- go语言
- GO语法
- 专项功能
- 经验总结
- go面试题
- 1、在进行项目开发时,遇到的关于golang的问题有哪些?
- 2、golang中grpc和rest优劣势
- 3、golang里面常用到的技术栈有哪些?
- 4、gin框架的好处是什么?
- 什么是 goroutine
- 什么是 channel
- 5、无缓冲通道和缓冲通道的区别是什么?
- 6 、select的用处是什么?
- 7、defer的用途和使用场景是什么?
- 8、defer的执行顺序是什么?
- 9、defer函数遇到return以后是怎么执行的?
- 10、对于进程,线程,协程的理解是什么?
- 什么是panic?
- 如何定义一个常量?
- 18、make和new的区别是什么?
- 如何避免内存泄漏?
- 如何定义一个结构体?
- 11、空结构体的作用
- 17、怎么判断两个结构体是否相等?
- 12、map怎么顺序读取?
- 13、项目里用到什么数据结构,例如map、slice
- 14、用range修改切片元素的值会发生什么?
- 15、了解空指针吗?
- 16、怎么用go去实现一个set
- 19、说一下你对并发编程的理解?
- 如何实现多线程同步?
- 20、碰到过分布式锁的问题吗?分布式锁的原理你清楚吗?
- 如何实现继承?
- 如何实现接口?
- Go的50坑:陷阱、技巧和常见错误
- go面试题
- 结束
go语言
go介绍
go语言不像C或C++那样难于学习,但速度仍然很快,并且拥有一个强大的社区以及许多有趣且有用的软件包和库。该语言也是由Google计算机科学界的一些最聪明的人开发的。
go是一种编译型(翻译成更低级的语言,如汇编)、具有静态类型和类c风格语法的语言,并具具备垃圾回收机制,编译型语言特点:运行快,开发慢;不同于解释型语言
Go程序员常常被称为地鼠(gopher), img

更多编程语言介绍:
go 特点
大公司为什么用go
字节为啥全面转Go?
- 最初使用Python,由于性能问题换成了Go
- C++不适合在线Web业务
- 早期团队非Java背景
- 性能比较好
- 部署简单、学习成本低
- 内部RPC和HTTP框架推广
go 特性
Go有很多特性,部分独有,部分借鉴其它编程语言:
- 内置并发编程支持:
- 使用
协程(goroutine)做为基本的计算单元。轻松地创建协程。 - 使用
通道(channel)来实现协程间的同步和通信。
- 使用
- 内置了
映射(map)和切片(slice)类型。 - 支持
多态(polymorphism)。 - 使用
接口(interface)来实现裝盒(value boxing)和反射(reflection)。 - 支持
指针。 - 支持
函数闭包(closure)。 - 支持
方法。 - 支持
延迟函数调用(defer)。 - 支持类型
内嵌(type embedding)。 - 支持类型
推断(type deduction or type inference)。 - 内存安全。
- 自动垃圾回收。
- 良好的代码跨平台性。
- 自定义
泛型(从Go 1.18开始)。
除了以上特性,Go还有如下亮点:
- 语法简洁且和其它流行语言相似。 这使得具有一定编程经验的程序员很容易上手Go编程。 当然,对于没有编程经验的初学者,Go也比很多其它流行编程语言更容易上手一些。
- 标准库齐全。这个标准库提供了很多常用的功能。
- 活跃和回应快速的社区。 社区贡献了大量高质量的第三方库包和应用。
go 优点
优点
- 高性能、高并发
- 语法简单、学习曲线平缓
- 丰富的标准库
- 完善的工具链
- 静态编译
- 跨平台
- 垃圾回收
go的优点
- 编译速度、执行速度、内存管理以及并发编程
Go 为什么快
总结
Go还无法达到C++那样的极致性能,但是在大部分情况下已经很接近了;Go和Java在算法的时间开销上难分伯仲,但在内存的开销上Java就要高得多了;Go在绝大部分情况下,至少时间和内存开销都比Python要优秀得多;
主因:静态编译
静态编译和动态编译区别
静态编译:编译器在编译可执行文件时,把用到的链接库提取出来,链接打包进可执行文件中,编译结果只有一个可执行文件动态编译:可执行文件需要附带独立的库文件,不打包库到可执行文件中,减少可执行文件体积,在执行的时候再调用库即可
两种方式有各自的优点和缺点
- 前者不需要去管理不同版本库的兼容性问题
- 后者可以减少内存和存储的占用(因为可以让不同程序共享同一个库)
两种方式孰优孰弱,要对应到具体的工程问题上,Go默认的编译方式是静态编译。
Go 静态编译为什么快
Go编译速度快主要四个原因:
- import 引用管理方式
- 没有模板编译负担
- 1.5版本后的自举编译器优化
- 更少的关键字(25个),简化在编译过程中的代码解析
为了加快编译速度、放弃C++而转入Go时,也要考虑一下是否要 放弃泛型编程的优点
C++编译慢的主要两个原因:
- 头文件的include方式
- 模板编译
C++使用include方式引用头文件,让需要编译的代码有乘数级的增加
- 例如,当同一个头文件被同一个项目下的N个文件include时,编译器会将头文件引入到每一份代码中,头文件会被编译N次(这在大多数时候都是不必要的)
C++使用的模板,是为了支持泛型编程,在编写对不同类型的泛型函数时,可以提供很大的便利,但是这对于编译器来说,会增加非常多不必要的编译负担。
头文件方式,import解决了重复编译的问题
- 当然Go也用import方式;在模板的编译问题上,由于Go在设计理念上遵循从简入手,所以没有将泛函编程纳入到设计框架中,所以天生的没有模版编译带来的时间开销
【2024-1-26】Go 为什么这么“快”
单台服务器处理能力越来越强,迫使编程模式由串行模式升级到并发模型。
并发模型包含 IO 多路复用、多进程以及多线程,这几种模型都各有优劣,现代复杂的高并发架构大多是几种模型协同使用,不同场景应用不同模型,扬长避短,发挥服务器的最大性能。
而多线程,因为其轻量和易用,成为并发编程中使用频率最高的并发模型,包括后衍生的协程等其他子产品,也都基于它。
并发 ≠ 并行
并发 (concurrency) 和 并行 ( parallelism) 不同。
- 单个 CPU 核上,线程通过时间片或让出控制权来实现任务切换,达到 “同时” 运行多个任务的目的,即并发。但实际上任何时刻都只有一个任务被执行,其他任务通过某种算法来排队。
- 多核 CPU 让同一进程内的 “多个线程” 做到真正意义上的同时运行,这才是并行。
进程、线程、协程
说明
进程:进程是系统进行资源分配的基本单位,有独立的内存空间。线程:线程是 CPU 调度和分派的基本单位,线程依附于进程存在,每个线程会共享父进程的资源。协程:协程是一种用户态的轻量级线程,协程的调度完全由用户控制,协程间切换只需要保存任务的上下文,没有内核的开销。
线程上下文切换
由于中断处理,多任务处理,用户态切换等原因会导致 CPU 从一个线程切换到另一个线程,切换过程需要保存当前进程的状态并恢复另一个进程的状态。
上下文切换的代价是高昂的,因为在核心上交换线程会花费很多时间。上下文切换的延迟取决于不同的因素,大概在在 50 到 100 纳秒之间。考虑到硬件平均在每个核心上每纳秒执行 12 条指令,那么一次上下文切换可能会花费 600 到 1200 条指令的延迟时间。实际上,上下文切换占用了大量程序执行指令的时间。
如果存在跨核上下文切换(Cross-Core Context Switch),可能会导致 CPU 缓存失效(CPU 从缓存访问数据的成本大约 3 到 40 个时钟周期,从主存访问数据的成本大约 100 到 300 个时钟周期),这种场景的切换成本会更加昂贵。
Golang 为并发而生
Golang 从 2009 年正式发布以来,依靠其极高运行速度和高效的开发效率,迅速占据市场份额。Golang 从语言级别支持并发,通过轻量级协程 Goroutine 来实现程序并发运行。
Goroutine 非常轻量,主要体现在以下两个方面:
- 上下文切换代价小:Goroutine 上下文切换只涉及到三个寄存器(PC / SP / DX)的值修改;而对比线程的上下文切换则需要涉及模式切换(从用户态切换到内核态)、以及 16 个寄存器、PC、SP…等寄存器的刷新;
- 内存占用少:线程栈空间通常是 2M,Goroutine 栈空间最小 2K; Golang 程序中可以轻松支持10w 级别的 Goroutine 运行,而线程数量达到 1k 时,内存占用就已经达到 2G。
Go 调度器实现机制
Go 通过调度器来调度 Goroutine 在内核线程上执行,但是 Goroutine 并不直接绑定 OS 线程 M - Machine 运行,而是由 Goroutine Scheduler 中的 P - Processor (逻辑处理器)来作获取内核线程资源的『中介』。
Go 调度器模型我们通常叫做 G-P-M 模型,他包括 4 个重要结构,分别是 G、P、M、Sched:
G: Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。P: Processor,表示逻辑处理器,对 G 来说,P 相当于 CPU 核,G 只有绑定到 P 才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量)。P 的数量由用户设置的 GoMAXPROCS 决定,但是不论 GoMAXPROCS 设置为多大,P 的数量最大为 256。M: Machine,OS 内核线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取。M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。Sched:Go 调度器,它维护有存储 M 和 G 的队列以及调度器的一些状态信息等。调度器循环的机制大致是从各种队列、P 的本地队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 Goexit 做清理工作并回到 M,如此反复。 理解 M、P、G 三者的关系,可以通过经典的地鼠推车搬砖的模型来说明其三者关系:
地鼠(Gopher)的工作任务:
工地上有若干砖头,地鼠借助小车把砖头运送到火种上去烧制。
- M 就可以看作地鼠
- P 就是小车
- G 就是小车里装的砖。

地鼠如何搬运砖块?
- Processor(
P):根据用户设置的GoMAXPROCS值创建一批小车(P)。 - Goroutine(
G):通过Go 关键字创建一个 Goroutine,也就相当于制造一块砖(G),然后将砖(G)放入当前这辆小车(P)中。 - Machine (
M):地鼠(M)不能通过外部创建出来,只能砖(G)太多了,地鼠(M)又太少了,实在忙不过来,刚好还有空闲的小车(P)没有使用,那就从别处再借些地鼠(M)过来直到把小车(P)用完为止。这里有一个地鼠(M)不够用,从别处借地鼠(M)的过程,这个过程就是创建一个内核线程(M)。
注意:
- 地鼠(M) 没有小车(P)就不能运砖
- 小车(P)数量决定了能够干活的地鼠(M)数量,Go 程序对应活动线程数;
G-P-M 模型:
- P 代表可以“并行”运行的逻辑处理器,每个 P 都被分配到一个系统线程 M
- G 代表 Go 协程。
- Go 调度器中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ)。
- 每个 P 都有一个 LRQ,用于管理分配给在 P 的上下文中执行的 Goroutines,这些 Goroutine 轮流被和 P 绑定的 M 进行上下文切换。GRQ 适用于尚未分配给 P 的 Goroutines。
- G 的数量可以远远大于 M 的数量,换句话说,Go 程序可以利用少量的内核级线程来支撑大量 Goroutine 的并发。多个 Goroutine 通过用户级别的上下文切换来共享内核线程 M 的计算资源,但对于操作系统来说并没有线程上下文切换产生的性能损耗。
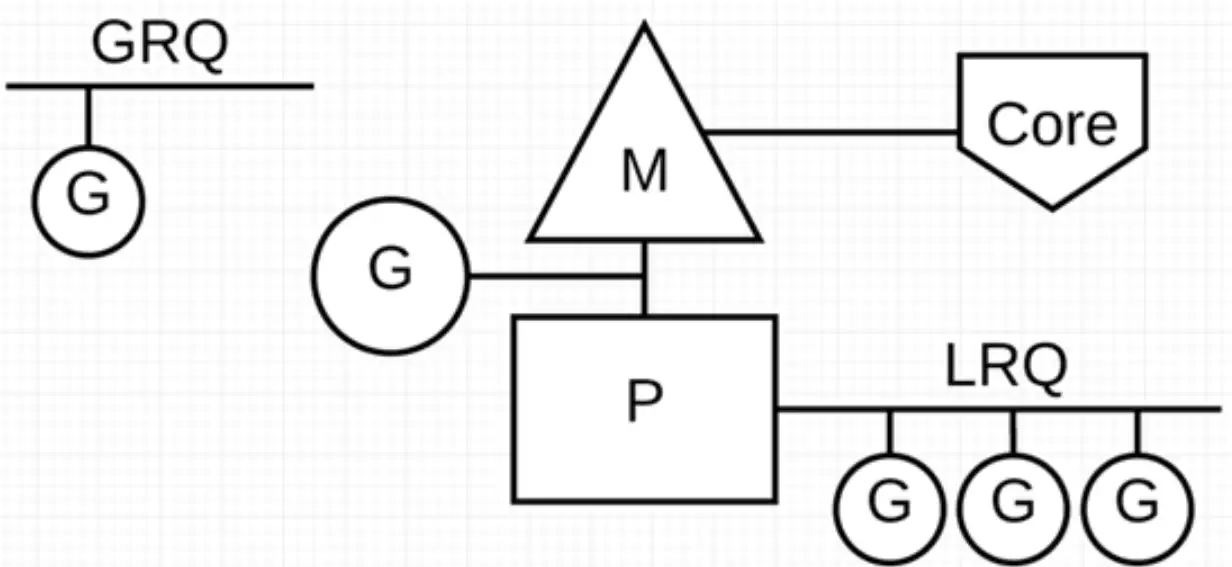
为了更加充分利用线程的计算资源,Go 调度器采取了以下几种调度策略:
- 任务窃取(work-stealing)
- 现实情况有的 Goroutine 运行的快,有的慢,那么势必肯定会带来的问题就是,忙的忙死,闲的闲死,Go 肯定不允许摸鱼的 P 存在,势必要充分利用好计算资源。为了提高 Go 并行处理能力,调高整体处理效率,当每个 P 之间的 G 任务不均衡时,调度器允许从 GRQ,或者其他 P 的 LRQ 中获取 G 执行。
- 减少阻塞
- 如果正在执行的 Goroutine 阻塞了线程 M 怎么办?P 上 LRQ 中的 Goroutine 会获取不到调度么?
Go 阻塞主要分为一下 4 种场景:图解见原文
- 场景 1:由于原子、互斥量或通道操作调用导致 Goroutine 阻塞,调度器将把当前阻塞的 Goroutine 切换出去,重新调度 LRQ 上的其他 Goroutine;
- 场景 2:由于网络请求和 IO 操作导致 Goroutine 阻塞,这种阻塞的情况下,我们的 G 和 M 又会怎么做呢?
- Go 程序提供了网络轮询器(NetPoller)来处理网络请求和 IO 操作的问题,其后台通过 kqueue(MacOS),epoll(Linux)或 iocp(Windows)来实现 IO 多路复用。通过使用 NetPoller 进行网络系统调用,调度器可以防止 Goroutine 在进行这些系统调用时阻塞 M。这可以让 M 执行 P 的 LRQ 中其他的 Goroutines,而不需要创建新的 M。有助于减少操作系统上的调度负载。下图展示它的工作原理:G1 正在 M 上执行,还有 3 个 Goroutine 在 LRQ 上等待执行。网络轮询器空闲着,什么都没干。
- 接下来,G1 想要进行网络系统调用,因此它被移动到网络轮询器并且处理异步网络系统调用。然后,M 可以从 LRQ 执行另外的 Goroutine。此时,G2 就被上下文切换到 M 上了。
- 最后,异步网络系统调用由网络轮询器完成,G1 被移回到 P 的 LRQ 中。一旦 G1 可以在 M 上进行上下文切换,它负责的 Go 相关代码就可以再次执行。这里的最大优势是,执行网络系统调用不需要额外的 M。网络轮询器使用系统线程,它时刻处理一个有效的事件循环。
- 这种调用方式看起来很复杂,值得庆幸的是,Go 语言将该“复杂性”隐藏在 Runtime 中:Go 开发者无需关注 socket 是否是 non-block 的,也无需亲自注册文件描述符的回调,只需在每个连接对应的 Goroutine 中以“block I/O”的方式对待 socket 处理即可,实现了 goroutine-per-connection 简单的网络编程模式(但是大量的 Goroutine 也会带来额外的问题,比如栈内存增加和调度器负担加重)。
- 用户层眼中看到的 Goroutine 中的“block socket”,实际上是通过 Go runtime 中的 netpoller 通过 Non-block socket + I/O 多路复用机制“模拟”出来的。Go 中的 net 库正是按照这方式实现的。
- 场景 3:当调用一些系统方法的时候,如果系统方法调用的时候发生阻塞,这种情况下,网络轮询器(NetPoller)无法使用,而进行系统调用的 Goroutine 将阻塞当前 M。让我们来看看同步系统调用(如文件 I/O)会导致 M 阻塞的情况:G1 将进行同步系统调用以阻塞 M1。
- 调度器介入后:识别出 G1 已导致 M1 阻塞,此时,调度器将 M1 与 P 分离,同时也将 G1 带走。然后调度器引入新的 M2 来服务 P。此时,可以从 LRQ 中选择 G2 并在 M2 上进行上下文切换。
- 阻塞的系统调用完成后:G1 可以移回 LRQ 并再次由 P 执行。如果这种情况再次发生,M1 将被放在旁边以备将来重复使用。
- 场景 4:如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了。Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。只要下次这个 Goroutine 进行函数调用,那么就会被强占,同时也会保护现场,然后重新放入 P 的本地队列里面等待下次执行。
Go 思考
Go 语言不足
【2023-2-17】go 问题
- 1)异常处理:写的挺难受的, if err != nil 各种一堆,希望接下来能优化
- 2)想有OOP但不完全OOP的语法。定义结构体方法 func (o obj) method(…)…,定义在结构体外边但是仅这个结构体使用,这种语法不如直接在方法定义在结构体的{}里边。(这个可能是我OOP的思想毒害比较深…)
- 3)像chan的->,<-这种写法有点奇怪,其实个人还是比较喜欢用类似 send(chan, data) 或 chan.send(data),receive(chan) 或 chan.receive(),等有明确字符能够见名知义的语法形式
- 4)还有三目运算符。。。
- 5)还有一些生态确实也很影响使用者的感受
其它
- 弱引用:几乎所有带GC的语言都有这个特性, 甚至Lua和JS这些小巧的脚本语言也支持, 唯独Go没有弱引用(或弱指针). Go只要持有某个指针那就是强引用, 无法自动或手动释放.
- goroutine的烦恼:无法指定goroutine跑在哪个线程上, 有时要N个goroutine像
协程一样交替地跑在固定一个线程上, 这样不用考虑数据共享问题. 而且又不能因此设置GOMAXPROC=1, 因为需要其它goroutine能并行. - interface的实现是胖指针, 也就是双字, 对于经常调试并发问题的老手不友好. 双字就代表读写非原子性, 对C++/Java/C#这些不用胖指针的语言来说, 即使不使用任何同步机制, 读写指针操作的本身都是安全的, 有时不需要实时性也是可以这么用的(尤其是对带GC的语言来说更能确保指针的有效性). 而胖指针就会导致读写胖指针弄不好得到了一个旧指针加一个新指针, 这种隐患带来的后果不堪设想.
作者:dwing
【2023-2-20】go语言问题
- 浅拷贝: slice, map等赋值操作都是浅拷贝,并未实现clone,很容易线上bug。 深层次来说,这不仅容易误用,而且给GC也带来了巨大的压力,还可能导致循环引用等问题。
type S struct {
A string
B []string
}
func main() {
x := S{"x-A", []string{"x-B"}}
y := x // copy the struct
y.A = "y-A"
y.B[0] = "y-B"
fmt.Println(x, y)
// Outputs "{x-A [y-B]} {y-A [y-B]}" -- x 被修改
}
- Append黑魔法。通过Append修改slice,cap不够时,会出现类似”Copy On Write”的奇效。 例子来自参考1.
func doStuff(value []string) {
fmt.Printf("value=%v\n", value)
value2 := value[:]
value2 = append(value2, "b")
fmt.Printf("value=%v, value2=%v\n", value, value2)
value2[0] = "z"
fmt.Printf("value=%v, value2=%v\n", value, value2)
}
func main() {
slice1 := []string{"a"} // length 1, capacity 1
doStuff(slice1)
// Output:
// value=[a] -- ok
// value=[a], value2=[a b] -- ok: value unchanged, value2 updated
// value=[a], value2=[z b] -- ok: value unchanged, value2 updated
slice10 := make([]string, 1, 10) // length 1, capacity 10
slice10[0] = "a"
doStuff(slice10)
// Output:
// value=[a] -- ok
// value=[a], value2=[a b] -- ok: value unchanged, value2 updated
// value=[z], value2=[z b] -- WTF?!? value changed???
}
- 空指针nil/除0问题想必困扰了大家不少,稍不留意就Panic。更现代的语言会参考代数类型(参考4)来避免类型设计上的缺失。 例如Rust采用Option
代替T完成相关类型的常规计算,从逻辑层面控制消除可能存在的漏洞。 - 错误处理,重复代码太高。例子看参考2, 但是从 官方来看, Golang将引入对应的try语法。
- 还是重复代码多,首字母大写,导致使用反射来序列化struct成json格式的时候,struct tags 99%的概率要手写。例如:
type User struct {
Id string `json:"id"`
Email string `json:"email"`
Name string `json:"name,omitempty"`
}
最后推荐一个flaws set
- 可以返回局部变量(优点?): 编程教材中强调 不要返回一个局部变量(栈变量)地址,因为在函数调用结束后,栈被销毁,引用已经销毁的栈中的变量可能会出现内存问题。然而,这样的代码在 Go 中工作的很好,也很常用,Go 编译器替我们做了额外的内存分配和回收工作。Java也可以这么用,堆内存实现
func CreateItem(id int, name string) *Item {
myItem := Item{ID: id, Name: name}
return &myItem
}
但C++也可以使用堆内存实现, 但需要开发者自己必要时释放 myItem 占用的内存
- C++ 最让人诟病的就是自己管理内存,必须学习与内存相关的各种操作系统原理,至少知道:物理内存与虚拟内存、栈内存与堆内存、内存分配与释放时机、进程地址空间的内存分布、各个内存地址区间的内存读写属性、如何避免内存越界等等相关知识
- 自己管理内存是把双刃剑,高手可以用来写出高效的程序来,但是对于新手或者水平不够的开发者来说,这将是企业产品事故甚至灾难的源泉。
Item* CreateItem(int id, string name) {
Item* myItem = new Item(id, name);
return myItem;
}
Go 面试
常见题目
| 问题 | 解答 | 解释 | 其它 |
|---|---|---|---|
| go如何调度 | |||
| go struct 能否比较 | struct是强类型, 不能比较 | 实例是指针类,不能比,但同类型实例值可以比较 | |
| go defer原理 | 先进后出, 后进先出 | ||
| select 作用 | 监听io操作 | 每个case是一个面向channel的io操作 | |
| context包 | 上下文管理包 | 存在上下层的传递,上会把内容传递给下 | |
| client长链接 | server是设置超时时间,for循环遍历 | ||
| 主进程与协程 | 使用channel进行通信,context,select | ||
| map如何顺序读取 | map不能顺序读取,因为无序 | 把key变为有序,所以把key放入切片,进行排序,遍历切片 | |
| 实现消息队列 | 多生产者,多消费者 | 用切片加锁 | |
Go vs Java vs C++
Java 最大的问题是编译出来的程序不是操作系统原生支持的可执行文件,必须运行在 Java 虚拟机之中,这样要想运行必须依赖于 Java 虚拟机,而对于复杂业务来说,生成的 Jar 文件也偏臃肿。所以无论是安装 Java 程序的本身需要的运行环境还是生成的 Jar 文件的执行效率大大折扣。
- 【2023-7-28】写给想去字节写 Go 的你
(1)性能与效率
C++、Java 与 Go 在性能与可执行文件体积上的差别
| 语言 | 执行效率 | 可执行文件体积 | 依赖环境 |
|---|---|---|---|
| C++ | 高 | 小 | 无 |
| Java | 低 | 大 | 虚拟机 |
| Go | 高 | 小 | 无 |
(2)语法
C/C++ 和 Java 进行编程时,曾思考这些问题:
- 既然大多数的代码行末尾必须都要以分号结束,那为啥编译器不直接代劳此事?
- 从编译原理的角度来说,大多数代码行末尾的分号都是没有任何作用的。
- 写 switch - case 语句的时候,有时候因为忘记在特定的 case 语句之后写上 break 语句,从而导致程序执行时出现非预期的行为
- 一对大括号中的第一个大括号是否要单独放在一行;
- if/for 等执行体只有一条语句时,是否应该使用一对大括号包裹起来
这类问题在开发者之间争论了几十年,并且将继续在后来者那里争论下去,就算是像《代码大全》这样经典的书籍也花了好几页去讨论这两种代码风格哪种好,更不用说各个公司为了统一编码风格而制定的各种代码规范和 lint 检查规则了。
Go 语言大刀阔斧地去除了一些其他语言中看起来不是很必要的功能,这些功能的去除让 Go 的风格变得统一、简洁,在 Go 项目中,大家不会再为上文中提到的几个风格问题而争论了。
- 每一行语句的结尾不再强行要求加上分号
- 一对大括号的第一个不能单独占一行
- if/for 等语句体只有一行时也必须使用一对大括号包裹起来
- if/for 等条件不再需要括号
- 只有 for 循环,不再支持 while 和 do - while 循环
- switch - case 语句默认加了 break 语句
- 自增自减运算符只支持后缀形式,不支持前缀形式
- 不支持条件运算符(? :)
- 给一个结构体多个字段设置值时,最后一个字段也必须以逗号结束
(3)功能完备性
Go 与 Java 相比较于 C++,其语言自带的 API 库功能是相当完善的,从基本的字符串操作到网络编程、文件读写等等应用尽有
因此 Go 开发者可使用的原生 API 就很丰富
- 比如编写一个网络通信程序,Go 和 Java 都在 net 包中提供了大量可使用的 API,而 C++ 必须直接借助操作系统的 Socket API。
C++ 语言自身的功能完备性也在逐步完善,例如从 C++11 开始,就可以直接使用 stl 中的线程相关的类,而不用再使用操作系统提供的线程接口。
Go 入门
【2022-9-30】go学习路线图
-
- Go言语法:变量声明、控制语句、函数、错误处理
- 标准库:
- fmt:输入输出
- net/http:构建 HTTP 服务
- io 和 os:文件操作
- context:管理 goroutine 生命周期
- 并发模型:
- goroutine:轻量级线程
- channel:数据通信
- sync 包:同步原语
- 垃圾回收机制:理解 Go 的内存管理
- 工具链:熟悉 go run、go build、go test、go mod
Go 安装
- 从链接Go下载 中下载最新版本的Go可安装的归档文件。将/usr/local/go/bin添加到PATH环境变量
- win地址:https://go.dev/dl/go1.17.6.windows-amd64.msi
- mac地址: wget https://go.dev/dl/go1.17.6.darwin-amd64.pkg
- linux地址: wget https://go.dev/dl/go1.17.6.linux-amd64.tar.gz
# (1) 下载安装包
# (2) 解压, sudo 权限执行,不要在/usr/local/go目录
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.22.1.linux-amd64.tar.gz
# (3) 设置环境变量
export PATH=$PATH:/usr/local/go/bin
source ~/.bashrc # source ~/.bash_profile
# (4) 测试
go version
go 在线体验
【2023-3-27】
go 环境变量
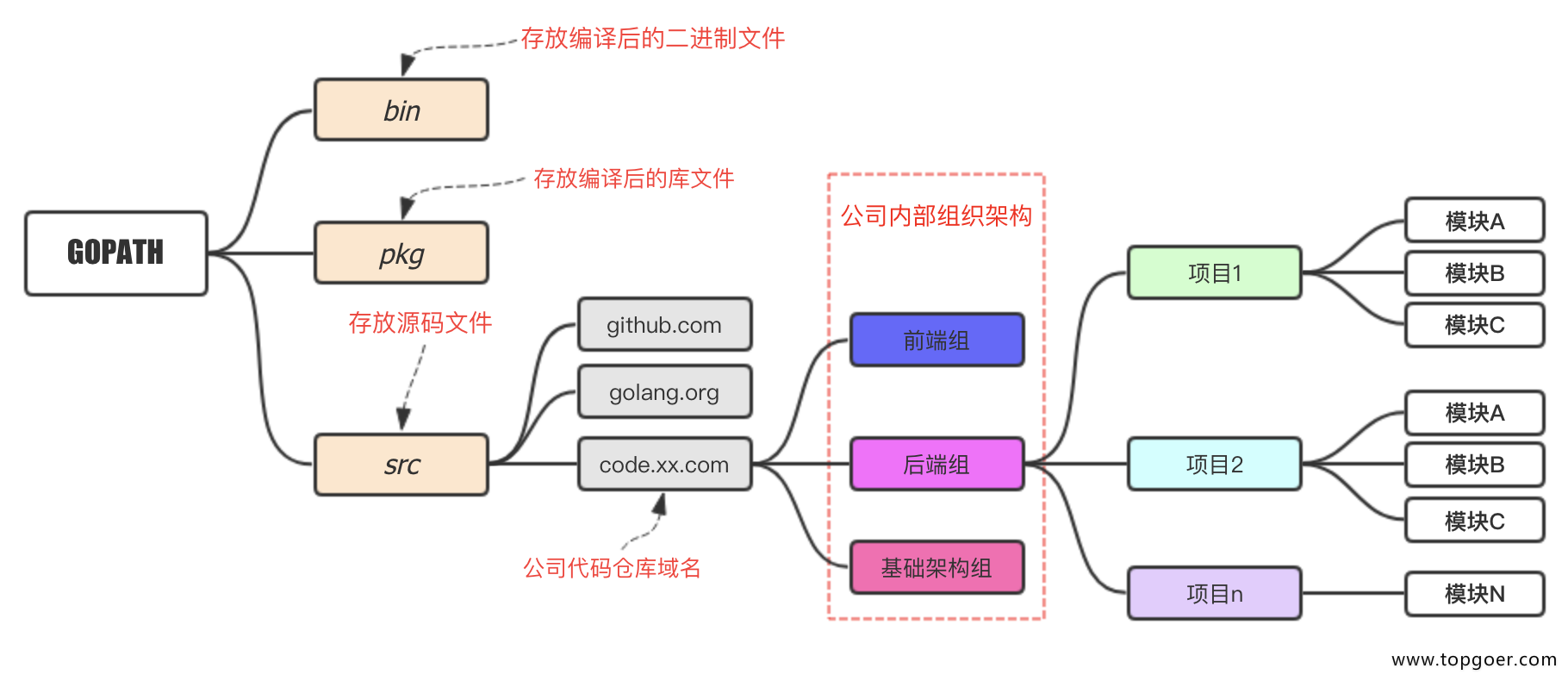
GOPATH 与 GOROOT
不同于其他语言,go中没有项目的说法,只有包, 其中有两个重要的路径,GOROOT 和 GOPATH
Go开发相关的环境变量如下:
GOROOT:GOROOT 是Go的安装目录(类似于java的JDK)- GOROOT 下有
bin,doc和src目录。bin目录下有熟悉的go和gofmt工具 - GOROOT在绝大多数情况下都不需要修改.
- Mac中安装Go会自动配置好GOROOT,路径为/usr/local/go。
- Win中默认的GOROOT是在 C:\Go中,也可自己指定
- GOROOT 下有
GOPATH:GOPATH 是工作空间, 保存go项目代码和第三方依赖包. GOPATH是开发时的工作目录。用于:- 保存编译后的二进制文件。
go get和go install命令会下载go代码到GOPATH。- import包时的搜索路径
GOPATH可以设置多个,其中,第一个将会是默认包目录
- 使用
go get下载的包都会在第一个path中的src目录下 - 使用
go install时,在哪个GOPATH中找到了这个包,就会在哪个GOPATH下的bin目录生成可执行文件
注意:go get 只能在包里使用,go install 不限
'go get' is no longer supported outside a module.
To build and install a command, use 'go install' with a version,
like 'go install example.com/cmd@latest'
使用GOPATH时,GO会在以下目录中搜索包:
- GOROOT/src:该目录保存了Go标准库代码。
- GOPATH/src:该目录保存了应用自身的代码和第三方依赖的代码。
假设程序中引入了如下的包:
// 自定义库
import "Go-Player/src/chapter17/models"
查找顺序
- 第一步:Go先去 GOROOT 的src目录中查找,很显然它不是标准库的包,没找到。
- 第二步:继续在 GOPATH 的src目录去找,准确说是GOPATH/src/Go-Player/src/chapter17/models这个目录。如果该目录不存在,会报错找不到package。
go modules 是 golang 1.11 新加的特性。Modules官方定义为:
- 模块是相关Go包的集合。modules是源代码交换和版本控制的单元。
- go命令直接支持使用modules,包括记录和解析对其他模块的依赖性。
- modules替换旧方法:基于GOPATH的方法来指定在给定构建中使用哪些源文件。
开启了GO111MODULE,仍然使用GOPATH模式的方法,在引入自定义模块时会报错。
GO111MODULE 有三个值:off, on和auto(默认值)。
- GO111MODULE=off,go命令行将不会支持module功能,寻找依赖包的方式将会沿用旧版本那种通过vendor目录或者GOPATH模式来查找。
- GO111MODULE=on,go命令行会使用modules,而一点也不会去GOPATH目录下查找。
- GO111MODULE=auto,默认值,go命令行将会根据当前目录来决定是否启用module功能。这种情况下可以分为两种情形:
- 当前目录在 GOPATH/src之外且该目录包含go.mod文件
- 当前文件在包含 go.mod 文件的目录下面。
当modules 功能启用时,依赖包的存放位置变更为$GOPATH/pkg,允许同一个package多个版本并存,且多个项目可以共享缓存的 module。
环境变量设置
- 环境变量:
# vim ~/.bash_profile
export GOROOT=/usr/local/go
export PATH=$PATH:$GOROOT/bin
安装新包时,会下载到 GOPATH/src下
# go get github.com/jmoiron/sqlx
import "github.com/test"
# 下载到 src/github.com/test
IDE
JetBrains 的 GoLand
helloworld
无外部依赖
验证:
- 创建一个test.go的go文件。编写并保存以下代码到 test.go 文件中。
- 所有Go源代码文件必须以.go后缀结尾
package main // 声明 main 包
import (
"fmt" // 导入 fmt 包,输入和输出的默认库,打印字符串是需要用到
)
func main() { // 声明 main 主函数
fmt.Println("Hello World!") // 打印 Hello World!
}
现在运行test.go查看结果并验证输出结果如下:
go run test.go- Hello, World!
有外部依赖
【2023-7-27】以 langchain go代码库为例
- import 包含一个外部包 openai
// connect2gpt.go
package main
import (
"context"
"log"
"github.com/tmc/langchaingo/llms/openai"
)
func main() {
llm, err := openai.New()
if err != nil {
log.Fatal(err)
}
prompt := "What would be a good company name for a company that makes colorful socks?"
completion, err := llm.Call(context.Background(), prompt)
if err != nil {
log.Fatal(err)
}
log.Println(completion)
}
编译运行
# 直接执行报错
go run connect2gpt.go
# 初始化包,自定义包名 match
go mod init match # 生成 go.mod
# 下载第三方包, 生成 go.sum
go get github.com/tmc/langchaingo/llms/openai
# 准备工具包超参环境, vim ~/.bash_profile
export OPENAI_API_KEY="sk-****"
source ~/.bash_profile
# 编译运行
go run connect2gpt.go
vim语法高亮
go vim颜色显示:
- 进入目录 ~/.vim/bundle
- git clone https://github.com/fatih/vim-go.git
# (1)下载Vundle.vim(vim安装插件的工具).
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
# (2) 配置。在~/.vimrc粘贴如下代码
# (3) 安装vim-go插件。在vim中使用`:PluginInstall`命令进行vim-go的安装
打开go文件即可看到:

go 命令
命令行:
- go
version查看版本 - go
env: 显示go环境变量配置
Go常用命令:
- go
build: 测试编译,检查是否有编译错误 - go build 将Go语言程序代码编译成二进制的可执行文件,但是需要手动运行该二进制文件;
- (1) main包:生成一个与第一个 fileName 同名的可执行文件
- (2) 非main包:编译器将只对该包进行语法检查,不生成可执行文件
- go
run: 直接运行程序;命令则更加方便,go run命令将编译和执行指令合二为一- 编译后直接运行Go语言程序,编译过程中会产生一个临时文件,但不会生成可执行文件,很适合用来调试程序。
- go
fmt: 格式化源码(部分IDE在保存时自动调用),使用同一种代码风格 - go
install: 编译包文件并编译整个程序- go
installexample.com/program@latest 来安装一个第三方Go程序的最新版本(至GOBIIN目录)。 - Go官方工具链1.16版本前,命令:go get -u example.com/program(已废弃)。
- 实际上, go get = git clone + go install
- go install 是 Go 中自动包安装工具:如需要将包安装到本地, 会从远端仓库下载包:检出、编译和安装一气呵成。
- go install 只是将编译的中间文件放在 GOPATH 的 pkg 目录下,以及固定地将编译结果放在 GOPATH 的 bin 目录下。
- 分成了两步操作:第一步是生成结果文件(可执行文件或者 .a 包),第二步会把编译好的结果移到
$GOPATH/pkg或者$GOPATH/bin。
- go
- go
test: 运行测试文件 - go
doc: 查看文档(chm手册)- 在浏览器上浏览go官方网站:
- 命令行输入:go doc -http=:8080
- 即可在浏览器输入:localhost:8080查看
- go
vet- 子命令可以用来检查可能的代码逻辑错误(即警告);run、build和install不会输出代码逻辑错误!
- go
mod:go模块特性,简化依赖管理- go mod init example.com/myproject 命令可以用来在当前目录中生成一个go.mod文件。 当前目录将被视为一个名为example.com/myproject的模块(即当前项目)的根目录。 此go.mod文件将被用来记录当前项目需要的依赖模块和版本信息。 可以手动编辑或者使用go子命令来修改此文件。
go mod tidy清理无效依赖,增加缺失依赖- 扫描当前项目所有代码, 添加未被记录的依赖至go.mod文件或从go.mod文件中删除不再被使用的依赖。
- go
get: 获取远程包,需提前安装git或hg- go get命令用拉添加、升级、降级或者删除单个依赖。此命令不如 go mod tidy 命令常用。
- 第三方包下载并解压到GOPATH路径下的src文件夹里面
注意:
- go run 只是用来临时运行单个文件,正式项目不推荐使用 → go build
go 运行
Go 目录结构
Go语言中通过包来组织代码文件,可以引用第三方包也可以发布自己的包,但为了防止不同包的项目名冲突,通常使用顶级域名来作为包名的前缀,这样就规避了项目名冲突问题。
因为不是每个个人开发者都拥有自己的顶级域名,所以目前流行的方式是使用个人的github用户名来区分不同的包。
常见目录
示意图
注:设置 GoRoot(安装目录)和 GoPath (工作目录)!
一个Go语言项目的目录一般包含以下三个子目录:
- src 目录:放置项目和库的源文件;
- pkg 目录:放置编译后生成的包/库的归档文件;
- bin 目录:放置编译后生成的可执行文件。
GoPath:go项目工作目录,需在环境变量中设置,多个用分号隔开
- /src:项目源文件
- project_1:具体项目代码
- hello.go
- hello_test.go
- project_2:
- project_1:具体项目代码
- /bin:编译后的可执行文件
- /pkg:编译后的包文件(hello.a) 注:bin和pkg可不用创建,执行go install会自动创建
# GOPATH
bin # 存放编译后的二进制文件
pkg # 存放编译后的库文件,如 go module
src # 自己的代码
\-- github.com
------ project1
------------ module1
------------ module2
------ project2
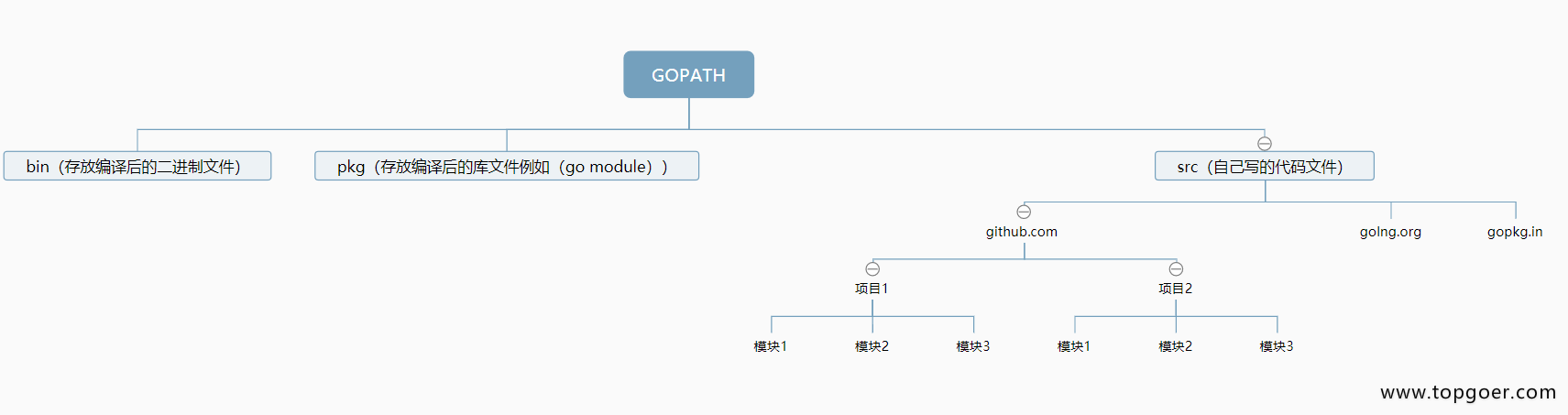
大项目
正式大项目中,不推荐使用 go run
- 最好使用 go build 或者 go install 子命令构建可执行程序文件来运行Go程序。
- 支持Go模块特性的Go项目, 根目录下需要一个 go.mod 文件。此文件可以使用 go mod init 子命令来生成
- 名称以 _ 和 . 开头的源代码文件将被Go官方工具链工具忽略掉。
【2023-2-24】工程化目录 — 代码示例:tf_server,参考文章
- /
pkg:- 外部应用程序可以使用的库代码,也即可以被其他项目引用的包。在pkg内部可以按照功能分类。
- 根目录下的pkg文件夹是作为整个项目的共享包库使用。
- 当然在非根目录的下也可以很好的加入pkg目录,很多项目会在internal目录下加入pkg表示内部共享包库。
- /
internal- 大多数开源项目及官方代码等代码仓库中,总会见到internal目录。它表示私有应用程序和库代码,即不希望其他项目中导入的代码,一般存储一些比较专属于当前项目的代码包。这是在代码编译阶段就会被限制的,该目录下的代码不可被外部访问到。
- internal目录并不局限在根目录,在各级子目录中也可以有internal子目录,也会同样起到作用。
- /
config- config/configs目录是配置文件或者配置文件模板所在的文件夹。
- /
test- test目录经常用于存放整个应用的测试、测试数据及一些集成测试等,相较于单元测试在每个go文件对应的目录下,test目录偏向于整体,当然在某些子项目内也会有局部项目的测试会放在子项目的test中。
- /
docs- 各类文档所在目录。
- /
third_party- 可以放一些第三方的资源工具文件。
- 还有一些/api、/example、/cmd等等
编译命令
Go语言是编译型的静态语言(和C语言一样),所以在运行Go语言程序之前,先要将其编译成二进制的可执行文件。
- go build:
go文件–(go build 编译)–>可执行文件–(运行)–>结果 - go run:
go文件–(go run 编译+运行)–>结果
go build test.go # 先编译再运行(推荐build)
go run test.go # 直接运行
# 可以自定义生成可执行文件名,在mac/linux上是可执行文件,在window下必须是.exe后缀
go build -o 自定义文件名 test.go # 自定义名字. 【2023-2-12】注意:go源码文件放最后,否则报错,named files must be .go files: -o
go build -o myHelloWorld HelloWorld.go # mac
go build -o myHelloWorld.exe HelloWorld.go # win
go 编译器
GO的标准编译器常称为gc(Go compiler的缩写,不是垃圾回收garbage collection)。
- Go官方团队也维护着另外一个编译器,
gccgo。 gccgo是gcc编译器项目的一个子项目。 gccgo的使用广泛度大不如gc, 它的主要作用是做为一个参考,来保证gc的实现正确性。 - 目前两个编译器的开发都很活跃,尽管Go开发团队在gc的开发上花费的精力更多。
gc编译器是Go官方工具链中一个组件。
- Go官方工具链1.0发布于2012年三月。
- Go语言规范的最新版本和Go官方工具链的最新版本总是保持一致。 每年Go官方工具链发行两个主版本。
gc支持跨平台编译。 比如,可以在Linux平台上编译出Windows程序,反之亦然。
使用Go编写的程序常常编译得非常快。
- 编译时间的长短是开发愉悦度的一个重要因素。
- 编译时间短是很多程序员喜欢Go的一个原因。
Go程序生成的二进制可执行文件常常拥有以下优点:
- 内存消耗少
- 执行速度快
- 启动快
很多C家族语言,比如C/C++/Rust等,也拥有上述的优点。 但它们缺少Go语言的几个重要优点:
- 程序编译时间短
- 像动态语言一样灵活
- 内置并发支持
目前,Go主要用于网络开发、系统工具开发、数据库开发和区块链开发。 随着从Go 1.18开始支持自定义泛型,预期Go会在更多开发领域流行起来,比如图形界面、游戏、大数据和人工智能等。
go 执行顺序
go 代码如何执行?
