汇总linux下开发知识
Linux系统
良好的 Linux 素养会让你在日常的工作中如鱼得水,在命令行里体会流水般的畅快感。
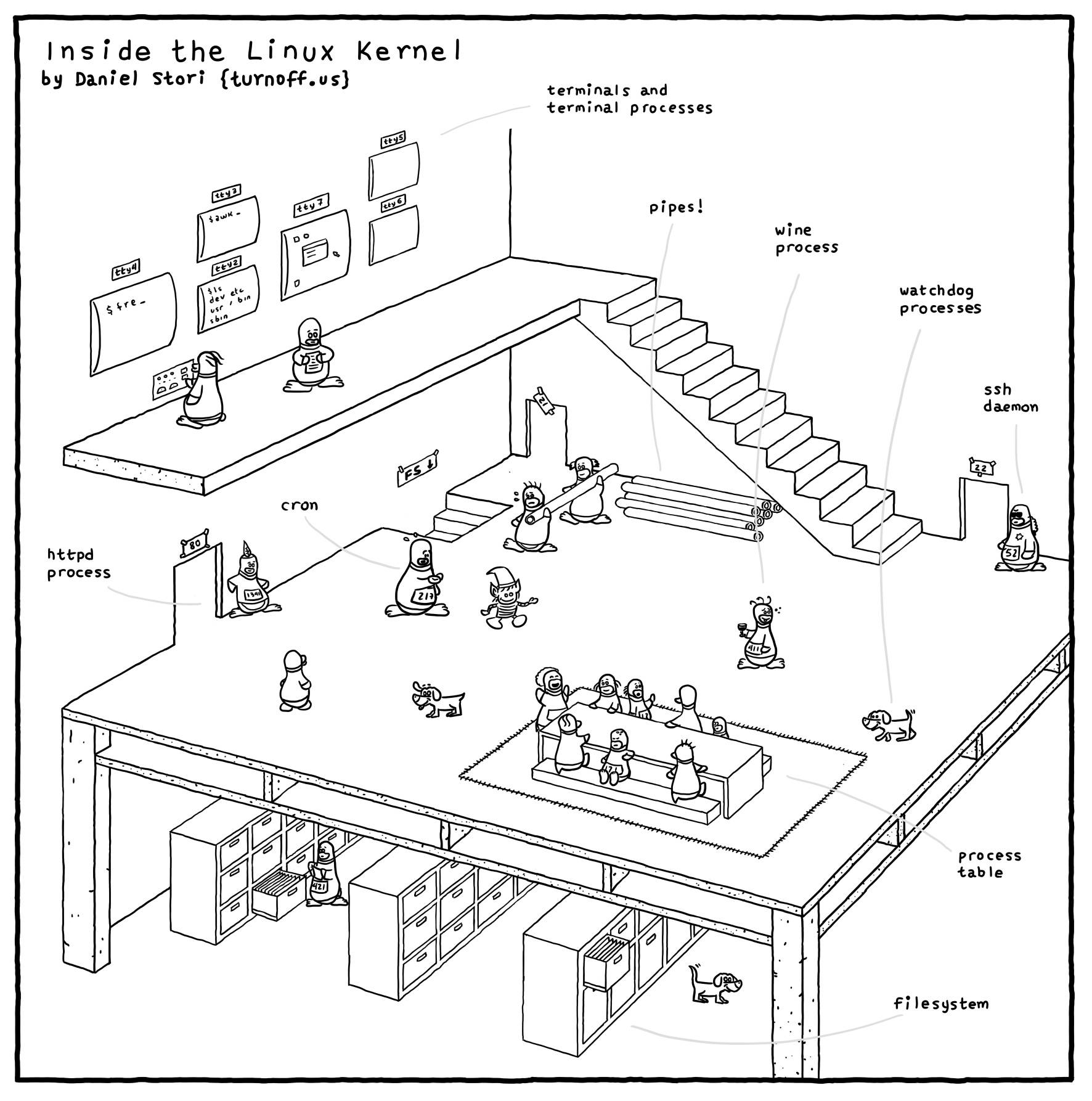
内核
- 漫画图解linux内核-原版,国内源
- 解读一幅来自 TurnOff.us 的漫画 “InSide The Linux Kernel[1]”
环境
操作系统信息
cat /etc/issue
# Debian GNU/Linux 10 \n \l
cat /etc/redhat-release # redhat 专用
cat /proc/version
# Linux version 5.4.56.bsk.10-amd64 (root@n14-042-020) (gcc version 8.3.0 (Debian 8.3.0-6)) #5.4.56.bsk.10 SMP Debian 5.4.56.bsk.10 Fri Sep 24 12:17:03 UTC
uname -a
# Linux n37-139-225 5.4.56.bsk.10-amd64 #5.4.56.bsk.10 SMP Debian 5.4.56.bsk.10 Fri Sep 24 12:17:03 UTC x86_64 GNU/Linux
为什么ssh登录linux服务器后,bashrc里的变量没生效?非要单独source一遍?
bash 文件
更多 shell 语言内容见站内专题: Sehll语言
bash startup 文件
Linux shell是用户与Linux系统进行交互的媒介,而bash作为目前Linux系统中最常用的shell,它支持的startup文件也并不单一,甚至容易让人感到费解。本文以CentOS7系统为例
/etc/profile:登入时执行,The systemwide initialization file, executed for login shells/etc/bash.bash_logout:登出时执行,The systemwide login shell cleanup file, executed when a login shell exits~/.bash_profile:用户自定义,The personal initialization file, executed for login shells~/.bashrc:The individual per-interactive-shell startup file~/.bash_logout:The individual login shell cleanup file, executed when a login shell exits
此外,bash还支持~/.bash_login和~/.profile文件,作为对其他shell的兼容,它们与~/.bash_profile文件的作用是相同的。
备注:Debian系统会使用~/.profile文件取代~/.bash_profile文件,因此在相关细节上,会与CentOS略有不同。
.bashrc vs .bash_profile
- 当Bash作为交互式登录shell调用时,将读取并执行.bash_profile
- 对于交互式非登录shell,则执行.bashrc。
- 仅应运行一次的命令应该使用.bash_profile ,例如自定义 $PATH 环境变量。
- 将每次启动新Shell时应该运行的命令放在.bashrc文件中。 这包括您的别名和function,自定义提示,历史记录自定义等。
通常,~/.bash_profile包含以下类似于.bashrc文件来源的行。 这意味着每次您登录到终端时,都会读取并执行两个文件。
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
大多数Linux发行版都使用 ~/.profile 而不是 ~/.bash_profile。 所有Shell程序都读取 ~/.profile文件,而Bash仅读取 ~/.bash_profile 文件。
如果系统上没有任何启动文件,则可以创建该文件。
登录顺序
bash 运行模式
- “登陆shell”启动时会加载“profile”系列的startup文件
- “profile”系列的代表文件为~/.bash_profile,它用于“登录shell”的环境加载,这个“登录shell”既可以是“交互式”的,也可以是“非交互式”的。
- 而“交互式非登陆shell”启动时会加载“rc”系列的startup文件
总结:
交互式shell是读取和写入用户终端的shell程序- 交互式shell程序可以是登录shell程序,也可以是非登录shell程序。
- 而
非交互式shell程序是与终端无关的shell程序,例如执行脚本时。
CentOS规定了startup文件的加载顺序如下:
交互式登陆 shell
登陆过程:
- 读取并执行
/etc/profile文件; - 读取并执行
~/.bash_profile文件;- 若文件不存在,则读取并执行
~/.bash_login文件; - 若文件不存在,则读取并执行
~/.profile文件;
- 若文件不存在,则读取并执行
当Bash作为交互式非登录shell程序调用时,它会从~/.bashrc中读取并执行命令(如果该文件存在并且可读)
登出过程:
- 读取并执行
~/.bash_logout文件; - 读取并执行
/etc/bash.bash_logout文件;
非交互式登陆shell
对于非交互式的登陆shell而言,CentOS规定了startup文件的加载顺序如下:
登陆过程:
- 读取并执行
/etc/profile文件; - 读取并执行
~/.bash_profile文件;- 若文件不存在,则读取并执行
~/.bash_login文件; - 若文件不存在,则读取并执行
~/.profile文件;
- 若文件不存在,则读取并执行
与“交互式登陆shell”相比,“非交互式登陆shell”并没有登出的过程
登录历史
【2024-3-6】查看服务器登录历史
last
# 输出信息
root@singapore:~/wqw# last
root pts/1 120.244.236.142 Wed Mar 6 11:32 still logged in
root pts/1 120.244.236.142 Wed Mar 6 11:19 - 11:32 (00:13)
root pts/4 114.251.196.89 Tue Mar 5 13:13 - 14:50 (01:36)
root pts/4 2.59.151.97 Sun Mar 3 16:52 - 16:56 (00:03)
Mac OS 技巧
macbook 配置总结
| 功能 | 方法 | 备注 |
|---|---|---|
| 终端用户名自定义 | 系统偏好设置->共享->编辑电脑名称 | - |
| 画图工具 OmniGraffle+Pro 6 | 下载地址,注册码;7下载地址(含许可证) | 兼容viso,功能强大 |
| Mac Office 2016破解 | 操作简单,安装完mac office正式版后,下载破解文件,双击锁,就可以 | 参考地址 |
| Mac下安装Windows | Mac电脑上用VMware Fusion安装Windows7 | 提前下载vmware+Windows安装包,添加Windows虚拟机后默认无法启动,需要单独指定iso镜像位置,再重启即可 |
| 画图工具OmniGraffle+Pro | OmniGraffle Pro 7.19.2 中文破解版,下载地址,注册码;7下载地址(含许可证) | 兼容viso,功能强大(【2017-12-6】注:7.4版才能用许可证,7.5以上不行) |
| 安装pip | sudo easy_install pip | pip直接安装其他工具 |
| 软件包管理器 | homebrew安装(参考地址);安装wget:brew install wget | brew安装命令:ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)” |
| 翻墙 | 1.有代理ip的直接设置:网络->高级->代理->勾选网页代理+安全网页代理,输入服务器域名及端口,无需填入账号。 2.用lantern下载,蓝灯无限制版 |
备选方案很多,汇总地址, chromego, ss, 拥有一家小飞机是怎样的体验,shadowsocks地址,【2019-07-31】撸油管、刷INS、访推特,完美支持高清1080P视频,无任何流量限制,真正免费的旋风加速器 |
| vim颜色显示 | 1.vim ~/.vimrc 2.添加colorscheme desert;syntax on |
vim sublime颜色主题 |
| vim开发环境 | vim IDE部署 | 其他主题包,vim-go开发环境 |
| shell目录颜色显示 | 开启方法:编辑~/.bash_profile 增加:export CLICOLOR=1;export LSCOLORS=exfxaxdxcxegedabagacad |
注:如何在shell字符串中显示彩色字符?,显示白色:echo -e “\033[37m white \033[0m” |
| mac免密码远程登录 | 使用ssh创建rsa公钥密码。基本步骤: 1.ssh-keygen生成密钥(ssh-keygen -t rsa) 2.复制密钥文件到远程机器(scp ~/.ssh/id_rsa.pub wangqiwen@ip.com:/home/wangqiwen/.ssh) 3.登录远程机器,修改文件权限(cd ~/.ssh && cat id_rsa.pub » authorized_keys; chmod 644 authorized_keys;chmod 700 ~/.ssh/) |
参考地址:mac无密码登录,Linux 下 SSH 命令实例指南,菜鸟学Linux命令:ssh命令 远程登录 |
| ssh会话管理 | ssh配置文件实现别名快捷登录,【2018-9-29】图解ssh及登录原理 | |
| chrome浏览器中右键失灵 | 双指触碰链接时,并未弹出右键菜单,而是“图片另存为” | 解决办法:这是由于chrome浏览器上开启了鼠标手势,造成干扰,关闭或删除插件即可 |
| chrome域名自动跳转 | 【2022-8-5】更改个人网站域名,恢复GitHub page地址,结果chrome浏览器自动跳转到老地址,其它浏览器正常 | 解决:清除域名缓存;打开开发者工具(F12),选择 Network——Disable cache 即可 |
| image not recognized | dmg文件无法安装,原因:文件损坏,dmg权限不允许任意来源的包;换浏览器 | 如何开启任意来源包?sudo spctl –master-disable |
| redis安装 | brew install redis | 使用方法:启动服务,redis-server,连接服务:redis-cli |
| mac mail客户端设置 | 连接163时,需要先去163邮箱开启pop3/imap选项,通过手机验证码设置连接密码;mail终端配置时填入的密码是连接密码(非登录密码!) | wqw3721 |
| 安装虚拟机 | vmware安装,下载地址 | vmware fusion 8 激活码:FY75A-06W1M-H85PZ-0XP7T-MZ8E8,ZY7TK-A3D4N-08EUZ-TQN5E-XG2TF,FG1MA-25Y1J-H857P-6MZZE-YZAZ6 |
| Mac下运行Windows软件 | (1)boot camp安装Windows虚拟机(win 10文件过大); (2)安装wine |
步骤:(1)brew cask install xquartz (2)brew install wine |
| Mac下无法安装第三方软件 | 软件源受限,需要打开 | 步骤:sudo spctl –master-disable,参考方法 |
| java | 官方下载地址 | 优先使用绿色版(tar.gz,非二进制的rpm)。环境变量配置方法:修改/etc/profile文件,在文件的最下边加入下边的文本: export JAVA_HOME=/opt/jdk1.7; export CLASSPATH=.:$JAVA_HOME/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar; export PATH=$JAVA_HOME/bin:$PATH |
| Web服务 | Mac OS 启用web服务,简网教程 | |
| linux 服务器mail | mail command not found | 解决方法:sudo yum install mailx;echo “test” (竖线) mail -s “content” wangqiwen@p1.com |
| linux下安装http服务 | 安装httpd | 1.yum install httpd -y 2.随系统启动:chkconfig httpd on 3.开启Apache:service httpd start |
| terminal下如何开启应用? | 用open命令开启(open .用finder打开当前位置目录;open file自动调用默认程序打开文件;say hello语音说话),可以传参,备注:放到别命中,alias view=’open /Applications/Preview.app’或alias edit=’open /Applications/Sublime\ Text.app’ | open /Applications/Sublime\ Text.app README.md |
| shell美化 | Oh My ZSH! | 安装:sh -c “$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)” |
| 刻盘 | Etcher全平台工具 | 操作过程极其简单 |
| 移动硬盘无法写入 | 原因:mac不支持ntfs格式,需要安装特殊软件:ntfs for mac | |
| mac显示当前路径 | 命令:defaults write com.apple.finder _FXShowPosixPathInTitle -bool YES | 顶栏出现路径,还可以点击定位到子目录 |
| mac当前位置打开终端 | 命令 | mac右键新建文件 |
| mac下excel打开csv中文乱码 | 原因是mac底下中文一律utf8编码,而excel文档默认中文是gbk编码,需要单独设置下才行。地址 | 亲测有效 |
| mac下锁屏 | 系统自带锁屏快捷键:Ctrl + Command + Q Ctrl+Shift+Power: 关闭屏幕 Cmd+Opt+Power: 睡眠 (sleep) Cmd+Ctrl+Power: 重启 (restart) |
windows下:Windows + L |
| 【2022-7-19】 | pdf文档拆分/合并 | mac分拆pdf方法:mac自带的预览软件,用侧边栏设置看缩略图,然后点选pdf,然后复制、黏贴,或者直接拖到桌面,放开鼠标,就会在桌面生成一份后缀带加了带“(拖移项目)”的文件。; 合并方法:打开一个pdf,“插入”→导入另一个文档→保存即可 |
| 【2018-1-11】 | 网易mumu模拟器 | |
| 【2018-1-11】 | mac下安装adb,调试Android | brew cask install android-platform-tools |
| 【2018-6-25】 | crossover mac版 | mac上运行ie浏览器,使用步骤 |
| 【2018-12-25】 | 复制高亮代码到ppt | 方法:notepad++或sublime text插件SublimeHighlight,详见, Plugin commands - Copy Text with Syntax Highlighting |
| 【2019-05-07】 | pycharm专业版激活 | |
| 【2020-6-29】 | 十款Windows命令行工具 | powercmd,xshell,consolez,git bash,全能王mobaxterm等 |
| 【2021-12-21】 | markdown转ppt,pandoc | |
| 【2021-12-31】 | 文档复制受限 | 右键开发者模式: ①从html源码中抠 ②debugger里disable js代码即可获取纯文本 |
| 【2022-8-6】 | vscode无法打开终端 | 解决:更改默认终端配置,“文件”→“首选项”→“设置”,弹出配置文件,按照链接修改接口 |
| 【2024-5-9】 | vscode里编辑输入时,卡顿,延迟1-3s,尝试更改setting里各种参数,无效 | 解决:重启电脑 |
【2022-11-22】windows 的图标打架效果,steam平台程序the lcon battles,还可以设置成屏保,效果, 仅 windows可用
原因:Github没有fork项目代码,或没加所在机器的sshkey(settings->deplot keys)
软件包 brew
Homebrew 安装
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 默认保存目录 /opt/homebrew/bin
# 添加到 ~/.bash_profile 中
export PATH="$PATH:/opt/homebrew/bin"
source ~/.bash_profile
# 安装工具包
brew install wget
鼠标、触摸板方向设置
【2023-7-31】mac用鼠标滚轮滚动方向相反
- 点击屏幕左上角的苹果标志,在下拉列表中选择“系统偏好设置”。
- 在打开的“系统偏好设置”窗口中,选择“鼠标”。
- 在打开的“鼠标”窗口中,将“滚动方向:自然”前面的勾去掉。 之后,再使用鼠标,就跟在windows中使用的一样。
终端启动 sublime text
自带命令行工具 subl, 便于在终端启动,不用点icon
# 安装sublime text
brew install sublimetext # 使用brew工具安装,Application下有显示,而单独下载安装不会
# 应用程序地址, 自带命令行工具 subl, 便于在终端启动
ls /Applications/Sublime\ Text.app/Contents/SharedSupport/bin/subl
subl your_file # 快速办法
# 通用办法
open -a "sublime text" your_file # 单行命令
echo 'export PATH="/Applications/Sublime Text.app/Contents/SharedSupport/bin:$PATH"' >> ~/.bash_profile # 或导入路径
ln -s /Applications/Sublime\ Text.app/Contents/SharedSupport/bin/subl /usr/local/bin/subl # 或建立软连接
文件
linux 目录结构
下级目录结构
- bin (binaries)存放二进制可执行文件
- sbin (super user binaries)存放二进制可执行文件,只有root才能访问
- etc (etcetera)存放系统配置文件
- usr (unix shared resources)用于存放共享的系统资源
- home 存放用户文件的根目录
- root 超级用户目录
- dev (devices)用于存放设备文件
- lib (library)存放跟文件系统中的程序运行所需要的共享库及内核模块
- mnt (mount)系统管理员安装临时文件系统的安装点
- boot 存放用于系统引导时使用的各种文件
- tmp (temporary)用于存放各种临时文件
- var (variable)用于存放运行时需要改变数据的文件
文件权限
linux文件权限的描述格式解读
- r 可读权限,w可写权限,x可执行权限(也可以用二进制表示 111 110 100 –> 764)
- 第1位:文件类型(d 目录,- 普通文件,l 链接文件)
- 第2-4位:所属用户权限,用u(user)表示
- 第5-7位:所属组权限,用g(group)表示
- 第8-10位:其他用户权限,用o(other)表示
- 第2-10位:表示所有的权限,用a(all)表示
文件大小
du 命令
du 是 Disk Usage 的缩写, Linux 上最受欢迎的命令之一,用来估算文件或目录占用的磁盘空间
- -a: 显示目录中所有文件以及文件夹大小
- -h: 以 Kb、Mb 、Gb 等易读的单位显示大小
- –si: 类似 -h 选项,但是计算是用 1000 为基数而不是1024
- -s: 显示目录总大小
- -d: 是
--max-depth=N选项的简写,表示深入到第几层目录,超过指定层数目录则忽略 - -c: 除了显示目录大小外,额外一行显示总占用量
--time: 显示每一个目录下最近修改文件的时间- -t: 是
--threshold=SIZE的简写,过滤掉小于 SIZE 大小的文件以及目录 --exclude=PATTERN:过滤与 PATTERN 匹配的文件名或者目录名
tree -d temp/ # 显示目录深度
du -d 1 temp/ # 指定目录深度(1级)
du --max-depth=2 temp/ # 最多两级
du temp # 默认情况下只显示目录大小,不显示文件大小。即执行du temp/ 只会显示目录大小
du -a temp/ # 子目录大小
du -b temp/ # 默认显示的大小只有一个孤零零的数字,没有单位
du -h temp/ # 易读方式显示
du -sh temp/ # 易读方式显示目录总大小,基数是 1024
du --si temp/ # --si 选项默认计算基数是 1000,更精确
tree 命令
yum install tree -y # centos
apt install tree -y # ubuntu
tree
tree -d temp/ # 显示目录深度
问题: disk quota exceeded
【2024-8-2】Disk quota exceeded problem
错误原因
- 文件过大, 超过磁盘容量
- 个别文件数过多, 超过目录限制, 此时删大文件无效, linux 系统几乎瘫痪
| 错误 | 说明 | 解决 |
|---|---|---|
| 1 | 文件过大, 超过磁盘容量 | 删除大文件 扩容 |
| 2 | 个别文件数过多, 超过目录限制 | 删大文件无效 rm问题目录失效 |
df -h # 查看磁盘分区使用情况
df -i
# 超看文件数超限的目录
find /mnt/bn/flow-algo-intl/wangqiwen -type d -size +256k
文件颜色
颜色区分不同类型文件,详见
- 白色:普通文件
- 蓝色:目录
- 绿色:可执行文件
- 浅蓝色:链接文件
- 黄色:设备文件
- 红色:压缩文件
- 红色闪烁:链接的文件有问题
- 灰色:其它文件
linux 颜色设置
如果遇到linux系统上,文件夹与文件颜色无区分,非蓝色,可以这么做:
vim ~/.bashrc
# 添加以下代码
alias ls="ls --color" # 默认蓝色
export LS_COLORS='di=01;34;40' # 粗体-蓝色字体-黑色背景
# export LS_COLORS=${LS_COLORS}:'di=01;37;44' # 【可忽略】自定义:灰色字体,蓝色背景
source ~/.bashrc
更多颜色区分
【2023-8-5】debian 系统下目录颜色恢复
- old方法不管用!
