在线蒸馏 OPD
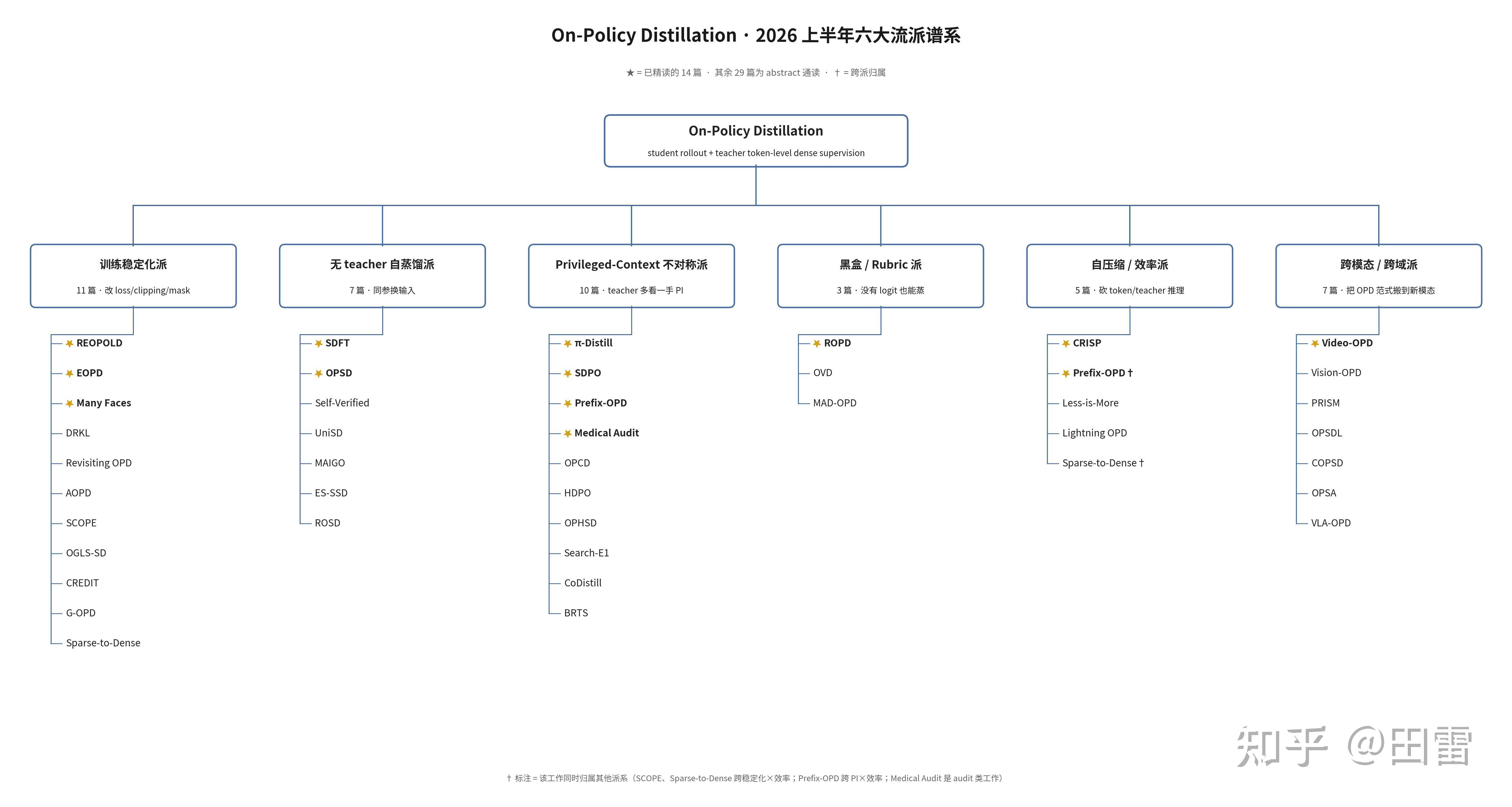
opd综述: 【OPD综述】三万字长文精讲 2026 上半年的 On-Policy Distillation
【2026-4-16】搞懂大模型在线蒸馏OPD:成败关键、底层机理与工程方案
- 论文:《Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe》
- 代码地址 OPD
论文核心创新点总结
- 首次系统揭示OPD成败的两大必要条件(思维对齐+新知识),打破“强老师必成”的固有认知;
- 拆解OPD的token级底层机理,证明成功源于高概率token的渐进对齐,且97%–99%的收益集中在共享token;
- 提出两个可工程化的修复方案(离线冷启动、老师对齐提示词),直接解决OPD失败问题;
- 指出OPD的长文本局限,明确其适用边界,为未来混合蒸馏路线提供指导。
在线蒸馏OPD不是“越大越好”的暴力魔法,而是“思维对齐、知识增量、局部监督”的精细艺术。 想让小模型高效追上大模型,关键就3点:让老师和学生“同频”(思维对齐),让老师有“真东西”(新知识),让学生“精准学”(聚焦共享高概率token)。
离线蒸馏
传统离线蒸馏:“看录像学习”
流程:
- 老师先完成所有任务、生成标准答案,学生全程照着老师的“录像”模仿学习。
核心问题:
- 暴露偏差——学生平时练的是老师的正确轨迹,一旦自己生成时出错,后续会一步步错下去,无法自我修正。
离线蒸馏 vs 在线蒸馏
【2026-7-9】On-Policy Distillation(OPD):为什么越来越多的大模型开始采用它
传统知识蒸馏(Supervised KD,Hinton et al., 2015)通常采用离线(Offline)范式。
- 核心流程: 利用 Teacher 模型在给定输入x下生成(或采样)高质量的序列y,随后指导 Student 模型进行学习。
- 训练目标: 通常定义为 Token 级的 Forward KL 散度
强假设:
- Student 在推理阶段自回归生成时的前缀分布
p_s(y|x)与训练阶段 Teacher 所暴露出的前缀分布p_t(y|x)完全一致。
然而,自回归生成中,假设并不成立。
GKD 论文(Sec 3.1)指出:传统 KD 存在严重 Train-Inference Distribution Mismatch(又称 Exposure Bias):
- 训练时:Student 始终在 “正确的”(Teacher 生成的)前缀上进行预测。
- 推理时:Student 依赖自身的历史输出。一旦某一步采样出现偏差(例如生成了低概率 Token),后续所有预测都将基于这个从未在训练中见过的错误前缀展开。
因此,传统 KD 只能让 Student 学习 Teacher 的正确路径,却无法指导 Student 如何处理自身生成的错误轨迹,导致误差逐步累积,并限制最终蒸馏效果
OPD(On-Policy Distillation)核心思想 on-policy imitation learning:
- 不再使用 Teacher 提前生成的固定轨迹,而是让 Student 根据当前策略自行生成样本,并由 Teacher 在 Student 实际会遇到的状态上提供 token-level 监督信号。
