- 大数据
- 相关性分析
- 数据分析
- 数据库
- 分析工具
- 大数据分析
- 数据的游戏:冰与火
- 服务质量评价
- 结束
数据挖掘方向知识点、经验总结
大数据
总结
【2021-11-4】美团王庆:当老板对指标进行灵魂拷问时,该如何诊断分析?,主要从四个方面进行展开:
- 为什么要做诊断分析?
- 第一类是发生型问题。昨天相比订单量为什么下降10%?现状就是今天的订单量,期望是昨天的大量问题。
- 第二类是潜在型问题。天气变冷,客服人力是否够用,现状是当前的供需关系,期望是按这个趋势走下去,供需关系会怎样?是否存在差距,过剩还是不足?
- 第三类为理想型的问题,比如如何完成Q3的OKR,当前的访购率是10%,期望下个季度的访购率是12%,差距就是2pp。
- 如何做诊断分析?
- 一种相对普适性的方法就是“逻辑树+假设驱动”。 因为逻辑树能够帮助我们确定分析问题的框架,而假设驱动可以确定分析问题的视角。这里,逻辑树是表达指标(问题)内部结构的最佳方法,适用于外卖业务多数指标的问题诊断。
- 智能诊断案例解析
- Tips:诊断分析中易犯的错误
- 原因1:问题界定不清楚。问题是现状与期望的差距。对现状认识不清、期望不合理、问题定义不对
- 原因2:舒适地带偏见。在有限的时间、有限的维度内进行诊断,只寻找局部最优解,很容易导致漏诊和误诊。
- 【2021-2-22】27岁华裔小伙一战成名!搞出美国新冠最准预测模型,一人干翻专业机构,彭博:Superstar,凭一己之力,仅用一周时间打造的新冠预测模型,准确度方面碾压那些数十亿美元、数十年经验加持的专业机构。不仅如此,他的模型还被美国疾控中心采用。模型地址
- fast.ai创始人Jeremy Howard高度评价道:唯一看起来合理的模型。他是唯一一个真正查看数据,并且做得正确的人。
- 2家专业机构打造的预测系统——伦敦帝国理工学院、总部位于西雅图的健康指标与评估研究所(IHME)。
- 但2家机构给出的预测结果却是天差地别:
- 伦敦帝国理工学院:到夏天,美国因新冠病毒而死亡的人数将达到200万。
- IHME:预计到8月,死亡人数将达到6万。
- (后来的事实证明,死亡人数是16万。)
概念
大数据
【2018-5-23】IBM大中华区 谢国忠:大数据在金融领域实践应用
计算机技术的发展历程与演变,三个时代: 早期的制表系统时代、现在的可编程系统时代和正在跨越的认知系统时代。
未来的计算模式:可编程系统+认知系统,可编程系统实现“交易”,认知系统实现“分析”。
大数据是认知系统的基础。
- 大交易数据: OLTP(联机交易处理)、OLAP(联机分析处理) 和 数据仓库
- 大交互数据: 移动终端、物联网、互联网、社交网络
- 大数据集成和融合
- 大数据处理与分析
统计特性
详见站内专题 概率统计
数据可视化
【2021-11-9】用python进行描述性统计。描述性统计是借助图表或者总结性的数值来描述数据的统计手段
总结:频次分析(定性、定量)、关系分析、探索分析
数值分析
- 1 基本概念
- 2 中心位置(均值、中位数、众数)
- 3 发散程度(极差,方差、标准差、变异系数)
- 4 偏差程度(z-分数)
- 5 相关程度(协方差,相关系数)
import numpy as np
#from numpy import array
#from numpy.random import normal, randint
data = [1, 2, 3]#使用List来创造一组数据
data = np.array([1, 2, 3])#使用ndarray来创造一组数据
data = np.random.normal(0, 10, size=10)#创造一组服从正态分布的定量数据(μ=0,σ=10)
data = np.random.randint(0, 10, size=10)#创造一组服从均匀分布的定性数据([0,10)之间的均匀分布)
# ------- 中心位置 -------
#from numpy import mean, median
import numpy as np
np.mean(data)#计算均值,期望
np.median(data)#计算中位数
# 对于定性数据来说,众数是出现次数最多的值,使用SciPy计算众数:
import scipy as sp
sp.stats.mode(data)#计算众数,注报错!
from scipy.stats import mode
mode(data)#ModeResult(mode=array([2]), count=array([2])),方法:mode、count和index
# -------- 发散程度 ---------
#from numpy import mean, ptp, var, std
import numpy as np
np.min(data);np.max(data)
np.ptp(data)#极差:|max-min|
np.var(data)#方差
np.std(data)#标准差
np.mean(data)/np.std(data)#变异系数——近似正态分布变换
# --------- 偏差程度 ---------
# z-分数的绝对值大于3将视为异常。#注:三倍标准差以外视为小概率事件
(data[0]-np.mean(data)) / np.std(data)#计算第一个值的 z-分数
# --------- 相关程度 ---------
data = np.array([data1, data2])
# ① 协方差的绝对值越大表示相关程度越大,协方差为正值表示正相关,负值为负相关,0为不相关。
# ② 相关系数是基于协方差但进行了无量纲处理。使用NumPy计算协方差和相关系数:
data = np.array([data1, data2])
#计算两组数的协方差.参数bias=1表示结果需要除以N,否则只计算了分子部分.返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的协方差。对角线为方差
np.cov(data, bias=1)
#计算两组数的相关系数.返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的相关系数。对角线为1
np.corrcoef(data)
可视化分析
- 1 基本概念
- 2 频数分析
- 2.1 定性分析(柱状图、饼形图)
- 2.2 定量分析(直方图、累积曲线)
- 3 关系分析(散点图)
- 4 探索分析(箱形图)
描述性统计是容易操作,直观简洁的数据分析手段。但是由于简单,对多元变量的关系难以描述。现实生活中,自变量通常是多元的:决定体重不仅有身高,还有饮食习惯,肥胖基因等等因素。通过一些高级的数据处理手段,我们可以对多元变量进行处理,例如特征工程中,可以使用互信息方法来选择多个对因变量有较强相关性的自变量作为特征,还可以使用主成分分析法来消除一些冗余的自变量来降低运算复杂度。
数据金字塔
- 数据金字塔可以帮助我们理解数据与信息、知识和人工智能的关系。
- 数据本身是没有意义的,如果它不能转化为信息和知识的话;
- 但如果没有数据,或者数据匮乏,信息和知识的产生也就成了无水之源。
- 图
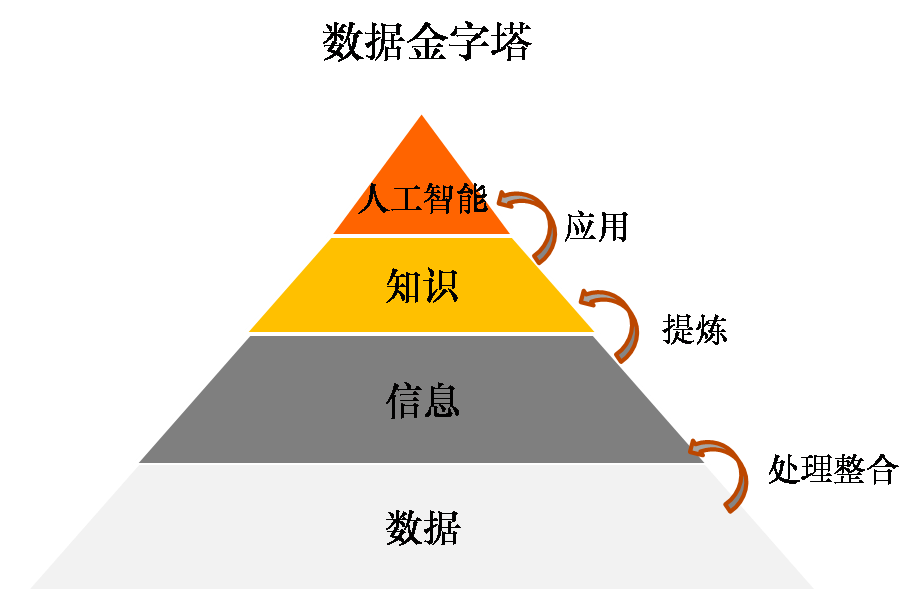
- 数据
- 问题
- 数据存在缺失
- 数据采集的无效性
- 问题
- 信息:是被组织起来的数据
- 为了特定目标对数据进行处理和建立内在关联,让数据具有意义,可以回答谁(who)、什么(what)、哪里(where)、什么时候(when)的问题,对于企业经营而言,信息的作用在于过程管理和绩效评估。
- 问题
- 缺乏有效的数据分析工具
- 缺乏将数据转化为信息的分析能力
- 知识:对信息的总结和提炼。
- 基于信息之间的联系,总结出来的规律和方法论,主要用于回答为什么(why)和怎么做(how)的问题,在企业里的应用包括问题诊断、预测和最佳做法。
- 知识来源于经验(数据),来源于人类对这个三维世界的观察,而智慧可以无需通过经验,有可能通过与高维度建立连接而获得
- 人工智能:机器对信息和知识的自主应用
- 人工智能是系统基于数据、信息和知识,形成类似于人脑的思维能力(包括学习、推理、决策等)。
- 在信息和知识层面,数据都是提供决策支持作用,而到了人工智能阶段,则是系统模仿人类应用信息和知识进行自主决策了。
- 人工智能永远无法超越人类的智慧。由此也可以看到数据的局限性:
- 它可以将人类的理性发挥到极致,但它只会模仿却无法创造,它无法替代人类的感性和直觉,而正是这份感性和直觉,让生命多了一些有趣和柔软,真正的创造也由此发生!
相关性分析
- 注意: $ 相关关系 ≠ 因果关系 $
- 相关分析的方法很多
- 初级方法:快速发现数据之间的关系,如正相关,负相关或不相关。
- 中级方法:对数据间关系的强弱进行度量,如完全相关,不完全相关等。
- 高级方法:将数据间的关系转化为模型,并通过模型对未来的业务发展进行预测。

相关系数总结
| 系数 | 数值类型 | 顺序因素 | 适用条件 | 示例 |
|---|---|---|---|---|
| pearson | 连续 | 无序 | 连续数据,正态分布,线性关系 | T恤与空调销售量关系 |
| kendall | 离散 | 有序 | 定序变量或不满足正态分布的等间隔数据 | 商品排名关系 |
| spearman | 不限 | 有序 | 定序变量或不满足正态分布的等间隔数据 | 有序即可,数据类型分布不限,适用范围广但统计效能低 |
相关系数分析
参考:
(1)协方差及协方差矩阵
协方差用来衡量两个变量的总体误差,如果两个变量的变化趋势一致,协方差就是正值,说明两个变量正相关。如果两个变量的变化趋势相反,协方差就是负值,说明两个变量负相关。如果两个变量相互独立,那么协方差就是0,说明两个变量不相关。协方差只能对两组数据进行相关性分析,当有两组以上数据时就需要使用协方差矩阵。协方差通过数字衡量变量间的相关性,正值表示正相关,负值表示负相关。但无法对相关的密切程度进行度量。面对多个变量时,无法通过协方差来说明那两组数据的相关性最高。要衡量和对比相关性的密切程度,就需要使用下一个方法:相关系数。


(2)相关系数
- 相关系数(Correlation coefficient)是反应变量之间关系密切程度的统计指标,相关系数的取值区间在1到-1之间。1表示两个变量完全线性相关,-1表示两个变量完全负相关,0表示两个变量不相关。数据越趋近于0表示相关关系越弱。
- 缺点是无法利用这种关系对数据进行预测,简单的说就是没有对变量间的关系进行提炼和固化,形成模型。要利用变量间的关系进行预测,需要使用到下一种相关分析方法,回归分析。
- pearson(皮尔逊), kendall(肯德尔)和spearman(斯伯曼/斯皮尔曼)三种相关分析方法有什么异同
- (2.1)pearson(皮尔逊) 线性相关系数
- r = Cov(x,y) / σᵪσ
- $ \rho_{X, Y}=\frac{\operatorname{cov}(X, Y)}{\sigma_{X} \sigma_{Y}} $
- 两个连续变量间呈线性相关时
- 满足积差相关分析的适用条件时,使用Pearson积差相关系数
- 不满足积差相关分析的适用条件时,使用Spearman秩相关系数来描述.
- (2.2)Spearman(斯皮尔曼)相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。Pearson相关系数的计算公式可以完全套用Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
- 1.连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用spearman相关系数也可以, 就是效率没有pearson相关系数高。
- 2.上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
- 3.两个定序数据之间也用spearman相关系数,不能用pearson相关系数。
- 定序数据是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。
- 斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用。
- (2.3)Kendall’s tau-b等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。对相关的有序变量进行非参数相关检验;取值范围在-1-1之间,此检验适合于正方形表格;
- 计算积距pearson相关系数,连续性变量才可采用;
- 计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据;
- 计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
- 计算相关系数:当资料不服从双变量正态分布或总体分布未知,或原始数据用等级表示时,宜用 spearman或kendall相关
- Pearson 相关复选项 积差相关计算连续变量或是等间距测度的变量间的相关分析
- Kendall 复选项 等级相关 计算分类变量间的秩相关,适用于合并等级资料
- Spearman 复选项 等级相关计算斯皮尔曼相关,适用于连续等级资料
- 注:
- 1 若非等间距测度的连续变量 因为分布不明-可用等级相关/也可用Pearson 相关,对于完全等级离散变量必用等级相关
- 2 当资料不服从双变量正态分布或总体分布型未知或原始数据是用等级表示时,宜用 Spearman 或 Kendall相关。
- 3 若不恰当用了Kendall 等级相关分析则可能得出相关系数偏小的结论。则若不恰当使用,可能得相关系数偏小或偏大结论而考察不到不同变量间存在的密切关系。对一般情况默认数据服从正态分布的,故用Pearson分析方法。



(3)一元回归及多元回归
- 回归分析(regression analysis)是确定两组或两组以上变量间关系的统计方法。两个变量使用一元回归,两个以上变量使用多元回归。

- 详情见专题:机器学习之回归分析
(4)信息熵及互信息
- 影响最终效果的因素可能有很多,并且不一定都是数值形式
互信息可以发现哪一类特征与最终的结果关系密切.- 互信息是用来衡量信息之间相关性的指标。当两个信息完全相关时,互信息为1,不相关时为0。
- 信息之间是有相关性的,互信息是度量相关性的尺子。互信息越高,相关性也越高。

相关系数vs互信息:- 线性相关系数,从统计学出发度量信息A、B的关系,范围在-1到1,即有正相关和负相关。0表示相关
- 互信息,从联合概率的角度计算,可以理解为A出现的时候B出现的概率,概率范围是从0到1,即完全不确定到完全确定
- 计算方法见:决策树分类和预测算法的原理及实现

- 离散
- 连续
- 代码
# 方法1:
#sklearn 计算
from sklearn import metrics as mr
if __name__ == '__main__':
A = [1, 1, 1, 2, 3, 3]
B = [1, 2, 3, 1, 2, 3]
result_NMI=metrics.normalized_mutual_info_score(A, B)
print("result_NMI:",result_NMI)
#备注:计算A和B的互信息,A,B为list或array。
#方法2:
from scipy.stats import chi2_contingency
def calc_MI(x, y, bins):
c_xy = np.histogram2d(x, y, bins)[0]
g, p, dof, expected = chi2_contingency(c_xy, lambda_="log-likelihood")
mi = 0.5 * g / c_xy.sum()
# 备注:唯一区别就是这样实现使用自然对数而不是基2对数(因此它以“nats”而不是“bits”表示信息)。如果你喜欢bit,只需把mi除以log(2)
#方法3:
import numpy as np
def calc_MI(X,Y,bins):
c_XY = np.histogram2d(X,Y,bins)[0]
c_X = np.histogram(X,bins)[0]
c_Y = np.histogram(Y,bins)[0]
H_X = shan_entropy(c_X)
H_Y = shan_entropy(c_Y)
H_XY = shan_entropy(c_XY)
MI = H_X + H_Y - H_XY
return MI
def shan_entropy(c):
c_normalized = c / float(np.sum(c))
c_normalized = c_normalized[np.nonzero(c_normalized)]
H = -sum(c_normalized* np.log2(c_normalized))
return H
A = np.array([[ 2.0, 140.0, 128.23, -150.5, -5.4 ],
[ 2.4, 153.11, 130.34, -130.1, -9.5 ],
[ 1.2, 156.9, 120.11, -110.45,-1.12 ]])
bins = 5 # ?
n = A.shape[1]
matMI = np.zeros((n, n))
for ix in np.arange(n):
for jx in np.arange(ix+1,n):
matMI[ix,jx] = calc_MI(A[:,ix], A[:,jx], bins)
【2020-12-07】
Sperman或kendall等级相关分析, Sperman 连续,kendall 离散Person相关(样本点的个数比较多),无顺序关系,一般常用皮尔逊相关Copula相关(比较难,金融数学,概率密度)- 一般这样认为:
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
- 参考
Pearson——无序、连续
皮尔逊相关系数( Pearson correlation coefficient),又称皮尔逊积矩相关系数(Pearson product-moment correlation coefficient,简称 PPMCC或PCCs)。用于衡量两个变量X和Y之间的线性相关相关关系,值域在-1与1之间。- 给定两个连续变量x和y,皮尔森相关系数被定义为
- img
- img
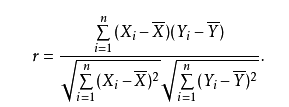
- $ \rho_{\mathrm{X}, \mathrm{Y}}=\frac{\operatorname{cov}(\mathrm{X}, \mathrm{Y})}{\sigma_{\mathrm{X}} \sigma_{\mathrm{Y}}}=\frac{\mathrm{E}[(\mathrm{X}-\mathrm{EX})(\mathrm{Y}-\mathrm{EY})]}{\sigma_{\mathrm{X}} \sigma_{\mathrm{Y}}}=\frac{\mathrm{E}(\mathrm{XY})-\mathrm{E}(\mathrm{X}) \mathrm{E}(\mathrm{Y})}{\sqrt{\mathrm{E}\left(\mathrm{X}^{2}\right)-\mathrm{E}^{2}(\mathrm{X})} \sqrt{\mathrm{E}\left(\mathrm{Y}^{2}\right)-\mathrm{E}^{2}(\mathrm{Y})}} $
- img

Pearson相关系数的一个关键数学特性:
- 它在两个变量的位置和尺度的单独变化下是不变的。可以将X变换为a+bX并将Y变换为c+dY,而不改变相关系数,其中a,b,c和d是常数,b,d > 0
|r|相关强度
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
注意以下几个问题:
- 1、 积差相关系数适用于线性相关的情形,对于曲线相关等更为复杂的情形,积差相关系数大小并不能代表相关性的强弱
- 2、 样本中存在的极端值对Pearson积差相关系数的影响极大,因此要慎重考虑和处理,必要时可以对其进行剔出,或者加以变量变换,以避免因为一两个数值导致出现错误的结论。
-
3、 Pearson积差相关系数要求相应的变量呈双变量正态分布,注意双变量正态分布并非简单的要求x变量和y变量各自服从
正态分布,而是要求服从一个联合的双变量正态分布 - 代码
# (1)numpy库
pccs = np.corrcoef(x, y)
# (2)scipy库
from scipy.stats import pearsonr
pccs = pearsonr(x, y)
# (3)直接计算
def cal_pccs(x, y, n):
"""
warning: data format must be narray
:param x: Variable 1
:param y: The variable 2
:param n: The number of elements in x
:return: pccs
"""
sum_xy = np.sum(np.sum(x*y))
sum_x = np.sum(np.sum(x))
sum_y = np.sum(np.sum(y))
sum_x2 = np.sum(np.sum(x*x))
sum_y2 = np.sum(np.sum(y*y))
pcc = (n*sum_xy-sum_x*sum_y)/np.sqrt((n*sum_x2-sum_x*sum_x)*(n*sum_y2-sum_y*sum_y))
return pcc
Spearman——有序(不限)
Spearman秩相关系数:使利用两变量的秩次大小作线性相关分析,对原始变量的分布不做要求,属于非参数统计方法。因此适用范围比Pearson相关系数要广的多。即使原始数据是等级资料也可以计算Spearman相关系数。
- 对于服从Pearson相关系数的数据也可以计算Spearman相关系数,但统计效能比Pearson相关系数要低一些(不容易检测出两者事实上存在的相关关系)。如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或−1。
-
Spearman相关系数即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对Spearman相关性系数的影响也非常小。
- 由于原则上无法准确定义顺序变量各类别之间的距离,导致计算出来的相关系数不是变量间的关联性的真实表示。因此,建议对顺序变量使用斯皮尔曼相关系数。
- 斯皮尔曼相关系数的计算采用的是取值的等级,而不是取值本身。例如,给定三个值:33,21,44,它们的等级就分别是2,1,3. 计算斯皮尔曼相关系数的公式与计算皮尔森相关系数的类似,但用等级代替了各自的取值。
- 相对于皮尔森相关系数,斯皮尔曼相关系数对于数据错误和极端值的反应不敏感。
- 斯皮尔曼相关系数的另一种公式表示如下:
- img
- $\rho=\frac{\sum_{i}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sqrt{\sum_{i}\left(x_{i}-\bar{x}\right)^{2} \sum_{i}\left(y_{i}-\bar{y}\right)^{2}}}$ 对于样本容量为n的样本,n个原始数据被转换成等级数据,相关系数ρ为:
- img
- img
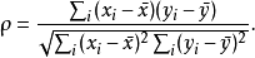

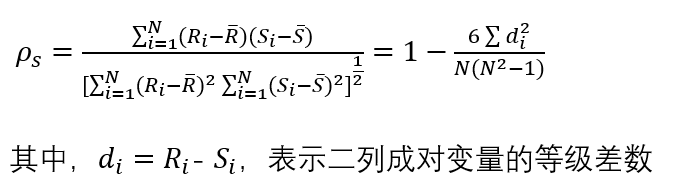
【2024-7-3】计算公式
$\rho=1-\frac{6 \sum_{i=1}^{n} d_{i}^{2}}{n\left(n^{2}-1\right)}=1-\frac{6 \times(4+9+1+4)}{4\left(4^{2}-1\right)}=-0.8$
示例
# 原始数值
x = [9.2, 2.1, 7.2, 9.1]
y = [2.4, 8.1, 4.2, 1.1]
# 离散化为等级数据,如 分成4档, n=4
x = [4,1,2,3]
y = [2,4,3,1]
# 计算等级差
d = [-2,3,1,-1]
d2 = [4,9,1,4] # 平方
# 计算 spearman 系数
ro = -0.8
Kendall——有序、离散
Kendall秩相关系数是一种秩相关系数,用于反映分类变量相关性的指标,适用于两个变量均为有序分类的情况,用希腊字母τ(tau)表示其值。
- 分类变量可以理解成有类别的变量,可以分为无序的,比如性别(男、女)、血型(A、B、O、AB);
- 有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。通常需要求相关性系数的都是有序分类变量
Kendall相关系数的取值范围在-1到1之间
- 当τ为1时,表示两个随机变量拥有一致的等级相关性;
- 当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;
- 当τ为0时,表示两个随机变量是相互独立的。
计算公式:
- Kendall系数是基于协同的思想。对于X,Y的两对观察值Xi,Yi和Xj,Yj,如果$ X_i<Y_i$ 并且 $ X_j<Y_j$, 或者$X_i>Y_i$并且$X_j>Y_j$,则称这两对观察值是和谐的,否则就是不和谐。
- $\tau=\frac{\text { (一致的pairs数) }-\text { (不一致的pairs数) }}{\frac{1}{2} n(n-1)}$
Kendall系数可以度量两个排序之间的相关性强弱
- k<0.5:负相关,数值越接近0,负相关性越强
- 如:[1,2,3,4], [4,3,2,1], 肯德尔系数为0
- k=0.5:不相关
- k>0.5:正相关,数值越接近1,正相关性越强
- 如:[1,2,3,4], [1,2,3,4], 肯德尔系数为1
- 一致性评价中,通常认为
- k>0.7 较好
- k>0.9 优秀
三种相关系数都是对变量之间相关程度的度量,由于其计算方法不一样,用途和特点也不一样。
- 1)Pearson相关系数是在原始数据的方差和协方差基础上计算得到,所以对离群值比较敏感,它度量的是线性相关。因此,即使pearson相关系数为0,也只能说明变量之间不存在线性相关,但仍有可能存在曲线相关。
- 2)Spearman相关系数和kendall相关系数都是建立在秩和观测值的相对大小的基础上得到,是一种更为一般性的非参数方法,对离群值的敏感度较低,因而也更具有耐受性,度量的主要是变量之间的联系。
代码
import pandas as pd
df = pd.read_csv('demo.csv')
## 计算相关度系数 ##
df.corr() #计算pearson相关系数
#df.corr('kendall') #计算kendall相关系数
#df.corr('spearman') #计算spearman相关系数
# Dataframe.corr(method='spearman'), 返回相关关系矩阵
from scipy.stats import spearmanr
# spearmanr(array)返回 Pearson 系数和检验P值, 样本要求>20。
无序分类变量的统计推断:卡方检验

- $\chi^{2}=\sum_{i=1}^{k}\left(\left(A_{i}-n p_{i}\right)^{2} / n p_{i}\right)$
Ai为i水平的观测频数,Ei为i水平的期望频数,n为总频数,Pi为i水平的期望概率。
主要用于检验某无序分类变量各水平在两组或多组间的分布是否一致。还可以用于检验一个分类变量各水平出现的概率是否等于指定概率;一个连续变量的分布是否符合某种理论分布等。其主要用途:
- 1、 检验某个连续变量的分布是否与某种理论分布相一致。
- 2、 检验某个分类变量各类的出现概率是否等于制定概率。
- 3、 检验某两个分类变量是否相互独立。
- 4、 检验控制某种或某几种分类因素的作用以后,另两个分类变量是否相互独立。
- 5、 检验某两种方法的结果是否一致。
数据分析
- 【2021-6-9】阿里巴巴:数据分析思维及意义
Google的数字营销传播者Avinash Kaushik曾说“All data in aggregate is crap”,即“所有汇总的数据都是废话”,汇总的数据掩盖了很多问题,即需要下钻分析数据指标,以理解指标的各种取值或者趋势背后的真正原因(特别是指标取值或者趋势异常时),以便于优化指标。
5W2H分析法又叫七问分析法,简单、方便,易于理解、使用,富有启发意义,广泛用于企业管理和技术活动,对于决策和执行性的活动措施也非常有帮助,也有助于弥补考虑问题的疏漏。
- 5W是指:what(是什么)、when(何时)、where(何地)、why(为什么)、who(是谁)。
- 2H是指:how(怎么做)、how much(多少钱)。
案例
幸存者偏差
【2023-12-16】中国工程院资深院士金涌:人还有一种反向思维能力
- 二战期间,统计飞机中弹点,好商议哪些部位需要加强,没考虑到真正需要加强的位置并没有采样(飞机没飞回来)
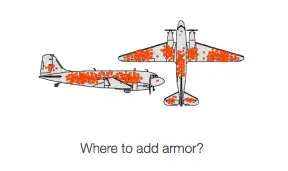
幸存者偏差(Survivorship bias)是一种常见的逻辑谬误(所以我说叫“谬误”而不是“偏差”)
- 只能看到经过某种筛选而产生的结果,而没有意识到筛选过程,因此忽略了被筛选掉的关键信息。
- 别名有很多,比如“沉默的数据”、“死人不会说话”等等。
举例
- 仅通过研究大学生来探究高中教育的问题,那就忽略了高考这个筛选器:没有通过高考、没有考上大学的人,他们才是在高中教育真正出现问题的人,而他们不在大学生的研究样本中。
因果分析
流浪地球
【2023-10-15】真实故事:
- 某互联网平台通过大数据发现,《流浪地球》观众喜欢喝热饮,而《战狼2》的观众喜欢喝冷饮。
- 这是为什么呢?他们百思不得其解,却唯独忘记了前者是在冬天上映,后者是在夏天上映……
教科书般的过度理论化,一个不懂得领导带着一帮刚出社会的985就大概率干这样的事,依赖所谓的科学工具
- 过分话追求数据分析 天天看各种无意义的报表 根本挖掘不出数据背后隐藏的意义
- 研究了大半天,发现忘记了常识:数据分析时,必须要对比分析时间、地点、人群等
数据和AI都是建立在统计学上,需要植入了因果分析
高压线麦田
现象:
- 高压线下的小麦长势更好
于是,专家申请课题:研究电磁与小麦生长关系,历时两年,一通折腾,没有成果
农民一语点醒
- 高压线上鸟儿多,掉下来的粪便成了小麦养料。
数据分析常见技巧
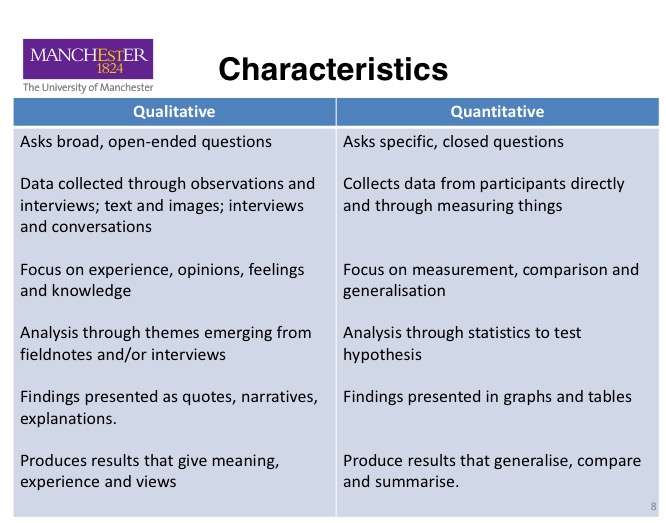
- 【2020-9-29】数据分析知识点:定性分析和定量分析的根本区别在于
- ① 画图前想想是定性分析还是定量分析
- 定性分析描述性质,侧重结论,如占比,一般用饼图、四分位图等;
- 分析1:郭小明胃口很大
- 分析2:郭晓明胃口很小
- 定量分析描述量级变化,侧重数字,一般用折线图、曲线图等。
- 分析1:郭小明一顿可以吃3个Schweinshaxe
- 分析2:郭小明在吃了3个Schweinshaxe之后还可以吃5个蛋挞

