- 分布式训练库
- 结束
分布式训练库
常见框架
常见分布式训练框架:
- 第一类:深度学习框架自带分布式训练功能。如:TensorFlow、PyTorch、MindSpore、Oneflow、PaddlePaddle等。
- 第二类:基于现有深度学习框架(如:PyTorch、Flax)进行扩展和优化,从而进行分布式训练。
- 如:
Megatron-LM(张量并行)、DeepSpeed(Zero-DP)、Colossal-AI(高维模型并行,如2D、2.5D、3D)、Alpa(自动并行)等
- 如:
框架对比
LLM 训练/微调工具
| 工具名称 | 作者 | 时间 | 定位 | 核心优势/技术亮点 | 适用场景/典型用户 |
|---|---|---|---|---|---|
Unsloth |
Unsloth AI | 2023-12-01 | 面向个人的轻量化微调工具,API简洁且文档详细,新手友好 | - 极简操作:提供开箱即用的Colab Notebook,支持”Run All”一键完成数据加载、训练、模型导出(GGUF/Ollama格式) - 性能优化:宣称比传统方法快2倍,显存节省最高80%(如Qwen3 4B版本) - 免费支持:开放所有Notebook,覆盖Kaggle/GRPO/TTS/Vision等场景,与Meta合作提供合成数据集 |
- 个人开发者快速微调中小模型(支持到14B参数) - 资源受限环境(低VRAM显卡) |
LLaMA-Factory |
北航博士生 | 2023-6-3 | 图形界面(Gradio UI)和命令行工具,工业级微调平台 | - 企业背书:被Amazon/NVIDIA等公司采用,提供生产级工具链(含Colab集成) - 生态整合:支持HuggingFace模型库,内置warp等辅助工具 - 社区活跃:GitHub高星项目,持续更新 |
- 企业需要稳定、可扩展的微调框架 - 希望快速复现论文方案的团队 |
DeepSpeed |
微软 | 超大规模训练基础设施 | - 万亿参数支持:曾赋能MT-530B/BLOOM等顶级模型 - 四大创新支柱: - 训练优化:MoE模型/RLHF/长序列支持 - 推理加速:超低延迟部署方案 - 模型压缩:极致量化技术 - 科研支持:分布式科学计算 |
- 千亿参数级大模型训练 - 需要跨GPU集群扩展的场景 |
|
Axolotl |
Wing Lian + Axolotl AI Cloud | 2023‑03‑21 | 全流程后训练解决方案 | - 全面训练方法:支持LoRA/QLoRA/DPO/RLHF等前沿技术,兼容多模态任务 - 企业级扩展:支持云存储(S3/Azure)、多节点训练(FSDP/DeepSpeed)、Docker部署 - 配置复用:通过YAML文件统一管理数据预处理、训练、量化全流程 |
- 需要定制化训练策略的研究团队 - 企业级多GPU/多节点训练场景 |
ms-SWIFT |
阿里云魔搭社区 | 2024‑08‑05 | 依赖ModelScope生态,需熟悉框架集成技术,但官方文档可能提供支持 | 全流程覆盖、多模态支持较好 | - |
总结
- LLaMA-Factory:适合需要多模态支持、分布式训练或自定义复杂任务(如PPO/DPO)的场景,尤其在多硬件环境中表现优异。
- Unsloth:资源受限或追求极致效率的首选,大数据量微调速度显著领先,适合快速迭代和单卡优化。
- ms-SWIFT:适用于ModelScope生态用户,依赖官方集成技术,可能在参数高效微调场景中表现突出
作者:zjp
| 维度 | LLaMA-Factory | Unsloth | ms-SWIFT |
|---|---|---|---|
| 上手难度 | 中等,提供图形界面(Gradio UI)和命令行工具,适合不同层次用户。 | 低,API简洁且文档详细,新手友好,支持快速上手。 | 中等,依赖ModelScope生态,需熟悉框架集成技术,但官方文档可能提供支持。 |
| 资源需求 | 支持多硬件(NVIDIA/AMD GPU、Ascend NPU),量化技术降低内存占用,全参微调显存要求高。 | 显存占用优化显著,手动优化GPU内核,资源效率高,适合有限硬件环境。 | 集成PEFT技术,可能降低显存需求,具体资源优化依赖ModelScope底层实现。 |
| 性能表现 | 灵活支持多种算法(LoRA、DPO等)和优化技术(FlashAttention),但速度较Unsloth慢。 | 微调速度最快(快2.5-10倍),尤其大数据量场景,计算图优化显著提升效率。 | 未知,依赖PEFT技术,可能在特定任务中表现高效,但缺乏直接对比数据。 |
| 训练成本 | 支持量化(4/8位)和分布式训练,全参微调成本高,但灵活性高。 | 显存和时间成本低,适合快速迭代,尤其适合资源受限场景。 | 参数高效微调(PEFT)减少可调参数量,可能降低训练成本,但生态依赖性强。 |
| 模型支持 | 广泛(100+模型),包括多模态(LLaVA)和MoE架构(Mixtral),社区活跃。 | 主流模型兼容(Llama、Mistral等),但覆盖范围略少于LLaMA-Factory。 | 支持多架构和训练范式,依赖ModelScope生态,可能针对特定模型优化。 |
| 分布式训练 | 支持多GPU/多节点分布式训练,适合大规模任务。 | 未明确支持,侧重单卡优化,可能依赖外部工具扩展。 | 未明确说明,可能依赖ModelScope基础设施。 |
| 适用场景 | 多硬件环境、复杂任务(多模态/RLHF)、需灵活配置的场景。 | 资源有限、追求快速微调、单卡高效运行的场景。 | ModelScope生态内任务、参数高效微调需求、特定领域模型适配。 |
框架依赖关系
模型训练生态系统
LLM 复现选择
如何选择分布式训练框架? 参考
- 训练成本:不同训练工具,训练同样大模型,成本不一样。对于大模型,训练一次动辄上百万/千万美元的费用。合适的成本始终是正确的选择。
- 训练类型:是否支持数据并行、张量并行、流水线并行、多维混合并行、自动并行等
- 效率:将普通模型训练代码变为分布式训练所需编写代码的行数,希望越少越好。
- 灵活性:选择的框架是否可以跨不同平台使用?
目前训练超大规模语言模型主要有两条技术路线:
- TPU + XLA + TensorFlow/JAX :由Google主导,由于TPU和自家云平台GCP深度绑定
- GPU + PyTorch + Megatron-LM + DeepSpeed :由 NVIDIA、Meta、MicroSoft 大厂加持,社区氛围活跃,也更受到大家欢迎。
云平台
火山引擎
火山引擎类似, 还多了 GRPO 方法
训练类型
- SFT精调:通过已标注好的数据对模型进行精调优化,以适应其特定的任务或领域。适用场景是有明确标注数据的情况,比如客服问答或者特定领域的任务。 直接偏好学习(DPO):通过偏好数据对模型进行直接策略优化,以适应其特定的任务或领域。适合有用户偏好数据的场景,比如推荐系统或者需要优化用户体验的任务。
- 继续预训练(申请使用):通过无标注的数据对专有预训练模型进行训练,完成训练后,可通过 SFT 精调继续调优。适用场景是拥有大量领域相关未标注数据,想先增强模型的领域知识,再微调。
- GRPO精调(申请使用):基于群组相对策略优化的强化学习方法,属于强化学习的一种。适用场景可能是多用户群体或需要考虑不同群组偏好的任务,比如个性化推荐或多领域适应。
可微调模型列表
- doubao-1-5-pro-32k-250115
- doubao-1-5-lite-32k-250115
- doubao-pro-32k
-
doubao-lite-32k
| 方法 | 数据需求 | 训练成本 | 难度 | 核心优势 | 典型场景 |
|---|---|---|---|---|---|
SFT 精调 |
大量标注数据(如问答对) | 中 | 简单 | 任务针对性强,效果可控 | 垂直领域问答(如医疗、法律) |
DPO 直接偏好学习 |
偏好对比数据(如 A/B 选择) | 中 | 中等 | 低成本拟合用户偏好,无需构建奖励模型 | 回答排序优化、用户体验提升 |
GRPO 精调 |
群组偏好数据 + 标注数据 | 高 | 复杂 | 多群体/目标平衡,动态适应 | 个性化推荐、多语言/用户画像场景 |
| 继续预训练 | 大量未标注领域数据 | 高 | 中等 | 增强领域知识,适配新场景 | 跨领域迁移(如通用→金融) |
阿里百炼
阿里云上通过 UI 启动模型训练
百炼 支持 3种 调参模式
- 全参训练
- 全参训练通过全量更新模型参数的方式进行学习,训练时间较长,收敛速度较慢,可实现模型新能力的学习和全局效果的优化提升。
- 高效训练
- 高效训练采用低秩适应的方式,通过矩阵分解的方法,更新分解后的低秩部分参数,训练时间较短,收敛速度较快,适用于模型局部效果优化。
- RLHF训练(尚未开放)
- RLHF训练通过在强化学习的训练过程中加入奖励模型的方式,实现强化学习结果的持续性自动优化,从使得模型效果显著符合预期,功能开发中,敬请期待..
