搜索引擎
趋势
Perplexity AI
- 【2022-12-9】搜索引擎 Perplexity.AI 发布,将LLM(Large Language Model)和搜索引擎结合来进行问答,Perplexity.AI 发布的推广语是 LLM powered products for search。该引擎由大规模语言模型驱动,通过对话形式提供用户需要的答案。以对话交互作为检索形式的新方法,或将逐渐成为主流。无需登录,直接可用。
- Aravind Srinivas是 Perplexity.AI 创始人之一,毕业于加州大学伯克利分校。在创建Perplexity AI之前,他曾就职于OpenAI,研究语言和扩散生成模型。
- Denis Yarats是Perplexity AI的另一位创始人,是纽约大学人工智能的博士生,同时还是加州大学伯克利分校的访问博士生,曾在Facebook AI Research工作六年。他的研究方向是通过学习有效的视觉表征,提高样本效率,使强化学习变得实用。
- Perplexity 是一个基于 OpenAI API 的搜索引擎,但与 ChatGPT 不同的是它的答案中不仅包括训练数据,还包括来自互联网的内容。
- 在答案中以脚注数字的形式引用了来源。
- 但是他的问题与 You.com 类似,就是答案的质量仍然参差不齐。
- 但是搜索结果和聊天响应的混合显示是引领潮流的。 可以想象未来的 Google 或 Bing 可能看起来像这样,或者至少是类似的东西。
- Perplexity 不是聊天机器人,而是搜索引擎(或者更准确地说,是答案引擎),其输出中不包含过去的问题或搜索词。
- 【2023-2-1】Magi创始人季逸超连夜实现了中文版 如何评价perplexity ai,会是未来搜索的趋势吗?
搜索引擎简介
从最基本的搜索引擎的概念谈起,到全文检索的概念,由网络蜘蛛,分词技术,系统架构,排序的讲解(结合google搜索引擎的技术原理),而后到图片搜索的原理,最后是几个开源搜索引擎软件的介绍。
什么是搜索引擎
搜索引擎指自动从因特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。因特网上的信息浩瀚万千,而且毫无秩序,所有的信息像汪洋上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为用户绘制一幅一目了然的信息地图,供用户随时查阅。
工作原理以最简单的语言描述,即是:
- 搜集信息:首先通过一个称为网络蜘蛛的机器人程序来追踪互联网上每一个网页的超链接,由于互联网上每一个网页都不是单独存在的(必存在到其它网页的链接),然后这个机器人程序便由原始网页链接到其它网页,一链十,十链百,至此,网络蜘蛛便爬满了绝大多数网页。
- 整理信息:搜索引擎整理信息的过程称为“创建索引”。搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。
- 接受查询:用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。
网络蜘蛛
网络蜘蛛即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
在抓取网页的时候,网络蜘蛛一般有两种策略:广度优先和深度优先。
- 广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。
- 深度优先是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。这个方法有个优点是网络蜘蛛在设计的时候比较容易。至于两种策略的区别,下图的说明会更加明确。
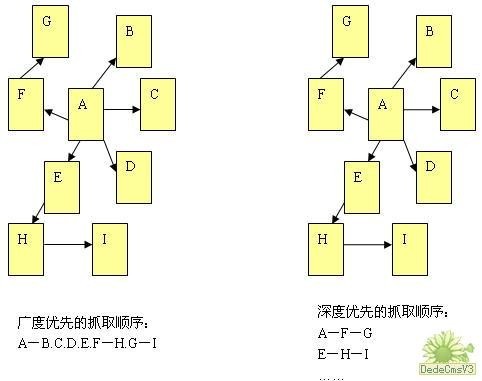
由于不可能抓取所有的网页,有些网络蜘蛛对一些不太重要的网站,设置了访问的层数。例如,在上图中,A为起始网页,属于0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。如果网络蜘蛛设置的访问层数为2的话,网页I是不会被访问到的。这也让有些网站上一部分网页能够在搜索引擎上搜索到,另外一部分不能被搜索到。 对于网站设计者来说,扁平化的网站结构设计有助于搜索引擎抓取其更多的网页。
更新周期
【2022-8-5】百度、谷歌搜索引擎收录及更新周期分析
(1)百度更新周期
- 据统计:百度收录的大更新时间是每月11号和26号,特别是26号,更新幅度最大,K站也是最多的。
- 小更新时间:每周四,更新时刻都在凌晨4点。一般凌晨4点更新,也有在早上九点以后更新的。对网站流量都没啥影响,只有到中午的时候,百度对网站的关键字搜索进行重新调整之后,才会有流量上的大的变化。流量有增自然有降。个人站长可以关注一下百度。更新时间!根据最新观察分析百度更新时间大致为:一个月2次!我的外贸网站建设好久没有收录,直到昨天27号被收录了,说明26号百度进行了大更新。
(2)谷歌更新周期
- google更新时间:
- 收录时间:更新后第1天;T+1
- 更新时间:每七天更新一次(排名影响小);
- 大更新时间:每月更新一次(排名影响大),PR数值更新3个月更新一次,因为存在不同服务器更新总时间为一星期。
- GOOGLE有两种搜索引擎蜘蛛爬虫: 一种是收录蜘蛛爬虫,此种爬虫是专门收录网站用的,还有一种是增加排名的蜘蛛爬虫,此种爬虫是综合计算反向链接用的爬虫,并且对排名的稳定和位置很重要。所以有的新站,在刚收录的时候排名不是很好就是很差,这是因为第一个爬虫的原因,但是网站掉了不要着急,真正排站要在三个月后第二个爬虫来的时候来会生效。
- GOOGLE谷歌研究者们发现了一个很简单的办法,就是查看GOOGLE的几个镜像站点是否相同,因为在GOOGLE更新期间,他总是将www2.google.com或者www3.google.com作为更新测试站点,在这期间,后两个站点中索引的页面数量和主站点将会不同。比如当我们www.google.com www2.google.com www3.google.com还有就是一种情况:三个网站搜索同一个关键词,得到的结果的数量不相同,这就说明GOOGLE正在更新。GOOGLE这种大规模的更新在国外被称为GOOGLE DANCE,有一个专门协助我们检查他是否正在Dance的网站www.google-dance-tool.com这个网站提供一个工具,通过这个工具,我们只需要输入一个关键词然后点击一个按钮,就可以看到GOOGLE三个镜像站点的搜索结果,很方便我们对比。PR数值更新3个月更新一次。
网页排序 Page Rank
到2004年为止,Google( http://www.google.com )已经连续两年被评为全球第一品牌,Google成立仅五年时间,最初只是两个斯坦福大学学生的研究项目。这不能不说是一个奇迹,就像比尔?盖茨创制奇迹一样。比尔?盖茨能创造奇迹,是因为他看准了个人计算机软件市场的趋势,所以创建的公司叫Microsoft(微软):Micro(小)Soft(软件)。那么Google呢?在Google出来之前已经有一些很有成就的搜索引擎公司,其实力也很强,看来不只是Google看见了搜索的趋势。Google究竟成功的秘密在哪儿?
Google的成功有许多因素,最重要的是Google对搜索结果的排序比其它搜索引擎都要好。Google保证让绝大部分用搜索的人,都能在搜索结果的第一页找到他想要的结果。客户得到了满足,下一次还过来,而且会向其他人介绍,这一来一往,使用的人就多了。所以Google在没有做任何广告的前提下,让自己成为了全球最大的品牌。Google究竟采用了哪种排序技术?PageRank,即网页级别。
Google有一个创始人叫Larry Page,据说PageRank的专利是他申请的,于是依据他的名字就有了Page Rank。国内也有一家很成功的搜索引擎公司,叫百度。百度的创始人李彦宏说,早在1996年他就申请了名为超链分析的专利,PageRank的原理和超链分析的原理是一样的,而且PageRank目前还在Paten-pending(专利申请中)。言下之意是这里面存在专利所有权的问题。这里不讨论专利所有权,只是从中可看出,成功搜索引擎的排序技术,就其原理上来说都差不多,那就是链接分析。超链分析和PageRank都属于链接分析。
PageRank的原理类似于科技论文中的引用机制:谁的论文被引用次数多,谁就是权威。说的更白话一点:张三在谈话中提到了张曼玉,李四在谈话中也提到张曼玉,王五在谈话中还提到张曼玉,这就说明张曼玉一定是很有名的人。在互联网上,链接就相当于“引用”,在B网页中链接了A,相当于B在谈话时提到了A,如果在C、D、E、F中都链接了A,那么说明A网页是最重要的,A网页的PageRank值也就最高。
计算PageRank值有一个简单的公式

- 系数为一个大于0,小于1的数。一般设置为0.85。网页1、网页2至网页N表示所有链接指向A的网页。 可以看出:
- 链接指向A的网页越多,A的级别越高。即A的级别和指向A的网页个数成正比,在公式中表示,N越大, A的级别越高;
- 链接指向A的网页,其网页级别越高, A的级别也越高。即A的级别和指向A的网页自己的网页级别成正比,在公式中表示,网页N级别越高, A的级别也越高;
- 链接指向A的网页,其链出的个数越多,A的级别越低。即A的级别和指向A的网页自己的网页链出个数成反比,在公式中现实,网页N链出个数越多,A的级别越低。
每个网页有一个PageRank值,这样形成一个巨大的方程组,对这个方程组求解,就能得到每个网页的PageRank值。互联网上有上百亿个网页,那么这个方程组就有上百亿个未知数,这个方程虽然是有解,但计算毕竟太复杂了,不可能把这所有的页面放在一起去求解的。
SEO 搜索引擎优化
【2022-8-5】SEO优化入门一篇就够-SEO教程(2021年最新)
SEO是什么
搜索引擎优化 (SEO) 是提高一个网站在搜索引擎中的排名(能见度)的过程。如果网站能够在搜索引擎中有良好的排名,有助于网站获得更多的流量。
