Shell语言
更多编程语言介绍:
- 编程语言发展历史
- 【2022-11-20】linux bash shell 最常用的函数和指令
- 【2024-3-5】Bash Shell脚本进阶
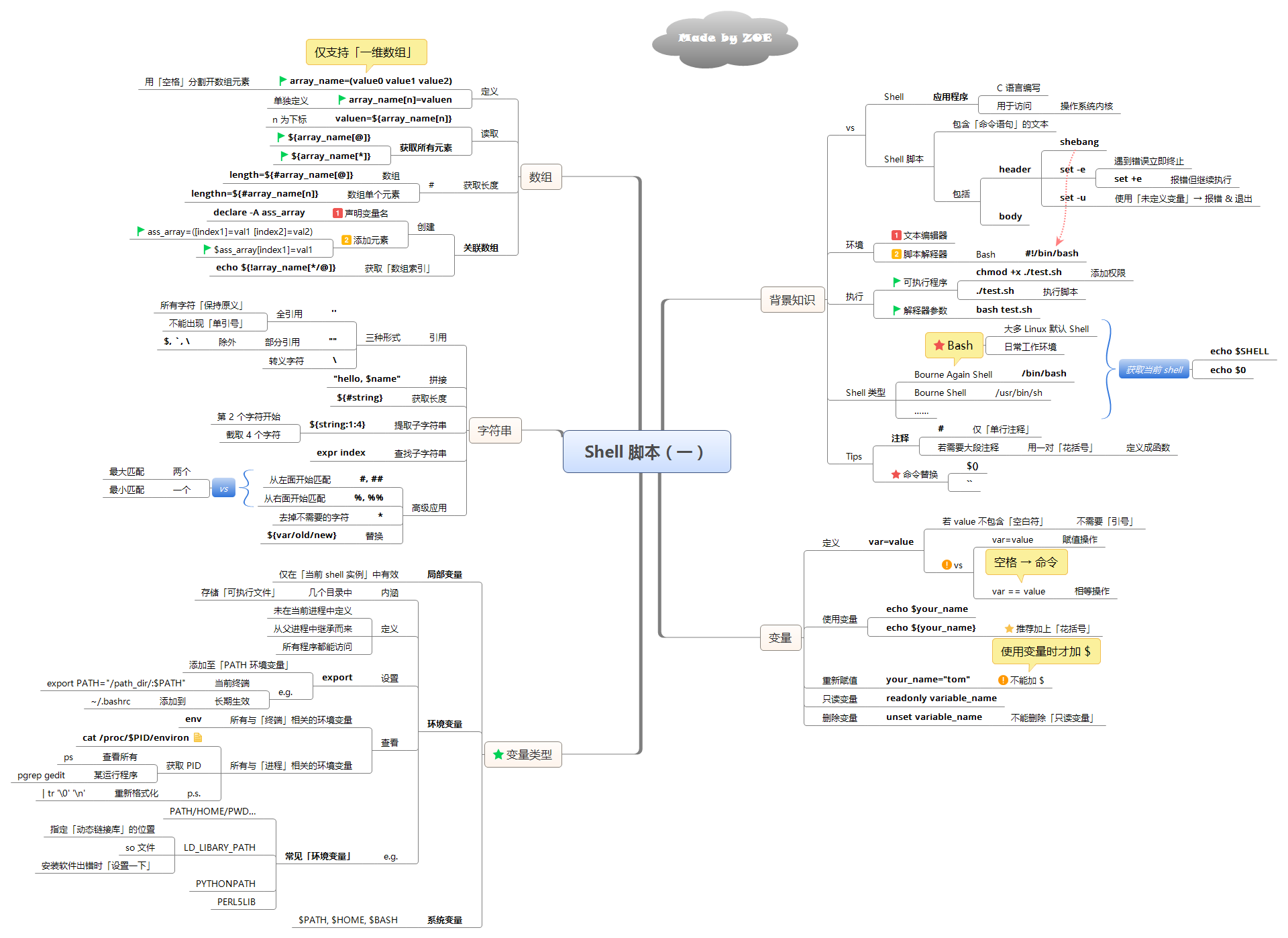
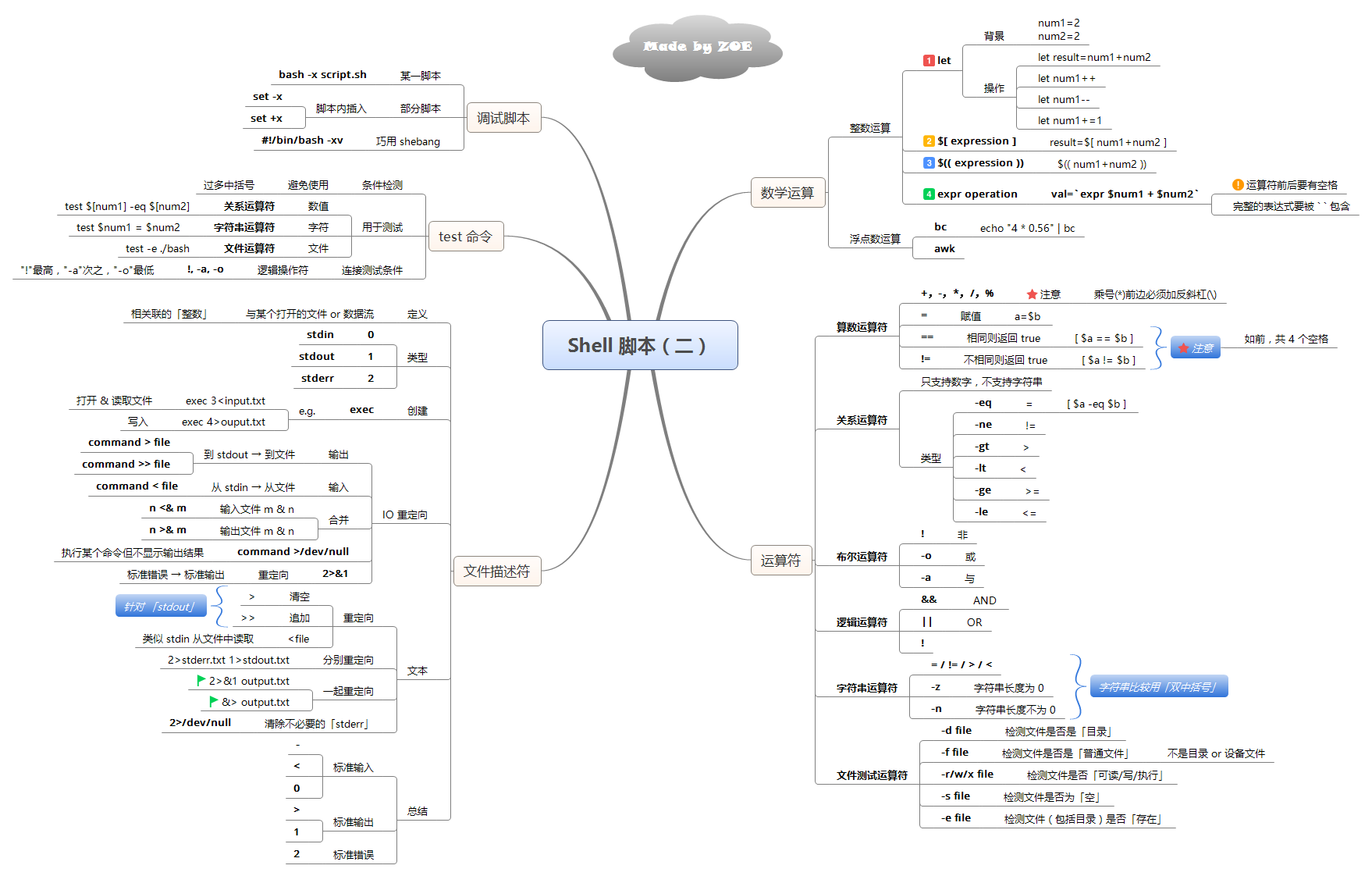
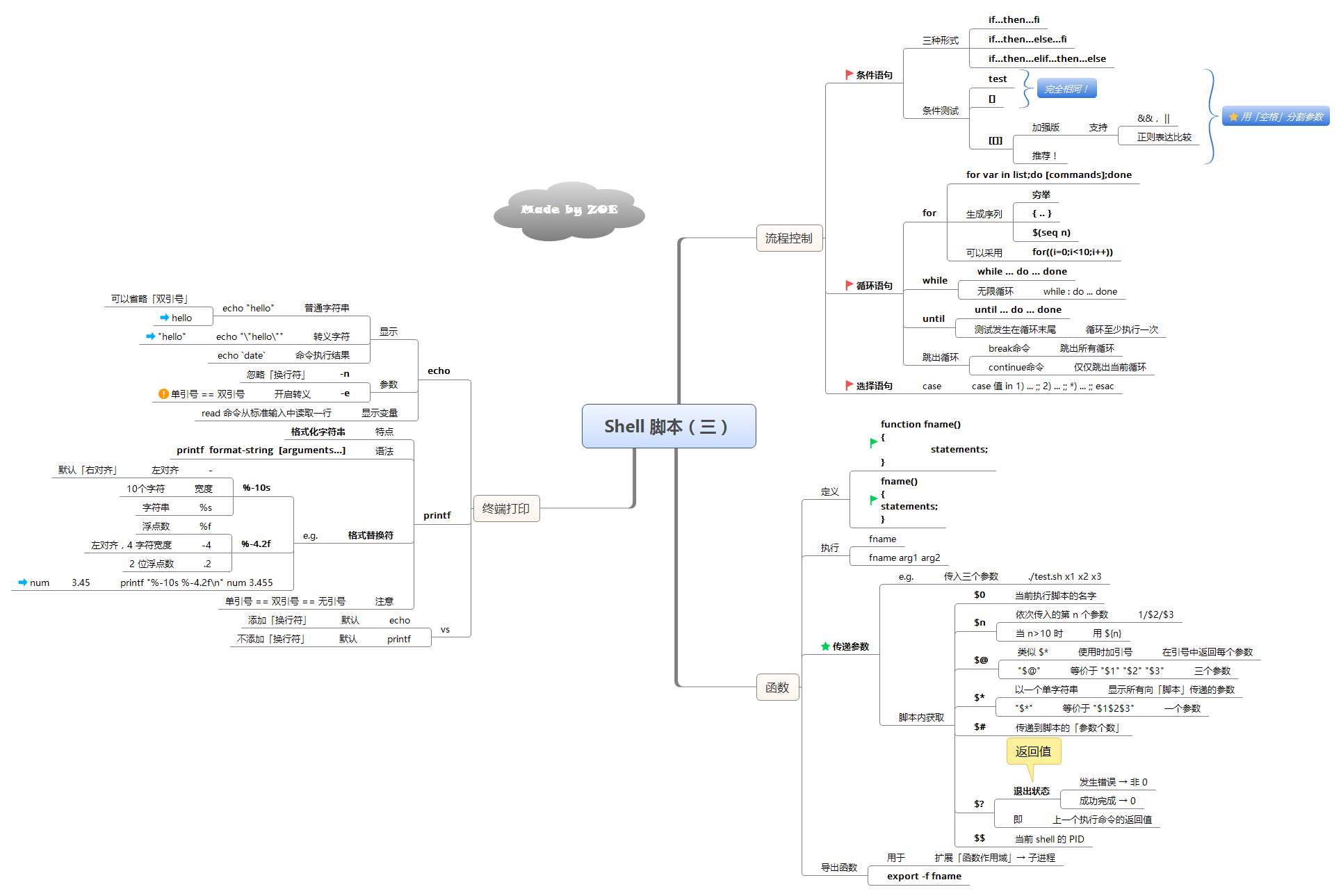
Shell 知识点
在 Linux 的基础上再度深入学习 Shell,可以极大的减少重复工作的压力。毕竟批量处理才是工作的常态呢~
总结
经验
Bash Shell,使用反斜线时,中途注释语句无效!
- 【2024-4-11】 如下注释行无效
deepspeed --master_port 30001 ./llm/training/conversation_reward/main.py \
--max_seq_len 2048 \
--per_device_train_batch_size 1 \
#--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--weight_decay 0.01
常规语法
查看 Shell 版本
bash --version
echo "$BASH_VERSION"
执行 shell
sh 命令
# ----- test.sh -----
#!/bin/bash
VAR="world"
echo "Hello $VAR!" # => Hello world!
# -------------------
# 执行
bash test.sh # 执行shell脚本
source "${0%/*}/../share/foo.sh" # 当前shell中执行
(cd somedir; echo "I'm now in $PWD") # 执行子shell
# 条件执行
git commit && git push # 成功才继续
git commit || echo "Commit failed" # 失败才继续
# 命令嵌入: ${}或``
echo "I'm in $(PWD)"
# Same as:
echo "I'm in `pwd`"
source
当前shell中引用外部shell文件,并生效
脚本
source common.sh
echo "yes"
【2026-3-9】ubuntu 下执行 带 source 命令的脚本,报错:
source: not found
原因
- Ubuntu 系统中的默认shell是dash,不是bash,而source是bash语法,dash不支持
解法:
- (1)更改Ubuntu系统默认shell:dash→bash,或加链接
- (2)shell文件头部注明bash路径(
#!/bin/bash),提示使用bash执行
# 方法①
ls -l /bin/sh # 若得到结果/bin/sh -> dash
sudo dpkg-reconfigure dash # 选 no
sudo ln -s /bin/bash /bin/sh # 或,加链接
# 方法②
#!/bin/bash
系统命令
history # 显示历史
sudo !! # 使用 sudo 运行上一个命令
shopt -s histverify # 不要立即执行扩展结果
!$ # 展开最新命令的最后一个参数
!* # 展开最新命令的所有参数
!-n # 展开第 n 个最近的命令
!n # 展开历史中的第 n 个命令
!<command> # 展开最近调用的命令 <command>
!! # 再次执行最后一条命令
!!:s/<FROM>/<TO>/ # 在最近的命令中将第一次出现的 <FROM> 替换为 <TO>
!!:gs/<FROM>/<TO>/ # 在最近的命令中将所有出现的 <FROM> 替换为 <TO>
!$:t # 仅从最近命令的最后一个参数扩展基本名称
!$:h # 仅从最近命令的最后一个参数展开目录
# !! 和 !$ 可以替换为任何有效的扩展
# 切片 Slices
!!:n # 仅扩展最近命令中的第 n 个标记(命令为 0;第一个参数为 1)
!^ # 从最近的命令展开第一个参数
!$ # 从最近的命令中展开最后一个标记
!!:n-m # 从最近的命令扩展令牌范围
!!:n-$ # 从最近的命令中将第 n 个标记展开到最后
# 重定向
python hello.py > output.txt # 标准输出到(文件)
python hello.py >> output.txt # 标准输出到(文件),追加
python hello.py 2> error.log # 标准错误到(文件)
python hello.py 2>&1 # 标准错误到标准输出
python hello.py 2>/dev/null # 标准错误到(空null)
python hello.py &>/dev/null # 标准输出和标准错误到(空null)
python hello.py < foo.txt # 将 foo.txt 提供给 python 的标准输入
变量操作
sheel变量
默认值
# 默认值
${FOO:-val} # $FOO,如果未设置,则为 val
${FOO:=val} # 如果未设置,则将 $FOO 设置为 val
${FOO:+val} # val 如果设置了$FOO
${FOO:?message} # 如果 $FOO 未设置,则显示消息并退出
变量拼接
NAME="John"
echo ${NAME} # => John (变量)
echo $NAME # => John (变量)
echo "$NAME" # => John (变量)
echo '$NAME' # => $NAME (字符串原样输出),单引号时,不解析变量
echo "${NAME}!" # => John! (变量)
NAME = "John" # => 报错:Error (注意不能有空格)
# {}扩展
echo {A,B} # 与 A B 相同
echo {A..D}.js # 与 A.js B.js C.js D.js相同
echo {1..5} # 与 1 2 3 4 5 相同
# 数值计算
a=2
$((a + 200)) # Add 200 to $a
$(($RANDOM%200)) # 随机数 Random number 0..199
# 注释:多行注释使用 :' 打开和 ' 关闭
: '
这是一个
非常整洁的
bash 注释
'
# Heredoc
cat <<END
hello world
END
特殊变量
#!/bin/bash
# 特殊变量
$? # 最后一个任务的退出状态
$! # 最后一个后台任务的 PID
$$ # shell PID
$0 # shell 脚本的文件名
echo "Process ID: $$"
echo "File Name: $0"
echo "First Parameter : $1"
echo "Second Parameter : $2"
echo "All parameters 1: $@"
echo "All parameters 2: $*"
echo "Total: $#"
控制判断
# 如何避免变量控制?
[ s"$choice" == "sy" ] # ①
[ $choice -a $choice == "y" ] # ②
变量作用域
变量的作用域(Scope)
Shell 变量作用域分三种:
- 全局变量(global variable): 当前 Shell 会话中使用
- 局部变量(local variable): 只能在函数内部使用
- 环境变量(environment variable): 在其它 Shell 中使用。
解析
- 全局变量:变量在当前的整个 Shell 会话中都有效。每个 Shell 会话都有自己的作用域,彼此之间互不影响。在 Shell 中定义的变量,默认就是全局变量。
- 局部变量:Shell 函数中定义的变量默认是全局变量,它和在函数外部定义变量拥有一样的效果
- 环境变量:环境变量被创建时所处的 Shell 被称为父 Shell,如果在父 Shell 中再创建一个 Shell,则该 Shell 被称作子 Shell。当子 Shell 产生时,它会继承父 Shell 的环境变量为自己所用,所以说环境变量可从父 Shell 传给子 Shell。
- 注意,环境变量只能向下传递而不能向上传递,即“传子不传父”
a=3 # 全局变量
global a=3 # 报错,没有global关键词
export a # 将自定义变量设定为系统环境变量
fun f(){
c='1' # 全局变量
local t='2' # 局部变量,仅函数内使用
}
local t='2' # 报错,local必须出现在函数内
export
Linux export 命令用于设置/显示环境变量。
shell 中执行程序时,shell 会提供一组环境变量。export 可新增,修改或删除环境变量,供后续执行的程序使用。
export 命令的作用域:
当前终端中直接输入的 export 变量仅当前shell终端及其子shell可见,另起一个终端将无法访问。
注意
- 父shell中的export变量,子shell可读
- 子shell变量是父shell的一个拷贝,不影响父shell取值
- 子shell export变量,父shell读不到
export WORD="hello"
echo $WORD # 可以看到输出 hello
env | grep WORD # 可以看到有WORD变量
sh -c "echo $WORD" # 子shell中执行,同样可以看到输出了 hello
如何保证其他终端可见?
