- Pandas
- 结束
Pandas
- Pandas 提供了数据结构 —— DataFrame,可以高效的处理一些数据分析任务。我们日常分析的数据,大多是存储在类似 excel 的数据表中,Pandas 可以灵活的按列或行处理数据,几乎是最常用的工具了。
- 官方api大全
介绍
Pandas(Python data analysis)是一个Python数据分析的开源库。名字源于panel data(计量经济学术语,面板数据)和python data analysis
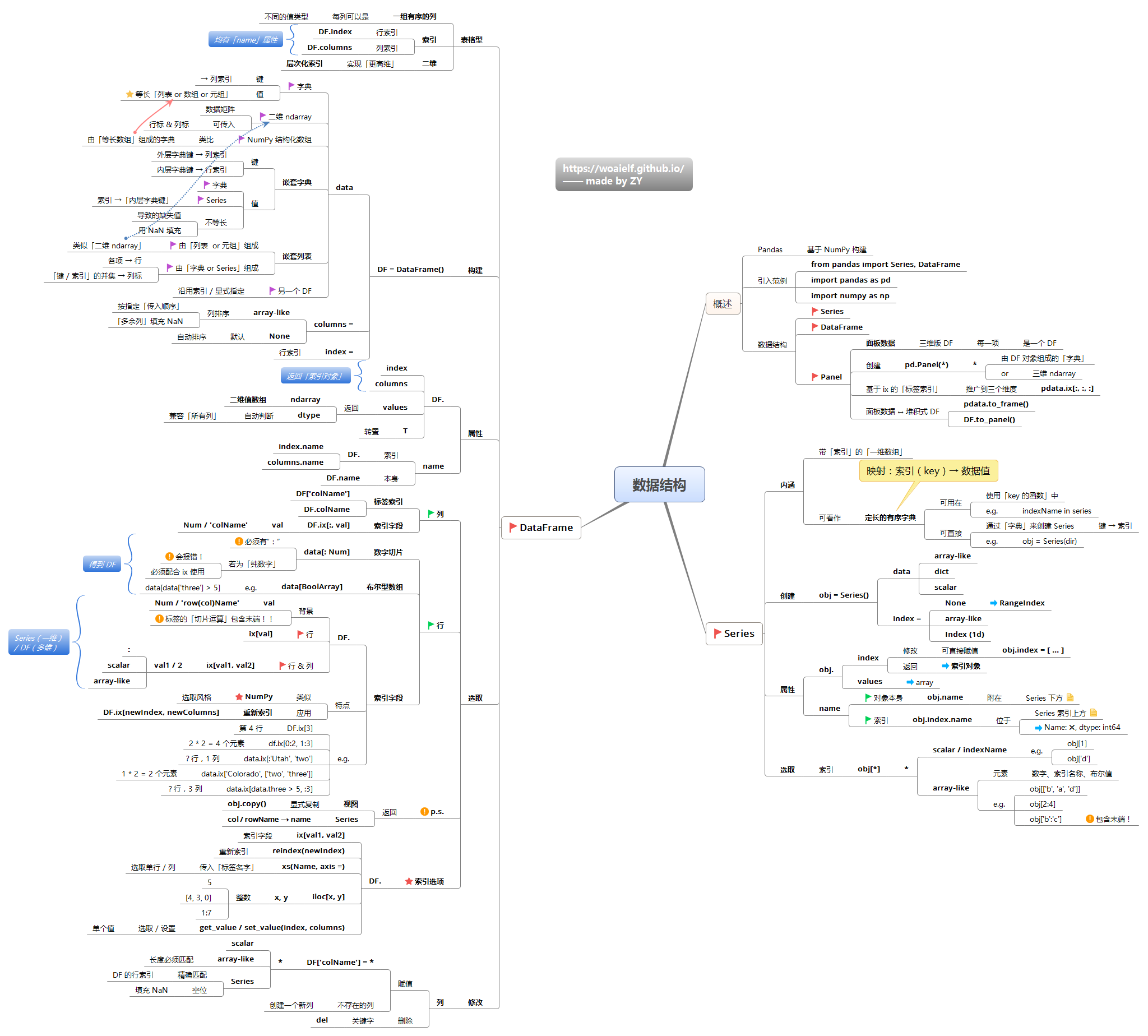
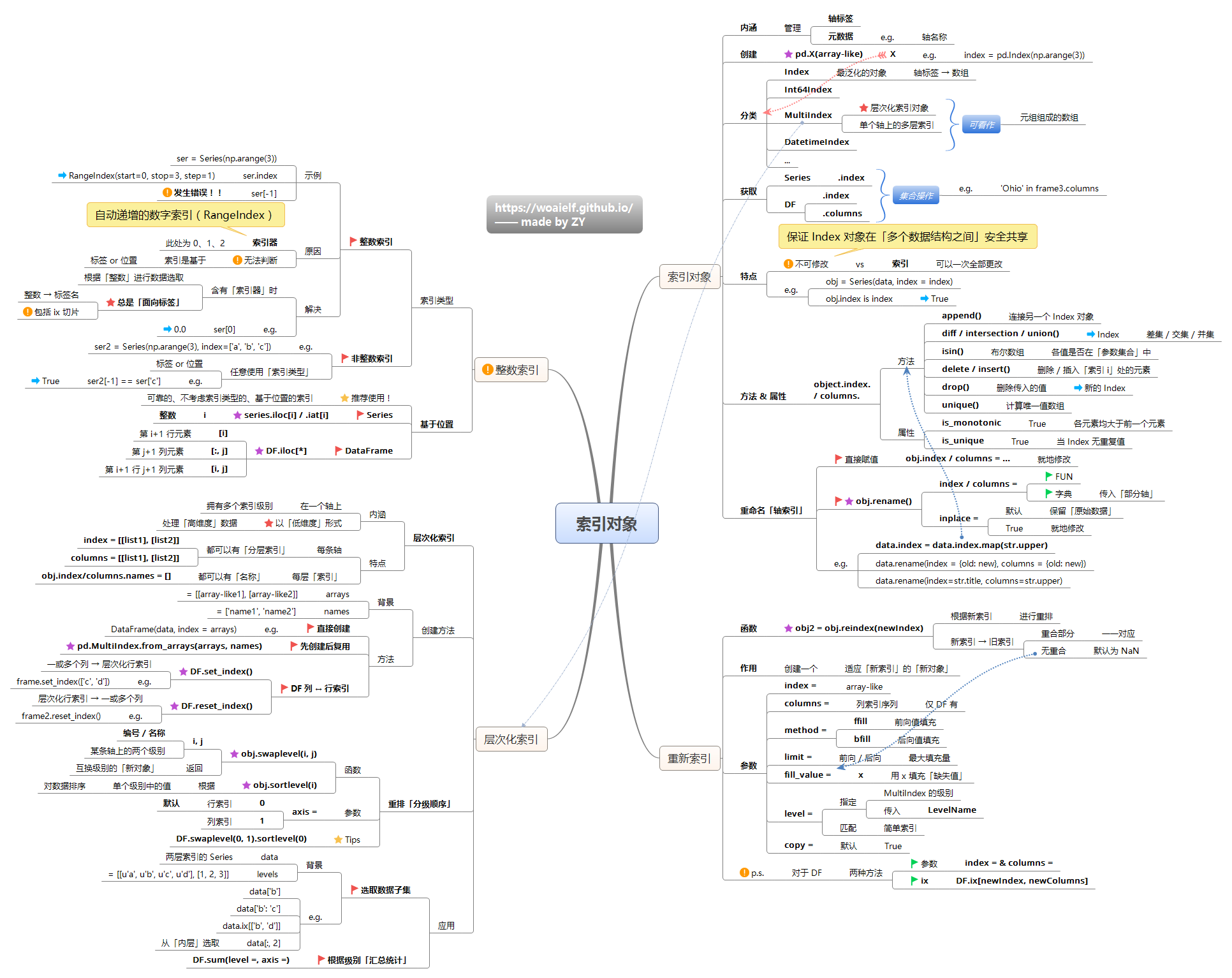
pandas三种数据结构:
Series(一维): 系列(Series)是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引。DataFrame(二维)Panel(三维)

简单对上面三种方法进行说明:
- iterrows(): 按行遍历,将DataFrame的每一行迭代为(index, Series)对,可以通过row[name]对元素进行访问。
- itertuples(): 按行遍历,将DataFrame的每一行迭代为元祖,可以通过row[name]对元素进行访问,比iterrows()效率高。
- iteritems():按列遍历,将DataFrame的每一列迭代为(列名, Series)对,可以通过row[index]对元素进行访问。
Series
系列(Series)是能保存任何类型数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引

- 数据访问
- 序列聚合


官方文档
import pandas as pd
import numpy as np
d = {'a': 1, 'b': 2, 'c': 3}
ser = pd.Series(data=d, index=['a', 'b', 'c'])
# 从 ndarray 创建series
pd.Series(np.array([1,2,3,4])) # index自动设置:0-3
pd.Series([1, 2, 3]).values # array([1, 2, 3])
pd.Series(list('aabc')).values # array(['a', 'a', 'b', 'c'], dtype=object)
pd.Series(list('aabc')).astype('category').values # ['a', 'a', 'b', 'c'] Categories (3, object): ['a', 'b', 'c']
# 从字典创建series
pd.Series({'a':1, 'b':2, 'c':3}) # index为字典的key: a,b,c
# 生成连续日期
d.Series(pd.date_range('20130101', periods=3, tz='US/Eastern')).values # 2013-01-01 ~ 01-03
DataFrame
DataFrame(数据帧)是带有标签的二维数据结构,列的类型可能不同。可以想象成一个电子表格或SQL表,或者 Series 对象的字典。它一般是最常用的pandas对象。


创建 DataFrame
创建方式:列表、字段
import pandas as pd
import numpy as np
# 从 list 创建 dataframe
pd.DataFrame([[1,2],[3,4]]) # index自动设置
# List1
lst = [['tom', 'reacher', 25], ['krish', 'pete', 30],
['nick', 'wilson', 26], ['juli', 'williams', 22]]
df = pd.DataFrame(lst, columns =['FName', 'LName', 'Age'], dtype = float)
print(df)
# 从 字典 创建 dataframe
pd.DataFrame({'a':[1,3], 'b':[2,4]}) # columns 为字典的key: a,b
pd.DataFrame({'a':[1,3], 'b':[2,4]}, columns=['a','b'])
data = {'col_1': [3, 2, 1, 0], 'col_2': ['a', 'b', 'c', 'd']}
pd.DataFrame.from_dict(data)
# col_1 col_2
# 0 3 a
# 1 2 b
# 2 1 c
# 3 0 d
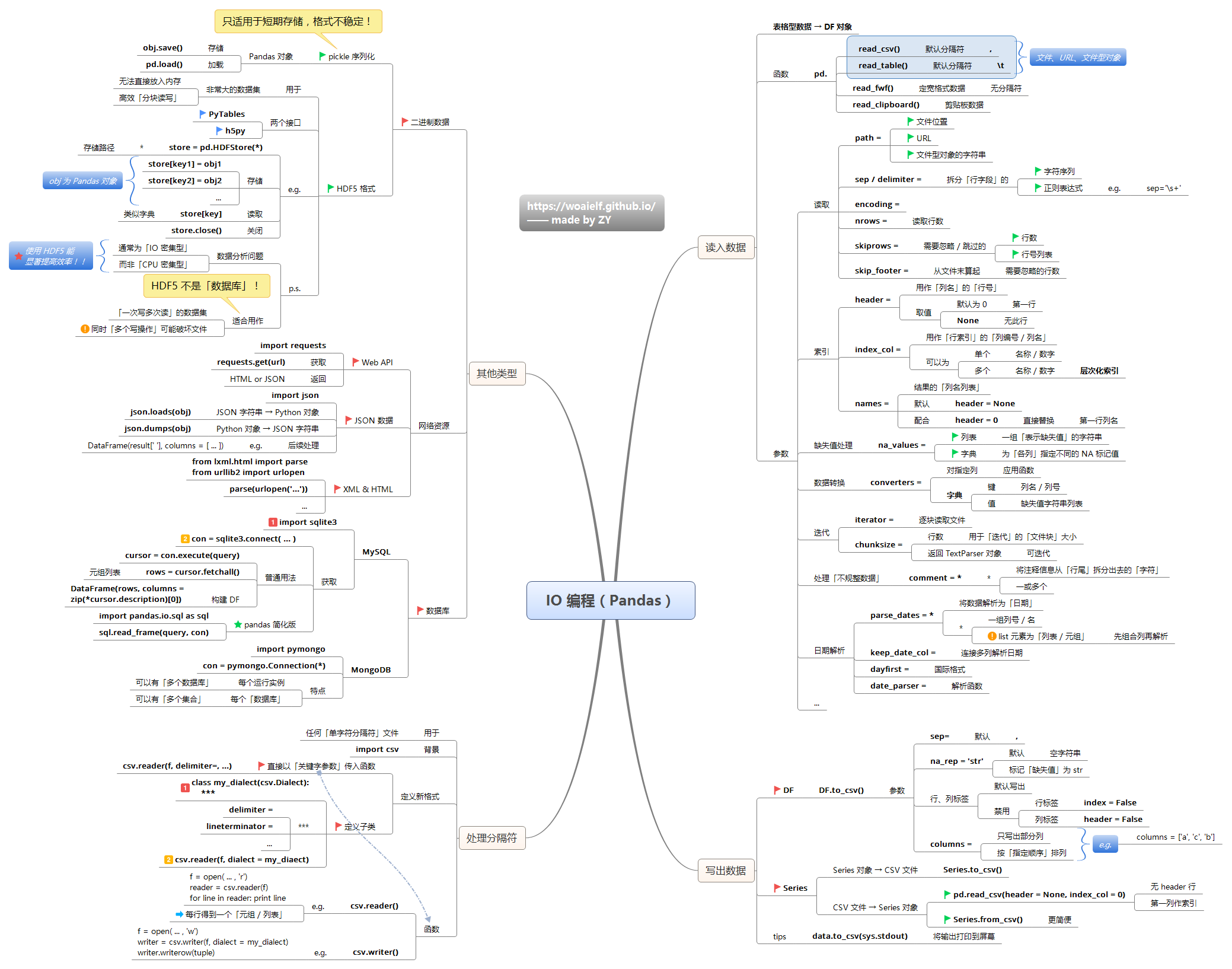
读文件
pd读取文件
- parse_dates(动词,主动解析格式)
- date_parser(名词,指定解析格式去解析某种不常见的格式)
parse_dates = True # 尝试解析index为日期格式;
parse_dates = [ 0,1,2,3,4] # 尝试解析0,1,2,3,4列为时间格式;
parse_dates = [ [ '考试日期','考试时间'] ] # 传入多列名,尝试将其解析并且拼接起来,parse_dates[[0,1,2]]也有同样的效果;
parse_dates = {'考试安排时间':[ '考试日期','考试时间']} # 将会尝试解析日期和时间拼接起来,并将列名重置为'考试安排时间';
# 注意:重置后列名不能和原列名重复
# date_parser 需要配合parse_dates工作,具体需要传入函数
# 例如时间为2021年2月24日,可以传入
parse_dates=[ 0 ]
date_parser=lambda x:pd.to_datetime(x,format='%Y年%m月%d日')
read_csv
【2022-1-24】直接加载github数据
import pandas as pd
# github repo 中文件地址,需要转换:"https://github.com/sksujan58/Multivariate-time-series-forecasting-using-LSTM/blob/main/train.csv"
url = "https://raw.githubusercontent.com/sksujan58/Multivariate-time-series-forecasting-using-LSTM/master/train.csv"
#df = pd.read_csv(url,parse_dates=["Date"])
#df0 = pd.read_csv(url)
#df = pd.read_csv("train.csv", parse_dates=["Date"],index_col=[0])
df = pd.read_csv(url, parse_dates=["Date"], index_col=[0]) # Date格式转换(str→date),指定Date作为索引列
# 文件读取
pd.read_csv("girl.csv")
# URL 文件读取
pd.read_csv("http://localhost/girl.csv")
# 文件流读取 _io.TextIOWrapper
f = open("girl.csv", encoding="utf-8")
pd.read_csv(f)
# 参数
pd.read_csv('girl.csv', sep='\t') # 指定分隔符
pd.read_csv('girl.csv', delimiter='\t')
pd.read_csv('girl.csv', delim_whitespace=True) # 分割符为空白字符、空格、"\t"等等
# 指定表头,默认 header=0. 不指定names,指定header为1,则选取第二行当做表头,第二行下面为数据
pd.read_csv('girl.csv',delim_whitespace=True, header=1)
# 指定表头,names 自定义表头信息
pd.read_csv('girl.csv', delim_whitespace=True, names=["编号", "姓名", "地址", "日期"])
# header 和 names 同时存在,优先 header
pd.read_csv('girl.csv', delim_whitespace=True, names=["编号", "姓名", "地址", "日期"], header=0)
# 没有 header 时,自动设置表头,predix 指定 字段前缀
pd.read_csv('girl.csv', delim_whitespace=True, header=None, prefix="夏色祭")
# 设置索引
pd.read_csv('girl.csv', delim_whitespace=True, index_col="name")
# 筛选指定列
pd.read_csv('girl.csv', delim_whitespace=True, usecols=["name", "address"])
# 读取1行
pd.read_csv('girl.csv', sep="\t", nrows=1)
# 跳过指定行
pd.read_csv('girl.csv', sep="\t", skiprows=[0])
pd.read_csv('girl.csv', sep="\t", skiprows=lambda x: x > 0 and x % 2 == 0)
# 设置字段类型 id 为字符串
df = pd.read_csv('girl.csv', delim_whitespace=True, dtype={"id": str})
# 取值矫正
pd.read_csv('girl.csv', sep="\t", true_values=["对"], false_values=["错"])
pd.read_csv('girl.csv', sep="\t", na_values=["对", "古明地觉"])
# 时间、日期处理
from datetime import datetime
pd.read_csv('girl.csv', sep="\t", parse_dates=["date"], date_parser=lambda x: datetime.strptime(x, "%Y年%m月%d日"))
【2025-7-6】windows 下使用 read_csv 时,务必注意路径!
