量化交易
- 【2022-10-12】如何学习量化交易
业界观点
- 【2022-3-6】全国政协委员贺强:量化交易虽不违法,但对散户不公平,要加以监管
全国政协委员、中央财经大学证券期货研究所所长贺强:
- (1)在发达国家、特别是美国股市中,个人投资占比不大,主要是机构投资、法人投资。机构与机构之间采用量化交易,是对等的、公平的。
- 量化交易在发达国家已经成为一种趋势,美国与欧洲的机构量化交易数值已达到70%左右。
- (2)但我国股市以散户为主,散户在机构面前没有优势,量化交易大量从散户身上收割利益,这不太公平。对量化交易必须加以规范。
- 股民为主的市场,股市开户人数已达2亿户,99%以上可能都是散户。股民在股市中是弱势群体,信息不灵通,没有资金实力,更没有能力进行量化交易,在机构面前股民毫无优势。
- 光大证券量化交易事件,使我国投资者第一次感受到了量化交易的巨大影响。在2015年股灾中,公安部在上海查处了很多外资背景开立的贸易公司。这些公司大量进行股指期货量化交易,参与过度投机活动,导致了股指期货大涨大跌。投资者再一次对量化交易产生了深刻印象。
- 这两年,我国股票现货市场又出现了量化交易的热潮。量化交易像雨后春笋一样生长起来,规模不断扩大,几乎绝大多数机构都在进行量化交易。量化交易行业规模已经破万亿,在A股市场的成交占比达到了20%左右。
看法
- 从理论上讲,量化交易具有一些优点,可以增加市场的成交量、促进股市活跃、有利于形成合理价格,但是如果盲目发展,也会出现一些严重问题。
- 从性质上讲,量化交易短线操作获取的大量差价收益,就是从千千万万股民身上获得的利益,量化交易获利的主要方法是大量收割散户。以前机构是用镰刀割“韭菜”,现在是用智能化的机器人和联合收割机割“韭菜”。尤其要注意量化交易中的高频交易,主要是以博取短线差价为主,不是依靠长期投资分享上市公司业绩为主。
- 实际上,股市量化交易的问题已经引起了证监会的关注。证监会主席易会满在2021年第60届世界交易所联(WFE)会员大会暨年会上强调:量化交易、高频交易在增强市场流动性、提升定价效率的同时,也容易引发交易趋同、波动加剧、有违市场公平等问题。
在基金投顾业务开展过程中存在一些问题,基金投顾覆盖的投资者范围较小,投顾市场还存在“重投轻顾”的情况。如果独立基金销售机构参与基金投资顾问业务,恰好利于解决上述问题。
- 我国股市中的量化交易属于金融科技创新,要纳入监管范围,不能无序发展。特别是在股票现货市场,对量化交易必须进行一定的限制。
什么是量化交易
量化交易(Quantitative trading)
- 量化交易(量化投资)是指借助现代统计学和数学(机器学习)的方法,利用计算机技术来进行交易的证券投资方式。
- 量化交易从庞大的历史数据中海选能带来超额收益的多种“大概率”事件以制定策略,用数量模型验证及固化这些规律和策略,然后严格执行已固化的策略来指导投资,以求获得可以持续的、稳定且高于平均收益的超额回报。
技能
高频交易 vs 量化交易
【2022-10-21】高频交易与量化交易到底有什么区别?
- 高频策略对比低频策略有什么优势呢?Marcos Lopez的著名大作《Advances in Financial Machine Learning》第15章给出了数学推导。
- 高频交易几乎成为量化交易的代名词,主要原因可能不是它的效果比低频好,而是它能充分发挥计算机的算力优势,无论是训练过程还是执行交易过程,计算机在高频方面有天然的优势,人脑无法踏入这个领域。而如果是低频策略的话,人脑也能生成,未必需要用到计算机。
高频交易属于量化交易的一种,只是交易的频次非常高。
相同点都是利用数学、统计学、计量经济学等方法,从海量数据中寻找能够带来超额收益的”大概率”策略,并纪律严明地按照这些策略所构建的数量化模型来指导投资。
不同点
高频交易侧重于:
- 从极为短暂的市场变化中获利;
- 交易的交易量巨大,对计算处理速度、网速有着极高的要求,而且必须全自动化完成;
- 持仓时间很短,日内交易次数很多 ,每笔收益率很低,但是总体收益稳定;
量化交易(中低频)侧重:
- 通过海量数据挖掘,搜索可能产生超额收益的“大概率”事件来制定相应的投资策略;
- 通过资产估值来计算获利空间
- 通过投资组合和仓位管理来分散风险
- 可以自动化,也可以半自动化(即提供决策依据,交易由人工完成)
作者:觉行
量化交易历史

国际发展历史
量化交易全球的发展历史
- 量化投资的产生(60年代)
- 1969年,爱德华·索普利用他发明的“科学股票市场系统”(实际上是一种股票权证定价模型),成立了第一个量化投资基金。索普也被称之为量化投资的鼻祖
- 量化投资的兴起(70~80年代)
- 1988年,詹姆斯·西蒙斯成立了大奖章基金,从事高频交易和多策略交易。基金成立20多年来收益率达到了年化70%左右,除去报酬后达到40%以上。西蒙斯也因此被称为”量化对冲之王”。
- 量化交易的繁荣(90年代)
- 1991年,彼得·穆勒发明了alpha系统策略等,开始用计算机+金融数据来设计模型,构建组合
国内发展历史
2012年到2016年量化对冲策略管理的资金规模增长了20倍,管理期货策略更是增长了30倍,增长的速度是所有策略中最快的。相比美国量化基金发展历程,中国现在基本处于美国90年代至21世纪之间的阶段。
- 量化投资元年
- 2010年,沪深300股指期货上市,此时的量化基金终于具备了可行的对冲工具,各种量化投资策略如alpha策略、股指期货套利策略才真正有了大展拳脚的空间,可以说2010年是中国量化投资元年。
- 量化投资高速发展、多元化发展
- 2013-2015年股指新政之前可以说是国内量化基金有史以来最风光的一段时期。国内量化投资机构成批涌现,国内量化投资高速发展。
量化交易分类
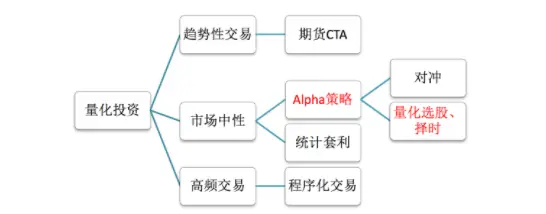
三种分类特点以及要求
- (1)趋势性交易
- 适合一些主观交易的高手,用技术指标作为辅助工具在市场中如鱼得水的,但如果只用各种技术指标或指标组合作为核心算法构建模型,从未见过能长期盈利的。
- 一般也会做一些量化分析操作,使用编程如python/matlab 。
- (2)市场中性
- 在任何市场环境下风险更低,收益稳定性更高,资金容量更大。适合一些量化交易者,发现市场中的alpha因子赚取额外收益,例如股票与股指期货的对冲策略等。
- 会做一些量化分析操作,使用编程如python/matlab。
- (3)高频交易
- 在极短的时间内频繁买进卖出,完成多次大量的交易,此类交易方式对硬件系统以及市场环境的要求极高,所以只有在成熟市场中的专业机构才会得到应用
- 适合一些算法高手,使用C/C++编程语言,去进行算法交易,对软硬件条件要求比较高。
- 1、金融专业出生,对金融市场环境非深入了解(交易员、基金经理)
- 2、基本了解金融基础、投资知识,对数据挖掘、机器学习方法擅长,挖掘股票等的价值 (quanter)
- 3、非常擅长算法,C/C++ ,编写程序化的一些交易方法 (程序化交易员)
更多:如何学习量化交易
炒股工具
- 【2022-1-12】WnStock, WnStock是个开源的查看股票行情软件,使用VC++/MFC开发,IDE选用Visual Studio 2010,如IDE版本非2010可能会存在编译错误
- 股票告警分析工具
机器学习炒股
- 【2019-1-4】利用深度学习和机器学习预测股票市场
- DL炒股算法
机器学习预测靠谱吗
- 深度学习做股票预测靠谱吗?
- 预测股市将如何变化历来是最困难的事情之一。这个预测行为中包含着如此之多的因素——包括物理或心理因素、理性或者不理性行为因素等等。所有这些因素结合在一起,使得股价波动剧烈,很难准确预测。
- 事实证明:
- 股票价格没有特定的趋势或季节性
- 股价受到公司新闻和其他因素的影响,如公司的非货币化或合并/分拆。还有一些无形的因素往往是无法事先预测的。
【2022-10-21】为何机器学习不被二级市场玩家重用?