训练方式
SFT微调训练: 有监督微调,增强模型指令跟随能力,提供全参和高效训练方式DPO偏好训练: 引入负反馈,降低幻觉,使得模型输出更符合人类偏好CPT继续预训练: 通过无标注数据进行无监督继续预训练,强化或新增模型特定能力
数据
最大支持 300 MB 数据上传
样例
数据格式 jsonl
【SFT 方式】
示例
{"messages": [{"role": "system", "content": "You are a helpful assistant"}, {"role": "user", "content": "谁在文艺复兴时期绘制人体?"}, {"role": "assistant", "content": "文艺复兴时期是一个关于艺术、文化和学术的复兴运动,在这个时期,许多艺术家都绘制了人体。"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant"}, {"role": "user", "content": "谁在文艺复兴时期绘制人体?"}, {"role": "assistant", "content": "文艺复兴时期是一个关于艺术、文化和学术的复兴运动,在这个时期,许多艺术家都绘制了人体。"}]}
【CPT 方式】
{"text":"基本竞争战略是由美国哈佛商学院著名的战略管理学家迈克尔·波特提出的,分别为:成本领先战略,差异化战略,集中化战略.企业必须从这三种战略中选择一种,作为其主导战略.要么把成本控制到比竞争者更低的程度;要么在企业产品和服务中形成与众不同的特色,让顾客感觉到你提供了比其他竞争者更多的价值;要么企业致力于服务于某一特定的市场细分,某一特定的产品种类或某一特定的地理范围."}
{"text":"交通运行监测调度中心,简称TOCC(Transportation Operations Coordination Center)TOCC围绕综合交通运输协调体系的构建,实施交通运行的监测,预测和预警,面向公众提供交通信息服务,开展多种运输方式的调度协调,提供交通行政管理和应急处置的信息保障.\nTOCC是综合交通运行监测协调体系的核心组成部分,实现了涵盖城市道路,高速公路,国省干线三大路网,轨道交通,地面公交,出租汽车三大市内交通方式,公路客运,铁路客运,民航客运三大城际交通方式的综合运行监测和协调联动,在综合交通的政府决策,行业监管,企业运营,百姓出行方面发挥了突出的作用."}
{"text":"美国职业摄影师协会(简称PPA)创立于1880年,是一个几乎与摄影术诞生历史一样悠久的享誉世界的非赢利性国际摄影组织,是由世界上54个国家的25000余名职业摄影师个人会员和近二百个附属组织和分支机构共同组成的,是世界上最大的专业摄影师协会.本世纪初PPA创立了美国视觉艺术家联盟及其所隶属的美国国际商业摄影师协会,美国新闻及体育摄影师协会,美国学生摄影联合会等组织.PPA在艺术,商业,纪实,体育等摄影领域一直引领世界潮流,走在世界摄影艺术与技术应用及商业规划管理的最前沿."}
混合训练
混合训练
- 将自定义训练数据与千问通用多领域、多行业、多场景数据混合训练,从而提高训练效果避免基础模型能力的遗失(灾难遗忘)
注意:
- 选择混合训练后,混合采样的数据将计入训练Token数一并计费
- 举例:训练数据10B Tokens,混合比例2,最终送入训练的Tokens总数为30B(10B+2*10B)
超参
| 配置项 | 值 |
|---|---|
| 混合比例 | 0.0 |
| 循环次数 | 1 |
| 学习率 | 1e-5 |
| 批次大小 | 16 |
| 学习率调整策略 | cosine |
| 验证步数 | 500 |
| 序列长度 | 8192 |
| 权重衰减 | 0.1 |
| 学习率预热比例 | 0.005 |
分布式框架
底层分布式训练框架
总结
【2025-12-15】LLaMA-Factory分布式训练实战指南
LLaMA-Factory 支持 DDP、DeepSpeed、FSDP 三种模式,各有侧重,具体看硬件条件和训练目标。
| 引擎 | 公司 | 要点 | 显存效率 | 并行策略 | 配置复杂度 | 多机支持 | 推荐场景 | 劣势 |
|---|---|---|---|---|---|---|---|---|
| DDP | pytorch | - | 中等 | ddp | 极简 | 支持 | 快速验证、中小模型(<13B)、调试首选 | - |
| FSDP | pytorch | 原生,易用性;全参数分片(类似zero-3) | 高 | 中等 | 支持 | 多机部署、偏好原生 PyTorch 生态 | 千亿级扩展效率低 | |
| DeepSpeed | 微软 | 显存优化+扩展性;zero系列 | 极高(ZeRO-3 + Offload) | DP(ZeRO-1/2/3/++) + 有限 TP | 较高 | 支持 | 中小模型、显存紧张、极致显存压缩、异构集群 | 配置复杂,推理弱 |
| Megatron-LM | 英伟达 | 极致吞吐、细粒度张量并行(3D并行,tp/dp/pp)、Kernel 融合; | 极高(ZeRO-3 + Offload) | DP+TP + PP(原生支持)+EP | 较高 | 支持 | 超大模型、高带宽集群((NVLink+RoCE))、显存紧张、极致显存压缩 | 硬件锁定英伟达、改造成本高 |
| Megatron-DeepSpeed | 微软 | 兼顾吞吐与显存 | 极高(ZeRO分片) | TP(Megatron) + ZeRO-DP(DeepSpeed) | 较高 | 支持 | 百亿~万亿级模型、高性能集群、生产级训练 | 硬件锁定英伟达、改造成本高 |
分析:DDP是pytorch初始模式,显存效率一般,微软推出 deepspeed 提升显存利用率,随后 pytorch 也推出自己的优化版 FSDP,NVIDIA 也推出 Megatron-LM
- DDP 中,每张 GPU 都各自保留一份完整的模型参数和优化器参数。
- 而 FSDP 切分了模型参数、梯度与优化器参数,使得每张 GPU 只保留部分参数。
- 除了并行技术之外,FSDP 还支持将模型参数卸载至CPU,进一步降低显存需求。
- DeepSpeed 是微软分布式训练引擎,并提供ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水线并行等优化技术。
选型方法
核心选型建议
- 快速迭代/调试:选 DDP,配置最简单,适合中小模型快速跑通流程。
- 显存极度受限/超大模型:选 DeepSpeed,通过 ZeRO-3 + Offload 能把显存占用压到极低,支持 100B+ 模型训练。
- 只有 2×A100 却要训 13B 模型
- 多机生产部署/PyTorch 原生党:选 FSDP,和 PyTorch 生态深度集成,适合稳定的多机分布式训练。
- 未来可能扩展到多机集群
训练框架选型:
- 追求速度和极致吞吐:选择 Megatron-LM。
- 资源有限、显存优化优先:选择 DeepSpeed。
- 快速验证、易用性和 PyTorch 原生集成:选择 FSDP。 三者也可组合使用,如在 Megatron-LM 模型并行基础上结合 DeepSpeed 数据并行和 ZeRO 优化,实现性能与显存的平衡
Megatron-DeepSpeed,github 2023年后, 不再更新
原则:
- 新项目先用 DDP + LoRA 快速验证 pipeline;
- 显存不够就上 DeepSpeed,尤其是 ZeRO-3;
- 多机部署优先考虑 FSDP,减少外部依赖;
- 所有场景下,QLoRA 都值得尝试,显存节省 70%+,收敛更快。
| 引擎 | 模型 | 显存/卡 | 速度(tokens/s) | 稳定性 |
|---|---|---|---|---|
| DDP | Qwen-7B | ~18GB | ~900 | ★★★★★ |
| DeepSpeed (ZeRO-2) | Baichuan2-13B | ~14GB | ~700 | ★★★★☆ |
| DeepSpeed (ZeRO-3 + Offload) | Llama-2-13B | ~26GB | ~550 | ★★★☆☆ |
| FSDP (full_shard) | ChatGLM3-6B | ~10GB | ~800 | ★★★★☆ |
| FSDP + Offload | Qwen-7B(多机) | ~12GB | ~750 | ★★★★ |
关键结论
- 速度天花板:DDP 最快(~900 tokens/s),稳定性拉满,适合中小模型快速训练。
- 显存最优:FSDP (full_shard) 单卡显存仅 ~10GB,适合显存有限的 6B/7B 级模型。
- 超大模型妥协:DeepSpeed ZeRO-3 + Offload 显存占用反而更高(~26GB),速度最慢(~550 tokens/s),稳定性也最差,更适合极端显存受限场景。
- 多机平衡:FSDP + Offload 在多机 Qwen-7B 上表现均衡,显存 ~12GB、速度 ~750 tokens/s,稳定性良好。
🎯 选型建议
- 如果 Qwen-7B/ChatGLM3-6B 这类中小模型,优先选 DDP 或 FSDP (full_shard),兼顾速度和显存。
- 如果训 13B 级模型,DeepSpeed ZeRO-2 是更均衡的选择,比 ZeRO-3 更快更稳。
- 如果 多机部署,FSDP + Offload 是原生 PyTorch 生态下的优质方案。
结论很清晰:
- 稳定性优先 → 选 DDP
- 显存极度紧张 → DeepSpeed ZeRO-3 + Offload 是唯一选择
- 未来要扩展多机 → FSDP 更易维护
FSDP
FSDP(Fully Sharded Data Parallel)
- 定位:PyTorch 原生替代 ZeRO-3 的方案。
- 优势:
- 无需额外依赖,API 简洁(torch.distributed.fsdp)。
- 自动分片参数、梯度、优化器状态,显存效率接近 ZeRO-3。
- 对 AMD GPU、AWS Trainium 等非 NVIDIA 硬件支持更好。
- 劣势:
- 缺乏细粒度张量并行,无法像 Megatron 那样拆分单个 Attention 算子。
- 通信调度不如 Megatron 精细,在高带宽集群中吞吐落后 20%+ [³]。
- 适用场景:适合研究者快速迭代模型,或在非 NVIDIA 生态中部署 LLM。
Megatron-LM
Megatron-LM
- 优势:
- 原生支持 算子级张量并行(Tensor Parallelism),将 QKV、FFN 等操作切分到多个 GPU。
- 深度定制 CUDA Kernel 融合(如 fused QKV、LayerNorm+残差),减少 kernel launch 开销。
- 通信与计算重叠设计优秀,通信占比仅 18%(vs DeepSpeed 32%)[¹]。
- 劣势:
- 显存优化弱,依赖模型并行降低单卡负载。
- 仅支持 PyTorch,对非 NVIDIA 硬件(如 AMD、TPU)适配差。
- 适用场景:“在具备充足 A100/H100 和 NVLink 的超算中心,Megatron 是吞吐优先的首选。”
DeepSpeed
DeepSpeed
- 优势:
- ZeRO 系列(尤其是 ZeRO-3 和 ZeRO-Infinity)可将优化器、梯度、参数分片到所有 GPU,显存占用降低 10 倍以上。
- 支持 CPU/NVMe Offload,可在消费级 GPU 上训练百亿模型。
- 通用性强,兼容 TensorFlow、Horovod 等。
- 劣势:
- 张量并行需额外集成(如与 Megatron 结合),原生不支持。
- 通信开销大,扩展效率在千卡级明显下降。
- 适用场景:“资源受限或需要快速验证模型架构时,DeepSpeed 的 ZeRO 是最佳选择。”
Megatron-DeepSpeed
Megatron-DeepSpeed(融合方案)
- 设计理念: 利用 Megatron 的 TP/PP 处理模型内并行,DeepSpeed 的 ZeRO-DP 处理跨节点数据并行。
- 性能表现:
- 在 Megatron-Turing NLG 530B 模型训练中,该方案实现 SOTA 吞吐与扩展效率。
- 显存利用率高达 95%,通信占比降至 17%。
- 工程复杂度: 需同时配置两套框架,调试难度高,但 NVIDIA 与 Microsoft 已提供联合示例(如 Megatron-DeepSpeed GitHub 仓库)[⁶]。
- 适用场景:“工业级千亿模型训练的事实标准。”
架构本质差异:
- DeepSpeed = 显存扩展优先(让大模型跑在有限硬件上)
- Megatron-LM = 计算性能优先(榨干 NVIDIA 集群算力)
- FSDP = 易用性优先(PyTorch 用户开箱即用)
DeepSpeed + Megatron-LM(最强性能组合)
- 企业级训练:DeepSpeed + Megatron 组合(性能与扩展兼顾);
- 中小规模微调:FSDP(24GB 显卡跑 30B 模型);
- 国产化需求:DeepSpeed + 昇腾插件(已支持 910B 显存优化)。
详见:【2025-7-18】大模型推理框架对比(DeepSpeed、Megatron-LM 、FSDP)
DeepSpeed – 微软
DeepSpeed 是 Microsoft 基于 PyTorch 研发的开源深度学习优化库。
- 目的: 降低大模型训练的门槛,提升大模型的训练的效率,帮助开发者更有效率地管理及优化大模型的训练、部署任务。
详见站内专题: DeepSpeed
【2023-8-28】LLaMA Efficient Tuning
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ||
| PPO 训练 | ✅ | ✅ | ||
| DPO 训练 | ✅ | ✅ | ✅ |
DeepSpeed
- 定位:超大规模训练基础设施
技术突破:
- 万亿参数支持:曾赋能MT-530B/BLOOM等顶级模型
四大创新支柱:
- 训练优化:MoE模型/RLHF/长序列支持
- 推理加速:超低延迟部署方案
- 模型压缩:极致量化技术
- 科研支持:分布式科学计算
适用领域:
- 千亿参数级大模型训练
- 需要跨GPU集群扩展的场景
trl
【2024-3-13】TRL - Transformer Reinforcement Learning
huggingface 推出的全栈库,包含一整套工具,用于使用强化学习 (Reinforcement Learning) 训练 transformer 语言模型。
- 从监督调优 (Supervised Fine-tuning step, SFT),到训练奖励模型 (Reward Modeling),再到近端策略优化 (Proximal Policy Optimization),全面覆盖

- TRL 库已经与 🤗 transformers 集成,直接使用!