import os
import pandas as pd
# data_dir = 'E:\llm\text-style\stylellm_models\dataset\sft' # 报错,read_csv 无法识别文件,报错 invalid arguments
data_dir = 'E:\\llm\\text-style\\stylellm_models\\dataset\\sft' # 正确,\ -> \\
file_name = 'XiYouji_Parallel.csv'
# os.chdir(data_dir)
# df = pd.read_csv(data_file)
data_file = os.path.join(data_dir, file_name)
df = pd.read_csv(data_file)
df
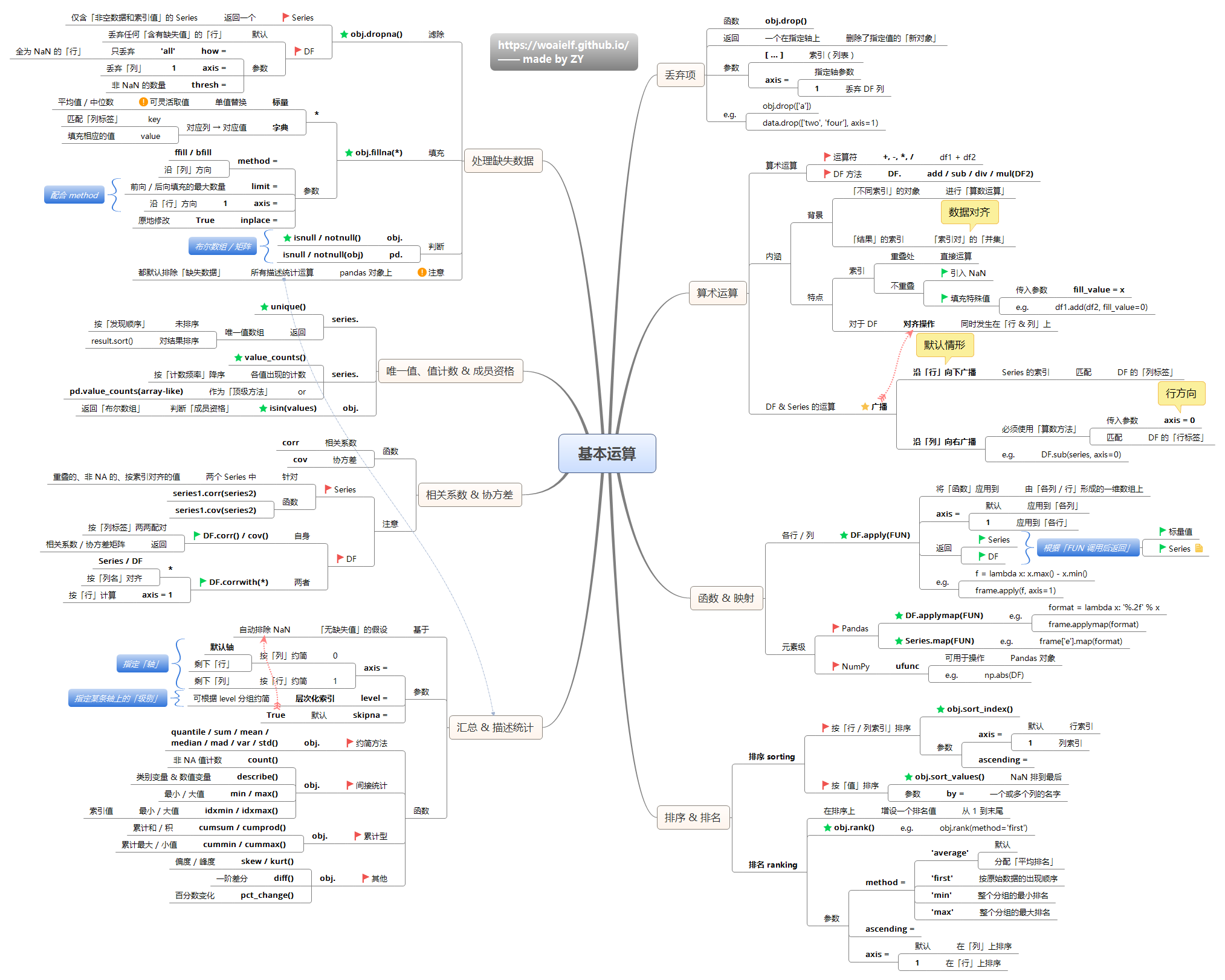
常规操作
- 列选择
- 行选择
- 元素选择
- 条件查询:对各类数值型、文本型,单条件和多条件进行行选择
- 聚合


- 聚合函数:
- data.function(axis=0) 按列计算
- data.function(axis=1) 按行计算

- 分组统计
- 透视表:透视表是pandas的一个强大的操作,大量的参数完全能满足你个性化的需求。
- 缺失值
- 查找替换: pandas提供简单的查找替换功能,如果要复杂的查找替换,可以使用map(), apply()和applymap()
- 数据合并: 两个DataFrame的合并,pandas会自动按照索引对齐,可以指定两个DataFrame的对齐方式,如内连接外连接等,也可以指定对齐的索引列。
- 更改列名(columns index)
- apply函数: 单值运算















类型转换
数值类型转换
【2023-6-4】使用 round 方法直接对浮点数做数值位数转换
- round()函数是做四舍五入,而decimals参数是设置保留小数的位数
import numpy as np
import pandas as pd
df = pd.DataFrame([(.21, .32), (.01, .6), (.66, .03), (.21, .183)],columns=['dogs', 'cats'])
df
# dogs cats
# 0 0.21 0.320
# 1 0.01 0.600
# 2 0.66 0.030
# 3 0.21 0.183
df['NewColumn'] = df['Column'].astype(float)
# --------------
# 统一保持2位小数
df.round(2)
# 统一保持一位小数
df.round(1)
# ------------
# 等效表示
df['dogs'] = df['dogs'].map(lambda x: ('%.2f')%x)
df['dogs'] = df['dogs'].map(lambda x: format(x,'%.2%')) # 加百分号
df['dogs'] = df['dogs'].map(lambda x: format(x,',')) # 设置千分位
# 指定列名设置精度,未指定的则保持原样
df.round({'dogs': 2})
# dogs cats
# 0 0.21 0.320
# 1 0.01 0.600
# 2 0.66 0.030
# 3 0.21 0.183
# 两列分别设置不同的精度
df.round({'dogs':2, 'cats':1})
# dogs cats
# 0 0.21 0.3
# 1 0.01 0.6
# 2 0.66 0.0
# 3 0.21 0.2
变量类型转换
pandas 中的 to_dict 可以对DataFrame类型的数据进行转换,可以选择六种的转换类型,分别对应于参数 ‘dict’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’
to_dict()函数有两种用法
- (1)pd.DataFrame.todict()
- ‘dict’: {column->{index->values}}
- ‘list’: {column:[values]}
- ‘series’:{column->series}
- ‘split’:{index->[index], column->[column], value->[value]}
- ‘record’:[{column->value}] ,返回的为列表, 记录每个样本
- ‘index’:{index->{column->value}} ,与”dict”类似,只不过index与column互换位置
- (2)pd.Series.to_dict() : 将Series转换成{index:value}
- 其中Series.to_dict()较简单
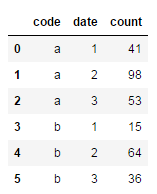
df = pd.DataFrame(data=[11,22,33,44], index=['a','b','c','d']).rename(columns={0:'code'})`
# 转换类型
# (1)利用itertuples()转成字典格式
{i:v for i,v in df.itertuples()}
# (2)使用to_dict方法
df.T.to_dict('r')[0]
df.code.to_dict()
# (3)高级版
new_df = df.set_index(['code', 'date']).unstack(level=0).droplevel(level=0, axis=1).to_dict()
#--------------
for t in ('dict', 'list', 'records', 'split', 'index', 'series'):
print(t, df.to_dict(t))
# dict {'code': {'a': 11, 'b': 22, 'c': 33, 'd': 44}}
# list {'code': [11, 22, 33, 44]}
# records [{'code': 11}, {'code': 22}, {'code': 33}, {'code': 44}]
# split {'index': ['a', 'b', 'c', 'd'], 'columns': ['code'], 'data': [[11], [22], [33], [44]]}
# index {'a': {'code': 11}, 'b': {'code': 22}, 'c': {'code': 33}, 'd': {'code': 44}}
# series {'code': a 11
# b 22
# c 33
# d 44
# Name: code, dtype: int64}
可视化讲解
- 【2022-8-15】超强图解Pandas 18招
- 【2021-12-8】PandasTutor——一个用于可视化pandas操作的神器,Pandas Tutor将pandas的操作变成可视化的过程,让我们充分理解这个过程。
import pandas as pd
import io
csv = '''
breed,type,longevity,size,weight
German Shepherd,herding,9.73,large,
Beagle,hound,12.3,small,
Yorkshire Terrier,toy,12.6,small,5.5
Golden Retriever,sporting,12.04,medium,60.0
Bulldog,non-sporting,6.29,medium,45.0
Labrador Retriever,sporting,12.04,medium,67.5
Boxer,working,8.81,medium,
Poodle,non-sporting,11.95,medium,
Dachshund,hound,12.63,small,24.0
Rottweiler,working,9.11,large,
Boston Terrier,non-sporting,10.92,medium,
Shih Tzu,toy,13.2,small,12.5
Miniature Schnauzer,terrier,11.81,small,15.5
Doberman Pinscher,working,10.33,large,
Chihuahua,toy,16.5,small,5.5
Siberian Husky,working,12.58,medium,47.5
Pomeranian,toy,9.67,small,5.0
French Bulldog,non-sporting,9.0,medium,27.0
Great Dane,working,6.96,large,
Shetland Sheepdog,herding,12.53,small,22.0
Cavalier King Charles Spaniel,toy,11.29,small,15.5
German Shorthaired Pointer,sporting,11.46,large,62.5
Maltese,toy,12.25,small,5.0
'''
dogs = pd.read_csv(io.StringIO(csv))
dogs['longevity'] # 选择一列
dogs.drop(columns=['type']) # 删除列
df.loc[:, df.loc['two'] <= 20] # 过滤行(按two列取值过滤)
# 多条件过滤, 用 & 符号连接
dogs.loc[(dogs['size'] == 'medium') & (dogs['longevity'] > 12), 'breed']
dogs.groupby('size').mean() # 按size分组,组内求均值
dogs.groupby(['type', 'size']) # 多列分组
(dogs[dogs['size'] == 'medium'] # 筛选中型犬(size)
.sort_values('type') # 按type列排序
.groupby('type').median() # 按type列分组
)
(dogs
.sort_values('size')
.groupby('size')['height'] # 分组后取height列,应用到后面的聚合运算
.agg(['sum', 'mean', 'std'])
)
# join操作
ppl.join(dogs)
ppl.merge(dogs, left_on='likes', right_on='breed', how='left') # merge操作
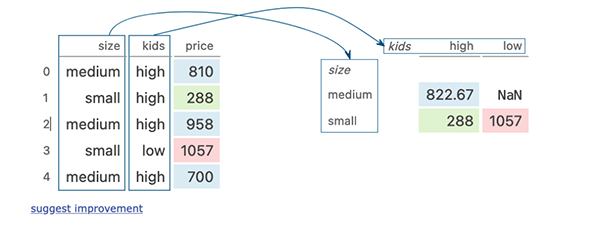
dogs.pivot_table(index='size', columns='kids', values='price') # 按kids钻取、聚合
图
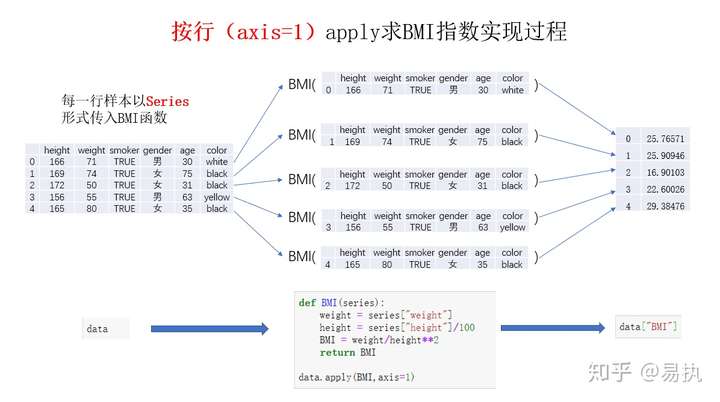
map/apply/applymap
Pandas三板斧(map、apply和applymap)可以对DataFrame进行逐行、逐列和逐元素的操作,对应这些操作
map: 字典还是函数进行映射,map方法把对应数据逐个当作参数传入到字典或函数中,得到映射后的值。apply: 和map方法类似,区别 apply能够传入功能更为复杂的函数。applymap: 对DataFrame中每个单元格执行指定函数的操作,虽然用途不如apply广泛,但在某些场合下还是比较有用的- 数据
# 数据准备
boolean=[True,False]
gender=["男","女"]
color=["white","black","yellow"]
data=pd.DataFrame({
"height":np.random.randint(150,190,100),
"weight":np.random.randint(40,90,100),
"smoker":[boolean[x] for x in np.random.randint(0,2,100)],
"gender":[gender[x] for x in np.random.randint(0,2,100)],
"age":np.random.randint(15,90,100),
"color":[color[x] for x in np.random.randint(0,len(color),100) ]
})
# ----- map ------
# ① 使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
# ② 使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
# 注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)
# ------ apply -----
def apply_age(x,bias):
return x+bias
#以元组的方式传入额外的参数
data["age"] = data["age"].apply(apply_age, args=(-3,))
# 沿着0轴求和
data[["height","weight","age"]].apply(np.sum, axis=0)
# 沿着0轴取对数
data[["height","weight","age"]].apply(np.log, axis=0)
# 计算BMI
def BMI(series):
weight = series["weight"]
height = series["height"]/100
BMI = weight/height**2
return BMI
data["BMI"] = data.apply(BMI,axis=1)
# ------ applymap -----
# 浮点数保留两位小数
df.applymap(lambda x:"%.2f" % x)
【2024-4-11】传入多列
import numpy as np
import pandas as pd
df = pd.DataFrame ({'a' : np.random.randn(6),
'b' : ['foo', 'bar'] * 3,
'c' : np.random.randn(6)})
def my_test(a, b):
"""
多输入处理函数
"""
return a + b
df['Value'] = df.apply(lambda row: my_test(row['a'], row['c']), axis=1)
print (df)
#输出结果形如:
# a b c Value
# 0 -0.276507 foo -3.122166 -3.398672
# 1 -0.589019 bar -1.150915 -1.739934
# 2 -0.485433 foo 1.296634 0.811200
# 3 0.469688 bar -0.554992 -0.085304
# 4 1.297845 foo 1.672957 2.970802
# 5 -0.702724 bar -1.609585 -2.312309
查看数据
宏观统计
import pandas as pd
#查看、检查数据
df.head(n)# 查看DataFrame对象的前n行
df.tail(n)# 查看DataFrame对象的最后n行
df.shape()# 查看行数和列数
df.info()# 查看索引、数据类型和内存信息
df.describe()# 查看数值型列的汇总统计
s.value_counts(dropna=False)# 查看Series对象的唯一值和计数
df.apply(pd.Series.value_counts)# 查看DataFrame对象中每一列的唯一值和计数
dict(df_out['关键路径'].map(parse).value_counts()) # 转成dict格式
# 数据统计
df.describe()# 查看数据值列的汇总统计
df.mean()# 返回所有列的均值
df.corr()# 返回列与列之间的相关系数
df.count()# 返回每一列中的非空值的个数
df.max()# 返回每一列的最大值
df.min()# 返回每一列的最小值
df.median()# 返回每一列的中位数
df.std()# 返回每一列的标准差
# ------ numpy --------
import numpy as np
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(np.median(a)) # 中位数
print(np.percentile(a, 25)) # 25%分位数
print(np.percentile(a, 75)) # 75%分位数
# 查找数据
df = pd.DataFrame({'BoolCol': [1, 2, 3, 3, 4],'attr': [22, 33, 22, 44, 66]}, index=[10,20,30,40,50])
df = pd.DataFrame({'BoolCol': [1, 2, 3, 3, 4],'attr': [22, 33, 22, 44, 66]})
print(df)
print(df['attr']) # series对象
a1 = df[(df.BoolCol==3)&(df.attr==22)].index.tolist() # 返回下标
a2 = df[(df.BoolCol==3)&(df.attr==22)].values.tolist() # 返回数值
print(a1,a2)
#df.index # 行序号
df.columns # 列名
df.values # 数据内容, 当df是series类型时直接转ndarray类型
df.values.tolist() # 转list结构
df.drop_duplicates().values.tolist() # 去除重复行
np.array(df).tolist() # 成功
df._get_value(2,'price') # 取指定元素数值
#df['lon'],df['lat'],df[:30] # 按照列名读取数据
#df.ix[:30,:3] # 使用ix、loc或者iloc(按照下标组合)进行行列双向读取,即切片操作
#df.ix[:20,['lon','lat']] # 跨属性组合选取
key_list = ['total_bedrooms','population']
df.loc[:100, key_list] # 同上?