总结:
import–>const–>var –>init()–>main()`
简版
启动顺序通常如下:
- 导入包:Go 编译器源文件 import 语句, 导入所有需要的包。
- 初始化常量和变量:编译器初始化包级别(全局)的常量和变量。它们的
- 初始化顺序: 按照源文件中出现的顺序进行。
- 执行
init 函数:编译器会执行包级别的init函数。- 如果一个包有多个
init函数,执行顺序和出现顺序一致。
- 如果一个包有多个
- 执行 main.
main函数:编译器会执行 main 函数。
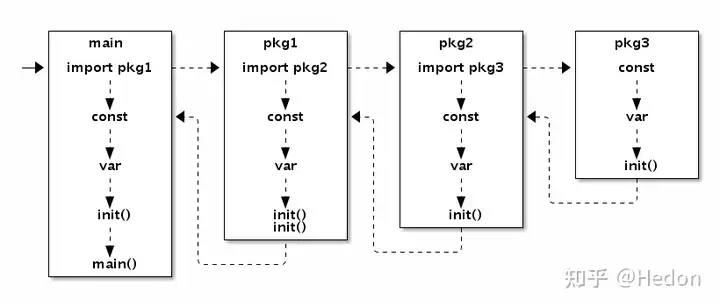
package main
import "fmt"
func init() {
fmt.Println("init1:", a)
}
func init() {
fmt.Println("init2:", a)
}
var a = 10
const b = 100
func main() {
fmt.Println("main:", a)
}
// 执行结果
// init1: 10
// init2: 10
// main: 10
每个包可以有多个 init 函数
原理
深入原理版
- 命令行参数复制:读取命令行参数,复制到 argc 和 argv。
- 初始化 g0 栈:g0 是运行时系统的一个特殊的 goroutine,程序启动时被创建,用于执行系统调用和协程调度。
- runtime.check 运行时检查:类型长度、指针操作、结构体字段偏移量、CAS、atomic 操作、栈大小是否为 2 的幂次。
- runtime.args 参数初始化:将 argc 和 argv 的参数赋值到 Go 的变量中。
- runtime.osinit 初始化操作系统特点的设置:主要是判断系统字长和 CPU 核数。
- runtime.schedinit 初始化调度器:
- 锁初始化
- 竞态检测器初始化
- 调度器设置,设置调度器可以管理的最大线程(M)数目
- 系统初始化,初始化内存管理、CPU 设置、算法等,这些都是调度器正常工作的基础
- 设置当前 M 的信号掩码
- 解析程序参数和环境变量
- 垃圾收集器初始化
- 设置 process 的数量
- runtime.newproc 创建主协程 g0 并将其放入队列中等待执行。
- runtime. mstart 启动调度器:初始化 m0,并调度 g0 去执行 runtime.main。
- runtime.main 程序真正入口:
- runtime.init
- 启动 gc
- 执行用户包 init
- 执行用户函数 main.main
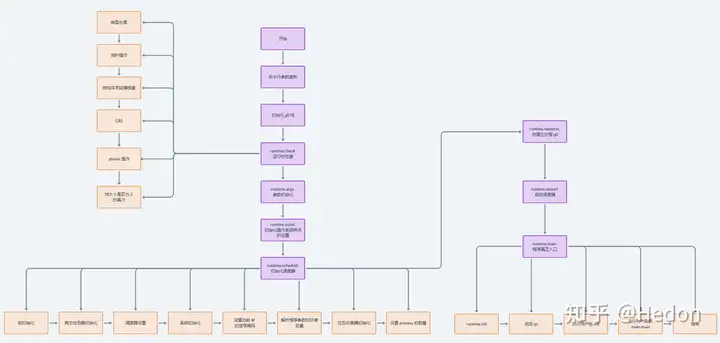
Go Runtime。
- Runtime,即 Go 的运行时环境,可以理解为 Java 的 JVM、JavaScript 依赖的浏览器内核。
- Go Runtime 是一份代码,随着用户程序一起打包成二进制文件,随着程序一起运行。
- Runtime 具有内存管理、GC、协程、屏蔽不同操作系统调用等能力。
综上,Go 程序运行都依赖于 Runtime 运行,所以分析 Go 语言程序的启动过程的时候,首先要确定程序的入口,即 Runtime。
作者:后端工程师 Hedon
垃圾回收
GC(垃圾回收)工作原理
常见的垃圾回收算法有标记清除(Mark-Sweep) 和引用计数(Reference Count)
Go 语言采用标记清除算法。并在此基础上使用了三色标记法和写屏障技术,提高了效率。
标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表。
标记清除算法的一大问题是在标记期间需要暂停程序(Stop the world,STW),标记结束之后,用户程序才可以继续执行。为了能够异步执行,减少 STW 的时间,Go 语言采用了三色标记法。
三色标记算法将程序中对象分成白色、黑色和灰色三类。
- 白色:不确定对象。
- 灰色:存活对象,子对象待处理。
- 黑色:存活对象。
标记开始时,所有对象加入白色集合(这一步需 STW )。
- 首先将根对象标记为灰色,加入灰色集合,垃圾搜集器取出一个灰色对象,将其标记为黑色,并将其指向的对象标记为灰色,加入灰色集合。
- 重复这个过程,直到灰色集合为空为止,标记阶段结束。那么白色对象即可需要清理的对象,而黑色对象均为根可达的对象,不能被清理。
三色标记法因为多了一个白色的状态来存放不确定对象,所以后续的标记阶段可以并发地执行。当然并发执行的代价是可能会造成一些遗漏,因为那些早先被标记为黑色的对象可能目前已经是不可达的了。所以三色标记法是一个 false negative(假阴性)的算法。
三色标记法并发执行仍存在一个问题: GC 过程中,对象指针发生了改变。例子:
A (黑) -> B (灰) -> C (白) -> D (白)
正常情况下,D 对象最终会被标记为黑色,不应被回收。但在标记和用户程序并发执行过程中,用户程序删除了 C 对 D 的引用,而 A 获得了 D 的引用。标记继续进行,D 就没有机会被标记为黑色了(A 已经处理过,这一轮不会再被处理)。
- A (黑) -> B (灰) -> C (白)
- ↓
- D (白)
为了解决这个问题,Go 使用了内存屏障技术,在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,类似于一个钩子。
垃圾收集器使用了写屏障(Write Barrier)技术,当对象新增或更新时,会将其着色为灰色。这样即使与用户程序并发执行,对象的引用发生改变时,垃圾收集器也能正确处理了。
一次完整的 GC 分为四个阶段:
- 1)标记准备(Mark Setup,需 STW),打开写屏障(Write Barrier)
- 2)使用三色标记法标记(Marking, 并发)
- 3)标记结束(Mark Termination,需 STW),关闭写屏障。
- 4)清理(Sweeping, 并发)
go 包
使用import导入包的3个好处:
- 降低函数方法重名的可能,让函数保持简短和简洁。
- 有效地组织代码,很方便导向到标的。
- 只需重新编译小的程序块,从而加快编译速度。例如包fmt,我们不必在每次更改程序时都重新编译它。
go 包管理
包管理历程
Go语言的包管理工具随着开源社区的讨论、贡献不断进化: GOPATH–> vendor—>go mod
- 从最初单一的
GOPATH目录的”GOPATH 模式” - 到加入
vendor目录,用于将依赖包与工程保存到同一个目录树下 - 最终官方结合社区版本的包管理工具正式将
go mod融入 go 语言官方版本中,更好的支持多版本的依赖管理.
- 2012年3月 Go 1 发布,此时没有版本的概念
- 2013年 Golang 团队在 FAQ 中提议开发者保证相同 import path 的兼容性,后来成为一纸空文
- 2013年10月 Godep
- 2014年7月 glide
- 2014年 有人提出 external packages 的概念,在项目的目录下增加一个 vendor 目录来存放外部的包
- 2015年8月 Go 1.5 实验性质加入 vendor 机制
- 2015年 有人提出了采用语义化版本的草案
- 2016年2月 Go 1.6 vendor 机制 默认开启
- 2016年5月 Go 团队的 Peter Bourgon 建立委员会,讨论依赖管理工具,也就是后面的 dep
- 2016年8月 Go 1.7: vendor 目录永远启用
- 2017年1月 Go 团队发布 Dep,作为准官方试验
- 2018年8月 Go 1.11发布 Modules 作为官方试验
- 2019年2月 Go 1.12发布 Modules 默认为 auto
- 2019年9月 Go 1.13 版本默认开启 Go Mod 模式


go vendor
vendor 是 Go 1.5 版本引入的,用于在项目本地缓存特定版本依赖包的机制,在 go modules 机制引入前,基于vendor可以实现可重现的构建(reproducible build),保证基于同一源码构建出的可执行程序是等价的。
go mod
go module 是 go官方自带的go依赖管理库,在1.13版本正式推荐使用。
- go module 将某个项目(文件夹)下的所有依赖整理成一个 go.mod 文件,写入了依赖的版本等
- 用go module之后不用关心GOPATH,也不用将代码放置在src下了。
- go module 管理依赖后, 在项目根目录下生成两个文件
go.mod(记录当前项目的所依赖)和go.sum(记录每个依赖库的版本和哈希值)
GO111MODULE是 go modules 功能的开关
- GO111MODULE=off: 不使用 modules 功能。
- GO111MODULE=on: 使用 modules 功能,不会去 GOPATH 下面查找依赖包。
- GO111MODULE=auto: Golang 自己检测是不是使用 modules 功能。这种情况下可以分为两种情形:
- (1)当前目录在GOPATH/src之外且该目录包含go.mod文件,开启模块支持。
- (2)当前文件在包含go.mod文件的目录下面。
推荐使用 Go 模块时,将 GO111MODULE 设置为 on 而不是 atuo,将以下语句添加进 ~/bashrc 中,然后重开Terminal
gedit ~/.bashrc
# 添加
export GO111MODULE=on
【2024-5-27】实践
cd test # go 项目目录: start.go(main函数) -> fornax_api.go
go mod init llm_provider # 新增 go.mod
cat go.mod
# 内容如下:
# module llm_provider
# go 1.17
go mod tidy # 自动检测当前目录下的go文件依赖包
# go: finding module for package code.byted.org/flow/paas_news_event/configuration/config_model
# go: finding module for package code.byted.org/flowdevops/fornax_sdk
# go: finding module for package code.byted.org/lang/gg/gptr
# go: finding module for package code.byted.org/flow/paas_news_event/observability/logging
# go: finding module for package code.byted.org/flowdevops/fornax_sdk/domain
# go: finding module for package code.byted.org/lang/gg/gslice
# go: finding module for package code.byted.org/flowdevops/fornax_sdk/domain/prompt
# go: finding module for package code.byted.org/flow/paas_news_event/configuration
# 接下来就可以直接使用 go get 下载所有工具包
go get
go mod 配置
初次使用 GO MODULE(项目中还没有go.mod文件) ,cd进入项目文件夹,初始化 MODULE
cd /home/zhongzhanhui/GoProject/Seckill
go mod init Seckill #Seckill是项目名
go.mod 文件一旦创建后,内容将会被 go toolchain全面掌控。go 会自动生成一个 go.sum 文件来记录 dependency tree
- go toolchain 会在各类命令执行时,比如 go get、go build、go mod 等修改和维护 go.mod文件。
go.mod 提供了module, require、replace和exclude 四个命令
- module 语句指定包的名字(路径)
- require 语句指定的依赖项模块
- replace 语句可以替换依赖项模块
- exclude 语句可以忽略依赖项模块
此时项目根目录会出现一个 go.mod 文件,此时的 go.mod 文件只标识了项目名和go的版本,这是正常的,因为只是初始化了。
go.mod 文件内容如下:
module SecKill
go 1.13
go mod tidy
- tidy会检测该文件夹目录下所有引入的依赖,写入 go.mod 文件,写入后会发现 go.mod 文件有所变动
module SecKill
go 1.13
require (
github.com/gin-contrib/sessions v0.0.1
github.com/gin-gonic/gin v1.5.0
github.com/jinzhu/gorm v1.9.11
github.com/kr/pretty v0.1.0 // indirect
gopkg.in/yaml.v2 v2.2.2
)
【2022-9-29】go安装依赖包(go get, go module)
go mod 命令
# 初始化模块:
go mod init <项目模块名称>
# 依赖关系处理,根据go.mod文件
go mod tidy
# 将依赖包复制到项目的vendor目录
go mod vendor
# 显示依赖关系
go list -m all
# 显示详细依赖关系
go list -m -json all
# 其它命令
go mod download # 下载 module 到本地
go mod download [path@version]
go mod edit # 编辑 go.mod
go mod graph # 打印 modules 依赖图
go mod verify # 验证依赖
go mod why # 解释依赖使用
go mod 错误
【2022-9-30】如果设置为on,但是当前目录没有go.mod文件,就会出现错误信息,详见
no required module provides package xxx: go.mod file not found in current directory or any parent directory; see ‘go help modules’
解决方法
- go env -w GO111MODULE=auto
【2024-5-17】go mod 文件出错
- RLock …: Function not implemented
- 官方 Go issue, Open 状态,暂无解决
go: RLock /storage/8D8B-150E/Go/secure-api/go.mod: function not implemented
分析
- Stack Overflow上提到:Go 使用文件锁, 确保多个go程序并行时 go.mod 文件读取一致, 这个错误表示 当前文件系统不支持文件读锁, 如:大多数Unix系统使用flock系统调用
- go在parse工作区代码时使用了阻塞型的文件锁。
- 共享文件系统(内部NAS的FUSE,NFS),阻塞文件锁难以保证正确,所以, Merlin开发机只对系统盘开启了允许阻塞文件锁,代价是在多机访问时正确性不能保证。
解法
- 更改文件系统配置,支持文件锁
- 更换文件系统
- Merlin: 将云盘上的go文件放系统盘
go 包介绍
Go语言以“包”作为管理单位,每个 Go 源文件必须先声明所属包
所以, 每个 Go 源文件的开头都是一个 package 声明
包是结构化代码的一种方式:
- 每个程序都由
包(通常简称为 pkg)概念组成,使用自定义包或其它包中导入内容。 - 如同其它编程语言中的
类库或命名空间
Go语言包与文件夹一一对应,几点特性:
- 一个目录下的同级文件属于同一个包。
- 一个包可以由许多以
.go为扩展名的源文件组成,因此 文件名和包名一般来说都是不相同
- 一个包可以由许多以
- 每个 Go 文件都属于且仅属于1个包。
- 必须在源文件非注释的第一行, 指明本文件属于哪个包,如:
package main package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 包
- 必须在源文件非注释的第一行, 指明本文件属于哪个包,如:
- 包名可以与其目录名不同。
main包是Go语言程序入口包,一个Go语言程序必须有且仅有一个 main包。- 如果一个程序没有 main 包,那么编译时将会出错,无法生成可执行文件。
- package main 包下可以有多个文件,但所有文件中只能有一个 main () 方法,代表程序入口。
每个 Go 程序都是由包组成的。
- 程序运行的入口是包
main。 - 这个程序使用并导入了包 “fmt“ 和 “math/rand“ 。
- 按惯例, 包名与导入路径的最后一个目录一致。例如,”math/rand“ 包由 package rand 语句开始。
注意:
- 这个程序的运行环境是确定性的,因此 rand.Intn 每次都会返回相同的数字。
- 导入的包中不能含有代码中没有使用到的包,否则Go编译器会报编译错误,例如 imported and not used: “xxx”,”xxx” 表示包名。
Go 程序的执行(程序启动)顺序如下:
- 按顺序导入所有被 main 包引用的其它包,然后在每个包中执行如下流程:
- 如果该包又导入了其它的包,则从第一步开始递归执行,但是每个包只会被导入一次。
- 然后以相反的顺序在每个包中初始化常量和变量,如果该包含有 init 函数的话,则调用该函数。
- 在完成这一切之后,main 也执行同样的过程,最后调用 main 函数开始执行程序。
go 包安装
go get
go get 安装工具包
go get # 自动下载go.mod里的文件包
go get code.byted.org/flowdevops/fornax_sdk
go get -u -v code.byted.org/flowdevops/fornax_sdk
问题
dial tcp [64:ff9b::8efb:2b11]:443: i/o timeout
【2024-5-17】go get 下载工具包时, 自动加了proxy链接,导致失败
go get code.byted.org/lang/gg/gslice
# code.byted.org/lang/gg/gslice: module code.byted.org/lang/gg/gslice: Get "https://proxy.golang.org/code.byted.org/lang/gg/gslice/@v/list": dial tcp [64:ff9b::8efb:2b11]:443: i/o timeout
分析
- 启用 Go Module 后,Golang 默认通过 Go Mod Proxy 代理拉取代码
- 但由于公司代码库只在内网解析,所以 Go 使用默认proxy(谷歌proxy.golang.org)时, 无法在 8.8.8.8 解析公司域名 byted.org, 于是触发以上错误
解法:
- (1) 关闭 Go Module, 带来的问题是无法使用 go mod 功能
- (2) 设置 Go Module 环境变量, 公司代码库不通过 Go Proxy 拉取
export GO111MODULE=on
export GOPROXY="https://go-mod-proxy.byted.org,https://proxy.golang.org,direct"
export GOPRIVATE="*.byted.org,*.everphoto.cn,git.smartisan.com"
export GOSUMDB="sum.golang.google.cn"
go install
【2022-9-29】go install 命令——编译并安装
go install 只是将编译的中间文件放在 GOPATH 的 pkg 目录下,以及固定地将编译结果放在 GOPATH 的 bin 目录下。
这个命令在内部实际上分成了两步操作:
- 第一步是生成结果文件(可执行文件或者 .a 包)
- 第二步会把编译好的结果移到 $GOPATH/pkg 或者 $GOPATH/bin。
本小节需要用到的代码位置是./src/chapter11/goinstall。
go install 的编译过程有如下规律:
- go install 是建立在 GOPATH 上的,无法在独立的目录里使用 go install。
- GOPATH 下的 bin 目录放置的是使用 go install 生成的可执行文件,可执行文件的名称来自于编译时的包名。
- go install 输出目录始终为 GOPATH 下的 bin 目录,无法使用-o附加参数进行自定义。
- GOPATH 下的 pkg 目录放置的是编译期间的中间文件。
使用 go install 来执行代码,参考下面的 shell:
export GOPATH=/home/davy/golangbook/code
go install chapter11/goinstall
编译完成后的目录结构如下:
.
├── bin
│ └── goinstall
├── pkg
│ └── linux_amd64
│ └── chapter11
│ └── goinstall
│ └── mypkg.a
└── src
└── chapter11
├── gobuild
│ ├── lib.go
│ └── main.go
└── goinstall
├── main.go
└── mypkg
└── mypkg.go
go 包导入
一个 Go 程序是通过 import 关键字将一组包链接在一起
导入包的多种方式:三种模式:正常模式、别名模式、简便模式
- 直接(绝对路径): 根据
$GOPATH/src目录导入import "test/lib"(路径其实是$GOPATH/src/test/lib )
- 别名导入:
import alias_name "test/lib",这样使用的时候,可以直接使用别名
- 使用点号导入:
import . "test/lib",作用是使用的时候直接省略包名
- 使用下划线导入:
improt _ "test/lib",只是引入该包, 不使用时不会报错。- 包前面加下划线空格表示匿名引入包,不使用这个包不会报错。
- 导入包时,init()函数就会被执行,但有时并非真的需要这些包,仅仅是希望init()函数被执行而已。这个时候就可以使用_操作引用该包。即使用_操作引用包是无法通过包名来调用包中的导出函数,而是只是为了简单的调用其init函数()。往往这些init函数里面是注册自己包里面的引擎,让外部可以方便的使用,例如实现database/sql的包,在init函数里面都是调用了sql.Register(name string, driver driver.Driver)注册自己,然后外部就可以使用了。
- 相对路径导入 :
import "./model"//当前文件同一目录的model目录,但是不建议这种方式import
注意
- 升级到 go mod 方式后,不支持相对路径,都是从
$GOPATH/src下一层一层找
main 函数
单个可执行Go代码必须有1个main函数,而且对应main包
// package src // main包
package main
import "fmt"
func main(){
fmt.Print("hello go")
}
否则报错:
package command-line-arguments is not a main package
package main //必备,go程序在包中运行(每个包都有个相关的路径)
import ( //圆括号批量导入包
"fmt" //预处理命令,包含fmt里的所有文件(如Println方法)
"math/rand" // 包名与最后一个目录一致,如rand
"./haoel" //import当前目录里haoel子目录里的所有的go文件
"haoel" //import 环境变量 $GOPATH/src/haoel子目录里的所有的go文件
_ "demo/calc" // 使用自定义包,包前面加下划线空格表示匿名引入包,如果不使用这个包,则不会报错。
) //可以使用相对路径,如./,../,如果没有使用相对路径, go会去找$GOPATH/src/目录
//main是程序入口
func main() { // 括号必须这种方式,否则报错!
fmt.Println("My favorite number is", rand.Intn(10))
/* 只能导入包里的首字母大写的方法(如fmt.Println,go包方法导出的命名规定),Foo 和 FOO 都是被导出的名称。名称 foo 是不会被导出的 */
//fmt包和libc里的那堆使用printf, scanf,fprintf,fscanf 很相似
fmt.Printf("%t\n", 1==2)
fmt.Printf("二进制:%b\n", 255)
fmt.Printf("八进制:%o\n", 255)
fmt.Printf("十六进制:%X\n", 255)
fmt.Printf("十进制:%d\n", 255)
fmt.Printf("浮点数:%f\n", math.Pi)
fmt.Printf("字符串:%s\n", "hello world")
fmt.Printf("打印:%v\n", 255) //v 通用类型,自动适配,http://www.cnblogs.com/golove/p/3284304.html
}
从go 1.11开始,您可以使用新的模块系统;
- 切换到go mod模式后, 原先基于GOPATH方式的模块引用可能会不正常, 可用如下命令关闭:go env -w GO111MODULE=off
生成go.mod包
- go mod init suggestion
init 函数
Go 语言中 init 函数用于包 (package) 的初始化,该函数是 Go 语言的一个重要特性
- main 包中,
init函数优先于main函数。 - 最后被导入的包, 最先初始化并调用其 init() 函数。
特征:
- init 函数是用于程序执行前做包的初始化函数,比如初始化包里的变量等
- 每个包可以拥有多个 init 函数
- 包的每个源文件也可以拥有多个 init 函数
- 同一个包中多个 init 函数的执行顺序 Go 语言没有明确的定义 (说明)
- 初始化顺序是按照解析的依赖关系的顺序执行,没有依赖的包最先初始化。
- 不同包的 init 函数按照包导入的依赖关系决定该初始化函数的执行顺序
- init 函数不能被其他函数调用,而是在 main 函数执行之前,自动被调用
- init() 和 main() 一样,没有任何参数和返回值,不能够被其他函数调用。
- 【2023-2-24】init 函数不能有返回值!
init函数
- init 函数最主要的作用: 完成一些初始化的工作
- 每个源文件都可以包含一个 init 函数,该函数会在 main 函数执行前,被 Go 运行框架调用,也就是说 init 会在 main 函数前被调用
- 如果文件同时包含全局变量定义,init 函数和 main 函数,则执行流程:
- 全局变量定义 -> init函数 -> main 函数。
- import –> const –> var –> init()
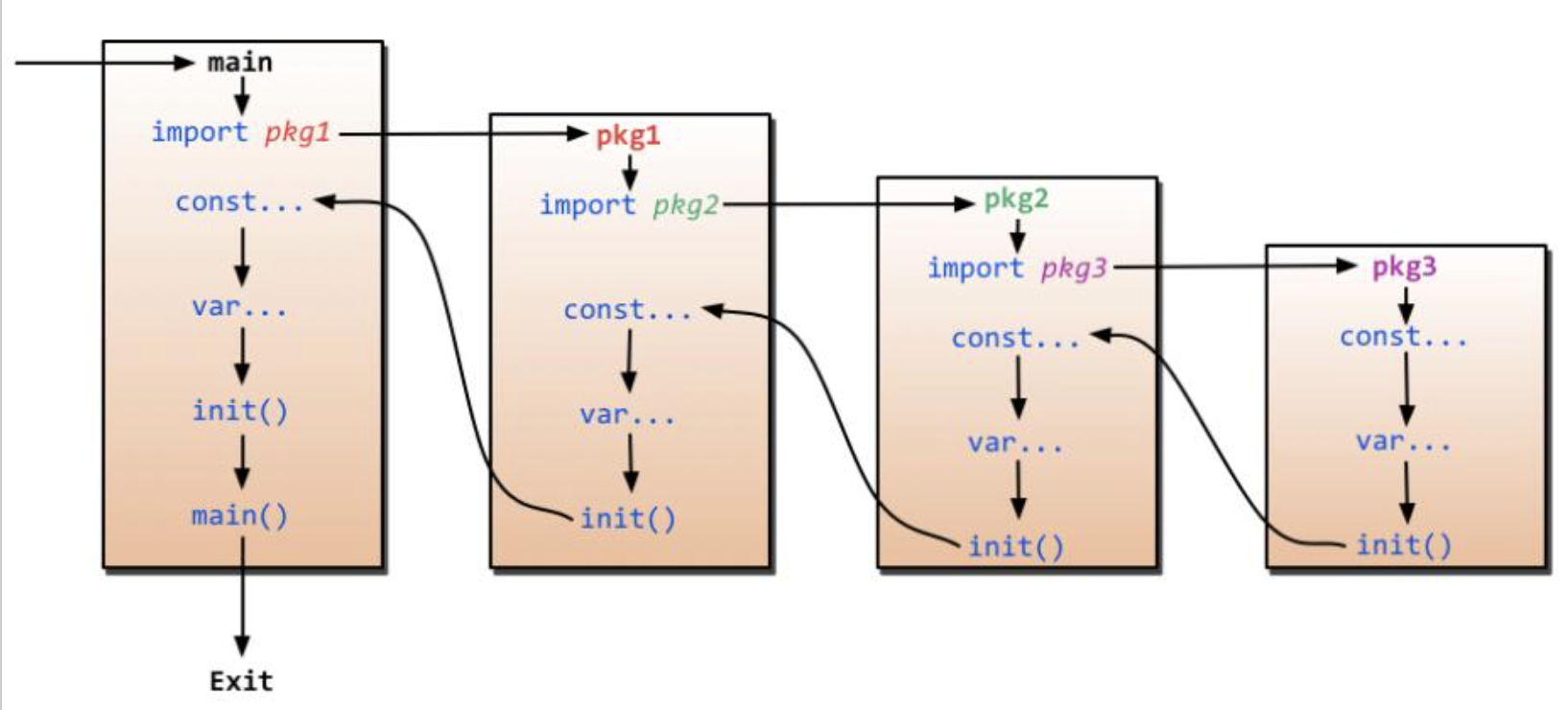
- 图来源
package main
import "fmt"
var num = setNumber()
func setNumber() int {
return 42
}
// init 函数不能有返回值!
func init() {
num = 0
// return ... // 报错!
}
func main() {
fmt.Println(num) // => 0
}
// ----------------------
var g_a int = 10 // 全局变量
type new_type struct {
x int
y string
}
func init(){
fmt.Println("系统自动调用:main函数前")
fmt.Println("init: ", g_a)
}
func change(p *new_type){
p.x = 5
p.y = "changing ..."
}
func main(){
fmt.Println("hello")
s := new_type{x:3, y:"world"}
fmt.Println(s)
fmt.Println(s.y)
//change(s)
change(&s)
fmt.Println(s)
g_a = 30
fmt.Println("main: ", g_a)
}
输出
系统自动调用:main函数前
init: 10
hello
{3 world}
world
{5 changing ...}
main: 30
自定义包
创建自定义包基本步骤:
- 新建目录,用于存放包的源文件。
- 在新建目录中编写 Go 代码,第一行应该是
package 包名。 - 使用 import 语句, 在其他地方导入和使用这个包。
注意
- 每个包都有1个
go.mod文件。- Go Modules 是 Go 1.11 引入的官方包管理工具,用于管理项目的依赖
go.mod记录项目的模块路径
- 自定义包名:
go mod init foo- 所在目录名、包名不用跟包同名
- import 自定义包, 导入路径格式尤其注意:
- 格式: 包名/本地目录名(包含包定义文件foo_def.go)
否则会出现各种错误
- 路径不在 GOROOT 中:
"foo_dir/foo" - 循环导入 import cycle:
"foo"
自定义包
go path
文件目录
├── hello.go
└── my_pkg
├── mymath1.go
└── mymath2.go
my_pkg 目录包含自定义工具包 mathClass
myMath1.go 文件
// myMath1.go
package mathClass
func Add(x,y int) int {
return x + y
}
myMath2.go 文件
// myMath2.go
package mathClass
func Sub(x,y int) int {
return x - y
}
hello.go 内容
// hello.go
package main
import (
"fmt"
"./my_pkg" // 相对目录导入
)
func main(){
fmt.Println("Hello World!")
fmt.Println(mathClass.Add(1,1))
fmt.Println(mathClass.Sub(1,1))
}
调用自定义包
go run hello.go
# 环境: go version go1.18.3 darwin/arm64
# 执行正常, 输出:
# Hello World!
# 2
# 0
自定义包 foo
【2024-5-22】示例
# 创建自定义包测试目录 tmp
mkdir tmp
cd tmp
# 创建 包所在目录 foo_dir, 跟 main 包隔离
mkdir foo_dir
cd foo_dir # 填入包内容 foo_def.go, foo_test.go
# 创建包结构文件
cd ..
go mod init foo # 生成 go.mod 文件
go mod tidy # 自动添加依赖包信息到 go.mod 文件
# 查看文件结构
tree
.
├── foo_dir
│ ├── foo_def.go
│ └── foo_test.go
├── go.mod
└── main.go
包定义文件 foo_def.go
package foo
import (
"fmt"
)
func Hello(name string) {
fmt.Printf("包内函数: Hello %s !\n", name)
}
调用自定义包: main.go
package main
import (
"fmt"
// 格式: 包名/本地目录名(包含包定义文件foo_def.go)
"foo/foo_dir"
// 错误示例如下:
//"foo_dir/foo" // error: main.go:6:2: package foo_dir/foo is not in GOROOT (/usr/local/go/src/foo_dir/foo)
//"foo" // error: imports foo: import cycle not allowed
// "foo_dir" // error: "foo_dir" is relative, but relative import paths are not supported in module mode, go mod 禁用相对路径导入, 解决方法: ① 使用绝对路径(git项目地址) ② 切回go path模式 ③ 复制 mv foo_dir /usr/local/go/src
)
func main(){
fmt.Println("主函数调用自定义包foo")
foo.Hello("world")
}
问题: relative import paths are not supported in module
go mod 禁用相对路径导入
解决方法:
- ① 使用绝对路径(git项目地址)
- ② 切回go path模式:
go env -w GO111MODULE=auto - ③ 复制
mv foo_dir /usr/local/go/src, 再使用import "foo_dir"
问题: 包太多 found packages in
错误信息:
start.go:7:2: found packages llm_provider (fornax.go) and main (s.go) in ...
分析:
- 同一个目录下发现多个包
解法:
- 当前目录只保留 main 包
- 新建子目录把其他包单独隔离起来
问题: 循环导入
【2024-5-22】循环导入: import cycle not allowed
- 调用自定义包时, 直接
import foo会触发此错误- go 认为要引用自身
- 解法: 矫正路径
- A依赖于B,而B又依赖于A
- golang会检测到这种循环依赖关系,并报告编译错误
- 解法: AB之间引入interface, 更多方法见golang包循环引用的几种解决方案
// foo.go
package foo
func Foo() {...}
// foo_test.go
package foo
// try to access Foo()
foo.Foo() // WRONG <== This was the issue. You are already in package foo, there is no need to use foo.Foo() to access Foo()
Foo() // CORRECT
第三方包
goproxy
Go 第三方依赖 GOPROXY 默认值:https://proxy.golang.org,direct
- 由于某些原因, 国内无法正常访问该地址,所以需要配置可访问地址。
- 目前有两个:
https://goproxy.cn和https://goproxy.io
设置 GOPAROXY 命令:
go env -w GOPROXY=https://goproxy.cn,direct
pinyin
【2022-9-29】安装汉字转拼音工具包
原理
- 将所有的汉字对应的 rune码,对应上它的拼音,也即是,有一个这样的 map[rune]string, 其中 key 为汉字的 rune码,value 就是汉字的拼音了。这个 map 是通过文件来生成的。
文件内容示例
- 其中的拼音都是带声调的。不需要声调的话,可以替换成没有声调的字符。
3400=>qiū
3401=>tiàn
3404=>kuà
3405=>wǔ
3406=>yǐn
340C=>yí
3416=>xié
341C=>chóu
Mode 介绍
- InitialsInCapitals: 首字母大写, 不带音调
- WithoutTone: 全小写,不带音调
- Tone: 全小写带音调
# 安装pinyin
#go install github.com/mozillazg/go-pinyin/cmd/pinyin@latest
# 1.8之前用get get
# 新建测试目录
mkdir pinyin && cd pinyin
touch pinyin_test.go
echo "...." > pinyin_test.go # 内容如下
# 初始化当前目录为模块,解除path依赖
go mod init
# 获取 go-pinyin工具包
go get github.com/mozillazg/go-pinyin
#go get github.com/chain-zhang/pinyin
# 执行测试脚本
go run pinyin_test.go
pinyin (失败)
pinyin 示例
package main
import(
"fmt"
"github.com/chain-zhang/pinyin"
)
func main() {
str, err := pinyin.New("我是中国人").Split("").Mode(InitialsInCapitals).Convert()
if err != nil {
// 错误处理
}else{
fmt.Println(str)
}
str, err = pinyin.New("我是中国人").Split(" ").Mode(pinyin.WithoutTone).Convert()
if err != nil {
// 错误处理
}else{
fmt.Println(str)
}
str, err = pinyin.New("我是中国人").Split("-").Mode(pinyin.Tone).Convert()
if err != nil {
// 错误处理
}else{
fmt.Println(str)
}
str, err = pinyin.New("我是中国人").Convert()
if err != nil {
// 错误处理
}else{
fmt.Println(str)
}
}
go-pinyin (测试通过)
测试代码:go-pinyin
package main
import (
"fmt"
"github.com/mozillazg/go-pinyin"
)
func main() {
hans := "中国人"
// 默认
a := pinyin.NewArgs()
fmt.Println(pinyin.Pinyin(hans, a)) // [[zhong] [guo] [ren]]
// 包含声调
a.Style = pinyin.Tone
fmt.Println(pinyin.Pinyin(hans, a)) // [[zhōng] [guó] [rén]]
// 声调用数字表示
a.Style = pinyin.Tone2
fmt.Println(pinyin.Pinyin(hans, a)) // [[zho1ng] [guo2] [re2n]]
// 开启多音字模式
a = pinyin.NewArgs()
a.Heteronym = true
fmt.Println(pinyin.Pinyin(hans, a)) // [[zhong zhong] [guo] [ren]]
a.Style = pinyin.Tone2
fmt.Println(pinyin.Pinyin(hans, a)) // [[zho1ng zho4ng] [guo2] [re2n]]
fmt.Println(pinyin.LazyPinyin(hans, pinyin.NewArgs())) // [zhong guo ren]
fmt.Println(pinyin.Convert(hans, nil)) // [[zhong] [guo] [ren]]
fmt.Println(pinyin.LazyConvert(hans, nil)) // [zhong guo ren]
}
常用包
fmt
fmt包用于格式化输入和输出数据, 实现了类似C语言printf和scanf的格式化I/O。
- 名称 “fmt” 来自于 “format”,因为主要用于格式化数据
主要分为输出内容和获取输入两大部分。
【2023-10-25】Go 常用标准库之 fmt 介绍与基本使用
fmt 包的主要功能包括:
- 格式化输出:fmt 包提供了函数
- 如
Print,Printf,Println,Fprint,Fprintf, 和Fprintln用于将数据输出到标准输出或指定的io.Writer。 - 这些函数将数据以不同的格式打印到屏幕上或文件中。
- 如
- 格式化输入:fmt 包也支持从输入源(通常是标准输入)读取数据,并根据格式规范解析数据。
- 通过
Scan,Scanf, 和Scanln函数实现。 - 这对于从用户获取输入数据非常有用。
- 通过
- 字符串格式化:
- 可用
Sprintf函数将数据格式化为字符串而不是直接输出到标准输出,对构建日志消息或其他需要格式化的字符串很有用。
- 可用
- 错误格式化:fmt 包也提供了
Errorf函数,用于将格式化的错误消息作为 error 类型返回,方便错误处理。 - 格式化占位符:格式化字符串中,可使用占位符来指定如何格式化数据。常见的占位符包括
%d(整数),%f(浮点数),%s(字符串)等。
示例
func main() {
fmt.Print("在终端打印该信息。")
name := "沙河小王子"
fmt.Printf("我是:%s\n", name)
fmt.Println("在终端打印单独一行显示")
}
格式化占位符
格式化占位符
*printf系列函数都支持format格式化参数,按照占位符将被替换的变量类型划分,方便查询和记忆。
| 占位符 | 说明 |
|---|---|
| %v | 值的默认格式表示 |
| %+v | 类似%v,但输出结构体时会添加字段名 |
| %#v | 值的Go语法表示 |
| %T | 打印值的类型 |
| %% | 百分号 |
| %t | 布尔型, true或false |
| %b | 表示为二进制 |
| %c | 该值对应的unicode码值 |
| %d | 表示为十进制 |
| %o | 表示为八进制 |
| %x | 表示为十六进制,使用a-f |
| %X | 表示为十六进制,使用A-F |
| %U | 表示为Unicode格式:U+1234,等价于”U+%04X” |
| %q | 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示 |
| %s | 直接输出字符串或者[]byte |
| %q | 该值对应的双引号括起来的go语法字符串字面值,必要时会采用安全的转义表示 |
| %x | 每个字节用两字符十六进制数表示(使用a-f) |
| %X | 每个字节用两字符十六进制数表示(使用A-F) |
| %p | 表示为十六进制,并加上前导的0x |
| %f | 默认宽度,默认精度 |
| %9f | 宽度9,默认精度 |
| %.2f | 默认宽度,精度2 |
| %9.2f | 宽度9,精度2 |
| %9.f | 宽度9,精度0 |
| ‘+’ | 总是输出数值的正负号;对%q(%+q)会生成全部是ASCII字符的输出(通过转义); |
| ’ ’ | 对数值,正数前加空格而负数前加负号;对字符串采用%x或%X时(% x或% X)会给各打印的字节之间加空格 |
| ‘-’ | 在输出右边填充空白而不是默认的左边(即从默认的右对齐切换为左对齐); |
| ‘#’ | 八进制数前加0(%#o),十六进制数前加0x(%#x)或0X(%#X),指针去掉前面的0x(%#p)对%q(%#q),对%U(%#U)会输出空格和单引号括起来的go字面值; |
| ‘0’ | 使用0而不是空格填充,对于数值类型会把填充的0放在正负号后面; |
func main() {
fmt.Printf("%v\n", 100)
fmt.Printf("%v\n", false)
o := struct{ name string }{"jarvis"}
fmt.Printf("%v\n", o)
fmt.Printf("%#v\n", o)
fmt.Printf("%T\n", o)
fmt.Printf("100%%\n")
// 整型
n := 65
fmt.Printf("%b\n", n)
fmt.Printf("%c\n", n)
fmt.Printf("%d\n", n)
fmt.Printf("%o\n", n)
fmt.Printf("%x\n", n)
fmt.Printf("%X\n", n)
// 浮点型
f := 12.34
fmt.Printf("%b\n", f)
fmt.Printf("%e\n", f)
fmt.Printf("%E\n", f)
fmt.Printf("%f\n", f)
fmt.Printf("%g\n", f)
fmt.Printf("%G\n", f)
// 字符串和 []byte
s := "jarvis"
fmt.Printf("%s\n", s)
fmt.Printf("%q\n", s)
fmt.Printf("%x\n", s)
fmt.Printf("%X\n", s)
// 指针
a := 18
fmt.Printf("%p\n", &a)
fmt.Printf("%#p\n", &a)
// 宽度标识符
n := 88.88
fmt.Printf("%f\n", n)
fmt.Printf("%9f\n", n)
fmt.Printf("%.2f\n", n)
fmt.Printf("%9.2f\n", n)
fmt.Printf("%9.f\n", n)
// 其它flag
s := "jarvis"
fmt.Printf("%s\n", s)
fmt.Printf("%5s\n", s)
fmt.Printf("%-5s\n", s)
fmt.Printf("%5.7s\n", s)
fmt.Printf("%-5.7s\n", s)
fmt.Printf("%5.2s\n", s)
fmt.Printf("%05s\n", s)
}
Print 系列
Print 系列
Print:将文本输出到标准输出。- 接受任意数量的参数,并将它们串联成一个字符串输出,不会添加换行符。
Printf:格式化输出到标准输出。- 它接受一个格式化字符串和一系列参数,根据格式化字符串的占位符将参数格式化并输出。
Println:类似于Print,但会在输出后自动添加一个换行符。
func main() {
fmt.Print("Hello, ", "world")
name := "Alice"
age := 30
fmt.Printf("Hello, %s. You are %d years old.\n", name, age)
fmt.Println("Hello, world")
}
Fprint 系列
Fprint 系列函数用于将文本输出到指定的 io.Writer 接口,而不仅仅是标准输出。
- 可将文本输出到文件、网络连接等。
这些函数的参数列表包括一个 io.Writer 参数,以及任意数量的参数。
Fprint:将文本输出到指定的 io.Writer。Fprintf:将格式化文本输出到指定的 io.Writer。Fprintln:将带有换行符的文本输出到指定的 io.Writer。
func main() {
// 向标准输出写入内容
fmt.Fprintln(os.Stdout, "向标准输出写入内容")
fileObj, err := os.OpenFile("./output.txt", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("打开文件出错,err:", err)
return
}
name := "jarvis"
// 向打开的文件句柄中写入内容
fmt.Fprintf(fileObj, "往文件中写如信息:%s", name)
}
Sprint 系列
Sprint 系列函数用于将文本输出到字符串中,而不是标准输出或文件。
将文本格式化为字符串并返回结果。
Sprint:将文本输出到字符串。Sprintf:将格式化文本输出到字符串。Sprintln:将带有换行符的文本输出到字符串。
func main() {
s1 := fmt.Sprint("jarvis")
name := "jarvis"
age := 18
s2 := fmt.Sprintf("name:%s,age:%d", name, age)
s3 := fmt.Sprintln("jarvis")
fmt.Println(s1, s2, s3)
}
Scan
fmt 包提供了 fmt.Scan、fmt.Scanf 和 fmt.Scanln 这三个函数,用于从标准输入获取用户的输入。这些函数允许你与用户交互,从标准输入流中读取不同类型的数据并将其存储在相应的变量中。
package main
import "fmt"
func main() {
var name string
var age int
fmt.Print("Enter your name: ")
fmt.Scan(&name)
fmt.Scanln(&name) // 遇到换行时才停止扫描。最后一个数据后面必须有换行或者到达结束位置
var name string
var age int
fmt.Scanf("%s %d", &name, &age) // 根据格式规范解析输入,并将数据存储在变量中
fmt.Printf("Name: %s, Age: %d\n", name, age)
fmt.Print("Enter your age: ")
fmt.Scan(&age)
fmt.Printf("Name: %s, Age: %d\n", name, age)
}
Fscan
Fscan 系列函数允许从 io.Reader 接口中读取数据,而不仅仅是标准输入。
这些函数与 fmt.Scan、fmt.Scanf 和 fmt.Scanln 类似,但允许从任何实现 io.Reader 接口的地方读取数据。
Fscan:从 io.Reader 中读取数据。Fscanln:从 io.Reader 中读取一行数据。Fscanf:根据指定的格式从 io.Reader 中读取数据。
package main
import (
"fmt"
"strings"
)
func main() {
input := "42 John"
reader := strings.NewReader(input) // 从字符串生成读对象
var age int
var name string
n, err := fmt.Fscanf(reader, "%d %s", &age, &name)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("Read %d values: Age: %d, Name: %s\n", n, age, name)
}
Sscan
Sscan 系列函数允许从字符串中读取数据,而不仅仅是从标准输入。
这些函数与 fmt.Scan、fmt.Scanf 和 fmt.Scanln 类似,但允许你从字符串中读取数据。
- Sscan:从字符串中读取数据。
- Sscanln:从字符串中读取一行数据。
- Sscanf:根据指定的格式从字符串中读取数据。
package main
import (
"fmt"
)
func main() {
input := "Alice 30"
var name string
var age int
n, err := fmt.Sscanf(input, "%s %d", &name, &age)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Printf("Read %d values: Name: %s, Age: %d\n", n, name, age)
}
bufio
bufio 包提供了一种更灵活的方式来处理输入,特别是在需要完整读取一行或多行输入的情况下。
- 用 bufio.NewReader 创建一个输入缓冲区
- 然后使用 ReadString 函数来读取输入,直到指定的分隔符(例如换行符 \n)。
这允许获取包含空格在内的完整输入内容。
func bufioDemo() {
reader := bufio.NewReader(os.Stdin) // 从标准输入生成读对象
fmt.Print("请输入内容:")
text, _ := reader.ReadString('\n') // 读取直到换行符
text = strings.TrimSpace(text)
fmt.Printf("%#v\n", text)
}
Errorf 系列
Errorf 系列函数用于创建格式化的错误消息并返回一个 error 类型的值。
将格式化的错误消息返回给调用者,以便更好地进行错误处理。
这些函数的用法类似于 Sprintf,但返回一个 error 值而不是字符串。
Errorf:根据format参数生成格式化字符串并返回一个包含该字符串的错误。
err := fmt.Errorf("这是一个错误")
context
【2024-6-4】问题
- goroutine 启动后, 无法控制, 等自己结束
- 如果 goroutine 不结束,就不会一直运行下去
怎么办?
