总结
- 【2021-5-8】深度学习模型部署资源全集,Deep-Learning-in-Production
- 部署PyTorch/TensorFlow/keras/MXNet Models,转C++/go
- Python加速,GPU加速
- 由于python的灵活性和完备的生态库,使得其成为实现、验证ML算法的不二之选。但是工业界要将模型部署到生产环境上,需要考略性能问题,就不建议再使用python端的服务
- 可以采用 Saver (python) + Serving (tensorflow serving) + Client (Java) 作为解决方案,从零开始记录线上模型部署流程。
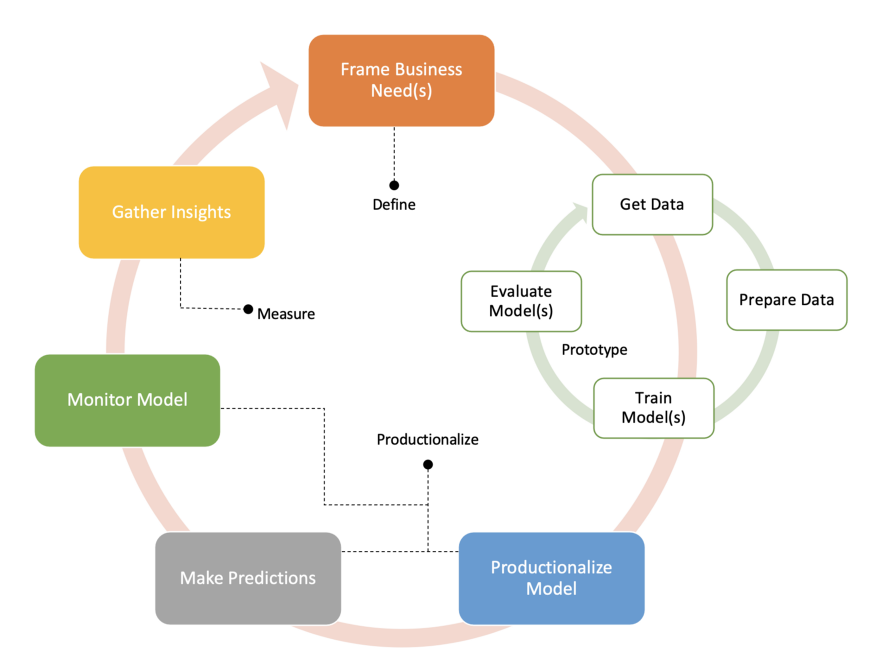
机器学习生命周期
机器学习周期的三个阶段 图
- 数据准备
- 模型建立
- 线上部署
教程
【2021-11-12】《生产系统中的机器学习工程 (MLOps) 专业课程》介绍, 2021 年 11 月 16 日正式上线, 讲师:Andrew Ng
MLOps
【2022-5-6】机器学习端到端流程比较复杂,涉及:数据探索与分析、特征工程、模型开发、模型训练、模型评估、模型部署和效果评估等多个环节。机器学习下的持续交付(Continuous Delivery For Machine Learning,CD4ML),涉及数据(Data)、代码(Code)和模型(Model)3个维度的交付,任何一个维度的更新,都会触发持续交付的流程。
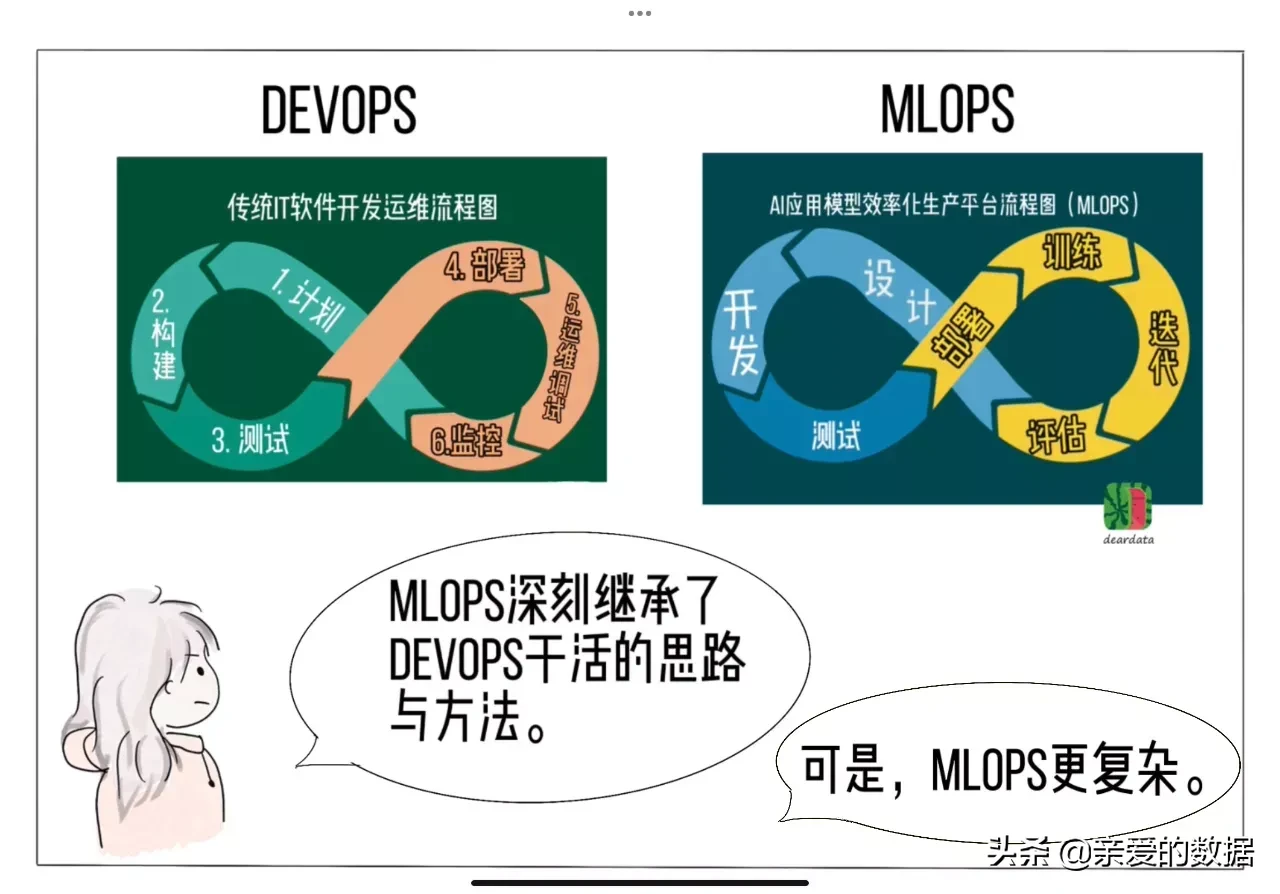
Ops=Operation,MLOps深刻继承了DevOps干活的思路与方法,都涉及一组最佳实践、流程、工具和理念。尽管存在相似之处,但后者复杂得一言难尽。机器学习模型高质量规模化交付很困难。
- DevOps:传统软件开发运维流程:计划 → 构建 → 测试 → 部署 → 运维调试 → 监控
- MLOps:AI应用模型效率化生产平台流程:设计 → 开发 → 测试 → 部署 → 训练 → 迭代 → 评估
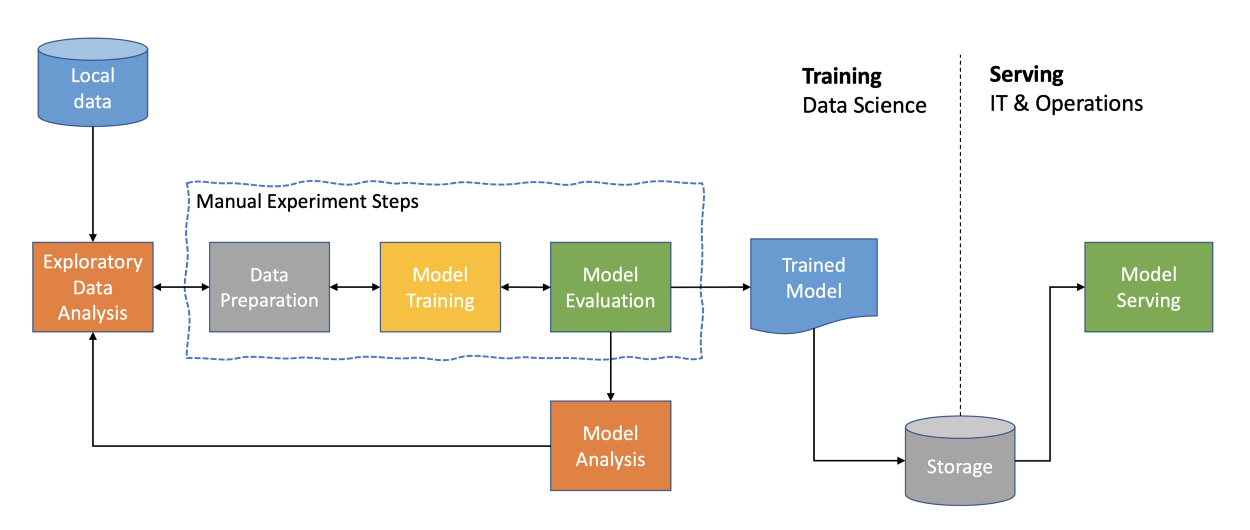
完整的端到端自动化管道

