899:1999 | -std=gnu99 | |
| 2011 | ISO/IEC 9899:2011 | C11 | - | -std=c11, -std=iso9899:2011 | -std=gnu11 | |
| 2018 | ISO/IEC 9899:2018 | C18 | - | -std=c18, -std=iso9899:2018 | -std=gnu18 |
- C语言早期
- 最早由丹尼斯·里奇(Dennis Ritchie)为了在PDP-11电脑上运行的Unix系统所设计出来的编程语言
- 第一次发展在1969年到1973年之间。
- 在PDP-11出现后,丹尼斯·里奇与肯·汤普逊着手将Unix移植到PDP-11上
- 1973年,Unix操作系统的核心正式用C语言改写,这是C语言第一次应用在操作系统的核心编写上。
- 1975年C语言开始移植到其他机器上使用。史蒂芬·强生实现了一套“可移植编译器”
- K&R C
- 1978年,丹尼斯·里奇和布莱恩·柯林汉合作出版了《C程序设计语言》的第一版。 “K&R C”(柯里C)。
- C89
- 1989年,C语言被美国国家标准协会(ANSI)标准化,这个版本又称为C89
- 标准化的一个目的是扩展K&R C,增加了一些新特性。
- C90
- 1990年,国际标准化组织(ISO)规定国际标准的C语言
- 通过对ANSI标准的少量修改,最终制定了 ISO 9899:1990,又称为C90。
- 随后,ANSI亦接受国际标准C,并不再发展新的C标准。
- C99
- 1994年为C语言创建了一个新标准,但是只修正了一些C89标准中的细节和增加更多更广的国际字符集支持。
- 不过,这个标准引出了1999年ISO 9899:1999的发表。它通常被称为C99。
- C99被ANSI于2000年3月采用。
- C11
- 2011年12月8日,ISO正式发布了新的C语言的新标准C11,之前被称为C1X
- 官方名称为ISO/IEC 9899:2011
- 新的标准提高了对C++的兼容性,并增加了一些新的特性。
- 这些新特性包括泛型宏、多线程、带边界检查的函数、匿名结构等。
- C18
- C18没有引入新的语言特性,只对C11进行了补充和修正。
C++版本更迭
| 年份 | C++标准 | 通用名 | 别名 | 标准编译选项 | GNU扩展选项 |
|---|---|---|---|---|---|
| 1978 | C with Classes | - | - | - | - |
| 1998 | ISO/IEC 14882:1998 | C++98 | - | -std=c++98 | -std=gnu++98 |
| 2003 | ISO/IEC 14882:2003 | C++03 | - | -std=c++03 | -std=gnu++03 |
| 2011 | ISO/IEC 14882:2011 | C++11 | C++0x | std=c++11, std=c++0x | std=gnu++11, std=gnu++0x |
| 2014 | ISO/IEC 14882:2014 | C++14 | C++1y | std=c++14, std=c++1y | std=gnu++14, std=gnu++1y |
| 2017 | ISO/IEC 14882:2017 | C++17 | C++1z | std=c++17, std=c++1z | std=gnu++17, std=gnu++1z |
| 2020 | to be determined | C++20 | C++2a | -std=c++2a | std=gnu++2a |
注解
- 1998年是C++标准委员会成立的第一年,以后每5年视实际需要更新一次标准。
- 2009年,C++标准有了一次更新,一般称该草案为C++0x。C++0x是C++11标准成为正式标准之前的草案临时名字。
- 2011年,C++新标准标准正式通过,更名为ISO/IEC 14882:2011,简称C++11。
- 2014年8月18日,经过C++标准委员投票,C++14标准(C++11的一个小扩展,主要提供漏洞修复和小的改进)获得一致通过。ISO/IEC 14882:2014
- 2017年,C++17 又称C++1z,是继 C++14 之后,C++ 编程语言 ISO/IEC 标准的下一次修订的非正式名称。官方名称 ISO/IEC 14882:2017
Python与c
C++的世界中,只有强者才能生存到最后成功吃鸡。它更像是一把锋利的瑞士军刀,语法复杂但是功能超级强大,一般人难以驾驭。
Python作为一名“胶水语言”,其优点就是库多库多库多!是一种高性能的重武器。
C++留下库少的原因,也许是它少了那个「中心化的库分发机制」
python从出生开始就注定了跑的慢,现在几乎没有什么其他流行语言比它还慢的,多年来人们绞尽脑汁提高它的速度都没辙,甚至还推出了cython,但也最多只是小范围使用罢了,无法改变python的内在基因。一旦python离开c/c++,基本就只能像蜗牛一样爬!
Python转C语言
【2021-12-9】算法工程师的c++要会哪些
- 第一阶段,把你Python写的代码能复现成c++,比如strip,split,index,len,replace这样的方法,数值的类型,因为Python没有int,float的概念,所以在c++中特别要注意精度。模型侧,树模型怎么用Python复现,然后怎么转化成c++。输入输出,大家都用json,你也得保证一致吧!
- 第二阶段,在功能没问题基础上实现动态可配置,可实时干预。像我们用的ude,如果你在设计方案时就想到了,那基本就比较简单,文件加载就可以。如果你没想到,后面打补丁,那就恶心了。所以在工程侧设计时,要考虑动态可配置,可及时干预,快速上线的原则。这个阶段特别容易看出是不是菜鸡。
- 第三阶段,代码要轻量级,功能可扩展。以我做搜索为例哈。比如要做分桶实验,老p7们会在第一次上线时就完成测试版本切换功能,就是你在配置页面改个bucket参数,就能自动切换版本,而不需要来回推索引。这个做的好,每次实验至少可以给你节约两个工作日。你问的c++,看起来是第一阶段内容,但是真干起活来,你会发现大部分函数都有前辈给封装好了,所以你到网上找一下c++实现Python的代码,能看懂,能验证对不对就可以了
评论:
- 会serving部署,会写sdk,并发处理推理,多线程,异步调用;github拉两个开源项目做一下就差不多了,如果做算子和工程化的话要求更高
- 学会用cuda;工程化部署yolo的tensorRT
- C++对算法工程师基本上就是浪费时间。连服务端工程师都很少用C++了。对互联网来说属于过时的语言
- 用C++造个算法模型的轮子,整个下来你对算法的理解,语言的理解以及架构的理解都会上好几个档次
知乎:为什么AI算法工程师要求C++?:训练的时候用Python,部署的时候用C++,大公司通常是用c++,Java,golang
- 用 Tensorflow/Pytorch 来训模型,算法通常有数据预处理、特征提取等步骤,这些步骤未必是深度学习框架支持的(也就是你无法用 Tensorflow/Pytorch 的 Op 来组合出这写步骤,服务部署的时候这些步骤又不能缺少),但在部署的时候为了性能不能用 python,对吧,那这些步骤怎么弄呢?你可以用 C++ 写 数据预处理、特征提取,将其封装成 Op 挂到框架里面去,加个 python wrapper,训练的时候用 python 调,服务部署的阶段就用 C++ 的;其次只满足于 python 调包侠的话,框架不支持的事情就做不了啊,这些框架的底层实现是 C++ 的,Python 只是个壳,长远来说应该从底层掌握框架,能在其基础上进行扩展,有一天可能需要你设计一个框架、挖个坑的。
Python调C语言包
Python、Java支持调用C接口,但不支持调用C++接口,因此对于C++语言实现的接口,必须转换为C语言实现。为了不修改原始C++代码,在C++接口上层用C语言进行一次封装,这部分代码通常被称为“胶水代码”(Glue Code)。
流程:
- C++ 代码
- C语言封装代码,C wrapper
- 编译生成C动态库
- 第三方语言接口,如Python、Java
str_print.h
#pragma once
#include <string>
class StrPrint {
public:
void print(const std::string& text);
};
str_print.cpp
#include <iostream>
#include "str_print.h"
void StrPrint::print(const std::string& text) {
std::cout << text << std::endl;
}
c_wrapper代码
- 需要对C++库进行封装,改造成对外提供C语言格式的接口。
c_wrapper.cpp
#include "str_print.h"
extern "C" {
void str_print(const char* text) {
StrPrint cpp_ins;
std::string str = text;
cpp_ins.print(str);
}
}
生成动态库
为了支持Python与Java的跨语言调用,我们需要对封装好的接口生成动态库,生成动态库的方式有以下三种。
- 方式一:源码依赖方式,将c_wrapper和C++代码一起编译生成libstr_print.so。
- 这种方式业务方只需要依赖一个so,使用成本较小,但是需要获取到C++源码。对于一些现成的动态库,可能不适用。
- g++ -o libstr_print.so str_print.cpp c_wrapper.cpp -fPIC -shared
- 方式二:动态链接方式,这种方式生成的libstr_print.so,发布时需要携带上其依赖库libstr_print_cpp.so。
- 业务方需要同时依赖两个so,使用的成本相对要高,但是不必提供原动态库的源码。
- g++ -o libstr_print.so c_wrapper.cpp -fPIC -shared -L. -lstr_print_cpp
- 方式三:静态链接方式,这种方式生成的libstr_print.so,发布时无需携带上libstr_print_cpp.so。
- 业务方只需依赖一个so,不必依赖源码,但是需要提供静态库。
- g++ c_wrapper.cpp libstr_print_cpp.a -fPIC -shared -o libstr_print.so
上述三种方式,各自有适用场景和优缺点。在我们本次的业务场景下,因为工具库与封装库均由我们自己开发,能够获取到源码,因此选择第一种方式,业务方依赖更加简单。
Python接入代码
Python标准库自带的ctypes可以实现加载C的动态库的功能,使用方法如下:
str_print.py
# -*- coding: utf-8 -*-
import ctypes
# 加载 C lib
lib = ctypes.cdll.LoadLibrary("./libstr_print.so")
# 接口参数类型映射
lib.str_print.argtypes = [ctypes.c_char_p]
lib.str_print.restype = None
# 调用接口
lib.str_print('Hello World')
LoadLibrary会返回一个指向动态库的实例,通过它可以在Python里直接调用该库中的函数。argtypes与restype是动态库中函数的参数属性,前者是一个ctypes类型的列表或元组,用于指定动态库中函数接口的参数类型,后者是函数的返回类型(默认是c_int,可以不指定,对于非c_int型需要显示指定)。该部分涉及到的参数类型映射,以及如何向函数中传递struct、指针等高级类型,可以参考附录中的文档。
java方式、更多信息见原文:Linux下跨语言调用C++实践
C语言语法
C 语言是一种通用的高级语言,最初是由丹尼斯·里奇在贝尔实验室为开发 UNIX 操作系统而设计的。C 语言最开始是于 1972 年在 DEC PDP-11 计算机上被首次实现。
- 1978 年,布莱恩·柯林汉(Brian Kernighan)和丹尼斯·里奇(Dennis Ritchie)制作了 C 的第一个公开可用的描述,现在被称为 K&R 标准。
- UNIX 操作系统,C编译器,和几乎所有的 UNIX 应用程序都是用 C 语言编写的。由于各种原因,C 语言现在已经成为一种广泛使用的专业语言。
- 易于学习。
- 结构化语言。
- 产生高效率的程序。 C 语言所产生的代码运行速度与汇编语言编写的代码运行速度几乎一样,所以采用 C 语言作为系统开发语言。
- 可以处理底层的活动。
- 可以在多种计算机平台上编译。
- C 语言是一种通用的、面向过程式的计算机程序设计语言。1972 年,为了移植与开发 UNIX 操作系统,丹尼斯·里奇在贝尔电话实验室设计开发了 C 语言。
- C 语言是一种广泛使用的计算机语言,它与 Java 编程语言一样普及,二者在现代软件程序员之间都得到广泛使用。
- 当前最新的 C 语言标准为 C18 ,在它之前的 C 语言标准有 C17、C11…C99 等。
参考
helloworld
代码: test.c
- 所有的 C 语言程序都需要包含 main() 函数。 代码从 main() 函数开始执行。
- /* … */ 用于注释说明。
- printf() 用于格式化输出到屏幕。printf() 函数在 “stdio.h” 头文件中声明。
- stdio.h 是一个头文件 (标准输入输出头文件) , #include 是一个预处理命令,用来引入头文件。 当编译器遇到 printf() 函数时,如果没有找到 stdio.h 头文件,会发生编译错误。
- return 0; 语句用于表示退出程序
// 预处理器指令,告诉 C 编译器在实际编译之前要包含 stdio.h 文件
#include <stdio.h> // 系统库,包含printf函数
// 所有代码的入口函数main
int main()
{
int a=3; // 变量名区分大小写
/* 多行注释 */
printf("Hello, World! %d\n", a); // 输出到屏幕
return 0; // 返回状态码
}
//每个语句必须以分号结束
// ------------------
#include <stdio.h>
#include <string.h>
// 三种形式
// int main(void){}
// int main(int argc, char *argv[]){}
// int main(int argc, char **argv){}
int main(int argc, char *argv[])
{
printf("共传入%d个参数\n", argc);
for(int i = 0; i < argc; i ++)
{ // argv[0]是程序文件本身
printf("传入的第%d个参数为:%s\n", i + 1, argv[i]);
}
if(!strcmp(argv[argc - 1], "thride"))
{
printf("Hello World!\n");
}
return 0;
}
运行:gcc编译器安装
- .c -> .o -> exe/a.out
# 检查gcc编译器
gcc -v
# 直接编译出可执行文件
gcc test.c
# 生成a.out
./a.out # Hello, World! 3
gcc test.c -o main.out # 自定义可执行文件
# 多个源码文件依赖
gcc test1.c test2.c -o main.out
头文件
| 头文件类型 | 约定 | 示例 | 说明 |
|---|---|---|---|
| C++旧式风格 | 以.h结尾 | iostream.h | C++程序可以使用 |
| C旧式风格 | 以.h结尾 | math.h | C、C++程序可以使用 |
| C++新式风格 | 没有扩展名 | iostream | C++程序可以使用,使用namespace std |
| 转换后的C | 加上前缀c,没有扩展名 | cmath | C++程序可以使用,可以使用不是C的特性,如namespace std |
编译
【2022-9-22】C语言编译器的实战教程,acwj
- 实战循序渐进,一步步教你如何用 C 语言写一个可以自己编译自己(自举)、能够在真正的硬件上运行的 C 语言编译器。
- C代码高级语言输入(high level) → 文法分析(lexical analysis)→ 语法分析(grammar analysis)→ 翻译(translate Meaning,如机器语言)→ 低级输出(low-level output)
C语言的数据类型
- (1)基本类型
- a.
整型:整型int Visual c++6.0 中占4个字节; Turbo c 2.0占2个字节,取值:-2147483648 -2147483647短整型short int 2个字节 取值:-32768 - 32767长整型long int 4个字节取值:-2147483648 - 2147483647无符号整型unsigned int 4个字节 取值:0-4294967295无符号短整型unsigned short int 2个字节无符号长整型unsigned long int 4个字节- 注:对于不同的编译环境,整型在内存中所占的字节数也不一样。各种类型的存储大小与系统位数有关,但目前通用的以64位系统为主
- b.
字符型:- char (\n 回车 \t 下一制表位置 \r 回车 '单引号 \ :反斜杠字符”")
- 一个字节(八位), 这是一个整数类型
- 注:对于c语言的任何一个字符都可用转义字符来表示
- 如:\101表示字符”A”,\134表示反斜杠,\XOA表示换行
- 对于字符串常量内存字节数要加1,用来存放字符结束标志符”\0”
- c.
实数型:单精度float 占4个字节,32位(1位符号,8位指数,23位小数)。取值为:3.4E-38 ~ 3.4E+38 ,可提供6到7位有效数字双精度double 占8位字节,64位(双精度是1位符号,11位指数,52位小数)。取值:1.7E-308 ~1.7E+38
- d.
枚举:- enum
- a.
- (2)构造类型
- a.
数组array - b.
结构体struct - c.
共用体union
- a.
- (3)指针类型 *
- (4)空类型 void
- 函数返回空:void exit (int status);
- 函数参数为空:int rand(void);
- 空指针:void *malloc( size_t size );

#include <stdio.h>
#include <limits.h>
#include <float.h>
#define LENGTH 10 // 预定义常量
// 函数外定义变量 x 和 y
int x;
int y;
int addtwonum()
{
// 函数内声明变量 x 和 y 为外部变量
extern int x;
extern int y;
// 给外部变量(全局变量)x 和 y 赋值
x = 1;
y = 2;
return x+y;
}
int main()
{
// 变量声明,不带初始化的定义:带有静态存储持续时间的变量会被隐式初始化为 NULL(所有字节的值都是 0),其他所有变量的初始值是未定义的。
int i, j, k;
char c, ch;
float f, salary;
double d;
extern int i; // 引用外部变量,只声明,不定义
// 声明时给初始值
extern int d = 3, f = 5; // d 和 f 的声明与初始化
int d = 3, f = 5; // 定义并初始化 d 和 f
byte z = 22; // 定义并初始化 z
char x = 'x'; // 变量 x 的值为 'x'
const int WIDTH = 5; // const定义常量必须一句话完成,分开就报错! const int x; x=5;
printf("float 存储最大字节数 : %lu \n", sizeof(float));
printf("float 存储最大字节数 : %lu \n", sizeof(float)); // float 存储最大字节数 : 4
printf("float 最小值: %E\n", FLT_MIN ); // float 最小值: 1.175494E-38
printf("float 最大值: %E\n", FLT_MAX ); // float 最大值: 3.402823E+38
printf("精度值: %d\n", FLT_DIG ); // 精度值: 6
return 0;
}
存储类定义 C 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。
下面列出 C 程序中可用的存储类:
- (1)
auto:所有局部变量默认的存储类,auto 只能用在函数内,即只能修饰局部变量 - (2)
register:定义存储在寄存器中而不是 RAM 中的局部变量,变量的最大尺寸等于寄存器的大小(通常是一个字),且不能对它应用一元的 ‘&’ 运算符(因为它没有内存位置)。- 寄存器只用于需要快速访问的变量,比如计数器。还应注意的是,定义 ‘register’ 并不意味着变量将被存储在寄存器中,变量可能存储在寄存器中,这取决于硬件和实现的限制。
- (3)
static:指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。- static 修饰符也可以应用于全局变量。当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
- 全局声明的一个 static 变量或方法可以被任何函数或方法调用,只要这些方法出现在跟 static 变量或方法同一个文件中
- (4)
extern:提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 extern 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
#include <stdio.h>
/* 函数声明 */
void func1(void);
extern void write_extern(); // a.c中引用其他文件(b.c)中定义的函数
static int count=10; /* 全局变量 - static 是默认的 */
int main()
{
int mount;
auto int month; // auto 变量
register int miles; // 寄存器变量
while (count--) {
func1();
}
return 0;
}
void func1(void)
{
/* 'thingy' 是 'func1' 的局部变量 - 只初始化一次
* 每次调用函数 'func1' 'thingy' 值不会被重置。
*/
static int thingy=5;
thingy++;
printf(" thingy 为 %d , count 为 %d\n", thingy, count);
}
结构体示例 strcut_test.c
- 编译: gcc strcut_test.c -o test
#include <stdio.h>
#include <stdlib.h>
// 先定义链表的结构体
typedef struct Link{
int elem;
struct Link * next;//这个是一个结构体型的指针
}link;
link *initLink(){
link *p= (link*)malloc(sizeof(link));
link *temp=p;
for(int i=1;i<5;i++){
link *a=(link*)malloc(sizeof(link));
a->elem=i;
a->next=NULL;
temp->next=a;
temp = temp->next;//这个地方不能是a->next;为什么?因为a->next指向的是NULL,temp=NULL,这是不行的,这相当于野指针。所以我们要用temp->next。
}
return p;
}
void display(link*p){
link *temp = p;
while (temp->next) {
temp = temp->next;//这个地方要注意,需要手动的将指针下移一个位置
printf("打印:%d\n",temp->elem);
}
printf("\n");
}
int main(){
link *p = initLink();
display(p);
return 0;
}
元素交换:实现两个数组元素对齐,数组内禁止比较
#include <stdio.h>
void output(int a[], int size){
for(int i=0;i<size;i++){
printf("%d\t", a[i]);
//printf("%d:%d\t", i, a[i]);
//printf("第%d个元素:%d", i, a[i]);
}
printf("\n");
}
//void swap(int &a, int &b){
void swap(int a, int b){
// 交换两个元素值的4种方法
// ① 临时变量
int tmp = a;
a = b;
b = tmp;
// ② 异或
a ^= b;
b ^= a;
a ^= b;
// ③ 加减
a = a + b;
b = a - b;
a = a - b;
// ④ 乘除
a = a * b;
b = a / b;
a = a / b;
}
// 模板(不限元素类型)
/*
template<typename T>
void swapr(T &a, T &b) {
T temp = a;
a = b;
b = temp;
}
*/
int main()
{
printf("C for测试...\n");
int size=3;
int A[3]={4,2,1};
int B[3]={2,4,1};
output(A, size);
output(B, size);
for(int i=0;i<size;i++)
{
printf("第%d个元素: %d\n",i, A[i]);
}
// 数组b中查找
int ia=0, ib=0;
while(ib<size)
{
if(A[ia]==B[ib]) {
if(ia!=ib){
printf("交换: %d(%d), %d(%d) \n", ia, B[ia], ib, B[ib]);
swap(B[ia], B[ib]);
ib=++ia;
}else{
ia++;ib++;
}
}else{
ib++;
}
}
output(A, size);
output(B, size);
return(0);
}
输入输出函数
- printf(格式控制字符串,输出列表) //格式控制字符串可由格式字符串(以%开头)和非格式字符串(原样输出)组成.
- scanf(格式控制字符串,地址表列)
- putchar() //字符数据的输出 等同与 printf(%c,.) 位于
中 - getchar() //从键盘输入中读取一个字符。scanf(%c,&mchar)
#include<stdio.h>
int main()
{
int num;
printf("输入一个数字 : ");
scanf("%d",&num);
// 条件运算符
(num%2==0)?printf("偶数"):printf("奇数");
}
字符串
C语言中,没有专门的字符串变量,没有string类型,通常就用一个字符数组来存放一个字符串。
字符串操作
- 定义:char
- 赋值
- 直接初始化,一次性定义大小
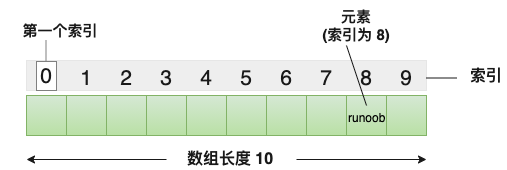
- 单个字符逐个复制,结束后一定要自行添加 ‘\0’!如:字符串长度为 9,数组长度为 10
- 否则,就会出现:AB烫烫烫烫烫烫烫 ]D痨“ 的编译结果
- 间接复制:C语言中,将一个字符串赋值给另一个字符串,只能使用strcpy函数
- 输出:不能直接输出
用于输入输出的字符串函数,例如
- printf、puts、scanf、gets等,使用时应包含头文件stdio.h
- puts():直接输出字符串,并且只能输出字符串。
- printf():通过格式控制符 %s 输出字符串。除了字符串,printf() 还能输出其他类型的数据。
- scanf():通过格式控制符 %s 输入字符串。除了字符串,scanf() 还能输入其他类型的数据。
- gets():直接输入字符串,并且只能输入字符串。
- 使用其它字符串函数则应包含头文件string.h。
- 字符串长度函数strlen
- 字符串连接函数 strcat
- 字符串复制函数strcpy
- 字符串比较函数strcmp
#include <stdio.h>
int main()
{
// 单个字符赋值,必须加\0
char str1[10];
str1[0] = 'A';
str1[1] = 'B';
str1[2] = '\0';
// 指针赋值
char* string = "I Love China";
printf("string = %s", string);
// 数组赋值
char str[30] = {"1234567890"}; // 编译器已经在末尾自动添加了’\0’
char str[30] = "1234567890"; // 编译器已经在末尾自动添加了’\0’; 这种形式更加简洁,实际开发中常用
char str3[30] = "1234567890 \0 123"; // \0后面的部分自动截断
printf("%s\n", str);
char a_static[] = { 'q', 'w', 'e', 'r', '\0' };
char b_static[] = { 'a', 's', 'd', 'f' };
printf("value of a_static: %.4s\n", a_static); // 指定大小
printf("value of b_static: %.*s\n", (int)sizeof(b_static), b_static); // 大小未知,取size
// 逐个输出字符
char str[4] = "abc";
for (size_t i = 0; i < 3; i++) {
printf("%c\n", str[i]);
}
}
逻辑运算
逻辑运算: &&(与)、||(或)、!(非)
#include <stdio.h>
int main()
{
int a = 21;
int b = 10;
int c ;
if( a == b ) // 类似 a < b, a > b
{
printf("Line 1 - a 等于 b\n" );
}else
{
printf("Line 1 - a 不等于 b\n" );
}
/* 改变 a 和 b 的值 */
a = 5;
b = 20;
if ( a <= b )
{
printf("Line 4 - a 小于或等于 b\n" );
}
int a = 5;
int b = 20;
int c ;
if ( a && b ) // 类似的,|| 或,非 !
{
printf("Line 1 - 条件为真\n" );
}
/* 改变 a 和 b 的值 */
a = 0;
b = 10;
if ( !(a && b) )
{
printf("Line 4 - 条件为真\n" );
}
// 位运算符
unsigned int a = 60; /* 60 = 0011 1100 */
unsigned int b = 13; /* 13 = 0000 1101 */
int c = 0;
c = a & b; /* 12 = 0000 1100 */
printf("Line 1 - c 的值是 %d\n", c );
c = a | b; /* 61 = 0011 1101 */
printf("Line 2 - c 的值是 %d\n", c );
c = a ^ b; /* 49 = 0011 0001 */
printf("Line 3 - c 的值是 %d\n", c );
c = ~a; /*-61 = 1100 0011 */
printf("Line 4 - c 的值是 %d\n", c );
c = a << 2; /* 240 = 1111 0000 */
printf("Line 5 - c 的值是 %d\n", c );
c = a >> 2; /* 15 = 0000 1111 */
printf("Line 6 - c 的值是 %d\n", c );
// 其他运算符
int a = 4;
short b;
double c;
int* ptr;
/* sizeof 运算符实例 */
printf("Line 1 - 变量 a 的大小 = %lu\n", sizeof(a) );
printf("Line 2 - 变量 b 的大小 = %lu\n", sizeof(b) );
printf("Line 3 - 变量 c 的大小 = %lu\n", sizeof(c) );
/* & 和 * 运算符实例 */
ptr = &a; /* 'ptr' 现在包含 'a' 的地址 */
printf("a 的值是 %d\n", a);
printf("*ptr 是 %d\n", *ptr);
/* 三元运算符实例 */
a = 10;
b = (a == 1) ? 20: 30;
printf( "b 的值是 %d\n", b );
b = (a == 10) ? 20: 30;
printf( "b 的值是 %d\n", b );
}
逻辑判断
| 语句 | 描述 |
|---|---|
| if 语句 | 一个 if 语句 由一个布尔表达式后跟一个或多个语句组成。 |
| if…else 语句 | 一个 if 语句 后可跟一个可选的 else 语句,else 语句在布尔表达式为假时执行。 |
| 嵌套 if 语句 | 您可以在一个 if 或 else if 语句内使用另一个 if 或 else if 语句。 |
| switch 语句 | 一个 switch 语句允许测试一个变量等于多个值时的情况。 |
| 嵌套 switch 语句 | 您可以在一个 switch 语句内使用另一个 switch 语句。 |
C 语言提供了以下几种循环类型。点击链接查看每个类型的细节。
| 循环类型 | 描述 |
|---|---|
| while 循环 | 当给定条件为真时,重复语句或语句组。它会在执行循环主体之前测试条件。 |
| for 循环 | 多次执行一个语句序列,简化管理循环变量的代码。 |
| do…while 循环 | 除了它是在循环主体结尾测试条件外,其他与 while 语句类似。 |
| 嵌套循环 | 您可以在 while、for 或 do..while 循环内使用一个或多个循环。 |
循环控制语句
- break
- continue
- goto
- 无限循环: for( ; ; )
二维数组
数组:
定义:
- 类型说明符 数组名[常量表达式1][常量表达式2]
注:
- a.存储器单元是一维线性排列的。是按行存放的。
- b.对于全部元素赋初值,则数组第一维的长度可以省略,但是第二维不能省。如:int a[][3]= {1,2,3,4,5,6}
- c.可以只对部分元素赋初值,没赋初值的元素自动取0值。
- d.一个二维数组可以分解为一个多个一维数组。例:a[3][4]可分解为三个一维数组,其数组名分别为a[0],a[1],a[2],而这个 一维数组都有4个元素。如一维数组a[0]有元素为:a[0][0],a[0][1],a[0][2],a[0][3]
字符数组
c中没有字符串数据类型,是用字符数组来表示字符串变量的。
- 字符串总是以’\0’作为串结束符,所以,字符串就是一种以‘\0’结束的字符数组。
- 在求字符串长度时,不包含结束符’\0’。但是sizeof却要包含。
double balance[10]; // 声明数组
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0}; // 初始化数组
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0}; // 不指定大小
char c[]="string";
char c1[]={'s','t','r','i','n','g','\0','\0'};
printf("%d\n",sizeof(c)); // 7 ,默认在string后加'\0'
printf("%d\n",sizeof(c1)); //8,对于字符数组只能自己加结束符
printf("%d\n",strlen(c)); //6 求字符串长度时,不包含结束符'\0'
printf("%d\n",strlen(c1)); //6 求字符串长度时,不包含结束符'\0'
常用的字符串处理函数(在stdio.h中与string.h中):
- puts(字符数组名)—把字符数组中的字符串输出到显示器。
- gets(字符串数组名)–从输入设备得到字符串。
- strcat(字符数组名1,字符数组名2)–把字符数组中2中的字符串连接到字符数组1中字符串的后面,并删除字符串1后的串标志”\0”;
- strcpy(字符数组名1,字符数组名2)–把字符数组2中的字符串复制到字符数组1中,串结束标识’\0’也一同复制。
- strcmp(字符数组名1,字符数组名2)–按照ASCII码顺序比较两个数组中的字符串,并由函数返回比较结果。
- strlen(字符数组名)—返回字符实际长度(不含字符’\0’)
函数
对于被调用函数的声明和函数一般形式:
- 类型说明符 被调函数名(类型,类型,..);
注:
- 如果被调用函数的返回值是整型或字符型时,可以不对被调用函数作说明而直接调用。
- 如果被调用函数定义出现在主调用函数之前,在主函数可以不对被调用函数作说明而直接调用。
#include <stdio.h>
/* 函数声明 */
int max(int num1, int num2);
/* 全局变量声明 */
int a=11;
int main ()
{
/* 局部变量定义 */
int a = 100; // 局部变量和全局变量的名称可以相同,但是在函数内会优先用局部变量值
int b = 200;
int ret;
/* 调用函数来获取最大值 */
ret = max(a, b);
printf( "Max value is : %d\n", ret );
return 0;
}
/* 函数返回两个数中较大的那个数 */
int max(int num1, int num2)
{ // 形式参数被当作该函数内的局部变量,优于同名全局变量
/* 局部变量声明 */
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
- 传值调用:该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数不会影响实际参数。
- 引用调用:通过指针传递方式,形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作。
全局变量与局部变量在内存中的区别:
- 全局变量保存在内存的全局存储区中,占用静态的存储单元;
- 局部变量保存在栈中,只有在所在函数被调用时才动态地为变量分配存储单元。 更多内容可参考:C/C++ 中 static 的用法全局变量与局部变量
变量的作用域及存储特性
- a. 局部变量:又称内部变量。在函数内作定义说明,其作用域仅限于函数内。
- 注:允许在不同的函数中使用变量名,它们代表不同的对象,分配不同的单元,互不干扰。
- b. 全局变量:又称外部变量,它是在函数外部定义的变量。它不属于哪一个函数,而属于一个源程序文件。其作用域是整个源程序。在函数中使用全局变量,一般应作全局变量说明。只有在函数中经过说明的全局变量才能使用,说明符为:extern.但是在一个函数之前定义的全局变量,在该函数内可以再加以说明。
- 另注:外部变量在定义时就已分配了内存单元,外部变量定义可作为始赋值,外部变量说明不能再初始值,只是表明在函数内要使用某外部变量。
- 在同一源文件内,允许全局变量和局部变量同名,在局部变量的作用域内,全局变量不起作用。
- 变量的存储特性:
- a. auto(自动变量)默认。为动态存储,既只有在使用它才分配存储单元,开始它的生命周期。
- b. extern(外部变量)为静态存储,外部变量等同与全局变量。当一个源程序由若干个源文件组成时,在一个源文件中定义的外部变量在其它的源文件中也有效。
- c. static(静态变量) 为静态存储方式,可分为静态局部变量和静态全局变量。
- 静态局变量:在局部变量的说明前再加上static说明。
- 如:在一个函数 f() { static int a,b; static float a[5]; …}
- 特点:
- (1).静态局部变量在函数内定义,当调用时已存在。当函数f()退出时仍然存在,生存周期为整个源程序。
- (2).静态局部变量虽然生存周期为整个源程序,但是退出其函数后存在但是不能使用。
- (3).允许对构造类静态局部量赋初值。若未赋值,则系统自动赋值为0值。
- (4).对基本类型的静态局部变量若没赋值,则系统自动赋值为0.而对于自动变量不赋初值,则其值是不固定的。
- 静态全局变量:全局变量再加以static就成了静态全局变量。对于静态全局变量其则只在定义该变量的源文件有效,在同一源文件的其他源文件中是不能使用的。
- (5).把局部变量改变为静态变量后就是改变它的存储方式,即生存周期。把全局变量改变为静态变量后改变它的作用域,限制了它的使用范围。
- d.寄存器变量(register). 当一个变量反复访问时,就可将此变量声明为register。放在cpu的寄存器中。
- 别注:只有局部自变量和形式参数才能定义为寄存器变量。使用个数很有限。对于Truboc 、MS C等使用是按自动变量处理的。
内部函数和外部函数
- 内部函数 – 一个只能被本文件中的其他函数所调用的函数。
- 形式:static 类型 函数名(形参表)
- 外部函数 — 如果在函数标识符前面加上extern
- 形式:extern int fun(int a,int b) 其中,extern为默认。
指针变量声明
- [ 存储类型 ] 类型标识符 *指针变量名;
- [ 存储类型 ] 类型标识符 *指针变量名=变量地址;
- 注:int *p; 变量p表示指针变量;另外P可用来存放整数变量的地址。
- 指针变量本身存储的都是地址,每个指针(地址)占4个字节(在VC中),例:char *p, size(p)为==4 );
指针运算
- a.指针赋值:
- 注意:在没赋初值时,指针变量的内容是不确定的。如果此时引用指针指向的变量,将会产生不可预料的后果。 如:
- b.指针的加减:指针变量加1不能是简单的地址加1,加上一sizof(指针变量所指类型)。
- 两个指针变量在指向同一存储区域(数组)的元素时,可以进行相减。其差绝对值表示两指针元素之间相差的元素个数。
// 指针赋值
int x; int *p=&x;
// 也可在程序中对其初始化:
int x,*p;
p=&x;
// 没赋初值时,指针变量的内容不确定,此时引用指针指向的变量,将会产生不可预料的后果
int *p; *p=100; //错误,p没有初始化。
p += 1; // 指针变量加1不能是简单的地址加1,加上一sizof(指针变量所指类型)。
指针与一维数组
注:c语言中规定,数组名代表第一个元素的地址,是指针常量。数组a的首地址可用&a[0]表示,或a表示。
int a[10],*p;
p=a;
p =&a[0];
// 或定义为:
int a[10];
int *p = a;
// 小结:指针与一维数组的关系
&a[i],&p[i],a+i,p+i // 表示数组元素a[i]的地址
a[i],*(a+i),*(p+i),p[i] // 表示元素a[i]的内容。
p++,p-- // 表示使p后移或前移一个元素的存储空间
*p++,*p-- // 表示先取p所指对象*p,然后使p后移或前移一个元素的存储空间。
(*p)++,(*p)-- // 使p所指对象的值加1或减1.相当于:*p = *p + 1;
*++p;*--p; // 取指针变量p加1或减1后的内容。相当于:*(++p),*(--p);
++*p,--*p; // 使p所指向的变量的内容加1或减1
动态申请存储空间
- 内存申请库函数: void *malloc(size);
- 例: int *p = (int *) malloc(10 * sizeof(int));
- 内存释放库函数: void free(p); free(p);
预处理
指在进行编译的第一遍扫描(词法扫描、语法分析、代码生成、代码优化)之前所做的工作。C中是由预处理程序负责完成。
当对一源文件进行编译时,系统将自动引用预处理程序对源程序中的预处理部分进行处理,处理完毕后自动对源程序进行编译,将预处理的结果和源程序一起再进行通常的编译处理,以得到目标代码。(在C中如宏定义、文件包含、条件编译等为预处理)。
宏定义:
- 不带参数的宏定义 #define 标识符字符串 例:#define PI 3.1415926
- 带参数的宏定义 #define 宏名(形参表) 字符串
- 带参数的宏调用:宏名(实参表) 例:#define M(y) (yy+3) 调用:k=M(5)10; 注:
- a.带参数的宏定义中,宏名和形参之间不能有空格出现。
- b.在宏定义中的形参是标识符,而宏调用中的实参可以是表达式。
- c.在宏定义中,字符串内的形参通常要用括号括起来以避免出错。
- d.带参的宏和带参函数很相似,但有本质上的不同。在带参宏定义中,形式参数不分配内存单元,因此不用定义类型。 而宏调用中的实参有具体的值,要用它们去代换形参,因此进行类型说明。在函数中,形参和实参是两个不同的量,各有自己的作用域,调用时把实参值赋予形参,进行值传递。
#include "stdio.h"
#define SQ(y) ((y)*(y))
main()
{
int i=1;
while(i<=5)
{
//printf("%d\n",SQ(i++)); //输出为:1,9,25
printf("%d\n",SQ(++i)); //输出为:9,25,49 注:对SQ(++i) 首先用((++i)*((++i))来替换
}
}
文件包含
一个源程序通过#include命令把另外一个源文件的全部内容嵌入到源程序中来。在编译时并不是作为两个文件连接,而是作为一个源程序编译,得到一个目标文件。
- 格式:#include “文件名” 注:
- #include “file.h” 首先在使用包含文件的源文件目录查找file.h文件,若没有找到指定的文件,再到系统指定的标准目录查找。
- #include < file.h > 仅在编译系统指定的标准目录查找文件file.h.
条件编译
希望部分行在满足一定条件才进行编译,即按不同的条件去编译不同的程序部分,因而产生不同的目标代码条件。使用条件编译功能,为程序的调试和移植提供了有力的机制,使程序可以适应不同系统和硬件设置的通用性和灵活性。
#ifdef 标识符
程序段1
#else
程序段2
#endif
// 示例
#define R 1
#include <stdio.h>
main()
{
double c,r,s;
printf("请输入圆的半径或矩形的边长:\n");
scanf("%d",&c);
#ifdef R
r = 3.14 *c *c;
printf("圆的面积=%f\n",r);
#else
s=c*c;
printf("矩形面积=%f\n",s);
#endif ..
}
指针型函数
指函数返回指针值的函数。
- 格式: 类型说明符 *函数名([参数列表]){}
- 多用于构造类型数据结构(创建一个链表、返回指向头结点的指针)。
#include <stdio.h>
int *max(int *a,int *b)
{
return (*a>*b)?a:b;
}
void main()
{
int a,b,*p;
scanf("%d,%d",&a,&b);
p = max(&a,&b);
printf("max=%d",*p);
}
指向函数的指针
C语言规定,函数名就表示该函数所点内存区域的首地址,将函数首地址赋给某一指针变量,则通过该指针变量就可以调用这个函数。这种指向函数的指针变量就称为函数指针变量。
定义:
- 类型标识符 (*指针变量名)([参数列表]);
- 类型标识符:表示指针所指函数的返回值的类型。(指针变量名)表示”“后面定义的变量为指针变量,括号表示指针变量所指的是一个函数,而参数列表则列出函数的类型。 用函数指针变量调用函数格式:(*指针变量名)(实参表) 或指针变量名(实参表)
#include<stdio.h>
#include<math.h>
float area(int a,int b)
{
return (float)a*b/2;
}
float length(int a,int b)
{
return (float)sqrt(a*a + b*b);
}
void main()
{
int m,n;
float s,l;
float (*f)(int,int); //定义一个指向函数的指针变量
scanf("%d,%d",&m,&n);
f = area;
s = (*f)(m,n);
f = length;
l =(*f)(m,n);
printf("area=%.2f,length=%.2f\n",s,l);
}
要注意区分定义语句int(p)()和int *p()。这类组合说明符遵循“从里到外,先右后左”的规则。 对于int(p)() 的阅读顺序是:从标识符p开始,说明p是一个指针变量,它指向一个函数(先读右边),它返回int类型(再读左边)。 对于int *p(),从标识符p开始,p是一个函数(先读右边),返回值为类型为int *(再读左边),即它是一个指针型函数。
二维数组和指针
二维数组中的行、圾元素的地址
a、&a[0] // 二维数组首行(第0行)的首地址。
a[0]、*(a+0)、*a // 0行0列元素地址
a+1 // 1行首地址
a[1],*(a+1) // 1行0列元素地址。
a[i]+j、*(a+i)+j 、&a[i][j] // 第i行第j列的首地址
*(a[i]+j)、*(*(a+i)+j)、a[i][j] // 第i行第j列元素值
指向二维数组中一行元素的指针
数据类型(*指针名)[N]
int a[3][4], int (*p)[4]; //p是一个指针变量,它指向包含4个整型元素的一维数组。可以进行p=a初始化。但是不能p=&a[0][0],因为数组名a是指针常量,它的基类型是包含4个整型元素的一维数组,与行指针变量p的基类是一样的。但是a[0][0]是数组中的一个元素,它的基类是整型。所以不能将引地址赋给p.
int a[3][4] ={ {1,3,4,9}, {7,12,24,17}, {11,31,25,30} };
int i;
int (*p)[4] =a;
for(p=a;p<a+3;p++){
for(i=0;i<4;i++)
printf("%3d", *(*p +i));
printf("\n");
}
指针数组
可以使若干个行指针分别指向二维数组中的每一行,把这些指指针存放在一个数组中,称为指针数组。
- 指针数组的定义形式为: 类型说明符 *数组名[常量] 例:char *p[10];
- 按照右结合的原则,p先与[10]结合,说明了是数组的形式,它有10个元素,p[10]再与前面的*结合,表示数组p[10]是一个指针变量,即每一个数组元素都是一个指针变量,现由左面的类型char,可知指针数组中的每一个指针变量都指向一个字符串。
#include <stdio.h>
#include<string.h>
void sort(char *a[],int n)
{
char *temp;
int i,j,p;
for(i=0;i<n;i++)
{
p =i;
for(j=i+1;j<n;j++)
{
if(strcmp(a[p],a[j])>0) p=j;
}
if(p!=i)
{
temp = a[i];
a[i] = a[p];
a[p] = temp;
}
}
}
// 将"china","india","japan","america","canada"按字母顺序(由小到大)输出。
main()
{
char *name[]={"china","india","japan","america","canada"};
int i,n=5;
sort(name,n);
for(i=0;i<n-1;i++)
printf("%s\n",name[i]);
}
二级指针
是指向一级指针的指针。即二级指针中存放的是一级指针的地址。
- 定义: [ 存储形式 ] 数据类型 **指针名;
int a,*p,**q; p=&a; q=&p;
char *name[]={"china","india","japan","american","canada"};
char **p;
int i;
for(i=0;i<5;i++)
{
p = name +i;
printf("%s\n",*p);
}
指针数组作main函数的形参
定义:main(int argc, *argv[]) 或 main(int argc, **argv);
- argc是命令行中的参数个数(可执行文件名本身也算一个)
- argv是一个指向字符串的指针数组,用来存放命令行中各个参数的首地址。
结构体
struct student{
long int num;
char *name;
float scorce[3];
}stud1,stud2;
struct student stud3,stud4;
// 结构体的引用:结构体变量名.成员名 如:
stud1.num = 101;
stud1.name ="dick";
typedef的使用方法
利用某个已有的数据类型定义一个新的数据类型。格式:typedef 数据类型或数据类型名新数据类型名
typedef float REAL;
typedef struct student STU; //定义STU结构体struct student的别名
有了上定义后就可以用如下的定义方式如:REAL f1,f2; STU s;
注意:
- a.typedef没有创造新的数据类型,它是用来定义类型,不能定义变量。
- b.typedef并不是作简单的字符串替换,与#define的作用不同。
- c.用typedef定义类型名时往往用大写字母表示,并单独存于一个文件中。
- d.用typedef定义类型名有利于程序的移植,并增加程序的可读性。
结构体数组
数组元素是结构体类型的数组。 例:
struct person{
char *name;
int count;
}leader[3] ={"li",0,"zhang",0,"wang",0};
void main()
{
int i,j;
char leader_name[20];
for(i=1;i<=10;i++)
{
printf("请输入第%d个用户的名字",i);
scanf("%s",leader_name);
for(j=0;j<3;j++)
if(strcmp(leader_name,leader[j].name)==0)
leader[j].count++;
}
printf("\n");
for(i=0;i<3;i++)
printf("%5s:%d\n",leader[i].name,leader[i].count);
}
指向结构体的指针
说明一个结构类型的变量后,它就在内存获得了存储区,该存储区的起始地址,就是这个变量的地址(指针)。如果说明一个这种结构类型的指针变量,把结构类型变量的地址赋给它,这个指针就指向这个变量了。
结构体指针变量定义的一般形式:struct 结构体名 *指针变量名; 例:struct student *p;
用指针变量访问结构变量成员的方法:
- 1).直接利用结构变量: 结构变量名.成员名
- 2).利用指向结构变量的指针和指针运算符”“,形式: (指针变量名).成员名
- 3).利用指向结构变量的指针和指向成员运算符”->”,一般形式:指针变量名–>成员名
#include<stdio.h>
#include<string.h>
void main()
{
struct student{
long int num;
char name[20];
char sex;
float score;
}stu_1,*p;
p = &stu_1;
stu_1.num = 89101;
strcpy(stu_1.name,"li li");
p->sex = 'M';
p->score= 89.5;
printf("\nNum:%ld\nname:%s\nsex:%c\nscore:%f\n",(*p).num,p->name,stu_1.sex,p->score);
}
共同体
由若干个不同类型的数据项组成,但共享同一存储空间的结构类型。(与结构体的区别是:结构体类型变量的每一个成员都占有各自的存储区,而共同体类型变量的所有成员共用一个存储区。常称它是一种可变身份的数据类型,可在不同的时候在同一存储单元中存储不同类型的变量。)
#include<stdio.h>
union u{
char u1;
int u2;
float f;
double d;
};
main()
{
union u a ={0x9843};
printf("1.%c %x\n",a.u1,a.u2); //输出:1.C 43 由于第一个成员是字符型,用一个字节,所以对对于初值0x9843仅接受0x43,初值的高字节被截取。
a.u1 = 'B';
printf("2.%c %x\n",a.u1,a.u2); //输出:2.B 62
}
枚举类型
它的值有固定的范围(如一年只有12个月),这些值可以用服限个常量来描述。
格式: enum 枚举类型名{ 标识符1[=整型常量1], // 要注意最后结束符是”,”不是“,” 标识符2[=整型常量2], ….. };
enum weekday{
Mon = 1,
Tue,
Wed,
Thu,
Fri,
Sat,
Sun
};
char *name[8] ={"error","Mon","Tue","Wed","Thu","Fri","Sat","Sun"};
void main()
{
enum weekday d;
printf("请输入今天的数字(1-7):\n");
scanf("%d",&d);
if(d>0&&d<7)
d++;
else if(d==1)
d=1;
else
d=0;
if(d) printf("明天是%s\n",name[d]);
else
printf("%s\n",name[d]);
}
文件操作
文件类型指针
在c语言中有一个FILE类型,它是存放有关文件信息的结构体,FILE类型结构在stdio.h定义,如下:
typedef struct{
short level; //缓冲区满或空的程度
unsigned flags; //文件状态标志
char fd; //与文件相关的标示符,即文件句柄
unsigned hold; //如无缓冲则不读字符
short bsize; //缓冲区大小,默认为512字节
unsigned char *buffer; //数据缓冲区的指针
unsigned char *curp; //当前激活文件指针
unsigned istemp; //临时文件标示
short token; //用于文件有效性检查
}FILE;
定义文件类型指针: FILE *fp;
文件的打开和关闭
文件的打开:
- 文件指针名 = fopen(文件名,打开文件方式);
- 其中文件指针名必须是说明为FILE类型的指针变量。
- 文件名是打开文件的文件名,它可以是字符串常量或者字符数组。
- 打开方式:指文件的类型和操作要求。
| 打开方式 | 意义 |
|---|---|
| rt | 只读打开一个文本文件,只允许读数据。 |
| wt | 只写打开或建立一个文本文件,只允许写数据 |
| at | 追加打开一个文本文件,并在文件末尾写数据 |
| rb | 只读打开一个二进制文件,只能读数据 |
| rt+ | 读写打开一个文本文件,允许读和写。 |
| wt+ | 读写或建立一个文本文件,允许读写 |
| at+ | 读写打开一个文本文件,允许读,或在文件未追加数据。 |
| rb+ | 读写打开一个二进制文件,允许读和写。 |
注:
- a. r(read)、w(write)、a(append)、t(text)、b(binary)、+(读写).
- b. 用”w”打开的文件只能向该文件写入。若打开的文件不存在,则以指定的文件名建立该文件,若打开的文件已存在,则将该文件删去。
- c.若要向一个已存在的文件追加新的信息,只能用”a”方式打开文件,但此时文件必须是存在的,否则将会出错。
FILE *fp;
if(fp = fopen("c:\\cp\red.txt","rt")==NULL){ exit(1);}
else{
...//从文件中读取数据
}
// 文件的关闭
fclose(文件指针); //正常返回0,否则返回EOF;
文件读写
a.字符输入/输出函数
- 写字符函数 fputc() —将一个字符写入指定的文件中,其调用格式为:fputc(字符量,文件指针);
- 读字符函数 fgetc() —从指定的文件中读取一个字符,其调用格式:字符变量 = fgetc(文件指针);
#include<stdio.h>
void main()
{
FILE *fp;
char c,fileName[30];
printf("请输入文件名:");
gets(fileName);
if((fp=fopen(fileName,"w"))==NULL){
printf("不能打开文件..");
exit(0);
}
printf("请输入你字符串直到*为\n");
c = getchar();
while(c!='*')
{
fputc(c,fp);
c = getchar();
}
fclose(fp);
//读取文件
fp = fopen(fileName,"r");
while(c=getc(fp)!=EOF)
{
putchar(c);
}
fclose(fp);
}
}
b.文件字符串输入/输出函数
- 从指定的文件中读出一个字符串到字符数组中,格式:fgets(字符数组名,n,文件指针); //表示从文件中读出的字符串不超过n-1个字符。字符最后一个字符前加上串标志’\0’.读取过程中若遇到换行符或者文件结束符(EOF),则读取结束。
- 写字符串函数:fputs(字符串,文件指针); //字符串可以是字符常量,也可以是字符数组。
c.数据块输入/输出函数
- 数据块读函数fread(p,size,n,fp); p指向要要输入/输出数据块的首地址的指针;size:某类型数据存储空间的字节数;n:此次从文件中读取的数据项数。fp:文件指针变量
- 数据块写函数fwrite(p,size,n,fp);
#include<stdio.h>
#define N 5
struct worker{
char name[10];
int id;
float salary;
char addr[15];
}worker[N];
void save()
{
FILE *fp;
int i;
if((fp=fopen("worker.txt","wt"))==NULL){
printf("打开文件失败..\n");
return;
}
for(i=0;i<N;i++){
if(fwrite(&worker[i],sizeof(worker[i]),1,fp)!=1)
printf("写文件失败\n");
}
fclose(fp);
}
void dispaly()
{
FILE *fp;
int i;
if(( fp=fopen("worker.txt","rt"))==NULL){
printf("不能打开文件\n");
return;
}
for(i=0;i<N;i++){
fread(&worker[i],sizeof(worker[i]),1,fp);
printf("%s%d%f%s\n",worker[i].name,worker[i].id,worker[i].salary,worker[i].addr);
}
fclose(fp);
}
void main()
{
FILE *fp;
int i;
if( (fp=fopen("worker.txt","rt"))==NULL){
printf("不能打开文件");
return;
}
for(i=0;i<N;i++)
{
printf("name:");
scanf("%s",worker[i].name);
printf("id:");
scanf("%d",&worker[i].id);
printf("salary:");
scanf("%f",&worker[i].salary);
printf("address:");
scanf("%s",worker[i].addr);
}
save();
dispaly();
fclose(fp);
}
d.字输入/字输出
- putw(w,fp)—将整型数w写入fp所指的文件(以写方式打开的二进制文件).w是要输出的整型数据,可以是常量或变量
- getw(fp) —从fp所指向的文件中读取一个整型数。
文件的定位
- rewind(文件指针)—重置文件位置指针到文件开头。
- fseek(文件指针,位移量,起始位置); 位移量:指被移动的字节数,大于0表示新的位置在初始值的后面。小于0表示在新的位置在初始值的前面。起始位置:0(文件开始处)、1(当前位置)、2(文件末尾处)
- ftell(文件指针)—返回当前指针位置。
案例
#include <stdio.h>
int main(void){
// c语法
int a[3] = {1,2};
int arr1[3] = {1, 2, 3};
int arr2[] = {1, 2, 3}; //在这里,我们arr[3]里边的数字可以不用写;
int arr3[3] = {1, 2}; //也是可以的,只是把最后一个数初始化为0了而已
int arr4[3] = {1, 2, 3, 4}; //是不可以的,不能超过数组长度
char arr5[3] = {'a', 98, 'c'}; //因为是字符类型,所以98其实就是字符'b'
char arr6[] = "abcdef";
printf("数组第一个元素的地址是:%d\n",&a[0]);
printf("数组第一个元素的地址是:%d\n",a);
int i = 0;
for(i = 0 ; i< 3; i++){
printf("对应的值是:%d\n",a[i]);
}
// 下面这就是错误的使用方式。因为a[4]这个不属于数组的范畴。访问到了其他地方的数据,非法访问
printf("a[3]对应的值是:%d\n",a[4]);
// ------ 指针用法 -----
int * p;
p = a;
printf("数组的地址是:%d\n",a);
printf("数组的地址是:%d\n",p);
printf("数组的第一个元素是:%d\n",*(p+1));
// 查看指针变量所占用的字节大小
printf("p占用的字节大小是:%d\n",sizeof(p));
printf("int数据类型占用的字节大小是:%d\n",sizeof(int));
// 指针运算
int a[300] = {1,2};
int * p;
p = &a[50];
int * q ;
q = &a[60];
printf("数组中两个元素相差的个数是:%d\n",(q-p));
return 0;
}
C语言工具
打日志
zlog是一个高可靠性、高性能、线程安全、灵活、概念清晰的纯C日志函数库。zlog在效率、功能、安全性上大大超过了log4c,并且是用c写成的,具有比较好的通用性。
zlog有这些特性: – syslog分类模型,比log4j模型更加直接了当 – 日志格式定制,类似于log4j的pattern layout – 多种输出,包括动态文件、静态文件、stdout、stderr、syslog、用户自定义输出函数 – 运行时手动、自动刷新配置文件(同时保证安全) – 高性能,在作者的笔记本上达到25万条日志每秒, 大概是syslog(3)配合rsyslogd的1000倍速度 – 用户自定义等级 – 多线程和多进程环境下保证安全转档 – 精确到微秒 – 简单调用包装dzlog(一个程序默认只用一个分类) – MDC,线程键-值对的表,可以扩展用户自定义的字段 – 自诊断,可以在运行时输出zlog自己的日志和配置状态 – 不依赖其他库,只要是个POSIX系统就成(当然还要一个C99兼容的vsnprintf)
zlog有3个重要的概念:
- 分类 (Category) 用于区分不同的输入。代码中的分类变量的名字是一个字符串,在一个程序里面可以通过获取不同的分类名的category用来后面输出不同分类的日志,用于不同的目的。
- 格式 (Format) 是用来描述输出日志的格式,比如是否有带有时间戳,是否包含文件位置信息等,上面的例子里面的格式simple就是简单的用户输入的信息+换行符。
- 规则 (Rule) 则是把分类、级别、输出文件、格式组合起来,决定一条代码中的日志是否输出,输出到哪里,以什么格式输出。
# x86 平台安装
git clone git@github.com:HardySimpson/zlog.git
cd zlog
make
sudo make install
# 指定目录安装
mkdir build_x86
make
sudo make PREFIX=../build_x86 install
使用zlog
- test.conf
[rules]
my_cat.INFO >stdout
- test.c
#include <stdio.h>
#include "zlog.h"
int main(int argc, char** argv)
{
int rc;
zlog_category_t *zc;
rc = zlog_init("test.conf");
if (rc)
{
printf("init failed\n");
return -1;
}
zc = zlog_get_category("my_cat");
if (!zc)
{
printf("get cat fail\n");
zlog_fini();
return -2;
}
zlog_info(zc, "微信公众号:嵌入式大杂烩");
zlog_info(zc, "hello, zlog");
zlog_fini();
return 0;
}
编译
export LD_LIBRARY_PATH=./build_x86/lib:$LD_LIBRARY_PATH # 导入 libzlog.so库
# -I:指定头文件路径
# -L:指定动态库的路径。
# -lxxx:链接时需要xxx库。
# 编译test.c
gcc test.c -o test_zlog -I ./build_x86/include -L ./build_x86/lib/ -lzlog -lpthread
GUI 界面开发
【2022-3-10】C 语言桌面端图形界面开发库
LCUI 是一个用 C 编写的图形界面开发库,你可以用 C、XML 和 CSS 创建简单的桌面应用,包括传统的 Win32 桌面应用、Windows 通用应用。
功能特性
- C 语言编写: 适用于体积较小且主要使用 C 语言实现的应用程序,以及偏向使用 C 语言编写简单应用的开发者。
- 跨平台: 支持 Windows 和 GNU/Linux 系统,可开发简单的 Windows 桌面应用和通用应用,以及 Linux 桌面应用。
- XML + CSS: 预置 XML 和 CSS 解析器,你可以使用 XML 和 CSS 来描述界面结构和样式。
- 与网页类似的开发体验: 由于 LCUI 的布局、样式和渲染器等相关功能的设计和实现大都参考了 MDN 文档和一些 Web 前端流行的开发库,因此开发体验和界面效果会与网页有一些相似之处,如果你已经有用 HTML 和 CSS 编过网页的经验,那么会比较容易上手。
- 可缩放: 支持全局缩放,支持使用基于屏幕密度的 sp 和 dp 单位表示界面元素的位置和大小。
效果:
用于开发 LCUI 应用程序的命令行工具
- lcui-cli 项目地址
- LCUI 的路由管理器,用于解决 LCUI 应用内多视图的切换和状态管理问题
- 专为 LCUI 开发的组件库 lc-design,包含了一些通用组件和 CSS 样式,组件设计参考自 Bootstrap、ElementUI、AntDesign
- 图片管理器,LCUI 的旗舰级应用程序 LC-Finder
- 基于 JavaScript 语法且可编译为 C 的语言,预置 LCUI 绑定,提供类似于 React 的声明式 UI 开发体验,trad
C++
C++ 组件
- C++语言的四个层次:
- C。没有C++的面向对象,没有模板,没有异常,没有重载等。
- Object-Oriented C++。这部分也就是C with Classes。classes、封装、继承、多态、虚函数。这部分是面向对象的特性。
- Template C++。这部分是C++的泛型编程部分。这部分带来的是template metaprogramming,也就是所谓的模板元编程。
- STL。STL是个template程序库。它对容器、迭代器、算法及函数对象的规约,并且是以templates及程序库的方式构建出来。
每个层次应该有自己的最佳实践。
- 例如对于C层次,传入函数最佳的实践应该是传入值,而不是指针,而对于C with classes层次,则以传递引用为最佳的实践。
配套工具
- 编译器:gcc, Clang
- 调试器:GDB
- 内存测试:Valgrind,用于测试c内存使用的错误
- Make:让你不用直接调用编译器
- pkg-config: 查找库
- Doxyen:生成程序文档
C/C++区别
【2022-4-23】C语言和C++的区别和联系
C++和C语言本来就是两种不同的编程语言,但C++确实是对C语言的扩充和延伸,并且对C语言提供后向兼容的能力。对于有些人说的C++完全就包含了C语言的说法也并没有错。
| 编程模式 | 解释 | 优点 | 缺点 |
|---|---|---|---|
| 面向过程编程 | 分解步骤,逐步实现,依次调用 | 性能高,如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发 | 不好维护 |
| 面向对象编程 | 定义对象,调用方法,解决问题 | 封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易维护、易复用、易扩展, | 类调用时需要实例化,开销比较大,比较消耗资源 |
C++一开始被本贾尼·斯特劳斯特卢普(Bjarne Stroustrup)发明时,起初被称为“C with Classes”,即「带类的C」。是在C语言的基础上扩充了类class等面向对象的特性和机制。但是后来经过一步步修订和很多次演变,最终才形成了现如今这个支持一系列重大特性的庞大编程语言。
从结构体到类
C++ 是一门面向对象的编程语言,理解 C++,首先要理解类(Class)和对象(Object)这两个概念。
C++ 中的类(Class)可以看做C语言中结构体(Struct)的升级版。结构体是一种构造类型,可以包含若干成员变量,每个成员变量的类型可以不同;可以通过结构体来定义结构体变量,每个变量拥有相同的性质。
结构体和类都可以看做一种由用户自己定义的复杂数据类型,在C语言中可以通过结构体名来定义变量,在 C++ 中可以通过类名来定义变量。不同的是,通过结构体定义出来的变量还是叫变量,而通过类定义出来的变量有了新的名称,叫做对象(Object)。
C语言版本
#include <stdio.h>
//定义结构体 Student
struct Student{
//结构体包含的成员变量
char *name;
int age;
float score;
};
//显示结构体的成员变量,函数与结构体分离
void display(struct Student stu){
printf("%s的年龄是 %d,成绩是 %f\n", stu.name, stu.age, stu.score);
}
int main(){
struct Student stu1; // 用struct关键词
//为结构体的成员变量赋值
stu1.name = "小明";
stu1.age = 15;
stu1.score = 92.5;
//调用函数
display(stu1);
return 0;
}
C++版本
#include <stdio.h>
//通过class关键字类定义类
class Student{
public:
//类包含的变量
char *name;
int age;
float score;
//类包含的函数
void say(){
printf("%s的年龄是 %d,成绩是 %f\n", name, age, score);
}
};
int main(){
//通过类来定义变量,即创建对象
class Student stu1; //也可以省略关键字class
//为类的成员变量赋值
stu1.name = "小明";
stu1.age = 15;
stu1.score = 92.5f;
//调用类的成员函数
stu1.say();
return 0;
}
分析
- C语言中的 struct 只能包含变量,而 C++ 中的 class 除了可以包含变量,还可以包含函数。
- display() 是用来处理成员变量的函数,在C语言中,将它放在了 struct Student 外,它和成员变量是分离的;
- 而在 C++ 中,将它放在了 class Student 内部,使它和成员变量聚集在一起,看起来更像一个整体。
总结
- C语言是面向过程语言,而C++是面向对象语言
- 面向过程:分析出解决问题的步骤,然后把这些步骤一步一步的实现,使用的时候一个一个的依次调用就可以了。
- 面向对象:把问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为。
- 1、关键字的不同
- C语言有32个关键字;C++有63个关键字;
- 2、后缀名不同
- C源文件后缀.c,C++源文件后缀.cpp,在VS中,如果在创建源文件时什么都不给,默认是.cpp。
- 3、返回值类型
- C语言中,如果一个函数没有指定返回值类型,默认返回int类型;C++中,如果一个函数没有返回值则必须指定为void。
- 4、参数列表
- C语言中,函数没有指定参数列表时,默认可以接收任意多个参数;
- 但在C++中,因为严格的参数类型检测,没有参数列表的函数,默认为 void,不接收任何参数
- 5、缺省参数
- 缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的参。(C语言不支持缺省参数)
- 6、函数重载
- 函数重载:函数重载是函数的一种特殊情况,指在同一作用域中,声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数、类型、顺序)必须不同,返回值类型可以相同也可以不同,常用来处理实现功能类似数据类型不同的问题。(C语言没有函数重载,C++支持函数重载)。
- C语言不存在函数重载,C++根据函数名参数个数参数类型判断重载,属于静多态,必须同一作用域下才叫重载。
- 7、const
- C中的const叫只读变量,只是无法做左值的变量;C++中的const是真正的常量,但也有可能退化成c语言的常量,默认生成local符号。
- C语言中被const修饰的变量不是常量,叫做常变量或者只读变量,这个常变量是无法当作数组下标的。然而在C++中const修饰的变量可以当作数组下标使用,成为了真正的常量,这就是C++对const的扩展。
- C语言中的const:被修饰后不能做左值,可以不初始化,但是之后没有机会再初始化。不可以当数组的下标,可以通过指针修改。它和普通变量的区别只是不能做左值而已,其他地方都是一样的。
- C++中的const:真正的常量。定义的时候必须初始化,可以用作数组的下标。const在C++中的编译规则是替换(和宏很像),所以它被看作是真正的常量。
- 8、引用
- 引用从底层来说和指针就是同一个东西,但是在编译器中它的特性和指针完全不同。
- 9、malloc,free && new,delete
- 重点需要关注的问题。malloc()和free()是C语言中动态申请内存和释放内存的标准库中的函数。而new和delete是C++运算符、关键字。new和delete底层其实还是调用了malloc和free。
- 它们之间的区别有以下几个方面:
- 1)、malloc和free是函数,new和delete是运算符。
- 2)、malloc在分配内存前需要大小,new不需要。
- 3)、malloc不安全,需要手动类型转换,new不需要类型转换。
- 4)、free只释放空间,delete先调用析构函数再释放空间(如果需要)。与第⑤条对应,如果使用了复杂类型,先析构再call operator delete回收内存。
- 5)、new是先调用构造函数再申请空间(如果需要)
- 6)、内存不足(开辟失败)时处理方式不同。malloc失败返回0,new失败抛出bad_alloc异常。
- 7)、new和malloc开辟内存的位置不同。malloc开辟在堆区,new开辟在自由存储区域。
- 8)、new可以调用malloc(),但malloc不能调用new。new就是用malloc()实现的,new是C++独有malloc当然无法调用。
- 10、作用域
- C语言中作用域只有两个:局部,全局。C++中则是有:局部作用域,类作用域,名字空间作用域三种。所谓名字空间就是namespace,我们定义一个名字空间就是定义一个新作用域
C++为什么没有开源库
【2022-5-3】C++为什么没那么多开源库
c++很多静态或者动态的类库都是闭源的,比如Linux里面的.a文件是静态库,.so文件是动态库,比如windows里面的.lib文件是静态库,.dll文件是动态库,都是二进制文件。所以如果问题把“开源”去掉,就值得商榷了,可以这么说,只要你c++玩的溜,整个操作系统API都是你的类库。c++太底层了,导致其实很多著名的python的库都衍生自c++库。c++的开源库最终都要编译成静态库或者动态库被你自己的代码调用。Linux下面./configure,然后make
为什么C++没有Python这样活跃的生态?
- 根本原因在于C++没有解决好一个问题:菱形依赖
什么叫菱形依赖呢?
- A依赖B,A也依赖C,但是B和C同时依赖D,并且限定D并不是STL这样的标准库,BCD都是开源库。
- D –> {B, C} –> A
- 为了限定到C++,这里BCD都是C++库,采用源码的方式发布。
C++当中会怎样呢?
- B和C中至少一个将D的源码合并到了自己的源码里面,放到thirdparty之类的目录里。A将两份源代码加自己的一起放到thirdparty里面,编译,符号冲突,爆炸。
- B和C在install说明中提到,必须把依赖放到某个地方,然后修改 Makefile/CMAKE/Bazel 配置,将D的源码目录加进来。结果B和C编译出来的.a里面还是带着D的全部符号,A尝试二进制链接,符号冲突,爆炸。
- B和C在install说明中提到,需要将D的依赖放在某个地方,先编译成.a,设置好参数直接链接.a。但是B和C要求的D的编译参数不一样,链接不到一起,爆炸。
- 把所有的依赖都一个个放在独立的位置上,设置好include目录,每个都用自己的Makefile独自编译成.a,编译参数用同一套,最后再一个一个指定起来链接到一起——人工成本爆炸。
- A希望B和C通过动态链接方式连接,方便升级。动态链接库里面链接了D的符号,加载起来符号冲突,爆炸。B和C一个动态链接了D,一个静态链接了D,还是符号冲突,爆炸。
- D把自己改成了header only的库,终于不需要单独编译了。B和C在引用D的时候设置的宏不一样,导致编译出的弱符号不兼容,链接完运行崩溃,爆炸。
最后对于C++库作者来说,就变成了这样一个结果:
- 如果要提供一个好用、好编译、不给我天天找事情的库,那么不能引用其它的开源库 没有比这更矛盾的事情了,要造轮子,第一件事情是不能用别人的轮子。
Linux上面唯一有点生态意思的做法,是引用yum/apt源里面的xxx-dev这样的库,这些库通过pkgconfig方式组织,而且通过包管理系统保证大家下载到的都是相同且兼容而且编译好了的二进制库,引用起来很方便。但是,只有把接口限定到纯C才能发布确保二进制兼容的库,那折腾了半天,就算内部是C++开发的,一到库的边界上还得转成纯C,也就失去了C++语言的优势了。
知识点及学习路径
【2022-3-16】用一年时间如何能掌握 C++
一、C++基础(3个月)
- 1、面向对象的三大特性:封装、继承、多态
- 2、类的访问权限:private、protected、public
- 3、类的构造函数、析构函数、赋值函数、拷贝函数
- 4、移动构造函数与拷贝构造函数对比
- 5、深拷贝与浅拷贝的区别
- 6、空类有哪些函数?空类的大小?
- 7、内存分区:全局区、堆区、栈区、常量区、代码区
- 8、C++与C的区别
- 9、struct与class的区别
- 10、struct内存对齐
- 11、new/delete与malloc/free的区别
- 12、内存泄露的情况
- 13、sizeof与strlen对比
- 14、指针与引用的区别
- 15、野指针产生与避免
- 16、多态:动态多态、静态多态
- 17、虚函数实现动态多态的原理、虚函数与纯虚函数的区别
- 18、继承时,父类的析构函数是否为虚函数?构造函数能不能为虚函数?为什么?
- 19、静态多态:重写、重载、模板
- 20、static关键字:修饰局部变量、全局变量、类中成员变量、类中成员函数
- 21、const关键字:修饰变量、指针、类对象、类中成员函数
- 22、extern关键字:修饰全局变量
- 23、volatile关键字:避免编译器指令优化
- 24、四种类型转换:static_cast、dynamic_cast、const_cast、reinterpret_cast
- 25、右值引用
- 26、std::move函数
- 27、四种智能指针及底层实现:auto_ptr、unique_ptr、shared_ptr、weak_ptr
- 28、shared_ptr中的循环引用怎么解决?(weak_ptr)
- 29、vector与list比较
- 30、vector迭代器失效的情况
- 31、map与unordered_map对比
- 32、set与unordered_set对比
- 33、STL容器空间配置器
参考书籍:《C++ Primer》(第5版)、《STL源码剖析》、《深度探索C++对象模型》
二、计算机网络(1个月)
- 1、OSI7层网络模型:应用层、表示层、会话层、运输层、网络层、链路层、物理层
- 2、TCP/IP四层网络模型:应用层、运输层、网际层、接口层
综合OSI与TCP/IP模型,学习五层网络模型:
- 从上向下架构:应用层、运输层、网络层、链路层、物理层
- 链路层:
- 3、MTU
- 4、MAC地址
- 网络层:
- 5、地址解析协议
- 6、为啥有IP地址还需要MAC地址?同理,为啥有了MAC地址还需要IP地址?
- 7、网络层转发数据报的流程
- 8、子网划分、子网掩码
- 9、网络控制报文协议ICMP
- 10、ICMP应用举例:PING、traceroute
- 运输层:
- 11、TCP与UDP的区别及应用场景
- 12、TCP首部报文格式(SYN、ACK、FIN、RST必须知道)
- 13、TCP滑动窗口原理
- 14、TCP超时重传时间选择
- 15、TCP流程控制
- 16、TCP拥塞控制(一定要弄清楚与流量控制的区别)
- 17、TCP三次握手及状态变化。为啥不是两次握手?
- 18、TCP四次挥手及状态变化。为啥不是三次挥手?
- 19、TCP连接释放中TIME_WAIT状态的作用
- 20、SYN泛洪攻击。如何解决?
- 21、TCP粘包
- 22、TCP心跳包
- 23、路由器与交换机的区别
- 24、UDP如何实现可靠传输
- 应用层:
- 25、DNS域名系统。采用TCP还是UDP协议?为什么?
- 26、FTP协议(了解)
- 27、HTTP请求报文与响应报文首部结构
- 28、HTTP1.0、HTTP1.1、HTTP2.0对比
- 29、HTTP与HTTPS对比
- 30、HTTPS加密流程
- 31、方法:GET、HEAD、POST、PUT、DELETE
- 32、状态码:1、2、3、4、5**
- 33、cookie与session区别
- 34、输入一个URL到显示页面的流程(越详细越好,搞明白这个,网络这块就差不多了)
参考书籍:《计算机网络》(第5版)、《TCP/IP详解卷1:协议》、《图解HTTP》
三、操作系统(1个月)
- 1、进程与线程区别
- 2、线程同步的方式:互斥锁、自旋锁、读写锁、条件变量
- 3、互斥锁与自旋锁的底层区别
- 4、孤儿进程与僵尸进程
- 5、死锁及避免
- 6、多线程与多进程比较
- 7、进程间通信:PIPE、FIFO、消息队列、信号量、共享内存、socket
- 8、管道与消息队列对比
- 9、fork进程的底层:读时共享,写时复制
- 10、线程上下文切换的流程
- 11、进程上下文切换的流程
- 12、进程的调度算法
- 13、阻塞IO与非阻塞IO
- 14、同步与异步的概念
- 15、静态链接与动态链接的过程
- 16、虚拟内存概念(非常重要)
- 17、MMU地址翻译的具体流程
- 18、缺页处理过程
- 19、缺页置换算法:最久未使用算法、先进先出算法、最佳置换算法
ps:操作系统的内容看起来不是很多,实际上每个问题答案的底层原理要弄懂还是很考验基本功的。比如:互斥锁与自旋锁的区别,实际上涉及到阻塞时线程的状态是不一样的。互斥锁阻塞的线程是挂起的,此时系统会优先执行其它可执行的线程,就会将阻塞的线程切换到可执行线程,而当临界区执行的时间非常短时,此时线程切换频繁、开销较大,此时就会采用自旋锁的方式,让阻塞的线程处于忙等状态。
参考书籍:《深入理解计算机系统》
四、网络编程(1个月)
- 1、IO多路复用:select、poll、epoll的区别(非常重要,几乎必问,回答得越底层越好,要会使用)
- 2、手撕一个最简单的server端服务器(socket、bind、listen、accept这四个API一定要非常熟练)
- 3、线程池
- 4、基于事件驱动的reactor模式
- 5、边沿触发与水平触发的区别
- 6、非阻塞IO与阻塞IO区别
参考书籍:《Unix网络编程》
ps:网络编程掌握以上几点就够了,要搞明白还是要花很久时间的。
五、数据结构与算法及刷题(2个月)
- 1、数组
- 2、链表
- 3、栈
- 4、队列
- 5、堆
- 6、二叉树:二叉搜索树、平衡树、红黑树
- 7、B树、B+树
- 8、哈希表及哈希冲突
- 9、排序算法:冒泡排序、简单选择排序、插入排序、希尔排序、归并排序、堆排序、快速排序(要求能够面试时手写出堆排序和快速排序)
- 10、二分法:旋转数组找target
- 11、回溯法:全排列、复原IP地址
- 12、动态规划(掌握基本的动态规划的几个题其实就够了,如:斐波那契数列、接雨水、股票的最佳买入时机) 参考书籍:《图解算法》《剑指offer》 ps:建议刷题与数据结构算法同时进行,这样理解得更深入。刷题网站leetcode,刷完《剑指offer》其实就能解决大部分面试手撕了。
六、mySQL数据库(7天~15天)
- 1、数据存储引擎:InnoDB、myISAM、Memory
- 2、数据库索引类型及原理:B+树索引、哈希表索引
- 3、锁:悲观锁、乐观锁
- 4、事务:事务的四大特性(ACID)、事务并发的三大问题、事务隔离级别及实现原理
- 5、多版本并发控制实现机制(MCVV)原理
参考书籍:《高性能MySQL》
ps:这里也可以参考本人写的博客:mysql知识点总结。
七、项目(2个月)
- 如果时间够的话就可以写一个项目,当然大部分人写的项目都是一个烂大街的项目,也就是“web高性能服务器”。其实就是根据陈硕大神写的《Linux高性能服务器编程:使用muduo C++网络库》进行改编,当然啦,读懂这本书还是很耗时的,学习其中的思想也会受益匪浅的。 总结
- 按照上面推荐的内容来学习的话,要学习得深入一点的话1年的时间肯定需要的,甚至2年也不足为其。当然对于非科班的学生来说,大部分都没有充足的时间的,这时候建议尽量把C++基础、计算机网络、操作系统、网络编程、数据结构与算法这五个部分的内容学得很扎实,大概6个月的时间。
然后说一下我本人的学习情况:
- 2020年3~8月:疫情在家大概3月份开始准备学习C++,因为在家效率极低,玩三天学一天,到7、8月份也只是会用C++,然后写了个MFC的小项目练了练手。
- 2020年9月:前半个月学习计算机网络,后半个月学习深入理解计算机系统(当然第一遍只看懂个大概)
- 2020年10月-12月:写多线程服务器项目(即改编muduo),这个过程中伴随学习网络编程、操作系统、C++各种知识(之前C++只学了皮毛)
- 2021年1月-2月:学习数据结构与算法并刷题,刷了不到200题。(其中寒假在家玩了半个月)
- 2021年3月:开启海投模式,先投了一批小公司,基本都简历挂,总算有几个小厂给了面试机会,边面试边复习。3月中旬开始投大厂,除了美团一面挂,字节、腾讯、百度面试都很顺利,没挂过,清明之前拿到了字节的口头offer。
- 2021年4月:字节的正式offer邮件。
C++发展历史
- 1978年Bjarne Stroustrup就开始了C++雏形的使用,直到20年后的1998年才确定了第一个C++标准
- C++11之前被称为C++0x,据说C++0x是C++11的草案,所以有些编译器使用C++11的编译参数是:-std=c++0x,后来使用:-std=c++11,但是据说不完全相同
- 关于C++20,协程的加入应该是一大惊喜了,值得期待!官方还表示,C++20 应该会是一个像 C++11 那样的大版本
- C++11,(即ISO/IEC 14882:2011),是目前的C++编程语言的最新正式标准。它取代了第二版标准
- 第一版公开于1998年,第二版于2003年更新,分别通称C++98以及C++03,两者差异很小。
- 新的标准包含核心语言的新机能,而且扩展C++标准程序库。C++11新标准由C++标准委员会于2011年8月12日公布,并于2011年9月出版。此次标准为C++98发布后13年来第一次重大修正。
- 编译的时候添加-std=c++11选项
- C++11 是第二个真正意义上的 C++ 标准,也是 C++ 的一次重大升级。C++11 增加了很多现代编程语言的特性,比如自动类型推导、智能指针、lambda 表达式等,这使得 C++ 看起来又酷又潮,一点也不输 Java 和 C#。
- C++11 新特性
- 关键字及新语法
- auto 关键字及用法
- C++11 之前,auto 具有存储期说明符的语义。auto在C++98中的标识临时变量的语义,由于使用极少且多余,在C++11中已被删除。前后两个标准的auto,完全是两个概念。
- nullptr 关键字及用法
- 引入nullptr,是因为重载函数处理 NULL 的时候会出问题,二义性
void foo(int); //(1)
void foo(void*); //(2)
foo(NULL); // 重载决议选择 (1),但调用者希望是 (2)
foo(nullptr); // 调用(2)
- for 循环语法
- for ( 范围声明 : 范围表达式 ) 循环语句
STL 容器
- std::array
- std::array 提供了静态数组,编译时确定大小、更轻量、更效率,当然也比 std::vector 有更多局限性。
- std::forward_list
- 单向链表
- std::unordered_map
- std::unordered_set
#include <iostream>
//需要引入 array 头文件
#include <array>
using namespace std;
int main()
{
std::array<int, 4> values{};
//初始化 values 容器为 {0,1,2,3}
for (int i = 0; i < values.size(); i++) {
values.at(i) = i;
}
//使用 get() 重载函数输出指定位置元素
cout << get<3>(values) << endl;
//如果容器不为空,则输出容器中所有的元素
if (!values.empty()) {
for (auto val = values.begin(); val < values.end(); val++) {
cout << *val << " ";
}
}
std::vector<int> v {1,2,3,4,5};
std::vector<int> v1 (5,2); // 5个2
// print all elements of vector to console
for (int x : v) { cout << x << '\n'; }
int j = 10;
do {
cout << j << ' ';
--j;
} while (j > 0);
}
【2021-6-11】STL用法示例
#include <iostream>
#include <vector>
#include<list>
#include<map>
using namespace std;
int main()
{
vector<int> a={4,7,2};
//a.insert(1,30);
a.push_back(12);
std::cout<<"front: "<<a.front()<<", back:"<<a.back();
try{
a.at(10);
}catch (out_of_range e) {
std::cout<<"\n 异常捕获:"<<e.what()<<std::endl;
}
std::cout<<"\n 数组取值:";
for(size_t i=0;i<a.size();i++)
{
std::cout<<i<<"->"<<a[i]<<",";
}
std::cout<<"\n 迭代器取值:";
vector<int>::iterator i1; // 迭代器
vector<int>::const_iterator i2; // 常量迭代器
vector<int>::reverse_iterator i3; // 常量迭代器
std::cout<<"\n while: ";
i1 = a.begin();
while(i1<a.end())
{
std::cout<<*i1<<", ";
i1 += 2;
}
std::cout<<"\n for: ";
for(i1=a.begin();i1!=a.end();i1++)
{
std::cout<<*i1<<", ";
}
std::cout<<"\n反向迭代器:";
for(i3=a.rbegin();i3!=a.rend();i3++)
{
std::cout<<*i3<<", ";
}
std::cout<<"\n test"<<std::endl;
std::cout<<"\n list用法"<<std::endl;
list<int> b(4); // 初始化4个0的数组
list<int>::iterator i4;
for(i4=b.begin();i4!=b.end();i4++)
{
std::cout<<*i4<<",";
}
std::cout<<"\n map"<<std::endl;
map<string,int> dict;
dict["a"] = 1;
dict.insert(make_pair("b",2));
map<string,int>::iterator d;
for(d=dict.begin();d!=dict.end();d++)
{
std::cout<<(*d).first<<": "<<(*d).second<<", ";
}
}
多线程
- std::thread
- 在 C++11 以前,C++ 的多线程编程均需依赖系统或第三方接口实现
- 一定程度上影响了代码的移植性。
- C++11 中,引入了 boost 库中多线程的部分内容,形成标准后的接口与 boost 库基本没有变化,这样方便了使用者切换使用 C++ 标准接口。
- std::atomic
- 从实现上,可以理解为这些原子类型内部自己加了锁。
- std::condition_variable
智能指针内存管理
- std::shared_ptr
- std::weak_ptr
其他
- std::function、std::bind 封装可执行对象
- lambda 表达式
- lambda 表达式用于定义并创建匿名的函数对象,以简化编程工作。
C++11 编译器支持
参考的知乎问答:
- 编译器对C++0x和C++11的支持
- GCC编译器对C++11的特性支持
- codecvt用于编码转换,在GCC 5时引入,在GCC 7(C++17)时废弃。
- GCC 4.9时正则表达式
- GCC 4.8时引入了类成员变量函数返回值的左值、右值引用
- GCC 4.7时正式启用-std=c++11,之前都是使用-std=c++0x
- GCC 4.6时引入了range based for,即for each。
- GCC 4.5时引入了lambda表达式,大大方便了函数式编程。
- stoi/stod和to_string系列函数其实很早就引入了GCC(< 4.5)
参考zh.cppreference.com整理的对于各个标准特性的支持情况(包含C++11,C++14,17等等):
【2021-6-30】每当我C++学习不下去的时候,我就会打开这14个网站
选取GCC中个人目前注意的几个:
- auto, 4.4
- C++0x/C++11 为 auto 关键字定义了完全不同的语义,4.5开始支持 参考:GCC 4.5 中的 C++0x 特性支持
- nullptr, 4.6
- 范围 for 循环, 4.6
- for ( 范围声明 : 范围表达式 ) 循环语句
- noexcept, 4.6
- 指定函数是否抛出异常。
void f() noexcept; // 函数 f() 不抛出
- 指定函数是否抛出异常。
- override 与 final, 4.7
- override 指定一个虚函数覆盖另一个虚函数。 override 说明符
- final 指定某个虚函数不能在子类中被覆盖,或者某个类不能被子类继承。 final 说明符
- decltype 4.8.1
- 检查实体的声明类型,或表达式的类型和值类别。
- 代码示例, 在线编译器:
- dooccn,带补全,高亮,可以输入数据,关键是在大陆,速度快; 覆盖40多种编程语言
- c++ insights,可以切换c++版本,看到解析结果,类似的,gcc.godbolt.org可以展示汇编结果
- wandbox,除了c++版本,还能选择gcc、boost版本,指定编译命令
#include<iostream>
#include<cstring>
#include<cctype>
using namespace std;
int main()
{
string str("some string");
// range for 语句
for(auto &c : str)
{
c = toupper(c);
}
cout << str << endl;
return 0;
}
- 相比于C++03,C++11标准包含核心语言的新机能,而且扩展C++标准程序库,并入了大部分的C++ Technical Report 1程序库(数学的特殊函数除外)。
程序编译
gcc 编译器
GNU CC(简称gcc)是GNU项目中符合ANSI C标准的编译系统,能够编译用C、C++、Object C、Jave等多种语言编写的程序。
gcc又可以作为交叉编译工具,它能够在当前CPU平台上为多种不同体系结构的硬件平台开发软件,非常适合在嵌入式领域的开发编译,如常用的arm-linux-gcc交叉编译工具
通常后跟一些选项和文件名来使用 GCC 编译器。
GCC:GNU Compiler Collection(GNU 编译器集合),在为Linux开发应用程序时,绝大多数情况下使用的都是C语言,因此几乎每一位Linux程序员面临的首要问题都是如何灵活运用C编译器。
- 目前 Linux下最常用的C语言编译器是GCC(GNU Compiler Collection),它是GNU项目中符合ANSI C标准的编译系统,能够编译用C、C++和Object C等语言编写的程序。GCC不仅功能非常强大,结构也异常灵活。
g++ 编译器
gcc与g++区别
GNU:一个操作系统- 1、gcc 和 g++ 都是
GNU(组织)的一个编译器- GCC:GNU Compiler Collection(GNU编译器集合)的缩写,一组GNU操作系统中的编译器集合,用于编译C、C++、Java、Go、Fortan、Pascal、Objective-C等语言。
- 2、gcc 是 GCC 中的
GUNC Compiler(C 编译器) - 3、g++ 是 GCC 中的
GUNC++ Compiler(C++编译器) - 4、更准确:
gcc调用了C compiler,而g++调用了C++ compiler - 5、对于
*.c和*.cpp文件gcc分别当做c和cpp文件编译(c和cpp的语法强度是不一样的);g++则统一当做cpp文件编译
编译过程
编译流程
C++开发时,编译的过程主要分为 4 个阶段:预处理(预编译)、编译和优化、汇编和链接。GCC 的编译器可以将这 4 个步骤合并成一个。
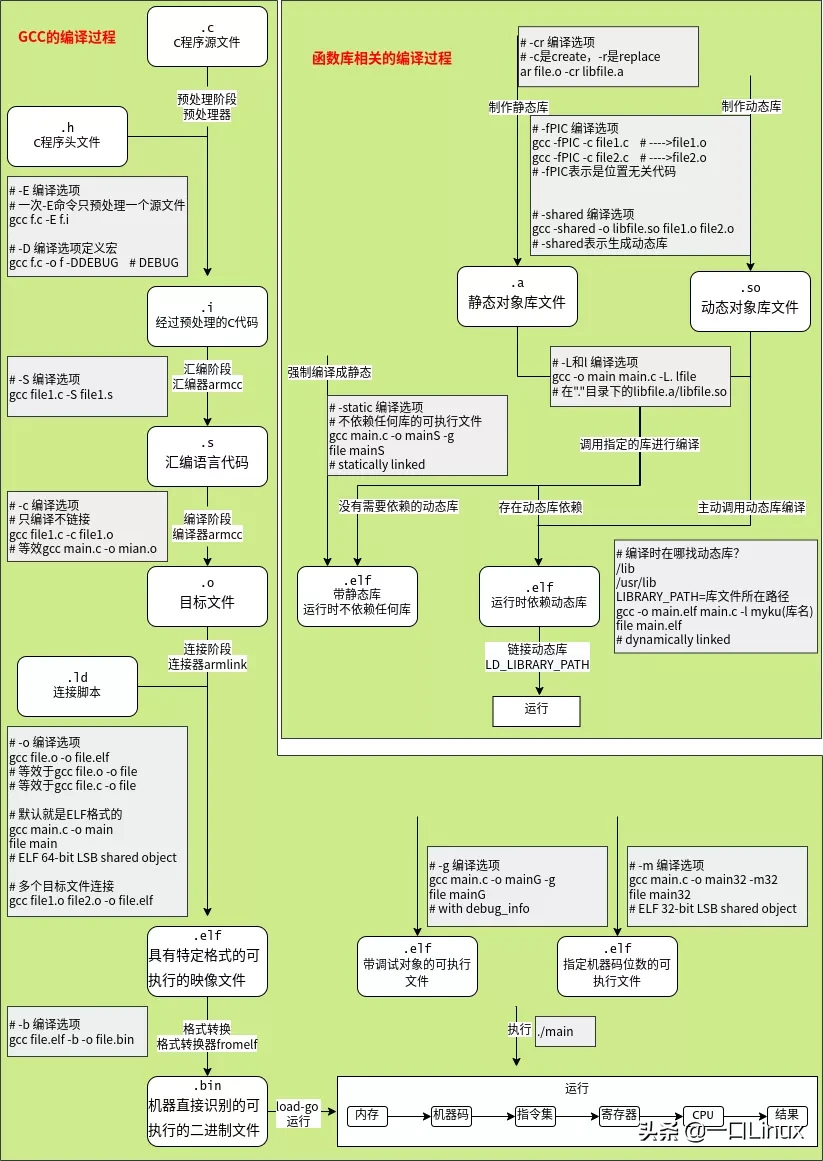
预处理:主要做了三件事: 展开头文件 、宏替换 、去掉注释行. 这个阶段需要 GCC 调用预处理器来完成,最终得到的还是源文件,文本格式编译:GCC 调用编译器对文件进行编译,最终得到一个汇编文件汇编:GCC 调用汇编器对文件进行汇编,最终得到一个二进制文件链接:GCC 调用链接器对程序需要调用的库进行链接,最终得到一个可执行的二进制文件
详情
- 预处理器:宏定义替换,头文件展开,条件编译展开,删除注释。
- gcc -E选项可以得到预处理后的结果,扩展名为.i 或 .ii。
- C/C++预处理不做任何语法检查,不仅是因为它不具备语法检查功能,也因为预处理命令不属于C/C++语句(这也是定义宏时不要加分号的原因),语 - 法检查是编译器要做的事情。
- 预处理之后,得到的仅仅是真正的源代码。
- 编译器:生成汇编代码,得到汇编语言程序(把高级语言翻译为机器语言),该种语言程序中的每条语句都以一种标准的文本格式确切的描述了一条低级机器语言指令。
- gcc -S选项可以得到编译后的汇编代码文件,扩展名为.s。
- 汇编语言为不同高级语言的不同编译器提供了通用的输出语言。
- 汇编器:生成目标文件。
- gcc -c选项可以得到汇编后的结果文件,扩展名为.o。
- .o文件,是按照的二进制编码方式生成的文件。
- 链接器:生成可执行文件或库文件。
- 静态库:指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了,其后缀名一般为“.a”。
- 动态库:在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可执行文件比较小,动态库一般后缀名为“.so”。
- 可执行文件:将所有的二进制文件链接起来融合成一个可执行程序,不管这些文件是目标二进制文件还是库二进制文件。
编译命名
单文件编辑
# 预处理,生成预编译文件
g++ –E hello.cpp –o hello.i
# 编译,生成汇编代码
g++ –S hello.i –o hello.s
# 汇编,生成目标文件
g++ –c hello.s –o hello.o
# 链接,生成可执行文件
g++ hello.o –o hello # -o指定输出文件名
# 调试
g++ -g -o test test.cpp
多文件编译
- 文件:func.h,func.cpp,main.cpp
- 头文件只是起到声明作用,编译两个*.cpp文件并链接即可。
# 输入下面两行分别编译两个文件:
g++ -c func.cpp
g++ -c main.cpp
# 编译完成后生成两个文件:func.o,main.o
# 通过链接就可以得到最终的可执行程序:
g++ main.o func.o -o main
编译选项
编译选项
-std=c++11 : 指明项目使用c++11-I(大写的i)./include/ : 指定项目使用的头文件路径,这样项目中使用头文件就不用写全路径了;-L./lib/ : 指定项目链接的库路径-lopencv_ml452(小写的L):链接libopencv_ml452.a库;(链接动态库和静态库都是这样使用,默认链接动态库) 如果需要链接静态库,可以将静态库改个名字,例如改成libopencv_ml4521.a,然后就可以这样去链接静态库:-lopencv_ml4521
参数介绍:
- -l(小写的L):指定要链接的库。
- -L:指定库的搜索路径。
- -I(大写的i): 指定头文件所在目录。
- -static :此选项将禁止使用动态库,所以,编译出来的可执行文件,一般都很大。不需要其他什么运行环境就可以直接运行。
- -share :编译尽量使用动态库,所以生成文件比较小,但是需要运行该代码的机器包含有程序需要的动态链接库。
- -O0,-O1,-O2,-O3:编译器的优化选项的 4 个级别,-O0 表示没有优化, -O1 为默认值,-O3 优化级别最高。
图解
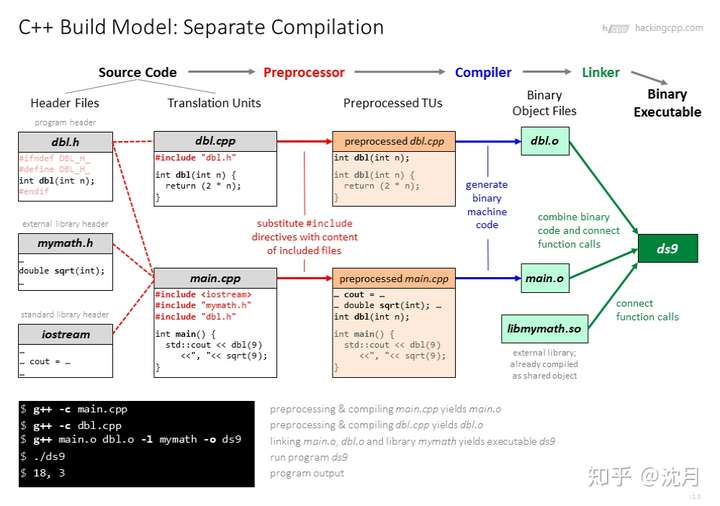
- 【2020-12-28】超好C++ cheatsheet

