- LTR 排序学习
- 工程实现
- 结束
LTR 排序学习
互联网的出现,意味着”信息大爆炸”。用户担心的,不再是信息太少,而是信息太多。如何从大量信息之中,快速有效地找出最重要的内容,成了互联网的一大核心问题。
各种各样的排名算法,是目前过滤信息的主要手段之一。对信息进行排名,意味着将信息按照重要性依次排列,并且及时进行更新。排列的依据,可以基于信息本身的特征,也可以基于用户的投票,即让用户决定,什么样的信息可以排在第一位。
下面整理和分析一些基于用户投票的排名算法。
- 参考资料
- 【2020-8-5】十张图带你领略知乎答案排序算法之美
- 基于用户投票的 6 个排名算法【转载+整理】
Learning to Ranking简介
Learning to Rank (LTR)是指一系列基于机器学习的排序算法,最初主要应用于信息检索(Information Retrieval,IR)领域,最典型的是解决搜索引擎对搜索结果的排序问题。除了信息检索以外,Learning to Rank 也被应用到许多其他排序问题上,如商品推荐、计算广告、生物信息学等。
Facebook用它来优化你的朋友圈文章,Airbnb用它来优化你的搜索结果排序,Quora用它来给各种答案进行排序。Bing常常标榜它有着最好的机器学习得到的搜索结果,但是Google从前常常标榜不怎么用Learning to rank。
排序学习的定义为:基于机器学习中用于解决分类与回归问题的思想,提出利用机器学习方法解决排序的问题。排序学习的目标在于自动地从训练数据中学习得到一个排序函数,使其在文本检索中能够针对文本的相关性、重要性等衡量标准对文本进行排序。机器学习的优势是:整合大量复杂特征并自动进行参数调整,自动学习最优参数,降低了单一考虑排序因素的风险;同时,能够通过众多有效手段规避过拟合问题。
机器学习的几个关键组成部分:
- 输入空间(input space),以特征向量来表示的样本,特征是以某种方式提取出来的。
- 输出空间(output space),对input处理后的展现形式,包括两种,一是task的最后形式,另一种是Machine Learning 中间便于处理的形式。
- 假设空间(hypothesis space),它定义了一系列从input space 到output space的映射函数。
- 损失函数(loss function),ML的目的就是在training set上定义一个loss function来学习一个optimal hypothesis。loss function在ML中扮演了一个非常关键的角色。
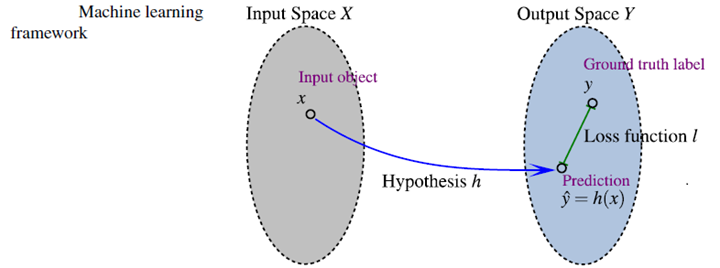
LTR的定义:
广义定义:使用机器学习技术来解决ranking问题的都称为LTR方法。 狭义定义:满足以下两点的ranking方法:
- Feature Based,样本以特征向量的形式体现。
- Discriminative Training,(有识别性的训练)a learning-to-rank method has its own input space, output space, hypothesis space, and loss function.Discriminative Training是一个基于训练集的自动学习过程。
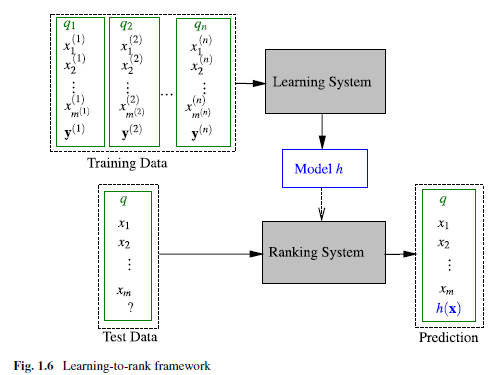
LTR框架
LTR是有监督学习,因此是需要有标注的training set。很多机器学习都可以套在上述流程图中。不同的方法主要体现在不同的input space,不同的的output space,不同的假设空间,不同的损失函数。经典Learning to Rank框架如下:
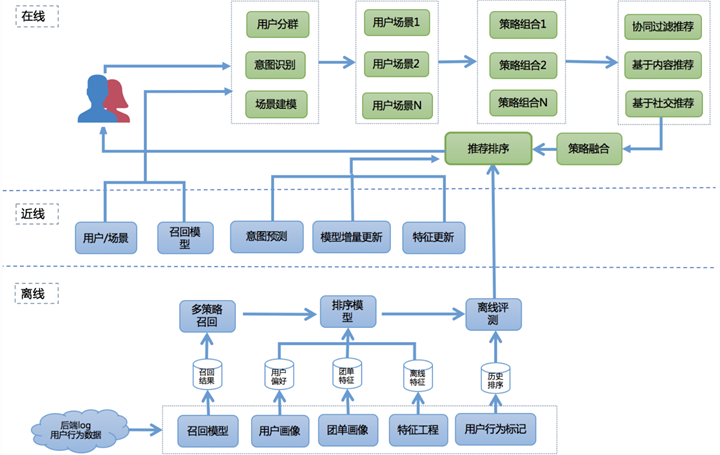
排序学习在现代推荐架构中处于非常关键的环节,它可以完成不同召回策略的统一排序,也可将离线、近线、在线的推荐结果根据用户所处的场景进行整合和实时调整,完成打分重排并推荐给用户。美团推荐框架:
LTR的优点
LTR 则是基于特征,通过机器学习算法训练来学习到最佳的拟合公式,相比传统的排序方法,优势有很多:
- 可以根据反馈自动学习并调整参数
- 可以融合多方面的排序影响因素
- 避免过拟合(通过正则项)
- 实现个性化需求(推荐)
- 多种召回策略的融合排序推荐(推荐)
- 多目标学习(推荐)
LTR的局限性
- 在一个机器学习的系统当中,人们很难理解为什么一个结果比另一个结果要好。机器学习系统像一个黑盒子,大部分时候告诉我们结果1比结果2更加相关的概率,但不会告诉我们是因为什么原因结果1比结果2要好。
- 很多information retrieval当中发现的特征很难在机器学习模型中产生效果。因为这些特征常常是针对某一类检索问题,然而对于那一类检索问题,常见的机器学习算法可能会为了模型的概括性以及防止overfitting,忽略特定的特征。这也是为什么当有了足够多的ranking engineer,大部分人都会专注改进rule-based scoring方法,去直接针对特定问题进行改进。
Learning to Rank 算法分类
排序学习的模型通常分为单点法(Pointwise Approach)、配对法(Pairwise Approach)和列表法(Listwise Approach)三大类,三种方法并不是特定的算法,而是排序学习模型的设计思路,主要区别体现在损失函数(Loss Function)、以及相应的标签标注方式和优化方法的不同。
单点法(Pointwise)
单点法排序学习模型的每一个训练样本都仅仅是某一个查询关键字和某一个文档的配对。它们之间是否相关,与其他文档和其他查询关键字都没有关系。很明显,单点法排序学习是对现实的一个极大简化,但是对于训练排序算法来说是一个不错的起点。单点法将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果。
单点排序学习可以按照标注和损失函数设计的不同,将排序问题转化成回归、分类、和有序分类问题(有些文献也称有序回归)问题,可参考下图:

分别看一下损失函数的设计思想:
- 分类(Classification):输出空间包含的是无序类别,对每个查询-文档对的样本判断是否相关,可以是二分类的,如相关认为是正例,不相关认为是负例;也可以是类似 NDCG 那样的五级标注的多分类问题。分类模型通常会输出一个概率值,可根据概率值的排序作为排序最终结果。
- 回归(Regression):输出空间包含的是真实值相关度得分,可通过回归来直接拟合相关度打分。
