语言学
语言学家乔姆斯基曾经尝试挑战语言学界构造了一个符合语法规范但无意义的句子 —— “无色的绿思狂暴地沉睡”(“Colorless green ideas sleep furiously”),然而 中国语言学之父赵元任在他的名文《从胡说中寻找意义》中给予了这个句子一个充满哲思的阐释。
语言是科学之母
语文是一切科学之母
人类的智慧分为几种境界,其中艺术是最高境界。
- 第一重境界叫
技术(techniques)。对于一个问题,能给出一个解法的人就算达到这个境界了。这样的人叫 technician(技术工人)。大部分程序员是这个级别的。 - 第二重境界叫
科学(science)。- 经历了很多问题,提出了很多解法之后,技工可能会总结出一些规律,称之为
理论(theory)。 - 每个 theory 的出发点是一些抽象描述物理世界的
公理(axioms)。比如欧式几何这个理论有五个公理,就是记录在欧几里得老师的《几何原本》(Elements)里的。 - 从
公理出发,大家可以按照逻辑可以导出很多推论(theorems)。很多推论恰好也符合对物理世界的描述。比如沿着欧式几何的公理,大家推导了两千多年,一些推理帮着人类把阿波罗发射到月亮上还能活着回来
- 经历了很多问题,提出了很多解法之后,技工可能会总结出一些规律,称之为
- 数学真是tmd一个巧合啊 —— 没事没事,语文才是科学之母。
- 严正声明,这不是玩笑 —— 20 世纪人类最伟大的科学发现是
哥德尔定理。- 用俗话说,就是沿着逻辑推导,推着推着一定会发现一个推论和之前的某个推论是相悖的,比如一个说老王家的鸡是公的,另一个说老王家的鸡是母的。
- 所以,真的,用数学计算出来的阿波罗轨迹能把人安全的带回来,真是一个奇迹 —— 说它是公的,它恰好就是公的。
- 什么样的程序员可以算是 scientist 呢?给定一个问题,能分析设计出最优解法的,而不是随便给一个解法了事的。
- 第三重境界叫
哲学(philosophy)。- 小学思想品德课制造的一个误区是让人以为哲学是文科,其实哲学是理科。理工科的硕士研究生毕业之后的学位是 Master of Science。而博士研究生毕业之后就是 Ph.D. 了 —— Philosophy Doctor(哲学博士),也有人说是 permanent head damage,也有道理,不是悖论。
- 哲学是归纳了很多 theory 的人归纳出来的
原则(principles),说的是怎么思考问题,可以归纳出好的 theories —— 别从公理出发刚推了没几步就出现悖论 —— 这tm多尴尬)。因为哲学是指导人们归纳 theory 的,所以我们说哲学原理(principles)是帮助我们拓展人类知识边界的工具。 - 什么样的程序员可以称为哲学家呢?有一套哲学思想叫 Unix Philosophy。看进去就明白了。
- 第四重境界叫
艺术(art)。- Paul Graham 有一本书叫《Hackers & Painters》,说的就是最高境界的程序员和画家一样。徐悲鸿画的马,大家都说好!而且每个人都能说出一些好的理由 —— 比如简练却生动、比如线条刚柔相济、比如动感十足。既然人人都能说出来的评价标准,恐怕算不上 theories,估计可以算 techniques。徐老师无疑是大家!他也明白自己不同寻常,可以他却没法把自己的高才总结成一些 theories 或者 techniques,让徒弟照着弄就能画出一样好看的马。
- 艺术家的直觉(英语叫 gut feeling,直译为猪肚和肥肠的感受)只可意会,不可言传。汉语里的“道可道非常道”,这个道不是 principles 而是 arts。老子不是哲学家,而是艺术家啊。
- 有些程序员,每次碰到一个难题,其猪肚和肥肠的都会有一些感受,照着这灵感做,总是没错,基本就是最优选择。如果他不是蒙的,那么他就算一个艺术家了。
英语
- 【2022-10-16】英语到底是怎么来的呢?
- 【Langfocus】为什么英语成为了国际通用语 Why Did English Become the International Language
日语
【2024-10-22】视频号 五月日语教室 详解日语五十音
中文
中文表达能力
【2024-2-8】中文是全世界最简洁的文字, 《联合国宪章》6大官方语言简洁度对比
- 字数:中文一个汉字表现为两个字
- 词数:中文使用分词工具解析,其它语言按空格
- 六大国际语言《联合国宪章》对比,中文赋予中国人无与伦比的效率
| 维度 | 中文 |
俄语 |
法语 |
英语 |
西班牙语 |
阿拉伯语 |
|---|---|---|---|---|---|---|
| 字数统计 | 26650 | 55345 | 57753 | 55614 | 59564 | 40633 |
| 词数统计 | 459 | 8133 | 9711 | 9691 | 10307 | 718 |
| 词数(去重) | 372 | 2077 | 1631 | 1322 | 1666 | 2217 |
字数
- 中文版共有26650字,英文版55614字,法文版57753字,俄文版56345字,西班牙文版59694字,阿拉伯文版40533字。
- 文字效率排名:中文100% > 阿拉伯文65% > 英文47.9% > 俄文47.3% > 法文46.1% > 西班牙文44.6%
- 中文效率最高,是欧洲语系的2倍以上,领先阿拉伯文35%,优势非常明显
词数统计
- 中文版共有459个词汇,英文版有9691个词汇,法文版有9711个词汇,俄文版有8133个词汇,西班牙文版有10307个词汇,阿拉伯文版有7188个词汇。
- 中文词汇量简洁、高效得令人发指,是其它语言的10-20倍!
中文是如何做到如此逆天的高效率的?