- 方法1: 维护一个全局变量, 记录 goroutine 是否结束
- 风险: 需要保证 线程安全
- 实现方案:
chan+select - 局限: 很多 goroutine 都需要控制结束时, 层层嵌套,越来越复杂
- 方法2:
context.Context
func main() {
stop := make(chan bool)
go func() {
for {
select {
case <-stop: // 收到了停滞信号
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}()
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
stop<- true
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}
场景
- 一个网络请求 Request,每个 Request 都需要开启一个 goroutine 做一些事情,这些 goroutine 又可能会开启其他的 goroutine。
此时, 需要一个可以跟踪 goroutine 的方案来控制他们
context 是 go 中控制协程的一种方式
context.Context 是 上下文, Go 接口类型,从1.7版本中开始引入。
网络请求示例
package main
import (
"context"
"fmt"
"time"
)
func main() {
// 初始化 context
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
// 启动 gorutine, 等待 0.5s
go handle(ctx, 500*time.Millisecond)
// 等待 context.Context 超时并打印出 main context deadline exceeded
// select 让 Goroutine 同时等待多个 Channel 可读或者可写,在多个文件或者 Channel状态改变之前,select 会一直阻塞当前线程或者 Goroutine
select {
case <-ctx.Done():
fmt.Println("main", ctx.Err())
}
}
func handle(ctx context.Context, duration time.Duration) {
select {
case <-ctx.Done():
fmt.Println("handle", ctx.Err())
case <-time.After(duration):
fmt.Println("process request with", duration)
}
}
// go run context.go
// process request with 500ms
// main context deadline exceeded
// 请求超时
// handle context deadline exceeded
Context 接口
- 4个方法中最有用的就是 Done()
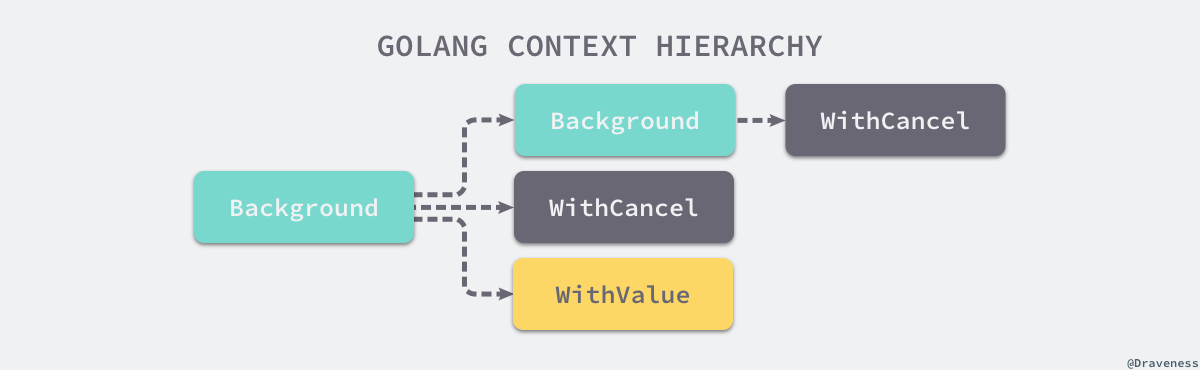
type Context interface {
// 获取设置的截止时间, 时间到了Context 会自动发起取消请求; ok 表示是否设置截止时间,如果没有设置时间,当需要取消的时候,需要调用取消函数进行取消
Deadline() (deadline time.Time, ok bool)
// 返回只读 chan,类型为 struct{}; parent context 发起取消请求,通过 Done 方法收到信号后,就做清理操作,然后退出 goroutine,释放资源
Done() <-chan struct{}
// 返回取消的错误原因
Err() error
// 获取该 Context 上绑定的值,是一个键值对,所以要通过一个 Key 才可以获取对应的值,这个值一般是线程安全的。
Value(key interface{}) interface{}
}
// ======= 内置方法 ======
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
// 用于 main 函数、初始化以及测试代码中,作为 Context 这个树结构的最顶层的 Context,也就是根 Context。
func Background() Context {
return background
}
// 不知道该使用什么 Context 时,可以使用这个
func TODO() Context {
return todo
}
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}
Context 接口不需要用户实现,Go 内置已经实现了 2 个
主要作用:
- 一次请求经过的所有协程或函数间, 传递取消信号及共享数据,以达到父协程对子协程的管理和控制的目的。
注意
- context.Context 作用范围: 一次请求的生命周期,即随着请求的产生而产生,随着本次请求的结束而结束。
func main() {
ctx, cancel := context.WithCancel(context.Background())
go func(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}(ctx)
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
cancel()
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}
select+chan 控制的协程改为 Context 控制即可:
- context.
Background() 返回一个空的 Context,用于整个 Context 树的根节点。 - 用 context.
WithCancel(parent) 函数创建可取消的子 Context,然后当作参数传给 goroutine 使用,就可以使用这个子 Context 跟踪这个 goroutine
Context 使用原则
- 不要把 Context 放在结构体中,要以参数的方式传递。
- 以 Context 作为参数的函数方法,应该把 Context 作为第一个参数,放在第一位。
- 给一个函数方法传递 Context 的时候,不要传递 nil,如果不知道传递什么,就使用 context.TODO。
- Context 的 Value 相关方法应该传递必须的数据,不要什么数据都使用这个传递。
- Context 是线程安全的,可以放心的在多个 goroutine 中传递。
Context 控制多个 goroutine
- 启动了 3 个监控 goroutine 进行不断的监控,每一个都使用了 Context 进行跟踪
- 当用 cancel 函数通知取消时,这 3 个 goroutine 都会被结束。
- Context 控制能力, 像控制器一样,按下开关后,所有基于这个 Context 或者衍生的子 Context 都会收到通知,这时就可以进行清理操作了,最终释放 goroutine,这就优雅的解决了 goroutine 启动后不可控的问题。
func main() {
ctx, cancel := context.WithCancel(context.Background())
go watch(ctx,"【监控1】")
go watch(ctx,"【监控2】")
go watch(ctx,"【监控3】")
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
cancel()
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}
func watch(ctx context.Context, name string) {
for {
select {
case <-ctx.Done():
fmt.Println(name,"监控退出,停止了...")
return
default:
fmt.Println(name,"goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}
子 context: 衍生
- WithCancel 函数,传递一个父 Context 作为参数,返回子 Context,以及一个取消函数用来取消 Context。
- WithDeadline 函数,和 WithCancel 差不多,它会多传递一个截止时间参数,意味着到了这个时间点,会自动取消 Context,当然我们也可以不等到这个时候,可以提前通过取消函数进行取消。
- WithTimeout 和 WithDeadline 基本上一样,这个表示是超时自动取消,是多少时间后自动取消 Context 的意思。
- WithValue 函数和取消 Context 无关,它是为了生成一个绑定了一个键值对数据的 Context,这个绑定的数据可以通过 Context.Value方法访问到。
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
func WithValue(parent Context, key, val interface{}) Context
参考:
go语言极速入门
2015年09月28日 Go语言极速入门手册.go
《Go语言编程》
package main
import (
"errors"
"fmt"
"github.com/stretchr/testify/assert"
"io"
"io/ioutil"
"log"
"math"
"os"
"path/filepath"
"regexp"
"strings"
"sync"
"testing"
"time"
)
规范:
- 命名:骆驼命名法(不要用下划线)
命令:
- go get github.com/coderzh/xxx
- go build calc
- go run xxx.go
- go install calc
// 1. Hello World
func helloWorld() {
fmt.Println("Hello, 世界")
}
// 2.变量类型
func typeDemo() {
// 变量声明
var v1 int
var (
v2 int
v3 string
)
//var p *int // 指针类型
var v4 int = 10 // 变量初始化
var v5 = 10 // 等价于:
v6 := 10 // 一般这样就好
v1 = 10 // 赋值
v2, v3 = 20, "test" // 多重赋值
_, v4 = v5, v6 // 匿名变量 _
fmt.Println(v1, v2, v3, v4)
const Pi float64 = 3.1415926 // 常量
const MaxPlayer = 10
const ( // 枚举
Sunday = iota // iota从0递增
Mondy
Tuesday
// ...
)
// 类型
var b1 bool // 1. 布尔
b1 = true
b1 = (1 == 2)
fmt.Println(b1)
// 2. 整形
// int8 uint8 int16 uint16 int32 uint32 int64 uint64 int uint uintptr
var i32 int32
i32 = int32(64) // 强制转换
// 运算:+, -, *, /, %(求余)
// 比较:>, <, ==, >=, <=, !=
// 位运算:x << y, x >> y, x ^ y, x & y, x | y, ^x (取反)
fmt.Println(i32)
// 3. 浮点
var f1 float64 = 1.0001 // float32, float64
var f2 float64 = 1.0002
isEqual := math.Dim(f1, f2) < 0.0001 // 浮点比较
fmt.Println(isEqual)
// 4. 字符串
var s1 string
s1 = "abc"
s1 = s1 + "ddd" // 字符串连接
n := len(s1) // 取长度
c1 := s1[0] // 取字符
s1 = `\w+` // 反引号,不转义,常用于正则表达式
fmt.Println(c1)
fmt.Println(strings.HasPrefix("prefix", "pre")) // true
fmt.Println(strings.HasSuffix("suffix", "fix")) // true
// 字节遍历
for i := 0; i < n; i++ {
ch := s1[i]
fmt.Println(ch)
}
// Unicode字符遍历
for i, ch := range s1 {
fmt.Println(i, ch)
}
// 5. 数组
var arr1 [32]int
//var arr2 [3][8]int // 二维数组
// 初始化
arr1 = [32]int{0}
array := [5]int{1, 2, 3, 4, 5}
// 临时结构体数组
structArray := []struct {
name string
age int
} { {"Tim", 18}, {"Jim", 20} }
// 数组遍历
for i := 0; i < len(array); i++ {
fmt.Println(array[i])
}
for i, v := range structArray {
fmt.Println(i, v)
}
// 数组是值类型,每次参数传递都是一份拷贝
// 数组切片Slice
var mySlice []int = arr1[:2]
mySlice1 := make([]int, 5)
mySlice2 := make([]int, 5, 10)
fmt.Println("len(mySlice2:", len(mySlice2)) // 5
fmt.Println("cap(mySlice2:", cap(mySlice2)) // 10
mySlice3 := append(mySlice, 2, 3, 4)
mySlice4 := append(mySlice, mySlice1...)
copy(mySlice3, mySlice4)
// 6. Map
var m map[int]string
m[1] = "ddd"
m1 := make(map[int]string)
m2 := map[int]string{
1: "a",
2: "b",
}
delete(m2, 1) // 删除map元素
value, ok := m1[1]
if ok {
fmt.Println(value)
}
for k, v := range m2 {
fmt.Println(k, v)
}
}
// 3. 流程控制
func flowDemo() {
// if else
a := 10
if a < 10 {
// ..
} else {
// ..
}
// switch
switch a {
case 0:
fmt.Println("0")
case 10:
fmt.Println("10")
default:
fmt.Println("default")
}
switch { // 无判断条件
case a < 10:
fmt.Println("<10")
case a < 20:
fmt.Println("<20")
}
// 循环
for i := 0; i < 10; i++ {
}
// 无限循环
sum := 0
for {
sum++
if sum > 10 {
break
// 指定break
// break JLoop
}
}
goto JLoop
JLoop:
// break to here
}
// 4. 函数
// func 函数名(参数列表)(返回值列表) {
// }
func sum1(value1 int, value2 int) (result int, err error) {
// err = errors.New("xxxx")
return value1 + value2, nil
}
func sum2(value1, value2 int) int {
return value1 + value2
}
// 不定参数
// myFunc(1, 2, 3, 4, 5)
func myFunc(args ...int) {
for _, arg := range args {
fmt.Println(arg)
}
// 传递
// myFunc2(args...)
// myFunc2(args[1:]...)
}
// 任意类型的不定参数
func myPrintf(args ...interface{}) {
for _, arg := range args {
switch arg.(type) {
case int:
fmt.Println(arg, "is int")
case string:
fmt.Println(arg, "is string")
default:
fmt.Println(arg, "is unknown")
}
}
}
// 匿名函数
func anonymousFunc() {
f := func(a, b int) int {
return a + b
}
f(1, 2)
}
// defer
func deferDemo(path string) {
f, err := os.Open(path)
if err != nil {
return
}
defer f.Close()
// or
defer func() {
if r := recover(); r != nil {
fmt.Printf("Runtime error caught: %v", r)
}
}()
}
// 5. 结构体
type Rect struct {
x, y float64 // 小写为private
Width, Height float64 // 首字母大写为public
}
// 大写方法为public,小写为private
func (r *Rect) Area() float64 {
return r.Width * r.Height
}
func netRect(x, y, width, height float64) *Rect {
// 实例化结构体
// rect1 := new(Rect)
// rect2 := &Rect{}
// rect3 := &Rect{Width:100, Height:200}
return &Rect{x, y, width, height}
}
// 匿名组合: “类”的继承顺序:Base → Foo → Bar
type Base struct {
Name string
}
func (base *Base) Foo() {}
func (base *Base) Bar() {}
type Foo struct {
Base
*log.Logger
}
func (foo *Foo) Bar() {
foo.Base.Bar()
// ...
}
// 非侵入式接口
type IFile interface {
Read(buf []byte) (n int, err error)
Write(buf []byte) (n int, err error)
}
type File struct {
}
func (file *File) Read(buf []byte) (n int, err error) {
return 0, nil
}
func (file *File) Write(buf []byte) (n int, err error) {
return 0, nil
}
func interfaceDemo() {
// 只要实现了Read, Write方法即可
var file IFile = new(File)
// 接口查询
// 是否实现了IFile接口
if file2, ok := file.(IFile); ok {
file2.Read([]byte{})
}
// 实例类型是否是File
if file3, ok := file.(*File); ok {
file3.Read([]byte{})
}
// 类型查询
switch v := file.(type) {
}
}
// 6. 并发编程
func counting(ch chan int) {
ch <- 1
fmt.Println("counting")
}
func channelDemo() {
chs := make([]chan int, 10)
for i := 0; i < len(chs); i++ {
chs[i] = make(chan int)
// 带缓冲区大小
// c: = make(chan int, 1024)
// for i:= range c {
// }
go counting(chs[i])
}
for _, ch := range chs {
<-ch
// channel select
/*
select {
case <-ch:
// ...
case ch <- 1:
}
*/
}
// 单向Channel
var ch1 chan<- int // 只能写入int
var ch2 <-chan int // 只能读出int
// 关闭Channel
close(ch1)
_, ok := <-ch2
if !ok {
// already closed
}
}
// 锁
var m sync.Mutex
func lockDemo() {
m.Lock()
// do something
defer m.Unlock()
}
// 全局唯一操作
var once sync.Once
once.Do(someFunction)
// 7. 网络编程
import "net"
net.Dial("tcp", "127.0.0.1:8080")
// 8. json处理
import "encoding/json"
json.Marshal(obj) 序列化
json.Unmarshal() 反序列化
// 9. Web开发
import "net/http"
import "html/template" // 模板
// 10. 常用库
import "os"
import "io"
import "flag"
import "strconv"
import "crypto/sha1"
import "crypto/md5"
// 11. 单元测试
// _test结尾的go文件: xxx_test.go
// 函数名以Test开头
func TestDemo(t *testing.T) {
r := sum2(2, 3)
if r != 5 {
t.Errorf("sum2(2, 3) failed. Got %d, expect 5.", r)
}
assert.Equal(t, 1, 1)
}
// 12. 性能测试
func benchmarkAdd(b *testing.B) {
b.StopTimer()
// dosometing
b.StartTimer()
}
其他常用的代码片段
// 1. 遍历文件 filepath.Walk
// import "path/filepath"
func doHashWalk(dirPath string) error {
fullPath, err := filepath.Abs(dirPath)
if err != nil {
return err
}
callback := func(path string, fi os.FileInfo, err error) error {
return hashFile(fullPath, path, fi, err)
}
return filepath.Walk(fullPath, callback)
}
func hashFile(root string, path string, fi os.FileInfo, err error) error {
if fi.IsDir() {
return nil
}
rel, err := filepath.Rel(root, path)
if err != nil {
return err
}
log.Println("hash rel:", rel, "abs:", path)
return nil
}
// 2. 读取文件
import "io/ioutil"
func readFileDemo(filename string) {
content, err := ioutil.ReadFile(filename)
if err != nil {
//Do something
}
lines := strings.Split(string(content), "\n")
fmt.Println("line count:", len(lines))
}
// 判断目录或文件是否存在
func existsPathCheck(path string) (bool, error) {
// 判断不存在
if _, err := os.Stat(path); os.IsNotExist(err) {
// 不存在
}
// 判断是否存在
_, err := os.Stat(path)
if err == nil {
return true, nil
}
if os.IsNotExist(err) {
return false, nil
}
return true, err
}
// 文件目录操作
func fileDirDemo() {
// 级联创建目录
os.MkdirAll("/path/to/create", 0777)
}
// 拷贝文件
func copyFile(source string, dest string) (err error) {
sf, err := os.Open(source)
if err != nil {
return err
}
defer sf.Close()
df, err := os.Create(dest)
if err != nil {
return err
}
defer df.Close()
_, err = io.Copy(df, sf)
if err == nil {
si, err := os.Stat(source)
if err != nil {
err = os.Chmod(dest, si.Mode())
}
}
return
}
// 拷贝目录
func copyDir(source string, dest string) (err error) {
fi, err := os.Stat(source)
if err != nil {
return err
}
if !fi.IsDir() {
return errors.New(source + " is not a directory")
}
err = os.MkdirAll(dest, fi.Mode())
if err != nil {
return err
}
entries, err := ioutil.ReadDir(source)
for _, entry := range entries {
sfp := filepath.Join(source, entry.Name())
dfp := filepath.Join(dest, entry.Name())
if entry.IsDir() {
err = copyDir(sfp, dfp)
if err != nil {
fmt.Println(err)
}
} else {
err = copyFile(sfp, dfp)
if err != nil {
fmt.Println(err)
}
}
}
return nil
}
// 3. 时间处理
import "time"
func TestTimeDemo(t *testing.T) {
// Parse
postDate, err := time.Parse("2006-01-02 15:04:05", "2015-09-30 19:19:00")
fmt.Println(postDate, err)
// Format
assert.Equal(t, "2015/Sep/30 07:19:00", postDate.Format("2006/Jan/02 03:04:05"))
assert.Equal(t, "2015-09-30T19:19:00Z", postDate.Format(time.RFC3339))
}
// 4. 正则表达式
import "regexp"
func TestRegexp(t *testing.T) {
// 查找匹配
re := regexp.MustCompile(`(\d+)-(\d+)`)
r := re.FindAllStringSubmatch("123-666", -1)
assert.Equal(t, 1, len(r))
assert.Equal(t, "123", r[0][1])
assert.Equal(t, "666", r[0][2])
}
func main() {
helloWorld()
}
GO语法
Go 教程资料
- 【2022-7-28】Go语言圣经(中文版)
- Go语言101是关于Go语言编程的一系列丛书。 github 目前本系列丛书包括:
- 《Go语言(基础知识)101》是一本着墨于Go语法语义(除了自定义泛型)以及运行时相关知识点的编程指导书。
- 《Go自定义泛型101》详细介绍了Go自定义泛型中的方方面面。
- 《Go编程优化101》列出了一些Go编程中的一些性能优化技巧和建议。
- 《Go细节和小技巧101》搜集了很多Go编程中的细节和小技巧。
git clone https://github.com/golang101/golang101.git
cd golang101
git pull
go run . # 启动服务: 本地阅读
# 未打开浏览器?手动访问 http://localhost:12345
# 命令行选项:
# -port=1234
# -theme=light # 或者 dark (默认为 auto)
特殊符号
单引号、双引号、反引号
Go语言的字符串类型string在本质上就与其他语言的字符串类型不同:
- Java的String、C++的std::string以及Python3的str类型都只是定宽字符序列
- Go语言的字符串是一个用UTF-8编码的变宽字符序列,它的每一个字符都用一个或多个字节表示 即:一个Go语言字符串是一个任意字节的常量序列。
Golang的双引号和反引号都可用于表示一个常量字符串,不同在于:
- 双引号用来创建可解析的字符串字面量(支持转义,但不能用来引用多行)
- 反引号用来创建原生的字符串字面量,这些字符串可能由多行组成(不支持任何转义序列),原生的字符串字面量多用于书写多行消息、HTML以及正则表达式
- 单引号则用于表示Golang的一个特殊类型:
rune,类似其他语言的byte但又不完全一样,是指:码点字面量(Unicode code point),不做任何转义的原始内容。
分隔符
Go语言中,行分隔符键是语句终止符,无需指明用;分割
- 和C一样,Go的正式的语法使用分号来终止语句。和C不同的是,这些分号由词法分析器在扫描源代码过程中使用简单的规则自动插入分号,因此输入源代码多数时候就不需要分号了。
- 规则是这样的:如果在一个新行前方的最后一个标记是一个标识符(包括像int和float64这样的单词)、一个基本的如数值这样的文字、或以下标记中的一个时,会自动插入分号:
- break continue fallthrough return ++ – ) }
通常Go程序仅在for循环语句中使用分号,以此来分开初始化器、条件和增量单元。如果你在一行中写多个语句,也需要用分号分开。
- 注意:无论任何时候,你都不应该将一个控制结构((if、for、switch或select)的左大括号放在下一行。如果这样做,将会在大括号的前方插入一个分号,这可能导致出现不想要的结果。
空值 nil
Golang 有个预先声明的标识符 nil
介绍
nil 标识符可作为多种数据结构的零值,通常将 nil 认为是空,就像 C 语言里面的 NULL 一样
零值其实是一种数据类型还没有被初始化时的默认值,对一个零值
- nil 占用的空间因不同数据结构而不同
例如:
- 整形的零值,是 0
- 字符串的零值是 “”
- 布尔类型的零值自然就是 false
零值默认为 nil 的数据结构有这些:
- 函数
- 指针
- interface{}
- Map
- 切片 slice
- 通道 channel
func main() {
log.SetFlags(log.Lshortfile)
// 可将 nil,true/false 作为变量名,赋值和输出
nil := 123
true := 111
false := 222
log.Printf("nil == %+v,true == %+v,false==%+v", nil,true,false)
var ptr *int = nil
log.Println("nil 指针:",unsafe.Sizeof(ptr))
var in interface{} = nil
log.Println("nil interface{}:",unsafe.Sizeof(in))
var mp map[string]string = nil
log.Println("nil map:",unsafe.Sizeof(mp))
var sli []int = nil
log.Println("nil slice:",unsafe.Sizeof(sli))
var ch chan string = nil
log.Println("nil channel:",unsafe.Sizeof(ch))
var fun func() = nil
log.Println("nil 函数:",unsafe.Sizeof(fun))
}
问题
两个 nil 可能不相等吗?可能。
接口(interface) 是对非接口值(例如指针,struct等)的封装,内部实现包含 2 个字段,类型 T 和 值 V。一个接口等于 nil,当且仅当 T 和 V 处于 unset 状态(T=nil,V is unset)。
- 两个接口值比较时,先比较 T,再比较 V。
- 接口值与非接口值比较时,会先将非接口值尝试转换为接口值,再比较。
func main() {
var p *int = nil
var i interface{} = p
fmt.Println(i == p) // true
fmt.Println(p == nil) // true
fmt.Println(i == nil) // false
}
将 nil 非接口值 p 赋值给接口 i,此时,i 内部字段为(T=*int, V=nil),i 与 p 作比较时,将 p 转换为接口后再比较,因此 i == p,p 与 nil 比较,直接比较值,所以 p == nil。
但是当 i 与 nil 比较时,会将 nil 转换为接口 (T=nil, V=nil),与i (T=*int, V=nil) 不相等,因此 i != nil。因此 V 为 nil ,但 T 不为 nil 的接口不等于 nil。
数据类型
基础类型
四种重要的数据类型,即整数,浮点数,字符串和布尔值。
- 整数是整数,浮点数是数字,字符串是”文本”,布尔值是真值,因此是true或false。
- 无符号变量,数值永远不能为负。使用带符号的变量,可以为负
详解:
- Numeric:分 int 和 float
- String
- Boolean:true 或 false
- Derived:分 Pointer、Array、Structure、Mp以及Interface
| 编号 | 类型 | 说明 |
|---|---|---|
| 1 | 布尔类型 | 由两个预定义常量组成:(a) true (b) false |
| 2 | 数字类型 | 算术类型,在整个程序中表示: a)整数类型 b)浮点值。 |
| 3 | 字符串类型 | 字符串类型表示字符串值的集合。它的值是一个字节序列。 字符串是不可变的类型,一旦创建后,就不可能改变字符串的内容。预先声明的字符串类型是string。 |
| 4 | 派生类型 | 包括 (a)指针类型 (b)数组类型 (c)结构类型 (d)联合类型 (e)函数类型 (f)切片类型 (g)函数类型 (h)接口类型 (i) 类型 |
所有类型:
bool
string
int int8(byte) int16 int32(rune) int64
uint uint8 uint16 uint32 uint64 uintptr
byte // uint8 的别名
rune // int32 的别名。代表一个Unicode码
float32 float64
complex64 complex128
- int,uint 和 uintptr 类型在32位的系统上一般是32位,而在64位系统上是64位。当需要使用一个整数类型时,应该首选 int,仅当有特别的理由才使用定长整数类型或者无符号整数类型。
package main
import (
"fmt"
"math/cmplx"
)
var ( //组合定义变量
ToBe bool = false
MaxInt uint64 = 1<<64 – 1
z complex128 = cmplx.Sqrt(-5 + 12i)
x // 变量在定义时没有明确的初始化时会赋值为 零值(“”,0,false…)
var i int = 42
var f float64 = float64(i) //类型强转,不同于C,必须显示转换,不存在隐式转换
f := float64(i) //短声明,简洁形式
const Pi = 3.14 //定义常量
const World = "世界"
)
const (
Big = 1 << 100
Small = Big >> 99
)
func main() {
const f = "%T(%v)\n"
fmt.Printf(f, ToBe, ToBe)
fmt.Printf(f, MaxInt, MaxInt)
fmt.Printf(f, z, z)
}
类型转换
用法同C
i := 90
f := float64(i)
u := uint(i)
// 将等于字符Z
s := string(i)
// int->字符串
i := 90
// 需要导入“strconv”
s := strconv.Itoa(i)
fmt.Println(s) // Outputs: 90
// string转成int:
int, err := strconv.Atoi(string)
// string转成int64:
int64, err := strconv.ParseInt(string, 10, 64)
// int转成string:
string := strconv.Itoa(int)
// int64转成string:
string := strconv.FormatInt(int64,10)
自定义类型 type
type-keyword创建的模板
type people []string
func main() {
var stu = people{"max", "anna"}
fmt.Println(stu)
}
结构体
结构体( struct )是字段的集合。(而 type 含义跟其字面意思相符。)
- Go 结构体和C基本上一样,不过初始化时有些不一样,Go支持带名字的初始化
- struct可实现oop中的类、方法 —— 面向对象编程
- struct成员可以是任何类型,如普通类型、复合类型、函数、struct、interface等。
结构体定义
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{X: 1, Y: 2} // 完整初始化
// Field names can be omitted
v := Vertex{1, 2} // 省略变量名称,按顺序逐个赋值
// Y is implicit
v := Vertex{X: 1} // 省略部分变量
fmt.Println(Vertex{1, 2}) //大括号!初始化
v = Vertex{}
fmt.Println(v.X)
p := &v //结构体指针
p.X = 19
//结构体符文
v1 = Vertex{1, 2} // 类型为 Vertex
v2 = Vertex{X: 1} // Y:0 被省略
v3 = Vertex{} // X:0 和 Y:0
p = &Vertex{1, 2} // 类型为 *Vertex
}
注意:
- Go语言中没有public, protected, private的关键字
- 让一个方法可以被别的包访问,需要把这个方法的第一个字母大写。这是一种约定。
// 【2017-6-8】
type A struct {
MemberA string
}
type B struct {
A //展开结构体A的数值,没有类型
MemberB string
}
结构体方法
go语言中的oop很另类,类在go里面叫做receiver,receiver可以是除了interface之外的任何类型。
- 方法和类并非组织在一起,传统的oop方法和类放在一个文件里面,而go语言只要在同一个包里就可,可分散在不同文件里。
- go的理念就是数据和实现分离
type IntVector []int
func (v IntVector) Sum() (s int) {
for _, x := range v {
s += x
}
return
}
// reciever最好定义成指针的形式。对已非指针形式的reciever会自动转换成指针形式。如
func (u *User) Iter() {
// …
}
u:=User{"liming",22}
u.Iter() //会转换成&User
// 大写方法为public,小写为private
枚举
go 没有枚举类型,可用常量(const) 来表示枚举值。
type StuType int32
const (
Type1 StuType = iota
Type2
Type3
Type4
)
func main() {
fmt.Println(Type1, Type2, Type3, Type4) // 0, 1, 2, 3
}
字符串
Go 语言中的字符串和其他高级语言(Java、C#)一样,默认是不可变的(immutable),好处:
- 天生线程安全,都是只读对象,无须加锁;
- 方便内存共享,而不必使用写时复制(Copy On Write)等技术;
- 字符串 hash 值也只需要制作一份。
string 修改
注意
- Go字符串一旦定义,不可修改!
字符串无法修改,只能复制原字符串,在复制版本上修改
- 方法1:转换为
[]byte() - 方法2:转换为
[]rune() - 方法3:新字符串代替原字符串的子字符串, 用strings包中的 strings.
Replace() []byte和string通过强制类型转换互转
package main
import "fmt"
func main() {
s := "Heros never die" // string类型默认不可修改
str := "a中文cd"
// 转换类型,便于修改: string -> byte 或 rune
// ① 转 byte 序列
s1 := []byte(s) // byte
s1[1] = 'B'
fmt.Println(string(s1))
// ② 转 rune 序列
s2 := []rune(s) // rune, 适配中文
s2[1] = 'B'
fmt.Println(string(s2))
// ③ 使用 replace
new := "ABC"
old := "abc"
s4 := strings.Replace(s1, old, new, 2)
s2 := string(c) // 再转换回 string 类型
fmt.Printf("%s", s2)
// 遍历
for i := 5; i <= 10; i++ {
angleBytes[i] = ' '
}
fmt.Println(string(angleBytes))
}
总结
- Go 语言中没有字符概念,一个字符就是一堆字节,可能是单字节(ASCII 字符集),也可能是多字节(Unicode 字符集)
- byte 是 uint8 的别名,长度为 1 个字节,用于表示 ASCII 字符
- rune 则是 int32 的别名,长度为 4 个字节,用于表示以 UTF-8 编码的 Unicode 码点
- 字符串的截取是以字节为单位的
- 使用下标索引字符串会产生字节
- 要遍历 rune 类型的字符则使用 range 方法
字符串、字符、字节、位:
位bit:bit是计算机中最小的存储单位,一个bit表示一个二进制位,存储0或1。字节byte:一个byte由8个bit组成。- 在Go中,byte也是一种类型,其底层实际上是一种uint8类型的别名,主要是为了区分字节类型和uint8类型,可以指代一个ASCII的字符。
字符:字符表示一个可以正常显示的一个符号,譬如一个字符串abc,其中a、b、c都是字符,在Go中,一个字符对应一个rune类型值。字符串string:Go中的字符串,实际上是只读的字节切片。Unicode码点:实际上,字符的概念非常难以定义,在Unicode标准中,使用码点来代指,一个Unicode表示的个体。其表示是码点,其值是一串数字。rune类型:其是Go中,用以表示一个字符的类型,是int32类型的别名,为了区别表示字符类型以及int32类型。
字符串是字节的切片slice
修改示例
- 将中英文杂的字符串中特定字符(如:中,d)删除
package main
import "fmt"
import "strings"
func main() {
str := "a中文cddd" // string 类型
str_new := []rune(str)
//str_new := string([]rune(str)[:4]) // string 转 rune,再转回 string
fmt.Println(str_new) // 输出:[97 20013 25991 99 100 100 100]
// 设置一个特殊字符,用于后续替换
special_token := '㇎'
for i,v := range []rune(str) {
fmt.Printf("%d, %c\n", i, v)
if v == '中' || v == 'd' {
str_new[i] = special_token
}
}
// 一次性替换所有特殊字符, 等同于删除
str_out := strings.Replace(string(str_new), string(special_token), "", -1)
fmt.Printf("%s --> %s --> %s\n", str, string(str_new), str_out)
}
中文编码
字符编码
ASCII码只需要 7 bit 就可以完整地表示,但只能表示英文字母在内的128个字符- 为了表示世界上大部分的文字系统,发明了
Unicode,ASCII的超集,包含世界上书写系统中存在的所有字符,并为每个代码分配一个标准编号(称为Unicode CodePoint) - Go 语言中称之为
rune,是 int32 类型的别名。
汉字 Unicode 编码范围:参考
- 详见站内专题:字符编码
Unicode 是全球文字统一编码。它把世界上的各种文字的每一个字符指定唯一编码,实现跨语种、跨平台的应用。
中文用户最常接触的是汉字 Unicode 编码。中文字符数量巨大,日常使用的汉字数量有数千个,再加上生僻字,数量达到数万个。这个表格将中文字符集的 Unicode 编码范围列出,点击字库条目可见具体字符。
| 字符集 | 字数 | Unicode编码 |
|---|---|---|
| 基本汉字 | 20902字 | 4E00-9FA5 |
| 基本汉字补充 | 90字 | 9FA6-9FFF |
| 扩展A | 6592字 | 3400-4DBF |
| 扩展B | 42720字 | 20000-2A6DF |
| 扩展C | 4154字 | 2A700-2B739 |
| 扩展D | 222字 | 2B740-2B81D |
| 扩展E | 5762字 | 2B820-2CEA1 |
| 扩展F | 7473字 | 2CEB0-2EBE0 |
| 扩展G | 4939字 | 30000-3134A |
| 扩展H | 4192字 | 31350-323AF |
| 康熙部首 | 214字 | 2F00-2FD5 |
| 部首扩展 | 115字① | 2E80-2EF3 |
| 兼容汉字 | 472字② | F900-FAD9 |
| 兼容扩展 | 542字 | 2F800-2FA1D |
| 汉字笔画 | 36字 | 31C0-31E3 |
| 汉字结构 | 12字 | 2FF0-2FFB |
| 汉语注音 | 43字 | 3105-312F |
| 注音扩展 | 32字 | 31A0-31BF |
| 〇 | 1字 | 3007 |
字数备注:
- ① 部首扩展:2E9A 是空码位。
- ② 兼容汉字:FA6E、FA6F 是空码位。
byte 与 rune
Go 语言没有字符类型,字符只是整数的特殊用例。
- 用于表示字符的
byte和rune类型都是整型的别名。 byte是uint8的别名,长度为 1 个字节,用于表示 ASCII 字符rune是int32的别名,长度为 4 个字节,用于表示以 UTF-8 编码的 Unicode 码点
推荐使用
byte或rune,仅包含Ascii码时,使用byte,其余使用rune
注意
- Unicode 从 0 开始,为每个符号指定一个编号,这叫做「码点」(code point)
- Unicode 和 ASCII 一样,是一种字符集,UTF-8 则是一种编码方式
字母1个字节,汉字3个字节
fmt.Println(len("Go语言")) // 8
fmt.Println(len([]rune("Go语言"))) // 4
存储过程:
- 字符 -> 码值(数字) -> 二进制 -> 保存
type byte = uint8
type rune = int32
// byte 指定字符变量
var byteC byte = 'j' // byte 实质上是整型 uint8,所以可以直接转成整型值。
fmt.Printf("字符 %c 对应的整型为 %d\n", byteC, byteC)
// Output: 字符 j 对应的整型为 106
//rune 与 byte 相同
var runeC rune = 'J'
// runeC := 'J' // 字符变量未指定类型时,默认是 rune 类型
fmt.Printf("字符 %c 的类型为 %T\n", runeC, runeC)
// Output: 字符 J 的类型为 int32
为什么要两种类型呢?
- byte 占用一个字节,可用于表示 ASCII 字符。
- 而 UTF-8 是一种变长的编码方法,字符长度从 1~4 个字节不等。byte 显然不擅长这样的表示,就算想用多个 byte 进行表示,也不知道要处理的 UTF-8 字符究竟占了几个字节。
go采用utf-8来对Unicode进行编码

- 常用汉字一般使用3个字节
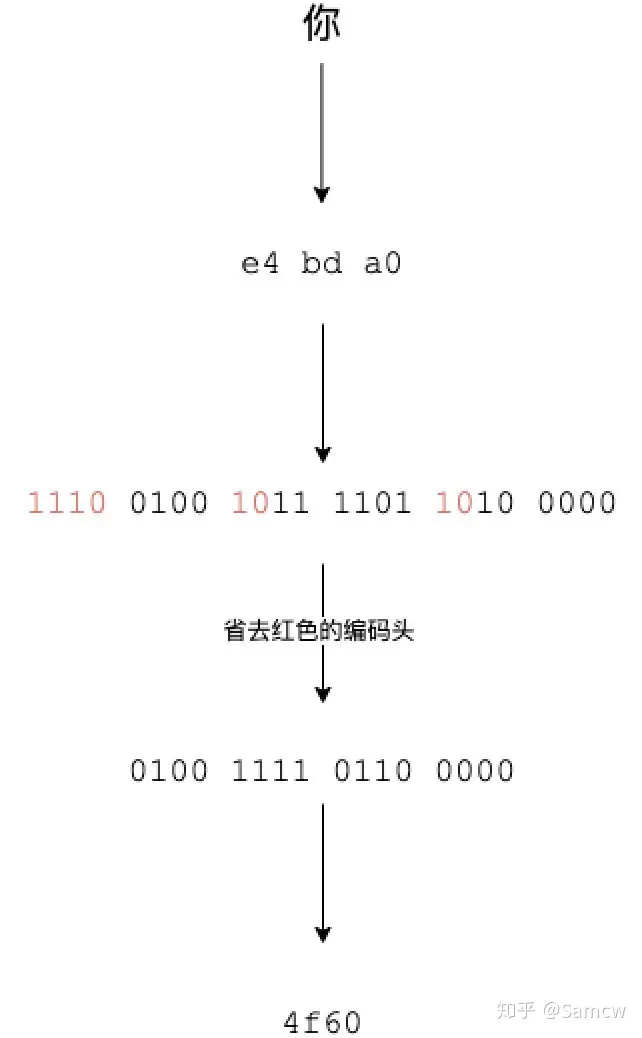
Go为字符定义了字符类型rune, int32类型的别名,主要用来处理Unicode字符。之所以对应的是int32类型,是因为utf-8编码,最大会产生4个字节的大小的值,故对应了int32类型。
testString := "你好,世界"
fmt.Println(testString[:2]) // 输出乱码,因为截取了前两个字节
fmt.Println(testString[:3]) // 输出「你」,一个中文字符由三个字节表示
// 用 []rune() 将字符串转为 Unicode 码点,再进行截取,无需考虑字符串中含有 UTF-8 字符
fmt.Println(string([]rune(testString)[:2])) // 输出:「你好」
func test() {
s := "Hello,世界"
for _, val := range s {
fmt.Printf("%#U\n", val)
}
}
/*
U+0048 'H'
U+0065 'e'
U+006C 'l'
U+006C 'l'
U+006F 'o'
U+002C ','
U+4E16 '世'
U+754C '界'
*/
除了range方法遍历,也可以用标准库对字符串进行处理,如unicode/utf8库中的DecodeRuneInString方法,输入一个字节切片,返回一个rune值和其使用utf-8编码的字节宽度。
- 详见:go字符串初探
字符串定义
字符串
- 单行定义: 使用双引号
- 多行定义: 使用反引号
package main
import (
"fmt"
"strings"
// s "strings" // 包别名
)
func main() {
//x := 'a' // rune类型
//x := "a" // string
a := "这是单行测试字符串..."