- OPD 训练数据采样自 Student 当前参数化策略,而非固定数据集或 Teacher 的策略
OPD 不再要求 Student 去复现 Teacher 已经走过的路径,而是在 Student 自己可能遇到的状态上,让 Teacher 提供更加贴近实际推理过程的指导。
从根本上缓解了传统 KD 中由于 train–inference distribution mismatch 导致的 exposure bias 和误差累积问题。
OPD 最容易让人误解:
- Teacher 并不是读取 Student 的最终答案进行打分,而是将 Student 已生成的 prefix 作为输入,通过一次 forward,计算当前位置的 next-token probability distribution
KL 散度衡量两个概率分布之间的差异。 对于每一个 token 位置,Teacher 都会给出整个词表上的概率分布,KL loss 会推动 Student 调整自己的预测,使其逐渐逼近 Teacher 的分布,而不仅仅是学习某一个正确 token。 因此,OPD 学习的是 Teacher 的决策偏好(decision distribution),而不是单一答案。这也是知识蒸馏通常采用 KL 散度而非交叉熵监督的重要原因。
Teacher 不提供一条标准答案,而是在 Student 自己生成的轨迹上,为每一个 token 位置提供概率分布指导,最终通过 token-level KL loss 完成能力迁移。
OPD 更适合 Reasoning Model
Reasoning Model 的推理过程通常包含较长的自回归轨迹,每一步生成都会影响后续的推理状态。
一旦早期 token 出现偏差,后续生成的上下文也会随之发生变化,误差会在整个推理过程中不断累积。
传统 Offline KD 只能学习 Teacher 提供的标准轨迹,而 OPD 则直接在 Student 自己生成的轨迹上进行蒸馏,使监督信号覆盖 Student 实际会访问到的状态分布,从而有效缓解长链推理中的 train–inference distribution mismatch。
因此,对于数学、代码、Agent 等依赖长程推理的任务,OPD 能够更有效地完成能力迁移,这也是其成为近年来 Reasoning Model 后训练重要技术路线的原因之一
OPD 行业标配
OPD成为大厂标配的原因
- 工业落地广泛:Qwen3、MiMo、GLM-5等主流大模型后训练均采用;
- 成本优势显著:比传统强化学习(RL)计算成本低一个量级;
- 效果更稳定:相比传统SFT,有效减少错误累积,小模型能快速追上大模型推理能力。
【2026-6-9】On-Policy Distillation (OPD):起源、发展路线与当今现状
OPD 在 18 个月内完成了从 ICLR 论文到后训练新范式的跨越。
2026 年的核心命题从”要不要用 OPD”变成了”如何用 latent space / multi-teacher / adaptive KL / offline precompute 来突破 OPD 的 token 空间瓶颈和长序列限制”。路线图现已覆盖 56 篇参考文献、17 种 OPD 变体、14 篇深度论文分析(含 4 篇 latent reasoning)、完整的 Forward/Reverse KL 理论基础。