~/.bashrc或者/etc/profile中使用export命令配置全局的环境变量,然后source,所有终端都可见
read 用法
read 命令可使脚本暂停并等待用户响应。
- 从标准输入或另一个文件描述符中接受输入,并将数据放入一个变量中
#!/bin/bash
echo "测试开始"
echo -n "Enter your name: " # 不输出换行符
read name # 默认保存用户输入的字符串
read -p "Please enter your name: " name # 加提示语
read -n1 -p "Please enter your name: [y/n]" name # 加提示语, 字符长度为1
read -s -p "Enter your password: " pass # 密码输入模式,不显示
echo "Hello $name, welcome to my program"
# 加输入超时机制,避免死等
# 5 秒内没有输入,脚本会显示超时提示。
if read -t 5 -p "Please enter your name: " name
then
echo "Hello $name, welcome to my script"
else
echo "Sorry, too slow"
fi
菜单选择实现
weather_options=("sunny" "cloudy" "windy")
echo "Choose today's weather:"
select choice in "${weather_options[@]}"
do
case $choice in
"sunny")
echo "You chose sunny."
break
;;
"cloudy")
echo "You chose cloudy."
break
;;
"windy")
echo "You chose windy."
break
;;
*)
echo "Invalid option. Please choose a valid option."
;;
esac
done
变量传递
如何从子shell向父shell传递变量
- 命令传输
- 中间文件
- 管道
- here文档
# 命令传输
pvar=`subvar='hello shell'`
echo $pvar
# 文件传输
(
subvar='hello shell'
echo "$subvar" > tmp.txt
)
read pvar < tmp.txt
echo $pvar
# 管道传输
mkfifo -m 777 npipe # 创建管道 npipe
(
subsend="hello world"
echo "$subsend" > npipe &
)
read pread < npipe
echo "$pread"
# here 文档
read pvar <<HERE
`subvar="hello shell"
echo $subvar`
HERE
echo $pvar
函数参数
函数
# function get_name() { # function 关键字可以省略
get_name() {
echo "John $1"
}
echo "You are $(get_name)"
# 带返回值的函数
myfunc() {
local myresult='some value'
echo $myresult
}
result="$(myfunc)"
参数
【2024-7-22】参数解析, 详见
- 手工处理:
$1~${10} getopts: shell内置,不支持长选项, 如: –a=1getopt: 外部工具,支持长选项
getopt 与 getopts 都是 Bash 中获取命令行参数的工具。
两者比较
- (1)getopts 是 Shell 内建命令, getopt 是一个独立外部工具
- (2)getopts 使用语法简单, getopt 使用语法较复杂
- (3)getopts 不支持长参数(如:–option ),getopt 支持
- (4)getopts 不会重排所有参数的顺序,getopt 会重排参数顺序
- (5)getopts 为了代替 getopt 较快捷的执行参数分析工作
$1
$0 # 脚本本身的名称
$1 … $9 # 参数 1 ... 9
$1 # 第一个参数
${10} # 位置参数 10
$# # 参数数量
$$ # shell 的进程 id
$* # 所有参数
$@ # 所有参数,从第一个开始
$- # 当前选项
$_ # 上一个命令的最后一个参数
getopts
用法
#!/bin/bash
# 选项后面的冒号, 表示该选项需要参数
while getopts "a:bc" arg
do
case $arg in
a)
echo "a's arg:$OPTARG" #参数存在$OPTARG中
argument1=$OPTARG
;;
b)
echo "b"
branch=1
;;
c)
echo "c"
iscar=1
;;
?) #当有不认识的选项的时候arg为?
echo "unkonw argument"
exit 1
;;
esac
done
# 使用
./test.sh -a arg -b -c
./test.sh -a arg -bc
局限:
- 选项参数的格式必须是
-d val,中间没有空格的-dval, 不行。 - 所有选项参数必须写在其它参数的前面,因为getopts是从命令行前面开始处理,遇到非
-开头的参数,或者选项参数结束标记--就中止了,如果中间遇到非选项的命令行参数,后面的选项参数就都取不到了。 - 不支持
长选项, 也就是--debug之类的选项
【2024-7-22】 实践
cur_dir=`pwd`
project='change_query' # session_cut
mode='train'
# 参数解析
while getopts "e:p:m" arg
do
case $arg in
e)
echo "环境路径(environment), $OPTARG";cur_dir=${OPTARG};;
p)
echo "项目名(project): $OPTARG";project=$OPTARG;;
m)
echo "运行模式(mode): $OPTARG";model='infer';;
?)
echo "未知参数: $OPTARG";break;;
esac
done
echo -e "[参数解析]: \n\t环境路径(environment)\t${cur_dir}\n\t项目名(project)\t${project}\n\t运行模式(mode)\t${mode}"
改进 getopt
外部改进版
# 经过getopt 处理,具体选项。
while true;
do
case "$1" in
-a|--a-long) echo "Option a" ; shift ;;
-b|--b-long) echo "Option b, argument \`$2'" ; shift 2 ;;
-c|--c-long)
# c has an optional argument. As we are in quoted mode,
# an empty parameter will be generated if its optional
# argument is not found.
case "$2" in
"") echo "Option c, no argument"; shift 2 ;;
*) echo "Option c, argument \`$2'" ; shift 2 ;;
esac ;;
--) shift ; break ;;
*) echo "Internal error!" ; exit 1 ;;
esac
done
echo "Remaining arguments:"
for arg do
echo '--> '"\`$arg'" ;
done
#!/bin/bash
ARGS=`getopt -o "ao:" -l "arg,option:" -n "getopt.sh" -- "$@"`
eval set -- "${ARGS}"
while true; do
case "${1}" in
-a|--arg)
shift;
echo -e "arg: specified"
;;
-o|--option)
shift;
if [[ -n "${1}" ]]; then
echo -e "option: specified, value is ${1}"
shift;
fi
;;
--)
shift;
break;
;;
esac
# 使用
./test -a -b arg arg1 -c
# 命令行中多了个arg1参数,在经过getopt和set之后,命令行会变为:
-a -b arg -c -- arg1
# $1指向-a,$2指向-b,$3指向arg,$4指向-c,$5指向--,而多出的arg1则被放到了最后。
控制
操作系统差异
debain(乌班图)linux 下,字符串判断时,会出现以下错误
- 因为 ubuntu 默认 shell 使用 dash,dash 与 bash 一些指令上有些差异
- 解法: 改回
/bin/sh -> bash,修改默认shsudo dpkg-reconfigure dash启动可视化编辑页面- 然后选 No,改回
/bin/sh -> bash - 把 == 改成 =
[: =~: binary operator expected
[[: =~: binary operator expected
if 条件判断
# 字符串比较
[[ -z STR ]] # 空字符串
[[ -n STR ]] # 非空字符串
[[ STR == STR ]] # 相等
[[ STR = STR ]] # 相等(同上)
[[ STR < STR ]] # 小于 (ASCII)
[[ STR > STR ]] # 大于 (ASCII)
[[ STR != STR ]] # 不相等
[[ STR =~ STR ]] # 正则表达式
# 整数比较
[[ NUM -eq NUM ]] # 等于 Equal
[[ NUM -ne NUM ]] # 不等于 Not equal
[[ NUM -lt NUM ]] # 小于 Less than
[[ NUM -le NUM ]] # 小于等于 Less than or equal
[[ NUM -gt NUM ]] # 大于 Greater than
[[ NUM -ge NUM ]] # 大于等于 Greater than or equal
(( NUM < NUM )) # 小于
(( NUM <= NUM )) # 小于或等于
(( NUM > NUM )) # 比...更大
(( NUM >= NUM )) # 大于等于
# 文件
[[ -e FILE ]] # 存在
[[ -d FILE ]] # 目录
[[ -f FILE ]] # 文件
[[ -h FILE ]] # 符号链接
[[ -s FILE ]] # 大小 > 0 字节
[[ -r FILE ]] # 可读
[[ -w FILE ]] # 可写
[[ -x FILE ]] # 可执行文件
[[ f1 -nt f2 ]] # f1 比 f2 新
[[ f1 -ot f2 ]] # f2 比 f1 新
[[ f1 -ef f2 ]] # 相同的文件
# 高级
[[ X && Y ]] # 条件组合
[[ "$A" == "$B" ]] # 是否相等
[[ -o noclobber ]] # 如果启用 OPTION
[[ ! EXPR ]] # 不是 Not
[[ X && Y ]] # 和 And
[[ X || Y ]] # 或者 Or
# 整型
if (( $a < $b )); then
echo "$a is smaller than $b"
fi
# 字符串
if [[ -z "$string" ]]; then
echo "String is empty"
elif [[ -n "$string" ]]; then
echo "String is not empty"
fi
# 正则表达式
if [[ '1. abc' =~ ([a-z]+) ]]; then
echo ${BASH_REMATCH[1]}
fi
# 文件是否存在
if [[ -e "file.txt" ]]; then
echo "file exists"
fi
# 逻辑运算
if [ "$1" = 'y' -a $2 -gt 0 ]; then
echo "yes"
fi
if [ "$1" = 'n' -o $2 -lt 0 ]; then
echo "no"
fi
复合条件判断
&& ||-a –o处理
#!/bin/bash
# 等效表达: [[]] = []
[ exp1 -a exp2 ] = [[ exp1 && exp2 ]] = [ exp1 ]&& [ exp2 ] = [[ exp1 ]] && [[ exp2 ]]
[ exp1 -o exp2 ] = [[ exp1 || exp2 ]] = [ exp1 ]|| [ exp2 ] = [[ exp1 ]] || [[ exp2 ]]
# [2024-7-22]
read -p "是否使用如下配置? [y/n]" choice
echo "你选择了: $choice"
# 如何避免变量控制?
[ s"$choice" == "sy" ] # ①
[ $choice -a $choice == "y" ] # ②
[ $choice -a $choice == "y" ] && { echo "开始训练..."; } || { echo "不训练, 退出...";exit 0; }
# 整型比较
count="$1"
if [ $count -gt 15 -o $count -lt 5 ];then
echo right
fi
# 字符串
if [[ "a" == "a" ]] || [[ 2 -gt 1]] ;then
echo "ok";
fi
实测
=和==等效[]和test等效[[]]和[]大体等效,但正则表达式只能用双括号=两边要留空,否则结果错误
echo "单括号(识别错误)"
if [ "1"="" ] && [ "1"="1" ]; then echo A; else echo B; fi # A
if [ "1"="" -a "1"="1" ]; then echo A; else echo B; fi # A
echo "留空格(正确)"
if [ "1" = "" ] && [ "1" = "1" ]; then echo A; else echo B; fi # B
if [ "1" = "" -a "1" = "1" ]; then echo A; else echo B; fi # B
echo "双括号"
if [[ "1"="" ]] && [[ "1"="1" ]]; then echo A; else echo B; fi # A
if [[ "1" = "" ]] && [[ "1" = "1" ]]; then echo A; else echo B; fi # B
# if [[ "1"="" -a "1"="1" ]]; then echo A; else echo B; fi # 报错
echo "双等号(正确)"
if [ "1" == "" ] && [ "1" == "1" ]; then echo A; else echo B; fi # B
if [ "1" == "" -a "1" == "1" ]; then echo A; else echo B; fi # B
# 正则表达式需要双括号,否则报错
if [[ ${BASEDIR} =~ ^hdfs ]];then
echo "y"
else
echo 'n'
fi
# 组合条件中, 正则表达式单独使用[[]]括起来,不能混用!
# if [ $mode = 'local' -a ${BASEDIR} =~ ^hdfs ];then
if [ $mode = 'local' ] && [[ ${BASEDIR} =~ ^hdfs ]]; then
echo "y"
else
echo 'n'
fi
for 循环判断
# 基本 for 循环
for i in /etc/rc.*; do
echo $i
done
# 类似 C 的 for 循环
for ((i = 0 ; i < 100 ; i++)); do
echo $i
done
for i in `ls`;
do
echo $i is file name\! ;
done
# 字符串,[2023-2-4]注意:不能省略变量name_list,直接用字符串
name_list="httpd-init.service httpd.service httpd.socket httpd@.service httpd.service.d";
for file in $name_list;
do
echo "[$file]"
done
# 范围
for i in {1..5}; do
# for i in {5..50..5}; do # 设置步长
echo "Welcome $i"
done
# awk版
awk 'BEGIN{for(i=1; i<=10; i++) print i}'
# 自动递增
i=1
while [[ $i -lt 4 ]]; do
echo "Number: $i"
((i++))
done
# 自动递减
i=3
while [[ $i -gt 0 ]]; do
echo "Number: $i"
((i--))
done
# Continue, break
for number in $(seq 1 3); do
if [[ $number == 2 ]]; then
continue;
# break;
fi
echo "$number"
done
# Until
count=0
until [ $count -gt 10 ]; do
echo "$count"
((count++))
