总结
机器学习学科关系
- 【2021-4-6】图灵奖得主Jeff Ullman直言:机器学习不是数据科学的全部!统计学也不是, 原文链接
- 我并不认为机器学习可以完全取代数据库社区开发的算法
三个问题:
- 统计真的是数据科学的重要组成部分吗?no
- 机器学习就是数据科学的全部吗?no
- 数据科学是否会对社会规范是否构成威胁?no
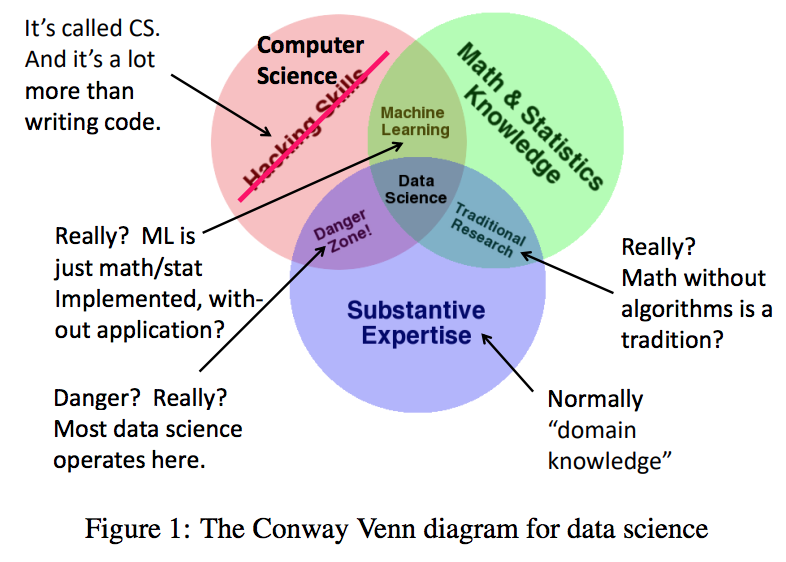
- 几乎图表中的每一个区域在某种程度上都有误导性。
- 1、首先,一个小问题: 所谓的“实质性专门知识”一般要统称为”领域知识”或类似的东西。
- 2、最严重的问题是将计算机科学称为“黑客技能”。计算机科学给数据科学带来的远不止是编写代码的能力。我们提供算法、模型和框架,来解决各种各样的问题。所有这些在处理数据时都是必不可少的。
- 3、“传统研究”在图中显示为数学/统计与应用的交叉领域。换句话说,在这种形式的研究中,人们只考虑实际应用,而不编写任何代码,因此不会影响现实世界。我不知道这是哪来的传统,但我认为,这可不是数据库社区的传统。
- 4、机器学习在这个图表中有一个奇怪的位置。它被描述为“黑客”加上数学/统计。这意味着机器学习和实际应用没有任何关系。实际上,它与应用之间有着千丝万缕的联系,这就是为什么今天机器学习的算法如此受重视,不仅在数据库界,而且在整个计算机科学界都是如此。
- 5.然后还有 Conway 所说的“危险区域”——通过编写代码来解决应用领域中的问题,而不需要统计学家的明智指导。几乎所有的数据科学都是这样的。举一个例子,谷歌和其他邮件服务商在检测网络钓鱼邮件方面做得很好。有多好?我们真的不知道,即使我们今天可以做一个统计分析,明天也不会奏效,因为这种威胁是不断变化的。真正的危险是我们本来可以做得更好,却放任那些骗子骗走可怜虫们毕生的积蓄。
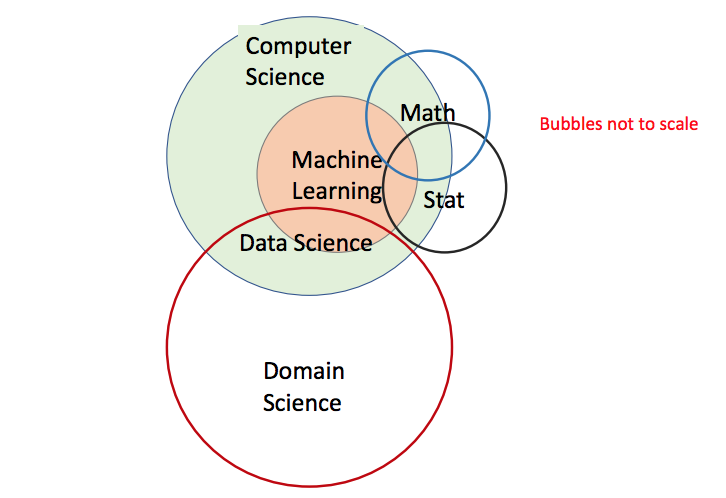
- 新图
- 机器学习的黑箱理论一直让人诟病,不放心
- 那么,机器学习的本质到底是什么?怎么提升可解释性?
机器学习本质
监督学习本质是函数拟合
【2020-8-5】机器学习的本质(摘自:机器学习漫谈)
要点:
- 机器学习的本质是归纳推理(不完全归纳)
- 监督学习本质是函数拟合(任意连续函数)</span>
解释
归纳法:机器学习本质上就是在做归纳推理,并且是不完全归纳法- 利用某种算法从数据中自动归纳出有意义的规律的一种方法
- 人类的推理方法大致可以分为两种
- 一种是
演绎法:从一般到特殊 - 另一种是
归纳法:从特殊到一般
- 一种是
函数拟合:监督学习本质上就是在函数拟合,而且很多模型可以拟合任意连续函数- 分类和回归的区别在于拟合的目标变量y的取值构成的是无限集合(回归)还是有限集合(分类)
- 模型拟合能力,事实上已经有很多模型可以做到对任意连续函数做到任意精度的逼近。
通用逼近定理(Universal approximation theorem):
通用逼近定理
通用逼近定理 Universal Approximation Theorem
- a feed-forward network with a single hidden layer containing a finite number of neurons can approximate any continuous function.
- 单隐层神经网络即可任意逼近闭集上的任意连续函数,只要隐层节点数量足够多
- By approximate, we mean that by using enough hidden neurons, we can always find a neural network whose output $ g(x) $ satisfies
|g(x)−f(x)|<ϵ, for all inputs x. - In other words, the approximation will be good to within the desired accuracy for every possible input. And if a function is discontinuous, i.e., makes sudden, sharp jumps, then it won’t, in general, be possible to approximate using a neural net.
