代码评审 Code Review
Code Review 的首要目的是改善和保证代码质量,预防 bug。
- 时机:每次代码CheckIn之前进行
- 此外还有益于制定团队代码规范,形成团队技术氛围,加深技术团队成员沟通,老带新互助成长等等。
- 有些团队里 Code Review 处于开发流程的边缘位置,有些团队 Code Review 处于代码编写到部署的必经部分。
- 对于我们来说,Code Review 是代码编写到部署的必经部分,所有代码都必须经过 Review 才能 merge。
git 和 gitlab 系列:
- master: 枝干, 拿到手后第一件事请就是设置为 Protected.
- 所有 Master Branch的变化必须经过PR来改变, 避免初级程序员犯错误. 基本上和 Production 挂钩
- dev: active branch, 基本上和 Staging 挂钩.
- adong/feat-branch: 用 用户名/feature 格式来命名, 可以在 SourceTree 和 Github里面用树形结构来显示.
【2020-7-11】陈皓:代码有这几种级别:
- 1)可编译
- 2)可运行
- 3)可测试
- 4)可读
- 5)可维护
- 6)可重用
分析
- 通过自动化测试的代码只能达到第 3)级
- 通过 Code Review 代码,至少在第 4)级甚至更高。
- 关于 Code Review 参考《Code Review中的几个提示》
GitLab Code Review
GitLab 在分支合并时支持两种方式:
- 在本地将源分支(Source branch)代码合并到目标分支(Target branch)然后Push到目标分支(Target branch)
- 将源分支(Source branch)Push到远端,然后在GitLab指定目标分支(Target branch)发起Merge Request,对目标分支(Target branch)拥有Push权限的用户执行Merge操作,完成合并。
使用 GitLab 进行 Code Review, 就是在分支合并环节发起 Merge Request,然后 Code Review完成后将代码合并到目标分支。
为什么要做CR?
CodeReview 目的: 提升代码质量,尽早发现常见、普通的缺陷与BUG降低修复成本,同时促进团队内部知识共享,帮助更多人更好地理解系统;
Code Review 主要目的:
- 发现错误:人都会不可避免的出现一些纰漏,而这些纰漏在另一个人眼中也许显而易见。
- 健壮性检查:代码是否健壮,是否有潜在安全、性能风险。代码是否可以回滚。
- 质量保证:在一般情况下,新提交的代码一定需要写测试,测试不只可以保证你的提交符合预期,还可以在后人改你的代码时有一层保障。同时,MR 阶段也有机器人自动检查当前分支的测试覆盖率是否低于主分支,当低于主分支时会标红警示,但不会禁止 merge。
- 统一风格:对于整个团队来说,代码风格的统一很重要。风格统一除了人 Review,引入了静态代码检查,不符合团队风格的代码,是无法 CI。
- 完善注释:包括 commit message、代码中复杂实现是否有解释性的注释、紧急 hack 是否明确标注等。
- 互相学习:保证组内人员良好的沟通,使得产品代码更容易维护
一般单个 MR 不宜过大。如果是大的 feature 改动,可以分成多个小 MR 分次提交。
- 人是不可靠的,所以写测试非常重要。
- 人是不可靠的,所以静态代码检查非常重要。
- 人是不可靠的,所以各种自动化工具非常重要。
怎么保证CR质量
目标
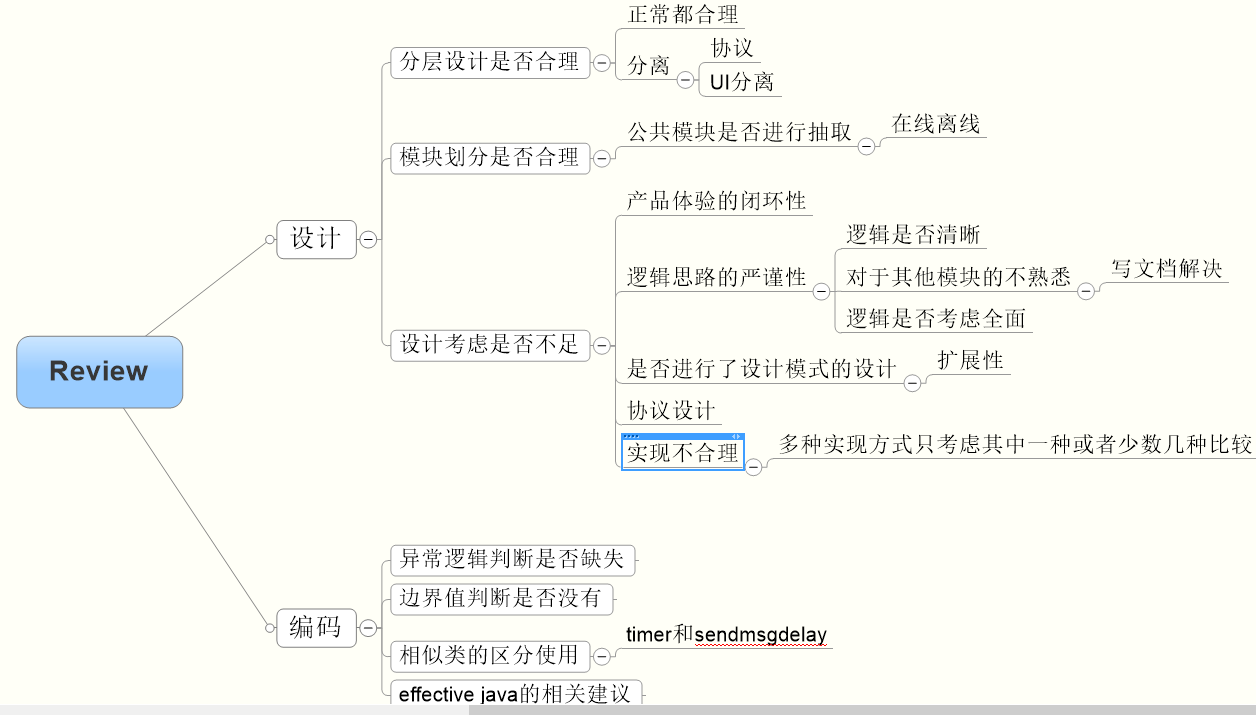
注意:
- Code reviews 不应该承担发现代码错误的职责。
- Code Review 主要审核代码质量,如可读性,可维护性,以及程序的逻辑和对需求和设计的实现。
- 代码中的bug和错误,应该由
单元测试,功能测试,性能测试,回归测试保证(其中主要是单元测试,因为那是最接近Bug,也是Bug没有扩散的地方)
- Code reviews 不应该成为保证代码风格和编码标准的手段。
编码风格和代码规范都属于死的东西,每个程序员在把自己的代码提交团队Review的时候,代码就应该是符合规范的,这是默认值,属于每个人自己的事情,不应该交由团队来完成,否则只会浪费大家本来就不够的时间。- 集中开发很奢侈,因为要大家在同一时刻都挤出时间。代码规范比起程序的逻辑和对需求设计的实现来说,太不值得让大家都来了。
【2021-2-2】第一天上班看到这段注释就想辞职
代码设计
代码设计原则
体系结构和代码设计
单一职责原则:一个类有且只能一个职责。用这个原则去衡量,如果必须使用“和”来描述一个方法做的事情,这可能在抽象层上出了问题。开闭原则:对于面向对象语言,对象在可扩展方面开放、对在修改方面关闭。如果需要添加另外的内容会怎样?代码复用:根据“三振法”,如果代码被复制一次,虽然不喜欢这种方式,但通常没什么问题。但如果再一次被复制,就应该通过提取公共的部分来重构它。换位考虑,如果换位考虑,这行代码是否有问题?用这种模式是否可以发现代码中的问题。用更好的代码: 如果在一块混乱的代码做修改,添加几行代码也许更容易,但我建议更进一步,用比原来更好的代码。潜在的bugs:是否会引起的其他错误?循环是否以我们期望的方式终止?错误处理:错误确定被优雅的修改?会导致其他错误?如果这样,修改是否有用?效率: 如果代码中包含算法,这种算法是否是高效? 例如,在字典中使用迭代,遍历一个期望的值,这是一种低效的方式。
优秀程序设计的18大原则
Diggins是加拿大一位有25年编程经验的资深技术人员,曾效力于Microsoft和Autodesk,并创办过两家赢利的互联网公司。
良好的编程原则
- 避免重复原则(DRY - Don’t repeat yourself)
- 编程的最基本原则是避免重复。在程序代码中总会有很多结构体,如循环、函数、类等等。一旦你重复某个语句或概念,就会很容易形成一个抽象体。
- 抽象原则(Abstraction Principle )
- 与DRY原则相关。要记住,程序代码中每一个重要的功能,只能出现在源代码的一个位置。
- 简单原则(Keep It Simple and Stupid )
- 简单是软件设计的目标,简单的代码占用时间少,漏洞少,并且易于修改。
- 避免冗余代码 Avoid Creating a YAGNI (You aren’t going to need it)
- 除非你需要它,否则别创建新功能。
- 尽可能做可运行的最简单的事(Do the simplest thing that could possibly work)
- 尽可能做可运行的最简单的事。在编程中,一定要保持简单原则。作为一名程序员不断的反思“如何在工作中做到简化呢?”这将有助于在设计中保持简单的路径。
- 易懂(Don’t make me think )别让我思考!
- 这是Steve Krug一本书的标题,同时也和编程有关。所编写的代码一定要易于读易于理解,这样别人才会欣赏,也能够给你提出合理化的建议。相反,若是繁杂难解的程序,其他人总是会避而远之的。
- 开闭原则(Open/Closed Principle) —— 复用、可扩展(实体开源、细节封闭)
- 你所编写的软件实体(类、模块、函数等)最好是开源的,这样别人可以拓展开发。不过,对于你的代码,得限定别人不得修改。换句话说,别人可以基于你的代码进行拓展编写,但却不能修改你的代码。
- 代码维护(Write Code for the Maintainer) —— 易于交接
- 一个优秀的代码,应当使本人或是他人在将来都能够对它继续编写或维护。
- 代码维护时,或许本人会比较容易,但对他人却比较麻烦。因此你写的代码要尽可能保证他人能够容易维护。
- 书中原话: “如果一个维护者不再继续维护你的代码,很可能他就有想杀了你的冲动。”
- 最小惊讶原则(Principle of least astonishment) —— 不要秀神技!