- 参考
# ---- old -----
export CLICOLOR=1;
export LSCOLORS=exfxaxdxcxegedabagacad
# ------new-------
export LS_OPTIONS='--color=auto'
eval "`dircolors`"
alias ls='ls $LS_OPTIONS'
source /etc/bash.bashrc; source ~/.bashrc
MacOS颜色设置
macos terminal 颜色设置
编辑本地文件 .profile, .bashrc, 或 /etc/profile
export CLICOLOR=1
export LSCOLORS=GxFxCxDxBxegedabagaced
vim 颜色设置
vim 颜色套餐
syntax on
colorscheme desert
或者
echo "syntax on" >> ~/.vimrc
时间戳
三种时间戳
- 访问时间:读一次文件的内容,这个时间就会更新。比如more、cat等命令。ls、stat命令不会修改atime
- 修改时间:修改时间是文件内容最后一次被修改的时间。比如:vim操作后保存文件。ls -l列出的就是这个时间
- 状态改动时间是该文件的inode节点最后一次被修改的时间,通过chmod、chown命令修改一次文件属性,这个时间就会更新。
stat字段说明及ls命令查询时间戳
| column | column | column | column |
|---|---|---|---|
| 字段 | 说明 | 例子 | ls(-l) |
| st_atime | 文件内容最后访问时间 | read | -u |
| st_mtime | 文件内容的最后修改时间 | write | 缺省 |
| st_ctime | 文件状态的最后更改时间 | chown、chmod | -c |
touch命令修改文件时间
- -a 修改文件的存取时间
- -c 不创建文件file
- -m 修改文件file的修改时间
- -r ref_file 将参照文件ref_file相应的时间戳的数值作为指定文件file时间戳记的新值
- -t time 使用指定时间值time作为指定文件file相应时间戳的新值,此处的time规定如下形式的十进制数
#!/bin/bash
stat filename # 显示三种时间戳
stat -c %Y log_cron.txt # 获取最后修改的时间戳
date +%s -d "2022-01-04 09:00:17" # 字符串转时间戳
# 时间戳比较
date1="2008-4-09 12:00:00"
date2="2008-4-10 15:00:00"
t1=`date -d "$date1" +%s`
t2=`date -d "$date2" +%s`
if [ $t1 -gt $t2 ]; then
echo "$date1 > $date2"
elif [ $t1 -eq $t2 ]; then
echo "$date1 == $date2"
else
echo "$date1 < $date2"
fi
# 过期删除功能(超过两分钟)
dir=`ls /root/20160705/`
DIR_PATH="/root/20160705/"
for fi in $dir
do
FILE_NAME=${DIR_PATH}${fi}
echo $FILE_NAME
a=`stat -c %Y $FILE_NAME`
b=`date +%s`
if [ $[ $b - $a ] -gt 120 ];then
echo "delete file:$FILE_NAME"
rm -rf $FILE_NAME
fi
done
echo "done"
软连接
如何建立软链接?
- 大文件,复制多份不环保
# (1) 创建
ln –s /var/www/test(源) /var/test(目标)
# 将/source/file1目录链接到./file
ln -s /source/file1 ./file
# [2024-4-25] 将远程大文件链接到本地小文件
ln -s /mnt/bn/flow-algo-intl/zhouzefan/aidp_result/20240331/20240331_witheval.json 20240331_witheval.json
du -sh 20240331_witheval.json # 4k
less 20240331_witheval.json # 内容正常
# (2) 修改
# 将./file的链接目录改成/source/file2
ln -snf /source/file2 ./file
# (3) 删除
rm -rf file
rm -rf file/ # 目录
文件操作命令
ls
ls 默认没有颜色区分
【2026-4-3】现代版 ls 工具:lsd、eza
结论:
- 日常使用推荐 eza(更活跃、兼容性强、默认更友好);
- 追求极致视觉与自定义选 lsd。
| 维度 | eza | lsd |
|---|---|---|
| 维护状态 | 极活跃(社区驱动) | 稳定、更新较慢 |
| 默认输出 | 简洁、清晰、接近 ls -l |
更花哨、图标多、排版密 |
| 图标支持 | 良好(Nerd Font) | 更丰富、样式更统一 |
| Git 集成 | 内置、稳定 | 支持、略弱 |
| 树形视图 | --tree 好用、层级可控 |
支持、样式不同 |
| 性能 | 快、内存低 | 同样快、几乎无差别 |
| 跨平台 | Linux/macOS/BSD/Windows 全支持 | 同上 |
| 配置 | 环境变量 + 主题文件 | 完整 lsd.yml 配置、高度自定义 |
最终建议
- 日常主力:eza(平衡、稳定、维护好、默认友好)
- 美化/展示:lsd(视觉更强、自定义更强)
lsd
lsd 是现代化的 ls 命令,Rust 语言开发,将文件和目录以更美观、结构化方式显示在终端中。
与传统的 ls 命令不同,lsd 提供了丰富的色彩和图形化的信息展示,帮助用户更快地浏览和查找文件。

功能特点
- 直观的输出:
- 使用丰富的颜色来显示不同类型的文件。
- 支持在文件名旁边显示标识图标。
- 过滤和排序: 支持按照多种标准(如名称、大小、修改时间等)对文件和目录进行排序和过滤。
- 详细信息显示: 提供详细的文件信息,包括权限、所有者、大小、时间戳等,让用户更好地了解文件属性。
- 自定义配置: 用户可以通过配置文件自定义颜色、图标和其他显示选项。
- 跨平台支持: lsd 可在 Linux、macOS 和 Windows 等多种平台上运行,方便用户在不同系统上使用。
安装
# Ubuntu 23.04 以上自带
sudo apt update
sudo apt install lsd
# mac 安装
brew install lsd
命令
# 列出当前目录下的所有文件
lsd
# 以长格式列出所有文件和目录
lsd -ltr
# 仅列出目录
lsd -d
# 显示隐藏文件
lsd -a
设置别名
alias l='lsd -l'
alias la='lsd -a'
alias lla='lsd -la'
alias lt='lsd --tree'
eza
eza 是现代化的替代方案,取代 Unix 和 Linux 系统默认附带的 ls 命令+tree 命令,传统 ls 基础上,提供了更多功能、更优的默认输出、更现代的风格。
支持颜色区分文件类型、权限、Git 状态等,还支持符号链接、扩展属性等内容。最重要的是,它是一个小巧的单一二进制文件,运行非常快,安装也方便。
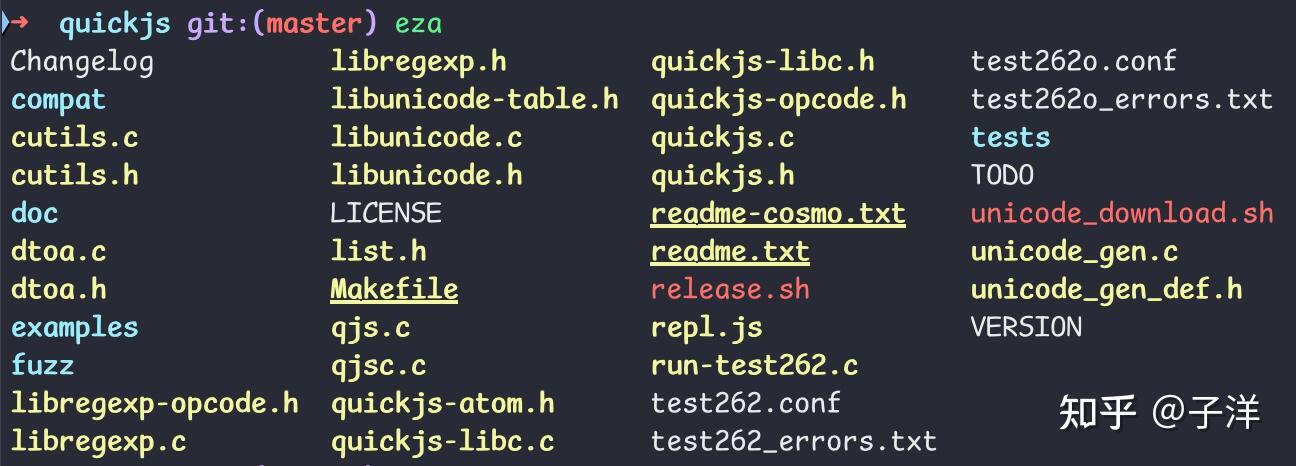
安装
brew install eza
eza
# T 树状结构, L 目录层级, I 忽略文件
eza -T -L 2 -I node_modules
eza 还支持在输出中显示图标,但需要单独安装字体 Nerd Fonts
- 下载地址 font-downloads
- 打开字体文件夹,找到 .ttf 或 .otf 的字体文件,双击安装即可
- 终端配置, 选择新字体
定义别名
# 推荐别名(~/.bashrc / ~/.zshrc)
alias ls='eza --icons --git'
alias ll='eza -l --icons --git'
alias lt='eza --tree --level=2 --icons'
cp
linux cp命令
cp(copy)
功能说明:复制文件/目录。
语法:
cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:
- cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参数:
- -a或–archive 此参数的效果和同时指定”-dpR”参数相同。
- -b或–backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
- -d或–no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
- -f或–force 强行复制文件或目录,不论目标文件或目录是否已存在。
- -i或–interactive 覆盖既有文件之前先询问用户。
- -l或–link 对源文件建立硬连接,而非复制文件。
- -p或–preserve 保留源文件或目录的属性。
- -P或–parents 保留源文件或目录的路径。
- -r 递归处理,将指定目录下的文件与子目录一并处理。
- -R或–recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
- -s或–symbolic-link 对源文件建立符号连接,而非复制文件。
- -S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
- -u或–update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
- -v或–verbose 显示指令执行过程。
- -V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
- -x或–one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
- –help 在线帮助。
- –sparse=<使用时机> 设置保存稀疏文件的时机。
- –version 显示版本信息
# 复制文件, vi ~/.bashrc 中 alias cp='cp -i'
cp -rf zongguofeng linuxzgf # 遇到重复文件时,需要挨个提示
cp -i zongguofeng linuxzgf # 同名文件覆盖前提示, 确认后才覆盖
# 免提示
cp -rf zongguofeng linuxzgf
解压命令
如下:
- (1)
*.tar用tar –xvf解压 - (2)
*.gz用gzip -d或者gunzip解压 - (3)
*.tar.gz和*.tgz用tar –xzf解压 - (4)
*.bz2用bzip2 -d或者用bunzip2解压 - (5)
*.tar.bz2用tar –xjf解压 - (6)
*.Z用uncompress解压 - (7)
*.tar.Z用tar –xZf解压 - (8)
*.rar用unrar e解压 - (9)
*.zip用unzip解压 - (10)
*.xz用xz -d解压 - (11)
*.tar.xz用tar -zJf解压
文件压缩
- .tar 使用tar命令压缩或解压
- .bz2 使用bzip2命令操作
- .gz 使用gzip命令操作
- .zip 使用unzip命令解压
- .rar 使用unrar命令解压
tar cvfz archive.tar.gz dir/
tar xvfz. archive.tar.gz
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2 或 tar --bzip xvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
中文乱码
linux 文件里中文乱码
echo "$LANG"
locale # 显示的字体中,没有zh cn,意味着没有中文语言
locale -a | grep "zh_CN"
# zh_CN
# zh_CN.gb18030
# zh_CN.gb2312
# zh_CN.gbk
# zh_CN.utf8
# 下载安装中文语言包
sudo yum groupinstall "fonts"
yum groupinstall chinese-support # 或
# 设置中文字体
LANG="zh_CN.UTF-8"
终端乱码
【2023-2-13】linux系统终端中文显示异常(方块或一堆??),vim显示正常
- 修复方法
- 参考:CentOS命令行中文显示方块
echo 'export LC_ALL="zh_CN.UTF-8"' >> /etc/profile
source /etc/profile
echo 'LANG="zh_CN.UTF-8"' > /etc/locale.conf
source /etc/locale.conf
less 乱码
【2025-8-18】用 less 查看文件内容时,中文乱码
less a.txt
解决方法
- 设置 LESSCHARSET 环境变量
export LESSCHARSET=utf-8
debian系统中文乱码
以上方法在debian系统中无效,因为yum无法正常使用,总是提示libssl.so问题
# error: libssl.so.1.0.0: cannot open shared object file: No such file or directory
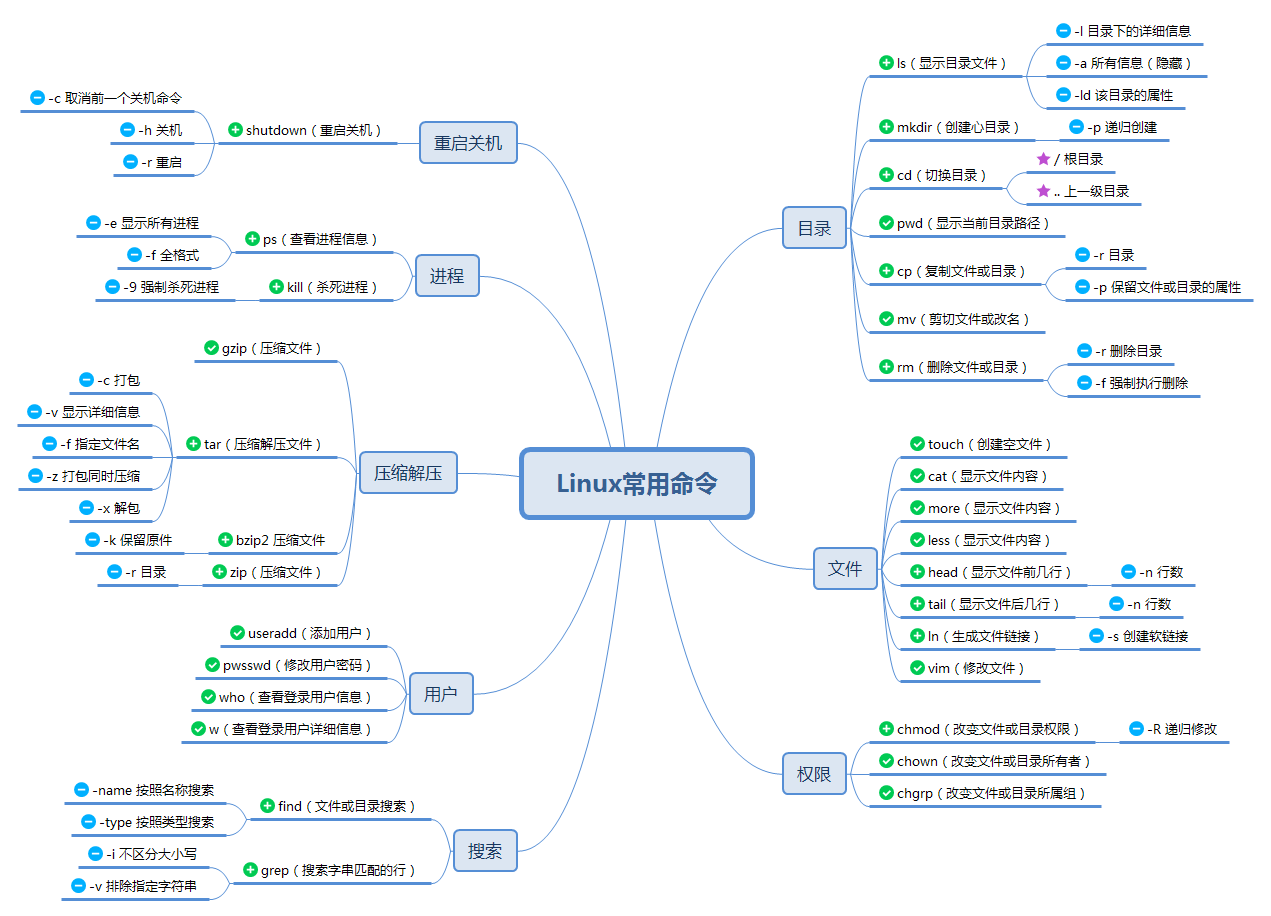
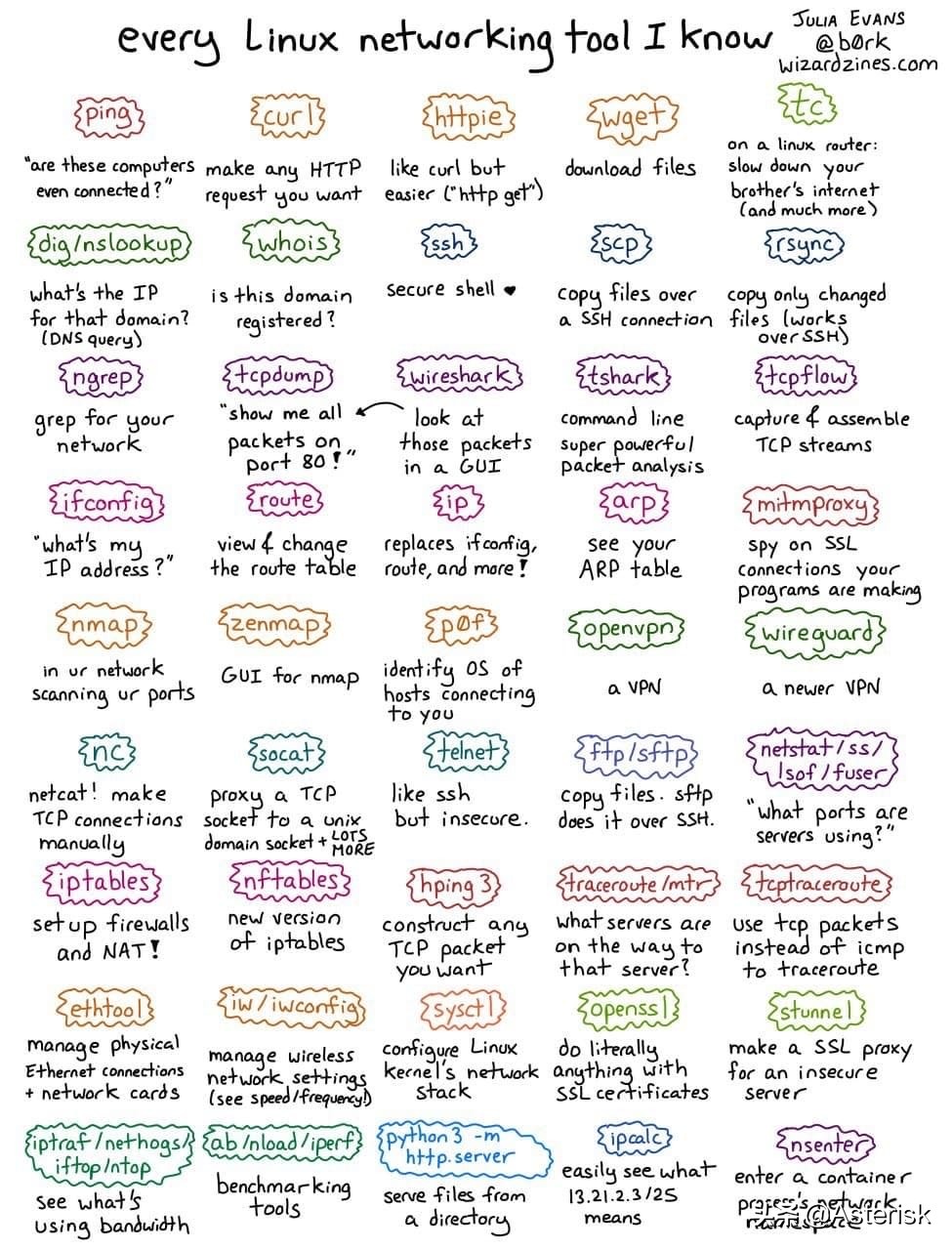
常用命令
账户管理
Linux 系统中,具有最高权限的用户——root。
- root 用户是系统中唯一的一个超级管理员,拥有了系统中的所有权限,可以执行任何想要执行的操作,也正因为如此,处于安全考虑,一般情况下不推荐使用 root 用户进行日常使用。