- 有序分类(Ordinal Classification):有序分类也称有序回归(Ordinal Regression),输出空间一般包含的是有序类别,通常的做法是找到一个打分函数,然后用一系列阈值对得分进行分割,得到有序类别。
单点法(Pointwise)的应用
推荐系统领域,最常用就是二元分类的 Pointwise,比如常见的点击率(CTR)预估问题,之所以用得多,是因为二元分类的 Pointwise 模型的复杂度通常比 Pairwise 和 Listwise 要低,而且可以借助用户的点击反馈自然地完成正负样例的标注,而其他 Pairwise 和 Listwise 的模型标注就没那么容易了。成功地将排序问题转化成分类问题,也就意味着我们机器学习中那些常用的分类方法都可以直接用来解决排序问题,如 LR、GBDT、SVM 等,甚至包括结合深度学习的很多推荐排序模型,都属于这种 Pointwise 的思想范畴。
代表算法有:
- 基于神经网络的排序算法 RankProp
- 基于感知机的在线排序算法 Prank(Perception Rank)/OAP-BPM
- 基于 SVM 的排序算法
- Subset Ranking
- McRank
- Prank
- OC SVM
推荐系统中使用较多的 Pointwise 方法是 LR、GBDT、SVM、FM 以及结合 DNN 的各种排序算法。
单点法(Pointwise)的缺点
Pointwise 方法通过优化损失函数求解最优的参数,可以看到 Pointwise 方法非常简单,工程上也易实现,但是 Pointwise 也存在很多问题:
- Pointwise 只考虑单个文档同 query 的相关性,没有考虑文档间的关系,然而排序追求的是排序结果,并不要求精确打分,只要有相对打分即可;
- 通过分类只是把不同的文档做了一个简单的区分,同一个类别里的文档则无法深入区别,虽然我们可以根据预测的概率来区别,但实际上,这个概率只是准确度概率,并不是真正的排序靠前的预测概率;
- Pointwise 方法并没有考虑同一个 query 对应的文档间的内部依赖性。一方面,导致输入空间内的样本不是 IID 的,违反了 ML 的基本假设,另一方面,没有充分利用这种样本间的结构性。其次,当不同 query 对应不同数量的文档时,整体 loss 将容易被对应文档数量大的 query 组所支配,应该每组 query 都是等价的才合理。
- 很多时候,排序结果的 Top N 条的顺序重要性远比剩下全部顺序重要性要高,因为损失函数没有相对排序位置信息,这样会使损失函数可能无意的过多强调那些不重要的 docs,即那些排序在后面对用户体验影响小的 doc,所以对于位置靠前但是排序错误的文档应该加大惩罚。
配对法(Pairwise)
配对法的基本思路是对样本进行两两比较,构建偏序文档对,从比较中学习排序,因为对于一个查询关键字来说,最重要的其实不是针对某一个文档的相关性是否估计得准确,而是要能够正确估计一组文档之间的 “相对关系”。因此,Pairwise 的训练集样本从每一个 “关键字文档对” 变成了 “关键字文档文档配对”。也就是说,每一个数据样本其实是一个比较关系,当前一个文档比后一个文档相关排序更靠前的话,就是正例,否则便是负例,如下图。试想,有三个文档:A、B 和 C。完美的排序是 “B>C>A”。我们希望通过学习两两关系 “B>C”、“B>A” 和 “C>A” 来重构 “B>C>A”。
这里面有3个非常关键的假设:
- 我们可以针对某一个关键字得到一个完美的排序关系。在实际操作中,这个关系可以通过相关标签来获得,也可以通过其他信息获得,比如点击率等信息。然而,这个完美的排序关系并不是永远都存在的。试想在电子商务网站中,对于查询关键字 “哈利波特”,有的用户希望购买书籍,有的用户则希望购买含有哈利波特图案的 T 恤,显然,这里面就不存在一个完美排序。
- 我们寄希望能够学习文档之间的两两配对关系从而 “重构” 这个完美排序。然而,这也不是一个有 “保证” 的思路。用刚才的例子,希望学习两两关系 “B>C”、“B>A” 和 “C>A” 来重构完美排序 “B>C>A”。然而,实际中,这三个两两关系之间是独立的。特别是在预测的时候,即使模型能够正确判断 “B>C” 和 “C>A”,也不代表模型就一定能得到 “B>A”。注意,这里的关键是 “一定”,也就是模型有可能得到也有可能得不到。两两配对关系不能 “一定” 得到完美排序,这个结论其实就揭示了这种方法的不一致性。也就是说,我们并不能真正保证可以得到最优的排序。
- 我们能够构建样本来描述这样的两两相对的比较关系。一个相对比较简单的情况,认为文档之间的两两关系来自于文档特征(Feature)之间的差异。也就是说,可以利用样本之间特征的差值当做新的特征,从而学习到差值到相关性差异这样的一组对应关系。
Pairwise 最终的算分,分类和回归都可以实现,不过最常用的还是二元分类,如下图:
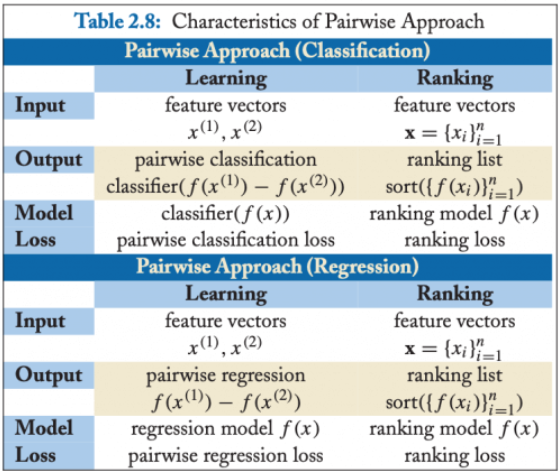
配对法(Pairwise)的应用
代表算法:
- 基于 SVM 的 Ranking SVM 算法
- 基于神经网络的 RankNet 算法(2007)
- 基于 Boosting 的 RankBoost 算法(2003)
推荐系统中使用较多的 Pairwise 方法是贝叶斯个性化排序(Bayesian personalized ranking,BPR)。
配对法(Pairwise)的缺点
Pairwise 方法通过考虑两两文档之间的相关对顺序来进行排序,相比 Pointwise 方法有明显改善。但 Pairwise 方法仍有如下问题:
- 使用的是两文档之间相关度的损失函数,而它和真正衡量排序效果的指标之间存在很大不同,甚至可能是负相关的,如可能出现 Pairwise Loss 越来越低,但 NDCG 分数也越来越低的现象。
- 只考虑了两个文档的先后顺序,且没有考虑文档在搜索列表中出现的位置,导致最终排序效果并不理想。
- 不同的查询,其相关文档数量差异很大,转换为文档对之后,有的查询可能有几百对文档,有的可能只有几十个,这样不加均一化地在一起学习,模型会优先考虑文档对数量多的查询,减少这些查询的 loss,最终对机器学习的效果评价造成困难。
- Pairwise 方法的训练样例是偏序文档对,它将对文档的排序转化为对不同文档与查询相关性大小关系的预测;因此,如果因某个文档相关性被预测错误,或文档对的两个文档相关性均被预测错误,则会影响与之关联的其它文档,进而引起连锁反应并影响最终排序结果。
列表法(Listwise)