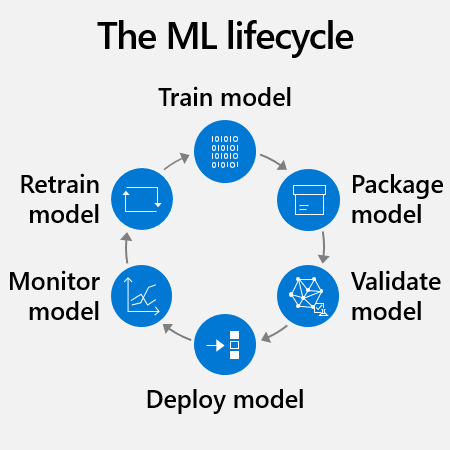
典型 ML 生命周期 —— 微软MLOps 和 ML 生命周期简介
- 训练和测试: 首先,数据科学家需要准备训练数据。 这通常是生命周期中最大的时间投入。 准备工作包括将数据标准化,使其采用可重用格式并标识各自的“特征”或变量。 例如,要预测信用风险,特征可能包括客户年龄、帐户大小和帐户期限。 接下来,将算法应用于数据,对机器学习模型进行训练。 然后,通过新数据对其进行测试,了解其预测的准确性。
- 打包: ML 工程师使用其环境将模型容器化,这意味着通过其所有依赖项为模型创建一个在其中运行的 docker 容器。 模型环境包含模型需要无缝执行的元数据,如代码库。
- 验证: 此时,团队评估模型性能如何匹配其业务目标。 例如,在某些情况下公司希望针对准确性而非速度进行优化。
- 重复步骤 1 到 3: 找到满意的模型可以需要成百上千的训练小时。 开发团队可以通过调整训练数据、优化算法超参数或尝试完全不同的算法,针对多个版本的模型进行训练。 理想情况下,模型每轮调整都会改善。 最终,开发团队确定哪个模型版本最适合业务用例。
- 部署: 最后,在云中(通常通过 API)、本地服务器或边缘设备(如相机、IoT 网关或机器)上部署模型。
- 监视和重新训练: 即使模型最初能够正常运行,也需要持续监视和重新训练以保持有用且准确。
为何需要监视和重新训练 ML 模型?
- 所有模型(包括那些部署时完美运行的模型)都需要随着时间推移进行监视和重新训练,以保持高性能。
- 预测不准确的原因可能包括:
- 训练不足。 例如:应用使用者提交夜间拍摄的照片用于对象识别,但该模型仅针对光照良好的照片进行了训练。
- 模型计算的“实时数据”问题。 例如:卖方在公司 CRM 系统中不一致地记录客户数据。
- 随着时间推移模型本身发生“偏移”或者衰退。 这包括“概念偏移”,就是说要预测的内容的概念发生改变。 “数据偏移”(即数据的属性发生变化)也很常见。 “上游数据更改”(即数据收集的方式或内容发生操作性更改)也会影响模型。
- 外界变化。 例如:基于 2001 年数据的财务交易模型在 2020 可能无效。
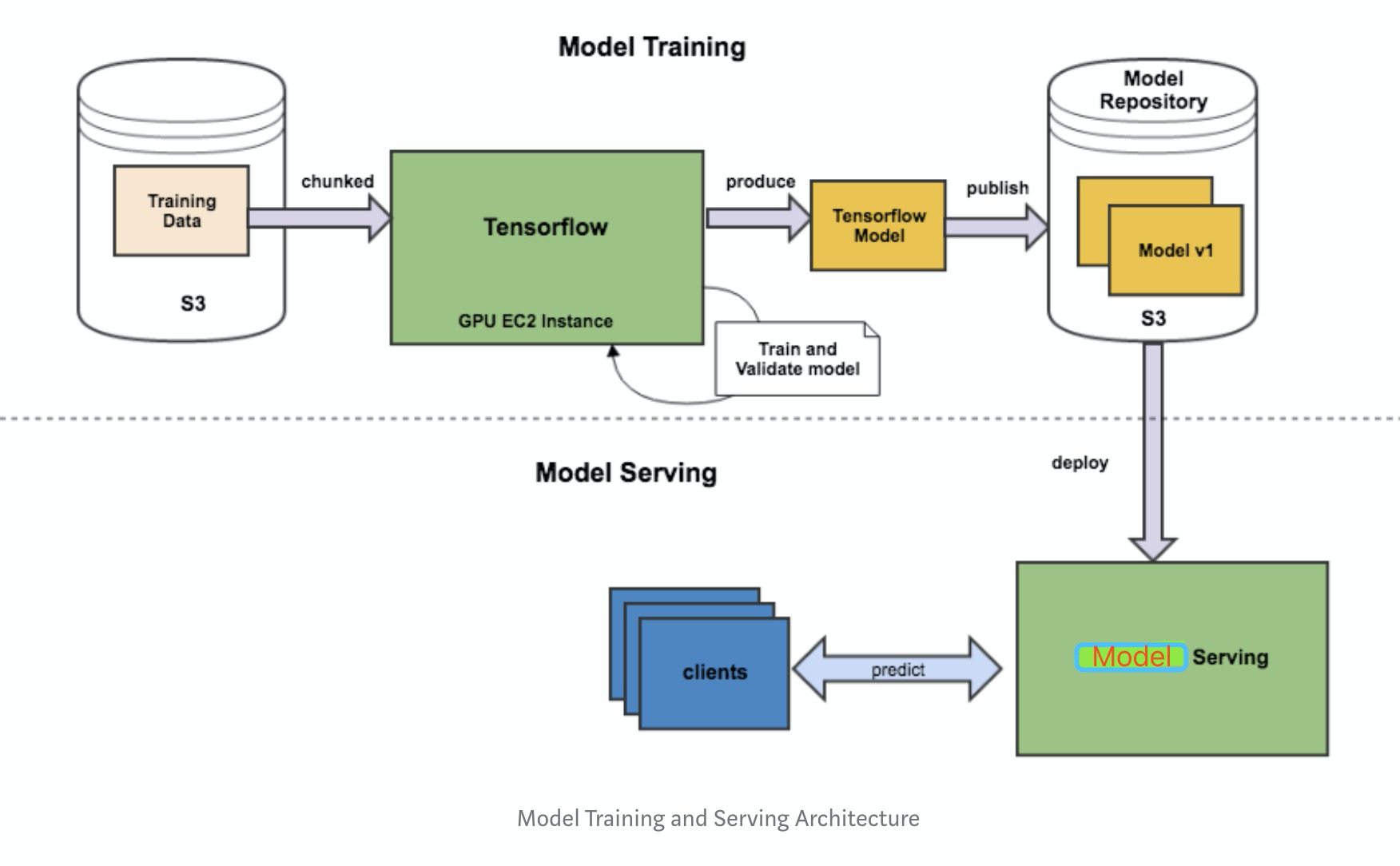
- 从训练到部署的整个流程
- 基本可以把工作分为三块:
- Saver端:将训练好的整个模型导出为一系列标准格式的文件,在不同的平台上部署模型文件。
- TensorFlow 使用 SavedModel(pb文件) 这一格式用于模型部署。
- 与Checkpoint 不同,SavedModel 包含了一个 TensorFlow 程序的完整信息: 不仅包含参数的权值,还包含计算图。
- SavedModel最终保存结果包含两部分saved_model.pb和variables文件夹。
- Serving端:模型加载与在线预测
- Client端:构建请求
- Saver端:将训练好的整个模型导出为一系列标准格式的文件,在不同的平台上部署模型文件。
LLM Ops
什么是 LLMOps
LLMOps 代表大型语言模型操作,“LLM 的 MLOps”,是 MLOps 的一个子类别,专注于新的工具集、架构原则和最佳实践,以实现基于 LLM 的应用程序的生命周期。
- 【2023-9-8】LLMOps 与 MLOps 有何不同?
以下是 LLMOps 的关键方面,展示了它们在成功实施基于 LLM 的应用程序中的重要性。
- 数据管理:摄入、清洁、标签、存储。
- 模型开发:选择基础模型、微调、评估。
- 模型部署:监控、维护、优化。
- 安全和隐私:护栏、访问控制、加密、合规性、保密性。
- 道德与公平:消除偏见、负责任、透明。
MLOps 与 LLMOps
LLMOps 是 MLOps 的一个特殊用例,预计它将继续以新的维度发展,并以惊人的速度增长。在某种程度上,LLMOps 可以被视为 MLOps 关键方面的重大偏差,包括培训、部署和维护
MLOps 和 LLMOps 有许多相似之处,但是,它们之间的差异取决于我们使用经典 ML 模型与 LLM 构建 AI 产品的方式。
- 1)数据管理
- MLOps 中,数据预处理是 ML 模型开发过程中最关键的步骤,因为它会影响模型的质量和性能。从头开始训练神经网络通常需要大量标记数据,然而,微调预训练模型所需的数据量相对较少。
- LLMOps 中,数据质量和多样性对于有效的大型语言模型非常重要。然而,微调预训练模型与 MLOps 非常相似。此外,提示词工程引入了零样本和少样本学习等新技术,涉及使用精心挑选的样本和精确策划的数据,而不是大量潜在的不规则数据,最终提高模型完成特定任务的能力。
- 2)模型实验
- 在 MLOps 中,开发过程涉及运行许多实验并将其结果与其他实验进行比较,并开发性能最佳的配置,其中包括跟踪代码、训练和验证数据、模型架构和超参数等输入以及评估指标等输出和模型权重。
- LLMOps 中,由于 LLM 能够从原始数据中有效学习,特征工程的重要性已变得不那么重要。微调与 MLOps 具有类似的路径,但是,它的目的是使用特定领域的数据集来提高模型在特定任务上的性能。提示词工程也越来越受到LLM的欢迎,其中输入的调整方式使得输出以更少的努力和资源满足期望。
- 3)模型评估
- MLOps 中,模型性能是通过评估其在保留验证集上执行的能力来评估的,评估指标包括准确度、精确度、召回率、F1 分数或均方误差 (MSE),具体取决于问题类型(分类、回归等)以及其他技术,如交叉验证、学习曲线、基线模型比较、交叉验证、超参数调整和混淆矩阵。
- LLMOps 中,使用 ROUGE、BERT 和 BLEU 分数等内在指标来评估模型性能,这些指标侧重于测量响应与提供的参考答案的相似性。人工评估涉及专家或众包工作人员在给定背景下评估LLM的产出或表现。特定于任务的基准(例如 GLUE 或 SuperGLUE)使用一组预定义的任务以及每个任务的完善指标来评估 LLM。
- 4)成本
- MLOps 中,成本因素包括与数据收集和准备、实验计算资源、特征工程和超参数调整相关的费用。
- LLMOps 中,主要成本因素是生产中的模型推理,这需要昂贵的基于 GPU 的计算实例,并且使用 OpenAI 的 GPT-3.5 和 GPT-4 模型等闭源专有 LLM 也会产生许可成本。
- 5)延迟
- MLOps 中,由于计算复杂性、模型大小、硬件限制、数据预处理开销、网络延迟、并发用户需求以及软件相关的低效率等因素,可能会出现延迟问题。它可能会阻碍依赖及时预测的应用程序的实时或近实时性能,影响自治系统、实时决策和快速响应至关重要的场景中的用户体验等领域。
- LLMOps 中,由于 LLM 的巨大规模和复杂性,加上文本理解和生成所需的大量计算,延迟问题更加突出,这可能会导致显著的处理时间,影响使用这些模型的应用程序的响应能力。此类延迟问题可能会影响实时交互、聊天机器人、内容生成和其他与语言相关的任务,其中快速、无缝的语言理解和生成对于令人满意的用户体验至关重要。
【2023-8-29】LLMOPs meetup v3 如何快速搭建生产级 LLM 应用-骆庚
- 一、如何快速搭建生产级的IM应用,包括大模型、MOS和MLP等概念,以及云音乐的数据智能中心的应用实践。
- 二、在选择语言模型时需要注意的几点,包括模型效果、成本、服务性能、安全性、迭代性和领域适用性,同时提供了几个开源排行榜供大家参考。
- 三、在垂类场景下,做好SFT数据积累比基础模型选择更高效,同时强调了PROMOTE的管理和迭代的重要性,以及IM加知识库的应用。
- 四、如何使用不同方法对模型进行测试,包括标准测试、垂类业务理解测试、自动化评测和部署等,并提到了一些工具和流程。
- 五、推理优化的方法,包括硬件、软件、计算图层面的优化,以及如何结合使用,建议关注社区生态,持续迭代改进。
- 33:20 - 推理参数和GPU选择
- 33:43 - 推理效果和量化优化
- 35:54 - 量化对模型前向推理加速
- 38:57 - TENSRT和TDB的优化
- 41:03 - ONEX和TENSRT的适配和改进
- 六、关于M模型微调的几个方法,包括有监督微调、并行计算和参数高效微调等,并提到了如何扩展样本数量和提高样本质量的方法。
- 41:40 - 介绍模型微调的方法,包括人工标注、业务指标、用户反馈和用户反馈挖掘
- 42:55 - 介绍有监督微调,通过指定金条提高模型准确度
- 44:54 - 除了方法外,微调数据来源和处理也很重要,可以通过开源社区等方式扩展语料数据
- 47:07 - 建议结合promote promote和策略迭代进行,利用反馈迭代优化模型效果和质量
深度学习模型部署
- 【2021-5-6】「AI大咖谈」FLAG资深工程师谈ML Infra和分布式模型服务
- 深度学习在业界的应用进入一个全新的阶段,复杂模型的结构红利正在被吃尽,深度学习模型和工程架构的协同演进正在成为新的效果增长极。国内外的巨头互联网公司在分布式深度学习框架,线上大规模模型服务领域可以说优势颇大,有时候也略显神秘。
- 新同学往往不喜欢也不屑于做所谓的dirty work,但本质上来说,工业界的机器学习问题几乎全都是dirty work,不存在什么训练一个模型,创新一个模型结构就交给其他人的事情,你说的根本不是新人,而是老板。
问题:
- ①模型漂移:运行一段时间后,效果逐步下滑,如何做到自动更新模型?
- ②自动降级:资源有限,根据不同的qps压力,适配不同版本的模型
什么是 Model Serving?
一句话解释就是:
Model Serving解决的是模型离线训练好之后,如何进行线上实时推断的问题。
在每个服务器节点动辄几千上万QPS的压力下,必然不可能在tensorflow,spark mllib等训练环境中进行实时推断。必须有一个模型服务器来承载模型相关的参数或者数据,进行几十毫秒级别的实时推断,这就是model serving面临的主要挑战。
ML模型部署方式
【2023-7-2】 机器学习模型部署四种方式 链接
- (1) Batch 批处理部署
- (2) Stream 流式部署
- (3) Real Time 实时部署
-
(4) Edge 边缘部署
批处理部署
流式部署
实时部署
端侧部署
xgb 部署在端侧设备
js 库
- xgboost 参考
- mljs/xgboost
npm install xgboost # ①
npm install ml-xgboost # ②
方法②使用
import IrisDataset from 'ml-dataset-iris';
require('ml-xgboost').then(XGBoost => {
var booster = new XGBoost({
booster: 'gbtree',
objective: 'multi:softmax',
max_depth: 5,
eta: 0.1,
min_child_weight: 1,
subsample: 0.5,
colsample_bytree: 1,
silent: 1,
iterations: 200
});
var trainingSet = IrisDataset.getNumbers();
var predictions = IrisDataset.getClasses().map(
(elem) => IrisDataset.getDistinctClasses().indexOf(elem)
);
booster.train(dataset, trueLabels);
var predictDataset = /* something to predict */
var predictions = booster.predict(predictDataset);
// don't forget to free your model
booster.free()
// you can save your model in this way
var model = JSON.stringify(booster); // string
// or
var model = booster.toJSON(); // object
// and load it
var anotherBooster = XGBoost.load(model); // model is an object, not a string
});
模型部署对比
【2023-2-3】AI模型部署落地综述(ONNX/NCNN/TensorRT等
实际应用场景往往需要模型速度与精度能达到平衡。因此这就需要在算法(剪枝,压缩等)与底层(手写加速算作)去优化模型。
- ONNX、NCNN、OpenVINO、 TensorRT、Mediapipe
对比,详见原文
| 模型部署 | 优点 | 缺点 |
|---|---|---|
| ONNX | ||
| NCNN | ||
| OpenVINO | ||
| TensorRT | ||
| Mediapipe |
常见serving方法
Model Serving的主要方法: 文章如何解决推荐系统工程难题——深度学习推荐模型线上serving 中提到了几种主流的方法,分别是:
- (1)自研平台
- 为什么要自研?TensorFlow 等通用平台为了灵活性和通用性支持大量冗余的功能,导致平台过重,难以修改和定制。而自研平台的好处是可以根据公司业务和需求进行定制化的实现,并兼顾模型serving的效率。
- 弊端:实现模型的时间成本较高,自研一到两种模型是可行的,但往往无法做到数十种模型的实现、比较、和调优。而在模型结构层出不穷的今天,自研模型的迭代周期过长。
- 因此自研平台和模型往往只在大公司采用,或者在已经确定模型结构的前提下,手动实现inference过程的时候采用。
- (2)预训练embedding+轻量级模型 —— 业界主流
- 初衷:结合通用平台的灵活性、功能的多样性,和自研模型线上inference高效性
- 工业界很多公司采用了“复杂网络离线训练,生成embedding存入内存数据库,线上实现LR或浅层NN等轻量级模型拟合优化目标”的上线方式。百度曾经成功应用的“双塔”模型是非常典型的例子; 阿里妈妈提出的Model Serving方法 User Interest Center, UIC架构
- 百度的双塔模型分别用复杂网络对“用户特征”和“广告特征”进行了embedding化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。在完成双塔模型的训练后,可以把最终的用户embedding和广告embedding存入内存数据库。而在线上inference时,也不用复现复杂网络,只需要实现最后一层的逻辑,在从内存数据库中取出用户embedding和广告embedding之后,通过简单计算即可得到最终的预估结果。图
- 同样,在graph embedding技术已经非常强大的今天,利用embedding离线训练的方法已经可以融入大量user和item信息。那么利用预训练的embedding就可以大大降低线上预估模型的复杂度,从而使得手动实现深度学习网络的inference逻辑成为可能。
- (3)PMML等模型序列化和解析工具
- Embedding+线上简单模型的方法实用且高效,但还是把模型割裂了,不完全是End2End训练+End2End部署这种最“完美”的形式。有没有能够在离线训练完模型之后,直接部署模型的方式呢?一种脱离于平台的通用的模型部署方式PMML
- PMML的全称是“预测模型标记语言”(Predictive Model Markup Language, PMML)是一种通用的以XML的形式表示不同模型结构参数的标记语言。在模型上线的过程中,PMML经常作为中间媒介连接离线训练平台和线上预测平台。
- 以Spark mllib模型的训练和上线过程为例解释PMML在整个机器学习模型训练及上线流程中扮演的角色
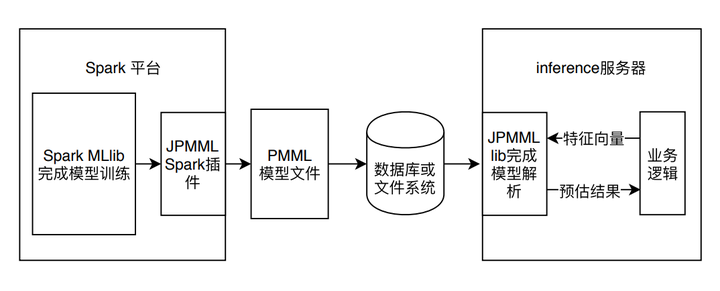
- 使用了JPMML作为序列化和解析PMML文件的library。JPMML项目分为Spark和Java Server两部分。Spark部分的library完成Spark MLlib模型的序列化,生成PMML文件并保存到线上服务器能够触达的数据库或文件系统中;Java Server部分则完成PMML模型的解析,并生成预估模型,完成和业务逻辑的整合。由于JPMML在Java Server部分只进行inference,不用考虑模型训练、分布式部署等一系列问题,因此library比较轻,能够高效的完成预估过程。与JPMML相似的开源项目还有Mleap,同样采用了PMML作为模型转换和上线的媒介。
- JPMML和MLeap也具备sk-learn,TensorFlow简单模型的转换和上线能力。但针对TensorFlow的复杂模型,PMML语言的表达能力是不够的,因此上线TensorFlow模型就需要TensorFlow的原生支持——TensorFlow Serving。
- (4)TensorFlow serving等平台原生model serving工具
- TensorFlow Serving 是TensorFlow推出的原生的模型serving服务器。本质上, TensorFlow Serving的工作流程和PMML类的工具的流程是一致的。不同之处在于TensorFlow定义了自己的模型序列化标准。利用TensorFlow自带的模型序列化函数可将训练好的模型参数和结构保存至某文件路径。
- TensorFlow Serving最普遍也是最便捷的serving方式是使用Docker建立模型Serving API。
- 要搭建一套完整的TensorFlow Serving服务并不是一件容易的事情,因为其中涉及到模型更新,整个docker container集群的维护和按需扩展等一系例工程问题;此外,TensorFlow Serving的性能问题也仍被业界诟病。但Tensorflow Serving的易用性和对复杂模型的支持仍使其是上线TensorFlow模型的第一选择。
- 除了TensorFlow Serving之外,Amazon的Sagemaker,H2O.ai的H2O平台都是类似的专业用于模型serving的服务。平台的易用性和效率都有保证,但都需要与离线训练平台进行绑定,无法做到跨平台的模型迁移部署。