done
# 死循环
# while :; do # 简写
while true; do
# here is some code.
done
Case
类似 switch 用法
case "$1" in
start | up)
vagrant up
;;
*)
echo "Usage: $0 {start|stop|ssh}"
;;
esac
【2024-7-22】 实践
[ $# -lt 1 ] && { cur_dir=`pwd`; echo "未指定环境, 开始自动检测"; } || { cur_dir=$1; echo "使用传入的参数环境, $1"; }
env="cn"
case $cur_dir in
*"flow-algo-cn"*) env="cn"; echo "国内环境";;
*"flow-algo-intl"*) env="va"; echo "美国环境";;
*"flow-algo-my2"*) env="my2"; echo "马来西亚环境";;
*) echo "默认环境";;
esac
时间日期
cal # 日历
date +%Y%m%d
date +%F
now=$(date +%y%m%d) # 获取今天时期
date +%Y%m%d%H%M%S # 当前时间,时分秒
date +%m%d%H%M%y.%S # 具体到毫秒
date +%w # 今天是星期几
date +%W # 当前为今年的第几周
# 时间戳
date +%s # 获取时间戳
date -d @1521563928 # 将时间戳换算成日期
date +%s -d "2017-03-21 00:38:48" # 将日期换算成时间戳
# 相对时间
date -d 'now' #显示当前时间
date -d tomorrow +%y%m%d # 明天
date -d yesterday +%Y%m%d # 获取昨天时期
date -d '30 second ago' #显示30秒前的时间
date -d -2day +%Y%m%d # 获取前天日期
date -d '7 days ago' +%Y%m%d # 一星期前
date -d '1 weeks ago' +%Y%m%d # 一星期前
date -d '2 days ago' #显示2天前的时间
date -d -10day +%Y%m% # 获取10天前的日期
date -d `date +%y%m01`"-1 day" # 上月最后一天
date -d '3 month 1 day' # 显示3月零1天以后的时间
date -d "n days ago" +%y%m%d # 或n天前的
date -d '25 Dec' +%j #显示12月25日在当年的哪一天
# [2024-7-18] 设置参考日期(20231010), 前3天
date -d '3 days ago 20231010' +%Y%m%d
date -d "-3 day" # 3天前
date -d "+3 month" # 3月后
date -d "-3 year" # 3年前,类似的,hour、minute、second
date -d `date -d "-3 month" +%y%m01`"-1 day" # 4个月前最后一天
date -d `date -d "+12 month" +%y%m01`"-1 day" # 11个月后第一天
date -d `date -d "+12 month" +%y%m01`"-1 day" +%Y%m%d # 11个月前最后一天
字符串
特殊的字符串处理方法
- #前 %后
# ----- 总结 -----
${FOO%suffix} # 删除后缀
${FOO#prefix} # 删除前缀
${FOO%%suffix} # 去掉长后缀
${FOO##prefix} # 删除长前缀
${FOO/from/to} # 替换第一个匹配项
${FOO//from/to} # 全部替换
${FOO/%from/to} # 替换后缀
${FOO/#from/to} # 替换前缀
echo ${food:-Cake} #=> 如果没定义food变量,就赋默认值(Cake) $food or "Cake"
${FOO:0:3} # 子串 (位置,长度)
${FOO:(-3):3} # 从右边开始的子串
${#FOO} # $FOO 的长度
# -------------
STR="/path/to/foo.cpp"
echo ${STR%.cpp} # /path/to/foo 删短后缀
echo ${STR%.cpp}.o # /path/to/foo.o
echo ${STR%/*} # /path/to
echo ${STR##*.} # cpp (extension)
echo ${STR##*/} # foo.cpp (basepath)
echo ${STR#*/} # path/to/foo.cpp
echo ${STR##*/} # foo.cpp
echo ${STR/foo/bar} # /path/to/bar.cpp
url="http://c.biancheng.net/index.html"
echo ${url#*/} # 结果为 /c.biancheng.net/index.html
echo ${url##*/} # 结果为 index.html
str="---aa+++aa@@@"
echo ${str#*aa} # 结果为 +++aa@@@
echo ${str##*aa} # 结果为 @@@
echo ${url%/*} # 结果为 http://c.biancheng.net
echo ${url%%/*} # 结果为 http:
str="---aa+++aa@@@"
echo ${str%aa*} # 结果为 ---aa+++
echo ${str%%aa*} # 结果为 ---
# ---- 切片 -----
# 切片 Slicing
name="John"
echo ${name} # => John
echo ${name:0:2} # => Jo
echo ${name::2} # => Jo
echo ${name::-1} # => Joh
echo ${name:(-1)} # => n 逆序
echo ${name:(-2)} # => hn 逆序
echo ${name:(-2):2} # => hn 逆序
length=2
echo ${name:0:length} # => Jo
# 大小写转换:,小写 ^大写
STR="HELLO WORLD!"
echo ${STR,} # => hELLO WORLD! 首字母小写
echo ${STR,,} # => hello world! 全部小写
STR="hello world!"
echo ${STR^} # => Hello world! 首字符大写
echo ${STR^^} # => HELLO WORLD! 全部大写
ARR=(hello World)
echo "${ARR[@],}" # => hello world 数组元素首字母小写
echo "${ARR[@]^}" # => Hello World 数组元素首字母大写
字符串包含
【2024-7-18】实测结果
cur_dir=$(pwd)
# 通配符 [[ $A == *$B* ]]
# 正则匹配
[[ $cur_dir =~ "change_query" ]] && {
echo "目标目录: $cur_dir"
} || {
echo "非目标目录, 退出: $cur_dir"
exit 0
}
main_dir="${cur_dir%%/change_query}"
# main_dir='/mnt/bn/flow-algo-intl/wangqiwen'
# 项目主目录
project_dir="${main_dir}/change_query"
data_dir="${project_dir}/data"
# 识别结果
echo -e "自动识别结果:\n本地主目录: ${main_dir}\n项目主目录: ${project_dir}\n数据目录: ${data_dir}"
方法一:grep查找
strA="long string"
strB="string"
result=$(echo $strA | grep "${strB}")
if [[ "$result" != "" ]]
then
echo "包含"
else
echo "不包含"
fi
先打印长字符串,然后在长字符串中 grep 查找要搜索的字符串,用变量result记录结果,如果结果不为空,说明strA包含strB。如果结果为空,说明不包含。
这个方法充分利用了grep 的特性,最为简洁。
方法二:正则
正则表达式
strA="helloworld"
strB="low"
if [[ $strA =~ $strB ]]
then
echo "包含"
else
echo "不包含"
fi
利用字符串运算符 =~ 直接判断strA是否包含strB。
方法三:通配符
A="helloworld"
B="low"
if [[ $A == *$B* ]]
then
echo "包含"
else
echo "不包含"
fi
用通配符*号代理strA中非strB的部分,如果结果相等说明包含,反之不包含。
方法四:case in 语句
thisString="1 2 3 4 5" # 源字符串
searchString="1 2" # 搜索字符串
case $thisString in
*"$searchString"*) echo "包含";;
*) echo "不包含" ;;
esac
方法五:字符串替换
替换子串后,字符串是否跟原来相同
STRING_A="helloworld"
STRING_B="low"
if [[ ${STRING_A/${STRING_B}//} == $STRING_A ]]
then
echo "不包含"
else
echo "包含"
fi
数组
- 代码:
string="hello,shell,split,test"
#将,替换为空格
array=(${string//,/ }) # 空格区分,用()转数组
array=(`echo $string | tr ',' ' '` ) # 方法2
# 元素遍历
for var in ${array[@]} # 元素值遍历
do
echo $var
done
for i in "${!array[@]}"; do # 下标遍历
printf "%s\t%s\n" "$i" "${array[$i]}"
done
Fruits=('Apple' 'Banana' 'Orange') # 一次性定义
Fruits[0]="Apple" # 逐个赋值
Fruits[1]="Banana"
Fruits[2]="Orange"
# 批量定义
ARRAY1=(foo{1..2}) # => foo1 foo2
ARRAY2=({A..D}) # => A B C D
# 合并 => foo1 foo2 A B C D
ARRAY3=(${ARRAY1[@]} ${ARRAY2[@]})
# 声明构造
declare -a Numbers=(1 2 3)
Numbers+=(4 5) # 附加 => 1 2 3 4 5
# 索引含义
${Fruits[0]} # 第一个元素
${Fruits[-1]} # 最后一个元素
${Fruits[*]} # 所有元素
${Fruits[@]} # 所有元素 ""包围每个元素
${#Fruits[@]} # 总数
${#Fruits} # 第一节长度
${#Fruits[3]} # 第n个长度
${Fruits[@]:3:2} # 范围
${!Fruits[@]} # 所有 Key,索引index
# 数组操作
Fruits=("${Fruits[@]}" "Watermelon") # 添加
Fruits+=('Watermelon') # 也是添加
Fruits=( ${Fruits[@]/Ap*/} ) # 通过正则表达式匹配删除
unset Fruits[2] # 删除一项
Fruits=("${Fruits[@]}") # 复制
Fruits=("${Fruits[@]}" "${Veggies[@]}") # 连接
lines=(`cat "logfile"`) # 从文件中读取
# 数组作为参数
function extract()
{
local -n myarray=$1
local idx=$2
echo "${myarray[$idx]}"
}
Fruits=('Apple' 'Banana' 'Orange')
extract Fruits 2 # => Orangle
字典
declare -a sounds # 生命字典
# declare -A sounds # 生命字典, A在mac下执行失败
sounds[dog]="bark" # 赋值
sounds[cow]="moo"
# 取值
echo ${sounds[dog]} # Dog's sound
echo ${sounds[@]} # All values 所有取值
echo ${!sounds[@]} # All keys 所有key
echo ${#sounds[@]} # Number of elements 元素个数
unset sounds[dog] # Delete dog
# 遍历元素
for val in "${sounds[@]}"; do
echo $val
done
for key in "${!sounds[@]}"; do
echo $key
done
彩色日志
- 特效格式
- \033[0m 关闭所有属性
- \033[1m 设置高亮度
- \03[4m 下划线
- \033[5m 闪烁
- \033[7m 反显
- \033[8m 消隐
- \033[30m ~ \033[37m 设置前景色
- \033[40m ~ \033[47m 设置背景色
- 光标位置
- \033[nA 光标上移n行
- \03[nB 光标下移n行
- \033[nC 光标右移n行
- \033[nD 光标左移n行
- \033[y;xH设置光标位置
- \033[2J 清屏
- \033[K 清除从光标到行尾的内容
- \033[s 保存光标位置
- \033[u 恢复光标位置
- \033[?25l 隐藏光标
- \33[?25h 显示光标
- 特效可以叠加,需要使用“;”隔开
- 例如:闪烁+下划线+白底色+黑字为 \033[5;4;47;30m闪烁+下划线+白底色+黑字为\033[0m
| 编码 | 颜色/动作 |
|---|---|
| 0 | 重新设置属性到缺省设置 |
| 1 | 设置粗体 |
| 2 | 设置一半亮度(模拟彩色显示器的颜色) |
| 4 | 设置下划线(模拟彩色显示器的颜色) |
| 5 | 设置闪烁 |
| 7 | 设置反向图象 |
| 22 | 设置一般密度 |
| 24 | 关闭下划线 |
| 25 | 关闭闪烁 |
| 27 | 关闭反向图象 |
| 30 | 设置黑色前景 |
| 31 | 设置红色前景 |
| 32 | 设置绿色前景 |
| 33 | 设置棕色前景 |
| 34 | 设置蓝色前景 |
| 35 | 设置紫色前景 |
| 36 | 设置青色前景 |
| 37 | 设置白色前景 |
| 38 | 在缺省的前景颜色上设置下划线 |
| 39 | 在缺省的前景颜色上关闭下划线 |
| 40 | 设置黑色背景 |
| 41 | 设置红色背景 |
| 42 | 设置绿色背景 |
| 43 | 设置棕色背景 |
| 44 | 设置蓝色背景 |
| 45 | 设置紫色背景 |
| 46 | 设置青色背景 |
| 47 | 设置白色背景 |
| 49 | 设置缺省黑色背景 |
# !/bin/bash
#【2021-12-28】
echo -e "\033[4;31m 下划线红字 \033[0m"
echo -e "\033[5;34m 红字在闪烁 \033[0m" #闪烁
echo -e "\033[8m 消隐 \033[0m " #反影
# 彩色文字设置
prefix="\033["
Color_Off="0m" # Text Reset
# Bold High Intensty
BIBlack="30m" # "[1;90m" # Black
BIRed="31m" # "[1;91m" # Red
BIGreen="32m" # "[1;92m" # Green
BIYellow="33m" # "[1;93m" # Yellow
BIBlue="34m" # "[1;94m" # Blue
BIPurple="35m" # "[1;95m" # Purple
BICyan="36m" # "[1;96m" # Cyan
BIWhite="37m" # "[1;97m" # White
echo ${BRed} "===开始检测===!" ${Color_Off}
function log(){
[ $# -eq 0 ]&& { echo "date [`"+%Y-%m-%d %H:%M:%S"`] 请输入要打印的日志!";exit 1; }
[ $# -eq 1 ]&& { level="INFO";log_info=$1; }
[ $# -gt 1 ]&& { level=$1;log_info=$2; }
#echo "[`"+%Y-%m-%d %H:%M:%S"`] [$level] $log_info"
cur_color="$BIWhite"
case $level in
"INFO") cur_color="$BIWhite";;
"WARNING") cur_color="$BIYellow";;
"ERROR") cur_color="$BIPurple";;
"FETAL") cur_color="$BIRed";;
*) cur_color="$BIWhite";;
esac
# echo -e "\033[4;31;42m 文字 \033[0m"
echo -e "${prefix}${cur_color} [`date "+%Y-%m-%d %H:%M:%S"`] [$level] $log_info ${prefix}${Color_Off}"
}
log "INFO" "TEST INFO"
log "WARNING" "TEST WARNING"
log "ERROR" "TEST ERROR"
log "FETAL" "TEST FETAL"
# ------- 失效 -------
【2018-10-12】
# 彩色文字设置
Color_Off="[0m" # Text Reset
# Bold High Intensty
BIBlack="[1;90m" # Black
BIRed="[1;91m" # Red
BIGreen="[1;92m" # Green
BIYellow="[1;93m" # Yellow
BIBlue="[1;94m" # Blue
BIPurple="[1;95m" # Purple
BICyan="[1;96m" # Cyan
BIWhite="[1;97m" # White
echo ${BRed} "===开始检测===!" ${Color_Off}
function log(){
[ $# -eq 0 ]&& { echo "date [`"+%Y-%m-%d %H:%M:%S"`] 请输入要打印的日志!";exit 1; }
[ $# -eq 1 ]&& { level="INFO";log_info=$1; }
[ $# -gt 1 ]&& { level=$1;log_info=$2; }
#echo "[`"+%Y-%m-%d %H:%M:%S"`] [$level] $log_info"
cur_color="$BIWhite"
case $level in
"INFO") cur_color="$BIWhite";;
"WARNING") cur_color="$BIYellow";;
"ERROR") cur_color="$BIPurple";;
"FETAL") cur_color="$BIRed";;
*) cur_color="$BIWhite";;
esac
echo ${cur_color} "[`date "+%Y-%m-%d %H:%M:%S"`] [$level] $log_info" ${Color_Off}
}
随机抽奖
Shell随机创建手机号码与随机抽奖:
- 随机生成1000个以136开头的手机号码
#! usr/bin/bash
# 生成的手机号码存放到指定的目录的文件
filePath="/home/phoneNum.txt"
#(())语法类似C语法的括号
for((i=1;i<=1000;i++))
do
# 取模
num1=$[$RANDOM%10] # $RANDOM代表随机函数,是操作系统的全局变量
num2=$[$RANDOM%10]
num3=$[$RANDOM%10]
num4=$[$RANDOM%10]
num5=$[$RANDOM%10]
num6=$[$RANDOM%10]
num7=$[$RANDOM%10]
num8=$[$RANDOM%10]
num9=$[$RANDOM%10]
# 将结果输到指定的文件里面
echo "136$num1$num2$num3num4$num5$num6$num7$num8$num9" >> $filePath
done
# 寻找第100个的手机号码
head -100 phoneNum.txt | tail -1
# 查看是否有重复的手机号码
cat phoneNum.txt | sort -u|wc -l
# ================
# 抽取幸运的5位手机号码并去除已经抽取过的用户
#! usr/bin/bash
filePath="/home/phoneNum.txt"
# 循环读取5位用户手机号码
for((i=1;i<=5;i++))
do
# 定位幸运观众所在行数
#line=`wc -l $filePath | cut -d ' ' -f1`
line=`wc -l $filePath | awk '{print $1}'
#计算幸运行
luck_line=$[RANDOM%line+1]
#取出幸运观众所在行的电话号码,-1代表是一个
luck_num=`head -$luck_line $filePath | tail -1`
#显示到屏幕,截取后位的号码数字
echo "136****${luck_num:7:4}"
# 将抽中的手机号码放到一个文本
echo $luck_num >> luck.txt
# 将抽中的手机号码在文本删除,防止下一次又抽中
sed -i "/$luck_num/d" $filePath
done
# 查看还有多少行手机号码
wc -l /home/phoneNum.txt
输出
系统输出
echo 和 printf
echo -n "Proceed? [y/n]: "
echo -e "a\tb" # 支持转移
read ans # 读入到变量 ans
read -n 1 ans # 只有一个字符
echo $ans
printf
printf "Hello %s, I'm %s" Sven Olga #=> "Hello Sven, I'm Olga
printf "1 + 1 = %d" 2 #=> "1 + 1 = 2"
printf "Print a float: %f" 2 #=> "Print a float: 2.000000"
文件读取
cat file.txt | while read line; do
echo $line
done
yaml 文件
yaml 示例
configuration:
account: account1
warehouse: warehouse1
database: database1
object_type:
schema: schema1
functions: funtion1
tables:
- table: table1
sql_file_loc: some_path/some_file.sql
- table: table2
sql_file_loc: some_path/some_file.sql
代码1
#! /bin/bash
# 关键词
key="vehicle_type"
# yaml文件位置
yaml_name="/home/xxxx/vehicle_param/vehicle_params.yaml"
function read_key(){
flag=0
# 逐行读取内容
cat $1 | while read LINE
do
if [ $flag == 0 ];then
# 属性开始标志 vehicle_type:
if [ "$(echo $LINE | grep "$key:")" != "" ];then
if [ "$(echo $LINE | grep -E ' ')" != "" ];then