- 最小惊讶原则通常是在用户界面方面引用,但同样适用于编写的代码。
- 代码应该尽可能减少让读者惊喜。编写的代码只需按照项目的要求来编写。其他华丽的功能就不必了,以免弄巧成拙。
- 单一责任原则(Single Responsibility Principle)
- 某个代码的功能,应该保证只有单一的明确的执行任务。
- 低耦合原则(Minimize Coupling)
- 代码的任何一个部分应该减少对其他区域代码的依赖关系。尽量不要使用共享参数。低耦合往往是完美结构系统和优秀设计的标志
- 最大限度凝聚原则(Maximize Cohesion)
- 相似的功能代码应尽量放在一个部分
- 隐藏实现细节(Hide Implementation Details)
- 隐藏实现细节原则,当其他功能部分发生变化时,能够尽可能降低对其他组件的影响
迪米特法则又叫作最少知识原则(Law of Demeter)- 代码只和与其有直接关系的部分连接。(比如:该部分继承的类,包含的对象,参数传递的对象等)
- 避免过早优化(Avoid Premature Optimization)
- 除非代码运行的比想像中的要慢,否则别去优化。假如真的想优化,就必须先想好如何用数据证明,它的速度变快了。
- “过早的优化是一切罪恶的根源” —— Donald Knut
- 代码重用原则(Code Reuse is Good)
- 重用代码能提高代码的可读性,缩短开发时间。
- 关注点分离(Separation of Concerns)
- 不同领域的功能,应该由不同的代码和最小重迭的模块组成。
- 拥抱改变(Embrace Change)
- 这是Kent Beck一本书的标题,同时也被认为是极限编程和敏捷方法的宗旨。
- 许多其他原则都是基于这个概念的,即你应该积极面对变化。事实上,一些较老的编程原则如最小化耦合原则都是为了使代码能够容易变化。无论是否是个极限编程者,基于这个原则去编写代码会让你的工作变得更有意义。
面向对象设计原则
面向对象设计原则
- 面向对象七大设计原则。
- 《设计模式之禅》
| 设计原则名称 | 定义 | 使用频率 |
|---|---|---|
| 单一职责原则(Single Responsibility Principle, SRP) | 一个类只负责一个功能领域中的相应职责 | ★★★★☆ |
| 开闭原则(Open-Closed Principle, OCP) | 软件实体应对扩展开放,而对修改关闭 | ★★★★★ |
| 里氏代换原则(Liskov Substitution Principle, LSP) | 所有引用基类对象的地方能够透明地使用其子类的对象 | ★★★★★ |
| 依赖倒转原则(Dependence Inversion Principle, DIP) | 抽象不应该依赖于细节,细节应该依赖于抽象 | ★★★★★ |
| 接口隔离原则(Interface Segregation Principle, ISP) | 使用多个专门的接口,而不使用单一的总接口 | ★★☆☆☆ |
| 合成复用原则(Composite Reuse Principle, CRP) | 尽量使用对象组合,而不是继承来达到复用的目的 | ★★★★☆ |
| 迪米特法则(Law of Demeter, LoD) | 一个软件实体应当尽可能少地与其他实体发生相互作用 | ★★★☆☆ |
代码风格
代码风格
- 方法名: 在计算机科学中,命名是一个难题。一个函数被命名为
get_message_queue_name,但做的却是完全不同的事情,比如从输入内容中清除html,那么这是一个不准确的命名,并且可能会误导。 - 值名:对于数据结构,foo or bar 可能是无用的名字。相比exception, e同样是无用的。如果需要(根据语言)尽可能详细,在重新查看代码时,那些见名知意的命名是更容易理解的。
- 函数长度: 对于一个函数的长度,我的经验值是小于20行,如果一个函数在50行以上,最好把它分成更小的函数块。
- 类长度:我认为类的长度应该小于300行,最好在100内。把较长的类分离成独立的类,这样更容易理解类的功能。
- 文件长度: 对于Python,一个文件最多1000行代码。任何高于此的文件应该把它分离成更小更内聚,看一下是否违背的“单一职责” 原则。
- 文档:对于复杂的函数来说,参数个数可能较多,在文档中需要指出每个参数的用处,除了那些显而易见的。
- 注释代码: 移除任何注释代码行。
- 函数参数个数:不要太多, 一般不要超过3个。。
- 可读性: 代码是否容易理解?在查看代码时要不断的停下来分析它?
如何执行CR
CR流程
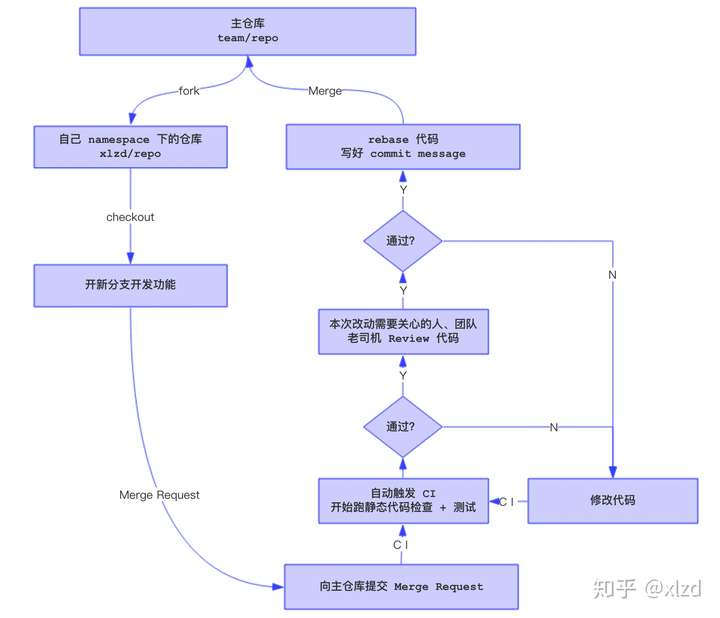
之前也思考过怎么充分发挥code review作用,积累的经验:
- (1)ci/cd流程(genkins)与git集成,每次git push都会自动触发code review机制
- (2)cr评审方法:每个子方向设置1-2个owner,几个commiter,3人以上通过才算过,owner有一票否决权,特殊场景可以授权
- (3)如何统一标准?每次组会留出5-15min,随机抽取commit代码片段,公开评审
- (4)如何保证评审质量?对照Google开发规范,建立代码委员会,不止是资深工程师,谁都可以申请,但需要公开评审,过关
- (5)如何提升积极性?每次cr的质量和次数算个人积分,作为”华山论剑“得分项之一,季度评奖,重奖轻惩(考虑到自尊心)
工作流
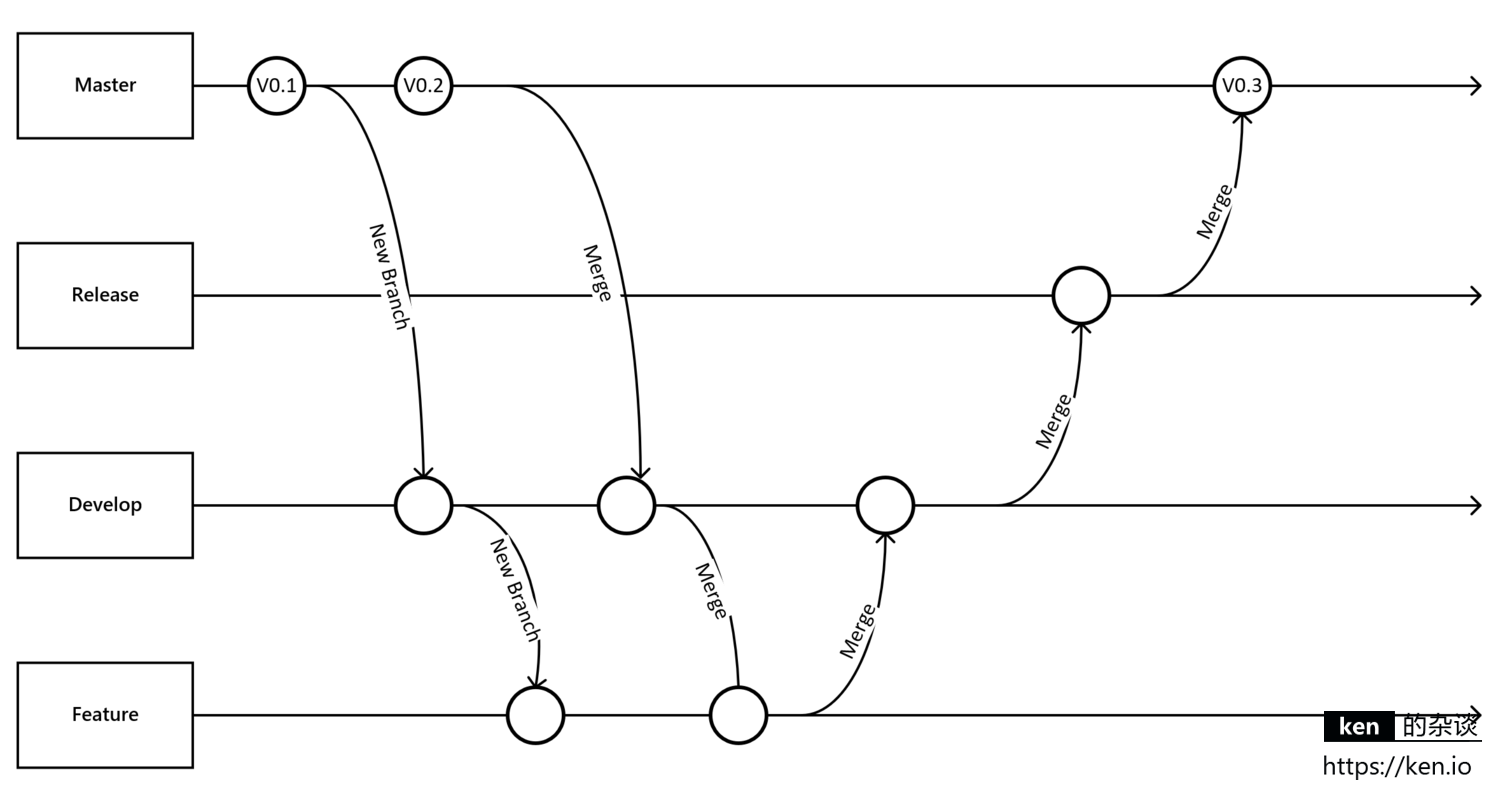
解说:
- 需求确认后,从master创建develop分支
- 开发人员从develop分支创建自己的feature分支进行开发
- master分支发生变更,需要从master分支合并到develop分支、可以考虑定期合并一次
- feature分支合并到对应的develop分支之前,需要从develop分支合并到feature分支
- feature分支合并到对应的develop分支之后,发布到测试环境进行测试
- develop分支在测试环境测试通过之后,合并到release分支并发布到预发布环境进行测试
- release分支在预发布环境验证通过后,合并到master分支并发布到生产环境进行验证
CR工具
- Code Review 工具:
- Crucible:Atlassian 内部代码审查工具;
- Gerrit:Google 开源的 git 代码审查工具;
- GitHub:程序员应该很熟悉了,上面的 “Pull Request” 在代码审查这里很好用;
- LGTM:可用于 GitHub 和 Bitbucket 的 PR 代码安全漏洞和代码质量审查辅助工具;
- Phabricator:Facebook 开源的 git/mercurial/svn 代码审查工具;
- PullRequest:GitHub pull requests 代码审查辅助工具;
- Pull Reminders:GitHub 上有 PR 需要你审核,该插件自动通过 Slack 提醒你;
- Reviewable:基于 GitHub pull requests 的代码审查辅助工具;
- Sider:GitHub 自动代码审查辅助工具;
- Upsource:JetBrain 内部部署的 git/mercurial/perforce/svn 代码审查工具。
CR的实用建议
- 转自:程序员客栈
- Code Review 的几点实用性建议:
-
- 对事不对人。
- 大家是同事,在一个团队工作和气很重要。不要在 Code Review 中说“你写的什么垃圾东西这种话”,你可以说“这个变量名不好理解,咱们换成巴拉巴拉是不是更好”。
- 对事不对人。
-
- 每个 Review 至少给一条正面评价。保持积极态度
- Code Review 本意是改善代码质量,增强团队成员之间的沟通,但是我一提交代码就有人说我写的垃圾,这很打击自信心啊,也不利于团队成员和平相处。代码有问题,指出问题是必须的,要实事求是,但是有的时候也需要给队友一点鼓励,例如简单的 或者“赞一个”我都很开心了。
- 每个 Review 至少给一条正面评价。保持积极态度
-
- 保证发布的代码和评审意见的可读性。
- 大家都是程序员,你提交代码的时候,在符合团队风格的同时,把代码弄的好看点,如果你明确自己这个代码哪个地方不足,Highlight 出来让大家给意见。如果你是来 Review 代码的,把意见写的通顺点,评论有条理一些。对反引号 (
) 嵌入代码或三个反引号 (``) 写代码块,这样看的舒服得多,效率也高。
- 大家都是程序员,你提交代码的时候,在符合团队风格的同时,把代码弄的好看点,如果你明确自己这个代码哪个地方不足,Highlight 出来让大家给意见。如果你是来 Review 代码的,把意见写的通顺点,评论有条理一些。对反引号 (
- 保证发布的代码和评审意见的可读性。
-
- 用工具进行基础问题的自动化检查。
- 用 Tab 还是空格,用两个空格还是四个空格,函数后面怎么换行等基础问题检查,可以使用 eslint 和Rubocop 等类似的工具进行,团队成员应该把更多精力放在代码规范,代码性能优化等地方。
- 用工具进行基础问题的自动化检查。
-
- 全员参加 Code Review,并设定各部分负责人。
- 扩大 Code Review 参与面,参与不是说一定去审核别人的代码,可以是代码被审核,也可以是看别人审核意见,这都是学习的过程。并且每部分设定负责人,该负责人对这部分代码质量负责,负责人需要是资深工程师。全员参与 Code Review 可以让团队成员更快的成长,新人在看大佬 Review 代码的过程就能学到很多。
- 全员参加 Code Review,并设定各部分负责人。
-
- 每个代码 PR 内容一定要少。
- Code Review 效果和质量与 PR 代码量成反比,你一下提交这么多代码,我今天还下不下班了? 我女朋友你帮我陪?每次 PR 代码量小一些,看起来速度快,又不至于失去耐心,这样才能达到 Code Review 的效果,所以要经常进行 Code Review,但是每个 PR 代码量要少。我建议要少于 300 行/PR。
- 每个代码 PR 内容一定要少。
-
- 在写新代码之前,先 Review 掉需要评审的代码。
- 你让我去 Review 一周前的代码?我还得把思维和项目进度切换到一周前?大家肯定不愿意,所以要形成规定,写新代码之前先把旧的 Review 掉,提交 PR 的时候也保证代码量小,这样 Review 起来不需要大块时间,改起来也快。不能因为 Code Review 大幅耽误项目进度,进度是全团队的事,不是某个人的事。
- 在写新代码之前,先 Review 掉需要评审的代码。
-
- 如果你有更好的方案,尽管提出来。