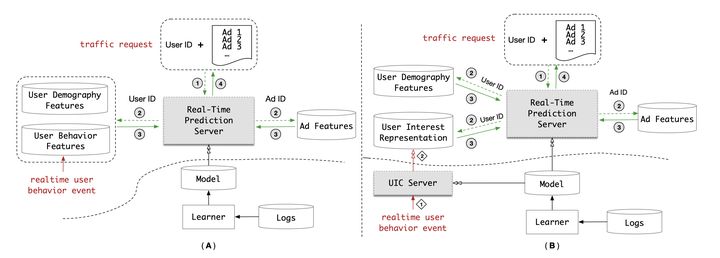
阿里妈妈的服务架构(从阿里的User Interest Center看模型线上实时serving方法)
- (A)和(B)分别代表了两种不同的模型服务架构,横向虚线代表了在线环境和离线环境的分隔
- (A)是经典的解决方案
- 离线部分做模型训练,在线部分根据用户各类特征(User Demography Features 和 User Behavior Features)以及广告特征(Ad Features),在模型服务器(Real-Time Prediction Server)中进行预估。
- 问题:模型越来越复杂之后,特别是像DIEN或者MIMN这类模型加入序列结构之后,这些序列结构的推断时间实在是太长了。结构已经复杂到模型服务器在几十毫秒的时间内根本没有可能推断完的地步。
- (B) 阿里改进版:大幅降低模型在线推断复杂度,达到准实时
- B架构将A架构的“用户行为特征(User Behavior Features)在线数据库”替换成了“用户兴趣表达(User Interest Representation)在线数据库”。
- 如果在线获取的是用户行为特征序列,对实时预估服务器(Real-time Prediction Server)来说,需要运行复杂的序列模型推断过程生成用户兴趣向量
- 如果在线获取的是用户兴趣向量,实时预估服务器就可以跳过序列模型阶段,直接开始 MLP 阶段的运算。MLP 的层数相较序列模型大大减少,而且便于并行计算,因此整个实时预估的延迟可以大幅减少。
- “用户兴趣表达模块”本质上是以类似redis的内存数据库为主实现的。
- 结果:每个服务节点在 500 QPS(Queries Per Second, 每秒查询次数)的压力下,DIEN 模型的预估时间从 200 毫秒降至 19 毫秒。
推荐系统 serving
【2021-11-12】推荐系统Serving架构分析
NSDI 2017年发表的Clipper
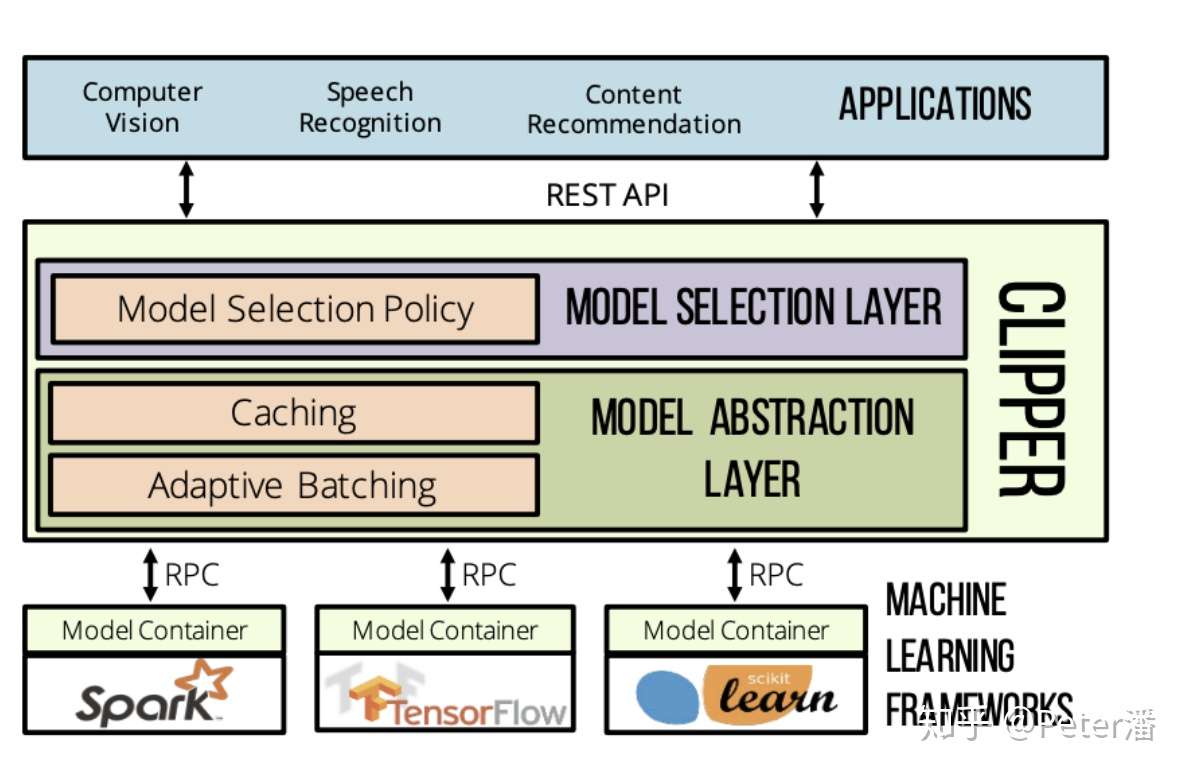
经典的Serving架构通常包含以下设计。
- 独立的服务化部署。独立的服务化部署提供了灵活的扩所容能力。解偶了复杂的上游系统。可以比较独立的开发,运营。
- 统一的RPC/Http接口,搭配插件化的框架。统一抽象的接口基本能适配主流场景的Tensor-In/Tensor-Out需求。同时又能统一抽象封装不同的计算框架,满足用户使用TensorFlow, Pytorch, TensorRT等不同框架的需求。
推荐系统Serving
- 在大规模推荐场景,整个系统呈现一种漏斗架构。不同阶段的数据量,计算量,精确度需求都不一样,是一个绝佳的思考系统设计trade-off 场景。很多时候需要考虑易用性、性能、成本和业务场景,综合作出判断。
召回
- 召回面向的是百万级,甚至亿级的候选item池。如果每次用户请求都对所有item进行精细计算打分,在当前成本和算力情况下是基本是不现实的。 一般会通过通过聚类和索引的方法分割搜索空间,减少计算量。比如基于KNN的聚类,基于HNSW的图索引,基于局部敏感Hash的索引,或者是基于树结构的索引。
召回Serving的关键词是:索引,局部,海量。
召回的Serving架构有如下特点:
- 预计算
- 通过图,树或者其他一些聚类算法,提前切分搜索空间,建立索引。这样在每次进行匹配的时候,只需要处理一小部分候选集。
- 计算跟随数据。
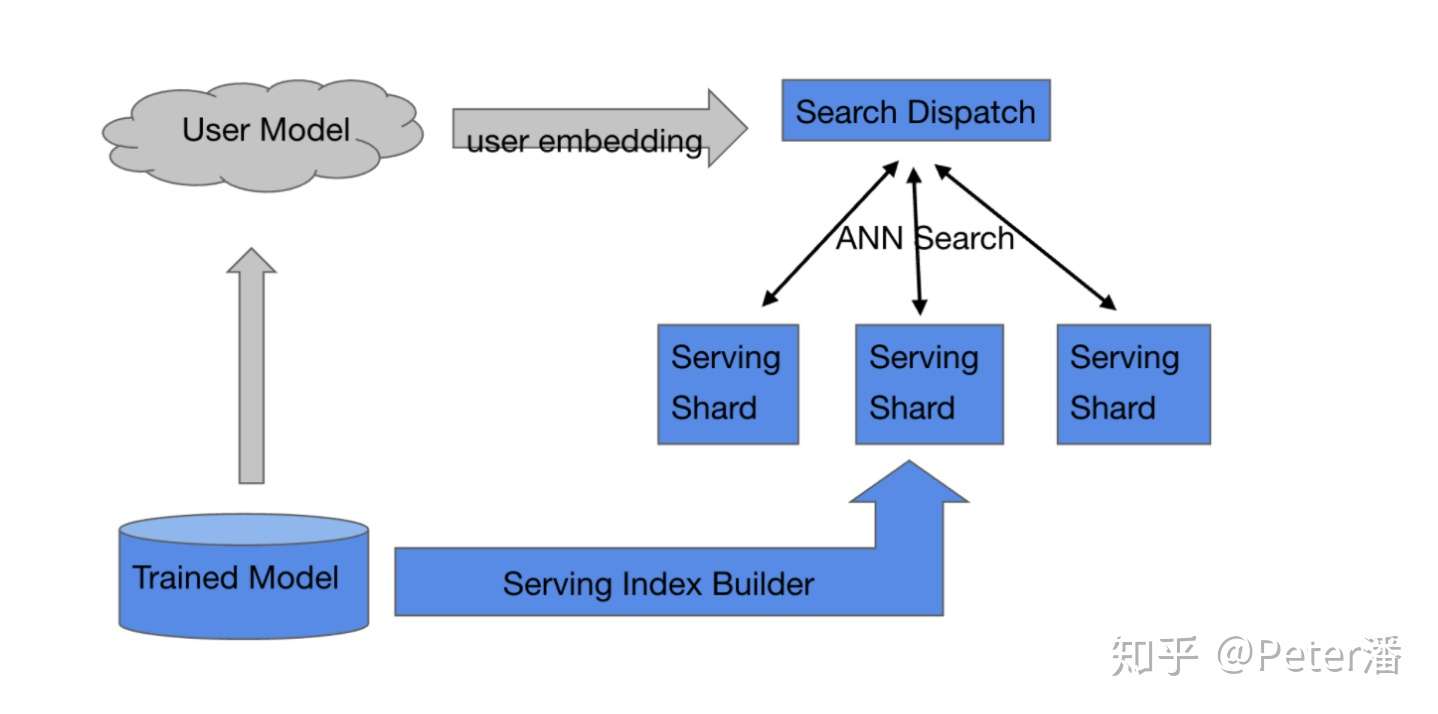
- 因为数据的规模很大(千万),难以挪动,而计算的量比较小(比如余弦,内积计算),所以匹配计算一般是在数据所在的机器上进行的。类似OLAP引擎的MPP架构,或者是MapReduce架构,数据在哪里,计算就在哪里。在多个数据节点上完成匹配和过滤。 基于以上两点,召回模型的Serving架构一般如下:
- 训练后的模型一般是拆分上线的。user侧的embedding是在线实时计算的(比如考虑用户当时的浏览历史),然后user embedding会用来匹配item。关于这部分模型的Serving先不讨论。
- 海量item特征的上线一般需要经过一个索引构建的过程。比如基于item向量做聚类,产生N个聚类中心,这样ANN Search只需要关心一部分聚类中心就可以了。也可以基于HNSW的方法构建图索引,这样能够更快速的找到最“匹配”的item向量。
- 索引建完之后需要一个sharding和replication的过程。目标是尽量能够将workload在多个物理节点上进行balance,同时做到fault-tolerance和scale-out。这里面可能涉及到扩所容,动态增删等高级能力,需要通过分布式一致性协议处理,本文不深入讨论。
对于每个请求,需要并发的调用candidate shards进行匹配,然后将匹配后的结果组装形成召回结果。
排序
经过召回后还有数千,甚至上万个候选item。通常需要对所有item进行排序。这个阶段有两个选择:
- 直接使用最精确的模型对所有item排序,一步到位。使用先进的硬件、付出比较昂贵的计算成本,是有可能做得到的。
- 分成粗排和精排两个阶段。先对这些item再进行一轮粗筛,比如过滤90%的item,同时确保剩下的10%的item“大致”包括了所有item中最好的那一部分,后续再进行精排。
通常需要具体实验,再结合业务本身的场景规模,成本预算,线上性能等因素,综合考虑后选择。
(1)粗排
- 假如选择了粗排,那么就必须确保粗排是真的能够“相对快速”的对item进行“相对准确”的过滤。这里“相对”是和精排对比。
- 粗排模型Serving必须比精排快很多,否则就没有存在的意义了。另外粗排的Serving结果不能和精排差距太大。粗排选出来的item(比如前10%)在精排看来应该也是相对靠前的(比如前15%)。假如粗排结果在精排看来是随机的,那还不如减少召回量,直接使用精排。
粗排Serving的关键是:相对精排更加快速,和精排准确度差距不是太大。
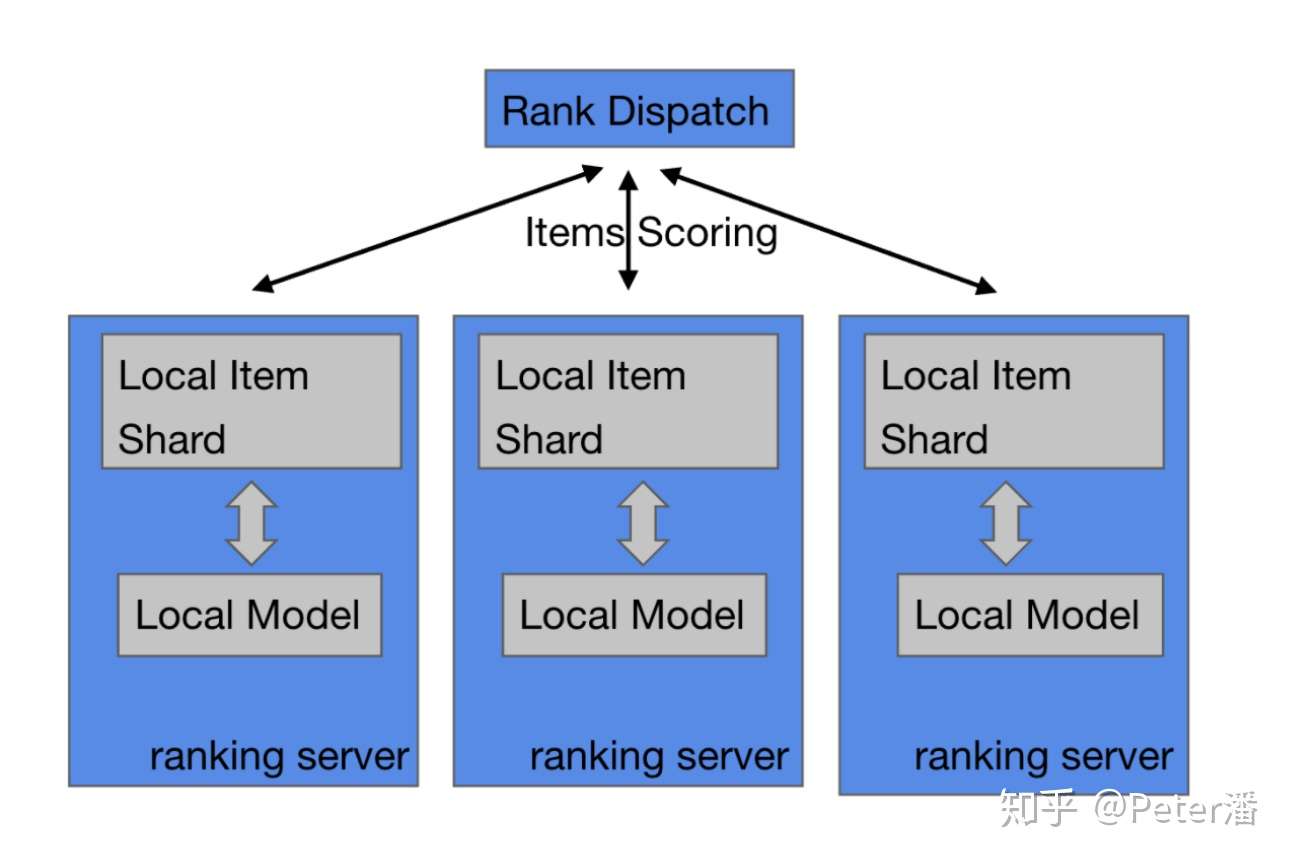
基于以上考虑。粗排的模型常常是耦合在业务系统内部。换句话说Feature Maker和模型计算是在一台机器上完成的。更具体的:
- Rank Dispatch获得了所有召回的item id后,分发给各个Ranking服务器。
- Ranking服务器Feature Maker从线上存储服务获得需要的相关特征和Embedding,拼接出模型的完整输入。
- 调用本地的模型计算框架库,完成模型打分计算。