#new = df.iloc[:20,[1,2]]
#new.describe # 基本统计信息
#type(new)
#df[df.lon>117] # 按照数值过滤筛选
#df[df.time<'2016-07-20']
#new.values.tolist() # DataFrame转成list结构
#[2018-11-2]另外一种方法:np.array(new).tolist()
#df.sort(columns='time') # 排序
#[2018-10-12] 将pandas元素提取(numpy结构)并转化为list结构
for idx in xrange(df.size):
item = df.ix[idx,key_list].get_values().tolist()
#提取某个取值的数据,注意:==,不是=!
df[df.businesstype==7]
describe 用法
describe生成描述性统计数据,统计数据集的集中趋势,分散和行列的分布情况,不包括 NaN值。
- 对于数值型数据,输出结果指标包括: count, mean,std,min,max以及第25百分位,中位数(第50百分位)和第75百分位。
- 对于对象类型数据(例如字符串或时间戳),结果指数将包括 count,unique, top,和freq。top标识最常见的值。freq标识最常见的值的出现频次。时间戳还包括first和last指标。如果多个对象值具有最高计数,那么将从具有最高计数的那些中任意选择count和top结果。
- 对于混合数据类型 DataFrame,默认情况下仅返回数值类型列的分析。如果数据框仅包含没有任何数值列的对象和文本类型数据,则默认情况下将返回对象和文本类型数据列的分析结果。如果include=’all’作为选项提供,则结果将包括每种类型数据的并集。当然,我们可以使用include和exclude参数限制其列在DataFrame被分析时的输出。在分析Series时会忽略这些参数。
三个参数:
percentiles:赋值类似列表形式,可选- 表示百分位数,介于0和1之间。默认值为 [.25, .5, .75],分别返回第25,第50和第75百分位数。
- 可自定义其它值,用法为df.describe(percentiles=[.xx])。
include:’all’,类似于dtypes列表或None(默认值),可选- 要包含在结果中的数据类型的白名单。对于Series不可用。以下是选项:
- ‘all’:输入的所有列都将包含在输出中。
- 类似于dtypes的列表:将结果限制为提供的数据类型。将结果限制为数字类型用法:numpy.number。要将其限制为对象列用法:numpy.object。字符串也可以以select_dtypes(例如df.describe(include=[‘O’]))的方式使用。要选择分类类型,请使用’category’
- 无(默认):结果将包括所有数字列。
exclude:类似于dtypes列表或None(默认值),可选,- 要从结果中除去的黑名单数据类型列表。Series不可用。以下是选项:
- 类似于dtypes的列表:从结果中排除提供的数据类型。排除数值类型用法:numpy.number。要排除对象列,使用numpy.object。字符串也可以以select_dtypes(例如df.describe(include=[‘O’]))的方式使用。要排除分类类型,请使用’category’
- 无(默认):结果将不包含任何内容。
【2022-8-29】pandas.DataFrame.describe方法小析
import pandas as pd
import re
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True) # 剔除空值
# percentile list
perc =[.20, .40, .60, .80] # 分位数列表
# list of dtypes to include
include =['object', 'float', 'int'] # 要统计的列
# calling describe method
desc = data.describe(percentiles = perc, include = include)
desc = data.describe([.30]) # 限定输出30%分位数
desc = data.describe([0.05 * x for x in range(20)]) # 限定多个分位数
desc = data.describe(include='all') # 输出所有列
desc = data.describe(include=[np.number]) # 仅输出数值列
desc = data.describe(include=[np.object]) # 仅输出对象类型
desc = data.describe(include=[np.category]) # 仅输出离散类型
desc = data.describe(exclude=["category", np.number]) # 排除离散类型
# display
desc
表格样式
【2022-11-4】表格格式调整,pandas 样式配置操作
- 右对齐(默认)→ 左对齐
import pandas as pd
# initialise data of lists.
data = [['Raghav', 'Jeeva', 'Imon', 'Sandeep'],
['Deloitte', 'Apple', 'Amazon', 'Flipkart'],
[2,3,7,8]]
# Create DataFrame
df = pd.DataFrame(data)
# 设置对齐方式
df_new = df.style.set_properties(**{'text-align': 'left'})
# 设置表格标题
df.style.set_caption('学生成绩表')
# 保留两个小数
df.style.set_precision(2)
# 等同于
df.round(2).style
# 设置缺失值
df.style.set_na_rep("暂无")
data.style.format(None, na_rep="-")
# 隐藏索引和列
df.style.hide_index() # 不输出索引
df.style.hide_columns(['C','D']) # 不输出指定列
# ---- 单元格设置 CSS 样式 ----
# 指定列,设置字色为红色
df.style.set_properties(subset=['Q1'], **{'color': 'red'})
# 一些其他示例
df.style.set_properties(color="white", align="right")
df.style.set_properties(**{'background-color': 'yellow'})
df.style.set_properties(**{'width': '100px', 'font-size': '18px'})
df.style.set_properties(**{'background-color': 'black',
'color': 'lawngreen',
'border-color': 'white'})
# 给 <table> 标签增加属性,可以随意给定属性名和属性值。
df.style.set_table_attributes('class="pure-table"')
# ... <table class="pure-table"> ...
df.style.set_table_attributes('id="gairuo-table"')
# 固定表头:便于查看数据
df.style.set_sticky(axis='columns').to_html('333.html')
# 固定索引行标签
df.style.set_sticky(axis='index').to_html('333.html')
display(df_new)
表格美化
# 指定列最大值背景高亮
def highlight_max(s):
''' 对列最大值高亮(黄色)处理 '''
is_max = s == s.max()
return ['background-color: yellow' if v else '' for v in is_max]data.style.apply(highlight_max,subset=['2021人口', '2020人口', '面积','单位面积人口','人口增幅','世界占比'])
# 数值颜色突出
def color_red(s):
is_max = s > 200
return ['color : red' if v else '' for v in is_max]data.style.apply(color_red,subset=['单位面积人口'])
# 数据条显示
import pandas as pd
data = pd.read_excel(r"2021世界人口数据.xlsx")# 数据条显示指定列数据大小
data.style.bar(subset=['2021人口', '2020人口'], color='#FFA500')
# 色阶显示, 用df.style.background_gradient实现
import seaborn as sns
# 使用seaborn获取颜色
cm = sns.light_palette("green", as_cmap=True)# 色阶实现
data.style.background_gradient(cmap=cm,subset=['2021人口', '2020人口', '面积','单位面积人口','人口增幅','世界占比'])
# 使用内置色阶类型,调节颜色范围
data.style.background_gradient(cmap='viridis',high=0.5,low=0.3,subset=['2021人口', '2020人口', '面积','单位面积人口','人口增幅','世界占比'])
# 将样式输出到表格
import pandas as pd
import numpy as np
data = pd.read_excel(r"2021世界人口数据.xlsx")
data.style.background_gradient(cmap='viridis',subset=['2021人口', '2020人口', '面积','单位面积人口','人口增幅','世界占比']).to_excel('style.xlsx', engine='openpyxl')
数据查找
【2026-6-25】多种方法查找 dataframe 指定数值所在位置
- mask.values.nonzero()
- .idxmax()
- .index
import pandas as pd
excel_file = '/Users/didi/work/model_eva/data/intent-result-all.xlsx'
df_details = pd.read_excel(excel_file, sheet_name='意图理解评测详情', header=None)
a = (df_details[0]=='快车乘客').values.nonzero() # (array([13]),)
a[0][0]
# 查找矩阵内容
pos = (df_details=='快车乘客').stack().idxmax() # (13, 0)
pos[0]
# 仅查找某列内容
pos = (df_details[0]=='快车乘客').idxmax() # (13, 0)
pos
pos = df_details[df_details[0]=='快车乘客'].index
pos[0]
数据选择
代码:
- 【2022-9-17】使用复合条件时,务必使用()将单个条件括起来!否则逻辑容易失效!
条件筛选
#数据选取
df[col]# 根据列名,并以Series的形式返回列
df[[col1, col2]]# 以DataFrame形式返回多列
s.iloc[0]# 按位置选取数据
s.loc['index_one']# 按索引选取数据
df.iloc[0,:]# 返回第一行
df.iloc[0,0]# 返回第一列的第一个元素
DataFrame.lookup(row_labels,col_labels) # DataFrame基于标签的“花式索引”功能。
DataFrame.pop(item) # 返回项目并从框架中删除。 类似方法del
# 空值筛选
df.notnull().sum() # 非空样本统计
df.isnull().sum() # 空样本统计
df.notna().sum() # NaN样本统计
df_useful = df[df['a'].notnull()] # 选出非空值
df_useful = df[df['a'].isnull()] # 选出空值
df_useful = df[df['a'].notna()] # 选出NaN
# 多个条件通过&、|连接
student[(student['Sex']=='F') & (student['Age']>12)]
# Pandas实现where filter
df[df['sex'] == 'Female']
df[df['total_bill'] > 20]
#在where子句中常常会搭配and, or, in, not关键词,Pandas中也有对应的实现
df[(df['sex'] == 'Female') & (df['total_bill'] > 20)] # and
df[(df['sex'] == 'Female') | (df['total_bill'] > 20)] # or
df[(df['sex'] == 'Female') | (~df['total_bill'] > 20)] # not,非,用~符号
df[~(df['sex'] == 'Female')]
# 存在性判断
df[df['total_bill'].isin([21.01, 23.68, 24.59])] # in
df[-(df['sex'] == 'Male')] # not
df[-df['total_bill'].isin([21.01, 23.68, 24.59])]
# 判断元素是否存在 isin
a = 1 if 'NLU泛化' in stat['failure'].values else 0
# string function 使用str函数
df = df[(-df['sex'].isin(['male', 'female'])) & (-df.sex.str.contains('^m\d+$'))] # 不管用!
