- 总结
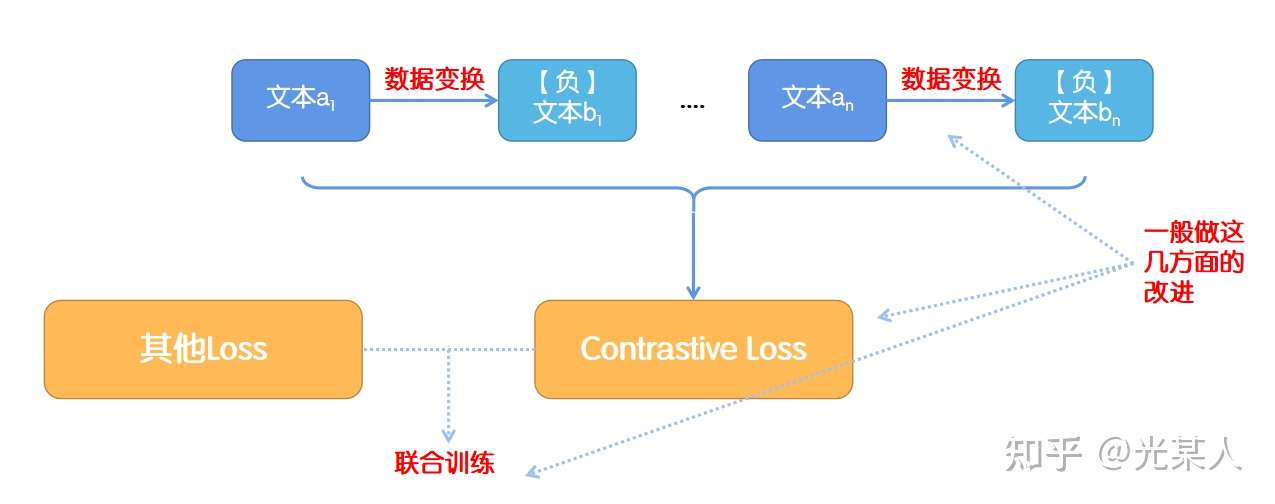
- 对比学习
- SimCSE
- SimCSR
- 进化
- 应用
- 结束
总结
- Contrastive Learning 学习笔记, 最近深度学习两巨头 Bengio 和 LeCun 在 ICLR 2020 上点名 Self-Supervised Learning(SSL,自监督学习) 是 AI 的未来,而其的代表的 Framework 便是 Contrastive Learning(CL,对比学习)。 另一巨头 Hinton 和 Kaiming 两尊大神也在这问题上隔空过招,MoCo、SimCLR、MoCo V2 打得火热
- 【2021-10-26】张俊林:从对比学习视角,重新审视推荐系统的召回粗排模型
- 对比学习(Contrastive Learning)综述
- 【2021-4-11】一文梳理2020年大热的对比学习模型:对比学习的概念很早就有了,但真正成为热门方向是在2020年的2月份,Hinton组的Ting Chen提出了SimCLR,用该框架训练出的表示以7%的提升刷爆了之前的SOTA,甚至接近有监督模型的效果。
- 【2021-5-27】SimCLR: 用对比学习生成图像表征,利用对比学习生成图像表征的算法 SimCLR,SimCLR 出自 Google 的论文《A Simple Framework for Contrastive Learning of Visual Representations》
- 《SimCSE: 通过对比学习获得句子向量》:SimCSE 采用对比学习训练得到句子向量
对比学习
很多自然语言处理任务都需要学习到一个良好的句向量表示。例如向量检索,文本语义匹配等任务中,模型将输入的两个句子进行编码得到句向量,然后计算句向量之间的相似度,从而判断两个句子是否匹配。
- 【2022-5-25】从各大顶会看对比学习在句子表征研究进展
句子相似度
Sentence Embeddings 即能表征句子语义的特征向量
获取句子特征向量的方法有无监督和有监督两种
- 无监督学习中,首先会考虑利用预训练好的大型预训练模型获取 [CLS]或对句子序列纬度做 MeanPooling来得到一个输入句子的特征向量。获取论文中所有句子的特征向量后传入DGCNN来抽取摘要。
但这种方法有一个致命缺点: Anisotropy(各向异性)
- language models trained with tied input/output embeddings lead to anisotropic word embeddings.
- 在预训练模型训练过程中, 会导致word embeddings的各维度特征表示不一致。导致句子级别的特征向量也无法进行直接比较。
目前流行解决方法
线性变换:bert-flow或bert-whitening- 无论是在bert中增加flow层还是对得到句子向量矩阵进行白化, 本质都是通过一个线性变换来缓解Anisotropy。
对比学习:先对句子进行传统的文本增广,如转译、删除、插入、调换顺序等等,再将一个句子通过两次增广得到的新句子作为正样本对,取其他句子的增广作为负样本,进行对比学习,模型的目标也很简单,即拉近正样本对的embeddings,同时增加与负样本的距离。
而SimCSE(Simple Contrastive Learning of Sentence Embeddings)发现利用预训练模型中自带的Dropout mask作为“增广手段”得到的Sentence Embeddings,其质量远好于传统的增强方法,其无监督和有监督方法无监督语义上达到SOTA。
BERT改造成句向量
最直接的做法:将两个句子输入到BERT模型中,使用[CLS]对应的输出或者整个句子序列的输出的平均向量作为句向量,然后再计算两个句向量的相似度。
- 但是由于BERT模型的
MLM与NSP这两个预训练任务的局限性,模型无法很好地学习到句子表征能力。 
为什么经过MLM与NSP任务训练之后,BERT无法学习到良好的句向量表示呢?回顾一下MLM与NSP任务的做法。
MLM任务是遮住某个单词,让模型去预测遮住的单词:- 在这个训练中,模型并没有显式地对[CLS]向量进行训练,没有告诉模型[CLS]这个向量就是用来编码句子的语义信息的。在MLM任务中[CLS]学习到的并不是句子的语义表征。
NSP任务是给定两个句子,让模型判断两个句子是否为上下文关系,使用[CLS]的输出来进行二分类。- 在这个任务中,[CLS]是用来编码两个句子之间的关系的,而不是描述某个句子的语义信息。
综上所述,未经过fintune的BERT模型,必然无法得到良好的句子的语义表征。
BERT坍塌
美团的ConSERT论文表明,如果BERT模型不经过微调的话,模型输出的句向量会坍塌到一个非常小的区域内。

- 图示是在STS数据集中,文本相似度的分布情况,其中横坐标表示人类标注的句子相似度等级,纵坐标表示没有经过finetune的BERT模型预测的句子相似度分布。可以很明显看到模型预测的所有句子对的相似度,几乎都落到了0.6-1.0这个区间,即使含义完全相反的两个句子,模型输出的相似度也非常高。这便是BERT的句子表示的“坍塌”现象。
- BERT的句向量的坍缩和句子中的高频词有关。当使用整个句子序列的输出的平均向量作为句向量时,句子中的高频词将会主导句向量,使得任意两个句向量之间的相似度都非常高。为了验证该想法,美团的ConSERT论文对此也进行了实验。

- 去除若干高频词后,BERT模型在STS数据集上的Spearman得分。得分越高,说明模型在数据集上的表现越好。可以看到,当计算句向量时,如果去除若干个top-k的高频词,Spearman得分显著提高,句向量的坍塌现象得到了一定程度的缓解。
结论:
- BERT的MLM与NSP预训练任务难以胜任下游的语义匹配任务。
为了解决该问题,可以使用对比学习的方法对模型进行预训练,从而使模型能够学习到更好的句子语义表示,并且更好地应用到下游任务中。
SimCSE
介绍
SimCSE:简单有效的句向量对比学习方法, EMNLP 2021, 陈丹琦的论文
- 一种简单有效的NLP对比学习方法,通过Dropout的方式进行正样本增强,模型能够学习到良好的句向量表示。按照惯例,我们也对该模型在STS-B数据集上进行了实验复现。
- 论文: SimCSE: Simple Contrastive Learning of Sentence Embeddings
- SimCSE 代码
- 实验复现代码
为什么计算相似度时要对句子向量做L2正则?
- 张俊林:对比学习研究进展精要给出了一个非常形象的解释,目的是将所有的句子向量映射在一个半径为1的超球体上
- 一方面将所有向量统一至单位长度,去除了长度信息是为了让模型的训练更加稳定;
- 另一方面如果模型表示能力足够好,能够把相似的句子在超球面上聚集到较近区域,那么很容易使用线性分类器把某类和其它类区分开,图示。当然在图像领域上很多实验也证明了,增加L2正则确实能提升模型效果。
总结
- 相比于 Pre-trained Bert, Fine-tune Sup. Bert, Bert-whitening等模型,SimCSE 有极大程度的优势,可以说是碾压。
- 对于 Unsup. SimCSE来说,CLS 的效果远好于 Pooler,且 Unsup. SimCSE只需要8000+个句子样本即可收敛,且多样本反而会使效果变差。
- 对于 Sup. SimCSE来说,$Batchsize_{128}+CLS$ 达到最好效果,尽管 Pooler最终能得到接近的效果,但需要的数据量是CLS的三倍左右。
详见原文: SimCSE对比学习
基本概念
【2021-8-31】张俊林:对比学习在微博内容表示的应用
对比学习是一种新型自监督学习范式。对比学习跟以下两个目前比较流行的技术关联较深。
- Bert采用的自监督学习。Bert 采用自监督学习,节约了大量的人工标注成本,可以有效发挥海量数据的潜力。对比学习借鉴了自监督学习的思路,旨在充分利用海量的无标注数据;
- 度量学习。
度量学习基本思路是让正例特征编码内容距离拉近,负例编码结果距离推远。其中的正例一般是源自有监督数据。对比学习主体思路跟度量学习接近,最大的区别在于其正例是由自监督方式得来。
综上,可以认为对比学习是一种自监督版本的度量学习。
对比学习起源于计算机视觉任务,核心思想: 拉近每个样本与正样本之间的距离,拉远其与负样本之间的距离。
分析
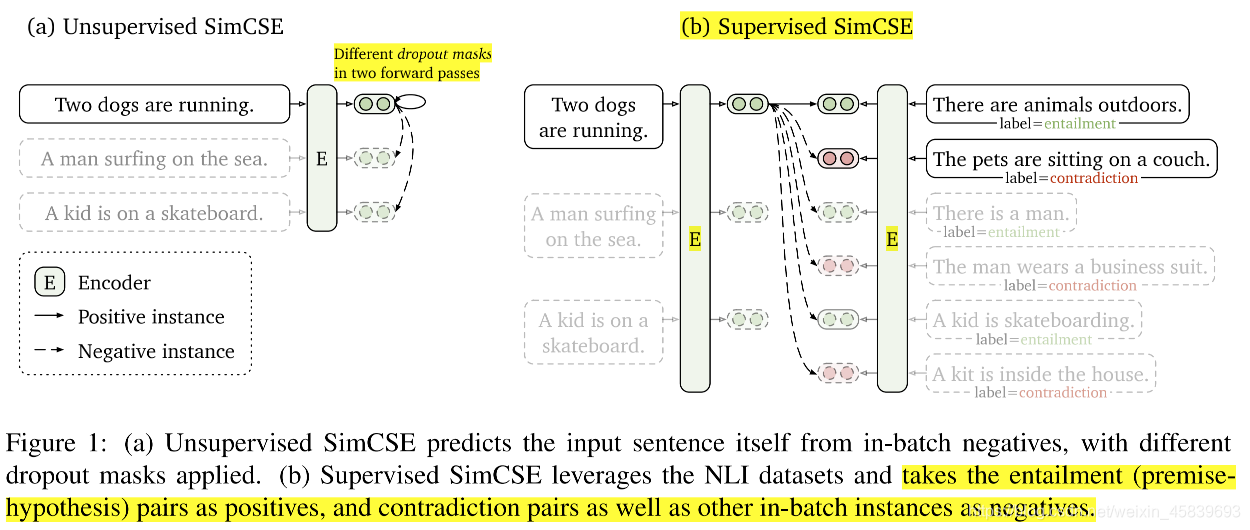
无监督学习:通过将输入句子预测自身,使用标准的dropout作为噪声,这种方法出人意料地有效,与以前的监督方法表现相当。监督学习:利用自然语言推理(NLI)数据集中的标注句子对,通过将“蕴含”对作为正例,“矛盾”对作为硬负例,进一步提高性能。
| 正例/蓝框 | 负例/黄框 | |
|---|---|---|
| 无监督学习 | 预测自己 | batch内其它无关的sentence |
| 有监督学习 | 支持假设的蕴含sentence | 不支持假设的sentence、batch内其它无关的sentence |
无监督SimCSE:
- 将同一个文本送入预训练的编码器两次,经过两次应用Dropout后, 得到两个不同的embedding向量作为”正例对”,
- 将同一批次内的其他文本作为”负例对”。
- 再计算批次内负采样交叉熵损失。
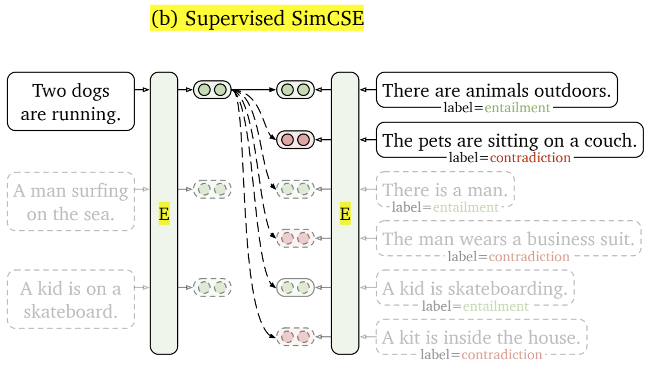
有监督SimCSE:
- 首先,前序研究证实,NLI自然语言推理,在sentence emb中有用处。
- NLI之后,有三种结果:entailment、neural、contradiction
SimCSE