大家口中的 SEO(Search Engine Optimization),中文翻译为“搜索引擎优化”,本质上是如何迎合搜索引擎的规则,使得网站在搜索结果中能有更好的排名。
- 比如一个PDA行业网站,当用户输入“PDA数据采集器”,在没有进行SEO优化的情况下,也许这个网站排在第2页或者第3页之后,通过用户行为分析,我们得知,用户在搜索的时候,基本80%左右的用户在浏览完第一页之后就会放弃继续浏览,这样对一个公司来说,如何让你的网站排在尽可能靠前的位置,获得更多流量,就意味着能有更多展示公司产品和品牌的机会。
- 简单一句话,SEO就是让网站在搜索引擎自然排序中能尽量排在靠前的位置。
- 眼动实验热力图

SEO 优化
SEO主要研究搜索引擎是工作的原理(什么人搜索,输入什么搜索关键字)。优化一个网站,可能涉及内容的编辑,增加关键字的相关性。推广一个网站,可以增加网站的外链数量。
搜索引擎是根据用户输入的搜索词来展现用户想要知道的内容,这个搜索词有可能是几个字,也有可能是一段文字,在SEO中,叫做关键词,如:“女神”。SEO所做的一切都是围绕着关键词展开
所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。
- 比如说垃圾链接,隐藏网页,桥页,关键词堆砌等等。
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特点就是短平快,为了短期内的利益而采用的作弊方法。同时随时因为搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词堆砌,垃圾链接,桥页等等。
下面是我所知道的一些常用方法:
- 关键词剖析、关键词挖掘、关键词密度剖析、关键词在页面中的布局、长尾关键词排名、关键词指数等。
- 网站内部优化:网站URL优化、网页伪静态操作、死链(404链接)查询与处理、内链网状优化、网站地图Sitemap、301重定向设置、robots.txt文件编写、404错误页面设置、图片优化技巧、网站原创输出等。
- 网站外部优化:合理外链、友情链接交换、站长平台提交入口、站外软文推广等。
还有一些其它手段,短期内可能会有很好的排名效果,但是不利于网站的长期排名,所有的分享都是基于白帽SEO,如果想学习黑帽SEO可以在网上搜索其他SEOer。
【2022-8-19】什么是语义搜索?它是如何影响SEO的
SEO调整的提示和技巧
向搜索引擎提交网站
目前大多数搜索引擎提供了网站的提交路口,我们可以通过他们提供的入口提交站点,让搜索引擎能够及时抓取网站的数据。
- 360搜索引擎登录入口
- 百度搜索网站登录口
- 百度单个网页提交入口
- Google网站登录口
- Google新闻网站内容
- bing(必应)网页提交登录入口
- 搜狗网站收录提交入口
- SOSO搜搜网站收录提交入口
- 雅虎中国网站登录口
- 网易有道搜索引擎登录口
- MSN必应网站登录口
- Alexa网站登录入口
更多站长工具
向搜索引擎提交你的站点首页即可,搜索引擎会根据你的站点页面关联的链接找到其他页面。还可以在网页中添加描述和关键字,但不要期望这些影响您的网站排名。搜索引擎索引会定期更新。如果你的站点有修改或者页面已删除,搜索引擎会定期进行修改与清理。并不是所有的链接都会出现在搜索引擎当中。
关键词剖析与挖掘
对于SEO来说,老站可能比新站还更麻烦,新站在建站的时候就可以把SEO考虑进去,进行合理的关键词布局,给后期的SEO打好基础。
每个网站都有它的定位,如果在不确定网站定位的情况下去盲目的选择关键词,对网站的排名优化起不到什么正面的效果,反而有可能会被搜索引擎判罚。
当确定了网站的定位,就可以进行关键词剖析和挖掘,我做的一般是行业网站的SEO,行业网站都是有些特定的关键词,你可以搜索一些关键词,看看同行业网站都是用的什么关键词,然后再通过站长工具,去查看这些关键词的指数,还有相关关键词,长尾关键词,再分析做这些词的难易程度,根据自身情况来决定首先选择哪几个关键词作为主要关键词,主要关键词最好控制在3-5个范围内,随着网站排名(权重)的提升,再进行调整。
长尾关键词可以放在内页去做,这里也许你还不懂什么叫长尾关键词
- 比如:“广州租车”这个关键词,那“广州哪家公司租车”、“广州租车哪家公司好”之类就算“广州租车”这个关键词的长尾关键词。
具体如何去剖析和挖掘关键词,长尾关键词,我会单独写文章去说。看到这里你大概就已经算入门SEO了,其实很简单,不要觉得SEO是什么高大上遥不可及的东西,首先要有两个意识:
- 明白SEO的含意
- 所有的SEO操作就是围着网站关键词转
其它就是具体如何实现的方法,这些常用的方法我上面已经提到,具体如何实现,需要慢慢的学习,实践和积累,也需要根据实际情况不断的作调整,SEO优化不是一尘不变的,但是有一点至关重要,那就是以用户为导向,不断提高网站质量。
搜索指标
衡量搜索系统有效性时,主要依赖两个广泛认可的指标:命中率和平均倒数排名(MRR)。
- 1️⃣命中率(Hit Rate):命中率是指在前k个检索的文档中找到正确答案的查询比例。系统在最初的几次猜测中得到正确答案的频率。
- 2️⃣平均倒数排名(Mean Reciprocal Rank ,MRR):对每个查询,MRR通过查看排名最高的相关文档的位置来评估系统的准确性。所有查询中这些排名的倒数的平均值。
因此,如果第一个相关文档是最顶端的结果,其倒数排名为1;如果是第二位,倒数排名则为1/2,以此类推。
相关功能
输入提示
- 【2022-1-19】百度等搜索引擎智能提示api,覆盖谷歌、必应、百度、好搜、搜狗、淘宝等输入提示结果,js代码
需求分析
智能提示一般满足如下功能:
- 支持前缀匹配原则
- 在搜索框中输入“海底”,搜索框下面会以海底为前缀,展示“海底捞”、“海底捞火锅”、“海底世界”等等搜索词;输入“万达”,会提示“万达影城”、“万达广场”、“万达百货”等搜索词。
- 同时支持汉字、拼音输入
- 由于中文的特点,如果搜索自动提示可以支持拼音的话会给用户带来更大的方便,免得切换输入法。比如,输入“haidi”提示的关键字和输入“海底”提示的一样,输入“wanda”与输入“万达”提示的关键字一样。
- 支持多音字输入提示
- 比如输入“chongqing”或者“zhongqing”都能提示出“重庆火锅”、“重庆烤鱼”、“重庆小天鹅”。
- 支持拼音缩写输入
- 对于较长关键字,为了提高输入效率,有必要提供拼音缩写输入。比如输入“hd”应该能提示出“haidi”相似的关键字,输入“wd”也一样能提示出“万达”关键字。
- 基于用户的历史搜索行为,按照关键字热度进行排序
- 为了提供suggest关键字的准确度,最终查询结果,根据用户查询关键字的频率进行排序,如输入[ 重庆,chongqing,cq,zhongqing,zq ] —> [ “重庆火锅”(f1),“重庆烤鱼”(f2),“重庆小天鹅”(f3),… ],查询频率f1 > f2 > f3。
技术方案
【2021-8-11】搜索引擎关键字智能提示的一种实现
美团基于solrcloud实现了商家搜索模块。用户在查找商家时主要输入商户名、商户地址进行搜索,为了提升用户的搜索体验和输入效率
- 关键字收集
- 当用户输入一个前缀时,碰到提示的候选词很多的时候,如何取舍,哪些展示在前面,哪些展示在后面?这就是一个搜索热度的问题。用户在使用搜索引擎查找商家时,会输入大量的关键字,每一次输入就是对关键字的一次投票,那么关键字被输入的次数越多,它对应的查询就比较热门,所以需要把查询的关键字记录下来,并且统计出每个关键字的频率,方便提示结果按照频率排序。搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
- 汉字转拼音
- 用户输入的关键字可能是汉字、数字,英文,拼音,特殊字符等等,由于需要实现拼音提示,我们需要把汉字转换成拼音,java中考虑使用pinyin4j组件实现转换。
- 拼音缩写提取
- 考虑到需要支持拼音缩写,汉字转换拼音的过程中,顺便提取出拼音缩写,如“chongqing”,”zhongqing”—>”cq”,”zq”。
- 多音字全排列
- 要支持多音字提示,对查询串转换成拼音后,需要实现一个全排列组合,字符串多音字全排列算法
- 索引与前缀查询
索引与前缀查询
- 方案一:Trie树 + TopK算法:
- Trie树即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。
- TopK算法用于解决统计热词的问题。解决TopK问题主要有两种策略:hashMap统计+排序、堆排序
- hashmap统计: 先对这批海量数据预处理。具体方法是:维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可,最终在O(N)的时间复杂度内用Hash表完成了统计。
- 堆排序:借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是:O(N) + N’ * O(logK),(N为1000万,N’为300万)
- 问题
- 建索引和查询的时候都要把汉字转换成拼音,查询完成后还得把拼音转换成汉字显示,且需要考虑数字和特殊字符。
- 需要维护拼音、缩写两棵Trie树。
- 方案二:Solr自带Suggest智能提示
- Solr作为一个应用广泛的搜索引擎系统,它内置了智能提示功能,叫做Suggest模块。该模块可选择基于提示词文本做智能提示,还支持通过针对索引的某个字段建立索引词库做智能提示。
- 方案三:Solrcloud建立单独的collection,利用solr前缀查询实现
- 以上两个方案在实施起来都存在一些问题,Trie树+TopK算法,在处理汉字suggest时不是很优雅,且需要维护两棵Trie树,实施起来比较复杂;Solr自带的suggest智能提示组件存在问题是使用freq排序算法,返回的结果完全基于索引中字符的出现次数,没有兼顾用户搜索词语的频率,因此无法将一些热门词排在更靠前的位置。
