- 回归分析
- 时间序列回归
- 结束
回归分析经验总结
回归分析
- 【2022-8-31】19种回归分析你知道几种呢?
- 【2020-12-09】7种回归分析方法,数据分析师必须掌握,代码源自:五种回归方法的比较
什么是回归分析
- 回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这一技术被用在预测、时间序列模型和寻找变量之间因果关系。
- 回归分析是研究X对于Y的影响关系
通俗理解回归分析
如何简明地解释「线性回归」「贝叶斯定理」「假设检验」这些术语?
- 领导给你一个任务,调查某地算不算美女多的地方。
- 领导有自己的美女判定标准,假设评价一个女子的好看程度有三个属性:脸蛋,身材,气质。
- 首先给你一些例子,比如她觉得奶茶是美女,高圆圆长的一般,范冰冰长的不好看。
- 从这些例子里面,大概能知道领导的审美标准,脸蛋、身材、气质这三个属性大概各占什么样的比例。这就是
回归。 - 如果最终的美丑得分是把这三个标准的结果线性相加,就是
线性回归。 - 现在能够判断一个女子是否是美女。来到这个地方,一连碰到5个女子,按之前的标准判断,全是美女,那么你会不会认为这个地方的女子全都是美女呢?一般来说不会。
- 因为经验告诉你,任何地方都有美女和丑女,不太可能只能出现只有美女没有丑女的地方,这个就是
先验。
- 因为经验告诉你,任何地方都有美女和丑女,不太可能只能出现只有美女没有丑女的地方,这个就是
- 如果按这种方式思考,这个地方可能美女的比例比较高,但不会认为这里的女子全是美女,这就是
贝叶斯的思想。 - 最后,领导目的是调查这个地方的美女多不多,那么多不多最终是要有一个标准的,而没有办法遍历当地的每一个女性。所以肯定有一套方案,比如说随机访问100个女性,如果超过80个女性是美女,你就认为该地是一个美女多的地方,反之则不是。那么之前提到的方案可以看成是一个
假设检验。
SVM和logistic回归
首先说: LR和SVM是线性分类问题是不精确的
- LR可以使用特征离散化实现拟非线性结果,LR+ regularization可以让分类结果有比较好的结果;
- SVM有线性和非线性核函数,一般性都会使用非线性核效果比较好。SVM是个被理论证明得很好的理论,实际应用挺弱的,还不如用一些简单的模型来说更好。
在工业界实际使用中,SVM用的不多,速度慢并且效果也很难保证,用好的特征+LR+regularization可以取得不错的效果,上线后响应速度快。
两种方法都是常见的分类算法,从目标函数来看,区别在于
- 逻辑回归采用的是logistical loss
- svm采用的是hinge loss。
这两个损失函数的目的都是: 增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- SVM的处理方法是只考虑support vectors支持向量,也就是和分类最相关的少数点,去学习分类器。
- 而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
- 两者的根本目的都是一样的。
此外,根据需要,两个方法都可以增加不同的正则化项,如l1,l2等等。所以在很多实验中,两种算法的结果是很接近的。
- 但是逻辑回归相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便。
- 而SVM的理解和优化相对来说复杂一些。但是SVM的理论基础更加牢固,有一套
结构化风险最小化的理论基础,虽然一般使用的人不太会去关注。还有很重要的一点,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
作者:orangeprince
国立台湾大学林智仁的讲义
回归分析种类
一共有19种回归分析
- 这19种回归都可以在SPSSAU上面找到,关于各类回归方法的使用以及具体原理,可查看SPSSAU官网,以及可使用SPSSAU上面的案例数据,逐一进行操作分析。
常见的回归分析中,线性回归和logistic回归最为常见。也是当前研究最多,并且使用最为普遍,以及最为人接受容易理解的研究方法。
各种回归方式有主要有三个度量方式
- 自变量的个数
- 因变量的类型
- 回归线的形状
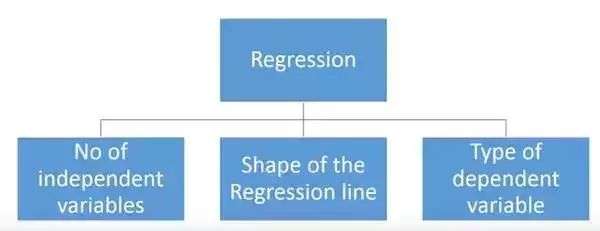
按回归目标Y的类型分类
将回归分析中的Y(因变量)进行数据类型区分
- 如果是定量且1个(比如身高),通常我们会使用
线性回归 - 如果Y为定类且1个(比如是否愿意购买苹果手机),此时叫
logistic回归 - 如果Y为定量且多个,此时应该使用
PLS回归(即偏最小二乘回归)
细分
- (1)线性回归再细分:
- 如果回归模型中X仅为1个,此时就称为简单线性回归或者
一元线性回归; - 如果X有多个,此时称为
多元线性回归。
- 如果回归模型中X仅为1个,此时就称为简单线性回归或者
- (2)Logistic回归再细分:
- 如果Y为两类,比如0和1(比如1为愿意和0为不愿意,1为购买和0为不购买),此时就叫
二元logistic回归; - 如果Y为两类时,有时候也会使用
二元Probit回归模型。 - 如果Y为多类比如1,2,3(比如DELL,Thinkpad,Mac),此时就会
多分类logistic回归; - 如果Y为多类且有序,比如1,2,3(比如1为不愿意,2为中立,3为愿意),此时可以使用
有序logistic回归。
- 如果Y为两类,比如0和1(比如1为愿意和0为不愿意,1为购买和0为不购买),此时就叫
- (3)除此之外,如果Y为定量且为多个,很多时候会将Y合并概括成1个(比如使用平均值),然后使用线性回归,反之可考虑使用PLS回归(但此种情况使用其实较少,PLS回归模型非常复杂)。
如何正确选择回归模型?
可选择的越多,选择正确的一个就越难。
- 在多类回归模型中,基于自变量和因变量的类型,数据的维数以及数据的其它基本特征的情况下,选择最合适的技术非常重要。
- 关键因素
- 数据探索是构建预测模型的必然组成部分。在选择合适的模型时,比如识别变量的关系和影响时,它应该首选的一步。
- 比较适合于不同模型的优点,我们可以分析不同的指标参数,如统计意义的参数,R-square,Adjusted R-square,AIC,BIC以及误差项,另一个是Mallows’ Cp准则。这个主要是通过将模型与所有可能的子模型进行对比(或谨慎选择他们),检查在你的模型中可能出现的偏差。
- 交叉验证是评估预测模型最好额方法。在这里,将你的数据集分成两份(一份做训练和一份做验证)。使用观测值和预测值之间的一个简单均方差来衡量你的预测精度。
- 如果你的数据集是多个混合变量,那么你就不应该选择自动模型选择方法,因为你应该不想在同一时间把所有变量放在同一个模型中。
- 它也将取决于你的目的。可能会出现这样的情况,一个不太强大的模型与具有高度统计学意义的模型相比,更易于实现。
- 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多重共线性情况下运行良好。
线性回归(Linear Regression)
线性回归使用最为成熟,研究最多,而且绝大多数生活现象均可使用线性回归进行研究,因而结合回归分析还会多出一些回归方法;同时回归分析模型会有很多假定,或者满足条件,如果不满足这些假定或者条件就会导致模型使用出错,此时就有对应的其它回归模型出来解决这些问题,因而跟着线性回归后面又出来很多的回归。
线性回归种类
-
- 线性回归是研究X对于Y的影响,如果说有多个X,希望让模型自动找出有意义的X,此时就可以使用
逐步回归。 - 另外在很一些管理类研究中会涉及到中介作用或者调节作用,此时就可能使用到
分层回归或者分组回归等。 - 在进行线性回归分析时,如果说模型出现共线性问题VIF值很大,此时就可以使用
岭回归进行解决,岭回归的使用较为广泛,其实还有Lasso回归也可以解决共线性问题,但是使用非常少而已。 - 如果数据中有异常值,常见解法是先把异常值去除掉,但有的时候确实无法去除掉异常值,此时可考虑使用
稳健回归分析模型。 - 线性回归的前提是X和Y之间有着线性关系,但有的时候X和Y并不是线性关系,此时就有
曲线回归和非线性回归供使用曲线回归将曲线模型表达式转换成线性关系表达式进行研究非线性回归较为复杂当然使用也非常少,其和线性回归完全不是一回事情。Poisson回归(泊松回归)是指Y符合泊松分布特征时使用的回归研究模型。
- 除此之外,还有比如
加权WLS回归等,使用较少 -
Cox回归是医学研究中使用较多的一种方法,是研究生存影响关系,比如研究抑郁症生存时间,癌症的死亡时间影响关系情况等。 - 因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
- 线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
- 用一个方程式来表示它,即 Y=a+b*X + e,其中a表示截距,b表示直线的斜率,e是误差项。img
- 多元线性回归有(>1)个自变量,而一元线性回归通常只有1个自变量。
- 最小二乘法是拟合回归线最常用的方法。对于观测数据,它通过最小化每个数据点到线的垂直偏差平方和来计算最佳拟合线。因为在相加时,偏差先平方,所以正值和负值没有抵消。
- R-square指标来评估模型性能。要点:
- ● 自变量与因变量之间必须有线性关系。
- ● 多元回归存在多重共线性,自相关性和异方差性。
- ● 线性回归对异常值非常敏感。它会严重影响回归线,最终影响预测值。
-
多重共线性会增加系数估计值的方差,使得在模型轻微变化下,估计非常敏感。结果就是系数估计值不稳定,在多个自变量的情况下,可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
- 代码

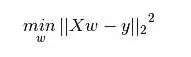

import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import metrics
data=datasets.load_boston()# load data
#定义评估函数
def evaluation(y_true,y_pred,index_name=['OLS']):
df=pd.DataFrame(index=[index_name],columns=['平均绝对误差','均方误差','r2'])
df['平均绝对误差']=metrics.mean_absolute_error(y_true, y_pred).round(4)
df['均方误差']=metrics.mean_squared_error(y_true,y_pred)
df['r2']=metrics.r2_score(y_true,y_pred)
return df
df=pd.DataFrame(data.data,columns=data.feature_names)
target=pd.DataFrame(data.target,columns=['MEDV'])
# 可视化分析
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid", color_codes=True)
g=sns.pairplot(data[list(data.columns)[:5]], hue='ZN',palette="husl",diag_kind="hist",size=2.5)
for ax in g.axes.flat:
plt.setp(ax.get_xticklabels(), rotation=45)
plt.tight_layout()
# 相关系数图
cm = np.corrcoef(data[list(data.columns)[:5]].values.T) #corrcoef方法按行计算皮尔逊相关系数,cm是对称矩阵
#使用np.corrcoef(a)可计算行与行之间的相关系数,np.corrcoef(a,rowvar=0)用于计算各列之间的相关系数,输出为相关系数矩阵。
sns.set(font_scale=1.5) #font_scale设置字体大小
cols=list(data.columns)[:5]
hm = sns.heatmap(cm,cbar=True,annot=True,square=True,fmt='.2f',annot_kws={'size': 15},yticklabels=cols,xticklabels=cols)
# plt.tight_layout()
# plt.savefig('./figures/corr_mat.png', dpi=300)
- 可视化分析
- 相关系数图

多元线性回归
线性回归通过使用最佳的拟合直线(又被称为回归线),建立因变量(Y)和一个或多个自变量(X)之间的关系。
- 表达式为:$Y=a+b*X+e$,其中 a 为直线截距,b 为直线斜率,e 为误差项。
- 如果给出了自变量 X,就能通过这个线性回归表达式计算出预测值,即因变量 Y
如何获得最佳拟合直线(确定 a 和 b 值)?
- 用
最小二乘法(Least Square Method). 最小二乘法是一种拟合回归线的常用算法。通过最小化每个数据点与预测直线的垂直误差的平方和来计算得到最佳拟合直线。因为计算的是误差平方和,所有,误差正负值之间没有相互抵消。 - 指标 R-square 来评估模型的性能
重点:
- 自变量和因变量之间必须满足线性关系。——LR回归不用
- 多元回归存在多重共线性,自相关性和异方差性。
- 线性回归对异常值非常敏感。异常值会严重影响回归线和最终的预测值。
- 多重共线性会增加系数估计的方差,并且使得估计对模型中的微小变化非常敏感。结果是系数估计不稳定。
- 在多个自变量的情况下,可以采用正向选择、向后消除和逐步选择的方法来选择最重要的自变量。
逻辑回归(Logistic Regression)
逻辑回归是一个学习f: X −> Y 方程或 P(Y|X)的方法
- Y是离散取值的
- X = < X1,X2…,Xn > 是任意一个向量其中每个变量离散或者连续取值。


