- 投机采样
- 总结
- 【2022】投机采样
- 改进
- 应用
- 结束
投机采样
总结
投机解码逻辑:
小模型先草拟一串 token,大模型一次性并行验证,接受最长的合法前缀。
决定速度的主要有两点:草稿的接受长度 τ,和每轮验证的开销。
方法
投机采样(Speculative decoding)针对 LLM 推理串行解码特点,通过引入近似模型来执行串行解码,原始模型执行并行评估采样,通过近似模型和原始模型的互相配合,在保证精度一致性的同时降低了大模型串行解码的次数,进而降低了推理时延。美杜莎头(Medusa head)则是对投机采样的进一步改进,摒弃了近似模型,原始模型结构上新增了若干解码头,每个解码头可并行预测多个后续 tokens,然后使用基于树状注意力机制并行处理,最后使用典型接收方案筛选出合理的后续 tokens。该方法同样降低了大模型串行解码的次数,最终实现约两倍的时延加速。
对比
- 投机采样和多头美杜莎相对于原始自回归推理带来的提速效果。
- 投机采样在参数规模大的模型中性能提升更高,不过这取决于小模型的选择;
- 多头美杜莎则在不同参数规模的模型中拥有更一致的性能提升
【2026-4-*】Speculative decoding 机制解释:投机采样→美杜莎→MTP
【2022】投机采样
2022年, Google DeepMind 推出大模型推理加速方法: Speculative Decoding,投机采样或推测解码
利用蒸馏学习中小模型近似大模型,不损失生成效果前提下,获得 3x 以上加速比
vllm 框架支持投机采样(Speculative Decoding), 见 spec_decode
总结
原理
核心思想:许多常见的单词和句子都是很容易预测。
因此,大模型只需要在关键部分中指导小模型,就能够带来性能提升。
- 小模型在收到用户提问后会做出单个字的预测,当预测到一定长度后,大模型会判断是否接受小模型预测的多字,这里大模型会一次性处理多字
与传统自回归推理方法不同,投机采样采用草稿模型(draft model),通常是规模更小的模型,进行自回归推理。而原始的大模型则会根据小模型推理的结果进行判断,决定是否接受小模型推理出的多字
推测解码是一种推理优化技术,生成当前 Token 时,对未来 Token 进行有根据猜测,这一切都在一次前向传播中完成。
融入了验证机制,以确保这些 Token 正确性,从而保证推测解码的整体输出与普通解码的输出相同。
优化大语言模型(LLMs)的推理成本,是降低成本并提高其应用率的关键因素。
实现方案
为了实现这一目标,有各种推理优化技术可用,包括自定义内核、输入请求的动态批处理以及大型模型的量化。
推测解码有主要方法
- (1)用同型号小模型:例如,将 Llama 1B/7B 用作 Llama 70B 的推测器
- 用同家族小模型给大模型打草稿
- (2)多头预测:如美杜莎
- 添加推测头:原始模型不动,只训练新增的头
- IBM 的 PyTorch 团队实验中,添加推测头的方法在模型质量和延迟改善方面都更为有效。
- 优点:参数效率高
- 缺点:位置越远越不准
- (3)模型内部加草稿头
- 示例:EAGLE-3,当前最优方案, 2025年被NIPS接受,已集成到vLLM和SGLang等所有主流框架
- LLM内部附加草稿头,通过融合transformer底层、中层和高层特征来预测未来token
- 效果:论文实测最高加速6.5倍,比 EAGLE-2提升1.4倍
- (4)MTP:多token预测,示例 DeepSeek V3和R1
- 训练时,让模型多个轻量模块预测第二个、第三个token,与主模型共享输出头;训练时提供密集信号,推理时,复用为草稿头(不需要额外草稿模型),走标准推测解码流程
- 效果:MTP草稿接受率超过80%,配合推测解码可达 1.8 倍加速,SGLang 一条命令就可开启
效果
效率说明:
- 投机者架构:目前方法允许修改头的数量,对应可选择的 token 数量。增加头的数量也会增加所需的额外计算量和训练的复杂性。在实践中,对于语言模型,我们发现 3 - 4 个头在实际应用中效果良好,而代码模型则可以从 6 - 8 个头中获益。
- 计算量:增加头的数量会在两个维度上导致计算量增加,一是单次前向传播的延迟增加,二是处理多个 Token 所需的计算量增加。如果推测器在增加头的数量后准确率不高,就会导致计算资源浪费,增加延迟并降低吞吐量。
- 内存:每次前向传递都需要与高带宽内存(HBM)进行往返通信,增加的计算量由此得到抵消。请注意,如果我们提前正确预测 3 个 Token,那么就节省了三次与 HBM 的往返时间。
思考
- 投机采样核心原理总结:猜对直接用、猜偏按比例拒绝
- 同时用两个模型,不会变慢吗?小红书解答: 瓶颈不在计算而在显存带宽。小模型(draft model)利用了大模型的闲置CPU时间,并不占用额外计算
