- 总结
- 1 背景介绍
- 2 2015-凸包-Pointer Networks
- 3 2016-落地NLP-Pointing the Unknown Words
- 4 2016-copy机制-Incorporating Copying Mechanism in Seq2Seq Learning
- 5 Summarization with Pointer-Generator Networks
- 参考资料
- 结束
总结
- 【2021-3-29】NLP硬核入门-PointerNet和CopyNet
PointerNet和CopyNet是同一类网络模型,只是在不同的论文里叫法不同,后文统一用PtrNet来表示。
1 背景介绍
1.1 OOV
在NLP领域中,由于词表大小的限制,部分低频词无法被纳入词表,这些词即为OOV(Out Of Bag)。它们会统一地被UNK替代显示,其语义信息也将被丢弃。 OOV难以完全规避,有两个主要原因:
- (1)命名实体常常包含重要的信息,但是许多命名实体也是低频词,常常无法被纳入词表。
- (2)网络新词层出不穷,旧词表无法及时的更新。尤其是在模型越来越大的现状下,加入新词后模型重新训练的成本代价很高。
应对OOV的三个主要方法
- (1)扩大词表:扩大词表后,可以将部分低频词纳入了词表,但是这些低频词由于缺乏足够数量的语料,训练出来的词向量往往效果不佳,所以扩大词表在提升模型的效果方面,存在一定的瓶颈。
- (2)指针拷贝网络:这正是本文将要介绍的模型。
- (3)字向量/n-gram:中文任务使用字向量(例如BERT),英文任务使用n-gram。
1.2 PtrNet
本文将要介绍的PtrNet模型脱胎于Attention机制,使用了Attention机制里的对齐向量a。
PtrNet主要应用于NLP的文本摘要任务、对话任务、(特定条件下)的翻译任务,目的在于应对OOV问题。
本文选取了4篇PtrNet论文,我按照论文的发表顺序,分别在本文的2~5节进行呈现,以此来介绍PtrNet提出、改进和发展的过程。
2 2015-凸包-Pointer Networks
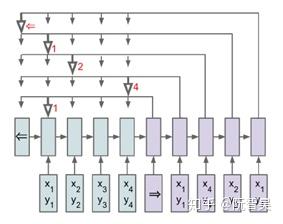
图2.1 Pointer Network
《Pointer Networks》论文是PtrNet模型的开山之作,发表于2015年。
论文提出了当前文本序列生成模型(seq2seq)的三个问题,这三个问题都可以通过使用PtrNet解决:
- (1)目标序列的词表,和源序列的词语内容是强相关的。面对不同语言、不同应用场景的任务,往往需要重新构造词表。
- (2)词表的长度需要在模型构建之前作为超参数进行配置。如果需要变更词表的长度,就需要重新训练模型。
- (3)在部分任务场景里,不允许有OOV的存在。
本论文的思路是让decoder输出一个由目标序列指向源序列的指针序列,而如何去选择这个指针,就是论文的主要内容。
PtrNet利用了Attention模型的一个中间变量:对齐系数a。因为对齐系数a表示目标序列当前step和源序列所有step之间的相关性大小,所以可以通过选取对齐系数向量a(向量a长度为源序列的step长度)中数值最大的那个维度(每个维度指向源序列的一个step),实现一个从目标序列step到源序列step的指针。最后,根据这个指针指向的源序列的词,直接提取这个词进行输出。
通过以上方法,就能够在decoder的每一个step,从源序列的所有step中抽取出一个,进行输出。这样,由于decoder输出的是一个指针序号的序列,而不是具体的词,也就没有了OOV问题;同时,因为不需要构建词表,就从根本上解决了词表内容和词表长度的问题。
很遗憾的,虽然论文中有提及:PtrNet可以在翻译任务中提取命名实体,在摘要任务中提取关键词,但是论文中并没有更进一步,将PtrNet应用于NLP任务,而是利用凸包求解问题、旅行商问题进行了实验和论证。
3 2016-落地NLP-Pointing the Unknown Words

