R语言
R是一个用于统计分析、图形表示和报告的编程语言和软件环境。R由罗斯·伊哈卡(Ross Ihaka)和罗伯特·杰尔曼(Robert Gentleman)在新西兰奥克兰大学创建,目前由R开发核心团队进行开发。
R根据两位R作者(Robert Gentleman和Ross Ihaka)的名字首字母命名,并且部分是对贝尔实验室语言 S 的变异。
部署
安装
- R
- R Studio
先安装R再安装Rstudio
语法
R语法
环境
工作目录
getwd() # [1] "C:/Users/橙/Documents"
setwd("C:/Users“) # 设置工作目录
变量
命名
注意:
- 数字不能开头;
- %号是非法字符,不可以用来命名;
- .号后面不可以跟数字;
- 不可以下划线开头。
查看
# 查看
ls()
# 清除指定变量:
rm()
# 清除所有变量:
rm(list=ls())
?sum # 查看函数sum用法
help(sum) # 同上
example(sum) # 同上
赋值
赋值方式有三种
- 左箭头<-(<键+-键(等号左边的那个,不要按Shift))
- 等号=
- 右箭头->
代码
a<-2
b=3
c->4 #注意右箭头使用方法,被赋值的应该在右边,简单点说,就是某某赋值给谁,箭头就指向谁
# Error in 4 <- c : invalid (do_set) left-hand side to assignment
4->c
a # 键盘敲出变量名,回车后就会显示结果
b # [1] 3
c # [1] 4
字符串操作
字符串在文本挖掘中很重要,使用正则表达式很方便。
string1 <- "Hello" # first string
string2 <- "World" # second string
# concatenate by using whitespace as a separator.
S <- paste(string1, string2, sep =" ")
print(S)
列表
列表(list) 是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分,component)的有序集合。列表允许整合若干(可能无关的)对象到单个对象名下。
列表允许以一种简单的方式组织和重新调用不相干的信息。 许多R函数的运行结果都是以列表的形式返回的。函数需要返回两个以上变量时需采用list形式返回。
向量
向量(vector)是R语言的最基本的数据类型、R语言的核心、R语言中的战斗机 ,向量是用于存储数值型、字符型或逻辑型数据的一维结构
矩阵
矩阵(matrix) 是一种特殊的向量,包含两个附加的属性:行数和列数,R生存矩阵时按列存储。
注意向量不能看成只有1列或1行的矩阵
数据框
数据框的创建
数据框类似矩阵,有行列两个维度。数据框允许不同的列可以包含不同类型的数据。注意:数据框可以看成每个组件长度相同的列表。。个人见解:数据框就像excel表格一样,比矩阵高级一点。很多东西都可以参考矩阵。
x<-data.frame(col1, col2, col3,……) # 其中的列向量col1, col2, col3,… 可为任何类型(如字符型、数值型或逻辑型)。数据框可以看成每个组件长度相同的列表,数据框类似矩阵,有行列两个维度。建议数据框在Rstudio的左上角框里查看。
因子和表
因子(factor) 是R语言中许多强大运算的基础,因子的设计思想来着统计学中的名义变量(分类变量),因子可以简单的看做一个附加了更多信息的向量。
使用方法:
factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x), nmax = NA)
函数
数学运算与模拟
这部分介绍部分常用与数学计算与模拟的函数