中文最小不可分割单位是“字”,“字”再组合成“词”,这种“自由组合”造词方法,有两大优势:
- 1、大大简化了“词汇”的难度,大部分词汇不需要刻意学习就能知其意。
- 2、有效控制了字和词的增长。3500个常用汉字,理论上能组合出“天文数量”的词汇,所以中文基本不需要创造新汉字。过去100年,中文新造的汉字屈指可数,只有元素周期表上的几十个汉字。而新造词汇也没有生僻词,都是常见汉字的新组合,理解起来没难度,不需要刻意学习,所以中国人能很轻松地应付新词汇的增长。
而表音文字最小单位是“单词”,这就如同一个萝卜一个坑,想表达新的内容,就要创造新的“单词”,而人类认识世界是无穷无尽的,新事物、新理论、新概念、新现象、新发现层出不穷,新“单词”也是无穷无尽的。据牛津大学统计,英文每年新增“单词”(词组)达8500个,在过去一百年英语词汇量翻了足足五倍,从1900年的20多万个,增长到今天的100多万。
中文不仅仅是文字,它把世间万物进行了科学的“归纳”、“分类”、“标签化”,是一门系统性非常强的文字体系。而西方文字,更像是野蛮生长的野草,蔓延到哪就是哪,系统性很弱。
民族分布
中国有56个民族,因此语言和文字也多。少数民族的分布空间占据全国一半,因此少数民族的语言也是中国主要的方言之一。汉族和回族、满族使用汉语,其他的53个民族都有自己的语言。由于一部分民族出现了使用几种语言的现象,导致中国的语言数量比民族的数量更多,全国共有72种语言。总体说来,中国的语言可以分为汉藏语系、阿尔泰语系、南岛语系、南亚语系和印欧语系。img
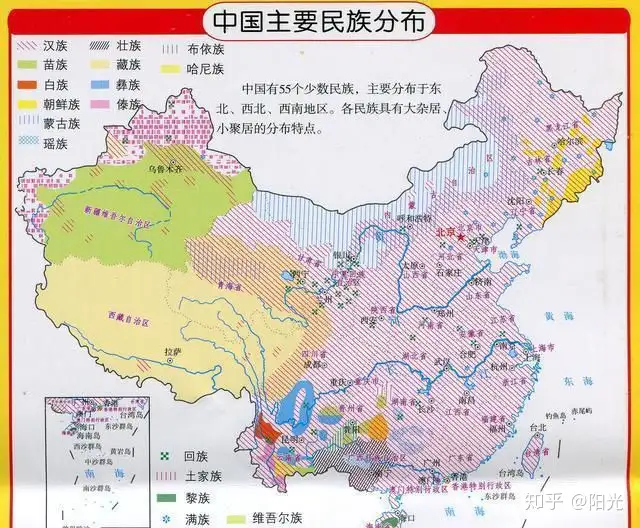
语言分布
汉语是中国使用最广泛的语言,也是世界上使用人数最多的语言。由于中国的面积大,人口多,因此汉语的方言也较多。
一般说来,汉语有7大方言,分别是: 晋语、吴语、闽语、粤语、客家语、赣语、湘语。同时在复杂的方言区内,有的还可以再分列为若干个方言片(又称为次方言),甚至再分为“方言小片”,明确到一个个地点(某市、某县、某镇、某村)的方言,就叫做地方方言。
方言分布
官话是以之为母语的人口最多、分布范围最广的汉语一级方言,周朝称之为“雅言”、明清称为“官话”,现在称为“国语”或者“普通话”。目前使用官话为方言的人有9亿多,官话的内部又分为东北官话、胶辽官话、北京官话、冀鲁官话、中原官话、江淮官话、兰银官话、西南官话,共八种。
方言分布 img

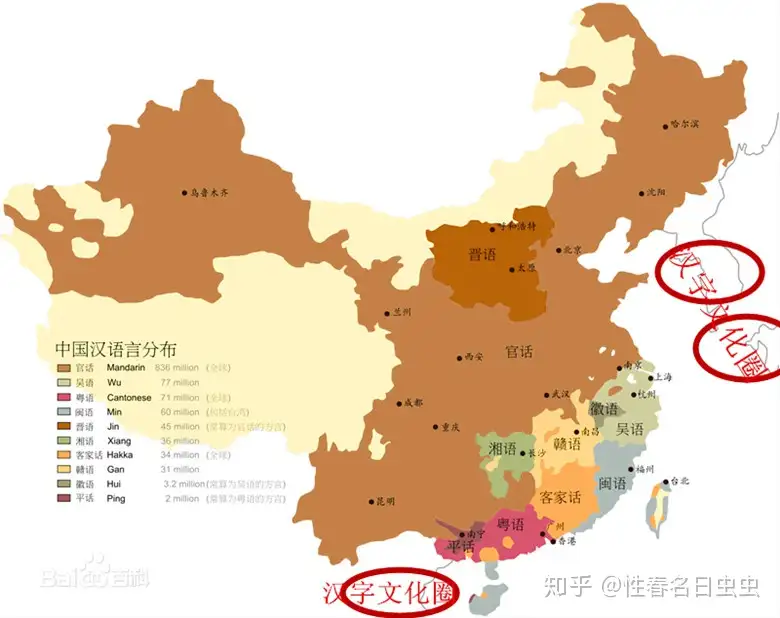
官话中,作为全国普通话标准的是北京官话。
-
北京官话主要分布于北京市、河北省,辽西地区,其中
承德滦平县是全国普通话标准音采集地。 - 在中国上古时期,官方通用语言是中原的“
雅言”,到了魏晋南北朝,大量中原人南迁,这种雅言也迁徙到了南京一带。 - 明朝永乐年间迁都北京,并且从南京迁徙了40万人口,改变了北京的语言结构。
- 清朝时期,以北京话为标准话
- 民国时期定为“国音”
- 新中国定为“普通话”,并向全国推广。
汉语的非官话方言基本都分布在南方,但是晋语却是一个例外,主要分布在山西一带。晋方言的使用人口大约为6300万,除了山西使用之外,还包括陕北、河套一带以及河北张家口。晋语别于官话的最大特点就是保留入声,多数晋语有五个声调,部分地区有六个、七个或四个声调。晋语声调有复杂的连读变调现象。晋语全浊音清化有四种不同的演化方式。晋语有很多与官话差异较大的特征词以及保留的古语词。img

详见:中国方言分布
方言数据集
- MagicHub.com 是爱数智慧发布的一个开源社区。爱数智慧为从事语音识别、语音合成、自然语言理解等人工智能领域研发与应用研究的企业、科研机构提供数据服务。
- MagicHub 开源数据覆盖多个场景、行业、语种。自 2021 年 4 月 15 日正式发布以来,已经覆盖 3000+ 全球开发者,累计下载超过 15 万小时数据集。目前开源 50 多种用于人工智能训练/测试的数据集,包括方言和小语种。数据集种类包含 NLP、ASR、TTS 数据集和 LEX 发音词典等。MagicHub 帮助 AI 开发者快速找到适合自己模型的数据集,用开源数据加速创新
方言翻译
【2022-10-19】教你实现方言翻译器:方言听不懂,手把手教你用 Milvus 搭建方言翻译器
- 熟悉开源数据集,在日常的模型训练中应用这些数据集
- 亲自动手搭建 Demo,真正解决实际生活场景中问题
- 学会使用 Milvus 后,还有更多的可以结合 Milvus 的应用场景等着你去发现
- Milvus 是基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。最近, Milvus 2.0 版本已经发布了,在向量检索库的基础上,Milvus 支持了数据分区分片、持久化、增量数据摄取、标量向量混合查询、Time Travel 等功能,同时大幅优化了向量检索的性能。推荐用户使用 Kubernetes 部署 Milvus ,以获得最佳的可用性和弹性。
闽南语
闽南语分布 img

【2022-10-21】闽南语与英语翻译,直接沟通;2022年10月19日,Meta开发闽南语AI翻译,解决无文字语言翻译难题,视频
- 参考
- 机器学习翻译系统通常需要大量可标记的语言实例来进行训练,包括书面和口头语言,这正是像闽南语这种没有文字的语言所不具备的。Meta的研究团队利用普通话作为中间语言来建立伪标签,首先将英语(或闽南语)语音翻译成普通话文本,然后再翻译成
闽南语(或英语),并将其加入训练数据。 - “我们希望最终能够实现多种语言的实时语音到语音翻译。我们相信,无论人们身处何地,口语交流都能将他们聚集在一起——即使是在元宇宙。”
- 世界上大约7000种已知的语言中,有近一半的语言仍然在被使用,其中40%没有广泛的书写系统。这些没有文字的语言给现代机器学习翻译系统带来了一个独特的问题,因为它们通常需要先将口头语言转换为书面文字,翻译后再将文字还原为语音,但Meta公司10月19日宣布,已经通过其最新的开源语言人工智能(AI)解决了这个问题。
- 作为Meta通用语音翻译器(UST)项目的一部分,Meta 为闽南语建立了第一个AI驱动的语音翻译系统,并在视频中展示了一段闽南语和英语之间的实时翻译。该项目正致力于开发更多实时语音到语音的翻译,以便元宇宙居民更方便地互动。
- Meta宣布,除了从这个项目中获得开源的模型和训练数据外,该公司正在发布首个基于闽南语语料库的语音翻译基准系统,以及语音矩阵(SpeechMatrix),“一个使用Meta的LASER数据挖掘技术的大型语音到语音翻译语料库”,这个系统将使研究人员能够创建他们自己的语音到语音翻译(S2ST)系统。
普通话
1953年,我国以承德市滦平县为普通话标准音主要采集地。
1955年10月,中国文字改革委员会和教育部联合召开了全国文字改革会议,这场会议通过了《汉字简化方案》,出于对少数民族语言文字的尊重、突出民族语言文字上的平等精神,名称上改“国语”为“普通话”,并确定普通话的内容:“以北京语音为标准音,以北方话为基础方言,以典范的现代白话文著作为语法规范。”最终普通话作为、现代标准汉语在全国通用,我国法律明确规定:“国家推广全国通用的普通话。”
普通话为何源自承德
【2022-10-19】承德方言是怎么成为普通话的?