- 【2022-2-11】一图总结gcc编译&函数库编译、加载过程
静态库
- 静态库与动态库(C++静态库与动态库)
- 库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。库有两种:静态库(.a、.lib)和动态库(.so、.dll)
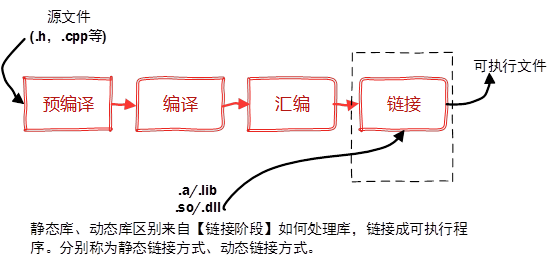
- 静态库
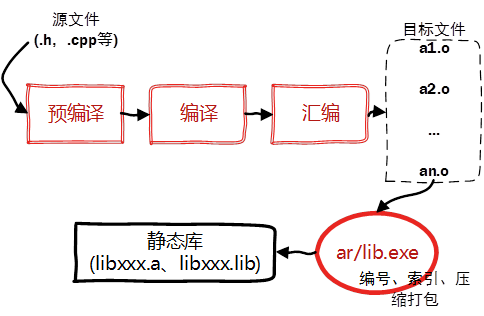
- 【静态库】,是因为在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件中。
- Linux下使用ar工具、Windows下vs使用lib.exe,将目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索。
- g++ -c StaticMath.cpp
- 或:g++ TestStaticLibrary.cpp -L../StaticLibrary -lstaticmath
- ar -crv libstaticmath.a StaticMath.o
- 生成静态库libstaticmath.a
- 测试代码:TestStaticLibrary.cpp
- #include “StaticMath.h”
- StaticMath sm; sm.print();
- Linux下使用静态库,只需要在编译的时候,指定静态库的搜索路径(-L选项)、指定静态库名(不需要lib前缀和.a后缀,-l选项)。
- g++ TestStaticLibrary.cpp -L../StaticLibrary -lstaticmath
- -L:表示要连接的库所在目录
- -l:指定链接时需要的动态库,编译器查找动态连接库时有隐含的命名规则,即在给出的名字前面加上lib,后面加上.a或.so来确定库的
动态库
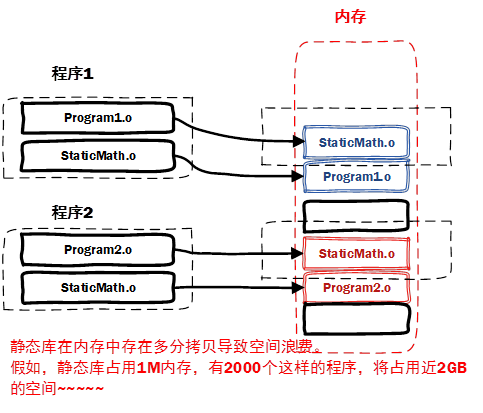
- 为什么还需要动态库?静态库的特点导致。
- 空间浪费是静态库的一个问题。
- 静态库对程序的更新、部署和发布麻烦。如果静态库liba.lib更新了,所以使用它的应用程序都需要重新编译、发布给用户(对于玩家来说,可能是一个很小的改动,却导致整个程序重新下载,全量更新)。
- 空间浪费是静态库的一个问题。
- 动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦。用户只需要更新动态库即可,增量更新。
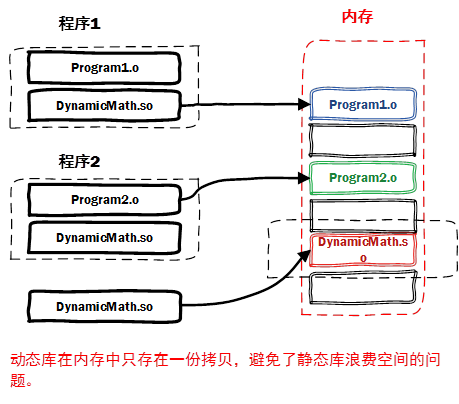
- 动态库特点总结:
- 动态库把对一些库函数的链接载入推迟到程序运行的时期。
- 可以实现进程之间的资源共享。(因此动态库也称为共享库)
- 将一些程序升级变得简单。
- 甚至可以真正做到链接载入完全由程序员在程序代码中控制(显示调用)。
- Window与Linux执行文件格式不同,在创建动态库的时候有一些差异。
- 在Windows系统下的执行文件格式是PE格式,动态库需要一个DllMain函数做出初始化的入口,通常在导出函数的声明时需要有_declspec(dllexport)关键字。
- Linux下gcc编译的执行文件默认是ELF格式,不需要初始化入口,亦不需要函数做特别的声明,编写比较方便。
- 创建动态库
- 与创建静态库不同的是,不需要打包工具(ar、lib.exe),直接使用编译器即可创建动态库。
- 动态链接库的名字形式为 libxxx.so,前缀是lib,后缀名为”.so”。
- 针对于实际库文件,每个共享库都有个特殊的名字”soname”。在程序启动后,程序通过这个名字来告诉动态加载器该载入哪个共享库。
- 在文件系统中,soname仅是一个链接到实际动态库的链接。对于动态库而言,每个库实际上都有另一个名字给编译器来用。它是一个指向实际库镜像文件的链接文件(lib+soname+.so)。
- ①生成目标文件,此时要加编译器选项-fpic
- g++ -fPIC -c DynamicMath.cpp
- -fPIC 创建与地址无关的编译程序(pic,position independent code),是为了能够在多个应用程序间共享。
- ②生成动态库,此时要加链接器选项-shared
- 或一步到位:
- g++ -fPIC -shared -o libdynmath.so DynamicMath.cpp
- g++ -shared -o libdynmath.so DynamicMath.o
- shared指定生成动态链接库。
- 使用动态库
- 引用动态库编译成可执行文件(跟静态库方式一样):
- g++ TestDynamicLibrary.cpp -L../DynamicLibrary -ldynmath
- 引用动态库编译成可执行文件(跟静态库方式一样):
编译命令
-g 选项告诉 GCC 产生能被 GNU 调试器使用的调试信息以便调试你的程序。
# 1.预处理-Pre-Processing
# 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面.
# 例子用法:
gcc -E hello.c > pianoapan.txt
gcc -E hello.c | more
gcc -E test.c -o test.i # .i文件
# 2.编译-Compiling
# 只激活预处理和编译,就是指把文件编译成为汇编代码。
gcc -S test.i -o test.s # .s文件
# 3.汇编-Assembling //.o文件
gcc -c test.s -o test.o
# 4.链接-Linking //bin文件
gcc test.o -o test
二、gcc工程惯用
# 1.编译, 如果是c++ 直接将gcc改为g++即可。
gcc -c test.c # .o文件,汇编
gcc -o test test.c # bin可执行文件
gcc test.c # a.out可执行文件
# -------- 编译优化 -------
gcc test.c -O3
gcc -O3 test.c
gcc -o tt test.c -O2
gcc -O2 -o tt test.c
常用参数
- 1)-E参数:只激活预处理,不生成文件
- -E 选项仅对输入文件进行预处理。当这个选项被使用时, 预处理器的输出被送到标准输出而不是储存在文件里.
- -Dmacro 相当于C语言中的#define macro
- -Dmacro=defn 相当于C语言中的#define macro=defn
- -Umacro 相当于C语言中的#undef macro
- -undef 取消对任何非标准宏的定义
- 2)-S参数:只激活预处理和编译,就是指把文件编译成为汇编代码。
- -S 编译选项告诉 GCC 在为 C 代码产生了汇编语言文件后停止编译。 GCC 产生的汇编语言文件的缺省扩展名是 .s 。
- 3)-c参数:只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
- -c 选项告诉 GCC 仅把源代码编译为目标代码。缺省时 GCC 建立的目标代码文件有一个 .o 的扩展名。
- 4)-o参数:生成可执行文件
- -o 编译选项来为将产生的可执行文件用指定的文件名。
- 5)-O参数:源码优化级别
- -O 选项告诉 GCC 对源代码进行基本优化。这些优化在大多数情况下都会使程序执行的更快。 -O2 选项告诉 GCC 产生尽可能小和尽可能快的代码。 如-O2,-O3,-On(n 常为0–3);
- -O 主要进行跳转和延迟退栈两种优化;
- O0 表示不做优化
- O1 为默认优化
- O2 除了完成-O1的优化之外,还进行一些额外的调整工作,如指令调整等。
- O3 则包括循环展开和其他一些与处理特性相关的优化工作。
- 选项将使编译的速度比使用 -O 时慢, 但通常产生的代码执行速度会更快。
- 6)调试选项-g和-pg
- GCC 支持数种调试和剖析选项,常用到的是 -g 和 -pg 。
- -g 选项告诉 GCC 产生能被 GNU 调试器使用的调试信息以便调试你的程序。GCC 提供了一个很多其他 C 编译器里没有的特性, 在 GCC 里你能使-g 和 -O(产生优化代码)联用。
- -gstabs:以stabs格式声称调试信息,但是不包括gdb调试信息.
- -gstabs+:以stabs格式声称调试信息,并且包含仅供gdb使用的额外调试信息.
- -ggdb:将尽可能的生成gdb的可以使用的调试信息.
- -glevel:请求生成调试信息,同时用level指出需要多少信息,默认的level值是2
- -pg 选项告诉 GCC 在编译好的程序里加入额外的代码。运行程序时, 产生 gprof 用的剖析信息以显示你的程序的耗时情况。
- 7) -l参数(引用链接库) 和 -L参数(添加链接库路径)
- -l参数就是用来指定程序要链接的库,-l参数紧接着就是库名,那么库名跟真正的库文件名有什么关系呢?他的库名是m,他的库文件名是libm.so,很容易看出,把库文件名的头lib和尾.so去掉就是库名了。
- -L添加链接库路径,或添加运行时库路径
- 8) -include 和 -I参数
- -include用来包含头文件,但一般情况下包含头文件都在源码里用#include xxxxxx实现,-include参数很少用。-I参数是用来指定头文件目录,/usr/include目录一般是不用指定的,gcc知道去那里找,但 是如果头文件不在/usr/icnclude里我们就要用-I参数指定了,比如头文件放在/myinclude目录里,那编译命令行就要加上-I/myinclude 参数了,如果不加你会得到一个”xxxx.h: No such file or directory”的错误。
- -I参数可以用相对路径,比如头文件在当前 目录,可以用-I.来指定。上面我们提到的–cflags参数就是用来生成-I参数的。
- 9)-Wall、-w 和 -v参数
- -Wall 打印出gcc提供的警告信息
- -pedantic 允许发出ANSI/ISO C标准所列出的所有警告
- -pedantic-errors 允许发出ANSI/ISO C标准所列出的错误
- -werror 把所有警告转换为错误,以在警告发生时中止编译过程
- -w 关闭所有警告信息
- -v 列出所有编译步骤
- -fpic
- 编译器就生成位置无关目标码.适用于共享库(shared library).
- -fPIC
- 编译器就输出位置无关目标码.适用于动态连接(dynamic linking),即使分支需要大范围转移.
链接多个文件生成动态链接库
- g++ -Wl,-rpath,./lib BrowseThumbDll.cpp CreateThumbImg.cpp -I ../include/gdalnew/include/ -L ../Release/lib/ -lgdal -fPIC -shared -o libBrose.so
链接选项
| 链接选项 | 功能 | 优点 | 缺点 |
|---|---|---|---|
| -static | 禁止使用动态库 | 程序不依赖于其他库 | 文件大 |
| -shared(-G) | 尽量使用动态库(默认值) | 文件小 | 运行时需要系统提供动态库 |
| -symbolic | 建立共享目标文件时,把引用绑定到全局符号上 |
-symbolic 对所有无法解析的引用作出警告(除非用连接编辑选项 `-Xlinker -z -Xlinker defs’取代)。
- 注:只有部分系统支持该选项.
环境变量
- PKG_CONFIG_PATH:用来指定pkg-config用到的pc文件的路径,默认是/usr/lib/pkgconfig,pc文件是文本文件,扩展名是.pc,里面定义开发包的安装路径,Libs参数和Cflags参数等等。
- CC:用来指定c编译器。
- CXX:用来指定cxx编译器。
- LIBS:跟上面的–libs作用差不多。
- CFLAGS:跟上面的–cflags作用差不多。
CC,CXX,LIBS,CFLAGS手动编译时一般用不上,在做configure时有时用到,一般情况下不用管。
环境变量设定方法:export ENV_NAME=xxxxxxxxxxxxxxxxx
交叉编译通俗地讲就是在一种平台上编译出能运行在体系结构不同的另一种平台上,比如在我们地PC平台(X86 CPU)上编译出能运行在arm CPU平台上的程序,编译得到的程序在X86 CPU平台上是不能运行的,必须放到arm CPU 平台上才能运行。当然两个平台用的都是linux。
内存分配
内存分配方式
通常内存分配方式有以下三种:
- (1)从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
- (2)在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
- (3)从堆上分配,亦称动态内存分配。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由程序员决定,使用非常灵活,但如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,频繁地分配和释放不同大小的堆空间将会产生堆内碎块。
程序内存分配
一个程序将操作系统分配给其运行的内存分为五个区域:
- (1)
栈区:由编译器自动分配释放,存放为函数运行的局部变量,函数参数,返回数据,返回地址等。操作方式与数据结构中的类似,栈区有以下特点:- 1)由系统自动分配。比如在函数运行中声明一个局部变量int b = 10;,系统自动在栈中为b开辟空间;
- 2)只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
- (2)
堆区:一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收;分配方式类似于链表,堆区有以下特点:- 1)需要程序员自己申请,并指明大小,在C中是有malloc函数,在C++中多使用new运算符
- 从C++角度上说,使用 new 分配堆空间可以调用类的构造函数,而 malloc() 函数仅仅是一个函数调用,它不会调用构造函数,它所接受的参数是一个unsigned long类型。同样,delete在释放堆空间之前会调用析构函数,而free函数则不会。
- 2)在操作系统中有一个记录空闲内存地址的表,这是一种链式结构。它记录了有哪些还未使用的内存空间。当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
- 1)需要程序员自己申请,并指明大小,在C中是有malloc函数,在C++中多使用new运算符
- (3)
全局数据区:也叫做静态区,存放全局变量,静态数据。程序结束后由系统释放。 - (4)
文字常量区:可以理解为常量区,常量字符串存放这里。程序结束后由系统释放。“常量”是指它的值是不可变的,同时,虽然常量也是存储在内存的某个地方,但是无法访问常量的地址的。 - (5)
程序代码区:存放函数体的二进制代码。但是代码段中也分为代码段和数据段。
示例
int a = 0; //全局初始化区
char *p1; //全局未初始化区
int main() {
int b; //栈区
char s[] = "abc"; //栈区
char *p2; //栈区
char *p3 = "123456"; // 123456 在常量区,p3在栈区。
static int c =0; //全局(静态)初始化区
p1 = new char[10];
p2 = new char[20];
//分配得来得和字节的区域就在堆区。
strcpy(p1, "123456"); // 123456 放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
内存溢出
内存泄露与内存溢出
【2022-3-11】C++ 内存管理中内存泄漏问题产生原因以及解决方法
C++内存管理中内存泄露(memory leak)指 程序在申请内存后,无法释放已经申请的内存空间,内存泄露的积累往往会导致内存溢出。
内存溢出原因
内存溢出原因
- (1)在类的构造函数和析构函数中没有匹配调用new和delete函数;两种情况下会出现这种内存泄露:
- 1)在堆里创建了对象占用了内存,但是没有显示地释放对象占用的内存;
- 2)在类的构造函数中动态的分配了内存,但是在析构函数中没有释放内存或者没有正确的释放内存。
- (2)没有正确地清除嵌套的对象指针
- (3)在释放对象数组时在delete中没有使用方括号
- 方括号是告诉编译器这个指针指向的是一个对象数组,同时也告诉编译器正确的对象地址值并调用对象的析构函数,如果没有方括号,那么这个指针就被默认为只指向一个对象,对象数组中的其他对象的析构函数就不会被调用,结果造成了内存泄露。如果在方括号中间放了一个比对象数组大小还大的数字,那么编译器就会调用无效对象(内存溢出)的析构函数,会造成堆的奔溃。如果方括号中间的数字值比对象数组的大小小的话,编译器就不能调用足够多个析构函数,结果会造成内存泄露。
- 释放单个对象、单个基本数据类型的变量或者是基本数据类型的数组不需要大小参数,释放定义了析构函数的对象数组才需要大小参数。
- (4)指向对象的指针数组不等同于对象数组
- 对象数组是指:数组中存放的是对象,只需要delete [ ] p,即可调用对象数组中的每个对象的析构函数释放空间
- 指向对象的指针数组是指:数组中存放的是指向对象的指针,不仅要释放每个对象的空间,还要释放每个指针的空间,delete [ ] p只是释放了每个指针,但是并没有释放对象的空间,正确的做法,是通过一个循环,将每个对象释放了,然后再把指针释放了。
- (5)缺少拷贝构造函数
- 两次释放相同的内存是一种错误的做法,同时可能会造成堆的奔溃。
- 按值传递会调用(拷贝)构造函数,引用传递不会调用。
- 在C++中,如果没有定义拷贝构造函数,那么编译器就会调用默认的拷贝构造函数,会逐个成员拷贝的方式来复制数据成员,如果是以逐个成员拷贝的方式来复制指针被定义为将一个变量的地址赋给另一个变量。这种隐式的指针复制结果就是两个对象拥有指向同一个动态分配的内存空间的指针。当释放第一个对象的时候,它的析构函数就会释放与该对象有关的动态分配的内存空间。而释放第二个对象的时候,它的析构函数会释放相同的内存,这样是错误的。
- 所以,如果一个类里面有指针成员变量,要么必须显示的写拷贝构造函数和重载赋值运算符,要么禁用拷贝构造函数和重载赋值运算符。
- (6)缺少重载赋值运算符
- 这种问题跟上述问题类似,也是逐个成员拷贝的方式复制对象,如果这个类的大小是可变的,那么结果就是造成内存泄露.
- (7)关于nonmodifying运算符重载的常见错误
- 1)返回栈上对象的引用或者指针(也即返回局部对象的引用或者指针)。导致最后返回的是一个空引用或者空指针,因此变成野指针(指向被释放的或者访问受限内存的指针);
- 2)返回内部静态对象的引用;
- 3)返回一个泄露内存的动态分配的对象。导致内存泄露,并且无法回收。
- 解决这一类问题的办法是重载运算符函数的返回值不是类型的引用,二应该是类型的返回值,即不是 int&而是int。
- (8)没有将基类的析构函数定义为虚函数
- 当基类指针指向子类对象时,如果基类的析构函数不是虚函数,那么子类的析构函数将不会被调用,子类的资源没有正确是释放,因此造成内存泄露。造成野指针的原因:
- 1)指针变量没有被初始化(如果值不定,可以初始化为NULL);
- 2)指针被free或者delete后,没有置为NULL, free和delete只是把指针所指向的内存给释放掉,并没有把指针本身干掉,此时指针指向的是“垃圾”内存。释放后的指针应该被置为NULL;
- 3)指针操作超越了变量的作用范围,比如返回指向栈内存的指针就是野指针;
- 4)shared_ptr循环引用。
- (9)析构的时候使用void*
- delete掉一个void*类型的指针,导致没有调用到对象的析构函数,析构的所有清理工作都没有去执行从而导致内存的泄露。
- (10)构造的时候浅拷贝,释放的时候调用了两侧delete
如何检测内存泄露
方法, 知乎
- 第一:自己写一个内存泄漏检测小工具,检测小工具的原理很简单
- C语言侧可以使用宏覆盖 malloc 和 free 函数,或者使用 malloc 和 free 的hook钩子,或者貌似也可以直接使用强符号覆盖掉libc里的malloc和free这种弱符号
- C++侧则也可以覆盖 operator new 和 operator delete 这种弱符号函数。
- 内存在哪里释放的我们没必要监测,只需要检测出内存是在哪里申请的即可,如何检测呢?整体思路很简单:在申请内存时记录下该内存的地址和在代码中申请内存的位置,在内存销毁时删除该地址对应的记录,程序最后统计下还有哪条记录没有被删除,如果还有没被删除的记录就代表有内存泄漏。
- 第二:使用各种已有的内存泄漏检测工具,这种工具有很多:
- valgrind
- mtrace
- dmalloc
- ccmalloc
- memwatch
- debug_new
- AddressSanitizer(ASan),该工具为gcc自带,4.8以上版本都可以使用,支持Linux、OS、Android等多种平台,不止可以检测内存泄漏,它其实是一个内存错误检测工具,可以检测的问题有:内存泄漏堆栈和全局内存越界访问free后继续使用局部内存被外层使用Initialization order bugs(中文不知道怎么翻译才好,但很重要)
- 第三:静态代码检测工具,灵活使用静态代码检测工具,可以在编码时就提前发现部分潜在的内存泄漏,但毕竟是静态代码检测,准确性不一定高,检测的也不一定全面,但也是一种方法。静态代码检测工具可以使用:
- cppcheck
- PC-lint
- Coverity
- QAC C/C++
- Clang-Tidy(推荐)
- Clang Static Analyzer
- 还有些平台型的检测工具:SonarQube+sonar-cxx, Facebook infer
- 第四:像素眼代码分析,轻易不要使用,费眼睛。
// new, delete 不匹配就造成泄露
void func() {
A* a = new A();
delete a;
A* b = new int[4];
delete[] b;
}
// ==========
void* operator new(std::size_t sz)
void* operator delete(void* ptr)
// 解法:重载new方法,记录对应行数
void* operator new(std::size_t size, const char* file, int line);
void* operator new[](std::size_t size, const char* file, int line);
// 使用宏定义,使代码调用new时,自动切换到新的new方法
#define new new (__FILE__, __LINE__) // 自动调用新函数
// 重载delete
void operator delete(void* ptr) noexcept {
free_pointer(ptr, nullptr, false);
}
// 内存泄露检测
// 思路:遍历链表即可,每次new时候会把这段内存插入链表,delete时候会把这段内存从链表中移出,如果程序最后链表长度不为0,即为有内存泄漏,代码如下:
int checkLeaks() {
int leak_cnt = 0;
int whitelisted_leak_cnt = 0;
new_ptr_list_t* ptr = new_ptr_list.next;
while (ptr != &new_ptr_list) {
const char* const usr_ptr = (char*)ptr + ALIGNED_LIST_ITEM_SIZE;
printf("Leaked object at %p (size %lu, ", usr_ptr, (unsigned long)ptr->size);
if (ptr->line != 0) {
print_position(ptr->file, ptr->line);
} else {
print_position(ptr->addr, ptr->line);
}
printf(")\n");
ptr = ptr->next;
++leak_cnt;
}
return leak_cnt;
}
解决方法
常见解决办法
- (1)shared_ptr 共享的智能指针:
- shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。在最后一个shared_ptr析构的时候,内存才会被释放。
- 注意事项:
- 1)不要用一个原始指针初始化多个shared_ptr;
- 2)不要再函数实参中创建shared_ptr,在调用函数之前先定义以及初始化它;
- 3)不要将this指针作为shared_ptr返回出来;
- 4)要避免循环引用。
- (2)unique_ptr 独占的智能指针:
- 1)unique_ptr是一个独占的智能指针,他不允许其他的智能指针共享其内部的指针,不允许通过赋值将一个unique_ptr赋值给另外一个 unique_ptr;
- 2)unique_ptr不允许复制,但可以通过函数返回给其他的unique_ptr,还可以通过std::move来转移到其他的unique_ptr,这样它本身就不再 拥有原来指针的所有权了;
- 3)如果希望只有一个智能指针管理资源或管理数组就用unique_ptr,如果希望多个智能指针管理同一个资源就用shared_ptr。
- (3)weak_ptr 弱引用的智能指针:
- 弱引用的智能指针weak_ptr是用来监视shared_ptr的,不会使引用计数加一,它不管理shared_ptr内部的指针,主要是为了监视shared_ptr的生命 周期,更像是shared_ptr的一个助手。 weak_ptr没有重载运算符*和->,因为它不共享指针,不能操作资源,主要是为了通过shared_ptr获得资源的监测权,它的构造不会增加引用计数,它的析构不会减少引用计数,纯粹只是作为一个旁观者来监视shared_ptr中关连的资源是否存在。 weak_ptr还可以用来返回this指针和解决循环引用的问题。
- (4)set_new_handler(out_of_memroy); //注意参数传递的是函数的地址
总结:现在C++程序员面临的竞争压力越来越大。那么,作为一名C++程序员,怎样努力才能快速成长为一名高级的程序员或者架构师,或者说一名优秀的高级工程师或架构师应该有怎样的技术知识体系,这不仅是一个刚刚踏入职场的初级程序员,也是工作三五年之后开始迷茫的老程序员,都必须要面对和想明白的问题。为了帮助大家少走弯路,技术要做到知其然还要知其所以然。
文件操作
数据文件类型
数据文件分为 ASCII文件 和 二进制文件。
- ASCII 文件,又称字符文件或者文本文件,它的每一个字节放一个 ASCII 代码,代表一个字符。
- 二进制文件,又称内部格式文件或字节文件,是把内存中的数据按其在内存中的存储形式原样输出到磁盘上存放。
如 数字 64 在内存中表示为 0100 0000
- 若将其保存为 ASCII 文件,则要分别存放十位 6 和个位 4 的 ASCII 码,为 0011 0110 0011 0100,占用两个字节;
-
若将其保存为二进制文件,则按内存中形式直接输出,为 0100 0000,占用一个字节。
- ASCII 文件中数据与字符一一对应,一个字节代表一个字符,可以直接在屏幕上显示或打印出来,这种方式使用方便,比较直观,便于阅读,但一般占用存储空间较大,而且输出时要将二进制转化为 ASCII 码比较花费时间。
- 二进制文件,输出时不需要进行转化,直接将内存中的形式输出到文件中,占用存储空间较小,但一个字节并不对应一个文件,不能直观显示文件中的内容。
文件流
文件流是以外存文件未输入输出对象的数据流。
- 输出文件流是从内存流向外存文件的数据
- 输入文件流是从外存文件流向内存的数据。
- 每一个文件流都有一个内存缓冲区与之对应。
C++ 中有三个用于文件操作的文件类:
ifstream类,它是从 istream 类派生来的,用于支持从磁盘文件的输入。ofstream类,它是从 ostream 类派生来的,用于支持向磁盘文件的输出。fstream类,它是从 iostream 类派生来的,用于支持对磁盘文件的输入输出。
要以磁盘文件为对象进行输入输出,必须
- 定义一个文件流类的对象,通过文件流对象将数据从内存输出到磁盘文件,或者将磁盘文件输入到内存。
- 定义文件流对象后,还需要将文件流对象和指定的磁盘文件建立关联,以便使文件流流向指定的磁盘文件,并确定文件的工作方式(输入还是输出,二进制还是 ASCII)。
- 可以在定义流对象的时候指定参数来调用构造函数,或者通过成员函数 open 来进行文件流对象和指定文件的关联。
创建流对象
包括:
- 1)ofstream : 写文件
- 2)ifstream : 读文件
- 3)fsream : 读写文件
如:
ifstream fin;
ofstream fout;
打开文件
打开文件
- fin.open(“文件路径”, 打开方式)
打开方式包括:
- ios::in 读文件
- ios::out 写文件(直接用的话会丢丢弃已有数据,即隐含为trunc)
- ios::binary 二进制方式
- ios::app 追加写(要配合out使用,直接写的话会隐含用ios::out
- ios::trunc 覆盖写(要配合out使用)
-
ios::out ios::binary 二进制写 - ……
fin.open("ch2/test1.txt",ios::in);
if(!fin)
// if(!fin.is_open())
{
std::cerr<<"cannot open the file";
}
fout << x << " " << y << endl; // 写数据
fout.close();
读文件
读取方式
- 第一种读的方式(按元素直接读)
- 第二种读的方式(使用getline按行读)
- 第三种读的方式(get)
- 第四种读的方式:
- 若已知文件里头数据的顺序,则直接定义字符变量存储单个元素,以白色字符为分割
默认读取数据时,会传递并忽略任何白色字符(空格、制表符或换行符)。一旦它接触到第一个非空格字符即开始阅读,当读取到下一个空白字符时,它将停止读取。
为了解决这个问题,可以使用一个叫做 getline 的 C++ 函数。此函数可读取整行白色字符,只看换行符,即不看,包括前导和嵌入的空格,并将其存储在字符串对象中。
getline:
- getline()函数是istream类中的一个成员函数,所以使用时,要用istream的对象cin来调用它。getline(char* s, streamsize n),作用是从istream中读取至多n个字符保存在s对应的数组中。即使还没读够n个字符,如果遇到换行符’\n’则读取终止
文件内容:
1 2 3
a b c
112
// 方法①:按元素读
char buf[1024]={0}; // 临时申请一个 1024大的读空间(又叫buffer),并且初始化为0。
while (fin >> buf)
{
cout << buf << endl;//每次的buf是空格或回车键(即白色字符)分开的元素
}
// 方法②:按行读
char buf[1021]={0};
while(fin.getline(buf,sizeof(buf)))
{
std::cout<<buf<<std::endl;
}
// 方法③:get
char c;
while ((c = fin.get()) != EOF)
{
std::cout << c;
}
// 方法④:get,知晓文件格式
char a,s1,s2,s3,s4,s5;
std::string s6;
fin >> a >> s1 >> s2 >> s3>>s4>>s5>>s6;
std::cout<<a<<" "<<s1<<" "<<s2<<" "<<s3<<" "<<s4<<" "<<s5<<" "<<s6;
// 读取结果:
// 1 2 3 a b c 112
ASCII 文件操作
用类似 cin 或者 cout 的方式将数据读出或写入文件,只不过是输入输出的对象变成了文件而已。在对磁盘文件完成读写操作后,通过 close 方法来解除磁盘文件和文件流对象的关联。
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
// 输出流:ios::out
ofstream outfile("a.txt", ios::out); // 打开文件
if (!outfile)
{
cerr << "Failed to open the file!";
return 1;
}
// 写数据:数字 1-5 到文件中
for (int i = 1; i < 6; i++)
{ // 写入数字:<<操作
outfile << i << '\n';
}
for (char i = '1'; i < '6'; i++)
{ // 写入字符:put操作
outfile.put(i); // 输出一个字符到文件中去
}
outfile.close(); // 关闭文件
// 输入流:ios::in
ifstream infile("a.txt", ios::in);
if (!infile)
{
cerr << "Failed to open the file!";
return 1;
}
char data;
for (int i = 1; i < 6; i++)
{// 从文件中读出数字 >> 操作
infile >> data;
cout << data << '\n';
}
char data[5];
infile.get(data, 6); // 从文件中读出 5 个字符
for (int i = 0; i < 5; i++)
{
cout << data[i] << '\n';
}
char a;
for (int i = 0; i < 5; i++)
{// 从文件中读出字符 get方法
infile.get(a); // 从文件中读出 1 个字符
cout << a << '\n';
}
infile.close();
return 0;
}
二进制文件操作
二进制文件的操作需要在打开文件的时候指定打开方式为 ios::binary,并且还可以指定为既能输入又能输出的文件,通过成员函数 read 和 write 来读写二进制文件。
- istream& read (char* s, streamsize n);
- ostream& write (const char* s, streamsize n);
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ofstream outfile("a.txt", ios::binary);
if (!outfile)
{
cerr << "Failed to open the file!";
return 1;
}
char a[] = {'h', 'e', 'l', 'l', 'o', ','};
char b[] = {'s', 'e', 'n', 'i', 'u', 's', 'e', 'n', '!'};
outfile.write(a, 6); // 将以 a 为首地址的 6 个字符写入文件
outfile.write(b, 9);
outfile.close();
ifstream infile("a.txt", ios::binary);
if (!infile)
{
cerr << "Failed to open the file!";
return 1;
}
char data[6];
infile.read(data, 6); // 从文件中读出 6 个字符到以 data 为首地址的字符数组中
for (int i = 0; i < 6; i++)
{
cout << data[i];
}
char datb[6];
infile.read(datb, 9);
for (int i = 0; i < 9; i++)
{
cout << datb[i];
}
infile.close();
return 0;
}
在磁盘文件中有一个文件指针,用来指明当前读写的位置。每次写入或者读出一个字节,指针就向后移动一个字节。对于二进制文件,允许对指针进行控制,使它移动到所需的位置,以便在该位置上进行读写。
- ostream& seekp (streampos pos); 将输出文件中指针移动到指定的位置
- ostream& seekp (streamoff off, ios_base::seekdir way); 以参照位置为基准对输出文件中的指针移动若干字节
- streampos tellp(); 返回输出文件指针当前的位置
- istream& seekg (streampos pos); 将输入文件中指针移动到指定的位置
- istream& seekg (streamoff off, ios_base::seekdir way); 以参照位置为基准对输入文件中的指针移动若干字节
- streampos tellg(); 返回输入文件指针当前的位置 其中,参照位置有以下几个选择:
- ios_base::beg 文件开始位置
- ios_base::cur 文件当前位置
- ios_base::end 文件末尾位置
读表格文件(类型转换)
数据:
gyb 1333 12212
lck 212 33113
ddl 332 41311
要点:
- 从文件中提取“行”
- fin.getline(line,sizeof(line))
- 从“行”中提取“单词”
- sstream用来做类型转换
- std::stringstream word(line);
C++标准库中的<sstream>提供了比ANSI C的<stdio.h>更高级的一些功能,即单纯性、类型安全和可扩展性。自动选择所必需的转换。
- sstream用于分割被空格、制表符等符号分割的字符串
<sstream>库定义了三种类:
- istringstream、ostringstream和stringstream
- 分别用来进行流的输入、输出和输入输出操作。
- istringstream类 用于执行C++风格的串流的输入操作。
- ostringstream类 用于执行C风格的串流的输出操作。
- strstream类 同时可以支持C风格的串流的输入输出操作。
继承关系
- istringstream类是从istream(输入流类)和stringstreambase(c++字符串流基类)派生而来
- ostringstream是从ostream(输出流类)和stringstreambase(c++字符串流基类)派生而来
- stringstream则是从iostream(输入输出流类)和和stringstreambase(c++字符串流基类)派生而来。
- img

#include<iostream>
#include<sstream> //istringstream 必须包含这个头文件
#include<string>
using namespace std;
int main(){
string str="i am a boy";
istringstream is(str); // string类型导入输入流中
string s;
while(is>>s) {
cout<<s<<endl;
}
int n;
// str用法
std::istringstream in; // could also use in("1 2")
in.str("1 2");
in >> n;
std::cout << " \"1 2\" 中读取一个整数:"
<< n << ", str() = \"" << in.str() << "\"\n";
std::ostringstream out("1 2");
out << 3;
std::cout << "写入'3'到\"1 2\"中"
<< ", str() = \"" << out.str() << "\"\n"; // "3 2"
std::ostringstream ate("1 2", std::ios_base::ate);
ate << 3;
std::cout << "追加'3'到\"1 2\"后面"
<< ", str() = \"" << ate.str() << "\"\n"; // "1 23"
}
另外,每个类都有一个对应的宽字符集版本。
- 注意,<sstream>使用string对象来代替字符数组。这样可以避免缓冲区溢出的危险。而且,传入参数和目标对象的类型被自动推导出来,即使使用了不正确的格式化符也没有危险。
代码
#include<iostream>
#include<fstream>
#include<string>
#include<vector>
#include <sstream>
// 定义每行数据格式,存入结构体中
struct people{ // 格式:姓名、手机号
std::string name;
std::vector<int> phonenum;
};
int main( int argc, char** argv )
{
std::ifstream fin;
fin.open("data_test.txt",std::ios::in);
if(!fin.is_open())
{
std::cerr<<"cannot open the file";
}
char line[1024]={0};
std::vector<people> People; // 数据存储
while(fin.getline(line,sizeof(line)))
{//从文件中提取“行”
people p; //定义局部变量
std::stringstream word(line); //“行”里提取“单词”
word>>p.name; // 第一个单词
int num;
while(word>>num) // 一次读取后面的字段——若没东西可读写,则返回-1
p.phonenum.push_back(num);
// 一行读取完毕
People.push_back(p);
}
// 输出读取结果
std::cout<<People[1].name<<"'s phonenumber is:"<< People[1].phonenum[1];
}
网络IO模型
单服务器高性能的关键之一就是服务器采取的网络编程模型。服务器如何管理连接,如何处理请求等。这两个设计点最终都和操作系统的I/O模型及进程模型相关。
- I/O模型:阻塞、非阻塞、同步、异步
- 进程模型:单进程、多进程、多线程。
I/O模型是指网络I/O模型,就是服务端如何管理连接,如何请求连接的措施,是用一个进程管理一个连接(PPC),还是一个线程管理一个连接(TPC),亦或者一个进程管理多个连接(Reactor)。
因此IO多路复用中多路就是多个TCP连接(或多个Channel),复用就是指复用一个或少量线程,理解起来就是多个网路IO复用一个或少量线程来处理这些连接。
什么是流、I/O、阻塞、epoll?
【2022-3-24】流?I/O操作?阻塞?epoll?
- (1) 流
- 可以进行I/O操作的内核对象,如:文件、管道、套接字……
- 流的入口:文件描述符(fd)
- (2) I/O操作
- 所有对流的读写操作,都可以称之为I/O操作。
- 当一个流中, 在没有数据read的时候,或者说在流中已经写满了数据,再write,IO操作就会出现一种现象,阻塞。
- (3) 阻塞
- 阻塞场景: 你有一份快递,家里有个座机,快递到了主动给你打电话,期间你可以休息。
- 非阻塞,忙轮询场景: 你性子比较急躁, 每分钟就要打电话询问快递小哥一次, 到底有没有到,快递员接你电话要停止运输,这样很耽误快递小哥的运输速度。
- 阻塞等待:空出大脑可以安心睡觉, 不影响快递员工作(不占用CPU宝贵的时间片)。
- 非阻塞,忙轮询:浪费时间,浪费电话费,占用快递员时间(占用CPU,系统资源)。
- 很明显,阻塞等待这种方式,对于通信上是有明显优势的, 那么它有哪些弊端呢?
二、解决阻塞死等待的办法
- 阻塞死等的缺点
- 同一时刻,你只能被动的处理一个快递员的签收业务,其他快递员打电话打不进来,只能干瞪眼等待。那么解决这个问题,家里多买N个座机, 但是依然是你一个人接,也处理不过来,需要用影分身术创建都个自己来接电话(采用多线程或者多进程)来处理。
- 这种方式就是没有多路IO复用的情况的解决方案, 但是在单线程计算机时代(无法影分身),这简直是灾难。
那么如果我们不借助影分身的方式(多线程/多进程),该如何解决阻塞死等待的方法呢?
- 办法一:非阻塞、忙轮询(不停电话)
- 非阻塞忙轮询的方式,可以让用户分别与每个快递员取得联系,宏观上来看,是同时可以与多个快递员沟通(并发效果)、 但是快递员在于用户沟通时耽误前进的速度(浪费CPU)。
- 办法二:select(代收点)
- 我们可以开设一个代收网点,让快递员全部送到代收点。这个网店管理员叫select。这样我们就可以在家休息了,麻烦的事交给select就好了。当有快递的时候,select负责给我们打电话,期间在家休息睡觉就好了。
- 但select 代收员比较懒,她记不住快递员的单号,还有快递货物的数量。她只会告诉你快递到了,但是是谁到的,你需要挨个快递员问一遍。
- 办法三:epoll(代收点秘书)
- epoll的服务态度要比select好很多,在通知我们的时候,不仅告诉我们有几个快递到了,还分别告诉我们是谁谁谁。我们只需要按照epoll给的答复,来询问快递员取快递即可。
- 三、epoll:与select,poll一样,对I/O多路复用的技术,只关心“活跃”的链接,无需遍历全部描述符集合,能够处理大量的链接请求(系统可以打开的文件数目)
阻塞/同步
阻塞和同步的概念:
阻塞:若读写未完成,调用读写的线程一直等待非阻塞:若读写未完成,调用读写的线程不用等待,可以处理其他工作异步:读写过程完全托管给操作系统完成,操作系统完成后通知调用读写的线程同步:读写过程由本线程完成,期间可以处理其他工作,但要轮询读写是否完毕
同步和异步的概念描述的是用户线程与内核的交互方式,这里所说的用户进程/线程和内核是以传输层为分割线的,传输层以上是指用户进程,传输层以下(包括传输层)是指内核(处理所有通信细节,发送数据,等待确认,给无序到达的数据排序等,这四层是操作系统内核的一部分)。
- 同步是指用户线程发起IO请求后需要等待或者轮询内核IO操作,完成后才能继续执行。
- 异步是指用户线程发起IO请求后仍继续执行,当内核IO操作完成后回通知用户线程,或者调用用户线程注册的回调函数。
阻塞和非阻塞的概念描述的是用户线程调用内核IO操作的方式
- 阻塞时指IO操作需要彻底完成后才能返回用户空间
- 非阻塞时指IO操作被调用后立即返回给用户一个状态值,无需等待IO操作彻底完成。
I/O模型
常见I/O模型
- 同步阻塞IO(Blocking IO):即传统IO模型
- 同步非阻塞IO(Non-blocking IO):默认常见的socket都是阻塞的,非阻塞IO要求socket被设置成NONBLOCK
- IO多路复用(IO Multiplexing):即经典的Reactor设计模式,也被称为异步阻塞IO,Java中的selector和linux中的epoll都是这种模型
- 异步IO(Asychronous IO):即Proactor设计模式,也被称为异步非阻塞IO
同步阻塞IO
同步阻塞IO是最简单的IO模型,用户线程在内核进行IO操作时被阻塞。用户线程通过调用系统调用read发起IO读操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接受的数据拷贝到用户空间,完成read操作。整个IO请求过程,用户线程都是被阻塞的,对CPU利用率不够
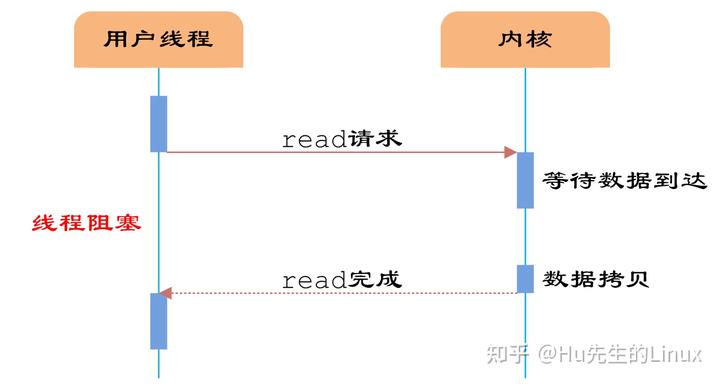
同步非阻塞IO
在同步基础上,将socket设置为NONBLOCK,这样用户线程可以在发起IO请求后立即返回。虽说可以立即返回,但并未读到任何数据,用户线程需要不断的发起IO请求,直到数据到达后才能真正读到数据,然后去处理。 整个IO请求中,虽然可以立即返回,但是因为是同步的,为了等到数据,需要不断的轮询、重复请求,消耗了大量的CPU资源。因此,这种模型很少使用,实际用处不大。

同步非阻塞IO
在同步基础上,将socket设置为NONBLOCK,这样用户线程可以在发起IO请求后立即返回。虽说可以立即返回,但并未读到任何数据,用户线程需要不断的发起IO请求,直到数据到达后才能真正读到数据,然后去处理。 整个IO请求中,虽然可以立即返回,但是因为是同步的,为了等到数据,需要不断的轮询、重复请求,消耗了大量的CPU资源。因此,这种模型很少使用,实际用处不大。
IO多路复用
不管是同步阻塞还是同步非阻塞,对系统性能的提升都是很小的。而通过复用可以使一个或一组线程(线程池)处理多个TCP连接。IO多路复用使用两个系统调用(select/poll/epoll和recvfrom),blocking IO只调用了recvfrom。select/poll/epoll核心是可以同时处理多个connection,而不是更快,所以连接数不高的话,性能不一定比多线程+阻塞IO好。
select是内核提供的多路分离函数,使用它可以避免同步非阻塞IO中轮询等待问题。

用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回,用户线程正式发起read请求,读取数据并继续执行。
这么一看,这种方式和同步阻塞IO并没有太大区别,甚至还多了添加监视socket以及调用select函数的额外操作,效率更差。但是使用select以后,用户可以在一个线程内同时处理多个socket的IO请求,这就是它的最大优势。用户可以注册多个socket,然后不断调用select读取被激活的socket,即可达到同一个线程同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程方式才能达到这个目的。所以IO多路复用设计目的其实不是为了快,而是为了解决线程/进程数量过多对服务器开销造成的压力。
虽然这种方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket,然后去做自己的事情,等到数据到来时在进行处理,则可以提高CPU利用率。
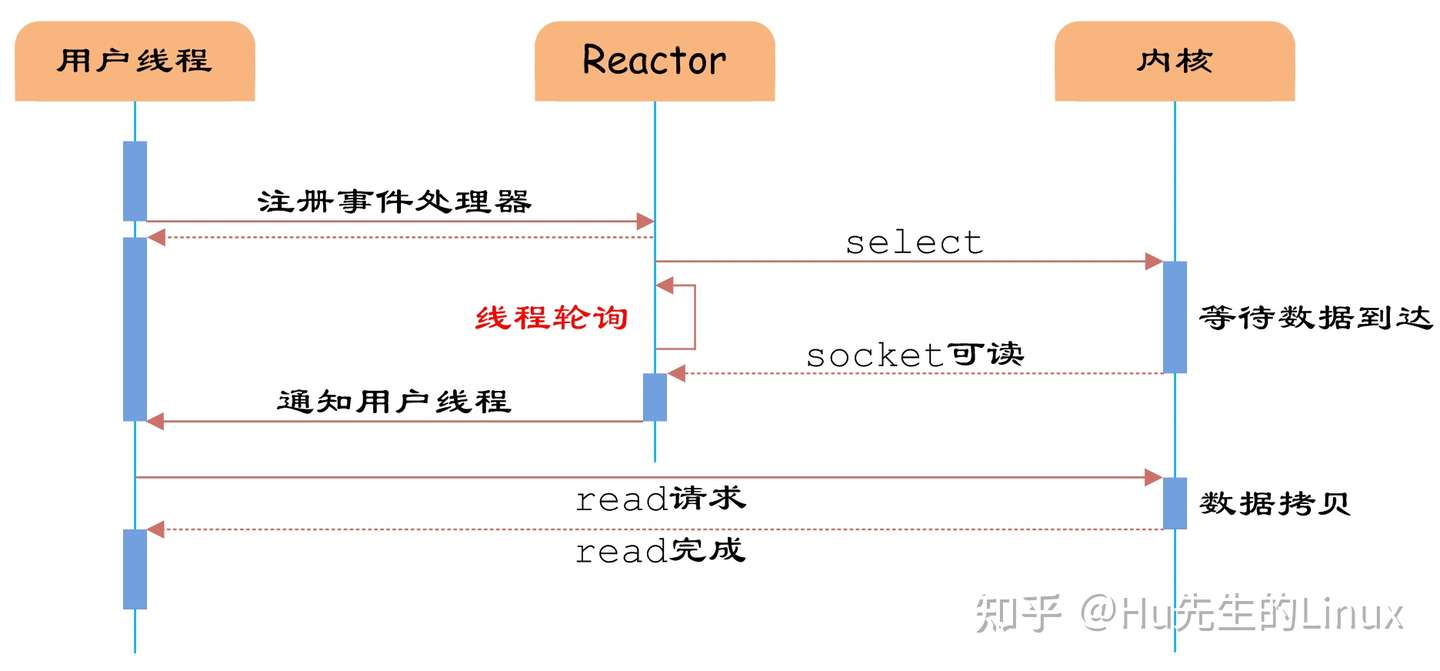
通过Reactor方式,用户线程轮询IO操作状态的工作统一交给handle_events事件循环处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handel_envent进行数据的读取、处理工作。
由于select函数是阻塞的,因此多路IO复用模型就被称为异步阻塞IO模型,这里阻塞不是指socket。因为使用IO多路复用时,socket都设置NONBLOCK,不过不影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
IO多路复用是最常用的IO模型,但其异步程度还不彻底,因为它使用了回阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
异步非阻塞IO
在IO多路复用模型中,事件循环文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而异步IO中,当用户线程收到通知时候,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用就行了。因此这种模型需要操作系统更强的支持,把read操作从用户线程转移到了内核。
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用IO多路复用+多线程任务处理的架构基本可以满足需求。不过最主要原因还是操作系统对异步IO的支持并非特别完善,更多的采用IO多路复用模拟异步IO方式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区)。
select、poll、epoll详解 select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符(socket),一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。虽说IO多路复用被称为异步阻塞IO,但select,poll,epoll本质上都是同步IO,因为它们都需要在续写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而真正意义上的异步IO无需自己负责进行读写。
select
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select函数监视的文件描述符有三类,readfds,writefds,exceptfds。调用后函数会阻塞,直到有描述符就绪(有数据读、写、或者有except),或者超时(timeout指定时间,如果立即返回设置null),函数返回。当select函数返回后,可以通过便利fdset,来找到就绪的描述符。
- 优点:良好的跨平台性。
- 缺点:单个进程能够监视的文件描述符的数量存在最大限制,在Linux上为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但这样会造成效率的降低。
poll
int poll(struct poll *fds, unsigned int nfds, int timeout);
struct pollfd{
int fd;
short events;
short revents;
};
与select使用三个位图来表示fdset,poll使用一个pollfd的指针实现。pollfd结构包含了要监视的event和发生的event,不在使用select参数传值的方式。同时pollfd并没有最大数量的限制(但数量过大性能也会下降)。和select一样,poll返回后,需要轮询pollfd来或许就绪的描述符。
epoll
epoll是select和poll的增强版本,相比于前两者,它更加的灵活,没有描述符的限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需要一次。
作者:Hu先生的Linux
I/O模型种类
三种网络IO模型:
- BIO 同步的、阻塞式 IO:一个线程处理一个连接
- BIO 虽然可以使用线程池+等待队列进行优化,避免使用过多的线程,但是依然无法解决线程利用率低的问题。
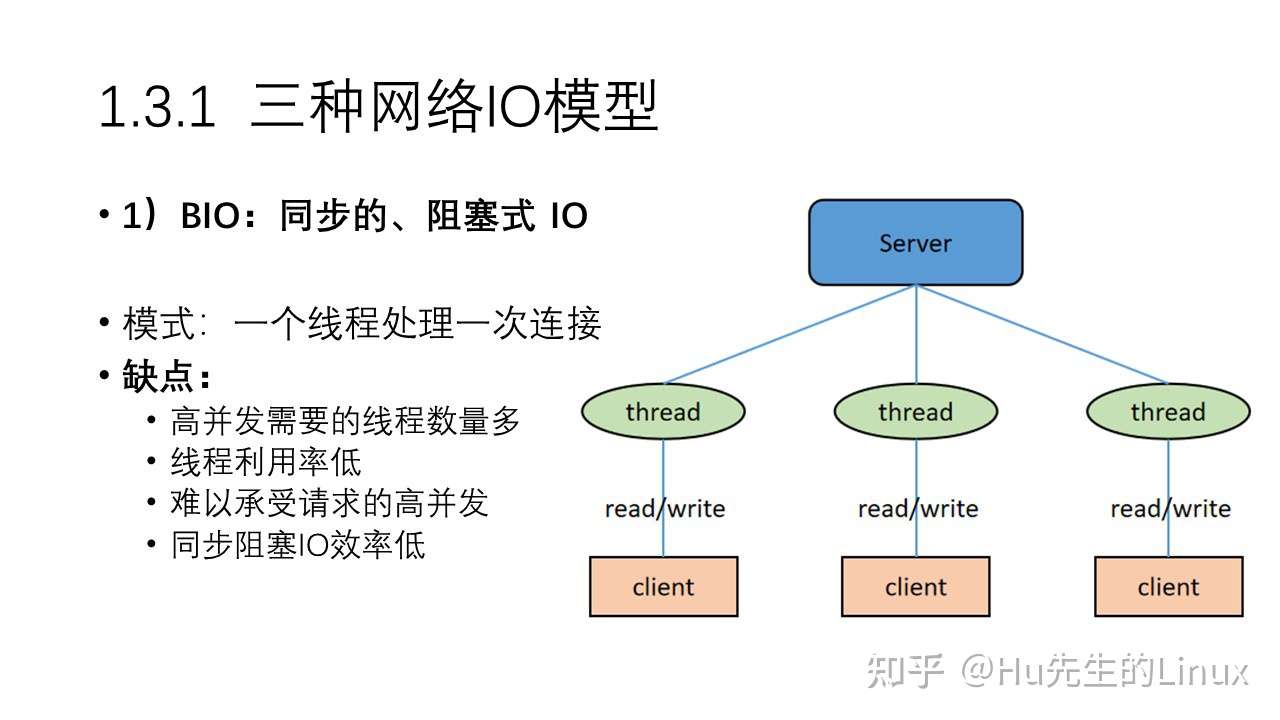
- NIO 同步的、非阻塞式 IO:一个线程处理多个连接
- 数据通过通道 Channel 传输,往Channel中读写数据需要先经过缓冲区Buffer
- NIO为每个客户端连接分配Channel和Buffer,并注册到多路复用器 Selector上,Selector通过轮询,找到有IO活动的连接进行处理,这种处理模式称为Reactor模式
- 若当前通道无可用数据,线程不会阻塞,而是可以处理其他通道的读写
- 这样 降低了线程的需求量,提高了线程的利用率 实现了IO 多路复用
- IO 多路复用的定义:单个线程 管理多个IO流

- AIO 异步非阻塞式 IO

Reactor模式
【2022-3-11】C++后台开发—网络IO模型与Reactor模式
Reactor模式基本原理是
- 1)Reactor:Reactor 在一个单独的线程中运行,负责监听和分发多个客户端的事件,分发给适当的handler线程来对 IO 事件做出反应。
- 2)Handlers:处理线程 会执行处理方法来 响应 I/O 事件
Reactor 模式就是实现网络 IO 程序高并发特性的关键。
它又可以分为
- 单Reactor单线程模式
- 单Reactor多线程模式
- 主从Reactor多线程模式
单Reactor单线程模式
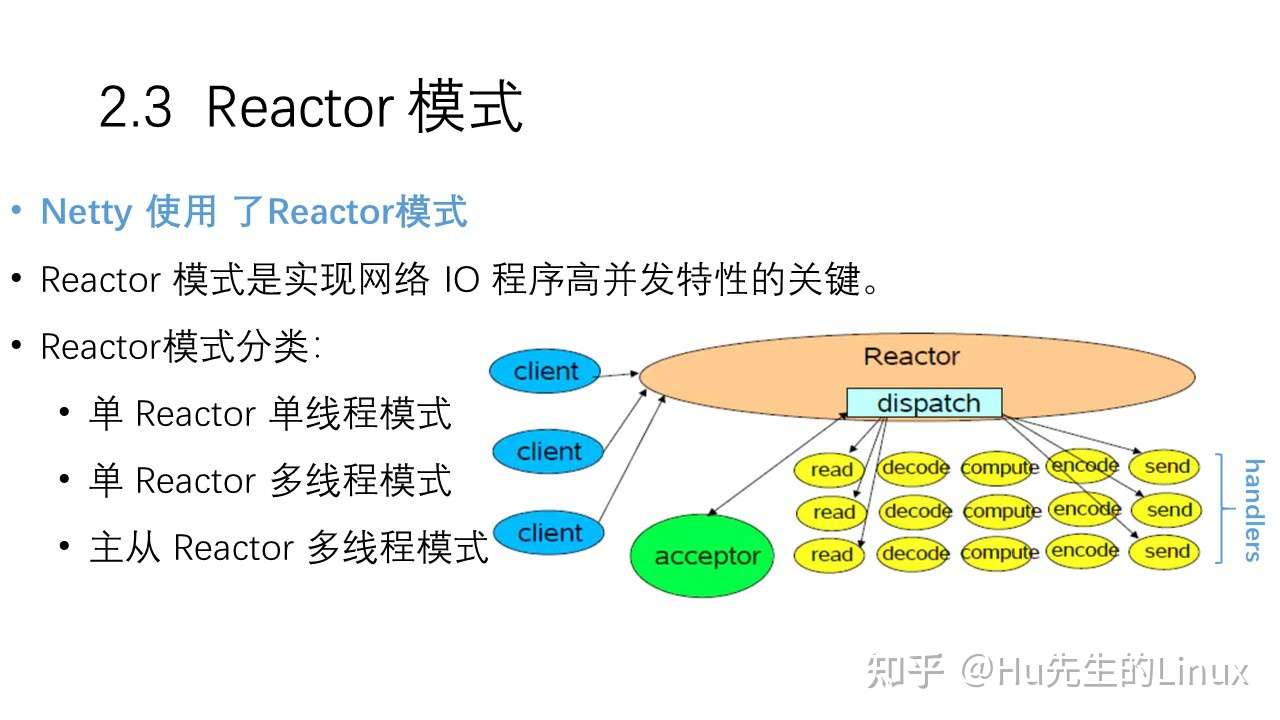
这种模式的基本工作流程为:
- 1)Reactor 通过 select 监听客户端请求事件,收到事件之后通过 dispatch 进行分发
- 2)若事件是建立连接的请求,则由 Acceptor 通过 accept 处理连接请求,然后创建一个 Handler 对象处理连接建立后的后续业务。
- 3)若不是建立连接的请求,则分发给此连接对应的 Handler 处理。
- 4)Handler 会完成 read–>业务处理–>send 的完整处理流程。
简单来说就是:一个线程 处理多个连接的请求、分发、read,send、业务处理 操作
- 优点是:模型简单,没有多线程、进程通信、竞争的问题,一个线程完成所有的事件响应和业务处理。
- 缺点是:
- 1)存在性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
- 2)存在可靠性问题,若线程意外终止,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。 使用场景为:客户端的数量有限,业务处理非常快速,比如 Redis // 在业务处理的时间复杂度为 O(1)的情况。
单Reactor多线程模式
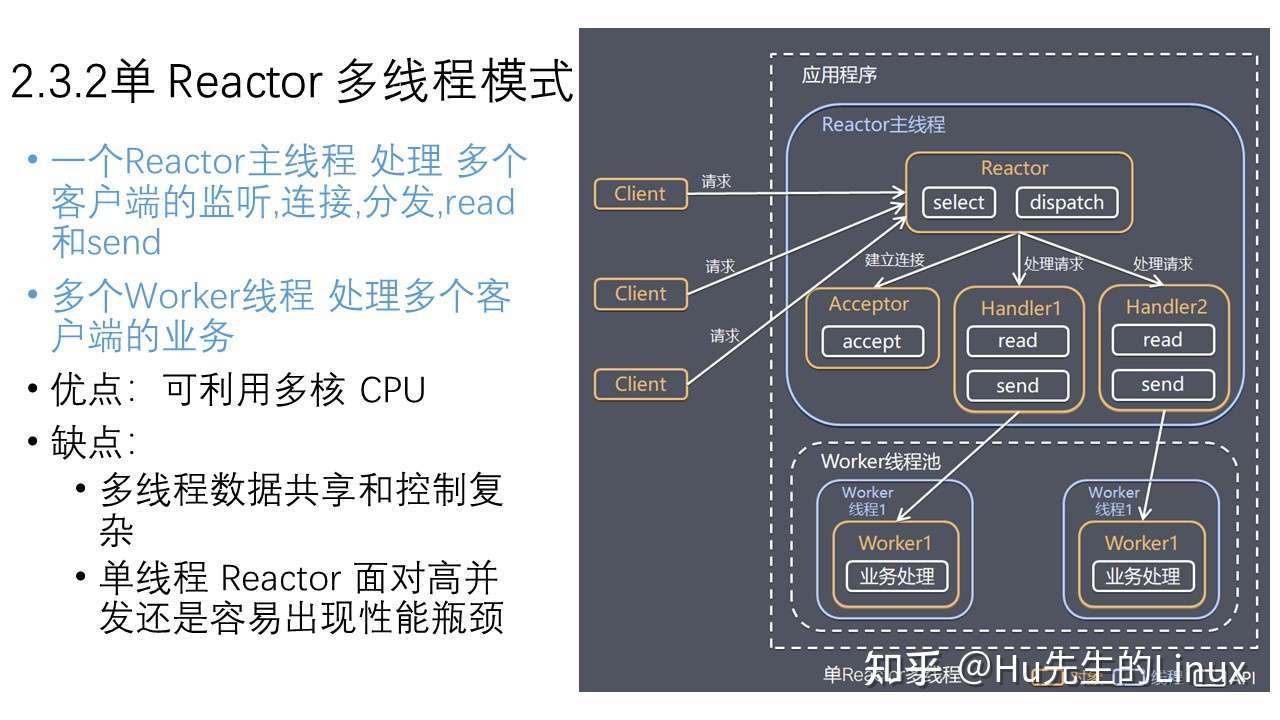
单 Reactor 多线程模式 使用了
- 一个Reactor主线程 处理 多个客户端的 监听 连接 分发 read和send
- 多个Worker线程 处理多个客户端的业务
这种模式
- 优点是可以充分的利用多核 CPU的处理能力,
- 缺点是多线程数据共享和控制比较复杂,Reactor 处理所有的事件的监听和响应,在单线程中运行,面对高并发场景还是容易出现性能瓶颈。
主从Reactor多线程模式
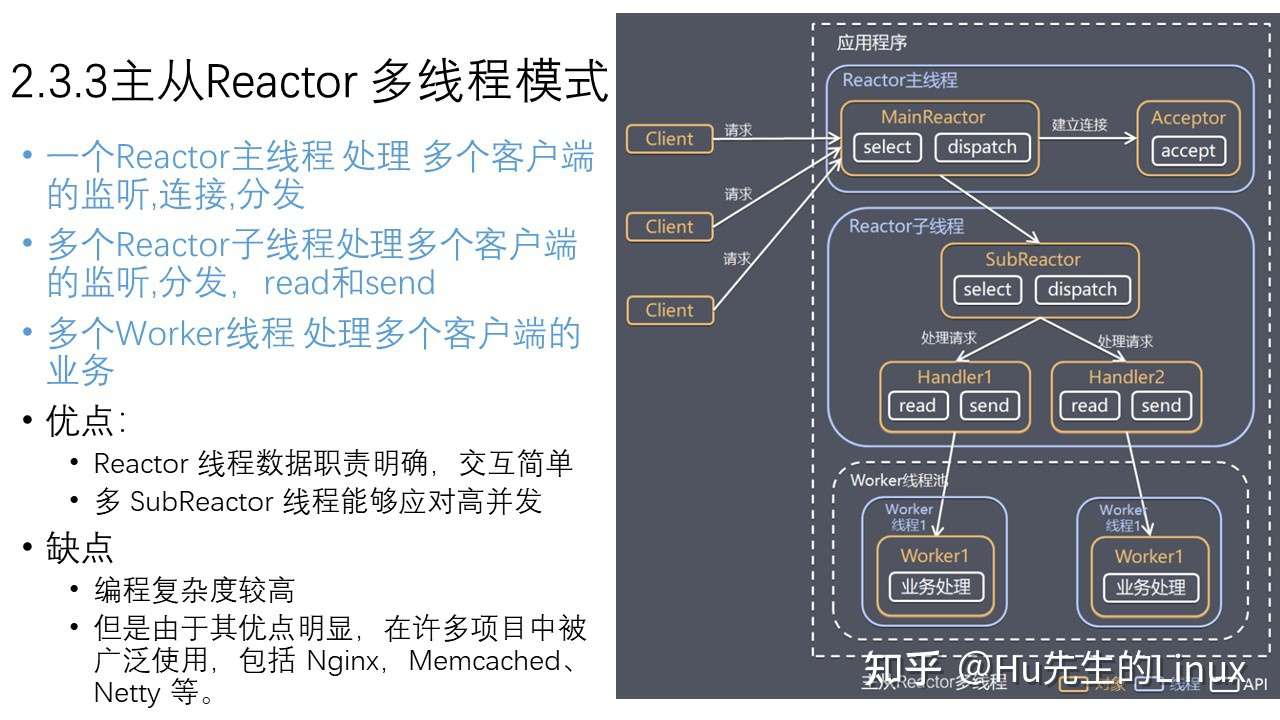
主从 Reactor 多线程模式 使用了
- 一个Reactor主线程 处理 多个客户端的监听,连接,分发
- 多个Reactor子线程处理多个客户端的 read和send
- 多个Worker线程 处理多个客户端的业务
- MainReactor 只负责监听客户端连接请求,和客户端建立连接之后将连接交由 SubReactor 监听后面的 IO 事件。
这种模式的优点是:
- 1)MainReactor 线程与 SubReactor 线程职责明确,MainReactor 线程只需要接收新连接,SubReactor 线程完成后续的业务处理。
- 2)交互简单, MainReactor 线程只需要把新连接传给 SubReactor 线程,由SubReactor 返回数据给客户端
- 3)多个 SubReactor 线程能够应对更高的并发请求。
这种模式的缺点是编程复杂度较高。但是由于其优点明显,在许多项目中被广泛使用,包括 Nginx、Memcached、Netty 等。
这种模式也被叫做服务器的 1+M+N 线程模式,即使用该模式开发的服务器包含一个(或多个,1 只是表示相对较少)连接建立线程+M 个 IO 线程+N 个业务处理线程。这是业界成熟的服务器程序设计模式。
C++调试
gdb调试
调试程序的方法
- 通过设置断点进行调试
- 打印log进行调试
-
打印中间结果进行调试
- gdb调试
- gcc -g main.c -o main // 源码调试,编译时加参数g
- gdb main // 进入调试环境
- gdb命令:help, list, step, b(break), c(continue)
coredump
-
coredump是程序由于异常或者bug在运行时异常退出或者终止,在一定的条件下生成的一个叫做core的文件,这个core文件会记录程序在运行时的内存,寄存器状态,内存指针和函数堆栈信息等等。对这个文件进行分析可以定位到程序异常的时候对应的堆栈调用信息。
-
使用gdb命令对core文件进行调试
以下例子在Linux上编写一段代码并导致segment fault 并产生core文件
mkdir coredumpTest
vim coredumpTest.cpp
在编辑器内键入
#include<stdio.h>
int main(){
int i;
scanf("%d",i);//正确的应该是&i,这里使用i会导致segment fault
printf("%d\n",i);
return 0;
}
- 执行:
# 编译
g++ coredumpTest.cpp -g -o coredumpTest
# 运行
./coredumpTest
# 使用gdb调试coredump
gdb [可执行文件名] [core文件名]
编译特征
- C++编译特点
- 每个源文件独立编译
- C/C++的编译系统和其他高级语言存在很大的差异,其他高级语言中,编译单元是整个Module,即Module下所有源码,会在同一个编译任务中执行。而在C/C++中,编译单元是以文件为单位。每个.c/.cc/.cxx/.cpp源文件是一个独立的编译单元,导致编译优化时只能基于本文件内容进行优化,很难跨编译单元提供代码优化。
- 每个编译单元,都需要独立解析所有包含的头文件
- 如果N个源文件引用到了同一个头文件,则这个头文件需要解析N次(对于Thrift文件或者Boost头文件这类动辄几千上万行的头文件来说,简直就是“鬼故事”)。
- 如果头文件中有模板(STL/Boost),则该模板在每个cpp文件中使用时都会做一次实例化,N个源文件中的std::vector会实例化N次。
- 模板函数实例化
- 在C++ 98语言标准中,对于源代码中出现的每一处模板实例化,编译器都需要去做实例化的工作;而在链接时,链接器还需要移除重复的实例化代码。显然编译器遇到一个模板定义时,每次都去进行重复的实例化工作,进行重复的编译工作。此时,如果能够让编译器避免此类重复的实例化工作,那么可以大大提高编译器的工作效率。在C++ 0x标准中一个新的语言特性 – 外部模板的引入解决了这个问题。
- 在C++ 98中,已经有一个叫做显式实例化(Explicit Instantiation)的语言特性,它的目的是指示编译器立即进行模板实例化操作(即强制实例化)。而外部模板语法就是在显式实例化指令的语法基础上进行修改得到的,通过在显式实例化指令前添加前缀extern,从而得到外部模板的语法。
- ① 显式实例化语法:template class vector。
- ② 外部模板语法:extern template class vector。
- 一旦在一个编译单元中使用了外部模板声明,那么编译器在编译该编译单元时,会跳过与该外部模板声明匹配的模板实例化。
- 虚函数
- 编译器处理虚函数的方法是:给每个对象添加一个指针,存放了指向虚函数表的地址,虚函数表存储了该类(包括继承自基类)的虚函数地址。如果派生类重写了虚函数的新定义,该虚函数表将保存新函数的地址,如果派生类没有重新定义虚函数,该虚函数表将保存函数原始版本的地址。如果派生类定义了新的虚函数,则该函数的地址将被添加到虚函数表中。
- 调用虚函数时,程序将查看存储在对象中的虚函数表地址,转向相应的虚函数表,使用类声明中定义的第几个虚函数,程序就使用数组的第几个函数地址,并执行该函数。
- 使用虚函数后的变化:
- ① 对象将增加一个存储地址的空间(32位系统为4字节,64位为8字节)。
- ② 每个类编译器都创建一个虚函数地址表。
- ③ 对每个函数调用都需要增加在表中查找地址的操作。
- 编译优化
- GCC提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对编译时间,目标文件长度,执行效率这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类:
- ① 精简操作指令。
- ② 尽量满足CPU的流水操作。
- ③ 通过对程序行为地猜测,重新调整代码的执行顺序。
- ④ 充分使用寄存器。
- ⑤ 对简单的调用进行展开等等。
- 如果全部了解这些编译选项,对代码针对性的优化还是一项复杂的工作,幸运的是GCC提供了从O0-O3以及Os这几种不同的优化级别供大家选择,在这些选项中,包含了大部分有效的编译优化选项,并且可以在这个基础上,对某些选项进行屏蔽或添加,从而大大降低了使用的难度。
- O0:不做任何优化,这是默认的编译选项。
- O和O1:对程序做部分编译优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。
- O2:是比O1更高级的选项,进行更多的优化。GCC将执行几乎所有的不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环展开以及函数内 - 联优化。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。
- O3:在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。
- Os:主要是对代码大小的优化, 通常各种优化都会打乱程序的结构,让调试工作变得无从着手。并且会打乱执行顺序,依赖内存操作顺序的程序需要做相关处理才能确保程序的正确性。
- 编译优化有可能带来的问题:
- ① 调试问题:正如上面所提到的,任何级别的优化都将带来代码结构的改变。例如:对分支的合并和消除,对公用子表达式的消除,对循环内load/store操作的替换和更改等,都将会使目标代码的执行顺序变得面目全非,导致调试信息严重不足。
- ② 内存操作顺序改变问题:在O2优化后,编译器会对影响内存操作的执行顺序。例如:-fschedule-insns允许数据处理时先完成其他的指令;-fforce-mem有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用Volatile关键字限制变量的操作方式,或者利用Barrier迫使CPU严格按照指令序执行。
- GCC提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对编译时间,目标文件长度,执行效率这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类:
- C/C++ 跨编译单元的优化只能交给链接器
- 当链接器进行链接的时候,首先决定各个目标文件在最终可执行文件里的位置。然后访问所有目标文件的地址重定义表,对其中记录的地址进行重定向(加上一个偏移量,即该编译单元在可执行文件上的起始地址)。然后遍历所有目标文件的未解决符号表,并且在所有的导出符号表里查找匹配的符号,并在未解决符号表中所记录的位置上填写实现地址,最后把所有的目标文件的内容写在各自的位置上,就生成一个可执行文件。链接的细节比较复杂,链接阶段是单进程,无法并行加速,导致大项目链接极慢。
编译加速方案
- 业内有不少通用编译加速工具(方案),无需侵入代码就能提高编译速度,非常值得尝试。
- 并行编译
- 在Linux平台上一般使用GNU的Make工具进行编译,在执行make命令时可以加上-j参数增加编译并行度,如make -j 4将开启4个任务。在实践中我们并不将该参数写死,而是通过$(nproc)方法动态获取编译机的CPU核数作为编译并发度,从而最大限度利用多核的性能优势。
- 分布式编译
- 使用分布式编译技术,比如利用Distcc和Dmucs构建大规模、分布式C++编译环境,Linux平台利用网络集群进行分布式编译,需要考虑网络时延与网络稳定性。分布式编译适合规模较大的项目,比如单机编译需要数小时甚至数天。DQU服务从代码规模以及单机编译时长来说,暂时还不需要使用分布式的方式来加速,具体细节可以参考Distcc官方文档说明。
- 预编译头文件
- PCH(Precompiled Header),该方法预先将常用头文件的编译结果保存起来,这样编译器在处理对应的头文件引入时可以直接使用预先编译好的结果,从而加快整个编译流程。PCH是业内十分常用的加速编译的方法,且大家反馈效果非常不错。在我们的项目中,由于涉及到很多Shared Library的编译生成,而Shared Library相互之间无法共享PCH,因此没有取得预想效果。
- CCache
- CCache(Compiler Cache)是一个编译缓存工具,其原理是将cpp的编译结果保存在文件缓存中,以后编译时若对应文件无变动可直接从缓存中获取编译结果。需要注意的是,Make本身也有一定缓存功能,当目标文件已编译(且依赖无变化)时,若源文件时间戳无变化也不会再次编译;但CCache是按文件内容做的缓存,且同一机器的多个项目可以共享缓存,因此适用面更大。
- Module编译
- 如果你的项目是用C++ 20进行开发的,那么恭喜你,Module编译也是一个优化编译速度的方案,C++20之前的版本会把每一个cpp当做一个编译单元处理,会存在引入的头文件被多次解析编译的问题。而Modlues的出现就是解决这一问题,Modlue不再需要头文件(只需要一个模块文件,不需要声明和实现两个文件),它会将你的(.ixx 或者 .cppm)模块实体直接编译,并自动生成一个二进制接口文件。import和include预处理不同,编译好的模块下次import的时候不会重复编译,可以大幅度提高编译器的效率。
- 自动依赖分析
- Google也推出了开源的Include-What-You-Use工具(简称IWYU),基于Clang的C/C++工程冗余头文件检查工具。IWYU依赖Clang编译套件,使用该工具可以扫描出文件依赖问题,同时该工具还提供脚本解决头文件依赖问题,我们尝试搭建了这套分析工具,这个工具也提供自动化头文件解决方案,但是由于我们的代码依赖比较复杂,有动态库、静态库、子仓库等,这个工具提供的优化功能不能直接使用,其它团队如果代码结构比较简单的话,可以考虑使用这个工具分析优化,会生成如下结果文件,指导哪些头文件需要删除。
编译器
- C/C++版本更迭历程
- gcc发展到今天已经不单单可以编译C语言了,还可以编译C++、Java、Object-C等多种其他语言。有一种说法是
GCC的全名是GNU Compiler Collection(GUN 编译器集合),而gcc是GCC中用于编译c语言的编译器. 事实上,gcc看起来并不像是一个编译器,而像一个调度器,针对于不同的文件调用不同编程语言的编译器- 对于后缀为*.c的文件,gcc把它当作是C语言程序源代码,而g++当作是C++程序源代码
- 对于后缀为*.cpp的文件,gcc和g++都会当作是C++程序源代码
- 使用g++编译文件时,g++会自动链接标准库STL,而gcc不会自动链接STL,所以再使用gcc编译C++程序是有时会报错
- 在用gcc编译C++文件时,为了能够使用STL,需要加参数 –lstdc++ ,但这并不代表 gcc –lstdc++ 和 g++等价
- 据说g++会调用gcc,对于C++代码,因为gcc命令不能自动和C++程序使用的库联接,所以通常用g++来完成链接
- 需要注意的是,虽说g++会调用gcc,对于*.c文件来说,编译出来的可执行文件也不一样,因为gcc会当成C语言程序编译,而g++调用的gcc会把它当做C++语言程序来编译,这或许就能解释为什么用g++就可以编译所有C/C++的程序,还要有gcc的存在(就我测试来看,同样的C语言代码,g++编译出来的程序体积要大一些)
高效编译(makefile系列)
- gcc
- 它是GNU Compiler Collection(就是GNU编译器套件),也可以简单认为是编译器,它可以编译很多种编程语言(括C、C++、Objective-C、Fortran、Java等等)。
- 程序只有一个源文件时,直接就可以用gcc命令编译它。
- 如:g++ tmp.cpp -std=c++11 -o run/tmp
- 可是,如果程序包含很多个源文件时,该咋整?用gcc命令逐个去编译时,就发现很容易混乱而且工作量大,所以出现了下面make工具。
- make
- make工具可以看成是一个智能的批处理工具,它并没有编译和链接的功能,而是用类似于批处理的方式—通过调用makefile文件中用户指定的命令来进行编译和链接的。
- makefile
- 简单的说就像一首歌的乐谱,make工具就像指挥家,指挥家根据乐谱指挥整个乐团怎么样演奏,make工具就根据makefile中的命令进行编译和链接的。makefile命令中就包含了调用gcc(也可以是别的编译器)去编译某个源文件的命令。
- makefile在一些简单的工程完全可以人工拿下,但是当工程非常大的时候,手写makefile也是非常麻烦的,如果换了个平台makefile又要重新修改,这时候就出现了下面的Cmake这个工具。
- cmake
- cmake就可以更加简单的生成makefile文件给上面那个make用。当然cmake还有其他更牛X功能,就是可以跨平台生成对应平台能用的makefile,我们就不用再自己去修改了。
- 可是cmake根据什么生成makefile呢?它又要根据一个叫CMakeLists.txt文件(学名:组态档)去生成makefile。
- CMakeList.txt
- 到最后CMakeLists.txt文件谁写啊?亲,是你自己手写的。
- nmake
- nmake又是啥东西?
- nmake是Microsoft Visual Studio中的附带命令,需要安装VS,实际上可以说相当于linux的make,明白了么?
-
更多转:makefile笔记
- 【2020-12-28】九张图记住makefile
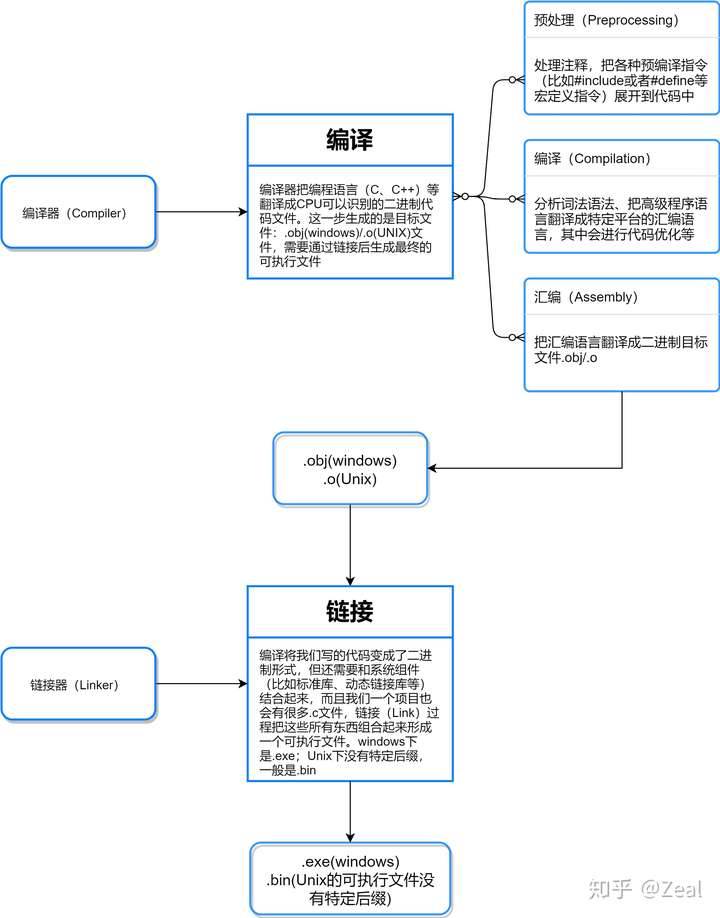
- makefile工作流
-
- 示例
- 编译:makefile–参数传递、条件判断、include (五)
- make 或 make hello
- make -f Makefile.rule # 执行指定的makefile文件
- make HOST_CFLAGS=tmp.cpp # 传参指定编译哪个文件,HOST_CFLAGS变量将会替换相应Makefile中的HOST_CFLAGS
- 清理现场:make clean
- 编译:makefile–参数传递、条件判断、include (五)
# 目录变量
SRC = tmp.cpp # 源码
SRC = $(HOST_CFLAGS) # 从外部参数指定源文件
DIR = ./out # 二进制文件目录
FILE_NAME = $(basename $(SRC)) # 提取路径文件
# include $(SRC_BASE)/Makefile.rule # 包含别的makefile文件
# 自动寻找本目录源码文件 wildcard表示文件匹配
#OBJS = $(patsubst %.cpp, %.o, $(wildcard *.cpp))
# 指定源码文件 patsubst表示模式替换
OBJS = $(patsubst %.cpp, %.o, $(SRC))
# 公共变量
CC = g++ # 编译器
CFLAGS = -c -Wall # 配置信息
LFLAGS = -Wall
# 目标 hello
hello: $(OBJS)
$(CC) $(LFLAGS) $^ -o $(DIR)/$@
# 伪目标
.PHONY : clean
# 目标clean,清理冗余文件
clean :
rm -rf *.o hello
# 帮助文件
help:
@echo "编译$(SRC)..."
@echo "make HOST_CFLAGS=test.cpp # 编译指定文件"
@echo "make -f makefile # 编译指定makefile"
@echo "make clean # 清理现场"
案例
- 【2020-12-10】美团C++优化案例
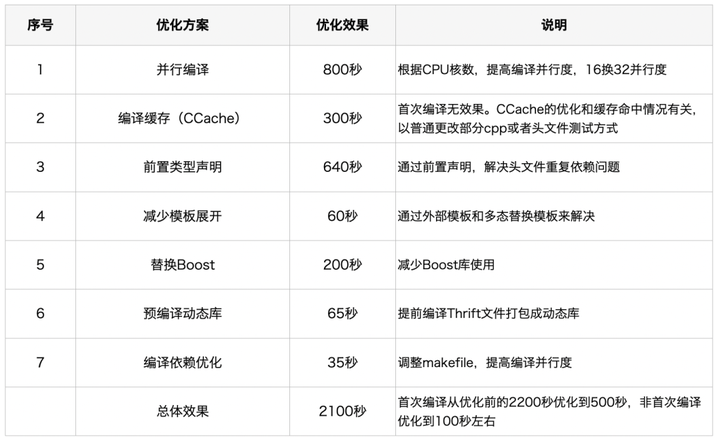
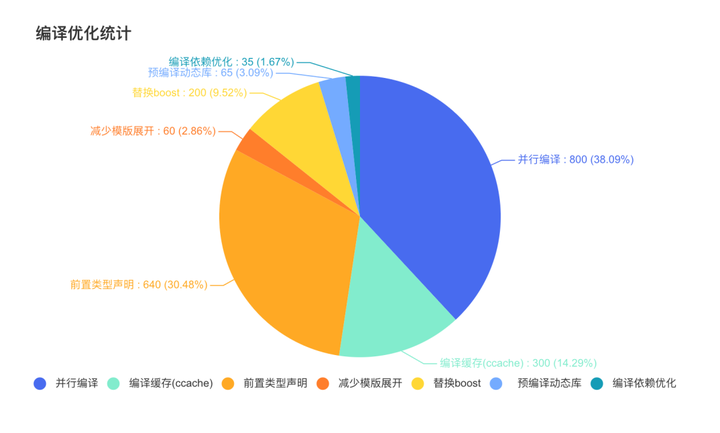
GUI 界面开发
【2022-3-10】一个零依赖的C++ 图形用户界面库
Dear ImGui 是一个基于 C++ 的零依赖图形用户界面库,它特别适合集成到游戏引擎(用于工具)、实时 3D 应用程序、全屏应用程序、嵌入式应用程序或操作系统功能非标准的控制台平台上的任何应用程序中。
功能特性
- ImGui的核心是独立包含在几个与平台无关的文件中,您可以在应用程序或者引擎中轻松编译存储库根文件夹中的所有文件(imgui.cpp、imgui.h)。
- ImGui不需要特定的构建过程,您可以将 .cpp 文件添加到现有项目中。
- ImGui可以渲染从后端传递的鼠标、键盘、游戏手柄输入等各种设置。
- /backends文件夹中提供了各种图形 api 和渲染平台的后端,以及/examples文件夹中的示例应用程序。
示例代码:
// Create a window called "My First Tool", with a menu bar.
ImGui::Begin("My First Tool", &my_tool_active, ImGuiWindowFlags_MenuBar);
if (ImGui::BeginMenuBar())
{
if (ImGui::BeginMenu("File"))
{
if (ImGui::MenuItem("Open..", "Ctrl+O")) { /* Do stuff */ }
if (ImGui::MenuItem("Save", "Ctrl+S")) { /* Do stuff */ }
if (ImGui::MenuItem("Close", "Ctrl+W")) { my_tool_active = false; }
ImGui::EndMenu();
}
ImGui::EndMenuBar();
}
// Edit a color (stored as ~4 floats)
ImGui::ColorEdit4("Color", my_color);
// Plot some values
const float my_values[] = { 0.2f, 0.1f, 1.0f, 0.5f, 0.9f, 2.2f };
ImGui::PlotLines("Frame Times", my_values, IM_ARRAYSIZE(my_values));
// Display contents in a scrolling region
ImGui::TextColored(ImVec4(1,1,0,1), "Important Stuff");
ImGui::BeginChild("Scrolling");
for (int n = 0; n < 50; n++)
ImGui::Text("%04d: Some text", n);
ImGui::EndChild();
ImGui::End();
安装
mac环境
- (1)mac下源码安装
- (2)XCode集成开发环境
- (3)Homebrew安装
- 先安装Homebrew,命令如下:
- /bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
- 首次安装:brew install gcc
- 升级安装:brew reinstall gcc6 –without-multilib
- 检查版本:gcc -v
- 注意:gcc 4.7之后才支持c11. 而mac默认版本4.2.1
- 环境变量配置
- vim ~/.bash_profile,填加如下代码
- export PATH=”/usr/local/Cellar/gcc/6.3.0_1/bin:$PATH”
- vim ~/.bash_profile,填加如下代码
- 先安装Homebrew,命令如下:
- helloworld示例
- g++ helloworld.cpp
- g++ -c helloworld.cpp # 生成helloworld目标文件,非可执行文件
- g++ -o run helloworld.cpp # -o 指定可运行文件(将所有.O文件链接起来),缺失时生成a.out
- ./a.out
helloworld.cpp,内容如下:
#include <iostream>
using namespace std;
int main()
{
cout << "Hello, world!" << endl;
return 0;
}
- 参考:如何在mac下安装gcc
- example, 获取最大的几个数
#include <iostream>
#include <vector>
#include <array>
#include <limits>
#include <type_traits>
#include <algorithm>
#include <iterator>
/// <summary>
/// 极限值数组
/// 用于获取序列的最小或者最大的多个值.
/// </summary>
/// <typeparam name="T">数据类型</typeparam>
template <typename T,size_t _size,bool _minimum>
class LimitArray:public std::array<T,_size> {
static_assert(std::is_arithmetic<T>::value,
"template parameter must arithmetic types");
static_assert(_size > 1, "please use min_element or max_element");
public:
LimitArray()
{
if (_minimum) {
this->fill(std::numeric_limits<T>::max());
}
else {
this->fill(std::numeric_limits<T>::lowest());
}
}
/// <summary>
/// 添加一个值 value
/// 如果获取小值,且 value < fornt 则所有元素后移一位,弹出 back, value作为首元素
/// 如果获取大值,且 value > back 则所有元素前移一位,弹出 front, value作为末元素
/// </summary>
/// <param name="value"></param>
inline void push(T value)
{
if (_minimum) {
// 留小不留大,如果比当前最大值都大,就不用继续了
if (value >= this->back()) { return; }
// 下面的操作就是,把最大的元素移除,把 value 插入合适位置
// 查找合适的插入点;第一个大于 value 的元素的迭代器
auto iter = std::upper_bound(this->begin(), this->end(), value);
// 移动 [插入点,倒数第二个] 数据往后一位
// 注意,参数是半闭半开区间 ,第三个参数是目标序列的最后一个的后一个
std::move_backward(iter, this->end() - 1, this->end());
*iter = value;
}
else {
// 留大不留小
if (value <= this->front()) { return; }
// 查找合适的插入点;第一个不小于 value 的元素的迭代器的前一个
auto iter = std::lower_bound(this->begin(), this->end(), value) - 1;
// 移动 [第二个,插入点] 数据往前一位
std::move(this->begin() + 1, iter+1, this->begin());
*iter = value;
}
}
};
// 简单测试一下
int main()
{
std::vector<int> v = {1,3,2,6,4,7,5,0,9,8};
LimitArray<int,7,true> la1;
LimitArray<int,2,false> la2;
for(size_t i=0;i<v.size();++i){
la1.push(v[i]);
la2.push(v[i]);
}
std::copy(la1.begin(), la1.end(),
std::ostream_iterator<int>(std::cout, " "));
std::cout << '\n';
std::copy(la2.begin(), la2.end(),
std::ostream_iterator<int>(std::cout, " "));
std::cout << '\n';
return 0;
}
- 执行报错,原因是vector赋值是c++ 11以后的特性
error: non-aggregate type 'vector<string>' cannot be initialized with an initializer list
vector<string> vs1 = {"a", "an", "the"};
- 解决:升级c++ 11、编译时指定版本
- g++ hi.cpp -std=c++11
STL
- 参考
- 【2021-3-20】STL教程:C++ STL快速入门(非常详细)
- C++ STL精华笔记
STL介绍
- STL 是“Standard Template Library”的缩写,中文译为“标准模板库”。STL 是 C++ 标准库的一部分,不用单独安装。
- C++ 对模板(Template)支持得很好,STL 就是借助模板把常用的数据结构及其算法都实现了一遍,并且做到了数据结构和算法的分离。
- 例如,vector 的底层为顺序表(数组),list 的底层为双向链表,deque 的底层为循环队列,set 的底层为红黑树,hash_set 的底层为哈希表。
STL三个核心
- 容器:容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。
- < algorithm > 是所有STL头文件中最大的一个(尽管它很好理解),它是由一大堆模版函数组成的,可以认为每个函数在很大程度上都是独立的,其中常用到的功能范围涉及到比较、交换、查找、遍历操作、复制、修改、移除、反转、排序、合并等等。
- 算法:算法作用于容器。它们提供了执行各种操作的方式,包括对容器内容执行初始化、排序、搜索和转换等操作。
- < numeric > 体积很小,只包括几个在序列上面进行简单数学运算的模板函数,包括加法和乘法在序列上的一些操作。
- STL中算法大致分为四类:
- 1)非可变序列算法:指不直接修改其所操作的容器内容的算法。
- 2)可变序列算法:指可以修改它们所操作的容器内容的算法。
- 3)排序算法:对序列进行排序和合并的算法、搜索算法以及有序序列上的集合操作。
- 4)数值算法:对容器内容进行数值计算。
- 迭代器:迭代器用于遍历对象集合的元素。这些集合可能是容器,也可能是容器的子集。
- < functional > 中则定义了一些模板类,用以声明函数对象。
STL中六大组件
- 1)容器(Container),是一种数据结构,如list,vector,和deques ,以模板类的方法提供。为了访问容器中的数据,可以使用由容器类输出的迭代器;
- 队列容器:
Vectors:将元素置于一个动态数组中加以管理,可以随机存取元素(用索引直接存取),数组尾部添加或移除元素非常快速。但是在中部或头部安插元素比较费时;Deques:是“double-ended queue”的缩写,可以随机存取元素(用索引直接存取),数组头部和尾部添加或移除元素都非常快速。但是在中部或头部安插元素比较费时;Lists:双向链表,不提供随机存取(按顺序走到需存取的元素,O(n)),在任何位置上执行插入或删除动作都非常迅速,内部只需调整一下指针;
- 关联容器:元素位置取决于特定的排序准则,和插入顺序无关,set、multiset、map、multimap;
Sets/Multisets:内部的元素依据其值自动排序,Set内的相同数值的元素只能出现一次,Multisets内可包含多个数值相同的元素,内部由二叉树实现,便于查找;Maps/Multimaps:Map的元素是成对的键值/实值,内部的元素依据其值自动排序,Map内的相同数值的元素只能出现一次,Multimaps内可包含多个数值相同的元素,内部由二叉树实现,便于查找;- 容器类自动申请和释放内存,无需new和delete操作。vector基于模板实现,需包含头文件vector。
- 容器适配器(congtainer adapters:stack,queue,priority queue)
- 位集(bit_set)
- 串包(string_package)等
- 队列容器:
- 2)迭代器(Iterator),提供了访问容器中对象的方法,又称Cursor(游标)模式。例如,可以用一对迭代器指定list或vector中的一定范围的对象。迭代器就如同一个指针。事实上,C++的指针也是一种迭代器。但是,迭代器也可以是那些定义了operator*()以及其他类似于指针的操作符地方法的类对象;
- 常见的一些迭代器类型:iterator、const_iterator、reverse_iterator和const_reverse_iterator
- 3)算法(Algorithm),是用来操作容器中的数据的模板函数。例如,STL用sort()来对一个vector中的数据进行排序,用find()来搜索一个list中的对象,函数本身与他们操作的数据的结构和类型无关,因此他们可以在从简单数组到高度复杂容器的任何数据结构上使用;
- 4)仿函数(Function object)
- 5)迭代适配器(Adaptor)
- 6)空间配制器(allocator)
STL分类
STL中的容器大致分为两类:序列式容器和关联式容器,涵盖了常用的各种数据结构。
- 序列式容器:array、vector、list
- 关联式容器:set、map
- 容器适配器:stack、queue、priority_queue
- stack和queue基于deque实现,而priority_queue基于vector
- queue有push_front操作,因此不能用vector
- priority_front要求随机访问,因此要用vector
序列式容器
序列是指容器中的元素可序,但未必有序。用线性方式存储数据,不会自动排序
除了C++提供的array之外,STL另外提供了vector,list,deque,stack,queue等。
array:定长数组,C++11以上版本vector: 动态数组,与array相似,采用线性连续空间,但是提供了扩容的功能,当新的元素加入,且原空间不足的时候,它内部会自动分配空间,移动拷贝数据,释放旧空间。注意vector有容量的概念,为了防止频繁的分配拷贝,因此申请的空间比需求的要更大一些。- vector<\bool>:vector的bool特化
list:双向链表,list相对于vector这种线性空间的好处就是利用率高,插入删除一个元素,就分配释放一个元素的空间,元素的插入和删除是常数时间。STL的list就是一个环形的双向链表,使用bidirection Iterators,就是具备前移,后移能力的迭代器,注意stl中的几种不同型别迭代器。其操作就是一些指针操作。forward_list:单链表,C++11以上版本
stack:栈,先进后出(FILO)的数据结构,只有一个出口,结构就是以deque为底部结构,然后封闭其头端开口,形成单向结构。这种改法称为适配器。queue:队列,两个出口,先进先出(FIFO)。元素的操作都在顶端和底端,最顶端取出,最底端加入。结构同样是以deque为底部结构,然后封闭底端出口和顶端的入口。至于怎么封闭,你不给出相对应接口函数就好了嘛。priority_queue:拥有权值观念的queue。权值最高的排在队列头部,元素入队的时候会按照权值排列。priority_queue缺省情况下用vector作为容器,然后使用堆的一些泛型算法实现。deque:双向动态数组,deque是双向开口的连续线性空间,vector也可以做成双向的,但是其头部的操作效率奇差,需要大量的移动后面的数据。deque通过动态的分段的连续空间的组合,完成头端常数时间内的插入删除操作。deque内部通过对各种指针操作的重载,完成缓冲区边缘的处理。
#include <iostream>
#include <array>
#include <string>
using namesapce std;
int main(){
array<int, 5U> s = {3,7,1,2,5};
//int s[5] = {3,7,1,2,5}; // 等效表达
for(auto i:s){
cout << s[i] << "\t";
}
cout << endl;
return 0;
}
关联式容器
关联容器的每个数据都有一个key和value。当元素插入容器时,容器内部依照键值的大小和某种规则将其放置到合适位置。
STL中关联式容器分为set和map两大类。
- set/multiset:key与value相同
- map/multimap:key对应value
分类
set:set所有元素会根据键值自动排序,set的key就是value。并且不允许两个元素有相同的key。set的底层就是红黑树,这里不对红黑树做直接的介绍了。注意set的插入使用了RB-tree的insert_unique()函数来保证没有重复的key,其结构本身是不限制key的重复的。multiset:和set主要的区别就是允许有重复的key值,用法和其他特性和set相同。插入操作使用insert-equal()。unordered_set/unordered_multiset:C++11以上版本,无序集合,key=valuemap:map的元素都是一对pair,同时拥有key和value,不允许同key。注意map的key不可更改,value可更改。map的数据类型是pair,结构底层使用RB-tree。multimap:类似set和multiset,差别只是插入函数的不同。unordered_map/unordered_multimap:C++11以上版本,无序集合,key=value,单独访问元素较快,逐个遍历速度不如maphash_set:使用hashtable为底层机制,就是一个vector+list的开链法的hash结构。hash_map:同样是以hashtable为底层,转调用其操作。只是数据节点的类型是map而已。hash_multiset:和hash_set插入函数不同。hash_multimap:和hash_map插入函数不同。
容器适配器
如下:
- stack:栈
- queue:队列
- priority_queue:优先队列
- bitset:位组
| 类型 | 结构 | 顺序 | 成员函数 |
|---|---|---|---|
| stack | 栈 | FILO 先进后出 | top返回栈顶元素 push栈顶追加元素 pop栈顶移除元素 size元素个数 empty判空 |
| queue | 队列 | FIFO 先进先出 | front返回队头元素 push队尾追加元素 pop移除队头元素 size元素个数 empty判空 |
| priority_queue | 优先队列 | 队列基础上加内部排序,用堆实现 | top返回队头元素 push队尾追加元素并排序 pop移除队头元素 size元素个数 empty判空 swap交换内容 emplace原地构造元素并插入队列 |
#include <iostream>
#include <stack>
using namesapce std;
int main(){
stack<int> my;
int n = 123;
cout << n << "的二进制是:";
// 计算二进制
while(n/2 != 0){
my.push(n%2);
n /= 2;
}
// 输出二进制
while(!my.empty()){
cout << my.top();
my.pop(); // pop不返回栈顶元素,所以需要单独用top取数
}
return 0;
}
#include <iostream>
#include <queue>
#include <string>
using namespace std;
int main(){
queue<string> my;
my.push("点赞");
my.push("转发");
my.push("评论");
cout << "队列大小:" << my.size() << endl;
// 输出
while(!my.empty()){
cout << my.front() << endl;
my.pop();
}
return 0;
}
优先级队列通过大顶堆/小顶堆实现
#include <iostream>
#include <queue>
using namespace std;
int main(){
int a[5] = {4,7,1,3,8};
// 升序,小顶堆:元素类型,容器类型,比较准则
priority_queue <int, vector<int>, greater<int>> maxheap;
for (auto i:a){
maxheap.push(a[i]);
}
while(!maxheap.empty()){
cout << maxheap.top() << "\t";
maxheap.pop();
}
cout << endl;
// 降序,大顶堆
priority_queue <int, vector<int>, less<int>> minheap;
while(!minheap.empty()){
cout << minheap.top() << "\t";
minheap.pop();
}
cout << endl;
return 0;
}
- 【2020-6-26】代码示例,sort用法
#include <iostream> // std::cout
#include <algorithm> // std::sort
#include <vector> // std::vector
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector<int> myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用第一种语法格式,对 32、71、12、45 进行排序
std::sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater<T>)进行排序
std::sort(myvector.begin(), myvector.begin() + 4, std::greater<int>()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序
std::sort(myvector.begin(), myvector.end(), mycomp2());//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
return 0;
}
vector
元素遍历
C++不同版本实现方法不同
before 20:
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec { 1, 2, 3 };
std::for_each(vec.rbegin(), vec.rend(),
[](const int& e) { std::cout << e << " "; });
}
C++11
std::vector<int> nums{31, -41, 59, 26, -53, 58, 97, -93, -23, 84};
std::for_each(nums.rbegin(), nums.rend(), [](int num) {
std::cout << num << " ";
});
C++20:
#include <algorithm>
#include <iostream>
#include <ranges>
#include <vector>
auto main() -> int {
std::vector vec { 1, 2, 3 };
std::ranges::for_each(std::views::reverse(vec),
[](const auto& e) { std::cout << e << " "; });
}
C++23:
import std;
auto main() -> int {
std::vector vec { 1, 2, 3 };
std::print("{}\n", std::views::reverse(vec)); // Output: [3, 2, 1]
}
智能指针
【2022-4-14】STL里的四种智能指针:auto_ptr、scoped_ptr、shared_ptr、weak_ptr
auto_ptr< string> ps (new string ("I reigned lonely as a cloud.”);
auto_ptr<string> vocation;
vocaticn = ps;
程序将试图删除同一个对象两次,要避免这种问题,方法有多种:
- (1)定义赋值运算符,使之执行深复制。这样两个指针将指向不同的对象,其中的一个对象是另一个对象的副本,缺点是浪费空间,所以智能指针都未采用此方案。
- (2)建立所有权概念。对于特定对象,只能有一个智能指针可拥有,这样只有拥有对象的智能指针的析构函数会删除该对象。然后让赋值操作转让所有权。这就是用于auto_ptr和unique_ptr 的策略,但unique_ptr的策略更严格。
- (3)创建更高的智能指针,跟踪引用特定对象的智能指针数。这称为引用计数。例如,赋值时,计数将加1,而指针过期时,计数将减1,。当减为0时才调用delete。这是shared_ptr采用的策略。
总结:
- auto_ptr 被复制后,将失去原来所致资源的所有权;
- scoped_ptr永远不能被复制或被赋值!scoped_ptr 拥有它所指向的资源的所有权,并永远不会放弃这个所有权;
- shared_ptr 是可以共享所有权的智能指针;
1. unique_ptr:替代不安全的auto_ptr
unique_ptr由C++11引入,旨在替代不安全的auto_ptr。
- unique_ptr不共享所管理的对象。它无法复制到其他unique_ptr,无法通过值传递到函数,也无法用于需要副本的任何标准模板库 (STL)算法。只能移动 unique_ptr,即对资源管理权限可以实现转移。
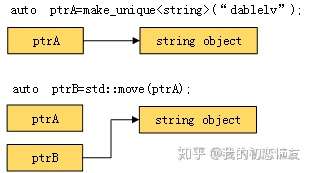
//智能指针的创建
unique_ptr<int> u_i; //创建空智能指针
u_i.reset(new int(3)); //"绑定”动态对象
unique_ptr<int> u_i2(new int(4));//创建时指定动态对象
unique_ptr<T,D> u(d); //创建空unique_ptr,执行类型为T的对象,用类型为D的对象d来替代默认的删除器delete
//所有权的变化
int *p_i = u_i2.release(); //释放所有权
unique_ptr<string> u_s(new string("abc"));
unique_ptr<string> u_s2 = std::move(u_s); //所有权转移(通过移动语义),u_s所有权转移后,变成“空指针”
u_s2.reset(u_s.release());//所有权转移
u_s2=nullptr;//显式销毁所指对象,同时智能指针变为空指针。与u_s2.reset()等价
2. auto_ptr
为什么不用它而用unique_ptr
- 使用unique_ptr时编译出错,与auto_ptr一样,unique_ptr也采用所有权模型,但在使用unique_ptr时,程序不会等到运行阶段崩溃,而在编译期因下述代码行出现错误。
- 一句话总结就是:避免因潜在的内存问题导致程序崩溃。
int main()
{
auto_ptr<string> films[5] ={
auto_ptr<string> (new string("Fowl Balls")),
auto_ptr<string> (new string("Duck Walks")),
auto_ptr<string> (new string("Chicken Runs")),
auto_ptr<string> (new string("Turkey Errors"))
};
auto_ptr<string> pwin;
pwin = films[2];
// films[2] loses ownership. 将所有权从films[2]转让给pwin,此时films[2]不再引用该字符串从而变成空指针
for(int i = 0; i < 4; ++i)
{
cout << *films[i] << endl;
}
return 0;
}
从上面可见,unique_ptr比auto_ptr更加安全,因为
- auto_ptr有拷贝语义,拷贝后原象变得无效,再次访问原对象时会导致程序崩溃;
- unique_ptr则禁止了拷贝语义,但提供了移动语义,即可以使用std::move()进行控制权限的转移
unique_ptr<string> upt(new string("lvlv"));
unique_ptr<string> upt1(upt); //编译出错,已禁止拷贝
unique_ptr<string> upt1=upt; //编译出错,已禁止拷贝
unique_ptr<string> upt1=std::move(upt); //控制权限转移,正确的写法
auto_ptr<string> apt(new string("lvlv"));
auto_ptr<string> apt1(apt); //编译通过
auto_ptr<string> apt1=apt; //编译通过
- 使用shared_ptr时运行正常,因为shared_ptr采用引用计数,pwin和films[2]都指向同一块内存,在释放空间时因为事先要判断引用计数值的大小因此不会出现多次删除一个对象的错误。
3. shared_ptr
- 麻烦:确保用 new 动态分配的内存空间在程序的各条执行路径都能被释放
- 解法:C++ 11 模板库的 < memory> 头文件中定义的智能指针,即 shared _ptr 模板;
只要将 new 运算符返回的指针 p 交给一个 shared_ptr 对象“托管”,就不必担心在哪里写delete p语句——实际上根本不需要编写这条语句,托管 p 的 shared_ptr 对象在消亡时会自动执行delete p。而且,该 shared_ptr 对象能像指针 p —样使用,即假设托管 p 的 shared_ptr 对象叫作 ptr,那么 *ptr 就是 p 指向的对象。
#include <iostream>
#include <memory>
using namespace std;
class A
{
public:
int i;
A(int n):i(n) { };
~A() { cout << i << " " << "destructed" << endl; }
};
int main()
{
// shared_ptr<T> ptr(new T); // T 可以是 int、char、类等各种类型, ptr 就可以像 T* 类型的指针一样使用,即 *ptr 就是用 new 动态分配的那个对象。
shared_ptr<A> sp1(new A(2)); //A(2)由sp1托管
// 多个 shared_ptr 对象可以共同托管一个指针 p,当所有曾经托管 p 的 shared_ptr 对象都解除了对其的托管时,就会执行delete p。
shared_ptr<A> sp2(sp1); //A(2)同时交由sp2托管
shared_ptr<A> sp3;
sp3 = sp2; //A(2)同时交由sp3托管
cout << sp1->i << "," << sp2->i <<"," << sp3->i << endl;
A * p = sp3.get(); // get返回托管的指针,p 指向 A(2)
cout << p->i << endl; //输出 2
sp1.reset(new A(3)); // reset导致托管新的指针, 此时sp1托管A(3)
sp2.reset(new A(4)); // sp2托管A(4)
cout << sp1->i << endl; //输出 3
sp3.reset(new A(5)); // sp3托管A(5),A(2)无人托管,被delete
cout << "end" << endl;
return 0;
}
boost::shared_ptr
boost::scoped_ptr虽然简单易用,但它不能共享所有权的特性却大大限制了其使用范围,而boost::shared_ptr可以解决这一局限。
- boost::shared_ptr是可以共享所有权的智能指针,基本用法:
#include <string>
#include <iostream>
#include <boost/shared_ptr.hpp>
class implementation
{
public:
~implementation() { std::cout <<"destroying implementation\n"; }
void do_something() { std::cout << "did something\n"; }
};
void test()
{
boost::shared_ptr<implementation> sp1(new implementation());
std::cout<<"The Sample now has "<<sp1.use_count()<<" references\n";
boost::shared_ptr<implementation> sp2 = sp1;
std::cout<<"The Sample now has "<<sp2.use_count()<<" references\n";
sp1.reset();
std::cout<<"After Reset sp1. The Sample now has "<<sp2.use_count()<<" references\n";
sp2.reset();
std::cout<<"After Reset sp2.\n";
}
void main()
{
test();
}
boost::shared_ptr指针sp1和sp2同时拥有了implementation对象的访问权限,且当sp1和sp2都释放对该对象的所有权时,其所管理的的对象的内存才被自动释放。在共享对象的访问权限同时,也实现了其内存的自动管理。
boost::shared_ptr的内存管理机制:
- boost::shared_ptr的管理机制其实并不复杂,就是对所管理的对象进行了引用计数,当新增一个boost::shared_ptr对该对象进行管理时,就将该对象的引用计数加一;减少一个boost::shared_ptr对该对象进行管理时,就将该对象的引用计数减一,如果该对象的引用计数为0的时候,说明没有任何指针对其管理,才调用delete释放其所占的内存。
上面的那个例子可以的图示如下:
- sp1对implementation对象进行管理,其引用计数为1
- 增加sp2对implementation对象进行管理,其引用计数增加为2
- sp1释放对implementation对象进行管理,其引用计数变为1
- sp2释放对implementation对象进行管理,其引用计数变为0,该对象被自动删除
boost::shared_ptr的特点:
- 和前面介绍的boost::scoped_ptr相比,boost::shared_ptr可以共享对象的所有权,因此其使用范围基本上没有什么限制(还是有一些需要遵循的使用规则,下文中介绍),自然也可以使用在stl的容器中。另外它还是线程安全的,这点在多线程程序中也非常重要。
boost::shared_ptr的使用规则:
- boost::shared_ptr并不是绝对安全,下面几条规则能使我们更加安全的使用boost::shared_ptr:
- 避免对shared_ptr所管理的对象的直接内存管理操作,以免造成该对象的重释放
- shared_ptr并不能对循环引用的对象内存自动管理(这点是其它各种引用计数管理内存方式的通病)。
- 不要构造一个临时的shared_ptr作为函数的参数。
// 可能导致内存泄漏:
void test()
{
foo(boost::shared_ptr<implementation>(new implementation()),g());
}
// 正确的用法为 :
void test()
{
boost::shared_ptr<implementation> sp (new implementation());
foo(sp,g());
}
4. weak_ptr
被设计为与shared_ptr共同工作,可以从一个shared_ptr或者另一个weak_ptr对象构造而来。
循环引用:
一般来讲,解除这种循环引用有下面三种可行的方法:
- (1)当只剩下最后一个引用的时候需要手动打破循环引用释放对象。
- (2)当parent的生存期超过children的生存期的时候,children改为使用一个普通指针指向parent。
- (3)使用弱引用的智能指针打破这种循环引用。 虽然这三种方法都可行,但方法1和方法2都需要程序员手动控制,麻烦且容易出错。这里主要介绍一下第三种方法,使用弱引用的智能指针std:weak_ptr来打破循环引用。
Boost智能指针——scoped_ptr
boost::scoped_ptr和std::auto_ptr非常类似,是一个简单的智能指针,它能够保证在离开作用域后对象被自动释放。
boost::scoped_ptr特点:
- boost::scoped_ptr的实现和std::auto_ptr非常类似,都是利用了一个栈上的对象去管理一个堆上的对象,从而使得堆上的对象随着栈上的对象销毁时自动删除。不同的是,boost::scoped_ptr有着更严格的使用限制——不能拷贝。
- 这就意味着:boost::scoped_ptr指针是不能转换其所有权的。
- 不能转换所有权:boost::scoped_ptr所管理的对象生命周期仅仅局限于一个区间(该指针所在的”{}”之间),无法传到区间之外,这就意味着boost::scoped_ptr对象是不能作为函数的返回值的(std::auto_ptr可以)。
- 不能共享所有权:这点和std::auto_ptr类似。这个特点一方面使得该指针简单易用。另一方面也造成了功能的薄弱——不能用于stl的容器中。
- 不能用于管理数组对象:由于boost::scoped_ptr是通过 delete来删除所管理对象的,而数组对象必须通过 deletep[]来删除,因此boost::scoped_ptr是不能管理数组对象的,如果要管理数组对象需要使用boost::scoped_array类。
#include <string>
#include <iostream>
#include <boost/scoped_ptr.hpp>
class implementation
{
public:
~implementation() { std::cout <<"destroying implementation\n"; }
void do_something() { std::cout << "did something\n"; }
};
void test()
{
boost::scoped_ptr<implementation> impl(new implementation());
impl->do_something();
}
void main()
{
std::cout<<"Test Begin ... \n";
test();
std::cout<<"Test End.\n";
}
boost::scoped_ptr和std::auto_ptr的选取:
- boost::scoped_ptr和std::auto_ptr的功能和操作都非常类似,如何在他们之间选取取决于是否需要转移所管理的对象的所有权(如是否需要作为函数的返回值)。如果没有这个需要的话,大可以使用boost::scoped_ptr,让编译器来进行更严格的检查,来发现一些不正确的赋值操作。
工程实践
C++练手项目
- 有哪些适合新手练手的C/C++项目?
- 【2021-12-9】这些C++的练手项目,相当于你2年的工作经验,拿走不谢:C++学习路径。通过使用 C++ 语言实现 Web 服务器,Markdown 解析器,内存池以及 Docker 容器管理工具等,学习并实践 C++ 编程基础,C++ 11/14 标准,C++ 图像处理及增强现实技术。完成本路径所有教程,将能够使用 C++ 独立实现复杂的应用程序。
入门项目
- CPlusPlusThings
- CPlusPlusThings 是国人开源一个 C++ 学习项目。它系统地将 C++ 学习分为了【基础进阶】、【实战系列】、【C++2.0 新特性】、【设计模式】和【STL 源码剖析】、【并发编程】、【C++ 惯用法】、【学习课程】、【工具】、【拓展】。
- 作为一个全面系统的 C++ 学习项目,CPlusPlusThings 是优秀的,它合理地安排了 10 Days 的实战部分,在实战中了解语法和函数用法,唯一不足的是,在注释部分有些不尽人意,对部分新手程序员并不是很友好。【基础进阶】部分内容:
- const 那些事
- static 那些事
- decltype 那些事
- 引用与指针那些事
- 宏那些事
- 基础算法:C-Plus-Plus
- C-Plus-Plus 是收录用 C++ 实现的各种算法的集合,并按照 MIT 许可协议进行授权。这些算法涵盖了计算机科学、数学和统计学、数据科学、机器学习、工程等各种主题。除外,你可能会发现针对同一目标的多个实现使用不同的算法策略和优化。
- C++ 实现太阳系行星系统
- 使用 C++实现 OpenGL GLUT 实现一个简单的太阳系行星系统,将涉及一些三维图形技术的数学基础、OpenGL 里的三维坐标系、OpenGL 里的光照模型、GLUT 的键盘事件处理。
- C++实现运动目标的追踪
- 利用 OpenCV 来实现对视频中动态物体的追踪。进行本教程学习时,您需要先完成 C++实现太阳系行星运行系统的相关实验,才能进行之后的学习。
- C++ 实现银行排队服务模拟
- 使用 C++对银行排队服务进行模拟,以事件驱动为核心思想,手动实现模板链式队列、随机数产生器等内容,进而学习概率编程等知识。
- 1小时入门增强现实技术
- 基于OpenCV实现一个将3D模型显示在现实中的小例子,学习基于Marker的AR技术,既简单又有趣。
- C++ 基于 OpenCV 实现实时监控和运动检测记录
- 使用 C++ 和 OpenCV 提供的库函数,实现摄像头的实时监控功能,并通过监控画面的运动检测选择是否记录视频。监控人员可选择输出图像的模式以更容易的分辨监控中的异常情况。
- 使用OpenCV&&C++进行模板匹配
- 使用OpenCV&&C++进行模板匹配,在一张大图中去查找并圈出目标小图。你将学习到关于OpenCV的一些函数用法和模板匹配的完整流程。
- 使用OpenCV进行图片平滑处理打造模糊效果
- 利用OpenCV中的平滑处理和线性滤波器对图片进行处理,打造模糊效果。将介绍归一化滤波器,高斯滤波器,中值滤波器,双边滤波器这四种滤波器的相关知识,并且会对“核”和卷积进行相应的讲解。
- C++ 实现即时通信软件
- 使用C++实现一个具备服务端和客户端的即时通信聊天室,涉及网络编程,C++面向对象程序设计等知识。
- 目实现客户端和服务端编程,服务端使用epoll机制,高并发必备,支持多客户聊天室聊天;客户端使用epoll和fork,父进程与子进程通过pipe通信。 代码
- C++实现课程管理系统
- 使用 C++ 实现一个课程管理系统,在这个过程中会介绍C++11的很多特性,同时可以熟悉Linux下的C++语言编译方法及简单的Makefile编写。
- STL
- MyTinySTL 的作者 Alinshans 用 C++11 重新复写了一个小型 STL(容器库+算法库)。代码结构清晰规范、包含中文文档与注释,并且自带一个简单的测试框架,适合 C++ 新手来实践一番。
- 计算器
- 微软开源的 Windows 系统预装的计算器工具。该工具提供标准、科学、程序员计算器的功能,以及各种度量单位和货币之间的转换功能:caculator