- 在 Code Review 中经常会发现写的不好的地方,如果你有更好的方法,欢迎提出来!首先能改进这个 PR 的代码,其次能体现你的能力,团队应该定期对这种提出好的解决方案的同事进行奖励。
- 如果你有更好的方案,尽管提出来。
-
- 不要在 review 中讨论需求,review 就是 review。
- 不要在 Code Review 里搞别的,有需要就另安排时间进行,要明确 Code Review 是完善代码,不是需求和功能讨论,始终要以代码质量为中心。
- 不要在 review 中讨论需求,review 就是 review。
-
- 尽可能的让不同的人Reivew你的代码
-
编码规范
编码规范资料
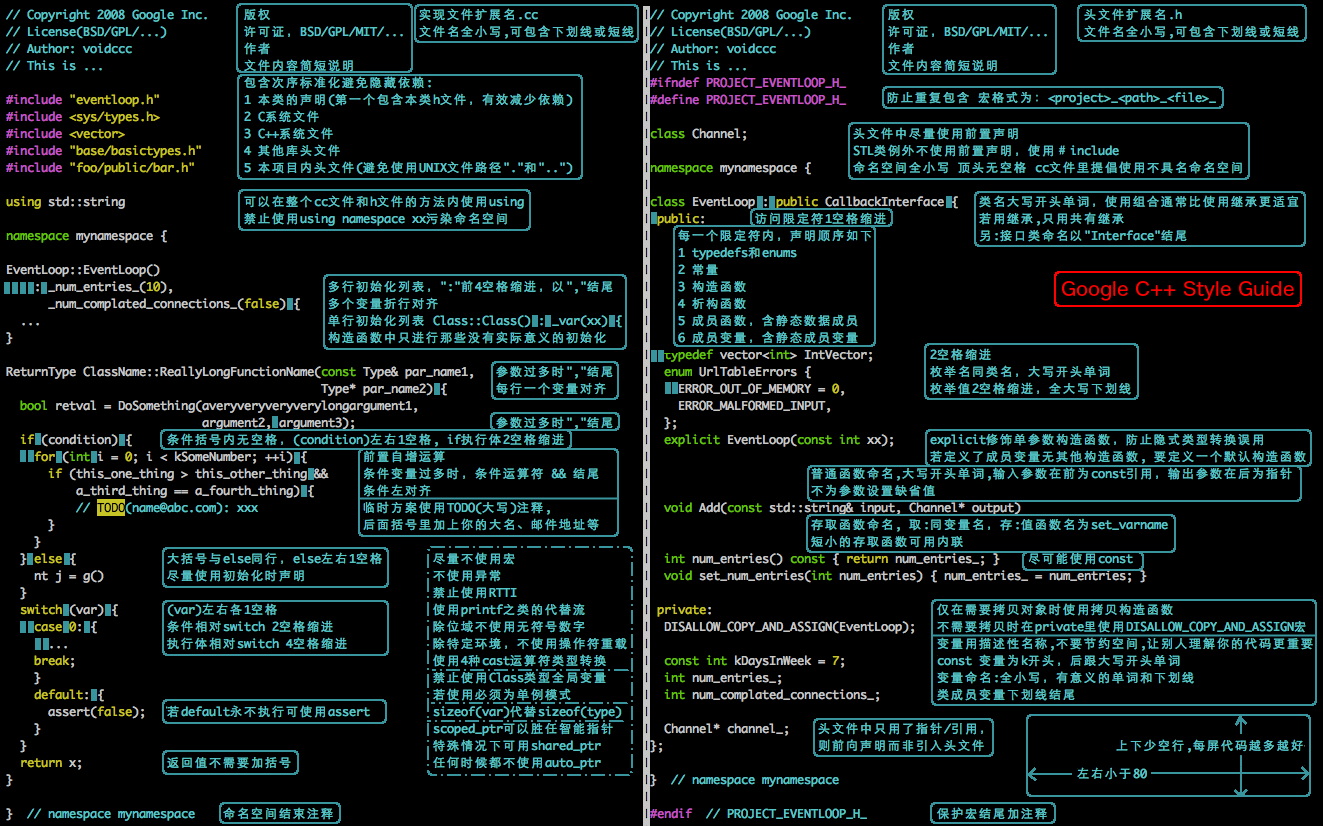
Google专门在 code.google.com 上建立了一个项目:Google Style Guide ,给出了一系列 google style guides,Google 开源项目风格指南 (中文版),包括:
- C/C++编码规范,中文版
- 【2020-8-4】C/C++语法规范,摘自:一张图总结Google C++编程规范(Google C++ Style Guide)
- 【2020-8-4】C/C++语法规范,摘自:一张图总结Google C++编程规范(Google C++ Style Guide)
- Python编码规范
- JavaScript编码规范
- Objective-C编码规范,中文版
- HTML/CSS 编码规范
- Json编码规范
- Shell编码规范
日志规范
日志级别等级
CRITICAL>ERROR>WARNING>INFO>DEBUG>NOTSET
# coding:utf8
import logging
if __name__ == '__main__':
#[2018-1-17]http://blog.csdn.net/zyz511919766/article/details/25136485/
# 设置日志格式,日志文件(默认打到标准输出),模式(追加还是覆盖)
# 日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET
#logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%a, %d %b %Y %H:%M:%S',filename='test.log',filemode='w')
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%Y-%M-%d %H:%M:%S',filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.critical('critical message')
# 创建一个logger,不用调logging包
log = logging.getLogger()
log.debug('debug')
# 日志等级大全
log.debug('logger debug message')
log.info('logger info message')
log.warning('logger warning message')
log.error('logger error message')
log.critical('logger critical message')
C++编码规范
【2022-4-3】现代C++ 整洁代码最佳实践
KISS(Keep It Simple,Stupid)保持简单和直接原则:代码的实现、设计在满足需求的前提下越简单越好。大道至简,把简单的事情复杂化就是没事找事,把复杂的事情简单化才是一种能力。YAGNI(You Are NOT Gonna Need It)不需要原则:不要进行过度的设计。不要写现在用不上,将来或许可能也许用得上的一些代码,将来的事情谁也说不清楚。DRY(Do not Repeat Yourself)避免重复原则:尽量在项目中减少重复的代码行、重复的方法和模块。任何时候尽量避免Ctrl+C, Ctrl+V,因为重复意味着用中。可以想象,当修改一段代码时,也必须相应地修改另一段重复的代码,功能一样如果出了bug也一样。事实是,往往会漏改或忘记那段重复的代码。Information Hiding信息隐藏原则:只提供必要的接口,并通过接口对外交互。通过接口一定程度上限制了变化范围,接口通常在一段时间内是相对稳定的,其实现可能是频繁变化的。高内聚松耦合:小心优化原则:建议没有明确的性能要求,就避免优化。不成熟的优化是编程中绝大部分问题的根源。
Python编码规范
pep8与google
【2017-11-23】python编码规范,目前有google和pep8两种,pylint默认pep8,Google python编码规范,如何用pylint规范代码风格
- 安装方法:sudo pip install -U pep8/pylint
- 【2018-7-13】python性能优化的20条建议,【2019-1-11】Python如何正确使用import?,总结import的各种用法及区别,精华
Pylint
pylint工具安装:
sudo pip install pylint --ingore-installed
使用:pylint test.py
MESSAGE_TYPE 有如下几种:
- (C) 惯例。违反了编码风格标准
- (R) 重构。写得非常糟糕的代码。
- (W) 警告。某些 Python 特定的问题。
- (E) 错误。很可能是代码中的错误。
- (F) 致命错误。阻止 Pylint 进一步运行的错误。
问题:
No config file found, using default configuration—— 解决:生成pylint配置文件,touch ~/.pylintrcC: 19, 0: Trailing newlines (trailing-newlines)—— 删除多余的空行C: 17, 4: Invalid constant name "new" (invalid-name)—— 全局变量名字全部大写C: 9, 0: Exactly one space required after comma—— 多参数时,逗号后加空格C: 13, 4: Invalid variable name "s" (invalid-name)—— 局部变量命名过短,3个字符以上(避免单字母,除了计数器+迭代器;避免双下划线开头并结尾;避免包/模块名中的连字符-),_开头表示protected,__开头表示privateC: 10, 0: Old-style class defined. (old-style-class)—— 类定义中没有加object。,类名大写字母开头(pascal风格,如CapWord,模块、函数名小写字母与_,如lower_with_under.py)R: 10, 0: Too few public methods (1/2) (too-few-public-methods)—— 缺少修改类属性值的方法C: 25, 0: Trailing whitespace (trailing-whitespace)—— 行尾有空格

代码示例
#!/usr/bin/env python
# coding:utf8
"""
test sample. google编码规范:(URL不受80字符限制)
https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/
2020-7-16
wangqiwen004@ke.com
"""
#(1)、以单下划线开头,表示这是一个保护成员,只有类对象和子类对象自己能访问到这些变量。以单下划线开头的变量和函数被默认当作是内部函数,使用from module improt *时不会被获取,但是使用import module可以获取
#(2)、以单下划线结尾仅仅是为了区别该名称与关键词
#(3)、双下划线开头,表示为私有成员,只允许类本身访问,子类也不行。在文本上被替换为_class__method
#(4)、双下划线开头,双下划线结尾。一种约定,Python内部的名字,用来区别其他用户自定义的命名,以防冲突。是一些 Python 的“魔术”对象,表示这是一个特殊成员,例如:定义类的时候,若是添加__init__方法,那么在创建类的实例的时候,实例会自动调用这个方法,一般用来对实例的属性进行初使化,Python不建议将自己命名的方法写为这种形式。
#import的包一定要使用;import包分成3部分,依次排序:
# ①系统包
# ②第三方包
# ③自定义包。
# 每部分按照字母顺序排序,一次不能导入多个包
import sys
class MyClass(object):
"""class测试: 类名满足Pascal风格"""
public_name = '-public-' # public
_myname = '-protected' # protected,不能通过import *导入,其它正常
__private_name = '-private-' # private,实例、子类不能使用
def __init__(self, name="wang"): # 特殊函数方法
self._myname = name
print '我的名字是%s'%(self._myname)
def say(self):
"""打招呼"""
print '你好,我是%s,%s,%s'%(self._myname, self.public_name, self.__private_name)
return 'yes'
def modify(self, name="-"):
"""更改属性值"""
self._myname = name
def my_fun(value=0, delta=9):
"""
外部函数:名字_连接。多参数时,逗号后面加一个空格
"""
res = value + delta
return res
def main():
"""main function"""
#main里的都是全局变量,需要大写
value = 3
new = my_fun(value)
v_result = MyClass("wqw")
#不能访问protected、private变量.W._myname, W.__private_name
#超过80字符时,可以用\换行,注:(),[]时可省略\
print >> sys.stdout, 'hello,related values are listed as : %s , %s,I am \
%s,%s ...'%(value, new, v_result.say(), v_result.public_name)