内置函数
R中含有大量的函数,比如求和函数sum(),求均值mean()等
自定义函数
#函数名<-function(){·······}
f<-function(a,b) # 写一个求和函数,function()是固定格式
{
k<-a+b
return(k) # 返回结果为k,如果没有设置返回值,则函数会返回最后一行执行的结果
}
f(3,4) # 使用函数名加一个括号调用函数 [1] 7
包
安装包
安装R包需要使用 install.packages() 或 BiocManager::install() 函数安装,library() 函数调用
以安装openxlsx为例,如下:
# 安装R包代码如下
install.packages("openxlsx")
# 或
BiocManager::install("openxlsx")
library(openxlsx)
文件
读文件
多个函数可以读取文件
- scan()函数: 文件读取
- readline()函数: 键盘读取
- readLines()函数: 文件一次性读取
- read.table()函数: 读取矩阵数据
- read.xlsx()函数: excel 文件
示例
scan(file="C://Users//橙//Desktop//juli.txt",what=" ",sep=" ")
duru2<-readline()
duru3<-readline("请输入:")
readLines("C://Users//juli.txt")
read.table()函数
read.xlsx() # 安装"openxlsx包"
写文件
文件的输出
- write.table()函数,参数与read.table()对应
- cat()函数
write("Hello,wrold","C://Users//橙//Desktop//juli.txt")
cat("hello wrold",file="C://Users//橙//Desktop//juli.txt",append=T)#追加写入,(里面有内容)
cat("hello wrold",file="C://Users//橙//Desktop//juli1.txt") #覆盖写入,里面的内容被覆盖了
### 保存
软件
1. 可以直接输入q()函数;也可以右上角直接叉掉,后根据提示操作
2. 当写完一个文件时,可以点击保存按钮,根据提示选择保存位置,文件后缀有多种,看你保存哪种文件,有.R、.Rdata等后缀,.R一般是保存代码的,.Rdata是保存处理后的数据的
文件保存 save()函数可以保存多种格式的文件
```r
save(b,file="xxx.Rdata") #保存b,文件是xxx,格式为.Rdata
save(b,c,file="xxx.Rdata") #保存b,c,文件是xxx,格式为.Rdata
save.image("xxx.Rdata") #保存所有(你定义的所有变量及数据),文件是xxx,格式为.Rdata
画图
R语言画图
- R自带plot函数
- ggplot2函数
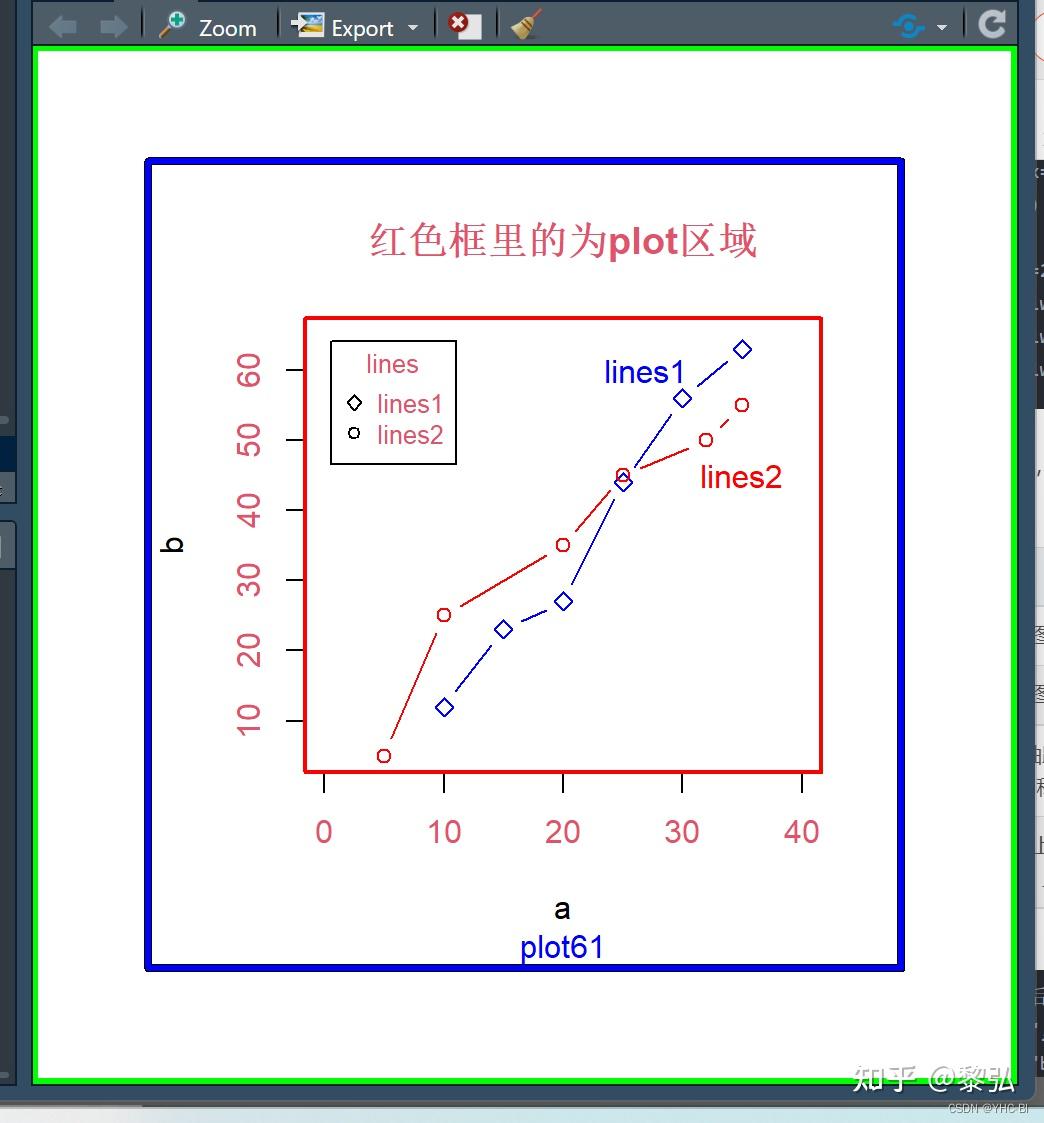
plot
R自带的画图工具,R绘图基础图形系统的核心 plot()函数,plot 是一个泛型函数,使用plot 时真正被调用的时函数依赖于对象所属的类。
plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL,log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL,ann = par("ann"), axes = TRUE, frame.plot = axes,panel.first = NULL, panel.last = NULL, asp = NA, ...)