/* // 或: "a " + "b" 模式
b := "这是多行测试字符串..." +
"b, 第二行" */
b := `这是多行测试字符串...
b, 第二行`
greetings := []string{"Hello","world!"}
fmt.Println(strings.Join(greetings, " ")) //字符串连接
fmt.Print(a)
log.Print(b) // 输出字符串要用双引号,否则:more than one character in rune literal
}
// 前缀:
strings.HasPrefix("prefix", "pre")
// 后缀:
strings.HasSuffix("suffix", "fix")
字符串格式化
【2022-9-16】fmt.Sprintf 格式化字符串
sprintf
- 格式化样式:字符串形式,格式化符号以 % 开头, %s 字符串格式,%d 十进制的整数格式。
- 参数列表:多个参数以逗号分隔,个数必须与格式化样式中的个数一一对应,否则运行时会报错。
| 格式 | 描述 | 示例 |
|---|---|---|
| %v | 按值的本来值输出 | {1 2} |
| %+v | 在基础上,对结构体字段名和值进行展开 | {x:1 y:2} |
| %#v | 输出Go 语言语法格式的值 | main.point{x:1, y:2} |
| %T | 输出Go 语言语法格式的类型和值 | main.point |
| %% | 输出%本体 | |
| %b | 整型以二进制方式显示 | |
| %o | 整型以八进制方式显示 | |
| %d | 整型以十进制方式显示 | |
| %x | 整型以十六进制方式显示 | |
| %X | 整型以十六进制、字母大写方式显示 | |
| %U | Unicode字符 | |
| %f | 浮点数 | |
| %p | 指针,十六进制方式显示 |
package main
import (
"fmt"
"os"
)
type point struct {
x, y int
}
func main() {
p := point{1, 2}
fmt.Printf("%v\n", p) // {1 2}
fmt.Printf("%+v\n", p) // {x:1 y:2}
fmt.Printf("%#v\n", p) // main.point{x:1, y:2}
fmt.Printf("%T\n", p) // main.point
fmt.Printf("%t\n", true)
fmt.Printf("%d\n", 123)
fmt.Printf("%b\n", 14)
fmt.Printf("%c\n", 33)
fmt.Printf("%x\n", 456)
fmt.Printf("%f\n", 78.9)
fmt.Printf("%e\n", 123400000.0)
fmt.Printf("%E\n", 123400000.0)
fmt.Printf("%s\n", "\"string\"")
fmt.Printf("%q\n", "\"string\"")
fmt.Printf("%x\n", "hex this")
fmt.Printf("%p\n", &p)
fmt.Printf("|%6d|%6d|\n", 12, 345)
fmt.Printf("|%6.2f|%6.2f|\n", 1.2, 3.45)
fmt.Printf("|%-6.2f|%-6.2f|\n", 1.2, 3.45)
fmt.Printf("|%6s|%6s|\n", "foo", "b")
fmt.Printf("|%-6s|%-6s|\n", "foo", "b")
s := fmt.Sprintf("a %s", "string")
fmt.Println(s)
fmt.Fprintf(os.Stderr, "an %s\n", "error")
}
字符串遍历
字符串遍历有两种方式
- 一种是下标遍历
- 一种是使用 range
for i:=0;i<len(world1);i=i+3{
fmt.Print(world1[i:i+3])
}
for _,s := range world1{
fmt.Printf("%c",s)
}
注意:
- 中文是3个取一次,否则没意义。
- 推荐使用for range方式,有字符和中文时都可以。
下标遍历
字符串以 UTF-8 编码方式存储
- 用 len() 函数获取字符串长度时,获取到的是该 UTF-8 编码字符串的字节长度
- 通过下标索引字符串, 将会产生一个字节。
因此,如果字符串中含有 UTF-8 编码字符,就会出现乱码
testString := "Hello,世界"
for i := 0; i < len(testString); i++ {
c := testString[i]
fmt.Printf("%c 的类型是 %s\n", c, reflect.TypeOf(c))
}
/* Output:
H 的类型是 uint8(ASCII 字符返回正常)
e 的类型是 uint8
l 的类型是 uint8
l 的类型是 uint8
o 的类型是 uint8
ï 的类型是 uint8(从这里开始出现了奇怪的乱码)
¼ 的类型是 uint8
的类型是 uint8
ä 的类型是 uint8
¸ 的类型是 uint8
的类型是 uint8
ç 的类型是 uint8
的类型是 uint8
的类型是 uint8
*/
range遍历
range 遍历则会得到 rune 类型的字符:
testString := "Hello,世界"
for _, c := range testString {
fmt.Printf("%c 的类型是 %s\n", c, reflect.TypeOf(c))
}
/* Output:
H 的类型是 int32
e 的类型是 int32
l 的类型是 int32
l 的类型是 int32
o 的类型是 int32
, 的类型是 int32
世 的类型是 int32
界 的类型是 int32
*/
字符串操作大全
strings 判等
- == 直接比较,区分大小写
strings.Compare(a,b)该函数返回值为 int, 0 表示两数相等,1 表示 a>b, -1 表示 a< b。区分大小写strings.EqualFold(a,b)直接返回是否相等,不区分大小写。
strings使用方法
- Contains* 包含
- Count 技术
- HasPrefix,HasSuffix 前缀、后缀判断
- Index* 找子串
- Join 连接
- Split 分割
- Replace 替换
package main
import s "strings" //strings取个别名
import "fmt"
var p = fmt.Println//给 fmt.Println 一个短名字的别名,随后将会经常用到。
func main() {
// 字符串判等
fmt.Println("go"=="go") // true ① ==,区分大小写,最简单
fmt.Println("GO"=="go") // false
fmt.Println(strings.Compare("GO","go")) // -1 Compare 区分大小写,速度慢于 ==
fmt.Println(strings.Compare("go","go")) // 0
fmt.Println(strings.EqualFold("GO","go")) // true 比较utf-8在小写情况下是否相等,不区分大小写
// 注意都是包中的函数,不是字符串对象自身的方法,调用时传递字符作为第一个参数进行传递。
// 从字符串中读取内容
cisco_cert_level := "CCIE CCNP CCNA"
cisco := strings.NewReader(cisco_cert_level)
fmt.Printf("%T\n", cisco)
fmt.Printf("%v\n", cisco)
fmt.Printf("%p\n", cisco)
//注意都是包中的函数,不是字符串对象自身的方法,调用时传递字符作为第一个参数进行传递。
p("Contains: ", s.Contains("test", "es")) // true,包含判断,注意s.Contains("", "")=true
p(s.ContainsAny("test", "e")) // e&s(且),e|s(或)
p(s.ContainsRune("我爱中国", '我')) //字符匹配,注意是单引号!
p(s.EqualFold("Go", "go")) //判等,忽略大小写
// Fields 去除s字符串的空格字符,并按照空格分割返回slice
fmt.Println(strings.Fields(" I love you ! ")) // 返回 ["I","love","you","!"]
p(s.Fields("a b c")) //字符串变列表["a" "b" "c"]
p("Count: ", s.Count("test", "t")) //2 计数
p("HasPrefix: ", s.HasPrefix("test", "te"))// true 前缀判断
p("HasSuffix: ", s.HasSuffix("test", "st"))// true 后缀判断
// Contains 字符串s中是否包含substr,返回bool值
fmt.Println(strings.Contains("seafood", "foo"))
fmt.Println(strings.Contains("seafood", "bar"))
// Index 在字符串s中查找substr所在的位置,返回位置值,找不到返回-1
fmt.Println(strings.Index("zhaoxu", "ox"))
fmt.Println(strings.Index("zhaoxu", "oocc"))
p("Index: ", s.Index("test", "e"))// 1 查找子串
p("Index: ", s.IndexAny("我是中国人", "中"))// 返回任意一个
p("Index: ", s.IndexRune("我是中国人", '中'))// 字符
p("Index: ", s.LastIndex("go gopher", "go"))// 1 查找子串
p("Index: ", s.LastIndexAny("go gopher", "go"))// 1 查找子串
rot13 := func(r rune) rune {
switch {
case r >= 'A' && r <= 'Z':
return 'A' + (r-'A'+13)%26
case r >= 'a' && r <= 'z':
return 'a' + (r-'a'+13)%26
}
return r
}
fmt.Println(strings.Map(rot13, "'Twas brillig and the slithy gopher...")) //相当于python中的map
// Join 字符串连接,将slice a通过sep连接
fmt.Println(strings.Join([]string{"I", "Love", "You"}, "-->"))
p("Join: ", s.Join([]string{"a", "b"}, "-")) //a-b slice连接成字符串
// Repeat 重复s,count次,返回重复的字符串
fmt.Println(strings.Repeat("Love", 5))
p("Repeat: ", s.Repeat("a", 5)) // aaaaa 重复
p("Replace: ", s.Replace("foo", "o", "0", -1)) //f00 全部替换
p("Replace: ", s.Replace("foo", "o", "0", 1))//f0o 1次替换
p("Replace: ", s.Replace("foo", "o", "0", 2))//f0o 2次替换,从前往后逐个替换
// Split 把字符串按照sep分割,返回分割后的slice
fmt.Println(strings.Split("I love you", " ")) // 按空格分隔字符串
fmt.Println(strings.Split(" zxy ", ""))
p("Split: ", s.Split("a-b-c-d-e", "-"))//[a b c d e] string转array(slice?)
fmt.Printf("%qn", strings.SplitAfter("/home/m_ta/src", "/")) //["/" "home/" "m_ta/" "src"]
fmt.Printf("%qn", strings.SplitAfterN("/home/m_ta/src", "/", 2)) //["/" "home/m_ta/src"]
fmt.Printf("%qn", strings.SplitN("/home/m_ta/src", "/", 2)) //["/" "home/" "m_ta/" "src"]
fmt.Printf("%qn", strings.SplitN("/home/m_ta/src", "/", -1)) //["" "home" "m_ta" "src"]
fmt.Println(strings.Title("her royal highness")) //首字符大写?
fmt.Println(strings.ToTitle("loud noises"))
p("ToLower: ", s.ToLower("TEST"))//test 小写
p("ToUpper: ", s.ToUpper("test"))//TEST 大写
// 截断,删除
fmt.Printf("[%q]", strings.Trim(" !!! Achtung !!! ", "! ")) // ["Achtung"]
fmt.Printf("[%q]", strings.TrimLeft(" !!! Achtung !!! ", "! ")) // ["Achtung !!! "]
fmt.Println(strings.TrimSpace(" tn a lone gopher ntrn")) // a lone gopher
p("Len: ", len("hello"))// 5 长度
p("Char:", "hello"[1])// 101 取字符
}
类似于Python的strip()、rsrip()、lstrip(),Go的strings包也有TrimSpace()、TrimLeft()、TrimRight()
参考:go字符串操作示例
数组(array)—— 固定大小
数组
- 数组支持 “==“、”!=” 操作符,因为内存总是被初始化过的
- [n]*T 表示指针数组,*[n]T表示数组指针
┌────┬────┬────┬────┬─────┬─────┐
| 2 | 3 | 5 | 7 | 11 | 13 |
└────┴────┴────┴────┴─────┴─────┘
0 1 2 3 4 5
数组定义
var a [10]int //定义数组时需要制定大小s
var stu = [2]string{"a", "b"}
stu[0] = "c"
ftm.Println(stu)
// 变长数组
var stu = []string{"a", "b"}
std = append(std, "c")
fmt.Println(stu)
// 遍历数组
for i, v := range stu {
fmt.Println(i, v)
}
// 不要下标
for _, v := range stu {
fmt.Println(v)
}
// ---------------------
var a [2]string
a[0] = "Hello"
a[1] = "World"
fmt.Println(a[0], a[1]) //=> Hello World
fmt.Println(a) // => [Hello World]
// 切片操作
primes := [...]int{2, 3, 5, 7, 11, 13}
fmt.Println(len(primes)) // => 6
// 输出:[2 3 5 7 11 13]
fmt.Println(primes)
// 与 [:3] 相同,输出:[2 3 5]
fmt.Println(primes[0:3])
// ----- 二维数组 ------
var twoDimension [2][3]int
for i := 0; i < 2; i++ {
for j := 0; j < 3; j++ {
twoDimension[i][j] = i + j
}
}
// => 2d: [[0 1 2] [1 2 3]]
fmt.Println("2d: ", twoDimension)
字符串替换
字符串替换
- sprintf
- 格式化样式:字符串形式,格式化符号以 % 开头, %s 字符串格式,%d 十进制的整数格式。
- 参数列表:多个参数以逗号分隔,个数必须与格式化样式中的个数一一对应,否则运行时会报错。
- os.Expand:参考go模板替换
- 正则表达式
package main
import (
"fmt"
"io"
"os"
)
func main() {
// ======= 方法一 ========
// go 中格式化字符串并赋值给新串,使用 fmt.Sprintf
// %s 表示字符串
var stockcode="000987"
var enddate="2020-12-31"
var url="Code=%s&endDate=%s"
var target_url=fmt.Sprintf(url,stockcode,enddate)
fmt.Println(target_url)
// 另外一个实例,%d 表示整型
const name, age = "Kim", 22
s := fmt.Sprintf("%s is %d years old.\n", name, age)
io.WriteString(os.Stdout, s) // 简单起见,忽略一些错误
// ======== 方法二 ========
var config = `
app.name = ${appName}
app.ip = ${appIP}
app.port = ${appPort}
`
var dev = map[string]string{
"appName": "my_app",
"appIP": "0.0.0.0",
"appPort": "8080",
}
// config 字符串模板(占位符 ${x},其中{}是可以省略),dev是变量字典,通过匿名函数来实现替换
s := os.Expand(config, func(k string) string { return dev[k] })
fmt.Println(s)
}
- 数组的长度是其类型的一部分,因此数组不能改变大小——怎么办?用slice!
- 数组在Go语言中很重要,应该需要了解更多的信息。
以下几个与数组相关的重要概念应该向Go程序员明确:
| 概念 | 描述 | |—|—| | 多维数组 | Go支持多维数组,多维数组的最简单的形式是二维数组。| | 将数组传递给函数 | 可以通过指定数组的名称而不使用索引,将指向数组的指针传递给函数。|
切片 (slice) —— 大小不定
数组长度不可变, 有很多局限性
slice 定义
slice 是拥有相同类型元素的可变长度的序列,基于数组类型做的一层封装,支持自动扩容
- 切片是一个引用类型,内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
- 一个 slice 会指向一个序列的值,并且包含了长度信息。slice包含了array的基本操作
指定大小就是array,否则 slice
切片的底层数据结构: 指针 ptr (指向一个数组) + cap (切片容量) + len (切片中已有数据长度)
slice 用法
典型方法
- 长度信息:
len()实际长度,cap()容量 - 判空: nil
- 切片操作
append()copy()函数
func main() {
// array
x := [3]int{3,5,6} //指定大小就是array!否则slice
x := [3]int{} // 数组
// 数组切片操作
var arr = [5]int{0, 1, 2, 3, 4}
s := arr[1:3]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s)) //s:[1 2] len(s):2 cap(s):4
fmt.Printf("typeof s:%T\n", s) //typeof s:[]int
// slice
s := []int{2, 3, 5, 7, 11, 13} // slice
a := make([]int, 5) // len(a)=5,用make构造slice(默认取值0)
b := make([]int, 0, 5) // len(b)=0, cap(b)=5,指定容量
if a == nil {
fmt.Printf("空slice\n")
}
var z []int //nil slice空切片,z=nil
// var声明的零值切片可以在append()函数直接使用,无需初始化。
z := []int{} // 没有必要初始化
var s = make([]int) // 没有必要初始化
z = append(z, 0) //append追加元素
//添加多个
z = append(z, 1,4,3)//多个元素
n3 := []int{4, 5}
n2 = append(n2, n3...)
n2 = append(n2, 2, 3, 4)
z[2:] // 等同于 z[2:len(a)]
z[:3] // 等同于 z[0:3]
z[:] // 等同于 z[0:len(a)]
// 复制
a := []int{1, 2, 3, 4, 5}
b := a
copy(a,b) //复制
fmt.Println("s ==", s)
fmt.Println("s[1:4] ==", s[1:4]) //s[:4],s[:5]同python
game := [][]string{ //二维切片
[]string{"_", "_", "_"},
[]string{"_", "_", "_"}
}
for i := 0; i < len(s); i++ {
fmt.Printf("s[%d] == %d\n", i, s[i])
fmt.Printf("%s\n", strings.Join(s[i], " ")) //连接二维切片里的一维
}
// 删除切片元素:GO没有删除切片元素的方法,可用切片本身的特性来删除元素
aaa := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 1}
aaaa := append(aaa[:3], aaa[4:]...)
}
func test_array(array [5]int){ //array值传递,未改变原参数值
newarray := array
newarray[0] = 88
}
func test_slice(slice []int){ //slice引用传递,值改变了
newslice := slice
newslice[0] = 88
}
- 不只是数组,go语言中的大多数类型在函数中当作参数传递都是值语义的。任何值语义的一种类型当作参数传递到调用的函数中,都会经过一次内容的copy,从一个方法栈中copy到另一个方法栈
- go不是一种纯粹的面向对象语言,更多的是一种更简单高效的C,所以在参数传递上跟C保持着基本的一致性。一些较大的数据类型,比如结构体、数组等,最好使用传递指针的方式,这样就能避免在函数传递时对数据的copy。
- 虽然slice在传递时是按照引用语义传递,但是又因为append()操作的问题,导致即使是引用传递还是不能顺利解决一些问题
slice 特殊用途
slice 判等
go 语言可用反射 reflect.DeepEqual(a, b) 判断 a、b 两个切片是否相等
- 但是不推荐,反射非常影响性能。
常用方法
- 遍历比较切片每个元素(注意处理越界的情况)。
func StringSliceEqualBCE(a, b []string) bool {
if len(a) != len(b) {
return false
}
if (a == nil) != (b == nil) {
return false
}
b = b[:len(a)]
for i, v := range a {
if v != b[i] {
return false
}
}
return true
}
范围(range)
range关键字在for循环中用于遍历数组,切片,通道或映射的项目
| 范围表达式 | 第1个值 | 第2个值(可选) |
|---|---|---|
| 数组或切片a[n]E | 索引 i 整数 | a[i]E |
| Strubg s字符串 | 索引 i 整数 | 符文整数 |
| map m map[K]V | key k K | value m[k] V |
| channel c chan E | element e E | none |
循环遍历slice、map
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow { //取index、value
fmt.Printf("2**%d = %d\n", i, v)
}
pow := make([]int, 10)
for i := range pow { // 取index
pow[i] = 1 << uint(i)
}
for _, value := range pow { //取value(index用_忽略)
fmt.Printf("%d\n", value)
}
}
哈希map
哈希原理
定义
- 在计算机科学里,被称为
相关数组、map、符号表或者字典,是由一组 < key, value> 对组成的抽象数据结构,,并且同一个 key 只会出现一次。
有两个关键点:
- map 是由 key-value 对组成的;
- key 只会出现一次。
和 map 相关的操作主要是:
- 增加一个 k-v 对 —— Add or insert;
- 删除一个 k-v 对 —— Remove or delete;
- 修改某个 k 对应的 v —— Reassign;
- 查询某个 k 对应的 v —— Lookup;
简单说就是最基本的增删查改。
map 的设计也被称为 “The dictionary problem”,任务是设计一种数据结构用来维护一个集合的数据,并且可以同时对集合进行增删查改的操作。
最主要的数据结构有两种:
- (1)
哈希查找表(Hash table): 哈希查找表用一个哈希函数将 key 分配到不同的桶(bucket,也就是数组的不同 index)。这样开销主要在哈希函数的计算以及数组的常数访问时间- 在很多场景下,哈希查找表的性能很高。
- 哈希查找表一般会存在“碰撞”的问题,不同的 key 被哈希到了同一个 bucket。一般有两种应对方法:
链表法和开放地址法。- 链表法将一个 bucket 实现成一个链表,落在同一个 bucket 中的 key 都会插入这个链表。
- 开放地址法则是碰撞发生后,通过一定的规律,在数组的后面挑选“空位”,用来放置新的 key。
- (2)
搜索树(Search tree): 搜索树法一般采用自平衡搜索树,包括:AVL 树,红黑树。- 面试时经常会被问到,甚至被要求手写红黑树代码,很多时候,面试官自己都写不上来,非常过分。
- 自平衡搜索树法的最差搜索效率是 O(logN),而哈希查找表最差是 O(N)。当然,哈希查找表的平均查找效率是 O(1),如果哈希函数设计的很好,最坏的情况基本不会出现。还有一点,遍历自平衡搜索树,返回的 key 序列,一般会按照从小到大的顺序;而哈希查找表则是乱序的。
map 实现的几种方案,Go 语言采用的是哈希查找表,并且使用链表解决哈希冲突。
go map
映射(Map),它将唯一键映射到值。
- 键是用于在检索值的对象。 给定一个键和一个值就可以在Map对象中设置值
Map 使用方法
- ① 先声明map、再初始化、最后赋值
- ② 直接创建(限方法内)、再赋值
- ③ 初始化 + 赋值一体化(限方法内)
package main
import (
"fmt"
)
var AutoReply map[string]string
type EvaluateItem struct {
ItemName string
ItemBase float64
Reason string
Alpha float64
}
func main(){
//================
// ① 先声明map、再初始化、最后赋值
var m1 map[string]string
// string -> struct 映射到结构体
evaluateItemRef := map[string][]EvaluateItem{}
// 再使用make函数创建一个非nil的map,nil map不能赋值
m1 = make(map[string]string)
// 最后给已声明的map赋值
m1["a"] = "aa"
m1["b"] = "bb"
// ② 直接创建(限方法内)、再赋值
m2 := make(map[string]string)
// 然后赋值
m2["a"] = "aa"
m2["b"] = "bb"
// ③ 初始化 + 赋值一体化(限方法内)
m3 := map[string]string{
"a": "aa",
"b": "bb",
}
// ------ 查找键值是否存在 ------
if v, ok := m1["a"]; ok {
fmt.Println(v)
} else {
fmt.Println("Key Not Found")
}
// 遍历map
for k, v := range m1 {
fmt.Println(k, v)
}
// ======== [2-23-2-24]实测 ==========
// 方法一:直接赋值
AutoReply = map[string]string{"":"什么也没输入..."}
// 方法二:使用make
AutoReply = make(map[string]string)
AutoReply[""] = "什么也没输入..."
for k,v:=range AutoReply{
fmt.Print(k, v)
}
str := []string{"i", ""}
for i,v := range str{
// 格式化输出时,需使用 Printf,否则 %s 失效
fmt.Printf("开始检查:[%s]\n", v)
if res,ok := AutoReply[v];ok {
fmt.Printf("[res] %s 在字典%d中\n", v, i)
}else{
fmt.Printf("[res] %s 不在字典%d中\n", v, i)
}
}
fmt.Print("done")
}
其它示例
var countryCapitalMap map[string]string // 创建map
countryCapitalMap = make(map[string]string) // string -> string
// [2023-2-24] map 定义是要初始化,否则:panic: assignment to entry in nil map
/* insert key-value pairs in the map*/
countryCapitalMap["France"] = "Paris" // 插入元素
delete(countryCapitalMap,"France"); // 删除
/* print map using keys*/
for country := range countryCapitalMap { // (1)按照key遍历map
fmt.Println("Capital of",country,"is",countryCapitalMap[country])
}
// `range` on map iterates over key/value pairs.
kvs := map[string]string{"a": "apple", "b": "banana"} //初始化!
for k, v := range kvs { // (2)按照键值对遍历map
fmt.Printf("%s -> %s\n", k, v)
}
// `range` can also iterate over just the keys of a map.
for k := range kvs { // (1)按照key遍历map
fmt.Println("key:", k)
}
// `range` on strings iterates over Unicode code points. The first value is the starting byte index of the `rune` and the second the `rune` itself.
for i, c := range "go" { //字符串时遍历字符
fmt.Println(i, c)
}
m := map[string]map[string]string{} // 嵌套map
// 字典判重
mm, ok := m["kkk"]
if !ok {
mm = make(map[string]string)
m["kkk"] = mm
}
mm[k1k1k1] = "sssss"
//【2017-06-21】map存在性判断
//【教训】go禁止对map成员取地址。。。但slice成员可以,好变态
if _, ok := map[key]; ok {//存在
}
test := map[string]int{"a":1,"b":2}
// ./multi_map.go:34: cannot take the address of test["a"]
fmt.Println("三层取地址:",©WriteDict["female"][1]) //slice成员可以取地址
fmt.Println("三层取地址:",©WriteDict["female"][1]["real"]) //cannot take the address of copy
解决办法:
- (1)不传指针
- (2)提前用临时变量缓存,再传非map类的地址
有序map:orderedmap
【2023-1-9】如何有序遍历map
map为什么无序
原生的 Map 为什么无序?
- 遍历 Map 的打印的时候,会注意到内容是无序的。
- map中的元素迭代的时候是无序的,所以使用 encoding/json 进行序列化时,默认是按照字典序排序的。
Map 底层实现原理:
- 遍历 Map 时,是按顺序遍历 bucket ,然后再按顺序遍历 bucket 中 的 key(bucket 里面是个链表)。
- 然而,Map 在扩容时,key 会发生迁移,从旧 bucket 迁移到新的 bucket,这种情况下,是做不到有序遍历的。
map 核心元素是桶,key通过哈希算法被归入不同的bucket中,key是无序的
-
很多应用场景可能需要map key有序(例如交易所订单撮合),C++ 的stl map实现了key有序,实际上是
TreeMap是基于树(红黑树)的实现方式,即添加到一个有序列表,在O(logn)的复杂度内通过key值找到value,优点是空间要求低,但在时间上不如HashMap。 -
Go 官方直接在遍历开始,使用 fastrand 随机选一个 buckct 作为起始桶。
如何实现有序遍历
思路一:实现快
- 将 Map 中的 key 拿出来,放入 slice 中做排序
func main() {
m := make(map[string]string)
m["name"] = "Bob"
m["age"] = "25"
m["gender"] = "male"
keys := make([]string, 0)
for k := range m {
keys = append(keys, k)
}
//排序 key
sort.Strings(keys)
for _, key := range keys {
println(m[key])
}
}
思路二:一劳永逸
- 利用官方库里的 list(链表) 封装一个结构体,实现一个有序的 K-V 存储结构,在里面维护一个 keys 的 list。
为什么使用 list 而不是参考思路一用 slice 来保证有序?
- 因为 list 可以实现 insertBefore、insertAfter 类似的方法,而 slice 实现相对复杂。
- 参考: orderedmap
package orderedmap
import "container/list"
//......更多细节请看源码
//OrderedMap 核心数据结构
type OrderedMap struct {
//存储 k-v,使用 *list.Element 当做 value 是利用 map O(1) 的性能找到 list 中的 element
kv map[interface{}]*list.Element
//按顺序存储 k-v,保证插入、删除的时间复杂度O(1)
ll *list.List
}
//......更多细节请看源码
总结
- Golang 中 Map之所以放弃有序遍历,也是出于性能和复杂度的考虑。
- 这也是为什么上面的思路都或多或少地都比原生Map使用起来复杂了许多。
orderedmap
源码说明
- orderedmap数据结构
有序map包含三个元素。其中escapeHTML表示是否转义HTML字符,默认为true表示转义。可以调用SetEscapeHTML(false)方法来设置不转义HTML字符。
type OrderedMap struct {
keys []string // 存放所有的key,用来记录元素顺序
values map[string]interface{} //存放key和value
escapeHTML bool //是否转义HTML字符。默认为true表示转义。
}
- 排序函数
//对key进行排序
// SortKeys Sort the map keys using your sort func
func (o *OrderedMap) SortKeys(sortFunc func(keys []string)) {
sortFunc(o.keys)
}
//对value进行排序。其中结构体Pair实现了排序接口的Len()、Less()、Swap()这三个方法。可以直接使用标准库中的排序方法
// Sort Sort the map using your sort func
func (o *OrderedMap) Sort(lessFunc func(a *Pair, b *Pair) bool) {
pairs := make([]*Pair, len(o.keys))
for i, key := range o.keys {
pairs[i] = &Pair{key, o.values[key]}
}
sort.Sort(ByPair{pairs, lessFunc})
for i, pair := range pairs {
o.keys[i] = pair.key
}
}
- 序列化函数
// 主要是分别序列化key和value,然后组装带一起
func (o OrderedMap) MarshalJSON() ([]byte, error) {
var buf bytes.Buffer
buf.WriteByte('{')
encoder := json.NewEncoder(&buf)
encoder.SetEscapeHTML(o.escapeHTML)
for i, k := range o.keys {
if i > 0 {
buf.WriteByte(',')
}
// add key
if err := encoder.Encode(k); err != nil {
return nil, err
}
buf.WriteByte(':')
// add value
if err := encoder.Encode(o.values[k]); err != nil {
return nil, err
}
}
buf.WriteByte('}')
return buf.Bytes(), nil
}
- 反序列化函数
func (o *OrderedMap) UnmarshalJSON(b []byte) error {
if o.values == nil {
o.values = map[string]interface{}{}
}
// 1. 先直接对整体进行反序列化
err := json.Unmarshal(b, &o.values)
if err != nil {
return err
}
dec := json.NewDecoder(bytes.NewReader(b))
if _, err = dec.Token(); err != nil { // skip '{'
return err
}
o.keys = make([]string, 0, len(o.values))
// 2. 解析出源数据中key,主要分为了map和slice两种情况分别解析
return decodeOrderedMap(dec, o)
}
使用方法
package main
import (
"encoding/json"
"fmt"
"sort"
"github.com/iancoleman/orderedmap"
)
func start() {
o := orderedmap.New()
o.Set("name", "tom")
o.Set("age", "10")
o.Set("height", "170")
o.Set("hobby", "ball")
x, _ := json.Marshal(o)
var m map[string]interface{}
_ = json.Unmarshal(x, &m)
y, _ := json.Marshal(m)
fmt.Println("ordered map: ", string(x))
fmt.Println("map: ", string(y))
//ordered map: {"name":"tom","age":"10","height":"170","hobby":"ball"}
//map: {"age":"10","height":"170","hobby":"ball","name":"tom"} map序列化后默认按照key的字典序排序
//按照key的字典序升序排序
o.SortKeys(sort.Strings)
x, _ = json.Marshal(o)
fmt.Println("asc sort key: ", string(x))
//asc sort key: {"age":"10","height":"170","hobby":"ball","name":"tom"} 这是就是标准库中的map序列化后结果一致
//按照key的字典序降序排序
o.SortKeys(func(keys []string) {
sort.Slice(keys, func(i, j int) bool {
return keys[i] > keys[j]
})
})
x, _ = json.Marshal(o)
fmt.Println("desc sort key: ", string(x))
//desc sort key: {"name":"tom","hobby":"ball","height":"170","age":"10"}
//按照value的字典序升序排序
o.Sort(func(a *orderedmap.Pair, b *orderedmap.Pair) bool {
return a.Value().(string) < b.Value().(string)
})
x, _ = json.Marshal(o)
fmt.Println("sort value: ", string(x))
//sort value: {"age":"10","height":"170","hobby":"ball","name":"tom"}
}
func main() {
start()
}
常量(Constants)
不同于C,变量后面类型可有可无
const s string = "constant"
const Phi = 1.618
const n = 500000000
const d = 3e20 / n
fmt.Println(d)
变量
Go标识符是用于标识变量、函数或任何其他用户定义项目的名称。
- 标识符以字母A到Z或a到z或下划线_开头,后跟零个或多个字母,下划线和数字(0到9)组成。
- 标识符 = [字母_] {字母 | unicode数字_}。
Go不允许在标识符中使用标点符号,例如@, $ 和 %。 Go是一种区分大小写的编程语言。
- 因此,Manpower和manpower在Go中是两个不同的标识符
go 变量的特殊之处:没有空值描述尚未分配值的变量的值。而是,每个变量类型都有一个默认值,具体取决于变量的数据类型。
- 如果声明没有值的变量,则必须指定数据类型,否则变量类型是可选的
两种定义变量的方法:
- 经典方法(使用variable-keyword)
- 简写语法
注意
- := 只能用于方法内,当定义全局变量时只能通过 var 关键字来定义
// ---- 经典方式 -----
var name string
var name string = "max" // 指定初始值
var name = "max" // 不提供类型,go自动根据取值推断类型
var age int
var age, grade int = 15, 9 // 一次定义多个
var adult bool
var height float32
const name =" Max" // 常量变量,不容修改
// ---- 简写方式 -----
tmp := "max" // 函数外部失效
func main(){
fmt.Println(name) // ""
fmt.Println(age) // 0
fmt.Println(adult) // false
fmt.Println(height) // 0
tmp := "max" // 简写方式函数内部才行
tmp = "变量覆盖"
fmt.Println(tmp)
var first string
fmt.Scanln(&first) // 读值到变量中
fmt.Print("输入了值:"+first+"\n")
}
命名规范
命名规范
- 1、golang的命名推荐使用
驼峰命名法,必须以一个字母(Unicode字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。 - 2、golang中根据首字母大小写来确定可以访问权限。
- 无论是方法名、常量、变量名还是结构体的名称,如果首字母大写,则可以被其他包访问;如果首字母小写,则只能在本包中使用
- 首字母大写是公有,小写是私有
- 3、结构体中属性名的大写
- 如果属性名小写, 则数据(如json解析,或将结构体作为请求或访问参数)无法解析
【2023-2-24】采坑
作用域
Go 语言局部变量分配在栈还是堆上?
- 由编译器决定。Go 语言编译器自动决定把变量放在栈/堆
- 编译器会做
逃逸分析(escape analysis),当发现变量的作用域没有超出函数范围,可在上,反之则必须分配在上。
func foo() *int {
v := 11
return &v
}
func main() {
m := foo()
println(*m) // 11
}
解释
- foo() 函数中,如果 v 分配在
栈上,foo 函数返回时,&v就不存在了,但是这段函数是能够正常运行的。 - Go 编译器发现 v 的引用脱离了 foo 作用域,会将其分配在
堆上。 - 因此,main 函数中仍能够正常访问该值。
函数返回局部变量的指针安全吗?
- 安全,Go 编译器对每个局部变量进行逃逸分析。
- 如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上。
关键词
关键词总结
- break, default, func, interface, select, case, defer, go, map, struct, chan, else, goto, package, switch, const, fallthrough, if, range, type, continue, for, import, return, var
函数
- 类型:按值调用、按引用调用
- 局部变量、全局变量(main函数之外定义)
- 函数可以接受任意参数(类型在变量后面),返回任意参数
注意
- 函数必须包含return语句!
自定义函数
Go中自定义函数由6部分组成:关键字func、函数名、参数列表、返回值类型(可选)、函数体、关键字return(可选)
- 其中参数列表又分为带参数和不带参数两种类型
- 如果带参数的话,必须在参数列表里指明该参数的数据类型。
注意
- 自定义函数中如果注明了返回值类型,就必须包含return关键字
- 如果缺失了return关键字的话,系统会报错”missing return at end of function”提醒
自定义函数还可以作为另一个自定义函数中的参数,称为自定义函数嵌套。
package main
import "fmt"
// 自定义函数:有返回值类型,所以必须有return
func hostname(model string, number string) string {
result := model + "-" + number
return result
}
// 自定义函数:无返回值类型,其中一个参数是函数
func hostname_with_ip(original_hostname func(string, string) string, ip string) {
result := original_hostname("ISR4400", "1")
fmt.Println(result + "-" + ip)
}
func main() {
// 将函数当做参数传入
hostname_with_ip(hostname, "192.168.1.1")
}
显式函数
package main
import "fmt"
var c, python, java bool //全局变量定义,var声明
var c, python, java = true, false, "no!" //带初始化语句时可省略类型
c, python, java := true, false, "no!"//短声明:=,可以省略var关键字,注:func外不能使用短声明
// 参数
func add(x int, y int) int {
return x + y
//return // 裸返回:没有参数的 return 语句返回各个返回变量的当前值
}
func swap(x, y string) (string, string) { //多个输出,返回多个值
//函数参数同类型时可以缩写
return y, x
}
func main() {
fmt.Println(add(42, 13))
a, b := swap("hello", "world") // :=,局部变量,函数体内定义
fmt.Println(a, b)
}
匿名函数
Go语言支持匿名函数,通过闭包方式实现。匿名函数在想要定义函数而不必命名时非常有用(内联函数)
import "fmt"
// 匿名函数→初始化变量值
r1, r2 := func() (string, string) {
x := []string{"hello", "world"}
return x[0], x[1]
}()
// => hello world
fmt.Println(r1, r2)
func intSeq() func() int { //i记录调用次数,相当于计数器
i := 0 //定义初始值
return func() int { //通过闭包方式隐藏变量i
i += 1
return i
}
}
func main(){
nextInt := intSeq() // 返回函数,nextInt是函数名
fmt.println(nextInt()) //1,每次调用都会更新
fmt.println(nextInt()) //2
newInt := intSeq()
fmt.println(newInt()) //1
}
值函数
函数赋给变量,不同于匿名函数,函数体末尾没有双括号()!
func main() {
// 将函数赋给名称
add := func(a, b int) int {
return a + b
}
// 使用名称调用函数
fmt.Println(add(3, 4)) // => 7
}
func名前(): 接受者
函数名前括号表示函数将在这种类型上运行
- ()里面是
接受者 - 该函数可被
接受者当做属性一样调用 - refer
package main
import "fmt"
type Mutatable struct {
a int
b int
}
// 不修改接收器
func (m Mutatable) StayTheSame() {
m.a = 5
m.b = 7
}
// 修改接收器--指针
func (m *Mutatable) Mutate() {
m.a = 5
m.b = 7
}
func main() {
m := &Mutatable{0, 0} // 定义对象m
fmt.Println("原始:", m) // &{0 0}
m.StayTheSame() // m调用方法(不可变)
fmt.Println("值调用:",m) // &{0 0}
m.Mutate() // m调用方法(可变)
fmt.Println("引用调用:",m) // &{5 7}
}
【2024-6-4】实际案例
- 该类型的变量可以直接调用函数
- 一个同名函数可以对应多个接受者
type ScoreGenerator struct {
Score float64
EvaluationItems []EvaluateItem
}
type EvaluateItem struct {
ItemName string
ItemBase float64
Reason string
Beta float64
Alpha float64
}
// ScoreGenerator 类型的函数
func (s ScoreGenerator) ToJSON() string {
jsonStr, err := json.Marshal(s)
if err != nil {
return ""
}
return string(jsonStr)
}
// ScoreGenerator 类型的函数
func (s ScoreGenerator) GenScore() float64 {
score := float64(1)
for _, evaluation := range s.EvaluationItems {
score += evaluation.GenScore()
}
s.Score = score
return score
}
// EvaluateItem 类型的函数, 函数名可以相同
func (e EvaluateItem) GenScore() float64 {
score := float64(1)
if int(e.ItemBase) == 0 {
return 0
}
score += e.ItemBase / e.Beta
return math.Pow(score, e.Alpha)
}
// 调用: 该类型的变量直接调用方法
result := ScoreGenerator{}
result.Score = result.GenScore()
特殊函数
自定义函数时要避开系统内置的特殊函数
Go 语言设计过程中保留了默认的两个函数,分别是 main() 和 init() 函数。
两者的区别在于:
main() 函数只能使用于 main 包中,而且每个 main 包只能有 一个 main() 函数- 但对于
init() 函数, 则能够使用在所有的包中。而且一个程序(甚至一个文件)中可以写任意多个init() 函数。
注意:
- 一个程序(甚至一个文件)中可以写任意多个 init() 函数,但对于维护代码可读性、排查问题并没有任何好处
main 函数
详见:main函数
init 函数
详见:init函数
关闭
关闭 1
func scope() func() int{
outer_var := 2
foo := func() int {return outer_var}
return foo
}
// Outpus: 2
fmt.Println(scope()())
关闭 2
func outer() (func() int, int) {
outer_var := 2
inner := func() int {
outer_var += 99
return outer_var
}
inner()
return inner, outer_var
}
inner, val := outer()
fmt.Println(inner()) // => 200
fmt.Println(val) // => 101
参数
外部参数
运行:
- go run main.go name = max
import (
"fmt"
"os"
)
func main() {
arg := os.Args[1] // 访问第二个参数,即 name
fmt.Println(arg) // 输出 max
// os.Args[0] 是程序本身
// 一次性输出所有参数
fmt.Println(os.Args[1:]) // 不在乎输出格式
fmt.Println(strings.Join(os.Args[1:], " ")) // 空格分隔
// 批量处理外部参数
var s, sep string
// for _, arg := range os.Args[1:] { // range 方法遍历
for i := 1; i < len(os.Args); i++ { // for 遍历
s += sep + os.Args[i]
sep = " "
}
fmt.Println(s)
}
函数参数
func add(x int, y int) int {
return x + y
//return // 裸返回:没有参数的 return 语句返回各个返回变量的当前值
}
// 多个参数简写
func add(x, y int) int {
return x + y
}
// 多个返回值
func vals() (int, int) {
return 3, 7
}
a, b := vals()
fmt.Println(a) // => 3
fmt.Println(b) // => 7
变参函数
参数数量不确定时,可以使用变参
package main
import "fmt"
var x string = "hello" //错误!字符串要用双引号,字节才是单引号
var sms = [...]string{"a","b","x"} //可变参数
// 这个函数可以传入任意数量的整型参数
func sum(nums ...int) {
fmt.Print(nums, " ")
total := 0
for _, num := range nums {
total += num
}
fmt.Println(total)
}
func main() {
// 支持可变长参数的函数调用方法和普通函数一样
// 也支持只有一个参数的情况
sum(1, 2)
sum(1, 2, 3)
// 如果你需要传入的参数在一个切片中,像下面一样
// "func(slice...)"把切片打散传入
nums := []int{1, 2, 3, 4}
sum(nums...)