- 金融市场本身的低
信噪比(signal-to-noise) 导致机器学习很容易出现过拟合。而这一特性导致投资管理人员很难有针对性地对投资组合进行调控。因此机器学习这一工具本身在选股场景下的应用场景还有待商榷。
机器学习的优势
2019年,Keywan Christian Rasekhschaffe 和Robert C. Jones 两位作者就在CFA旗下期刊Financial Analyst Journal (FAJ)发表论文论述机器学习在选股方面的应用。
- 在机器学习本身的特性,使得其能够帮助挖掘传统线性回归等统计工具所难以发现的规律,例如非线性关系以及解决多重共线性方面具备无可比拟的优势。论文原文链接: Machine Learning for Stock Selection
机器学习的缺点
机器学习的缺点也显而易见,金融市场本身数据噪音很大。这和传统机器学习擅长的数据场景有很大的不同。
- 以图像识别为例,一张照片到底是猫还是狗本身的争议性基本上很小很小。
- 但一个公司在某一阶段能否产生超额的资产回报这件事儿本身就见仁见智了,而且很可能存在市场内个别资产在某一时间内非理性的大涨大跌,而干扰整个数据集。
这也是为什么在金融市场应用中,常常见到的量化策略在样本内猛如虎,样本外哈士奇的原因。更可怕的是,典型的机器学习算法,在面对如此低信噪比的数据时,很容易出现过拟合的问题。
二位作者利用模拟数据测算,基本上在50次迭代 (iteration) 后,算法模型在样本外的误差不降反升,基本上只是在做过拟合的无用功。
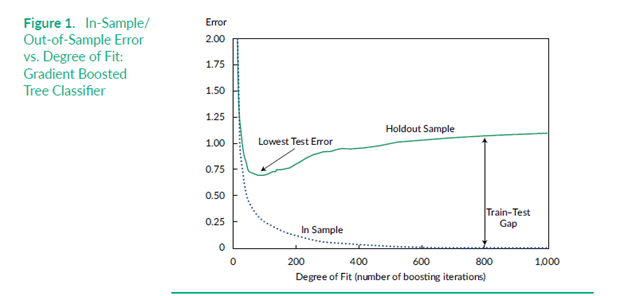
模拟数据内,机器学习迭代次数和样本外误差的关系当然,两位作者同样提及了一些技术性的解决方案,例如
- 合并多个算法模型的结果,基于不同样本、风险因子库数据、时间窗口进行数据训练和预测,并采用合并结果等等。
- 特征工程(feature engineering)则是采用另一种思路,对数据进行处理变形以提升数据本身的信噪比。最终结果也非常惊艳,合并算法的选股收益高于任何单一算法的收益,在纸面上取得了每年接近2%的超额回报,Rank IC达到了惊人的6.5%。绝对是优秀的主动管理组合的水平。
用LR预测股票
【2022-3-29】如何使用机器学习在股票市场交易
- 股市最基本的策略是低买高卖。但这并不简单。所以,建立一个模型,尽可能准确地预测股票的低点和高点。
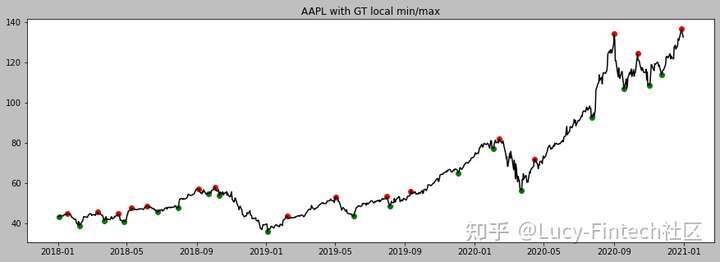
- 苹果股票从2018到2021的趋势, 绿点是局部极小值(低点),红点是局部极大值(高点)
用机器学习预测数据点是绿点(0类)还是红点(1类)。目标是如果模型预测到一个绿点,就买入,当股价上涨一定百分比时卖出。
四个步骤
- (1)使用机器学习模型预测某一天买入股票是否有利可图。
- (2)如果有利(绿点),买入股票。
- (3)一旦股票上涨了一定的百分比,就卖出股票获利。(红点前)
- (4)如果股票下跌了一定的百分比,就亏损出售股票。(红点后)
用股票价格和成交量作为LR模型的输入,并预测它是局部最小值还是局部最大值。
- 简单起见,创建一个0到1之间的值,表示所有四个值。该值由方程1计算得出。
- 如果标准化值接近1,这意味着该股票已接近当日高点收盘
- 如果标准化值接近0,则意味着该股票已接近当日低点收盘。
- 使用该值的优势在于与使用单一值(如当日收盘价或平均价)相比,它包含了全天价格行为的信息.

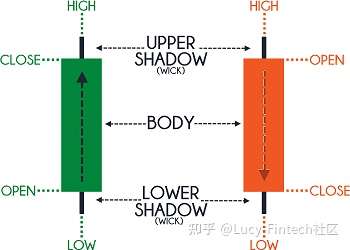
标准化股价
- 不直接使用股价,而是使用标准化股价作为第一个输入参数。
- 股票的价格包含最高价、最低价、开盘价和收盘价
- 成交量:模型中使用的第二个参数是每日成交量。表示特定日期的交易量。
- 3日回归系数:下一个参数是3日回归系数。通过对过去三天的收盘价进行线性回归计算得出的。代表了过去三天的股票走势。
- 5日回归系数:与3日回归系数类似的参数。
- 10日回归系数:同上。
- 20日回归系数:同上。
训练和验证模型定义模型之后,使用的数据集是道琼斯30指数的30家公司和标准普尔500指数的20家其他知名公司。
- 训练数据的时间跨度为2007年至2020年。
- 验证数据为2021年的数据。
-
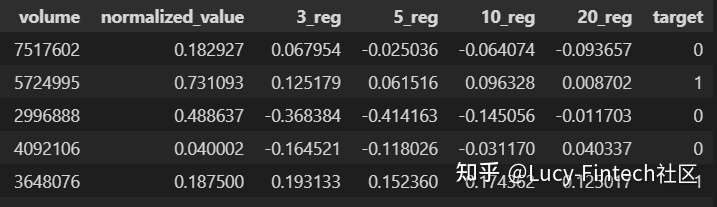
- 首先要找到代表买入点(图1中的0类或绿点)或卖出点(1类)的数据点。这是通过算法来实现的,该算法用于搜索局部最小值和最大值点。选择数据点后,收集交易量数据,并计算标准化价格值和回归参数。
- 用python的scikit包将数据拆分为训练集和验证集,并训练LR模型。
- 验证结果和分析验证集包含507个数据样本。经过充分训练的LR模型能够预测验证数据,准确率为88.5%
- 选择高盛(Goldman Sachs)的股价数据,并使用经过训练的LR模型预测了每天的股票走势。
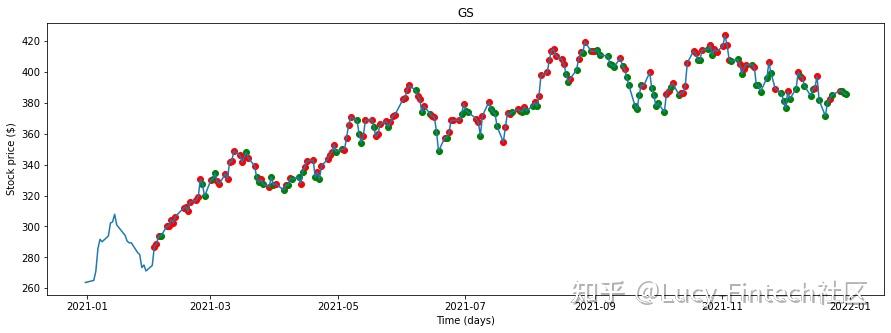
- 结果看起来很诱人,但模型预测了大量错误买入点。虽然它似乎能正确预测几乎所有的局部最小值,但它却错误地预测了买入点。因为训练阶段只使用局部极大值和局部极小值来训练模型。因此,模型对中间数据点的预测非常弱。
- 这是一个代价高昂的投资错误。毕竟,高买低卖不是我们的本意。那么如何解决这个问题,并更准确的选择买入点呢?