- 草稿模型提前预估,能保证最终正确性吗?2023年,DeepMind 严格论证过,猜对直接用+猜偏按比例拒绝+差值采样=大模型原始采样
- 推测解码什么时候快、慢?当前推理时瓶颈是 内存带宽 还是 计算?变量:并发、上下文长度、接受率
- 低并发时,显存带宽瓶颈,gpu闲置,推测解码效果最好;
- 高并发时,GPU打满,瓶颈是计算,额外的草稿和验证计算无法倍免费消化
- 上下文长度:长度大时,kv cache消耗大,瓶颈回到显存带宽
- 接受率:接受率>60%, 投机token>5时,可实现 2-3 倍加速;接受率太低时,草稿和验证计算浪费,反而更慢
不足
GPT4 技术细节泄露后,对于投机采样【Speculative Decoding】策略加速推理的研究比较多,但是问题
- 投机采样依赖一个小而强的模型, 生成对于原始模型来说比较简单的token
- 其次在一个系统中维护2个不同模型,导致架构上的复杂性,占额外空间
- 最后使用投机采样的时候,会带来额外的解码开销,尤其是当使用一个比较高的采样温度值时。
更多见站内专题:投机采样
改进
最早提出的投机解码(Speculative Decoding)算法使用 Target Model + Draft Model 范式,其加速效果很大程度上受到 Draft Model 对齐程度以及自身解码时延的影响。要得到高对齐同时低时延的 Draft Model 可能需要微调或蒸馏,成本高且不具有通用性。
【2024-9-11】最全LLM自投机算法汇总
因此,许多自投机(Self-Speculative Decoding)算法被提出作为原始投机解码的替代。
- 让 Target Model 根据特定算法直接生成 draft tokens,不借助额外的 Draft Model。
- 并且,简单修改 Target Model 结构,比如增加 LM Head 或者增加几层网络构成一个小型的 Draft Model,只要训练成本可接受,也可认为是自投机算法的一类。
【2023-4-10】微软 Inference with Reference
RAG、语法纠错、文档 QA 等任务场景中,LLM 生成结果往往与输入内容(reference)之间有较多重合。
基于一定匹配规则,将 reference 中匹配当前已生成序列的部分直接作为 draft,而不用 Draft Model 生成,来提高 LLM 推理速度。
【2023-4-10】微软推出 LLMA
最简单匹配规则就是前缀匹配:
- 以当前已生成序列的最后 n 个 tokens 作为前缀,在 reference 中匹配满足此前缀的连续 k 个 draft tokens。
因此,该算法的两个重要超参是前缀匹配的长度 n 和 draft 长度 k。
步骤
- LLM 正常执行自回归解码;
- 当已生成序列与 reference 中的某部分具有长度为 n 的前缀匹配时,选取后续 k 个 tokens 作为 draft 拼接到 output 中;
- 下一解码步中并行地验证这些 draft tokens,抛弃第一个不匹配的 token 及其后续 tokens;
- 存在不匹配时重新生成 token,进入到下一轮解码步。
效果
- 通过网格搜索最优的 n 和 k,该算法在特定场景下可以达到 2~3 倍的加速效果。
分析
- 使用场景限制了其通用性;RAG、语法纠错、文档 QA
- 但因设计和实现简单、不需要额外训练而工程友好。
【2024-1-14】Google Medusa 美杜莎
投机采样虽好,但某些场景下,小模型选择棘手,如何同时部署大模型和小模型?
Medusa 是自投机领域较早的一篇工作。
【2023-9-18】LLM推理加速-Medusa
- 项目主页: medusa-llm
- Github Medusa
- 【2024-1-14】论文: Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
抛弃独立的 Draft Model,同时保留 Draft-then-Verify 范式,Medusa 在主干模型的最终隐藏层之后,添加若干 Medusa Heads,这些 Heads 具有预测对应位置 token 的能力,并且可以并行地执行,从而实现在一次前向中得到多个 draft tokens。
Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads
解读
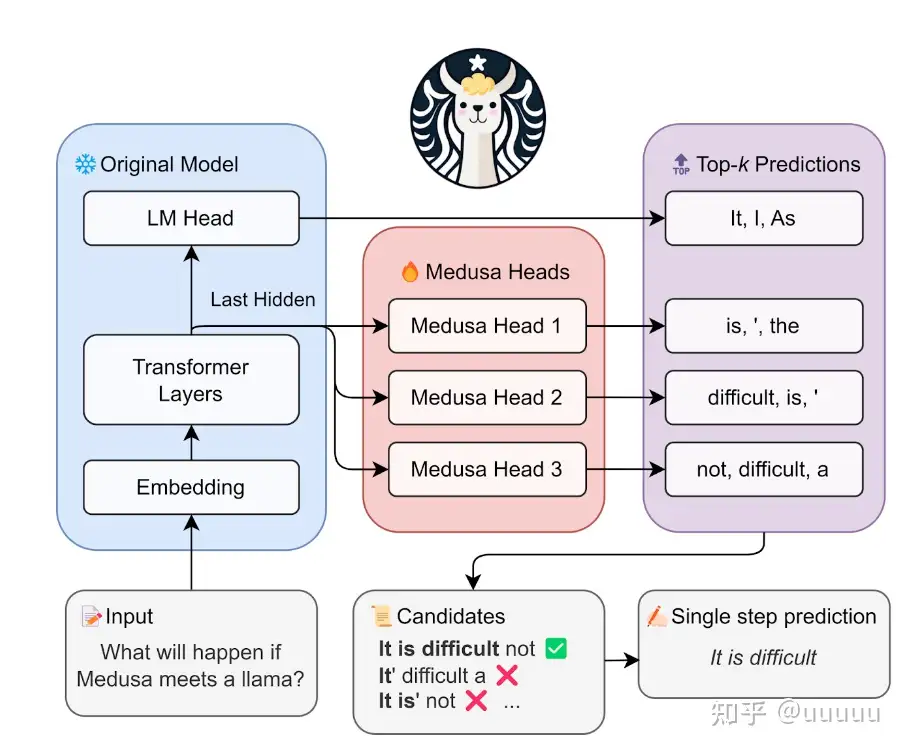
多头美杜莎利用了多个预测头(language model heads)来进行多字预测,这些额外的预测头被称为美杜莎头
正常的LLM 基础上,增加几个解码头,并且每个头预测的偏移量是不同的,比如原始的头预测第i个token,而新增的medusa heads分别为预测第i+1,i+2…个token。如上图,并且每个头可以指定topk个结果,这样可以将所有的topk组装成一个一个的候选结果,最后选择最优的结果