}
包:文件导入
Golang项目中,一次只应有一个main.go,但是所有文件都可以使用同一个包,即main。
- 只需要在使用它的文件中导入像fmt这样的外部包即可
- 如 main.go 和 greet.go
- 运行;go run greet.go main.go
main.go
//-------- main.go ----------
package main
func main() {
greet()
}
greet.go
//--------greet.go----------
package main
import "fmt"
func greet() {
fmt.Println("hello")
}
相对导入
【2022-1-19】
- 错误信息:
- build command-line-arguments: cannot find module for path XXX
- 原因:
- 解决办法:参考解法
- 执行:go env -w GO111MODULE=auto
src/add/add.go
package add
func Add(a int ,b int) int {
return a+b
}
文件:src/main.go
package main
import (
"fmt"
"./add"
)
func main() {
res := add.Add(10, 20)
fmt.Println(res)
}
go.mod 导入
代码结构:
- cfg
- test.go
- go.mod
- main.go
包代码
- 导出函数名首字母大写!
//test.go
package cfg
import "fmt"
func Test() { // 导出函数名首字母大写!
fmt.Println("test")
}
主函数代码
package main
import (
"fmt"
"demo/cfg" // 错误用法, demo包不存在
//"app/cfg" // 正确用法, demo→app
)
func main() {
cfg.Test()
fmt.println("Hello")
}
- 错误信息:local import “./cfg” in non-local package
- 原因:命令 go mod init app 和代码 import “demo/cfg” 不对应
- 解决办法:包名保持一致,详情
运行:
go mod init app # 创建本地包app
go build # 编译
注意:
- module名和工程所在文件夹名无必然关联。
控制流
Go编程语言提供以下类型的决策语句。
| 语句 | 描述 |
|---|---|
| if语句 | if语句由布尔表达式后跟一个或多个语句组成。 |
| if…else语句 | if语句后面可以是一个可选的else语句,当布尔表达式为false时执行else语句。 |
| 嵌套if语句 | 可在另一个if或else if语句中使用一个if或else if语句。 |
| switch语句 | switch语句允许根据值列表测试变量的相等性。 |
| select语句 | select语句与switch语句类似,因为case语句指的是通道通信。 |
循环控制语句:
- break、continue、goto
if 语句
就像 for 循环一样,Go 的 if 语句也不要求用 () 将条件括起来,同时,{}还是必须有的
- 跟 for 语句一样, if 语句可以在条件之前执行一个简单语句
if x < 0 {
//if v := math.Pow(x, n); v < lim { //判断前增加一条语句,v的作用于尽在if-else中
return sqrt(-x) + "i"
} else if x < 20 {
fmt.Println("%d", x)
else {
fmt.Printf("%g\n", x)
}
// ------- if 组合语句 -------
x := "hello go!"
if count := len(x); count > 0 {
fmt.Println("Yes")
}
// 常见写法,执行某个命令,处理异常情形
if _, err := doThing(); err != nil {
fmt.Println("Uh oh")
}
for 循环
Go 只有一种循环结构 —— for 循环。(while语句通过for实现)
基本的 for 循环包含三个由分号分开的组成部分:
- 初始化语句:在第一次循环执行前被执行
- 循环条件表达式:每轮迭代开始前被求值
- 注意:for循环部分没有()!
- 后置语句:每轮迭代后被执行
初始化语句是一个短变量声明,仅在整个 for 循环语句可见。
- 如果条件表达式的值变为 false,那么迭代将终止。
- 注意:不像 C,Java,或者 Javascript 等其他语言,for 语句的三个组成部分并不需要用括号括起来,但循环体必须用{ }括起来。
package main
import "fmt"
func main() {
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
for ; sum < 1000; {//前置和后置语句可以省略
//for sum < 1000 { //for是go语言里的while实现
//for { //死循环!
sum += sum
}
fmt.Println(sum)
// range 遍历
nums := []int{2, 3, 4}
sum := 0
for _, num := range nums {
sum += num
}
}
while(没有)
没有while关键词,通过for循环实现
// 用for循环实现while效果
for 6 > 5 {
fmt.Println("hi")
}
// 简洁版
for {
fmt.Println("hi")
}
// --------
i := 1
for i <= 3 {
fmt.Println(i)
i++
}
switch 语句
从上至下,直至匹配成功才停止
func main() {
fmt.Print("Go runs on ")
//switch {//没有条件的 switch 同 switch true 一样,等效于if-then-else
switch os := runtime.GOOS; os {
case "darwin": fmt.Println("OS X.")
case "linux": fmt.Println("Linux.")
default: fmt.Printf("%s.", os)
}
}
// ----------
x := 42.0
switch x {
case 0:
case 1, 2:
fmt.Println("Multiple matches")
case 42: // Don't "fall through".
fmt.Println("reached")
fallthrough // 执行完接着执行下一个
case 43:
fmt.Println("Unreached")
default:
fmt.Println("Optional")
}
注意:没有break!
continue
Continue 关键字
for i := 0; i <= 5; i++ {
if i % 2 == 0 {
continue
}
fmt.Println(i)
}
break
Break 关键字
for {
fmt.Println("loop")
break
}
Defer栈
Go语言引入了Defer来确保那些被打开的文件能被关闭
Go的defer语句预设一个函数调用(延期的函数),该调用在函数执行defer返回时立刻运行。该方法显得不同常规,但却是处理上述情况很有效,无论函数怎样返回,都必须进行资源释放。img

defer
- return先赋值(对于命名返回值),然后执行defer,最后函数返回
- defer函数调用的执行顺序与它们分别所属的defer语句的执行顺序相反
- defer后面的表达式可以是func或者是method的调用,如果defer的函数为nil,则会panic
一个defer函数的示例:
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
注意:没有break!
指针(Pointers)
类型 *T 是指向类型 T的值的指针, 零值是 nil 。不同于C,go指针没有指针运算!
var p *int
i := 42
p = &i // 取地址
fmt.Println(*p) // 通过指针 p 读取内容
i *p = 21 // 通过指针 p 设置 i
// -----------
func main () {
b := *getPointer()
fmt.Println("Value is", b)
}
func getPointer () (myPointer *int) {
a := 234
return &a
}
a := new(int)
*a = 234
指针有很多但很简单的概念,它们对Go编程非常重要。下面几个重要的指针概念,对于Go程序员应该要清楚:
| 概念 | 描述 |
|---|---|
| Go指针数组 | 可以定义数组来保存一些指针 |
| Go指针的指针 | Go允许有指针指向指针等等 |
| 传递指针到函数 | 通过引用或地址传递参数都允许被调用函数在调用函数中更改传递的参数。 |
defer栈
Go语言引入了Defer来确保那些被打开的文件能被关闭
Go的defer语句预设一个函数调用(延期的函数),该调用在函数执行defer返回时立刻运行。该方法显得不同常规,但却是处理上述情况很有效,无论函数怎样返回,都必须进行资源释放。
一个defer函数的示例:
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
被延期的函数以后进先出(LIFO)的顺行执行,因此以上代码在返回时将打印:4 3 2 1 0
defer 语句会延迟函数的执行直到上层函数返回。
- 延迟调用的参数会立刻生成,但是在上层函数返回前函数都不会被调用
- 延迟的函数调用被压入一个
栈中。当函数返回时, 会按照后进先出的顺序调用被延迟的函数调用。func main() { fmt.Println("counting") for i := 0; i < 10; i++ { //defer会将后面的语句压栈 defer fmt.Println(i) } //输出9,8,7,。。。 fmt.Println("done") }
一般接口
Golang’s log模块主要提供了3类接口。分别是: Print 、Panic 、Fatal。当然是用前先包含log包。
- import( “log”)
为了方便是用,Golang和Python一样,在提供接口时,提供一个简单的包级别的使用接口。不同于Python,其输出默认定位到标准错误 可以通过SetOutput 进行修改。 对每一类接口其提供了3中调用方式,分别是 “Xxxx 、 Xxxxln 、Xxxxf” 比如对于Print就有:
- log.Print, log.Printf, log.Println
- log.Print :表示其参数的调用方式和 fmt.Print 是类似的,即输出对象而不用给定特别的标志符号。
- log.Printf : 表示其参数的调用方式和 fmt.Printf 是类似的,即可以用C系列的格式化标志表示输出对象的类型,具体类型表示 可以参考fmt.Printf的文档
- log.Println: 表示其调用方式和fmt.Println 类似,其和log.Print基本一致,仅仅是在输出的时候多输出一个换行
更多参考
接口 interface
interface 介绍
Go编程提供了另一种称为接口(interfaces)的数据类型,它代表一组方法签名。
struct数据类型实现这些接口以具有接口的方法签名的方法定义。
类似面向对象里的多态
/* define an interface */
type Shape interface {
area() float64
}
/* define a circle */
type Circle struct {
x,y,radius float64
}
/* define a rectangle */
type Rectangle struct {
width, height float64
}
/* define a method for circle (implementation of Shape.area())*/
func(circle Circle) area() float64 {
return math.Pi * circle.radius * circle.radius
}
/* define a method for rectangle (implementation of Shape.area())*/
func(rect Rectangle) area() float64 {
return rect.width * rect.height
}
/* define a method for shape */
func getArea(shape Shape) float64 {
return shape.area()
}
问题
interface 可以比较吗
interface 可以比较吗?
- interface 的内部实现包含了 2 个字段,类型 T 和 值 V
- interface 可以使用
==或!=比较。
2 个 interface 相等, 有以下 2 种情况
- 两个 interface 均等于 nil(此时 V 和 T 都处于 unset 状态)
- 类型 T 相同,且对应的值 V 相等。
例子:
type Stu struct {
Name string
}
type StuInt interface{}
func main() {
var stu1, stu2 StuInt = &Stu{"Tom"}, &Stu{"Tom"}
var stu3, stu4 StuInt = Stu{"Tom"}, Stu{"Tom"}
fmt.Println(stu1 == stu2) // false
fmt.Println(stu3 == stu4) // true
}
stu1和stu2对应的类型是*Stu,值是 Stu 结构体的地址,两个地址不同,因此结果为 false。
stu3和stu4对应的类型是Stu,值是 Stu 结构体,且各字段相等,因此结果为 true。
错误处理
Go编程提供了一个非常简单的错误处理框架,以及内置的错误接口类型
func Sqrt(value float64)(float64, error) {
if(value < 0){
return 0, errors.New("Math: negative number passed to Sqrt")
}
return math.Sqrt(value)
}
内存分配new和make
Go具有两个分配内存的机制,分别是内建的函数new和make。他们所做的事不同,所应用到的类型也不同,这可能引起混淆,但规则却很简单。
- new 是一个分配内存的内建函数,但不同于其他语言中同名的new所作的工作,它只是将内存清零,而不是初始化内存。new(T)为一个类型为T的新项目分配了值为零的存储空间并返回其地址,也就是一个类型为*T的值。用Go的术语来说,就是它返回了一个指向新分配的类型为T的零值的指针。
- make(T, args)函数的目的与new(T)不同。它仅用于创建切片、map和chan(消息管道),并返回类型T(不是*T)的一个被初始化了的(不是零)实例。这种差别的出现是由于这三种类型实质上是对在使用前必须进行初始化的数据结构的引用。例如,切片是一个具有三项内容的描述符,包括指向数据(在一个数组内部)的指针、长度以及容量,在这三项内容被初始化之前,切片值为nil。对于切片、映射和信道,make初始化了其内部的数据结构并准备了将要使用的值
new不常使用
go routine 并发
高并发
主流并发实现方式:
- 多线程:每个线程一次处理一个请求,线程越多可并发处理的请求数就越多,但是在高并发下,多线程开销会比较大。
- 协程:无需抢占式的调度,开销小,可以有效的提高线程的并发性,从而避免了线程的缺点的部分
- 基于异步回调的IO模型
- 比如nginx使用的就是epoll模型,通过事件驱动的方式与异步IO回调,使得服务器持续运转,来支撑高并发的请求
为了追求更高效和低开销的并发,golang的goroutine来了
go routine 简介
goroutine的简介
- 定义:在go里面,每一个并发执行的活动成为goroutine。
- 详解:goroutine 是轻量级的线程,与创建线程相比,创建成本和开销都很小,每个goroutine的堆栈只有几kb,并且堆栈可根据程序的需要增长和缩小(线程的堆栈需指明和固定),所以go程序从语言层面支持了高并发。
- 程序执行的背后:当一个程序启动的时候,只有一个goroutine来调用main函数,称它为主goroutine,新的goroutine通过go语句进行创建。
go routine 使用
Go Routine主要是使用go关键字来调用函数,还可以使用匿名函数。可以把go关键字调用的函数想像成pthread_create,创建线程。
Go Routine可以使用go关键字来调用函数,还可以使用匿名函数。
- go关键字调用的函数想像成 pthread_create,创建线程。 ```go package main import “fmt”
func f(msg string) { fmt.Println(msg) } func main(){ // (1)go关键词使用 go routine go f(“goroutine”) // (2)匿名函数调用 go routine go func(msg string) { fmt.Println(msg) }(“going”) }
并发安全性
- goroutine有个特性,如果一个goroutine没有被阻塞,那么别的goroutine就不会得到执行。这并不是真正的并发,如果要真正并发,在main函数的第一行加上下面的这段代码:
```go
import "runtime"
runtime.GOMAXPROCS(4) // 真正的并发
以上代码存在并发安全性问题,需要上锁
- 参考地址
- 【2022-8-25】一看就懂系列之Golang的goroutine和通道
单个goroutine创建
在函数或者方法前面加上关键字go,即创建一个并发运行的新goroutine
- 注意:main函数返回时,所有的gourutine都是暴力终结的,然后程序退出。
package main
import (
"fmt"
"time"
)
func HelloWorld() {
fmt.Println("Hello world goroutine")
}
func main() {
go HelloWorld() // 开启一个新的并发运行
time.Sleep(1*time.Second) // 执行速度很快,一定要加sleep,不然你一定可以看到goroutine里头的输出
// 匿名函数
go func(msg string) {
fmt.Println(msg)
}("going")
fmt.Println("我后面才输出来")
}
输出:
- Hello world goroutine
- 我后面才输出来
多个goroutine创建
当程序执行go FUNC()的时候,只是简单的调用然后就立即返回了,并不关心函数里头发生的故事情节,所以不同的goroutine直接不影响,main会继续按顺序执行语句。
- DelayPrint里头有sleep,第二个goroutine并不会堵塞/等待
package main
import (
"fmt"
"time"
)
func DelayPrint() {
for i := 1; i <= 4; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Println(i)
}
}
func HelloWorld() {
fmt.Println("Hello world goroutine")
}
func main() {
go DelayPrint() // 开启第一个goroutine
go HelloWorld() // 开启第二个goroutine
time.Sleep(2*time.Second)
fmt.Println("main function")
}
输出
Hello world goroutine
1
2
3
4
5
main function
go routine 问题
死锁
并发安全性
- goroutine有个特性,如果一个goroutine没有被阻塞,那么别的goroutine就不会得到执行。这并不是真正的并发,如果真正并发,在main函数的第一行加上下面的这段代码:
import "runtime"
...
runtime.GOMAXPROCS(4)
以上代码存在并发安全性问题,需要上锁
死锁现场
// (1) 现场一
package main
func main() {
ch := make(chan int)
<- ch // 阻塞main goroutine, 通道被锁
}
// (2) 现场二
package main
func main() {
cha, chb := make(chan int), make(chan int)
go func() {
cha <- 1 // cha通道的数据没有被其他goroutine读取走,堵塞当前goroutine
chb <- 0
}()
<- chb // chb 等待数据的写
}
// (3) 例外
func main() {
ch := make(chan int)
go func() {
ch <- 1
}()
}
为什么会有死锁的产生?
- 非缓冲通道上如果发生了流入无流出,或者流出无流入,就会引起死锁。
- goroutine的非缓冲通道里头一定要一进一出,成对出现才行。
上面例子属于:
- (1) 流出无流入;
- fatal error: all goroutines are asleep - deadlock!
- (2) 流入无流出
- fatal error: all goroutines are asleep - deadlock!
- (3) 无报错,因为没有数据流入,不会被阻塞报错——goroutine还没执行完,main函数自己就跑完了
如何解决死锁?
- 把没取走的取走便是
- 创建缓冲通道
package main
func main() {
cha, chb := make(chan int), make(chan int)
go func() {
cha <- 1 // cha通道的数据没有被其他goroutine读取走,堵塞当前goroutine
chb <- 0
}()
<- cha // 取走便是
<- chb // chb 等待数据的写
}
package main
func main() {
cha, chb := make(chan int, 3), make(chan int)
go func() {
cha <- 1 // cha通道的数据没有被其他goroutine读取走,堵塞当前goroutine
chb <- 0
}()
<- chb // chb 等待数据的写
}
协程泄露
什么是协程泄露(Goroutine Leak)
协程泄露指协程创建后,长时间得不到释放,并且还在不断地创建新的协程,最终导致内存耗尽,程序崩溃。
导致协程泄露的场景:
- 缺少接收器,导致发送阻塞
- 例子中,每执行一次 query,则启动1000个协程向信道 ch 发送数字 0,但只接收了一次,导致 999 个协程被阻塞,不能退出。
- 缺少发送器,导致接收阻塞
- 如果启动 1000 个协程接收信道的信息,但信道并不会发送那么多次的信息,也会导致接收协程被阻塞,不能退出。
- 死锁(dead lock)
- 两个或两个以上的协程在执行过程中,由于竞争资源或者由于彼此通信而造成阻塞,这种情况下,也会导致协程被阻塞,不能退出。
- 无限循环(infinite loops)
- 这个例子中,为了避免网络等问题,采用了无限重试的方式,发送 HTTP 请求,直到获取到数据。那如果 HTTP 服务宕机,永远不可达,导致协程不能退出,发生泄漏。
func query() int {
ch := make(chan int)
for i := 0; i < 1000; i++ {
go func() { ch <- 0 }()
}
return <-ch
}
func main() {
for i := 0; i < 4; i++ {
query()
fmt.Printf("goroutines: %d\n", runtime.NumGoroutine())
}
}
// goroutines: 1001
// goroutines: 2000
// goroutines: 2999
// goroutines: 3998
线程数限制
Go 能限制运行时操作系统线程数吗
The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit.
可用环境变量 GOMAXPROCS 或 runtime.GOMAXPROCS(num int) 设置,例如:
- runtime.GOMAXPROCS(1) // 限制同时执行Go代码的操作系统线程数为 1
官方文档解释:
- GOMAXPROCS 限制同时执行用户态 Go 代码的操作系统线程的数量,但是对于被系统调用阻塞的线程数量是没有限制的。
- GOMAXPROCS 默认值等于 CPU 的逻辑核数,同一时间,一个核只能绑定一个线程,然后运行被调度的协程。
- 因此对于 CPU 密集型的任务,若该值过大,例如设置为 CPU 逻辑核数的 2 倍,会增加线程切换的开销,降低性能。对于 I/O 密集型应用,适当地调大该值,可以提高 I/O 吞吐率。
通道channel
goroutine间通信机制
什么是通道
如果说goroutine是Go并发的执行体,那么通道就是他们之间的连接。
- 通道: 让一个goroutine发送特定值到另外一个goroutine的通信机制
- goroutine1 -> chan -> goroutine2
通道是连接并发goroutine的管道。(队列,先进先出,非栈)
- 可以从一个goroutine向通道发送值,并在另一个goroutine中接收到这些值。
- 使用 make(chan val-type)创建一个新通道,通道由输入的值传入。
- 使用通道 <- 语法将值发送到通道
通道定义
var ch chan int // 声明一个传递int类型的channel
ch := make(chan int) // 使用内置函数make()定义一个channel
//=========
ch <- value // 将一个数据value写入至channel,这会导致阻塞,直到有其他goroutine从这个channel中读取数据
value := <-ch // 从channel中读取数据,如果channel之前没有写入数据,也会导致阻塞,直到channel中被写入数据为止
// 注意:阻塞是默认的channel的接收和发送,其实也有非阻塞的
//=========
close(ch) // 关闭channel
通道种类
四种通道使用
无缓冲通道- 无缓冲通道上的发送操作将会被阻塞,直到另一个goroutine在对应的通道上执行接收操作,此时值才传送完成,两个goroutine都继续执行。
管道:通道可以用来连接goroutine,这样一个的输出是另一个输入。- goroutine1 -> chan -> goroutine2 -> chan -> goroutine3
单向通道类型- 当程序则够复杂的时候,为了代码可读性更高,拆分成一个一个的小函数是需要的。
- go提供了单向通道的类型,来实现函数之间channel的传递。
缓冲管道- goroutine的通道默认是是阻塞的,那么有什么办法可以缓解阻塞?加一个缓冲区。
图解
无缓冲的 channel 和 有缓冲的 channel 的区别
- 对于无缓冲 channel,发送方将阻塞该信道,直到接收方从该信道接收到数据为止,而接收方也将阻塞该信道,直到发送方将数据发送到该信道中为止。
- 对于有缓存 channel,发送方在没有空插槽(缓冲区使用完)的情况下阻塞,而接收方在信道为空的情况下阻塞。
无缓冲通道
package main
import (
"fmt"
"time"
)
var done chan bool
func HelloWorld() {
fmt.Println("Hello world goroutine")
time.Sleep(1*time.Second)
done <- true
}
func main() {
done = make(chan bool) // 创建一个无缓冲channel
go HelloWorld()
<-done
}
示例:
package main
import "fmt"
func main() {
// Create a new channel with `make(chan val-type)`.
// Channels are typed by the values they convey.
messages := make(chan string)//默认无缓冲,只能存储一个值
// messages := make(chan string, 2) //设置缓冲,存储2个值(先进先出)
// _Send_ a value into a channel using the `channel <-`
// syntax. Here we send `"ping"` to the `messages`
// channel we made above, from a new goroutine.
go func() { messages <- "ping" }() //匿名函数
// The `<-channel` syntax _receives_ a value from the
// channel. Here we'll receive the `"ping"` message
// we sent above and print it out.
msg := <-messages
fmt.Println(msg)
}
缓冲通道
goroutine的通道默认是是阻塞的,那么有什么办法可以缓解阻塞?
- 答案是:加一个缓冲区。
ch := make(chan string, 3) // 创建了缓冲区为3的通道
len(ch) // 长度计算
cap(ch) // 容量计算
//=========
// Here we `make` a channel of strings buffering up to 2 values.
messages := make(chan string, 2)
// Because this channel is buffered, we can send these values into the channel without a corresponding concurrent receive.
messages <- "buffered"
messages <- "channel"
// Later we can receive these two values as usual.
fmt.Println(<-messages)
fmt.Println(<-messages) //输出buffered、channel
管道
package main
import (
"fmt"
"time"
)
var echo chan string
var receive chan string
// 定义goroutine 1
func Echo() {
time.Sleep(1*time.Second)
echo <- "咖啡色的羊驼"
}
// 定义goroutine 2
func Receive() {
temp := <- echo // 阻塞等待echo的通道的返回
receive <- temp
}
func main() {
echo = make(chan string)
receive = make(chan string)
go Echo()
go Receive()
getStr := <-receive // 接收goroutine 2的返回
fmt.Println(getStr)
}
不一定要去关闭channel,因为底层的垃圾回收机制会根据它是否可以访问来决定是否自动回收它
单向通道
package main
import (
"fmt"
"time"
)
// 定义goroutine 1
func Echo(out chan<- string) { // 定义输出通道类型
time.Sleep(1*time.Second)
out <- "咖啡色的羊驼"
close(out)
}
// 定义goroutine 2
func Receive(out chan<- string, in <-chan string) { // 定义输出通道类型和输入类型
temp := <-in // 阻塞等待echo的通道的返回
out <- temp
close(out)
}
func main() {
echo := make(chan string)
receive := make(chan string)
go Echo(echo)
go Receive(receive, echo)
getStr := <-receive // 接收goroutine 2的返回
fmt.Println(getStr)
}
通道通信
类似信号量
package main
import "fmt"
import "time"
// This is the function we'll run in a goroutine. The `done` channel will be used to notify another goroutine that this function's work is done.
func worker(done chan bool) {
fmt.Print("working...")
time.Sleep(time.Second)
fmt.Println("done")
// Send a value to notify that we're done.
done <- true
}
func main() {
// Start a worker goroutine, giving it the channel to notify on.
done := make(chan bool, 1)
go worker(done)
// Block until we receive a notification from the worker on the channel. <-done
}
通道路线
当使用通道作为函数参数时,可以指定通道是否仅用于发送或接收值。这种特殊性增加了程序的类型安全性。
select 多通道等待
Go语言的选择(select)可等待多个通道操作。
将 goroutine 和 channel 与 select 结合, 是Go语言的一个强大功能。
定义:
- select 功能与 epoll(nginx)/poll/select 功能类似,都是坚挺IO操作,当IO操作发生的时候,触发相应的动作。
select 让 Goroutine 同时等待多个 Channel 可读或者可写,在多个文件或者 Channel状态改变之前,select 会一直阻塞当前线程或者 Goroutine
【2022-8-25】一看就懂系列之Golang的goroutine和通道
select 用法
select 有几个要点:
- 如果有多个case都可以运行,select会随机公平地选出一个执行,其他不会执行
- case后面必须是channel操作,否则报错。
- select中的default子句总是可运行的。所以没有default的select才会阻塞等待事件
- 没有运行的case,那么将会阻塞事件发生报错(死锁)
package main
import "fmt"
func main() {
ch := make (chan int, 1)
ch<-1 // 如果注释此句,会报错!没有输入 → 死锁报错
select {
case <-ch:
fmt.Println("咖啡色的羊驼")
case <-ch:
fmt.Println("黄色的羊驼")
//case 3: // case后面(3)非channel操作,报错!
// fmt.Println("黄色的羊驼")
default: // default子句总是可运行的。没有default的select会阻塞等待事件
fmt.Println("黄色的羊驼")
}
}
// 输出:两种羊驼随机出现
select应用场景
select应用场景
- timeout 机制(超时判断)
- 判断channel是否阻塞(或者说channel是否已经满了)
- 退出机制
(1)超时判断
package main
import (
"fmt"
"time"
)
func main() {
timeout := make (chan bool, 1)
go func() {
time.Sleep(1*time.Second) // 休眠1s,如果超过1s还没I操作则认为超时,通知select已经超时啦~
timeout <- true
}()
ch := make (chan int)
select {
case <- ch:
case <- timeout:
fmt.Println("超时啦!")
}
}
正规版
package main
import (
"fmt"
"time"
)
func main() {
ch := make (chan int)
select {
case <-ch:
case <-time.After(time.Second * 1): // 利用time来实现,After代表多少时间后执行输出东西
fmt.Println("超时啦!")
}
}
(2)判断是否阻塞
package main
import (
"fmt"
)
func main() {
ch := make (chan int, 1) // 注意这里给的容量是1
ch <- 1
select {
case ch <- 2:
default:
fmt.Println("通道channel已经满啦,塞不下东西了!")
}
}
(3)退出机制
package main
import (
"fmt"
"time"
)
func main() {
i := 0
ch := make(chan string, 0)
defer func() {
close(ch)
}()
go func() {
DONE:
for {
time.Sleep(1*time.Second)
fmt.Println(time.Now().Unix())
i++
select {
case m := <-ch:
println(m)
break DONE // 跳出 select 和 for 循环
default:
}
}
}()
time.Sleep(time.Second * 4)
ch<-"stop"
}
select死锁
select不注意也会发生死锁
- 如果没有数据需要发送,select中又存在接收通道数据的语句,那么将发送死锁
- 空select,也会引起死锁
package main
// (1)没有数据要发送
func main() {
ch := make(chan string)
select {
case <-ch:
}
}
// (2)空select
package main
func main() {
select {}
}
超时等待
超时对于连接到外部资源或在不需要绑定执行时间的程序很重要。在Go编程中由于使用了通道和选择(select),实现超时是容易和优雅的。
### 非阻塞通道
通道的基本发送和接收都阻塞。但是,可以使用select和default子句来实现非阻塞发送,接收,甚至非阻塞多路选择(select)。
关闭通道
关闭通道表示不会再发送更多值。这对于将完成通信到通道的接收器是很有用的。
在这个例子中,我们将使用一个作业通道来完成从main()goroutine到worker goroutine的工作。当没有更多的工作时,则将关闭工作通道。
范围通道
在前面的例子中,我们已经看到了for和range语句如何为基本数据结构提供迭代。还可以使用此语法对从通道接收的值进行迭代。 此范围在从队列接收到的每个元素上进行迭代。因为关闭了上面的通道,迭代在接收到2个元素后终止。
Sync 用法
刚才看golang的sync的包,看见一个很有用的功能。就是WaitGroup。
WaitGroup的用途:它能够一直等到所有的goroutine执行完成,并且阻塞主线程的执行,直到所有的goroutine执行完成。
注意:执行结果是没有顺序的,调度器不能保证多个 goroutine 执行次序,且进程退出时不会等待它们结束。
WaitGroup总共有三个方法:Add(delta int),Done(),Wait()。简单的说一下这三个方法的作用。
- Add:添加或者减少等待goroutine的数量
- Done:相当于Add(-1)
- Wait:执行阻塞,直到所有的WaitGroup数量变成0 如:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
for i := 0; i > 5; i = i + 1 {
wg.Add(1)
go func(n int) {
// defer wg.Done(),注意这个Done的位置,是另一个函数
defer wg.Add(-1)
EchoNumber(n)
}(i)
}
wg.Wait()
}
func EchoNumber(i int) {
time.Sleep(3e9)
fmt.Println(i)
}
golang中的同步是通过sync.WaitGroup来实现的.WaitGroup的功能:
- 实现了一个类似队列的结构,可以一直向队列中添加任务,当任务完成后便从队列中删除,如果队列中的任务没有完全完成,可以通过Wait()函数来出发阻塞,防止程序继续进行,直到所有的队列任务都完成为止.
- WaitGroup的特点是Wait()可以用来阻塞直到队列中的所有任务都完成时才解除阻塞,而不需要sleep一个固定的时间来等待.但是其缺点是无法指定固定的goroutine数目.但是其缺点是无法指定固定的goroutine数目.可能通过使用channel解决此问题。
另一个例子:
package main
import (
"fmt"
"sync"
)
//声明一个全局变量
var waitgroup sync.WaitGroup
func Afunction(shownum int) {
fmt.Println(shownum)
waitgroup.Done() //任务完成,将任务队列中的任务数量-1,其实.Done就是.Add(-1)
}
func main() {
for i := 0; i < 10; i++ {
waitgroup.Add(1) //每创建一个goroutine,就把任务队列中任务的数量+1
go Afunction(i)
}
waitgroup.Wait() //.Wait()这里会发生阻塞,直到队列中所有的任务结束就会解除阻塞
}
面向对象
面向对象特征
- 封装,是面向对象方法的重要原则,就是把对象的属性和操作(或服务)结合为一个独立的整体,并尽可能隐藏对象的内部实现细节。
- 继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
- 多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作
【2022-8-12】详解go面向对象
go 是面向对象语言吗
官方回答:是也不是
- go是明显允许面向对象的编程风格的,但同时又缺乏一些Java和C++中的常见类型或者说是关键字。
- Go的interface也和Java中的用法十分不同, 官方觉得这一套挺好的,更加的容易使用且通用性更强。大多数情况下我们都是使用OOP 的思想来组织 go 项目的,但是如果你要完全按照 Java 这种思想去思考 go,会发现十分的别扭。
go 如何实现面向对象
GO没有 class、extend 怎么才能实现面向对象呢?
- go以结构体的方式去定义一个所谓的类,将相关的方法绑定在这个结构体上,作为一个整体的集合, 也就是类。
结构体
type Person struct {
name string
age int32
}
// 类实例化的两种方式
p1 := new(Persion)
p2 := &Person{
name : "MClink"
age : 25
}
p3 := &Person{}
p4 := &Person{"MClink", 25}
var p5 Person{}
- p1 和 p3 的效果是一样的,但是分配的内存大小是不同,类的属性在不主动初始化赋值的情况下都是默认的零值。
- 字符串的零值是 “”, int32 的零值是 0。
- p2 、p4 则是在实例化的同时,对属性也做了相应的赋值。
所谓的类实际上是一种类型。因此 new 函数实际上的形参是一种类型,而不是值,返回的是这个类型的零值的指针。
方法
- go 种的方法实际上是依附于某个类(结构体类型,或者说是接收者)的 func。
- go 的 func 是支持多返回值的,十分特别的。以前,如果要返回多个返回值,一般通过使用数组或者集合的方式进行返回。
- 两个方法的接收者有点不同,一个是 p *T ,一个是 p T,分别称之为 指针方法和值方法
- 指针方法集合包含了值方法的集合;如果返回值需要改动,就用指针方法。
// 指针方法
func (p *Person) GetName(name string) error {
p.name = name
return nil
}
// 值方法
func (p Person) SetName() (string, error) {
return p.name, nil
}
继承
Go 语言没有 public、protected、private 三种范围修饰词;
- Go 使用组合的方式来实现继承
- 组合方式,让一些公共的部分单独抽离出来,像搭积木那样,将多个积木进行组合,达到自己所需的功能集合。组合内外如果出现名字重复问题,只会访问到最外层,内层会被隐藏,不会报错,即类似java中方法覆盖/重写。
type Person struct {
name string
age int32
}
func (p *Person) GetName(name string) error {
p.name = name
return nil
}
func (p Person) SetName() (string, error) {
return p.name, nil
}
type Man struct {
Person // 继承了Person类的所有方法和成员属性
phone string
}
type WoMan struct {
*Person // 以指针继承了 Person类的所有方法和成员属性
phone string
}
接口
Go 保留了接口。接口的作用主要是将定义与实现分离,降低耦合度。
接口是一堆方法的集合,定义了对象的一组行为,主要是用来规范行为的。
- 其他语言的接口实现是显式的,一般使用 implement 显式实现。
- 而Go是隐式的,只要实现了 接口内的所有方法,便是继承了这个接口。
func (p *Man) Say() string {
return ""
}
func (p *Man) Eat(something string) error {
fmt.Print("man eat " + something)
return nil
}
func (w *WoMan) Say() string {
return ""
}
func (w *WoMan) Eat(something string) error {
fmt.Print("woman eat " + something)
return nil
}
type ManI interface {
Say() string
Eat(something string) error
}
var mi ManI = new(Man)
mi.Say()
var mi2 ManI = new(Woman)
mi2.Eat("好吃的")
Man 类就实现了 ManI 接口。只要类实现了该接口的所有方法,即可将该类赋值给这个接口,接口主要用于多态化方法。即对接口定义的方法,不同的实现方式。
接口赋值
// 接口赋值
func Call (mi ManI) {
mi.Eat("牛肉粿条")
}
var mi ManI
t := "woman"
switch t {
case "woman":
mi = new(Woman)
case "man":
mi = new(Man)
}
Call(mi)
也可以将一个接口赋值给另一个接口,需要满足以下的条件
- 两个接口拥有相同的方法列表(与次序无关),即使是两个相同的接口,也可以相互赋值
- 接口赋值只需要接口A的方法列表是接口B的子集(即假设接口A中定义的所有方法,都在接口B中有定义),那么B接口的实例可以赋值给A的对象。反之不成立。
type ManI interface {
Say() string
Eat(something string) error
}
type ManI2 interface {
Say() string
}
func (p *Man) Say() string {
return ""
}
func (p *Man) Eat(something string) error {
return nil
}
var mi ManI
var mi2 ManI2
mi = mi2 // 会报错
mi2 = mi // 可以
接口的判断
- 可以使用类型断言的方式,判断一个接口类型是否实现了某个接口。
func (p *Man) Say() string {
return ""
}
func (p *Man) Eat(something string) error {
return nil
}
type Man struct {
Person // 继承了 Person类的所有方法
phone string
}
type ManI interface {
Say() string
Eat(something string) error
}
func main() {
var mi ManI = &Man{
Person: Person{},
phone: "",
}
if _, ok := mi.(*Man); ok {
fmt.Print("true") //结果是true
} else {
fmt.Println("false")
}
return
}
接口的组合
- 接口和类型一样,也是可以组合的。几个小接口可以组合成一个大接口
type Human interface {
ManI
WoManI
}
type ManI interface {
Say() string
Eat(something string) error
}
type WoManI interface {
Born() error
}
万能的黑洞
- 空接口 interface{} 是一个没有方法的接口,因此任何类型都是他的实现,当你的参数无法确定类型时,interface{} 就是一个很好的容器。
oop实例
package main
import "fmt"
// 定义接口
type Human interface {
Say(string)
Eat(string)
}
// 定义类
type Man struct {
}
// 实例化方法,一般是 New+类名作为实例化的方法
func NewMan() *Man {
return &Man{}
}
// 实现Human接口的Say
func (m *Man) Say(something string) {
fmt.Println(something)
}
// 实现Human接口的Eat
func (m *Man) Eat(something string) {
fmt.Println(something)
}
// 定义员工类,其中包含 Human 接口的值
type employees struct {
man Human
}
// 实现实例化方法
func newEmployees() *employees {
return &employees{
man: NewMan(), // 实现该类型的接口值可以赋值该类型的对象
}
}
func main() {
// 获取员工类实例化对象
emp := newEmployees()
// 通过员工类中包含的 Human 接口值间接调用 Man 类的 Say 方法
emp.man.Say("EAT")
}
设计模式
设计原则
SOLID设计原则
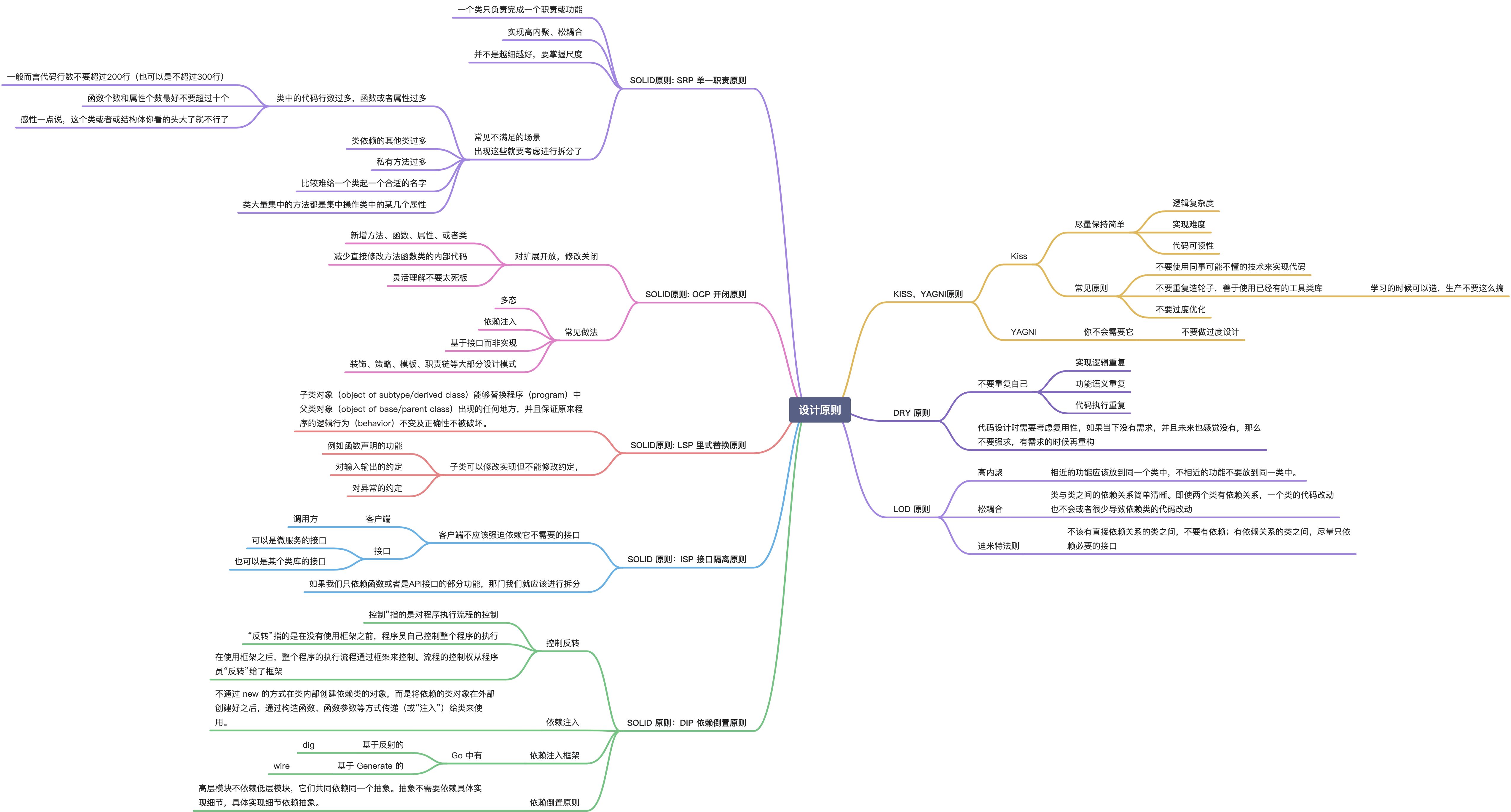
go设计模式
Go 设计模式
- 单例模式包含饿汉式和懒汉式两种实现
- 工厂模式包含简单工厂、工厂方法、抽象工厂、DI 容器
- 代理模式包含静态代理、动态代理(采用 go generate 模拟)
- 观察者模式包含观察者模式、eventbus
汇总: img
专项功能
命令行参数
package main
import (
"flag"
"fmt"
"os"
)
//先编译 go build -o args.exe args_test.go
//执行 args.exe -name ..
func main() {
// ----- 第一种 ------
//获取命令行参数
//fmt.Print(os.Args)
for i,v := range os.Args{
fmt.Print(i,v)
}
//------ 第二种 ------
//自定义命令行参数
//定义参数
//String代表获取的参数类型为字符串,参数的名字为-name,值默认为空,usage为提示
namePtr := flag.String("name", "", "姓名")
agePtr := flag.Int("age",18,"年龄")
rmbPtr := flag.Float64("rmb",10000,"资产")
alivePtr := flag.Bool("alive",true,"是否健在")
//解析获取参数,丢入参数的指针中
flag.Parse()
fmt.Print(*namePtr,*agePtr,*rmbPtr,*alivePtr)
//------ 第三种 ------
//var name *string 这里在栈里面占了名字,但是没有分配内存空间,所以没有地址
// //flag.StringVar(name,"name", "", "姓名")
var name string//这里是有地址的
var age int
var rmb float64
var alive bool
flag.StringVar(&name,"name", "", "姓名")
flag.IntVar(&age,"age",18,"年龄")
flag.Float64Var(&rmb,"rmb",10000,"资产")
flag.BoolVar(&alive,"alive",true,"是否健在")
flag.Parse()
fmt.Print(name,age,rmb,alive)
}
配置文件
从配置文件读取信息
文本文件
【2023-3-21】文件的读写是编程语言的常见操作
读文件
读取文件有三种方式:
- (1)将文件整体读入内存
- (2)按字节数读取
- (3)按行读取
(1)整体读入内存
- 将文件整个读入内存,效率比较高,占用内存也最高。
package main
import (
"os"
"io/ioutil"
"fmt"
)
func main() {
filepath := "example/log.txt"
// 使用 os.Open
file, err := os.Open(filepath)
if err != nil {
panic(err)
}
defer file.Close()
content, err := ioutil.ReadAll(file)
fmt.Println(string(content))
// 或使用ReadFile
content ,err := ioutil.ReadFile(filepath)
if err !=nil {
panic(err)
}
}
(2)按字节读取
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
)
func main() {
filepath := "example/log.txt"
fi, err := os.Open(filepath)
if err != nil {
panic(err)
}
defer fi.Close()
r := bufio.NewReader(fi)
chunks := make([]byte, 0)
buf := make([]byte, 1024) //一次读取多少个字节
for {
n, err := r.Read(buf)
if err != nil && err != io.EOF {
panic(err)
}
fmt.Println(string(buf[:n]))
break
if 0 == n {
break
}
chunks = append(chunks, buf[:n]...)