# [2022-10-15] str里使用正则表达式
df_out['关键路径'].str.contains('进入IM=>初始faq=>输入\([^=>]*?\)=>接通人工', regex=True)
# 对where条件筛选后只有一行的dataframe取其中某一列的值,其两种实现方式如下:
total = df.loc[df['tip'] == 1.66, 'total_bill'].values[0]
total = df.get_value(df.loc[df['tip'] == 1.66].index.values[0], 'total_bill')
极值
nlargest和nsmallest获取最大和最小值
df.nlargest(5, 'ColumnName')
df.nsmallest(5, 'ColumnName')
采样
Pandas 行采样/抽样技术:
- (1) 随机抽样
- (2) 有条件采样
- (3) 以恒定速率采样
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
print('----- 随机采样 ----- ')
subset = df.sample(n=100) # 行采样
print('行数采样: ', subset.shape)
subset = df.sample(frac=0.5)
print('比例采样: ', subset.shape)
print('----- 条件采样 ----- ')
condition = df['sepal width (cm)'] < 3
subset = df[condition].sample(n = 10)
print('条件采样: ', subset.shape)
print('----- 恒定速率采样 ----- ')
subset = df[::10] # 每隔10个采样
resample
对时间序列数据进行重新采样。
df.resample('D').sum()
query SQL
Pandas中的.query()函数像sql一样操作, 使用bool表达式
- 不完全是SQL,但使一些基本查询变得更容易,一个简单的
WHERE或.filter()等价方法。 - 使用&或者and、or、not等逻辑运算符,以及其它常见的操作符(例如==,<,>,!=等)来连接过滤器
# 常见的切片语法
query_df = df[df[df['Col_1'] > df['Col_2']]]
# query 语法
query_df = df.query("Col_1 > Col_2") # 不能用and/or, 改成 &,|
df.query('total_bill > 20')
SQL
pandas DataFrame是二维表格,数据库中的表也是二维表格,因此使用sql语句就显得水到渠成
pandasql
pandasql使用SQLite作为其操作数据库,Python自带SQLite模块,不需要安装,便可直接使用。
注意
- pandasql读取DataFrame中日期格式的列,默认会读取年月日、时分秒,因此要学会使用sqlite中的日期处理函数,方便转换日期格式
- sqlite函数大全
# !pip install pandasql
import pandas as pd
from pandasql import sqldf
df = pd.read_excel('test.xlsx')
# ======== 单次声明全局变量 ========
global df
query = "select * from df limit 10"
sqldf(query)
merge_data_sql = sqldf(""" SELECT *
FROM apm_data_df
LEFT OUTER JOIN pingips_data_df
ON apm_data_df.pingip = pingips_data_df.pingip
WHERE apm_data_df IS null
""")
# 一条语句合并
merge_result = sqldf(merge_data_sql, globals())
# ======== 或一次性申明 ========
pysqldf = lambda q: sqldf(q, globals())
pysqldf(query)
DuckDB
DuckDB来查询DataFrame
DuckDB 是一个开源的内存分析型数据库,专为高效处理分析工作负载而设计。
- 被称为SQLite的分析/OLAP等效工具,因为提供了类似SQL的查询语言,并支持在Pandas DataFrame上执行SQL查询。
DuckDB是一个强大而灵活的分析型数据库,它的集成性和性能优势使得在Pandas中使用SQL查询变得更加便捷和高效
# pip install duckdb
import duckdb
# pd读取
df = ....
# 简单查询
duckdb.query("select * from a limit 5").df()
# 使用复杂SQL
sql = """
select *
a."x", x
from a
where
x == 'usa' and a."y" > 10
"""
duckdb.query(sql).df()
pandas 正则表达式
可使用函数:str.*
matchfullmatch- Stricter matching that requires the entire string to match.
contains- Analogous, but less strict, relying on re.search instead of re.match.
extract- Extract matched groups.
repalce- str.replace(r’(“.),(.”)’, r’\1 \2’, regex=True)
使用函数:
- Series.str.contains(pat,case = True,flags = 0,na = nan,regex = True)
- 测试 pattern 或 regex 是否包含在Series或Index的字符串中。
- 返回布尔值系列或索引,具体取决于给定模式或正则表达式是否包含在系列或索引的字符串中。
参数说明
| 参数 | 类型 | 说明 |
|---|---|---|
| pat | str类型,字符序列或正则表达式 | 字符串或正则表达式 |
| case | bool,默认为True | 如果为True,区分大小写。 |
| flags | int,默认为0(无标志) | 标志传递到re模块,例如re.IGNORECASE。na : 默认NaN, 填写缺失值的值。 |
| regex | bool,默认为True | 如果为True,则假定pat是正则表达式。 如果为False,则将pat视为文字字符串。 |
除此之外,还可以使用以下函数
import pandas as pd
import numpy as np
s1 = pd.Series(['Mouse', 'dog', 'house and parrot', '23', np.NaN])
s1.str.contains('\d', regex=True) # 启动正则,匹配数字,结果:23
s1.str.contains('og', regex=False) # 关闭正则,当做字符串,结果:只匹配到 dog
s1.str.contains('oG', case=True, regex=True) # 区分大小写,结果:无匹配
s1.str.contains('og', na=True, regex=True) # 把有NAN的转换为True,即空值都命中
s1.str.contains('og', na=False, regex=True) # 把有NAN的转换为False,即空值都过滤
import re
s1.str.contains('PARROT', flags=re.IGNORECASE, regex=True) # 使用re里的正则选项
# 正则替换
str.replace(r'(".*),(.*")', r'\1 \2', regex=True)
# 结合re工具包
import re
regex_pat = re.compile(r'FUZ', flags=re.IGNORECASE)
pd.Series(['foo', 'fuz', np.nan]).str.replace(regex_pat, 'bar', regex=True)
# 逆序
pat = r"(?P<one>\w+) (?P<two>\w+) (?P<three>\w+)"
repl = lambda m: m.group('two').swapcase()
ser = pd.Series(['One Two Three', 'Foo Bar Baz'])
ser.str.replace(pat, repl, regex=True)
# [2022-10-15] str里使用正则表达式
df_out['关键路径'].str.contains('进入IM=>初始faq=>输入\([^=>]*?\)=>接通人工', regex=True)
# 抽取
s.str.extract(r'(?P<letter>[ab])(?P<digit>\d)')
s.str.extract(r'[ab](\d)') # 返回字符串
s.str.extract(r'[ab](\d)', expand=False) # 返回 series格式(False)、dataframe格式(True)
赋值
多列赋值
如果列已存在,直接赋值
data1[['月份','企业']]=int(month),parmentname
否则,报错
如何一次对多列赋值?
- 方法一:使用
apply的参数result_type来处理 - 方法二:使用
zip打包返回结果来处理
import pandas as pd
df_tmp = pd.DataFrame([
{"a":"data1", "cnt":100},{"a":"data2", "cnt":200},
])
def formatrow(row):
"""
传入 pandas 一行
"""
a = row["a"] + str(row["cnt"])
b = str(row["cnt"]) + row["a"]
return a, b
# 方法一 apply 【2024-5-9】实测通过
df_tmp[["fomat1", "format2"]] = df_tmp.apply(formatrow, axis=1, result_type="expand")
# 方法二 zip
df_tmp["fomat1-1"], df_tmp["format2-2"] = zip(*df_tmp.apply(formatrow, axis=1))
预处理
重复值
duplicated和drop_duplicates处理重复值
- duplicated 检测重复值
- drop_duplicates 删除重复值
df.duplicated(subset=['Column1', 'Column2'])
df.drop_duplicates(subset=['Column1', 'Column2'], keep='first')
# 查找并删除重复行
df.duplicated(subset=['Name'])
df.drop_duplicates(subset=['Name'], keep='first')
缺失值
清理缺失值
# 数据清理
df.columns = ['a','b','c']# 重命名列名
pd.isnull()# 检查DataFrame对象中的空值,并返回一个Boolean数组
pd.notnull()# 检查DataFrame对象中的非空值,并返回一个Boolean数组
df.drop([16,17]) # 删除16,17行,得到新的dataframe, df仍然保留
df.drop(inex=['a', 'b']) # 或者这样
df.drop([16,17], inplace=True) # 删除16,17行, 原地操作
df.dropna()# 删除所有包含空值的行
df.dropna(axis=1)# 删除所有包含空值的列
df.drop(['a', 'b'], axis=1) # 删除列a,b
df.drop(columns=['a', 'b']) # 或者这样
df.dropna(axis=1,thresh=n)# 删除所有小于n个非空值的行
df.drop_duplicates() # 删除重复
df.drop_duplicates(keep='first') # 重复数据只保留第一个
df.fillna(x)# 用x替换DataFrame对象中所有的空值
s.astype(float)# 将Series中的数据类型更改为float类型
重命名
s.replace(1,'one')# 用'one'代替所有等于1的值
s.replace([1,3],['one','three'])# 用'one'代替1,用'three'代替3
#Series对象值替换
s = df.iloc[2]#获取行索引为2数据
#原文链接:https://blog.csdn.net/kancy110/article/details/72719340
df.rename(columns=lambda x: x + 1)# 批量更改列名
df.rename(columns={'old_name': 'new_name'})# 选择性更改列名
df.rename(columns={'ID': 'EmployeeID'}, inplace=True) # 原地生效
df.set_index('column_one')# 更改索引列
df.rename(index=lambda x: x + 1)# 批量重命名索引
日期
df['DateTimeColumn'] = pd.to_datetime(df['DateTimeColumn'])
分组
# 数据处理:Filter、Sort和GroupBy
df[df[col] > 0.5]# 选择col列的值大于0.5的行
df.sort_values(col1)# 按照列col1排序数据,默认升序排列
df.sort_values(col2, ascending=False)# 按照列col1降序排列数据
df.sort_values([col1,col2], ascending=[True,False])# 先按列col1升序排列,后按col2降序排列数据
df.groupby(col)# 返回一个按列col进行分组的Groupby对象
df.groupby([col1,col2])# 返回一个按多列进行分组的Groupby对象
df.groupby(col1)[col2]# 返回按列col1进行分组后,列col2的均值
df.groupby(col1).agg(np.mean)# 返回按列col1分组的所有列的均值
df.pivot_table(index=col1, values=[col2,col3], aggfunc=max)# 创建一个按列col1进行分组,并计算col2和col3的最大值的数据透视表
pd.pivot_table(df, values='ValueColumn', index='IndexColumn', columns='ColumnToPivot', aggfunc='mean')
data.apply(np.mean)# 对DataFrame中的每一列应用函数np.mean
data.apply(np.max,axis=1)# 对DataFrame中的每一行应用函数np.max
# -------------
tmp = lambda x:x.sort_values(ascending = False).iloc[0]
tmp.__name__ = 'func'
df['real_cost'].applymap(tmp) # 元素级别变换
df[['customer_type','real_cost']].agg({'customer_type':['sum','mean'],'real_cost':['sum',tmp]}) # 多个属性的统计信息(统计值不同,自定义聚合函数)
df.groupby(['real_cost']).transform(('sum')) # transform元素级别的变换
# -------------
# 数据过滤
import pandas as pd
data_file = 'name.csv'
df = pd.read_csv(data_file)
# 编码转换 gbk -> utf8
df['path'] = df['path_name'].apply(lambda x:x.decode('gbk').encode('utf8'))
#print df['path_name'][3].decode('gbk').encode('utf8')
df
# 数据合并
# 【2024-3-15】新版pandas不再支持append, 改用concat方法
df1.append(df2)# 将df2中的行添加到df1的尾部
df1.concat(df2)# 【2024-3-15】不能这么用 'DataFrame' object has no attribute 'concat'
df.concat([df1, df2],axis=1)# 正确
df1.join(df2,on=col1,how='inner')# 对df1的列和df2的列执行SQL形式的join
字符串
str方法
- 含有特定字符串的行:contains()
- 字符串分割: split, 官方文档
import pandas as pd
data = pd.DataFrame({'班级':['1班','1班','1班','1班','1班','2班','2班','2班','2班','2班'],
'姓名':['韩愈','柳宗元','欧阳修','苏洵','苏轼','苏辙','曾巩','王安石','张三','小伍哥'],
'成绩':[80,70,70,40,10,60,60,50,50,40]})
#姓名长度不一样的,加个符号调整下
data['姓名'] = data['姓名'].str.rjust(3,'〇') # 填充o
# 看1班成绩名次
data_1 = data[data['班级']=='1班']
data_1['成绩_first'] = data_1['成绩'].rank(method='first',ascending=False)
# 字符串处理
## 1、空格处理
df[col_name] = df[col_name].str.lstrip()
# 去除特定字符strip(包括lstrip和rstrip)
df1['expression']=df1['expression'].str.lstrip('mid:')
## 前缀/后缀判断,startswith 与 endswith
df1=df[df['expression'].str.startswith('m')]
## 3、字符串分割:expand=True不加的话,df1中将只有一列,其实就是一个series。
df[col_name].str.split('分割符')
s.str.split(n=2) # 限定分割次数
s.str.rsplit(n=2) # 从右边开始分割, 类似的, lsplit
s.str.split(pat="/") # 按字符分割
s.str.split(r"\.jpg", regex=True, expand=True) # 正则
s.str.split(re.compile(r"\.jpg"), expand=True) # 先编译
df1=df['columns_name'].str.split(':',expand=True) # 生成新的df
df[['exp1','exp2']]=df['expression'].str.split(':',expand=True) # 直接追加到原来的df
df['exp2']=df['exp2'].astype(int) # 类型转换
## 正则表达式
s=df['expression'].str.findall('[a-z]+')
## 4、字符串拼接
df[col_name].str.cat()
## 2、*%d等垃圾符处理
df[col_name].replace(' &#.*', '', regex=True, inplace=True)
#单值替换
s.replace('?', np.nan)#用np.nan替换?
s.replace({'?':'NA'})#用NA替换?
#多值替换
s.replace(['?',r'$'],[np.nan,'NA'])#列表值替换
s.replace({'?':np.nan,'$':'NA'})#字典映射
#同缺失值填充方法类似
s.replace(['?','$'],method='pad')#向前填充
s.replace(['?','$'],method='ffill')#向前填充
s.replace(['?','$'],method='bfill')#向后填充
#limit参数控制填充次数
s.replace(['?','$'],method='bfill',limit=1)
#DataFrame对象值替换
#单值替换
df.replace('?',np.nan)#用np.nan替换?
df.replace({'?':'NA'})#用NA替换?
#按列指定单值替换
df.replace({'EMPNO':'?'},np.nan)#用np.nan替换EMPNO列中?
df.replace({'EMPNO':'?','ENAME':'.'},np.nan)#用np.nan替换EMPNO列中?和ENAME中.