重点:
- 逻辑回归广泛用于分类问题。
- 逻辑回归不要求因变量和自变量之间是线性关系,它可以处理多类型关系,因为它对预测输出进行了非线性 log 变换。
- 为了避免过拟合和欠拟合,应该涵盖所有有用的变量。实际中确保这种情况的一个好的做法是使用逐步筛选的方法来估计逻辑回归。
- 训练样本量越大越好,因为如果样本数量少,最大似然估计的效果就会比最小二乘法差。
- 自变量不应相互关联,即不存在多重共线性。然而,在分析和建模中,可以选择包含分类变量相互作用的影响。
- 如果因变量的值是序数,则称之为序数逻辑回归。
- 如果因变量是多类别的,则称之为多元逻辑回归。
【2022-8-31】数说工作室:logistic回归:从生产到使用【上:使用篇】
LR回归的组成部分
Logistic Regression 有三个主要组成部分:回归、线性回归、Logsitic方程。
- 1)回归
- Logistic regression是线性回归的一种,线性回归是一种回归。回归其实就是对已知公式的未知参数进行估计。比如已知公式是 y = a*x + b,未知参数是a和b。现在有很多真实的(x,y)数据(训练样本),回归就是利用这些数据对a和b的取值去自动估计。估计的方法大家可以简单的理解为,在给定训练样本点和已知的公式后,对于一个或多个未知参数,机器会自动枚举参数的所有可能取值(对于多个参数要枚举它们的不同组合),直到找到那个最符合样本点分布的参数(或参数组合)。(当然,实际运算有一些优化算法,肯定不会去枚举的)
- 注意,回归的前提是公式已知,否则回归无法进行。而现实生活中哪里有已知的公式啊(G=m*g 也是牛顿被苹果砸了脑袋之后碰巧想出来的不是?哈哈),因此回归中的公式基本都是数据分析人员通过看大量数据后猜测的(其实大多数是拍脑袋想出来的,嗯…)。根据这些公式的不同,回归分为线性回归和非线性回归。线性回归中公式都是“一次”的(一元一次方程,二元一次方程…),而非线性则可以有各种形式(N元N次方程,log方程 等等)。具体的例子在线性回归中介绍吧。
- 2)线性回归
- 例子:假设要找一个y和x之间的规律,其中x是鞋子价钱,y是鞋子的销售量。(为什么要找这个规律呢?这样的话可以帮助定价来赚更多的钱嘛,小学的应用题经常做的呵呵)。已知一些往年的销售数据(x0,y0), (x1, y1), … (xn, yn)做样本集, 并假设它们满足线性关系:y = a*x + b (其中a,b的具体取值还不确定),线性回归即根据往年数据找出最佳的a, b取值,使 y = a * x + b 在所有样本集上误差最小。
- 也许你会觉得—晕!这么简单! 这需要哪门子的回归呀!我自己在草纸上画个xy坐标系,点几个点就能画出来!(好吧,我承认我们初中时都被这样的画图题折磨过)。事实上一元变量的确很直观,但如果是多元就难以直观的看出来了。比如说除了鞋子的价格外,鞋子的质量,广告的投入,店铺所在街区的人流量都会影响销量,我们想得到这样的公式:$ sell = ax + by + cz + dzz + e$。这个时候画图就画不出来了,规律也十分难找,那么交给线性回归去做就好。(线性回归具体是怎么做的并不重要,对程序员来说,我们就把它当成一条程序命令就好。若看完本文还想了解更多,求解方法可见本文末尾的注1)。这就是线性回归算法的价值。
- 注意: 这里线性回归能过获得好效果的前提是 $y = a*x + b$ 至少从总体上是有道理的(因为我们认为鞋子越贵,卖的数量越少,越便宜卖的越多。另外鞋子质量、广告投入、客流量等都有类似规律);但并不是所有类型的变量都适合用线性回归,比如说x不是鞋子的价格,而是鞋子的尺码),那么无论回归出什么样的(a,b),错误率都会极高(因为事实上尺码太大或尺码太小都会减少销量)。总之:如果公式假设是错的,任何回归都得不到好结果。
- 3)Logistic方程
- 上面的sell是一个具体的实数值,然而很多情况下要回归产生一个类似概率值的0~1之间的数值(比如某一双鞋子今天能否卖出去?或者某一个广告能否被用户点击?)。这个数值必须是0~1之间,但sell显然不满足这个区间要求。于是引入了Logistic方程,来做归一化。这里再次说明,该数值并不是数学中定义的概率值。那么既然得到的并不是概率值,为什么我们还要费这个劲把数值归一化为0~1之间呢?归一化的好处在于数值具备可比性和收敛的边界,这样当你在其上继续运算时(比如你不仅仅是关心鞋子的销量,而是要对鞋子卖出的可能、当地治安情况、当地运输成本 等多个要素之间加权求和,用综合的加和结果决策是否在此地开鞋店时),归一化能够保证此次得到的结果不会因为边界 太大/太小 导致 覆盖其他feature 或 被其他feature覆盖。(举个极端的例子,如果鞋子销量最低为100,但最好时能卖无限多个,而当地治安状况是用0~1之间的数值表述的,如果两者直接求和治安状况就完全被忽略了)这是用logistic回归而非直接线性回归的主要原因。到了这里,也许你已经开始意识到,没错,Logistic Regression 就是一个被logistic方程归一化后的线性回归,仅此而已。
- 至于所以用logistic而不用其它,是因为这种归一化的方法往往比较合理(人家都说自己叫logistic了嘛 呵呵),能够打压过大和过小的结果(往往是噪音),以保证主流的结果不至于被忽视。具体的公式及图形见本文的一、官方定义部分。其中f(X)就是我们上面例子中的sell的实数值了,而y就是得到的0~1之间的卖出可能性数值了。(本段 “可能性” 并非 “概率” ,感谢zjtchow同学在回复中指出)
为什么用LR?
机器学习中有几十种分类器,那么我们为什么偏偏挑LR来讲呢?原因有三:
- LR模型原理简单,并且有一个现成的叫LIBLINEAR 的工具库,易于上手,并且效果不错。
- LR可以说是互联网上最常用也是最有影响力的分类算法。LR几乎是所有广告系统中和推荐系统中点击率(Click Through Rate(CTR))预估模型的基本算法。
- LR同时也是现在炙手可热的“深度学习”(Deep Lerning)的基本组成单元,扎实的掌握LR也将有助于你的学好深度学习。
Logistic Regression的适用性
- 1) 可用于概率预测,也可用于分类。
- 并不是所有的机器学习方法都可以做可能性概率预测(比如SVM就不行,它只能得到1或者-1)。可能性预测的好处是结果可比性:比如得到不同广告被点击的可能性后,就可以展现点击可能性最大的N个。这样以来,哪怕得到的可能性都很高,或者可能性都很低,我们都能取最优的topN。当用于分类问题时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
- 2) 仅能用于线性问题
- 只有在feature和target是线性关系时,才能用 Logistic Regression(不像SVM那样可以应对非线性问题)。这有两点指导意义
- 一方面当预先知道模型非线性时,果断不使用Logistic Regression;
- 另一方面,在使用Logistic Regression时注意选择和target呈线性关系的feature。
- 只有在feature和target是线性关系时,才能用 Logistic Regression(不像SVM那样可以应对非线性问题)。这有两点指导意义
- 3) 各feature之间不需要满足条件独立假设,但各个feature的贡献是独立计算的。
- 逻辑回归不像朴素贝叶斯一样需要满足条件独立假设(因为它没有求后验概率)。但每个feature的贡献是独立计算的,即LR是不会自动帮你combine 不同的features产生新feature的 (时刻不能抱有这种幻想,那是决策树,LSA, pLSA, LDA或者你自己要干的事情)。举个例子,如果你需要TFIDF这样的feature,就必须明确的给出来,若仅仅分别给出两维 TF 和 IDF 是不够的,那样只会得到类似 $aTF + bIDF$ 的结果,而不会有 $cTF*IDF$ 的效果。
LR特性
逻辑回归是用来计算“事件=Success”和“事件=Failure”的概率。当因变量的类型属于二元(1 / 0,真/假,是/否)变量时,就应该使用逻辑回归。- 为什么要在公式中使用对数log呢
- 因为用是的
二项分布(因变量),需要选择一个对于这个分布最佳的连结函数,Logit函数。 - 通过观测样本的极大似然估计值来选择参数,而不是最小化平方和误差(如在普通回归使用的)

- 因为用是的
- 要点:
- ● 它广泛的用于分类问题。
- ● 逻辑回归不要求自变量和因变量是线性关系。它可以处理各种类型的关系,因为它对预测的相对风险指数OR使用了一个非线性的log转换。
- 为了避免过拟合和欠拟合,我们应该包括所有重要的变量。有一个很好的方法来确保这种情况,就是使用逐步筛选方法来估计逻辑回归。它需要大的样本量,因为在样本数量较少的情况下,极大似然估计的效果比普通的最小二乘法差。
- 自变量不应该相互关联的,即不具有多重共线性。然而,在分析和建模中,我们可以选择包含分类变量相互作用的影响。
- 如果因变量的值是定序变量,则称它为序逻辑回归;
- 如果因变量是多类的话,则称它为多元逻辑回归。
二分类LR
1970年,Cox首先研究了log变换(也叫logit变换),或许此名就是“log it”的意思
多分类LR
多分类变量的logistic回归
- (1)无序多分类logistic回归:
- 因变量Y的分类大于2个,且之间不存在等级关系
- (2)有序多分类:比例优势模型
- 因变量Y的分类多于2个,且之间存在等级关系
- (3)有序多分类:偏比例优势模型
- 有些变量的系数不满足平行性假定,那么就要使用“偏比例优势模型”(partialproportional odds model),这个模型其实也就是在比例优势模型的基础上,把不平行的系数做一个改动
多项式回归(Polynomial Regression)
- 对于一个回归方程,如果自变量的指数大于1,那么它就是
多项式回归方程。 - 能够建模非线性可分离数据,完全控制特征变量的建模(指定要设置),需要一些背景知识,如果指数选择不当,容易过度拟合。
- 如:$ y=a+b*x^2 $
- 多项式回归中,最佳的拟合线不是直线,而是拟合数据点的曲线
- 虽然可以拟合一个高次多项式并得到较低的错误,但会导致过拟合。

重点:
- 虽然可能会有一些诱导去拟合更高阶的多项式以此来降低误差,但是这样容易发生
过拟合。应该画出拟合曲线图形,重点放在确保曲线反映样本真实分布上 -
尤其要注意曲线的两端,看看这些形状和趋势是否有意义。更高的多项式可以产生怪异的推断结果
- 代码
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree = 4)
X_Poly = poly_reg.fit_transform(X)
lin_reg_2 =linear_model.LinearRegression()
lin_reg_2.fit(X_Poly, y)
y_pred=lin_reg_2.predict(poly_reg.fit_transform(X))
evaluation(y,y_pred,index_name=['poly_reg'])
- 最小二乘法
# (1)statsmodels实现
import statsmodels.api as sm
X=df[df.columns].values
y=target['MEDV'].values
#add constant
X=sm.add_constant(X)
# build model
model=sm.OLS(y,X).fit()
prediction=model.predict(X)
print(model.summary())
# (2)sklearn 实现
from sklearn import linear_model
lm = linear_model.LinearRegression()
model = lm.fit(X,y)
y_pred = lm.predict(X)
lm.score(X,y)
lm.coef_ #系数
lm.intercept_<br><br>evaluation(y,y_pred) #截距
逐步回归(Stepwise Regression)
- 适用于处理多个自变量
- 自变量的选择是在一个自动的过程中完成的,其中包括非人为操作。
- 通过观察统计的值,如R-square,t-stats和AIC指标,来识别重要的变量。逐步回归通过同时添加/删除基于指定标准的协变量来拟合模型。
- 下面列出了一些最常用的逐步回归方法:
- ● 标准逐步回归法做两件事情。即增加和删除每个步骤所需的预测。
- ● 向前选择法从模型中最显著的预测开始,然后为每一步添加变量。
- ● 向后剔除法与模型的所有预测同时开始,然后在每一步消除最小显着性的变量。
- 这种建模技术的目的是使用最少的预测变量数来最大化预测能力。这也是处理高维数据集的方法之一。
岭回归(Ridge Regression)
- 岭回归分析是一种用于存在多重共线性(自变量高度相关)数据的技术。此时,线性回归或多项式回归失效
- 在多重共线性情况下,尽管最小二乘法(OLS)对每个变量很公平,但它们的差异很大,使得观测值偏移并远离真实值。
- 共线性是独立变量之间存在近线性关系。
- 高共线性的存在可以通过几种不同的方式确定:
- 即使理论上该变量应该与Y高度相关,回归系数也不显着。
- 添加或删除X特征变量时,回归系数会发生显着变化。
- X特征变量具有高成对相关性(检查相关矩阵)。
- 岭回归通过给回归估计上增加一个偏差度,来降低标准误差。
- 线性回归方程可以表示为:y=a+ b*x,但完整版:
- $ y = a + b*x + e $ (error term)
- [error term is the value needed to correct for a prediction error between the observed and predicted value]
- => $ y = a+y = a+ b1x1+ b2x2+….+e $, for multiple independent variables.
- 线性方程中,预测误差可以分解为2个子分量:偏差+方差。预测错误可能会由这两个分量或者这两个中的任何一个造成。
- 岭回归通过收缩参数λ(lambda)解决多重共线性问题。
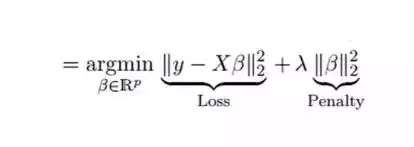
- 第一个是最小二乘项,另一个是β2(β-平方)的λ倍,其中β是相关系数。为了收缩参数把它添加到最小二乘项中以得到一个非常低的方差。
- 要点
- 除常数项以外,这种回归的假设与最小二乘回归类似;它收缩了相关系数的值,但没有达到零,这表明它没有特征选择功能,这是一个正则化方法,并且使用的是L2正则化。
- 回归的假设与最小二乘回归类似,但没有正态性假设。
- 它会缩小系数的值,但不会达到零,这表明没有特征选择功能
- 代码
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky")
ridge_reg.fit(X, y)
y_pred=ridge_reg.predict(X)
evaluation(y,y_pred,index_name='ridge_reg')
套索回归(Lasso Regression)
- 类似于岭回归。Lasso (Least Absolute Shrinkage and Selection Operator)也会惩罚回归系数的绝对值大小。此外,它能够减少变化程度并提高线性回归模型的精度
- Lasso 回归与Ridge回归有一点不同,它使用的惩罚函数是绝对值,而不是平方。这导致惩罚(或等于约束估计的绝对值之和)值使一些参数估计结果等于零。使用惩罚值越大,进一步估计会使得缩小值趋近于零。这将导致我们要从给定的n个变量中选择变量。
- 要点:
- ● 除常数项以外,这种回归的假设与最小二乘回归类似;
- ● 它收缩系数接近零(等于零),确实有助于特征选择;
- ● 这是一个正则化方法,使用的是L1正则化;
-
如果预测的一组变量是高度相关的,Lasso 会选出其中一个变量并且将其它的收缩为零。
- L2和L1正则化的属性差异:
- 内置特征选择:经常被提及为L1范数的有用属性,而L2范数则不然。这实际上是L1范数的结果,它倾向于产生稀疏系数。例如,假设模型有100个系数,但 - 只有10个系数具有非零系数,这实际上是说“其他90个预测变量在预测目标值方面毫无用处”。 L2范数产生非稀疏系数,因此不具有此属性。因此,可以说 - Lasso回归做了一种“参数选择”,因为未选择的特征变量的总权重为0。
- 稀疏性:指矩阵(或向量)中只有极少数条目为非零。 L1范数具有产生许多具有零值的系数或具有很少大系数的非常小的值的特性。这与Lasso执行一种特 - 征选择的前一点相关联。
- 计算效率:L1范数没有解析解,但L2有。在计算上可以有效地计算L2范数解。然而,L1范数具有稀疏性属性,允许它与稀疏算法一起使用,这使得计算在计算上更有效。
- 代码