# 截取出key值
echo "$LINE" | awk -F " " '{print $2}'
continue
else
# 如果关键词后面没有空格,则跳出继续查找
continue
fi
fi
fi
done
}
value=($(read_key $yaml_name))
echo ${value}
代码2
function parse_yaml {
local prefix=$2
local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
sed -ne "s|^\($s\):|\1|" \
-e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
-e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
awk -F$fs '{
indent = length($1)/2;
vname[indent] = $2;
for (i in vname) {if (i > indent) {delete vname[i]}}
if (length($3) > 0) {
vn=""; for (i=0; i<indent; i++) {vn=(vn)(vname[i])("_")}
printf("%s%s%s=\"%s\"\n", "'$prefix'",vn, $2, $3);
}
}'
}
随机抽样
shell 中随机抽取数据,有多种方法
bash
bash 随机数
random=${RANDOM} # 25256
sort
「sort」命令的「-R」选项。
sort -R filename | head -n 100
例如,以下命令会随机抽取文件「data.txt」中的一行:
shuf
shuf 类似sort的命令行实用程序,包含在Coreutils中
Mac 需要单独安装
brew install coreutils
shuf 命令
shuf -n 100 data.txt
shuf -e line1 line2 line3 line4 line5 # 指定输入集合(字符串)
shuf -e 1 2 3 4 5 # 指定输入集合 1~5
shuf -n 3 -e 1 2 3 4 5 # 从指定集合中抽取3个
shuf -i 1-10 # 指定范围: 1~10
awk
或用「awk」命令,例如:
awk 'BEGIN{srand()} {if(rand()<0.01) print $0}' data.txt
awk 'BEGIN{srand()} {print rand()"\t"$0}' filename | sort -nk 1 | head -n100 | awk -F '\t' '{print $2}' # 假如输出的内容只有一列
这两个命令都可以随机地从文件中抽取一行数据。
#!/bin/bash
IN_FILE=$1
LINE_NUM=$2
awk -vN=${LINE_NUM} -vC="`wc -l ${IN_FILE}`" 'BEGIN{srand();while(n<N){i=int(rand()*C+1);if(!(i in a)){a[i]++;n++}}}NR in a' ${IN_FILE}
抽样
sh my_shuf.sh datas.txt 100 | awk '{print $1}' > random_data_100
三剑客
grep 、sed、awk被称为linux中的”三剑客”。
- grep 更适合单纯的查找或匹配文本
- sed 更适合编辑匹配到的文本
- awk 更适合格式化文本,对文本进行较复杂格式处理
编码转换
- 【2021-6-4】linux下转换文件编码格式,命令:
# 从gbk转utf8
iconv -f gbk -t utf8 pattern_0603.txt -o pattern.txt
# 上面命令失败的用下面
iconv -f gbk -t utf8 pattern_0603.txt > pattern.txt
grep
文件内容查找
if grep -q 'foo' ~/.bash_history; then
echo "您过去似乎输入过“foo”"
fi
# 文件内容查找: 目录wqw里查找包含yes的文件
grep yes /wqw
# 从文件内容查找与正则表达式匹配的行:
grep –e “^yes” myfile
# 查找时不区分大小写:
grep –i “yes” myfile
# 查找匹配的行数:
grep -c “yes” myfile
# 从文件内容查找不匹配指定字符串的行:
grep –v “yes” myfile
# 从根目录开始查找所有扩展名为.log的文本文件,并找出包含”ERROR”的行
find / -type f -name “*.log” | xargs grep “ERROR”
# 从当前目录开始查找所有扩展名为.in的文本文件,并找出包含”thermcontact”的行
find . -name “*.in” | xargs grep “thermcontact”
awk
- awk是逐行处理的,逐行处理的意思就是说,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以”换行符”为标记,识别每一行,也就是说,awk跟我们人类一样,每次遇到”回车换行”,就认为是当前行的结束,新的一行的开始,awk会按照用户指定的分割符去分割当前行,如果没有指定分割符,默认使用空格作为分隔符。
awk内建变量
变量
- $0 当前记录(这个变量中存放着整个行的内容)
- $1~$n 当前记录的第n个字段,字段间由FS分隔
- FS 输入字段分隔符 默认是空格或Tab
- NF 当前记录中的字段个数,就是有多少列,如果加上$符号,即$NF,表示一行的最后一个字段
- NR 已经读出的记录数,就是行号,从1开始,如果有多个文件话,这个值也是不断累加中。
- FNR 当前记录数,与NR不同的是,这个值会是各个文件自己的行号
- RS 输入的记录分隔符, 默认为换行符
- OFS 输出字段分隔符, 默认也是空格
- ORS 输出的记录分隔符,默认为换行符
- FILENAME 当前输入文件的名字
- ARGC 命令行参数个数
- ARGV 命令行参数排列
- ENVIRON 支持队列中系统环境变量的使用
- BEGIN{这里面放的是执行前的语句}
- END{这里面放的是处理完所有的行后要执行的语句}
- {这里面放的是处理每一行时要执行的语句}

常用命令
awk '{print $1, $3}' netstat.txt
awk '{printf "%-8s %-8s %-18s %-22s %-15s\n",$1,$3,$4,$5,$6}' netstat.txt
awk '$3 == 0 && $6 == "LAST_ACK"' netstat.txt
awk '$3 > 0 && NR != 1 {print $3}' netstat.txt
awk 'BEGIN{FS=":"} {print $1,$3,$6}' semi_colon_FS #awk -F: '{print $1,$3,$6}' semi_colon_FS
awk '/WAIT/' netstat.txt
awk 'NR != 1 {print > $6}' netstat.txt
awk 'NR!=1{a[$6]++;} END {for (i in a) print i ", " a[i];}' netstat.txt
cat shuf.txt | awk 'BEGIN{srand()} {print rand() "\t" $0}' | sort -n | cut -f2- #shuffle一个文件
awk 'BEGIN{FS=" "}{if ($1 == "payment") {print;}}' /data/log/maui.data.log #抽出所有第一个字段是payment的行
awk 'BEGIN{FS=" "}$1 == "payment"' /data/log/maui.data.log #或者ACTION部分不要用花括号圈引,则自动打印符合条件的相应行
awk '$2 == "beat"{print $3}' /data/log/budweiser.data.log | sort | uniq -c #取出第二列等于beat的行的第3列,然后统计出现的数量
awk '$2 == "beat"{print $3}' logfile | sort | uniq -c
awk '{ print length, $0 }' file | sort -nrk1 -s | cut -d" " -f2- #根据文件的每行长度进行排序
字符串切割
test="cluster 8 平使用面积|你有啥用|使用多少?|使用年限|使用率|使用率多少|套内使用面积|车位使用权多久"
echo $test | awk '{split($3,a,"|");for(i in a) print $2"\t"a[i]}' > out.txt
# split用法,将真个字符串按照:切割,结果存入数组a中
echo "12:34:56" | awk '{split($0,a,":" ); print a[1]}' # 输出 12
echo "123" | awk '{print length}' # 字符串长度
awk -F ',' '{print substr($3,6)}' # 表示是从第3个字段里的第6个字符开始,一直到设定的分隔符","结束.
substr($3,10,8) # 表示是从第3个字段里的第10个字符开始,截取8个字符结束.
substr($3,6) # 表示是从第3个字段里的第6个字符开始,一直到结尾
awk '$0 ~ /abc/ {gsub("a\d+c", "def", $0); print $1, $3}' abc.txt # 字符串替换,正则模式
正则表达式
【2023-1-10】awk的正则表达式,是属于:扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs),详见
awk 常见调用正则表达式方法:
- ① 直接过滤:使用
- ② if条件判断
- ③ 正则函数
# ①
awk '/REG/{action}'
# /REG/为正则表达式,可以将$0中,满足条件记录 送入到:action进行处理.
# ②
# awk正则运算语句(~,~!等同!~)
awk 'BEGIN{info="this is a test";if( info ~ /test/){print "ok"}}'
# ok
#1:仿豆瓣电影微信小程序
# https://github.com/zce/weapp-demo
#
#2:微信小程序移动端商城
# https://github.com/liuxuanqiang/wechat-weapp-mall
# 两行合并,剔除空格
cat m.txt | awk '{if($1~/^[1-9]+/){gsub("\s+","",$1);printf "["$1"]"}else{gsub("\s+","",$1);if($1)printf "("$1")\n"}}'
③ awk内置使用正则表达式函数
- gsub( Ere, Repl, [ In ] ) 原地替换
- sub( Ere, Repl, [ In ] )
- match( String, Ere )
- split( String, A, [ Ere] )
# 将tab替换为 |
cat a.txt | awk -F'\t' '{gsub("\t"," | ",$0);print "|"$0"|"}'
详细函数使用,可以参照:linux awk 内置函数详细介绍(实例)
多路输出
- 代码:
【2019-06-04】awk多路输出: head data_ivr_20190401_20190430.txt | awk -F'\t' '{if($2~/01:/){print $0>>"tmp_a.txt"}else{print $0>>"tmp_b.txt"}}' head data_ivr_20190401_20190430.txt | awk -F'\t' 'BEGIN{a="tmp_a.txt";b="tmp_b.txt";system(">"a";>"b);}{if($2~/01:/){print $0>>a}else{print $0>>b}}' # 文件分流示例 train_file='a.txt' test_file='b.txt' [ -e $train_file ] && > $train_file; [ -e $test_file ] && > $test_file; less error.txt | awk -v a=$train_file -v b=$test_file 'BEGIN {srand();OFS="\t";N=20} {r=int(rand()*N); if(r%N==1)print $0>>a; else{print $0>>b}}' less error.txt | awk 'BEGIN {srand();OFS="\t"} {print $0,rand()*1000}' |sort -k2nr -k5n|awk 'BEGIN {OFS="\t"} {print}'
输出特殊字符
【2022-12-21】输出单引号、双引号
测试数据:
1.1 微客主页-个人主页
1.2 微客主页-热门资讯
1.3 微客主页-热门房源
1.4 微客主页-热门楼盘
1.6 获客宝主页-我的微店-个人主页
1.7 获客宝主页-我的微店-单个二手房
1.8 获客宝主页-我的微店-单个新房
2.1 二手房-详情页
2.2 二手房-列表页
2.3 二手房-详情页cpt
3.1 新房-楼盘详情页
3.2 新房-户型详情页
3.3 新房-项目资料详情页
3.4 新房-列表页
3.5 新房-详情页cpt
4.1 获客宝主页-资讯详情页(gid)
4.2 获客宝主页-获客资讯模块(gid)
4.3 获客宝主页-今日必推模块(gid)
4.4 获客宝主页-资讯详情页(h5)
4.5 获客宝主页-获客资讯模块(h5)
4.6 获客宝主页-今日必推模块(h5)
5.1 霸屏海报-海报
6.1 租赁-详情页
6.2 租赁-列表页
7.1 拉新工具-h5拉新链接
7.2 拉新工具-拉新海报
8.1 首页-好房分享-单个二手房
8.2 首页-好房分享-单个新房
8.3 首页-获客资讯(gid)
8.4 首页-获客资讯(h5)
9.9 幸福楼市
10.1 RGC经纪人
awk 命令
- 双引号:只需使用 \ 即可
- 单引号:需要额外用单引号围起来,再加转义符
# 双引号:
awk '{print "\""}' # 放大:awk '{print " \" "}'
# 使用“”双引号把一个双引号括起来,然后用转义字符\对双引号进行转义,输出双引号。
# 单引号:
awk '{print "'\''"}' # 放大: awk '{print " ' \ ' ' " }'
# 使用一个双引号“”,然后在双引号里面加入两个单引号‘’,接着在两个单引号里面加入一个转义的单引号\',输出单引号。
cat share.txt | awk '{print "when substr(source_from,1,3)='\''" $1 "'\'' then '\''" $2"'\''"}'
# when substr(source_from,1,3)='1.1' then '微客主页-个人主页'
# when substr(source_from,1,3)='1.2' then '微客主页-热门资讯'
# when substr(source_from,1,3)='1.3' then '微客主页-热门房源'
# when substr(source_from,1,3)='1.4' then '微客主页-热门楼盘'
sed
- sed是一款优秀的文本处理程序,但是其不同版本在用法和参数上存在着较大差异,建议大家在使用时一定要查询相关文档,以免出错。
# 删除只有空白字符行
sed -i -e '/^\s\+$/d' file #GNU
sed '1!G;h;$!d' pets.txt #反转一个文件的行
sed 'N; s/\n /, /' pets.txt #将两行合并,并用逗号分开
sed -e 's/'$(echo -e "\x15")'//g' file # sed用于去除ascii不可打印的控制字符
# 常规的替换功能
sed "s/my/Hao Chen's/" pets.txt
sed "3s/my/your/" pets.txt
sed "3,6s/my/your/" pets.txt #只替换第3到第6行的文本
sed -n '/cat/,/fish/p' pets.txt # 只打印匹配cat和fish之前的行,-n表示不输出那些未匹配的行
sed -e 3,6{ -e /This/d -e } pets.txt
sed '3,6{/This/d;}' pets.txt #BSD sed, must add semi-colon
sed '3,6 {/This/{/fish/d;};}' pets.txt
sed '1,${/This/d;s/^ *//g;}' pets.txt
sed -E '/dog/{N;N;N;s/(^|\n)/&# /g;}' pets.txt #BSD sed
sed '/dog/,+3s/^/# /g' pets.txt #GNU sed
sed = pets.txt | sed 'N;s/\n/'$'\t''/' > line_num_pets.txt
sed = my.txt | sed 'N; s/^/ /; s/\(.\{5,\}\)\n/\1 /' #对文件中的所有行编号(行号在左,文字左端对齐)。
#sed = my.txt | sed -E 'N; s/(.*)\n/ \1 /' #貌似,我也可以这么写
sed '/'"$name"'/,/};/d' back_slash.txt
#实际应用,用来做代码重构时:(err) -> next err => next
find . -name '*.coffee' | xargs sed -i '' -E '/\(err\) ->/{N;s/\(err\) ->\n +next err/next/g;}'
#在多行的时候,[[:space:]]才会匹配换行符\n,只有单行的时候,字符串尾部的换行符已经被sed截掉,所以匹配不到
#使用GNU sed去掉首行的BOM
find . -name '*.srt' -exec gsed -i -e '1s/^\xEF\xBB\xBF//' {} \;
gsed '1~2G' -i *.txt #奇数行后加空行
gsed -i -e '$a\' file #如果文件末尾没有换行符,则自动添加,解决"No newline at end of file"的问题,OSX sed中:sed -i '' -e '$a\'
# 在第1行插入内容
sed "1i\\"$'\n'"my monkey's name is wukong"$'\n' my.txt
# 在最后一行追加内容
sed "$ a \\"$'\n'"my monkey's name is wukong"$'\n' my.txt
# 在匹配行之前插入内容
sed "/fish/i\\"$'\n'"my monkey's name is wukong"$'\n' my.txt
# 在指定行修改为特定内容
sed "2c \\"$'\n'"my monkey's name is wukong"$'\n' my.txt
# 匹配行后追加内容
gsed -i '/matchpattern/a content' tmp.txt
# 如果content是以空白字符开头,比如tab或者空格,则用一个反斜线标记出来
gsed -i '/matchpattern/a \ content' tmp.txt
# 命令行中输入tab键:先按ctrl+v,然后再按tab
gsed -i '/matchpattern/a \ content' tmp.txt
# 匹配行后追加多行内容,可以把需要追加的内容写到一个文件中,然后使用r命令
gsed -i '/abcd/r otherfile.txt' tmp.txt
# 删除匹配行之前的内容,也就是保留匹配行之后的所有内容
sed -i '/^package /,$!d' *.go
# 显示一定范围内的行
sed -n '190,200p' tmp.txt
【2024-4-10】生成连续数字、字符串
# -f 或 --format=FORMAT:使用printf风格的浮点格式(使用%g或者%f占位,可指定宽度),可自定义格式输出序列。例如:
seq -f "ID-%05g" 3
# ID-00001
# ID-00002
# ID-00003
# -s 或 --separator=STRING:使用STRING分隔数字(默认值:\n)。例如:~$
seq -s , 3
# 1,2,3
# -w 或 --equal-width:使用前导零填充以均衡宽度。例如:~$
seq -w 8 10
# 08
# 09
# 10
grep
- 待补充
shell案例
自定义通用函数
common.sh 包含的函数:
- 打日志
- 发邮件
- 发短信
- 多功能等待
#!/bin/bash
# -*- coding: utf-8 -*-
#===============================================================================
# File: common.sh
# Usage: sh common.sh
# Description: 定义了常用函数
# LastModified: 6/12/2012 16:28 PM CST
# Created: 1/4/2012 11:06 AM CST
#
# AUTHOR: wangqiwen(wangqiwen@*.com)
# COMPANY: baidu Inc
# VERSION: 1.0
# NOTE:
# input:
# output:
#===============================================================================
ulimit -c unlimited
#init_log <log_file>
init_log()#清空log文件打一条日志
{
>$LogFile # conf/var.sh中定义
log "====================================="
log "LogFile=$LogFile"
log "\t\tshort-cut-pretreat"
local day=`date "+%Y-%m-%d %H:%M:%S"`
log "\t\t$day"
log "====================================="
declare -i log_count=0 # 整型局部变量
}
log()
{
let log_count++
echo -e "\n--------------------------[$log_count]th log--------------------------------\n"
echo -e `date "+%Y-%m-%d %H:%M:%S"`"\t$@"
}
#read_mail <mail.conf> 结果在mail_receivers变量中
read_alarm_mail(){
declare -i flag=0 # 整型局部变量
if [ -f "$1" ];then
cut -d "#" -f 1 "$1" |grep -v "^$" >tmp.$$
while read line; do
if [ $flag -eq 0 ];then
mail_receivers=$line # 整型全局变量
flag=1
else
mail_receivers="$mail_receivers,$line"
fi
done < tmp.$$
rm -f tmp.$$
else
#设定一个默认值
mail_receivers="-"
fi
echo "报警邮件接收人:$mail_receivers"
}
#向指定的邮件发送邮件告警
#$1: 告警主题
#$2: 需要被告警的详细内容
send_alarm_mail( )
{
if [ $# -ne 2 ]; then
return -1
fi
# 获取收件人列表
echo "$2" | mail -s "$1" "$mail_receivers"
if [ $? -ne 0 ]; then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] 发送到 $mail_receivers 的邮件($1)失败!"
