混合推理
LLM推理
OpenAI O 系列发布之后,Inference Time Scaling 的模型一直备受关注,这种具有长思考能力的模型倍称为:Large Reasoning Model(LRM)
详见站内专题 大模型推理思考
为什么要混合推理
长思考能力指 Long Chain-of-Thought(LongCoT)
思考更长效果更好,但推理耗时更长。然而并不是所有问题都要长思考
人类处理问题,简单问题快速回答,复杂问题才要打草稿思考后再给出回复。
快慢思考(fast-slow-thinking)或混合思考(thinking-nonthinking mixed)】方式减少不必要的推理消耗而不损害模型的最终效果, 成了业界新方向。
实现方法
混合
【2025-5-25】自适应快慢思考推理模型(Adaptive Reasoning Model):Qwen3混合思考->字节AdaCoT->清华AdaptThinking
混合思考模式
- 阿里巴巴通义实验室的 Qwen3 混合思考方式
- 字节跳动 Seed 提出的 AdaCoT 的自适应(adaptive)CoT 方式。
- 【2025-5-19】清华大学提出 AdaThinking 框架
备注:AdaCoT 和 AdaThinking 出发点几乎一模一样,都可用下图表示(from adathinking)。
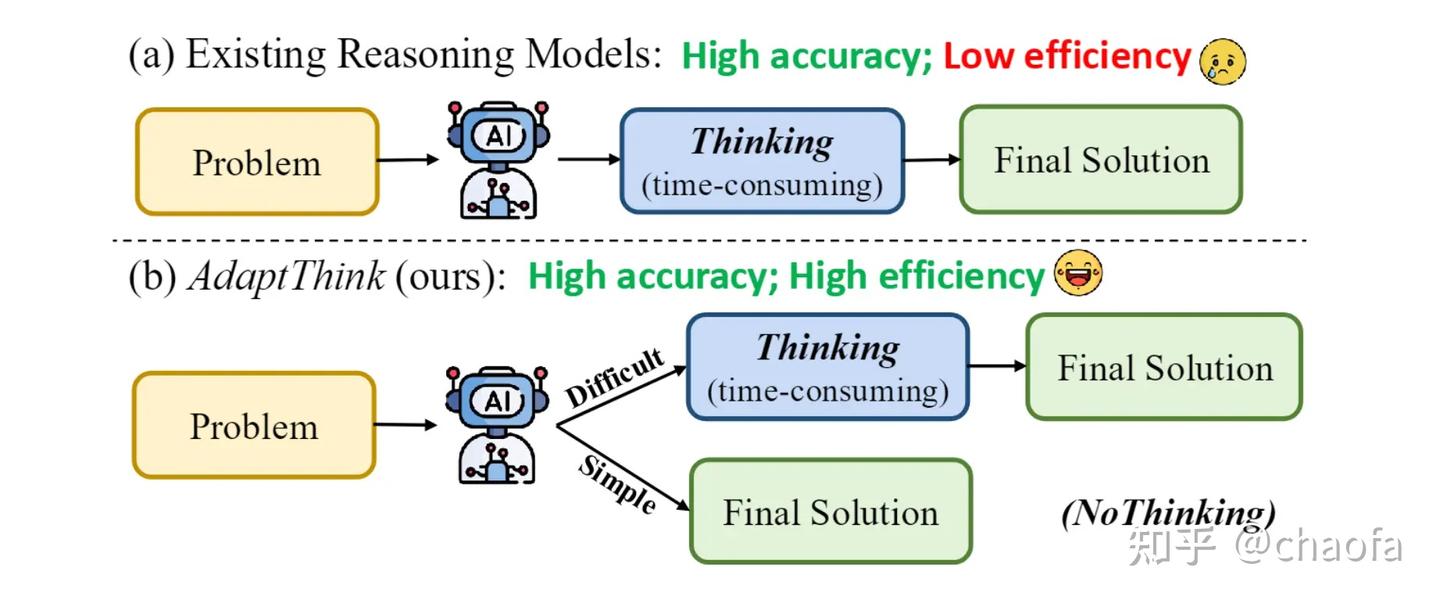
- Qwen3 主要通过 SFT训练 让模型天然具备遵循【思考、非思考】模式,但需要人为控制。
AdaCoT和AdaThinking让模型自己决定,简单问题不用思考,复杂问题可以思考。- 其中
AdaCoT通过把优化目标转换成Paretooptimization,然后利用 PPO 算法进行优化 AdaThinking也是通过 PPO 算法优化,把问题视为:尽量少触发 CoT 的情况下,新模型的回复大于【旧模型回答】且大于【Thinking 模式模型的回答】。
- 其中
Qwen 3 混合推理
Qwen3 的整体训练流程:四阶段,思考混合模式(Thinking Mode Fusion)位于第三个阶段
字节Seed AdaCoT
字节Seed AdaCoT 把是否要输出 CoT(思考过程 Thinking)当做多目标帕累托最优的方式。
模型主动触发思考和非思考过程,而不是像 qwen3 一样人为控制。
【2025-5-19】清华 AdaptThink
和 Seed-AdaCoT 这个文章出发点一样
【2025-5-22】推理or不推理?AdaptThink实现思维模式的自动切换
【2025-5-19】清华KEG实验室 论文 paper 让推理模型学会何时推理、何时不推理,并自行决策。
实验
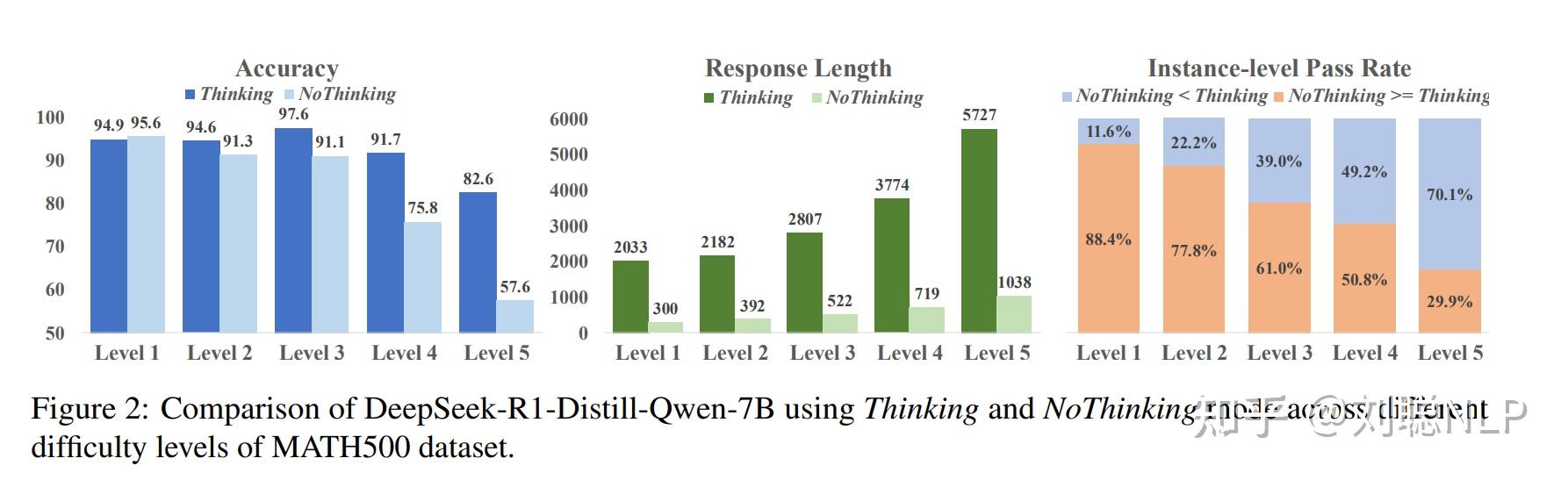
- 让 DeepSeek-R1-Distill-Qwen-7B 模型使用 NoThinking 和 Thinking 两种模式,预测5个难度等级的MATH500问题
结果
- 在1-3级问题上,NoThinking 和 Thinking 效果相当
- 甚至在1级上NoThinking效果还更优,但回答长度明显变短。