- 俄罗斯方块:Tinytetris
- Tinytetris 是一个用 C++ 编写的终端版俄罗斯方块游戏。它提供了两个版本的源码,分为注释版和库版,注释较多易于理解和学习。
- GitHub 地址
进阶项目
- 现代 C++:modern-cpp-tutorial
- modern-cpp-tutorial 是现代 C++ 教程,它的目的是提供关于现代 C++(2020 年前)的相关特性的全面介绍。除了介绍了代码之外,它还尽可能简单地介绍了其技术需求的历史背景,这对理解为什么会出现这些特性提供了很大的帮助。
- CppTemplateTutorial
- CppTemplateTutorial 为中文的 C++ Template 的教学指南。与知名书籍 C++ Templates 不同,该系列教程将 C++ Templates 作为一门图灵完备的语言来讲授,以求帮助读者对 Meta-Programming 融会贯通。本项目写作初衷,就是通过 “编程语言” 的视角,介绍一个简单、清晰的 “模板语言”。我会尽可能地将模板的诸多要素连串起来,用一些简单的例子帮助读者学习这门 “语言”,让读者在编写、阅读模板代码的时候,能像 if(exp) { dosomething(); } 一样的信手拈来,让 “模板元编程” 技术成为读者牢固掌握、可举一反三的有用技能。
- 0.前言
- 1.Template 的基本语法
- 2.模板元编程基础
- 3.深入理解特化与偏特化
- 4.元编程下的数据结构与算法 (尚未开始)
- 5.模板的进阶技巧(尚未开始)
- 6.模板的威力:从 foreach, transform 到 Linq(尚未开始)
- 7.结语:讨论有益,争端无用(尚未开始)
- C++11/14 高速上手教程
- 如果你还在使用传统 C++,打着 C++ 的名号写出 C 语言代码,请停下来。本教程将带领你快速上手 C++11/14 的重要特性。
- ffmpeg 结合 SDL 编写播放器
- 学习 C++ 利用 ffmpeg 解码视频数据,将解码后的视频数据播放出来。学习 ffmpeg 和 SDL 基本的用法。
- 100 行 C++ 代码实现线程池
- 使用 C++ 及大量 C++11新特性设计并实现一个线程池库。
- C++ 实现高性能内存池
- 获得内存池所分配的内存速度高于从堆中获得分配的内存的速度,一个长期稳定运行的服务在追求极致的过程中,实现内存池是必不可少的。和标准库中的默认分配器一样,内存池本质上也是分配器
- C++ 开发 Web 服务框架
- 综合使用 C++11 及 Boost 中的 Asio 实现 HTTP 和 HTTPS 的服务器框架。
- C++ 打造 Markdown 解析器
- 使用 C++ 实现 Markdown 解析器,并将解析的内容生成为 HTML。
- C++ 使用 Crypto++ 库实现常用的加密算法
- 利用 Cryto++库 对字符串进行 AES 加密和解密,RSA 加密和解密,生成 MD5 值。其中主要用到了 Crypto++ 库,这是开源的C++数据加密算法库,支持如下算法:RSA、MD5、DES、AES、SHA-256等等。
- C++ 编写 json 生成器
- 介绍 json 和一些常见的 json 库,并用 C++ 编写一个 json 生成器,生成 json 数据,并学习编写测试用例。
- C++ 实现基数树 radix tree
- Radix树 , 这是一种基于二进制表示的键值的查找树,尤其适合处理非常长的、可变长度的键值,Patricia 的基本思想是构建一个二叉树。
- C++ 实现智能指针
- 使用C++语言实现智能指针的过程,来了解C++基本程序设计的方法,包括类的定义与使用,运算符的重载,模板类的使用方法,以及引用计数技术。
高级项目
- C++操作 redis 实现异步订阅和发布
- 操作 redis 实现异步订阅和发布,其中将介绍 redis 基础知识,在linux中安装和使用 redis ,常用的 hiredis API,并实现一个例程。
- C++ 实现简易 Docker 容器
- Docker 的本质是使用 LXC 实现类似虚拟机的功能,进而节省的硬件资源提供给用户更多的计算资源。本项目将 C++ 与 Linux 的 Namespace 及 Control Group 技术相结合,实现一个简易 Docker 容器。
- C++ 实现内存泄露检查器
- 内存泄漏一直是 C++ 中比较令人头大的问题, 即便是很有经验的 C++程序员有时候也难免因为疏忽而写出导致内存泄漏的代码。除了基本的申请过的内存未释放外,还存在诸如异常分支导致的内存泄漏等等。本项目将使用 C++ 实现一个内存泄漏检查器。
- C++ 实现高性能 RTTI 库
- RTTI 是运行时类型识别的英文缩写,C++ 本身提供了运行时类型检查的运算符 dynamic_cast 和 typeid,然而 dynamic_cast 的效率其实并不理想,需要牺牲一定性能。本项目将手动实现一个高性能 RTTI 库。
业界项目
【2022-3-15】C++后台开发有哪些练基础的开源项目?
- WebSocket服务器
- 聊天软件:Flamingo IM, 视频中介绍了 Flamingo 的编译和部署方法、整体架构、各个模块的技术实现细节以及如何学习Flamingo的方法
- 百度云,h9av
- 蘑菇街开源的即时通讯Teamtalk
- C++服务器游戏源码,同时支持Windows和Linux部署
- 百度云,lww0
- 紫光拼音输入法, balloonwj/unispim
- 金山卫士源码
- 百度云,wdc2
- Filezilla
多功能计算器
libqalculate
- 使用 C++ 编写的多功能计算器桌面应用、库和 CLI 程序。
- 它易于使用功能强大,支持大型可定制函数库、单位计算和转换、符号计算(包括积分和方程)。
作为用户你可以直接在命令行中使用,作为开发者你也可以在自己的项目中使用这个库。官方还制作了Qt和GTK两个版本的 GUI 计算器应用。
数独游戏
sudoku
- C++ 实现的命令行数独游戏。600 余行代码
后端开发
后端开发技术栈
【2022-3-11】C++后台开发,以我之见
招聘网站上有一个岗位叫后台开发。
- 这个岗位范围很广,开发语言也很多,如:php,node.js,java,C/C++,go ,每一个公司都有自己主打的语言,如腾讯和百度的后端开发中,C++用的比较多,当然php也用得比较多,阿里和美团,java用得比较多。
- 语言只是一种实现工具而已,不能单一地认为那种语言好那种语言不好,没有最好,只有最适合。
- 后台开发,是相对前端开发而言,所有跟前端直接交互的开发都可以认为是后台开发。
C++后端的研发工程师
- 首先需要掌握C++的基础语法,STL里常用库和算法
- 再系统地学习下boost库,包含很多STL不具备的功能,看看C++11就知道了,很多新增的东西都是来自boost库。
仅仅掌握语言还远远不够,C++做后台开发时,模块跟模块交互方式:
- ① 直接通过库(lib库/so库)的方式相互调用
- ② 更多的是采用网络交互,
- 还需要掌握多线程编程和网络编程的基础知识,由于开发效率有限,现在不需要从零搭建一个网络服务框架,比如:ACE、boost的asio和libevent。有各种开源的RPC框架了,比如google-rpc,你可以通过调用本地函数来完成网络包的发送与接收,so easy!
- 那么网络通信包的格式如何定义呢?客户端和服务端需要提前约定?数据交互格式,常用的包括:json、xml 和 protobuffer
- 通常前端、后端交互会采用
json - 后端各个模块的交互,可以随便选择;
- 对于HTTP协议的交互,比较多的是
json - tcp协议,用的比较多的是
protobuffer。
- 通常前端、后端交互会采用
当然,服务端的平台有很重要,国内后台开发,基本都是运行在Linux系统上,所以需要掌握Linux系统的常用的命令,这样才可以在Linux系统上运用自如,所以,如果想从事或者即将从事C++后台开发,请暂时抛下VS下的C++学习,从现在开始,转向Linux平台下的C++开发,那里有编译器 GCC/G++ ,调试时用到的 gdb,如果你想依次性一个命令编译所有的文件,请学习下如何编写 makefile 。
好了,有了编程语言,有了编译和调试方法,就可以将应用程序放在Linux系统上监听客户端的请求了。如果某一天,程序出core了怎么办?你必须要学会如果找出bug,除了前面提到的gdb,在大型的应用里面,必须要学会掌握如何追bug,这个时候,就要学会打日志,并且分等级打印日志,这样一出问题了就能够快速定位问题的所在。
日志有了,程序也能正常跑了,那你怎么算你程序的性能或者收益呢?所以,你需要学会编写脚本语言,我个人推荐你去掌握 shell脚本 和 python脚本,脚本语言能够一边执行一边编译,具有比较高的开发效率,不用每次执行前编译,掌握了脚本,你不用再那么忙了,哈哈。
提高自己的技术硬实力。技术瓶颈是认知问题,认知不是知其名,还需要知其因,更需要知其原。这个话题更大,但是适合很多技术岗位。在工作中不能只跟项目中的业务逻辑打交道,那样会觉得自己做的事情越来越没意思,越来越没技术含量。你应该有一种开源情怀,找一个比较NB的开源软件,如 redis, zookeeper,nginx等,去阅读其中的源码,当然,也可以将一些库上传到gitlab上,让大家给你提建议,相信开源让人进步;可以去gitlab上下载和学习各种有意思的开源库,这会给你带来更多的成就感。同时你要学会利用各种资源来解决你所遇到的各种问题,如segmentfault,stackoverflow等国外著名的网站。
C++开发库
linyacool大佬的项目,webserver
C++ 后端开发常会问到的基础知识:
- 使用 Epoll 边沿触发的 IO 多路复用技术,非阻塞 IO,使用 Reactor 模式
- 使用多线程充分利用多核 CPU,并使用线程池避免线程频繁创建销毁的开销
- 使用基于小根堆的定时器关闭超时请求
- 主线程只负责 accept 请求,并以 Round Robin 的方式分发给其它 IO 线程(兼计算线程),锁的争用只会出现在主线程和某一特定线程中
- 使用 eventfd 实现了线程的异步唤醒
- 使用双缓冲区技术实现了简单的异步日志系统
- 为减少内存泄漏的可能,使用智能指针等 RAII 机制
- 使用状态机解析了 HTTP 请求,支持管线化
- 支持优雅关闭连接
跨国际支持的库
- gettext :GNU `gettext’
- IBM ICU:提供Unicode 和全球化支持的C、C++ 和Java库
- libiconv :用于不同字符编码之间的编码转换库
C++工具库汇总
【2022-4-27】C++常用代码库 CppUtil
【2020-12-07】强大全面的C++框架和库推荐
- 关于 C++ 框架、库和资源的一些汇总列表,内容包括:标准库、Web应用框架、人工智能、数据库、图片处理、机器学习、日志、代码分析等
Web服务
C Web服务
- 不到 500 行的超轻量型 HTTP Server,可以用来理解服务器程序的原理和本质。
C++ Web服务
C++ Web服务框架
- Civetweb :提供易于使用,强大的,C/C++嵌入式Web服务器,带有可选的CGI,SSL和Lua支持。
- CppCMS :免费高性能的Web开发框架(不是 CMS).
- Crow :一个C++微型web框架(灵感来自于Python Flask)
- Kore :使用C语言开发的用于web应用程序的超快速和灵活的web服务器/框架。
- libOnion:轻量级的库,帮助你使用C编程语言创建web服务器。
- QDjango:使用C++编写的,基于Qt库的web框架,试图效仿Django API,因此得此名。
- Wt :开发Web应用的C++库。
- 【2021-3-24】CppHttpDemo:c++框架代码
- TinyWebServer,Linux下C++轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器. 支持数据库,图片,视频播放
- 使用 线程池 + 非阻塞socket + epoll(ET和LT均实现) + 事件处理(Reactor和Proactor均实现) 的并发模型
- 使用状态机解析HTTP请求报文,支持解析GET和POST请求
- 访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件
- 实现同步/异步日志系统,记录服务器运行状态
- 经Webbench压力测试可以实现上万的并发连接数据交换
- 【2021-5-3】Drogon,是 an-tao 在 Github 上开源的基于 C++ 14/17 的 Http 应用框架,目前版本为 v1.4.1,跨平台,可以方便地使用 C++ 构建各种类型的 Web 应用服务端程序。其网络层使用基于 epoll,使用全异步编程模式;实现了简单的反射机制,支持后端渲染,支持运行期的视图页面动态加载;支持过滤器链,支持 websocket,支持pipelining. 详见:Drogon - 真正现代化的 C++ 网络服务框架
通用库
C++通用框架和库
- Apache C++ Standard Library:是一系列算法,容器,迭代器和其他基本组件的集合
- ASL :Adobe源代码库提供了同行的评审和可移植的C++源代码库。
- Boost :大量通用C++库的集合。
- BDE :来自于彭博资讯实验室的开发环境。
- Cinder:提供专业品质创造性编码的开源开发社区。
- Cxxomfort:轻量级的,只包含头文件的库,将C++ 11的一些新特性移植到C++03中。
- Dlib:使用契约式编程和现代C++科技设计的通用的跨平台的C++库。
- EASTL :EA-STL公共部分
- ffead-cpp :企业应用程序开发框架
- Folly:由Facebook开发和使用的开源C++库
- JUCE :包罗万象的C++类库,用于开发跨平台软件
- libPhenom:用于构建高性能和高度可扩展性系统的事件框架。
- LibSourcey :用于实时的视频流和高性能网络应用程序的C++11 evented IO
- LibU : C语言写的多平台工具库
- Loki :C++库的设计,包括常见的设计模式和习语的实现。
- MiLi :只含头文件的小型C++库
- openFrameworks :开发C++工具包,用于创意性编码。
- Qt :跨平台的应用程序和用户界面框架
- Reason :跨平台的框架,使开发者能够更容易地使用Java,.Net和Python,同时也满足了他们对C++性能和优势的需求。
- ROOT :具备所有功能的一系列面向对象的框架,能够非常高效地处理和分析大量的数据,为欧洲原子能研究机构所用。
- STLport:是STL具有代表性的版本
- STXXL:用于额外的大型数据集的标准模板库。
- Ultimate++ :C++跨平台快速应用程序开发框架
- Windows Template Library:用于开发Windows应用程序和UI组件的C++库
- Yomm11 :C++11的开放multi-methods.
数据库
- 用 C 从零创建一个简单的数据库。
数据库,SQL服务器,ODBC驱动程序和工具
- hiberlite :用于Sqlite3的C++对象关系映射
- Hiredis: 用于Redis数据库的很简单的C客户端库
- LevelDB: 快速键值存储库
- LMDB:符合数据库四大基本元素的嵌入键值存储
- MySQL++:封装了MySql的C API的C++ 包装器
- RocksDB:来自Facebook的嵌入键值的快速存储
- SQLite:一个完全嵌入式的,功能齐全的关系数据库,只有几百KB,可以正确包含到你的项目中。
调试库
调试库, 内存和资源泄露检测,单元测试
- Boost.Test:Boost测试库
- Catch:一个很时尚的,C++原生的框架,只包含头文件,用于单元测试,测试驱动开发和行为驱动开发。
- CppUnit:由JUnit移植过来的C++测试框架
- CTest:CMake测试驱动程序
- googletest:谷歌C++测试框架
- ig-debugheap:用于跟踪内存错误的多平台调试堆
- libtap:用C语言编写测试
- MemTrack —用于C++跟踪内存分配
- microprofile- 跨平台的网络试图分析器
- minUnit :使用C写的迷你单元测试框架,只使用了两个宏
- Remotery:用于web视图的单一C文件分析器
- UnitTest++:轻量级的C++单元测试框架
GUI
图形用户界面
- CEGUI : 很灵活的跨平台GUI库
- FLTK :快速,轻量级的跨平台的C++GUI工具包。
- GTK+: 用于创建图形用户界面的跨平台工具包
- gtkmm :用于受欢迎的GUI库GTK+的官方C++接口。
- imgui:拥有最小依赖关系的立即模式图形用户界面
- libRocket :libRocket 是一个C++ HTML/CSS 游戏接口中间件
- MyGUI :快速,灵活,简单的GUI
- Ncurses:终端用户界面
- QCustomPlot :没有更多依赖关系的Qt绘图控件
- Qwt :用户与技术应用的Qt 控件
- QwtPlot3D :功能丰富的基于Qt/OpenGL的C++编程库,本质上提供了一群3D控件
- OtterUI :OtterUI 是用于嵌入式系统和互动娱乐软件的用户界面开发解决方案
- PDCurses 包含源代码和预编译库的公共图形函数库
- wxWidgets C++库,允许开发人员使用一个代码库可以为widows, Mac OS X,Linux和其他平台创建应用程序
图像处理
图像处理
- Boost.GIL:通用图像库
- CImg :用于图像处理的小型开源C++工具包
- CxImage :用于加载,保存,显示和转换的图像处理和转换库,可以处理的图片格式包括 BMP, JPEG, GIF, PNG, TIFF, MNG, ICO, PCX, TGA, WMF, WBMP, JBG, J2K。
- FreeImage :开源库,支持现在多媒体应用所需的通用图片格式和其他格式。
- GDCM:Grassroots DICOM 库
- ITK:跨平台的开源图像分析系统
- Magick++:ImageMagick程序的C++接口
- MagickWnd:ImageMagick程序的C++接口
- OpenCV : 开源计算机视觉类库
- tesseract-ocr:OCR引擎
- VIGRA :用于图像分析通用C++计算机视觉库
- VTK :用于3D计算机图形学,图像处理和可视化的开源免费软件系统。
序列化
国际化
- gettext :GNU `gettext’
- IBM ICU:提供Unicode 和全球化支持的C、C++ 和Java库
- libiconv :用于不同字符编码之间的编码转换库
序列化
- Cap’n Proto :快速数据交换格式和RPC系统。
- cereal :C++11 序列化库
- FlatBuffers :内存高效的序列化库
- MessagePack :C/C++的高效二进制序列化库,例如 JSON
- protobuf :协议缓冲,谷歌的数据交换格式。
- protobuf-c :C语言的协议缓冲实现
- SimpleBinaryEncoding:用于低延迟应用程序的对二进制格式的应用程序信息的编码和解码。
- Thrift :高效的跨语言IPC/RPC,用于C++,Java,Python,PHP,C#和其它多种语言中,最初由Twitter开发。
Jason
- frozen : C/C++的Jason解析生成器
- Jansson :进行编解码和处理Jason数据的C语言库
- jbson :C++14中构建和迭代BSON data,和Json 文档的库
- JeayeSON:非常健全的C++ JSON库,只包含头文件
- JSON++ : C++ JSON 解析器
- json-parser:用可移植的ANSI C编写的JSON解析器,占用内存非常少
- json11 :一个迷你的C++11 JSON库
- jute :非常简单的C++ JSON解析器
- ibjson:C语言中的JSON解析和打印库,很容易和任何模型集成。
- libjson:轻量级的JSON库
- PicoJSON:C++中JSON解析序列化,只包含头文件
- qt-json :用于JSON数据和 QVariant层次间的相互解析的简单类
- QJson:将JSON数据映射到QVariant对象的基于Qt的库
- RapidJSON: 用于C++的快速JSON 解析生成器,包含SAX和DOM两种风格的API
- YAJL :C语言中快速流JSON解析库
日志
日志
- Boost.Log :设计非常模块化,并且具有扩展性
- easyloggingpp:C++日志库,只包含单一的头文件。
- Log4cpp :一系列C++类库,灵活添加日志到文件,系统日志,IDSA和其他地方。
- templog:轻量级C++库,可以添加日志到你的C++应用程序中
机器学习
机器学习
- Caffe :快速的神经网络框架
- CCV :以C语言为核心的现代计算机视觉库
- mlpack :可扩展的C++机器学习库
- OpenCV:开源计算机视觉库
- Recommender:使用协同过滤进行产品推荐/建议的C语言库。
- SHOGUN:Shogun 机器学习工具
- sofia-ml :用于机器学习的快速增量算法套件
数学
数学
- Armadillo :高质量的C++线性代数库,速度和易用性做到了很好的平衡。语法和MatlAB很相似
- blaze:高性能的C++数学库,用于密集和稀疏算法。
- ceres-solver :来自谷歌的C++库,用于建模和解决大型复杂非线性最小平方问题。
- CGal: 高效,可靠的集合算法集合
- cml :用于游戏和图形的免费C++数学库
- Eigen :高级C++模板头文件库,包括线性代数,矩阵,向量操作,数值解决和其他相关的算法。
- GMTL:数学图形模板库是一组广泛实现基本图形的工具。
- GMP:用于个高精度计算的C/C++库,处理有符号整数,有理数和浮点数。
多媒体
多媒体
- GStreamer :构建媒体处理组件图形的库
- LIVE555 Streaming Media :使用开放标准协议(RTP/RTCP, RTSP, SIP) 的多媒体流库
- libVLC :libVLC (VLC SDK)媒体框架
- QtAv:基于Qt和FFmpeg的多媒体播放框架,能够帮助你轻而易举地编写出一个播放器
- SDL :简单直控媒体层
- SFML :快速,简单的多媒体库
编译器
C/C++编译器列表
- Clang :由苹果公司开发的
- GCC:GNU编译器集合
- Intel C++ Compiler :由英特尔公司开发
- LLVM :模块化和可重用编译器和工具链技术的集合
- Microsoft Visual C++ :MSVC,由微软公司开发
- Open WatCom :Watcom,C,C++和Fortran交叉编译器和工具
- TCC :轻量级的C语言编译器
在线C/C++编译器列表
- codepad :在线编译器/解释器,一个简单的协作工具
- CodeTwist:一个简单的在线编译器/解释器,你可以粘贴的C,C++或者Java代码,在线执行并查看结果
- coliru :在线编译器/shell, 支持各种C++编译器
- Compiler Explorer:交互式编译器,可以进行汇编输出
- CompileOnline:Linux上在线编译和执行C++程序
- Ideone :一个在线编译器和调试工具,允许你在线编译源代码并执行,支持60多种编程语言。
调试
C/C++调试器列表
- Comparison of debuggers :来自维基百科的调试器列表
- GDB :GNU调试器
- Valgrind:内存调试,内存泄露检测,性能分析工具。
静态代码分析,提高质量,减少瑕疵的代码分析工具列表
- Cppcheck :静态C/C++代码分析工具
- include-what-you-use :使用clang进行代码分析的工具,可以#include在C和C++文件中。
- OCLint :用于C,C++和Objective-C的静态源代码分析工具,用于提高质量,减少瑕疵。
- Clang Static Analyzer:查找C,C++和Objective-C程序bug的源代码分析工具
- List of tools for static code analysis :来自维基百科的静态代码分析工具列表
构建
构建系统
- Bear :用于为clang工具生成编译数据库的工具
- Biicode:基于文件的简单依赖管理器。
- CMake :跨平台的免费开源软件用于管理软件使用独立编译的方法进行构建的过程。
- CPM:基于CMake和Git的C++包管理器
- FASTBuild:高性能,开源的构建系统,支持高度可扩展性的编译,缓冲和网络分布。
- Ninja :专注于速度的小型构建系统
- Scons :使用Python scipt 配置的软件构建工具
- tundra :高性能的代码构建系统,甚至对于非常大型的软件项目,也能提供最好的增量构建次数。
- tup:基于文件的构建系统,用于后台监控变化的文件。
并发
并发执行和多线程
- Boost.Compute :用于OpenCL的C++GPU计算库
- Bolt :针对GPU进行优化的C++模板库
- C++React :用于C++11的反应性编程库
- Intel TBB :Intel线程构件块
- Libclsph:基于OpenCL的GPU加速SPH流体仿真库
- OpenCL :并行编程的异构系统的开放标准
- OpenMP:OpenMP API
- Thrust :类似于C++标准模板库的并行算法库
- HPX :用于任何规模的并行和分布式应用程序的通用C++运行时系统
- VexCL :用于OpenCL/CUDA 的C++向量表达式模板库。
IDE
集成开发环境(IDE),C/C++集成开发环境列表
- AppCode :构建与JetBrains’ IntelliJ IDEA 平台上的用于Objective-C,C,C++,Java和Java开发的集成开发环境
- CLion:来自JetBrains的跨平台的C/C++的集成开发环境
- Code::Blocks :免费C,C++和Fortran的集成开发环境
- CodeLite :另一个跨平台的免费的C/C++集成开发环境
- Dev-C++:可移植的C/C++/C++11集成开发环境
- Eclipse CDT:基于Eclipse平台的功能齐全的C和C++集成开发环境
- Geany :轻量级的快速,跨平台的集成开发环境。
- IBM VisualAge :来自IBM的家庭计算机集成开发环境。
- Irony-mode:由libclang驱动的用于Emacs的C/C++微模式
- KDevelop:免费开源集成开发环境
- Microsoft Visual Studio :来自微软的集成开发环境
- NetBeans :主要用于Java开发的的集成开发环境,也支持其他语言,尤其是PHP,C/C++和HTML5。
- Qt Creator:跨平台的C++,Javascript和QML集成开发环境,也是Qt SDK的一部分。
- rtags:C/C++的客户端服务器索引,用于 跟基于clang的emacs的集成
- Xcode :由苹果公司开发
- YouCompleteMe:一个用于Vim的根据你敲的代码快速模糊搜索并进行代码补全的引擎。
boost库
简介
Boost 是一个功能强大、构造精巧、跨平台、开源并且完全免费的 C++ 程序库。
- 1998 年,Beman G.Dawes(C++标准委员会成员之一)发起倡议并建立了 Boost 社区,其目的是向 C++ 程序员提供免费的、经同行审查的、可移植的、高质量的 C++ 源程序库。
- Boost 官方于 2019 年 12 月发布的 1.72 版本,共包含 160 余个库/组件,涵盖字符串与文本处理、容器、迭代器、算法、图像处理、模板元编程、并发编程等多个领域,使用 Boost,将大大增强 C++ 的功能和表现力。
Boost 强调程序库要与 C++ 标准库很好地共同工作,建立在“既有的实践”之上并提供参考实现,因此 Boost 库可以适合最后的标准化。
自创立以来,Boost 社区的工作已经取得了卓越的成果,C++ 标准库中有三分之二来自 Boost 库,而且将来 Boost 库中还会有更多的库进入新标准。
C++ 四十余年的发展历史中产生了数不清的程序库,有影响力的程序库也不计其数,然而其中没有一个程序库能够与 Boost 相提并论,Boost 有着其他程序库无法比拟的优点,具体如下:
- 1) 许多 Boost 库的作者本身就是 C++ 标准委员会成员,因此,Boost“天然”成了标准库的后备,负责向新标准输送组件,这也使得 Boost 获得了“准”标准库的荣誉。
- 2) Boost 独特的同行审查制度保证了每一个 Boost 库组件都经过了严格的审查和验证,使其具有很高的工业强度,甚至超过大多数商业产品的实现。
- 3) Boost 采用了类似 STL 的编程范式,但却并没有 STL 那样晦涩难懂,其代码格式优美清晰、易于阅读,而且 Boost 附带丰富的说明文档——它既是一个程序库,也是一个很有价值的学习现代 C++ 编程的范本。
- 4) Boost 的发布采用 Boost Software License,这是一个不同于 GPL 和 Apache 的非常宽松的许可证,该许可证允许库用户将 Boost 用于任何用途,既鼓励非商业用途,也鼓励商业用途。用户无须支付任何费用,不受任何限制,即可轻松享有 Boost 的全部功能。
安装
Boost 提供源码形式的安装包,可以从 Boost 官方网站下载最新版本。以 boost_1_72_0.tar.gz 为例,把该文件解压缩到磁盘任意位置即可
Boost 的目录结构
Boost 压缩包解压后有5万多个文件,占据近 700MB 的磁盘空间,但其目录结构却很简洁清晰:
boost_1_72_0/ #存放配置脚本和说明文件
├──── boost #最重要的目录,90%以上的Boost程序库源码都在这里
├──── doc #HTML格式的文档,也可以生成PDF格式的文档
├──── libs #所有组件的示例、测试、编译代码和说明文档
├──── more #库作者的相关文档
├──── status #可用于测试Boost库的各个组件
└──── tools #b2、quickbook 等自带工具
在大多数情况下,我们只需要关心 boost 子目录,这里面以头文件的形式分门别类地存放了我们要使用的库代码:
boost_1_72_0/ #Boost 安装根目录
├──── boost #boost子目录
│ ├──── accumulators #累加器库
│ ├──── algorithm #算法库
│ ├──── align #内存对齐库
│ ├──── archive #序列化库
│ ├──── asio #异步并发库
│ ├──── assign #赋值初始化库
│ ├──── atomic #原子操作库
│ ├──── beast #高级网络通信库(HTTP/WebSocket)
│ ├──── bimap #双向关联数组
│ ├──── bind #bind表达式
│ ├──── chrono #时间处理库
│ ├──── ... #其他库……
│ └──── yap #表达式模板库
Boost 使用方式
- Boost 库的大多数组件不需要编译链接,我们在自己的源码里直接包含头文件即可。例如,如果要使用 boost::tribool,只需要在 C++ 源文件中添加如下 include 语句:
#include <boost/logic/tribool.hpp> //使用tribool库
Boost 库的头文件与平常用的头文件(*.h)或 C++ 标准库的头文件(没有后缀名)不同,这正是 Boost 的独特之处。
- 它把 C++ 类的声明和实现放在了一个文件中,而不是分成两个文件,即.h+, .cpp,故文件的后缀是.hpp。
- 之所以这么做当然是有理由的。其中一个原因就是与普通的C头文件(*.h)区分,另一个很重要的原因就是使 Boost 库不需要预先编译,直接将其引入程序员的工程即可编译链接,方便了 Boost 库的使用。
Java、C#、PHP、Python 程序员应该对这种代码文件形式很熟悉,这几种语言都在一个文件中编写所有代码。
剩下的少量库(如 chrono、date_time、program_options、test、thread 等)必须编译成静态库或动态库,并在构建时指定链接选项才能使用。
不过有个好消息,其中有的库不需要编译也可以使用部分或全部功能,而更好的消息是有的库已经有了不需要编译的替代品。
C/S软件开发
Qt
【2022-9-14】Qt 官方在线下载
- mac安装失败,在线安装途中提示装xcode,然而后者对macos版本有要求
【2022-10-8】使用brew工具直接安装qt,未报错
- 参考:Mac下brew安装和配置Qt5的坑与解决办法
- 应用中出现 QT Creator
brew install qt
brew install qt-creator --cask
进行中,图解Qt安装(Linux平台)
编译器
C/C++编译器列表
- Clang :由苹果公司开发的
- GCC:GNU编译器集合
- Intel C++ Compiler :由英特尔公司开发
- LLVM :模块化和可重用编译器和工具链技术的集合
- Microsoft Visual C++ :MSVC,由微软公司开发
- Open WatCom :Watcom,C,C++和Fortran交叉编译器和工具
- TCC :轻量级的C语言编译器
在线编译器
在线C/C++编译器列表
- codepad :在线编译器/解释器,一个简单的协作工具
- CodeTwist:一个简单的在线编译器/解释器,你可以粘贴的C,C++或者Java代码,在线执行并查看结果
- coliru :在线编译器/shell, 支持各种C++编译器
- Compiler Explorer:交互式编译器,可以进行汇编输出
- CompileOnline:Linux上在线编译和执行C++程序
- Ideone :一个在线编译器和调试工具,允许你在线编译源代码并执行,支持60多种编程语言。
调试器
C/C++调试器列表
- Comparison of debuggers :来自维基百科的调试器列表
- GDB :GNU调试器
- Valgrind:内存调试,内存泄露检测,性能分析工具。
集成开发环境(IDE)
C/C++集成开发环境列表
- AppCode :构建与JetBrains’ IntelliJ IDEA 平台上的用于Objective-C,C,C++,Java和Java开发的集成开发环境
- CLion:来自JetBrains的跨平台的C/C++的集成开发环境
- Code::Blocks :免费C,C++和Fortran的集成开发环境
- CodeLite :另一个跨平台的免费的C/C++集成开发环境
- Dev-C++:可移植的C/C++/C++11集成开发环境
- Eclipse CDT:基于Eclipse平台的功能齐全的C和C++集成开发环境
- Geany :轻量级的快速,跨平台的集成开发环境。
- IBM VisualAge :来自IBM的家庭计算机集成开发环境。
- Irony-mode:由libclang驱动的用于Emacs的C/C++微模式
- KDevelop:免费开源集成开发环境
- Microsoft Visual Studio :来自微软的集成开发环境
- NetBeans :主要用于Java开发的的集成开发环境,也支持其他语言,尤其是PHP,C/C++和HTML5。
- Qt Creator:跨平台的C++,Javascript和QML集成开发环境,也是Qt SDK的一部分。
- rtags:C/C++的客户端服务器索引,用于 跟基于clang的emacs的集成
- Xcode :由苹果公司开发
- YouCompleteMe:一个用于Vim的根据你敲的代码快速模糊搜索并进行代码补全的引擎。
构建系统
- Bear :用于为clang工具生成编译数据库的工具
- Biicode:基于文件的简单依赖管理器。
- CMake :跨平台的免费开源软件用于管理软件使用独立编译的方法进行构建的过程。
- CPM:基于CMake和Git的C++包管理器
- FASTBuild:高性能,开源的构建系统,支持高度可扩展性的编译,缓冲和网络分布。
- Ninja :专注于速度的小型构建系统
- Scons :使用Python scipt 配置的软件构建工具
- tundra :高性能的代码构建系统,甚至对于非常大型的软件项目,也能提供最好的增量构建次数。
- tup:基于文件的构建系统,用于后台监控变化的文件。
静态代码分析
提高质量,减少瑕疵的代码分析工具列表
- Cppcheck :静态C/C++代码分析工具
- include-what-you-use :使用clang进行代码分析的工具,可以#include在C和C++文件中。
- OCLint :用于C,C++和Objective-C的静态源代码分析工具,用于提高质量,减少瑕疵。
- Clang Static Analyzer:查找C,C++和Objective-C程序bug的源代码分析工具
- List of tools for static code analysis :来自维基百科的静态代码分析工具列表
序列化
序列化
- Cap’n Proto :快速数据交换格式和RPC系统。
- cereal :C++11 序列化库
- FlatBuffers :内存高效的序列化库
- MessagePack :C/C++的高效二进制序列化库,例如 JSON
- protobuf :协议缓冲,谷歌的数据交换格式。
- protobuf-c :C语言的协议缓冲实现
- SimpleBinaryEncoding:用于低延迟应用程序的对二进制格式的应用程序信息的编码和解码。
- Thrift :高效的跨语言IPC/RPC,用于C++,Java,Python,PHP,C#和其它多种语言中,最初由Twitter开发。
Jason
- frozen : C/C++的Jason解析生成器
- Jansson :进行编解码和处理Jason数据的C语言库
- jbson :C++14中构建和迭代BSON data,和Json 文档的库
- JeayeSON:非常健全的C++ JSON库,只包含头文件
- JSON++ : C++ JSON 解析器
- json-parser:用可移植的ANSI C编写的JSON解析器,占用内存非常少
- json11 :一个迷你的C++11 JSON库
- jute :非常简单的C++ JSON解析器
- ibjson:C语言中的JSON解析和打印库,很容易和任何模型集成。
- libjson:轻量级的JSON库
- PicoJSON:C++中JSON解析序列化,只包含头文件
- qt-json :用于JSON数据和 QVariant层次间的相互解析的简单类
- QJson:将JSON数据映射到QVariant对象的基于Qt的库
- RapidJSON: 用于C++的快速JSON 解析生成器,包含SAX和DOM两种风格的API
- YAJL :C语言中快速流JSON解析库
XML
XML
XML就是个垃圾,xml的解析很烦人,对于计算机它也是个灾难。这种糟糕的东西完全没有存在的理由了。-Linus Torvalds
- Expat :用C语言编写的xml解析库
- Libxml2 :Gnome的xml C解析器和工具包
- libxml++ :C++的xml解析器
- PugiXML :用于C++的,支持XPath的轻量级,简单快速的XML解析器。
- RapidXml :试图创建最快速的XML解析器,同时保持易用性,可移植性和合理的W3C兼容性。
- TinyXML :简单小型的C++XML解析器,可以很容易地集成到其它项目中。
- TinyXML2:简单快速的C++CML解析器,可以很容易集成到其它项目中。
- TinyXML++:TinyXML的一个全新的接口,使用了C++的许多许多优势,模板,异常和更好的异常处理。
- Xerces-C++ :用可移植的C++的子集编写的XML验证解析器。
日志
- Boost.Log :设计非常模块化,并且具有扩展性
- easyloggingpp:C++日志库,只包含单一的头文件。
- Log4cpp :一系列C++类库,灵活添加日志到文件,系统日志,IDSA和其他地方。
- templog:轻量级C++库,可以添加日志到你的C++应用程序中
spdlog
spdlog: 快速、上手简单的 C++ 日志库。
#include "spdlog/spdlog.h"
int main()
{
spdlog::info("Welcome to spdlog!");
spdlog::error("Some error message with arg: {}", 1);
spdlog::warn("Easy padding in numbers like {:08d}", 12);
spdlog::critical("Support for int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}", 42);
spdlog::info("Support for floats {:03.2f}", 1.23456);
spdlog::info("Positional args are {1} {0}..", "too", "supported");
spdlog::info("{:<30}", "left aligned");
spdlog::set_level(spdlog::level::debug); // Set global log level to debug
spdlog::debug("This message should be displayed..");
// change log pattern
spdlog::set_pattern("[%H:%M:%S %z] [%n] [%^---%L---%$] [thread %t] %v");
// Compile time log levels
// define SPDLOG_ACTIVE_LEVEL to desired level
SPDLOG_TRACE("Some trace message with param {}", 42);
SPDLOG_DEBUG("Some debug message");
}
dbg-macro
打日志是 C++ 开发中必不可少的一种 debug 方式,dbg-macro 受 rust-lang 中 的 dbg 启发,提供比 printf 和 std::cout 更好的宏函数。dbg-macro特点:
- 美观的彩色输出(当输出不是交互式终端时,颜色将自动禁用)
- 兼容 C++11,并且是 header-only
- 支持基础类型和 STL 容器类型的输出
- 除了基本信息外,还输出变量名和类型
- 启用 DBGMACRODISABLE 生成 release 版
#include <vector>
#include <dbg.h>
// You can use "dbg(..)" in expressions:
int factorial(int n) {
if (dbg(n <= 1)) {
return dbg(1);
} else {
return dbg(n * factorial(n - 1));
}
}
int main() {
std::string message = "hello";
dbg(message); // [example.cpp:15 (main)] message = "hello" (std::string)
const int a = 2;
const int b = dbg(3 * a) + 1; // [example.cpp:18 (main)] 3 * a = 6 (int)
std::vector<int> numbers{b, 13, 42};
dbg(numbers); // [example.cpp:21 (main)] numbers = {7, 13, 42} (size: 3) (std::vector<int>)
dbg("this line is executed"); // [example.cpp:23 (main)] this line is executed
factorial(4);
return 0;
}
数学
数学
- Armadillo :高质量的C++线性代数库,速度和易用性做到了很好的平衡。语法和MatlAB很相似
- blaze:高性能的C++数学库,用于密集和稀疏算法。
- ceres-solver :来自谷歌的C++库,用于建模和解决大型复杂非线性最小平方问题。
- CGal: 高效,可靠的集合算法集合
- cml :用于游戏和图形的免费C++数学库
- Eigen :高级C++模板头文件库,包括线性代数,矩阵,向量操作,数值解决和其他相关的算法。
- GMTL:数学图形模板库是一组广泛实现基本图形的工具。
- GMP:用于个高精度计算的C/C++库,处理有符号整数,有理数和浮点数。
可视化
QtCharts
【2022-9-10】QtCharts
机器学习库
机器学习
- Caffe :快速的神经网络框架
- CCV :以C语言为核心的现代计算机视觉库
- mlpack :可扩展的C++机器学习库
- OpenCV:开源计算机视觉库
- Recommender:使用协同过滤进行产品推荐/建议的C语言库。
- SHOGUN:Shogun 机器学习工具
- sofia-ml :用于机器学习的快速增量算法套件
网络
网络
- ACE:C++面向对象网络变成工具包
- Boost.Asio:用于网络和底层I/O编程的跨平台的C++库
- Casablanca:C++ REST SDK
- cpp-netlib:高级网络编程的开源库集合
- Dyad.c:C语言的异步网络
- libcurl :多协议文件传输库
- Mongoose:非常轻量级的网络服务器
- Muduo :用于Linux多线程服务器的C++非阻塞网络库
- net_skeleton :C/C++的TCP 客户端/服务器库
- nope.c :基于C语言的超轻型软件平台,用于可扩展的服务器端和网络应用。 对于C编程人员,可以考虑node.js
- Onion :C语言HTTP服务器库,其设计为轻量级,易使用。
- POCO:用于构建网络和基于互联网应用程序的C++类库,可以运行在桌面,服务器,移动和嵌入式系统。
- RakNet:为游戏开发人员提供的跨平台的开源C++网络引擎。
- Tuf o :用于Qt之上的C++构建的异步Web框架。
- WebSocket++ :基于C++/Boost Aiso的websocket 客户端/服务器库
- ZeroMQ :高速,模块化的异步通信库
机器人开发
机器人学
- MOOS-IvP :一组开源C++模块,提供机器人平台的自主权,尤其是自主的海洋车辆。
- MRPT:移动机器人编程工具包
- PCL :点云库是一个独立的,大规模的开放项目,用于2D/3D图像和点云处理。
- Robotics Library (RL): 一个独立的C++库,包括机器人动力学,运动规划和控制。
- RobWork:一组C++库的集合,用于机器人系统的仿真和控制。
- ROS :机器人操作系统,提供了一些库和工具帮助软件开发人员创建机器人应用程序。
Web服务
C++ Web服务框架
- cpp-net lib cpp-netlib: The C++ Network Library,号称是要进入标准的,但是感觉还不stable;
- facebook做了一个HTTP库 facebook/proxygen · GitHub,只对Linux系统比较友好;
- 另外还有一个叫pion的HTTP库 splunk/pion · GitHub
C/C++好的网络库有很多,像asio, libevent, libuv等的性能都是极好的,可以在这个基础上加上HTTP协议解析,比如用joyent的http_parser,然后就是处理HTTP协议本身了,但这个时候问题就来了,是支持到1.1还是2.0?要不要支持SPDY、WebSocket?
没有GC的语言处理字符串是很虐心的,如果一定要强求用C++,那我只能安慰题主:node也是C++写的,你就当node的框架是C++ Web服务器咯~
- Drogon
- Nginx : 一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。
- Lighttpd : 一款开源 Web 服务器软件,安全快速,符合行业标准,适配性强并且针对高配置环境进行了优化。
- Libmicrohttpd : GNU软件下的简单c库的Web服务器。API简单,快速。
- shttpd : 基于Mongoose的Web服务器框架。
- CivetWeb : 提供易于使用,强大的,C/C++嵌入式Web服务器,带有可选的CGI,SSL和Lua支持。
- CppCMS : 免费高性能的Web开发框架(不是 CMS).
- Crow : 一个C++微型web框架(灵感来自于Python Flask)
- Kore : 使用C语言开发的用于web应用程序的超快速和灵活的web服务器/框架。
- libOnion : 轻量级的库,帮助你使用C编程语言创建web服务器。
- QDjango : 使用C++编写的,基于Qt库的web框架,试图效仿Django API,因此得此名。
- Wt : 开发Web应用的C++库。
Web应用框架
- Civetweb :提供易于使用,强大的,C/C++嵌入式Web服务器,带有可选的CGI,SSL和Lua支持。
- CppCMS :免费高性能的Web开发框架(不是 CMS).
- Crow :一个C++微型web框架(灵感来自于Python Flask)
- Kore :使用C语言开发的用于web应用程序的超快速和灵活的web服务器/框架。
- libOnion:轻量级的库,帮助你使用C编程语言创建web服务器。
- QDjango:使用C++编写的,基于Qt库的web框架,试图效仿Django API,因此得此名。
- Wt :开发Web应用的C++库。
web服务原理
网络编程重要知识点
- 孤儿进程、僵尸进程和守护进程
- 进程间通信方式signal、file、pipe、shm、sem、msg、socket
- 线程同步机制线程:互斥量、锁机制、条件变量、信号量、读写锁
- fork返回值
- 五大IO模型:阻塞I/O、非阻塞I/O、I/O复用、信号驱动I/O、异步I/O
- IO复用机制
- epoll与select/poll
- LT水平触发和ET边缘触发
- Reactor和Proactor模式
- 反向代理、负载均衡
C++服务端开发其实已经是一个很成熟的领域,存在着大量公认的编程规范和主流技术:
- 主流服务器模型:C/S模型和P2P模型
- I/O模型:同步I/O 与 异步I/O
- 事件处理模式:Reactor模式 / Proactor模式
- 并发模式:半同步/半异步模式、领导者/追随者模式
主流的C++网络编程库和I/O框架库有:Boost.Asio、libevent 和 muduo,这些库封装了网络编程中的繁琐操作同时兼顾了效率和安全性。
并发服务器开发
- (1)建立连接
- 网络连接的发起依赖于套接字接口,一组函数,它们与Unix I/O函数结合起来,用于创建网络应用,其中我们最常用到的函数有getaddrinfo、getnameinfo、socket、connect、bind、listen、accept。
- 建立连接包括两部分,一部分是客户端发起连接,另一部分是服务端接收连接。
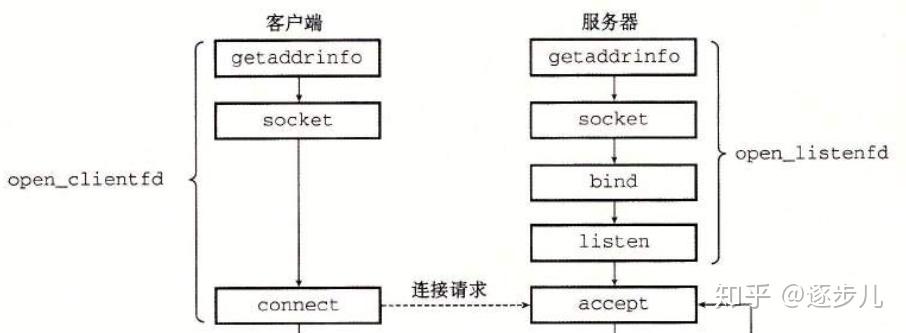
- (2)I/O多路复用
- I/O多路复用,I/O指的是I/O事件(包括I/O读写、I/O异常等事件), 多路指多个独立连接(或多个Channel),复用指多个事件复用一个控制流(线程或进程)。串起来就是多个独立I/O事件的处理依赖于一个控制流
- I/O复用函数有select、poll和epoll三组函数,这3组函数都通过某种结构体变量来告诉内核监听哪些文件描述符上的哪些事件,并使用该结构体类型的参数来获取内核处理的结果。
- (3)多进程并发
- 进程是一个执行中的程序实例。系统的每个程序都运行在一个进程的上下文中。上下文是由程序正常运行所需维护的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符的集合。内核通过调度器来实现对不同进程的调度,并通过上下文切换实现控制到新进程的转移,从而提供给应用程序两个抽象:
- 一个独立的逻辑控制流,它提供一个假象,好像我们程序独占地使用处理器。
- 一个私有的地址空间,它提供一个假象,好像我们的程序独立地使用内存系统。
- 进程的内存地址空间如图所示,对于多进程并发,重点关注的是内存泄漏问题和进程通信问题。
- (a)多进程环境的内存泄漏问题: 多进程的实现依赖于父进程派生子进程(fork函数实现)。新创建的子进程与父进程不完全相同,子进程得到与父进程完全相同(但相互独立)的用户虚拟地址空间,包括代码和数据段、堆、栈以及打开文件描述符的副本,它们最大的区别在于PID不同。由于子进程与父进程共享文件描述符,这意味着子进程可以打开父进程中打开的任何文件,这也导致了共享文件的在多进程环境下存在的内存泄漏问题。
- 由于文件表的引用计数的存在,因此父进程派生子进程时会导致父进程中打开的文件描述符对应的文件表表项引用计数加1,如果子进程和父进程其中有一个进程没有关闭文件描述符,则会导致无用文件表表项对内存空间的占用从而导致内存泄漏。因此,我们需要保证在父进程足够“干净”(没有打开大量的文件描述符和申请大量空间)的时候派生子进程来得到一个同样足够干净的子进程,从而避免内存泄漏。
- (b)多进程环境的通信问题: 多进程环境下各个进程内存地址空间相互独立,因此内存的通信只能依赖于内核。
- 内核为多进程提供的通信机制有管道(以先进先出的方式接受数据)、共享内存(最高效的IPC机制,不涉及进程之间的数据传输,提供共享读机制)、消息队列(在两个进程之间传输二进制数据块)。
- 进程是一个执行中的程序实例。系统的每个程序都运行在一个进程的上下文中。上下文是由程序正常运行所需维护的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符的集合。内核通过调度器来实现对不同进程的调度,并通过上下文切换实现控制到新进程的转移,从而提供给应用程序两个抽象:
- (4)多线程并发:
- 线程是运行在进程上下文之中的逻辑流,线程由内核调度,每个线程都有它自己的线程上下文,包括一个唯一的整数线程ID、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有运行在一个进程的线程共享该进程的虚拟地址空间。
- 由于多线程共享一个进程的虚拟地址空间,因此在多线程访问某些共享量时可能会出现“竞争”问题和“同步错误”,因此多线程并发要考虑的一个重要问题就是多线程同步。避免“同步错误”主要有以下几种机制。
- 使用内核辅助来避免同步错误:在多线程环境中我们可以像多进程环境一样,依赖于内核的管道机制或者IPC机制来实现不同线程之间的通信从而避免对共享变量的读写带来的同步错误,然而这种机制会造成逻辑流在用户态和内核态的反复切换,从而降低程序运行效率。
- 使用互斥锁来避免同步错误:互斥锁由信号量实现,获得锁的线程独占对共享变量的访问,其他线程在访问该变量时会由于锁的存在而阻塞从而进入睡眠状态,这种机制保证了在任一时刻只有一个线程对共享变量的操作从而避免同步错误。然而锁的创建和解锁都依赖于内核,这也会导致一定的开销从而降低程序运行效率。
- 使用自旋锁来避免同步错误:自旋锁与互斥锁有点类似,只是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。其作用是为了解决某项资源的互斥使用。因为自旋锁不会引起调用者睡眠,所以自旋锁的效率远 高于互斥锁。虽然它的效率比互斥锁高,但是自旋锁在自旋期间一直占用CPU,如果不能在很短的时间内获得锁这无疑会使CPU效率降低。
- 使用原子变量来避免同步错误:C++ 11提供atomic原子类来实现对变量的原子操作,我们可以使用atomic_flag类型和atomic_int类型避免同步错误,使用原子变量还可以减少上锁带来的开销。