plot 函数中有许多的参数,其中x,y指横纵坐标对应的参数
案例
数据分析
代码:
- 读取 excel 文件,筛选属性,并输出 excel 文件
# 加载必要的库
if (!require("readxl")) install.packages("readxl")
if (!require("writexl")) install.packages("writexl")
if (!require("mice")) install.packages("mice")
if (!require("dplyr")) install.packages("dplyr") # 用于数据处理
library(readxl)
library(writexl)
library(mice)
library(dplyr)
main_dir <- "/Users/wqw/Desktop/tmp_med"
input_file <- paste(main_dir, "med_data.xlsx", sep ="/")
output_file <- paste(main_dir, "med_data_out.xlsx", sep ="/")
# 读取数据
data <- read_excel(input_file)
# 1. 属性筛选:移除空值超过20%的列
null_ratio <- colMeans(is.na(data))
filtered_data <- data[, null_ratio <= 0.2]
# 2. 预处理:移除常量或近常量变量(方差接近0的变量)
# 计算每列的方差
variances <- apply(filtered_data, 2, function(x) var(x, na.rm = TRUE))
# result = valid_variances[valid_variances > 0]
# 保留方差大于0的变量(可根据需要调整阈值)
filtered_data <- filtered_data[, variances > 0 & !is.na(variances)]
# 3. 尝试插值(若仍报错,会自动切换到简单插值方法)
tryCatch({
# 方法1:使用mice包,调整参数减少复杂度
imputed_data <- mice(filtered_data,
m = 1,
method = "pmm", # 预测均值匹配
maxit = 20, # 减少迭代次数
seed = 123)
completed_data <<- complete(imputed_data, 1) # 全局变量
# completed_data <- complete(imputed_data, 1) # 局部变量
}, error = function(e) {
# 方法2:若mice失败,使用简单插值(均值/中位数)
message("多重插补失败,使用简单插值替代:", e$message)
completed_data <<- filtered_data %>%
mutate(across(everything(),
~ifelse(is.na(.),
ifelse(is.numeric(.), median(., na.rm = TRUE), .[!is.na(.)][1]),
.)))
})
# 保存结果
write_xlsx(completed_data, output_file)
# 提示信息
cat("数据处理完成!\n")
cat("处理后的数据已保存\n")
cat("原始列数:", ncol(data), "\n")
cat("筛选后保留的列数:", ncol(filtered_data), "\n")
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