2026年4月,多家大模型开始重度使用 OPD
- DeepSeek-V4:先训练领域专家,再用 on-policy distillation 统一整合
- 论文 5 (Tsinghua):OPD 机制深度分析,分布不可区分性,97-99% 概率质量
- MAD-OPD:多智能体辩论突破单教师天花板
- StableOPD / SCOPE:训练稳定性与采样策略改进
- Qwen3.5-Omni:全模态模型技术报告;此处不再作为 OPD 直接证据引用
在线蒸馏
在线蒸馏OPD:“实战陪练式学习”
OPD = 强化学习思路 + 蒸馏的密集监督
本质是“边练边改”,流程极简:
- 学生自主完成任务,生成属于自己的推理轨迹(相当于“自己做题”);
- 老师对学生生成的每一个token(每一个字、每一个词)打分,给出密集奖励信号(相当于“逐字点评”);
学生只在自己真实会踩的坑上学习,逐步对齐老师的分布(相当于“边错边改”)。
OPD 在学什么
token级机理拆解:OPD到底在学什么?
OPD训练过程拆解到每一个token,揭开了其底层逻辑——成功的OPD,本质是“高概率token的逐步对齐”。
成功OPD的三大核心特征
- 重叠率渐进提升:学生与老师的top-k token重叠率,从初始72%逐步提升到91%以上;
- 熵差持续缩小:学生和老师的熵(反映输出的不确定性)差距不断减小,自信程度逐步对齐;
- 概率高度集中:共享token集(学生和老师都认为是高概率的token),集中了97%–99%的概率质量。
关键发现:只学共享token就够了
论文通过消融实验验证:
- 仅优化“学生与老师的共享top-k token”,效果和优化全词表几乎一致;
- 仅优化“非共享token”,学生几乎没有任何提升。
结论:OPD 99%的收益,都来自极少数高概率共享token,非共享token几乎没有贡献。
强老师带不动弱学生
灵魂拷问:为什么强老师反而带不动弱学生?
论文最反直觉、最有价值的发现:
老师更强 ≠ 蒸馏一定成功,老师的“强”(参数大、分数高),不等于蒸馏一定成功。
实验中多次出现:
- 7B大模型老师,反而带不动1.5B小模型学生;
- 同一家族的大模型,效果不如经过RL优化的小模型。
论文给出OPD成败的两大铁律,缺一不可。
- 铁律1:思维模式必须对齐(最关键)
- 核心判断标准:学生和老师的top-k token(高概率候选词)重叠度要高。
- 思维对齐:即使老师不是最强,学生也能快速进步;
- 思维错位:哪怕老师分数更高,早期重叠度低,后期训练也无法挽回,蒸馏必然失败。
- 铁律2:老师必须有“真·新知识”
- “强老师”的核心不是参数大、分数高,而是拥有学生没有的新知识:
- 无效老师:仅参数更大、训练数据和学生一致,没有额外能力提升;
- 有效老师:经过额外RL后训练,掌握了学生没学过的能力(如更精准的推理逻辑)。
结论:高分 ≠ 新知识,没有新知识的老师,再强也带不动学生。
关键实验:反向蒸馏验证
实验设计:用“经过RL优化、变强后的1.5B模型”当学生,用“未优化的原始1.5B模型”和“未优化的原始7B模型”分别当老师。
实验结果:
- 学生在蒸馏后,直接退回未RL优化前的水平;
- 7B老师虽然分数更高,但蒸馏效果和1.5B老师完全一致。
核心证明:OPD本质是学习老师的思维模式,而非单纯复制分数。
理解
小模型后训练选 SFT 还是 RL ?
