总结
- 【2022-1-14】疫情相关小工具
- 国务院客户端(小程序)查询出行政策、核酸地点;
- 核酸地点查询:支付宝阿里健康可以查看附近核酸地点、价位详情信息
- 21世纪财经:全国中高风险查询、出行政策查询
新冠肺炎微博热搜挖掘分析
- 【2020-2-25】大数据文摘,文章(两个月微博热搜分析:疫情之下,哪些时、地、人、物处在舆论的风口浪尖),附属代码、可视化结果
效果图
数据导入
- 使用2019.12.23-2020.2.21的微博热搜(top50)数据
- 原排行榜小时级更新,为了便于分析,选取每天12:00的数据作为当天搜索排行榜数据
原始数据
- 微博热搜1223-0210.csv:原始小时级数据
- 一共近8w条 (79278),每条数据5个字段
- 格式:【时间 排名 热搜内容 最后时间 上榜时间】
import pandas as pd
# 导入小时级数据
df_hour = pd.read_csv(open("微博热搜1223-0210.csv", encoding='utf8'), sep=',',dtype=str)
df1 = df_hour.filter(like='钟南山', axis=0)
#df1 = df_hour.filter(regex='12:00$', axis=0)
print(df_hour.size, df_hour.shape)
df_hour.head()
396390 (79278, 5)
| 时间 | 排名 | 热搜内容 | 最后时间 | 上榜时间 | |
|---|---|---|---|---|---|
| 0 | 2020/2/10 12:00 | 1 | 全国累计确诊40171例新冠肺炎 | 2020/2/10 14:52 | 2020/2/10 8:04 |
| 1 | 2020/2/10 12:00 | 2 | 致84人遭隔离男子被立案侦查 | 2020/2/10 15:04 | 2020/2/10 11:16 |
| 2 | 2020/2/10 12:00 | 3 | 发改委专家 人口流动是SARS时6倍 | 2020/2/10 14:58 | 2020/2/10 10:42 |
| 3 | 2020/2/10 12:00 | 4 | 四川禽流感 | 2020/2/10 18:22 | 2020/2/10 10:12 |
| 4 | 2020/2/10 12:00 | 5 | 上班 | 2020/2/10 17:46 | 2020/2/10 7:22 |
疫情相关数据
- 原始数据是小时级,量大,而且很多热搜内容与疫情无关,不便分析,需要提炼疫情相关的内容,单独分析
- 微博热搜1.1-2.21.csv:缩减后的天级数据,仅保留疫情相关的搜索词,人工标注完成
- 一共899条,数据量大规模减少,8w→900条
- 格式【时间 排名 热搜内容 标注1 标注2 上榜时间 最后时间】
- 注:
- 标注1:地域信息,取值范围:全国数据、疫情地图、地区、新闻、人物、医院、物质、军队、新闻、知识、专家
- 标注2:主题信息,取值范围:
import datetime
#str_p = '2020/2/7 12:00'
#dateTime_p = datetime.datetime.strptime(str_p,'%Y/%m/%d %H:%M')
# 导入天级数据,1.30以后标注完整(地域+主题)
df_day = pd.read_csv(open("微博热搜1.1-2.21.csv", encoding='gbk'), sep=',',dtype=str)
# 时间格式矫正,规范,便于字符串排序
df_day['时间'] = df_day['时间'].apply(lambda x:str(datetime.datetime.strptime(x,'%Y/%m/%d %H:%M')).split(' ')[0])#.sort_index()
# 按照日期升序排列
df_day = df_day.sort_values(by='时间')
print(df_day.size, df_day.shape)
df_day.head()
6279 (897, 7)
| 时间 | 排名 | 热搜内容 | 地域 | 主题 | 上榜时间 | 最后时间 | |
|---|---|---|---|---|---|---|---|
| 896 | 2020-01-09 | 7 | 武汉不明原因肺炎病原体为新型冠状病毒 | 国内-湖北-武汉 | 知识 | 2020/1/9\n17:36 | 2020/1/9 8:38 |
| 895 | 2020-01-09 | 7 | 武汉不明原因肺炎病原体为新型冠状病毒 | 国内-湖北-武汉 | 疫情-知识 | 2020/1/9\n17:36 | 2020/1/9 08:38 |
| 894 | 2020-01-11 | 48 | 专家解读武汉不明原因肺炎 | 国内 | 专家|疫情-知识 | 2020/1/11 14:50 | 2020/1/11\n8:18 |
| 893 | 2020-01-14 | 8 | 泰国发现1例新型冠状病毒病例 | 国外-泰国 | 疫情-新增 | 2020/1/14 20:30 | 2020/1/14\n11:42 |
| 892 | 2020-01-15 | 14 | 武汉肺炎不排除有限人传人可能 | 国内-湖北-武汉 | 疫情-知识 | 2020/1/15 13:40 | 2020/1/15\n7:52 |
df_day.sort_values(by='时间', ascending=False) # 逆序排列
df_day[df_day['排名'].isin(['1','2','3'])] # 提取每天的前三名
df_day[df_day['时间']=='2020-02-06'].head() # 查看某天的热门搜索
| 时间 | 排名 | 热搜内容 | 地域 | 主题 | 上榜时间 | 最后时间 | |
|---|---|---|---|---|---|---|---|
| 373 | 2020-02-06 | 11 | 医护夫妻通过声音眼神认出彼此 | 国内 | 人物-医护夫妻 | 2020/2/6 15:36 | 2020/2/6\n10:06 |
| 378 | 2020-02-06 | 22 | 四川内江查获50余万个三无口罩 | 国内-四川 | 物资-三无口罩 | 2020/2/6 15:24 | 2020/2/6\n10:32 |
| 377 | 2020-02-06 | 19 | 广东发布二号口罩令 | 国内-广东 | 政府-口罩令 | 2020/2/6 17:18 | 2020/2/6\n10:50 |
| 376 | 2020-02-06 | 16 | 纸尿裤内衣工厂转做口罩 | 国内 | 物资-口罩|生产 | 2020/2/6 18:18 | 2020/2/6\n11:30 |
| 375 | 2020-02-06 | 13 | 北京减免中小微企业房租 | 国内-北京 | 政府-小微企业|房租 | 2020/2/6 13:54 | 2020/2/6\n9:48 |
import numpy as np
#df_new.groupby(['时间']).count().sort_values(by='时间')
df_day.groupby(['时间'])['排名'].agg([sum])
#df_day['时间'].groupby(['时间']).count().reset_index().rename(columns={'0':'数目'})
#df_day['排名'].astype(float).groupby(['时间']).size()
#df_day['排名'].astype(float).groupby(by=['时间'])
df_day.groupby('时间')['排名'].count().reset_index().rename(columns={'0':'数目'})
df_day.groupby('时间').count()[:2]
| 排名 | 热搜内容 | 地域 | 主题 | 上榜时间 | 最后时间 | |
|---|---|---|---|---|---|---|
| 时间 | ||||||
| 2020-01-09 | 2 | 2 | 2 | 2 | 2 | 2 |
| 2020-01-11 | 1 | 1 | 1 | 1 | 1 | 1 |
趋势分析
- 疫情相关热词近期有什么变化?
疫情热度如何变化?
- 每天疫情相关热门搜索词有多少?