- root 用户所在的用户组称为 “root组”,处于 root 组的普通用户,能够通过 sudo 命令获取 root 权限。
Linux 将用户账号、密码等相关的信息分别存储在四个文件夹下:
/etc/passwd—— 管理用户UID/GID重要参数- 账号名称 : 密码 : UID : GID : 用户信息说明列 : 主文件夹 : shell
- root : x : 0 : 0 : root : /root : /bin/bash
- 密码项显示 “x” 是出于安全考虑,Linux 将密码信息移到 /etc/shadow 进行存储;
/etc/shadow—— 管理用户密码- 账号名称 : 密码 : 最近改动密码的日期 : 密码不可被改变的天数 : 密码需要重新更改的天数 : 更改提醒天数 : 密码过期后账号的宽限时间 : 账号失效日期 : 保留
- root : (字符串,此处打码) : 200 : 0 : 99999 : 7 : : :
/etc/group—— 管理用户组相关信息- 用户组名称 : 用户组密码 : GID : 此用户组包含的账号名称
- root : x : 0 : root
/etc/gshadow—— 管理用户组管理员相关信息- 用户组名 : 密码 : 用户组管理员账号 : 该用户组包含的账号名称
- root : : : root
修改文件权限
ls -l a.txt
# -rw-r--r-- 12 linuxize users 12.0K Apr 8 20:51 a.txt
# |[-][-][-]- [------] [---]
# | |
# | +-----------> Group
# +-------------------> Owner
# 格式
chown -R owner_name:group_name folder_name
chown -R new_owner_name directory1 directory2 directory3 # 多个目录
# 示例
sudo chown wqw a.txt # 修改文件所属权限(不含目录子文件)
sudo chown -R wqw test_dir # 递归修改文件所属权限
chown wqw:root a.txt # 同事设置user和group
chown --reference=b.txt a.txt # 参考 文件 b.txt 设置 a.txt 权限
adduser 与 useradd 在一些方面存在不同。
- useradd 创建用户,但是不创建密码等其他用户信息,需要使用 passwd 设置密码才能使用;而 adduser 能通过交互界面,由用户直接输入密码等,设置用户信息。
- useradd 默认不在 /home 下创建用户同名的主文件夹,而 adduser 默认创建。
- useradd 是一个命令,而 adduser 被理解为一个 “简单的应用程序”。
# 查询用户信息
id <user> # 展示指定user的UID、GID、用户组信息等,默认为当前有效用户
who am i # 等同于 who -m,仅显示当前登录用户相关信息
whoami # 仅显示当前有效用户的用户名
w # 展示当前正在登录主机的用户信息及正在执行的操作
who # 展示当前正在登录主机的用户信息
last <user> # 展示指定用户的历史登录信息,默认为当前有效用户
lastlog -u <user> # 展示指定用户最近的一次登录信息,默认显示所有用户
useradd # 新增用户,只是创建了一个用户名,如 (useradd +用户名 ),它并没有在/home目录下创建同名文件夹,也没有创建密码,因此利用这个用户登录系统,是登录不了的
useradd -m wqw # 添加用户:
useradd -g nginx -M nginx # -M 参数用于不为nginx建立home目录
passwd wqw # 设置密码
passwd -d wqw # root权限下清楚用户wqw的密码
passwd -l hadoop # 锁定用户hadoop不能更改密码;
passwd -u hadoop # 解除锁定用户hadoop不能更改密码;
passwd -S hadoop # 查询hadoop用户密码状态
# ------ 用户切换 -------
su wqw # 切换用户
sudo -i -u aisearch # 【2022-1-16】root下切换账户
userdel -r wqw # 删除用户
# 类似useradd,但adduser更实用,交互式创建用户
adduser tommy # 添加一个名为tommy的用户,
#passwd tommy # 修改密码
# 赋予root权限: 修改 /etc/sudoers 文件,找到下面一行,把前面的注释(#)去掉
# %wheel ALL=(ALL) ALL
# 修改用户,使其属于root组(wheel)
usermod -g root tommy
# 用户组的添加和删除:
groupadd testgroup # 组的添加
groupdel testgroup # 组的删除
sudo
- 普通用户可以通过 sudo 命令,使用 root 用户权限来执行命令。
- 当然,不是所有的用户都能执行 sudo 命令的,而是在 /etc/sudoers 文件内的用户才能执行这个命令。
sudo 的执行流程大致为:
- 系统到 /etc/sudoers 下检查用户是否有执行 sudo 的权限
- 若有 sudo 权限,则需要输入本用户的密码(root 用户执行 sudo 不需要密码)
- 验证成功后执行命令
- 因此,关键在于执行 sudo 的用户是否存在于 /etc/sudoers 文件内
【2023-2-3】root 账户下输入 visudo 即可进入sudo配置,这个命令要比 vim /etc/sudoers 要好很多
# 找到这行
root ALL=(ALL) ALL
# 复制出来,改成新用户
wqw ALL=(ALL) ALL
# 保存,退出
# 测试
su liudiwei
cd ~
sudo mkdir test
- 用adduser命令添加一个普通用户 tommy
- 赋予root权限
- 方法一: 修改 /etc/sudoers 文件,找到下面一行,把前面的注释(#)去掉
- \%wheel ALL=(ALL) ALL
- 修改用户,使其属于root组(wheel),命令如下:usermod -g root wqw
- 命令 su – ,即可获得root权限进行操作
- 方法二: 修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行
- tommy ALL=(ALL) ALL
- 方法三: 修改 /etc/passwd 文件,找到如下行,把用户ID修改为 0
- tommy:x:500:500:tommy:/home/tommy:/bin/bash
- tommy:x:0:500:tommy:/home/tommy:/bin/bash
- 方法一: 修改 /etc/sudoers 文件,找到下面一行,把前面的注释(#)去掉
su 是最简单的用户切换命令,通过该命令可以实现任何身份的切换,包括从普通用户切换为 root 用户、从 root 用户切换为普通用户以及普通用户之间的切换。
- 普通用户之间切换
- 普通用户切换至 root 用户,都需要知晓对方的密码,只有正确输入密码,才能实现切换;
- 从 root 用户切换至其他用户,无需知晓对方密码,直接可切换成功。
su [选项] 用户名
- -:当前用户不仅切换为指定用户的身份,同时所用的工作环境也切换为此用户的环境(包括 PATH 变量、MAIL 变量等),使用 - 选项可省略用户名,默认会切换为 root 用户。
- -l:同 - 的使用类似,也就是在切换用户身份的同时,完整切换工作环境,但后面需要添加欲切换的使用者账号。–login加了这个参数之后,就似乎是重新登陆为该使用者一样,大部分环境变量(例如HOME、SHELL和USER等)都是以该使用者(USER)为主,并且工作目录也会改变。假如没有指定USER,缺省情况是root。
- -p:表示切换为指定用户的身份,但不改变当前的工作环境(不使用切换用户的配置文件)。
- -m:和 -p 一样;–preserve-environment:执行su时不改变环境变数。
- -c 命令:仅切换用户执行一次命令,执行后自动切换回来,该选项后通常会带有要执行的命令。
- -f , –fast:不必读启动文件(如 csh.cshrc 等),仅用于csh或tcsh两种Shell。
- -c command:变更账号为USER的使用者,并执行指令(command)后再变回原来使用者。
- USER:欲变更的使用者账号,ARG传入新的Shell参数
su root # 切换到root,但是没有切换环境变量。注意:普通用户切换到root需要密码
su -root # "-"代表连带环境变量一起切换,不能省略
# 密码: <-- 输入 root 用户的密码
whoami # lamp 当前我是lamp
su - -c "useradd user1" root
# 不切换成root,但是执行useradd命令添加user1用户
grep "user1" /etc/passwd
# userl:x:502:504::/home/user1:/bin/bash
su - lamp1 # Password: <--输入lamp1用户的密码 # 切换至 lamp1 用户的工作环境
whoami # lamp1
# 什么也不做,立即退出切换环境
exit # logout
whoami # lamp
su 命令时,有 - 和没有 - 是完全不同的
- - 选项表示在切换用户身份的同时,连当前使用的环境变量也切换成指定用户的
- 不使用 su - 的情况下,虽然用户身份成功切换,但环境变量依旧用的是原用户的,切换并不完整。
echo $PATH 命令看一下su和su -以后的环境变量有何不同
- su 后面不加用户是默认切到 root
- su username是不改变当前变量
- su - username是改变为切换到用户的变量
系统命令
- 系统常用命令
- 快捷键
软件包
linux软件包:如yum、apt等
apt
# 指定软件包版本
apt-get install package=version
sudo apt-get install python=2.7
sudo apt-get install python3.10 # Ubuntu
brew install python@3.10 # Mac
yum
debian安装yum
# Debian 安装 yum
sudo apt-get update
sudo apt-get install build-essential
sudo apt-get install yum
sudo yum install python38 # [2023--3-2] 阿里云服务器上安装 python
软件包命令
apt install yum # 通过apt安装yum
# 或下载安装
wget http://yum.baseurl.org/download/3.2/yum-3.2.28.tar.gz
tar xvf yum-3.2.28.tar.gz
cd yum-3.2.28
sudo apt install yum
# 更新到新版
yum -y update # 升级所有包,改变软件设置和系统设置,系统版本内核都升级
yum -y upgrade # 升级所有包,不改变软件设置和系统设置,系统版本升级,内核不改变
yum check-update # 列出所有可更新的软件清单
yum update # 安装所有更新软件
yum update gcc # 安装gcc更新软件
yum -y update gcc # 安装gcc更新软件,自动yes
yum install gcc # 仅安装指定的软件
yum -y install gcc # 自动回答yes
yum list # 列出所有可安裝的软件清单
yum list pam* # pam开头的软件包
yum search samba # 查找
yum info samba # 显示软件信息
yum remove samba # 删除samba
# 清楚缓存
yum clean all
yum clean packages # 清除缓存目录下的软件包
yum clean headers # 清除缓存目录下的 headers
yum clean oldheaders # 清除缓存目录下旧的 headers
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) # 清除缓存目录下的软件包及旧的 headers
yum makecache # 生成缓存
linux工具
史上最全,linux内核调试工具都在这里了,我们来看看:
- 内存相关的:free, vmstate, slabtop
- cpu相关的:top, ps, pidstat, mpstat
- 【2021-8-23】根据关键词快速杀死进程:ps axu | grep start_all | awk ‘{print $2}’ | xargs kill
- 块设备IO相关的:iostat, iotop, blktrace
- 网络相关的:ping, tcpdump, traceroute, ip, nicstat, netstat
- 系统调用相关的:strace, lstrace, sysdig, perf
- linux内核调试和优化相关的:perf, dtrace, stap, lttng, ktap, sysdig
重点说一下perf,这个工具非常强大,可以说是做linux性能优化的首选工具,它可以:
- 统计出你的程序是花在cpu计算上、还是IO上;
- 统计出你的程序执行的时候经过了多少次进程切换。进程切换的多,说明系统的吞吐率较好,但是频繁的切换也会影响性能;
- 统计出你的程序运行过程中的cache-misses的计数,我们知道cache-misses过多,则表示访问内存的性能不佳;
- 统计出你的进程在运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行;
这个工具简直就是做linux内核性能优化的”瑞士军刀“,有木有?
perf既然这么强大,那它的实现原理是什么呢?