Listwise方法是直接优化排序列表,输入为单条样本为一个文档排列。相对于尝试学习每一个样本是否相关或者两个文档的相对比较关系,列表法排序学习的基本思路是尝试直接优化像 NDCG(Normalized Discounted Cumulative Gain)这样的指标,从而能够学习到最佳排序结果。列表法的相关研究有很大一部分来自于微软研究院。列表法排序学习有两种基本思路。第一种称为 Measure-specific,就是直接针对 NDCG 这样的指标进行优化。目的简单明了,用什么做衡量标准,就优化什么目标。第二种称为 Non-measure specific,则是根据一个已经知道的最优排序,尝试重建这个顺序,然后来衡量这中间的差异。

1)Measure-specific,直接针对 NDCG 类的排序指标进行优化
直接优化排序指标的难点在于,希望能够优化 NDCG 指标这样的 “理想” 很美好,但是现实却很残酷。NDCG、MAP 以及 AUC 这类排序标准,都是在数学的形式上的 “非连续”(Non-Continuous)和 “非可微分”(Non-Differentiable)。而绝大多数的优化算法都是基于 “连续”(Continuous)和 “可微分”(Differentiable)函数的。因此,直接优化难度比较大。
针对这种情况,主要有这么几种解决方法。
- 既然直接优化有难度,那就找一个近似 NDCG 的另外一种指标。而这种替代的指标是 “连续” 和 “可微分” 的 。只要我们建立这个替代指标和 NDCG 之间的近似关系,那么就能够通过优化这个替代指标达到逼近优化 NDCG 的目的。这类的代表性算法的有 SoftRank 和 AppRank。
- 尝试从数学的形式上写出一个 NDCG 等指标的 “边界”(Bound),然后优化这个边界。比如,如果推导出一个上界,那就可以通过最小化这个上界来优化 NDCG。这类的代表性算法有 SVM-MAP 和 SVM-NDCG。
- 希望从优化算法上下手,看是否能够设计出复杂的优化算法来达到优化 NDCG 等指标的目的。对于这类算法来说,算法要求的目标函数可以是 “非连续” 和 “非可微分” 的。这类的代表性算法有 AdaRank 和 RankGP。
2)Non-measure specific,尝试重建最优顺序,衡量其中差异
这种思路的主要假设是,已经知道了针对某个搜索关键字的完美排序,那么怎么通过学习算法来逼近这个完美排序。我们希望缩小预测排序和完美排序之间的差距。值得注意的是,在这种思路的讨论中,优化 NDCG 等排序的指标并不是主要目的。这里面的代表有 ListNet 和 ListMLE。
3)列表法和配对法的中间解法
第三种思路某种程度上说是第一种思路的一个分支,因为很特别,这里单独列出来。其特点是在纯列表法和配对法之间寻求一种中间解法。具体来说,这类思路的核心思想,是从 NDCG 等指标中受到启发,设计出一种替代的目标函数。这一步和刚才介绍的第一种思路中的第一个方向有异曲同工之妙,都是希望能够找到替代品。找到替代品以后,接下来就是把直接优化列表的想法退化成优化某种配对。这第二步就更进一步简化了问题。这个方向的代表方法就是微软发明的 LambdaRank 以及后来的 LambdaMART。微软发明的这个系列算法成了微软的搜索引擎 Bing 的核心算法之一,而且 LambdaMART 也是推荐领域中可能用到一类排序算法。
列表法(Listwise)的应用
代表算法:
- 基于 Measure-specific 的 SoftRank、SVM-MAP、SoftRank、LambdaRank、LambdaMART
- 基于 Non-measure specific 的 ListNet、ListMLE、BoltzRank。
推荐中使用较多的 Listwise 方法是 LambdaMART。
列表法(Listwise)的缺点
列表法相较单点法和配对法针对排序问题的模型设计更加自然,解决了排序应该基于 query 和 position 问题。但列表法也存在一些问题:
- 一些算法需要基于排列来计算 loss,从而使得训练复杂度较高,如 ListNet 和 BoltzRank。
- 位置信息并没有在 loss 中得到充分利用,可以考虑在 ListNet 和 ListMLE 的 loss 中引入位置折扣因子。
Learning to Ranking的评估指标
P@K
对于现在的大规模 IR 任务,每个 query 都有大量相关的 doc,因此很难再用查全率进行衡量召回质量,但是可以用 Precision at K 对召回质量进行评价。
Precision at K 通常表示为 P@K
MAP(Mean Average Precision)
DCG系列对比
累计增益(CG)- CG,cumulative gain,只考虑到了相关性的关联程度,没有考虑到位置因素。它是一个搜素结果相关性分数的总和。
折损累计增益(DCG)- DCG, Discounted 的CG,就是在每一个CG的结果上处以一个折损值,为什么要这么做呢?目的就是为了让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低。
归一化折损累计增益(NDCG)- NDCG, Normalized 的DCG,由于搜索结果随着检索词的不同,返回数量是不一致的,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理,这里是处以IDCG。
【2022-9-13】Ranking算法评测指标之 CG、DCG、NDCG
举例,搜索到5个结果,其相关性分数分别是:3、2、3、0、1、2
- (0)Gain: 列表中每一个item的相关性分数
- 公式:$f(G)=r_i$
- (1)CG:Cumulative Gain, 对K个item的Gain进行累加;
- 只是对相关的分数进行了一个关联的打分,并没有召回的所在位置对排序结果评分对影响。
- 公式:$ f(CG@K)=\sum_{i=0}^{K}r_i $
- 得分:11
- (2)NCG:Discounted Cumulative Gain, 考虑了排序位置因素,排名越靠前,权重越大,反之,越低;权重通过log函数实现
- 公式:$ f(DCG@K)= \sum_{i=0}^{K}\frac{r_i}{log_2^{(i+1)}} $
- 当相关性分数r(i)只有(0,1)两种取值时,DCG@K有另一种表达。其实就是如果算法返回的排序列表中的item出现在真实交互列表中时,分子加1,否则跳过。
- $ f(DCG@K)= \sum_{i=0}^{K}\frac{2^{r_i}-1}{log_2^{(i+1)}} $
- 得分:6.86, img

- 公式:$ f(DCG@K)= \sum_{i=0}^{K}\frac{r_i}{log_2^{(i+1)}} $
- (3)NDCG:考虑了排序数量的影响,通过归一化消除排序数量对权重影响