}
fmt.Println(string(chunks))
}
(3)按行读取
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
"strings"
)
func main() {
filepath := "example/log.txt"
file, err := os.OpenFile(filepath, os.O_RDWR, 0666)
if err != nil {
fmt.Println("Open file error!", err)
return
}
defer file.Close()
stat, err := file.Stat()
if err != nil {
panic(err)
}
var size = stat.Size()
fmt.Println("file size=", size)
buf := bufio.NewReader(file)
for {
line, err := buf.ReadString('\n')
line = strings.TrimSpace(line)
fmt.Println(line)
if err != nil {
if err == io.EOF {
fmt.Println("File read ok!")
break
} else {
fmt.Println("Read file error!", err)
return
}
}
}
}
写文件
写入方式
- 1、ioutil.WriteFile
- 2、os: io.WriteString
- 3、os:
- 4、bufio
1、ioutil.WriteFile
package main
import (
"io/ioutil"
)
func main() {
content := []byte("测试1\n测试2\n")
err := ioutil.WriteFile("test.txt", content, 0644)
if err != nil {
panic(err)
}
}
这种方式每次都会覆盖 test.txt内容,如果test.txt文件不存在会创建。
2、os
- 在文件内容末尾添加新内容
package main
import (
"fmt"
"io"
"os"
)
func checkFileIsExist(filename string) bool {
if _, err := os.Stat(filename); os.IsNotExist(err) {
return false
}
return true
}
func main() {
var wireteString = "测试1\n测试2\n"
var filename = "./test.txt"
var f *os.File
var err1 error
if checkFileIsExist(filename) { //如果文件存在
f, err1 = os.OpenFile(filename, os.O_APPEND, 0666) //打开文件
fmt.Println("文件存在")
} else {
f, err1 = os.Create(filename) //创建文件
fmt.Println("文件不存在")
}
(3)
package main
import (
"fmt"
"os"
)
func checkFileIsExist(filename string) bool {
if _, err := os.Stat(filename); os.IsNotExist(err) {
return false
}
return true
}
func main() {
var str = "测试1\n测试2\n"
var filename = "./test.txt"
var f *os.File
var err1 error
if checkFileIsExist(filename) { //如果文件存在
f, err1 = os.OpenFile(filename, os.O_APPEND, 0666) //打开文件
fmt.Println("文件存在")
} else {
f, err1 = os.Create(filename) //创建文件
fmt.Println("文件不存在")
}
defer f.Close()
n, err1 := f.Write([]byte(str)) //写入文件(字节数组)
fmt.Printf("写入 %d 个字节n", n)
n, err1 = f.WriteString(str) //写入文件(字符串)
if err1 != nil {
panic(err1)
}
fmt.Printf("写入 %d 个字节n", n)
f.Sync()
}
4、bufio
package main
import (
"bufio"
"fmt"
"os"
)
func checkFileIsExist(filename string) bool {
if _, err := os.Stat(filename); os.IsNotExist(err) {
return false
}
return true
}
func main() {
var str = "测试1\n测试2\n"
var filename = "./test.txt"
var f *os.File
var err1 error
if checkFileIsExist(filename) { //如果文件存在
f, err1 = os.OpenFile(filename, os.O_APPEND, 0666) //打开文件
fmt.Println("文件存在")
} else {
f, err1 = os.Create(filename) //创建文件
fmt.Println("文件不存在")
}
defer f.Close()
if err1 != nil {
panic(err1)
}
w := bufio.NewWriter(f) //创建新的 Writer 对象
n, _ := w.WriteString(str)
fmt.Printf("写入 %d 个字节n", n)
w.Flush()
}
几种方法效率对比
行结果:
- Cost time 6.0003ms
- Cost time 3.0002ms
- Cost time 7.0004ms
- Cost time 11.0006ms
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
"time"
)
func read0(path string) string {
file, err := os.Open(path)
if err != nil {
panic(err)
}
defer file.Close()
content, err := ioutil.ReadAll(file)
return string(content)
}
func read1(path string) string {
content, err := ioutil.ReadFile(path)
if err != nil {
panic(err)
}
return string(content)
}
func read2(path string) string {
fi, err := os.Open(path)
if err != nil {
panic(err)
}
defer fi.Close()
r := bufio.NewReader(fi)
chunks := make([]byte, 0)
buf := make([]byte, 1024) //一次读取多少个字节
for {
n, err := r.Read(buf)
if err != nil && err != io.EOF {
panic(err)
}
if 0 == n {
break
}
chunks = append(chunks, buf[:n]...)
}
return string(chunks)
}
func read3(path string) string {
fi, err := os.Open(path)
if err != nil {
panic(err)
}
defer fi.Close()
chunks := make([]byte, 0)
buf := make([]byte, 1024)
for {
n, err := fi.Read(buf)
if err != nil && err != io.EOF {
panic(err)
}
if 0 == n {
break
}
chunks = append(chunks, buf[:n]...)
}
return string(chunks)
}
func main() {
file := "D:/gopath/src/example/example/log.txt"
start := time.Now()
read0(file)
t0 := time.Now()
fmt.Printf("Cost time %v\n", t0.Sub(start))
read1(file)
t1 := time.Now()
fmt.Printf("Cost time %v\n", t1.Sub(t0))
read2(file)
t2 := time.Now()
fmt.Printf("Cost time %v\n", t2.Sub(t1))
read3(file)
t3 := time.Now()
fmt.Printf("Cost time %v\n", t3.Sub(t2))
}
json
JSON(Javascript Object Notation)是一种轻量级的数据交换语言,以文字为基础,具有自我描述性且易于让人阅读。
在go语言中编码解码注意事项
- Go语言中一些特殊的类型,比如 Channel、complex、function 是不能被解析成JSON的;
- JSON对象只支持string作为key,所以要编码一个map,那么必须是map[string]T这种类型(T是Go语言中任意的类型);
- 嵌套的数据是不能编码的,不然会让JSON编码进入死循环;
- 指针在编码的时候会输出指针指向的内容,而空指针会输出null。
go这种强类型的语言中,对json取值比较麻烦,一般有三种方法
- 把 json 映射为
map格式 - 把 json 映射为
stuct格式 - 借助于 第三方库,直接对
json对象取值
json 标准库
encoding/json 标准库用法,
- Valid-校验json是否合法
- Marshal-json编码 生成json
- Unmarshal-解码已知的json 解析json
- Indent-json字符串格式化输出
- MarshalIndent-编码JSON后,带格式化的输出
encoding/json 使用时需要预定义struct,原理是通过reflection和interface来完成工作, 性能低。
//--------- 解析json ----------
var jsonBlob = []byte(`[
{"Name": "Platypus", "Order": "Monotremata"},
{"Name": "Quoll", "Order": "Dasyuromorphia"}
]`)
type Animal struct {
Name string
Order string
}
var animals []Animal
err := json.Unmarshal(jsonBlob, &animals) // 解析json
if err != nil {
fmt.Println("error:", err)
}
fmt.Printf("%+v", animals)
// [{Name:Platypus Order:Monotremata} {Name:Quoll Order:Dasyuromorphia}]
// --------- 生成json -----------
type ColorGroup struct {
ID int
Name string
Colors []string
}
group := ColorGroup{
ID: 1,
Name: "Reds",
Colors: []string{"Crimson", "Red", "Ruby", "Maroon"},
}
b, err := json.Marshal(group) // 生成json
if err != nil {
fmt.Println("error:", err)
}
os.Stdout.Write(b)
// {"ID":1,"Name":"Reds","Colors":["Crimson","Red","Ruby","Maroon"]}
标准库性能的瓶颈在反射。 easyjson , ffjson 并没有使用反射方式实现,而是在Go中为结构体生成静态 MarshalJSON 和 UnmarshalJSON函数,类似于预编译。
- 调用编码解码时直接使用生成的函数,从而减少了对反射的依赖,所以通常快2到3倍。
- 但相比标准JSON包,使用起来略为繁琐。
使用步骤:详见
- 1、定义结构体,每个结构体注释里标注 //easyjson:json或者 //ffjson: skip;
- 2、使用 easyjson或者ffjson命令将指定目录的go结构体文件生成带有Marshal、Unmarshal方法的新文件;
- 3、代码里如果需要进行生成JSON或者解析JSON,调用生成文件的 Marshal、Unmarshal方法即可。
package main
import (
"encoding/json" // Marshal 和 Unmarshal
"fmt"
"github.com/tidwall/gjson"
)
func main() {
byt := []byte(`{
"num":6.13,
"strs":["a","b"],
"obj":{"foo":{"bar":"zip","zap":6}}
}`)
fmt.Println("func1**************************************")
jsonByMap(byt)
fmt.Println("func2**************************************")
jsonByStruct(byt)
fmt.Println("func3**************************************")
jsonBygjson(byt)
}
func jsonByMap(byt []byte) {
var dat map[string]interface{}
if err := json.Unmarshal(byt, &dat); err != nil {
panic(err)
}
//fmt.Println(dat)
num := dat["num"].(float64)
fmt.Println(num)
strs := dat["strs"].([]interface{})
str1 := strs[0].(string)
fmt.Println(str1)
obj := dat["obj"].(map[string]interface{})
obj2 := obj["foo"].(map[string]interface{})
fmt.Println(obj2)
}
func jsonByStruct(byt []byte) {
type ourData struct {
Num float64 `json:"num"`
Strs []string `json:"strs"`
Obj map[string]map[string]string `json:"obj"`
}
res := ourData{}
json.Unmarshal(byt, &res)
fmt.Println(res.Num)
fmt.Println(res.Strs)
fmt.Println(res.Obj)
}
func jsonBygjson(byt []byte) {
//首先校验 json库是否合法
str := string(byt)
if !gjson.Valid(str) {
fmt.Println("json字符串不合法")
return
}
//从json中取string
value := gjson.Get(str, "obj.foo.bar")
fmt.Println(value.String())
//从json中取int
num := gjson.Get(str, "num")
fmt.Println(num.Int())
//json中取数组
strs := gjson.Get(str, "strs")
if strs.IsArray() {
for _, v := range strs.Array() {
fmt.Println("数组", v.String())
}
}
//json的链式调用
foo := gjson.Get(str, "obj.foo")
fmt.Println(foo.Get("zap"))
}
其它用法
package main
/*
JSON 数据解析
注意:struct 类型数据 命名时 首字母大写,如果不大写会出现滞空,看不见变量后的数据
*/
import (
"bufio" // 读取文件,按行读取
"encoding/json"
"fmt"
"io/ioutil" // 读取文件
"os" // 处理命令行参数
)
// 注意:struct 类型数据 命名时 首字母大写
// 第二层 JSON 的 struct 创建
type Hello struct {
CubeType string
High int
Width int
Long int
}
// 第一层 JSON 的 struct 创建
type Study struct {
Name string
Age int
Skill []string
SkillType map[string]string
// 在 A struct 中使用 B struct 就需要指定 B 的内存地址
Cube *Hello
}
// 创建一个错误处理函数,避免过多的 if err != nil{} 出现
func dropErr(e error) {
if e != nil {
panic(e)
}
}
func main() {
fmt.Println("Hello,today we will study Golang read JSON data")
// 获取 参数,请传入一个文件路径
filePath := os.Args[1]
fmt.Printf("The file path is :%s\n", filePath)
// ioutil 方式读取,会一次性读取整个文件,在对大文件处理时会有内存压力
fileData, err := ioutil.ReadFile(filePath)
dropErr(err)
fmt.Println(string(fileData))
// bufio 读取
f, err := os.Open(filePath)
dropErr(err)
bio := bufio.NewReader(f)
// ReadLine() 方法一次尝试读取一行,如果过默认缓存值就会报错。默认遇见'\n'换行符会返回值。isPrefix 在查找到行尾标记后返回 false
bfRead, isPrefix, err := bio.ReadLine()
dropErr(err)
fmt.Printf("This mess is [ %q ] [%v]\n", bfRead, isPrefix)
// 解析 JSON 数据使用 json.Unmarshal([]byte(JSON_DATA),JSON对应的结构体) ,也就是说我们在解析 JSON 的时候需要确定 JSON 的数据结构
res := &Study{}
json.Unmarshal([]byte(bfRead), &res)
fmt.Println(res.Cube)
}
第三方库
【2023-5-26】Go JSON 三方包哪家强?
Go json 标准库 encoding/json 提供了足够舒适的 json 处理工具,广受 Go 开发者的好评,但还是存在以下两点问题:
- API 不够灵活:如没有提供按需加载机制等;
- 性能不太高:标准库大量使用反射获取值
- 首先 Go 的反射本身性能较差,较耗费 CPU 配置;
- 其次频繁分配对象,也会带来内存分配和 GC 的开销;
基于上面的考量,业务会根据使用场景、降本收益等诉求,引入合适的第三方库
| 库名 | encoder | decoder | compatible | star 数 (2023.04.19) | 社区维护性 |
|---|---|---|---|---|---|
StdLib(encoding/json)[2] |
✔️ | ✔️ | N/A | - | - |
FastJson(valyala/fastjson)[3] |
✔️ | ✔️ | ❌ | 1.9k | 较差 |
GJson(tidwall/gjson)[4] |
✔️ | ✔️ | ❌ | 12.1k | 较好 |
JsonParser(buger/jsonparser)[5] |
✔️ | ✔️ | ❌ | 5k | 较差 |
JsonIter(json-iterator/go)[6] |
✔️ | ✔️ | 部分兼容 | 12.1k | 较差 |
GoJson(goccy/go-json)[7] |
✔️ | ✔️ | ✔️ | 2.2k | 较好 |
EasyJson(mailru/easyjson)[8] |
✔️ | ✔️ | ❌ | 4.1k | 较差 |
Sonic(bytedance/sonic)[9] |
✔️ | ✔️ | ✔️ | 4.1k | 较好 |
功能划分上,根据主流 json 库 API,将它们的使用方式分为三种:
- 泛型(generic)编解码:json 没有对应的 schema,只能依据自描述语义将读取到的 value 解释为对应语言的运行时对象,例如:json object 转化为 Go map[string]interface{};
- 定型(binding)编解码:json 有对应的 schema,可以同时结合模型定义(Go struct)与 json 语法,将读取到的 value 绑定到对应的模型字段上去,同时完成数据解析与校验;
- 查找(get)& 修改(set):指定某种规则的查找路径(一般是 key 与 index 的集合),获取需要的那部分 json value 并处理。
评测对比见Go JSON 三方包哪家强?
业务选型上需要根据具体情况、不同领域的业务使用场景和发展趋势进行选择,综合考虑各方面因素。最适配业务的才是最好的
- 例如:如果业务只是简单的解析 http 请求返回的 json 串的部分字段,并且字段都是确定的,偶尔需要搜索功能,那 Gjson 是很不错的选择。
个人观点,仅供参考:
- 不太推荐使用 Jsoniter 库,原因在于: Go 1.8 之前,官方 Json 库的性能就收到多方诟病。不过随着 Go 版本的迭代,标准 json 库的性能也越来越高,Jsonter 的性能优势也越来越窄。如果希望有极致的性能,应该选择 Easyjson 等方案而不是 Jsoniter,而且 Jsoniter 近年已经不活跃了。
- 比较推荐使用 Sonic 库,因不论从性能和功能总体而言,Sonic 的表现的确很亮眼;此外,通过了解 Sonic 的内部实现原理,提供一种对于 cpu 密集型操作优化的“野路子”,即:通过编写高性能的 C 代码并经过优化编译后供 Golang 直接调用。其实并不新鲜,因为实际上 Go 源码中的一些 cpu 密集型操作底层就是编译成了汇编后使用的,如:crypto 和 math。
yaml
YAML是一种流行格式,用于以人类友好的格式序列化数据, 类似JSON但更易于阅读。由于其表达能力和可读性,YAML作为配置文件的格式很受欢迎。也用于更复杂的场景中,例如推动Ansible服务器自动化。
标准库中没有用于处理YAML格式的软件包,但是社区库包括 gopkg.in/yaml.v2
# 先下载外部包
go get -u gopkg.in/yaml.v2
yaml文件
dependencies:
- name: apache
version: 1.2.3
repository: http://example.com/charts
- name: mysql
version: 3.2.1
repository: http://another.example.com/charts
YAML文件读取到Go结构中:
YAML解码与JSON解码非常相似。
- 如果知道YAML文件的结构,可以定义映射结构,并将指向顶级结构的结构指针传递给 yaml.Decoder.Decode() 函数(或从[]进行解码的yaml.Unmarshal())。 字节片)。
- YAML解码器在结构字段名称和YAML文件中的名称之间进行智能映射,以便 YAML中的名称值被解码为结构中的字段名称。
- 最好使用yaml struct标签创建显式映射。 我仅在示例中省略了它们,以说明未指定它们时的行为。
// Dependency describes a dependency
type Dependency struct {
Name string
Version string
RepositoryURL string `yaml:"repository"`
}
type YAMLFile struct {
Dependencies []Dependency `yaml:"dependencies"`
}
f, err := os.Open("data.yml")
if err != nil {
log.Fatalf("os.Open() failed with '%s'\n", err)
}
defer f.Close()
dec := yaml.NewDecoder(f)
var yamlFile YAMLFile
err = dec.Decode(&yamlFile)
if err != nil {
log.Fatalf("dec.Decode() failed with '%s'\n", err)
}
fmt.Printf("Decoded YAML dependencies: %#v\n", yamlFile.Dependencies)
写入yaml文件
// 带有struct标签的自定义映射
type Person struct {
fullName string // 未初始化
Name string
Age int `yaml:"age"` // 指示YAML编码器/解码器将名称age用于表示字段Age的字典关键字。
City string `yaml:"city"`
}
p := Person{
Name: "John",
Age: 37,
City: "SF",
}
// 序列化
d, err := yaml.Marshal(&p) // yaml.Marshal 将 interface {}作为参数
if err != nil {
log.Fatalf("yaml.Marshal failed with '%s'\n", err)
}
fmt.Printf("Person in YAML:\n%s\n", string(d))
yaml.Marshal 将 interface {}作为参数。可以传递任何Go值,并将其类型包装到 interface {}中。
- Marshaller 将使用反射检查传递的值并将其编码为YAML字符串。
- 在序列化结构时,仅对导出的字段(其名称以大写字母开头)进行序列化/反序列化。
在示例中,未对fullName进行序列化。结构被序列化为YAML字典。
- 默认情况下,字典键与结构字段名称相同。结构字段名称在字典键名称下序列化。
可以提供带有struct标签的自定义映射。将任意的struct标签字符串附加到struct字段。
序列化结构时,将值和指针传递给它会产生相同的结果。
- 传递指针效率更高,因为按值传递会创建不必要的副本。
【2023-2-23】go 操作 yaml 文件示例
- 从字符串解析yml
package main
import (
"fmt"
"log"
"gopkg.in/yaml.v2"
)
var data = `
a: Easy!
b:
c: 2
d: [3, 4]
`
// Note: struct fields must be public in order for unmarshal to correctly populate the data.
type T struct {
A string
B struct {
RenamedC int `yaml:"c"`
D []int `yaml:",flow"`
}
}
func main() {
t := T{}
err := yaml.Unmarshal([]byte(data), &t) // 解析 yaml 文件
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t:\n%v\n\n", t)
d, err := yaml.Marshal(&t) // 生成 yaml字符串文件
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- t dump:\n%s\n\n", string(d))
m := make(map[interface{}]interface{})
err = yaml.Unmarshal([]byte(data), &m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m:\n%v\n\n", m)
d, err = yaml.Marshal(&m)
if err != nil {
log.Fatalf("error: %v", err)
}
fmt.Printf("--- m dump:\n%s\n\n", string(d))
}
go 亲测
- 从文件解析yml
reply:
-
"keyword":"hi"
"value":"...."
代码
import (
"fmt"
"log"
"os"
"gopkg.in/yaml.v2"
)
type replyItem struct {
Key string `yaml:"keyword"`
Value string `yaml:"value"`
}
type YAMLFile struct {
ReplyList []replyItem `yaml:"reply"`
}
func main(){
f, err := os.Open("conf.yml")
if err != nil {
log.Fatalf("os.Open() failed with '%s'\n", err)
}
defer f.Close()
// 解析 yaml 文件
dec := yaml.NewDecoder(f)
fmt.Println("打开文件...")
var yamlFile YAMLFile
err = dec.Decode(&yamlFile)
if err != nil {
log.Fatalf("dec.Decode() failed with '%s'\n", err)
}
fmt.Printf("Decoded YAML file: %#v\n", yamlFile.ReplyList)
for i,v:= range yamlFile.ReplyList{
fmt.Println(i, v.Key, v.Value)
//fmt.Println(i,v['Key'],v['Value'])
}
}
os库
package main
import (
"fmt"
"os"
"strings"
)
func main(){
//获得当前工作目录:默认当前工程目录
dir,err := os.Getwd()
fmt.Print(dir)
fmt.Print(err)
// 设置环境变量
os.Setenv("FOO", "1")
// 获取环境变量
fmt.Println(os.Getenv("HOME"))
fmt.Println("FOO:", os.Getenv("FOO"))
fmt.Println("BAR:", os.Getenv("BAR"))
//获得指定环境变量
//paths := os.Getenv(key:"Path")
//goroot := os.Getenv(key:"GOROOT")
//fmt.Print(paths)
//fmt.Print(goroot)
//修改文件访问时间和修改时间
//err2 := os.Chtimes(
// name:"",
// time.Now().AddDate(years:-1,months:0,days:0)
// )
//获得所有环境变量
envs := os.Environ()
for _, env := range envs{
fmt.Print(env)
// 拆分
pair := strings.SplitN(e, "=", 2)
fmt.Println(pair[0])
}
//在网络中的主机名
hostname,err := os.Hostname()
if err == nil {
fmt.Print(hostname)
}else {
fmt.Print("出错了")
}
//获得系统的临时文件夹路径:临时数据的保存路径
fmt.Print(os.TempDir())
//判断某字符是否路径分隔符
fmt.Print("//是路径分隔符吗?",os.IsPathSeparator('\\'))
//fmt.Print("\\是路径分隔符吗?",os.IsPathSeparator(c:'\'))
fmt.Print("$是路径分隔符吗?",os.IsPathSeparator('\\'))
//fmt.Print(os.IsPathSeparator(c:'\\'))
//fmt.Print(os.IsPathSeparator(c:'$'))
//获得文件信息
fileInfo,err := os.Stat("C:/users/...")
if err == nil {
fmt.Print(fileInfo)
}else {
fmt.Print("出错了")
}
}
go的第三方工具viper解析环境变量时,同样的只能得到PATH、HOME这些系统变量,自定义得不到。
package main
import (
"fmt"
"github.com/spf13/viper"
)
func main() {
viper.AutomaticEnv()
if env := viper.Get("GOPATH"); env == nil {
println("error!")
} else {
fmt.Printf("%#v\n", env)
}
}
怎么办?自定义变量时,使用export命令
export OPENAI_API_KEY="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"
时间处理
时间戳
- 当前时间戳
- fmt.Println(time.Now().Unix()) # 1389058332
- str格式化时间
- 当前格式化时间
- fmt.Println(time.Now().Format(“2006-01-02 15:04:05”)) // 这是个奇葩,必须是这个时间点, 据说是go诞生之日, 记忆方法:6-1-2-3-4-5 # 2014-01-07 09:42:20
- 时间戳转str格式化时间
- str_time := time.Unix(1389058332, 0).Format(“2006-01-02 15:04:05”)
- fmt.Println(str_time) # 2014-01-07 09:32:12
- str格式化时间转时间戳
- the_time := time.Date(2014, 1, 7, 5, 50, 4, 0, time.Local)
- unix_time := the_time.Unix()
- fmt.Println(unix_time) # 389045004
- 还有一种方法,使用time.Parse
the_time, err := time.Parse("2006-01-02 15:04:05", "2014-01-08 09:04:41")
if err == nil {
unix_time := the_time.Unix()
fmt.Println(unix_time)
}
// 1389171881
time库使用
package main
import (
"time"
"fmt"
)
func main(){
//本地时间
nowTime := time.Now()
//年月日
year := nowTime.Year(); fmt.Printf("%s",year)
month := nowTime.Month(); fmt.Printf("%s",month)
y,m,d := nowTime.Date(); fmt.Printf("%d:%d:%d",y,m,d)
//周月年中的第几天
day := nowTime.Day(); fmt.Printf("%d",day)
yearDay := nowTime.YearDay(); fmt.Printf("%d",yearDay)
weekDay := nowTime.Weekday(); fmt.Printf("%d",weekDay)
//时分秒
fmt.Printf("%s",nowTime.Hour())
fmt.Printf("%s",nowTime.Minute())
fmt.Printf("%s",nowTime.Second())
fmt.Printf("%s",nowTime.Nanosecond())
//创建时间
date := time.Date(2019,time.September,8,15,0,0,0,time.Now().Location()); fmt.Printf("%s",date)
//Add方法和Sub方法是相反的
//获取t0和t1的时间距离d是使用Sub
//将t0加d获取t1就是使用Add方法
now := time.Now()
//一天之前
duration,_ := time.ParseDuration("-24h0m0s"); fmt.Printf("%s",now.Add(duration))
//一周之前
fmt.Printf("%s",now.Add(duration * 7))
//一月之前
fmt.Printf("%s",now.Add(duration * 30))
//计算时间差
fmt.Printf("%s",now.Sub(now.Add(duration)))
}
// 01: 获取当前时间
dateTime := time.Now()
fmt.Println(dateTime)
// 02: 获取年 月 日 时 分 秒 纳秒
year := time.Now().Year() //年
fmt.Println(year)
month := time.Now().Month() //月
fmt.Println(month)
day := time.Now().Day() //日
fmt.Println(day)
hour := time.Now().Hour() //小时
fmt.Println(hour)
minute := time.Now().Minute() //分钟
fmt.Println(minute)
second := time.Now().Second() //秒
fmt.Println(second)
nanosecond := time.Now().Nanosecond() //纳秒
fmt.Println(nanosecond)
// 03: 获取当前时间戳
timeUnix := time.Now().Unix() //单位秒
timeUnixNano := time.Now().UnixNano() //单位纳秒
fmt.Println(timeUnix)
fmt.Println(timeUnixNano)
// 04: 将时间戳格式化
fmt.Println(time.Now().Format("2006-01-02 15:04:05"))
// 05: 时间戳转为go格式的时间
var timeUnix int64 = 1562555859
fmt.Println(time.Unix(timeUnix,0))
// 之后可以用Format 比如
fmt.Println(time.Unix(timeUnix, 0).Format("2006-01-02 15:04:05"))
// 06: str格式化时间转时间戳
t := time.Date(2014, 1, 7, 5, 50, 4, 0, time.Local).Unix()
fmt.Println(t)
// 时间的计算
// 01: 获取今天0点0时0分的时间戳
currentTime := time.Now()
startTime := time.Date(currentTime.Year(), currentTime.Month(), currentTime.Day(), 0, 0, 0, 0, currentTime.Location())
fmt.Println(startTime)
fmt.Println(startTime.Format("2006/01/02 15:04:05"))
// 02: 获取今天23:59:59秒的时间戳
currentTime := time.Now()
endTime := time.Date(currentTime.Year(), currentTime.Month(), currentTime.Day(), 23, 59, 59, 0, currentTime.Location())
fmt.Println(endTime)
fmt.Println(endTime.Format("2006/01/02 15:04:05"))
// 03: 获取1分钟之前的时间
m, _ := time.ParseDuration("-1m")
result := currentTime.Add(m)
fmt.Println(result)
fmt.Println(result.Format("2006/01/02 15:04:05"))
// 04: 获取1小时之前的时间
m, _ := time.ParseDuration("-1h")
result := currentTime.Add(m)
fmt.Println(result)
fmt.Println(result.Format("2006/01/02 15:04:05"))
// 05: 获取1分钟之后的时间
m, _ := time.ParseDuration("1m")
result := currentTime.Add(m)
fmt.Println(result)
fmt.Println(result.Format("2006/01/02 15:04:05"))
// 06: 获取1小时之后的时间
m, _ := time.ParseDuration("1h")
result := currentTime.Add(m)
fmt.Println(result)
fmt.Println(result.Format("2006/01/02 15:04:05"))
// 07 :计算两个时间戳
afterTime, _ := time.ParseDuration("1h")
result := currentTime.Add(afterTime)
beforeTime, _ := time.ParseDuration("-1h")
result2 := currentTime.Add(beforeTime)
m := result.Sub(result2)
fmt.Printf("%v 分钟 \n", m.Minutes())
h := result.Sub(result2)
fmt.Printf("%v小时 \n", h.Hours())
d := result.Sub(result2)
fmt.Printf("%v 天\n", d.Hours()/24)
// 08: 判断一个时间是否在一个时间之后
stringTime, _ := time.Parse("2006-01-02 15:04:05", "2019-12-12 12:00:00")
beforeOrAfter := stringTime.After(time.Now())
if true == beforeOrAfter {
fmt.Println("2019-12-12 12:00:00在当前时间之后!")
} else {
fmt.Println("2019-12-12 12:00:00在当前时间之前!")
}
// 09: 判断一个时间相比另外一个时间过去了多久
startTime := time.Now()
time.Sleep(time.Second * 5)
fmt.Println("离现在过去了:", time.Since(startTime))
正则表达式(regexp)
在线测试
代码示例
package main
import "bytes"
import "fmt"
import "regexp"
func main() {
match, _ := regexp.MatchString("p([a-z]+)ch", "peach")//是否匹配(每次运行都得编译,慢)
fmt.Println(match)
r, _ := regexp.Compile("p([a-z]+)ch")
fmt.Println(r.MatchString("peach"))//先用 Compile 优化,再匹配 Regexp 结构体
fmt.Println(r.FindString("peach punch"))//查找匹配字符串
fmt.Println(r.FindStringIndex("peach punch"))//查找第一次匹配,但返回开始和结束位置索引,非匹配的内容
fmt.Println(r.FindStringSubmatch("peach punch"))//返回完全匹配和局部匹配的字符串。返回 p([a-z]+)ch 和 `([a-z]+) 的信息。
fmt.Println(r.FindStringSubmatchIndex("peach punch"))//类似的,返回完全匹配和局部匹配的索引位置。
fmt.Println(r.FindAllString("peach punch pinch", -1))//带 All 的这个函数返回所有的匹配项
fmt.Println(r.FindAllStringSubmatchIndex("peach punch pinch", -1))//All 同样可以对应到上面的所有函数。
fmt.Println(r.FindAllString("peach punch pinch", 2))//这个函数提供一个正整数来限制匹配次数。
//上面的例子中,我们使用了字符串作为参数,并使用了如 MatchString 这样的方法。我们也可以提供 []byte参数并将 String 从函数命中去掉。
fmt.Println(r.Match([]byte("peach")))
//创建正则表示式常量时,可以使用 Compile 的变体MustCompile 。因为 Compile 返回两个值,不能用语常量。
r = regexp.MustCompile("p([a-z]+)ch")
fmt.Println(r)
fmt.Println(r.ReplaceAllString("a peach", "<fruit>"))//regexp 包也可以用来替换部分字符串为其他值。
in := []byte("a peach")
out := r.ReplaceAllFunc(in, bytes.ToUpper)//Func变量允许传递匹配内容到一个给定的函数中,
fmt.Println(string(out))
}
go与json
Go内置了对JSON数据的编码和解码,这些数据的类型包括内置数据类型和自定义数据类型。 内置的encoding/json反序列化方法:《go语言json简洁》
- struct:需要提前知道json内容格式
- interface:未限定格式,任意动态的内容都可以解析成 interface,但缺点是必须自己做类型转换
- 延迟解析:json.RawMessage
- 自定义解析
package main
import "fmt"
import "encoding/json"
type Student struct {
Name string `json:"name"`
Age int `json:"age"`
Data []string `json:"data"`
}
func main() {
jsonString := `{"name":"张三","age":20,"data":["男","未婚"]}`
// 指定解析格式
var stu Student
// 不指定格式
// m := make(map[string]interface{}, 4)
err := json.Unmarshal([]byte(jsonString), &stu)
if err!= nil {
fmt.Println(err)
return
}
fmt.Println(stu)
}
simplejson工具
package main
import "encoding/json"
import "fmt"
import "os"
// 我们使用两个结构体来演示自定义数据类型的JSON数据编码和解码。
type Response1 struct {
Page int
Fruits []string
}
// 【2022-10-11】json里的变量名(page)要加双引号!
type Response2 struct {
Page int `json:"page"`
Fruits []string `json:"fruits"`
} //golang json里的struct变量首字母需要大写的,如果json是小写咋办?在type后面跟着别名就可以了,格式是 json:"字段名"
// http://xiaorui.cc/2016/03/06/golang%E8%A7%A3%E6%9E%90%E5%88%9B%E5%BB%BA%E5%A4%8D%E6%9D%82%E5%B5%8C%E5%A5%97%E7%9A%84json%E6%95%B0%E6%8D%AE/
func main() {
// 首先我们看一下将基础数据类型编码为JSON数据
bolB, _ := json.Marshal(true);fmt.Println(string(bolB))//true
intB, _ := json.Marshal(1);fmt.Println(string(intB)) //1
fltB, _ := json.Marshal(2.34);fmt.Println(string(fltB)) //2.34
strB, _ := json.Marshal("gopher");fmt.Println(string(strB)) //gopher
// 这里是将切片和字典编码为JSON数组或对象
slcD := []string{"apple", "peach", "pear"}
slcB, _ := json.Marshal(slcD);fmt.Println(string(slcB))//["apple","peach","pear"]
mapD := map[string]int{"apple": 5, "lettuce": 7}
mapB, _ := json.Marshal(mapD);fmt.Println(string(mapB)) // {"apple":5,"lettuce":7}
// JSON包可以自动地编码自定义数据类型。结果将只包括自定义类型中的可导出成员的值并且默认情况下,这些成员名称都作为JSON数据的键
res1D := &Response1{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res1B, _ := json.Marshal(res1D)
fmt.Println(string(res1B))//{"Page":1,"Fruits":["apple","peach","pear"]}
// 你可以使用tag来自定义编码后JSON键的名称
res2D := &Response2{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res2B, _ := json.Marshal(res2D)
fmt.Println(string(res2B))//{"page":1,"fruits":["apple","peach","pear"]}
// 现在我们看看解码JSON数据为Go数值
byt := []byte(`{"num":6.13,"strs":["a","b"]}`)
// 我们需要提供一个变量来存储解码后的JSON数据,这里的`map[string]interface{}`将以Key-Value的方式保存解码后的数据,Value可以为任意数据类型
var dat map[string]interface{}
// 解码过程,并检测相关可能存在的错误
if err := json.Unmarshal(byt, &dat); err != nil {
panic(err)
}
fmt.Println(dat)//map[num:6.13 strs:[a b]]
// 为了使用解码后map里面的数据,我们需要将Value转换为它们合适的类型,例如我们将这里的num转换为期望的float64
num := dat["num"].(float64)
fmt.Println(num) // 6.13
// 访问嵌套的数据需要一些类型转换
strs := dat["strs"].([]interface{})
str1 := strs[0].(string)
fmt.Println(str1) //a
// 我们还可以将JSON解码为自定义数据类型,这有个好处是可以为我们的程序增加额外的类型安全并且不用再在访问数据的时候进行类型断言
str := `{"page": 1, "fruits": ["apple", "peach"]}`
res := &Response2{}
json.Unmarshal([]byte(str), &res)
fmt.Println(res)//&{1 [apple peach]}
fmt.Println(res.Fruits[0])//apple
// 上面的例子中,我们使用bytes和strings来进行原始数据和JSON数据之间的转换,我们也可以直接将JSON编码的数据流写入`os.Writer`或者是HTTP请求回复数据。
enc := json.NewEncoder(os.Stdout)
d := map[string]int{"apple": 5, "lettuce": 7}
enc.Encode(d) //{"apple":5,"lettuce":7}
}
运行结果
- 6.13
- a
- apple
打日志-log使用
官方log包
Golang的标准库提供了log的机制,但是该模块的功能较为简单(看似简单,其实他有他的设计思路)。不过比手写fmt. Printxxx还是强很多的。至少在输出的位置做了线程安全的保护。其官方手册见Golang log (天朝的墙大家懂的)。
log包定义了Logger类型,该类型提供了一些格式化输出的方法。
type Logger struct {
mu sync.Mutex // ensures atomic writes; protects the following fields
prefix string // prefix on each line to identify the logger (but see Lmsgprefix)
flag int // properties
out io.Writer // destination for output
buf []byte // for accumulating text to write
}
- mu属性主要是为了确保原子操作
- prefix设置每一行的前缀
- flag设置输出的各种属性,比如时间、行号、文件路径等。
- out输出的方向,用于把日志存储文件。
log标准库中的Flags函数会返回标准logger的输出配置,而SetFlags函数用来设置标准logger的输出配置。
func Flags() int
func SetFlags(flag int)
flag 选项
const (
// 控制输出日志信息的细节,不能控制输出的顺序和格式。
// 输出的日志在每一项后会有一个冒号分隔:例如2009/01/23 01:23:23.123123 /a/b/c/d.go:23: message
Ldate = 1 << iota // 日期:2009/01/23
Ltime // 时间:01:23:23
Lmicroseconds // 微秒级别的时间:01:23:23.123123(用于增强Ltime位)
Llongfile // 文件全路径名+行号: /a/b/c/d.go:23
Lshortfile // 文件名+行号:d.go:23(会覆盖掉Llongfile)
LUTC // 使用UTC时间
LstdFlags = Ldate | Ltime // 标准logger的初始值
)
log标准库中还提供了一个创建新logger对象的构造函数–New,支持创建自己的logger示例。New函数的签名如下:
func New(out io.Writer, prefix string, flag int) *Logger
New创建一个Logger对象。其中,参数out设置日志信息写入的目的地。参数prefix会添加到生成的每一条日志前面。参数flag定义日志的属性(时间、文件等等)。
func main() {
logger := log.New(os.Stdout, "<New>", log.Lshortfile|log.Ldate|log.Ltime)
logger.Println("这是自定义的logger记录的日志。")
// <New>2017/06/19 14:06:51 main.go:34: 这是自定义的logger记录的日志。
}
一个简单使用的例子:
package main
import (
"log"
)
func main(){
log.Print("常规日志输出,相当于 info \n")
log.Println("常规日志输出,相当于 info(不用换行)")
v := "优雅的"
log.Printf("这是一个%s日志\n", v)
log.Panic("日志输出,相当于 warning \n")
log.Panicln("日志输出,相当于 warning \n")
// Fatal系列函数会在写入日志信息后调用os.Exit(1)。Panic系列函数会在写入日志信息后panic。
log.Fatal("错误日志输出,相当于 fatal \n")
log.Fatalln("错误日志输出,相当于 fatal \n")
// 自定义日志文件地址
logFile, err := os.OpenFile("D:/logs/xxxx/Payment/test.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("open log file failed, err:", err)
return
}
log.SetOutput(logFile)
log.SetFlags(log.Llongfile | log.Lmicroseconds | log.Ldate) // 时间信息
log.SetPrefix("[小王子]") // 前缀
log.Println("这是一条很普通的日志。")
// [小王子]2021/03/03 15:16:19.921021 D:/GoProject/src/main/gobase/log/loogfile.go:19: 这是一条很普通的日志。
}
编译运行后,会看到程序打印了 Come with fatal,exit with 1 然后就退出了,如果用 echo $? 查看退出码,会发现是 “1”。
优化log包
基于官方的log包,封装出自己的log日志包
- 获取当前事件
- 对 Logger实例进行加锁操作
- 判断Logger的标志位是否包含 Lshortfile 或 Llongfile, 如果包含进入步骤4, 如果不包含进入步骤5
- 获取当前函数调用所在的文件和行号信息
- 格式化数据,并将数据写入到 l.out 中,完成输出
- 解锁操作
// logger.go
package logger
import (
"io"
"log"
"os"
)
const (
flag = log.Ldate | log.Ltime | log.Lshortfile
preDebug = "[DEBUG]"
preInfo = "[INFO]"
preWarning = "[WARNING]"
preError = "[ERROR]"
)
var (
logFile io.Writer
debugLogger *log.Logger
infoLogger *log.Logger
warningLogger *log.Logger
errorLogger *log.Logger
defaultLogFile = "/var/log/web.log"
)
func init() {
var err error
logFile, err = os.OpenFile(defaultLogFile, os.O_CREATE|os.O_APPEND|os.O_RDWR, 0666)
if err != nil {
defaultLogFile = "./web.log"
logFile, err = os.OpenFile(defaultLogFile, os.O_CREATE|os.O_APPEND|os.O_RDWR, 0666)
if err != nil {
log.Fatalf("create log file err %+v", err)
}
}
debugLogger = log.New(logFile, preDebug, flag)
infoLogger = log.New(logFile, preInfo, flag)
warningLogger = log.New(logFile, preWarning, flag)
errorLogger = log.New(logFile, preError, flag)
}
func Debugf(format string, v ...interface{}) {
debugLogger.Printf(format, v...)
}
func Infof(format string, v ...interface{}) {
infoLogger.Printf(format, v...)
}
func Warningf(format string, v ...interface{}) {
warningLogger.Printf(format, v...)
}
func Errorf(format string, v ...interface{}) {
errorLogger.Printf(format, v...)
}
func SetOutputPath(path string) {
var err error
logFile, err = os.OpenFile(path, os.O_CREATE|os.O_APPEND|os.O_RDWR, 0666)
if err != nil {
log.Fatalf("create log file err %+v", err)
}
debugLogger.SetOutput(logFile)
infoLogger.SetOutput(logFile)
warningLogger.SetOutput(logFile)
errorLogger.SetOutput(logFile)
}
调用logger包
package main
import "yourPath/logger"
func main() {
author := "korbin"
logger.Debugf("hello,%s",author)
logger.Infof("hello,%s",author)
logger.Warningf("hello,%s",author)
logger.Errorf("hello,%s",author)
}
/*
[DEBUG]2020/12/01 11:33:07 logger.go:43: hello,korbin
[INFO]2020/12/01 11:33:07 logger.go:47: hello,korbin
[WARNING]2020/12/01 11:33:07 logger.go:51: hello,korbin
[ERROR]2020/12/01 11:33:07 logger.go:55: hello,korbin
*/
文件读写
两种方案
package main
import (
"bufio" //这是什么包?
"fmt"
"io"
"io/ioutil"
"os"
)
// Reading files requires checking most calls for errors.This helper will streamline our error checks below.
func check(e error) {
if e != nil {
panic(e)
}
}
func main() {
// Perhaps the most basic file reading task is slurping(咕噜咕噜的喝) a file's entire contents into memory.
dat, err := ioutil.ReadFile("/tmp/dat") //一次性加载到内存
check(err)
fmt.Print(string(dat))
// You'll often want more control over how and what parts of a file are read. For these tasks, start by `Open`ing a file to obtain an `os.File` value.
f, err := os.Open("/tmp/dat") //
check(err)
// Read some bytes from the beginning of the file. Allow up to 5 to be read but also note how many actually were read.
b1 := make([]byte, 5)
n1, err := f.Read(b1) //读一部分内容
check(err)
fmt.Printf("%d bytes: %s\n", n1, string(b1))
// You can also `Seek` to a known location in the file and `Read` from there.
o2, err := f.Seek(6, 0) //自定义开始点
check(err)
b2 := make([]byte, 2)
n2, err := f.Read(b2)
check(err)
fmt.Printf("%d bytes @ %d: %s\n", n2, o2, string(b2))
// The `io` package provides some functions that may be helpful for file reading. For example, reads like the ones above can be more robustly implemented with `ReadAtLeast`.
o3, err := f.Seek(6, 0)
check(err)
b3 := make([]byte, 2)
n3, err := io.ReadAtLeast(f, b3, 2)
check(err)
fmt.Printf("%d bytes @ %d: %s\n", n3, o3, string(b3))
// There is no built-in rewind, but `Seek(0, 0)` accomplishes this.