- 普通话是以北京语音为标准音,以北方官话为基础方言,以典范的现代白话文著作为语法规范的通用语。但是全国最标准的普通话却不在北京,而位于承德,特别是承德市滦平县。承德方言在谱系上属于北京官话——怀(怀柔)承(承德)片,与普通话极为接近。
- 承德,位于河北省东北部,东与辽宁省交界,西南紧依北京,地理位置决定了承德方言与北京方言、东北方言相接近,其对语言文化的影响是显而易见的。但是,同样是邻近北京,天津、唐山、保定等地的方言就远不如承德更接近普通话,其中还有着深刻的历史渊源
- 历史上的承德是农耕民族与游牧民族之间的缓冲区,且常年人烟稀少,“名号不掌于职方,形胜无闻于地志”。
- 明朝初期,出于对抗蒙古的需要,明成祖放弃对承德的管辖,将长城以北的承德地区让给了蒙古,并将承德一带所有的原住民强行迁徙到今天的北京、保定和廊坊,人为地制造了“无人区”,使得承德出现了200年的历史空白,自身故有的方言传承消失殆尽,但这反而为清朝北京官话的扎根奠定了基础。
- 1616年,努尔哈赤建立后金,1636年皇太极改后金为清,新的民族共同体满族逐渐形成。满族虽然有自己的语言文字,但在满族形成的时候,汉语早已在东北广泛通行,且满族深受汉文化的影响。通过与明朝的战争,使得满族治下的汉人越来越多,由于有较高的文化和生产技术,且不少汉人自愿加入满族或者与满族通婚,有所谓“生于辽不如走于胡”的说法,汉语就逐渐取代了满语的地位
- 满清入关后,出于巩固统治的需要,清廷鼓励广大满人学习满语汉语,直至康熙末年,北京的八旗满洲子弟皆能汉语,“间巷则满汉皆用汉语,从此清人后生小儿多不能清语。”
- 1644年满清入关,为了解决八旗兵丁的生计,顺治帝下谕:“今我朝定都燕京,期于久远,凡近京州县无主荒田及明朝皇帝亲属、驸马、公、侯、伯、太监等,凡殁于寇乱者,无主田地甚多。田主或有或无,其田地尔部(户部)概行清查。若本主尚存,或本主已过世而子弟尚存者,量口给予。其余田地尽分给东来诸王、勋臣、兵丁人等。”八旗贵族开始大量圈占北京城郊的土地,建立皇庄、王庄和八旗官兵庄田。承德就是八旗子弟圈占土地的主要地区。后来康熙皇帝废除圈地实施“占田立庄”政策,鼓励旗人到古北口外开荒种地,建立“口外庄田”。
- 承德是北京通往东北及蒙古的要道,背靠长城,有着重要的军事地位。气候上,由于承德四面环山,冬季能部分削弱了西伯利亚寒流,使得这里比同纬度地区更为温暖,夏季也能阻挡海洋季风熙皇帝称赞这里:“风清夏爽,宜人调养之功。”
- 为了“合内外之心,成巩固之业”,康熙四十二年(1703)皇帝在此修建热河行宫,至乾隆五十七年(1792)避暑山庄竣工,承德一跃成为了清朝第二个政治中心。大量的满族移民进入承德,彻底改变了当地的人口结构,也使得满式汉语成为这里的正统语言。
- 滦平县,因乾隆皇帝亲题“滦水无患、民得平安”而得名。位置正处于承德与北京的中间,素有“北京北大门”之称。是清朝皇帝来往两地的必经之路。皇帝在滦平设有行宫、御道、驿站并派兵驻守,大批的八旗子弟从北京迁到古北口外的滦平,直到清末,滦平共有皇庄24个,王庄、旗庄130多个,而“口外建庄”的过程,恰好与清朝政府推行北京官话的政策同步,北京官话被旗人带往滦平进行了有效的辐射。且滦平正位于燕山山脉之中,更加闭塞的环境使得当地的官话最为纯正。
- 满族人的汉语,大体上融合了东北方言词汇和北京方言词汇。北京话的语音和语调,直到 20 世纪二三十年代仍然带着满语语音、语调的残存影响。儿化、轻声等语言特征也有满语的影子,今天的京腔也是满族北京话的体现。
- 在地理环境上,承德更是一块相对封闭的皇家区域。满洲贵族及其随从家眷、留守行宫的护卫就成为了当地人口的主要组成部分,北京官话在此扎根以后就成为了这里唯一的方言,其封闭性也使得周围地区方言的影响力非常薄弱。这就与北京的开放和流动迥然不同,所以我们会发现北京话有明显的儿化音、省字、尾音,仍然带有清以前北京话的色彩,而承德方言相比就音准分明、字正腔圆,语调清脆,这完全符合雅音的要求。而它一旦被统治者标准化,则自然成为全国人模仿学习的官话。
承德方言之所以能走向全国,并最终成为现代普通话发音标准的基础,是与雍正乾隆年间的官话运动、晚清民国的国语运动分不开的。
普通话 vs 广东话
【2022-10-16】普通话和广东话有何异同?
汉语历史
汉语演变
【2022-10-16】中国汉语演变过程,youtube视频讲解,作者:langfocus
- 汉语与日语有多像?【Langfocus】汉语和日语有多相似?