【2022-4-7】SimCSE:简单有效的句向量对比学习方法
- EMNLP2021的一篇论文:SimCSE。一种简单有效的NLP对比学习方法,通过Dropout的方式进行正样本增强,模型能够学习到良好的句向量表示。
- 实验复现代码
- 中文数据集的复现结果可以参考苏剑林的复现实验
对比学习起源于计算机视觉任务,核心思想: 拉近每个样本与正样本之间的距离,拉远其与负样本之间的距离。
如何为每个样本构造正样本与负样本是对比学习中的关键问题。
- 负样本的构造往往比较容易,随机采样或者把同一个batch里面的其他样本作为负样本即可,难点在于如何构造正样本。
- 对于图像来说,对图像进行翻转、裁剪、旋转、扭曲等操作即可很容易地生成正样本。
- 对于NLP来说,往往会采用替换、删除、添加词语的方法来进行正样本构造,但是上述操作非常容易引入噪声,并且改变原有文本的语义。
- 例如对【我爱你】进行替换操作得到【我恨你】,就改变的原来的文本的语义。
为了解决上述问题,SimCSE论文中提出了一种基于Dropout的无监督对比学习方法,同时也对有监督对比学习方法进行了探索。

有两种形式:
- 无监督 unsupervised SimCSE。将相同的输入语句两次传递给经过预训练的编码器,并通过应用独立采样的dropout掩码获得两个嵌入,作为“正例对”。通过仔细的分析,作者们发现dropout本质上是作为数据扩充来使用,而删除它会导致表示崩溃。
- 有监督 supervised SimCSE。利用了基于自然语言推理(NLI)数据集进行句子嵌入学习,并将受监督的句子对纳入对比学习中。
无监督SimCSE
Dropout是一种用来防止神经网络过拟合的方法,在训练的时候,通过dropout mask的方式,模型中的每个神经元都有一定的概率会失活。所以在训练的每个step中,都相当于在训练一个不同的模型。在推理阶段,模型最终的输出相当于是多个模型的组合输出
- Dropout可以视为一种数据增强的手段,通过dropout mask的方式,模型在编码同一个句子的时候,引入了数据噪声,从而为同一个句子生成不同的句向量,并且不影响其语义信息。其中dropout rate的大小可以视为引入的噪声的强度。
- 为了验证模型dropout rate对无监督SimCSE的影响,作者在STS-B数据集上进行了消融实验,其中训练数据是作者从维基百科中随机爬取的十万个句子。
损失函数计算方法
def simcse_unsup_loss(y_pred, device, temp=0.05):
"""无监督的损失函数
y_pred (tensor): bert的输出, [batch_size * 2, dim]
"""
# 得到y_pred对应的label, [1, 0, 3, 2, ..., batch_size-1, batch_size-2]
y_true = torch.arange(y_pred.shape[0], device=device)
y_true = (y_true - y_true % 2 * 2) + 1
# batch内两两计算相似度, 得到相似度矩阵(对角矩阵)
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
# 将相似度矩阵对角线置为很小的值, 消除自身的影响
sim = sim - torch.eye(y_pred.shape[0], device=device) * 1e12
# 相似度矩阵除以温度系数
sim = sim / temp
# 计算相似度矩阵与y_true的交叉熵损失
# 计算交叉熵,每个case都会计算与其他case的相似度得分,得到一个得分向量,目的是使得该得分向量中正样本的得分最高,负样本的得分最低
loss = F.cross_entropy(sim, y_true)
return torch.mean(loss)
有监督SimCSE
作者还尝试了使用各种人工标注的数据集对模型进行有监督训练,包括QQP、Flickr30k、ParaNMT、NLI数据集。
- 与无监督SimCSE一样,作者利用数据集中人工标注的正样本对,使用InfoNCE loss对模型进行训练,可以看到使用SNLI+MNLI数据集训练的模型效果最好,并且其指标也比无监督SimCSE提高了2.4个点。
对于无监督SimCSE与有监督SimCSE,论文的实验结果如下表,可以看到,在STS任务中,无论是无监督还是有监督的训练方法,都比之前的方法有了较大幅度的提高,这证明了论文方法的有效性。
损失函数计算方法
def simcse_sup_loss(y_pred, device, temp=0.05):
"""
有监督损失函数
y_pred (tensor): bert的输出, [batch_size * 3, dim]
"""
similarities = F.cosine_similarity(y_pred.unsqueeze(0), y_pred.unsqueeze(1), dim=2)
row = torch.arange(0, y_pred.shape[0], 3)
col = torch.arange(0, y_pred.shape[0])
col = col[col % 3 != 0]
similarities = similarities[row, :]
similarities = similarities[:, col]
similarities = similarities / temp
y_true = torch.arange(0, len(col), 2, device=device)
loss = F.cross_entropy(similarities, y_true)
return loss
方法
一个抽象的对比学习系统的构造方式如下:
- 首先,利用自监督方式,构造好一些正例,一些负例(即正样本,负样本);
- 之后,将样本输入encoder进行编码;
- 然后,将样本编码之后的结果投影到一个单位超球面。
对比学习系统的优化目标是:如果输入样本为正例,则希望在投影空间中样本之间的embedding越近越好,反之,为负例时两者距离越远越好。常见做法是利用损失函数来达成。损失函数是机器学习的驱动力,它决定系统的学习方向。对比学习系统中最常用的损失函数为InfoNCE函数,分子部分表征正例,分母部分表征负例,由此可以达成优化目标。
三个关键问题需要解决。
- 正例和负例分别如何构造?这是对比学习和度量学习的主要区别。一般对比学习的负例大多可以通过随机抽取构造,所以对比学习中最核心的问题是如何构造正例。
- 样本到特征的映射函数f如何设计?对比学习中样本通过encoder之后,经过映射函数f将其投影至单位超球面。所以,投影空间的选择和投影函数的设计构造也是一个关键问题。
- 损失函数如何设计?前文所说InfoNCE是一个具体损失函数,在实际应用时并非一成不变,应该根据使用场景灵活设计。
表示学习的目标是为输入x学习一个表示z,最好的情况就是知道z就能知道x.
无监督表示学习的第一种做法:生成式自监督学习。比如还原句子中被mask的字,或者还原图像中被mask的像素。但这种方式的前提需要假设被mask的元素是相互独立的,不符合真实情况。
如凭空画一张美元:
 真实的美元:
真实的美元:
另一方面,研究者们也质疑如此细粒度的还原是否真正必要。记住的事物特征,不一定是像素级别的,而是更高维度的. 如用编码去做分类任务,我们不需要知道每个数据的细节,只要抓住每个类别的主要特征,自然就能把他们分开了
不重构数据,那如何衡量表示z的好坏呢?这时也可以用互信息I(X,Z),代表我们知道了Z之后,X的信息量减少了多少。

对比学习经典方法
对比学习是无监督表示学习中一种非常有效的方法,核心思路是训练query和key的Encoder,让这个Encoder对相匹配的query和key生成的编码距离接近,不匹配的编码距离远。想让对比学习效果好,一个核心点是扩大对比样本(负样本)的数量,即每次更新梯度时,query见到的不匹配key的数量。负样本数量越多,越接近对比学习的实际目标,即query和所有不匹配的key都距离远。
对比学习目前有4种最典型的范式,分别为 End-to-End、Memory Bank、Momentum Encoder以及In-Batch Negtive。这几种对比学习结构的差异主要体现在对负样本的处理上,4种方法是一种逐渐演进的关系。

End-to-End
End-to-End是一种最直接的对比学习方法,对于一个query,每次采样一个正样本以及多个负样本,使用对比学习loss计算损失,正样本和负样本都进行梯度反向传播。
Memory Bank
针对End-to-End负样本采样数量受GPU内存限制的问题,基于Memory Bank的方法进入人们视野。Memory Bank的核心思路是,将某一轮模型对数据集中所有样本的表示存储起来,这些样本在作为负样本时,可以不进行梯度更新,极大提升了每个batch负样本数量。
- Memory Bank对比学习的主要论文是Unsupervised feature learning via non-parametric instance discrimination(ICLR 2018)
- 利用InfoNCE loss来近似拟合softmax多分类损失,它与层次softmax、negative sampling都是解决类别较多时多分为问题的高效方法。InfoNCE loss将多分类问题转换为多个二分类问题,原来是预测当前样本属于哪个类别,转换成判断每个样本(一个正样本和多个负样本)是否和当前样本匹配,或区分数据样本和噪声样本。
问题