_, err = f.Seek(0, 0)
check(err)
// The `bufio` package implements a buffered reader that may be useful both for its efficiency with many small reads and because of the additional reading methods it provides.
r4 := bufio.NewReader(f)
b4, err := r4.Peek(5)
check(err)
fmt.Printf("5 bytes: %s\n", string(b4)
// Close the file when you're done (usually this would be scheduled immediately after `Open`ing with `defer`).
f.Close()
//开始写文件部分
// To start, here's how to dump a string (or just bytes) into a file.
d1 := []byte("hello\ngo\n")
err := ioutil.WriteFile("dat1.txt", d1, 0644)//一次性写文件
check(err)
// For more granular(粒状,精细) writes, open a file for writing.
f, err := os.Create("dat2.txt")
check(err)
// It's idiomatic(惯用的) to defer a `Close` immediately after opening a file.
defer f.Close()
// You can `Write` byte slices as you'd expect.
d2 := []byte{115, 111, 109, 101, 10}
n2, err := f.Write(d2)
check(err)
fmt.Printf("wrote %d bytes\n", n2)
// A `WriteString` is also available.
n3, err := f.WriteString("writes\n")
fmt.Printf("wrote %d bytes\n", n3)
// Issue a `Sync` to flush writes to stable storage.
f.Sync()
// `bufio` provides buffered writers in addition to the buffered readers we saw earlier.
w := bufio.NewWriter(f)
n4, err := w.WriteString("buffered\n")
fmt.Printf("wrote %d bytes\n", n4)
// Use `Flush` to ensure all buffered operations have been applied to the underlying writer.
w.Flush()
//追加
f, err := os.OpenFile(fileName, os.O_WRONLY|os.O_APPEND, 0666)
}
定时器
在将来的某个时间点执行Go代码,或者在某个时间间隔重复执行。 Go的内置计时器和自动接收器功能使这两项任务变得容易。
定时器代表未来的一个事件。可告诉定时器您想要等待多长时间,它提供了一个通道,在当将通知时执行对应程序
package main
import "time"
import "fmt"
func main() {
// Timers represent a single event in the future. You tell the timer how long you want to wait, and it provides a channel that will be notified at that time. This timer will wait 2 seconds.
timer1 := time.NewTimer(time.Second * 2)
// The `<-timer1.C` blocks on the timer's channel `C` until it sends a value indicating that the timer expired.
<-timer1.C //<-timer1.C阻塞定时器的通道C,直到它发送一个指示定时器超时的值。如果只是想等待,可以使用time.Sleep。定时器可能起作用的一个原因是在定时器到期之前取消定时器
fmt.Println("Timer 1 expired")
// If you just wanted to wait, you could have used `time.Sleep`. One reason a timer may be useful is that you can cancel the timer before it expires.Here's an example of that.
timer2 := time.NewTimer(time.Second)
go func() {
<-timer2.C
fmt.Println("Timer 2 expired")
}()
stop2 := timer2.Stop() //提前取消计时器
if stop2 {
fmt.Println("Timer 2 stopped")
}
t := time.Tick(10)//
<- t //
}
socket编程
系统调用
执行命令行
用标准输入输出
命令行参数:用os.Args,像python的getops一样
随机数
package main
import (
"fmt"
"math/rand"
)
func main() {
// 根据时间设置随机数种子
rand.Seed(int64(time.Now().Nanosecond()))
// 获取随机整数
for i := 0; i < 5; i++ {
fmt.Printf("%v ", rand.Int())
}
fmt.Println()
// 获取随机的32位整数
for i := 0; i < 5; i++ {
fmt.Printf("%v ", rand.Int31())
}
fmt.Println()
// 获取指定范围内的随机数
for i := 0; i < 5; i ++ {
fmt.Printf("%v ", rand.Intn(10))
}
fmt.Println()
// 获取浮点型数[0.0, 1.0)之间
for i := 0; i < 5; i ++ {
fmt.Printf("%v ", rand.Float32())
}
fmt.Println()
}
//获取两个数字之间的数字
func RandInt64(min,max int64) int64{
maxBigInt:=big.NewInt(max)
i,_:=rand.Int(rand.Reader,maxBigInt)
if i.Int64()<min{
RandInt64(min,max)
}
return i.Int64()
}
//产生不重复的随机数
//rand库的Perm方法可以返回[0,n)直接的随机数
CGO
C 语言作通用语言,很多库会选择提供一个 C 兼容的 API,用其他不同语言实现。
Go 语言通过自带的 CGO 工具支持 C 语言函数调用,同时可用 Go 语言导出 C 动态库接口给其它语言使用。
- 【2024-7-13】参考
用法
示例
- 启用 CGO 特性,同时包含 C 语言的
<stdio.h>头文件。 - 然后通过 CGO 包的
C.CString函数将 Go 语言字符串转为 C 语言字符串 - 最后调用 CGO 包的
C.puts函数向标准输出窗口打印转换后的 C 字符串。
// hello.go
package main
import "C"
func main() {
println("hello cgo")
}
自定义 C 函数
// hello.go
package main
/*
#include <stdio.h>
static void SayHello(const char* s) {
puts(s);
}
*/
import "C"
func main() {
C.SayHello(C.CString("Hello, World\n"))
}
问题
注意
- C 代码一定要和import 贴着,中间不能有空行,如果有空行会找不到C函数
错误案例
/*
#include<stdio.h>
void printint(){
printf("Hello World!");
}
*/
import "C"
func main(){
C.printint()
}
单元测试
【2017-07-13】新功能引入旧策略bug(回归测试)
Go语言似乎是个偏执狂,牺牲了不必要的灵活性,带来一些强制的编程风格和约定。比如:
- 无任何形式的Makefile,模块就是目录、包就是目录、编译配制就是目录!
- 不光目录被用上了,文件名还能指定用途。文件名后缀为_test.go的都是单元测试文件,_linux32.go就是32位linux特定的代码。
- 不光文件名被用上了,函数名还有特定用途。
- 在单元测试文件中,测试函数以Test开头。
- 以大写字母开头的变量、类型和函数是外部可见的,小写字母开头的变量、类型和函数是外部不可见的。 类似的约定也不好说是go语言首创,在一些文件格式中也有类似规范。但是我暂时不知道到有什么其它编程语言对编程风格这么带强制性。
Go Test
Go语言通过testing包提供自动化测试功能。包内测试只要运行命令 go test,就能自动运行符合规则的测试函数。
Go语言测试约定规则
- 一般测试func TestXxx(*testing.T)
- 测试行必须Test开头,Xxx为字符串,第一个X必须大写的[A-Z]的字幕
- 为了测试方法和被测试方法的可读性,一般Xxx为被测试方法的函数名。
- 性能测试func BenchmarkXxx(*testing.B)
- 性能测试用Benchmark标记,Xxx同上。
- 测试文件名约定
- go语言测试文件名约定规则是必须以_test.go结尾,放在相同包下,为了方便代码阅读,一般go源码文件加上_test
- 比如源文件my.go 那么测试文件如果交your_test.go,her_test.go,my_test.go都可以,不过最好的还是my_test.go,方便阅读
举例,源文件my.go
package my
func add(x, y int) int {
return x + y
}
创建一个my_test.go文件,需要引入testing
package my
import "testing"
func TestAdd(t *testing.T) {
if add(1, 2) != 3 {
t.Error("test foo:Addr failed")
} else {
t.Log("test foo:Addr pass")
}
}
func BenchmarkAdd(b *testing.B) {
// 如果需要初始化,比较耗时的操作可以这样:
// b.StopTimer()
// .... 一堆操作
// b.StartTimer()
for i := 0; i < b.N; i++ {
add(1, 2)
}
}
运行测试 go test,输出:
- PASS
- ok github.com/my 0.010s
要运行性能测试,执行命令
- go test -test.bench=”.*”
输出
- PASS
- BenchmarkAdd 2000000000 0.72 ns/op
- ok github.com/my 1.528s
调试
运行时间
【2023-1-12】trace 包,跟踪函数执行时间
代码
package main
import (
"fmt"
"os"
"runtime"
"runtime/trace"
"sync/atomic"
"time"
)
var (
stop int32
count int64
sum time.Duration
)
func concat() {
for n := 0; n < 100; n++ {
for i := 0; i < 8; i++ {
go func() {
s := "Go GC"
s += " " + "Hello"
s += " " + "World"
_ = s
}()
}
}
}
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
go func() {
var t time.Time
for atomic.LoadInt32(&stop) == 0 {
t = time.Now()
runtime.GC()
sum += time.Since(t)
count++
}
fmt.Printf("GC spend avg: %v\n", time.Duration(int64(sum)/count))
}()
concat()
atomic.StoreInt32(&stop, 1)
}
图片
动图生成

- go build gopl.io/ch1/lissajous
- ./lissajous >out.gif
// Lissajous generates GIF animations of random Lissajous figures.
package main
import (
"image"
"image/color"
"image/gif"
"io"
"math"
"math/rand"
"os"
"time"
)
var palette = []color.Color{color.White, color.Black}
const (
whiteIndex = 0 // first color in palette
blackIndex = 1 // next color in palette
)
func main() {
// The sequence of images is deterministic unless we seed
// the pseudo-random number generator using the current time.
// Thanks to Randall McPherson for pointing out the omission.
rand.Seed(time.Now().UTC().UnixNano())
lissajous(os.Stdout)
}
func lissajous(out io.Writer) {
const (
cycles = 5 // number of complete x oscillator revolutions
res = 0.001 // angular resolution
size = 100 // image canvas covers [-size..+size]
nframes = 64 // number of animation frames
delay = 8 // delay between frames in 10ms units
)
freq := rand.Float64() * 3.0 // relative frequency of y oscillator
anim := gif.GIF{LoopCount: nframes}
phase := 0.0 // phase difference
for i := 0; i < nframes; i++ {
rect := image.Rect(0, 0, 2*size+1, 2*size+1)
img := image.NewPaletted(rect, palette)
for t := 0.0; t < cycles*2*math.Pi; t += res {
x := math.Sin(t)
y := math.Sin(t*freq + phase)
img.SetColorIndex(size+int(x*size+0.5), size+int(y*size+0.5),
blackIndex)
}
phase += 0.1
anim.Delay = append(anim.Delay, delay)
anim.Image = append(anim.Image, img)
}
gif.EncodeAll(out, &anim) // NOTE: ignoring encoding errors
}
Web服务
Go 管理后台
【2024-1-26】Github高星GoLang管理后台:GO语言Web后台管理系统推荐
Gin-Vue-Admin 19k星星
Gin-Vue-Admin
- 官网地址, Github:gin-vue-admin
- 基于vite+vue3+gin搭建的全栈开发基础平台(支持TS,JS混用),集成jwt鉴权,权限管理,动态路由,显隐可控组件,分页封装,多点登录拦截,资源权限,上传下载,代码生成器,表单生成器,chatGPT自动查表等开发必备功能。
特点
- 前端:用基于vue3的Element-Plus构建基础页面。
- 后端:用Gin快速搭建基础restful风格API,Gin是一个go语言编写的Web框架。
- 数据库:采用MySql>5.7版本,数据库引擎 innoDB,使用gorm实现对数据库的基本操作,已添加对sqlite数据库的支持。
- 缓存:使用Redis实现记录当前活跃用户的jwt令牌并实现多点登录限制。
- API文档:使用Swagger构建自动化文档。
- 配置文件:使用fsnotify和viper实现yaml格式的配置文件。
- 日志:使用zap实现日志记录。
go-admin 10k星星
go-admin
基于Gin + Vue + Element UI / Arco Design / Ant Design的前后端分离权限管理系统,系统初始化极度简单,只需要配置文件中,修改数据库连接,系统支持多指令操作,迁移指令可以让初始化数据库信息变得更简单,服务指令可以很简单的启动api服务。
特点
- 遵循 RESTful API 设计规范
- 基于 GIN WEB API 框架,提供了丰富的中间件支持(用户认证、跨域、访问日志、追踪ID等)
- 基于Casbin的 RBAC 访问控制模型
- JWT 认证
- 支持 Swagger 文档(基于swaggo)
- 基于 GORM 的数据库存储,可扩展多种类型数据库
- 配置文件简单的模型映射,快速能够得到想要的配置
- 代码生成工具
- 表单构建工具
- 多指令模式
- 多租户的支持
- 界面演示
GoAdmin 7.6k星星
GoAdmin
GoAdmin是一个基于 golang 面向生产的数据可视化管理平台搭建框架,可以让你使用简短的代码在极短时间内搭建起一个管理后台。内置支持对主流SQL数据库(mysql/postgresql/sqlite/mssql)增删改查的管理插件。免费支持Adminlte、Sword两个主题。
特性
- 内置完善的rbac权限系统
- 支持多个web框架接入
- 本地化支持
- 整个系统可以编译成一个二进制文件
- 提供多个插件(开发中)
- 多个好看的ui主题(更多主题开发中)
Hugo 70k星星
Hugo
Hugo声称是全球最快的构建网站框架,最受欢迎的开源静态站点生成器之一。凭借其惊人的速度和灵活性,Hugo让构建网站再次变得有趣。
虽然Hugo主要是一个静态站点生成器,但其强大的主题系统和模板引擎使其成为一个理想的后台管理系统的基础。Hugo使用Go语言编写,速度极快,并且易于部署。如果你寻求一个快速而灵活的管理后台解决方案,Hugo也可以是一个选择。
浏览原理
浏览器访问过程
- 浏览器本身是一个客户端,当你输入 URL 的时候,首先浏览器会去请求 DNS 服务器,通过 DNS 获取相应的域名对应的 IP
- 然后通过 IP 地址找到 IP 对应的服务器后,要求建立 TCP 连接,等浏览器发送完 HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务,返回 HTTP Response(响应)包;
- 客户端收到来自服务器的响应后开始渲染这个 Response 包里的主体(body),等收到全部的内容随后断开与该服务器之间的 TCP 连接。
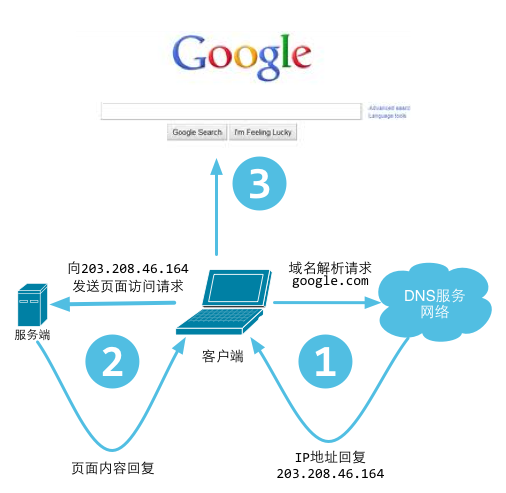
Web 服务器的工作原理可以简单地归纳为:
- 客户机通过 TCP/IP 协议建立到服务器的 TCP 连接
- 客户端向服务器发送 HTTP 协议请求包,请求服务器里的资源文档
- 服务器向客户机发送 HTTP 协议应答包,如果请求的资源包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理 “动态内容”,并将处理得到的数据返回给客户端
- 客户机与服务器断开。由客户端解释 HTML 文档,在客户端屏幕上渲染图形结果
Web 框架
Go 提供的 net/http库 对于HTTP协议实现非常好,基于此再构造框架会更容易,因此生态中出现了很多框架。
常见的web框架
主流框架对比
【2019-10-14】
- Golang六款优秀Web框架对比
- Golang框架选型比较: goframe, beego, iris和gin, 最终采用 GoFrame,但性能不如 gin
六款Web框架
- 从流行度、社区支持及内建功能等角度对六款知名Go语言Web框架做对比。
| 框架 | 代码 | 流行度(stars) | 简介 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Gin | gin | 24181 | HTTP Web框架,更好的性能实现类似Martini的API,性能更好 | 轻量级MVC框架,提供路由和中间件支持 | |
| Beego | beego | 18812 | 开源高性能web框架 | ||
| Iris | iris | 13565 | 完备MVC支持,拥抱未来 | ||
| Echo | echo | 12861 | 高性能、极简Go语言Web框架 | 高性能微服务框架 | |
| Revel | revel | 10723 | 高效、全栈Web框架 | ||
| Buffalo | buffalo | 3935 | 快速构建Web应用 |
Web框架核心功能对比 img
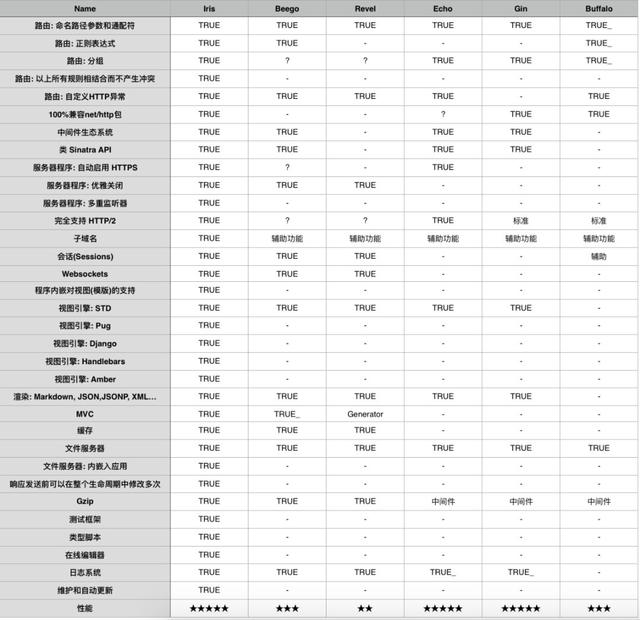
几个知名的Go语言Web框架(Echo、Gin和Buffalo)由于没有完备支持所有功能,并不能算是真正意义上的Web框架,但大部分go社区认为是,因此,将这几个框架也列在表格中可以和Iris、Beego、Revel做比较。
- 以上这些框架,除了Beego和Revel之外,都可以适配任意 net/http中间件,其中一部分框架可以轻松地做适配,另外一些可能就需要额外的努力
- 目测goframe类似django,Gin类似flask。
众多Go Web框架中, Gin 和 Echo 成为突出的竞争者,每个都有自己独特的优势和特性。
(1) GIN:
极简主义但功能强大的框架,GIN优先考虑性能和简单性。
- 基于
net/http构建,极快的路由和最小开销,使其成为构建高性能API和微服务的理想选择。 - GIN 轻量级设计和直观API使开发人员能够用最少的样板代码创建健壮的Web应用,确保快速开发而不牺牲性能。
(2) Echo:
Echo以其灵活性和可定制性脱颖而出。
- 凭借其优雅和富有表现力的API,Echo使开发人员能够轻松构建复杂的Web应用。
- 提供广泛的中间件支持、动态路由生成和内置验证
- Echo为构建RESTful API和复杂Web应用提供了全面的工具包。对开发者生产力和灵活性的强调使其成为需要广泛定制和高级功能的项目的首选
net/http (原生)
简介
Go 提供完善的 net/http 包,通过 http 包快速搭建可运行的 Web 服务。同时很简单地对 Web 路由,静态文件,模版,cookie 等数据进行设置和操作。
- net/http 涵盖了HTTP客户端和服务端具体的实现方式。
- 内置的net/http 包 提供最简洁的HTTP客户端实现方式,无须借助第三方网络通信库,就可以直接使用HTTP中用得最多的GET和POST方式请求数据。
使用方法
(1) HTTP协议客户端实现
- request请求:含 GET/POST
- http.
NewRequest()
- http.
- GET 方法
- client.
Get() - http.
Get()
- client.
- POST 方法
- client.
Post() 或 client.PostForm() - http.
Post() 或 http.PostForm() - http 的
Post()函数或PostForm(),就是对 DefaultClient.Post() 或 DefaultClient.PostForm()的封装
- client.
(2) HTTP协议服务端实现
HTTP服务器主要应完成如下功能
- ① 处理动态请求:处理浏览网站,登录帐户或发布图片等用户传入的请求。
- 用 http.
HandleFunc函数注册一个新的 Handler 来处理动态请求。- 第一个参数是请求路径的匹配模式
- 第二个参数是一个函数类型,表示针对这个请求要执行的功能。
- 用 http.
- ② 提供静态文件:将JavaScript,CSS和图像等静态文件提供给浏览器,服务于用户。
- http.
FileServer() 方法提供 Javascript,CSS或图片等静态文件。 - 参数是文件系统接口,可以使用http.Dir()来指定文件所在的路径。如果该路径中有index.html文件,则会优先显示html文件,否则会显示文件目录。
- http.
- ③ 接受连接请求:HTTP服务器必须监听指定端口从而接收来自网络的连接请求。
- http.
ListenAndServer()函数用来启动HTTP服务器,并且在指定的 IP 地址和端口上监听客户端请求
- http.
- ④ 获取客户端数据
- 客户端提交的数据全部位于 *http.Request 中
package main
import (
"fmt"
"net/http"
)
func main() {
testHttpNewRequest()
// 处理动态请求
http.HandleFunc("/", func (w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Welcome to my website!")
})
// 提供静态文件
fs := http.FileServer(http.Dir("static/")) // 返回值是 Handler 类型
http.Handle("/static/", http.StripPrefix("/static/", fs)) // 添加路由
// 接收请求,两个参数:监听地址、HTTP处理器 Handler
http.ListenAndServe(":80", nil)
}
func testHttpNewRequest() {
//1.创建一个客户端
client := http.Client{}
//2. 创建一个请求,请求方式可以是GET或POST
request, err := http.NewRequest("GET", "http://www.baidu.com", nil)
checkErr(err)
// 或调用http/client.Get方法
response, err := http.Get("http://www.baidu.com")
response, err := client.Get("http://www.baidu.com")
checkErr(err)
fmt.Printf("响应状态码: %v\n", response.StatusCode)
if response.StatusCode == 200 {
fmt.Println("网络请求成功")
defer response.Body.Close()
}
// 或调用client.Post 方法
resp, err := http.Post("http://example.com/upload", "image/jpeg", &buf)
// 或调用client.PostForm 方法
resp, err := http.PostForm("http://example.com/form",
url.Values{"key": {"Value"}, "id": {"123"}})
//3.客户端发送请求
cookName := &http.Cookie{Name: "username", Value: "Steven"}
//添加cookie
request.AddCookie(cookName)
response, err := client.Do(request)
checkErr(err)
//设置请求头
request.Header.Set("Accept-Lanauage", "zh-cn")
defer response.Body.Close()
//查看请求头的数据
fmt.Printf("Header:%+v\n", request.Header)
fmt.Printf("响应状态码: %v\n", response.StatusCode)
//4.操作数据
if response.StatusCode == 200 {
fmt.Println("网络请求成功")
checkErr(err)
} else {
fmt.Println("网络请求失败", response.Status)
}
}
//检查错误
func checkErr(err error) {
defer func() {
if ins, ok := recover().(error); ok {
fmt.Println("程序出现异常: ", ins.Error())
}
}()
if err != nil {
panic(err)
}
}
代码示例
【2022-7-28】启动web服务
// web_test.go
package main
import (
"fmt"
"net/http"
"strings"
"log"
"sync"
)
var mu sync.Mutex // 互斥锁
var count int // 全局变量
func sayhello(w http.ResponseWriter, r *http.Request) {
r.ParseForm() // 解析参数,默认是不会解析的
fmt.Print("path: ", r.URL.Path, "\tscheme: ", r.URL.Scheme, "\turl_long: ", r.Form["url_long"])
// 读取表单
for k, v := range r.Form {
fmt.Println("key: ", k, "\tval: ", strings.Join(v, ""))
}
// 读取Header
for name, headers := range req.Header {
for _, h := range headers {
fmt.Fprintf(w, "%v: %v\n", name, h)
}
}
// 输出信息到客户端: Fprintf
fmt.Fprintf(w, "Hello astaxie!") // 这个写入到 w 的是输出到客户端的
}
type indexHandler struct {
content string
}
func counter(w http.ResponseWriter, r *http.Request) {
mu.Lock()
fmt.Fprintf(w, "Count %d\n", count)
mu.Unlock()
}
func main() {
// 注册路由: Handle, HandleFunc这两个函数最终都由 DefaultServeMux 调用 Handle 方法来完成路由的注册
// 区别:Handle直接返回结构体信息,不用经过自定义函数
http.Handle("/", &indexHandler{content: "hello world!"}) // 直接返回内容
http.HandleFunc("/", sayhello) // 设置访问的路由
http.HandleFunc("/count", counter) // 另一个路由
err := http.ListenAndServe(":9090", nil) // 设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
// 更新全局变量
mu.Lock()
count++
mu.Unlock()
}
过程
- go build web_test.go
- ./web_test
- 或直接运行:
- go run web_test.go &
- 浏览器访问:http://localhost:9090,页面显示:Hello astaxie!
- 换一个地址:http://localhost:9090/?url_long=111&url_long=222,浏览器显示输入的参数
注:
- PHP 程序员也许就会问,nginx、apache 服务器不需要吗?—— Go 就是不需要这些,因为直接就监听 tcp 端口了,做了 nginx 做的事情,然后 sayhelloName 这个其实就是我们写的逻辑函数了,跟 php 里面的控制层(controller)函数类似。
- Python 程序员,会觉得跟 tornado 代码很像—— 没错,Go 就是拥有类似 Python 这样动态语言的特性,写 Web 应用很方便。
- Ruby 程序员会发现和 ROR 的 /script/server 启动有点类似。
路由
Go 标准库中的 net/http 实现HTTP请求路由
net/http本身不直接提供路由功能(如模式匹配)- 解法: 通过
http.ServeMux(http.Handle和http.HandleFunc背后的默认路由器)和条件逻辑(如switch语句或if-else块)手动管理路由:
main.go
package main
import (
"fmt"
"net/http"
)
func homeHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Welcome to the home page!")
}
func aboutHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "This is the about page.")
}
func main() {
// 创建一个新的ServeMux实例(通常不需要,因为http.DefaultServeMux是默认的)
// 但这里为了演示如何显式使用它,我们创建一个新的
mux := http.NewServeMux()
// 将路由绑定到处理器函数
mux.HandleFunc("/", homeHandler)
mux.HandleFunc("/about", aboutHandler)
// 注意:如果你使用http.DefaultServeMux(通过http.Handle和http.HandleFunc),
// 你不需要显式地创建一个ServeMux实例,并且可以直接使用http.ListenAndServe。
// 但由于我们创建了一个新的ServeMux实例,我们需要将它传递给http.ListenAndServe。
// 监听并在 0.0.0.0:8000 上启动服务
fmt.Println("Server is running on http://localhost:8000")
http.ListenAndServe(":8000", mux) // 注意这里我们传递了mux实例
// 如果你使用http.DefaultServeMux,则只需调用:
// http.ListenAndServe(":8000", nil)
// 并且在上面使用http.HandleFunc("/")和http.HandleFunc("/about")来注册路由
}
运行命令:
go run main.go
打开浏览器访问:http://localhost:8000, http://localhost:8000/about
http包原理
服务器端的几个概念
- Request:用户请求的信息,用来解析用户的请求信息,包括 post、get、cookie、url 等信息
- Response:服务器需要反馈给客户端的信息
- Conn:用户的每次请求链接
- Handler:处理请求和生成返回信息的处理逻辑
工作模式流程图
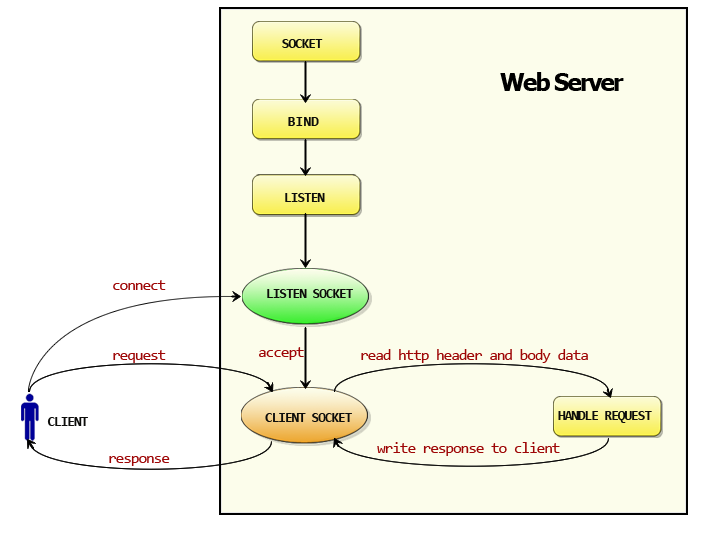
http 包执行流程
- 创建 Listen Socket, 监听指定的端口,等待客户端请求到来。
- Listen Socket 接受客户端的请求,得到 Client Socket, 接下来通过 Client Socket 与客户端通信。
- 处理客户端的请求,首先从 Client Socket 读取 HTTP 请求的协议头,如果是 POST 方法,还可能要读取客户端提交的数据,然后交给相应的 handler 处理请求,handler 处理完毕准备好客户端需要的数据,通过 Client Socket 写给客户端。
基于 HTTP 构建的网络应用包括两个端,即客户端 ( Client ) 和服务端 ( Server )。
- 两个端的交互行为包括从客户端发出 request、服务端接受 request 进行处理并返回 response 以及客户端处理 response。
- http 服务器的工作就在于如何接受来自客户端的 request,并向客户端返回 response。
典型的 http 服务端的处理流程:
- 服务器在接收到请求时,首先会进入路由 ( router ),这是一个 Multiplexer,路由的工作在于为这个 request 找到对应的处理器 ( handler )
- 处理器对 request 进行处理,并构建 response。
- Golang 实现的 http server 同样遵循这样的处理流程。
问题
- 如何监听端口?
- 如何接收客户端请求?
- 如何分配 handler?
Go 是通过一个函数 ListenAndServe 来处理这些事情的,这个底层其实这样处理的:
- 初始化一个 server 对象,然后调用了 net.Listen(“tcp”, addr),也就是底层用 TCP 协议搭建了一个服务,然后监控我们设置的端口。
源码
// 处理接收客户端的请求信息
func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
var tempDelay time.Duration // how long to sleep on accept failure
// 循环接受 Listener 请求
for {
rw, e := l.Accept()
if e != nil {
if ne, ok := e.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
log.Printf("http: Accept error: %v; retrying in %v", e, tempDelay)
time.Sleep(tempDelay)
continue
}
return e
}
tempDelay = 0
c, err := srv.newConn(rw)
if err != nil {
continue
}
go c.serve()
}
}
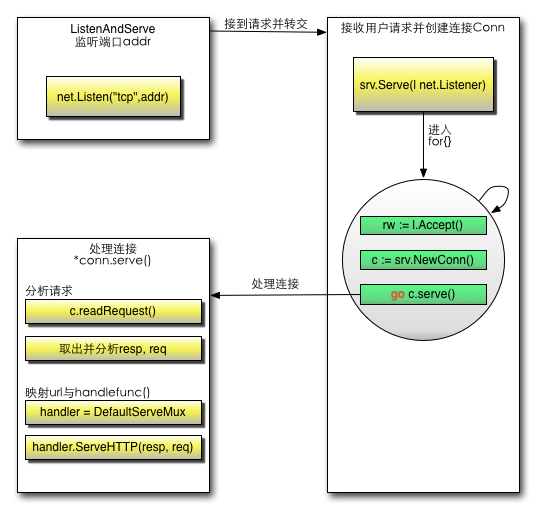
Go 的 http 有两个核心功能:Conn、ServeMux
http/template 模板引擎
【2022-9-22】Go语言标准库之http/template
html/template包实现了数据驱动的模板,用于生成可防止代码注入的安全的HTML内容。它提供了和text/template包相同的接口,Go语言中输出HTML的场景都应使用html/template这个包
- 模板:事先定义好的HTML文档文件
- 模板渲染机制:文本替换操作–使用相应的数据去替换HTML文档中事先准备好的标记。
- 类似Python语言中Flask框架中使用的jinja2模板引擎。
Go语言内置文本模板引擎 text/template 和 用于HTML文档的 html/template。
text/template与html/tempalte的区别
- html/template针对的是需要返回HTML内容的场景,在模板渲染过程中会对一些有风险的内容进行转义,以此来防范跨站脚本攻击。
作用机制归纳如下:
- 模板文件通常定义为 .tmpl 和 .tpl 为后缀(也可以使用其他的后缀),必须使用UTF8编码。
- 模板文件中使用{{和}}包裹和标识需要传入的数据。
- 传给模板这样的数据就可以通过点号(.)来访问,如果数据是复杂类型的数据,可以通过{ { .FieldName }}来访问它的字段。
- 除{{和}}包裹的内容外,其他内容均不做修改原样输出。
模板引擎组成
Go语言模板引擎的使用可以分为三部分:
- 定义模板文件: 按照相关语法规则去编写
- 解析模板文件: 常用方法去解析模板文件,得到模板对象
- func (t *Template) Parse(src string) (*Template, error)
- func ParseFiles(filenames …string) (*Template, error)
- func ParseGlob(pattern string) (*Template, error)
- 用func New(name string) *Template函数创建一个名为name的模板
- 模板渲染: 用数据去填充模板,当然实际上可能会复杂很多
- func (t *Template) Execute(wr io.Writer, data interface{}) error
- func (t *Template) ExecuteTemplate(wr io.Writer, name string, data interface{}) error
模板引擎示例
Go模板语法定义一个 hello.tmpl 的模板文件
- 模板语法都包含在双大括号中,其中的.表示当前对象
- 传入结构体对象时,可以根据.来访问结构体的对应字段
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Hello</title>
</head>
<body>
<p>Hello \{\{.\}\}</p>
<p>Hello \{\{.Name\}\}</p>
<p>性别:\{\{.Gender\}\}</p>
<p>年龄:\{\{.Age\}\}</p>
<img src="https://go.dev/images/gophers/motorcycle.svg" width=400>
</body>
</html>
HTTP server端代码: main.go
type UserInfo struct {
Name string
Gender string
Age int
}
func sayHello(w http.ResponseWriter, r *http.Request) {
// 解析指定文件生成模板对象
tmpl, err := template.ParseFiles("./hello.tmpl")
if err != nil {
fmt.Println("create template failed, err:", err)
return
}
user := UserInfo{
Name: "小王子",
Gender: "男",
Age: 18,
}
// 利用给定数据渲染模板,并将结果写入w
// tmpl.Execute(w, "沙河小王子")
tmpl.Execute(w, user) // 传入结构体
}
func main() {
http.HandleFunc("/", sayHello)
err := http.ListenAndServe(":9090", nil)
if err != nil {
fmt.Println("HTTP server failed,err:", err)
return
}
}
将上面的main.go文件编译执行,然后使用浏览器访问http://127.0.0.1:9090就能看到页面上显示了“Hello 沙河小王子”。
模板语法
- {{}}: 模板变量
- pipeline:管道操作,|连接
- 移出空格: {{- .Name -}}, 去除模板内容左侧的所有空白符号
- 条件判断
- {{if pipeline}} T1 {{end}}
- {{if pipeline}} T1 {{else}} T0 {{end}}
- {{if pipeline}} T1 {{else if pipeline}} T0 {{end}}
- range: 遍历元素,数组、切片、字典或者通道
- {{range x}} T1 {{end}} x长度为0,不会有任何输出
- {{range x}} T1 {{else}} T0 {{end}} x长度为0,会执行T0
- with:
- {{with pipeline}} T1 {{end}}
- 如果pipeline为empty不产生输出,否则将dot设为pipeline的值并执行T1。不修改外面的dot。
- {{with pipeline}} T1 {{else}} T0 {{end}}
- 如果pipeline为empty,不改变dot并执行T0,否则dot设为pipeline的值并执行T1。
- 预定义函数
- 执行模板时,函数从两个函数字典中查找:首先是模板函数字典,然后是全局函数字典。一般不在模板内定义函数,而是使用Funcs方法添加函数到模板里
- and, or, not, len, index, print, printf, println, html, urlquery, js, call
- 比较函数
- eq, ne, lt, le, gt, ge
- 自定义函数: go中定义,tmpl中调用
- 嵌套template: 单独的模板文件、代码块
- {{template “ol.tmpl”}}
- block:定义模板和执行模板的缩写
- 修改默认的标识符
- 自定义标志符,不用{{}}
- template.New(“test”).Delims(“{[”, “]}”).ParseFiles(“./t.tmpl”)
Gin
Gin 是轻量级MVC框架,提供快速的路由和中间件支持。
例如,创建一个简单的HTTP服务器
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
r.Run() // listen and serve on 0.0.0.0:8080
}
Echo
Echo 是另一个高性能微框架,更注重性能和灵活性。
创建Echo服务器类似
package main
import "github.com/labstack/echo/v4"
func main() {
e := echo.New()
e.GET("/ping", func(c echo.Context) error {
return c.String(http.StatusOK, "pong")
})
e.Start(":8080")
}
hertz
【2023-7-31】Go Web框架——Hertz基础教程
Hertz是字节内部开源的http框架,参考了其他开源框架的优势,结合字节跳动内部的需求,具有高易用性、高性能、高扩展性等特点。
hertz 简介
【2022-8-8】字节跳动开源的go微服务框架hertz
- CloudWeGo: A leading practice for building enterprise cloud native middleware!
- 包含的开源组件:
- Kitex: Kitex [kaɪt’eks] is a high-performance and strong-extensibility Golang
RPCframework - Hertz: Hertz [həːts] is a high-performance, high-usability, extensible
HTTPframework for Go; - Netpoll:Netpoll is a high-performance non-blocking I/O networking framework, which focused on RPC scenarios, developed by ByteDance.
- RPC is usually heavy on processing logic and therefore cannot handle I/O serially. But Go’s standard library net is designed for blocking I/O APIs, so that the RPC framework can only follow the One Conn One Goroutine design. It will waste a lot of cost for context switching, due to a large number of goroutines under high concurrency. Besides, net.Conn has no API to check Alive, so it is difficult to make an efficient connection pool for RPC framework, because there may be a large number of failed connections in the pool.
- On the other hand, the open source community currently lacks Go network libraries that focus on RPC scenarios. Similar repositories such as: evio, gnet, etc., are all focus on scenarios like Redis, HAProxy.
- But now, Netpoll was born and solved the above problems. It draws inspiration from the design of evio and netty, has excellent Performance, and is more suitable for microservice architecture. Also Netpoll provides a number of Features, and it is recommended to replace net in some RPC scenarios.
- We developed the RPC framework Kitex and HTTP framework Hertz (coming soon) based on Netpoll, both with industry-leading performance.