CGI
公共网关接口(CGI),是一套标准,定义了信息是如何在 Web 服务器和客户端脚本之间进行交换的。
CGI 规范目前是由 NCSA 维护的,NCSA 定义 CGI 如下:
- 公共网关接口(CGI),是一种用于外部网关程序与信息服务器(如 HTTP 服务器)对接的接口标准
点击一个超链接,浏览一个特定的网页或 URL,会发生什么?
- 浏览器联系上 HTTP Web 服务器,并请求 URL,即文件名。
- Web 服务器将解析 URL,并查找文件名。
- 如果找到请求的文件,Web 服务器会把文件发送回浏览器,否则发送一条错误消息,表明您请求了一个错误的文件。
- Web 浏览器从 Web 服务器获取响应,并根据接收到的响应来显示文件或错误消息。 然而,这种方式搭建起来的 HTTP 服务器,不管何时请求目录中的某个文件,HTTP 服务器发送回来的不是该文件,而是以程序形式执行,并把执行产生的输出发送回浏览器显示出来。
公共网关接口(CGI),是使得应用程序(称为 CGI 程序或 CGI 脚本)能够与 Web 服务器以及客户端进行交互的标准协议。这些 CGI 程序可以用 Python、PERL、Shell、C 或 C++ 等进行编写。
CGI架构图:
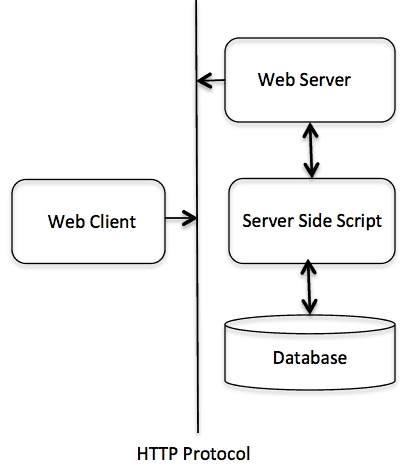
- CGI 目录,按照惯例命名为 /var/www/cgi-bin。虽然 CGI 文件是 C++ 可执行文件,但是按照惯例它的扩展名是 .cgi。默认情况下,Apache Web 服务器会配置在 /var/www/cgi-bin 中运行 CGI 程序。如果您想指定其他目录来运行 CGI 脚本,您可以在 httpd.conf 文件中修改
- CGI 库,下载这个 CGI 库, C++ CGI Lib Documentation
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>
简易CGI程序示例:
- 输出写在 STDOUT 文件上,即显示在屏幕上
- 编译代码,把可执行文件命名为 cplusplus.cgi,并把这个文件保存在 /var/www/cgi-bin 目录中。
- 在运行 CGI 程序之前,请使用 chmod 755 cplusplus.cgi UNIX 命令来修改文件模式,确保文件可执行
#include <iostream>
using namespace std;
int main ()
{
// 发送回浏览器,并指定要显示在浏览器窗口上的内容类型,形式:HTTP 字段名称: 字段内容
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Hello World - 第一个 CGI 程序</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<h2>Hello World! 这是我的第一个 CGI 程序</h2>\n";
cout << "</body>\n";
cout << "</html>\n";
// CGI环境变量
const string ENV[ 24 ] = {
"COMSPEC", "DOCUMENT_ROOT", "GATEWAY_INTERFACE",
"HTTP_ACCEPT", "HTTP_ACCEPT_ENCODING",
"HTTP_ACCEPT_LANGUAGE", "HTTP_CONNECTION",
"HTTP_HOST", "HTTP_USER_AGENT", "PATH",
"QUERY_STRING", "REMOTE_ADDR", "REMOTE_PORT",
"REQUEST_METHOD", "REQUEST_URI", "SCRIPT_FILENAME",
"SCRIPT_NAME", "SERVER_ADDR", "SERVER_ADMIN",
"SERVER_NAME","SERVER_PORT","SERVER_PROTOCOL",
"SERVER_SIGNATURE","SERVER_SOFTWARE" };
// 打印环境变量
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>CGI 环境变量</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
for ( int i = 0; i < 24; i++ )
{
cout << "<tr><td>" << ENV[ i ] << "</td><td>";
// 尝试检索环境变量的值
char *value = getenv( ENV[ i ].c_str() );
if ( value != 0 ){
cout << value;
}else{
cout << "环境变量不存在。";
}
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
使用 GET 方法传递两个值给 hello_get.py 程序。
- cpp_get.cgi CGI 程序,用于处理 Web 浏览器给出的输入。
- 编译生成 cpp_get.cgi,并把它放在 CGI 目录中,并尝试使用下面的链接进行访问
- $g++ -o cpp_get.cgi cpp_get.cpp -lcgicc
- /cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALI
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main ()
{
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>使用 GET 和 POST 方法</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("first_name");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "名:" << **fi << endl;
}else{
cout << "No text entered for first name" << endl;
}
cout << "<br/>\n";
fi = formData.getElement("last_name");
if( !fi->isEmpty() &&fi != (*formData).end()) {
cout << "姓:" << **fi << endl;
}else{
cout << "No text entered for last name" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}
更多案例
简易Web服务
- 【2022-4-27】基于epoll的简易web服务, 代码地址
- 简单web服务器的实现(C++)
- C++写一个http服务器/web服务器
- C++实现轻量级极简httpserver和httpclient,CppHttpDemo源码
- 编译环境:win10,vs2015, C++11 (其实是跨平台的)
- 请求:http://localhost:7999/api/hello
- 返回:{ “result”: welcome to httpserver }
具体功能实现
- GET方法请求解析
- POST方法请求解析
- 返回请求资源页面
- 利用GET方法实现加减法
- 利用POST方法实现加减法
- HTTP请求行具体解析
- 400、403、404错误码返回的处理
最简单的web服务代码:
#include<stdio.h>
#include<stdlib.h>
#include<sys/socket.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<sys/sendfile.h>
#include<fcntl.h>
#include<netinet/in.h>
#include<arpa/inet.h>
#include<assert.h>
#include<unistd.h>
#include<string.h>
const int port = 8888;
int main(int argc,char *argv[])
{
if(argc<0)
{
printf("need two canshu\n");
return 1;
}
int sock;
int connfd;
struct sockaddr_in sever_address;
bzero(&sever_address,sizeof(sever_address));
sever_address.sin_family = PF_INET;
sever_address.sin_addr.s_addr = htons(INADDR_ANY);
sever_address.sin_port = htons(8888);
sock = socket(AF_INET,SOCK_STREAM,0);
assert(sock>=0);
int ret = bind(sock, (struct sockaddr*)&sever_address,sizeof(sever_address));
assert(ret != -1);
ret = listen(sock,1);
assert(ret != -1);
while(1)
{
struct sockaddr_in client;
socklen_t client_addrlength = sizeof(client);
connfd = accept(sock, (struct sockaddr*)&client, &client_addrlength);
if(connfd<0)
{
printf("errno\n");
}
else{
char request[1024];
recv(connfd,request,1024,0);
request[strlen(request)+1]='\0';
printf("%s\n",request);
printf("successeful!\n");
char buf[520]="HTTP/1.1 200 ok\r\nconnection: close\r\n\r\n";//HTTP响应
int s = send(connfd,buf,strlen(buf),0);//发送响应
//printf("send=%d\n",s);
int fd = open("hello.html",O_RDONLY);//消息体
sendfile(connfd,fd,NULL,2500);//零拷贝发送消息体
close(fd);
close(connfd);
}
}
return 0;
}
html文件:
<html>
<body bgcolor="blue">
this is the html.
<hr>
<p>hello word! waste young! </p><br>
</body>
</html>
运行web.c文件,生成执行文件a.out,在终端执行后,我们在浏览器的网址栏中输入:http://localhost:8888 然后确认后,就会返回hello.html的文件页面
TinyWeb
![]()
【2022-1-19】TinyWeb, High-Performance Web Server which is based on C++11.
- Event-driven Epoll + Asynchronous I/O.
- High-performance, Stable, Sample Configuration.
- Modularization programming.
【2022-1-20】mac+centos下都编译失败
- github issue
# 下载
git clone https://github.com/GeneralSandman/TinyWeb
# 编译
cd TinyWeb/src
mkdir build
cd build
# 修复步骤
cp ../test/main_test.cc .. # 【2022-1-20】否则cmake报错,找不到main.cc
cmake ../ && make
# 【2022-1-20】mac+centos下都编译失败
# 配置信息
sudo cp TinyWeb.conf /
sudo ./TinyWeb --tcf /path/path/configfile # 测试配置文件是否有效
# 显示版本
sudo ./TinyWeb -v
# 启动服务
sudo ./TinyWeb
sudo ./TinyWeb -c <config-file> # 指定配置文件
sudo ./TinyWeb -d -c <config-file> # 调试模式
sudo ./TinyWeb -o stop # 安全关闭服务
#cat <pid-file>
#sudo kill -s SIGQUIT <master-pid>
#sudo kill -s SIGTERM <master-pid> # 立即停止服务
#sudo kill -s SIGINT <master-pid>
# 重启服务
sudo ./TinyWeb -o restart
sudo ./TinyWeb -o reload [-c <config-file>] # 带配置文件
#cat /var/run/TinyWeb.pid
#sudo kill -s SIGUSR2 <master-pid>
drogon
C++也能快速开发web项目了: Drogon 性能绝对第一,吊打java、go、php、c#等一众语言框架。
Drogon是一个基于C++14/17的Http应用框架,使用Drogon可以方便的使用C++构建各种类型的Web应用服务端程序。Drogon是一个跨平台框架,它支持Linux,也支持macOS、FreeBSD,OpenBSD,HaikuOS,和Windows。
主要特点
- 网络层使用基于epoll(macOS/FreeBSD下是kqueue)的非阻塞IO框架,提供高并发、高性能的网络IO。详细请见TFB Tests Results;
- 全异步编程模式;
- 支持Http1.0/1.1(server端和client端);
- 基于template实现了简单的反射机制,使主程序框架、控制器(controller)和视图(view)完全解耦;
- 支持cookies和内建的session;
- 支持后端渲染,把控制器生成的数据交给视图生成Html页面,视图由CSP模板文件描述,通过CSP标签把C++代码嵌入到Html页面,由drogon的命令行工具在编译阶段自动生成C++代码并编译;
- 支持运行期的视图页面动态加载(动态编译和加载so文件);
- 非常方便灵活的路径(path)到控制器处理函数(handler)的映射方案;
- 支持过滤器(filter)链,方便在控制器之前执行统一的逻辑(如登录验证、Http Method约束验证等);
- 支持https(基于OpenSSL实现);
- 支持websocket(server端和client端);
- 支持Json格式请求和应答, 对Restful API应用开发非常友好;
- 支持文件下载和上传,支持sendfile系统调用;
- 支持gzip/brotli压缩传输;
- 支持pipelining;
- 提供一个轻量的命令行工具drogon_ctl,帮助简化各种类的创建和视图代码的生成过程;
- 基于非阻塞IO实现的异步数据库读写,目前支持PostgreSQL和MySQL(MariaDB)数据库;
- 基于线程池实现sqlite3数据库的异步读写,提供与上文数据库相同的接口;
- 支持Redis异步读写;
- 支持ARM架构;
- 方便的轻量级ORM实现,支持常规的对象到数据库的双向映射操作;
- 支持插件,可通过配置文件在加载器动态拆装;
- 支持内建插入点的AOP
- 支持C++协程
#include <drogon/drogon.h>
using namespace drogon;
int main()
{
app().setLogPath("./")
.setLogLevel(trantor::Logger::kWarn)
.addListener("0.0.0.0", 80)
.setThreadNum(16)
.enableRunAsDaemon()
.run();
}
使用配置后,进一步简化:
#include <drogon/drogon.h>
using namespace drogon;
int main()
{
app().loadConfigFile("./config.json").run();
}
Drogon也提供了一些接口,使用户可以在main()函数中直接添加控制器逻辑,比如,用户可以注册一个lambda处理器到drogon框架中
app().registerHandler("/test?username={name}",
[](const HttpRequestPtr& req,
std::function<void (const HttpResponsePtr &)> &&callback,
const std::string &name)
{
Json::Value json;
json["result"]="ok";
json["message"]=std::string("hello,")+name;
auto resp=HttpResponse::newHttpJsonResponse(json);
callback(resp);
},
{Get,"LoginFilter"});
方便,但是这并不适用于复杂的应用, 包含多个接口时,每个处理函数要注册进框架,main()函数将膨胀到不可读的程度。
显然,让每个包含处理函数的类在自己的定义中完成注册是更好的选择。所以,更好的实践是,可以创建一个HttpSimpleController对象
- 大部分代码都可以由drogon_ctl命令创建(这个命令是drogon_ctl create controller TestCtr)。用户所需做的就是添加自己的业务逻辑。
- 例子中,当客户端访问URL http://ip/test 时,控制器简单的返回了一个Hello, world!页面
/// The TestCtrl.h file
#pragma once
#include <drogon/HttpSimpleController.h>
using namespace drogon;
class TestCtrl:public drogon::HttpSimpleController<TestCtrl>
{
public:
virtual void asyncHandleHttpRequest(const HttpRequestPtr& req, std::function<void (const HttpResponsePtr &)> &&callback) override;
PATH_LIST_BEGIN
PATH_ADD("/test",Get);
PATH_LIST_END
};
/// The TestCtrl.cc file
#include "TestCtrl.h"
void TestCtrl::asyncHandleHttpRequest(const HttpRequestPtr& req,
std::function<void (const HttpResponsePtr &)> &&callback)
{
//write your application logic here
auto resp = HttpResponse::newHttpResponse();
resp->setBody("<p>Hello, world!</p>");
resp->setExpiredTime(0);
callback(resp);
}
json格式改进
/// The header file
#pragma once
#include <drogon/HttpSimpleController.h>
using namespace drogon;
class JsonCtrl : public drogon::HttpSimpleController<JsonCtrl>
{
public:
virtual void asyncHandleHttpRequest(const HttpRequestPtr &req, std::function<void(const HttpResponsePtr &)> &&callback) override;
PATH_LIST_BEGIN
//list path definitions here;
PATH_ADD("/json", Get);
PATH_LIST_END
};
/// The source file
#include "JsonCtrl.h"
void JsonCtrl::asyncHandleHttpRequest(const HttpRequestPtr &req,
std::function<void(const HttpResponsePtr &)> &&callback)
{
Json::Value ret;
ret["message"] = "Hello, World!";
auto resp = HttpResponse::newHttpJsonResponse(ret);
callback(resp);
}
通过HttpController类创建一个RESTful API, 用户可以同时映射路径和路径参数,这对RESTful API应用来说非常方便。
另外,前面所有的处理函数接口都是异步的,处理器的响应是通过回调对象返回的。这种设计是出于对高性能的考虑,因为在异步模式下,可以使用少量的线程(比如和处理器核心数相等的线程)处理大量的并发请求。
#pragma once
#include <drogon/HttpController.h>
using namespace drogon;
namespace api
{
namespace v1
{
class User : public drogon::HttpController<User>
{
public:
METHOD_LIST_BEGIN
//use METHOD_ADD to add your custom processing function here;
METHOD_ADD(User::getInfo, "/{id}", Get); //path is /api/v1/User/{arg1}
METHOD_ADD(User::getDetailInfo, "/{id}/detailinfo", Get); //path is /api/v1/User/{arg1}/detailinfo
METHOD_ADD(User::newUser, "/{name}", Post); //path is /api/v1/User/{arg1}
METHOD_LIST_END
//your declaration of processing function maybe like this:
void getInfo(const HttpRequestPtr &req, std::function<void(const HttpResponsePtr &)> &&callback, int userId) const;
void getDetailInfo(const HttpRequestPtr &req, std::function<void(const HttpResponsePtr &)> &&callback, int userId) const;
void newUser(const HttpRequestPtr &req, std::function<void(const HttpResponsePtr &)> &&callback, std::string &&userName);
public:
User()
{
LOG_DEBUG << "User constructor!";
}
};
} // namespace v1
} // namespace api
C Web服务 —— 嵌入式设备(IoT)
参考:
Mongoose是一个用C语言编写的网络库,它是一把用于嵌入式网络编程的瑞士军刀。它为TCP、UDP、HTTP、WebSocket、CoAP、MQTT实现了事件驱动的非阻塞API,用于客户机和服务器模式功能包括:
- 跨平台:适用于linux/unix、macos、qnx、ecos、windows、android、iphone、freertos。
- 自然支持PicoTCP嵌入式TCP/IP堆栈,LWIP嵌入式TCP/IP堆栈。
- 适用于各种嵌入式板:ti cc3200、ti msp430、stm32、esp8266;适用于所有基于linux的板,如Raspberry PI, BeagleBone等。
- 单线程、异步、无阻塞核心,具有简单的基于事件的api。
内置协议:
- 普通TCP、普通UDP、SSL/TLS(单向或双向)、客户端和服务器。
- http客户端和服务器。
- WebSocket客户端和服务器。
- MQTT客户机和服务器。
- CoAP客户端和服务器。
- DNS客户端和服务器。
- 异步DNS解析程序。
Mongoose只需微小的静态和运行时占用空间,源代码既兼容ISO C又兼容ISO C++,而且很容易集成。
- 源码只有两个文件:moogoose.c、mongoose.h
Mongoose有三种基本数据结构:
- struct mg_mgr 是保存所有活动连接的事件管理器;事件分为5种类型, 共享同一个回调函数,事件类型通过传参区分。重要成员:
- active_connections :当前活动的连接,如果有多个,则以链表形式挂接
- tl: broadcast 的socket
- ifaces:网络相关的接口集合,在linux下默认为socket相关接口
- struct mg_connection 描述连接;重要成员
- next、prev: 下、上一个连接
- mgr:对应的事件管理
- sock: 对应的socket
- sa: socket的地址
- recv_mbuf、send_mbuf : 发送和接受的buffer
- proto_handler、handler: 协议的回调函数和事件回调函数
- struct mbuf 描述数据缓冲区(接收或发送的数据);
connetions可以是listening, outbound 和 inbound。outbound连接由mg_connect()调用创建的。listening连接由mg_bind()调用创建的。inbound连接是侦听连接接受的连接。每个connetion都由struct mg_connection结构描述,该结构有许多字段,如socket、事件处理函数、发送/接收缓冲区、标志等。
整个流程其实很简单,可分为以下三步
- mg_mgr_init:先对mgr进行初始化,主要是将相关的socket接口函数集合赋值给mgr.ifaces
- mg_bind:该步骤主要为一个mg_connection申请内存,并将事件回调函数ev_handler注册到该连接里,并且初始化若干个(由网卡数量决定)http端口的socket进行监听
- mg_mgr_poll:该函数调用mongoose中提供的poll接口:mg_socket_if_poll。在该函数中,对所有初始化的socket进行select操作, 在退出select的阻塞后,根据read_fd_set, write_fd_set, err_fd_set 进行判断,将退出阻塞的socket分类,然后进行分类处理。
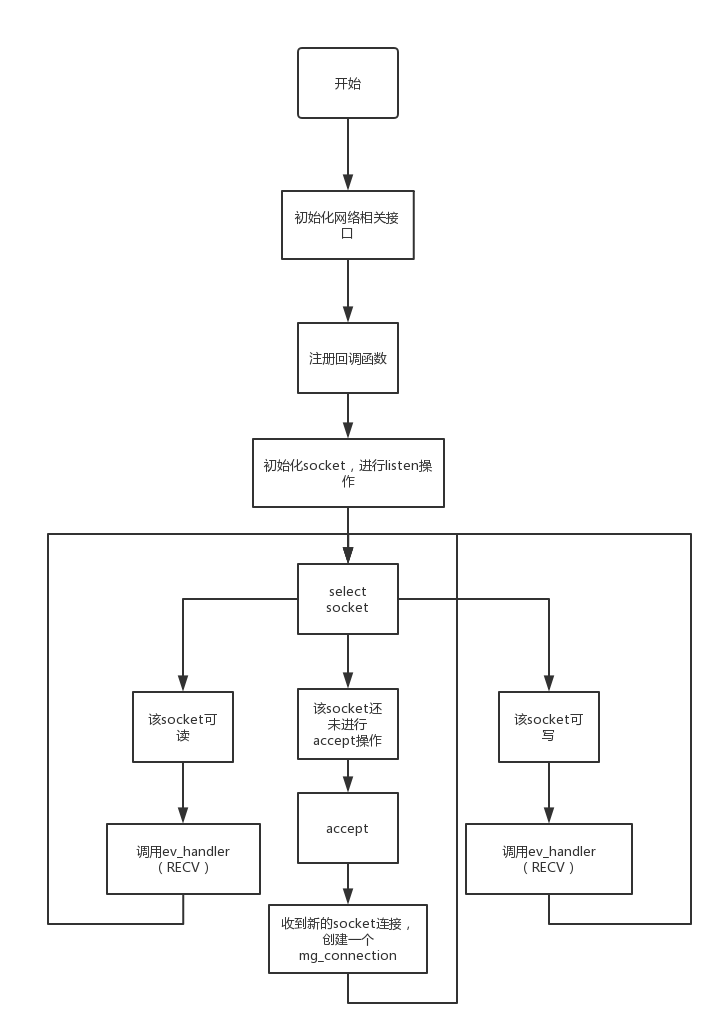
使用Mongoose的应用程序应遵循事件驱动应用程序的标准模式:
// 定义和初始化事件管理器:
struct mg_mgr mgr;
mg_mgr_init(&mgr, NULL);
// 创建连接。例如,一个服务程序需要创建监听连接。
struct mg_connection *c = mg_bind(&mgr, "80", ev_handler_function);
mg_set_protocol_http_websocket(c);
//在一个循环里使用calling mg_mgr_poll()创建一个事件循环。
for (;;) {
mg_mgr_poll(&mgr, 1000);
}
mg_mgr_poll() // 遍历所有socket,接受新连接,发送和接受数据,关闭连接并调用事件处理函数。
内存缓存
- 每个连接都有一个发送和接收缓存。分别是struct mg_connection::send_mbuf 和 struct mg_connection::recv_mbuf 。
- 当数据接收后,Mongoose将接收到的数据加到recv_mbuf后面,并触发一个MG_EV_RECV事件。用户可以使用其中一个输出函数将数据发送回去,如mg_send() 或 mg_printf()。输出函数将数据追加到send_mbuf。
- 当Mongoose成功地将数据写到socket后,它将丢弃struct mg_connection::send_mbuf里的数据,并发送一个MG_EV_SEND事件。
- 当连接关闭后,发送一个MG_EV_CLOSE事件。
事件处理函数
- 每个连接都有一个与之关联的事件处理函数。这些函数必须由用户实现。事件处理器是Mongoose程序的核心元素,因为它定义程序的行为。以下是一个处理函数的样子:
static void ev_handler(struct mg_connection *nc, int ev, void *ev_data) {
switch (ev) {
/* Event handler code that defines behavior of the connection */
...
}
}
- struct mg_connection *nc : 接收事件的连接。
- int ev : 时间编号,定义在mongoose.h。比如说,当数据来自于一个inbound连接,ev就是MG_EV_RECV。
- void *ev_data : 这个指针指向event-specific事件,并且对不同的事件有不同的意义。举例说,对于一个MG_EV_RECV事件,ev_data是一个int *指针,指向从远程另一端接收并保存到接收IO缓冲区中的字节数。ev_data确切描述每个事件的意义。Protocol-specific事件通常有ev_data指向保存protocol-specific信息的结构体。
- 注意:struct mg_connection有void *user_data,他是application-specific的占位符。Mongoose并没有使用这个指针。事件处理器可以保存任意类型的信息。
事件
- Mongoose接受传入连接、读取和写入数据,并在适当时为每个连接调用指定的事件处理程序。典型的事件顺序是:
- 对于出站连接:MG_EV_CONNECT -> (MG_EV_RECV, MG_EV_SEND, MG_EV_POLL …) -> MG_EV_CLOSE
- 对于入站连接:MG_EV_ACCEPT -> (MG_EV_RECV, MG_EV_SEND, MG_EV_POLL …) -> MG_EV_CLOSE
以下是Mongoose触发的核心事件列表(请注意,除了核心事件之外,每个协议还触发特定于协议的事件):
- MG_EV_ACCEPT: 当监听连接接受到一个新的服务器连接时触发。void *ev_data是远程端的union socket_address。
- MG_EV_CONNECT: 当mg_connect()创建了一个新出站链接时触发,不管成功还是失败。void *ev_data是int *success。当success是0,则连接已经建立,否则包含一个错误码。查看mg_connect_opt()函数来查看错误码示例。
- MG_EV_RECV:心数据接收并追加到recv_mbuf结尾时触发。void *ev_data是int *num_received_bytes。通常,时间处理器应该在nc->recv_mbuf检查接收数据,通过调用mbuf_remove()丢弃已处理的数据。如果必要,请查看连接标识nc->flags(see struct mg_connection),并通过输出函数(如mg_send())写数据到远程端。
- 警告:Mongoose使用realloc()展开接收缓冲区,用户有责任从接收缓冲区的开头丢弃已处理的数据,请注意上面示例中的mbuf_remove()调用。
- MG_EV_SEND: Mongoose已经写数据到远程,并且已经丢弃写入到mg_connection::send_mbuf的数据。void *ev_data是int *num_sent_bytes。
- 注意:Mongoose输出函数仅追加数据到mg_connection::send_mbuf。它们不做任何socket的写入操作。一个真实的IO是通过mg_mgr_poll()完成的。一个MG_EV_SEND事件仅仅是一个关于IO完成的通知。
- MG_EV_POLL:在每次调用mg_mgr_poll()时发送到所有连接。该事件被用于做任何事情,例如,检查某个超时是否已过期并关闭连接或发送心跳消息等。
- MG_EV_TIMER: 当mg_set_timer()调用后,发送到连接。
TCP服务器示例
#include "mongoose.h" // Include Mongoose API definitions
// Define an event handler function
static void ev_handler(struct mg_connection *nc, int ev, void *ev_data) {
struct mbuf *io = &nc->recv_mbuf;
switch (ev) {
case MG_EV_RECV:
// This event handler implements simple TCP echo server
mg_send(nc, io->buf, io->len); // Echo received data back
mbuf_remove(io, io->len); // Discard data from recv buffer
break;
default:
break;
}
}
int main(void) {
struct mg_mgr mgr;
mg_mgr_init(&mgr, NULL); // Initialize event manager object
// Note that many connections can be added to a single event manager
// Connections can be created at any point, e.g. in event handler function
mg_bind(&mgr, "1234", ev_handler); // Create listening connection and add it to the event manager
for (;;) { // Start infinite event loop
mg_mgr_poll(&mgr, 1000);
}
mg_mgr_free(&mgr);
return 0;
}
workflow: 高性能http服务-搜狗
【2021-4-28】10行C++代码实现高性能HTTP服务
C++写个服务太累,十几年前写的github代码 kevwan,但又沉迷于C++的真香性能而无法自拔?10行C++代码怎么实现一个高性能的Http服务,轻松QPS几十万。Linus说:talk is cheap,show me the code
搜狗公司C++服务器引擎,支撑搜狗几乎所有后端C++在线服务,包括所有搜索服务,云输入法,在线广告等,每日处理超百亿请求。这是一个设计轻盈优雅的企业级程序引擎,可以满足大多数C++后端开发需求。
编译和运行环境
- 项目支持
Linux,macOS,Windows,Android等操作系统。Windows版以windows分支发布,使用iocp实现异步网络。用户接口与Linux版一致。
- 支持所有CPU平台,包括32或64位
x86处理器,大端或小端arm处理器,国产loongson龙芯处理器实测支持。 - 需要依赖于
OpenSSL,推荐OpenSSL 1.1及以上版本。- 不喜欢SSL的用户可以使用nossl分支,代码更简洁。但仍需链接
crypto。
- 不喜欢SSL的用户可以使用nossl分支,代码更简洁。但仍需链接
- 项目使用了
C++11标准,需要用支持C++11的编译器编译。但不依赖boost或asio。 - 项目无其它依赖。如需使用
kafka协议,需自行安装lz4,zstd和snappy几个压缩库。
安装编译都非常简单
【2022-1-10】
- centos上编译通过
- mac上编译,官方步骤, brew install openssl cmake
- 报错: 找不到openssl → 按照以上官方文档,加环境变量后解决
- 直接安装 brew reinstall openssl
- 源码安装:
- 报错:ld: cannot link directly with dylib/framework, your binary is not an allowed client of /usr/lib/libcrypto.dylib for architecture x86_64
- 提交issue
./config –prefix=/usr/local/openssl -g3
# 下载
git clone https://github.com/sogou/workflow
cd workflow
# 编译
make # centos上正常
# ----- mac -------
brew install openssl
brew install cmake
# MacOS下默认有LibreSSL,因此在brew安装后,并不会自动建软链
echo 'export PATH="/usr/local/opt/openssl@1.1/bin:$PATH"' >> ~/.bash_profile
echo 'export LDFLAGS="-L/usr/local/opt/openssl@1.1/lib"' >> ~/.bash_profile
echo 'export CPPFLAGS="-I/usr/local/opt/openssl@1.1/include"' >> ~/.bash_profile
echo 'export PKG_CONFIG_PATH="/usr/local/opt/openssl@1.1/lib/pkgconfig"' >> ~/.bash_profile
echo 'export OPENSSL_ROOT_DIR=/usr/local/opt/openssl' >> ~/.bash_profile
echo 'export OPENSSL_LIBRARIES=/usr/local/opt/openssl/lib' >> ~/.bash_profile
source ~/.bash_profile
# 提示没找到openssl
brew reinstall openssl # mac默认安装到 /usr/local/Cellar/openssl
# 或源码安装 /usr/local/openssl
git clone git@github.com:openssl/openssl.git
./config --prefix=/usr/local/openssl -g3
make test
make install
# 源码安装后,额外指定openssl路径
make -e OPENSSL_ROOT_DIR=/usr/local/openssl OPENSSL_LIBRARIES=/usr/local/openssl/lib
# -----------------
# 编译所有案例
cd tutorial
make
# 测试 web服务实例
./helloworld
# helloworld 可以直接运行,侦听在 8888 端口,curl 即可访问:
curl -i http://localhost:8888
亮点:纯异步下的高并发
int main() {
WFHttpServer server([](WFHttpTask *task) {
task->get_resp()->append_output_body("Hello World!");
});
if (server.start(8888) == 0) {
getchar(); // press "Enter" to end.
server.stop();
}
return 0;
}
纯异步就是这个 Http 服务器的高性能所在:
- 第一,多线程提供服务
- 如果收到请求后在这个函数里做了一些阻塞的事情(比如等锁、io请求或者忙碌的计算等),那么再有用户请求的时候,就没有线程去处理新用户了
- 第二,网络线程和执行线程有优秀的调度策略
- 再多的线程也可能会有被霸占完的时候。需要无论 server 函数想要做任何耗时的操作,都不会影响到网络线程
- 第三,以 linux 为例,对epoll的封装高效好用
- 如果服务只打算支持一万的QPS,其实底层怎么实现都很简单,但如果我们希望十万,甚至接近百万,则对server底层做收发的I/O模型有非常高的要求
workflow高并发流程:
基于以上的架构,基于 workflow 的 server 轻轻松松就可以达到几十万 QPS,高吞吐、低成本、开发快,完美支撑了搜狗的所有后端在线服务!详细代码实现请参考 workflow源码。通过跟名誉全球的高性能 Http 服务器 nginx 和国内开源框架先驱 brpc 一起做比较,看一下固定数据长度下 QPS 与并发度的关系:
- 同一台机器上用相同的变量做的 wrk 压测,具体可以到 github 查看机器配置、参数及压测工具代码。当数据长度保持不变,QPS 随着并发度提高而增大,后趋于平稳。此过程中 workflow 一直有明显优势,高于 nginx 和 brpc。 特别是数据长度为64和512的两条曲线, 并发度足够的时候,可以保持50W的QPS。
系统设计特点
一个典型的后端程序由三个部分组成,并且完全独立开发。即:程序 = 协议 + 算法 + 任务流
- (1) 协议
- 大多数情况下,用户使用的是内置的通用网络协议,例如http,redis或各种rpc。
- 用户可以方便的自定义网络协议,只需提供序列化和反序列化函数,就可以定义出自己的client/server。
- (2) 算法
- 算法是与协议对称的概念。
- 如果说协议的调用是rpc,算法的调用就是一次apc(Async Procedure Call)。
- 提供了一些通用算法,例如sort,merge,psort,reduce,可以直接使用。
- 与自定义协议相比,自定义算法的使用要常见得多。任何一次边界清晰的复杂计算,都应该包装成算法。
- 算法是与协议对称的概念。
- (3) 任务流
- 任务流就是实际的业务逻辑,就是把开发好的协议与算法放在流程图里使用起来。
- 典型的任务流是一个闭合的串并联图。复杂的业务逻辑,可能是一个非闭合的DAG。
- 任务流图可以直接构建,也可以根据每一步的结果动态生成。所有任务都是异步执行的。
基础任务,任务工厂与复合任务
- 系统中包含六种基础任务:通讯,文件IO,CPU,GPU,定时器,计数器。
- 一切任务都由任务工厂产生,并且在callback之后自动回收。
- server任务是一种特殊的通讯任务,由框架调用任务工厂产生,通过process函数交给用户。
- 大多数情况下,用户通过任务工厂产生的任务,都是一个复合任务,但用户并不感知。
- 例如,一次http请求,可能包含许多次异步过程(DNS,重定向),但对用户来讲,就是一次通信任务。
- 文件排序,看起来就是一个算法,但其实包括复杂的文件IO与CPU计算的交互过程。
- 如果把业务逻辑想象成用设计好的电子元件搭建电路,那么每个电子元件内部可能又是一个复杂电路。
异步性和基于C++11 std::function的封装
- 不是基于用户态协程。使用者需要知道自己在写异步程序。
- 一切调用都是异步执行,几乎不存在占着线程等待的操作。
- 虽然我们也提供一些便利的半同步接口,但并不是核心的功能。
- 尽量避免派生,以
std::function封装用户行为,包括:- 任何任务的callback。
- 任何server的process。符合
FaaS(Function as a Service)思想。 - 一个算法的实现,简单来讲也是一个
std::function。但算法也可以用派生实现。
内存回收机制
- 任何任务都会在callback之后被自动内存回收。如果创建的任务不想运行,则需要通过dismiss方法释放。
- 任务中的数据,例如网络请求的resp,也会随着任务被回收。此时用户可通过
std::move()把需要的数据移走。 - SeriesWork和ParallelWork是两种框架对象,同样在callback之后被回收。
- 如果某个series是parallel的一个分支,则将在其所在parallel的callback之后再回收。
- 项目中不使用
std::shared_ptr来管理内存。
服务端代码:
- 使用 Http 协议,因此构造了一个WFHttpServer;
- 一次网络交互就是一次任务,因为是 Http 协议,WFHttpTask;
- 对server来说,交互任务就是收到请求之后,填好回复,这些通过:task->get_req() 和 task->get_resp() 可以获得;
- 逻辑在一个函数中(即上面的 lambda),表示收到消息之后要做的事情,这里填了一句 “Hello World!”;
- Server启动和退出使用start()和stop()两个简单的api,而中间要用getchar();卡住,是因为 workflow 是个纯异步的框架。
快速搭建http服务器(Linux, macOS)
- 改进版的web服务示例程序
#include <stdio.h>
#include "workflow/WFHttpServer.h"
int main()
{
WFHttpServer server([](WFHttpTask *task) {
task->get_resp()->append_output_body("<html>Hello World!</html>");
});
//int port=8888; // 默认端口可能被占用
int port=8898;
if (server.start(port) == 0) { // start server on port 8888
printf("服务启动成功, 端口:%d\n", port);
getchar(); // press "Enter" to end.
server.stop();
}else{
printf("服务启动失败, 端口:%d\n", port);
}
return 0;
}
- 作为万能异步客户端。目前支持
http,redis,mysql和kafka协议。- 轻松构建效率极高的spider。
- 实现自定义协议client/server,构建自己的 RPC系统。
- srpc就是以它为基础,作为独立项目开源。支持
srpc,brpc,trpc和thrift等协议。
- srpc就是以它为基础,作为独立项目开源。支持
- 构建异步任务流,支持常用的串并联,也支持更加复杂的DAG结构。
- 作为并行计算工具使用。除了网络任务,也包含计算任务的调度。所有类型的任务都可以放入同一个流中。
- 在
Linux系统下作为文件异步IO工具使用,性能超过任何标准调用。磁盘IO也是一种任务。 - 实现任何计算与通讯关系非常复杂的高性能高并发的后端服务。
- 构建微服务系统。
- 项目内置服务治理与负载均衡等功能。
- 使用workflow-k8s插件,可将服务治理与kubernetes的自动部署融合。
- Wiki链接 : PaaS 架构图
快速开始(Linux, macOS):
git clone https://github.com/sogou/workflow # From gitee: git clone https://gitee.com/sogou/workflow
cd workflow
make
cd tutorial
make
示例教程
- Client基础
- Server基础
- 并行任务与工作流
- 几个重要的话题
- 计算任务
- 文件异步IO任务
- 用户定义协议基础
- 其它一些重要任务与组件
- 服务治理
- 连接上下文的使用
- 内置客户端
C++ Primer学习笔记
- 《C++ Primer》第五版,英文本习题答案, 中文版习题答案, 笔记和课后练习答案
- 2019-4-17 地址
- C++ Primer 5 Answers(C++11/14)
- 《C++ Primer》第五版中文版习题答案
目录及笔记
第1章 开始
标准I/O
一个流就是一个字符序列。
- “流” 随时间的推移,字符是顺序生成或消耗的
标准库的四个标准输入输出流:cin、cout、cerr、clog。
- cout 可以重定向(比如输出到文件),通过缓冲区。
- cerr 不可以重定向(只能输出到显示器),不通过缓冲区。cerr的作用是在一些特殊的紧急情况下还可以输出(比如调用栈用完了,没有出口的递归等)。缓冲区的目的是减少刷屏的次数,多个字符同时输出到显示器。
- 缓冲区能减少刷屏的次数,endl 可以刷新缓冲。在添加打印语句时,应保证一直刷新流,以防程序崩溃,输出还留在缓冲区内。
std::cin 中的循环流使用
_参考链接:
C++ 中可以使用while(std::cin >> value){//Code }的方式来进行循环数据的读入,直到没有输出为止;
示例代码如下:
/*
输入样例: 3 4 5 6
输出 : Sum is :18
*/
#inlude <iostream>
int main()
{
int sum =0;
int value=0;
//循环读取数据
while(std::cin>>value){
// 文件结束或出错时终止; windows的文件结束符是 Ctrl+Z 然后按 Enter
sum += value;
}
std::out<<"Sum is:"<<sum<<std:endl;
return 0;
}
注意:
- 当键盘向程序中输入数据时,对于文件结束;Windows是
Ctrl+Z然后Enter或者Return;UNIX 中是Ctrl+D然后再加enter; - 当缓冲区中有残留数据时,
std::cin会直接去读取缓冲区的数据而不会请求键盘输入。重要的是,回车符也会被存在输入缓冲区中。 - 当程序中有多个等待循环输入时,需要使用
cin.clear()来重置循环状态,方便再次输入;
第二章 变量和基本类型
问题
- 指针和引用有4点不同,分别是哪些?
- 指针是对象,而引用不是;
- 指针可以重定向,引用不可以;
- 有指向指针的指针,无引用的引用;
- 引用必须初始化,指针不需要
- const 对象必须初始化
- const 对象的作用范围:默认范围是文件内
- 什么是常量引用,如何声明,是顶层还是底层
- 不能改变对象的引用是常量引用,const int& i = a,是底层 const
- 常量引用与常量对象、非常量对象的关系。
- 不能用非常量引用绑定常量对象,可以用常量引用绑定非常量对象。
- 什么是常量指针,如何声明,是顶层还是底层
- 常量指针表明 指针是个常量,其内存储的地址不能改变
- 但是指针还能修改所指对象的值。int* const p = a,是顶层const。
- 常量指针与常量对象、非常量对象的关系。
- 可以用常量指针指向非常量对象
- 顶层 const 和底层 const 都是什么,在什么位置
- 顶层 const 表示指针本身是常量,底层 const 表示所指对象是常量。
- 顶层 const 在右边,底层 const 在左边
- 如何区分顶层 const 和底层 const
- 只有指针同时有顶层和底层,const 在星号右边是顶层,左边是底层。
- 引用的 const 是底层,其他类型 const 是顶层。
- constexpr 是什么,特点是什么
- 常量表达式。两个点:值不能改变、在编译阶段就可以计算出值
- 浮点数赋给整型变量时如何舍入?
- 只保留小数点前的部分,即向零舍入(类似floor)
- decltype 是什么,如何使用?
- 用来获取变量类型,decltype(c) a;
- 如何声明而非定义一个变量?
- 使用 extern 修饰符: extern int i:
- 如果指针不初始化会有什么影响
- 在块作用域中,未初始化的指针的值是未定义的。
- 如何在多个文件间共享 const 对象
- 须在变量的定义前添加extern关键字,并在本文件中声明。声明和定义都要加extern
- 使用 auto 来定义引用时要注意什么
- 用 auto 定义引用时,必须要加 & 符号。尤其是在范围 for 循环中,当想要修改值时,一定要记得加上引用符。
- 预处理变量的作用范围是什么?文件内
- C++属于静态类型语言,静态类型语言的含义是什么?
- 静态类型语言在编译时检查变量类型。
- C++有两种定义类型别名的方式,分别是什么
- typedef unsigned int size_type
- using size_type = unsigned int;
C++变量和基本类型
C++定义了几种基本内置类型,如:字符、整型、浮点数等
C++中的基本类型
C++中定义了算术类型(arithmetic type)和空类型(void)在内的基础数据结构,算术类型表如下:
| 类型 | 含义 | 最小尺寸 |
|---|---|---|
| bool | 布尔类型 | 未定义 |
| char | centered | 8位 |
| wchart_t | 宽字符 | 16位 |
| chart16_t | Unicode字符 | 16位 |
| chart32_t | Unicode字符 | 32位 |
| short | 短整型 | 16位 |
| int | 整型 | 16位 |
| long | 长整型 | 32位 |
| long long | 长整型 | 64位 |
| float | 单精度浮点数 | 6位有效数字 |
| double | 双精度浮点数 | 10位有效数字 |
| long double | 扩展精度浮点数 | 10位有效数字 |
注意:
- 关于不同类型,字节内存分配的问题,不同的操作系统存在不同的内存分配策略;因此不一定按照上面的进行分配;详细内容参看参考链接。
- 对于C++中的字节对齐内容需要重点考虑(C++ 字节对齐的总结(原因和作用);C/C++ 字节对齐);
- c++中除去布尔类型和扩展的字符类型之外,其它类型可以划分为带符号的(signed)和无符号的(unsigned)两种;无符号仅能表示大于0的值。器字节内存分配也有所不同;(C/C++ unsigned 详细探讨);
注意
- 初始化不是赋值,初始化是创建变量时赋予一个初始值,赋值是把对象的当前值擦除并用一个新值来替代
// 同一条定义语句中使用先定义的变量去初始化后定义的其他变量。
double price = 109.99, discount = price * 0.6;
// 列表初始化。四种初始化方式,其中使用花括号的方式叫做列表初始化。
int i=0;
int i={0}; // 列表初始化
int i{0}; // 列表初始化
int i(0);
long double ld = 3.1415926536;
int a{ld}, b={ld}; //错误,存在信息丢失的风险,转换未执行。
int c(ld), d=ld; //正确
C++中的声明和定义
- C++中使用分离式编译机制,允许每个文件被单独编译;为了支持这种模式;C++语言将声明和定义区分开来;
- 声明(declaration) 使得名字为程序所知;
- 定义(definition)负责创建与名字关联的实体。
- 如果想要声明一个变量而非定义它,就在变量名字前添加关键字
extern; 而且不要显示的初始化变量:
extern int i; // 声明 i,而非定义i
int i; // 声明并定义i;
extern int i = 1; // 定义i,初始化抵消了 extern 的作用。
声明和定义是严格区分的。要声明一个变量加 extern,声明变量不能赋值。任何包含了显式初始化的声明即成为定义。
- 变量只能被定义一次,但是可以多次声明。
- 声明和定义的区分很重要;c++是静态类型语言,其含义是在编译阶段检查类型。
C++中的类型转换:
- C++中的类型转换分为显式转换和隐式转换2种;
- 显式转换直接在代码中注明其转换类型; 如 double a=1.002;int i=(int)a; 将类型进行显式转换;
- 同时也存在隐式转换; 如
int i=10/1.0;其中10/1.0即包含隐式的int到double的转换,=又进行了一次double到int的隐式转换; - 隐式转换在编码规范中不推荐;应该劲量使用显式转换;
bool b=42; //b为真
int i=b; //i的值为1
i=3.14; //i的值为3
double pi=i; //pi的值为3.0
unsigned char c=-1; //假设char占a比特,c的值为255
signed char c2=256; //假设char:占8比特,c2的值是未定义的
-
当数字加减超过数据类型的取值范围的时候,就会按照位运算进行取模,输出结果是取模之后的结果(C++ 带符号和无符号char类型赋值超出表示范围的情况);
- 把浮点数赋给整型时,结果仅保留小数点前的部分。
- 赋给无符号类型超出范围的值时,结果是初始值对无符号类型表示数值总数取模后的余数。
- 比如 -1 赋给 8 位 unsigned char 的结果是 255(-1=256*(-1)+255)
- 赋给带符号类型超出范围的值时,结果是未定义的。程序可能工作,可能崩溃。
例如:8比特大小的unsigned char可以表示0至255区间内的值,如果我们赋了一个区间以外的值,则实际的结果是该值对256(总数)取模后所得的余数。
有整数a和b,a对b进行取模或取余运算
- 1、求整数商:c=a/b
- 取模运算在计算商值向负无穷方向舍弃小数位
- 取余运算在计算商值向0方向舍弃小数位
- 2、计算模或者余数:r=a-(c*b)
- 取模运算遵循尽可能让商小,取余运算遵循尽可能让余数的绝对值小。因此,取模和取余的结果不同。
- mod为取模,rem为取余,取模和取余所得的结果在a和b(同为整数) 符号相同 的时候是相等的
- 当a和b符号一致时,求模运算和求余运算所得的c的值一致,因此结果一致。但是当符号不一致的时候,结果不一样。
- 具体来说,求模运算结果的符号和b一致,求余运算结果的符号和a一致
在本例中,将-1和256带入a和b,c=-1/256,向负无穷方向舍弃小数得-1,计算得r=255.
计算机中带符号的整数采用二进制的补码进行存储; 正数的补码等于其二进制编码; 负数的补码等于其绝对值的二进制编码,取反,再加1; 在本例中,-1的绝对值是1,二进制编码为0000 0001,取反加1就是1111 1111; unsigned是无符号数,会把1111 1111看成正数,刚好是255的二进制编码。
unsigned u=10;
int i=-42;
std::cout<<i+i<<std::endl; //正确:输出32
std::cout<<u+i<<std::endl; //如果int占32位,输出4294967264
//上面讲-42转化为unsigned int 负数转化为无符号函数,类似于直接给无符号数赋值一个负值;等于这个负数加上无符号数的模。
unsigned ul=42,u2=10;
std::cout<<u1-u2<<std::endl;//正确:输出32;
std::cout<<u2-u1<<std::endl;//正确:不过,结果是取模后的值;
GCC编译器32位机和64位机各个类型变量所占字节数
| C类型 | 32位机器(字节) | 64位机器(字节) |
|---|---|---|
char |
1 | 1 |
short |
2 | 2 |
int |
4 | 4 |
long int |
4 | 8 |
long long |
8 | 8 |
char * |
4 | 8 |
float |
4 | 4 |
double |
8 | 8 |
字面常量值
字面常量值就是常量;如10/*十进制*/;014/*八进制*/;0x14/*十六进制*/;包含整数和字符;C++11标准中允许使用{}进行数据对象的初始化,但是C++98中并不允许;例
vector<int > main_test={1,2,3};
C++中的关键字
参考链接:
C++中存在预定义的关键字;如下图所示

注:
- 上表中为C++98/03中的63个关键字,其中红色标注为C语言中的32个关键字。
- C++11中有73个关键字,新增加的10个为:
alignas、alignof、char16_t、char32_t、constexpr、decltype、noexpect、nullptr、static_assert、thread_local
- asm: _asm是一个语句的分隔符。不能单独出现,必须接汇编指令。一组被大括号包含的指令或一对空括号。 例:
_asm
{
mov al,2
mov dx,0xD007
out al,dx
}
也可以在每个汇编指令前加_asm
_asm mov al,2
_asm mov dx,0xD007
_asm out al,dx
- auto
- auto关键字会根据初始值自动推断变量的数据类型。不是每个编译器都支持auto。
auto x = 7; //使用整数7对变量x进行初始化,可推断x为int型。
auto y=1.234; //使用浮点数1.234对变量y进行初始化,可推断y为double型。
- *_cast:C++类型风格类型转换。
- 即
const_cast、dynamic_cast、reinterpret_cast、static_cast。 const_cast删除const变量的属性,方便赋值;dynamic_cast用于将一个父类对象的指针转换为子类对象的指针或引用;reinterpret_cast将一种类型转换为另一种不同的类型;static_cast用于静态转换,任何转换都可以用它,但他不能用于两个不相关的类型转换。
- 即
bool、true、falsebool即为布尔类型,属于基本类型中的整数类型,取值为真和假。true和false是具有布尔类型的字面量,为右值,即表示真和假。- 注
:字面量:用于表达源代码中一个固定值的表示法。
break、cotinue、gotobreak用于跳出for、while循环或switch语句。continue用于调到一个循环的起始位置。- goto用于无条件跳转到函数内得标号处。一般情况不建议使用
goto,风险较大。
switch、case、defaultswitch分支语句的起始,根据switch条件跳转到case标号或defalut标记的分支上。
catch、throw、try- 用于异常处理。
try指定try块的起始,后面的catch可以捕获异常。 - 异常由
throw抛出。throw在函数中还表示动态异常规范。
- 用于异常处理。
char、wchar_t- 表示字符型和宽字符型这些整数类型(属于基本类型),但一般只专用于表示字符。
char(和signed char、unsigned char一起)事实上定义了字节的大小。char表示单字节字符,wchar_t表示多字节字符。
const、volatileconst和volatile是类型修饰符,语法类似,用于变量或函数参数声明,也可以限制非静态成员函数。const表示只读类型(指定类型安全性,保护对象不被意外修改),volatile指定被修饰的对象类型的读操作是副作用(因此读取不能被随便优化合并,适合映射I/O寄存器等)。volatile: 寄存器变量
- 当读取一个变量时,为提高存取速度,编译器优化时有时会先把变量读取到一个寄存器中,以后再取变量值时,就直接从寄存器中取值。
- 优化器在用到
volatile变量时必须每次都小心地重新读取这个变量的值,而不是使用保存到寄存器里的备份。 volatile适用于多线程应用中被几个任务共享的变量。
struct、class、union- 用于类型声明。
class是一般的类类型。struct在C++中是特殊的类类型,声明中仅默认隐式的成员和基类访问限定与class不同(struct是public,class是private)。union是联合体类型。满足特定条件类类型——POD struct或POD union可以和C语言中的struct和union对应兼容。 - 注:POD类型(Plain Old Data),plain—代表普通类型,old—代表可以与C语言兼容。
- 用于类型声明。
new、deletenew、delete属于操作符,可以被重载。new表示向内存申请一段新的空间,申请失败会抛出异常。new会先调用operator new函数,再在operator new函数里调用malloc函数分配空间,然后再调构造函数。delete不仅会清理资源,还会释放空间。delete先调用析构函数,其次调用operator delete函数,最后在operator delete函数里面调用free函数。malloc申请内存失败会返回空。free只是清理了资源,并没有释放空间。
do、for、while- 循环语句的组成部分,C和C++都支持这3种循环。
- 数值类型,如
int、double、float、short、long、signed、unsignedsigned和unsigned作为前缀修饰整数类型,分别表示有符号和无符号。signed和unsigned修饰char类型,构成unsigned char和signed char,和char都不是相同的类型;不可修饰wchar_t、char16_t和char32_t。其它整数类型的signed省略或不省略,含义不变。signed或unsigned可单独作为类型,相当于signed int和unsigned int。double和float专用于浮点数,double表示双精度,精度不小于float表示的浮点数。long double则是C++11指定的精度不小于double的浮点数。
if和else条件语句的组成部分。if表示条件,之后else表示否定分支。enum构成枚举类型名的关键字。explicit该关键字的作用就是避免自定义类型隐式转换为类类型。export使用该关键字可实现模板函数的外部调用。对模板类型,可以在头文件中声明模板类和模板函数;在代码文件中,使用关键字export来定义具体的模板类对象和模板函数;然后在其他用户代码文件中,包含声明头文件后,就可以使用该这些对象和函数。extern当出现extern "C"时,表示extern "C"之后的代码按照C语言的规则去编译;- 当
extern修饰变量或函数时,表示其具有外部链接属性,即其既可以在本模块中使用也可以在其他模块中使用。
- 当
friend友元。使其不受访问权限控制的限制。- 例如,在1个类中,私有变量外部是不能直接访问的。可是假如另外1个类或函数要访问本类的1个私有变量时,可以把这个函数或类声明为本类的友元函数或友元类。这样他们就可以直接访问本类的私有变量。
inline内联函数,在编译时将所调用的函数代码直接嵌入到主调函数中。各个编译器的实现方式可能不同。mutable:mutable也是为了突破const的限制而设置的。被mutable修饰的变量,将永远处于可变的状态,即使在一个const函数中。namespace: C++标准程序库中的所有标识符都被定义于一个名为std的namespace中。命名空间除了系统定义的名字空间之外,还可以自己定义,定义命名空间用关键字namespace,使用命名空间时用符号::指定。operator: 和操作符连用,指定一个重载了的操作符函数,比如,operator+。public、protected、private: 这三个都为权限修饰符。public为公有的,访问不受限制;protected为保护的,只能在本类和友元中访问;private为私有的,只能在本类、派生类和友元中访问。
register: 提示编译器尽可能把变量存入到CPU内部寄存器中。return:return表示从被调函数返回到主调函数继续执行,返回时可附带一个返回值,由return后面的参数指定。return通常是必要的,因为函数调用的时候计算结果通常是通过返回值带出的。如果函数执行不需要返回计算结果,也经常需要返回一个状态码来表示函数执行的顺利与否(-1和0就是最常用的状态码),主调函数可以通过返回值判断被调函数的执行情况.static:可修饰变量(静态全局变量,静态局部变量),也可以修饰函数和类中的成员函数。static修饰的变量的周期为整个函数的生命周期。具有静态生存期的变量,只在函数第一次调用时进行初始化,在没有显示初始化的情况下,系统把他们初始化微0.sizeof返回类型名或表达式具有的类型对应的大小。template声明一个模板,模板函数,模板类等。模板的特化。this每个类成员函数都隐含了一个this指针,用来指向类本身。this指针一般可以省略。但在赋值运算符重载的时候要显示使用。静态成员函数没有this指针。typedef:typedef声明,为现有数据类型创建一个新的名字。便于程序的阅读和编写。virtual: 声明虚基类,虚函数。虚函数=0时,则为纯虚函数,纯虚函数所在的类称为抽象类。typeid:typeid是一个操作符,返回结果为标准库种类型的引用。typename:typename关键字告诉编译器把一个特殊的名字解释为一个类型。using- (1)、在当前文件引入命名空间,例
using namespace std; - (2)、在子类中使用,
using声明引入基类成员名称。
- (1)、在当前文件引入命名空间,例
void: 特殊的”空”类型,指定函数无返回值或无参数。
标识符
标识符
- 标识符组成:字母、数字、下划线。不能以数字开头,对大小写敏感。标识符的长度没有限制。
- 用户自定义的标识符不能连续出现两个下划线,也不能以下划线紧连大写字母开头。定义在函数体外的标识符不能以下划线开头。 变量命名规范:
- 标识符要体现其实际含义。
- 变量名一般用小写字母。
- 用户自定义类型一般以大写字母开头。
- 包含多个单词的标识符,使用驼峰命名法或使用下划线连接不同单词。
- 对于嵌套作用域,可以在内层作用域中重新定义外层作用域已有的名字,但是最好不要这样做。
复合类型(指针和引用)
- C++中的复合类型是指基于其他类型定义的类型;
- C++语言中基本的复合类型有:引用(&)和指针(*);
- 引用(&)主要是为对象起了另外一个名字;注意引用类型的初始值必须是一个对象。
定义复合类型的变量要比定义基本类型的变量复杂很多。
- 一条声明语句是由一个基本数据类型和紧随其后的声明符列表组成的。
- 引用符 & 和指针符 * 都是类型说明符,类型说明符是声明符的一部分。
int &a=b, &c=b;
int *a=nullptr, b=1;
引用
引用是给对象起的别名。初始化引用时,是将引用和对象绑定在一起。
- 引用无法重定向,只能一直指向初始值。
- 引用必须初始化。引用的初始值必须是一个对象,不能是字面值。
- 对引用的所有操作都是对与之绑定的对象的操作。
- 引用非对象。
- 不能定义对引用的引用,因为引用非对象。
- 引用只能绑定在对象上,不能与字面值或表达式绑定。
- 引用只能绑定同类型对象。
指针(对象)
指针(*)也是间接指向另外一种类型的复合类型;但其相对引用有一下不同点:
- 指针本身是一个对象,允许对指针赋值和拷贝; 而且在指针的声明周期内它可以先后指向几个不同的对象
- 指针无需在定义时赋值。和其它的内置类型一样,在块作用域内定义的指针如果没有初始化,也将拥有一个不确定的值。
- 指针操作中
&操作符,表示取地址作用
注意
- 在块作用域内,指针如果没有被初始化,值将不确定。
- 指针必须指向指定类型,不能指向其他类型。
int ival = 42;
int *p = &ival;//p存放变量ival的地址,即p指针指向ival;
//
int i = 0;
double *dp = &i; // 类型错误
long *lp = &i; // 类型错误
int *ip = i; // 这个也是错误的,但 int *ip = 0; 是正确的 (不能定义指向引用的指针!)
int *ip = 0; // 正确
int *p;
int* &r = p; // r是对指针p的引用
指针与引用的不同:
- 指针是一个对象而引用不是;
- 指针可以重定向引用不可以;
- 有指向指针的指针无引用的引用;
- 指针不需要在定义时赋初值而引用需要。
- 不能定义指向引用的指针。可以定义指向指针的引用。
指针的值:
- 指向一个对象
- 指向紧邻对象所占空间的下一个位置
- 空指针,意味着指针没有指向任何对象
- 无效指针,上述情况之外的其它值。 注意:
- 如果指针指向了一个对象;则允许使用解应用符
*来访问对象。 - 对于指针变量,初始化时可以使用NULL来方便内存分配判断;但是在C++11标准中对象指针使用 nullptr; 对于未初始化的int 等基本数据类型可以使用NULL;
空指针
建议初始化所有指针。非零指针对应的条件值是 ture,零指针对应的条件值是 false。
// 空指针定义
int *p = nullptr; // 三种定义空指针的方式。最好用第一种
int *p = 0;
int *p = NULL; // NULL 是在头文件 cstdlib 中定义的预处理变量,值为 0。
void* 指针
void* 指针是C语言中的保留项目,它是一种特殊的指针类型;可以用于存放任意对象的地址;
- 但是因为void* 指针的不确定性,也意味着无法确定能够在这个对象上进行哪些操作。
int* p1, p2; // p1指向int的指针;p2是int类型
int** pi; // 一个指向int指针的指针
// 空指针定义
int *p = nullptr; // 三种定义空指针的方式。最好用第一种
int *p = 0;
int *p = NULL; // NULL 是在头文件 cstdlib 中定义的预处理变量,值为 0。
void*指针
- void* 指针和空指针不是一回事。
- void* 指针是特殊的指针类型,可以存放任意对象的地址。它的用处比较有限。
智能指针(重点)
C++中的智能指针先后有:
auto_ptr(新指针接管,就指针瘫痪) –>unique_ptr(新旧指针统一成一个) –>shared_ptr(一个对象多个智能指针) –>weak_ptr(仅用于观测引用计数)
智能指针其实是将指针进行了封装,可以像普通指针一样进行使用,同时可以自行进行释放,避免忘记释放指针指向的内存地址造成内存泄漏。
auto_ptr是较早版本的智能指针,在进行指针拷贝和赋值的时候,新指针直接接管旧指针的资源并且将旧指针指向空- 但是这种方式在需要访问旧指针时会出现问题。
unique_ptr是auto_ptr的一个改良版,不能赋值也不能拷贝,保证一个对象同一时间只有一个智能指针。shared_ptr可以使得一个对象可以有多个智能指针,当这个对象所有的智能指针被销毁时就会自动进行回收。(内部使用计数机制进行维护)weak_ptr为了协助 shared_ptr 而出现的。它不能访问对象,只能观测shared_ptr的引用计数,防止出现死锁。
const限定符
- const 对象必须初始化,因为一旦创建就不能再改变值。
- 默认情况下,const 对象仅在文件内有效。
- 如果想在多个文件间共享 const 对象,必须在变量的定义前添加 extern 关键字并在本文件中声明。声明和定义都要加 extern
(1) const的引用
- 常量引用是对 const 的引用,对象不必是常量。对 const 对象的引用也必须是常量。
- 引用必须初始化,因此常量引用也必须初始化。 注意
- 引用不是对象,因此常量引用不是说引用是常量,引用本来就只能绑定一个对象,而是引用不能改变引用的对象了。
const int ci = 42;
const int &r = ci; // 用于声明引用的 const 都是底层 const
- 不能用非常量引用指向一个常量对象。可以用常量引用指向一个非常量对象。
- 引用的类型必须与其所引用对象的类型一致,但是有两个例外。其中一个例外就是初始化常量引用时允许用任意表达式作为初始值(包括常量表达式),只要该表达式结果可以转换为引用的类型。
- const int &r = 42; // 常量引用可以绑定字面值
- 当用常量引用绑定一个非常量对象时,不能通过引用改变引用对象的值,但是可以通过其他方式改变值。常量指针也一样。
(2) 指针和const
指向常量的指针的用法和常量引用相似,但是是不一样的。它既可以指向常量也可以指向非常量,不能改变对象的值。但是非常量对象可以通过其他途径改变值
- 常量指针不能改变对象值
顶层 const 对任何数据类型通用,底层 const 只用于引用和指针。
- 顶层 const:表示指针本身是个常量
- 底层 const:表示指针所指的对象是一个常量。 顶层 const 的指针表示该指针是 const 对象,因此必须初始化。底层 const 的指针则不用。
实际上只有指针类型既可以是顶层 const 也可以是底层 const,因为引用实际上只能是底层 const,常量引用即为底层 const,不存在顶层 const 的引用。
- const int &const p2 = p1;// 错误 从右向左读来判断是顶层 const 还是底层 const。
对于指针和引用而言,顶层 const 在右边,底层 const 在左边。对于其他类型,全都是顶层 const
const int* const p3 = p2; // 从右向左读,右侧const是顶层const,表明p3是一个常量,左侧const是底层const,表明指针所指的对象是一个常量
const int* p2 = &c; // 这是一个底层const,允许改变 p2 的值
int* const p1 = &i; // 这是一个顶层const,不能改变 p1 的值
执行对象的拷贝操作时,不能将底层 const 拷贝给非常量,反之可以,非常量将会转化为常量。
const * int 和int *const、const int * cosnt、const int &
参考链接:const int、const int *、int *cosnt、const int * const、const int &的区别;
const int *:该指针变量指向的是常量,即该指针变量的内容可以改变,但是该内容指向的内容不可改变!;即底层const(常量指针);(其与const int *相同);int *const:声明该指针变量为常变量,即指针变量里面的内容不可改变,但是该内容指向的内容可以改变;即为常指针。const int * cosnt:指向一个内容不可变的指针,且指向对象地址不能变;const int &:在引用前面加上const,代表该引用为常引用,即被引用的对象不可改变。若是在形参中使用,则不可达到在函数里面修改变量值的目的。
const关键字修饰的变量会在编译的时候将定义的字符串替换掉,为了提高编译效率和防止文件冲突,默认状态下const对象仅在文件内有效;
注意:
const是变量的值无法改变(有待商榷);static是指变量直接在堆上分配内存,内存不会销毁,但是值可以改变;- 当某一个文件中的const变量希望它能够在其它文件之间共享的时候;即在一个问价中定义const,而在其它多个文件中使用它,需要在
const关键字前添加extern关键字;
constexpr和常量表达式
constexpr和常量表达式
- 常量表达式是指值不会改变并且在编译过程就能得到计算结果的表达式。
- 字面值属于常量表达式,由常量表达式初始化的 const 对象也是常量表达式。
const int a = 32; // 是常量表达式
const int b = a + 1; // 是常量表达式
const int sz = get_size(); // 不是常量表达式,因为虽然 sz 是常量,但它的具体值等到运行时才知道。
常量表达式:(const expression)是指不会改变并且在编译过程中就能得到计算结果的表达式;一个对象/表达式是不是常量表达式;由它的数据类型和初始值共同决定。
const int max_files=20;//max_files 是常量表达式
const int limit=max_files+1;//limit 是常量表达式
int staff_size=27;//staff_size 不是常量表达式
const int sz=get_size();//运行时才知道值,因此不是常量;
constexpr变量
C++11允许将变量声明为constexpr类型以便由编译器来验证变量的值是否是一个常量表达式。
实际应用中很难分辨一个初始值是否是常量表达式,通过将变量声明为 constexpr 类型即可由编译器来检查。
由 constexpr 声明的变量必须用常量表达式初始化。建议:
- 如果认定一个变量是常量表达式,就把它声明为 constexpr 类型。
- 新标准允许定义 constexpr,这种函数应该足够简单以使得编译时就可以计算其结果。
- 不能用普通函数初始化 constexpr 变量,但可以使用 constexpr 函数初始化 constexpr 变量。
声明为constexpr的变量移动是一个常量,而且必须用常量表达式初始化:
constexpr int mf=20; //20是常量表达式
constexpr int limit=mf+1; //mf+1是常量表达式
constexpr int sz=size(); //只有当size是一个constexpr函数时才是一条正确的声明语句
指针和constexpr 在constexpr声明中如果定义了一个指针,限定符constexpr仅对指针有效,与指针所指对象无关;
const int *p=nullptr;//p是一个指向整型常量的指针
constexpr int *q=nullptr;//q是一个指向整数的常量指针;constexpr把她所东一的对象置为了顶层const
字面值类型
- 算术类型、引用、指针都属于字面值类型,自定义类则不属于。
- cosntexpr 指针的初始值必须是 nullptr 或 0 或存储于固定地址的对象。函数体之外的对象和静态变量的地址都是固定不变的。 指针和constexpr
- 注意区分 constexpr 和 const 。constexpr 都是顶层 const,仅对指针本身有效。
const int *p = nullptr; // p 是一个指向整型常量的指针
constexpr int *q = nullptr; // q 是一个指向整数的常量指针
区分const和constexpr
- constexpr 限定了变量是编译器常量,即变量的值在编译器就可以得到。
- const 则并未区分是编译器常量还是运行期常量。即 const 变量可以在运行期间初始化,只是初始化后就不能再改变了。
- constexpr 变量是真正的“常量”,而 const 现在一般只用来表示 “只读”。
类型别名
有两种方法定义类型别名。
- typedef
- using
typedef double wages; // 使用 typedef 关键字
using wages = double; // 使用 using 关键字进行别名声明
typedef wages base, *p; // base 是 double 的别名,p 是 double* 的别名。
// 指针、常量和类型别名
typedef char* pstring;
const pstring cstr = 0; // 注意:const 是一个指向 char 的常量指针。不能采用直接替换的方式将其理解为 const char* cstr = 0,这是错误的。
typedef 作为声明语句中的基本数据类型的一部分出现。
- 含有 typedef 的声明语句定义的不再是变量而是类型别名。
- 和其他声明语句一样,typedef 的声明语句中也可以包含类型修饰符,从而构造符合类型。
typedef关键字
typedef int my_int:将int取别名为my_int;typedef 函数:定义函数类型(常用语C语言中;C++慎用);
typedef long SetStringPtr(char *);//预定于函数输入输出类型
typedef long GetStringPtr(char *, long);//预定于函数输入输出类型
typedef struct {
SetStringPtr * SetString;//初始化函数指针
GetStringPtr * GetString;//初始化函数指针
DWORD count;
char buffer[80];
} IExample;
//实例化函数
long SetString(char * str)
{
return(0);
}
IExample * example;//使用结构体对象
example->SetString = SetString;//使用函数;
auto关键字;
auto 说明符让编译器根据初始值来分析表达式所属的类型。
- 使用 auto 会增加编译时间,但不会增加运行时间。 auto 可以在一条语句中声明多个变量,但是多个变量必须是同一个基本数据类型(整型与整型指针和整型引用算一个类型)。
auto关键字在C++11中得到了广泛使用;但是他是基于C++模板类型推断的,因此需要慎重使用;多用于循环迭代中;
#include <iostream>
#include <vector>
using namespace std;
int main(int arc,char const *argv[])
{
std::vector<int> v={1,1,12,3};
for(auto temp : v){
std::cout<<temp<<'\t'<<std::endl;;
}
return 0;
}
编译器推断出的 auto 类型有时和初始值并不一样,编译器会进行适当的调整:
- auto 根据引用来推断类型时会以引用对象的类型作为 auto 的类型。
- auto 一般会忽略掉顶层 const,因此对于非指针类型的常量对象,auto 推断出的结果是不含 const 的。如果希望 auto 是一个顶层 const,需要明确指出。
- auto 会保留底层 const。 auto 会忽略引用与顶层 const
const int ci = 1, cr = ci;
auto b = ci; // b 是一个普通的 int。
auto c = cr; // c 是一个普通的 int。
const auto d = ci; // d 是一个 const int
// auto 定义引用时,必须用 & 指明要定义的是引用。
auto &e = ci; // e 是一个常量引用(常量引用是底层 const)。注意这个微妙的地方。
auto f = &ci; // f 是一个 const int*(位于左边的 const 是底层 const)
int 与 int *、int & 是一个基本数据类型,而 const int 与 int 不是一种类型。
decltype类型指示符
- decltype 是C++11新引入的关键字,帮助从表达式推断定义的变量的类型。
注意:
- decltype 处理顶层const和引用的方式与auto有些许不同;
- 如果decltype使用的表达式不是一个变量,则decltype返回表达式结果对应的类型,当有时返回一个引用类型的时候;表达式的结果对象,能够作为一条赋值语句的左值。
- dectype((variable)) (注意是双层括号)的结果永远是引用,而decltype(variable)结果只有当variable本身就是一个引用时才是。
const int ci=0,&cj=ci;
decltype(cj) x=0;//x 类型是const int
decltype(cj) y=x;//y的类型是const int&,y绑定到变量x
decltype(cj) z;//错误,z是一个引用必须初始化
//decltype 的结果可以是引用类型
int i=42,*p=&i,&r=i;
decltype(r+0) b;//加法的结果是int,因此b是一个(未初始化的)int
decltype(*p) c;//错误:c是int&,必须初始化
头文件
头文件
- 类通常定义在头文件中,类所在头文件的名字应与类的名字一样。
- 头文件通常定义那些只能被定义一次的实体,比如类、const、constexpr 等。
- 头文件一旦改变,相关的源文件必须重新编译以获取更新过的声明。 预处理器概述
- 确保头文件多次包含仍能安全工作的常用技术是预处理器。
- 预处理变量有两种状态:已定义和未定义。一般把预处理变量的名字全部大写。
- 整个程序中的预处理变量包括头文件保护符必须唯一,通常基于头文件中类的名字来构建保护符的名字,以确保其唯一性。 c++ 中包含三个头文件保护符:
- #define:把一个名字设定为预处理变量
- #ifndef:当且仅当变量已定义时为真,一旦检查结果为真,则执行后续操作直到遇到 #endif 为止
- #endif
预处理变量无视作用域的规则,作用范围是文件内
第三章 字符串、向量和数组
string、vector是两种最重要的标准库类型,迭代器是一种与 string 和 vector 配套的标准库类型。
内置数组和其他内置类型一样,数组的实现和硬件密切相关,因此与string和vector相比,数组在灵活性上稍显不足。
问题
问题
- 使用加号连接字符串/string时要注意什么
- string 的索引是什么类型,s.size() 返回什么类型。
- 如何方便地判断 string 中的某个字符的类型(比如是数字还是字母)以及转换某个字符的大小写。
- 值初始化的结果是怎样的
- 定义 c 风格数组时数组维度的限制条件
- 如何使用数组来初始化 vec
- string 类型可以隐式转化为 c 风格字符串(即字符数组)吗?
- 如何将 string 类型转化为 c 风格字符串
- 使用 getline() 函数从输入流读取字符串存到 string 中,存储的内容有换行符吗?
- 使用范围for循环要注意什么?
- 如果容器为空,begin() 的返回值是什么?
- 使用数组时要注意数组维度的什么特点?
- 区分 int ptrs[10]; int (ptrs)[10]; int (&ptrs)[10] 的不同含义
- C风格字符串属于什么类型?
回答
- 加号两边至少有一个是 string 类型,不能都是字符串
- 都是 string::size_type 类型,是无符号值。
- 使用 cctype 头文件中的 isalnum(), isalpha(), isdigit(), isupper(), islowwer(), ispunct(), isspace(), tolower(), toupper() 等类型。
- 值初始化会将内置类型初始化为 0,类类型由类自己来默认初始化。
- 维度必须是个常量表达式,即在编译阶段就可以确定值。(因为数组维度是数组的类型的一部分,而 C++ 是静态语言,即在编译阶段就要确定类型)
- vector
vec(begin(arr),end(arr)); - 不可以(从 C 风格字符串到 string 的转换是用了 string 的转换构造函数,而 string 并没有定义到 C 风格字符串的类型转换运算符)
- 使用 c_str() 函数
- 没有换行符。
- 如果要修改循环变量的值要将其声明为引用类型:auto &
- 返回的是尾后迭代器,和 end() 的返回值一样。
- 使用数组时注意数组的维度必须是个常量表达式,因为数组的维度也属于数组类型的一部分,而编译器在编译阶段就需要知道数组类型。
- 他们分别定义了:一个包含10个整型指针的数组,一个指向包含10个整型值的数组的指针,一个包含10个整型值的数组的引用。
- C风格字符串本身不是类型,而是一种写法,它的类型是字符数组。要从字符数组的角度来理解C风格字符串的各项操作。
使用using name space
- c++中使用
using name space来进行命名空间的选择,但是一般不建议直接在声明中使用。 - 建议使用
spacename:: function的格式;例如std::cout; 并且头文件中,不应该包括using声明。
标准库类型 string
string 表示可变长的字符序列。
- string 定义在命名空间 using 中。 string的常用初始化方法:
- 拷贝初始化:使用等号
- 直接初始化:不使用等号
- 列表初始化:使用花括号{}
std::string s1; //默认初始化,s1市一个空字符
std::string s2=s1; //s2是s1的副本(拷贝初始化)
std::string s3="hiya";//s3市该字符串字面值的副本(直接初始化)
std::string s5("hiya");//s3是字面值“value”的副本,除了字面值最后的那个空字符除外 (拷贝初始化)
std::string s4(10,'c'); //s4 的内容是cccccccccc
string s1; //将 s1 默认初始化为一个空的 string
string s1(s2); //使用拷贝构造函数进行的拷贝初始化。s1 是 s2 的拷贝。
string s1 = s2; //使用拷贝赋值运算符进行的拷贝初始化。s1 是 s2 的拷贝。
string s1("value"); //s1 是字面值 "value" 去除最后一个空字符后的拷贝。
string s1 = "value"; //同上。
string s1(n,'c'); //s1 初始化为 n 个 'c'。
os<<s、is>>s;从字符串的输入,输出流。
#include <iostream>
using namespace std;
int main(int argc, char const *argv[])
{
string s;
cin>>s; //将string 对象读入s,遇到空白停止
cout<<s<<endl;//输出
return 0;
}
string操作函数
getline():读取函数整行,直到遇到换行符为止。- getline() 定义在头文件 string 中,以一个 istream 对象和一个 string 对象为输入参数。getline() 读取输入流的内容直到遇到换行符停止,然后将读入的数据存入 string 对象。
- getline 会将换行符也读入,但是不将换行符存入 string 对象。即触发 getline() 函数返回的那个换行符实际上被丢弃掉了。
- getline() 只要一遇到换行符就结束读取操作并返回结果,即使一开始就是换行符也一样,这种情况下会得到一个空 string。
- getline() 与 « 一样,会返回它的流参数。所以可以用 getline 的结果作为条件。
getline(is, s2);//从输入流 is 中读取一行赋给 s2,is 是输入流。
s.empty();//s为空则返回 ture
s.size(); //返回字符数,类型为 size_type,无符号整数
s[n]; //对 s 中元素的索引
s3 = s1 + s2;//连接 s1 与 s2,加号两边必须至少有一个是 string,不能都是字面值,比如 "world"+"hello" 是错误的
<.<=,>,>=; //比较时从前往后比较单个字母的大小
读写string对象
- 用 cin, cout 来读写 string 对象,也可以用 stringstream 来读写 string 对象。
- cin 会自动忽略开头的空白并遇到空白就停止读取,因此不能使用 cin 读取句子
注意
- string 的 size() 成员函数返回一个 string::size_type 类型的值。
- string::size_type 是无符号值,可以确定的是它足够存放任何 string 对象的大小。
- C++11 允许通过 auto 和 decltype 来获得此类型
- 当他与一个具有负号的n比较时,肯定为true,因此建议使用
auto来进行返回值的定义。防止int和unsigned可能带来的问题。
标准库string重点字符处理–< cctype >头文件
cctype 头文件中有下列标准库函数来处理 string 中的字符。
- 函数的输入和返回值实际都是 int 类型的,且输入的值 c 必须满足 -1<=c<=255,即输入必须是 ASCII 字符。
- 建议:使用 c++ 版本的标准库头文件,即 cname 而非 name.h 类型的头文件。cname 头文件中的名字都从属于命名空间 std;
| 函数名称 | 功能 |
|---|---|
isalnum(c) |
当c是字母或数字时为真 |
isalpha(c) |
当c是字母时为真 |
iscntrl(c) |
当c是控制字符时为真 |
isdigit(c) |
当c是数字时为真 |
isgraph(c) |
当c不是空格但可以打印时为真 |
isalower(c) |
当c是小写字母时为真 |
isprint(c) |
当c是可打印字符时为真 |
ispunct(c) |
当c是标点符号时为真 |
isspace(c) |
当c是空白时为真(空格,制表符、回车符、换行符、进纸符中的一种) |
issupper(c) |
当c是大写字母时为真 |
isxdigit(c) |
当c是十六进制数字时为真 |
tolower(c) |
转换字母为小写 |
toupper(c) |
转换字母为大写 |
使用示例:
string s("hello word !!!");
decltype(s.size()) punct_cnt=0;
for (auto c : s)//注意这里auto是拷贝无法改变其中的char的值,可以使用&c进行值的改变。
{
if(ispunct(c))
{
++punct_cnt;//标点负号计数值加1;
}
cout<< punct_cnt <<"punctuation characters in"<< s <<endl;
}
//输出结果: 3 punctuation characters in hello word!!!
string str;
// 读取字符串
for(auto c:str) // 对于str中的每个字符
cout << c << endl; // 输出当前字符,后面紧跟一个换行符
// 修改字符串,加引用
for(auto &c:str) // 循环内不能改变元素数目
c = toupper(c); // 转换为大写
- 对 string 的最后一个字符进行索引:s[ s.size()-1];
- 索引必须大于等于 0 小于 size,使用索引前最好用 if(!s.empty()) 判断一下字符串是否为空。
- 任何表达式只要是整型值就可以作为索引。索引是无符号类型 size_type;
将输入十进制数字转化为十六进制:
#include <iostream>
#include <stack>
#include <sstream>
#include <string>
using namespace std;
int main(int argc, char const *argv[]) {
const string test="0123456789ABCDEF";
cout<<"please input number between 0 and 15"<<endl;
string::size_type n, temp;//用于保存从输入流读取的数;
while((cin.peek()!=EOF)&&(cin.peek()!='\n'))
{
cin>>n;
string result;//用于保存十六进制的字符串
//else if(n>test.size()){
for(int i=n;i>0;){
temp=i%16;
auto s1 = test[temp];//转化为十六进制
result=s1+result;
i=i>>4;
}
printf("%X\n",n);
std::cout<<"this result is :"<<result<<std::endl;
//result.clear();
}
printf("hello word");
return 0;
}
vector 向量介绍
vector 是一个类模板
- vector 是模板,vector< int> 是类型
vector定义
- 值初始化
- 值初始化的方式:如果对象是内置类型,则初始值为 0,如果是类类型,则由类默认初始化。
- 列表初始化
- 使用花括号一般表示列表初始化:初始化过程会尽量把花括号内的值当作一个初始值列表来处理。
- 如果花括号内的值不能用来列表初始化,比如对一个 string 的 vector 初始化,但是花括号内的值为整型
vector<string> v2(v1); // v2=v1
vector<string> v3(10,"hi"); // 10个string
vector<string> v4(10); // 10个空string
// 列表初始化
vector<string> v5{"an","the"}; // 列表初始化
vector<string> v {10}; // v 有 10 个默认初始化的元素
vector<string> v {10, "hi"}; // v 有 10 个值为 "hi" 的元素
// vector操作
v.size();
v.empty();
v.push_back(t);
vector可以高效增长,通常先定义一个空 vector,然后在添加元素会更快速。 定义 vector 时,已知 vector 的大小,如果初始值都一样,初始化时确定大小与值会更快。如果初始值不全一样,即使已知大小,最好也先定义一个空的 vector,再添加元素。
迭代器(iterator)介绍
- 迭代器类似于指针但是不同于指针;利用地址进行一次间接的迭代访问。 标准迭代器的运算符:
| 运算符 | 功能 |
|---|---|
| *iter | 返回迭代器iter所指元素的引用 |
| iter->mem | 解引用iter并获取该元素的名为mem的成员,等价于(*iter).mem |
| ++iter | 令iter指示容器的下一个元素 |
| –iter | 令iter指示容器的上一个元素 |
| iter1==iter2 | 判断是否指向同一个元素 |
| iter1!=iter2 | 判断是否指向同一个元素 |
string s("some string ");
vector<string> v(s);
// 使用迭代器
auto b = v.begin(), e = v.end();
auto d = v.cbegin(); f = v.cend(); // 返回的是const_iterator
if(s.begin()!=s.end())
{
auto it=s.begin();//it表示s的第一个字符
*it=toupper(*it);//当前字符改写成大写格式
}
vector<int>::iterator it = v.begin();
string::iterator it;
// string 和 vector 支持的迭代器运算。注意不能将两个迭代器相加。
iter + n;
iter += n;
iter1 - iter2; // 返回两个迭代器之间的距离,difference_type类型的带符号整数
>, >=, <, <=; // 比较运算符
注意:
- c++中定义了箭头运算符:(
->)把解引用和成员访问两个操作结合在一起,it->mem和(*it).mem表达的意思相同。 - 两个迭代器相减结果是它们之间的距离。迭代器加整数还是迭代器。
数组
- 数组的大小确定不变;
- 数组和 vector 的元素都必须是对象,不能是引用
- 数组不能用 auto 来定义。
初始化
char a1[] = {'c', '+', '+'}; // 列表初始化,没有空字符,维度是3
char a2[] = "c++"; // 有空字符,维度是4
const char a4[3] = "c++"; // 错误,没有空间存放空字符
// 不能用数组为另一个数组赋值或拷贝。可以按元素一个一个拷贝,但不能直接拷贝整个数组。
// 按照由内向外的顺序理解数组的类型
int *ptrs[10]; // ptrs是一个含有10个整型指针的数组
int (*ptrs)[10] = &arr; // ptrs是一个指针,指向一个含有10个整数的数组
int (&ptrs)[10] = &arr; // ptrs是一个引用,引用一个含有10个整数的数组
使用数组下标的时候,通常将其定义为size_t类型;
unsigned scores[11]={};//11个分数段,全部初始化为0
unsigned grade;
while(cin>>grade) {
/* code */
if (grade<=100)
{
/* code */
++scores[grade/10];//将当前分数段的计数值加1
}
}
- 数组下标通常用 size_t 类型
- 使用范围 for 语句遍历数组元素
注意:
- 数组中的
int *parr[10]表示含有10个整型指针的数组;int (*parr)[10]表示指向含有10个整数的数组的指针。int *(&array)[10]表示含有10个int型指针的数组的引用。
c 风格字符串
- c++中支持c风格字符串,但是在c++程序中最好还是不要使用他们。因为字符串使用起来不太方便,而且极易产生程序内存泄露
- c++中string对象使用c_str()函数,实现string对象到 char*[]的转换。
- 尽量使用标准类库而非数组。
c++ 支持 c 风格字符串,但是最好不要使用,c 风格字符串使用不便,并且极易引发程序漏洞
- c 风格字符串不是一种类型,而是一种写法,是为了表达和使用字符串而形成的一种约定俗成的写法。
- 用这种写法书写的字符串存放在字符数组中并以空字符(’\0’)结束。
多维数组的初始化:
int ia[3][4]={
//内嵌`{`并不是必须的但是,可以似的文件更加整洁,代码更加规范
{0,1,2,3},
{4,5,6,7},
{8,9,10,11}
}
遍历数组
3 种方式来输出 arr 的元素
// 范围 for 语句-不使用类型别名
for (const int (&row)[4] : arr)
for (int col : row)
cout << col << " ";
cout << endl;
// 范围 for 语句-使用类型别名
using int_array = int[4];
for (int_array &p : ia)
for (int q : p)
cout << q << " ";
cout << endl;
// 普通 for 循环
for (size_t i = 0; i != 3; ++i)
for (size_t j = 0; j != 4; ++j)
cout << arr[i][j] << " ";
cout << endl;
// 指针
for (int (*row)[4] = arr; row != arr + 3; ++row)
for (int *col = *row; col != *row + 4; ++col)
cout << *col << " ";
cout << endl;
第四章 表达式
左值和右值问题
参考链接:理解C和C++中的左值和右值;C++11 左值、右值、右值引用详解;
左值:代表一个在内存中占有确定位置的对象(存在地址);例如int a=0;中a就是一个左值
右值:通过排他性来定义,每个表达式不是lvalue就是rvalue。因此从上面的lvalue的定义,rvalue是在不在内存中占有确定位置的表达式。
左值引用就是对一个左值进行引用的类型。右值引用就是对一个右值进行引用的类型,事实上,由于右值通常不具有名字,我们也只能通过引用的方式找到它的存在。
右值引用和左值引用都是属于引用类型。无论是声明一个左值引用还是右值引用,都必须立即进行初始化。而其原因可以理解为是引用类型本身自己并不拥有所绑定对象的内存,只是该对象的一个别名。左值引用是具名变量值的别名,而右值引用则是不具名(匿名)变量的别名。
左值引用通常也不能绑定到右值,但常量左值引用是个“万能”的引用类型。它可以接受非常量左值、常量左值、右值对其进行初始化。不过常量左值所引用的右值在它的“余生”中只能是只读的。相对地,非常量左值只能接受非常量左值对其进行初始化。
int &a = 2; // 左值引用绑定到右值,编译失败
int b = 2; // 非常量左值
const int &c = b; // 常量左值引用绑定到非常量左值,编译通过
const int d = 2; // 常量左值
const int &e = c; // 常量左值引用绑定到常量左值,编译通过
const int &b =2; // 常量左值引用绑定到右值,编程通过
右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要std::move()将左值强制转换为右值,例如:
int a;
int &&r1 = c; # 编译失败
int &&r2 = std::move(a); # 编译通过
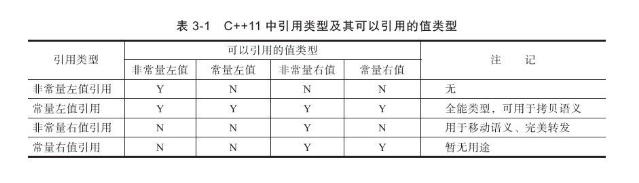
// lvalues:
int i = 42;
i = 43; // ok, i is an lvalue
int* p = &i; // ok, i is an lvalue
int& foo();
foo() = 42; // ok, foo() is an lvalue
int* p1 = &foo(); // ok, foo() is an lvalue
// rvalues:
int foobar();
int j = 0;
j = foobar(); // ok, foobar() is an rvalue
int* p2 = &foobar(); // error, cannot take the address of an rvalue
j = 42; // ok, 42 is an rvalue
运算符优先级顺序
运算符优先级顺序如下表所示:
| 运算符 | 功能 | 用法 |
|---|---|---|
+ |
一元正号 | + expr |
- |
一元负号 | - expr |
* |
乘法 | expr * expr |
/ |
除法 | expr / expr |
% |
求余 | expr % expr |
+ |
加法 | expr + expr |
- |
减法 | expr - expr |
注意
- 使用数据类型赋值的时候不要超出类型的上界;例如:
short short_value=32767;//short类型占16位,则能表示的最大值是32767
short_value+=1;//该计算导致溢出,实际值:-32768
- 如果
m%n不等于0,则它的负号和m相同 - 赋值运算符
=的左侧运算对象必须是一个可以修改的左值。
位运算符
位运算符主要使用方法如下表:
| 运算符 | 功能 | 用法 |
|---|---|---|
~ |
位求反 | ~ expr |
<< |
左移,相当于乘2^n |
expr1 >> expr2 |
>> |
右移,相当于除2^n |
expr1 >> expr2 |
& |
位与 | expr & expr |
^ |
位异或 | expr ^ expr |
"|" |
位或 | "expr|expr" |
sizeof运算符
sizeof来进行对象或者类型名称所占用的字节数目
类型转换
参考链接: C++强制类型转换:static_cast、dynamic_cast、const_cast、reinterpret_cast;C++ 类型转换(C风格的强制转换);
c++中的隐式类型转换,已经在之前介绍过了,同时c++中还存在显示的强制类型转换cast-name<type>(expression);其中cast-name是指:static_cast、dynamic_cast、const_cast和reinterpret_cast
| 名称 | 区别 |
|---|---|
static_cast |
静态强制转换,编译时就转换 |
dynamic_cast |
动态强制转换,运行时转换 |
const_cast |
编译时进行检查,强制消除对象的常量性 |
reinterpret_cast |
编译时进行检查,是特意用于底层的强制转型,主要用于二进制的强制类型转换 |
static_cast
static_cast相当于传统的C语言里的强制转换,该运算符把expression转换为new_type类型,用来强迫隐式转换,例如non-const对象转为const对象,编译时检查,用于非多态的转换,可以转换指针及其他,但没有运行时类型检查来保证转换的安全性。它主要有如下几种用法:
- 用于类层次结构中基类(父类)和派生类(子类)之间指针或引用的转换。
- 进行上行转换(把派生类的指针或引用转换成基类表示)是安全的;
- 进行下行转换(把基类指针或引用转换成派生类表示)时,由于没有动态类型检查,所以是不安全的。
- 用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性也要开发人员来保证。
- 把空指针转换成目标类型的空指针。
- 把任何类型的表达式转换成void类型。
注意:static_cast不能转换掉expression的const、volatile、或者__unaligned属性。
dynamic_cast
主要用于执行“安全的向下转型(safe downcasting)”,也就是说,要确定一个对象是否是一个继承体系中的一个特定类型。支持父类指针到子类指针的转换,这种转换时最安全的转换。它 是唯一不能用旧风格语法执行的强制类型转换,也是唯一可能有重大运行时代价的强制转换。
- 其他三种都是编译时完成的,
dynamic_cast是运行时处理的,运行时要进行类型检查。 - 不能用于内置的基本数据类型的强制转换。
dynamic_cast转换如果成功的话返回的是指向类的指针或引用,转换失败的话则会返回NULL。- 使用
dynamic_cast进行转换的,基类中一定要有虚函数,否则编译不通过。B中需要检测有虚函数的原因:类中存在虚函数,就说明它有想要让基类指针或引用指向派生类对象的情况,此时转换才有意义。这是由于运行时类型检查需要运行时类型信息,而这个信息存储在类的虚函数表(关于虚函数表的概念,详细可见<Inside c++ object model>)中。只有定义了虚函数的类才有虚函数表。 - 要求<>内部所描述的目标类型必须为指针或引用。
- 在类的转换时,在类层次间进行上行转换时,
dynamic_cast和static_cast的效果是一样的。在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。 - 向上转换,即为子类指针指向父类指针(一般不会出问题);向下转换,即将父类指针转化子类指针。 - 向下转换的成功与否还与将要转换的类型有关,即要转换的指针指向的对象的实际类型与转换以后的对象类型一定要相同,否则转换失败。 - 在C++中,编译期的类型转换有可能会在运行时出现错误,特别是涉及到类对象的指针或引用操作时,更容易产生错误。Dynamic_cast操作符则可以在运行期对可能产生问题的类型转换进行测试。
- const_cast
而const_cast则正是用于强制去掉这种不能被修改的常数const特性,但需要特别注意的是const_cast不是用于去除变量的常量性,而是去除指向常数对象的指针或引用的常量性,其去除常量性的对象必须为指针或引用。
- 该运算符用来修改类型的const或volatile属性。除了const 或volatile修饰之外, type_id和expression的类型是一样的。
- 常量指针被转化成非常量指针,并且仍然指向原来的对象;
- 常量引用被转换成非常量引用,并且仍然指向原来的对象;常量对象被转换成非常量对象。
- const_cast强制转换对象必须为指针或引用
- const_cast一般用于修改底指针。如const char *p形式
- reinterpret_cast
是特意用于底层的强制转型,导致实现依赖(就是说,不可移植)的结果,例如,将一个指针转型为一个整数。这样的强制类型在底层代码以外应该极为罕见。操作 结果只是简单的从一个指针到别的指针的值得二进制拷贝。在类型之间指向的内容不做任何类型的检查和转换。 new_type必须是一个指针、引用、算术类型、函数指针或者成员指针。它可以把一个指针转换成一个整数,也可以把一个整数转换成一个指针(先把一个指针转换成一个整数,再把该整数转换成原类型的指针,还可以得到原先的指针值)。
运算符优先级表格如下
| 优先级 | 运算符 | 说明 | 结合性 |
|---|---|---|---|
| 1 | :: | 范围解析 | 自左向右 |
| 2 | ++ - - | 后缀自增/后缀自减 | |
| () | 括号 | ||
| [] | 数组下标 | ||
| . | 成员选择(对象) | ||
| -> | 成员选择(指针) | ||
| 3 | ++ - - | 前缀自增/前缀自减 | 自右向左 |
| + - | 加减 | ||
| ! ~ | 逻辑非/按位取反 | ||
| (type) | 强制类型转换 | ||
| * | 取指针指向的值 | ||
| & | 某某的地址 | ||
| sizeof | 某某的大小 | ||
| new,new[] | 动态内存分配/动态数组内存分配 | ||
| delete,delete[] | 动态内存分配/动态数组内存释放 | ||
| 4 | .* ->* - - | 成员对象选择/成员指针选择 | 自左向右 |
| 5 | * / % | 乘法/除法/取余 | |
| 6 | + - | 加号/减号 | |
| 7 | << >> | 位左移/位右移 | |
| 8 | < <= | 小于/小于等于 | |
| > >= | 大于/大于等于 | ||
| 9 | == != | 等于/不等于 | |
| 10 | & | 按位与 | |
| 11 | ^ | 按位异或 | |
| 12 | | | 按位或 | |
| 13 | && | 与运算 | |
| 14 | || | 或运算 | |
| 15 | ?: | 三目运算符 | 自右向左 |
| 16 | = | 赋值 | |
| += -= | 相加后赋值/相减后赋值 | ||
| *= /= %= | 相乘后赋值相值/取余后赋值 | ||
| <<= >>= | 位左移赋值/位右移赋值 | ||
| &= ^= |= | 位与运算后赋值/位异或运算后赋值/位或运算后赋值 | ||
| 17 | throw | 抛出异常 | |
| 18 | , | 逗号 | 自左向右 |
第五章 语句
没什么好写的。
第六章 函数
函数基础
在函数中可以使用static来进行静态局部变量的全局作用域。使得局部变量的生存周期可以一直持续到程序结束。
注意当使用指针作为函数传入参数的时候,函数内部会拷贝传入参数指针,指针不同但是指向的地址和变量相同。当使用引用时,是传给函数使用对象的另外一个名字。因此在函数参数传递时应该,尽量使用引用参数。如下:
bool isShorter(const string &sl;const string &s2)
{
return s1.size()<s2.size();
}
int main(int argc,char *argv[])
{
}
//第二个形参argv是一个数组,它的元素是指向c风格字符串的指针;因为第二个形参是数组,所以main函数也可以定义成:
int main(int argc, char const **argv) {
/* code */
return 0;
}
initialzer_list 形参
当函数的实参数量未知;但是全部实参的类型相同,我们可以使用initializer_list类型的形参。详细描述如下表:
| 操作 | 解释 |
|---|---|
initializer_list <T> lst |
默认初始化;类型的空列表 |
initializer_list <T> lst {a,b,c...} |
lst的元素数量和初始值一样多;lst的元素是对应初始值的副本;列表中的元素是const |
lst2(lst) or lst2=lst |
拷贝复制一个元素 |
lst.size() |
列表中的元素数量 |
lst.begin() |
返回指向lst中首元素的指针 |
lst.end() |
返回指向lst中尾元素下一位置的指针 |
下面是代码示例:
void error_msg(initializer_list<string> il)
{
for(auto beg=il.begin();beg!=il.end();++beg)
{
cout<<*beg<<" ";//连续输出错误的函数信息
}
cout<<endl;
}
省略符形参
为了方便c++程序访问某些特殊的c代码而设置的,这些大妈使用了名为varargs的c标准库功能。
void foo(parm_list,...);
void foo(...);
值是如何被返回的
返回复制一个临时变量,该临时变量就是函数调用的结果。 注意:
- 不要返回局部对象的引用或者指针,因为局部变量的引用和指针会随着局部变量的结束而终止,因此,返回的引用和指针会不在有效的内存区域内。
- 函数的返回类型决定函数是否是左值,调用一个返回引用的函数得到左值,其它返回类型得到右值。
- 数组不能被返回,但是函数可以通过返回数组指针来进行返回操作。
- c++11新标准,允许使用尾置返回类型;或者使用
decltype声明返回指针的类型;例如:
//func 接受一个int类型的实际参数,返回一个指针,该指针指向含有10个整数的数组
auto funct(int i) -> int(*)[10];
int odd[]={1,3,5,7,9};
int odd[]={2,4,6,8,10};
decltype(odd) *arrPtr(int i)
{
return (i%2)?&odd:&even;//返回一个指向数组的指针
}
函数重载(overloaded 和over)
参考链接: C++的重载(overload)与重写(override);C++中 overload 、override、overwrite 之间的区别;
因为c++是强类型语言,因此当相同函数名称处理不同的输入数据时需要设置多个函数,实现相同函数名称的查找匹配最佳值。这一点c++中的模板很好的解决了这个问题,但是函数的重载也很好的解决了这个问题。例如:
//定义重载函数
void print(const char *cp);//函数1
void print(const int *beg,const int *end);//函数2
void print(const int ia[],size_t size);//函数3
//接受参数不同,使用也不相同
int j[2]={0,1};
print("Hello word ");//调用函数1
print(j,end(j),-begin(j));//调用函数2
print(begin(j),end(j));//调用函数3
注意:
main函数不能重载。- c++中函数名字查找发生在类型检查之前。因此建议,函数重载,针对不同输入直接取名不同。
- 当函数传入参数是拷贝传递时
const int a与int a是同一个函数,即重写了前一个函数。当使用&作为引用参数时,使用const为新参数。例如int &a与const int &a是两个不同的函数。 - 注意当查找同名函数时,编译器首先查找当前作用域(局部作用域)内的同名函数。
overload 、override、overwrite 之间的区别
Overload 重载
在C++程序中,可以将语义、功能相似的几个函数用同一个名字表示,但参数不同(包括类型、顺序不同),即函数重载。条件:
- 相同的范围(在同一个类中)
- 函数名字相同
- 参数不同
- 重载解析中不考虑返回类型,而且在不同的作用域里声明的函数也不算是重载。重载可以理解为一个类内部的函数重载
Override 覆盖
是指派生类函数覆盖基类函数,实际上是c++多态的衍生品;特征是:
- 不同的范围(分别位于派生类与基类)
- 函数名字相同;
- 参数名字相同
- 基类函数必须有
virtual关键字。
示例:
#include <iostream>
using namespace std;
class base
{
public:
virtual void Fun1()
{
cout<<"Base Fun1..."<<endl;
}
virtual void Fun2()
{
cout<<"Base Fun2..."<<endl;
}
void Fun3()
{
cout<<"Base Fun3..."<<endl;
}
};
class Derived: public Base
{
public:
void Fun1()
{
cout<<"Derived Fun1..."<<endl;
}
void Fun1()
{
cout<<"Derived Fun2..."<<endl;
}
void Fun3()
{
cout<<"Derived Fun3..."<<endl;
}
};
int main()
{
Base* p;
Derived d;
p=&d;
p->Fun1(); //因为Fun1是虚函数,所以调p指向的对象的Fun1
p->Fun2(); //同Fun1
p->Fun3(); //Fun3不是虚函数,所以根据指针的类型,是基类指针,调基类的Fun3
return 0;
}
/*
结果:
Derived Fun1...
Derived Fun2...
Base Fun3...
*/
overwrite:重定义
是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
- 如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无
virtual关键字,基类的函数将被隐藏。 - 如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有
virtual关键字。此时,基类的函数被隐藏(注意别与覆盖混淆) - 重定义分两种:
- 对基类数据成员的重定义:不改变基类的数据成员,改变派生类的数据成员。
- 对基类成员函数的重定义
- 派生类的成员函数与基类完全相同;基类中的函数被隐藏
- 派生类的成员函数与语言基类成员函数名相同但参数不同;使用派生类的函数,如果要方位基类方法使用
<class_name>.Base::<function>或者<class_name>.Base::<成员变量名>;
特殊用途语言实参
c++中存在特殊用途的语言实参:
默认实参
函数可以使用默认初始值,这点称为默认实参例如:string function1(int hz=24,int wid=80,char backgrnd='n');
注意:
- 默认实参最好放在头文件中
- 已经给予初始值的默认实参不得再定义初始值,只能给未定义的给予初始值;重复声明会发生错误。
内联函数和constexpr函数
内联函数说明只是向编译器发出的一个请求,编译器可以选择忽略这个请求,在编译时将其替换。可以多次定义
constexpr函数用于指示常量表达式。
帮助调试
c++中有许多帮助调试的信息;其中包括assert预处理宏;在<assert>头文件中定义。assert(expr)中判断表达式为假时,函数终止。
同时还存在NDEBUG预处理变量;使用静态预处理变量,说明当前文件信息。
ANSI标准中预定义宏名:
| 关键字 | 作用 |
|---|---|
__FILE__ |
存放文件名字的字符串字面值 |
__LINE__ |
存放当前行号整形字面值 |
__TIME__ |
存放编译时间字符串字面值 |
__DATE__ |
存放编译日期字符串字面值 |
__STDC__ |
编译器,区分C还是C++(cplusplus) |
例如:
#include <iostream>
using namespace std;
int main(void)
{
std::cout<<"function name"<<__func__<<"\n";
std::cout<<"file name "<<__FILE__<<"\n";
std::cout<<"line "<<__LINE__<<"\n";
std::cout<<"time"<<__TIME__<<"\n";
return 0;
}
输出:
- function namemain
- file name test.cpp
- line 8
- time20:39:05
函数指针
指针的实质是指向内存的地址的一个变量,函数存在于堆栈中,因此指针也可以指向函数,成为函数指针。例如:
//定义函数function2
bool function2(const string &,const string &);
//定义指针指定输入参数的指针
bool *pf(const string &,const string &);
pf=function2;//将指针pf指向lengthCompare的函数
auto b1=pf("hello","goodbye");//调用函数
auto b2=(*pf)("hello","goodbye");//一个等价的调用
//使用指针函数,方便我们在某些状况下使用指定的重载函数,避免产生隐式转换的错误
void ff(int* )//重载函数1
void ff(unsigned int)//重载函数2
//定义函数指针,并初始化
void (*pf1)(unsigned int )=ff;
我们也可以使用函数指针,作为函数返回值,指向一个函数;只要返回类型写成指针形式。使用类型别名可以声明一个返回函数指针的函数。
using F=int(int*,int);//F是函数类型,不是指针
using PF=int(*)(int *,int);//PF是指针类型
PF f1(int);//正确:PF是指向函数的指针,f1返回指向函数的指针
F f1(int); //错误:F是函数类型,f1不能返回一个函数
F *f1(int);//正确:显式地指定返回类型是指向函数的指针
类
定义抽象数据
c++中类的实质就是数据的抽象实现和封装。抽象数据依赖于接口和实现,分离的编程技术;定义在函数内部的函数是隐式的inline函数
类中的this关键字
参考链接: C++类中this指针的理解; C++ this 指针;关于this指针;
首先声明this指针是c++为了方便管理类中的函数而产生的,每个对象的this指针都指向对象本身,可以使用对象的非静态方法。this指针是编译器给予的每个成员函数的隐含参数,用来指向调用对象。
注意:
- 友元函数没有 this 指针,因为友元不是类的成员。只有成员函数才有 this 指针。
- this指针其本身的内容是不能被改变的,其类型为:类类型 * const
- this指针不是对象本身的一部分,不影响该对象的大小
- this指针的作用域在类的 非静态成员函数的内部,只能在其内部进行使用,其他任何函数都不能,静态成员函数内部无this指针,后面会详述。
- this指针是类中非静态成员函数的第一个默认隐含参数,编译器自动传递和维护,用户不可显示传递
- this指针可以为空但是类内部的成员变量数据不能为空,因此当调用使用成员变量时,请确保成员变量不为空。
函数调用约定如下:
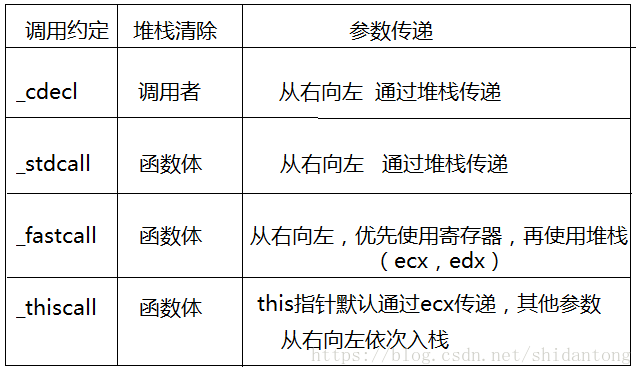
_thiscall关键调用:
- 它只能用在类的成员函数上
- 参数从右向左进行压栈
- 若参数个数确定,this指针通过ecx寄存器传递给被调用者;若参数不确定,this指针在所有参数被压栈后压入堆栈
- 对于参数不确定的函数,调用者清理堆栈,否则函数自己清理堆栈。
构造函数
- 构造函数主要有三种类型:默认构造函数、重载构造函数和拷贝构造函数
- 默认构造函数是当类没有实现自己的构造函数时,编译器默认提供的一个构造函数。
- 重载构造函数也称为一般构造函数,一个类可以有多个重载构造函数,但是需要参数类型或个数不相同。可以在重载构造函数中自定义类的初始化方式。
- 拷贝构造函数是在发生对象复制的时候调用的。
构造函数主要是c++中对于类对象的实例化的函数,这里需要强调一下c++中new A、new A()与new A[]的区别;
参考链接: C++中new 一个对象的时候加括号和不加括号的区别;C++ new A 和 new A() 的区别详解以及引申的各种初始化类型;
先说结论:
- 加括号调用没有参数的构造函数,不加括号调用默认构造函数或唯一的构造函数,看需求。
- C++在new时的初始化的规律可能为:对于有构造函数的类,不论有没有括号,都用构造函数进行初始化;如果没有构造函数,则不加括号的new只分配内存空间,不进行内存的初始化,而加了括号的new会在分配内存的同时初始化为0。
POD(Plain old data):它是一个struct或者类,且不包含构造函数、析构函数以及虚函数。POD class没有用户定义的析构函数、拷贝构造函数和非静态的非POD类型的数据成员。而且,POD class必须是一个aggregate,没有用户定义的构造函数,没有私有的或者保护的非静态数据,没有基类或虚函数。它只是一些字段值的集合,没有使用任何封装以及多态特性。
对于[new] T [object] {};初始化一般有三种处理方式:
- 如果T有用户定义的缺省构造函数,直接调用;
- 如果T有编译器生成的缺省构造函数,先0值初始化再调用;
- 如果T根本不是类,直接0值初始化。
对于[new] T object;如果T是非class类型,则给出非确定值(不赋值),比如:int i; double d; bool b;;
0值初始化也单独作用于静态(或者线程局部)变量:static T object;
五种初始化类型:
- list initialization (since C++11)
- aggregate initialization 这是list initialization对aggregate类型的特例
- value initialization 值初始化
- default initialization 缺省初始化
- zero initialization 0值初始化
示例代码:
#include <iostream>
using namespace std;
class A { public:int m; }; // POD
class B { public:~B() {}; int m; }; // non-POD, compiler generated default ctor
class C { public:C() :m() {}; ~C() {}; int m; }; // non-POD, list-initialising m
class D { public:D() {}; ~D() {}; int m; }; // non-POD,default-initialising m
int main()
{
A *aObj1 = new A;
A *aObj2 = new A();
cout << aObj1->m << endl; // -842150451
cout << aObj2->m << endl; // 0
B *bObj1 = new B;
B *bObj2 = new B();
cout << bObj1->m << endl;
cout << bObj2->m << endl;
C *cObj1 = new C;
C *cObj2 = new C();
cout << cObj1->m << endl;
cout << cObj2->m << endl;
D *dObj1 = new D;
D *dObj2 = new D();
cout << dObj1->m << endl;
cout << dObj2->m << endl;
delete aObj1;
delete aObj2;
delete bObj1;
delete bObj2;
delete cObj1;
delete cObj2;
getchar();
return 0;
}
/*result -842150451 0 -842150451 0 0 0 -842150451 -842150451 */
注意不同编译器可能产生不同的结果,GCC中结果:
/* 0 0 38158368 0 0 0 38158400 0 */
结论(以GCC为准): /* new A:0 new A():0 new B:不确定的值 new B():0 new C:0 new C():0 new D:不确定的值 new D():0 */
注意:
- 只有当类没有声明任何构造函数时,编译器才会自动地生成默认构造函数。
- 可以在构造函数之后添加
=default来要求编译器生成默认构造函数。
访问控制与封装
访问说明符public、private、protect来加强类的封装性。注意struct关键字中定义第一个访问说明符之前的成员是public,如果使用class关键字,成员是private的。因此当希望所有的类成员是public时使用struct;希望是private时使用class。
友元(friend):类允许其他类或者函数访问它的非公有成员,将函数成为友元只需要增加一条friend关键字就可以了。注意友元函数,必须在友元声明之外再专门对函数进行一次声明。
定义类型的成员必须先定义后使用例如:
class Screen
{
public:
//使用类型别名等价地声明一个类型名字
typedef std::string::size_type pos;
Screen();
~Screen();
private:
pos cursor=0;
pos height=0,width=0;
std::string contents;
};
类的友元使用示例如下
//screen.cpp
class Screen
{
public:
//使用类型别名等价地声明一个类型名字
typedef std::string::size_type pos;
Screen();
~Screen();
//定义友元
//Windows类可以访问Screen类的私有部分
friend class Windows;
//成员函数作为友元
friend void Windows::clear(ScreenIndex);
private:
pos cursor=0;
pos height=0,width=0;
std::string contents;
}
//windows.cpp
class Windows
{
public:
//窗口中每个屏幕的编号
using ScreenIndex=std::vector<Screen>::size_type;
//按照编号将指定的Screen重置为空白
private:
std::vector<Screen> screen{screen(24,80,'')};
public:
void clear(ScreenIndex i)
{
//s是一个Screen的引用,指向我们想清空的那个平米
Screen &s=screen[i];
//将那个选定的Screen重置为空白
s.contents=string(s.height*s.width,'');
}
}
注意:
- 友元的函数未声明直接出现时,我们隐式的假定该名字在当前作用域中是可见的,要想正常使用,该函数必须先被定义过。
mutable关键字: 类成员变量使用mutable关键字即便是const对象也能更改类的成员变量。
类的成员函数后添加const关键字,表示不会修改类中的成员变量;并且有一下几点规则:
- 在类中被const声明的成员函数只能访问const成员函数,而非const函数可以访问任意的成员函数,包括const成员函数
- 在类中被const声明的成员函数不可以修改对象的数据,不管对象是否具有const性质,它在编译时,以是否修改成员数据为依据,进行检查。
- 加上mutable修饰符的数据成员,对于任何情况下通过任何手段都可修改,自然此时的const成员函数是可以修改它的
向前声明: 仅仅声明类而不去定义它。对于类而言,当类的名字出现过后,它就被认为是声明过了(但是尚未定义),因此类允许包含指向它自身类型的引用或者指针。例如:
class Link_screen
{
Screen windows;
Link_screen *next;
Link_screen *prev;
}
类中普通块作用域的名字查找
- 首先,成员函数内查找该名字的声明,只有在函数使用之前出现的声明才被考虑。
- 如果在成员函数内没有找到,则在类内继续查找,这时类的所有成员都可以被考虑
- 如果类内也没有找到该名字的声明,在成员函数定义之前的作用域内继续查找。
- 类作用域之后,在外围的作用域中查找;如果编译器在函数和类的作用域中都没有找到名字,它将接着在外围的作用域中查找
构造函数再探
如果成员是是const、引用,或者属于某种未提供默认构造函数的类类型,我们必须通过构造函数初始值列表为这些成员提供初值。最好令构造函数初始值的顺序与成员声明的顺序保持一致;而且如果有可能的话,尽量避免使用某些成员变量初始化其他成员。
注意:成员的初始化顺序与他们在类中定义的出现顺序一致;第一个成员先被初始化,然后第二个
class X
{
int i;
int j;
public:
X(int val):j(val),i(j){}
//错误:i在j之前被初始化,因此初始化i之前发生错误,j未定义。
}
委托构造函数
C++中可以使用委托构造函数,即预定义一个基础的构造函数其它的构造函数可以调用这个构造函数。
隐式的类类型转换与转换避免。
c++语言之间存在隐式的转换规则;构造函数实际上也定义了转换为此类类型的隐式转换机制。我们将这种构造函数称之为 转换构造函数;隐式转换,相当于构造了一个临时的变量对象。再给类一个临时成员变量。但是这种转换只允许一步类型转换,并且类型转换并不是总有效。
为了防止这种状况的发生,我们在单参数构造函数前面添加explicit关键字使得构造函数只能直接初始化。但是使用static_cast强制类型转化可以使用带有explicit关键字的构造函数。
聚合类
聚合类中可以使得用户直接访问其成员,并且具有特殊的初始化语法形式。聚合类的特征:
- 所有成员都是public的
- 没有定义任何构造函数
- 没有类内初始值
- 没有基类,也没有
virtual函数
例如:
struct Data
{
int ival;
string a;
};
//这就是一个聚合类
注意:显示地初始化类的对象的成员存在三个明显的缺点
- 要求类的所有成员都是
public的。 - 将正确初始化每个对象的每个成员的重任交给了类的用户。因为用户很容易忘掉某个初始值,或者提供一个不恰当的初始值,所以这样的初始化过程冗长乏味且容易出错。
- 添加或者删除一个成员之后,所有的初始化语句都需要重新更新。
字面常量类
要求:
- 数据成员都必须是字面类型值
- 类必须至少含有一个
constexpr构造函数 - 如果一个数据成员含有类内初始值,则内置类型成员的初始值必须是一条常量表达式;如果成员属于某种类型,则初始值必须使用成员自己的
constexpr构造函数。 - 类必须使用析构函数的默认定义,该成员负责销毁类的对象。
constexpr构造函数
首先需要明确构造函数不能是const的,因为const修饰函数表示该函数的返回值是const类型的,改返回值只能赋值给同类型的const变量,不符合类的构造函数的需求。const是可以修饰类的成员函数,但是该函数不能修改数据成员。构造函数也属于类的成员函数,但是构造函数是要修改类的成员变量,所以类的构造函数不能申明成const类型的。
但是字面常量类的构造函数时可以constexpr的函数,实际上一个字面值常量类必须至少提供一个constexpr构造函数。并且该构造函数一般是空的。因为它必须符合构造函数的要求–不能存在返回值;又符合constexpr函数要求–能拥有的唯一可执行语句就是返回语句。示例如下;
class Debug {
private:
/* data */
public:
constexpr Debug(bool b=true):hw(b),io(b),other(b){};
constexpr Debug(bool h,bool i,bool o):hw(h),io(i),other(o){};
constexpr bool any(){return hw || io || other;}
//.....
};
类的静态成员
c++中的内存分配
参考链接: C/C++程序内存的分配;【C++】动态内存分配详解(new/new[]和delete/delete[]);
首先c/c++中内存分为以下几种类型
- 栈(stack):由编译器自动分配与释放,存放为运行时函数分配的局部变量、函数参数、返回数据、返回地址等。其操作类似于数据结构中的栈。
- 堆区(heap):一般由程序员自动分配,如果程序员没有释放,程序结束时可能有OS回收。其分配类似于链表。
- 全局区(静态区static):存放全局变量、静态数据、常量。程序结束后由系统释放。全局区分为已初始化全局区(data)和未初始化全局区(bss)。
- 常量区(文字常量区):存放常量字符串,程序结束后有系统释放。
- 代码区:存放函数体(类成员函数和全局区)的二进制代码。
内存分成5个区,他们分别是堆、栈、全局/静态存储区和常量存储区和代码区。
- 栈,在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
- 堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
- 全局/静态存储区,内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。它主要存放静态数据(局部static变量,全局static变量)、全局变量和常量。
- 常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量字符串,不允许修改。
- 代码区,存放程序的二进制代码
关于这个有很多种说法,有的会增加一个自由存储区,存放malloc分配得到的内存,与堆相似。
具体的内存分配如下:
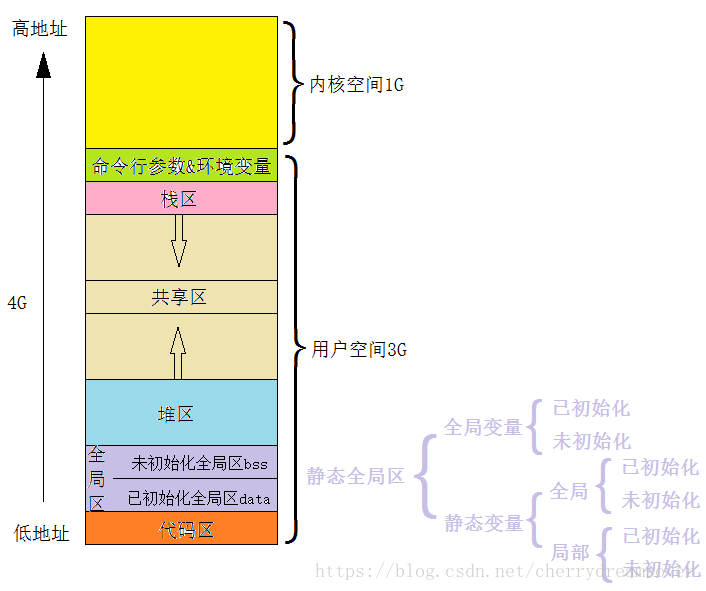
注意:栈的地址由高到低,堆的地址由低到高。
内存分配的方式
- 从静态存储区分配:内存在程序编译的时候已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
- 在栈上创建:在执行函数时,函数内局部变量的存储单元可以在栈上创建,函数执行结束时,这些内存单元会自动被释放。栈内存分配运算内置于处理器的指令集,效率高,但是分配的内存容量有限。
- 从堆上分配: 亦称为动态内存分配。
- 程序在运行的时候使用malloc或者new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。
- 动态内存的生命周期有程序员决定,使用非常灵活,但如果在堆上分配了空间,既有责任回收它,否则运行的程序会出现内存泄漏,频繁的分配和释放不同大小的堆空间将会产生内存碎片。
- 在 C 语言中,全局变量又分为初始化的和未初始化的(未被初始化的对象存储区可以通过 void* 来访问和操纵,程序结束后由系统自行释放),在 C++ 里面没有这个区分了,他们共同占用同一块内存区。
堆和栈的区别
- 管理方式不同:栈是由编译器自动申请和释放空间,堆是需要程序员手动申请和释放;
- 空间大小不同:栈的空间是有限的,在32位平台下,VC6下默认为1M,堆最大可以到4G;
- 能否产生碎片:栈和数据结构中的栈原理相同,在弹出一个元素之前,上一个已经弹出了,不会产生碎片,如果不停地调用malloc、free对造成内存碎片很多;
- 生长方向不同:堆生长方向是向上的,也就是向着内存地址增加的方向,栈刚好相反,向着内存减小的方向生长。
- 分配方式不同:堆都是动态分配的,没有静态分配的堆。栈有静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 malloc 函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,无需我们手工实现。
- 分配效率不同: 栈的效率比堆高很多。栈是机器系统提供的数据结构,计算机在底层提供栈的支持,分配专门的寄存器来存放栈的地址,压栈出栈都有相应的指令,因此比较快。堆是由库函数提供的,机制很复杂,库函数会按照一定的算法进行搜索内存,因此比较慢。
静态全局变量、全局变量区别
- 静态全局变量和全局变量都属于常量区
- 静态全局区只在本文件中有效,别的文件想调用该变量,是调不了的,而全局变量在别的文件中可以调用。
- 如果别的文件中定义了一个该全局变量相同的变量名,是会出错的。
静态局部变量、局部变量的区别
- 静态局部变量是属于常量区的,而函数内部的局部变量属于栈区
- 静态局部变量在该函数调用结束时,不会销毁,而是随整个程序结束而结束,但是别的函数调用不了该变量,局部变量随该函数的结束而结束;
- 如果定义这两个变量的时候没有初始值时,静态局部变量会自动定义为0,而局部变量就是一个随机值
- 静态局部变量在编译期间只赋值一次,以后每次函数调用时,不在赋值,调用上次的函数调用结束时的值。局部变量在调用期间,每调用一次,赋一次值。
通过以上基础知识我们知道c++的静态成员都是直接在静态全局区域分配内存。因此在编译时就已经内存就已经开始分配成功了,因此不需要实例化类并且解引用,可以直接使用。
第II部分 C++ 标准库
第8章 IO库
C++中没有直接的输入和输出库,而是使用标准库的IO库来进行IO操作,下面让我们进入IO的世界吧
8.1 IO类
IO基本类和头文件如下表:
IO库的类型和对应头文件
| 头文件 | 类型 |
|---|---|
iostream |
istream,wistream 从流读取数据;ostream,wostream 从流输出数据;iostream,wiostream读写流 |
fstream |
ifstream,wifstream 从文件读取数据;ofstream,wofstream 从文件写入数据;fstream,wfstream 读写文件; |
sstream |
istringstream,wistringstream从string读取数据;ostringstream,wostringstream向string写入数据;stringstream,wstringstream 读写string |
注意:
- IO对象无拷贝或者赋值–通过重载拷贝构造函数和赋值操作,禁止拷贝和赋值;或者将拷贝构造函数与赋值函数,声明为private,并且不给出实现
- 在函数后面使用
=delete;例如:NoCopyable(const NoCopyable&) = delete;;其中 delete表明函数已删除。使用会报错:”尝试使用已删除的函数”;(参考:C++禁止对象拷贝)
c++中的浅拷贝和深拷贝
参考链接: C++本质:类的赋值运算符=的重载,以及深拷贝和浅拷贝;C++的拷贝构造函数、operator=运算符重载,深拷贝和浅拷贝、explicit关键字;
c++默认的拷贝构造函数和赋值运算符都是简单的浅拷贝,直接使用其它变量初始化对象,并没有重新分配内存,但是如果实行浅拷贝,也就是把对象里的值完全复制给另一个对象,如A=B。这时,如果B中有一个成员变量指针已经申请了内存,那A中的那个成员变量也指向同一块内存。这就出现了问题:当B把内存释放了(如:析构),这时A内的指针就是野指针了,出现运行错误。因此类的成员变量需要动态开辟堆内存,此时,深拷贝尤为重要。默认类的缺省函数都是浅拷贝函数。简单示例如下:
//原始浅拷贝
#include <iostream>
using namespace std;
class Data {
public:
Data() {}
Data(int _data) :data(_data)
{
cout << "constructor" << endl;
}
//简单赋值浅拷贝
Data& operator = (const int _data)
{
cout << "operator = (const int _data)" << endl;
data = _data;
return *this;
}
private:
int data;
};
int main()
{
Data data1(1);
Data data2, data3;
data2 = 1;
data3 = data2;//调用编译器提供的默认的赋值运算符重载函数,当自定义析构函数的时候会存在问题
return 0;
}
//深拷贝
#include <iostream>
#include <string>
using namespace std;
class MyStr {
public:
MyStr() {}
MyStr(int _id, char *_name)
{
cout << "constructor" << endl;
id = _id;
name = new char[strlen(_name) + 1];
strcpy_s(name,strlen(_name) + 1,_name);
}
//深拷贝构造函数
MyStr(const MyStr &str)
{
cout << "copy constructor" << endl;
id = str.id;
if (name != NULL)
delete name;
name = new char[strlen(str.name) + 1];
//拷贝数据
strcpy_s(name,strlen(str.name) + 1,str.name);
}
MyStr& operator=(const MyStr& str)
{
cout << "operator=" << endl;
if (this != &str)
{
if (name != NULL)
delete name;
this->id = str.id;
name = new char[strlen(str.name) + 1];
//拷贝字符长度
strcpy_s(name,strlen(str.name) + 1,str.name);
return *this;
}
}
~MyStr()
{
cout << "deconstructor" << endl;
delete name;
}
private:
char *name;
int id;
};
void main()
{
MyStr str1(1,"Jack");
MyStr str2;
str2 = str1;
MyStr str3 = str2;
return;
}
IO库条件状态:
| 状态 | 含义 |
|---|---|
strm::iostate |
strm是一种IO类型。iostream是一种机器相关的整型提供了表达条件状态的完整功能 |
strm::badbit |
strm::badbit用来指出流已崩溃 |
strm::failbit |
strm::failbit用来指出一个IO操作失败了 |
strm::eofbit |
strm::eofbit用来指出流达到了文件结束 |
strm::goodbit |
strm::goodbit用来指出流未处于错误状态。此值保证为零 |
s.eof() |
流 s 的 eofbit 置位,则返回 true |
s.fail() |
流 s 的 failbit 或 badbit 置位,则返回 true |
s.bad() |
流 s 的 badbit 置位,则返回 true |
s.good() |
若流 s 处于有效状态,则返回 true |
s.clear() |
将流 s 中的所有条件状态位复位,将流的状态设置为有效。返回void |
s.clear(flag) |
根据给定的 flags 标志位,将流 s 中对于条件状态位复位。 flag 的类型是strm::iostate。返回 void |
s.setstate(flag) |
根据给定的 flags 标志位,将流 s 中对于条件状态位置位。 flag 的类型是strm::iostate。返回 void |
s.rdstate() |
返回流 s 的当前条件,返回值类型为 strm::iostate |
四种条件状态
| 状态 | 含义 | 数值 | good() |
eof() |
bad() |
fail() |
rdstate() |
|---|---|---|---|---|---|---|---|
ios::goodbit |
流状态完全正常 | 0 | 1 | 0 | 0 | 0 | goodbit |
ios::eofbit |
已达到文件结束 | 2 | 0 | 1 | 0 | 0 | eofbit |
ios::badbit |
输入(输出)流出现非致命错误,可挽回 | 1 | 0 | 0 | 1 | 0 | badbit |
ios::failbit |
输入(输出)流出现致命错误,不可挽回 | 4 | 0 | 0 | 0 | 1 | failbit |
文件结束
| 状态 | 解释 |
|---|---|
strm::eofbit |
strm::eofbit用来指出流达到了文件结束 |
s.eof() |
流 s 的 eofbit 置位,则返回 true |
注意:
- 一个流一旦发生错误,其上后续的IO操作都会失败。因此一般使用
while(cin>>word)来检测是否成功。
iostate 类型用来表示流状态的完整功能。使用示例如下:
auto old_state=cin.restate(); //记住cin的状态
cin.clear();//使得cin有效
process_input(cin); //使用cin
cin.setstate(old_state);//设置cin为原有状态。
cin.clear(cin.rdstate() & ~cin.failbit & ~cin.badbit);//复位failbit和badbit,保持其他标志位不变。
管理输出缓冲
每个输出流都管理一个缓冲区,用来保存程序读写的数据;例如os<<"Please enter a value:";中文本串可能被立即打印出来,但也有可能被操作系统保存在缓冲区中,随后打印。
注意:如果程序异常崩溃,输出缓冲区不会更新,数据很可能停留在缓冲区中等待打印。因此当程序崩溃后,需要确定已经输出的数据确实已经刷新了,否则可能将大量时间浪费在追踪代码为什么没有执行上面。
输入和输出流也是可以正常关联的:利用ostream的tie实现相关操作。tie()当前关联到的输出流,tie(&o)关联到o输出流。多个流可以关联到同一个ostream;下面是使用示例:
cin.tie(&cout); //将标准cin与cout关联在一起。
ostream *old_tie=cin,tie(nullptr);//关联空流
cin.tie(&cerr); //读取cin会刷新cerr而不是cout
cin.tie(old_tie); //重建cin和cout间的正常关联。
文件操作
参考链接:
C++文件处理与C语言不同,C++文件处理使用的是:流(stream)
C++头文件 fstream 定义了三个类型来支持文件IO👇
- ifstream 从一个给定文件读数据
- ofstream 向一个给定文件写数据
- fstream 可以读写文件
这和 cin 和 cout 操作一样。可以用IO运算符(»和«)来读写文件,也可用getline从一个ifstream中读取数据。
fstream特有操作:
| 名称 | 操作 |
|---|---|
fstream fstrm |
创建一个未绑定的文件流 |
fstream fstrm(s) |
创建一个fstream,并打开名为s的文件。默认的文件模式mode依赖于fstream的类型 |
fstream fstrm(s,mode) |
与前一个构造函数类似,但按指定mode打开文件 |
fstrm.open(s) |
打开名为s的文件,并将文件与fstrm绑定,默认的文件mode依赖于fstream的类型,返回void |
fstrm.close() |
关闭与fstrm绑定的文件,返回void |
fstrm.is_open() |
返回一个bool值,指出与fstrm关联的文件是否成功打开且尚未关闭 |
文件的打开有两种方式:
- 在初始化输入输出对象时,直接构建;如:
ifstream in(ifile) - 先声明,再使用
open函数关联文件;例如:
| 标识符 | 描述 |
|---|---|
| ios::in | in |
| ios::out | out |
| ios::app | append |
| ios::ate | 打开文件用于输出,如果文件已经存在,移动到文件末尾,数据可写入到文件任何位置 |
| ios::trunc | 如果文件已存在,丢弃文件内容,ios::out的默认方式 |
| ios::binary | 二进制输入输出 |
| ios::in | ios::out | 以输出和输入方式打开文件 |
| ios::in | ios::binary | 以输入方式打开一个二进制文件 |
| ios::out | ios::binary | 以输出方式打开一个二进制文件 |
#include<fstream>
#include<iomanip>
std::string ifile="c:/Windows/assembly/test";
// 文件模式
inout.open("city.txt", ios::out | ios::app);
// ------- 读文件 ---------
ifstream in(ifile); //构筑一个ifstream并打开给定文件
// in.open(ifile);
if(input.fail()){
/* 检测文件是否存在 */
cout << "文件不存在! " << ifile << endl;
}
// eof() 函数通过操作系统得知是否已经到达文件末尾
while(! input.eof()){
/* 文件读取 */
}
in >> s1;
in >> s2;
in >> s3;
in.close(); //关闭文件
// ------- 写文件 -----------
// 类ofstream操作一个已经存在的文件后,原有内容将被清除。
ofstream out; //输出文件流未与任何文件相关联。
out.open(ifile + ".txt"); //打开指定文件
out << "写入文件的字符串" << std::endl;
// iomanip 格式化输出流
out << setw(6) << "Jhon" << setw(2) << "T" << setw(6) << "Smith" << " " << setw(4) << 85;
out.close();
注意:
- 当一个
fstream对象呗销毁时,close会自动被调用。 - 默认模式打开文件进行输出将自动打开文件的长度截为零,即 删除已有内容。 (细节!!)
文件读写模式:
| 模式 | 作用 |
|---|---|
in |
读方式打开 |
out |
写方式打开 |
app |
每次写操作前均定位到文件末尾 |
ate |
打开文件后立即定位到文件末尾 |
trunc |
截断文件 |
binary |
二进制方式进行io |
注意:以out模式打开文件会丢弃已有数据,因此常需要附加app模式;例如:
ofstream out("file1");// 输出模式打开文件并截断文件
ofstream out2("file1", ofstream::out);//隐含第截断文件
ofstream out3("file1", ofstream::out | ofstream::trunc);
//保留文件内容显式指定app模式。
ofstream app("file2", ofstream::app);
//隐含为输出模式
ofstream app2("file2", ofstream::out | ofstream::app);
每次使用open函数都可以再次更改文件模式。
文件流使用示例:
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
int main()
{
// ----- 读文件,并输出显示 ------
string path = "guest.txt";
ifstream in_file;
in_file.open(path);
// 或一步到位
// ifstream in_file(path, ios::in); //按照指定mode打开文件
char ch;
if (in_file.is_open()) // 或 if ( in_file )
{
cout << "文件读取成功" <<endl;
while (in_file.get(ch))
cout << ch;
// 或一次读一行
string line;
while(getline(in_file, line)) {
cout << line << endl;
}
cout << endl;
in_file.close();
}else { // 文件读取失败!
cout << "文件读取失败 " << path << endl;
getchar();
return EXIT_FAILURE;
}
// ----- 写文件 ------
string path_out = "./log.txt";
ofstream out;
out.open(path_out, ofstream::app);
//out.open("people.txt", ios_base::app);
// 或者一步到位
// ofstream out_file(path_out, ios::out | ios::app); //按照指定mode打开文件
if (!out.is_open())
{
cout << "failed to open file" << endl;
}
cout << "Please enter content:";
string str;
while (getline(cin, str) && str.size() > 0)
{
out << "\n"<<str << endl;
}
out.close();
//读取修改后的文件内容,并输出显示
in.open("guest.txt");
if (in.is_open())
{
cout << "Here are the revised contents of the people.text's file:" << endl;
while (in.get(ch))
cout << ch;
cout << endl;
in.close();
}
return 0;
}
string 流
string相关流继承关系如下图:

stringstream的特有操作
| 操作 | 含义 |
|---|---|
sstream strm |
定义字符串头文件类型 |
sstream strm(s) |
保存string s的一个拷贝 |
strm.str() |
返回strm所保存的string的拷贝 |
strm.str(s) |
将string s 拷贝到strm中。返回void |
第 9 章顺序容器
容器是一些特定类型对象的集合。顺序容器为程序员提供了控制元素存储和访问顺序的能力。下面是简介表
| 类型 | 特点 |
|---|---|
vector |
可变大小数组。支持快速随机访问。在尾部之外的位置插入或者删除元素 |
deque |
双端队列。支持快速随机访问。在头尾插入/删除速度很快 |
list |
双向链表。只支持双向顺序访问。在list中任何位置进行插入/删除操作速度都很快 |
forward_list |
单向链表。只支持单向顺序访问。在链表任何位置进行插入/删除操作速度都很快 |
array |
固定大小数组。支持快速随机访问。不能添加或者删除元素 |
string |
与vector相似的容器,但是专门保存字符。随机访问快。在尾部插入/删除速度很快 |
下面是一些选择容器的基本原则:
- 除非有很好的理由,否则应使用
vector - 如果你的程序有很多小元素,且额外开销很重要,则不要使用
list或者forward_list。 - 如果程序要求随机访问元素,应该使用
vector或者deque。 - 如果程序要求在容器的中间插入或者删除元素,应该使用
list或者forward_list。 - 如果程序需要在头尾位置插入或者删除元素,但不会在中间位置进行插入,则使用
deque。 - 如果程序只有在读取输入时才需要在容器中间位置插入元素,随后需要随机访问元素,则:
- 首先,确定是否真的需要在容器中间位置添加元素,当处理输入数据时,通常可以很容易地向
vector追加数据,然后再调用标准库sort函数来重新排列容器中的元素,从而避免在中间位置添加元素。 - 如果必须在中间位置插入元素,考虑在输入阶段使用
list,一旦输入完成,将list中的内容拷贝到一个vector中。
- 首先,确定是否真的需要在容器中间位置添加元素,当处理输入数据时,通常可以很容易地向
容器操作:
| 类型别名 | 操作 |
|---|---|
iterator |
此容器类型的迭代器类型 |
const_iterator |
可以读取元素,但不能修改元素的迭代器类型 |
size_type |
无符号整数类型,足够保存此种容器类型最大可能容器的大小 |
difference_type |
带符号整数类型,足够保存两个迭代器之间的距离 |
value_type |
元素类型 |
reference |
元素的左值类型;与value_type&含义相同 |
const_reference |
元素的const左值类型(即,const value_type&) |
| 构造函数 | 操作 |
|---|---|
C c |
默认构造函数,构造空容器(array) |
C c1(c2) |
构造c2的拷贝c1 |
C c(b,e) |
构造c,将迭代器b和e指定的范围内的元素拷贝到c |
C c{a,b,c ...} |
列表初始化c |
赋值与swap |
操作 |
|---|---|
c1=c2 |
将c1中的元素替换为c2中元素 |
c1={a,b,c...} |
将c1中的元素替换为列表中元素(不适用于array) |
a.swap(b) or swap(a,b) |
交换a和b的元素 |
| 大小 | 操作 |
|---|---|
c.size() |
c中元素的数目(不支持forward_list) |
c.max_size() |
c可保存的最大元素数目 |
c.empty() |
若c中存储了元素,返回fasle,否则返回true |
| 添加/删除元素 | 操作 |
c.insert(args) |
将args中的元素拷贝进c |
c.emplace(inits) |
适用inits构造c中的一个元素 |
c.clear() |
删除c中所有的元素,返回void |
| 关系运算符 | 解释 |
|---|---|
==,!= |
所有容器都支持相等(不等)运算符 |
<,<=,>,>= |
关系运算符(无序关联容器不支持) |
| 获取迭代器 | 解释 |
|---|---|
c.begin(),c.end() |
返回指向c的首元素和尾元素之后位置的迭代器 |
c.cbegin(),c.cend() |
返回const_iterator |
反向容器的额外成员(不支持forward_list) |
解释 |
|---|---|
reverse_iterator |
按逆序寻址 |
const_reverse_iterator |
不能修改元素的逆序迭代器 |
c.rbegin(),c.rend() |
返回指向cz的尾元素和首元素之前位置的迭代器 |
c.crbegin(),c.crend() |
返回const_reverse_iterator |
迭代器
迭代器范围是标准库的基础,标砖库的很多操作都是基于迭代器产生的。begin迭代器迭代器指向迭代器开头的元素;last迭代器指向尾元素之后的元素;即不是指向尾部元素,元素范围为左闭右开
代码示例:
list<string> a={"string1","string2","string3"};
auto it1=a.begin(); //lsit<string>::iterator;
auto it2=a.rbegin(); //list<string>::reverse_iterator;
auto it3=a.cbegin(); //list<string>::const_iterator;
auto it4=a.crbegin(); //list<string>::const_reverse_iterator
注意:
- 顺序容器不需要写访问时,应该尽量使用
cbegin和cend; - 只有顺序容器不包括(array)的构造函数才能接受大小参数
- 拷贝构造只有当容器类型匹配时才能成立,
- 当将一个容器初始化为另外一个容器的拷贝的时候,两个容器的容器类型和元素类型都必须相同。
标准库array具有固定大小
与内置数组一样,标准库array的大小也是类型的一部分。当定义一个array时,除了指定元素类型,还要指定容器大小;使用array类型,也必须指定元素类型的大小;array初始化会自动给与0值。内置数组不允许拷贝,但是array类型允许拷贝。
array<int ,42>; //类型为:保存42个int的数组
array<string,10>; //类型为:保存10个 string的数组
array<int,10>::size_type i;//数组类型包括元素类型和大小
array<int>::size_type j; //错误:array<int>不是一个类型
替换操作 assign
| 函数 | 功能 |
|---|---|
seq.assign(b,e) |
将seq中的元素替换为迭代器b和e所示到范围中的元素。迭代器b和eb不能指向seq中的元素 |
seq.assign(li) |
将seq中的元素替换为初始化列表li中的元素 |
seq.assign(n,t) |
将seq中的元素替换为n个值为t的元素 |
使用:vector<int > b(10,5);vector<int> a;a.assgin(b.cbegin(),b.cend());
注意:赋值运算会导致指向左边容器内部的迭代器、引用和指针失效。而swap操作将容器内容交换不会导致容器的迭代器、引用和指针失效(容器类型为array和string的情况除外);例如,假定iter在swap之前指向svecl[3]中的string,那么在swap之后它指向svec2[3]的元素。但是array会真正交换他们的元素。因此交换两个array所需的时间与array中元素的数目成正比。
关系运算符
每个容器类型都支持相等运算符(==和!=)除了无序关联容器外,都支持关系运算符(>、>=、<、<=)。关系运算符两边必须是相同类型的容器,且必须保存相同类型的元素。元素相等比较规则如下:
- 如果两个容器具有相同大小且所有元素都两两对应相等,则这个容器相等,否则不相等。
- 如果两个容器大小不相同,但较小容器中每个元素都等于较大容器中的对应元素,则较小容器小于较大容器
- 如果两个容器都不是另外一个容器的前缀子序列,则他们的比较结果取决于第一个不相等的元素的比较结果。
- 只有当其元素类型也定义了相应的比较运算符的时候,我们才可以使用关系运算符来,比较两个容器。
向顺序容器中添加元素
| 操作名称 | 作用 |
|---|---|
c.push_bcak(t) |
在c的尾部创建并插入一个元素 |
c.push_back(t) |
在c的头部创建并插入一个元素 |
c.insert(p,t) |
在迭代器p指向的元素之前创建插入一个元素,返回指向新添加元素的迭代器 |
c.insert(p,n,t) |
在迭代器p指向的元素之前创建插入n个元素,返回指向新添加元素第一个元素的迭代器 |
c.insert(p,b,e) |
将迭代器b和e指定的范围内的元素插入到迭代器p指向的元素之前,返回指向新添加元素第一个元素的迭代器;若p为空则返回p |
c.insert(p,il) |
il是一个花括号包围的元素值列表。将这些给定值插入到迭代器p指向的元素之前,返回指向新添加的第一个元素的迭代器 |
注意:
- 向一个
vector、string或者deque插入元素会使所有指向容器的迭代器、引用和指针失效。 - 容器元素插入和初始化都是拷贝
- 使用插入
insert的时候会返回插入的值
使用emplace操作
新标准中引入了三个新成员函数-emplace_front、emplace和emplace_back它们与insert系列操作相同,
注意:
emplace函数在容器中直接构造元素,传递给emplace函数的参数必须与元素类型的构造函数相匹配。
例如:
c.emplace_back("99999",25,15.99);//错误没有接受三个参数的`push_back`版本
c.push_back("99999",25,15.99);//正确创建一个临时的`push_back`版本
顺序容器中访问元素操作
| 操作 | 含义 |
|---|---|
c.back() |
返回c中尾元素的引用。若c空,函数行为未定义 |
c.front() |
返回c中首元素的引用。若c空,函数行为未定义 |
c[n] |
返回c中下标为n元素的引用。若c空,n>=c.size()函数行为未定义 |
c.at(n) |
返回c中下标为n元素的引用。若越界抛出异常 |
建议:尽量使用at函数,避免下标越界
顺序容器中删除元素操作
| 操作 | 含义 |
|---|---|
c.pop_back() |
删除c中尾部元素,若c空,函数行为未定义 |
c.pop_front() |
删除c中首元素的引用。若c空,函数行为未定义 |
c.erase(n) |
删除迭代器p所指的元素,返回一个指向被删除元素之后元素的迭代器 |
c.erase(b,e) |
删除迭代器b和e所指定范围内的元素。返回指向最后一个被删除元素之后元素的迭代器 |
c.clear() |
删除c中所有元素。返回void |
注意对于单链表而言有许多不同之处