【2023-2-19】Jason Wei的老师 Cybenko:
- It was quite humorous when Professor Cybenko showed us a blog post in which he was accused of “substantially delaying the explosion of deep learning” because of his 1989 paper proving the Universal Approximation Theorem (basically says a one hidden layer neural net can approximate any function).
机器学习黑魔法
【2022-7-11】鄂维南:从数学角度,理解机器学习的“黑魔法”,并应用于更广泛的科学问题
2022年7月8日,鄂维南院士在 2022 年的国际数学家大会上作一小时大会报告 (plenary talk)。
- 首先,对机器学习数学本质的理解(
函数逼近、概率分布的逼近与采样、Bellman方程的求解); - 然后,介绍机器学习模型的逼近误差、泛化性质以及训练等方面的数学理论;
- 最后,介绍如何利用机器学习来求解困难的科学计算和科学问题,即 AI for science。
总结
- (1)
监督学习(supervised learning)本质是基于一个有限训练集S,给出目标函数的一个高效逼近。- 图像分类问题
- (2)
无监督学习本质就是利用有限样本逼近并采样问题背后未知的概率分布。- 对于人脸生成问题,其本质是逼近并采样一个未知的概率分布。在这一问题中,“人脸”是随机变量,不知道概率分布。然而,有“人脸”的样本:数量巨大的人脸照片。便利用这些样本,近似得到“人脸”的概率分布,并由此产生新的样本(即生成人脸)。
- (3)
强化学习本质是求解马尔可夫过程的最优策略。- 对于下围棋的Alphago来说,如果给定了对手的策略,围棋的动力学是一个动态规划问题的解。其最优策略满足Bellman方程。因而Alphago的本质便是求解Bellman方程。
然而,这些问题都是计算数学领域的经典问题. 毕竟,函数逼近、概率分布的逼近与采样,以及微分方程和差分方程的数值求解,都是计算数学领域极其经典的问题。
那么,这些问题在机器学习的语境下,到底和在经典的计算数学里有什么区别呢?答案便是:维度(dimensionality)
- 维度增加时,计算代价呈指数级增长。这种现象通常被称为:
维度灾难(curse of dimensionality) - 所有的经典算法,例如多项式逼近、小波逼近,都饱受维度灾难之害。很明显,机器学习的成功告诉我们,在高维问题中,深度神经网络的表现比经典算法好很多。然而,这种“成功”是怎么做到的呢?为什么在高维问题中,其他方法都不行,但深度神经网络取得了前所未有的成功呢?
从数学出发,理解机器学习的“黑魔法”:监督学习的数学理论
机器学习本质上是高维中的数学问题。
- 神经网络是高维函数逼近的有效手段;为人工智能领域、科学以及技术领域提供了众多新的可能性。
这也开创了数学领域的一个新主题:高维分析学。
总结如下:
- 监督学习:高维函数理论;
- 无监督学习:高维概率分布理论;
- 强化学习:高维Bellman方程;
- 时间序列学习:高维动力系统。
概念漂移
概念漂移
- 【2020-3-26】摘自:为什么机器学习模型会在生产过程中退化?
- 所有ML项目中,预测数据将如何随时间变化
- 【概念漂移】: 表示模型试图预测的目标变量的统计特性随着时间以不可预见的方式发生变化。这导致了一些问题,因为随着时间的推移,预测的准确性会降低。
- 在概念漂移的情况下,对数据的解释随时间而变化,而数据分布则没有变化。这导致最终用户将模型预测解释为随着时间的推移,对相同/相似数据的预测已经恶化。数据和概念都可能同时漂移,使问题更加棘手。
- 大多数模型只能捕获训练数据的模式。好的模型捕获了这些数据的基本部分,而忽略了不重要的部分。这创建了泛化的性能,但是任何模型都有一定程度的局限性。
周志华:机器学习本质
注:
根据周志华教授今天上午在 CNCC 2016 上所做的大会特邀报告《机器学习:发展与未来》编辑整理而来,在未改变原意的基础上略作了删减。