汉字演变
【2024-1-11】汉字演进过程
- B站视频:汉字演变过程1,演变过程2
- 参考:敢问世界上还有哪种语言,能有汉字这般壮丽和神奇?
【2024-5-20】耗时360个小时,用甲骨文制作《千里江山图》
古汉语
【2023-9-18】古人是咋说话的?穿越过去,咱听不懂

汉语拼音
汉语拼音(Hànyǔ Pīnyīn),简称拼音,是一种以拉丁字母作普通话(现代标准汉语)标音的方案,为中文罗马拼音的国际标准规范。
- 汉语拼音在小学《语文》作为基础教育内容全面使用,是义务教育的重要内容。
汉语拼音是中华人民共和国官方颁布的汉字注音拉丁化方案,
- 1955年-1957年文字改革时被原中国文字改革委员会(现国家语言文字工作委员会)汉语拼音方案委员会研究制定。该拼音方案主要用于汉语普通话读音的标注,作为汉字的一种普通话音标。
- 1958年2月11日的全国人民代表大会批准公布该方案。
- 1982年,成为国际标准ISO7098(中文罗马字母拼写法)。部分海外华人地区如新加坡在汉语教学中采用汉语拼音。
- 2008年9月,中国台湾地区确定中文译音政策由“通用拼音”改为采用“汉语拼音”,涉及中文音译的部分,都将要求采用汉语拼音,自2009年开始执行
汉语拼音是一种辅助汉字读音的工具。《中华人民共和国国家通用语言文字法》第十八条规定:“《汉语拼音方案》是中国人名、地名和中文文献罗马字母拼写法的统一规范,并用于汉字不便或不能使用的领域。”根据这套规范写出的符号叫做汉语拼音
汉语拼音也是国际普遍承认的现代标准汉语拉丁转写标准。国际标准ISO 7098(中文罗马字母拼写法)写道:“中华人民共和国全国人民代表大会(1958年2月11日)正式通过的汉语拼音方案,被用来拼写中文。撰写者按中文字的普通话读法记录其读音。
汉语拼音表

声母表
声母表
- 汉拼拼音字母表,
声母(shēng mǔ),是使用在韵母前面的辅音,跟韵母一起构成的一个完整的音节。 - 辅音的主要特点是发音时气流在口腔中要分别受到各种阻碍
- 因此可以说,声母发音的过程也就是气流受阻和克服阻碍的过程。
- 声母通常响度较低、不可任意延长、而且不用于押韵。
汉语拼音声母:23个。
- 分别是:b、p、m、f、d、t、n、l、g、k、h、j、q、x、zh、ch、sh、r、z、c、s、y、w 。
汉语拼音声母按发音部位分类:(发音时发音器官构成阻碍的部位)
- (一)双唇音:b、p、m;
- (二)唇齿音:f;
- (三)舌尖前音:z、c、s;
- (四)舌尖中音:d、t、n、l;
- (五)舌尖后音:zh、ch、sh、r;
- (六)舌面音:j、q、x;
- (七)舌根音:ɡ、k、h。
韵母表
韵母表
- 汉拼拼音字母表,
韵母(yùn mǔ)是一个中国汉语音韵学术语,汉语字音中声母、字调以外的部分。旧称为韵。 - 韵母由韵头(介音)、韵腹(主要元音)、韵尾三部分组成;
- 按韵母结构可分为
单韵母、复韵母、鼻韵母。
汉语拼音韵母表:
- a、o、e、i、u、ü、ai 、ei、 ui 、ao、 ou、 iu 、ie 、üe、 er、 an 、en 、in、 un 、ün 、ang 、eng、 ing 、ong。
汉语拼音韵母的分类(以小学《语文》中的《汉语拼音》课本为基础):
- (一)单韵母:a、o、e、i、u、ü;
- (二)复韵母:ai、ei、ui、ao、ou、iu、ie、üe;
- (三)特殊韵母:er;
- (四)鼻韵母:an、en、in、un、ün、ang、eng、ing、ong;
- (1)前鼻韵母:an、en、in、un、ün;
- (2)后鼻韵母:ang、eng、ing、ong。
小学《语文》中的《汉语拼音》的韵母表总共24个,其中单韵母6个,复韵母8个,特殊韵母1个,鼻韵母9个(前鼻韵母5个,后鼻韵母4个)。
声调符号
汉语拼音声调符号:
- 声调符号标在音节的主要母音上。轻声不标。
- 例如: 妈 mā(阴平) 麻 má(阳平) 马 mǎ(上声) 骂 mà(去声) 吗 mɑ(轻声)
汉语注音
台湾人打字不用 汉音拼音,而用 ㄅㄆㄇㄈ,也就是注音符号, 历史更久。
注音符号历史
1918年就制定了“ㄅㄆㄇㄈ”,但汉语拼音则是1958年才制定。
- 现在80-90后的朋友当然莫明其妙,但50前的长辈们肯定会发出会心的微笑。
- 电视剧《南下南下》,赫然就发现某个场景的墙壁上正贴着熟悉的“ㄅㄆㄇㄈ”!这证明这个剧组真的很考究,每个细节都有注意到。
注音符号简介
注音符号一共有37个,分别是:ㄅㄆㄇㄈㄉㄊㄋㄌㄍㄎㄏㄐㄑㄒㄓㄔㄕㄖㄗㄘㄙㄧㄨㄩㄚㄛㄜㄝㄞㄟㄠㄡㄢㄣㄤㄥㄦ。
- 还有分五种
声调:一声、二声、三声、四声 和 轻声
例如断崖的“崖”,注音就会是“ㄧㄞˊ”
- 大陆喜欢横着写,在台湾都只会竖着写,也就是上面是“ㄧ”,下面是“ㄞ”
- 然后,在右边偏中间注个“ˊ”,表示这是四声。
- 如果是汉语拼音的话,就是注成ya。
台湾人键盘

注音符号跟日语的关系
- “ㄅㄆㄇㄈ”很多大陆朋友以为是日文字,看起来很像,但它其实和汉语拼音一模一样,只是前者是用“符号”,后者是用英文字母。例如ㄅ就是b,ㄆ就是p,ㄇ就是m,ㄈ就是f……全都都有对应的。
- 差别就如此而己,和什么日本阿拉伯韩国甚至闽南都没什么关系。
注音 vs 拼音
拼音、注音对照表
对照表,详情

哪个更好用
哪一种拼音方式更好用?