- perf其实依赖的是内核里的Tracepoint。
- Tracepoint 是散落在内核源代码中的一些 hook,一旦使能,它们便可以在特定的代码被运行到时被触发,这一特性可以被各种 trace/debug 工具所使用。Perf 就是该特性的用户之一。假如您想知道在应用程序运行期间,内核内存管理模块的行为,便可以利用潜伏在 slab 分配器中的 tracepoint。当内核运行到这些 tracepoint 时,便会通知 perf。Perf 将 tracepoint 产生的事件记录下来,生成报告,通过分析这些报告,调优人员便可以了解程序运行时期内核的种种细节,对性能症状作出更准确的诊断。
总结:
-
- nl的功能和cat -n一样,同样是从第一行输出全部内容,并且把行号显示出来
- more的功能是将文件从第一行开始,根据输出窗口的大小,适当的输出文件内容。当一页无法全部输出时,可以用“回车键”向下翻行,用“空格键”向下翻页。退出查看页面,请按“q”键。另外,more还可以配合管道符“|”(pipe)使用,例如:ls -al | more
- less的功能和more相似,但是使用more无法向前翻页,只能向后翻。less可以使用【pageup】和【pagedown】键进行前翻页和后翻页,这样看起来更方便。
- cat的功能是将文件从第一行开始连续的将内容输出在屏幕上。当文件大,行数比较多时,屏幕无法全部容下时,只能看到一部分内容。所以通常使用重定向的方式,输出满足指定格式的内容
- cat语法:cat [-n] 文件名 (-n : 显示时,连行号一起输出)
- tac的功能是将文件从最后一行开始倒过来将内容数据输出到屏幕上。我们可以发现,tac实际上是cat反过来写。这个命令不常用。
- tac语法:tac 文件名。

终端访问
终端客户端工具
- Xshellicon
- Mobaxterm
- FinalShell
- XTerminal 是一个功能强大的远程终端管理平台,支持多平台支持、安全、终端控制、远程监控、远程协作、脚本自动化、插件icon扩展等功能。
自动登录
- [2018-3-26]自动登录鲁班测试机
方法一:
#参考expect用法
passwd="***"
expect -c "
spawn ssh user@host -p 8022
expect {
\"*assword:\" {send \"$passwd\r\"; exp_continue }
}
"
方法二:
- login.sh内容:
#!/usr/bin/expect -f
set host luban@10.84.176.174
set port 8022
set pwd M95B8RBR
spawn ssh "$host" -p $port
set timeout 30
expect "password:"
send "$pwd\r"
interact
- 执行:expect login.sh
- 自动登录, ~/.bash_profile 里配置别名即可一直使用
- alias luban=’expect ~/login.sh’
日期
- 【2020-9-21】时间矫正
sudo ntpdate cn.pool.ntp.org # 矫正系统时间
IP 地址
获取 IP 地址方法
Linux下
- ifconfig:要确保已安装
- ifconfig 命令可以获取本机网卡的配置信息,包括 IP 地址。可以通过 grep 命令过滤出 IP 地址信息,再使用 awk 命令提取出具体的 IP 地址
- hostname 无需安装
- ip:ifconfig 命令的替代品,可以获取本机网卡的配置信息,包括 IP 地址。使用 ip addr show 命令可以获取所有网卡的信息,再使用 grep 命令过滤出 IP 地址信息,最后使用 awk 命令提取出具体的 IP 地址
# (1)ifconfig
ip=$(ifconfig | grep -E 'inet [0-9]' | awk '{print $2}')
# (2)hostname
hostname # 获取本机的主机名
hostname -I # 获取ip地址
ip=$(hostname -I)
# (3)ip
ip=$(ip addr show | grep -E 'inet [0-9]' | awk '{print $2}' | awk -F '/' '{print $1}')
# 127.0.0.1
# 10.191.61.23
echo "本机 IP 地址为:$ip"
hostname -I # 直接输出地址
任务启动
自定义批量启动
【2023-8-9】批量启动服务
- 若已有任务端口在跑,跳过(参数空)/杀死
#lsof -i:9001 | awk '{if($2=="PID")next;print $2}'
source common.sh # 定义彩色日志函数 log
run_cmd(){
# 批量启动任务
name=$1 # 任务名
cmd=$2 # 命令
port=$3 # 端口,用于已有任务检测重启
[ $port ] && {
log "INFO" "检测已有任务端口:$port"
detect=`lsof -i:$port | awk '{if($2=="PID")next;print $2}'`
[ $detect ] && { log "检测到已有任务, 关闭任务"; kill $detect; }
}
log "INFO" "开始执行 $cmd"
eval $cmd
[ $? -eq 0 ] && log "INFO" "服务 $name 启动完毕" || log "ERROR" "服务 $name 启动失败"
}
run_cmd "test" "ls" 9002
run_cmd "test" "ls" 9001
返回结果
[2023-08-09 17:38:18] [INFO] 检测已有任务端口:9002
[2023-08-09 17:38:18] [INFO] 开始执行 ls
a.sh bak bin common.sh files log.txt log_file.txt start_all.sh work
[2023-08-09 17:38:18] [INFO] 服务 test 启动完毕
[2023-08-09 17:38:18] [INFO] 检测已有任务端口:9001
[2023-08-09 17:38:18] [INFO] 检测到已有任务, 关闭任务
kill 2303865
[2023-08-09 17:38:18] [INFO] 开始执行 ls
a.sh bak bin common.sh files log.txt log_file.txt start_all.sh work
[2023-08-09 17:38:18] [INFO] 服务 test 启动完毕
md5
Mac下安装MD5工具
- 安装md5sum和sha1sum
brew install md5sha1sum
代理
本地终端代理
本地 Terminal 设置代理
# Set HTTP and HTTPS proxies
export http_proxy="http://proxy.server.com:8080"
export https_proxy="https://proxy.server.com:8080"
# Exclude local addresses from proxy
export no_proxy="localhost,127.0.0.1,*.local"
远程服务器转本地代理
场景
- 服务器端无法使用vpn,导致很多安装包无法正常使用,如 uv 安装
【2026-3-28】解法:ssh 端口映射
- ① 本地机器开启代理,记住本地端口 local_port
- ② 服务器端设置代理
- ③ 本地并启动 ssh 转发
# 服务器端设置代理 端口 7897(使用时自行更新)
# 远程服务器
host=10.191.60.224
local_port=2080 # 本地端口
remote_port=8022
export https_proxy=http://127.0.0.1:$local_port http_proxy=http://127.0.0.1:$local_port all_proxy=socks5://127.0.0.1:$local_port
# 本地mac执行
ssh -fCNR $local_port:localhost:$local_port luban@$host -p $remote_port # 绑定本地代理服务
ssh 端口映射
本机打开cmd,输入以下命令
ssh -vvv -N -R 7890:localhost:7890 -p <远程服务器端口号>
@
参数说明
- -vvv:输出调试信息;
- -N:不执行远程命令,只建立 SSH 连接并进行端口转发;
- -R 7890:localhost:7890:将远程服务器上的 7890 端口绑定到本地的 7890 端口;
- -p:指定远程服务器ssh端口,若为默认的22可不写
curl 网络请求
curl功能非常强大,命令行参数多达几十种。如果熟练的话,完全可以取代 Postman 这一类的图形界面工具。
- curl支持包括HTTP、HTTPS、ftp等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。
- GET:
- curl http://127.0.0.1:8080/login?admin&passwd=12345678
- POST
- curl -d “user=admin&passwd=12345678” http://127.0.0.1:8080/login
- curl -H “Content-Type:application/json” -X POST -d ‘{“user”: “admin”, “passwd”:”12345678”}’ http://127.0.0.1:8000/login
- GET:
- curl用法指南
# ------ GET --------
# 直接GET请求
curl https://www.example.com
# 指定客户端的用户代理表头(User-Agent), -A参数; 等效于直接使用chrome浏览器
curl -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36' https://google.com
curl -H 'User-Agent: php/1.0' https://google.com # -H 也可以直接指定标头,更改UA
curl -H 'Accept-Language: en-US' https://google.com # 添加 HTTP 请求的标头
curl -H 'Accept-Language: en-US' -H 'Secret-Message: xyzzy' https://google.com # 添加 HTTP 标头Accept-Language: en-US
curl -d '{"login": "emma", "pass": "123"}' -H 'Content-Type: application/json' https://google.com/login # 添加两个标头
# -i参数打印出服务器回应的 HTTP 标头
curl -i https://www.example.com
# -I参数向服务器发出 HEAD 请求,然会将服务器返回的 HTTP 标头打印出来
curl -I https://www.example.com
# --head参数等同于-I
curl --head https://www.example.com
# -k参数指定跳过 SSL 检测。不会检查服务器的 SSL 证书是否正确。
curl -k https://www.example.com
# -L参数会让 HTTP 请求跟随服务器的重定向。curl 默认不跟随重定向
curl -L -d 'tweet=hi' https://api.twitter.com/tweet
# --limit-rate用来限制 HTTP 请求和回应的带宽,模拟慢网速的环境
curl --limit-rate 200k https://google.com # 每秒 200K 字节
# -o参数将服务器的回应保存成文件,等同于wget命令
curl -o example.html https://www.example.com # 将http://www.example.com保存成example.html
# -O参数将服务器回应保存成文件,并将 URL 的最后部分当作文件名。
curl -O https://www.example.com/foo/bar.html # 将服务器回应保存成文件,文件名为bar.html
# -s参数将不输出错误和进度信息
curl -s https://www.example.com
curl -s -o /dev/null https://google.com # # 不产生任何输出
curl -s -o /dev/null https://google.com # -S参数指定只输出错误信息,通常与-o一起使用
# -u参数用来设置服务器认证的用户名和密码。
curl -u 'bob:12345' https://google.com/login
curl https://bob:12345@google.com/login # curl 能够识别 URL 里面的用户名和密码,将其转为上个例子里面的 HTTP 标头
curl -u 'bob' https://google.com/login # 只设置了用户名,执行后,curl 会提示用户输入密码
# -v参数输出通信的整个过程,用于调试。
curl -v https://www.example.com
# --trace参数也可以用于调试,还会输出原始的二进制数据。
curl --trace - https://www.example.com
# -x参数指定 HTTP 请求的代理。
curl -x socks5://james:cats@myproxy.com:8080 https://www.example.com # 指定 HTTP 请求通过http://myproxy.com:8080的 socks5 代理发出。如果没有指定代理协议,默认为 HTTP。
curl -x james:cats@myproxy.com:8080 https://www.example.com # 请求的代理使用 HTTP 协议。
# -X参数指定 HTTP 请求的方法。
curl -X POST https://www.example.com
# 移出UA标头
curl -A '' https://google.com
# 发送cookie给服务器,生成一个标头Cookie: foo=bar
curl -b 'foo=bar' https://google.com
curl -b 'foo1=bar' -b 'foo2=baz' https://google.com # 两个cookie
curl -b cookies.txt https://www.google.com # 本地文件cookies.txt
# 服务器端cookie写入本地文件cookies.txt
curl -c cookies.txt https://www.google.com
# -e参数用来设置 HTTP 的标头Referer,表示请求的来源
curl -e 'https://google.com?q=example' https://www.example.com
curl -H 'Referer: https://google.com?q=example' https://www.example.com # -H参数可以通过直接添加标头Referer,达到同样效果
# ------ POST --------
# -d参数,HTTP请求会自动加上标头Content-Type : application/x-www-form-urlencoded。并且会自动将请求转为 POST 方法,因此可以省略-X POST。
curl -d 'login=emma&password=123' -X POST https://google.com/login
curl -d 'login=emma' -d 'password=123' -X POST https://google.com/login
curl -d '@data.txt' https://google.com/login # 省略-X POST; 读取data.txt文件的内容,作为数据体向服务器发送
# --data-urlencode参数等同于-d,发送 POST 请求的数据体,区别在于会自动将发送的数据进行 URL 编码
curl --data-urlencode 'comment=hello world' https://google.com/login
# -F参数用来向服务器上传二进制文件
curl -F 'file=@photo.png' https://google.com/profile # 给 HTTP 请求加上标头Content-Type: multipart/form-data,然后将文件photo.png作为file字段上传
# -F参数可以指定 MIME 类型
curl -F 'file=@photo.png;type=image/png' https://google.com/profile # 指定 MIME 类型为image/png,否则 curl 会把 MIME 类型设为application/octet-stream
curl -F 'file=@photo.png;filename=me.png' https://google.com/profile # -F参数也可以指定文件名,原始文件名为photo.png,但是服务器接收到的文件名为me.png
# -G参数用来构造 URL 的查询字符串
curl -G -d 'q=kitties' -d 'count=20' https://google.com/search # GET 请求,实际请求的 URL 为https://google.com/search?q=k...。如果省略--G,会发出一个 POST 请求。如果数据需要 URL 编码,可以结合--data--urlencode参数。
curl -G --data-urlencode 'comment=hello world' https://www.example.com
wget
【2022-11-16】wget用法:wget用法详解
# wget http://cn.wordpress.org/wordpress-3.1-zh_CN.zip
filename = 'http://cn.wordpress.org/wordpress-3.1-zh_CN.zip'
wget ${filename} # 下载单个文件, 以默认名字显示
wget -O wordpress.zip ${filename} # 下载并命名文件
wget -o download.log ${filename} # 下载日志
wget –limit-rate=300k ${filename} # 限速下载
wget –c ${filename} # 断点续传,下载大文件时突然由于网络等原因中断,不用重新下载
wget –b ${filename} # 后台下载
tail -f wget-log # 后台下载,查看进度
wget –user-agent="Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16" ${filename} # 伪装代理下载
wget –spider ${filename} # 测试下载链接
wget –tries=40 ${filename} # 设置重试次数
wget -i filelist.txt # 批量下载,filelist.txt 中一行一个链接
wget –mirror -p –convert-links -P ./LOCAL ${filename} # 使用镜像下载
# –miror:开户镜像下载
# -p:下载所有为了html页面显示正常的文件
# –convert-links:下载后,转换成本地的链接
# -P ./LOCAL:保存所有文件和目录到本地指定目录
wget –reject=gif ${filename} # 过滤特定格式的文件
wget -Q5m -i filelist.txt # 递归下载时,限制文件大小 5m
wget -r -A.pdf ${filename} # 下载一个网站里指定格式的文件
wget ftp-url # ftp匿名下载
wget –ftp-user=USERNAME –ftp-password=PASSWORD ${filename} # ftp使用账户下载
ssh
SSH连接服务器
SSH提供了两种级别的安全验证:
- 第一种级别是基于密码的安全验证,知道账号和密码就可以登陆到远程主机。
- Team的开发工作使用这种方式登陆编译服务器,或者开发机器。因为是在内网中,这种级别的安全验证已经足够了。
- 第二种级别是基于 Public-key cryptography (公开密匙加密)机制的安全验证,原理如下图所示:
- 其优点在于无需共享的通用密钥,解密的私钥不发往任何用户。即使公钥在网上被截获,如果没有与其匹配的私钥,也无法解密,所截获的公钥是没有任何用处的。
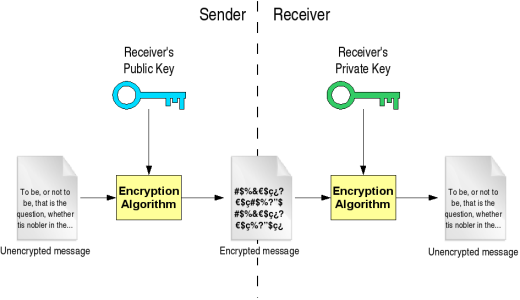
登录命令
模版
ssh -t 用户名@IP “命令1; 命令2; 命令3; exec bash”
用法
- -l user:指定要登录的用户。
- -p port:指定连接到远程主机的端口号,默认是22。
- -i identity_file:指定身份验证文件(私钥文件)。
- -v:详细模式,可以显示调试信息。
- -C:启用压缩。
- -N:不执行远程命令,只进行端口转发。
- -f:后台运行。
- -L local_port:remote_host:remote_port:本地端口转发。
- -R remote_port:local_host:local_port:远程端口转发。
- -D
[bind_address:]port:动态应用程序级端口转发
# ssh -t 用户名@IP "命令1; 命令2; 命令3; exec bash"
ssh wqw@10.1.2.3
ssh wqw@10.1.2.3 -p 8000 # 指定端口
# 执行远程命令,再退出——一次性
ssh wqw@10.1.2.3 "ls" # 登录后执行命令,执行完毕后退出登录
ssh wqw@10.1.2.3 ls -l # 登录后执行命令,执行完毕后退出登录
ssh wqw@10.1.2.3 ls -l; pwd # 多个命令
ssh wqw@10.1.2.3 < test.sh # 登录后,执行本地脚本
# 执行命令后,不退出
ssh -t wqw@10.1.2.3 "ls" # 执行完成后,不退出!
ssh wqw@10.1.2.3 "ls; exec bash"
ssh -q wqw@10.1.2.3 # 静默模式
ssh -v wqw@10.1.2.3 # 详细模式
ssh -C wqw@10.1.2.3 # 启用压缩
ssh -i ~/.ssh/id_rsa wqw@10.1.2.3 # 使用身份验证文件
ssh -f -N test@runoob.com # 后台运行,不执行(只转发)
ssh -L 8080:localhost:80 test@runoob.com # 本地端口转发
ssh -R 8080:localhost:80 test@runoob.com # 远程端口转发
ssh -D 1080 test@runoob.com # 动态端口转发
ssh -A test@runoob.com # 代理转发
配置
配置文件
SSH 客户端配置文件位于 ~/.ssh/config,可以在其中设置常用配置。
示例:
Host example
HostName example.com
User john
Port 2222
IdentityFile ~/.ssh/id_rsa
使用时只需:ssh example
sshkey-gen
【2022-11-01】sshkey-gen的作用
- 通过数字签名RSA或DSA让两个linux机器之间使用ssh,而不需要用户名和密码。
ssh-keygen 用于 生成、管理和转换认证密钥
常用参数
- -t type:指定要生成的密钥类型,有 rsa1(SSH1), dsa(SSH2), ecdsa(SSH2), rsa(SSH2) 等类型,较为常用的是 rsa类型
- -C comment:提供一个新注释
- -b bits:指定要生成的密钥长度 (单位:bit),对于RSA类型的密钥,最小长度768bits,默认长度为2048bits。DSA密钥必须是1024bits
- -f filename: 指定生成的密钥文件名字
ssh-keygen # [rsa|dsa],默认生成密钥文件和私钥文件 id_rsa,id_rsa.pub或id_dsa,id_dsa.pub
# RSA身份认证,使用指定邮箱登录某机器
ssh-keygen -t rsa -C "wangqiwen.at@163.com"
# 生成 id_ras.pub 文件
cat ~/.ssh/id_rsa.pub # 查看公钥
# 添加pub key
本机生成一个公钥和一个私钥文件
ls ~/.ssh
注意
公钥相当于锁,私钥相当于钥匙- 这里相当于在客户端创建一对钥匙和锁,SSH免密码登录就相当于将锁分发到服务端并装锁,然后客户端就可以利用这个钥匙开锁。
ssh-copy-id命令将本机上的公钥文件拷贝到服务器上(服务器用户名比如为liujiakun,IP地址为192.168.3.105)
# 拷贝公钥文件到指定机器
ssh-copy-id -i ~/.ssh/id_ras.pub user@192.168.1.104
# 指定端口
ssh-copy-id -i ~/.ssh/id_ras.pub "-p 3300 user@192.168.1.104"
# ssh-add 指令将私钥 加进来
ssh-add ~/.ssh/id_rsa
# 服务器上查询~/.ssh/目录下多了一个文件:authorized_keys
【2025-8-18】实践
- 本机 → 服务器
- 使用方法
- 本地创建 ssh-keygen
- 复制 公钥密码 ids.pub
- 登录远程服务器
- 添加 公钥密码到认证文件:
vim ~/.ssh/authorized_keys
【2024-1-29】 网页版(Github/GitLab)上添加key,网页地址:
user settings→user profile→SSH Keys
单向登陆的操作过程:
- 1、登录A机器
- 2、ssh-keygen -t [rsa|dsa],将会生成密钥文件和私钥文件
id_rsa,id_rsa.pub或id_dsa,id_dsa.pub - 3、将
.pub文件复制到B机器的.ssh目录, 并cat id_dsa.pub >> ~/.ssh/authorized_keys - 4、大功告成,从A机器登录B机器的目标账户,不再需要密码了;(直接运行 #ssh 192.168.20.60 )
双向登陆的操作过程:
- 1、
ssh-keygen做密码验证可以使在向对方机器上ssh ,scp不用使用密码.具体方法如下: - 2、两个节点都执行操作:#
ssh-keygen -t rsa- 然后全部回车,采用默认值.
- 3、这样生成了一对密钥,存放在用户目录的
~/.ssh下。- 将公钥考到对方机器的用户目录下 ,并将其复制到
~/.ssh/authorized_keys中(操作命令:#cat id_dsa.pub >> ~/.ssh/authorized_keys)。
- 将公钥考到对方机器的用户目录下 ,并将其复制到
- 4、设置文件和目录权限:
- 设置 authorized_keys 权限:
chmod 600 authorized_keys - 设置 .ssh 目录权限:
chmod 700 -R .ssh
- 设置 authorized_keys 权限:
- 5、要保证 .ssh 和
authorized_keys都只有用户自己有写权限。否则验证无效。(今天就是遇到这个问题,找了好久问题所在),其实仔细想想,这样做是为了不会出现系统漏洞。
ssh 隧道
SSH隧道(即SSH代理、端口转发),SSH隧道概念主要理解映射二字。
- 把本地端口映射到远程机器端口,然后访问远程端口就相当于访问的本地端口,这就是远程SSH隧道。
- SSH隧道
建立SSH隧道命令
ssh -C -f -N -L listen_port:DST_Host:DST_port user@Tunnel_Host
ssh -C -f -N -R listen_port:DST_Host:DST_port user@Tunnel_Host
ssh -C -f -N -D listen_port user@Tunnel_Host
参数
-L port:host:hostport #建立本地SSH隧道(本地客户端建立监听端口)
# 将本地机(客户机)的某个端口转发到远端指定机器的指定端口.
-R port:host:hostport #建立远程SSH隧道(隧道服务端建立监听端口)
# 将远程主机(服务器)的某个端口转发到本地端指定机器的指定端口.
# 有本地映射肯定有远程映射,就是把-L换成-R,这样我们访问远程主机的端口就相当于访问本地的端口,但感觉作用不大。
-D port
# 指定一个本地机器 “动态的’’ 应用程序端口转发.
-C 压缩数据传输。
-N Do not execute a shell or command.
# 不执行脚本或命令,仅仅做端口转发。通常与-f连用。
-f Fork into background after authentication.
