Swift 框架
【2024-7-4】 阿里推出训练框架 (Scalable lightWeight Infrastructure for Fine-Tuning)
介绍
ms-swift 是 ModelScope 社区提供的官方框架,用于微调和部署大型语言模型和多模态大型模型。
目前支持 450+ 大型模型和 150+ 多模态大型模型的训练(预训练、微调、人工对齐)、推理、评估、量化和部署。
ms-swift
- 采用最新训练技术,包括 LoRA、QLoRA、Llama-Pro、LongLoRA、GaLore、Q-GaLore、LoRA+、LISA、DoRA、FourierFt、ReFT、UnSloth 和 Liger 等轻量级技术,以及 DPO、GRPO、RM、PPO、KTO、CPO、SimPO 和 ORPO 等人工对齐训练方法。
- 支持使用 vLLM 和 LMDeploy 加速推理、评估和部署模块,并支持使用 GPTQ、AWQ 和 BNB 等技术进行模型量化。
- 提供了基于 Gradio 的 Web UI 和丰富的最佳实践
Swift 框架(Scalable lightWeight Infrastructure for Fine-Tuning)由魔搭社区(ModelScope)开发, 基于PyTorch的轻量级、灵活且高效的模型微调与推理,开源框架。专为大模型(LLM)和多模态大模型(MLLM)的开发设计,支持从数据处理到模型部署的全流程操作,适用于科研、企业和个人开发者。
功能
核心功能与特点
- Swift 框架支持超过 450 种大语言模型(如 GPT、Llama、ChatGLM)和 150 种多模态模型(如图像、视频、语音任务)。
- 集成多种高效微调技术,包括 LoRA、QLoRA 和 ResTuning,能够显著降低显存需求和训练成本。框架还支持分布式训练、量化模型、RLHF(人类偏好对齐)等功能,适配多种硬件平台(如 RTX 系列、A100、H100、Ascend NPU)。
- Swift 提供了丰富工具箱能力,包括推理加速引擎(如 vLLM、LmDeploy)和全面的模型评测体系(EvalScope)。开发者可以通过简单的接口实现模型训练、推理、评测和部署,甚至支持多种 tuner 的混合使用。
优点
优点
- (1)全模态覆盖能力
- 与主流框架专注于单一模态(如纯文本)不同,MS-Swift 支持 450+ 纯文本大模型、150+ 多模态大模型(涵盖图像、视频、语音),包括 LLaVA、MiniCPM-V、Phi3.5-Vision 等复杂模型。
- (2)轻量化技术创新: MS-Swift 集成了 20+ 高效微调技术,显存占用和训练成本显著低于同类产品
- 参数优化:持 LoRA、QLoRA、DoRA 等主流轻量化方法,独创 GaLore 技术,预训练内存节省 65%
- 量化加速:支持 GPTQ/AWQ 4/8 比特量化,相比传统全量微调显存需求降低 80%;兼容 Unsloth 加速引擎,吞吐量提升 2 倍
- (3)全流程工具链
- MS-Swift 提供 从训练到部署的一站式解决方案,覆盖其他框架未涉及的环节
- 训练阶段:
- 内置 150+ 预训练/微调数据集,支持自定义数据自动预处理
- 集成 DPO、PPO 等 8 种 RLHF 对齐算法,优化模型指令遵循能力
- 推理阶段:
- 支持 vLLM、LMDeploy 加速引擎,推理速度提升 3-5 倍
- 提供 Gradio WebUI 和 OpenAI 风格 API,降低部署门槛
- 生产级支持:
- 分布式训练(DeepSpeed ZeRO3、FSDP)支持 8 卡 A100 并行,速度提升 400%
- 企业级功能如多模态任务模板、生产环境量化导出等
- (4)开发者友好生态
- 相比同类工具,MS-Swift 更注重降低使用门槛与生态整合:零代码(webui+命令行工具封装)、生态兼容(modelscope+huggingface)、扩展灵活性
- (5)行业场景适配性:MS-Swift 在垂直领域优化上表现突出
- 低成本部署:通过量化技术(如 4 比特 GPTQ)在边缘设备运行百亿模型
- 多语言支持:优化中文、英语等混合训练,适配全球化客服场景
- 长文本处理:集成 LongLoRA 和 RoPE 扩展技术,上下文窗口提升至 32k tokens
竞品分析
对比优势:
- Unsloth 虽能加速训练但缺乏多模态支持
- XTuner 需依赖 LMDeploy 等外部工具完成部署
- MS-Swift 提供端到端的量化训练与推理加速闭环