- DCG能够对一个用户的推荐列表进行评价,如果用该指标评价某个推荐算法,需要对所有用户的推荐列表进行评价,由于用户真实列表长度不同,不同用户之间的DCG相比没有意义。所以要对不同用户的指标进行归一化,自然的想法就是计算每个用户真实列表的DCG分数,用IDCG表示,然后用每个用户的DCG与IDCG之比作为每个用户归一化后的分值,最后对每个用户取平均得到最终的分值,即NDCG。
-
公式:$ f(DCG@K)= \frac{DCG@K}{\left u \right }$, r是相关性分数,u表示用户 - 得分:8.37, IDCG@6
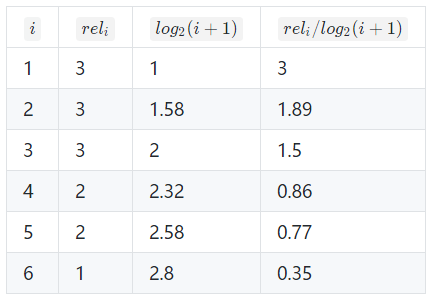
- $ NDCG=DCG/IDCG $
- NDCG值域是 $[0,1]$
NDCG(Normalized Discounted Cumulative Gain)
NDCG,Normalized Discounted cumulative gain 直接翻译为归一化折损累计增益。这个指标通常是用来衡量和评价搜索结果算法。DCG的两个思想:
- 高关联度的结果比一般关联度的结果更影响最终的指标得分
- 有高关联度的结果出现在更靠前的位置的时候,指标会越高
NDCG 优点
- NDCG 的主要优势是它考虑到了分等级的相关性值。当它们在数据集中可用时,NDCG 是一个很好的选择。
- 与 MAP 度量相比,它在评估排名项目的位置方面做得很好。它适用于二元的相关/非相关场景。
- 平滑的对数折现因子有一个很好的理论基础,该工作的作者表明,对于每一对显著不同的排名推荐系统,NDCG 度量始终能够确定更好的一个。 NDCG 缺点
- NDCG 在部分反馈方面有一些问题。当我们有不完整的评级时,就会发生这种情况。这是大多数推荐系统的情况。如果我们有完整的评级,就没有真正的任务去实现!在这种情况下,recsys 系统所有者需要决定如何归罪于缺失的评级。将缺少的值设置为 0 将把它们标记为不相关的项。其他计算值(如用户的平均/中值)也可以帮助解决这个缺点。
- 接下来,用户需要手动处理 IDCG 等于 0 的情况。当用户没有相关文档时,就会发生这种情况。这里的一个策略是也将 NDCG 设置为 0。
- 另一个问题是处理 NDCG@K。recsys 系统返回的排序列表的大小可以小于 k。为了处理这个问题,我们可以考虑固定大小的结果集,并用最小分数填充较小的集合。 正如我所说的,NDCG 的主要优势在于它考虑到了分级的相关性值。如果你的数据集有正确的形式,并且你正在处理分级相关性,那么 NDCG 度量就是你的首选指标。
import numpy as np
def getDCG(scores):
return np.sum(
np.divide(np.power(2, scores) - 1, np.log2(np.arange(scores.shape[0], dtype=np.float32) + 2)),
dtype=np.float32)
def getNDCG(rank_list, pos_items):
relevance = np.ones_like(pos_items)
it2rel = {it: r for it, r in zip(pos_items, relevance)}
rank_scores = np.asarray([it2rel.get(it, 0.0) for it in rank_list], dtype=np.float32)
idcg = getDCG(relevance)
dcg = getDCG(rank_scores)
if dcg == 0.0:
return 0.0
ndcg = dcg / idcg
return ndcg
l1 = [1, 4, 5]
l2 = [1, 2, 3]
a = getNDCG(l1, l2)
print(a)
# 0.4692787
MRR(Mean Reciprocal Rank)
平均倒数排名(Mean Reciprocal Rank, MRR)是一个国际上通用的对搜索算法进行评价的机制,其评估假设是基于唯一的一个相关结果,即第一个结果匹配,分数为 1 ,第二个匹配分数为 0.5,第 n 个匹配分数为 1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
MRR 的优点
- 该方法计算简单,解释简单。
- 这种方法高度关注列表的第一个相关元素。它最适合有针对性的搜索,比如用户询问“对我来说最好的东西”。
- 适用于已知项目搜索,如导航查询或寻找事实。 MRR 的缺点
- MRR 指标不评估推荐项目列表的其余部分。它只关注列表中的第一个项目。
- 它给出一个只有一个相关物品的列表。如果这是评估的目标,那找个度量指标是可以的。
- 对于想要浏览相关物品列表的用户来说,这可能不是一个好的评估指标。用户的目标可能是比较多个相关物品。
WTA(Winners Take All)
WTA,全称 Winners Take All,对于给定的查询 Query,如果模型返回的结果列表中,第一个文档是相关的,则 WTA =1, 否则为 0。
如对于一个 Query,本来有 5 个相关结果,查询结果中如果第一个结果是相关的,那么 WTA = 1,如果第一个结果是不相关的,则 WTA = 0。
ERR(Expected Reciprocal Rank)
ERR是受到cascade model的启发。点击模型中的cascade model,考虑到在同一个检索结果列表中各文档之间的位置依赖关系,假设用户从上至下查看,如果遇到某一检索结果项满意并进行点击,则操作结束;否则跳过该项继续往后查看。
NDCG和ERR指标的优势在于,它们对doc的相关性划分多个(>2)等级,而MRR和MAP只会对doc的相关性划分2个等级(相关和不相关)。并且,这些指标都包含了doc位置信息(给予靠前位置的doc以较高的权重),这很适合于web search。然而,这些指标的缺点是不平滑、不连续,无法求梯度,如果将这些指标直接作为模型评分的函数的话,是无法直接用梯度下降法进行求解的。
wilson 得分
【2022-8-15】威尔逊得分 Wilson Score 排序算法
如何选出最受欢迎的产品?
如何给出”某个时段”的排名,比如”过去24小时最热门的文章”。但是,很多场合需要的是”所有时段”的排名,比如”最受用户好评的产品”。
常见解法
- 得分 = 赞成票 - 反对票
- 得分 = 好评率 = 赞成票 / (赞成票 + 反对票)
当市场样本量过少,以上方法都不对!
场景:
- 假设平台售卖两款手机A和B。A手机有800人喜欢,200人不喜欢;B手机有9人喜欢,2人不喜欢。那么,用户更喜欢哪款手机?
那么,如何科学衡量喜好程度?
正确的算法是什么呢?