- 趋势图见末尾,分析如下:
- 1.19前,只有1-2个热搜,此时疫情刚刚爆发,原因不明,只知道是冠状病毒,不确定是否人传人
- 1.20开始,突然上涨到8个热搜,武汉新增136例,卫健委发布病毒性肺炎高发注意事项,同时疫情已经开始蔓延到省外:浙江发现5例、深圳出现8例(1例确诊)、北京确诊2例,上海也开始加强筛查
- 1.21以后,武汉同济协和医院出现15名医护感染,钟南山站肯定新型冠状病毒肺炎人传人,民众开始高度关注,top 50榜单里至少一半是疫情相关
- 1.23,武汉封城,31个热搜
- 1.25,物资缺乏,除夕夜医护吃泡面,承受极大的压力,接近奔溃,大年初一,政府开始调度资源,医护、军队进入疫区
- 1.26,榜单达到高峰:41个热搜,全国疫情迅速发展,民众焦虑,不知所措
- 1.29,热词数目开始下滑,31个,小汤山医院投入使用,火神山马上完工,虽然各地确诊人数仍然不断增加,但大家没那么害怕
- 2.6,小高峰,35个
- 2.20,减少到15个
- 其他分析。。。
- 每天疫情相关热门搜索词平均排名高吗?
- 前期,热词少,突发情况排名较高,如武汉出现疫情
- 中期,平均排名15-20,霸占榜单前几名
- 后期,继续上升到8-10
- 每天关注度是如何变化?
-
关注度 = 热门搜索排名累加
-
import json
day_info_dict = {} # 趋势信息
loc_info_dict = {'total':{}, 'overseas':{}, 'prov':{}} # 地域信息
#for i in df.iteritems(): # iterrows()
for i in df_day.iterrows():
# 记录每天的搜索词数目
(dt, rank, query, location, topic) = i[1]['时间'], float(i[1]['排名']), i[1]['热搜内容'], i[1]['地域'], i[1]['主题']
if dt not in day_info_dict:
# 记录排名信息,最大,最小,平均
day_info_dict[dt] = {'query_num':1, 'min_rank':50-rank, 'max_rank':50-rank, 'avg_rank':50-rank}
else:
day_info_dict[dt]['query_num'] += 1 # 热词数目
if rank < day_info_dict[dt]['min_rank']:
day_info_dict[dt]['min_rank'] = 50-rank
if rank > day_info_dict[dt]['max_rank']:
day_info_dict[dt]['max_rank'] = 50-rank
day_info_dict[dt]['avg_rank'] = round((day_info_dict[dt]['query_num']+day_info_dict[dt]['avg_rank']*(
day_info_dict[dt]['query_num']-1))/day_info_dict[dt]['query_num'],2)
# 地域信息 国内-湖北-武汉,国外-日本
loc_list = location.split('-')
loc_len = len(loc_list)
if loc_len > 0: # 国内外信息
area = loc_list[0]
if area not in loc_info_dict['total']:
loc_info_dict['total'][area] = [0, 0] # 频次、累计热度(50-名次)
loc_info_dict['total'][area][0] += 1
loc_info_dict['total'][area][1] += 50-rank # 排名越靠前,权重越大
if loc_len > 1: # 省份信息、国家信息
prov = loc_list[1]
k = 'prov'
if area == '国外':
k = 'overseas'
if prov not in loc_info_dict[k]:
loc_info_dict[k][prov] = [0, 0, {}] # 频次、累计热度、城市信息
loc_info_dict[k][prov][0] += 1
loc_info_dict[k][prov][1] += 50-rank # 排名越靠前,权重越大
if loc_len > 2: # 城市信息
city = loc_list[2]
if city not in loc_info_dict[k][prov][2]:
loc_info_dict[k][prov][2][city] = [0,0]
loc_info_dict[k][prov][2][city][0] += 1
loc_info_dict[k][prov][2][city][1] += 50-rank
#print(day_info_dict)
out_dict = {'趋势':{'日期':[], '热词数目':[], '最大关注度':[], '最小关注度':[], '平均关注度':[]},
'地域':{}}
out_dict['趋势']['日期'] = list(day_info_dict.keys())
out_dict['趋势']['热词数目'] = [day_info_dict[dt]['query_num'] for dt in out_dict['趋势']['日期']]
out_dict['趋势']['最大关注度'] = [day_info_dict[dt]['max_rank'] for dt in out_dict['趋势']['日期']]
out_dict['趋势']['最小关注度'] = [day_info_dict[dt]['min_rank'] for dt in out_dict['趋势']['日期']]
out_dict['趋势']['平均关注度'] = [day_info_dict[dt]['avg_rank'] for dt in out_dict['趋势']['日期']]
#print(json.dumps(out_dict, ensure_ascii=False))
tmp_df = pd.DataFrame(out_dict['趋势'])
tmp_df[:10]
# 世界地图只支持英文,需要先翻译过去
country_dict = {'泰国':'Thailand', '日本':'Japan', '美国':'United States', '英国':'United Kingdom', '韩国':'Korea', '新加坡':'Singapore', '法国':'French',
'德国':'German', '巴西':'Brazil', '澳大利亚':'Australian', '芬兰':'Finland', '意大利':'Italian', '俄罗斯':'Russia',
'伊拉克':'Iraq', '伊朗':'Iran', '叙利亚':'Syria', '以色列':'Israel','巴勒斯坦':'Palestine','蒙古':'Mongolia','朝鲜':'Dem. Rep. Korea',
'印度':'Indian', '阿富汗':'Afghanistan', '加拿大':'Canadia', '中国':'China'}
out_dict['地域']['总体'] = loc_info_dict['total']
out_dict['地域']['世界'] = {
'国家':[country_dict[k] for k,v in loc_info_dict['overseas'].items() if k in country_dict],
'频次':[v[0] for k,v in loc_info_dict['overseas'].items() if k in country_dict],
'关注度':[v[1] for k,v in loc_info_dict['overseas'].items() if k in country_dict],
}
# 补充中国总体信息
out_dict['地域']['世界']['国家'].append('China')
out_dict['地域']['世界']['频次'].append(loc_info_dict['total']['国内'][0])
out_dict['地域']['世界']['关注度'].append(loc_info_dict['total']['国内'][1])
# 省份信息
out_dict['地域']['中国'] = {
'省份':[k for k,v in loc_info_dict['prov'].items()],
'频次':[v[0] for k,v in loc_info_dict['prov'].items()],
'关注度':[v[1] for k,v in loc_info_dict['prov'].items()],
}