使用场景
- Swift 框架广泛应用于多种场景,包括智能客服、内容生成、企业级软件定制、智能物联网和多模态任务(如图像识别与自然语言处理结合)。例如,在智能客服中,Swift 可通过 RLHF 技术训练模型,使其更好地理解用户意图并提供自然的回答。
- SWIFT支持300+ LLM和50+ MLLM(多模态大模型)的训练(预训练、微调、对齐)、推理、评测和部署。开发者可以直接将我们的框架应用到自己的Research和生产环境中,实现模型训练评测到应用的完整链路。我们除支持了PEFT提供的轻量训练方案外,也提供了一个完整的Adapters库以支持最新的训练技术,如NEFTune、LoRA+、LLaMA-PRO等,这个适配器库可以脱离训练脚本直接使用在自己的自定流程中。
swift vs llama-factory
【2025-11-13】【开源框架】ms-swift为什么比llama-factory好?
ms-swift优势:
- 1、ms-swift 提倡 “training is not the end”,将inference、deploy、evaluation 集成的很深入(在llm时代更one-stop),llama-facotry 虽然这些工具能力也支持,但支持很有限
- 2、ms-swift 自定义参数、算法更多,例如 loss计算位置、moe负载均衡策略、megatron支持更好(llama-factory最近也支持)、高效微调的算法等
llama-factory 专注 “模型训练”框架,核心是三大核心模块(Model Loader、Data Worker、Trainer),和一些其他工具能力(llamaboard、model_inference、model_evaluation)
【2025-3-16】MS-Swift部署实战:微调大模型MS-Swift开源解决方案
| 特性 | MS-Swift | 同类框架(如 LLaMA-Factory) |
|---|---|---|
| 模型覆盖 | 450+ LLM + 150+ MLLM | 100+ LLM(侧重文本) |
| 多模态支持 | 图像/视频/语音全模态 | 仅文本或有限多模态 |
| 显存优化 | GaLore + QLoRA(显存降80%) | 标准 LoRA(显存降50%–70%) |
| 部署便捷性 | 内置 WebUI + vLLM 加速 | 依赖第三方工具链 |
| 企业级功能 | RLHF 对齐 + 生产量化导出 | 侧重学术研究场景 |
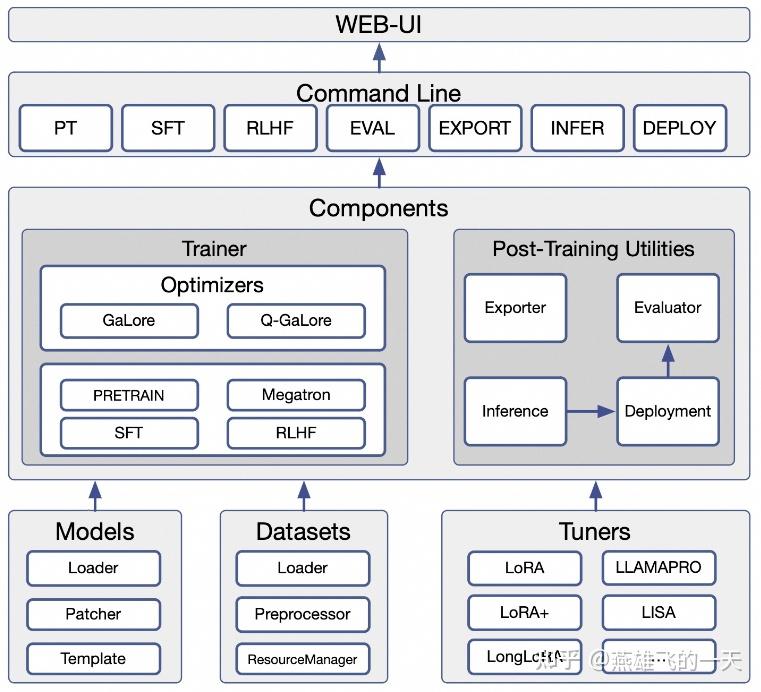
架构
ms-swift “以训练为中心,上下游全链路整合”
Models提供基础模型加载器,支持自定义配置,ms-swift/swift/llm/modelDatasets支持 ModelScope 数据集、Hugging Face 数据集、自定义本地数据集(CSV/JSONL),统一转换为标准格式,ms-swift/swift/llm/datasetTrainer目录ms-swift/swift/trainers/trainers.py- 使用Transformers库中Trainer 用于 SFT / 预训练,使用 TRL 库用于 RLHF(DPO/ORPO/KTO 等)
- 使用 Megatron-LM库并行预训练,支持 Mamba 等非 Attention 结构模型
Post-Traing Utilities- Inference:使用 PyTorch Native、vLLM、LMDeploy 三种后端
- Deployment:使用 FastAPI 库实现 OpenAI 兼容接口,支持工具调用
- Evaluator:使用基于 EvalScope 库,覆盖 100+ 纯文本和多模态评估集
- Exporter:支持 Transformers 格式与 Megatron 格式的双向转换,支持导出为 Ollama 兼容格式
Post-Traing Utilities
分布式训练
ms-swift 原生支持多种分布式训练策略:
- 数据并行 (DDP): 最简单的多卡训练方式。
- DeepSpeed ZeRO: 显存优化神器,特别是ZeRO-3阶段,可以将优化器状态、梯度和参数都分散到多张卡上。
- 完全分片数据并行 (FSDP): PyTorch官方的全参数分片方案。
- Megatron 并行: 支持更极致的模型并行(TP)、流水线并行(PP)等,适合超大规模模型训练。