美杜莎(Medusa)推理框架使推测解码流行起来;
- 现有模型上添加一个头,然后对其进行训练以进行推测。
通过使“头”呈分层结构来修改美杜莎架构,其中每个头阶段预测单一 Token,然后将其输入到下一个头阶段。
图解
多头美杜莎的top-1推理(假设每个字都为单个token)。
- 大模型在收到用户提问后会做出多个字的预测,这里大模型会一次性处理多字。具体为主预测头会预测下1个字,第一个和第二个美杜莎头分别会预测第2个和第3个字。更多的美杜莎头也以此类推。
- 美杜莎头为独立模块,可加在现有预训练/微调好的基础模型中(例如Vicuna-13B)
如果直接使用top-1(贪婪)策略来进行推理会很容易掉进局部最优概率组合。
因此,为了提高推理效果,多头美杜莎使用了top-k 方式来进行推理
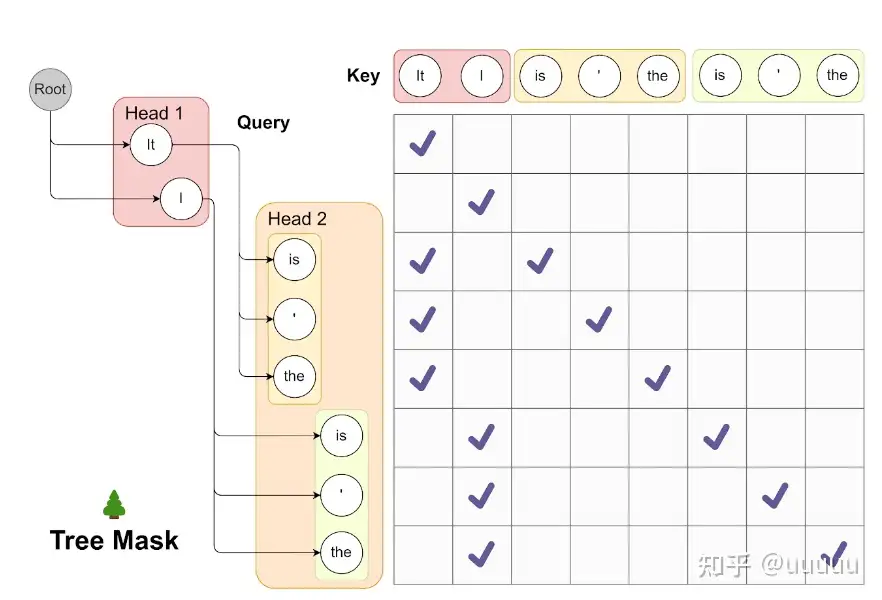
为了更高效地验证这些 draft tokens,Medusa 构造了 Tree Attention 结构。
实现方法
- 基于主干 Transformer 的最终隐藏层输出,原有的 LM Head 可以生成 next token,而 Medusa Heads 可以生成对应位置的后续 tokens(例如,有 3 个 Medusa Heads,一次前向一共可以生成后续的 4 个 tokens);
- Medusa Heads 是一个增强了残差连接的单层前馈网络,需要额外的训练。训练过程根据主干模型参数是否冻结可以分为 Medusa-1 和 Medusa-2:Medusa-1 仅对 Medusa Heads 进行微调,Medusa-2 会对主干模型也进行微调,计算量更大但能提升 Medusa Heads 的预测质量;
- 使用 Top-K Sampling,每一个 Head 都会输出 k 个 tokens,对着 k 个 tokens 的验证需要构造 Tree Attention,以保证位置的对应性
分析
- 如果使用 Greedy Search 解码策略,draft tokens 正确率不够高,加速效果不够显著;
- 如果采用 Top-K 解码,当取 k=5 时,draft tokens 正确率可以达到 80%。
实验
- Medusa-1 可以达到 2.2 倍的加速效果,Medusa-2 可以达到 2.3~2.8 倍的加速效果;
- Medusa 增加了模型参数量,会增加显存占用;
- Medusa 增加 Head 以及构造 Tree Attention 均对后续工作带来了启发。
更多解读见文章
【2024-1-26】北大 EAGLE
大部分投机解码方案都是在 token level 预测生成 draft,EAGLE 在 feature level (feature 即 LM head 前的 hidden states) 自回归地生成 draft 可能具有更好的效果,另外,采样过程的不确定性会对下一步 feature 的预测产生影响
因此,在 feature level 应用投机解码以获得更好的加速效果。
【2024-1-26】北大推出 EAGLE
方法对比: 原生投机采样、lookahead、medusa和eagle
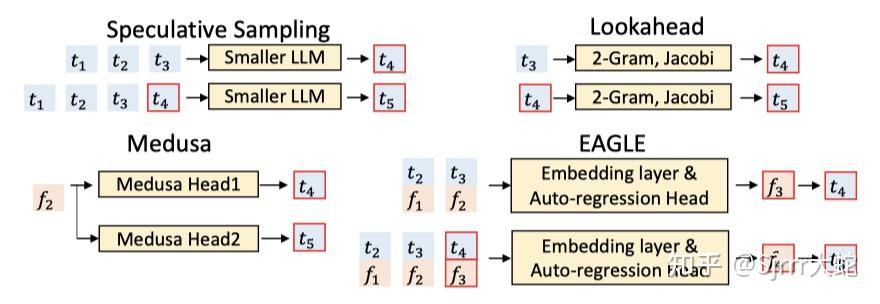
实现方法
EAGLE 引入结构简单的 Draft Model,包含一个 Embedding Layer,一个 LM Head 和一个 AR head。其中,只有 AR head 需要额外训练,Embedding Layer 和 LM Head 可以复用 Target Model 的参数。
EAGLE 生成的 draft 过程如下所示:
- Draft Model 接收两个输入:feature sequence of shape [bs, seq_len, hidden_dim] 和 token sequence of shape [bs, seq_len],并将 token sequence 传入 Embedding Layer 得到 embedding sequence of shape [bs, seq_len, hidden_dim];
- AR Head 包含一个 FC Layer(用于降维)和一个 Decoder Layer ;将当前步 token 的 embedding 与上一时间步 token 的 feature 拼接后传入 AR Head,得到 draft token 的 feature;
- 将 draft feature 传入 LM Head,通过采样得到多个 draft tokens;
- 基于第二点发现,EAGLE 会采样不止一个 draft token,构造一棵 draft tree 供后续验证。
EAGLE 的验证与 SpecInfer 类似,对 draft tree 中的每个结点递归地调用原始 Speculative Decoding 的验证算法。此外,还需记录被接受 token 的 feature 以进行下一次迭代。