代码实现
前端实现

css样式
#auto_div {
position: absolute;
z-index: 999;
left: 0px;
top: 33px;
width: 468px;
border: 1px solid #74c0f9;
display: none;
background: #FFF;
}
Jquery代码
获取提示词
var highlightindex = -1; //高亮设置(-1为不高亮)
//自动完成
function AutoComplete(auto, search) {
if ($("#" + search).val() != "") {
var autoNode = $("#" + auto); //缓存对象(弹出框)
var carlist = new Array();
var n = 0;
var mylist = [];
var maxTipsCounts = 8 // 最大显示条数
var aj = $.ajax({
url: '/xxx/xxx' + "&str=" + $("#" + search).val(), // 跳转到后台
data: {},
type: 'get',
cache: false,
dataType: 'json',
success: function(data) {
if (data.error == "0") {
mylist = data.info;
if (mylist == null) {
autoNode.hide();
return;
}
autoNode.empty(); //清空上次的记录
for (i in mylist) {
if (i < maxTipsCounts) {
var wordNode = mylist[i]; //弹出框里的每一条内容
var newDivNode = $("<div>").attr("id", i); //设置每个节点的id值
document.querySelector("#auto_div").style.width = $("#search_text").outerWidth(true) + 'px'; //设置提示框与输入框宽度一致
newDivNode.attr("style", "font:14px/25px arial;height:25px;padding:0 8px;cursor: pointer;");
newDivNode.html(wordNode).appendTo(autoNode); //追加到弹出框
//鼠标移入高亮,移开不高亮
newDivNode.mouseover(function() {
if (highlightindex != -1) { //原来高亮的节点要取消高亮(是-1就不需要了)
autoNode.children("div").eq(highlightindex).css("background-color", "white");
}
//记录新的高亮节点索引
highlightindex = $(this).attr("id");
$(this).css("background-color", "#ebebeb");
});
newDivNode.mouseout(function() {
$(this).css("background-color", "white");
});
//鼠标点击文字上屏
newDivNode.click(function() {
//取出高亮节点的文本内容
var comText = autoNode.hide().children("div").eq(highlightindex).text();
highlightindex = -1;
//文本框中的内容变成高亮节点的内容
$("#" + search).val(comText);
$("#search-form").submit();
})
if (mylist.length > 0) { //如果返回值有内容就显示出来
autoNode.show();
} else { //服务器端无内容返回 那么隐藏弹出框
autoNode.hide();
//弹出框隐藏的同时,高亮节点索引值也变成-1
highlightindex = -1;
}
}
}
}
}
});
}
}
键盘操作部分
var highlightindex = -1; //高亮设置(-1为不高亮)
//自动完成
function AutoComplete(auto, search) {
if ($("#" + search).val() != "") {
var autoNode = $("#" + auto); //缓存对象(弹出框)
var carlist = new Array();
var n = 0;
var mylist = [];
var maxTipsCounts = 8 // 最大显示条数
var aj = $.ajax({
url: '/xxx/xxx' + "&str=" + $("#" + search).val(), // 跳转到后台
data: {},
type: 'get',
cache: false,
dataType: 'json',
success: function(data) {
if (data.error == "0") {
mylist = data.info;
if (mylist == null) {
autoNode.hide();
return;
}
autoNode.empty(); //清空上次的记录
for (i in mylist) {
if (i < maxTipsCounts) {
var wordNode = mylist[i]; //弹出框里的每一条内容
var newDivNode = $("<div>").attr("id", i); //设置每个节点的id值
document.querySelector("#auto_div").style.width = $("#search_text").outerWidth(true) + 'px'; //设置提示框与输入框宽度一致
newDivNode.attr("style", "font:14px/25px arial;height:25px;padding:0 8px;cursor: pointer;");
newDivNode.html(wordNode).appendTo(autoNode); //追加到弹出框
//鼠标移入高亮,移开不高亮
newDivNode.mouseover(function() {
if (highlightindex != -1) { //原来高亮的节点要取消高亮(是-1就不需要了)
autoNode.children("div").eq(highlightindex).css("background-color", "white");
}
//记录新的高亮节点索引
highlightindex = $(this).attr("id");
$(this).css("background-color", "#ebebeb");
});
newDivNode.mouseout(function() {
$(this).css("background-color", "white");
});
//鼠标点击文字上屏
newDivNode.click(function() {
//取出高亮节点的文本内容
var comText = autoNode.hide().children("div").eq(highlightindex).text();
highlightindex = -1;
//文本框中的内容变成高亮节点的内容
$("#" + search).val(comText);
$("#search-form").submit();
})
if (mylist.length > 0) { //如果返回值有内容就显示出来
autoNode.show();
} else { //服务器端无内容返回 那么隐藏弹出框
autoNode.hide();
//弹出框隐藏的同时,高亮节点索引值也变成-1
highlightindex = -1;
}
}
}
}
}
});
}
}
后端实现
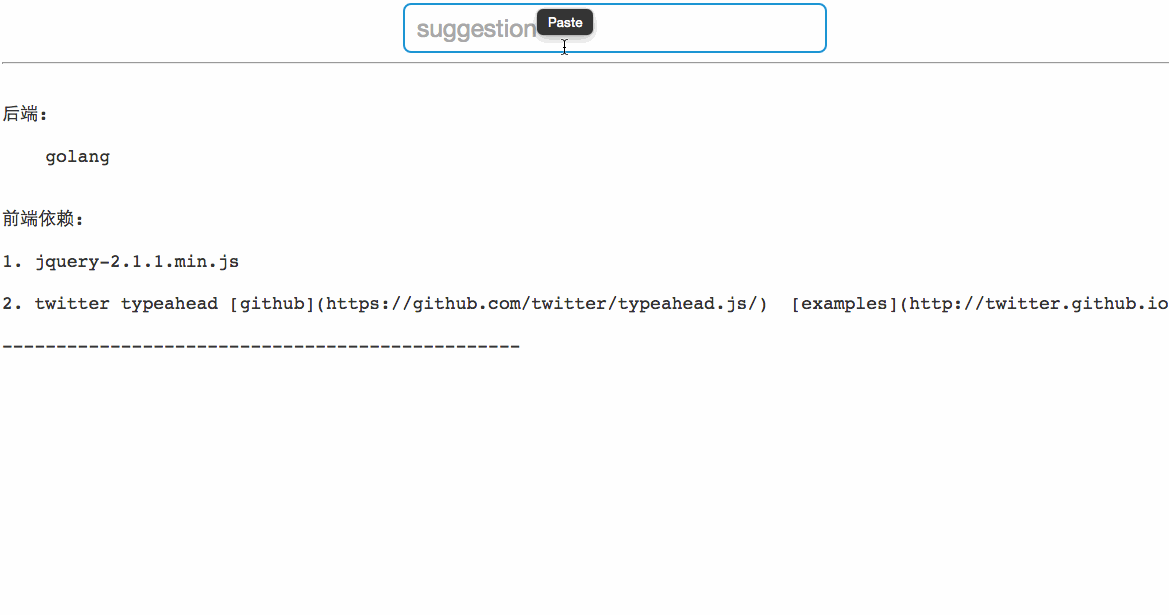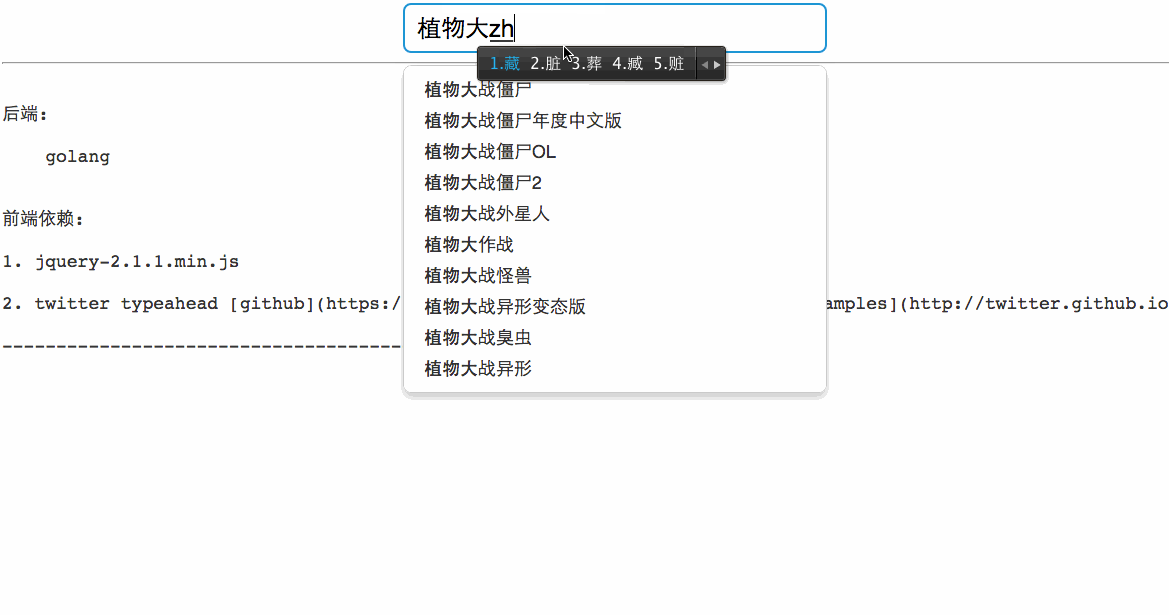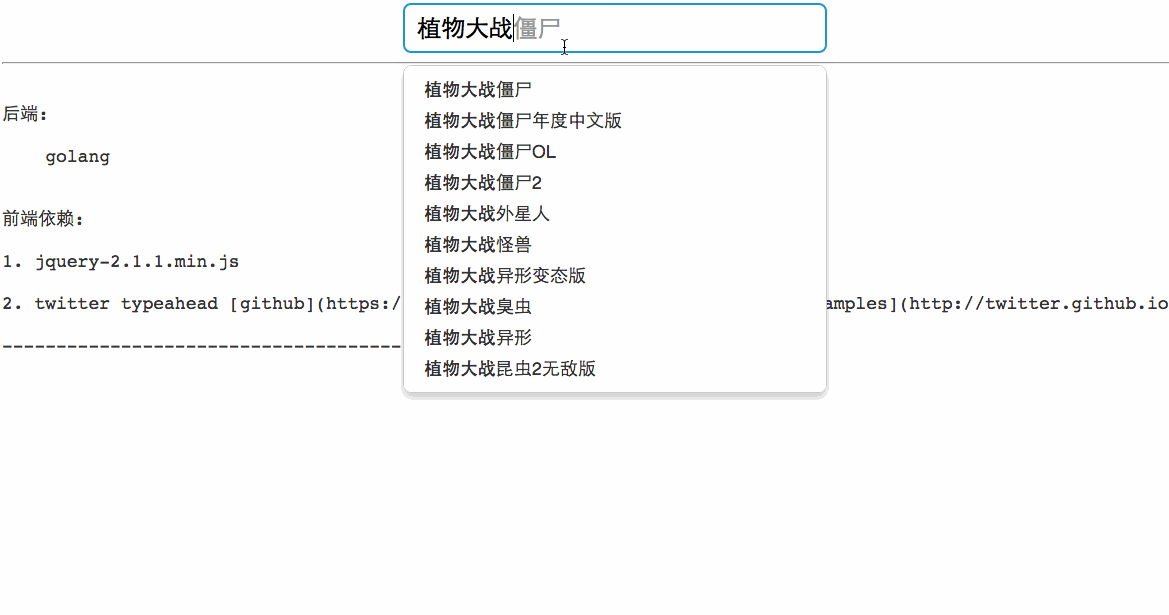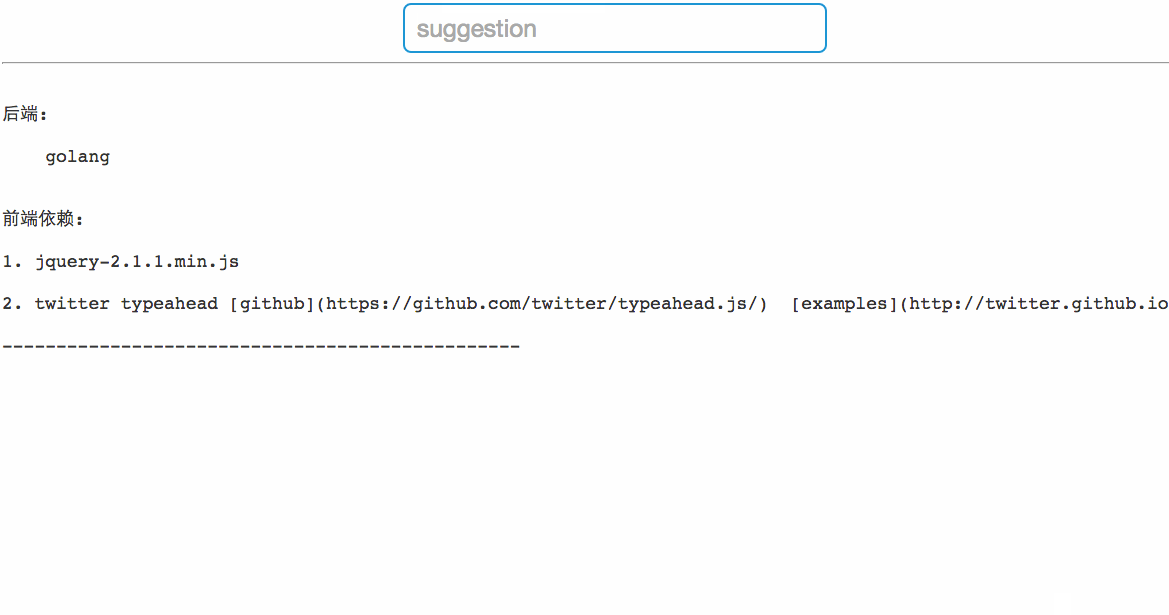
git clone https://github.com/wklken/suggestion.git
cd suggestion/easymap
python suggest.py
自动纠错
- 待补充
图片搜索
阮一峰介绍了一个简单的图片搜索原理,可分为下面几步:
- 缩小尺寸。将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
- 简化色彩。将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
- 计算平均值。计算所有64个像素的灰度平均值。
- 比较像素的灰度。将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
- 计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
这种方法对于寻找一模一样的图片是有效的,但并不能够去搜索“相似”的照片,也不能局部搜索,比如从一个人的单人照找到这个人与别人的合影。这些Google Images都能做到。