- 青菜豆腐各有所爱了,大陆肯定觉得经过改良的好,但台湾也认为谨遵古法的才实用。
台湾人从小受注音符号的影响,自然还是注音符号用得顺手,要改也改不过来。
- 不过,听说很多台湾老乡来了大陆,只要下点工夫就能记住英文字母和注音符号的对应,立马就用得顺风顺水。
- 相形之下,大陆朋友要会用注音符号就困难多了,感觉好像要他们学外国字母似的。
台湾人小时候学注音符号,光是背那37个符号就不知道挨多少个手心。大概是小学一年级就要开始学,然后整个小学六年之间,都会考你“注音符号”,简直就是无时无刻不被它的阴影所笼罩。就算学了这么久,至今还是 ㄣㄥ 不分(也就是en和enɡ)。
台湾人也开始学拼音
台湾除了注音符号之外,如今也用字母拼音了,一共有两种拼音方式。一种就是大陆的“汉语拼音”,一种是台湾人自己发明的“通用拼音”(也就是“罗马拼音”)。
- 马英九上任之后,力倡“汉语拼音”,主要体现地标地名上,例如以前“新店”拼做“Sindian”,但是现在就会拼成“Xindian”。
- 不过小学生学语文,用的还是“注音符号”。
- 学闽南语时,才会用“通用拼音” ── 是的,现在规定每个小学生都要学
闽南语。
做台湾人多麻烦,一套注音符号还不够,又要学汉语拼音,又要学通用拼音。普通话学完又要学闽南语……
网络简化
输入完整的音符麻烦,于是,大家都是简化,诞生一批网络热词
- 大陆的年轻人喜欢把拼音简写,例如,牛逼就是NB。
- 台湾的小年轻也爱把注音符号简写,这是因为网络太流行的缘故,很多字会读却不会写,于是直接用注音的;或者为了求快,干脆打注音。
- “注音文”,例如“你看得懂这句话吗”,翻成“注音文”就是──“你看ㄉ懂这句话ㄇ”。白痴他们可以写成“ㄅㄔ”、流氓就是“ㄌㄇ”,就算仔细阅读上下文,可能还猜不出注音背后的含意。
外国人已经觉得中文很难学了,今天又杀出了个注音文来。他们肯定认为中文和外星文一样困难吧?
简体字
1986年推出的简化字总表,涉及350个

毛泽东:
汉字简化最终目的是拼音化
二简字
二简字是中国文字改革委员会继1950年代提出的《汉字简化方案》后,于1977年12月20日提出的《第二次汉字简化方案(草案)》中的简化汉字。
二简方案分为两个表:
- 第一表收录了248个简化字,推出后直接实行;
-
第二表收录了605个简化字,共853字
- 1977年12月20日,官方曾公布过第二批简化字(即“二简字”),使用时间不长,但对当时乃至现在的人们还是产生了很大影响。
- 1978年7月,《人民日报》《解放军报》停止使用这批简化字。
- 到1986年,这批简化字被正式废除。
现在很多年轻人不知道这些,以至于误认为是什么人随意杜撰的文字,其实这些字也是有“来头”的。
汉字简化历程中被否定的产物——“第二次汉字简化方案”。
- 曾经,“副总理”被写为 “付总理”;发展的“展”字是尸体的“尸”字下面加一横。
这种“超简化的”字体,仅仅试用过半年就被叫停。
【2016-8-19】中国官方公布的“第二批简化字”为何如此短命?
简体字 vs 繁体字
简体字
- 优点:笔画少,写得快,容易学,利于扫盲,减少了通用汉字字数。
- 缺点:简化过程使用了符号代替,使汉字缺少了表意性的功能,而且不利于对传统文化的继承,不利于中国大陆与台湾港澳地区进行文化交流。
繁体字
- 优点:符合“六书”造字原则,利于研究字的起源、发展,利于研究古书,利于与台湾、港澳等地区进行文化交流,也更具书法美感。
- 缺点:复杂,掌握门槛高,学习难度大。
简体字发展史
视频讲解简体字演进过程
@knowledge_encyclopedia 汉字为什么要简化? 2分钟说清楚繁简之争!为什么我们用简体字 而台湾省仍在用繁体字?#台湾省#简体字#繁体字 ♬ 原声 - 科普_知识大百科
大陆为什么用简体字
扫盲,文字推广到普通民众
冷知识:
- 清末文盲率99.99。
- 民国文盲率98。
- 1949年新中国文盲率95。
- 1952年中国第一次开展了轰轰烈烈的大扫盲运动。
因为
- 大陆既不是殖民地,也没有一个偏激的地方领导人
- 香港使用繁体字理由很简单,殖民地时期官方语言用英语,没有推行简体字的动力。
- 台湾省就比较有意思了,大陆简体字方案是国民党提出的,常凯申到台湾后也一直努力推进简体字改革,直到大陆先推出简体字,常凯申看大陆抢了头筹,大陆的必须反对,所以放弃了简体字。
- 另外,实际上台湾学生记笔记的时候,也会用简体字,否则笔画那么多,真的会写到忧郁
- 新加坡、马来西亚也用简体字

简体字:
一只忧郁台湾乌龟寻衅几群肮脏变态啮齿鳄龟,几群肮脏变态啮齿鳄龟围殴一只忧郁台湾乌龟。
繁体字:
壹隻憂鬱臺灣烏龜尋釁幾羣骯髒變態囓齒鱷龞,幾羣骯髒變態囓齒鱷龞圍毆壹隻憂鬱臺灣烏龜。
作者:换一个时空
中文输入法
【2022-09-30】为什么中文输入法之神,是且只能是五笔?
