总结
读研有什么用
【2018-7-27】比文凭、技能更重要的是独立思考的习惯+解决问题的能力:
- 遇到问题(选题)
- 分析问题(文献综述):旁征博引,海纳百川
- 提出方法(解决方法):独立思考
- 不断实践(实验论证):逻辑推理,反复论证
- 沉淀反思(总结展望): 完善知识体系(广度+深度)+方法论 参考:
- 读研究生的意义在哪里? - Leee的回答
- 读研究生的意义
什么是博士?

- 英文原文:what is a Ph.D.—-by Dr. Matt Might
- 中文版:什么是博士?看完我懂了。最佳图解——人类知识的拓荒者!,进一步扩展
解析
-
- 圆圈表示人类现有知识的总和
- Imagine a circle that contains all of human knowledge
- 圆圈表示人类现有知识的总和
-
- 上完初中,学了一点常识
- By the time you finish elementary school, you know a little
- 上完初中,学了一点常识
-
- 高中毕业已经掌握了数理化生,基础扎实很重要
- By the time you finish high school, you know a bit more
- 高中毕业已经掌握了数理化生,基础扎实很重要
-
- 大学分专业,对知识不可能面面俱到了,专业知识占主导,图中有了小突起
- With a bachelor’s degree, you gain a specialty
- 大学分专业,对知识不可能面面俱到了,专业知识占主导,图中有了小突起
-
- 研究生阶段更加深入,在领域内的高深知识开始触及。(这里不讨论研究生毕业)
- A master’s degree deepens that specialty
- 研究生阶段更加深入,在领域内的高深知识开始触及。(这里不讨论研究生毕业)
-
- 博士阶段,导师给了方向,看了很多文献,触及到人类知识的边缘
- Reading research papers takes you to the edge of human knowledge
- 博士阶段,导师给了方向,看了很多文献,触及到人类知识的边缘
-
- 瞄准一个点,这个点或许是一个参数、一个可能性,开始攻克
- Once you’re at the boundary, you focus
- 瞄准一个点,这个点或许是一个参数、一个可能性,开始攻克
-
- 努力做实验,心无旁骛,again and again
- You push at the boundary for a few years
- 努力做实验,心无旁骛,again and again
-
- 有一天,成功了!突破了知识边界
- Until one day, the boundary gives way
- 有一天,成功了!突破了知识边界
-
- 因为这份成果,可以申请博士学位了
- And, that dent you’ve made is called a Ph.D.
- 因为这份成果,可以申请博士学位了
-
- 会当凌绝顶,一览众山小!博士很自豪,很开心,突破了人类知识极限
- Of course, the world looks different to you now
- 会当凌绝顶,一览众山小!博士很自豪,很开心,突破了人类知识极限
-
- 但对于整个人类知识圈来说,这个突破也是极小极小的。积跬步以至千里,一个博士很渺小的。
- So, don’t forget the bigger picture,Keep pushing.
- 但对于整个人类知识圈来说,这个突破也是极小极小的。积跬步以至千里,一个博士很渺小的。
- Q1:上面的博士生涯看似很简单,为什么需要5年甚至更久?
- A1:因为不是所有方向都能有所突破,导师给博士一个课题,就像下面这张图:
- 博士接到课题,需要自己去找领域的边界,不断看文献、学习、买药品、搭设备…然后很可能做不出来,博士毕业前换几个方向很正常,所以需要大量的试错时间。
- Q2:博士既然这么独立,导师有什么用?
- A2:提供平台和物质基础;教基础知识,带入门;告诉博士可能的突破点;在博士突破之后帮助他把论文发出来;津贴等等。
- Q3:导师不能做什么?
- A3:最最重要的是,导师不知道准确的突破方案,大罗神仙都不能预测,不能难为导师,他不是高中老师。这事得博士去探索,博士是知识的主要拓荒者。
博士经验
- 【2022-1-5】田渊栋2021年总结
- (1)战略上,分清主次。没必要的工作不用做,搞清楚什么是对自己最重要,什么该果断放弃,说一句“没时间”并不丢人,反而是逐渐走向成熟的体现。
- 博士毕业之后,特别是最近几年,开始奉行“deadline前做不出来就放到下个deadline”的原则
- 中年人再与年轻人们内卷拼体力是没有意义的,要拼眼界与思考的格局,找到问题的关键,并把时间花在刀刃上。首要任务不是一味自己埋头工作,而是总结过去走过的弯路;其次,预判别人看不到的问题和陷阱,并采取一切手段,包括技术或是非技术的,以尽量避免这样的事情发生。
- (2)执行上,安排好事情。
- 如何快速进行多任务切换:多任务切换的关键在于能不能在一段时间内集中火力,把一件事做好,再去做下一件事。如果已经定下具体的目标,一切的工具都只是辅助,必要时可以全都舍弃掉。
- 如何不忘记不紧急但重要的事情
- 如何使用碎片时间进行一些有意义的阅读和思考,是相当重要的。
- (3)记得别人给自己的批评,并且时常反思
- 去年花很多时间去逐条反驳投稿ICLR2021文章的那个给3分的评委给出的18个问题,当时觉得这位评委竟然把我们的工作贬斥得一文不值,列举的每个问题都简直在胡说八道,非常气愤。但现在回头看来没必要,人家提问的根本动机是文章里想要表达的思路太多太杂,也没写得特别清楚。一切都是有内在原因的,而理解了就可以使自己的工作质量更上一层楼。这样,被拒稿的坏事就变成了好事。
- 批评是稀缺资源,高质量的批评更是少见,因为别人根本没有时间和精力去认真阅读自己的成果,更不用说提出什么有用建议。
- (4)不能故步自封,要经常把棋盘翻过来想。
- 自己曾经的优点,可能反而成为下一步成长道路上的绊脚石。认识到每种能力都有用处与局限,能够在恰当时间和场合去运用这种能力,在另一些时间和场合刻意限制使用这种能力,这是比拥有及炫耀“一技之长”更难更艰辛的道路。
- 善游者溺,善骑者堕”,做自己擅长的事,往往会掉以轻心阴沟翻船,其实它还有更深一层的意义——有一技之长的人,稍不小心,就可能变成自己技术的奴隶。
- (5)有空多看历史。
- 历史就是一个大规模离线强化学习训练集,多少比自己厉害百倍,能在史书上留下一笔的人杰,在关键时刻走错了一步前功尽弃,这些都一字一句记录在案,给后人以警醒。
- (1)战略上,分清主次。没必要的工作不用做,搞清楚什么是对自己最重要,什么该果断放弃,说一句“没时间”并不丢人,反而是逐渐走向成熟的体现。
- 【2021-2-28】研究生自救指南,一张图形象描述论文作者间的关系
- Facebook田渊栋:博士五年之后五年的总结
- 【2020-8-28】【Eric的博士生生存指南】《Syllabus for Eric’s PhD students - Google Docs》by Eric Gilbert
- 【2021-1-8】谷歌大脑高级研究科学家:在康奈尔读博6年,我收获了什么,谷歌大脑高级研究科学家 Maithra Raghu 发布了自己的博士生涯总结,包括期望值管理、读博的常见挑战,以及论文那些事儿,等等。原文地址:Reflections on my (Machine Learning) PhD Journey
- 论文太多怎么办?准备一个相关论文的链接列表。对我来说,这需要结合 arXiv 的机器学习子目录、arXiv-sanity、推特、reddit 的 MachineLearning 板块(有时)、paperwithcode、Semantic Scholar 和 Google Scholar。
- 记录并更新论文阅读列表。如果看到了有趣的论文但没时间读,先记录下来之后再来看。
- 寻找一种阅读论文的节奏。如果论文和自己的研究方向强相关就仔细看,否则就快速看摘要和论文中的重要图片。
- 偶尔阅读不同领域的研究。有些时候(也许一年一次),我会尝试看一些不是自己研究领域里的论文,以便对前沿研究进展有大致了解。
- 孤独无助?可以:
- 1)与高年级学生或博士后建立合作;
- 2)从导师、实验室负责人、研究合作者那里获取有关自己工作进展的反馈;
- 3)积极参与更广泛的社区,无论是简单地参会,还是组织和指导 workshop。
- 读博最有用的三项能力说起:主动、专注和毅力。
- 论文太多怎么办?准备一个相关论文的链接列表。对我来说,这需要结合 arXiv 的机器学习子目录、arXiv-sanity、推特、reddit 的 MachineLearning 板块(有时)、paperwithcode、Semantic Scholar 和 Google Scholar。
编者按:田渊栋,在硅谷年轻一代华人工程师和计算机科研工作者中具有不小的知名度。身为Facebook人工智能研究院研究员的他在专注科研的同时,一直笔耕不辍。他的文章具有深邃的思想,又兼具可读性。五年前,他在知乎上分享的文章《博士五年总结》曾引起关注;五年后,他再用《博士五年之后五年的总结》系列文章,回顾了博士毕业五年,在硅谷从谷歌无人驾驶转到Facebook人工智能研究院的所思与所得。本文汇总了该系列文章的前言、其一、其二和其三。