2025年10月,Thinking Machines Lab 的On-Policy Distillation 文章核心结论:
用RL”在策略采样”+蒸馏的”稠密反馈”,在推理任务上复现了Qwen3用RI才能达到的效果,成本却只是零头。
三种后训练区别:两个维度,采样是否 on-policy、奖励是否稠密:
- SFT (off-policy+稠密): 学老师轨迹,但学「老师常处的状态」,推理时自己一旦走偏会误差累积(compoundingerrorexposure bias)
- RL (on-policy+稀疏): 在自己轨迹上学,但一整条 rollout 只回传一个标量奖励,「每个 episode 只教固定比特」,token 利用率极低
- 【On-policy 蒸馏(on-policy+稠密)】: 在学生自己采样的轨迹上,让teacher对每个Token打分
| 训练模式 | 采样策略 | 奖励类型 | 核心逻辑 | 优势 | 局限 |
|---|---|---|---|---|---|
| SFT(监督微调) | off-policy(离线策略,仅学习专家轨迹) | 稠密奖励(逐Token提供监督信号) | 完全模仿老师/专家的输出轨迹,学习专家的Token生成逻辑与常出现的状态 | 训练过程稳定,Token利用率高,可快速对齐专家的行为与输出风格 | 仅覆盖专家常出现的状态,推理时模型一旦偏离专家轨迹,会出现误差累积(暴露偏差),泛化能力弱 |
| RL(强化学习) | on-policy(在线策略,在模型自身采样的轨迹上学习) | 稀疏奖励(单条轨迹仅提供1个标量奖励) | 基于模型自身采样的完整轨迹学习,仅在整条rollout结束后,回传最终的标量奖励信号 | 可探索模型自身的行为空间,适配推理时的真实输出分布,泛化能力强 | 单条轨迹仅能提供极少有效学习信号,Token利用率极低,训练过程不稳定,收敛难度大 |
| On-policy蒸馏 | on-policy(在线策略,在学生模型自身采样的轨迹上学习) | 稠密奖励(逐Token提供监督信号) | 在学生模型自身采样的轨迹上,由老师模型对每一个Token进行打分,提供逐Token的稠密监督信号 | 结合SFT的稠密监督与RL的在线探索优势,既适配模型自身的推理分布,又保持高Token利用率,训练更稳定 | 需要老师模型持续提供逐Token的打分,计算成本相对较高,最终效果强依赖于老师模型的质量 |
OPD vs offline KD
SFT、Offline KD、OPD 和 GRPO 核心区别并不在于模型结构,而在于训练状态(State Distribution)和监督信号(Supervision)。
- SFT 与 Offline KD 都属于 Off-Policy 方法,训练过程始终基于固定数据;
- OPD 与 GRPO 都属于 On-Policy 方法,训练数据来自 Student 当前策略生成的轨迹;
- Offline KD 与 OPD 的监督信号都是 Teacher 的概率分布,区别仅在于 Teacher 提供监督的状态不同;
- GRPO 不依赖 Teacher,而是根据 Reward 更新策略,更强调探索与策略优化。
| 方法 | 训练状态(Prefix) | 监督信号 | 优化目标 |
|---|---|---|---|
| SFT | 固定数据集(Ground Truth) | One-hot Label | 学习标注数据 |
| Offline KD | Teacher / 固定数据集 | Teacher Probability Distribution | 模仿 Teacher |
| OPD | Student 当前策略 | Teacher Probability Distribution | 在 Student 轨迹上迁移 Teacher 能力 |
| GRPO | Student 当前策略 | Reward | 优化当前策略 |
两个维度的组合:
- SFT:离策略+独热监督
- Offline KD:离策略+教师分布监督
- OPD:在策略+教师分布监督
- GRPO:在策略+奖励监督
💡解答
识别并还原Markdown表格
| | Off-Policy | On-Policy | | —- | —- | —- | | One-hot Supervision | SFT | —— | | Teacher Distribution | Offline KD | OPD | | Reward | —— | GRPO |