from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
y_pred=lasso_reg.predict(X)
evaluation(y,y_pred,index_name='lasso_reg')
弹性网络回归(ElasticNet)
- ElasticNet是Lasso和Ridge回归技术的混合体。它使用L1来训练并且L2优先作为正则化矩阵。当有多个相关的特征时,ElasticNet是很有用的。Lasso 会随机挑选他们其中的一个,而ElasticNet则会选择两个。
- Lasso和Ridge之间的实际的优点是,它允许ElasticNet继承循环状态下Ridge的一些稳定性。
- 要点:
- ● 在高度相关变量的情况下,它会产生群体效应;
- ● 选择变量的数目没有限制;
- ● 它可以承受双重收缩。
- 代码
enet_reg = linear_model.ElasticNet(l1_ratio=0.7)
enet_reg.fit(X,y)
y_pred=enet_reg.predict(X)
evaluation(y,y_pred,index_name='enet_reg ')
- 除了这7个最常用的回归技术,你也可以看看其他模型,如Bayesian、Ecological和Robust回归。
广义线性模型
【2020-12-09】广义线性模型(GLM)从人话到鬼话连篇
- 了解一个模型的顺序是:
- 1)为什么要用这个模型解决问题?
- 2)这个模型是什么,可以解决什么问题?
- 3)模型怎么用?
- 4)应用领域是什么?解决了哪些问题?
- 5)模型的归档与应用划分?
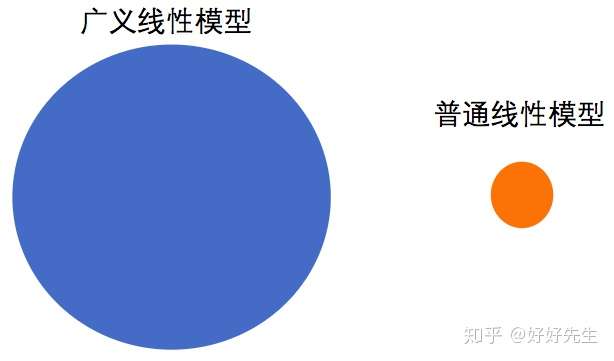
- 普通线性模型对数据有着诸多限制,真实数据并不总能满足。而广义线性模型正是克服了很多普通线性模型的限制。在笔者的心里,广义模型能解决的问题种类比普通线性模型多很多,用图来表示,大概就是这样的
- 广义线性模型的本质,从广义线性模型的三个要素——线性预测、随机性、联系函数入手,在理论层面系统深入地了解广义线性模型。
- 线性预测:各路线性模型的共同点。
- 「线性」指的是多个自变量的「线性组合」对模型预测产生贡献,也叫做线性预测,具有类似于下面的形式
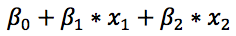
- 统计模型中的β0、β1、β2等是模型的参数,类似音箱上的按钮。虽然拧每一个旋钮达到的效果不同,可能β0管的是低音炮部分,β1管的是中音区,β2管的是高音区,模型里面需要这么多参数也是为了控制各种自变量对因变量的影响的。
- 为什么各种常用的模型都选择线性预测?统计模型寻找最优参数其实就是调节音量,使用线性预测使得β0、β1、β2这些参数改变的值与预测的结果的改变值成正比,这样才能有效地找到最佳参数。
- 随机性 — 统计模型的灵魂
- 建立模型时,希望能准确地抓住自变量与因变量之间的关系,但是当因变量能够100%被自变量决定时,这时候反而没有统计模型什么事了。
- 统计模型的威力就在于帮助我们从混合着噪音的数据中找出规律。
- 怎样从具有随机性的数据中找到自变量和因变量之间的关系?测量随机误差也是有规律的。在测量不存在系统性的偏差的情况下,测量到的加速度会以理论值为平均值呈正态分布。抓住这一统计规律,统计模型就能帮我们可以透过随机性看到自变量与因变量之间的本质联系,找出加速度与受力大小的关系。如果不对自变量的随机性加以限制,再好的统计模型也无可奈何。
- 实际应用中,y的随机性远不止测量误差,也有可能是影响y值变化的一些变量没有包含在模型中。
- 统计模型并不在意y的随机性是由什么产生的:统计模型把因变量y中不能被模型解释的变化都算在误差项里面,并且通过对误差作出合理的假设,帮助我们找到自变量与因变量之间内在的关系。
- 误差项得满足什么样的分布?
- 1)普通线性模型的基本假设之一是误差符合方差固定的正态分布(高斯分布)
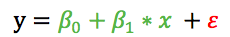
- 普通线性模型中的方差不随自变量x取值的变化而变化。线性回归模型假设误差项 ε 服从平均值为 0,方差为 σ2 的正态分布,而且方差的大小不随着预测变量 x 值改变,也叫做同方差性(Homoscedasticity)。换句话说,同方差性就是指误差项的方差是一个常数,与实验条件无关。
- 当误差项ε不再满足正太分布,或者误差项的方差会随着x的变化而变化的时候,普通线性模型就不够用了。改用广义线性模型
- 正态分布的数据是连续的,对称的,并在整个数字线上定义。这意味着任何离散,不对称或只能在有限范围内使用的数据,实际上都不应使用线性回归建模。广义线性模型专门设计用于非正态数据
- 2)逻辑回归
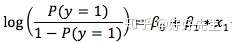
- y的随机性恰好被y的平均值刻画了,与普通线性回归完全不一样,模型的预测值同时也决定了方差
- 3) 泊松回归
- 因变量是整数变量情形的泊松回归
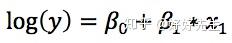
- 泊松回归模型认为给定自变量的取值,因变量y满足泊松分布,模型的输出e^(β0+β1*x1)预测的是y的平均值,由于泊松分布只有一个参数,知道了分布的平均值整个分布也就确定了. 与逻辑回归异曲同工
- 1)普通线性模型的基本假设之一是误差符合方差固定的正态分布(高斯分布)
- 总结
- 对比普通线性模型,逻辑回归模型,以及泊松回归模型,我们可以发现这几个模型除了等式左边形式不同,当因变量取特定值时,这些模型所假设的y的随机分布形式也不一样
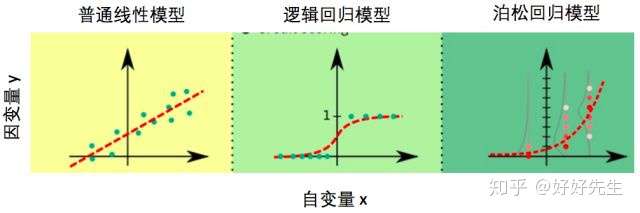
- 红色虚线代表模型预测的因变量y的平均值,图中的点代表了实际数据值,泊松回归模型中的灰色细线代表了特定自变量取值下因变量y的分布。
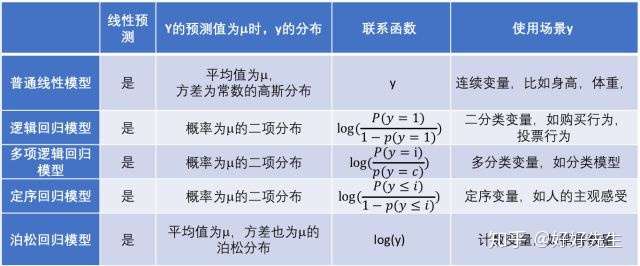
- 联系函数
- 广义线性模型绕不开的联系函数(link function), 它是一个关于因变量y的函数,它把前面说到的线性预测的结果与因变量y的值之间建立一座桥梁。

- 线性预测:各路线性模型的共同点。

时间序列回归
- 【2022-8-31】利用Auto ARIMA构建高性能时间序列模型
- 【2020-9-30】时间序列预测的7种方法, 7 methods to perform Time Series forecasting (with Python codes)
典型任务
- 根据历史数据预测比特币价格。

- 预测高铁乘客量
什么是时间序列
时间序列的定义:一系列在相同时间间隔内测量到的数据点。
- 时间序列是指以固定的时间间隔记录下的特定值
- 时间间隔可以是小时、每天、每周、每10天等等。
- 时间序列的特殊性:该序列中的每个数据点都与先前的数据点相关。
什么是平稳
【2022-8-31】手把手教你用Python处理非平稳时间序列
“平稳”是处理时间序列数据时遇到的最重要的概念之一:
- 平稳序列是指其特性-
均值、方差和协方差不随时间而变化的序列。 - 第一幅图中,均值随时间而变化(增加),呈现上升的趋势。因此,这是一个非平稳序列。平稳序列不应该呈现出随时间变化的趋势。
- 第二幅图显然看不到序列的趋势,但序列的变化是一个时间的函数。正如前面提到的,平稳序列的方差必须是一个常数。
- 第三幅图,随着时间的增加,序列传播后变得更近,这意味着协方差是时间的函数。
三个例子均是非平稳时间序列, 均值、方差和协方差都是常数,才是平稳时间序列。
大多数统计模型都要求序列是平稳的,这样才能进行有效和精确的预测。
- 平稳时间序列是一个不依赖时间变化 (即均值、方差和协方差不随时间变化)的时间序列。
如何验证平稳
如何检验序列是否平稳?
- 人工检验
- 统计检验:如单位根平稳检验。单位根表名给定序列的统计特性(均值,方差和协方差)不是时间的常数,这是平稳时间序列的先决条件。最常用的单位根平稳检测方法:
- ① ADF(增补迪基-福勒)检验
- ADF检验结果:ADF检验的统计量为1%,p值为5%,临界值为10%,置信区间为10%。
- 平稳性检验:如果检验统计量小于临界值,可以拒绝原假设(也就是序列是平稳的)。当检验统计量大于临界值时,不能拒绝原假设(这意味着序列不是平稳的)。
- ② KPSS(科瓦特科夫斯·基菲利普·斯施密特·辛)检验KPSS检验是另一种用于检查时间序列的平稳性 (与迪基-福勒检验相比稍逊一筹) 的统计检验方法。KPSS检验的原假设与备择假设与ADF检验的原假设与备择假设相反,常造成混淆。
- KPSS检验结果:KPSS检验-检验统计量、p-值和临界值和置信区间分别为1%、2.5%、5%和10%。
- 平稳性检验:如果检验统计量大于临界值,则拒绝原假设(序列不是平稳的)。如果检验统计量小于临界值,则不能拒绝原假设(序列是平稳的)
- ① ADF(增补迪基-福勒)检验
平稳种类
平稳的种类
严格平稳:严格平稳序列满足平稳过程的数学定义。严格平稳序列的均值、方差和协方差均不是时间的函数。我们的目标是将一个非平稳序列转化为一个严格平稳序列,然后对它进行预测。趋势平稳:没有单位根但显示出趋势的序列被称为趋势平稳序列。一旦去除趋势之后,产生的序列将是严格平稳的。在没有单位根的情况下,KPSS检测将该序列归类为平稳。这意味着序列可以是严格平稳的,也可以是趋势平稳的。差分平稳:通过差分可以使时间序列成为严格平稳的时间序列。ADF检验也称为差分平稳性检验。
应用两种平稳检验后的可能结果:
- 结果1:两种检验均得出结论:序列是非平稳的->序列是非平稳的
- 结果2:两种检验均得出结论:序列是平稳的->序列是平稳的
- 结果3:KPSS =平稳;ADF =非平稳->趋势平稳,去除趋势后序列严格平稳
- 结果4:KPSS =非平稳;ADF =平稳->差分平稳,利用差分可使序列平稳。
时序平稳化
为了建立时间序列预测模型,必须首先将任何非平稳序列转换为平稳序列
- 差分:计算序列中连续项的差值, yt‘ = yt – y(t-1)
- 季节差分:计算观察值与同一季节的先前观察值之间的差异,yt‘ = yt – y(t-n)
- 变换:变换用于对方差为非常数的序列进行平稳化。常用的变换方法包括幂变换、平方根变换和对数变换。
如何衡量序列相似度
【2022-12-30】有哪些有效的可以衡量两段或多段时间序列相似度的方法?
一个好的相似度度量方法(Similarity Measure)需要具备哪些好的性质?
- Similarity Measure 能够识别在感觉上比较相似、但是在数学意义上不完全一样的物体。
- Similarity Measure 的结果应该和人类直觉相符合。如果枫叶和扇形叶子的形状很相似,那只能说扯蛋。
- Similarity Measure, 不管在全局(global),还是局部(local)水平上,都应该重点关注一个物体的显著特征,而不是鸡毛蒜皮的无关细节。
- 比如说,枫叶和扇形叶子很相似,因为它们的边缘都是呈现小锯齿状(local feature)。
- 两片扇形叶子很相似,因为它们都是扇形(global feature)。有道理。
- 但是枫叶和扇形叶子很相似,因为它们上面都有泥巴,只能说“我不关心这个”。