- Model Bank中存储的样本表示不是最新训练的encoder产出的,和当前encoder生成的表示有一定差异,导致模型训练过程存在问题,例如当前encoder产出的编码可能要和n轮迭代之前产出的encoder编码做比较。同时,Model Bank侧两次样本表示更新不具备连续性,也会导致训练不稳定
Momentum Encoder
Momentum Encoder主要为了解决Model Bank中每个样本缓存的表示和Encoder更新不一致的问题。Momentum Encoder的核心思路是,模型在key侧的encoder不进行训练,而是平滑拷贝query侧encoder的参数
典型的Momentum Encoder工作是Facebook提出的MoCo,论文Momentum Contrast for Unsupervised Visual Representation Learning
In-Batch Negtive
In-Batch Negtive也是对比学习中经常采用的一种扩大负样本数量的方法。对于匹配问题,假设每个batch内有N个正样本对,那么让这N个正样本之间互为负样本,这样每个样本就自动生成了2*(N-1)个负样本。
在图像和文本匹配的多模态领域,In-Batch Negtive也非常常用,例如Learning Transferable Visual Models From Natural Language Supervision提出的CLIP模型。In-Batch Negtive的优点是非常简单,计算量不会显著增加。缺点是负样本只能使用每个batch内的数据,是随机采样的,无法针对性的构造负样本。
聚类对比学习
【2022-9-7】聚类对比学习:SwAV & PCL模型浅析
- 作为一种自监督学习方法,
对比学习(Contrastive Learning)由于在表征学习上有效性和在不同领域中的普适性,已经成为了近年来的研究热点之一,这篇文章将介绍对比学习的一个分支——聚类对比学习,涉及到两篇论文:SwAV 和 PCL
对比学习是通过比较正负样本对来进行学习的,对于一般的对比学习方法
- 正样本往往是从样本自身得到的,比如对该样本做增强(augmentation)
- 而负样本则是从 batch 中随机挑选的样本。
然而这种构造方法可能会面临两个问题:
- 为了加强模型的分辨能力,往往需要在一个 batch 中加入足够多的负样本,许多实验也表明大的 batch size 可以提高模型性能。然而由于一般的对比学习方法需要对 batch 中的样本进行两两比较,计算复杂度为 $O(N^2)$,这就导致 batch size 会受到显存大小的约束,给对比学习的应用带来了障碍。
- 随机挑选负样本的方式可能会将一些实际上很相似的样本作为负样本,这样可能会影响模型的性能。
- 例如若锚定样本是一只狗的图片,而随机挑出来的负样本恰好也是一只狗的图片,那么即使两个样本实际上很相似,模型也会将其作为负样本
聚类对比学习就是想要解决上述的问题,顾名思义,该方法不直接做两两样本的对比,而是先对样本进行聚类,然后在类之间进行对比学习,由于样本的“类别”是通过无监督的聚类方法得到的,因此整个学习过程中并不需要样本标签,仍然还是在做自监督学习。通过聚类后再对比的操作,我们就可以大大减小对比的数量,降低计算复杂度,而且同一类下的不同样本也互为正样本,不会将相似的样本当做负样本。
两种聚类对比学习的方法,其核心问题在于如何保证对比学习过程中聚类的稳定性,SwAV 采用了给定约束条件下的最优运输理论来实现均匀的聚类;而 PCL 则通过引入自适应的聚类集中度 来调节聚类。完成对样本聚类之后,SwAV 得到的是“软”的分类概率,然后通过计算两个 view 之间的分类交叉熵进行对比学习;而 PCL 得到的是 one-hot 聚类结果,然后把每个聚类看做是一个高斯分布,通过最大化对数似然的方式对比进行学习
SwAV 和 PCL,两者都将聚类的思想引入到了对比学习当中
SwAV
要想在对比学习中引入聚类,首先需要解决的就是聚类稳定性的问题,即要避免所有样本都被分到同一类这种极端情况。因此这里 SwAV 就设计了一种聚类的方法,使得模型可以直接对 batch 中的样本进行稳定的聚类,然后按照聚类结果进行对比学习,帮助模型获得样本表征。
先简单说一下 SwAV 的思路,SwAV 与传统对比学习的区别如下所示。为了帮助聚类,模型中引入了 K 个原型(prototype)变量,每个 prototype 可以理解为是一类样本的通用特征,一共有 K 类;模型会根据原型变量,online 计算出 batch 中的样本属于某类的概率,然后再通过不同 view 的对比,令正样本对的属于同一类的概率更大(即相似的样本属于同一类的概率更大),以此来实现对于样本表征的学习。
PCL
PCL 采用了期望-最大化框架,即 EM 算法的思路,流程如下图所示,简单来说可以分为 E 步和 M 步
A.引入
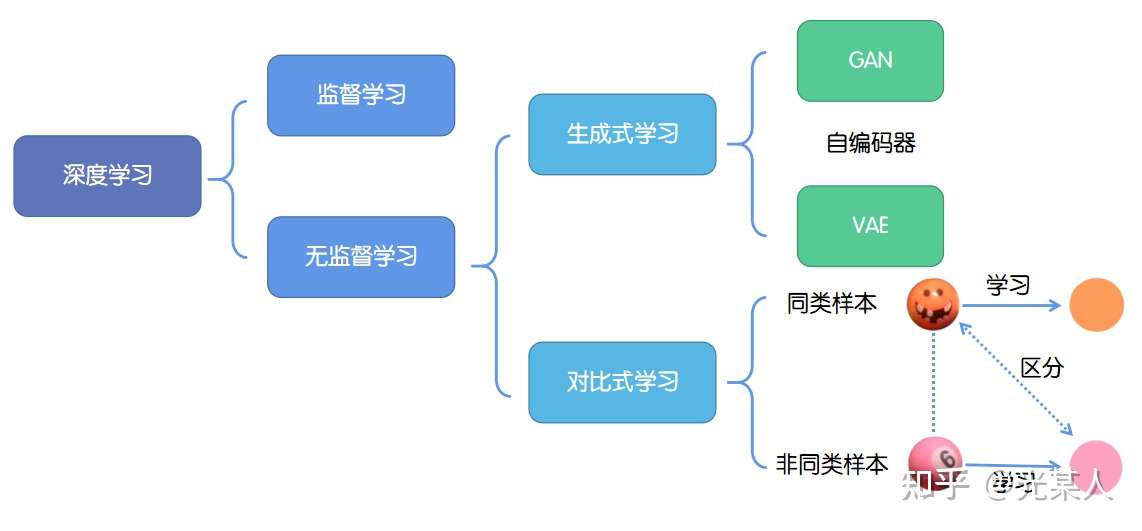
深度学习的成功往往依赖于海量数据的支持,其中对于数据的标记与否,可以分为监督学习和无监督学习。
- 监督学习:技术相对成熟,但是对海量的数据进行标记需要花费大量的时间和资源。
- 无监督学习:自主发现数据中潜在的结构,节省时间以及硬件资源。
- 2.1 主要思路:自主地从大量数据中学习同类数据的相同特性,并将其编码为高级表征,再根据不同任务进行微调即可。
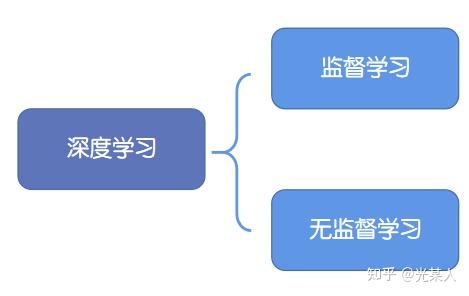
- 2.2 分类:
- 2.2.1 生成式学习:生成式学习以自编码器(例如GAN,VAE等等)这类方法为代表,由数据生成数据,使之在整体或者高级语义上与训练数据相近。
- 2.2.2 对比式学习:对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。与生成式学习比较,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
- 近况
最近深度学习两巨头 Bengio 和 LeCun 在 ICLR 2020 上点名 Self-Supervised Learning(SSL,自监督学习) 是 AI 的未来,另外,Hinton 和 Kaiming 两位神仙也在这问题上隔空过招,MoCo、SimCLR、MoCo V2 打得火热,这和 BERT 之后,各大公司出 XL-Net、RoBerta 刷榜的场景何其相似。
- 感谢
写这篇综述,花了大概一个多月时间整理【刚大二,有篇复旦的论文确实看不懂,这里就没写】,感谢各位大佬的博客,给了我莫大的帮助,还有学长 @忆臻和同学@认真玩家的鼓励,才让我有信心肝完这篇国内资料不那么完善的综述。
本文对目前的对比学习相关,尤其是NLP方面的工作进行较为全面的介绍,希望能够为感兴趣的同学提供一些帮助。
B. 对比引入
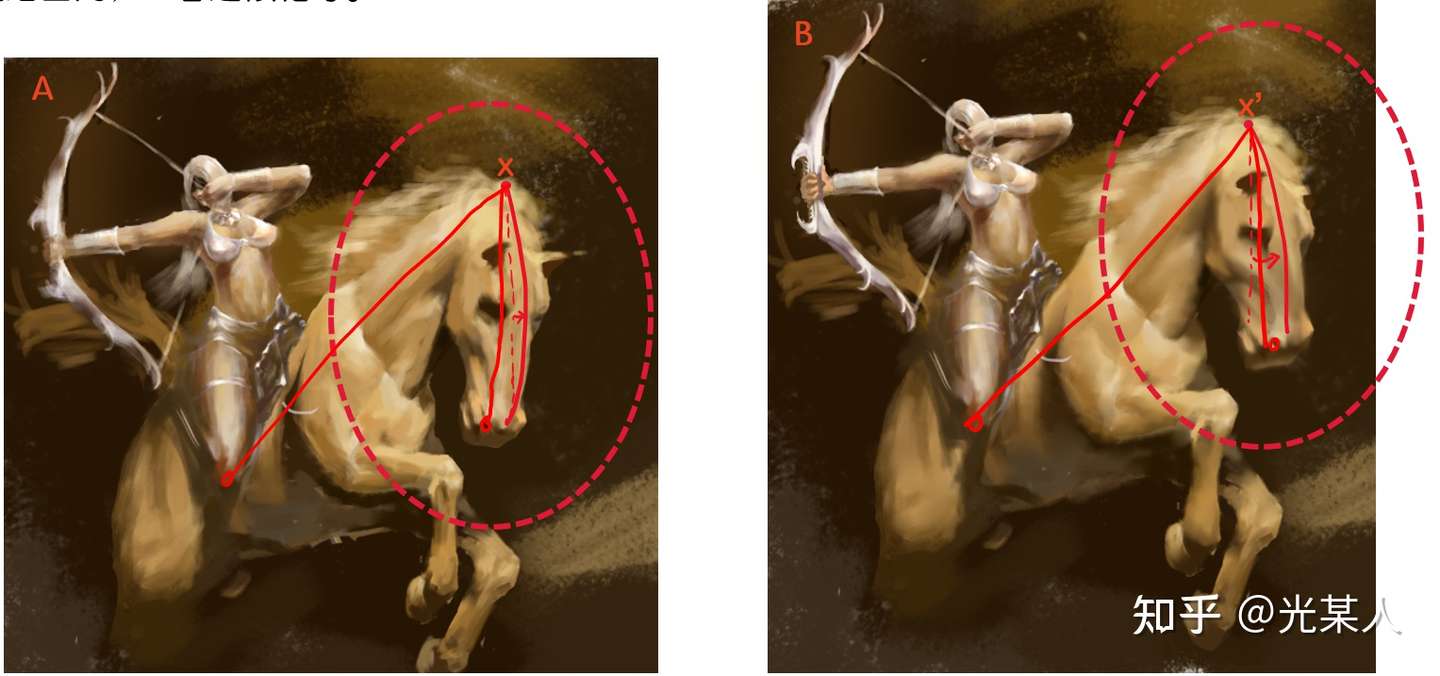
【拿我的画举个例子】我们可以看到下面两张图的马头和精细程度都是不同的,但是我们显然能判断这两张是类似的图,这是为什么呢

对于某个固定锚点x来说,其位置是由与其他点相对位置决定的,而不是画布的绝对位置。
A中与 x 邻近的点在B图中相应点距 x’ 距离小,A中与 x 相距较远的点在B图中相应点距 x’ 距离大。
在一定误差范围内,二者近似相等。
可以这么认为,通过对比学习,忽略了细节,找到并确定所以关键点相对位置。
C. 聚类思想
在这里,我们将之前的想法进行抽象,用空间考虑对比学习。
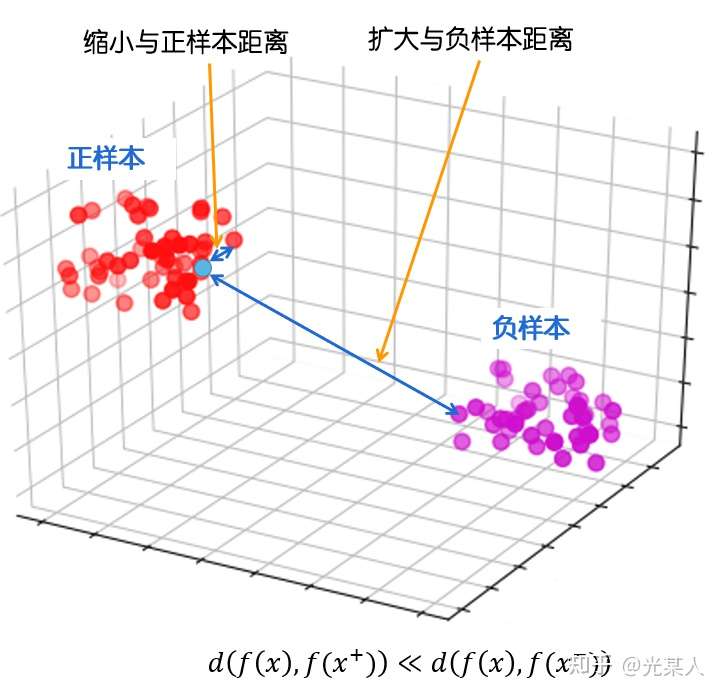 最终目标:
最终目标:
,(或使正样本与锚点的相似度远远大于负样本与锚点的相似度),从而达到他们间原有空间分布的真实距离。
- 距离度量:欧几里得距离,余弦相似度,马氏距离(没人试过,但原理是一样的)
- 目标优化:给定锚点,通过空间变换,使得锚点与正样本间距离尽可能小,与负样本距离尽可能大
D. 对比思想
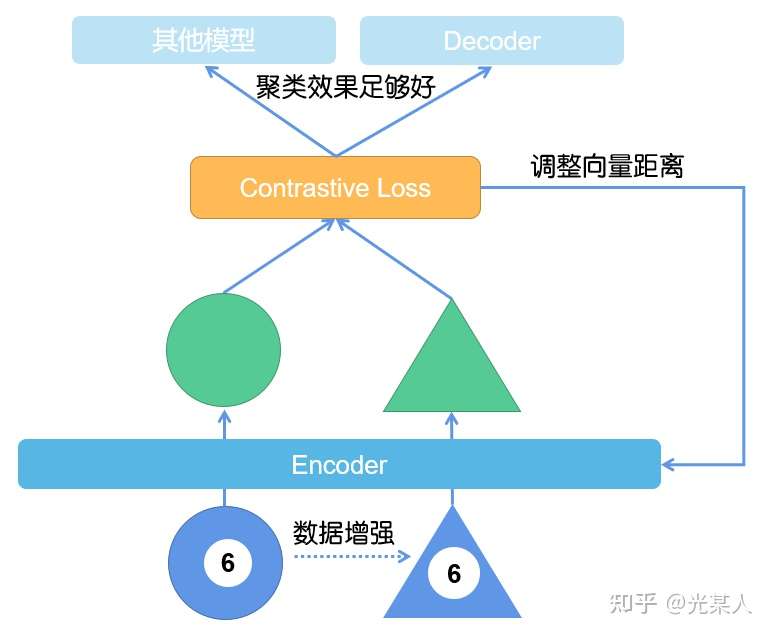
动机:
- 人类不仅能从积极信号中学习,还能从纠正不良行为中获益。
对比学习其实是无监督学习的一种范式。根据经典的SIMCLR,我在这里就直接提供了对比学习中模型的常见形式。
E. 对比损失【重要*数学警告】
本章的数学公式可以只看结论(NCE可以不看),如果想了解细节请仔细阅读【附录】,如果不懂可以评论私信,或者移步参考博客学习。
损失函数总结
- 表示学习的目的是将原始数据转换成更好的表达,以提升下游任务的效果。在表示学习中,损失函数的设计一直是被研究的热点。损失指导着整个表示学习的过程,直接决定了表示学习的效果。
- 表示学习中的7大损失函数的发展历程,以及演进过程中的设计思路,主要包括: contrastive loss、triplet loss、n-pair loss、infoNce loss、focal loss、GHM loss、circle loss。
- (1)
contrastive loss:对比损失- Dimensionality Reduction by Learning an Invariant Mapping(CVPR 2006)
- 输入两个样本,经过相同的编码器得到两个样本的编码。
- 如果两个样本属于同一类别,则优化目标为让两个样本在某个空间内的距离小;
- 如果两个样本不属于同一类别,并且两个样本之间的距离小于一个超参数m,则优化目标为让两个样本距离接近m。
- Contrastive Loss是后面很多表示学习损失函数的基础,通过这种对比方式,让模型生成的表示满足相似样本距离近,不同样本距离远的条件,实现更高质量的表示生成
- (2)
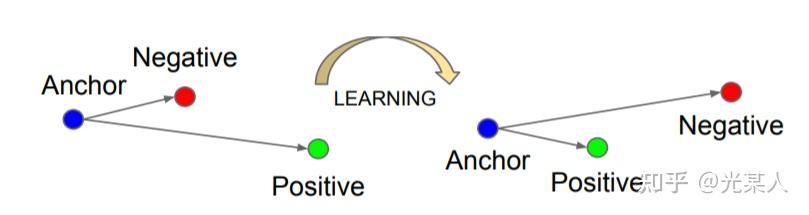
triplet loss:三元组损失- FaceNet: A unified embedding for face recognition and clustering(CVPR 2015)