# 湖北城市信息
out_dict['地域']['湖北'] = {
'城市':[k for k,v in loc_info_dict['prov']['湖北'][2].items()],
'频次':[v[0] for k,v in loc_info_dict['prov']['湖北'][2].items()],
'关注度':[v[1] for k,v in loc_info_dict['prov']['湖北'][2].items()],
}
print(loc_info_dict['total'])
print(loc_info_dict['prov'])
print(loc_info_dict['overseas'])
{'国内': [823, 21522.0], '国外': [74, 1879.0]}
{'湖北': [171, 4569.0, {'武汉': [120, 3316.0], '黄冈': [6, 124.0], '松滋': [1, 5.0], '随州': [1, 3.0], '荆州': [2, 29.0], '孝感': [1, 37.0]}], '浙江': [29, 647.0, {'杭州': [4, 79.0], '龙港': [1, 17.0], '宁波': [1, 42.0], '义乌': [1, 31.0]}], '广东': [23, 635.0, {'深圳': [2, 79.0], '广州': [1, 0.0], '汕头': [2, 42.0], '东莞': [1, 12.0], '中山': [1, 5.0]}], '上海': [12, 326.0, {}], '北京': [28, 781.0, {}], '湖南': [7, 180.0, {'长沙': [2, 47.0], '张家界': [1, 40.0]}], '山东': [11, 267.0, {'济南': [2, 30.0], '济宁': [1, 26.0]}], '福建': [3, 87.0, {}], '四川': [9, 202.0, {'成都': [1, 31.0], '汶川': [1, 22.0]}], '黑龙江': [10, 235.0, {'哈尔滨': [1, 48.0], '齐齐哈尔': [1, 25.0]}], '江苏': [15, 273.0, {'南京': [3, 55.0]}], '重庆': [8, 253.0, {}], '河南': [22, 510.0, {'信阳': [1, 49.0], '郑州': [1, 19.0]}], '江西': [3, 17.0, {}], '海南': [2, 28.0, {}], '河北': [7, 138.0, {'承德': [1, 26.0]}], '山西': [2, 35.0, {}], '香港': [3, 116.0, {}], '安徽': [10, 147.0, {}], '广西': [2, 87.0, {'贵州': [1, 48.0]}], '西藏': [9, 237.0, {}], '新疆': [1, 9.0, {}], '天津': [6, 152.0, {}], '吉林': [2, 23.0, {}], '陕西': [5, 132.0, {'西安': [1, 7.0]}], '内蒙古': [3, 40.0, {'呼和浩特': [1, 9.0]}], '贵州': [2, 32.0, {}], '湖难': [1, 17.0, {}], '云南': [1, 0.0, {}], '秦皇岛': [1, 17.0, {}], '青海': [2, 46.0, {}], '山东|浙江': [1, 4.0, {}]}
{'泰国': [2, 84.0, {}], '日本': [18, 509.0, {}], '美国': [3, 60.0, {}], '英国': [2, 50.0, {}], '韩国': [6, 198.0, {}], '新加坡': [2, 69.0, {}], '法国': [2, 26.0, {}], '德国': [2, 19.0, {}], '巴西': [1, 9.0, {}], '澳大利亚': [1, 1.0, {}], '芬兰': [1, 10.0, {}], '意大利': [1, 31.0, {}], '菲律宾': [1, 24.0, {}], '俄罗斯': [5, 136.0, {}], '欧盟': [1, 7.0, {}], '阿富汗': [1, 8.0, {}], '非洲': [1, 44.0, {}], '游轮': [7, 162.0, {}]}
主题分析
- 热搜内容分布在不同主题里
- 疫情数据:全国确诊人数、疫情地图
- 医护
- 专家
- 政府措施
- 其他
- 以全国确诊人数为例,提取“全国累计确诊”前缀的热搜
import re
df_c_total = df_day[df_day['热搜内容'].str.contains('全国累计确诊*')] # 字符串匹配,查找类似搜索
# 提取热搜里的数字
pattern_num = re.compile(r'[\D+]*(\d+).*')
def get_number(text):
""" 提取数字 """
res = pattern_num.match(text)
if not res:
return 0
return res.groups()[0]
total_num_dict = {}
# for i in df_c_total.iterrows():
# # 记录每天的搜索词数目
# (dt, rank, query) = i[1]['时间'].split()[0], float(i[1]['排名']), i[1]['热搜内容']
df_c_total['确诊人数'] = df_c_total['热搜内容'].apply(get_number)
out_dict['确诊'] = {'日期':list(df_c_total['时间']), '排名':list(df_c_total['排名']), '确诊人数':list(df_c_total['确诊人数'])}
#out_dict['确诊']
df_c_total.head()
<ipython-input-40-b8f0e5aa866d>:17: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_c_total['确诊人数'] = df_c_total['热搜内容'].apply(get_number)
| 时间 | 排名 | 热搜内容 | 地域 | 主题 | 上榜时间 | 最后时间 | 确诊人数 | |
|---|---|---|---|---|---|---|---|---|
| 686 | 2020-01-27 | 5 | 全国累计确诊新型肺炎2744例 | 国内 | 疫情-播报 | 2020/1/27 18:04 | 2020/1/27\n8:08 | 2744 |
| 649 | 2020-01-28 | 1 | 全国累计确诊病例4515例 | 国内 | 疫情-播报 | 2020/1/28 19:02 | 2020/1/28\n10:40 | 4515 |
| 622 | 2020-01-29 | 5 | 全国累计确诊新型肺炎5974例 | 国内 | 疫情-播报 | 2020/1/29 16:34 | 2020/1/29\n8:28 | 5974 |
| 588 | 2020-01-30 | 4 | 全国累计确诊新型肺炎7711例 | 国内 | 疫情-播报 | 2020/1/30 16:18 | 2020/1/30\n8:04 | 7711 |
| 555 | 2020-01-31 | 2 | 全国累计确诊9692例 | 国内-湖北-武汉 | 疫情-播报 | 2020/1/31 13:20 | 2020/1/31\n8:28 | 9692 |
df_c_map = df_day[df_day['热搜内容'].str.contains('地图')] # 字符串匹配,查找类似搜索
#df_c_map
out_dict['疫情地图'] = {'日期':list(df_c_map['时间']), '关注度':list(df_c_map['排名'])}
df_c_map.head()
| 时间 | 排名 | 热搜内容 | 地域 | 主题 | 上榜时间 | 最后时间 | |
|---|---|---|---|---|---|---|---|
| 833 | 2020-01-23 | 21 | 疫情地图 | 国内 | 疫情-地图 | 2020/1/24 22:14 | 2020/1/22\n23:54 |
| 803 | 2020-01-24 | 26 | 疫情地图 | 国内 | 疫情-地图 | 2020/1/24 22:14 | 2020/1/22\n23:54 |
| 727 | 2020-01-26 | 15 | 最新疫情地图 | 国内 | 疫情-地图 | 2020/2/10 14:30 | 2020/1/25\n17:12 |
| 687 | 2020-01-27 | 9 | 最新疫情地图 | 国内 | 疫情-地图 | 2020/2/10 14:30 | 2020/1/25\n17:12 |