print >> sys.stdout, 'hello,related values are listed as : %s , %s,I am %s,%s ...'%(value, new, v_result.say(), v_result.public_name) # pylint: disable=line-too-long
#参考:怎么关闭某类检测:How do I disable a Pylint warning?
#https://stackoverflow.com/questions/4341746/how-do-i-disable-a-pylint-warning
if __name__ == '__main__':
A = 3 # 此处为全局变量,一律大写
main()
# */* vim: set expandtab ts=4 sw=4 sts=4 tw=400: */
代码文档
文档自动生成
swagger 插件,自动生成接口服务说明
代码逻辑可视化
【2025-11-16】代码库自动生成可视化文档 davia
- github davia
Let your knowledge update itself
测试
业界经验
【2022-2-17】脉脉 各业务线qps:一般来说qps>5k的都算高
- 腾讯微信热门服务,全年峰值qps也才3w;qps过万就不错了,用户产品日常qps 500-1000,上千的已经到顶了,遇上运营活动偶尔过万,注意是偶尔
- 国民级app(抖音)推荐接口的qps几十万,抖音电商10w,国内百万级别qps的只有微信、抖音之类,需要加codis缓存服务
- 淘宝搜索多年前,双十一前几天的qps峰值是27w-40w
- 韵达C端系统,每天110w请求,高峰期上午9点,下午14点,峰值qps 不到 200
- 全世界只有google搜索/fb的feed流的qps能达到百万级别
测试种类
【2021-11-18】一文带你了解测试类型
按照测试阶段可以将软件测试分为单元测试、冒烟测试、集成测试、系统测试与验收测试。这种分类方式与软件开发过程相契合,是为了检验软件开发各个阶段是否符合要求。
- (1) 单元测试:单元测试是软件开发的第一步测试,目的是为了验证软件单元是否符合软件需求与设计。单元测试大多是开发人员进行的自测。
- (2) 冒烟测试:冒烟测试最初是从电路板测试得来的,当电路板做好以后,首先会加电测试,如果电路板没有冒烟再进行其他测试,否则就必须重新设计后再次测试。后来这种测试理念被引入到软件测试中。在软件测试中,冒烟测试是指软件构建版本建立后,对系统的基本功能进行简单的测试,这种测试重点验证的是程序的主要功能,而不会对具体功能进行深入测试。如果测试未通过,需要返回给开发人员进行修正;如果测试通过则再进行其他测试。因此,冒烟测试是对新构建版本软件进行的最基本测试。
- (3) 集成测试:集成测试是冒烟测试之后进行的测试,它是将已经测试过的软件单元组合在一起测试它们之间的接口,用于验证软件是否满足设计需求。
- (4) 系统测试:系统测试是将经过测试的软件在实际环境中运行,并与其他系统的成分(如数据库、硬件和操作人员等)组合在一起进行的测试。
- (5) 验收测试:验收测试主要是对软件产品说明进行验证,逐行逐字地按照说明书的描述对软件产品进行测试,确保其符合客户的各项要求。
按照测试技术分类,按照使用的测试技术可以将软件测试分为黑盒测试与白盒测试。
- (1)黑盒测试
- 黑盒测试就是把软件(程序)当作一个有输入与输出的黑匣子,它把程序当作一个输入域到输出域的映射,只要输入的数据能输出预期的结果即可,不必关心程序内部是怎么样实现的,下图所示。
- 
- (2)白盒测试
- 白盒测试又叫透明盒测试,它是指测试人员了解软件程序的逻辑结构、路径与运行过程,在测试时,按照程序的执行路径得出结果。白盒测试就是把软件(程序)当作一个透明的盒子,测试人员清楚地知道从输入到输出的每一步过程,如下图所示。
- 
相对于黑盒测试来说,白盒测试对测试人员的要求会更高一点,他要求测试人员具有一定的编程能力,而且要熟悉各种脚本语言。但是在软件公司里,黑盒测试与白盒测试并不是界限分明的,在测试一款软件时往往是黑盒测试与白盒测试相结合对软件进行完整全面的测试。
按照软件质量特性分类,按照软件质量特性可以将软件测试分为功能测试与性能测试。
- (1)功能测试
- 功能测试就是测试软件的功能是否满足客户的需求,包括准确性、易用性、适合性、互操作性等。
- (2)性能测试
- 性能测试就是测试软件的性能是否满足客户的需求,性能测试包括负载测试、压力测试、兼容性测试、可移植性测试和健壮性测试。
按照自动化程度分类,按照自动化程度可以将软件测试分为手工测试与自动化测试。
- (1)手工测试
- 手工测试是测试人员一条一条地执行代码完成测试工作。手工测试比较耗时费力,而且测试人员如果是在疲惫状态下,则很难保证测试的效果。
- (2)自动化测试
- 自动化测试是借助脚本、自动化测试工具等完成相应的测试工作,它也需要人工的参与,但是它可以将要执行的测试代码或流程写成脚本,执行脚本完成整个测试工作。
按照测试类型分类,软件测试类型有多种,包括界面类测试、功能测试、性能测试、安全性测试、文档测试等,其中功能测试与性能测试前面已经介绍,下面主要介绍其他几种测试。
- (1)界面类测试
- 界面类测试是验证软件界面是否符合客户需求,包括界面布局是否美观、按钮是否齐全等。
- (2)安全性测试
- 安全性测试是测试软件在没有授权的内部或外部用户的攻击或恶意破坏时如何进行处理,是否能保证软件与数据的安全。
- (3)文档测试
- 文档测试以需求分析、软件设计、用户手册、安装手册为主,主要验证文档说明与实际软件之间是否存在差异。
其他分类:还有一些软件测试无法具体归到哪一类,但在测试行业中也会经常进行这些测试,如α测试、β测试、回归测试等,具体介绍如下。
- (1) α测试
- α测试是指对软件最初版本进行测试。软件最初版本一般不对外发布,在上线之前,由开发人员和测试人员或者用户协助进行测试。测试人员记录使用过程中出现的错误与问题整个测试过程是可控的。
- (2) β测试
- β测试是指对上线之后的软件版本进行测试,此时软件已上线发布,但发布的版本中可能会存在较轻微的Bug,由用户在使用过程中发现错误与问题并进行记录,然后反馈给开发人员进行修复。
- (3)回归测试
- 当测试人员发现缺陷以后,会将缺陷提交给开发人员,开发人员对程序进行修改,修改之后,测试人员会对修改后的程序重新进行测试,确认原有的缺陷已经消除并且没有引入新的缺陷,这个重新测试的过程就叫作回归测试。回归测试是软件测试工作中非常重要的一部分,软件开发的各个阶段都会进行多次回归测试。
- (4)随机测试
- 随机测试是没有测试用例、检查列表、脚本或指令的测试,它主要是根据测试人员的经验对软件进行功能和性能抽查。随机测试是根据测试用例说明书执行测试用例的重要补充手段,是保证测试覆盖完整性的有效方式和过程。
测试工具
- (1)
压力测试- wrk(请求)
- htop(cpu和内存占用)
- dstat(硬盘读写)
- tcpdump(网络包)
- iostat(io读写)
- netstat(网络连接)
- (2)
代码测试- unittest(单元测试)
- selenium(浏览器测试)
- mock/stub
- (3)
黑盒测试 - (4)
功能测试
指标概念
概念做下了解:
- 响应时间 (RT)
- 响应时间是指系统对请求作出响应的时间。直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。当然,往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。
- 对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的。
- 吞吐量 (Throughput)
- TPS 每秒完成的请求数(Request per Second)
- 吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。前面已经说过,对于单用户的系统,响应时间(或者系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统,通常需要用吞吐量作为性能指标。
- 对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t,当有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n×t小很多(当然,在某些特殊情况下也可能比n×t大,甚至大很多)。这是因为处理每个请求需要用到很多资源,由于每个请求的处理过程中有许多不走难以并发执行,这导致在具体的一个时间点,所占资源往往并不多。也就是说在处理单个请求时,在每个时间点都可能有许多资源被闲置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应时间并不随用户数的增加而线性增加。实际上,不同系统的平均响应时间随用户数增加而增长的速度也不大相同,这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致。
- 并发用户数
- 并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。一网站系统为例,假设用户只有注册后才能使用,但注册用户并不是每时每刻都在使用该网站,因此具体一个时刻只有部分注册用户同时在线,在线用户就在浏览网站时会花很多时间阅读网站上的信息,因而具体一个时刻只有部分在线用户同时向系统发出请求。这样,对于网站系统我们会有三个关于用户数的统计数字:注册用户数、在线用户数和同时发请求用户数。由于注册用户可能长时间不登陆网站,使用注册用户数作为性能指标会造成很大的误差。而在线用户数和同事发请求用户数都可以作为性能指标。相比而言,以在线用户作为性能指标更直观些,而以同时发请求用户数作为性能指标更准确些。
- QPS 每秒查询率 (Query Per Second)
- 每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 (类似于TPS,只是应用于特定场景的吞吐量)
压力测试
什么是压力测试
压力测试就是被测试的系统,在一定的访问压力下,看程序运行是否稳定/服务器运行是否稳定(资源占用情况)。压力测试涵盖性能测试,负载测试,并发测试等等,这些测试点常常交织耦合在一起。
压测方法
【2021-11-16】线上压测方法论
成熟的互联网研发体系下,一般会有测试环境和生产环境(线上环境)之分。
- 测试环境下进行功能测试、异常测试等
- 压力测试一般在线上环境进行。 这是为什么呢?