# 后台认证用户/密码,不用登录到远程主机。
-L X:Y:Z的含义是,将IP为Y的机器的Z端口通过中间服务器映射到本地机器的X端口。把其他远程机器的端口通过中间服务器映射到本地端口上来。然后本地就能通过中间服务器访问了远程服务器了。
-R X:Y:Z 的含义就是把我们本地的Y机器的Z端口映射到远程机器的X端口上。把本地端口映射到远程机器的端口上去。然后远程机器访问X端口,就相当于访问的是本地机器了。前提是,本地到远程机器的网络是通的,才能把本地的端口映射到远程机器上去
文件服务
一行命令搭建文件服务
# python2
python -m SimpleHTTPServer 8001
# python3下直接执行以下命令即可
cd $your_dir # 要共享的目录
# 启动文件服务,ip填下本机ip,默认端口8000
python -m http.server
python -m http.server 8001 # 指定端口
nohup python -m http.server -b 10.200.24.101 &>log.txt &
# 打开网页: http://10.200.24.101:8000/
注意:
- 当前目录下不要放index.html,会被服务识别为主页,自动加载
- http.server建的文件服务器是单线程的,意味着如果多个用户访问会被阻塞,同时只能一个用户访问
多线程改进方案
import socket
import SocketServer
import BaseHTTPServer
from SimpleHTTPServer import SimpleHTTPRequestHandler
class ForkingHTTPServer(SocketServer.ForkingTCPServer):
allow_reuse_address = 1
def server_bind(self):
"""Override server_bind to store the server name."""
SocketServer.TCPServer.server_bind(self)
host, port = self.socket.getsockname()[:2]
self.server_name = socket.getfqdn(host)
self.server_port = port
def test(HandlerClass=SimpleHTTPRequestHandler,
ServerClass=ForkingHTTPServer):
BaseHTTPServer.test(HandlerClass, ServerClass)
if __name__ == '__main__':
test()
代码命名为MultiHTTPServer.py 放置到 python的lib库里面, 如Python/2.7/lib/python/site-packages
# 多线程文件服务器版本
python -m MultiHTTPServer.py
邮件
【2021-11-19】Linux 命令行发送邮件的 5 种方法
Linux中邮件命令怎么把邮件传递给收件人的?
- 邮件命令撰写邮件并发送给一个本地邮件传输代理(MTA,如 sendmail、Postfix)。邮件服务器和远程邮件服务器之间通信以实际发送和接收邮件。下面的流程可以看得更详细。
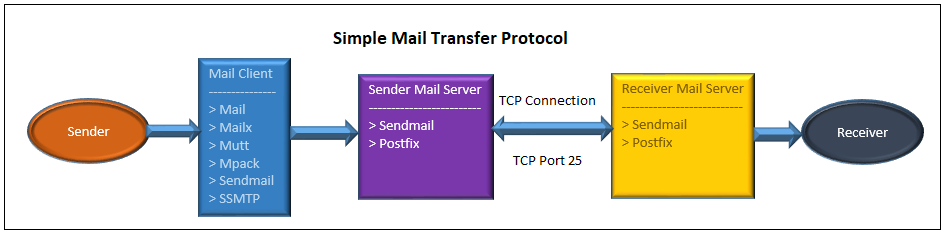
最流行的 5 个命令行邮件客户端,你可以选择其中一个。这 5 个命令分别是:
- mail / mailx
- 安装: yum install mailx
- mutt
- 安装:yum install mutt
- mpack
- 安装:yum install mpack
- sendmail
- 安装:yum install sendmail
- ssmtp
- ssmtp 是类似 sendmail 的一个只发送不接收的工具,可以把邮件从本地计算机传递到配置好的 邮件主机(mailhub)。用户可以在 Linux 命令行用 ssmtp 把邮件发送到 SMTP 服务器。可以运行下面的命令从官方发行版仓库安装 ssmtp 命令。
- 安装:yum install ssmtp
# ------ mail ------
echo "This is the mail body" | mail -s "Subject" 2daygeek@gmail.com
# 带附件
# -a:用于在基于 Red Hat 的系统上添加附件。
# -A:用于在基于 Debian 的系统上添加附件。
# -s:指定消息标题。
echo "This is the mail body" | mail -a test1.txt -s "Subject" 2daygeek@gmail.com
# -------- mutt -------
echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com
# 带附件
echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com -a test1.txt
# -------- mpack ---------
echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com
# 附件
echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com -a test1.txt
# --------- sendmail ---------
# 准备邮件内容:
echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/send-mail.txt
# 发送
sendmail 2daygeek@gmail.com < send-mail.txt
# ---------- ssmtp ------------
echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/ssmtp-mail.txt
ssmtp 2daygeek@gmail.com < /tmp/ssmtp-mail.txt
Python自动发送多封邮件
【2022-1-25】5个方便好用的Python自动化脚本
自动发送多封邮件
这个脚本可以帮助我们批量定时发送邮件,邮件内容、附件也可以自定义调整,非常的实用。相比较邮件客户端,Python脚本的优点在于可以智能、批量、高定制化地部署邮件服务。
需要的第三方库:
- Email - 用于管理电子邮件消息
- Smtlib - 向SMTP服务器发送电子邮件,它定义了一个 SMTP 客户端会话对象,该对象可将邮件发送到互联网上任何带有 SMTP 或 ESMTP 监听程序的计算机
- Pandas - 用于数据分析清洗地工具
import smtplib
from email.message import EmailMessage
import pandas as pd
def send_email(remail, rsubject, rcontent):
email = EmailMessage() ## Creating a object for EmailMessage
email['from'] = 'The Pythoneer Here' ## Person who is sending
email['to'] = remail ## Whom we are sending
email['subject'] = rsubject ## Subject of email
email.set_content(rcontent) ## content of email
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("deltadelta371@gmail.com","delta@371") ## login id and password of gmail
smtp.send_message(email) ## Sending email
print("email send to ",remail) ## Printing success message
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]
send_email(email,subject,content)
tcpdump常用命令
- 用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具。 tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
实用命令实例
#将某端口收发的数据包保存到文件
sudo tcpdump -i any port 端口 -w 文件名.cap
# 打印请求到屏幕<br>
sudo tcpdump -i any port 端口 -Xnlps0
# 默认启动
tcpdump
# 普通情况下,直接启动tcpdump将监视第一个网络接口上所有流过的数据包。
#监视指定网络接口的数据包
tcpdump -i eth1
#如果不指定网卡,默认tcpdump只会监视第一个网络接口,一般是eth0,下面的例子都没有指定网络接口。
端口显示
lsof
lsof(list open files)是一个列出当前系统打开文件的工具。
lsof 查看端口占用语法格式:
- lsof -i:端口号
lsof -i:8080 # 查看8080端口占用(NAME字段就是端口)
# COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
# nodejs 26993 root 10u IPv4 37999514 0t0 TCP *:8000 (LISTEN)
lsof abc.txt # 显示开启文件abc.txt的进程
lsof -c abc # 显示abc进程现在打开的文件
lsof -c -p 1234 # 列出进程号为1234的进程所打开的文件
lsof -g gid # 显示归属gid的进程情况
lsof +d /usr/local/ # 显示目录下被进程开启的文件
lsof +D /usr/local/ # 同上,但是会搜索目录下的目录,时间较长
lsof -d 4 # 显示使用fd为4的进程
lsof -i -U # 显示所有打开的端口和UNIX domain文件
netstat
netstat -tunlp 用于显示 tcp,udp 的端口和进程等相关情况
netstat 查看端口占用语法格式:
- netstat -tunlp | grep 端口号
- 参数
- -t (tcp) 仅显示tcp相关选项
- -u (udp)仅显示udp相关选项
- -n 拒绝显示别名,能显示数字的全部转化为数字
- -l 仅列出在Listen(监听)的服务状态
- -p 显示建立相关链接的程序名
netstat -tunlp | grep 8000
# tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 26993/nodejs
netstat -ntlp # 查看当前所有tcp端口
netstat -ntulp | grep 80 # 查看所有80端口使用情况
netstat -ntulp | grep 3306 # 查看所有3306端口使用情况
kill
命令杀死进程
- kill -9 26993
java安装
export JAVA_HOME=/usr/local/src/jdk1.8.0_171 #根据自己的完整路径修改
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
wc
wc命令 统计指定文件中的字节数、字数、行数,并将统计结果显示输出
-c # 统计字节数,或--bytes:显示Bytes数。
-l # 统计行数,或--lines:显示列数。
-m # 统计字符数,或--chars:显示字符数。 中文
-w # 统计字数,或--words:显示字数。单词数, 一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L # 打印最长行的长度,或--max-line-length。
-help # 显示帮助信息。
--version # 显示版本信息。
示例
wc test.txt
# 输出结果
7 8 70 test.txt
# 行数 单词数 字节数 文件名
# ------------
wc -m # 字符数, 中文占3个字节(utf8), m可以统计中文
wc -l * # 统计当前目录下的所有文件行数及总计行数。
wc -l *.js # 统计当前目录下的所有 .js 后缀的文件行数及总计行数。
find . * | xargs wc -l # 当前目录以及子目录的所有文件行数及总计行数。
录盘/gif
录屏
Gif
【2023-8-28】Terminalizer, github

# Start recording your terminal using the record command.
terminalizer record demo
# A file called demo.yml will be created in the current directory. You can open it using any editor to edit the configurations and the recorded frames. You can replay your recording using the play command.
terminalizer play demo
# Now let's render our recording as an animated gif.
terminalizer render demo
聊天
smallchat
【2023-11-15】 Redis创始人开源最小聊天服务器 SmallChat ,C语言实现,仅200行代码
cd smallchat
# 编译
# gcc smallchat.c -o smallchat && ./smallchat
make
# 启动服务, 默认端口 SERVER_PORT 7711
./smallchat-server
# 启动客户端连接
/nick # 设置昵称
./smallchat-client 127.0.0.1 7711
文件传输
【2017-12-16】远程文件传输的几种方式:
- secureCRT、ftpxp客户端
- scp命令
- rsync命令
- ftp、http服务
- 【2018-1-4】python搭建简易web服务,可以下载文件
- 服务端:python -m SimpleHTTPServer 8088
- 客户端浏览器:http://uemc-train-srv00.gz01:8088/
- 参考:三种Shell脚本编程中避免SFTP输入密码的方法
- 【2018-1-4】python搭建简易web服务,可以下载文件
- sftp服务
- szrz命令:ubuntu下无法使用
- 【2026-3-28】故障:ubuntu tty终端里 输入 rz , 然后一直卡住,按 ctrl + C 不管用
- 解法:按住 Ctrl键, 再按五次x键 (强行终止)
- nc命令
- Linux网络工具中的“瑞士军刀”盛誉的netcat,能通过TCP和UDP在网络中读写数据
- (1) 检测端口是否可用:
- nc -v www.thanks.live 80
- (2)文件传输
- 接收端:nc -l 9995 > tmp
- 发送端:nc 10.200.0.79 9995 < send_file
- 注:
- 端口范围(1024,65535)
- 发送、接收顺序不限
- 传输目录
- 接收端:nc -l 9995 | tar xfvz -
- 发送端:tar cfz - * | nc 10.0.1.162 9995
- (3)聊天功能
- 类似文件传输操作步骤,去掉文件定向(<>)即可
- A:nc -l 9995
- B:nc 10.200.0.79 9995
- (4)telnet服务器(远程登录)
- 服务端:nc -l -p 9995 -e bash
- 客户端:nc 10.200.0.79 9995
- samba
- Git LFS
nc(NetCat,瑞士军刀)
NetCat(简称nc),在网络工具中有“瑞士军刀”美誉,其有Windows和Linux的版本。
- 因为它短小精悍(1.84版本也不过25k,旧版本或缩减版甚至更小)、功能实用,被设计为一个简单、可靠的网络工具,可通过TCP或UDP协议传输读写数据。
- 还是一个网络应用Debug分析器,因为它可以根据需要创建各种不同类型的网络连接。
- 参考:nc命令详解
【2021-12-8】亲测,使用nc命令局域网跨系统传输大文件夹(13G),mac → Ubuntu,Windows也可以安装,但安装包被win10拦截
安装:
- Windows系统安装:nc下载链接,把解压的文件存到c:\WINDOWS\system32路径下。 打开cmd 输入nc -help,查看命令使用方法。
- linux/mac一般自带,安装命令如下:
# linux yum
yum install -y nc
# linux rpm
rpm -q nc
参数:
- -g<网关> 设置路由器跃程通信网关,最多可设置8个。
- -G<指向器数目> 设置来源路由指向器,其数值为4的倍数。
- -h 在线帮助。
- -i<延迟秒数> 设置时间间隔,以便传送信息及扫描通信端口。
- -l 使用监听模式,管控传入的资料。
- -n 直接使用IP地址,而不通过域名服务器。
- -o<输出文件> 指定文件名称,把往来传输的数据以16进制字码倾倒成该文件保存。
- -p<通信端口> 设置本地主机使用的通信端口。
- -r 乱数指定本地与远端主机的通信端口。
- -s<来源地址> 设置本地主机送出数据包的IP地址。
- -u 使用UDP传输协议。
- -v 显示指令执行过程。
- -w<超时秒数> 设置等待连线的时间。
- -z 使用0输入/输出模式,只在扫描通信端口时使用。
注意:
- 端口范围(1024,65535)
- 发送、接收顺序不限
用法:
# (0)远程聊天:a与b两台机器
# --- 接收 ----
nc -l 1234 # a端开启监听
nc -lp 22222 # 或者
# --- 发送 ----
nc 192.168.200.27 1234 # b端开启
nc -nv 40.2.214.139 22222 # 或者
# (1)远程复制
# s1(发送端) → s2(接收端)
nc -l 1234 > 1234.txt # s2上开通监听端口1234
nc -w 1 192.168.200.27 1234 < abc.txt # 发送端,传入文件abc.txt
nc -lp 22222 > log.rar # 接收端
nc -nc -vn 26.5.189.16 22222 < log.rar # 发送端
# 发送完后自动断开连接(超时3s)
nc –n ip port > yyy # 接收
nc –n –l –p port –vv –w 3 < xxx # 发送
# 传目录
nc -l 9995 | tar xfvz - # 发送端
tar cfz - * | nc 10.0.1.162 9995 # 发送端,当前目录
# (2)硬盘/分区 克隆
# 基本相似,由dd获得硬盘或分区的数据,然后传输即可。克隆硬盘或分区的操作,不应在已经mount的的系统上进行。
nc -l -p 1234 | dd of=/dev/sda # s2开启监听
dd if=/dev/sda | nc 192.168.200.27 1234 # s1上开始传输
# (3)端口扫描
nc -nvv 192.168.0.1 80 //扫描 80端口
nc -v www.thanks.live 80 # 检测端口80是否可用
nc -v -w 1 192.168.200.29 -z 20-30 # 从20依次扫描到30
nc -v -z -w2 192.168.0.3 1-100 # TCP端口扫描
nc -u -z -w2 192.168.0.1 1-1000 # UDP扫描192.168.0.3 的端口 范围是 1-1000
# (4)telnet服务器(远程登录)
nc -l -p 9995 -e bash # 服务端
nc 10.200.0.79 9995 # 客户端
第三方工具
最强跨平台传输软件,速度快体积小,比苹果隔空传送好…
- syncthing和localsend都有用,localsend日常跨设备分享很方便, syncthing 偏向同步
reep.io 网页
- 【2018-6-21】webrtc peer to peer文件传输工具reep.io失效,send-anywhere全终端覆盖, 基于浏览器,直接选中本地文件,生成下载链接,速度400kb;Snapdrop,免软件免登录的一款工具,只需在同一WIFI环境下打开Snapdrop网页,就能侦测到彼此,并开始传输文件。知乎大文件传输工具有哪些, 示例:mathematica下载,【2019-05-16】mathematica快速入门
LocalSend 开源
LocalSend 是一款免费开源的跨平台文件传输工具
- 支持 Android、Windows、macOS、iOS、Linux等平台,安装后只需要在设置中打开快速保存开关即可使用。
- 速度快、支持跨平台传输,还能自定义保存目录。
- 电脑端安装包只有15MB,不会占用资源,可以在后台运行,需要时随时反应。
相比于苹果的隔空传送,LocalSend更方便快捷,适合办公人士使用。
syncthing
Syncthing 是一个开源免费的数据同步神器,被称为 Resilio Sync 的替代品,支持 Android、Linux、Windows、Mac OS X 等系统
- 在 2 台任何系统任何设备之间,实现文件实时同步,很强大。
- 而且数据很安全,不会存储在你的设备以外的其他地方。
- 所有通信都使用 TLS 进行保护。
- 所使用的加密包括完美的前向保密,以防止窃听者获得对您的数据的访问权限。
很适合用来搭建私有同步网盘。
二维码传输
【2024-9-24】二维码文件传输
- No internet/bluetooth/NFC/etc is used. All data is transmitted through the camera lens.