#多值替换
df.replace(['?','.','$'],[np.nan,'NA','None'])##用np.nan替换?用NA替换. 用None替换$
df.replace({'?':'NA','$':None})#用NA替换? 用None替换$
df.replace({'?','$'},{'NA',None})#用NA替换? 用None替换$
#正则替换
df.replace(r'\?|\.|\$',np.nan,regex=True)#用np.nan替换?或.或$原字符
df.replace([r'\?',r'\$'],np.nan,regex=True)#用np.nan替换?和$
df.replace([r'\?',r'\$'],[np.nan,'NA'],regex=True)#用np.nan替换?用NA替换$符号
df.replace(regex={r'\?':None})
#value参数显示传递
df.replace(regex=[r'\?|\.|\$'],value=np.nan)#用np.nan替换?或.或$原字符
# [2019-08-29]
d = pd.DataFrame({'BoolCol': [1, 2, 3, 3, 4],'attr': ['a.,b', 'hello', 'world', ',', '4,5']})
d.replace({'attr':','}, '->') # 完全匹配
d.replace(r',', '->',regex=True) # 正则替换
d.replace(r',', '->',regex=True, inplace=True) # 修改原值
d[(df_2.ocr.isnull) & (d.ocr.str.contains(','))] # 检测是否包含,
哑编码
将分类变量转换为独热编码
pd.get_dummies(df, columns=['CategoricalColumn'])
合并
- pandas-数据的合并与拼接
- Pandas包的
merge、join、concat方法可以完成数据的合并和拼接- merge 基于两个dataframe的共同列进行合并
- join 基于两个dataframe的索引进行合并
- concat 对series或dataframe进行行拼接或列拼接。
分析
- concat和append可以实现的是表间”拼接“,而merge和join则实现的是表间”合并“。区别在于是否基于”键“来进行合并。
- 如果只是简单地”堆砌“,则用concat和append比较合适
- 而如果遇到关联表,需要根据”键“来合并,则用merge和join。
- concat 和 merge是pandas的属性,所以调用时写成pd.concat()或者pd.merge();而append和join是对DataFrame的方法,所以调用的时候应该写成df.append()或者df.join()。
- append 只能实现行拼接,concat的功能更加强大。理论上append可以完成的操作concat都可以完成,只需要更改相应的参数即可。
- 类似于append之于concat,join可以完成的操作merge也都可以完成,因此merge更加强大。
- append和join存在的意义在于简洁和易用。
concat后面对于df的参数形式是objs,这个objs可以是一个列表或者集合,里面可以有很多个df;而merge后面跟的参数形式是left和right,只有两个df。因此concat其实可以快速实现多表的拼接,而merge只能实现两表的合并。
append 追加
添加行、列
- 添加行有
df.loc[]以及df.append()两种方法 - 添加列有
df[]和df.insert()两种方法
df = pd.DataFrame(columns=['name','number'])
# .loc 方法: df后追加list
df.loc[0]=['cat', 3] # 插入df索引,默认整数型
df.loc['a'] = ['123',30]
cur_list = ['123',30]
df[df.shape[0]] = cur_list # 【2024-7-8】踩坑,结果有误!格式变成了列向,混乱
df.loc[len(df.index)] = cur_list # 正确做法
# append: 两个pandas表之间的追加
df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
# 合并, ignore_index设置为 True可以重新排列索引
df.append(df2, ignore_index=True)
# 2. 采用append方法添加多行
df = pd.DataFrame(columns=['A'])
for i in range(5):
df = df.append({'A': i}, ignore_index=True)
# 插入一列
df.insert(1, 'tail', 1, allow_duplicates=False)
merge (两表关联)
pandas 的 merge方法是基于共同列,将两个dataframe连接起来。
merge 主要参数:
left/right:左/右位置的dataframe。how:数据合并的方式。- left:基于左dataframe列的数据合并;
- right:基于右dataframe列的数据合并;
- outer:基于列的数据外合并(取并集);
- inner:基于列的数据内合并(取交集);默认为’inner’。
on:用来合并的列名,这个参数需要保证两个dataframe有相同的列名。left_on/right_on:左/右dataframe合并的列名,也可为索引,数组和列表。left_index/right_index:是否以index作为数据合并的列名,True表示是。sort:根据dataframe合并的keys排序,默认是。suffixes:若有相同列且非合并列,suffixes设置该列的后缀名,一般为元组和列表类型。
示例:
- 内连接:
- 外链接
- index和column的内连接方法



# 单列的内连接
# 定义df1
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'alpha':['A','B','B','C','D','E'],'feature1':[1,1,2,3,3,1],
'feature2':['low','medium','medium','high','low','high']})
# 定义df2
df2 = pd.DataFrame({'alpha':['A','A','B','F'],'pazham':['apple','orange','pine','pear'],
'kilo':['high','low','high','medium'],'price':np.array([5,6,5,7])})
# print(df1)
# print(df2)
pd.merge(left,right) # (1)
left.merge(right) # (2)
# 基于共同列alpha的内连接
df3 = pd.merge(df1,df2,how='inner',on='alpha')
# 基于共同列alpha的内连接,若两个dataframe间除了on设置的连接列外并无相同列,则该列的值置为NaN。
df4 = pd.merge(df1,df2,how='outer',on='alpha')
# 基于共同列alpha的左连接
df5 = pd.merge(df1,df2,how='left',on='alpha')
# 基于共同列alpha的右连接
df6 = pd.merge(df1,df2,how='right',on='alpha')
# 基于共同列alpha和beta的内连接
df7 = pd.merge(df1,df2,on=['alpha','beta'],how='inner')
# 基于共同列alpha和beta的右连接
df8 = pd.merge(df1,df2,on=['alpha','beta'],how='right')
# 基于df1的beta列和df2的index连接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True)
# 基于df1的alpha列和df2的index内连接(修改相同列的后缀名)
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True, suffixes=('_df1','_df2'))
df3
多表merge
总结:
- pd.concat() 适用于多个dataframe的合并,可以选择inner和outer的方式; pd.merge() 只能合并2个dataframe,可以选择inner,outer,left,right的合并方式。
- pd.concat() 默认合并方式为outer, 及对行进行叠加式的合并,即合并后行的数目为合并前之和。pd.merge() 默认合并方式为inner。两种合并方式得到的合并后dataframe列都是合并前列名的合集。
- pd.concate(key=[…]) 是在你想要合并后的dataframe为multiindex设置的,不要和pd.merge()中合并需要一个key的概念混了。
- pd.concat() 默认以index作为key来合并,pd.merge() 设置为index,也可以指定 column。其默认是找到两个dataframe中相同的列名作为合并的key。
- 即使两个dataframe中没有相同的行或列,pd.concat() 也可以把他们拼接起来,并且用NaN填充空缺值。pd.merge()必须要有相同的列。可以使用 df1.join(df2) 把df2的列合并到df1上。
作者:GPZ_Lab
【2024-1-23】多表merge
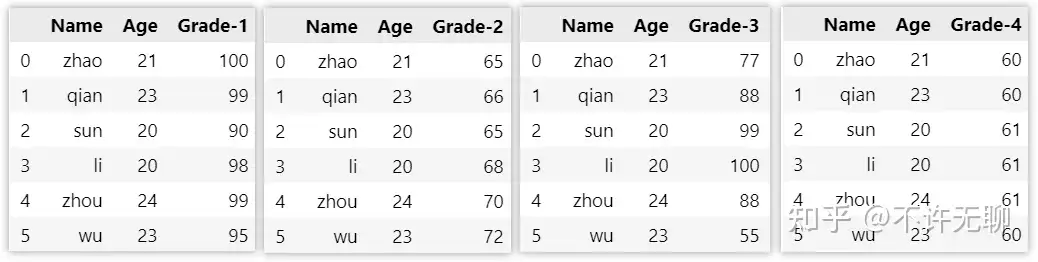
# 数据定义
import pandas as pd
import functools
df1 = pd.DataFrame({
"Name":['zhao','qian','sun','li','zhou','wu'],
"Age":[21,23,20,20,24,23],
"Grade-1":[100,99,90,98,99,95],
})
df2 = pd.DataFrame({
"Name":['zhao','qian','sun','li','zhou','wu'],
"Age":[21,23,20,20,24,23],
"Grade-2":[65,66,65,68,70,72],
})
df3 = pd.DataFrame({
"Name":['zhao','qian','sun','li','zhou','wu'],
"Age":[21,23,20,20,24,23],
"Grade-3":[77,88,99,100,88,55],
})
df4 = pd.DataFrame({
"Name":['zhao','qian','sun','li','zhou','wu'],
"Age":[21,23,20,20,24,23],
"Grade-4":[60,60,61,61,61,60],
})
# ------ 多表 merge ------
# ① 迭代merge —— 低效
# pd.merge(([df1, df2], on='key', how='left')
df1.merge(df2, on='key', how='left').merge(df3, on='key', how='left')
# ② reduce函数,将pd.merge函数递归应用于四个表单 —— 4个df遍历了一遍
df = functools.reduce(
lambda left, right: pd.merge(left, right, how='left',on=['Name','Age']),
[df1,df2,df3,df4]
)
print(df)
# 改进
all_files = []
for fn in glob.glob("../data/temp*.csv"):
all_files.append(pandas.read_csv(fn))
df = functools.reduce(
lambda left, right: pd.merge(left, right, how='left',on=['Name','Age']),
all_files
)
# ③ concat 方法
#
join
- (2) join方法
- join方法基于index连接dataframe,merge方法是基于column连接,连接方法有内连接,外连接,左连接和右连接,与merge一致。
- join和merge的连接方法类似,建议用merge
- 示例

caller = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
other = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(caller)
print(other)# lsuffix和rsuffix设置连接的后缀名
# 基于index连接
caller.join(other,lsuffix='_caller', rsuffix='_other',how='inner')
# 基于key列进行连接
caller.set_index('key').join(other.set_index('key'),how='inner')
concat (拼接)
concat方法是拼接函数, 非常规意义上的join
- 行拼接和列拼接
- 默认: 行拼接,外拼接(并集)
- 拼接的对象是pandas数据类型。
示例
df1 = pd.Series([1.1,2.2,3.3],index=['i1','i2','i3'])
df2 = pd.Series([4.4,5.5,6.6],index=['i2','i3','i4'])
print(df1)
print(df2)
# 行拼接
pd.concat([df1,df2])
# 对行拼接分组,行拼接若有相同的索引,为了区分索引,我们在最外层定义了索引的分组情况。
pd.concat([df1,df2],keys=['fea1','fea2'])
# 列拼接,默认是并集
pd.concat([df1,df2],axis=1)
# 列拼接的内连接(交)
pd.concat([df1,df2],axis=1,join='inner')
# 列拼接的内连接(交)
pd.concat([df1,df2],axis=1,join='inner',keys=['fea1','fea2'])
# 指定索引[i1,i2,i3]的列拼接
pd.concat([df1,df2],axis=1,join_axes=[['i1','i2','i3']])
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
print(df1)
print(df2)
# 行拼接
pd.concat([df1,df2])
# 列拼接
pd.concat([df1,df2],axis=1)
# 判断是否有重复的列名,若有则报错
pd.concat([df1,df2],axis=1,verify_integrity = True)
Reference
《Python for data analysis》
pandas: powerful Python data analysis toolkit — pandas 0.20.1 documentation
集合运算
【2024-6-6】pandas dataframe 集合运算,通过 merge 实现
import pandas as pd
df1=pd.DataFrame([['a',10,'男'],['b',11,'女']],columns=['name','age','gender'])
df2=pd.DataFrame([['a',10,'男']],columns=['name','age','gender'])
df1
集合运算
# 交集, 默认内连接
pd.merge(df1,df2,on=['name','age','gender'])
# 并集, 使用外连接
pd.merge(df1,df2,on=['name','age','gender'],how='outer')
# 差集,追加后,再去重
df1=df1.append(df2)
df1=df1.drop_duplicates(subset=['name','age','gender'],keep=False)
df1
遍历
【2020-12-25】遍历dataframe
- iterrows:最慢
- itertuples
- zip:最快
# 总结
DataFrame.iteritems() # 迭代器结束(列名,系列)对。
DataFrame.iterrows() # 将DataFrame行重复为(索引,系列)对。
DataFrame.itertuples([index,name]) # 将DataFrame行迭代为namedtuples,索引值作为元组的第一个元素。
df = pd.DataFrame({'a': range(0, 10000), 'b': range(10000, 20000)})
import time
list1 = []
start = time.time()
for i,r in df.iterrows():
list1.append((r['a'], r['b']))
print("iterrows耗时 :",time.time()-start)
list1 = []
start = time.time()
for ir in df.itertuples():
list1.append((ir[1], ir[2]))
print("itertuples耗时:",time.time()-start)
list1 = []
start = time.time()
for r in zip(df['a'], df['b']):
list1.append((r[0], r[1]))
print("zip耗时 :",time.time()-start)
- 结果:
- iterrows耗时 : 0.7355637550354004
- itertuples耗时: 0.008462905883789062
- zip耗时 : 0.003980875015258789
多表合并
- 【2020-12-31】一次合并多张表
import pandas as pd
from functools import reduce
data_dir = '/home/work/data/北链讲盘培训价值分析'
#data_file = '/home/work/data/北链讲盘过关用户业绩样例.csv'
bu = ['京北', '京东南']
group = ['未参加', '低分', '高分']
df_dict = {}
for b in bu:
df_dict[b] = {}
for g in group:
data_file = '{}/{}-{}.csv'.format(data_dir, b, g)
print('开始读数据:{}'.format(data_file))
df_dict[b][g] = pd.read_csv(data_file, encoding='gbk')
df_dict[b][g] = df_dict[b][g].rename(columns={'stat_date':'日期', 'avg(assign_amt)':'培训{}的经纪人日均业绩'.format(g)})
df_final.loc[:,'alpha'].apply(lambda x:'{}-hh'.format(x))
df_dict[b][g]['日期'] = df_dict[b][g]['日期'].apply(lambda x: '{}-{}-{}'.format(str(x)[:4],str(x)[4:6],str(x)[6:8]))
# .dt.dayofweek
df_dict[b][g]['星期几'] = pd.to_datetime(df_dict[b][g]['日期']).dt.dayofweek
#df_dict[b]['合并'] = df.merge(df_dict[b]['未参加'], df_dict[b]['低分'], df_dict[b]['高分'], how='inner', on='日期')
merge_list = [df_dict[b]['未参加'], df_dict[b]['低分'], df_dict[b]['高分']]
df_dict[b]['合并'] = reduce(lambda left,right: pd.merge(left,right,on='日期',how='outer'), merge_list).fillna(0)
#df_dict[b]['合并'].to_excel('{}/{}_合并后.xlsx'.format(data_dir, b), encoding='utf8') # 指定编码utf8
df_dict[b]['合并'].to_excel('{}/{}_合并后.xlsx'.format(data_dir, b), encoding='utf8')
#df = pd.read_csv(data_file, encoding='gbk')
#!head $data_file
#df3 = pd.merge(df1,df2,how='inner',on='alpha')
df_dict['京北']['合并']
crosstab进行交叉表
explode展开列表
pd.crosstab(df['Column1'], df['Column2'])
# explode展开列表
df.explode('ListColumn')
# pipe进行链式操作
df.pipe(func1).pipe(func2, arg1='value').pipe(func3)
日期转换
#提取年月日时分秒:方法1
df = pd.read_csv(r"spider.csv",header=None,names=['datetime','url','name','x','y'],encoding='utf-8')
df['datetime'] = pd.to_datetime(df['datetime'],errors='coerce') #先转化为datetime类型,默认format='%Y-%m-%d %H:%M:%S'
df['date'] = df['datetime'].dt.date #转化提取年-月-日
df['year'] =df['datetime'].dt.year.fillna(0).astype("int") #转化提取年 ,
#如果有NaN元素则默认转化float64型,要转换数据类型则需要先填充空值,在做数据类型转换
df['month'] = df['datetime'].dt.month.fillna(0).astype("int") #转化提取月
df['%Y_%m'] = df['year'].map(str) + '-' + df['month'].map(str) #转化获取年-月
df['day'] = df['datetime'].dt.day.fillna(0).astype("int") #转化提取天
df['hour'] = df['datetime'].dt.hour.fillna(0).astype("int") #转化提取小时
df['minute'] = df['datetime'].dt.minute.fillna(0).astype("int") #转化提取分钟
df['second'] = df['datetime'].dt.second.fillna(0).astype("int") #转化提取秒
df['dayofyear'] = df['datetime'].dt.dayofyear.fillna(0).astype("int") #一年中的第n天
df['weekofyear'] = df['datetime'].dt.weekofyear.fillna(0).astype("int") #一年中的第n周
df['weekday'] = df['datetime'].dt.weekday.fillna(0).astype("int") #周几,一周里的第几天,Monday=0, Sunday=6
df['quarter'] = df['datetime'].dt.quarter.fillna(0).astype("int") #季度
display(df.head())
百分比计算
按 行 计算对应列的数值、百分比、累积占比
非重复
按取值去重,再用 value_counts 方法