- 从压力测试的目的来看,进行压力测试往往是为了评估线上系统的容量,在正式上线对外前根据压测情况进行系统性能优化、性能bug修复、机器扩容,已使线上系统承压能力达到预期。
- 直接在线上环境做压测,能更加准确地得到结果,毕竟测试环境的机器数量、机器性能、网络拓扑、机房部署、链路结构(测试环境可能存在链路的某些模块是mock出来的,不真实)等和线上环境是有差别的。
但直接在线上环境做压测,会有什么风险呢?
- 向线上数据库写入大量脏数据,如果一次压测涉及多个表的联动写入,那么脏数据的清理将是非常繁琐的事,而且脏数据的清理操作也很可能造成线上事故。如果不清理脏数据,将对后续数据核对产生干扰,大量的数据存在也会造成数据库读变慢,存储压力变大等问题。
- 压力过大,造成线上系统瘫痪。
业界常用的线上压测的方案是进行影子链路改造,即将真实流量和压测流量区分开,压测流量经过影子链路流入影子表。具体步骤如下:
- step1: 创建影子表。一般直接复制真实表的表结构,根据需求构造一些数据写入影子表。
- step2:链路改造。修改代码,引入流量识别逻辑。一般对于ToC产品,在压测时选择userId为识别标识,在压测时构造一批压测userId(带有特定识,例如最后一位为特定字母等)。代码识别是压测userId,转入影子链路。
- step3: 压测执行。在压测执行时特别注意需要缓慢加压,防止压力过大压垮线上系统。压测前需理清压测链路涉及的各个系统,压测时做好系统监控察(观察机器资源情况(CPU、内存)、系统报错日志是否激增)。
- step4: 压测报告编写。压测完成后需产出压测报告。
- 报告格式可参考
压力测试与性能测试
压力测试和性能测试的区别:二者区别在于他们不同的测试目的
- 软件压力测试是为了发现系统能支持的最大负载,前提是要求系统性能处在可以接受的范围内,比如经常规定的页面3秒钟内响应;
- 所以一句话概括就是:在性能可以接受的前提下,测试系统可以支持的最大负载。
- 软件性能测试是为了检查系统的反映,运行速度等性能指标,他的前提是要求在一定负载下,如检查一个网站在100人同时在线的情况下的性能指标,每个用户是否都还可以正常的完成操作等。
- 概括就是:在不同负载下(负载一定)时,通过一些系统参数(如反应时间等)检查系统的运行情况。比如某个网站的性能差,严格上应该说在N人同时在线情况下,这个站点性能很差)。
总之,就像一个方程式:
综合性能 = 压力数 * 性能指数
综合性能是固定的:
- 软件压力测试是为了得到性能指数最小时候(可以接受的最小指数)最大的压力数
- 软件性能测试是为了得到压力数确定下的性能指数。
总结:
- 在项目上线之前,都需要做压力测试,目的是看下网站能抗住多少的压力,能承担多少并发,如果不做压力测试,一旦出现大访问量时,网站会挂掉,所以压力测试真的很重要,都应该重视起来!
- 压力测试总共需要几个步骤?思路总结篇
压测工具
- 【2022-2-18】如何做“健康码”的性能压测
- Web 高并发压测工具之 WRK, AB
业内常用的压测工具包括 JMeter、Gatling、Locust、k6、Tsung、阿里云 PTS 等。这些工具无一例外,都需要将压测业务的 API,编排为一个压测脚本。重点在确认压测的 API,不要有遗漏,且 API 编排的顺序要符合用户的操作逻辑。
常见压力测试工具有: ab, wrk
ab
安装
- yum -y install httpd-tools
命令选项
- -n 请求数
- -c 并发数
- -s 等待响应的时间默认 30 秒
- -H 自定义请求头参数,可多次使用该选项
- -T 设置 Content-Type 请求头信息
- -k 启用 HTTP KeepAlive 功能,即在一个 HTTP 会话中执行多个请求。默认时,不启用 KeepAlive 功能。
ab 示例
# 1. 基本实例
ab http://192.168.31.92/
# 2. 100 并发,5000 请求
ab -c 100 -n 5000 http://192.168.31.92/
# 3. 设置请求头信息 User-Agent
ab -c 500 -n 10000 \
-H "User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" http://192.168.31.92/
# 4. GET 传参
ab "http://192.168.31.91/api/test/?username=chris&password=123456"
# 5. POST 传参
echo "username="chris"&password="123456"" >> post.data
ab -p post.data -T "application/x-www-form-urlencoded" http://192.168.31.91/api/test/
wrk
wrk 是一种现代 HTTP 基准测试工具,当在多核 CPU 上运行时,能够产生大量负载, 它结合了多线程设计和可扩展的事件通知系统如 epoll 和 kqueue; 支持大多数类 Unix,不支持 Windows。基于 wrk 优化版的 wrk2, 其提供的额外参数 -R,用以指定每秒多少个请求限制
优势:
- 轻量级性能测试工具;
- 安装简单(相对 Apache ab 来说);
- 学习曲线基本为零,几分钟就能学会咋用了;
- 基于系统自带的高性能 I/O 机制,如 epoll, kqueue, 利用异步的事件驱动框架,通过很少的线程就可以压出很大的并发量;
劣势
- wrk 目前仅支持单机压测,后续也不太可能支持多机器对目标机压测,因为它本身的定位,并不是用来取代 JMeter, LoadRunner 等专业的测试工具,wrk 提供的功能,对我们后端开发人员来说,应付日常接口性能验证还是比较友好的。
钩子函数
- (1)启动阶段: 每个线程执行一次
- function setup(thread)
- function init(args) args 用于获取命令行中传入的参数
- (2)运行阶段: 每次请求调用 1 次
- function delay() 每次请求之前延迟多少毫秒
- function request() 生成请求
- function response(status, headers, body) 解析响应
- (3)结束阶段: 整个压测过程运行一次
- function done(summary, latency, requests) 可从参数给定的对象中,获取压测结果;
安装及命令选项
安装
git clone https://github.com/wg/wrk.git
cd wrk && make
cp wrk /usr/sbin/wrk && chmod +x /usr/sbin/wrk
命令选项
- 使用方法: wrk <选项> <被测HTTP服务的URL> Options:
- -c, –connections < N > 跟服务器建立并保持的TCP连接数量
- -d, –duration < T > 压测持续时间
- -t, –threads < N > 使用多少个线程进行压测
- -s, –script < S > 指定Lua脚本路径
- -H, –header < H > 为每一个HTTP请求添加HTTP头
- –latency 在压测结束后,打印延迟统计信息
- –timeout < T > 超时时间
- -v, –version 打印正在使用的wrk的详细版本信息
< N > 代表数字参数,支持国际单位 (1k, 1M, 1G) < T > 代表时间参数,支持时间单位 (2s, 2m, 2h)
wrk 示例
# 1. 基本示例
wrk -t2 -c30 -d30s --latency http://192.168.31.92/
# 对 www.baidu.com 发起压力测试,线程数为 12,模拟 400 个并发请求,持续 30 秒。
wrk -t12 -c400 -d30s http://www.baidu.com
# -------- 压测报告 -------
# Running 30s test @ http://192.168.31.92/
# 2 threads and 30 connections
# Thread Stats Avg Stdev Max +/- Stdev
# Latency 1.59ms 1.16ms 47.58ms 91.91% // 线程延迟状态
# Req/Sec 9.23k 846.07 12.38k 68.83% // 单个线程每秒请求数平均9.23k, 最大12.38k
# Latency Distribution // 所有请求的延迟分布, 75%的请求延迟小于1.77毫秒
# 50% 1.38ms
# 75% 1.77ms
# 90% 2.39ms
# 99% 5.95ms
# 551551 requests in 30.05s, 2.02GB read // 2个线程, 30s内55万次请求
# Requests/sec: 18355.61 // 2个线程每次请求1.8万次
# Transfer/sec: 68.95MB
# 2. POST|GET 传参请求测试
wrk -t2 -c10 --latency --script=params.data http://192.168.31.91/api/test/
请求参数 params.data
cat > post.data <<EOF
wrk.method = "POST"
wrk.body = "username=chris&password=123456"
wrk.headers["Content-Type"] = "application/x-www-form-urlencoded"
EOF
# 3. 修改请求头信息 User-Agent 测试
wrk -t2 -c10 -d10s --latency \
-H "User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" \
http://192.168.31.92/
# 4. 基于 lua 脚本定制测试报告
wrk -t2 -c10 -d10s -s setup.lua --latency http://192.168.31.92/
【2021-11-17】Jenkins + Jmeter,线上用kePTs
(1)收费:
- 阿里云性能测试PTS: PTS无需安装软件;脚本场景监控简单化,省时、省力;分布式并发压测,施压能力无上限;快速大规模集群扩容、支持几十万用户及百万级TPS性能压测;可模拟海量用户的真实业务场景,全方位验证业务站点的性能、容量和稳定性。
- 腾讯云压测大师:WeTest 压测大师(Load Master,LM)是简单易用的自动化性能测试平台,为用户提供测试框架及压测环境、创建虚拟机器人模拟产品多用户并发场景,支持 http 或https 协议,包括 Web/H5 网站、移动应用、API 、游戏等主流压测场景,适用于产品发布前及运营中的服务器压力测试及性能优化。
(2)免费:
- ① http_load:程序非常小,解压后也不到100K,http_load以并行复用的方式运行,用以测试web服务器的吞吐量与负载。但是它不同于大多数压力测试工具,它可以以一个单一的进程运行,一般不会把客户机搞死。还可以测试HTTPS类的网站请求。
- 下载地址:http_load-12mar2006.tar.gz
- 使用方法:http_load -p 并发访问进程数 -s 访问时间 需要访问的URL文件
- ② webbench:webbench是Linux下的一个网站压力测试工具,最多可以模拟3万个并发连接去测试网站的负载能力。
- 下载地址:webbench-1.5.tar.gz,这个程序更小,解压后不到50K
- 用法:webbench -c 并发数 -t 运行测试时间 URL
- ③ apache bench(主要是用来测试apache的): ab是apache自带的一款功能强大的测试工具。
- 安装了apache一般就自带了。
- webbench -c 1000 -t 130 https://iil.ink/m6c5a
- ④ Siege:一款开源的压力测试工具,可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
- Siege官方:http://www.joedog.org/
- Siege下载:siege-latest.tar.gz
- Siege使用: siege -c 100 -r 10 -f site.url
- ⑤ JMiter压测软件:一款通过不断提高对系统压力,用于测试系统性能,如负载,功能,性能,回归等;的有简洁明了的图形界面软件。参考地址
- ⑥ LoadRunner
- LoadRunner是惠普旗下一款自动负载测试工具,它能预测系统行为,优化性能。LoadRunner强调的是整个企业的系统,它通过模拟实际用户的操作行为和实行实时性能监测,来帮助更快的确认和查找问题。此外,LoadRunner 能支持最宽范的协议和技术,量身定做地提供解决方案。
单元测试
单元测试是开发人员编写的、用于检测在特定条件下目标代码正确性的代码。
- 软件开发天生就具有复杂性,没人敢打包票说自己写的代码没有问题,或者不经测试就能保证代码正确运行,因此,要保证程序的正确性就必须要对代码进行严格测试。