- 👉 文档地址
API 文档里功能:
- Model Class: 公开模型各自用途
- SFTTrainer: SFTTrainer 实现模型监督调优
- RewardTrainer: RewardTrainer 训练奖励模型
- PPOTrainer: PPO 算法对经过监督调优的模型再调优
- Best-of-N Samppling: 将“拔萃法”作为从模型的预测中采样的替代方法
- DPOTrainer: 用 DPOTrainer 完成直接偏好优化
文档中给出了几个例子:
- Sentiment Tuning: 调优模型以生成更积极的电影内容
- Training with PEFT: 执行由 PEFT 适配器优化内存效率的 RLHF 训练
- Detoxifying LLMs: 通过 RLHF 为模型解毒,使其更符合人类的价值观
- StackLlama: 在 Stack exchange 数据集上实现端到端 RLHF 训练一个 Llama 模型
- Multi-Adapter Training: 使用单一模型和多适配器实现优化内存效率的端到端训练
Trl 实践
【2023-6-30】使用TRL强化学习PPO控制文本的生成
步骤
- 初始化 GPT2 对话模型, 即LLM模型。Huggface中的这个中文对话模型
- 初始化一个情感分类模型即RM模型。这里笔者使用的是Huggface中的这个情感分类模型
- 样本情感极性越正向,模型输出的得分越大。
- c2-roberta-base-finetuned-dianping-chinese
- 通过PPO强化学习算法,利用情感分类模型评估对话模型的输出,对GPT2对话模型进行优化,让GPT2对话模型的输出的结果在情感分类模型中得到高分。同时不破坏GPT2对话模型输出通顺对话的能力。
强行学习训练
- 输入样本给GPT2, 拿到对话语言模型 GPT2的输出。
- 将对话语言模型GPT2的输出 输入到 情感分类模型 拿到 情感分类模型的输出,作为reward。
- 将对话语言模型GPT2 输入,输出, 以及 情感分类模型的 reward 一并输入给PPO优化器,让PPO优化器去优化对话语言模型GPT2。
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
import random
import torch.nn.functional as F
# get models
gen_model = AutoModelForCausalLMWithValueHead.from_pretrained('dialoggpt/')
model_ref = create_reference_model(gen_model)
tokenizerOne = AutoTokenizer.from_pretrained('dialoggpt/',padding_side='left')
tokenizerOne.eos_token_id = tokenizerOne.sep_token_id
# 初始化一个情感分类模型,输入文本,判断文本的情感极性
from transformers import AutoModelForSequenceClassification , AutoTokenizer, pipeline
ts_texts = ["我喜欢下雨。", "我讨厌他."]
cls_model = AutoModelForSequenceClassification.from_pretrained("./chineseSentiment/", num_labels=2)
tokenizerTwo = AutoTokenizer.from_pretrained("./chineseSentiment/")
classifier = pipeline('sentiment-analysis', model=cls_model, tokenizer=tokenizerTwo)
classifier(ts_texts)
# 数据预处理
from torch.utils.data import Dataset
import torch.nn.utils.rnn as rnn_utils
import json
data = []
with open("./train.txt", "r", encoding="utf-8") as f:
for i in f.readlines():
line = json.loads(i)
data.append(line)
def preprocess_conversation(data):
sep_id = tokenizerOne.sep_token_id
cls_id = tokenizerOne.cls_token_id
dialogue_list = []
for conver in data:
input_ids = [cls_id]
start = conver["conversation"][0]
# print(start["utterance"])
input_ids += tokenizerOne.encode(start["utterance"], add_special_tokens=False)
input_ids.append(sep_id)
dialogue_list.append(input_ids)
return dialogue_list
# 数据处理
dialogue_list = preprocess_conversation(data)
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
x = self.data[index]
return torch.tensor(x)
def __len__(self):
return len(self.data)
mydataset = MyDataset(dialogue_list)
def collate_fn(batch):
padded_batch = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=tokenizerOne.sep_token_id)
return padded_batch
# 定义PPO优化器: 学习率,强化学习steps,batch_size等参数,学习率不宜调大,容易把LLM语言模型调坏。
config = PPOConfig(
model_name="gpt2-positive",
learning_rate=1.41e-5,
steps = 2000,
batch_size = 16
)
ppo_trainer = PPOTrainer(config, gen_model, model_ref, tokenizerOne, dataset=mydataset, data_collator=collate_fn)
rewards_list = []
for epoch, batch in enumerate(ppo_trainer.dataloader):
#### Get response from gpt2
query_tensors = []
response_tensors = []
query_tensors = [torch.tensor(t).long() for t in batch]
for query in batch:
input_ids = query.unsqueeze(0)
response = []
for _ in range(30):
outputs = ppo_trainer.model(input_ids=input_ids)
logits = outputs[0]
next_token_logits = logits[0, -1, :]
next_token_logits[ppo_trainer.tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')
next_token = torch.multinomial(F.softmax(next_token_logits, dim=-1), num_samples=1)
if next_token == ppo_trainer.tokenizer.sep_token_id: #
break
input_ids = torch.cat((input_ids, next_token.unsqueeze(0)), dim=1)
response.append(next_token.item())
response_tensors.append(torch.Tensor(response).long())
responseSet = ["".join(ppo_trainer.tokenizer.convert_ids_to_tokens([i.item() for i in r])) for r in response_tensors]
print(responseSet)
#### Get reward from sentiment model
pipe_outputs = classifier(responseSet)
rewards = [torch.tensor(output["score"]) for output in pipe_outputs]
#### Run PPO step
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
print("epoch{}, reword is {}".format(epoch, sum(rewards)))
rewards_list.append(sum(rewards))
Trainer
Trainer 名称歧义
- PyTorch Lightning有个 Trainer
- HuggingFace Transformers也有 Trainer
- 还有一些github上封装的或者基于这两个继续封装的Trainer
这里的 Trainer 指 Huggingface 的 Trainer 训练框架
Trainer 介于原生 torch 和 pytorch-lighning 之间,是轻量级的辅助torch模型训练的utils,因为其实稍微改造一下,huggingface的trainer 可用来训练常规的非nlp的torch模型。
- 封装程度:
torch<pytorch lightning<trainer
Trainer 封装了 PyTorch 训练过程,包括:前向传播、反向传播和参数更新等步骤,用户只需要设计模型,调参就行
高级的 Trainer 加上了各种功能,比如:日志记录,断点重训,训练方式与精度,支持各种分布式训练框架像原生、Apex、Deepspeed和Fairscale,支持自定的回调函数等等
Lightning 官网gif比较生动形象
Trainer 定义
do_train,do_eval,do_predict 这三个参数和trainer没什么关系
自定义
model_init
model_init
def model_init():
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None
)
return model
compute_metrics
def compute_metrics(p: EvalPrediction) -> Dict:
preds,labels=p
preds = np.argmax(preds, axis=-1)
#print('shape:', preds.shape, '\n')
precision, recall, f1, _ = precision_recall_fscore_support(lables.flatten(), preds.flatten(), average='weighted', zero_division=0)
return {
'accuracy': (preds == p.label_ids).mean(),
'f1': f1,
'precision': precision,
'recall': recall
}
加权loss
分类任务中,类目不均衡时,采用加权loss
做法