田渊栋
ReLU神经网络的可证明理论性质
2020-08-05 20:56:17
Facebook人工智能研究院研究员、卡耐基梅隆大学机器人系博士田渊栋以ReLU网络为例,分享了深度学习理论和可解释性方面的研究进展。田渊栋博士提到,在学生-教师设置下的ReLU神经网络中,存在学生网络和教师网络的节点对应关系,通过对这种关系的分析,可以帮助我们理解神经网络的学习机制,以及剪枝、优化、数据增强等技术的理论基础。
2020年7月31日至8月5日,VALSE 2020视觉与学习青年学者研讨会在线上举行。在主题为《机器学习前沿进展》的论坛中,田渊栋博士发表了题目为《深度ReLU网络中可证明的理论性质》的演讲。
VALSE年度研讨会的主要目的是为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。截至目前,VALSE已举办9届。
以下是讲座全文,AI科技评论进行了不改变原意的整理。
1 神经网络的三个理论研究方向
深度学习模型缺乏可解释性,它的工作模式对于我们而言就是个黑盒,意思是我们不关心深度学习的内部机制,只需要知道输入对应的输出就好。但问题是,如果以后我们要提高神经网络的性能,就需要把黑盒打开,理解其机制。
神经网络的理论研究有三个的方向,第一个是可表达性(Expressibility),即神经网络能多大程度上拟合函数。现在我们知道,只要有一层无限神经元的隐层,神经网络就能拟合任何函数,这个结论在80年代就已经有人证明出来了。
但是关于泛化能力的理解,还需要解决后面两个问题,即优化和泛化。
在非凸优化中,损失函数有很多局部最小值,但是神经网络能找到一个比较好的最小值,这应该如何解释?
对于神经网络,不同的学习设置导致的学习效果几乎没有什么区别,这令人惊讶。因为按照一般假设,不同的初始化设置学习的结果应该是完全不一样的。我们现在在这些问题上还没有很好的理论解释。最后一个问题是泛化问题。
2 学生-教师设置的ReLU神经网络
今天讨论ReLU 网络,ReLU激活函数在神经网络的应用非常广泛。因为它很容易实现,而且学习比较快,能自然地实现网络稀疏性。除此之外,它还有一些非常有趣的理论性质,并且它的函数性质对理论分析来说有好处。当然,它也有不足的地方,比如说不可微的、不可逆,存在参数化奇点等。
ReLU函数(图源:维基百科)
接下来讨论ReLU网络在学生-教师设置下的理论性质。设置是什么意思呢?举个例子,比如监督学习。在监督学习设置中,我们有将x标记为y的数据集,然后我们训练一个神经网络,输入x能得到y。
而在学生-教师的设置中,我们把数据集替换成一个教师网络(或者Oracle Network)。
这种设置有一些良好的性质,首先是解决可表达性,按照万能逼近定理,任给一个数据集总存在一个教师网络能拟合数据集。假设总有教师神经网络能够完全拟合所有数据,然后用学生神经网络去学习教师神经网络,就可以拥有参考点,这个参考点可以用来做细致的优化分析。以前只能通过损失函数来学习,现在可以通过学生网络和教师网络之间的权重对应关系来进行。
这种设置对于理解泛化能力有更多的优势。因为如果我们能证明,学生网络跟教师网络的节点存在对应关系,就可以证明泛化能力。因为学生网络不仅仅只是在输出结果上相同,而且在内部结构上也相同,也即是学生网络学到了教师的“精髓”。对于新的输入,我们可以预言学生网络和教师网络的输出是一样的。所以这种设置其实在某种程度上可以简化一些理论分析。
3 节点对齐
学生-教师设置在1995年就已经有物理学家提出来,当时使用的是两层神经网络,并且没有使用ReLU函数,此外他们还假设,输入样本的维度必须是无穷大的。
在现代的理论看来,无穷维不是一个很好的假设。我们可以假设ReLU网络的输入是有限维的,并且服从高斯分布。这样,我们可以解析地得到梯度的期望值。
梯度有两个部分,分别是线性部分和ReLU函数导致的非线性部分。如果只有线性部分,神经网络会收敛到最小值。
我们现在来看多层的学生神经网络和教师神经网络,其中m和n是相对宽度,都是有限的,学生神经网络比教师神经网络稍微宽一点。
我们可以证明,至少对于最靠近输入的那一层,学生网络的每个节点跟教师网络的节点都是有对应关系的,也就是说学生网络可以学到一些教师网络的精髓。
什么叫学到了教师网络的精髓?就是说我们把学生网络节点和教师网络节点的边界显示出来,他们的边界之间会存在重叠。
现在问题在于,如果我们假设在训练过程中,对每个训练样本都得到了很小的梯度,与学生网络和教师网络的节点对齐之间存在关系呢?
首先,我们能得到一个引理,即学生网络的梯度其实可以写成教师网络激活函数和学生网络激活函数的线性组合。
1、理想化假设
我们来通过两个案例解释如何使用这个引理来导出学生与教师网络节点的对应关系。
先考虑理想化假设,两层ReLU神经网络,梯度等于0,样本数无限。其中有6个学生网络节点,用点画线表示,2个教师网络节点,用粗体线表示,下图显示了这些节点的边界。
随着训练迭代进行,有些学生网络节点会慢慢收敛到教师网络节点,有些则不会,而是随机排列,比如下图中红色和绿色的点画线。
与此同时,这两个学生网络节点对外的输出权重的范围刚好是很小的。
下图是另外一个实验的结果,横轴是学生网络节点和最佳关联教师网络节点之间的相关程度,纵轴是输出权重的范围。从图中我们可以看出,这两个变量形成了“L”形曲线关系。如果学生节点和教师节点没有太大关联,那它输出权重的范数就很小,反之则有很强的关联。
要证明这个结论成立,其实需要很多假设。那么其中一个假设是数据集样本数无限。之后我们会把这个假设去掉。但是关键在于我们不需要对数据的分布做任何的假设。
第二个假设是,教师神经网络的每个节点的ReLU边界对于数据集都是可见的。
有了这两个条件,我们可以得出,对于任意一个教师网络节点j,至少存在一个学生网络节点k’与它对齐。
对于任何一个教师网络节点,都存在一个学生网络节点与它对齐,实际上对齐的节点可能会有2到3个。反过来,并不是所有的学生网络节点都一定和教师网络节点对齐,有些学生网络节点可能没有跟任何教师网络节点对齐。
这样我们能得到另外一个定理,可以证明在满足某些条件时,那些没有对齐的学生网络节点(下图的黑色点),它的输出权重会是0,这就给我们提供了如何对神经网络进行剪枝的理论基础。
这个结论对于多层神经网络同样成立,因为之前提到的引理能应用到任何深度神经网络。
下图展示了多层神经网络的实验,我们同样得到了“L”形曲线关系。
同样的思路可以用来解释神经网络的一些非常奇怪的现象,比如说将神经网络训练到两个局部最小值,这两个解如果用折线(而不是直线)连起来,可以保证折线上的每个解的错误率都比较小,这跟凸优化的情况很不一样。
2、非理想化假设
我们之前做了一些理想化的假设,比如说梯度等于0,数据集样本数无限,现在我们做一些更加实际的假设,即两层ReLU神经网络,梯度很小但不等于0,数据集样本数有限。
我们规定梯度不等于0,而且比较小,是小于某个样本复杂度上界。然后我们对数据集也做了增强,增强数据本身会影响到最后样本复杂度上界的松紧。
最后能得到两个结论,第一个是,更强的教师网络节点学习更快。简单来说就是,那些输出权重较大的教师网络节点,有更多的学生网络节点与其对齐。此外由于样本复杂度上界和学生网络节点与教师网络节点的点积正相关,当教师网络节点更强时,梯度的样本复杂度上界更加宽松。
反过来结论也成立,更弱的教师网络节点学习更慢。下图展示了不同教师网络节点的关联强度随训练的变化。
另外,不同的数据增强的技术会得到不同的样本复杂度上界。如果数据增强的方向,跟教师网络节点的样本复杂度上界的方向一致的话,样本复杂度上界就会变得更紧。
使用不同数据增强技术的数据集,样本复杂度可能会非常不同。如果我们利用教师网络的知识增强数据集,即使只有少量样本,经过训练的学生网络也不会过拟合,并能大大降低评估损失。
对于多层神经网络,也有类似的结果。
我们还在CIFAR-10上进行了实验。首先在CIFAR-10训练集上使用64-64-64-64 ConvNet对教师网络进行预训练。然后以结构化方式对教师网络进行剪枝,以保留更强的教师网络节点,并且剪掉那些对输出没有太大影响的节点。基于教师网络的剩余通道,学生网络被“过实现”(over-realized)。
下图展示了学生网络的收敛和专业化行为。“过实现”会导致在CIFAR-10评估集上教师节点和学生节点的相关性更强,泛化能力得到改善。
参考链接:
- https://arxiv.org/pdf/1703.00560.pdf
- https://arxiv.org/pdf/1909.13458.pdf
博士毕业这五年
前 言
光阴如梭,时光荏苒。博士之后又是五年,离上次的《博士五年总结》也已经有五年时间了。在繁忙的工作中,我觉得有必要再写些东西,一是分享给大家自己新的经验,二是借此机会总结思考自己五年来的成败得失,以后能更进一步。
一句话总结:选对人生的职业方向,及坚持这个方向,是最重要的。
我2013年毕业的时候,正赶上深度学习的大潮起步。AlexNet的文章一出,整个CMU机器人系做视觉的组里,许多人抱持怀疑态度,觉得这个一定是实验出了什么问题,或者代码写错了,或者是因为过拟合。我当时正在折腾我自己多层组合以矫正图像扭曲的理论,看到多层神经网络能有效果非常兴奋,还发了信给Alex讨论他开源代码的细节。我和我导师讨论说想去做这个,我导师一个劲地摇头,以他一贯反对机器学习的态度,觉得这完全不靠谱——但一个快毕业的博士,应该有自己的判断。
当然,作为学生仍然会被现实问题所左右。拿了几个offer,其中就有硅谷做深度学习的职位,可最后还是没能坚持到底,还是去了谷歌无人车组。刚进组时满怀热情,眼界大开,发现工业界的问题还可以用算法之外的办法处理,颇有新鲜感;但到后来,越来越觉得这不是我想要走的路。每天工作时,看到一篇一篇新出的深度学习的文章,看着各类任务的性能一天天地变好,想着自己每天晚上的业余民科理论研究,厌倦于每天的小修小补还有对变量命名和接口设计的纠结,憋屈于想做的方向得不到支持——正是这每一天每一晚在脑中回响的声音,让自己明白,自己并不属于这里。
不属于的话,就走吧。
当时作这个决定非常难,家里反对,毕竟无人车听上去高大上,毕竟谷歌工资高有保障,毕竟我们仍在为生计努力,没有那么多自由。我充分发挥小说的想像力,认真写了跳槽之后可能的结局,上中下三条,惨的非常惨。我写完之后给老婆看,我说我们好好讨论下,老婆说可行。
今天,在Facebook人工智能研究院已经快四年了,回想起来,这次跳槽是非常成功的。我充分发挥了自己的能力,选对了课题,做成了我想做的事情,研究和工程都有成果,理论和应用并重,也开始积攒一定的管理经验。如果我还一直待在原来的组,可能会因为现在的无人车大火而获得相对比较高的工资待遇,但绝不会有现在的精气神,也就不会有这些文章了。
回想起来,这才是属于我的青春。
博士五年总结(一)
这五年最重要的,是渐渐知道了怎么去做一件比较大的事情。
说得很大,其实就一点,心要静下来。
- 首先,心静下来才能钻进某个领域里认真做事。现在的社交媒体太多了,各类新闻也太多,每天忙于应付这些广泛却又浅薄的信号,或是忙着去评点别人,是没有办法做成一件事情的。就比如一个人要去旅游,按图索骥地走一圈著名的景点,并不会给自己新的体悟,最多只增些与人的谈资而已。真要体会大自然的美丽,那是一定要涉足别人达不到的地方,要有目标有耐心有毅力,做长久的打算。
- 其次,有毅力有决心不一定能成事,方法也是不可少的。做研究的每个环节都需要方法:如何做基本调查,如何下手,如何分析问题,如何坚持自己的观点,如何给任务定优先级,如何处理细节和局部的关系,如何将直观一点一点地转化成严格的数学语言并且验证。在任何一个地方卡住,都会让自己的研究停步不前。面对这么多要求,要同时都准备好再开始研究是不可能的,只有先定目标,然后一步一步摸索。在摸索的开始,会做很多无用功,调查没有头绪,题目不知道如何选,没有经验就 不起效率,没有效率就容易心浮气燥,心浮气燥就会轻言放弃,完全否定已有的成就。只有把自己强按在位置上一点一点地对以往的教训做分析总结,才能打破这个恶性循环,渐渐地积累起经验来,看见以前看不见的方向。要达到这一点,心静是很重要的。
- 再次,研究是会碰到很多困难,老板不给力,数据不给力,公式推不出来,电脑坏了,等等。在博士阶段可以有一千个理由把问题归咎于别人,不过我觉得最好的态度是“不抱怨,不解释”,把自己力所能及的事情做好,把自己的错误搬回家,好好分析,才能有所进步。理想和信念是一定要有的,不然如何在孤独的长跑中奋勇向前?但调子不能放得太高,因为没有实现的理想,对他人而言,一文不值。要做到这些,同样需要静下心来,克服困难的过程中,没人喝彩。
举一个我自己的例子。自己的博士论文其最后一部分的理论可算是历经艰辛
- 2010年借着第一篇 ORAL 的劲头试过第一次,却根本不知如何下手,花了四五个月完全失败,最后临近论文截止时不得不让老板换题;
- 2011 年的时候在 MSR 实习时又试过一次,因为陷入了诸如
一定要有个目标函数,求目标函数的最优解的常规思路而再次失败,虽然已经有一点结果,但是总体上路子是走偏的,也没能就这个理论发文章,最后只好做成一篇应用,以给实习一个交代。 - 直到 2013 年的年初,在投出博士阶段最后一篇 ICCV 之后,才发现自己想做的这个理论和自己之前已经做过的研究的极大关联,终于突破了之前思维的瓶颈,才有了现在令人满意的理论。
回想过往的思维过程,最早是经常在自设的思维困局中转圈,然后是在推公式、想直观和堆 hack 中左右摇摆,最后才发现理论和现实的黄金结合点,找到和现实吻合又干脆利落的假设,推出意料之外却情理之中的定理。
一旦进入了这个阶段,反应就会一次比一次快,建模速度也一次比一次迅捷,出的文章也会越来越好。从这个意义上来说,这五年的 PhD 并没有浪费,这样的训练让我有自信去学习任何新东西,合理规划自己的时间,来面对任何一个自己想要做的,具有挑战性的项目。
另外,分享一下主要的技巧:
- 第一,要喜欢自己的研究题目。做研究有
内心动力(motivation)是非常重要的。- 研究的本义,是在一个宽松的环境下,由研究者自由探索去寻找未知世界的答案。再牛的导师,尽管有模糊的直觉,如果不参与研究的每个细节,是不能预知精确答案的。精确答案只能由学生来获得,导师直觉的错误只能由学生来推翻,如果学生没有内心动力,那导师只能看见他能看见的,就不需要学生了,研究也就失败了。
- 因此,研究的成败,归根结底是靠研究者永不停息的探索着的内心。
- 如果自觉是个安于现状,听人号令,懒得动脑的人,那博士不是那么适合的;
- 如果家里或是同学的压力大过内心的渴望,那么读博可能是地狱的开始;
- 如果只是为了获取某领域更多的知识,那可能在博士后期承担巨大的论文压力,不如读个硕士方便。
- 如果自己确实喜欢探索,喜欢解难题,但是导师的方向自己不喜欢怎么办?
- 我的答案是,多发挥主观能动性,找一个喜欢的小点慢慢扩大。
- 我刚去 cmu 的时候,因为口语和交流能力不怎么好,选导师的过程并不顺利,第一选落空,后来听师兄的建议选了现在的导师,可他做的方向和我想做的一点关系也没有,怎么办?解决方案是先找一个两边都能接受的题目,把它做好,我当时是选了图像因为水面的波动而扭曲的题目,既切合导师的物理背景,又突破了他在每个像素上单独求解问题的思路,更像是主流的计算机视觉。等到出了第一篇文章(ICCV 09)之后,再慢慢地切入自己想要做的方向,自 2010 年末开始,出了一系列 ORAL,渐渐把握了主动权。
- 在自己喜欢的方向上,导师是永远比不过自己的进度的,因此乘着环境宽松时未雨绸缪相当重要,追着导师走,而不是让导师追着走。若是没有内心动力,等到三年级后老板看情况不对,开始缩小研究领域催论文,自己就会陷入“
啊啊,我真的不喜欢这个却被逼不得不做”的状态,那就很难挽回,再怨天尤人也没有用了。
- 第二,牢记本校校训,
My heart is in the work。 做研究需要每天都花时间想,沉浸入要解决的问题。-
这并不是说做研究是 24x7 全天候,其它什么都不用干,一直干到永久性脑损伤为止,而是需要培养思考的习惯, 高思考的效率。为达到这一步,一开始需要大量的投入来找到适合自己的正确方案。可能会很不习惯,想到晚上睡不着,做事吃饭都没心思,生活琐事全都不管,俗话说是“入魔了”。像我经常有做梦做到自己要思考的问题,或者每天一早还没完全醒来,就想着某个问题要怎么解,结果真醒来一看发现全想错了-_-。在这个阶段,挫折感会特别强烈,会有放弃的念头。但是只要坚持下去,大脑会适应,会成习惯,效率会高,会知道一个问题中有哪些地方是关键,会知道思考到什么地步是可以停手的存盘点。然后你就有了一具不论何时何地都能进行后台运行的思考机器,能够积累上每天的边角时间,每时每刻在 升进步。正如一句话所说,不疯魔,怎成活。
-
当然开车或者做其它重要的事情时请不要思考,出事的话,本文概不负责。
-
- 第三,有思路(idea)就写下来。
- 有一句话说得好(出处忘记了),光思考不纪录,人脑是有限自动机;既思考又记录,人脑就是图灵机。其原因在于,一支笔一张纸增强了人脑的记忆力,让思考的空间及范围变大了,能看出本来没看出的联系,能发现本来发现不了的细节。有时候看似很平凡的思路,写着写着就变成了非平凡的阶段性结果,以为是很有前途的想法,一写就发现问题所在。而若只是思考,花几个小时都在原地转圈,头还晕得不行。另外,写下来本身就是一种“我已经完成了什么”的标志,对士气是很鼓舞的,也有利于下一次从中断点恢复思考。
- 第四,多看看别人的工作,但别看太多,抓住主线就好。
- 近年来每年发表的论文数有上升的趋势,文章越来越多,每篇都细细看就是在浪费时间了,事倍功半。我目前认为的最好办法,莫过于在看完几篇本领域最重要的文章后认真总结,猜出大部分人的路数还有各自方法的优缺点,然后在面对新文章时采用跳跃式读法,边看边猜,猜对有奖。这样不仅快,而且能把握大局忽略细节,自己想新思路的时候也能自然而然地避开大部分人的招式,攻击其命门,从而保证自己工作的创新性。这似乎不符合学术严谨性的定义,不过……人生就这么点长,看着办吧。
博士五年总结(二)
回到刚才的话题,自己刚入 cmu 的时候,因为种种原因没有选到理想的导师,不知如何是好,就向师兄征询意见。师兄劝我说:
“其实这些都不重要,重要的是你可以从他那里学到什么,我认为他人不错,另外演讲和写作技能非常好。”
事实证明师兄说的话是对的。选导师,他做什么研究并不是最重要的,比这更重要的,是人品及交流和表达能力。我导师虽然是印度人,不过人品相当不错,对学生既严格又负责,也不拖毕业的时间。我从他那里学到最多的,其一是演讲,其二是写作。
先来谈谈写作
以我五年的经验来看,其实中国人写作的最大瓶颈并不是英语能力,而是组织。论文的英语水平充其量是高中水准,多看几篇就大致可以掌握词汇和句型,更何况很多论文都不是以英语为第一母语的研究者们写的,照样拿最优论文奖,照样在学术圈产生极大影响力。
但在组织上,我们的论文确实问题多多。我就犯过很多错误。
- 其一是
挤牙膏,通过堆砌句子来达成长度要求,这个可能和我们从小要求文章有字数下限有关,结果就造成文章空洞,许多句子许多段落翻来覆去同一个意思,让人倒胃口。 - 其二是
把文章写成技术报告,先做啥,再做啥,最后做啥,实验结果是啥,没了。至于为什么这样做,原因是什么,是什么激发了这样的思考,这样的方法对什么样的数据会有效,有什么局限,全都不知道。(潜台词是:是老板让我这样做的,我只想毕业,有问题别来找我......)论文是要引人深思的,要给人启发的,要让人受教的,要让读者读完后,觉得这篇文章公正地评价了前人的工作,明白这篇文章的创新意义所在,并且同意作者的出发点,认为这是一个很有前途的方向才行。
本质上来说,产生这两个问题的原因是懒得思考。论点挖不深,导致觉得没啥好写只好挤牙膏;方法想不透,于是便罗列若干步骤草草了事。其实只要稍微想下,就能补上很多东西。
举个例子,写目标函数是什么,如何用梯度下降优化,数学上就两个公式,但是段落里可以说明如何选初始点,初始点在这个具体应用中的意义何在,如何取步长,为何这样选,收敛速度通常多快,哪里可以加速,哪里可以并行化再加 GPU,等等,这样内容就丰富多了。又比如,一个算法的若干步骤,本来是毫无意义的流程图,但在介绍它之前做些解释,阐明设计的一些基本原则,然后在解释每步时充分使用这些原则,那读来就会觉得容易接受得多。
克服了这两点,做到开局有理有据,正文言之有物,实验让人信服,那这篇文章基本上可以中稿了。接下来,就可以进入高级模式了。
- 首先,立意要高远。
- 一篇文章规矩着写,说“我们加了新特征,因为新特征针对数据集的某些特性建模,实验效果更好”,虽然基本可被录用,但一般不会出彩;
- 如果说“我们用了新的框架,统一了以前的诸多方法,在这个框架下,算法能自动分析数据加入新特征,实验效果更好”,那这篇就有戏。
- 为什么呢?
- 工业界看重效果,因为效果和经济利益直接挂钩;
- 而学术界是想要为一个领域找一个简洁明了的理论,是要仰望星空,问天几何的——因此每一篇好文章,都必须建造出自己的一套世界出来,给出自己的世界观和方法论,在这个宏大的图景下,给前人的工作标好地位,给自己的工作定下基调,然后拿着这张画好的地图,去解决实际问题。而所谓的博士研究和博士论文,则是在一套统一自洽的世界观下,含有两至三篇或者更多的文章,以证明这套世界观的合理性。
- 这听起来像是忽悠的游戏。因为像计算机视觉这种实用的领域,哪有那么多理论可挖。是的,在一定程度上确实如此。但是建筑世界观本身,会促使研究者对已有的工作进行排列,得到新的启发,看到新的联系,因此仍然是对研究本身有益的。有些表面上的联系可能被证明是偶然,但有些则会揭示本质,促进人们深化认识,为将来的突破性进展作准备。另一方面,功利地来说,有一个宏大的世界观有利于一位博士生发大量文章,早点毕业:-)
- 其次,故事要流畅。
- 我老板说过,一篇好的文章,就如同带着读者在一个花园里行走,路面平坦舒适,左边有山,右边有水,引人入胜,读者漫步欣赏美景,走过亭台楼阁,一点不费劲,一下子就逛完所有还意犹未尽。迄今为止,我对这种抽象的诗一般的表达还不能完全理解,但是既然他声称读完了所有哈利波特的同人小说,而我只不过写过一部二十五万字的小长篇,我想我还是宁愿相信他比较好-_-。
- 在大的方面来说,一篇文章从开篇开始,就要让人有所期待,各种背景知识交代自然,详略得当,指出前人工作各有缺陷,然后自身的贡献娓娓道来,最后各种证据证明自己所言得当;或是先摆出正反证据,引人思索,指出前人各种问题,再列出自己方案,教人拍案叫绝。细节上,全篇重要的论点要适当重复,每次出现都要和上下文语境相符,无聊冗长的段落适当精简,但必要的实验步骤需要交代;每一段都要有总起有概括,像是花园的指路牌,让读者不至于晕头转向;不设弯路,反复推敲逻辑关系,能用一层逻辑说清的绝不用两层,能用简单故事说明白的不用复杂公式,就算有复杂公式也放进附录里;繁简要有计划,细节要略写以免让人费解,主干则要用重笔让人印象深刻;插图要不言自明,要出现在该出现的地方,能恰当地作成段落注解;语句不能太长,避免从句套从句,长短结合比较好,等等。
- 这里所有的要求,都是为了读者着想。每条单独做起来都相对容易,但要合在一起就难,需要充分的思考和不停地修改。每过一段时间,脑中就会浮现出更好的组织方式,而这种新的组织方式,又反过来会启发出新的理解,推进整个研究的进展。接着,各部分贡献大小又有变化,详略又会调整,文章又得修改,如此往复。渐渐地,才会从斧凿拼接模样的文章,变成一气呵成的神作。到这个时候,写作和研究浑然一体,写作促进研究,研究促进写作,才终于算是步入专家级别了。
- 还记得在今年 ICCV 最后期限的前一个晚上,老板看了看我要在二十四小时之内要投稿的文章,说了一句:“组织还是有问题,要不我们不用投了。”我当时就惊了,当然不能接受这个可怕的事实,于是回去连夜修改,第二天早晨总算让他满意,后来这篇文章被评为 very well written,并且拿了 ORAL。我不得不承认他有想推迟我毕业的小小私心,不过他对写作的执着,可见一斑,他说过自己的第一篇投稿改了三个月,原稿他一直珍藏,对比第一稿和最后一稿,差距有如天壤。
我想正是因为如此,才能有他的这些锦绣文章。
博士五年总结(三)
接下来谈下上台演说
我天性是个内向的人,不太愿意说话,高中时候虽然语法规则一条一条记得很牢,但最怕在英语课上回答问题,有一次略开小差,不幸被老师抽到,足足站了五分钟,憋得一句话也说不出来。下课那一个羞愧郁闷啊,至今记忆犹深。TOEFL 的口语也不过 19,还是运气好发挥的最高水准。
刚入博士的我,基本上就是这个样子。
然后我选了我现在的导师。我要特别感谢他,2010 年第一次 CVPR ORAL 的演讲,在他的督促(或是逼迫?)下,我其它什么也没干,足足准备了两个月。第一个月改幻灯片,去除所有数学公式,费尽心思准备一个浅显易懂的流畅故事;第二个月不停地改演讲稿并且反复操练,连每句话重音在哪里都细细标明。演讲那天面对台下一千观众,我紧张到了极致,但亏得准备充分,闭着眼都能背出来,于是看着天花板,流畅地做完了整个演讲(见《CVPR2010 赴旧金山开会全程记录》)。这次演讲至今已有三年,但看到每一张幻灯片,我脑中仍会浮现应说的话,一点也没有忘记。
之后准备第二篇 ORAL 所用的时间就变少了,大概两周。演讲的前一天,导师还对我的熟练程度不甚满意,但是真到了台上,演讲效果居然不错,眼神也可以看着观众了,讲到最后,居然没有用事先准备好的词句,开始自由发挥,直到结束。
这样,第一关就已经过去。看着十几年来一直害怕着的东西终于有一天被自己征服,这是何等开心的事情。以前的我,演讲烂了一两次就不想说,越逃避就越不愿说,于是失去了锻炼的机会。改变这个困局的,一方面是充分的准备,另一方面是对自己研究课题的自信。自己热爱它,为它自豪,愿意讲给别人听,也知道自己如何遣词造句,那这时大脑就会聚焦到内容上,说着说着就入情入境,英语也就自然地变得慢了,流畅了。等到说完,发现自己居然说得还可以,那下一次就更不会紧张,久而久之,终于就可以摆脱恶性循环,进入良性轨道。
读博读到这样,就算没做出什么来,也是不枉了。接下来,只要有了好的讲稿,完成漂亮的演讲只是耐心和毅力的问题。但是,如何才是好的讲稿呢?
如同写作一样,最好的演讲是一个有唯一主题的流畅故事。所谓流畅故事,是指幻灯片和幻灯片之间要有自然过渡,让人不知不觉就听完整个演讲,而不觉得有什么转折生硬的地方。相比作文,演讲的流畅性更为重要,因为读者看文章时可以细细琢磨,听众听演讲时则是一晃而过。为了流畅性,一个好的演讲可以不惜牺牲大量细节,只把最重要最易记忆的主线说出来——但条件是,这最重要的主线不能失了应有的大转折和大逻辑,不能让人觉得太过简单无聊,或太过跳跃而没有说服力。
最好的平衡点,在于“意料之外,情理之中”,听完有一种“原来如此,我怎么没有想到”的感受。
对学生而言,这个找主线砍细节的过程相当痛苦。学生往往见木不见林,不知道什么是重点,而且下意识地,总是会把花去最多时间的细节认为是重点,到准备演讲时就往往恋恋不舍;或者感觉千头万绪,不知从何说起。目标函数的细节要不要说?梯度下降的具体公式要不要说?训练样本归一化要不要说?一个 升百分之五性能的小技巧要不要说?对这些 问的回答永远是:看具体目标是什么。如果是 高性能的系统性工作,小技巧就成为主线;若是新算法设计,那目标函数的精巧构造就是看点;若是研究数据的统计特征,那归一化至关重要;若是讨论大规模分布式的可行性,那梯度下降公式中参数间的相互依赖关系及相应的计算复杂度就成关键。一句话,如果细节不能为自己构建的宏大世界添砖加瓦,那就不能在演讲时大段及。相比之下,导师们不直接参与研究,反而能跳出圈子,看得清庐山真面目,知道工作的重点及工作间的重要联系是什么,面临决断时能果断丢卒保车。
因此,一个博士生,要能够做好演讲,就要能“上得厅堂,下得厨房”,既能在细节上做改进,切实推进研究;又能够跳出自己每天思考的细节圈子,站在高处看问题想问题,是自己的将军,也是自己的士兵。当然,这个说得容易做起来难,没有几年的努力尝试是没办法灵活切换的。
一个看似无关却很有效的办法是,先把幻灯片做好,写好演讲词,然后看看是否能在规定时间脱稿讲得出来。最好的演讲,是看了幻灯片自然而然能说出句子,而不需要死记硬背,转折流畅,故事清楚。若是怎么都无法在规定时间内讲完,或是总觉得雾里探花讲不清楚,或总是把接应的句子搞错,或是总觉得前后别扭,那就是主线有问题,细节或者太多,或者大逻辑没有一针见血地点出,需要修改。这里一个重要的地方,是要脱稿讲而不是照稿念,脱稿讲时,演讲者的“可用内存”只比听众稍多一点,如果连演讲者都不能凭自己对工作的了解而流畅干脆地讲完,那听众肯定不能跟上,演讲者就可以知道自己的问题所在;若是照稿朗读,那就没有这种敏锐的直觉,更不用说 高自己的演讲水平了。
找到主线之后,就要开始设计每张幻灯片。幻灯片最懒的做法,就是列几个 纲,每个 纲下一大把条目或者一大堆公式,演讲时照着读即可。这样做省了演讲者的工作,却让台下观众苦不堪言。稍好些的,放几张流程图,从上到下或者从左到右细细说。这种办法步骤简单时可以,步骤一复杂,照样让人不知所云。其实,每张幻灯片只能表现一个小主题,多了反而嚼不烂。比如说文字过多,台下听众既会看得疲累不堪,又会犹豫究竟是听演讲者说的,还是看他写的?而颜色或是字体太花哨则会分散重点,让人头晕目眩。另一个常见的错误,是把自己想说的话写在幻灯片上。但其实幻灯片上写的,应该是在演讲者说完之后,最希望观众记得的内容(所谓的“take home message”)。为此,一张幻灯片来来回回做个几次都是正常的,往往是初稿的字数非常多,往后思考越深则字数越少,到最后只放一张图或者两张图,但在观众看来,一望即明。
好的幻灯片有几种类型,可以只含一张大图,或互有联系的若干图片,或一个前人工作的列表,或一件事物的优劣二分法,或一个算法的三个主要步骤,或一些事物的相互关系,等等。一句话,如果盯着它十秒钟没看出来重点是什么,那就打回去重做吧。制作精美的幻灯片是一种艺术,我现在还学不到导师的十分之一,只好多看别人的范例,慢慢改进了。
博士五年总结(四)
时间管理
之前的三篇,谈的是如何做研究,写文章,做演讲。这一篇,讲一下时间管理。
人一天只有二十四小时,如何合理安排利用以成事,是每个人关心的问题。我觉得最关键的,是要有计划。
首先,制订计划会让人对任务的难度有更清醒的认识,增强利用时间的动机。出于本能,人都愿舒服地活在当下,就算做博士有大理想大目标,也不愿意细细去想,而是以“未来的事情再议”了事。可只要我们做一个简单的规划,就不禁会头皮发麻,恨不得要立即动手了。计算一下,一边,人生几十年,两万天,三十万个清醒小时,要吃喝拉撒,要履行家庭和社会责任,要享受各种放松休闲,要生病要变老,最后能有五分之一是自己的就不错了;另一边,想要成为大拿专家,甚至改变世界,至少需要几万小时的努力。两相抵扣,还能有多少余裕?至少我会觉得浪费时间是一种大大的罪过了。从另一方面规划,博士阶段比少年时思想成熟,比老年时身体健康,比中年时负担轻得不止一点两点,此时不好好干,做大事还有什么机会呢?就这样两个简单的规划,若是想通了,那再懒散也会动起脑筋来,在尽量短的时间内做尽量多的事情,整个人的精气神,也会大大不同。
另外,计划能 高做事效率。我校著名教授兰迪在《最后一课》(The Last Lecture)中说过重要事和紧急事的辩证关系,人生若是一直赶最后期限,忙着紧急的事情,天天当救火队长,看起来东奔西跑,甚是辛苦,但到头来人累心疲,还事倍功半。其实有些紧急的事真是无解的,但是如果早一两周甚至是一两天想到,就能统筹安排,这就是计划的好处。
那么,如何做计划呢?三点。
第一,宽松。
一天只计划一件或者两件最重要的事情,一定要把它们做完,然后再去做次重要的,可选的事情。
太紧的计划,比如说每小时都规定做完一件事,不很可取。因为每天的事务总有不可预知性,可能在任务转换中倒个水,刷个微博,也可能有人打扰,或者程序有错
需要更多时间调试,一旦现实没有如计划中的顺利,就会有完不成的挫败感,长此以往就会放弃。而宽松的计划,其整体期望值就会降低,原来必须得完成的事情,现在就变成“哇,我又做成一件事情啦”的情感奖励,整个人就会愿意坚持下去。如果发现计划太宽松,那再乐呵呵地慢慢加码就行。
做一件事,每天做多少不重要,重要的是经常做。
当然,计划的宽松不是绝对的,有时需要适当一鼓作气,特别是在一件事快完成的时候。因为在这些时间点上,需要人高度集中精神将之前的结果综合起来,克服最后的难关。写论文是一个经典例子,平时想思路推公式跑实验,作为零散的积累,最后一个月到一周集中精神把论文赶出来,效率特别高,要是没有最后期限,那结果很有可能散佚,自己也就忘记了。另一个例子是写长篇小说,这个是博士期间的业余创作,不可能每天都花大量时间。一开始文笔很烂,剧情简单,人物苍白,怎么办?没事,一点一点地积累,每周或者每月有空时花几十分钟写情景段落,这些段落有的可做开头,有的可做高潮,有的可做结尾,但相互之间没有紧密关联。然后,慢慢列大纲把故事串起来,花小段时间不停地做局部调整,这样日积月累,文笔变得越来越好,可用的大段素材也越来越多,放在人物上则人物丰满,放在剧情上则剧情生动,最后集中一段时间(大约是三周)把整个故事前后接起来,补上需要的过渡段落和场景。故事一旦接完,就已经活了,身为作者自然就有动力修补精化,等到完稿时还在不停地起劲改哩。而这个博士毕业总结系列,也是每天慢慢写一点积累素材,最后觉得差不多了,花几小时反复调整组织,终于定稿。
第二,简洁。
有人说,计划不如变化,越是长远的计划,越有可能中途夭折,还不如不用去费神细想。这话不假,但并不是不订计划的理由。其实计划不必像写报告书那样详尽,不必精细到每时每刻,在等车走路发呆锻炼的时候,如同简笔画一般,寥寥几笔,勾勒出几小时,几天或者几年后的方针图景就行。就算有改变,也可以马上重新规划,不至于缺乏弹性,船大难掉头。而且计划想多了,自然知道哪些部分靠谱,哪些不靠谱,哪些重要,哪些不重要,哪些部分可能出错,以后再做计划,就能一下子点到点子上,效率和质量都会 高。
三国演义里曹操大兵压境,千头万绪,孙刘联军如何是好?瑜亮两人,大书一个“火”字摆平。这个,就是最简洁的计划。有了这个字,接下来草船借箭,连环计,苦肉计,一切细节都是自然而然的。至于什么时候才能如此精炼,什么时候能精炼到点子上,就靠平时反复制订事前计划,与事后反思总结了。
第三,劳逸结合。
工作效率和所花时间从来就不成正比,功劳和苦劳也从不划等号,时间利用得好,少干活反而多出成果。保证睡觉和锻炼是两个最典型的例子。这五年来我每天平均
睡眠时间在七到八小时左右,事情再多,十一点半至十二点必定入睡,天塌下来也不管,然后七八点起,睡得好早上自然有思路冒出来,一天就有东西可以忙活;要是睡得晚贪一两小时,换来第二天毫无精神,得不偿失。
另外,锻炼身体很重要,再忙都不能不做。锻炼付出一两小时,精神得到放松,大脑得到休息,同时还能促进心肺功能,增强免疫力,绝对是稳赚不赔的买卖。我一般隔一天跑步五公里,或是游泳一公里,或是打壁球/羽毛球一小时。跑步太勤快会伤膝盖,因此需要和其它运动配合。跑步时什么也不想,挥洒汗水的时刻,就单纯地开心就好了。
博士五年总结(五)
五年过去了,我经历了很多,学到了很多,个性也改变了很多,从内向变得有些外向,认识了很多人,变得喜欢和别人交流,喜欢听更牛的人的见解,也会从别人的观点出发去看待问题。以前做得不错的事,现在可以做得更有效率;以前自卑的事,现在不害怕了;以前不敢想的事,现在可以去规划去计算了。还有很多做得一般甚至很糟糕的地方,没事,静下来好好分析前因后果,然后继续改进就好。
这样的改变,就好比坐过山车,一开始很紧张惶恐,特别是从高处冲下的时候,于是在大家的嘲笑中选择逃避,但是真的被逼着上去了好多次,适应了之后,就会在心理上有个准备,甚至期待,甚至在下坡时大吼,好像这车是自己开着,可以由自己掌控的一样。为什么会从害怕变成期待?因为发现了适应和掌握的窍门。而要发现窍门,先得要承认自己坐在过山车上颠簸这个现实。做梦没有用,幻想没有用,每个人身处的现实才是最大最大的真实,在这个真实之下,客观评价自己在人群中的地位,承认自己的弱点,找到属于自己的问题,然后不断地优化 升,如之前四篇所说,坚持不懈,注重方法,制订计划,一点一点地达成目的。
而这所有之上的第一推动力,是直面现实的勇气。
我之所以不写细则,一是因为每个人情况不同,具体问题要具体分析,适合我的不一定适合别人,所以只写总纲;另一个原因,是因为我其实根本记不得细则是什么,根据不同的环境,大脑自然会作出下意识的行动。要把这些行动全采集起来是很困难的,今天想到漏了一条,明天可能又发现漏了一条,把它们全列出来,需时很久不说,这个系列就会变得很长很零碎,读起来就不那么流畅了。
写这些文章,主要是给自己留个记录,以免日后忘记,荒废了这五年的时光,要是能顺带帮到大家,那是再好不过的事情:-)
多谢观赏!
博士五年总结(外一篇)
最后谈一下职业发展。
如我一位 CMU 的同学所说,这年头已经没有铁饭碗可言,公司是以赚钱为导向的,今天工资高福利好,明天业绩不佳就可能变卦。到五年十年后再被裁员,那时上有老下有小,就真是从天堂跌落地狱,无处立命安生。因此危机感和长远规划是非常重要的,年岁渐长,相关的能力也要渐长,让将来的选择面越来越宽是王道。因此,要把时间放在那些越陈越香的技能上面,比如说交流沟通和写作能力,比如说系统化的知识储备,比如说研究解决实际问题的经验,比如说对基本工具基本准则的深刻理解和熟练运用。有了这些东西之后,不管将来接手本领域的哪类工作,都能快速融入团队,快速理解别人需求,快速对着手的问题有深刻认识,快速出成果。
那么,怎么一直向前呢?不满意现在的职业,如何能更进一步做自己想要做的工作 呢?
首先要循序渐进。羡慕别人想要一步登天的意义不大,因为只看到了光鲜的外表而没有看到辛苦的实质。世界上任一项工作都有潜力可挖,如果在工作的时候有百分之三十到五十的时间觉得喜欢,那就很不错了,不必换。如果的确非常不喜欢现在的工作,想要换,那前 是一定要把现在的工作做好。做好了才有经济基础换工作,才能积累充分理由换工作,也有闲心换工作。转行不是拍脑袋的,是一点一点来的,先是兴趣,接着是爱好,再变成副业,最后孵化成熟,终于转为主业。这样在任何一步遇到挫折,或者家里发生变故,都有办法退回去,保证生活的稳定性。我在博士期间做课题就遵循这个原则,没有因为导师方向和我想做的不完全一致而换,而是在完成导师的任务同时也一点一点地建立自己的方向,最后把局面扭转过来。
为此,有些工作是不太能选的。像钱多但是熬夜拼命的、三班倒的工作,他们的共同特点是只拼眼前而没有积累。时间长了,自己的精力和身体不如从前,但待遇要求却要 高,和刚入行身强力壮没有牵挂的年轻人一比,只有走人的份。如果是我,宁愿选待遇低些,但是要有自己自由支配时间的工作。另外,若要发展好,两线作战是经常的事情,白天忙公司的,下班后忙自己的,效率如何,就看时间管理的成效了。
其次,是要发挥自己的长处。很多工作是需要天份的,自己想做的和自己能做的往往是两回事。有志者不一定事竟成。除了少数靠蛮力取胜的例子,大部分成功是需要巧劲的,不仅要耐心和坚韧,还要动脑分析问题在哪里,如何下次更有效率。往往一个聪明的决定抵过几个月的辛劳,一个好的总体规划,决定了整个项目的成败。
因此,在勤奋和努力之上的,是要有能“看见”问题关键的直感。这正是专家和门外汉的区别。专家对问题的些微变化都能灵敏捕捉,并且依此改变工作的重点和方向;而门外汉往往对重要的细节视而不见,把精力浪费在不重要的部分上。举个例子,让一个程序员画肖像素 ,老师在旁边干着急说某根线条不够柔和,某块阴影过于生硬,程序员却茫然无知,当然画不好;但程序员对一段程序中遗漏的分号或是缩进空格的多少却极为敏感,往往在计算机还没抱怨之前,自己先解决了。又比如,一个优化算法专家对目标函数的某些细节非常敏感,知道目标函数中多一项就是难解问题,少一项就有现成算法,若是多两项则又有高效方案;但把同样的问题丢给大一新生,可能就一律求梯度下降了事,也不明白问题的精细结构在哪里。
因此,要从事一个以前从来没有尝试过的领域,是要非常小心。要不断地考虑自己的思维模式是否适合,能否在有限的时间内达成这种高度敏感性。每个人都有自己适合的工作,在自己擅长的思维模式下不断前进拓展,我想这是最稳妥,最实际也最有效率的做法。
有人会问了,如果是一张白纸,没有积累,也没有形成任何有效的思维模式怎么办?这时候只能依靠时间和耐心来一点一点积累,并且多开口尽量向前辈请教。若说从业两年,是坚持还是放弃?这其中的度,谁也说不清。有时候再坚持一下就柳暗花明,有时候则注定在绝路上越走越远,究竟现在处于哪个状态,或许到人生的尽头都是不明白的。我唯一能说的,就是看在做这件事情的时候,是不是内心感到快乐,哪怕是一刹那也好。若是如此,那就会不知不觉做很久,也就根本不会有坚持或是放弃的内心挣扎。日积月累,花的时间多了,经验就比别人丰富,敏感性也就越强,效率也就越高,越有满足感,良性循环就起来了。对我来说,思考是有趣的,钻研是快乐的,是今天做了就会有的满足感,那就可以了。而成就则是第二位的,因为它不是自己可以控制的,是姗姗来迟的,是别人出于各自的心情给的随机评价而已。
最后,就算有铁饭碗了,就算三十岁时发了笔大财,有车有房以后都不愁吃穿,人生也没有就此结束。身为老板的员工需要完成项目,身为导师的学生需要做研究出成果以申报课题,身为妻儿的支柱需要为他们 供殷实的收入和稳定的生活,身为老人的儿女需要 供赡养,延续香火,给他们争光。对这些要求,要尽可能地满足,但是在这一切之外,永远永远要有不甘平凡的心,有自己的主心骨,那是一切的发动机和克服困难的力量源泉——因为那是活这一辈子,身为自己,所要完成的事情。
博士五年之后五年的总结
其 一
现在回头想来,其实博士阶段是很单纯的。拿着微薄的薪水,带着毕业的压力,待在一个交通闭塞的地方,在导师的指导、鼓励或是逼迫下,在周围各种牛人的压力下,花一些时间,专心地做一些东西。在这些条件下,很多人可以在一个从未尝试过的领域里面获得成功。
等到成家立业放飞自我了,往往问题就来了。再好的公司,也希望员工努力干活,而不是培养人的地方。不管表面上如何温情脉脉,最终还是要看绩效的,绩效好升职加薪,绩效不好卷铺盖走人,就这样简单。
而个人的成长方向,自始至终得要由自己负责。
- 选方向?先要控制自己阅读的入口
-
读什么东西,就成为什么样的人
。
- 读什么东西,就成为什么样的人。
- 读什么东西,就成为什么样的人。
重要的事情要说三遍。人是很容易被周围的东西影响的,在现在这个手机时代尤其如此,你关注谁,就会成为相似的人。刷一刷各类新闻和朋友圈,几十分钟就很容易过去了。而且这些东西大多可以定制,所以你的命运,可能完全取决于你,也可能完全交给你周围的人,不可不察。
另外如之前我的答案里所说,书和文章可以多看,但还是要多想,多去提炼其中隐藏的主线和趋势,多去做小小的预测,形成自己的世界观和方法论,然后才自然而然会有个人的见解和想做的方向,这种思考往往是很累人的,而且在这个信息过载的时代可能大家都更习惯去接受已有的观点,并且躲在自己的安全区里面。
但在日积月累之下,做或者不做这些,会让每个人最终成为不一样的人。
所以多看点动脑的内容,就不会让大脑生锈。做科研一个比较好的地方是工作本身并不重复,而是一直在开拓边界,这样自然会有更多的动脑时间。在闲暇时间,我经常会多看知乎上做数学和物理的同学们的回答,最好有几个不懂的名词需要自己去查去想想,手机上有个刷Arxiv的app经常看看,看一看一些优秀的github代码,也会动手刷刷题。
在走管理职位之后,这个尤其重要。“管理”这个词除了在国企之外,都是“支持”的同义词,支持的意思是帮人成事,事情搞完,功劳大部分是下属的,我鼓个掌说两句好听的。而“领导”另有个词叫“技术带头人”(tech leader),那个才是带大家冲锋在前的人。而要保证自己能做技术领导加管理的路子,技术的能力是一概不能少的。而参与了管理事务之后,每天开点会议,会让人产生“自己已经干了很多”的幻觉,一旦松懈下来,就再难再追上。在人工智能这个进展以月来计算的领域,要是对将来的方向不是很有见解,大家马上就不会再听你的了。
如何选方向?
有了选方向的点滴积累,接下来的问题是如何去选。
我们常说高考难,难如千军万马过独木桥,路只有一条,如何在最短时间内获得最高的分数,这是“术”;其实博士毕业之后更难,面对山高水远大路小路,往哪个方向跑,那是“道”的问题了。
然而,“道”和“术”并非完全分离,再高明的“道”,还是要“术”去贯彻的。
博士阶段其实就在寻找“道”中之“术”。博士努力学习如何探索如何试错,如何在纷乱的线头里找到关键点,才能在将来更大的挑战前降低试错成本,在有限的时间里找到对的方向。所以读博在某种程度上是预支了人生的风险,在二十几岁的时候犯几个错不要紧,大不了浪费一年从头再来;在四十来岁的时候再拍脑袋决策,轻率犯错就会比较麻烦了。
- 选方向,不管是科研选课题,还是VC投资,还是说选个人职业发展方向,其实是有一些通用的大原则的,比如说多从第一性原理出发从头解构分析,仔细思考每一步逻辑链条,多做调查,不要被三分钟热度冲昏头脑,不要挤人多的方向,从自己的独立分析和思考中找到突破口。别人都说好但自己觉得有硬伤的要三思后行,别人没注意到但自己觉得有前途的就要勇于尝试。在此之上,再发扬个人的风格喜好。
- 选方向,立意是第一重要的。所谓“立意”是指先对这个世界有一个精炼的模型,然后在所选的方向上,思考这个模型能否给出不错的未来。强调立意,其实是要强调要找到最重要的脉络和趋势。一个博士生往往拼命干活,为一篇文章呕心沥血;但导师则可以集中在一些“一定有效”的大思路上,举重若轻地指导学生做出几篇甚至十几篇文章来。这五年来,如何从一个博士生变成导师,如何去找到能深挖大挖的金矿,是比具体技巧更重要的事情。
- 我在《博士五年总结》里,把立意当成是一种写好文章的“术”,以归纳总结的方式,去为每篇文章或者是博士论文去寻找一个故事;但其实,它的重要性要远高于此。事物的发展在大尺度上是有脉络的,是有章可循的,而历史,往往重复它自己。这些,我就先不展开说了。
- 选方向要考虑到自己的能力。定一个不那么简单但又切实可行的小目标,往往是一切的开始。不要好高骛远,也不要自卑自弃。回头看我自己的五年总结,我会觉得在博士阶段时过早去啃一些相对困难的方向,且没能经常和牛人们合作,是一个比较遗憾的地方,不然的话会走得更好。不过幸亏自己还可以在每次deadline之前迷途知返,专心做应用文章,所以整个博士阶段还算顺利。毕业前博士是一座山,毕业后博士只是一道关,过关之后,将来才有机会继续搞下去。
在这方面,成熟的人会把问题分解,按照难易排序,知道轻重缓急,知道充分交流,也知道做事节奏,在没做出什么东西之前也吃得下睡得着;而不成熟的人往往盯着一两个比较近的目标,不管三七二十一先爽过再说,而碰上比较难的问题,往往先过于乐观,然后马上放弃,缺少韧劲和思考的深度。
要去验证这个小目标。可能最重要的,是要找到第一个会出错的地方,并且修正对问题的建模。这里就是考验面对现实的勇气的时候,很多人事事都做好了,但偏偏最重要的地方不去试验,心里幻想着这事可以成,越往后拖,损失最大。举研究的例子,比如说拼命做漂亮的UI但不考虑算法会不会有效果,拼命做简单实验但不去做最可能失败的,拼命折腾编辑器设置但却不写文章。另一个例子比如说想转强化学习,在略微过一下教材之后,就可以上实验试着把东西调通,然后就可以在之前的经验之上开始思考什么方向可以发文章,然后再试。
这种有选择性的跳跃方式,可以以比较快的速度找到关键所在,并且修正自己脑中对问题的建构模型。要记得不管自己多聪明,保留”自己可能全错“的这种可能,并且经常听取别人意见或是采纳实验上的证据,不仅对于选方向是重要的,也是一个人可以持续发展的根基。
如何抓紧时间?
踏入工作之后,时间就变得非常宝贵。可能在博士阶段花一个月做的事情,工作时花两周或者一周就要能做出来。并且时间变得零碎,变得资深后及担任管理职位之后,开会等各种其它的事务也变多了,如果没有一个明确的方向,那很快就会陷入琐事里面去。
这方面例子非常多。一天开会,忙的时候留给自己的工作时间只有两三个小时,基本上是早上十点前及下午四点后,要是不能坐下来马上进入状态,稍微刷一刷或者聊一聊,那就啥都干不了;反过来要是心里有明确计划和目标,那就算是10分钟都可以做些事情。一天有多少个十分钟碎片?很多很多,公车上,走路时,马桶上——做好计划,这些时间都可以被利用起来。古人说“马上、枕上、厕上,盖惟此尤可以属思尔”。一千年后,还是一样的。
如何坚持一个长期的方向?
我记得前一阵子在将门直播的时候,我被问到一个问题,说做研究要如何平衡短期工作和长期工作的关系,如何应对外界的压力。我觉得这个问题非常好。在博士阶段我就得要处理这个矛盾,导师想做的,未必是我自己喜欢的;我喜欢的,未必是马上能做出来的,现在工作了,仍然要处理这样的矛盾,并且因为节奏变快,责任更重,矛盾会变得更加尖锐。如同我在《博士五年总结》里面说的那样,要习惯于两线作战,要有“进可攻”的长期课题,也要有“退可守”的短期课题,这样既减少对短期绩效评估的担心,又怀抱有长远的希望。然而要做到这一点,是需要大量的技术和细节支撑,一点一点地从严苛的现实世界中,从每天24小时里面,取回自己想要的东西。
在理完纷乱的俗务之后,还能心向茫茫的星辰大海。
其 二
这五年来,交流上的改进是另一个非常重要的环节。
之前的《博士五年总结》介绍了博士阶段应有的交流能力,做演讲,和同行交流,论文要写得流畅,等等。这些是作为一个科研工作者的应有水准。然而要是只做到这一点,只能说是一个合格的从业者。
再往上走,就应该要知道如何通过交流,去理解别人的期望,去争取自己的利益。
理解别人的期望
中国和美国有一点非常不同:中国人往往努力干活,相互谦让,遇事忍耐,心里期待着上头的领导能公平安排;美国的惯例则是每个人都需要为自己说话,往往在会上吵得鸡飞狗跳,直到找到大家满意的平衡点为止。
中国这一套体系对领导的能力素养提出了非常高的要求,领导需要了解每个人的脾气性格,需要估计会发生的可能情况,并且及时处理,而员工可以专心完成自己的工作。美国则把责任分摊给个人进行分布式决策,只要大家都理性,都愿意为自己争取,总会有一个还不错的结果。
在美国这样的环境下,交流就变得非常重要。我们常觉得自己工作非常努力,周末加班无数,修完各种bug,却看见别人和老板关系好升职快,觉得自己在职场上被欺负而愤愤不平——但很多时候,并不是活干得不够多,并不是因为被人歧视,而是因为没有产生有效的交流,没有找到正确的方向并且努力。对公司来说,员工找到正确的方向,做正确的事情是非常重要的,这比每天工作时长要重要得多。可能打照面说个一两句话,就抵得上几周的工作和几万行代码。这可能被以工作量作为唯一准绳的人认为是作弊,但世界往往就是如此运行的。
而为了找到正确的方向,需要一些“能说会道”或者说是“溜须拍马”的能力,去作沟通。一个很关键的技巧是不要对任何事情说“好的”,“没问题”,而是要停一下,想一想,多思考多询问,多提关键问题。这样一方面可以显示出你确实理解了对方的想法,另一方面,给自己留足斡旋的空间。经常见到的例子是还没开始怎么讨论,就一个劲地说没问题包在我身上,回头发现自己没听懂要求也没想过怎么做,然后又碍于面子不敢问,这样把自己折腾得够呛,绩效又不好,责任又全在自己身上,真是亏大了。
在中国我们很少思考这样的问题,因为我们往往都假定领导全知全能,自己付出的努力,领导应该都看在眼里,并且及时给予公正的奖励。但现实并非如此,大家都是人,没有人多长几只眼睛,偏偏往自己这边多看两眼。把它们归为肤色问题,躲在受害者的被窝里哭一哭,说两句风凉话,心里好过是好过了,但就没办法进步了。
再往上走,成为管理者之后,对交流的能力要求就更高。不仅对上对下都要理解期望,而且要从行为举止中摸清游戏规则,并且在游戏规则里为组员争取最大的权益。这可以说是做管理非常枯燥的地方,但也是有意思之处。
而如何去摸清规则,就要靠交流。很多时候规则会完全出乎我们的意料,经常会有“为什么我的建议总被人否决?”“为什么他们居然提这样的项目?而上面居然会批准?”这样的疑问,有时候甚至会怀疑人生。主要原因是不同职阶的人想的东西是完全不一样的,往往是普通员工想升职,经理们想招更多的人扩大团队,总监们想的是如何提高项目的影响力,VP们会去想如何提升公司的品牌,维护公司的价值观,等等。这里举的例子都只是通常的思路,实际情况要复杂得多,经常有惊掉下巴的清奇脑回路出现。而每个组里每个人思路的不同,各类人的个性和人员配比的不同,会造成千变万化的游戏规则和团队微环境,必须既要谨言慎行,却又要在关键时刻挺身而出。要能真正做到这一点,与各个利益团队充分及深入的交流是必不可少的。如果是摸不到脉络却又随便说话,可能一两个照面就被搞下去了。
能说会道,溜须拍马的背后,是更充分的沟通;使盘外招,出无理牌的背后,是对规则更深的了解。不了解规则的时候,就应当虚心谨慎。我记得某部书里说过一句话:“居上位者,定有其过人之处”,深以为然。对此,我们得先存敬畏之心,后寻理解之道。而要解开这些谜团,就只有靠充分交流与认真思考。反过来,要是觉得自己很厉害,觉得大家都要听自己的,没有“我可能会犯错“的意识,结局可能就如《三体》所说——“弱小和无知不是生存的障碍,傲慢才是”。
类似说法:
所有的优越感都不是来自容貌、身材、知识、家族、财富、地位、成就和权利,它只来自
缺见识和缺悲悯。
附:
- 读书的意义
- 不读书的人,看到的只是别人画给他看的美好世界;
- 读了书之后,你认识了黑暗和丑陋;
- 只有读了更多的书之后,你就站在了巨人的肩上,看到了希望和光明