分析
- 对应 7B/13B/33B/70B 的 Target Model,EAGLE 的 Draft Model 可训练参数量分别为 0.24B/0.37B/0.56B/0.99B;使用单卡 A100 40G 在 ShareGPT 数据集上训练 70B 模型的 AR Head 需要 1-2 天。
- 论文在对话、代码以及数学等领域的进行了实验,结果表示 EAGLE 对 Llama-2-Chat 70B 推理有 2.7~3.5 倍的加速效果;
- EAGLE 通过包含更多信息的 feature 来进行 token 预测,因此生成的 draft 质量相比 Medusa、Lookahead 等方法更高。
【2024-2-3】谷歌 Lookahead Decoding
【2024-2-3】UCSD、Google和伯克利推出 Lookahead Decoding
基于 Jacobi Decoding 过程中生成的 Jacobi Trajectory,可构造若干 N-grams。
推理过程中进行前缀匹配:
- 若当前步生成的 token 匹配了 N-gram pool 中的若干个元素,将这些候选 N-grams 作为 draft 拼接到输入中,并构造 Attention 得到前向结果,进行验证。
实现
关于 Lookahead Decoding 的具体技术细节参考文章,讲解得十分详细:Lookahead Decoding 图文详解。
分析
Lookahead Decoding
- 在 MT-Bench、GSM8K、HumanEval 等多个不同任务数据集上取得了 1.5~2.3 倍推理加速;
- 不需要额外训练,但是会引入额外的计算量,在计算能力强的设备上拥有更高的加速上限,应用在具体业务中应缓解这一问题。
【2024-2-28】上海交大 CLLMs
【2024-2-28】上海交大、加州大学推出 CLLMs
如果想让模型在推理过程中一次生成多个 tokens,并且不增加显存占用,可以让模型在 Jacobi Decoding 过程中生成的 Jacobi Trajectory 上进行训练,使其能够从轨迹中任意一点仅通过一步解码就达到不动点,从而实现一步解码多个 tokens 的效果。
该想法与 Consistency Models(CMs,diffusion model 加速技术)不谋而合,因此命名为 Consistency LLMs。
实现
CLLMs 的训练过程:
- 对要加速的模型 M 及某一特定任务领域的数据集 D,令 M 在 D 上执行 Jacobi Decoding(每步解码的 draft 长度为 n),收集解码过程中产生的 Jacobi Trajectory ,构造原始数据集 D’;
- 由于 D’ 中的数据均为“前面正确,后面错误”(由 Jacobi Decoding 的性质决定),对 D’ 进行数据增强,增加一些样本满足“前面正确,中间错误,后面正确”或更多模式,以提升模型在位于轨迹中任意点时的收敛能力;另外,删除 D’ 中出现重复 token 的样本,防止模型推理过程中出现重复;
- 选择 Loss 进行训练,CLLMs 提供了两类可选的 Loss
分析
- CLLMs 可以做到一次解码得到 2~6 个 token,从而实现 2.4~3.4 倍的加速;
- CLLMs 在推理过程中会出现两类 LLM 不具备的现象:
- 在一次 forward 中解码多个连续的 token(2~6 个);
- 提前预测正确的 token。即如果位置 i 的 token t 是正确的,而小于 i 位置的 token 依然是错误的,那么在后续的 forward 过程中,t 将不会被替换掉。
- CLLMs 代码仓库提供了 Llama-2-7B 和 Deepseek-coder-7B-instruct 的组网和训练代码;该算法的复现难度较大,具体应用到业务场景中的难度较大。
【2024-3-14】苹果 ReDrafter – 美杜莎改进
【2024-3-14】苹果推出 ReDrafter
受 Medusa 启发,在投机解码中使用 single-model strategy 更加工程友好,但是 Medusa 增加了显存占用,并且对 Tree Attention 构造需要在解码前提前固定。
ReDrafter 用单个 RNN 代替 Medusa Head,并且应用 Beam Search 在解码过程中动态地构造 Attention。
实现
ReDrafter 使用标准 RNN 作为 Draft Model,根据当前步生成 token 的 embedding 更新 RNN 的 hidden state,并使用上一步解码时主干 Transformer 最后一层的输出来预测下一个 token;循环迭代上述步骤,持续生成 draft。