基座模型选择 DeepSeek-R1-Distill-Qwen-1.5B 和 DeepSeek-R1-Distill-Qwen-7B,训练框架为VeRL。
训练上下文长度、batch size 和学习率分别为 16K、128 和 2e-6。AdaptThink 中的超参数K、 δ和 ϵ 分别为 16、0.05 和 0.2。
在GSM8K、MATH500和AIME 2024上进行评测,如下表所示,与原始的1.5B和7B模型相比,AdaptThink平均响应长度分别降低了53.0%和40.1%,,同时平均准确率分别提高了2.4%和2.3%。
AdaptThink 核心优化:
- 约束优化目标:在保证整体性能不下降的情况下,鼓励模型选择NoThinking模式。
- 重要性采样策略:在在线策略训练期间,平衡 Thinking 和 NoThinking 样本,探索和利用两种思考模式。
附录
- 模型 DeepSeek-R1-Distill-Qwen-1.5B
- 代码 THU-KEG/AdaptThink
- 数据 AdaptThink-1.5B-delta 系列
-
训练框架 VeRL
多模型决策
如今的 AI 应用,大多依赖单一模型推理,即用户问题会直接被送入某个固定的 LLM 中进行回答。
这种方式虽然简单,但却意味着:
- 简单问题可能导致算力浪费;
- 复杂问题又可能因模型能力不足而回答错误。
MoE
单个问题自动路由到对应模型
MoE 在 Token-level 路由
LLM Router
“LLM Router” 成为 AI 系统的新前台大脑:
- 不同于 Token-level Router(如 MoE),LLM Router 在 Query-level 层面进行路由,它能够判断一个问题的复杂度、匹配最合适的模型,甚至动态组合多个模型完成推理。
然而,现有的 LLM Router(如 GraphRouter、RouterDC 等)大多采用单轮决策机制:
- 给定一个问题,只路由到一个候选模型完成回答,这种单轮路由机制难以处理多跳推理或跨领域的复杂任务。
Router-R1:让 Router 本身成为一个「会思考的 LLM」
【2025-10-16】首个多轮LLM Router问世, Router-R1可让大模型学会「思考–路由–聚合」
伊利诺伊大学厄巴纳-香槟分校(UIUC)NeurIPS 2025 上发布新作,首个多轮 LLM Router 框架 Router-R1,让 LLM 不止会 “回答”,还会 “思考、调度与协调其他模型” 来达到可控的性能与成本平衡
- 论文 Router-R1:Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning
- 代码 Router-R1
Router-R1 核心创新:让 Router 自身成为一个具备推理能力的 Policy LLM。
Router-R1 不再只是一个 “Query 分发器”,而是一个拥有思维链,能主动进行 “思考 — 选择模型 — 聚合” 的智能体,可以在思考,路由,聚合几种行为之间反复切换并进行多轮路由迭代,逐步构建最终答案:
- 1️⃣ Think(思考):在接收到 User Query 后,Router-R1 会首先执行 “思考” 阶段进行内部推理分析,并判断是否需要外部信息进行辅助;
- 2️⃣ Route(路由):若发现需要额外信息,Router-R1 则触发 “路由” 指令根据每个 LLM 的 Descriptor Prompt 动态调用合适的外部候选模型(如 Qwen、LLaMA、Gemma、Mixtral 等)进行回答子问题;
- 3️⃣ Aggregate(聚合):外部模型调用的回复结果返回后继续插入 Policy LLM 的 Evolving Context 进行聚合,并继续进行后续的多轮推理逐步生成最终答案。
这种 “思考–路由–聚合” 的交替机制,使 Router-R1 能充分利用不同 LLM 的互补优势(例如一个擅长数学推理、另一个擅长知识检索),潜在实现真正的多模型协同推理。
Router-R1 将整个多轮路由过程形式化为一个序列决策问题,并通过强化学习训练 Router 使之学会在复杂决策空间中优化 Performance-Cost Trade-off。论文中设计了三类直观的奖励函数:
- 1️⃣ Format Reward:输出 Format 正确性奖励,模型输出严格遵守如
、 等格式约束,防止训练早期生成无效文本。 - 2️⃣ Final Outcome Reward:结果正确性奖励,采用 Exact Match(EM)指标衡量生成答案与标准答案是否完全一致,直接激励 Router 输出正确结果。
- 3️⃣ Cost Reward:成本约束奖励,Router-R1 创新地引入了计算成本奖励机制,根据被调用模型的参数规模及输出 Token 数设计反比例奖励函数
7 个 QA Benchmark 上对 Router-R1 进行了系统评测,涵盖单跳与多跳推理任务,包括 NQ、TriviaQA、PopQA、HotpotQA、2WikiMultiHopQA、Musique 和 Bamboogle。Router-R1 仅在 NQ 与 HotpotQA 数据集上进行训练,在其余数据集上执行 Out-of-domain Evaluation。
- 当 α=0 时(即只优化 performance 不考虑 cost),Router-R1 在所有数据集上达到了综合最强的性能,击败了如 GraphRouter/RouterDC 等单轮路由方法,并展现出了对 Unseen Dataset 的较强泛化性。
- 当继续改变超参 α 来探究性能成本权衡时,随着 α 增加,调用成本显著下降,为可控成本的 LLM 智能调度策略开辟了新的范式。
Router-R1 不是又一个 “更大的模型”,而是让多个模型协同工作的新范式。Router-R1 通过强化学习,让 LLM 从 “单一回答者” 进化为「多智能体协调者」,在性能与成本之间实现动态平衡。得益于此,Router-R1 能在减少算力和成本开销的同时保持高质量输出,降低大模型部署的环境与资源压力。Router-R1 天然支持模型重用与模块化组合,只需添加新模型描述即可快速集成,为构建可扩展、多模型共生的 AI 基础设施奠定了基础。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