其实早在2008年,Google公布了一篇图片搜索的论文(PDF版),和文本搜索的思路是一样的:
- 对于每张图片,抽取其特征。这和文本搜索对于网页进行分词类似。
- 对于两张图片,其相关性定义为其特征的相似度。这和文本搜索里的文本相关性也是差不多的。
- 图片一样有image rank。文本搜索中的page rank依靠文本之间的超链接。图片之间并不存在这样的超链接,image rank主要依靠图片之间的相似性(两张图片相似,便认为它们之间存在超链接)。具有更多相似图片的图片,其image rank更高一些。
搜索相关性
【2021-8-5】NLP文本相关性在搜广推的应用(包含丰富完整的图片信息),NLP最赚钱的落地莫属搜索、广告、推荐三大场景。
搜广推这三个场景的架构都差不多,主要就是通过对内容/商品的召回和排序,来优化Query-Doc的匹配结果。可以将这个过程分为三部分:
- Doc理解:现在的候选Doc/Item是各种模态的,比如视频、商品、图片、文本,但不管哪种形式,文本都是其中的重要一种,可以利用阅读理解、信息抽取、文本匹配打标签等技术加深对内容的理解
- Query理解:在搜索、广告中输入都是真实的Query,可以基于NLP进行意图、分词、NER等各种解析,而推荐中则是把User当作Query,这时可以把用户历史消费的内容作为用户兴趣,这件又回归到了Doc理解
- Query-Doc相关性:通过用户行为、用户信息、时空信息、上述的Query和Doc理解等海量特征来找出符合用户需求的结果。搜索和广告是命题作文,其中文本层面的Query-Doc很重要,而推荐中内容信息则可以解决用户、物品冷启动问题,也起着不可或缺的作用
本文聚焦于Query-Doc文本相关性的应用调研,该相关性分数作为特征,对召回以及排序结果都有很大影响。
业界方案
- 蘑菇街
- 蘑菇街在最初的迭代时,通过频率、tfidf、BM25、布尔模型、空间向量模型、语言模型等统计方式抽取了文本的稠密特征,输入到树模型进行相关性打分就能得到不错的效果。同时他们也加入了Q-D的交互特征,也就是对Query、Doc进行同义词扩展后,计算重合ngram term占Query term和Doc term的比例。但字面匹配的可扩展性较差,需要好的同义词表提升泛化性能,因此下一个阶段就是引入词向量。蘑菇街在19年也尝试了用tfidf筛选出核心词,并对Query、Doc的核心词进行Self-Attention计算再融合,得到更好的文本相关性结果,将佣金收入提升了5.56%。
- 深度学习时代,各厂门都开始不满足字面匹配的相关性,因为这个方案需要大量的人工特征工程以及同义词、停用词的挖掘,这时便出现了著名的DSSM模型。
- 小米移动搜索
- 小米采用的方案是在人工GBDT的方案基础上融合C-DSSM的结果,利用大规模用户行为数据进行训练,提升了长尾Query的查询效果。
- 阿里妈妈
- 阿里妈妈也采用了DSSM进行广告语义匹配,但他们在应用中发现pairwise loss会导致Q-D预测结果偏向正太分布,这就导致阈值对召回结果有很大影响,不同天的Query召回集合变动很大,给广告效果带来了不确定性。因此他们改为拟合伯努利分布,使预测结果成哑铃的形状,降低阈值对截断的影响。同时为了弥补DSSM缺少交互的缺点,他们在中间加入了Q-D的attention交互计算,最终新的方案在各个指标上都超越了DSSM。
- 京东电商搜索
- 当然,文本相关性也可以不单独作为一个特征,而是直接融合到召回中。京东电商搜索则是分别给Query和商品建立了一个encoder,在输入Query文本、商品名称的同时融合其他特征进行计算,比如用户基础信息、历史行为、商品品牌、品类等。值得注意的是,左侧的Query编码器采用了multi-head机制,用于捕获不同的语义,比如品牌属性、商品属性等,丰富Query的表示
- 阿里飞猪
- 阿里飞猪和京东采取的融合方案相似,不同的是他们更关注Doc的理解,提前对商品的目的地和类目id进行了编码,作为Doc侧的输入
- 当然,讲NLP肯定少不了BERT。
- 知乎搜索
- 作为重内容的社区,知乎在他们的搜索召回和排序中都有用到BERT,在召回中会分别对Query和Doc编码,通过向量检索的方式召回候选,同时在二轮精排也会用交互式的小BERT进行相关性计算
数据天花板
字面匹配和语义匹配各阶段的模型,但在应用场景中,数据才是真正的天花板,模型只是在不断拟合上线而已。训练数据的构造在文本相关性任务中是十分重要的。
- 把用户点击的数据当作正例是无可后非的,但一个很常见的错误就是把召回结果中未点击的内容作为负例。腾讯全民K歌的分享中指出,在召回和排序这两个步骤中我们的视角是不一样的,召回阶段的视角是内容全集,同时未点击也不意味着就不是好结果,所以更好的做法是在全局范围内进行随机负采样,实践的效果也证明这样会更好。
- 但单纯的随机负例也有问题,就是可能会把相关商品变成负例,降低结果与Query的相关性。京东电商搜索采用的方案是按一定比例将随机负例与batch negatives相融合,因为batch内的doc都有对应的batch query作为正例,打散的话更大概率与当前正例不相关,之后再通过控制参数来平衡召回结果的多样性与相关性。
- 知乎搜索还提出了一种hard负例的挖掘方法,就是将query和doc映射到一个空间中,再对doc进行聚类,这样就可以找到与query相近的类别,从其中采样一些较难的负例。或者也可以参考阿里飞猪的做法,在一个类目或者目的地下随机选择负例,提升训练数据的难度。
- 当然有资源的话最好还是进行人工标注,而搜广推数据量那么大,都标注肯定是不可能的,需要更高效的问题样本发现机制。阿里文娱基于Q-Learning的思想,对于线上预测较差的样本,再用一层模型进行挖掘,把低置信度的样本、或者高置信度但和线上预测不一致的样本拿去给人工标注,这样就可以快速迭代出问题集并有针对性地优化
线上化
怎么用还是问题,之所以不是所有厂都用BERT,主要还是因为代价太大。虽然Doc的表示都可以离线预测好存起来,但Query来了真心受不了。
- 第一种解决方案就是把模型做小。
- 知乎搜索直接把BERT用到了二轮精排中,因此他们的做法是基于Roberta-large进行蒸馏,采用Patient-KD方式,将12层蒸馏到了6层。同时他们也对BERT表示模型进行了维度压缩,在不影响线上效果的情况下,将768维压缩到了64维,减少了存储空间占用。
- 阿里文娱只用到基于表示的方案,因此他们蒸馏了一个非对称的双塔模型,并且在doc端采用multi-head方式来减少指标衰减。
- 第二种解决方案就是把数据尽可能存起来。
- 360搜索广告在训练阶段用了16层transformer,因此在应用到线上时选择了离线的方式,先从日志中挖出一部分Q-D对,进行相关性预测,再通过CTR预测进行过滤,把最终结果存储到线上KV系统。
- 不过这种方案只限于数据量可以承受的场景,也可以把两种方式进行融合,将一些高频Query提前存好,剩下的长尾Query用小模型预测。
推荐场景
上述的介绍主要还是集中在搜索、广告场景下,因为推荐场景没有query,花样会更多一些,也会利用其他很多特征,基本上都是把文本作为一个维度来训练相关性模型。
- 百度凤巢
- 对于搜索广告这种命题作文来说,召回阶段最重要的目标就是Q-D相关性,但这个优化目标其实跟最终的ctr是有gap的,尤其是在广告场景中,最终影响收益的指标和ctr有很强的关系。所以百度凤巢团队提出了MOBIUS系统,将ctr预估引入到搜索召回阶段
- 最单纯的想法是直接在召回阶段以ctr为目标进行训练,但由于ctr目标本身的问题,很可能将相关性不高的广告预测为正例。MOBIUS提出了一个数据增强模块,先从日志里捞一批Q-D对,再用相关性模型进行打分,找出相关性低的pair作为badcase,让最终的模型预测。这样模型从二分类变成了三分类,就具备了过滤不相关case的能力,将相关性预测与ctr预测较好地融合在了一起。
- 陌陌
- 陌陌有个场景是根据用户发布的动态推荐相似的内容,这个动态不仅有文本,也有图像,我觉得可借鉴的点是他们利用用户提供的文本和图像内容训练了两个编码器,很好地把文本和图像映射到了一个空间内。具体的做法是,利用用户发表的图文动态,训练一个双塔模型
- 模型两个塔分别对文本和图像编码,有三个loss:①图文匹配②文本语言模型③图片内容一致性:有的动态包含多张图片,我们认为多张图片在表达一个意思
总结
在社会上混得越久,越觉得技术只是工具,自己在工作中总拿着模型找问题,却不思考问题本身对于业务的重要程度。
Query理解
【2021-8-5】搜索中的Query理解 Query理解的落地技巧。
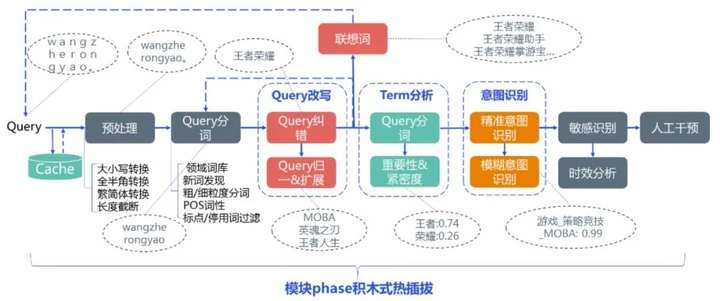
Query理解是搜索引擎中的必备模块,它的主要功能是对Query进行深入理解,保证召回的数量和最终排序精度。系统中的整个理解模块通常被称为QU(Query Understanding)或QP(Query Parser),主要由以下几部分构成:
- 基础解析:包括预处理、分词、词性识别、实体识别、词权重等多个基础任务
- Query改写:包括纠错、扩展、同义替换功能,可以进行扩召回
- 意图识别:判断Query的具体类目,便于召回和最终排序
下图是腾讯搜索的例子,在实际应用中每家的实现顺序都各有不同,有些子模块也可以是并行的,最终的输出多个处理后的Query进行召回,比如原始Query解析后的倒排索引召回、改写后Query的倒排索引召回、以及向量化召回。
基础解析
基础解析包含很多功能,比如腾讯搜索分享的预处理、分词、词性识别,以及去停用词、实体识别和链接、词权重等。
词法分析任务已经有很多开源工具了,本来这个模块对速度的要求就比较高,基本都是采用词表或者很浅的模型来解决。在实际选择工具时,更重要的是考虑工具的效率和可控性,包括:
- 分词及NER在业务数据的精度、速度