ms-swift 支持使用 Megatron 并行技术加速训练,包括大规模集群训练和MoE模型训练。
- 预训练、SFT
- RL系列:grpo、dpo、kto、rm等
- embedding
- reranker
- 序列分类
安装
命令安装
# 设置pip全局镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装ms-swift
pip install ms-swift
pip install ms-swift[all] -U # 全量能力
pip install ms-swift[llm] -U # 仅使用LLM
pip install ms-swift[aigc] -U # 仅使用AIGC
pip install ms-swift -U # 仅使用adapters
# 配套设施
pip install swanlab
源码安装
#从源码安装
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]
# 环境对齐 (如果你运行错误, 可以跑下面的代码, 仓库使用最新环境测试)
pip install -r requirements/framework.txt -U
pip install -r requirements/llm.txt -U
问题
【2026-3-24】Mac OS上安装swift,启动时报错
error: unable to invoke subcommand: swift-web-ui (No such file or directory)
原因:官方issue
- Mac 上有两个 swift,跟 mac默认安装的swift语言重复
解决办法
- 使用全路径启动
- 换别名
使用
【2026-1-28】ms-swift命令行参数详解
支持多种方式
- Web UI
- CLI
- 代码推理
CLI
CLI 用法
所有命令都以 swift [子命令] 开头,比如 swift sft 是微调,swift infer 是推理
ms-swift 所有命令都围绕三件事展开:训练(sft/pt/rlhf)→ 推理(infer)→ 部署(deploy/eval/export)
| 动作 | 常用子命令 | 典型用途 | 注意 |
|---|---|---|---|
| 训练 | swift sftswift ptswift rlhf |
微调指令、预训练、强化学习对齐 | 参数最多、最易出错,本文重点覆盖 |
| 推理 | swift inferswift app |
本地测试、Web界面交互、批量生成 | 参数精简,重在“快跑通” |
| 部署评测 | swift evalswift deployswift export |
模型打分、服务化上线、量化导出 | 多数参数可默认,优先保证--model和--infer_backend正确 |
训练代码
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model_type qwen1half-7b-chat \
--model_id_or_path /jppeng/app/models/Qwen1.5-7B-Chat \
--eval_human true \
完整参数
# 22GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-7B-Instruct \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot \
--report_to swanlab \
--swanlab_project swift-robot
推理代码
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import ModelType, InferArguments, infer_main
infer_args = InferArguments(
model_type='qwen1half-7b-chat',
model_id_or_path='/jppeng/app/models/Qwen1.5-7B-Chat',
eval_human=True)
infer_main(infer_args)
开启 SwanLab 实验可视化
- ms-swift CLI中添加
--report_to和--swanlab_project两个参数,即可使用SwanLab进行实验跟踪与可视化
swift sft \
...