上面三点描述的是通用的Similarity Measure,现在来讨论 Time Series Similarity Measure.
- 除了以上的通用方面外,对于一个好的 Time Series Similarity Measure 来讲,它应该能够比较两个长度不相等的时间序列。(然而,如果两条时间序列长度相差太大,计算它们的相似度也会变得没有意义)
- 一个好的Time Series Similarity Measure的复杂度应该越低越好。换句话说,Time Complexity 和 Space Complexity 都要小。
- 一个好的Time Series Similarity Measure 应该对各种扭曲(distortion)和变换(transformation)不敏感。
具体有哪些distortion和transformation呢?
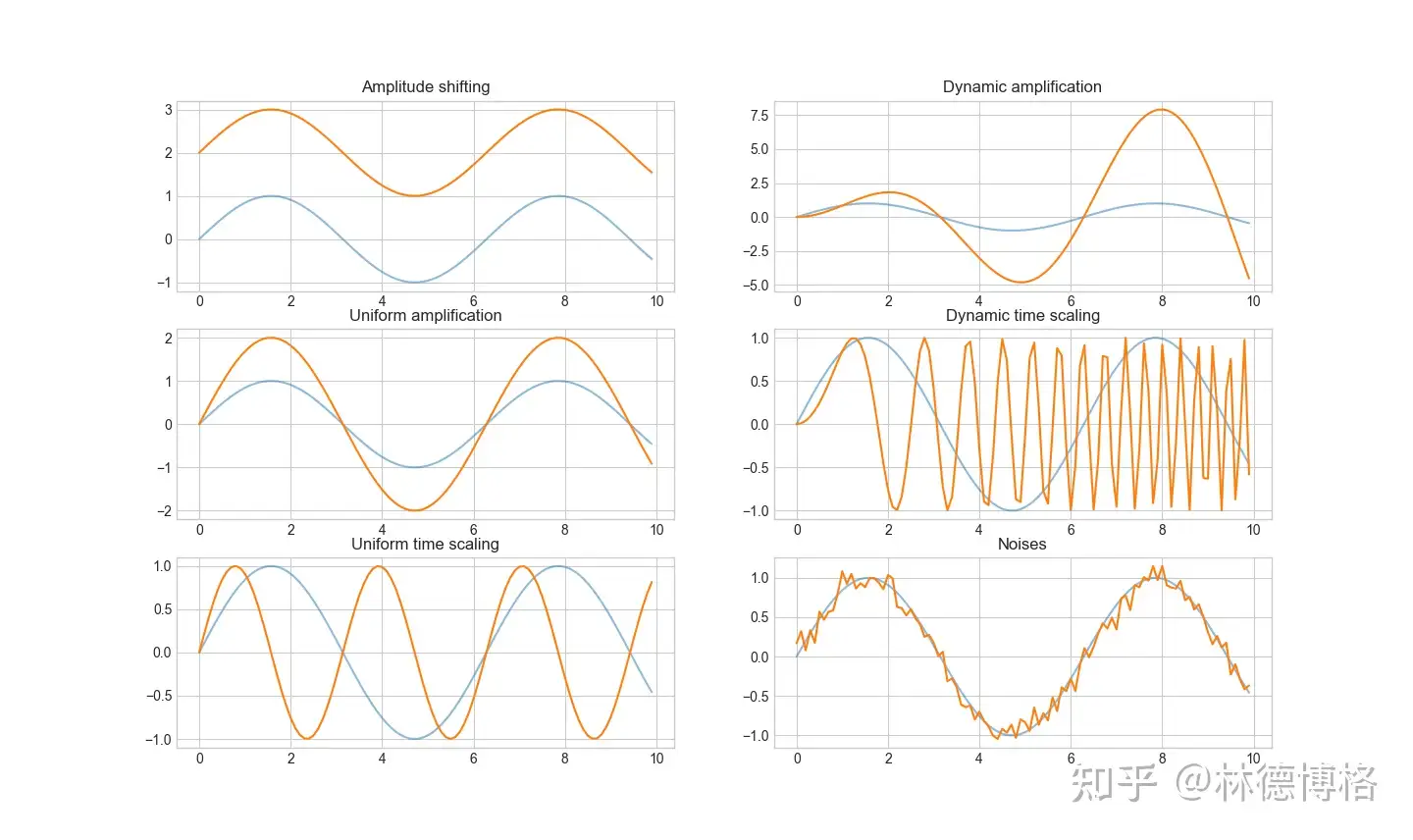
理想情况下,上面六对时间序列应该被看作是相似的。也就是说,一个好的Time Series Similarity Measure应该对这些扭曲和变换不敏感。
# 用于复现上述distortion, transformation 的python代码
import numpy as np
import matplotlib.pyplot as plt
fig, axs = plt.subplots(3,2)
## Raw time series
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)
axs[0,0].plot(time, amplitude, alpha = 0.5)
axs[1,0].plot(time, amplitude, alpha = 0.5)
axs[2,0].plot(time, amplitude, alpha = 0.5)
axs[0,1].plot(time, amplitude, alpha = 0.5)
axs[1,1].plot(time, amplitude, alpha = 0.5)
axs[2,1].plot(time, amplitude, alpha = 0.5)
## Amplitude shifting
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)+2
axs[0,0].plot(time, amplitude)
axs[0,0].set_title("Amplitude shifting")
## Uniform amplification
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)*2
axs[1,0].plot(time, amplitude)
axs[1,0].set_title("Uniform amplification")
## Uniform time scaling
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time*2)
axs[2,0].plot(time, amplitude)
axs[2,0].set_title("Uniform time scaling")
## Dynamic amplification
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)*time
axs[0,1].plot(time, amplitude)
axs[0,1].set_title("Dynamic amplification")
## Dynamic time scaling
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time*time)
axs[1,1].plot(time, amplitude)
axs[1,1].set_title("Dynamic time scaling")
## Noises
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)+np.random.normal(0,0.1,100)
axs[2,1].plot(time, amplitude)
axs[2,1].set_title("Noises")
现有的时间序列相似度度量方法(Time Series Similarity Measure)分类
Time Series Similarity Measure大概可以分为四类:
- 基于形状的(Shape Based Time Series Similarity Measure)
- 通过比较时间序列的整体形状来计算相似度。
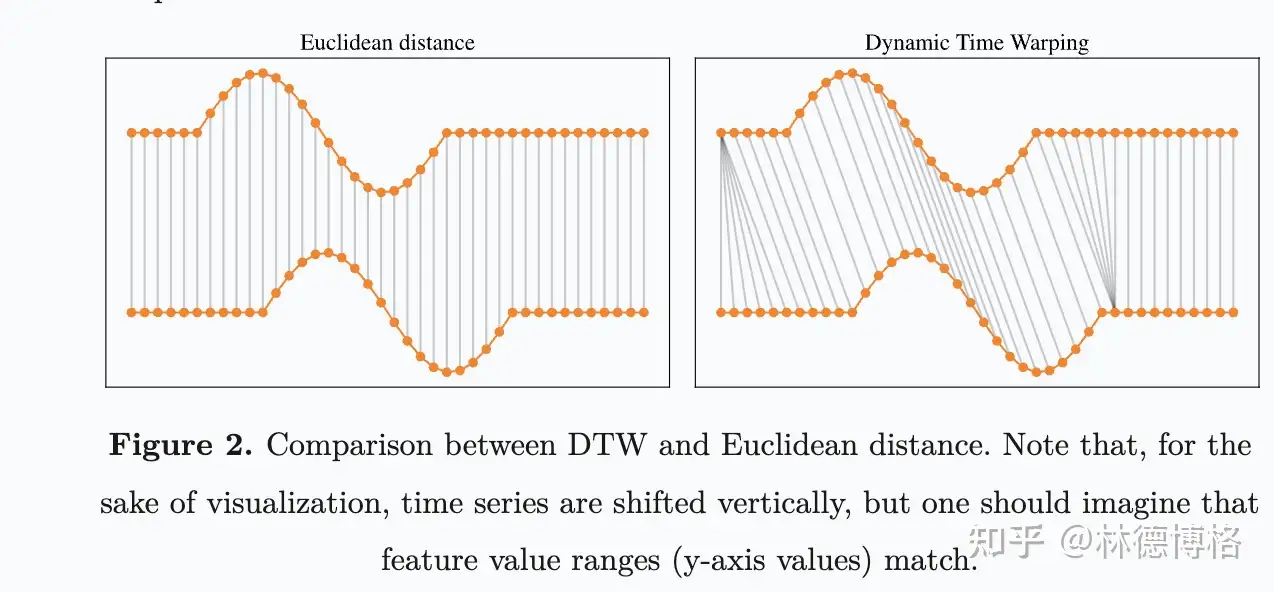
- 这一类方法包括了大名鼎鼎的 Euclidean distance 和 DTW。主要包括以下方法:
- Euclidean Distance and other Lp norms.
- Dynamic Time Warping (DTW)
- Spatial LB-Keogh (variant of DTW)
- Assembling (SpADe)
- Optimal Bijection (OSB)DISSIM
- 基于编辑距离的(Edit Based Time Series Similarity Measure)
- 通过计算“最少需要多少步基本操作来把一段时间序列变成另外一段时间序列”来衡量相似度。

- 举个例子,给定两个序列:ABC,ABD,以及三个基本操作“删除、添加、替换”,我们最少需要一个基本操作“替换”(C替换成D),将ABC编程ABD.
- 主要包括以下方法:
- Levenshtein
- Weighted Levenshtein
- Edit with Real Penalty (ERP)
- Time Warp Edit Distance (TWED)
- Longest Common SubSeq (LCSS)
- Sequence Weighted Align (Swale)
- Edit Distance on Real(EDR)
- Extended Edit Distance(EED)
- Constraint Continuous Edit(CCED)
- 基于特征的(Feature Based Time Series Similarity Measure)
- 首先提取出时间序列的特征,比如说统计学特征(最大值、最小值、均值,方差等),或者是通过FFT提取出Amplitude, Energy, Phase, Damping Ratio, Frequency)等特征,然后直接计算这些特征之间的Eclidean distance 然后再求和。
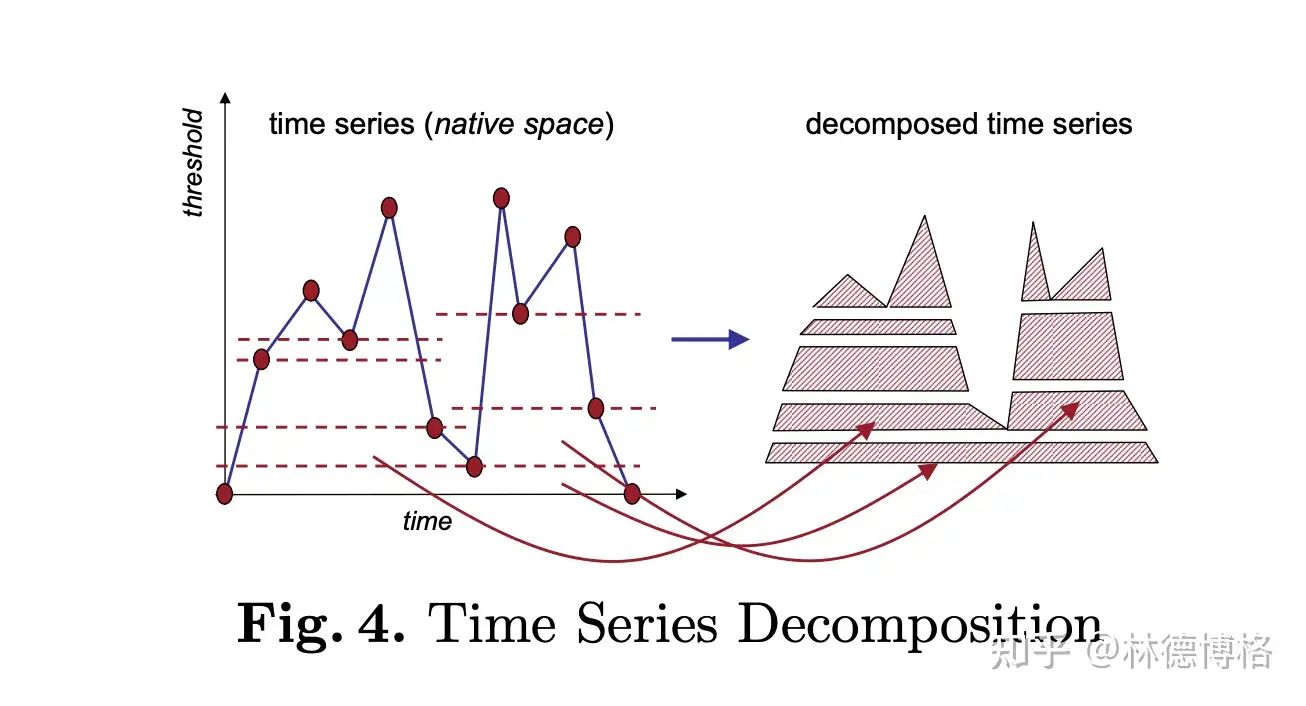
- 主要包括以下方法(也就是不同的特征提取和比较方法):
- Likelihood
- Autocorrelation
- Vector quantization
- Threshold Queries (TQuest)
- Random Vectors
- Histogram
- WARP
- 基于结构的(Structure Based Time Series Similarity Measure)
- 上面三种时间序列相似度度量方法适用于短时间序列,对于较长的时间序列(比如说几万个点的时间序列),前面三大类方法很可能会失效。于是,就有了第四类方法。前面三大类方法之所以失效,是因为它们过多关注局部特征(local feature),而忽略了全局特征(Global feature)。
- 而第四类方法的基本思想是:关注全局特征。这一类方法可以进一步分为两类:基于模型的(model-based distance) 和 基于压缩的(Compression-based distance).
- Model-based distance假设时间序列服从某个分布/模型,然后估计模型参数,最后通过比较模型参数之间的差异来反映时间序列的相似度。主要包括以下方法:
- Markov Chain(MC)
- Hidden Markov Models(HMM)
- Auto-Regressive(ARMA)
- Kullback-Leibler
- Compression-based distance通过研究两个时间序列在一起压缩的压缩率来反映相似度。直观上,如果两个时间序列比较相似,则它们在一起压缩就比较容易。
- Compression Dissimilarity(CDM)
- Parsing-Based
- 详见原文:林德博格的回答
时间序列预测方法
数据集准备
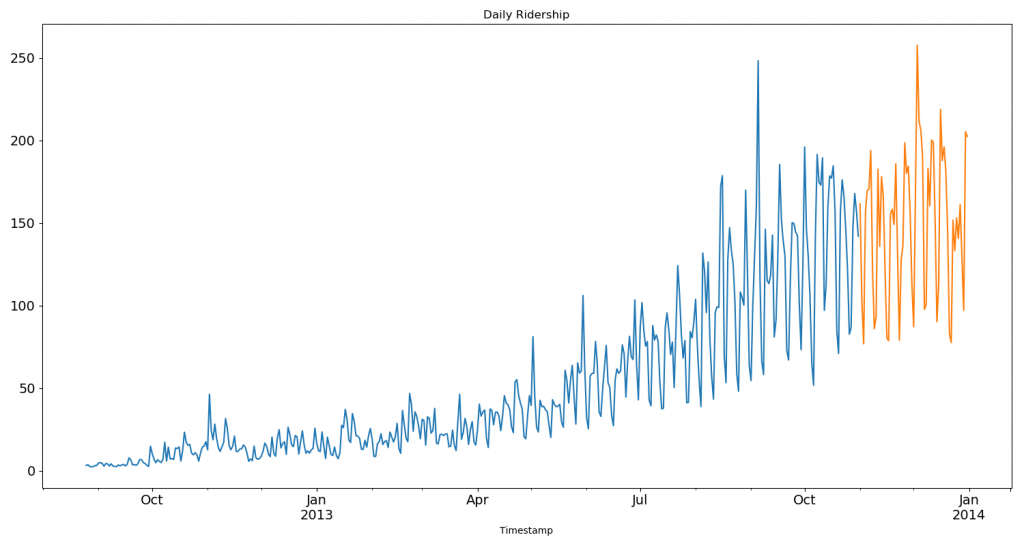
2012-2014 年两年每个小时的乘客数量。为了解释每种方法的不同之处,以每天为单位构造和聚合了一个数据集。
- 从 2012 年 8 月- 2013 年 12 月的数据中构造一个数据集。
- 创建 train/test 文件用于建模。
- 前 14 个月( 2012年8月-2013年10月)用作训练数据
- 后2个月(2013年11月–2013年12月)用作测试数据。
- 以每天为单位聚合数据集。
import pandas as pd
import matplotlib.pyplot as plt
# Subsetting the dataset
# Index 11856 marks the end of year 2013
df = pd.read_csv('train.csv', nrows=11856)
# Creating train and test set
# Index 10392 marks the end of October 2013
train = df[0:10392]
test = df[10392:]
# Aggregating the dataset at daily level
df['Timestamp'] = pd.to_datetime(df['Datetime'], format='%d-%m-%Y %H:%M')
df.index = df['Timestamp']
df = df.resample('D').mean()
train['Timestamp'] = pd.to_datetime(train['Datetime'], format='%d-%m-%Y %H:%M')
train.index = train['Timestamp']
train = train.resample('D').mean()
test['Timestamp'] = pd.to_datetime(test['Datetime'], format='%d-%m-%Y %H:%M')
test.index = test['Timestamp']
test = test.resample('D').mean()
#Plotting data
train.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
test.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
plt.show()
总结
方法总结
方法
朴素预测法:在这种预测方法中,新数据点预测值等于前一个数据点的值。简单平均值法:下一个值是所有先前值的平均数。该方法优于“朴素预测法”,但是在简单平均值法中,过去的所有值都被考虑进去了,而这些值可能并不都是有用的移动平均法:这是对前两个方法的改进。不取前面所有点的平均值,而是将n个先前的点的平均值作为预测值加权移动平均法:加权移动平均是带权重的移动平均,先前的n个值被赋予不同的权重。简单指数平滑法:更大的权重被分配给更近期的观测结果,来自遥远过去的观测值则被赋予较小的权重霍尔特(Holt)线性趋势模型:该方法考虑了数据集的趋势(数据的递增或递减的性质)。假设旅馆的预订数量每年都在增加,那么可以说预订数量呈现出增加的趋势。该方法的预测函数是值和趋势的函数。霍尔特-温特斯(Holt Winters)方法:该算法同时考虑了数据的趋势和季节性。例如,一家酒店的预订数量在周末很高,而在工作日则很低,并且每年都在增加;因此存在每周的季节性和增长的趋势。ARIMA:ARIMA是一种非常流行的时间序列建模方法。它描述了数据点之间的相关性,并考虑了数值之间的差异。ARIMA的改进版是SARIMA (或季节性ARIMA)。
几种模型的准确度
基线模型:
- ARIMA:将自回归(AR)的算子加上移动平均(MA),就是 ARIMA 算法。回归能够反映数据的周期性规律,和移动平均形成互补,从统计学的角度可以很好的预测一元与时间强相关场景下的时间序列。
- TRMF:矩阵分解方法。
- DeepAR:基于LSTM的自回归概率预测方法。
- DeepState: 基于RNN的状态空间方法。
- transformer
【时间序列】Transformer for TimeSeries时序预测算法详解