设定:
- (1)每个用户的投票都是独立事件。
- (2)用户只有两个选择,要么投赞成票,要么投反对票。
- (3)如果投票总人数为n,其中赞成票为k,那么赞成票的比例p就等于k/n。
以上是一种统计分布,叫做”二项分布“(binomial distribution)
- p越大,就代表这个项目的好评比例越高,越应该排在前面。
- 但是,p的可信度取决于有多少人投票,如果样本太小,p就不可信。
那么需要计算出p的置信区间。
- 所谓”置信区间”,就是说,以某个概率而言,p会落在的那个区间。
- 比如,某个产品的好评率是80%,但是这个值不一定可信。根据统计学,只能说有95%的把握可以断定,好评率在75%到85%之间,即置信区间是[75%, 85%]。
排名算法改进:
- 第一步,计算每个项目的”好评率”(即赞成票的比例)。
- 第二步,计算每个”好评率”的置信区间(以95%的概率)。
- 第三步,根据置信区间的下限值,进行排名。这个值越大,排名就越高。
原理是置信区间的宽窄与样本的数量有关。
- 比如,A有8张赞成票,2张反对票;B有80张赞成票,20张反对票。这两个项目的赞成票比例都是80%,但是B的置信区间(假定[75%, 85%])会比A的置信区间(假定[70%, 90%])窄得多,因此B的置信区间的下限值(75%)会比A(70%)大,所以B应该排在A前面。
置信区间的本质是进行可信度修正,弥补样本量过小的影响。
- 如果样本多,就说明比较可信,不需要很大的修正,所以置信区间会比较窄,下限值会比较大;
- 如果样本少,就说明不一定可信,必须进行较大的修正,所以置信区间会比较宽,下限值会比较小。
二项分布的置信区间有多种计算公式,最常见的是”正态区间“(Normal approximation interval),教科书里几乎都是这种方法。但是,它只适用于样本较多的情况(np > 5 且 n(1 − p) > 5),对于小样本,它的准确性很差。
1927年,美国数学家 Edwin Bidwell Wilson提出了一个修正公式,被称为”威尔逊区间“,很好地解决了小样本的准确性问题。
什么是wilson得分?
- 威尔逊得分排序算法,Wilson Score,用于质量排序,数据含有好评和差评,综合考虑评论数与好评率,得分越高,质量越高
- 公式
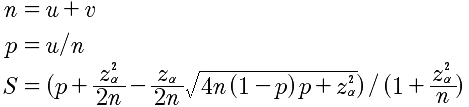
- u表示正例数(好评),v表示负例数(差评),n表示实例总数(评论总数),p表示好评率,z是正态分布的分位数(参数),S表示最终的威尔逊得分。z一般取值2即可,即95%的置信度
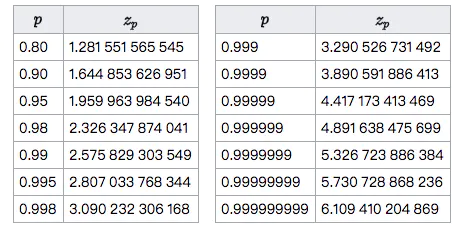
- 正态分布分位表
- 源码
算法性质:
- 得分S的范围是[0,1),效果:已经归一化,适合排序
- 当正例数u为0时,p为0,得分S为0;效果:没有好评,分数最低;
- 当负例数v为0时,p为1,退化为1/(1 + z^2 / n),得分S永远小于1;效果:分数具有永久可比性;
- 当p不变时,n越大,分子减少速度小于分母减少速度,得分S越多,反之亦然;效果:好评率p相同,实例总数n越多,得分S越多;
- 当n趋于无穷大时,退化为p,得分S由p决定;效果:当评论总数n越多时,好评率p带给得分S的提升越明显;
- 当分位数z越大时,总数n越重要,好评率p越不重要,反之亦然;效果:z越大,评论总数n越重要,区分度低;z越小,好评率p越重要;
实例:
- 假设医生A有100个评价,1个差评99个好评。医生B有2个评价,都是好评,那哪个应该排前面?
- 在z=2时,即95%的置信度,医生A的得分是0.9440,医生B的得分是0.3333,医生A排在前面。
PS:评分等级问题:如五星评价体系,或者百分评价体系,该怎么办呢?
- 将威尔逊得分的公式由
伯努利分布修改为正态分布即可。
威尔逊计算
Go 版
package main
import (
"fmt"
"math"
)
// 威尔逊得分(Wilson Score)排序算法
func main() {
// 计算结果:0.46844027984510983
wilsonScore(500, 1000, 2)
}
// 计算威尔逊得分
// u:好评数 zP:正态分布的分位数(一般取值2即可,即95%的置信度) s:威尔逊得分
func wilsonScore(u float64, n float64, zP float64) float64 {
p := u / n
println()
fmt.Println("好评率为:", p)
s := (p + (math.Pow(zP, 2) / (2. * n)) - ((zP / (2. * n)) * math.Sqrt(4.*n*(1.-p)*p+math.Pow(zP, 2)))) / (1. + math.Pow(zP, 2)/n)
fmt.Println("威尔逊得分为:", s)
return s
}
Python版
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Created by C.L.Wang
import numpy as np
def wilson_score(pos, total, p_z=2.):
"""
威尔逊得分计算函数
参考:https://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval
:param pos: 正例数
:param total: 总数
:param p_z: 正太分布的分位数
:return: 威尔逊得分
"""
pos_rat = pos * 1. / total * 1. # 正例比率
score = (pos_rat + (np.square(p_z) / (2. * total))
- ((p_z / (2. * total)) * np.sqrt(4. * total * (1. - pos_rat) * pos_rat + np.square(p_z)))) / \
(1. + np.square(p_z) / total)
return score
# 归一化后的威尔逊得分
def wilson_score_norm(mean, var, total, p_z=2.):
"""
威尔逊得分计算函数 正态分布版 支持如5星评价,或百分制评价
:param mean: 均值
:param var: 方差
:param total: 总数
:param p_z: 正太分布的分位数
:return:
"""
# 均值方差需要归一化,以符合正太分布的分位数
score = (mean + (np.square(p_z) / (2. * total))
- ((p_z / (2. * total)) * np.sqrt(4. * total * var + np.square(p_z)))) / \
(1 + np.square(p_z) / total)
return score
def test_of_values():
"""
五星评价的归一化实例,百分制类似
:return: 总数,均值,方差
"""
max = 5. # 五星评价的最大值
min = 1. # 五星评价的最小值
values = np.array([1., 2., 3., 4., 5.]) # 示例
norm_values = (values - min) / (max - min) # 归一化
total = norm_values.size # 总数
mean = np.mean(norm_values) # 归一化后的均值
var = np.var(norm_values) # 归一化后的方差
return total, mean, var
total, mean, var = test_of_values()
print "total: %s, mean: %s, var: %s" % (total, mean, var)
print 'score: %s' % wilson_score_norm(mean=mean, var=var, total=total)
print 'score: %s' % wilson_score(90, 90 + 10, p_z=2.)
print 'score: %s' % wilson_score(90, 90 + 10, p_z=6.)
print 'score: %s' % wilson_score(900, 900 + 100, p_z=6.)