- 思路:分析混淆矩阵,通过改变LR模型的阈值来尝试减少这些误报,并确保模型以极高准确性预测买入点。为了确保模型更准确地预测买入点。
- 模型在类别0(买入点/局部最低)中预测了29个实例,而实际上它是类别1(卖点/局部最高)。这些都是假阳性值(错误地将阴性识别为阳性。阳性代表买入点)。
- 改进:模型的阈值更改为0.03,减少误报,并确保模型以极高准确性预测买入点
- 效果:错误预测的数量为零。然而,该模型忽略了许多真正的正值。模型只识别了5个买入点,没有识别出其它买入点。
| 调整前(0.5) | 调整后(0.03) | |
|---|---|---|
| 混淆矩阵 | 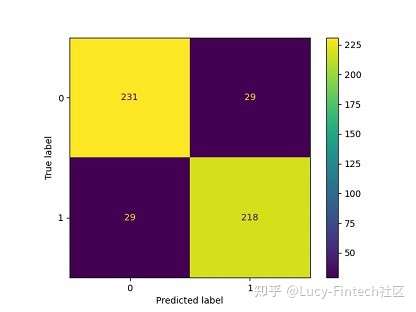 |
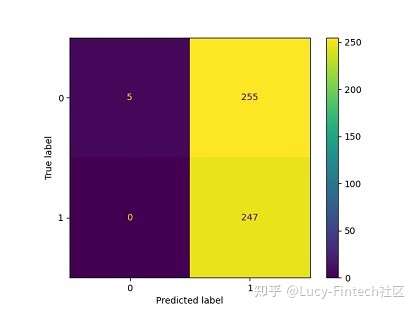 |
使用新阈值并重新绘制2021高盛股票的买入点

- 现在该模型可以更确定地预测购买机会。然而也错过了多次购买机会。这是必须做出的牺牲,以便以极高的确定性买入。
用2021个股票市场数据上测试策略。先创建一个股票模拟器和一个反向测试脚本
- 每天使用LR模型和给定阈值(t)扫描道琼斯30指数的买入机会。如果有可用的股票,模拟器就会购买股票并持有股票,直到达到一定的百分比收益(g)、一定的百分比损失(l)或在一定的天数(d)后卖出。
- 最终的回测模拟有四个参数: (t、g、l、d)
- 目标是利润最大化。
四种投资者类型。“没耐心的交易者”、“适度交易者”、“耐心摇摆交易者”和“非理性交易者”。
- 没耐心的交易者:这类交易者购买并持有股票的时间非常短。这类交易者害怕亏损,并且只为获得很小的收益。所以如果股价下跌一点点,此类交易者往往会以亏损卖出股票。所以,这类交易者的参数是: t=0.3,g=0.005,l=0.001和d=3。
- 适度交易者:这类交易者购买股票并持有一段适度的时间。交易者正在寻找信心较高的股票,因此阈值往往较低。与不耐烦的交易者相比,交易者也寻求更高收益,对损失有更高的容忍度。对于这类交易者,参数为 t=0.1、g=0.03、l=0.03和d=10。
- 耐心摇摆交易者:正如“摇摆”一词所暗示的那样,这类交易者往往持有股票的时间更长。此外,交易者喜欢选择成功概率高的股票。所以这类交易者的门槛很低。这类交易者的参数为: t=0.05、g=0.04、l=0.003和d=21。
- 非理性交易者:婴儿型交易者是对股票市场不熟悉的交易者。他们倾向于不合理地选择股票。因此,投资者不会使用任何策略来选择股票。这类投资者会随机挑选股票,并在任何时候随意抛售。
| 投资者类型 | t(阈值) | g(百分比收益) | l(百分比损失) | d(卖出天数) | 特点 | 2021年模拟收益率 |
|---|---|---|---|---|---|---|
| 没耐心 | 0.3 | 0.005 | 0.001 | 3 | 害怕亏损,短期持有,见好就收 | 30.41% |
| 适度 | 0.1 | 0.03 | 0.03 | 10 | 容忍亏损,中期持有,寻求更高收益 | 26.95% |
| 摇摆 | 0.05 | 0.04 | 0.003 | 21 | 长期持有,寻求成功率高的股票 | 47.77% |
| 非理性 | 婴儿型,随机选择、抛售股票 | 13.72% |
基于2021年的股票数据,每个投资者有3000美元作为他们的起始余额。
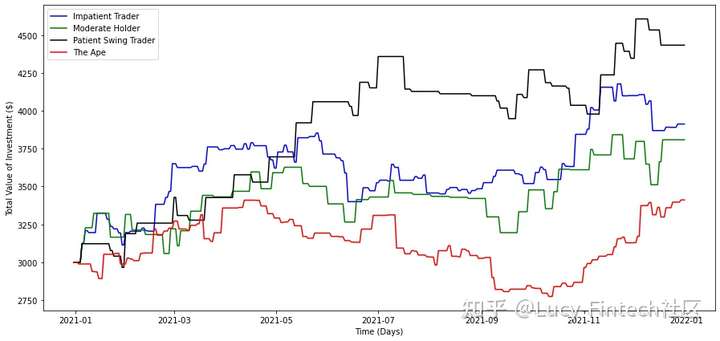
- 摇摆型交易者能够在2021年底获得47.77%的收益,其次是没耐心的交易者获得30.41%的收益。非理性交易者的回报率最低,涨幅为13.72%。
- 结果表明,在使用LR模型时,与频繁购买信心较低的股票相比,购买信心较高的股票并持有更长时间是有益的。我们也应该注意到,在2021美股股市是一个牛市,因为即使是非理性投资者,“猿类”,也有13.72%的回报率,这表明美股市场在2021年是慷慨的。
- 与标准普尔500指数的比较:前两个投资者模型(摇摆+没耐心)与标普2021年的业绩。
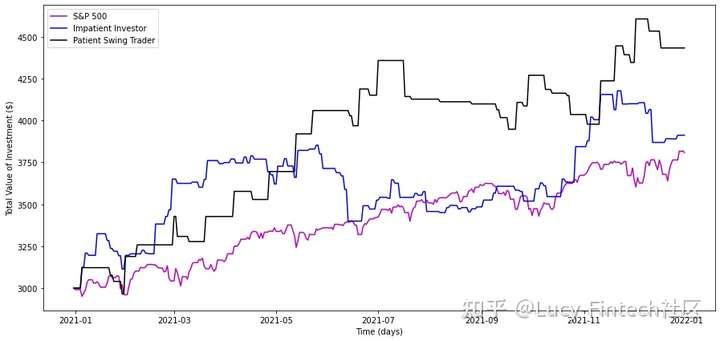
- 1月份向标准普尔500指数投资3000美元的表现。
- 结果表明,投资增长了26.9%。相比之下,“摇摆交易者”的回报率为47.77%,而“没耐心的交易者”的回报率为30.41%。

机器学习预测股票靠谱吗
观点:
- 文兄:日度的数据,用ML预测无卵用,加上盘口的高频数据ML倒是有可做的空间,但是还是无法满足DL对数据的质量要求。当然,如果是对策略进行优化,而不是纯以预测股价为目的,ML应该会有更多的应用空间。总之,DL现在做量化的应该是几乎不用的。
- solo:如果说机构还能构建模型,对散户来说应该是通过归纳找出某周期内胜率大于50%的操作方式,合理设置盈亏比,严格执行之。并时时统计这个周期内胜率变化,一旦变化,相应策略也要调整。市场是混沌的,预测冇意义,一切都是概率变化而已
- 子皿:股市预测的问题本质上是一个online learning 的问题,因为股票市场上的规律是不断地在变的。这也是为什么传统机器学习方法和深度学习方法在金融市场上容易被当成笑话的原因。也因此,reinforcement learning 是显然不适合金融市场的,reinforcenment learning的反馈太慢了,所以需要大量的数据才能学到数据背后的规律。显然,在online learning场景下我们没有办法提供大量的数据。
- Cerulean:深度强化学习靠不靠谱?
- 深度强化学习的本质还是监督学习,仅以离散动作空间为例,最大化多回合平均奖励函数的梯度和监督学习的最小化交叉熵的梯度公式是非常相似的,他们的唯一区别仅仅是前者乘以了一个根据具体问题正规化处理的奖励函数值。
- 张校长:深度学习来预测普遍存在的问题有两点。
- 数据缺失严重:数据当然是越精确越好, tick 级别的最好, 最近几年tick 级的数据好找,应该也比较准确。 但10 年之前 tick 级的数据就比较难找了, 就算找到也不能保证这是准确的。 导致能拿去训练的,只有08年 - 17 年这么多的数据。
- 过拟合:拿过去9年的数据做training , 最近1年做validation 。 调参数, 调出了一个比较好的参数。 但要怎么保证这个参数在未来的几个月内依然表现良好 ?为什么有很多策略回测表现完美,但实盘就不行了? 就是因为过拟合。
- 经济学到底能不能用数学来解释 ?