如果Feature Maker不从中心化的存储服务获得特征,还有另一个变种如下图:
- 提前把Item和它们的特征做Sharding,然后把召回的item根据item sharding路由,分发到各个Item Shard上去做特征拼接和模型计算。
是不是跟上文说的召回架构,MPP架构非常像,或者是说Share-Nothing架构?和召回的区别是
- 粗排被计算的item是提前知道的
- 也是全部都需要计算的(不是局部索引)。
粗排使用经典Serving架构理论上是可以的,但是和上图中的本地化架构相比,经典架构有个明显劣势:Ranking Server需要通过RPC调用远程Serving服务,如果优化不够极致,会导致“比较显著”的额外开销。
- 推荐的模型输入有大量稀疏特征,每个item会有成百上千个feature。RPC的请求的构造成本,序列化和反序列化成本都会比较高,需要进行非常定制化的设计来优化。Serving服务剩下用来做计算的时间预算就很少了。导致发每个Serving容器的batch size需要减少(比如本地计算是30, Serving容器是15)。比如:bs=30, iteam feature=1000, 800qps, 主调带宽可能到200~300MB/s,视优化情况有不同。通过压缩手段,理想情况能控制在100MB/s附近。如果优化不好可能成为性能瓶颈。
- 几千个item需要被切分到上百个batch,同时发送到Serving容器上同时打分。超大扇出且高QPS的情况下,必然会有慢机。这样延迟预算要按P99来算。进而又压缩batch size,进而导致需要被切分出更多的请求,陷入恶性循环。
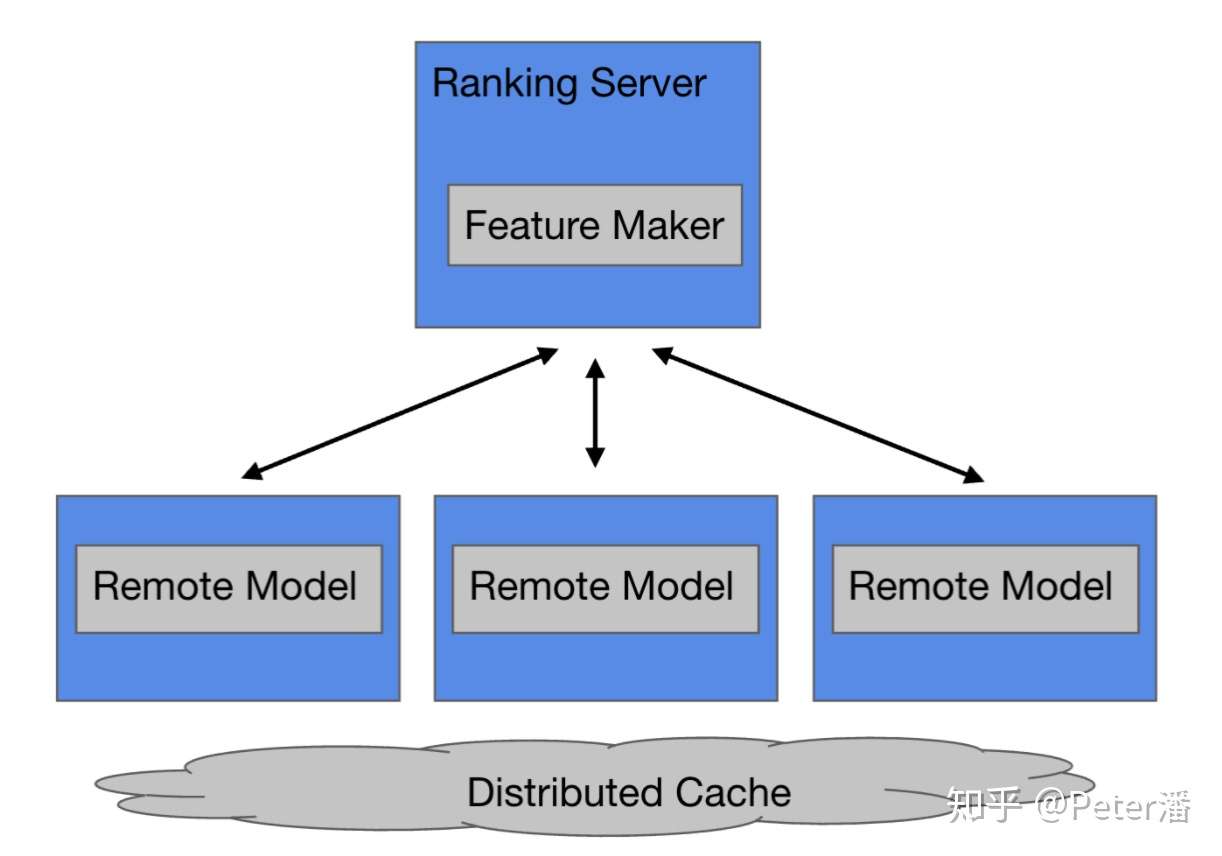
(2)精排
假如经过了粗排阶段对成千上万个item进行过滤,最终还会剩下数百个item。上文提到粗排的精确度相对精排还是又差距的。所以粗排的结果还有进一步的优化空间(在计算和成本可以承受的前提下)。 所以精排Serving的关键词是:精确,少量。
下图的架构就和前文的经典Serving架构就非常相似了。Ranking的业务逻辑和底层平台Serving逻辑做了比较好的解偶。
- 精排模型的计算量比较大,所以相对而言,远程调用和请求数据传输的额外开销占比较少。
- 精排模型需要排序的item个数较少,所以需要被拆分的并行请求包也会比较少,慢机延迟的问题不是特别严重。
- 精排模型的体积也比较大,可以达到几百GB到TB,更适合拆分到独立的服务上解决分布式存储、运营部署等相关问题。 综上,数据被发送到计算节点上,在精排场景是比较合理的。这和召回的Serving架构正好是相反的。
(3)中台视角
复杂系统的架构除了考虑性能、成本这些因素,还要考虑团队分工,运营成本等问题。
下图一种很有争议的方案。绿色的是业务系统。蓝色的中台Serving系统。如果将DNN嵌入到业务系统里面,可以将DNN Inference计算进行本地化。Feature Maker生成样本后可以直接计算。和经典架构相比,省去了样本通过RPC发送给远程服务。通过本地Cache可以命中90%的远程Embedding请求。理论上是一种比较高性能的方案。
然而,假如中台支持的业务场景达到几十个,甚至上百个,部署和运营问题会变得比较复杂。1. Dnn Lib的升级需要和上百个业务方沟通协调,需要重新编译发布。2. 由于同一个模型拆分到不同团队管理,Serving Controller很难自动化的进行新服务部署,模型上线,扩缩容。
从长期趋势上看
- 数据中心网络速度发展非常迅速,网络开销逐渐下降。
- DNN模型变得更加复杂,迭代更加敏捷,计算量更大。 考虑到以上两点,我们更倾向于通过经典架构来解决精排模型的Serving问题。