周志华, CCF 会士、常务理事、人工智能专委主任。南京大学教授,校学术委员会委员,计算机软件新技术国家重点实验室常务副主任。AAAI Fellow, IEEE Fellow, IAPR Fellow,ACM 杰出科学家。长江学者特聘教授、国家杰出青年科学基金获得者。- 主要从事人工智能、机器学习、数据挖掘等领域的研究。著有《Ensemble Methods: Foundations and Algorithms》、《机器学习》。在本领域顶级期刊会议发表论文百余篇,被引用2万余次。获发明专利14项,多种技术在企业应用中取得成效。
- 任《Frontiers in Computer Science》执行主编及多种国内外学术期刊副主编、编委;亚洲机器学习大会创始人,国际人工智能联合大会(IJCAI)顾问委员会成员,IEEE 数据挖掘大会(ICDM)等数十次国内外学术会议主席;IEEE 计算智能学会数据挖掘技术委员会主席等。曾获国家自然科学二等奖、两次教育部自然科学一等奖、亚太数据挖掘卓越贡献奖、12 次国际期刊 / 会议论文 / 竞赛奖等。

周志华教授作为特邀嘉宾发表报告
在过去的二十年中,人类手机、存储、传输、处理数据的能力取得了飞速发展,亟需能有效地对数据进行分析利用的计算机算法。机器学习作为智能数据分析算法的源泉,顺应了大时代的这个迫切需求,因此自然地取得了巨大发展、受到了广泛关注。
“现在是大数据时代,但是大数据不等于大价值。”
我们要从大数据里面得到价值的话,就必须要有一些有效的数据分析。正因为这个原因,这几年机器学习特别热。这是从人工智能里面产生的一个学科,利用经验改善系统学习。在计算机系统里面,不管是什么经验,一定是以数据的形式呈现的。所以机器学习必须对数据分析,这个领域发展到今天主要是研究智能数据分析的理论和方法。我们可以看到图灵奖连续两年授予在这方面取得突出成就的学者,这其实一定程度上也表现出了大会对此的重视。