缩写体
缩写体无疑是当下最具争议的网络亚文化。
- 无论是饭圈用于「圈地自萌」的「db(豆瓣)」,「rs(热搜)」,「ns(泥塑)」;
- 还是老一辈看了直挠头的 YYDS,AWSL,YYGQ…… 又或者是前不久刚刚上热搜的「抖音 B 文化」。 都引发了大范围的讨论和质疑。
对于内地的这场文化讨论,港台的吃瓜网友多少有点状况外:
- 因为中国台湾的输入法是
注音,而不是拼音。中国香港的输入法是仓颉,也不是拼音。
中国台湾的一些手机键盘甚至没有字母,而是长这样:img
- 同时数字键除常用功能外,还有加声调功能。空格键是一声,6对应二声,3能打三声,4就是四声,而7是轻声。
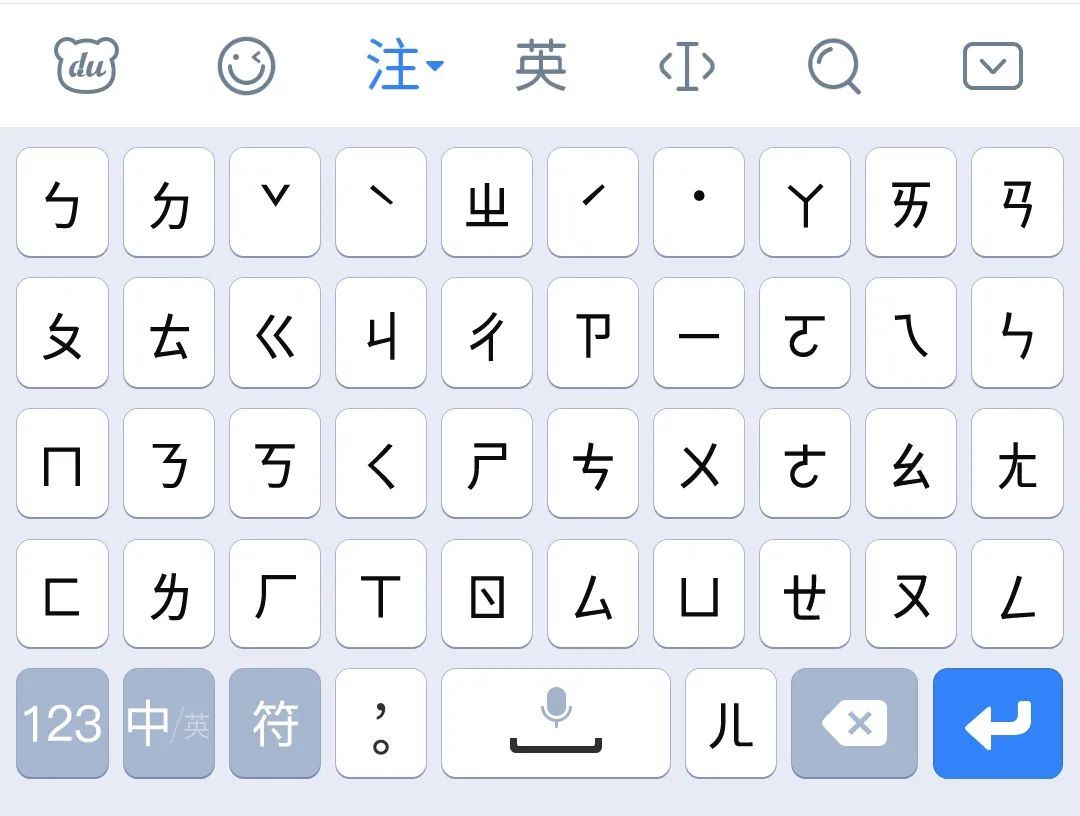
仓颉输入法
中国香港的仓颉输入法,发明人是台湾人朱邦复,取「仓颉造字」之典命名。将汉字以笔画部首拆分,例如ABCDEFG代表日月金木水火土,HIJKLMN分别是斜点交叉纵横钩。像「拼图」那样,将汉字拼出来。
五笔输入法
与仓颉和注音相对,在中国大陆也曾流传一套将汉字拆解的输入法。它曾被誉为中文输入法之神;它曾是各大公司打字员的标配技能;在拼音大行其道的今天,依然有一小群发烧友对它念念不忘。
诞生之初
计算机是洋人发明的,自然从未考虑过中文输入的问题。初进中国时,英文的系统,英文的键盘,想操作这台大家伙,没点英文功底连咋开机都不一定会。
- 英语只有26个字母,随机排列就行了。
- 汉字不一样,浩如烟海,各个写法不同,用 26 个字母想把 30000 多汉字敲进电脑?怎么可能?
1977年,汉字迎来攸关生死的大危机,曾被热议过的「废除汉字」,再次在社会上掀起波澜。
- 激进派主张:方块字不能适应26个字母的键盘时代,计算机就是汉字的掘墓人。我们要从用汉字改成用拼音文字,要么用电脑,要么废汉字。
电脑要革汉字的“命”?
- 中华上下5000年文明,汉字是最宝贵的文化和精神遗产,废除汉字岂非笑谈!
1982年,北大教授王选做出一个“超级”键盘,解决中文输入问题。说超级,是因为这个键盘有多达256个键,上千个零部件。
- 键盘是有了,但应用是难题,且不说这么多键怎么操作,就是学会了打字,打字员不是章鱼,这么大的键盘,使用成本得多高。
当知识分子热议汉字电子化时,远在河南,一座名为南阳的小城,一场改革已经悄然酝酿。在南阳科技局上班的王永民,从小研究书法和篆刻,喜欢汉字。高考那年,以市级状元的身份考进中科大,成了全村的希望。
学成回老家的王永民,也关注到了汉字信息化这一问题。痴迷汉字的他从1978年开始抄写了12万张卡片,以一己之力统计出一套汉字字形规律。
1982年,王永民觉得几年的量变要引起质变了,他向河南省副省长汇报想法方案。领导听完眼睛亮光,这种利国利民的重大技术必须全力支持。王永民也当场承诺,如果一年后拿不出结果,跳黄河!
一年后质变发生,王永民发明出一套打字方法,完美适配国际通用键盘,无需 200 多键,只需 26 键一样可敲出一撇一捺。
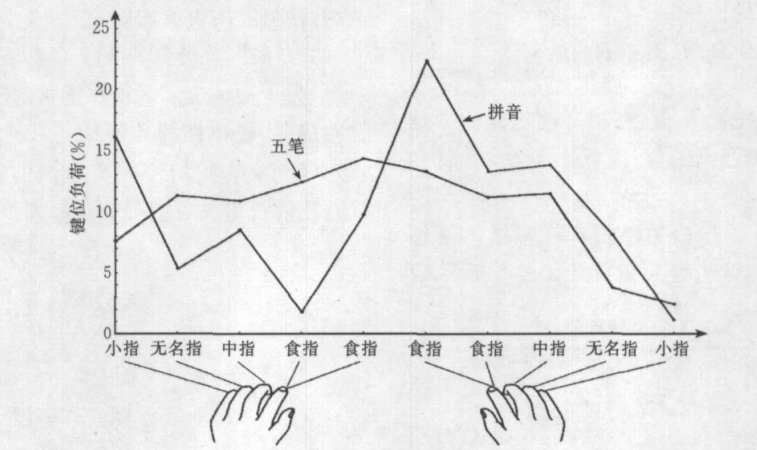
- 王永民统计的每根手指打五笔和打拼音击键概率图
这套输入法有个响彻中文互联网的名字——五笔。
- 五笔把汉字拆分成120多个基本字根,分成横、竖、撇、捺、折五大部分,分别对应到键盘的五大区域。
- 除了功能键 Z 外,每个字母键都有分工。
- 想打什么汉字,按它的书写笔画规则走就行。
五笔虽叫五笔,但最多只需要点4下键盘就能打出一个字。
- 熟练工一分钟可打100多个字,效率无敌。
- 以笔画为基础,杜绝了拼音的谐音错字问题,不会让你把老师好打成拉屎好。
那时候的河南,有小麦、有玉米,有黄牛,就是没有电脑。
- 1984年,王永民背井离乡一路北上,去北京推广他的王码五笔输入法。他在北京各大高校和政府部门做免费培训——免费,意味着他在北京没有收入。王永民住在地下室,一日三餐窝头就咸菜,王府井大街上自来水不要钱,喝到饱。长此以往严重营养不良得了肝病,出去推广五笔时,他甚至身上揣着遗嘱。
- 1987年,美国DEC公司出20万美元买了王永民的五笔授权,王大才子终于挖到了第一桶金。不仅搬出地下室,还成了中关村第一代村民,开了家王码门市部。
- 随后几年,国家大力推广五笔字型,全国掀起学五笔热潮,大大小小的五笔培训班遍地开花,颇有点今天「9.9 学Python」广告刷屏的架势。
- 1986年,四通电脑公司推出加载五笔输入法的MS-2400打字机,一年卖了一个亿,风靡职场。在那个年代,打字是一门职业。窗明几净的办公室里,正襟危坐敲键盘,不用风吹日晒就能跻身「白领」行业——只要你会五笔,就能成为其中一员。
- 望子成龙的家长们,开始像送孩子学乐器一样带孩子学五笔,江西人段永平嗅到了商机,在任天堂红白机外加了个键盘壳子,推出了「
中英文打字学习机」产品——小霸王。这也成了很多小孩要买小霸王的幌子,嘴上说着练打字,实际上全练打游戏去了。

而那时五笔的确是需要练的,不管是小霸王,还是后来的金山打字通,都需要付出时间成本。资质好的得狂练好几个月,手指反应慢的至少练半年。除了练,别忘了还得背字根,还得学拆字。
2022年5月有媒体报道,如今使用五笔输入法的人数仍有3%。以最新网民人数 10.51 计算,那也是多达3000 万人——比不少国家总人口都多了。
无论拼音打字还是语音输入,基本要素都是音。这对听障人士来说极其不友好。而五笔不需要音节,会写就会打。背五笔字根对普通人很繁琐,却是特殊群体打字最好走的捷径。
拼音输入法
大陆的网友自小接受的是拼音教育,一代代的学生们从小便掌握了一套「字母-汉字」的映射方案。当他们第一次坐在电脑前打字时,直接上手便可敲出横平竖直。
拼音输入法确实为最好学的输入法——然而,却远非最「高效」的方案。
大人们苦练五笔打字,小孩子却开始接触到另一套「编码」——拼音。
- 1982年黑龙江三所小学开始试点,一改过去重汉字的教育方式,一年级新生入学先学拼音,边读书边识字,结果学生的读写能力非常好。
- 1992年,全国开始推广这套教学方法,80、90后,成了第一批赶上这趟车的幸运儿。
智能ABC
五笔输入法这么难学,年轻人拼音又不错。拼音之父周有光提出一个想法,为什么不能用拼音打字呢?