争取自己的利益
我们从小到大的教育,特别是历史教育,往往会让人去信奉弱肉强食的达尔文主义。大家常常对近代史耿耿于怀,想着落后就要挨打,想着要吃亏了要赚回来,看到赢者通吃为所欲为,看到输者只能躲在角落里瑟瑟发抖。很多小说都走这样的路子,大家看了,代入主角爽一把,然后继续这样的思维方式。其实这种理解虽然有一定道理,但太过粗糙也失之极端。人和动物一个很大的区别,在于互惠互利成为主流,因此制定出来的规则也更加复杂。在这种情况下,其实已经分不出绝对的强者或者弱者,有人人脉广,有人主意多,有人经验丰富,有人写代码厉害,有人文章看得深,有人交流能力强,缺一不可,大家合作,才能双赢或者多赢。
在这种情况下,明白自己的地位,决定自己想要扮演什么样的角色,并努力争取相应的权益,就是理所当然的事情。这样就要具体问题具体分析,在不同情况采用不同的策略。按照这样的逻辑,一个人的处世哲学,也无法用几个简单的词去概括,不管是“无私奉献”或者是“明哲保身”还是“闷声发大财”,都无法成为事前奉行的准则,而更多是事后的标签和注脚。
在决定了自己的角色之后,当然要尽职尽责,但同时也要尽力争取回报。可能是因为有长期互撕的历史,美国很多细节都按照权责分明的方案设计,义务和利益是对等的,能站出来挑大梁,做成了就有好的回报。想负责一个大项目?给人给资源给时间,而压力马上就会来。我们的ELF OpenGo项目拿到很多资源,但与此同时每三天就要写一个进度报告。而一旦有了结果,那就有机会给上面汇报和展示工作,提高知名度和影响力。像这样露脸的机会,就要好好抓住,把平时演讲的功夫全都展示出来;写总结的时候也要如实写明,若是自己都谦虚退让,那还有谁可以替着说话?
- 负责招人?可以拍板,但得陈述理由,仔细分析个人面试意见,还要接受各种询问、异议甚至是质问。更大的责任是招完人还要负责对方的职业发展,经常听到的问题是“你招进来,你带不带?”像这种单刀直入的问题,基本上杜绝了随便招人的现象,更不用说关系户了。这一块往往殚精竭虑,因为风险是相当大的——招个牛人事半功倍;反之若是招人不慎,给组里制造各种混乱,那得要脱掉半层皮了。
- 想管理团队?那得要负责把握方向,定下目标,花时间去开会去沟通,给组员们以各种方便,还要在评定会上公平公正地讲述组员的贡献,找到各种理由给他们更好的待遇。如果自己的组员做得比别人好,那就找各种攻击点据理力争,直到大家相互间找到各自有利的地方妥协为止。这无关道德品行,纯粹是管理者的义务。若是开会时畏畏缩缩,那为什么大家还要跟着你?能吵架,才有尊重;而获得尊重,对于管理者本身就是回报的一部分。
- 我以前实习时的老板从微软跳入了我们的组,一开始他是我的老板,后来成为同事,然后在会上为各自组里的利益争得面红耳赤,开完会他对我说干得好(good job)——在那一刻,我觉得这是对自己最大的褒奖。
其 三
从小到大,常听长辈们说:“好好读书,好好学习,长大了才有好工作。”,似乎只要努力十几年,接下来就如童话般有一个美好的结局。但等我们真的到了而立之年,真的去找了一份工作,才发现人生才刚刚开始,接下来要怎么成长,怎么发展,长辈们已经没有故事再编给我们听了。
工作之后,很容易进入舒适区和回音室(echo chamber),每天挤同样的地铁,处理同样的事务,聊熟悉的话题,结婚生娃养娃,不知不觉间韶华已逝,直到退休老死。有句话说的好:“有的人25岁就死了,75岁才埋”,现在的人平均寿命已经超过75了,要是刚开始工作就看完了一生,那还有一多半时间要如何处理呢?
若是想要继续成长,那就不得不发挥更多的主观能动性了。
走出舒适区和离开回音室
“走出舒适区”这五个字,我想大家在各类鸡汤文里面看到很多次了,无非是不甘平庸,要努力,要抓紧时间提升自己,要尝试新事物。我在之前的博文里面也提过一些,这里也不想多说了。
但“离开回音室”,却鲜少有人提及。
从小到大,外界的反馈信号是越来越弱的。上大学前有老师和家长管头管脚,本科硕士时有师兄师姐,博士时还有导师。工作了之后,中肯有益的批评会越来越少,大家都忙于自己的工作,没有空也没有义务去评论别人,能得到的评论都是“还不错啊”,“挺好的”,“很厉害”。而有一两条不顺眼的评价,或许拉黑关评论也就可以了,再没有强制听取的必要了,久而久之,能听到的都只是赞美了。
然而,别人的反馈是一面镜子,能照到自己看不到的角落。一般足够勤奋足够用心的人,很多时候并不是因为没达到预定的目标,而是有意无意地忽略了其它的方向。很多时候,不将棋盘掀掉再来想问题,问题是无解的;而掀桌子的那些人,往往是门清的旁观者,他们会残酷地把筋疲力尽的奋斗者拖起来,撕开“勤奋向上”的保护罩,在他的耳边吼道:你的路子是错的,迄今为止的所有努力都是毫无意义的。
工作了,真心的批评会越来越少,而噪音则会越来越多。有时候可能皱个眉头或者话里有话,几秒钟的事情,态度就已经说出来了;有时候被人无端贬损,其实对方只是发泄情绪,自己并未做错;更高段的是出于各自利益相互攻击。这时候能不能把得住舵,既能听从别人的意见完善自己,又过滤不实之辞予以反击,就是个很难的事情,精神不够强韧的人,往往就躲到回音室里再不出来了。这里面的“度”很难控制,看得准不准,解读得对不对,一是取决于自己的阅历,二是要多方了解再做评判。一个受着冒名顶替综合症(Impostor syndrome)困扰的人,可能一两句随便的批评就会被毁自信,这时候多听听各种人的意见,同时把自己的功绩和自己的努力联系起来,再建立不依赖于别人的自我评价体系,会在很大程度上平衡这种困扰。
听取别人的意见,并不只是说做做表面文章。我们常说谦虚是一种美德,虚怀若谷是一种君子气度,这种说法其实是很肤浅的——也许自我感觉良好,别人不过尔尔,但碍于面子让一让也无妨。这种假谦虚是无法改变自己的,只会通过暗地贬损别人的方式来加强回音室的效果。只有意识到自己可能真是错的,也许事情真不是所想的那样,这样在看到清楚的逻辑和充足的证据后,才能听进去。
多听别人的意见,但要记得选择权在自己。自己出了错不要全怪他人,不要怪老师怪师兄怪父母,那样只会让自己在弱者的循环里越陷越深。自己的路是自己走的,盲听盲从是自己的失误,去伪存真是自己的责任。把锅全都甩给别人的那一刻,虽然获得了一时的轻松,却也在不知不觉间,停下前进的脚步。
最后,不要太过经常去评判别人。大家做事都有背后的逻辑,或者有不得已的苦衷,拿自身的幸运去对比别人的苦难,既不仁也不智。而更重要的是,经常评判别人会陷入强者的幻想中,浑身舒坦,似乎自己全知全能,别人错漏百出,久而久之,每天沐浴在和煦的阳光下,只聆听脑海中的掌声,那又陷入回音室的陷阱里面去了。相比之下,忙着赶路的人,更关注自己要面对要解决的问题,往往对别人更宽容—只要别人不挡着道,他们做什么和我有什么关系呢?
选一个好环境
虽然个人因素是很重要的,但环境因素也不可或缺。
一个好的环境和平台,首先给人的是成长空间。有句话叫宁作鸡头不当凤尾。当了鸡头,最重要的是有了责任感,事情得要好好想,决策得要好好做,做对了有成就感,做错了有切肤之痛。处于这种状态,压力会大,但不知不觉会进步,会想办法更好地分析问题。反之要是凡事都有上头罩着,一举一动都不需要自己负责,那不出半年人就会退化,再要赶上就难了。
回想读博本身,就是找了一个很好的平台。周围都是懂行的人,提出的问题往往一针见血切中要害。而工作了之后,周围的人的背景变杂了,往往你是在本公司里最懂某一块的人,其它人也没能力也没必要挑战权威。这时候找一些同道经常交流,就是很有必要的了。
另一个是格局要大,或者有能变大的潜力。天天为代码缩进一个空格还是两个空格而讨论,或者重复机器能做的工作,或只在原有的平台上修补bug,或者总做小事情,得不到上头的信任和委托,那年薪百万都是没有意义的。更大格局也会降低以后被自动工具替代的风险。人工智能的进步是很快的,看着海水很平静,待到涨潮漫上滩涂时,再往山上跑就晚了。
平衡收入和可持续的职业发展
如果说有什么地方我的观念和读博时截然相反,那可能是对金钱的态度上。学生的时候觉得钱不重要,理想最重要,为了理想光荣,沾了铜臭可耻。
事实上不得不说这个世界是由经济和交换驱动的,即便是去当教授,也一样要写各种grant和各种proposal,为自己的利益争得头破血流。除开“挣得面子”或是“获得安全感”这些,有一个好的经济基础,对我更重要的是有两点。
- 首先收入的多少是一种筛选机制。虽然牛人不都是冲着钱而来,但总的来说,还是工资高的地方牛人较多,无他,每个人都有现实的压力,能够获取高工资也是实力的证明,对将来有好处。更重要的一点是,有钱可以节省大量花费在琐事上的时间。没有足够的收入,就不得不去讨论和争执一些平凡的事务,这样会耗费掉大量资源,不管是时间资源还是情感资源。这种耗费,反过来会把人一直锁在糟糕的状态下而无法成长。就算自己不问世事,对小事漠不关心或是逃避,也会有各种外界因素逼得自己去处理和面对。这种被动的推动,是不愉快的主要缘由之一。与其处处被动,不如找到一份有足够回报的,“体面”的工作。钱确实买不来时间,但钱可以帮你打消掉很多琐事,也是在很多情况下说服亲戚和长辈们的唯一办法,这样才可以把有限的时间和精力集中在更重要的事情上面。
- 另一方面,如果找工作只看钱,则是走进了另一个极端里面了。市场是在不断变化的,今年可能前端做网页火了,明年是虚拟现实元年,后年人工智能迎来一波大热潮,再后来区块链成新宠,如果每次只找挣钱最多的方向,频繁跳槽,那肯定会中断自己职业发展的历程。从长远看,有一个自己喜爱的方向,在专业上有长期的积累,才能越老越香。人生这场马拉松,其实一开始跑得快点或者慢点没太大关系,重要的是能不能一直朝着某个方面坚持,一直往前走。现在知识不再被垄断,网上材料那么多,想学什么都是容易的,只要愿意,弱点总是可以被弥补的。
这里举个计算机的例子。我们经常听到两种截然不同的说法,一说计算机是青春饭,三十岁以后就做不动了;另一说资深员工很受欢迎。到底哪句话是对的?很简单,职业发展越往后,人和人之间的差距越大,年龄得要和水平成正比。小年轻只要聪明努力肯干,给个入门职位招进来不是问题;一旦年岁渐涨,招人就要考虑投资回报比的问题。有些资深员人能带人管人,关键时刻以一当十,公司不付几倍工资出来,真是不好意思;有些所谓资深员工,水平也就和刚入门的人差不多,那为什么还要花更多的钱呢?
在这点上,计算机这个方向其实比很多其它方向好得多,因为一个牛人往往顶十人甚至百人,一个水平不高的人在团队里会产生巨大的反效果,所以人和人的区分度很大,牛人的价值要高得多。要是大家都只能干些搬砖的活,那么人和人的差别就不大了——在这种情况下,差别一定还是会有,但就不得不体现在技术之外了,这一点我相信大家都会有体会,我就不谈了。
总之,找到自己的位置并且充分发挥自己的特长,然后适当地和现实妥协,我觉得会是比较可行的方案,至于什么可以妥协,什么需要坚持,则是见仁见智的事情,需要具体问题具体分析。在此我很推荐科研的道路,这份职业没有通常工种“望尽天涯路”的厌倦无聊,只要思想开明就有各种新奇东西可以玩一辈子,只要努力那么能取得的成就上不封顶,工资也足够养家,在新技术的浪潮面前有较少被替代的风险——科研本身,就是开启和推动浪潮的原动力。
而科学家所带来的,乃是我们这些渺小的尘埃,在亿万光年的冷暗宇宙中传播火种的希望。
我想要成长么?
说了那么多,其实成长并非每个人都想要的东西。
对大部分人而言,日复一日的安稳平淡生活,就已经很不错了。不管是辉煌的荣耀也好,平凡的生活也罢,最终不过沦为几分钟的饭后谈资,或者几秒钟的脑海片段,敬佩或是感叹、讥笑或是遗憾,喜乐或是悲哀——哪天不在了,太阳还是照常升起,而后大家该如何活就如何活,所谓“亲戚或余悲,他人亦已歌”,并非世态炎凉,确是人之常情。
所以啊,是满足于岁月静好,还是决意于前行远方,都只是为个体的快乐而做出的决定罢了——而做出这个决定本身,就已经是成长的一部分了。
补 充
最后再私心分享渊栋之前写过的特别喜欢的一段话:
有人问我,梦想如何坚持?梦想破灭了怎么办?我想要回答,但是真要提笔的时候,又不知道如何说起。其实,这世界上没有破灭和未破灭这两种状态,没有是或非两种结论,这世界上有的,只是日升日落,人来人往。你说要有光,那就有光,光在你心里;你要追求什么,那东西就不曾离你而去;而你若忘却,它就消亡。所以,若是要坚持所谓的梦想,那么就如同小说中写的那样——
求道之人,不问寒暑。
李沐
博士这五年
- 2017年2月6日
前言
12年8月提着一个行李箱降落在匹兹堡机场。没找住的地方,也不知道CMU应该怎么去。对未来一片迷茫,但充满乐观。 现在,刚完成了博士期间最后的一场报告,在同样的机场,不过是在等待离开的航班。
回想过去的五年,是折腾的五年,也是自我感悟和提升的五年。这里我尝试记录这五年主要做过的事情和其中的感想,希望对大家有所启发。
第0年:3/11-8/12
我第一次申请美国的博士是在11年,但拿到的offer并没有特别合适的导师,于是就北上投奔文渊去了。 我当时在百度商务搜索部门做广告的点击预估。具体是使用机器学习来预测一个广告是不是会被用户点击。 这时候离“大数据”这个词流行还有两年,但百度那时候的数据即使现在来看仍然是大的。我的任务是如何高效的利用数百台机器快速的在数十T的数据上训练出模型。
当时产品用的算法基于LBFGS,我于是想是不是可以换个收敛更快的算法。没几天就找到个不错 。但实现上发现了各种问题,包括性能,收敛,和稳定性。而且那时有的就是一个裸的Linux和很老版本的GCC,什么都是需要从头开始写。花了大量时间做系统优化,算法改动,和线上实验,最后一年后在整个广告流量上上了线。
现在再回顾会觉得整个一年时间都在打磨各种细节上,有时候为了5%的性能提升花上上千行代码。这些都导致算法过于复杂,有过度设计之嫌。但深入各个细节对个人能力提升很大,而且很多遇到的问题成为了之后研究方向的来源。一些算法上的思考曾写在这里,当时候深度学习刚刚出来,冥冥中觉得这个应该是大规模机器学习的未来,不过真正开始跟进是好几年以后了。
11年12月中的时候突然心血来潮随手把材料重新寄了一遍,就选了CMU和MIT,结果意外收到了CMU的offer。有天在百度食堂同凯哥(余凯)和潼哥(张潼)吃饭,我说收了CMU offer,在纠结去不去。他们立马说去跟Alex Smola啊,他要要加入CMU了,我们给你引荐下。
记得是离开的前一天才开始打包行李,早上去公司开完会,中午离职,跟小伙伴打招呼说出个国,然后就奔机场了。那天北京天气特别好,完全不记得前一天雾霾刚爆了表。
第一年:9/12-8/13
第一年的主要事情是熟悉环境和上课。CMU课程比较重,博士需要学8门课,每门课工作量巨大。而且要求做两门课助教,做助教比上课更累。
这一年上的课中对我最有用的是“高级分布式系统”。之前在上交ACM班的时候已经学过很多质量都还不错课,纯知识性的课程一般对我帮助不大。但这门课主要是读论文,然后大家讨论。不仅仅是关于知识,很多是对设计理念的领悟。大家知道对于系统而言,设计是一门艺术而不是科学,这是设计者审美和哲学理念的体现。同时系统界历史也是由一波又一波的潮流组成,了解历史的发展以及其中不断重复的规律非常有意义。
那年这门课上课老师是Hui Zhang(神人之一,20多岁就在CMU任教了,学生包括了Ion Stoica,他是Spark作者Matei的导师),他有非常好的大局观,对于“Why”这个问题阐述非常到位。我是通过这门课才对分布式系统有了比较清晰的认识。两年之后我偶然发现我的一篇论文也在这门课的阅读列表里了,算是小成就达成 。
除了上课,更重要是做研究。我去CMU的时候Alex那时还在Google,而且没经费,所以把我丢给了 Dave Andersen。于是我有了两个导师,一个做机器学习,一个做分布式系统。
前面半年都是在相互熟悉的过程。我们每周会一起聊一个小时。前半年因为Alex不在,所以我们只能视频。Alex那边信号经常不好,而且他有德国和澳大利亚口音,外加思维跳跃,经常我听不懂他说啥只能卖萌傻笑。还是靠着Dave不断的打字告诉我Alex说了什么才度过了前几次的会。
两个导师风格迥异。Alex是属于反应特别快,通常你说一点,他已经想好了接下来十点,要跟上他节奏很难。一般抛出问题的时候他就想好了好几个解决方法。这时候要证明自己的想法比他的更好不容易,需要大量的沟通和实验数据支撑。我想我大概是花了两年证明了在某些方向上我的方案一般更好,所以这时候他就不那么hands-on了。
Dave不会给很多想法,但会帮助把一个东西理解透,然后讲得很清楚。因为我研究方向主要是机器学习上,基本上前两年基本都是我在教Dave什么叫机器学习,而且是尽量不用公式那种教法。
我的第一个研究工作是关于如果划分数据和计算使得减少机器学习求解中的网络通讯量。Alex体现了他的强项,几分钟就把问题归纳成了一个优化问题,然后我们三各自提出一个解法。我做了做实验发现Dave的算法更好。接下来两个月把算法做了很多优化,然后又做了点理论分析就把论文写了。
可惜这个想法似乎有点超前,虽然我们一遍又一遍的改进写作,但投了好几个会审稿人就是不理解,或者觉得这个问题不重要。那个时候学术界已经开始吹嘘“大数据”,但我觉得其实大部分人是不懂的,或者他们的“大数据”仍然是几个GB的规模,烤U盘需要十来分钟的那种。
这是我在CMU的一个工作,我觉得挺有用,但却是唯一没能发表的。
当时跟我坐同一个办公室的是Richard Peng,他做的是理论研究。我经常跟他讨论问题,然后有了些想法合作了一个工作。大体思想是把图压缩的快速算法做到矩阵的低秩近似上。这个工作写了三十页公式但没有任何实验,我主要当做写代码间隙的悠闲娱乐,不过运气很好的中了FOCS。
坦白说我不是特别喜欢纯理论这种,例如在bound的证明中很多大量的项直接丢掉了,导致我觉得bound特别的近似。对于做系统的人来说,最后拼的是常数。这个工作中这种大开大合的做法我觉得很不踏实。所以我觉得以后还是应该做更实在点的东西。
在CMU回到了去百度前的一周七天工作无休的节奏。每周至少80个小时花在学校。如果累了就去健身房,我一般晚上12点去。不仅是我一个人,大家都很努力,例如凌晨的健身房,早3点的办公室,四处都可以见到中国或者印度学生。我那时候的室友田渊栋花在学校的时候比我多很多。
那一阵子有读了很多关于优化的文章。其中对我启发最大的是Bertsekas写于80年代末的那本关于分布式计算的书。此书可以认为是MIT控制领域黄金一代研究成果总结,换到现在仍然不过时。
受启发我转去研究异步算法,就是分布式下不保证数据的及时性来提升系统性能。我基于在百度期间做的算法,做了一些改进和理论分析,然后投了NIPS。
投完NIPS就动身去了Google Research实习。那时候Google Brain成立不久,在“宇宙的答案”42楼,包括Jeff Dean,Geoffrey Hinton,Prabhakar Raghavan好些大牛挤在一起,加起来论文引用率能超80万。
Alex跟我说,你去读读Jure Leskovec的文章,学学人家怎么讲故事。我在Google也尝试用了些用户GPS数据来对用户行为建模。可是写文章的时候怎么也写不出Jure的那种故事感,发现自己不是那块料。这篇文章因为用了用户数据,恰逢Snowden让大家意识到隐私的重要性,历经艰辛删了一半结果Google才允许发出来。有些累觉不爱。
不过在Google期间我主要时间花在研究内部代码和文档上。Google的基础架构很好,文档也很健全。虽然没有直接学到了什么,但至少是开了眼界。
第二年:9/13-8/14
这学期上了Tuomas Sandholm的机制设计,此乃另一大神,例如最近德州扑克赢了专业选手,之前开公司也卖了上亿。不过这门课我是完完全全没学懂,连承诺的课程大作业都没怎么做出来。之后的两年里我一遇到Tuomas他都会问下有什么进展没。我只能远远看见他就绕开。
NIPS被拒了,发现审稿人不懂线程和进程的区别,有点沮丧。隔壁实验室一篇想法类似但简单很多的论文倒是中了oral,所以那阵子压力很大。Alex安慰说这种事情常有发生,看淡点,然后举了很多自己的例子。
之后想了想,一篇好文章自然需要有足够多的“干货”,或者说信息量, 但一篇能被接受的文章需要满足下面这个公式:
文章的信息量 / 文章的易读性 < 审稿人水平 * 审稿人花的时间 对于机器学习会议,因为投稿量大,所以审稿人很多自然平均水平就会下降。而且很多审稿人就花半个小时到一个小时来读文章,所以公式右边数值通常是很小,而且不是我们能控制。
如果文章的信息量不大,例如是改进前面工作或者一些简单的新想法,那么公式成立的概率很大。而对于信息量大的文章,就需要努力提升易读性,包括清晰的问题设定,足够的上下文解释等等。而前面投的那篇NIPS,以及更早的那个被拒工作,就是因为我们假设了审稿人有足够多的相关专业知识,而我们塞进了太多干货使得大家都读糊涂了。
即使对于已经发表的文章,上面那个公式同样可以用来衡量一篇论文的引用率。例如经常见到干货很多的文章没有什么人引用,而同时期的某些工作就是考虑了其中简单特殊情况结果被大引特引。
接下来的半年我主要在做一个通用的分布式机器学习框架,是想以后做实验方便些。名字就叫parameter server,沿用了Alex 10年论文提出的名字。花了很多时间在接口设计上,做了好几个版本实现,也跑了些工业界级别的大规模的实验。
不过真正花了我大量时间的是在写论文上。目标是把这个工作投到OSDI上,OSDI是系统界两大会之一。我们预计审稿人跟Dave两年前状态差不多,不会有太多机器学习和数学背景,所以需要尽量的少用公式。整整一个月就花在写论文上,14页的文章满满都是文字和示意图。不过努力没有白费,最终论文被接受了。随后又花了好几周准备大会报告上。相对于平时花一周写论文,两三天准备报告,这次在写作和报告水平上有了很大的提升。没有放进去的公式和定理投了接下来的NIPS,这次运气很好的中了。
有了文章后稍微心安了点可以更自由的做些事情。
寒假回了趟国,跑去百度找了凯哥和潼哥。潼哥说他最近有个想法,于是快糙猛的把实验做了然后写了篇论文投了KDD。同时期Alex一个学生也把他一个一直想让我做但我觉得这个小trick不值得我花时间的想法投了KDD,结果中了最佳论文。作报告那天我在的会场稀稀疏疏几个人,他们隔壁会场人山人海。这个使得好长一段时间我都在琢磨是不是还是要跟着导师走比较好。
那时凯哥在百度搞少帅计划,觉得蛮合适就加入了。这时凯哥正带着一大帮兄弟轰轰烈烈的搞深度学习,我自然也是跳坑了。试过好几个想法后,我觉得做做分布式的深度学习框架比较对胃口。我挑了CXXNet作为起点,主要是因为跟天奇比较熟。同时也慢慢上手跑一些Alexnet之类的实验。
我是因为少帅计划才开始开始做深度学习相关项目,凯哥也很支持我做开源开发回馈社会而不是只做公司内部的产品。但在少帅期间并没有做出什么对公司有帮助的事,很是惭愧。
第三年:9/14-8/15
回CMU后Alex看见深度学习这么火,说我们也去买点GPU玩玩。但我们比较穷,只能去newegg上掏点便宜货。这个开启了轰轰烈烈的机器折腾之旅。整个一年我觉得我都在买买买装装装上。最终我们可能就花了小几万刀攒出了一个有80块GPU的集群。现在想想时间上花费不值得,而且为了图便宜买了各种型号的硬件导致维护成本高。但当时候乐在其中。具体细节可以看这篇blog
这一年写了很多parameter server代码,同时花了很时间帮助用户使用这些代码。很难说做得很成功,现在想想有几个原因。写代码时我会优先考虑性能和支持最多的机器学习算法。但正如前面的错误,忽略了代码的易读性,从而导致只有少部分人能理解代码从而做一些开发。例如我尝试让Alex组的学生来使用这些代码,但其中的各种异步和callback让他们觉得很是难懂。其次是没有人能一起审核代码接口,导致这些接口有浓浓的个人味道,很难做到对所有人都简单明了。
不过幸运的是找到一帮志同道合的小伙伴。最早是我发现天奇在写xgboost的分布式启动脚本,我看了看发现挺好用,就跟他聊了聊。聊下的发现有很多基础部件例如启动脚本,文件读取应该是可以多个项目共同使用,而不是每个项目都造一个轮子。于是跟天奇在Github上创建了一个叫DMLC的组织,用来加强合作和沟通。第一个项目是dmlc-core,放置了启动和数据读取代码。
DMLC的第二个新项目叫wormhole。想法是提供一系列分布式机器学习算法,他们使用差不多相同的配置参数来统一用户体验。我把parameter server里面的机器学习相关算法移植了过来,天奇移植了xgboost。Parameter server原有的系统代码简化到了ps-lite。
中途我听百度同学说factorization machine(FM)在广告数据上效果不错,所以在wormhole上实现了下。针对分布式做了一些优化,然后投了WSDM。前后没有花到一个月,但神奇的竟然拿了最佳论文提名。
在wormhole的开发中发现一个问题,就是各个算法还是挺不一样,他们可以共用一些代码,但又有各自的特点,需要特别的优化来保证性能。这样导致维护有些困难,例如对共用代码的改动导致所有项目都要检查下。总结下来觉得一个项目最好只做一件事情。所以天奇把xgboost代码放回原来项目,我也把FM独立出来一个项目叫difacto。
通过一系列的项目,我学到的一点是,以目前的水平和人力,做一个通用而且高效的分布式机器学习框架是很难的一件事情。比较可行的是针对一类相似的机器学习算法做针对性的项目。这个项目的接口必须是符合这类算法结构,所以做算法开发的同学也能容易理解,而不是过多暴露底层系统细节。
真正的让DMLC社区壮大的项目是第三个,叫做MXNet。当时的背景是CXXNet达到了一定的成熟度,但它的灵活性有局限性。用户只能通过一个配置项来定义模型,而不是交互式的编程。另外一个项目是zz和敏捷他们做的Minerva,是一个类似numpy的交互式编程接口,但这个灵活的接口对稳定性和性能优化带来很多挑战。我当时候同时给两个项目做分布式的扩展,所有都有一定的了解。然后一个自然的想法是,把两个项目合并起来取长补短岂不是很好。
召集了两个项目的开发人员讨论了几次,有了大致的眉目。新项目取名MXNet,可以叫做mixed-net,是前面两个名字(Minerva和CXXNet)的组合。放弃开发了几年的项目不是容易的决定,但幸运的是小伙伴都愿意最求更好,所以 MXNet进展挺顺利。很快就有了可以跑的第一个版本。
第四年:9/15-8/16
前半年为difacto和MXNet写了很多代码。其实一开始的时候我觉得difacto更重要些,毕竟它对于线性算法的提升非常显著而且额外的计算开销并不大,这对广告预估之类的应用会有非常大的提升。但有次遇到Andrew Ng,我跟他说我同时在做这两个项目,他立即告诉我我应该全部精力放在MXNet上,这个的未来空间会大很多。我一直很佩服Andrew的眼光,所以听了他的建议。
11月的时候MXNet就有了很高的完成度。写了个小论文投去了NIPS的workshop也算是歇了口气。但随后就听到了TensorFlow(TF)开源的消息。由 Jeff Dean领导大量全职工程师开发,Google庞大的宣传机器支持,不出意料迅速成为最流行的深度学习平台。TF对我们压力还是蛮大,我们有核心开发者转去用了TF。不过TF的存在让我领悟到一点,与其过分关心和担忧对手,不如把精力集中在把自己的做得更好。
NIPS的时候MXNet的小伙伴聚了一次,有好几个我其实是第一次见面。随后Nvidia的GTC邀请我们去做报告。在这两次之间大家爆发了一把,做了很多地方的改进。同时用户也在稳步增长。我们一直觉得MXNet是小开发团队所以做新东西快这是一个优势,但随着用户增加,收到抱怨说开发太快导致很多模块兼容性有问题。有段时间也在反思要在新技术开发速度和稳定性之间做一些权衡。
这时一夜之间大数据不再流行,大家都在谈深度学习了。
我也花了很多力气在宣传MXNet和争取开发者上。包括微博知乎上吼一吼,四处给报告。在大量的点赞声中有些陶醉,但很多中肯的批评也让我意识到重要的一点,就是应该真诚的分享而不是简单的吹嘘。
因为大量的媒体介入,整个深度学习有娱乐化的趋势。娱乐化的报道很多都只是一些简单信息,(有偏见)的观点,而没有太多干货。不仅对别人没营养,对自己来说也就是满足虚荣心。与其写这些简单的水文,不如静下心做一些有深度的分享,包括技术细节,设计思路,和其中的体会。
此类分享一个容易陷入的误区是只关注自己做了什么,结果多么好。这些确实能证明个人能力,对于想重复这个工作的人来说会有很大帮助。但更多的人更关心的是适用范围在哪里,就是什么情况下效果会减弱;为什么结果会那么好;insight是什么。这个需要更多深入的理解和思考,而不是简单的展示结果。
这个对写论文也是如此。只说自己的结果比基线好多少只能说明这是不错的工作,但结果再好并不能意味这个工作有深度。
深度学习的火热导致了各种巨资收购初创司不断。Alex也有点按耐不住, 结果是他,Dave,Ash(曾经是YahooCTO)和我合伙弄了一家公司,拿了几十万的天使投资就开工了。Alex写爬虫,Dave写框架,我跑模型,风风火火干了好一阵子。可惜中途Dave跑路去跟Jeff做TF了。后来这个公司卖给了一个小上市公司。再后来我们觉得这个公司不靠谱也就没考虑跟他们干了。
第一次创业不能说很成功,从中学到几点:一是跟教授开公司一定要注意有太多想法但没死死的掐住一个做,二是找一堆兼职的博士生来干活不是特别靠谱,尤其是产品不明确的时候,三是即使要卖公司也一定要做一个产品出来。我们卖的时候给很多人的感觉是团队人太强但产品太弱,所以他们只想要人而已。四是试图想要通过技术去改变一个非技术公司是很难的事情,尤其是过于新的技术。
然后我们就奔去折腾下一个公司。Ash早财务自由所以想做一个大的想法,但这时Alex刚在湾区买了个房,有还贷压力,他选择去了Amazon。于是算是胎死腹中。
随后收到Jeff的邮件说有没有兴趣加入Google,自然这是一个很诱人的机会。同时我觉得小的创业技术性强的公司是不错的选择。但从MXNet的发展上来书,去Amazon是最好选择之一。自己挖的坑,总是要自己填的。所以我以兼职的身份去了Amazon,领着一帮小弟做些MXNet开发和AWS上深度学习的应用。
第五年:9/16-2/17
早在15年初Alex就表示我可以毕业了,但作为拖延晚期患者,迟迟没开始准备。这时候感觉不能再拖了,于是窝在湾区写毕业论文。Alex觉得毕业论文应该好好写,但我对把前面都做完的东西再捣鼓写写实在是没兴趣,尤其是加州太阳那么好,大部分时间我都是躺在后院晒太阳。此时B站已经完全被小学生占领,这边买书也不方便,无聊之余刷了很多起点。然后还写了篇炼丹文。
CMU要求答辩委员会需要有三个CMU老师和一个学校外的。除了两个导师外,我找了Jeff Dean和刚加入CMU的Ruslan Salakhutdinov. 结果Russ随后就加入了Apple,整个委员会的人都在湾区了。Jeff开玩笑说可以来Google答辩。可惜跟CMU争吵了好多次,还是不允许在校外答辩,而且必须要三个人委员会成员在场。这些限制导致答辩一拖再拖,而且临时加了Barnabas Poczos来凑人数。最后是Jeff的助理快刀斩乱麻的协调好了时间把所有东西定好了。没有她估计我还可以拖几个月。
答辩的时候是一个比较奇异的状态,委员会里有Google, Amazon, Apple的AI负责人,剩下两个和我又分别在这三家公司兼职。这个反应了当下AI领域学术界纷纷跑去工业界的趋势。
不过答辩这个事情倒是挺简单,跟平常做个报告没什么太多区别。一片祥和,即使Russ问了MXNet和TensorFlow哪家强这个问题也没有打起来。
答辩后我问委员会说,我在考虑找个学术界的工作,有什么建议没。大家介绍了一大堆经验,不过大家都强调的一个重点是:学术界好忙好忙,而且好穷好穷,工业界的薪水(就差指自己脸了)分分钟秒掉CMU校长。你要好好想。
总结
答辩前一天的晚上,我想了两个问题,一个是“博士收获最大的是什么”,另一个是“如果可以重来会怎么办”。对于第一个问题,这五年时间自然学到了很多东西,例如系统的学习了分布式系统,紧跟了机器学习这五年的发展,写文章做幻灯片做报告水平有提升,代码能力也加强了些。自信上有所提高,觉得既可以做一流的研究,也可以写跟大团队PK的代码。只要努力,对手没什么可怕的。
但更重要的是博士的五年的时间可以专注的把一些事情从技术上做到最好,做出新的突破,这个氛围没有其他地方能给予。
第二个问题的一个选项是当年留在国内会怎么样? 当年百度的伙伴们多数现在都做得很好,都在引领这一波AI的潮流,甚至有好几个创造了上亿价值的公司。所以从金钱或者影响力角度来看,一直在工业界也不差,说不定现在已经是土豪了。
不过我觉得还是会选择读博。赚钱以后还有大把时间可以,但是能花几年时间在某个领域从入门到精通甚至到推动这个领域发展的机会就一次。站在这个领域的高点会发现世界虽然很大,但其实其他领域也使用差不多的技术,有着同样的发展规律。博士期间领悟到的学习的方法可以在各个方向上都会大有作为。
更重要的是理想和情怀。人一生要工作五十年,为什么不花五年来追求下理想和情怀呢?
工作五年总结
【2021-5-24】摘自:知乎
五年前的今天我飞往西雅图参加亚马逊的面试。面试完后连夜做红眼航班飞往波士顿赶去参加老婆在MIT的博士答辩。答辩一半的时候电话响了,对方说恭喜你面试通过,想聊下薪水。我说其实就面了你们一家,直接给就是,先挂了。