- (1) 继承 Trainer 类, 重定义 compute_loss 函数
- (2) 使用回调函数 callback
示例
- 三分类问题,各类目加权 1 : 2 : 3
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss (suppose one has 3 labels with different weights)
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
参数详解
Trainer 官网文档,版本为4.34.0
Trainer类 参数
Transformers Trainer类 参数:
model(PreTrainedModel或torch.nn.Module, 可选):训练、评估或预测的实例化模型- 如果不提供,必须传递一个
model_init来初始化一个模型。
- 如果不提供,必须传递一个
args(TrainingArguments, 可选):训练参数- 如果不提供,用 TrainingArguments 默认参数,其中 output_dir 设置为当前目录中的名为 “tmp_trainer” 的目录。
data_collator(DataCollator, 可选):用于从 train_dataset 或 eval_dataset 中构成batch的函数- 如果未提供tokenizer,将默认使用 default_data_collator();如果提供,将使用 DataCollatorWithPadding 。
train_dataset(torch.utils.data.Dataset或 torch.utils.data.IterableDataset, 可选):训练数据集- 如果是 torch.utils.data.Dataset,则会自动删除模型的 forward() 方法不接受的列。
eval_dataset(Union[torch.utils.data.Dataset, Dict[str, torch.utils.data.Dataset]), 可选):同上,评估数据集- 如果是字典,将对每个数据集进行评估,并在指标名称前附加字典的键值。
tokenizer(PreTrainedTokenizerBase, 可选):预处理数据的分词器- 如果提供,将在批量输入时自动对输入进行填充到最大长度,并会保存在模型目录下中,为了重新运行中断的训练或重复微调模型时更容易进行操作。
model_init(Callable[[], PreTrainedModel], 可选):模型实例化函数- 如果提供,每次调用 train() 时都会从此函数给出的模型的新实例开始。
compute_metrics(Callable[[EvalPrediction], Dict], 可选):评估时计算指标的函数,必须接受 EvalPrediction 作为入参,并返回一个字典,其中包含了不同性能指标的名称和相应的数值,一般是准确度、精确度、召回率、F1 分数等。callbacks(TrainerCallback 列表, 可选):自定义回调函数- 如果要删除使用的默认回调函数,要使用 Trainer.remove_callback() 方法。
optimizers(Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR], 可选):指定包含优化器和学习率调度器的元组(Tuple)- 元组的两个元素分别是优化器(torch.optim.Optimizer)和学习率调度器(torch.optim.lr_scheduler.LambdaLR),默认会创建一个基于AdamW优化器的实例,并使用 get_linear_schedule_with_warmup() 函数创建一个学习率调度器。
preprocess_logits_for_metrics(Callable[[torch.Tensor, torch.Tensor], torch.Tensor], 可选):指定函数,每次评估步骤(evaluation step)前,进入compute_metrics函数前对模型的输出 logits 进行预处理。- 接受两个张量(tensors)作为参数,一个是模型的输出 logits,另一个是真实标签(labels)。
- 然后返回一个经过预处理后的 logits 张量,给到compute_metrics函数作为参数。
TrainingArguments 参数
args:超参数定义,trainer的重要功能,大部分训练相关的参数都是这里设置
TrainingArguments 有接近100个参数
TrainingArguments 参数
output_dir(str):模型checkpoint/最终结果的输出目录。overwrite_output_dir(bool, 可选,默认为 False):如果设置为True,将覆盖输出目录中已存在的内容- 继续训练模型并且输出目录, 指向一个checkpoint目录。
do_train(bool, 可选,默认为 False):是否执行训练- 其实Trainer 不直接使用此参数,主要是用于写脚本时,作为if的条件来判断是否执行接下来的代码。
do_eval(bool, 可选):是否在验证集上进行评估,如果评估策略(evaluation_strategy)不是”no”,将自动设置为True。- 与do_train类似,不直接由Trainer使用,主要是用于写训练脚本。
do_predict(bool, 可选,默认为 False):是否在测试集上预测。evaluation_strategy(str, 可选,默认为 “no”):指定训练期间采用的评估策略,可选值包括:- “no”:在训练期间不进行任何评估。
- “steps”:每隔 eval_steps 步骤进行评估。
- “epoch”:每个训练周期结束时进行评估。
prediction_loss_only(bool, 可选, 默认为 False):- 如果设置为True,评估和预测时,只返回损失值,而不返回其他评估指标。
per_device_train_batch_size(int, 可选, 默认为 8):训练阶段,每个GPU/XPU/TPU/MPS/NPU/CPU的batch,每个训练步骤中每个硬件上的样本数量。per_device_eval_batch_size(int, 可选, 默认为 8):评估阶段的每个GPU/XPU/TPU/MPS/NPU/CPU的batch,每个评估步骤中每个硬件上的样本数量。gradient_accumulation_steps(int, 可选, 默认为 1):执行反向传播之前,梯度积累的更新步数。- 梯度积累可以在多个batch上累积梯度,然后一次性执行反向传播,显存不够的情况下执行大batch的反向传播。
- 假设4张卡,每张卡的batch size为8,那么一个steps的batch size就是32,如果这个参数设置为4,那么做反向传播的训练样本数量就是128。
- 两个好处:①显存不够增大此参数;②能加快训练速度,毕竟做反向传播的次数少了。
eval_accumulation_steps(int, 可选):执行评估时,模型会累积多少个预测步骤的输出张量,然后才从GPU/NPU/TPU移动到CPU上,默认是整个评估的输出结果将在GPU/NPU/TPU上累积,然后一次性传输到CPU,速度更快,但占显存。eval_delay(float, 可选):等待执行第一次评估的轮数或步数。- 如果evaluation_strategy为”steps”,设置此参数为10,则10个steps后才进行首次评估。
learning_rate(float, 可选, 默认为 5e-5):AdamW优化器的初始学习率。weight_decay(float, 可选, 默认为 0):权重衰减的值,应用在 AdamW 优化器所有层上,除了偏置(bias)和 Layer Normalization 层(LayerNorm)的权重上。- 权重衰减是一种正则化手段,通过向损失函数添加一个额外的项,来惩罚较大的权重值,有助于防止模型过拟合训练数据。
adam_beta1(float, 可选, 默认为 0.9):AdamW优化器的beta1超参数。adam_beta2(float, 可选, 默认为 0.999):AdamW优化器的beta2超参数。adam_epsilon(float, 可选, 默认为 1e-8):AdamW优化器的epsilon超参数。max_grad_norm(float, 可选, 默认为 1.0):梯度剪裁的最大梯度范数,可以防止梯度爆炸,一般都是1,如果某一步梯度的L2范数超过了 此参数,那么梯度将被重新缩放,确保它的大小不超过此参数。num_train_epochs(float, 可选, 默认为 3.0):训练的总epochs数。max_steps(int, 可选, 默认为 -1):如果设置为正数,执行的总训练步数,会覆盖 num_train_epochs。- 注意:如果使用此参数,就算没有达到这个参数值的步数,训练也会在数据跑完后停止。
lr_scheduler_type(str, 可选, 默认为”linear”):学习率scheduler类型,根据训练进程来自动调整学习率。详细见:- “linear”:线性学习率scheduler,学习率以线性方式改变
- “cosine”:余弦学习率scheduler,学习率以余弦形状的方式改变。
- “constant”:常数学习率,学习率在整个训练过程中保持不变。
- “polynomial”:多项式学习率scheduler,学习率按多项式函数的方式变化。
- “piecewise”:分段常数学习率scheduler,每个阶段使用不同的学习率。
- “exponential”:指数学习率scheduler,学习率以指数方式改变。
warmup_ratio(float, 可选, 默认为0.0):线性热身占总训练步骤的比例,线性热身是一种训练策略,学习率在开始阶段从0逐渐增加到其最大值(通常是设定的学习率),然后在随后的训练中保持不变或者按照其他调度策略进行调整。如果设置为0.0,表示没有热身。warmup_steps(int,可选, 默认为0):线性热身的步骤数,这个参数会覆盖warmup_ratio,如果设置了warmup_steps,将会忽略warmup_ratio。log_level(str, 可选, 默认为passive):主进程上要使用的日志级别,debug:最详细的日志级别。info:用于一般的信息性消息。warning:用于警告信息。error:用于错误信息。critical:用于严重错误信息。passive:不设置任何内容,将会使用Transformers库当前的日志级别(默认为”warning”)。- 建议训练时使用info级别。
log_level_replica(str, 可选, 默认为warning):副本上要使用的日志级别,与log_level相同。log_on_each_node(bool, optional, defaults to True):在多节点分布式训练中,是否在每个节点上使用log_level进行日志记录。logging_dir(str, 可选):TensorBoard日志目录。默认为output_dir/runs/CURRENT_DATETIME_HOSTNAME。logging_strategy(str, 可选, 默认为”steps”):训练过程中采用的日志记录策略。可选包括:- “no”:在训练过程中不记录任何日志。
- “epoch”:在每个epoch结束时记录日志。
- “steps”:根据logging_steps参数记录日志。
logging_steps(int or float,可选, 默认为500):- 如果logging_strategy=”steps”,则此参数为每多少步记录一次步骤。
logging_nan_inf_filter(bool, 可选, 默认为 True):是否过滤日志记录中为nan和inf的loss- 如果设置为True,将过滤每个步骤的loss,如果出现nan或inf,将取当前日志窗口的平均损失值。
save_strategy(str , 可选, 默认为 “steps”):训练过程中保存checkpoint的策略,包括:- “no”:在训练过程中不保存checkpoint。