OPD 并不是一种新的损失函数,而是在保持 Teacher Distribution 监督的同时,将训练状态从 Teacher 轨迹切换到了 Student 自己的轨迹,从而缓解了 train–inference distribution mismatch。
OPD vs SFT
SFT(forward kl)与OPD(Reverse KL)本质区别
【2026-6-11】LLM后训练知识:从数学原理区分SFT与OPD
SFT(Supervised Fine-Tuning,监督微调) 和 OPD(On-Policy Distillation,同策略蒸馏 / 在线偏好蒸馏)是两种截然不同的训练范式。数学原理和目标函数上的根本区别,主要体现在数据状态分布的采样来源以及优化的散度(Divergence)类型上。
数学原理上
- SFT 是基于 离线静态数据、优化 前向 KL散度(寻求全面模仿) 的开环优化,存在训练和推理状态不一致的问题;
- 而 OPD 是基于 模型自生成动态数据、通常优化 反向 KL散度(寻求精准专精) 的闭环优化,通过让模型在“自己的失误”中接受教师的实时纠正,从根本上解决了长链条推理过程中的误差累积问题。
OPD vs RL
sft与rl之间是opd
新观点
【2026-6-8】港科大:OPD 并非 SFT 与 RLVR 的折中方案,而是具备独立特性的参数更新范式
SFT、RL、OPD 都在改变语言模型的“输出分布”;
真正决定模型会不会大幅遗忘的,不只是 loss 长什么样,而是训练数据是不是来自模型自己,也就是 on-policy。
把语言模型看成“序列上的概率分布”,后训练就是在重塑这个分布;
SFT、RL、OPD 差异在于: 目标分布是谁、数据从哪里来、梯度在哪里发力。
- SFT:给出示范答案,让模型往数据集答案拉, 因此产生
灾难性遗忘。- 例如模型学习时不管是否写作习惯风格token(therefore),还是答案,都要一视同仁
- SFT 目标: 作用于外部数据集上,而不是新任务相关的分布,因此泛化性也会变差,把自己的能力给忘了
- RL:让模型自己生成答案,通过reward打分,通过policy gradient提高期望奖励,这就相当于从当前模型自己采样的行为发出的,训练数据来自模型自己,学生自己做,通过reward自己修正自己写出的东西,从而在自己的路径下(符合自身分布前提下),把更好的路加粗。
- OPD:On-Policy Distillation 介于SFT和RL之间,就是学生生成样本,学生主导下,reverse KL 把学生的logits分布往老师的logits分布靠拢。
- 还是以学生和老师的例子,普通蒸馏下:老师生成答案,学生模仿老师答案,OPD的视角下,学生生成prefix,老师应该告诉学生下一步token的概率分布是什么样。
- 普通 SFT / hard token imitation 只学一个目标 token;传统 soft KD 本身是学老师的 token-level 分布。
- OPD 特别之处不是第一次学分布,而是在学生自己生成的状态上学老师分布,即:让学生走自己的路,但每一步让老师告诉它:在你现在这个位置,下一步应该更像什么分布。
SFT、RL、OPD 核心区别
| 维度 | SFT(监督微调) |
RL(强化学习) |
OPD(在线策略蒸馏) |
|---|---|---|---|
| 核心本质 | 用外部示范答案,强行将模型输出分布对齐外部数据集 | 模型生成样本,借助奖励函数优化自身输出分布 | 介于SFT与RL之间,模型生成前缀,再对齐教师模型的概率分布 |
| 训练数据来源 | 外部人工/标注数据集(非模型自身产出) | 模型自身采样生成(on-policy) | 模型自身生成前缀/样本(on-policy) |
| 优化方式 | 逐Token硬模仿,统一学习风格、答案等所有内容 | 策略梯度,最大化整体期望奖励 | 反向KL散度,对齐教师模型Token级概率分布 |
| 遗忘风险 | 易出现灾难性遗忘,原有能力丢失 | 遗忘风险低,在自身分布基础上优化 | 遗忘风险介于两者之间 |
| 泛化能力 | 偏向拟合固定数据集,泛化性变差 | 保留原有能力,泛化表现更优 | 兼顾模仿与原生分布,泛化能力中等 |