那么究竟什么是机器学习?这里给出一个具体的实例。
“文献筛选”的故事
- 什么是文献筛选呢?
这是“循证医学”中,针对特定的临床问题,先要对相关研究报告进行详尽评估。那么人们一般通过 PubMed 获取相关候选论文的摘要,然后通过人工的方式找到值得全文审读的文章。
- 为什么要这么做呢?
我们都知道,现在优质医学资源非常稀缺,为了缓解这个问题,国外产生了一种叫做“循证医学”的做法。以后患病了不是先去找专家,而是先去看一看文选资料,因为很可能已经有人患过,甚至已经有医生诊治过这个病,发表过论文。那么如果我们暴露里面和这个病相关的最新技术,把它汇集起来,很可能就能得到很好的解决方案。
- 如何实现这个想法呢?
第一步,我们要从这个浩如烟海的医学文献里面,把可能有关的文章汇集出来。现在有很多基础工作建设,例如在医学上有 Pub Med 的系统,我们还可以用谷歌学术等搜索关键词,就能搜到很多文章。但这些检索出来的文章和我们真正需要的可能还有很大的距离,因为他可能只是仅仅包含搜索的关键词而已。
所以第二步就需要请人类专家来过滤它们,找出到底哪些东西需要深入研究。这部分的工作量有多大呢?我们举个例子,在一个关于婴儿和儿童残疾的疾病研究里面,这个美国 Tufts 医学中心在第一步的筛选之后就拿到了 33000 篇摘要。中心的专家效率非常高,他们每三十秒钟就可以过滤 1 篇。但就算这样,这个工作还是要做 250 个小时。可想而知,就算一个医生三十秒钟看一篇文章,一天八小时不吃饭、不喝水、不休息,也需要一个多月才能完成。而且糟糕的是每一项新的研究我们都要重复这个麻烦的过程。还有更可怕的是,随着医学的发展,我们发表的论文数量也越来越多。

所以如果没有其他解决途径,“循证医学”可能就没有未来了。为了解决这个问题,降低昂贵的成本,Tufts 医学中心引入了机器学习技术。
- 怎么来做呢?
我们挑出大量的文章,只邀请熟练的专家判断是有关还是无关的,然后基于这个信息建立一个分类模型,用这个分类模型对剩下没有看过的文章做一次预测。其中相关的文章再请专家来审读,这样的话,专家需要读的东西就会大幅度减少。
这样做之后,得到的性能指标已经非常接近、甚至一定程度上超过了原来专家过滤的效果。因为我们知道一个专家三十秒钟读一篇文章,需要连续工作一个月,而且中间出错的可能性太多。现在用机器学习来做只需要一天时间,所以被当成是机器学习对现在机器医学发展的一个很重要贡献而报道出来。

这里面非常关键的一步就是我们怎么样把这个分配模型做出来,其实就是用的机器学习。
一张 PPT 说清机器学习过程
现在假设把数据组织成一个表格的形式,每一行表示一个对象或者一个事件,每一列表示我刻画的对象的属性。比如说每一行指的就是“西瓜”,那最后我们特别关心的是这个“西瓜”好还是不好,我们把它叫做类别标签。
之后,我们经过一个训练过程就得到了模型,今后我们拿到一个没有见过的新数据时,只要知道它的输入,把输入提供给这个模型,这个模型就可以给你一个结果,究竟是好的还是不好的“西瓜”。
所以在现实生活中,我们碰到的各种各样的分类预测预报问题,抽样出来看,如果在计算机上通过数据驱动的方式来解决它,其实就是在做一个机器学习的过程。
把数据变成模型要用到学习算法。有一种说法是计算机科学就是关于算法的学问。那如果从这个道理上来讲的话,机器学习其实就是关于学习算法的设计分析和每个学科领域的应用。

人工智能的三个阶段
机器学习本身确实是起源于人工智能,而我们都知道人工智能是 1956 年达特茅斯会议上诞生的。到今天恰恰是六十周年。那么在过去的六十年里面,其实我们从人工智能的主流技术上看,可以认为是经过了三个阶段。