另外,ReDrafter 使用了 Beam Search 作为解码策略,通过 tensor operations 在解码过程中动态构造前缀匹配,基于前缀匹配的结果构造 Attention,实现了高效的验证
分析
- ReDrafter 使用单个 RNN 生成 drafter,减少了显存占用,但是 draft 的生成是串行的;
- ReDrafter 应用 Beam Search 的操作是高效的,且实现了解码过程中动态构造 Attention,更高效;
- ReDrafter 与 EAGLE 均使用了 feature + embedding 作为 Draft Model 输入,说明这一设计具有一定的效果,或许可以应用在其他算法中。
【2024-4-30】META Multi-Token Prediction
【2024-4-30】META FAIR 推出 Multi-Token Prediction
现有 LLM 训练大多基于自回归 Loss,推理时一次前向只能预测一个 next token。
为了提高解码效率,新训练架构 Multi-Token Prediction,让 LLM 一次预测多个 token,同时不会造成显著显存占用增长和训练时间增加。
一次预测 4 个 tokens 的模型结构
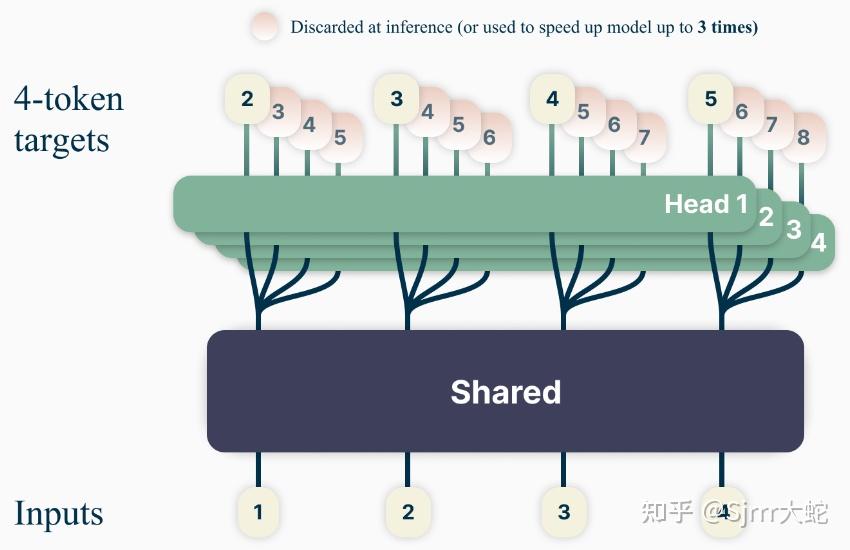
分析
- 该方法使模型在代码问题上能力提升,且使用 4-tokens 预测能达到 3 倍加速;
- 在大 batch size 下加速效果更好;并且在更大的模型上加速效果更显著;
- Multi-Token Prediction
- 与 CLLMs 想法相近,但没有使用 Jacobi Trajectory;
- 与 Medusa 方法相近,但更适合用于训练 pretrained model。
【2024-4-29】华为 Kangaroo
【2024-4-29】Huawei Noah’s Ark Lab 华为诺亚方舟推出 Kangaroo
- 论文 Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting, Apr 2024, .
- 代码 Kangaroo
Kangaroo 试图解决两个问题:
- 如何不依赖独立的 Draft Model 实现自投机,以缓解获取高对齐的 Draft Model 所需的成本?
- 由于 draft 的生成难度因任务而异,如何根据任务困难程度动态地调整 draft 的生成策略?
基于 Early Exit 的思想,Kangaroo 给出了解决方法:
- 自投机:使用模型固定的浅层子网的 hidden states 来生成 draft(需要经过一个可训练的 Adapter);由完整的模型自身进行验证。
- 动态 draft 策略:为 draft 设置一个置信度阈值,当生成的某一个 draft token 低于该阈值时,结束生成 draft。
Kangaroo 方案基于 Double Early Exit。
- 从浅层子网中提取 hidden states(第一步 Early Exit),通过一个 Adapter 网络将这些 hidden states 直接映射到最终层的 hidden states;经过原本模型的 LM Head 输出得到 draft tokens。
- 为 draft token 设置一个置信度阈值,当 draft logits 的最大值低于该阈值时,停止生成后续的 draft(第二步 Early Exit)
分析
- Kangaroo 在 Spec-Bench 上达到了 1.68 倍的加速,相比于 Medusa-1 减少了 88.7% 的显存占用;
- Kangaroo 提出了衡量 draft token 接受率的新指标 Consistent Token Accept Rate,表示 w 个 draft tokens 全部被接收的概率
- Kangaroo 还对浅层子网深度、Adapter 结构以及动态 draft 长度进行了探索
MTP
为了减少NTP前向传播次数,MTP(Multi-Token Prediction)应运而生
MTP机制也被广泛用于 DeepSeek和Claude等版本中,核心:把原先NTP要预测的Token的位置,换成了多个独立的预测头,分别并行地预测下一个Token、下下一个Token、下下下一个Token,以此类推。
这样子的好处就是可以直接预测出接下来的3-5个Token,生成10个Token句子就只需要前向传播2-4次,效率大大提升。
历史
核心定位:现代大模型主流 MTP 训练 / 推理加速方案,首次标准化并行多头多 Token 预测架构,成为行业通用技术底座。
- 早期雏形(同类并行预测思想)
- 2018 年 NIPS Google《Blockwise Parallel Decoding》,最早提出并行多 Token 解码思路,但未形成适配现代 LLM 的标准化 MTP 训练目标,不属于当前行业通用 MTP 体系。