else
log "[`date "+%Y-%m-%d %H:%M:%S"`] [NOTE] 成功将邮件($1---$2) 发送至 $mail_receivers !"
fi
return 0
}
#对所有手机报警
#$1: 报警内容
send_list_msgs()
{ # 传入两个参数: $1 --> 报警短信内容 $n (n>=2) --> 报警接收人的手机号
if [ $# -lt 2 ]; then
echo "短信报警函数send_list_msgs参数不够!"
return -1
fi
local i="-"
local phone_number="-"
for((i=2;i<=$#;i++))
do
eval "phone_number=\${$i}"
# 向$phone_number发送报警信息$1
gsmsend -s $GSMSERVER1:$GSMPORT1 -s $GSMSERVER2:$GSMPORT2 *$GSMPIORITY*"$phone_number@$1"
if [ $? -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] 报警短信发送失败 !"
else
log "[`date "+%Y-%m-%d %H:%M:%S"`] [NOTE] 报警信息 ($1) 成功发送到 $phone_number !"
fi
done
}
#------------------------------------------------------
# 2012-2-25 PM 22:33 wangqiwen@*.com
# input: 每次等5min
# type=1 检测多个目录,各目录tag文件命名规则一致,且都在上一级目录
#(1) wait_hadoop_file hadoop time 1 tag_file hadoop_dir1 hadoop_dir2 hadoop_dir3
# 公用tag文件名(非绝对路径,tag文件默认在目录的上一层)
# 示例:wait_hadoop_file $hadoop 10 1 done /a/b/c /a/m/c /a/m/d
# 或: wait_hadoop_file $hadoop 10 1 finish.txt /a/b/c /a/m/c /a/m/d
# 目录/a/b/c,/a/m/c,/a/m/d
# 若tag文件分别为:/a/b/c.done和/a/m/c.done和/a/m/d.done,那么,tag_file="done"
# 否则,所有目录的tag文件名相同,tag_file可自定义为某文件名
#
# type=2 检测多个目录,各目录的tag文件路径无规则,需直接指定其完整路径
#(2) wait_hadoop_file hadoop time 2 hadoop_dir1 tag_file1 hadoop_dir2 tag_file2 # 私用tag文件名,绝对路径
# 示例:wait_hadoop_file $hadoop 10 2 /a/b/c /a/b/c.done /a/m/c /a/m/c.txt /a/m/d /a/m_d.txt
# 目录与tag文件要依次成对出现
#
# type=3 检测多个集群文件(非目录),无须tag文件
#(3) wait_hadoop_file hadoop time 3 hadoop_file1 hadoop_file2 hadoop_file3 # 判断多个hadoop文件的存在性
# 示例:wait_hadoop_file $hadoop 10 3 /a/b/file1.txt /a/b/file2.txt /a/m/file3.log
#
# output: 通过变量FILE_READY记录,返回状态值0~3
# 0 : 检查完毕,或成功删除临时目录
# 1 : 参数输入有误:个数、奇偶性不对。type=2时要保证tag文件与目录依次成对出现
# 2 : 超时,停止检查
# 3 : _temporary目录删除失败,但不影响hadoop任务,属于成功状态
# 成功状态值: 0 和 3
#------------------------------------------------------
#shopt -s -o nounset # 变量声明才能使用
wait_hadoop_file(){
local FILE_READY=1 # 检查结果
local ARG_NUM=$# # 参数个数
[ $ARG_NUM -lt 4 ] && { echo -e "input error ! $ARG_NUM < 4 , please check !\t参数有误,小于4个,请确认!";return $FILE_READY;}
local HADOOP=$1 # Hadoop集群客户端地址
local HADOOP_CHECK_PATH="/" # 待检查的集群目录或文件
local HADOOP_TEMP_PATH="/" # _temporary目录
local HADOOP_CHECK_TAG="/" # 待检查的tag文件
local HADOOP_WATI_TIME=$2 # 最长等待时间(单位:分钟)
local CURRENT_ERRORTIME=1 # 等待时间
local CURRENT_PATH=1 # 当前遍历目录数
local PATH_INDEX=0 # 当前检测目录所在的参数位置
local TAG_INDEX=0 # 当前检测tag文件所在的参数位置
local TAG_NAME="/"
local DIR_NUM=0 # 待检测目录数
local TYPE=$3 # type
# 根据类型分别处理
# type=1,2时,输入参数至少5个;type=3时,输入参数至少4个
case $TYPE in
1)
[ $ARG_NUM -eq 4 ] && { echo -e "input error ! $ARG_NUM < 5 , please check !\t参数有误,小于5个,请确认!";return $FILE_READY;}
DIR_NUM=$(($ARG_NUM-4));; # 待检测的目录数
2)
[ $ARG_NUM -eq 4 ] && { echo -e "input error ! $ARG_NUM < 5 , please check !\t参数有误,小于5个,请确认!";return $FILE_READY;}
[ $((($ARG_NUM-3)%2)) -ne 0 ] && { FILE_READY=1; echo -e "Input error ! Dirs miss to match tags in pairs ...";return $FILE_READY;} # 目录和tag文件不成对,退出case
DIR_NUM=$((($ARG_NUM-3)/2));; # 待检测的目录数
3)
DIR_NUM=$(($ARG_NUM-3));; # 待检测文件数
*)
echo "Input error ! Type value $TYPE illegal... type参数值错误,1-3,非$TYPE"
return $FILE_READY;;
esac
while [ $CURRENT_PATH -le $DIR_NUM ]
do
# path/tag参数位置获取
if [ $TYPE -eq 1 ];then
PATH_INDEX=$((4+$CURRENT_PATH))
TAG_INDEX=4
eval "HADOOP_CHECK_PATH=\${$PATH_INDEX}" # 待检查的集群目录
eval "TAG_NAME=\${$TAG_INDEX}"
if [ "$TAG_NAME" == "done" ];then #tag文件在上一级目录
HADOOP_CHECK_TAG="${HADOOP_CHECK_PATH%/*}/${HADOOP_CHECK_PATH##*/}.$TAG_NAME" # tag文件名为:上一级目录名字.done
else
HADOOP_CHECK_TAG="${HADOOP_CHECK_PATH%/*}/$TAG_NAME" # 上一级目录自定义tag文件名
fi
elif [ $TYPE -eq 2 ];then
PATH_INDEX=$((4+2*($CURRENT_PATH-1)))
TAG_INDEX=$(($PATH_INDEX+1))
eval "HADOOP_CHECK_PATH=\${$PATH_INDEX}" # 待检查的集群目录
eval "HADOOP_CHECK_TAG=\${$TAG_INDEX}" # tag文件的绝对路径
else
PATH_INDEX=$((3+$CURRENT_PATH))
eval "HADOOP_CHECK_PATH=\${$PATH_INDEX}" # 待检查的集群文件
fi
while [ $CURRENT_ERRORTIME -le $HADOOP_WATI_TIME ]
do
$HADOOP fs -test -e $HADOOP_CHECK_PATH # 检测path目录是否存在
if [ $? -eq 0 ];then # 目录存在
break
else # 目录不存在,等待生成
CURRENT_ERRORTIME=$(($CURRENT_ERRORTIME+1))
date "+%Y-%m-%d %H:%M:%S"
sleep 5m
fi
done
[ $CURRENT_ERRORTIME -gt $HADOOP_WATI_TIME ] && { FILE_READY=2; echo -e "Time out when checking dirs[$HADOOP_CHECK_PATH] ...\t等待超时,目录未检查完毕!" ;break;}
if [ $TYPE -eq 3 ];then
CURRENT_PATH=$(($CURRENT_PATH+1)) # 检查下一个目录
else
HADOOP_TEMP_PATH="${HADOOP_CHECK_PATH}/_temporary" # 临时目录
# 检测tag文件,并删除临时目录
while [ $CURRENT_ERRORTIME -le $HADOOP_WATI_TIME ]
do
$HADOOP fs -test -e $HADOOP_CHECK_TAG # 检测tag文件是否存在
if [ $? -eq 0 ];then # tag文件存在 [2012-12-4]停止临时文件删除
#$HADOOP fs -test -e $HADOOP_TEMP_PATH # 检查临时目录是否存在
#if [ $? -eq 0 ];then # 临时目录存在
# $HADOOP fs -rmr $HADOOP_TEMP_PATH # 删除临时目录
# [ $? -ne 0 ] && { FILE_READY=3; echo -e "Failed to delete temp dir[$HADOOP_TEMP_PATH]...\t临时目录删除失败";} #break 2; } # 删除失败,退出2重循环 [2012-2-23]不退出,继续检查
#fi
CURRENT_PATH=$(($CURRENT_PATH+1)) # 检查下一个目录
break
else # tag文件不存在,错误次数自增,循环等待
CURRENT_ERRORTIME=$(($CURRENT_ERRORTIME+1))
date "+%Y-%m-%d %H:%M:%S"
sleep 5m
fi
done
fi
done
[ $CURRENT_PATH -gt $DIR_NUM ] && { [ $FILE_READY -ne 3 ] && FILE_READY=0; echo "All dirs ready ! 目录检查完毕!";} # 所有目录都准备好,新增成功状态3,[2012-2-23]
return $FILE_READY
}
循环任务
从某个日期开始,往前递推N天,并启动任务
[ $# -ge 1 ] && date=$1 || date=`date -d "1 days ago" +%Y%m%d`
readonly rp_hadoop="/home/work/bin/hadoop-client-rp-product/hadoop/bin/hadoop"
i=1;n=3
while [ $i -le $n ]
do
d=`date -d "${i} days ago $date" +%Y%m%d`
echo "[`date "+%Y-%m-%d %H:%M:%S"`] 第 $i 天 ($d)"
sh start.sh $d
[ $? -ne 0 ] && { echo "[`date "+%Y-%m-%d %H:%M:%S"`] 第 $i 天 ($d) oneday-pretreat 执行失败...";exit -1; } || { echo "[`date "+%Y-%m-%d %H:%M:%S"`] 第 $i 天( $d ) oneday-pretreat 执行成功..."; }
cd ../../short-cut-pretreat-v2/navigation
sh start.sh $d
[ $? -ne 0 ] && { echo "[`date "+%Y-%m-%d %H:%M:%S"`] 第 $i 天 ($d) short-cut-pretreat 执行失败...";exit -1; } || { echo "[`date "+%Y-%m-%d %H:%M:%S"`] 第 $i 天( $d ) short-cut-pretreat 执行成功..."; ((i++)); }
cd -
done
shell调度MapReduce任务
单次案例:
#!/bin/bash
# -*- coding: utf-8 -*-
#===============================================================================
# File: start_hadoop.sh [session]
# Usage:
# Description: pc端session日志的hadoop启动脚本
# LastModified: 2013-3-28 12:51 PM
# Created: 27/12/2012 11:17 AM CST
# AUTHOR: wangqiwen(wangqiwen@*.com)
# COMPANY: baidu Inc
# VERSION: 1.0
# NOTE:
# input:
# output:
#===============================================================================
#:<<note
# online
set -x
if [ $# -ne 9 ]; then
echo "[$0] [ERROR] [`date "+%Y-%m-%d %H:%M:%S"`] [session] input error ! \$#=$# not 9"
exit -1
fi
hadoop=$1;input=${2//;/ -input };output=$3
jobname=$4;main_dir=$5;date=$6;task_prefix=$7
map_con_num=$8;reduce_num=$9
#note
:<<note
# test
date="20130314"
jobname="session"
hadoop="/home/work/hadoop-rp-rd-nj/hadoop/bin/hadoop"
#input="/log/22307/nj_rpoffline_session_ting/$date/0000/szwg-ston-hdfs.dmop/0000"
input="/log/22307/nj_rpoffline_session_ting/$date/0000/szwg-ston-hdfs.dmop/0000/part-00000"
# baike http://cq01-test-nlp2.cq01.baidu.com:8130/table/view?table_id=347
output="/user/rp-rd/wqw/test/sm/$jobname/$date/0000"
map_con_num=200
reduce_num=200
main_dir="/home/work/wqw/sm-navi-data-cookie/new/bin"
note
echo "=========================$jobname start ============================="
done_file="${output%/*}/${output##*/}.done"
${hadoop} fs -test -e ${output} && ${hadoop} fs -rmr ${output}
${hadoop} fs -test -e ${done_file} && ${hadoop} fs -rm ${done_file}
echo "-------输出目录,标记文件清理完毕---------------------"
echo "[$0] [NOTE] [`date "+%Y-%m-%d %H:%M:%S"`] [$jobname] start to commit hadoop job"
${hadoop} streaming \
-jobconf mapred.job.name="${task_prefix}" \
-jobconf mapred.job.priority=HIGH \
-jobconf mapred.task.timeout=600000 \
-jobconf mapred.map.tasks=$map_con_num \
-jobconf mapred.reduce.tasks=$reduce_num \
-jobconf stream.memory.limit=1000 \
-jobconf stream.num.map.output.key.fields=2 \
-jobconf num.key.fields.for.partition=1 \
-cacheArchive /user/rp-product/dcache/thirdparty/python2.7.tar.gz#py27 \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-jobconf mapred.job.map.capacity=$map_con_num -jobconf mapred.job.reduce.capacity=$reduce_num \
-jobconf mapred.map.max.attempts=10 -jobconf mapred.reduce.max.attempts=10 \
-file $main_dir/hadoop_jobs/session/*.py \
-file $main_dir/tools/hadoop_tool/py27.sh \
-file $main_dir/tools/url_normalize/m \
-cmdenv date_of_data=$date \
-output ${output} \
-input ${input} \
-mapper "sh py27.sh mapper.py" \
-reducer "./m"
if [ $? -ne 0 ]; then
echo "[$0] [Error] [`date "+%Y-%m-%d %H:%M:%S"`] [$jobname] job failed !"
exit -1
fi
#${hadoop} fs -touchz ${done_file}
echo "[$0] [NOTE] [`date "+%Y-%m-%d %H:%M:%S"`] [$jobname] hadoop job finished"
echo "=========================$jobname end ============================="
exit 0
多任务调度
#!/bin/bash
# -*- coding: utf-8 -*-
#
#===============================================================================
# File: start.sh [oneday-pretreat]
# Usage:
# 运行指定日期: sh start.sh 20120104
# 正常运行(昨天): sh start.sh
# 查看运行日志: tail -f ../log/20120104/run_log_20120103.txt
# Description: oneday-pretreat总控脚本
# LastModified: 12/13/2012 15:29 AM CST
# Created: 1/4/2012 11:16 AM CST
#
# AUTHOR: wangqiwen(wangqiwen@*.com)
# COMPANY: baidu Inc
# VERSION: 1.0
# NOTE:
# input: mergeOneDay和dump
# output: 作为short-cut-pretreat的输入
#===============================================================================
#搭建执行环境
source ./build.sh
#读入路径、时间配置
if [ $# -eq 1 ];then
date_check=`echo "$1" | sed -n '/^[0-9]\{8\}$/p'`
if [ -z $date_check ];then
# 如果字符串为空,表明输入参数不当
echo "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] date of start.sh input error ... 启动脚本的日期参数错误!"
exit -1
else
source $ConfDir/vars.sh $1
fi
else
source $ConfDir/vars.sh
fi
#####################for mini#############################
export HADOOP_HOME=${rp_hadoop%/*/*}
export JAVA_HOME=${HADOOP_HOME%/*}/java6
# build.sh中读入BinDir
source $BinDir/oneday_onlyUrl_mini/mini/output/jjpack2text/conf/dlb_env.sh
export PATH=$PATH:$HADOOP_HOME/bin
##########################################################
#是否开启调试模式
if [ $debug_on -eq 1 ];then
set -x
else
set +x
fi
#导入公共函数
source ./common.sh #增加./,防止与环境变量重名
#日志初始化
init_log #common.sh中定义
#重定向标准输入和输出到指定文件
exec 3<>$LogFile #LogFile在conf/var.sh中定义
exec 1>&3 2>&1
log "$alarm_module_info" #模块信息
log "[`date "+%Y-%m-%d %H:%M:%S"`] [NOTE] load conf file 加载配置文件..."