在最早的一个阶段,大家都认为要把逻辑推理能力赋予计算机系统,这个是最重要的。因为我们都认为数学家特别的聪明,而数学家最重要的能力就是逻辑推理,所以在那个时期的很多重要工作中,最有代表性的就是西蒙和纽厄尔做的自动定理证明系统,后来这两位也因为这个贡献获得了七五年的图灵奖。

但是后来慢慢的就发现光有逻辑推理能力是不够的,因为就算是数学家,他也需要有很多知识,否则的话也证明不出定理来。所以这个时候,主流技术的研究就很自然地进入了第二阶段。
大家开始思考怎么样把我们人类的知识总结出来,交给计算机系统,这里面的代表就是知识工程专家系统。像知识工程之父爱德华·费根鲍姆就因为这个贡献获得了 1994 年的图灵奖。
但是接下来大家就发现要把知识总结出来交给计算机,这个实在太难了。一方面总结知识很难,另外一方面在有些领域里面,专家实际上是不太愿意分享他的经验的。

所以到底怎么解决这个问题呢?我们想到人的知识就是通过学习来的,所以很自然的人工智能的研究就进入了第三个阶段。
这时候机器学习作为这个阶段的主流研究内容,可以看到机器学习本身其实就是作为突破知识工程的一个武器而出现的。但是,事实上并没有达到目的,今天大多数的机器学习的结果都是以黑箱的形式存在的。另外一方面,为什么机器学习这么热门呢?其实恰恰是因为在二十世纪九十年代中后期,我们人类搜集、存储、管理、处理数据的能力大幅度提升,这时候迫切需要数据分析的技术,而机器学习恰恰是迎合了这个大时代的需求,所以才变得特别的重要。

今天的社会,机器学习已经可以说是无所不在了,不管是互联网搜索、生物特征识别、汽车自动驾驶、还是火星机器人,甚至是美国总统选举,包括军事决策助手等等,基本上只要有数据需要分析,可能就可以用到机器学习。

机器学习这个学科里产生出了很多种有效的机器学习的技术和算法,但是更重要的就是机器学习是一个有坚实理论基础的学科,其中最重要的就是计算学习理论。
而计算学习理论中最重要的一个理论模型就是概率近似正确模型 —— PAC。它的提出者 Valiant 教授也因此获得了图灵奖。

关于未来 —— 技术

2006 年 Hinton 在 Nature 发表了关于深度学习的文章。2012 年他又组队参加 ImageNet,获得冠军。冠军没什么特别的,因为每年都有冠军。但超过第二名 10 个百分点的成绩引起了大家的注意,深度学习就此兴起,现在深度学习的应用越来越广泛了。
所以如果折中一下,从 2010 年至今,深度学习的热潮已经 6 年了。

从技术层面来看,深度学习其实就是很多层的神经网络。这里画了一个三层的神经网络,就是所谓的一个神经元,通过很多连接连接在一起。那么每个神经元就是一个所谓的 M-P 模型。
所谓的一个神经元其实就是这么一个函数,我们所谓的神经网络其实就是很多这样的多层函数嵌套形式的数学模型,它在一定程度上受到了这个生物神经技术的启发,但是更重要的是数学和工程上的东西在支撑。
最著名的深度学习模型叫做卷积神经网络(CNN),其实早在 1995 年就提出了,但为什么现在才火呢?要先提两个问题:
- 有多深?
- 为何深?

提升模型的复杂度可以提升学习能力,增加模型深度比宽度更有效,但提升模型的复杂度并不一定有利,因为存在过拟合和计算开销大的问题。
跳出这些技术细节来看,深度学习最重要的作用是表示学习。所以也就知道了深度学习究竟适用何处?


那么关于深度学习会有很多问题,这里统一到一句话:深度学习会不会“一统江湖、千秋万载”?