| 653 | 2020-01-28 | 9 | 最新疫情地图 | 国内 | 疫情-地图 | 2020/2/10 14:30 | 2020/1/25\n17:12 |
df_day[df_day['热搜内容'].str.contains('[医生|护士]')].head()
| 时间 | 排名 | 热搜内容 | 地域 | 主题 | 上榜时间 | 最后时间 | |
|---|---|---|---|---|---|---|---|
| 870 | 2020-01-21 | 1 | 武汉15名医务人员感染新型冠状病毒 | 国内-湖北-武汉 | 医护|疫情-新增 | 2020/1/21 18:52 | 2020/1/21\n7:36 |
| 875 | 2020-01-21 | 24 | 朱一龙鼓励医生粉丝 | 国内 | 医护 | 2020/1/21 13:36 | 2020/1/21\n7:26 |
| 848 | 2020-01-22 | 2 | 新型冠状病毒来源是野生动物 | 国内 | 疫情-知识 | 2020/1/22 19:34 | 2020/1/22\n11:26 |
| 857 | 2020-01-22 | 13 | 协和医院骨科医生自愿支援 | 国内-湖北-武汉 | 医护 | 2020/1/22 15:50 | 2020/1/22\n8:24 |
| 865 | 2020-01-22 | 31 | 全副武装的白衣战士 | 国内 | 医护 | 2020/1/22 16:08 | 2020/1/22\n7:10 |
疫情内容分析
- 采用NLP技术肢解热门搜索词,尝试挖掘内部隐藏的信息
#import requests
import pandas as pd
import datetime
import re
import jieba
from jieba import analyse
import jieba.posseg as pseg
#import matplotlib.pyplot as plt
#import jieba.analyse
# 分词
# sent_words = [list(jieba.cut(sent0)) for sent0 in sentences]
# document = [" ".join(sent0) for sent0 in sent_words]
# print(document)
# 自定义词库
#jieba.set_dictionary(file_name)
#jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
entity_list = ['新型冠状病毒/8/nz', '冠状病毒/8/nz','疫情地图/8/nz','武汉肺炎/8/nz','人传人','病毒/8/nz','疫情/8/nz',
'病例','新冠/8/nz', 'SARS/8/nz','隔离', '口罩', '卫健委/5/nt','双黄连/8/nz','埃博拉/3/nz','瑞德西韦/5/nz',
'金银潭/5/nr','百步亭/5/nr','火神山/5/nr','雷神山/5/nr','张家界/5/ns', '小汤山/5/nr','威斯特丹号/5/nr','钻石公主号/5/nr',
'方舱医院/5/nr','紫外线', '蝙蝠/3/nz','酒精','消毒','确诊',
'康复/3/n','封城/3/n','汤圆/3/n', '武软/3/nt', '红十字会/3/nt', '马拉松/3/n', '小姐姐/3/r',
'医护人员/5/nr','医疗队/5/nr','医院院长/5/nr','张定宇/5/nr','护士/5/nr','医生/5/nr',
'钟南山/5/nr', '李兰娟/5/nr','李文亮/5/nr', '应勇/5/nr','王贺胜/5/nr', '王忠林/5/nr']
for w in entity_list:
#print(w)
w_list = w.split('/')
freq, tag = 1, None
if len(w_list) > 1:
# [word freq]
freq = w_list[1]
if len(w_list) > 2:
# [word freq tag]
tag = w_list[2]
#jieba.add_word(w)
jieba.add_word(w_list[0], freq=freq, tag=tag)
word_list = []
for index, row in df_day.iterrows():
content = row[2]
#TextRank 关键词抽取,只获取固定词性
#words = analyse.textrank(content, topK=50, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
#words = analyse.textrank(content, topK=50)
# res = analyse.extract_tags(text) # TF-IDF关键词提取
# 不用关键词工具,因为无法导入自定义词库
for w in pseg.cut(content):
if not ( w.flag.startswith('n') or w.flag in ('v','vn','x')):
continue
if len(w.word) == 1:
continue
# 记录全局分词
word_list.append({'word':w.word,'pos':w.flag, 'count':1})
df_kw = pd.DataFrame(word_list)
# 词频统计
df_kw = df_kw.groupby(['word','pos'])['count'].sum().reset_index().sort_values(by='count', ascending=False)
df_kw.head()
| word | pos | count | |
|---|---|---|---|
| 922 | 肺炎 | n | 191 |
| 634 | 新增 | v | 130 |
| 712 | 武汉 | ns | 102 |
| 861 | 确诊 | v | 85 |
| 631 | 新冠 | nz | 68 |
print('\t'.join(df_kw['word'][:100]))
df_day[df_day['热搜内容'].str.contains('威斯特')]
#df_kw[df_kw['word'].str.contains('小汤山')]
# 关键词分门别类
tag_dict = {'n':'名词', 'nr':'人物', 'ns':'地名', 'nt':'机构组织', 'v':'动词', 'vn':'动作'}
# 词性:n,v,ns,nr,vn,nt,nz,x,ng,nrt
df_kw[df_kw.pos=='nr'][:50] # 人名
#df_kw[df_kw.pos=='ns'][:50] # 各地地名
#df_kw[df_kw.pos=='n'][:50] # 名词
#df_kw[df_kw.pos=='v'][:50] # 动词
#df_kw.groupby(['pos']).count().sort_values(by='count', ascending=False)
df_kw[df_kw.pos=='vn'][:50] # 动作
df_kw[df_kw.pos=='nt'][:50] # 各机构
out_dict['关键词'] = {}
for tag in tag_dict:
out_dict['关键词'][tag] = {'含义': tag_dict[tag],
'数据':df_kw[['word','count']][df_kw.pos==tag].values.tolist()}
#out_dict['关键词']
肺炎 新增 武汉 确诊 新冠 病例 湖北 疫情 口罩 诊病 累计 全国 患者 新型冠状病毒 浙江 北京 医院 感染 河南 隔离 复工 疫情地图 首例 广东 回应 日本 病毒 钟南山 医生 死亡 出院 乘客 中国 江苏 专家 物资 上海 防控 医护人员 出现 山东 防疫 安徽 抗疫 发现 火神山 治愈 检测 四川 企业 加油 医疗 黑龙江 方舱医院 驰援 重庆 连降 疑似 护士 人员 隐瞒 取消 西藏 卫健委 开学 医疗队 要求 医用 钻石公主号 可能 邮轮 河北 防护 硬核 解放军 感染者 医护 天津 核酸 病人 武汉市 李兰娟 重症 聚集 韩国 湖南 工作 医院院长 男子 双黄连 金银潭 救治 捐赠 黄冈 疫苗 居家 地区 时间 治疗 不力
import jieba.posseg as pseg
#df_kw
content = '钟南山承认人传人现象,李文亮说了'
words = analyse.textrank(content, topK=50)
words = analyse.extract_tags(content, topK=50)