sort=True: 是否要进行排序;默认进行排序ascending=False: 默认降序排列;normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。bins=None: 可以自定义分组区间,默认是否dropna=True:是否删除缺失值nan,默认删除
返回 Series, 非 DataFrame
import pandas as pd
df = pd.DataFrame({'col1': [1, 2, 3, 4, 5, 6]})
# 频次统计
df['col1'].value_counts() # 忽略空值
df['col1'].value_counts(dropna=False) # 考虑空值(NaN)
df['col1'].value_counts().loc[lambda x : x>4] # 选择查看部分数据
df['col1'].value_counts().to_frame() # 保存为 dataframe 格式
df.groupby('Embarked')['Sex'].value_counts() # 分组统计
# 同时显示 频次和比例:1.5.3 版本出错, 2.2才可以
pd.merge(df['col1'].value_counts(), df['col1'].value_counts(normalize=True), on='col1')
df['col1'].value_counts(ascending=True) # 按频次升序排列
df['col1'].value_counts(ascending=True).sort_index(ascending=True) # 按 key 升序排列
df['col1'].value_counts(normalize=True) # 统计比例值, 纯小数
pd.set_option('display.float_format', '{:.2f}%'.format)
df['col1'].value_counts(normalize=True) # 统计比例值, 百分比形式
# 连续值
df['col1'].value_counts(bins=3) # 分3个桶,离散化
df['col1'].value_counts(bins=[-1, 20, 100, 550]) # 自定义分桶
value_counts = df['col1'].value_counts(normalize=True) * 100
cumsum = value_counts.cumsum()
print(cumsum)
# 【2024-7-1】按取值统计,并按频次升序排列、画图: 两次 value_counts
df['session_id'].value_counts(ascending=True).value_counts().sort_index().plot(kind='bar')
查看频次分布函数
- pandas 2.2.2 实测成功
import pandas as pd
a = pd.DataFrame([['wang', 23], ['wang', 21], ['li', 10], ['zhang', 40]], columns=['name', 'age'])
# 百分比格式
pd.set_option('display.float_format', '{:.2f}%'.format)
def countInfo(df, k):
"""
data 要统计的series
pd.merge( a['name'].value_counts(), a['name'].value_counts(normalize=True), on='name')
"""
# Series 格式, 分别计算 频次、占比 分布
df_frequence = df[k].value_counts().sort_index(ascending=True) # 频次
df_percent = df[k].value_counts(normalize=True).sort_index(ascending=True) # 占比
df_cumsum = df_percent.cumsum() # 累积占比
df_merge = pd.merge(df_frequence, df_percent*100, on=k).reset_index() # k 是索引, ['count', 'proportion'], 加 .reset_index() 保证 index 常规的整型, 将k值单独成列
# print(df_merge.columns)
return df_merge.sort_values(by='count', ascending=False)
x = countInfo(a, 'name')
y = countInfo(a, 'name')
z = countInfo(a, 'name')
# 多表merge
s_all = pd.merge(x, y, on='name', suffixes=['_val', '_test']).merge(z, on='name')
含重复行
直接计算,不去重
df['percent'] = (df['c'] / df['c'].sum()) * 100
详情
# 合并训练集、测试集轮数分布
df_stat_turn_merge = pd.merge(df_train['turns'].value_counts(), df_test['turns'].value_counts(), on='turns')
df_stat_turn_merge.rename(columns={"turns":"会话轮数", "count_x":"训练集轮数","count_y":"测试集轮数"},inplace=True)
df_stat_turn_merge = df_stat_turn_merge.sort_values(by='turns')
df_stat_turn_merge['占比-训练'] = df_stat_turn_merge['训练集轮数']/df_stat_turn_merge['训练集轮数'].sum() * 100
df_stat_turn_merge['累积占比-训练'] = df_stat_turn_merge['占比-训练'].cumsum()
df_stat_turn_merge['占比-测试'] = df_stat_turn_merge['测试集轮数']/df_stat_turn_merge['测试集轮数'].sum() * 100
df_stat_turn_merge['累积占比-测试'] = df_stat_turn_merge['占比-测试'].cumsum()
df_stat_turn_merge.to_csv('../data/session_turn.csv')
df_stat_turn_merge
调整列顺序
两种方法
- 直接重组
- 局部调整:先把需要调整的列的数据拿出来,之后,再将这个列删掉,最后,再用插入的方式把这个列调整到对应的位置上。
# 方法一
order = ['date', 'time', 'open', 'high', 'low', 'close', 'volumefrom', 'volumeto']
df = df[order]
# 方法二
df_id = df.id
df = df.drop('id',axis=1)
df.insert(0,'id',df_id)
sort 用法
数据排序sort_index()和sort_values()
sort_values()
- 作用:既可以根据列数据,也可根据行数据排序。
- 注意:必须指定by参数,即必须指定哪几行或哪几列;无法根据index名和columns名排序(由.sort_index()执行)
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’)
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。by:str or list of str;如果axis=0,那么by=”列名”;如果axis=1,那么by=”行名”。ascending:布尔型,True则升序,如果by=[‘列名1’,’列名2’],则该参数可以是[True, False],即第一字段升序,第二个降序。inplace:布尔型,是否用排序后的数据框替换现有的数据框。kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
sort_index()
- 作用:默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
- 注意:df. sort_index()可以完成和df. sort_values()完全相同的功能,但python更推荐用只用df. sort_index()对“根据行标签”和“根据列标签”排序,其他排序方式用df.sort_values()。
sort_index(axis=0, level=None, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’, sort_remaining=True, by=None)
- axis:0按照行名排序;1按照列名排序
- level:默认None,否则按照给定的level顺序排列—貌似并不是,文档
- ascending:默认True升序排列;False降序排列
- inplace:默认False,否则排序之后的数据直接替换原来的数据框
- kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。
- na_position:缺失值默认排在最后{“first”,”last”}
- by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用
import pandas as pd
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
df.sort_values(by='b') #等同于df.sort_values(by='b',axis=0)
df.sort_values(by=['b'], na_position='first') # 空值放前面
df.sort_values(by=['b','c'], ascending=False) # 多列,降序
df.sort_values(by=['b'], ascending=False, inplace=True, na_position='first') # 替换原数据
df.sort_values(by=0, ascending=False, axis=1) # 按第一行值降序排列
df.sort_values(by=[3,0], axis=1,ascending=[True,False]) # 排序故障
df.sort_values(by=['b','c'],ascending=[True,False]) # [2023-8-23] 实测有效,去掉 exis=1,下标改字符串
df.sort_values(by=3,axis=1) #按第三行升序,必须指定axis=1
df.sort_index() #默认按“行标签”升序排序,或df.sort_index(axis=0, ascending=True)
df.sort_index(axis=1) #按“列标签”升序排序
#先按b列“降序”排列,因为b列中有相同值,相同值再按a列的“升序”排列
df.sort_index(by = ['b','a'],ascending = [False,True])
Rank用法
【2022-9-13】python中分组排序–groupby(),rank()
rank()函数参数设置
- ascending :1 表示升序,0表示降序
- method : {‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}, default ‘average’ 主要用来当排序时存在相同值参数设置;
- 默认为average平均值:年龄为32的数值,排序应该为8,9取平均值则为8.5
- min:排序中最小值,年龄排序中取值为8
- max:排序中最大值,年龄排序中取值9
- first:同样数值按照值出现的前后进行排序 5号性别为男的年龄排序为8,7号性别为女的排序为9
- dense: like ‘min’, but rank always increases by 1 between groups 排序时当值相同时,相同的值为同一排名类似min值排序,后续值排名在此排名基础上加一
- na_option : {‘keep’, ‘top’, ‘bottom’}, default ‘keep’ 当排序数据中存在空值时,默认值设置为keep
- How to rank NaN values:
- keep: assign NaN rank to NaN values 默认空值不参与排序
- top: assign smallest rank to NaN values if ascending 默认为升序时从空值为最小值排序
import pandas as pd
df = pd.DataFrame([['男',13,1], ['男',15,0], ['男',12,0],['男',14,1],['女',13,1],['女',14,0],['女',15,1],['男',13,0]],columns=['gender', 'age', 'is_good'])
# 累积和
df['sum_age'] = df['age'].cumsum()
df['sum_age_new'] = df.groupby(['gender','is_good'])['age'].cumsum() # 多维度分组,再累加求和
# 全局排序
df['rank_age'] = df['age'].rank(ascending=0, method='min')
df['rank'] = df['age'].rank()
df['rank_mean'] = df['age'].rank(method='average')
df['rank_min'] = df['age'].rank(method='min')
df['rank_max'] = df['age'].rank(method='max')
df['rank_first'] = df['age'].rank(method='first')
print(df)
# 局部排序:分组排序(按gender内容分组)
df['rank_group'] = df['age'].groupby(df['gender']).rank(ascending=0, method='min')
df['rank_g'] = df.groupby(['gender'])['age'].rank()
# 查看数据:依次按gender、rank_group排序
df.sort_values(by=['gender','rank_group'],ascending=(1,1))
# 默认值处理
df['rank'] = df['age'].rank(method='first')
df['rank_k'] = df['age'].rank(method='first',na_option='keep')
df['rank_t'] = df['age'].rank(method='first',na_option='top')
df['rank_b'] = df['age'].rank(method='first',na_option='bottom')
print(df)
groupby 聚合统计
词频统计,类似collections里的Counter
- 聚合函数:sum,cumsum,prod,mean,max,min,idxmax,rank
【2022-8-22】25个例子学会Pandas Groupby 操作
import pandas as pd
sales = pd.read_csv("sales_data.csv")
sales.head()
df = pd.DataFrame([['Toyota', 40], ['Ford', 20], ['Ford', 30],['Toyota', 30]], columns=['brand', 'price'])
# 单列聚合
sales.groupby("store")["stock_qty"].mean()
# 输出storeDaisy 1811.861702Rose 1677.680000Violet 14622.406061Name: stock_qty, dtype: float64
sales.groupby("store",as_index=False)["stock_qty"].mean() # 不用分组值作为index
# 输出结果保留key值
out=pd_month_short.groupby('corp_name')['corp_name'].agg('count') # value作为index参数, 直接转list时,分组值丢失
list(out.to_dict().items()) # 结果转成dict,再list
# 多列聚合
sales.groupby("store")[["stock_qty","price"]].mean()
# 多列多个聚合 agg函数
sales.groupby("store")["stock_qty"].agg(["mean", "max"])
# 对聚合结果命名
sales.groupby("store").agg( avg_stock_qty = ("stock_qty", "mean"),max_stock_qty = ("stock_qty", "max"))
# 多个聚合和多个函数
sales.groupby("store")[["stock_qty","price"]].agg(["mean", "max"])
# 对不同列的聚合进行命名
sales.groupby("store").agg(avg_stock_qty = ("stock_qty", "mean"),avg_price = ("price", "mean"))
# as_index参数:groupby操作的输出是DataFrame,可以使用as_index参数使它们成为DataFrame中的一列
sales.groupby("store", as_index=False).agg(avg_stock_qty = ("stock_qty", "mean"),avg_price = ("price", "mean"))
# 用于分组的多列
sales.groupby(["store","product_group"], as_index=False).agg(avg_sales = ("last_week_sales", "mean")).head()
# 排序输出
sales.groupby(["store","product_group"], as_index=False).agg( avg_sales = ("last_week_sales", "mean")).sort_values(by="avg_sales", ascending=False).head()
# 最大的Top N:max扩展
sales.groupby("store")["last_week_sales"].nlargest(2)
# store Daisy 413 1883231 947Rose 948 883263 623Violet 991 3222339 2690Name: last_week_sales, dtype: int64
# 最小的Top N
sales.groupby("store")["last_week_sales"].nsmallest(2)
# 第n个值
sales_sorted = sales.sort_values(by=["store","last_month_sales"], ascending=False, ignore_index=True)
sales_sorted.groupby("store").nth(4)
# 第n个值,倒排序
sales_sorted.groupby("store").nth(-2)
# 唯一值:unique函数可用于查找每组中唯一的值
sales.groupby("store", as_index=False).agg(unique_values = ("product_code","unique"))
# 唯一值的数量: 用nunique函数找到每组中唯一值的数量
sales.groupby("store", as_index=False).agg(number_of_unique_values = ("product_code","nunique"))
# Lambda表达式
sales.groupby("store").agg(total_sales_in_thousands = ("last_month_sales", lambda x: round(x.sum() / 1000, 1)))
# apply函数:使用apply函数将Lambda表达式应用到每个组
sales.groupby("store").apply(lambda x: (x.last_week_sales - x.last_month_sales / 4).mean())
# storeDaisy 5.094149Rose 5.326250Violet 8.965152dtype: float64
# dropna: groupby函数默认忽略缺失值,dropna参数来改变这个行为
sales.groupby("store", dropna=False)["price"].mean()
# storeDaisy 69.327426Rose 60.513700Violet 67.808727NaN 96.000000Name: price, dtype: float64
# 求组的个数
sales.groupby(["store", "product_group"]).ngroups # 18
# 获得一个特定分组:get_group函数可获取特定组并且返回DataFrame
aisy_pg1 = sales.groupby(["store", "product_group"]).get_group(("Daisy","PG1"))daisy_pg1.head()
# rank函数
sales["rank"] = sales.groupby("store"["price"].rank(ascending=False, method="dense")sales.head()
# 累计操作
import numpy as np
df = pd.DataFrame({"date": pd.date_range(start="2022-08-01", periods=8, freq="D"),"category": list("AAAABBBB"),"value": np.random.randint(10, 30, size=8)})
df["cum_sum"] = df.groupby("category")["value"].cumsum()
# expanding函数:提供展开转换。但是对于展开以后的操作还是需要一个累计函数来堆区操作。例如它与cumsum 函数一起使用,结果将与与sum函数相同。
df["cum_sum_2"] = df.groupby("category")["value"].expanding().sum().values
# 累积平均:利用展开函数和均值函数计算累积平均
df["cum_mean"] = df.groupby("category")["value"].expanding().mean().values
# 展开后的最大值:用expand和max函数记录组当前最大值。
df["current_highest"] = df.groupby("category")["value"].expanding().max().values
单列聚合
# 对train表里的intent列计算频次,并给出百分比(不用单独计算)
train.intent.value_counts() # 频次统计
train.intent.value_counts(ascending=True) # 升序
train.intent.value_counts(normalize=True) # 计算比例
# 聚合统计
df.groupby('total_bedrooms')['population'].agg(['count', 'sum', 'mean'])[:10]
df.groupby(['real_cost']).size().loc[10] # 查询某个分组下的聚合值