图3.1 Pointer Softmax Network
论文《Pointing the Unknown Words》发表于2016年,将PtrNet模型在NLP领域的文本摘要任务和翻译任务上进行了落地实践。
这篇论文提出的Pointer Softmax Network模型包含三个主要模块。用通俗的语言解释,如果传统模型效果好,就选择传统模型的输出值进行输出,如果PtrNet模型效果好,就选择PtrNet模型的输出值进行输出,然后需要有一个开关网络来判断,传统模型效果好还是PtrNet模型效果好。这三个模块的描述如下:
- (1)Shortlist Softmax:这个模块由传统的Attention Mechanism实现,输出一个在词表里的词的条件概率。这个模块需要维护一个固定大小的词表。在下面的公式中,_p(w)_就是Shortlist Softmax的输出:
- (2)Location Softmax:这个模块利用了Attention Mechanism的对齐系数a。对齐系数a的向量长度是源序列的step长度,并且对齐系数a每个维度的值,表示decoder当前step输出源序列每个step的概率大小。我们就可以在对齐系数a的各个维度中,取出数值最大的那个维度,作为decoder当前step的指针,这个维度上的值就是其概率大小。该模块输出词表的大小为输入序列的step序列长度。在下面的公式中,_p(l)_就是Location Softmax的输出:
- (3)Switching Network:前面两个模块的公式里的_p(z)_项,就是由Switching Network模块生成输出的。Switching Network模型通过_p(z)_选择是采纳Shortlist Softmax输出的预测词,还是采纳Location Softmax输出的预测词。Switching Network由一个多层感知机MLP实现,并在最后接一个sigmoid激活函数。Switching Network的输出值如下:
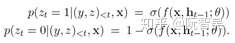
- 将整个模型拼接起来,公式如下:
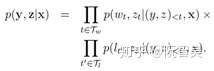
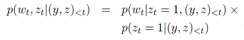
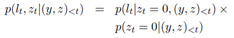
关于这篇论文,还有额外的几点需要说明下:
- (1)在decoder的公式中,每个step有且仅有一个softmax会生效并输出预测值。这个比较理想化,因为开关网络最后一层接的是sigmoid,不能完全保证输出的是0或者1。所以工程实践估计是采用0.5作为判决门限,来选择使用哪个softmax。
- (2)这篇论文和论文[4],都有提及:虽然引入PtrNet机制会扩大网络规模,增加网络的参数,但是在模型训练环节,反而会让模型收敛得更快。
- (3)要将PtrNet用于翻译任务,需要做一些额外的工作:遇到OOV词时,在使用Location Softmax模块前,会进行两个判定,一个是对OOV词进行查表(法语-英语字典)判断相应的词是否在target和source中同时出现,另一个是查找OOV词是否直接在target和source中同时出现,如果其中一个判定成功,则模型可以使用Location Softmax(逻辑上很麻烦对不对,特别是还要额外引入一个词典)。
4 2016-copy机制-Incorporating Copying Mechanism in Seq2Seq Learning
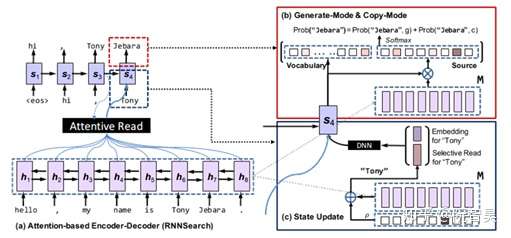
图4.1 CopyNet
论文《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》也发表于2016年,将PtrNet应用于文本摘要任务和单轮对话任务。
(这篇论文的参考资料里包含《Pointing the Unknown Words》,所以我将这篇论文排在[2]之后)