- “epoch”:在每个epoch束时保存checkpoint。
- “steps”:根据save_steps参数保存checkpoint。
save_steps(int or float, 可选, 默认为500):- 如果save_strategy=”steps”,就是指两次checkpoint保存之间的更新步骤数。如果是在[0, 1)的浮点数,则就会当做与总训练步骤数的比例。
save_total_limit(int, 可选):如果给定了参数,将限制checkpoint的总数,因为checkpoint也是很占硬盘的,将会删除输出目录中旧的checkpoint。- 当启用load_best_model_at_end时,会根据metric_for_best_model保留最好的checkpoint,以及最近的checkpoint。
- 当save_total_limit=5和指定load_best_model_at_end时,将始终保留最近的四个checkpoint以及最好的checkpoint;
- 当save_total_limit=1和指定load_best_model_at_end时,会保存两个checkpoint:最后一个和最好的一个(如果不同一个)。
load_best_model_at_end(bool, 可选, 默认为False):是否在训练结束时,加载在训练过程中最好的checkpoint- 设置为 True 时,找到在验证集上指标最好的checkpoint并且保存,然后还会保存最后一个checkpoint
- 在普通的多epoch训练中,最好设置为True
- 但在大模型训练中,一般是一个epoch,使用的就是最后一个checkpoint。
save_safetensors(bool, 可选, 默认为False):是否在保存和加载模型参数时使用 “safetensors”- “safetensors” 更好地处理了不同 PyTorch 版本之间的模型参数加载的兼容性问题。
save_on_each_node(bool, 可选, 默认为 False):多节点分布式训练时,是否在每个节点上保存checkpoint,还是仅在主节点上保存。- 注意如果多节点使用的是同一套存储设备,比如都是外挂一个nas,开启后会报错,因为文件名称都一样。
use_cpu(bool, 可选, 默认为 False):是否用CPU训练。如果设置为False,将使用CUDA或其他可用设备。seed(int, 可选, 默认为42):训练过程的随机种子,确保训练的可重现性,主要用于model_init,随机初始化权重参数。data_seed(int, 可选):数据采样的随机种子,如果没有设置将使用与seed相同的种子,可以确保数据采样的可重现性。jit_mode_eval(bool, 可选, 默认为False):是否在推理(inference)过程中使用 PyTorch 的 JIT(Just-In-Time)跟踪功能- PyTorch JIT 是 PyTorch 的一个功能,用于将模型的前向传播计算编译成高性能的机器代码,会加速模型的推理。
use_ipex(bool, 可选, 默认为 False):是否使用英特尔扩展(Intel extension)来优化 PyTorch,需要安装IPEX- IPEX是一组用于优化深度学习框架的工具和库,提高训练和推理的性能,特别针对英特尔的处理器做了优化。
bf16(bool, 可选, 默认为False):是否使用bf16进行混合精度训练,而不是fp32训练,需要安培架构或者更高的NVIDIA架构,关于精度的问题可以看这篇文章:Glan格蓝:LLM大模型之精度问题(FP16,FP32,BF16)详解与实践- 混合精度训练:模型训练时将模型参数和梯度存储为
fp32,但在前向和后向传播计算中使用fp16,这样可以减少内存使用和计算时间,并提高训练速度。
- 混合精度训练:模型训练时将模型参数和梯度存储为
fp16(bool,** 可选, 默认为**False):是否使用fp16进行混合精度训练,而不是fp32训练。fp16_opt_level(str, 可选, 默认为 ‘‘O1’’):对于fp16训练,选择的Apex AMP的优化级别,可选值有 [‘O0’, ‘O1’, ‘O2’和’O3’]。详细信息可以看Apex文档。half_precision_backend(str, 可选, 默认为”auto”):混合精度训练(Mixed Precision Training)时要使用的后端,必须是 “auto”、”cuda_amp”、”apex”、”cpu_amp” 中的一个。- “auto”将根据检测到的PyTorch版本来使用后端,而其他选项将会强制使用请求的后端。使用默认就行。
bf16_full_eval(bool, 可选, 默认为 False):是否使用完全的bf16进行评估,而不是fp32。这样更快且省内存,但因为精度的问题指标可能会下降。fp16_full_eval(bool, 可选, 默认为 False):同上,不过将使用fp16.tf32(bool, 可选):是否启用tf32精度模式,适用于安培架构或者更高的NVIDIA架构,默认值取决于PyTorch的版本torch.backends.cuda.matmul.allow_tf32 默认值。local_rank(int, 可选, 默认为 -1):在分布式训练中的当前进程(本地排名)的排名,这个用户不用设置,使用PyTorch分布式训练时会自动设置,默认为自动设置。ddp_backend(str, 可选):处理分布式计算的后端框架,用于多个计算节点协同工作以加速训练,处理模型参数和梯度的同步、通信等操作,可选值如下- “
nccl“:这是 NVIDIA Collective Communications Library (NCCL) 的后端。 - “
mpi“:Message Passing Interface (MPI) 后端, 是一种用于不同计算节点之间通信的标准协议。 - “
ccl“:这是 Intel的oneCCL (oneAPI Collective Communications Library) 的后端。 - “
gloo“:这是Facebook开发的分布式通信后端。 - “
hccl“:这是Huawei Collective Communications Library (HCCL) 的后端,用于华为昇腾NPU的系统上进行分布式训练。 - 默认会根据系统自动设置,一般是nccl。
- “
tpu_num_cores(int, 可选):TPU上训练时,TPU核心的数量。dataloader_drop_last(bool, 可选, 默认为False):是否丢弃最后一个不完整的batch,发生在数据集的样本数量不是batch_size的整数倍的时候。eval_steps(int or float, 可选):如果evaluation_strategy=”steps”,两次评估之间的更新步数,如果未设置,默认和设置和logging_steps相同的值,如果是在[0, 1)的浮点数,则就会当做与总评估步骤数的比例。dataloader_num_workers(int, 可选, 默认为 0):数据加载时的子进程数量(仅用于PyTorch), PyTorch的num_workers参数,0表示数据将在主进程中加载。past_index(int, 可选, 默认为 -1):一些模型(如TransformerXL或XLNet)可用过去的隐藏状态进行预测,如果将此参数设置为正整数,Trainer将使用相应的输出(通常索引为2)作为过去状态,并将其在下一个训练步骤中作为mems关键字参数提供给模型,只针对一些特定模型。run_name(str, 可选):训练运行(run)的字符串参数,与日志记录工具(例如wandb和mlflow)一起使用,不影响训练过程,就是给其他的日志记录工具开了一个接口,个人还是比较推荐wandb比较好用。disable_tqdm(bool, 可选):是否禁用Jupyter笔记本中的~notebook.NotebookTrainingTracker生成的tqdm进度条,如果日志级别设置为warn或更低,则将默认为True,否则为False。remove_unused_columns(bool, 可选, 默认为True):是否自动删除模型在训练时,没有用到的数据列,默认会删除,比如你的数据有两列分别是content和id,如果没有用到id这一列,训练时就会被删除。label_names(List[str], 可选):在模型的输入字典中对应于标签(labels)的键,默认情况下不需要显式指定。metric_for_best_model(str, 可选):与 load_best_model_at_end 结合使用,比较不同模型的度量标准,默认情况下,如果未指定,将使用验证集的 “loss” 作为度量标准,可使用accuracy、F1、loss等。greater_is_better(bool, 可选):与 load_best_model_at_end 和 metric_for_best_model 结合使用,这个和上面的那个参数是对应的,那个指标是越大越好还是越小越好- 如果是loss, 越小越好,这个参数就会被设置为False;
- 如果是accuracy,把这个值设为True。
ignore_data_skip(bool, 可选,默认为False):是否断点训练,即训练终止又恢复后,是否跳过之前的训练数据。resume_from_checkpoint(str, 可选):从checkpoint恢复训练的路径。sharded_ddp(bool, str 或 ShardedDDPOption 列表, 可选, 默认为’’):是否在分布式训练中使用 Sharded DDP(Sharded Data Parallelism),FairScale提供的,默认不使用- FairScale 是Mate开发的一个用于高性能和大规模训练的 PyTorch 扩展库。这个库扩展了基本的 PyTorch 功能,同时引入了最新的先进规模化技术,通过可组合的模块和易于使用的API,提供了最新的分布式训练技术。详细的可以看其官网。
fsdp(bool, str 或 FSDPOption 列表, 可选, 默认为’’):是否启用 PyTorch 的FSDP(Fully Sharded Data Parallel Training),以及如何配置分布式并行训练。fsdp_config(str 或 dict, 可选):配置 PyTorch 的 FSDP(Fully Sharded Data Parallel Training)的配置文件deepspeed(str 或 dict, 可选):是否启用 DeepSpeed,以及如何配置 DeepSpeed。- 目前分布式训练使用最多的框架,比上面pytorch原生分布式训练以及FairScale用的范围更广,详细的可以看其官网。
label_smoothing_factor(float, 可选,默认为0.0):标签平滑的因子。debug(str 或 DebugOption 列表, 可选, 默认为’’):启用一个或多个调试功能,支持选项:- “underflow_overflow”:此选项用于检测模型输入/输出中的溢出。
- “tpu_metrics_debug”:此选项用于在 TPU 上打印调试指标。
optim(str 或 training_args.OptimizerNames, 可选, 默认为 “adamw_torch”):要用的优化器。可选项:- “adamw_hf”
- “adamw_torch”
- “adamw_torch_fused”
- “adamw_apex_fused”
- “adamw_anyprecision”
- “adafactor”