--report_to swanlab \
--swanlab_project swift-robot \
...
参数:
- swanlab_token: SwanLab的api-key
- swanlab_project: swanlab的project
- swanlab_workspace: 默认为None,会使用api-key对应的username
- swanlab_exp_name: 实验名,可以为空,为空时默认传入–output_dir的值
- swanlab_mode: 可选cloud和local,云模式或者本地模式
Web UI
启动WebUI方式:swift web-ui
启动后,会自动打开浏览器,显示微调界面(或者访问 http://localhost:7860/ ):
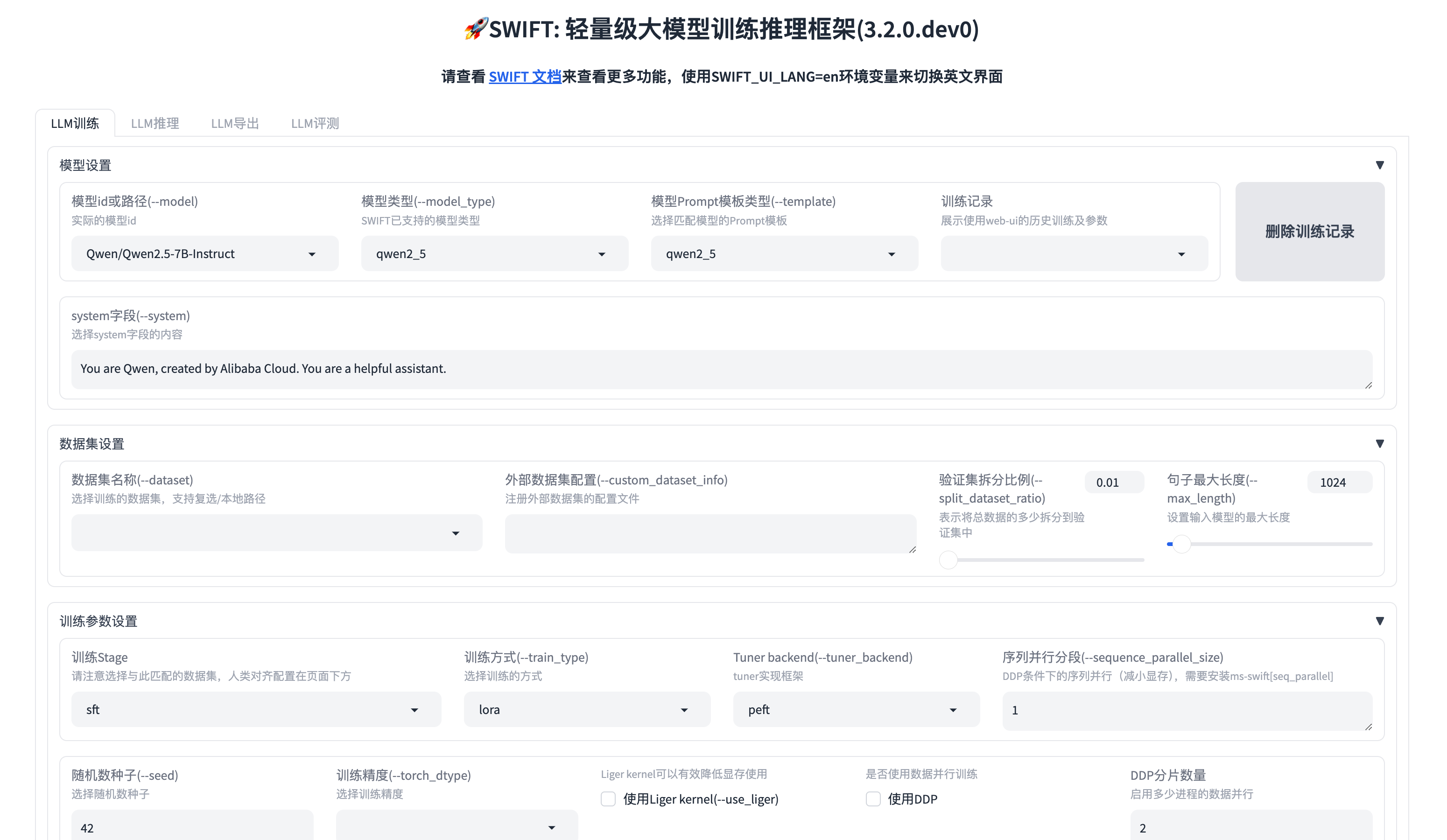
SWIFT 支持界面化的训练和推理,参数支持和脚本训练相同
swift web-ui --lang zh # 中文
swift web-ui --lang en # 英文
# share模式,请添加--share true 参数
swift web-ui --lang zh --server_port 8081 --server_name wqw
swift web-ui --lang zh --server_port 8081 --server_name wqw --share
web-ui 特性:
- 每个超参数描述都带有 –xxx 标记,与命令行参数的内容是一致的
- 一台多卡机器上并行启动多个训练/部署任务
- 服务关闭后,后台服务是仍旧运行,这防止了web-ui被关掉后影响训练进程,如果需要关闭后台服务,只需要选择对应的任务后在界面上的运行时tab点击杀死服务
- 重新启动web-ui后,如果需要显示正在运行的服务,在运行时tab点击找回运行时任务即可
- 训练界面支持显示运行日志,请在选择某个任务后手动点击展示运行状态,在训练时运行状态支持展示训练图表,图标包括训练loss、训练acc、学习率等基本指标,在人类对齐任务重界面图标为margin、logps等关键指标
- 训练不支持PPO,该过程比较复杂,建议使用examples的shell脚本直接运行
ms-swift额外支持了界面推理模式(即Space部署):
swift app --model '<model>' --studio_title My-Awesome-Space --stream true
# 或者
swift app --model '<model>' --adapters '<adapter>' --stream true
# 或更多参数
CUDA_VISIBLE_DEVICES=0 swift app \
--model Qwen/Qwen2.5-7B-Instruct \
--stream true \
--infer_backend transformers \
--max_new_tokens 2048 \
--lang zh
Web UI 上启动微调模型
- swift web-ui
CLI
# 直接使用web-ui
CUDA_VISIBLE_DEVICES=0 \
swift app-ui\
--model_type qwen1half-7b-chat \
--model_id_or_path /jppeng/app/models/Qwen1.5-7B-Chat \
--ckpt_dir /jppeng/gitapp/swift/output/qwen1half-7b-chat/v0-20240324-001719/checkpoint-62 \