- 许多人把深度学习作为万能法宝, 但Andrew Ng 曾经说过,有些问题 如果人解决不了,那机器也不行。
- 张大雄:中低频交易不可能,高频有空间
一家量化交易公司实习时,一次meeting,我和老总还有一个资深大佬谈机器学习在股票和期货里面的应用。
| 实习生 | 大佬 | 场景 |
|---|---|---|
| LSTM在时间序列上应用的效果比较好,我们可以尝试把LSTM应用在股票预测上。 | 阴笑 | 大佬在阴笑,老总默不作声… |
| 你为啥笑 | 不work啊! 大佬终于忍不说有两个原因: 第一个是你如何保证你的因子有效? |
老总也在旁边强掩笑容 老总就补充到:对啊,你的模型很可能garbage in garbage out. |
| 那你们提供因子来训练模型啊 | 阴笑…. 第二个就是,你非常可能过拟合! |
|
| 那我们可以加regularization啊 | 他们忽略我,老总接着说: 其实我们是想要一个模型能根据每天的数据进行反馈,自动更新。 |
|
| 这TM的不就是reinforcement learning嘛,我说: 可以用reinforcement learning试试。 |
大佬又开始笑了,我很纳闷 大佬说:我就是知道他们有些人在用reinforcement learning,我才能赚钱!!! |
最后实习结束之后,在大佬的带领下,我才明白了交易的三重境界
- 归纳
- 演绎
- 博弈
所谓深度学习不过是基于历史数据进行拟合的归纳法罢了
- 如果把深度学习用来做股票预测,长期的是expected亏钱的
- 因为市场在变,规律在变,历史可能重演,但是又不尽相同。
深度学习肯定是可以用在股票市场的,比如针对某只股票的新闻情感分析等。但是不能用来预测市场走向!!!
- 想在市场上赚钱,就得博弈,你得知道其他人在干什么,因为市场是有所有的参与者共同决定的。 举个简单的博弈方法:
- 中国的期货市场之前很长一段时间,很多人,包括一些机构,都在用趋势策略,不同人和机构之间不外乎就是趋势的策略参数不同,让策略性能稍有不同,入市出市点不同,但是大体是类似的。
- 所以这时,你应该知道市场上有一部分资金是在用这种趋势策略在跑的,那么在未来的某一个时间点,这些策略会相继的发出信号,然后人们去执行买入卖出的操作。
- 有趣的地方来了,既然你已经知道有一部分人在干嘛了,你是不是就可以设计策略来巧妙的利用其他的人的策略呢?是不是可以设计一个类似的趋势策略,来告知你别人在这个时候可能会干嘛,而你来选择做更有意义的事情,而不是是不断去改进所谓的趋势策略呢?
所以,回到深度学习预测股票上:
- 用深度学习来归纳过去的数据,然后来预测股票走势,不靠谱。
- 但是如果能想办法把深度学习用在博弈问题上,那么有可能靠谱。 更新:我在另一个回答里举了一个应用深度学习和博弈思想的例子,有兴趣的可以了解下。
- MilKY:机器学习(非传统统计方法如回归)在量化金融方面有哪些应用?
- 参与交易的人,分为三类:
- 短期交易者
- 中期投机者
- 长期投资者。
- 大家喜欢说的价值投资就是长期投资者吧。这里的深度学习策略针对的是交易者和投机者。
- 尽管这里是深度学习在量化金融领域的应用,但是仍然是离不开人性和博弈的,深度学习在这里面更多的是一种工具性质的存在。
方法:
- 由于大部分散户的冲动和一部分基金从业者的新生力量需要时间磨练,市场上总是存在着因为走势而心情大变的人,心情一变,交易就受到影响,于是就犯错了,然后有老道者就可以抓住机会赚这一波钱。
- 一个简单情绪分析办法就是:拿到用爬虫爬取的这一天或这一周所有的新闻,以及你公司能够拿到的所有分析报告。然后分别用 LSTM模型 对新闻和报告进行情绪分析。
为什么这么做呢?首先新闻太多,报告太多,个体交易员或者一般的基金公司根本不可能有时间来全部消化,那么只能用机器来解决,而深度学习中的 LSTM模型 在自然语言处理领域的不错效果就可以被用在这里做情感分析了。然后用了LSTM之后能怎么样呢?
- 新闻:要时刻了解中国大妈们每天在看什么,可能会想什么,进而大概掌握大妈们未来的可能动向,从而设计相应的策略进行狙击。
- 报告:分析报告可能不是一般的散户能拿到的,所以拿到报告的大多数是机构,那么我们如果能用深度学习快速得到分析报告能带来信息,是不是可以抢人先机呢。
总结一下对博弈在交易里的理解。
核心思想:股市是零和博弈,无论你用不用深度学习,除了价值投资,你要赚钱,那么就得有人亏钱
- 所以说你的交易逻辑本身得是正确的才行,即设计好一个策略后,要知道你赚的钱是从哪来的。
- 很多人赚钱的时候稀里糊涂的,我们不妨称之为运气好。但是如果明白是运气好,并且不断探索原因的话,很有可能未来还会赚钱。
- 而事实是大多数人明明是运气好但是却觉得是自己聪明,从而未来大亏甚至倾家荡产。
- 如何应用深度学习呢,假设你已经明白了你得赚钱逻辑,但是这个逻辑里有些事情你一个人做不完,用计算机帮你做,用深度学习帮你做效率更好更快,那么深度学习不是就派上用场了。
深度学习不过是个复杂的函数映射逼近算法,你的逻辑就是函数,逻辑都不正确,逼近得再好又如何?
我自从2017年暑期在上海某私募基金实习之后,又在2017年圣诞节前后在湾区一家bitcoin fund实习了,然后自己私下做了一段时间交易,有一些新的理解分享给大家。
- 高频的东西不太懂,对于中低频而言,个人感觉,市场宏观分析,包括大国博弈,对世界进程有影响的大机构的发展,左右资源分配的局部战争,各个国家指定的政策,新兴事物的崛起等等,都会一定程度上影响到你关注的市场,这些才是决定市场走向的根本原因。
- 把握好大局之后,才是对具体标的的筛选,符合大趋势的标的,也有会做的好和做的不好区别,这个时候你可能要更进一步的阅读财报等更细节的信息。在筛选出标的之后,才是用技术分析对具体的某个标的的行情进行分析,选择对自己有利的入场点。
举个简单的例子
- 3/12/2020美股,币市等都因为COVID-19暴跌,虽然由疫情带来暴跌的黑天鹅事件很难预测,但是这暴跌之后,央行放水却是可以某种程度上预测的。那么这个时候需要选择在疫情中可能会崛起更快的标的(如Zoom,Amaozn)的股票,同时,高风险一点的,可以选择一些对抗央行放水的标的,比如BTC。
个人的PhD方向是做深度学习在医学影像领域的应用,目前深度学习的局限性还很大(连一个病灶分割的问题也没有办法彻底解决,而这对医生来说是很容易的事情)。虽然深度学习可以一定程度帮你分析问题,但是要依靠深度学习从市场中寻找规律预测涨跌,无异于大海捞针。
- 现在对大佬的话理解更深刻了,garbage in garbage out是常态,即便 gold in garbage out也是常态
- 毕竟给深度学习一张图,让它分割一下,都搞不定,你还指望它提取变幻万千的金融市场的特征?高频交易有可能,但我不了解,中低频,靠深度学习预测,你就是进来送钱的。
方法总结
| 预测方法 | 指标(RMSE) | 效果 | 备注 |
|---|---|---|---|
| 移动平均 | 104.5141 |  |
不理想 |
| 线性回归 | 121.1629 |  |
表现很差 |
| k近邻 | 115.1708 |  |
与线性回归模型近似 |
| 自动ARMIA | 44.9545 |  |
忽略了季节的影响 |
| 先知 | 57.4944 |  |
表现良好,但在本例中没有达到预期效果 |
| LSTM | 11.7722 |  |
轻松超越以上任何算法,但还不能确定未来涨跌 |
数据准备
Quandl为投资专业人士提供金融,经济和替代数据的首选平台,拥有海量的经济和金融数据。
- 拥有超过500个与金融相关的数据集,里面的数据包括港股数据、沪深股、加拿大股票
- 每个ip访问quandl有次数(50次)的限制,如果访问次数比较多的话,可以到官网注册一个账号。
- 除了Python之外,quandl也支持用excel、R等来获取数据。
- 更多参考:Quandl快速入门
import quandl # pip install quandl
# 获取数据集, Google股票数据
df = quandl.get('WIKI/GOOGL')
# 获得美国能源部的WTI原油价格:
mydata = quandl.get("EIA/PET_RWTC_D") # 默认pandas
mydata = quandl.get("EIA/PET_RWTC_D", returns="numpy") # 改变返回格式:numpy
# 还可以改变获取的时间区间啊,只选择特定的栏位
# 获取特定时间段的数据:
data = quandl.get("FRED/GDP", start_date="2001-12-31", end_date="2005-12-31")
# 获取特定列的数据:
data = quandl.get(["NSE/OIL.1", "WIKI/AAPL.4"])
# 获取特定行的数据:
data = quandl.get("WIKI/AAPL", rows=5) #后5行
# 改变采样频率:
data = quandl.get("EIA/PET_RWTC_D", collapse="monthly") #按月份
# 对数据进行基本的计算:
data = quandl.get("EIA/PET_RWTC_D") #原始数据
data = quandl.get("EIA/PET_RWTC_D", transformation="diff") # 变化
data = quandl.get("EIA/PET_RWTC_D", transformation="rdiff") # 百分比变化
data = quandl.get("EIA/PET_RWTC_D", transformation="normalize") # 标准化为100
data = quandl.get("EIA/PET_RWTC_D", transformation="cumul") # 累计和
# 下载整个时间序列数据集
quandl.bulkdownload("ZEA")
# 调用整个数据表:数据表API限制每次调用10,000行,添加参数paginate=True则可以扩大到1,000,000行。
data = quandl.get_table('MER/F1', paginate=True)
NSE-TATAGLOBAL

- 数据集中有多个变量 —— 日期(date)、开盘价(open)、最高价(high)、最低价(low)、最后交易价(last)、收盘价(close)、总交易额(total_trade_quantity)和营业额(turnover)。
- 开盘价 和 收盘价 代表股票在某一天交易的起始价和最终价。
- 最高价、最低价 和 最后交易价 表示当天股票的最高价、最低价和最后交易价格。
- 交易总量 是指当天买卖的股票数量,而营业额(Lacs)是指某一特定公司在某一特定日期的营业额。
- 注意:市场在周末和公共假期休市。