这篇论文提出的CopyNet模型包含两个具有创新点的模块(encoder模块不算在内):
(1)Generate-Mode & Copy-Mode
CopyNet把[2]中的两个预测输出模块融合到一起去了。Generate-Mode & Copy-Mode模块会维护两个词表,一个是传统的词表(但是这个词表不包含UNK),一个是源序列中的词构成的词表。
(a)对于传统词表中的词和UNK,模型采用Generate-Mode计算词语输出概率:
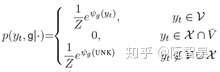
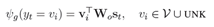
其中v是词的onehot表示,W是Generate-Mode的词向量表,s是decoder的状态。公式的意思也就是拿词向量乘以状态s,得到一个分数,再进行归一化,获得概率值。
这个概率是直接计算出来的,不像attention要经过好几层网络。
(b)对于源序列词表中的词,模型采用Copy-Mode计算词语输出概率:
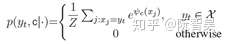
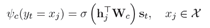
其中h是encoder输出的output,w是待训练矩阵,s是decoder的状态。
需要注意的有两点:
- 第一点是:这里词表的长度是源序列中的词去重后的数量,和[2]中源序列的长度不一样。
- 第二点是:如果目标序列中的词y有在源序列词表中,那么Copy-Mode输出的概率就不为0。y在源序列的各个step中每出现一次,就要根据公式计算一次概率值,最后Copy-Mode输出的概率,等于源序列的所有step中有出现y的概率值之和。
(c)最后,模型会将Generate-Mode和Copy-Mode输出的词语概率进行相加汇总,得到最终的词语概率分布。
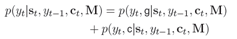
(2)State Update
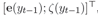
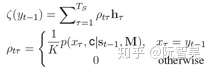
在CopyNet的decoder中,要将e与ζ拼接,作为前一个step的状态s,传入下一个step。其中e是上一步输出词的词向量,ζ是一个类似上下文的向量。
在论文结尾的分析部分,提出了两个很棒的思路和想法:
(1)CopyNet模型融合了生成式(abstractive)摘要任务和抽取式(extractive)摘要任务的思想。decoder输出的大部分关键词来源于Copy-Mode,这体现了extractive summarization。然后再由Generate-Mode把语句撸通顺,这体现了abstractive summarization。
(2)拷贝机制的本质是提取关键词,这个输出可以作为上游模块,和其它任务相结合,例如文本分类任务。
另外说几个我对这篇论文的吐槽:
(1)论文读起来比较累,尤其是模型结构图。
(2)Generate-Mode使用的是固定的词向量,没有利用attention机制引入上下文信息。
(3)Generate-Mode的计算公式有点冗余,把OOV词都标注为UNK会简单点,而且我估计模型效果也不会下降。
(4)State Update模块中的ζ,从计算公式来看,很像上下文向量c。论文里解释说这个ζ是用来为Copy-Mode提供信息的,但是根据Copy-Mode的计算公式,其中本来就带有上下文信息和对齐信息了,再加上ζ里的信息就有点多余了。反而是Generate-Mode里缺乏上下文信息。并且,论文里没有给出权重ρ的具体计算公式,所以我猜测,这个ζ可能用的就是attention的计算公式,实际上起到了给Generate-Mode提供上下文信息的作用。
(5)State Update中的e使用的是上个step输出词的word embedding,这样在解码时候,岂不是只能用greedy search,而不能用beam search了?