optim_args(str, 可选):用于向特定类型的优化器(如adamw_anyprecision)提供额外的参数或自定义配置。group_by_length(bool, 可选, 默认为 False):是否在训练数据集中对大致相同长度的样本进行分组然后放在一个batch里,目的是尽量减少在训练过程中进行的padding,提高训练效率。length_column_name(str, 可选, 默认为 “length”):当上个参数设置为True时,可以给训练数据在增加一列”长度“,就是事先计算好的,可以加快分组的速度,默认是length。report_to(str 或 str 列表, 可选, 默认为 “all”):要将训练结果和日志报告到的不同日记集成平台,有很多”azure_ml”, “clearml”, “codecarbon”, “comet_ml”, “dagshub”, “flyte”, “mlflow”, “neptune”, “tensorboard”, and “wandb”。直接默认就行,都发。ddp_find_unused_parameters(bool, 可选):使用分布式训练时,这个参数用于控制是否查找并处理那些在计算中没有被使用的参数,如果启用了梯度检查点(gradient checkpointing),表示部分参数是惰性加载的,这时默认值为 False,因为梯度检查点本身已经考虑了未使用的参数,如果没有启用梯度检查点,默认值为 True,表示要查找并处理所有参数,以确保它们的梯度被正确传播。ddp_bucket_cap_mb(int, 可选):在分布式训练中,数据通常分成小块进行处理,这些小块称为”桶”,这个参数每个桶的最大内存占用大小,一般自动分配即可。ddp_broadcast_buffers(bool, 可选):分布式训练中,模型的某些部分可能包含缓冲区,如 Batch Normalization 层的统计信息,这个参数用于控制是否将这些缓冲区广播到所有计算设备,以确保模型在不同设备上保持同步,如果启用了梯度检查点,表示不需要广播缓冲区,因为它们不会被使用,如果没有启用梯度检查点,默认值为 True,表示要广播缓冲区,以确保模型的不同部分在所有设备上都一致。gradient_checkpointing(bool, 可选, 默认为False):是否开启梯度检查点,简单解释一下:训练大型模型时需要大量的内存,其中在反向传播过程中,需要保存前向传播的中间计算结果以计算梯度,但是这些中间结果占用大量内存,可能会导致内存不足,梯度检查点会在训练期间释放不再需要的中间结果以减小内存占用,但它会使反向传播变得更慢。dataloader_pin_memory(bool, 可选, 默认为 True):dataloader加载数据时,是否启用“pin memory”功能。“Pin memory” 用于将数据加载到GPU内存之前,将数据复制到GPU的锁页内存(pinned memory)中,锁页内存是一种特殊的内存,可以更快地传输数据到GPU,从而加速训练过程,但是会占用额外的CPU内存,会导致内存不足的问题,如果数据量特别大,百G以上建议False。skip_memory_metrics(bool, 可选, 默认为 True):是否将内存分析报告添加到性能指标中,默认情况下跳过这一步,以提高训练和评估的速度,建议打开,更能够清晰的知道每一步的内存使用。include_inputs_for_metrics(bool, 可选, 默认为 False):是否将输入传递给 compute_metrics 函数,一般计算metrics用的是用的是模型预测的结果和我们提供的标签,但是有的指标需要输入,比如cv的IoU(Intersection over Union)指标。auto_find_batch_size(bool, 可选, 默认为 False):是否使用自动寻找适合内存的batch size大小,以避免 CUDA 内存溢出错误,需要安装 accelerate(使用 pip install accelerate),这个功能还是比较NB的。full_determinism(bool, 可选, 默认为 False):如果设置为 True,将调用 enable_full_determinism() 而不是 set_seed(),训练过程将启用完全确定性(full determinism),在训练过程中,所有的随机性因素都将被消除,确保每次运行训练过程都会得到相同的结果,注意:会对性能产生负面影响,因此仅在调试时使用。torchdynamo(str, 可选):用于选择 TorchDynamo 的后端编译器,TorchDynamo 是 PyTorch 的一个库,用于提高模型性能和部署效率,可选的选择包括 “eager”、”aot_eager”、”inductor”、”nvfuser”、”aot_nvfuser”、”aot_cudagraphs”、”ofi”、”fx2trt”、”onnxrt” 和 “ipex”。默认就行,自动会选。ray_scope(str, 可选, 默认为 “last”):用于使用 Ray 进行超参数搜索时,指定要使用的范围,默认情况下,使用 “last”,Ray 将使用所有试验的最后一个检查点,比较它们并选择最佳的。详细的可以看一下它的文档。ddp_timeout(int, 可选, 默认为 1800):用于 torch.distributed.init_process_group 调用的超时时间,在分布式运行中执行较慢操作时,用于避免超时,具体的可以看 PyTorch 文档 。torch_compile(bool, 可选, 默认为 False):是否使用 PyTorch 2.0 及以上的 torch.compile 编译模型,具体的可以看 PyTorch 文档 。torch_compile_backend(str, 可选):指定在 torch.compile 中使用的后端,如果设置为任何值,将启用 torch_compile。torch_compile_mode(str, 可选):指定在 torch.compile 中使用的模式,如果设置为任何值,将启用 torch_compile。include_tokens_per_second(bool, 可选):确定是否计算每个设备的每秒token数以获取训练速度指标,会在整个训练数据加载器之前进行迭代,会稍微减慢整个训练过程,建议打开。push_to_hub(bool, 可选, 默认为 False):指定是否在每次保存模型时将模型推送到Huggingface Hub。hub_model_id(str, 可选):指定要与本地 output_dir 同步的存储库的名称。hub_strategy(str 或 HubStrategy, 可选, 默认为 “every_save”):指定怎么推送到Huggingface Hub。hub_token(str, 可选):指定推送模型到Huggingface Hub 的token。hub_private_repo(bool, 可选, 默认为 False):如果设置为 True,Huggingface Hub 存储库将设置为私有。hub_always_push(bool, 可选, 默认为 False):是否每次都推送模型。
详见
Firefly
Firefly 是开源的大模型一站式训练框架
- 支持对各种大模型进行预训练、指令微调、
DPO,支持全量参数、LoRA、QLoRA等训练方式。 - 支持包括但不限于Gemma、Qwen1.5、MiniCPM、Mixtral-8x7B、Mistral、Llama等绝大多数主流的大模型。
【2024-3-5】使用Firefly在单卡V100上对Qwen1.5进行SFT和DPO,大幅超越Qwen1.5和Gemma
用Firefly项目对Qwen1.5-7B进行训练的实验。我们对训练数据进行精细化筛选,然后在单张V100上进行SFT和DPO。经过两阶段的训练,我们的模型在Open LLM Leaderboard上的表现显著优于官方的Qwen1.5-7B-Chat、Gemma-7B-it、Vicuna-13B等模型。比Qwen1.5-7B-Chat高7.12分,比Gemma-7B-it高8.8分。
TorchTune
【2024-3-23】PyTorch官方发布LLM微调工具TorchTune
PyTorch官方最近发布了支持LLM微调的工具:TorchTune。
- TorchTune 是一个原生的 PyTorch 库,用于轻松编写、微调和实验大型语言模型(LLMs)
TorchTune 功能
功能:
- 原生 PyTorch 实现的流行大型语言模型
- 支持多种格式的checkpoints,包括 Hugging Face 格式的checkpoints
- 针对流行微调技术的训练策略,带有参考基准和全面的校验检查
- 与 HuggingFace 数据集集成用于训练,以及与 EleutherAI 的评估工具 Eval Harness 集成用于评估
- 支持使用 PyTorch 分布式中的 FSDP 进行分布式训练
- YAML 配置文件,便于轻松配置训练运行
- [即将推出] 支持来自 TorchAO 的低精度数据类型和量化技术
- [即将推出] 与各种推理引擎的互操作性
TorchTune 微调
TorchTune 已经支持了Llama2 7B模型的微调:
- 单卡微调:https://github.com/pytorch/torchtune/blob/main/recipes/full_finetune_single_device.py
- 分布式微调:https://github.com/pytorch/torchtune/blob/main/recipes/full_finetune_distributed.py
- 单卡LoRA:https://github.com/pytorch/torchtune/blob/main/recipes/lora_finetune_single_device.py
- 分布式LoRA:https://github.com/pytorch/torchtune/blob/main/recipes/lora_finetune_distributed.py
- QLoRA:https://github.com/pytorch/torc
torchtune 安装
torchtune 必须通过克隆仓库并按照以下方式安装来构建:
# ①
pip install torchtune
# ②
git clone https://github.com/pytorch/torchtune.git
cd torchtune
pip install -e .
torchtitan
【2024-4-28】torchtitan - 用于大型模型训练的原生 PyTorch 库
torchtitan is a proof-of-concept (概念验证阶段) for Large-scale LLM training using native PyTorch.
- It is (and will continue to be) a repo to showcase PyTorch’s latest distributed training features in a clean, minimal codebase.
torchtitanis complementary (补充) to and not a replacement (替代) for any of the great large-scale LLM training codebases such asMegatron,Megablocks,LLM Foundry,Deepspeed, etc.- Instead, we hope that the features showcased in
torchtitanwill be adopted by these codebases quickly. torchtitan is unlikely to ever grow a large community around it.
Our guiding principles when building torchtitan:
- Designed to be easy to understand, use and extend for different training purposes.
- Minimal changes to the model code when applying 1D, 2D, or (soon) 3D Parallel.
- Modular components instead of a monolithic codebase.
Get started in minutes, not hours!