- 1987年,北大教授
朱守涛写了一个汉字拼音输入系统,取名为「智能ABC」。- ▲你还记得微机课电脑右下角的这个图标吗
- 1993年这款软件被微软买走,捆绑在office里,成为windows自带输入法。凭借拼音教育普及的东风,短时间内,智能ABC成为大陆使用人数最多的输入法。
紫光输入法
- 清华有位研究生叫
李国华,研究课题是「中文信息处理」。他根据统计数据规律开发了另一套拼音输入法,可以全拼也可以双拼。- 清华紫光近水楼台先得月,立马买了下来,1999年包装成
紫光拼音输入法上线。 - 清华紫光有张王牌:清华同方电脑。自家硬件装自家软件顺理成章,清华同方带着紫光输入法飞进千家万户。
- 清华紫光近水楼台先得月,立马买了下来,1999年包装成
微软拼音输入法
- 新世纪初,微软和哈工大合作,推出
微软拼音输入法。从windows2000开始,智能ABC逐渐没落。 - 如今,这两款一度辉煌的输入法都已寿终正寝,留下的宝贵遗产,是培养起大多数80/90后拼音打字的习惯。
搜狗输入法
2006年,中文互联网的“亲儿子” 搜狗输入法来了。
- 整句输入、联想输入、个性化词库,敲几个字母能出来一整句话,黑科技把前浪拍死沙滩上。img
- 2011年5月11日,王小川在知乎发帖:五笔已经没落了,大家改用拼音吧
QQ拼音输入法
一年后,美国西海岸诞生一款改变人类通讯方式的产品:iPhone。从此,手机进入虚拟键盘触屏时代。
- 在这块小小屏幕上,
九宫格党和全键盘党谁也不服输,输的只有五笔,因为它连入场竞争的机会都没有。
要说整花活还得是互联网公司会玩,企鹅祭出大招,和好友聊天用QQ拼音,将额外获得0.1天活跃天数奖励。
- 在那个年代的中小学生心里,QQ等级是不亚于考试成绩的「身份标志」,多个太阳见同学说话都能大点声。
- 大批学生开始用
QQ拼音输入法,用了发现鹅真不错,词库自带劲舞团和跑跑卡丁车,拿捏小学生可太会了。- ▲这输入法皮肤,当年谁看了不是狠狠爱了的状态

其它:谷歌、百度、讯飞
此后十几年,万“码”奔腾,谷歌输入法、百度输入法、讯飞输入法……一代更比一代强。
现在甚至都不用打字,对着手机说几句话自动转成文字。
只有五笔在某个角落的摇椅上,默默怀念着自己昔日的旧时光。
乔姆斯基
乔姆斯基简介
-
艾弗拉姆·诺姆·乔姆斯基(Avram Noam Chomsky,1928年12月7日—),美国哲学家。是麻省理工学院语言学的荣誉退休教授。乔姆斯基的《句法结构》被认为是20世纪理论语言学研究上最伟大的贡献。
- 20世纪最著名的100位心理学家:38 乔姆斯基 Noam Chomsky
- 【纪录片】乔姆斯基:manufacture consent
- 福柯、乔姆斯基的一场世纪辩论——关于人性、公正与权力
- 诺姆·乔姆斯基访谈——语言与知识【中英文字幕】

转换生成说
转换生成说又称“先天语言能力学说”,是美国语言学家乔姆斯基1957年在其《句法结构》一书中提出的一种语言理论。
- 乔姆斯基认为语言是创造的,语法是生成的,人类之所以能获得语言,是因为存在着特殊的获得语言的学习机制。该学说经历了五个发展阶段逐渐完善。
- 1959年他对斯金纳《言语行为》中“强化生成说”的深刻批判,一时震撼了美国语言学和心理学界,被称为“语言学的革命”,对世界各国心理、语言、哲学、认知科学等产生了广泛影响。
转换生成说的发展历程
- 古典理论时期(1957—1965)
- 《句法结构》(1957)的出版标志着转换生成语法(TG)的诞生。该理论有三个特征:首先,强调语言的生成能力;其次,引入了转换规则;最后,语法描写中不考虑语义。
- 标准理论时期(1965—1972)
- 《句法理论若干问题》(1965)的出版标志着标准理论时期的到来。该理论论述语义应当如何在语言理论中进行研究。在标准理论时期,乔姆斯基作了较大调整,把语义纳入了他的语法体系。他认为生成语法应该包含三大组成部分。句法部分,音系部分和语义部分。
- 扩展的标准理论时期(1972—1979)
- 从20世纪70年代到80年代初,乔姆斯基对标准理论进行了两次修正:第一次修正被称为”扩展的标准理论”(EST),以《深层结构,表层结构和语义解释》为转折;第二次修正被称为“修正的扩展标准理论”(REST),以《关于形式和解释的论文集》为代表。它们被统称为“扩展的标准理论”。
- 管辖和约束理论时期(1979—1993)
- “管辖和约束时期”(GB)这一时期以《管辖与约束讲演集》为代表。
- 最简方案时期(1993—)
- 1993年乔姆斯基《语法理论的一个最简方案》的发表使他开创的生成语法进入了一个崭新的阶段—最简方案阶段。
基于前述对斯金纳的分析与批判,他指出:
- ①语言是创造的,也即获得语言并不是去学会特定的句子,而是利用组句规则去理解和创造句子,句数是无限的;
- ②语法是生成的,儿童生下来就具有一种普遍语法,这种普遍语法的实质就是一种大脑具有的与语言知识相关的特定状态,一种使婴儿能学会人类任何语言的物理及相应的心理机制。婴儿就是凭借这个普遍语法去分析和理解后天语言环境中的语言素材。婴儿言语获得过程就是由普遍语法向个别语法转化的过程。这个转化是由先天的“语言获得装置”(language acquisition device,LAD)实现的;
- ③每—个句子都有两个结构层次——深层结构和表层结构。
- 深层结构显示基本的句法关系,决定句子的意义;
- 表层结构则表示用于交际中的句子的形式,决定句子的语音等。