- triplet loss需要比较3个样本,分别为
anchor、position和negtive。 - 目标: 让anchor和positive样本(类别相同)的距离尽可能近,而和negtive样本(类别不同)的距离尽可能远。
- 因此, triplet loss设计为,让anchor和positive样本之间的距离比anchor和negtive样本要小,并且要小至少一个margin的距离才不计入loss。
- (3)
n-pair loss:n对损失(使用多个负样本)- Improved Deep Metric Learning with Multi-class N-pair Loss Objective(NIPS 2016)
- contrastive loss和triplet loss中,每次更新只会使用1个负样本,而无法见到多种其他类型负样本信息,因此模型优化过程只会保证当前样本的embedding和被采样的负样本距离远,无法保证和所有类型的负样本都远,会影响模型收敛速度和效果。即使多轮更新,但是这种情况仍然会导致每轮更新的不稳定性,导致学习过程持续震荡。
- 为了解决这个问题,让模型在每轮更新中见到更多的负样本,提出了N-pair loss,主要改进是每次更新的时候会使用多个负样本的信息。N-pair loss可以看成是一种triplet loss的扩展
- (4)
infoNce loss:噪声对比损失- Representation learning with contrastive predictive coding(2018)
- infoNce loss 是对比学习中最常用的loss之一,它和softmax的形式很相似,主要目标是给定一个query,以及k个样本,k个样本中有一个是和query匹配的正样本,其他都是负样本。当query和正样本相似,并且和其他样本都不相似时,loss更小。InfoNCE loss可以表示为如下形式,其中r代表temperature,采用内积的形式度量两个样本生成向量的距离,InfoNCE loss也是近两年比较火的对比学习中最常用的损失函数之一;相比softmax,InfoNCE loss使用了temperature参数,以此将样本的差距拉大,提升模型的收敛速度
- (5)
focal loss:聚焦损失(数据不均衡)- Focal Loss for Dense Object Detection(2018)
- 最开始主要是为了解决目标检测中的问题,但是在很多其他领域也可以适用。
- Focal Loss解决的核心问题:当数据中有很多容易学习的样本和较少难学习样本时,如何调和难易样本的权重。如果数据中容易的样本很多,难的样本很少,容易的样本就会对主导整体loss,对难样本区分能力弱。
- 为了解决这个问题,Focal Loss根据模型对每个样本的打分结果给该样本的loss设置一个权重,减小容易学的样本(即模型打分置信的样本)的loss权重。
- (6)
GHM loss:(focal loss改进)- Focal Loss中强制让模型关注难分类样本,但是数据中可能也存在一些异常点,过度关注这些难分类样本,反而会让模型效果变差。
- Gradient Harmonized Single-stage Detector(AAAI 2019)提出了GHM Loss
- (7)
circle loss- Circle Loss: A Unified Perspective of Pair Similarity Optimization(CVPR 2020)
- circle loss 从一个统一视角融合了class-level loss和pair-wise loss。这两种优化目标都是在最小化sn-sp,其中sn表示between-class similarity,即不同类别的样本表示距离应该尽可能大;sp表示within-class similarity,即相同类别的样本表示距离尽可能小。




1. 欧几里得距离
线性空间中,上述相似度就可以表示为二者向量间的欧几里得距离:
2. 对比损失定义
由 Hadsell, R. , Chopra, S. , & Lecun, Y. . (2006)提出[1] ,原文只是作为一种降维方法:
- 只需要训练样本空间的相对关系(对比平衡关系)即可在空间内表示向量。
损失定义如下:
为了下文方便解释,这里的参数详细解释如下:
:网络权重;
:标志符,
:是
与
在潜变量空间的欧几里德距离。
:表示第i组向量对。
:研究中常常在这里做文章,定义合理的能够完成最终目标的损失函数往往就成功了大半。
2.1 细节定义
只需满足红色虚线趋势。
只需满足蓝线趋势【都有趋于0的区域】。
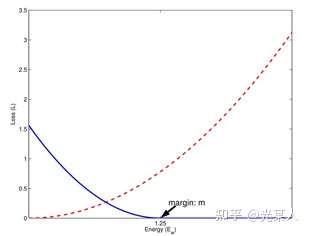
2.2 过程/主流程
原文类比弹性势能,将正负样本分类讨论。
正样本:
- 当与锚点是正样本时,由于对比思想,二者之间会逐渐靠近。原文将它假设成一个原长
的弹簧,那么就会将正样本无限的拉近,从而完成聚类。
将锚点设为势能零点:
那么 E 即可作为
,且满足定义要求:
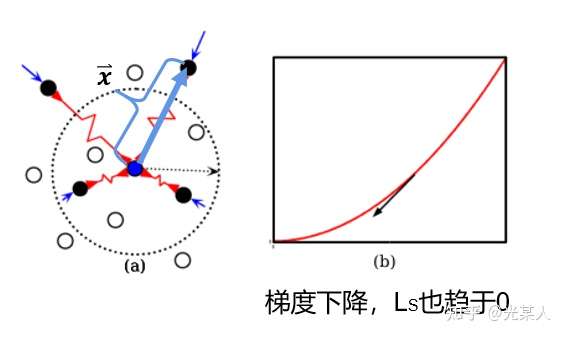
负样本
当与锚点是负样本时,由于对比思想,二者之间会逐渐原理。原文将它假设成一个原长 的弹簧,那么就会将负样本至少拉至m,从而完成划分。
将锚点设为势能零点:
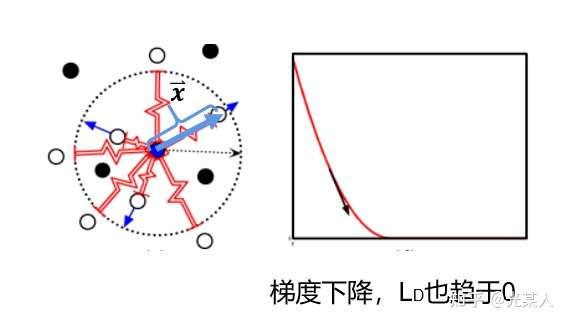
L原定义:
这样我们就获得了Loss函数最基本的定义:
- 当Y=0,调整参数最小化
。
- 当Y=1,设二者向量最大距离为m,
- 如果
, 则增大两者距离到m;
- 如果
,则不做优化。
空间角度:
空间内点间相互作用力动态平衡。
2.3 效果
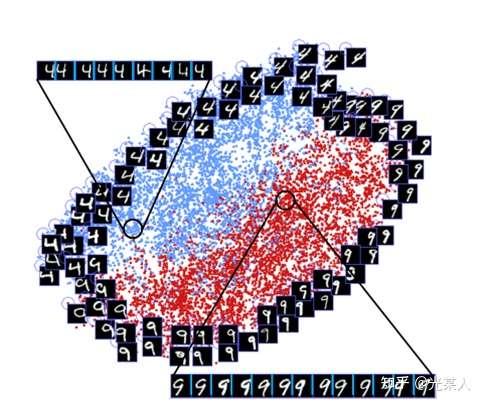
可以看到,和4不那么像的9会被拉远离4,和4相似的9会在交界面上十分接近地分布。这和我们的的对比想法是一致的。
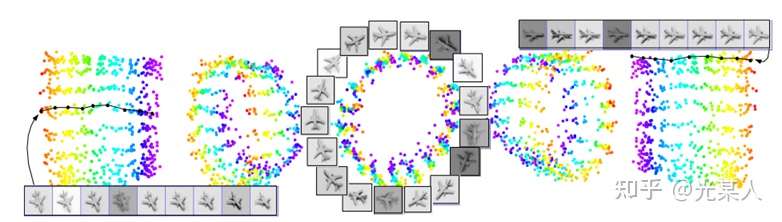
同时,该论文还发现许多对比学习中有趣的现象。
不同光照下,不同角度下,像素间欧氏距离尽管很远,但是能聚集在一个环上。
3. Triplet Loss
(简化版原方法)
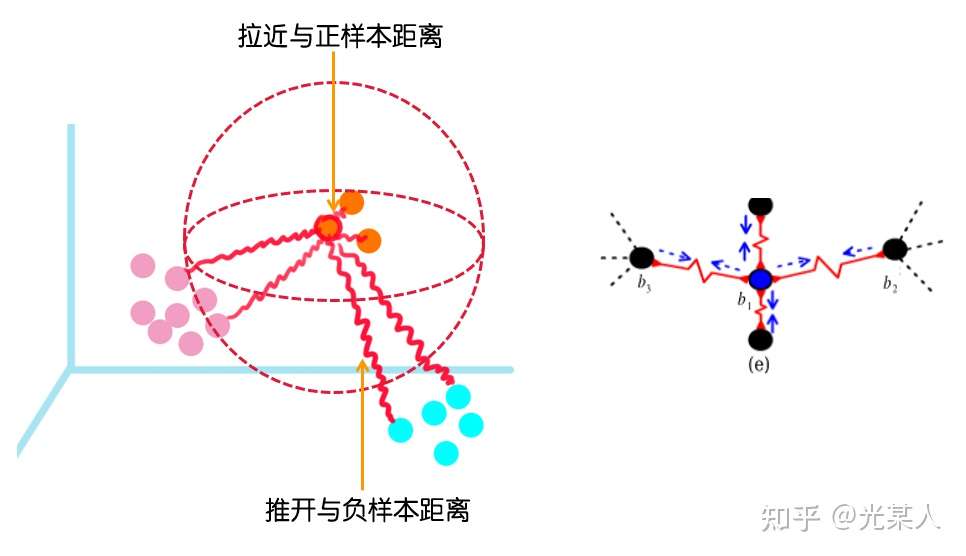
结论
我们将三元组重新描述为 。
那么三元组的总体距离可以表示为:【近年论文好像也有沿用的,比较经典】
相较定义来说,Triplet Loss认为,假如所有正样本之间无限的拉近,会导致聚类过拟合,所以,就只要求
当然在比例尺上看来, 也会趋于0。
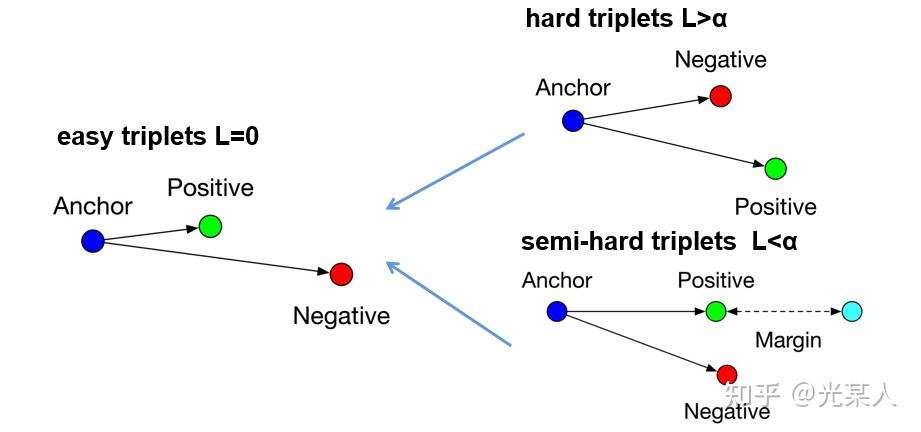
原文将所有三元组的状态分为三类:
- hard triplets 正样本离锚点的距离比负样本还大
- semi-hard triplets 正样本离锚点的距离比负样本小,但未满足
- easy triplets 满足
前两个状态会通过loss逐渐变成第三个状态。
4. NCE Loss
注:
后续研究并没有怎么使用原始的NCELoss,而是只使用这里的结论,这里引入是为了说明应该多采用负样本。
之前从向量空间考虑,NCE从概率角度考虑【原证明为贝叶斯派的证法】,NCE是对于得分函数的估计,那也就是说,是对于你空间距离分配的合理性进行估计。
总之NCE通过对比噪声样本与含噪样本,从而推断真实分布。
【与对比学习思想一致,可以当做是另一角度】
结论
越大,约接近NCE 对于噪声分布的依赖程度也就越小,越接近真实期望。
5. 互信息
在预测未来信息时,我们将目标x(预测)和上下文c(已知)编码成一个紧凑的分布式向量表示(通过非线性学习映射),其方式最大限度地保留了定义为的原始信号x和c的互信息
通过最大化编码之间互信息(它以输入信号之间的MI为界),提取输入中的隐变量。
互信息往往是算不出来的,但是我们这里将他进行估计,通过不同方法进行估计,从而衍生出自监督的两种方式:生成式和对比式【详见A 2.2.2】
- 互信息上界估计:减少互信息,即VAE的目标。
- 互信息下界估计:增加互信息,即对比学习(CL)的目标。【后来也有CLUB上界估计和下界估计一起使用的对比学习。】
6. InfoNCE Loss
具体详见CPC论文1.3节。
通过二者互信息【详见附录】来衡量二者距离/相似度,可逼近其下界。
结论
后续研究
后续研究的核心往往就聚焦于的两个方面:
- 如何定义目标函数?【详见附录】
- 简单内积函数
- InfoNCE【近年火热】
- triplet 【近年火热】 【知乎的问题,后边的s函数的负号上标可能消失】
- 如何构建正实例对和负实例对?
这个问题是目前很多 paper 关注的一个方向,设计出合理的正实例与负实例对,并且尽可能提升实例对,才能表现的更好。
F. 基础论文
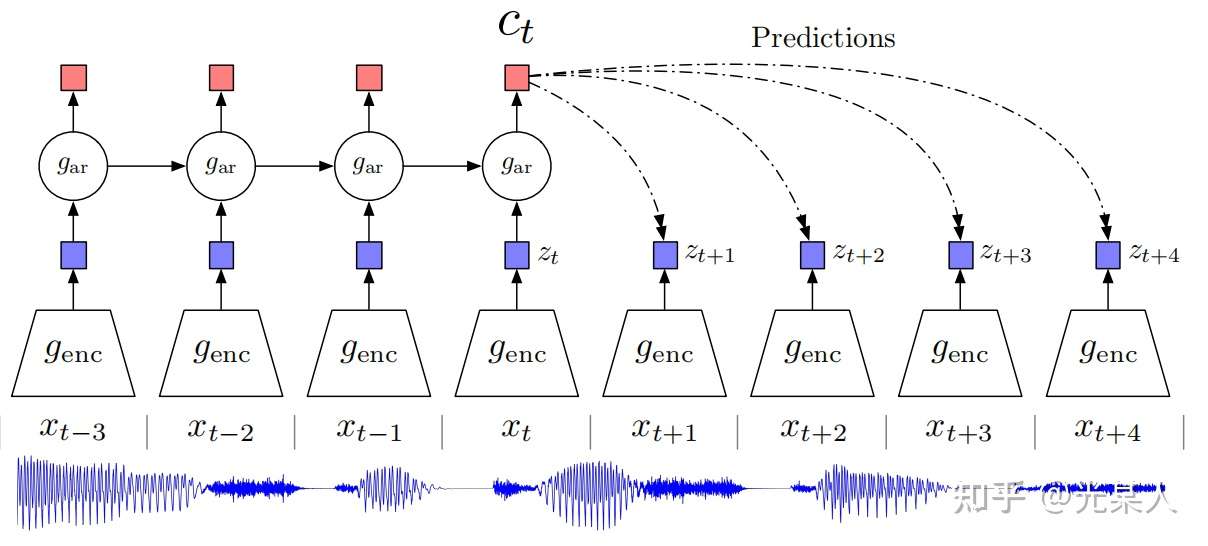
1. CPC
- 论文标题:Representation Learning with Contrastive Predictive Coding
- 论文链接:https://arxiv.org/abs/1807.03748
- 代码链接:https://github.com/davidtellez/contrastive-predictive-coding
很多时候,很多数据维度高、label相对少,我们并不希望浪费掉没有label的那部分data。所以在label少的时候,可以利用无监督学习帮助我们学到数据本身的高级信息,从而对下游任务有很大的帮助。
Contrastive Predictive Coding(CPC) 这篇文章就提出以下方法:
- 将高维数据压缩到更紧凑的隐空间中,在其中条件预测更容易建模。
- 用自回归模型在隐空间中预测未来步骤。
- 依靠NCE来计算损失函数(和学习词嵌入方式类似),从而可以对整个模型进行端到端的训练。
- 对于多模态的数据有可以学到高级信息。
可以利用一定窗口内的 和
作为正实例对,并从输入序列之中随机采样一个输入作为
负实例。
1.1 问题描述

给定声音序列上下文 ,由此我们推断预测
位置上的声音信号。题目假设,声音序列全程伴随有噪音。为了将噪音序列与声音序列尽可能的分离编码,这里就随机采样获得
代替
位置信号,作为负样本进行对比学习。
1.2 CPC
下图说明了 CPC 的工作过程:
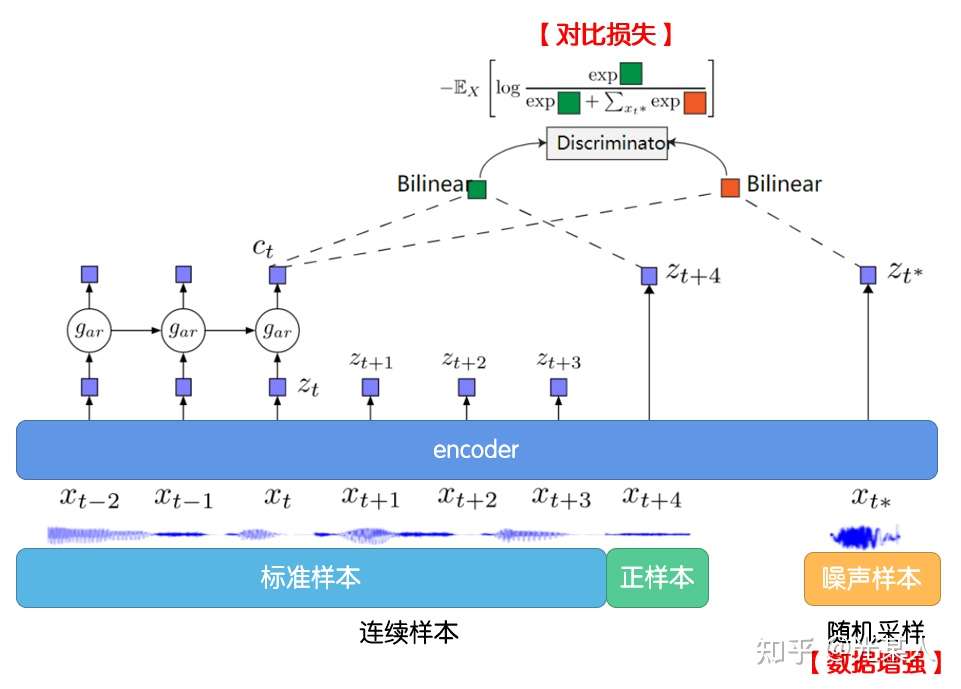
首先我们在原信号上选取一些时间窗口,对每一个窗口,通过encoder ,得到表示向量
。
通过自回归模型:
,从而生成上下文隐变量
。
然后通过Bi-linear:【采用 和
从而能够压缩高维数据,并且计算
和
的未来值是否符合】
1.3 InfoNCE Loss
CPC用到了NCE Loss, 并推广为InfoNCE:(证明见【附录】)
选取 ,这里面只有一个正样本对
来自于
,即声音原本的信号,其他N-1个均是负样本(噪声样本)来自于
,即随机选取的信号片段。
损失函数定义如下:【 _f _可自由定义,甚至为MLP】
我们用softmax的思路来理解这个损失函数, 越大,
应该越接近于0(越接近最大值),而损失就越小。
回到对比学习的思想,W将做c到z的映射, 均经过归一化,那么,二者余弦相似度为
,这样
,即可看做softmax,将
正样本的值加大,负样本值缩小。
2. MoCo
本文提出了高效的对比学习的结构。使用基于 MoCo 的无监督学习结构学习到的特征用于 ImageNet 分类可以超过监督学习的性能。证明了无监督学习拥有巨大的潜力。
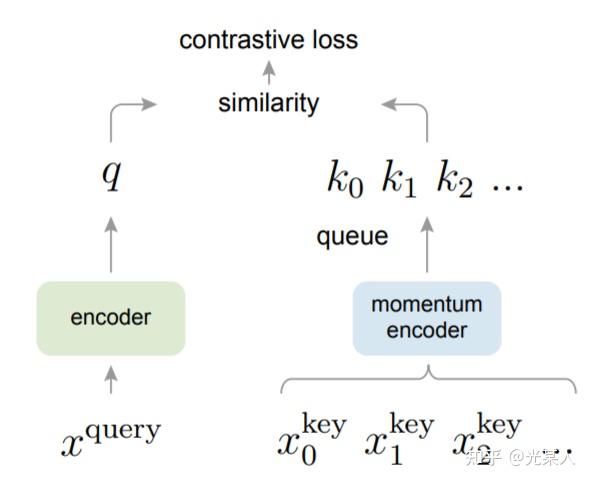
受NLP任务的启发,MOCO将图片数据分别编码成查询向量和键向量,即,查询 q 与键队列 _k _,队列包含单个正样本和多个负样本。通过 对比损失来学习特征表示。
主线依旧是不变的:在训练过程中尽量提高每个查询向量与自己相对应的键向量的相似度,同时降低与其他图片的键向量的相似度。
MOCO使用两个神经网络对数据进行编码:encoder和momentum encoder。
encoder负责编码当前实例的抽象表示。
momentum encoder负责编码多个实例(包括当前实例)的抽象表示。
对于当前实例,最大化其encoder与momentum encoder中自身的编码结果,同时最小化与momentum encoder中其他实例的编码结果。
2.1 InfoNCE Loss
这个Loss只能更新q向量的encoder。如果同时更新q和k没有意义。
交叉熵损失:
交叉熵损失(Cross-entropy Loss) 是分类问题中默认使用的损失函数:
分类模型中,最后一层一般是linear layer+softmax。所以如果将之前的特征视为, linear layer的权重视为
,则有:
每个权重矩阵 事实上代表了每一类样本其特征值的模板(根据向量乘法我们知道越相似的两个向量其内积越大)。
实际上,现有的分类问题是通过一系列深度网络提取特征,然后依据大量的样本学习到一个有关每一类样本特征的模板。在测试的阶段则将这个学到的特征模板去做比对。
非参数样本分类:
所谓非参数样本分类,则是将每个计算出的样本特征作为模板,即看做是计算所得的样本特征模板。
对比损失:
我们最终的目标还是不变的:
这里与CPC类似地,我们使用cosine距离,假设已经归一化特征值,则优化上式实际上等同于最大化下式中的softmax概率,
假设其中有一个正样本 其余均是负样本,则根据 InfoNCE Loss表示为:
其中 和
可以有多种构造方式,比如对图像进行裁剪变色等随机变化。
但是呢,实现上来说,将 看做一体为
,那么
,即为交叉熵损失。
2.2 Memory Bank
由于对比学习的特性,参与对比学习损失的实例数往往越多越好,但Memory Bank中存储的都是 encoder 编码的特征,容量很大,导致采样的特征具有不一致性(是由不同的encoder产生的)。
所以,对所有参与过momentum encoder的实例建立动态字典(dynamic dictionary)作为Memory Bank,在之后训练过程中每一个batch会淘汰掉字典中最早被编码的数据。
2.3 Momentum 更新
在参数更新阶段,MOCO只会对encoder中的参数进行更新。
由于Memory Bank,导致引入大量实例的同时,会使反向传播十分困难,而momentum encoder参数更新就依赖于Momentum 更新法,使momentum encoder的参数逐步向encoder参数逼近:
其中 ,
指encoder部分的参数。
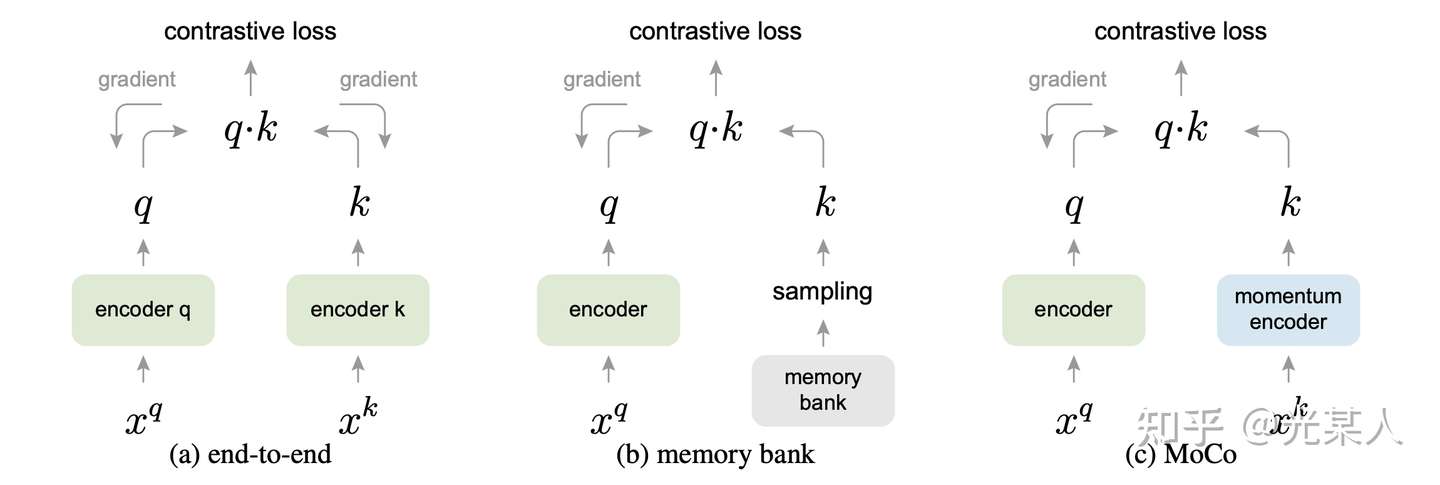
下图形式化的表示了三种结构,end-to-end,memory-bank和MoCo的区别。MoCo的特点是:
(1)用于负采样的队列是动态的
(2)用于负样本特征提取的编码器与用于query提取的编码器不一致,是一种Momentum更新的关系。
(3)与Memory Bank类似,NCE Loss只影响 Query ,不更新key。
2.4 代码流程

3. SimCLR
论文标题:A Simple Framework for Contrastive Learning of Visual Representations
论文链接:https://arxiv.org/abs/2002.05709
代码链接:https://github.com/google-research/simclr
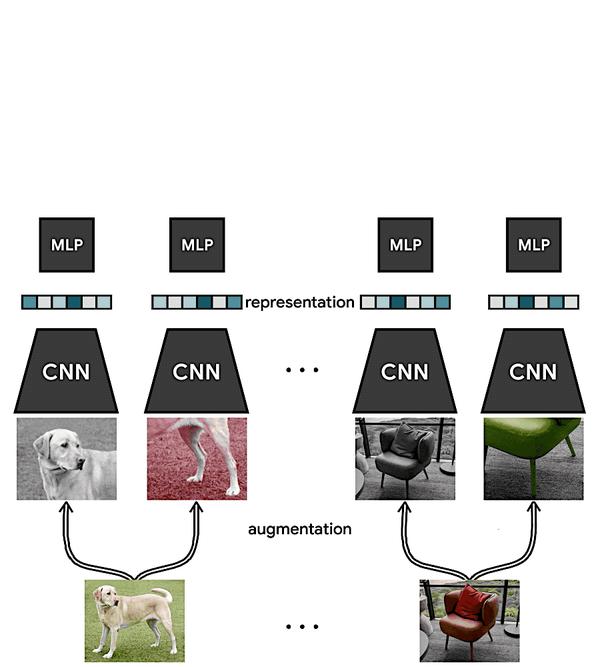
3.1 做法:
simCLR背后的想法非常简单:
视觉表征对于同一目标不同视角的输入都应具有不变性。
simCLR对输入的图片进行数据增强,以此来模拟图片不同视角下的输入。之后采用对比损失最大化相同目标在不同数据增强下的相似度,并最小化同类目标之间的相似度。
用下面这张图来说明:
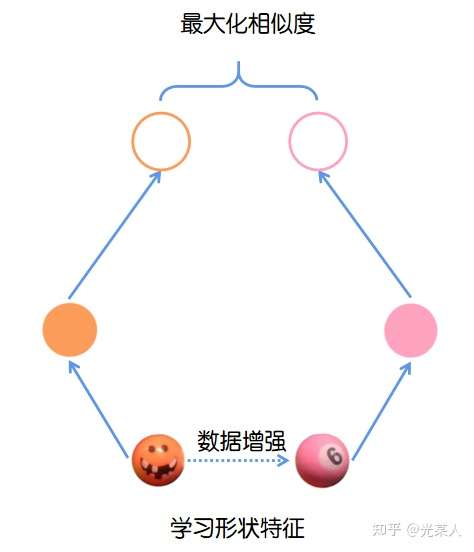
simCLR的架构由两个相同的网络模块组成。对于每一个输入网络的minibatch:
-
对mini batch中每张输入的图片进行两次随机数据增强(随机剪裁、滤镜、颜色过滤、灰度化等)来得到图片两种不同的视角;
-
将得到的两个表征送入两个卷积编码器(如resnet)获得抽象表示,之后对这些表示形式应用非线性变换进行投影得到投影表示;
-
使用余弦相似度来度量投影的相似度。
simCLR使用了多组对比,直接加强了效果【可以看成完全图,将相邻点拉近,不相似的点拉开】:
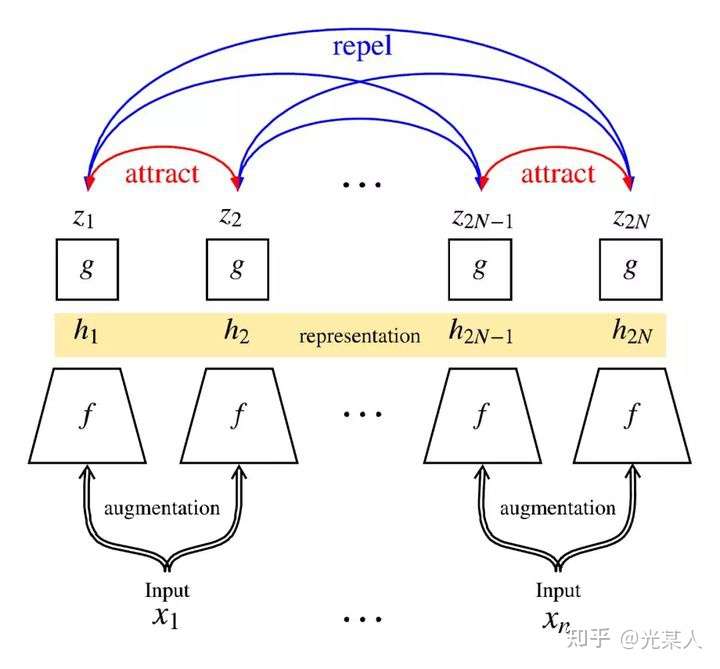
由此可以得到优化目标:对于minibatch中同一图片,最大化其两个数据增强投影的相似度,并最小化不同图片之间的投影相似度。
3.2 思想
以我的角度看,SimCLR的思想是值得借鉴的:
表示学习中,表示向量如果在空间内相对确定,那么在绝对空间中是较为准确的。
我们可以认为,是向量空间中的其他点决定了锚点的正确位置。做个比喻,你在学术界的人际关系,和同行评价决定了你所处的学术地位。【尽管这些是由你的科研工作决定的,但也是相对真实的反映了你的地位】。
但是,如果参考点过少,位置的确定则过于片面。所以,SimCLR的batch-size也达到了8192,用了128块TPU,又是算力党的一大胜利。
3.3 代码

-
神仙打架
4.1 MoCo-v2
MoCo v2 也是利用了上面SimCLR的第一点和第三点,并在MoCo-v1的基础上,将余弦相似度更换为一层MLP。在 MoCo 基础上得到了进一步的提升,然后作者还也明确的点名了 SimCLR,称不需要使用那么大的 batch size 也能超过它,可能这就是神仙打架吧。
4.2 SimCLR-v2
知识蒸馏
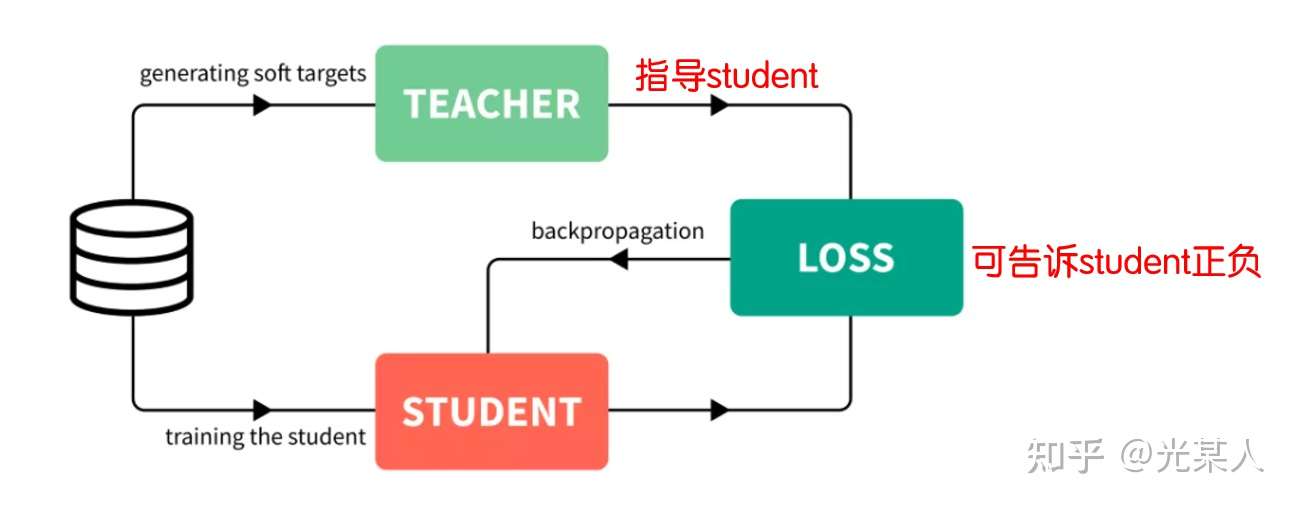
具体结构
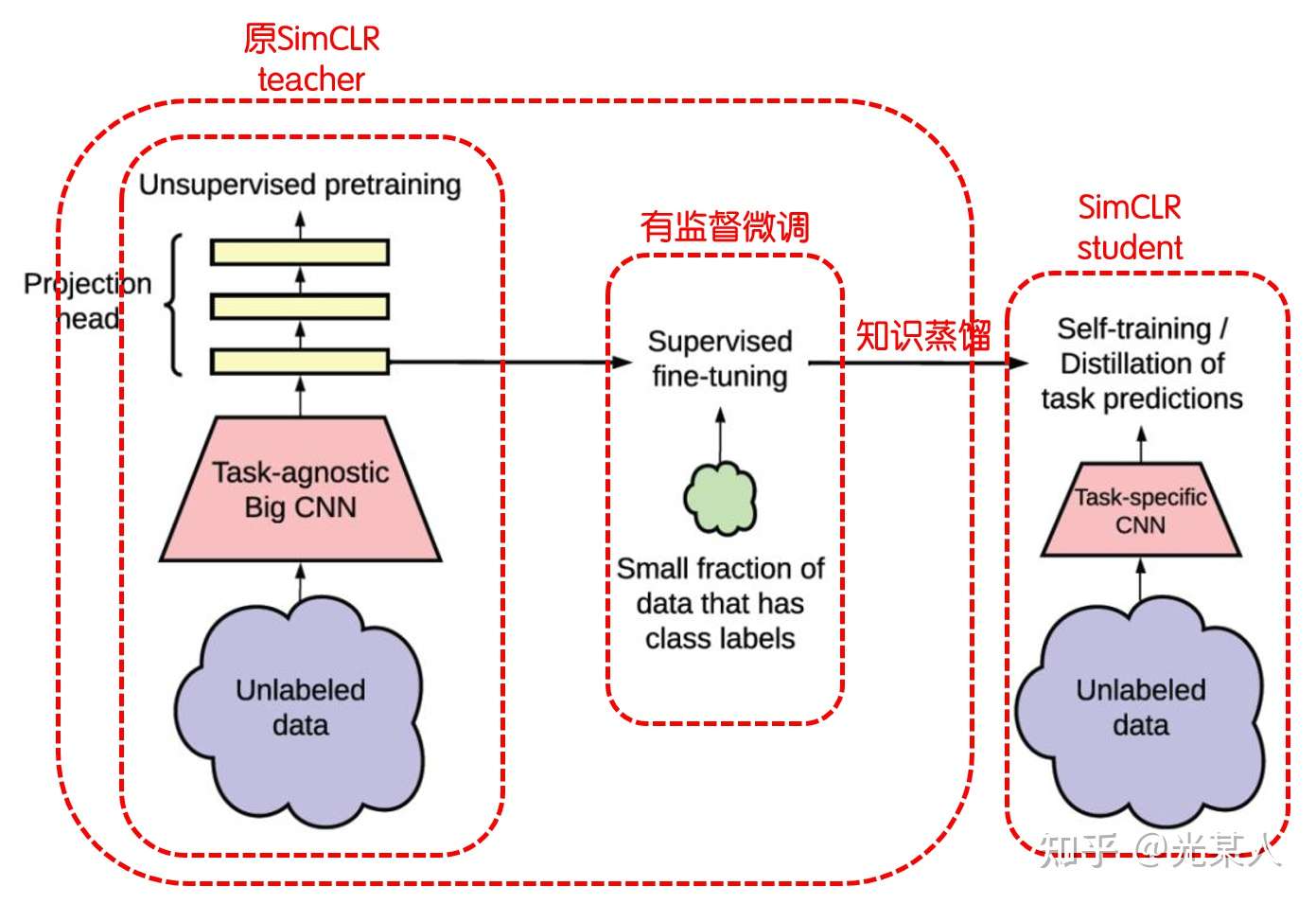
-
有监督对比学习
论文标题:Supervised Contrastive Learning
论文链接:https://arxiv.org/abs/2002.05709
5.1 动机
之前的论文都是自监督学习,自监督只做自己的变换,可能会过拟合。比如会把另一个品种的够对比到另一个类。
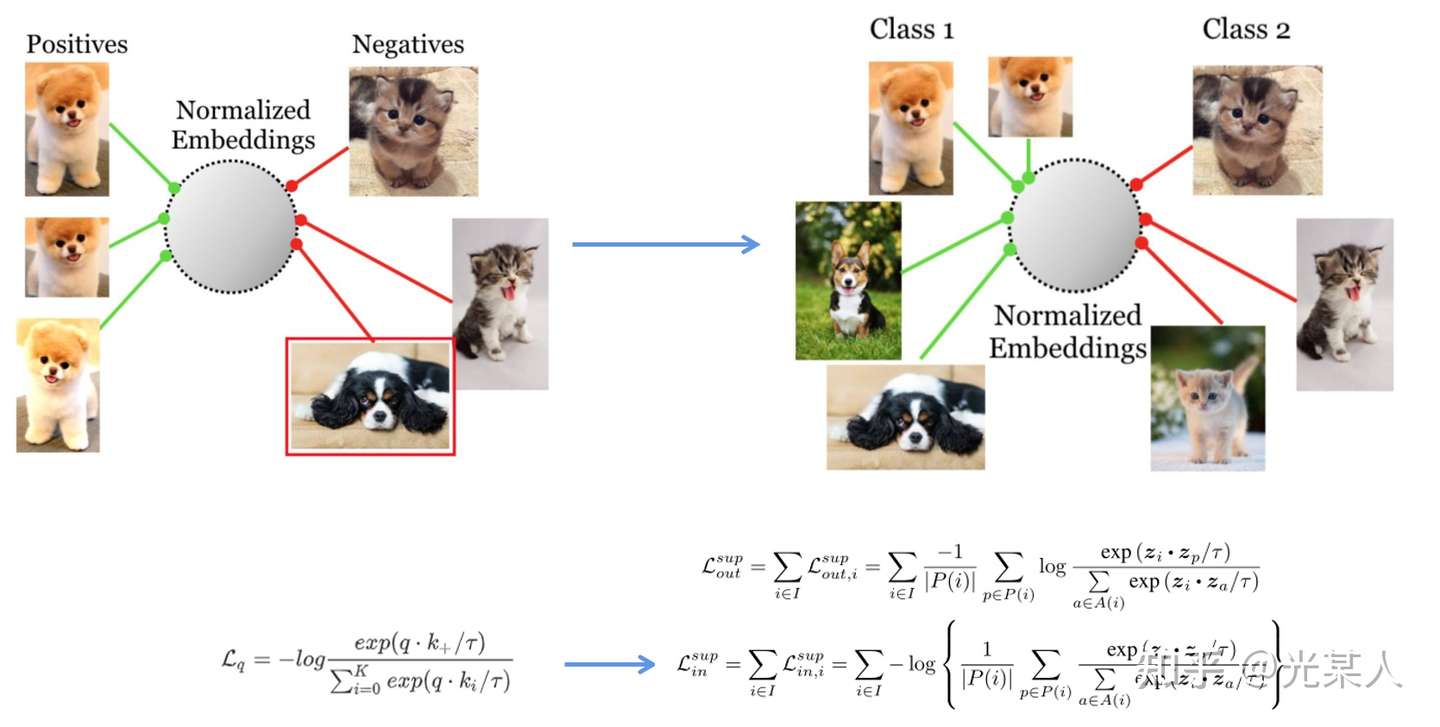
5.2 想法
5.3 证明
该论文还证明了Triplet Loss和InfoNCE Loss近似等价,统一了理论。
如果InfoNCE Loss中k=1,则:
6. 后续研究
6.1 主线
拉大正负样本的距离
6.2 后续研究核心
- 如何定义目标函数?【详见附录】
- 简单内积函数
- InfoNCE【近年火热】
- triplet 【近年火热】
2. 如何构建和实现正实例对和负实例对?
这个问题是目前很多 paper 关注的一个方向,设计出合理的正实例与负实例对,并且尽可能提升实例对,才能表现的更好。
- 联合其他模型作为较为准确的向量空间通过对比学习微调。
6.3 重兴原因
- BERT等预训练模型成效显著 [核心3]
- 数据变换有了一些评估模型作为依据 [核心2]
- 提出了更好的Loss函数 [核心1]
- 其他模型的改进效应 [核心3]
- MoCo解决了对比学习大量负样本带来的更新缓慢的问题 [核心2]
6.4 联合模型思考