- 定性分析描述性质,侧重结论,如占比,一般用饼图、四分位图等;
- ② 数据分析三大类:趋势、比较、细分。参考:数据分析的三个常用方法:数据趋势、对比和细分分析
- 趋势
- 比较
- 细分
宏观战略分析
常用战略分析方法有PEST、SWOT和波特五力模型
PEST
PEST分析是指宏观环境的分析,P是政治(politics),E是经济(economy),S是社会(society),T是技术(technology)。
SWOT
SWOT即基于内外部竞争环境和竞争条件下的态势分析,可以对研究对象所处的情景进行全面、系统、准确的研究。分析角度:优势(Strengths)、劣势(Weaknesses)、机会(Opportunities)和威胁(Threats)。
波特五力
波特五力即行业中存在着决定竞争规模和程度的五种力量,这五种力量综合起来影响着产业的吸引力以及现有企业的竞争战略决策。五种力量分别为同行业内现有竞争者的竞争能力、潜在竞争者进入的能力、替代品的替代能力、供应商的讨价还价能力与购买者的议价能力。
微观数据分析
由于业务数据指标往往是由多个微观原因引起的,上面的方法难以定位这类问题(如“订单量为什么下降”)的根本原因,这时候就需要运用其他微观数据分析方法。
逻辑树分析法
逻辑树分析方法是把复杂问题拆解成若干个简单的子问题,然后像树枝那样逐步展开。
多维度拆解法
假设在每个医院最近收治的1000例患者中,A医院有900例患者存活。然而,B医院只有800例患者存活(如下图)。这样看起来,A医院的存活率更高,应该选择A医院。你的选择真的是正确的吗?
对比方法
1)什么是对比方法
数据分析中,我们通过对比分析方法,来追踪业务是否有问题。例如,我的CTR是4%,你说是高还是低?这个CTR有问题吗?这时候,就需要用对比分析方法来追踪业务是不是有问题。正所谓,没有对比就没有好坏。
心理学家给这种现象发明了一个术语叫作价格锚定,也就是通过和价格锚点对比,一些商品会卖得更好。
2)与谁比
与谁比一般分为两种:与自己比,与行业比。
3)如何比较
一般从3个维度比较:数据整体的大小、数据整体的波动、趋势变化。
- a)数据整体的大小:某些指标可用来衡量整体数据的大小。常用的是平均值、中位数,或者某个业务指标。
- b)数据整体的波动:标准差除以平均值得到的值叫作变异系数。变异系数可用来衡量整体数据的波动情况。
- c)趋势变化:趋势变化是从时间维度来看数据随着时间发生的变化。常用的方法是时间折线图,环比和同比。
- 时间折线图是以时间为横轴、数据为纵轴绘制的折线图。从时间折线图上可以了解数据从过去到现在发生了哪些变化,还可以通过过去的变化预测未来的动向。
- 环比是和上一个时间段对比,用于观察短期的数据集。例如某数据在2020年12月比2020年11月下降10%。
- 同比是与去年同一个时间段进行对比,用于观察长期的数据集。例如某数据在2020年12月比2019年12月下降10%。
假设检验分析法
1)什么是假设检验分析法
假设检验分析方法分为3步:
- 提出假设:根据要解决的问题,提出假设。例如警察破案的时候会根据犯罪现场提出假设:这个人有可能是嫌疑人。
- 收集证据:通过收集证据来证明。例如警察通过收集嫌疑犯的犯罪数据,来作为证据。
- 得出结论:这里的结论不是你主观猜想出来的,而是依靠找到的证据得到的结论。例如警察不能主观地去猜想,然后下结论说这个人是罪犯,而是要通过收集的数据(证据)来证明这个人是不是罪犯。
2)假设检验分析方法有什么用
由于假设检验分析方法背后的原理是逻辑推理,所以学会这个方法以后,可以显著提高我们的逻辑思维能力。
假设检验分析方法的另一个作用是可以分析问题发生的原因,也叫作归因分析。例如是什么原因导致活跃率下降、CTR下降、订单量下降等。这类问题就是分析原因,通过找到问题发生的原因,才能根据原因制定对应的策略。
3)如何使用假设检验分析方法?
我们可以按用户、产品、竞品这3个维度提出假设(如下图),来检查提出的假设是否有遗漏。这3个维度分别对应公司的3个部门:用户对应运营部,产品对应产品部,竞品对应市场部。这3个维度有助于在发现问题原因以后,对应落实到具体部门上,有利于把问题说清楚。还可以从4P营销理论出发来提出假设。
相关分析
1)什么是相关分析法
时候我们研究的问题只有一种数据,例如人的身高;但是,还有另外一些问题需要研究多种数据,例如身高和体重之间的关系。当我们研究两种或者两种以上的数据之间有什么关系的时候,就要用到相关分析。如果两种数据之间有关系,叫作有相关关系;如果两种数据之间没有关系,叫作没有相关关系。
我们看一个例子。某个地区的用户在搜索引擎里搜的信息,和这个地区房价有什么关系呢?
谷歌首席经济学家哈尔·瓦里研究发现,如果更多人搜索“八成按揭贷款”,或者“涨幅”“涨价的速度”,这个地区的房价就会上涨;如果更多人搜索“快速卖房的流程”或者“按揭超过房价”,这个地区的房价就会下跌。也就是说,用户在搜索引擎里搜的信息和这个地区的房价有相关关系。
2)相关分析方法有什么用?
相关分析的作用有以下三点:
- 在研究两种或者两种以上数据之间有什么关系,或者某个事情受到其他因素影响的问题时,可以使用相关分析,以量化两个量的相关性。例如在分析产品的各个功能对产品用户留存的影响时,就可以使用相关分析,得出各个功能与产品用户留存的相关性。
- 在解决问题的过程中,相关分析可以帮助我们扩大思路和找到优先级,将视野从一种数据扩大到多种数据,扩展经验之外的因素,另外就是找到问题后可以根据相关性找到各个影响因素的重要性,进而先解决相关性高的主要问题。举个例子,在分析“为什么销量下降”的过程中,可以研究哪些因素和销售量有关系,例如产品价格、售后服务等。使用相关分析,可以知道哪些因素影响销量,哪些对销量没有影响,从而快速锁定问题的原因。
- 相关分析通俗易懂。这在实际工作中很重要,因为数据分析的结果需要得到其他人的理解和认可,所以要方便大家沟通。很多分析方法看上去很高端,但是没有相关知识的人不容易理解。而相关分析通俗易懂,你不需要向对方解释什么是“相关”的含义及分析结果的意义,对方也能够理解。
3)相关系数的含义?
相关系数数值的正负可以反映两种数据之间的相关方向,也就是说两种数据在变化过程中是同方向变化,还是反方向变化。
相关系数的范围是-1~1,-1、0和1这三个值是相关系数的极值(如下图),下面解释一下相关系数的3个极值。假如有两种数据a和b,把这两种数据画在散点图上,横轴用来衡量数据a,纵轴用来衡量数据b。
- 如果相关系数=1,数据点都在一条直线上,表示两种数据之间完全正相关,两种数据是同方向变化。也就是数据a的值越大,数据b的值也会越大。
- 如果相关系数=-1,数据点都在一条直线上,表示两种数据之间完全负相关,两种数据是反方向变化。也就是数据a的值越大,数据b的值反而会越小。
- 如果相关系数=0,表明两种数据之间不是线性相关,但有可能是其他方式的相关(例如曲线方式)。
- 如果相关系数>0,说明两种数据是正相关,是同方向变化,也就是一种数据的值越大,另一种数据的值也会越大;如果相关系数<0,说明两种数据是负相关,是反方向变化,也就是一种数据的值越大,另一种数据的值反而会越小,如下图所示。
6)区别相关关系和因果关系
群组分析
1)什么是群组分析法
群组分析方法”(也叫同期群分析方法)是按某个特征,将数据分为不同的组,然后比较各组的数据,说白了就是对数据分组然后来对比。比如按时间划分新用户、按职责划分人群。
2)群组分析的作用
产品会随着时间发布新的版本,产品改版的效果如何?版本更新后用户是增长了,还是流失了?像这类问题,就需要将用户按时间分组,然后比较不同组的用户留存率。所以,群组分析方法常用来分析用户留存率(或者流失率)随时间发生了哪些变化,然后找出用户留下或者离开的原因。
漏斗分析法
1)什么是漏斗分析法
用户建模
session 分析、切分、用户行为序列
详见站内专题:用户画像
数据驱动
- 摘自:关于数据驱动增长的四个问题:是什么?为什么?有何用?怎么用?
- 数据驱动增长”在2015年开始在国内被人提及,作为“Growth Hacking”的一部分,伴随Growth Hacking概念的流行而逐渐被互联网行业的产品、运营、数据分析人员所接受。
“增长”是什么?
- 通常认为增长是提升DAU、PV、UV,最好的办法就是多引流量。然而事实是:只有“拉新”,没有“留存”的DAU/PV/UV提升不是增长!
- 只拉新不留存”的作死姿势
- 那增长该怎么定义?
- DAU、UV这样的指标属于“虚荣指标”,关注这些指标很容易误入歧途。
- 目前对“增长”最好的解释就是“AARRR”模型,在有的地方也被称为“海盗模型”

- ①获取。就是从搜索引擎、应用市场等渠道,获得产品的“访问新用户”。提升的目标要是:渠道的质量、数量、新用户比例等。
- ②激活。完成“体验完整产品”所需的所有前置操作,如注册、购买等,由“访问新用户”变成“使用用户”。
- ③留存。用户认同产品带给他的价值,持续使用产品。由“使用用户”变成“活跃用户”。
- ④变现。通过点击广告、流量售卖、服务付费等方式回收获客成本并盈利。提升的目标要是:付费转化率、客单价等。
- ⑤推荐。用户对产品的价值非常满意,并推荐他人使用。由“活跃用户”转变为“粉丝用户”。
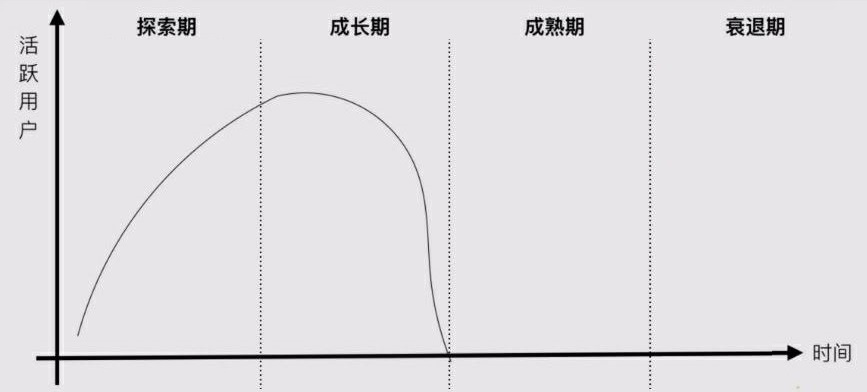
- 这5个核心指标共同构成了增长,5个指标在产品生命周期的不同阶段中有所侧重
- 探索期更关注“激活”和“留存”
- 增长期更关注“获取”和“推荐”
- 稳定期更关注“变现”。

数据能为增长带来什么
- “转化漏斗”和“留存图(表)”是分析增长数据不可或缺的2个基础工具,可以应用到AARRR模型的每个阶段。具体来说,可以用“转化漏斗”来衡量渠道质量、激活转化率、付费转化率、推荐转化率,可以用“留存图(表)”来衡量日/周/月的留存率。如图6。
- 这2个基本工具再结合下个小节提到的“用户分群”、“用户细查”等工具,可以让我们通过数据发现AARRR中每一步的提升空间和提升方法,这就是数据为增长带来的价值。

数据驱动增长需要什么样的工具
工欲善其事必先利其器,数据驱动增长需要有具备特定功能的工具。从上一小节可以看出,最常用到的数据工具是以下5个:
- ①转化漏斗。如图7。用于量化用户在某个功能的一组操作行为中,各个步骤的转化/流失情况,以及产品内各个功能的使用率。
- ②留存图(表)。如图8。用于分析7日留存、1月后周留存、1年后月留存等数据,可以通过它寻找留存率的提升空间、提升方法,检验产品优化方向的正确性等等。
- ③用户分群。通过用户行为筛选用户群体,达到标记重要功能的作用。
- ④用户细查。可以查看某个用户的所有点击和页面浏览行为,是进行定性研究的利器。
- ⑤来源管理。用于标记用户来源,进而可以分析各渠道的转化率、留存率、新用户占比等流量质量指标。
数据驱动增长的局限性
- 没有数据是万万不能的,但是数据也不是万能的!
- 数据驱动的2个局限性:
- ①数据很难启发重大创新。
- ②某些问题压根没有数据可供分析。
- 除了数据驱动之外,产品的优化一定还要依赖其他驱动力。
数据库
教程
【2023-12-16】数据库教程
在线写sql的网页,不用本地安装;
数据库分类
数据库按照数据结构来组织、存储和管理数据,实际上,数据库一共有三种模型:层次模型,网状模型,关系模型
- 层次模型:以“上下级”的层次关系来组织数据的一种方式,层次模型的数据结构看起来就像一颗树:
- 网状模型:把每个数据节点和其他很多节点都连接起来,它的数据结构看起来就像很多城市之间的路网:
- 关系模型:把数据看作是一个二维表格,任何数据都可以通过行号+列号来唯一确定,它的数据模型看起来就是一个Excel表:
随着时间的推移和市场竞争,最终,基于关系模型的关系数据库获得了绝对市场份额。
- (1)根据数据库的类型划分。
- 关系型数据库: mysql,oracle,sqlserver,postgresql等。
- nosql数据库: mongodb,hbase,cassandra,redis,CouchDB,Riak,Membase等。
- (2)根据数据库的用途划分。
- 缓存数据库:redis,memcached,h2db等
- 日志数据库:kahadb等。
- k-v型数据库:leveldb,redis等。
- (3)检索型存储中间件有:elasticsearch、solr、Lucene等。
NoSQL
NoSQL,主要有四大类型,不同类型适用于不同的存储需求场景:
- 键值数据库:Key-Value Database是一个哈希表,一个特定的值可以指定一个特定的内容(value)。key用来定位。value可以是任何类型。key可以无限扩展。典型代表是内存数据库Redis。
- 列族数据库:以列的形式存储数据,适合批量数据处理和即时查询,降低I/O开销,支持大量并发的用户查询。典型的代表是HBase。
- 文档数据库:文档数据库通过键值定位一个文档。可以看成是键值数据库的衍生品。典型代表产品MangoDB。
- 图数据库:存储有关网络的信息,是为了满足对象之间有很多关系的场景,用于处理具有高度相互关系的数据。比较适合设计网络,依赖分析,路径寻找,模糊识别等,典型代表产品Neo4j。
数据库选型
演变:
- 传统的关系型数据库(RDBMS)是用途最广泛也是用的最多的数据库。关系型数据库是强事物一致性(ACID),使用比较早,技术相对成熟,查询可以根据字段,以及表现各个数据对象之间的关系。在CAP理论中实现的是CA。没有P分区性,单点瓶颈是硬伤。
- 当关系型数据库越来越成为瓶颈时,为解决单点瓶颈牺牲CAP属性中的C,出现了nosql数据库。针对某些特殊的使用场景,出现了非关系型数据库。如:nosql,缓存等。以下针对不同的业务场景阐述各个数据库的特性。
对于数据库的选型,ACID是重要的考虑指标
- 如果对ACID要求很高,应该选择关系型数据库。
- 其次部分对一致性要求不高的,写并发非常大的可以考虑其他的nosql数据库。
- 但是有的业务并发非常高,对ACID要求也非常高,则对业务数据和数据库进行拆分
业务场景
- (1)读多写少
- 对于一般的量级,免费的关系型数据库mysql、postgresql是首选。支持事物,稳定性和成熟度比较好。
- 当访问量越来越大,数据量不大时。写不是瓶颈,而读成为主要瓶颈。改进方法:
- 主从分离:增加从库分担读的压力
- 加缓存:在数据库和应用系统之间加一层缓存 memcache,redis。增加缓存之后,能抗住很多压力,大大降低了数据库的读请求。
- (2)读多写多
- 高并发场景中,对数据库的操作往往提现在高并发读和高并发写。当读和写都成为瓶颈时,这时采用的方案有:
- 1)对数据库进行横向和纵向扩展。按业务划分,把一个数据库实例扩展成多个实例。按数据分片,把单表大数据量,水平分片成多个小表。
- 2)使用内存表负载压力。常见的内存表有:redis开启aof功能。业务数据要持久化落盘。否则进程一旦重启,内存数据就会丢失。
- 数据库举例
- redis:是有硬盘存储的内存数据库,可以支持Master-Slave复制,其可以提供并发量远高于关系型数据库。支持的数据结构:K-V,K-Sets,K-Queue,K-Hash。可适用于高并发读写业务场景,但局限于其数据结构,不能做复杂查询,只能以Key键值为基础数据结构操作。
- memcachedb:是基于memcache添加了BerkeleyDB存储机制和主辅复制而来。支持的数据结构只要K-V结构。可适用于高并发读写业务场景,同样只局限于其数据结构,不能做复杂查询,只能以Key键值为基础数据结构操作。
- MongoDB:支持Master-Salve复制,无schema,json结构。字段可以任意扩展,可以建立字段索引和全字段索引。可以对任意字段建立索引查询。数据量越来越大时,是吃内存的大户,数据一致性问题会越来越严重。如果对数据一致性要求不高的读多写多业务,可以考虑使用此数据库存储。
- (3)读少写多
- 海量数据的写入。如货车app中的gps路线轨迹数据,每天的写入库的数据量上亿条。如此巨大的写入量用关系型数据库显然是不合适的。关系型数据库虽然可以采用批量导入的方式增强写入能力,但其强制落盘,对磁盘IO是影响主要因素。cassandra和habase其先写内存,异步落盘机制对磁盘IO消耗更低。
- 数据库示例
- Cassandra:java开发,结构简单。其数据采用分片机制,副本备份与容错复制。面向列式存储。内存写入与异步刷盘的机制,使其在写操作远高于读操作场景中,也能轻松应对。
- HBASE:支持数十亿行,数百万列。对于海量数据的宽表,面向列式存储,无schema,可任意扩展列。
- (4)读少写少
- 在小系统,业务量低、数据量少的系统,对读写操作都比较少,当然是怎么快就怎么来。选用mysql免费数据库是最合适的选择。
- (5)复杂条件检索
- 关系型数据库通常使用b+tree索引,非关系型数据库如cassandra使用LSM结构索引。所有的索引多列复杂条件查询的检索效率远远低于索引引擎。
- 常用开源的搜索引擎有luence,solr,elasticsearch,sphinx等。
- solr:查询快,但是更新索引速度偏慢。主要应用于那种对数据的实时性要求不高的业务。
- elasticserach:更新速度比solr快,但是查询速度相对solr较慢。主要应用于实时索引查询的业务。
总结
- 1)对ACID有强要求业务一般使用的数据存储采用关系型数据库,如mysql,postgresql、oracle、sql server等。
- 2)读多写少的场景,使用非关系型数据库Cassandra、hbase、MongoDB等。
- 3)缓解高并发读对数据库造成的读瓶颈,使用缓存:memcached、redis等。
- 4)复杂的数据检索,使用外置索引:elasticsearch、solr等。
MySQL
python使用mysql方法
mysql安装方法
- 【2021-6-17】mysql官方下载,适配各种操作系统,含UI界面工具workbench
# 下载mysql包
# 解压,如果是tar.xz文件,使用xz -d命令解压
tar -xzvf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
# 创建用户和组
groupadd mysql
useradd -r -g mysql mysql
# 将安装目录所有者及所属组改为mysql
chown -R mysql.mysql /usr/local/mysql
# 创建data目录
mkdir data #进入mysql文件夹
#
yum install libaio
/usr/local/mysql/bin/mysqld --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data --initialize
连接mysql
shell 代码,shell脚本中调用sql脚本
#mysql初始化-shell
mysql=/usr/local/mysql/bin/mysql
$mysql -uroot -pwqw < init.sql
或者shell脚本中直接执行sql
mysql=/usr/local/mysql/bin/mysql
$mysql -uroot -p123456 <<EOF
source /root/temp.sql;
select current_date();
delete from tempdb.tb_tmp where id=3;
select * from tempdb.tb_tmp where id=2;
EOF
PostGreSQL
分析工具
excel数据分析
常用函数
常用的是文本函数,逻辑函数,日期与时间函数,查找与引用函数,数学函数等

相对引用于绝对引用:
- 相对引用:单元格或单元格区域的相对引用是指相对于包含公式的单元格的相对位置。例如,单元格 B2 包含公式 =A1 ;Excel 将在距单元格 B2 上面一个单元格和左面一个单元格处的单元格中查找数值。
- 绝对引用:1 乘以单元格 A2 (=A1*A2)放到A4中,现在将公式复制到另一单元格中,则 Excel 将调整公式中的两个引用。如果不希望这种引用发生改变,须在引用的”行号”和”列号”前加上美元符号($),这样就是单元格的绝对引用。A4中输入公式如下:
=$A$1*$A$2 复制A4中的公式到任何一个单元格其值都不会改变
【2021-11-18】Excel最常用函数介绍, 一篇说尽Excel常见函数用法
| 函数名 | 作用 | 用法 | 示例 |
|---|---|---|---|
| LEN | 统计文本字符串中字符数目(计算文本的长度) | LEN(text) | |
| SEARCH | 检索字符位置(不区分大小写) | SEARCH(find_text,within_text,start_num) | |
| FREQUENCY | 计算区间里所含数值的个数 | FREQUENCY(data_array,bins_array) | =FREQUENCY($C$19:$C$30,$E$19:$E$23) |
| INDEX | (数组形式)返回行和列交叉位置的值;(单元格引用方式)返回行和列交差位置的单元格引用 | INDEX(array,row_num,column_num) | |
| MATCH | 返回搜索值的相对位置 | MATCH(lookup_value,lookup_array,match_type) | MATCH(“b”,{“a”,”b”,”c”},0) |
| OFFSET | 计算指定位置的单元格引用 | OFFSET(reference,rows,cols,height,width) | =SUM(OFFSET(B5,6,2,1,2)) |
| MID | 文本字符串截取指定数目的子串 | MID(text, start_num, num_chars) |  |
| REPLACE | 替换 | =REPLACE( old_text , start_num , num_chars , new_text ) | |
| CONCATENATE(或&) | 单元格(文本、数字)连接 | CONCATENATE(text1,text2,……) |  |
| AND/OR/NOT | 条件是否都满足;可以IF配合使用;逻辑值或数值时,函数AND返回错误值#VALUE | AND(logical1,logical2,……logical30) |  |
| IF | 分支判断 | IF(logical_test,value_if_true,value_if_false) | 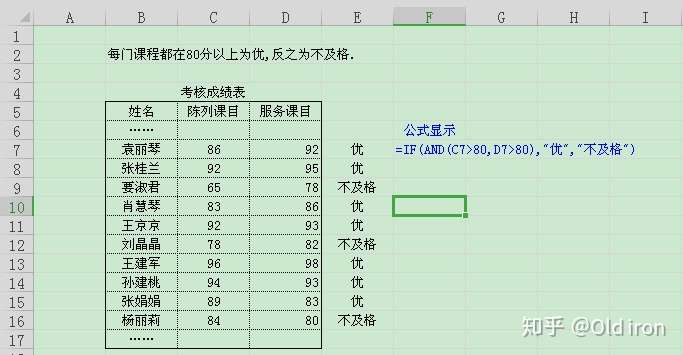 |
| IS | |||
| MIN/MAX | |||
| SUM/SUMIF | SUMIF ( range , criteria , sum_range ) | ||
| SUMPRODUCT | 数组点积(对应元素相乘) | ||
| DATEDIF | 计算期间内的年数、月数、天数 | =DATEDIF(start_date,end_date,”m”) |  |
| COUNTIF | 计算满足条件的单元格计数 | COUNTIF(range,criteria) |  |
| SUMIF | 对满足条件的单元格的数值求和 | SUMIF(range,criteria,sum_range) | =SUMIF($B$4:$B$14,”家居*”,$C$4:$C$14) |
| DCOUNT | 计算满足条件的数值的个数 | DCOUNT(database,field,criteria) |  |
| ISERROR | 查看是否为错误,查看是否值为任意错误值 | ISERROR(value) | |
| VLOOKUP | 按照垂直方向搜索区域 | VLOOKUP(lookup_value,table_array,col_index_num,range_lookup) |
COUNTIF函数几种用法:
- 求包含值139的单元格数量 ‘=COUNTIF($D$4:$D$14,139)
- 求包含负值的单元格数量 ‘=COUNTIF($C$4:$C$14,”<0”)
- 求不等于0 的单元格数量 ‘=COUNTIF($C$4:$C$14,”<>0”)
- 求大于等于5的单元格数量 ‘=COUNTIF($C$4:$C$14,”>=5”)
- 求等于单元格B45中内容的单元格数量 ‘=COUNTIF($B$4:$B$14,B4)
- 求大于单元格E45中内容的单元格数量 ‘=COUNTIF($E$4:$E$14,”>”&E4)
- 求包含文本内容的单元格数量 ‘=COUNTIF($B$4:$B$14,”*”)
- 求包含六个字符内容的单元格数量 ‘=COUNTIF($B$4:$B$14,”??????”)
- 求在文本中任何位置包含单词”文胸”字符内容的单元格数量 ‘=COUNTIF($B$4:$B$14,”文胸”)
- 求包含以英文”D”(不分大小写)开头内容的单元格数量 ‘=COUNTIF($B$4:$B$14,”D*”)
- 求包含当前日期的单元格数量 ‘=COUNTIF($E$4:$E$14,TODAY())
- 求大于平均值的单元格数量 ‘=COUNTIF($D$4:$D$14,”>”&AVERAGE($D$5:$D$14))
vlookup
loopup