- 粒度控制:比如“2021日本奥运会直播”可以切成“2021/日本/奥运会/直播”,也可以切成“2021日本奥运会/直播”,用phrase级别召回会比细粒度更准确,但phrase结果不够时还是需要细粒度的结果补充
- 自定义词典、模型迭代的支持:之前我早年用词向量做检索式问答的时候,遇到的困境就是虽然词表配好了,但如果同时配了“奥运”和“奥运会”,有时候还会切成“奥运/会”,这就需要对模型增量训练,现有工具很多是不支持的
- 新词发现:因为涉及建立倒排索引,Query和Doc需要用同一套分词。但互联网总是会出现各种新型词汇,这就需要分词模块能够发现新词,或者用更重的模型挖掘新词后加到词典里
除了词法分析之外,还有个比较重要的模块是词权重。比如“女士牙膏”这个Query,“牙膏”明显比“女士”要重要,即使无法召回女士牙膏类的内容,召回牙膏内容也是可以的。
权重可以用分数或分类表达,在计算最终相似度结果时把term weight信息加入召回排序模型中,比如腾讯搜索就给term分成了四类:

对于Term weighting可以有以下方法:
- 基于统计+词表:比如根据doc统计出词的tfidf,直接存成词典就行了。但这种方法无法解决OOV,知乎搜索的解决方法是对ngram进行统计,不过ngram仍然无法捕获长距离依赖、不能根据上下文动态调整权重
- 基于Embedding:针对上下文动态调整的问题,知乎搜索的迭代方案是用term的向量减去query整个的pooling向量来算term权重,diff越小词越重要;腾讯搜索则是用移除term之后的query和原始query的embedding做差值,diff越大词越重要
- 基于统计模型:用速度更快的统计分类/回归模型同样可以解决上述问题,腾讯搜索采用了term 词性、长度信息、term 数目、位置信息、句法依存 tag、是否数字、是否英文、是否停用词、是否专名实体、是否重要行业词、embedding 模长、删词差异度、前后词互信息、左右邻熵、独立检索占比 ( term 单独作为 query 的 qv / 所有包含 term 的 query 的 qv 和)、iqf、文档 idf、统计概率等特征,来预测term权重。训练语料可以通过query和被点击doc的共现词来制作
- 基于深度学习模型:腾讯搜索还提出了一种利用其他模型副产物的方式得到term权重,可以解决长距离依赖问题,就是把带有attention机制的意图模型、文本向量化模型的attention矩阵拿出来作为weight。但这种方法个人认为不太可控,毕竟深度模型太过黑盒,有可能换模型之后波动较大
Query改写
Query改写是个很重要的模块,因为用户的输入变化太大了,有短的有长的,还有带错别字的,如果改写成更加规范的query可以很大地提升搜索质量。
改写模块又可以分为纠错、扩展、同义替换等多个功能,这个模块会提前把高频Query都挖掘好,存储成pair对的形式,线上命中后直接替换就可以了,所以能上比较fancy的模型。
纠错
基于Query本身是否有在字典中的词,腾讯搜索把错误分词了Non-word和Real-word两类:

对于不同类错误有不同的解决方案
- 比如英文、数字、拼音的拼写错误,可以利用编辑距离挖掘出改写的pair;
- 比如拼音汉字混合、漏字、颠倒等可以通过人工pattern生成一批pair。
- 不过更通用的方法还是批量挖掘或生成。挖掘可以对用户session、点击同一个doc的不同query的行为日志进行统计,计算n-gram语言模型的转移概率;也可以直接利用业务语料上预训练的BERT,mask一部分之后得到改写的词。当有了第一批pair语料后,就可以用seq2seq的方式来做了。这方面可以做的很fancy,有不少论文。
扩展(推荐)
用户的表述不一定总是精确的,有时候会输入很短的query,或者很模糊的词,改几次才知道自己要什么。扩展则起到了「推荐」的作用,可以对搜索结果进行扩召回、在搜索时进行提示以及推荐相关搜索给用户。目的主要是丰富短query的表达,更好捕捉用户意图。
Query扩展pair的挖掘方式和纠错差不多,可以建模为pair对判别或者seq2seq生成任务。丁香园分别写过两篇扩展模型的总结,这里就不再赘述:
除了用模型发现之外,也可以利用知识图谱技术,将一些候选少的query扩展到上位词,或者某种条件下的相关词,比如把“能泡澡的酒店”改写成“带浴缸的酒店”,普通的相关性扩展不一定能学到这些知识。
同义替换
同义替换的挖掘主要解决query和doc表述不一致的问题。比如“迪士尼”和“迪斯尼”、“理发”和“剪发”,或者英文和中文等,保证能召回到用户想找的item。
同义词的判定标准会更严格一些,除了在行为日志挖掘,也可以在doc中挖到很多同义pair。但这个模块面临的困境是不同垂搜下的标准不一致,比如我们在挖掘教育领域下的同义词时,“游泳”和“游泳培训”就是同义的。对于这个问题一方面可以针对不同领域训练不同模型,但每个领域一个模型不太优雅,所以也可以在语料上做文章,比如加一个统一的后缀,教育领域都变成XX培训,旅游领域都变成XX的地方。
搜索意图
搜索场景下用户需求
| 问题类型 | 占比 | 答案形式 | 示例 |
|---|---|---|---|
| 事实型(factoid) | 15% | 短答案(实体短语) | 单/多实体:刘德华的妻子、中国四大名著 时间/数字:曹操有几个儿子、刘德华哪天出生的 |
| 观点型(opinion) | 6% | 短答案(yes/no) | 高铁可以逃票吗、月经期可以吃榴莲吗、张学友是水瓶座吗 |
| 摘要型(abstract) | 64% | 长答案(多句摘要) | 为什么会脑缺血、苹果手机电量低怎么办、太阳能热水器工作原理 |
| 列表型(list) | 15% | 长答案(列表) | 按揭房产抵押贷款办理流程、银行修改密码步骤 |
用户需求:
- 基于图谱的问答
事实型query,答案形式是实体短语类的短答案。例如“刘德华的妻子”,或者实体集合“中国四大名著”,还有时间/数字等。 - 第二类是
观点型query,答案形式是“是或否”,例如像“高铁可以逃票吗”等。 - 第三类是
摘要型query,不同于前两类短答案,答案可能需要用长句的摘要来回答,通常是“为什么”、“怎么办”、“怎么做”等问题。 - 最后一类是
列表型query,通常是流程、步骤相关的问题,答案需要用列表做精确的回答。
答案来源
- 结构化数据,来源于百科、豆瓣等垂类网站的infobox。优点是质量高,便于获取和加工;缺点是只覆盖头部知识,覆盖率不够。例如“易建联的身高”、“无间道1的导演是谁”。
- 非结构化的通用文本,来源于百科、公众号等互联网网页文本库。优点是覆盖面广,但缺点在于文本质量参差不齐,对医疗、法律等专业领域知识的覆盖度和权威度不够。
- 非结构化的专业垂类网站问答库,来源于专业领域垂类站点的问答数据,通常以问答对的形式存在。优点是在专业领域知识覆盖广、权威度高。
意图识别
意图识别模块通常是一个分类任务,目的是识别用户要查询的类目,再输出给召回和排序模块,保证最后结果的类目相关性。
除了明确的名词外,很多query都是模糊的,可能有多个类别满足情况,所以意图模块主要是输出一个类目的概率分布,进行多路召回,让排序层进行汇总。
构建意图分类模型之前,首先是对类目的梳理,因为大厂们的业务越来越复杂,类目也随之越来越多,通常会采用层级式的类目体系,模块先判断大类目,再去判断更细化的类目。
在构建模型时,由于这个模块对速度的要求大于精度,所以一般会有很浅的模型,比如统计方法或者浅层神经网络。在微信和第四范式的分享中都提到说Fasttext的效果就很好了。在浅层模型下要想提升效果,可以增加更多的输入信息,比如微信就提供了很多用户画像的feature:
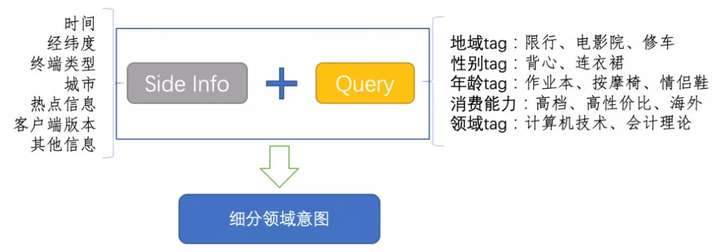
实际上,由于类目层级和数目的增加,光靠一两个模型是很难同时满足速度和精度的,在这个模块少不了词表和pattern的帮助,比如:
查询词语:澳洲[addr]cemony[brand]水乳[product]面霜[sub_product]
查询pattern: [brand]+[product];[addr]+[product]+[sub_product]
虽然NLP只有几个基础任务,但在最终落地时却是很复杂的,一个几十毫秒的Query理解模块包含着这么多逻辑,需要几人甚至十几人的团队来维护,不仅要上高效率的模型,还需要增加各种策略来解决业务问题。
智能问答
【2022-9-20】杨韬:微信搜一搜中的智能问答技术
智能问答的技术路线主要分两种:KBQA(基于图谱的问答)和DocQA(基于文档的问答)。
- KBQA的优点是扩展性强,能查询实体的各种属性,同时支持推理,可以解析复杂查询。例如图中右边的一个例子,“姚明的老婆有多高”可以解析得到中间的语义表达式,从而转换成知识图谱的查询,得到问题的答案。涉及的关键技术是图谱构建(包括schema构建、实体挖掘、关系抽取、开放信息抽取技术)和问题解析(包括实体链接、基于semantic parsing的问题解析方法、基于检索的问题解析方法等技术)。
- DocQA相较于KBQA的优点是覆盖面更广,能覆盖更多中长尾的问题,同时能解决一些KBQA难以解析的问题。例如,“中国历史上第一个不平等条约”这个query,很难解析成结构化的表达,涉及到的技术主要包括阅读理解(MRC)、开放域问答(OpenQA)。
知识图谱问答
介绍KBQA的整体流程:
- 实体链接,识别出query中的实体,并关联到图谱中的节点;
- 关系识别,query询问的具体属性;
- Topic实体识别,当query涉及到多个实体时,判断哪个实体是问题的主实体;
- 条件/约束识别,解析query中涉及到的一些约束条件;
- 查询推理,将前几步的结果组合成查询推理的语句,通过知识图谱获得答案。
整个流程中,比较关键的是实体链接和关系识别这两个模块
文档问答
DocQA总体流程
- ① 针对Query Log进行问答意图的过滤。
- ② 通过检索模块去段落库中检索相应的一些段落。