由于对比学习是对相对空间中的向量表示,单纯地运算相对关系算力要求很高【SimCLR暴力美学证明可以纯算,但一般做不起】,一般作为其他模型绝对空间相对准确后的对任务的相对微调。
比如说,Bert能使空间词向量绝对空间的位置,相对准确,但是针对某些任务,它的聚类效果不够好,我们使用对比学习调整它们间的相对关系,从而适应我们的任务。
G. NLP近年论文
【这里仅做总括,细节会迁到另一篇博客,毕竟太长没人看】

由于NLP一般进行数据增强时,负例构造比较容易,而且NCE Loss也鼓励负例构造。这里就做了一些NLP处理方法的一些统计【至2021.2】。





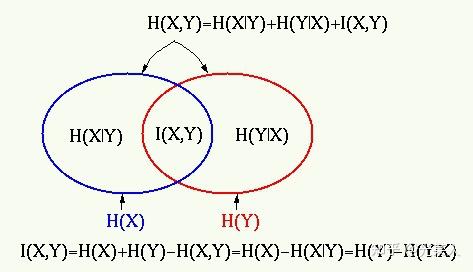
互信息
假设 ,
为X的信息熵,
为条件熵,信息表述如下:
如果X与Y有关联,则Y已知的条件下,X的不确定性会变化。
若设X,Y的联合概率分布为p(x,y),边缘概率为p(x),p(y)概率分布可以表示为:
互信息与信息熵的关系:
通常我们使用的最大化互信息条件,就是最大化两个随机事件的相关性。
互信息上界
VAE估计
VAE的思想是用 【一般取正态分布】去变分估计
,为了衡量二者分布的相似程度,这里用KL散度进行比较。【注:KL散度统计意义上永远大于等于0】
即 ,所以
CLUB估计
ICML2020
由于没有进行先验估计,所以是更加紧的上界。
由于log函数是凹函数,根据 Jensen 不等式:
因此:
对比损失的一些分类
Triplet Loss
核心代码
def cl_forward(cls,...): #对比学习的部分代码
return_dict = return_dict if return_dict is not None else cls.config.use_return_dict
ori_input_ids = input_ids
batch_size = input_ids.size(0)
# Number of sentences in one instance
# 2: pair instance; 3: pair instance with a hard negative
num_sent = input_ids.size(1)
mlm_outputs = None
# Flatten input for encoding
input_ids = input_ids.view((-1, input_ids.size(-1))) # (bs * num_sent, len)
attention_mask = attention_mask.view((-1, attention_mask.size(-1))) # (bs * num_sent len)
if token_type_ids is not None:
token_type_ids = token_type_ids.view((-1, token_type_ids.size(-1))) # (bs * num_sent, len)
# Get raw embeddings,得到原句子特征
outputs = encoder(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=True if cls.model_args.pooler_type in ['avg_top2', 'avg_first_last'] else False,
return_dict=True,
)
# MLM auxiliary objective,执行MLM任务
if mlm_input_ids is not None:
mlm_input_ids = mlm_input_ids.view((-1, mlm_input_ids.size(-1)))
mlm_outputs = encoder( #得到特征
mlm_input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=True if cls.model_args.pooler_type in ['avg_top2', 'avg_first_last'] else False,
return_dict=True,
)
# Pooling,池化
pooler_output = cls.pooler(attention_mask, outputs)
pooler_output = pooler_output.view((batch_size, num_sent, pooler_output.size(-1))) # (bs, num_sent, hidden)
# If using "cls", we add an extra MLP layer
# (same as BERT's original implementation) over the representation.
if cls.pooler_type == "cls":
pooler_output = cls.mlp(pooler_output)
# Separate representation,分别得到两个表示z1,z2
z1, z2 = pooler_output[:,0], pooler_output[:,1]
cos_sim = cls.sim(z1.unsqueeze(1), z2.unsqueeze(0)) #计算对比loss
labels = torch.arange(cos_sim.size(0)).long().to(cls.device)
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(cos_sim, labels)
结论
我们将三元组重新描述为 。
那么最小化损失就是使 。
那么三元组的总体距离可以表示为:【近年论文好像也有沿用的,比较经典】
原理
Triplet Loss,即三元组损失,是Google在2015年发表的FaceNet论文中提出[2]。
定义:最小化锚点和具有相同身份的正样本之间的距离,最小化锚点和具有不同身份的负样本之间的距离。
主线:使相同标签的特征在空间位置上尽量靠近,同时不同标签的特征在空间位置上尽量远离。
同时为了不让样本的特征聚合到一个非常小的空间中,要求对于同一类的两个正实例和一个负实例,负例应该比正例的距离至少为margin值 。如下图所示:
因为我们期望的是下式成立,即:【给不记得欧几里得范数的兄弟补个知识: 】
为样本容量为N的数据集的各种三元组。
根据上式,Triplet Loss可以写成:
对应的针对三个样本的梯度计算公式为:
这样我们可以看到这些个三元组的关系是联系紧密,又对称的。
NCE Loss
【这部分证明参考[b]博客,这位大佬写的非常详细,这里做了一些简化方便讲解。】
结论
推导
NCE,也就是 Noise Contrastive Estimate(噪声对比估计)[3]中提出,不过是连续的概率密度函数。由[4]提出了其离散分布时的表现形式,将 NCE 应用到 NLP 领域。
对于n-grams语言模型(n元语法),设单词序列为 ,
为上下文
,满足:
设
那么上式的最大似然函数为
那么最关键的F该怎么求呢?
设 为量化 _w_与_c _匹配性的scoring函数,经过softmax,则可表示如下:
式子中 表示下一个单词是w在单词库中的概率;
表示当前单词库中所有单词的概率的累和(即“归一化因子“)
一般来说,单词库 的数量是非常巨大的,因此计算“归一化因子“是非常昂贵、耗时的一件事,这也就是 NCE 要解决的问题。
根本方法:通过最大化同一个目标函数来估计模型参数 和归一化常数。
核心思想:通过学习数据分布样本和噪声分布样本之间的区别,从而发现数据中的一些特性。
更具体来说,NCE 将问题转换成了一个二分类问题,分类器能够对数据样本和噪声样本进行二分类。
现在假设一个特定上下文 c 的数据分布为 ,称从它里面取出的样本为正样本,令其类别
;而另一个与 _c _无关的噪声分布为
,称从里面取出的样本为负样本,令其类别为
。
假设现在取出了 个正样本和
个负样本。
我们得到下面这些概率:
所以根据贝叶斯公式,可以计算后验概率:
设 :
同理
好了,现在就是求(3)式中 的问题了。
NCE将问题进行了转换,引入了噪声分布:
-
将
作为一个参数
来进行估计,相当于引进了一个新参数。
-
由[4]中实验证明,我们将
所以(3)可化简为
所以(4),(5),(6)联合,可得
现在我们有了参数为 的二元分类问题。标签
可近似为伯努利分布,那么很容易写出条件对数似然
。
实际上在它前面加上负号后,也就等价于交叉熵损失函数:
NCE 的目标函数还需要在(9)式的基础上除以正样本的数量 ,即
根据大数定律,上式可化为:
要最大化上述对数似然函数,也就是最大化如下目标函数:
可以看到实际上这个比例k对我们的 NCE 优化是有影响的。
根据[5]的结论:对于设置的噪声分布 ,当负样本和正样本数量之比
越大,那么NCE 对于噪声分布的依赖程度也就越小。换句话说,尽可能增大比值
。也许这也就是大家都默认将正样本数量设置为 1 的原因:正样本至少取要 1 个,所以最大化比值k,也就是尽可能取更多负样本的同时,将正样本数量取最小值 1。
另外,如果我们希望目标函数不是只针对一个特定的上下文 ,而是使不同的上下文可以共享参数,也就是设置一批上下文的全局目标函数:
总结:
-
从上下文
中取出单词作为正样本,从噪声分布中取出单词作为负样本,正负样本数量比为
-
训练一个二分类器,通过一个类似于交叉熵损失函数的目标函数进行训练(如果取正样本数量为 1,那么(9)与(10) 式等价,NCE 目标函数就等价于交叉熵损失函数)。
原理
上面虽然推导了那么多公式,但实际只是按照 NCE 的思想进行问题的转换,那么这样做究竟是否正确呢?