--eval_human true \
--server_name 0.0.0.0 \
--server_port 8000 \
--share True \
# Merge LoRA增量权重并使用web-ui
swift merge-lora --ckpt_dir 'xxx/vx_xxx/checkpoint-xxx'
CUDA_VISIBLE_DEVICES=0 \
swift app-ui \
--ckpt_dir xxx/vx_xxx/checkpoint-xxx \
--eval_human true \
代码调用
使用python 启动 lora 微调模型
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import InferArguments, merge_lora_main, app_ui_main
best_model_checkpoint = '/jppeng/gitapp/swift/output/qwen1half-7b-chat/v0-20240324-001719/checkpoint-62'
infer_args = InferArguments(
model_type='qwen1half-7b-chat',
model_id_or_path='/jppeng/app/models/Qwen1.5-7B-Chat',
ckpt_dir=best_model_checkpoint,
eval_human=True)
# merge_lora_main(infer_args)
result = app_ui_main(infer_args)
推理
CLI: infer
swift infer 命令核心参数
- –
model:可选,要推理的初始模型,非 lora- 示例
swift infer --model Qwen/Qwen2.5-7B-Instruct
- 示例
- –
adapters:可选,但LoRA必用; 指向 –output_dir 下的具体checkpoint文件夹- 示例
--adapters output/vx-xxx/checkpoint-100 - 如果–adapters路径下有args.json,ms-swift会自动读取训练时的–model、–system等参数
- 示例
- –temperature: 推荐填,写代码/答事实:0(最严谨);创意写作/聊天:0.7~0.9(有灵感但不胡说)
- –max_new_tokens:必填,最多生成多少字符
- –stream:推荐开,流式输出
# 直接推理
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model_type qwen1half-7b-chat \
--model_id_or_path /jppeng/app/models/Qwen1.5-7B-Chat \
--ckpt_dir /jppeng/gitapp/swift/output/qwen1half-7b-chat/v0-20240324-001719/checkpoint-62 \
--eval_human true \
# gpu 推理
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--temperature 0 \
--max_new_tokens 2048
# Merge LoRA增量权重并推理
swift merge-lora --ckpt_dir 'xxx/vx_xxx/checkpoint-xxx'