- ③ 对检索到的TopK段落,做一个Reader模型(多段落-MRC)。
- ④ 对答案进行重排序和拒识判定。
- ⑤ 输出最终答案。
可以看到全流程中比较重要的是检索模块和多段落的MRC模块
语义搜索
【2022-8-19】什么是语义搜索?它是如何影响SEO的
- 语义搜索是现代搜索引擎用来返回最相关搜索结果的一种信息检索过程。它侧重于搜索查询背后的意图,而不是传统的关键词匹配。
- 大约40%的英语单词是多义词——它们有两个或更多的含义。这可以说是语义搜索要解决的最重大的挑战。
到2020年,语义搜索发展到今天的成果,一共经历了四个重要的里程碑。
- (1) 知识图谱
- 启动并实现了从关键字匹配到语义匹配转变的技术。
- 向知识图谱提供信息的方法主要有两种:
- 结构化数据(稍后详述)
- 从文本中提取实体
- 第二点,需要搜索引擎理解自然语言,3个算法如下:
- (2) 蜂鸟算法
- 早在2013年,Google推出了一个名为Hummingbird(蜂鸟)的搜索算法,以返回更好的搜索结果。 这个算法尤其有助于应对复杂的搜索查询。
- 蜂鸟算法是第一个重大更新,它更加强调搜索请求背后的意图,而非单个关键词。 它极速催化了“为话题而创作内容”的热潮,而不是“为单个关键词而写作”。
- (3) RankBrain算法——升级版
- Google用RankBrain算法解决了LSI(潜在语义索引)产生的问题: 搜索请求中所使用的语言和所需内容之间的不匹配
- Google的RankBrain采用了优于LSI的技术。通俗地说,通过使用复杂的机器学习算法,RankBrain甚至可以理解不熟悉的单词和短语的含义。
- 而考虑到15%的搜索请求都是新的,这可是一项巨大的工程。可以认为
RankBrain是蜂鸟算法的升级版,而不是一个独立的搜索算法。它是最强的排名信号之一,但你能主动为其做出的优化,也就只有满足搜索意图了。 - (4) BERT模型
- 基于Transformer的双向编码器表示(BERT)这一自然语言表示模型,是对语义搜索运作方式的最新的重大升级。自2019年底以来,它影响了大约10%的查询。
- BERT可以提高对长而复杂的句子以及查询的理解。它是一种处理歧义和细微差别的解决方案,因为它力图更好地理解单词的上下文。
Omnity
Omnity是一款专为研究人员设计的全新搜索引擎,旨在帮助解决这些难题,加速“在学科领域内和学科领域之间发现隐藏的高价值互连模式”,使跨学科的研究变得更加容易。Omnity对学术界尤其有用,允许科学家、工程师、医疗专业人士、金融专家和律师搜索信息,数据来源包括科学期刊、专利、资助申请、临床试验、法律记录、财务报告等等。
乍一看,这不就是google 学术做的事情吗?这个新系统还能比google学术跟全更好?不同于谷歌的关键字搜寻机制,Omnity采用语义搜寻方法。对于任何查询,Omnity能帮助用户跨越不同的文件与网页、新闻、专利等进行搜索,返回的搜索结果也不再限于关键字本身,而是根据词语背后的意义找出关连性更强的资讯。所以当研究人员试图调研跨学科文献或者搜索不太熟悉的研究主题时,使用Omnity除了可以看到文章被引用次数最多的作者或是该研究主题的权威学术机构外,还可以得到一些意想不到的有用信息。
根据Omnity的官方网站(https://www.omnity.io/)的介绍,Omnity是一个可以利用文档中所有文本内容的匹配引擎,是一种完全颠覆式的革命。当Omnity对整个文档进行搜索时,会忽略像像he、she、it,but等之类没有实际意义的词,然后更专注于文件的独特性,从而找出关连性更强的信息。Omnity还会将文档与服务器的数百万个其他文档进行比较,从而提供更有效和更有创意的搜索。
相比于传统的依靠关键词和引用链接的搜索方式,Omnity具有以下三个明显的特征:
- Omnity允许用户使用整个文件作为搜索源进行查询。
- 文件之间是以文本的内容进行相互关联,而不是基于链接和引用关系。这样一来,即便文件之间并无链接或引用关系,凭借文本内容间的相关性也可完成精确搜索。
- 这种形式的文件相关性搜索所要检索的文件数量非常庞大,但Omnity使用了独特的搜索方式,检索过程非常迅速。即便是在现在这个不断增长的大数据环境下,Omnity也能帮助用户实现快速检索。
Magi
90后技术宅(季逸超)与他的非主流另类搜索引擎 Magi
- Magi是由Peak Labs研发、基于机器学习的自然语言搜索引擎以及知识图谱服务。该搜索引擎不仅可以提供全网规模的普通搜索结果,还可将任何领域的自然语言文本中的知识提取成结构化的数据,通过终身学习持续聚合和纠错,进而为用户和其他人工智能提供可解析、可检索、可溯源的知识体系。
- 相比于其他搜索引擎,Magi采用了原创succinct索引结构的分布式搜索引擎,使用专门设计的Attention网络的神经提取系统、并且不依赖Headless浏览器的流式抓取系统,可支持混合处理170余种语言的自然语言处理管线等技术。而随着数据的积累以及来源多样性的扩充,Magi还能够持续学习与调整,自动消除学习到的噪音和错误结果。
- Magi 搜索引擎的最大卖点,就是使用了 AI 技术驱动的知识引擎,提供基于知识图谱的结构化搜索体验。根据介绍,Magi 不仅仅能够简单抓取网络上的信息,而且能够识别信息中的语句,将其中的知识提取成为结构化数据,为用户提供一个“可解析、可检索、可溯源的知识体系”

- Magi 搜索官网显示,magi.com 定于 2022 年 2 月 19 日暂停服务
原文網址:https://kknews.cc/tech/rno2g54.html
搜索引擎国家队
【2023-1-18】国家力量在互联网不太管用 -中移动飞信白白浪费了用户粘性,包装安卓推出自主系统ophone,守着短信彩铃现金流,没法革自己的命…
- 好一点的估计就12306,诞生于中科院自动化所,找了几个研究生写出初版,bug拼出,但用户依然又恨又爱,直到接入阿里云,终于稳定下来…强国学习是阿里uc团队开发的…
原因:国家背景的产品重在向上负责,而不是用户,也不太在乎营收
人民搜索
- 2010年,人民网推出”人民搜索”,使用”goso”域名。
- 2010年9月,邓亚萍任人民搜索网络股份有限公司总经理。
- 2011年6月20日,运营1年后的”人民搜索”使用新域名”jike”。邓亚萍表示,新域名可以理解为即刻、极客、饥渴等含义。
- 2012年6月19日,”即刻搜索”全新改版,使用全新商标,突出字母”i”与”即刻”两个字。
- 2011年,邓亚萍挂帅,联合Google中国副院长刘俊,成立搜索国家队“人民搜索”,在清华开宣讲会,招聘广告简单粗暴:16w+户口,参加笔试的人挤满清华教学楼…接着更名即刻搜索,刘俊带着自己的公司云壤,与不懂技术但懂政治的王江斗了几个来回,最终败北…
- 2012年,新华网如法炮制,建立了盘古搜索…
- 2014年,二者合并为中国搜索…
- 上线三年,市占几乎为零,传出《邓亚萍做搜索引擎两年花20亿被指不懂行》
开源搜索引擎
主流搜索引擎调用
- 谷歌可以用:Google Custom Search API。如何使用谷歌搜索API来获取结果
- 接口地址: https://www.googleapis.com/customsearch/v1?key={YOUR_KEY}&q={SEARCH_WORDS}&cx={YOUR_CX}&start={10}&num={10}
- KEY 从 谷歌云 API 控制台 来的,需要有外币卡先注册谷歌云账号。但似乎付费的话就不用这个 KEY 了,仅用 CX 即可,这个待查。
- CX 是 id 标识,从 谷歌可编程搜索 中来
- 一天只有 100 次的免费搜索限额,但最高只能查询前 100 条。如需增加则 5 刀 1000 次,但一天上限 10000。 次,对于我来说已经足够用了
- 百度没有公开api,自己分析:LittleCoder
#coding=utf8
import requests, re
url = 'https://www.baidu.com/s'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36'}
r = re.compile('<h3[\s\S]*?<a[^>]*?href[^>]*?"(.*?)"[^>]*?>(.*?)</a>')
def baidu_search(keyword):
params = {'wd': keyword, 'pn': 0, 'ie': 'utf-8'}
try:
while 1:
for i in r.findall(requests.get(url, params, headers = headers).content):
yield (re.compile('<.*?>').sub('', i[1]).decode('utf8'), i[0])
params['pn'] += 10
except GeneratorExit:
pass
except:
while 1: yield ('', '')
for i, result in enumerate(baidu_search(u'知乎')):
if 30 < i: break
print('%s: %s'%result)
MeiliSearch
一款开源免费、功能强大、快速、易于使用和部署的搜索引擎 MeiliSearch。从搜索到展示结果速度达到小于 50 毫秒,可高度自由定制搜索与索引,能理解错字和拼写错误,支持中文字符、同义词等功能。
ES:ElasticSearch
ES 的全文搜索是将文本进行分词,然后基于词通过 BM25 算法计算相关性得分,从而找到与搜索语句相似的文本,其本质上是一种 term-based(基于词)的搜索。
全文搜索的实际使用已经非常广泛,核心技术也非常成熟。
但是,除了文本内容之外,现实生活中还有非常多其它的数据形式,例如:图片、音频、视频等等,我们能不能也对这些数据进行搜索呢?
- 答案是 Yes !