变数:上面介绍的只是常见的几个架构。不同业务场景间的差异很大,没有可以自动套用的最佳Serving方案。更多是知己知彼,随机应变。举几个例子。
- 长视频的item候选集可能要比短视频少几个数量级。图文和视频的特征规模可能也不太一样。
- 大业务的主场景对性能和成本的要求更高,倾向于舍弃一些灵活性。而小场景更关注的是算法人员快速应用。
- 有些业务更倾向于自己定制Serving,投入较大的工程团队。有些业务倾向于关注业务效果和算法,而将工程交给中台团队。
- 不同场景处在很不同的阶段。有些场景没有粗排,有些场景使用了简单的模型和复杂的特征,有些场景使用了复杂的模型和较少的特征。
Serving系统优化
- Serving系统在代码实现的微观层面有非常大的优化空间。优化的好的Serving系统可以有几倍的性能提升和成本优化空间,进而影响最终的架构选型。比如
- Embedding的计算可以是
- 拆分成Emb拉取,矩阵构造,Tensor计算等细粒度算子。
- 也可以通过配置化的融合算子一步完成。两者有数倍的性能差距
- Serving服务调用RPC接口可以是
- 多层嵌套Request { repeated Sample { repeated FeatureGroup { map Feature { repeated float }}};
- 也可以是拍平后的bytes&index,比如Request { bytes data, list FeatureGroupOffset, list FeatureOffset }。前者有相对结构化且易理解,后者有更高的序列化/反序列化效率和更高的计算效率。
- 另外在线程池调参,框架优化,RPC数据压缩等方面还有许多可以Profile和优化的地方。
GPU Serving
- 前面提到,在大量item打分时,需要将item分成多个batch。大量batch远程调用Serving服务时会有显著的额外开销。额外开销本身不产生价值,可是压缩了模型计算的时间预算。模型计算时间预算压缩导致每个batch需要更小才能完成目标,导致了更多更小的batch,导致更多的额外开销。如此陷入恶性循环。
破局需要通过增大batch size来减少batch分片的个数,进而减少额外开销。GPU非常擅长大规模并行计算,在CV/NLP等场景被证明了可以在非常短的延迟内完成较大batch size的模型计算。
但是GPU在推荐场景的应用还有几个难点,需要逐一解决。1. GPU的显存是不可能放得下大的推荐模型的,这里需要一些比较巧妙的Cache设计。2. GPU本身比较贵,GPU Embedding计算效率是否足够高来产生较大的性价比优势。
合理利用存储 Serving的部署方式其实有非常大的提升空间。
- 双buffer机制虽然比较容易实现和部署,但是却要浪费一倍的内存。是否可以通过滚动发布的方式代替。
- 单机内存可以很容易放下上百GB模型。但是现在很多模型刚到几十GB就需要部署分布式Cache存储,既提高了成本,又降低了性能。PMEM可以让单机达到TB级的规模。
- HashMap的实现也会显著的影响Serving的资源占用和性能。
端到端推荐
- 关于是否能端到端的解决推荐系统的Serving,可以读下百度和阿里这两篇论文(突然发现标题惊人的类似)。
- MOBIUS: Towards the Next Generation of Query-Ad Matchingin Baidu’s Sponsored Search
- COLD: Towards the Next Generation of Pre-Ranking System
算法与工程合作
- Infra/ML engineer与data scientist/researcher们的合作中最显著的一个特点是大家在不同的抽象层面思考问题,有些看起来有一定创新性的模型结构调整其实在产品化、工程化的道路上困难重重。
- 比如最近关注的一个项目,offline training的时候发现效果很好,模型CTR的提升非常显著,但是在推进到生产环境阶段时,会发现90%的剩余工作都是infra方面。
- 比如如何处理模型变大之后offline training阶段的各种限制,典型的像模型推断时间过长,内存占用过多,online training如何避免数据丢失,并且能以合理的速度更新,inference阶段如何在不显著增加系统开销的前提下顺利满足所有的在线推理要求(比如实时特征的准备)等等。
- 一个模型在离线效果上验证有收益只是第一步,甚至是比较小的第一步,尤其是在模型规模、复杂度显著增加的基础上,模型效果上的收益扣除Infra上的开销之后,实际还剩多少收益是要打一个问号的。在第一步之后,剩下的路肯定会有很多infra上的限制要去处理。所以,从我的角度来说,无论是Infra engineer,还是researcher们,都要加深对对方领域的理解,只有一个人对这些可能的问题越熟悉越了解,也就越能增加自己的模型落地的可能。
总结
- 无论是Infra engineer,还是researcher们,都要加深对对方领域的理解,只有一个人对这些可能的问题越熟悉越了解,也就越能增加自己的模型落地的可能
- 有些看起来有一定创新性的模型结构调整其实在产品化、工程化的道路上困难重重,所以在构建模型的时候,也要提前充分考虑工程化的关键问题
- 实现庞大模型线上服务最可行的手段就是选择在Embedding层进行拆解。因为模型大小完全由Embedding size主导。
- 在分布式inference的过程中,我们首先要关心的就是节点间的通信开销问题
- 在分布式inference的过程中,尽量从模型中拆解出可以并行的部分
- 巨大Embedding table的sharding和replication策略是需要精确设计的
- 当模型足够复杂之后,一个最有效的办法其实是返璞归真到模型本身:你能直接或者间接支持起更多的 feature,用更大的 embedding,用更多的参数,一样的模- 型效果就会显著 out-perform 现有的,于是 ML 的问题其实就又变成了一个 infra 问题。
- embedding 模型 incremental checkpointing 效率上会比全量更新高效很多,是一个极有价值的方向
模型结构 vs ML infra哪个更重要?
分阶段:
- 早期,数据量不够时,各种传统ML算法可以取得不错的效果,而使用神经网络只在数据量和 infra 到了一定程度之后才会有明显效果
- 传统机器学习模型 → 简单深度学习模型 → 大规模深度学习模型
- 当模型足够复杂之后,一个最有效的办法其实是回到模型本身:你能直接/间接支持起更多的feature,用更大的embedding,用更多的参数,一样的模型效果就会显著 out-perform 现有的模型,于是 ML 的问题其实就又变成了一个 infra 问题。
模型更新
Embedding 模型 incremental checkpointing 效率上会比全量更新高效很多。
全量更新?增量训练?如何做版本控制?
如何部署大模型
深度学习中典型的有sparse feature的ads/recommendation model。这类模型的特点就是参数量巨大,单机内存放不下,自然也就无法做推断。这个时候如你所问,我们就必须进行模型的拆解,而且最可行的手段就是选择在Embedding层进行拆解。因为模型大小完全由Embedding size主导(后续的MLP等结构的参数量级远小于Embedding层)。
针对Embedding,可以通过sharding和partitioning(分表、分片)等手段把一个完整的推断过程从单节点的执行过程拆解成单节点推断主过程+多RPC call分布式Embedding查找过程。
具体来说,这里会有一个单节点做End2End的推理执行,包括最开始的特征准备、预处理以及最后几层FC layers的矩阵运算,但是中间的Embedding查找以及相关运算因为内存原因就没法在单节点上完成,但是可以通过blocking RPC call来和几个专门存放embedding 的service或者数据库做交互,这样一个完整的推断过程就可以在多个节点上分开运行。
分布式inference
当模型体积大到一定程度的时候,就无法通过单机进行预测,这时候就得靠分布式inference了
首先要关心节点间的通信开销问题(Communication overhead)。
- 单机的推断其实是有非常好的性质的,比如具备着极致的执行效率,良好的服务接口的特性,像便于 replication(复制), load balancing(负载平衡); 而拆解到多个分布式的模块之后,每个模块内部的串并联解耦、不同模块之间的通信开销,根据我们的观察会占到很大比重,这是非常值得优化的方向。
-
但总的原则是固定的,就是尽量从模型中拆解出可以并行的部分(比如最后的MLP部分就很难并行化,那么就完全在单节点内完成,但是Embedding的部分,模型中可以并行化的部分,独立的特征生成的部分,都可以拆解成不同的服务模块)。在这个拆解的过程中,还要尽量去减少模块间的通信总次数,所以这个过程是一个非常细致,非常考验基本功的地方。
- 【2021-5-7】一文读懂「Parameter Server」的分布式机器学习训练原理
Parameter Server采取了和Spark MLlib一样的数据并行训练产生局部梯度,再汇总梯度更新参数权重的并行化训练方案。物理上,PS其实是和spark的master-worker的架构基本一致的
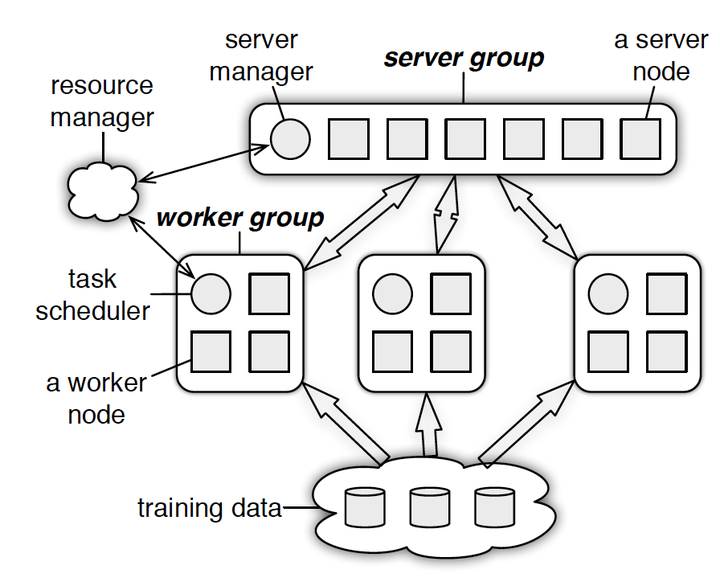
Parameter Server由server节点和worker节点组成,其主要功能分别如下:
- server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
- worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点。
PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
- server group内部包含多个server node,每个server node负责维护一部分参数,server manager负责维护和分配server资源;
- 每个worker group对应一个application(即一个模型训练任务),worker group之间,以及worker group内部的worker node互相之间并不通信,worker node只与server通信。
多server节点的协同和效率问题
- 导致Spark MLlib并行训练效率低下的另一原因是每次迭代都需要master节点将模型权重参数的广播发送到各worker节点。这导致两个问题:
- master节点作为一个瓶颈节点,受带宽条件的制约,发送全部模型参数的效率不高;
- 同步地广播发送所有权重参数,使系统整体的网络负载非常大。
那么PS是如何解决单点master效率低下的问题呢?从图2的架构图中可知,PS采用了server group内多server的架构,每个server主要负责一部分的模型参数。模型参数使用key value的形式,每个server负责一个key的range就可以了。
那么另一个问题来了,每个server是如何决定自己负责哪部分key range呢?如果有新的server节点加入,又是如何在保证已有key range不发生大的变化的情况下加入新的节点呢?这两个问题的答案涉及到一致性哈希(consistent hashing)的原理。
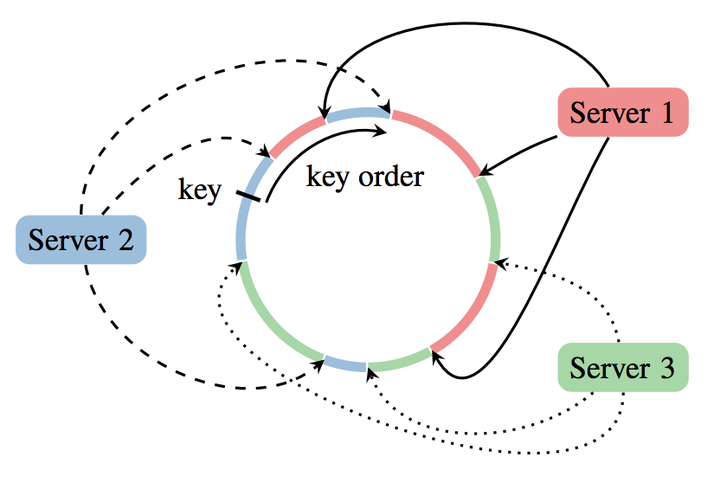
PS的server group中应用一致性哈希的原理大致有如下几步:
- 将模型参数的key映射到一个环形的hash空间,比如有一个hash函数可以将任意key映射到0~(2^32)-1的hash空间内,我们只要让(2^32)-1这个桶的下一个桶是0这个桶,那么这个空间就变成了一个环形hash空间;
- 根据server节点的数量n,将环形hash空间等分成n*m个range,让每个server间隔地分配m个hash range。这样做的目的是保证一定的负载均衡性,避免hash值过于集中带来的server负载不均;
- 在新加入一个server节点时,让新加入的server节点找到hash环上的插入点,让新的server负责插入点到下一个插入点之间的hash range,这样做相当于把原来的某段hash range分成两份,新的节点负责后半段,原来的节点负责前半段。这样不会影响其他hash range的hash分配,自然不存在大量的rehash带来的数据大混洗的问题。
- 删除一个server节点时,移除该节点相关的插入点,让临近节点负责该节点的hash range。
- PS server group中应用一致性哈希原理,其实非常有效的降低了原来单master节点带来的瓶颈问题。比如现在某worker节点希望pull新的模型参数到本地,worker节点将发送不同的range pull到不同的server节点,server节点可以并行的发送自己负责的weight到worker节点。
此外,由于在处理梯度的过程中server节点之间也可以高效协同,某worker节点在计算好自己的梯度后,也只需要利用range push把梯度发送给一部分相关的server节点即可。当然,这一过程也与模型结构相关,需要跟模型本身的实现结合起来实现。总的来说,PS基于一致性哈希提供了range pull和range push的能力,让模型并行训练的实现更加灵活。
总结一下Parameter Server实现分布式机器学习模型训练的要点:
- 用异步非阻断式的分布式梯度下降策略替代同步阻断式的梯度下降策略;
- 实现多server节点的架构,避免了单master节点带来的带宽瓶颈和内存瓶颈;
-
使用一致性哈希,range pull和range push等工程手段实现信息的最小传递,避免广播操作带来的全局性网络阻塞和带宽浪费。
- Parameter Server仅仅是一个管理并行训练梯度的权重的平台,并不涉及到具体的模型实现,因此PS往往是作为MXNet,TensorFlow的一个组件,要想具体实现一个机器学习模型,还需要依赖于通用的,综合性的机器学习平台。
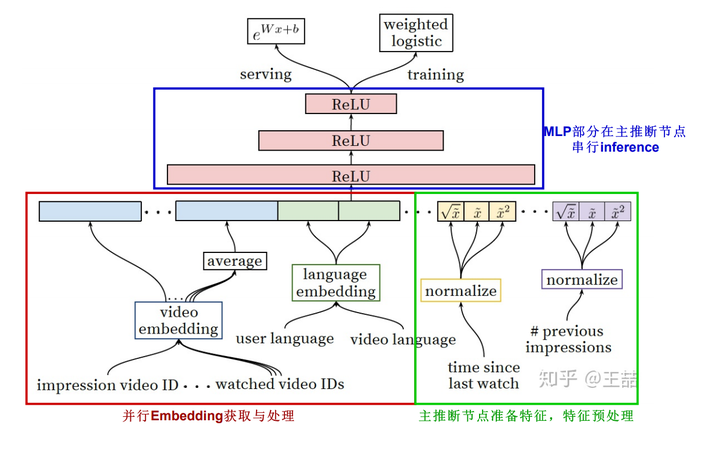
Embedding
聚焦到Embedding部分来说,如何把一个巨大的embedding table分配到不同的服务模块是很讲究策略的,会对最终的整个推断效率产生非常大的影响。讲一个简单的例子,比如说有一个embedding table,有10台参数服务器,如果把这个embedding table拆成十份,分配给10台参数服务器,好处当然是每台服务器上的embedding规模只是1/10。但坏处是如果有一个average pooling的操作,要查找10次embedding,那么很有可能我们要向不同参数服务器节点发出多次请求,才能最终在主推断节点完成average pooling的操作。
但是如果我们采用replication的策略,把这个embedding table全量的分配到10个参数服务器,那么在参数服务器内部就可以完成average pooling的操作,通信一次就可以了。这对于节省整个网络的通信开销贡献是巨大的。当然了,这个策略浪费了宝贵的服务器内存资源。
类似sharding和replication的权衡在Embedding规模变得更大之后会变得更加复杂,我们往往需要更加复杂的策略才能找到一个平衡通信开销和系统内存开销的平衡点。