使用格式:VLOOKUP(lookup_value,table_array,col_index_num,range_lookup)
参数定义:
- Lookup_value:为需要在数组第一列中查找的数值.Lookup_value可以为数值、引用或文本字符串.
- Table_array: 为需要在其中查找数据的数据表.可以使用对区域或区域名称的引用,例如数据库或列表.
- Col_index: 为table_array中待返回的匹配值的列序号. Col_index_num为1时,返回table_array第一列中的数值;col_index_num为2,返
- table_array第二列中的数值,以此类推.如果col_index_num小于1,函数VLOOKUP返回错误值值#VALUE!;如果col_index_num大于table_array的
- 数, 函数VLOOKUP返回错误值#REF!.
- Range_lookup:为一逻辑值,指明函数VLOOKUP返回时是精确匹配还是近似匹配.如果为TRUE或省略,则返回近似匹配值.也就是说.如果找不到精确匹配值,则返回小于lookup_value的最大数值;如果range_value为FALSE,函数VLOOKUP将返回精确匹配值.如果找不到,则返回错误值#N/A.
注意:
- 如果range_lookup为TRUE,则table_array的第一列中的数值必须按升序排列:…、 -2、-1、0、1、2、…、-Z、FALSE、TRUE;否则,函数VLOOKUP不能返回正确的数值.如果range_lookup为FALSE,table_array不必进行排序.
- Table_array的第一列中的数值可以为文本、数字或逻辑值.
- 文本不区分大小写.
- 如果函数VLOOKUP找不到lookup_value,且range_lookup为TRUE,则使用小于等于lookup_value的最大值.
- 如果lookup_value小于table_array第一列中的最小数值,函数VLOOKUP返回错误值#N/A.
- 如果函数VLOOKUP找不到lookup_value且range_lookup为FALSE,函数VLOOKUP返回错误值#N/A.
- 若有多个符合条件的情况:vlookup返回的是第一个满足条件的值,lookup返回的是最后一个满足条件的值.
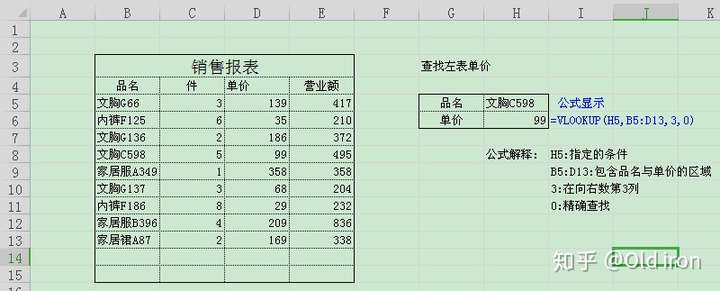
公式:=VLOOKUP(H5,B5:D13,3,0)
精确查找是vlookup最基本也是最常用的功能,对于数据量大的查找,其速度比菜单中的查找还快.设置vlookup第四个参数为false或0,即为精确查找.
爬虫
网页抓取
html→text
将 html格式 文件转换成 文本文件
- 直接使用BeautifulSoup的get_text方法
- 结合 BeautifulSoup+html2text 工具
- html.parser
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
print(soup.get_text()) # 不含换行符
print(soup.get_text('\n')) # 保留换行符
soup.get_text().replace('\n','\n\n') # To be identical to your example, you can replace a newline with two newlines
import html2text
from BeautifulSoup import BeautifulSoup
soup = BeautifulSoup(urllib2.urlopen('http://example.com/page.html').read())
txt = soup.find('div', {'class' : 'body'})
print(html2text.html2text(txt))
from html.parser import HTMLParser
class HTMLFilter(HTMLParser):
text = ""
def handle_data(self, data):
self.text += data
f = HTMLFilter()
f.feed(data)
print(f.text)
可视化爬虫
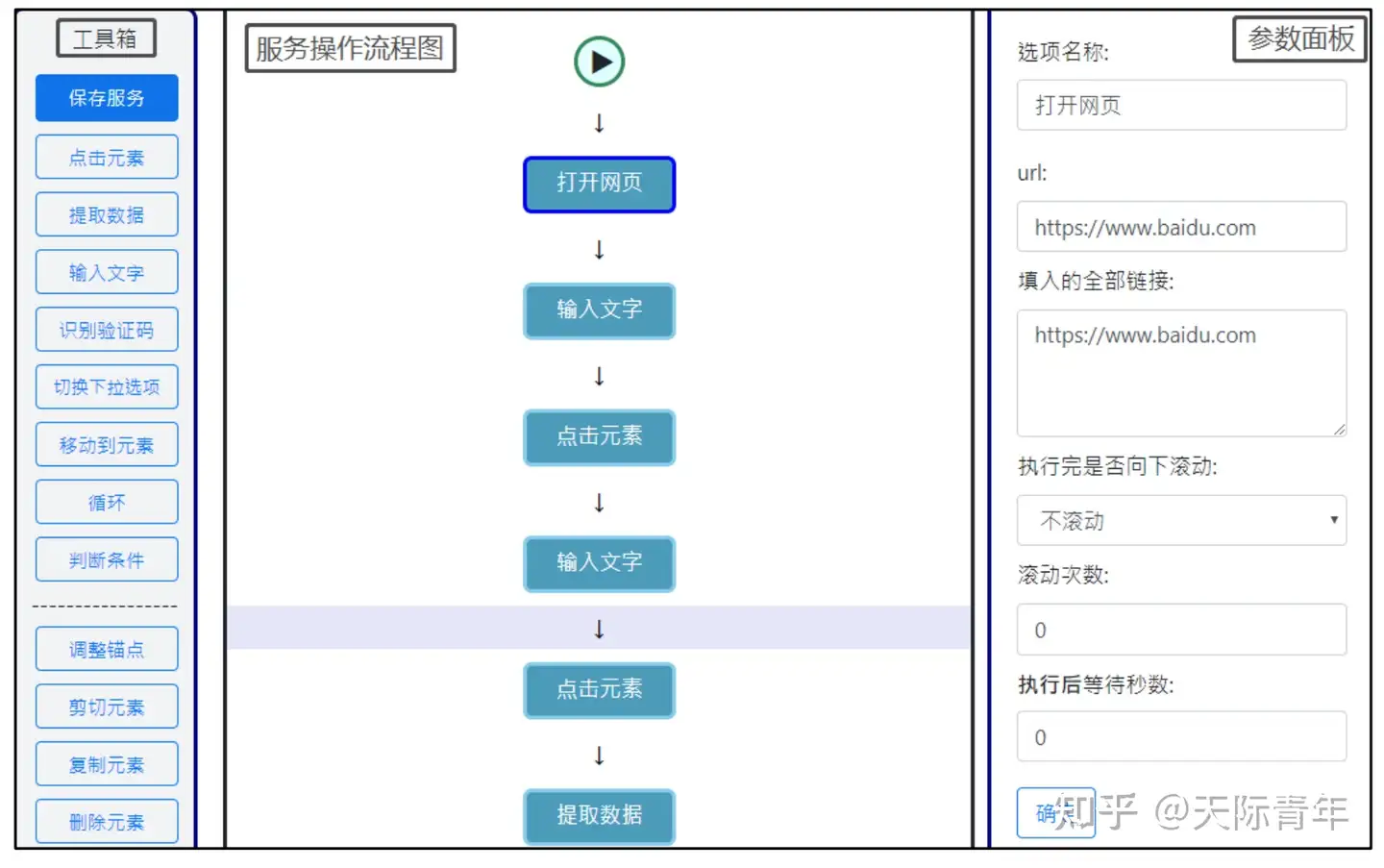
【2021-12-28】可视化爬虫工具:spider-flow,智能高效的在线爬虫,以流程图的方式定义爬虫
EasySpider
EasySpider 是一款完全免费和开源的可视化爬虫软件,此软件可以让大家使用图形化界面,无代码可视化的设计和执行爬虫任务。只需要在网页上选择自己想要爬的内容并根据提示框操作即可完成爬虫设计和执行。同时软件还可以直接在命令行中通过传参的方式执行,从而可以很方便的嵌入到其他系统中。
- github
- 下载图片,元素截图,执行任意JS指令和系统命令,通过JS代码进行条件判断,OCR识别等等功能,想要的功能应有尽有,而且这些功能完全免费
python抓取链接二手房数据
- 链家二手房数据分析
- scrapy爬链家成都房价并可视化
- 抓知乎爬虫
- 【2019-11-24】链家房源爬虫及可视化,github
模拟登录
cookie 与 session
cookie信息是保存在本地浏览器里面的,服务器上并不存储相关的信息。
- 在发送请求时,cookie的这些内容是放在 Http协议中的header 字段中进行传输的。
cookie不安全,所以有了session机制。
整过过程:
- 服务器根据用户名和密码,生成一个session ID,存储到服务器的数据库中。
- 用户登录访问时,服务器会将对应的session ID发送给用户(本地浏览器)。
- 浏览器会将这个session ID存储到cookie中,作为一个键值项。
- 以后,浏览器每次请求,就会将含有session ID的cookie信息,一起发送给服务器。
- 服务器收到请求之后,通过cookie中的session ID,到数据库中去查询,解析出对应的用户名,就知道是哪个用户的请求了。
总结
【2022-12-5】Python模拟登录的几种方法
- 方法一:直接使用已知的cookie访问
- 特点:简单,但需要先在浏览器登录
- 方法二:模拟登录后再携带得到的cookie访问
- 方法三:模拟登录后用session保持登录状态
- 方法四:使用无头浏览器访问
方法一:直接使用已知的cookie访问
特点:简单,但需要先在浏览器登录
原理:
- cookie保存在发起请求的客户端中,服务器利用cookie来区分不同的客户端。因为http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的。
- 只要得到了别的客户端的cookie,就可以假冒成它来和服务器对话。
操作
- 用浏览器登录,用开发者工具查看cookie。
- network选项卡。在左边的Name一栏找到当前的网址,选择右边的Headers选项卡,查看Request Headers,这里包含了该网站颁发给浏览器的cookie。
- 在程序中携带该cookie向网站发送请求,就能让程序假扮成刚才登录的那个浏览器,得到只有登录后才能看到的页面。
requests库的版本:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
# 登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
# 浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
# 把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
方法二:模拟登录后再携带得到的cookie访问
方法二:模拟登录后再携带得到的cookie访问
原理:
- 先在程序中向网站发出登录请求,提交包含登录信息的表单(用户名、密码等)。从响应中得到cookie,访问其他页面时也带上这个cookie,就能得到只有登录后才能看到的页面。
具体步骤:
- 找出表单提交到的页面
- 开发者工具, 转到network选项卡,并勾选Preserve Log(重要!)。在浏览器里登录网站。
- 然后在左边的Name一栏找到表单提交到的页面。
- 找出要提交的数据
- 虽然浏览器登陆时只填了用户名和密码,但表单里包含的数据可不只这些。从Form Data里就可以看到需要提交的所有数据。
requests库的版本:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
# 登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
# 浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
# 把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
# 设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
# 在发送get请求时带上请求头和cookies
resp = requests.get(url, headers = headers, cookies = cookies)
print(resp.content.decode('utf-8'))
方法三:模拟登录后用session保持登录状态
原理:
- session是会话的意思。和cookie的相似之处在于,它也可以让服务器“认得”客户端。
- 把每一个客户端和服务器的互动当作一个“会话”。既然在同一个“会话”里,服务器自然就能知道这个客户端是否登录过。
具体步骤:
- 找出表单提交到的页面
- 找出要提交的数据
这两步和方法二的前两步是一样的
写代码
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
# 登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
# 设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
# 登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal'
# 构造Session
session = requests.Session()
# 在session中发送登录请求,此后这个session里就存储了cookie
# 可以用print(session.cookies.get_dict())查看
resp = session.post(login_url, data)
# 登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
# 发送访问请求
resp = session.get(url)
print(resp.content.decode('utf-8'))
方法四:使用无头浏览器访问
特点:
- 功能强大,几乎可以对付任何网页,但会导致代码效率低
原理:
- 如果能在程序里调用一个浏览器来访问网站,那么像登录这样的操作就轻而易举了。
- 在Python中可以使用 Selenium库 来调用浏览器,写在代码里的操作(打开网页、点击……)会变成浏览器忠实地执行。这个被控制的浏览器可以是Firefox,Chrome等,但最常用的还是 PhantomJS 这个无头(没有界面)浏览器。
- 只要把填写用户名密码、点击“登录”按钮、打开另一个网页等操作写到程序中,PhamtomJS就能确确实实地让你登录上去,并把响应返回给你。
具体步骤:
- 安装selenium库、PhantomJS浏览器
- 在源代码中找到登录时的输入文本框、按钮这些元素
- 因为要在无头浏览器中进行操作,所以就要先找到输入框,才能输入信息。找到登录按钮,才能点击它。
- 在浏览器中打开填写用户名密码的页面,将光标移动到输入用户名的文本框,右键,选择“审查元素”,就可以在右边的网页源代码中看到文本框是哪个元素。同理,可以在源代码中找到输入密码的文本框、登录按钮。
- 考虑如何在程序中找到上述元素
import requests
import sys
import io
from selenium import webdriver
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') #改变标准输出的默认编码
# 建立Phantomjs浏览器对象,括号里是phantomjs.exe在你的电脑上的路径
browser = webdriver.PhantomJS('d:/tool/07-net/phantomjs-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe')
# 登录页面
url = r'http://ssfw.xmu.edu.cn/cmstar/index.portal'
# 访问登录页面
browser.get(url)
# 等待一定时间,让js脚本加载完毕
browser.implicitly_wait(3)
# 输入用户名
username = browser.find_element_by_name('user')
username.send_keys('学号')
# 输入密码
password = browser.find_element_by_name('pwd')
password.send_keys('密码')
# 选择“学生”单选按钮
student = browser.find_element_by_xpath('//input[@value="student"]')
student.click()
#点击“登录”按钮
login_button = browser.find_element_by_name('btn')
login_button.submit()
# 网页截图
browser.save_screenshot('picture1.png')
# 打印网页源代码
print(browser.page_source.encode('utf-8').decode())
browser.quit()
文件下载
wget
windows版 wget
- Windows系统使用wget批量下载NASA遥感数据
- wget批量下载txt文件内的所有链接
# windows 终端命令
wget --load-cookies C:\.urs_cookies --save-cookies C:\.urs_cookies --auth-no-challenge=on --keep-session-cookies --user=<your username> --ask-password --content-disposition -i myfile.dat
wget 包
- 用 pip 安装这个包
- 实际下载只有一行
- wget.download(url, path) ,只有两个参数,第一个是网址,第二个是存放路径。
- 如果下载网址有规律的话,使用一个 for 循环就能批量下载了。
import wget
import tempfile
url = 'https://p0.ifengimg.com/2019_30/1106F5849B0A2A2A03AAD4B14374596C76B2BDAB_w1000_h626.jpg'
# 获取文件名
file_name = wget.filename_from_url(url)
print(file_name) #1106F5849B0A2A2A03AAD4B14374596C76B2BDAB_w1000_h626.jpg
# ① 下载文件,使用默认文件名,结果返回文件名
file_name = wget.download(url)
print(file_name) #1106F5849B0A2A2A03AAD4B14374596C76B2BDAB_w1000_h626.jpg
# ② 下载文件,重新命名输出文件名
target_name = 't1.jpg'
file_name = wget.download(url, out=target_name)
print(file_name) #t1.jpg
# ③ 创建临时文件夹,下载到临时文件夹里
tmpdir = tempfile.gettempdir()
target_name = 't2.jpg'
file_name = wget.download(url, out=os.path.join(tmpdir, target_name))
print(file_name) #/tmp/t2.jpg
#===============
# 批量下载 pdf
import wget
path = 'D:\Desktop'
for i in range(1,20):
if i < 10:
new_i = "0"+str(i) # 如果是单个数字,前面加零
else:
new_i = str(i)
url = f'https://see.stanford.edu/materials/lsocoee364a/transcripts/ConvexOptimizationI-Lecture{new_i}.pdf'
wget.download(url, path)
requests
单个文件下载
#引用 requests文件
import requests
Download_addres='' # 下载地址
# 把下载地址发送给requests模块
f=requests.get(Download_addres)
# 下载文件
with open("12.xlsx","wb") as code:
code.write(f.content)
多文件下载
批量文件下载
- excel文档中,保存url和文件名/编号。
- request读取网页内容,filetype判断文件类型,批量下载保存。
需要安装filetype包:pip install filetype
# -*- coding: utf-8 -*-
"""
Created on Mon Feb 22 10:24:35 2021
@author: wangqiwen
"""
import requests
import pandas as pd
import filetype
myHeaders = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"}
# 定义文件下载函数 downloadFile
def downloadFile(url,savePath):
# 将网页链接 url,文件夹路径 savePath 作为参数传入
try:
webPage = requests.get(url, headers = myHeaders, timeout=5)
#print(webPage.status_code)
# 获取网页
webContent = webPage.content
# 网页内容
file_type = filetype.guess(webContent).extension
# 识别文件类型
#print(file_type)
file_path = savePath + fileId + '.' + file_type
# 根据文件夹路径、文件名id、文件类型,组合文件保存路径
f = open(file_path, 'wb')
f.write(webContent)
# 将网页内容写入保存路径中
f.close()
except requests.exceptions.RequestException:
print(fileId + '超时')
# 读取excel表格
data = pd.read_excel(r'D:\保存url和文件编号的文档.xlsx')
#data = pd.read_excel(r'D:\保存url和文件编号的文档.xlsx', sheet_name='abc')
# 下载文件保存文件夹
savePath = 'D:/文件下载/'
for i in data.index:
fileId = str(data.loc[i, '编号'])
url = str(data.loc[i, 'url'])
if url == 'nan':
continue
else:
downloadFile(url,savePath)
带进度条
实现分段、连续下载文件。
import requests
# 文件下载直链
url = 'https://issuecdn.baidupcs.com/issue/netdisk/yunguanjia/BaiduNetdisk_7.2.8.9.exe'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
# 发起 head 请求,即只会获取响应头部信息
head = requests.head(url, headers=headers)
# 文件大小,以 B 为单位
file_size = head.headers.get('Content-Length')
if file_size is not None:
file_size = int(file_size)
response = requests.get(url, headers=headers, stream=True)
# 一块文件的大小
chunk_size = 1024
# 记录已经读取的文件大小
read = 0
for chunk in response.iter_content(chunk_size=chunk_size):
read += chunk_size
read = min(read, file_size)
print(f'已读取: {read} 总大小: {file_size}')
但是输出显然太多了,有一个单行的进度条更好。 tqdm 这个进度条库
import time
from tqdm import tqdm
total = 100
for _ in tqdm(range(total)):
time.sleep(0.1)
# ---- 自定义进度更新次数 ----
# 每次刷新的进度
step = 10
# 总共要刷新的次数
flush_count = total//step
bar = tqdm(total=total)
for _ in range(flush_count):
time.sleep(0.1)
bar.update(step)
bar.close()
下载进度条
import requests
# 导入 tqdm
from tqdm import tqdm
# 文件下载直链
url = 'https://issuecdn.baidupcs.com/issue/netdisk/yunguanjia/BaiduNetdisk_7.2.8.9.exe'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
file_name = 'BaiduNetdisk_7.2.8.9.exe'
# 发起 head 请求,即只会获取响应头部信息
head = requests.head(url, headers=headers)
# 文件大小,以 B 为单位
file_size = head.headers.get('Content-Length')
if file_size is not None:
file_size = int(file_size)
response = requests.get(url, headers=headers, stream=True)
# 一块文件的大小
chunk_size = 1024
bar = tqdm(total=file_size, desc=f'下载文件 {file_name}')
with open(file_name, mode='wb') as f:
# 写入分块文件
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
bar.update(chunk_size)
# 关闭进度条
bar.close()
多线程
multitasking 工具
import time
# 导入用于多线程操作的库
# 这样子仅需要在自定义的函数前面使用装饰器即可将函数开启新的线程
import multitasking
import signal
# 按快捷键 ctrl + c 终止已开启的全部线程
signal.signal(signal.SIGINT, multitasking.killall)
# 多线程装饰器
@multitasking.task
def say(number: int):
print(number)
time.sleep(0.5)
start_time = time.time()
for i in range(5):
say(i)
# 等待全部线程执行完毕
multitasking.wait_for_tasks()
end_time = time.time()
print('耗时:', end_time-start_time, '秒')
带进度条的多线程下载器
from __future__ import annotations
from tqdm import tqdm # 用于显示进度条
import requests # 用于发起网络请求
import multitasking # 用于多线程操作
import signal
# 导入 retry 库以方便进行下载出错重试
from retry import retry
signal.signal(signal.SIGINT, multitasking.killall)
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
# 定义 1 MB 多少为 B
MB = 1024**2
def split(start: int, end: int, step: int) -> list[tuple[int, int]]:
# 分多块
parts = [(start, min(start+step, end))
for start in range(0, end, step)]
return parts
def get_file_size(url: str, raise_error: bool = False) -> int:
'''
获取文件大小
url : 文件直链
raise_error : 如果无法获取文件大小,是否引发错误
------
文件大小(B为单位), 如果不支持则会报错
'''
response = requests.head(url)
file_size = response.headers.get('Content-Length')
if file_size is None:
if raise_error is True:
raise ValueError('该文件不支持多线程分段下载!')
return file_size
return int(file_size)
def download(url: str, file_name: str, retry_times: int = 3, each_size=16*MB) -> None:
'''
根据文件直链和文件名下载文件
----------
url : 文件直链
file_name : 文件名
retry_times: 可选的,每次连接失败重试次数
'''
f = open(file_name, 'wb')
file_size = get_file_size(url)
@retry(tries=retry_times)
@multitasking.task
def start_download(start: int, end: int) -> None:
'''
根据文件起止位置下载文件
----------
start : 开始位置
end : 结束位置
'''
_headers = headers.copy()
# 分段下载的核心
_headers['Range'] = f'bytes={start}-{end}'
# 发起请求并获取响应(流式)
response = session.get(url, headers=_headers, stream=True)
# 每次读取的流式响应大小
chunk_size = 128
# 暂存已获取的响应,后续循环写入
chunks = []
for chunk in response.iter_content(chunk_size=chunk_size):
# 暂存获取的响应
chunks.append(chunk)
# 更新进度条
bar.update(chunk_size)
f.seek(start)
for chunk in chunks:
f.write(chunk)
# 释放已写入的资源
del chunks
session = requests.Session()
# 分块文件如果比文件大,就取文件大小为分块大小
each_size = min(each_size, file_size)
# 分块
parts = split(0, file_size, each_size)
print(f'分块数:{len(parts)}')
# 创建进度条
bar = tqdm(total=file_size, desc=f'下载文件:{file_name}')
for part in parts:
start, end = part
start_download(start, end)
# 等待全部线程结束
multitasking.wait_for_tasks()
f.close()
bar.close()
if "__main__" == __name__:
# url = 'https://mirrors.tuna.tsinghua.edu.cn/pypi/web/packages/0d/ea/f936c14b6e886221e53354e1992d0c4e0eb9566fcc70201047bb664ce777/tensorflow-2.3.1-cp37-cp37m-macosx_10_9_x86_64.whl#sha256=1f72edee9d2e8861edbb9e082608fd21de7113580b3fdaa4e194b472c2e196d0'
url = 'https://issuecdn.baidupcs.com/issue/netdisk/yunguanjia/BaiduNetdisk_7.2.8.9.exe'
file_name = 'BaiduNetdisk_7.2.8.9.exe'
# 开始下载文件
download(url, file_name)
json使用
shell中使用json
- #[2016-12-31] shell中使用json
- 安装:
pip install git+https://github.com/dominictarr/JSON.sh#egg=JSON.sh
- 使用:
echo '{"a":2,"b":[3,6,8]}' |JSON.sh详情参考:https://github.com/dominictarr/JSON.sh
Python工具包
命令:
- mysql -h10.26.21.38 -utest -p123
两个工具包:
- MySQLdb:MySQLdb(MySQL-python)仅支持python2
- pymysql:MySQL-python不支持py3,可以pip install pymysql代替
要想使python可以操作mysql,就需要MySQL-python驱动,它是python 操作mysql必不可少的模块。
- 下载地址
- 下载MySQL-python-1.2.5.zip 文件之后直接解压。
- 进入MySQL-python-1.2.5目录:
python setup.py install
#!pip install mysqldb
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "test123", "TESTDB", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 使用execute方法执行SQL语句
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取一条数据
data = cursor.fetchone()
print("Database version : %s " % data)
# 关闭数据库连接
db.close()
【2021-7-8】pymysql使用教程
import pymysql
# 连接database
conn = pymysql.connect(
host='10.26.21.38',
user='test',password='123456',
#database='test',
charset='utf8')
# 得到一个可以执行SQL语句的光标对象
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
# 得到一个可以执行SQL语句并且将结果作为字典返回的游标
#cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 定义要执行的SQL语句
sql = """
CREATE TABLE USER1 (
id INT auto_increment PRIMARY KEY ,
name CHAR(10) NOT NULL UNIQUE,
age TINYINT NOT NULL
)ENGINE=innodb DEFAULT CHARSET=utf8; #注意:charset='utf8' 不能写成utf-8
"""
#============= 查询数据 ========
sql = "select * from nlp_data_collection.t_intention limit 10"
res = cursor.execute(sql) # 执行SQL语句,只返回条数
print(res)
#cursor.scroll(1,mode='absolute') # 相对绝对位置移动,第一个参数是相对绝对位置移动的记录条个数
# cursor.scroll(1,mode='relative') # 相对当前位置移动,第一个参数是相对当前位置移动的记录条个数
#通过fetchone、fetchmany、fetchall拿到查询结果
res1=cursor.fetchone() #以元组的形式,返回查询记录的结果,默认是从第一条记录开始查询
# res2=cursor.fetchone() #会接着上一次的查询记录结果继续往下查询
# res3=cursor.fetchone()
# res4=cursor.fetchmany(2) #查询两条记录会以元组套小元组的形式进行展示
res5=cursor.fetchall()
print(res5)
#============= 插入数据 ========
# 获取一个光标
cursor = conn.cursor()
# 定义要执行的sql语句
sql = 'insert into userinfo(user,pwd) values(%s,%s);'
data = [
('july', '147'),
('june', '258'),
('marin', '369')
]
# 拼接并执行sql语句
rows = cursor.execute(sql,data[0]) # 单条语句
cursor.executemany(sql, data) # 多条语句
print(cursor.lastrowid) # 当前插入的第一条记录
conn.commit() # 涉及写操作要注意提交
#============= 删除数据 ========
cursor = conn.cursor() # 获取一个光标
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
cursor.execute(sql, [name]) # 拼接并执行SQL语句
conn.commit() # 涉及写操作注意要提交
#============= 更改数据 ========
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "update userinfo set pwd=%s where user=%s;"
# 拼接并执行SQL语句
cursor.execute(sql, ["july", "july"])
conn.commit() # 涉及写操作注意要提交
cursor.close() # 关闭光标对象
conn.close() # 关闭数据库连接
大数据分析
- Hadoop 是基础,其中的HDFS提供文件存储,Yarn进行资源管理。在这上面可以运行MapReduce、Spark、Tez等计算框架。
- MapReduce 是一种离线计算框架,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。
- Spark : Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
- Storm : MapReduce也不适合进行流式计算、实时分析,比如广告点击计算等。Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域
- Tez : 是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间
技术工具