- 无需网络、蓝牙和NFC,所有数据只通过摄像头传输
GitHub: libcimbar
- 发送端: Web 站点 cimbar 上传文件(33M以内)
- 接收端: CameraFileCopy (简称 cfc) apk下载
- 下载速度: (~106 KB/s)

编译安装
编译安装常见命令
./configure # 配置
make # 构建
make install # 安装
整个过程分为三步:
配置configure脚本负责在系统软件构建环境。确保构建和安装过程所需要的依赖准备好,并且搞清楚使用这些依赖需要的东西。- Unix 程序一般是用 C 语言写,所以需要一个 C 编译器去构建。在这个例子中 configure 要做的就是确保系统中有 C 编译器,并确定它的名字和路径。
构建- 当 configure 配置完毕后,可以使用
make命令执行构建。这个过程会执行在 Makefile 文件中定义的一系列任务将软件源代码编译成可执行文件。 - 下载的源码包一般没有一个最终的 Makefile 文件,一般是一个模版文件 Makefile.in 文件,然后 configure 根据系统的参数生成一个定制化的 Makefile 文件。
- 当 configure 配置完毕后,可以使用
安装- 软件已经被构建好且可执行,接下来将可执行文件复制到最终路径。
make install命令将可执行文件、第三方依赖包和文档复制到正确路径。- 可执行文件被复制到某个 PATH 包含的路径,程序调用文档被复制到某个 MANPATH 包含的路径,还有程序依赖的文件也会被存放在合适的路径。
- 因为安装这一步也是被定义在 Makefile 中,所以程序安装的路径可以通过 configure 命令的参数指定,或者 configure 通过系统参数决定。
如果要将可执行文件安装在系统路径,执行这步需要赋予相应的权限,一般是通过 sudo。
不直接写 configure 脚本文件,而是通过创建一个描述文件 configure.ac 来描述 configure 需要做的事情。
configure.ac使用m4sh写,m4sh 是 m4 宏命令和 shell 脚本的组合。
make 和 make install 区别
- make 用来编译,从Makefile中读取指令,然后编译。
- make install 用来安装,也从Makefile中读取指令,安装到指定的位置。
常见目标:
- make all:编译程序、库、文档等(等同于make)
- make install:安装已经编译好的程序。复制文件树中到文件到指定的位置
- make unistall:卸载已经安装的程序。
- make clean:删除由make命令产生的文件
- make distclean:删除由./configure产生的文件
- make check:测试刚刚编译的软件(某些程序可能不支持)
- make installcheck:检查安装的库和程序(某些程序可能不支持)
- make dist:重新打包成packname-version.tar.gz
【2024-4-20】configure、 make、 make install 背后的原理
linux进程
进程查看
进程查看
- pstree 查看进程的树型结构
- tree 查看目录的树型结构
pstree # 查看进程树
pstree -p # 查看并打印进程树,含pid
pstree -p 123232 # 查看某个进程的树型结构
tree /tmp # 查看某个目录的目录树
tree -h /tmp # 查看某个目录的目录树,并打印文件大小
fork
一个进程包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
- 一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。
- 然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
fork函数创建子进程
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid; //fpid表示fork函数返回的值
int count=0;
fpid = fork(); // 创建子进程(克隆),返回0,错误时返回负数
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0) {
printf("i am the child process, my process id is %d\n", getpid());
printf("我是爹的儿子\n");//对某些人来说中文看着更直白。
count++;
}
else {
printf("i am the parent process, my process id is %d\n", getpid());
printf("我是孩子他爹\n");
count++;
}
printf("统计结果是: %d\n",count);
return 0;
}
top/htop
htop官网是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台orX终端中),需要ncurses。
- 与Linux传统的
top相比,htop更加人性化。它可以让用户交互式操作,支持颜色主题,可横向或者纵向滚动浏览进程列表,并支持鼠标操作。
与top相比,htop有以下优点:
- 可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整命令行;
- 在启动时,比top要快;
- 杀进程时不需要输入进程号;
- htop支持鼠标操作;
- top已经很老了;
crontab使用
- Linux定时任务Crontab命令详解,crontab在线测试
- 通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script脚本。时间间隔的单位可以是分钟、小时、日、月、周及以上的任意组合。这个命令非常设合周期性的日志分析或数据备份等工作。
- 命令参数:
- -u user:用来设定某个用户的crontab服务,例如,“-u ixdba”表示设定ixdba用户的crontab服务,此参数一般有root用户来运行。
- file:file是命令文件的名字,表示将file做为crontab的任务列表文件并载入crontab。如果在命令行中没有指定这个文件,crontab命令将接受标准输入(键盘)上键入的命令,并将它们载入crontab。
- -e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。
- -l:显示某个用户的crontab文件内容,如果不指定用户,则表示显示当前用户的crontab文件内容。
- -r:从/var/spool/cron目录中删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。
- -i:在删除用户的crontab文件时给确认提示。
#安装crontab:
yum install crontabs
#服务操作说明:
/sbin/service crond start # 启动服务
/sbin/service crond stop # 关闭服务
/sbin/service crond restart # 重启服务
/sbin/service crond reload # 重新载入配置
/sbin/service crond status # 启动服务
# 查看
crontab [-u user] file
crontab [-u user] [ -e | -l | -r ] # l显示,e编辑
# 看日志
tail -n 2 /var/log/cron
# 更新系统时间
ntpdate time.windows.com
- 每一行都代表一项任务,每行的每个字段代表一项设置,它的格式共分为六个字段,前五段是时间设定段,第六段是要执行的命令段,格式如下:minute hour day month week command
- minute: 表示分钟,可以是从0到59之间的任何整数。
- hour:表示小时,可以是从0到23之间的任何整数。
- day:表示日期,可以是从1到31之间的任何整数。
- month:表示月份,可以是从1到12之间的任何整数。
- week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
- command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
- 示例

#分 时 天 月 周 命令
* * * * * cd /home/work/code/training_platform/web && python t.py
# 每一分钟执行一次 /bin/ls
* * * * * /bin/ls
# 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup
0 6-12/3 * 12 * /usr/bin/backup
# 周一到周五每天下午 5:00 寄一封信给 alex@domain.name:
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata
# 每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha":
20 0-23/2 * * * echo "haha"
0 */2 * * * /sbin/service httpd restart # 每两个小时重启一次apache
50 7 * * * /sbin/service sshd start # 每天7:50开启ssh服务
50 22 * * * /sbin/service sshd stop # 每天22:50关闭ssh服务
0 0 1,15 * * fsck /home # 每月1号和15号检查/home 磁盘
1 * * * * /home/bruce/backup # 每小时的第一分执行 /home/bruce/backup这个文件
00 03 * * 1-5 find /home "*.xxx" -mtime +4 -exec rm {} \; # 每周一至周五3点钟,在目录/home中,查找文件名为*.xxx的文件,并删除4天前的文件。
30 6 */10 * * ls # 每月的1、11、21、31日是的6:30执行一次ls命令
# 当程序在你所指定的时间执行后,系统会发一封邮件给当前的用户,显示该程序执行的内容,若是你不希望收到这样的邮件,请在每一行空一格之后加上 > /dev/null 2>&1 即可
20 03 * * * . /etc/profile;/bin/sh /var/www/runoob/test.sh > /dev/null 2>&1
- 用crontab来定时执行脚本无法执行,但是如果直接通过命令(如:./test.sh)又可以正常执行,这主要是因为无法读取环境变量。
- 解决方法:
- 1、所有命令需要写成绝对路径形式,如: /usr/local/bin/docker。
- 2、在 shell 脚本开头使用以下代码,. /etc/profile; . ~/.bash_profile
- 3、在 /etc/crontab 中添加环境变量,在可执行命令之前添加命令 . /etc/profile;/bin/sh,使得环境变量生效
- 20 03 * * * . /etc/profile;/bin/sh /var/www/runoob/test.sh
linux I/O模式
【2021-12-17】Linux 五种 IO 模式及 select、poll、epoll 详解
从事 Web 服务器开发的后端程序员,必然绕不开网络编程,而其中最基础也是最重要的部分就是 Linux I/O模式 及 Socket 编程。
基础概念
基础概念
- 1.1、用户空间和内核空间
- 对于32位操作系统而言,它的寻址空间是4G(2的32次方),注意这里的4G是虚拟内存空间大小。以 Linux 为例,它将最高的1G字节给内核使用,称为内核空间,剩下的3G给用户进程使用,称为用户空间。这样做的好处就是隔离,保证内核安全。
- 1.2、进程切换
- 这是内核要干的事,字面意思很好理解,挂起正在运行的 A 进程,然后运行 B 进程,当然这其中的流程比较复杂,涉及到上下文切换,且非常消耗资源,感兴趣的同学可以去深入研究。
- 1.3、进程的阻塞
- 进程阻塞是本进程的行为,比如和其他进程通信时,等待请求的数据返回;进程进入阻塞状态时不占用CPU资源的
- 1.4、文件描述符
- 在 Linux 世界里,一切皆文件。怎么理解呢?当程序打开一个现有文件或创建新文件时,内核会向进程返回一个文件描述符,文件描述符在形式上是一个非负整数,其实就是一个索引值,指向该进程打开文件的记录表(它是由内核维护的)。
- 1.5、缓存 I/O
- 和标准 IO 是一个概念,当应用程序需要从内核读数据时,数据先被拷贝到操作系统的内核缓冲区(page cache),然后再从该缓冲区拷贝到应用程序的地址空间。
当应用程序发起一次 read 调用时,会经历以下两个阶段:
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process) 正式因为这两个阶段,Linux 系统产生了下述五种 IO 方式:
- 阻塞 I/O(blocking IO):blocking IO的特点就是在IO执行的两个阶段都被block了
- 非阻塞 I/O(nonblocking IO):non-blocking IO 的特点是用户进程需要不断的主动询问内核 “ 数据好了吗?”
- 异步 I/O(asynchronous IO)
- 同步:synchronous IO做”IO operation”的时候会将process阻塞。之前所述的blocking IO,non-blocking IO,IO multiplexing 都属于 synchronous IO。各IO模式比较:
- 对于 non-blocking IO中,虽然进程大部分时间都不会被 block,但是它仍然要求进程去主动的 check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。 - 异步:asynchronous IO 完全不同于 no-blocking IO,它就像是用户进程将整个 IO 操作交给了内核完成,然后内核做完后发出信号通知。在此期间,用户进程不需要去检查 IO 操作的状态,也不需要主动的去拷贝数据。
- I/O 多路复用( IO multiplexing):
- 通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
- select,poll,epoll 都是 IO 多路复用的机制,它们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
- 信号驱动 I/O( signal driven IO)(很少见,可忽略)
网络编程(socket)
socket编程基于传输层,是应用层和传输层之间的一个抽象层。在使用socket API时,实际上每创建一个socket,都会分配两个缓冲区:输入缓冲区和输出缓冲区(大小一般是8K)
- Linux下一切皆文件的思想,两台主机在进行通信时,write 函数是向缓冲区里写,read 函数是从缓冲区里读,至于缓冲区里的数据什么时候被传输,有没有达到目标主机,这些都交给传输层的TCP/UDP来做。
- 但Windows中,将 socket文件 和 普通文件 分开,所以不能用write函数和read函数实现,而是用send函数和recv函数。
每次通信都打开了一个socket文件,所以通信结束后,在进程关闭前,要关闭所有的socket文件。
进程通信的概念最初来源于单机系统。由于每个进程都在自己的地址范围内运行,为保证两个相互通信的进程之间既互不干扰又协调一致工作,操作系统为进程通信提供了相应设施,如
- UNIX BSD有:管道(pipe)、命名管道(named pipe)软中断信号(signal)
- UNIX system V有:消息(message)、共享存储区(shared memory)和信号量(semaphore)等. 仅限于用在本机进程之间通信。网间进程通信要解决的是不同主机进程间的相互通信问题(同机进程通信是特例)。
- 同一主机上,不同进程可用进程号(process ID)唯一标识。
- 但在网络环境下,各主机独立分配的进程号不能唯一标识该进程。不同机器有相同进程号,另外,操作系统支持的网络协议众多,不同协议的工作方式不同,地址格式也不同。网间进程通信还要解决多重协议的识别问题。
- TCP/IP协议族已经解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)。这样利用三元组(ip地址,协议,端口)就可以标识网络的进程了,网络中的进程通信就可以利用这个标志与其它进程进行交互。 TCP/IP协议的应用程序通常采用应用编程接口:UNIX BSD的套接字(socket)和UNIX System V的TLI(已经被淘汰)来实现网络进程之间的通信。目前几乎所有的应用程序都是采用socket,而现在又是网络时代,网络中进程通信是无处不在,这就是我为什么说“一切皆socket”。
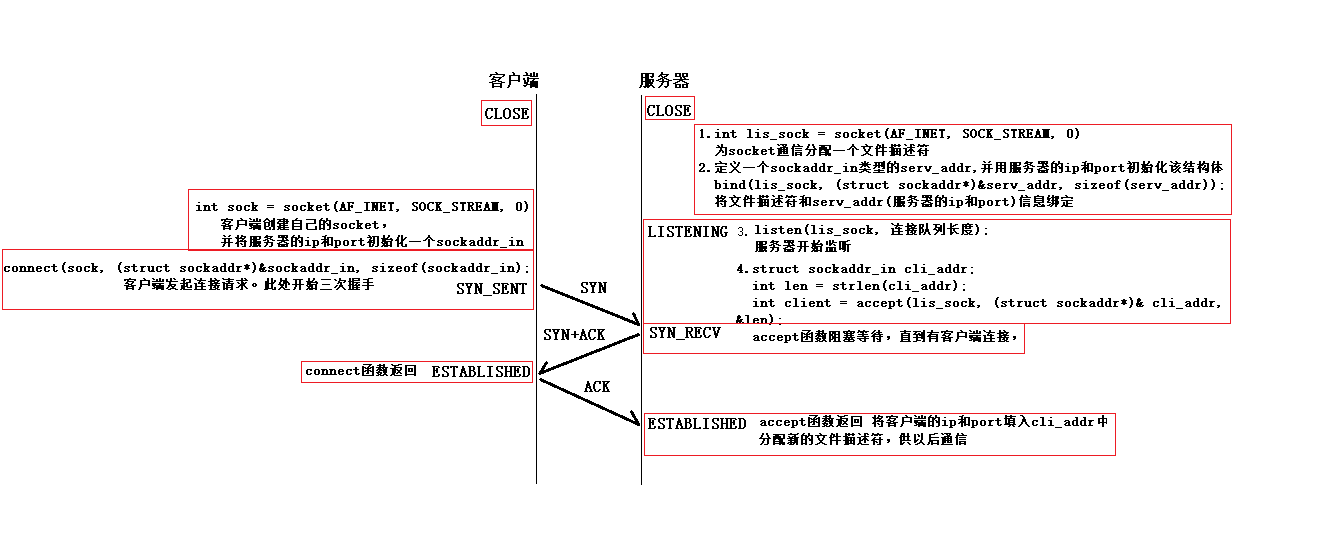
TCP – 三次握手、四次挥手
socket的API是在三次握手和四次挥手的基础上设置的接口
- 结构体:ip地址 + 端口号,如:sockaddr、sockaddr_in 总的来说,不管是 struct sockaddr 还是 struct sockaddr_in 都是存放了一个ip地址,一个端口号,和ip的类型(IPV4还是IPV6)
注意:
- 每次输入的ip要通过inet_addr(“127.0.0.1”)函数转化,将一个点分十进制ip转换成长无符号整形,头文件在<arpa/inet.h>中
- 端口号要转换成小端
三次握手
- 一个客户端只有一个sock(文件描述符),而一个服务器最少有两个(一个是自己创建socket时的sock,剩下的是每有一个客户端连接服务器就生成一个sock文件描述符)。数据传输过程相当于文件的读写操作
 四次挥手
四次挥手- 四次挥手在socket API上的接口表示为关闭各自拥有的文件描述符即可
什么是socket
什么是 Socket 呢?简单理解,就是: ip地址 + 端口号。
当两个进程间需要通信时,首先要创建五元组(源ip地址、目的ip地址、源端口号、目的端口号、协议),建立 tcp 连接,建立好连接之后,两个进程各自有一个 Socket 来标识,这两个 socket 组成的 socket pair 也就唯一标识了一个连接。有了连接之后,应用程序得要从 tcp 流上获取数据,然后再处理数据。
socket工作原理
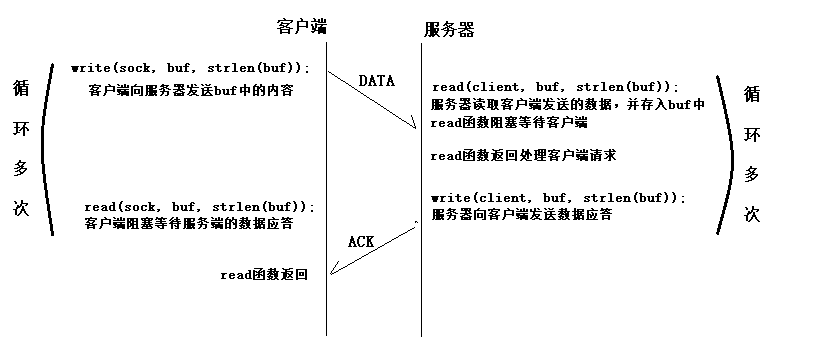
工作原理:“open—write/read—close”模式。
- 服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。
- 这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。
- 客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据
- 最后关闭连接,一次交互结束。 涉及的函数
- (1)socket初始化:
- int socket(int protofamily, int type, int protocol); //返回sockfd
- (2)bind()函数把一个地址族中的特定地址赋给socket。
- int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- (3)listen():调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求
- int listen(int sockfd, int backlog); // backlog排队的最大连接个数
- socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
- (4)connect()函数: 客户端通过调用connect函数来建立与TCP服务器的连接
- int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- (5)accept()函数
- TCP服务器端依次调用socket()、bind()、listen()之后,就会监听指定的socket地址了。TCP客户端依次调用socket()、connect()之后就向TCP服务器发送了一个连接请求。TCP服务器监听到这个请求之后,就会调用accept()函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
- int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); //返回连接connect_fd
- (6)read()、write()等函数:调用网络I/O进行读写操作
- read()/write()
- recv()/send()
- readv()/writev()
- recvmsg()/sendmsg() // 最通用的I/O函数
- recvfrom()/sendto()
- (7)close()函数
- 在服务器与客户端建立连接之后,会进行一些读写操作,完成了读写操作就要关闭相应的socket描述字,好比操作完打开的文件要调用fclose关闭打开的文件。
- close一个TCP socket的缺省行为时把该socket标记为以关闭,然后立即返回到调用进程。该描述字不能再由调用进程使用,也就是说不能再作为read或write的第一个参数。
- 注意:close操作只是使相应socket描述字的引用计数-1,只有当引用计数为0的时候,才会触发TCP客户端向服务器发送终止连接请求。
socket 实现 TCP
参考
代码:
- 客户端向服务器发送数据
- 服务器向客户端响应
- C编译:gcc socket_test.cpp -o socket
- C++:g++ socket_test.cpp -o socket -std=c++11
// 一直监听本机的8000号端口,如果收到连接请求,将接收请求并接收客户端发来的消息,并向客户端返回消息。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include <unistd.h> // fork/close
#define DEFAULT_PORT 8000
#define MAXLINE 4096
int main(int argc, char** argv)
{
int socket_fd, connect_fd;
struct sockaddr_in servaddr;
char buff[4096];
int n;
//初始化Socket
if( (socket_fd = socket(AF_INET, SOCK_STREAM, 0)) == -1 ){
printf("create socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
//初始化
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY); //IP地址设置成INADDR_ANY,让系统自动获取本机的IP地址。
servaddr.sin_port = htons(DEFAULT_PORT); //设置的端口为DEFAULT_PORT
//将本地地址绑定到所创建的套接字上
if( bind(socket_fd, (struct sockaddr*)&servaddr, sizeof(servaddr)) == -1){
printf("bind socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
//开始监听是否有客户端连接
if( listen(socket_fd, 10) == -1){
printf("listen socket error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("======waiting for client's request======\n");
while(1){
//阻塞直到有客户端连接,不然多浪费CPU资源。
if( (connect_fd = accept(socket_fd, (struct sockaddr*)NULL, NULL)) == -1){
printf("accept socket error: %s(errno: %d)",strerror(errno),errno);
continue;
}
//接受客户端传过来的数据
n = recv(connect_fd, buff, MAXLINE, 0);
//向客户端发送回应数据
if(!fork()){ /*紫禁城*/
if(send(connect_fd, "Hello,you are connected!\n", 26,0) == -1)
perror("send error");
close(connect_fd);
exit(0);
}
buff[n] = '\0';
printf("recv msg from client: %s\n", buff);
close(connect_fd);
}
close(socket_fd);
}
/* File Name: client.c */
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define MAXLINE 4096
int main(int argc, char** argv)
{
int sockfd, n,rec_len;
char recvline[4096], sendline[4096];
char buf[MAXLINE];
struct sockaddr_in servaddr;
if( argc != 2){
printf("usage: ./client <ipaddress>\n");
exit(0);
}
if( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0){
printf("create socket error: %s(errno: %d)\n", strerror(errno),errno);
exit(0);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8000);
// inet_pton 是Linux下IP地址转换函数,可以在将IP地址在“点分十进制”和“整数”之间转换 ,是inet_addr的扩展。
if( inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0){
printf("inet_pton error for %s\n",argv[1]);
exit(0);
}
if( connect(sockfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) < 0){
printf("connect error: %s(errno: %d)\n",strerror(errno),errno);
exit(0);
}
printf("send msg to server: \n");
fgets(sendline, 4096, stdin);
if( send(sockfd, sendline, strlen(sendline), 0) < 0)
{
printf("send msg error: %s(errno: %d)\n", strerror(errno), errno);
exit(0);
}
if((rec_len = recv(sockfd, buf, MAXLINE,0)) == -1) {
perror("recv error");
exit(1);
}
buf[rec_len] = '\0';
printf("Received : %s ",buf);
close(sockfd);
exit(0);
}
测试:
# 编译server.c
gcc -o server server.c
# 启动进程:
./server
# 显示结果并等待客户端连接。
# ======waiting for client's request======
# 编译 client.c
gcc -o client server.c
# 客户端去连接server:
./client 127.0.0.1
# 等待输入消息
# 发送一条消息,输入:c++,服务端就能看到
# 可以不用client,可以使用telnet来测试:
telnet 127.0.0.1 8000
服务端:
/*serve_tcp.c*/
#include<stdio.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
int main(){
//创建套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
//初始化socket元素
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
serv_addr.sin_port = htons(1234);
//绑定文件描述符和服务器的ip和端口号
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
//进入监听状态,等待用户发起请求
listen(serv_sock, 20);
//接受客户端请求
//定义客户端的套接字,这里返回一个新的套接字,后面通信时,就用这个clnt_sock进行通信
struct sockaddr_in clnt_addr;
socklen_t clnt_addr_size = sizeof(clnt_addr);
int clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_addr, &clnt_addr_size);
//接收客户端数据,并相应
char str[256];
read(clnt_sock, str, sizeof(str));
printf("client send: %s\n",str);
strcat(str, "+ACK");
write(clnt_sock, str, sizeof(str));
//关闭套接字
close(clnt_sock);
close(serv_sock);
return 0;
}
客户端:
/*client_tcp.c*/
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<arpa/inet.h>
#include<sys/socket.h>
int main(){
//创建套接字
int sock = socket(AF_INET, SOCK_STREAM, 0);
//服务器的ip为本地,端口号1234
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
serv_addr.sin_port = htons(1234);
//向服务器发送连接请求
connect(sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
//发送并接收数据
char buffer[40];
printf("Please write:");
scanf("%s", buffer);
write(sock, buffer, sizeof(buffer));
read(sock, buffer, sizeof(buffer) - 1);
printf("Serve send: %s\n", buffer);
//断开连接
close(sock);
return 0;
}
Socket编程方法
三种高效的 Socket 编程方法:select、poll 和 epoll.