- 上表缺失了一些日期值——2/10/2018、6/10/2018、7/10/2018。其中2号是国庆节,6号和7号是周末。
- 损益的计算通常由股票当日的收盘价决定,因此将收盘价作为目标变量。

import pandas as pd
import numpy as np
#to plot within notebook
import matplotlib.pyplot as plt
%matplotlib inline
#setting figure size
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20,10
#for normalizing data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
#read the file
df = pd.read_csv('NSE-TATAGLOBAL(1).csv'
#print the head
df.head()
# 以收盘价为目标
df['Date'] = pd.to_datetime(df.Date,format='%Y-%m-%d')
df.index = df['Date']
#plot
plt.figure(figsize=(16,8))
plt.plot(df['Close'], label='Close Price history')
统计:移动平均
用一组先前观测值的平均值作为每天的预期收盘价。
- 使用移动平均法,而不是使用简单的平均值
- 移动平均法使用最近的一组数据计算预测值。对于后续的每个新的时间,在考虑预测值时,将从集合中删除最早的观测值,并加入上一个观测值。

data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
# 数据分割为训练和验证时,不能使用随机分割,因为这会破坏时间顺序。所以将去年的数据作为验证集,将之前4年的数据作为训练集。
# splitting into train and validation
train = new_data[:987] # 训练集
valid = new_data[987:] # 验证集
new_data.shape, train.shape, valid.shape # ((1235, 2), (987, 2), (248, 2))
train['Date'].min(), train['Date'].max(), valid['Date'].min(), valid['Date'].max()
# (Timestamp('2013-10-08 00:00:00'),
# Timestamp('2017-10-06 00:00:00'),
# Timestamp('2017-10-09 00:00:00'),
# Timestamp('2018-10-08 00:00:00'))
# 为验证集创建预测值,并使用真实值来检查RMSE误差
# make predictions
preds = []
for i in range(0,248):
a = train['Close'][len(train)-248+i:].sum() + sum(preds)
b = a/248
preds.append(b)
# ---------- 结果 ------------
#calculate rmse
rms=np.sqrt(np.mean(np.power((np.array(valid['Close'])-preds),2)))
rms # 104.51415465984348
# 仅仅检查RMSE并不能帮助我们评估模型预测效果的。
#plot
valid['Predictions'] = 0
valid['Predictions'] = preds
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
推论:
- RMSE值接近105,但是结果不是很理想(从图中可以看出)。预测值与训练集的观测值的范围相同(开始有上升趋势,然后缓慢下降)。
机器学习:线性回归
最基本的机器学习算法是线性回归。线性回归模型生成一个确定自变量和因变量之间关系的方程。

- 股票预测中,没有太多的自变量,只有日期。于是用时间(date)列提取特征,如- day, month, year, mon/fri等,然后拟合线性回归模型。
# 首先按升序对数据集进行排序,然后创建一个单独的数据集
# setting index as date values
df['Date'] = pd.to_datetime(df.Date,format='%Y-%m-%d')
df.index = df['Date']
# sorting
data = df.sort_index(ascending=True, axis=0
# creating a separate dataset
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
#create features
from fastai.structured import add_datepart # pip install fastai
add_datepart(new_data, 'Date')
new_data.drop('Elapsed', axis=1, inplace=True) #elapsed will be the time stamp
# ‘Year’, ‘Month’, ‘Week’, ‘Day’, ‘Dayofweek’, ‘Dayofyear’, ‘Is_month_end’, ‘Is_month_start’, ‘Is_quarter_end’, ‘Is_quarter_start’, ‘Is_year_end’, and ‘Is_year_start’
# 创建星期特征(头、尾几天),如果是星期日或星期五,列值将为1,否则为0。
new_data['mon_fri'] = 0
for i in range(0,len(new_data)):
if (new_data['Dayofweek'][i] == 0 or new_data['Dayofweek'][i] == 4):
new_data['mon_fri'][i] = 1
else:
new_data['mon_fri'][i] = 0
# 数据集划分
#split into train and validation
train = new_data[:987]
valid = new_data[987:]
x_train = train.drop('Close', axis=1)
y_train = train['Close']
x_valid = valid.drop('Close', axis=1)
y_valid = valid['Close']
#implement linear regression
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train,y_train)
# ------- 结果 --------
#make predictions and find the rmse
preds = model.predict(x_valid)
rms = np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
rms # 121.16291596523156
#plot
valid['Predictions'] = 0
valid['Predictions'] = preds
valid.index = new_data[987:].index
train.index = new_data[:987].index
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
推论:
- RMSE值高于之前的方法,这清楚地表明线性回归的表现很差。
- 线性回归是一种简单的技术,很容易解释,但也有一些明显的缺点。使用回归算法的一个问题是,模型过度拟合了日期和月份。模型将考虑一个月前相同日期或一年前相同日期/月的值,而不是从预测的角度考虑以前的值。
- 从上图可以看出,2016年1月和2017年1月,股价出现下跌。该模型预测2018年1月也将如此。线性回归技术可以很好地解决像大卖场销售这样的问题,在这些问题中,独立的特征对于确定目标值是有用的。
机器学习:k-近邻
另一个有趣的ML算法是kNN (k近邻)。基于自变量,kNN可以发现新数据点与旧数据点之间的相似性。
from sklearn import neighbors
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
#scaling data
x_train_scaled = scaler.fit_transform(x_train)
x_train = pd.DataFrame(x_train_scaled)
x_valid_scaled = scaler.fit_transform(x_valid)
x_valid = pd.DataFrame(x_valid_scaled)
#using gridsearch to find the best parameter
params = {'n_neighbors':[2,3,4,5,6,7,8,9]}
knn = neighbors.KNeighborsRegressor()
model = GridSearchCV(knn, params, cv=5)
#fit the model and make predictions
model.fit(x_train,y_train)
preds = model.predict(x_valid)
# --------- 结果 ---------
#rmse
rms=np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
rms # 115.17086550026721
valid['Predictions'] = 0
valid['Predictions'] = preds
plt.plot(valid[['Close', 'Predictions']])
plt.plot(train['Close'])
推论:
- RMSE值并没有太大的差异,但是一个预测值和实际值的曲线图应该提供一个更清晰的理解
- RMSE值与线性回归模型近似,图中呈现出相同的模式。与线性回归一样,kNN也发现了2018年1月的下降,因为这是过去几年的模式。我们可以有把握地说,回归算法在这个数据集上表现得并不好。
时间序列:自动ARIMA
ARIMA是一种非常流行的时间序列预测统计方法。ARIMA模型使用过去的值来预测未来的值。ARIMA中有三个重要参数:
- p (用来预测下一个值的过去值)