不足
【2025-4-9】时间序列预测的 “雷区”,你踩了几个, 含 ppt
Christoph Bergmeir 对时间序列模型的剖析,让人警醒。
时间序列预测模型看似风光无限,实则暗藏诸多问题。
常见的深度学习时间序列模型在公开数据集表现亮眼,在私有数据集却不尽人意。
Informer基准测试设置不合理;- 天气和电力负荷数据预测中,进行长期预测(如720天)极具挑战,因为气象专家认为超过两周的预测就如同随机猜测。
- Informer 模型的原始基准测试设置不够合理,没有考虑季节性因素。研究人员采用动态谐波回归(DHR)结合ARIMA误差(DHR - ARIMA)作为更合理的基准进行测试,结果显示,在ETTh1和ECL数据集上,Informer等模型的表现不如 DHR - ARIMA。
TimesNet实际表现被夸大;- M4数据集的评估中,TimesNet 整体加权平均(OWA)为0.851。
- 尽管在其论文中排名第一,但在原始M4竞赛中仅位列第七,甚至落后于一些未使用深度学习,可能也未使用机器学习的传统方法。
- 这表明该模型的实际效果可能被夸大,与论文声称的表现存在差距。
PatchTST评估设置不公平;- 重新运行Informer实验时,PatchTST等新方法的表现较差。在ETTh1数据集上,尽管PatchTST“获胜”,但其均方误差(MSE)和平均绝对误差(MAE)较大。
- 评估设置存在不公平之处,例如PatchTST使用“Drop Last trick”,在比较新方法时限制输入窗口长度,这种做法有利于复杂模型。
Autoformer在指标上不占优势。- Autoformer在不同预测期的MAE和MSE指标上,与简单预测方法相比并无优势。
- 该数据集存在数据缺失问题,可能排除了银行假日等非交易日。其他研究也表明,在汇率预测中,Dlinear和ForecastPFN等简单预测模型的表现优于Autoformer、Informer等方法。
TimeLLM评估结果可能被操纵;- TimeLLM 在M4数据集上的OWA为0.859。
- 它对TimesNet和NBEATS的OWA进行“更新”后,结果仍落后于未使用深度学习的方法。
- 这让人怀疑该模型的评估结果可能被操纵,以呈现出更好的性能。
基于语言模型的预测器通常不如简单非语言模型,还需更多计算资源。
问题
- 以 TimeLLM 为代表的基于语言模型的时间序列预测器,不如简单的非语言模型,不仅预测效果欠佳,还会消耗更多计算资源。
- 语言模型处理时间序列时,由于难以获取上下文信息,难以精准把握数据内在联系,使得预测结果存在偏差。
- 时间序列数据存在噪声干扰大、有效信息少的特点,这使得选择合适的模型变得困难,增加了建模难度。
- 一般认为数据越多越好,但在时间序列预测中,过多的数据可能引入更多不确定因素,反而让模型性能降低。
- 不同类型的时间序列,像电力负荷和天气数据,具有各自独特的变化规律,现有模型在区分和处理这些差异时,能力还有所欠缺。
实用技巧:引入上下文信息可提高模型准确性,避免过度依赖语言模型。
- 时间序列预测时,为模型补充上下文信息,例如 对时间序列的详细解释、背景情况等,能让模型更好地理解数据,从而提升预测的精准度。
- 尽量不要过度依赖语言模型来做时间序列预测,特别是在没有足够上下文信息支撑的时候,否则可能导致预测结果不理想。
实时榜单
实时榜单
- 清华整理的时序预测任务榜单 Time-Series-Library
Leaderboard for Time Series Analysis
Till March 2024, the top three models for five different tasks are:
| Model Ranking |
Long-term Forecasting Look-Back-96 |
Long-term Forecasting Look-Back-Searching |
Short-term Forecasting |
Imputation | Classification | Anomaly Detection |
|---|---|---|---|---|---|---|
| 🥇 1st | TimeXer | TimeMixer | TimesNet | TimesNet | TimesNet | TimesNet |
| 🥈 2nd | iTransformer | PatchTST | Non-stationary Transformer |
Non-stationary Transformer |
Non-stationary Transformer |
FEDformer |
| 🥉 3rd | TimeMixer | DLinear | FEDformer | Autoformer | Informer | Autoformer |
Compared models of this leaderboard. ☑ means that their codes have already been included in this repo.
- TimeXer - TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables [NeurIPS 2024] [Code]
- TimeMixer - TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting [ICLR 2024] [Code].
- TSMixer - TSMixer: An All-MLP Architecture for Time Series Forecasting [arXiv 2023] [Code]
- iTransformer - iTransformer: Inverted Transformers Are Effective for Time Series Forecasting [ICLR 2024] [Code].
- PatchTST - A Time Series is Worth 64 Words: Long-term Forecasting with Transformers [ICLR 2023] [Code].
- TimesNet - TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis [ICLR 2023] [Code].
- DLinear - Are Transformers Effective for Time Series Forecasting? [AAAI 2023] [Code].
- LightTS - Less Is More: Fast Multivariate Time Series Forecasting with Light Sampling-oriented MLP Structures [arXiv 2022] [Code].
- ETSformer - ETSformer: Exponential Smoothing Transformers for Time-series Forecasting [arXiv 2022] [Code].
- Non-stationary Transformer - Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting [NeurIPS 2022] [Code].
- FEDformer - FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting [ICML 2022] [Code].
- Pyraformer - Pyraformer: Low-complexity Pyramidal Attention for Long-range Time Series Modeling and Forecasting [ICLR 2022] [Code].
- Autoformer - Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting [NeurIPS 2021] [Code].
- Informer - Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting [AAAI 2021] [Code].
- Reformer - Reformer: The Efficient Transformer [ICLR 2020] [Code].
- Transformer - Attention is All You Need [NeurIPS 2017] [Code].
See our latest paper [TimesNet] for the comprehensive benchmark. We will release a real-time updated online version soon.
Newly added baselines. We will add them to the leaderboard after a comprehensive evaluation.
- WPMixer - WPMixer: Efficient Multi-Resolution Mixing for Long-Term Time Series Forecasting [AAAI 2025] [Code]
- PAttn - Are Language Models Actually Useful for Time Series Forecasting? [NeurIPS 2024] [Code]
- Mamba - Mamba: Linear-Time Sequence Modeling with Selective State Spaces [arXiv 2023] [Code]
- SegRNN - SegRNN: Segment Recurrent Neural Network for Long-Term Time Series Forecasting [arXiv 2023] [Code].
- Koopa - Koopa: Learning Non-stationary Time Series Dynamics with Koopman Predictors [NeurIPS 2023] [Code].
- FreTS - Frequency-domain MLPs are More Effective Learners in Time Series Forecasting [NeurIPS 2023] [Code].
- MICN - MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting [ICLR 2023][Code].
- Crossformer - Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting [ICLR 2023][Code].
- TiDE - Long-term Forecasting with TiDE: Time-series Dense Encoder [arXiv 2023] [Code].
- SCINet - SCINet: Time Series Modeling and Forecasting with Sample Convolution and Interaction [NeurIPS 2022][Code].
- FiLM - FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting [NeurIPS 2022][Code].
- TFT - Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting [arXiv 2019][Code].
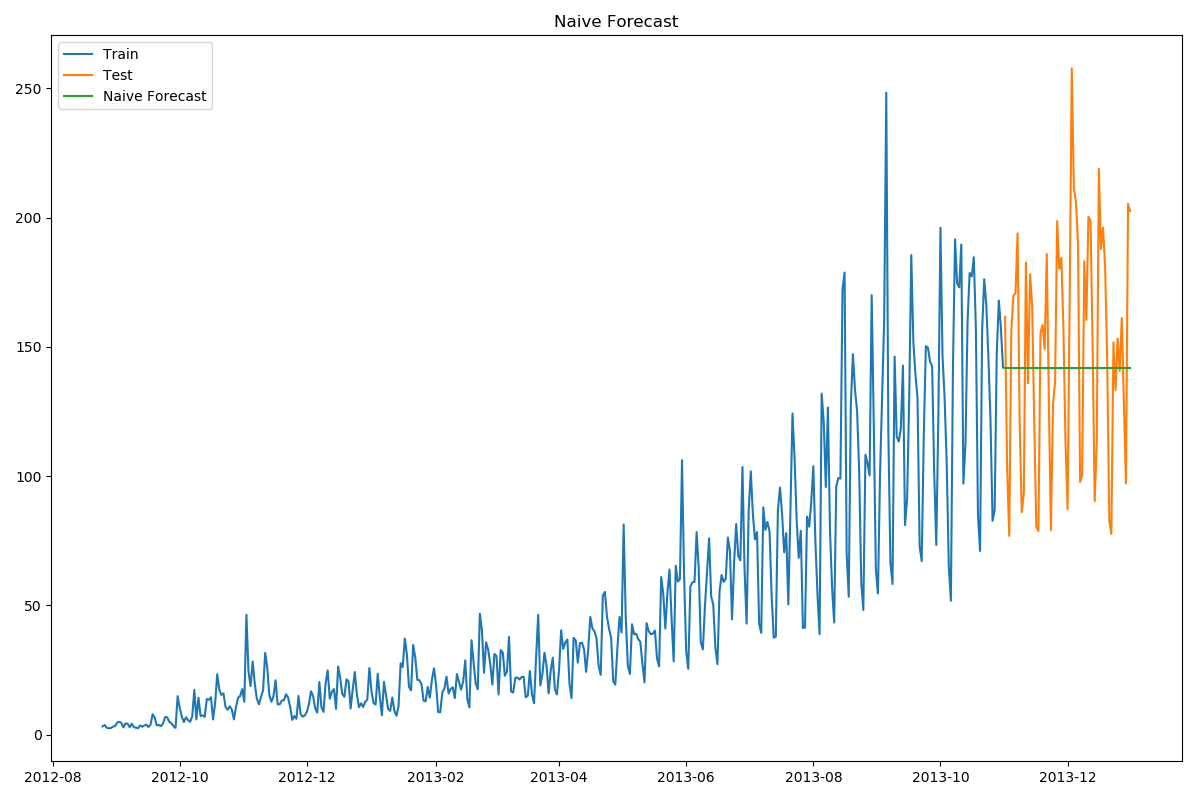
朴素法
朴素法:
- 假设第一个预测点和上一个观察点相等的预测方法
- $ \hat{y}{t+1}=y{t} $
dd = np.asarray(train['Count'])
y_hat = test.copy()
y_hat['naive'] = dd[len(dd) - 1]
plt.figure(figsize=(12, 8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
# ----- 评估效果 -------
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print(rms) # 43.91640614391676
分析
- 朴素法并不适合变化很大的数据集,最适合稳定性很高的数据集。
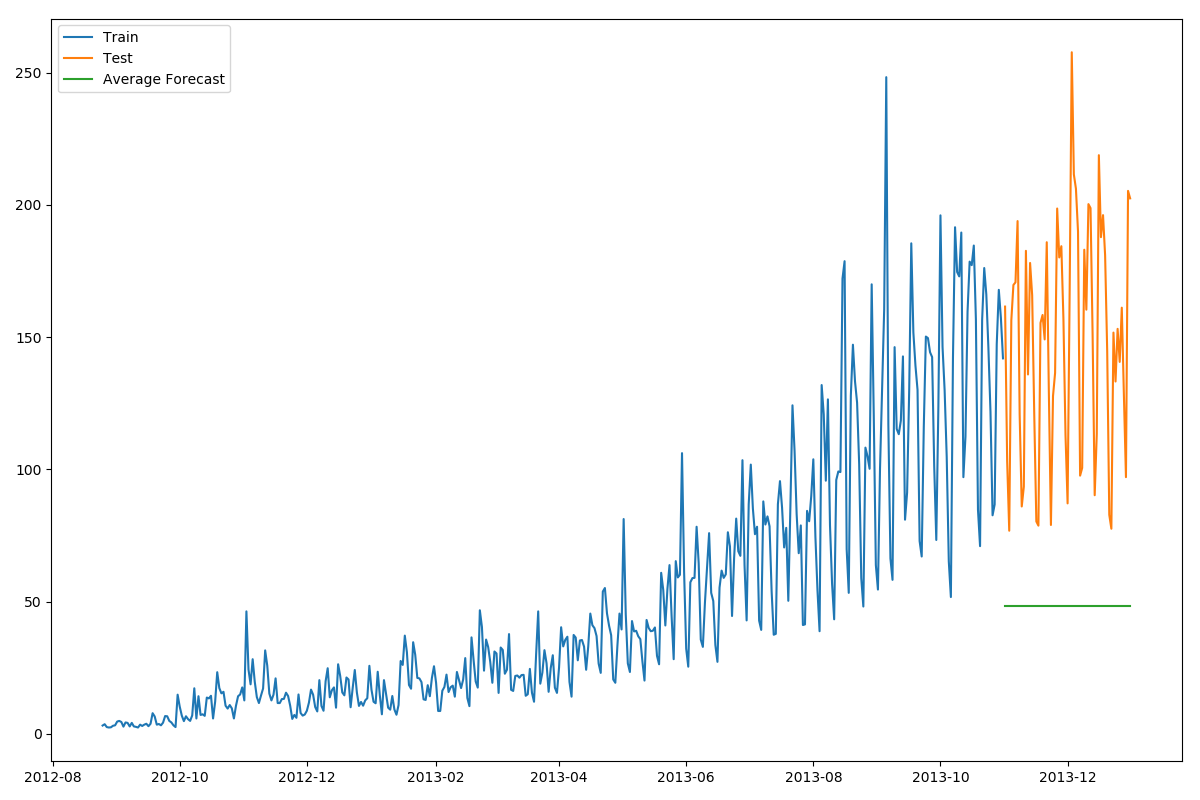
简单平均法
数据在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。
- 预测出第二天的价格大致和过去天数的价格平均值一致。
这种将预期值等同于之前所有观测点的平均值的预测方法就叫简单平均法。
- $\hat{y}{x+1}=\frac{1}{x} \sum{i=1}^{x} y_{i}$
y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
plt.figure(figsize=(12,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.show()
# ===========
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['avg_forecast']))
print(rms) # 109.88526527082863
移动平均法——改进
用某些窗口期计算平均值的预测方法就叫移动平均法。
- 思想:最近的数据更重要
- 移动平均值涉及到一个有时被称为“滑动窗口”的大小值p。使用简单的移动平均模型,根据之前数值的固定有限数p的平均值预测某个时序中的下一个值
公式
- $\hat{y}{l}=\frac{1}{p}\left(y{i-1}+y_{i-2}+y_{i-3}+\ldots+y_{i-p}\right)$
y_hat_avg = test.copy()
# 窗口为60
y_hat_avg['moving_avg_forecast'] = train['Count'].rolling(60).mean().iloc[-1]
plt.figure(figsize=(16,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
# ===========
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['moving_avg_forecast']))
print(rms) # 46.72840725106963
效果

- 这个数据集里,
朴素法比简单平均法和移动平均法的表现要好 - 可以试试简单指数平滑法,它比移动平均法的一个进步之处就是相当于对移动平均法进行了加权。加权移动平均法其实还是一种移动平均法,只是“滑动窗口期”内的值被赋予不同的权重,通常来讲,最近时间点的值发挥的作用更大了。
- $\hat{y}{l}=\frac{1}{m}\left(w{1} * y_{i-1}+w_{2} * y_{i-2}+w_{3} * y_{i-3}+\ldots+w_{m} * y_{i-m}\right)$
简单指数平滑法
简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异。两种方法之间折中,将所有数据考虑在内的同时也能给数据赋予不同非权重。
- 相比更早时期内的观测值,它会给近期的观测值赋予更大的权重。按照这种原则工作的方法就叫做
简单指数平滑法。 - 通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关
- $\hat{y}{T+1 \mid T}=\alpha y{T}+\alpha(1-\alpha) y_{T-1}+\alpha(1-\alpha)^{2} y_{T-2}+\ldots$
- 0≤α≤1是平滑参数。对时间点T+1的单步预测值是时序y1,…,yT的所有观测值的加权平均数。权重下降的速率由参数α控制
- $\hat{y}{t+1 \mid t}=\alpha y{t}+(1-\alpha) \hat{y}_{t-1 \mid t}$
- 用两个权重α和1−α得到一个加权移动平均值
from statsmodels.tsa.api import SimpleExpSmoothing
y_hat_avg = test.copy()
fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False)
y_hat_avg['SES'] = fit.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
# ==========
rom sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['SES']))
print(rms) # 43.357625225228155
效果