不写单元测试的理由
- 单元测试太花时间
- 测试不是研发的工作:测试确实不是开发人员的工作,但单元测试确实是开发人员的工作
- 代码都编译通过了,还测什么:代码编译通过只能说你写的代码符合语法要求,并不代表能保证正确性
- 代码原来就没有单元测试,并且难以测试
单元测试优点
- 便于后期重构。单元测试可以为代码的重构提供保障,只要重构代码之后单元测试全部运行通过,那么在很大程度上表示这次重构没有引入新的BUG,当然这是建立在完整、有效的单元测试覆盖率的基础上。
- 优化设计。编写单元测试将使用户从调用者的角度观察、思考,特别是使用TDD驱动开发的开发方式,会让使用者把程序设计成易于调用和可测试,并且解除软件中的耦合。
- 文档记录。单元测试就是一种无价的文档,它是展示函数或类如何使用的最佳文档,这份文档是可编译、可运行的、并且它保持最新,永远与代码同步。
- 具有回归性。自动化的单元测试避免了代码出现回归,编写完成之后,可以随时随地地快速运行测试,而不是将代码部署到设备之后,然后再手动地覆盖各种执行路径,这样的行为效率低下,浪费时间。
良好的接口设计、正确性、可回归、可测试、完善的调用文档、高内聚、低耦合
- 一个完整的测试脚本(用例)一般包含以下几个步骤:
- 环境准备或检查
- 执行业务操作
- 断言结果
- 清理环境
-
而测试框架一般还要完成用例加载,批量执行,异常控制,结果输出等功能。基础的测试框架一般只提供执行控制方面的功能。
- 【2020-10-15】单元测试
- ①单元测试,系统测试,集成测试,百度要求必须有单测代码,一般是正式代码的1.2倍,单测不过不能提测
- ②python单测有好多种方法,除了pytest,还有nosetest,unitest,后面两种除了mock,还有别的定制方法setup和teardown,分别指执行命令前后的操作
- ③执行单测后一般有自动生成的测试报告,通过率,覆盖率(条件覆盖,分支覆盖)
- ④断言assert仅适用于单测和非正式代码,线上模块避免使用,因为触发异常时整个进程会挂掉
- ⑤python类分新式类和旧式类,区别在于继承方式,多继承时出现重名函数时,一个深度遍历,一个广度遍历
单元测试工具
单测框架
- unittest: Python自带,最基础的单元测试框架
- nose: 基于unittest开发,易用性好,有许多插件
- pytest: 同样基于unittest开发,易用性好,信息更详细,插件众多
- robot framework:一款基于Python语言的关键字驱动测试框架,有界面,功能完善,自带报告及log清晰美观
总结(Python测试框架对比—-unittest, pytest, nose, robot framework对比)
- unittest比较基础,二次开发方便,适合高手使用;pytest/nose更加方便快捷,效率更高,适合小白及追求效率的公司;robot framework由于有界面及美观的报告,易用性更好,灵活性及可定制性略差。
各测试工具横向对比
 如果不想/不允许安装第三方库,那么 unittest 是最好也是唯一的选择。反之,pytest无疑是最佳选择,众多 Python 开源项目(如大名鼎鼎的 requests)都是使用 pytest 作为单元测试框架。甚至,连 nose2 在官方文档上都建议大家使用 pytest
如果不想/不允许安装第三方库,那么 unittest 是最好也是唯一的选择。反之,pytest无疑是最佳选择,众多 Python 开源项目(如大名鼎鼎的 requests)都是使用 pytest 作为单元测试框架。甚至,连 nose2 在官方文档上都建议大家使用 pytest
unitest
【2021-11-23】Python 单元测试 - unittest
unittest 是 python内置的用于测试代码的模块,无需安装, 使用简单方便。
- unittest中最核心的部分是:TestFixture、TestCase、TestSuite、TestRunner

unittest case的运行流程:
- 写好一个完整的TestCase
- 多个TestCase 由TestLoder被加载到TestSuite里面, TestSuite也可以嵌套TestSuite
- 由TextTestRunner来执行TestSuite,测试的结果保存在TextTestResult中
- TestFixture指的是环境准备和恢复
import unittest
# 继承 unittest.TestCase 来创建一个测试用例
class TestStringMethods(unittest.TestCase):
# 以 test 开头的方法,测试框架将把它作为独立的测试去执行。
# 每个用例都采用 unittest 内置的断言方法来判断被测对象的行为是否符合预期
def test_upper(self):
# 是否等于预期值
self.assertEqual('foo'.upper(), 'FOO')
# 检查字符串是否包含在其他字符串中
self.assertEqual('foo', 'this is foo my fool', '字符串确认包含')
self.assertNotIn('foo', 'this is foo my fool', '字符串不包含')
def test_isupper(self):
# 是否符合条件
self.assertTrue('FOO'.isupper()) # 真
self.assertFalse('Foo'.isupper()) # 假
def test_split(self):
s = 'hello world'
# 是否等于预期值
self.assertEqual(s.split(), ['hello', 'world'])
# check that s.split fails when the separator is not a string
# 是否抛出特定异常
with self.assertRaises(TypeError):
s.split(2)
if __name__ == '__main__':
unittest.main()
断言
| 断言语法 | 解释 | python最低版本 |
|---|---|---|
| assertEqual(a, b) | 判断a==b | - |
| assertNotEqual(a, b) | 判断a!=b | - |
| assertTrue(x) | bool(x) is True | - |
| assertFalse(x) | bool(x) is False | - |
| assertIs(a, b) | a is b | 3.1 |
| assertIsNot(a, b) | a is not b | 3.1 |
| assertIsNone(x) | x is None | 3.1 |
| assertIsNotNone(x) | x is not None | 3.1 |
| assertIn(a, b) | a in b | 3.1 |
| assertNotIn(a, b) | a not in b | 3.1 |
| assertIsInstance(a, b) | isinstance(a, b) | 3.1 |
| assertNotIsInstance(a, b) | not isinstance(a, b) | 3.1 |
| assertAlmostEqual(a, b) | round(a-b, 7) == 0 | |
| assertNotAlmostEqual(a, b) | round(a-b, 7) != 0 | |
| assertGreater(a, b) | a > b | |
| assertGreaterEqual(a, b) | a >= b | |
| assertLess(a, b) | a < b | |
| assertLessEqual(a, b) | a <= b | |
| assertRegexpMatches(s, re) | regex.search(s) | |
| assertNotRegexpMatches(s, re) | not regex.search(s) | |
| assertItemsEqual(a, b) | sorted(a) == sorted(b) and works with unhashable objs | |
| assertDictContainsSubset(a, b) | all the key/value pairs in a exist in b | |
| assertMultiLineEqual(a, b) | strings | |
| assertSequenceEqual(a, b) | sequences | |
| assertListEqual(a, b) | lists | |
| assertTupleEqual(a, b) | tuples | |
| assertSetEqual(a, b) | sets or frozensets | |
| assertDictEqual(a, b) | dicts | |
| assertMultiLineEqual(a, b) | strings | |
| assertSequenceEqual(a, b) | sequences | |
| assertListEqual(a, b) | lists | |
| assertTupleEqual(a, b) | tuples | |
| assertSetEqual(a, b) | sets or frozensets 2.7assertDictEqual(a, b) dicts |
核心功能
nittest中最核心的部分是:TestFixture、TestCase、TestSuite、TestRunner
测试夹具(Fixtures)
- 测试夹具也就是测试前置(setUp)和清理(tearDown)方法。
- 测试前置方法 setUp() 用来做一些准备工作,比如建立数据库连接。它会在用例执行前被测试框架自动调用。
- 测试清理方法 tearDown() 用来做一些清理工作,比如断开数据库连接。它会在用例执行完成(包括失败的情况)后被测试框架自动调用。
- 测试前置和清理方法可以有不同的执行级别。
- ① 方法:setUp、tearDown,每个测试方法执行时分别执行一次
- ② 类:setUpClass、tearDownClass,只执行一次
- ③ 模块: setUpModule()、tearDownModule(),单个测试模块中只执行一次前置方法,再执行该模块中所有测试类的所有测试,最后执行一次清理方法
(1)Test Fixture用于测试环境的准备和恢复还原, 一般用到下面几个函数。
- setUp():准备环境,执行每个测试用例的前置条件
- tearDown():环境还原,执行每个测试用例的后置条件
- setUpClass():必须使用@classmethod装饰器,所有case执行的前置条件,只运行一次
- tearDownClass():必须使用@classmethod装饰器,所有case运行完后只运行一次
(2)Test Case
- 参数verbosity可以控制错误报告的详细程度:默认为1。0表示不输出每一个用例的执行结果;2 表示详细的执行报告结果。
- Verbosity=1 情况下成功是 .,失败是 F,出错是 E,跳过是 S
- 测试的执行跟方法的顺序没有关系, 默认按字母顺序
- 每个测试方法均以 test 开头
- Verbosity=2情况下会打印测试的注释
(3)Test Suite
- 一般通过 addTest() 或者 addTests() 向 suite 中添加。case的执行顺序与添加到Suite中的顺序是一致的
跳过测试或预计失败
unittest 支持直接跳过或按条件跳过测试,也支持预计测试失败:
- 通过 skip 装饰器或 SkipTest 直接跳过测试
- 通过 skipIf 或 skipUnless 按条件跳过或不跳过测试
- 通过 expectedFailure 预计测试失败
@unittest.skip()装饰器跳过某个case
- ① skip():无条件跳过
- @unittest.skip(“i don’t want to run this case. “)
- ② skipIf(condition,reason):如果condition为true,则 skip
- @unittest.skipIf(condition,reason)
- ③ skipUnless(condition,reason):如果condition为False,则skip
- @unittest.skipUnless(condition,reason)
class MyTestCase(unittest.TestCase):
@unittest.skip("直接跳过")
def test_nothing(self):
self.fail("shouldn't happen")
@unittest.skipIf(mylib.__version__ < (1, 3),
"满足条件跳过")
def test_format(self):