关于z参数,即正态分位数。正态分位数影响wilson得分的分布,z参数取值依据就是样本数量级。
- 举个例子:同样是100个样本,90个好评,z取值2或6,分数差别很大,体系所容纳(或区分)的样本数也相差较大(同样是0.82分和90%好评率,z=2需要100个样本,z=6需要1000个样本),一般而言,样本数的量级越大,z的取值大。
绘制威尔逊得分图
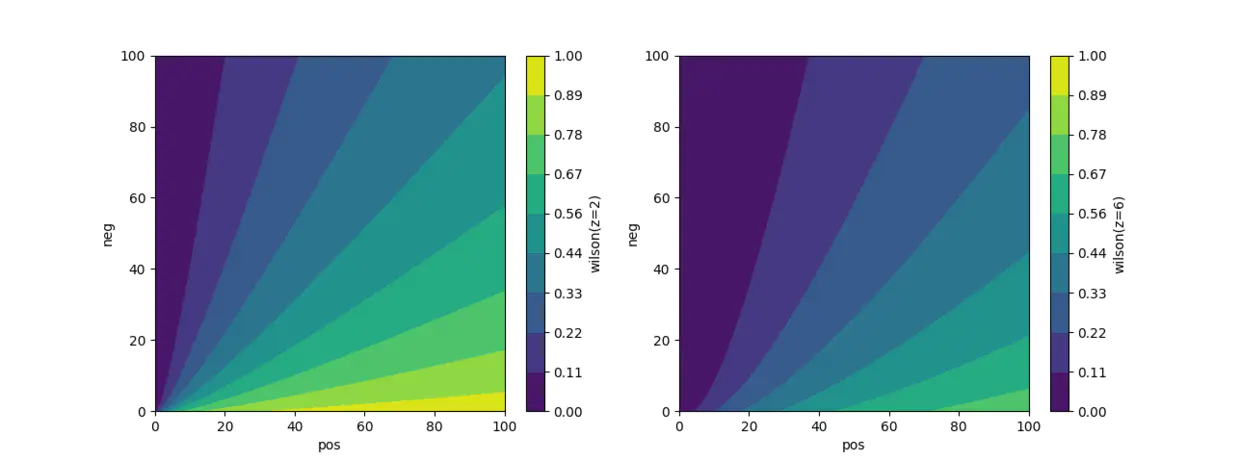
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Created by C.L.Wang
import matplotlib.pyplot as plt
import numpy as np
from wilson_score.wilson_score_model import wilson_score
def show_wilson():
value = np.linspace(0.01, 100, 1000)
u, v = np.meshgrid(value, value)
fig, ax = plt.subplots(1, 2)
levels = np.linspace(0, 1, 10)
cs = ax[0].contourf(u, v, wilson_score(u, u + v), levels=levels)
cb1 = fig.colorbar(cs, ax=ax[0], format="%.2f")
cs = ax[1].contourf(u, v, wilson_score(u, u + v, 6.), levels=levels)
cb2 = fig.colorbar(cs, ax=ax[1], format="%.2f")
ax[0].set_xlabel(u'pos')
ax[0].set_ylabel(u'neg')
cb1.set_label(u'wilson(z=2)')
ax[1].set_xlabel(u'pos')
ax[1].set_ylabel(u'neg')
cb2.set_label(u'wilson(z=6)')
plt.show()
if __name__ == '__main__':
show_wilson()
抖音推荐应用
- 抖音的上热门的方法类似于威尔逊得分排序算法,但是远远又比威尔逊得分排序算法更复杂。
- 大概就是:机器审核 + 人工双重审核。
当一个视频初期上传
- 平台会给你一个初始流量,如果初始流量之后,根据点赞率,评论率,转发率,进行判断:该视频是否受欢迎,如果第一轮评判为受欢迎的,那么他会进行二次传播。
- 当第二次得到了最优反馈,那么就会给与推荐你更大的流量。
- 相反,在第一波或者第N波,反应不好,就不再推荐,没有了平台的推荐,你的视频想火的概率微乎其微,因为没有更多的流量能看见你。
- 你的视频火的第一步是被别人看见,第一步就把路给走死了,后续也只能依靠朋友星星点点的赞。
其实,不难看出这个抖音推荐机制算法背后思维逻辑:流量池,叠加推荐,热度加权及用户心理追求。
威尔逊得分(Wilson Score)排序算法:
- 对质量进行排序,评论中含有好评还有差评,综合考虑评论数与好评率,得分越高,质量越高。
Learning to Rank 常用算法
Pointwise常用算法:
- Classification
- Discriminative model for IR (SIGIR 2004)
- McRank (NIPS 2007)
- Regression
- Least Square Retrieval Function (TOIS 1989)
- Regression Tree for Ordinal Class Prediction (Fundamenta Informaticae, 2000)
- Subset Ranking using Regression (COLT 2006)
- Ordinal Classification
- Ranking with Large Margin Principles (NIPS 2002)
- Constraint Ordinal Regression (ICML 2005)
Pairwise常用算法:
- Learning to Retrieve Information (SCC 1995)
- Learning to Order Things (NIPS 1998)
- Ranking SVM (ICANN 1999)
- RankBoost (JMLR 2003)
- LDM (SIGIR 2005)
- RankNet (ICML 2005)
- Frank (SIGIR 2007)
- MHR(SIGIR 2007)
- GBRank (SIGIR 2007)
- QBRank (NIPS 2007)
- MPRank (ICML 2007)
- IRSVM (SIGIR 2006)
- LambdaRank (NIPS 2006)
- LambdaMART (inf.retr 2010)
Listwise常用算法:
- Measure-specific
- AdaRank (SIGIR 2007)
- SVM-MAP (SIGIR 2007)
- SoftRank (LR4IR 2007)
- RankGP (LR4IR 2007)
- LambdaMART (inf.retr 2010)(也可以做Listwise)
- Non-measure specific
- ListNet (ICML 2007)
- ListMLE (ICML 2008)
- BoltzRank (ICML 2009)
涉及的Learning to Rank的算法非常多。这楼里主要学习RankNet、LambdaRank、LambdaMART。
RankNet