- α值为0.6,用测试集继续调整参数以生成一个更好的模型。
霍尔特(Holt)线性趋势法
问题
- 以上方法都没有考虑趋势因素:一段时间内观察到的价格的总体模式
无需假设的情况下,准确预测出价格趋势,这种考虑数据集变化趋势的方法就叫做霍尔特线性趋势法。
- 每个时序数据集可以分解为相应的几个部分:
趋势(Trend),季节性(Seasonal)和残差(Residual)。任何呈现某种趋势的数据集都可以用霍尔特线性趋势法用于预测。
import statsmodels.api as sm
sm.tsa.seasonal_decompose(train['Count']).plot()
result = sm.tsa.stattools.adfuller(train['Count'])
plt.show()
数据集特征
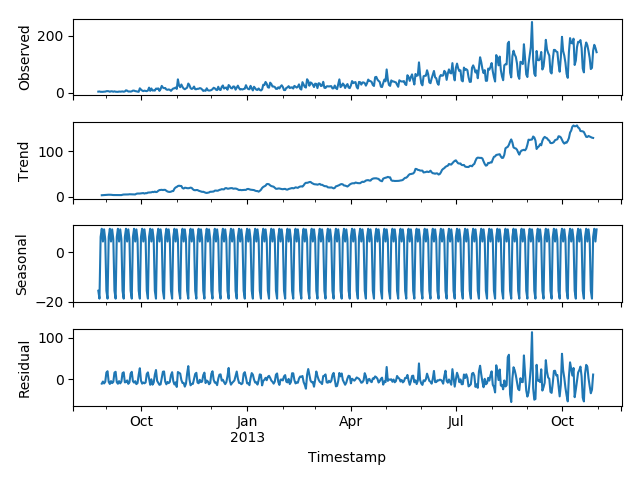
- 数据集呈上升趋势。因此用霍尔特线性趋势法预测未来价格。
- 该算法包含三个方程:一个水平方程,一个趋势方程,一个方程将二者相加以得到预测值, 也可以将两者相乘得到一个乘法预测方程
- 当趋势呈线性增加/下降时,用相加得到的方程;
- 当趋势呈指数级增加/下降时,用相乘得到的方程。
- 用相乘得到的方程,预测结果会更稳定,但用相加得到的方程,更容易理解。
from statsmodels.tsa.api import Holt
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear')
plt.legend(loc='best')
plt.show()
# ========
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['Holt_linear']))
print(rms) # 43.056259611507286
效果

- 这种方法能够准确地显示出趋势,因此比前面的几种模型效果更好。如果调整一下参数,结果会更好。
Holt-Winters季节性预测模型
如果每年夏季的收入会远高于其它季节,那么这种重复现象叫做“季节性”(Seasonality)。如果数据集在一定时间段内的固定区间内呈现相似的模式,那么该数据集就具有季节性。
- 5种模型在预测时并没有考虑到数据集的季节性
Holt-Winters季节性预测模型是一种三次指数平滑预测,其背后的理念就是除了水平和趋势外,还将指数平滑应用到季节分量上。
Holt-Winters季节性预测模型由预测函数和三次平滑函数
- ① 水平函数 ℓt
- ② 一个是趋势函数 bt
- ③ 一个是季节分量 st
- ④ 以及平滑参数 α,β和γ
- s 为季节循环的长度,0≤α≤ 1, 0 ≤β≤ 1 , 0≤γ≤ 1。
- 水平函数为季节性调整的观测值和时间点t处非季节预测之间的加权平均值。
from statsmodels.tsa.api import ExponentialSmoothing
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_Winter'], label='Holt_Winter')
plt.legend(loc='best')
plt.show()
# =========
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['Holt_Winter']))
print(rms) # 23.961492566159794
效果

- 趋势和季节性的预测准确度都很高。选择了 seasonal_period = 7作为每周重复的数据。也可以调整其它其它参数,我在搭建这个模型的时候用的是默认参数。
自回归移动平均模型(ARIMA)
另一个场景的时序模型是自回归移动平均模型(ARIMA)。
- 指数平滑模型都是基于数据中的趋势和季节性的描述
- 而自回归移动平均模型的目标是描述数据中彼此之间的关系。
ARIMA的一个优化版就是季节性ARIMA。它像Holt-Winters季节性预测模型一样,也把数据集的季节性考虑在内。
import statsmodels.api as sm
y_hat_avg = test.copy()
fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4), seasonal_order=(0, 1, 1, 7)).fit()
y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
plt.legend(loc='best')
plt.show()
# =======
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['SARIMA']))
print(rms) # 26.052705330843708
效果