大数据的计算引擎分成了 4 代。
- 第一代计算引擎,无疑是Hadoop MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。上层应用需要自己手写map任务和reduce任务。
- 第一代框架基于简单的 Map Reduce 模型,计算框架和运算的基础是分布式文件系统 HDFS 和分布式资源管理系统 一起被创建出来。
- 第二代计算引擎,支持 DAG(有向无环图) 的框架: Tez ,主要还是批处理任务
- Spark沿用现有的分布式文件系统和分布式资源管理系统,在计算模型方面有很大的创新。
- 第三代计算引擎,以 Spark 为代表,特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。
- 第四代计算引擎,以Flink、Blink为代表,一统批流,支持DAG运算,并具备进一步的实时性。
大数据技术漫谈 ——从Hadoop、Storm、Spark、HBase到Hive、Flink、Lindorm
离线计算历史演进
离线计算就是在计算开始前已知所有输入数据,输入数据不会产生变化。离线计算领域主要有Hadoop MapReduce、Spark、Hive/ODPS等计算框架。
- Hadoop MapReduce进行数据处理,需要用java、python等语言进行开发调试,分别编写Map、Reduce函数,并需要开发者自己对于Map和Reduce过程做性能优化,开发门槛较高,计算框架提供给开发者的助益并不多。在性能优化方面,常见的有在做小表跟大表关联的时候,可以先把小表放到缓存中(通过调用MapReduce的api),另外可以通过重写Combine跟Partition的接口实现,压缩从Map到reduce中间数据处理量达到提高数据处理性能。
- Spark 基于内存计算的准MapReduce,在离线数据处理中,一般使用Spark SQL进行数据清洗,目标文件一般是放在HDFS或者NFS上。
- Hive 是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析与管理。Hive在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce,从而降低了数据开发的门槛。
目前业内离线数据处理,阿里的Odps平台(阿里内部的离线处理平台)底层利用自己的一套Hadoop集群每天提供PB级的数据处理,华为目前还是在基于Hadoop集群云化ETL处理数据,而字节跳动的数据平台在离线计算方向也主要运用Hive。
综合来看,Hive的学习成本最低,各大公司应用最广泛。
流式计算历史演进
目前主流的流式计算框架有Storm/Jstorm、Spark Streaming、Flink/Blink三种。
- Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有最高的摄取率。在Storm中,需要先设计一个实时计算结构,我们称之为拓扑(topology)。之后,这个拓扑结构会被提交给集群,其中主节点(master node)负责给工作节点(worker node)分配代码,工作节点负责执行代码。在一个拓扑结构中,包含spout和bolt两种角色。数据在spouts之间传递,这些spouts将数据流以tuple元组的形式发送;而bolt则负责转换数据流。Jstorm则是阿里巴巴使用Java语言复刻的Apache Storm,号称性能四倍于Apache Storm,于2016年停止更新。
- Spark Streaming,即核心Spark API的扩展,不像Storm那样一次处理一个数据流。相反它在处理数据流之前,会按照时间间隔对数据流进行分段切分。Spark针对连续数据流的抽象,我们称为DStream(Discretized Stream)。DStream是小批处理的RDD(弹性分布式数据集),RDD则是分布式数据集,可以通过任意函数和滑动数据窗口(窗口计算)进行转换,实现并行操作。
- Apache Flink是针对流数据+批数据的计算框架。把批数据看作流数据的一种特例,延迟性较低(毫秒级),且能够保证消息传输不丢失不重复。Flink创造性地统一了流处理和批处理,作为流处理看待时输入数据流是无界的,而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。Flink程序由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
三种计算框架的对比如下
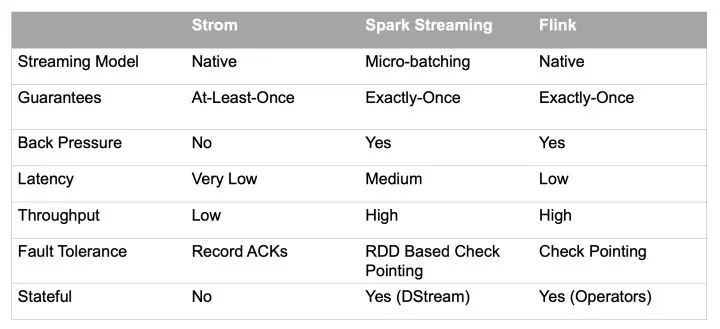 Flink/Blink是当前流式计算领域的主流框架
Flink/Blink是当前流式计算领域的主流框架
列式存储NOSQL数据库历史演进
NOSQL的概念博大精深,有键值(Key-Value)数据库、面向文档(Document-Oriented)数据库、列存储(Wide Column Store/Column-Family)数据库、图(Graph-Oriented)数据库等,主要讲述列存储数据库中最流行的HBase及其替代品Lindorm。
- HBase 是一个基于HDFS的、分布式的、面向列(列族)的非关系型数据库(NOSQL)。HBase巧妙地将大而稀疏的表放在商用的服务器集群上,单表可以有十亿行百万列,而且可以通过线性方式从下到上增加节点来进行横向扩展,读写性能优秀,支持批量导入,无需分库分表,存储计算分离,成本低,弹性好。
- Lindorm 是新一代面向在线海量数据处理的分布式数据库,适用于任何规模、多种模型的云原生数据库服务,其基于存储计算分离、多模共享融合的云原生架构设计,具备弹性、低成本、稳定可靠、简单易用、开放、生态友好等优势。
总体来说,Lindorm是HBase的升级版本,性能和稳定性等等通通优于HBase,如果需要使用海量数据提供在线服务,可以考虑Lindorm。
大数据开发语言历史演进
Scala语言曾是大数据开发的宠儿,行业内热度最高的消息中间件kafka就是使用Scala写就的,而大数据领域杀手级框架Spark也是由Scala编写的。另外,Scala语言函数式编程风格、天然适合处理大规模数据的Lambda表达式、简洁优雅的语法糖、陡峭的学习曲线也深受对代码美感有极致追求的程序员所喜爱。
- 曾经,Kafka + Scala + Spark + Spark Streaming的技术体系可以通吃批处理和流处理,直到一统批流、学习曲线也更平缓的Flink/Blink出现,彻底打破了这个局面,SQL语言在大数据处理中的占比大大提高。 当前,大数据开发语言可谓百花齐放、各领风骚。
- SQL语言(编写Flink/Blink、Hive任务)在数据仓库建设和数据分析领域应用广泛
- JVM语系(Java、Scala为主)在Hadoop生态中举足轻重并且是数据平台开发的首选
- Python在人工智能方向极为受宠
- R语言则是数据建模和数据可视化的利器。 每种语言都有自己的适用场景,建议根据自身的工种和兴趣来做选择。
建议学习的大数据组件:
- 1)流式、实时计算:Flink
- 2)离线计算:Hive
- 3)列式存储NOSQL数据库:Lindorm
Hadoop
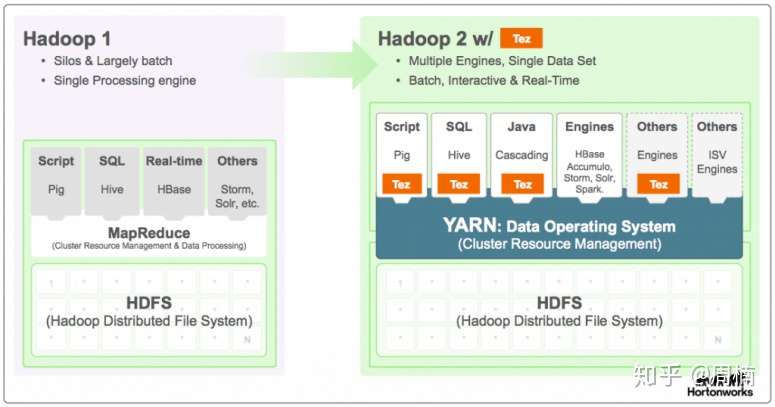
- Hadoop1到Hadoop2所做的改变,Hadoop1主要使用MapReduce引擎,到了Hadoop2,基于yarn,可以部署spark,tez等计算引擎,这里MapReduce作为一种引擎实现用的越来越少了,但是作为框架思路,tez本身也是MapReduce的改进。
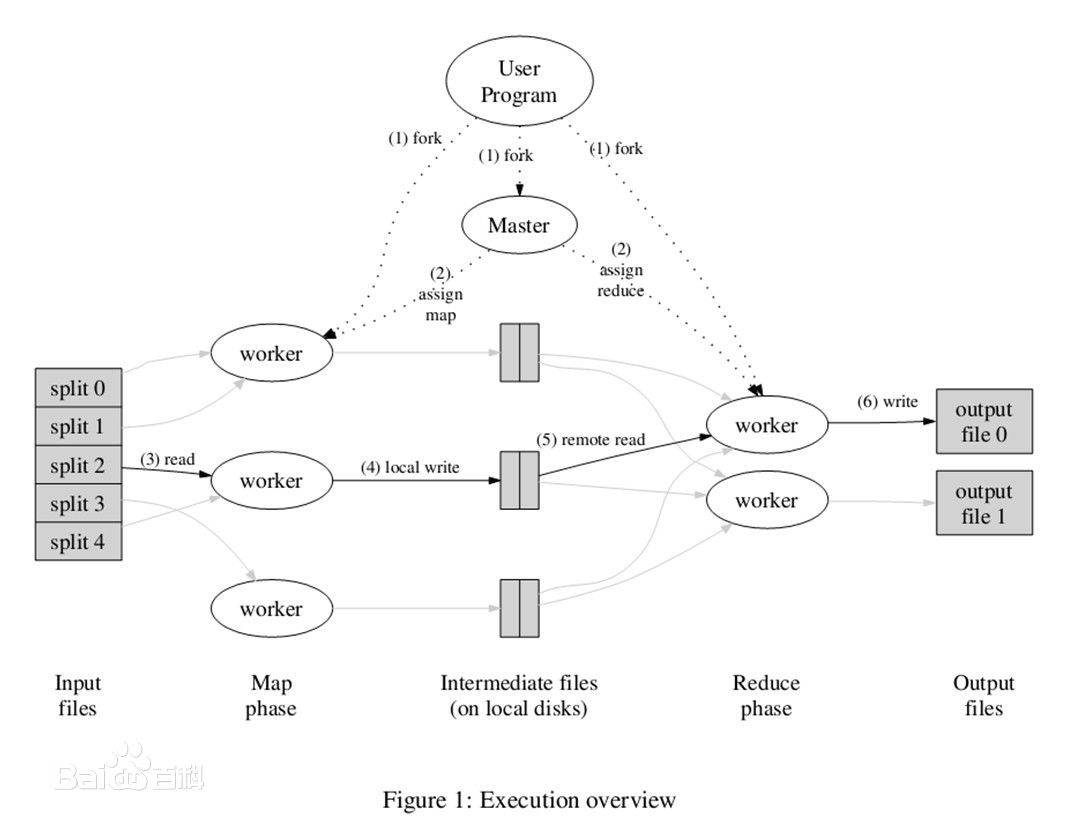
- MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”。
Hadoop 资讯
数据湖
【2021-10-27】抛弃Hadoop,数据湖才能重获新生, 十年前,Hadoop 是解决大规模数据分析的“白热化”方法,如今却被企业加速抛弃。曾经顶级的 Hadoop 供应商都在为生存而战,Cloudera于本月完成了私有化过程,黯然退市。MapR 被 HPE 收购,成为 HPE Ezmeral 平台的一部分,该平台尚未在调查中显示所占据的市场份额。
从数据湖方向发力的 Databricks,却逃脱了“过时”的命运,于今年宣布获得 16 亿美元的融资。另一个大数据领域的新星——云数仓 Snowflake,去年一上市就创下近 12 年来最大 IPO 金额,成为行业领跑者。
行业日新月异,十年时间大数据的领导势力已经经历了一轮更替。面对新的浪潮,我们需要做的是将行业趋势和技术联系起来,思考技术之间的关联和背后不变的本质。
百度Hadoop
【2013-1-25】李彦宏的“罪己诏”
Hadoop之前,百度也曾开发自己的 GFS+MapReduce+BigTable
- 没错,百度想要开发的系统就是基于Google那三篇著名的论文的2。
- 这个系统叫做
Pyramid,其领衔人是王选的高徒阳振坤博士。 Pyramid大约开发了2-3年,最终以失败告终,据说最后与HadoopPK时, 完败下来,阳振坤也在其后离职加盟淘宝
不知道Google开发GFS+MapReduce+BigTable用了多久,但是GFS论文是2003年,MapReduce论文是2004年,BigTable应该是2007年,想来Google应该也是开发了4-6年左右的时间。
- Pyramid的失败直接导致了Hadoop在百度的崛起,不到两年,Hadoop的机器数量从无到有,很快就突破了万台的规模,并且机房也从北京开始像长三角扩展,百度也终于迈出了跨数据中心的步子,尽管这个步伐似乎比Google慢了5-8年4?
不过百度虽然Hadoop用得很High,负载什么的,报表都弄得不错,集群规模也上了国内少有的3000+台,但是却很少对Hadoop社区进行开源回馈。
- 其内部Hadoop是基于Hadoop 0.19-0.20改进的。
- 好处就是快,一方面依赖社区拿到已有的代码基,整合测试就可上线,同时也不用管什么伦理道德奉献回馈的鸟事
- 但其缺点是内部Hadoop和官方Hadoop会逐渐越走越远,上游的Patch和改进越到后来会越难引进合并。
- 结果就是和社区分离,用自己一人之力对抗全球智慧,最终只能自讨苦吃。
- 有一次内部年会上,有位工程师跳起来问,“公司可不可以做一些开源的产品呢?很多东西本来就是从外边拿过来的。”
- 只记得当时台上的两位高管,其中一位女高管脸色稍变,过了一会又开始讲什么“做开源需要时间精力;好的东西才好意思开源出去,否则会丢脸”。
- 一个IT公司有没有勇气拥抱开源,是一个公司是否对自己的技术有足够自信的一个表现。在这方面,百度乏陈可善,不但没有代码,连论文也很少。而淘宝在
章文嵩带领下,其开源已经做的如火如荼,算是国内IT企业中开源做的最好的一个。
三驾马车
【2022-2-8】Google 引爆大数据时代的三篇论文-《GFS》、《BigTable》、《MapReduce》
大数据起源于– 谷歌于2003年起发布一系列论文(大数据三驾马车):
- 《The Google File System 》
- 《MapReduce: Simplified Data Processing on Large Clusters》在大型集群中简化数据处理
- 《Bigtable: A Distributed Storage System for Structured Data》结构化数据的分布式存储系统
1. GFS
- GFS 是一个大型的分布式文件系统。一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。
- 为 Google 大数据处理系统提供海量存储,并且与 MapReduce 和 BigTable 等技术结合得十分紧密,处于系统的底层。
- GFS 的系统架构如图 所示,主要由一个 Master Server(主服务器)和多个 Chunk Server(数据块服务器)组成。
- Master Server 主要负责维护系统中的名字空间,访问控制信息,从文件到块的映射及块的当前位置等元数据,并与 Chunk Server 通信。
- Chunk Server 负责具体的存储工作。数据以文件的形式存储在 Chunk Server 上。Client 是应用程序访问 GFS 的接口。
- Master Server 的所有信息都存储在内存里,启动时信息从 Chunk Server 中获取。这样不但提高了 Master Server 的性能和吞吐量,也有利于 Master Server 宕机后把后备服务器切换成 Master Server。
GFS 的系统架构设计有两大优势。
Client 和 Master Server 之间只有控制流,没有数据流,因此降低了 Master Server 的负载。 由于 Client 与 Chunk Server 之间直接传输数据流,并且文件被分成多个 Chunk 进行分布式存储,因此 Client 可以同时并行访问多个 Chunk Server,从而让系统的 I/O 并行度提高。
- Chunk Server 在硬盘上存储实际数据。Google 把每个 chunk 数据块的大小设计成 64MB,每个 chunk 被复制成 3 个副本放到不同的 Chunk Server 中,以创建冗余来避免服务器崩溃。如果某个 Chunk Server 发生故障,Master Server 便把数据备份到一个新的地方。
- HDFS (Hadoop Distributed File System)最早是根据 GFS(Google File System)的论文概念模型来设计实现的。
- HDFS 参照了它所以大部分架构设计概念是类似的,比如 HDFS NameNode 相当于 GFS Master,HDFS DataNode 相当于 GFS chunkserver。
2、MapReduce
GFS 解决了 Google 海量数据的存储问题,MapReduce 则是为了解决如何从这些海量数据中快速计算并获取期望结果的问题。
MapReduce 是由 Google 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。
MapReduce 实现了 Map 和 Reduce 两个功能。Map 把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集,而 Reduce 是把两个或更多个 Map 通过多个线程、进程或者独立系统进行并行执行处理得到的结果集进行分类和归纳。
用户只需要提供自己的 Map 函数及 Reduce 函数就可以在集群上进行大规模的分布式数据处理。与传统的分布式程序设计相比,MapReduce 封装了并行处理、容错处理、本地化计算、负载均衡等细节,具有简单而强大的接口。正是由于 MapReduce 具有函数式编程语言和矢量编程语言的共性,使得这种编程模式特别适合于非结构化和结构化的海量数据的搜索、挖掘、分析等应用。
Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。hive是用于OLAP,提供类sql语言的分析与计算的框架,底层就是MR。
3、BigTable
BigTable 是 Google 设计的分布式数据存储系统,是用来处理海量数据的一种非关系型数据库。BigTable 是一个稀疏的、分布式的、持久化存储的多维度排序的映射表。
BigTable 的设计目的是能够可靠地处理 PB 级别的数据,并且能够部署到上千台机器上。
BigTable 开发团队确定了 BigTable 设计所需达到的几个基本目标。
- 广泛的适用性(要满足一系列 Google 产品而并非特定产品的存储要求。)
- 很强的可扩展性(根据需要随时可以加入或撤销服务器。)
- 高可用性(确保几乎所有的情况下系统都可用。对于客户来说,有时候即使短暂的服务中断也是不能忍受的。)
- 简单性(底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来了便利。)
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
- HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
Hadoop架构
hadoop分为几大部分:
- yarn负责资源和任务管理
- hdfs负责分布式存储
- map-reduce负责分布式计算
- Map-reduce依赖于yarn和hdfs
hadoop虽然有多个模块分别部署,但是所需要的程序都在同一个tar包中,所以不同模块用到的配置文件都在一起,几个最重要的配置文件:
- 各种默认配置:core-default.xml, hdfs-default.xml, yarn-default.xml, mapred-default.xml
- 各种web页面配置:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml
还有一些重要的配置:hadoop-env.sh、mapred-env.sh、yarn-env.sh,用来配置程序运行时的java虚拟机参数以及一些二进制、配置、日志等的目录配置
- Hadoop:是一个分布式计算的开源框架
- HDFS:是Hadoop的三大核心组件之一
- HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。
- Hive与Hbase的数据一般都存储在HDFS上。Hadoop HDFS为他们提供了高可靠性的底层存储支持。
- Hive:用户处理存储在HDFS中的数据,hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
- Hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
- Hbase:是一款基于HDFS的数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
- Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
- HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
- Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
- Pig
- Pig语言层包括一个叫做PigLatin的文本语言,Pig Latin是面向数据流的编程方式。Pig和Hive类似更侧重于数据的查询和分析,底层都是转化成MapReduce程序运行。
- 区别是Hive是类SQL的查询语言,要求数据存储于表中,而Pig是面向数据流的一个程序语言。
- Sqoop:
- Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
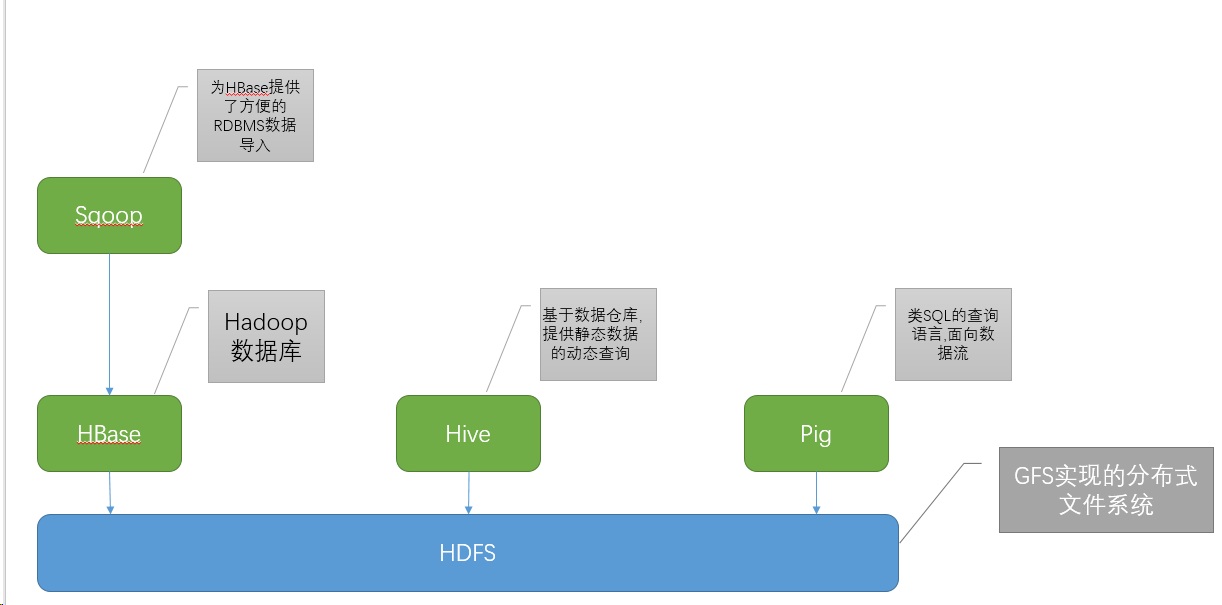
Hive与HBase的区别与联系
区别:
- Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。
- Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
- hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
- HBase:HBase是Hadoop的数据库,一个分布式、可扩展、大数据的存储。
- hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作
- hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
联系:
- Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
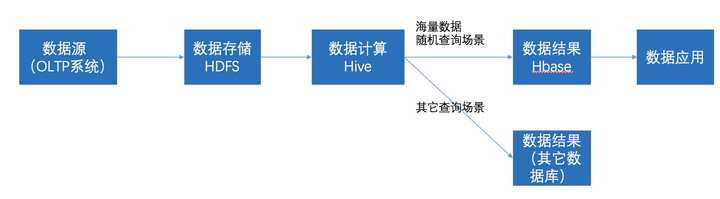
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
HDFS
HDFS的设计思路主要有三点:
- 一是普通服务器的硬性故障是常态,而不是“异常”,所以分布式文件系统要有自动化的容错性;
- 二是和Linux或者Windows的文件系统相比,分布式文件系统存储的文件要大得多,所以存储粒度大;
- 三是存储的大文件,很少需要修改其中的某一小部分,通常情况下只需要在尾部追加内容。有了HDFS,TB、PB基本的数据存取很容易了,不但如此,HDFS还要多并行处理提供支持,并行处理需要并发地读和写文件。
hdfs部分由 NameNode、SecondaryNameNode 和 DataNode组成。
- DataNode 是真正的在每个存储节点上管理数据的模块
- NameNode 是对全局数据的名字信息做管理的模块
- SecondaryNameNode 是它的从节点,以防挂掉。
Yarn
yarn的两个部分:资源管理、任务调度。
- 资源管理需要一个全局的ResourceManager(RM)和分布在每台机器上的NodeManager协同工作,RM负责资源的仲裁,NodeManager负责每个节点的资源监控、状态汇报和Container的管理
- 任务调度也需要ResourceManager负责任务的接受和调度,在任务调度中,在Container中启动的ApplicationMaster(AM)负责这个任务的管理,当任务需要资源时,会向RM申请,分配到的Container用来起任务,然后AM和这些Container做通信,AM和具体执行的任务都是在Container中执行的
yarn区别于第一代hadoop的部署(namenode、jobtracker、tasktracker)
Yarn由一个ResourceManager和每台机器上的一个NodeManager组成。ResourceManage拥有为系统中所有应用分配资源的绝对权力。NodeManager作为每个机器上的容器,管理系统资源(cpu,memory,disk,network)的使用情况,并向ResourceManager或者Scheduler报告。
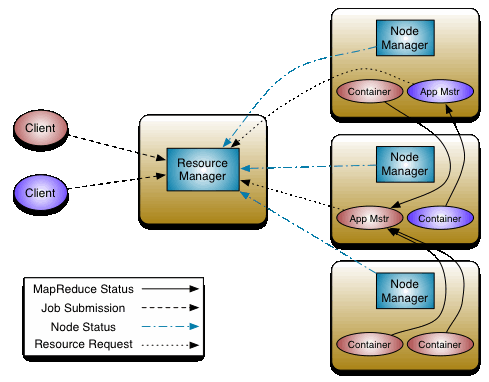 在Yarn上运行分布式应用,是通过ApplicationsMaster进行的,这里的应用指一个MapR job或者构成DAG图的多个job,应用运行结束相应的ApplicationsMaster就关闭退出了。
在Yarn上运行分布式应用,是通过ApplicationsMaster进行的,这里的应用指一个MapR job或者构成DAG图的多个job,应用运行结束相应的ApplicationsMaster就关闭退出了。
有些持续运行的框架,比如Hbase比较特殊,可以部署在yarn上,也可以不部署在yarn上。还有flink在yarn上运行,有两种部署方式: 一是long-running Flink cluster on YARN;另一种是 run a Flink job on YARN。
Mesos也是一个分布式集群的资源管理框架,相比较yarn它更底层,使用mesos需要它上面计算框架实现更多东西。使用Hadoop组件有这样一种部署方式,是先启动mesos,然后再在上面部署hdfs,yarn,这样就可以运行mapreduce了。Spark,flink这种计算框架都支持直接部署到mesos上(需要用到hdfs的话,需要在mesos上部署hdfs)。
Mrv2
再了解了解ApplicationsMaster
- Yarn支持不同的计算框架是通过ApplicationsMaster来实现的,不同的计算框架实现各自的类库,然后由ApplicationsMaster运行,比如Mrv2,Spark,Flink都可以通过这种方式在Yarn上运行。
- Mrv2运行时,首先作为ApplicationsMaster向Yarn的ResourceManager请求所需的资源,然后通过和NodeManager配合启动这些资源,监控它们的执行情况,直到任务运行结束,然后这个ApplicationsMaster实例退出。
Hadoop 命令
Hadoop HDFS Commands with Examples
【2024-3-4】touch和touchz区别
- touch 命令在指定路径下创建一个空文件
- 如果该文件不存在,则创建一个新文件。
- 如果文件已经存在,则也不会报错,只是会修改文件的访问时间。
- touchz 命令只会创建一个空文件
- 但是如果文件已经存在,则不会更改现有文件的时间戳
hadoop fs -ls /user/hadoop
hadoop fs -lsr [-d] [-h] [-R] / # 递归
hadoop fs -touch /usr/test.txt # 创建文件,修改访问时间
hadoop fs -touchz /usr/test.txt # 创建空文件,不修改访问时间
# 文件信息
hadoop fs -stat /in/appendfile # 2014-11-26 04:57:04
hadoop fs -stat %Y /in/appendfile # 1416977824841
hadoop fs -stat %o /in/appendfile # 134217728
# 目录
hadoop fs -mkdir /user/hadoop/
hadoop fs -chmod [-R] PATH # 改权限
# 查看内容
hadoop fs -cat /user/data/sampletext.txt
hadoop fs -tail /user/data/sampletext.txt
hadoop fs -head /user/data/sampletext.txt
# This command appends the contents of all the given local files to the provided destination file on the HDFS filesystem. The destination file will be created if it is not existing earlier.
# hadoop fs -appendToFile
hadoop fs -appendToFile derby.log data.tsv /in/appendfile # 追加文件到hdfs文件上
hadoop fs -cat /in/appendfile
# hdfs 文件 复制
hadoop fs -cp /user/data/sample1.txt /user/hadoop1
hadoop fs -cp /user/data/sample2.txt /user/test/in1
# hdfs 文件移动
hadoop fs -mv /user/hadoop/sample1.txt /user/text/
# hdfs 文件删除
hadoop fs -rm /user/test/sample.txt
hadoop fs -rmdir /user/test/ # 删除目录
hadoop fs -rm -r /user/test/sample.txt # 递归删除
hadoop fs -rm -rR /user/test/sample.txt # 递归删除目录
hadoop fs -rm -f /user/test/sample.txt # 无文件提示
hadoop fs -rm -skipTrash /user/test/sample.txt # 避开trash目录
# 获取hdfs文件到本地
hadoop fs -get [-f] [-p]
hadoop fs -get /user/data/sample.txt workspace/
hadoop fs -moveToLocal /user/data/sample.txt workspace/ # 文件获取
hadoop fs -getmerge /user/data # 热门命令:将hdfs目录合并复制到本地, used for merging a list of files in a directory on the HDFS filesystem into a single local file on the local filesystem.
# 上传本地文件到Hadoop
hadoop fs -put /usr/tmp/test1.txt /test1.txt
hadoop fs -copyFromLocal /usr/tmp/test1.txt /test1.txt # local -> hdfs
hadoop fs -put sample.txt /user/data/
hadoop fs -moveFromLocal sample.txt /user/data/
# change the replication factor of a file to a specific count instead of the default replication factor for the remaining in the HDFS file system
hadoop fs -setrep -R /user/hadoop/
# create a file of zero bytes size in HDFS filesystem.
hadoop fs -touchz URI
# test an HDFS file’s existence of zero length of the file or whether if it is a directory or not.
hadoop fs -test -[defsz] /user/test/test.txt
# used to empty the trash available in an HDFS system
hadoop fs –expunge
# This command is used to show the capacity, free and used space available on the HDFS filesystem
hadoop fs -du [-s] [-h] # 文件大小
hadoop fs -dus [-s] [-h] # 目录总大小
# This command is used to count the number of directories, files, and bytes under the path that matches the provided file pattern.
hadoop fs -count [-q]
# This command is used to run the MapReduce JobTracker node, which coordinates the data processing system for Hadoop
hadoop jobtracker –dumpConfiguration
【2023-11-10】HDFS不支持用户磁盘配额和访问权限控制,也不支持硬链接和软链接
Hive
Hive的出现是为了自动化编写MapReduce程序。
- 复杂业务中,逐个写Mapreduce比较繁琐,并且对不同的数据集,处理方式可能类似,都是筛选、分组统计、排序等相似的功能。于是Hive通过熟悉的SQL语句来描述需要对数据进行的处理,然后通过hive引擎把sql转换成一个或多个mapreduce任务并调度执行,这就大大减少了相似的mapreduce编写工作,提高了效率。
环境设置
设置变量
set k=v;
set date='20240130';
reduce 数目
用局部排序 sort 实现全局排序
- top k 功能
set mapred.reduce.tasks=1; -- 旧版 mapred
select * from sales
sort by amount desc
limit 10
yarn 队列
Hive设置运行参数
- Hive设置YARN执行队列
- Hive3.0默认引擎是tez,所以写mapreduce那一套指定队列不生效。
MapReduce引擎
设置执行任务时的yarn资源队列:
- 进入hive命令行后:
set mapreduce.job.queuename=队列名 - 启动hive时指定:
--hiveconf mapreduce.job.queuename=队列名
TEZ引擎
设置执行任务时的yarn资源队列:
- 进入Hive命令行后:
set tez.queue.name=队列名 - 启动hive时指定:
--hiveconf tez.queue.name=队列名
-- 多级队列
root.xxx.yyy
-- 进入hive命令行后:
set mapreduce.job.queuename=队列名
-- 在启动hive时指定
--hiveconf mapreduce.job.queuename=队列名
数据结构
Hive 复杂数据结构
- 数组 array
- 映射 map
- 结构体 struct
-- 一组有序字段,类型相同
Array(1,2)
-- 一组无序键值对, key必须原子,同一个映射的键值必须同类型
Map('a', 1)
-- 一组命名字段, 类型不要求
Struct('a',1,1,o)
-- named_struct 主要用于字段拼接,定义别名
named_struct("a", a, "b":b) as new
array
使用array[下标]方式访问
-- 创建 array
create table test4(field4 array<string>);
-- sql 插入数据
insert into test4(field4) values(array("zhangsan","lisi","wangwu"));
insert into test4(field4) values(`array`("lily","bob","alice"));
insert into test4(field4) values(`array`("A","B","C"));
-- 查询数据
select * from test4;
select field4[0] from test4;
select * from test4 where field4[0]="zhangsan";
struct
-- 创建 struct 结构
create table test2(field1 struct<name:string, age:int> comment "test field") row format delimited fields terminated by "," collection items terminated by ":";
-- 插入 struct 类型
insert into test2(field1)values(named_struct("name",'zhangsan',"age",25));
insert into test2(field1)values(named_struct("name","lisi","age",23));
-- 或从文件导入
-- name:wangwu|age:27
-- name:zhaoliu|age:28
load data local inpath '/Users/.../test.txt' into table test2;
-- 查询所有数据
select * from test2;
-- 查询name字段
select field1.name from test2;
-- 查询name为zhangsan的记录
select field1 from test2 where field1.name = "zhangsan";
map
map的用法基本相似
-- 创建 map 结构
create table test3(field2 map<string,string>) row format delimited fields terminated by ',' collection items terminated by "|" map keys terminated by ":";
-- sql插入
insert into test3(field2)values(str_to_map("name:zhangsan,age:25")),(str_to_map("name:lisi,age:23"));
-- 文件导入
load data local inpath '/Users/zhangsheng/hive/note/hive/test.txt' into table test3;
-- 查询数据
select * from test3;
select field2["name"] as name,field2["age"] as age from test3;
select * from test3 where field2["age"] > 25;
join
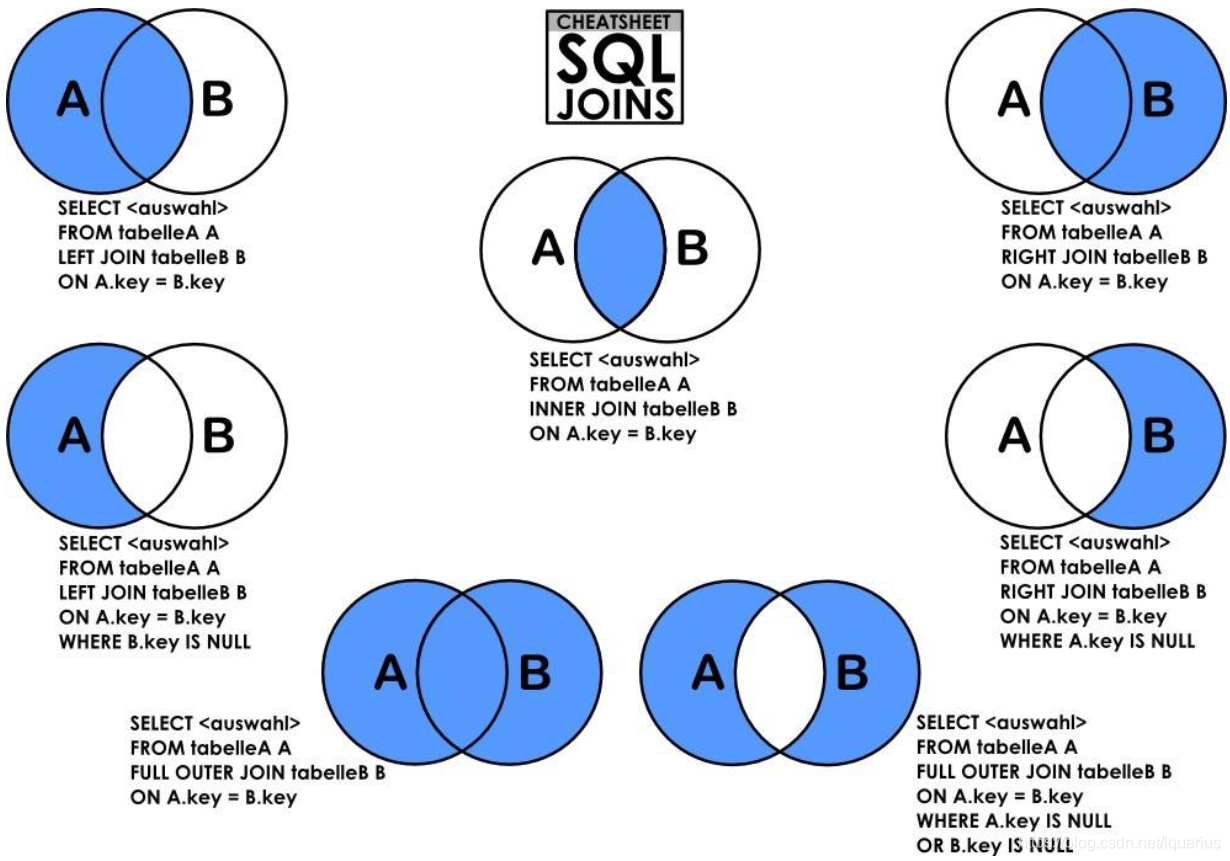
Hive中,JOIN是一种常用的操作,用于将两个或多个表中的数据按照指定的条件进行关联
- 1、左连接 left outer join
- 以左边表为准,逐条去右边表找相同字段,如果有多条会依次列出。
- 2、连接join
- 找出左右相同同的记录。
- 3、全连接 full outer join
- 包括两个表的join结果,左边在右边中没找到的结果(NULL),右边在左边没找到的结果。
- 会对结果去重,返回并集。
多种JOIN类型,包括:
内连接(inner join或者简写成join):只返回两个表中匹配的行。内连接基于一个或多个条件(通常是相等条件),匹配两个表中的行,并将匹配的行返回为结果。只有满足条件的行才会被包含在结果中。左外连接(left outer join或者简写成left join):返回左表中的所有行以及与右表匹配的行。如果右表中没有匹配的行,则对应的结果列将包含NULL值。右外连接(right outer join或者简写成right join):返回右表中的所有行以及与左表匹配的行。如果左表中没有匹配的行,则对应的结果列将包含NULL值。全外连接(full outer join或者简写成full join):返回两个表中的所有行,如果某一行在另一个表中没有匹配,则对应的结果列将包含NULL值。- full outer join 无效
SELECT *
FROM table1
JOIN table2 -- 内连接
-- LEFT JOIN table2 -- 左连接
-- RIGHT JOIN table2 -- 右连接
-- FULL OUTER JOIN table2 -- 全外连接
ON table1.id = table2.id;
-- 多表连接
SELECT *
FROM table1
INNER JOIN table2
ON table1.id = table2.id
INNER JOIN table3
ON table2.id = table3.id;
图解
MapJoin
- 常规 join 时,Hive 会启动 MapJoin优化,将小表加载内存,提速
- FULL JOIN 时,Hive不会使用 MapJoin来优化
除此之外,Hive还支持 LEFT SEMI JOIN 和 CROSS JOIN,但这两种JOIN类型也可以用前面的代替。
数据准备
create external table IF NOT EXISTS temp_testjoin_ta
(
label string,
qu string
)
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as textfile;
ALTER TABLE temp_testjoin_ta ADD IF NOT EXISTS PARTITION (dt = '2014-08-08') location '/temp/jinlong10/testjoin/ta';
-- l1 q1
-- l1 q2
create external table IF NOT EXISTS temp_testjoin_tb
(
qu string,
inmyway string
)
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as textfile;
ALTER TABLE temp_testjoin_tb ADD IF NOT EXISTS PARTITION (dt = '2014-08-08') location '/temp/jinlong10/testjoin/tb/';
-- q1 i1
-- q1 i1
-- q1 i2
-- q1 i3
-- q2 i1
-- q2 i2
-- q3 i10
join
select * from (select label,qu from temp_testjoin_ta where dt = '2014-08-08') ta join (select qu,inmyway from temp_testjoin_tb where dt = '2014-08-08') tb on ta.qu = tb.qu ;
-- l1 q1 q1 i1
-- l1 q1 q1 i1
-- l1 q1 q1 i2
-- l1 q1 q1 i3
-- l1 q2 q2 i1
-- l1 q2 q2 i2
select * from (select label,qu from temp_testjoin_ta where dt = '2014-08-08') ta join (select qu,inmyway from temp_testjoin_tb where dt = '2014-08-08') tb on ta.qu = tb.qu group by label,inmyway;
-- l1 i1
-- l1 i2
-- l1 i3
left outer
select * from (select label,qu from temp_testjoin_ta where dt = '2014-08-08') ta left outer join (select qu,inmyway from temp_testjoin_tb where dt = '2014-08-08') tb on ta.qu = tb.qu ;
-- l1 q1 q1 i1
-- l1 q1 q1 i1
-- l1 q1 q1 i2
-- l1 q1 q1 i3
-- l1 q2 q2 i1
-- l1 q2 q2 i2
select * from (select label,qu from temp_testjoin_ta where dt = '2014-08-08') ta left outer join (select qu,inmyway from temp_testjoin_tb where dt = '2014-08-08') tb on ta.qu = tb.qu group by label,inmyway;
-- l1 i1
-- l1 i2
-- l1 i3
full outer
select * from
(select label,qu from temp_testjoin_ta where dt = '2014-08-08') ta
full outer join (select qu,inmyway from temp_testjoin_tb where dt = '2014-08-08') tb
on ta.qu = tb.qu ;
-- l1 q1 q1 i3
-- l1 q1 q1 i2
-- l1 q1 q1 i1
-- l1 q1 q1 i1
-- l1 q2 q2 i2
-- l1 q2 q2 i1
-- NULL NULL q3 i10
left semi join
从a表中提取命中b表的数据
SELECT a.id,
a.name
FROM lxw1234_a a
LEFT SEMI JOIN lxw1234_b b
ON (a.id = b.id);
--执行结果:
1 zhangsan
2 lisi
--等价于:
SELECT a.id,
a.name
FROM lxw1234_a a
WHERE a.id IN (SELECT id FROM lxw1234_b);
--也等价于:
SELECT a.id,
a.name
FROM lxw1234_a a
join lxw1234_b b
ON (a.id = b.id);
--也等价于:
SELECT a.id,
a.name
FROM lxw1234_a a
WHERE EXISTS (SELECT 1 FROM lxw1234_b b WHERE a.id = b.id);
笛卡尔积关联(CROSS JOIN)
返回两个表的笛卡尔积结果,不需要指定关联键。
- 表不大时,才适合CROSS JOIN,否则内存爆满
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
CROSS JOIN lxw1234_b b;
Hive SQL优化
【2022-8-12】Hive/HiveSQL常用优化方法全面总结
影响Hive效率的几乎从不是数据量过大,而是数据倾斜、数据冗余、job或I/O过多、MapReduce分配不合理等等。对Hive的调优既包含对HiveSQL语句本身的优化,也包含Hive配置项和MR方面的调整。
- 列裁剪和分区裁剪: 查询时只读取需要的列、分区
- 当列很多或者数据量很大时,如果select *或者不指定分区,全列扫描和全表扫描效率都很低。
- Hive中与列裁剪优化相关的配置项是 hive.optimize.cp,与分区裁剪优化相关的则是 hive.optimize.pruner,默认都是true。在HiveSQL解析阶段对应的则是ColumnPruner逻辑优化器。
- 谓词下推: 将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
- 将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
- sort by代替order by: 局部排序 vs 全局排序
- order by 全局排序,只使用1个reducer,数据量大时节点的时间开销大
- sort by启动多个reducer进行排序,并且保证每个reducer内局部有序。配合distribute by一同使用
- group by代替distinct
- 统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑只会有很少的reducer来处理。这时可以用group by来改写
- group by配置调整
- map端预聚合
- 倾斜均衡配置项
- join基础优化
- build table(小表)前置
- 多表join时key相同
- 利用map join特性
- 分桶表map join
- 倾斜均衡配置项
- 优化SQL处理join数据倾斜
- 空值或无意义值
- 单独处理倾斜key
- 不同数据类型
- build table过大
- MapReduce优化
- 调整mapper数
- 调整reducer数
- 合并小文件
- 启用压缩
- JVM重用
- 并行执行与本地模式
- 严格模式
- 采用合适的存储格式
-- 列/分区裁剪
select uid,event_type,record_data
from calendar_record_log
where pt_date >= 20190201 and pt_date <= 20190224 and status = 0;
-- 谓词下推
select a.uid,a.event_type,b.topic_id,b.title
from calendar_record_log a left outer join (
select uid,topic_id,title from forum_topic
where pt_date = 20190224 and length(content) >= 100
) b on a.uid = b.uidwhere a.pt_date = 20190224 and status = 0;
-- sort by与group by
select uid,upload_time,event_type,record_data
from calendar_record_log
where pt_date >= 20190201 and pt_date <= 20190224
distribute by uid
sort by upload_time desc,event_type desc;
-- group by代替distinct
select count(1) from (select uid from calendar_record_log where pt_date >= 20190101 group by uid) t;
-- 其它看原文
Hive SQL经验
- 【2021-12-10】统计代码:test.sql,多年Hive学习总结 飞书文档
- 函数使用:sum、if、round、count
- 环境变量:hivevar
--- 拼接 ---
-- ①多个字符串连接(任意个数字段) concat(a, b, c)
select concat(‘abc’,'def’,'gh’) from lxw_dual; -- CONCAT
-- ②多个字符串连接,指定分隔符 concat_ws('-', a, b, c)
SELECT CONCAT_WS(",","First name","Second name","Last Name");
-- ③分组连接多个字符串字段 group_concat
SELECT locus,GROUP_CONCAT(id) FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus; -- 直接连接字段,分隔符默认逗号,
SELECT locus,GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus; -- 组内去重排序后,按照指定分隔符连接
SELECT locus,GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus; -- 组内处理后,再连接
-- coalesce 选择第一个非空值
select coalesce(a,b,c);
select COALESCE(is_test, -1) as saas_is_test,
-- 参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null。
-- 【2023-4-5】spark, 同组数值聚合, 自定义,非官方