答辩完第二天跟老婆去市政局登记结婚。在宣誓厅门口排队的时候,老板打电话过来,很兴奋的说你来了后可以做这个做那个。我说是挺好的,但先要结婚去了。老板一愣,道了一声恭喜,继续往下说。我不得不打断:得先走了,轮到我们进去宣誓了。
五年一眨眼就过去了。外面来看最大的变化是多了两个娃。但最大的变化来自认知,是人生观、世界观、价值观的改变。博士毕业的时候曾写过我的体会

很多同学留言说深受鼓舞。现在我想同样给大家分享这五年工作中的经验和感悟。更确切说是失败的教训,因为每一点就是付出了学费后获得的教训。希望这些同样能对大家有所帮助和启发。
事情的价值是对社会的价值
读书的时候,你会有明确的目标,例如考试的分数、深造的学校、或找到好工作。工作后的最大不同是你有太多可以最求的目标。这个带来的改变是你需要决定哪些事情现在做,哪些以后做,哪些可以不去做。
决定优先级应该是根据事情的价值。我现在评估一件事的价值是它对社会的价值,用公式来写就是
受益人数 x 人均时间 x 单位时间价值差
这里能从一件事情受益的人数,和受益的人均时间是这件事本身属性。第三项取决于你对这件事完成的好坏,就是你做得比别人做的类似的事情要好,从而受益人从你这里受益比从别人那里多。
这个公式可以用在各种不同的事情上,接下来我们会不断使用它。这里先举几个例子。例如伟大的产品一般具有极高的价值。拿微信来说,它是手机通讯软件,面向几十亿手机用户,每人每天会使用数小时,所以它价值的前两项非常大。因为微信用户体验很好,它比其它替代品的用户体验好给用户带来的价值就是价值差。所以微信是一个非常有价值的产品。
举个小点的例子,例如你带人写一篇论文。论文影响的人数就是这个研究领域的大小;作用时间是别人做一个跟你工作相关的研究所花的时间,可能一辈子就几个月;价值差则是你的研究相在前人工作之上的贡献。这样看来,你需要做热门领域和跨时代论文才能取到高价值。但我们知道一篇论文一般贡献不大、也就几个人会读,所以算下来基本没什么价值,为什么大家还是会积极“灌水”呢?
这里我们还要细看两个价值:一是你通过这个研究熟悉了一个新领域或者新方法,对你个人有学习价值。二是你带人做研究能提升他们在想方法、做实验、和写论文上能力,对他们价值很大。所以即使是知名研究者,名字也会出现在很多新手习作一样的论文上面。
再举一个更小的例子。过去四年里我花在带娃上的时间比工作多。在相当一段时间内都觉得事业被娃耽搁了。直到后来我用这个公式来算:虽然人数只是两个人,但受益时间相当高,一周五十小时以上。而且父亲就一个,有我陪和没我陪对小孩来说区别巨大(自我感觉),所以价值公式的后两项很高。此外,带娃对我个人也有价值,包括如何去理解思维方式完全不一样的他人,以及时刻跟自己想暴怒的冲动做斗争,最终达到佛性的状态。这样算下来心里就顺了