- 季节性 ARIMA 的效果和Holt-Winters差不多。根据
ACF(自相关函数)和PACF(偏自相关) 图选择参数。如果你为 ARIMA 模型选择参数时遇到了困难,可以用 R 语言中的 auto.arima。
ARIMA
ARIMA是一种非常流行的时间序列预测方法,它是自回归综合移动平均(Auto-Regressive Integrated Moving Averages)的首字母缩写。
ARIMA模型建立在以下假设的基础上:
- 数据序列是平稳的,即均值和方差不应随时间而变化。通过对数变换或差分可以使序列平稳。
- 输入的数据必须是单变量序列,因为ARIMA利用过去的数值预测未来的数值。
ARIMA有三个分量:AR(自回归项)、I(差分项)和MA(移动平均项)。
- AR项是指用于预测下一个值的过去值。AR项由ARIMA中的参数‘p’定义。“p”的值是由PACF图确定的。
- MA项定义了预测未来值时过去预测误差的数目。ARIMA中的参数‘q’代表MA项。ACF图用于识别正确的‘q’值,
- 差分顺序规定了对序列执行差分操作的次数,对数据进行差分操作的目的是使之保持平稳。像ADF和KPSS这样的测试可以用来确定序列是否是平稳的,并有助于识别d值。
ARIMA计算步骤
通用步骤如下:
- 加载数据:构建模型的第一步当然是加载数据集。
- 预处理:根据数据集定义预处理步骤。包括创建时间戳、日期/时间列转换为d类型、序列单变量化等。
- 序列平稳化:为了满足假设,应确保序列平稳。这包括检查序列的平稳性和执行所需的转换。
- 确定d值:为了使序列平稳,执行差分操作的次数将确定为d值。
- 创建ACF和PACF图:这是ARIMA实现中最重要的一步。用ACF PACF图来确定ARIMA模型的输入参数。
- 确定p值和q值:从上一步的ACF和PACF图中读取p和q的值。
- 拟合ARIMA模型:利用从前面步骤中计算出来的数据和参数值,拟合ARIMA模型。
- 在验证集上进行预测:预测未来的值。
- 计算RMSE:通过检查RMSE值来检查模型的性能,用验证集上的预测值和实际值检查RMSE值。
Auto ARIMA
虽然ARIMA是一个非常强大的预测时间序列数据的模型,但是数据准备和参数调整过程是非常耗时的。在实现ARIMA之前,需要使数据保持平稳,并使用前面讨论的ACF和PACF图确定p和q的值。Auto ARIMA让整个任务实现起来非常简单,因为它去除了我们在上一节中提到的步骤3至6。下面是实现AUTO ARIMA应该遵循的步骤:
- 加载数据:此步骤与ARIMA实现步骤1相同。将数据加载到笔记本中。
- 预处理数据:输入应该是单变量,因此删除其他列。
- 拟合Auto ARIMA:在单变量序列上拟合模型。
- 在验证集上进行预测:对验证集进行预测。
- 计算RMSE:用验证集上的预测值和实际值检查RMSE值。
完全绕过了选择p和q的步骤。
将使用国际航空旅客数据集,此数据集包含每月乘客总数(以千为单位),有两栏-月份和乘客数。
Auto ARIMA如何选择参数
- 仅需用.efit()命令来拟合模型,而不必选择p、q、d的组合,但是模型是如何确定这些参数的最佳组合的呢?Auto ARIMA生成AIC和BIC值(正如你在代码中看到的那样),以确定参数的最佳组合。
AIC(赤池信息准则)和BIC(贝叶斯信息准则)值是用于比较模型的评估器。这些值越低,模型就越好。
Prophet(先知)
Facebook 开源 Prophet: Automatic Forecasting Procedure
- Prophet is a procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well.
- Facebook 时间序列预测算法 Prophet 的研究
Prophet 基于信号分解,本质上将一个时间序列分解为趋势项,季节周期,离散时间事件和外部regressor。
- 趋势项是分段线性的,相比于一般信号分解的线性是创新,也是坑点。因为趋势项如果七拐八拐(过拟合)和周期很容易冲突,而且我感觉这是最容易过拟合的一部分。
- 周期项,对于指定的频率(周期)可以调整傅里叶级数,也是一个创新点,这样就提高了精度。
- 离散时间事件和外部regressor还可以添加外部协变量,虽然是线性,但是有胜于无。
Prophet 中,用户一般可以设置以下四种参数:
- Capacity:在增量函数是逻辑回归函数的时候,需要设置的容量值。
- Change Points:可以通过 n_changepoints 和 changepoint_range 来进行等距的变点设置,也可以通过人工设置的方式来指定时间序列的变点。
- 季节性和节假日:可以根据实际的业务需求来指定相应的节假日。
- 光滑参数:
- t=changepoint_prior_scale 可以用来控制趋势的灵活度
- δ=seasonality_prior_scale 用来控制季节项的灵活度
- v=holidays prior scale 用来控制节假日的灵活度
推论
- 先知(像大多数时间序列预测技术一样)试图从过去的数据中捕捉趋势和季节性。该模型通常在时间序列数据集上表现良好,但在本例中没有达到预期效果。
- 事实证明,股票价格没有特定的趋势或季节性。价格的涨跌很大程度上取决于目前市场上的情况。因此,像ARIMA、SARIMA和Prophet这样的预测技术并不能很好地解决这个特殊的问题。
python -m pip install prophet
import pandas as pd
from prophet import Prophet
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
df.head()
# 重命名
# df = df.rename(columns={'timestamp':'ds', 'value':'y'})
# df['ds'] = pd.to_datetime(df['ds'],unit='s') # 将时间戳转成时间格式(YYYY-MM-DD hh:mm:ss)
m = Prophet() # 模型初始化,默认使用linear增长函数
#m = Prophet(growth='logistic')
m.fit(df) # 开始训练
# 计算预测值:periods 表示需要预测的点数,freq 表示时间序列的频率。
future = m.make_future_dataframe(periods=365)
future.tail()
forecast = m.predict(future) # 预测
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
# 画出预测图
fig1 = m.plot(forecast)
# 画出时间序列的分量
fig2 = m.plot_components(forecast)
# ------------ Prophet默认参数 --------
def __init__(
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
)
AR-Net
AR-Net: A simple Auto-Regressive Neural Network for time-series
传统模型,如用最小二乘拟合的自回归(classic-ar)用一个简洁和可解释的模型来建模时间序列。
- 在处理长期依赖关系时,ClassicAR模型可能会变得难以适应大数据。
最近,序列到序列的模型,如递归神经网络在时间序列中流行起来。然而,对于典型的时间序列数据,可能过于复杂,并且缺乏可解释性。需要一个可扩展和可解释的模型来连接基于统计和基于深度学习的方法。
三个主要结论:
- 首先,AR-Net学习了与ClassicAR相同的ar系数,因此同样可解释。
- 其次,与经典-AR的二次复杂度相比,AR-net的AR过程的计算复杂度是线性的。这使得在细粒度数据中建模长期依赖关系成为可能。
- 第三,通过引入正则化,AR-Net自动选择和学习稀疏的ar系数。这就不需要知道ar过程的确切顺序,并允许学习具有长期依赖关系的模型的稀疏权值。
相关工作
- ARIMA、Prophet:强假设,模型简洁可解释。无法大量数据训练,难以扩展
- RNN:LSTM等,克服可扩展性。无法解释
| 模型 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| ARIMA | 强假设,模型简洁可解释 | 无法大量数据训练,高维数据慢,难以扩展 | |
| Prophet | 强假设,模型简洁可解释 | 无法大量数据训练,难以扩展 | |
| LSTM | 克服可扩展性 | 无法解释 |
论文内容
- 解决的问题(如有实际应用场景请说明)
- AR处理高维拟合(拟合高阶p阶AR)慢
- RNN常用于NLP,CNN于CV
- 常见网络无法解释
可行性
有两个属性使一般神经网络对时间序列建模具有吸引力。
- 首先,神经网络具有一般的非线性函数映射能力,可以逼近任何连续函数。因此,只要有足够的数据,它就能够解决许多复杂的问题。
- 其次,神经网络是一种非参数数据驱动模型,它不需要对生成数据的基础过程进行限制性假设。由于这个特性,与大多数参数非线性方法相比,它不太容易出现模型错误指定问题 [ Hornik:1989:MFN:70405.70408 , Cybenko1989 ] 这是一个重要的优势,因为时间序列建模不显示特定的非线性模式。不同的时间序列可能具有参数模型无法捕获的独特行为。
解决问题的方法(采用什么模型框架等)
- 基本形式的
AR-Net与Classic-AR一样可解释,因为学习的参数几乎相同。 - AR-Net 可以很好地扩展到大p-orders,可以估计远程依赖关系(在高分辨率监控应用程序中很重要)。
- AR-Net 自动选择和估计稀疏 AR 过程的重要系数,从而无需了解 AR 过程的真实顺序。
AR-Net 是一个模仿 Classic-AR 模型的简单神经网络,唯一的区别是如何适应数据。以最简单的形式,与线性回归相同,符合随机梯度下降(SGD)。
- AR-Net 与 Classic-AR 模型 具有相同的可解释性,并且可以扩展到大的p阶。
- 愿景是利用更强大的深度学习时间建模技术,而不通过时间序列组件的显式建模来牺牲可解释性。
AR-Net is now part of a more comprehensive package NeuralProphet.
NeuralProphet( = Prophet + AR-Net)
Neural Prophet是升级版的Prophet
NeuralProphet = Prophet + AR-Net
介绍
【2022-9-3】NeuralProphet:基于神经网络的时间序列建模库
斯坦福、META 推出 NeuralProphet , 一个python库,基于神经网络对时间序列数据进行建模。 它建立在PyTorch之上,并受到Facebook Prophet和AR-Net库的极大启发。
Facebook的Prophet库和NeuralProphet之间的主要区别:
- 使用PyTorch的Gradient Descent进行优化,使建模过程比Prophet快得多
- 使用AR-Net建模时间序列自相关(也称为序列相关)
- 自定义损失和指标
- 具有前馈神经网络的可配置非线性层,
要点
- 分解分量增加了重量级的AR(自回归)
- Pytorch作为backend
使用示例
使用
安装
# pip install neuralprophet
# pip install neuralprophet[live] # notebook 版本
from neuralprophet import NeuralProphet
import pandas as pd
df = pd.read_csv('toiletpaper_daily_sales.csv')
m = NeuralProphet()
metrics = m.fit(df)
metrics = m.fit(df, freq="D")
forecast = m.predict(df)
# 预测未来
df_future = m.make_future_dataframe(df, periods=30)
forecast = m.predict(df_future)
# 可视化
fig_forecast = m.plot(forecast)
fig_components = m.plot_components(forecast)
fig_model = m.plot_parameters()
模型初始化,复杂用法
model = NeuralProphet(
growth="linear", # Determine trend types: 'linear', 'discontinuous', 'off'
changepoints=None, # list of dates that may include change points (None -> automatic )
n_changepoints=5,
changepoints_range=0.8,
trend_reg=0,
trend_reg_threshold=False,
yearly_seasonality="auto",
weekly_seasonality="auto",
daily_seasonality="auto",
seasonality_mode="additive",
seasonality_reg=0,
n_forecasts=1,
n_lags=0,
num_hidden_layers=0,
d_hidden=None, # Dimension of hidden layers of AR-Net
ar_sparsity=None, # Sparcity in the AR coefficients
learning_rate=None,
epochs=40,
loss_func="Huber",
normalize="auto", # Type of normalization ('minmax', 'standardize', 'soft', 'off')
impute_missing=True,
log_level=None, # Determines the logging level of the logger object
)
AutoBNN
2024年3月28日,谷歌发布了开源时间序列预测库 AutoBNN。
AutoBNN 结合传统概率方法的可解释性和神经网络的可扩展性和灵活性,能够自动发现可解释的时间序列预测模型,提供高质量的不确定性估计,并可有效扩展以用于大型数据集。
它基于组合核高斯过程和组合贝叶斯神经网络,使用加权求和等技术进行结构发现。
- 该库用 JAX 实现,可与 TensorFlow 概率集成。
- AutoBNN 旨在为社区提供一个强大而灵活的框架,用于构建复杂的时间序列预测模型。
transformer
时序预测模型
- Transformer 模型:
PatchTST(2023)、Crossformer(2023)、FEDformer(2022)、Stationary(2022)、Autoformer(2021); - 线性预测模型:
TiDE(2023)、DLinear(2023)、RLinear(2023); - TCN 系模型:
TimesNet(2023)、SCINet(2022)。
iTransformer
现实世界的时序数据往往是多维的,除了时间维之外,还包括变量维度。
- 通过分析大量预测场景,多变量时间序列上,Transformer的建模能力没有得到充分发挥。
- 多变量时序数据非常广泛,每个变量代表一条独立记录的序列,
- 不同的物理量,例如气象预报中的风速,温度,气压等指标;
- 不同的主体,例如工厂的不同设备,各个国家的汇率等。
- 因此,变量之间一般具有不同的含义,即使相同,其测量单位以及数据分布也可能存在差异。
然而,现有模型没有充分考虑上述变量差异。
【2024-3-14】蚂蚁、清华提出 iTransformer 考虑多维时间序列的数据特性,未修改任何Transformer模块,而是打破常规模型结构,在复杂时序预测任务中取得了全面领先,试图解决Transformer建模时序数据的痛点。
- 论文地址:ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING
- 代码实现:Time-Series-Library
- 解读
Inverted Transformer:无需修改任何模块,倒置建模多变量时间序列。
- 通过倒置Transformer原本的模块,iTransformer 先将同一变量的整条序列映射成高维特征表示(Variate Token),得到的特征向量以变量为描述的主体,独立地刻画了其反映的历史过程。
- 此后,注意力模块可天然地建模变量之间的相关性(Mulitivariate Correlation),前馈网络则在时间维上逐层编码历史观测的特征,并且将学到的特征映射为未来的预测结果。
- 相比之下,以往没有在时序数据上深入探究的层归一化(LayerNorm),也将在消除变量之间分布差异上发挥至关重要的作用。
多变量时序数据
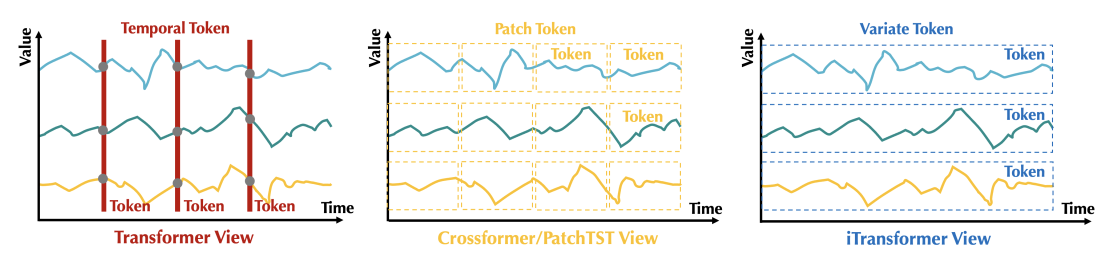
基于 Transformer 进行时序分析,重新考虑词的构建方式:
- (1)
Temporal Token: 以往模型的主流做法,将所有变量同一时刻的时间点表示为词,获得以时间点为单位的词序列。 - (2)
Patch Token:在时间维度上对序列进行分块,扩大的感受野包含局部序列变化,从而获得语义性更强的词。
iTransformer 着眼于变量的整体性,提出 Variate Token,关注以变量为主体的关联建模,适合变量较多且互相关联的多维时序数据。
iTransformer基于仅编码器(Encoder-only)结构,包括嵌入层(Embedding),映射层(Projector)和若干Transformer模块(TrmBlock),可堆叠深度来建模多变量时序数据。
iTransformer 在多维时序预测基准上实验,部署在蚂蚁线上服务负载预测场景,涵盖19个数据集,76种不同的预测设置。
对比10种深度预测模型,包含领域代表性
- Transformer 模型:PatchTST(2023)、Crossformer(2023)、FEDformer(2022)、Stationary(2022)、Autoformer(2021);
- 线性预测模型:TiDE(2023)、DLinear(2023)、RLinear(2023);
- TCN 系模型:TimesNet(2023)、SCINet(2022)。
iTransformer 在基准比较中显著超过此前领域最优效果
iTransformer 是建模多变量时序数据的通用框架。
- 提升预测效果:在预测效果上,每个模型相较倒置前均取得了大幅度的提升,也证明iTransformer可以受益于高效注意力组件的相关研究。
- 受益于变长观测:以往Transformer模型的效果不一定随着输入的历史观测的变长而提升,在使用倒置框架后,模型随着历史观测长度的增加,呈现明显的预测误差降低趋势。
- 泛化到未知变量:通过倒置,模型在推理时可以输入不同于训练时的变量数,结果表明该框架在仅使用部分变量训练时能够取得较低的误差,证明证明倒置结构在变量特征学习上的泛化性。
应用
LTV
用户的 LTV(生命周期价值)是游戏从用户获取到流失所得到的全部收益总和。在游戏行业,LTV 是大多数运营策略的最终衡量指标,也是一个游戏的价值体现,被广泛应用于广告推量投放的决策行为中。
LTV 定义为: 用户生命周期价值(Life Time Value)
其值大小由两部分决定:
- a. 生命周期,即 Lt 部分
- b. 价值,即 V 部分
放到产品中,即单个用户在产品中存活的时间乘以用户在存活时间期间内单位时间所付的费
用通俗的表达就是:
LTV = 单用户存活 Days *ARPU(per Day)= 所有人在总存活期内总付费 / 所有人的人数
由于用户的存活行为是连续生成的,同时付费行为也是伴随存活行为连续生成的,所以 LTV 是一个【连续变化的积累值】,绝不是一个固定值。
游戏留存预测
【2021-12-13】游戏用户 LTV 预测实践
游戏广告推量领域,如何进行高质量的推量投放以达到用户持续性增长的目标,是行业的普遍痛点。
- 传统游戏广告推量行业中,投放及运营人员根据几款游戏的历史 LTV 数据,凭借长久的行业经验,对游戏未来的发展性价值进行评估;继而调整相应的游戏投放权重与力度,或进行相应的运营策略(如:开展活动)。
- 随着市场规模扩大、用户群体复杂化,依赖行业经验的人为决策难度越来越大,对游戏及用户群体的价值进行准确评估的可行性也愈来愈低。
- 因此,对于依赖数学算法的、可信的、拥有相对稳定准确性的 LTV 预估方法的开发研究,在游戏行业得到越来越多的重视。
LTV 作为衡量游戏中用户的价值的重要指标,在游戏评级、用户质量评级、用户增长等应用中具有至关重要的参考价值。
历史的 LTV 数据与当前的 LTV 数据仅体现游戏发展至今的市场价值,而该游戏未来的市场效益是否能持续稳定发展、是否会陷入瓶颈甚至停滞,往往不得而知。
相关人员仅依赖行业经验进行判断与决策将不可避免地伴随主观风险;加入数据分析与算法模型作为决策辅助可以降低决策风险、提高决策效益。
不同游戏的 LTV 直接影响其 ROI(投资回报率),体现游戏的市场价值。以游戏 LTV 的发展趋势与幅值为参考指标,对游戏进行评级,可以帮助游戏广告投放人员合理地调整不同游戏的资源投放比例;以用户群 LTV 的发展趋势与幅值为参考指标,对用户群的价值评估,可以帮助游戏广告投放人员合理地调整用于不同用户渠道的资源投放比例。
某些游戏在发布初期表现良好,之后在某一时间玩家开始大量流失,收益增长停滞,迅速进入瓶颈期。这样的发展趋势在初期也许稍显端倪,却容易被表面的良好数据掩盖(如,初期具有较高的留存率,但已出现异常的衰减情况)。此时运营人员再针对此情况商讨、研究、开发相应的运营策略,往往难以及时降低玩家流失。可预测未来 LTV 的算法模型可以为运营方提供游戏 LTV 在未来某时间段的潜在停滞风险,帮助运营方及时甚至提前做好调整运营策略的准备。
刚上线的产品,如何预测未来 LTV?
- 产品上线后,根据已有的 LTV 数预测未来 LTV 走势和节点值,我们将会应用到——时序预测。
时序预测的思路:围绕四个部分来构建预测算法:趋势(T)、季节(S)、周期(C)、不规则波动(I)
时序预测的模型分为加法模型和乘法模型两种:
- 加法:
Y=T+S+C+I - 乘法:
Y=T*S*C*I
考虑到 LTV 曲线本身的特性
- 其
趋势(T)的影响占比非常非常大,而季节、周期和不规则波动影响非常非常小 - 所以从运营人员的角度出发,简化为
Y=T,直接找出符合 LTV 趋势的函数来做拟合,把时序预测领域的事情又变回为函数拟合的事情。
当然,可以使用更多更复杂的时序预测方法来预测未来的短期 LTV,但是通过函数拟合找到描述趋势的函数表达式,可以更有效的预测未来更长时间段内的节点 LTV 值。
为了更细致地把握留存率的变化对 LTV 的影响,我们试用通过拟合留存率来预测 LTV 的算法。
- 首先拟合玩家的留存率,并预测出未来留存率的情况;
- 再对留存率进行积分得到 LT(生命周期);
- 假设 ARPU 变化稳定(即使用其平均值),由 LT 乘 ARPU 即可得到 LTV 的预测值。
此算法通过优先拟合留存率,将各因素(如:活动)对留存率的直接影响体现出来,可以一定程度预测未来的留存率波动对 LTV 的影响。但是对于 ARPU 值变化较明显的情况不适用。
仅仅使用幂函数对留存率进行拟合的方式适用于 arpu 稳定的游戏。如果游戏的 arpu 存在波动,则直接用均值代替会产生预测误差为了能将 ARPU 变化对 LTV 的影响体现,同时从宏观上修正拟合留存率时造成的 LTV 预测值和 LTV 真实值之间的偏差
参考
- 【2021-12-30】游戏用户 LTV 预测实践
- 【2024-7-25】游戏用户生命周期价值预测模型综述
预测算法
- 曲线拟合法
- 留存 ARPU 拆解法
- 基于机器学习的 LTV 预测
(1)传统模型
- RFM模型
- RFM(最近一次消费、消费频率和消费金额)模型作为一种经典的用户细分和价值评估工具
- BG/NBD模型
- BG/NBD模型(结合Gamma-Gamma模型),也称为Beta-Geometric/Negative Binomial Distribution模型。它由Peter Fader、Bruce Hardie和Ka Lok Lee创建,发表于2005年期刊《营销科学》文章《Counting Your Customers the Easy Way: An Alternative to the Pareto/NBD Model》。
(2)机器学习模型
- 两阶段随机森林模型
- 2016年来自Ali Vanderveld等人的论文《An Engagement-Based Customer Lifetime Value System for E-commerce》第一次提出用两阶段的随机森林模型预测用户生命周期价值。
(3)深度学习模型
- ZLIN
- 使用深度神经网络模型预测用户生命周期价值的论文很多,最有代表性的是2019年来自Xiaojing Wang等人的《A Deep Probabilistic Model for Customer Lifetime Value Prediction》,从事用户生命周期价值预测接触的第一篇相关论文。
- 该论文使用深度神经网络模型,因为深度神经网络在性能上有竞争力,并且能够捕捉预测特征与用户生命周期价值之间复杂和非线性的关系。
(4)Transformer模型
- Transformer
- Transformer 模型代表了自然语言处理和人工智能领域的一项突破性进展,它在自然语言处理(NLP)领域取得了显著的成就,并随着GPT等大模型的火爆而出圈,被越来越多的人所了解。Transformer模型最初由Google在2017年的论文《Attention Is All You Need》中提出。它很快取代了循环神经网络(RNN)和卷积神经网络(CNN),成为NLP任务的主流模型。
- Transformer模型基于自注意力机制(Attention Mechanisms),完全摒弃了循环和卷积的结构,以其独特的自注意力机制和并行计算能力,允许模型同时处理序列中的所有元素,而不受序列长度的限制,解决了传统模型在处理长序列时的长距离依赖问题和计算效率问题,从而在各种NLP任务中取得了优异的性能。Transformer模型的成功也促进了各种Transformer模型变体的开发,每种变体都针对特定的应用场景进行了定制。
- MDLUR
- 对于用户生命周期价值预测最新并且最成功的模型是 2023年8月Junwoo Yun等人发表的《Multi Datasource LTV User Representation (MDLUR)》。根据论文的表述,该模型正是采用了最新的Transformer模型架构,并达到了行业内SOTA的水平。SOTA
- MDLUR模型的新颖之处在于其能够利用多种数据模态和频谱(multiple data modalities and spectrums),并针对每个数据源量身定制单独和独特的模型架构,主要数据源包括用户信息、画像和行为序列等各种数据(用户画像数据是指时间序列的用户状态数据)。每个数据源的输出通过SAE(Skip-connected Autoencoder)进行聚合和压缩,从而得到一个丰富而强大的用户数据表示,它包含了各个维度的信息。这种方法使MDLUR模型在预测任务中表现出色,特别是用户生命周期价值预测,并提供了对玩家行为更深入的理解
- 代码 Bagelcode_MDLUR
曲线拟合法
在游戏行业中,曲线拟合 LTV 算法是最普遍的一种,其中以逻辑回归拟合法和幂函数拟合法应用最广。
- 根据前 7 日的历史 LTV 数据,拟合出未来 90、180 乃至 365 天的 LTV 预测值。
留存 ARPU 拆解法
拆解成:留存率预测+ARPU预测
(1)留存率预测
相比于业内普遍的幂函数直接拟合方法,考虑到积分系统具有更高对鲁棒性,采用幂函数拟合 LT(用户生命周期,即留存率的积分),再对预测 LT 求微分得到预测留存率,来降低由运营活动等原因造成的留存率波动对留存率预测的影响,提升预测的稳定性。
在我们的场景中,这种方法将 30 天留存率的平均预测准确率由 78%提升至 92%,并在 365 天留存率的预测中平均达到 77%的准确率。
(2)ARPU 预测
ARPU 预测相比留存率的预测则显得更为复杂,不同游戏不同渠道不同用户群体的 ARPU 表现参差不齐,需要结合实际业务场景进行算法选择。
- a) 平均 ARPU
- b) 活动修正 ARPU
(3)基于机器学习的 LTV 预测
应用场景中,批量获取到多个游戏的长期运营活动信息做辅助并不是一件容易的事,因此采用了一种基于机器学习的 LTV 预测方法。
特征工程
筛选出共两类特征:游戏基础信息特征和用户短期付费信息特征。
- 前者包括游戏 ID、类型等游戏基础信息
- 而后者包括历史留存、LTV 等付费信息。
模型选型
提取多种类且多数量的游戏信息,其不同特征的重要性各不相同。
因此 采用 Xgboost 模型,其对于特征的透明特性可以在模型中分类出重要性低的特性,给予较低的权重,避免过拟合。
架构设计
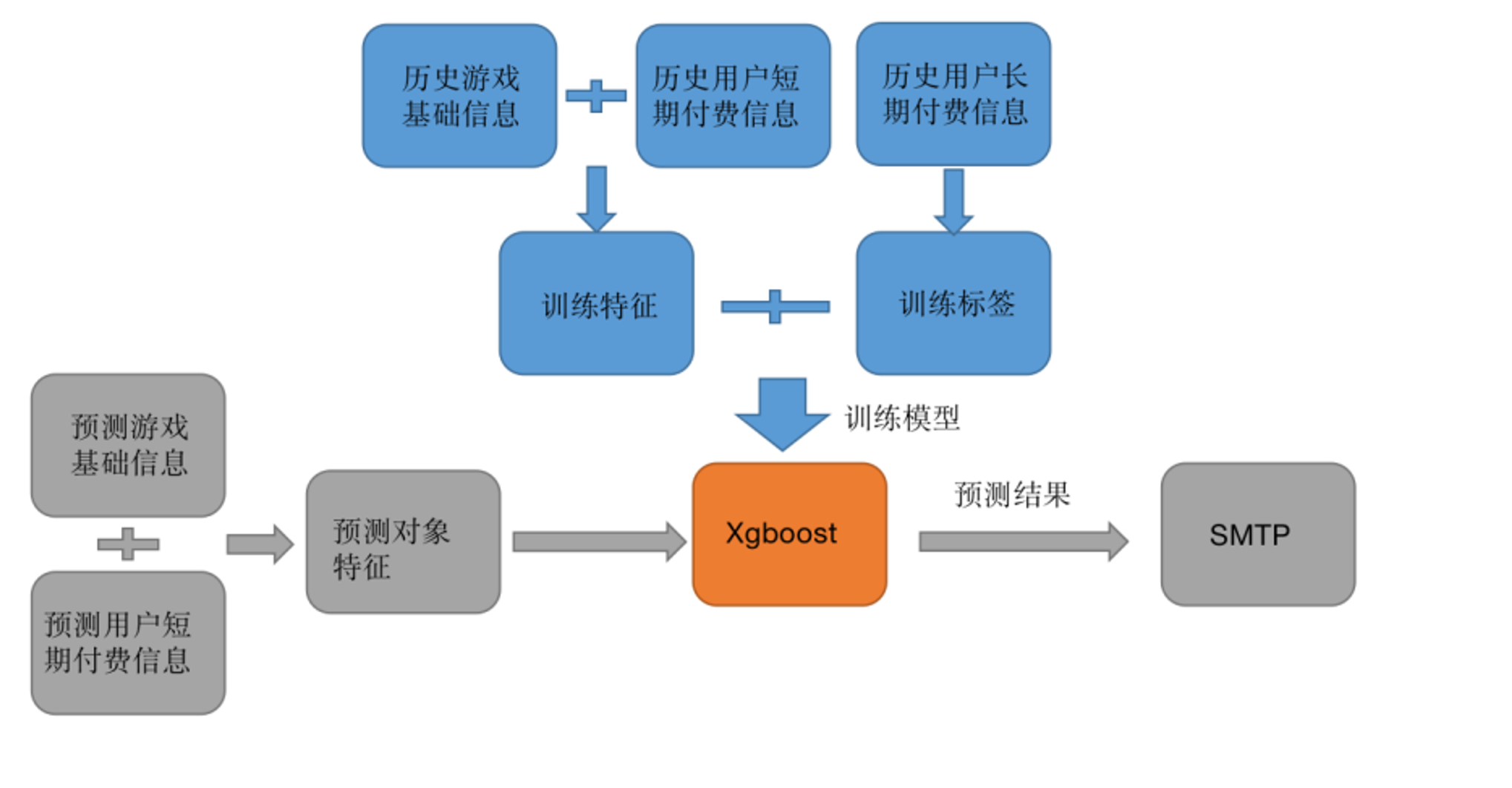
过特征工程提取、结合游戏基础信息和用户短期付费信息,得到训练特征集,使用用户长期付费信息(如 365 天 LTV)作为训练标签,输入到 Xgboost 模型训练模型。
对于待预测对象同样进行特征工程得到预测对象的特征集合输入训练后的模型,Xgboost 模型将输出预测结果并通过 SMTP 服务器传送到下行链路。
场景中,这个模型对 30 天 LTV 平均预测准确率达到 90%,对 365 天 LTV 平均预测准确率达到 71%。
视频观看预测
预测短视频的用户观看时间
【2024-12-28】复旦、快手论文提出 Generative Regression(GR) 新型预测模型,用于预测短视频推荐系统中用户的观看时间。
GR模型通过结构化离散化和序列生成方法,将连续的观看时间预测问题转化为序列生成问题,从而无损重建原始值并保持预测准确性。
- 它利用数据驱动的词汇表构建方法和标签编码策略,提高了模型的泛化能力,并引入了课程学习和嵌入混合策略来加快模型训练。
实验结果表明,GR模型在多个数据集上的性能显著优于现有技术,并且在快手平台上的在线A/B测试中也显示出提高用户观看时间的潜力。
此外,GR模型还成功应用于生命周期价值(LTV)预测任务,显示了其作为一般回归问题解决方案的潜力。
定价系统
机票动态定价
机票价格一般随着时间的推移而波动
机票动态定价旨在构建机票售价策略以最大化航班座位收益。
动态定价是航空公司收益管理的一种手段, 起源于70年代的美国
- 当时,廉价航空公司进入市场,并凭借劳动力成本低,操作简单,以及技术变革等优势,以远低于全服务航空公司的票价来获利。这也吸引了大部分对价格敏感的,以休闲为目的飞行客户。
全服务航空公司提供更稳定且频繁的行程安排,地域范围更广,且具有较好的声誉。
- 常旅客户对于价格并不敏感,而更看重行程是否便捷稳定
所以对于全服务航空公司,这部分市场并未受到很大波及。尽管如此,由于总体客流量的减少而造成的收入损失还是严重影响了各大航空公司的生计。
为了重新抓住休闲飞行客户,全服务航空公司必须想出一些革新性的解决方案,因为与低成本的廉价航空公司进行“全面价格战”几乎是自杀式的。
美国航空营销副总裁Robert Crandall 是革新者。
机票销售中,由于飞机大部分成本(资本成本、工资、燃料)固定,一架飞机上增加一位乘客,所增加的成本(边际成本)仅仅相当于一份飞机餐的成本,所以只要座位是空的,且票价高于边际成本,就应销售出去。
美国航空便开始利用飞机上的余位与廉价航空公司进行“价格战”,通过以较低的价格销售余位,并对折扣机票的数量及退改政策进行一定的限制,不仅保留了原有的常旅用户,还重新吸引了许多休闲客户。
问题
- 起初,美国航空的折扣机票投放方案是在每趟航班上设置一定比例的折扣机票座位。
- 但同一比例的座位并不适用于所有航班。
- 客户对机票的需求是会随着不同的日子及一天中的不同时间而变化。
- 比如有一些航班的需求十分火热,航司其实根本没有理由再给机票打折。
所以航空公司需要一套完备的系统及算法, 来计算不同航班在不同时间价格与需求的关系,以获取最大利润。
定价算法
简易动态定价:运用价格歧视的策略,通过动态价格来调节控制波动的需求,并帮助航空公司获得最大的利润。
- 价格歧视:对不同群体制定不同价格,比如对商务用户和休闲用户采取不同的定价。