- q (用来预测未来值的过去预测误差)
- d (差分的顺序)
ARIMA的参数优化需要大量时间。因此我们将使用 自动ARIMA,自动选择误差最小的(p,q,d)最佳组合。
from pyramid.arima import auto_arima
data = df.sort_index(ascending=True, axis=0)
train = data[:987]
valid = data[987:]
training = train['Close']
validation = valid['Close']
model = auto_arima(training, start_p=1, start_q=1,max_p=3, max_q=3, m=12,start_P=0, seasonal=True,d=1, D=1, trace=True,error_action='ignore',suppress_warnings=True)
model.fit(training)
forecast = model.predict(n_periods=248)
forecast = pd.DataFrame(forecast,index = valid.index,columns=['Prediction'])
# --------- 结果 ----------
rms=np.sqrt(np.mean(np.power((np.array(valid['Close'])-np.array(forecast['Prediction'])),2)))
rms # 44.954584993246954
#plot
plt.plot(train['Close'])
plt.plot(valid['Close'])
plt.plot(forecast['Prediction'])
推论:
- 自动ARIMA模型使用过去的数据来理解时间序列中的模式。利用这些值,该模型捕捉到该系列中的增长趋势。虽然使用这种技术的预测比以前实现的机器学习模型的预测要好得多,但是这些预测仍然与实际值相距甚远。
- 该模型在序列中捕捉到了一种趋势,但忽略了季节的影响。
时间序列方法
【2022-4-20】时间序列预测方法汇总,包含理论及实践案例集合
时序问题都看成是回归问题,只是回归的方式(线性回归、树模型、深度学习等)有一定的区别。
(1) 传统时序建模,如arma模型或者arima模型
- arima模型是arma模型的升级版;arma模型只能针对平稳数据进行建模,而arima模型需要先对数据进行差分,差分平稳后在进行建模。这两个模型能处理的问题还是比较简单,究其原因主要是以下两点:
- arma/arima模型归根到底还是简单的线性模型,能表征的问题复杂程度有限;
- arma全名是自回归滑动平均模型,它只能支持对单变量历史数据的回归,处理不了多变量的情况。
- 总结:如果是处理单变量的预测问题,传统时序模型可以发挥较大的优势;但是如果问题或者变量过多,那么传统时序模型就显得力不从心了。
(2)机器学习模型方法,这类方法以lightgbm、xgboost为代表
- 这类方法一般就是把时序问题转换为监督学习,通过特征工程和机器学习方法去预测;这种模型可以解决绝大多数的复杂的时序预测模型。支持复杂的数据建模,支持多变量协同回归,支持非线性问题。
- 不过这种方法需要较为复杂的人工特征过程部分,特征工程需要一定的专业知识或者丰富的想象力。特征工程能力的高低往往决定了机器学习的上限,而机器学习方法只是尽可能的逼近这个上限。特征建立好之后,就可以直接套用树模型算法lightgbm/xgboost,这两个模型是十分常见的快速成模方法,除此之外,他们还有以下特点:
- 计算速度快,模型精度高;
- 缺失值不需要处理,比较方便;
- 支持category变量;
- 支持特征交叉。 (3)深度学习模型方法,这类方法以LSTM/GRU、seq2seq、wavenet、1D-CNN、transformer为主
- 深度学习中的LSTM/GRU模型,就是专门为解决时间序列问题而设计的;但是CNN模型是本来解决图像问题的,但是经过演变和发展,也可以用来解决时间序列问题。总体来说,深度学习类模型主要有以下特点:
- 不能包括缺失值,必须要填充缺失值,否则会报错;
- 支持特征交叉,如二阶交叉,高阶交叉等;
- 需要embedding层处理category变量,可以直接学习到离散特征的语义变量,并表征其相对关系;
- 数据量小的时候,模型效果不如树方法;但是数据量巨大的时候,神经网络会有更好的表现;
- 神经网络模型支持在线训练。
- 实际上,基于实际预测问题,可以设计出各式各样的深度学习模型架构。假如我们预测的时序问题(如预测心跳频率),不仅仅只和统计类的数据有关,还和文本(如医师意见)以及图像(如心电图)等数据有关 ,我们就可以把MLP、CNN、bert等冗杂在一起,建立更强力的模型。
【2022-4-23】Google发布用于时间序列预测的可解释深度学习
- 深度神经网络(DNN)越来越多地用于多层面预测,与传统时间序列模型相比,表现出强大的性能改进。虽然许多模型(例如DeepAR、MQRNN)都专注于循环神经网络( RNN ) 的变体,但最近的改进,包括基于 Transformer 的模型,已经使用基于注意力的层来增强过去对相关时间步长的选择。 RNN 归纳偏置——信息的顺序有序处理,包括。然而,这些通常不考虑多层次预测中普遍存在的不同输入,或者假设所有外生输入 未来已知或忽略重要的静态变量。
- 传统的时间序列模型受许多参数之间复杂的非线性相互作用控制,因此很难解释这些模型是如何得出预测的。不幸的是,解释 DNN 行为的常用方法有局限性。例如,事后方法(例如,LIME和SHAP)不考虑输入特征的顺序。提出了一些具有内在可解释性的基于注意力的模型对于顺序数据,主要是语言或语音,但多层面预测有许多不同类型的输入,而不仅仅是语言或语音。基于注意力的模型可以提供对相关时间步长的洞察,但它们无法区分给定时间步长不同特征的重要性。需要新方法来解决多层面预测中数据的异质性以实现高性能,并使这些预测具有可解释性。 为此,Google宣布发表在International Journal of Forecasting 上的“用于可解释多水平时间序列预测的时间融合变换器”,Google在其中提出了时间融合变换器 (TFT),一种基于注意力的 DNN 模型,用于多水平预测. TFT 旨在将模型与通用多水平预测任务明确对齐,以实现卓越的准确性和可解释性,Google在各种用例中展示了这一点。
时间序列:先知(Prophet)
有许多时间序列技术可以用在股票预测数据集上,但是大多数技术在拟合模型之前需要大量的数据预处理。
Prophet(先知)由 Facebook 设计和开发,是一个时间序列预测库,不需要数据预处理,并且非常容易实现。
- 先知的输入是一个带有两列的数据框: 日期 和 目标(ds和y)。
先知试图在过去的数据中捕捉季节性,并且在数据集很大的时候依然表现良好
from fbprophet import Prophet
#creating dataframe
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
new_data['Date'] = pd.to_datetime(new_data.Date,format='%Y-%m-%d')
new_data.index = new_data['Date']
#preparing data
new_data.rename(columns={'Close': 'y', 'Date': 'ds'}, inplace=True)
#train and validation
train = new_data[:987]
valid = new_data[987:]
#fit the model
model = Prophet()
model.fit(train)
#predictions
close_prices = model.make_future_dataframe(periods=len(valid))
forecast = model.predict(close_prices)
#rmse
forecast_valid = forecast['yhat'][987:]
rms=np.sqrt(np.mean(np.power((np.array(valid['y'])-np.array(forecast_valid)),2)))
rms # 57.494461930575149
#plot
valid['Predictions'] = 0
valid['Predictions'] = forecast_valid.values
plt.plot(train['y'])
plt.plot(valid[['y', 'Predictions']])
推论
- 先知(像大多数时间序列预测技术一样)试图从过去的数据中捕捉趋势和季节性。该模型通常在时间序列数据集上表现良好,但在本例中没有达到预期效果。
- 事实证明,股票价格没有特定的趋势或季节性。价格的涨跌很大程度上取决于目前市场上的情况。因此,像ARIMA、SARIMA和Prophet这样的预测技术并不能很好地解决这个特殊的问题。
神经网络:长短期记忆网络(LSTM)
LSTM 算法广泛应用于序列预测问题中,并被证明是一种非常有效的方法。它们之所表现如此出色,是因为LSTM能够存储重要的既往信息,并忽略不重要的信息。
LSTM有三个门:
- 输入门:输入门将信息添加到细胞状
- 遗忘门:它移除模型不再需要的信
- 输出门:LSTM的输出门选择作为输出的信息
双向LSTM
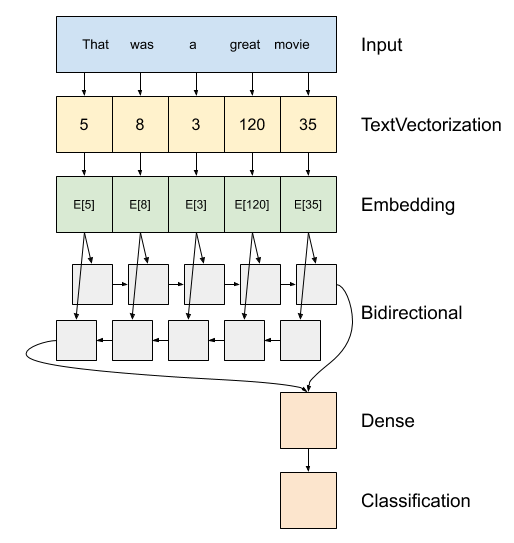
- encoder: 将字符转id,额外准备词表,oov单词统一设置为UNK;字符串 → id列表
- embedding:一个单词一个向量(维数可定义),权重可修改,训练完毕后,相近单词词向量越近 —— 词向量副产物
- rnn层:逐个元素迭代,时间步
- dense层:全连接,对接回归(mse)、分类任务(logit)
Tensorflow实现:
# 序列结构
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()), # 设置词表
output_dim=64, # 嵌入维度
# Use masking to handle the variable sequence lengths
mask_zero=True), # 用0来填充空白位置
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)), # 双向LSTM
tf.keras.layers.Dense(64, activation='relu'), # 全连接层
tf.keras.layers.Dense(1) # 目标值
])