随着机器学习和人工智能等技术的发展,万物皆可 Embedding。
- 可以对文本、图片、音频、视频等等一切数据通过 Embedding 相关技术将其转换成特征向量,而一旦向量有了,向量搜索的需求随之也越发强烈,向量搜索的应用场景也变得一望无际、充满想象力。
ES 向量搜索目前有两种方式:
- script_score
- _knn_search
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
Kibana是官方推出的把 Elasticsearch 数据可视化的工具, 官方下载地址
什么是Elasticsearch?
- Elasticsearch is a real-time, distributed storage, search, and analytics engine
- Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
介绍那儿有几个关键字:
- 实时
- 分布式
- 搜索
- 分析
为什么要使用Elasticsearch?传统数据库也能做到(实时、存储、搜索、分析)。相对于数据库,Elasticsearch的强大之处就是可以模糊查询。
- SQL里的模糊查询效率低(数据量很大(1亿条)时,查询是秒级别),返回大量结果;无法兼容拼写错误
- select * from user where name like ‘% 公众号Java3y %’
Elasticsearch是专门做搜索的,就是为了解决上面所讲的问题而生的:
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
Elasticsearch为什么可以实现快速的“模糊匹配”/“相关性查询”?写入数据到Elasticsearch的时候会进行分词,建倒排索引

Elasticsearch内置了一些分词器
- Standard Analyzer 。按词切分,将词小写
- Simple Analyzer。按非字母过滤(符号被过滤掉),将词小写
- WhitespaceAnalyzer。按照空格切分,不转小写
- ….等等等
Elasticsearch分词器主要由三部分组成:
- *Character Filters(文本过滤器,去除HTML)
- Tokenizer(按照规则切分,比如空格)
- TokenFilter(将切分后的词进行处理,比如转成小写)
Elasticsearch是老外写的,内置的分词器都是英文类的,而我们用户搜索的时候往往搜的是中文,现在中文分词器用得最多的就是IK。
Elasticsearch的数据结构是怎么样的?

- 输入一段文字,Elasticsearch会根据分词器对我们的那段文字进行分词(也就是图上所看到的Ada/Allen/Sara..),这些分词汇总起来我们叫做Term Dictionary,而我们需要通过分词找到对应的记录,这些文档ID保存在PostingList
- 在Term Dictionary中的词由于是非常非常多的,所以我们会为其进行排序,等要查找的时候就可以通过二分来查,不需要遍历整个Term Dictionary
- 由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是Elasticsearch还抽了一层叫做Term Index,这层只存储 部分 词的前缀,Term Index会存在内存中(检索会特别快)
- Term Index在内存中是以FST(Finite State Transducers)的形式保存的,其特点是非常节省内存。FST有两个优点:
- 1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
- 2)查询速度快。O(len(str))的查询时间复杂度。
前面讲到了Term Index是存储在内存中的,且Elasticsearch用FST(Finite State Transducers)的形式保存(节省内存空间)。Term Dictionary在Elasticsearch也是为他进行排序(查找的时候方便),其实PostingList也有对应的优化。PostingList会使用Frame Of Reference(FOR)编码技术对里边的数据进行压缩,节约磁盘空间。

PostingList里边存的是文档ID,我们查的时候往往需要对这些文档ID做交集和并集的操作(比如在多条件查询时),PostingList使用Roaring Bitmaps来对文档ID进行交并集操作。
使用Roaring Bitmaps的好处就是可以节省空间和快速得出交并集的结果。

所以到这里我们总结一下Elasticsearch的数据结构有什么特点:

基本概念
Elasticsearch的一些常见术语。
Index:Elasticsearch的Index相当于数据库的TableType:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type–有点类似于消息队列一个topic下多个group的概念)Document:Document相当于数据库的一行记录Field:相当于数据库的Column的概念Mapping:相当于数据库的Schema的概念DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
索引 Index、类型 Type 和文档 Document 对比MySQL 数据库:
- index → db
- type → table
- document → row

如果要访问一个文档元数据应该包括囊括 index/type/id 这三种类型,很好理解。
- Node & Cluster
- 单个 Elasticsearch 实例称为一个节点(Node);一组节点构成一个集群(Cluster)。
- Index
- Elasticsearch 数据管理的顶层单位就叫做 Index(索引);相当于 MySQL、MongoDB 等里面的数据库的概念;
- 注意:每个 Index (即数据库)的名字必须是小写。
- Document
- Index 里面单条的记录称为 Document(文档);Document 使用 JSON 格式表示;
- 同一个 Index 的Document,不要求有相同的结构(scheme),但最好保持相同,有利于提高搜索效率。
- Type
- Document 可以分组,这种分组就叫做 Type;它是虚拟的逻辑分组,用来过滤 Document,类似 MySQL 中的数据表,MongoDB 中的 Collection;
- 不同的 Type 应有相似的结构。(根据规划 Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会移除 Type。)
- Fields
- 即字段,每个 Document 都类似一个 JSON 结构,它包含了许多字段,每个字段都有其对应的值;可以类比 MySQL 数据表中的字段。
Elasticsearch的架构是怎么样的呢?
- 一个Elasticsearch集群会有多个Elasticsearch节点,所谓节点实际上就是运行着Elasticsearch进程的机器。
- 在众多的节点中,其中会有一个Master Node,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点。
- Elasticsearch最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片
- 为什么要分片?
- 如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
- 多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
- 分片会有主分片和副本分片之分(为了实现高可用),数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。
- 为什么要分片?

节点 Node、集群 Cluster 和分片 Shards ElasticSearch 是分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个实例。
- 单个实例称为一个节点(node),一组节点构成一个集群(cluster)。
- 分片是底层的工作单元,文档保存在分片内,分片又被分配到集群内的各个节点里,每个分片仅保存全部数据的一部分。
安装
- 下载:官网下载地址
- wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.1-linux-x86_64.tar.gz
- 解压到/usr/local/目录:
- tar -avxf elasticsearch-7.1.1-linux-x86_64.tar.gz -C /usr/local/
- 进入elasticsearch目录:
- 新建data目录:mkdir data
- 修改配置
- vim config/elasticsearch.yml,开启以下配置项:
- network.host: 10.200.24.101
- http.port: 9200
- discovery.seed_hosts: [ “10.200.24.101” ]
- vim config/elasticsearch.yml,开启以下配置项:
- 启动es
- 进入/bin目录执行命令:./elasticsearch
- 后台启动:./elasticsearch -d
- 查看es进程:ps -ef | grep elasticsearch 注:
- ①若提示内存不够,elasticsearch使用java的jvm默认是使用1G的内存,需要修改配置vim ./config/jvm.options, -Xms200m
- 【2021-8-12】错误提示:max virtual memory areas vm.max_map_count [ 65530 ] is too low, increase to at least [ 262144 ]
- 解法:sysctl -w vm.max_map_count=262144
- 【2021-8-12】错误提示:max virtual memory areas vm.max_map_count [ 65530 ] is too low, increase to at least [ 262144 ]
- ②can not run elasticsearch as root:不能使用root用户操作,添加一个其他的用户:
- 添加用户:adduser es
- 输入密码:passwd es
- 更改目录所属用户:chown es /usr/local/elasticsearch-7.1.1/ -R
- 编辑配置:/etc/security/limits.conf
- 后续详细配置见:Linux安装Elasticsearch7.x
参考:
cluster.name: my-application #集群名称
node.name: node-1 #节点名称
#数据和日志的存储目录
path.data: /usr/local/elasticsearch-7.1.1/data
path.logs: /usr/local/elasticsearch-7.1.1/logs
#设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
http.port: 9200 #端口
#设置在集群中的所有节点名称,这个节点名称就是之前所修改的,当然你也可以采用默认的也行,目前是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]
web页面示例:所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
'
Python操作ES
中文分词插件:
elasticsearch默认是英文分词器,所以我们需要安装一个中文分词插件 elasticsearch-analysis-ik (注意和elasticsearch的版本对应),安装之后重新启动 Elasticsearch 自动加载安装好的插件
- 命令:elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
- 创建 Index
- es.indices.create(index=’ ‘)
- 即字段,每个 Document 都类似一个 JSON 结构,它包含了许多字段,每个字段都有其对应的值;可以类比 MySQL 数据表中的字段。
- 删除 Index
- es.indices.delete(index=’news’)
result = es.indices.delete(index='news', ignore=[400, 404])
print(result)
- 插入数据
- es.create() & es.index()
es.indices.create(index='news', ignore=400)
data = {'title': '美国留给伊拉克的是个烂摊子吗', 'url': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm'}
# 方法一:es.create() 手动指定 id 唯一标识
result = es.create(index='news', doc_type='politics', id=1, body=data)
print(result)
# 方法二:es.index() 自动生成id
es.index(index='news', doc_type='politics', body=data)
- 更新数据
data = {
'title': '美国留给伊拉克的是个烂摊子吗',
'url': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm',
'date': '2011-12-16'
}
result = es.update(index='news', doc_type='politics', body=data, id=1)
print(result)
# 第二种方法:index -- 数据不存在,增加; 如果已经存在,更新
es.index(index='news', doc_type='politics', body=data, id=1)
- 删除数据
# delete -- 指定对应的id
result = es.delete(index='news', doc_type='politics', id=1)
print(result)
- 查询数据
- 优势:其异常强大的检索功能
新建一个索引并指定需要分词的字段, 更新 mapping 信息
from elasticsearch import Elasticsearch
es = Elasticsearch()
mapping = {
'properties': {
'title': {
'type': 'text',
'analyzer': 'ik_max_word',
'search_analyzer': 'ik_max_word'
}
}
}
es.indices.delete(index='news', ignore=[400, 404])
es.indices.create(index='news', ignore=400)
# 设置mapping 信息:指定字段的类型 type 为 text,分词器 analyzer 和 搜索分词器 search_analyzer 为 ik_max_word,即中文分词插件,默认的英文分词器。
result = es.indices.put_mapping(index='news', doc_type='politics', body=mapping)
print(result)
插入几条新的数据
datas = [
{
'title': '美国留给伊拉克的是个烂摊子吗',
'url': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm',
'date': '2011-12-16'
},
{
'title': '公安部:各地校车将享最高路权',
'url': 'http://www.chinanews.com/gn/2011/12-16/3536077.shtml',