select
collect_list(COALESCE(deal_cnt,0)) as deal_cnts, -- 当日成交量
from tbl
group by a
-- 交互成功率
select city_name as `城市`, count(*) as `总交互数`,
sum(if(intent!='other',1,0)) as `成功数`, round(sum(if(intent!='other',1,0))*100/count(*),2) as `成功率`,
sum(if(intent!='other',1,0)) as `失败数`, round(sum(if(intent=='other',1,0))*100/count(*),2) as `失败率`
from aisearch.aisearch_olap_speech_dialog_management_log_data_raw_di
-- where pt between '20210923000000' and '20210926000000' and bot_id='contract_center' group by city_name
where pt between '${hivevar:start_dt}' and '${hivevar:end_dt}' and bot_id='contract_center' group by city_name
union
select '所有', count(*), sum(if(intent!='other',1,0)), round(sum(if(intent!='other',1,0))*100/count(*),2),
sum(if(intent!='other',1,0)), round(sum(if(intent=='other',1,0))*100/count(*),2)
from aisearch.aisearch_olap_speech_dialog_management_log_data_raw_di
where pt between '20210923000000' and '20210926000000' and bot_id='contract_center' group by '所有'
order by `总交互数` desc;
-- 【2022-11-30】时间戳转换
select from_unixtime(1605108612); -- 2020-11-11 15:30:12
select from_unixtime(1605108612,'MM-dd-yyyy HH:mm:ss'); -- 11-11-2020 15:30:12
【2023-4-5】参考
IF/COALESCE 条件
SELECT
SUM(COALESCE(sex_age.age, 0)) AS age_sum,
SUM(IF(sex_age.sex='Female',sex_age.age,0)) AS female_age_sum
FROM employee;
CASE WHEN 分支条件
SELECT SUM(
CASE WHEN sex_age.sex='Male' THEN sex_age.age ELSE 0 END
)/COUNT(
CASE WHEN sex_age.sex='Male' THEN 1 ELSE NULL END
) AS male_age_avg
FROM employee;
CONCAT_{WS}
字符串连接:横向
- CONCAT 逐个链接
- CONCAT_WS 统一指定分隔符
select subtype
,concat_ws('&',collect_set(cast(from as string))) from
,concat_ws('&',collect_set(cast(id as string))) id
,concat_ws('&',collect_set(cast(name as string)))name
,concat_ws('&',collect_set(cast(type as string))) type
from aaaaaaa
group by subtype;
聚合函数(UDAF)
聚合函数
- SUM 求和
- AVG 均值
Hive聚合中,如果某个聚合列的值中有null,则包含该null的行将在聚合时被忽略。
为了避免这种情况,可以使用 COALESCE 来将null替换为一个默认值。
SELECT AVG(COUNT(*)) AS row_cnt FROM employee;
SELECT COUNT(DISTINCT sex_age.sex) AS sex_uni_cnt, COUNT(DISTINCT name) AS name_uni_cnt FROM employee;
-- 使用 COALESCE 保留空值行
SELECT SUM(COALESCE(val1, 0)), SUM(COALESCE(val1, 0)+val2) FROM t;
高级聚合主要有以下几种情况:
- GROUPING SETS
- 对同一个数据集的多重GROUP BY操作。事实上 GROUPING SETS是多个GROUP BY进行UNION ALL操作的简单表达,仅使用一个stage完成这些操作。GROUPING SETS 的子句中如果包换()数据集,则表示整体聚合。
- 然而GROUPING SETS目前还有未解决的问题,参考HIVE-6950
- ROLLUP和CUBE
- 这两个关键字都是GROUP BY的高级实现。
-- 一次标记多种 group
SELECT name, work_place[0] AS main_place,
count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY name, work_place[0]
GROUPING SETS((name, work_place[0]), name, work_place[0], ());
-- 或 ---
SELECT name, work_place[0] AS main_place,
count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY name, work_place[0]
UNION ALL
SELECT name, NULL AS main_place, count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY name
UNION ALL
SELECT NULL AS name, work_place[0] AS main_place,
count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY work_place[0]
UNION ALL
SELECT NULL AS name, NULL AS main_place,
count(employee_id) AS emp_id_cnt
FROM employee_id;
SELECT sex_age.sex, sex_age.age,
count(name) AS name_cnt
FROM employee
GROUP BY sex_age.sex, sex_age.age
GROUPING SETS((sex_age.sex, sex_age.age));
- 对比于规定了n层聚合的GROUPING SETS,ROLLUP会创建n+1层聚合,在此n表示分组列的个数。
- GROUP BY a, b, c WITH ROLLUP 等价于 GROUP BY a,b,c GROUPING SETS ((a,b,c),(a,b),(a),())
- CUBE将会对分组列进行所有可能的组合聚合。如果为CUBE指定了n列,则将返回2^n个聚合组合。
- GROUP BY a, b, c WITH ROLLUP 等价于 GROUP BY a,b,c GROUPING SETS ((a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),())
collect_{set/list}
列转行
collect_list 与 collect_set
- 都将分组中某列转为一个数组返回
- 不同:
collect_list不去重- 而
collect_set去重。返回没有重复元素的集合
select collect_list('1','2','3','2') -- [“1,2,3”] 返回是一个 list
select collect_set('1','2','3','2') -- [“1","2","3”] 返回是一个 set, 去重
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name))
from ods_sku_sale_attr_value
where dt='2020-06-14'
group by sku_id;
结构化输出
collect_list(
to_json(
named_struct(
'user_type',
all_message.user_type,
'message_index',
all_message.message_index,
'message_content',
all_message.message_content
)
)
) as message_session
json 格式
从 json 字符串中提取字段 get_json_object
SELECT get_json_object(src_json.json, '$.owner') FROM src_json;
SELECT get_json_object(src_json.json, '$.store.fruit\[0]') FROM src_json; -- {"weight":8,"type":"apple"}
SELECT get_json_object(src_json.json, '$.non_exist_key') FROM src_json; -- NULL
-- inputs: {"message":[[["kwargs":{"content":"question"}]],[]]}
get_json_object(inputs, '$.messages[0][0].kwargs.content')
-- 【2023-10-24】list下标可以连续,但不支持 -1
-- 返回2222。
select get_json_object('{"array":[["aaaa",1111],["bbbb",2222],["cccc",3333]]}','$.array[1][1]');
-- 返回["h0","h1","h2"]。
set odps.sql.udf.getjsonobj.new=true;
select get_json_object('{"aaa":"bbb","ccc":{"ddd":"eee","fff":"ggg","hhh":["h0","h1","h2"]},"iii":"jjj"}','$.ccc.hhh[*]');
-- 返回["h0","h1","h2"]。
set odps.sql.udf.getjsonobj.new=false;
select get_json_object('{"aaa":"bbb","ccc":{"ddd":"eee","fff":"ggg","hhh":["h0","h1","h2"]},"iii":"jjj"}','$.ccc.hhh');
-- 返回h1。
select get_json_object('{"aaa":"bbb","ccc":{"ddd":"eee","fff":"ggg","hhh":["h0","h1","h2"]},"iii":"jjj"}','$.ccc.hhh[1]');
select get_json_object('[{"website":"https://blog.csdn.net/lz6363","name":"浮云"},{"website":"https://blog.csdn.net/lz6363/article/details/86606379","name":"hive中的开窗函数"},{"website":"https://blog.csdn.net/lz6363/article/details/82470278","name":"利用hive统计连续登陆的用户数"}]'
, "$.[0,1,2].website"); -- 返回第一、二、三个
虽然 get_json_object 函数能通过下标解析指定位置的json,但当不知道json数组元素个数时,或者数组长度不断变化,无法进行解析
解决:
- 通过正则表达式将数组中的,用;代替
- 再通过正则表达式把数组中的[]去掉
- 用split函数按;进行分割
json_tuple
select json_tuple('{"website":"https://blog.csdn.net/lz6363/article/list/1","name":"浮云"}', 'website', 'name');
ck SQL语法不一样,json用法,hive里的get_json_object → visitParamExtractRaw
【2023-11-30】问题:如何获取数组最后一个元素?
hive -e "select regexp_extract(shopList,'(\,[^\,]+)',1) from shopTable"; # 能跑,但结果不对
hive -e "select reverse(split(reverse(shopList), ',')[1]) from shopTable"; # 成功
字符串
【2024-1-18】字符串替换
regexp_replace("foobar", "oo|ar", "") -- fb
regexp_replace(description, '\\t', '') as description
select translate(description,'\\t','') from myTable;
统计字符串中某个字符出现的次数
-- 方法一
select size(split('abcdcefc','c')) from bdm.cemar_imei_idfa_base limit 1;
-- 注意: 如果str是空/null,那么split成数组后,计算数据的长度居然是1
-- 方法二
select abs(length(regexp_replace("love hive", "ve", '')) - length("love hive")) / length("ve") str_l;
正则表达式
- regexp 功能同 rlike,只匹配,不抽取
- regexp_extract 匹配1次,并抽取
- regexp_extract_all 第三方定义的udf,匹配多次,一行转多行,详见
- regexp_replace 匹配并替换
-- 取子串:取baiduid的后两位,31、32;等效于 substr(baiduid, -2, 2),负数表示从尾部开始算。
substr(baiduid, 31, 2)
-- like 通配符
select 'abcde' like '_bc%';
-- rlike:
select 'football' rlike '^footba';
where x rlike ‘^\\d+$’ -- \需要转义
-- 字符串查询:
instr(x, 'wpt%3A') -- x是否匹配模式。失败返回0,否则下标。
-- regexp
select * from table where a regexp 'key1|key2';
-- 正则替换:index为0时,会返回所有匹配,index为其他值n时,只返回第n段匹配
-- idx是返回结果 取表达式的哪一部分 默认值为1。
-- 0表示把整个正则表达式对应的结果全部返回
-- 1表示返回正则表达式中第一个() 对应的结果 以此类推
regexp_replace(x, '_', ',') -- x中的_替换为, regexp_replace("foobar", "oo|ar", "")=’fb’
select regexp_extract('x=a3&x=18abc&x=2&y=3&x=4','x=([0-9]+)([a-z]+)',0) from default.dual; -- 18abc, 提取完整片段
select regexp_extract('x=a3&x=18abc&x=2&y=3&x=4','x=([0-9]+)([a-z]+)',1) from default.dual; -- 18 提取第1个括号里的片段
select regexp_extract('x=a3&x=18abc&x=2&y=3&x=4','x=([0-9]+)([a-z]+)',2) from default.dual; -- abc 提取第2个括号里的片段
-- 正则抽取:
regexp_extract('foothebar', 'foo(.*?)(bar)', 2)='bar' -- 提取子串
-- 注:java正则风格,有时需要\\转义
-- Str转map:
str_to_map(x, '%3B', '%3A') -- 将K/V形式的字符串转成map类型。
-- 示例:str_to_map(‘’)返回空字典:{"":null}
select str_to_map(a, '\\+', ':'), str_to_map(b, '\\+', ':') from query_click_str
-- 数组查询:
array_contains(a, '1012') -- a是否包含’1012’
-- hive 0.9后支持:
select * from login where dt=20130101 and !array_contains(split('a,b,d,g',','),ver);
-- 或者:
x in (222, 228) all any exist somy
-- 【2014-2-19】
hive -e "select * from log_rs.log_merged where dt='20140211' and array_contains(split('$user',','),uid)" >data_user.txt
-- 特殊字符串查询:find_in_set('1012', x),x必须是逗号链接的字符串,成功返回1,否则0
map(k1,v1,k2,v2) -- 根据KV对创建map类型数据
map_keys(m) -- 提取map的所有keys,返回一个array
map_values(m) -- 提取map的所有values,返回一个array
-- 随机数:
rand -- 生成[0,1]小数
length(s),reverse(s)
concat(s1,s2,s3,…) -- 连接,concat('foo', 'bar')='foobar'
concat_ws(‘+’,s1,s2,s3,…) -- 按+连接各字符串
-- 注:concat连接的变量值不能为空(null),若为空,需要指定空字符串。
concat('tm:',tm,'+query_type:', query_type, '+keywords:', COALESCE(req['keywords'],'null'))
coalesce -- 联合,依次取第一个非空值。
substr('foobar', 4)='bar',substr('foobar', 4, 1)='b' -- sudstring等效于substr
-- 【2014-6-4】
substr('foobar', -2, 1)='a' -- 负数表示倒数位置
-- upper(s)或ucase(s):大写
-- lower(s)或lcase(s):大写
trim(s),ltrim(s),rtrim(s)
parse_url('http://facebook.com/path/p1.php?query=1', 'HOST')='facebook.com' -- 解析url,HOST, PATH, QUERY, REF, PROTOCOL, FILE, AUTHORITY, USERINFO
parse_url_tuple
space(int n) -- n个空格的字符串
repeat(s, 3) -- s重复三遍
ascii(s) -- s第一个字符串的ascii码
-- l(或r)pad(s,10,’0’):左(右)端补齐字符串到10位,不足部‘0’
split('foobar', 'o')[2] = 'bar' -- 使用正则表达式分隔字符串
find_in_set('ab', 'abc,b,ab,c,def')=3 -- 返回集合(逗号分隔的字符串)中的位置
sentences(‘Hello there! How are you?’) -- 返回:( (“Hello”, “there”), (“How”, “are”, “you”) ):提取句子中的单词,返回array
【2023-12-5】如何获取json list里的最后一个元素?
- regexp_extract 失败
- size(split()) 成功
regexp_extract(inputs, '.*\"content\"\:\"(.*?)\"') -- 失败
-- 先通过 size(split) 获取元素下标, 再调用 get_json_object
get_json_object(inputs, concat('$.messages[0][', size(split(inputs, '"content":'))-2, '].kwargs.content')),
map 字符串
select get_json_object('{"a":1,"b":2}','$.a') from client_log_on1 limit 5;
select str_to_map(para,'\001','\002')['diu'] from client_log_on limit 10;
子查询
Hive中只支持 WHERE 和 FROM子句中的子查询
- 子查询用括号
- 主查询和子查询可以不是同一张表
- 子查询中的空值问题,若子查询中有空值Null时,主查询不能使用IN或Not IN
from 子查询
格式
- SELECT … FROM(subquery) name …
- SELECT … FROM(subquery) AS name …
SELECT col
FROM (
SELECT a+b AS col
FROM t1
) t2;
-- 包含union all:
SELECT t3.col
FROM (
SELECT a+b AS col
FROM t1
UNION ALL
select c+d AS col
FROM t2
) t3
where子查询
- 一般用于IN,EXISTS,NOT EXISTS
SELECT * FROM A
WHERE A.a IN (
SELECT foo FROM B);
SELECT A FROM T1
WHERE EXISTS(
SELECT B FROM T2 WHERE T1.X=T2.X
);
-- 查询部门为’SALES‘和’ACCOUNTING‘的员工有哪些
-- 解:先查出’SALES‘和’ACCOUNTING‘的部门号,然后再根据部门号再查询emp表的员工姓名
select e.name from emp e where e.deptno in (
select d.deptno from dept d where d.dname='SALES' and d.dname='ACCOUNTING');
子查询中的空值问题
- 若子查询中有空值 Null,主查询不能使用 IN 或 Not IN
-- 查询所有员工的老板的员工号,如果这个员工就是老板,那数据就是空值
select * from emp e where e.empno not in (select e1.mgr from emp e1); #会报错,因为子查询有空值
-- 正确的操作如下:
select * from emp e where e.empno not in (select e1.mgr from emp e1 where el.mgr is not null);
注:
- 子句必须有一个别名,否则会解析语句失败。
SELECT COUNT(DISTINCT sex_age.sex) AS sex_uni_cnt FROM employee; -- 性能瓶颈
-- 改成子查询
SELECT COUNT(*) AS sex_uni_cnt FROM (
SELECT DISTINCT sex_age.sex FROM employee
) a;
join改写: left join
select DISTINCT a.userid
FROM TABLE_A AS a
left JOIN TABLE_B AS b on a.userid=b.userid
WHERE b.userid is NULL;
exists 改写
select DISTINCT a.userid FROM TABLE_A AS a WHERE a.dt >= '20200209'
AND NOT EXISTS (
SELECT DISTINCT b.userid FROM TABLE_B AS b WHERE b.dt >= '20200209' AND a.userid = b.userid
);
having
聚合条件 – HAVING
- 从 Hive0.7.0开始, HAVING被添加到Hive作为GROUP BY结果集的条件过滤。HAVING可以作为子句的替代。
-- 两种表达效果一样
SELECT sex_age.age FROM employee GROUP BY sex_age.age HAVING count(*)<=1;
SELECT a.age FROM (
SELECT COUNT(*) AS cnt, sex_age.age FROM employee GROUP BY sex_age.age
) a WHERE a.cnt<=1;
hive中实现group_concat
mysql中的group_concat分组连接功能相当强大,可以先分组再连接成字符串,还可以进行排序连接。但hive没有这个函数
那么hive中怎么实现这个功能呢?
- 借助这几个函数:concat_ws、collect_list、collect_set
- 建立测试表(无分区表):
create table if not exists db_name.test_tb(id string,content string,comment string) row format delimited fields terminated by '\1' stored as textfile
- 插入几条数据:
insert into db_name.test_tb values('1','Tom','测试1')
insert into db_name.test_tb values('1','Bob','测试2')
insert into db_name.test_tb values('1','Wendy','测试3')
insert into db_name.test_tb values('2','Bob','测试22')
insert into db_name.test_tb values('2','Tom','测试11')
| a | b | c |
|---|---|---|
| 1 | Tom | 测试1 |
| 1 | Bob | 测试2 |
| 1 | Wendy | 测试3 |
| 2 | Bob | 测试22 |
| 2 | Tom | 测试11 |
- concat_ws + collect_set + group by:
select
id,
concat_ws(',',collect_set(content)) as con_con,
concat_ws(',',collect_set(comment)) as con_com
from db_name.test_tb
group by id
结果:无序且不对应(con_con与con_com的位置) —— 但是注意 collect_set会将重复的数据删除,因为集合的性质。
每次运行连接的结果顺序都可能不一样。
- concat_ws + collect_list + group by:
select
id,
concat_ws(',',collect_list(content)) as con_con,
concat_ws(',',collect_list(comment)) as con_com
from db_name.test_tb
group by id
结果:对应(con_con与con_com的位置)但无序。
- concat_ws + collect_list + group by + row_number():
select
id,
concat_ws(',',collect_list(content)) as con_con,
concat_ws(',',collect_list(comment)) as con_com,
concat_ws(',',collect_list(cast(rn as string))) as con_rn
from db_name.test_tb
(
select
id,
content,
comment,
row_number() over(partition by id order by content asc) as rn
from db_name.test_tb
)
group by id
结果:对应(con_con与con_com的位置)且有序。
随机数
语法:
rand()rand(int seed)
返回值: double
说明:
- 返回一个0到1范围内的随机数。
- 如果指定种子seed,则会等到一个稳定的随机数序列
随机整数:
- 两位整数:
rand() * 100 - 三位整数:
rand() * 1000
举例:
select rand() from lxw_dual; -- 0.5577432776034763
select rand() from lxw_dual; -- 0.6638336467363424
select rand(100) from lxw_dual; -- 0.7220096548596434
select rand(100) from lxw_dual; -- 0.7220096548596434
-- 随机数 [1,10]
cast(ceiling(rand() * 10) as int) as num
cast(floor(rand() * 10) as int) as num
-- 将[0, 1]的随机数映射到[0.7, 0.8]
select ((0.8-0.7)/(1-0))*(rand()-0)+0.7 from lxw_dual;
随机字符串
-- 随机字符串:
SUBSTRING(MD5(RAND()),1,5)
-- 随机字符串+拼接:
concat(SUBSTRING(MD5(RAND()),1,5),"_xiaowang")
hive取随机数据可用
rand()函数,用rand()对数据排序,取topN- 如果分组取随机数,比如每个班级随机取10人,针对这种每个分组取topN的情况,可以使用
row_number
row_number() over(partition by fieldx order by rand()) as rn
采样
在大规模数据分析及建模任务中,往往针对全量数据进行挖掘分析时, 十分耗时和占用集群资源
因此需要抽取一小部分数据进行分析及建模操作。数据集非常大时,找一个子集来加快数据分析。此时要数据采集工具以获得需要的子集。
三种方式获得采样数据:
- 随机采样 random sampling
- 分桶采样 bucket sampling
- 分块采样 block sampling
Hive提供了数据取样(SAMPLING)的功能,根据一定的规则进行数据抽样,目前支持数据块抽样,分桶抽样和随机抽样
1. 随机抽样 Random sampling
随机抽样(rand()函数)
- 1)使用
rand()函数进行随机抽样,limit关键字限制抽样返回的数据- 其中rand函数前的
distribute和sort关键字可以保证数据在mapper和reducer阶段是随机分布的
- 其中rand函数前的
- 2)使用
order关键词
-- rand, 局部排序
select * from table_name where col=xxx distribute by rand() sort by rand() limit num;
-- order, 数据量小时全局排序
select * from table_name where col=xxx order by rand() limit num;
经测试对比,千万级数据中进行随机抽样 order by方式耗时更长,大约多30秒左右。
使用 RAND() 函数和 LIMIT 关键字来获取样例数据。
- 使用
DISTRIBUTE和SORT关键字来保证数据是随机分散到mapper和reducer的。 - ORDER BY
RAND()语句可以获得同样效果,但是性能没这么高。
SELECT * FROM a DISTRIBUTE BY RAND() SORT BY RAND() LIMIT 10;
2. 分桶抽样 Bucket table sampling
分桶抽样
hive中分桶是根据某一个字段Hash取模,放入指定数据的桶中
- 比如将表 table_1 按照ID分成100个桶,其算法是
hash(id) % 100 hash(id) % 100 = 0的数据被放到第一个桶中hash(id) % 100 = 1的记录被放到第二个桶中。- 创建分桶表的关键语句为:
CLUSTER BY语句。
分桶抽样语法:
TABLESAMPLE (BUCKET x OUT OF y [ON colname])
其中x是要抽样的桶编号,桶编号从1开始,colname表示抽样的列,y表示桶的数量。
例如:将表随机分成10组,抽取其中的第一个桶的数据
select * from table_01 tablesample(bucket 1 out of 10 on rand())
最佳化采样bucket表。RAND()函数也可用来采样整行。如果采样列同时使用了CLUSTERED BY,使用TABLESAMPLE语句会更有效率。
- 2: specified bucket number to sample
- 4: total number of buckets
SELECT * FROM a TABLESAMPLE(BUCKET 2 OUT OF 4 ON col1 ) a1;
SELECT * FROM a TABLESAMPLE(BUCKET 2 OUT OF 4 ON RAND()) a1;
3. Block sampling
数据块抽样(tablesample()函数)
- 1)
tablesample(n percent)根据hive表数据的大小按比例抽取数据,并保存到新的hive表中。- 如:抽取原hive表中10%的数据
- 注意:测试过程中发现,select语句不能带where条件且不支持子查询,可通过新建中间表或使用随机抽样解决
create table xxx_new as select * from xxx tablesample(10 percent)
- 2)
tablesample(n M)指定抽样数据的大小,单位为M。 - 3)
tablesample(n rows)指定抽样数据的行数,其中n代表每个map任务均取n行数据,map数量可通过hive表的简单查询语句确认(关键词:number of mappers: x)
允许Hive随机抽取N行数据,数据总量的百分比(n百分比)或N字节的数据。
SELECT * FROM a TABLESAMPLE(N PERCENT|ByteLengthLiteral|N ROWS) s;
--ByteLengggthLiteral:
--(Digit)+ ('b' | 'B' | 'k' | 'K' | 'm' | 'M' | 'g' | 'G')
例:按行抽样
SELECT name FROM employee_id_buckets TABLESAMPLE(4 ROWS) a;
例:按数据量百分比抽样
SELECT name FROM employee_id_buckets TABLESAMPLE(10 PERCENT) a;
注:
- 此方法有待考证,在Hive 0.11.0中将所有25条数据全取出来了,在 Hive0.13.0 中取出了其中的12条,但是都不符合要求!
例:按数据大小采样
SELECT name FROM employee_id_buckets TABLESAMPLE(1M) a;
分层抽样 row_number
分组取随机数
- 每个班级随机取10人,每个分组取topN,可以使用
row_number
row_number() over(partition by fieldx order by rand()) as rn
示例
select date, imei
from(
select date, imei, row_number() over(partition by sp_modify order by rand()) as rn
from tmp_mod
) mod
where mod.rn <= 1000
执行SQL
执行语句:
# 传变量方式:hivevar、hiveconf等
hive -f test.sql -hivevar start_dt='20210923000000' -hivevar end_dt='20210926000000' > out.txt
【2023-11-29】指定hadoop队列
-- 3 种方式
set mapred.job.queue.name=queue3; -- 老版本
set mapred.queue.names=queue3;
SET mapreduce.job.queuename=queue3; -- 新版本
select advertiser_id,crt_id,a.media,city,price, b.media_id, b.ratio
from tb_pmp_report_log_count a
left join mapping_tb_4_media_with_ratio b on (a.media = b.media)
分桶
【2023-9-13】将时间戳(ms级别)按照30s分桶
toDateTime(30*CAST(start_time/30/1000 AS BIGINT))
加密
Hive支持许多加密函数,其中包括:
- MD5() - 计算输入表达式的128位MD5哈希值。
- sha1() - 计算输入表达式的160位SHA1哈希值。
- sha2() - 计算输入表达式的256位SHA2哈希值。
- crc32() - 计算输入表达式的32位循环冗余校验值(CRC)。
- murmur_hash() - 计算输入表达式的MurmurHash哈希值。
这些函数可用于加密敏感信息,例如密码,以保护隐私。
-- sha2 位数可以是 224,256,384,512和0
select sha2('123456',256) -- 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
select sha2('123456',256) -- 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
select sha2('123456',224) -- f8cdb04495ded47615258f9dc6a3f4707fd2405434fefc3cbf4ef4e6
-- md5
select md5('123456') -- e10adc3949ba59abbe56e057f20f883e
select md5('123456') -- e10adc3949ba59abbe56e057f20f883e
select md5('1234567') -- fcea920f7412b5da7be0cf42b8c93759
-- base64
select base64(cast('abcd' as binary)) -- YWJjZA==
select unbase64('YWJjZA==') -- abcd
shell调度MapReduce任务
案例:
#!/bin/bash
# -*- coding: utf-8 -*-
#===============================================================================
# File: start_hadoop.sh [session]
# Usage:
# Description: pc端session日志的hadoop启动脚本
# LastModified: 2013-3-28 12:51 PM
# Created: 27/12/2012 11:17 AM CST
# AUTHOR: wangqiwen(wangqiwen@baidu.com)
# COMPANY: baidu Inc
# VERSION: 1.0
# NOTE:
# input:
# output:
#===============================================================================
#:<<note
# online
set -x
if [ $# -ne 9 ]; then
echo "[$0] [ERROR] [`date "+%Y-%m-%d %H:%M:%S"`] [session] input error ! \$#=$# not 9"
exit -1
fi
hadoop=$1;input=${2//;/ -input };output=$3
jobname=$4;main_dir=$5;date=$6;task_prefix=$7
map_con_num=$8;reduce_num=$9
#note
:<<note
# test
date="20130314"
jobname="session"
hadoop="/home/work/hadoop-rp-rd-nj/hadoop/bin/hadoop"
#input="/log/22307/nj_rpoffline_session_ting/$date/0000/szwg-ston-hdfs.dmop/0000"
input="/log/22307/nj_rpoffline_session_ting/$date/0000/szwg-ston-hdfs.dmop/0000/part-00000"
# baike http://cq01-test-nlp2.cq01.baidu.com:8130/table/view?table_id=347
output="/user/rp-rd/wqw/test/sm/$jobname/$date/0000"
map_con_num=200
reduce_num=200
main_dir="/home/work/wqw/sm-navi-data-cookie/new/bin"
note
echo "=========================$jobname start ============================="
done_file="${output%/*}/${output##*/}.done"
${hadoop} fs -test -e ${output} && ${hadoop} fs -rmr ${output}
${hadoop} fs -test -e ${done_file} && ${hadoop} fs -rm ${done_file}
echo "-------输出目录,标记文件清理完毕---------------------"
echo "[$0] [NOTE] [`date "+%Y-%m-%d %H:%M:%S"`] [$jobname] start to commit hadoop job"
${hadoop} streaming \
-jobconf mapred.job.name="${task_prefix}" \
-jobconf mapred.job.priority=HIGH \
-jobconf mapred.task.timeout=600000 \
-jobconf mapred.map.tasks=$map_con_num \
-jobconf mapred.reduce.tasks=$reduce_num \
-jobconf stream.memory.limit=1000 \
-jobconf stream.num.map.output.key.fields=2 \
-jobconf num.key.fields.for.partition=1 \
-cacheArchive /user/rp-product/dcache/thirdparty/python2.7.tar.gz#py27 \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-jobconf mapred.job.map.capacity=$map_con_num -jobconf mapred.job.reduce.capacity=$reduce_num \
-jobconf mapred.map.max.attempts=10 -jobconf mapred.reduce.max.attempts=10 \
-file $main_dir/hadoop_jobs/session/*.py \
-file $main_dir/tools/hadoop_tool/py27.sh \
-file $main_dir/tools/url_normalize/m \
-cmdenv date_of_data=$date \
-output ${output} \
-input ${input} \
-mapper "sh py27.sh mapper.py" \
-reducer "./m"
if [ $? -ne 0 ]; then
echo "[$0] [Error] [`date "+%Y-%m-%d %H:%M:%S"`] [$jobname] job failed !"
exit -1
fi
#${hadoop} fs -touchz ${done_file}
echo "[$0] [NOTE] [`date "+%Y-%m-%d %H:%M:%S"`] [$jobname] hadoop job finished"
echo "=========================$jobname end ============================="
exit 0
Pig
Pig类似Hive,使用Pig Latin语言写逻辑,翻译成MapReduce任务执行.
HBase
HBase是一种Key/Value系统,它运行在HDFS之上。
- Hbase是为了解决Hadoop的实时性需求。
- HBase是一个分布式 NoSql 数据库,是google的bigtable论文的开源实现。
- HBase可以被理解成一个大的Map数据结构,类似 Map< primarkey, map< key, value» 这种。但是它自动地处理海量数据存储的扩展,通过增加或减少机器来改变数据库的容量限制。
- HBase底层依赖HDFS来实现数据的高可用性,hbase集群由HMaster和HregionServer组成,这两个组件可以独立部署到集群上,也可以部署到Yarn上。
- HBase也是Hadoop家族的成员,所以它对Mrv2,Hive的支持很好,可以作为它们的数据源或者结果存储位置;作为Mrv2数据源的时候,Hbase可以提供在HDFS上的位置信息,实现高效的并行计算。
Tez
- Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:
- (1)Apache二级开源项目(源代码今天发布的)
- (2)运行在YARN之上
- (3) 适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
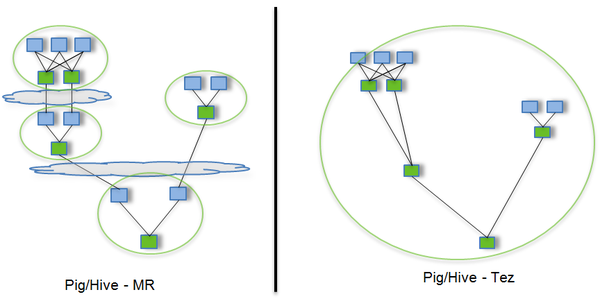
- MapReduce模型虽然很厉害,但不够灵活,一个简单的join都需要很多骚操作才能完成,又是加标签又是笛卡尔积。那有人就说我就是不想这么干那怎么办呢?Tez应运起,图飞入MR。
- Tez采用了DAG(有向无环图)来组织MR任务(DAG中一个节点就是一个RDD,边表示对RDD的操作)。它的核心思想是把将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。
- 图中蓝色框表示Map任务,绿色框表示Reduce任务,云图表示写动作,可以看出,Tez去除了MR中不必要的写过程和Map,形成一张大的DAG图,在数据处理过程中没有网hdfs写数据,直接向后继节点输出,从而提升了效率。
-
- TEZ的构成
- Tez对外提供了6种可编程组件,分别是:
- Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个Key/value
- Output:对输出数据源的抽象,它将用户程序产生的Key/value写入文件系统
- Paritioner:对数据进行分片,类似于MR中的Partitioner
- Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出
- Task:对任务的抽象,每个Task由一个Input、Ouput和Processor组成
- Maser:管理各个Task的依赖关系,并按顺依赖关系执行他们
- 除了以上6种组件,Tez还提供了两种算子,分别是Sort(排序)和Shuffle(混洗),为了用户使用方便,它还提供了多种Input、Output、Task和Sort的实现,具体如下:
- Input实现:LocalMergedInput(文件本地合并后作为输入),ShuffledMergedInput(远程拷贝数据且合并后作为输入)
- Output实现:InMemorySortedOutput(内存排序后输出),LocalOnFileSorterOutput(本地磁盘排序后输出),OnFileSortedOutput(磁盘排序后输出)
- Task实现:RunTimeTask(非常简单的Task,基本没做什么事)
- Sort实现:DefaultSorter(本地数据排序),InMemoryShuffleSorter(远程拷贝数据并排序)
Zeppelin是什么?