print(words)
pos = [ '{}/{}'.format(w.word,w.flag) for w in pseg.cut(content) if w.flag.startswith('n') or w.flag in ('v','vn','x')]
print('\t'.join(pos))
print('\t'.join(df_kw[df_kw.pos=='nr']['word']))
df_kw[['word','count']][df_kw.pos=='nr'][:10].values.tolist()
['李文亮', '钟南山', '传人', '承认', '现象']
钟南山/nr 承认/v 人/n 传人/n 现象/n ,/x 李文亮/nr 说/v
钟南山 医生 医护人员 火神山 方舱医院 护士 医疗队 钻石公主号 李兰娟 医院院长 金银潭 韩红 雷神山 小汤山 李文亮 连闯 王辰 王贺胜 黄祥龙 钱七虎 齐齐哈尔 齐喊 黑名单 洪山 胡绍任 陶勇 解密 阿富汗 阿婆 萨日朗 蒋超良 谢娜 百步亭 纪检监察 谢谢 秦皇岛 司法厅 卫星 周琪 大吉 太贵 唐志红 任城 余姚 刘传健 丁香 慈善 戴法 承德 朱一龙 杜绝 柳叶刀 显微镜 晋升 富士康 寻超 小学生 少林寺 岳云鹏 威斯特丹号 宝宝 张流波 张挪富 康复者 张定宇
[['钟南山', 16],
['医生', 15],
['医护人员', 12],
['火神山', 10],
['方舱医院', 9],
['护士', 8],
['医疗队', 7],
['钻石公主号', 7],
['李兰娟', 6],
['医院院长', 5]]
可视化
#先安装pip install pyecharts==0.5.1
#from IPython.display import HTML, SVG
# from IPython.core.magic import register_cell_magic
import pyecharts as pe
page = pe.charts.Page('疫情搜索词分析')
opts = pe.options # 配置信息
t1 = '疫情搜索词分析(每天12:00的数据)'
s1 = '2020-2-22 鹤啸九天'
# (1) 每天热搜数目排名变化
line_trend = pe.charts.Line()
line_trend.set_global_opts(title_opts=opts.TitleOpts(title='疫情热搜趋势分析',pos_left='center',pos_top='8%',subtitle=s1),
# legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle',orient='vertical'), # 靠左居中垂直排列
toolbox_opts=opts.ToolboxOpts())
line_trend.add_xaxis(out_dict['趋势']['日期'])\
.add_yaxis('疫情热搜-数目', out_dict['趋势']['热词数目'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5),)\
.add_yaxis('疫情热搜-最大关注度(50-rank)', out_dict['趋势']['最大关注度'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5))\
.add_yaxis('疫情热搜-最小关注度(50-rank)', out_dict['趋势']['最小关注度'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5))\
.add_yaxis('疫情热搜-平均关注度(50-rank)', out_dict['趋势']['平均关注度'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5))
#page.add(line)
bar = pe.charts.Bar()
bar.set_global_opts(title_opts=opts.TitleOpts(title='疫情热搜趋势分析',pos_left='center',subtitle=s1),
legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle',orient='vertical'), # 靠左居中垂直排列
toolbox_opts=opts.ToolboxOpts())
bar.add_xaxis(out_dict['趋势']['日期'])\
.add_yaxis('疫情热搜-数目', out_dict['趋势']['热词数目'],
label_opts=opts.LabelOpts(is_show=False)) # 隐藏标签,避免重影
bar.overlap(line_trend)
#page.add(bar)
page.add(line_trend)
# 确诊人数及疫情地图分析
line = pe.charts.Line()
line.set_global_opts(title_opts=opts.TitleOpts(title='疫情热搜-确诊人数变化',pos_left='center',pos_top='8%',subtitle=s1),
# legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle',orient='vertical'), # 靠左居中垂直排列
toolbox_opts=opts.ToolboxOpts())
line.add_xaxis(out_dict['确诊']['日期'])\
.add_yaxis('确诊人数', out_dict['确诊']['确诊人数'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5))
page.add(line)
# 排名分析--确诊人数
line = pe.charts.Line()
line.set_global_opts(title_opts=opts.TitleOpts(title='疫情热搜关注度分析',pos_left='center',pos_top='8%',subtitle=s1),
# legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle',orient='vertical'), # 靠左居中垂直排列
toolbox_opts=opts.ToolboxOpts())
line.add_xaxis(out_dict['确诊']['日期'])\
.add_yaxis('疫情热搜-确诊人数', out_dict['确诊']['排名'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5))
# 排名分析--疫情地图
line1 = pe.charts.Line()
line1.set_global_opts(title_opts=opts.TitleOpts(title='疫情热搜关注度分析',subtitle=s1),
#legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle',orient='vertical'), # 靠左居中垂直排列
toolbox_opts=opts.ToolboxOpts())
line1.add_xaxis(out_dict['疫情地图']['日期'])\
.add_yaxis('疫情热搜-疫情地图', out_dict['疫情地图']['关注度'], linestyle_opts=opts.LineStyleOpts(width=5, opacity=0.5))
line.overlap(line1)
page.add(line)
# 地图可视化
# 世界地图
for k in ('频次', '关注度'):
map_p = pe.charts.Map()
num_range = (min(out_dict['地域']['中国'][k]), sorted(out_dict['地域']['中国'][k])[-2])
t = "(国内频次:{}, 关注度:{},国外频次:{},, 关注度:{})".format(
out_dict['地域']['总体']['国内'][0], out_dict['地域']['总体']['国内'][1],
out_dict['地域']['总体']['国外'][0], out_dict['地域']['总体']['国外'][1])
map_p.set_global_opts(title_opts=opts.TitleOpts(
title="新冠肺炎疫情全球分布-{}".format(k),
pos_left='center',subtitle='微博热搜榜单-{}'.format(t)),
legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle',orient='vertical'), # 靠左居中垂直排列
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(min_=num_range[0], max_=num_range[1]))
map_p.add(k, zip(out_dict['地域']['世界']['国家'], out_dict['地域']['世界'][k]), maptype="world")
map_p.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 世界地图不显示label
#map_p.add('关注度', zip(out_dict['地域']['中国']['省份'], out_dict['地域']['中国']['关注度']), maptype="china")
page.add(map_p)
# 中国地图
for k in ('频次', '关注度'):
map_p = pe.charts.Map()
num_range = (min(out_dict['地域']['中国'][k]), sorted(out_dict['地域']['中国'][k])[-2])
t = "(国内频次:{}, 关注度:{},国外频次:{},, 关注度:{})".format(
out_dict['地域']['总体']['国内'][0], out_dict['地域']['总体']['国内'][1],
out_dict['地域']['总体']['国外'][0], out_dict['地域']['总体']['国外'][1])
map_p.set_global_opts(title_opts=opts.TitleOpts(
title="新冠肺炎疫情全国分布-{}".format(k),
pos_left='center',subtitle='微博热搜榜单-{}'.format(t)),
legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle'),
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(min_=num_range[0], max_=num_range[1]))
map_p.add(k, zip(out_dict['地域']['中国']['省份'], out_dict['地域']['中国'][k]), maptype="china")
#map_p.add('关注度', zip(out_dict['地域']['中国']['省份'], out_dict['地域']['中国']['关注度']), maptype="china")
page.add(map_p)
# 湖北省内城市地图
for k in ('频次', '关注度'):
map_hubei = pe.charts.Map()
num_range = (min(out_dict['地域']['湖北'][k]), max(out_dict['地域']['湖北'][k]))
map_hubei.set_global_opts(title_opts=opts.TitleOpts(
title="新冠肺炎疫情(湖北省内)-{}".format(k),
pos_left='center',subtitle='微博热搜榜单'),
legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle'),
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(min_=num_range[0], max_=num_range[1]))
city_name = ['{}市'.format(i) for i in out_dict['地域']['湖北']['城市']]
map_hubei.add(k, zip(city_name, out_dict['地域']['湖北'][k]), maptype='湖北')
#map_hubei.add('关注度', zip(city_name, out_dict['地域']['湖北']['关注度']), maptype='湖北')
page.add(map_hubei)
# (2) 标题关键词词云
#-饼图
top_n = 30
pie = pe.charts.Pie() #subtitle=s1, title_pos='center'
pie.set_global_opts(title_opts=opts.TitleOpts(title='疫情热词分析-饼图',pos_left='center',subtitle=s1),
#legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle'),
toolbox_opts=opts.ToolboxOpts())
pie.add("饼图可视化(Top {})".format(top_n), df_kw[['word','count']].values.tolist()[:top_n])
page.add(pie)
# 关键词词云可视化
wc = pe.charts.WordCloud()
wc.set_global_opts(title_opts=opts.TitleOpts(title='疫情热词分析-{}'.format('全部关键词'),
pos_left='center',subtitle=s1))
wc.add("疫情热词分析-所有关键词", df_kw[['word','count']].values.tolist(), shape='circle') # word_size_range=[10, 500]
page.add(wc)
# 显示各类词云
for tag in tag_dict:
wc = pe.charts.WordCloud()
wc.set_global_opts(title_opts=opts.TitleOpts(title='疫情热词分析-{}'.format(out_dict['关键词'][tag]['含义']),
pos_left='center',subtitle=s1),
legend_opts=opts.LegendOpts(pos_left='left',pos_top='middle'),
toolbox_opts=opts.ToolboxOpts())
wc.add(out_dict['关键词'][tag]['含义'],
out_dict['关键词'][tag]['数据'], shape='circle') # word_size_range=[10, 500]
page.add(wc)
# 统一绘制、落地
out_file = 'wqw_sari.html'
page.render(out_file)
#page.render_notebook()
#HTML(out_file)
疫情地图
- 新型冠状病毒爆发后,一直高度关注日益增长的数字,各个渠道先后提供了可视化展示工具,如下:
- 丁香园首先给出疫情可视化信息,覆盖辟谣、实时信息、医学知识等
- 互联网公司纷纷上阵:新浪、百度、腾讯、头条、搜狗等
- 人民日报只有全国数据,没有城市信息
- IT码农整理的疫情地图,可视化效果最好
- 有城市分布,包含历史趋势图,有热力图等,功能全,外观最好
- 但颜色区间定死,不灵活;图无法交互缩放
- 【2020-3-10】全球新冠肺炎疫情数据可视化看板“Coronavirus COVID-19 updates: dashboard and report”
- 【2020-4-12】三综一蓝传染病模拟-web动画,An interactive inspired by 3Blue1Brown’s ‘Simulating an Epidemic’ video
- 【2020-4-14】一亩三分地1point3acres(北美最有影响力的华人社区)
- 丁香园首先给出疫情可视化信息,覆盖辟谣、实时信息、医学知识等
- 周边有哪些疫情信息?下面是第一财经制作的小工具,根据你所在位置显示周边疫情信息,可拖动、缩放

- 周边有哪些疫情信息?下面是第一财经制作的小工具,根据你所在位置显示周边疫情信息,可拖动、缩放
- 覆盖全国大部分疫情信息
- 补充:湖北小地方做到了确诊案例地图精确标记 ,以下页面来自蕲春通
- excel也可以画地图数据,如下:
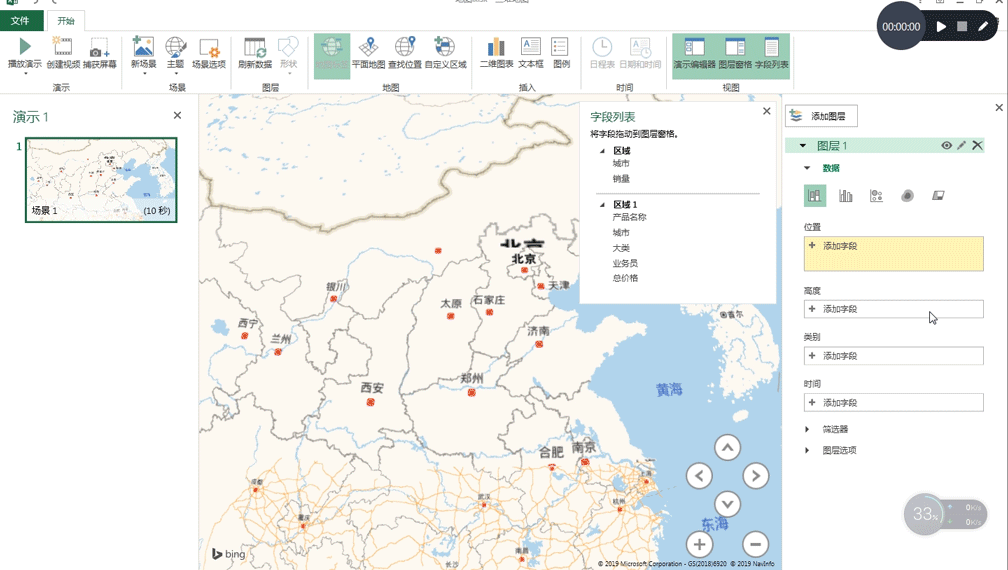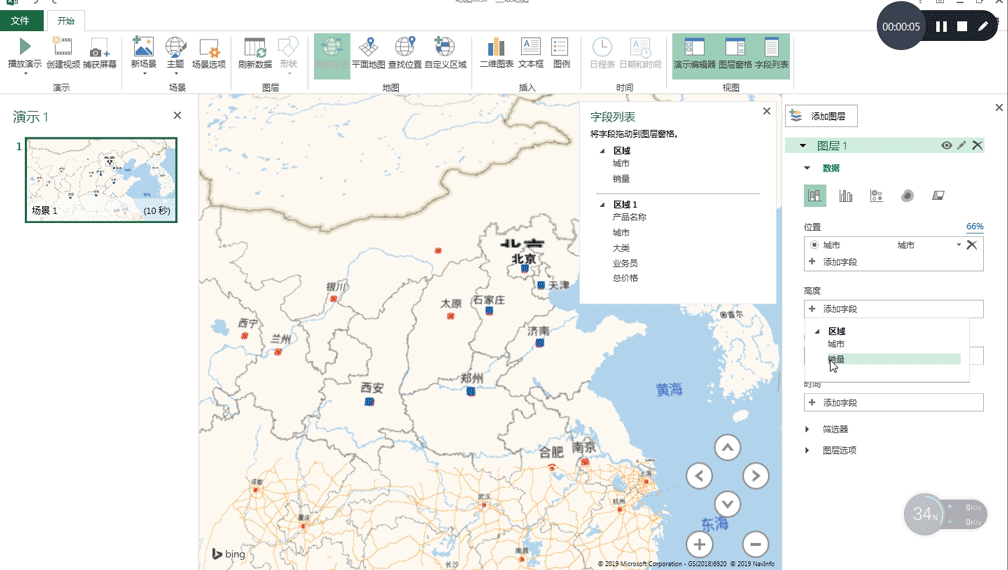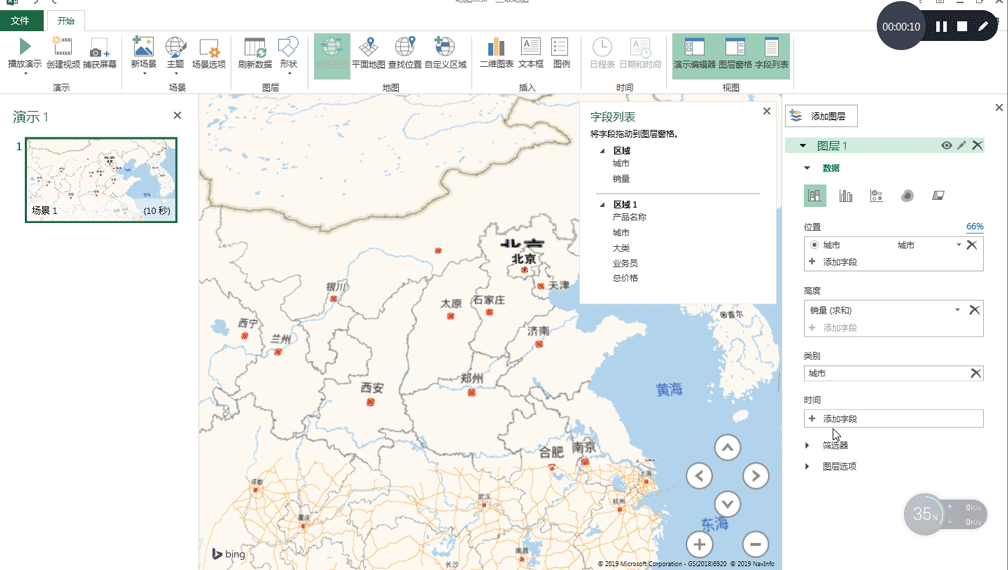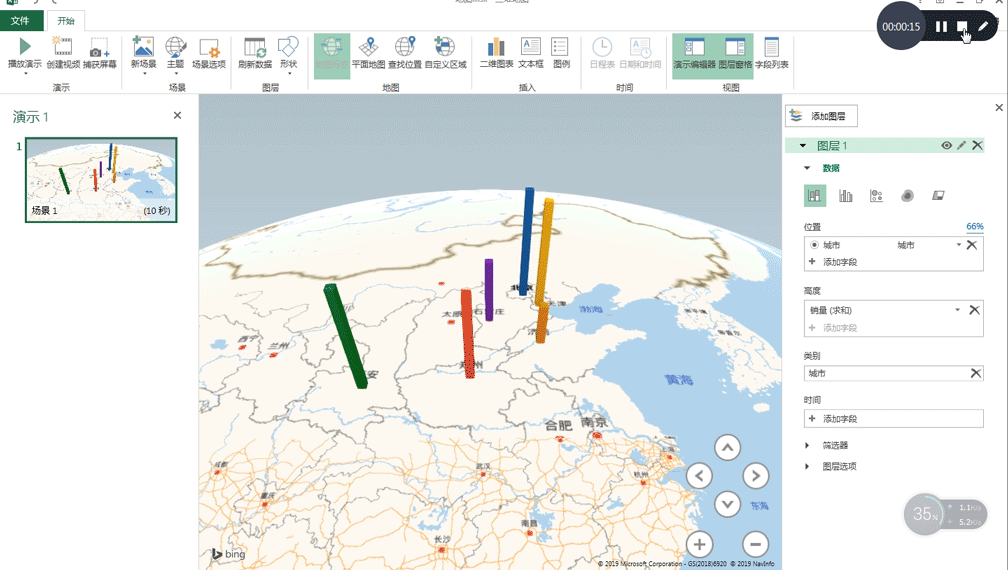
- 要不自己做一个具体到城市、可缩放且美观的疫情地图?