# predict on a sample text without padding.
sample_text = ('The movie was cool. The animation and the graphics '
'were out of this world. I would recommend this movie.')
# 不用padding
predictions = model.predict(np.array([sample_text]))
# 使用padding
padding = "the " * 2000
predictions = model.predict(np.array([sample_text, padding]))
print(predictions[0])
# Compile the Keras model to configure the training process:
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Train the model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# 评估效果
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)
# 绘图
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plot_graphs(history, 'accuracy')
plt.ylim(None, 1)
plt.subplot(1, 2, 2)
plot_graphs(history, 'loss')
plt.ylim(0, None)
两种类型的时间序列分析:
- 单变量时间序列:如,日期 → 销量
- 多元时间序列:如,日期、月份、星期、天气等 → 销量
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
#creating dataframe
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
#setting index
new_data.index = new_data.Date
new_data.drop('Date', axis=1, inplace=True)
#creating train and test sets
dataset = new_data.values
train = dataset[0:987,:]
valid = dataset[987:,:]
#converting dataset into x_train and y_train
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset)
x_train, y_train = [], []
for i in range(60,len(train)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2)
#predicting 246 values, using past 60 from the train data
inputs = new_data[len(new_data) - len(valid) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
closing_price = model.predict(X_test)
closing_price = scaler.inverse_transform(closing_price)
# ------------- 结果 -----------
rms=np.sqrt(np.mean(np.power((valid-closing_price),2)))
rms # 11.772259608962642
#for plotting
train = new_data[:987]
valid = new_data[987:]
valid['Predictions'] = closing_price
plt.plot(train['Close'])
plt.plot(valid[['Close','Predictions']])
推论:
- LSTM轻松地超越了目前看到的任何算法。
- LSTM模型可以对各种参数进行调优,如改变LSTM层数、增加dropout值或增加训练迭代轮数(epoch)数。
- 但LSTM的预测是否足以确定股票价格将上涨还是下跌? 当然不行!
- 股价受到公司新闻和其他因素的影响,如公司的非货币化或合并/分拆。还有一些无形的因素往往是无法事先预测的。
神经网络:STHAN-SR
量化交易和投资决策是复杂的金融任务,依赖于准确的股票选择。目前深度学习学习的策略使用于股票的问题的方案面临两个重大局限。
- 不直接优化利润方面的投资目标;
- 将每只股票视为独立于其他股票,忽略了相关股票之间的丰富信号股票价格变动。 本文基于该局限性,将股票预测重新表述为一个学习排序问题,并提出了STHAN-SR,一种用于股票选择的神经超图结构,从而定制一种新的时空注意超图网络结构,通过联合建模股票相互依赖性及其价格的时间演变,根据利润对股票进行排序。
在三个市场上进行为期六年的实验,发现STHAN-SR显著优于最先进的神经股票预测方法。通过对STHAN-SR的空间和时间组件进行烧蚀和探索性分析来验证我们的设计选择,并证明其实用性。
工程实践
kaggle股票预测
比赛介绍
- 【2022-4-7】kaggle股票预测比赛:Tokyo Stock Exchange Prediction
- How do you know when to buy a stock(股票) or derivative(衍生品)? When should you sell instead? Your data science skills could help you predict markets and explore
quantitative trading([ˈkwɑːntəteɪtɪv], 量化交易).This competition will compare your models against real future returns after the training phase is complete. This dataset contains historic data for a variety of Japanese stocks(股票) and options(期权). Your challenge is to predict future returns. The competition will involve buildingportfolios ( [portˈfolɪˌo],档案,文件夹,证券投资组合) from around 2,000 stocks eligible for predictions. Specifically, each participant will rank the stocks from highest to lowest expected returns and be evaluated on the difference between the returns of the highest and lowest 200 stocks. Sharpe ratio:夏普指数,用来衡量每单位风险所能换得的平均报酬率
【2022-9-22】比赛分析:JPX 东京证券交易所预测01 理解竞赛
- 任何金融市场的成功都需要确定可靠的投资。当股票或衍生品的价值被低估时,购买就是有意义的。如果它被高估,也许就可以考虑出售。
- 虽然这些财务决策历来是由专业人士手动做出的,但技术为散户投资者带来了新的机会。数据科学家通过编程,根据训练模型的预测做出决策,探索量化交易。 现有大量量化交易工作用于分析金融市场和制定投资策略。创建和执行这样的策略需要历史和实时数据,但是散户投资者很难获得这些数据,因为本次比赛提供了日本市场的金融数据,以便散户对市场进行最全面的分析。
- Japan Exchange Group, Inc. (JPX) 是一家控股公司,经营着世界上最大的证券交易所之一,包括东京证券交易所 (TSE) 以及衍生品交易所大阪交易所 (OSE) 和东京商品交易所 (TOCOM)。 JPX 是本次比赛的主办方,并得到了 AI 技术公司 AlpacaJapan Co.,Ltd. 的支持。
目标
本次比赛将在训练阶段完成后将模型与真实的未来回报进行比较。比赛将从符合预测条件的股票(约 2,000 只股票)中建立投资组合。具体来说,每个参与者从最高到最低的预期回报对股票进行排名,并根据前 200 只股票和后 200 只股票之间的回报差异进行评估。比赛提供日本市场的财务数据,例如股票信息和历史股票价格,以训练和测试模型。
#导入需要的库
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
sample = pd.read_csv(r"jpx-tokyo-stock-exchange-prediction\example_test_files\sample_submission.csv")
sample
sample.nunique() # 按日期和证券代码(股票)预测排名
按日期和证券代码(股票)预测排名。
Date SecuritiesCode Rank
0 2021-12-06 1301 0
1 2021-12-06 1332 1
2 2021-12-06 1333 2
3 2021-12-06 1375 3
4 2021-12-06 1376 4
Rank 表示 2000 只股票中每只股票次日和次日收盘价(Close)变化率的排名,从 2000 只股票中最大的一个开始排序。(变化率大的话就是正方向,变化率小的话就是负方向大。)
评估指标
评估指标
- 提交是根据每日买卖价差的
夏普比率(sharpe ratio)进行评估的,需要对给定日期的每只活跃股票进行排名。单日回报将排名最高的 200 只股票(例如 0 到 199)视为买入,将排名最低的 200 只股票(例如 1999 到 1800 股)视为卖空。 然后根据股票的排名对股票进行加权,并假设股票在第二天购买并在第二天卖出,从而计算投资组合的总回报。
数据概览
数据概览
- stock_prices.csv 核心数据集,包括每只股票的每日收盘价和目标行。
- options.csv 基于大盘的各种期权的状态数据。许多选项包括对股票市场未来价格的隐含预测,因此即使这些选项没有直接评分,也可能会引起人们的兴趣。
- secondary_stock_prices.csv 核心数据集涵盖了2000 种最常交易的股票,但许多流动性较低的证券也在东京市场上交易。该文件包含这些证券的数据,这些证券没有评分,但可能对评估整个市场有帮助。
- trades.csv 上一个交易周的交易量汇总。
- Financials.csv 季度收益报告的结果。
- stock_list.csv - 安全码和公司名称之间的对应关系,以及有关公司所在行业的一般信息
计算过程
过程
- 计算rate值:计算出来的rate与原数据中的target是一致的
- 排序计算
- 只关注一天内的情况。(请注意,并非所有 2000 只股票都有数据,具体取决于日期。)
- 每日价差收益
- 分数计算

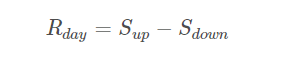
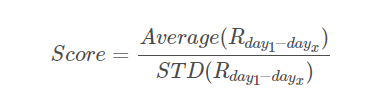