总结
Megatron-DeepSpeed 实施 3D 并行以可以让大型模型以非常有效的方式进行训练。
- DataParallel (
DP) - 相同的初始化模型被复制多次,并且每次都被馈送 minibatch 的一部分。处理是并行完成的,所有设置在每个训练步骤结束时进行同步。 - TensorParallel (
TP) - 每个张量都被分成多个块,因此不是让整个张量驻留在单个 GPU 上,而是张量的每个分片都驻留在其指定的 GPU 上。在处理过程中,每个分片在不同的 GPU 上分别并行处理,最终结果在步骤结束时同步。这也被称作横向并行。 - PipelineParallel (
PP) - 模型在多个 GPU 上垂直(层级)拆分,因此只有模型的一个或多个层放置在单个 GPU 上。每个 GPU 并行处理管道的不同阶段,并处理一小部分批处理。 - 零冗余优化器 (
ZeRO) - 也执行与 TP 有点类似的张量分片,除了整个张量会及时重建以进行前向或反向计算,因此不需要修改模型。它还支持各种卸载技术以补偿有限的 GPU 内存。
训练超大规模语言模型主要有两条技术路线:
- TPU + XLA + TensorFlow/JAX
- GPU + PyTorch + Megatron-LM + DeepSpeed
- 前者由Google主导,由于TPU和自家云平台GCP深度绑定,对于非Googler来说, 只可远观而不可把玩
- 后者背后则有NVIDIA、Meta、MS大厂加持,社区氛围活跃,也更受到群众欢迎。
Deepspeed 是微软的大规模分布式训练工具。专门用于训练超大模型。
- 大模型的训练工具(1)—Deepspeed
DP+PP: DeepSpeed 将 DP 与 PP 结合起来DP+PP+TP: 为了获得更高效的训练,PP 与 TP 和 DP 相结合,称为 3D 并行性- ZeRO DP+PP+TP: DeepSpeed 的主要功能之一是 ZeRO,它是 DP 的超级可扩展扩展。
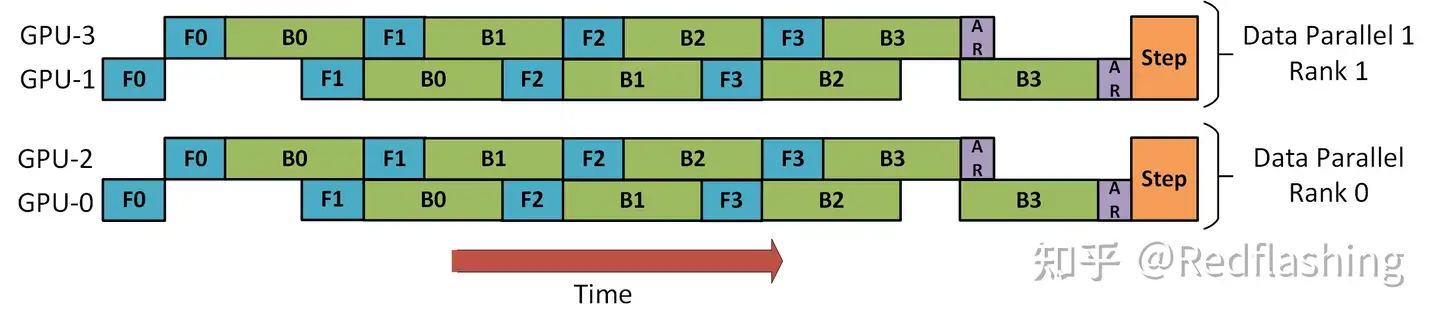
- 【2023-3-16】大型语言模型(LLM)训练指南

增加的功能主要有:
- 3个维度并行化实现万亿参数模型训练
- ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型
- 通过 DeepSpeed Sparse Attention 用6倍速度执行10倍长的序列
- 1 比特 Adam 减少 5 倍通信量
3D 并行:扩展至万亿参数模型
3D 并行同时解决了训练万亿参数模型的两个基本挑战:显存效率和计算效率。因此,DeepSpeed 可以扩展至在显存中放下最巨大的模型,而不会牺牲速度。
- 显存效率:集群上所能训练的LLM的参数量。
- 计算效率:单纯计算占系统的开销的比例。
(1)数据并行是分布式训练普遍使用的技术。
在该技术中,每批输入的训练数据都在数据并行的 worker 之间平分。反向传播后需要通信并规约梯度,以保证优化器在各个 worker 上进行相同的更新。数据并行性具有几个明显的优势,包括计算效率高和实现起来工作量小。但是,数据并行的 batch 大小随 worker 数量提高,而我们往往无法在不影响收敛性的情况下一直增加 batch 大小。
- 显存效率:数据并行会在所有 worker 之间进行模型和优化器的复制,因此显存效率不高。DeepSpeed 开发了 ZeRO ,它是一系列用于提高数据并行的显存效率的优化器。 这项工作依赖于 ZeRO 的 1 阶段,该阶段在 worker 之间划分优化器状态量以减少冗余。
- 计算效率:随着我们提高并行度,每个 worker 执行的计算量是恒定的。数据并行可以在小规模上实现近乎线性扩展。但是,在 worker 之间规约梯度的通信开销跟模型大小成正相关,所以当模型很大或通信带宽很低时,计算效率会受限。。梯度累积是一种用来均摊通信成本的一种常用策略。它会进一步增加batch大小,在本地使用 micro-batch 多次进行正向和反向传播积累梯度后,再进行梯度规约和优化器更新。
(2)模型并行是包含范围很广的一类技术。
它会在多个 worker 之间划分模型的各个层。就其本质而言,模型并行性的计算和通信因模型结构而异,因此在实现上有很大的工作量。DeepSpeed 借用了英伟达的 Megatron-LM 来为基于 Transformer 的语言模型提供大规模模型并行功能。模型并行会根据 worker 数量成比例地减少显存使用量,也是这三种并行度中显存效率最高的。但是其代价是计算效率最低。
- 显存效率:模型并行会根据 worker 数量成比例地减少显存使用量。至关重要的是,这是减少单个网络层的激活显存的唯一方法。DeepSpeed 通过在模型并行 worker 之间划分激活显存来进一步提高显存效率。
- 计算效率:由于每次前向和反向传播中都需要额外通信激活值,模型并行的计算效率很低。模型并行需要高通信带宽,并且不能很好地扩展到通信带宽受限的节点。此外,每个模型并行worker 都会减少每个通信阶段之间执行的计算量,从而影响计算效率。模型并行性通常与数据并行性结合使用,以在内存和计算效率之间进行权衡。
(3)流水线并行训练引擎也被包含在了这次发布的DeepSpeed中
流水线并行将模型的各层划分为可以并行处理的阶段。当一个阶段完成一个 micro-batch 的正向传递时,激活内存将被通信至流水线的下一个阶段。类似地,当下一阶段完成反向传播时,将通过管道反向通信梯度。必须同时计算多个 micro-batch 以确保流水线的各个阶段能并行计算。目前已经开发出了几种用于权衡内存和计算效率以及收敛行为的方法,例如 PipeDream。DeepSpeed 采用的方法是通过梯度累积来实现并行,并保持与传统数据并行和模型并行训练在相同的总 batch 大小下收敛情况相同。
- 显存效率:流水线并行减少的显存与流水线的阶段数成正比,使模型的大小可以随 worker 的数量线性扩展。但是,流水线并行不会减少每一层的激活函数的显存占用量。此外,每个 worker 必须存储同时运行的各个 micro-batch 的激活值。这导致流水线第一阶段的激活内存与单个 mirco batch 的总激活内存大致相同。一个万亿参数模型将需要为一个 micro batch 提供大约 19 GB 的显存的激活内存,这几乎占到新推出的英伟达 A100 GPU 总显存的一半。
- 计算效率:流水线并行具有最低的通信量,因为它的通信量只和在各阶段边界的各层的激活值大小成正比。但是,它不能无限扩展。像模型并行一样,增加流水线大小会减少每个流水线阶段的计算量,这会降低计算与通信的比率。如果要实现好的计算效率,流水线并行还要求其每个阶段的计算负载完美的均衡。
LLaMA-Factory
北航博士生郑耀威,开发的大模型训练框架
- 2022年开始北航博士学业
- github hiyouga
- 【2024-3-20】ACL 2024 论文 LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
- 【2024-7-18】LLaMA-Factory QuickStart
- 官方文档
详见站内专题:LLaMA-Factory 使用指南
Xtuner
上海AI实验室推出的 XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。与 LLaMA-Factory 类似,不过,在长序列训练、token生成速度等方面要比 LLaMA-Factory 更强。
简析
- 数据集: LLaMA-Factory 支持多种格式的数据集,更通用泛化;而
XTuner只支持类似ShareGPT格式的数据集。 - 模型支持: LLaMA-Factory 支持模型种类也要比XTuner更多;但 XTuner 多模态模型(LLaVA-Internlm2-7B / 20B、LLaVA-v1.5)的支持要比 LLaMA-Factory。
多轮对话训练时的loss计算。
- 从文档来看,XTuner更清晰,而且是我想要的效果;
- 而对于 LLaMA-Factory,其放出来的只是数据集格式文档,loss计算没那么透明,只能啃源码。
多轮对话所对应的长序列训练性能。随着 Gemini 1M context length 和 Sora 出世,如何训练超长上下文的大模型引起了大家广泛关注。同时在大多数的场景下,多轮对话一般也就是一个conversations包含几轮对话;但在实际情况中,一个conversations下有几百个对话,即长对话,这种场景还是比较多的。
解决方案比较麻烦,需要做拆分;在基座模型支持长上下文的情况下,如果微调框架能支持长序列训练,且性能不错,是很好的选择;
XTuner 在这方面要比 LLaMA-Factory 更好。
XTuner 序列并行设计思路参考了 DeepSpeed 的工作 DeepSpeed Ulysses,并加以优化,以达到直接基于 transformers 算法库或 Huggingface Hub 上的开源模型训练 1M 以上超长序列的目标。
| 模型 | 序列并行支持情况 |
|---|---|
| baichuan | 1/2 ❌ |
| chatglm | 2/3 ❌ |
| deepseek | ✅ |
| gemma | ❌ |
| internlm 2 | ✅ |
| llama 2 | ✅ |
| mistral | ❌ |
| qwen 1/1.5 | ❌ |
| starcoder | ❌ |
| yi | ✅ |
| zephyr | ✅ |
Swift
【2024-7-4】 阿里推出训练框架 (Scalable lightWeight Infrastructure for Fine-Tuning)
详见站内专题:ms-Swift框架使用笔记
Unsloth
【2025-3-4】 开源工具 Unsloth 加速大型语言模型(LLMs)微调过程,具备诸多实用功能与显著优势。
Unsloth
- 定位:面向个人开发者的轻量化微调工具
- 核心优势:
- 极简操作:提供开箱即用的Colab Notebook,支持”Run All”一键完成数据加载、训练、模型导出(GGUF/Ollama格式)
- 性能优化:宣称比传统方法快2倍,显存节省最高80%(如Qwen3 4B版本)
- 免费支持:开放所有Notebook,覆盖Kaggle/GRPO/TTS/Vision等场景,与Meta合作提供合成数据集
- 适用场景:
- 个人开发者快速微调中小模型(支持到14B参数)
- 资源受限环境(低VRAM显卡)
特点
特性
- 微调效率: Unsloth 表现极为出色,其微调速度相较于传统方法能够提升 2 - 5 倍,并且内存占用可降低 50% 到 80%。可利用更少的资源来完成微调任务,极大地提高了工作效率。
- 硬件设备要求:
- Unsloth 对显存的需求较低,即使是消费级 GPU,例如 RTX 3090,也能够轻松运行 Unsloth。
- 以训练 1.5B 参数的模型为例,仅需 7GB 显存就可以满足要求。
- 模型适配与量化技术: Unsloth 支持多种主流模型,包括 Llama、Mistral、Phi、Gemma 等。并且,通过采用动态 4-bit 量化技术,Unsloth 能够显著降低显存占用,同时几乎不会损失模型精度,这在很大程度上提升了模型的实用性和适用范围。
- Unsloth 还具有开源与免费的优势。提供了免费的 Colab Notebook,用户只需添加相应的数据集并运行代码,即可轻松完成微调工作。
内存优化
Unsloth 出现之前,模型微调的成本居高不下,对于普通人来说几乎难以企及。微调一次模型不仅需要耗费数万元的资金,还需要花费数天的时间才能完成。
Unsloth 通过运用特定的优化技术,能在配置相对较低的硬件设备资源环境下,更加高效地进行模型微调。
优化包括:
- 高效内存线性内核:将 GRPO 的内存使用量降低 8 倍以上,节省了 68.5GB 内存。
- 智能梯度检查点:异步将中间激活卸载到系统 RAM,节省了 52GB 内存,而速度仅慢 1%。
- 共享内存空间:与底层推理引擎(vLLM)共享 GPU/CUDA 内存空间,节省了 16GB 内存。
标准 GRPO 实现中,仅计算损失函数就需要 78.3GB VRAM。而 Unsloth 将长上下文 GRPO 的额外内存需求降低到仅 9.8GB。