- 论文上线:
- 2024 年 4 月 30 日,Meta FAIR 提交论文《Better & Faster Large Language Models via Multi-token Prediction》至 arXiv(编号:2404.19737)
- 产业落地关键节点
- 2024 年 12 月:DeepSeek-V3 大规模商用落地 MTP,将预测头复用为推测解码 Draft 模块;
- 2026 年:通义千问、Gemma 4、Step、小米 MIMO 等主流模型全面集成 MTP。
DeepSeek MTP
DeepSeek V3和R1
- DeepSeek-V3 采用序列式 MTP,保持因果链,逐层递进预测
核心优势
- 推理加速:减少前向传播次数,N=4 时推理速度可提升 2~3 倍,大幅降低时延与算力成本。
- 训练增效:单步提供多监督信号,提升样本利用率,收敛更快,小数据集上效果更明显。
- 质量保障:因果依赖设计 + 验证机制,避免多 token 生成的连贯性问题,生成质量接近 NTP。
MTP vs 投机解码
- MTP(Multi-Token Prediction 多令牌预测):模型原生训练出来,一次前向能看多步未来,天生会一次性预测后续多个 token。
- 投机解码 Speculative Decoding:推理时外挂算法,用小模型快速草稿、大模型逐枚校验,不改动主模型权重。
MTP 原理
MTP 原理
- 训练时给模型加多个预测头。
- 同一个 Transformer 隐层,同时预测:t+1、t+2、t+3…t+k 未来多步。
- 推理一次前向,直接吐出连续 k 个合理 token,直接往后跳 k 步。
- 本质:模型学会了“预判未来好几步”,是训练侧能力。
投机解码 Spec Decoding 原理
- 用一个小草稿模型 / 草稿策略,快速先猜 3~5 个候选 token。—— 多头并行预测,不知道上一轮结果,盲猜
- 送入大主模型,只做一次前向,并行批量校验这一串草稿。—— 怎么判定是否接受?每个token的概率分布重合部分面积,没有阈值
- 连续校验通过多少,就一次性 accept 多少,失败就停下重新猜。
- 本质:小模型瞎猜、大模型把关,纯推理调度算法,不用重新训练大模型。
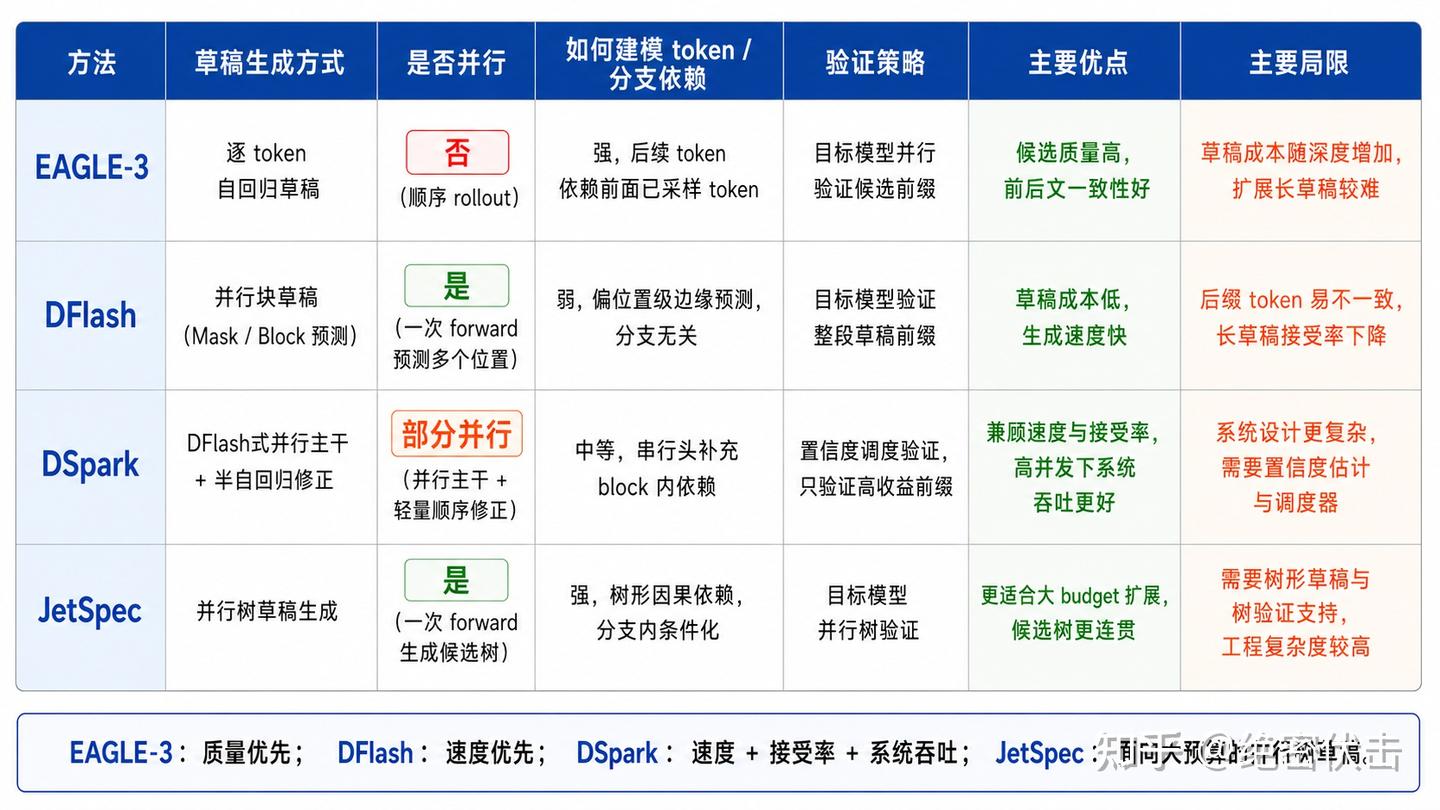
| 维度 | MTP 多令牌预测 | 投机解码 Speculative Decoding |
|---|---|---|
| 改造位置 | 训练侧,改模型结构+损失 | 推理侧,不改大模型权重 |
| 是否要重训 | 必须重新训练 | 无需训练,直接可用 |
| 多 token 来源 | 大模型原生多头预测 | 小模型快速草稿生成 |
| 校验机制 | 模型自洽,一般无需额外校验 | 大模型逐 token 严格校验 |
| 硬件适配 | 依赖模型结构优化 | 调度逻辑复杂,显存/调度开销略高 |
| 生成连贯性 | 天生因果,连贯性好 | 依赖小模型草稿质量,草稿差容易翻车 |
| 代表模型 | DeepSeek、LLaMA 衍生 MTP 版 | 主流框架 vLLM、TensorRT-LLM 都内置 |
两者可以叠加一起用
- 利用 MTP 模型 原生一次吐出多 token 作为高质量草稿。
- 再套一层投机解码校验逻辑,做批量合法性验证。
- 能 accept 就批量跳过,进一步减少前向次数、再提速。
总结
- MTP:模型自己会看多步未来,靠训练变强。
- 投机解码:小模型先乱写草稿,大模型来监考批改,靠算法提速。
- 可以叠加混用,达成推理速度天花板。
推理时, 结合并行生成 + 候选验证,在保证生成质量的同时最大化加速。
MTP 采用共享 Transformer 主干 + 独立并行输出头的结构,兼顾效率与一致性。
- 共享主干(Shared):Embedding 层 + 多层 Transformer,负责将输入序列编码为统一上下文表征(H_t),所有输出头共享该计算结果,避免重复计算。
- 多输出头(Heads):设置 N 个独立输出头,每个头对应预测未来 1 个 token:
- Head1:预测 t+1 位置 token
- Head2:预测 t+2 位置 token
- …
不足
但是,MTP 有问题,因为后面几个Token是被独立的预测头并行预测,而不是一个个串行预测,让大模型有瞎猜的概率。
所以,预测出的第2个Token 看不到第1个Token,同理,第3个Token也看不到前面2个Token是啥,怎么办呢?只能瞎猜。 第2个Token只能根据原始的输入来猜,第3个Token也只能根据原始的输入来猜,离输入越远,猜错的概率也就越大
造成输出非常容易产生幻觉,比如图中第三个Token就猜错了。
那么,有没有一种模式,能同时结合NTP的准确性,以及MTP带来的较快的推理速度呢?