当在forword_list中添加或者删除元素时,我们必须关注两个迭代器-一个指向我们要处理的元素,另外一个指向其前驱元素。例如:
forward_list<int> flst={0,1,2,3,4,5,6,7,8,9};
auto prev=flst.before_begin(); //表示flst的首前元素
auto curr=flst.begin(); //表示flst中的第一个元素
while(curr!=flst.end()) {
if(*curr%2){
curr=flst.erase_after(prev); //删除并移动curr
}else{
prev=curr;//移动迭代器curr,指向下一个元素,prev指向curr之前的元素
++curr;
}
}
容器操作可能会使迭代器失效
参考链接: C++迭代器失效的几种情况总结;C++之迭代器失效及解决;
在向容器中添加元素之后:
- 如果容器是
vector或者string,且存在存储空间被重新分配,则指向容器的迭代器、指针和引用内存都会失效。如果没有重新分配内存,指向插入位置之前的元素的迭代器、指针和引用仍然有效,但是指向插入之后的元素迭代器、指针和引用都会失效 - 对于
deque插入到除首尾位置之外的任何位置都会导致迭代器、指针和引用失效。如果在首尾位置添加元素,迭代器会失效,但是指向存在的元素的引用和指针不会失效。 - 对于
list和forward_list指向容器的迭代器(包括尾后迭代器和首前迭代器)、指针和引用仍有效。
在删除一个元素后
- 对于
list和forward_list指向容器其它位置的迭代器、引用指针任然有效。 - 对于
deque如果在首尾之外的任何位置删除元素,那么指向被删除元素之外其它元素的迭代器、引用或者指针也会失效。如果删除的是尾部元素,则尾后的迭代器也会失效,但其它迭代器、引用和指针不受影响;如果删除首尾元素,这些也不会受影响。 - 对于
vector和string,指向被删除元素之前元素的迭代器、引用和指针仍然有效。注意当我们删除元素时,尾后迭代器总是会失效。
因为添加删除原来的元素后,end迭代器总是会失效,因此尽量不要保存end返回的迭代器
vector和string 的容器大小管理操作
capacity()容器在不扩张内存空间的情况下可以容纳多少个元素,reserve允许我们通知容器它应该准备保存多少个元素
| 操作 | 含义 |
|---|---|
c.shrink_to_fit() |
将capacity()减小为和size相同大小 |
c.capacity() |
不重新分配内存空间的话,c可以保存多少元素 |
c.reserve(n) |
分配至少能容纳n个元素的内存空间 |
注意: reserve并不改变容器元素中的数量,它仅仅影响vector预先分配多大的内存空间。
额外的string操作
| 操作 | 含义 |
|---|---|
s.insert(pos,args) |
在迭代器pos之前插入args指定的字符 |
s.erase(pos,len) |
删除从位置pos开始的len个字符。如果len 被省略则删除从pos开始至s末尾的所有字符。返回一个指向s的引用 |
s.assign(args) |
将s中的字符串替换为args指定的字符。返回一个指向s的引用 |
s.append(args) |
将s后添加args指定的字符。返回一个指向s的引用 |
s.replace(range,args) |
删除range范围内的字符,替换为args指定的字符,返回s的引用 |
string搜索操作
| 操作 | 含义 |
|---|---|
s.find(args) |
查找s中第一次出现的位置 |
s.rfind(args) |
查找s中最后一次出现的位置 |
s.find_frist_of(args) |
在s中查找args中任何一个字符,第一次出现的位置 |
s.find_last_of(args) |
在s中查找args中任何一个字符,最后一次出现的位置 |
s.find_frist_not_of(args) |
在s中查找第一个不在args中的字符 |
s.find_last_not_of(args) |
在s中查找最后一个不在args中的字符 |
//循环查找下一个数
string::size_type pos=0;
while((pos=name.find_frist_of(number,pos))!=string::npos) {
cout<<"found number at index: "<<pos
<<"element is "<<name[pos]<<endl;
++pos;//移动到下一个字符
}
compare比较字符串;to_string()将数字转化为字符串。
string和数值之间的转换
| 操作 | 含义 |
|---|---|
to_string(val) |
将任意一种算术类型val转化为string |
stoi(s,p,b) |
返回s的起始字符子串(整数内容)的数值 int,b是转换基数,p是size_t指针 |
stol(s,p,b) |
返回s的起始字符子串(整数内容)的数值 long,b是转换基数,p是size_t指针 |
stoul(s,p,b) |
返回s的起始字符子串(整数内容)的数值 unsigned long,b是转换基数,p是size_t指针 |
stoll(s,p,b) |
返回s的起始字符子串(整数内容)的数值 long long,b是转换基数,p是size_t指针 |
stoull(s,p,b) |
返回s的起始字符子串(整数内容)的数值 unsigned long long,b是转换基数,p是size_t指针 |
stof(s,p) |
返回s的起始字符子串(整数内容)的数值 float,b是转换基数,p是size_t指针 |
stod(s,p) |
返回s的起始字符子串(整数内容)的数值 long long,b是转换基数,p是size_t指针 |
stold(s,p) |
返回s的起始字符子串(整数内容)的数值 long double,b是转换基数,p是size_t指针 |
容器适配
出来标准容器外还有三个顺序容器适配器: stack、queue和proiority_queue。本质上,一个适配器是一种机制,能使某种事物的行为看起来像另外一种事物一样。例如stack适配器接受一个顺序容器,并使其操作像一个stack一样。下面是使用示例:
stack<int> stk(deq);//从deq拷贝元素到stk
stack<string ,std::vector<string> > str_stk;//在vector上实现的空栈
stack<string ,vector<string > > str_stk2(svec);//str_stk2在vector上实现,初始化时保存svec的拷贝
泛型算法
泛型算法是指使用迭代器为媒介的通用型算法;泛型算法本身不会执行容器的操作,他们只会运行于迭代器智商,执行迭代器的操作–算法永远不会改变底层容器的大小。算法可能改变容器中保存的元素值。
accumulate 求和
int sum =accumulate(vec.cbegin(),vec.cend(),0);//对元素求和初值是0
string sum=accumulate(v.cbegin(),v.cend(),string(''));//字符串求和
equal(roster1.cbegin(),roster1.cend(),rosterl2.cbegin());//比较元素,数量相同且一样多的时候才返回`true`
fill(vec.begin(),vec.begin()+vec.size()/2,10);//将容器的一个子序列设置为10
back_inserter();//插入元素,检查是否存在
copy(begin(a1),end(a1),a2);//把a1的内容拷贝给a2
replace(ilist.begin(),ilist.end(),0,42);//查找所有元素为0的值,并将它更改为42
replace_copy(ilis.cbegin(),ilist.cend(),back_inserter(ivec),0,42);//ilist指出调整序列之后的保存位置。
sort(word.begin(),word.end());//按照字典排序
auto end_unique=unique(words.begin(),words.end());//除去重复单词
注意:
- 算法不检查写操作
- 向目的位置迭代器写入数据的算法,假定目的位置足够大,能容纳要写入的元素。
定制操作
许多算法的默认关键操作符,并不能满足我们的需求,因此,需要我们来重载sort的默认行为。
向算法传递函数
sort可以接受第三个参数,即谓词–一个可用的表达式,其返回结果是一个能用作条件的值。标准库中分为 一元谓词(只接受单一参数)和二元谓词(他们有两个参数)。例如下面的代码,重载了sort函数的基础比较操作
//排序函数
bool isShorter(const string &s1,const string &s2){
return s1.size()<s2.size();
}
//按照长度由短到长排序
sort(words.begin(),words.end(),isShorter);
elimDups(words);//将words按照字典重新排序,并消除重复单词
stable_sort(words.begin(),words.end(),isShorter);//按照长度重新排序,长度相同的单词维持字典序
//无需拷贝字符串
for (const auto &s :words)
{
cout<<s<<"";//打印每个元素,以空格分割
}
cout<<endl;
lambda 表达式
Lambda表达式是c++11之后引入的新特性。很多人说lambda表达式就是匿名函数语法糖,这话也没错。Lambda表达式在某些特殊场景下使用起来确实方便
参考链接:
lambda表达式的声明
[capture list] (params list) mutable exception-> return type { function body }
各项含义如下:
capture list: 捕获外部变量列表params list: 形参列表mutable:用来说明是否可以修改捕获的变量exception:异常设定return type:返回类型function body:函数体
省略的常见表达式有:
| 序号 | 格式 |
|---|---|
| 1 | [capture list] (params list) -> return type {function body} |
| 2 | [capture list] (params list) {function body} |
| 3 | [capture list] {function body} |
其中:
- 格式1声明了const类型的表达式,这种类型的表达式不能修改捕获列表中的值。
- 格式2省略了返回值类型,但编译器可以根据以下规则推断出Lambda表达式的返回类型: (1):如果function body中存在return语句,则该Lambda表达式的返回类型由return语句的返回类型确定; (2):如果function body中没有return语句,则返回值为void类型。
- 格式3中省略了参数列表,类似普通函数中的无参函数。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool cmp(int a, int b)
{
return a < b;
}
int main()
{
vector<int> myvec{ 3, 2, 5, 7, 3, 2 };
vector<int> lbvec(myvec);
sort(myvec.begin(), myvec.end(), cmp); // 旧式做法
cout << "predicate function:" << endl;
for (int it : myvec)
cout << it << ' ';
cout << endl;
sort(lbvec.begin(), lbvec.end(), [](int a, int b) -> bool { return a < b; }); // Lambda表达式
cout << "lambda expression:" << endl;
for (int it : lbvec)
cout << it << ' ';
cout << "lambda" << endl;
// 无参数:
[]{
cout << "无参数lambda" << endl;
}(); // ()可以省略
// 传参:导入了外部变量x,同时接收一个int型参数z,指明了返回类型为int型,在函数体中返回了x 和 z的和
int x = 1;
auto lsum = [x](int z)->int{
return x + z;
}
// 省略return类型
auto lsum = [x](int z){
return x + z;
}
// 修改外部变量,使用mutable,并传引用
auto lsum = [&x](int z) mutable {
return ++x + z; // 如果不加mutable关键字,++x这句话编译器会报错。
}
cout << lsum(10) << endl;
// 另一种写法
function<int(int)> f = [x](int z)->int{
return x + z;
}
cout << f(10) << endl;
}
lambde表达式的外部捕获
Lambda表达式通过在最前面的方括号[]来明确指明其内部可以访问的外部变量,这一过程也称过Lambda表达式“捕获”了外部变量。
值捕获方式:
| 捕获形式 | 说明 |
|---|---|
[] |
不捕获任何外部变量 |
[变量名, …] |
默认以值得形式捕获指定的多个外部变量(用逗号分隔),如果引用捕获,需要显示声明(使用&说明符) |
[this] |
以值的形式捕获this指针 |
[=] |
以值的形式捕获所有外部变量 |
[&] |
以引用形式捕获所有外部变量 |
[=, &x] |
变量x以引用形式捕获,其余变量以传值形式捕获 |
[&, x] |
变量x以值的形式捕获,其余变量以引用形式捕获 |
注意:如果一个lambda体包含return之外的任何语句,则编译器假定lambda返回void;被推断void的lambda不能返回值。因此当重写排序等操作的时候,只能有一句return语句;例如:
transform(vi.begin(),vi.end(),vi.begin(),
[](int i){
return i<0?-i:i;//返回绝对值
});
transform(vi.begin(),vi.end(),vi.begin(),
[](int i){
if(i<0){
return -i;
}else{
return i;
}
//错误,有多余语句,判定返回void
});
因此当我们使用一个lambda定义返回类型的时候,必须使用尾置返回类型,声明返回类型;例如:
transform(vi.begin(),vi.end(),vi.begin(),
[](int i)->int
{
if(i<0){
return -i;
}else{
return i;
}
//返回绝对值
});
lambda 参数绑定
lambda表达式,虽然可以进行简单的参数绑定,但是对于复杂的参数绑定而言,还是存在许多问题,因此可以利用函数对lambda表达式进行参数绑定。大致步骤如下:
- 使用
std:bind函数对函数参数和函数进行绑定 - 使用
placeholderd进行参数占位符的使用。
调用bind一般形式为:
auto newCallable=bind(callable,arg_list);
newCallable本身是一个可以调用对象,arg_list是一个逗号分隔的参数列表,对应给定的callable的参数,即调用的实际参数。
arg_list中的参数可能包含形如_n的名字,其中n是一个整数。表示占位符,数值n表示生成的可调用对象中参数的位置:_1为newCallble的第一个参数,_2为第二个参数。_n为第n个参数。
使用:
auto g=bind(f,a,b,_2,c,_1);
生成一个新的可调用函数对象,它有两个参数,分别使用占位符_2和_1表示。使得原本需要输入5个参数的函数变为,只需要2个参数的函数,对函数进行了再一次封装。f(a,b,_1,c,_2)等价于g(_1,_2)减少了函数的复杂程度。
std::ref():传递给bind一个对象但是不拷贝它
例如:
//1. 定义比较string大小函数
bool check_size(const string &s,string::size_type sz){
return s.size()>=sz;
}
//2. 使用bind绑定函数和参数
//将输入比较顺序颠倒,将单词长度由长至短排序
sort(words.begin(),words.end(),bind(isShorter,_2,_1));
//使用lambda表达式,输出表达式,os是一个局部变量,引用一个输出流
for_each(word.begin(),words.end(),[&os,c](const string &s){
os<<s<<c;
});
//bind相同的效果
ostream &print(ostream &os,const string &s,char c){
return os<<s<<c;
}
//ref返回一个对象,包含给定的引用,此对象是可以拷贝的
for_each(words.begin(),words.end(),
bind(print,std::ref(os),_1,' '));
再探迭代器
插入迭代器
插入迭代器有三种基本类型
back_inserter: 创建一个使用push_back的迭代器。front_inserter:创建一个使用push_front的迭代器。inserter:创建一个使用inserter的迭代器。此函数接受第二个参数,这个参数必须是一个指向容器的迭代器。元素将被插入到给定迭代器所表示的元素制之前。
注意: 只有在容器支持push_front/push_back的情况下,我们才可以使用front_inserter/back_inserter。
使用示例:
*it=val;
it=c.insert(it,val);//it指向插入的新元素
++it;//递增it使它指向原来的元素
list<int> lst={1,2,3,4};
list<int> lst2,lst3;//空list
//拷贝完成之后,lst3包含1 2 3 4
copy(lst.cbegin(),lst.cend(),front_inserter(lst2));
//拷贝完成之后,lst3包含1 2 3 4
copy(lst.cbegin(),lst.cend(),inserter(lst3,lst3.begin()));
iostream 迭代器
istream_iterator:读取输入流。ostream_iterator:向输出流写数据。
istream_iterator操作
| 操作 | 含义 |
|---|---|
istream_iterator<T> in(is) |
in从输入流is读取类型为T的值 |
istream_iterator<T> end |
读取类型为T的值的istream_iterator迭代器,表示尾后位置 |
in1=(!)=in2 |
in1和in2必须读取相同类型。如果他们都是尾后迭代器,或绑定到相同输入,则二者相等 |
*in |
返回从流中读取的值 |
in->mem |
与(*in).mem的含义相同 |
++in,in++ |
使用元素类型所定义的>>运算符从输入流中读取下一个值,并且前置版本返回一个指向递增后迭代器的引用,后置版本返回旧值 |
操作示例:
istream_iterator<int > int_it(cin); //从cin读取int
istream_iterator<int> int_eof; //尾后迭代器
ifstream in("afile");
istream_iterator<string> str_it(in); //从"afile"读取字符串
//读入数据并存储到vector向量组
while(int_it!=eof) {
//后置递增运算读取流,返回迭代器的旧值
//解引用迭代器,获得从流读取的前一个值
vec.push_back(*in_iter++);
}
//循环读取其中的int值存储在vec中
//使用算法操作流迭代器
istream_iterator<int > in(cin),eof;
cout<<accumulate(in,eof,0)<<endl;
//输入:23 109 45 89 6 34 12 90 34 23 56 23 8 89 23
//输出:664
注意:当我们将一个istream_iterator绑定到一个流时,标准库并不保证迭代器立即从流中读取数据。直到使用迭代器时才正真读取。标准库中的实现所保证的是,我们第一次解引用迭代器之前,从六中的数据操作已经完成了。
ostream_iterator操作
| 操作 | 含义 |
|---|---|
ostream_iterator<T> out(os) |
out将类型为T的值写入到流os中 |
ostream_iterator<T> out(os,d) |
将类型为T的值写到输出流os中,每个值后面都输出一个d。d指向一个空字符结尾的字符数组 |
out=val |
out和val必须类型兼容。用运算符<<将val写入到out输出流中 |
*out,++out,out++ |
这些运算符是存在的,但是不对out做任何事情。每个运算符都返回out |
泛型算法结构
对于向一个算法传递错误类别的迭代器的问题,很多编译器不会给出任何警告或者提示。因此需要迭代器类型的支持和认证。
迭代器类别
| 类别 | 含义 |
|---|---|
| 输入迭代器 | 只读,不写;单遍扫描,只能递增 |
| 输出迭代器 | 只写,不读;单遍扫描,只能递增 |
| 前向迭代器 | 可读写;多遍扫描,只能递增 |
| 双向迭代器 | 可读写;多遍扫描,可递增递减 |
| 随机访问迭代器 | 可读写;多遍扫描,支持全部迭代运算 |
第11章 关联容器
关联容器支持高效的关键字查找和访问。两个主要的关联容器类型是map和set;关联容器不支持顺序容器的位置相关的操作。也不支持构造函数或者插入操作这些接受一个元素值和一个数量值的操作。
使用示例:
std::map<string, size_t;> word_count;//空容器
set<string> exclude={"the","but","and","or","an","a"};
//三个元素;authors将姓映射为名
map<string ,string> authors={
{"Joyce","James"},
{"Austen","Jane"},
{"Dickens","Charles"}
};
注意:一个map或者set中的关键字必须是唯一的。但是multimap和multiset没有这个限制。允许多个元素,拥有相同的关键字。
11.2.2 关键字类型要求
传递给排序算法的可调用对象,必须满足于关联容器中关键字一样的类型要求。
11.2.3 pair类型
pair主要保存,两个数据成员,必须提供2个类型名,pair的数据成员,将具有应对的类型。
pair<string ,string > anon; //保存两个string
pair<string ,size_t> word_count; //保存一个string和一个size_t
pair<string ,vector<int>> line; //保存string和vector<int>
pair上的操作
| 操作 | 含义 |
|---|---|
pair <T1,T2> p |
p是一个pair,两个类型分别为T1和T2的成员都进行了初始化 |
pair <T1,T2> p(v1,v2) |
p是一个pair,两个类型分别为T1和T2的v1和v2都进行了初始化 |
pair <T1,T2> p={v1,v2} |
意义同上 |
make_pair(v1,v2) |
返回一个用v1,v2初始化的pair。pair的类型从v1和v2的类型中推断出来 |
p.first |
返回p的名称为first的公有数据成员 |
p1 relop p2 |
关系运算符(<、>、<=、>=)按照字典序定义:例如对应成立时返回true |
11.3 关联容器操作
| 操作类型 | 含义 |
|---|---|
key_type |
此容器类型的关键字类型 |
mapped_type |
每个关键字关联的类型;只适用于map |
value_type |
对于set,与key_type相同;对于map,为pair<const key_type,mapped_type> |
set<string>::value_type v1; //v1是一个string
set<string>::key_type v2; //v2是一个string
map<string,int>::value_type v3;//v3是一个pair <const string ,int>
map<string,int>::key_type v4; //v4是一个string
map<string,int>::mapped_type v5; //v5是一个int
注意:
- 一个
map的value_type是一个pair,我们可以改变pair的值,但不能改变关键字成员的值。 set的迭代器是const的,只能读取,不能修改。
11.3.1 关联容器迭代器
使用示例:
auto map_it=word_count.begin(); //*map_it 是一个指向pair<const string,size_t>对象的引用
cout<<map_it->first; //打印此元素的关键字
cout<<""<<map_it->second; //打印此元素的值
map_it->first="new key"; //错误:关键字是const的
++map_it->second; //正确:我们可以通过迭代器改变元素
因为关联容器set的迭代元素是const的,map中的元素是pair,其第一个成员是const的,因此关联容器,通常用于值读取元素的算法,多为搜索排序。
同时使用insert来添加元素
vector<int> ivec={2,4,6,8,10};//ivec有8个元素
set<int> set2; //空集合
set2.insert(ivec.cbegin(),ivec.cend());//set2有4个元素
set2.insert({1,3,5,7,9});//set2现在有8个元素
关联容器操作:
emplace(args):对于map和set,只有当元素的关键字不在c中时才插入(或者构造)元素。函数返回一个pair,包含一个迭代器,指向具体有指定关键字的元素,以及一个指示插入是否成功的bool值。
注意插入操作返回的是一个pair对象,第一个元素是差诶迭代器的坐标,第二个值是一个bool值,确定是否插入成功。
//统计每个单词在输入中出现的次数
map<string ,size_t> word_count;//从string到size_t的空map
string word;
while(cin>>word){
//插入一个元素,关键字等于word,值为1;
//若word已载word_count中,insert什么也不做
auto ret=word_count.insert({word,1});
if(!ret.second) //word已经在word_count中
++ret.first->second; //递增计数器
/*
等价形式 ++((ret.first)->second);
ret 保存insert返回的值,是一个pair
ret.first 是pair的第一个成员,是一个map迭代器,指向具有给定关键字的元素
ret.first-> 解引用此迭代器,提取map中的元素,元素也是一个pair
ret.first->second; map中元素值的部分
++ ret.first->second; 递增此值
*/
}
11.3.3 删除元素
使用erase函数来删除和释放元素;
auto cnt=authors.erase("Barth,Johns");
11.3.4 map的下表操作
| 操作 | 含义 |
|---|---|
c[k] |
返回关键字为k的元素;如果k不在c中,添加一个关键字为k的元素,对其进行值初试化 |
c.at(k) |
访问管家字为k的元素 |
示例:
map <string ,size_t> word_count; //empty map
//插入一个关键字为Anna的元素,关联值进行值初试化;然后将1赋予它
word_count["Anna"]=1;
注意:
- 对一个
map使用下表操作,使用一个不在容器中的关键字作为下表,会添加一个具有此关键字的元素到map中 - 与
vector与string不同,map的下标运算符,返回的类型与解引用map迭代器得到的类型不同。 map使用find代替下标操作lower_bound和upper_bound不适用于无序容器- 下标和
at操作只适用于非const的map和unordered_map
关联容器中查找元素的操作
| 操作 | 含义 |
|---|---|
c.find(k) |
返回一个迭代器,指向第一个关键字为k的元素,若k不在容器中则返回尾后迭代器 |
c.count(k) |
返回关键字等于k的元素的数量。对于不允许重复关键字的容器,返回值永远是0或者1 |
c.lower_bound(k) |
返回一个迭代器,指向第一个关键字不小于k的元素 |
c.upper_bound(k) |
返回一个迭代器,指向第一个关键字不大于k的元素 |
c.equal_range(k) |
返回一个迭代器pair,指向第一个关键字等于k的元素 |
注意:
- 当我们遍历一个
multimap或者multiset时,保证可以得到序列中所有具有给定关键字的元素。 lower_bound返回的迭代器可能指向一个具有给定关键字的元素,但也可能不指向。如果关键字不在容器中,则lower_bound会返回关键字的第一个安全插入点–不影响容器中元素顺序的插入位置。- 如果
lower_bound和upper_bound返回相同的迭代器,则给定关键字不在容器中。
11.4 无序容器
无序关联容器总共有4个:unordered_map和unordered_set;
桶管理 无序容器在存储组织上为一组桶,每个桶保存0个或者多个元素。无序容器使用一个哈希函数将元素映射到桶。
无序容器管理操作
| 操作 | 含义 |
|---|---|
| 桶接口 | |
c.bucket_count() |
正在使用的桶的数目 |
c.max_bucket_count() |
容器能容纳的最多的桶的数量 |
c.bucket_size(n) |
第n个桶中有多少个元素 |
c.bucket(k) |
关键字为k的元素在那个桶中 |
| 桶迭代 | |
local_iterator |
可以用来访问桶中元素的迭代器类型 |
const_local_iterator |
桶迭代器的const版本 |
c.begin(n),c.end(n) |
与前两个函数类似,但返回const_local_iterator |
| 哈希策略 | |
c.load_factor() |
每个桶的平均元素数量。返回float值 |
c.max_load_factor() |
c维护桶的大小,返回float值。c会在需要时添加新的桶。以使得load_factor<=max_load_factor |
c.rehash(n) |
重组存储,使得bucket_count>=n且bucket_count>size/max_load_factor |
c.reserve(n) |
重组存储,使得c可以保存n个元素且不必rehash |
第 12 章 动态内存
12.1 动态内存与智能指针
在c++中动态内存管理是通过一对运算符来完成的:new和delete;同时为了更加安全的管理指针;标准库提供了两种 智能指针 :shared_ptr、unique_ptr ;前者允许多个指针指向同一个对象;后者独占所指对象。同时还有 weak_ptr的伴随类,他是一种弱引用,指向shared_ptr所管理的对象。三种类都定义在头文件memory中
当我们创建指针时,必须提供指针可以指向的类型。
shared_ptr<string> p1; //shared_ptr,可以指向string
shared_ptr<list<int>> p2; //shared_ptr,可以指向int的list
shared_ptr和unique_ptr都支持的操作
| 操作 | 含义 |
|---|---|
shared_ptr<T> sp unique_ptr<T> up |
空智能指针,可以指向类型为T的对象 |
p |
将p用作一个条件判断,若p指向一个对象,则为true |
*p |
解引用p,获得它指向的对象 |
p->mem |
等价于(*p).mem |
p.get() |
返回p中保存的指针,要小心使用;若智能指针释放了其对象,返回的指针所指向的对象也就消失了 |
swap(p,q)/p.swap(q) |
交换p和q中的指针 |
share_ptr独有的操作
| 操作 | 含义 |
|---|---|
make_shared<T>(args) |
返回一个shared_ptr,指向一个动态分配的类型为T的对象。使用args初始化此对象 |
shared_ptr<T> p(q) |
p是shared_ptr q的拷贝;此操作会递增q中的计数器。q中的智能指针必须转化为*T |
p=q |
p和q都是shared_ptr,所保存的指针必须能够相互转换。此操作会递减p的引用计数,递增q的引用计数;若p的引用计数变为0,则将其管理的原内存释放 |
p.unique() |
若p.use_count()为1,返回true;否则返回false |
p.use_count() |
返回与p共享对象的智能指针数量;可能很慢,主要用于调试 |
注意:
- 我们通常使用
auto作为make_shared指针函数所对应的值。 - 不要使用引用传递,在函数体内对智能指针
shared_ptr进行赋值操作,计数会-1,离开函数作用域,局部变量销毁,计数可能为0.
计数递增情况:
- 一个
shared_ptr初始化另外一个shared_ptr - 作为参数传递给一个函数
- 作为函数的返回值
计数减少情况:
share_ptr赋予一个新值shared_ptr被销毁–局部的shared_ptr离开其作用域。
注意:
- 如果将
shared_ptr存放于一个容器中,而后不再需要全部元素,而只使用其中一部分,要记得erase()删除不再需要的那些元素。 - 使用动态内存的一个常见原因是允许多个对象,共享相同的状态。
12.1.2 直接管理内存
c++可以使用new和delete直接管理内存;尽量在分配内存时,对动态分配内存的对象进行初始化操作。
int *p1=new int; //如果分配失败,new抛出std::bad_alloc;
int *p2=new (nothrow) int; //如果分配失败,new 返回一个空指针
delete p1,p2;
注意:
- 我们传递给delete的指针必须指向动态分配的内存。或者是一个空指针。
- 不要随便删除一个空指针,可能在指针所指向的内存,被其它程序所使用,删除空指针,会造成极大的问题。
- 动态对象的生存周期是直到被释放为止。
- 由内置指针(而不是智能指针)管理的动态内存在被显式释放之前一直都会存在。
- 尽量坚持使用智能指针,防止内存分配错误
- 在删除指针之后使用
NULL/nullptr使得指针悬空。 - 悬空只真对当前指针,对于和当前其它指向销毁内存对象的指针是没有作用的,尽量减少使用指针赋值和拷贝,或者直接使用shared_ptr智能指针。例如:
shared_ptr<int> p1=new int(1024); //错误;必须使用直接初始化形式。
shared_ptr<int> p2(new int(1024)); //正确:使用了直接初始化形式。
定义和改变shared_ptr的其它方法
| 操作 | 含义 |
|---|---|
shared_ptr<T> p(q) |
p管理内置指针q所指的对象;q必须指向new分配的内存,且能够转换为T*类型 |
shared_ptr<T> p(u) |
p从unique_ptr u中接管了对象的所有权;将u置为空 |
shared_ptr<T> p(q,d) |
p接管了内置指针q所指向的对象的所有权。q必须能转换为T*类型。p将使用可调用对象d来代替delete |
shared_ptr<T> p(p2,d) |
p是shared_ptr p2的拷贝,唯一的区别是p将使用可调用对象d来代替delete |
p.reset() |
若p是唯一指向其对象的shared_ptr,reset会释放此对象。 |
p.reset(q) |
释放原有对象的同时,若传递了可选的内置参数指针q,会令p指向q,否则会将p置为空 |
p.reset(q,d) |
若还传递了参数d,将会调用d而不是delete来释放q |
注意:
- 不要混合使用普通指针和智能指针,很容易造成错误的析构
- 不要使用get初始化另外一个智能指针或者为智能指针赋值,赋值给内置指针时,需要注意,不要让它管理的指针被释放。
- 使用get返回指针的代码不能
delete此指针。防止智能指针失效,成为野指针。 - get用来将指针的访问权限传递给代码,只有确定代码不会delete指针的情况下,才能使用get。永远不要使用get初始化另外一个智能指针或者为另外一个智能指针赋值。
- 智能指针指向新指针时,需要检查自己是否是当前对象仅有的用户。如果不是,在改变之前要制作一份新的拷贝。
if(!p.unique())
p.reset(new string(*p)); //我们不是唯一的用户;分配新的拷贝
*p+=newVal; //可以改变对象的值
12.1.4 智能指针和异常
注意,智能指针陷阱
基本规范:
- 不使用相同的内置指针值初始化(或reset)多个智能指针
- 不delete get()返回的指针
- 不使用 get()初始化reset另外一个指针
- 如果你使用get()返回的指针,记住,当最后一个指针对应的智能指针销毁后,你的指针就变为无效了
- 如果你使用智能指针管理的资源不是new分配的内存,记住传递给它一个删除器。
12.1.5 unique_ptr
unique_ptr操作
| 操作 | 含义 |
|---|---|
unique_ptr <T> u1 |
空unique_ptr,可以指向类型为T的对象,u1会使用delete来释放它的指针 |
unique_ptr <T,D> u2 |
u2使用一个类型为D的可调用对象来释放它的指针 |
unique_ptr <T,D> u(d) |
空unique_ptr,指向类型为T的对象,用类型为D的对象d代替delete |
u=nullptr |
释放u指向的对象,将u置为空 |
u.release() |
u放弃对指针的控制权,返回指针,并将u置为空 |
u.reset() |
释放u指针对象 |
u.reset(q)/u.reset(nullptr) |
如果提供了内置指针q,令u指向这个对象;否则将u置为空 |
unqiue_ptr不能共享所有权,但是可以将所有权,进行转移
//将所有权从一个unique_ptr转移给另一个unique
unique_ptr<string> p2(p1.release()); //release 将p1置为空
unique_ptr<string> p3(new string("Text"));
//将所有权从p3转移给p2
p2.reset(p3.release()); //reset释放了p2原来指向的内存
12.1.6 weak_ptr
weak_ptr是一种不控制所指向兑现生存周期的智能指针,它指向一个由shared_ptr管理的对象。
weak_ptr
| 操作 | 含义 |
|---|---|
weak_ptr <T> w |
空weak_ptr可以指向类型为T的对象 |
weak_ptr <T> w(sp) |
与shared_ptr sp指向相同对象的weak_ptr,T必须可以指向类型为sp的对象 |
w=p |
p可以是一个shared_ptr或者一个weak_ptr。赋值后w与p共享对象 |
w.reset() |
将w置为空 |
w.use_count() |
与w共享对象的shared_ptr的数量 |
w.expired() |
若w.use_count()为0,返回true,否则返回false |
w.lock() |
如果expired为true,返回一个空shared_ptr;否则返回一个指向w的对象的shared_ptr |
我们创建一个weak_ptr时,要用一个shared_ptr来初始化它:
auto p=make_shared<int>(42);
weak_ptr<int> wp(p);//wp 弱共享p;p的引用计数未改变,因此使用时必须使用函数lock()
if(shared_ptr<int> np=wp.lock()){//如果np不空则条件成立
//在if中,np与p共享对象
}
12.2 动态数组
数组主要是为了更好的快速分配内存;大多数应用应该使用标准库容器而不是动态分配的数组。使用容器更为简单、更不容易出现内存管理错误并且拥有更好的性能。
注意:
- 分配数组,会得到一个元素类型的指针。
- 动态分配一个空数组是合法的。
- 释放动态数组使用
delete [],数组中的元素按逆序销毁。 - 数组指针需要使用
delete [],单个对象需要使用delete,换用的行为都是未定义的。 - 未使用匹配的delete时,编译器很可能不会给出警告。程序可能在执行过程中没有任何警告的情况下行为异常。
初始化动态分配对象的数组
int *pia=new int[10]; //10个没有初始化的int
int *pia2=new int[10](); //10个初始化为0的int
string *psa=new string[10]; //10个空string
string *psa2=new string[10](); //10个空string
string *psa3=new string[10]{"a","an","the",sting(3,'x')}; //10个string初始化
指针和动态数组
unique_ptr<int []> up(new int[10]); //up指向10个未初始化int的数组
up.release(); //自动调用delete销毁其指针。
12.2.2 allocator类
通常因为指针数组的定额分配可能产生内存浪费,因此需要allocator来进行内存分配。类似vector,allocator是一个模板,为了定义一个allocator对象,我们必须指明这个allocator可以分配的对象类型。当一个allocator对象分配内存时,它会根据给定的对象类型来确定恰当的内存大小和对齐位置:
allocator<string > alloc; //可以分配stringd allocator对象
auto const p=alloc.allocate(n); //分配n个未初始化的string
标准库allocator类及其算法
| 算法 | 解释 |
|---|---|
allocator <T> a |
定义了一个名为a的allocator对象,他可以为类型T的对象分配内存 |
a.allocate(n) |
分配一段原始的、未构造的内存,保存n个类型为T的对象 |
a.deallocate(n) |
释放从T*指针p中地址开始的内存,这块内存保存了n个类型为T的对象;p必须是一个先前由allocator返回的指针,且n必须是p创建时所要求的大小。调用dealocator之前,用户必须对每个在这块内存中创建的对象调用destroy |
a.construct(p,args) |
p必须是一个类型为T*的指针,指向一块原始内存;arg被传递给类型为T的构造函数,用来在p指向的内存中构造一个对象 |
a.destroy(p) |
p为T*类型的指针,此算法对p指向的对象执行析构函数 |
注意:
- allocator分配的内存时未构造函数的。我们按照需要在此内存中构造对象。
- 为了使用allocator返回的内存,我们必须使用construct构造对象。未使用构造的内存,其行为是未定义的。
- 我们只能对真正构造了的元素进行destory操作。
auto q=p; // q指向最后构造的元素之后的位置
alloc.construct(q++); //*q为空字符串
alloc.construct(q++,10,'c'); // *q为cccccccccc
std::cout<<*p<<endl; //正确:使用string 的输出运算符
cout<<*q<<endl; // 灾难: q指向未构造的内存。
//使用完成必须对每个构造的元素调用destory来销毁它们
while (q!=p)
alloc.destory(--q); //释放我们真正构造的string,此时元素被销毁,可以重新使用这部分内存来保存其它string
alloc.deallocate(p,n); //释放内存操作
allocator 算法
| 算法 | 含义 |
|---|---|
uninitialized_copy(b,e,b2) |
将迭代器b和e之间的输入,拷贝到迭代器b2指定的未构造的原始内存中,b2指向的内存必须足够大,能够容纳输入序列中元素的拷贝 |
uninitialized_copy_n(b,n,b2) |
同上,从b开始拷贝n个元素到b2 |
uninitialized_fill(b,e,t) |
在迭代器b和e指定的原始内存范围中创建对象,对象的值,均为t的拷贝 |
uninitialized_fill_n(b,n,t) |
从b指向的内存地址开始创建n个对象,b必须指向足够大的内存 |
使用示例:
//分配比vi中元素所占用空间大一倍的动态内存
auto p=alloc.allocate(vi.size()*2);
//通过拷贝vi中的元素来构造从p中开始的元素
auto q=uninitialized_copy(vi.begin(),vi.end(),p);
//将剩余元素初始值为42
uninitialized_fill_n(q,vi.size(),42);
第III 部分类设计者的工具
第13 章拷贝控制
类的五种特殊成员函数:
- 拷贝构造函数
- 拷贝赋值构造函数
- 移动构造函数
- 移动赋值运算符
- 析构函数
注意:定义任何C++类的时候,拷贝控制操作都是必要部分。即使我们不显示定义这些操作,编译器也会为我们定义,但是编译器定义的版本的行为可能并非我们所想象。
13.1 拷贝、赋值与销毁
合成拷贝构造函数:用来阻止我们拷贝该类类型的对象。一般情况,合成的拷贝构造函数会将其参数的成员逐个拷贝到正在创建的对象中。编译器给定对象中依次将每个非static成员拷贝到正在创建的对象中。
拷贝初始化发生情况:
- 使用
=定义变量时会发生 - 将一个对象作为实参传递给一个非引用类型的形参
- 从一个返回类型为非引用类型的函数返回一个对象
- 用
{}列表初始化一个数组中的元素或者一个聚合类中的成员 - 接收参数的构造函数,一般是explicit的
- 编译器可以绕过拷贝构造函数
vector<int> v1(10); //正确:直接初始化
vector<int> v2=10; //错误:接受大小参数的构造函数时explicit的
void f(vector<int>); //f的参数进行拷贝初始化
f(10); //错误;不能用一个explicit的构造函数拷贝一个实参
f(vector<int>(10));正确:从一个int直接构造一个临时的vector
string null_book="9-99-99";//拷贝初始化
string null_book("9-99-99"); //编译器略过了拷贝构造函数
//重载赋值运算符
class Foo{
public:
Foo& operator=(const Foo&); //赋值运算符
...
}
Foo& Foo::operator=(const Sales_data &rhs){
bookNo=rhs.bookNo; //调用 string::opeator=
units_sold=rhs.units_sold; //使用内置的int赋值
...
return *this;
}
赋值运算符通常应该返回一个指向其左侧运算对象的引用
如果类没有定义自己的拷贝赋值运算符,编译器会为它生成一个 合成拷贝赋值运算符
析构函数调用情况
- 变量在理考作用域时被销毁
- 一个对象在被销毁时,其成员被销毁
- 容器(无论是标准库容器还是数组) 被销毁时,其元素被销毁
- 对于动态分配的对象,当对指向它的指针应用delete运算符进行销毁
- 临时对象,当创建它的完整表达式结束时被销毁。
注意:
- 析构函数调用时,先调用父类,再调用子类;与构造函数正好相反。
- 当指向一个对象的引用或者指针离开作用域时,析构函数不会执行。
- delete 删除指针,是删除指针指向的那块内存,指针本身仍旧存在,因此需要,键指针指向NULL防止错误
三/五法则 三个基本操作可以控制类的拷贝操作:
- 拷贝构造函数
- 拷贝赋值运算符
- 析构函数
- 如果一个类需要自定义析构函数,几乎可以肯定它也需要自定义拷贝赋值运算符和拷贝构造函数;反之亦然。
- 可以通过使用
=default来显示地要求编译器生成合成的版本(默认构造函数)。 - 可以使用
=delete来阻止默认的拷贝个赋值函数。 - 将拷贝和赋值拷贝设为私有函数,将使得用户代码不能拷贝这个类型的函数,用户代码在编译时错误,成员函数或者有元函数在连接诶时错误。
- 希望阻止拷贝的类应该使用
=delete来定义他们自己的拷贝构造函数和拷贝赋值运算符,而不应该将他们声明为private的。
HasPtr HasPtr::operator=(const HasPtr &rhs)
{
auto newp=new string(*rhs.ps) ;// 拷贝底层string
delete ps; //释放旧内存
ps=newp; //从右侧运算对象拷贝数据到本对象
i=rhs.i;
return this; //返回对象本身
}
当编写一个赋值运算符的时候,最好先将右侧运算对象拷贝到一个局部临时对象。当拷贝完成后,销毁左侧运算对象的现有成员就是安全的了。一旦左侧运算对象的资源被销毁,就只剩下将数据从临时对象拷贝到左侧运算对象的成员中了。
拷贝赋值运算符通常执行拷贝构造函数和析构函数也要做的工作,公共的工作应该放在private的工具函数中。
13.5 动态内存管理
简单标准库vector类的简化实现版本。
//stdvec.h
//类vector类内存分配策略的简化实现
class StrVec{
public:
StrVec():
elements(nullptr),first_free(nullptr),cap(nullptr){}
StrVec(const StrVec&); //拷贝构造函数
StrVec &operator=(const StrVec&); //拷贝赋值运算符
~StrVec(); //析构函数
void push_back(const std::string&); //拷贝元素
size_t size() const {return first_free-elements;}
size_t capacity() const {return cap-elements;}
std::string *begin() const {return elements;}
std::string *end() const {return first_free;}
// ...
private:
Static std::allocator<std::string> alloc; //分配元素
//被添加元素的函数所使用
void chk_n_alloc() {if(size()==capacity()) reallocate();}
//工具函数,被拷贝构造函数、赋值运算符和析构函数所使用
std::pair<std::string*,std::string*> alloc_n_copy(const std::string*,const std::string*);
void free(); //销毁元素并释放内存
void reallocate(); //获得更多内存并拷贝已有元素
std::string *elemets; //指向数组首元素的指针
std::string *frist_free; //指向数组第一个空闲元素的指针
std::string *cap; // 指向数组尾后位置的指针
};
//strvec.cpp
void Strvec::push_back(const string& s)
{
chk_n_alloc(); //确保有空间容纳新元素
//在frist_free指向的元素中构造s的副本
alloc.construct(first_free++,s);
};
std::pair<std::string*,std::string*> alloc_n_copy(const std::string* b,const std::string* e)
{
//分配空间保存给定范围中的元素
auto data=alloc.allocate(e-b);
//初始化并返回一个pair,该pair由data和uninitialized_copy的返回值构成
return {data.uninitialized_copy(b,e,data)};
}
void StrVec::free()
{
//不能传递给deallocate 一个空指针,如果elements为0,函数什么也不做
if(elements){
//逆序销毁旧元素
for(auto p=first_free;p!=elements;)
{
alloc.destory(--p);
alloc.deallocate(elements,cap-elements);
}
}
}
StrVec::StrVec(const StrVec &s)
{
//调用alloc_n_copy 分配内存空间以容纳与s中一样多的元素
auto newdata=alloc_n_copy(s.begin(),s.end());
elements=newdata.frist;
frist_free=cap=newdata.second;
}
StrVec::~StrVec(){free();}
StVec &StrVec::operator=(const StrVec &rhs)
{
//调用alloc_n_copy 分配内存,大小与rhs中元素占用空间一样多
auto data=alloc_n_copy(rhs.begin(),rhs.end());
free();
elements=data.first;
frist_free=cap=data.second;
return *this;
}
void StrVec::reallocate()
{
//我们将分配当前大小两倍的内存空间
auto newcapacity=size()?2*size():1;
//分配新内存
auto newdata=alloc.allocate(newcapacity);
//将数据从旧内存移动到新内存
auto dest=newdata; //指向新数组中下一个空闲位置
auto elem=elements; //指向旧数组中下一个元素
for(size_t i=0;i!=size();++i)
{
alloc.construct(dust++,std::move(*elem++));
}
free(); //一旦我们移动完成元素就释放旧内存空间
//更新我们的数据结构,执行新元素
elements=newdata;
first_free=dest;
cap=element+newcapacity;
}
13.6 对象移动
注意:标准容器库、string和shared_ptr类既支持移动也支持拷贝。IO类和unique_ptr类可以移动但不能拷贝。
使用&&来进行右值引用。右值引用–只能绑定到一个将要销毁的对象。左值持久;右值短暂。右值引用只能绑定到临时对象。
对于右值有:
- 所引用的对象,将要被销毁
- 该对象没有其他用户
- 使用右值引用的代码可以自由地接管所引用的对象的资源
- 变量是左值,因此我们不能将一个右值引用直接绑定到一个变量上,即使这个变量是右值引用类型。
- 可以销毁一个移后对象,也可以赋予它新值,但不能够使用一个移后源对象的值。
使用move来获得绑定到左值上的右值引用int &&rr3=std::move(rr1);
注意:
- 不抛出异常的移动构造函数和移动赋值运算符必须标记为
noexcept。 - 只有当一个类没有定义任何自己版本的拷贝控制成员,且它的所有数据成员都能移动构造或者移动赋值时,编译器才会为它合成移动构造函数或者移动赋值运算符。
- 定义了一个移动构造函数或者移动赋值运算符符类,必须也定义自己的拷贝构造操作。否则,这些成员默认地被定义为删除的。
- 如果一个类有一个可用的拷贝构造函数而没有移动构造函数,则其对象是通过拷贝构造函数来“移动”的。拷贝赋值运算符和移动赋值运算符的情况类似。
- 移动赋值函数,相对拷贝构造函数,更减少资源的使用。
- 对象移动数据并不会销毁此对象,但有时在移动完之后,源对象会被销毁。编写移动操作时,必须保证源对象可以析构。
- 一个类集邮移动构造,又有拷贝构造,则移动是右值,拷贝是左值。
- 没有移动构造函数,右值也会被拷贝。但是编译器不会合成移动构造函数。即便是使用std::move也是调用的拷贝构造函数。
- 不要随意使用移动操作,一个移动源对象具有不确定的状态。当我们使用
move时,必须绝对确认移后源对象没有其它用户。 - 移动接收
T&&,拷贝接收T&
左值和右值引用成员函数 c++中允许右值进行赋值例如:
auto s1="hello";
auto s2="word";
s1+s2="wow!";
为了阻止这种情况的发生,使用 引用限定符:& 来强制指定左侧运算对象(即,this指向的对象)是一个左值。或者使用&&,强制指明,左侧运算对象是一个右值,例如:
class Foo{
public:
Foo &operator=(const Foo&) &; //只能向可修改的左值赋值
}
class Foo{
public:
Foo someMem() & const; //错误限定符const 必须在前
Foo anotherMem() const &; //正确
}
Foo &retFoo(); //返回一个引用;retFoo调用时一个左值
Foo retVal(); // 返回一个值;retVal调用时一个右值
Foo i,j; //i,j均是左值
i=j; //正确:i是左值
retFoo()=j ;// 正确:retFoo()返回一个左值
retVal()=j; //错误:retVal()返回一个右值
i=retVal(); //正确:我们将一个右值作为赋值操作的右侧运算对象
//成员函数可以根据const区分其重载版本,引用也可以区分重载版本
class Foo{
public:
Foo sorted() &&; //可用于可改变的右值
Foo sorted() const &; //可用于任何类型的Foo
}
//本对象为右值,因此可以原址排序
Foo Foo::sorted() &&
{
sort(data.begin(),data.end());
return *this;
}
//本对象是const或者是一个左值,不论何种情况我们都不能对其进行原址排序
Foo Foo::sorted() const & {
Foo ret(*this); //拷贝一个副本
sort(ret.data.begin(),ret.data.end()); //排序副本
return ret; //返回副本
}
//这里编译器会根据sorted 的对象的左值/右值属性来确定使用那个sorted版本
注意: 如果一个成员函数有引用限定符,则具有相同参数列表的所有版本都必须有引用限定符。
第14 章 重载运算符与类型转换
重载的运算符是具有特殊名字的函数;他们的名字由关键字,operator和其后要定义的运算符共同组成。 注意:
- 一个类成员运算符函数,第一个运算对象绑定到隐式的
this指针上。因此成员函数运算符函数的显示参数数量比运算符的运算对象,总少一个。 - 我们无法改版内置类型的运算符含义。
- 我们只能重载已有的运算符,而无权发明新的运算符号。例如我们不能提供operator**来执行幂操作。
可重载运算符
| 运算符类型 | 运算符种类 |
|---|---|
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于>,<=(小于等于),>=(大于等于) |
| 逻辑运算符 | //(逻辑或),&&(逻辑与),!(逻辑非) |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
| 自增自减运算符 | ++(自增),--(自减) |
| 位运算符 | / (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移) |
| 赋值运算符 | =, +=, -=, *=, /= , % = , &=, /(其实是竖着的)=, ^=, <<=, >>= |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
| 其他运算符 | ()(函数调用),->(成员访问),,(逗号),[](下标) |
不可重载的运算符列表
| 运算符 | 含义 |
|---|---|
. |
成员访问运算符 |
.*, ->* |
成员指针访问运算符 |
:: |
域运算符 |
sizeof |
长度运算符 |
?: |
条件运算符 |
# |
预处理符号 |
注意:
- 运算重载符不可以改变语法结构。
- 运算重载符不可以改变操作数的个数。
- 运算重载符不可以改变优先级。
- 运算重载符不可以改变结合性。
类重载、覆盖、重定义之间的区别:
重载指的是函数具有的不同的参数列表,而函数名相同的函数。重载要求参数列表必须不同,比如参数的类型不同、参数的个数不同、参数的顺序不同。如果仅仅是函数的返回值不同是没办法重载的,因为重载要求参数列表必须不同(发生在同一个类里)。
覆盖是存在类中,子类重写从基类继承过来的函数。被重写的函数不能是static的。必须是virtual的。但是函数名、返回值、参数列表都必须和基类相同(发生在基类和子类)
重定义也叫做隐藏,子类重新定义父类中有相同名称的非虚函数 ( 参数列表可以不同 ) (发生在基类和子类)。
操作符的等价调用:
data1+data2; //普通的表达式
operator+(data1,data2); //等价的函数调用
data1.operator+=(data2); //等价的函数调用
注意:尽量明智地使用运算符重载。只有当操作的含义对于用户磊说清晰明了时才能使用运算符。当其存在二意性时,最好不要使用。
14.2 输入和输出运算符
输出<<重载示例:
ostream &operator<<(ostream &os,const Sales_data &item)
{
os<<item.isbn()<<" "<<item.units_sold<<""
<<item.revenue<<" "<<item.avg_price();
return os;
}
注意:
- 输出运算符应该主要负责打印对象的内容而非控制格式,输出运算符不应该打印换行符。
- 输入输出运算符必须是非成员函数,不能是类的成员函数。否则,他们左侧运算对象将是我们的类的一个对象。
输入>>重载示例:
istream &opertaor>>(istream &is,Sales_data &item)
{
double price;// 不需要初始化,因为我们将先读入数据到`price`,之后才使用它
is>>item.bookNo>>iten.units_sold>>price;
//检查输入是否成功
if(is)
{
item.revenue=item.units_sold*price;
}else{
item=Sales_data(); //输入失败:对象呗赋予默认的状态
}
return is;
}
注意:
- 当流含有错误类型的数据时,读取操作可能失败。之后的其他使用都将失败
- 当读取操作达到文件末尾或者遇到输入流的其它错误时,也会失败
- 当读取操作发生错误时,输入运算符应该负责从错误中恢复。
14.3 算术和关系运算符
注意:
- 如果同时定义了算术运算符和相关的复合赋值运算符,则通常情况下应该使用复合赋值来实现算术运算符。
- 如果某个类在逻辑上有相等性的含义,则该类应该定义
operator==。 - 如果存在唯一一种可靠的
<定义,则应该考虑为这个类定义<运算符。如果类同时还包含==,则当且仅当<的定义和==产生的结果一致时才睡定义<运算符。 - 重载赋值运算符。不论形参的类型是什么,赋值运算符都必须定义为成员函数。
- 赋值运算符必须定义为类的成员,复合赋值运算符通常情况下也应该这样做。这两类运算符都应该返回左侧运算对象的引用。
使用示例:
//重载赋值运算符
StrVec &StrVec::operator=(initializer_list<string> il)
{
//alloc_copy分配内存空间,并从给定安慰内拷贝元素
auto data=alloc_n_copy(il.begin(),il.end());
free(); // 销毁对象中的元素并释放内存空间
elements=data.frist;//更新数据成员,使其指向新空间
first_free=cap=data.second;
return *this;
}
//重载复合赋值运算符
StrVec &StrVec::operator+=(initializer_list<string> il)
{
unit_sold+=rhs.units_sold;
revenue+=rhs.revenue;
return *this;
}
14.5 下标运算符 operator []
注意:
- 下标运算符必须是成员函数。
- 如果一个类包含下标运算符,则它通常会定义两个版本;一个返回普通引用,一个是类的常量成员并且返回常量引用。
使用示例:
class StrVec{
public:
std::string& operator [](std::size_t n){return elements[n];}
const std::string& operator[] (std::size_t n) const
{ return element[n];}
private:
std::string *elements; //指向数组首元素的指针
}
const StrVec cvec=svec; //把svec的元素拷贝到cvec中
//如果svec中含有元素,对第一个元素运行string的empty函数
if(svec.size()&&svec[0].empty){
svec[0]="zero"; //正确:下标运算符返回string的引用
svec[0]="Zip"; //错误;对cvec取下标返回的是常量引用
}
14.6 递增和递减运算符
注意:
- 定义递增和递减运算符的类应该同时定义前置版本和后置版本。这些运算符通常应该被定义成类的成员。
- 为了与内置版本保持一致,前置运算符应该返回递增或者递减后对象的引用。
- 为了与内置版本保持一致,后置运算符应该返回对象的原值(递增或者递减之前的值),返回的形式是一个值而非引用。
- 因为我们不会用到
int形参,所以无需为其命名。
//前置版本:返回递增/递减对象的引用
StrBlobPtr& StrBlobPtr::operator++()
{
//如果curr已经指向了容器的尾后位置,则无法递增它
check(curr,"xxxx");
++curr; //将curr在当前状态下向前移动一个元素
return *this;
}
//后置版本:递增/递减对象的值,但是返回原值
StrBlobPtr StrBlobPtr::operator++(int)
{
//此处无需检查有效性,调用前置递增运算时才需要检查
StrBlobPtr ret=*this; //记录当前的值
++*this //向前移动一个元素,前置++需要检查递增的有效性
return ret; //返回之前记录的状态
}
C++中 i++ 与++i 的区别
- i++ 是指先使用i,只用之后再讲i的值加一,
- ++i 是将i的值先加一,然后在使用i;
如果i是一个整型变量那么i++ 与++i 几乎是没有区别的,在学习C++的后面会有迭代器,迭代器是一个对象,当i是迭代器时,那么++i的效率运行速度就比i++快;所以我们在一般的for循环语句中当i++与++i都可以使用时,可以考虑使用++i,养成一种良好的风格。
14.7 成员访问运算符
成员访问运算符,在 迭代器及智能指针类中常常见到解引用运算符*和箭头运算符->。我们以如下形式向StrBlobPtr类添加这两种运算符:
class StrBlobPtr{
public:
std::string& operator*() const
{
auto p=check(curr,"dereference past end");
return (*p)[curr]; //(*p)是对象所指的vector
}
std::string* operator->() const
{
//将实际工作委托给解引用运算符
return& this->operator*();
}
//将两个运算符定义成了const成员,这是因为与递增和递减预算符不一样,获取一个元素并不会改变StrBlobPtr对象的状态
}
注意:
- 箭头运算符必须是类的成员。解引用运算符通常也是类的成员,尽管并非必须如此。
- 重载的箭头运算符必须返回类的指针或者自定义了箭头运算符的某个类的对象
14.8 函数调用运算符
如果类重载了函数调用运算符,则我们可以像使用函数一样灵活使用该类的对象。因为这样的类同时也能存储状态,所以与普通函数相比它们更加灵活。例如:
strcut absInt{
int operator()(int val) const
{
return val<0?-val:val;
}
};
//使用
int i=-42;
absInt absObj; // 含有函数调用运算符符对象
int ui=absObj(i); //将i传递给absObj.operator()
注意:
- 函数调用运算符必须是成员函数。一个类可以定义多个不同版本的调用运算符,相互之间应该在参数数量或者类型上有所区别。
- 如果类定义了调用运算符,则该类的对象称作 函数对象。因为可以调用这种对象,所以我们说这些对象的“行为就像函数一样”。
- lambda是就是一个典型的函数对象。但是lambda表达式的类不含默认构造函数、赋值运算符及默认析构函数;它是否含有默认的拷贝/移动构造函数则通常要视捕获的数据成员类型而定。
- 对于比较两个无关指针的内存地址,将产生未定义的行为,标准函数库提供了相关函数兑现进行定义。
标准库函数对象
| 算术 | 关系 | 逻辑 |
|---|---|---|
plus<Type> |
equal_to<Type> |
logical_and<Type> |
minus<Type> |
not_equal_to<Type> |
logical_or<Type> |
multiplies<Type> |
greater<Type> |
logical_not<Type> |
divides<Type> |
greater_equal<Type> |
|
modulus<Type> |
less<Type> |
|
negate<Type> |
less_equal<Type> |
vector<string *> nameTable; //指针的vector
//错误会产生未定义的行为
sort(nameTable.begin(),nameTable.end(),[](string *a,string *b){return a<b;});
//正确:标准库规定指针的less是定义良好的
sort(nameTable.begin(),nameTable.end(),less<string *>());
可调用对象与function c++中的可调用对象:
- 函数
- 函数指针
- lambda表达式
- bind创建的对象
- 重载了函数调用运算符的类
对于相似操作但是输入参数不同的情况,我们可以使用一个名为function的新标准库类型解决上述问题,function定义在functional头文件中。
function的操作
| 操作 | 含义 |
|---|---|
function<T> f |
f是一个用来存储可调用对象的空function,这些课调用对象的调用形式应该与T相同 |
function<T> f(nullptr) |
显示构造一个空function |
function<T> f(obj) |
在f中存储可调用对象obj的副本 |
| ` f` | 将f作为条件:当f含有一个可调用对象时为真;否则为假 |
f(args) |
调用f中的对象,参数时args |
**定义为function
使用示例:
function<int(int,int)> f1=add; //函数指针
function<int(int,int)> f2=divide(); //函数对象类的指针
function<int(int,int)> f3=[](int i,int l){return i*j;}; //函数指针
cout<<f1(4,2)<<endl; //打印
cout<<f2(4,2)<<endl; //打印
cout<<f3(4,2)<<endl; //打印8
//使用map映射
map<string,function<int(int,int)> > binops={
{"+",add}, //函数指针
{"-",std::minus<int>()}, //标准库函数对象
{"/",divide()}, // 用户定义的函数对象
{"*",[](int i,int j){return i*j;}}, //未命名的lambda
{"%",mod} //已命名的lambda对象
};
注意:
新版本标准库中的function类与旧版本中的unary_function和binary_function没有关联,后两个类已经被更加通用的bind函数代替了。
14.9 重载、类型转换和运算符
类类型转换: 将实参类型对象隐式转换为类类型,转换构造函数和类型转换运算符共同定义类类型转换,也称作 用户定义的类类型转换。
例如:double b=3.141516;int a=(int)b;
类型转换运算符: 将一个类类型的值转换成其它类型。一般形式如下:
operator type() const
注意:
- 一个类型转换函数必须是类的成员函数;它不能声明返回类型,形参类表也必须为空。类型转换函数通常应该是
const。 - 类型转换运算符可能产生意外结果,例如bool类型转换,能被隐式地转换为int类型输出。
- 为了防止上一条情况发撒恒,c++11定义了显示的类型转换运算符;例如:
class SmallInt{
public:
//编译器不会自动执行这一类型转换
explicit operator int() const {return val;}
}
//显式地请求类型转换
SmallInt si=3;
static_cast<int>(si)+3;
- 向bool的类型转换通常用在条件部分,因此
operator bool一般定义成explicit的。 - 通常情况下,不要为类定义相同的类型转换,也不要在类中定义两个及两个以上转换源或者转换目标是算术类型的转换。
- 当我们使用两个用户定义的类型转换时,如果转换函数之前或者之后存在标准类型转换,则标准类型转换将决定最佳匹配到底是哪个
- 除了显式向bool类型的转换为,应该尽量避免定义类型转换函数并尽可能地限制“显然正确”的非显式构造函数。
- 如果在调用重载函数时,需要构造函数或者强制类型转换来改变实参类型,则这通常意味着程序设计存在不足。
- 在调用重载函数时,如果需要额外的标准类型转换,则该转换的级别只有当所有可行函数都请求同一个用户定义的类型转换时才有用。如果所需的用户定义的类型不止一个,则该调用具有二义性。
14.9.3 函数匹配与重载运算符
注意:
- 表达式中运算符的候选函数集即应该包括成员函数,也应该包括非成员函数。
- 如果我们对同一个类既提供了转换目标是算术类型的类型转换,也提供了重载的运算符,则将会遇到运算符与内置运算符符二义性问题。
例如:
class SmallInt{
friend SmallInt operator+ (const SmallInt&,const SmallInt&);
public:
SmallInt(int =0); // 转换源为int的类型转换
operator int() const {return val;} //转换目标为int的类型转换
private:
std::size_t val;
};
SmallInt s1,s2;
SmallInt s3=s1+s2; //使用重载的operator+
int i=s3+0; //二义性错误
第15章 面向对象程序设计
面向对象的三大特性是:封装,继承和多态。
- 封装隐藏了类的实现细节和成员数据,实现了代码模块化,如类里面的private和public;
- 继承使得子类可以复用父类的成员和方法,实现了代码重用;
- 多态则是“一个接口,多个实现”,通过父类调用子类的成员,实现了接口重用,如父类的指针指向子类的对象。
15.1 oop:概述
面向对象程序设计的核心思想是数据抽象、继承和动态绑定。
虚函数: 基类希望它的派生类各自定义适合自身版本,将这些函数声明为虚函数;派生类必须通过派生类列表明确指明他是从那个基类继承而来的。即 基类希望派生类能进行覆盖的函数
动态绑定 通过动态绑定,我们能用同一段代码分别处理不同的对象。相同函数,根据动态绑定的对象实质进行区别。在运行时选择函数的版本,所以动态绑定有时又被称为 运行时绑定
注意:
- 在c++语言中,当我们使用基类的引用(或者指针)调用一个虚函数时将发生动态绑定。
15.2 定义基类和派生类
注意:
- 基类同城都应该定义一个虚析构函数,计时该函数不执行任何实际操作也是如此。
- 如果一个派生类没有覆盖其基类中的某个虚函数,则该函数的行为类似于其他成员,派生类会直接继承其在基类中的版本。
- 同一个对象中,继承自基类的部分和派生类自定义的部分不一定是连续存储的。
class Quote{
public:
Quote()=default;
Quote(const std::string &book,double sales_price):bookNo(book),price(sales_price){}
std::string isbn() const {return bookNo;}
//返回给定数量的书籍的销售总额
//派生类负责改写并使用不同的折扣计算算法
virtual double net_price(std::size_t n) const
{return n*price;}
virtual ~Quote()=default; //对析构函数进行动态绑定
private:
std::string bookNo; //书籍编号
protected:
double price=0.0 //普通状态下不打折扣的价格
}
可以将派生类的对象当成基类来使用,而且也能将基类的指针或者引用绑定到派生类对象中的基类部分上。
Quote item; //基类对象
Bulk_quote bulk; //派生类对象
Quote *p=&item; //p指向Quote对象
p=&bulk; //p指向bulk的Quote的部分
Quote &r=bulk; //r绑定到bulk的Quote部分
上述转换可以把派生类对象的指针用在需要基类指针的地方。 注意:
- 在派生类对象中含有与基类对应的组成部分,这一事实是继承的关键。
- 派生类不能直接初始化继承的基类成员,必须使用基类的构造函数来初始化它的基类部分;每个类控制它自己的成员初始化过程。
- 除非我们特别指出,否则派生类的基类部分会像数据成员一样执行默认初始化。如果需要使用基类的构造函数需要,使用
基类名(参数1,参数2)的形式进行显式调用。否则进行一般空参数的默认初始化。 - 首先初始化基类的部分,然后按照声明的顺序依次初始化派生类的成员。
- c++中类,是在实例化时才会查找相关代码,没有使用就不会生成对应代码,函数无论使用都会生成。
- 类会自动生成一个
namespace,其中的静态成员和静态变量,相当于namespace中的变量和函数。 - 如果基类定义了一个静态成员,则在整个继承体系中只存在该成员的唯一定义。不论从基类中派生出来多少个派生类,对于每个静态成员来说都只存在唯一的实例。
- 如果我们想要某个类用作基类,则该类函数必须已经定义而非仅仅声明。主要是构造函数和成员变量必须定义,因为子类的构造函数必须使用父类的构造函数。
- 在类后面添加关键字
final可以有效防止类被继承。 - 和内置指针一样,智能指针类也支持派生类向基类的类型转换,意味着我们可以将一个派生类对象的指针存储在一个基类指针的只能指针内。
基类和派生类
不存在基类向派生类的隐式类型转换,但是当编译器无法确定某个特定的转换在运行时是否安全的时候,则可以,但这是很危险的,并且基类函数的析构函数最好是虚析构函数。(C++中虚析构函数的作用)
Bulk_quote bulk;
Quote *itemP=&bulk; //正确;动态类型是Bulk_quote
Bulk_quote *bulkP=itemP; //错误,不能将基类转换成派生类
派生类向基类的自动类型转换,支队指针或者引用类型有效,在派生类类型和基类类型之间不存在这样的转换。
当我们用一个派生类对象为一个基类对象初始化或赋值时,只有该派生类对象中的基类部分会被拷贝、移动或赋值,它的派生类部分将被忽略掉。
存在继承关系的类型之间的转换规则
- 从派生类向基类的类型转换只对指针或引用类型有效
- 基类向派生类不存在隐式类型转换
- 和任何其他成员一样,派生类向基类的类型转换也可能会由于访问受限而变得不可行。
15.3 虚函数
虚函数的调用可能在运行时才被解析
注意:
- 一旦某个函数被声明成虚函数,则在所有派生类中它都是虚函数。
- 一个派生类的函数如果覆盖了继承来的虚函数,则它的形参类型必须被它覆盖的基类函数完全一致;返回类型也必须相同。形参列表不同时会产生新的函数,继承的基类函数仍旧有效。
- 使用
override关键字可以明确重载,原函数中没有函数,或者参数不对应则都会产生错误。 - 如果虚函数使用默认实参,则基类和派生类中定义的默认实参最好一致。
回避虚函数的机制
可以使用作用域运算符,实现虚函数的强行绑定,而非动态绑定;例如:
double undiscounted=baseP->Quote::net_price(42);
//强行调用基类中定义的函数版本而不管baseP的动态类型到底是什么
通常情况下,只有成员函数(或者友元)中的代码才需要使用作用域运算符来回避虚函数的机制。通常是一个派生类的虚函数调用它覆盖的基类的虚函数版本时。
注意:如果一个派生类虚函数需要调用它的基类版本,但是没有使用作用域运算符,则在运行时该调用将被解析为对派生类版本自身的调用,从而导致无限递归。
15.4 抽象基类
含有纯虚函数的类是抽象基类;不能创建抽象基类的对象,只能被继承
重构:负责重新设计类的体系以便将操作或数据从一个类移动到另外一个类中。
15.5 访问控制与继承
protect:希望派生类分享但是不想被其他公共访问使用的成员。
- 受保护的成员对于类的用户来说是不可访问的。
- 受保护的成员,对于派生类的成员和友元来说是可以访问的
- 派生类或友元只能通过派生类对象来访问基类的受保护成员。派生类对于一个基类的受保护成员没有任何访问特权。
class Base{
protected:
int prot_mem; //protected 成员
};
class Sneaky:public Base{
friend void clobber(Sneaky&); //能访问Sneaky::prot_mem
friend void clobber(Base&); //不能访问Base::prot_mem
int j;
}
void clobber(Sneaky& s) {s.j=s.prot_mem=0;} //正确能访问Sneaky对象的private和protected成员
void clobber(Base& b){b.prot_mem=0;}//错误不能访问protected的成员
private 不影响派生类的访问权限,主要影响,相关函数的使用。
派生类向基类转换的可访问性
- 只有当D公有地继承B时,用户代码才能够使用派生类向基类的转换;如果D继承B的方式是保护的或者私有的,则用户代码不能使用该转换。
- 不论D以什么方式继承B,D的成员函数和友元都能使用派生类向基类的的转换;派生类向其会直接基类的类型转换对于派生类的成员和友元来说是永远可以访问的。
- 如果D继承B的方式是公有的或者受保护的,则D的派生类的成员和友元可以使用D向B的类型转换;反之,如果D继承B的方式是私有的,则不能使用
- 对于代码中的某个给定节点来说,如果基类的公有成员是可以访问的,则派生类向基类的类型转换也是可访问的;反之则不行。
友元与继承
友元关系不能继承,友元关系也不能传递,基类的友元在访问派生类成员时,不具有特殊性,类似的,派生类的友元也不能随意访问基类的成员。– 不能继承友元关系,每个类负责控制各自成员的访问权限
改变个别成员的可访问性
通过using声明可以改变派生类继承的某个名字的访问级别。
class Base{
public:
std::size_t size() const {return n;}
protected:
std::size_t;
};
class Derived: private Base{
public:
using Base::size; //保持对象尺寸相关的成员的访问级别
protected:
using Base::n; //使用using关键字改变成员变量的访问级别。
};
private using该名字能被类的成员和友元访问;public using类的所有成员都能访问。protectde using类的成员、友元和派生类是可访问的。
15.6 继承中的类作用域
每个类定义自己的作用域,;当存在继承关系时,派生类的作用域嵌套在其基类的作用域之内。如果一个名字在派生类的作用域内无法正常解析,则编译器将继续在外层的基类作用域中寻找该名字的定义。例如:
Bulk_quote bulk;
cout<<bulk.isbn();
//查找步骤:先找自身作用域内函数,再找父类,和父类的父类
静态类型:在编译时总是已知的,它是变量声明时的类型或表达式生成的类型 动态类型:变量或表达式表示的内存中的对象的类型。
注意:
- 派生类的成员将隐藏同名的基类成员
- 可用通过作用域运算符来使用一个呗隐藏的基类成员
struct Derived:Base{ int get_base_mem(){ return Base::mem; } } - 除了覆盖继承而来的虚函数之外,派生类最好不要中庸其它定义在基类中的名字。
关键概念:名字夜找与继承
理解函数调用的解析过程刘一于理解C++的继承至关重要,假定我们调用p->mem()(或者obj.mem()),则依次执行以下4个步骤:
- 首先确定p(或obj)的静态类型因为我们调用的是一个成员,所以该类型必然是类类型
- 在p(或。bj)的静态类型对应的类中查找mem如果找不到,则依次在直接基类中不断查找直至到达继承链的顶端如果找遍了该类及其基类仍然找不到,则编译器将报错
- 一旦找到了mem,就进行常规的类型检查(参见6.1节,第183页)以确认对于当前找到的mem,本次调用是否合法
- 假设调用合法,则编译器将根据调用的是否是虚函数而产生不同的代码: 一如果mem是虚函数且我们是通过引用或指针进行的调用,则编译器产生的代 码将在运行时确定到底运行该虚函数的哪个版本,依据是对象的动态类型、 一反之,如果mem不是虚函数或者我们是通过对象(而非引用或指针)进行的 调用,则编译器将产生一个常规函数调用。
struct Base{
int memfcn();
};
struct DerivPd:Base{
int memfcn(int); //隐藏基类的memfn
};
Derived d;Base b;
b.memfcn(); //调用Base::memfn
d.memfcn(10); //调用Derived::memfcn
d.memfcn(); //错误:参数列表为空的memfcn被隐藏了
d.Base::memfcn(); //正确:调用Base::memfcn()
通过基类调用隐藏的虚函数
class Base{
public:
virtual int fcn();
};
class D1:public Base{
public:
//隐藏基类的fcn,这个fcn不是虚函数
//D1继承了Base::fcn()的定义
int fcn(int); //形参列表与Base中的fcn不一致
virtual void f2(); //是一个新的虚函数,在Base中不存在
};
class D2:public D1{
public:
int fcn(int); //一个非虚函数,隐藏了D1::fcn(int)
int fcn(); //覆盖了Base的虚函数fcn
void f2(); // 覆盖了D1的虚函数f2
}
Base bobj;
D1 d1obj;
D2 d2obj;
Base *bp1=&bobj,*bp2=&d1obj,*bp3=&d2obj;
bp1->fcn(); //虚调用,将在运行时调用Base::fcn()
bp2->fcn(); //虚调用,将在运行时调用Base::fcn()
bp2->fcn(); //虚调用,将在运行时调用D2::fcn()
Base *pd=&d2obj;
D1 *p2=&d2obj;
D2 *p3=&d2obj;
p1->fcn(42); //错误:Base中没有接受一个int的fcn
p2->fcn(42); //静态绑定,调用D1::fcn(int)
p3->fcn(42); //静态绑定,调用D2::fcn(int)
类内using声明的一般规则同样适用于重载函数的名字,基类函数的每个实例在派生类中都必须是可访问的,对派生类没有重新定义的重载版本的访问,实际上是对using 声明点的访问。
15.7 构造函数与拷贝控制
虚析构函数将阻止合成移动操作:
如果一个类定义了析构函数,即使它通过=default的形式使用了合成的版本,编译器也不会为这个类合成移动操作。
派生类中删除的拷贝控制与基类的关系
某此定义基类的万式也可能导致有的派产仁类成员成为被删除的函数:
- 如果基类中的默认构造函数、拷贝构造函数、拷贝赋值运算符或析构函数是被删除的函数或艺不可访问,则派生类中对应的成员将是被删除的,原因是编译器小能使用基类成员来执行派生类对象基类部分的构造、赋值或销毁操作。
- 如果在基类中有一个不可访问或删除掉的析构函数,则派生类中合成的默认拷贝和构造函数将是被删除的,因为编译器无法销毁派生类对象的基类部分。
- 和过去一样,编译器将不会合成一个删除掉的移动操作。当我们使用=default请求一个移动操作时,如果基类中的对应操作是删除的或不可访问的,那么派生类中该函数将是被删除的,原因是派生类对象的基类部分不可移动,如果基类的析构函数是删除或不可访问的,则派牛类的移动构造函数也将是被删除的。
注意:
- 当派生类定义了拷贝或者移动操作时,该操作负责拷贝或移动包括基类部分成员在内的整个对象。
- 在默认情况下,基类默认构造函数初始化派生类对象的基类部分如果我想拷贝(或移动)基类部分,则必须在派生类的构造函数初始值列表中显地使用基类的拷贝(或移动)构造函数。
- 如果构造函数或析构函数调用了某个虚函数,则我们应该执行与构造函数或析构函数所属类型相对应的虚函数版本。
- 构造函数的using 声明不会改变该构造函数的访问级别。
- 基类构造函数的默认实参,并不会被继承。相反,派生类将获得多个继承的构造函数,其中每个构造函数分别省略掉一个含有默认实参的形参。如果一个构造函数接收两个形参后一个由模式实参,则派生类将获得两个构造函数一个函数接受两个形参(没有默认实参),另外一个构造函数只接受一个形参,它对应于基类中最左侧的没有默认值的那个形参。
- 如果派生类定义的构造函数与基类的构造函数具有相同的参数列表,则该构造函数将不会被继承。定义在派生类中的构造函数将替换继承来的构造函数
- 继承的构造函数不会被作为用户定义的构造函数来使用,如果一个类只含有继承的构造函数,则他也将拥有一个合成的默认构造函数。
15.8 容器与继承
当派生类对象被赋值给基类对象的时候,其中的派生部分将被“切掉”,因此容器和存在继承关系的类型无法兼容;因此最好在容器中放置(智能)指针而非对象
模拟拷贝 给类添加一个虚拷贝函数,该函数将申请一份当前对象的拷贝。处理动态的内存分配
class Quote{
public:
//该虚函数返回当前对象的一份动态分配的拷贝
virtual Quote* clone() const& {return new Quote(*this);} // const& 是对this的修饰,标明这个this是 const引用
virtual Quote* clone() && {return new Quote(std::move(*this));} // && 也是对this的修饰,表示由对象this指针生成的一个右值
}
第16章 模板与泛型编程
通用函数模板实现函数的泛化(函数模板的定义实现分别放在.h和cpp中将会遭遇symbol问题参考):
template <typename T>
int compare(const T &v1,const T &v2){
if(v1<v2) return -1;
if(v2<v1) return 1;
return 0;
}
cout<<compare(1,0)<<endl;// T为int
cout<<compare(vec1,vec2)<<endl; // T 为vector<int >
注意: 在模板定义中模板参列表不能为空
当使用模板的时候,我们指定模板实参,将其绑定到模板参数上。 模板类型参数,可以像内置类型或者类类型说明符一样使用。
template <typename T,class u> T foo (T* p,u test)
{
T tmp=*p; //tmp的类型将是指针p指向的类型
//...
return tmp;
}
非类型模板参数
可以在模板中定义非类型模板参数。一个非类型模板参数表示一个值而非一个类型。
template <unsigned N,unsigned M>
int compare(const char (&p1)[N],const char (&p2)[M])
{
return strcmp(p1,p2);
}
compare("hi","mom");
//编译器实例化版本
int compare(const char (&p1)[3],const char (&p2)[4]);
注意:
- 非类型模板参数的模板实参必须是常量表达式。
- 模板程序应该尽量减少对实参类型的要求。
- 编译器遇到一个模板定义的时,并不生成代码。只有当我们实例化出模板的一个特定版本时,编译器才会生成代码。
- 保证传递给模板的实参支持模板所要求的操作,以及这些操作在模板中能够正确工作,是调用者的责任。
inline和constexpr的函数模板
//正确:inline说明符跟在模板参数列表之后
template <typename T> inline T min(const T&,const T&);
//错误:inline说明符的位置不正确
inline template <typename T> T min(const T&,const T&);
16.1.2 类模板
编译器不能为类模板推断模板参数类型,为了使用类模板,我们必须在模板名后的尖括号中提供额外的信息。用来代替模板参数的模板实参列表。这也决定了使用模板的时候需要我们提供 显示模板实参;
注意:
一个类模板的每个实例都形成了一个独立的类。类型Blob<string>与任何其他Blob类型都没有关联,也不会对任何其它Blob类型的成员有特殊访问权限。
//定义模板类
template <typename T> class Blob
{
public:
typedef T value_type;
typedef typename std::vector<T>::size_type size_type;
Blob(std::initializer_list<T> il);
}
//模板类成员
template <typename T>
T& Blob<T>::back()
{
check(0,"back on empty Blob");
return data->back();
}
template <typename T>
T& Blob<T>::operator[](size_type i)
{
//如果i太大,check会抛出异常,阻止访问一个不存在的元素
check(i,"subscript out of range");
return (*data)[i];
}
默认情况下,一个类模板的成员函数只有当程序用到它时才进行实例化。如果成员函数没有被使用,则它不会被实例化。
在类模板自己的作用域中,我们可以直接使用模板名而不提供实参
在类模板外使用类模板名时,我们并不在类的作用域中,直到遇到类名才表示进入类的作用域
template <typename T>
BlobPtr<T> BlobPtr<T>::operator++(int)
{
//此处无需检查;调用前置递增时会进行检查
BlobPtr ret=*this; //保存当前值
++*this; //推进一个元素;前置++检查递增是否合法
return ret; //返回保存的状态
}
在一个类模板的作用域内,我们可以指直接使用模板名而不必指定模板实参。
可以使用typedef来定义模板类的别名。
一个static成员函数只有在使用的时候才会实例化。
16.1.3 模板参数
一个模板参数名的可用范围是在其声明之后,至模板声明或定义结束之前。模板参数会隐藏外层作用域中声明的相同的名字。与大多数其他上下文不同,在模板内不能重用模板参数名。
typedef double A;
template <typename A,typename B> void f(A a,B b)
{
A tmp=a;// tmp的类型为模板参数A的类型,而非double
double B; //错误: 重声明模板参数
}
模板声明
//声明但不定义compare和Blob
template <typename T> int compare(const T &,const T&)
template <typename T> class Blob;
一个特定文件所需要的所有模板的声明通常一起放置在文件开始位置,出现与任何使用这些模板的代码之前
注意:
当我们希望通知班一起一个名字表示类型的时候,必须使用关键字typename,而不能使用class;
对于static修饰的函数使用函数模板的时候,为了处理模板,编译器必须知道名字是否表示一个类型。默认情况下,c++语言假定通过作用域运算访问的名字不是类型。使用一个模板类型参数的类型成员,就必须显示告诉编译器该名字是一个类型,使用typename实现
template <typename T>
typename T::value_type top(const T& c)
{
if(!c.empty())
return c.back();
else
retrun typename T::value_type();
}
默认模板实参 c++11允许为函数和类模板提供默认实参。例如:
template <typename T,typename F=less<T> >
int compare(const T &v1,const T &v2, F f=F())
{
if(f(v1,v2)) return -1;
if(f(v2,v1)) return 1;
return 0;
}
//compare 有一个默认模板实参 less<T> 和一个默认函数实参F()
template <class T=int> class Numbers{ //T 默认为int
public:
Numbers(T v=0):val(v){}
}
16.1.4 成员模板
一个类可以包含本身就是模板的成员函数。这种成员被称为 成员模板。成员模板不能是函数。
class DebugDelete{
public:
DebugDelete(std::ostream &s=std::cerr):os(s){}
//与任何函数模板相同,T的类型由编译器推断
template <typename T> void operator() (T *p) const
{os<<"deleting unique_ptr"<<std::endl;delete p;}
private:
std::ostream &os;
}
16.1.5 控制实例化
模板使用的时候会通过编译器推断,生成对应类型的函数。当两个或者多个独立编译的源文件使用了相同的模板,并提供了相同的模板参数时,每个文件中就都会有该模板的一个示例,使得相同模板的额外开销特别严重。在新标准中通过 显示实例化来避免这种开销。 先声明再实例化,但是extern 声明必须出现在任何使用实例化版本的代码之前。参考链接
extern template declaration; //示例化声明
template declaration; //实例化定义
//下面的这些模板类型必须在程序其它位置进行实例化
extern template class Blob<string>;
extern template int compare(const int&.const int&);
Blob<string> sa1,sa2; //示例化会出现在其它位置
Blob<int> a1={0,1,2,3,4,5,6,7,8,9};
Blob<int> a2(a1); //拷贝构造函数在本文件中实例化
int i=compare(a1[0],a2[0]); //实例化出现在其它位置
//templateBuild.cc
//实例化文件必须为每个在其它文件中声明为extern的类型和函数提供一个(非extern)的定义
template int compare(const int&,const int&);
template class Blob<string>;
//实例化类模板的所有成员
当编译器遇到一个实例化定义(与声明相对)时,它为其生成代码。需要将生成的.o文件链接到一起。
注意:
- 对每个实例化声明,在程序中某个位置必须有其显示的实例化定义。
- 一个类模板的示例化定义会实例化该模板的所有成员,包括内联的成员函数。
- 在一个类模板的实例化定义中,所用类型必须能用于模板的所有成员函数。
16.2 模板实参推断
编译器利用调用中的函数实参来确定其模板参数的过程被称为 模板实参推断。在模板实参推断过程中,编译器使用函数调用中的实参类型来寻找模板实参,用这些模板实参生成的函数版本与给定的函数调用最为匹配。
- 顶层
const无论是在形参还是实参中,都会被忽略。 - const转换:可以将一个非const对象的引用(或指针)传递给一个const的引用(或指针)形参。
- 数组或函数指针转换:如果函数形参不是引用来兴,则可以对数组或者函数类型的实惨应用正常的指针转换。一个数组实参可以转化为一个指向其首元素的指针。类似的,一个函数实参可以转换为一个该函数类型的指针。
不能应用与函数模板的转换
- 算术转换
- 派生类向基类的转换
- 用户定义的转换 使用示例:
template <typename T> T fobj(T,T); //实参拷贝
template <typename T> T fref(const T&,const T&); //引用
string s1("a value");
const string s2("nihao ");
fobj(s1,s2); //调用fobj(string,string);const 被忽略
fref(s1,s2);//调用fref(const string&,const string&) 将s1转换为const是允许的
int a[10],b[42];
fobj(a,b); //调用 f(int*,int*)
fref(a,b); //错误:数组类型不匹配;如果形参是一个引用,则数组不会转换为指针,大小不匹配因此不合法。
注意:
- 将实参传递给带模板类型的函数形参时,能够自动应用的类型转换只有const转换及数组或函数到指针的转换。
- 如果函数参数类型不是模板参数,则对实参进行正常的类型转换。
16.2.2 函数模板显示实参
指定显式模板实参
定义返回类型的第三个模板参数,从而允许用户控制返回类型:
template <typename T1,typename T2,typename T3>
T1 sum(T2,T3);
//编译器无法推断T1,它未出现在函数参数列表中
//显示指定T1帮助实参进行类型推断。
auto val3=sum<long long>(i,lng); // long long sum(int ,long)
//用户必须指定所有三个模板参数
template <typename T1,typename T2, typename T3>
T3 alternative_sum(T2,T1);
//错误:不能推断前几个模板参数
auto val3=alternative_sum<long long>(i,lng);
//正确: 显示指定了所有三个参数
auto val2=alternative_sum<long long ,int,long>(i,lng);
显式模板实参按照由左至右的顺序与对应的参数模板匹配
16.2.3 尾置返回类型与类型转换
尾置返回允许我们在参数累彪之后声明返回类型;编译器会根据实例化的输入,动态判断返回类型。
template <typename It>
auto fcn(It beg,It end)->decltype(*beg)
{
//处理序列
return *beg; // 返回序列中一个元素的引用
}
template <typename It>
auto fcn2(It beg,It end)->
typename remove_reference<decltype(*beg)>::type //获取元素类型
//decltype(*beg)返回元素类型的引用类型
//remove_reference::type 脱去引用,剩下元素类型本身
{
//处理序列
return *beg; // 返回序列中一个元素的拷贝
}
标准类型转换模板
对Mod<T>,其中Mod为 |
若T为 |
则Mod<T>::type为 |
|---|---|---|
remove_reference |
X&或X&& |
X |
| 否则 | T |
|
add_const |
X&或const X或函数 |
T |
| 否则 | const T |
|
add_lvalue_reference |
X& |
T |
X&& |
X& |
|
| 否则 | T& |
|
add_rvalue_reference |
X&或X&& |
T |
| 否则 | T&& |
|
remove_pointer |
X* |
X |
| 否则 | T |
|
add_pointer |
X&或X&& |
X* |
| 否则 | T* |
|
make_signed |
unsigned X |
X |
| 否则 | T |
|
make_unsigned |
带符号类型 | unsigned X |
| 否则 | T |
|
remove_extent |
X[n] |
X |
| 否则 | T |
|
remove_all_extent |
X[n1][n2]... |
X |
| 否则 | T |
16.2.4 函数指针和实参推断
可以使用指针指向模板函数的实例;
template <typename T> int compare(const T&,const T&);
//指针pf1指向实例 int compare(const int&, const int&)
int (*pf1)(const int& ,const int&)=compare
//pf1中参数的类型决定了T的模板实参的类型
当参数是一个函数模板实例的地址时,程序上下文必须满足对每个模板参数,能唯一确定其类型或值。
16.2.5 模板实参推断和引用
从左值引用函数参数推断类型
template <typename T> void f1(T&); //实参必须是一个左值
//实参类型为模板参数类型
f1(i); // i是int T是int
f1(ci);//ci 是const int;模板参数T是const int
f1(5); // 错误传递给&参数的实参必须是一个左值
template <typename T> void f2(const T&); // 可以接受一个右值
//f2中的参数是const &;实参中的const 是无关的。
//在每个调用中,f2的函数参数都被推断为 const int&
f2(i); //模板参数是int
f2(ci); // 模板参数是 int
f2(5); //一个const &参数可以绑定到一个右值;T是int
从右值引用函数参数推断类型
类型推断过程类似普通左值引用函数参数的推断过程。
引用折叠和右值引用参数
- 当文将一个左值传递给函数的右值引用参数,且此右值引用指向模板类型参数(T&&)时,编译器推断模板类型参数为实参的左值引用类型。因此,当使用f3(i)时,编译器推断T的类型为int&,而非int
- 如果我们间接创建一个引用的引用,则这些引用形成了“折叠”。在所有情况下,引用会折叠成一个普通的左值引用类型。
- 特殊情况下,引用会折叠成右值引用:右值引用的右值引用。即,对于一个给定类型X:
- X& &、X& &&和X&& &都折叠成类型X&
- 类型X&& && 折叠成X&&
- 引用折叠只能应用于间接创建的引用的引用,如类型别名或模板参数。
折叠规则和右值引用的特殊类型推断规则结合在一起的时候,可以左值调用f3,编译器推断T为一个左值引用类型:
f3(i); //实参是一个左值;模板参数T是 int&
f3(ci); //实参是一个左值;模板参数T是一个const int&
void f3<int&>(int& &&); //当T是int&时,函数参数为int& &&
void f3<int&>(int&); //当T是int&时,函数参数折叠为 int&
结果:
- 如果一个函数参数是一个指向模板类型参数的右值引用(如,T&&),则它可以被绑定到一个左值;可以传递给它任意类型的实参。
- 如果一个左值传递给这样的参数,则函数参数被示例化为一个普通的左值引用(T&)。
接受右值引用参数的模板函数
template <typename T> void f3(T&& val)
{
T t=val; //右值调用f3,f3(42),T为int ;左值i调用f3,T为int&;t类型为 int& .t的初始化值绑定到了val,对t赋值时,也改变了val的值。在下面的判断中永远得到true
t=fcn(t);//当T为右值时,职高部t,当T为左值时,都改变
if(val==t){
/*若T是引用类型,则一直为true*/
}
}
template <typename T> void f(T&&); //绑定到非const右值
template <typename T> void f(const T&); //左值和const右值
16.2.6 理解std::move
std::move的定义:
template <typename T>
typename remove_reference<T>::type&& move(T&& t)
{
return static_cast<typename remove_reference<T>::type&& >(t);
}
// move的函数参数T&&是一个指向模板类型参数的右值引用。通过引用折叠,参数可以与任何类型的实参匹配。
//接下来使用remove_reference获取T的真实类型
//最后使用静态指针变量使得获得指针的右值引用。
16.2.7 转发
- 如果一个函数参数是指向模板类型参数的右值引用(如T&&),它对应的实参的const属性和左值/右值属性将得到保持。
- 当用于一个指向模板参数类型的右值引用函数参数(T&&)时,forward会保持实参类型的所有细节。
- 与
std::move相同,对std::forward不使用using声明是一个号主意。
对于模板函数,尽量使用右值引用,避免被使用时,末班类型的推导失去&符号,造成拷贝使用。相关参数不能使用。
16.3 重载与模板
函数匹配规则与影响:
- 对于一个调用,其候选函数包括所有模板实参推断成功的函数模板实例。
- 候选的函数模板总是可行的,因为模板实参推断会排除任何不可行的模板
- 可行函数(模板与非模板)按照类型转换来排序;可以用于函数模板调用的类型转换是非常有限的。
- 如果存在多个匹配函数则:
- 同样号的函数中只有一个是非模板函数,选择此函数
- 没有非模板函数,其中一个模板比其它模板更特例话,则选择此模板
- 不符合上述两条规则,此调用有歧义。
注意: 正确定义一组重载的函数模板需要对类型间的关系及模板函数允许的有限的实参类型转换有深刻的理解。
编写重载模板
例如:debug_rep(const T&);本质上可以用于任何类型,包括指针类型。
注意:
- 当有多个重载模板对一个调用提供童颜好的匹配时,应该选择最特例化的版本。
- 对于一个调用,如果一个非函数模板与一个函数模板提供同样好的匹配,则选择非模板版本。
对于cout<<debug_rep("hi word!")<<endl;而言有:
debug_rep(const T&),T被绑定到char[10]。debug_rep(T*),T被绑定到const char。debug_rep(const string&),要求从const char*到string的类型转换。
T*版本更加特例化,编译器会选择它。
注意: 在定义任何函数之前,记得声明所有重载的函数版本。这样就不必担心编译器由于未遇到你希望调用的函数而实例化一个非你所需要的版本。
16.4 可变参数模板
可变参数模板:接受一个可变数目参数的模板函数或模板类。可变数目的参数被称为 参数包。
参数包分为两种:
- 模板参数包:表示0或者对个模板参数。
- 函数参数包:表示0或者多个函数参数。
使用class...或者typename...指出接下来的参数表示0个或者多个类型的列表;一个类型名后面跟一个省略号表示0或者多个给定类型的非类型参数的列表。例如:
//Args 是一个模板参数包;rest 是一个函数参数包
//Args 表示0个或多个模板类型参数
//rest 表示0个或者多个函数参数
template <typename T,typename... Args>
void foo(const T &t,const Args& ... rest);
//使用
int i=0;
double d=3.14;
string s="how now brown cow";
foo(i,s,42,d);//包中有三个参数
foo(s,42,"hi");//包中有两个参数
foo(d,s); //包中有一个参数
foo("hi"); //空包
//编译器会分别为他们实例化不同的版本。
//可以使用sizeof...运算符,计算包中有多少个元素
template<typename ... Args> void g(Args ...args){
cout<<sizeof...(Args)<<endl; //类型参数的数目
cout<<sizeof...(args)<<endl; //函数参数的数目
}
16.4.1 编写可变参函数模板
可变参函数通常是递归的。第一步调用处理包中的第一个实参,然后用剩余实参调用自身。我们的print函数也是这样的模式,每次递归调用将第二个实参打印到第一个实参表示的流中。为了终止递归,我们还需要定义一个非可变参数的print 函数,它接受一个流和一个对象。
template <typename T>
//最后一次会优先调用它
ostream &print(ostream &os,const T &t)
{
return os<<t; //包中最后一个元素之后不打印分隔符
}
//包中除了最后一个元素之外的其它元素都会调用这个版本的print
template <typename T,typename... Args>
ostream &print(ostream &os,const T &t,const Args&... rest)
{
os<<t<<","; //打印第一个实参
return print(os,rest...);//递归调用,打印其它实参
}
当定义可变参数版本的print时,非可变参数版本的声明必须在作用域中。否则,可变参数版本会无限递归。
16.4.2 包扩展
包括展:将它分解为构成的元素,对每个元素应用模式,获得扩展后的列表。
template <typename T,typename... Args>
ostream &print(ostream &os,const T &t,const Args&... rest)//扩展Args
{
os<<t<<",";
return print(os,rest...); //扩展rest
}
注意:
- 扩展中的模式会独立地应用与包中的每个元素。
16.4.3 转发参数包
参考链接: std::forward;c++11 完美转发 std::forward(); C++11 std::move和std::forward
使用可变参数模板与forward机制来编写函数,实现将实参不变地传递给其它函数。使用示例如下:
class StrVec{
public:
template <class... Args> void emplace_back(Args&&...);
...
};
//函数实现
template <class... Args>
inline void StrVec::emplace_back(Args&&... args)
{
chk_n_alloc(); //如果需要的话,重新分配StrVec内存空间
alloc.construct(frist_free++,std::forward<Args>(args)...);
}
使用扩展std::forward<Args>(args)...它即扩展了模板参数包Args,也扩展了函数参数包args。生成如下形式元素:
`std::forward<Ti>(ti)`
对于std::forward<Ti>(ti);其中Ti表示模板参数包中第i个元素的类型,ti表示函数参数包中第i个元素。例如:
svec.emplace_back(10,'c'); //将c*10添加为新的尾部元素
construct调用中的模式会扩展出:
std::forward<int>(10),std::forward<char>(c)。
16.5 模板特例化
特例化版本就是模板的一个独立定义,在其中一个或多个模板参数被指定为特定的类型。 定义函模板特例话
特例话一个模板时,必须为原模板中的每个模板参数都提供实参。为了指出我们正在实例化一个模板,应使用关键字template后跟一个空尖括号对(<>`)。指出我们将为原模板的所有模板参数提供实参:
//compare 的特殊版本,处理字符串数组的指针
template <>
int compare(const char* const &p1, const char* const &p2)
{
return strcmp(p1,p2);
}
在使用特例化版本时,函数参数类型必须与一个先前声明的模板中对应的类型匹配。
template <typename T> int compare(const T&,const T&);
特例化版本的本质上是一个实例化模板,而非重载它。因此,特例化不影响函数匹配。 特例化版本主要是为了,提供特殊函数优先级,方便在使用函数时,优先搜索。 类模板特例化 示例:
namespace std{
template <> //定义特例化版本,模板参数为Sales_data
struct hash<Sales_data> //特例化模板名为hash
{
...
};
}
注意:特例化版本应该尽量在头文件中事先定义。
类模板部分特例化
我们只能部分特例化类模板函数,而不能部分特例化函数模板。
//原始的最通用版本
template <class T> struct remove_reference
{
typedef T type;
};
// 部分特例化版本,将用于左值引用和右值引用
template <class T> struct remove_reference<T&> //左值引用
{
typedef T type;
};
template <class T> struct remove_reference<T&&> //右值引用
{
typedef T type;
};
//使用
int i;
//decltype(42)为int,使用原始模板
remove_reference<decltype(42)>::type a;
//decltype(i)为int&,使用第一个(T&)部分特例化版本
remove_reference<decltype(i)>::type b;
//decltype(std::move(i))为int&& ,使用第二个(即 T&&)部分特例化版本
remove_reference<decltype(std::move(i)>::type c;
特例化成员
template <typename T> struct Foo
{
Foo(const T &t=T()):mem(t) { }
void Bar() {/*...*/}
T mem;
...
};
//特例化模板函数
template <>
void Foo<int>::Bar()
{
//进行应用于int的特例化处理
}
//实例化操作
Foo<string > fs; //实例化Foo<string>::Foo()
fs.Bar(); //实例化 Foo<string>::Bar()
Foo<int> fi; //实例化 Foo<string>::Foo()
fi.Bar(); //使用我们特例化版本的Foo<int>::Bar()
第IV部分高级主题
第17 章标准库特殊设施
标准库设施是:tuple 、bittest、随机生成数及正则表达式。
17.1 tuple 类型
tuple类似于pair是将一些数据组合成单一的对象。可以将其看做一个“快速随意”的数据结构
tuple支持的操作
| 操作 | 含义 |
|---|---|
tuple<T1,T2,...,Tn> t; |
t是一个tuple,成员数为n,第i个成员的类型为Ti。所有成员都进行值初始化 |
tuple<T1,T2,...,Tn> t(v1,v2,...,vn); |
t是一个tuple,成员数为n,第i个成员的类型为Ti。所有成员都使用vi进行值初始化 |
make_tuple(v1,v2,...,vn) |
返回一个给定初始值初始化的tuple。tuple的类型从初始值的类型推断 |
t1=t2 |
当两个tuple具有相同数量的成员且成员对应相等时 |
t1!=t2 |
当两个tuple具有相同数量的成员且成员对应相等时之外的情况 |
t1 relop t2 |
tuple的关系运算符使用字典序。两个tuple必须具有相同数量的成员。使用<运算符比较t1的成员和t2中的对应成员 |
get<i>(t) |
返回t的第i个数据成员的引用;如果t是一个左值,结果是一个左值引用;否则,结果是一个右值引用。tuple的所有成员都是public的 |
tuple_size<tupleType>::value |
一个类模板,可以通过一个tuple类型来初始化。它有一个名为value的public constecpr static 数据成员,类型为size_t,表示给定tuple类型中成员的数量。 |
tuple_element<i,tupleType>::type |
一个类模板,可以通过一个整形常量和一个tuple类型来初始化。它有一个名为type的public成员,表示给定tuple类型中指定成员的类型。 |
使用示例:
//定义和初始化
tuple<size_t,size_t,size_t> threeD; //成员都初始化为0
tuple<string,vector<double>,int,list<int> > someVal("constants",{3.14,2.718},42,{0,1,2,3,4,5});
tuple<size_t,size_t,size_t> threeD2{1,2,3};
auto item=make_tuple("0-999-78345-X",x,20.00);
//成员的访问
auto book=get<0>(item); //返回第一个成员
//细节信息访问
typedef decltype(item) trans; // trans 是item的类型
//返回trans类型对象中成员的数量
size_t sz=tuple_size<trans>::value; //返回3
//获取第二个成员的类型
tuple_element<1,trans>::type cnt=get<1>(item); // cnt 是一个int
tuple常见用法是,函数返回多个值
17.2 bitset类型
标准库定义了bitset类,使得位运算的使用更为容易,并且能够处理超过最长整形类型大小的位集合。bitset类定义在头文件bitset中。bitset类是一个模板,它类似array类,具有固定的大小。可以在定义时声明:
bit<32> bitvec(1U); // 32位;低位为1,其他位为0
大小必须是一个常量表达式
初始化bitset方法
| 操作 | 含义 |
|---|---|
bitset<n> b; |
b有n位;每位均为0.此构造函数是一个constexpr |
bitset<n> b(u); |
b是unsigned long long值u的低n位的拷贝。如果n大于unsigned long long 的大小,则b中超出的高位被置为0.此构造函数是一个constexpr |
bitset<n> b(s,pos,m,zero,one); |
b是string s从位置pos开始m个字符符拷贝。s只能包含字符zero或one;如果s包含任何其它字符,构造函数会抛出invalid_argument异常。字符在b中分别保存为zero和one。pos默认为0,m默认为string::npos,zero 默认为0,one默认为1 |
bitset<n> b(cp,pos,m,zero,one); |
与上一个构造函数相同,但从cp指向的字符串数组中拷贝字符,如果m未提供,则cp必须指向一个c风格字符串,如果提供了m,则从cp开始必须至少有m个zero或one字符 |
使用示例:
// bitvec1初始值小;初始值中的高位被丢弃
bitset<13> bitvec1(0xbeef); // 二进制位序列为 1111011101111
//比初始值大;高位被置为0
bitset<20> bitvec2(0xbeef); // 二进制位序列为 0000101111011101111
//64 位机中, long long 0ULL 是64个0比特,因此~0ULL是64个1
bitset<128> bitvec3(~0ULL); // 0~63 位为1; 63~127位为0
//string 初始化 bitset
bitset<32> bitvec4("1100"); //2、3 两位为1,剩余两位为0;高位被置为0。
注意:
string 的下标编号习惯与bitset恰好相反;string中下标最大的字符(最右字符)用来初始化bitset中的低位(下标为0的二进制位)。
string str("1111111000000011001101");
bitset<32> bitvec5(str,5,4); // 从str[5]开始的四个二进制位,1100
bitset<32> bitvec6(str,str.size()-4); //使用最后四个字符

17.2.2 bitset操作
bitset操作表
| 操作 | 含义 |
|---|---|
b.any() |
b中是否存在置位的二进制位 |
b.all() |
b中所有位都置位了吗 |
b.none() |
b中不存在位置的二进制位吗 |
b.count() |
b中置位的位数 |
b.size() |
一个constexpr函数,返回b中的位数 |
b.test(pos) |
若pos位是置位的,则返回true,否则返回false |
b.set(pos,v) |
将位置pos处的位设置为bool值v。v默认为true。如果未传递实参,将b中所有位置复位 |
b.set() |
|
b.reset(pos) |
将位置pos处的位复位或将b中所有位复位 |
b.reset() |
|
b.flip(pos) |
改变位置pos处的位的状态或改变b中每一位的状态 |
b.flip() |
|
| b[pos] | 访问b中位置pos处的位,如果b是const的,则当该位置位时b[pos]返回一个bool值true,否则返回fasle |
b.to_ulong()/b.to_ullong() |
返回一个unsigned long 或者一个unsigned long long值,其位模式与b相同。如果b中位模式不能放入指定的结果类型,则抛出一个overflow_error异常 |
b.to_string(zero,one) |
返回一个string,表示b中的位模式。zero和one的默认值分别为0和1,用来表示b中的0和1 |
os<<b |
将b中二进制位打印为字符1或者0,打印到流os |
is>>b |
从is读取字符存入b。当下一个字符不是1或者0时,或是已经读入b.size()个位时,读取过程停止 |
提取bitset的值
unsigned long ulong=bitvec3.to_ulong();
cout<<"ulong ="<<ulong<<endl;
注意:
- 如果bitset中的值不能放入给定类型中,则这两个操作会抛出一个
overflow_error异常
bitset的IO运算符
bitset<16> bits;
cin>> bits; // 从cin读取最多16个0或1
cout<<"bits: "<<bits<<endl; //打印刚刚读取的内容
17.3 正则表达式
参考链接: regex;
正则表达式是一种描述字符序列的方法,是一种极其强大的计算工具。本章重点介绍正则表达式库(RE)
正则表达式库组件
| 组件 | 含义 |
|---|---|
regex |
表示有一个正则表达式的类 |
regex_match |
将一个字符序列与一个正则表达式匹配 |
regex_search |
寻找第一个与正则表达式匹配的子序列 |
regex_replace |
使用给定格式替换一个正则表达式 |
sregex_iterator |
迭代适配器,调用regex_sreach来遍历一个string中所有匹配的子串 |
smatch |
容器类,保存在string中搜索的结果 |
ssub_match |
string中匹配的子表达式的结果 |
regex_search和regex_match的参数
| 参数 | 解释 |
|---|---|
(seq,m,r,mft) |
在字符序列seq中查找regex对象r中的正则表达式。seq可以是一个string、表示范围的一对迭代器以及一个指向空字符皆为的字符数组的指针 |
(seq,r,mft) |
m是一个match对应,用来保存匹配结果的相关细节,m和seq必须具有兼容的类型 |
mft是一个可选的regex_constants::match_flag_type值。他们会影响匹配过程 |
正则表达式简单使用示例
//查找不在字符c之后的字符串ei
string pattern("[^c]ei");
//包含pattern的整个单词
pattern="[[:alpha:]]*"+pattern+"[[:alpha:]]*";
regex r(pattern); //构造一个用于查找模式的regex
smatch result; //定义一个对象保存搜索结果
//定义一个string保存于模式匹配和不匹配的文本
string test_str="receipt freind theif receive";
//查找匹配的字符串
if(regex_search(test_str,result,r)){
std::cout<<result.str()<<endl; //打印匹配的单词
}
regex(和wregex)选项
| 选项 | 含义 |
|---|---|
regex r(re) |
re表示一个正则表达式,它可以是一个string、一个表示字符范围的迭代器对、一个指向空字符结尾的字符数组的指针、一个字符指针和一个计数器或是一个花括符包围的字符列表。 |
regex r(re,f) |
f是指出对象如何处理的标志。通过下面列出的值来设置。如果未指定f,其摩恩值为ECMAScript |
r1=re |
将r1中的正则表达式替换为re。re表示一个正则表达式,它可以是另外一个regex对象、一个string、一个指向空字符结尾的字符串数组的指针或是一个花括号保卫的字符串列表 |
r1.assign(re,f) |
与使用赋值运算符(=)效果相同;可选的标志f也与regex的构造函数中对应的参数含义相同 |
r.mark_count() |
r中子表达式的数目 |
r.flags |
返回r的标志 |
定义regex时指定的标志 定义则regex和regex_constants::syntax_option_type中
| 选项 | 含义 |
|---|---|
icase |
在匹配过程中忽略大小写 |
nosubs |
不保存匹配的子表达式 |
optimize |
执行速度优先于构造速度 |
ECMAScript |
使用ECMA-262指定的语法 |
basic |
使用POSIX基本的正则表达式语法 |
extended |
使用POSIX扩展的正则表达式语法 |
awk |
使用POSIX版本的awk语言的语法 |
grep |
使用POSIX版本的grep的语法 |
egrep |
使用POSIX版本的egrep的语法 |
std::regex_match使用示例
// regex_match example
#include <iostream>
#include <string>
#include <regex>
int main ()
{
if (std::regex_match ("subject", std::regex("(sub)(.*)") ))
std::cout << "string literal matched\n";
const char cstr[] = "subject";
std::string s ("subject");
std::regex e ("(sub)(.*)");
if (std::regex_match (s,e))
std::cout << "string object matched\n";
if ( std::regex_match ( s.begin(), s.end(), e ) )
std::cout << "range matched\n";
std::cmatch cm; // same as std::match_results<const char*> cm;
std::regex_match (cstr,cm,e);
std::cout << "string literal with " << cm.size() << " matches\n";
std::smatch sm; // same as std::match_results<string::const_iterator> sm;
std::regex_match (s,sm,e);
std::cout << "string object with " << sm.size() << " matches\n";
std::regex_match ( s.cbegin(), s.cend(), sm, e);
std::cout << "range with " << sm.size() << " matches\n";
// using explicit flags:
std::regex_match ( cstr, cm, e, std::regex_constants::match_default );
std::cout << "the matches were: ";
for (unsigned i=0; i<cm.size(); ++i) {
std::cout << "[" << cm[i] << "] ";
}
std::cout << std::endl;
return 0;
}
/*
result:
string literal matched
string object matched
range matched
string literal with 3 matches
string object with 3 matches
range with 3 matches
the matches were: [subject] [sub] [ject]
*/
注意:
一个正则表达式的语法是否正确是在运行时解析的。可以使用regex_error来抛出异常。
异常类型表
| 异常类型 | 含义 |
|---|---|
error_collate |
The expression contained an invalid collating element name. |
error_ctype |
The expression contained an invalid character class name. |
error_escape |
The expression contained an invalid escaped character, or a trailing escape. |
error_backref |
The expression contained an invalid back reference. |
error_brack |
The expression contained mismatched brackets ([ and ]). |
error_paren |
The expression contained mismatched parentheses (( and )). |
error_brace |
The expression contained mismatched braces ({ and }). |
error_badbrace |
The expression contained an invalid range between braces ({ and }). |
error_range |
The expression contained an invalid character range. |
error_space |
There was insufficient memory to convert the expression into a finite state machine. |
error_badrepeat |
The expression contained a repeat specifier (one of *?+{) that was not preceded by a valid regular expression. |
error_complexity |
The complexity of an attempted match against a regular expression exceeded a pre-set level. |
error_stack |
There was insufficient memory to determine whether the regular expression could match the specified character sequence. |
注意: 正则表达式的编译是一个非常慢的操作,特别是你在使用了扩展的正则表达式语法或者复杂的正则表达式的时候。应该尽量避免使用。
正则表达式库类
| 如果输入序列类型 | 则使用正则表达式类 |
|---|---|
string |
regex、smatch、ssub_match和sregex_iterator |
const char* |
regex、smatch、ssub_match和cregex_iterator |
wstring |
wregex、wsmatch、wssub_match和wsregex_iterator |
const wchar_t* |
wregex、wsmatch、wcsub_match和wcregex_iterator |
ECMAScript正则表达式语句基本特性
\{d}表示单个数字而\{d}{n}则表示一个n个数字的序列。如,\{d}{3}匹配三个数组的序列。- 在方括号中的字符集和表示匹配这些字符中任意一个。如
[-. ]匹配一个-或.或 - 后接’?’的组件是可以选的。如,
\{d}{3}[-. ]?\{d}{4}匹配这样的序列:开始是三个数字,后接一个可选的短横线或点或空格,然后是四个数字。 - 使用反斜线
\表示一个字符本身而不是其特殊含义。因此必须使用\(和\)来表示括号是我们模式的一部分而不是特殊字符。 - 由于反斜线是c++中的特殊字符,在模式中,每次出现
\的地方,我们都必须使用一个额外的反斜线来告诉c++我们需要一个反斜线字符而不是特殊符号。例如\\{d}{3}来表示正则表达式\{d}{3}
一个正则表达式的字符串分析:
"(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ]?)(\\d{4})";
整个正则表达式包含一个字表达式: (ddd)分隔符ddd分隔符dddd。剥离子表达式:
(\\()?表示区号可选的左括号(\\d{3})表示区号(\\))?表示区号部分可选的右括号([-. ])?表示区号部分可选的分隔符(\\d{3})表示号码的下三位数字[-. ]?表示可选的分隔符(\\d{4})表示号码的最后四位数字
使用示例:
string phone="(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ]?)(\\d{4})";
regex r(phone); // regex对象,用于查找我们的模式
smatch m;
string s;
//从文件中读取每条记录
while (getline(cin,s)){
//对每个匹配的电话号码
for(sregex_iterator it(s.begin(),s.end(),r),end_it;it!=end_it;++it){
//检查号码的格式是否合法
if(valid(*it)){
std::cout<<"valid:"<<it->str()<<endl;
}else{
cout<<"not valid:"<< it->str()<<endl;
}
}
}
regex_replace
参考链接: regex_replace;
正则表达式替换操作
// regex_replace example
#include <iostream>
#include <string>
#include <regex>
#include <iterator>
int main ()
{
std::string s ("there is a subsequence in the string\n");
std::regex e ("\\b(sub)([^ ]*)"); // matches words beginning by "sub"
// using string/c-string (3) version:
std::cout << std::regex_replace (s,e,"sub-$2");
// using range/c-string (6) version:
std::string result;
std::regex_replace (std::back_inserter(result), s.begin(), s.end(), e, "$2");
std::cout << result;
// with flags:
std::cout << std::regex_replace (s,e,"$1 and $2",std::regex_constants::format_no_copy);
std::cout << std::endl;
return 0;
}
/*
result :
there is a sub-sequence in the string
there is a sequence in the string
sub and sequence
*/
正则表达式匹配选项
| flag* | effects | notes |
|---|---|---|
match_default |
Default | Default matching behavior. This constant has a value of zero**. |
match_not_bol |
Not Beginning-Of-Line | The first character is not considered a beginning of line (“^” does not match). |
match_not_eol |
Not End-Of-Line | The last character is not considered an end of line (“$” does not match). |
match_not_bow |
Not Beginning-Of-Word | The escape sequence “\b” does not match as a beginning-of-word. |
match_not_eow |
Not End-Of-Word | The escape sequence “\b” does not match as an end-of-word. |
match_any |
Any match | Any match is acceptable if more than one match is possible. |
match_not_null |
Not null | Empty sequences do not match. |
match_continuous |
Continuous | The expression must match a sub-sequence that begins at the first character.Sub-sequences must begin at the first character to match. |
match_prev_avail |
Previous Available | One or more characters exist before the first one. (match_not_bol and match_not_bow are ignored) |
format_default |
Default formatting | Uses the standard formatting rules to replace matches (those used by ECMAScript’s replace method). This constant has a value of zero**. |
format_sed |
sed formatting | Uses the same rules as the sed utility in POSIX to replace matches. |
format_no_copy |
No copy | The sections in the target sequence that do not match the regular expression are not copied when replacing matches. |
format_first_only |
First only | Only the first occurrence of a regular expression is replaced. |
string fmt="$2.$5.$7"; //将号码格式改为 ddd.ddd.dddd
regex r(phone); //用来寻找模式的regex对象
string number="(908) 555-1800";
cout<<regex_replace(number,r,fmt)<<endl;
17.4 随机数
参考链接: random;
c++中的随机数标准库定义在random头文件中。包含 随机数引擎类(random-number engines)和 随机数分布类(random-number distribution)。一个引擎类可以生成unsigined随机数序列,一个分布类使用一个引擎类生成指定类型的、在戈丁范围内的、服从特定概率分布的随机数。
注意:
c++程序不应该使用库函数rand,而应该使用default_random_engine类和恰当的分布类对象。
17.4.1 随机数引擎和分布
注意:
- 使用随机数引擎应该使用
static关键字修饰。从而每次都生成新的数,否则产生的两次数可能相同。 - 一个给定的随机数发生器一直会生成相同的随机数序列,一个函数如果定义了局部的随机数发生器,应该将其(包括引擎和分布对象)定义为static的。否则,每次调用函数都会生成相同的序列。
vector<unsigned> good_randVec()
{
//定义为static的,从而每次调用都生成新的数
static default_random_engine e;
static uniform_int_distribution<unsigned> u(0,9);
vector<unsigned> ret;
for(size_t i=0;i<100;++i){
ret.push_back(u(e));
}
return ret;
}
随机数引擎基本操作
| 操作 | 含义 |
|---|---|
Engine e |
默认构造函数;使用该引擎类型默认的种子 |
Engine e(s) |
使用整型值s作为种子 |
e.seed(s) |
使用种子s重置引擎的状态 |
e.min() |
此引擎可生成的最大和最小值 |
设置随机数种子 通过设置随机数种子引擎可以产生不同的随机数结果。
default_random_engine e1; //使用默认的种子
default_random_engine e2(2147483646); //使用给定的种子值
default_random_engine e3;
e3.seed(32767);
default_random_engine e4(32767); //e3和e4种子相同将会产生相同的随机数。
default_random_engine e5(time(0)); //稍微随机些的种子
注意:
- time生成的随机种子,作为一个自动的过程反复运行,将time的返回值作为种子的方式就无效了;它可能多次使用的都是相同的种子。
- 引擎必须在循环外,否则可能每步循环都产生相同的随机值。
可以使用uniform_real_distribution来实现函数的映射。使用示例如下:
default_random_engine e; //生成无符号的随机数
uniform_real_distribution<double> u(0,1); // 0到1(包含)的均匀分布
for(size_t i=0;i<10;++i){
cout<<u(e)<<"";
}
非均匀分布的随机数
| 函数方法 | 说明 |
|---|---|
normal_distribution(a,b) |
标准随机分布,a为均值,b为标准差 |
bernoulli_distribution(m) |
布尔分布,不接受任何额外的参数时,都是50/50的机会,当m为0.55时则双方机会不均等 |
17.5 IO库再探
当操作符改变流的格式状态的时候,通常改变后的状态对所有后续IO都生效。
对于bool值的输出需要添加关键字boolalpha;如:
cout<<"default bool values: "<<true<<" "<<false
<<"\nalpha bool values: "<<boolalpha
<<true<<" "<< false<<endl;
/*
result:
default bool values: 1 0
alpha bool value: true false
*/
指定整型的进制
cout<<showbase; //打印的时候显示进制
cout<<"default: "<<20<<" "<<1024<<endl;
cout<<"octal: "<<oct<<20<<" "<<1024<<endl;
cout<<"hex: "<<hex<<20<<" "<<1024<<endl;
cout<<"decimal: "<<dec<<20<<" "<<1024<<endl;
cout<<noshowbase; //恢复流状态
/*
default: 20 1024
octal: 024 2000
hex: 0x14 0x400
decimal: 20 1024
*/
指定打印精度
可以通过cout的precision()函数和setprecision()函数设置显示的精度。
输入输出流中的格式控制符
| 控制符 | 说明 | 示例 |
|---|---|---|
boolalpha |
设置 bool 类型在数据流中显示为 true 或 false。默认情况下,bool 类型变量显示为1或0。 | cout << boolalpha ; 或 boolalpha (cout); |
noboolalpha |
设置 bool 类型在数据流中显示为 1 或 0 (恢复 bool 类型的显示状态至默认)。 | cout « noboolalpha ; 或 hex(noboolalpha ); |
scientific |
设置浮点数以科学计数法显示。 | cout « scientific ; 或 hex(scientific ); |
fixed |
设置浮点数以标准显示法显示。 | cout « fixed ; 或 hex(fixed ); |
hex |
设置整数类型以十六进制显示。 | cout « hex; 或 hex(cout); |
dec |
设置整数类型以十进制显示(默认情况下,整数类型是以十进制显示)。 | cout « dec; 或 dec(cout); |
cot |
设置整数类型以八进制显示 | cout « oct; 或 oct(cout); |
internal |
数值的符号位在域宽内左对齐,数值右对齐,中间由填充字符填充。 | cout « internal ; 或 oct(internal ); |
left |
设置输出数值或文本的显示形式为左对齐。 | cout « left ; 或 oct(left ); |
right |
设置输出数值或文本的显示形式为右对齐。 | cout « right ; 或 oct(right ); |
showbase |
设置数值前缀不显示 | cout « showbase ; 或 oct(showbase ); |
noshowbase |
将数值显示的形式恢复至默认状态。 | cout « noshowbase ; 或 oct(noshowbase ); |
showpoint |
即使小数部分为零,也显示浮点数的整数部分和小数点右侧的数字 | cout « showpoint ; 或 oct(showpoint ); |
noshowpoint |
仅显示数值的整数部分。 | cout « noshowpoint ; 或 oct(noshowpoint ); |
showpos |
显示正数值的 + 号。 | cout « showpos ; 或 oct(showpos ); |
noshowpos |
忽略正数值前面的 + 号。 | cout « noshowpos ; 或 oct(noshowpos ); |
skipws |
使 cin 获取输入时忽略空格。 | cout « skipws ; 或 oct(skipws ); |
noskipws |
使输入流读取空格 | cout « noskipws ; 或 oct(noskipws ); |
unitbuf |
每次执行输出操作后均会清空缓冲区。 | cout « unitbuf ; 或 oct(unitbuf ); |
nounitbuf |
将 unitbuf 复位至默认状态。 | cout « nounitbuf ; 或 oct(nounitbuf ); |
uppercase |
设置十六进制数值和科学计数法中的指数以大写形式显示。 | cout « uppercase ; 或 oct(uppercase ); |
nouppercase |
设置十六进制数字和科学计数法的指数以小写形式显示 | cout « nouppercase ; 或 oct(nouppercase ); |
flush |
刷新缓冲区 | cout « “str” « flush; 或 flush(cout); |
endl |
刷新缓冲区并插入一个换行符 | cout « “str” « endl; 或 endl(cout); |
定义在iomanip中的操作符
| 操作符 | 含义 |
setfill(ch) |
用ch填充空白 |
setprecision(n) |
将浮点精度设置为n |
setw(w) |
读或写值的宽度为w个字符 |
setbase(b) |
将整数输出为b进制 |
17.5.2 未格式化的输入/输出操作
标准库提供了一组低层操作,支持未格式化IO.这些操作允许我们将一个流当做一个无解释的字节序列来处理。
char ch;
while(cin.get(ch)) {
cout.put(ch);
}
单字节低层IO操作
| 操作 | 含义 |
|---|---|
is.get(ch) |
从istream is读取下一个字节存入字符ch中。返回is |
os.put(ch) |
将字符ch输出到ostream os。返回is |
is.get() |
将is的下一个字节作为int返回 |
is.putback(ch) |
将字符ch放回is。返回is |
is.unget() |
将is向后移动一个字节。返回is |
is.peek() |
将下一个字节作为int返回,但不从流中删除它 |
将字符放回输入流
标准库提供了三种方法退回字符:
peek: 返回输入流中一个字符的副本,但不会将它从流中删除,peek返回的值仍然留在流中。unget:输入流向后移动,从而最后读取的值又回到流中。即使我们不知道最后从流中读取什么值,仍然可以调用unget。putpack: 退回从流汇总读取的最后一个值,但它接受一个参数,此参数必须与最后读取的值相同。
这些函数返回整型的主要原因是可以返回文件尾标记符。
//检测是否达到文件尾部
int ch; //使用一个int,而不是一个char来保存get()的返回值
//循环读取并输出输入中的所有数据
while((ch==cin.get())!=EOF){
cout.put(ch);
}
多字节操作
多字节操作要求我们自己分配管理用来保存和提取数据的字符组操作
多字节低层IO操作
is.get(sink,size,delim) |
从is中读取最多size个字节,并保存在字符数组中,字符数组的其实地址由sink给出。读取过程直至遇到字符delim或读取了size个字节或遇到文件末尾时停止。如果遇到了delim,则将其留在输入流中,不读取出来存入sink |
is.getline(sink,size,delim) |
与接受三个参数的get版本类似,但会读取并丢弃delim |
is.read(sink,size) |
读取最多size个字节,存入字符数组sink中。返回is |
is.gcount() |
返回上一个未格式化读取操作从is读取的字节数 |
os.write(source,size) |
将字符数组source中的size个字节写入os。返回os |
is.ignore(size,delim) |
读取并忽略最多size个字节,包括delim。与其他未格式化函数不同,ignore有默认参数:size的默认值为1,delim的默认值为文件尾 |
注意:
- 一个常见的错误是本想从流中删除分隔符,但却忘了做。
- get和getline读取字符时,get将分隔符留作istream中的下一个字符,而getline则读取并丢弃分隔符。无论哪个函数都不会将分隔符保存在
sink中
17.5.3 流随机访问
随机IO本质上是依赖于系统的。为了理解如何使用这些特性,必须查询系统相关文档
seek和tell函数
一个函数通过将标记seek到一个给定位置来重定位它;另外一个函数tell我们标记的当前位置。后缀g表示正在”获得”,后缀p表示正在放入
| 函数 | 定义 |
|---|---|
tellg()/tellp() |
返回一个输入流中(tellg)或输出流中(tellp)标记的当前位置 |
seekg(pos)/seekp(pos) |
根据标定的pos值,重定位到输入/输出流中的绝对地址 |
seekp(off,from)/seekg(off,from) |
在一个输入流或输出流中将标记定位到from之前或之后off个字符,from可以是下列值之一:beg,偏移量相对于流开始位置,cur,偏移量相对于流当前结束位置;end,偏移量相对于流结尾位置 |
注意:由于只有单一的标记,因此只要我们在读写操作间切换,就必须进行seek操作来重定位标记。
使用示例:
#include <iostream>
#include <fstream>
using namespace std;
int main(){
//以读写方式打开文档
fstream inOut("copyout",fstream::ate|fstream::in|fstream::out);
if(!inOut){
cerr<<"Unable to open file"<<endl;
return 0;
}
auto end_mark=inOut.tellg(); //记住原文件尾位置
inOut.seekg(0,fstream::beg); //重定位带文件开始
size_t cnt=0; //字节数累加器
string line; //保存输入中的每行
// 还未遇到错误且未到末尾,持续读取
while(inOut&& inOut.tellg()!=end_mark
&&getline(inOut,line))
{
cnt+=line.size()+1; //+1表示换行
auto mark=inOut.tellg(); //记住读取位置
inOut.seekp(0,fstream::end); // 将写标记移动到问价尾
inOut<<cnt; //输出累计长度
if(mark!=end_mark){
inOut<<" ";
}
inOut.seekp(0,fstream::end); //定位到文件尾
}
inOut<<"\n"; //文件尾部输出换行符
return 0;
}
第18章 用于大型程序的工具
18.1 异常处理
参考链接: C++异常处理(try catch)从入门到精通;
注意:
- 一个异常如果没有被捕获,则它将终止当前的程序
- 在钱展开的过程中,运行类类型的局部叶象的析构函数,因为这些析构函数是自动执行的,所以它们不应该抛出异常_一旦在钱展开的过程中析构函数抛出了异常,并且析构函数自身没能捕获到该异常,则程序将被终止。
- 抛出指针要求在任何时应的处理代码存在的地方,指针所指的对象都必须存在。
- 通常情况下,如果catch接收的异常与额某个继承体系有关,则最好将该catch的参数定义成类型引用
- 如果在多个catch语句的类型之间存在着继承关系,则我们应该把继承链最底端的类(most derived type )放在前面,而将继承链最顶端的类(least derivedtype)放在后面。
异常类型和catch声明的类型是精确匹配的:
- 允许从非常量向常量的类型转换
- 允许派生类向基类的转换
- 数组被转换成指向数组(元素)类型的指针,函数被转换成指向该函数类型的指针。
- 处理构造函数初始值异常的唯一方法是讲构造函数写成try语句块
catch(...)可以匹配任意的异常类型。其通常与重新抛出语句一起使用,其中catch执行当前局部能完成的工作,随后重新抛出异常;当其与其它几个catch语句一起出现的时候,必须放在最后否则后面的语句永远不会被执行。
void manip(){
try{
//这里的操作将引发并抛出一个异常
}
catch (...){
//处理异常的某些特殊操作
throw;
}
}
注意: 由于构造函数执行的时候,try语句可能还未能成功初始化,所以不能正常的抛出异常。我们必须将构造函数携程 函数try语句块的形式。才能正真使用。例:
temlate <typename T>
Blob<T>::Blob(std::initializer_list<T> il) try :
data(std::make_shared<std::vector<T>>(il)){
// 函数体
} catch (const std:bad_alloc &e){handle_out_of_memory(e);}
18.1.4 noexcept 异常说明
C++11新标准中,可以通过提供noexceot说明,指定某个函数不会抛出异常。使用时关键字紧跟函数的参数列表后面。
void recoup(int) noexcept; //不会抛出异常
void alloc(int); //可能抛出异常
注意:
- 通常情况下,编译器不能也不必在编译时验证异常说明。
- noexcept有两层含义:当跟在函数参数列表后面时它是异常说明符;而当作为noexcept异常说明的bool实参出现时,它是一个运算符。
18.1.5 异常类层次

18.2 命名空间
18.2.2 命名空间的定义
namespcae cplusplus_primer{
...
}
注意:
- 命名空间作用域后面无须分号;每个命名空间都是一个作用域
- 命名空间可以是不连续的
- 命名空间的部分成员的作川是定义类,以及声明作为类接口的函数及对象,则这个 成员应该放置几头文件中,这namespace,头文件将被包含在使用了这些成员的文件中。
- 命名空间成员的z义部分则置于另外的源文件中。
- 在程序III某此实体只能定义一次:如非内联函数、静态数据成员、变量等。
- 定义多个类型不相关的命名空间应该使用单独的文件分别表示每个类型(或关联类型构成的集合)。
- 对于多个命名空间使用时可以使用
::spcaename::subspacename的方式来寻找命名空间。 - 模板特例化必须定义在原始模板所属的命名空间中。
- 使用
::全局作用域,隐式的将函数添加到全局作用域中。 - 未命名的命名空间仅仅在特定的文件内部有效,其作用范围不会横跨多个文件。
内联命名空间
内联命名空间和普通的嵌套命名空间不同,内联命名空间可以被外层命名空间直接使用。无需使用外层命名空间名字,就可以直接访问它。
inline namespace FifthEd{
//使用内联命名空间
}
namespace FifthEd{ //隐式内联
class Query_base{
/**/
};
//其它相关命名
}
18.2.2 使用命名空间成员
可以使用通用赋值给命名空间别名,例如:
namespace primer=cplusplus
namespace Qlib=cplusplus_primer::Querylib;
注意避免使用using 指示
18.2.3 类、命名空间与作用域
对命名空间内部名字的查找遵循常规的查找规则:即由内向外依次查找每个外层作川域。外层作川域也可能是一个或多个嵌套的命名空间,直到最外层的个局命名空间查找过程终止。只有位于开放的块中且在使用点之前声的名字才被考虑:
可以从函数的限定名推断出查找名字时检查作用域的次序,限定名以相反次序指出被查找的作用域。
18.2.4 重载与命名空间
一个。using明引入的函数将重载声明语句所属作作用域已有的其他同名函数。如果using声明出现在局部作川域中,则引入的名字将隐藏外层作用域的相关声明。如果using声明所在的作用域中已经有一个函数与新引入的函数同名且形参列表相同,则该using声明将引发错误。除此之外,using声明将为引入的名字添加额外的重载实例,并最终扩充候选函数集的规模。
using指示将命名空间的成员提升到外层作用域中,如果命名空间的某个函数与该命名空间所属作用域的函数同名,则命名空间的函数将被添加到重载集合。
如果存在多个using指示,则来自每个命名空间的名字都会成为候选函数集的一部分。
18.3 多重继承与虚继承
注意:
- 如果从多个基类中继承了相同的构造函数(即形参列表完全相同),则程序将产生错误。
- 当一个类拥有多个基类时,有可能出现派生类从两个或更多基类中继承了同名成员的情况、此时,不加前缀限定符直接使用该名字将引发二义性。
18.3.4 虚继承
- 在默认情况下,派生类中含有继承链上每个类对应的f-部分.如果某个类派生类,中出现了多次,则派之卜类中将包含该类的多个子对象。
- 为了解决上述多次继承的情况,设置了 虚继承它的是令某个类做出声明,承诺愿意共享它的基类。其中,共享的基类子对象称为虚基类( virtual base class ) 。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生中都只包含唯一一个共享的虑基类子对象。
- 虚派生只影响从指定了虚基类的派生类中进一步派生出的类,它不会影响派生类本身。
- 虚继承在后续的派生类中共享虚基类的同一份实例。
- 对于相同虚函数的继承,可能存在二义性,最好的办法是在派生类中自定义实例。
18.3.5 构造函数与虚继承
含有虚基类的对象的构造书序与一般的顺序稍有叙别:首先使用提供给最低层派生类(最低层公共部分)构造函数的初始值初始化该对象的虚基类子部分,接下来按照直接基类在派生表中出现的次序从左向右对其进行初始化。
虚基类总是先于非虚基类构造,与它们在继承体系中的次序和位置无关。
第 19 章 特殊工具与技术
19.1 控制内存分配
new 的过程:
- 分配内存空间
- 赋予初值。
- 指向该指针。
delete过程
- 执行指针所指对象的析构函数
- 调用标准函数库,释放指针。
当只传入一个指针类型的实参时,定位new表达式构造对象但是不分配内存。 调用析构函数会销毁对象,但是不会释放内存。
19.2 运行时类型识别
运行时类型识别(run-time type identification, RTTI)的功能由两个运算符实现:
- typeid 运算符,用于返回表达式的类型;可以作用于任意类型的表达式。
- dynamic_cast 运算符,用于将基类的指针或引用安全的转换成派生类的指针或者引用。
- 在条件部分执行dynamic cast操作可以确保类型转换和结果检查在同一条表达式中完成。
- 当typeid作用于指针时(而非指针所指的对象),返回的结果是该指针的静态编译时类型。
type_info类,用来鉴定类型是否相同。
type_info类在不同的编译器上有所区别。有的编译器提供了额外的成员函数以提供程序中所用类型的额外信息。读者应该仔细阅读你所用编译器的使用手册,从而获取关于type-info的更多细节。
19.3 枚举类型
C++包含两种枚举类型:限定作用域的和不限定作用域的。 限定作用域的枚举类型: enum class(struct) {…}。不限定枚举可以省略掉关键字class,枚举类型名字可选。
enum color {red,yellow,green}; //不限定作用域的枚举类型
enum stoplight {red,yellow,green}; //错误:重复定义了枚举成员
enum class peppers {red,yellow,green}; //正确:枚举成员被隐藏了
color eyes=green; //正确: 不限定作用域的枚举类型位于有效的作用域中
pepper p=green; // 错误:pepper的枚举成员不在有效的作用域中
color hair=color::red; //正确:允许显式地访问枚举成员
peppers p2=pepper::red; //正确:使用pappers的red
//指定序号
enum class intType{
charTyp=8,shortTyp=16,intTyp=16,
longTyp=32,long_longTyp=64
}
//利用冒号指定类型
enum intValues:unsigned long long {
charType=255,shortTyp=65535,
......
}
注意:
- 即使某个整型值恰好与枚举成员的值相等,它也不能作为函数的enum实参使用。
- 但是可以使用强制类型转换,将enum提升成int或更大的整型。
19.4 指针类成员
成员指针 是指可以指向类的排静态成员的指针。类的静态成员不属于任何对象。
我们令其指向类的某个成员,但是不指定该成员所属的对象;直到使用成员指针时,才提供成员所属的对象。
19.4.1 数据成员指针
与普通指针不同的是成员指针必须包含成员所属的类
//pdata可以指向一个常量(非常量)Screen对象的string成员
const string Screen::*pdata;
pdata=&Screen::contents;//获取成员对象
auto pdata=&Screen::contents;
//使用成员指针
Screen myScreen,*pScreen=&myScreen;
//.*解引用pdata以获得myScreen对象的contents成员
auto s=primaryScreen.*pdata;
//->*解引用pdata以获得pScreen所指对象的contents成员
s=pScreen->*pdata;
19.4.2 成员函数指针
//利用auto关键字指向一个常量成员函数
//前提是该函数不接受任何实参,并且返回一个char
auto pmf=&Screen::get_cursor;
//指向含有两个形参的get
char (Screen::*pmf2)(Screen::pos,Screen::pos) const;
pmf2=&Screen::get;
//成员函数的使用
Screen myScreen,*pScreen=&myScreen;
//通过pScreen 所指的对象pmf所指的函数
char c1=(pScreen->*pmf)();
//通过myScreen对象将实参0,0传给含有两个形参的get函数
char c2=(myScreen.*pmf2)(0,0);
//使用成员指针的类型别名
//Action 是一种可以指向Screen成员函数的指针,它接受两个pos实参,返回一个char
using Action=char (Screen::*)(Screen::pos,Screen::pos) const;
Action get=&Screen::get; //指向Screen的get成员。
//使用函数指针成员表
class Screen{
public:
Screen& home(); //光标移动函数
Screen& forward();
Screen& back();
Screen& up();
Screen& down();
//Action 是一个指针,可以用任意一个光标移动函数对其赋值
using Action=Screen& (Screen::*)();
//具体移动方向指定
enum Directions {HOME,FORWARD,BACK,UP,DOWN};
Screen& move(Directions){
//运行this对象中索引值为cm的元素
return (this->*Menu[cm])(); //Menu[cm]指向一个函数成员
};
private:
static Action Menu[]; //函数表
}
Screen myScreen;
myScreen.move(Screen::HOME); //调用myScreen.home
myScreen.move(Screen::DOWN); //调用myScreen.down
//初始化函数表
Screen::Action Screen::Menu[]={
&Screen::home,
&Screen::forword,
...
};
19.4.3 将成员函数用作可调用对象
使用function生成一个可调用对象
使用标准模板库function 可以凶函数指针获取可调用对象。
function<bool (const string&)> fcn=&string::empty;
find_if(svec.begin(),svec.end(),fcn);
使用mem_fn生成一个可调用对象
auto f=mem_fn(&string::empty);
使用bind生成一个可调用对象
auto it=find_if(svec.begin(),svec.end(),bind(&string::empty,_1));
19.5 嵌套类
一个类可以定义在另外一个类的内部。可以在类之外声明一个类内的嵌套类:
class class1_name::class2_name{}
- 在嵌套类在其外层类之外完成真正的定义之前,它都是一个不完全类型。
- 嵌套类的作用域查找,比一般类多了一个外层类作用域的查找。
- 外层类可以直接使用嵌套类的名字。
- 外层类和嵌套类相互独立,都各自只包含自己的成员名字。
19.6 union: 一种节省空间的类
联合(( union )是一种特殊的类一个union 可以有多个数据成员,但是在仟愈时刻只有一个数据成员可以有直。当我们给union的某个成员赋值之后, 该union的其它成员就变成末定义的状态了。分配给一个union对象的存储空间至少要能容纳它的最大的数据成员。和其他类一样,一个union定义了一种新类型。
匿名union
是一个未命名的union,并且在符号之间没有任何声明。一旦我们定义了一个匿名union,编译器自动地位该union创建一个未命名的对象。在union的定义所在的作用域内该union的成员都是可以直接访问的。
注意:
- 匿名union不能包含受保护的成员或者私有成员,也不能定义成员函数。
- union中成员类中成员没有定义默认构造函数,则编译器删除类中的该成员。
19.7 局部类
定义在某个函数内部的类称为,局部类。局部类定义的类型只在定义它的作用域内可见。
注意:
- 局部类的所有成员(包括函数在内)都必须完整定义在类的内部。因此,局部类的作用与嵌套类相比相差很远。
- 局部类只能访问外层作用域定义的类型名、静态变量以及枚举成员。
- 局部类不能使用函数作用域中的变量。
- 常规的访问保护规则对局部类同样适用。
19.8 固有的不可移植的特性
是指因机器而异常的特性,当机器转移时,需要重新编写该程序。
19.8.1 位域
位域在内存中的布局是与机器相关的
位域的类型必须是整型或枚举类型。因为带符号位域的行为是由具体实现确定的。 位域的声明形式是成员名字后紧跟一个冒号以及一个常量表达式,该表达式用于指定成员所占的二进制位数。
typedef unsigned int Bit;
class File{
Bit mode: 2; //mode占2位
Bit modified:1; //占1位
...
public:
//文件类型以八进制表示
enum modes{READ=01,WRITE=02,EXECUTE=03};
}
注意: 通常情况下最好将位域设为无符号类型,存储在带符号类型中的位域的行为将因具体实现而定。
19.8.2 volatile 限定符
volatile的确切含义与机器有关,只能通过阅读编译器文档来理解、要想让使用了volatile的程序在移植到新机器或新编译器后仍然有效,通常需要对该程序进行某些改变。关键字volatile告诉编译器不应对这样的对象进行优化。
注意:
- 关键字volatile告诉编译器不应对这样的对象进行优化。
- 合成的拷贝对volatile对象无效。
- volatile 不能使用合成的拷贝/移动构造函数和赋值运算符初始化。
19.8.3 链接指示: extern “C”
要想把c++代码和其他语言(包括c语言)编写的代码放在一起使用.要求我们必须有权访问该语言的编译器,并且这个编译器与当前的c++编译器是兼容的。
当一个#include指示被放置在复合链接指示的花括号中时,文件中的所有普通函数声明都被认为是由链接指示的语言编写的。链接指示可以嵌套,因此如果头文件包含自带链接指示的函数,则该函数的链接不受影响。
ectern "C"{
#include <string.h>
}
指向extern “C”函数的指针
//pf指向一个c函数,该函数接受一个int返回void
extern "C" void (*pf)(int);
void (*pf1)(int); //指向一个c++函数
注意:
- 有的C++编译器会接受之前的这种赋值操作并将其作为对语言的扩展,尽管从严格意义上来看它是非法的。
- 链接指示对整个声明都有效。当我们使用链接指示时,它不仅仅对函数有效,而且对作为返回内省或形参类型的函数指针也有效。
导出C++函数到其他语言 通过使用链接器指示对函数进行定义,我们可以令一个C++函数在其它语言编写的程序中使用
//calc 函数可以被C程序调用
extern "C" double calc(double dparm){
/**/
}
有时可以使用预处理器定义__cplusplus来有条件的包含代码
#if defined(__cplusplus) || defined (c_plusplus)
extern "C"
{
#endif
#include <stdio.h>
#include <stdlib.h>
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavutil/pixfmt.h"
#include "libavutil/mathematics.h"
#include "libavutil/time.h"
#include "libswscale/swscale.h"
#if defined(__cplusplus) || defined (c_plusplus)
}
#endif
注意:extern “…“的重载和链接与语言本身有关。
深度探索C++对象模型
-
深度探索C++对象模型 笔记汇总
第1章 关于对象(Object Lessons)
C++的额外成本
- C++较之C的最大区别,无疑在于面向对象。类相较于C的struct不仅只包含了数据,同时还包括了对于数据的操作。在语言层面上C++带来了很多面向对象的新特性,类、继承、多态等等。新特性使得C++更加强大,但却伴随着空间布局和存取时间的额外成本。作为一个以效率为目标的语言,C++对于面向对象的实现,其实不大优雅.
- 额外成本主要由virtual引起,包括:
- virtual function 机制,用来支持“执行期绑定”。
- virtual base class ——虚基类机制,以实现共享虚基类的 subobject。
- 除此之外C++没有太多理由比C迟缓
三种对象模型
- C++类包含两种数据成员和三种成员函数:
- 静态数据成员, 非静态数据成员
- 成员函数, 静态函数, 虚函数
- 在C++对象中表现为中有三种模型(C++对象模型是在前两种对象模型上发展而来的,甚至于局部上直接用到前两种对象模型):
- 简单对象模型、
- 表格驱动对象模型
- C++对象模型。
- 假定有一个 Point类,我们将用三种对象模型来表现它。Point类定义如下:
class Point { public: Point( float xval ); virtual ~Point(); float x() const; static int PointCount(); protected: virtual ostream& print( ostream &os ) const; float _x; static int _point_count; };简单对象模型
- 简单对象模型的概念:
- 一个C++对象存储了所有指向成员的指针,而成员本身不存储在对象中。
-
也就是说不论数据成员还是成员函数,也不论这个是普通成员函数还是虚函数,它们都存储在对象本身之外,同时对象保存指向它们的指针。
- 简单对象模型对于编译器来说虽然极尽简单,但同时付出的代价是空间和执行期的效率.
- 对于每一个成员都要额外搭上一个指针大小的空间
- 对于每成员的操作都增加了一个间接层。
- 因此C++并没有采用这样一种对象模型,但是被用到了C++中 “指向成员的指针” 的概念当中。