- Kitex: Kitex [kaɪt’eks] is a high-performance and strong-extensibility Golang
架构图
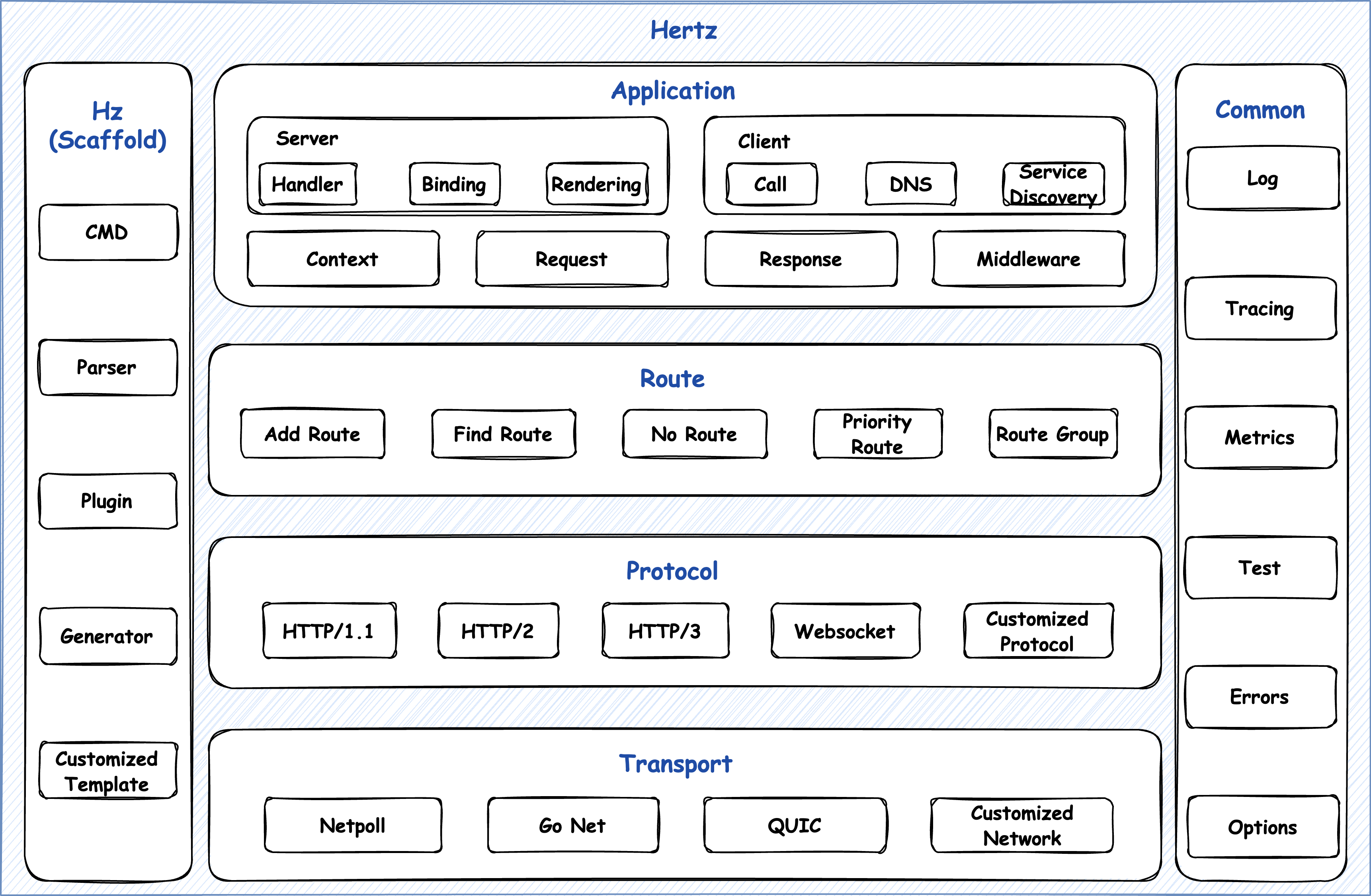
hertz 发展历史
大约 2014 年左右,字节就已经开始尝试做一些 Golang 业务的转型。
- 2016 年,基于已开源的 Golang HTTP 框架 Gin 框架,封装了 Ginex。
- 2020 年初 Hertz 立项
- 2020 年 10 月,Hertz 发布第一个可用版本。
- 2022 年 6 月,Hertz 正式开源。
- 截至目前,Hertz 在字节内部已经支撑超过 1.4 万个业务服务,日峰值 QPS 超过 5000 万。
Ginex
2017 - 2019 年期间,也就是 Ginex 发布之后,问题逐渐显现。
主要有以下几点:
- 迭代受开源项目限制
- Ginex 是一个基于 Gin 的开源封装,所以它本身在迭代方面是受到一些限制的。一旦有针对公司级的需求开发,以及 Bugfix 等等,我们都需要和开源框架 Gin 做联合开发和维护,这个周期不能完全由我们自己控制。
- 代码混乱膨胀、维护困难
- 由于和业务同学共同开发和维护 Ginex 框架,因此对于控制整个框架的走向没有完全的自主权,从而导致了整体代码混乱膨胀,到后期发现越来越难维护。
- 无法满足性能敏感业务需求
- 另外,能用 Gin 做的性能优化非常少,因为 Gin 的底层是基于 Golang 的一个原生库,所以如果要做优化,需要在原生库的基础上做很多改造,这个其实是非常困难的。
- 无法满足不同场景的功能需求
- 内部逐渐出现了一些新的场景,因此会有对 HTTP Client 的需求,支持 Websocket、支持 HTTP/2 以及支持 HTTP/3 等等需求,而在原生的 Ginex 上还是很难扩展的这些功能需求。
KiteX
- 2016年,Kite 和 Ginex 发布
- 由于很多功能版本过低,包括 Thrift 当时只有 v0.9.2,它们其实存在很多问题,再加上 Golang 迎来数轮大版本迭代,Kite 甚至连 golang context 参数都没有 。
- 综上种种原因,Kite 已经满足不了内部使用需求。
- 2019 年中,服务框架团队正式启动了 Kite 这个字节自有 RPC 框架的重构。
- 这是一个自下而上的整体升级重构,围绕性能和可扩展性的诉求展开设计。
- 2020 年 10 月,团队完成了 KiteX 发布,仅仅两个月后,KiteX 就已经接入超过 1000 个服务。
Kite 作为字节跳动第一代 Golang RPC 框架,主要存在以下缺陷:
- Kite 为了快速支持业务发展需求,不可避免地耦合了部分中台业务的功能;
- Kite 对 Go modules 支持不友好(Go modules 在 2019 年才进入语言核心);
- Kite 自身的代码拆分成多仓库,版本更新时推动业务升级困难;
- Kite 强耦合了早期版本的 Apache Thrift,协议和功能拓展困难;
- Kite 的生成代码逻辑与框架接口强耦合,成为了性能优化的天花板。
因此,业务的快速发展和需求场景的多样化,催生了新一代 Golang RPC 框架 Kitex。
Hertz 安装
安装 hertz
# hertz源码
git clone https://github.com/cloudwego/hertz.git
# go命令行安装hertz
# 确保PATH、GOPATH 已配置
# export GOPATH=~/go
# export PATH=${PATH}:${GOPATH}/bin;
# export PATH=$GOPATH/bin:$PATH # 或
# 安装命令行工具hz
go install github.com/cloudwego/hertz/cmd/hz@latest
hz -v # 测试,输出版本信息 hz version v0.5.2
注
- 错误信息: hz command not found
- 解法:配置 GO_PATH 目录
#PATH需要有GO_PATH
export PATH=$GOPATH/bin:$PATH
# 或者 /etc/profile里添加
PATH=$GOPATH/bin:$PATH
source /etc/profile
Hertz 性能
Hertz是一个高性能Web框架,之所以高性能是因为以下几点:
- 使用高性能网络库Netpoll
- Json编解码Sonic,Sonic是一个高性能Json编解码库
- 使用sync.Pool复用对象协议层数据解析优化
Hertz 生态
Hertz拥有非常丰富的扩展生态:
- Http2扩展
- opentelemetry扩展
- 国际化扩展
- 反向代理扩展
- JWT鉴权扩展
- Websocket扩展
- 丰富的代码示例
Hertz 使用
- 当前目录下创建 hertz_demo 文件夹,进入该目录中
- 创建
main.go文件, 内容如下 - 生成
go.mod文件:go mod init hertz_demo - 整理 & 拉取依赖:
go mod tidy - 直接编译并启动 Server:
go build -o hertz_demo && ./hertz_demo - 访问: ping
package main
import (
"context"
"fmt"
"github.com/cloudwego/hertz/pkg/app"
"github.com/cloudwego/hertz/pkg/app/server"
"github.com/cloudwego/hertz/pkg/common/utils"
"github.com/cloudwego/hertz/pkg/protocol/consts"
)
type Test struct {
A string
B string
}
func main() {
h := server.Default() // Defalt 会自带错误恢复中间件,若想要纯净的实例请使用 server.New()
// 静态文件目录
h.StaticFS("/", &app.FS{Root: "./", GenerateIndexPages: true})
// get 接口 ping,返回json传
h.GET("/ping", func(c context.Context, ctx *app.RequestContext) {
ctx.JSON(consts.StatusOK, utils.H{"message": "pong"})
})
// json, 返回自定义格式json串(Test)
h.GET("/json", func(c context.Context, ctx *app.RequestContext) {
ctx.JSON(consts.StatusOK, &Test{
A: "aaa",
B: "bbb",
})
})
// post 请求
h.POST("/post", func(c context.Context, ctx *app.RequestContext) {
// ctx.String(consts.StatusOK, "post") // 返回 string
ctx.JSON(consts.StatusOK, utils.H{"message": "pong_post"}) // 返回json 串
})
// 重定向
h.GET("/redirect", func(c context.Context, ctx *app.RequestContext) {
ctx.Redirect(consts.StatusMovedPermanently, []byte("http://www.google.com/"))
})
// Group 什么含义?一组接口
v1 := h.Group("/v1")
{
v1.GET("/hello/:name", func(c context.Context, ctx *app.RequestContext) {
fmt.Fprintf(ctx, "Hi %s, this is the response from Hertz.\n", ctx.Param("name"))
})
}
h.Spin() // 什么作用?等待结束符号。Spin() 运行服务器直到捕获 os.Signal 。 SIGTERM 触发器立即关闭。 SIGHUP|SIGINT 触发正常关闭。
}
Hertz 命令行+创建代码
hertz 命令行工具
hz是 Hertz 框架提供的一个用于生成代码的命令行工具。
(1) 直接生成
Hertz 提供了代码生成工具 Hz,hz 是 Hertz 框架提供的一个用于生成代码的命令行工具,hz 可基于 thrift 和 protobuf 的 IDL 生成 Hertz 项目的脚手架。
使用 hz命令直接生成示例代码,步骤如下:
- 当前目录下创建
hertz文件夹,进入该目录中 - 执行生成代码命令
hz new或者使用hz new -module example - 执行命名
go mod tidy整理、拉取依赖
mkdir hertz_demo
cd hertz_demo
hz new # 当前目录下创建
hz new wqw # wqw下创建
# 以上两种方法需要单独执行: go mod init
hz new -module hertz_demo
go mod tidy
tree ./ # mac 下先安装 tree工具: brew install tree, 或: alias tree="find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'"
生成文件
[root@hecs-74066 hertz_demo]# tree ./
./
├── biz
│ ├── handler
│ │ └── ping.go # handler层,实现具体接口逻辑
│ └── router
│ └── register.go # 路由注册层,这个适用于使用thrift生成的hz项目
├── go.mod
├── go.sum
├── build.sh
├── main.go
├── router_gen.go
└── router.go # 注册路由的地方,将方法注册到对应的url中
├── script
└── bootstrap.sh
业务逻辑主要在 main.go 和 handler目录即可,ping.go是已经实现好的逻辑,就是一个/ping接口
编译执行
# 编译+执行
go build -o api
./api
# 或直接执行
go run main.go
结果
curl http://127.0.0.1:8888/ping
{"message":"pong"}
(2) 使用IDL
目前,hz 可以基于 thrift 和 protobuf 的 IDL 生成 Hertz 项目的脚手架
- 使用 thrift 或 protobuf 的 IDL 生成代码,需要安装相应的编译器:thriftgo 或 protoc
- hz 生成的代码里
- 一部分是底层的编译器生成的(通常是关于 IDL 里定义的结构体)
- 另一部分是 IDL 中用户定义的路由、method 等信息。用户可直接运行该代码。
- 从执行流上来说,当 hz 使用 thrift IDL 生成代码时,hz 会调用 thriftgo 来生成 go 结构体代码,并将自身作为 thriftgo 的一个插件(名为 thrift-gen-hertz)来执行来生成其他代码。当用于 protobuf IDL 时亦是如此。
先定义一个IDL文件,如 hello.thrift
namespace go hello.example
struct HelloReq {
// 添加 api 注解为方便进行参数绑定
1: string Name (api.query="name");
}
struct HelloResp {
1: string RespBody;
}
service HelloService {
HelloResp HelloMethod(1: HelloReq request) (api.get="/hello");
}
执行命令生成代码,并整理依赖:
hz new -idl hello.thrift
go mod tidy
生成的文件结构
Hertz 路由
Hertz路由
Hertz提供了多种路由规则,路由的优先级为: 静态路由 > 命名路由 > 通配路由。
(1) 静态路由
- Hertz 提供 GET、POST、PUT、DELETE、ANY 等方法用于注册路由。
- 官方代码 ertz-examples/blob/main/route/main.go
package main
import (
"context"
"github.com/cloudwego/hertz/pkg/app"
"github.com/cloudwego/hertz/pkg/app/server"
"github.com/cloudwego/hertz/pkg/protocol/consts"
)
funcmain(){
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
h.StaticFS("/", &app.FS{Root: "./", GenerateIndexPages: true})
h.GET("/get", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "get")
})
h.POST("/post", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "post")
})
h.PUT("/put", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "put")
})
h.DELETE("/delete", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "delete")
})
h.PATCH("/patch", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "patch")
})
h.HEAD("/head", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "head")
})
h.OPTIONS("/options", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "options")
})
h.Any("/ping_any", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "any")
})
h.Handle("LOAD","/load", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "load")
})
h.Spin()
(2) 路由组
Hertz提供了路由组(Group)的能力,用于支持路由分组的功能。
package main
import (
"context"
"github.com/cloudwego/hertz/pkg/app"
"github.com/cloudwego/hertz/pkg/app/server"
"github.com/cloudwego/hertz/pkg/protocol/consts"
)
funcmain(){
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
v1 := h.Group("/v1")
v1.GET("/get", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "get")
})
v1.POST("/post", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "post")
})
v2 := h.Group("/v2")
v2.PUT("/put", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "put")
})
v2.DELETE("/delete", func(ctx context.Context, c *app.RequestContext) {
c.String(consts.StatusOK, "delete")
})
h.Spin()
}
(3) 参数路由
Hertz 支持使用 :name 这样的命名参数设置路由,并且命名参数只匹配单个路径段。
如果设置/hertz/:version路由,匹配情况如下:
| 路径 | 是否匹配 |
|---|---|
| /hertz/v1 | 匹配 |
| /hertz/v2 | 匹配 |
| /hertz/v1/detail | 不匹配 |
| /hertz/ | 不匹配 |
通过使用 RequestContext.Param 方法,我们可以获取路由中携带的参数。
h.GET("/hertz/:version", func(ctx context.Context, c *app.RequestContext) {
version := c.Param("version")
c.String(consts.StatusOK, "Hello %s", version)
})
(4) 通配路由
Hertz 支持使用 *path 这样的通配参数设置路由,并且通配参数会匹配所有内容。
如果设置/hertz/*path路由,匹配情况如下
| 路径 | 是否匹配 |
| /hertz/v1 | 匹配 |
| /hertz/v1/detail | 匹配 |
| /hertz/ | 匹配 |
GET 通过使用 RequestContext.Param 方法,可以获取路由中携带的参数。
h.GET("/hertz/:version/*action", func(ctx context.Context, c *app.RequestContext) {
version := c.Param("version")
action := c.Param("action")
message := version + " is " + action
c.String(consts.StatusOK, message)
})
POST 通过 PostForm 获取
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
// content-type : application/x-www-form-urlencoded
h.POST("/urlencoded", func(ctx context.Context, c *app.RequestContext) {
name := c.PostForm("name")
message := c.PostForm("message")
c.PostArgs().VisitAll(func(key, value []byte) {
if string(key) == "name" {
fmt.Printf("This is %s!", string(value))
}
})
c.String(consts.StatusOK, "name: %s; message: %s", name, message)
})
// content-type : multipart/form-data
h.POST("/formdata", func(ctx context.Context, c *app.RequestContext) {
id := c.FormValue("id")
name := c.FormValue("name")
message := c.FormValue("message")
c.String(consts.StatusOK, "id: %s; name: %s; message: %s\n", id, name, message)
})
(5) 参数绑定
Hertz提供了 Bind 、 Validate 、 BindAndValidate 函数用于进行参数绑定校验。
- 绑定使用的是 BindAndValidate 方法
绑定的作用
- 把http请求的参数封装到定义的结构体里面方便开发使用,Hertz使用的是tag的方式进行绑定的。
| Tag | 说明 |
|---|---|
| path | 绑定 url 上的路径参数,相当于 hertz 路由 :param 或 *param 中拿到的参数 |
| form | 绑定请求的 body 内容query绑定请求的 query 参数 |
| header | 绑定请求的 header 参数json绑定 |
| json | 参数 |
| vd | 参数校验 |
Hertz Client
Hertz 提供 Http Client 帮助用户发送 Http 请求,可在代码逻辑中请求第三方服务。
例如,使用GET发送一个Http请求:
func Get() { // GET
c, err := client.NewClient()
if err != nil {
return
}
status, body, _ := c.Get(context.Background(), nil, "http://www.example.com")
fmt.Printf("status=%v body=%v\n", status, string(body))
}
func Post() { // POST
c, err := client.NewClient()
if err != nil {
return
}
var postArgs protocol.Args
postArgs.Set("arg", "a") // 发送参数
status, body, _ := c.Post(context.Background(), nil, "http://www.example.com", &postArgs)
fmt.Printf("status=%v body=%v\n", status, string(body))
}
KiteX
kitex 是字节跳动使用的go的rpc框架,类似 protobuf\trpc\tarf\thrift,可用于内部应用之间的高效通讯
- 根据指定好的idl文件生成对应的server代码和stub代码,提供给服务端和客户端的使用,由于底层的编码逻辑比http所使用的json要高效,所以内部应用比较适合使用rpc协议进行通讯
- kitex可以使用thrift/proto文件去定义idl
KiteX 安装
go install github.com/cloudwego/kitex/tool/cmd/kitex@latest
go install github.com/cloudwego/thriftgo@latest
kitex --version
thriftgo --version // 出现cmd找不到的情况,如同hertz的处理办法
创建 kitex项目需要依赖idl文件的生成
- 一份idl文件可定义整个服务的对外暴露的接口,让后台服务间的调用更加明确
因此先定义一份thrift文件,根据thrift文件让kitex工具生成框架代码
cd .. #回到hertz_demo的前一个目录
vim biz.thrift
biz.thrift 内容
namespace go biz
struct BaseResponse {
1: i32 code; // 1成功,-1失败
2: string msg;
}
struct LoginRequest {
1: required string username;
2: required string password;
}
struct LoginResponse {
1: BaseResponse base;
2: string userToken; // token使用username代替
}
struct LogoutRequest {
1: required string userToken; // token使用username代替
}
struct LogOutResponse {
1: BaseResponse base;
}
struct User {
1: string username;
2: string password;
3: string email;
}
service UserService {
LoginResponse Login(1: LoginRequest request)
LogOutResponse LogOut(1: LogoutRequest request)
list<User> GetUsers()
}
执行以下命令创建kitex-server项目
mkdir kitex_demo
cd kitex_demo
kitex -module kitex_demo -service kitex_demo ../biz.thrift
go mod tidy
项目结构
[root@hecs-74066 kitex_demo]# tree ./
./
├── build.sh #编译脚本
├── go.mod
├── handler.go # 目前阶段实现的逻辑为handler.go
├── kitex_gen # kitex根据thrift生成的一堆struct的定义和调用框架层的细节,暂时可以不关注
│ └── biz
│ ├── biz.go
│ ├── k-biz.go
│ ├── k-consts.go
│ └── userservice
│ ├── client.go
│ ├── invoker.go
│ ├── server.go
│ └── userservice.go
├── kitex.yaml
├── main.go # server启动的main.go
└── script
└── bootstrap.sh
4 directories, 13 files
启动项目
go mod edit -replace github.com/apache/thrift=github.com/apache/thrift@v0.13.0 #防止编译报错,如果编译没有thrift的依赖报错,不需要添加这个replace到go.mod
sh build.sh
./output/bin/kitex_demo
# 2023/01/15 15:55:55.415010 server.go:81: [Info] KITEX: server listen at addr=[::]:8888
主要在 handler.go 中实现业务逻辑,实现真正后端的login和logout逻辑(copy一下即可)
- 代码见笔记:go hertz框架和kitex的入门笔记
启动服务
go mod tidy
sh build.sh
./output/bin/kitex_demo
caddy web服务框架
【2022-3-10】自带 HTTPS 的开源 Web 服务器
常见的开源 Web 服务器有久负盛名的 Apache、性能强劲的 Nginx。
采用 Go 编写的 Web 服务端“后起之秀”:Caddy
- 拥有下载无需安装就能用、零配置实现 HTTPS 等特点,从而在强者如云的 Web 服务器中占据了一席之地。
- Caddy 凭借无需额外配置自动 HTTPS,分分钟完成 HTTPS 站点搭建,使它成为了中小型 Web 服务的首选服务器。Caddy 深受开源爱好者们的喜爱,2014 年开源至今共收获了 3.6 万颗星。
Caddy 可以在 Linux、Mac、Windows 上快速部署 http(s) 站点或反向代理服务。支持:
- HTTP/1.1 和 HTTP/2
- 同时接受 HTTPS 自动签发和手动管理
- 虚拟主机 (多个站点工作在单个端口上)
- 原生 IPv4 和 IPv6 支持
- 静态文件分发
- 平滑重启/重载
- 反向代理 (HTTP 或 WebSocket)
- 负载均衡和健康性检查
- Markdown 渲染
- 文件浏览服务 与传统的 Nginx 或者 Apache 相比,Caddy 整体只有一个可执行文件,安装便捷不易出现奇怪的依赖问题,配置文件结构清晰语法简单易于上手,依托于模块化架构可以使用 Go 语言快速开发扩展模块。
输入提示
【2022-1-19】用go实现输入提示功能,suggestion代码;
- 在搜索输入框等位置,用户输入关键词,系统提示可以使用的关键字,提升用户体验
方法一:easymap
- 适用: 小型系统, 关键词在 10W 左右(中文+拼音+拼音首字母共30W左右)
- 优点: 逻辑简单结构清晰, 代码足够少, 方便扩展(e.g. 可自行修改存储结构,在返回中加入图片等额外信息)
- 缺点: 内存占用,30W关键词,平均词长3,占用800M内存, 另外对cpu也有一定消耗
- 处理和实践:
- python版本 加一层redis/memcached, python版本, 单机8进程, 16核, 占用1G内存, 每天总请求量在300-500w左右, qps峰值在 300 左右, 没什么压力
- golang版本完全没在生产上试过, 应该毫无压力 方法二:double-array-trie
- 用实现了double-array-trie的darts实现
- 适用: 关键词在10w 以上的系统
- 优点: 内存占用小, 性能保证
- 缺点: 底层依赖double-array-trie,逻辑有点绕,自定义不是很方便
- 处理和实践: 加一层redis/memcached
使用方法:
git clone https://github.com/wklken/suggestion.git # 下载代码库
# 方法一:简易版,easymap
cd suggestion/easymap
python suggest.py
go run suggest.go
# 方法二:double-array-trie, 启动web服务
go run test_run.go # 无web服务
go run test_web.go # 有web服务
# 访问本地服务 http://localhost:9090
# 输入检索词,input
test_web.go 代码
package main
import (
"./darts"
"encoding/json"
"fmt"
"log"
"net/http"
//"strings"
// "path"
)
//【2022-10-11】json字符串转结构体时,转换后变量名(value)要加双引号!
type ValueJson struct {
Value string `json:"value"`
}
func dartsInit() (darts.Darts, error) {
d, err := darts.Import("data.txt", "data.lib")
if err != nil {
fmt.Println("ERROR: darts initial failed!")
} else {
fmt.Println("INFO: darts initial success!")
}
return d, err
}
var dart, err = dartsInit()
// 输入提示api
func simpleSuggest(w http.ResponseWriter, r *http.Request) {
// valueList := make([]ValueJson, 10)
var valueList []ValueJson
r.ParseForm() //解析参数,默认是不会解析的
keyword := r.Form["keyword"]
fmt.Println("keyword:", keyword)
if len(keyword) == 0 {
} else {
results := dart.Search([]rune(keyword[0]), 0)
for i := 0; i < len(results); i++ {
var value ValueJson
value.Value = string(results[i].Key)
valueList = append(valueList, value)
}
}
if len(valueList) > 10 {
valueList = valueList[:10]
}
fmt.Println("return", valueList)
if len(valueList) > 0 {
b, err := json.Marshal(valueList)
if err != nil {
fmt.Println("json err:", err)
}
fmt.Fprintf(w, string(b)) //这个写入到w的是输出到客户端的
} else {
fmt.Fprintf(w, "[]") //这个写入到w的是输出到客户端的
}
return
}
// 主页api
func index(w http.ResponseWriter, r *http.Request) {
http.ServeFile(w, r, "templates/index.html")
}
func main() {
// index
http.HandleFunc("/", index) //设置访问的路由
// suggest
http.HandleFunc("/suggest/", simpleSuggest) //设置访问的路由
// static
http.HandleFunc("/static/", func(w http.ResponseWriter, r *http.Request) {
http.ServeFile(w, r, r.URL.Path[1:])
})
var host = "127.0.0.1"
var port = "9090"
var url = host + ":" + port
err := http.ListenAndServe(url, nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}else {
log.Println("服务开启:"+url)
}
}
模型部署
【2022-8-2】Go 语言部署TensorFlow机器学习模型
Python 是当下最流行的机器学习语言,有很多开源资源可以使用。而 Go语言的速度快,能很好地处理并发,可以编译成单一的二进制文件。所以在实际开发时综合二者的优势,用 Python做模型训练,用Go做预测服务。
TensorFlow模型
保存模型
from tensorflow.python.saved_model.builder_impl import SavedModelBuilder
with tf.Session() as session:
# 训练模型操作。。。
# 保存模型
builder = SavedModelBuilder("存储路径")
# 保存时需要定义tag
builder.add_meta_graph_and_variables(session, ["tag"])
builder.save()
Go 推理模型
注意:
- 载入模型时,需要传参:
- 模型保存路径,Python保存模型时定义的Tag。这里tag 需要为[]string{}类型。
- 模型入参需要通过 tf.NewTensor() 转为 Tensor;
- 输入输出节点操作名称需要根据Python定义的模型操作节点名称填写;
- 输出节点和Python类似,可以传递多个操作名获取多个值。
package main
import (
"fmt"
tf "github.com/tensorflow/tensorflow/tensorflow/go"
)
func main() {
m, err := tf.LoadSavedModel("modelPath", []string{"modelTag"}, nil) // 载入模型
if err != nil {
// 模型加载失败
fmt.Printf("err: %v", err)
}
// 打印出所有的Operator
for _, op := range m.Graph.Operations() {
fmt.Printf("Op name: %v", op.Name())
}
// 构造输入Tensor。根据你的模型入参格式来定义
x := [1][8]int32{
{0,1,2,3,4,5,6,7},
}
tensor_x, err := tf.NewTensor(x)
if err != nil {
fmt.Printf("err: %s", err.Error())
return
}
kb, err := tf.NewTensor(float32(1))
if err != nil {
fmt.Printf("err: %s", err.Error())
return
}
s := m.Session
feeds := map[tf.Output]*tf.Tensor{
// operation name 需要根据你的模型入参来写
m.Graph.Operation("input_x").Output(0): tensor_x,
m.Graph.Operation("keep_prob").Output(0): kb,
}
fetches := []tf.Output{
// 输出层的name 也要根据你的模型写
m.Graph.Operation("score/ArgMax").Output(0),
}
result, err:= s.Run(feeds, fetches,nil)
if err != nil {
// 模型预测失败
fmt.Printf("err: %s ", err.Error())
}
fmt.Printf("%#v", result)
}
流程引擎
【2022-9-16】workflow引擎
引擎代码
流程引擎代码
import (
"errors"
"fmt"
"github.com/go-redis/redis"
"sync"
)
//分布式workflow
type DFlow struct {
RC *redis.ClusterClient
LockKey string
Func map[string]Func
Depend map[string][]string
Force bool
}
//workflow引擎
type flowCore struct {
funcs map[string]*flowStruct
}
type Func func(interface{}) (interface{}, error)
type flowStruct struct {
Deps []string
Ctr int
Fn Func
C chan error
Res interface{}
force bool
once sync.Once
}
//workflow节点已执行
func (fs *flowStruct) done(e error) {
for i := 0; i < fs.Ctr; i++ {
fs.C <- e
}
}
//关闭workflow节点channel
func (fs *flowStruct) close() {
fs.once.Do(func() {
close(fs.C)
})
}
//初始化channel
func (fs *flowStruct) init() {
fs.C = make(chan error)
}
//创建workflow
func create() *flowCore {
return &flowCore{
funcs: make(map[string]*flowStruct),
}
}
//增加workflow节点
func (flw *flowCore) add(name string, d []string, fn Func, fc bool) *flowCore {
flw.funcs[name] = &flowStruct{
Deps: d,
Fn: fn,
Ctr: 1,
force: fc,
}
return flw
}
//workflow检查并启动
func (flw *flowCore) start() map[string]error {
for name, fn := range flw.funcs {
for _, dep := range fn.Deps {
// prevent self depends
if dep == name {
return map[string]error{name: errors.New(name + " not depends of it self")}
}
// prevent no existing dependencies
if _, exists := flw.funcs[dep]; exists == false {
return map[string]error{dep: errors.New(dep + " not exists")}
}
flw.funcs[dep].Ctr++
}
}
return flw.do()
}
//执行workflow节点
func (flw *flowCore) do() map[string]error {
result := map[string]error{}
for name, f := range flw.funcs {
f.init()
go func(name string, fs *flowStruct) {
do := true
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
if len(fs.Deps) > 0 {
for _, dep := range fs.Deps {
err, ok := <-flw.funcs[dep].C
if !fs.force && (err != nil || !ok) {
do = false
}
}
}
if do {
//匹配pipeline条件
if len(fs.Deps) == 1 {
fs.Res, result[name] = fs.Fn(flw.funcs[fs.Deps[0]].Res)
} else {
fs.Res, result[name] = fs.Fn(nil)
}
fs.done(result[name])
} else {
for _, fn := range flw.funcs {
fn.close()
}
}
}(name, f)
}
return result
}
//运行workflow
func (df *DFlow) Run() map[string]error {
lock := SyncMutex{LockKey: df.LockKey, LockTime: 15, Rc: df.RC}
//加锁
if lock.Lock() {
defer func() {
// 释放锁
lock.UnLock()
}()
fl := create()
for k, v := range df.Depend {
fl.add(k, v, df.Func[k], df.Force)
}
return fl.start()
}
return nil
}
运行示例:
var (
RC, _ = RedisConnect()
)
type test struct {
}
func (t *test) a(interface{}) (interface{}, error) {
fmt.Println("a")
fmt.Println("==========")
return "a ok", nil
}
func (t *test) b(i interface{}) (interface{}, error) {
fmt.Println(i)
fmt.Println("b")
fmt.Println("==========")
return "b ok", nil
}
func (t *test) c(i interface{}) (interface{}, error) {
fmt.Println(i)
fmt.Println("c")
fmt.Println("==========")
return nil, errors.New("c error")
}
func (t *test) d(i interface{}) (interface{}, error) {
fmt.Println(i)
fmt.Println("d")
fmt.Println("==========")
return "d ok", nil
}
func init() {
t := test{}
Func := map[string]common.Func{"a": t.a, "b": t.b, "c": t.c, "d": t.d}
Depend := map[string][]string{"a": {}, "b": {"a"}, "c": {"b"}, "d": {"c"}}
df := common.DFlow{RC: RC, LockKey: "workflow_test", Func: Func, Depend: Depend}
result := df.Run()
fmt.Println(result)
}
示例
运行示例:
var (
RC, _ = RedisConnect()
)
type test struct {
}
func (t *test) a(interface{}) (interface{}, error) {
fmt.Println("a")
fmt.Println("==========")
return "a ok", nil
}
func (t *test) b(i interface{}) (interface{}, error) {
fmt.Println(i)
fmt.Println("b")
fmt.Println("==========")
return "b ok", nil
}
func (t *test) c(i interface{}) (interface{}, error) {
fmt.Println(i)
fmt.Println("c")
fmt.Println("==========")
return nil, errors.New("c error")
}
func (t *test) d(i interface{}) (interface{}, error) {
fmt.Println(i)
fmt.Println("d")
fmt.Println("==========")
return "d ok", nil
}
func init() {
t := test{}
Func := map[string]common.Func{"a": t.a, "b": t.b, "c": t.c, "d": t.d}
Depend := map[string][]string{"a": {}, "b": {"a"}, "c": {"b"}, "d": {"c"}}
df := common.DFlow{RC: RC, LockKey: "workflow_test", Func: Func, Depend: Depend}
result := df.Run()
fmt.Println(result)
}
执行结果
执行结果
a # 执行
# ==========
a ok # a执行输出
b # 执行
# ==========
b ok # b执行输出
c # 执行错误,流水线中断
# ==========
map[a:<nil> b:<nil> c:c error]
# 流水线节点执行结果
go 项目
go 游戏开发
【2024-7-15】 go开发坦克大战
- GitHub tankgame, 基于游戏引擎 Ebitengine

更多游戏示例见知乎
经验总结
go面试题
【2022-9-29】go面试题
1、在进行项目开发时,遇到的关于golang的问题有哪些?
工作中用到的东西,协程,通道,框架、加密等等,说一些关键的技术点
2、golang中grpc和rest优劣势
两种API架构概述
RPC(remote procedure call 远程过程调用)框架目标就是让远程服务调用更加简单、透明。RPC 框架负责屏蔽底层的传输方式(TCP 或者 UDP)、序列化方式(XML/Json/ 二进制)和通信细节。服务调用者可以像调用本地接口一样调用远程的服务提供者,而不需要关心底层通信细节和调用过程。grpc:gRPC是RPC框架中的一种, RPC是一种设计理念,而gRPC是基于此种设计理念设计的真实框架。rest:描述的是在网络中client和server的一种交互形式;一个架构样式的网络系统,指的是一组架构约束条件和原则。
grpc相对于rest的优势
- gRPC 对接口有严格的约束条件,安全性更高,对于高并发的场景更适用
为什么选择grpc
- grpc有明确的接口规范和对于流的支持;
- RPC 效率更高。RPC使用自定义的 TCP 协议,可以让请求报文体积更小,或者使用 HTTP2 协议,也可以很好的减少报文的体积,提高传输效率。
3、golang里面常用到的技术栈有哪些?
协程、通道、web框架、密码学等
4、gin框架的好处是什么?
gin框架
- 快速:基于Radix树的路由,性能非常强大。
- 支持中间件:内置许多中间件,如 Logger,Gzip,Authorization 等。
- 崩溃恢复:可以捕捉 pani c引发的程序崩溃,使Web服务可以一直运行。
- JSON验证:可以验证请求中 JSON 数据格式。
- 多种数据渲染方式:支持 HTML、JSON、YAML、XML 等数据格式的响应。
- 扩展性:非常简单扩展中间件。
什么是 goroutine
什么是goroutine?
- goroutine 是一种轻量级的线程实现,程序中同时运行多个相互独立的函数。
- 使用 goroutine 时,不需要显式的创建线程,只需通过 go 关键字来启动一个新的 goroutine。
什么是 channel
什么是channel?
- channel 是一种用来在 goroutine 之间传递数据的数据结构。
- 可以通过 make 函数创建一个新的 channel,然后通过 <- 运算符来发送和接收数据。
- channel 可以是无缓冲的,也可以带有缓冲区。
5、无缓冲通道和缓冲通道的区别是什么?
无缓冲通道,在通道满了之后就会阻塞所在的goroutine。- 需要在其他goroutine中取出该通道中的元素,才能解除它所在通道的阻塞,不然就会一直阻塞下去。
缓冲通道,存完了东西可以不取出来,不会阻塞;- 缓冲通道相较于无缓冲区的通道在用法上是要灵活一些的,不会出现一次写入,一次读完就会堵塞。
6 、select的用处是什么?
过select可以监听channel上的数据流动。
select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述。
示例代码如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
7、defer的用途和使用场景是什么?
什么是defer?
- defer 是一种在函数返回时延迟执行的语句。
- 用 defer 关键字来指定一个函数或方法在执行完毕后再被调用,而不用手动添加额外的代码。
defer作用:
- 可用于捕获程序异常,方法中出现异常时,defer可捕获此异常并进行打印,使用关键字defer向函数声明退出调用,即主函数退出时,defer后的函数才被调用。
- defer语句的作用是不管程序是否出现异常,均在函数退出时自动执行相关代码。
8、defer的执行顺序是什么?
defer语句并不会马上执行,而是会进入一个栈,函数return前,会按先进后出的顺序执行。也说是说最先被定义的defer语句最后执行。
注:
- 先进后出的原因是后面定义的函数可能会依赖前面的资源,自然要先执行;
- 否则,如果前面先执行,那后面函数的依赖就没有
9、defer函数遇到return以后是怎么执行的?
先defer再return,函数执行之后,return返回之前,按照先进后出的顺序执行
10、对于进程,线程,协程的理解是什么?
线程可以理解为轻量级的进程, 协程可以理解为轻量级的线程进程→线程→协程
- 协程最大的优势就是可以轻松的创建上百万个,而不会导致系统资源衰减
进程拥有资源和独立运行,也是资源分配的最小单位。任务调度采用的是时间片轮转的抢占式调度方式线程是处理器调度/分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)线程不拥有系统资源,除了必不可少的程序计数器、寄存器和栈,与同进程下其它线程共享资源线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。协程是一种用户态的轻量级线程,协程调度完全由用户控制。线程之上更加轻量级的存在,协程并不是取代线程, 而且抽象于线程之上,线程是协程的资源- 一个
线程可以多个协程,一个进程也可以单独拥有多个协程。 - 线程/进程都是同步机制,而协程则是异步
协程能保留上一次调用时的状态线程是抢占式,而协程是非抢占式的
什么是panic?
panic 是一种运行时错误,表示程序执行时遇到了无法处理的情况。
- 当程序遇到 panic 时,会停止执行,并向调用栈上的所有函数传递一个错误值。
- 可以使用 recover 函数来捕获这个错误值,并进行相应的处理。
如何定义一个常量?
用 const 关键字来定义常量。
- 常量的值不能被修改,并且只可以是布尔值、数字(整数、浮点数等)、字符串、字符或注释等基本类型。
18、make和new的区别是什么?
Go分为数据类型分为值类型和引用类型,其中
值类型是 int、float、string、bool、struct和array,它们直接存储值,分配栈的内存空间,它们被函数调用完之后会释放引用类型是 slice、map、chan和值类型对应的指针 它们存储是一个地址(或者理解为指针),指针指向内存中真正存储数据的首地址,内存通常在堆分配,通过GC回收
区别
- new 的参数要求传入一个类型,而不是一个值,它会申请该类型的内存大小空间,并初始化为对应的零值,返回该指向类型空间的一个指针
-
make 也用于内存分配,但它只用于引用对象 slice、map、channel的内存创建,返回的类型是类型本身
- make 只用于 chan,map,slice 的初始化;
- new 用于给类型分配内存空间,并且置零;
- make 返回类型本身,new 返回指向类型的指针。
值传递和指针传递有什么区别
- 值传递:会创建一个新的副本并将其传递给所调用函数或方法
- 指针传递:将创建相同内存地址的新副本
- 需要改变传入参数本身的时候用指针传递,否则值传递
另外,如果函数内部返回指针,会发生内存逃逸
如何避免内存泄漏?
GO语言的垃圾回收机制可以自动回收不再使用的内存,但是仍然需要注意一些细节以避免内存泄漏。
- 例如,应该确保及时关闭打开的文件和网络连接,避免创建过多的无用 goroutine,以及使用 defer 关键字确保资源正确释放等。
Go语言的内存分配器采用了跟 tcmalloc 库相同的实现,是一个带内存池的分配器,底层直接调用操作系统的 mmpa 等函数。
如何定义一个结构体?
用 type 和 struct 关键字来定义一个结构体。结构体可以包含多个字段,每个字段可以是不同的类型。例如:
type person struct {
Name string
Age int
}
11、空结构体的作用
空结构体不占任何内存,使用空结构体,可以帮咱们节省内存空间,提升性能golang
17、怎么判断两个结构体是否相等?
一般没有效率太高的方法:
- if判断比较:使用if一个个比较两个结构体中元素的值:if(p1->age==p2->age),如果有一个元素不等,即是两个实例不相等。
- 指针直接比较:如果保存的是同一个实例地址,则(p1==p2)为真。
12、map怎么顺序读取?
map不能顺序读取,是因为他是无序的,想要有序读取,首先的解决的问题就是,把key变为有序,所以可以把key放入切片,对切片进行排序,遍历切片,通过key取值。
代码示例:
package main
import (
"fmt"
"sort" // 排序包
)
func main() {
map1 := make(map[int]string)
map1[1] = "红孩儿"
map1[2] = "牛魔王"
map1[3] = "白骨精"
map1[4] = "小钻风"
map1[5] = "黄袍怪"
map1[6] = "孔雀大明王"
map1[7] = "白毛鼠"
//获取所有的key,取值后存储到切片
keys := make([]int,0,len(map1))
for k,_ := range map1{
keys = append(keys,k)
}
fmt.Println(keys)
//对key值进行排序
//内置函数sort包下的排序方法
sort.Ints(keys)
fmt.Println(keys)
for _,key := range keys{
fmt.Println(key,"-->",map1[key])
}
//冒泡排序方法
for i := 1;i<len(keys);i++ {
for j := 0;j<len(keys)-1;j++ {
if keys[j] > keys[j+1] {
keys[j],keys[j+1] = keys[j+1],keys[j]
}
}
}
for i := 1;i<=len(keys);i++ {
fmt.Println(i,"-->",map1[i])
}
}
13、项目里用到什么数据结构,例如map、slice
都会用到,包括
- 基本数据类型:int、float、string、bool
- 复合数据类型有:指针、数组、切片、字典(map)、通道、结构和接口
注:map和slice也会用到,当有明确的key值时,使用map,如果没有明显的key,就使用切片
14、用range修改切片元素的值会发生什么?
我们经常会使用到range来帮助我们遍历一些数据,通常情况下都是查看操作多一些,但是当需要对其原地址上的内容进行变更时,通常都是使用 for i:=0; i<len(); i++ 来修改值。在使用range的时候,通常会将该数据结构进行拷贝,来遍历这一份拷贝后的副本,使用的是一个值传递,如果我们进行修改,修改的就只是副本,对原地址上的值不会产生任何影响。
15、了解空指针吗?
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
- nil 指针也称为
空指针。 - nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
16、怎么用go去实现一个set
Go中是不提供Set类型,Set是一个集合,其本质就是一个List,只是List里的元素不能重复。
- Go提供了map类型,但map类型的key是不能重复的,所以,咱们能够利用这一点,来实现一个set
构造一个Set的方法
- 构造一个set,首先定义set的类型svg
//set类型
type Set struct {
m map[int]Empty
}
为一个结构体类型,内部一个成员为一个map,这也是主要咱们存储值的容器函数产生set的工厂性能
//返回一19et
func SetFactory() *Set{
return &Set{
m:map[int]Empty{} // 所谓并发编程是指在一台处理器上“同时”处理多个任务。
}
}
19、说一下你对并发编程的理解?
所谓并发编程是指在一台处理器上“同时”处理多个任务。
- 宏观的并发是指在一段时间内,有多个程序在同时运行。
- 并发在微观上,是指在同一时刻只能有一条指令执行,但多个程序指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个程序快速交替的执行。
如何实现多线程同步?
GO语言中可以使用 channel 和 sync 包来实现多线程同步。
- 使用 channel 可以通过发送和接收数据来实现同步,而使用 sync 包中的 Mutex 和 WaitGroup 可以实现更为复杂的同步操作。
20、碰到过分布式锁的问题吗?分布式锁的原理你清楚吗?
golang中的分布式锁可使用etcd进行实现,实现原理如下:
- 在ectd系统里创建一个key
- 如果创建失败,key存在,则监听该key的变化事件,直到该key被删除,回到1
- 如果创建成功,则认为我获得了锁
如何实现继承?
GO语言中没有继承的概念,但是可以通过嵌入其他类型来实现类似的功能。可以将一个类型嵌入到另一个类型中,从而让后者可以继承前者的属性和方法。例如:
type animal struct {
Name string
}
type dog struct {
animal
Breed string
}
如何实现接口?
用 interface 关键字来定义一个接口。接口定义了一组方法,只要某个类型实现了这些方法,就可以被视为实现了该接口。例如:
type Speaker interface {
Speak() string
}
type Dog struct {}
func (d Dog) Speak() string {
return "Woof!"
}
Go的50坑:陷阱、技巧和常见错误
Go的50坑:新Golang开发者要注意的陷阱、技巧和常见错误
初级篇
- 开大括号不能放在单独成行
- 未使用的变量
- 未使用的Imports
- 简式的变量声明仅可以在函数内部使用
- 使用简式声明重复声明变量
- 偶然的变量隐藏 Accidental Variable Shadowing
- 不使用显式类型,无法使用“nil”来初始化变量
- 使用“nil” Slices and Maps
- Map的容量
- 字符串不会为“nil”
- Array函数的参数
- 在Slice和Array使用“range”语句时的出现的不希望得到的值
- Slices和Arrays是一维的
- 访问不存在的Map Keys
- Strings无法修改
- String和Byte Slice之间的转换
- String和索引操作
- 字符串不总是UTF8文本
- 字符串的长度
- 在多行的Slice、Array和Map语句中遗漏逗号
- log.Fatal和log.Panic不仅仅是Log
- 内建的数据结构操作不是同步的
- String在“range”语句中的迭代值
- 对Map使用“for range”语句迭代
- “switch”声明中的失效行为
- 自增和自减
- 按位NOT操作
- 操作优先级的差异
- 未导出的结构体不会被编码
- 有活动的Goroutines下的应用退出
- 向无缓存的Channel发送消息,只要目标接收者准备好就会立即返回
- 向已关闭的Channel发送会引起Panic
- 使用”nil” Channels
- 传值方法的接收者无法修改原有的值
进阶篇
- 关闭HTTP的响应
- 关闭HTTP的连接
- 比较Structs, Arrays, Slices, and Maps
- 从Panic中恢复
- 在Slice, Array, and Map “range”语句中更新引用元素的值
- 在Slice中”隐藏”数据
- Slice的数据“毁坏”
- “走味的”Slices
- 类型声明和方法
- 从”for switch”和”for select”代码块中跳出
- “for”声明中的迭代变量和闭包
- Defer函数调用参数的求值
- 被Defer的函数调用执行
- 失败的类型断言
- 阻塞的Goroutine和资源泄露
高级篇
- 使用指针接收方法的值的实例
- 更新Map的值
- “nil” Interfaces和”nil” Interfaces的值
- 栈和堆变量
- GOMAXPROCS, 并发, 和并行
- 读写操作的重排顺序
- 优先调度
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