| 通俗理解 | 照着标准答案全盘模仿学习 | 自己做题,根据评分自主修正优化 | 自己先动笔走流程,每一步由老师指导最优方向 |
| 学习特点 | 仅学习单一目标Token(硬模仿) | 基于自身行为迭代,强化优质输出路径 | 在模型自身生成的状态下,学习教师的完整分布 |
改进
【2026-6-5】港科大 OPD 原理
在线策略蒸馏(OPD)是2026年热议的大模型后训练方案,训练动态机制仍缺乏清晰认知,大多被视作介于监督微调(SFT)与强化学习(RL)之间的黑盒技术。
【2026-6-5】港科大论文 On the Geometry of On-Policy Distillation
论文从参数几何维度刻画 OPD 对模型权重的改动规律,并提出观点:
OPD 并非 SFT 与带人类反馈的强化学习(RLVR)的折中方案,而是一种具备独立特性的参数更新范式。
- 更新权重数量更少: 相较于 SFT,OPD 仅更新极少数参数,且基本不会触及权重空间的主方向,这也是其样本利用率更高的核心原因。
- 子空间提前锁定: 训练初期,OPD 的累积更新会快速收敛至一个狭窄的低维子空间;而 SFT 的参数更新会分散到多个方向,二者形成明显差异。
- 该子空间具备完整有效功能: 将训练限定在 OPD 早期形成的子空间内,模型仍可保留原有性能;但该约束会严重损害 SFT 效果。这证明该小子空间确实承载了有效学习信息,并非训练产生的无效附属特征。
多组参数空间诊断实验
- OPD 处于弱偏离主方向的更新区间:相较于 SFT,OPD 的参数更新范围更小,且对权重主方向的规避程度更高;而对比 RLVR,其约束又相对宽松。
除上述静态分布特征外,OPD 还存在子空间锁定现象:累积参数更新会快速收敛至一个狭窄的低维通道。若将训练限定在模型早期形成的该更新子空间内,OPD 性能可基本维持,但会大幅破坏 SFT 的效果。这说明该锁定子空间足以承载 OPD 的有效学习信息。
对照实验结论:
- 对更新 token 做稀疏化处理、将模型推理生成改为离线策略,均不会改变秩动态特征;
- 但将 OPD 训练目标与 RLVR 融合后,该特征会发生明显变化。
研究价值
厘清 OPD 在权重空间中的作用区域,让这项应用广泛却原理模糊的训练方案形成机理解释。
这有助于研究者理解其内在逻辑、将与其他训练目标组合优化,并实现定向迭代改进,摆脱以往试错式调优的研发模式
【2026-6-29】北大、小米 MOPD
MOPD:多Teacher蒸馏实现能力整合
小米罗福莉解决大模型多专家融合难题
问题:强化学习后训练中极易产生“跷跷板效应”与多领域能力融合瓶颈
LLM 后训练的核心难题:
数学、代码、指令遵循各有最佳 RL recipe,但最终要一个模型全干好。
现有方案
- Mix-RL 跨域干扰跷跷板
- Cascade RL 前域衰减
- Off-Policy FT 有 exposure bias
- Param-Merge 权重融合不稳定。
没有一个令人满意。
【2026-6-29】小米提出“多教师同策略蒸馏(MOPD)”新范式。
巧妙实现了工程解耦,允许不同团队基于统一基座并行训练专属领域专家,随后在核心蒸馏阶段,让学生模型自主生成数据(消除曝光偏差),并由各领域专家进行Token级密集概率打分指导。
基于严格的“初始模型同源”机制,MOPD 不仅克服了传统参数合并带来的灾难性遗忘,更在高达3000亿参数的工业级模型上完美实现了所有专家能力的无损吸收,成功打造出各领域表现全面顶尖的“全能大模型”。
MOPD 思路:
- 在 policy space 而非 weight/dataset space 做整合。
- 三阶段——共享 SFT → 各域并行 RL 出专家 → 冻结专家,student 自己 rollout,按 prompt 路由到对应域 teacher,teacher 在 rollout 每个 token 上提供 log-prob,student 最小化 reverse KL。域间零干扰、无 exposure bias、dense per-token 监督。
Qwen3-30B-A3B 上 norm score 0.937,超次优 Mix-RL +5.5,三域 range 仅 0.044(Cascade RL 0.41)。样本效率远超 Mix-RL:IF 域 25K vs 150K 达 teacher 水平。已落地 MiMo-V2-Flash 309B,匹配或超越各域 teacher。