表格驱动对象模型
- 表格驱动模型则更绝,
- 它将对象中所有的成员都抽离出来在外建表,
- 而对象本身只存储指向这个表的指针。
- 下图可以看到,
- 它将所有的数据成员抽离出来建成一张 数据成员表,
- 将所有的函数抽取出来建成一张 函数成员表,
- 而对象本身只保持一个 指向数据成员表的指针。

- ==侯大大认为,在对象与成员函数表中间应当加一个虚箭头,他认为这是Lippman的疏漏之处,应当在对象中保存指向函数成员表的指针。==
- 然而我在这儿还是保留原书(而非译本)的截图,因为以我之拙见,不保存指向成员函数表的指针也没有妨碍。因为形如float Point::x()的成员函数实际上相当于float x(Point*)类型的普通函数,因此保存指向成员函数表的指针当属多此一举。
- 当然C++也没有采用这一种对象模型,但C++却以此模型作为支持虚函数的方案。
C++对象模型
- C++对象模型的组成:
- 所有的非静态数据成员存储在对象本身中。
- 所有的静态数据成员、成员函数(包括静态与非静态)都置于对象之外。
- 另用一张虚函数表(virtual table) 存储所有指向虚函数的指针,并在表头附加上一个该类的type_info对象,在对象中则保存一个指向虚函数表的指针。
- 如下图:

class和struct关键字的差异
- 按照lippman的意思是,struct仅仅是给想学习C++的C程序员攀上高峰少一点折磨。但遗憾的是当我开始学C++的时候这个问题给我带来更多的疑惑。以我的认识class与struct仅限一个默认的权限(后者为public前者为private)的不同。有时我甚至觉得只有一点畸形,他们不应当如此的相像,我甚至认为struct不应该被扩充,仅仅保存它在C中的原意就好了。[^1] [^1]: 实际上struct还要复杂一点,它有时表现的会和C struct完全一样,有时则会成为class的胞兄弟。 —
- 一个有意思的C技巧(但别在C++中使用)
- 在C中将一个一个元素的数组放在struct的末尾,可以令每个struct的对象拥有可变数组。
- 这是一个很有意思的小技巧,但是别在C++中使用。因为C++的内存布局相对复杂。例如被继承,有虚函数… 问题将不可避免的发生。
- 看代码:
struct mumble { /* stuff */ char pc[ 1 ]; }; // grab a string from file or standard input // allocate memory both for struct & string struct mumble *pmumb1 = ( struct mumble* ) malloc(sizeof(struct mumble)+strlen(string)+1); strcpy( &mumble.pc, string );三种编程典范
- 程序模型:数据和函数分开。
- 抽象数据类型模型:数据和函数一起封装以来提供。
-
面向对象模型:可通过一个抽象的base class封装起来,用以提供共同接口,需要付出的就是额外的间接性。
- 纯粹使用一种典范编程,有莫大的好处,如果混杂多种典范编程有可能带来意想不到的后果,例如将继承类的对象赋值给基类对象,而妄想实现多态,便是一种ADT模型和面向对象模型混合编程带来严重后果的例子。
一个类的对象的内存大小
- 一个类对象的内存:
- 所有非静态数据成员的大小。
- 由内存对齐而填补的内存大小。
- 为了支持virtual有内部产生的额外负担。(只增加虚表指针,虚表在对象之外[^2]) [^2]:Ref: C++虚函数表,虚表指针,内存分布
- 以下类:
class ZooAnimal { public: ZooAnimal(); virtual ~ZooAnimal(); virtual void rotate(); protected: int loc; String name; }; - 在32位计算机上所占内存为16字节:int四字节,String8字节(一个表示长度的整形,一个指向字符串的指针),以及一个指向虚函数表的指针vptr。对于继承类则为基类的内存大小加上本身数据成员的大小。
- 其内存布局如下图:
 —
—
一些结论1
- C++在加入封装后(只含有数据成员和普通成员函数)的布局成本增加了多少?
- 答案是并没有增加布局成本。就像C struct一样,memeber functions虽然含在class的声明之内,却不出现在object中。每一个non-inline member function只会诞生一个函数实体。至于每一个“拥有零个或一个定义的” inline function则会在其每一个使用者(模块)身上产生一个函数实体。
</br>
- C++在布局以及存取时间上主要的额外负担是哪来的?
- virtual funciton机制,用以支持一个有效率的“执行期绑定”
- virtual base class,用以实现“多次出现在继承体系中的base class,有一个单一而被共享的实体”
</br>
- 继承关系指定为虚拟继承,意味着什么?
- 在虚拟继承的情况下,base class不管在继承链中被派生(derived)多少次,永远只会存在一个实例(称为subobject)。
</br>
- 什么时候应该在c++程序中以struct取代class?
- 答案之一是当他让人感觉比较好的时候。单独来看,关键词本身并不提供任何差异,c++编译器对二者都提供了相同支持,我们可以认为支持struct只是为了方便将c程序迁移到c++中。
</br>
- 那为什么我们要引入class关键词?
- 这是因为引入的不只是class这个关键词,更多的是它所支持的封装和继承的哲学。
</br>
- 怎么在c++中用好struct?
- 将struct和class组合起来,组合,而非继承,才是把c和c++结合在一起的唯一可行的方法。另外,当你要传递“一个复杂的class object的全部或部分”到某个c函数去时,struct声明可以将数据封装起来,并保证拥有与c兼容的空间布局。
</br>
- C++支持多态的方式?
- 经由一组隐式的转化操作。例如把一个derived class指针转化为一个指向其public base type的指针
shape *ps=new circle();
- 经由virtual function机制
ps->rotate();
- 经由dynamic_cast和typeid运算符
if(circle *pc=dynamic_cast<circle *>(ps))...
- 多态的主要用途是经由一个共同的接口来影响类型的封装,这个接口通常被定义在一个抽象的base class中。这个共享接口是以virtual function机制引发的,它可以在执行期根据object的真正类型解析出到底是哪一个函数实体被调用。
- 经由一组隐式的转化操作。例如把一个derived class指针转化为一个指向其public base type的指针
</br>
- 需要多少内存才能表现一个class object? [^4]
[^4]:详情请参考: C++中的类所占内存空间总结
- 其nonstatic data members的总和大小
- 加上任何由于aliginment的需求而填补上去的空间(可能存在于members之间,也可能存在于集合体边界),aliginement就是将数值调整到某数的倍数,如在32位的计算机上为4。
- 加上为了支持virtual而由内部产生的任何额外负担(对象内的新增需求仅为一个指针)
</br>
- 转型(cast)其实是一种编译器指令。
- 大部分情况下它并不改变一个指针所含的真正地址,它只影响“被指出之内存大大小和其内容”的解释方式。
- 如一个类型为void *的指针只能够持有一个地址,但不能 通过它操作所指object。
</br>
- 一个基类指针和其派生类指针有什么不同?(单一一层继承,且其都指向派生类对象)
- 二者都指向基类对象的第一个byte,其间的差别是,派生类指针涵盖的地址包含整个派生类对象,而一个基类指针所涵盖的地址只包含派生类对象的基类子对象部分。
- 但基类指针可以通过virtual机制访问派生类对象的函数。
- 如果基类存在虚函数, 即使派生类被强转为基类, 虚表内依旧保存有原派生的类型,可以通过typeid 获取原派生类类型[^5] [^5]:参考一下实现: 二重调度问题:解决方案之虚函数+RTTI
- 以下结论貌似有问题:
</br> - 当一个base class object被直接初始化为(或被指定为)一个derived class object时,会发生什么?
- derived object就会被切割(sliced)以塞入较小的base type内存中,derived type将没有留下任何蛛丝马迹。
- 多态于是不再呈现,而一个严格的编译器可以在编译器解析一个“通过此object而触发的virtual function调用操作”,因而回避virtual机制。
- 如果virtual function被定义为inline,则更有效率上的大收获。
第2章 构造函数语意学(The Semantics of constructors)
2.1 构造函数
- 通常很多C++程序员存在两种误解:
- 没有定义默认构造函数的类都会被编译器生成一个默认构造函数。
- 编译器生成的默认构造函数会明确初始化类中每一个数据成员。
- C++标准规定:
- 如果类的设计者并未为类定义任何构造函数,那么会有一个默认构造函数被暗中生成,而这个暗中生成的默认构造函数通常是不做什么事的(无用的). 只有下面四种情况除外.
- 换句话说,只有以下四种情况编译器必须为未声明构造函数的类生成一个会做点事的默认构造函数。我们会看到这些默认构造函数仅“忠于编译器”,而可能不会按照程序员的意愿程效命。
包含有带默认构造函数的对象成员的类
- 包含有带默认构造函数的对象成员的类(某成员变量为带默认构造函数的类的对象)
- 若一个类X没有定义任何构造函数,但却包含一个或以上定义有默认构造函数的对象成员,此时编译器会为X合成默认构造函数,该默认函数会调用对象成员的默认构造函数为之初始化。
- 如果对象的成员没有定义默认构造函数,那么编译器合成的默认构造函数将不会为之提供初始化。
- 例:
- 类A包含两个数据成员对象,分别为:string str 和 char Cstr那么编译器生成的默认构造函数将只提供对string类型成员的初始化,而不会提供对char类型的初始化。
- 假如类X的设计者为X定义了默认的构造函数来完成对str的初始化,形如:A::A(){Cstr=”hello”};因为默认构造函数已经定义,编译器将不能再生成一个默认构造函数。但是 编译器将会扩充程序员定义的默认构造函数——在最前面插入对初始化str的代码。若有多个定义有默认构造函数的成员对象 ,那么这些成员对象的默认构造函数的调用将依据声明顺序排列。
继承自带有默认构造函数的基类的类
- 继承自带有默认构造函数的基类的类(基类带有默认构造函数)
- 若该派生类没有定义任何构造函数但是派生自带有默认构造函数的基类,那么编译器为它定义的默认构造函数,将按照声明顺序为之依次调用其基类的默认构造函数。
- 若该派生类没有定义默认构造函数而定义了多个其他构造函数,同样派生自带有默认构造函数的基类,那么编译器扩充它的所有构造函数——加入必要的基类默认构造函数, 但是不会合成默认构造函数。
另外,编译器会将基类的默认构造函数代码加在对象成员的默认构造函数代码之前。
带有虚函数的类
- 带有虚函数的类
- *带有虚函数(来自声明或继承)的类,与其它类不太一样,因为它多了一个vptr,而vptr的设置是由编译器完成的,因此编译器会为类的每个构造函数添加代码来完成对vptr的初始化。
带有一个虚基类的类
- 带有一个虚基类的类
- 在这种情况下,编译器要将虚基类在类中的位置准备妥当,提供支持虚基类的机制。也就是说要在所有构造函数中加入实现前述功能的的代码。没有构造函数将合成默认构造函数。
- 编译器所做的工作包括:
- 合成默认构造函数(如果不存在任何构造函数)
- 在对象中插入一个指向虚基类对象的指针
- 将原来的执行存取操作改变为执行期间决定(原来是在编译时候通过偏移获取不同的值, 现改为通过指向虚基类对象的指针进行访问)
总结
-
从概念来上来讲,每一个没有定义构造函数的类都会由编译器来合成一个默认构造函数,以使得可以定义一个该类的对象,但是默认构造函数是否真的会被合成,将视是否有需要而定。C++ standard 将合成的默认构造函数分为 trivial(不重要) 和 notrivial(重要) 两种,前文所述的四种情况对应于notrivial默认构造函数,其它情况都属于trivial。对于一个trivial默认构造函数,编译器的态度是,既然它全无用处,干脆就不合成它。在这儿要厘清的是概念与实现的差别,概念上追求缜密完善,在实现上则追求效率,可以不要的东西就不要。
2.2 拷贝构造函数(copy constuctor)
- 通常C++初级程序员会认为当一个类为没有定义拷贝构造函数的时候,编译器会为其合成一个,答案是否定的。
- 编译器只有在必要的时候在合成拷贝构造函数。
- 这是的重点是探索: 那么编译器什么时候合成,什么时候不合成,合成的拷贝构造函数在不同情况下分别如何工作呢?
- 拷贝构造函数的定义有一个参数的类型是其类类型的构造函数是为拷贝构造函数。如下:
X::X( const X& x); Y::Y( const Y& y, int =0 ); //可以是多参数形式,但其第二个即后继参数都有一个默认值拷贝构造函数的应用:
- 当一个类对象以另一个同类实体作为初值时,大部分情况下会调用拷贝构造函数。
- 一般为以下三种具体情况:
- 显式地以一个类对象作为另一个类对象的初值,形如X xx=x;
- 当类对象被作为参数交给函数时(会产生一个临时对象)
- 当函数返回一个类对象时(会产生一个临时对象)
- 编译器何时合成拷贝构造函数
- 并不是所有未定义有拷贝构造函数的类编译器都会为其合成拷贝构造函数,编译器只有在必要的时候才会为其合成拷贝构造函数。
- 必要的时刻是指编译器在普通手段无法完成解决“当一个类对象以另一个同类实体作为初值”时,才会合成拷贝构造函数。也就是说,当常规武器能解决问题的时候,就没必要动用非常规武器。
- 如果**一个类没有定义拷贝构造函数,通常按照“成员逐一初始化(Default Memberwise Initialization)”的手法来解决“一个类对象以另一个同类实体作为初值”.**
- 也就是说把内建或派生的数据成员从某一个对象拷贝到另一个对象身上,如果数据成员是一个对象,则递归使用“成员逐一初始化(Default Memberwise Initialization)”的手法。
- **成员逐一初始化(Default Memberwise Initialization)具体的实现方式则是位逐次拷贝(Bitwise copy semantics)**[^6]。
[^6]: Bitwise copy semantics 是Default Memberwise Intializiation的具体实现方式。[别人的解释]
- 以下几种情况,如果类没有定义拷贝构造函数,那么**编译器将必须为类合成一个拷贝构造函数**
- 类**内含一个声明有拷贝构造函数成员对象**(不论是设计者定义的还是编译器合成的)。
- 类**继承自一个声明有拷贝构造函数的类**(不论拷贝构造函数是被显示声明还是由编译器合成的)。
- 类中**声明有虚函数**。
- 当类的派生串链中**包含有一个或多个虚基类**。
继承带拷贝构造函数的基类以及内含带拷贝构造函数的对象成员
- 不论是基类还是对象成员,既然后者声明有拷贝构造函数时,就表明其类的设计者或者编译器希望以其声明的拷贝构造函数来完成“一个类对象以另一个同类实体作为初值”的工作. 而设计者或编译器这样做——声明拷贝构造函数,总有它们的理由,而通常最直接的原因莫过于因为他们想要做一些额外的工作或“位逐次拷贝”无法胜任。
有虚函数的类
- 对于有虚函数的类,如果两个对象的类型相同那么位逐次拷贝其实是可以胜任的。但问题在于, 按照位逐次拷贝是无法正常对类中的vptr进行copy的,这将导致无法预料的后果——调用一个错误的虚函数实体是无法避免的,轻则带来程序崩溃,更糟糕的问题可能是这个错误被隐藏了。所以 对于有虚函数的类编译器将会明确的使被初始化的对象的vptr指向正确的虚函数表。因此有虚函数的类没有声明拷贝构造函数,编译将为之合成一个,来完成上述工作,以及初始化各数据成员,声明有拷贝构造函数的话也会被插入完成上述工作的代码。
继承串链中有虚基类
- 对于继承串链中有虚基类的情况,问题同样出现在继承类向基类提供初值的情况,此时位逐次拷贝有可能破坏对象中虚基类子对象的位置。
- 当一个相同派生类以另一个同类对象为初值时,使用位逐次拷贝是OK的,问题在于,一个class Object以派生类对象作为初值时.
总结
- 编译器需要合成拷贝构造函数的主要原因有三个:
- 用户反应使用“位逐次拷贝”无法胜任,或有额外操作(通过声明拷贝构造函数)
- 类中指向虚表的指针(估计是无法隐式的复制)
- 类中有指向虚基类的指针(问题发生于 一个class Object以派生类对象作为初值时)
2.3 命名返回值优化
- 对于一个如foo()这样的函数,它的每一个返回分支都返回相同的对象,编译器有可能对其做Named return Value优化(下文都简称NRV优化),方法是以一个参数result取代返回对象。
- foo()的原型:
X foo() { X xx; if(...) return xx; else return xx; } - 优化后的foo()以result取代xx:
void foo(X &result) { result.X::X(); if(...) {//直接处理result return; } else {//直接处理result return; } } - 对比优化前与优化后的代码可以看出,对于一句类似于X a = foo()这样的代码,NRV优化后的代码相较于原代码节省了一个临时对象的空间(省略了xx),同时减少了两次函数调用(减少xx对象的默认构造函数和析构函数,以及一次拷贝构造函数的调用,增加了一次对a的默认构造函数的调用)。
- 附加[^7]:
[^7]:命名返回值优化和成员初始化队列
- Lippman在《深度探索C++》书中指出NRV的开启与关闭取决于是否有显式定义一个拷贝构造函数,我 实在想不出有什么理由必须要有显示拷贝构造函数才能开启NRV优化,于是在vs2010中进行了测试,
- 测试结果表明
- 在release版本中,不论是否定义了一个显式拷贝构造函数,NRV都会开启。由此可见vs2010并不以是否有一个显式拷贝构造函数来决定NRV优化的开启与否。
- 但同时,立足于这一点,可以得出Lippman所说的以是否有一个显式定义的拷贝构造函数来决定是否开启NRV优化,应该指的是他自己领导实现的cfront编译器,而非泛指所有编译器。
- 那么cfront又为什么要以是否定义有显示的拷贝构造函数来决定是否开启NRV优化呢?我猜测,他大概这样以为,当显式定义有拷贝构造函数的时候一般代表着要进行深拷贝,也就是说此时的拷贝构造函数将费时较长,在这样的情况下NRV优化才会有明显的效果。反之,不开启NRV优化也不是什么大的效率损失。
-
另外,有一点要注意的是,NRV优化,有可能带来程序员并不想要的结果,最明显的一个就是——当你的类依赖于构造函数或拷贝构造函数,甚至析构函数的调用次数的时候,想想那会发生什么。由此可见、Lippman的cfront对NRV优化抱有更谨慎的态度,而MS显然是更大胆。
2.4 成员初始化队列(Member Initialization List)
- 对于初始化队列,厘清一个概念是非常重要的:(大概可以如下定义)
- 把初始化队列直接看做是对成员的定义,
- 构造函数体中进行的则是赋值操作。
- 有四种情况必须用到初始化列表:
- 有const成员
- 有引用类型成员
- 成员对象没有默认构造函数
- 基类对象没有默认构造函数
- 前两者因为要求定义时初始化,所以必须明确的在初始化队列中给它们提供初值。
- 后两者因为不提供默认构造函数,所有必须显示的调用它们的带参构造函数来定义即初始化它们。
- 显而易见的是当类中含有对象成员或者继承自基类的时候,在初始化队列中初始化成员对象和基类子对象会在效率上得到提升——省去了一些赋值操作嘛。
- 最后,一个关于初始化队列众所周知的陷阱,初始化队列的顺序
- 无论在初始化列表中是什么顺序总是会按照定义的顺序进行初始化
第3章 Data语意学(The Semantics of Data)
3.1 C++对象的大小
- 无论在初始化列表中是什么顺序总是会按照定义的顺序进行初始化
- 一个实例引出的思考
class X{}; class Y:virtual public X{}; class Z:virtual public X{}; class A:public Y, public Z{}; - 猜猜sizeof上面各个类都为多少?
// Lippman的一个法国读者的结果是 sizeof X yielded 1 sizeof Y yielded 8 sizeof Z yielded 8 sizeof A yielded 12 // vs2010上的结果是 sizeof X yielded 1 sizeof Y yielded 4 sizeof Z yielded 4 sizeof Z yielded 8 //gcc sizeof X yielded 1 sizeof Y yielded 8 sizeof Z yielded 8 sizeof A yielded 16 - 事实上,对于像X这样的一个的空类,编译器会对其动点手脚——隐晦的插入一个字节。为什么要这样做呢?插入了这一个字节,那么X的每一个对象都将有一个独一无二的地址。如果不插入这一个字节呢?哼哼,那对X的对象取地址的结果是什么?两个不同的X对象间地址的比较怎么办?
- 我们再来看Y和Z。首先我们要明白的是实现虚继承,将要带来一些额外的负担——额外需要一个某种形式的指针。到目前为止,对于一个32位的机器来说Y、Z的大小应该为5,而不是8或者4。我们需要再考虑两点因素:内存对齐(alignment—)和编译器的优化。
- alignment[^8]会将数值调整到某数的整数倍,32位计算机上位4bytes。内存对齐可以使得总线的运输量达到最高效率。所以Y、Z的大小被补齐到8就不足为奇了。 [^8]: 关于更多的memory alignment(内存对齐)的知识见VC内存对齐准则(Memory alignment), VC对齐
- 那么在vs2010中为什么Y、Z的大小是4而不是8呢?我们先思考一个问题,X之所以被插入1字节是因为本身为空,需要这一个字节为其在内存中给它占领一个独一无二的地址。但是当这一字节被继承到Y、Z后呢?它已经完全失去了它存在的意义,为什么?因为Y、Z各自拥有一个虚基类指针,它们的大小不是0。既然这一字节在Y、Z中毫无意义,那么就没必要留着。也就是说vs2010对它们进行了优化,优化的结果是去掉了那一个字节,而Lippman的法国读者的编译器显然没有做到这一点。
- 当我们现在再来看A的时候,一切就不是问题了。对于那位Lippman的法国读者来说,A的大小是共享的X实体1字节,X和Y的大小分别减去虚基类带来的内存空间,都是4。A的总计大小为9,alignment以后就是12了。而对于vs2010来说,那个一字节被优化后,A的大小为8,也不需再进行alignment操作。
总结
- 影响C++类的大小的三个因素[^8]:
- 支持特殊功能所带来的额外负担(对各种virtual的支持)。
- 编译器对特殊情况的优化处理。
- alignment操作,即内存对齐。
3.2 DataMember 的绑定(略,狗啊!)
3.3 VC内存对齐准则(Memory alignment)
- 本文所有内容在建立在一个前提下:使用VC编译器。
- 着重点在于:
- VC的内存对齐准则;
- 同样的数据,不同的排列有不同的大小;
- 在有虚函数或虚拟继承情况下又有如何影响?
- 内存对齐?!What?Why?
- 对于一台32位的机器来说如何才能发挥它的最佳存取效率呢?当然是每次都读4字节(32bit),这样才可以让它的bus处于最高效率。实际上它也是这么做的,即使你只需要一个字节,它也是读一个机器字长(这儿是32bit)。更重要的是,有的机器在存取或存储数据的时候它要求数据必须是对齐的,何谓对齐?它要求数据的地址从4的倍数开始,如若不然,它就报错。还有的机器它虽然不报错,但对于一个类似int变量,假如它横跨一个边界的两端,那么它将要进行两次读取才能获得这个int值。比方它存储在地址为2-5的四个字节中,那么要读取这个int,将要进行两次读取,第一次读取0-3四个字节,第二次读取4~7四个字节。但是如果我们把这个整形的起始地址调整到0,4,8…呢?一次存取就够了!这种调整就是内存对齐了。我们也可以依次类推到16位或64位的机器上。
结论
- Ref:
- 假设规定对齐量为4,
- char(1byte)变量应该存储在偏移量为1的倍数的地方,
- int(4byte)则是从偏移量为4的倍数的地方,
- double(8 byte)也同样应存储在偏移量为4的倍数的地方
- 结构体整体的大小也应该对齐,对齐依照规定对齐量与最大数据成员两者中较小的进行。
-
Vptr影响对齐而VbcPoint(Virtual base class pointer)不影响。
3.4 C++对象的数据成员
- 数据成员的布局
-
对于一个类来说它的对象中只存放非静态的数据成员,但是除此之外,编译器为了实现virtual功能还会合成一些其它成员插入到对象中。我们来看看这些成员的布局。
- C++ 标准的规定:
- 在同一个Access Section(也就是private,public,protected片段)中,要求较晚出现的数据成员处在较大的内存中。这意味着同一个片段中的数据成员并不需要紧密相连,编译器所做的成员对齐就是一个例子。
- 允许编译器将多个Acess Section的顺序自由排列,而不必在乎它们的声明次序。但似乎没有编译器这样做。
- 对于继承类,C++标准并未指定是其基类成员在前还是自己的成员在前。
- 对于虚基类成员也是同样的未予规定。
- 一般的编译器怎么做?
- 同一个Access Section中的数据成员按期声明顺序,依次排列。
- 但成员与成员之间因为内存对齐的原因可能存在空当。
- 多个Access Section按其声明顺序排放。
- 基类的数据成员总放在自己的数据成员之前,但虚基类除外。
- 编译器合成的成员放在哪?
- 为了实现虚函数和虚拟继承两个功能,编译器一般会合成Vptr和Vbptr两个指针。那么这两个指针应该放在什么位置?C++标准肯定是不曾规定的,因为它甚至并没有规定如何来实现这两个功能,因此就语言层面来看是不存在这两个指针的。
- 对于Vptr来说有的编译器将它放在末尾,如Lippman领导开发的Cfront。有的则将其放在最前面,如MS的VC,但似乎没人将它放在中间。为什么不放在中间?没有理由可以让人这么做,放在末尾,可以保持C++类对C的struct的良好兼容性,放在最前可以给多重继承下的指针或引用调用虚函数带来好处。
- 在VS2010和VC6.0中运行的结果都是地址值&x.a比&x大4,可见说vc的vptr放在对象的最前面此言非虚。
- 实验如下:
class X{ public: int a; virtual void vfc(){}; }; int main() { using namespace std; X x; cout<<&x.a<<" "<<&x<<endl; system("pause"); }
- 对于Vbptr而言一般的看法为:在每一个虚派生对象中安插一个指向虚基对象的指针
- 缺点: - 多占用了一个指针的空间 - 随着虚继承链增长, 可能会存在多次间接存取问题, 不能得到固定的存取时间 有好几种方法:
- cfront 对第二个问题的解决方案: 在虚继承链上取nest virtual base class ptr
- VC方案:对第二个问题的解决方案: 在虚继承体系下新增加一个vitual base class table(虚基类表),虚基类表中则存放有指向虚基类的指针,而对象内增加一个指向虚基类表的指针.
- 另一种解决方案: 在虚函数表中放置 虚基类对象 的偏移量(相对于对象起始位置的偏移量)
- 如虚基类对象指针 = rhs + rhs._vptr[-1][^9] [^9]:Sun公司实现的编译器 - 虚函数表取负值,表示取回虚基类对象的偏移量,rhs 表示一个存在虚基类的对象.
</br>
- 对象成员或基类对象成员后面的填充空白不能为其它成员所用
- 看一段代码:
class X{ public: int x; char c; }; class X2:public X { public:char c2; };- X2的布局应当是x(4),c(1),c2(1),这么说来sizeof(X2)的值应该是8?错了,实际上是12。原因在于X后面的三个字节的填充空白不能为c2所用。也就是说X2的大小实际上为:X(8)+c2(1)+填补(3)=12。
- 看一段代码:
- Vptr与Vbptr
- 在多继承情况下,即使是多虚拟继承,继承而得的类只需维护一个Vbptr;
- 而多继承情况下Vptr则可能要维护多个Vptr,看其基类有几个虚函数。
- 一条继承线路只有一个Vptr,但可能有多个Vbptr,视有几次虚拟继承而定。换句话说:
- 对于继承类对象来说,不需要新合成vptr,而是使用其基类子对象的vptr。
- 而虚拟继承类对象,必须新合成一个自己的Vbptr。
- 实例:
class X{ virtual void vf(){}; }; class X2:virtual public X { virtual void vf(){}; }; class X3:virtual public X2 { virtual void vf(){}; } - X3将包含有一个Vptr,两个Vbptr。确切的说这两个Vbptr一个属于X3,一个属于X3的子对象X2,X3通过其Vbptr找到子对象X2,而X2通过其Vbptr找到X。
- 其中差别在于vptr通过一个虚函数表可以确切地知道要调用的函数,而Vbptr通过虚基类表只能够知道其虚基类子对象的偏移量。这两条规则是由虚函数与虚拟继承的实现方式,以及受它们的存取方式和复制控制的要求决定的。
数据成员的存取
- 静态数据成员相当于一个仅对该类可见的全局变量,因为程序中只存在一个静态数据成员的实例,所以其地址在编译时就已经被决定。不论如何静态数据成员的存取不会带来任何额外负担。
- 非静态数据成员的存取,相当于对象起始地址加上偏移量。效率上与C struct成员的效率等同。因为它的偏移量在编译阶段已经确定。但有一种情况例外:pt->x=0.0。当通过指针或引用来存取——x而x又是虚基类的成员的时候。因为必须要等到执行期才能知道pt指向的确切类型,所以必须通过一个间接导引才能完成
- 附加:
-
类中对静态成员变量取址: 对静态成员取地址,将会得到一个指向数据类型的指针,而不是一个指向class member的指针,因为静态成员并不内含与class object中.
小结
-
- 在VC中数据成员的布局顺序为:
- vptr部分(如果基类有,则继承基类的)
- vbptr (如果需要)
- 基类成员(按声明顺序)
- 自身数据成员
- 虚基类数据成员(按声明顺序)
第4章 Function语意学(The Semantics of Function)
4.1 C++之成员函数调用
- c++支持三种类型的成员函数,每一种调用方式都不尽相同
- static-Function
- nostatic-Function
- virtual-Function
非静态成员函数(Nonstatic Member Functions)
- 保证nostatic member function至少必须和一般的nonmember function有相同的效率是C++的设计准则之一。 事实上在c++中非静态成员函数(nostatic member function)与普通函数的调用也确实具有相同的效率,因为本质上非静态成员函数就如同一个普通函数.
- 编译器内部会将成员函数等价转换为非成员函数,具体是这样做的: 改写成员函数的签名,使得其可以接受一个额外参数,这个额外参数即是this指针, 当然如果成员函数是const的,插入的this 参数类型将为 const xxx 类型。
- 例:
- 非静态成员函数X float Point::X();就相当于一个普通函数float X(Point* this);
float Point::X(); //成员函数X被插入额外参数this float Point:: X(Point* this );- 将每一个对非静态数据成员的操作都改写为经过this操作。
- 将成员函数写成一个外部函数,对函数名进行“mangling”处理,使之成为独一无二的名称。
- 将一个成员函数改写成一个外部函数的关键在于两点,
- 一是给函数提供一个可以直接读写成员数据的通道,给函数提供一个额外的指针参数
-
二是解决好有可能带来的名字冲突,通过一定的规则将名字转换,使之独一无二。
- T:2019/10/16 19:13
-
起始对于一个类中的成员函数(包括虚函数),提供一个可以直接读写成员数据的通道, 至关重要!!!, 看面关于多继承下的多态问题,对这个概念尤为深刻。
- 由此可以做出一点总结:
- 一个成员函数实际上就是一个被插入了一个接受其类的指针类型的额外参数的非成员函数,还要额外对函数的名称进行处理。额外插入的参数用来访问数据成员,而名称的特殊处理用来避免名字冲突。
- 对于名称的特殊处理并没有统一的标准,各大编译器厂商可能有不同的处理规则。
- 在VC下上述的成员函数X()的名称X处理后就 成了?X@Point@@QAEMXZ
- 更多信息可以参见维基百科的Visual C++名字修饰。
- VC中对于上面的例子中的成员函数的调用将发生如下的转换:
//p->X();被转化为 ?X@Point@@QAEMXZ(p); //obj.X();被转化为 ?X@Point@@QAEMXZ(&obj);虚拟成员函数(Virtual Member Functions)
- 如果function()是一个虚拟函数,
- 那么用指针或引用进行的调用将发生一点特别的转换 —— 一个中间层被引入进来。
- 例如:
// p->function() // 将转化为 (*p->vptr[1])(p);- 其中vptr为指向虚函数表的指针,它由编译器产生。vptr也要进行名字处理,因为一个继承体系可能有多个vptr。
- 1是虚函数在虚函数表中的索引,通过它关联到虚函数function().
- 何时发生这种转换?答案是在必需的时候——一个再熟悉不过的答案。
- 当通过指针调用的时候,要调用的函数实体无法在编译期决定,必需待到执行期才能获得,所以上面引入一个间接层的转换必不可少。
- 但是当我们通过对象(不是引用,也不是指针)来调用的时候,进行上面的转换就显得多余了,因为在编译器要调用的函数实体已经被决定。此时调用发生的转换,与一个非静态成员函数(Nonstatic Member Functions)调用发生的转换一致。
静态成员函数(Static Member Functions)
- 静态成员函数的一些特性:
- 不能够直接存取其类中的非静态成员(nostatic members),包括不能调用非静态成员函数(Nonstatic Member Functions)。
- 不能够声明为 const、voliatile或virtual。
- 它不需经由对象调用,当然,通过对象调用也被允许。
- 除了缺乏一个this指针他与非静态成员函数没有太大的差别。 在这里通过对象调用和通过指针或引用调用,将被转化为同样的调用代码。
- 需要注意的是通过一个表达式或函数对静态成员函数进行调用,C++ Standard要求对表达式进行求值。
- 如:
(a+=b).static_fuc();
- 如:
- 虽然省去对a+b求值对于static_fuc()的调用并没有影响,但是程序员肯定会认为表达式a+=b已经执行,一旦编译器为了效率省去了这一步,很难说会浪费多少程序员多少时间。这无疑是一个明智的规定。
4.2 C++之虚函数(Virtual Member Functions)
- 深度探索C++对象模型》是这样来说多态的:
- 在C++中,多态表示“以一个public base class的指针(或引用),寻址出一个derived class object”的意思。
- C++ 多态包括编译时多态和运行时多态,编译时多态体现在函数重载和模板上,运行时多态体现在虚函数上。
-
虚函数:在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数.
- C++的虚函数是实现多态的机制。它是通过虚函数表实现的,虚函数表是每个类中存放虚函数地址的指针数组,类的实例在调用函数时会在虚函数表中寻找函数地址进行调用,如果子类覆盖了父类的函数,则子类的虚函数表会指向子类实现的函数地址,否则指向父类的函数地址。一个类的所有实例都共享同一张虚函数表。详见:C++虚函数表剖析
静态多态性与动态多态性2
- 多态:以一个 “public base class” 的指针寻址出一个 “derived class object”(深入探索C++对象模型定义)
- 静态多态性: 通常称为编译时多态,到底模板是不是多态???我个人认为不是
- 动态多态性: 通常称为运行时多态,通过虚函数来实现
- 动态多态性的两个条件:
- 在基类中必须使用虚函数或纯虚函数
- 调用函数时使用基类的指针或引用
消极多态与积极多态
- 消极多态(没有进行虚函数的调用)
- 用基类指针来寻址继承类的对象,我们可以这样:
Point ptr=new Point3d; //Point3d继承自Point
- 在这种情况下,多态可以在编译期完成(虚基类情况除外),因此被称作消极多态(没有进行虚函数的调用, 指针的多态机能主要扮演一个输送机制的角色)。
- 用基类指针来寻址继承类的对象,我们可以这样:
- 积极多态(对象类型需要在执行期才能决定)
- 积极多态的例子如虚函数和RTTI
- 如下例关于虚函数的调用, 虚函数的实现机制,将保证调用的z()函数实现,为Point3d:: z()而不是调用了Point:: z()。
- 例子:
//例1,虚函数的调用 ptr->z(); //例2,RTTI 的应用 if(Point3d *p=dynamic_cast<Point3d*>(ptr) ) return p->z();虚函数的实现
- 虚函数的实现:
- 为每个有虚函数的类配一张虚函数表,它存储该类类型信息和所有虚函数执行期的地址。
- 为每个有虚函数的类插入一个指针(vptr),这个指针指向该类的虚函数表。
- 给每一个虚函数指派一个在表中的索引。
- 用这种模型来实现虚函数得益于在C++中,虚函数的地址在编译期是可知的,而且这一地址是固定不变的。而且表的大小不会在执行期增大或减小。
- 类的虚函数表中存储有类型信息:
- 有类型信息(存储在索引为0的位置)
- 所有虚函数地址
- 部分编译器还把虚基类的指针放到了虚函数表里面,如早期的Sum编译器
- 虚函数地址包括三种:
- 这个类定义的虚函数,会改写(overriding)一个可能存在的基类的虚函数实体——假如基类也定义有这个虚函数。
- 继承自基类的虚函数实体,——基类定义有,而这个类却没有定义。直接继承之。
- 一个纯虚函数实体。用来在虚函数表中占座,有时候也可以当做执行期异常处理函数。
- 每一个虚函数都被指派一个固定的索引值,这个索引值在整个继承体系中保持前后关联,例如,假如z()在Point虚函数表中的索引值为2,那么在Point3d虚函数表中的索引值也为2。
单继承下的虚函数
- 类单继承自有虚函数的基类时,将按如下步骤构建虚函数表:
- 继承基类中声明的虚函数——这些虚函数的实体地址被拷贝到继承类中的虚函数表中对于的slot中。
- 如果有改写(override)基类的虚函数,那么在1中应将改写(override)的函数实体的地址放入对应的slot中而不是拷贝基类的。
- 如果有定义新的虚函数,那么将虚函数表扩大一个slot以存放新的函数实体地址。
- 例子:
ptr->z(); //被编译器转化为: (*ptr->vptr[4])(ptr); - 我们假设z()函数在Point虚函数表中的索引为4,回到最初的问题——要如何来保证在执行期调用的是正确的z()实体?其中微妙在于,编译将做一个小小的转换:
- 这个转换保证了调用到正确的实体,因为:
- 虽然我们不知道ptr所指的真正类型,但它可以通过vptr找到正确类型的虚函数表。在整个继承体系中z()的地址总是被放在slot 4。
多重继承下的虚函数
- 多重继承中支持virtual functions,其复杂度围绕在第二个及后继的base classes身上,以及“必须在执行期调整this指针”这一点。如下是多重继承体系:
class Base1 { public: Base1(); virtual ~Base1(); virtual void speakClearly(); virtual Base1* clone() const; protected: float data_Base1; }; class Base2 { public: Base2(); virtual ~Base2(); virtual void mumble(); virtual Base2* clone() const; protected: float data_Base2; }; class Derived: public Base1,public Base2 { public: Derived(); virtual ~Derived(); virtual Derived* clone() const; protected: float data_Derived; }; - “Derived 支持virtual functions”困难度,都落在Base2 suboject身上,有三个问题要解决:
- 1.virtual destructor;(进行删除对象的时候,需要把指针调整至于派生类上)
- 2.被继承下来的Base2::mumble();(需要把指针调整至Base2上)
- 3.一组clone()函数实例。
- 分析: (注意编译器需要调整Base2的指针)
Base2* pbase2 = new Derived; //编译器转化,新的Derived对象必须调整 //以指向Base2 subobject Derived* temp = new Derived; Base2* pbase2 = temp?temp + sizeof(Base1):0; //调整后,调用虚函数正确 pbase2->data_Base2; // 指向base2 //删除pbase2时候,必须正确调用virtual destructor实例 //然后delete delete pbase2; // 指向derived - 实现过程(Thunk技术):
- 在多重继承之下,一个derived class内含n-1个额外的virtual tables,n表示其上一次base classes的个数(因此单一继承将不会产生额外的virtual tables)。对于本例而言的Derived,会有两个virtual tables被编译器产生:
- 一个主要实例,与Base1(最左端base clss)共享,
vtbl_Derived; //主要表格 - 一个次要实例,与Base2(第二个base class)有关,
vtbl_Base2_Derived; //次要表格
- 一个主要实例,与Base1(最左端base clss)共享,
- Thunk允许 虚函数表中的slot包括的地址包括两个类型:
- 不需要调整地址, 指向虚函数实体地址
- 需要调整地址,指向一个相关的Thunk(估计是一个偏移量之类的)
- 当将一个Derived对象地址指定给一个Base1指针或Derived指针,被处理的virtual table主要表格vtbl_Derived;
- 当将一个Derived对象地址指定给一个Base2指针时,被处理的virtual tables是次要表格vtbl_Base2_Derived;
- 分析
- 通过“指向第二个base class”的指针,调用derived class virtual function。ptr必须调整指向Baes2 subobject。
- 通过“指向derived class”的指针,调用第二个base class中一个继承而来的virtual function。derived class 指针必须再次调整指向第二Base2 subobject
- 在多重继承之下,一个derived class内含n-1个额外的virtual tables,n表示其上一次base classes的个数(因此单一继承将不会产生额外的virtual tables)。对于本例而言的Derived,会有两个virtual tables被编译器产生:
- 图示
 —
— - 做如下小结:
- 多继承下的虚函数,影响到虚函数的调用的实际质上为this的调整。而this调整一般为两种:
- 调整指针指向对应的sub object,一般发生在继承类类型指针向基类类型指针赋值的情况下。
- 将指向sub object的指针调整回继承类对象的起始点,一般发生在基类指针对继承类虚函数进行调用的时候。
- 第一点,使得该基类指针指向一个与其指针类型匹配的子对象,唯有如此才能保证使得该指针在执行与其指针类型相匹配的特定行为的正确性。比方调用基类的成员,获得正确的虚函数地址。
- 第二点,显然是让一个继承类的虚函数获取一个正确的this指针,因为一个继承类虚函数要的是一个指向继承类对象的this指针,而不是指向其子对象。
- 第一顺序继承类之所以不需要进行调整的关键在于,其sub object的起点与继承类对象的起点一致。
虚拟继承下的虚函数
- Lippman说,如果一个虚基类派生自另一虚基类,而且它们都支持虚函数和非静态数据成员的时候,编译器对虚基类的支持就像迷宫一样复杂。
- 图