服务社会最后也是服务自己
上面这个价值公式强调的是事情对他人的贡献。在用它之前,我的价值公式更关注自己。例如我常用一件事情的好玩程度,或者里面的技术含量来划分优先度。问题是虽然享受做事情这个过程,但之后的成就感不高。有点类似打完游戏后的空虚。因为做完后经常发现,这个虽然酷炫但没什么用,没多少人理睬。原因是对个人的有直接高价值的事情,对他人价值不一定大。很有可能这件事情本身只对很小群人有意义,可能每个人受益时间短,或者其实是重复造轮子,市面上已经有了差不多的替代品。
如果优化对社会的价值,你会得到对自己的延后回报。这个回报包括了你知道做这个事情对他人有用时带来的更高层次的内心满足,以及他人从你这里受益时给与的馈赠(给你点赞、或者老板给你升职加薪)。当然,这两者不一定同时出现。很多时候你创造的价值不一定被别人关注(数十年维护那些大家用起来习以为常的开源工具包),也有时候大家会夸大吹捧你的贡献。你应该积极寻求别人的肯定,这会给你更多的资源做更大事情。但你应该更关心内心的满足,因为更可控、不容易别他人误导。更多是它会给你内在动力去把事情做得更好,这是你能不断成长的根基。
技术最终是为产品服务
技术专业的同学刚进入公司通常会继续做技术。刚毕业那会儿我觉得进入大公司就是做技术,成为世界上最好的技术专家之一。而且不要做产品,因为如果做产品的话我为什么不自己创业呢,赚的钱还是自己的。后半句没什么问题,但前半句忽略了技术最终是为产品服务这一事实。虽然因为公司的不同,对技术进入产品的预期时间会不同,但通常在半年到五年之间。预期是超过五年的公司屈指可数,而且大多已经作古。所以就算你在公司的研究部门,也应该知道公司对于技术落地时间的预期。否则时间一到就会面临公司削减不达预期的技术的投资。最坏情况是你们上新闻了:某某公司研究院院长离职,部门成员各奔东西。
那么什么样的技术能进产品?通常你会根据公司现有的产品有个大致的想法。接下来你要知道这个产品的主要价值是什么(套用之前的公式)。然后你需要去琢磨你做的技术对这个产品的价值。如果你的技术能提升产品的核心功能,哪怕是一点点,也会得到资源来落地技术。例如提升微信的视频压缩技术、今日头条的推荐算法、苹果的外壳材料。反过来,如果没有抓住主干,例如微信装皮肤、今日头条网页版加速,苹果操作系统兼容其他硬件。就算你可以做到比现有技术提升很多,产品团队也可能没动力帮你,甚至一开始就告诉你别做这个。
所以不管你是在产品团队做技术,还是在公司研究院,都应该对产品的价值有所了解。例如深入理解产品经理的口头禅:市场、刚需、痛点、高频。同时也应该知道你手上的技术对产品的价值,用它来指导你对技术路线的规划。
不想当将军的士兵不是好士兵
人的满足感来自于对比,不管是对比别人还是对比自己过去。这个欲望驱动你去追求有更大价值的事情。这意味着你需要更多资源去做大做强。最起码的是你需要一个团队。你可能是这个团队的管理者、领导者、或者兼任两者。
也许你更喜欢一个人做技术,至少我一开始是这么想的。但随着你的能力的增长,别人对你的责任的期望也越大,你不可避免得去带一个团队。否则你得去其他地方找满足感。与其别动的被推到了这个位置,不如一开始就做好准备。
这里有大量的职场书籍可以参考。我自己的经验很简单:领导者是带路者,需要有好眼光。管理者是后勤官,让团队执行高效。下面分别解释这两点。
放眼在三年以后
领导者最重要的是在带着团队探索未知领域时找出正确的方向。也就是说保证你们做的产品或技术是有价值的。因为做一件事需要时间,所以你得预判事情在未来的价值。如果判断不准,大家辛苦做了很久,做完后发现效果一般,那么团队士气就会低下。各种问题就会接踵而来。
你去想一件事情未来的价值时,时间不要太短也不要太长,三年比较合适。假设你想继续沿着现在的方向走,那么需要考虑三年后你关注的用户群和使用时间是不是会发生变化。变多是好事,不变表示你做不了太大,但如果会变少,你得考虑要转向了。你还需要警惕新技术的出现,很可能新的技术会短短几年就完全推翻旧技术(深度学习、智能手机、电动车)。分析那些失败的例子,当事人其实很早就察觉到了新技术,但低估了它的能量。他们只看到了新技术比现有成熟技术的不足,然后套用成熟技术的发展速度在新技术上,低估了三年后新技术能到达的高度,和用户喜新厌旧的程度。
如果你要做一个新的方向,那你可能不再有技术积累优势,就是跟别人比你给用户带来的价值差可能不明显,甚至更低。那么你需要找到好赛道(投资人口头禅),通常是颠覆性的新技术,以及随之带来产品和用户的变化。只有在快速变化的赛道上,新入局者才更容易通过更准确的预测未来的价值来弯道超车。也就是乱世出英雄。
好的眼光需要一个长期的训练。你需要不断的去做深入思考,获得自己独特的观点,而不是靠朋友圈里大家的高见。所以你需要时不时放下手头的事情,给自己空出时间做深入思考。例如我会时不时去家附近的Bay Trail走上几个小时,边走边想。

管理的核心是诚心待人
如果你有一个明确的团队目标,和一个高质量的团队,高效执行是水到渠成的事情。所以管理者有三个核心事情:招人、留住厉害的成员、和帮助落后的。招人最理想是招比自己厉害的人。另外是每次招的人都比同级别的一半人厉害,这样能保证团队扩张时能不断提升团队质量。
能力突出的成员在哪里都会受欢迎。你的一个任务是让他们能尽可能长的留在团队里(虽然最终是要走的)。一个办法是把自己放在他们的位置,想象你想你的领导如何待你。例如我自己最希望的是不断做有更大价值的事情(成就感),并从中学到新东西(个人提升)。在我困难时候老板能给与支持(经常发生)。其他的都可以换算成当前待遇,例如可以多少时间做不喜欢的事情(不赞同一件事的价值,但又没能说服别人不做)、上下班路上很堵、食堂没中餐。所以大方向上是创造轻松的环境、每年能新立项有价值的项目、和尽量给大家争取待遇。
对于绩效不理想的队员,你需要经常性的指出问题并给予建议,如果一段时间没改进则需要讨论是不是当前项目不合适。如果仍然无进展的话,那只能帮助他们换组,或者要求他们离开。同样,你需要把自己代入对方的位置,明白想得到什么样的帮助和尊重。绝大部分时候,不是他们人不行,只是你们不合适。愉快的分手能让前成员更快的找到更合适的职位(从而避免他们给你寄刀片)。
专注!专注!
有人说创业公司一个常见死因是在有了一定成绩后盲目扩张。这个在哪里都成立。不管你是一个人,带一个团队,还是领导一家公司,资源总是有限。集中资源在最有价值的事情才能保证成功。例如苹果好几十万人,但对于产品线的扩张上非常谨慎。从而能保证每一款产品都砸上足够多资源来颠覆市场。在初期你也许可以广撒网多捕鱼,一旦事情的价值慢慢清晰,我们需要逐步集中资源。因为同时把做几件类似的事情最好,不如只把一件事情做到极致、做到市面上最好。这样你总是可以得到正的价值差。一个第一比十个第二好,第三通常都活不长。同样的道理也可以用在生活、社交、和学习上。
只要投入力气,短板可以变成优势
以前每次发布MXNet的新特性时,知乎同学都是吐槽:回去写好文档先。大家都知道程序员不喜欢写文档。我从小语文和英语都是在及格线徘徊,更是心有抵触。17年的时候痛下决心来写文档,我把我所有留下做技术的时间都花在上面,最后跟大家一起写出了《动手学深度学习》这本教科书,现在被全世界近200所大学采用做教材。所以,你的不足能成为你的机会。只要你直面它,狠下心来花力气,不断去改进,你的短板会变成优势。
扬长避短
所有命运的馈赠,都在暗中标好了价格。当我把精力都花在文档上时,便忽略了MXNet本身。没能组织投入大量资源去持续提升它的性能和易用性,导致它没能做到前二。从价值上来说,《动手学深度学习》和MXNet在用户数和用户价值上差不多,但用户使用深度学习框架时间多于读教材,所以MXNet价值更大。在不擅长的领域花费了大力气打赢一仗,但在优势领域失去了价值更大一个,很难说是划得来。所以,在扬长和补短上面,一定是要根据价值来判断,而不是面子。
分布式系统里通讯开销才是大头
当一台机器算力不够时,我们用多台机器协同工作来共同完成任务。虽然分布式系统是很多家互联网公司的基础架构,但提升性能仍然是很难。因为每台机器实际算力会有不同,时不时还会罢工。而且一台完成自己的小任务时,经常需要等其他机器任务的结果,导致频繁数据通讯和等待。所以大家都知道提升性能的关键是减少通讯开销。
当你需要一个大团队来协同做一件事时,同样通讯开销是大头,优化起来比分布式系统能难,因为人的差异性和不稳定性比机器大多了。人的能力不同,做事效率不同。每个人分工的不同,导致做事方式也不样,甚至优化的目标都不一样。大部分人只关心自己的事情,不想也不愿操心别人的事情。如果不能有效把所有人拧在一起,就是一盘散沙,做不成大事。如果你刚进职场,最关键的一点是你需要意识到:你需要预留足够多的时间和精力来沟通。不要抱怨这是你们公司的制度问题,这是大团队作战时的固有现象。
升职
我因为运气不错升到了一个比较高的职位,从而有机会经常参加公司的从高级工程师、科学家到总监的升职评定。虽然公司、职位、级别不同带来差异性,但总体来说,一个人能否升职成功取决于她做的最大项目对公司的价值是不是达到这个职位的要求。这里有三个要点:一是项目对公司的价值。意味着针对的人群和价值差都是公司关心的,而不是你个人或者社会关心的。这里价值通常就是给公司赚了多少钱,或者3-5年后可能会赚多少钱。二是看的是你最大的项目要够“档次”。累积很多项目,想通过不看功劳看苦劳升职可能是行不通的。三是你在项目中的贡献,例如你负责多大一块,是贡献了代码、团队协调、宣传、制定计划、还是申请到了资源。一个常见误解是跟人合作会降低我的贡献。如果你和合作者配合不好,导致1+1远小于2,那么你的贡献确实降低了。但如果通过合作把项目价值做大了,那么你分到的贡献是不会少的。特别是如果项目价值上了一个档次,那就更好了。
升职有一个经常被忽略的“潜规则”是影响力。随着职位的升高,公司对你的影响力的期望也越高。从能影响一个小团队,包括制定技术路线、帮助队员上手、解答疑惑、甚至是帮助别人来完成工作,到影响隔壁组(经理),影响隔壁部门(高级经理),影响隔壁集团(总监),最后到影响整个公司战略(副总裁)。
除非你是天生的领导者,不然你得花力气去培养自己的影响力。简单来说是在管好自己的事情外,积极的去帮助别人。当别人信你、咨询你意见、愿意找你合作时,那你就有了对他们的影响力。你可能会觉得帮别人会耽误自己的活。但从公司角度来看,是需要鼓励这种奉献精神,而且要予以奖励。此外,你从中赢下的信任给你带来名声和人脉,长远来看是很有用的。
加薪
大公司里薪酬相对透明,每个级别对应的薪酬通常可以在网上找到。一个级别内薪酬有浮动,一般有个最小值和最大值。80%在中值附近,两头各10%,分别是刚升到这个级别的人和快要到下一个级别的人。可以简单的认为,随着能力的提升,你的薪酬会从最小值逐步跳到最大值,然后升职到下一个级别对应的区间。
不同级别的薪酬中值通常是个等比序列,而不是等差。例如比你高一级的人可能工资比你多一半,但高三级的人不是比你多150%,而是多238%。在这个模型里,你需要优化你的五年后,或者十年后能到达的高度。所以在比较offer时,你不要太关心它们之间的数字差价,而是关心去你去了之后的发展(你说我现在多拿点去买币,说不定马上就财富自由了,那也是一个思路 )。
总结:专注于最有价值的事情
如果把这五年的感悟精炼成一句话的话,会是很平淡的一句:专注于最有价值的事情。首先,你需要对价值有清晰的认识。接着,对一件事情,不仅是要认识当下的价值,更多的是对未来价值的预测。其次,当你通过不断的快速试错对未来有了把握的时候,你需要逐步的把你能调用的资源专注到最有价值的那一件事情上,尽你可能的做好。
如果一生中能做好几件有着极大价值的事,那也就值了。
写此文的时候惊闻袁隆平老师逝世。谨以此文纪念他伟大的一生:专注于杂交水稻,创造了人类历史上最伟大的价值之一。我辈楷模。
创业一年,人间三年
【2024-8-15】李沐:创业一年,人间三年
BosonAI
创业前做了一系列用Gluon命名的项目。在量子物理里,Gluon是把夸克绑在一起的一种玻色子,象征这个项目一开始是Amazon和Microsoft的联合项目。
- 招聘信息(湾区和温哥华)
新公司干脆就用玻色子(Boson)来命名了。希望大家能get到“Boson和费米子组成了世界”这个梗时会会心一笑。但没料到很多人会看成Boston。
“我来波士顿了,找个时间碰碰?” “哈?可我在湾区呀😅”
签字前一天领投方跑路
22年年底, 想到两个用大语言模型(LLM)做生产力工具的想法。
碰巧遇到张一鸣,就向他请教。
- 讨论之后他反问:为什么不做LLM本身呢?
- 下意识退缩:我们之前在Amazon的团队做了好几年这个,得上万张卡,和blabla这么一大堆困难。
- 一鸣呵呵表示:这些都是短期困难,眼光得看长远点。
我听劝,真去做LLM了。凑齐了数据、预训练、后训练、和架构各方向负责人的创始团队,就去融资了。
- 运气不错,很快拿到了种子投资。但钱还不够买卡,得去拿第二轮。
- 这一轮领头是一家非常大的机构,做了几个月文档、商讨条款。但签字前一天,领头说不投了,直接导致了跟投的几家退出。很感激剩下的投资方,还是做完了这一轮,拿到了做LLM的入场券。
机器:第一批吃螃蟹的人
各个供应商统一回复: H100交货得一年以后了。我直接给老黄写邮件。
- 老黄秒回说他来看下。一个小时后超微的CEO就打电话过来了。
多付了些钱,插了个队,20天后拿到了机器。
GPU集群搭建时 遇到各种匪夷所思的bug。
- GPU供电不足导致不稳定,后来靠超微工程师修改bios代码打上补丁;
- 光纤切开角度不对,导致通讯不稳定;
- Nvidia 推荐网络布局不是最优,重新做一个方案,后来Nvidia自己也采用了这个方案。
至今都不理解,我们就买了不到1000张卡,算小买家吧。但遇到的这些问题,难道大买家没遇到吗,为啥需要我们的debug?
同时还租了同样多 H100,一样是各种bug,GPU每天都出问题,甚至怀疑是不是这个云上就吃螃蟹的。
后来看到Llama 3 技术报告说他们改用H100后,训练一次模型被打断几百次,对字里行间的痛苦,很是共情。
自建 vs 租卡
- 租3年,成本和自建成本差不多。
- 租卡好处是省心。
- 自建的好处有两个
- 三年后如果Nvidia技术还遥遥领先,那么它能控制价格使得GPU仍然保值😭。
- 自建数据存储成本低。存储需要跟GPU比较近,不管是大云还是小GPU云,存储价格都高。但一次模型训练可以用几TB空间存checkpoint,训练数据存储是10PB起跳。如果用AWS S3的话,10PB一年两百万。这钱用来自建的话,可以上100PB。
商业:感恩客户,第一年收支平衡
第一年收入和支出是打平。支出主要在人力和算力上,感谢Openai的财力和Nvidia的瑶瑶领先,这两项支出都挺大的😭。
收入来源是给大客户做定制模型。很早就上LLM的公司大都是因为CEO非常有决策力,没被高昂的算力和人力成本吓到,果断的去推动内部团队配合尝试新技术。
LLM在toC上的落地。
- 上一波顶流, 如 c.ai 和 perplexity 还在找商业模式,但也有小十来家LLM原生应用收入还不错。
- 我们给一家做角色扮演的创业公司提供了模型,主打深度玩家,打平了收入和支出,也是厉害的。模型能力还在进化,更多模态(语音、音乐、图片、视频)在融合,相信接下来还会有更有想象力的应用出现。
整体来说行业和资本还是急躁的。今年好几家成立一年多但融资上十亿的公司选择退出。从技术到产品就是一个很长的过程,花2、3年实属正常。算上用户的需求的涌现,可能得花更长时间。
技术:LLM认知的四个阶段
对LLM的认知经历了四个阶段。
- 第一阶段, Bert到GPT3: 感受是新架构,大数据,可以搞。
- 在Amazon的时候也是第一时间进去做了大规模的训练和在产品上的落地。
- 第二阶段, 刚创业时,GPT4了放出来,大受震撼。大半原因来自技术不公开了。
- 一次模型训练一个亿,标数据成本几千万。很多投资人问我, 复现GPT4成本得多少,我说3-4亿。后来他们中一家真一把投了大几亿出去。
- 第三阶段, 创业第一个半年。我们做不动GPT4,从具体问题出发吧。
- 于是开始找客户,有游戏的、教育的、销售的、金融的、保险的。针对具体的需求去训练模型。
- 一开始市面上没有好的开源模型,我们就从头训练,后来很多很好的模型出来了,降低了成本。
- 然后针对业务场景设计评估方法,标数据,去看模型哪些地方不行,针对性提升。
- 23年年底时,惊喜发现
Photon(Boson的一种)系列模型在客户应用上的效果都打赢GPT4了。 - 定制模型的好处: 推理成本是调用API的1/10。虽然今天API已经便宜很多,但我们自己技术也同样在进步,仍然是1/10成本。另外,QPS,延时等都更好控制。这个阶段的认知是对于具体应用,可以打赢市面最好模型的。
- 第四阶段, 创业的第二个半年。
- 虽然客户拿到了合同里要的模型,但还不是他们理想中的东西,因为GPT4还远不够。年初时发现针对单一应用训练,模型很难再次飞跃。
- 如果AGI是达到普通人类水平,客户要的是专业人士水平。游戏要专业策划和专业演员、教育要金牌老师、销售要金牌销售、金融保险要高级分析师。
- 这都是AGI加上行业专业能力。虽然当时我们内心对AGI充满敬畏,但感觉是避不开的。
- 年初我们设计了
Higgs(上帝粒子,Boson的一种)系列模型。主打通用能力紧跟最好的模型,但在某个能力上突出。我们挑选的能力是角色扮演:扮演虚拟角色、扮演老师、扮演销售、扮演分析师等等。24年年中的时候迭代到第二代,在测试通用能力的Arena-Hard和AlpacaEval 2.0上,V2跟最好的模型打得有来有回,在测试知识的MMLU-Pro上也没差很远。
我们做了个评估角色扮演的评测集,包含按照人设扮演,和按照场景扮演。模型在自己的榜单上拿了第一。
好的垂直模型通用能力也不能弱,例如 reasoning,instruction following 这些能力垂直上也是需要的。长远来看,通用和垂直模型都得朝着AGI去。只是垂直模型可以稍微偏科一点,专业课高分,通用课还行,所以研发成本稍微低一点,研发方式也会不一样点。
团队:有挑战的事情得靠团队
创业之后才真正觉得团队的重要性。
- 大厂时,觉得自己是个螺丝钉,团队成员是螺丝,甚至团队也是个螺丝钉。
- 但创业团队就是一辆车。车小点,但能跑,能载重,转弯灵活,各个角落都能去。
公司成立不久的时候,米哈游老蔡来看了眼,看见所有人在一间房子里,他感慨说小团队真好。
每个成员都很重要,没有冗余,一个人不给力,就可能是一个轮胎没气。人也宝贵,走一个人就可能少一个轮胎。
个人追求:名还是利?
到目前为止, 我都靠跟着内心声音做决定,工作后再去读博、去做视频、去创业。
创业需要强烈动机的支撑,才能克服层出不穷的困难。这需要对自己的动机做更深入的分析。
动机要么来自欲望,要么来自恐惧。十年前我可能更热衷名利,但到了现在的年纪,觉得金钱的边际效用已经不高,名声带来的情绪价值也已经很小。我深层的动机来自对生命可能没有意义的恐惧。先不说宇宙的浩瀚,就是在人类的历史长河,一个人也只是一粒沙。意外的到来,迅速的消失。地球上生活过一千亿人,绝大部分人不会在历史上留下痕迹。我家家谱上那些人名,我几乎都不认识。
那么一个人的存在的意义是什么呢?
- 小时候曾因为想不清这个问题而抑郁。
- 潜意识里,我想去创造价值,获得存在的意义。
我选择“上进”,去提升自己的创造价值的能力;
- 选择录长视频和写教材,创造教育价值;
- 选择去写读博、工作、创业的总结,描述里面的纠结和困难,创造事例的价值;
- 选择去创业,团结很多人的力量去创造更大价值。
李沐上海交大演讲
【2024-8-23】李沐重返母校上海交大,从LLM聊到个人生涯,这里是演讲全文
语言模型的现在,以及未来情况的预测。
语言模型分为三块:算力、数据和算法。
语言模型也好,整个机器学习模型也好,本质上把数据通过算力和算法压进中间那个模型里面,有一定识别能力,在面对新数据时,在原数据里面找到相似的东西,然后做一定的修改,输出你要的东西。
(1) 算力层面:
- 大模型性价比不高
- 带宽:让芯片靠得更近一些
- 内存:制约模型尺寸的一大瓶颈
- 算力:长期来看会越来越便宜
- 短期看,算力翻倍,价格可能会有 1.4 倍的提升。但长期看,当竞争变得越来越激烈,摩尔定律会发挥作用,算力翻倍,价格不一定变
- 自建机房比租 GPU 更划算,原因: 大头被英伟达吃掉,利润 90%
- 自建的好处: 节省 CPU 算力,以及存储和网络带宽, 但云很贵,因为过去10年没有太大技术变革
(2) 模型:从语言到多模态
- 语言模型:100B 到 500B 参数会是主流
- 无论是 OpenAI 还是别的模型,基本都是用 10T 到 50T token 做预训练。开源模型基本在 10T token 以上。这个数据量差不多,不会再往更大的尺寸发展。原因是,人类历史上的数据比这个多,但是看多样性、质量,10T 到 50T 这个规模就差不多
- 语音模型:延迟更低、信息更丰富
- 以前把ASR/TTS与语言模型分开, 现在直接让原始语音信号进去,然后原始的语音信号再出来。好处:
- ① 语音里有很多东西,包括情绪、语调以及哪类人,还有背景音乐、场景音乐及节奏,上一代技术做不到
- ② 延迟更短:上一代技术延迟可能 1 秒。现在可以做到 300 毫秒,好处是交互途中可以打断,更像真人
- 音乐模型:不是技术问题,而是商业问题
- 音乐比语音麻烦些,比人说话更复杂,但音乐还涉及版权问题
- 图像模型:生成的图越来越有神韵
- 图片是整个 AIGC 领域做得最早,效果最好
- 视频模型:尚属早期
- Sora 出来后,引起大众视频模型的关注。但视频生成还比较早期,通用的 video 生成非常贵,因为 video 数据特别难处理,视频模型的训练成本很有可能低于数据处理的成本
- 多模态模型:整合不同模态信息
- 多模态技术的发展趋势:整合不同类型的模态信息,尤其文本信息,因为文本含有丰富的信息并且易于获取。
- 通过利用在文本上学到的技能,将这些能力泛化到其他模态,如图片、视频和声音。
- 两大好处:
- ① 借助强大的文本模型进行泛化。
- ② 通过文本定制和控制其他模态的输出
- 用简单的文本指令控制图片、视频和声音的生成,而不再需要专业的编程技能或工具;
- 写代码,以前可能需要专业的写代码工具,现在交给 ChatGPT,你通过文本下达要求就行
- 用文本去控制,是未来常态,大家用自然语言交互。
总结
- 语言模型水平较高,大约在 80 到 85 分之间。
- 音频模型可接受,能用阶段,大约在 70-80 分之间。
- 但视频生成方面,尤其是生成具有特定功能的视频尚显不足,整体水平大约在 50 分左右。
模型训练
- 预训练是工程问题,后训练才是技术问题
- 两年前预训练还是技术问题,现在变成工程问题
- 后训练,高质量数据和改进的算法,能够极大地提升模型效果,而高质量的数据一定是结构化的,并且与应用场景高度相关,以保证数据的多样性和实用性
- 算法层面,OpenAI 提出了 RLHF,大家评价很高,但这个算法有点牵强,还需要结合业务场景继续优化
- 垂直模型也需要通用知识
- 没有真正的垂直模型,即便是很垂直领域的模型,它的通用能力也不能差
- 让GPT模型角色扮演,可能迭代好几代都不行,主要原因:它是一个通用维度,需要各个方面都有提升,如果刚好满足要求,需要指数级的数据,并且模型会变得很大。
- 评估很难,但很重要
- 评估是最重要的事情,先把评估做好,再去做别的事情;好的评估可以解决 50% 的问题
- 因为:一旦评估解决了,就能:① 进行优化 ② 拥有数据
- 自然语言很难评价其正确性、逻辑性和风格。通常不想让人来评估,因为比较昂贵,但使用模型评估会带来偏差
- 数据决定模型上限
- 数据决定了模型的上限,算法决定了模型的下限。
- 目前,我们离 AGI 还很远, AGI 能够做自主的学习,目前的模型就是填鸭式状态。
- Claude 3.5 做的还不错,一个相对来说不那么大的模型,能在各种榜单上优于 GPT-4 ,并且在使用上确实还不错。因为他们70-80%的时间在做数据
(3) 应用
人机交互会有一点改变
- UI点选操作: 最简单,能不说就不说
- ChatGPT之后, 大家开始愿意用长文本交互,或者用语音交互
- 未来,语音控制系统将处理更加复杂和具体的任务,这种技术的自然和便捷性将显著提高。
这次技术革命还没有出现 killer APP(杀手级应用)。
- killer APP: 一个新技术出现后, 涌现出非常受欢迎的应用形态。
- 手机的 killer APP 是什么吗?短视频。
LLM 时代的 killer APP 是什么?
- 上一波的顶级 AI 公司基本上快死得差不多了,包括: Character.AI、Inflection、Adept 也都被卖了,还剩一个 Perplexity 搜索还在支撑着。
- 但是下一代 killer APP 是什么? 不知道, 要等技术更成熟,用户习惯变化才会涌现
LLM 应用
- AI 本质上是去辅助人类完成任务,给人类提供无限的人力资源
分三类
文科白领: 用自然语言去跟人、跟世界打交道,如写文章- 人花1h完成的事情, LLM 能实现80-90%
- LLM 做的好的领域: 个人助理、Call centers、文本处理、游戏和舆论以及教育
工科白领: 目前 AI 取代程序员, 还早得很- 过去,编程往往需要程序员自行查找代码示例, 修改、调试, 以适配项目需求
- 现在,优秀的LLM把这些步骤自动化, 但这仅限于简单业务场景,还不是真正的写代码
蓝领阶级: 最难, 唯一做的好的是自动驾驶。- 自动驾驶为什么出色?路况是一个封闭的世界,相对稳定,比如有些地方路况十年都不会改变,封闭路况里面开车比较简单。
- 无人驾驶还没有完全解决,但进步很大;路上的车多,每个车上都有传感器,从而采集大量的数据,基于大数据做技术开发,比如特斯拉,车上有大量摄像头,有很多车在路上跑,可以采集很多数据来优化算法,而且路况变化不大
- 蓝领做的事情, 如端盘子、运货等;而AI 跟这个世界打交道,还很难,机器人理解房间里有什么东西很难(① 缺乏传感器/数据 ② 现实场景不会有很多机器人进入/采集很多数据),除非有技术突破,不然要大量数据作为辅助
- AI 理解蓝领的世界,包括和这个世界互动,可能需要至少 5 年时间
总结:
- 文科白领的工作,AI 已经能完成简单任务,复杂任务需要继续努力。
- 工科白领的工作,简单任务还需要努力,复杂任务存在困难。
- 蓝领的工作,除了无人驾驶和特定场景(比如工厂,场景变化不大,也能采集大量数据),AI 连简单任务都做不了,完成复杂任务更难。
陈天奇
机器学习科研十年
- 2019-07-19, 陈天奇
- 【2020-3-26】陈天奇创业公司首个SaaS产品:快速构建部署ML应用,跨平台优化
- 将机器学习模型部署到设备时需要耗费大量的时间和算力,有时会力不从心。去年,知名人工智能青年学者、华盛顿大学博士陈天奇参与创建了 ML 创业公司
OctoML。该公司致力于打造一个可扩展、开放、中立的端到端栈,用于深度学习模型的优化和部署。这不,他们推出了首个 SaaS 产品 Octomizer,其能够帮助开发者或数据科学家更方便、更省事省力地将 ML 模型部署到设备上。 - 解决问题:机器学习社区中,所有人都会遇到以下两个难题:
- 痛点 1:机器学习库和服务依然处在低层等级,不能够很好地抽象复杂性。尽管有很多开源项目力求加快 ML 模型的应用,但是这些项目无疑都需要使用者对底层算法和计算细节有很好的认识。另外,这些项目的抽象性不一定很好,所以它们声称能够实现的「一键部署」或「易用」特性是达不到的。
- 痛点 2:ML 的计算很慢,而且不能够很好地支持移动端。很多时候,在某些硬件和软件上拟合地很好的模型换了平台和部署环境就会出现性能下降的问题。例如,你有一个不错的 ResNet-50 模型,在你最喜欢的硬件或软件平台上有着不错的性能表现。但是,如果将其部署在其他平台上,或者增加了几个训练的窍门,性能会大幅下降。
- Octomizer 的整体工作流程
- 将机器学习模型部署到设备时需要耗费大量的时间和算力,有时会力不从心。去年,知名人工智能青年学者、华盛顿大学博士陈天奇参与创建了 ML 创业公司
十年前,MSRA的夏天,刚开始尝试机器学习研究的我面对科研巨大的不确定性,感到最多的是困惑和迷茫。十年之后,即将跨出下一步的时候,未来依然是如此不确定,但是期待又更多了一些。这其中的变化也带着这十年经历的影子。
起始: 科研是什么
我从大三开始进入交大APEX实验室,有幸随着戴文渊学长做机器学习,当时的我觉得“机器学习”这个名字十分高大上然后选择了这个方向,但是做了一年之后依然摸不着头脑,心中十分向往可以做科研,独立写论文的生活,却总是不知道如何下手。文渊在我进实验室的一年后去了百度。当时还没有得到学长真传的我,开始了我科研的第一阶段,从大四到硕士的第二年,期间一直自己摸索,不断地问自己 “科研是什么”。
和课程作业不同,学术研究没有具体的问题,具体的方法,具体的答案。文渊的离开让我一下子不知道该怎么做,当时的我的想法很简单,快点寻找一个具体的方向,完成一篇论文。因为ACM班的机会暑假在MSRA的短暂实习,虽然学会了很多东西,但并没有给我答案。MSRA回来之后,在实验室薛老师的建议下,我选择了一个现在看来正确而又错误的方向 – 深度学习。那是AlexNet出现之前两年,深度学习的主流热点是非监督学习和限制玻尔兹曼机。没有导师的指导,没有工具,当时我靠着实验室的两块显卡和自己写的CUDA代码开始了死磕深度学习的两年半。
实验室的学长问我,你准备要干啥,我说:
“我要用卷积RBM去提升ImageNet的分类效率。”
这一个回答开启了图书馆和实验室的无数个日日夜夜,为了给实验室的老机器多带一块高功率的显卡,我们打开了一台机器的机箱,在外面多塞了一个外接电源。我的生活就持续在调参的循环中:可视化权重的图片, 看上去那么有点像人脸,但是精度却总是提不上来,再来一遍。从一开始hack显卡代码的兴奋,到一年之后的焦虑,再到时不时在树下踱步想如何加旋转不变的模型的尝试,在这个方向上,我花费了本科四年级到硕士一年半的所有时间,直到最后还是一无所获。现在看来,当时的我犯了一个非常明显的错误 – 常见的科学研究
- 要么是问题驱动,比如“如何解决ImageNet分类问题”;
- 要么是方法驱动,如 “RBM可以用来干什么”。 当时的我同时锁死了要解决的问题和用来解决问题的方案,成功的可能性自然不高。如果我在多看一看当时整个领域的各种思路,比如Lecun在很早的时候就已经做end to end,或许结局会不那么一样吧。
当然没有如果,赌上了两年半的时间的我留下的只是何时能够发表论文的紧张心情。焦虑的我开始打算换一个方向,因为RBM当时有一个比较经典的文章应用在了推荐系统上,我开始接触推荐系统和kddcup。比较幸运的是,这一次我并没有把RBM作为唯一的一个方法,而是更加广泛地去看了推荐系统中的矩阵分解类的算法,并且在实验室搭建了一个比较泛用的矩阵分解系统。推荐系统方向的耕耘逐渐有了收获,我们在两年KDDCup11中获得了不错的成绩。KDD12在北京,放弃了一个过年的时间,我完成了第一篇关于基于特征的分布式矩阵分解论文,并且非常兴奋地投到了KDD。四月底的时候,我们收到了KDD的提前拒搞通知 – 论文连第一轮评审都没有过。收到拒搞通知时候的我的心情无比沮丧,因为这是第一篇自己大部分独立推动完成的文章。转折在五月,KDDCup12 封榜,我们拿到了第一个track的冠军,我依然还记得拿到KDDCup12冠军的那一个瞬间,我在状态里面中二地打了excalibur,仿佛硕士期间的所有阴霾一扫而尽。那时候的我依然还不完全知道科研是什么,但是隐隐之中觉得似乎可以继续试试。
第零年: 可以做什么
我对于科研看法的第一个转折,在于我硕士临近毕业的时候。李航老师来到我们实验室给了关于机器学习和信息检索的报告,并且和我们座谈。在报告的过程中,我异常兴奋,甚至时不时地想要跳起来,因为发现我似乎已经知道如何可以解决这么多有趣问题的方法,但是之前却从来没有想过自己可以做这些问题。联系了李航老师之后,在同一年的夏天,我有幸到香港跟随李航和杨强老师实习。实验室的不少学长们曾经去香港和杨强老师工作,他们回来之后都仿佛开了光似地在科研上面突飞猛进。去香港之后,我开始明白其中的原因 – 研究视野。经过几年的磨练,那时候的我或许已经知道如何去解决一个已有的问题,但是却缺乏其他一些必要的技能
- 如何选择一个新颖的研究问题
- 如何在结果不尽人意的时候转变方向寻找新的突破点
- 如何知道整个领域的问题之间的关系等等。 “你香港回来以后升级了嘛。” – 来自某大侠的评论。
这也许是对于我三个月香港实习的最好概括的吧。香港实习结束的时候我收获了第一篇正式的一作会议论文(在当年的ICML)。因为KDDCup的缘故,我认识了我现在博士导师Carlos的postdoc Danny,Danny把我推荐给了Carlos(UW)和Alex(CMU)。我在申请的时候幸运地拿到了UW和CMU的offer。在CMU visit的时候我见到了传说中的大神学长李沐,他和我感叹,现在正是大数据大火的时候,但是等到我们毕业的时候,不知道时代会是如何,不过又反过来说总可以去做更重要的东西。现在想起这段对话依然依然唏嘘不已。我最后选择了UW开始了我六年的博士生活。
感谢博士之前在APEX实验室和香港的经历,在博士开始的时候我似乎已经不再担心自己可以做什么了。
第一年: 意外可以收获什么
如果给我在UW的第一年一个主题的话,或许是“意外”。在交大时候因为兴趣的关系一直去蹭系统生物研究员敖平老师的组会探讨随机过程和马尔可夫链。到UW的第一个学期,我无意看到一篇探讨如何用Lagevin过程做采样的文章,我想这不就是之前组会上探讨过的东西么,原来这些方法也可以用到机器学习上。我直接借用了原来的交大学会的知识完成了第一篇高效采样HMC的文章。我后来并没有继续在这个方向上面耕耘下去,不过另外一位同在组会的学弟继续基于这个方向完成了他的博士论文。
同样的在这一年,我和导师开始“质疑深度学习”
- 如果别的的机器学习模型,有足够大的模型容量和数据,是否可以获得和深度学习一样的效果呢?
当时Carlos看好kernel methods,而我因为过去的一些经历决定尝试Tree Boosting。虽然最后在vision领域依然被卷积网络打败而尝试挑战失败,但是为了挑战这一假说而实现高效Tree boosting的系统经过小伙伴建议开源成为了后来的
XGBoost。
在第一年暑假结束的时候,因为偶然的原因,我开始对quantile sketch算法感兴趣。这里主要的问题是如何设计一个近似的可以合并的数据结构用来查找quantile。这个方向有一个经典的方案GK-sketch的论文,但是只能够解决数据点没有权重的情况。经过一两天的推导,我在一次去爬山的路上终于把结论推广到了有权重的情况。有趣的是新的证明比起原来的证明看起来简单很多。这个结论没有单独发表,但是后来意想不到地被用到了分布式XGBoost算法中,证明也收录在了XGboost文章的附录中。
研究并不是一朝一夕,做想做的事情把它做好,开始的时候兴趣使然,而在几年之后意想不到的地方获得的收获,这样的感觉走非常不错。
第二年和第三年: 选择做什么
在新生聚会上,Carlos对我说,你已经有论文的发表经历了,接下来要静下心来做发大的,“只做best paper水平的研究”。和很多nice的导师不同,Carlos对于学生的要求非常严格,说话也是非常直白甚至于“尖刻“。很多的老师不论我们提出什么样的想法,总会先肯定一番,而Carlos则会非常直接地提出质疑。一开始的时候会非常不习惯,感觉到信心受到了打击,但是慢慢习惯之后开始习惯这样风格。到现在看来,诚实的反馈的确是我收益最大的东西。我进入博士的一年之后,主要在想的问题是做什么样的问题,可以值得自己深入付出,做扎实有影响力的工作。
在博士的第三年,Carlos在建议我把XGBoost写成论文,用他的话说:“写一篇让读者可以学到东西的文章”。和传统的写法不同,我们在文章的每一个章节插入了实验结果验证当章节提出的观点。而他对于做图的处理也成为了我现在的习惯,直接在图里面插入箭头注释,减少读者的阅读负担。经过几次打磨论文终于成为了我们想要的模样。
博士前对于深度学习遗憾让我又逐渐把目光转回到深度学习。这个时候,我选择了不再一个人作战,在博士的第二年和第三年,我和兴趣使然的小伙伴们合作,一起开始了MXNet的项目。项目从零开始,在短短的一年时间里面做出完整的架构。我第一次看到集合了大家的力量齐心协力可以创造出什么样的东西。研究的乐趣不光是发表论文,更多还是可以给别人带来什么,或者更加大胆地说 – 如何一起改变世界。
博士第二年暑假,我在小伙伴的介绍下进入Google Brain跟随Ian Goodfellow实习。当时GAN的论文刚刚发表,我也有幸在成为Ian的第一个实习生。实习的开始,我们讨论需要做的问题,Ian和我把可能要做的项目画在一个风险和回报的曲线上,让我选择。到最后我选择了自己提出的一个课题,在这个曲线里面风险最高,回报也最高。我一直有一个理想,希望可以构建一个终身学习的机器学习系统,并且解决其中可能出现的问题。这个理想过于模糊,但是我们想办法拿出其中的一个可能小的目标 – 知识迁移。如果一个机器学习系统要终生学习,那么在不断收集数据之后必然需要扩充模型的规模来学习更广或者更深,按照现在的做法我们在模型改变之后只能抛弃原来的模型重新训练,这显然是不够高效的。是否有一个方法可以从已经训练好的网络上面进行知识迁移也就成为了一个重要的问题。我先花了一个半月的时间尝试了比较显然的Knowledge distillation的方法一直没有得到正面的结果。在最后的一个月,我改变了思路。实习结束的前一个星期,我打开Tensorborard上最近一组实验的结果:实验表明新的思路正面的效果。这最后几步的幸运也让我的这一个冒险之旅有了一个相对圆满的结果。这篇论文最后被发表在了ICLR上,也是我最喜欢的结果之一。
博士的第三年,我和小伙伴们开发了一种可以用低于线性复杂度就可以训练更深模型的内存优化算法。当时我非常兴奋地把这一结果写下来然后把稿子后给导师看。他和我说:
Hmm,这个结果如果投到NeurIPS的话或许可以中一篇poster,但是这并不是特别有意思。 在我沉默之后他又补充了一句: 论文并非越多越好,相反你可能要尝试优化你的论文里面最低质量的那一篇。 最后我们只是把这篇论文挂在了Arxiv上。Carlos的说法或许比较极端(这篇论文依然影响了不少后面的工作),但也的确是对的,用李沐之前说过的一句话概括,保证每一篇论文的质量接近单调提升,已经是一件难以做到但是又值得最求的事情。
选择做什么眼光和做出好结果的能力一样重要,眼界决定了工作影响力的上界,能力决定了到底是否到达那个上界。交大时敖平老师曾经和我说过,一个人做一件简单的事情和困难的事情其实是要花费一样多的时间。因为即使再简单的问题也有很多琐碎的地方。要想拿到一些东西,就必然意味着要放弃一些其他东西,既然如此,为什么不一直选择跳出舒适区,选一个最让自己兴奋的问题呢。
第四年之后: 坚持做什么
博士第三年,我和小伙伴们参加GTC,结束后老黄party的角落里,我一个人在发呆。深度学习的框架发展已经铺开,可接下来应该做什么,我一下子感到迷茫。第三年的暑假我没有去实习,而是决定一个人在学校尝试开发脑海中显现的抽象概念 – 深度学习中间表示。暑假结束之后,我完成了第一个版本,可以比较灵活地支持深度学习系统里面的计算图内存优化。但是总是觉得还缺少着什么 – 系统的瓶颈依然在更接近底层的算子实现上。暑假之后在去加州的飞机上,我尝试在纸上画出为了优化矩阵乘法可能的循环变换,回来之后,我们决定推动一个更加大胆的项目 – 尝试用自动编译生成的方式优化机器学习的底层代码。
这个项目早在之前我也有一些想法,但是一直没有敢去吃这个螃蟹。原因是它的两个特点:从零开始,横跨多领域。
因为要做底层代码生成和想要支持新的硬件,我们需要重新重新搞清楚很多在之前被现有的操作系统和驱动隐藏掉的问题,这就好象是在一个荒岛上一无所有重新搭建起一个城堡一样。而这里面也涉及了系统,程序语言,体系结构和机器学习等领域。这让我想起之前在ACM班时候重头搭建编译器和MIPS处理器并且连接起来的经历。也是那段经历让我觉得为了解决问题去吃多个领域的螃蟹是个让人兴奋的事情。那段经历给我留下的第二个印记是理解了合作和传承的重要性。这门课程设计有一个传统,每一门课程的老师都由上一届学长担任。每一届的同学都会在之前的基础上有所改进。我也曾经为这门课做过一些微小的贡献。演化到现在,这门课程已经从只做简单的答辩,到现在已经有在线评测的OJ。大家一起的合作塑造了这个课程。推动新的机器学习系统和塑造这门课程一行,需要各个团队的同学合作,足够时间的耐心关注和不断地改进。
我的合作者们也被“卷入”到了这个项目中。我的体系结构合作者一直想要设计新的AI硬件,我在雏形完成之后花了大量的时间讨论如何协同设计新的硬件的问题。我们开始讨论怎么管理片上内存,怎么可以比较容易地生成指令集,甚至怎么调度内存读写和计算并行的问题都暴露出来。有一天,我和合作者说我们需要引入虚拟线程的概念来隐藏内存读写开销,然后他很快和我说,这是体系结构里面经典的超线程技术,发明人正是我们的系主任Hank。我们也在不断地重新发现经典的问题的解决方法在新场景的应用,让我觉得上了一堂最好的体系结构课程。
两年间的不少关键技术问题的突破都是在有趣的时候发生的。我在排队参观西雅图艺术博物馆的infinity mirror展览的途中把加速器内存拷贝支持的第一个方案写在了一张星巴克的餐巾纸上。到后来是程序语言方向的同学们也继续参与进来。我们争论最多的是如何如何平衡函数式语言和经典计算图做让大家都可以搞懂的中间表达,这一讨论还在不断继续。经过大家的努力,TVM的第一篇论文在项目开始的两年之后终于发表。两年间参与项目的同学也从两个人,到一个团队,再到一个新的lab和一个社区,这两年也是我博士期间最充实的两年。
因为做了不少“跨界”的工作,我常被问起你到底属于哪个领域。过去半年一直在各地给报告,报告这样开头:
算法突破,数据的爆发,计算硬件的提升三者支撑了机器学习的变革,而整合这三者的,则是机器学习系统。这也是为什么我要做机器学习系统的原因。 曾经一个教授问我这样的问题,如果明天有一样新的化学反应过程可能带来机器学习的变革,你会怎么做。我答道: “我投入会去学习研究这个化学过程” 虽然我不知道遥远的未来会需要什么,到底是系统,算法,还是化学,从问题出发,用尽所有可能的方法去最好地解决机器学习问题,应该这就是我想要坚持的研究风格吧。
总结
在写这篇总结的时候,心中有不少感叹。我常想,如果我在焦虑死磕深度学习的时候我多开窍一些会发生什么,如果我并没有在实习结束的时候完成当时的实验,又会是什么。但现在看来,很多困难和无助都是随机的涨落的一部分,付出足够多的时间和耐心,随机过程总会收敛到和付出相对的稳态。
每个人的研究道路都各不相同,我的经历应该也是千万条道路中其中一条罢了。博士的经历就好像是用五年多时间作为筹码投资给自己,去突破自己做自己原来想不到的事情。中不管坎坷曲折都是无可替代的一部分。
科研从来不是一个人的事情,对于我来说特别是如此。我在交大的时候和一群年轻的同学一起摸索推荐系统的算法,而在博士期间搭建的每一个系统都包含了很多合作者一起的努力。也正是大家一起的努力才带来了现在的成果。我个人在这十年间受到了不少老师,同学,家人的鼓励和帮助,感谢他们他们给予了我这无比珍贵的十年时光。
上海交大ACM班寄语
2019-09-20, 上海交大张伟楠老师引言
陈天奇在华盛顿大学做了三个机器学习系统,第一个是
XGBoost,第二个是MXNET,第三个是TVM。
- 首先,我们来看一下
XGBoost有多厉害。我先不谈在kaggle上,有多少人凭着XGBoost实现过的model去拿了冠军,应该这么讲,我大概有几次在中国的二线、三线城市的一些在民居里开办的小公司里面去访问过,他们真的是那种在民居的漆黑小屋里的团队,他对我说:“我现在其实在做一个很厉害的互联网项目,我里面的用户行为预测模型是用了一个叫XGBoost的model”。大家就可以想象一下XGBoost在中国甚至是国外的渗透力有多么广泛。- 第二个机器学习系统是
MXNet。现在我们已经可以认为google的TensorFlow、Facebook的PyTorch和Amazon的MXNet是三驾马车并驾齐驱。MXNet更多的是从开源社区里面成长出来的优秀的深度学习框架。- 第三个系统是
TVM。TVM系统是一个把前端深度学习的一些语言和后端的一些新的机器的芯片的指令集做了一个编译器的服务层,这个系统使得我们中国现在能够拥有一些例如希望能够打造自己的芯片或者说体系架构,同时国外的一些公司也希望能够颠覆像Nvidia这类的垄断的可能,其实这些都依靠TVM这一层,这个系统的诞生使得我们前端的工程师不需要去改变自己深度学习的代码,同样的,后端也可以非常灵活的去使用不同的芯片。在TVM发布的那天,我的朋友圈都炸了,其中有一个评论特别有意思,就是说如果我是AMD的老板,我一定会重金收购TVM,因为这可能是我逆袭Nvidia的唯一出路。- 所以天奇的这三个机器学习系统都是举世瞩目的,这也造就了他非凡的研究成果。他将于明年入职CMU机器学习系和计算机科学系做助理教授。