#读入邮件配置
read_alarm_mail $ConfDir/mail.conf # read_alarm_mail源于common.sh
#读入短信配置
source $ConfDir/msg_conf.sh
#=========================hadoop任务函数封装===================
check_jobs_input()
{ # 参数: job type name warning msg_receiver 外部依赖才有短信报警
[ $# -lt 5 ] && { echo "check_jobs_input input ($@) error ! ($#>= 5)";exit -1; }
local my_job=$1
local job_name="${my_job}-$date"
local my_type=$2
local hadoop_file="-"
case $my_type in
1) # 内部依赖,超时仅发送邮件
eval "hadoop_file=\$${my_job}_input_tag_in";;
2) # 外部依赖,超时发报警短信\短信,另外增加预警
eval "hadoop_file=\$${my_job}_input_tag_out";;
*)
echo "check_jobs_input input error ! type=[1,2]"
exit -1;;
esac
eval "local wait_time=\$${my_job}_wait_time" # 2012-5-22
local name=$3
local warning=$4 # 是否需要预警
local msg_receiver=$5
for((i=6;i<=$#;i++))
do
eval "msg_receiver=\"\$msg_receiver \${$i}\""
done
# 外部依赖,先等待,超时发出预警,继续等待最后时间
if [ $warning -ne 0 ];then
# 数据生成较晚,提醒相关人员关注
eval "local wait_time_notice=\$${my_job}_wait_time_notice"
# 验证${my_job}中是否定义提醒时间
[ -e $wait_time_notice ] && { log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] $job_name ---[check_jobs_input] 未定义的变量: ${my_job}_wait_time_notice ";exit -1; }
wait_hadoop_file $rp_hadoop $wait_time_notice 3 $hadoop_file # 等待文件ready 2012-5-22
return_value=$?
if [ $return_value -ne 0 ];then
rest_time=$(echo $wait_time_notice | awk '{print $0/12.0}')
log "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] [返回值: $return_value] $job_name 上游数据 ($date,$name) 还没生成,存在风险...再等待 $rest_time 小时..... "
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [WARNING] $job_name 预警时间已到,请及时推进" "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] [返回值:$return_value] $job_name 预警时间已到,上游数据 ($date,$name) 还未生成,存在风险,再等待 $rest_time 小时...请 [$alarm_module_RP_rd] 及时跟进, $alarm_module_info" # 邮件报警
[ $alarm_msg_off -eq 0 -a $my_type -eq 2 ] && send_list_msgs "[oneday-pretreat] [WARNING] [返回值]:$return_value] $job_name 预警时间已到,上游数据 ($date,$name) 还未生成,存在风险,再等待 $rest_time 小时,请 [$alarm_module_RP_rd] 及时跟进." $msg_receiver
else
return 0 # 预警时间内,数据ready,函数退出
fi
# 最晚抢救时间已到,当天挖掘无法更新,进入自动补数据阶段
eval "local wait_time_warning=\$${my_job}_wait_time_warning"
# 验证${my_job}中是否定义预警时间
[ -e $wait_time_warning ] && { log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] $job_name --- [check_jobs_input] 未定义的变量: ${my_job}_wait_time_warning ";exit -1; }
wait_hadoop_file $rp_hadoop $wait_time_warning 3 $hadoop_file # 等待文件ready 2012-5-22
return_value=$?
if [ $return_value -ne 0 ];then
rest_time=$(echo $wait_time_warning | awk '{print $0/12.0}')
log "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] [返回值: $return_value ] $job_name 接口数据最晚等待时间已到! 上游数据 ($date,$name) 还没生成,当天挖掘赶不上,自动进入补数据阶段...再等待 $rest_time 小时...请及时处理."
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [WARNING] $job_name 预警时间已到,请及时推进..." "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] [返回值:$return_value] $job_name 接口数据最晚等待时间已到 !上游数据 ($date,$name) 还未生成,当天挖掘赶不上,自动进入补数据阶段,再等待 $rest_time 小时...请 [$alalarm_module_RP_rd] 及时跟进,$alarm_module_info" # 邮件报警
[ $alarm_msg_off -eq 0 -a $my_type -eq 2 ] && send_list_msgs "[oneday-pretreat] [WARNING] [返回值 $return_value ] $job_name 接口数据最晚等待时间已到 !,上游数据 ($date,$name) 还未生成,当天挖掘赶不上,自动进入补数据阶段,再等待 $rest_time 小时,请[ $alarm_module_RP_rd ]及时跟进." $msg_receiver
else
return 0 # 补数据成功,程序返回
fi
fi
# 补数据超时失败,程序退出
wait_hadoop_file $rp_hadoop $wait_time 3 $hadoop_file # 等待文件ready 2012-5-22
return_value=$?
if [ $return_value -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] [返回值: $return_value] $job_name 等待超时 ! 上游数据 ($date,$name) 未按时生成..." # 打运行日志
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [ERROR] $job_name 等待超时!" " [`date "+%Y-%m-%d %H:%M:%S"`][ERROR][返回值: $return_value] $job_name 失败! 上游数据 ($date,$name) 未按时生成..请联系 [$alarm_module_RP_rd] 处理,$alarm_module_info" # 邮件报警
[ $alarm_msg_off -eq 0 -a $my_type -eq 2 ] && send_list_msgs "[oneday-pretreat] [ERROR] [返回值: $return_value] $job_name 等待超时!上游数据 ($date,$name) 未按时生成...请 [$alarm_module_RP_rd] 处理,$alarm_module_info" $msg_receiver # 短信报警
exit -1 # 超时等待,退出
fi
}
hadoop_dir_search()
{ # 参数: job_name type name
# 仅用于接口数据的自动查找,替换
[ $# -lt 3 ] && echo "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] hadoop_dir_search input error ! ($# >= 3)"
local job_name=$1
local my_type=$2 # 区分正常产出数据(type=1)和转储日志(type非1)
local name=$3
local tmp_date='-'
local tmp_path='-'
local tmp_tag='-'
eval "local days=\$${name}_findDays"
eval "wait_hadoop_file \$rp_hadoop \$${name}_wait_time 3 \$${name}_tag"
return_value=$?
if [ $return_value -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] [$job_name] 当天目录 ${name}_dir/$date/0000.done 不存在,请核实 !"
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [WARNING] 上游数据 $name($date) 不存在!" "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] 上游数据 $name($date) 不存在...请联系 [$alarm_module_RP_rd] 追查原因,$alarm_module_info"
# 当天数据超时未生成,common_query 需要自动搜索最近的数据
for((i=1;i<=$days;i++))
do
tmp_date=`date -d "-$i day $date" +%Y%m%d` # 获取前i天日期
if [ $my_type -eq 1 ];then
eval "tmp_path=\"\${${name}_dir%/*/*}/$tmp_date/0000\"" # 拼接临时目录----正常产出数据
eval "tmp_tag=\"\${${name}_dir%/*/*}/$tmp_date/0000.done\"" # 拼接临时目录----正常产出数据
else
eval "tmp_path=\"\${${name}_dir%/*/*/*}/$tmp_date/0000/0000\"" # 拼接临时目录----转储日志
eval "tmp_tag=\"\${${name}_dir%/*/*/*}/$tmp_date/0000/@manifest\"" # 拼接临时目录----转储日志
fi
$rp_hadoop fs -test -e $tmp_tag # 检查默认的目录标记文件 [20130218]
if [ $? -eq 0 ];then
eval "${name}_dir=\"$tmp_path\"" # 更改原目录值
eval "${name}_tag=\"$tmp_tag\"" # 更改原标记文件
break
else
log "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] [$job_name] $tmp_tag 不存在,请核实 !"
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [WARNING] 上游数据 $name($tmp_date) 不存在!" "[`date "+%Y-%m-%d %H:%M:%S"`] [WARNING] 上游数据 $name($d) 不存在...请联系 [$alarm_module_RP_rd] 追查原因,$alarm_module_info"
fi
done
[ $i -ge $days ] && exit -1
fi
}
start_hadoop_jobs()
{ # 参数: jobname arg1 arg2 ... 不包括基本参数
[ $# -lt 1 ] && echo "start_hadoop_jobs input error ! ($# >= 1)"
local myjob=$1
local myjob_name="${1}-$date"
local args=""
if [ $# -ge 2 ];then
# 获取额外参数
for((i=2;i<=$#;i++))
do
eval "args=\"$args \${$i}\""
done
fi
#启动任务
eval "cd \$${myjob}_local_dir"
eval "\$shellBin start_hadoop.sh \$rp_hadoop \$${myjob}_input \$${myjob}_output \$myjob_name \$${myjob}_map_con_num \$${myjob}_reduce_num \$args"
return_value=$?
if [ $return_value -eq 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [NOTE] [返回值: $return_value] $myjob_name finished ! $myjob_name 执行成功..."
eval output=\$${myjob}_output
${rp_hadoop} cr -register ${output} -cronID $cronID # zk注册数据状态
if [ $? -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] $myjob_name zk状态注册失败.."
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [ERROR] $myjob_name zk状态注册失败.." " [`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] $myjob_name zk状态注册失败...请联系 $alarm_module_stra_rd 处理,谢谢! $alarm_module_info"
fi
else
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] [返回值: $return_value] $myjob_name failed ! $myjob_name 执行失败..."
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [ERROR] $myjob_name Failed !" " [`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] $myjob_name failed when running ! $myjob_name 执行过程中失败...请联系 $alarm_module_stra_rd 处理,谢谢! $alarm_module_info"
exit -1
fi
cd -
}
#=======================启动子任务==============================
#---------------oneday_onlyUrl----------------------
# 作用: 抽取URL,去重,方便下一步的网页库查询 |
# 输入: mergeOneDay和database_dump |
# 输出: oneday_onlyUrl |
#-------------------------------------------------------
jobname1="oneday_onlyUrl"
oneday_onlyUrl()
{
# 等待接口数据
check_jobs_input $jobname1 2 "mergeOneDay&database_dump" 1 $MOBILE_LIST_ALL # 外部依赖,需要预警
#从集群上下载记录mergeOneDay信息的xml文件
local_xml_mergeOneDay_file="${DataDir}/${mergeOneDay_tag##*/}" #提取文件名
[ -e $local_xml_mergeOneDay_file ] && rm $local_xml_mergeOneDay_file # 删除已有文件
sleep 5 # 等待5S,防止原xml文件不完整
$rp_hadoop fs -copyToLocal $mergeOneDay_tag $DataDir #复制xml文件到本地
cd $CheckDir # 2012-12-11
$pythonBin mergeOneDay_check.py $local_xml_mergeOneDay_file #检验mergeOneDay数据源是否满足要求
cd - # 2012-12-11
return_value=$?
if [ $return_value -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] [返回值:$return_value] $jobname1 失败!上游数据 mergeOneDay-$date 缺失过多,不满足要求..."
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [ERROR] [返回值:$return_value] $jobname1 失败!" " [`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] $jobname1 失败!上游数据 mergeOneDay-$date 数据源缺失过多,不满足要求...请联系 [$alarm_module_RP_rd] 追查原因,$alarm_module_info"
[ $alarm_msg_off -eq 0 ] && send_list_msgs "[oneday-pretreat] [ERROR] [返回值:$return_value] $jobname1 失败!上游数据 mergeOneDay-$date 数据源缺失过多,不满足要求...请 [$alarm_module_RP_rd] 追查原因,谢谢! $alarm_module_info" $MOBILE_LIST_ALL
exit -1
fi
$rp_hadoop fs -touchz $mergeOneDay_ok # 数据验证通过,创建标记文件,通知下游模块启动
start_hadoop_jobs "oneday_onlyUrl"
}
if [ $oneday_onlyUrl_pass -eq 0 ];then
oneday_onlyUrl
$rp_hadoop fs -touchz $mergeOneDay_ok # 数据验证通过,创建标记文件,通知下游模块启动
${rp_hadoop} cr -register $mergeOneDay_ok -cronID $cronID # 注册数据状态
if [ $? -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] mergeOneDay_ok zk状态注册失败.."
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [ERROR] mergeOneDay_ok zk状态注册失败.." " [`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] mergeOneDay_ok zk状态注册失败...请联系 $alarm_module_stra_rd 处理,谢谢! $alarm_module_info"
fi
fi
#-----------oneday_onlyUrl_mini-------------------------
# 作用: mini网页库查询 |
# 输入: oneday_onlyUrl |
# 输出: oneday_onlyUrl_mini |
#-------------------------------------------------------
jobname2="oneday_onlyUrl_mini"
oneday_onlyUrl_mini()
{
check_jobs_input $jobname2 1 "oneday_onlyUrl" 0 $MOBILE_LIST_ALL # 内部依赖
cd $oneday_onlyUrl_mini_local_dir/mini/output
# ----------通过vars.sh中的路径配置,python程序解析修改test.xml
less $ConfDir/oneday_onlyUrl_mini_conf.xml | awk -v input=$oneday_onlyUrl_mini_hdfs_input -v output=$oneday_onlyUrl_mini_hdfs_output -v bin_path="$oneday_onlyUrl_mini_bin_path" '{
if($0~/<hdfs_input>.*<\/hdfs_input>/)
print "\t\t<hdfs_input>"input"</hdfs_input>"
else if($0~/<hdfs_output>.*<\/hdfs_output>/)
print "\t\t<hdfs_output>"output"</hdfs_output>"
else if($0~/<bin_path>.*<\/bin_path>/)
print "\t\t<bin_path>"bin_path"</bin_path>"
else
print $0
}' > test.xml
echo "=======================mini网页库========================="
$pythonBin Xml2stream.py test.xml # 启动网页库查询,后台操作
${rp_hadoop} fs -test -e "${oneday_onlyUrl_mini_output}/part-00999" # part-00999存在才证明mini查询成功
if [ $? -eq 0 ];then
# 任务执行完毕后,创建便于检测的tag文件
$rp_hadoop fs -touchz "${oneday_onlyUrl_mini_output%/*}/${oneday_onlyUrl_mini_output##*/}.done"
${rp_hadoop} cr -register ${oneday_onlyUrl_mini_output} -cronID $cronID # 注册数据状态
if [ $? -ne 0 ];then
log "[`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] oneday_onlyUrl_mini zk状态注册失败.."
[ $alarm_mail_off -eq 0 ] && send_alarm_mail "[oneday-pretreat] [ERROR] oneday_onlyUrl_mini zk状态注册失败.." " [`date "+%Y-%m-%d %H:%M:%S"`] [ERROR] oneday_onlyUrl_mini zk状态注册失败...请联系 $alarm_module_stra_rd 处理,谢谢! $alarm_module_info"
fi
fi
# 删除多余的临时目录
echo "----清除临时文件 $oneday_onlyUrl_mini_hdfs_tmp ------"
#exec 1>/dev/null 2>&1 # 将以下删除信息扔到位桶里
for dir in $oneday_onlyUrl_mini_hdfs_tmp
do
echo "删除临时目录:${oneday_onlyUrl_mini_output%/*}/$dir"
$rp_hadoop fs -rmr "${oneday_onlyUrl_mini_output%/*}/$dir" &>/dev/null
done
#exec 1>&3 2>&1 # 恢复重定向到日志文件
echo "========================结束============================"
cd -
log "[`date "+%Y-%m-%d %H:%M:%S"`] [NOTE] $jobname2 百灵库查询完毕..."