4.3 指向成员函数的指针
“指向Nonstatic Member Functions”的指针
- 取一个nonstatic data member的地址,得到的结果是该member在 class 布局中的byte位置(再加1),它是一个不完整的值,须要被绑定于某个 class object的地址上,才可以被存取.
- 取一个nonstatic member function的地址,假设该函数是nonvirtual,则得到的结果是它在内存中真正的地址.然而这个值也是不全然的,它也须要被绑定与某个 class object的地址上,才可以通过它调用该函数,全部的nonstatic member functions都须要对象的地址(以參数 this 指出).
- 关于指向成员函数指针的 声明 赋值 调用:
- 声明member function的指针:
double // return type (Point::* // class the function is member pmf) // name of the pointer to member (); // argument list- 定义并初始化该指针:
double (Point::*coord)() = &Point::x;- 指针赋值:
coord = &Point::y;- 调用它:
(origin.*coord)();或(ptr->*coord)();
- 这些操作会被编译器转化为:
(coord)(&origin);和(coord)(ptr);- 关于指向成员函数指针的分析
- 指向member function的指针的声明语法 中加入
Point::*的作用是是作为 this 指针的空间保留者.这这也就是为什么 static member function(没有 this 指针)的类型是”函数指针”,而不是”指向member function的指针”的原因.- 效率的讨论:
- 使用一个”member function指针”,(不用于 virtual function,多重继承,virtual base class 等情况的话),并不会比使用一个”nonmember function指针”的成本更高.
- virtual function,多重继承,virtual base class 三种情况的话对于”member function指针”的类型以及调用都太过复杂
“指向Virtual Member Functions”的指针
- 注意以下的程序片段:
float (Point::*pmf)() = &Point::z; Point *ptr = new Point3d; - pmf,一个指向member function的指针,被设值为Point::z()(一个 virtual function)的地址,ptr则被指定以一个Point3d对象,
- 直接经由ptr调用z():
ptr->z();则被调用的是point3d:: z(), - 从pmf间接调用z()
(ptr->pmf)();仍然是Point3d:: z()被调用
- 直接经由ptr调用z():
-
也就是说,虚拟机制仍然可以在使用”指向member function的指针”的情况下运行 !
- 对一个nonstatic member function取其地址,将获得该函数在内存中的地址,然而面对一个 virtual function,其地址在编译时期是未知的,所能直到的仅是 virtual function在其相关的 virtual table中的索引值.也就是说,对一个 virtual member function取其地址,所能获得的仅仅是一个索引值.
- 具体实现过程如下:
- 例子:
class Point { public: virtual ~Point(); float x(); float y(); virtual float z(); }; - 对nonstatic函数取地址:
- 取x()或y()的地址:
&Point::x();或&Point::y();得到的则是函数在内存中的地址,由于它们不是 virtual
- 取x()或y()的地址:
- 对virtual函数取地址:
- 取得destructor的地址:
&Point::~Point;得到的结果是1(索引值.) - 取z()的地址:
&Point:: z();得到的结果是2(索引值.)
- 取得destructor的地址:
- 对指向虚函数的函数指针调用:
- 通过pmf来调用z(),会被内部转化为一个编译时期的式子,一般形式例如以下:
(*ptr->vptr[(int)pmf])(ptr); - 对一个”指向member function的指针”评估求值(evaluted),会由于该值有两种意义而复杂化;其调用操作也将有别于常规调用操作.
- pmf的内部定义,为
float (Point::*pmf)();- 这里该定义可以指向nonvirtual x()和 virtual z()两个member functions,因为其有着同样的原型:
- 只是当中一个代表内存地址
- 还有一个代表 virtual table中的索引值
// 二者都能够被指定给pmf float Point::x() { return _x; } float Point::z() { return 0; }
- 这里该定义可以指向nonvirtual x()和 virtual z()两个member functions,因为其有着同样的原型:
- 因此,编译器必须定义pmf使它能够
- (1)还有两种数值,
- (2)更重要的是其数值能够被差别代表内存地址还是 virtual table中的索引值.
- 通过pmf来调用z(),会被内部转化为一个编译时期的式子,一般形式例如以下:
第5章 构造、解构、拷贝 语意学(Semantics of Construction,Destruction,and Copy)
几点类设计原则
-
即使是一个抽象基类,如果它有非静态数据成员,也应该给它提供一个带参数的构造函数,来初始化它的数据成员。 或许你可以通过其派生类来初始化它的数据成员(假如nostatic data member为publish或protected),但这样做的后果则是破坏了数据的封装性,使类的维护和修改更加困难。由此引申,类的data member应当被初始化,且只在其构造函数或其member function中初始化。
- 不要将析构函数设计为纯虚的,这不是一个好的设计。 将析构函数设计为纯虚函数意味着,即使纯虚函数在语法上允许我们只声明而不定义纯虚函数,但还是必须实现该纯虚析构函数,否则它所有的继承类都将遇到链接错误。
- 必须定义纯虚析构函数,而不能仅仅声明它的原因在于:
- 每一个继承类的析构函数会被编译器加以扩展,以静态调用方式其每一个基类的析构函数(假如有的话,不论是显示的还是编译器合成的),所以只要任何一个基类的析构函数缺乏定义,就会导致链接失败。
- 矛盾就在这里,纯虚函数的语法,允许只声明而不定义纯虚析构函数,而编译器则死脑筋的看到一个其基类的析构函数声明,则去调用它的实体,而不管它有没有被定义。
- 必须定义纯虚析构函数,而不能仅仅声明它的原因在于:
- 真的必要的时候才使用虚函数,不要滥用虚函数。 虚函数意味着不小的成本,编译很可能给你的类带来膨胀效应:
- 每一个对象要多负担一个word的vptr。给每一个构造函数(不论是显示的还是编译器合成的),插入一些代码来初始化vptr,这些代码必须被放在所有基类构造函数的调用之后,但需在任意用户代码之前。
- 没有构造函数则需要合成,并插入代码。
- 合成一个拷贝构造函数和一个复制操作符(如果没有的话),并插入对vptr的初始化代码,有的话也需要插入vptr的初始化代码。
- 意味着,如果具有bitwise语意,将不再具有,然后是变大的对象、没有那么高效的构造函数,没有那么高效的复制控制。
- 不能决定一个虚函数是否需要 const ,那么就不要它。
- 决不在构造函数或析构函数中使用虚函数机制(并不是说不要把构造函数和析构函数设置为虚函数)。
- 在构造函数中,每次调用虚函数会被决议为当前构造函数所对应类的虚函数实体,虚函数机制并不起作用。
- 当一个base类的构造函数含有对虚函数vf()的调用,当其派生类derived的构造函数调用基类base的构造函数的时候,其中调用的虚函数vf()是base中的实体,而不是derived中的实体。
- 这是由vptr初始化的位置决定的——在所有基类构造函数调用之后,在程序员供应的代码或是成员初始化队列之前。
- 因构造函数的调用顺序是:有根源到末端,由内而外,所以对象的构造过程可以看成是,从构建一个最基础的对象开始,一步步构建成一个目标对象。析构函数则有着与构造相反的顺序,因此在构造或析构函数中使用虚函数机制,往往不是程序员的意图。若要在构造函数或析构函数中调用虚函数,应当直接以静态方式调用,而不要通过虚函数机制。
构造、复制、析构语意学
- 一种所谓的Plain OI’Data声明形式:
struct Point { float x,y,z; }; - 概念上来讲,对于一段这样的C++代码,编译器会为之合成一个默认构造函数、复制构造函数、析构函数、赋值操作符。
- 然而实际上编译器会分析这段代码,并给Point贴上Plain OI’Data标签。编译器在此后对于Point的处理与在C中完全一样,也就是说上述的函数都不会被合成。可见概念上应当由编译器合成的函数,并不一定会合成,编译器只有在必要的时候才会合成它们。由此一来,原本在观念上应该调用这些函数的地方实质上不会调用,而是用其它的方法来完成上面的功能,比方复制控制会用bitwise copy。
- 对象构造语意学
- 无继承情况下的对象构造:略。
- 单继承体系下的对象构造 对照一下
- 对于简单定义的一个对象T object;,很明显它的默认构造函数会被调用(被编译器合成的或用户提供的)。但是一个构造函数究竟做了什么,就显得比较复杂了——编译器给了它很多的隐藏代码。编译器一般会做如下扩充操作:
- 调用所有虚基类的构造函数,从左到右,从最深到最浅:
- 如果该类被列于成员初始化列表中,任何明确指定的参数,都应该被传递过来。若没有列入成员初始化列表中,虚基类的一个默认构造函数被调用(有的话)。
- 此外,要保证虚基类的偏移量在执行期可存取,对于使用vbptr来实现虚基类的编译器来说,满足这点要求就是对vbptr的初始化。
- 然而,只有在类对象代表着“most-derived class”时,这些构造函数才可能会被调用。一些支持这个行为的代码会被放进去(直观点说就是,虚基类的构造由最外层类控制)。
- 调用所有基类构造函数,依声明顺序:
- 如果该基类被列入了成员初始化队列,那么所有明确指定的参数,应该被传递过来。
- 没有列入的话,那么调用其默认构造函数,如果有的话。
- 如果该基类是第二顺位或之后的基类,this 指针必须被调整。
- 正确初始化vptr,如果有的话。
- 调用没有出现在初始化成员列表中的member object的默认构造函数,如果有的话。
-
记录在成员初始化队列中的数据成员初始化操作以声明的顺序被放进构造函数中。
- 多重继承的构造函数流程:
- 在派生类构造函数中,所有虚基类以及上一层的基类的构造函数都被调用
- 对象的vptr(s)被初始化指向相关的virtual table(s)
- 执行构造函数的成员初始化列表
- 执行程序猿 提供的初始化代码段;
- 对象复制语意学
- 设计一个类,并考虑到要以一个对象指定给另一个对象时,有三种选择:
- 什么都不做,采用编译器提供默认行为(bitwise copy或者由编译器合成一个)。
- 自己提供一个赋值运算符操作。
- 明确拒绝将一个对象指定给另一个对象。
- 对于第三点,只要将赋值操作符声明为private,且不定义它就可以了。
- 对于第二点,只有在第一点的行为不安全或不正确,或你特别想往其中插入点东西的时候。
- 以下四种情况 copy assignment operator(还是用它的英文名,感觉顺畅点),不具有bitwise copy语意,也就是说这些情况下,编译器要合成copy assignment operator而不能依靠bitwise copy来完成赋值操作,这四种情况与构造函数、拷贝构造函数的情况类似,原因可以参考它们的。四种情况如下:
- 类包含有定义了copy assignment operator的class object成员。
- 类的基类有copy assignment operator。
- 类声明有任何虚函数的时候(问题同样会出现在由继承类对象向基类对象拷贝的时候)。
- 当class继承体系中有虚基类时。
- 在虚拟继承情况下,copy assignment opertator会遇到一个不可避免的问题,virtual base class sub object的复制行为会发生多次,与前面说到的在虚拟继承情况下虚基类被构造多次是一个意思,不同的是在这里不能抑制非most-derived class 对virtual base class 的赋值行为。
-
安全的做法是把虚基类的赋值放在最后,避免被覆盖。
-
- 设计一个类,并考虑到要以一个对象指定给另一个对象时,有三种选择:
- 对象析构语意学
- 只有在基类拥有析构函数,或者object member拥有析构函数的时候,编译器才为类合成析构函数,否则都被视为不需要。
- 析构的顺序正好与构造相反:
- 本身的析构函数被执行。
- 以声明的相反顺序调用member object 的析构函数,如果有的话。
- 重设vptr 指向适当的基类的虚函数表,如果有的话。
- 以声明相反的顺序调用上一层的析构函数,如果有的话。
- 如果当前类是 most-derived class,那么以构造的相反顺序调用虚基类的析构函数。
第6章 执行期语意学(Runting Semantics)
-
- 实际上struct还要复杂一点,它有时表现的会和C struct完全一样,有时则会成为class的胞兄弟。 ↩︎
-
- Ref: 深度探索c++对象模型(一)
-
- 详情请参考: C++中的类所占内存空间总结
-
- 参考一下实现: 二重调度问题:解决方案之虚函数+RTTI
-
- Bitwise copy semantics 是Default Memberwise Intializiation的具体实现方式。[别人的解释]
-
- 关于更多的memory alignment(内存对齐)的知识见VC内存对齐准则(Memory alignment),VC对齐
-
- Sun公司实现的编译器 - 虚函数表取负值,表示取回虚基类对象的偏移量,rhs 表示一个存在虚基类的对象. ↩︎
面试题
T:2019/11/28 W:四 17:0:11 [HTML]: @TOC
C++ 基础
1、引用和指针的区别?
- 初始化:
- 引用在定义的时候必须进行初始化,并且不能够改变
- 指针在定义的时候不一定要初始化,并且指向的空间可变
- 访问逻辑不同:
- 通过指针访问对象, 用户需要使用间接访问
- 通过引用访问对象, 用户只需使用直接访问, 编译器负责将其处理为间接访问
- 运算结果不同:
- 自增运算结果不同
sizeof运算的结果不同- 下标运算:
- 指针通过下标运算结果是指针所指值为基地址加上偏移, 且基地址可变.
- 引用通过下标运算结果是引用的是数组才能有这个操作.
- 函数参数:
- 传指针的实质是传值,传递的值是指针内储存的变量地址;
- 传引用的实质是传地址,传递的是变量的地址。
- 多级: 有多级指针,但是没有多级引用,只能有一级引用。
2、从汇编层去解释一下引用
- 参考两个语句
int a=1; int &b=a; // *** mov ptr [ebp-4], 1 lea eax, [ebp-4] mov dword ptr [ebp-8], eax a的地址为ebp-4,b的地址为ebp-8, 栈地址由高到底分配.- 可以发现这个和指针的复制几乎一样,所以引用其实是通过指针来实现的
3、C++中的指针参数传递和引用参数传递
- 指针参数传递的本质是值传递, 传递的值是对象的地址, 在调用时形参会在函数栈中开辟空间用于存放传递过来的对象的地址,此时形参相当于是实参的副本, 对形参的任何操作都不会反映到实参上, 但是通过形参间接访问对象的修改是会反应到函数之外的.
- 引用参数传递的本质是传地址, 传递的是实参变量的地址, 首先形参会在函数栈中开辟空间用来存放实参变量的地址, 然后对该形参的任何操作都会被处理未间接寻址,即通过形参中的地址访问主调函数中的实参变量, 因为通过形参的任何操作都将被应用于主调函数中.
- 从逻辑上引用相当于对变量起了一个别名, 通过该别名可以对变量进行直接访问, 由编译器负责将直接访问转换为间接访问; 而指针访问变量都是间接访问.
4、形参与实参的区别?
- 形参属于函数内部的局部变量, 在调用函数时才会分配内存, 在函数调用之后会被释放掉, 因此在函数内部才有效
- 实参可以使常量, 表达式, 函数等, 无论是何种类型,在函数调用时都必须有一个确定的值,以便把函数的值传递给形参
- 实参和形参的个数一定要严格匹配(当然可以忽略有默认值形参), 通常情况下函数类型也是应该严格匹配的, 但是允许隐式类型变换,如果类中定义了零参数构造函数,甚至可以使用空初始化列表
{}的方式调用零参数构造函数 - 实参到形参的传递是单向的
- 形参类型为非指针非引用, 则传递方式为值传递则, 形参为实参的副本, 对形参的任何修改都不会反应在主调函数中
4-2 三种传递方式
- 值传递是通过拷贝构造函数实现的
- 指针传递是属于值传递,实参指针向形参传递的是对象的地址
- 引用传是属于传地址, 相当于对变量起了一个别名, 本质上和指针传递类似传递的都是对象的地址,区别在于对该引用形参的任何操作都会被处理为间接云芝, 也就是会反应到调用函数中
5、static的用法
- 主要可以分为五个类型: 全局静态变量, 局部静态变量, 静态函数, 静态成员变量, 静态成员函数
- 全局静态变量
- 在全局变量前加上关键字
static,全局变量就定义成一个全局静态变量. - 内存中的位置:静态存储区,在整个程序运行期间一直存在。
- 初始化:未经初始化的全局静态变量会被自动初始化为
0(对于自动对象,如果没有显示初始化,会调用零参数构造函数,如不存在则编译失败); - 作用域:全局静态变量在声明他的文件之外是不可见的,准确地说是从定义之处开始,到文件结尾。
- 局部静态变量
- 在局部变量之前加上关键字
static,局部变量就成为一个局部静态变量。 - 内存中的位置:静态存储区
- 初始化:未经初始化的全局静态变量会被自动初始化为
0(对于自动对象,如果没有显示初始化,会调用零参数构造函数,如不存在则编译失败); - 作用域:作用域仍为局部作用域,
- 当定义它的函数或者语句块结束的时候,作用域结束。
- 但是当局部静态变量离开作用域后,并没有销毁,而是仍然驻留在内存当中,只不过我们不能再对它进行访问,直到该函数再次被调用,并且值不变;
- 静态函数
- 在函数返回类型前加
static,函数就定义为静态函数。函数的定义和声明在默认情况下都是extern的,但静态函数只是在声明他的文件当中可见,不能被其他文件所用。 - 函数的实现使用
static修饰,那么这个函数只可在本cpp内使用,不会同其他cpp中的同名函数引起冲突; warning:不要再头文件中声明static的全局函数,不要在cpp内声明非static的全局函数,如果你要在多个cpp中复用该函数,就把它的声明提到头文件里去,否则cpp内部声明需加上static修饰;
- 在函数返回类型前加
- 类的静态成员
- 在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性。
- 因此,静态成员是类的所有对象中共享的成员,而不是某个对象的成员。对多个对象来说,静态数据成员只存储一处,供所有对象共用
- 类的静态函数
- 静态成员函数和静态数据成员一样,它们都属于类的静态成员,它们都不是对象成员。因此,对静态成员的引用不需要用对象名。
- 在静态成员函数的实现中不能直接引用类中说明的非静态成员,可以引用类中说明的静态成员(这点非常重要)。*如果静态成员函数中要引用非静态成员时,可通过对象来引用。从中可看出,调用静态成员函数使用如下格式:<类名>::<静态成员函数名>(<参数表>);*
- 不能被
virtual修饰,静态成员函数没有this指针,虚函数的实现是为每一个对象分配一个vptr指针,而vptr是通过this指针调用的,所以不能为virtual;虚函数的调用关系,this->vptr->ctable->virtual function
6、静态变量什么时候初始化
- 静态局部变量和全局变量一样,数据都存放在全局区域,所以在主程序之前,编译器已经为其分配好了内存,
- 但在
C和C++中静态局部变量的初始化节点又有点不太一样。- 在
C中,初始化发生在代码执行之前,编译阶段分配好内存之后,就会进行初始化,所以我们看到==在C语言中无法使用变量对静态局部变量进行初始化==,在程序运行结束,变量所处的全局内存会被全部回收。 - 而在
C++中,初始化时在执行相关代码时才会进行初始化,主要是由于C++引入对象后,要进行初始化必须执行相应构造函数和析构函数,在构造函数或析构函数中经常会需要进行某些程序中需要进行的特定操作,并非简单地分配内存。所以C++标准规定为全局或静态对象是有首次用到时才会进行构造 ,并通过atexit()来管理。在程序结束,按照构造顺序反方向进行逐个析构。所以在C++中是可以使用变量对静态局部变量进行初始化的。
- 在
7、const?
- 一般可以分为如下六种类型
const变量: 表明标了为const类型, 通常需要被初始化否则后面将不能被修改, 对该变量的修改操作都会被编译器阻止.const指针对象: 标明该指针为普通的左值类型可以进行修改, 但是不能通过该变量修改做指向的对象, 则通过该指针只能访问const类型的成员函数.const引用: 它所绑定的对象不能被修改const形参: 和普通的实参分类一样分为const 变量, const指针对象, const 引用, 作用也类似,表示不能修改该变量.const返回值: 通常是为了表明返回值是一个const类型防止返回值被修改, 或则被当做左值放在赋值运算的左边const成员函数: 是指成员函数不会修改类对象的任何成员变量, 如果返回值为对象成员的引用则必须返回const引用, 同时const成员函数不能调用非const函数, 其主要是因为const成员函数所持有的this指针是一个const类型的指针, 因为不能调用非const类型的成员函数,
8、const 成员函数的理解和应用?
① const Stock & Stock::topval (②const Stock & s) ③const- ① 处
const:确保返回的Stock对象在以后的使用中不能被修改 - ② 处
const:确保此方法不修改传递的参数s - ③ 处
const:保证此方法不修改调用它的对象,const对象只能调用const成员函数,不能调用非const函数
9、指针和const的用法
- 当
const修饰指针时,由于const的位置不同,它的修饰对象会有所不同。 - (常指针对象)
int *const p2中const修饰p2的值,所以理解为p2的值不可以改变,即p2只能指向固定的一个变量地址,但可以通过*p2读写这个变量的值。顶层指针表示指针本身是一个常量 - (常指针)
int const *p1或者const int *p1两种情况中const修饰*p1,所以理解为*p1的值不可以改变,即不可以给*p1赋值改变p1指向变量的值,但可以通过给p赋值不同的地址改变这个指针指向。底层指针表示指针所指向的变量是一个常量。
10、mutable
- 如果需要在
const成员方法中修改一个成员变量的值,那么需要将这个成员变量修饰为mutable。即用mutable修饰的成员变量不受const成员方法的限制; - 可以认为
mutable的变量是类的辅助状态,但是只是起到类的一些方面表述的功能,修改他的内容我们可以认为对象的状态本身并没有改变的。实际上由于const_cast的存在,这个概念很多时候用处不是很到了。
- 通常情况下
const成员函数时不能被类对象的成员变量的, 但是可以修改被mutable修饰的成员变量- 通常我们任务
mutable位类的辅助状态, 只是类的一些表诉功能, 修改它不会改变对象的状态 - 通常我们可以是用
const_cast在const成员函数中修改所有的成员变量
11、extern 用法?
extern修饰变量的声明- 如果文件
a.c需要引用b.c中变量int v,就可以在a.c中声明extern int v,然后就可以引用变量v。
- 如果文件
extern修饰函数的声明- 如果文件
a.c需要引用b.c中的函数,比如在b.c中原型是int fun(int mu),那么就可以在a.c中声明extern int fun(int mu),然后就能使用fun来做任何事情。 - 就像变量的声明一样,
extern int fun(int mu)可以放在a.c中任何地方,而不一定非要放在a.c的文件作用域的范围中。 - 默认情况情况下函数都是
extern的, 除非使用static对函数进行了隐匿
- 如果文件
extern修饰符可用于指示C或者C++函数的调用规范。- 比如在
C++中调用C库函数,就需要在C++程序中用extern “C”声明要引用的函数。这是给链接器用的,告诉链接器在链接的时候用C函数规范来链接。主要原因是C++和C程序编译完成后在目标代码中命名规则不同。
- 比如在
12、int 转字符串, 字符串转int
C++11标准增加了全局函数std::to_string- 可以使用
std::stoi/std::stol/std::stoll等等函数
12.1 strcat,strcpy,strncpy,memset,memcpy 的内部实现?
strcat:char *strcat(char *dst, char const *src);- 头文件:
#include <string.h> - 作用: 将
dst和src字符串拼接起来保存在dst上 - 注意事项:
dst必须有足够的空间保存整个字符串dst和src都必须是一个由\0结尾的字符串(空字符串也行)dst和src内存不能发生重叠
- 函数实现:
- 首先找到
dst的end - 以
src的\0作为结束标志, 将src添加到dst的end上
- 首先找到
Codechar *strcat (char * dst, const char * src){ assert(NULL != dst && NULL != src); // 源码里没有断言检测 char * cp = dst; while(*cp ) cp++; /* find end of dst */ while(*cp++ = *src++) ; /* Copy src to end of dst */ return( dst ); /* return dst */ }
- 头文件:
strcpy:char *strcpy(char *dst, const char *src);- 头文件:
#include <string.h> - 作用: 将
src的字符串复制到dst字符串内 - 注意事项:
src必须有结束符(\0), 结束符也会被复制src和dst不能有内存重叠dst必须有足够的内存
- 函数实现:
char *strcpy(char *dst, const char *src){ // 实现src到dst的复制 if(dst == src) return dst; //源码中没有此项 assert((dst != NULL) && (src != NULL)); //源码没有此项检查,判断参数src和dst的有效性 char *cp = dst; //保存目标字符串的首地址 while (*cp++ = *src++); //把src字符串的内容复制到dst下 return dst; }
- 头文件:
strncpy:char *strncpy(char *dst, char const *src, size_t len);- 头文件:
#include <string.h> - 作用: 从
src中复制len个字符到dst中, 如果不足len则用NULL填充, 如果src超过len, 则dst将不会以NULL结尾 - 注意事项:
strncpy把源字符串的字符复制到目标数组,它总是正好向dst写入len个字符。- 如果
strlen(src)的值小于len,dst数组就用额外的NULL字节填充到len长度。 - 如果
strlen(src)的值大于或等于len,那么只有len个字符被复制到dst中。这里需要注意它的结果将不会以NULL字节结尾。
- 函数实现:
char *strncpy(char *dst, const char *src, size_t len) { assert(dst != NULL && src != NULL); //源码没有此项 char *cp = dst; while (len-- > 0 && *src != '\0') *cp++ = *src++; *cp = '\0'; //源码没有此项 return dst; }
- 头文件:
memset:void *memset(void *a, int ch, size_t length);- 头文件:
#include <string.h> - 作用:
- 将参数
a所指的内存区域前length个字节以参数ch填入,然后返回指向a的指针。 - 在编写程序的时候,若需要将某一数组作初始化,
memset()会很方便。 - 一定要保证
a有这么多字节
- 将参数
- 函数实现:
void *memset(void *a, int ch, size_t length){ assert(a != NULL); void *s = a; while (length--) { *(char *)s = (char) ch; s = (char *)s + 1; } return a; }
- 头文件:
memcpy- 头文件:
#include <string.h> - 作用:
- 从
src所指的内存地址的起始位置开始,拷贝n个字节的数据到dest所指的内存地址的起始位置。 - 可以用这种方法复制任何类型的值,
- 如果
src和dst以任何形式出现了重叠,它的结果将是未定义的。
- 从
- 函数实现:
void *memcpy(void *dst, const void *src, size_t length) { assert((dst != NULL) && (src != NULL)); char *tempSrc= (char *)src; //保存src首地址 char *tempDst = (char *)dst; //保存dst首地址 while(length-- > 0) //循环length次,复制src的值到dst中 *tempDst++ = *tempSrc++ ; return dst; }
- 头文件:
strcpy和memcpy的主要区别:- 复制的内容不同:
strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。 - 复制的方法不同:
strcpy不需要指定长度,它遇到被复制字符的串结束符\0才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度,遇到\0并不结束。 - 用途不同: 通常在复制字符串时用
strcpy,而需要复制其他类型数据时则一般用memcpy
- 复制的内容不同:
13、深拷贝与浅拷贝?
- 浅复制:
- 只是拷贝了基本类型的数据,而引用类型数据,复制后也是会发生引用,我们把这种拷贝叫做“(浅复制)浅拷贝”,
- 换句话说,浅复制仅仅是指向被复制的内存地址,如果原地址中对象被改变了,那么浅复制出来的对象也会相应改变。
- 深复制: 在计算机中开辟了一块新的内存地址用于存放复制的对象。
- 浅复制的问题:
- 在某些状况下,类内成员变量需要动态开辟堆内存,如果实行位拷贝,也就是把对象里的值完全复制给另一个对象,如A=B。
- 这时,如果B 中有一个成员变量指针已经申请了内存,那A 中的那个成员变量也指向同一块内存。
- 这就出现了问题:当B把内存释放了(如:析构),这时A 内的指针就是野指针了,出现运行错误。
14、C++模板是什么,底层怎么实现的?
- 编译器并不是把函数模板处理成能够处理任意类的函数;编译器从函数模板通过具体类型产生不同的函数;
- 编译器会对函数模板进行两次编译:
- 在声明的地方对模板代码本身进行编译,
- 在调用的地方对参数替换后的代码进行编译。
-
这是因为函数模板要被实例化后才能成为真正的函数,在使用函数模板的源文件中包含函数模板的头文件,如果该头文件中只有声明,没有定义,那编译器无法实例化该模板,最终导致链接错误。
- 模板可以重载返回值, 函数重载不行
- 如果我们试图通过在头文件中定义函数模板, 在
cpp文件中实现函数模板, 那么我们必须在在实现的那个cpp文件中手动实例化, 也就是使用你需要使用的参数替换模板, 从而使得编译器为你编译生成相应参数的模板函数.
15、C 语言struct 和C++ struct 区别
struct在C语言中:- 是用户自定义数据类型
(UDT); - 只能是一些变量的集合体, 成员不能为函数
- 没有权限设置
- 一个结构标记声明后,在
C中必须在结构标记前加上struct,才能做结构类型名;
- 是用户自定义数据类型
struct在C++中:- 是抽象数据类型
(ADT),支持成员函数的定义,(能继承,能实现多态)。 - 增加了访问权限, 默认访问限定符为
public(为了与C兼容),class中的默认访问限定符为private - 定义完成之后, 可以直接使用结构体名字作为结构类型名
- 可以使用模板
- 是抽象数据类型
16、虚函数可以声明为inline吗?
- 虚函数要求在运行时进行类型确定,而内敛函数要求在编译期完成相关的函数替换, 所以不能
- 虚函数用于实现运行时的多态,或者称为晚绑定或动态绑定。
- 内联函数用于提高效率, 对于程序中需要频繁使用和调用的小函数非常有用。它是在编译期间,对调用内联函数的地方的代码替换成函数代码。
17、类成员初始化方式?构造函数的执行顺序?为什么用成员初始化列表会快一些?
- 概念
- 赋值初始化,通过在函数体内进行赋值初始化;
- 列表初始化,在冒号后使用初始化列表进行初始化。
- 这两种方式的主要区别在于:
- 对于在函数体中初始化,是在所有的成员函数分配空间后才进行的。对于类对象类型成员变量, 则是先调用零参数构造函数, 如果零参数构造函数不存在编译器将会报错.
- 列表初始化是给数据成员分配内存空间时就进行初始化,就是说分配一个数据成员只要冒号后有此数据成员的赋值表达式(此表达式必须是括号赋值表达式)。
-
快的原因: 所以对于列表初始化: 只进行了一次初始化操作, 而赋值初始化则先进性了一次初始化,然后调用了一次复制构造函数.
- 一个派生类构造函数的执行顺序如下:
- 虚基类的构造函数(多个虚拟基类则按照继承的顺序执行构造函数)。
- 基类的构造函数(多个普通基类也按照继承的顺序执行构造函数)。
- 类类型的成员对象的构造函数(按照初始化顺序)
- 派生类自己的构造函数。
18、成员列表初始化?
- 必须使用成员初始化的四种情况
- 当初始化一个引用成员时;
- 当初始化一个常量成员时;
- 基类, 无零参数构造函数时
- 成员类, 无零参数构造函数时
- 成员初始化列表做了什么
- 编译器在调用用户代码之前, 会按照类成员声明顺序一一初始化成员变量, 如果成员初始化类别中有初值,则使用初值构造成员函数.
- 初始化顺序由类中的成员声明顺序决定的,不是由初始化列表的顺序决定的;
19、构造函数为什么不能为虚函数?析构函数为什么要虚函数?
构造函数为什么不能为虚函数?
- 首先是没必要使用虚函数:
- 由于使用间接调用(通过引用或则指针)导致类类型不可信, 而使用虚函数机制完成正确的函数调用.
- 但是构造函数本身是为了初始化对象实例, 创建对象必须制定它的类型, 其类类型是明确的, 因此在编译期间即可确定调用函数入口地址
- 因而没必要使用虚函数, 其调用在编译时由编译器已经确定.
- 其次不能使用虚函数:
- 虚函数的调用依赖于虚函数表, 虚函数表储存于静态储存区, 在存在虚函数的对象中都将插入一个指向虚函数表的指针,
- 在对象中插入一个指向虚函数表的指针是由构造函数完成的, 也就是说在调用构造函数时并没有指向虚函数表的指针, 也就不能完成虚函数的调用.
析构函数为什么要虚函数?
C++中基类采用virtual虚析构函数是为了防止内存泄漏。- 如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。
- 假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。
- 所以,为了防止这种情况的发生,
C++中基类的析构函数应采用virtual虚析构函数。
20、析构函数的作用,如何起作用?
- 析构函数名与类名相同,只是在函数名前增加了取反符号
~以区别于构造函数,其不带任何参数, 也没有返回值. 也不允许重载. - 析构函数与构造函数的作用相反, 当对象生命周期结束的时候,如对象所在函数被调用完毕时,析构函数负责结束对象的生命周期. 注意如果类对象中分配了堆内存一定要在析构函数中进行释放.
- 和拷贝构造函数类似,如果用户未定义析构函数, 编译器并不是一定会自动合成析构函数, 只有在成员变量或则基类拥有析构函数的情况下它才会自动合成析构函数.
- 如果成员变量或则基类拥有析构函数, 则编译器一定会合成析构函数, 负责调用成员变量或则基类的析构函数, 此时如果用户提供了析构函数,则编译器会在用户析构函数之后添加上述代码.
- 类析构的顺序为: 派生类析构函数, 对象成员析构函数, 基类析构函数.
21、构造函数和析构函数可以调用虚函数吗,为什么
- 在C++中,提倡不在构造函数和析构函数中调用虚函数;
- 在构造函数和析构函数调用的所有函数(包括虚函数)都是编译时确定的, 虚函数将运行该类中的版本.
- 因为父类对象会在子类之前进行构造,此时子类部分的数据成员还未初始化,因此调用子类的虚函数时不安全的,故而C++不会进行动态联编;
- 析构函数是用来销毁一个对象的,在销毁一个对象时,先调用子类的析构函数,然后再调用基类的析构函数。所以在调用基类的析构函数时,派生类对象的数据成员已经销毁,这个时候再调用子类的虚函数没有任何意义。
22、构造函数的执行顺序?析构函数的执行顺序?构造函数内部干了啥?拷贝构造干了啥?
- 构造函数顺序:
- 基类构造函数。如果有多个基类,则构造函数的调用顺序是某类在类派生表中出现的顺序,而不是它们在成员初始化表中的顺序。
- 成员类对象构造函数。如果有多个成员类对象则构造函数的调用顺序是对象在类中被声明的顺序,而不是它们出现在成员初始化表中的顺序。
- 派生类构造函数。
- 析构函数顺序:
- 调用派生类的析构函数;
- 调用成员类对象的析构函数;
- 调用基类的析构函数。
23、虚析构函数的作用,父类的析构函数是否要设置为虚函数?
C++中基类采用virtual虚析构函数是为了防止内存泄漏。- 如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。
- 假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。
- 所以,为了防止这种情况的发生,
C++中基类的析构函数应采用virtual虚析构函数。
- 纯虚析构函数一定得有定义,因为每一个派生类析构函数会被编译器加以扩张,以静态调用的方式调用其每一个虚基类以及上一层基类的析构函数。因此缺乏任何一个基类析构函数的定义,就会导致链接失败。==因此,最好不要把虚析构函数定义为纯虚析构函数。==
24、构造函数析构函数可以调用虚函数吗?
- 在
构造函数和析构函数中最好不要调用虚函数; - 在
构造函数和析构函数中调用的成员函数都是属于编译时确定的,并不具有虚函数的动态绑定特性, 有如下原因:- 在构造时, 父类对象总是先于子类对象构造的, 如果父类的析构函数使用虚函数机制调用子类的函数, 结果将是不可预料的
- 在析构时, 子类的析构函数总是先于父类执行, 如果父类的析构函数使用虚函数机制调用子类的函数, 结果将是不可预料的
25、构造函数, 析构函数可否抛出异常
- 构造函数异常
- 后果:
- (原因):
C++拒绝为没有完成构造函数的对象调用析构函数,原因是避免开销 - 构造函数中发生异常,控制权转出构造函数。如果构造函数中申请了堆内存, 则堆内存将无法释放, 从而造成内存泄漏
- 例如: 在对象
b的构造函数中发生异常,对象b的析构函数不会被调用。因此会造成内存泄漏。
- (原因):
- 解决方案:
- 使用智慧指针来管理堆内存. 其不需要在析构函数中手动释放资源. 在发生异常时, 智慧指针会自动释放资源从而避免了内存泄漏.
- 一般建议不要在构造函数里做过多的资源分配。
- 后果:
- 析构函数异常
- 后果:
- 在异常传递的堆栈辗转开解的过程中, 如果发生析构异常,
C++会调用terminate终止程序 - 如果析构函数发生发生异常,则异常后面的代码将不执行,无法确保完成我们想做的清理工作。
- 在异常传递的堆栈辗转开解的过程中, 如果发生析构异常,
- 解决方法:
- 如果异常不可避免,则应在析构函数内捕获,而不应当抛出。
- 在析构函数中使用
try-catch块屏蔽所有异常。
- 附加说明:
- (后果1): 如果某一个异常发生,某对象的析构函数被调用,而此时析构发生了异常并流出了函数之外,则函数会被立即terminate掉(函数外有catch也不能拯救)
- 后果:
- 参考:
More Effective: M9 使用析构函数防止资源泄漏More Effective: M10 在构造函数中防止资源泄漏More Effective: M11 禁止异常流出 destructors 之外
26、类如何实现只能静态分配和只能动态分配
- 建立类的对象有两种方式:
- 静态建立(栈空间)
- 静态建立一个类对象,就是由编译器为对象在栈空间中分配内存, 然后调用构造函数初始化这片内存空间.
- 使用这种方法,直接调用类的构造函数。
- 动态建立(堆空间),
A *p = new A();- 动态建立类对象, 使用new操作符将在堆空间分配内存, 然后调用构造函数初始化这片内存空间.
- 这种方法,间接调用类的构造函数。
- 静态建立(栈空间)
- 只能在堆上建立
- 分析: 类对象只能建立在堆上,就是不能静态建立类对象,即不能直接调用类的构造函数。
- 实现方式: 将析构函数设为私有或则受保护
- 方法分析:
- 静态建立:
- 当对象
建立在栈上面时,是由编译器分配内存空间的,调用构造函数来构造栈对象。 - 当对象使用
完后,编译器会调用析构函数来释放栈对象所占的空间。 - 编译器管理了对象的整个生命周期。
- 当对象
- 编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性,
- 其实不光是析构函数,只要是非静态的函数,编译器都会进行检查。
- 如果类的析构函数是私有的,则编译器不会在栈空间上为类对象分配内存。
- 因此,将析构函数设为私有,类对象就无法建立在栈上了。
- 由此引发的问题:
- 因为析构函数设置为了私有
- 需要设置一个
public函数来调用析构函数
- 代码如下:
class A { protected : A(){} ~A(){} public : static A* create() { return new A(); } void destory() { delete this ; } };
- 静态建立:
- 只能在栈上建立
- 只有使用new运算符,对象才会建立在堆上,因此,只要禁用new运算符就可以实现类对象只能建立在栈上。将operator new()设为私有即可。
- 注意: 重载了
new就需要重载delete - 代码如下:
class A { private : void * operator new ( size_t t){} // 注意函数的第一个参数和返回值都是固定的 void operator delete ( void * ptr){} // 重载了new就需要重载delete public : A(){} ~A(){} };
27、如果想将某个类用作基类,为什么该类必须定义而非声明?
- 因为在继承体系下, 子类会继承父类的成员, 并且编译器会在子类的构造函数和析构函数中插入父类的构造和析构部分, 因而父类必须有定义.
28、什么情况会自动生成默认构造函数?
- 四种情况:
- 类成员对象带有默认构造函数.
- 基类带有默认构造函数
- 类中存在虚函数
- 继承体系中存在虚继承
- 在合成的默认构造函数中,只有基类子对象和类类型对象会被初始化,而其他所有的非静态成员(如整数,指针,数组等),都不会初始化,对他们进行初始化的应该是程序员,而非编译器。
- 注意:值类型的默认值并不是默认构造的初始化。
29、什么是类的继承?
- 类与类之间的关系
(has-A)包含关系,即一个类的成员属性是另一个已经定义好的类(use-A)使用关系, 一个类使用另一个类,通过类之间的成员函数相互联系,定义友元或者通过传递参数的方式实现;(is-A)继承关系, 继承关系,关系具有传递性;
- 继承的相关概念
- 所谓的继承就是一个类继承了另一个类的属性和方法,这个新的类包含了上一个类的属性和方法,
- 被称为子类或者派生类,被继承的类称为父类或者基类;
- 继承的特点
- 子类拥有父类的所有属性和方法,子类对象可以当做父类对象使用;
- 子类可以拥有父类没有的属性和方法;
- 继承中的访问控制
public、protected、private
- 继承中的构造和析构函数
- 子类中构造函数的调用顺序为: 基类构造函数, 成员对象构造函数, 派生类构造函数
- 子类中析构函数的调用顺序为: 派生类析构函数, 成员对象析构函数, 基类析构函数
- 继承中的兼容性原则
- 类型兼容规则是指在需要基类对象的任何地方,都可以使用公有派生类的对象来替代。
- 参考: 继承中的类型兼容性原则 - Say舞步 - 博客园
30、什么是组合?
- 一个类里面的数据成员是另一个类的对象,即内嵌其他类的对象作为自己的成员;
- 如果内嵌类没有零参数构造函数, 则必须使用初始化列表进行初始化
- 构造函数的执行顺序:
- 按照内嵌对象成员在组合类中的定义顺序调用内嵌对象的构造函数。
- 然后执行组合类构造函数的函数体,析构函数调用顺序相反。
31、抽象基类为什么不能创建对象?
- 抽象类的定义:带有纯虚函数的类为抽象类。
- 抽象类的作用:
- 抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。
- 所以抽象类实际上刻画了一组子类的操作接口的通用语义,这些语义也传给子类,子类可以具体实现这些语义,也可以再将这些语义传给自己的子类。
- 使用抽象类时注意:
- 抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。
- 如果派生类中没有给出所有纯虚函数的实现,而只是继承基类的纯虚函数,则这个派生类仍然是一个抽象类。
- 如果派生类中给出了所有纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
- 抽象类是不能定义对象的。
- 纯虚函数定义: 纯虚函数是一种特殊的虚函数,它的一般格式如下:
class <类名> { virtual <类型><函数名>(<参数表>)=0; … }; - 纯虚函数引入原因
- 为了方便使用多态特性,我们常常需要在基类中定义虚拟函数。
- 在很多情况下,基类本身生成对象是不合情理的。
- 例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。
- 为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:
virtual ReturnType Function()= 0;)。- 若要使派生类为非抽象类,则编译器要求在派生类中,必须对纯虚函数予以重载以实现多态性。
- 同时含有纯虚函数的类称为抽象类,它不能生成对象。
- 相似概念
- 多态性
- 指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。
- C++支持两种多态性:编译时多态性,运行时多态性。
- 编译时多态性(静态多态):通过重载函数实现。
- 运行时多态性(动态多态):通过虚函数实现。
- 虚函数
- 虚函数是在基类中被声明为
virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态重载。
- 虚函数是在基类中被声明为
- 抽象类
- 包含纯虚函数的类称为抽象类。由于抽象类包含了没有定义的纯虚函数,所以不能定义抽象类的对象。
- 多态性
32、类什么时候会析构?
- 对于静态对象: 当离开作用区域之后, 对象生命周期结束, 编译器会自动调用析构函数
- 对于动态对象: 当对对象指针调用delete时, 会调用析构函数终止对象生命周期并释放内存. 其中对象指针指针可以对象类型的指针, 也可以时基类指针(注意基类析构函数位虚函数)
- 第三种情况: 当对象中存在嵌入对象时, 该对象析构时, 嵌入对象也会被析构
33、为什么友元函数必须在类内部声明?
- 因为编译器必须能够读取这个结构的声明以理解这个数据类型的大、行为等方面的所有规则。
- 有一条规则在任何关系中都很重要,那就是谁可以访问我的私有部分。
- 编译器通过读取类的声明从而进行类的访问权限控制, 而友元函数有权访问本类的所有成员, 因而它必须在类内部进行声明, 使得编译器可以正确处理他的权限.
34、介绍一下C++里面的多态?
- 静态多态(重载, 模板): 是在编译的时候,就确定调用函数的类型。
- 动态多态(覆盖, 虚函数实现): 在运行的时候,才确定调用的是哪个函数,动态绑定。运行基类指针指向派生类的对象,并调用派生类的函数。
- 参考: 理解的虚函数和多态
- 函数重载:
- 同一可访问区域内, 存在多个不同参数列表的同名函数, 由编译器根据调用参数决定那个函数应该被调用
- 函数重载不关心返回值类型, 但是对于函数类型时关心的, 例如类中的两个函数拥有相同参数列表的同名函数, 一个为const类型, 一个为非const类型, 依旧时属于函数重载.
- 函数模板:
- 模板函数会经历两遍编译:
- (模板编译)在定义模板函数时对模板本身进行编译
- (模板实例化)在调用时对参数进行替换, 对替换参数后的代码进行编译
- 虽然它和函数重载类似都可以根据参数确定将要调用的函数版本, 但是函数模板只会生成将要用到的函数版本, 而函数模板无论是否调用其代码都会生成.
- 模板函数会经历两遍编译:
- 覆盖: 是指派生类中重新定义了基类中的
virtual函数 - 隐藏:是指派生类的函数屏蔽了与其同名的基类函数,只要函数名相同,基类函数都会被隐藏. 不管参数列表是否相同。
35、用C 语言实现C++的继承
- 关键点:
- 使用函数指针保存函数
- 将基类放在结构题的头部, 这样强转的就不会出错了
```cpp
#include
using namespace std; //C++中的继承与多态 struct A{ virtual void fun() {//C++中的多态:通过虚函数实现 cout<<"A:fun()"<<endl; } int a; }; struct B:public A {//C++中的继承:B 类公有继承A 类 virtual void fun() { //C++中的多态:通过虚函数实现(子类的关键字virtual 可加可不加) cout<<"B:fun()"<<endl; } int b; };
//C 语言模拟C++的继承与多态 typedef void (FUN)(); //定义一个函数指针来实现对成员函数的继承 struct _A { //父类 FUN _fun; //由于C 语言中结构体不能包含函数,故只能用函数指针在外面实现 int _a; }; struct _B { //子类 _A _a_; //在子类中定义一个基类的对象即可实现对父类的继承 int _b; }; void _fA() { //父类的同名函数 printf(“_A:_fun()\n”); } void _fB() { //子类的同名函数 printf(“_B:_fun()\n”); } void Test() { //测试C++中的继承与多态 A a; //定义一个父类对象a B b; //定义一个子类对象b A p1 = &a; //定义一个父类指针指向父类的对象 p1->fun(); //调用父类的同名函数 p1 = &b; //让父类指针指向子类的对象 p1->fun(); //调用子类的同名函数 //C 语言模拟继承与多态的测试 A _a; //定义一个父类对象_a _B _b; //定义一个子类对象_b _a._fun = _fA; //父类的对象调用父类的同名函数 _b._a._fun = _fB; //子类的对象调用子类的同名函数 _A* p2 = &_a; //定义一个父类指针指向父类的对象 p2->_fun(); //调用父类的同名函数 p2 = (_A*)&_b; //让父类指针指向子类的对象,由于类型不匹配所以要进行强转 p2->_fun(); //调用子类的同名函数 } ```
36、继承机制中对象之间如何转换?指针和引用之间如何转换?
- 派生类的对象可以当做基类对象使用, 例如赋值或则初始化等
-
派生类对象的地址可以赋给指向基类的指针。 在替代之后,派生类对象就可以作为基类的对象使用,但只能使用从基类继承的成员。
- 向上类型转换(派生类转基类, 总是安全的)
- 将派生类指针或引用转换为基类的指针或引用被称为向上类型转换,向上类型转换会自动进行,而且向上类型转换是安全的。
- 向下类型转换(基类转派生类, 不安全)
- 将基类指针或引用转换为派生类指针或引用被称为向下类型转换,向下类型转换不会自动进行,因为一个基类对应几个派生类,所以向下类型转换时不知道对应哪个派生类,所以在向下类型转换时必须加动态类型识别技术。
RTTI技术,用dynamic_cast进行向下类型转换, 只有存在虚函数的类才能使用RTTI
37、组合与继承优缺点?
- 继承: 继承是Is a 的关系,比如说Student 继承Person,则说明Student is a Person。
- 继承的优点: 是子类可以重写父类的方法来方便地实现对父类的扩展。
- 继承的缺点有以下几点:
- ①:父类的内部细节对子类是可见的。(可以自己调用父类的方法)
- ②:子类从父类继承的方法在编译时就确定下来了,所以无法在运行期间改变从父类继承的方法的行为。
- ③:如果对父类的方法做了修改的话(比如增加了一个参数),则子类的方法必须做出相应的修改。所以说子类与父类是一种高耦合,违背了面向对象思想。
- 组合(嵌入式对象): 组合也就是设计类的时候把要组合的类的对象加入到该类中作为自己的成员变量。
- 组合的优点:
- ①:当前对象只能通过所包含的那个对象去调用其方法,所以所包含的对象的内部细节对当前对象时不可见的。(必须通过嵌入式对象调用嵌入式对象的方法)
- ②:当前对象与包含的对象是一个低耦合关系,如果修改包含对象的类中代码不需要修改当前对象类的代码。
- ③:当前对象可以在运行时动态的绑定所包含的对象。可以通过set 方法给所包含对象赋值。
- 组合的缺点:
- ①:容易产生过多的对象。
- ②:为了能组合多个对象,必须仔细对接口进行定义。
- 参考: 继承的优点和缺点
38、左值右值
39、移动构造函数
- 右值的概念: 将亡值, 不具名变量
- 右值引用
- 概念: 其本身是一个左值, 但是它绑定了一个右值, 此右值的生命周期将和此右值引用一致.
- 优点:
- 转移语意
- 精确语意传递(参数列表分别为左值引用和右值引用形成参数重载)
- 移动构造函数:
- 概念: 当我们使用一个即将消亡的对象A初始化对象B时, 使用移动语意可以避免额外的无意义的复制构造操作, 也避免了释放内存, 新分配内存的开销.
- 实现:
- 移动构造函数的参数和拷贝构造函数不同,拷贝构造函数的参数是一个左值引用,但是移动构造函数的初值是一个右值引用。
- 也就是说,只用一个右值,或者将亡值初始化另一个对象的时候,才会调用移动构造函数。
- 作为参数的右值将不会再调用析构函数。
move语句,就是将一个左值变成一个将亡值。
- 优点
- 避免了无畏的对下销毁和构造的开销
- 当该类对象申请了堆内存, 并在析构函数中进行释放时, 使用拷贝构造函数可能会存产生也野指针, 而使用移动构造可以避免野指针的产生.
40、C 语言的编译链接过程?
- 源代码-->预处理-->编译-->优化-->汇编-->链接–>可执行文件
- 参考: 源码到可执行文件的过程
41、vector与list的区别与应用?怎么找某vector或者list的倒数第二个元素
vectorvector和数组类似,拥有一段连续的内存空间,并且起始地址不变。- 因此能高效的进行随机存取,时间复杂度为
o(1); - 连续存储结构:
vector是可以实现动态增长的对象数组,支持对数组高效率的访问和在数组尾端的删除和插入操作,在中间和头部删除和插入相对不易,需要挪动大量的数据。- 它与数组最大的区别就是
vector不需程序员自己去考虑容量问题,库里面本身已经实现了容量的动态增长,而数组需要程序员手动写入扩容函数进形扩容。
- 随机访问
- 高效的尾部操作(增/删)
- 不那么高效的非尾部操作(增/删), 后面的迭代器会失效
- 动态扩容, 迁移, 迭代器全部失效 - `list`
- `list`是由双向链表实现的,因此内存空间是不连续的。
- 非连续存储结构:
- `list `是一个双链表结构,支持对链表的双向遍历。
- 每个节点包括三个信息:元素本身,指向前一个元素的节点`(prev)`和指向下一个元素的节点`(next)`。
- 因此`list `可以高效率的对数据元素任意位置进行访问和插入删除等操作。由于涉及对额外指针的维护,所以开销比较大。
- 高效的插入和删除, 后续迭代器不失效
- 指针维护开销大
- 不支持随机访问 - 区别:
- `vector `的随机访问效率高,但在插入和删除时(不包括尾部)需要挪动数据,不易操作。
- `list `的访问要遍历整个链表,它的随机访问效率低。
- 但对数据的插入和删除操作等都比较方便,改变指针的指向即可。
- `list `是单向的,`vector `是双向的。`vector `中的迭代器在使用后就失效了,而`list `的迭代器在使用之后还可以继续使用。
int mySize = vec.size();vec.at(mySize -2);list不提供随机访问,所以不能用下标直接访问到某个位置的元素,要访问list里的元素只能遍历,- 不过你要是只需要访问
list的最后N个元素的话,可以用反向迭代器来遍历:
42、STL vector的实现,删除其中的元素,迭代器如何变化?为什么是两倍扩容?释放空间?
- vector相关函数:
size / capacity: 已用空间 / 总空间resize / reserve: 改变容器的元素数目 / 概念容器的空间大小push_back / pop_back: 尾插 / 尾减insert / erase: 任意位置插入 / 任意位置删除
- 迭代器失效问题:
- 在
capacity内insert和erase都会导致在后续元素发生移动, 进而迭代器失效或则改变 - 如果
insert或则push_back导致空间不足, 则会发生整体的移动操作, 所有迭代器都将失效.
- 在
- 两倍扩容问题:
- 为什么呈倍数扩容(时间复杂度更优)
- 对于
n次插入操作, 采用成倍方式扩容可以保证时间复杂度O(n), 而指定大小扩容的时间复杂度为O(n^2)
- 对于
- 为什么是
1.5倍扩容(空间可重用)- 当
k == 2时:- 第n次扩容的时候需要分配的内存是:
an = a1*q^(n-1) = 4*2^(n-1) - 而前n-1项的内存和为:
Sn = a1*(1-q^(n-1))/(1-q) = 4*(1-2^(n-1)) /(1-2) = 4*2^(n-1)-4 差值 = an - Sn = 4 > 0- 所以第
n次扩容需要的空间恰好比前n-1扩容要求的空间总和要大,那么即使在前n-1次分配空间都是连续排列的最好情况下,也无法实现之前的内存空间重用
- 第n次扩容的时候需要分配的内存是:
- 当
k = 1.5时:- 第
n次扩容的时候需要分配的内存是:an = a1*q^(n-1) = 4*1.5^(n-1) - 而前
n-1项的内存和为:Sn = a1*(1-q^(n-1))/(1-q) = 4*(1-1.5^(n-1)) /(1-1.5) = 8*1.5^(n-1)-8 差值 = an - Sn = 8 - 4*1.5^(n-1)- 当
n增长到一定的数值后,差值就会变为小于0,那么如果前n-1次分配的空间都是连续的情况下, 就可以实现内存空间复用
- 第
- 当
- 为什么呈倍数扩容(时间复杂度更优)
- 释放空间:
- 使用
swap:vector<int>().swap(a);
- 使用
- 参考:
43、容器内部删除一个元素
- 顺序容器
erase 迭代器不仅使所指向被删除的迭代器失效,而且使被删元素之后的所有迭代器失效(list除外),所以不能使用erase(it++)的方式,但是erase的返回值是下一个有效迭代器;it = c.erase(it);
- 关联容器
erase 迭代器只使被删除元素的迭代器失效, 其他迭代器不失效,但是返回值是void,所以要采用erase(it++)的方式删除迭代器;c.erase(it++)
44、STL 迭代器如何实现
- 迭代器
Iterator- (总结)
Iterator使用聚合对象, 使得我们在不知道对象内部表示的情况下, 按照一定顺序访问聚合对象的各个元素. Iterator模式是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。- 由于
Iterator模式的以上特性:与聚合对象耦合,在一定程度上限制了它的广泛运用,一般仅用于底层聚合支持类,如STL的list、vector、stack等容器类及ostream_iterator等扩展iterator。
- (总结)
- 迭代器的基本思想:
- 迭代器不是指针,是类模板,表现的像指针。他只是模拟了指针的一些功能,通过重载了指针的一些操作符,
->、*、++、--等。 - 迭代器封装了指针,是一个“可遍历
STL( Standard Template Library)容器内全部或部分元素”的对象, 本质是封装了原生指针,是指针概念的一种提升(lift),提供了比指针更高级的行为,相当于一种智能指针,他可以根据不同类型的数据结构来实现不同的++,--等操作。 - 迭代器返回的是对象引用而不是对象的值。
- 迭代器不是指针,是类模板,表现的像指针。他只是模拟了指针的一些功能,通过重载了指针的一些操作符,
- 迭代器产生原因
Iterator类的访问方式就是把不同集合类的访问逻辑抽象出来,使得不用暴露集合内部的结构就可以实现集合的遍历,是算法和容器之间的桥梁.
- 最常用的迭代器的相应型别有五种:
value type、difference type、pointer、reference、iterator catagoly;
45、set 与hash_set 的区别
set底层是以RB-Tree实现,hash_set底层是以hash_table实现的;RB-Tree有自动排序功能,而hash_table不具有自动排序功能;set和hash_set元素的键值就是实值;hash_table有一些无法处理的型别;(例如字符串无法对hashtable的大小进行取模)
46、hashmap 与map 的区别
- 底层实现不同;
map具有自动排序的功能,hash_map不具有自动排序的功能;hashtable有一些无法处理的型别;(例如字符串无法对hashtable的大小进行取模)
47、map、set 是怎么实现的,红黑树是怎么能够同时实现这两种容器? 为什么使用红黑树?
map和set都是STL中的关联容器,其底层实现都是红黑树(RB-Tree)。由于map和set所开放的各种操作接口,RB-tree也都提供了,所以几乎所有的map和set的操作行为,都只是转调RB-tree的操作行为。map中的元素是key-value(关键字—值)对:关键字起到索引的作用,值则表示与索引相关联的数据, 红黑树的每个节点包括key和value;set只是关键字的简单集合,它的每个元素只包含一个关键字, 红黑树每个节点只包括key。- 红黑树的插入删除都可以在
O(logn)时间内完成, 性能优越
48、如何在共享内存上使用STL标准库?
- 为什么要在共享内存中使用模板容器?
- 共享内存可以在多进程间共享,到达进程间通信的方式。
- 共享内存可以在进程的生命周期以外仍然存在。这就可以保证在短暂停止服务(服务进程
coredump,更新变更)后,服务进程仍然可以继续使用这些共享内存的数据。 - 如果这些优势在加上
C++容器模板使用方便,开发快速的优势,无疑是双剑合璧,成为服务器开发的利刃。
………..太难了……….
- 参考: C++容器模板在共享内存中的使用
49、map插入方式有几种?
- 下表运算符插入
[] insert插入pair
50、STL 中unordered_map和map的区别,unordered_map如何解决冲突以及扩容
unordered_map和map都是键值对不可重复的关联容器,- 区别:
map的底层实现为红黑树, 会根据键值进行排序, 所以键值需要定义小于操作(operator<)unordered_map底层实现为hash_table, 不会根据键值进行排序, 但是需要键值提供等于操作(operator ==), 以防止重复键值
- 哈希表解决冲突常见办法:
- 开放定址法: 线性探测, 二次探测, 二次哈希
- (STL使用): 拉链法: 使用单链表来保存具有相同哈希值得集合
- 哈希表扩容
- 什么时候扩容: 哈希表键值发生碰撞的概率, 随着负载因子(负载/容量)的增加而增加, 所以当负载因子大于阈值(0.75)的时候就需要扩容了.
- 怎么扩容
(resize): 通过增加桶的数量(两倍扩张)以达到扩容的目的, 然后将原来的所有键值rehash到新的哈希表中, 增大哈希表并不会影响哈希表的插入删除时间, 那是rehash需要的时间复杂度为n, 所以对实时性非常严格的情况下不要使用
- 参考:
51、vector越界访问下标,map越界访问下标?vector删除元素时会不会释放空间?
vector通过下标访问时不会做边界检查,即便下标越界。- 也就是说,下标与
first迭代器相加的结果超过了finish迭代器的位置,程序也不会报错,而是返回这个地址中存储的值。 - 如果想在访问
vector中的元素时首先进行边界检查,可以使用vector中的at函数。 - 通过使用
at函数不但可以通过下标访问vector中的元素,而且在at函数内部会对下标进行边界检查。
- 我去是真的: 访问vector元素时的越界问题
- 也就是说,下标与
map通过校表访问会将不存在的key插入到map中map的下标运算符[]的作用是:将key作为下标去执行查找,并返回相应的值;如果不存在这个key,就将一个具有该key和value的某人值插入这个map。
-
erase()函数,只能删除内容,不能改变容量大小;erase成员函数,它删除了itVect迭代器指向的元素,并且返回要被删除的itVect之后的迭代器,迭代器相当于一个智能指针;clear()函数,只能清空内容,不能改变容量大小;
- 如果要想在删除内容的同时释放内存,那么你可以选择
deque容器。(deque也不总是erase之后就会释放内存, 当内存块不在被使用时会释放) - 参考: STL容器删除元素时内存释放情况
- 如果要想在删除内容的同时释放内存,那么你可以选择
52、map[]与find的区别?
1) map 的下标运算符[]的作用是:将关键码作为下标去执行查找,并返回对应的值;如果不存在这个关键码,就将一个具有该关键码和值类型的默认值的项插入这个map。 2) map 的find 函数:用关键码执行查找,找到了返回该位置的迭代器;如果不存在这个关键码,就返回尾迭代器。
53、STL 中list, queue之间的区别
vector: 连续空间存储, 支持随机访问, 高效尾部操作(增/删), 动态空间分配, 迭代器易失效list: 双向链表, 不支持随机访问(可以反向迭代), 任意位置操作(增/删)高效, 插入时分配空间, 迭代器不易失效deque: 双向开口的分段连续线性空间,可以在头尾端进行元素的插入和删除, 允许于常数时间内对头端进行插入或删除元素;可以增加一段新的空间, 不过迭代器设置复杂.queue: 先进先出队列, 默认基于deque容器, 可以对两端进行操作,但是只能在队列头部进行移除元素,只能在队列尾部新增元素,可以访问队列尾部和头部的元素,但是不能遍历容器
deque和vector的差异deque允许于常数时间内对头端进行插入或删除元素;deque没有空间包括, 当空间不足时,deque可以增加一段新的空间, 而不用进行整体迁移vector的迭代器是对指针的封装,deque的迭代器相对复杂
list和vector的差异vector空间是预先分配的,list是插入时分配的vector是连续数组, 增删操作都可能会造成内存迁移, 后续迭代器失效,list是双向链表, 增删操作都可以在常数时间内完成, 迭代器不会失效
54、STL 中的allocator,deallocator
- 参考: C++ STL 的内存优化
55、STL 中hash_map 扩容发生什么?
1) hash table表格内的元素称为桶(bucket),而由桶所链接的元素称为节点(node),其中存入桶元素的容器为STL本身很重要的一种序列式容器——vector 容器。之所以选择vector 为存放桶元素的基础容器,主要是因为vector 容器本身具有动态扩容能力,
无需人工干预。
2) 向前操作:首先尝试从目前所指的节点出发,前进一个位置(节点),由于节点被安置于list 内,所以利用节点的next 指针即可轻易完成前进操作,如果目前正巧是list 的尾端,就跳至下一个bucket 身上,那正是指向下一个list 的头部节点。
hash table表格内的元素称为桶(bucket),而由桶所链接的元素称为节点(node), 由线性表来储存所有的桶, 其底层实现为vector, 因为它支持随机访问, 和动态扩容- 哈表表键值发生碰撞的概率和负载因子正相关, 当负载因子过大, 哈希表的性能显著降低, 一般负载因子大于阈值(0.75)则对哈希表进行扩容, 然后通过rehash对所有节点进行重映射, 注意扩容并不会增加哈希表插入删除的复杂度, 但是rehash本身的的时间复杂度为n, 所以对高时效性的需求下, 要注意.
- 参考:
- 对 c++ unordered_map 源码的解析 | ZRJ - Hash table详解
- HASH TABLE::DYNAMIC RESIZING (Java, C++)
-
[对 c++ unordered_map 源码的解析 ZRJ](https://zrj.me/archives/1248)
56、map 如何创建?
vector底层数据结构为数组,支持快速随机访问list底层数据结构为双向链表,支持快速增删deque底层数据结构为一个中央控制器和多个缓冲区,详细见STL源码剖析P146,支持首尾(中间不能)快速增删,也支持随机访问,deque是一个双端队列(double-ended queue),也是在堆中保存内容的.它的保存形式 如下:[堆1] --> [堆2] -->[堆3] --> ..., 每个堆保存好几个元素,然后堆和堆之间有指针指向,看起来像是list 和vector 的结合品.stack底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时queue底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时(stack和queue其实是适配器,而不叫容器,因为是对容器的再封装)priority_queue的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现set底层数据结构为红黑树,有序,不重复multiset底层数据结构为红黑树,有序,可重复map底层数据结构为红黑树,有序,不重复multimap底层数据结构为红黑树,有序,可重复hash_set底层数据结构为hash表,无序,不重复hash_multiset底层数据结构为hash表,无序,可重复hash_map底层数据结构为hash表,无序,不重复hash_multimap底层数据结构为hash表,无序,可重复
- 红黑树的性质:
- 每个节点或是红色的,或是黑色的。
- 根节点是黑色的。
- 每个叶节点
(NULL)是黑色的。 - 如果一个节点是红色的,则它的两个孩子节点都是黑色的。
- 对每个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。
- 数据结构——红黑树(RB-Tree)
57、vector 的增加删除都是怎么做的?为什么是1.5 倍?
1) 新增元素:vector 通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,在插入新增的元素; 2) 对vector 的任何操作,一旦引起空间重新配置,指向原vector 的所有迭代器就都失效了; 3) 初始时刻vector 的capacity 为0,塞入第一个元素后capacity 增加为1; 4) 不同的编译器实现的扩容方式不一样,VS2015 中以1.5 倍扩容,GCC 以2 倍扩容。对比可以发现采用采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量只能达到O(n)的时间复杂度,因此,使用成倍的方式扩容。
1) 考虑可能产生的堆空间浪费,成倍增长倍数不能太大,使用较为广泛的扩容方式有两种,以2 二倍的方式扩容,或者以1.5 倍的方式扩容。
2) 以2 倍的方式扩容,导致下一次申请的内存必然大于之前分配内存的总和,导致之前分配的内存不能再被使用,所以最好倍增长因子设置为(1,2)之间: 3) 向量容器vector 的成员函数pop_back()可以删除最后一个元素. 4) 而函数erase()可以删除由一个iterator 指出的元素,也可以删除一个指定范围的元素。 5) 还可以采用通用算法remove()来删除vector 容器中的元素. 6) 不同的是:采用remove 一般情况下不会改变容器的大小,而pop_back()与erase()
58、函数指针?
- 什么是函数指针?
- 函数指针本质是一个指针, 它指向的是函数的入口地址, 它的类型是由函数的参数列表和返回值共同确定.
- 函数指针的声明方法
int (*pf)(const int&, const int&); (1)pf是一个返回类型为int, 参数为两个const int&的函数。注意*pf 两边的括号是必须的- 否则上面的定义就变成了:
int *pf(const int&, const int&); // 这声明了一个函数pf, 其返回类型为int *, 带有两个const int&参数.
- 为什么有函数指针
- 可以通过函数指针进行函数调用
- 而且函数指针本质是一个指针, 可以把它指向返回值类型和形参列表相同的不同函数
- 另外还能将函数指针作为函数参数进行传递.
- 通过函数指针可以把函数的调用者与被调函数分开。
- 调用者只需要确定被调函数是一个具有特定参数列表和特定返回值的函数,
- 而不需要知道具体是哪个函数被调用.
- 两种方法赋值:
指针名 = 函数名指针名 = &函数名
59、说说你对c 和c++的看法,c 和c++的区别?
- 面向过程 / 面向对象
- C中的函数编译时不会保留形参列表, 也不能重载; 而C++中的函数在编译时会保留形参列表, 有重载
- struct
- C中: struct是自定义数据类型; 是变量的集合, 不能添加拥有成员函数; 没有访问权限控制的概念; 结构体名称不能作为参数类型使用, 必须在其前加上struct才能作为参数类型
- C++中: struct是抽象数据类型, 是一个特殊的类, 可以有成员函数, 默认访问权限和继承权限都是public, 结构体名可以作为参数类型使用
- 动态管理内存的方法不一样:
malloc/free和new/delete - C语言没有引用的概念, 更没有左值引用, 右值引用
- C语言不允许只读数据(const修饰)用作下标定义数组, C++允许
- C语言的局部静态变量初始化发生于编译时,所以在函数中不能使用变量对局部静态变量进行初始化, 而C++因为增加了对象的概念,而对象需要调用构造函数进行初始化,所以编译器将局部静态变量的初始化推迟至该变量使用之前,也就是说可以使用变量来初始化局部静态变量。
- C++相比C,增加多许多类型安全的功能,比如强制类型转换
- C++支持范式编程,比如模板类、函数模板等
PS:C/C++的全局变量默认连接属性都是extern的啊, 参考:C语言:链接属性与存储类型- 参考:
60、c/c++的内存分配,详细说一下栈、堆、静态存储区?
- 栈区
(stack)— 由编译器自动分配释放,存放函数的参数值,局部变量的值等其操作方式类似于数据结构中的栈。 - 堆区
(heap)— 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS(操作系统)回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。 - 全局区(静态区)
(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。 - 文字常量区—常量字符串就是放在这里的。程序结束后由系统释放。
- 程序代码区—存放函数体的二进制代码。
- 参考: C++/C的内存分配
61、堆与栈的区别?
- 管理方式: 栈由编译器自动管理,无需我们手工控制;堆需要手动释放不再使用的堆空间
memory leak。 - 空间大小:
32位系统下, 堆内存可以达到4G(3G用户空间,1G内核空间).- 栈空间是受限的, 默认大小为
1M
- 碎片问题:
- 对于堆来说,频繁的
new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。 - 对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,永远都不可能有一个内存块从栈中间弹出
- 对于堆来说,频繁的
- 生长方向:
- 对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;
- 对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
- 分配方式:
- 堆都是动态分配的,没有静态分配的堆。
- 栈有2种分配方式:静态分配和动态分配。
- 静态分配是编译器完成的,比如局部变量的分配。
- 动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,无需我们手工实现。
- 分配效率:
- 栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。
- 堆则是
C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
- 参考: 动态栈: alloca_百度百科
62、野指针是什么?如何检测内存泄漏?
- 野指针:指向内存被释放的内存或者没有访问权限的内存的指针。
- “野指针”的成因主要有
3种:- 指针变量没有被初始化。任何指针变量刚被创建时不会自动成为
NULL指针,它的缺省值是随机的。 - 指针被
free或者delete之后,没有置为NULL; - 指针操作超越了变量的作用范围。
- 指针变量没有被初始化。任何指针变量刚被创建时不会自动成为
- 如何避免野指针:
- 对指针进行初始化, 或指向有效地址空间
- 指针用完后释放内存,将指针赋
NULL。char * p = NULL;char * p = (char * )malloc(sizeof(char));char num[ 30] = {0}; char *p = num;delete(p); p = NULL;
- 参考: 野指针和悬空指针
63、悬空指针和野指针有什么区别?
- 野指针:野指针指,访问一个已删除或访问受限的内存区域的指针,野指针不能判断是否为
NULL来避免。指针没有初始化,释放后没有置空,越界 - 悬空指针:一个指针的指向对象已被删除,那么就成了悬空指针。野指针是那些未初始化的指针。
- 参考: 野指针和悬空指针
64、内存泄漏
- 内存泄漏
- 内存泄漏是指由于疏忽或错误造成了程序未能释放掉不再使用的内存的情况。
- 内存泄漏并非指内存在物理上消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制, 导致此段内存不能被使用;
- 后果
- 只发生一次小的内存泄漏可能不被注意,但泄漏大量内存的程序将会出现各种证照:性能下降到内存逐渐用完,导致另一个程序失败;
- 如何排除
- 使用工具软件
BoundsChecker,BoundsChecker是一个运行时错误检测工具,它主要定位程序运行时期发生的各种错误;调试运行DEBUG版程序,运用以下技术:CRT(C run-time libraries)、运行时函数调用堆栈、内存泄漏时提示的内存分配序号(集成开发环境OUTPUT窗口),综合分析内存泄漏的原因,排除内存泄漏。
- 使用工具软件
- 解决方法
- 智能指针。
- 检查、定位内存泄漏
- 检查方法:在
main函数最后面一行,加上一句_CrtDumpMemoryLeaks()。调试程序,自然关闭程序让其退出,查看输出:输出这样的格式{453}normal block at 0x02432CA8,868 bytes long被{}包围的453就是我们需要的内存泄漏定位值,868 bytes long就是说这个地方有868比特内存没有释放。
- 检查方法:在
- 定位代码位置
- 在
main函数第一行加上_CrtSetBreakAlloc(453);意思就是在申请453这块内存的位置中断。然后调试程序,程序中断了,查看调用堆栈。加上头文件#include <crtdbg.h>
- 在
65、new和malloc的区别?
- 参考: malloc和new的区别
66、delete p;与delete[]p,allocator
- 动态数组管理
new一个数组时,[]中必须是一个整数,但是不一定是常量整数,普通数组必须是一个常量整数; new动态数组返回的并不是数组类型,而是一个元素类型的指针;delete[]时,数组中的元素按逆序的顺序进行销毁;new在内存分配上面有一些局限性,new的机制是将内存分配和对象构造组合在一起,同样的,delete也是将对象析构和内存释放组合在一起的。-
allocator将这两部分分开进行,allocator申请一部分内存,不进行初始化对象,只有当需要的时候才进行初始化操作。 - 参考下一个问题: 67、new和delete的实现原理,delete是如何知道释放内存的大小的额?
67、new和delete的实现原理,delete是如何知道释放内存的大小的额?
new- 简单类型直接调用
operator new分配内存; - 对于复杂结构,先调用
operator new分配内存,然后在分配的内存上调用构造函数;
- 简单类型直接调用
delete- 简单数据类型默认只是调用
free函数; - 复杂数据类型先调用析构函数再调用
operator delete;
- 简单数据类型默认只是调用
new[]- 对于简单类型,
new[]计算好大小后调用operator new; - 对于复杂数据结构
AA* P = new AA[10];new[]先调用operator new[]分配内存, 分配内存时多分配四个字节用于存放元素个数., 返回地址为pp的最开始的4个字节用于存放元素个数n, 然后从调用n次构造函数从p-4开始构造对象.- 返回地址,也就是
P, 即为p-4
- 对于简单类型,
delete[]- 对于简单类型, 直接调用
free进行释放(注意简单类型并没有利用4个字节保存元素个数, 由编译器自行优化) - 对于复制类型,
- 首先将指针前移
4个字节获得元素个数n, 然后执行n次析构函数, 最后并释放掉内存. - 因为指针指向的是
p-4并不是内存的起始地址, 所以使用delete将无法完成释放, 因为free需要通过起始地址进行释放, 而p-4不是起始地址
- 首先将指针前移
- 对于简单类型, 直接调用
- 参考: 一定要看看:深入理解C++ new/delete, new/delete 动态内存管理
68、malloc申请的存储空间能用delete释放吗
- 不能
malloc /free主要为了兼容C,new和delete完全可以取代malloc /free的。malloc /free的操作对象都是必须明确大小的。而且不能用在动态类上。new和delete会自动进行类型检查和大小,malloc/free不能执行构造函数与析构函数,所以动态对象它是不行的。- 当然从理论上说使用
malloc申请的内存是可以通过delete释放的。不过一般不这样写的。而且也不能保证每个C++的运行时都能正常。
69、malloc 与free 的实现原理?
70、malloc、realloc、calloc、alloca的区别
malloc函数: 在堆上申请空间, 随机初始化void* malloc(unsigned int num_size);int *p = malloc(20*sizeof(int)); // 申请20 个int 类型的空间;
calloc函数: 省去了人为空间计算;malloc申请的空间的值是随机初始化的,calloc申请的空间的值是初始化为0的;void* calloc(size_t n,size_t size);int *p = calloc(20, sizeof(int));
realloc函数: 给动态分配的空间分配额外的空间,用于扩充容量。(可能会导致内存迁移)void realloc(void *p, size_t new_size);
alloca函数:_alloca是在栈(stack)上申请空间,该变量离开其作用域之后被自动释放,无需手动调用释放函数。
71、__stdcall 和__cdecl 的区别?
- 在进行函数调用的过程中, 参数入栈肯定是调用者干的事, 但是参数出栈, 可以由调用者干, 也可以由被调函数干; 所以就需要对函数调用者和被调函数之间责任进行划分,
stdcall和cdecl正是两种划分方式 cdecl:- 是
c语言的默认定义, 它规定了由调用者负责回复堆栈, - 好处: 参数数量可以是任意多个
- 缺点: 代码存在冗余, 例如100次调用, 就会右100段回复堆栈的代码
- 是
stdcall:- 一般用于跨语言的协作, 例如系统调用, 都会使用这种方式, 它规定堆栈的恢复由被调函数负责
- 好处: 不会存在代码冗余, 100次低调用, 只有一段恢复堆栈的代码
- 缺点: 只能允许规定的参数个数, 无法实现不定参数个数的调用
__stdcall__stdcall是被函数恢复堆栈,只有在函数代码的结尾出现一次恢复堆栈的代码;- 在编译时就规定了参数个数,无法实现不定个数的参数调用;
__cdecl__cdecl是调用者恢复堆栈,假设有100个函数调用函数a,那么内存中就有100端恢复堆栈的代码;- 可以不定参数个数;
- 每一个调用它的函数都包含清空堆栈的代码,所以产生的可执行文件大小会比调用
__stacall函数大。
72、使用智能指针管理内存资源,RAII
RAII全称是“Resource Acquisition is Initialization”,直译过来是“资源获取即初始化”,也就是说在构造函数中申请分配资源,在析构函数中释放资源。- 编译器保证, 栈对象在创建时自动调用构造函数,在超出作用域时自动调用析构函数。
-
所以
RAII的思想下, 我们使用一个栈对象来管理资源, 将资源和对象的生命周期绑定。 - 智能指针
(std::shared_ptr和std::unique_ptr)即RAII最具代表的实现,使用智能指针,可以实现自动的内存管理,再也不需要担心忘记delete造成的内存泄漏。毫不夸张的来讲,有了智能指针,代码中几乎不需要再出现delete了。
73、手写实现智能指针类
- 参考: 说一下shared_ptr的实现
- 计数器: 取计数器,
- 指针相关: 取原始指针
- 运算符重载:
++,--,->,+,-,*,= - 构造函数: 更新计数器
- 复制构造函数: 更新计数器
- 移动构造函数: 计数器不变
-
析构函数: 更新计数器, 按条件释放内存
- 智能指针是一个数据类型,一般用模板实现,模拟指针行为的同时还提供自动垃圾回收机制。
- 它会自动记录SmartPointer<T*>对象的引用计数,一旦T 类型对象的引用计数为0,就释放该对象。
- 除了指针对象外,我们还需要一个引用计数的指针设定对象的值,并将引用计数计为1,需要一个构造函数。
- 新增对象还需要一个构造函数,析构函数负责引用计数减少和释放内存。
- 通过覆写赋值运算符,才能将一个旧的智能指针赋值给另一个指针,同时旧的引用计数减1,新的引用计数加1
- 一个构造函数、拷贝构造函数、复制构造函数、析构函数、移走函数;
74、内存对齐?位域?
- 字节对齐的原因:
- 更快: 如果数据未对齐自然边界, 则处理器需要两次寻址才能得到完整的数据
- 通用: 部分硬件平面不支持访问未对齐的数据, 会抛出硬件异常
- 具体操作
- 自定义对齐系数
- 可以通过预编译命令
#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是指定的“对齐系数”
- 可以通过预编译命令
- 数据成员对齐规则:
- 结构
(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行。 - 结构体作为成员:
- 如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。
- 结构
- 结构(或联合)的整体对齐规则:
- 在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照
#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
- 在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照
- 自定义对齐系数
- 位域
- 有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。
C语言又提供了一种数据结构,称为“位域”或“位段”。- 所谓“位域”是把一个字节中的二进位划分为几 个不同的区域,并说明每个区域的位数。
- 位段成员必须声明为
int、unsigned int或signed int类型(short char long)。 ```c struct 位域结构名{ 位域列表 // 其中位域列表的形式为: 类型说明符 位域名:位域长度 };
struct bs {
int a:8; int b:2; int c:6; };
```
75、结构体变量比较是否相等
- 重载了
==操作符struct foo { int a; int b; bool operator==(const foo& rhs) { // 操作运算符重载 return( a == rhs.a) && (b == rhs.b); } }; - 元素的话,一个个比;
- 指针直接比较,如果保存的是同一个实例地址,则(p1==p2)为真;
76、位运算
- 若一个数m 满足m = 2^n;那么k%m=k&(m-1)
- 判断奇偶
a&1 == 0; // 偶数a&1 == 1; // 奇数
int型变量循环左移k次,即a=a<<k|a>>16-k(设sizeof(int)=16)int型变量a循环右移k次,即a=a>>k|a<<16-k(设sizeof(int)=16)- 整数的平均值
- 对于两个整数
x,y,如果用(x+y)/2求平均值,会产生溢出,因为x+y可能会大于INT_MAX,但是我们知道它们的平均值是肯定不会溢出的,我们用如下算法:int average(int x, int y) { //返回X,Y 的平均值 return (x&y)+((x^y)>>1); }
- 对于两个整数
- 判断一个整数是不是
2的幂,对于一个数x >= 0,判断他是不是2的幂boolean power2(int x){ return ((x&(x-1))==0)&&(x!=0); } - 不用
temp交换两个整数void swap(int x, int y) { x ^= y; y ^= x; x ^= y; } - 计算绝对值
int abs(int x) { int y ; y = x >> 31 ; return (x^y)-y; //or: (x+y)^y } - 取模运算转化成位运算 (在不产生溢出的情况下)
a % (2^n)等价于a & (2^n - 1)a % 2等价于a & 1
- 乘法运算转化成位运算 (在不产生溢出的情况下)
a * (2^n)等价于a<< n
- 除法运算转化成位运算 (在不产生溢出的情况下)
a / (2^n)等价于a>> n- 例:
12/8 == 12>>3
if (x == a) x= b; else x= a;等价于x= a ^ b ^ x;x的相反数表示为(~x+1)
- 参考: 位运算总结 取模 取余
77、为什么内存对齐
- 平台原因(移植原因)
- 不是所有的硬件平台都能访问任意地址上的任意数据的;
- 某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异
- 性能原因:
- 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
- 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
78、函数调用过程栈的变化,返回值和参数变量哪个先入栈?
- 调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中,即:从右向左依次把被调函数所需要的参数压入栈;
- 调用者函数使用
call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中(这个压栈操作隐含在call指令中); - 在被调函数中,被调函数会先保存调用者函数的栈底地址
(push ebp),然后再保存调用者函数的栈顶地址,即:当前被调函数的栈底地址(mov ebp,esp); -
在被调函数中,从
ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小,即:这些变量的地址是按照栈的延伸方向排列的,先定义的变量先入栈,后定义的变量后入栈; - 关于返回值:
- 如果
返回值 <= 4字节,则返回值通过寄存器eax带回。 - 如果
4< 返回值 <=8字节,则返回值通过两个寄存器eax和edx带回。 - 如果
返回值 > 8字节,则返回值通过产生的临时量带回。
- 如果
- 参考: C语言是怎么进行函数调用的?
- 参数逆序入栈
- 返回地址入栈
- 调用函数栈顶入栈
- 被调用函数栈底入栈
- 局部变量入栈
79、怎样判断两个浮点数是否相等?
- 对两个浮点数判断大小和是否相等不能直接用
==来判断,会出错! - 明明相等的两个数比较反而是不相等!
- 对于两个浮点数比较只能通过相减并与预先设定的精度比较,记得要取绝对值!
- 浮点数与
0的比较也应该注意。与浮点数的表示方式有关。 fabs(a-b)<=1.0e-9
- 参考: 在程序中如何判断两个浮点数相等
80、宏定义一个取两个数中较大值的功能
#define MAX(x,y)((x>y?)x:y)
81、define、const、typedef、inline 使用方法?
const与#define的区别:作用阶段不同,功能不同,define作用丰富,占用的空间不同,作用域- 作用阶段不同:
const在编译和链接阶段其作用,define在预编译阶段起作用 - 功能不同:
const是定义一个变量, 拥有数据类型, 会进行语义语法检查define是宏定义, 简单的问题替代, 没有类型检查
define的作用更丰富:define可以配合条件预编译指令, 完成特殊的逻辑, 例如防止重复引用文件- 编译后占用的空间:
const定义的是变量, 会储存在数据段空间,define是宏替换, 其值会储存在代码段 - 作用域不同:
define没有作用域限制, 而const定义的变量通常有作用域的限制(全局变量默认为extern)
- 作用阶段不同:
-
#define和别名typedef的区别 1) 执行时间不同,typedef在编译阶段有效,typedef有类型检查的功能;#define是宏定义,发生在预处理阶段,不进行类型检查; 1) 功能差异,typedef用来定义类型的别名,定义与平台无关的数据类型,与struct的结合使用等。#define不只是可以为类型取别名,还可以定义常量、变量、编译开关等。 1) 作用域不同,#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用。而typedef有自己的作用域。 define与inline的区别 1)#define是关键字,inline是函数; 1) 宏定义在预处理阶段进行文本替换,inline函数在编译阶段进行替换; 1)inline函数有类型检查,相比宏定义比较安全;
82、printf 实现原理?
- 函数的调用过程: 参数逆序入栈, 返回地址入栈, 调用函数栈顶入栈, 设置被调函数栈底, 然后是被调函数的局部变量
- 在调用
printf时, 首先获取第一个形参, 也就是字符指针, 然后解析所指向的字符串, 得到后续参数的个数和数据类型, - 然后计算出偏移量, 并从当前函数栈的栈底往上偏移得到
printf("%d,%d",a,b);
83、#include的顺序以及尖叫括号和双引号的区别
- 路径不同, 参考: include头文件的顺序以及双引号””和尖括号<>的区别?
84、lambda 函数
- 包括五大部分: 捕获列表, 参数列表, 修饰符, 返回类型, 函数体
- 捕获列表: 对参数的捕获, 捕获方式为
值传递([=], [val])和引用([&], [&val]) - 参数列表: 参数列表, 和不同函数一样, 如果没有可以省略
- 修饰符: 默认情况下lambda函数总是一个const函数,Mutable可以取消其常量性。在使用该修饰符时,参数列表不可省略。
- 返回类型
- 函数体: 除了可以使用参数外, 还可以使用捕获的参数
85、hello world 程序开始到打印到屏幕上的全过程?
- 应用程序
- 应用程序载入内存变成进程
- 进程获取系统的标准输出接口
- 系统为进程分配CPU
- 触发缺页中断
- 通过puts系统调用, 往标准输出接口上写字符串
- 操作系统将字符串发送到显示器驱动上
- 驱动判断该操作的合法性, 然后将该操作变成像素, 写入到显示器的储存映射区
- 硬件将该像素值改变转变成控制信号控制显示器显示
- 用户告诉操作系统执行
HelloWorld程序(通过键盘输入等) - 操作系统:找到
helloworld程序的相关信息,检查其类型是否是可执行文件;并通过程序首部信息,确定代码和数据在可执行文件中的位置并计算出对应的磁盘块地址。 - 操作系统:创建一个新进程,将
HelloWorld可执行文件映射到该进程结构,表示由该进程执行helloworld程序。 - 操作系统:为
helloworld程序设置cpu上下文环境,并跳到程序开始处。 - 执行
helloworld程序的第一条指令,发生缺页异常 - 操作系统:分配一页物理内存,并将代码从磁盘读入内存,然后继续执行
helloworld程序 helloword程序执行puts函数(系统调用),在显示器上写一字符串- 操作系统:找到要将字符串送往的显示设备,通常设备是由一个进程控制的,所以,操作系统将要写的字符串送给该进程
- 操作系统:控制设备的进程告诉设备的窗口系统,它要显示该字符串,窗口系统确定这是一个合法的操作,然后将字符串转换成像素,将像素写入设备的存储映像区
- 视频硬件将像素转换成显示器可接收和一组控制数据信号
- 显示器解释信号,激发液晶屏
OK,我们在屏幕上看到了HelloWorld
86、模板类和模板函数的区别是什么?
- 函数模板的实例化是由编译程序在处理函数调用时自动完成的
- 类模板的实例化必须由程序员在程序中显式地指定。即函数模板允许隐式调用和显式调用而类模板只能显示调用。在使用时类模板必须加
,而函数模板不必
87、为什么模板类一般都是放在一个h 文件中
- 编译器并不是把函数模板处理成能够处理任意类型的函数;编译器从函数模板通过具体类型==产生==不同的函数;
- 编译器会对函数模板进行两次编译:
- 在声明的地方对模板代码本身进行编译,
- 在调用的地方对参数替换后的代码进行编译。
- 如果模板函数不是定义在
.h文件中- 编译器编译
.cpp文件时并不知道另一个.cpp文件的存在, 也不会去查找(查找通常是链接阶段的事)- 在定义模板函数的
.cpp文件中, 编译器对函数模板进行了第一次编译, 但是它并没有发现任何调用, 故而没有生产任何的函数实例 - 在调用了模板函数的
.cpp文件中, 编译器发现调用其他函数, 但是在此.cpp文件中并没有定义, 所以将此次调用处理为外部连接符号, 期望链接阶段由连接器给出被调函数的函数地址.
- 在定义模板函数的
- 在链接阶段, 连接器找不到被调函数故而报不能识别的外部链接错误.
- 编译器编译
- 模板定义很特殊。
- 由
template<…>处理的任何东西都意味着编译器在当时不为它分配存储空间,它一直处于等待状态直到被一个模板实例告知。 - 在编译器和连接器的某一处,有一机制能去掉指定模板的多重定义。
- 所以为了容易使用,几乎总是在头文件中放置全部的模板声明和定义。
- 由
- 在分离式编译的环境下
- 编译器编译某一个
.cpp文件时并不知道另一个.cpp文件的存在,也不会去查找(当遇到未决符号时它会寄希望于连接器)。 - 这种模式在没有模板的情况下运行良好,但遇到模板时就傻眼了,因为模板仅在需要的时候才会实例化出来,所以,当编译器只看到模板的声明时,它不能实例化该模板,只能创建一个具有外部连接的符号并期待连接器能够将符号的地址决议出来。
- 然而当实现该模板的
.cpp文件中没有用到模板的实例时,编译器懒得去实例化,所以,整个工程的.obj中就找不到一行模板实例的二进制代码,于是连接器也黔驴技穷了。
- 编译器编译某一个
88、C++中类成员的访问权限和继承权限问题。
- 参考: C++中类成员的访问权限
89、cout 和printf 有什么区别?
cout有缓冲区,printf无缓冲区; 有缓冲区意味着- 操作系统可以待用户刷新缓冲区时输出, 或则缓冲区存满的时候输出,
- 如果操作系统空闲的话也会检查缓冲区是否有值, 如果有的话立即输出.
endl相当于输出回车后,再强迫缓冲输出。flush立即强迫缓冲输出。
cout <<是一个函数, 它对常见数据类型进行了重载, 所以能自动识别数据的类型并进行输出.
90、重载运算符?
- 引入运算符重载,是为了实现类的多态性;
- 只能重载已有的运算符;对于一个重载的运算符,其
优先级和结合律与内置类型一致才可以;不能改变运算符操作数个数; .,:,?,sizeof,typeid**不能重载;- 两种重载方式,成员运算符和非成员运算符,成员运算符比非成员运算符少一个参数;下标运算符、箭头运算符(重载的箭头运算符必须返回类的指针)、解引用运算符必须是成员运算符;
- 当重载的运算符是成员函数时,
this绑定到左侧运算符对象。成员运算符函数的参数数量比运算符对象的数量少一个;至少含有一个类类型的参数; - 下标运算符必须是成员函数,下标运算符通常以所访问元素的引用作为返回值,同时最好定义下标运算符的常量版本和非常量版本;
- 当运算符既是一元运算符又是二元运算符(
+,-,*,&),从参数的个数推断到底定义的是哪种运算符;
91、函数重载函数匹配原则
- 首先进行名字查找, 确定候选函数
- 然后按照以下顺序进行匹配:
- 精确匹配:参数匹配而不做转换,或者只是做微不足道的转换,如数组名到指针、函数名到指向函数的指针、
T到const T; - 提升匹配:即整数提升(如
bool到int、char到int、short到int、float到double),; - 使用标准转换匹配:如
int到double、double到int、double到long double、Derived*到Base*、T*到void*、int到unsigned int; - 使用用户自定义匹配;
- 使用省略号匹配:类似于
printf中省略号参数。
- 精确匹配:参数匹配而不做转换,或者只是做微不足道的转换,如数组名到指针、函数名到指向函数的指针、
- 参考: 重载函数的调用匹配规则
92、定义和声明的区别
- 如果是指变量的声明和定义
- 从编译原理上来说,
- 变量声明是仅仅告诉编译器,有个某类型的变量会被使用,但是编译器并不会为它分配任何内存。
- 变量定义就是分配了内存。
- 从编译原理上来说,
- 如果是指函数的声明和定义
- 函数声明:一般在头文件里,对编译器说:这里我有一个函数叫
function()让编译器知道这个函数的存在。 - 函数定义:一般在源文件里,具体就是函数的实现过程写明函数体。
- 函数声明:一般在头文件里,对编译器说:这里我有一个函数叫
93、C++类型转换有四种
const_cast:- 用来移除
const或volatile属性。但需要特别注意的是const_cast不是用于去除变量的常量性,而是去除指向常数对象的指针或引用的常量性,其去除常量性的对象必须为指针或引用。 - 如果对一个指向常量的指针,通过
const_cast移除const属性, 然后进行修改, 编译通过,但是运行时会报段错误
- 用来移除
static_cast: 静态类型转换(不能移除const/volatile属性)是最常看到的类型转换, 几个功能.- 内置类型之间的转换, 精度耗损需要有程序员把握
- 继承体系中的上下行转换(上行:子类转父类,安全转换; 下行:父类转子类, 不安全转换)
- 指针类型转换:
空指针转换成目标类型的空指针,把任何类型转换成void 类型。
dynamic_cast: 主要用在继承体系中的安全向下转型- 它能安全地将指向基类的
指针/引用转型为指向子类的指针/引用, 转型失败会返回null(转型对象为指针时)或抛出异常bad_cast(转型对象为引用时)。 dynamic_cast会利用运行时的信息(RTTI)来进行动态类型检查,因此dynamic_cast 存在一定的效率损失。- 而且
dynamic_cast进行动态类型检查时, 利用了虚表中的信息, 所以只能用于函数虚函数的类对象中.
- 它能安全地将指向基类的
reinterpret_cast强制类型转换,非常不安全- 它可以把一个指针转换成一个整数,也可以把一个整数转换成一个指针(先把一个指针转换成一个整数,在把该整数转换成原类型的指针,还可以得到原先的指针值)。
94、全局变量和static 变量的区别
- static变量分为两个类型: 全局静态变量(在全局变量的类型前加上static)和局部静态变量(在局部变量的类型前加上static).
- 从储存形式看: 他们没有区别, 都储存于静态数据区
- 从作用域看:
- 全局变量默认具有extern属性, 它的作用域为整个项目, 可能和其他cpp文件中的全局变量发生命名冲突.
- 全局静态变量,作用域受限, 它的作用域仅限于定义它的文件内有效, 不会和其他cpp文件中的全局变量发生命名冲突.
- 局部静态变量, 作用域依旧不管, 当时当离开作用域时不会变量不会被释放, 其值保持不变只是被屏蔽了, 直到再次进入作用域, 其也只会被初始化一次.
static 函数与普通函数有什么区别?
static函数与普通函数有什么区别?static函数与普通的函数作用域不同。- 普通函数默认为
extern属性, 作用域为整个项目, 可能会和其他cpp文件中的函数发生命名冲突. static修饰的函数, 作用域受限仅为定义的文件, 不会和其他cpp文件中的函数发生命名冲突.
- 普通函数默认为
95、静态成员与普通成员的区别
- 储存位置不同: 普通成员变量存储在栈或堆中,而静态成员变量存储在静态全局区;
- 声明周期不同:
- 静态成员变量从类被加载开始到类被卸载,一直存在;
- 普通成员变量只有在类创建对象后才开始存在,对象结束,它的生命期结束;
- 初始化位置: 普通成员变量在类中初始化;静态成员变量在类外初始化;
- 拥有则不同: 静态成员变量可以理解为是属于类的变量,可以通过类名进行访问, 为本类的所有对象所共享;普通成员变量是每个对象单独享用的, 只能通过对象进行访问;
96、说一下理解ifdef endif
- 从源文件到可执行程序的过程, 通常要经历:
预编译,编译,汇编,链接等过程 ifdef,endif为条件预编译指令, 生效于预编译阶段, 根据条件可以完成一些特殊的逻辑, 例如防止文件重复引用#ifdef,#else,#endif为完整的逻辑, 分别表示, 如果定义了某个标识符, 则编译后续程序段, 否则编译另外一个程序段- 因为预编译阶段处于编译链的第一阶段, 它可以直接影响应用程序的大小.
97、隐式转换,如何消除隐式转换?
- 隐式转换,是指不需要用户干预,编译器私下进行的类型转换行为。很多时候用户可能都不知道进行了哪些转换,
- 例如:
- 类型提升:
(bool, int);(short, int);(float, double) - 类型转换:
(int, float);(int, double),(Derived*, Base*)
- 类型提升:
- 例如:
- 基本数据类型的转换, 通常发生于从小到大的变换, 以保证精度不丢失
- 对于用户自定义类型, 如果存在单参数构造函数, 或则除一个参数外其他参数都有默认参数的, 此时编译器可能完成由此参数类型到自定义类型的隐式变换, 消除方式为使用关键字
explicit禁止隐式转换.
98、虚函数的内存结构,那菱形继承的虚函数内存结构呢
- 如果一个类存在虚函数, 则会发生以下几个变化
- 如果不存在构造函数, 则编译器一定会合成默认构造函数
- 编译器会为类生成一个虚表(储存在静态区, 不占用对象内存), 并给该类的每个对象插入一个指向虚表的指针(通常此指针位于对象的起始位置), 虚函数表的每一项为函数的入口地址.
- 如果派生类的基类存在虚函数,则
- 编译器会复制基类的虚表形成一个副本, 然后给该派生类对象插入一个指向该虚表副本的指针
- 如果该派生类对基类的虚函数进行了重定义, 则会替换虚表副本中的对应函数入口地址
- 如果该派生类新增了虚函数, 则对该虚表副本增加对应的项
- 如果存在菱形结构的继承关系, 则通常回使用虚继承的方式, 防止同一类中存在基类的多个副本
- 虚表的继承方式和普通继承一样, 但是在 - 如果不存在构造函数, 则编译器一定会合成默认构造函数
- 如果类
B虚拟继承自类A, 则类B中存在一个虚基类表指针,指向一个虚基类表(储存在静态区, 不占用对象内存), 此虚基类表中存储中虚基类相对于当前类对象的偏移量. - 不同的编译器对虚基类表指针的处理方式不同, 例如
VS编译器将虚基类表指针插入到对象中(会占用对象内存), 而SUN/GCC公式的编译器则是插入到虚函数表中(不占用对象内存)
99、多继承的优缺点,作为一个开发者怎么看待多继承
C++允许为一个派生类指定多个基类,这样的继承结构被称做多重继承。- 优点: 对象可以调用多个基类中的接口;
- 缺点:
- 如果基类重存在多个相同的基类或则方法, 则会出现二义性(解决方案是调用时加上全局限定符)
- 容易存在菱形继承, 从而导致存在多个基类的副本(解决方案是使用虚拟继承)
- 个人觉得挺方便的, 虽然有缺点,但是也都用对应的解决方案
100、迭代器++it,it++哪个好,为什么
略
101、C++如何处理多个异常的?
C++中的错误情况:- 语法错误(编译错误):比如变量未定义、括号不匹配、关键字拼写错误等等编译器在编译时能发现的错误,这类错误可以及时被编译器发现,而且可以及时知道出错的位置及原因,方便改正。
- 运行时错误:比如数组下标越界、系统内存不足等等。这类错误不易被程序员发现,它能通过编译且能进入运行,但运行时会出错,导致程序崩溃。为了有效处理程序运行时错误,
C++中引入异常处理机制来解决此问题。
C++异常处理机制:- 异常处理基本思想:执行一个函数的过程中发现异常,可以不用在本函数内立即进行处理, 而是抛出该异常,让函数的调用者直接或间接处理这个问题。
C++异常处理机制由3 个模块组成:try(检查)、throw(抛出)、catch(捕获)- 首先是: 抛出异常的语句格式为:
throw 表达式; - 如果
try块中程序段发现了异常则抛出异常, 则依次尝试通过catch进行捕获, 如果捕获成功则调用相应的函数处理段, 如果捕获失败, 则条用terminal终止程序.try{ // 可能抛出异常的语句;(检查) } catch(类型名[形参名]){ //捕获特定类型的异常 //处理1; } catch(类型名[形参名]){//捕获特定类型的异常 //处理2; } catch (…){ //捕获所有类型的异常 }
C++标准的异常std::exception: 所有标准C++异常的父类。std::logic_error: 逻辑错误(无效的参数, 太长的std::string, 数组越界)std::runtime_error: 运行时错误(数据溢出)
- 我们可以通过这些类派生出自己的错误类型,尤其是对
logic_error进行重载
-
参考: [C++ 异常处理 菜鸟教程](https://www.runoob.com/cplusplus/cpp-exceptions-handling.html)
102、模板和实现可不可以不写在一个文件里面?为什么?
104、智能指针的作用;
C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。- 三个指针指针:
unique_ptr、shared_ptr、weak_ptr unique_ptr- 语意为唯一拥有所指向对象
- 其只支持移动语义, 不允许拷贝语义, 不允许强制剥夺, 有条件支持赋值语义(等号右边为右值的时候).
- 当unique_ptr指针生命周期结束, 且没有被使用移动语义, 则会将所指向对象释放掉.
shared_ptr- 语义为共享的拥有多指向的对象, 其支持拷贝语义, 支持移动语义, 支持赋值语义.
shared_ptr内部存在一个计数器, 为指向该对象的所有shared_ptr所共享,- 每减少一个
shared_ptr则计数器减一, 没多一个则计数器加一 - 当计数器为零时则释放所指向的对象.
weak_ptr: 解决交叉引用问题, 房子内存泄漏.
105、auto_ptr作用
- 已经被
unique_ptr替代, 其允许强制剥夺所有权, 会存在野指针风险.
1) auto_ptr 的出现,主要是为了解决“有异常抛出时发生内存泄漏”的问题;抛出异常,将导致指针p 所指向的空间得不到释放而导致内存泄漏;
2) auto_ptr 构造时取得某个对象的控制权,在析构时释放该对象。我们实际上是创建一个auto_ptr<Type>类型的局部对象,该局部对象析构时,会将自身所拥有的指针空间释放,所以不会有内存泄漏;
3) auto_ptr 的构造函数是explicit,阻止了一般指针隐式转换为auto_ptr 的构造,所以不能直接将一般类型的指针赋值给auto_ptr 类型的对象,必须用auto_ptr 的构造函数创建对象;
4) 由于auto_ptr 对象析构时会删除它所拥有的指针,所以使用时避免多个auto_ptr对象管理同一个指针;
5) Auto_ptr 内部实现,析构函数中删除对象用的是delete 而不是delete[],所以auto_ptr 不能管理数组;
6) auto_ptr 支持所拥有的指针类型之间的隐式类型转换。
7) 可以通过*和->运算符对auto_ptr 所有用的指针进行提领操作;
8) T* get(),获得auto_ptr 所拥有的指针;T* release(),释放auto_ptr的所有权,并将所有用的指针返回。
106、class、union、struct 的区别
struct在C和C++中是不同的C语言中:struct为自定义数据类型, 结构体名不能单独作为类型使用, 其结构名前必须加struct才行struct为变量的集合, 不能存定义函数(但是可以存在函数指针变量)struct不存在访问权限控制的概念
C++中:struct为抽象数据类型, 只一个特殊的class, 支持成员函数的定义, 可以继承和实现多态- 增加了访问权限控制的概念, 但是默认访问和继承权限为
public - 结构体名字可以为直接做为类型使用
C++中struct和class的区别- 默认的访问和继承权限不同
- 注意
C++中struct可以使用模板
- 总结
- 使用struct时,它的成员的访问权限默认是public的,而class的成员默认是private的
- struct的继承默认是public继承,而class的继承默认是private继承
- class可以用作模板,而struct不能
unionC语言中:union是一种数据格式,能够存储不同的数据类型,但只能同时存储其中的一种类型。union的数据成员是共享内存的, 以成员最大的做为结构体的大小- 每个数据成员在内存中的起始地址是相同的。
C++中:union结构式一种特殊的类。 默认访问权限是public。- 能包含访问权限、成员变量、成员函数(可以包含构造函数和析构函数)。
- 不能包含虚函数和静态数据变量。也不能被用作其他类的基类,它本身也不能从某个基类派生而来。
union成员是共享内存的,以size最大的结构作为自己的大小。- 每个数据成员在内存中的起始地址是相同的。
- 无论是
C/C++,union的储存方式都是小端模式储存的
107、动态联编与静态联编
-
在
C++中,联编是指一个计算机程序的不同部分彼此关联的过程。按照联编所进行的阶段不同,可以分为静态联编和动态联编; - 静态联编
- 是指联编工作在编译阶段完成的,这种联编过程是在程序运行之前完成的,又称为早期联编。
- 要实现静态联编,在编译阶段就必须确定程序中的操作调用(如函数调用)与执行该操作代码间的关系,确定这种关系称为束定,在编译时的束定称为静态束定。
- 静态联编对成员函数的选择是基于指向对象的指针或者引用的类型。
- 其优点是效率高,但灵活性差。
- 动态联编
- 是指联编在程序运行时动态地进行,根据当时的情况来确定调用哪个同名函数,实际上是在运行时虚函数的实现。这种联编又称为晚期联编,或动态束定。
- 动态联编对成员函数的选择是基于对象的类型,针对不同的对象类型将做出不同的编译结果。
C++中一般情况下的联编是静态联编,但是当涉及到多态性和虚函数时应该使用动态联编。- 动态联编的优点是灵活性强,但效率低。
- 动态联编规定,只能通过
指向基类的指针或基类对象的引用来调用虚函数,其格式为:指向基类的指针变量名->虚函数名(实参表);或基类对象的引用名.虚函数名(实参表)
- 实现动态联编三个条件:
- 必须把动态联编的行为定义为类的虚函数;
- 类之间应满足子类型关系,通常表现为一个类从另一个类公有派生而来;
- 必须先使用基类指针指向子类型的对象,然后直接或间接使用基类指针调用虚函数;
- 参考: c++动态联编与静态联编
108、动态编译与静态编译
静态编译- 静态编译,编译器在编译可执行文件时,把需要用到的对应动态链接库中的部分提取出来,连接到可执行文件中去
- 缺点: 编译慢, 可执行程序大
- 优点: 使可执行文件在运行时不需要依赖于动态链接库;
动态编译- 动态编译的可执行文件需要附带一个动态链接库,在执行时,需要调用其对应动态链接库的命令。
- 优点:
- 一方面是缩小了执行文件本身的体积,
- 另一方面是加快了编译速度,节省了系统资源。
- 缺点:
- 哪怕是很简单的程序,只用到了链接库的一两条命令,也需要附带一个相对庞大的链接库;
- 二是如果其他计算机上没有安装对应的运行库,则用动态编译的可执行文件就不能运行。
- 参考: 动态编译、静态编译区别(转)
109、动态链接和静态链接区别
-
静态链接: 1) 函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。 1) 空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,会出现同一个目标文件在多个程序内都存在一个副本; 1) 更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。 1) 运行速度快:但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
-
动态链接: 1) 动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。 1) 共享库:就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多个副本,而是这多个程序在执行时共享同一份副本; 1) 更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。 1) 性能损耗:因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失。
- 区别
- 使用静态链接生成的可执行文件可能会存在共享库的多个复本, 而使用动态链接库的可执行文件只有存在一份
- 使用静态链接库的可执行程序不需要依赖动态链接库, 依赖关系简单; 而使用动态链接库的可执行程序需要引用动态链接库, 故而依赖关系复杂
- 静态链接生成的静态链接库不能再包含其他的动态链接库或则静态库, 而动态链接库可以包括其他的动态库或则静态库.
- 参考: 动态编译、静态编译区别(转)
110、在不使用额外空间的情况下,交换两个数?
- 算术
x = x + y; y = x - y; x = x - y; - 异或
// 原理 x ^= y ^= x; 能对int,char.. x = x^y; y = x^y; x = x^y;
111、strcpy 和memcpy 的区别
- 复制的内容不同。
strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。 - 复制的方法不同。
strcpy不需要指定长度,它遇到被复制字符的串结束符\0才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
112、执行int main(int argc, char *argv[])时的内存结构
- 参数的含义是程序在命令行下运行的时候,需要输入
argc个参数,每个参数是以char类型输入的,依次存在数组里面,数组是argv[],所有的参数在指针char *指向的内存中,数组的中元素的个数为argc个,第一个参数为程序的名称。
main函数是用户代码的入口函数, 其调用过程依旧是函数调用过程, 区别在于main函数的参数有固定的规范- main函数参数规范如下:
- 第一个参数为:
int型, 表示参数的个数,argc - 第二个参数为:
char* 数组, 每一个char*元素指向一个以字符串形式储存在内存中的参数的首地址, 其中第一个参数为程序的名字
- 第一个参数为:
- main函数参数规范如下:
- 函数调用过程如下:
- 首先将参数以字符串的形式保存在内存中, 然后利用字符串起始字符指针组成char* 数组, 并计算参数的个数.
- 然后将进行函数调用,
- 首先, 将参数逆序入栈, 也就是(参数指针数组, 参数个数)
- 然后返回地址入栈
- 然后调用则栈顶入栈
- 将当前栈顶设置为被调函数栈底, 并将栈底入栈
- 然后被调函数建立形参以及局部变量, 处理相应的逻辑
113、volatile 关键字的作用?
volatile关键字是一种类型修饰符,被它修饰的变量拥有三大特性: 易变性, 不可优化性, 顺序性- 易变性: 编译器对
valatile的访问总是从内存中读取数据, 即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。 - 不可优化性:
volatile告诉编译器,不要对我这个变量进行各种激进的优化,甚至将变量直接消除,保证程序员写在代码中的指令,一定会被执行。 - 顺序性: 保证
Volatile变量间的顺序性,编译器不会进行乱序优化。但是可能会被CPU优化
- 易变性: 编译器对
- 声明时语法:
int volatile vInt; volatile用在如下的几个地方: 1) 中断服务程序中修改的供其它程序检测的变量需要加volatile; 2) 多任务环境下各任务间共享的标志应该加volatile; 3) 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
114、讲讲大端小端,如何检测(三种方法)
大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址端。 小端模式,是指数据的高字节保存在内存的高地址中,低位字节保存在在内存的低地址端。
- 直接读取存放在内存中的十六进制数值,取低位进行值判断(在GCC中测试,不可行!)
int a = 0x12345678; int *c = &a; c[0] == 0x12 大端模式 c[0] == 0x78 小段模式 - 用union来进行判断(union总是小端储存)
union w{ char ch; int i; }; union w p; p.i = 1; bool flag = p.ch==1;
115、查看内存的方法
- 首先打开vs 编译器,创建好项目,并且将代码写进去,这里就不贴代码了,你可以随便的写个做个测试;
- 调试的时候做好相应的断点,然后点击开始调试;
- 程序调试之后会在你设置断点的地方暂停,然后选择调试->窗口->内存,就打开了内存数据查看的窗口了。
116、空类会默认添加哪些东西?怎么写?
- 默认构造函数
- 析构函数
- 拷贝构造函数
- 赋值运算符
(operator=) - 两个取址运算符
(operator&)(const和非const) - 当然所有的这些函数都是需要才生成, 例如你都没使用过复制运算, 肯定不会生成的
117、标准库是什么?
1) C++ 标准库可以分为两部分:
- 标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的。函数库继承自C语言。
- 面向对象类库: 这个库是类及其相关函数的集合。
- 标准函数库: 输入
/输出I/O、字符串和字符处理、数学、时间、日期和本地化、动态分配、其他、宽字符函数 - 面向对象类库: 标准的
C++I/O类、String类、数值类、STL容器类、STL算法、STL函数对象、STL迭代器、STL分配器、本地化库、异常处理类、杂项支持库
118、const char* 与string 之间的关系,传递参数问题?
string是c++标准库里面其中一个,封装了对字符串的操作,实际操作过程我们可以用const char*给string类初始化- 三者的转化关系如下所示:
string转const char*string s = “abc”; const char* c_s = s.c_str();const char*转string,直接赋值即可const char* c_s = “abc”; string s(c_s);string转char*string s = “abc”; char* c; const int len = s.length(); c = new char[len+1]; strcpy(c,s.c_str());char*转stringchar* c = “abc”; string s(c);const char*转char*const char* cpc = “abc”; char* pc = new char[strlen(cpc)+1]; strcpy(pc,cpc);char*转const char*,直接赋值即可char* pc = **** “abc”; const char* cpc = pc;
119、new、delete、operator new、operator delete、placement new、placement delete
new operatornew operator完成了两件事情:用于申请内存和初始化对象。- 例如:
string* ps = new string("abc");
operator newoperator new类似于C语言中的malloc,只是负责申请内存。- 例如:
void* buffer = operator new(sizeof(string)); // 注意这里new 前要有个operator。
placement new- 用于在给定的内存中初始化对象。
- 例如:
void* buffer = operator new(sizeof(string)); buffer = new(buffer) string("abc"); - 调用了
placement new,在buffer所指向的内存中创建了一个string类型的对象并且初始值为“abc”。
- 因此可以看出:
new operator可以分解operator new和placement new两个动作,是operator new和placement new的结合。
- 与
new对应的delete没有placement delete语法- 它只有两种,分别是
delete operator和operator delete。 delete operator和new operator对应,完成析构对象和释放内存的操作。- 而
operator delete只是用于内存的释放,与C语言中的free相似。
- 它只有两种,分别是
120、为什么拷贝构造函数必须传引用不能传值?
- 拷贝构造函数的作用就是用来复制对象的,在使用这个对象的实例来初始化这个对象的一个新的实例。
-
两种不同的参数传递方式:
- 值传递:
- 对于内置数据类型的传递时,直接赋值拷贝给形参(注意形参是函数内局部变量);对于类类型的传递时,需要首先调用该类的拷贝构造函数来初始化形参(局部对象);
- 如
void foo(class_type obj_local){}, 如果调用foo(obj); 首先class_type obj_local(obj),这样就定义了局部变量obj_local供函数内部使用
- 引用传递:
- 无论对内置类型还是类类型,传递引用或指针最终都是传递的地址值!而地址总是指针类型(属于简单类型), 显然参数传递时,按简单类型的赋值拷贝,而不会有拷贝构造函数的调用(对于类类型).
- 拷贝构造函数使用值传递会产生无限递归调用,内存溢出。
- 拷贝构造函数用来初始化一个非引用类类型对象,如果用传值的方式进行传参数,那么构造实参需要调用拷贝构造函数,而拷贝构造函数需要传递实参,所以会一直递归。
121、空类的大小是多少?为什么?
C++空类的大小不为0,不同编译器设置不一样,vs设置为1;C++标准指出,不允许一个对象(当然包括类对象)的大小为0,因为不同的对象不能具有相同的地址;- 带有虚函数的
C++类大小不为1,因为每一个对象会有一个vptr指向虚函数表,具体大小根据指针大小确定; C++中要求对于类的每个实例都必须有独一无二的地址,那么编译器自动为空类分配一个字节大小,这样便保证了每个实例均有独一无二的内存地址。
122、你什么情况用指针当参数,什么时候用引用,为什么?
- 使用引用参数的主要原因有两个:
- 程序员能修改调用函数中的数据对象
- 通过传递引用而不是整个数据–对象,可以提高程序的运行速度
- 一般的原则:
- 对于使用数据对象不做修改的函数:
- 如果数据对象很
小(内置数据类型或者小型结构),则按照值传递; - 如果数据对象是
数组,则使用指针 (唯一的选择),并且指针声明为const的指针; - 如果数据对象是
较大的结构,则使用const指针或者引用,已提高程序的效率。这样可以节省结构所需的时间和空间; - 如果数据对象是
类对象,则使用const引用(传递类对象参数的标准方式是按照引用传递);
- 如果数据对象很
- 对于修改函数中数据的函数:
- 如果数据是
内置数据类型,则使用指针 - 如果数据对象
是数组,则只能使用指针 - 如果数据对象是
结构,则使用引用或者指针 - 如果数据是
类对象,则使用引用
- 如果数据是
- 对于使用数据对象不做修改的函数:
123、大内存申请时候选用哪种?C++变量存在哪?变量的大小存在哪?符号表存在哪?
- 大内存申请时,采用堆申请空间,用
new申请, 当大于128K的时候会在映射区分配内存. - 变量存储位置:
- 全局变量
- 静态变量
- 局部变量
- 堆对象:大, 小
- 符号表只存在于编译阶段, 符号表的每一项分别对应变量名和变量地址, 但是
C++对变量名不作存储,在汇编以后不会出现变量名,变量名作用只是用于方便编译成汇编代码,是给编译器看的,是方便人阅读的
124、为什么会有大端小端,htol 这一类函数的作用
- 计算机以字节为基本单位进行管理, 每个地址单元都对应着一个字节,一个字节为
8bit。但是我们常用到大于一个字节的数据类型, 例如short,int,float等, 此时就会存在字节如何放置的问题, 从而出现了大端模式和小端模式. - 大端: 低字节放于高地址处(网络字节序为大端)
-
小端: 低字节放于低地址处(通常主机字节序为小端)
- 例如(
16bit的short型 x)- 在内存中的地址为
0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。 - 对于大端模式,就将
0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
- 在内存中的地址为
125、静态函数能定义为虚函数吗?常函数?
- 不能 !
static成员不属于任何类对象或类实例,没有this指针(静态与非静态成员函数的一个主要区别)。- 虚函数调用链为:
vptr->vtable->virtual function - 但是访问
vptr需要使用this指针但是static成员函数没有this指针, 从而无法实现虚函数的调用
- 虚函数依靠`vptr` 和`vtable` 来处理。`vptr` 是一个指针,在类的构造函数中创建生成,并且只能用`this` 指针来访问它,因为它是类的一个成员,并且`vptr` 指向保存虚函数地址的`vtable.`对于静态成员函数,它没有`this`指针,所以无法访问`vptr.` 这就是为何`static` 函数不能为`virtual.`虚函数的调用关系:`this` -> `vtable` -> `virtual function`
126、this 指针调用成员变量时,堆栈会发生什么变化?
- 当我们在类中定义非静态成员函数时, 编译器会为此成员函数添加一个参数(最后一个形参), 类型为当前类型的指针
- 当我们进行通过对象或则对象指针调用此成员函数时, 编译器会自动将对象的地址传给作为隐含参数传递给函数,这个隐含参数就是
this指针。即使你并没有写this指针,编译器在链接时也会加上this的,对各成员的访问都是通过this的。 - 函数调用时,
this指针首先入栈,然后成员函数的参数从右向左进行入栈,最后函数返回地址入栈。
127、静态绑定和动态绑定的介绍
- 对象的静态类型:对象在声明时采用的类型。是在编译期确定的。
-
对象的动态类型:目前所指对象的类型。是在运行期决定的。对象的动态类型可以更改,但是静态类型无法更改。
- 静态绑定:绑定的是对象的静态类型,某特性(比如函数)依赖于对象的静态类型,发生在编译期。
- 动态绑定:绑定的是对象的动态类型,某特性(比如函数)依赖于对象的动态类型,发生在运行期。
128、设计一个类计算子类的个数
- 为类设计一个
static静态变量count作为计数器; - 类定义结束后初始化
count; - 在构造函数中对
count进行+1; - 设计拷贝构造函数,在进行拷贝构造函数中进行
count +1,操作; - 设计复制构造函数,在进行复制函数中对
count+1操作; - 在析构函数中对
count进行-1;
129、怎么快速定位错误出现的地方
- 如果是简单错误, 通常可以分析编译器辗转解栈过程, 定位到输出位置, 通常都是解栈的靠后位置
- 如果错误较复杂, 就最好使用gdb调试模式, 进行调试, 逐步定位错误位置, 或者添加更多的输出信息.
130、虚函数的代价?
1) 带有虚函数的类,每一个类会产生一个虚函数表,用来存储指向虚成员函数的指针,增大类; 1) 带有虚函数的类的每一个对象,都会有有一个指向虚表的指针,会增加对象的空间大小; 2) **不能再是内敛的函数**,因为内敛函数在编译阶段进行替代,而虚函数表示等待,在运行阶段才能确定到低是采用哪种函数,虚函数不能是内敛函数。
131、类对象的大小
1) 类的非静态成员变量大小,静态成员不占据类的空间,成员函数也不占据类的空间大小; 2) 内存对齐另外分配的空间大小,类内的数据也是需要进行内存对齐操作的; 3) 当该该类是某类的派生类,那么派生类继承的基类部分的数据成员也会存在在派生类中的空间中,也会对派生类进行扩展。 4) 虚函数的话,会在类对象插入vptr 指针,加上指针大小; 5) 如果是虚拟继承而来的话, 还会存在一个虚基类表指针, 不同的编译器对这个虚基类指针的处理是不一样的, gcc是存放在虚函数表中(意味着虚函数表指针和虚基类表指针只会存在一个), vc是存放在对象中的(意味着可能会虚函数表指针和虚基类表指针共存)
132、移动构造函数
- 移动构造函数是C++11中引入的移动语义的具体实现. 它的主要目的是避免无谓的构造和析构
- 例如: 当我们用右值初始化一个左值时, 通常是使用复制构造函数构造左值,然后对右值调用析构函数, 此时存在大量的浪费. 而且复制构造函数对于指针通常是浅复制, 容易产生野指针.
- 移动构造函数的参数为右值引用, 它的作用就是将此右值的内容转移到左值内, 从而避免右值调用构造函数. 也避免了左值分配内存进行构造.
Example6 (Example6&& x):ptr(x.ptr){ x.ptr = nullptr; } // move assignment Example6& operator= (Example6&& x){ delete ptr; ptr = x.ptr; x.ptr=nullptr; return *this; }
133、何时需要合成构造函数
- 如果一个类没有构造函数,一共四种情况会合成构造函数:
- 存在虚函数的情况
- 存在虚基类的情况
- 基类成员存在构造函数的情况
- 对象成员对象存在构造函数的情况
134、何时需要合成复制构造函数
-
有三种情况会以一个对象的内容作为另一个对象的初值: 1) 对一个对象做显示的初始化操作,
X xx = x;2) 当对象被当做参数交给某个函数时; 3) 当函数传回一个类对象时; -
如果一个类没有拷贝构造函数,合成复制构造函数的情况:
- 成员对象有拷贝构造函数
- 基类拷贝构造函数
- 存在虚函数
- 存在虚基类
135、何时需要成员初始化列表?过程是什么?
- 需要成员初始化列表:
- 引用类型的成员变量
- const类型的成员变量
- 基类不存在零参数构造函数
- 成员对象不存在零参数构造函数
- 过程:
- 编译器会根据成员变量定义顺序一一初始化成员变量, 如果相应成员在成员初始化列表中有初始化参数, 则用成员初始化列表中的参数进行构造
- 发生在用户自定义代码段之前.
136、程序员定义的析构函数被扩展的过程?
- 析构函数的执行顺序(和构造相反):
- 析构函数函数体被执行
- 本类的成员对象析构函数被调用, 调用顺序和声明的顺序相反
- 非虚基类拥有析构函数,会以声明的相反顺序被调用;
- 虚基类被析构
137、构造函数的执行算法?
- 扩展过程:
- 虚基类按照定义顺序被构造
- 基类按照定义顺序被构造
- 成员变量被构造
- 执行程序员所提供的代码
- 一个类被构造的执行过程:
- 虚基类按照定义顺序被构造
- 基类按照定义顺序被构造
- 然后是按照定义顺序构造成员变量, 如果某个成员在初始化成员变量列表内存在初始化参数, 则调用初始化成员变量列表内的参数初始化该成员变量
- 然后是执行构造函数函数体内用户提供的代码.
- 注意事项:
- 在构造函数函数体内的对虚函数的调用将不具备动态绑定的特性
138、构造函数的扩展过程?
- 虚基类按照定义顺序被构造
- 基类按照定义顺序被构造
- 成员变量被构造
- 执行程序员所提供的代码
139、哪些函数不能是虚函数
- 构造函数: 首先是没必要使用虚函数, 其次不能使用虚函数
- 内联函数: 表示在编译阶段进行函数体的替换操作,而虚函数意味着在运行期间进行类型确定,所以内联函数不能是虚函数;
- 静态函数: 静态函数不属于对象属于类,静态成员函数没有this 指针,因此静态函数设置为虚函数没有任何意义。
- 友元函数: 友元函数不属于类的成员函数,不能被继承。对于没有继承特性的函数没有虚函数的说法。
- 普通函数: 普通函数不属于类的成员函数,不具有继承特性,因此普通函数没有虚函数。
140. sizeof 和strlen 的区别
sizeof是一个取字节运算符,计算变量所占的内存数(字节大小), 可以用于任意类型strlen是个函数, 计算字符串的具体长度(只能是字符串),不包括字符串结束符(\0)。strlen是个不安全的函数, 如果没有\0将会发生段错误。sizeof和strlen对同一个字符串求值, 结果差一.- 数组做
sizeof的参数不退化,传递给strlen就退化为指针;
141、简述strcpy、sprintf 与memcpy 的区别
- 复制操作:
strcpy,memcpy- 复制类容不一样:
strcpy是用于复制字符串的, 不能用去其他类型, 而memcpy是用于复制任意类型的数据类型 - 复制防止不一样:
strcpy是通过检测支付中的\0判断结束的, 存在溢出风险(strncpy); 而memcpy是需要指定复制的字节数的.
- 复制类容不一样:
- 字符串格式化:
sprintf- 将格式化的数据写入字符串中
- 注意
sprintf对写入字符串没有限制大小, 也就存在溢出风险, 建议采用snprintf
142、编码实现某一变量某位清0 或置1
#define BIT3 (0x1 << 3 ) Satic int a;
//设置a 的bit 3:
void set_bit3( void ){
a |= BIT3; //将a 第3 位置1
}
//清a 的bit 3
void set_bit3( void ){
a &= ~BIT3; //将a 第3 位清零
}
143、将“引用”作为函数参数有哪些特点?
1) 传递引用给函数与传递指针的效果是一样的。 1) 这时,被调函数的形参就成为原来主调函数中的实参变量或对象的一个别名来使用,所以在被调函数中对形参变量的操作就是对其相应的目标对象(在主调函数中)的操作。 2) 使用引用传递函数的参数,在内存中并没有产生实参的副本,它是直接对实参操作; 1) 而使用一般变量传递函数的参数,当发生函数调用时,需要给形参分配存储单元,形参变量是实参变量的副本; 2) 如果传递的是对象,还将调用拷贝构造函数。 3) 因此,当参数传递的数据较大时,用引用比用一般变量传递参数的效率和所占空间都好。 3) 使用指针作为函数的参数虽然也能达到与使用引用的效果,但是,在被调函数中同样要给形参分配存储单元,且需要重复使用”*指针变量名”的形式进行运算,这很容易产生错误且程序的阅读性较差; 1) 另一方面,在主调函数的调用点处,必须用变量的地址作为实参。而引用更容易使用,更清晰。
- 引用传递 从逻辑上就好像是对主调函数中的实参取了一个别名, 在被调函数中对该别名的任何操作都会反应在主调函数中, 实际的实现过程中, 传递的其实是对象的地址, 和指针传递相似, 区别在于对该引用的任何操作都会被处理为间接寻址
- 引用传递 并没有对
对象进行拷贝, 只是对指针进行了拷贝, 避免了对对象的复制, 效率更高. - 引用传递 逻辑上相当于对主调函数中的实参取了一个别名, 阅读性更好.
144、分别写出BOOL,int,float, 指针类型的变量a 与“零”的比较语句。
BOOL : if ( !a ) or if(a)
int : if ( a == 0)
float : const EXPRESSION EXP = 0.000001 // 1.0e-10 浮点数有精度限制, 所以只能通过阈值来判断是否相等
if ( a < EXP && a >-EXP)
pointer : if ( a != NULL) or if(a == NULL)
145、局部变量全局变量的问题?
- 局部会屏蔽全局。
- 要用全局变量,需要使用”::”, 局部变量可以与全局变量同名,在函数内引用这个变量时,会用到同名的局部变量,而不会用到全局变量。
- 对于有些编译器而言,在同一个函数内可以定义多个同名的局部变量,比如在两个循环体内都定义一个同名的局部变量,而那个局部变量的作用域就在那个循环体内。
- 如何引用一个已经定义过的全局变量,可以用引用头文件的方式,也可以用
extern关键字,如果用引用头文件方式来引用某个在头文件中声明的全局变理,假定你将那个变写错了,那么在编译期间会报错,如果你用extern方式引用时,假定你犯了同样的错误,那么在编译期间不会报错,而在连接期间报错。 - 全局变量可不可以定义在可被多个
.C文件包含的头文件中,在不同的C文件中以static形式来声明同名全局变量。可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错
- 局部屏蔽全局
- 引用另一个文件中的变量, 使用
extern关键字, 或则引用头文件 - 全局变量冲突
146、数组和指针的区别?
- 对数组使用
sizeof操作符可以计算出数组的容量(字节数). 对指针使用sizeof操作符得到的是一个指针变量的字节数,而不是p所指的内存容量。 - 编译器为了简化对数组的支持,实际上是利用指针实现了对数组的支持。具体来说,就是将表达式中的数组元素引用转换为指针加偏移量的引用。
- 在向函数传递参数的时候,如果实参是一个数组,那用于接受的形参为对应的指针。也就是传递过去是数组的首地址而不是整个数组,能够提高效率;
- 在使用下标的时候,两者的用法相同,都是原地址加上下标值,不过数组的原地址就是数组首元素的地址是固定的,指针的原地址就不是固定的。
- 数组作为
sizeof参数时, 不会退化 - 数组在内存中是连续存放的,开辟一块连续的内存空间;
- 数组所占存储空间:
sizeof(数组名); - 数组大小:
sizeof(数组名)/sizeof(数组元素数据类型);
- 数组所占存储空间:
- 指针也可以使用下标, 表示指针指向地址
+偏移
147、C++如何阻止一个类被实例化?一般在什么时候将构造函数声明为private?
1) 将类定义为抽象基类或者将构造函数声明为private;
2) 不允许类外部创建类对象(也就是杜绝了静态构建的可能性),只能在类内部创建对象(成员函数通过new构建)
148、如何禁止自动生成拷贝构造函数?
1) 为了阻止编译器默认生成拷贝构造函数和拷贝赋值函数,我们需要手动去重写这两个函数,某些情况下,为了避免调用拷贝构造函数和拷贝赋值函数,我们需要将他们设置成private,防止被调用。 2) 类的成员函数和friend 函数还是可以调用private 函数,如果这个private 函数只声明不定义,则会产生一个连接错误; 3) 针对上述两种情况,我们可以定一个base 类,在base 类中将拷贝构造函数和拷贝赋值函数设置成private,那么派生类中编译器将不会自动生成这两个函数,且由于base 类中该函数是私有的,因此,派生类将阻止编译器执行相关的操作。
1) 拷贝构造函数的定义后面使用 =delete关键字
2) 将base类的拷贝构造函数和拷贝赋值构造函数设置为private, 这样编译器就不会自动生成这两个函数, 且由于base类的该函数为private, 所以编译器会阻止相关操作.
149、assert 与NDEBUG
1) assert 宏的原型定义在<assert.h>中,其作用是如果它的条件返回错误,则终止程序执行,原型定义:
c
#include <assert.h>
void assert( int expression );
- assert 的作用是计算表达式expression ,如果其值为假(即为0),那么它先向stderr 打印一条出错信息,然后通过调用abort 来终止程序运行。如果表达式为真,assert 什么也不做。
2) NDEBUG 宏是Standard C 中定义的宏,专门用来控制assert()的行为。
- 如果定义了这个宏,则assert 不会起作用。
- 定义NDEBUG 能避免检查各种条件所需的运行时开销,当然此时根本就不会执行运行时检查。
150、Debug 和release 的区别
1) 调试版本,包含调试信息
- 体积比Release 大很多,并且不进行任何优化(优化会使调试复杂化,因为源代码和生成的指令间关系会更复杂),便于程序员调试。
- Debug 模式下生成两个文件,除了.exe 或.dll 文件外,还有一个.pdb 文件,该文件记录了代码中断点等调试信息;
3) 发布版本,不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。(调试信息可在单独的PDB 文件中生成)。Release 模式下生成一个文件.exe 或.dll 文件。
4) 实际上,Debug 和Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
151、main 函数有没有返回值
1) 程序运行过程入口点main函数,main()函数返回值类型必须是int,这样返回值才能传递给程序激活者(如操作系统)表示程序正常退出。
2) main(int args, char**argv)参数的传递。参数的处理,一般会调用getopt()函数处理,但实践中,这仅仅是一部分,不会经常用到的技能点。
3) main函数事调用用户代码逻辑的接口有着固有的规范(或则逻辑):
- 返回值: int 程序退出状态
- 参数: 用于传递到用户代码中
- int args: 参数个数
- char** argv: 参数以字符串的形式储存, 然后将字符串首地址组成指针数组作为参数进行传递.
152、写一个比较大小的模板函数
#include<iostream>
using namespace std;
template<typename type1,typename type2>//函数模板
type1 Max(type1 a,type2 b){
return a > b ? a : b;
}
void main(){
cout<<"Max = "<<Max(5.5,'a')<<endl;
}
153、c++怎么实现一个函数先于main 函数运行
1) 全局对象/全局静态变量的生存期和作用域都高于mian函数, 在main函数之前初始化
cpp
class simpleClass{
public:
simpleClass( ){
cout << "simpleClass constructor.." << endl;
}
};
simpleClass g_objectSimple; //step1 全局对象
int _tmain(int argc, _TCHAR* argv[]) { //step3
return 0;
}
2) GCC编译器可以使用__attribute((constructor/deconstrucor))在main之前和之后注册函数
cpp
// 在main之前
__attribute((constructor)) void before_main(){
printf("befor\n");
}
// 在main之后
__attribute((deconstructor)) void after_main(){
printf("befor\n");
}
- 附加
Main函数执行之前,主要就是初始化系统相关资源;- 设置栈指针
- 初始化
static静态和global全局变量,即data段的内容 - 将未初始化部分的全局变量赋初值(即
.bss段的内容):- 数值型
short,int,long等为0, bool为FALSE- 指针为
NULL
- 数值型
- 全局对象初始化,在
main之前调用构造函数 - 将
main函数的参数,argc,argv等传递给main函数,然后才真正运行main函数
Main函数执行之后- 全局对象的析构函数会在
main函数之后执行; - 可以用
_onexit注册一个函数,它会在main之后执行;
- 全局对象的析构函数会在
- 参考:
154、虚函数与纯虚函数的区别在于
1) 纯虚函数只有定义没有实现,虚函数既有定义又有实现; 2) 含有纯虚函数的类不能定义对象,含有虚函数的类能定义对象;
155、智能指针怎么用?智能指针出现循环引用怎么解决?
1) unique_ptr: 独占式拥有一个对象, 当unique_ptr被销毁时,它所指向的对象也被销毁。
2) shared_ptr:
- 初始化:
- shared_ptr<int> p =make_shared<int>(42);
- 通常用auto更方便,auto p =make_shared<int>(42);
- shared_ptr<int> p2(new int(2));
- 每个shared_ptr都有一个关联的计数器,通常称为引用计数,一旦一个shared_ptr的计数器变为0,它就会自动释放自己所管理的对象;
- shared_ptr的析构函数就会递减它所指的对象的引用计数。
- 如果引用计数变为0,shared_ptr 的析构函数就会销毁对象,并释放它占用的内存。
3) weak_ptr:是一种不控制所指向对象生存期的智能指针,它指向由一个shared_ptr管理的对象,将一个weak_ptr 绑定到一个shared_ptr 不会改变引用计数,一旦最后一个指向对象的shared_ptr 被销毁,对象就会被释放,即使有weak_ptr 指向对象,对象还是会被释放。
4) 弱指针用于专门解决shared_ptr 循环引用的问题,weak_ptr 不会修改引用计数,即其存在与否并不影响对象的引用计数器。循环引用就是:两个对象互相使用一个shared_ptr 成员变量指向对方。弱引用并不对对象的内存进行管理,在功能上类似于普通指针,然而一个比较大的区别是,弱引用能检测到所管理的对象是否已经被释放,从而避免访问非法内存。
156、strcpy 函数和strncpy 函数的区别?哪个函数更安全?
1) 函数原型
c
char* strcpy(char* strDest, const char* strSrc)
char* strncpy(char* strDest, const char* strSrc, int pos)
2) strcpy 函数:
- 如果参数dest 所指的内存空间不够大,可能会造成缓冲溢出(bufferOverflow)的错误情况,在编写程序时请特别留意,或者用strncpy()来取代。
- strncpy 函数:用来复制源字符串的前n 个字符,src 和dest 所指的内存区域不能重叠,且dest 必须有足够的空间放置n 个字符。
4) 长度关系:
- 如果目标长>指定长>源长,则将源长全部拷贝到目标长,自动加上\0;
- 如果指定长<源长,则将源长中按指定长度拷贝到目标字符串,不包括\0;
- 如果指定长>目标长,运行时错误;
157、为什么要用static_cast转换而不用c语言中的转换?
1) 更加安全; 2) 更直接明显,能够一眼看出是什么类型转换为什么类型,容易找出程序中的错误; - 可清楚地辨别代码中每个显式的强制转; - 可读性更好,能体现程序员的意图
158、成员函数里memset(this,0,sizeof(*this))会发生什么
1) 如果类中的所有成员都是内置的数据类型的, 则不会存在问题 2) 如果有以下情况之一会出现问题: - 存在对象成员 - 存在虚函数/虚基类 - 如果在构造函数中分配了堆内存, 而此操作可能会产生内存泄漏
159、方法调用的原理(栈,汇编)
- 每一个函数都对应一个栈帧:
- 帧栈可以认为是程序栈的一段
- 它有两个端点
- 一个标识起始地址, 开始地址指针ebp;
- 一个标识着结束地址,结束地址指针esp;
- 函数调用使用的参数, 返回地址等都是通过栈来传递的.
- 函数调用过程:
- 参数逆序入栈(主调函数)
- 返回地址入栈(主调函数)(被调函数栈底往上4个子节为返回地址)
- 主调函数栈底入栈(被调函数)
- 栈顶给栈底赋值(被调函数)
- 被调函数局部变量...
- 被调函数局部变量析构
- 恢复主调函数栈帧
- 获取返回地址, 继续执行主调函数代码
- 关于返回值:
- 如果 `返回值 <= 4字节`,则返回值通过寄存器`eax`带回。
- 如果 `4< 返回值 <=8字节`,则返回值通过两个寄存器`eax`和`edx`带回。
- 如果 `返回值 > 8字节`,则返回值通过产生的临时量带回。
4) 过程调用和返回指令
- call 指令
- leave 指令
- ret 指令
160、MFC消息处理如何封装的?
161、回调函数的作用
- 回调函数一般可以分为两个类型:
- 中断处理函数
- 当发生某种事件时,系统或其他函数将会自动调用你定义的一段函数;
- 此时回调函数就相当于是中断处理函数, 由系统在符合你设定的条件时自动调用。
- 为此我们需要进行
- 函数声明
- 函数定义
- 设置中断触发, 就是把回调函数名称转化为地址作为一个参数,以便于系统调用;
- 通过函数指针调用的函数
- 如果函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用它所指向的函数时,我们就说这是回调函数;
- 因为可以把调用者与被调用者分开。调用者只需要确定被调函数是一个具有特定参数列表和特定返回值的函数, 而不需要知道具体是哪个函数被调用.
162、随机数的生成
#include<time.h>
srand((unsigned)time(NULL));
cout<<(rand()%(b-a))+a;
- 由于
rand()的内部实现是用线性同余法做的,所以生成的并不是真正的随机数,而是在一定范围内可看为随机的伪随机数。 - 种子写为
srand(time(0))代表着获取系统时间,电脑右下角的时间,每一秒后系统时间的改变,数字序列的改变得到的数字
164、C++临时对象产生的时机
- 为了使函数调用成功而进行隐式类型转换的时候。
- 传值方式
- const 引用传递(!!!!)
- 当函数返回对象的时候。
- 参考: 转:C++中临时对象及返回值优化
结束
-
Ref: 深度探索c++对象模型(一) ↩
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}