df.groupby(['real_cost']).get_group((10)) # 查询某个分组下所有记录
df.groupby(['real_cost'])['queuecount'].idxmin() # 各个分组下某个取值(queuecount)最小/大的记录数下标,idxmin,idxmax
df.groupby(['real_cost']).size().apply(lambda x:2*x).head() # apply,对统计值的二次处理
df.groupby(['real_cost']).size().reset_index()# reset_index重置index
# key内部求和,按照key分组,再对value求和
gp = data.groupby(["key"])["value"].sum().reset_index() # reset_index重置index
gp = data.groupby(["key"])["value"].cumsum().reset_index() # 累计和
gp = data.groupby(["key"])["value"].prod().reset_index() # 连乘,类似的min、max、mean、idxmin、idxmax
gp = data.groupby(["key"])["value"].rank().reset_index() # 编号
gp = data.groupby(["key"])["value"].agg(['count','sum']).reset_index() # agg多组值
gp.rename(columns={"value":"sum_of_value"},inplace=True) # rename改列名
grouped1 = df['data1'].astype(float).groupby(df['key1']).mean() #先将data1转换成浮点型,然后分组求均值
# [2021-10-22] 转成字典格式: key → value
prov_data = dict(stat['location'].groupby('省')['所有频次'].agg(['sum'])['sum'])
# pandas groupby常用功能
df.groupby(['real_cost']).size().reset_index()# reset_index重置index
df.groupby(['dt','msg']).size().reset_index().rename(columns={0:"count"})
df.rename(columns={0:"count"})
df.groupby(['real_cost']).size() # 分组,频次计算,size()计算数目
df.groupby(['real_cost']).size() # 分组,频次计算,count()不含Nan值
df.groupby(['real_cost']).size().loc[10] # 查询某个分组下的聚合值
df.groupby(['real_cost']).get_group((10)) # 查询某个分组下所有记录
df.groupby(['real_cost'])['queuecount'].idxmin() # 各个分组下某个取值(queuecount)最小/大的记录数下标,idxmin,idxmax
df.groupby(['real_cost']).size().apply(lambda x:2*x).head() # apply,对统计值的二次处理
# 用户当天第几次搜索某个brand_id
gp = data.groupby(["user_id","day","brand_id"])["hour"].rank().reset_index()
gp.rename(columns={"hour":"rank"},inplace=True)
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['A', 'B', 'C'])
df.agg(sum)
df.agg(['sum', 'min'] # 行向汇总
df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']}) # 每列统计方法不同
df.agg(x=('A', max), y=('B', 'min'), z=('C', np.mean)) # 列上聚合不同的函数,然后重命名结果DataFrame的索引
#agg 调用的时候要指定字段,apply 默认传入的是整个dataframe,transform 是针对输入的元素级别转换
df[['customer_type','real_cost']].agg(['sum','mean','min','max','median']) # 多个属性的统计信息
tmp = lambda x:x.sort_values(ascending = False).iloc[0]
tmp.__name__ = 'func'
df[['customer_type','real_cost']].agg({'customer_type':['sum','mean'],'real_cost':['sum',tmp]}) # 多个属性的统计信息(统计值不同,自定义聚合函数)
df.groupby(['real_cost']).transform(('sum')) # transform元素级别的变换
df['real_cost'].applymap(tmp) # 元素级别变换
分箱
cut函数将数值列分成不同的箱子,用标签表示
df['AgeGroup'] = pd.cut(df['Age'], bins=[20, 30, 40, 50], labels=['20-30', '30-40', '40-50'])
# groupby和transform进行组内操作
df['MeanSalaryByAge'] = df.groupby('Age')['Salary'].transform('mean')
数据集处理
采样
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
字段含义
- n 选取条数
- frac 选取比例
- replace 是否重复选
- weights 权重
- random_state 随机种子
- axis 0是选取行,为1是选取列。
pandas随机采样,用于数据集划分;
# 随机采样
df = pd.DataFrame([[1,'a'],[2,'b'],[3,'c'],[4,'d']], columns=['id','name'])
# DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
#df.sample(frac=1).reset_index(drop=True)
df.sample(frac=1) # 随机打乱,100%乱序,frac是比例,axis行还是列向,replace是否放回,weights字符索引或概率数组
df.sample(n=3,random_state=1) # 抽3行,可重复数据
df.sample(frac=0.8, replace=True, random_state=1) # replace可重复
# 直接打乱,根据序号划分
df_new = df_all.sample(frac=1) # 全部乱序
# 7k, 1.1k, 1k
df_train = df_new[:7000]
df_validation = df_new[7000:8100]
df_test = df_new[8100:]
划分
划分训练集、测试集和验证集
pandas
DataFrame.sample函数:
import pandas as pd
data_df = pd.read_csv(config.TRAIN_DATASET_PATH)
# 区分训练集(70%)、验证集(30%)
train_df = data_df.sample(frac=0.7, random_state=0, axis=0)
validation_df = data_df[~data_df.index.isin(train_df.index)]
# -------------
# 训练集、测试集
train = df.sample(frac=0.8, random_state=0)
test = df.drop(train.index)
sklearn
工具划分
from sklearn.model_selection import train_test_split
# split train set and test set
data_train, data_test = train_test_split(data, test_size=0.2, random_state=1234)
# split validate set and test set
data_test, data_val = train_test_split(data_test, test_size=0.5, random_state=1234)
train, test = train_test_split(df, test_size=0.2, random_state=0)
numpy
新方式: numpy
import numpy as np
data_num = data.shape[0] # 样本总数
# 按比例抽取测试集
test = np.random.choice(data_num, size=int(train_test_ratio * data_num),
replace=False)
#
test_idx = np.zeros(data_num, dtype=bool)
test_idx[test] = True
tp_test = data[test_idx]
tp_train = data[~test_idx]
# 测试集总数
data_num = tp_test.shape[0]
test_valid = np.random.choice(data_num, size=int(test_valid_ratio * data_num),
replace=False) ##replace:True表示可以取相同数字,False表示不可以取相同数字
valid_idx = np.zeros(data_num, dtype=bool)
valid_idx[test_valid] = True
tp_valid = tp_test[valid_idx]
tp_train = tp_test[~valid_idx]
窗口计算
【2022-9-20】pandas之滑动窗口学习笔记(shift, diff, pct_change)
pandas中有3类窗口,分别是:
- 滑动窗口 rolling
- 扩张窗口 expanding
- 指数加权窗口 ewm
df['Column'].rolling(window=size).mean()
协方差、相关系数
滑窗对象
- 要使用滑窗函数,就必须先要对一个序列使用 .rolling 得到滑窗对象,其最重要的参数为窗口大小 window
- 再用相应的聚合函数进行计算
- 注意:窗口包含当前行所在的元素,例如在第四个位置进行均值运算时,应当计算(2+3+4)/3,而不是(1+2+3)/3:
s = pd.Series([1,2,3,4,5])
roller = s.rolling(window = 3)
roller # Rolling [window=3,center=False,axis=0]
roller.mean() # 滑窗均值函数,得到:Nan Nan 2 3 4
roller.sum() # 滑窗求和函数,得到:Nan Nan 6 9 12
s2 = pd.Series([1,2,6,16,30])
roller.cov(s2) # 滑动协方差
roller.corr(s2) # 滑动相关系数
a = np.arange(1,10).reshape(3,3)
data = DataFrame(a,index=["a","b","c"],columns=["one","two","three"])
data.cov() # 协方差矩阵
data.one.cov(data.two) # 第一列、第二列协方差
data.one.corr(data.two) # 第一列、第二列相关系数
data.corr() # 相关系数矩阵
data.corrwith(data.three) # df各列与three列相关系数
roller.apply(lambda x:x.mean()) # apply 传入自定义函数
s = pd.Series(np.random.randint(-1,2,30).cumsum())
s.ewm(alpha=0.2).mean().head() # 指数加权
shift, diff, pct_change 是一组类滑窗函数,公共参数为 periods=n ,默认为1,这里的 n 可以为负,表示反方向的类似操作。
| 函数 | 说明 |
|---|---|
| shift | 取向前第 n 个元素的值 |
| diff | 与向前第 n 个元素做差(与 Numpy 中不同,后者表示 n 阶差分) |
| pct_change | 与向前第 n 个元素相比计算增长率 |
pct_change
df.pct_change()
- DataFrame.pct_change(periods=1, fill_method=’pad’, limit=None, freq=None, **kwargs)
- 表示当前元素与先前元素的相差百分比,当然指定periods=n,表示当前元素与先前n 个元素的相差百分比
# ---------------
s = pd.Series([90, 91, 85])
s.pct_change(periods=2)#表示当前元素与先前两个元素百分比
# ------ dataframe ------
df = pd.DataFrame({
'FR': [4.0405, 4.0963, 4.3149],
'GR': [1.7246, 1.7482, 1.8519],
'IT': [804.74, 810.01, 860.13]},
index=['1980-01-01', '1980-02-01', '1980-03-01'])
print(df)
print(df.pct_change())
print(df.pct_change(axis='columns'))#可以指定按照行还是列进行计算的
diff
将某行/列移动periods周期后,与原来数据进行对比,取得差值
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(24).reshape(6,4),index=['r1','r2','r3','r4','r5','r6'],columns=['A','B','C','D'])
df
df.diff(periods=2,axis=0)
shift
功能:数据移动
- 若freq=None时,根据axis的设置,行索引数据保持不变,列索引数据可以在行上上下移动或在列上左右移动;
-
若行索引为时间序列,则可以设置freq参数,根据periods和freq参数值组合,使行索引每次发生periods*freq偏移量滚动,列索引数据不会移动
- ① 对于DataFrame的行索引是日期型,行索引发生移动,列索引数据不变
- 结论:对于时间索引而言,shift使时间索引发生移动,其他数据保存原样,且axis设置没有任何影响
- ②对于DataFrame行索引为非时间序列,行索引数据保持不变,列索引数据发生移动
import pandas as p
import numpy as n
df = pd.DataFrame(np.arange(24).reshape(6,4), # 数据源,6*4矩阵
index=pd.date_range(start='20170101',periods=6), # 指定index为日期值
columns=['A','B','C','D']) # 指定列名
df
df.shift(2,axis=0,freq='2D')
df.shift(2,axis=1,freq='2D')
df.shift(2,freq='2D')
# ----- index非时间序列,行索引不变,列索引数据移动
df = pd.DataFrame(np.arange(24).reshape(6,4),index=['r1','r2','r3','r4','r5','r6'],columns=['A','B','C','D'])
df.shift(periods=2,axis=0) # 行数据向下移动两行
df.shift(periods=-2,axis=0)# 行数据向上移动两行
df.shift(periods=2,axis=1) # 列数据向右移动两列
df.shift(periods=-2,axis=1)# 列数据向左移动两列
文件读写
excel
excel文件:openpyxl、pandas、xlrd(2.0版本不再支持xlsx文件,因此我用的1.2版本)、xlwings分别读取测试性能
- openpyxl读取得到1048553行,耗时32秒pandas读取得到1048553行(包括表头行),耗时49秒
- xlrd读取得到63行,耗时15秒(将xlrd获取的数据用遍历方式读入list再转化为DataFrame的操作,耗时微秒级)
- xlwings读取得到1048553行,耗时6秒(将xlwings获取的数据用expand方法读入list可以获得正确的行数,再转化为DataFrame的操作,耗时毫秒级)
xlrd是python环境下对excel中的数据进行读取的一个模板,可以进行的操作有:
- 读取有效单元格的行数、列数
- 读取指定行(列)的所有单元格的值
- 读取指定单元格的值
- 读取指定单元格的数据类型
pandas文件操作
# pandas读取excel数据示例
# 【2016-7-30】 参考:十分钟搞定pandas
import pandas as pd
import numpy as np
# 读取数据 D:\work\用户建模画像\家公司挖掘\code\warren.xls
# 数据格式:time
print 'start'
df = pd.read_excel('C:\Users\warren\Desktop\warren.xlsx',index='time')
#[2018-4-11] 先安装!pip install xlrd才可以
df = pd.read_excel(open('your_xls_xlsx_filename','rb'), sheetname=1) # 读取第二个sheet
df = pd.read_excel(open('your_xls_xlsx_filename','rb'), sheetname='Sheet 1')
df = pd.read_excel('your_xls_xlsx_filename', names=['a','b']) # 自定义表头
df = pd.read_excel('your_xls_xlsx_filename', header=None) # 不用表头
df = pd.read_excel('your_xls_xlsx_filename', header=0) # 第1行作为表头
df = pd.read_excel('your_xls_xlsx_filename', header=1) # 第2行作为表头
df = pd.read_excel('your_xls_xlsx_filename', header=[1,2,3]) # 选择2、3、4行作为表头
# 默认读取全部列,可以自定义读取哪些列
pd.read_excel('tmp.xlsx', usecols='A,B') # 取 A 和 B 两列
pd.read_excel('tmp.xlsx', usecols='A:H') # 取 A 到 H 列
pd.read_excel('tmp.xlsx', usecols='A,C,E:H') # 取 A和C列,再加E到H列
pd.read_excel('tmp.xlsx', usecols=[0,1]) # 取前两列
pd.read_excel('tmp.xlsx', usecols=['姓名','性别']) # 取指定列名的列
# 表头包含 Q 的
pd.read_excel('team.xlsx', usecols=lambda x: 'Q' in x)
# 指定去读行数
pd.read_excel(data, nrows=1000) # 读取前1000行
pd.read_excel(filename, skipfooter=1) # 最后一行不加载
# 跳过指定行 skiprows;list-like, int or callable, optional
pd.read_excel(data, skiprows=2) # 跳过前三行
pd.read_excel(data, skiprows=range(2)) # 跳过前三行
pd.read_excel(data, skiprows=[24,234,141]) # 跳过指定行
pd.read_excel(data, skiprows=np.array([2, 6, 11])) # 跳过指定行
pd.read_excel(data, skiprows=lambda x: x % 2 != 0) # 隔行跳过
# 跳过最后几行用 skipfooter=2
# 读取 子页面
df = pd.read_excel('your_xls_xlsx_filename', sheet_name='Sheet') # [2022-9-13]实测通过
# 显示excel里的sheet列表
ReadSheets=pd.ExcelFile('test.xlsx')
for i in ReadSheets.sheet_names:
print(i)
# 替换控制
pd.read_excel(data, na_values=[5]) # 5 和 5.0 会被认为 NaN
pd.read_excel(data, na_values='?') # ? 会被认为 NaN
pd.read_excel(data, keep_default_na=False, na_values=[""]) # 空值为 NaN
pd.read_excel(data, keep_default_na=False, na_values=["NA", "0"]) # 字符 NA 字符 0 会被认为 NaN
pd.read_excel(data, na_values=["Nope"]) # Nope 会被认为 NaN
# a、b、c 均会被认为 NaN 等于 na_values=['a','b','c']
pd.read_excel(data, na_values='abc')
pd.read_excel(data, na_values={'c':3, 1:[2,5]}) # 指定列的指定值会被认为 NaN
# 保留默认空值 keep_default_na
# 指定 na_values 参数,并且 keep_default_na=False,那么默认的NaN将被覆盖,否则添加。
pd.read_excel(data, keep_default_na=False) # 不自动识别空值
# 自动解析时间日期
pd.read_excel(data, parse_dates=True) # 自动解析日期时间格式
pd.read_excel(data, parse_dates=['年份']) # 指定日期时间字段进行解析
# 将 1、4 列合并解析成名为 时间的 时间类型列
pd.read_excel(data, parse_dates={'时间':[1,4]})
长整数错乱
【2024-1-23】读取excel时,如果有数值较大的整数(id编号),会被自动转成科学计数法,无法恢复
- 工单编号、电话号码等变成科学计数法记录
- 当电话号码类型是float时采用科学计数法,而int不会。转化成int类型
- 强制将所有字段当 字符串 处理
怎么办? 知乎
- 读文件时 强制将所有字段当 字符串 处理
- 改用 read_csv 方法
- 后处理:空值转换,将float类型转成int64
df = pd.read_excel('data/botskill标注答案汇总1.23.xlsx')
#df['Bot编号'] = df['Bot编号'].astype('str') # 后置类型转换失败
# 解决方法:
# ① 读文件时,强制将所有字段当 字符串 处理
df = pd.read_excel('data/botskill标注答案汇总1.23.xlsx', dtype=object) # 或