陈天奇博士@上海交大
9月10日,我们有幸邀请到了上海交大ACM班06级校友陈天奇博士来校交流。来校之后,他首先向ACM班的同学们分享了自己在交大四年的学习经历以及这些经历是如何影响自己之后的科研及工作,并鼓励同学们珍惜自己四年的大学生活,利用交大优质的教学资源,做自己感兴趣的事,全力以赴,不留遗憾。紧接着,在电院3-200报告厅,他又为喜欢和热爱机器学习的老师、同学们带来了一场以“Learning-based Learning Systems”为主题的讲座,向大家详细介绍了机器学习如何反向优化机器学习系统本身。天奇老师的精彩分享,使到场同学和老师们受益良多。
下面,就请跟随小编,聆听陈天奇博士的精彩分享吧~
一、邂逅交大ACM班:“第一次”,成就现在的我
陈天奇老师与ACM班的相遇,始于06年的秋天,当时的他,没有荣耀光环加持,因此他笑称自己是被ACM班收留的“野生选手”。当他走到交大东下院的教室,将申请材料交给当时ACM班创始人俞勇教授的那一刻,他的人生轨迹已经悄然开始改变。
第一次参与学子讲坛,第一次在众人面前用PPT演讲“小王子”,正是在ACM班四年中学子讲坛对他表达和演讲能力的锻炼,他才能在大学甚至在美国的博士阶段的学习中向他人镇定从容的介绍自己的观点和想法。

小王子插画
第一次接触科研,兴趣变得至关重要。他坦言,自己第一次接触科研,就是代数课的大作业,通过这次经历,培养了他自主探讨的兴趣,能够让他主动去学习自己感兴趣的东西。虽然这门课程在短期内很难带来某些收益,但是兴趣是最好的老师,通过兴趣去多学习、多汲取一些知识,享受学习的过程,这对自己来说是非常有益的。
第一次参与专业比赛,快速获得专业知识,提升自身水平。不同的同学在进入班级时有不同的起点,每个人的起点不同,在学习中得到的收获也不同。陈天奇表示
意识到差距是一件好的事情,但当你将目光聚焦在自己与别人的差距的时候,不如换个角度,想想之前的自己与现在的自己有哪些不同或者进步,和自己做比较,这样的进步对自己的影响会更大、更积极。

陈天奇博士分享自己初入ACM班的感受
第一次进入实验室,探索“科研是什么”。在大三下学期,陈天奇开始进入实验室进行科研工作,他发现,进入实验室和平时做作业完全不同,科研没有固定的方向、固定的问题,也没有标准答案,这就意味着你无法知道自己的研究是否是正确的。但是,经过一段时间后,他找到了解决的方法:寻找自己感兴趣的问题,然后再逐渐突破。反过来说,他认为:
“ACM班的四年对我最大的培养,就是当我确定了问题之后,我能够有自信找到方法并且很快的解决,我并不会害怕,这也是ACM班可以传递给大家的”。 在本科四年级到硕士一年半的所有时间里,陈天奇将目光聚焦到深度学习领域,但经过两年半的努力,最后还是一无所获。现在看来,他认为自己当时犯了一个错误:没有充分考虑科研的灵活变通性,同时锁死了要解决的问题和用来解决问题的方案,所以降低了成功的可能性。这也让他明白一个道理: 我们在确定问题后可以选择不同的方法来解决自己的问题,同时,也可以多学习几门不同领域的知识,灵活变通,不要把自己局限在一个小领域里面,跳出自己的舒适圈,你就可能拥有更广阔的空间。
二、拥抱未知,享受成长,无知无畏
在经历了各种各样的挫折后,大家可能都会对自身产生自我怀疑,怀疑自己是不是在做好的研究,这个研究是不是还能做的更好等等。当你认为在你达成某些目标后,这种怀疑可能会消失,但令人不解的是,这种怀疑仍旧存在。陈天奇将这种怀疑概括为“人对未知、对不确定性的恐惧”。就像大家对自己能否顺利毕业、能否升入更好的大学继续深造,或者是自己在这个研究领域是否会有比较好的结果的恐惧等等。但反过来说,他认为
未来的不确定性正是现在的学生生活最精彩的地方:你可能不会预料到自己会完成什么事情。在青春最美好的时代,拥抱未知,享受学习的过程,是十分重要的。
陈天奇博士“Learning-based Learning Systems ”讲座
大家在学习的过程中,经常会有“做科研的最终目标是发表论文,打比赛就是要获得冠军”的想法,但当你在真正实现这些目标的时候,你会发现,其实你在这个过程中得到最多的是你获得了成长。因此,做科研、打比赛都是在让你学会如何享受成长。当你最终成功发表论文或者获得了比赛冠军,你可能会后悔自己在前段时间太过于焦虑而忽略了去享受这个过程。陈天奇鼓励同学们在大学四年中,可以多学习、多尝试新的东西,他认为,当你在享受成长的过程中,也就不会太在意其中的挫折。
“当你随着年龄的增长,经验也开始逐步积累,但有时可能会缺少一点锐气”。
陈天奇认为现在的大学生正处于自己最美好的年龄,可以自己努力的去尝试一些突破自己上限的事情。“锐气+无知+时间”是最佳的组合,虽然焦虑会一直存在,但是拥抱未知,拥有锐气,敢于尝试,就能够尽力做到最好。
三、选择与放弃
从硕士毕业到进入博士学习,陈天奇感触最深的地方在于:懂得放弃比知道自己想要什么更重要。陈天奇觉得,现在的大家拥有更好的资源,有更多的资本去做自己想做的事情,那么大家可以放弃一些自己觉得不重要的事情,不留遗憾,全力以赴地在自己最感兴趣的方向上努力,尝试去挑战自己,在未来就有可能会做得更好,收获更多的回报。
陈天奇博士的精彩分享使在场同学获益良多,下面让我们来听一听同学们的感想吧~