我们再看回(12)式,我们对它关于 进行求导:
分布对上面的两项分别进行求导:
(15),(16)代入(14)中,可得:
如果负样本与正样本比例 ,那么:
可以看到,(18)与(2)中 MLE 对数似然函数梯度是等价的,也就是说我们通过 NCE 转换后的优化目标,本质上就是对极大似然估计方法的一种近似,并且随着负样本和正样本数量比k的增大,这种近似越精确,这也解释了为什么作者建议我们将 k 设置的越大越好。
InfoNCE Loss
结论
推导
【建议看完CPC介绍再来看这里】
InfoNCE 是在[6]CPC中提出的。CPC(对比预测编码) 就是一种通过无监督任务来学习高维数据的特征表示,而通常采取的无监督策略就是根据上下文预测未来或者缺失的信息。
原文引入了互信息的思想,认为我们可以通过最大化当前上下文 和下
个时刻的数据
之间的互信息来构建预测任务,互信息的定义表示如下:
我们无法知道 和
之间的联合分布
,因此要最大化
,就需要最大化
。
把这个比例定义为密度比,那么,分子 就相当于
,是想得到的目标函数;分母就相
当于
,是用来进行对比的噪声。
因此,我们就可以根据NCE中提供的思路,将问题转换为一个二分类的问题,更具体来解释:
- 从条件
中取出数据称为“正样本”,它是根据上下文
所做出的预测数据,将它和这个上下文一起组成“正样本对”,类别标签设为 1。
- 将从
中取出的样本称为“负样本”,它是与当前上下文
- 正样本也就是与
的数据,根据 NCE 中说明的设定,正样本选取 1 个;
因为在 NCE 中证明了噪声分布与数据分布越接近越好,所以负样本就直接在当前序列中随机选取(只要不是那一个正样本就行),负样本数量越多越好。
所以要做的就是训练一个 logistics 分类模型,来区分这两个正负样本对。问题转换后,训练的模型能够“成功分辨出每个正负样本的能力”就等价于“根据 预测
的能力”。
根据 NCE 中的设置,现在假设给出一组大小为N的 ,其中包含1个从
中取的正样本和N-1个
中取得负样本。
设 是正样本,上下文
表示
之前的数据,那么能够正确的同时找到那一个正样本和
和 N-1 个负样本的情况可以写成如下形式:
【相当于把t+k的位置mask】
即
我们最大化上面这个式子,即最大化模型“成功分辨出每个正负样本的能力”,也就是最大化我们定义的密度比,也就是最大化 和
的互信息。
根据(3)式:
在上式中,我们知道 是一个scoring函数,CPC 文章中用余弦相似度来量化,定义为
那么(21)式可化为:
对比(20)和(22),我们可以发现:
现在我们的优化目标就是使(20)或(22) 式的结果最大,所以可以写出对应形式的交叉熵损失如下:
即
上式就是最终得到的 InfoNCE 损失函数了,并且最小化 InfoNCE,也就等价于最大化 和
的互信息的下限,从而做到了我们所要求的最大化
。
原理
为什么最小化InfoNCE等价于最大化 和
的互信息的下限?
证明如下:
对于(20)式,我们可以代入(24),并且,已知,除了 其余均是负样本:
如果正负样本距离能够拉的足够远,那么所有的负样本期望都会在margin
附近,且近乎相等。那么,就有下列式子成立:
代入(19)式即可算出互信息的下限:
在使用 InfoNCE 时把它当作一个对比损失,那么分子上的 表示正样本对, 分母上的
表示负样本对,我们只要构建好正负样本对,然后利用 InfoNCE 的优化过程,就可以使正样本对之间的互信息最大,使负样本对之间的互信息最小了:
SimCSR
- 【2021-5-27】SimCLR: 用对比学习生成图像表征,利用对比学习生成图像表征的算法 SimCLR,SimCLR 出自 Google 的论文《A Simple Framework for Contrastive Learning of Visual Representations》
- 《SimCSE: 通过对比学习获得句子向量》:SimCSE 采用对比学习训练得到句子向量
1. 概述
在前一篇文章《SimCSE: 通过对比学习获得句子向量》中我们介绍了 SimCSE 算法,SimCSE 采用对比学习训练得到句子向量。本文介绍一种利用对比学习生成图像表征的算法 SimCLR,SimCLR 出自 Google 的论文《A Simple Framework for Contrastive Learning of Visual Representations》。
对比学习 (Contrastive Learning) 的目标就是让模型学会区分样本是否相似,因此训练需要同时提供相似样本 (正样本) 和不相似样本 (负样本),如下图所示:
对比学习示意图
SimCLR 训练的数据无需人工标注,对于一幅图像 x,其采用数据增强的方式生成图片 x 的正样本对 (xi, xj),将 batch 里的其他图像当成负样本。然后 SimCLR 使用对比学习训练 Encoder (通常是 CNN 模型,例如 ResNet),从而生成高质量的图像表征。在实验中 SimCLR 取得了 SOTA 的效果,超越了之前的自监督学习算法,并且 top-1 准确率可以逼近有监督的 ResNet-50。
2. SimCLR
SimCLR 结构图
SimCLR 的结构如上图所示,图片出自博客 The Illustrated SimCLR Framework,SimCLR 包含三个部分:
- 数据增强 Data Augmentation,对图片进行随机的变换 (如裁剪、翻转、颜色抖动等),变换后的数据作为正样本。
- Encoder,图像编码模型 (如 ResNet、AlexNet 等),SimCLR 使用 Encoder 获得图像表征向量,Encoder 也可用于其他下游任务的微调。
- 非线性投影层,Projection Head,对 Encoder 输出的表征进行变换,投影层只用于训练 SimCLR,训练结束后使用 Encoder 得到图像表征。
2.1 数据增强
数据增强广泛用在视觉领域,能够增加样本的数量及多样性,使模型更加健壮。图像数据增强的方法多种多样,如下图所示:
数据增强
SimCLR 对图片进行数据增强时不是采用单一的增强方式,而是会随机使用多种不同的增强方法进行结合,这样能够产生更好的表征向量。
作者也通过一个小实验,证明结合不同的增强方法能够产生更好的表征向量。实验采用 ImageNet 数据集,指标为 top-1 准确率,实验结果如下图所示。其中对角线的位置表示采用单一的数据增强方法,其他位置表示两种数据增强方法结合,最后一列表示每一行的平均值。可以看到结合后的效果会大大提升。
不同数据增强方法组合的准确率
SimCLR 会为一个 batch 里的每一幅图像 x 进行两次数据增强,分别得到图像 xi 和 xj,则 (xi, xj) 作为一对正样本,如下图所示:
SimCLR 数据增强
经过数据增强后,我们就可以得到一个 batch 数据的正样本和负样本,如下图所示,SimCLR 需要让正样本的相似度尽可能高,让负样本之间的相似度尽可能低:
正负样本
2.2 非线性投影层
SimCLR 使用 ResNet-50 作为 Encoder,用于获取图像的表征向量 (Representation),同时 Encoder 也可用于后续的下游任务。但是 SimCLR 在训练时为了得到更好的效果,还需要在 Encoder 后增加非线性投影层 (Dense-Relu-Dense),如下图所示,注意非线性投影层只在训练时使用。
SimCLR 结构图
作者在原文里对非线性投影层的作用进行了一些解释,认为 Encoder 后的表征 h 包含更多的信息 (例如数据增强变换信息、颜色、方向),而非线性投影层的输出 z 可以去掉这些多余的信息,还原数据本质。Encoder 的输出信息丰富对于下游任务更有帮助,但并不适合对比学习任务,因此用非线性投影层对数据进行还原从而更好地训练。
2.3 损失函数
假设图像 xi 和 xj 经过 SimCLR 的输出为 zi 和 zj,则首先要计算 zi 和 zj 的余弦相似度,如下。
余弦相似度
如果一个 batch 里有 N 个图像,则数据增强后会有 2N 个图像,每一个图像 xi 会有 1 个正样本和 2N-2 个负样本,则对于一对正样本 (zi 和 zj),损失函数如下所示。
损失函数
3. 实验效果
下面的两幅图展示了 SimCLR 和其他自监督学习算法的对比,数据集为 ImageNet。可以看到 SimCLR 远超之前的算法,并且可以达到和有监督相近的准确率。
ImageNet 对比图
ImageNet 对比表
下图展示了 SimCLR 在图像分类上进行迁移学习的效果,用到了 12 个图像分类数据集。
SimCLR 迁移学习和有监督学习
4. 参考文献
- SimCLR: A Simple Framework for Contrastive Learning of Visual Representations 「链接」
- 代码 「链接」
- 博客: The Illustrated SimCLR Framework 「链接」
进化
SimCSE 进化版本
2022.5 华为 RetroMAE
【22.5 RetroMAE:华为】
- BGE-M3里用到了 RetroMAE 作为 text encoder
- 论文: RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
Masked Auto-Encoder(MAE)流程:
- 输入的句子会通过不同的掩码对编码器和解码器进行污染。
- 编码器的掩码输入用于生成句子嵌入,然后结合解码器的掩码输入和句子嵌入,通过掩码语言建模恢复原始句子。
不对称:
- 不对称的模型结构:编码器是类似BERT的全尺寸变换器,而解码器则是单层变换器。
- 为编码器和解码器设置了不同的掩码比例,前者掩码比例(15%至30%),而解码器使用50%至70%的比例,以提高重建任务对编码质量的要求。
2023.8 阿里 GTE
【2023-8】阿里达摩院
多阶段对比学习:GTE 模型采用对比学习方法,在多个阶段对模型进行训练。
- 首先是在大量无监督文本对上进行预训练
- 然后, 使用有监督的细粒度调整来进一步提升模型性能。
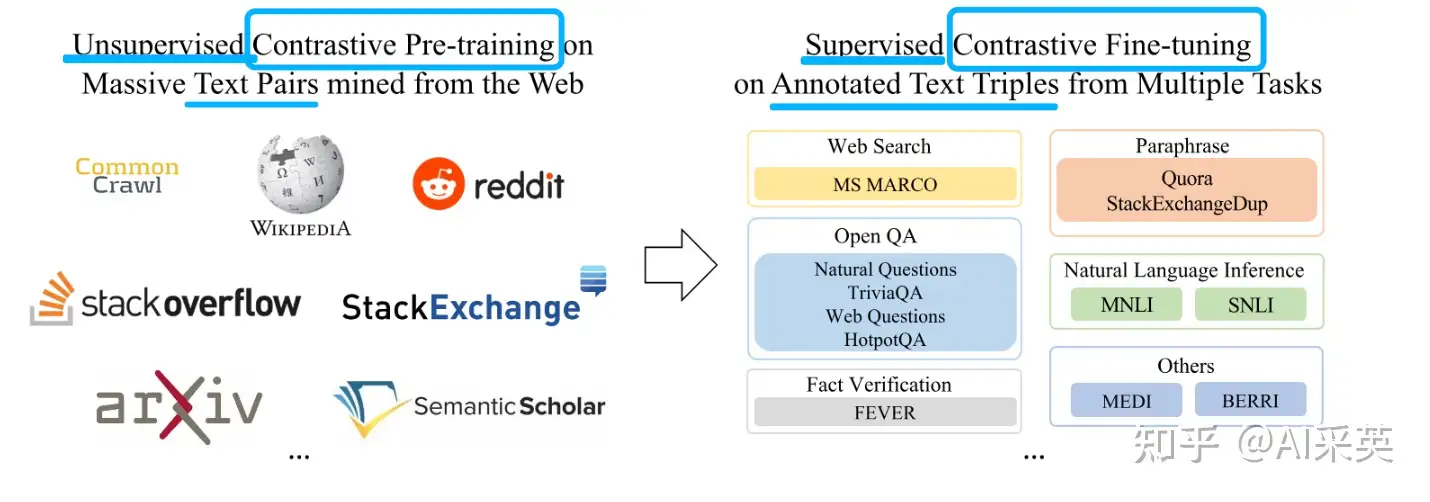
大规模数据集的利用
跨多种NLP任务的高性能:包括文本分类、文本检索、问答系统等。
代码搜索能力:GTE 模型在处理代码搜索任务时,即使没有针对每种编程语言进行特定的微调,也展现出了很好的性能。
改进的对比损失函数,它能够在固定的批次大小下有效扩大负样本池,从而提高训练效率。
- 样本是三元组的形式:(q, d+, d−),后面是正负样本
- Loss采用 InfoNCE
GTE模型的参数量相对较小(110M),但它在许多基准测试中的表现超过了更大的模型,甚至超过了OpenAI提供的黑盒嵌入API。
2024.2 智源 BGE-M3
【2024-2】BGE-M3:北京智源BAAI
概念
- BGE:BAAI/北京智源 General Embedding
- M3: 多语言性(Multi-Linguality)、多功能性(Multi-Functionality)和多粒度性(Multi-Granularity)
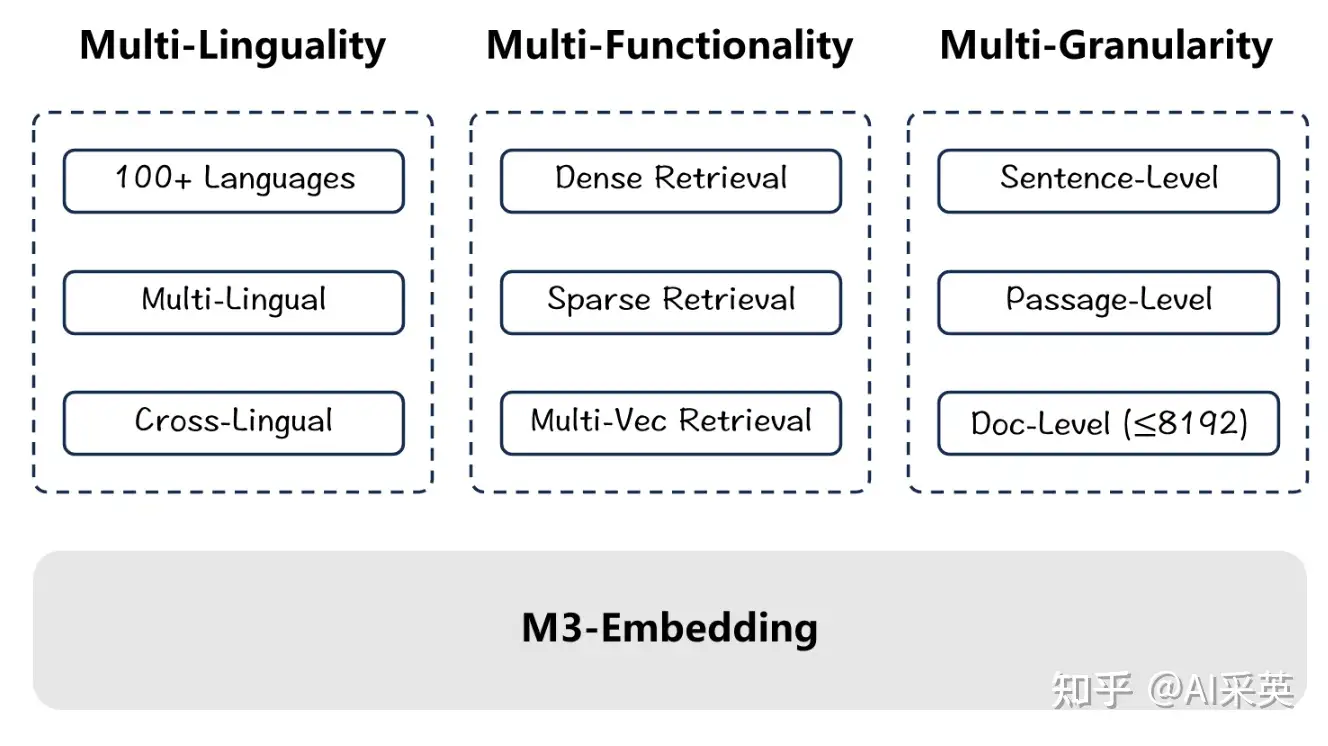
特性
- 多语言支持:M3-Embedding 能够支持超过100种工作语言的语义检索,实现了多语言内部检索和不同语言之间的交叉语言检索。
- 多功能检索:
- 密集检索(Dense Retrieval)
- 多向量检索(Multi-Vector Retrieval)
- 稀疏检索(Sparse Retrieval)
- 多粒度输入处理:M3-Embedding能够处理不同粒度的输入,从短句到长达8,192个令牌的长文档。
- 提出了一种新颖的自知识蒸馏方法,通过整合不同检索功能的相关性分数作为教师信号,以增强训练质量。
- 多阶段训练流程:
- 在预训练阶段,模型使用大规模无监督数据进行训练,主要训练密集检索。
- 在微调阶段,应用自知识蒸馏来建立->三种检索功能。
BGE-M3 模型训练分为三个阶段:
- 1)RetroMAE 预训练,在105种语言的网页数据和wiki数据上进行,提供可支持8192长度和面向表示任务的基座模型;
- 2)PreTrain 无监督对比学习,在194种单语言和1390种翻译对数据共1.1B的文本对上进行的大规模对比学习;
- 3)fineture 多检索方式统一优化,在高质量多样化的数据上进行多功能检索优化,使模型具备多种检索能力。
自知识蒸馏,只用于第二阶段-多模检索 FineTune;在第一阶段Pretrain时,只有dense retrieval用对比学习训练。
继续使用 InfoNCE,这基本成了Contrastive Learning的标配Loss。