- 【2020-12-24】一篇全面的zepplin教程
- zeppelin 安装使用,测试spark,spark sql
- Apache Zeppelin是一款基于Web的Notebook(类似于jupyter notebook),支持交互式地数据分析。
- Zeppelin可实现你所需要的:
- 数据采集
- 数据发现
- 数据分析
- 数据可视化和协作
- 支持多种语言,默认是Scala(背后是Spark shell),SparkSQL, Markdown ,SQL,Shell,Markdown和Python等,Apache Zeppelin提供内置的Apache Spark集成。您不需要为其构建单独的模块,插件或库。
- 安装
- 配置
- zeppelin-site.xml: 修改端口
- zeppelin-env.sh: 修改Hadoop、spark配置等
- 启动
- ./zeppelin-daemon.sh start
- 使用
- 语言

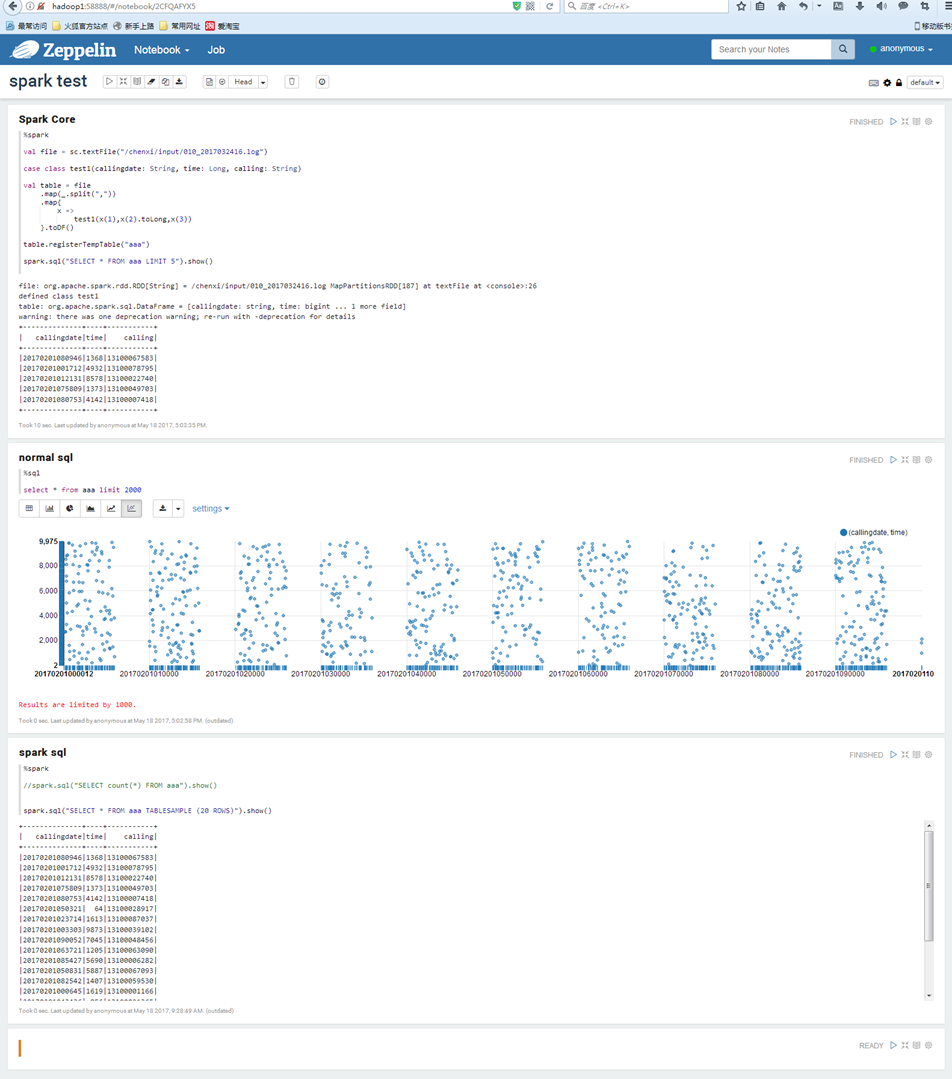

%spark
println("Hello "+z.input("name"))
Spark —— MapReduce进化而来
Spark是第二代大数据处理框架。第一代框架基于简单的 Map Reduce 模型,计算框架和运算的基础是分布式文件系统 HDFS 和分布式资源管理系统 一起被创建出来。Spark沿用现有的分布式文件系统和分布式资源管理系统,在计算模型方面有很大的创新。
Hive可以把sql语句转成多个Mapreduce任务并执行,这和逐个实现Mapper Reducer相比有很大的效率提升;
- Spark是改进了Mrv2运算模型,首先向上层用户提供更多的算子来表达业务逻辑,底层则把每次任务转换成DAG图,对DAG图进行物理运算的时候,更多地利用内存来缓存,减少JVM的启停次数等,通过这些方法大大提高了数据处理速度。
知识点
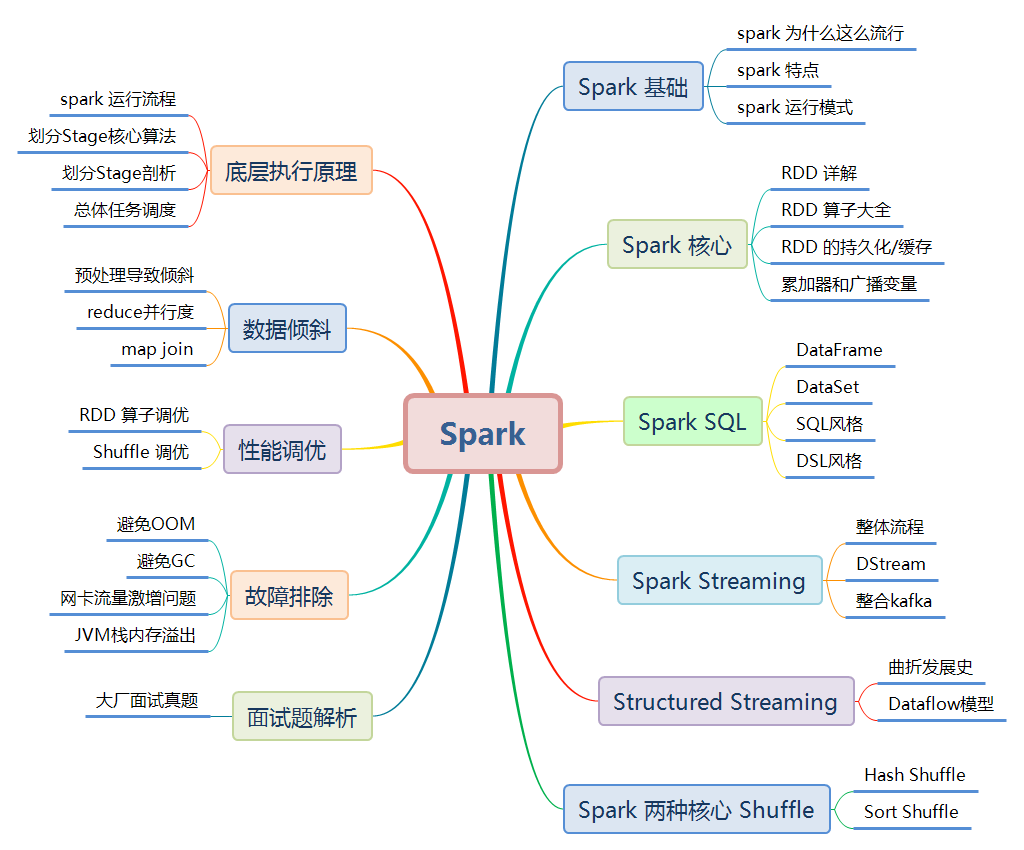
Hadoop vs Spark
| 维度 | Hadoop | Spark |
|---|---|---|
| 类型 | 分布式基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD 组成 DAG 有向无环图, API 较为顶层, 方便使用 |
| 数据存储结构 | MapReduce 中间计算结果存在 HDFS 磁盘上, 延迟大 | RDD 中间运算结果存在内存中 , 延迟小 |
| 运行方式 | Task 以进程方式维护, 任务启动慢 | Task 以线程方式维护, 任务启动快 |
注意:
- 尽管 Spark 相对于 Hadoop 而言具有较大优势,但 Spark 并不能完全替代 Hadoop,Spark 主要用于替代 Hadoop 中的 MapReduce 计算模型。存储依然可以使用 HDFS,但是中间结果可以存放在内存中;调度可以使用 Spark 内置的,也可以使用更成熟的调度系统 YARN 等。
- 实际上,Spark 已经很好地融入了 Hadoop 生态圈,并成为其中的重要一员,它可以借助于 YARN 实现资源调度管理,借助于 HDFS 实现分布式存储。
- 此外,Hadoop 可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark 对硬件的要求稍高一些,对内存与 CPU 有一定的要求。
Spark 运行模式
主要有local模式、Standalone模式、Mesos模式、YARN模式。
运行模式
- (1)local 本地模式(单机)–学习测试使用
- 分为 local 单线程和 local-cluster 多线程。
- (2)standalone 独立集群模式–学习测试使用
- 典型的 Mater/slave 模式。
- (3)standalone-HA 高可用模式–生产环境使用
- 基于 standalone 模式,使用 zk 搭建高可用,避免 Master 是有单点故障的。
- (4)on yarn 集群模式–生产环境使用
- 运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。
- 好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
- (5)on mesos 集群模式–国内使用较少
- 运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
- (6)on cloud 集群模式–中小公司未来会更多的使用云服务
- 比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon 的 S3。
RDD
许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,MapReduce 框架 采用非循环式的数据流模型,把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
AMP 实验室发表的一篇关于 RDD 的论文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》就是为了解决这些问题的。
RDD 提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduec/filter/groupBy…)。
什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。单词拆解:
- Resilient :它是弹性的,RDD 里面的中的数据可以保存在内存中或者磁盘里面;
- Distributed :它里面的元素是分布式存储的,可以用于分布式计算;
- Dataset: 它是一个集合,可以存放很多元素。
RDD 的全称是 Resilient Distributed Datasets,这是Spark的一种数据抽象集合,它可以被执行在分布式的集群上进行各种操作,而且有较强的容错机制。RDD可以被分为若干个分区,每一个分区就是一个数据集片段,从而可以支持分布式计算。
RDD运行时相关的关键名词
- 有 Client、Job、Master、Worker、Driver、Stage、Task以及Executor,这几个东西在调优的时候也会经常遇到的。
- Client:指的是客户端进程,主要负责提交job到Master;
- Job:Job来自于我们编写的程序,Application包含一个或者多个job,job包含各种RDD操作;
- Master:指的是Standalone模式中的主控节点,负责接收来自Client的job,并管理着worker,可以给worker分配任务和资源(主要是driver和executor资源);
- Worker:指的是Standalone模式中的slave节点,负责管理本节点的资源,同时受Master管理,需要定期给Master回报heartbeat(心跳),启动Driver和Executor;
- Driver:指的是 job(作业)的主进程,一般每个Spark作业都会有一个Driver进程,负责整个作业的运行,包括了job的解析、Stage的生成、调度Task到Executor上去执行;
- Stage:中文名 阶段,是job的基本调度单位,因为每个job会分成若干组Task,每组任务就被称为 Stage;
- Task:任务,指的是直接运行在executor上的东西,是executor上的一个线程;
- Executor:指的是 执行器,顾名思义就是真正执行任务的地方了,一个集群可以被配置若干个Executor,每个Executor接收来自Driver的Task,并执行它(可同时执行多个Task)。
RDD算子
RDD 的算子分为两类:
- Transformation
转换操作:返回一个新的 RDD- map、filter、flatmap 等
- Action
动作操作:返回值不是 RDD(无返回值或返回其他的)- reduce、collect、count、first、take 等
注意:
- 1、RDD 不实际存储真正要计算的数据,而是记录了数据的位置在哪里,数据的转换关系(调用了什么方法,传入什么函数)。
- 2、RDD 中的所有转换都是惰性求值/延迟执行的,不会直接计算。只有当发生一个要求返回结果给 Driver 的 Action 动作时,这些转换才会真正运行。
- 3、用惰性求值/延迟执行,是因为这样可以在 Action 时对 RDD 操作形成 DAG
有向无环图进行 Stage 的划分和并行优化,这种设计让 Spark 更加有效率地运行。
RDD操作
RDD 是一个数据集的表示,不仅表示了数据集,还表示了这个数据集从哪来,如何计算,主要属性包括:
- 分区列表
- 计算函数
- 依赖关系
- 分区函数(默认是 hash)
- 最佳位置
总结
- 分区列表、分区函数、最佳位置,这三个属性其实说的就是数据集在哪,在哪计算更合适,如何分区;
- 计算函数、依赖关系,这两个属性其实说的是数据集怎么来的。
示例
- key 表示图书名称,value 表示某天图书销量
- 请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
- 最终结果:(“spark”,4),(“hadoop”,5)。
val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
// 计算平均值
val rdd2 = rdd.groupByKey()
rdd2.collect
//Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4)))
rdd2.mapValues(v=>v.sum/v.size).collect
Array[(String, Int)] = Array((spark,4), (hadoop,5))
// 或
val rdd3 = rdd2.map(t=>(t._1,t._2.sum /t._2.size))
rdd3.collect
惰性执行是RDD的一个特性,在RDD中的算子可以分为Transform算子和Action算子,其中Transform算子操作都不会真正执行,只会记录一下依赖关系,直到遇见了Action算子,在这之前的所有Transform操作才会被触发计算,这就是所谓的惰性执行。具体哪些是Transform和Action算子
RDD 的持久化/缓存
实际开发中某些 RDD 的计算或转换可能会比较耗费时间,如果这些 RDD 后续还会频繁的被使用到,那么可以将这些 RDD 进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //缓存/持久化
rdd2.sortBy(_._2,false).collect//触发action,会去读取HDFS的文件,rdd2会真正执行持久化
rdd2.sortBy(_._2,false).collect//触发action,会去读缓存中的数据,执行速度会比之前快,因为rdd2已经持久化到内存中了
RDD 通过 persist 或 cache 方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
总结:
- RDD 持久化/缓存的目的是为了提高后续操作的速度
- 缓存的级别有很多,默认只存在内存中,开发中使用 memory_and_disk
- 只有执行 action 操作的时候才会真正将 RDD 数据进行持久化/缓存
- 实际开发中如果某一个 RDD 后续会被频繁的使用,可以将该 RDD 进行持久化/缓存
RDD 容错机制 Checkpoint
持久化的局限:
- 持久化/缓存可以把数据放在内存中,虽然是快速的,但也是最不可靠的;
- 也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
问题解决:
- Checkpoint 的产生就是为了更加可靠的数据持久化,在 Checkpoint 的时候一般把数据放在在 HDFS 上,这就天然的借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
SparkContext.setCheckpointDir("目录") //HDFS的目录
RDD.checkpoint
总结:
- 开发中如何保证数据的安全性及读取效率:可以对频繁使用且重要的数据,先做缓存/持久化,再做 checkpint 操作。
- 持久化和 Checkpoint 的区别:
- 位置:Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中) Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期:Cache 和 Persist 的 RDD 会在程序结束后会被清除或者手动调用 unpersist 方法 Checkpoint 的 RDD 在程序结束后依然存在,不会被删除。
RDD 依赖关系
RDD 和它依赖的父 RDD 的关系有两种不同的类型,即宽依赖(wide dependency/shuffle dependency)、窄依赖(narrow dependency)
图解

如何区分宽窄依赖:
窄依赖: 父 RDD 的一个分区只会被子 RDD 的一个分区依赖;宽依赖: 父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle)。
为什么要设计宽窄依赖
对于窄依赖:
- 窄依赖的多个分区可以并行计算;
- 窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
对于宽依赖:
- 划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
DAG
什么是DAG
什么是DAG
- 全称是 Directed Acyclic Graph,中文名是有向无环图。DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
- 原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
- Spark就是借用了DAG对RDD之间的关系进行了建模,用来描述RDD之间的因果依赖关系。因为在一个Spark作业调度中,多个作业任务之间也是相互依赖的,有些任务需要在一些任务执行完成了才可以执行的。在Spark调度中就是有DAGscheduler,它负责将job分成若干组Task组成的Stage。

DAG 的边界
- 开始: 通过 SparkContext 创建的 RDD;
- 结束: 触发 Action,一旦触发 Action 就形成了一个完整的 DAG。
DAG 划分 Stage
DAG划分Stage
-

- 一个 Spark 程序可以有多个 DAG(有几个 Action,就有几个 DAG,上图最后只有一个 Action(图中未表现),那么就是一个 DAG)。
- 一个 DAG 可以有多个 Stage(根据宽依赖/shuffle 进行划分)。
- 同一个 Stage 可以有多个 Task 并行执行(task 数=分区数,如上图,Stage1 中有三个分区 P1、P2、P3,对应的也有三个 Task)。
可以看到这个 DAG 中只 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage。
- 从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
为什么要划分 Stage? –并行计算
- 一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照 shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
如何划分 DAG 的 stage?
- 对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分(将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
- 对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 stage。
RDD 累加器和广播变量
在默认情况下,当 Spark 在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark 提供了两种类型的变量:
- 累加器 accumulators:累加器支持在所有不同节点之间进行累加计算(比如计数或者求和)。
- 广播变量 broadcast variables:广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
Spark生态
Spark的生态也很完善,比如Spark Sql,Spark Streaming,Spark MLlib等

Spark 已经发展成为一个包含多个子项目的集合,其中包含 SparkSQL、Spark Streaming、GraphX、MLlib 等子项目。
- Spark
Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。 - Spark
SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。 - Spark
Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。 - Spark
MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。 GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。- Structured Streaming:处理结构化流,统一了离线和实时的 API。
Spark SQL
命令式
命令式的优点
- 操作粒度更细,能够控制数据的每一个处理环节;
- 操作更明确,步骤更清晰,容易维护;
- 支持半/非结构化数据的操作。
命令式的缺点
- 需要一定的代码功底;
- 写起来比较麻烦。
对于一些数据科学家/数据库管理员/DBA, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以 SQL on Hadoop 是一个非常重要的方向。
SQL介绍
SQL 的优点
- 表达非常清晰, 比如说这段 SQL 明显就是为了查询三个字段,条件是查询年龄大于 10 岁的。
SQL 的缺点
- 试想一下 3 层嵌套的 SQL 维护起来应该挺力不从心的吧;
- 试想一下如果使用 SQL 来实现机器学习算法也挺为难的吧。
SQL 擅长数据分析和通过简单的语法表示查询,命令式操作适合过程式处理和算法性的处理。
- 在 Spark 出现之前,对于结构化数据的查询和处理, 一个工具一向只能支持 SQL 或者命令式,使用者被迫要使用多个工具来适应两种场景,并且多个工具配合起来比较费劲。
- 而 Spark 出现了以后,统一了两种数据处理范式是一种革新性的进步。
SparkSQL 前世今生
- SQL 是数据分析领域一个非常重要的范式,所以 Spark 一直想要支持这种范式,而伴随着一些决策失误,这个过程其实还是非常曲折的。

Hive
- 解决的问题:
- Hive 实现了 SQL on Hadoop,使用 MapReduce 执行任务 简化了 MapReduce 任务。
- 新的问题:
- Hive 的查询延迟比较高,原因是使用 MapReduce 做计算。
Shark
- 解决的问题:
- Shark 改写 Hive 的物理执行计划, 使用 Spark 代替 MapReduce 物理引擎 使用列式内存存储。以上两点使得 Shark 的查询效率很高。
- 新的问题:
- Shark 执行计划的生成严重依赖 Hive,想要增加新的优化非常困难;
Hive 是进程级别的并行,Spark 是线程级别的并行,所以 Hive 中很多线程不安全的代码不适用于 Spark;
由于以上问题,Shark 维护了 Hive 的一个分支,并且无法合并进主线,难以为继;
在 2014 年 7 月 1 日的 Spark Summit 上,Databricks 宣布终止对 Shark 的开发,将重点放到 Spark SQL 上。
SparkSQL-DataFrame
- 解决的问题:
- Spark SQL 执行计划和优化交给优化器 Catalyst;
- 内建了一套简单的 SQL 解析器,可以不使用 HQL;
- 还引入和 DataFrame 这样的 DSL API,完全可以不依赖任何 Hive 的组件
- 新的问题:
- 对于初期版本的 SparkSQL,依然有挺多问题,例如只能支持 SQL 的使用,不能很好的兼容命令式,入口不够统一等。
SparkSQL-Dataset
- SparkSQL 在 1.6 时代,增加了一个新的 API,叫做 Dataset,Dataset 统一和结合了 SQL 的访问和命令式 API 的使用,这是一个划时代的进步。
- 在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据,然后使用命令式 API 进行探索式分析。
SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行。