RankNet是2005年微软提出的一种pairwise的Learning to Rank算法,它从概率的角度来解决排序问题。RankNet的核心是提出了一种概率损失函数来学习Ranking Function,并应用Ranking Function对文档进行排序。这里的Ranking Function可以是任意对参数可微的模型,也就是说,该概率损失函数并不依赖于特定的机器学习模型,在论文中,RankNet是基于神经网络实现的。除此之外,GDBT等模型也可以应用于该框架。
LambdaRank
上面介绍了以错误pair最少为优化目标的RankNet算法,然而许多时候仅以错误pair数来评价排序的好坏是不够的,像NDCG或者ERR等评价指标就只关注top k个结果的排序,当我们采用RankNet算法时,往往无法以这些指标为优化目标进行迭代,所以RankNet的优化目标和IR评价指标之间还是存在gap的。
LambdaMART
LambdaMART是LambdaRank的提升树版本,LambdaMART本质上也是属于pairwise排序算法,只不过引入Lambda梯度后,还显示的考察了列表级的排序指标,如NDCG等,因此,也可以算作是listwise的排序算法。LambdaMART由微软于2010年的论文Adapting Boosting for Information Retrieval Measures提出。
LambdaMART是基于 LambdaRank 算法和 MART (Multiple Additive Regression Tree) 算法,将排序问题转化为回归决策树问题。MART 实际就是梯度提升决策树(GBDT, Gradient Boosting Decision Tree)算法。GBDT 的核心思想是在不断的迭代中,新一轮迭代产生的回归决策树模型拟合损失函数的梯度,最终将所有的回归决策树叠加得到最终的模型。LambdaMART 使用一个特殊的 Lambda 值来代替上述梯度,也就是将 LambdaRank 算法与 MART 算法结合起来,是一种能够支持非平滑损失函数的学习排序算法。
MART又称作GBDT,是是一种 Boosting 思想下的算法框架。它通过加法模型,将每次迭代得到的子模型叠加起来;而每次迭代拟合的对象都是学习率与损失函数梯度的乘积。这两点保证了 MART 是一个正确而有效的算法。MART 中最重要的思想,就是每次拟合的对象是损失函数的梯度。值得注意的是,在这里,MART 并不对损失函数的形式做具体规定。实际上,损失函数几乎只需要满足可导这一条件就可以了。这一点非常重要,意味着我们可以把任何合理的可导函数安插在 MART 模型中。LambdaMART 就是用LambdaRank中提出的Lambda梯度代替了损失函数的梯度,将 Lambda和MART结合起来罢了。
LambdaMART具有很多优势:
- 适用于排序场景:不是传统的通过分类或者回归的方法求解排序问题,而是直接求解
- 损失函数可导:通过损失函数的转换,将类似于NDCG这种无法求导的IR评价指标转换成可以求导的函数,并且赋予了梯度的实际物理意义,数学解释非常漂亮
- 增量学习:由于每次训练可以在已有的模型上继续训练,因此适合于增量学习
- 组合特征:因为采用树模型,因此可以学到不同特征组合情况
- 特征选择:因为是基于MART模型,因此也具有MART的优势,可以学到每个特征的重要性,可以做特征选择
- 适用于正负样本比例失衡的数据:因为模型的训练对象具有不同label的文档pair,而不是预测每个文档的label,因此对正负样本比例失衡不敏感
工程实现
TF-Ranking工具
TF-Ranking介绍
TF-Ranking,这是一个专为 Learning-to-Rank 打造的可扩展的 TensorFlow 库。它提供的统一框架包含一套最先进的 Learning-to-Rank 算法,并支持 Pairwise 或 Listwise 损失函数、多项目评分、排名指标优化以及无偏差 Learning-to-Rank。
TF-Ranking 运行速度快,易于使用,并可创建高质量的排名模型。统一的框架让机器学习研究人员、从业者和爱好者能够在单个库中评估并选择一组不同的排名模型。此外,作为一个实用的开源库,其核心不仅在于提供合理的默认值,还应当能让用户开发其自定义模型。因此,它提供了灵活的 API,用户可在此 API 中定义并插入自定义损失函数、评分函数和指标。
LTR 模型与标准的分类模型不同,标准的分类模型一次只对一个条目(item)进行分类,LTR 模型接收一个完整的条目列表作为输入,并学习一个排序算法,使整个列表的效用(utility)最大化。
虽然 LTR 模型最常用于搜索和推荐系统,但自其发布以来,我们已经看到 TF-Ranking 在除搜索以外的各领域,均有应用,其中包括电子商务、SAT 求解器和智能城市规划等。
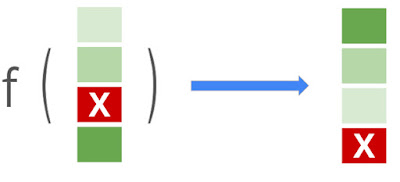
Learning-to-rank (LTR) 的目标是学习一个函数 f(),该函数会以项目列表(文件、产品、电影等)作为输入,并以最佳排序(相关性降序)输出项目列表。图解中,深浅不一的绿色表示项目的相关性水平,标有 “x” 的红色项目是不相关的
经验评估是所有机器学习或信息检索研究的重要一环。为确保兼容先前的研究,TF-Ranking 支持许多常用的排名指标,包括平均倒序排名 (MRR) 和标准化折扣累积收益 (NDCG)。训练期间,我们还可在 TensorBoard(一种开源的 TensorFlow 可视化信息中心)上轻松查看这些指标。
代码讲解
TF-Ranking 实现了 TensorFlow Estimator 接口,可通过封装训练、评估、预测和服务导出大幅度简化机器学习编程。TF-Ranking 与丰富的 TensorFlow 生态系统完美集成。如前文所述,您既可使用 Tensorboard 直观呈现 NDCG 和 MRR 等排名指标,也可以使用这些指标选出最佳模型检查点。待模型准备就绪,您便可使用 TensorFlow Serving 轻松将其部署至生产环境。
若有兴趣亲自试用 TF-Ranking,请查看GitHub 存储区,并浏览教程 示例。TF-Ranking 是一个活跃的研究项目,欢迎您为我们提供反馈和贡献。我们很高兴能见证 TF-Ranking 为信息检索和机器学习研究社区所带来的帮助。