df = pd.read_excel('data/botskill标注答案汇总1.23.xlsx', dtype=str)
# 多个字段格式不同时,不便挨个设置类型, dtype 直接把所有列都无损读取
from numpy import dtype
df = pd.read_excel('data/botskill标注答案汇总1.23.xlsx', dtype=dtype)
# ② 后处理:空值转换,将float类型转成int64 —— 【2024-1-23】这种方法不行!取值变化,原因:数字长度超过16位就会因为float的精度问题无法还原原来的数字
# 前 7290913086481940488
# 后 7290913086481939456
df['Bot编号'] = df['Bot编号'].fillna(-1).astype('int64')
删除空行
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行
- 如果设置 how=’all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
import pandas as pd
df=pd.read_excel(r'清洗空值.xlsx')
df = pd.read_excel('file.xlsx', skipna=True) # 忽略空行,不管用
# 删除空行
df1=df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) # 删除全部为空的行
df2=df.dropna(axis=0, how='all', thresh=None, subset=None, inplace=False) # 只有全部为空才回被删除
df3=df.dropna(axis=0, how='all', thresh=5, subset=None, inplace=False) # 原地删除
print(df1)
print(df2)
print(df3)
csv
读取csv/tsv文件
df = pd.read_table('data/raw_tmp_new.txt',header=None,names=['a','b','c'])
data_file = 'D:/project/python_instruct/test_data1.csv'
df = pd.read_csv(data_file)#用read_csv读取的csv文件
# skiprows:排除前3行是skiprows=3 排除第3行是skiprows=[3]
df = pd.read_csv(data_file, skiprows=3)
df = pd.read_csv(data_file, encoding='utf8') # 编码
df = pd.read_table(data_file, sep=',')#用read_table读取csv文件
df = pd.read_csv("data.txt",sep="\s+") # 不规则分隔符
df = pd.read_csv(data_file, header=None)#用read_csv读取无标题行的csv文件
df.columns = ['A','B','C'] # 事后修改列名
df = pd.read_csv(data_file, names=['a', 'b', 'c', 'd', 'message']) # 用read_csv读取自定义标题行的csv文件
df = pd.read_csv("./demo.txt",header=None, names=['a','b','c','d','e'])
df = pd.read_csv("./demo.txt",header=None, index_col=False,names=['a','b','c','d','e'])
# 自定义某列处理方法:converters 设置指定列的处理函数,可以用"序号"也可以使用“列名”进行列的指定
def fun(x):
return str(x)+"-haha"
df = pd.read_csv("./test.txt",sep=' ',header=None,index_col=0,converters={3:fun})
names=['a', 'b', 'c', 'd', 'message']
df=pd.read_csv(data_file, names=names, index_col='message')#'read_csv读取时指定索引
parsed=pd.read_csv(data_file, index_col=['key1', 'key2'])#read_csv将多个列做成一个层次化索引
print(list(open(data_file)))
# read_table ≈ read_csv,区别仅在与分隔符
result=pd.read_table(data_file, sep='\s+')#read_table利用正则表达式处理文件读取
# 固定宽度文件
colspecs = [(0, 6), (8, 20), (21, 33), (34, 43)]
df = pd.read_fwf('demo.txt', colspecs=colspecs, header=None, index_col=0)
# read_msgpack 函数
# pandas支持的一种新的可序列化的数据格式,这是一种轻量级的可移植二进制格式,类似于二进制JSON,这种数据空间利用率高,在写入(序列化)和读取(反序列化)方面都提供了良好的性能。
# read_clipboard 函数
# 读取剪贴板中的数据,可以看作read_table的剪贴板版本。在将网页转换为表格时很有用
# 直接用一个宽度列表,可以代替colspecs参数
widths = [6, 14, 13, 10]
df = pd.read_fwf('demo.txt', widths=widths, header=None)
# json
s = '{"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,5],[6,9]]}'
df = pd.read_json(s, orient='split')
s = '[{"a":1,"b":2},{"a":3,"b":4}]'
df = pd.read_json(s,orient='records')
# html
df = pd.read_html("http://data.stcn.com/2019/0304/14899644.shtml",flavor ='lxml')
# ------- 更多用法 ---------
DataFrame.from_csv(path [,header,sep,…]) # 读取CSV文件(DISCOURAGED,请改用pandas.read_csv())。
DataFrame.from_dict(data [,orient,dtype]) # 从类array或dicts的dict构造DataFrame
DataFrame.from_items(items [,columns,orient]) # 将(键,值)对转换为DataFrame。
DataFrame.from_records(data [,index,…]) # 将结构化或记录ndarray转换为DataFrame
DataFrame.info([verbose,buf,max_cols,…])# DataFrame的简明摘要。
DataFrame.to_pickle(path)# Pickle(序列化)对象到输入文件路径。
DataFrame.to_csv([path_or_buf,sep,na_rep,…]) # 将DataFrame写入逗号分隔值(csv)文件
# [2021-11-11] 注意:df.to_csv写入的字符串如果包含json串,结果会出现问题,所有"变成"",破坏json格式。
df = pd.DataFrame([{"test": 'id={"name":"test"}'}])
df.to_csv('t.txt', sep='\t') # 结果 id={""name"":""test""}
df.to_csv("test.txt", sep='|',index=False,header=True)
# 改进办法:
import csv
df.to_csv("test.csv", sep='|', quoting=csv.QUOTE_NONE, index=False, header=True)
# [2024-7-8] 踩坑:
df_ready.to_csv(ready_file) # 坑: header字段前面多了一个逗号, 导致手工追加新行时报错(列数目不一致)
df_ready.to_csv(ready_file, index=False) # 解决: 加 index=False
DataFrame.to_hdf(path_or_buf,key, kwargs) # 使用HDFStore将包含的数据写入HDF5文件。
DataFrame.to_sql(name,con [,flavor,…]) # 将存储在DataFrame中的记录写入SQL数据库。
DataFrame.to_dict([orient]) #将DataFrame转换成字典。
DataFrame.to_excel(excel_writer [,…]) #将DataFrame写入excel表
DataFrame.to_json([path_or_buf,orient,…]) # 将对象转换为JSON字符串。 默认是一个json串,未按记录换行
df.to_json(out_file, orient='records') # 【2024-3-15】保存为jsonl格式
df.to_json(out_file, orient='records', lines=True)
DataFrame.to_html([buf,columns,col_space,…]) # 将DataFrame呈现为HTML表格。
DataFrame.to_latex([buf,columns,…]) # 将DataFrame呈现为表格环境表。
DataFrame.to_stata(fname [,convert_dates,…]) # 从数组类对象中写入Stata二进制dta文件的类
DataFrame.to_msgpack([path_or_buf,encoding]) # msgpack(serialize)对象到输入文件路径
DataFrame.to_gbq(destination_table,project_id)# 将DataFrame写入Google - BigQuery表格。
DataFrame.to_records([index,convert_datetime64]) # 将DataFrame转换为记录数组。
DataFrame.to_sparse([fill_value,kind]) # 转换为SparseDataFrame
DataFrame.to_dense() # 返回NDFrame的密集表示(而不是稀疏)
DataFrame.to_string([buf,columns,…]) # 将DataFrame呈现为控制台友好的表格输出。
DataFrame.to_clipboard([excel,sep])
# 【2023-2-11】输出为markdown格式
# pip install tabulate 先安装插件
df.to_markdown()
import xlrd
data = xlrd.open_workbook("01.xls")#打开当前目录下名为01.xls的文档
#此时data相当于指向该文件的指针
table = data.sheet_by_index(0)#通过索引获取,例如打开第一个sheet表格
table = data.sheet_by_name("sheet1")#通过名称获取,如读取sheet1表单
table = data.sheets()[0]#通过索引顺序获取
# 以上三个函数都会返回一个xlrd.sheet.Sheet()对象
names = data.sheet_names() #返回book中所有工作表的名字
data.sheet_loaded(sheet_name or indx) # 检查某个sheet是否导入完毕
# ---- 行操作 ------
nrows = table.nrows #获取该sheet中的有效行数
table.row(rowx) #返回由该行中所有的单元格对象组成的列表
table.row_slice(rowx) #返回由该列中所有的单元格对象组成的列表
table.row_types(rowx, start_colx=0, end_colx=None) #返回由该行中所有单元格的数据类型组成的列表
table.row_values(rowx, start_colx=0, end_colx=None) #返回由该行中所有单元格的数据组成的列表
table.row_len(rowx) #返回该列的有效单元格长度
# ---- 列操作 ------
ncols = table.ncols#获取列表的有效列数
table.col(colx, start_rowx=0, end_rowx=None)#返回由该列中所有的单元格对象组成的列表
table.col_slice(colx, start_rowx=0, end_rowx=None)#返回由该列中所有的单元格对象组成的列表
table.col_types(colx, start_rowx=0, end_rowx=None)#返回由该列中所有单元格的数据类型组成的列表
table.col_values(colx, start_rowx=0, end_rowx=None)#返回由该列中所有单元格的数据组成的列表
# ---- 单元格操作 ------
table.cell(rowx, colx) # 返回单元格对象
table.cell_type(rowx, colx) # 返回单元格中的数据类型
table.cell_value(rowx,colx) #返回单元格中的数据
可视化
pandas 自带 matplotlib库
绘图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
a = pd.Series(np.random.randn(1000),index=pd.date_range('20100101',periods=1000))
b = a.cumsum()
# df.plot(x='Column1', y='Column2', kind='scatter')
b.plot()
df.plot.area() # 面积图
df.plot.bar() # 柱形图
df.plot.barh() # 水平柱形图
df.plot.density() # 密度图
df.plot.kde()
df.plot.hist() # 直方图
# [2022-8-18] 自定义背景大小、分桶数目,打开网格线 —— 绘图参数参考matplotlib
df['总数'].plot.hist(figsize=(50,30),bins=100,,grid=True)
df.plot.scatter()
df.plot.pie()
散点图示例
import pandas as pd
df_test = pd.DataFrame([[5.1, 3.5, 0], [4.9, 3.0, 0], [7.0, 3.2, 1], [6.4, 3.2, 1], [5.9, 3.0, 2]], columns=['length', 'width', 'species'])
ax1 = df_test.plot.scatter(x='length', y='width', c='DarkBlue') # 散点格式
ax2 = df_test.plot.scatter(x='length', y='width', c='species', colormap='viridis') # 散点颜色区分不同数值
表格级别美化(适用于jupyter notebook), 官方style介绍
# -------- (1) -------
pd_list[pd_list['前两位']>0.5]
# 按照数值范围显示不同颜色
def showColor(val):
color = 'red' if val <= 0 else 'green'
return 'color:%s'%(color)
#正规方式,单独定义函数
pd_list.style.applymap(showColor)
#简洁方式,使用匿名函数,lambda
pd_list.style.applymap(lambda val: 'color:red' if val <= 1 else 'color:green')
# -------- (2) -------
# 调用seaborn的颜色主题
import seaborn as sns
cm = sns.light_palette("green", as_cmap=True)
s = df.style.background_gradient(cmap=cm)
#df.loc[:4].style.background_gradient(cmap='viridis')
s
# -----------------
import seaborn as sns
#!sudo pip install seaborn
cm = sns.light_palette("green", as_cmap=True)
#s = dh.style.background_gradient(cmap=cm)
col_list = [u'问题项名称',u'展现量41',u'流量占比',u'评价量41',u'参评率41',u'解决量41',u'解决率41']
#dh[dh[u'参评率41']>0.1, col_list]
out = dh[col_list][dh[u'参评率41']>0.05][dh[u'展现量41']> 50]
out.style.background_gradient(cmap=cm)
#out.style.background_gradient(cmap='viridis').highlight_null('red')#突出极值.highlight_max(axis=0)
#out.style.bar(subset=['A', 'B'], color='#d65f5f') # 柱状图显示
#out.style.bar(subset=['A', 'B'], align='mid', color=['#d65f5f', '#5fba7d']) # 正负双向柱状图
pandasgui
【2021-9-24】一个 GUI 接口,可以帮助我们完成自动化探索性数据分析的过程,并节省时间和精力
安装Pandasgui
pip install pandasgui
# 直接从 Github 安装最新的未发布更改:
pip install git+https://github.com/adamerose/pandasgui.git
功能:过滤、统计、绘图等
示例
from pandasgui.datasets import iris
#importing the show function
from pandasgui import show
show(iris)
# 自定义数据
import pandas as pd
from pandasgui import show
df = pd.DataFrame(([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['a', 'b', 'c'])
show(df)
go 工具包
go语言版本的 pandas 工具包
- Gota 实现了 DataFrames, Series
- Gonum 面向机器学习+统计, github gonum
- dataframe-go 复现了 pandas 的 dataframe 操作
Gota
Gota: DataFrames, Series and Data Wrangling for Go
Gonum
go get -u gonum.org/v1/gonum/stat
dataframe-go
作者介绍: Dataframes for Go
package main
// go get -u github.com/rocketlaunchr/dataframe-go
import (
"fmt"
dataframe "github.com/rocketlaunchr/dataframe-go"
)
func main(){
fmt.Println("hello")
// 创建 dataframe
s1 := dataframe.NewSeriesInt64("day", nil, 1, 2, 3, 4, 5, 6, 7, 8)
s2 := dataframe.NewSeriesFloat64("sales", nil, 50.3, 23.4, 56.2, nil, nil, 84.2, 72, 89)
df := dataframe.NewDataFrame(s1, s2)
fmt.Print(df.Table())
// 读文件
csvStr := `
Country,Date,Age,Amount,Id
"United States",2012-02-01,50,112.1,01234
"United States",2012-02-01,32,321.31,54320
"United Kingdom",2012-02-01,17,18.2,12345
"United States",2012-02-01,32,321.31,54320
"United Kingdom",2012-02-01,NA,18.2,12345
"United States",2012-02-01,32,321.31,54320
"United States",2012-02-01,32,321.31,54320
Spain,2012-02-01,66,555.42,00241
`
df, err := imports.LoadFromCSV(ctx, strings.NewReader(csvStr))
// 更新
df.UpdateRow(0, nil, map[string]interface{}{
"day": 3,
"sales": 45,
})
// 插入、删除行
df.Append(nil, 9, 123.6)
df.Append(nil, map[string]interface{}{
"day": 10,
"sales": nil,
})
df.Remove(0)
// 排序
sks := []dataframe.SortKey{
{Key: "sales", Desc: true},
{Key: "day", Desc: true},
}
df.Sort(ctx, sks)
// 遍历
iterator := df.ValuesIterator(dataframe.ValuesOptions{0, 1, true}) // Don't apply read lock because we are write locking from outside.
df.Lock()
for {
row, vals, _ := iterator()
if row == nil {
break
}
fmt.Println(*row, vals)
}
df.Unlock()
}
绘图
绘图
package main
import (
"context"
dataframe "github.com/rocketlaunchr/dataframe-go"
chart "github.com/wcharczuk/go-chart"
"github.com/rocketlaunchr/dataframe-go/plot"
wc "github.com/rocketlaunchr/dataframe-go/plot/wcharczuk/go-chart"
)
func main(){
sales := dataframe.NewSeriesFloat64("sales", nil, 50.3, nil, 23.4, 56.2, 89, 32, 84.2, 72, 89)
ctx := context.Background()
cs, _ := wc.S(ctx, sales, nil, nil)
graph := chart.Chart{Series: []chart.Series{cs}}
plt, _ := plot.Open("Monthly sales", 450, 300)
graph.Render(chart.SVG, plt)
plt.Display(plot.None)
}
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