select,poll,epoll 都是 IO 多路复用的机制,它们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。select、poll、epoll 三者区别
总结:
- epoll是 Linux 目前大规模网络并发程序开发的首选模型。在绝大多数情况下性能远超 select 和 poll。目前流行的高性能web服务器Nginx正式依赖于epoll提供的高效网络套接字轮询服务。
- 但是,在并发连接不高的情况下,多线程 + 阻塞 IO 方式可能性能更好。
select – 数组,O(N)
select 最多能同时监视 1024 个 socket(因为 fd_set 结构体大小是 128 字节,每个 bit 表示一个文件描述符)。用户需要维护一个临时数组,存储文件描述符。当内核有事件发生时,内核将 fd_set 中没发生的文件描述符清空,然后拷贝到用户区。select 返回的是整个数组,它需要遍历整个数组才知道谁发生了变化。
代码:
#include<stdio.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<unistd.h>
#include<netinet/in.h>
#include<arpa/inet.h>
#include<stdlib.h>
#include<string.h>
#include<sys/time.h>
static void Usage(const char* proc)
{
printf("%s [local_ip] [local_port]\n",proc);
}
int array[4096];
static int start_up(const char* _ip,int _port)
{
int sock = socket(AF_INET,SOCK_STREAM,0);
if(sock < 0)
{
perror("socket");
exit(1);
}
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = inet_addr(_ip);
if(bind(sock,(struct sockaddr*)&local,sizeof(local)) < 0)
{
perror("bind");
exit(2);
}
if(listen(sock,10) < 0)
{
perror("listen");
exit(3);
}
return sock;
}
int main(int argc,char* argv[])
{
if(argc != 3)
{
Usage(argv[0]);
return -1;
}
int listensock = start_up(argv[1],atoi(argv[2]));
int maxfd = 0;
fd_set rfds;
fd_set wfds;
array[0] = listensock;
int i = 1;
int array_size = sizeof(array)/sizeof(array[0]);
for(; i < array_size;i++)
{
array[i] = -1;
}
while(1)
{
FD_ZERO(&rfds);
FD_ZERO(&wfds);
for(i = 0;i < array_size;++i)
{
if(array[i] > 0)
{
FD_SET(array[i],&rfds);
FD_SET(array[i],&wfds);
if(array[i] > maxfd)
{
maxfd = array[i];
}
}
}
switch(select(maxfd + 1,&rfds,&wfds,NULL,NULL))
{
case 0:
{
printf("timeout\n");
break;
}
case -1:
{
perror("select");
break;
}
default:
{
int j = 0;
for(; j < array_size; ++j)
{
if(j == 0 && FD_ISSET(array[j],&rfds))
{
//listensock happened read events
struct sockaddr_in client;
socklen_t len = sizeof(client);
int new_sock = accept(listensock,(struct sockaddr*)&client,&len);
if(new_sock < 0)//accept failed
{
perror("accept");
continue;
}
else//accept success
{
printf("get a new client%s\n",inet_ntoa(client.sin_addr));
fflush(stdout);
int k = 1;
for(; k < array_size;++k)
{
if(array[k] < 0)
{
array[k] = new_sock;
if(new_sock > maxfd)
maxfd = new_sock;
break;
}
}
if(k == array_size)
{
close(new_sock);
}
}
}//j == 0
else if(j != 0 && FD_ISSET(array[j], &rfds))
{
//new_sock happend read events
char buf[1024];
ssize_t s = read(array[j],buf,sizeof(buf) - 1);
if(s > 0)//read success
{
buf[s] = 0;
printf("clientsay#%s\n",buf);
if(FD_ISSET(array[j],&wfds))
{
char *msg = "HTTP/1.0 200 OK <\r\n\r\n<html><h1>yingying beautiful</h1></html>\r\n";
write(array[j],msg,strlen(msg));
}
}
else if(0 == s)
{
printf("client quit!\n");
close(array[j]);
array[j] = -1;
}
else
{
perror("read");
close(array[j]);
array[j] = -1;
}
}//else j != 0
}
break;
}
}
}
return 0;
}
poll – 链表,O(N)
poll 就是把 select 中的 fd_set 数组换成了链表,其他和 select 没什么不同。
代码:
- poll()函数返回fds集合中就绪的读、写,或出错的描述符数量,返回0表示超时,返回-1表示出错;
- fds是一个struct pollfd类型的数组,用于存放需要检测其状态的socket描述符,并且调用poll函数之后fds数组不会被清空;
- nfds记录数组fds中描述符的总数量;
- timeout是调用poll函数阻塞的超时时间,单位毫秒;
- 一个pollfd结构体表示一个被监视的文件描述符,通过传递fds[]指示 poll() 监视多个文件描述符。其中,结构体的events域是监视该文件描述符的事件掩码,由用户来设置这个域,结构体的revents域是文件描述符的操作结果事件掩码,内核在调用返回时设置这个域。events域中请求的任何事件都可能在revents域中返回。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include<arpa/inet.h>
#include<poll.h>
static void usage(const char *proc)
{
printf("%s [local_ip] [local_port]\n",proc);
}
int start_up(const char*_ip,int _port)
{
int sock = socket(AF_INET,SOCK_STREAM,0);
if(sock < 0)
{
perror("socket");
return 2;
}
int opt = 1;
setsockopt(sock,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = inet_addr(_ip);
if(bind(sock,(struct sockaddr*)&local,sizeof(local)) < 0)
{
perror("bind");
return 3;
}
if(listen(sock,10) < 0)
{
perror("listen");
return 4;
}
return sock;
}
int main(int argc, char*argv[])
{
if(argc != 3)
{
usage(argv[0]);
return 1;
}
int sock = start_up(argv[1],atoi(argv[2]));
struct pollfd peerfd[1024];
peerfd[0].fd = sock;
peerfd[0].events = POLLIN;
int nfds = 1;
int ret;
int maxsize = sizeof(peerfd)/sizeof(peerfd[0]);
int i = 1;
int timeout = -1;
for(; i < maxsize; ++i)
{
peerfd[i].fd = -1;
}
while(1)
{
switch(ret = poll(peerfd,nfds,timeout))
{
case 0:
printf("timeout...\n");
break;
case -1:
perror("poll");
break;
default:
{
if(peerfd[0].revents & POLLIN)
{
struct sockaddr_in client;
socklen_t len = sizeof(client);
int new_sock = accept(sock,\
(struct sockaddr*)&client,&len);
printf("accept finish %d\n",new_sock);
if(new_sock < 0)
{
perror("accept");
continue;
}
printf("get a new client\n");
int j = 1;
for(; j < maxsize; ++j)
{
if(peerfd[j].fd < 0)
{
peerfd[j].fd = new_sock;
break;
}
}
if(j == maxsize)
{
printf("to many clients...\n");
close(new_sock);
}
peerfd[j].events = POLLIN;
if(j + 1 > nfds)
nfds = j + 1;
}
for(i = 1;i < nfds;++i)
{
if(peerfd[i].revents & POLLIN)
{
printf("read ready\n");
char buf[1024];
ssize_t s = read(peerfd[i].fd,buf, \
sizeof(buf) - 1);
if(s > 0)
{
buf[s] = 0;
printf("client say#%s",buf);
fflush(stdout);
peerfd[i].events = POLLOUT;
}
else if(s <= 0)
{
close(peerfd[i].fd);
peerfd[i].fd = -1;
}
else
{
}
}//i != 0
else if(peerfd[i].revents & POLLOUT)
{
char *msg = "HTTP/1.0 200 OK \
<\r\n\r\n<html><h1> \
yingying beautiful \
</h1></html>\r\n";
write(peerfd[i].fd,msg,strlen(msg));
close(peerfd[i].fd);
peerfd[i].fd = -1;
}
else
{
}
}//for
}//default
break;
}
}
return 0;
}
epoll – 哈希,O(1),主流
epoll 是基于事件驱动的 IO 方式,它没有文件描述符个数限制,它将用户关心的文件描述符的事件存放到内核的一个事件表中(简单来说,就是由内核来负责存储(红黑树)有事件的 socket 句柄),这样在用户空间和内核空间的copy只需一次。优点如下:
- 没有最大并发连接的限制,能打开的fd上限远大于1024(1G的内存能监听约10万个端口)
- 采用回调的方式,效率提升。只有活跃可用的fd才会调用callback函数,也就是说 epoll 只管你“活跃”的连接,而跟连接总数无关;
- 内存拷贝。使用mmap()文件映射内存来加速与内核空间的消息传递,减少复制开销。 epoll 有两种工作方式:
- LT模式(水平触发):若就绪的事件一次没有处理完,就会一直去处理。也就是说,将没有处理完的事件继续放回到就绪队列之中(即那个内核中的链表),一直进行处理。
- ET模式(边缘触发):就绪的事件只能处理一次,若没有处理完会在下次的其它事件就绪时再进行处理。而若以后再也没有就绪的事件,那么剩余的那部分数据也会随之而丢失。 由此可见:ET模式的效率比LT模式的效率要高很多。只是如果使用ET模式,就要保证每次进行数据处理时,要将其处理完,不能造成数据丢失,这样对编写代码的人要求就比较高。
#include<stdio.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include<arpa/inet.h>
#include<stdlib.h>
#include<string.h>
#include<sys/epoll.h>
static Usage(const char* proc)
{
printf("%s [local_ip] [local_port]\n",proc);
}
int start_up(const char*_ip,int _port)
{
int sock = socket(AF_INET,SOCK_STREAM,0);
if(sock < 0)
{
perror("socket");
exit(2);
}
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = inet_addr(_ip);
if(bind(sock,(struct sockaddr*)&local,sizeof(local)) < 0)
{
perror("bind");
exit(3);
}
if(listen(sock,10)< 0)
{
perror("listen");
exit(4);
}
return sock;
}
int main(int argc, char*argv[])
{
if(argc != 3)
{
Usage(argv[0]);
return 1;
}
int sock = start_up(argv[1],atoi(argv[2]));
int epollfd = epoll_create(256);
if(epollfd < 0)
{
perror("epoll_create");
return 5;
}
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = sock;
if(epoll_ctl(epollfd,EPOLL_CTL_ADD,sock,&ev) < 0)
{
perror("epoll_ctl");
return 6;
}
int evnums = 0;//epoll_wait return val
struct epoll_event evs[64];
int timeout = -1;
while(1)
{
switch(evnums = epoll_wait(epollfd,evs,64,timeout))
{
case 0:
printf("timeout...\n");
break;
case -1:
perror("epoll_wait");
break;
default:
{
int i = 0;
for(; i < evnums; ++i)
{
struct sockaddr_in client;
socklen_t len = sizeof(client);
if(evs[i].data.fd == sock \
&& evs[i].events & EPOLLIN)
{
int new_sock = accept(sock, \
(struct sockaddr*)&client,&len);
if(new_sock < 0)
{
perror("accept");
continue;
}//if accept failed
else
{
printf("Get a new client[%s]\n", \
inet_ntoa(client.sin_addr));
ev.data.fd = new_sock;
ev.events = EPOLLIN;
epoll_ctl(epollfd,EPOLL_CTL_ADD,\
new_sock,&ev);
}//accept success
}//if fd == sock
else if(evs[i].data.fd != sock && \
evs[i].events & EPOLLIN)
{
char buf[1024];
ssize_t s = read(evs[i].data.fd,buf,sizeof(buf) - 1);
if(s > 0)
{
buf[s] = 0;
printf("client say#%s",buf);
ev.data.fd = evs[i].data.fd;
ev.events = EPOLLOUT;
epoll_ctl(epollfd,EPOLL_CTL_MOD, \
evs[i].data.fd,&ev);
}//s > 0
else
{
close(evs[i].data.fd);
epoll_ctl(epollfd,EPOLL_CTL_DEL, \
evs[i].data.fd,NULL);
}
}//fd != sock
else if(evs[i].data.fd != sock \
&& evs[i].events & EPOLLOUT)
{
char *msg = "HTTP/1.0 200 OK <\r\n\r\n<html><h1>yingying beautiful </h1></html>\r\n";
write(evs[i].data.fd,msg,strlen(msg));
close(evs[i].data.fd);
epoll_ctl(epollfd,EPOLL_CTL_DEL, \
evs[i].data.fd,NULL);
}//EPOLLOUT
else
{
}
}//for
}//default
break;
}//switch
}//while
return 0;
}
- epoll_create函数创建一个epoll句柄,参数size表明内核要监听的描述符数量。调用成功时返回一个epoll句柄描述符,失败时返回-1。
- epoll_ctl函数注册要监听的事件类型。四个参数解释如下: epfd表示epoll句柄; op表示fd操作类型:EPOLL_CTL_ADD(注册新的fd到epfd中),EPOLL_CTL_MOD(修改已注册的fd的监听事件),EPOLL_CTL_DEL(从epfd中删除一个fd);fd是要监听的描述符; event表示要监听的事件,
- epoll_wait 函数等待事件的就绪,成功时返回就绪的事件数目,调用失败时返回 -1,等待超时返回 0。maxevents告诉内核events的大小,timeout表示等待的超时事件
epoll_event结构体定义如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
本文编辑器
- 主流文本编辑器学习曲线
- 几个经典的文本编辑器的学习曲线,不排除其中有调侃和幽默的味道
终端
- 【2022-4-8】运维神器!一个可以通过Web访问Linux终端的工具——rtty
- rtty由客户端和服务端组成。客户端采用纯C实现,服务端采用GO语言实现,前端界面采用vue实现。使用rtty可以在任何地方通过Web访问您的设备的终端,通过设备ID来区分您的不同的设备。rtty非常适合远程维护Linux设备。
- 【2021-5-15】Next Terminal 是一款开源的远程登录工具,需要自己部署,可以在任何一个浏览器远程访问Windows/Linux/macOS系统,方便快捷。Next Terminal 基于 Apache Guacamole 开发,使用到了guacd 服务。在线DEMO,即开即用,(用户名/密码 test/test),打开后就能看到后台了
- 具体功能如下:
- 授权凭证管理(密码、密钥)
- 资产管理(支持RDP、SSH、VNC、TELNET 协议)
- 指令管理(预设命令行)
- 批量执行命令
- 在线会话管理(监控、强制断开)
- 离线会话管理(查看录屏)
- 双因素认证
- 多用户登录
- 资产授权
- 用户分组

- Next Terminal – 用浏览器访问远程桌面,支持 RDP、SSH、VNC 和 Telnet
- 【2021-5-10】terminus,下载地址

【2020-9-2】Linux:在终端中查看图片和电影
- 安装工具(cacaview):yum install caca-utils -y
- 查看图片:cacaview test.jpg
- 按d改变图片配色

总结
下面是Zellij / tmux / Byobu 完整对比表格,包含核心功能、体验、配置、生态等维度,方便直接对比选择。
Zellij · tmux · Byobu 功能对比总表
| 对比项 | Zellij | tmux | Byobu |
|---|---|---|---|
| 本质 | 全新现代化终端复用器 | 经典底层终端复用引擎 | tmux/screen 封装增强工具 |
| 开发语言 | Rust | C | Shell + Python |
| 默认前缀键 | Ctrl+g |
Ctrl+b |
F9 菜单 / 同 tmux |
| 适合人群 | 新手、现代终端爱好者 | 运维、重度命令行用户 | 不想折腾的服务器用户 |
| 上手难度 | 极低(自带提示) | 中高(需记快捷键) | 低(F 键 + 菜单) |
| 界面提示 | 底部常驻快捷键提示 | 无,需手动配置 | 顶部状态栏 + 提示 |
| 系统状态栏 | 原生支持 | 需插件/配置 | 开箱即用(CPU/内存/时间) |
| 窗格分割 | 支持水平/垂直/浮动 | 水平/垂直 | 同 tmux |
| 浮动窗口 | ✅ 原生支持 | ❌ 需插件 | ❌ |
| 鼠标支持 | ✅ 默认开启 | ✅ 需配置开启 | ✅ 默认开启 |
| 会话持久化 | ✅ 自动保存 | ✅ 手动 detach | ✅ 自动后台 |
| 多用户共享会话 | ✅ | ✅ | ✅ |