Spark 处理什么样的数据?
- RDD 主要用于处理非结构化数据 、半结构化数据、结构化;
- SparkSQL 主要用于处理结构化数据(较为规范的半结构化数据也可以处理)。
总结:
- SparkSQL 是一个既支持 SQL 又支持命令式数据处理的工具;
- SparkSQL 的主要适用场景是处理结构化数据(较为规范的半结构化数据也可以处理)。
SparkSql常用命令操作
- 进入spark-shell模式
- spark-shell –master yarn –executor-memory 4g –num-executors 3 –executor-cores 4
- spark sql查询Hive数据库
- import spark.sql
- sql(“use database_name”)
- sql(“show tables”).show
- 读取hdfs文件数据
- val data = spark.read.format(“csv”).option(“sep”, “,”).option(“header”,”true”).load(“file_path + file_name”)
- 存储文件(默认hdfs路径)
- data.write.format(“csv”).save(“/data/….”)
- 读取hive表数据
- val res = spark.sql(“select * from table_1 where day=’20181230’”)
- 注册成表
- res.registerTempTable(“Res”)
- 更换属性
- val ss = data.selectExpr(“_c0 as like”,”_c1 as session_id”,”_c2 as uid1”)
- 删除某列属性
- val s1 = data.drop(“_c0”)
- 一列转换成多列
- val df2 =df1.withColumn(“_corrupt_record”,split(col(“_corrupt_record”),”,”))
- .select(col(“_corrupt_record”).getItem(0).as(“uid”),col(“_corrupt_record”).getItem(1).as(“number”))
- 过滤数字(三个横线)
- val uid = df2.filter($”number”===1)
- 过滤空值
- val s_1 = res.filter(“like is not null”).filter(“session_id is not null”)
- Spark SQL CLI是一个很方便的工具,可以用来在本地模式下运行Hive的元数据服务,并且通过命令行执行针对Hive的SQL查询。但是要注意的是,Spark SQL CLI是不能与Thrift JDBC server进行通信的。如果要启动Spark SQL CLI,只要执行Spark的bin目录下的spark-sql命令即可
- sh ./bin/spark-sql –jars /usr/local/hive/lib/mysql-connector-java-5.1.17.jar
- 同样要注意的是,必须将我们的hive-site.xml文件放在Spark的conf目录下。也可以通过执行./bin/spark-sql –help命令,来获取该命令的所有帮助选项。
- spark sql命令模板
spark-sql
--conf spark.scheduler.listenerbus.eventqueue.size=90000000
--driver-cores 4
--driver-memory 10g
--executor-memory 80g
--num-executors 40
--executor-cores 20
--master yarn << EOF
**HIVESQL**
EOF
Spark SQL 数据抽象
1) DataFrame
什么是 DataFrame
- DataFrame 的前身是 SchemaRDD,从 Spark 1.3.0 开始 SchemaRDD 更名为 DataFrame。并不再直接继承自 RDD,而是自己实现了 RDD 的绝大多数功能。
- DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,带有 Schema 元信息(可以理解为数据库的列名和类型)。
总结:
- DataFrame 就是一个分布式的表;
- DataFrame = RDD - 泛型 + SQL 的操作 + 优化。
2) DataSet
DataSet:
- DataSet 是在 Spark1.6 中添加的新的接口。
- 与 RDD 相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
- 与 DataFrame 相比,保存了类型信息,是强类型的,提供了编译时类型检查。
调用 Dataset 的方法先会生成逻辑计划,然后被 spark 的优化器进行优化,最终生成物理计划,然后提交到集群中运行!
DataSet 包含了 DataFrame 的功能。
RDD、DataFrame、DataSet 的区别
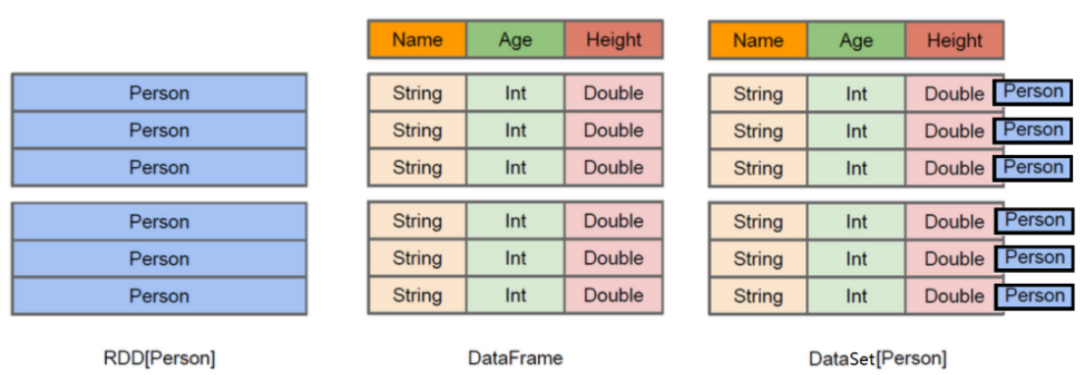
- RDD[ Person]:以 Person 为类型参数,但不了解 其内部结构。
- DataFrame:提供了详细的结构信息 schema 列的名称和类型。这样看起来就像一张表了。
- DataSet[ Person]: 不光有 schema 信息,还有类型信息。
总结
- DataFrame = RDD - 泛型 + Schema + SQL + 优化
- DataSet = DataFrame + 泛型
- DataSet = RDD + Schema + SQL + 优化
-- Spark为了提高性能会缓存Parquet的元数据信息
refresh table test.mytest; -- 刷新缓存里的表元数据
refresh table mytest; -- 刷新当前数据库里的表元数据
refer to here
Invalidates the cached entries for Apache Spark cache, which include data and metadata of the given table or view. The invalidated cache is populated in lazy manner when the cached table or the query associated with it is executed again.
Spark SQL 案例
# spark启动
spark-sql
# 退出
spark-sql> quit; # 退出spark-sql
spark-sql> exit;
show databases; -- 1、查看已有的database
use databaseName; -- 切换数据库
create database myDatabase; -- 2、创建数据库
use myDatabase -- 3、登录数据库myDatabase;
-- 4、查看已有的table
show tables; -- 查看所有表
show tables 'KHDX'; -- 支持模糊查询,表名包含KHDX
-- 5、创建表
-- 建表
create table tab_test(
name string,
age int,
num1 double,
num2 bigint,
msg varchar(80) --最后一个字段后面不能有 ',' 号
)
partitioned by (p_age int,p_name string) --分区信息
row format delimited fields terminated by ',' --数据中,属性间用逗号分隔
stored as textfile location '/tab/test/tab_test'; --保存路径,最后也可带'/' 即写成 '/tab/test/tab_test/'
-- stored as orc ;orc类型的表,手动推数据(txt / csv 文件;无需表头,行尾无需',',数据文件保存为unix utf-8 无bom格式)不行;
--可以借助textfile类型的临时表插入数据;插入时,要注意字段顺序对应一致。
--指定分区,追加插入;最好不要用 'seletc * ' 表字段变化时,*指代的内容不一样
insert into table tab_test_orc partition(p_age=10,p_name='lucy') select name,age,num1,num2,msg from tab_test_temp;
--指定分区,覆盖插入
insert overwrite table tab_test_orc partition(p_age=10,p_name='lucy') select name,age,num1,num2,msg from tab_test_temp;
-- 6、显示表结构
desc khdx_hy; -- 显示表khdx_hy的表结构
desc formatted khdx_hy; -- 格式化表khdx_hy的表结构信息,信息更详细,包括在hdfs的存储位置
show partitions khdx_hy; -- 显示表khdx_hy的分区信息
show create table khdx_hy; -- 查看建表语句
-- 7、修改表结构
alter table myDatabase.nbzz_ckmxz add partition(tjrq='20171231')add partition(tjrq='20180101') -- 手动给分区表增加2个分区
alter table myDatabase.nbzz_ckmxz drop if exists partition (tjrq='20171231'); -- 手动删除分区表某个分区
alter table myDatabase.nbzz_ckmxz add columns (fh string); -- 追加字段
alter table myDatabase.nbzz_ckmxz change hydh hydh1 string; -- 修改字段hydh名称为hydh1,类型为string
drop table myDatabase.nbzz_ckmxz; -- 删除表
alter table myDatabase.tmp_nbzz_ckmxz rename to myDatabase.nbzz_ckmxz; -- 重命名表
--删表中数据:
truncate table tab_test; --执行后,分区依然存在
truncate table tab_test partition(p_age=10,p_name='Tom'); --删除某分区
-- 8、操作表
select * from myDatabase.khdx_hy order by hydh limit 10; -- 查询表,显示前10条记录。
truncate table khdx_hy; -- 清空表数据
-- [2022-8-9] 实战用到这句
-- 数据写入
insert overwrite table myDatabase.tmp_khdx_hy select * from myDatabase.khdx_hy; -- 用khdx_hy的数据覆盖tmp_khdx_hy数据;
insert into myDatabase.tmp_khdx_hy select * from myDatabase.khdx_hy; -- 用khdx_hy的数据追加tmp_khdx_hy数据中,不覆盖原来数据。
-- 本地数据
load data local inpath '/home/myDatabase/data/org_info.txt' overwrite into table myDatabase.org_info ; -- 从文件中导入数据到表中
load data local inpath '/home/myDatabase/data/t_ma_fct_etl_acct_liyang_20171231.dat' overwrite into table myDatabase.T_MA_FCT_ETL_ACCT partition(tjrq="20171231");
-- 从文件导入数据至表的某个分区。
insert overwrite local directory '/home/myDatabase/data/khdx_hy.txt' row format delimited fields terminated by '\t' select * FROM myDatabase.KHDX_HY;
-- 从表khdx_hy导出数据至本地文件khdx_hy.txt
-- 9、分区操作
--增加分区:
alter table tab_test add if not exists partition(p_age=11,p_name="Tom");
alter table tab_test add partition(p_age=10,p_name='Tom'); --需要指定所有的分区,不能只是p_age或p_name;否则org.apache.spark.sql.execution.QueryExecutionException:doesn't contain all (2) partition columns
--查看分区:
show partitions tab_test;
-- 0: jdbc:hive2://vmax32:18000> show partitions tab_test;
+----------------------+ | result | +----------------------+ | p_age=10/p_name=Tom | +----------------------+ 1 row selected (0.083 seconds)
--删除分区
alter table tab_test drop if exists partition(p_age=10);
--删除分区时,可以只指定局部
alter table tab_test drop partition(p_name='Tom');
--只执行该条语句,p_age=10分区连同一起被删掉,show partitions 结果为空;hdfs dfs -ls 也看不到 p_age=10的分区
alter table tab_test add partition(p_age=10,p_name='cat');
--只drop p_name='Tome', p_name='cat' 的分区还存在,show partitions 可以查到
-- 动态分区
-- 动态分区匹配最后选出的字段;只与字段顺序有关系,与名字无关;同时存在静态和动态分区,动态分区必须在静态分区之后
insert into table tab_test(p_age,p_name)
select name,
age,
num1,
num2,
msg,
age as pppp_age, --取不取别名都可以;分区需要出现在select出来的字段的最后位置,为了匹配。
name as p_name --写个对应的别名,看上去好理解一点
from tab_test_temp;
PySpark
【2022-8-1】3万字长文 PySpark入门级学习教程,框架思维
读数据
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()
df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)
df.printSchema() # 显示表头
# 转成pandas格式
pd.DataFrame(df.take(5), columns=df.columns).transpose()
df.toPandas()
# 分组
df.groupby('Outcome').count().toPandas()
# 描述性统计
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']
df.select(numeric_features)\
.describe()\
.toPandas()\
.transpose()
常用算子
PySpark常用算子:
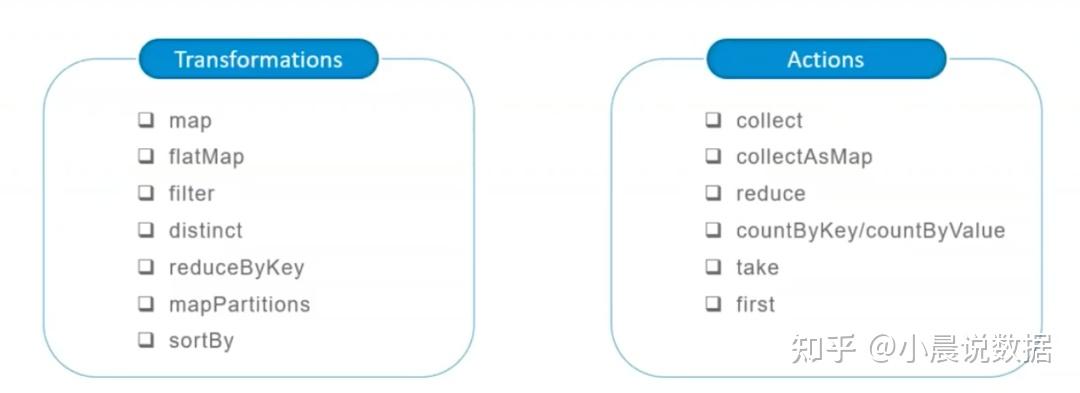
import os
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]")
sc = SparkContext(conf=conf)
# 使用 parallelize方法直接实例化一个RDD
rdd = sc.parallelize(range(1,11),4) # 这里的 4 指的是分区数量
rdd.take(100)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
transform算子
# 以下的操作由于是Transform操作,因为我们需要在最后加上一个collect算子用来触发计算。
# 1. map: 和python差不多,map转换就是对每一个元素进行一个映射
rdd = sc.parallelize(range(1, 11), 4)
rdd_map = rdd.map(lambda x: x*2)
print("原始数据:", rdd.collect())
print("扩大2倍:", rdd_map.collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 扩大2倍: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
# 2. flatMap: 这个相比于map多一个flat(压平)操作,顾名思义就是要把高维的数组变成一维
rdd2 = sc.parallelize(["hello SamShare", "hello PySpark"])
print("原始数据:", rdd2.collect())
print("直接split之后的map结果:", rdd2.map(lambda x: x.split(" ")).collect())
print("直接split之后的flatMap结果:", rdd2.flatMap(lambda x: x.split(" ")).collect())
# 直接split之后的map结果: [['hello', 'SamShare'], ['hello', 'PySpark']]
# 直接split之后的flatMap结果: ['hello', 'SamShare', 'hello', 'PySpark']
# 3. filter: 过滤数据
rdd = sc.parallelize(range(1, 11), 4)
print("原始数据:", rdd.collect())
print("过滤奇数:", rdd.filter(lambda x: x % 2 == 0).collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 过滤奇数: [2, 4, 6, 8, 10]
# 4. distinct: 去重元素
rdd = sc.parallelize([2, 2, 4, 8, 8, 8, 8, 16, 32, 32])
print("原始数据:", rdd.collect())
print("去重数据:", rdd.distinct().collect())
# 原始数据: [2, 2, 4, 8, 8, 8, 8, 16, 32, 32]
# 去重数据: [4, 8, 16, 32, 2]
# 5. reduceByKey: 根据key来映射数据
from operator import add
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print("原始数据:", rdd.collect())
print("原始数据:", rdd.reduceByKey(add).collect())
# 原始数据: [('a', 1), ('b', 1), ('a', 1)]
# 原始数据: [('b', 1), ('a', 2)]
# 6. mapPartitions: 根据分区内的数据进行映射操作
rdd = sc.parallelize([1, 2, 3, 4], 2)
def f(iterator):
yield sum(iterator)
print(rdd.collect())
print(rdd.mapPartitions(f).collect())
# [1, 2, 3, 4]
# [3, 7]
# 7. sortBy: 根据规则进行排序
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
print(sc.parallelize(tmp).sortBy(lambda x: x[0]).collect())
print(sc.parallelize(tmp).sortBy(lambda x: x[1]).collect())
# [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
# [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
# 8. subtract: 数据集相减, Return each value in self that is not contained in other.
x = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 3)])
y = sc.parallelize([("a", 3), ("c", None)])
print(sorted(x.subtract(y).collect()))
# [('a', 1), ('b', 4), ('b', 5)]
# 9. union: 合并两个RDD
rdd = sc.parallelize([1, 1, 2, 3])
print(rdd.union(rdd).collect())
# [1, 1, 2, 3, 1, 1, 2, 3]
# 10. intersection: 取两个RDD的交集,同时有去重的功效
rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5, 2, 3])
rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
print(rdd1.intersection(rdd2).collect())
# [1, 2, 3]
# 11. cartesian: 生成笛卡尔积
rdd = sc.parallelize([1, 2])
print(sorted(rdd.cartesian(rdd).collect()))
# [(1, 1), (1, 2), (2, 1), (2, 2)]
# 12. zip: 拉链合并,需要两个RDD具有相同的长度以及分区数量
x = sc.parallelize(range(0, 5))
y = sc.parallelize(range(1000, 1005))
print(x.collect())
print(y.collect())
print(x.zip(y).collect())
# [0, 1, 2, 3, 4]
# [1000, 1001, 1002, 1003, 1004]
# [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)]
# 13. zipWithIndex: 将RDD和一个从0开始的递增序列按照拉链方式连接。
rdd_name = sc.parallelize(["LiLei", "Hanmeimei", "Lily", "Lucy", "Ann", "Dachui", "RuHua"])
rdd_index = rdd_name.zipWithIndex()
print(rdd_index.collect())
# [('LiLei', 0), ('Hanmeimei', 1), ('Lily', 2), ('Lucy', 3), ('Ann', 4), ('Dachui', 5), ('RuHua', 6)]
# 14. groupByKey: 按照key来聚合数据
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(rdd.collect())
print(sorted(rdd.groupByKey().mapValues(len).collect()))
print(sorted(rdd.groupByKey().mapValues(list).collect()))
# [('a', 1), ('b', 1), ('a', 1)]
# [('a', 2), ('b', 1)]
# [('a', [1, 1]), ('b', [1])]
# 15. sortByKey:
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
print(sc.parallelize(tmp).sortByKey(True, 1).collect())
# [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
# 16. join:
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2), ("a", 3)])
print(sorted(x.join(y).collect()))
# [('a', (1, 2)), ('a', (1, 3))]
# 17. leftOuterJoin/rightOuterJoin
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
print(sorted(x.leftOuterJoin(y).collect()))
# [('a', (1, 2)), ('b', (4, None))]
action算子
# 1. collect: 指的是把数据都汇集到driver端,便于后续的操作
rdd = sc.parallelize(range(0, 5))
rdd_collect = rdd.collect()
print(rdd_collect)
# [0, 1, 2, 3, 4]
# 2. first: 取第一个元素
sc.parallelize([2, 3, 4]).first()
# 2
# 3. collectAsMap: 转换为dict,使用这个要注意了,不要对大数据用,不然全部载入到driver端会爆内存
m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap()
m
# {1: 2, 3: 4}
# 4. reduce: 逐步对两个元素进行操作
rdd = sc.parallelize(range(10),5)
print(rdd.reduce(lambda x,y:x+y))
# 45
# 5. countByKey/countByValue:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(sorted(rdd.countByKey().items()))
print(sorted(rdd.countByValue().items()))
# [('a', 2), ('b', 1)]
# [(('a', 1), 2), (('b', 1), 1)]
# 6. take: 相当于取几个数据到driver端
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(rdd.take(5))
# [('a', 1), ('b', 1), ('a', 1)]
# 7. saveAsTextFile: 保存rdd成text文件到本地
text_file = "./data/rdd.txt"
rdd = sc.parallelize(range(5))
rdd.saveAsTextFile(text_file)
# 8. takeSample: 随机取数
rdd = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量
rdd_sample = rdd.takeSample(True, 2, 0) # withReplacement 参数1:代表是否是有放回抽样
rdd_sample
# 9. foreach: 对每一个元素执行某种操作,不生成新的RDD
rdd = sc.parallelize(range(10), 5)
accum = sc.accumulator(0)
rdd.foreach(lambda x: accum.add(x))
print(accum.value)
# 45
DataFrame 创建
SparkDataFrame 几种创建的方法,分别是
- 使用RDD来创建
- 使用python的DataFrame来创建
- 使用List来创建
- 读取数据文件来创建
- 通过读取数据库来创建
RDD创建
rdd = sc.parallelize([("Sam", 28, 88), ("Flora", 28, 90), ("Run", 1, 60)])
df = rdd.toDF(["name", "age", "score"])
df.show()
df.printSchema()
# +-----+---+-----+
# | name|age|score|
# +-----+---+-----+
# | Sam| 28| 88|
# |Flora| 28| 90|
# | Run| 1| 60|
# +-----+---+-----+
# root
# |-- name: string (nullable = true)
# |-- age: long (nullable = true)
# |-- score: long (nullable = true)
DataFrame来创建
df = pd.DataFrame([['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]],
columns=['name', 'age', 'score'])
print(">> 打印DataFrame:")
print(df)
print("\n")
Spark_df = spark.createDataFrame(df)
print(">> 打印SparkDataFrame:")
Spark_df.show()
# >> 打印DataFrame:
# name age score
# 0 Sam 28 88
# 1 Flora 28 90
# 2 Run 1 60
# >> 打印SparkDataFrame:
# +-----+---+-----+
# | name|age|score|
# +-----+---+-----+
# | Sam| 28| 88|
# |Flora| 28| 90|
# | Run| 1| 60|
# +-----+---+-----+
List来创建
list_values = [['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]]
Spark_df = spark.createDataFrame(list_values, ['name', 'age', 'score'])
Spark_df.show()
# +-----+---+-----+
# | name|age|score|
# +-----+---+-----+
# | Sam| 28| 88|
# |Flora| 28| 90|
# | Run| 1| 60|
# +-----+---+-----+
读取数据文件来创建
# 4.1 CSV文件
df = spark.read.option("header", "true")\
.option("inferSchema", "true")\
.option("delimiter", ",")\
.csv("./test/data/titanic/train.csv")
df.show(5)
df.printSchema()
# 4.2 json文件
df = spark.read.json("./test/data/hello_samshare.json")
df.show(5)
df.printSchema()
通过读取数据库来创建
# 5.1 读取hive数据
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
spark.sql("LOAD DATA LOCAL INPATH 'data/kv1.txt' INTO TABLE src")
df = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
df.show(5)
# 5.2 读取mysql数据
url = "jdbc:mysql://localhost:3306/test"
df = spark.read.format("jdbc") \
.option("url", url) \
.option("dbtable", "runoob_tbl") \
.option("user", "root") \
.option("password", "8888") \
.load()\
df.show()
DataFrame API
SparkDataFrame API
- 查看DataFrame的APIs
- 简单处理DataFrame的APIs
- DataFrame的列操作APIs
- DataFrame的一些思路变换操作APIs
- DataFrame的一些统计操作APIs
数据集准备
from pyspark.sql import functions as F
from pyspark.sql import SparkSession
# SparkSQL的许多功能封装在SparkSession的方法接口中, SparkContext则不行的。
spark = SparkSession.builder \
.appName("sam_SamShare") \
.config("master", "local[4]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
# 创建一个SparkDataFrame
rdd = sc.parallelize([("Sam", 28, 88, "M"),
("Flora", 28, 90, "F"),
("Run", 1, 60, None),
("Peter", 55, 100, "M"),
("Mei", 54, 95, "F")])
df = rdd.toDF(["name", "age", "score", "sex"])
df.show()
df.printSchema()
# +-----+---+-----+----+
# | name|age|score| sex|
# +-----+---+-----+----+
# | Sam| 28| 88| M|
# |Flora| 28| 90| F|
# | Run| 1| 60|null|
# |Peter| 55| 100| M|
# | Mei| 54| 95| F|
# +-----+---+-----+----+
# root
# |-- name: string (nullable = true)
# |-- age: long (nullable = true)
# |-- score: long (nullable = true)
# |-- sex: string (nullable = true)
查看
# DataFrame.collect
# 以列表形式返回行
df.collect()
# [Row(name='Sam', age=28, score=88, sex='M'),
# Row(name='Flora', age=28, score=90, sex='F'),
# Row(name='Run', age=1, score=60, sex=None),
# Row(name='Peter', age=55, score=100, sex='M'),
# Row(name='Mei', age=54, score=95, sex='F')]
# DataFrame.count
df.count()
# 5
# DataFrame.columns
df.columns
# ['name', 'age', 'score', 'sex']
# DataFrame.dtypes
df.dtypes
# [('name', 'string'), ('age', 'bigint'), ('score', 'bigint'), ('sex', 'string')]
# DataFrame.describe
# 返回列的基础统计信息
df.describe(['age']).show()
# +-------+------------------+
# |summary| age|
# +-------+------------------+
# | count| 5|
# | mean| 33.2|
# | stddev|22.353970564532826|
# | min| 1|
# | max| 55|
# +-------+------------------+
df.describe().show()
# +-------+-----+------------------+------------------+----+
# |summary| name| age| score| sex|
# +-------+-----+------------------+------------------+----+
# | count| 5| 5| 5| 4|
# | mean| null| 33.2| 86.6|null|
# | stddev| null|22.353970564532826|15.582040944625966|null|
# | min|Flora| 1| 60| F|
# | max| Sam| 55| 100| M|
# +-------+-----+------------------+------------------+----+
# DataFrame.select
# 选定指定列并按照一定顺序呈现
df.select("sex", "score").show()
# DataFrame.first
# DataFrame.head
# 查看第1条数据
df.first()
# Row(name='Sam', age=28, score=88, sex='M')
df.head(1)
# [Row(name='Sam', age=28, score=88, sex='M')]
# DataFrame.freqItems
# 查看指定列的枚举值
df.freqItems(["age","sex"]).show()
# +---------------+-------------+
# | age_freqItems|sex_freqItems|
# +---------------+-------------+
# |[55, 1, 28, 54]| [M, F,]|
# +---------------+-------------+
# DataFrame.summary
df.summary().show()
# +-------+-----+------------------+------------------+----+
# |summary| name| age| score| sex|
# +-------+-----+------------------+------------------+----+
# | count| 5| 5| 5| 4|
# | mean| null| 33.2| 86.6|null|
# | stddev| null|22.353970564532826|15.582040944625966|null|
# | min|Flora| 1| 60| F|
# | 25%| null| 28| 88|null|
# | 50%| null| 28| 90|null|
# | 75%| null| 54| 95|null|
# | max| Sam| 55| 100| M|
# +-------+-----+------------------+------------------+----+
# DataFrame.sample
# 按照一定规则从df随机抽样数据
df.sample(0.5).show()
# +-----+---+-----+----+
# | name|age|score| sex|
# +-----+---+-----+----+
# | Sam| 28| 88| M|
# | Run| 1| 60|null|
# |Peter| 55| 100| M|
# +-----+---+-----+----+
简单处理
# DataFrame.distinct
# 对数据集进行去重
df.distinct().show()
# DataFrame.dropDuplicates
# 对指定列去重
df.dropDuplicates(["sex"]).show()
# +-----+---+-----+----+
# | name|age|score| sex|
# +-----+---+-----+----+
# |Flora| 28| 90| F|
# | Run| 1| 60|null|
# | Sam| 28| 88| M|
# +-----+---+-----+----+
# DataFrame.exceptAll
# DataFrame.subtract
# 根据指定的df对df进行去重
df1 = spark.createDataFrame(
[("a", 1), ("a", 1), ("b", 3), ("c", 4)], ["C1", "C2"])
df2 = spark.createDataFrame([("a", 1), ("b", 3)], ["C1", "C2"])
df3 = df1.exceptAll(df2) # 没有去重的功效
df4 = df1.subtract(df2) # 有去重的奇效
df1.show()
df2.show()
df3.show()
df4.show()
# +---+---+
# | C1| C2|
# +---+---+
# | a| 1|
# | a| 1|
# | b| 3|
# | c| 4|
# +---+---+
# +---+---+
# | C1| C2|
# +---+---+
# | a| 1|
# | b| 3|
# +---+---+
# +---+---+
# | C1| C2|
# +---+---+
# | a| 1|
# | c| 4|
# +---+---+
# +---+---+
# | C1| C2|
# +---+---+
# | c| 4|
# +---+---+
# DataFrame.intersectAll
# 返回两个DataFrame的交集
df1 = spark.createDataFrame(
[("a", 1), ("a", 1), ("b", 3), ("c", 4)], ["C1", "C2"])
df2 = spark.createDataFrame([("a", 1), ("b", 4)], ["C1", "C2"])
df1.intersectAll(df2).show()
# +---+---+
# | C1| C2|
# +---+---+
# | a| 1|
# +---+---+
# DataFrame.drop
# 丢弃指定列
df.drop('age').show()
# DataFrame.withColumn
# 新增列
df1 = df.withColumn("birth_year", 2021 - df.age)
df1.show()
# +-----+---+-----+----+----------+
# | name|age|score| sex|birth_year|
# +-----+---+-----+----+----------+
# | Sam| 28| 88| M| 1993|
# |Flora| 28| 90| F| 1993|
# | Run| 1| 60|null| 2020|
# |Peter| 55| 100| M| 1966|
# | Mei| 54| 95| F| 1967|
# +-----+---+-----+----+----------+
# DataFrame.withColumnRenamed
# 重命名列名
df1 = df.withColumnRenamed("sex", "gender")
df1.show()
# +-----+---+-----+------+
# | name|age|score|gender|
# +-----+---+-----+------+
# | Sam| 28| 88| M|
# |Flora| 28| 90| F|
# | Run| 1| 60| null|
# |Peter| 55| 100| M|
# | Mei| 54| 95| F|
# +-----+---+-----+------+
# DataFrame.dropna
# 丢弃空值,DataFrame.dropna(how='any', thresh=None, subset=None)
df.dropna(how='all', subset=['sex']).show()
# +-----+---+-----+---+
# | name|age|score|sex|
# +-----+---+-----+---+
# | Sam| 28| 88| M|
# |Flora| 28| 90| F|
# |Peter| 55| 100| M|
# | Mei| 54| 95| F|
# +-----+---+-----+---+
# DataFrame.fillna
# 空值填充操作
df1 = spark.createDataFrame(
[("a", None), ("a", 1), (None, 3), ("c", 4)], ["C1", "C2"])
# df2 = df1.na.fill({"C1": "d", "C2": 99})
df2 = df1.fillna({"C1": "d", "C2": 99})
df1.show()
df2.show()
# DataFrame.filter
# 根据条件过滤
df.filter(df.age>50).show()
# +-----+---+-----+---+
# | name|age|score|sex|
# +-----+---+-----+---+
# |Peter| 55| 100| M|
# | Mei| 54| 95| F|
# +-----+---+-----+---+
df.where(df.age==28).show()
# +-----+---+-----+---+
# | name|age|score|sex|
# +-----+---+-----+---+
# | Sam| 28| 88| M|
# |Flora| 28| 90| F|
# +-----+---+-----+---+
df.filter("age<18").show()
# +----+---+-----+----+
# |name|age|score| sex|
# +----+---+-----+----+
# | Run| 1| 60|null|
# +----+---+-----+----+
# DataFrame.join
# 这个不用多解释了,直接上案例来看看具体的语法即可,DataFrame.join(other, on=None, how=None)
df1 = spark.createDataFrame(
[("a", 1), ("d", 1), ("b", 3), ("c", 4)], ["id", "num1"])
df2 = spark.createDataFrame([("a", 1), ("b", 3)], ["id", "num2"])
df1.join(df2, df1.id == df2.id, 'left').select(df1.id.alias("df1_id"),
df1.num1.alias("df1_num"),
df2.num2.alias("df2_num")
).sort(["df1_id"], ascending=False)\
.show()
# DataFrame.agg(*exprs)
# 聚合数据,可以写多个聚合方法,如果不写groupBy的话就是对整个DF进行聚合
# DataFrame.alias
# 设置列或者DataFrame别名
# DataFrame.groupBy
# 根据某几列进行聚合,如有多列用列表写在一起,如 df.groupBy(["sex", "age"])
df.groupBy("sex").agg(F.min(df.age).alias("最小年龄"),
F.expr("avg(age)").alias("平均年龄"),
F.expr("collect_list(name)").alias("姓名集合")
).show()
# +----+--------+--------+------------+
# | sex|最小年龄|平均年龄| 姓名集合|
# +----+--------+--------+------------+
# | F| 28| 41.0|[Flora, Mei]|
# |null| 1| 1.0| [Run]|
# | M| 28| 41.5|[Sam, Peter]|
# +----+--------+--------+------------+
# DataFrame.foreach
# 对每一行进行函数方法的应用
def f(person):
print(person.name)
df.foreach(f)
# Peter
# Run
# Sam
# Flora
# Mei
# DataFrame.replace
# 修改df里的某些值
df1 = df.na.replace({"M": "Male", "F": "Female"})
df1.show()
# DataFrame.union
# 相当于SQL里的union all操作
df1 = spark.createDataFrame(
[("a", 1), ("d", 1), ("b", 3), ("c", 4)], ["id", "num"])
df2 = spark.createDataFrame([("a", 1), ("b", 3)], ["id", "num"])
df1.union(df2).show()
df1.unionAll(df2).show()
# 这里union没有去重,不知道为啥,有知道的朋友麻烦解释下,谢谢了。
# +---+---+
# | id|num|
# +---+---+
# | a| 1|
# | d| 1|
# | b| 3|
# | c| 4|
# | a| 1|
# | b| 3|
# +---+---+
# DataFrame.unionByName
# 根据列名来进行合并数据集
df1 = spark.createDataFrame([[1, 2, 3]], ["col0", "col1", "col2"])
df2 = spark.createDataFrame([[4, 5, 6]], ["col1", "col2", "col0"])
df1.unionByName(df2).show()
# +----+----+----+
# |col0|col1|col2|
# +----+----+----+
# | 1| 2| 3|
# | 6| 4| 5|
# +----+----+----+
列操作
- 针对列进行操作,比如说重命名、排序、空值判断、类型判断等
Column.alias(*alias, **kwargs) # 重命名列名
Column.asc() # 按照列进行升序排序
Column.desc() # 按照列进行降序排序
Column.astype(dataType) # 类型转换
Column.cast(dataType) # 强制转换类型
Column.between(lowerBound, upperBound) # 返回布尔值,是否在指定区间范围内
Column.contains(other) # 是否包含某个关键词
Column.endswith(other) # 以什么结束的值,如 df.filter(df.name.endswith('ice')).collect()
Column.isNotNull() # 筛选非空的行
Column.isNull()
Column.isin(*cols) # 返回包含某些值的行 df[df.name.isin("Bob", "Mike")].collect()
Column.like(other) # 返回含有关键词的行
Column.when(condition, value) # 给True的赋值
Column.otherwise(value) # 与when搭配使用,df.select(df.name, F.when(df.age > 3, 1).otherwise(0)).show()
Column.rlike(other) # 可以使用正则的匹配 df.filter(df.name.rlike('ice$')).collect()
Column.startswith(other) # df.filter(df.name.startswith('Al')).collect()
Column.substr(startPos, length) # df.select(df.name.substr(1, 3).alias("col")).collect()
变换
# DataFrame.createOrReplaceGlobalTempView
# DataFrame.dropGlobalTempView
# 创建全局的试图,注册后可以使用sql语句来进行操作,生命周期取决于Spark application本身
df.createOrReplaceGlobalTempView("people")
spark.sql("select * from global_temp.people where sex = 'M' ").show()
# +-----+---+-----+---+
# | name|age|score|sex|
# +-----+---+-----+---+
# | Sam| 28| 88| M|
# |Peter| 55| 100| M|
# +-----+---+-----+---+
# DataFrame.createOrReplaceTempView
# DataFrame.dropTempView
# 创建本地临时试图,生命周期取决于用来创建此数据集的SparkSession
df.createOrReplaceTempView("tmp_people")
spark.sql("select * from tmp_people where sex = 'F' ").show()
# +-----+---+-----+---+
# | name|age|score|sex|
# +-----+---+-----+---+
# |Flora| 28| 90| F|
# | Mei| 54| 95| F|
# +-----+---+-----+---+
# DataFrame.cache\DataFrame.persist
# 可以把一些数据放入缓存中,default storage level (MEMORY_AND_DISK).
df.cache()
df.persist()
df.unpersist()
# DataFrame.crossJoin
# 返回两个DataFrame的笛卡尔积关联的DataFrame
df1 = df.select("name", "sex")
df2 = df.select("name", "sex")
df3 = df1.crossJoin(df2)
print("表1的记录数", df1.count())
print("表2的记录数", df2.count())
print("笛卡尔积后的记录数", df3.count())
# 表1的记录数 5
# 表2的记录数 5
# 笛卡尔积后的记录数 25
# DataFrame.toPandas
# 把SparkDataFrame转为 Pandas的DataFrame
df.toPandas()
# DataFrame.rdd
# 把SparkDataFrame转为rdd,这样子可以用rdd的语法来操作数据
df.rdd
统计
# DataFrame.cov
# 计算指定两列的样本协方差
df.cov("age", "score")
# 324.59999999999997
# DataFrame.corr
# 计算指定两列的相关系数,DataFrame.corr(col1, col2, method=None),目前method只支持Pearson相关系数
df.corr("age", "score", method="pearson")
# 0.9319004030498815
# DataFrame.cube
# 创建多维度聚合的结果,通常用于分析数据,比如我们指定两个列进行聚合,比如name和age,那么这个函数返回的聚合结果会
# groupby("name", "age")
# groupby("name")
# groupby("age")
# groupby(all)
# 四个聚合结果的union all 的结果
df1 = df.filter(df.name != "Run")
print(df1.show())
df1.cube("name", "sex").count().show()
# +-----+---+-----+---+
# | name|age|score|sex|
# +-----+---+-----+---+
# | Sam| 28| 88| M|
# |Flora| 28| 90| F|
# |Peter| 55| 100| M|
# | Mei| 54| 95| F|
# +-----+---+-----+---+
# cube 聚合之后的结果
# +-----+----+-----+
# | name| sex|count|
# +-----+----+-----+
# | null| F| 2|
# | null|null| 4|
# |Flora|null| 1|
# |Peter|null| 1|
# | null| M| 2|
# |Peter| M| 1|
# | Sam| M| 1|
# | Sam|null| 1|
# | Mei| F| 1|
# | Mei|null| 1|
# |Flora| F| 1|
# +-----+----+-----+
保存数据/写入数据库
- 保存数据主要是保存到Hive中的栗子,主要包括了overwrite、append等方式。
结果集为SparkDataFrame
import pandas as pd
from datetime import datetime
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql import HiveContext
conf = SparkConf()\
.setAppName("test")\
.set("hive.exec.dynamic.partition.mode", "nonstrict") # 动态写入hive分区表
sc = SparkContext(conf=conf)
hc = HiveContext(sc)
sc.setLogLevel("ERROR")
list_values = [['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]]
Spark_df = spark.createDataFrame(list_values, ['name', 'age', 'score'])
print(Spark_df.show())
save_table = "tmp.samshare_pyspark_savedata"
# 方式1:直接写入到Hive
Spark_df.write.format("hive").mode("overwrite").saveAsTable(save_table) # 或者改成append模式
print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)
# 方式2:注册为临时表,使用SparkSQL来写入分区表
Spark_df.createOrReplaceTempView("tmp_table")
write_sql = """
insert overwrite table {0} partitions (pt_date='{1}')
select * from tmp_table
""".format(save_table, "20210520")
hc.sql(write_sql)
print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)
结果集为Python的DataFrame
- 多做一步把它转换为SparkDataFrame,其余操作就一样了。
import pandas as pd
from datetime import datetime
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql import HiveContext
conf = SparkConf()\
.setAppName("test")\
.set("hive.exec.dynamic.partition.mode", "nonstrict") # 动态写入hive分区表
sc = SparkContext(conf=conf)
hc = HiveContext(sc)
sc.setLogLevel("ERROR")
result_df = pd.DataFrame([1,2,3], columns=['a'])
save_table = "tmp.samshare_pyspark_savedata"
# 获取DataFrame的schema
c1 = list(result_df.columns)
# 转为SparkDataFrame
result = hc.createDataFrame(result_df.astype(str), c1)
result.write.format("hive").mode("overwrite").saveAsTable(save_table) # 或者改成append模式
print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)
实践
【2023-7-6】notebook 中使用 spark 方法
import pandas as pd
import warnings
import time
import pyspark
import datetime
warnings.filterwarnings('ignore')
from pyspark.sql import functions as F
# 刷新spark里的上游4张表头信息
spark.conf.set("spark.sql.shuffle.partitions", 1000)
# 刷新表
sql("refresh table d.a")
# 日期显示
date = str(${date})
# ----- spark -> pandas ------
raw_data = sql("""select * from d.a
where data = '{date}'
""".format(date=date)
raw_pd = raw_data.toPandas() # 转换为pandas格式
# ----- pandas -> spark------
spark_df = pandas_to_spark(write_pd)
spark_df.createOrReplaceTempView("realtor_score")
spark.sql("set hive.exec.dynamic.partition.mode = nonstrict")
spark.sql("set hive.exec.dynamic.partition=true")
spark.sql("refresh table d.out")
sql("""
insert overwrite table d.out
PARTITION (date='{date}')
select * from test
""".format(date=date))
Spark Streaming
Spark Streaming 是一个基于 Spark Core 之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