显然是有的,答案就是 DSpark 的半自回归生成。
【2026-6-28】DeepSeek DSpark
投机解码逻辑:
小模型先草拟一串 token,大模型一次性并行验证,接受最长的合法前缀。
决定速度的主要有两点:草稿的接受长度 τ,和每轮验证的开销。
草稿模型两条路线:
- 自回归草稿(代表 Eagle3):逐个 token 往后预测,每个都基于前一个。准确率高,但起草耗时随长度线性增长,只能写短、网络也只能浅。
- 并行草稿(代表 DFlash):一次前向就预测出整串 token,耗时几乎与长度无关,可以写得很长。缺点是各位置独立预测、彼此不知道对方的结果,越往后越容易前后不一致。
并行草稿的形象比喻:上下文同时支持 “of course” 和 “no problem” 两种续写,独立预测就可能拼出 “of problem” 或 “no course”。论文把它称为 multi-modal collision,结果是越靠后的 token 越容易被拒,接受率快速衰减。
投机解码经典方案在这两点上各有取舍。
- Eagle3 这类自回归草稿器逐token生成,依赖建模强,但延迟随块长线性增长,只能用小块浅网络。
- MTP,生产中常用的 MTP-1 每轮只草拟 1 个token,验证成本稳定可控,但既不建模块内依赖,也不看系统负载。想多产就得上 MTP-3/5,但静态多token在高并发下会因为验证那些大概率被拒的尾部token,白白占用batch容量,反而拖垮整体吞吐。正因如此,DeepSeek的生产环境此前一直使用MTP-1。
【2026-6-27】DeepSeek 放出 DeepSpec:投机解码(speculative decoding)draft model 的全栈代码库,数据准备、训练、评估,MIT 可商用。
- 报告链接:DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
- DeepSeek V4新成果发布,推理速度更快了
投机解码卷了两年「草稿写得多不多、准不准」, DSpark 把矛头指向被忽略的另一件事情:验证。
并行快但尾部不连贯,自回归连贯但慢,过去只能二选一;而 DSpark 想两个都要,DSpark 做法:
- 繁重的计算仍由并行骨干一次完成
- 再在后面接轻量的串行模块,专门补上「前一个 token」的信息,把连贯性补回来。
串行模块默认采用 Markov head:只参考紧邻的前一个 token,用低秩分解(r=256)把转移关系压得很小,几乎不增加计算量。
- 一旦第一个位置确定是 “of”,在下一个位置提高 “course” 的概率、压低 “problem”,前后就接上了。
论文也试过记忆更长的 RNN head,效果略好,但实现复杂、部署不划算,最终默认还是 Markov head。
直觉
- 逐字往后写的自回归,应该比各自独立预测的并行更连贯、接受率更高。
但论文实测结果相反:并行草稿反而更准。原因
- 第一个 token,并行天然占优。并行草稿的起草耗时与长度无关,因此网络可以做得更深;自回归为了控制延迟只能做浅。结果在第一个位置上,DFlash 的接受率反而高于 Eagle3(数学 0.88 对 0.81,对话 0.72 对 0.53)。而投机解码是前缀验证,第一个 token 一旦被拒、后面整串作废,所以起点的权重最高。
- 越往后,独立预测的短板才显现。位置 2 到 7,DFlash 持续衰减(代码从 0.87 降到 0.78,对话从 0.72 降到 0.63);自回归则能保持甚至回升(对话从 0.53 升到 0.74)。
DSpark 要的就是两者之长:用深并行骨干拿下高起点(数学第一位达到 0.93),再用轻量串行模块补平尾部的衰减。
三种 draft 算法:新作 DSpark、并行的 DFlash、基线 Eagle3,DSpark 全方位提升
DSpark 主角:半自回归 + 按服务器负载动态调度验证长度。
- 相比 Eagle3 平均接受长度 +27〜31%,相比 DFlash +16〜18%。
- DeepSeek-V4 serving 真实流量:相比 MTP-1 生产基线单用户生成速度 +60〜85%(V4-Flash)、+57〜78%(V4-Pro)。 默认 Qwen3-4B 作为 draft model
DSpark 两处改动:
- 半自回归生成。并行骨干一次产出整块草稿、保住速度,再挂极轻的Markov串行头,给每个位置注入依赖前一个token的偏置,缓解并行草稿后段的接受率衰减。同时仍然通过标准speculative verification保持目标模型分布不变,属于无损加速。
- 置信度调度。一个置信度头给每个草稿 token 估计存活概率,经温度缩放STS校准后,由硬件感知调度器结合预先 profile 的引擎吞吐曲线和当前负载,把“验证多长”建模成全局吞吐最大化问题——低负载放宽验证,高负载从尾部裁剪。
评测中
- DSpark 接受长度比Eagle3高约27%–31%,比并行草稿器DFlash高约 16%–18%,在Qwen3与Gemma4多个目标模型上都成立。
- MTP是固定长度,DSpark则让草稿块更长更准、验证长度随负载动态自适应,所以能在生产中替换MTP-1。
DSpark 已在 DeepSeek-V4 生产服务中替换了 MTP-1