# Tests that work for only a certain version of the library.
pass
@unittest.skipUnless(sys.platform.startswith("win"), "满足条件不跳过")
def test_windows_support(self):
# windows specific testing code
pass
def test_maybe_skipped(self):
if not external_resource_available():
self.skipTest("跳过")
# test code that depends on the external resource
pass
@unittest.expectedFailure
def test_fail(self):
self.assertEqual(1, 0, "这个目前是失败的")
子测试
- 在一个测试方法中传入不同的参数来测试同一段逻辑,但它将被视作一个测试,但是如果使用了子测试,就能被视作 N(即为参数的个数)个测试。
class NumbersTest(unittest.TestCase):
def test_even(self):
"""
Test that numbers between 0 and 5 are all even.
"""
for i in range(0, 6):
# 定义子测试, 即使单个子测试执行失败,也不会影响后续子测试的执行
with self.subTest(i=i):
self.assertEqual(i % 2, 0)
(4)Test Loader
- TestLoadder用来加载TestCase到TestSuite中。
loadTestsFrom*()方法从各个地方寻找testcase,创建实例,然后addTestSuite,再返回一个TestSuite实例
defaultTestLoader() 与 TestLoader()功能差不多,复用原有实例
- unittest.TestLoader().loadTestsFromTestCase(testCaseClass)
- unittest.TestLoader().loadTestsFromModule(module)
- unittest.TestLoader().loadTestsFromName(name,module=None)
- unittest.TestLoader().loadTestsFromNames(names,module=None)
- unittest.TestLoader().discover()
用例发现和执行
unittest 支持用例自动(递归)发现:
- 默认发现当前目录下所有符合 test*.py 测试用例
- 使用 python -m unittest 或 python -m unittest discover
- 通过 -s 参数指定要自动发现的目录, -p 参数指定用例文件的名称模式
- python -m unittest discover -s project_directory -p “test_*.py”
- 通过位置参数指定自动发现的目录和用例文件的名称模式
- python -m unittest discover project_directory “test_*.py”
unittest 支持执行指定用例:
- 指定测试模块
- python -m unittest test_module1 test_module2
- 指定测试类
- python -m unittest test_module.TestClass
- 指定测试方法
- python -m unittest test_module.TestClass.test_method
- 指定测试文件路径(仅 Python 3)
- python -m unittest tests/test_something.py
示例:常规函数测试
代码测试脚本demo.py内容:
#!/usr/bin/python
# -*- coding: utf-8 -*-
def add(a, b):
return a+b
def minus(a, b):
return a-b
单测编写步骤:
- 先导入unittest模块;
- 创建一个类(任意名)继承unittest.TestCase;
- 编写需要测试的代码对函数进行各方面的测试。
单测脚本:test_demo_class.py
# !/usr/bin/env python
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2021 ke.com, Inc. All Rights Reserved
# **************************************************************************
# * @function 单元测试(业务线功能说明,如:FAQ服务端)
# * @author wangqiwen004@test.com
# * @date 2021/11/24 17:35
# **************************************************************************
import unittest
# 导入待测试函数
from demo import add, minus
# def setUpModule():
# pass
# def tearDownModule():
# pass
class TestDemo(unittest.TestCase):
"""Test mathfuc.py"""
@classmethod
def setUpClass(cls):
# 所有测试用例公用的初始化
print ("this setupclass() method only called once.\n")
@classmethod
def tearDownClass(cls):
# 所有测试用例公用的销毁
print ("this teardownclass() method only called once too.\n")
def setUp(self):
#
print ("do something before test : prepare environment.\n")
def tearDown(self):
print ("do something after test : clean up.\n")
def test_add(self):
"""Test method add(a, b)"""
self.assertEqual(3, add(1, 2))
self.assertNotEqual(3, add(2, 2))
def test_minus(self):
"""Test method minus(a, b)"""
self.assertEqual(1, minus(3, 2))
self.assertNotEqual(1, minus(3, 2))
@unittest.skip("do't run as not ready")
def test_minus_with_skip(self):
"""Test method minus(a, b)"""
self.assertEqual(1, minus(3, 2))
self.assertNotEqual(1, minus(3, 2))
if __name__ == '__main__':
# verbosity=*:默认是1;设为0,则不输出每一个用例的执行结果;2-输出详细的执行结果
# ----- 运行所有用例 ------
unittest.main(verbosity=1)
# ------ 运行指定用例 ------
suite = unittest.TestSuite() # 实例化用例集合
suite.addTest(TestDemo("test_add")) #把testsub1测试用例添加到用例集
suite.addTest(TestDemo("test_minus"))
runner = unittest.TextTestRunner() #实例化运行类
runner.run(suite) #运行用例集,会根据添加的用例顺序进行用例的执行
import os
# ----- 通过路径自动识别测试用例 -------
test_dir = os.path.join(os.path.dirname(os.path.realpath(__file__))) # 获取当前工作目录
# 用discover的方法去覆盖所有的测试用例
# test_dir 要执行的测试用例目录
# test*表示匹配以test开头的所有.py文件
# top_level_dir=None 测试模块的顶级目录,没有的话就写None
discover = unittest.defaultTestLoader.discover(test_dir, pattern="test*.py", top_level_dir=None)
runner = unittest.TextTestRunner() # 实例化runner类
runner.run(discover) # 执行路径中匹配的所有test*.py用例
test_demo_module.py文件
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
import HTMLReport
import unittest
import test_demo_class
from test_demo_class import TestDemo
if __name__ == '__main__':
paras = sys.argv[1:]
args = paras[0]
report = paras[1]
suite = unittest.TestSuite()
if args == 'test': # 逐个测试
tests = [TestDemo("test_minus"), TestDemo("test_add"), TestDemo("test_minus_with_skip")]
suite.addTests(tests)
elif args == 'tests': # 批量测试
suite.addTest(TestDemo("test_minus"))
suite.addTest(TestDemo("test_add"))
suite.addTest(TestDemo("test_minus_with_skip"))
elif args == 'class': # 测试类
suite.addTests(unittest.TestLoader().loadTestsFromTestCase(TestDemo))
elif args == 'module': # 测试函数
suite.addTests(unittest.TestLoader().loadTestsFromModule(test_demo_class))
elif args == 'mix':
suite.addTests(unittest.TestLoader().loadTestsFromName('test_demo_class.TestDemo.test_minus'))
elif args == 'mixs':
suite.addTests(unittest.TestLoader().loadTestsFromNames(['test_demo_class.TestDemo.test_minus', 'test_demo_class.TestDemo', 'test_demo_class']))
elif args == 'discover': # 自动识别目录里的单测文件
suite.addTests(unittest.TestLoader().discover('.', 'test_*.py', top_level_dir=None))
if report == 'terminal': # 终端测试
runner = unittest.TextTestRunner(verbosity=1)
runner.run(suite)
elif report == 'txt': # 读文件
with open('ut_log.txt', 'a') as fp:
runner = unittest.TextTestRunner(stream=fp, verbosity=1)
runner.run(suite)
elif report == 'html': # 生成测试报告
runner = HTMLReport.TestRunner(report_file_name='test',
output_path='report',
title='测试报告',
description='测试描述',
sequential_execution=True
)
runner.run(suite)
示例:web服务测试
待测试代码:demo1_login.py
# !/usr/bin/env python
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2021 ke.com, Inc. All Rights Reserved
# **************************************************************************
# * @function 单元测试(业务线功能说明,如:FAQ服务端)
# * @author wangqiwen004@test.com
# * @date 2021/11/24 17:35
# **************************************************************************
from flasgger import Swagger
from flask import Flask, request, redirect
app = Flask(__name__)
Swagger(app)
@app.route('/login', methods=['POST'])
def login():
"""
用户登录
"""
username = request.form.get('username')
password = request.form.get('password')
# 判断参数是否为空
if not all([username, password]):
result = {
"errcode": -2,
"errmsg": "params error"
}
return jsonify(result)
# a = 1 / 0
# 如果账号密码正确
# 判断账号密码是否正确
if username == 'itheima' and password == 'python':
result = {
"errcode": 0,
"errmsg": "success"
}
return jsonify(result)
else:
result = {
"errcode": -1,
"errmsg": "wrong username or password"
}
return jsonify(result)
单元测试代码:
# !/usr/bin/env python
# -*- coding:utf8 -*-
# **************************************************************************
# * Copyright (c) 2021 ke.com, Inc. All Rights Reserved
# **************************************************************************
# * @function 单元测试(业务线功能说明,如:FAQ服务端)
# * @author wangqiwen004@test.com
# * @date 2021/11/24 17:35
# **************************************************************************
import json
import unittest
from demo1_login import app
class LoginTest(unittest.TestCase):
"""
为登录逻辑编写测试案例
"""
@classmethod
def setUpClass(cls):
# 所有测试用例公用的初始化
print ("this setupclass() method only called once.\n")
@classmethod
def tearDownClass(cls):
# 所有测试用例公用的销毁
print ("this teardownclass() method only called once too.\n")
def setUp(self):
# 用例前置工作
app.testing = True
self.client = app.test_client()
def tearDown(self):
# 用例后续销毁
print ("do something after test : clean up.\n")
def test_empty_username_password(self):
"""测试用户名与密码为空的情况[当参数不全的话,返回errcode=-2]"""
response = app.test_client().post('/login', data={})
json_data = response.data
json_dict = json.loads(json_data)
self.assertIn('errcode', json_dict, '数据格式返回错误')
self.assertEqual(json_dict['errcode'], -2, '状态码返回错误')
# TODO 测试用户名为空的情况
# TODO 测试密码为空的情况
def test_error_username_password(self):
"""测试用户名和密码错误的情况[当登录名和密码错误的时候,返回 errcode = -1]"""
response = app.test_client().post('/login', data={"username": "aaaaa", "password": "12343"})
json_data = response.data
json_dict = json.loads(json_data)
self.assertIn('errcode', json_dict, '数据格式返回错误')
self.assertEqual(json_dict['errcode'], -1, '状态码返回错误')
def test03(self):
"""
直接调用request包
"""
url = 'https://api.apiopen.top/searchMusic'
data = {
"name":"芒种"
}
r = requests.post(url,data=data)
a = '抖音'
b = r.text
try:
self.assertIn(a,b,msg='\n抖音不存在芒种歌曲信息中')
except Exception as msg:
print('错误信息%s'%msg)
print('第三个用例失败')
if __name__ == '__main__':
unittest.main()
示例:数据库测试
单元测试代码:
#coding=utf-8
import unittest
from author_book import *
#自定义测试类,setUp方法和tearDown方法会分别在测试前后执行。以test_开头的函数就是具体的测试代码。
class DatabaseTestCase(unittest.TestCase):
def setUp(self):
app.config['TESTING'] = True
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@localhost/test0'
self.app = app
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
#测试代码
def test_append_data(self):
au = Author(name='xxxxx')
bk = Book(info='python')
db.session.add_all([au,bk])
db.session.commit()
author = Author.query.filter_by(name='itcast').first()
book = Book.query.filter_by(info='python').first()
#断言数据存在
self.assertIsNotNone(author)
self.assertIsNotNone(book)
测试报告
Testing Report
- 终端报告: 如上terminal 分支
- TXT报告: 如上txt 分支,当前目录会生成ut_log.txt文件
- HTML 报告:如上html 分支,终端上打印运行信息同时会在当前目录生成report文件夹, 文件夹下有test.html和test.log文件 更多见Python 单元测试 - HTML report

-
如果想要生成 HTML 格式的报告,那么就需要额外借助第三方库(如 HtmlTestRunner)来操作。
自动生成测试用例
【2021-12-10】对于n条测试用例,还需要写满篇的test_1 ,test_2么?
nose
nose 是一个第三方单元测试框架,它完全兼容 unittest,并且号称是一个更好用的测试框架。
用例编写方式除了编写继承于 unittest.TestCase 的测试类外,还可以编写成没有继承的测试类。
- 没有继承 unittest.TestCase,将不能使用其内置的各类 assertXXX 方法,进而导致用例出错时无法获得更加详细的上下文信息。
from nose.tools import raises
class TestStringMethods:
def test_upper(self):
# nose 也支持定义函数来作为测试
assert 'foo'.upper() == 'FOO'
def test_isupper(self):
assert 'FOO'.isupper()
assert not 'Foo'.isupper()
@raises(TypeError)
def test_split(self):
s = 'hello world'
assert s.split() == ['hello', 'world']
# check that s.split fails when the separator is not a string
s.split(2)
示例:MapReduce任务
test目录结构:
- bin:存储单测代码
- 文件名:test_appsearch.py
- case:测试用例
- test:输入数据
- check:期望结果
#!/usr/bin/env python
#-*- coding:gbk -*-
from shunit import *
from nose.tools import *
import sys
sys.path.append("../../bin/hadoop_jobs")
job_name = 'appsearch'
source_dir = "../../bin/hadoop_jobs/%s"%(job_name) # 源代码目录
data_dir = "../case/%s"%(job_name) # 测试用例目录
call_cmd("touch "+source_dir+"/__init__.py")
exec 'from %s import mapper'%(job_name)
#-----setUp 和 teardown为总控函数,函数的执行顺序为setup 单测函数1 ... 单测函数n teardown---
def setUp():
call_cmd("[ ! -e "+data_dir+"/test ]&&mkdir "+data_dir+"/test")
pass ####本函数在测试函数执行前进行一些总体的初始化的工作###
def tearDown():
#print os.getcwd()
call_cmd("rm *.pyc diff file*")
# 创建test目录
call_cmd("rm "+source_dir+"/__init__.py "+source_dir+"/*pyc")
pass ####本函数在测试函数执行后进行一些总体的清理的工作###
#--------------------------------------------------------------------------------------------
def test_mapper():
# 准备环境变量
#sys.argv=['','cookie','mergeOneDay'] # 用于区分数据源的匹配字符串
input=open(data_dir+"/check/webmarket.txt",'r')
output=open(data_dir+"/test/mapper1.txt",'w')
# 调用主函数
ret = mapper.main(input,output)
output.flush();output.close();input.close()
# 检查结果
runDiffIsNotExist(data_dir+"/check/mapper1.txt",data_dir+"/test/mapper1.txt","diff")
def test_mapper_sort():
cmd1="cat "+data_dir+"/test/mapper?.txt | sort > "+data_dir+"/test/mapper_sort.txt"
(ret, stdout, stderr)=call_cmd(cmd1)
# 检查结果
runDiffIsNotExist(data_dir+"/check/mapper_sort.txt",data_dir+"/test/mapper_sort.txt","diff")
pytest 用法
主要特性:
- assert 断言失败时输出详细信息(再也不用去记忆
self.assert*名称了) - 自动发现 测试模块和函数
- 模块化夹具 用以管理各类测试资源
- 对
unittest完全兼容,对nose基本兼容 - 非常丰富的插件体系,有超过 315 款第三方插件,社区繁荣
同 nose 一样,pytest 支持函数、测试类形式的测试用例。最大的不同点是,你可以尽情地使用 assert 语句进行断言,丝毫不用担心它会在 nose 或 unittest 中产生的缺失详细上下文信息的问题。
- [2020-11-6] 经验总结, 提交代码前,执行单测,确保代码功能无误
- 主目录下执行命令: pytest使用笔记(一)
- pytest # 整体报告
- pytest -q # 运行简单模式测试报告
- pytest -x # 在第一个测试用例发生错误时就停止运行
- pytest –maxfail=2 # 在第2个测试用例发生错误时就停止运行
- pytest test_mod.py # 执行具体文件
- pytest test # 运行单个文件的用例
- pytest -k “TestClass” # 运行某些包含关键字的用例,如包含TestClass的用例
- pytest test_class.py::TestClass # 运行某一文件内特定模块的用例
- pytest -m slow # 运行用@ pytest.mark.slow装饰器修饰的用例
示例
import pytest
def test_upper():
assert 'foo'.upper() == 'FOO1'
class TestClass:
def test_one(self):
x = "this"
assert "h" in x
def test_two(self):
x = "hello"
with pytest.raises(TypeError):
x + []
而当使用 pytest 去执行用例时,它会输出详细的(且是多种颜色)上下文信息. pytest 既输出了测试代码上下文,也输出了被测变量值的信息。相比于 nose 和 unittest,pytest 允许用户使用更简单的方式编写测试用例,又能得到一个更丰富和友好的测试结果。
unittest 和 nose 所支持的用例发现和执行能力,pytest 均支持。 pytest 支持用例自动(递归)发现:
- 默认发现当前目录下所有符合 test_*.py 或 *_test.py 的测试用例文件中,以 test 开头的测试函数或以 Test 开头的测试类中的以 test 开头的测试方法
- 使用 pytest 命令
- 同 nose2 的理念一样,通过在配置文件中指定特定参数,可配置用例文件、类和函数的名称模式(模糊匹配)
pytest 也支持执行指定用例:
# 指定测试文件路径
pytest /path/to/test/file.py
# 指定测试类
pytest /path/to/test/file.py:TestCase
# 指定测试方法
pytest another.test::TestClass::test_method
# 指定测试函数
pytest /path/to/test/file.py:test_function
pytest 的测试夹具(Fixtures)和 unittest、nose、nose2的风格迥异,它不但能实现 setUp 和 tearDown这种测试前置和清理逻辑,还其他非常多强大的功能。
- 声明和使用
- 共享
- 生效级别,pytest 的测试夹具同样支持各类生效级别,且更加丰富。通过在 pytest.fixture 中指定 scope 参数来设置:
- function —— 函数级,即调用每个测试函数前,均会重新生成 fixture
- class —— 类级,调用每个测试类前,均会重新生成 fixture
- module —— 模块级,载入每个测试模块前,均会重新生成 fixture
- package —— 包级,载入每个包前,均会重新生成 fixture
- session —— 会话级,运行所有用例前,只生成一次 fixture
测试结果输出
pytest 的测试结果输出相比于 unittest 和 nose 来说更为丰富,其优势在于:
- 高亮输出,通过或不通过会用不同的颜色进行区分
- 更丰富的上下文信息,自动输出代码上下文和变量信息
- 测试进度展示
- 测试结果输出布局更加友好易读
robot framework
- 待添加
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