陈天奇博士与现场同学进行交流
-
- 分光计(17级ACM班):
- XGBoost, MXNet, tvm都是具有高度影响力的工作,和天奇学长的交流让我能够用更宽阔的视野去看待科研工作,让我看到一个顶尖工作者看待问题的态度和工作的方式,受益匪浅。
- 分光计(17级ACM班):
-
- zhc134(11级ACM班):
- 天奇学长在工业界和学术界的影响力很高,我自己也曾使用过天奇学长的svdfeature,xgboost和mxnet,非常有幸能够当面进行交流。这次TVM的talk拓展了我的视野,用机器学习技术优化深度学习算法本身在不同硬件的运行效率的想法很有趣,未来还可能用在偏底层的其他模块中。另一方面将好的科研想法实现,并做成实用且高质量的工具则更具挑战。天奇学长对待科研的这种态度也会激励我们做出有创新性又solid的工作。
- zhc134(11级ACM班):
-
- peter(17级ACM班):
- 天奇学长的交流方式让我很是佩服,他总是面带微笑从容不迫。这样的淡定给了我一种大研究家的风范,正是有这样的淡定他完成了XGBoost、TVM等具有超高影响力的工作。
- peter(17级ACM班):
陈天奇博士“Learning-based Learning Systems”的主题讲座赢得了现场同学的高度认可与赞赏,为了让大家也能够了解陈天奇博士讲座分享的精彩内容,小编特将此次讲座的录音置于微信公号文章中(知乎貌似不能插录音),有兴趣的小伙伴可以耐心聆听一下呦~
技术讲座主题
Learning-based Learning Systems
摘要:
数据、模型和计算是使机器学习能够大规模解决实际问题的三大支柱。要在这三个领域取得进展,不仅需要突破性的算法进步,还需要能够从现代硬件中压榨出更多性能的系统创新。学习系统是当今智能应用的核心。然而,不断增长的针对具体应用和硬件的需求给这些系统带来了巨大的工程负担,这些系统大多数依赖于启发式或手工优化。
在这次演讲中,我将介绍一种新的方法,它使用机器学习来自动化系统优化。我将在围绕深度学习部署问题这个场景介绍我们的方法。首先,我将讨论如何设计一种针对可迁移的统计成本模型的不变表示,并将这些表示应用于深度学习应用中的张量优化程序。然后,我将描述我们为支持各种硬件后端所做的系统改进。TVM,我们的端到端系统,提供跨硬件后端性能,与最先进的、手工调优的深度学习框架竞争。最后,我将讨论如何推广我们的方法来共同对模型、系统和硬件进行全堆栈优化,以及如何构建支持智能应用的终生演化的系统。
A Survival Guide to a PhD
Andrej Karpathy, Sep 7, 2016
This guide is patterned after my “Doing well in your courses”, a post I wrote a long time ago on some of the tips/tricks I’ve developed during my undergrad. I’ve received nice comments about that guide, so in the same spirit, now that my PhD has come to an end I wanted to compile a similar retrospective document in hopes that it might be helpful to some. Unlike the undergraduate guide, this one was much more difficult to write because there is significantly more variation in how one can traverse the PhD experience. Therefore, many things are likely contentious and a good fraction will be specific to what I’m familiar with (Computer Science / Machine Learning / Computer Vision research). But disclaimers are boring, lets get to it!
Preliminaries
First, should you want to get a PhD? I was in a fortunate position of knowing since young age that I really wanted a PhD. Unfortunately it wasn’t for any very well-thought-through considerations: First, I really liked school and learning things and I wanted to learn as much as possible, and second, I really wanted to be like Gordon Freeman from the game Half-Life (who has a PhD from MIT in theoretical physics). I loved that game. But what if you’re more sensible in making your life’s decisions? Should you want to do a PhD? There’s a very nice Quora thread and in the summary of considerations that follows I’ll borrow/restate several from Justin/Ben/others there. I’ll assume that the second option you are considering is joining a medium-large company (which is likely most common). Ask yourself if you find the following properties appealing:
- Freedom. A PhD will offer you a lot of freedom in the topics you wish to pursue and learn about. You’re in charge. Of course, you’ll have an adviser who will impose some constraints but in general you’ll have much more freedom than you might find elsewhere.
- Ownership. The research you produce will be yours as an individual. Your accomplishments will have your name attached to them. In contrast, it is much more common to “blend in” inside a larger company. A common feeling here is becoming a “cog in a wheel”.
- Exclusivity. There are very few people who make it to the top PhD programs. You’d be joining a group of a few hundred distinguished individuals in contrast to a few tens of thousands (?) that will join some company.
- Status. Regardless of whether it should be or not, working towards and eventually getting a PhD degree is culturally revered and recognized as an impressive achievement. You also get to be a Doctor; that’s awesome.
- Personal freedom. As a PhD student you’re your own boss. Want to sleep in today? Sure. Want to skip a day and go on a vacation? Sure. All that matters is your final output and no one will force you to clock in from 9am to 5pm. Of course, some advisers might be more or less flexible about it and some companies might be as well, but it’s a true first order statement.
- Maximizing future choice. Joining a PhD program doesn’t close any doors or eliminate future employment/lifestyle options. You can go one way (PhD -> anywhere else) but not the other (anywhere else -> PhD -> academia/research; it is statistically less likely). Additionally (although this might be quite specific to applied ML), you’re strictly more hirable as a PhD graduate or even as a PhD dropout and many companies might be willing to put you in a more interesting position or with a higher starting salary. More generally, maximizing choice for the future you is a good heuristic to follow.
- Maximizing variance. You’re young and there’s really no need to rush. Once you graduate from a PhD you can spend the next ~50 years of your life in some company. Opt for more variance in your experiences.
- Personal growth. PhD is an intense experience of rapid growth (you learn a lot) and personal self-discovery (you’ll become a master of managing your own psychology). PhD programs (especially if you can make it into a good one) also offer a high density of exceptionally bright people who will become your best friends forever.
- Expertise. PhD is probably your only opportunity in life to really drill deep into a topic and become a recognized leading expert in the world at something. You’re exploring the edge of our knowledge as a species, without the burden of lesser distractions or constraints. There’s something beautiful about that and if you disagree, it could be a sign that PhD is not for you.
- The disclaimer. I wanted to also add a few words on some of the potential downsides and failure modes. The PhD is a very specific kind of experience that deserves a large disclaimer. You will inevitably find yourself working very hard (especially before paper deadlines). You need to be okay with the suffering and have enough mental stamina and determination to deal with the pressure. At some points you will lose track of what day of the week it is and go on a diet of leftover food from the microkitchens. You’ll sit exhausted and alone in the lab on a beautiful, sunny Saturday scrolling through Facebook pictures of your friends having fun on exotic trips, paid for by their 5-10x larger salaries. You will have to throw away 3 months of your work while somehow keeping your mental health intact. You’ll struggle with the realization that months of your work were spent on a paper with a few citations while your friends do exciting startups with TechCrunch articles or push products to millions of people. You’ll experience identity crises during which you’ll question your life decisions and wonder what you’re doing with some of the best years of your life. As a result, you should be quite certain that you can thrive in an unstructured environment in the pursuit research and discovery for science. If you’re unsure you should lean slightly negative by default. Ideally you should consider getting a taste of research as an undergraduate on a summer research program before before you decide to commit. In fact, one of the primary reasons that research experience is so desirable during the PhD hiring process is not the research itself, but the fact that the student is more likely to know what they’re getting themselves into.
I should clarify explicitly that this post is not about convincing anyone to do a PhD, I’ve merely tried to enumerate some of the common considerations above. The majority of this post focuses on some tips/tricks for navigating the experience once if you decide to go for it (which we’ll see shortly, below).
Lastly, as a random thought I heard it said that you should only do a PhD if you want to go into academia. In light of all of the above I’d argue that a PhD has strong intrinsic value - it’s an end by itself, not just a means to some end (e.g. academic job).
Getting into a PhD program: references, references, references. Great, you’ve decided to go for it. Now how do you get into a good PhD program? The first order approximation is quite simple - by far most important component are strong reference letters. The ideal scenario is that a well-known professor writes you a letter along the lines of: “Blah is in top 5 of students I’ve ever worked with. She takes initiative, comes up with her own ideas, and gets them to work.” The worst letter is along the lines of: “Blah took my class. She did well.” A research publication under your belt from a summer research program is a very strong bonus, but not absolutely required provided you have strong letters. In particular note: grades are quite irrelevant but you generally don’t want them to be too low. This was not obvious to me as an undergrad and I spent a lot of energy on getting good grades. This time should have instead been directed towards research (or at the very least personal projects), as much and as early as possible, and if possible under supervision of multiple people (you’ll need 3+ letters!). As a last point, what won’t help you too much is pestering your potential advisers out of the blue. They are often incredibly busy people and if you try to approach them too aggressively in an effort to impress them somehow in conferences or over email this may agitate them.
Picking the school. Once you get into some PhD programs, how do you pick the school? It’s easy, join Stanford! Just kidding. More seriously, your dream school should 1) be a top school (not because it looks good on your resume/CV but because of feedback loops; top schools attract other top people, many of whom you will get to know and work with) 2) have a few potential advisers you would want to work with. I really do mean the “few” part - this is very important and provides a safety cushion for you if things don’t work out with your top choice for any one of hundreds of reasons - things in many cases outside of your control, e.g. your dream professor leaves, moves, or spontaneously disappears, and 3) be in a good environment physically. I don’t think new admits appreciate this enough: you will spend 5+ years of your really good years living near the school campus. Trust me, this is a long time and your life will consist of much more than just research.
Adviser

Image credit: PhD comics.
Student adviser relationship. The adviser is an extremely important person who will exercise a lot of influence over your PhD experience. It’s important to understand the nature of the relationship: the adviser-student relationship is a symbiosis; you have your own goals and want something out of your PhD, but they also have their own goals, constraints and they’re building their own career. Therefore, it is very helpful to understand your adviser’s incentive structures: how the tenure process works, how they are evaluated, how they get funding, how they fund you, what department politics they might be embedded in, how they win awards, how academia in general works and specifically how they gain recognition and respect of their colleagues. This alone will help you avoid or mitigate a large fraction of student-adviser friction points and allow you to plan appropriately. I also don’t want to make the relationship sound too much like a business transaction. The advisor-student relationship, more often that not, ends up developing into a lasting one, predicated on much more than just career advancement.
Pre-vs-post tenure. Every adviser is different so it’s helpful to understand the axes of variations and their repercussions on your PhD experience. As one rule of thumb (and keep in mind there are many exceptions), it’s important to keep track of whether a potential adviser is pre-tenure or post-tenure. The younger faculty members will usually be around more (they are working hard to get tenure) and will usually be more low-level, have stronger opinions on what you should be working on, they’ll do math with you, pitch concrete ideas, or even look at (or contribute to) your code. This is a much more hands-on and possibly intense experience because the adviser will need a strong publication record to get tenure and they are incentivised to push you to work just as hard. In contrast, more senior faculty members may have larger labs and tend to have many other commitments (e.g. committees, talks, travel) other than research, which means that they can only afford to stay on a higher level of abstraction both in the area of their research and in the level of supervision for their students. To caricature, it’s a difference between “you’re missing a second term in that equation” and “you may want to read up more in this area, talk to this or that person, and sell your work this or that way”. In the latter case, the low-level advice can still come from the senior PhD students in the lab or the postdocs.
Axes of variation. There are many other axes to be aware of. Some advisers are fluffy and some prefer to keep your relationship very professional. Some will try to exercise a lot of influence on the details of your work and some are much more hands off. Some will have a focus on specific models and their applications to various tasks while some will focus on tasks and more indifference towards any particular modeling approach. In terms of more managerial properties, some will meet you every week (or day!) multiple times and some you won’t see for months. Some advisers answer emails right away and some don’t answer email for a week (or ever, haha). Some advisers make demands about your work schedule (e.g. you better work long hours or weekends) and some won’t. Some advisers generously support their students with equipment and some think laptops or old computers are mostly fine. Some advisers will fund you to go to a conferences even if you don’t have a paper there and some won’t. Some advisers are entrepreneurial or applied and some lean more towards theoretical work. Some will let you do summer internships and some will consider internships just a distraction.
Finding an adviser. So how do you pick an adviser? The first stop, of course, is to talk to them in person. The student-adviser relationship is sometimes referred to as a marriage and you should make sure that there is a good fit. Of course, first you want to make sure that you can talk with them and that you get along personally, but it’s also important to get an idea of what area of “professor space” they occupy with respect to the aforementioned axes, and especially whether there is an intellectual resonance between the two of you in terms of the problems you are interested in. This can be just as important as their management style.
Collecting references. You should also collect references on your potential adviser. One good strategy is to talk to their students. If you want to get actual information this shouldn’t be done in a very formal way or setting but in a relaxed environment or mood (e.g. a party). In many cases the students might still avoid saying bad things about the adviser if asked in a general manner, but they will usually answer truthfully when you ask specific questions, e.g. “how often do you meet?”, or “how hands on are they?”. Another strategy is to look at where their previous students ended up (you can usually find this on the website under an alumni section), which of course also statistically informs your own eventual outcome.
Impressing an adviser. The adviser-student matching process is sometimes compared to a marriage - you pick them but they also pick you. The ideal student from their perspective is someone with interest and passion, someone who doesn’t need too much hand-holding, and someone who takes initiative - who shows up a week later having done not just what the adviser suggested, but who went beyond it; improved on it in unexpected ways.
Consider the entire lab. Another important point to realize is that you’ll be seeing your adviser maybe once a week but you’ll be seeing most of their students every single day in the lab and they will go on to become your closest friends. In most cases you will also end up collaborating with some of the senior PhD students or postdocs and they will play a role very similar to that of your adviser. The postdocs, in particular, are professors-in-training and they will likely be eager to work with you as they are trying to gain advising experience they can point to for their academic job search. Therefore, you want to make sure the entire group has people you can get along with, people you respect and who you can work with closely on research projects.
Research topics

t-SNE visualization of a small subset of human knowledge (from paperscape). Each circle is an arxiv paper and size indicates the number of citations. So you’ve entered a PhD program and found an adviser. Now what do you work on?
An exercise in the outer loop. First note the nature of the experience. A PhD is simultaneously a fun and frustrating experience because you’re constantly operating on a meta problem level. You’re not just solving problems - that’s merely the simple inner loop. You spend most of your time on the outer loop, figuring out what problems are worth solving and what problems are ripe for solving. You’re constantly imagining yourself solving hypothetical problems and asking yourself where that puts you, what it could unlock, or if anyone cares. If you’re like me this can sometimes drive you a little crazy because you’re spending long hours working on things and you’re not even sure if they are the correct things to work on or if a solution exists.
Developing taste. When it comes to choosing problems you’ll hear academics talk about a mystical sense of “taste”. It’s a real thing. When you pitch a potential problem to your adviser you’ll either see their face contort, their eyes rolling, and their attention drift, or you’ll sense the excitement in their eyes as they contemplate the uncharted territory ripe for exploration. In that split second a lot happens: an evaluation of the problem’s importance, difficulty, its sexiness, its historical context (and possibly also its fit to their active grants). In other words, your adviser is likely to be a master of the outer loop and will have a highly developed sense of taste for problems. During your PhD you’ll get to acquire this sense yourself.
In particular, I think I had a terrible taste coming in to the PhD. I can see this from the notes I took in my early PhD years. A lot of the problems I was excited about at the time were in retrospect poorly conceived, intractable, or irrelevant. I’d like to think I refined the sense by the end through practice and apprenticeship.
Let me now try to serialize a few thoughts on what goes into this sense of taste, and what makes a problem interesting to work on.
A fertile ground. First, recognize that during your PhD you will dive deeply into one area and your papers will very likely chain on top of each other to create a body of work (which becomes your thesis). Therefore, you should always be thinking several steps ahead when choosing a problem. It’s impossible to predict how things will unfold but you can often get a sense of how much room there could be for additional work.
Plays to your adviser’s interests and strengths. You will want to operate in the realm of your adviser’s interest. Some advisers may allow you to work on slightly tangential areas but you would not be taking full advantage of their knowledge and you are making them less likely to want to help you with your project or promote your work. For instance, (and this goes to my previous point of understanding your adviser’s job) every adviser has a “default talk” slide deck on their research that they give all the time and if your work can add new exciting cutting edge work slides to this deck then you’ll find them much more invested, helpful and involved in your research. Additionally, their talks will promote and publicize your work.
Be ambitious: the sublinear scaling of hardness. People have a strange bug built into psychology: a 10x more important or impactful problem intuitively feels 10x harder (or 10x less likely) to achieve. This is a fallacy - in my experience a 10x more important problem is at most 2-3x harder to achieve. In fact, in some cases a 10x harder problem may be easier to achieve. How is this? It’s because thinking 10x forces you out of the box, to confront the real limitations of an approach, to think from first principles, to change the strategy completely, to innovate. If you aspire to improve something by 10% and work hard then you will. But if you aspire to improve it by 100% you are still quite likely to, but you will do it very differently.
Ambitious but with an attack. At this point it’s also important to point out that there are plenty of important problems that don’t make great projects. I recommend reading You and Your Research by Richard Hamming, where this point is expanded on:
If you do not work on an important problem, it’s unlikely you’ll do important work. It’s perfectly obvious. Great scientists have thought through, in a careful way, a number of important problems in their field, and they keep an eye on wondering how to attack them. Let me warn you, important problem must be phrased carefully. The three outstanding problems in physics, in a certain sense, were never worked on while I was at Bell Labs. By important I mean guaranteed a Nobel Prize and any sum of money you want to mention. We didn’t work on (1) time travel, (2) teleportation, and (3) antigravity. They are not important problems because we do not have an attack. It’s not the consequence that makes a problem important, it is that you have a reasonable attack. That is what makes a problem important.
The person who did X. Ultimately, the goal of a PhD is to not only develop a deep expertise in a field but to also make your mark upon it. To steer it, shape it. The ideal scenario is that by the end of the PhD you own some part of an important area, preferably one that is also easy and fast to describe. You want people to say things like “she’s the person who did X”. If you can fill in a blank there you’ll be successful.
Valuable skills. Recognize that during your PhD you will become an expert at the area of your choosing (as fun aside, note that [5 years]x[260 working days]x[8 hours per day] is 10,400 hours; if you believe Gladwell then a PhD is exactly the amount of time to become an expert). So imagine yourself 5 years later being a world expert in this area (the 10,000 hours will ensure that regardless of the academic impact of your work). Are these skills exciting or potentially valuable to your future endeavors?
Negative examples. There are also some problems or types of papers that you ideally want to avoid. For instance, you’ll sometimes hear academics talk about “incremental work” (this is the worst adjective possible in academia). Incremental work is a paper that enhances something existing by making it more complex and gets 2% extra on some benchmark. The amusing thing about these papers is that they have a reasonably high chance of getting accepted (a reviewer can’t point to anything to kill them; they are also sometimes referred to as “cockroach papers”), so if you have a string of these papers accepted you can feel as though you’re being very productive, but in fact these papers won’t go on to be highly cited and you won’t go on to have a lot of impact on the field. Similarly, finding projects should ideally not include thoughts along the lines of “there’s this next logical step in the air that no one has done yet, let me do it”, or “this should be an easy poster”.
Case study: my thesis. To make some of this discussion more concrete I wanted to use the example of how my own PhD unfolded. First, fun fact: my entire thesis is based on work I did in the last 1.5 years of my PhD. i.e. it took me quite a long time to wiggle around in the metaproblem space and find a problem that I felt very excited to work on (the other ~2 years I mostly meandered on 3D things (e.g. Kinect Fusion, 3D meshes, point cloud features) and video things). Then at one point in my 3rd year I randomly stopped by Richard Socher’s office on some Saturday at 2am. We had a chat about interesting problems and I realized that some of his work on images and language was in fact getting at something very interesting (of course, the area at the intersection of images and language goes back quite a lot further than Richard as well). I couldn’t quite see all the papers that would follow but it seemed heuristically very promising: it was highly fertile (a lot of unsolved problems, a lot of interesting possibilities on grounding descriptions to images), I felt that it was very cool and important, it was easy to explain, it seemed to be at the boundary of possible (Deep Learning has just started to work), the datasets had just started to become available (Flickr8K had just come out), it fit nicely into Fei-Fei’s interests and even if I were not successful I’d at least get lots of practice with optimizing interesting deep nets that I could reapply elsewhere. I had a strong feeling of a tsunami of checkmarks as everything clicked in place in my mind. I pitched this to Fei-Fei (my adviser) as an area to dive into the next day and, with relief, she enthusiastically approved, encouraged me, and would later go on to steer me within the space (e.g. Fei-Fei insisted that I do image to sentence generation while I was mostly content with ranking.). I’m happy with how things evolved from there. In short, I meandered around for 2 years stuck around the outer loop, finding something to dive into. Once it clicked for me what that was based on several heuristics, I dug in.
Resistance. I’d like to also mention that your adviser is by no means infallible. I’ve witnessed and heard of many instances in which, in retrospect, the adviser made the wrong call. If you feel this way during your phd you should have the courage to sometimes ignore your adviser. Academia generally celebrates independent thinking but the response of your specific adviser can vary depending on circumstances. I’m aware of multiple cases where the bet worked out very well and I’ve also personally experienced cases where it did not. For instance, I disagreed strongly with some advice Andrew Ng gave me in my very first year. I ended up working on a problem he wasn’t very excited about and, surprise, he turned out to be very right and I wasted a few months. Win some lose some :)
Don’t play the game. Finally, I’d like to challenge you to think of a PhD as more than just a sequence of papers. You’re not a paper writer. You’re a member of a research community and your goal is to push the field forward. Papers are one common way of doing that but I would encourage you to look beyond the established academic game. Think for yourself and from first principles. Do things others don’t do but should. Step off the treadmill that has been put before you. I tried to do some of this myself throughout my PhD. This blog is an example - it allows me communicate things that wouldn’t ordinarily go into papers. The ImageNet human reference experiments are an example - I felt strongly that it was important for the field to know the ballpark human accuracy on ILSVRC so I took a few weeks off and evaluated it. The academic search tools (e.g. arxiv-sanity) are an example - I felt continuously frustrated by the inefficiency of finding papers in the literature and I released and maintain the site in hopes that it can be useful to others. Teaching CS231n twice is an example - I put much more effort into it than is rationally advisable for a PhD student who should be doing research, but I felt that the field was held back if people couldn’t efficiently learn about the topic and enter. A lot of my PhD endeavors have likely come at a cost in standard academic metrics (e.g. h-index, or number of publications in top venues) but I did them anyway, I would do it the same way again, and here I am encouraging others to as well. To add a pitch of salt and wash down the ideology a bit, based on several past discussions with my friends and colleagues I know that this view is contentious and that many would disagree.
Writing papers

Writing good papers is an essential survival skill of an academic (kind of like making fire for a caveman). In particular, it is very important to realize that papers are a specific thing: they look a certain way, they flow a certain way, they have a certain structure, language, and statistics that the other academics expect. It’s usually a painful exercise for me to look through some of my early PhD paper drafts because they are quite terrible. There is a lot to learn here.
Review papers. If you’re trying to learn to write better papers it can feel like a sensible strategy to look at many good papers and try to distill patterns. This turns out to not be the best strategy; it’s analogous to only receiving positive examples for a binary classification problem. What you really want is to also have exposure to a large number of bad papers and one way to get this is by reviewing papers. Most good conferences have an acceptance rate of about 25% so most papers you’ll review are bad, which will allow you to build a powerful binary classifier. You’ll read through a bad paper and realize how unclear it is, or how it doesn’t define it’s variables, how vague and abstract its intro is, or how it dives in to the details too quickly, and you’ll learn to avoid the same pitfalls in your own papers. Another related valuable experience is to attend (or form) journal clubs - you’ll see experienced researchers critique papers and get an impression for how your own papers will be analyzed by others.
Get the gestalt right. I remember being impressed with Fei-Fei (my adviser) once during a reviewing session. I had a stack of 4 papers I had reviewed over the last several hours and she picked them up, flipped through each one for 10 seconds, and said one of them was good and the other three bad. Indeed, I was accepting the one and rejecting the other three, but something that took me several hours took her seconds. Fei-Fei was relying on the gestalt of the papers as a powerful heuristic. Your papers, as you become a more senior researcher take on a characteristic look. An introduction of ~1 page. A ~1 page related work section with a good density of citations - not too sparse but not too crowded. A well-designed pull figure (on page 1 or 2) and system figure (on page 3) that were not made in MS Paint. A technical section with some math symbols somewhere, results tables with lots of numbers and some of them bold, one additional cute analysis experiment, and the paper has exactly 8 pages (the page limit) and not a single line less. You’ll have to learn how to endow your papers with the same gestalt because many researchers rely on it as a cognitive shortcut when they judge your work.
Identify the core contribution. Before you start writing anything it’s important to identify the single core contribution that your paper makes to the field. I would especially highlight the word single. A paper is not a random collection of some experiments you ran that you report on. The paper sells a single thing that was not obvious or present before. You have to argue that the thing is important, that it hasn’t been done before, and then you support its merit experimentally in controlled experiments. The entire paper is organized around this core contribution with surgical precision. In particular it doesn’t have any additional fluff and it doesn’t try to pack anything else on a side. As a concrete example, I made a mistake in one of my earlier papers on video classification where I tried to pack in two contributions:
- 1) a set of architectural layouts for video convnets and an unrelated
- 2) multi-resolution architecture which gave small improvements.
I added it because I reasoned first that maybe someone could find it interesting and follow up on it later and second because I thought that contributions in a paper are additive: two contributions are better than one. Unfortunately, this is false and very wrong. The second contribution was minor/dubious and it diluted the paper, it was distracting, and no one cared. I’ve made a similar mistake again in my CVPR 2014 paper which presented two separate models: a ranking model and a generation model. Several good in-retrospect arguments could be made that I should have submitted two separate papers; the reason it was one is more historical than rational.
The structure. Once you’ve identified your core contribution there is a default recipe for writing a paper about it. The upper level structure is by default Intro, Related Work, Model, Experiments, Conclusions. When I write my intro I find that it helps to put down a coherent top-level narrative in latex comments and then fill in the text below. I like to organize each of my paragraphs around a single concrete point stated on the first sentence that is then supported in the rest of the paragraph. This structure makes it easy for a reader to skim the paper. A good flow of ideas is then along the lines of 1) X (+define X if not obvious) is an important problem 2) The core challenges are this and that. 2) Previous work on X has addressed these with Y, but the problems with this are Z. 3) In this work we do W (?). 4) This has the following appealing properties and our experiments show this and that. You can play with this structure a bit but these core points should be clearly made. Note again that the paper is surgically organized around your exact contribution. For example, when you list the challenges you want to list exactly the things that you address later; you don’t go meandering about unrelated things to what you have done (you can speculate a bit more later in conclusion). It is important to keep a sensible structure throughout your paper, not just in the intro. For example, when you explain the model each section should: 1) explain clearly what is being done in the section, 2) explain what the core challenges are 3) explain what a baseline approach is or what others have done before 4) motivate and explain what you do 5) describe it.
Break the structure. You should also feel free (and you’re encouraged to!) play with these formulas to some extent and add some spice to your papers. For example, see this amusing paper from Razavian et al. in 2014 that structures the introduction as a dialog between a student and the professor. It’s clever and I like it. As another example, a lot of papers from Alyosha Efros have a playful tone and make great case studies in writing fun papers. As only one of many examples, see this paper he wrote with Antonio Torralba: Unbiased look at dataset bias. Another possibility I’ve seen work well is to include an FAQ section, possibly in the appendix.
Common mistake: the laundry list. One very common mistake to avoid is the “laundry list”, which looks as follows: “Here is the problem. Okay now to solve this problem first we do X, then we do Y, then we do Z, and now we do W, and here is what we get”. You should try very hard to avoid this structure. Each point should be justified, motivated, explained. Why do you do X or Y? What are the alternatives? What have others done? It’s okay to say things like this is common (add citation if possible). Your paper is not a report, an enumeration of what you’ve done, or some kind of a translation of your chronological notes and experiments into latex. It is a highly processed and very focused discussion of a problem, your approach and its context. It is supposed to teach your colleagues something and you have to justify your steps, not just describe what you did.
The language. Over time you’ll develop a vocabulary of good words and bad words to use when writing papers. Speaking about machine learning or computer vision papers specifically as concrete examples, in your papers you never “study” or “investigate” (there are boring, passive, bad words); instead you “develop” or even better you “propose”. And you don’t present a “system” or, shudder, a “pipeline”; instead, you develop a “model”. You don’t learn “features”, you learn “representations”. And god forbid, you never “combine”, “modify” or “expand”. These are incremental, gross terms that will certainly get your paper rejected :).
An internal deadlines 2 weeks prior. Not many labs do this, but luckily Fei-Fei is quite adamant about an internal deadline 2 weeks before the due date in which you must submit at least a 5-page draft with all the final experiments (even if not with final numbers) that goes through an internal review process identical to the external one (with the same review forms filled out, etc). I found this practice to be extremely useful because forcing yourself to lay out the full paper almost always reveals some number of critical experiments you must run for the paper to flow and for its argument flow to be coherent, consistent and convincing.
Another great resource on this topic is Tips for Writing Technical Papers from Jennifer Widom.
Writing code