}
if [ $oneday_onlyUrl_mini_pass -eq 0 ];then
oneday_onlyUrl_mini
fi
#------------oneday_baiduid---------------------------------
# 作用: |
# 输入: mergeOneDay和baiduid |
# 输出: oneday_baiduid |
#-------------------------------------------------------
jobname3="oneday_baiduid"
#-----------后台等待baiduid---------------------
oneday_baiduid(){
check_jobs_input $jobname3 2 "mergeOneDay" 0 $MOBILE_LIST_ALL # 外部依赖
start_hadoop_jobs $jobname3 $oneday_baiduid_max_freq $oneday_baiduid_min_time
}
if [ $oneday_baiduid_pass -eq 0 ];then
oneday_baiduid & # 后台运行
fi
#------------oneday_onlyUrl_mini_plus------------------
# 作用: 网页库查询结果上附加unifyUrl和commonQuery |
# 输入: oneday_onlyUrl_mini,urlunify,commonQuery |
# 输出: oneday_onlyUrl_mini_plus |
#-------------------------------------------------------
jobname4="oneday_onlyUrl_mini_plus"
oneday_onlyUrl_mini_plus(){
hadoop_dir_search $jobname4 1 "common_query" # 检查并查找可替代的commonQuery数据 统计产出(2013-5-15)
hadoop_dir_search $jobname4 1 "oneday_onlyUrl_mini" # 检查并查找可替代的mini数据 原始日志
#check_jobs_input $jobname4 1 "oneday_onlyUrl_mini" 0 $MOBILE_LIST_STRA # 内部
oneday_onlyUrl_mini_plus_input="$urlunify_dir $common_query_dir $oneday_onlyUrl_mini_dir"
start_hadoop_jobs $jobname4 $oneday_onlyUrl_mini_plus_input_str1 $oneday_onlyUrl_mini_plus_input_str2 $oneday_onlyUrl_mini_plus_input_str3
reset_common_query # 恢复common_query原始值
}
if [ $oneday_onlyUrl_mini_plus_pass -eq 0 ];then
oneday_onlyUrl_mini_plus
fi
#------------oneday_baiduid_plus----------------------------
# 作用: oneday_baiduid附加URL信息 |
# 输入: oneday_baiduid和oneday_onlyUrl_mini |
# 输出: oneday_baiduid_plus |
#-------------------------------------------------------
jobname5="oneday_baiduid_plus"
oneday_baiduid_plus()
{
check_jobs_input $jobname5 1 "oneday_baiduid|oneday_onlyUrl_mini_plus" 0 $MOBILE_LIST_STRA # 内部依赖
start_hadoop_jobs $jobname5 $oneday_baiduid_plus_input_str1 $oneday_baiduid_plus_input_str2
}
if [ $oneday_baiduid_plus_pass -eq 0 ];then
oneday_baiduid_plus
fi
#------------oneday_uid_plus----------------------------
# 作用: baiduid映射成uid |
# 输入: baiduid-uid-mapping和oneday_baiduid_plus |
# 输出: oneday_uid_plus |
#-------------------------------------------------------
jobname6="oneday_uid_plus"
#-----------后台等待baiduid-uid-mapping-------------------
oneday_uid_plus(){
hadoop_dir_search $jobname6 1 "baiduid_uid_mapping" # 检查并查找可替代的baiduid-uid数据---程序产出
check_jobs_input $jobname6 1 "oneday_baiduid_plus" 0 $MOBILE_LIST_STRA # 内部依赖
oneday_uid_plus_input="${baiduid_uid_mapping_dir} ${oneday_baiduid_plus_output}"
start_hadoop_jobs $jobname6 $oneday_uid_plus_input_str1 $oneday_uid_plus_input_str2
reset_baiduid_uid_mapping # 恢复baiduid_uid_mapping原始值
}
if [ $oneday_uid_plus_pass -eq 0 ];then
oneday_uid_plus & # 后台运行
fi
#------------oneday_activeBaiduid_plus------------------
# 作用: baiduid映射成uid |
# 输入: activeBaiduid和oneday_baiduid_plus |
# 输出: oneday_activeBaiduid_plus |
#-------------------------------------------------------
jobname7="oneday_activeBaiduid_plus"
#-----------后台等待 activeBaiduid-------------------
oneday_activeBaiduid_plus(){
hadoop_dir_search $jobname7 1 "activeBaiduid" # 检查并查找可替代的baiduid-uid数据---程序产出
check_jobs_input $jobname7 1 "oneday_baiduid_plus" 0 $MOBILE_LIST_STRA # 内部依赖
oneday_activeBaiduid_plus_input="${activeBaiduid_dir} ${oneday_baiduid_plus_output}"
start_hadoop_jobs $jobname7 $oneday_activeBaiduid_plus_input_str1 $oneday_activeBaiduid_plus_input_str2
reset_activeBaiduid # 恢复activeBaiduid原始值
}
if [ $oneday_activeBaiduid_plus_pass -eq 0 ];then
oneday_activeBaiduid_plus
fi
#------------oneday_dump_urlUnify----------------------
# 作用: 用网页库查询结果归一化全库数据database_dump |
# 输入: databse_dump和oneday_onlyUrl_mini |
# 输出: oneday_dump_urlUnify |
#-------------------------------------------------------
jobname8="oneday_dump_urlUnify"
oneday_dump_urlUnify(){ # 后台运行
check_jobs_input $jobname8 2 "database_dump" 0 $MOBILE_LIST_ALL # 外部依赖
check_jobs_input $jobname8 1 "oneday_onlyUrl_mini_plus" 0 $MOBILE_LIST_STRA # 内部依赖
start_hadoop_jobs $jobname8 $oneday_dump_urlUnify_input_str1 $oneday_dump_urlUnify_input_str2
}
if [ $oneday_dump_urlUnify_pass -eq 0 ];then
oneday_dump_urlUnify &
fi
#------------------end-----------------------
log "[`date "+%Y-%m-%d %H:%M:%S"`] [NOTE] oneday-pretreat success ! oneday-pretreat 模块执行完毕!"
#关闭重定向
exec 3<&-
批主机管理
pdsh、pssh 是之前运维管理人员的利器。
这俩工具已退出历史舞台,现在发光发热的已是 Ansible、Salt。
- 【2024-4-19】参考
pssh
pssh 是一个 python 编写可以在多台服务器上执行命令的工具,同时支持拷贝文件,是同类工具中很出色的,类似 pdsh 。为方便操作,使用前请在各个服务器上配置好密钥认证访问。
- 项目地址: parallel-ssh
- 总结
附加工具
- pscp 传输文件到多个 hosts,类似 scp
pscp -h hosts.txt -l irb2 foo.txt /home/irb2/foo.txt
- pslurp 从多台远程机器拷贝文件到本地
- pnuke 并行在远程主机杀进程
pnuke -h hosts.txt -l irb2 java
- prsync 使用rsync协议从本地计算机同步到远程主机
prsync -r -h hosts.txt -l irb2 foo /home/irb2/foo
pdsh
pdsh (Parallel Distributed Shell) 可并行执行对目标主机的操作,对于批量执行命令和分发任务有很大的帮助,在使用前需要配置 ssh 无密码登录
pdsh 全称 parallel distributed shell
- 与pssh类似,pdsh可并行执行对远程目标主机的操作,在有批量执行命令或分发任务的运维需求时,使用这个命令可达到事半功倍的效果。
- 同时,pdsh还支持交互模式,当要执行的命令不确定时,可直接进入pdsh命令行,非常方便。
pdsh应用场景
- 基本上与pssh相同,都用于大批量服务器的配置、部署、文件复制等运维操作。
- 使用pdsh时,仍需要配置本地主机和远程主机间的单向ssh信任。
- 另外,pdsh还附带了pdcp命令,此命令可以将本地文件批量复制到远程的多台主机上,这在大规模的文件分发环境下是非常有用的。
pdsh可以通过多种方式在远程主机上运行命令
- 默认是rsh方式
- 另外也支持ssh、mrsh、qsh、mqsh、krb4、xcpu等多种rcmd模块,这个可以在运行命令时通过参数指定。
pdsh -h
Usage: pdsh [-options] command ...
-S return largest of remote command return values
-h output usage menu and quit 获取帮助
-V output version information and quit 查看版本
-q list the option settings and quit 列出 `pdsh` 执行的一些信息
-b disable ^C status feature (batch mode)
-d enable extra debug information from ^C status
-l user execute remote commands as user 指定远程使用的用户
-t seconds set connect timeout (default is 10 sec) 指定超时时间
-u seconds set command timeout (no default) 类似 `-t`
-f n use fanout of n nodes 设置同时连接的目标主机的个数
-w host,host,... set target node list on command line 指定主机,host 可以是主机名也可以是 ip
-x host,host,... set node exclusion list on command line 排除某些或者某个主机
-R name set rcmd module to name 指定 rcmd 的模块名,默认使用 ssh
-N disable hostname: labels on output lines 输出不显示主机名或者 ip
-L list info on all loaded modules and exit 列出 `pdsh` 加载的模块信息
-a target all nodes 指定所有的节点
-g groupname target hosts in dsh group "groupname" 指定 `dsh` 组名,编译安裝需要添加 `-g` 支持选项 `--with-dshgroups`
-X groupname exclude hosts in dsh group "groupname" 排除组,一般和 `-a` 连用
available rcmd modules: exec,xcpu,ssh (default: ssh) 可用的执行命令模块,默认为 ssh
示例
# 单个主机测试
pdsh -w 192.168.0.231 -l root uptime
# 192.168.0.231: 16:16:11 up 32 days, 22:14, ? users, load average: 0.10, 0.14, 0.16
# 多个主机测试
pdsh -w 192.168.0.[231-233] -l root uptime
# 192.168.0.233: 16:17:05 up 32 days, 22:17, ? users, load average: 0.13, 0.12, 0.10
# 192.168.0.232: 16:17:05 up 32 days, 22:17, ? users, load average: 0.45, 0.34, 0.27
# 192.168.0.231: 16:17:06 up 32 days, 22:15, ? users, load average: 0.09, 0.13, 0.15
# 逗号分隔主机
pdsh -w 192.168.0.231,192.168.0.234 -l root uptime
# 192.168.0.234: 16:19:44 up 32 days, 22:19, ? users, load average: 0.17, 0.21, 0.20
# 192.168.0.231: 16:19:44 up 32 days, 22:17, ? users, load average: 0.29, 0.18, 0.16
# -x 排除某个主机
pdsh -w 192.168.0.[231-233] -x 192.168.0.232 -l root uptime
# 192.168.0.233: 16:18:24 up 32 days, 22:19, ? users, load average: 0.11, 0.12, 0.09
# 192.168.0.231: 16:18:25 up 32 days, 22:16, ? users, load average: 0.11, 0.13, 0.15
【2024-4-20】pdsh 安装
- sudo apt-get install pdsh – 错误
- 源码安装
- google code
sudo apt-get install pdsh
# 错误
pdsh -v
# pdsh@mlxlabqcvytu4a66056efe-20240328132206-317dg9-nqi3xt-worker: module path "/usr/lib/x86_64-linux-gnu/pdsh" insecure.
# pdsh@mlxlabqcvytu4a66056efe-20240328132206-317dg9-nqi3xt-worker: "/": Owner not root, current uid, or pdsh executable owner
# pdsh@mlxlabqcvytu4a66056efe-20240328132206-317dg9-nqi3xt-worker: Couldn't load any pdsh modules
# 源码编译安装
wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/pdsh/pdsh-2.29.tar.bz2
./configure --with-ssh --enable-static-modules --prefix=/home/wqw/bin && make && make install
# 问题: error: invalid variable name: –-prefix
# 解决: 复制过来的 -- 格式有问题, 重新输入
# 编译完后,生成 bin文件夹 /home/wqw/bin/pdsh/bin
# 修改配置 vim ~/.bashrc
export PATH=$PATH:/home/wqw/pdsh/bin
source ~/.bashrc
pdsh-2.29 (+static-modules)
# rcmd modules: ssh,rsh,exec (default: rsh)
# misc modules: (none)
win bat
批处理(Batch),称为批处理脚本
- 批处理就是对某对象进行批量的处理。
- 批处理文件的扩展名为 bat
批处理文件(batch file)包含系列 DOS命令,常用于自动执行重复性任务。
- 用户只需双击批处理文件便可执行任务,而无需重复输入相同指令。
- 编写批处理文件非常简单,但难点在于确保一切按顺序执行。
- 编写严谨的批处理文件可以极大程度地节省时间,在应对重复性工作时尤其有效
系统在解释运行批处理程序时,首先扫描整个批处理程序,然后从第一行代码开始向下逐句执行所有的命令,直至程序结尾或遇见exit命令或出错意外退出
【2024-12-10】Windows批处理(cmd/bat)常用命令教程
bat 文件编辑
批处理程序是多条DOS命令组成的普通文本文件
- 可用记事本直接编辑或用DOS命令创建
- 也可用DOS文本编辑器 Edit.exe 来编辑。
在“命令提示”下键入批处理文件的名称,或者双击该批处理文件,系统就会调用Cmd.exe运行该批处理程序
- 一般每条命令占据一行
-
当然也可以将多条命令用特定符号(如:&、&&、 、 等)分隔后写入同一行中 - 像if、for等较高级命令则要占据几行甚至几十几百行的空间。
bat 命令
批处理命令简介
- echo
- rem
- pause
- call
- start
- goto
- set
批处理符号简介
- 回显屏蔽 @
- 重定向1 >与»
- 重定向2 <
- 管道符号
| - 转义符 ^
- 逻辑命令符包括:&、&&、
|| - 常用DOS命令
- 文件夹管理:
- cd 显示当前目录名或改变当前目录。
- md 创建目录。
- rd 删除一个目录。
- dir 显示目录中的文件和子目录列表。
- tree 以图形显示驱动器或路径的文件夹结构。
- path 为可执行文件显示或设置一个搜索路径。
- xcopy 复制文件和目录树。
- 文件管理:
- type 显示文本文件的内容。
- copy 将一份或多份文件复制到另一个位置。
- del 删除一个或数个文件。
- move 移动文件并重命名文件和目录。(Windows XP Home Edition中没有)
- ren 重命名文件。
- replace 替换文件。
- attrib 显示或更改文件属性。
- find 搜索字符串。
- fc 比较两个文件或两个文件集并显示它们之间的不同
- 网络命令:
- ping 进行网络连接测试、名称解析
- ftp 文件传输
- net 网络命令集及用户管理
- telnet 远程登陆
- ipconfig显示、修改TCP/IP设置
- msg 给用户发送消息
- arp 显示、修改局域网的IP地址-物理地址映射列表
- 系统管理:
- at 安排在特定日期和时间运行命令和程序
- shutdown立即或定时关机或重启
- tskill 结束进程
- taskkill结束进程(比tskill高级,但WinXPHome版中无该命令)
- tasklist显示进程列表(Windows XP Home Edition中没有)
- sc 系统服务设置与控制
- reg 注册表控制台工具
- powercfg控制系统上的电源设置
环境变量
两款终端: cmd, powershell
环境变量的设置和修改只会在当前窗口下有效,设置和修改只是临时缓存,一旦关闭命令窗口,环境变量就会失效。
如果要设置真实的环境变量,还是要经过: 我的电脑->属性->更改设置->高级->环境变量,添加环境变量,注销/重启。