Embedding store
- 生产环境中最主要的方式还是去做全量更新。比如一个模型通过fully training/incremental training/online training得到一个新的模型,那么由于相应的embedding层结构会发生变化,那么还是会走完全部的模型压缩、发布流程生成一个全新的snapshot,然后让已经比较成熟的线上环境自主去发现、载入、进而使用新的snapshot进行推断。
- 当然国内有几家公司其实在这方面走的更靠前一些,比如做Embedding的增量更新。实际上同一个模型两个 snapshot 之间 embedding 的更新比例并不会特别高(大家可以思考一下哪些情况下某个id对应的embedding才会更新),因此实验和部署 incremental checkpointing 就会是一个很有意义的方向,尤其是模型大小越来越大的情况。
MLOps
- 【2021-6-30】机器学习工程(MLOps)实践:机器学习持续交付, 机器学习应用主要在三个维度变化:代码本身、模型算法、数据集。这些变化一般比较复杂并且难以预测,同时,它们也很难进行测试、解释和迭代更新。机器学习持续交付(CD4ML)是给机器学习应用带来持续性交付和实际实践的重要法则。
- 用一个监督学习算法和著名的scikit-learn Python库,我们使用标注过的输入数据来训练一个预测模型,并将这个模型集成到一个简单的Web应用中,然后部署在云服务器的生产环境中
- 端到端的过程仍然有着两个挑战。
- 第一个挑战是组织结构:不同的团队可能在整个流程中位于不同的部分,因此如何跨越这些障碍是一个关键。数据工程师可以通过构建流程来获得数据,但是数据科学家可能担心ML模型的构建和优化。机器学习工程师或者开发者将会担心如何集成模型和发布对应的产品。这会导致项目延迟和矛盾分化,一个普遍的现象是,工业场景下使用一个仅在实验室环境下可行的模型,未进行实用场景证明。或以手动临时方式将其投入生产,这样的产品就很难进行更新迭代。
- 第二个挑战是技术问题:如何实现过程的可重用和可审查。因为这些团队实用不同的工具,并且遵从不同的工作流程,这样对实现自动端到端开发造成困难。然而,除了代码意外还有很多需要管理的内容,以及对不同的组建进行版本化。其中一些内容工作量巨大,需要非常复杂的工具来实现高效的存储和货物。
- 机器学习流水线:“机器学习管道”,也称为“模型训练管道”,是以数据和代码为输入,生成经过训练的ML模型作为输出的过程。 这个过程通常涉及数据清洗和预处理、特征工程、模型和算法选择、模型优化和评估。
- 【2021-5-17】MLOps简介,作者字节,知乎原文:从小作坊到智能中枢: MLOps简介,其它系列文章
一、什么是 MLOps?
机器学习操作 (MLOps) 基于可提高工作流效率的 DevOps 原理和做法。 例如持续集成、持续交付和持续部署。 MLOps 将这些原理应用到机器学习过程,其目标是:
- 更快地试验和开发模型
- 更快地将模型部署到生产环境
- 质量保证
顾名思义,MLOps就是机器学习时代的DevOps。它的主要作用就是连接模型构建团队和业务,运维团队,建立起一个标准化的模型开发,部署与运维流程,使得企业组织能更好的利用机器学习的能力来促进业务增长。
举个简单的例子,几年前我们对于机器学习的印象主要是拿到一堆excel/csv数据,通过notebook等尝试做一些模型实验,最终产出一个预测结果。但对于这个预测结果如何使用,对业务产生了什么影响,大家可能都不是很有概念。这就很容易导致机器学习项目一直停留在实验室阶段,一个接一个做POC,但都没法成功“落地”。
最近几年,大家对于机器学习项目落地愈发重视起来,对业务的理解,模型应用流程等都做的越来越好,也有越来越多的模型被部署到真实的业务场景中。但是当业务真实开始使用的时候,就会对模型有各种各样的需求反馈,算法工程师们就开始需要不断迭代开发,频繁部署上线。随着业务的发展,模型应用的场景也越来越多,管理和维护这么多模型系统就成了一个切实的挑战。
回顾这个发展,是不是感觉似曾相识?20年前软件行业在数字化演进道路上也遇到过类似的挑战。我们从部署一个Web服务到要部署几十甚至上百个不同的应用,在各种规模化交付方面的挑战之下,诞生了DevOps技术。像虚拟化,云计算,持续集成/发布,自动化测试等软件工程领域的各类最佳实践基本都跟这个方向有关。在不远的将来,或许智能模型也会与今天的软件系统一样普遍。一个企业需要使用非常多的业务系统来实现数字化流程,同样也需要非常多的模型来实现数据驱动的智能决策,衍生出更多与模型相关的开发运维,权限,隐私,安全性,审计等企业级需求。
因此最近几年,MLOps也逐渐成为了一个热门话题。有了好的MLOps实践,算法工程师一方面能更专注于擅长的模型构建过程,减少对模型部署运维等方面的“感知”,另一方面也让模型开发迭代的方向更加清晰明确,切实为业务产生价值。就像今日的软件工程师很少需要关注运行环境,测试集成,发布流程等细节,但却做到了一天数次发布的敏捷高效,未来算法工程师应该也能更专注于数据insights获取方面,让模型发布成为几乎无感又快速的自动化流程。
二、MLOps 步骤
从大的方面看,MLOps分3个步骤:
- 项目设计,包括需求收集,场景设计,数据可用性检查等。
- 模型开发,包括数据工程,模型工程,以及评估验证等。
- 模型运维,包括模型部署,CI/CD/CT工作流,监控与调度触发等。
DevOps通过缩短开发部署的时间来更快地迭代软件产品,使得公司业务不断进化。MLOps的逻辑也是通过相似的自动化和迭代形式,加快企业从数据到insights的价值获取速度。

MLOps的核心要解决的问题之一是缩短模型开发部署的迭代周期,即各类efficiency问题。从Algorithmia的2020年的这份报告中可以看到,很大一部分公司需要31-90天上线一个模型,其中有18%的公司需要90天以上来上线一个模型。且在中小型公司中,算法工程师花在模型部署方面的时间比例也明显偏多。MLOps希望通过更标准化自动化的流程与基础设施支持,来提升模型交付的整体效率。

另外一方面,MLOps还希望能提供一个企业内各个角色无缝协作的平台,让业务,数据,算法,运维等角色能更高效率的进行协作,提升业务价值产出,即transparency的需求。后面我们的详细讨论中也会反复印证这两个核心诉求。

三、MLOps 原则
Automation
在整个workflow中所有可以自动化的环节,我们都应该进行自动化,从数据的接入到最后的部署上线。Google那篇经典的MLOps指导中就提出了3个层级的自动化,非常值得借鉴,后面我们会详细介绍。
Continuous
一说起DevOps,大家就很容易联想到CI/CD,也从侧面印证这条原则的重要性。MLOps在持续集成,持续部署,持续监控的基础上,还增加了持续训练的概念,即模型在线上运行过程中可以持续得到自动化的训练与更新。我们在设计开发机器学习系统时,要持续思考各个组件对“持续”性的支持,包括流程中用到的各种artifacts,他们的版本管理和编排串联等。
Versioning
版本化管理也是DevOps的重要最佳实践之一,在MLOps领域,除了pipeline代码的版本管理,数据,模型的版本管理属于新涌现的需求点,也对底层infra提出了新的挑战。
Experiment Tracking
实验管理可以理解为version control中commit message的增强。对于涉及模型构建相关的代码改动,我们都应该能记录当时对应的数据,代码版本,以及对应的模型artifacts存档,作为后续分析模型,选择具体上线的版本的重要依据。
Testing
机器学习系统中主要涉及到3种不同的pipeline,分别是数据pipeline,模型pipeline和应用pipeline(类似于模型与应用系统的集成)。针对这3个pipeline,需要构建对应的数据特征测试,模型测试以及应用infra测试,确保整体系统的输出与预期的业务目标相符,达到将数据insights转化为业务价值的目的。这方面Google的ML test score是一个很好的参考。
Monitoring
监控也是一项软件工程的传统最佳实践。上面提到的ML test score中也有一部分是与监控相关。除了传统的系统监控,例如日志,系统资源等方面外,机器学习系统还需要对输入数据,模型预测进行监控,确保预测的质量,并在出现异常情况时自动触发一些应对机制,例如数据或模型的降级,模型的重新训练与部署等。
Reproducibility
与传统软件系统的确定性行为不同,机器学习中带有不少“随机化”的成分,这对各种问题的排查,版本回滚,输出效果的确定性都提出了一定的挑战。因此我们在开发过程中也需要时刻将可复现原则放在心上,设计相应的最佳实践(如设定随机数种子,运行环境等各类依赖的版本化等)。
四、MLOps 流程细节
我们来看下具体的机器学习项目流程,并对每一个模块中MLOps需要提供的支持进行详细的展开。

项目设计
项目设计所需要受到的重视程度毋庸置疑,之前在Fullstack Deep Learning的课程介绍中我们也有很大的篇幅来进行介绍。在MLOps领域,我们应该为这部分的工作也设计一系列的标准与文档。业界可以参考的材料也有很多,例如 Machine Learning Canvas ,Data Landscape 等。

数据接入
数据接入方面,我们会利用成熟的数据平台,例如各类数据仓库,数据湖或实时数据源等。对于接入到平台后的数据存储,可以优先考虑带有数据版本支持的组件,例如Delta Lake等。当然也可以采用DVC或自行元数据维护等方案来进行ML相关数据资产的管理。
数据分析
在数据接入后,一般会需要进行各类EDA分析。传统的做法一般是使用notebook来进行交互式分析,但对于分析结果的保存管理,共享协作,数据更新后的自动刷新,高级交互分析能力方面,原生notebook本身还是有不少缺陷,难以很好满足。有一些研究与产品在这个方向上做了一些改进,例如Polynote,Facets,Wrattler等。

数据检查
对于接入的原始数据,通常会出现各类质量问题或数据类型,含义,分布等方面的变化。而机器学习pipeline即使在数据有变化的情况下基本也能顺利运行成功,造成意向不到的各种“静默失败”问题,其排查处理会相当艰难,耗费算法工程师大量的时间精力。因此设置各类自动化的数据检查就显得尤为重要,例如Tensorflow Data Validation就是这方面比较知名的一个library。
O’Reilly在20年做了个关于数据质量方面的调研,发现企业中存在的主要数据问题如下所示:

除上述问题外涉及到模型应用,各类drift的探测也相当重要,比如输入数据的分布变化(data drift),或者输入数据与预测目标之间关系的变化(concept drift)。为了应对这些数据质量问题,我们需要根据不同的业务领域设计相应的数据质量检查模板,并结合具体情况进行各类属性,统计,甚至基于模型的数据问题检查。

数据工程
这部分的工作包括数据清洗,数据转换,特征工程。根据业务形态的不同,这部分所占的比重可能会各不相同,但总体上来说这部分在整个模型开发过程中占的比重和遇到的挑战是比较大的。包括:
- 对于大量数据处理逻辑的管理,调度执行和运维处理。
- 对于数据版本的管理和使用。
- 对于数据复杂依赖关系的管理,例如数据血缘。
- 对于不同形式数据源的兼容和逻辑一致性,例如lambda架构对batch,realtime两种数据源类型的处理。
- 对于离线和在线数据服务需求的满足,例如离线模型预测和在线模型服务。
以数据血缘为例,一个经常遇到的场景是当我们发现下游数据有问题时,可以通过数据血缘图快速定位上游依赖项,分别进行排查。而在问题修复后,又可以通过血缘关系重新运行所有影响的下游节点,执行相关测试验证。

在建模应用领域,有不少数据处理特征工程方面的操作和应用会更加复杂,例如:
需要使用模型来生成特征,例如各种表达学习中学到的embedding信息。
需要考虑特征计算生成的实践开销与其所带来的模型效果提升的权衡。
跨组织的特征共享与使用。
在这些挑战下,feature store的概念逐渐兴起。

关于这方面又是一个比较大的话题,我们先不做细节展开。从上图可以看出的一个基础特性是我们会根据在线离线的不同访问pattern,选用不同的存储系统来存放特征数据。另外在下游消费时也要考虑特征的版本信息,确保整个流程的稳定可复现。
模型构建
模型构建方面总体来说是受到关注与讨论比较多的部分,有非常多成熟的机器学习框架来帮助用户训练模型,评估模型效果。这块MLOps需要提供的支持包括:
- 模型开发过程中的结果评估与分析,包括指标误差分析,模型解释工具,可视化等。
- 模型本身的各类元数据管理,实验信息,结果记录(指标,详细数据,图表),文档(model card)等。
- 模型训练的版本化管理,包括各种依赖库,训练代码,数据,以及最终生成的模型等。
- 模型在线更新和离线再训练,增量训练的支持。
- 一些模型策略的集成,例如embedding的提取与保存,stratified/ensemble模型支持,transfer learning之类的增量训练支持等。
- AutoML类的自动模型搜索,模型选择的支持。
在模型实验管理方面,可以借鉴的产品有MLflow,neptune.ai,Weights and Biases等。

从以模型为中心的角度来看,与feature store一样,我们需要进一步引入model repository,支持链接到实验结果的记录,以及模型部署状态,线上监控反馈等信息的打通。各类与模型运维相关的操作都可以在这个组件中进行支持。开源方面的实现可以关注 ModelDB 。
集成测试
完成数据和模型两大块pipeline的构建后,我们需要执行一系列的测试验证来评估是否能将新模型部署到线上。包括:
- 模型预测方面的测试,如精度,预测稳定性,特定case回归等。
- Pipeline执行效率的测试,如整体执行时间,计算资源开销量等。
- 与业务逻辑集成的测试,如模型输出的格式是否符合下游消费者的要求等。
参考Google经典的ML Test Score,具体有以下各类测试:
- 数据验证测试,除了对原始数据输入方面的数据质量检查外,在机器学习的pipeline中做的各类数据特征处理,也需要用一系列的测试来验证其符合预期。
- 特征重要度测试,对于各类构建的特征,我们需要确保其在模型中的贡献度,以免造成计算资源和特征存储上的浪费。对于无用的特征也需要及时清理,控制pipeline的整体复杂度。
- 隐私审计等相关要求测试。
- 模型训练测试,模型应该能够利用数据进行有效训练,如loss会在训练中呈下降趋势。并且预测目标相对于业务目标是有提升作用。
- 模型时效性测试,与旧版本模型的效果进行比对,测试模型指标的下降速度,并设计模型的重训练周期。
- 模型开销测试,确保复杂模型的训练时间投入产出比,相比简单的规则和基线模型有显著的效果提升。
- 模型指标测试,确保模型的测试集验证或特定回归问题验证能够通过。
- 模型公平性测试,对敏感信息,例如性别,年龄等,模型应该在不同特征分组的情况下表现出公平的预测概率。
- 模型扰动测试,对模型的输入数据进行微小的扰动,其输出值的变动范围应该符合预期。
- 模型版本比对测试,对于没有进行重大更新的模型,例如例行触发的retrain,两个模型版本的输出之间不应该有过大的差别。
- 模型训练框架测试,例如重复执行2次相同的训练,应该给出稳定可复现的结果。
- 模型API测试,对于模型服务的输入输出做验证测试。
- 集成测试,对整个pipeline进行运行和验证,确保各个环节的衔接正确。
- 线上测试,在模型部署但对外服务前,需要进行与离线环境相同的一系列验证测试,确保运行结果无误。

模型部署
通过测试后,我们就可以把模型部署上线啦。这里又根据业务形态的不同分成很多不同的类型,需要考虑不同的发布方式,例如:
- Batch预测pipeline
- 实时模型服务
- Edge device部署,如手机app,浏览器等
模型部署的assets除了模型本身外,也需要包含end-to-end测试用例, 测试数据和相应的结果评估等。可以在模型部署完成后再执行一遍相关测试用例,确保开发和部署环境中得到的结果一致。
对于输出较为critical的模型,还需要考虑一系列model governance的需求满足。例如在模型部署前需要进行各类人工审核,并设计相应的sign-off机制。顺带一提responsible AI近年来也是越来越受到重视,在MLOps中的各个环节也需要关注相应功能的支持。
模型服务
在模型服务流程中,也需要有许多检查与策略的融入,才能保证整体输出的可靠性和合理性。各类测试检查的逻辑可以借鉴前面的测试环节的例子。

模型服务在形式上也非常多变:

因此涉及到的话题也非常多,例如实时模型服务需要考虑模型的序列化,异构硬件利用,推理性能优化,动态batch,部署的形式(container, serverless),serving缓存,model streaming等。要是涉及到在线更新,还需要考虑online learning的实现。

对于edge deploy,我们需要考虑模型的不同打包方式,模型压缩等。甚至还可以做hybrid形式的serving或联邦学习,例如像智能音箱,可以在设备端部署一个简单的模型来接收唤醒指令,而将后续复杂的问答发送到云端的复杂模型进行处理。