stock_prices = pd.read_csv(r"jpx-tokyo-stock-exchange-prediction\train_files\stock_prices.csv")
stock_prices["Date"] = pd.to_datetime(stock_prices["Date"])
# 仅看一支股票
tmpdf = stock_prices[stock_prices["SecuritiesCode"]==1301].reset_index(drop=True)
tmpdf.head(3)
# 计算rate值
tmpdf["Close_shift1"] = tmpdf["Close"].shift(-1)
tmpdf["Close_shift2"] = tmpdf["Close"].shift(-2)
tmpdf["rate"] = (tmpdf["Close_shift2"] - tmpdf["Close_shift1"]) / tmpdf["Close_shift1"]
# 排序结果计算
tmpdf2 = stock_prices[stock_prices["Date"]=="2021-12-02"].reset_index(drop=True)
#按目标降序排列。Rank与0-1999绑定,所以不要忘记-1(不输入会报错)
tmpdf2["rank"] = tmpdf2["Target"].rank(ascending=False,method="first")-1
tmpdf2 = tmpdf2.sort_values("rank").reset_index(drop=True)
# 计算每日价差
#前200支股票
tmpdf2_top200 = tmpdf2.iloc[:200,:]
# tmpdf2_top200 = tmpdf2_top200.sort_values("rank",ascending = False).reset_index(drop=True)
weights = np.linspace(start=2, stop=1, num=200)
tmpdf2_top200["weights"] = weights
tmpdf2_top200["calc_weights"] = tmpdf2_top200["Target"] * tmpdf2_top200["weights"]
Sup = tmpdf2_top200["calc_weights"].sum()/np.mean(weights)
#后200支股票
tmpdf2_bottom200 = tmpdf2.iloc[-200:,:]
tmpdf2_bottom200 = tmpdf2_bottom200.sort_values("rank",ascending = False).reset_index(drop=True)
tmpdf2_bottom200["weights"] = weights
tmpdf2_bottom200["calc_weights"] = tmpdf2_bottom200["Target"] * tmpdf2_bottom200["weights"]
Sdown= tmpdf2_bottom200["calc_weights"].sum()/np.mean(weights)
daily_spread_return = Sup - Sdown
daily_spread_return
# 分数计算
#定义一个函数实现上述过程
import numpy as np
import pandas as pd
def calc_spread_return_sharpe(df: pd.DataFrame, portfolio_size: int = 200, toprank_weight_ratio: float = 2) -> float:
"""
Args:
df (pd.DataFrame): 预测结果
portfolio_size (int): 投资组合规模
toprank_weight_ratio (float): 排名最高的股票与排名最低的股票的相对权重。
Returns:
(返回一个浮点数): sharpe ratio 夏普比率
"""
def _calc_spread_return_per_day(df, portfolio_size, toprank_weight_ratio):
assert df['Rank'].min() == 0 #不出错则跳过,出错则返回异常
assert df['Rank'].max() == len(df['Rank']) - 1
weights = np.linspace(start=toprank_weight_ratio, stop=1, num=portfolio_size)
Sup= (df.sort_values(by='Rank')['Target'][:portfolio_size] * weights).sum() / weights.mean()
Sdowm = (df.sort_values(by='Rank', ascending=False)['Target'][:portfolio_size] * weights).sum() / weights.mean()
return purchase - short
#按照日期计算每天的价差收益
buf = df.groupby('Date').apply(_calc_spread_return_per_day, portfolio_size, toprank_weight_ratio)
sharpe_ratio = buf.mean() / buf.std()
return sharpe_ratio
数据源
实时股价数据
- 新浪股票实时数据接口: http://hq.sinajs.cn/list=sh600389
基础教程
- stochastic: 常见随机过程的实现,包括连续、离散、扩散过程、噪声等类别;
- ou_noise: O-U过程的生成、检验和参数估计;
- hawkes: 关于单变量以及多变量Hawkes过程的生成与参数估计,采用MAP EM算法进行参数估计;
- TimeSeriesAnalysisWithPython: 基础时间序列教程,包括时间序列数据的读取、趋势成分与季节成分的分解、谱分析、聚类等内容;
- yangwohenmai: 进阶时间序列教程,包括基于统计学、基于LSTM、基于深度学习进行时间序列预测的内容;
- leetcode-master: 数据结构与算法的刷题攻略,持续更新中;
- Advanced-Algorithmic-Trading: 《Advanced Algorithmic Trading》一书的代码实现,使用语言为python/R;
- bukosabino: 一位Affirm算法工程师的项目主页,内容丰富,包括TA库的实现、时间序列预测、特征工程选择等,主要集中于机器学习领域;
订单簿分析与做市策略
- LOB-feature-analysis: 对限价订单簿进行特征工程分析,包括订单大小的分布、用于价格预测的订单不平衡、知情交易的概率、波动性等方面。作者的文档与代码简洁清晰,包含部分原始文献;
- HFT_Bitcoin: BTC订单簿的数据分析以及一些传统高频策略的实例图示;
- High-Frequency: 基于level-2限价订单簿和分笔交易数据的研究,考察了订单不平衡与买卖压力的盘口拓展;
- High-Frequency-Data—Limit-Order-Books: 本项目包括高频数据描述性分析,Hawkes过程的生成与参数估计以及限价订单簿的模拟;
- https://github.com/Macosh/Order_Book: 一个订单簿模拟器,实现了创建不同类型的订单、订单匹配、模拟生成,数据库存储历史订单等功能;
- avellaneda-stoikov: Avellaneda-Stoikov做市算法的实现;
- Avellaneda-Stoikov: Avellaneda-Stoikov做市算法另一个实现版本,比前者更简明些;
- jshellen/HFT: 采用随机最优控制方法求解AS做市算法及其变种,包含HJB方程的求解程序以及AS做市策略的输出框架;
- OptimalExecution_stochastic_control: 本项目实现了Frei, C. and N. Westray (2015). Optimal execution of a vwap order: a stochastic control approach. Mathematical Finance 25(3), 612–639.一文提出的VWAP算法的最优执行,项目包括数据过程,参数校准,存货变动轨迹等;
- Order-Execution-Strategy: 三种最优订单执行策略的实现,此外还有Almgren-Chriss框架下的市场冲击函数的实现;
- machine-learning-market-maker: 《Intelligent Market-Making in Artificial Financial Market》一文的实现,基于贝叶斯估计的做市策略模型;
- armoreal/hft: 高频交易策略,测试了隐马尔科夫模型(HMM)与O-U过程对限价订单簿数据的拟合情况;此外,还测试了几种典型的高频因子;
传统技术分析、对冲
- quantitative_research_report: 一些券商研报的复现;
- bitmex-algo: 基于BitMEX平台ETH/USDT和XBT/USDT1分钟的交易数据的交易策略,采用传统技术分析指标进行交易;
- AlgoBot: 一个使用均值回归或趋势跟踪策略的自动交易机器人;
- High-Frequency-of-BTC-strategy: 跨交易所的BTC高频对冲策略;
- options-market-making: 基于期权市场的交易机器人,包含做市、统计套利、delta和vega对冲等;
- World_Quant_Alphas: World Quant 101 alphas的计算和策略化;
机器学习
- SGX-Full-OrderBook-Tick-Data-Trading-Strategy: 采用机器学习方法对限价订单簿动态进行建模的量化策略,包括数据获取、特征选择、模型选择,可作为机器学习类策略的baseline;
深度学习
- 《Pytorch深度学习实践》课程对应的代码, 很好的深度学习入门指引;
- lstm: 一个LSTM的简单实现;
- HighFrequency: 采用神经网络方法预测微观层面的价格跳跃,项目完整度较高,从获取数据、异常值清洗、跳跃的统计检验到LSTM、CNN、注意力机制等方法的预测应用;
- AlgorithmicTrading-MachineLearning: 用RNN,LSTM,GRU预测股价变动;
强化学习
- drlformm:《Deep Reinforcement Learning for Market Making Under a Hawkes Process-Based Limit Order Book Model》一文的代码实现,基于Hawkes过程的深度强化学习做市策略;
- algorithmicTrader: 一个采用强化学习进行算法交易的项目;
- moneyMaker: 一个基于强化学习的算法交易策略;
- TikhonJelvis/RL-book: 《Foundations of Reinforcement Learning with Applications in Finance》一书的对应代码实现;
- dq-MM: Deep Q-Learning用于做市,依赖于开源项目Trading Gym;
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