5 Summarization with Pointer-Generator Networks
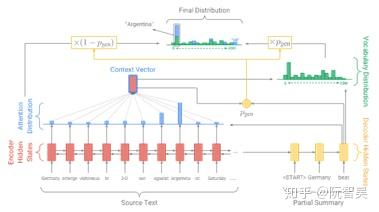
图5.1 Pointer-Generator Network
论文《Get To The Point: Summarization with Pointer-Generator Networks》发表于2017年,是一篇很棒的论文,如果只能从本文提及的四篇论文中选一篇来读,我建议读这篇。
如论文名所示,本论文模型被应用于文本摘要任务。
模型的结构和[2]类似,包含以下几个部分:
(1)传统的带Attention机制的Generator Network:




计算公式大部分和Bahdanau Attention一致,只有一个差异:输出层P_vocab用了个两层的MLP。
(2)用于从源序列拷贝词语的Pointer Network:
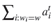
向量a^t代表的是decoder在step t的对齐向量a。对于任意一个词w,Pointer Network输出的w的概率值,等于输入序列中所有等于w的词所在的step,对应a^t的相应维度的概率值的和。
Pointer Network的词表长度,为源序列词语构成的集合的元素个数。
(3)最后,利用开关网络汇总概率值:
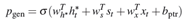
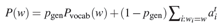
这篇论文还提出了一个创新点:Coverage Mechanism。这个创新点和本文主题无关,但是又非常经典,所以作个简单的介绍:Coverage Mechanism通过统计各个词语在历史对齐向量a中的出现的概率值的累积和,将累计和分别纳入Generator Network公式和惩罚项,以达到解决序列生成任务中,相同文本不停循环出现的问题。
这篇论文还非常详尽地描述了调参细节,并给出了一些能够在其它工作中借鉴的思路:
- (1)在模型训练到一定程度后,再使用Coverage Mechanism。否则模型容易收敛到局部最优点,影响整体效果。
- (2)传统Attention机制的基线模型包含21,499,600个参数,训练了33个epochs。本文模型添加了1153个额外的参数,训练了12.8个epochs。所以合适的模型不但效果好,而且快。
- (3)在模型的训练环节,刚开始的时候,大约有70%的输出序列是由Pointer Network产生的,随着模型逐渐收敛,这个概率下降到47%。然而,在测试环节中,有83%的输出序列是由Pointer Network产生的。作者猜测这个差异的原因在于:训练环节的decoder使用了真实的目标序列。
- (4)虽然Generator Network生效的概率不高,但是其依旧不可或缺,例如在下面的几个场合,模型有较大的概率会使用Generator Network:在句子的开头,在关键词之间的承接文本。
- (5)在摘要任务中,适当地截断句子反而能产生更好的预测效果,原因在于这篇论文用的语料是新闻语料,而新闻语料经常把最重要的内容放在开头。
- (6)作者曾尝试使用一个15万长度的大词表,但是并不能显著改善模型效果。
作为NLP算法工程师,seq2seq模型和attention机制,是基础中的基础,在没彻底搞懂之前,不建议去探索一些很时尚的算法。
阮智昊:NLP硬核入门-Seq2Seq和Attention机制zhuanlan.zhihu.com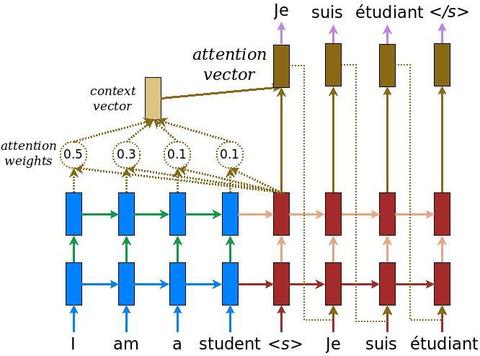
参考资料
- [1] Vinyals O, Fortunato M, Jaitly N. Pointer Networks[J]. Computer Science, 2015, 28.
- [2] Gulcehre C, Ahn S, Nallapati R, et al. Pointing the Unknown Words[J]. 2016.
- [3] Gu J , Lu Z , Li H , et al. Incorporating Copying Mechanism in Sequence-to-Sequence Learning[J]. 2016.
- [4] See A , Liu P J , Manning C D . Get To The Point: Summarization with Pointer-Generator Networks[J]. 2017.
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