TFR 框架主要这样实现的:
- 第一:tfr 通过 tfr.model.make_groupwise_ranking_fn 来对 Estimator 的 model_fn 进行了整体的封装。我们原有的基于 TensorFlow 的开发,在 Estimator 的 model_fn 这个参数内需要定义包括 Loss、Metrics 在内的完整的模型函数,但是在tfr这里就不需要了,make_groupwise_ranking_fn 会整体返回一个 Estimator 接收的 model_fn。
- 第二:tfr.model.make_groupwise_ranking_fn 函数的第一个参数 group_score_fn,这里是需要传入我们设计和开发的模型结构 (Scoring Function),但是这个模型是之前我们提到的,只需要计算出 logit 的模型。
- 第三:tfr.model.make_groupwise_ranking_fn 函数的第三个参数 transform_fn,对应调用 feature.py 中开发了兼容 TensorFlow 特征转换函数来对以 listwise 形式组织的数据(由 data.py 中的工具读取进来的 Dataset)进行转换,确保输入 Scoring Function 的数据格式正确。
- 第四:tfr.model.make_groupwise_ranking_fn 函数的第四个参数 ranking_head,对应调用了 tfr.head.create_ranking_head 函数,里面的三个参数分别定义了 loss、metrics 和 optimizer。loss 和 metrics 分别从 TFR 的 losses.py 和 metrics.py 中选择我们需要的,而 optimizer 还是使用 TensorFlow 中的 optimizer。
keras排序工作流
参考:
- TF-Ranking 中的 Keras API 让 LTR 模型构建更轻松
- TF-Ranking迎来大更新:兼容Keras更容易开发
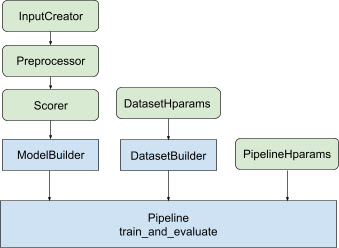
2021 年 5 月,谷歌发布了 TF-Ranking 的一个重要版本,实现了全面支持使用 Keras(TensorFlow 2 的一个高阶 API),以原生方式构建 LTR 模型。我们为原生 Keras 排序模型加入了全新的工作流设计,其中包括灵活的 ModelBuilder、用于设置训练数据的 DatasetBuilder, 以及利用给定数据集训练模型的 Pipeline。有了这些组件,构建自定义 LTR 模型会比以往更轻松,且有利于快速探索、生产和研究的新的模型结构。如果您选择的工具是 RaggedTensors,TF-Ranking 现在也可以和这些工具协作。
原生 Keras 的排序模型有一个全新的工作流设计,包括一个灵活的 ModelBuilder、一个用于设置训练数据的 DatasetBuilder 和一个用于使用所提供的数据集训练模型的 Pipeline。pipeline
利用 TFR-BERT 的 LTR
最近,BERT 之类的预训练语言模型在各种语言理解任务中性能表现突出。为利用这些模型,TF-Ranking 实现了一个新颖的 TFR-BERT 架构——通过结合 BERT 与 LTR 的优势,来优化列表输入的排序过程。举个例子,假设有一个查询和一个由 n 个文件组成的列表,而人们想要在对此查询响应中的文件进行排序。LTR 模型并不会为每个 <query, document> 学习独立的 BERT 表示,而是会应用一个排序损失来共同学习 BERT 表示,充分提升整个排序列表相对于参照标准标签的效用。图
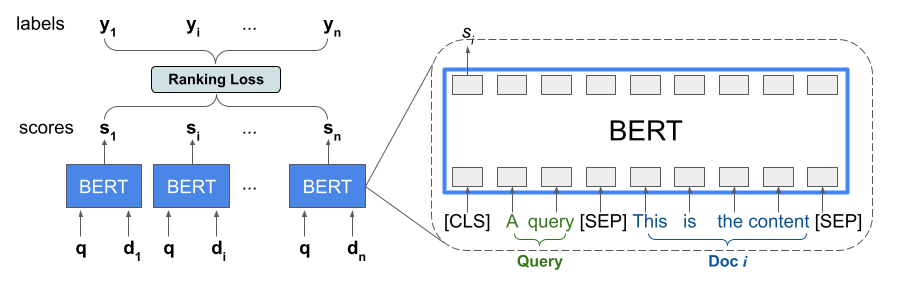 TFR-BERT 架构的说明,在这个架构中,通过使用单个 <query, document> 对的 BERT 表示,在包含 n 个文件的列表上构建了一个联合 LTR 模型
TFR-BERT 架构的说明,在这个架构中,通过使用单个 <query, document> 对的 BERT 表示,在包含 n 个文件的列表上构建了一个联合 LTR 模型具有可解释性的LTR
透明度和可解释性是在排序系统中部署 LTR 模型的重要因素,在贷款资格评估、广告定位或指导医疗决定等过程中,用户可以利用这些系统来确定结果。在这种情况下,每个单独的特征对最终排序的贡献应具有可检查性和可理解性,以此确保结果的透明度、问责制和公正性。
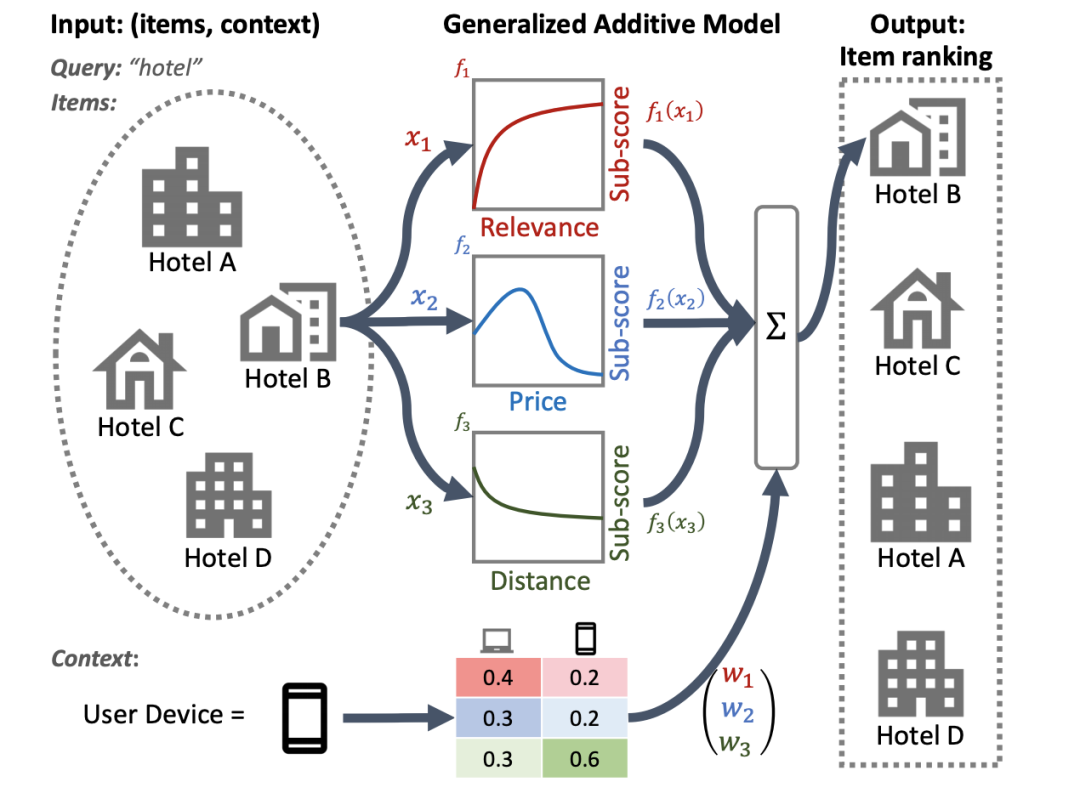
实现这一目标的可用方法之一是使用广义加性模型 (Generalized additive model,GAM),这是一种具有内在可解释性的机器学习模型,由唯一特征的平滑函数线性组合而成。然而,我们虽然已经在回归 (Regression analysis) 和分类任务方面对 GAM 进行了广泛的研究,但将其应用于排序设置的方法却并不明确。举个例子,虽然可以直接利用 GAM 对列表中的每个单独项目进行建模,然而对项目的相互作用和这些项目的排序环境进行建模,仍是一个更具挑战性的研究问题。为此,我们开发了神经排序 GAM,这是可为排序问题的广义加性模型所用的扩展程序。
与标准的 GAM 不同,神经排序 GAM 可以同时考虑到排序项目和背景特征(例如查询或用户资料),从而得出一个可解释的紧凑模型。这同时确保了各项目级别特征与背景特征的贡献具有可解释性。例如,在下图中,使用神经排序 GAM 可以看到在特定用户设备的背景下,距离、价格和相关性是如何对酒店最终排序作出贡献的。目前,神经排序 GAM 现已作为 TF-Ranking 的一部分发布。图
落地案例
爱奇艺
TensorFlow Ranking 框架在爱奇艺海外推荐业务中的实践与应用
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