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--ckpt_dir xxx/vx_xxx/checkpoint-xxx \
--eval_human true \
# 合并 lora 并用 vLLM加速
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--merge_lora true \
--infer_backend vllm \
--vllm_max_model_len 8192 \
--temperature 0 \
--max_new_tokens 2048
代码推理
Python 接入
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import ModelType, InferArguments, infer_main
infer_args = InferArguments(
model_type='qwen1half-7b-chat',
model_id_or_path='/jppeng/app/models/Qwen1.5-7B-Chat',
eval_human=True)
infer_main(infer_args)
Swift trainer 集成自 transformers,所以可直接使用swanlab与huggingface集成的SwanLabCallback:
from swanlab.integration.transformers import SwanLabCallback
from swift import Seq2SeqTrainer, Seq2SeqTrainingArguments
···
#实例化SwanLabCallback
swanlab_callback = SwanLabCallback(project="swift-visualization")
trainer = Seq2SeqTrainer(
...
callbacks=[swanlab_callback],
)
trainer.train()
微调方式
微调方式
- CLI
- 代码微调
CLI
微调命令
# Experimental environment: A10, 3090, V100, ...
# 22GB GPU memory
# 单卡: DP
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_type qwen1half-7b-chat \
--model_id_or_path /jppeng/app/models/Qwen1.5-7B-Chat \
--dataset alpaca-zh alpaca-en \
--train_dataset_sample 500 \
--eval_steps 20 \
--logging_steps 5 \
--output_dir output \
--lora_target_modules ALL \
--self_cognition_sample 500 \
--model_name 测试模型 'DEMO' \
--model_author wqw
# 多卡: DDP
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=2 \
swift sft ...(同上)...
# CPU 推理:模型规模更小
CUDA_VISIBLE_DEVICES=-1 \
swift sft ...(同上)...