在上述模型部署步骤完成时一般也不算是正式发布,一般会使用一些策略来逐渐用新模型来替代旧模型,包括shadow model,canary部署,A/B测试,甚至MAB自动模型选择策略等。
在云原生时代Kubeflow中提供的一系列serverless serving,弹性伸缩,流量管理,以及附加组件(异常检测,模型解释)等方面的能力非常强大,值得学习:

模型监控
最后,对于线上模型的运行,我们需要持续进行监控,包括:
- 模型依赖组件的监控,例如数据版本,上游系统等
- 模型输入数据的监控,确保schema与分布的一致性
- 离线特征构建与线上特征构建输出的一致性监控,例如可以对一些样本进行抽样,- - 比对线上线下结果,或者监控分布统计值
- 模型数值稳定性的监控,对NaN和Inf等情况进行记录
- 模型计算资源开销方面的监控
- 模型metric方面的监控
- 模型更新周期的监控,确保没有长时间未更新的模型
- 下游消费数量的监控,确保没有处于“废弃”状态的模型
- 对于排查问题有用的日志记录
- 对于提升模型有用的信息记录
- 外界攻击预防监控
上述的各类监控都要配合相应的自动/人工应对机制。
以模型效果监控为例,当效果出现下降时,我们需要及时介入排查处理,或触发重训练。对于重训练来说,需要综合考虑模型效果变化,数据更新频率,训练开销,部署开销,重新训练的提升度等,选择合适的时间点进行触发。虽然有很多模型也支持在线实时更新,但其稳定性控制,自动化测试等都缺少标准做法的参考,大多数情况下,重新训练往往比在线更新训练的效果和稳定性更好。

而如果出现了依赖数据的问题,我们也可以设计一系列的降级策略,例如使用最近一版正常的历史数据,或者丢弃一些非核心特征,使用更基础的模型/策略给出预测等。
另外这里还有一个比较有意思的trade-off,如果环境变化较快,而模型重训练的代价又很高,有时候可以考虑使用更简答一些的模型策略,往往对于环境变化的敏感度没有那么高,但代价是可能会有一些效果上的损失。
流程串联
Google的这篇文章中,提出了3个level的MLOps流程自动化,将上述我们介绍的各个流程中可以自动化的部分进行了整体的串联,堪称MLOps的最佳实践之一。其中两个关键的自动化提升是pipeline自动化和CI/CD/CT自动化。另外一个比较核心的思想是模型部署并不只是部署一个模型对外提供服务的API,而是把整个pipeline进行打包部署。另外一个值得参考的方法论来自于Martin Fowler的CD4ML,其中还包含了很多具体组件的选择建议。

在整体的串联过程中,一些通用的依赖项有:
- 版本控制系统,包括数据,代码,和各类机器学习相关artifacts。
- 测试与构建系统,可以将各类运行逻辑在版本更新后自动执行相应测试,通过后打包成pipeline执行的组件镜像。
- 部署系统,可以将pipeline整体部署到应用环境,包括线上服务和客户端等。
- 模型中心,储存已经训练好的模型,对于训练时间较长的场景来说尤为重要。
- Feature store,存储各类特征,并服务于离线场景的批量消费和在线场景的实时查询消费。
- ML meta store,存储实验训练中产生的各类数据,包括实验名称,使用的数据,代码版本信息,超参数,模型预测相关的数据和图表等。
- Pipeline框架,串联一系列工作流程的执行框架,包括调度执行,断点续跑,自动并行等等特性。
这些依赖组件中有不少是MLOps中出现的新需求,业界也开始有各类对应产品的涌现,例如Michelangelo,FBLearner,BigHead,MLflow,Kubeflow,TFX,Feast等等。但目前看起来各个组件还远没有达到像Web开发持续集成那样的标准化和成熟程度。例如对于workflow/pipeline组件的选择,可以参考这个调研。CI/CD方面,传统的Jenkins,GoCD,CircleCI,Spinnaker等基本也可以满足需求,当然也可以考虑DVC出品的CML,更加针对机器学习场景来定制。Arize AI的这篇整体ML infra的介绍包含的scope更加全面,对于MLOps中各个组件的选型都可以提供一些参考。对应的开源方面的资源可以参考 awesome production ML。

最后在设计选型过程中,可以根据以下这个canvas来进行思考规划。

针对整个流程的开发演进,建议通过敏捷迭代的形式进行。即先开发一个基础的能跑通的pipeline,使用最基础的数据和简单模型,把整个流程搭建起来。后续通过业务反馈,再去发现整个流程中的重要改进点,逐渐去迭代交付。
五、Summary
MLOps如果能做的好,可以获得很多回报。个人感觉其中价值最大的有两点,一是通过各种工程上的最佳实践,提升了团队整体开发交付模型的效率。二是由于项目运维成本的降低,我们将有机会大大提升机器学习类应用的scale能力,例如在企业内上线上千个模型来为各方面的业务场景产出价值。
Tensorflow Serving
Tensorflow自带Tensorflow Extended (TFX)。TFX使我们能够专注于优化ML管道,同时减少对每次重复的样板代码的关注。像数据验证和模型分析这样的组件可以很容易地完成,而不需要开发自定义代码来读取数据并在两次管道执行之间检测异常。使用TFX,只需要很少几行代码就可以完成,从而节省了大量开发管道组件的时间。数据验证和模型分析组件中的截图来自TFX。
- 【2021-7-1】如何用TF Serving部署TensorFlow模型,TF Serving文档,TensorFlow Serving可抽象为一些组件构成,每个组件实现了不同的API任务,其中最重要的是Servable, Loader, Source, 和 Manager
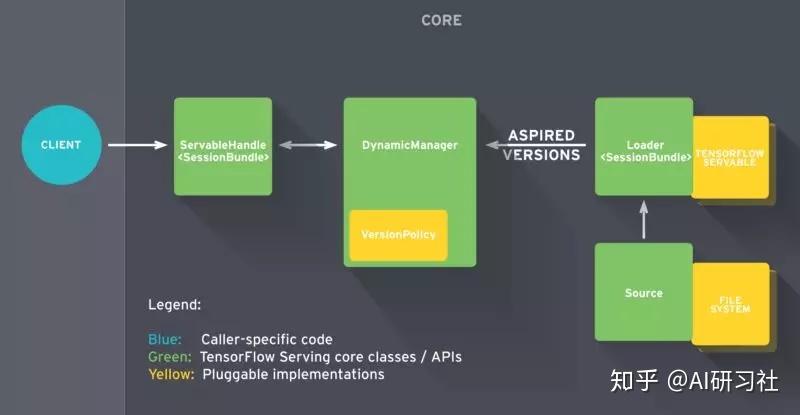
- 当TF Serving发现磁盘上的模型文件,该模型服务的生命周期就开始了。
- Source组件负责发现模型文件,找出需要加载的新模型。实际上,该组件监控文件系统,当发现一个新的模型版本,就为该模型创建一个Loader。总之,Loader需要知道模型的相关信息,包括如何加载模型如何估算模型需要的资源,包括需要请求的RAM、GPU内存。Loader带一个指针,连接到磁盘上存储的模型,其中包含加载模型需要的相关元数据。不过记住,Loader现在还不允许加载模型。Loader创建完成后,Source组件将其发送至Manager,作为一个待加载的版本。
- Manager收到待加载模型版本,开始模型服务流程。此处有两种可能性,第一种情况是模型首次推送部署,Manager先确保模型需要的资源可用,一旦获取相应的资源,Manager赋予Loader权限去加载模型。第二种情况是为已上线模型部署一个新版本。Manager会先查询Version Policy插件,决定加载新模型的流程如何进行。具体来说,当加载新模型时,可选择保持 (1) 可用性 或 (2) 资源。如果选(1)可用性,意味着我们倾向于确保系统对客户请求总能相应。Manager让Loader实例化新的计算图和新的权重。此时模型的两个版本被都被加载,也就是说Manager先加载新版本模型确保其可以安全服务后,然后再卸载原版本模型。如果选(2)资源,如果我们希望节省资源不为新版本模型申请额外的资源,可选择保持资源。对于重量级模型也许挺有用,模型切换间会有极短的可用性缺口,不过可以换取内存不足。
- 最后,当用户请求模型的句柄,Manager返回句柄给Servable。
TF特性
以下特性:
- 支持多种模型服务策略,比如用最新版本/所有版本/指定版本, 以及动态策略更新、模型的增删等
- 自动加载/卸载模型
- Batching
- 多种平台支持(非TF平台)
- 为gRPC expose port 8500,为REST API expose port 8501
服务框架
- Google在2017年的TensorFlow开发者Summit上便提出了TensorFlow Serving 官方文档。可以将训练好的模型直接上线并提供服务。
- 客户端和服务端的通信只支持gRPC。在实际的生产环境中比较广泛使用的C/S通信手段是基于RESTfull API的,幸运的是从TF1.8以后,TF Serving也正式支持RESTfull API通信方式了。

TF Serving工作流程
- 基于TF Serving的持续集成框架还是挺简明的,基本分三个步骤:
- 模型训练:主要包括数据的收集和清洗、模型的训练、评测和优化;
- 模型上线:前一个步骤训练好的模型在TF Server中上线;
- 服务使用:客户端通过gRPC和RESTfull API两种方式同TF Servering端进行通信,并获取服务;
- TF Serving的工作流程主要分为以下几个步骤:
- Source会针对需要进行加载的模型创建一个Loader,Loader中会包含要加载模型的全部信息;
- Source通知Manager有新的模型需要进行加载;
- Manager通过版本管理策略(Version Policy)来确定哪些模型需要被下架,哪些模型需要被加载;
- Manger在确认需要加载的模型符合加载策略,便通知Loader来加载最新的模型;
- 客户端像服务端请求模型结果时,可以指定模型的版本,也可以使用最新模型的结果;
- 示意图 img