思路
- 参考 用Python制作实时疫情图,采用Pyecharts绘制,数据源自新浪
- 步骤:
- 通过新浪抓取最新数据(json格式)
- 提取各省份的宏观信息,覆盖确诊、疑似、死亡和治愈几类
- 提取省内各城市、地区的数据
- 分别绘制疫情地图,瀑布方式排列
代码
- (1)环境准备
- Python 3版本,提前安装pyecharts包
pip install pyecharts # linux下加sudo权限
- (2)获取数据
import requests, re, json
import pyecharts as pe
import pprint as pp
result = requests.get(
'https://interface.sina.cn/news/wap/fymap2020_data.d.json?1580097300739&&callback=sinajp_1580097300873005379567841634181')
json_str = re.search("\(+([^)]*)\)+", result.text).group(1)
#print json_str
html = f"{json_str}"
table = json.loads(f"{html}")
#table = json.loads(json_str)
table
- (3)数据处理
- 每一张图,需要自动提取合适的颜色区间,提升对比度
# 全国信息
val_dict = {'gntotal': ['确诊', 'value'],
'sustotal': ['疑似', 'susNum'],
'deathtotal': ['死亡', 'deathNum'],
'curetotal': ['治愈', 'cureNum']}
data = {'gntotal':[], 'sustotal':[], 'deathtotal':[], 'curetotal':[]}
city_info = {}
#city_key = ['name', 'conNum', 'susNum', 'deathNum', 'cureNum'] #, 'mapName']
city_dict = {'conNum':'确诊', 'susNum':'疑似', 'deathNum':'死亡', 'cureNum':'治愈'}
for province in table['data']['list']:
#pp.pprint(province)
for k, v in val_dict.items():
data[k].append((province['name'], province[v[1]]))
city_info[province['name']] = dict([(c, []) for c in city_dict.keys()])
city_info[province['name']]['all'] = dict([(val_dict[i][1], province[val_dict[i][1]]) for i in val_dict])
city_info[province['name']]['all']['conNum'] = city_info[province['name']]['all']['value']
for city in province['city']:
# [{'name': '杭州', 'conNum': '141','susNum': '0', 'cureNum': '14','deathNum': '0','mapName': '杭州市'},...]
#pp.pprint(city)
for c_num in city_dict:
city_info[province['name']][c_num].append((city['mapName'], city[c_num]))
- 可视化
# 地图绘制
page = pe.charts.Page() # 瀑布方式
map_p = pe.charts.Map() # 全国地图
opts = pe.options # 配置信息
# 数据处理:数据范围(自适应)
# (1)全国地图
num_list = [int(i[1]) for i in data['gntotal']]
print(num_list)
num_range = [min(num_list), max(num_list)]
num_range[1] = sorted(num_list)[-2] * 1.2 # 以第二名的数字的1.2倍为上界,便于可视化
map_p.set_global_opts(title_opts=opts.TitleOpts(
title="2020年新型冠状病毒实时疫情图(全国)\n\t确诊:{},疑似:{},治愈:{},死亡:{}".format(
table['data']['gntotal'],
table['data']['sustotal'],
table['data']['curetotal'],
table['data']['deathtotal']),
subtitle='鹤啸九天-{}'.format(table['data']['times'])),
#legend_opts=opts.TooltipOpts(),
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(min_=num_range[0], max_=num_range[1])) #, is_piecewise=True))
for k, v in val_dict.items():
print(k, data[k])
map_p.add(v[0], data[k], maptype="china") # maptype="湖北"
#page.add(map_p, grid_opts=opts.GridOpts(pos_bottom="60%"))
page.add(map_p) # 添加大图里
# (2)城市地图(覆盖全国所有省市自治区)
p_list = ['湖北', '北京', '广东' , '浙江']
map_c = {}
print('city_info', city_info.keys())
for c in city_info:
# 获取数据范围
num_list = [int(i[1]) for i in city_info[c]['conNum']]
if not num_list:
print('{}省数据为空!'.format(c))
continue
num_range = [min(num_list), max(num_list)]
if len(num_list) < 2:
num_range[1] = num_list[0] * 1.2
else:
sort_list = sorted(num_list)
if sort_list[-1] / sort_list[-2] > 5:
num_range[1] = sort_list[-2] * 1.2 # 第一名差距过大时,以第二名的数字的1.2倍为上界,便于可视化
if num_range[1] < 20: # 最大值较小时,将最小值设置为0,提升区分度
num_range[0] = 0
map_c = pe.charts.Map()
map_c.set_global_opts(title_opts=opts.TitleOpts(
title="2020年新型冠状病毒实时疫情图({})\n\t确诊:{},疑似:{},死亡:{},治愈:{}".format(c,
city_info[c]['all']['conNum'],
city_info[c]['all']['susNum'],
city_info[c]['all']['deathNum'],
city_info[c]['all']['cureNum']),
subtitle='鹤啸九天-{}'.format(table['data']['times'])),
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(min_=num_range[0], max_=num_range[1]))
for k, v in city_dict.items():
map_c.add(v, city_info[c][k], maptype='{}'.format(c)) # maptype="湖北"
page.add(map_c)
# 输出
page.render("ncov.html") # 生成html文件
page.render_notebook() # notebook中直接显示
效果
疫情传播计算机仿真
流行病传播模型
- 【2020-2-15】毕导THU的流行病学模型:简单算算,你宅在家里究竟能为抗击肺炎疫情做出多大贡献?,病毒其实不可拍,你宅我宅它就挂;病毒其实不可怕,戴好口罩它也挂,文字版
- 《Going Critical原文》-读后感,病毒性传播的解释与探索

- 传染病模型迭代发展:
SI→SIS→SIR→SEIR - 注解:
- 1、
S类,易感者(Susceptible),指未得病者,但缺乏免疫能力,与感染者接触后容易受到感染; - 2、
E类,暴露者(Exposed),指接触过感染者,但暂无能力传染给其他人的人,对潜伏期长的传染病适用; - 3、
I类,感病者(Infective),指染上传染病的人,可以传播给 S 类成员,将其变为 E 类或 I 类成员; - 4、
R类,康复者(Recovered),指被隔离或因病愈而具有免疫力的人。如免疫期有限,R 类成员可以重新变为 S 类。
- 1、
- 模型迭代,摘自知乎酱紫君
SI:健康人感染后终身得病,如HIV- 动力学方程:
- 动力学方程:
SIS:感染后可恢复,如普通流感, 得病→恢复→不断循环;流感非常容易变异, 没有能杜绝流感的体质存在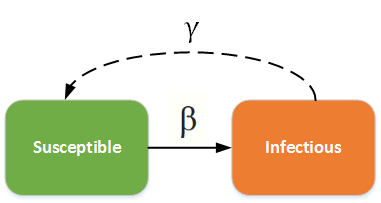
- 动力学方程
SIR:急性传染病,发病非常快, 没有潜伏期, 发病后一段时间痊愈
- 动力学方程
SEIR:带潜伏期的恶性传染病,常规的传染病发病形式, 潜伏→感染→痊愈
- 数学模型比较复杂, 且没有显式解, 一般用相轨线的方式来研究;也可以通过数值解法快速求解或拟合
- SEIR 模型不是万能的
- 有的人潜伏期长, 有的人潜伏期短;
- 还有超级潜伏者/超级感染者, 整个一移动的灾难;
- 有的潜伏者可能就直接痊愈了, 变成了抵抗者;
- 方程并没有单独处理这些情况, 因为一定程度内这些异类都可以被扰动因子所包含
- 研究一个固定的模型加扰动比不断地往模型里加扰动项好研究的多的多
传染病防治仿真
- 传染病防治计算机仿真, Github代码
- 《三体》中的一句话,再次提醒大家:“无知和弱小不是生存的最大障碍,傲慢才是。”
使用Python对城市中的冠状病毒流行进行建模
- 翻译自Gevorg Yeghikyan的文章《Modelling the coronavirus epidemic in a city with Python》
- 原始文章:冠状病毒,传染病python仿真,Urban policy in the time of Coronavirus
- 流行病袭击城市时会发生什么,应立即采取什么措施,以及这对城市规划,政策制定和管理有何影响。
-
以埃里温市为例进行研究,并对城市中冠状病毒的传播进行数学建模和仿真,研究城市流动性模式如何影响该疾病的传播。
- 建立一个简单的隔间模型来模拟城市中传染病的传播。
- 随着疫情的爆发,其传播动态会发生很大变化,这取决于最初感染的地理位置及其与城市其他地区的连通性。 这是从最近的数据驱动的城市人口流行病研究中获得的最重要的见解之一。 但是,正如我们将在下面进一步看到的,各种结果要求采取类似措施来遏制该流行病,并考虑到规划和管理城市中的这种可能性。
-
由于运行基于个人的流行病模型具有挑战性,并且由于我们的目标是展示城市流行病的一般原理,而不是建立精细的校准和准确的流行病模型,因此,将按照《自然》杂志中所述的方法,修改描述了我们需要的经典SIR模型。
- 该模型将总体分为三个部分。 对于时间t的每个位置i,三个隔室如下:
- · Si,t:尚未感染或不易感染该疾病的人数。
- · Ii,t:感染该疾病并能够将疾病传播给易感人群的人数。
- · Ri,t:由于恢复或死亡而被感染,然后从感染组中撤出的人数。 该组中的个体无法再次感染该疾病或将感染传播给他人。
-
时间将是离散变量,因为系统状态每天都在建模。 在时间t的位置j处完全易感的种群中,爆发的可能性为:
- 模拟代码
import numpy as np
# initialize the population vector from the origin-destination flow matrix
N_k = np.abs(np.diagonal(OD) + OD.sum(axis=0) - OD.sum(axis=1))
locs_len = len(N_k) # number of locations
SIR = np.zeros(shape=(locs_len, 3)) # make a numpy array with 3 columns for keeping track of the S, I, R groups
SIR[:,0] = N_k # initialize the S group with the respective populations
first_infections = np.where(SIR[:, 0]<=thresh, SIR[:, 0]//20, 0) # for demo purposes, randomly introduce infections
SIR[:, 0] = SIR[:, 0] - first_infections
SIR[:, 1] = SIR[:, 1] + first_infections # move infections to the I group
# row normalize the SIR matrix for keeping track of group proportions
row_sums = SIR.sum(axis=1)
SIR_n = SIR / row_sums[:, np.newaxis]
# initialize parameters
beta = 1.6
gamma = 0.04
public_trans = 0.5 # alpha
R0 = beta/gamma
beta_vec = np.random.gamma(1.6, 2, locs_len)
gamma_vec = np.full(locs_len, gamma)
public_trans_vec = np.full(locs_len, public_trans)
# make copy of the SIR matrices
SIR_sim = SIR.copy()
SIR_nsim = SIR_n.copy()
# run model
print(SIR_sim.sum(axis=0).sum() == N_k.sum())
from tqdm import tqdm_notebook
infected_pop_norm = []
susceptible_pop_norm = []
recovered_pop_norm = []
for time_step in tqdm_notebook(range(100)):
infected_mat = np.array([SIR_nsim[:,1],]*locs_len).transpose()
OD_infected = np.round(OD*infected_mat)
inflow_infected = OD_infected.sum(axis=0)
inflow_infected = np.round(inflow_infected*public_trans_vec)
print('total infected inflow: ', inflow_infected.sum())
new_infect = beta_vec*SIR_sim[:, 0]*inflow_infected/(N_k + OD.sum(axis=0))
new_recovered = gamma_vec*SIR_sim[:, 1]
new_infect = np.where(new_infect>SIR_sim[:, 0], SIR_sim[:, 0], new_infect)
SIR_sim[:, 0] = SIR_sim[:, 0] - new_infect
SIR_sim[:, 1] = SIR_sim[:, 1] + new_infect - new_recovered
SIR_sim[:, 2] = SIR_sim[:, 2] + new_recovered
SIR_sim = np.where(SIR_sim<0,0,SIR_sim)
# recompute the normalized SIR matrix
row_sums = SIR_sim.sum(axis=1)
SIR_nsim = SIR_sim / row_sums[:, np.newaxis]
S = SIR_sim[:,0].sum()/N_k.sum()
I = SIR_sim[:,1].sum()/N_k.sum()
R = SIR_sim[:,2].sum()/N_k.sum()
print(S, I, R, (S+I+R)*N_k.sum(), N_k.sum())
print('\n')
infected_pop_norm.append(I)
susceptible_pop_norm.append(S)
recovered_pop_norm.append(R)
- 效果
资料
- echarts地球可视化
- 生命科学
- 【2020-2-29】计算机仿真模拟疫情期间开学可能的后果
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