- DeepSeek-V4 出字速度比之前快了,尤其并发不高时。已经部署在 V4 的 Flash 和 Pro 两个版本的线上流量中,替换了上一代的 MTP-1 方案。
DSpark 不是全新架构的模型,而是在 V4 基础上加了推测性解码模块。更新重点在工程落地,而不是模型能力本身的迭代。
DeepSeek 在推理效率上一直投入较多:V2 的 MLA 压缩了 KV cache,V3 引入了 MTP(多 token 预测),V3.2 换用稀疏注意力。DSpark 是这条线上的最新一步,也是第一次直接用在主力产品上。
【2026-6-30】阶跃星辰 JetSpec
【2026-6-30】阶跃星辰提出全新的投机解码框架 JetSpec,直接把目标拉到了接近 10 倍解码加速。
JetSpec 整体流程:
- Step 1:目标模型特征提取
- Step 2:因果并行草稿头生成候选树
- Step 3:目标模型并行树验证
具体来说:
- 目标模型先处理当前前缀;
- 从目标模型不同层抽取隐藏状态,并融合成上下文特征;
- 这些融合特征送入因果并行草稿头;
- 草稿头一次 forward 生成候选树中多个节点的 logits;
- 根据节点得分构建候选树;
- 目标模型一次 forward 并行验证整棵候选树。
目标模型是冻结的,JetSpec 只训练草稿头。这样既能复用目标模型丰富的中间特征,又能保持部署成本较低。

JetSpec vs DSpark
解决问题
- DSpark 主要解决 高吞吐 serving 场景下,如何提升系统整体效率
- JetSpec 更像是在另一个方向上补齐了投机解码的能力边界。
DSpark 核心思路:保留 DFlash 式并行草稿主干低成本优势的基础上,引入轻量级串行头和置信度估计。
- 一方面,串行头用于缓解 DFlash 后缀 token 接受率下降的问题;
- 另一方面,置信度调度器用于判断哪些候选 token 值得送去验证,从而控制每个请求的验证成本。
因此,相比 EAGLE 这类纯自回归草稿方法,DSpark 的草稿生成成本更低;相比 DFlash 这类完全并行方法,DSpark 又能提升草稿 token 的接受率。
而 JetSpec 则可以看作是 DSpark 的互补方向。主要面向 低并发或中低负载场景:
- 此时系统拥有更充足的 FLOPs 预算,关键目标不再只是控制验证成本,而是尽可能提高草稿接受率,从而降低单用户延迟。
JetSpec 核心做法:引入 树形因果注意力掩码,让候选树中的每个节点只依赖自己所在分支上的祖先 token,从而恢复 token 之间的因果关系,解决 DFlash 放弃因果依赖后容易生成“不一致候选路径”的问题。
同时,JetSpec 又保留了一次 forward 生成候选树、并行验证候选树的机制,避免了 EAGLE 这类自回归草稿方法随着树深度增加而带来的高草稿成本。
🎯 总结版:
🌟 DeepSeek DSpark/阶跃 JetSpec
- 都站在 DFlash 低成本并行 Drafting 路线之上,对 causality-efficiency 困境的”同题不同解”,差异都由底层架构派生:把补充因果约束做成单链Chain(DSpark)还是树Tree(JetSpec)。
🌟 未来工作上互补:
- JetSpec 动态 serving-time 预算调度,而这恰是 DSpark 已经实现的。
- 反过来,JetSpec 多分支树是 DSpark 没有的(DSpark 是单链),两者正好补位。
应用
自适应投机采样用于小模型
【2026-3-27】单张显卡跑出15倍推理速度,aiX-apply-4B小模型加速企业AI研发落地
3月25日,北大系AI Coding赛道创企硅心科技(aiXcoder)发布专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。
20多种主流编程语言及Markdown等多类型文件格式的测试中,aiX-apply-4B的平均准确率达到 93.8%,超越Qwen3-4B基座模型 62.6% 准确度,甚至高于千亿级大模型DeepSeek-V3.2。
同一任务场景下,aiX-apply模型算力成本约为DeepSeek-V3.2的5%,推理速度则提升15倍,仅需一张消费级显卡即可在企业部署。
推理效率方面,aiXcoder引入自适应投机采样技术,极大压缩了端到端延迟。
企业级生产环境实测显示,aiX-apply-4B推理速度每秒可达2000 tokens,在单张RTX 4090消费级显卡上即可高效运行;而对比模型DeepSeek-V3.2则需要八卡H200高端集群部署。
综合不同的硬件部署成本与推理速度进行对比,aiX-apply-4B仅用DeepSeek-V3.2约5%的算力成本,实现了15倍的效率提升。
aiXcoder 已构建起覆盖多个研发关键环节的小模型矩阵,并创新提出“大模型+小模型”协同架构,让“通才”大模型与“专才”小模型各司其职、优势互补:
- 通用大模型聚焦复杂意图理解、代码逻辑分析、修改方案制定等需要深度推理的工作,发挥其智能优势;
- 垂直场景小模型则承接高频工程任务,以轻量化特性实现快速、精准执行。
这种架构设计,让企业的有限算力得到分层利用:小模型支持专项场景任务的高效完成,节约出更多算力用于大模型的复杂推理。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