【2026-6-17】三星中国研究院 TrOPD
【2026-6-17】三星中国研究院、牛津、北大提出 TrOPD 信赖域在策略蒸馏方法 TrOPD(Trust Region On-Policy Distillation)
在策略蒸馏(OPD) 问题
但当教师模型与学生模型的数据分布存在显著差异时,OPD训练会出现不稳定问题:
- 对学生模型自主生成的token施加教师监督信号,可能产生不可靠的策略梯度,甚至造成优化失败。
通过信用分配机制实现可靠的逐token在策略监督,提出信赖域在策略蒸馏方法 TrOPD(Trust Region On-Policy Distillation),具备三大核心特性:
- 信赖域在策略学习:仅在教师监督信号可靠的区域执行OPD训练,缓解分布失配场景下反向KL散度估计器(K1)的优化难题。
- 异常样本约束:针对异常分布区域,采用梯度裁剪、掩码过滤、前向KL散度估计等手段,降低不可靠监督信号带来的负面影响。
- 离策略引导:以教师模型生成的前缀文本作为上下文继续生成内容,并利用前向KL散度学习离策略监督信息,引导在策略探索偏向可靠分布区域。
实验结果
- 在数学推理、代码生成及通用领域评测基准上,TrOPD 整体优于现有主流OPD基线方法(OPD、EOPD、REOPOLD)。项目开源主页详见GitHub。
【2026-7-6】微软+港科大 TOP-D
微软和港科广新论文,把当下 LLM 后训练最主流的在线策略蒸馏(OPD)身上最出名的毛病——训练不稳定——追到了公式层面的根源,再用一行代数变换把它修掉。方法叫 TOP-D(信赖域策略蒸馏)
- 论文 Trust Region Policy Distillation
- 8B 学生在 AIME24 上从标准 OPD 的 24.58 分拉到 50.42 分,计算开销一点没加。
OPD 走红原因:
- 学生自己写答案、老师逐 token 打分,信号密集又不易遗忘,Qwen3、DeepSeek-V4、GLM-5 的后训练都在用。
但奖励是老师与学生概率之比的对数,一旦老师认为学生采出的某个 token 几乎不可能,这个对数就冲向负无穷——单个 token 的惩罚足以主导整批梯度。
- 此前的补丁(奖励裁剪、混合采样、全词表监督)都是经验性技巧,论文认为它们没有触到「无界惩罚」这个根。
TOP-D 切法分两步。
- 第一步,每次更新前把老师和当前学生按 α:(1−α) 混成一位「近端教师」,学生永远只追一个够得着的目标;代回公式后,这个概念上的教师塌缩成对奖励的一次代数变换 log(αρ+1−α),天然有下界,负无穷从此消失。
- 第二步,借鉴 PPO 把采样策略与更新策略解耦,同一批数据安全地分 16 个 mini-batch 反复用,把样本效率一并补上。理论侧,方差上界、全局收敛、单调改进三个定理互相咬合:α 是方差的直接调节器,而收敛差距 ε∞/α 的缺口恰好由内部迭代补齐。
结果相当全面:
- Qwen3-8B-Base 配 30B-A3B 老师,六个数学基准全部第一,AIME24 上比最强 RLVR 基线 DAPO 还高 17.5 个百分点;
- 学生缩到 1.7B、师生差距拉大时,标准 OPD 反而落后 GRPO 与 DAPO,TOP-D 依旧领先,与理论预测吻合。
- 消融显示两个组件缺一不可,α 在 0.1 到 0.3 之间怎么选都差不多,不需要调参。
局限:
- 验证止步于 8B 学生,训练窗口只有约 200–400 步——但也正因如此,作者说正文报告的数字远未到上限。
【2026-7-5】UI-MOPD 应用到GUI Agent
【2026-7-5】GUI Agent 跨平台蒸馏
清华大学深圳国际研究生院、小米及哈尔滨工业大学(深圳)等团队解决 GUI agent 跨平台持续学习的“跷跷板”问题。
桌面端和移动端的交互语义天差地别——关闭窗口 vs 返回键,鼠标点击 vs 手指滑动——把它们的数据混在一起做 SFT 或 RL,平台特定行为模式会被“平均”掉,甚至灾难性遗忘。
最直觉的跨平台做法有两类:
- 混合 SFT——把桌面和移动端轨迹混到一起做监督微调;
- 模型合并——分别训练平台专家再平均权重(Weight Averaging)或 TIES Merging。