Python 微调
# Experimental environment: A10, 3090, V100, ...
# 18GB GPU memory
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import DatasetName, ModelType, SftArguments, sft_main
sft_args = SftArguments(
model_type='qwen1half-7b-chat',
model_id_or_path='/jppeng/app/models/Qwen1.5-7B-Chat',
dataset=[DatasetName.alpaca_zh, DatasetName.alpaca_en],
train_dataset_sample=500,
eval_steps=20,
logging_steps=5,
output_dir='output',
lora_target_modules='ALL',
self_cognition_sample=500,
model_name=['我的测试模型', 'JPPeng'],
model_author=['长信', 'Changxin'])
output = sft_main(sft_args)
best_model_checkpoint = output['best_model_checkpoint']
print(f'best_model_checkpoint: {best_model_checkpoint}')
微调方法
方法
- pt
- sft
- rl
训练目标:
- 指令监督微调 (SFT): swift sft (我们刚才用的)
- 人类偏好对齐 (RLHF):
- DPO (直接偏好优化):
swift rlhf --rlhf_type dpo - KTO (Kahneman-Tversky优化):
swift rlhf --rlhf_type kto - GRPO (组相对策略优化):
swift rlhf --rlhf_type grpo
- DPO (直接偏好优化):
- 预训练 (PT):
swift pt(在海量无标注文本上继续训练) - 奖励模型训练 (RM):
swift rlhf --rlhf_type rm - 序列分类 & 嵌入模型训练: 也都有对应的命令支持。
核心参数
核心参数
- –model: 必填,Hugging Face或ModelScope上的模型ID,比如 Qwen/Qwen2.5-7B-Instruct 或 AI-ModelScope/qwen2-7b-instruct
- ❌ 不要天本地路径(除非加了–model_path)
- ❌ 不要漏掉斜杠(Qwen/Qwen2.5-7B-Instruct ≠ QwenQwen2.5-7B-Instruct)
- –dataset:必填,训练数据集,可以多个,用空格分开,#控制采样量
- 示例;
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh' 'swift/self-cognition#500' - ❌ 单引号必须加!尤其含空格或#时,否则shell会报错
- ❌ #500 表示只取前500条,不是“第500条”,别写成 #0500
- 示例;
- –train_type:必填,全参数训 还是 轻量微调
- 候选:
- full:A100/H100,显存≥40GB
- lora:LoRA微调,7B模型单卡3090(24GB)
- qlora:显存再砍一半,适合24GB以下显卡
- –per_device_train_batch_size:必填
- 3090/4090(24GB):填 1 或 2
- A100(40GB):可填 4
- 显存爆了?立刻减小
- 和
--gradient_accumulation_steps一起控制“实际batch size”,先填1保稳
- –gradient_accumulation_steps:推荐填
- batch size = per_device_train_batch_size × gradient_accumulation_steps × GPU数量
- 安全值:从 8 或 16 开始,显存不够就往上加
- –torch_dtype:推荐填,计算精度,直接影响显存和速度
- bfloat16:推荐,速度快、显存省、效果稳(A100/V100/RTX3090+必备)
- float16:兼容性更好,老卡可用
- float32:别用!慢且费显存,仅调试用
LoRA 微调
如果选了 –train_type lora,这三个参数必须成套出现,缺一不可。
- –lora_rank(必填!)LoRA 矩阵“宽度”,越大越强、越费显存
- 7B模型:8(安全)、16(进阶)
- 13B模型:8(保稳)、16(推荐)
- –lora_alpha(必填!)LoRA更新“力度”,一般设为 alpha = rank × 2
- –lora_rank 8 → –lora_alpha 16;
- –lora_rank 16 → –lora_alpha 32
- –target_modules(必填!)LoRA插在哪几层
- all-linear:自动找所有线性层(最省心,首选)
- q_proj,v_proj,k_proj,o_proj:手动指定(进阶用,需查模型结构)
训练流程:控制节奏的3个参数
- –num_train_epochs(推荐填!)
- 指令微调(sft):1~3 足够(数据多时1轮就够)
- 预训练(pt):10~100+(数据流式加载,看–max_steps)
- –max_steps(可选,但推荐!)训多少步就停,比epochs更精准
- max_steps 和 –num_train_epochs 二选一,同时填会冲突!