价格歧视策略相比于单一的定价策略存在明显的优势。
那么航司要怎么对客户群体进行分类,从而做到价格歧视呢?
客户对机票的需求与时间是存在一定的关系的,且越逼近起飞时间,机票余量减少越快,即需求越大。
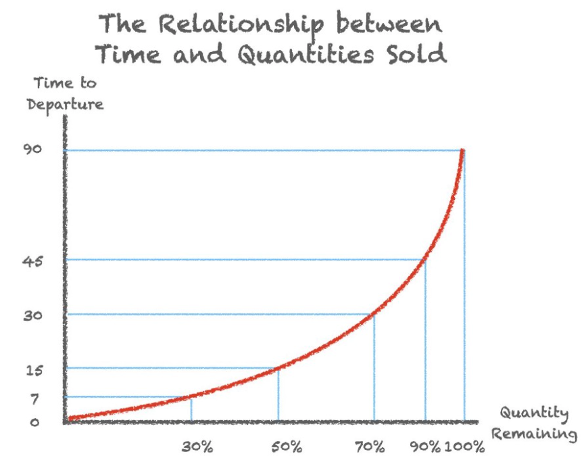
通过顾客对时间灵活性的偏好程度对顾客进行分类,实施价格歧视策略
- 比如买机票买得迟的人 (商务客户) 往往会比买机票买得早的人 (休闲客户)更在意时间的灵活性。
依据机票的需求变化,找到一个关于票价的时间序列,来实现关于时间的动态定价。
一个简单的方法是通过航班的历史数据分别生成票价与需求的函数和需求与时间的函数,然后将这两个函数整合最终获得一个票价与时间的函数,即一个关于票价的时间序列。
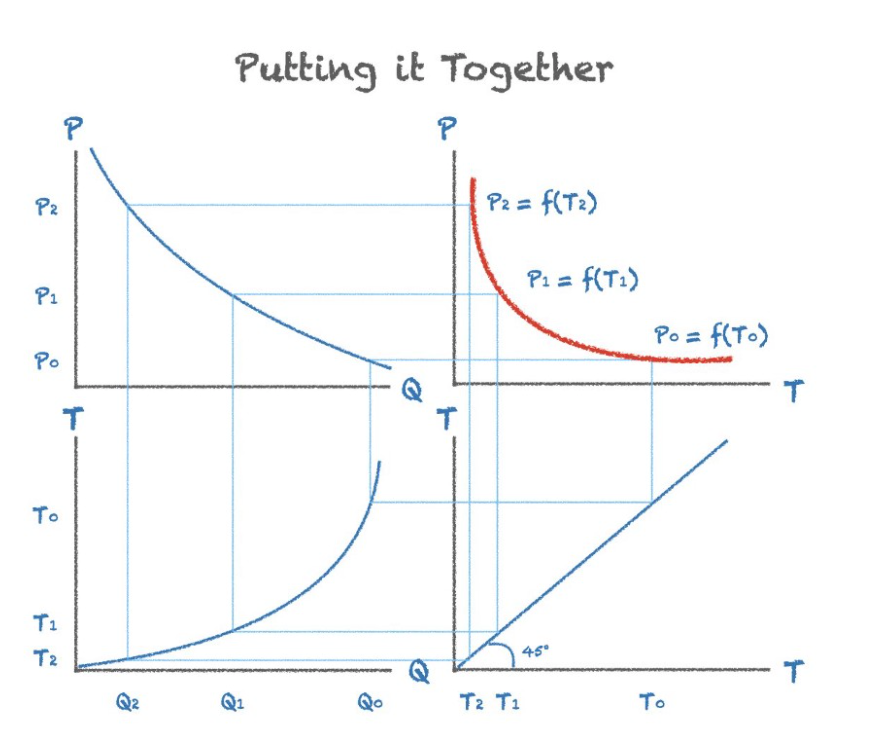
航司使用的动态定价模型复杂得多
- 需求预测: 航班需求可能会受到该航班多种因素影响,如飞行的航线,日期,季节,起飞的具体时间,竞争航司的机票价格等多个变量
随机森林
机票价格受多种因素影响,包括季节性需求、航班时刻、竞争对手价格、燃油成本等。
传统的固定价格策略已难以适应瞬息万变的市场环境。因此,引入动态调整算法,根据实时数据灵活调整价格,对于提升航空公司竞争力具有重要意义。
实现案例
(1)【2024-11-5】Python实现机票价格动态调整算法:优化旅行成本与收益
算法设计思路
- 数据收集:整合历史销售数据、实时预订信息、竞争对手价格等多元数据。
- 特征工程:提取影响价格的关键特征,如提前预订天数、航班满载率、节假日等。
- 模型选择:采用机器学习算法,如随机森林、梯度提升树等,预测未来需求。
- 价格调整策略:基于预测结果,制定动态价格调整规则,如需求旺盛时提价,需求低迷时降价。
- 反馈机制:实时监控价格调整效果,不断优化模型参数。
上述动态调整算法,其在国内热门航线上的平均票价提升了15%,同时旅客满意度并未下降。
- 旅游旺季,算法成功捕捉到需求激增的信号,及时上调价格,增加了收益;
- 而在淡季,通过降价策略吸引了更多旅客,提升了航班上座率。
(2)Flight-price-predict-by-python
项目自带程序运行需要的所有的包(是一个虚拟环境),使用Pycharm打开即可运行。
运行方式
- 直接运行Predict.py文件即可
数据
- Data文件夹下三个航班,是2019-1-1至2019-12-31的所有航班的价格及对应的观测日期。
访问: 127.0.0.1:5000 得到测试数据,方便前端通过接口获得值
- 浏览器输入
127.0.0.1:5000/?dep_city=PEK&arrive_city=HGH便可以返回2020-1-1至2020-12-31日,从北京到广州所有航班的最低价格,及观测日期还有往前20天,往后40天的机票价格数据。
强化学习
现有机票定价算法都建立在提前预测各票价等级的需求量基础之上,会因票价等级需求量的预测偏差而降低模型性能。
论文提出基于策略学习的机票动态定价算法,不再预测各票价等级的需求量,而是将机票动态定价问题建模为离线强化学习问题。
- 【2021】基于策略学习的机票动态定价算法
通过设计定价策略评估和策略更新的方式,从历史购票数据上学习具有最大期望收益的机票动态定价策略。同时设计了与现行定价策略和需求量预测方法的对比方法及评价指标。
在两趟航班的多组定价结果表明:相比于现行机票销售策略,策略学习算法在座位收益上的提升率分别为30.94%和39.96%,且比基于需求量预测方法提升了6.04%和3.36%
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