问题出在哪?桌面端要 mouse_move、left_click、scroll 这套操作语义,移动端靠的是 click、swipe、long_press、navigate_back。
把这两套截然不同的行为分布塞进同一个 loss,模型学到的不是“在什么平台做什么事”,而是一个被两头拉扯的折中策略。
- 混合 SFT 在 OSWorld 上 35.0%、MobileWorld 上只有 6.4%;
- TIES Merging 虽然桌面 36.8% 还行,但移动端直接崩到 0%。灾难性遗忘不是偶然现象,是这类方案的必然结果
UI-MOPD 思路:不是“用了蒸馏”,而是“把蒸馏条件化”。
- 先为每个平台分别训一个专家 teacher,再在在线 RL 阶段按平台路由选对应 teacher 做 on-policy distillation,让一个共享 student 同时吸收两个平台的行为先验。
- 把多教师蒸馏(MOPD)从通用大模型后训练搬到了 GUI agent 场景,用条件化的 KL 约束替代了简单的混合监督。
- 论文 UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
UI-MOPD 分两阶段。
- Stage 1:在 Uni-GUI 数据集上分别 SFT 出桌面 teacher π_ref^d 和移动 teacher π_ref^m。
- Stage 2:用一个 8B student 在线采样 rollout,按平台标签路由到对应 teacher,做 on-policy KL 蒸馏 + 强化学习。
关键设计在“条件化”三个字。student 在线采样时,桌面环境的 rollout 只对齐桌面 teacher,移动环境的 rollout 只对齐移动 teacher。teacher 信号不是混成一个 KL 惩罚,而是按平台分别约束。这把 KL 项的角色从 RLHF 里常见的“防漂移保守正则”变成了“平台行为先验的定向迁移器”。
UI-MOPD 在 AndroidControl* 上不降反升(78.73% → 80.05%),三个 grounding benchmark 基本持平。Model Merge 则全面下滑,ScreenSpot-Pro 跌了 6.6 个点。说明在线蒸馏比静态参数合并对基础 GUI 能力的破坏小得多。
OSWorld 是桌面端 361 个任务,MobileWorld 是移动端 117 个任务。
应用
工程落地:2个直接可用的失败蒸馏救场方案
针对“思维错位”“无新知识”导致的蒸馏失败,论文给出两个可直接落地的修复方案,工程价值拉满。
方案1:离线冷启动(Off-policy Cold Start)
核心逻辑:先用离线蒸馏缩小思维差距,再启动OPD,专治“思维错位”。
两步执行流程:
- 冷启动阶段:用老师生成的标准答案,对学生做一轮SFT(监督微调),让学生先熟悉老师的思维模式;
- OPD阶段:从SFT后的模型开始,启动标准OPD训练。
- 效果:初始重叠率大幅提升,训练全程更稳定,最终效果比直接启动OPD显著更高。
方案2:老师对齐提示词(Teacher-aligned Prompts)
核心逻辑:让训练用的提示词,和老师后训练时用的提示词保持一致,强化高概率token对齐。
两个关键操作:
- 提示模板对齐:使用老师后训练时用的提示模板(如老师习惯“请分步推理,答案放方框内”,学生训练也用同样模板);
- 提示内容对齐:使用老师后训练时见过的提示数据,让学生生成的轨迹更贴近老师熟悉的场景。
注意事项:需混合少量“分布外提示词”,防止学生熵崩塌(输出过于单一)。
OPD 问题
重要警告:OPD不是万能的,有明确天花板
OPD的致命缺陷:奖励质量随文本长度急剧退化,决定了适用边界。
文本长度的“甜蜜点”
- 短文本(0.5K–1K token):监督token太少,学习效率低;
- 中等长度(3K–7K token):奖励最可靠,效果最佳;
- 超长文本(10K+ token):奖励质量急剧下降,训练后期会崩溃(错误从末尾往前传染)。
结论:
OPD不适合长推理、多轮智能体等长文本场景。
未来最优路线:
- 短片段密集监督(OPD) + 长文本稀疏奖励(传统RL),兼顾效率与可靠性。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