- –learning_rate(必填!)模型“学习有多猛”,太大训飞、太小训不动
- LoRA微调:1e-4(0.0001)是黄金值
- 全参数训:2e-5~5e-5(0.00002~0.00005)
CPT
# 8*A100
NPROC_PER_NODE=8 \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
swift pt \
--model Qwen/Qwen2.5-7B \
--dataset swift/chinese-c4 \
--streaming true \
--tuner_type full \
--deepspeed zero2 \
--output_dir output \
--max_steps 10000 \
...
SFT
分全参微调、局部参数微调
NPROC_PER_NODE=2 CUDA_VISIBLE_DEVICES=0,1 megatron sft \
--model Qwen/Qwen2.5-7B-Instruct \
--save_safetensors true \
--dataset AI-ModelScope/alpaca-gpt4-data-zh \
--tuner_type lora \
--output_dir output \
...
RLHF
ms-swift支持丰富GRPO族算法:grpo、dapo、gspo、sapo、rloo等等
rlhf_type
- dpo
- grpo
CUDA_VISIBLE_DEVICES=0 swift rlhf \
--rlhf_type dpo \
--model Qwen/Qwen2.5-7B-Instruct \
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji \ # 一个包含偏好对的数据集
--train_type lora \
--output_dir dpo_output
部署
核心参数
- –
infer_backend(同eval,必填!)部署也得选引擎,逻辑一致。 - –
host& –port(推荐填!)指定API服务跑在哪个IP和端口--host 0.0.0.0 --port 8000
本地部署 deploy
模型部署成标准的OpenAI兼容的API服务
CUDA_VISIBLE_DEVICES=0 swift deploy \
--model Qwen/Qwen2.5-7B-Instruct \
--adapters output/vx-xxx/checkpoint-xxx \
--infer_backend vllm
通过 url 接口来调用你的模型了,和调用ChatGPT的API一模一样
- http://localhost:8000/v1/completions
- http://localhost:8000/v1/chat/completions
模型量化: quant_bits
# 将模型量化为4-bit AWQ格式,显著减小模型体积
CUDA_VISIBLE_DEVICES=0 swift export \
--model Qwen/Qwen2.5-7B-Instruct \
--adapters output/checkpoint-xxx \ # 可选,导出微调后的模型
--quant_bits 4 --quant_method awq \
--dataset AI-ModelScope/alpaca-gpt4-data-zh \ # 量化需要少量校准数据
--output_dir Qwen2.5-7B-Instruct-AWQ
模型导出 export
将模型推送到 ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>' \
--use_hf false
评测 eval
核心参数
参数
- –
eval_dataset(必填!)用哪个标准题库考模型- 填评测集名字,比如 gsm8k(数学题)、mmlu(综合知识)、ceval(中文考试)
- 去官方评测集列表 Ctrl+F搜关键词,比如搜“数学”看到gsm8k,直接抄。
- –
infer_backend(必填!)用什么引擎跑推理,决定速度和显存- pt:PyTorch原生,兼容最好,新手首选
- vllm:最快!但需A100/V100/RTX4090+,显存≥24GB
- lmdeploy:国产优化,华为昇腾/NPU用户选它
- –
eval_limit(推荐填!)只考前N道题,避免等1小时出结果- –eval_limit 100(考100题),新手从50起步
- 1分钟出分,快速验证模型是否训对。
示例
# 使用 OpenCompass 评测框架,在ARC_c数据集上评估模型
CUDA_VISIBLE_DEVICES=0 swift eval \
--model Qwen/Qwen2.5-7B-Instruct \
--adapters output/checkpoint-xxx \ # 可选,评测微调后的模型
--infer_backend lmdeploy \ # 使用LMDeploy引擎加速推理
--eval_backend OpenCompass \
--eval_dataset ARC_c
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