Unsloth 将 GRPO 的 VRAM 使用量相较于标准实现降低了 90% 以上。
| 指标 | Unsloth | 标准 + FA2 |
|---|---|---|
| 训练内存成本 (GB) | 42GB | 414GB |
| GRPO 内存成本 (GB) | 9.8GB | 78.3GB |
| 推理成本 (GB) | 0GB | 16GB |
| 20K 上下文长度的推理 KV 缓存 (GB) | 2.5GB | 2.5GB |
| 总内存使用量 | 54.33GB (少 90%) | 510.8GB |
安装
pip install unsloth
Unsloth Web UI
【2026-3-18】官方推出 Unsloth Studio ✨ 无需写代码即能训练和运行 LLMs 的开源 Web UI。
- 在 Mac、Windows、Linux 上本地运行模型
- 用 70%更少的 VRAM,将 500 多个模型训练速度提升 2 倍
- 支持 GGUF、视觉、音频、嵌入模型
- 从 PDF、CSV、DOCX 自动创建数据集
- 支持可视化节点工作流编辑数据
- 支持500+种模型,涵盖文本、视觉、音频、嵌入等类型,兼容GGUF格式;支持全量微调、预训练、4-bit、16-bit以及FP8训练
- 可以实时监控训练过程,追踪损失值与GPU使用率,并可自定义图表
pip install --upgrade pip && pip install uv
uv pip install unsloth --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
OpenRLHF
待定
VeRL
字节开源的框架
起因
RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。
大模型 RL 的计算流程比传统神经网络更为复杂。
RLHF 中,需要同时训练多个模型,如 Actor 、Critic 、参考策略(Reference Policy)和奖励模型(Reward Model),并在传递大量数据。
这些模型涉及不同的计算类型(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行策略。
传统分布式 RL 通常假设模型可在单个 GPU 上训练,或使用数据并行方式,将控制流和计算流合并在同一进程中。
- 这在处理小规模模型时效果良好,但面对大模型训练需要复杂的多维并行,涉及大量分布式计算,传统方法难以应对。
传统的 RL/RLHF 系统在灵活性和效率方面存在不足,难以适应不断涌现的新算法需求,无法充分发挥大模型潜力。
开发一个高效且灵活的大模型 RL 训练框架显得尤为重要。
这不仅需要高效地执行复杂的分布式计算流程,还要具备适应不同 RL 算法的灵活性,以满足不断发展的研究需求。
大模型 RL 本质上是一个二维的 DataFlow 问题:high-level 的控制流(描述 RL 算法的流程)+ low-level 的计算流(描述分布式神经网络计算)。
近期开源的 RLHF 框架,如: DeepSpeed-Chat、OpenRLHF 和 NeMo-Aligner,采用统一的多控制器(Multi-Controller)架构, 各计算节点独立管理计算和通信,降低了控制调度的开销。
然而,控制流和计算流高度耦合,当设计新的 RL 算法,组合相同的计算流和不同的控制流时,需要重写计算流代码,修改所有相关模型,增加了开发难度。
VeRL 介绍
VeRL是字节跳动seed团队和香港大学开发的强化学习仓库。
【2024-11-1】最高提升20倍吞吐量!豆包大模型团队发布全新 RLHF 框架,现已开源!
字节跳动豆包大模型团队与香港大学近期公开联合研究成果—— HybridFlow ,一个灵活且高效的大模型 RL 训练框架,兼容多种训练和推理框架,支持灵活的模型部署和多种 RL 算法实现。
- 论文 HybridFlow: A Flexible and Efficient RLHF Framework
- 论文已被 EuroSys 2025 接收,代码仓库也对外公开。
- 代码链接:veRL
- 文档地址 文档
HybridFlow 采用混合编程模型,融合单控制器(Single-Controller)的灵活性和多控制器(Multi-Controller),解耦了控制流和计算流,可更好实现和执行多种RL算法,显著提升训练吞吐量,降低开发和维护复杂度。
尽管相比纯粹的多控制器架构,这可能带来一定的控制调度开销,但 HybridFlow 通过优化数据传输,降低了控制流与计算流之间的传输量,兼顾了灵活性和高效性。
基于Ray的动态计算图、异构调度能力,通过封装单模型的分布式计算、统一模型间的数据切分,以及支持异步 RL 控制流,HybridFlow 能够高效地实现和执行各种 RL 算法,复用计算模块和支持不同的模型部署方式,大大提升了系统的灵活性和开发效率。
VeRL和OpenRLHF都依托Ray管理RL中复杂的Roles(比如PPO需要四个模型)和分配资源
对比
LLaMA-Factory、trl和verl,三个框架
- trl: 基于transformers, 完全封闭,没有太多可操作空间
- LLaMA-Facotry 和 verl 可操作性比较强,自定义很多东西。
verl和trl主要是针对强化学习设计,但也可以实现SFT
二者目前都实现了主流的RL算法。
verl还具备与现有LLM基础设施无缝集成的能力,无论是PyTorch FSDP、Megatron-LM还是vLLM,veRL都能轻松对接,实现高效的资源利用与扩展。
功能
强化学习三个步骤:
- (1) Rollout ->
- (2) Actor / Critic / Reward / Ref 计算梯度更新所需数据 ->
- (3) Actor / Critic 做 update
verl 使用 vllm、sglang 等推理引擎来优化rollout过程
以 vllm(<=0.6.3)为例,解析verl中涉及rollout的部分
场景:
- 假设有4张GPU,actor采用fsdp方式将参数均匀分布在各个GPU上。
- 当前,actor经过前一轮训练后,进入rollout阶段。
- 为了提高rollout阶段的吞吐,不对模型参数进行切分,即dp=4,tp=1。
【2025-09-07】利用 vLLM 进行 rollout
vLLM 允许设置 PP 和 DP
llm = LLM(
model=str(model_dir),
dtype='bfloat16',
gpu_memory_utilization=0.4,
tensor_parallel_size=2,
pipeline_parallel_size = 2,
data_parallel_size = 2
)
TP 和 PP 很好理解,而DP 的意思应该是,例如你有4张卡,设置 TP = 2 , PP = 1 ,此时 vLLM 内部会启动“两份模型”, 进行并行的数据处理
效果
实验结果
- HybridFlow 在运行各种 RL(HF) 算法时,吞吐量相较 SOTA 基线提升了 1.5-20 倍。
安装
工具包依赖
flash-attn==2.5.9.post1
numpy==1.26.4
pandas==2.2.3
peft==0.14.0
ray=2.42.1
torch=2.4.0+cu124
transformers=4.47.1
vllm==0.5.4
安装
# 克隆项目仓库
git clone https://gitcode.com/GitHub_Trending/ve/verl
# 进入项目目录
cd verl
# 创建虚拟环境
python -m venv verl_env
source verl_env/bin/activate
# 安装基础依赖
pip install -r requirements.txt
# 安装verl本体
pip install --no-deps -e .
示例
GRPO
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=1024 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=Qwen/Qwen3-8B \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name='verl_grpo_example_gsm8k' \
trainer.experiment_name='qwen3_8b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=20 \
trainer.test_freq=5 \
trainer.total_epochs=15
RLOO
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=rloo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=1024 \
data.max_prompt_length=512 \
data.max_response_length=1024 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=Qwen/Qwen2-7B-Instruct \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=80 \
actor_rollout_ref.actor.use_kl_loss=False \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=160 \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=160 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=True \
algorithm.kl_penalty=kl \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name='verl_rloo_example_gsm8k' \
trainer.experiment_name='qwen2_7b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=-1 \
trainer.test_freq=5 \
trainer.total_epochs=15
Axolotl
Axolotl
定位:全流程后训练解决方案
技术亮点:
- 全面训练方法:支持LoRA/QLoRA/DPO/RLHF等前沿技术,兼容多模态任务
- 企业级扩展:支持云存储(S3/Azure)、多节点训练(FSDP/DeepSpeed)、Docker部署
- 配置复用:通过YAML文件统一管理数据预处理、训练、量化全流程
典型用户:
- 需要定制化训练策略的研究团队
- 企业级多GPU/多节点训练场景
ROOL
【2025-6-6】ROLL 是阿里淘天联合爱橙推出的面向agentic场景的生产级大规模强化学习框架
- ROLL(Reinforcement Learning Optimization for Large-scale Learning)
- 开源:ROLL
- 报告:Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
【2026-4-15】Relax
【2026-4-15】小红书 Relax 开源发布:面向全模态 Agentic 的异步 RL 训练引擎
小红书 AI 平台团队今日正式开源 Relax —— 一款面向全模态与 Agentic 场景设计的大模型强化学习训练引擎。Relax 基于 Megatron-LM 和 SGLang 高性能后端构建,以协同设计为核心理念,将全模态数据支持、服务化容错架构和异步训练流水线三个维度统一解决。在 Qwen3-Omni-30B 上,Relax 验证了图像、文本、音频和视频四种模态的 RL 训练稳定收敛;在 16xH800 多机下,训练全异步相比 Colocate 基线端到端提速 76%,相比 veRL 的全异步端到端提速 20%。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