A lot of your time will of course be taken up with the execution of your ideas, which likely involves a lot of coding. I won’t dwell on this too much because it’s not uniquely academic, but I would like to bring up a few points.
Release your code. It’s a somewhat surprising fact but you can get away with publishing papers and not releasing your code. You will also feel a lot of incentive to not release your code: it can be a lot of work (research code can look like spaghetti since you iterate very quickly, you have to clean up a lot), it can be intimidating to think that others might judge you on your at most decent coding abilities, it is painful to maintain code and answer questions from other people about it (forever), and you might also be concerned that people could spot bugs that invalidate your results. However, it is precisely for some of these reasons that you should commit to releasing your code: it will force you to adopt better coding habits due to fear of public shaming (which will end up saving you time!), it will force you to learn better engineering practices, it will force you to be more thorough with your code (e.g. writing unit tests to make bugs much less likely), it will make others much more likely to follow up on your work (and hence lead to more citations of your papers) and of course it will be much more useful to everyone as a record of exactly what was done for posterity. When you do release your code I recommend taking advantage of docker containers; this will reduce the amount of headaches people email you about when they can’t get all the dependencies (and their precise versions) installed.
Think of the future you. Make sure to document all your code very well for yourself. I guarantee you that you will come back to your code base a few months later (e.g. to do a few more experiments for the camera ready version of the paper), and you will feel completely lost in it. I got into the habit of creating very thorough readme.txt files in all my repos (for my personal use) as notes to future self on how the code works, how to run it, etc.
Giving talks

So, you published a paper and it’s an oral! Now you get to give a few minute talk to a large audience of people - what should it look like?
The goal of a talk. First, that there’s a common misconception that the goal of your talk is to tell your audience about what you did in your paper. This is incorrect, and should only be a second or third degree design criterion. The goal of your talk is to 1) get the audience really excited about the problem you worked on (they must appreciate it or they will not care about your solution otherwise!) 2) teach the audience something (ideally while giving them a taste of your insight/solution; don’t be afraid to spend time on other’s related work), and 3) entertain (they will start checking their Facebook otherwise). Ideally, by the end of the talk the people in your audience are thinking some mixture of “wow, I’m working in the wrong area”, “I have to read this paper”, and “This person has an impressive understanding of the whole area”.
A few do’s: There are several properties that make talks better. For instance, Do: Lots of pictures. People Love pictures. Videos and animations should be used more sparingly because they distract. Do: make the talk actionable - talk about something someone can do after your talk. Do: give a live demo if possible, it can make your talk more memorable. Do: develop a broader intellectual arch that your work is part of. Do: develop it into a story (people love stories). Do: cite, cite, cite - a lot! It takes very little slide space to pay credit to your colleagues. It pleases them and always reflects well on you because it shows that you’re humble about your own contribution, and aware that it builds on a lot of what has come before and what is happening in parallel. You can even cite related work published at the same conference and briefly advertise it. Do: practice the talk! First for yourself in isolation and later to your lab/friends. This almost always reveals very insightful flaws in your narrative and flow.
Don’t: texttexttext. Don’t crowd your slides with text. There should be very few or no bullet points - speakers sometimes try to use these as a crutch to remind themselves what they should be talking about but the slides are not for you they are for the audience. These should be in your speaker notes. On the topic of crowding the slides, also avoid complex diagrams as much as you can - your audience has a fixed bit bandwidth and I guarantee that your own very familiar and “simple” diagram is not as simple or interpretable to someone seeing it for the first time.
Careful with: result tables: Don’t include dense tables of results showing that your method works better. You got a paper, I’m sure your results were decent. I always find these parts boring and unnecessary unless the numbers show something interesting (other than your method works better), or of course unless there is a large gap that you’re very proud of. If you do include results or graphs build them up slowly with transitions, don’t post them all at once and spend 3 minutes on one slide.
Pitfall: the thin band between bored/confused. It’s actually quite tricky to design talks where a good portion of your audience learns something. A common failure case (as an audience member) is to see talks where I’m painfully bored during the first half and completely confused during the second half, learning nothing by the end. This can occur in talks that have a very general (too general) overview followed by a technical (too technical) second portion. Try to identify when your talk is in danger of having this property.
Pitfall: running out of time. Many speakers spend too much time on the early intro parts (that can often be somewhat boring) and then frantically speed through all the last few slides that contain the most interesting results, analysis or demos. Don’t be that person.
Pitfall: formulaic talks. I might be a special case but I’m always a fan of non-formulaic talks that challenge conventions. For instance, I despise the outline slide. It makes the talk so boring, it’s like saying: “This movie is about a ring of power. In the first chapter we’ll see a hobbit come into possession of the ring. In the second we’ll see him travel to Mordor. In the third he’ll cast the ring into Mount Doom and destroy it. I will start with chapter 1” - Come on! I use outline slides for much longer talks to keep the audience anchored if they zone out (at 30min+ they inevitably will a few times), but it should be used sparingly.
Observe and learn. Ultimately, the best way to become better at giving talks (as it is with writing papers too) is to make conscious effort to pay attention to what great (and not so great) speakers do and build a binary classifier in your mind. Don’t just enjoy talks; analyze them, break them down, learn from them. Additionally, pay close attention to the audience and their reactions. Sometimes a speaker will put up a complex table with many numbers and you will notice half of the audience immediately look down on their phone and open Facebook. Build an internal classifier of the events that cause this to happen and avoid them in your talks.
Attending conferences

On the subject of conferences:
Go. It’s very important that you go to conferences, especially the 1-2 top conferences in your area. If your adviser lacks funds and does not want to pay for your travel expenses (e.g. if you don’t have a paper) then you should be willing to pay for yourself (usually about $2000 for travel, accommodation, registration and food). This is important because you want to become part of the academic community and get a chance to meet more people in the area and gossip about research topics. Science might have this image of a few brilliant lone wolfs working in isolation, but the truth is that research is predominantly a highly social endeavor - you stand on the shoulders of many people, you’re working on problems in parallel with other people, and it is these people that you’re also writing papers to. Additionally, it’s unfortunate but each field has knowledge that doesn’t get serialized into papers but is instead spread across a shared understanding of the community; things such as what are the next important topics to work on, what papers are most interesting, what is the inside scoop on papers, how they developed historically, what methods work (not just on paper, in reality), etcetc. It is very valuable (and fun!) to become part of the community and get direct access to the hivemind - to learn from it first, and to hopefully influence it later.
Talks: choose by speaker. One conference trick I’ve developed is that if you’re choosing which talks to attend it can be better to look at the speakers instead of the topics. Some people give better talks than others (it’s a skill, and you’ll discover these people in time) and in my experience I find that it often pays off to see them speak even if it is on a topic that isn’t exactly connected to your area of research.
The real action is in the hallways. The speed of innovation (especially in Machine Learning) now works at timescales much faster than conferences so most of the relevant papers you’ll see at the conference are in fact old news. Therefore, conferences are primarily a social event. Instead of attending a talk I encourage you to view the hallway as one of the main events that doesn’t appear on the schedule. It can also be valuable to stroll the poster session and discover some interesting papers and ideas that you may have missed.
It is said that there are three stages to a PhD. In the first stage you look at a related paper’s reference section and you haven’t read most of the papers. In the second stage you recognize all the papers. In the third stage you’ve shared a beer with all the first authors of all the papers.
Closing thoughts
I can’t find the quote anymore but I heard Sam Altman of YC say that there are no shortcuts or cheats when it comes to building a startup. You can’t expect to win in the long run by somehow gaming the system or putting up false appearances. I think that the same applies in academia. Ultimately you’re trying to do good research and push the field forward and if you try to game any of the proxy metrics you won’t be successful in the long run. This is especially so because academia is in fact surprisingly small and highly interconnected, so anything shady you try to do to pad your academic resume (e.g. self-citing a lot, publishing the same idea multiple times with small remixes, resubmitting the same rejected paper over and over again with no changes, conveniently trying to leave out some baselines etc.) will eventually catch up with you and you will not be successful.
So at the end of the day it’s quite simple. Do good work, communicate it properly, people will notice and good things will happen. Have a fun ride!
刘知远
好的研究想法从哪里来
- 2019-11-16
背景说明:
临近ACL 2020投稿截止时间,跟同学密集讨论,争论哪些研究想法适合投到ACL有机会命中。从自己十多年研究经历来看,如何判断一个研究想法好不好,以及这些研究想法从哪里来,对于初学者而言的确是个难题。所以,简单攒了这篇小短文,分享一些经验和想法,希望对刚进入NLP领域的新同学有用。多有舛误请指正。
王家卫的电影《一代宗师》中有段经典的比武桥段,宫会长对叶问说今天我们不比武术,比想法。其实,好的点子或者想法(idea),也是一篇优秀研究成果的灵魂。而计算机领域流行着一句话IDEA is cheap, show me the code,也说明对于重视实践的计算机学科而言,想法的好坏还取决于它的实际效能。这里就来谈下好的研究想法从哪里来。
什么算是好的想法
2015年,我在微博上写过一个调侃的小段子:
ML派坐落美利坚合众山中,百年来武学奇才辈出,隐然成江湖第一大名门正派,门内有三套入门武功,曰:图模型加圈,神经网加层,优化目标加正则。有童谣为证:熟练ML入门功,不会作文也会诌。
到了2018年,我又续了一小段:
不期数年,北方DL神教异军突起,内修表示学习,外练神经网络,心法众多,曰门,曰注意,曰记忆,曰对抗,曰增强。经ImageNet一役威震武林,豢Alpha犬一匹无人可近。一时家家筑丹炉,人人炼丹忙,门徒云集,依附者众,有一统江湖之势。有童谣为证:左手大数据,右手英伟达,每逢顶会炼丹忙。
这里面提到的图模型加圈、神经网络加层、优化目标加正则,神经网络中的门、注意、记忆等,都是一些改进模型性能的创新思路,被各大NLP任务广泛使用并发表论文,也许就是因为被不同NLP任务的重复使用和发表,多少有些审美疲劳而缺少更深的创新思想,被有些网友和学者诟为“灌水”,似乎都不算好的想法。
那么什么才是好的想法呢?我理解这个”好“字,至少有两个层面的意义。
学科发展角度的”好“
学术研究本质是对未知领域的探索,是对开放问题的答案的追寻。所以从推动学科发展的角度,评判什么是好的研究想法的标准,首先就在一个“新”字。
过去有个说法,人工智能学科有个魔咒,凡是人工智能被解决(或者有解决方案)的部分,就不再被认为代表“人类智能”。计算机视觉、自然语言处理、机器学习、机器人之所以还被列为人工智能主要方向,也许正是因为它们尚未被解决,尚能代表“人类智能”的尊严。而我们要开展创新研究,就是要提出新的想法解决这些问题。这其中的”新“字,可以体现在提出新的问题和任务,探索新的解决思路,提出新的算法技术,实现新的工具系统等。
在保证”新“的基础上,研究想法好不好,那就看它对推动学科发展的助力有多大。深度学习之所以拥有如此显赫的影响力,就在于它对于人工智能自然语言处理、语音识别、计算机视觉等各重要方向都产生了革命性的影响,彻底改变了对无结构信号(语音、图像、文本)的语义表示的技术路线。
研究实践角度的”好“
那是不是想法只要够”新“就好呢?是不是越新越好呢?我认为应该还不是。因为,只有能做得出来的想法才有资格被分析好不好。所以,从研究实践角度,还需要考虑研究想法的可实现性和可验证性。
- 可实现性,体现在该想法是否有足够的数学或机器学习工具支持实现。
- 可验证性,体现在该想法是否有合适的数据集合和广泛接受的评价标准。很多民间科学家的想法之所以得不到学术界的认同,就是因为这些想法往往缺乏可实现性和可验证性,只停留在天马行空的纸面,只是些虚无缥缈的理念。
好的研究想法从哪里来
想法好还是不好,并不是非黑即白的二分问题,而是像光谱一样呈连续分布,因时而异,因人而宜。计算机科技领域的发展既有积累的过程,也有跃迁的奇点,积累量变才会产生质变,吃第三个馒头饱了,也是因为前面两个馒头打底。
现在的学术研究已经成为高度专业化的职业,有庞大的研究者群体。”Publish or Perish“,是从事学术职业(如教授、研究员、研究生)的人必须做好平衡的事情,不能要求研究者的每份工作都是“诺贝尔奖”或“图灵奖”级的才值得发表。只要对研究领域的发展有所助力,就值得发表出来,帮助同行前进。鲁迅说:天才并不是自生自长在深林荒野里的怪物,是由可以使天才生长的民众产生,长育出来的,所以没有这种民众,就没有天才。这个庞大研究者群体正是天才成长的群众基础。同时,学术新人也是在开展创新研究训练中,不断磨砺寻找好想法能力,鲁迅也说:即使天才,在生下来的时候的第一声啼哭,也和平常的儿童的一样,决不会就是一首好诗。
那么,好的研究想法从哪里来呢?我总结,首先要有区分研究想法好与不好的能力,这需要深入全面了解所在研究方向的历史与现状,具体就是对学科文献的全面掌握。人是最善于学习的动物,完全可以将既有文献中不同时期研究工作的想法作为学习对象,通过了解它们提出后对学科发展的影响——具体体现在论文引用、学术评价情况等各方面——建立对研究想法好与不好的评价模型。我们很难条分缕析完美地列出区分好与不好想法的所有特征向量,但人脑强大的学习能力,只要给予足够的输入数据,就可以在神经网络中自动学习建立判别的模型,鉴古知今,见微知著,这也许就是常说的学术洞察力。
做过一些研究的同学会有感受,仅阅读自己研究方向的文献,新想法还是不会特别多。这是因为,读到的都是该研究问题已经完成时的想法,它们本身无法启发新的想法。如何产生新的想法呢?我总结有三种可行的基本途径:
实践法。即在研究任务上实现已有最好的算法,通过分析实验结果,例如发现这些算法计算复杂度特别高、训练收敛特别慢,或者发现该算法的错误样例呈现明显的规律,都可以启发你改进已有算法的思路。现在很多自然语言处理任务的Leaderboard上的最新算法,就是通过分析错误样例来有针对性改进算法的 [1]。类比法。即将研究问题与其他任务建立类比联系,调研其他相似任务上最新的有效思想、算法或工具,通过合理的转换迁移,运用到当前的研究问题上来。例如,当初注意力机制在神经网络机器翻译中大获成功,当时主要是在词级别建立注意力,后来我们课题组的林衍凯和沈世奇提出建立句子级别的注意力解决关系抽取的远程监督训练数据的标注噪音问题[2],这就是一种类比的做法。组合法。即将新的研究问题分解为若干已被较好解决的子问题,通过有机地组合这些子问题上的最好做法,建立对新的研究问题的解决方案。例如,我们提出的融合知识图谱的预训练语言模型,就是将BERT和TransE等已有算法融合起来建立的新模型[3]。
正如武侠中的最高境界是无招胜有招,好的研究想法并不拘泥于以上的路径,很多时候是在研究者对研究问题深刻认知的基础上,综合丰富的研究阅历和聪明才智产生”顿悟“的结果。这对初学者而言恐怕还很难一窥门径,需要从基本功做起,经过大量科研实践训练后,才能有登堂入室之感。
在科研实践过程中,除了通过大量文献阅读了解历史,通过深入思考总结产生洞察力外,还有一项必不可少的工作,那就是主动开放的学术交流和合作意识。不同研究领域思想和成果交流碰撞,既为创新思想提供了新的来源,也为”类比“和”顿悟“提供了机会。了解一下历史就可以知晓,人工智能的提出,就是数学、计算机科学、控制论、信息论、脑科学等学科交叉融合的产物。而当红的深度学习的起源,1980年代的Parallel Distributed Processing (PDP),也是计算机科学、脑认知科学、心理学、生物学等领域研究者通力合作的产物。下面是1986年出版的名著《Parallel Distributed Processing: Explorations in the Microstructure of Cognition》第一卷的封面。

作者在前言中是这么讲他们的合作过程的,在最初长达六个月的时间里,它们每周见面交流两次讨论研究进展。
We expected the project to take about six months. We began in January 1982 by bringing a number of our colleagues together to form a discussion group on these topics. During the first six months we met twice weekly and laid the foundation for most of the work presented in these volumes.
而书中提供的PDP研究组的成员名单,40年后的今天仍让我惊叹其高度的跨机构、跨学科的交叉特点。所以,特别建议同学们在科研训练中,在专注研究问题的前提下,保持主动的学术交流意识,无论是听讲座报告,参加学术会议,还是选修课程,都有意识地扩宽学术交流的广度,不仅与小同行打成一片,更有看似八竿子打不着的研究领域的学术伙伴。随着研究经历的丰富,会越来越强烈地感受到,越是大跨度交叉的学术报告,越让你受到更大的启发,产生更多让自己兴奋的研究想法。

初学者应该怎么做
与阅读论文、撰写论文、设计实验等环节相比,如何产生好的研究想法,是一个不太有章可循的环节,很难总结出固定的范式可供遵循。像小马过河,需要通过大量训练实践,来积累自己的研究经验。不过,对于初学者而言,仍然有几个简单可行的原则可以参考。
一篇论文的可发表价值,取决于它与已有最直接相关工作间的Delta。我们大部分研究工作都是站在前人工作的基础上推进的。牛顿说:如果说我看得比别人更远些,那是因为我站在巨人的肩膀上。在我看来,评判一篇论文研究想法的价值,就是看它站在了哪个或哪些巨人的肩膀上,以及在此基础上又向上走了多远。反过来,在准备开始一项研究工作之前,在形成研究想法的时候,也许要首先明确准备站在哪个巨人的肩膀上,以及计划通过什么方式走得更远。与已有最直接相关工作之间的Delta,决定了这个研究想法的价值有多大。
兼顾摘果子和啃骨头。人们一般把比较容易想到的研究想法,叫做Low Hanging Fruit(低垂果实)。低垂果实容易摘,但同时摘的人也多,选择摘果子就容易受到想法撞车的困扰。例如,2018年以BERT为首的预训练语言模型取得重大突破,2019年中就出现大量改进工作,其中以跨模态预训练模型为例,短短几个月里http://arxiv.org上挂出了超过六个来自不同团队的图像与文本融合的预训练模型 [4]。设身处地去想,进行跨模态预训练模型研究,就是一个比较容易想到的方向,你一定需要有预判能力,知道世界上肯定会有很多团队也同时开展这方面研究,这时你如果选择入场,就一定要做得更深入更有特色,有自己独特的贡献才行。相对而言,那些困难的问题,愿意碰的人就少,潜下心来啃硬骨头,也是不错的选择,当然同时就会面临做不出来的风险,或者做出来也得不到太多关注的风险。同学需要根据自身特点、经验和需求,兼顾摘果子和啃骨头两种类型的研究想法。清华:PLMPpapers

注意多项研究工作的主题连贯性。同学的研究训练往往持续数年,需要注意前后多项研究工作的主题连贯性,保证内在逻辑统一。需要考虑,在个人简历上,在出国申请Personal Statement中,或者在各类评奖展示中,能够将这些研究成果汇总在一起,讲出自己开展这些研究工作的总目标、总设想。客观上讲,人工智能领域研究节奏很快,技术更新换代快,所以成果发表也倾向于小型化、短平快。我有商学院、社科的朋友,他们一项研究工作往往需要持续一年甚至数年以上;高性能计算、计算机网络方向的研究周期也相对较长。人工智能这种小步快跑的特点,决定了很多同学即使本科毕业时,也会有多篇论文发表,更不用说硕士生、博士生。在这种情况下,就格外需要在研究选题时,注意前后工作的连贯性和照应关系。几项研究工作放在一起,到底是互相割裂说不上话,还是在为一个统一的大目标而努力,格外反映研究的大局意识和布局能力。例如,下图是我们课题组涂存超博士2018年毕业时博士论文《面向社会计算的网络表示学习》的章节设置,整体来看就比《社会计算的若干重要问题研究》等没有内在关联的写法要更让人信服一些。当然,对于初学者而言,一开始就想清楚五年的研究计划,根本不可能。但想,还是不去想,结果还是不同的。
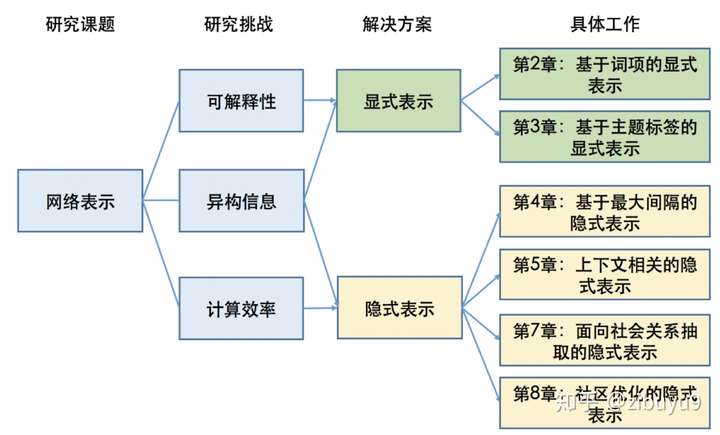
注意总结和把握研究动态和趋势,因时而动。2019年在知乎上有这样一个问题:”2019年在NLP领域,资源有限的个人/团队能做哪些有价值有希望的工作?“ 我当时的回答如下:
我感觉,产业界开始集团化搞的问题,说明其中主要的开放性难题已经被解决得差不多了,如语言识别、人脸识别等,在过去20年里面都陆续被广泛商业应用。看最近的BERT、GPT-2,我理解更多的是将深度学习对大规模数据拟合的能力发挥到极致,在深度学习技术路线基本成熟的前提下,大公司有强大计算能力支持,自然可以数据用得更多,模型做得更大,效果拟合更好。 成熟高新技术进入商用竞争,就大致会符合摩尔定律的发展规律。现在BERT等训练看似遥不可及,但随着计算能力等因素的发展普及,说不定再过几年,人人都能轻易训练BERT和GPT-2,大家又会在同一个起跑线上,把目光转移到下一个挑战性难题上。 所以不如提前考虑,哪些问题是纯数据驱动技术无法解决的。NLP和AI中的困难任务,如常识和知识推理,复杂语境和跨模态理解,可解释智能,都还没有可行的解决方案,我个人也不看好数据驱动方法能够彻底解决。更高层次的联想、创造、顿悟等认知能力,更是连边还没碰到。这些正是有远见的研究者们应该开始关注的方向。
需要看到,不同时期的研究动态和趋势不同。把握这些动态和趋势,就能够做出研究社区感兴趣的成果。不然的话,即使研究成果没有变化,只是简单早几年或晚几年投稿,结果也会大不相同。例如,2013年word2vec发表,在2014-2016年之间开展词表示学习研究,就相对比较容易得到ACL、EMNLP等会议的录用;但到了2017-2018年,ACL等会议上的词表示学习的相关工作就比较少见了。
最后的补充
这篇短文,主要是希望面向初学者,介绍一些求新过程中的经验和注意事项,希望大家少走一些弯路。但阅读文献,深入思考,接收拒稿不断改进的苦,该吃的还是要吃。学术研究和论文发表,对个人而言也许意味着高薪资和奖学金,但其最终的目的还是真正的推动学科的发展。所以,要做经得起考验的学术研究,关键就在”真“与”新“,需要我们始终恪守和孜孜以求。
著名历史学家、清华校友何炳棣先生曾在自传《读史阅世六十年》中提及著名数学家林家翘的一句嘱咐:“要紧的是不管搞哪一行,千万不要做第二等的题目。” 具体到每个领域,什么是一等的题目本身见仁见智,其实更指向内心“求真”的态度。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