调用方式
- TF Serving客户端和服务端的通信方式有两种(gRPC和RESTfull API)
- (1)RESTfull API
- (2)gRPC形式
Saver
存储格式:
- (1)ckpt:首先这种模型文件是依赖 TensorFlow 的,只能在其框架下使用;
- (2)pb:它具有语言独立性,可独立运行,封闭的序列化格式,任何语言都可以解析它,它允许其他语言和深度学习框架读取、继续训练和迁移 TensorFlow 的模型;保存为 PB 文件时候,模型的变量都会变成固定的,导致模型的大小会大大减小
代码示例
import tensorflow as tf
x = tf.placeholder(tf.float32, [1, 2], name='input_x')
y = tf.placeholder(tf.float32, [1, 2], name='input_y')
z = tf.Variable([[1.0, 1.0]], name='var_z')
a = x + y
tf.identity(a, name="output_a")
b = x - y
tf.identity(b, name="output_b")
sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op)
result_add = sess.run(a, feed_dict={x: [[1, 2]], y: [[3, 4]]})
result_del = sess.run(b, feed_dict={x: [[1, 2]], y: [[3, 4]]})
print(result_add)
print(result_del)
# ---- 保存(ckpt) -----
tf.train.Saver().save(sess, './ckpt_model/model.ckpt')
#checkpoint 文本文件,记录了模型文件的路径信息列表
#model.ckpt.data-00000-of-00001 网络参数值
#model.ckpt.index 文件保存了当前参数名和索引
#model.ckpt.meta 保存模型的网络结构
# ---- 保存(pb) -----
tf.saved_model.simple_save(sess, "./pb_model/", inputs={ "input_x": x, "input_y": y}, outputs={ "result_add": a, "result_sub": b})
# saved_model.pb 保存图形结构
# variables 保存训练所习得的权重。
# ---- 加载(ckpt) -----
ckpt = tf.train.get_checkpoint_state('./ckpt_model/')
saver = tf.train.import_meta_graph(ckpt.model_checkpoint_path + '.meta')
with tf.Session() as sess:
saver.restore(sess, ckpt.model_checkpoint_path)
x = sess.graph.get_tensor_by_name("input_x:0")
y = sess.graph.get_tensor_by_name("input_y:0")
a = sess.graph.get_tensor_by_name("output_a:0")
b = sess.graph.get_tensor_by_name("output_b:0")
result_add = sess.run(a, feed_dict={x: [[1, 2]], y: [[3, 4]]})
result_sub = sess.run(b, feed_dict={x: [[1, 2]], y: [[3, 4]]})
print(result_add)
print(result_sub)
# ---- 加载(pb) -----
with tf.Session() as sess:
tf.saved_model.loader.load(sess, ["serve"], "./pb_model")
graph = tf.get_default_graph()
x = sess.graph.get_tensor_by_name("input_x:0")
y = sess.graph.get_tensor_by_name("input_y:0")
a = sess.graph.get_tensor_by_name("output_a:0")
b = sess.graph.get_tensor_by_name("output_b:0")
result_add = sess.run(a, feed_dict={x: [[1, 2]], y: [[3, 4]]})
result_sub = sess.run(b, feed_dict={x: [[1, 2]], y: [[3, 4]]})
print(result_add)
print(result_sub)
# ---- 格式转换(ckpt→pb) -----
ckpt = tf.train.get_checkpoint_state('./ckpt_model/')
saver = tf.train.import_meta_graph(ckpt.model_checkpoint_path + '.meta')
with tf.Session() as sess:
saver.restore(sess, ckpt.model_checkpoint_path)
x = sess.graph.get_tensor_by_name("input_x:0")
y = sess.graph.get_tensor_by_name("input_y:0")
a = sess.graph.get_tensor_by_name("output_a:0")
b = sess.graph.get_tensor_by_name("output_b:0")
result_add = sess.run(a, feed_dict={x: [[1, 2]], y: [[3, 4]]})
result_sub = sess.run(b, feed_dict={x: [[1, 2]], y: [[3, 4]]})
tf.saved_model.simple_save(sess, "./ckpt2pb/", inputs={"input_x": x, "input_y": y}, outputs={"result_add": a, "result_sub": b})
print(result_add)
print(result_sub)
- 分别介绍,Tensorflow 1.0 和 2.0两个版本的导出方法
Tensorflow 1.0 export
- 两件事:
- Step 1、创建 SignatureDefs
- Step 2、保存计算图和权重
- 代码:参考链接
builder = tf.saved_model.builder.SavedModelBuilder("out_dir")
# define signature which specify input and out nodes
predict_sig_def = (saved_model.signature_def_utils.build_signature_def(
inputs={"input_x":saved_model.build_tensor_info(fast_model.input_x)},
outputs={"out_y": saved_model.build_tensor_info(fast_model.y_pred_cls),
"score": saved_model.build_tensor_info(fast_model.logits)},
method_name=saved_model.signature_constants.PREDICT_METHOD_NAME))
# add graph and variables
builder.add_meta_graph_and_variables(sess, ["serve"],
signature_def_map={"fastText_sig_def": predict_sig_def},
main_op=tf.compat.v1.tables_initializer(),
strip_default_attrs=True)
builder.save()
- 注意:此处保存时的signature、input、out的相关属性应与Client端传参对应:
- name(自定义,不用和图内节点名称相同)
- shape
- data type
Tensorflow 2.0 export
- Keras 模型均可方便地导出为 SavedModel 格式。不过需要注意的是,因为 SavedModel 基于计算图,所以对于使用继承 tf.keras.Model 类建立的 Keras 模型,其需要导出到 SavedModel 格式的方法(比如 call )都需要使用 @tf.function 修饰。
- 代码,参考
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
@tf.function
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
model = MLP()
- 使用下面的代码即可将模型导出为 SavedModel
tf.saved_model.save(model, "保存的目标文件夹名称")
检查SavedModel
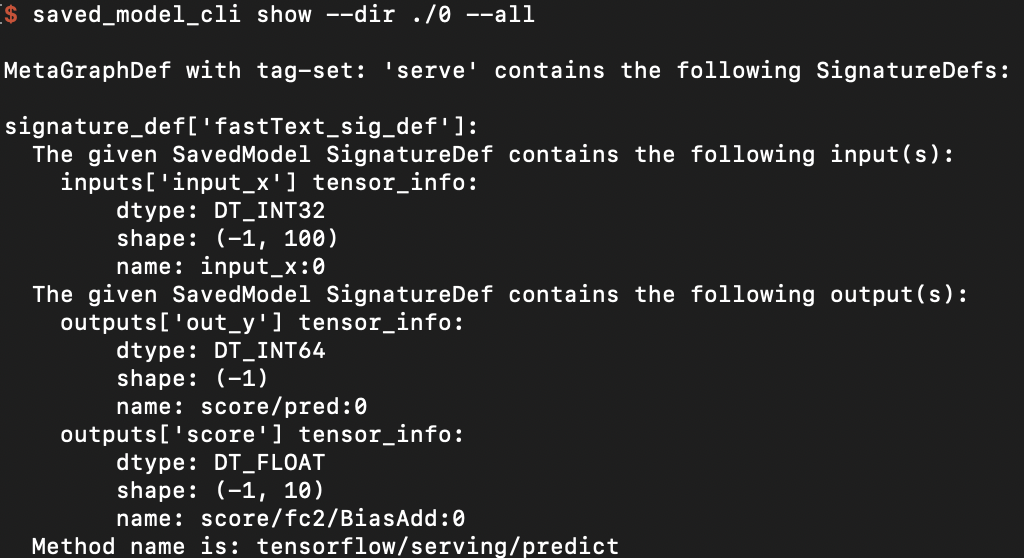
- 检查保存的模型的SignatureDef、Inputs、Outputs等信息,可在cmd下使用命令
saved_model_cli show --dir model_dir_path --all
- 结果
SavedModel是TensorFlow模型的一种通用序列化格式。如果你熟悉TF,你会使用 TensorFlow Saver to persist保存模型变量。TensorFlow Saver提供模型checkpoint磁盘文件的保存/恢复。事实上SavedModel封装了TensorFlow Saver,对于模型服务是一种标准的导出方法。
SavedModel对象有一些不错的特性。
- 首先,一个SavedModel对象中可存储一个或更多的meta-graph,换句话说,这个特性允许我们为不同的任务订制不同的计算图。例如模型训练完成后,大多数情况下使用推理模式时,计算图中不需要一些用于训练的特殊操作,包括优化器、学习率调度变量、额外的预处理操作等等。
- 另外,有时候可能需要将计算图简化作移动端部署。SavedModel允许用户以不同的配置保存计算图。SavedModel提供了SignatureDefs,简化了这一过程。SignatureDefs定义了一组TensorFlow支持的计算签名,便于在计算图中找到适合的输入输出张量。简单的说,使用这些计算签名,可以准确指定特定的输入输出节点。TF Serving要求模型中包含一个或多个SignatureDefs,以使用内建服务API。
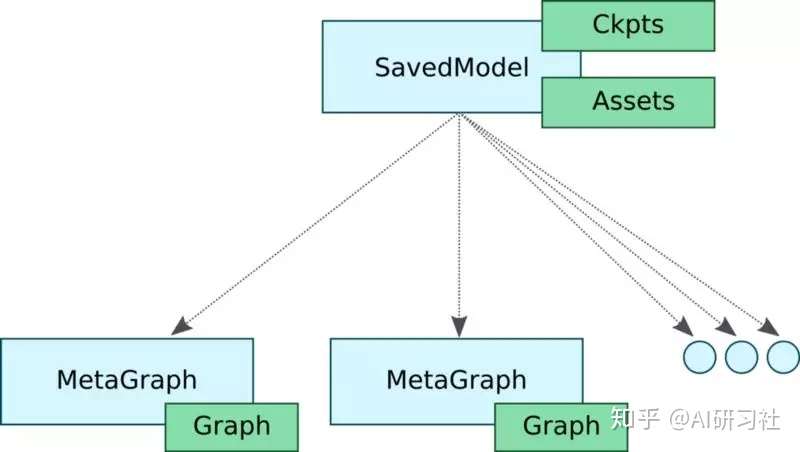
Serving
- 模型保存好,就到Serving端的加载与预测步骤了。在介绍Tensorflow Serving之前,先介绍下基于 Tensorflow Java lib 的解决方案
Tensorflow Java lib
- 参考链接
- Tensorflow提供了一个Java API(本质上是Java封装了C++的动态库), 允许在Java可以很方便的加载SavedModel, 并调用模型推理。
- 添加依赖
- 在maven的pom.xml中添加依赖(如下A),此处tensorflow的版本最好与python训练版本一致。
- Load & Predict
- 加载模型,调用模型在线预测。以fast text模型为例
- 预测代码(如下B)
- Pros & Cons
- Java 端和 Python 端调用模型推理,结果一致,可以满足基本使用
- 适用场景
- 需求简单,人力成本有限(一锤子买卖)
- 网络限制,不易搭建Tensorflow Serving
- 可能存在的问题
- 优化少,效率未必高
- Java 封装 C++ 动态库,有些变量需要手动释放,若使用不当,可能出现内存泄漏
- 无开箱即用的版本管理、并发处理等功能
- API 不在 Tensorflow稳定性保障范围内
- 资料匮乏,google投入的维护少
- 添加依赖
A 依赖文件
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.11.0</version>
</dependency>
B 预测代码:
package model;
import org.tensorflow.SavedModelBundle;
import org.tensorflow.Session;
import org.tensorflow.Graph;
import org.tensorflow.Tensor;
public class FastTextModel {
SavedModelBundle tensorflowModelBundle;
Session tensorflowSession;
void load(String modelPath){
this.tensorflowModelBundle = SavedModelBundle.load(modelPath, "serve");
this.tensorflowSession = tensorflowModelBundle.session();
}
public Tensor predict(Tensor tensorInput){
// feed()传参类似python端的feed_dict
// fetch()指定输出节点的名称
Tensor output = this.tensorflowSession.runner().feed("input_x", tensorInput).fetch("out_y").run().get(0);
return output;
}
public static void main(String[] args){
// 创建输入tensor, 注意type、shape应和训练时一致
int[][] testvec = new int[1][100];
for(int i=0; i<100; i++){
testvec[0][i] = i;
}
Tensor input = Tensor.create(testvec);
// load 模型
FastTextModel myModel = new FastTextModel();
String modelPath = "Your model path";
myModel.load(modelPath);
// 模型推理,注意resultValues的type、shape
Tensor out = myModel.predict(input);
float[][] resultValues = (float[][]) out.copyTo(new float[1][10]);
// 防止内存泄漏,释放tensor内存
input.close();
out.close();
// 结果输出
for(int i=0; i< 10; i++) {
System.out.println(resultValues[0][i]);
}
}
}
Tensorflow Serving
Tensorflow Serving 是google为机器学习模型生产环境部署设计的高性能的服务系统。具有以下特性:
- 支持模型版本控制和回滚
- 支持并发与GPU加速,实现高吞吐量
- 开箱即用,并且可定制化
- 支持多模型服务
- 支持 gRPC/ REST API 调用
- 支持批处理
- 支持热更新
- 支持分布式模型
- 支持多平台模型,如 TensorFlow/MXNet/PyTorch/Caffe2/CNTK等
Tensorflow Serving 丰富的、开箱即用的功能,使得其成为业内认可的部署方案。
Tensorflow Serving 内部的工作流如下图所示。
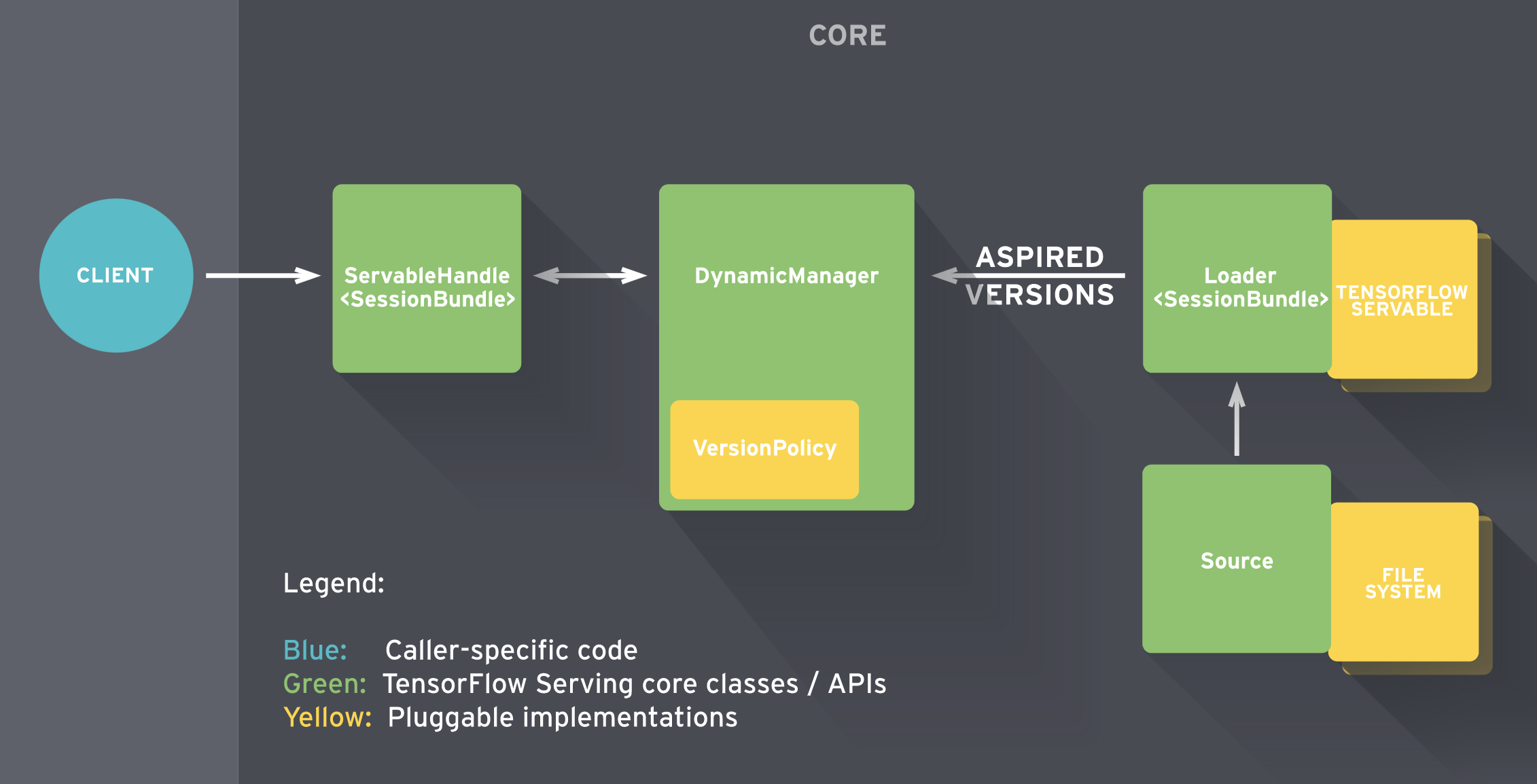
简单的说:
- Sources 创建 Servable(可理解为计算图)的 Loader
- Loader 传递版本号给 Manager 由其决定是否加载,同时 Manger 负责管理 Servable 并响应 Client的请求
详情见:参考链接
相比方案一,Tensorflow Serving要做的事情要多一点,但长远来看收益也更高。从零开始的话,大概要经过如下步骤:
- Tensorflow serving环境搭建
- 部署模型
- 解决Client依赖
- Client代码编写
基于Docker的环境搭建及部署见原文
Client
- Tensorflow Serving 支持 RESTful 和 gRPC 两种API。若使用 RESTful API 调用,相关协议请见参考链接。
- 这里着重介绍 gRPC的调用方法, Tensorflow Serving 的 gRPC API 在 protobuf 文件中定义,一般需要将其编译成相应的 Client 源码,再集成至应用。
解决依赖
- 若使用 Python 作为 Client , 安装对应包即可:
- pip install tensorflow-serving-api
- 若使用 Java 作为 Client,则需要编译 proto 文件,好处是用户可以编译自定义的API。编译流程参考了前人文档,此外还有一些要注意的点
- 获取 protobuf 文件
- 注意版本问题,因为由 .proto 文件编译出来的 java class 依赖 tensorflow的 jar 包,可能存在不兼容问题
- 生成 Java 源码
- 向maven项目中添加依赖
- 安装 protoc 工具
- 编译protobuf文件,两种方法可选择,通过插件编译或者手动编译
- 获取 protobuf 文件
Client编写
- 分别给出 Python 和 Java Client 的简单示例
Test
一致性测试
- 验证了 Text Cnn 和 base BERT 模型,分别用 Python 和 Tensorflow Serving 加载相同模型,输入10组不同数据,输出结果比对一致!
性能测试
- 以文本分类任务为例,这边一共训练了四个模型,基本覆盖了主流网络结构(Cnn/Rnn/Transformer):
- Fast text
- Text Cnn
- Rcnn (1 layer Bilstm + pooling)
- BERT (12 layer)
- 此外,还针对单线程和多线程请求作了对比测试。
测试结论
- Tensorflow Serving 的输出可靠;
- Tensorflow Serving 运行效率极高,达到生产上线要求。
资料
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