'date': '2011-12-16'
},
{
'title': '中韩渔警冲突调查:韩警平均每天扣1艘中国渔船',
'url': 'https://news.qq.com/a/20111216/001044.htm',
'date': '2011-12-17'
},
{
'title': '中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首',
'url': 'http://news.ifeng.com/world/detail_2011_12/16/11372558_0.shtml',
'date': '2011-12-18'
}
]
for data in datas:
es.index(index='news', doc_type='politics', body=data)
# 查询 -- 根据关键词查询一下相关内容
result = es.search(index='news', doc_type='politics')
print(result) # 返回所有结果
# 检索 -- 全文检索
# 使用 DSL 语句来进行查询: match 指定全文检索,检索字段 title,检索内容 “中国领事馆”
dsl = {
'query': {
'match': {
'title': '中国 领事馆'
}
}
}
es = Elasticsearch()
result = es.search(index='news', doc_type='politics', body=dsl)
print(json.dumps(result, indent=2, ensure_ascii=False))
返回的检索结果有两条,第一条的分数为 2.54,第二条的分数为 0.28。这是因为第一条匹配的数据中含有“中国”和“领事馆”两个词,第二条匹配的数据中不包含“领事馆”,但是包含了“中国”这个词,所以也被检索出来了,但是分数比较低。检索结果会按照检索关键词的相关性进行排序,这就是一个基本的搜索引擎雏形
汇总:
# 使用python操作ElasticSearch
from elasticsearch import Elasticsearch
# 连接ES,http://10.200.24.101:9200/
es = Elasticsearch([{'host':'10.200.24.101','port':9200}], timeout=3600)
# 创建数据
# 不指定id 自动生成
es.index(index="megacorp",body={"first_name":"xiao","last_name":"xiao", 'age': 25, 'about': 'I love to go rock climbing', 'interests': ['game', 'play']})
{'_index': 'megacorp',
'_type': '_doc',
'_id': '3oXEzm4BAZBCZGyZ2R40',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 1,
'_primary_term': 2}
# 指定IDwu
es.index(index="megacorp",id=4,body={"first_name":"xiao","last_name":"wu", 'age': 66, 'about': 'I love to go rock climbing', 'interests': ['sleep', 'eat']})
{'_index': 'megacorp',
'_type': '_doc',
'_id': '4',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 5,
'_primary_term': 2}
# 查询: query内的条件选其中一个
query = {
"query": {
"match_all": {} # 默认方式,查询所有文档,是没有查询条件下的默认语句
"match": {"about": "rock"} # 标准查询,只能就指定某个确切字段某个确切的值进行搜索
"multi_match": { # multi_match 查询--match查询的基础上同时搜索多个字段,在多个字段中同时查一个
"query": 'music',"fields": ["about","interests"]}
"bool": { # bool 查询--与 bool 过滤相似,用于合并多个查询子句。不同的是,bool 过滤可以直接给出是否匹配成功, 而bool 查询要计算每一个查询子句的 _score (相关性分值)。
"must": {"match": { "last_name": 'Smith' }},
"must_not":{"exists": {"field": "name"}}
}
"wildcard": {"about": "ro*"} # wildcards 查询--使用标准的shell通配符查询
"regexp": {"about": ".a.*"} # 正则查询
"prefix": {"about": "I love"} # prefix 查询 -- 以什么字符开头的
"match_phrase": {"about": "I love"} # 短语匹配(Phrase Matching) -- 寻找邻近的几个单词
"match_phrase": {"about": "I love"} # 统计查询, 配合语句:result = es.count(index="megacorp", body=query)
"term": {'age': 32} # term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经切词的文本数据类型)
"terms": {'age': [32, 25]} # terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。
"range": {'age': {"gt":34}} # range, 按照指定范围查找一批数据, gt/大于, gte/大于等于,lt/小于,lte/小于等于
"exists": {"field": "first_name"} # exists 和 missing 过滤--查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件
"bool": {"must": {"term": { "_score": 1 },"term": { "age": 32 }}, # bool 过滤--合并多个过滤条件查询结果的布尔逻辑
"must_not":{"exists": {"field": "name"}}}
# must/多个查询条件的完全匹配,相当于 and。
# must_not/多个查询条件的相反匹配,相当于 not。
# should/至少有一个查询条件匹配, 相当于 or。
}
}
result = es.search(index="megacorp", body=query)
print(result)
# DSL语句查询: term 过滤--term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经切词的文本数据类型)
# 根据ID删除
es.delete(index='megacorp', id='3oXEzm4BAZBCZGyZ2R40')
{'_index': 'megacorp',
'_type': '_doc',
'_id': '3oXEzm4BAZBCZGyZ2R40',
'_version': 2,
'result': 'deleted',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 3,
'_primary_term': 2}
# delete_by_query:删除满足条件的所有数据,查询条件必须符合DLS格式
query = {
"query": {
"match": {
"first_name": "xiao"
}
}
}
result = es.delete_by_query(index="megacorp", body=query)
print(result)
#{'took': 57, 'timed_out': False, 'total': 1, 'deleted': 1, 'batches': 1, 'version_conflicts': 0, 'noops': 0, 'retries': {'bulk': 0, 'search': 0}, 'throttled_millis': 0, 'requests_per_second': -1.0, 'throttled_until_millis': 0, 'failures': []}
# 根据ID更新
doc_body = {
'script': "ctx._source.remove('age')"
}
# 增加字段
doc_body = {
'script': "ctx._source.address = '合肥'"
}
# 修改部分字段
doc_body = {
"doc": {"last_name": "xiao"}
}
es.update(index="megacorp", id=4, body=doc_body)
{'_index': 'megacorp',
'_type': '_doc',
'_id': '4',
'_version': 2,
'result': 'updated',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 6,
'_primary_term': 2}
# update_by_query:更新满足条件的所有数据,写法同上删除和查询
query = {
"query": {
"match": {
"last_name": "xiao"
}
},
"script":{
"source": "ctx._source.last_name = params.name;ctx._source.age = params.age",
"lang": "painless",
"params" : {
"name" : "wang",
"age": 100,
},
}
}
result = es.update_by_query(index="megacorp", body=query)
print(result)
#{'took': 72, 'timed_out': False, 'total': 1, 'updated': 1, 'deleted': 0, 'batches': 1, 'version_conflicts': 0, 'noops': 0, 'retries': {'bulk': 0, 'search': 0}, 'throttled_millis': 0, 'requests_per_second': -1.0, 'throttled_until_millis': 0, 'failures': []}
【2021-8-20】实践
from elasticsearch import Elasticsearch
# 连接ES,http://10.200.24.101:9200/
es = Elasticsearch([{'host':'10.200.24.101','port':9200}]) #, timeout=3600)
text = '100平的板楼有没有'
data = {
"query": {
#"match_all": {} # 默认方式,查询所有文档,是没有查询条件下的默认语句
"match": {"words": text} # 标准查询,只能就指定某个确切字段某个确切的值进行搜索
}
}
result = es.search(index="query_info", body=data)
print('[{}]一共查询到{}条, top 10如下:'.format(text, result['took']))
for i in result['hits']['hits']:
res = [i['_index'],i['_type'],str(i['_score']),i['_source']['words'],i['_source']['intent'],i['_source']['ctime']]
print('\t'.join(res))
print('-'*30)
print(json.dumps(result, ensure_ascii=False))
#es.close()
全文检索引擎 Sphinx
不知是否还记得曾经出现在这篇文章从几幅架构图中偷得半点海量数据处理经验中的两幅图,如下所示:
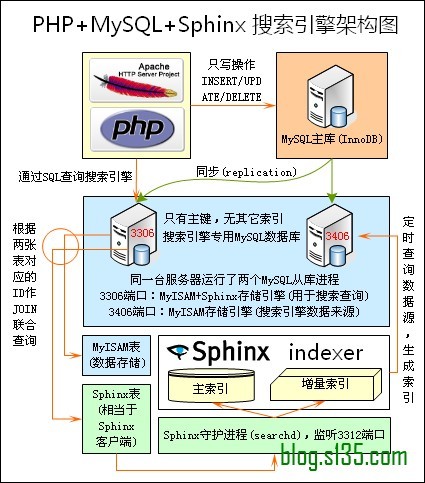
上图出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
基于以上几点,一网友 回忆未来-张宴设计出了这套搜索引擎架构。在生产环境运行了一周,效果非常不错。有时间我会专为配合Sphinx搜索引擎,开发一个逻辑简单、速度快、占用内存低、非表锁的MySQL存储引擎插件,用来代替MyISAM引擎,以解决MyISAM存储引擎在频繁更新操作时的锁表延迟问题。另外,分布式搜索技术上已无任何题。
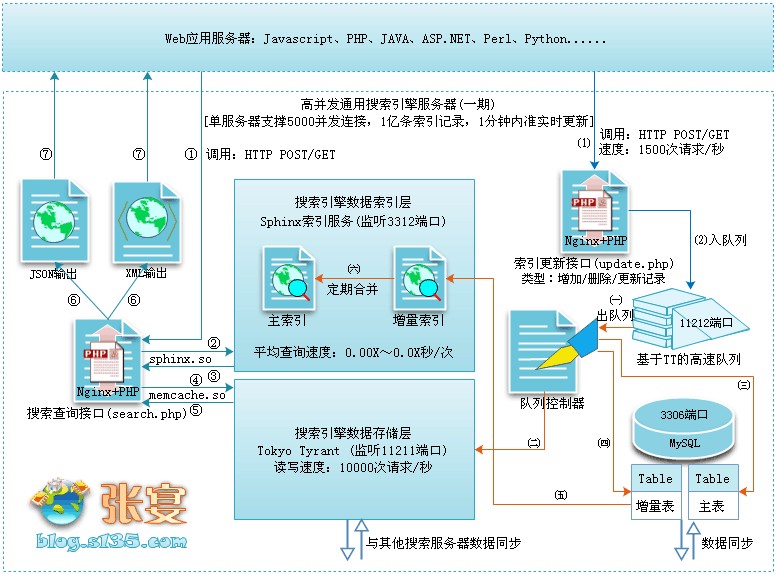
Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP,Python,Perl,Ruby等,同时为MySQL也设计了一个存储引擎插件。
C++检索引擎 Xapian
Xapian 是一个用C++编写的全文检索程序,他的作用类似于Java的lucene。尽管在Java世界lucene已经是标准的全文检索程序,但是C/C++世界并没有相应的工具,而 Xapian 则填补了这个缺憾。
Xapian 的api和检索原理和lucene在很多方面都很相似,但是也有一些地方存在不同,具体请看 Xapian 自己的文档:http://www. xapian .org/docs/
Xapian 除了提供原生的C++编程接口之外,还提供了Perl,PHP,Python和Ruby编程接口和相应的类库,所以你可以直接从自己喜欢的脚本编程语言当中使用 Xapian 进行全文检索了。
C++搜索引擎 CLucene
CLucene是Lucene的一个C++端口,Lucene即是上面所讲到的一个基于java的高性能的全文搜索引擎。CLucene因为使用C++编写,所以理论上要比lucene快。
Java搜索引擎 Lucene
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单确强大的应用程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费java资讯检索程式库。人们经常提到资讯检索程式库,就像是搜寻引擎,但是不应该将资讯检索程式库与网搜索引擎相混淆。
Lucene最初是由Doug Cutting所撰写的,是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后来在Excite担任高级系统架构设计师,目前从事 于一些INTERNET底层架构的研究。他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。
搜索引擎 Nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然 不利于广大Internet用户.
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码 搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的 费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有 动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到:
- 每个月取几十亿网页
- 为这些网页维护一个索引
- 对索引文件进行每秒上千次的搜索
- 提供高质量的搜索结果
- 以最小的成本运作
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