- 句子的深层结构通过转换规则变为表层结构,从而被感知和传达。
乔姆斯基的生成语法学理论使我们在一定程度上摆脱了行为主义言语获得理论的束缚,认识到婴儿言语获得过程中神经系统的重要作用,同时也向我们提出了研究言语过程的心理机制的问题,这是很有理论意义和借鉴价值的。当然,他的“语言获得装置”仅仅属于一种假设,要证实这个假设并不容易。事实上,目前它也没有得到有力的研究证据,而只是对科学事实的一种解释性假说而已。另外,他强调天赋观念,强调先天性,低估了环境和教育在言语获得过程中的重要作用,忽略了语言的社会性,这也是片面的。
语言对决
- 愤怒的语言:语言学家丹尼尔·埃弗雷特(Daniel Everett),前往偏远的亚马逊部落毗拉哈(Pirahã),去传播基督教。他原想把《圣经》翻译成当地语言,教毗拉哈人信仰上帝,结果反倒是自己放弃了信仰,不再笃信上帝,也开始质疑自己尊为圣人的语言学前辈,乔姆斯基。
- 诺姆·乔姆斯基(Noam Chomsky)(右图),现代语言学学界领袖,20 世纪最富盛名、最具影响力的学者之一。乔氏及其 “普遍语法论” 执掌现代语言学长达半世纪之久。乔姆斯基认为,语言是人类特有的一种先天机制。2002 年,乔姆斯基在一篇与人合著的论文中提出(或者看似可以理解为),递归性是人类语言唯一至关重要的特性 。
- 而埃弗雷特(左图)发现,毗拉哈语中不存在这种所谓的 “递归性”——毗拉哈人并不将语言单位互相套嵌,而是只讲简单的短句。也就是说,这种语言不符合现代语言学的一项基本原理。这一发现似乎足以颠覆整个语言学体系,事实也的确如此:2005 年,当埃弗雷特的论文发表时,引起巨大轰动,而他跟乔姆斯基的决斗,也就此开始。

语言的对决:乔姆斯基攻防战
- 语言的对决:乔姆斯基攻防战
- 【2021-2-22】机器如何获得与人类似的交流和推理能力
- 人与机器最大的不同是:逻辑的有无,人既可以逻辑,也可以非逻辑,机器只是人逻辑的产物。正如许多逻辑学家曾不无深意的指出:逻辑学所关心的是正确性与确实性,与创造性思维完全无关。法拉第就警告说,思维有”依赖于假定”的倾向,一旦假定与其它知识符合,就容易忘记这个假定尚未得到证明。未经证实的假定常由”显然”、”当然”、”无疑”、“应该”等词句引入,很容易潜入归纳、演绎等推理过程,而且这些推理隐患常常又会诱发出更多范围程度不同的不确定性。
- 人、机智能的不同还表现在:人可以反思,机器只能反馈!反思比反馈要复杂简单的多:反思的复杂性不但包含前馈、后馈、左馈、右馈、上馈、下馈,还涉及实馈、虚馈、复馈、隐馈、暗馈、灰馈;反思的简单性是可以产生意义(理解了可能性)、理解(看到了联系)和直觉(相关无关的感觉),机器对此无能为力,再好的逻辑、再好的数学也产生不出意义、理解、直觉这些人类特有的专属品来!
乔姆斯基精粹
- 《乔姆斯基精粹》一书,该书集合了乔姆斯基1959年以来最重要的作品,涉及的主题从对公司媒体和美国干预越南、中美洲、巴尔干的批评,到思想自由和有关人权的政治经济学,是对乔姆斯基思想前所未有的一次全面概览。
- 译者李梅:“《语言与自由》的开头讲到了语言,后面讲了一大段人类怎么追求自由的斗争,我在翻译完以后才意识到语言和政治追求,或者对人生的实践其实是密切相关的。乔姆斯基在这里引用了唯心主义哲学家和教育者谢林说的话:‘人生来就要采取行动,而不是胡思乱想。’回顾了各种人类斗争之后,谈到我们的哲学研究,或者一切哲学的开始和结束都是自由,如果我们研究语言的话,其实我们最终也是为了获得一种人类的自由。”
乔姆斯基北大演讲
【2022-9-4】
- 不要把伟大的批评者,当做国家的敌人
- 【2021-11-12】从语言学到政治批评,“90后”乔姆斯基仍然充满力量
2010年8月13日,美国重量级学者、麻省理工学院教授诺姆·乔姆斯基在北京大学接受名誉博士学位并发表演讲。
- 一个批评者,对于一个公民社会而言意义重大。他可以帮助警惕或规避可能存在的政策失误,也能抵消因为意见过于趋同而导致的独断和冒进。甚至,这样一个批评者能否存在,本身就是一个社会是否开明的评判标准。不要把伟大的批评者,当做国家的敌人。
乔姆斯基以“异见”姿态闻名世界,他对美国政府的批评立场一生不变,曾把美国政府比作“饿狼”或“世界上最大的恐怖组织”。他甚至抨击美国人最珍视的“民主”,认为它是虚伪的。
这些批评,并未给他带来太大麻烦,相反,却为他赢得卓越的声望。他被美国媒体评为当代全球最具影响力的100名公共知识分子之首。如果说乔姆斯基为我们带来了有益的启示,那也并不在于他的观点本身,而在于这种观点所持的姿态:批评者。
无论我们是否愿意承认,一个无法回避的事实是: 合格的批评者,以及对待批评者的宽容态度,是我们社会当下亟须拥有的资源。在目前这个变化急剧、事端丛生的发展阶段,缺少合格的批评者,或者缺少对于批评者的宽容态度,将会带来无穷恶果。
保持怀疑和批判的姿态,是知识分子的天职,因为知识分子享有知识的“特权”,并有专业能力对事物进行深刻剖析。在他看来,知识分子永远面临着两种选择:做一个向权威俯首帖耳的御用文人,或做一个独立的批评者。他认为,选择成为一个批评者尽管可能在当下遭遇烦恼,却能使知识分子最终避开历史和道义对他的审判。(也许正是基于这种观点,乔姆斯基成了美国政府永远的反对派。即使在中国之行的演讲中,他也会时不时地将话锋转回到大洋彼岸那个“政府”上。)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