| 布局保存/加载 | ✅ KDL 配置文件 | ✅ 插件/脚本 | ✅ 简单保存 |
| 启动速度 | 稍慢 | 极快 | 同 tmux |
| 资源占用 | 中等 | 极低 | 略高于 tmux |
| 配置文件 | KDL 声明式 | .tmux.conf |
简单文本配置 |
| 插件生态 | 年轻,Rust/Wasm | 极成熟(TPM 海量插件) | 依赖 tmux 插件 |
| 跨平台 | Linux/macOS/Windows | Linux/macOS/BSD | 主要 Linux |
| 默认预装 | 无 | 部分服务器自带 | Ubuntu/Debian 预装 |
选择建议
- 想要现代、好看、不用记快捷键 → 选 Zellij
- 服务器长期跑、追求稳定轻量、高度自定义 → 选 tmux
- Ubuntu 服务器、只想开箱即用带状态栏 → 选 Byobu
Terminal
系统自带终端
如何让终端开启时,自动执行某些脚本,如 颜色设置
macOS Terminal
- 新窗口启动时,只读取
~/.bash_profile - 加一行
source ~/.bashrc,自动加载配置 - 之后开新终端窗口,都会自动执行
.bashrc
echo "source ~/.bashrc" >> ~/.bash_profile
Superfile
【2024-11-29】Superfile:现代化终端文件管理器:简洁、美观、功能强大
命令行界面(CLI)
虽然命令行操作熟练后非常高效,但总感觉缺少一些直观和便捷性。
- 例如,命令行界面的文件管理往往不如图形用户界面(GUI)直观,而在命令行中预览和编辑文件,也远不如GUI中那样方便。
现有的Linux桌面GUI文件管理器往往显得过于沉重,使用起来有些”大炮打蚊子”的感觉。
精美的终端文件管理器——Superfile 结合了命令行的高效性和图形界面的便捷性,提供了一种更加精致、轻量级的文件管理体验,解决了传统CLI文件管理的种种不足。

安装
# linux
bash -c "$(curl -sLo- https://superfile.netlify.app/install.sh)" # 安装
rm ~/.local/bin/spf # 卸载
# windows
powershell -ExecutionPolicy Bypass -Command "Invoke-Expression ((New-Object System.Net.WebClient).DownloadString('https://superfile.netlify.app/install.ps1'))" # 安装
powershell -ExecutionPolicy Bypass -Command "Invoke-Expression ((New-Object System.Net.WebClient).Downl # 卸载
按键
spf # 启动
spf pl # 配置文件路径
tmux
nohup 简单场景有用,但不适用更复杂场景。
比如
- 用户无法再对后台进程进行输入操作,并且同时维护多个进程也很不方便。
解法:tmux
【2025–7-6】提升命令行使用体验──tmux 终端复用
tmux 是终端复用器(Terminal MUltipleXer)。
- 一个终端里创建多个窗口,并且将窗口分割成多个窗格,每个窗格都运行独立的 shell 进程。
- 让多个应用程序同时运行,而无需打开多个终端模拟器窗口(terminal emulator,如 Xshell、PuTTY、Windows Terminal 等)。
下图展示了使用 tmux 创建了一个窗口,并将窗口上下分屏成两个窗格,每个窗格都运行一个 zsh。
tmux 将终端和会话(session)进行了分离。把创建的窗口和窗格(和其中创建的所有 shell 进程及子进程)看成一个会话,用户可以随时退出(detach)当前会话,会话会在服务器后台保持运行。在之后,用户可以重新连接上(attach)这些会话,从而继续之前的工作。
tmux 采用客户端和服务器分离的架构(C/S 架构)。
- 用户看到和交互的是 tmux client,tmux client 中创建的窗口(和 shell 进程)连接在 tmux server 进程上。
- 因此,当用户退出 tmux client 后,会话内容可以在后台运行。 通过 pstree 命令,可以看到上图中运行的两个 zsh 的父进程是 tmux: server。
- 而和用户交互的其实是 tmux: client,其下面并无其他子进程。
【2020-9-1】tmux
- Tmux 是会话与窗口的”解绑”工具,彻底分离。
- (1)单个窗口中同时访问多个会话。这对于同时运行多个命令行程序很有用。
- (2) 让新窗口”接入”已经存在的会话。
- (3)每个会话有多个连接窗口,因此可以多人实时共享会话。
- (4)支持窗口任意的垂直和水平拆分。
tmux 有 session(会话), window(窗口), pane(窗格)三个粒度。
- session 是 tmux 最大的一个粒度,session 下可以创建多个 window
- window 可以分割成多个 pane。
大部分 Linux 发行版都提供 tmux 包
# 查看当前所有的会话信息
tmux ls # 或 tmux list-sessions
# 链接第一个会话
tmux a # 或 tmux attach
tmux list-keys # 查看 tmux 所有快捷键绑定
tmux source-file ~/.tmux.conf` 重新加载配置文件。
tmux list-keys # 列出所有绑定的快捷键。
tmux capture-pane # 捕获当前窗格内容到缓冲区或文件。
tmux display-message # 在状态栏显示消息。
# 附加到会话
tmux attach -t <session-name> 重新连接到指定会话。
tmux a -t <session-name> attach 简写
# 默认创建未命名的会话
tmux # 或 tmux new-session
# 后台进程 nohup替代方案
tmux new -s my_session # 创建进程,关掉终端
tmux attach -t my_session # 事后查看,重新连接到会话
# 结束会话
tmux kill-server # 结束所有会话
tmux kill-session -t my_session # 直接杀死指定会话
窗口操作
# 创建
Ctrl-B c # 创建新的窗口
Ctrl-B & # 删除当前窗口
# 切換
Ctrl-B Tab # 切换到刚刚的窗口
Ctrl-B p # 切换上一个
Ctrl-B n # 切换下一个
Ctrl-B 数字编号 # 切换到指定一个窗口
# 修改窗口名字
Ctrl-B , # 修改当前窗口名字
# 垂直划分窗格
tmux split-window -v
窗格操作
# 创建
Ctrl-B \" # 上下切分
Ctrl-B % # 左右切分
Ctrl-B x # 删除
# 切换
Ctrl-B 方向键 # 方向键上下左右
Ctrl-B [hjkl] # 使用 vi 风格的 hjkl 键切换,分别对应左上下右
Ctrl-B z # 切换全屏
# 翻页
先:Ctrl + b ,再fn + up
先:Ctrl + b ,再fn + down
退出翻页:q
tmux 像 vim 一样支持高度定制化,可以通过修改 ~/.tmux.conf 配置各种快捷键,网络上也有 oh-my-tmux 这样的项目来帮你做一些配置
在 ~/.bashrc 或 ~/.zshrc 中设置 alias t="tmux",tmux attach 效率立刻提升 300%
Zellij
- 官网
- github: zellij
- B站视频讲解:zellij - 比tmux更容易学习和上手的终端复用工具
Byobu
Byobu 易于使用的tmux(或screen )终端多路复用器包装器。轻松打开多个窗口并在单个终端连接中运行多个命令。
安装
sudo apt-get install byobu # 命令安装byobu
登录启动
- byobu-enable Byobu窗口管理器将在每次文本登录时自动启动
- byobu-disable Byobu窗口管理器将不再在登录时自动启动
色彩提示
- byobu-enable-prompt 启动Byobu的彩色提示
- byobu-disable-prompt 禁用Byobu的彩色提示
进程管理
需求
- 退出当前终端后,程序保持运行
nohup
当终端退出时(如关闭终端窗口,或者 ssh 网络中断),shell 进程会给所有子进程发送一个 SIGHUP 信号,从而导致进程结束。
而 nohup 可以让进程忽略掉 SIGHUP 信号,从而在后台保持运行。
使用方法
nohup 加让程序后台运行的方式
nohup ping 127.0.0.1 &
断开终端连接后,重新登陆到服务器,ping 进程仍然在运行。
nohup 默认将程序输出追加到 nohup.out 文件中
问题
问题汇总
- 不能直接使用命令别名,需要换成实际地址
- 不能传变量
【2026-1-29】示例
nohup GRADIO_SERVER_PORT=8080 lmf webui &>log_lmf.txt & # 报错,系统将GRADIO_SERVER_PORT当做命令执行
# 更改
# 将 GRADIO_SERVER_PORT=8080 lmf webui 写入shell文件(start.sh),再执行 nohup
nohup start.sh &>log_lmf.txt &
Visual Studio Code
问题
| 日期 | 问题 | 解决 |
| 【2022-8-6】 | vscode无法打开终端 | 解决:更改默认终端配置,“文件”→“首选项”→“设置”,弹出配置文件,按照链接修改接口 |
| 【2024-5-9】 | vscode里编辑输入时,卡顿,延迟1-3s,尝试更改setting里各种参数,无效 | 解决:重启电脑 |
卡顿
查看当前正在使用的插件
- MacOS: Cmd+Shift+P
- Windows: Ctrl+Shift+P
输入: Show Running Extensions
Vue Language Features 会导致 vscode 卡顿,可能是和别的格式化插件冲突
running file rename participant
vscode 中更改文件名后, 右下角进度条显示:
- 迟迟无响应, 未显示新文件
- 编辑文件中, 一直转圈
- 手工关掉窗口后, 恢复
- 进入设置: Code -> Settings -> Settings
- 搜索 rename
- Text Editors -> Files
- 将 Timeout 时间 改为 0
代理
github 库同步时,时常失败
- 参考 VSCode设置代理模式
原因
- 国内 github 访问不畅
解决
- 设置 vs code 代理
操作:
- 左下角齿轮 → Settings -> settings.json
- 增加一下代码
// [2025-3-18]
"http.proxy": "http://127.0.0.1:2080",
"https.proxy": "https://127.0.0.1:2080",
"http.proxyStrictSSL": false,
Vim 技能
vim 介绍
vim 编辑器好处
- 不使用鼠标,完全用键盘操作。
- 系统资源占用小,打开大文件毫无压力。
- 键盘命令变成肌肉记忆以后,操作速度极快。
- 服务器默认都安装 Vi 或 Vim
vi / vim是Linux上最常用的文本编辑器而且功能非常强大。只有命令,没有菜单,下图表示vi命令的各种模式的切换图。
- 【2019-07-18】编辑器学习曲线:
- 如何使用VIM搭建IDE?



- 【2017-12-14】awk思维导图,sed思维导图,更多linux工具总结
- pacvim,vim学习游戏
- 命令:git clone https://github.com/jmoon018/PacVim.git
键盘布局图
vim 工作模式
三种模式
- 命令模式
- 输入模式
- 底线命令模式
vim 主题
- 【2021-1-12】vim配色,大全
- 设置类似sublime的主题包:vim-monokai
# 下载sublime主题
git clone https://github.com/sickill/vim-monokai.git
# 创建主题目录
mkdir -p ~/.vim/colors
# 复制主题
cp vim-monokai/colors/monokai.vim ~/.vim/colors
# 设置vim主题, ~/.vimrc
syntax enable
colorscheme monokai
【2022-11-9】monokai主题
- 去github上下载 monokai.vim文件
- 放到指定目录: ~/.vim/colors 中
- 开启主题
# 下载主题, 进入github中monokai.vim文件页面,点raw按钮
wget https://raw.githubusercontent.com/sickill/vim-monokai/6fb52e32863646e38cdebce57ae0d1688f334a79/colors/monokai.vim
mkdir -p ~/.vim/colors
mv monokai.vim ~/.vim/colors
# 编辑 vimrc 文件
syntax enable
colorscheme monokai
vim 配置
Vim 的配置不太容易,它有自己的语法,许多命令
Vim 的全局配置一般在/etc/vim/vimrc或者/etc/vimrc,对所有用户生效。用户个人的配置在~/.vimrc。
- 如果只对单次编辑启用某个配置项,可以在命令模式下,先输入一个冒号,再输入配置。
- 如果是批量设置设置,详见:阮一峰的Vim配置入门
精简
set showmode " 在底部显示,当前处于命令模式还是插入模式
set number " 显示行号
syntax on " 打开语法高亮。自动识别代码,使用多种颜色显示
set cursorline " 光标所在的当前行高亮
set autoindent " 按下回车键后,下一行的缩进会自动跟上一行的缩进保持一致。
set tabstop=4 " 按下 Tab 键时,Vim 显示的空格数
set encoding=utf-8 " 编码,可以解决vim下的中文乱码问题
" colorscheme monokai " 配色
完整介绍
" ========== 一次性 =========
" 打开
set number
" 关闭
set nonumber
" 查询某个配置项是打开还是关闭
:set number?
" 帮助
:help number
" ========== 永久 ===========
" ===== 外观 ======
set number " 显示行号
set nonumber " 关闭显示行号
set relativenumber " 显示光标所在的当前行的行号,其他行都为相对于该行的相对行号。
syntax on " 打开语法高亮。自动识别代码,使用多种颜色显示
syntax enable " 开启代码语法高亮
colorscheme monokai " 配色
set cursorline " 光标所在的当前行高亮
set textwidth=80 " 设置行宽,即一行显示多少个字符。
set wrap " 自动折行,即太长的行分成几行显示。
set nowrap " 关闭自动折行
set linebreak " 只有遇到指定的符号(比如空格、连词号和其他标点符号),才发生折行。也就是说,不会在单词内部折行。
set wrapmargin=2 " 指定折行处与编辑窗口的右边缘之间空出的字符数。
set scrolloff=5 " 垂直滚动时,光标距离顶部/底部的位置(单位:行)
set sidescrolloff=15 " 水平滚动时,光标距离行首或行尾的位置(单位:字符)。该配置在不折行时比较有用
set laststatus=2 " 是否显示状态栏。0 表示不显示,1 表示只在多窗口时显示,2 表示显示。
set ruler " 在状态栏显示光标的当前位置(位于哪一行哪一列)
" ===== 缩进 ======
set autoindent " 按下回车键后,下一行的缩进会自动跟上一行的缩进保持一致。
set smartindent
set tabstop=4 " 按下 Tab 键时,Vim 显示的空格数
set shiftwidth=4 " 在文本上按下>>(增加一级缩进)、<<(取消一级缩进)或者==(取消全部缩进)时,每一级的字符数
set expandtab " 由于 Tab 键在不同的编辑器缩进不一致,该设置自动将 Tab 转为空格。
set softtabstop=2 " Tab 转为多少个空格。
" ===== 基本配置 ======
set showmode " 在底部显示,当前处于命令模式还是插入模式
set showcmd " 命令模式下,在底部显示,当前键入的指令。比如,键入的指令是2y3d,那么底部就会显示2y3,当键入d的时候,操作完成,显示消失。
set mouse=a " 支持使用鼠标
set encoding=utf-8 " 编码,可以解决vim下的中文乱码问题
set fileencoding=utf-8 " 文件
set fileencodings=ucs-bom,utf-8,chinese,cp936
set guifont=Consolas:h15
language messages zh_CN.utf-8
" set lines=45 columns=100 # 这行不能加,否则按O进入编辑状态时,视觉错位
set foldmethod=manual
set nocompatible " 不与 Vi 兼容(采用 Vim 自己的操作命令)
set nobackup
filetype indent on " 开启文件类型检查,并且载入与该类型对应的缩进规则
" ===== 编辑 ======
set spell spelllang=en_us " 打开英语单词的拼写检查
set nobackup " 不创建备份文件。默认情况下,文件保存时,会额外创建一个备份文件,它的文件名是在原文件名的末尾,再添加一个波浪号(〜)。
set noswapfile " 不创建交换文件。交换文件主要用于系统崩溃时恢复文件,文件名的开头是.、结尾是.swp
set undofile " 保留撤销历史。Vim 会在编辑时保存操作历史,用来供用户撤消更改。默认情况下,操作记录只在本次编辑时有效,一旦编辑结束、文件关闭,操作历史就消失了。打开这个设置,可以在文件关闭后,操作记录保留在一个文件里面,继续存在。这意味着,重新打开一个文件,可以撤销上一次编辑时的操作。撤消文件是跟原文件保存在一起的隐藏文件,文件名以.un~开头
set backupdir=~/.vim/.backup//
set directory=~/.vim/.swp//
set undodir=~/.vim/.undo//
" 设置备份文件、交换文件、操作历史文件的保存位置。
" 结尾的//表示生成的文件名带有绝对路径,路径中用%替换目录分隔符,这样可以防止文件重名
set autochdir " 自动切换工作目录。这主要用在一个 Vim 会话之中打开多个文件的情况,默认的工作目录是打开的第一个文件的目录。该配置可以将工作目录自动切换到,正在编辑的文件的目录
set noerrorbells " 出错时,不要发出响声
set visualbell " 出错时,发出视觉提示,通常是屏幕闪烁
set history=1000 " Vim 需要记住多少次历史操作
set autoread " 打开文件监视。如果在编辑过程中文件发生外部改变(比如被别的编辑器编辑了),就会发出提示
set listchars=tab:»■,trail:■
set list " 如果行尾有多余的空格(包括 Tab 键),该配置将让这些空格显示成可见的小方块
set wildmenu
set wildmode=longest:list,full
" 命令模式下,底部操作指令按下 Tab 键自动补全。第一次按下 Tab,会显示所有匹配的操作指令的清单;第二次按下 Tab,会依次选择各个指令。
" ===== 搜索/查找 ======
set showmatch " 光标遇到圆括号、方括号、大括号时,自动高亮对应的另一个圆括号、方括号和大括号
set hlsearch " 搜索时,高亮显示匹配结果
set incsearch " 输入搜索模式时,每输入一个字符,就自动跳到第一个匹配的结果。
set ignorecase " 搜索时忽略大小写
set smartcase " 如果同时打开了ignorecase,那么对于只有一个大写字母的搜索词,将大小写敏感;其他情况都是大小写不敏感。比如,搜索Test时,将不匹配test;搜索test时,将匹配Test
缩进统一:tab -> 4个空格,只需在代码文件中加一行
# */* vim: set expandtab ts=4 sw=4 sts=4 tw=400: */
vim 技巧
| 命令 | 说明 | 备注 |
|---|---|---|
| :s/searchStr/replaceStr/g | 替换当前行中的所有 searchStr 到 replaceStr | |
| :s/searchStr/replaceStr/ | 替换当前行中的第一个 searchStr 到 replaceStr | |
| :%s/searchStr/replaceStr/ | 替换每一行中的第一个 searchStr 到 replaceStr | |
| :%s/searchStr/replaceStr/g | 替换每一行中的每一个 searchStr 到 replaceStr | |
| h、j、k、l | 左下上右 | |
| i | 插入 | |
| A | 从末尾开始编辑 | |
| w / e | 下一个单词开头 / 结尾 | |
| b | 上一个单词 | |
| u | 撤消操作 | |
| x | 删除当前字符 | |
| H M L | 屏幕的上 / 中 / 下 |
vim 疑难杂症
积累常见问题解决方法
- vim粘贴多行文本时,编辑器自动换行,格式乱
- 解决:粘贴前,使用命令:set paste即可, 如果想恢复自动换行,set nopaste
- 【2022-11-16】web shell下打开vim,编辑后,无法退出
- 原因:
esc退出这个是无法屏蔽的,chrome 等浏览器把 esc 作为逃逸键,没有信号可以拦截 - 解法:vim 可以考虑使用
ctrl+c代替esc;
- ① Ctrl+C,vim就从编辑模式进入命令模式;Control + C 可以将代替 Esc 将 Vim 从 insert 模式切换到 normal 模式
- ② 按大写的ZZ,退出
- 参考:ESC退出全屏模式和vi编辑模式的ESC键冲突
- 原因:
项目
python健康打卡
- 【2020-7-9】python实现网页自动健康打卡以及腾讯文档打卡
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}
{kind=link}
{kind=link}