cmd
cmd设置环境变量
#查看所有环境变量
set
#查看单个环境变量
set NODE_ENV
#添加/更新环境变量
set NODE_ENV=development
#删除环境变量
set NODE_ENV=
powershell
【2016-01-23】Windows PowerShell基本语法及常用命令
Powershell 设置环境变量
#查看所有环境变量
ls env:
#搜索环境变量
ls env:NODE*
#查看单个环境变量
env:NODE_ENV
#添加/更新环境变量
env:NODE_ENV=development
#删除环境变量
del evn:NODE_ENV
历史命令
get-history # 查看历史命令
clear-history # 清空
invoke-history -id
常用命令
总结如下
1 echo 和 @
回显命令
@ #关闭单行回显
echo off #从下一行开始关闭回显
@echo off #从本行开始关闭回显。一般批处理第一行都是这个
echo on #从下一行开始打开回显
echo #显示当前是 echo off 状态还是 echo on 状态
echo. #输出一个”回车换行”,空白行
#(同echo, echo; echo+ echo[ echo] echo/ echo)
2 errorlevel
echo %errorlevel%
每个命令运行结束,可以用这个命令行格式查看返回码
默认值为0,一般命令执行出错会设 errorlevel 为1
3 dir
显示文件夹内容
dir #显示当前目录中的文件和子目录
dir /a #显示当前目录中的文件和子目录,包括隐藏文件和系统文件
dir c: /a:d #显示 C 盘当前目录中的目录
dir c: /a:-d #显示 C 盘根目录中的文件
dir c: /b/p #/b只显示文件名,/p分页显示
dir *.exe /s #显示当前目录和子目录里所有的.exe文件
4 cd
切换目录
cd #进入根目录
cd #显示当前目录
cd /d d:sdk #可以同时更改盘符和目录
5 md
创建目录
md d:abc #如果 d:a 不存在,将会自动创建中级目录
#如果命令扩展名被停用,则需要键入 mkdir abc
6 rd
删除目录
rd abc #删除当前目录里的 abc 子目录,要求为空目录
rd /s/q d:temp #删除 d:temp 文件夹及其子文件夹和文件,/q安静模式
7 del
删除文件
del d:test.txt #删除指定文件,不能是隐藏、系统、只读文件
del /q/a/f d:temp*.*
删除 d:temp 文件夹里面的所有文件,包括隐藏、只读、系统文件,不包括子目录
del /q/a/f/s d:temp*.*
删除 d:temp 及子文件夹里面的所有文件,包括隐藏、只读、系统文件,不包括子目录
8 ren
重命名命令
ren d:temp tmp #支持对文件夹的重命名
9 cls
清屏
10 type
显示文件内容
type c:boot.ini #显示指定文件的内容,程序文件一般会显示乱码
type *.txt #显示当前目录里所有.txt文件的内容
11 copy
拷贝文件
copy c:test.txt d:test.bak
复制 c:test.txt 文件到 d: ,并重命名为 test.bak
copy con test.txt
从屏幕上等待输入,按 Ctrl+Z 结束输入,输入内容存为test.txt文件
con代表屏幕,prn代表打印机,nul代表空设备
copy 1.txt + 2.txt 3.txt
合并 1.txt 和 2.txt 的内容,保存为 3.txt 文件
如果不指定 3.txt ,则保存到 1.txt
copy test.txt +
复制文件到自己,实际上是修改了文件日期
12 title
设置cmd窗口的标题
title 新标题 #可以看到cmd窗口的标题栏变了
13 ver
显示系统版本
14 label 和 vol
设置卷标
vol #显示卷标
label #显示卷标,同时提示输入新卷标
label c:system #设置C盘的卷标为 system
15 pause
暂停命令
16 rem 和 ::
注释命令
注释行不执行操作
17 date 和 time
日期和时间
date #显示当前日期,并提示输入新日期,按"回车"略过输入
date/t #只显示当前日期,不提示输入新日期
time #显示当前时间,并提示输入新时间,按"回车"略过输入
time/t #只显示当前时间,不提示输入新时间
18 goto 和 :
跳转命令
:label #行首为:表示该行是标签行,标签行不执行操作
goto label #跳转到指定的标签那一行
19 find (外部命令)
查找命令
find "abc" c:test.txt
在 c:test.txt 文件里查找含 abc 字符串的行
如果找不到,将设 errorlevel 返回码为1
find /i “abc” c:test.txt
查找含 abc 的行,忽略大小写
find /c "abc" c:test.txt
显示含 abc 的行的行数
20 more (外部命令)
逐屏显示
more c:test.txt #逐屏显示 c:test.txt 的文件内容
21 tree
显示目录结构
tree d: #显示D盘的文件目录结构
22 &
顺序执行多条命令,而不管命令是否执行成功
23 &&
顺序执行多条命令,当碰到执行出错的命令后将不执行后面的命令
find "ok" c:test.txt && echo 成功
如果找到了"ok"字样,就显示"成功",找不到就不显示
24 ||
顺序执行多条命令,当碰到执行正确的命令后将不执行后面的命令
find "ok" c:test.txt || echo 不成功
如果找不到"ok"字样,就显示"不成功",找到了就不显示
25 | 管道命令
dir *.* /s/a | find /c ".exe"
管道命令表示先执行 dir 命令,对其输出的结果执行后面的 find 命令
该命令行结果:输出当前文件夹及所有子文件夹里的.exe文件的个数
type c:test.txt|more
这个和 more c:test.txt 的效果是一样的
26 > 和 >> 输出重定向命令
> 清除文件中原有的内容后再写入
>> 追加内容到文件末尾,而不会清除原有的内容
主要将本来显示在屏幕上的内容输出到指定文件中
指定文件如果不存在,则自动生成该文件
type c:test.txt >prn
屏幕上不显示文件内容,转向输出到打印机
echo hello world>con
在屏幕上显示hello world,实际上所有输出都是默认 >con 的
copy c:test.txt f: >nul
拷贝文件,并且不显示"文件复制成功"的提示信息,但如果f盘不存在,还是会显示出错信息
copy c:test.txt f: >nul 2>nul
不显示”文件复制成功”的提示信息,并且f盘不存在的话,也不显示错误提示信息
echo ^^W ^> ^W>c:test.txt
生成的文件内容为 ^W > W
^ 和 > 是控制命令,要把它们输出到文件,必须在前面加个 ^ 符号
27 <
从文件中获得输入信息,而不是从屏幕上
一般用于 date time label 等需要等待输入的命令
@echo off
echo 2005-05-01>temp.txt
date <temp.txt
del temp.txt
这样就可以不等待输入直接修改当前日期
28 %0 %1 %2 %3 %4 %5 %6 %7 %8 %9 %*
命令行传递给批处理的参数
%0 批处理文件本身
%1 第一个参数
%9 第九个参数
%* 从第一个参数开始的所有参数
批参数(%n)的替代已被增强。您可以使用以下语法:
%~1 - 删除引号(" ), 扩充 %1
%~f1 - 将 %1 扩充到一个完全合格的路径名
%~d1 - 仅将 %1 扩充到一个驱动器号
%~p1 - 仅将 %1 扩充到一个路径
%~n1 - 仅将 %1 扩充到一个文件名
%~x1 - 仅将 %1 扩充到一个文件扩展名
%~s1 - 扩充的路径指含有短名
%~a1 - 将 %1 扩充到文件属性
%~t1 - 将 %1 扩充到文件的日期/时间
%~z1 - 将 %1 扩充到文件的大小
%~$PATH : 1 - 查找列在 PATH 环境变量的目录,并将 %1
扩充到找到的第一个完全合格的名称。如果环境
变量名未被定义,或者没有找到文件,此组合键会
扩充到空字符串
可以组合修定符来取得多重结果:
%~dp1 - 只将 %1 扩展到驱动器号和路径
%~nx1 - 只将 %1 扩展到文件名和扩展名
%~dp$PATH:1 - 在列在 PATH 环境变量中的目录里查找 %1,
并扩展到找到的第一个文件的驱动器号和路径。
%~ftza1 - 将 %1 扩展到类似 DIR 的输出行。
可以参照 call/? 或 for/? 看出每个参数的含意
echo load "%%1" "%%2">c:test.txt
生成的文件内容为 load "%1" "%2"
批处理文件里,用这个格式把命令行参数输出到文件
29 if 判断命令
if "%1"=="/a" echo 第一个参数是/a
if /i "%1" equ "/a" echo 第一个参数是/a
/i 表示不区分大小写,equ 和 == 是一样的,其它运算符参见 if/?
if exist c:test.bat
echo 存在c:test.bat文件
if not exist c:windows (
echo 不存在c:windows文件夹
)
if exist c:test.bat (
echo 存在c:test.bat
) else (
echo 不存在c:test.bat
)
30 setlocal 和 endlocal
设置”命令扩展名”和”延缓环境变量扩充”
SETLOCAL ENABLEEXTENSIONS #启用"命令扩展名"
SETLOCAL DISABLEEXTENSIONS #停用"命令扩展名"
SETLOCAL ENABLEDELAYEDEXPANSION #启用"延缓环境变量扩充"
SETLOCAL DISABLEDELAYEDEXPANSION #停用"延缓环境变量扩充"
ENDLOCAL #恢复到使用SETLOCAL语句以前的状态
“命令扩展名”默认为启用
“延缓环境变量扩充”默认为停用
批处理结束系统会自动恢复默认值
可以修改注册表以禁用"命令扩展名",详见 cmd /? 。所以用到"命令扩展名"的程
序,建议在开头和结尾加上 SETLOCAL ENABLEEXTENSIONS 和 ENDLOCAL 语句,以确
保程序能在其它系统上正确运行
"延缓环境变量扩充"主要用于 if 和 for 的符合语句,在 set 的说明里有其实用例程
31 set 设置变量
引用变量可在变量名前后加 % ,即 %变量名%
set #显示目前所有可用的变量,包括系统变量和自定义的变量
echo %SystemDrive% #显示系统盘盘符。系统变量可以直接引用
set p #显示所有以p开头的变量,要是一个也没有就设errorlevel=1
set p=aa1bb1aa2bb2 #设置变量p,并赋值为 = 后面的字符串,即aa1bb1aa2bb2
echo %p% #显示变量p代表的字符串,即aa1bb1aa2bb2
echo %p:~6% #显示变量p中第6个字符以后的所有字符,即aa2bb2
echo %p:~6,3% #显示第6个字符以后的3个字符,即aa2
echo %p:~0,3% #显示前3个字符,即aa1
echo %p:~-2% #显示最后面的2个字符,即b2
echo %p:~0,-2% #显示除了最后2个字符以外的其它字符,即aa1bb1aa2b
echo %p:aa=c% #用c替换变量p中所有的aa,即显示c1bb1c2bb2
echo %p:aa=% #将变量p中的所有aa字符串置换为空,即显示1bb12bb2
echo %p:*bb=c% #第一个bb及其之前的所有字符被替换为c,即显示c1aa2bb2
set p=%p:*bb=c% #设置变量p,赋值为 %p:*bb=c% ,即c1aa2bb2
set /a p=39 #设置p为数值型变量,值为39
set /a p=39/10 #支持运算符,有小数时用去尾法,39/10=3.9,去尾得3,p=3
set /a p=p/10 #用 /a 参数时,在 = 后面的变量可以不加%直接引用
set /a p=”1&0″ #”与”运算,要加引号。其它支持的运算符参见set/?
set p= #取消p变量
set /p p=请输入
屏幕上显示”请输入”,并会将输入的字符串赋值给变量p
注意这条可以用来取代 choice 命令
注意变量在 if 和 for 的复合语句里是一次性全部替换的,如
@echo off
set p=aaa
if %p%==aaa (
echo %p%
set p=bbb
echo %p%
)
结果将显示
aaa
aaa
因为在读取 if 语句时已经将所有 %p% 替换为aaa
这里的"替换",在 /? 帮助里就是指"扩充"、"环境变量扩充"
可以启用”延缓环境变量扩充”,用 ! 来引用变量,即 !变量名!
@echo off
SETLOCAL ENABLEDELAYEDEXPANSION
set p=aaa
if %p%==aaa (
echo %p%
set p=bbb
echo !p!
)
ENDLOCAL
结果将显示
aaa
bbb
还有几个动态变量,运行 set 看不到
%CD% #代表当前目录的字符串
%DATE% #当前日期
%TIME% #当前时间
%RANDOM% #随机整数,介于0~32767
%ERRORLEVEL% #当前 ERRORLEVEL 值
%CMDEXTVERSION% #当前命令处理器扩展名版本号
%CMDCMDLINE% #调用命令处理器的原始命令行
可以用echo命令查看每个变量值,如 echo %time%
注意 %time% 精确到毫秒,在批处理需要延时处理时可以用到
32 start
批处理中调用外部程序的命令,否则等外部程序完成后才继续执行剩下的指令
33 call
批处理中调用另外一个批处理的命令,否则剩下的批处理指令将不会被执行
有时有的应用程序用start调用出错的,也可以call调用
34 choice (外部命令)
选择命令
让用户输入一个字符,从而选择运行不同的命令,返回码errorlevel为1234……
win98里是choice.com
win2000pro里没有,可以从win98里拷过来
win2003里是choice.exe
choice /N /C y /T 5 /D y>nul
延时5秒
35 assoc 和 ftype
文件关联
assoc 设置'文件扩展名'关联,关联到'文件类型'
ftype 设置'文件类型'关联,关联到'执行程序和参数'
当你双击一个.txt文件时,windows并不是根据.txt直接判断用 notepad.exe 打开
而是先判断.txt属于 txtfile '文件类型'
再调用 txtfile 关联的命令行 txtfile=%SystemRoot%system32NOTEPAD.EXE %1
可以在"文件夹选项"→"文件类型"里修改这2种关联
assoc #显示所有'文件扩展名'关联
assoc .txt #显示.txt代表的'文件类型',结果显示 .txt=txtfile
assoc .doc #显示.doc代表的'文件类型',结果显示 .doc=Word.Document.8
assoc .exe #显示.exe代表的'文件类型',结果显示 .exe=exefile
ftype #显示所有'文件类型'关联
ftype exefile #显示exefile类型关联的命令行,结果显示 exefile="%1" %*
assoc .txt=Word.Document.8
设置.txt为word类型的文档,可以看到.txt文件的图标都变了
assoc .txt=txtfile
恢复.txt的正确关联
ftype exefile="%1" %*
恢复 exefile 的正确关联
如果该关联已经被破坏,可以运行 command.com ,再输入这条命令
36 pushd 和 popd
切换当前目录
@echo off
c: & cd & md mp3 #在 C: 建立 mp3 文件夹
md d:mp4 #在 D: 建立 mp4 文件夹
cd /d d:mp4 #更改当前目录为 d:mp4
pushd c:mp3 #保存当前目录,并切换当前目录为 c:mp3
popd #恢复当前目录为刚才保存的 d:mp4
37 for
循环命令
这个比较复杂,请对照 for/? 来看
for %%i in (c: d: e: f:) do echo %%i
依次调用小括号里的每个字符串,执行 do 后面的命令
注意%%i,在批处理中 for 语句调用参数用2个%
默认的字符串分隔符是"空格键","Tab键","回车键"
for %%i in (*.txt) do find "abc" %%i
对当前目录里所有的txt文件执行 find 命令
for /r . %%i in (*.txt) do find "abc" %%i
在当前目录和子目录里所有的.txt文件中搜索包含 abc 字符串的行
for /r . %%i in (.) do echo %%~pni
显示当前目录名和所有子目录名,包括路径,不包括盘符
for /r d:mp3 %%i in (*.mp3) do echo %%i>>d:mp3.txt
把 d:mp3 及其子目录里的mp3文件的文件名都存到 d:mp3.txt 里去
for /l %%i in (2,1,8) do echo %%i
生成2345678的一串数字,2是数字序列的开头,8是结尾,1表示每次加1
for /f %%i in ('set') do echo %%i
对 set 命令的输出结果循环调用,每行一个
for /f "eol=P" %%i in ('set') do echo %%i
取 set 命令的输出结果,忽略以 P 开头的那几行
for /f %%i in (d:mp3.txt) do echo %%i
显示 d:mp3.txt 里的每个文件名,每行一个,不支持带空格的名称
for /f "delims=" %%i in (d:mp3.txt) do echo %%i
显示 d:mp3.txt 里的每个文件名,每行一个,支持带空格的名称
for /f "skip=5 tokens=4" %%a in ('dir') do echo %%a
对 dir 命令的结果,跳过前面5行,余下的每行取第4列
每列之间的分隔符为默认的"空格"
可以注意到 dir 命令输出的前5行是没有文件名的
for /f "tokens=1,2,3 delims=- " %%a in ('date /t') do (
echo %%a
echo %%b
echo %%c
)
对 date /t 的输出结果,每行取1、2、3列
第一列对应指定的 %%a ,后面的 %%b 和 %%c 是派生出来的,对应其它列
分隔符指定为 - 和"空格",注意 delims=- 后面有个"空格"
其中 tokens=1,2,3 若用 tokens=1-3 替换,效果是一样的
for /f "tokens=2* delims=- " %%a in ('date /t') do echo %%b
取第2列给 %%a ,其后的列都给 %%b
38 subst (外部命令)
映射磁盘。
subst z: serverd #这样输入z:就可以访问serverd了
subst z: /d #取消该映射
subst #显示目前所有的映时
39 xcopy (外部命令)
文件拷贝
xcopy d:mp3 e:mp3 /s/e/i/y
复制 d:mp3 文件夹、所有子文件夹和文件到 e: ,覆盖已有文件
加 /i 表示如果 e: 没有 mp3 文件夹就自动新建一个,否则会有询问
shell 转 bat
【2024-12-10】将linux shell 脚本自动转化成 BAT 脚本
Shell 脚本
SOME_VAR="/c/cygwin/path"
rm -rf $SOME_VAR || echo "file not found"
cp /c/some/file /to/another/file
if [ $SOME_VAR == "" ]; then
echo "SOME_VAR is empty"
else
echo "SOME_VAR not empty"
fi
my_function () {
echo "hello from my_function: $1"
}
# call the function:
my_function
# call the function with param:
my_function "some param"
对应的 BAT 脚本
SET "SOME_VAR=c:\cygwin\path"
DEL /S "%SOME_VAR%" || echo "file not found"
COPY "c:\some\file" "\to\another\file"
IF "%SOME_VAR%" == "" (
echo "SOME_VAR is empty"
) ELSE (
echo "SOME_VAR not empty"
)
CALL :my_function
CALL :my_function "some param"
EXIT /B %ERRORLEVEL%
:my_function
echo "hello from my_function: %~1"
EXIT /B 0
问题
常见问题
- 如果编写的
.bat文件,双击打开,出现闪退- 原因:执行速度很快,执行完之后,自行关闭
- 解决办法:在最后面一行加上
pause
- 批处理
.bat文件中输出中文乱码- 原因:记事本新建的文件,编码不是 utf-8
- 解决方法:用【记事本】打开>【另存为】>【修改编码为:utf-8】
- 【2024-12-10】编码保存为 utf-8 依然乱码, 改成 ansi 才行
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