直接使用 InfoNCE,多种检索会冲突的,所以提出了 self-knowledge distillation。
应用
nlp领域研究进展
Bert在NLP领域应用广泛,但是它学习到的句子表征在向量空间内倾向于产生坍塌现象。这是因为输入语料存在大量高频词,所以语义的高阶表征容易被高频词主导,使得很多句子的高阶语义特征在空间中十分相近。对比学习可以很好地解决这一问题。
美团提出了ConSERT,发现在数据增广方法中,feature cutoff 和 shuffle 在对比学习中最有效。
SimCSE发现仅仅使用dropout就可以有效地解决语义坍塌的问题,且其性能优于ConSERT。出现这一现象的原因在于
- ConSERT集中在Embedding layer和Pool layer的扰动上
- 而SimCSE在网络结构中加入了扰动
所以这启发了我们在做数据增广时不仅需要考虑特征层面,也要考虑模型层面的增广。
cv领域研究进展
对比学习在CV领域的研究
- 首先,由于对比学习在使用越大的batch size得到的效果越好,但是受限于GPU的内存限制,无法使得batch size无限增大,而MoCo提出了memory bank的设计,它将样本的表征保存在一个字典中作为之后batch的负样本。
- 此外,MoCo的encoder采用了动量更新,保证embedding更新的稳定性。
- 随后Google提出了SimCLR框架,它舍弃了memory bank的结构,认为采用数据增广和加入线性头的方法就足以保证对比学习的模型效果。实际上,MoCo的改进版本也采用了这一策略,发现最终的效果比SimCLR更优。
- SimSiam采用了非对称的网络结构,创造性地提出在对比学习框架中不需要引入负样本,也不需要采用动量更新的方法优化encoder,而仅仅需要在没有线性头的分支加入stop gradient就可以达到防止模型坍塌,同时取得很好的性能的目的。
推荐系统与对比学习
【2022-5-30】罗清:对比学习在快手推荐排序的应用,pdf下载
推荐系统存在数据分布偏差与数据稀疏的问题,主要体现在
- 群体兴趣与用户个性化的差异不易捕捉
- 部分反馈信号稀疏
- 负反馈不灵敏等
分布偏差+数据稀疏
- 虽然整体数据量并不少,但是对于每个user,或者item来说,还是过于稀疏,产生了流行度偏差
- 模型在训练的时候也更容易主导梯度。这些问题严重影响了用户体验,比如,推送的都是很相似的视频,用户点击了dislike,还会出现类似视频,所以解决这些问题可以带来更好的推荐质量
而对比学习可以在一定程度上缓解上述问题,提高推荐质量,带来更好的内生态和用户体验。
- 解决数据稀疏问题的常用方法有数据降维(用更泛化的特征)和减少模型参数等。
- 但是这两个方法会损失一定的有用信息。
- 解决数据分布偏差问题的常用方法有IPW和重采样。
- 但是IPW需要计算高方差的概率,使得它在稀疏数据中的稳定性和准确性存在一定限制。
对比学习的优势在于:
- 通过挖掘数据本身蕴含的标签信息,缓解数据稀疏的问题;
- 通过样本增广拟合数据的真实分布,缓解数据分布偏差问题;
- 通过自监督信号抽取数据中包含的通用知识,为主任务提供有效的信息。
总的来说,对比学习通过挖掘自身数据的信息来为模型提供额外信号,从而带来信息增益,以此缓解数据稀疏和数据分布偏差的问题。
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据相似或相异来学习数据集的一般特征。
- 图例中,使用对比学习给模型输入一部分包含猫的图片和另一部分包含狗的图片,可以不使用任何图片标签的情况下使得模型学习猫的特征和狗的特征。随后再使用很少的标签信号对模型进行有监督训练即可得到很好的分类效果。
经典的SimCLR框架
- 首先输入一张图片,通过数据增广(裁剪、旋转等)得到两种不同的图片。
- 随后它们分别经过一个encoder得到图片的表征
- 再经过线性投影至同一向量空间中
- 最后,通过最大化空间中两个表征之间的相似度来学习更好的encoder表征。
经过优化的表征可以被用于下游任务中,使用fine-tuning来提升模型在目标任务的效果。
对比学习有以下三个常见的研究方向:
- 如何构造代理任务
- 常见的有图像与增广图像、图像与文本、句子与句子、句子与情感进行对比学习。不同应用场景构造相应的代理任务来达到自监督学习的目的。
- 如何防止模型坍塌
- 模型坍塌即特征经过encoder后得到的embedding都会聚类至空间的一个点上。解决这一问题的常见方法有采集更多的负样本(使用memory bank)、使用非对称的模型结构(网络一个分支包含线性头而另一分支不使用线性头)以及非对称的梯度更新。
- 如何增广样本
- 常用的方法有裁剪、旋转、mask、shuffle、dropout等。这里的增广样本其实对于防止模型坍塌也是非常重要的一环,因为增广的样本不能让模型太难学,也不能太简单,所以实践中会采用多种增广来尝试。
对比学习一般采用InfoNCE作为损失函数,其来源于Contrastive Predictive Coding任务,目标是最大化当前item和上下文c的互信息,使用的方法是利用NCE最大化互信息的下界估计。
NCE是一种近似的最大似然估计,它通过对噪音样本的分布估计来推断真实分布。在softmax计算中,分母的归一化项计算开销大。NCE将多分类任务转化为每个样本与标签的二分类任务来避免归一化的计算开销。如果负样本的数量趋近于无穷大,那么NCE就是最大似然估计。所以在对比学习中,采样的负样本数量越多,效果越好。
对比学习最终学习的理想表征需要满足alignment与uniformity两个性质。
- 前者alignment代表着相似样本在学习的向量空间中距离尽可能小
- 后者uniformity代表着样本表征在学习的向量空间中的分布尽可能均匀。
推荐领域研究进展
对比学习在推荐系统领域的研究进展
- 阿里巴巴借鉴了MoCo的思路,加入了memory bank来减少曝光偏差。相较于将曝光未点击的样本作为负样本,他们认为memory bank中存储的负样本更加符合全局的样本分布。在此基础之上,他们还提出了多意图对比学习推荐系统Multi-CLRec,在全局的memory bank的基础之上加入了意图层面的memory bank。在负采样时,他们不仅从全局memory bank中选取负样本,还在所有不同意图的memory bank中抽取负样本。
- 美团提出了S^3-Rec模型,首先使用设计的自监督训练目标对模型进行预训练,然后根据推荐任务对模型进行微调。此工作的主要新颖之处在预训练阶段,我们基于MIM的统一形式精心设计了四个自监督的辅助任务:
- item与attribute的对比学习
- sequence与item的对比学习(通过将sequence中的一个item进行mask操作来实现)
- sequence与attribute的对比学习以
- sequence与segment子序列的对比学习。
- 因此,S^3-Rec能够以统一的方式来表征不同粒度级别或不同形式数据之间的相关性,并且也可以灵活地适应新的数据类型或关联模式。通过这样的预训练方法,可以有效地融合各种上下文数据,并学习属性感知的上下文化的数据表示。
ICL认为用户在点击商品时存在多种意图,但这些意图都是隐性的,潜藏在用户行为序列里,我们如果利用好它就能提高推荐的效果。核心思路就是从用户的行为序列里面学习用户隐式意图的分布函数,然后构造对比学习任务,同一类的拉近,不同类的拉远。具体地,ICL对用户的行为序列经过一个encoder后得到表征,并将所有表征进行K-means聚类操作。如果一个行为序列位于其中一个聚类空间中, 拉近该user到他聚类中心的距离,拉远到其他聚类中心的距离。每次迭代优化后的表征将会在新的循环中重新进行K-means聚类得到新的意图类。对比学习子任务辅助推荐主任务,最终在实验中得到了不错的效果。
CauseRec结合了因果推断的思想。它认为用户的行为序列中存在部分噪声信息,所以它希望判断行为序列中的item是否可以被替代。进一步,它分别将可替代的item与不可替代的item进行mask操作,使用对比学习的思想将mask可替代item的序列作为正例,mask不可替代item的序列作为负例。可替代性是通过该item与用户的兴趣表征以及target item的相关性排名来进行定义。
快手视频推荐应用
快手的推荐场景是短视频,可以获取的监督信号有观看时长、喜欢(like)、dislike、收藏、转发等。
- 之前的做法是对每一种反馈信号都预估一次,最后将预测结果经过线性加权的方式进行打分排序。但是,由于不同类型的标签分布不一致,且它们的量纲也有一定差异,所以线性加权并不合适。
- 业界通用的做法是使用各类反馈信号的rank值,但是这一做法丢弃了每一类预测分数之间的绝对值信息。
- 最后,快手定义了短视频组合收益,其计算公式如上图所示。随后,我们借鉴了youtube的损失函数设计做了改进,它的好处在于数据兼容性较好,相比回归,模型的预估值在0到1之间。而且,相比回归任务,分类任务更加鲁棒。
快手排序模型的整体框架。其中
- 绿色框中的排序模型可以使用不同的base模型进行加载。框架中加入了三个辅助任务:
- user和item之间的辅助对比学习任务
- user和user之间的辅助对比学习任务
- user的正例子序列和负例子序列的辅助对比学习任务。
Q&A
问答
- Q:对比学习和pair-wise建模有什么区别?
-
A:Pair-wise旨在学习排序层面两个item的相对次序,而对比学习的目的是学习正负样本直接的表征相似度。
- Q:短视频组合收益公式中各参数的具体含义是什么?
-
A:每一项表示一个item是否被收到一类正反馈。如果item得到了相应的正反馈信号那么就取1,反之则取0。公式中的参数a,b是超参数。
- Q:行为序列少的用户会被采样到吗?
-
A:会。我们需要保证采样的序列符合样本的分布,从而尽可能保证分布的无偏性。
- Q:模型的耗时是在什么数量级?
-
A:排序模型使用在重排阶段,它的耗时较低,大约为40~50ms。值得注意的是,对比学习的辅助任务不参与inference,只在模型训练阶段使用。
- Q:召回时使用对比学习框架后,有没有具体数据证明它对长尾item有效果提升?
-
A:我们做过相应的分析,发现在召回阶段对比学习对长尾item的效果提升十分明显。由于今天分享的主题是排序相关应用,所以没有展示召回阶段的结果分析。
- Q:排序阶段的效果提升有没有可能是统计量随机误差导致的?
-
A:事实上,在相对效果提升层面不存在统计上的随机误差,因为在快手推荐场景下存在一个置信区间,一般为0.1%。而使用对比学习所带来的的增益已经超过了这一置信区间。
- Q:组合收益公式为什么是加法而不是乘法?
-
A:因为在快手场景,点赞、评论、进入个人页等都是独立的,没有先点击再点赞的关系,所以我们采用的是加法,乘法一般用于这种有先后关系的场景。
- Q:负采样和样本增广分别有什么作用?
-
A:样本增广的目的是让模型接受难度适中的输入来学习更好的向量表征。负采样需要考虑曝光偏差带来的影响,因为一般情况下我们任务曝光未点击的item为负样本,曝光且点击的样本为正样本,使用我们的负采样方法可以使用未曝光的样本。
- Q:模型更新的粒度是什么样的?训练数据有多大?
-
A:模型是根据数据流实时更新的,训练数据的体量是公司内部资产,不方便详细透露。
- Q:如何离线验证对比学习的效果以及debias的效果?
-
A:离线实验中我们与当前state-of-the-art的模型进行对比,即在同一基准模型的基础上加入对比学习框架后观察实验指标的提升程度。我们不仅使用了快手的数据集,还在学术界最新的推荐数据集上做了对比实验,最终都观察到了效果的提升。针对长尾item,我们将数据中的长尾商品单独抽取出来进行指标的计算与对比,最后也得到了更优的效果。
- Q:第三个辅助任务中正反馈的类型很多,那么在具体训练时有没有用到所有类型的正反馈?不同类型的正反馈的权重是一样的吗?
-
A:不同类型的正反馈的权重不一样。我们目前采用的正反馈类型有关注、喜欢和转发。我们会对这三种反馈按权重做随机采样,构造正反馈队列。相对地,由于负反馈较为稀疏,“hate”反馈是被全部采用的,对于”hate”反馈过少的,采用短播序列补充。
- Q:In-batch负采样需要流式纠偏吗?
-
A:需要进行纠偏。由于In-batch负采样对长尾item存在偏差,所以我们在负采样时是按照曝光频率进行采样的。此外,为了进一步接近无偏性,还加入了全局负采样。
- Q:针对全局负采样和In-batch负采样有没有做过消融实验验证效果吗?
- A:因为这一想法参考了youtube的文章中提出的方法,所以我们没有进行消融实验,而是认为使用这一方法可以得到增益。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}
{kind=link}
{kind=link}