我们可以看到非常清楚的交替模式:热十年冷十五年。
但这真的是巧合吗?我们不妨把每次繁荣的开始时间往前推 5-8 年,可以找到规律。

所以,在技术层面对于未来的一个判断是:未必是深度学习,但应该是能有效利用 GPU 等计算设备的方法。

| 关于未来 —— 任务 |

谈到任务,需要提一提前段时间的 AlphaGo,被认为是机器学习的伟大胜利。但是学界普遍认为这并不能代表机器学习就是人工智能的未来,尤其是通用人工智能。
为什么这么说?这里只讲简单的一点。


在 3 月 13 日李世石九段下出了“神之一手”,后来 Deepmind 团队透露:错误发生在第 79 手,但 AlphaGo 知道第 87 手才发觉,这期间它始终认为自己仍然领先。
这里点出了一个关键问题:鲁棒性。
人类犯错:水平从九段降到八段。 机器犯错:水平从九段降到业余。



传统的机器学习任务大都是在给定参数的封闭静态环境中,而现在正在慢慢转向开放动态环境。


“雪龙号”是国内的一个例子,下面介绍一些国外的探讨情况。这里也提到:
随着人工智能技术取得巨大发展,越来越多地面临“高风险应用”,因此必须有“鲁棒的AI”。




关于未来 —— 形态
要分析未来,首先得知道现状。那么机器学习现在的形态是什么?有人会说算法,有人会说数据。
“其实机器学习的形态就是算法 + 数据。”
但是这样的形态下,它有哪些局限性呢?主要分为 3 个大的方面和其他一些小方面:
- 局限 1:需要大量训练样本;
- 局限 2:难以适应环境变化;
- 局限 3:黑箱模型。






我们可以看到机器学习的技术局限性仍然很多,当然,我们可以针对每个问题一一解决,但这难免进入一种“头疼医头,脚疼医脚”的境地。所以我们是否可以跳出这个框架,从整体上来解决这些问题呢?
那么我们都知道有硬件(Hardware),有软件(Software),这里提出一个类似于这两者的新概念“学件”(Learnware):
学件(Learnware)= 模型(model)+规约(specification)
很多人可能在自己的应用中已经建立了这样的模型,他们也很愿意找到一个地方把这些模型分享出去。那以后一个新用户想要应用,也许不用自己去建立一个,而是先到“学件”的市场上找一找有没有合适的,可以拿来使用修改。
比如说,要找一把切肉的刀,可以先看看市场上有没有这样的刀,不会说自己从采矿开始重新打一把刀。如果没有合适的刀,也许会选择一把西瓜刀,然后用自己的数据重新“打磨”一下,让它满足自己应用的需要。
所以,这个想法就是希望能够部分地重用他人的结果,不必“从头开始”。

从规约的角度需要给出模型的合适刻画。
从模型的角度需要满足 3 个要求:
- 可重用
- 可演进
- 可了解


规约需要能清楚地说明在做什么,主要有三种方式:
- 基于逻辑
- 基于统计量
- 技术与精简数据
这些也许可以借鉴软件工程中的规约方法来处理。

我们可以看到,有了“学件”的框架以后,很多之前提到的局限可能都会迎刃而解:
- “可重用”的特性能够获取大量不同的样本;
- “可演进”的特性可以适应环境的变化;
- “可了解”的特性能有效地了解模型的能力;
- 因为是专家基础上建立的,所以比较容易得到专家级的结果;
- 因为共享出来的是模型,所以避免了数据泄露和隐私泄露的问题。
除了解决了原有的问题,“学件”很有可能会催生出一个新产业,类似于软件产业。因为大家可以把自己的模型放到市场上,提供给别人使用,如果被使用得很多,又很好用,用户很广泛,那么可以对这个“学件”定价使用,创造出经济价值。



总结
最后,对今天的报告内容进行一个总结,主要有下面几点:
- 深度学习可能有“冬天”,它只是机器学习的一种技术,总会出现更“潮”的新技术;
- 机器学习不会有“冬天”,只要有分析数据的需求,就会用到机器学习;
- 关于未来的思考:
- 1、技术上:一定是能有效利用 GPU 等计算设备的方法(未必是深度学习);
- 2、任务上:开放环境的机器学习任务特别重要(鲁棒性是关键);
- 3、形态上:希望是从现在的“算法 + 数据”过渡到“学件”的形态。
如果要对未来这三点加上一个预测期限的话,分别是 5 年、10 年、15 年。

 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