Spark调优
开发习惯调优
- 尽可能复用同一个RDD,避免重复创建,并且适当持久化数据
Q&A
【2022-8-24】pyspark执行问题
- 执行 .toPandas时,弹出错误信息
- pd_month_new = spark.table(“raw_month_score”).toPandas()
It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running ‘REFRESH TABLE tableName’ command in SQL or by recreating the Dataset/DataFrame involved.
- pd_month_new = spark.table(“raw_month_score”).toPandas()
解决方法:表数据变动,但缓存未清除,需要手工刷新 refresh table
spark.conf.set("spark.sql.shuffle.partitions", 1000)
# spark.conf.set("spark.executor.memory", '10g')
# spark.conf.set("spark.driver.maxResultSize", "4G")
sql("refresh table fproject_data.app_b_realtor_score_info_dwf") # 输入表
sql("refresh table fproject_data.app_b_realtor_score_info_dm ") # 输出表
Storm
Storm是第一代流处理框架,目前逐渐被spark streaming和Flink取代.
Spark和Storm都是通用的并行计算框架。
- 解决Hadoop只适用于离线数据处理,而不能提供实时数据处理能力的问题。
区别:
- Spark基于这样的理念,当数据庞大时,把计算过程传递给数据要比把数据传递给计算过程要更富效率。
- 而Storm是把数据传递给计算过程。
- 基于设计理念的不同,其应用领域也不同。
- Spark工作于现有的数据全集(如Hadoop数据)已经被导入Spark集群,Spark基于in-memory管理可以进行快讯扫描,并最小化迭代算法的全局I/O操作。
- Storm在动态处理大量生成的“小数据块”上要更好(比如在Twitter数据流上实时计算一些汇聚功能或分析)
Flink 流批一体
Flink很长一段时间被Spark的光环掩盖,Flink的特点是实时流计算(Spark Streaming可以轻松做到秒级别的实时计算),把实时计算提到了更高的优先级。
- Flink充分考虑事件的时间属性,通过WaterMark等机制,可以实时准确地完成完成流式计算,轻松实现CEP等功能,把批计算当成流计算的一种特例。
- Flink像Spark一样,也可以部署到Yarn上,可以用HDFS作为分布式存储。
Kylin
大部分的大数据处理结果是生成报表,供业务人员分析查阅,快速高效地生成报表就比较重要了。无论是hive还是Spark sql,通过计算生成报表的时间都在分钟级以上,Kylin对输入的hive表(组织成维度/度量的星形模型),预先通过MR进行计算,把计算结果以cube元数据的形式存到HBase里,然后用户可以通过JDBC Driver以sql的方式对数据进行快速查询
clickhouse
- 【2021-4-19】ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
- 行式存储: 传统的行式数据库系统中,处于同一行中的数据总是被物理的存储在一起。
- 常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。

- 列式存储: 来自不同列的值被单独存储,来自同一列的数据被存储在一起
- 常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+

- 列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解)
- 语法
- ck里的SQL语法不太一样,json用法,hive里的get_json_object → visitParamExtractRaw
SELECT
room_id, agent_id, pt, action,
visitParamExtractRaw(message, 'phase') as phase,
visitParamExtractRaw(visitParamExtractRaw(message, 'session'), 'utterance') as utterance,
message
--,room_id,get_json_object(message, '$.housedel_id') as housedel_id
--from spider_ods.spider_ods_swh_log_all_wa
from spider.spider_pm_agent_log_di_all
WHERE pt = '2021-04-01'
AND business_name = 'vr_practice'
AND action='3021' -- gds_asr响应, 3010 gds init请求
-- AND get_json_object(message, '$.level') = "normal"
-- AND city_id='110000'
-- AND room_id = '1800210355'
-- AND agent_id = '20091125'
limit 100
消息队列
消息队列是分布式系统中重要的中间件,在高性能、高可用、低耦合等系统架构中扮演着重要作用。
分布式系统可以借助消息队列的能力,轻松实现以下功能:
- 解耦,将一个流程的上游和下游拆开,上游专注生产消息,下游专注处理消息。
- 广播,一个上游生产的消息轻松被多个下游服务处理。
- 缓冲,应对流量突然上涨,消息队列可以扮演一个缓冲器的作用,保护下游服务使其可以根据实际的消费能力处理消息。
- 异步,上游发送消息后可以马上返回,下游可以异步处理消息。
- 冗余,保留历史消息,处理失败或当出现异常时可以进行重试或者回溯防止丢失。
举例——小明收快递的烦恼
消息队列主要由以下作用:解耦,削峰,异步,其实还有一个作用是提高接收者性能。
异步消息队列的作用
- 解耦,生产端和消费端不需要相互依赖
- 异步,生产端不需要等待消费端响应,直接返回,提高了响应时间和吞吐量
- 削峰,打平高峰期的流量,消费端可以以自己的速度处理,同时也无需在高峰期增加太多资源,提高资源利用率
- 提高消费端性能。消费端可以利用buffer等机制,做批量处理,提高效率。
快递员给小明送快递分为几步?分为3步,
- 第一步,把快递拿到小明家门口(省略了前n步,从小明家楼下开始)
- 第二步,敲门(类比编程世界的调用第三方接口)
- 第三步,小明开门拿走快递(第三方接口执行过程)
这简单的三步会有什么问题?
- (1)耦合
- 快递员是否能顺利完成十分依赖于小明的响应速度。如果小明还没起床,听见敲门声再穿衣服开门,可能消耗很多时间。如果小明没在家呢?那就要配送失败了,如何判断配送失败呢?快递员需要判断等多久开门(超时时间),打电话判断是否在家(健康检查),最终郁闷的离开,下次再来一次(重试)。
- 快递员直接与小明交互,对小明的状态强依赖,产生了耦合现象。那有办法避免这种耦合呢?
- (2)同步影响性能
- 快递员的配送速度收到小明的响应速度影响极大,有一两个需要长时间等待的快件,快递员的配送效率(吞吐率)会收到很大影响。
- (3)高峰期负载很高
- 双11,618,每次到购物节的时候,快递员都很烦躁。快递太多,来的比送得快,这可如何是好。
- 小明也很烦躁,一天要收100个快递,可是家里的空间都满了,要边收拾出地方边进一件快递。
- (4)接收方还有其他事情
- 如果小明准备和女朋友告白,此时来了一阵敲门声,你好,快递。
- 还双11,小明买了100件商品,明天不定时一件件送到,小明这一天都要搭进去了。
接收快递也成为了一件烦心事,好想把其他事情处理完再收快递,也好想一块收100件快递。
这时候有个叫 丰巢(没收广告费)的快递柜出现了,快递员可以把快递放到柜子里,发条短信通知小明过来取快递。小明看到短信可以先做自己的事情,有空的时候过来拿走快递。
终于,小明和快递员都笑容满面。
快递柜就相当于是编程世界的消息队列。
- 解偶
- 此时,快递员只需要把快递放到柜子里,不需要关心小明是否在家,是否在睡觉。小明也不需要一直等待给快递员开门,两个人解耦了。
- 异步
- 快递员把快递放到柜子里发个信息就可以去送下一件,不需同步等待结果。
- 这样每个快递的处理速度(响应时间)都变得极短,每天送的快递数量(吞吐量)也变多了。
- 削峰
- 这次又到了双十一,小明还是一天要到100个快递,由于小明一天只能消化10个快递,剩下的就放在了柜子里,等10天后才拿完。
- 快递员由于是异步送快递,双11根本不是事,这点吞吐量完全搞得定。
- 提高消费端性能
- 小明以前需要一件一件收取快递,现在放在了柜子(队列)里,那等攒够了10件去取一次(buffer->reduce),好省时间!其他时间都可以快快乐乐约会了。
消息队列对比
【2022-2-25】10分钟搞懂!消息队列选型全方位对比
- 对Kafka、Pulsar、RocketMQ、RabbitMQ、NSQ这几个消息队列组件进行了一些调研,并整理了相关资料,为业务对MQ中间件选型提供参考。
结论:
- 日志处理、大数据处理等场景,高吞吐量、低延迟的特性考虑,Kafka依旧是一个较好的选型。
- 针对业务交易数据,有延迟消息、队列模式消费、异地容灾,多消息主题等场景,可以选用TDMQ/Pulsar。
- 其他一些业务自定义的使用场景,由于后台技术栈是Golang,可以考虑采用NSQ进行定制开发或研究学习。
- 消息中间件性能跟服务端、客户端参数、使用场景等方面上有很大关系,在系统上线前,还需要根据实际应用场景进行压测调优。
kafka
Kafka是一种分布式的基于发布/订阅的消息系统,它的高吞吐量、灵活的offset是其它消息系统所没有的。
一个Kafka集群由多个Broker和一个ZooKeeper集群组成,Broker作为Kafka节点的服务器。同一个消息主题Topic可以由多个分区Partition组成,分区物理存储在Broker上。负载均衡考虑,同一个Topic的多个分区存储在多个不同的Broker上,为了提高可靠性,每个分区在不同的Broker会存在副本。
【2021-5-23】Kafka原理篇:图解kafka架构原理
- Kafka 架构设计哲学和原理
- Kafka 中 zookeeper 的作用
- Kafka Controller 实现原理
- Kafka Network 原理
资料
kafka运行在集群上,集群包含一个或多个服务器。kafka把消息存在topic中,每一条消息包含键值(key),值(value)和时间戳(timestamp)。
基本概念
Topic:一组消息数据的标记符;主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。Producer:生产者,用于生产数据,可将生产后的消息送入指定的Topic;向kafka broker发消息的客户端Consumer:消费者,消息的使用方,负责消费Kafka服务器上的消息; 获取数据,可消费指定的Topic;Consumer Group:消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。同一个group可以有多个消费者,一条消息在一个group中,只会被一个消费者获取;Partition:分区 partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的 id(offset)。为了保证kafka的吞吐量,一个Topic可以设置多个分区。同一分区只能被一个消费者订阅。Broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。备份作用Offset:消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息。
kafka分布式架构
 解释
解释- kafka将topic中的消息存在不同的partition中。如果存在键值(key),消息按照键值(key)做分类存在不同的partiition中,如果不存在键值(key),消息按照轮询(Round Robin)机制存在不同的partition中。默认情况下,键值(key)决定了一条消息会被存在哪个partition中。
- partition中的消息序列是有序的消息序列。kafka在partition使用偏移量(offset)来指定消息的位置。一个topic的一个partition只能被一个consumer group中的一个consumer消费,多个consumer消费同一个partition中的数据是不允许的,但是一个consumer可以消费多个partition中的数据。
- kafka将partition的数据复制到不同的broker,提供了partition数据的备份。每一个partition都有一个broker作为leader,若干个broker作为follower。所有的数据读写都通过leader所在的服务器进行,并且leader在不同broker之间复制数据。

# 安装kafka
# ①下载解压
wget https://archive.apache.org/dist/kafka/0.10.0.0/kafka_2.11-0.10.0.0.tgz
tar -xzf kafka_2.11-0.10.0.0.tgz
cd kafka_2.11-0.10.0.0
# ②启动Kafka: kafka需要用到zookeeper,所以需要先启动zookeeper。用下载包里自带的单机版zookeeper。
bin/zookeeper-server-start.sh config/zookeeper.properties # 启动zk
bin/kafka-server-start.sh config/server.properties # 启动kafka
# ③创建topic,test,一个分区
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
# ④查看创建的topic
bin/kafka-topics.sh --list --zookeeper localhost:2181 # test
# ⑤向topic中发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
# This is a message
# This is another message
# ⑤从topicc中消费消息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
# This is a message
# This is another message
# python的kafka客户端
pip install kafka-python
kafka-python是一个python的Kafka客户端,可以用来向kafka的topic发送消息、消费消息。
- 一个producer和一个consumer,producer向kafka发送消息,consumer从topic中消费消息。

【2022-3-18】python kafka订阅
Kafka发送消息主要有三种方式:
- 发送并忘记:1.88s, 吞吐量是最高的,但是无法保证消息的可靠性
- 同步发送:16s, 通过get方法等待Kafka的响应,判断消息是否发送成功
- 一条一条的发送,对每条消息返回的结果判断, 可以明确地知道每条消息的发送情况,但是由于同步的方式会阻塞,只有当消息通过get返回future对象时,才会继续下一条消息的发送
- 异步发送+回调函数:2.15s, 消息以异步的方式发送,通过回调函数返回消息发送成功/失败
- 调用send方法发送消息的同时,指定一个回调函数,服务器在返回响应时会调用该回调函数,通过回调函数能够对异常情况进行处理,当调用了回调函数时,只有回调函数执行完毕生产者才会结束,否则一直会阻塞
三种方式虽然在时间上有所差别,但并不是说时间越快的越好,具体看业务应用场景:
- 场景1:如果业务要求消息必须是按顺序发送的,那么可以使用同步的方式,并且只能在一个partation上,结合参数设置retries的值让发送失败时重试,设置max_in_flight_requests_per_connection=1,可以控制生产者在收到服务器晌应之前只能发送1个消息,从而控制消息顺序发送;
- 场景2:如果业务只关心消息的吞吐量,容许少量消息发送失败,也不关注消息的发送顺序,那么可以使用发送并忘记的方式,并配合参数acks=0,这样生产者不需要等待服务器的响应,以网络能支持的最大速度发送消息;
- 场景3:如果业务需要知道消息发送是否成功,并且对消息的顺序不关心,那么可以用异步+回调的方式来发送消息,配合参数retries=0,并将发送失败的消息记录到日志文件中;
三种发送方法:
import pickle
import time
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['192.168.33.11:9092'],
key_serializer=lambda k: pickle.dumps(k),
value_serializer=lambda v: pickle.dumps(v))
start_time = time.time()
# -------- (1) ----------
for i in range(0, 10000):
print('------{}---------'.format(i))
future = producer.send('test_topic', key='num', value=i, partition=0)
# 将缓冲区的全部消息push到broker当中
producer.flush()
producer.close()
# -------- (2) ----------
from kafka.errors import kafka_errors
for i in range(0, 10000):
print('------{}---------'.format(i))
future = producer.send(topic="test_topic", key="num", value=i)
# 同步阻塞,通过调用get()方法进而保证一定程序是有序的.
try:
record_metadata = future.get(timeout=10)
# print(record_metadata.topic)
# print(record_metadata.partition)
# print(record_metadata.offset)
except kafka_errors as e:
print(str(e))
# -------- (3) ----------
def on_send_success(*args, **kwargs):
"""
发送成功的回调函数
:param args:
:param kwargs:
:return:
"""
return args
def on_send_error(*args, **kwargs):
"""
发送失败的回调函数
:param args:
:param kwargs:
:return:
"""
return args
start_time = time.time()
for i in range(0, 10000):
print('------{}---------'.format(i))
# 如果成功,传进record_metadata,如果失败,传进Exception.
producer.send(
topic="test_topic", key="num", value=i
).add_callback(on_send_success).add_errback(on_send_error)
producer.flush()
producer.close()
# =================
end_time = time.time()
time_counts = end_time - start_time
print(time_counts)
producer代码
# producer.py
import time
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers="localhost:9092")
# 指定编码
# producer = KafkaProducer(bootstrap_servers=['localhost:9092'], value_serializer=lambda m: json.dumps(m).encode('ascii'))
# 压缩发送
# producer = KafkaProducer(bootstrap_servers=['localhost:9092'], compression_type='gzip') # gzip
# producer = KafkaProducer(value_serializer=msgpack.dumps) # msgpack为MessagePack的简称,是高效二进制序列化类库,比json高效
i = 0
while True:
ts = int(time.time() * 1000)
producer.send(topic="test", value=str(i), key=str(i), timestamp_ms=ts)
producer.flush()
print i
i += 1
time.sleep(1)
consumer代码
# consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer("test", bootstrap_servers=["localhost:9092"])
# 自动解码
# consumer = KafkaConsumer(group_id= 'group2', bootstrap_servers= ['localhost:9092'], value_deserializer=lambda m: json.loads(m.decode('ascii')))
# 手工分配partition
# consumer = KafkaConsumer(group_id= 'group2', bootstrap_servers= ['localhost:9092'])
# consumer.assign([TopicPartition(topic= 'my_topic', partition= 0)])
# 超时处理
# consumer = KafkaConsumer('my_topic', group_id= 'group2', bootstrap_servers= ['localhost:9092'], consumer_timeout_ms=1000)
for message in consumer:
print message
生产者和消费者的简易Demo演示:
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import kafka_errors
import traceback
import json
def producer_demo():
""" 生产者 """
# 假设生产的消息为键值对(不是一定要键值对),且序列化方式为json
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
key_serializer=lambda k: json.dumps(k).encode(),
value_serializer=lambda v: json.dumps(v).encode())
# 发送三条消息
for i in range(0, 3):
future = producer.send(
'kafka_demo',
key='count_num', # 同一个key值,会被送至同一个分区
value=str(i),
partition=1) # 向分区1发送消息
print("send {}".format(str(i)))
try:
future.get(timeout=10) # 监控是否发送成功
except kafka_errors: # 发送失败抛出kafka_errors
traceback.format_exc()
def consumer_demo():
""" 消费者 """
consumer = KafkaConsumer(
'kafka_demo',
bootstrap_servers=':9092',
group_id='test'
)
for message in consumer:
print("receive, key: {}, value: {}".format(
json.loads(message.key.decode()),
json.loads(message.value.decode())
)
)
- 先执行消费者:consumer_demo()
- 再执行生产者:producer_demo()
- 会看到如下输出:
producer_demo()
# send 0
# send 1
# send 2
consumer_demo()
# receive, key: count_num, value: 0
# receive, key: count_num, value: 1
# receive, key: count_num, value: 2
传统的消息引擎处理模型主要有两种:队列模型,和发布-订阅模型。
队列模型:早期消息处理引擎就是按照队列模型设计的,所谓队列模型,跟队列数据结构类似,生产者产生消息,就是入队,消费者接收消息就是出队,并删除队列中数据,消息只能被消费一次。 但这种模型有一个问题,那就是只能由一个消费者消费,无法直接让多个消费者消费数据。基于这个缺陷,后面又演化出发布-订阅模型。发布-订阅模型:发布订阅模型中,多了一个主题。消费者会预先订阅主题,生产者写入消息到主题中,只有订阅了该主题的消费者才能获取到消息。这样一来就可以让多个消费者消费数据。
借助kafka的消费者组机制,可以同时实现这两种模型。同时还能够对消费组进行动态扩容,让消费变得易于伸缩。
消费者组是由消费者组成的,组内可以有多个消费者实例,而这些消费者实例共享一个id,称为group id。
- 默认创建消费者的group id是在 KAFKA_HOME/conf/consumer.properties 文件中定义的,打开就能看到。
- 默认的group id值是test-consumer-group。
消费者组内的所有成员一起订阅某个主题的所有分区,注意一个消费者组中,每一个分区只能由组内的一消费者订阅。
注意:
- 消费者组内消费者小于或等于分区数,以及topic分区数刚好是消费者组内成员数的倍数。
- 消费者组内的消费者数量最好是与分区数持平,再不济,最好也是要是分区数的数量成比例。
重平衡(Rebalance)其实就是一个协议,它规定了如何让消费者组下的所有消费者来分配topic中的每一个分区。比如一个topic有100个分区,一个消费者组内有20个消费者,在协调者的控制下让组内每一个消费者分配到5个分区,这个分配的过程就是重平衡。
重平衡的触发条件主要有三个:
- 消费者组内成员发生变更,这个变更包括了增加和减少消费者。注意这里的减少有很大的可能是被动的,就是某个消费者崩溃退出了
- 主题的分区数发生变更,kafka目前只支持增加分区,当增加的时候就会触发重平衡
- 订阅的主题发生变化,当消费者组使用正则表达式订阅主题,而恰好又新建了对应的主题,就会触发重平衡 为什么说重平衡为人诟病呢?因为重平衡过程中,消费者无法从kafka消费消息,这对kafka的TPS影响极大,而如果kafka集内节点较多,比如数百个,那重平衡可能会耗时极多。数分钟到数小时都有可能,而这段时间kafka基本处于不可用状态。所以在实际环境中,应该尽量避免重平衡发生。
kafka提供了三种重平衡分配策略
- Range:基于每个主题的分区分配,如果主题的分区分区不能平均分配给组内每个消费者,那么对该主题,某些消费者会被分配到额外的分区。
- RoundRobin:基于全部主题的分区来进行分配的,同时这种分配也是kafka默认的rebalance分区策略。
- Sticky:最新的也是最复杂的策略,为了一定程度解决上面提到的重平衡非要重新分配全部分区的问题。称为粘性分配策略。
kafka订阅多个topic,可以同时接收多个topic消息
from kafka import KafkaConsumer
# 订阅多个topic
# (1)直接指定topic名称
consumer = KafkaConsumer(group_id= 'group2', bootstrap_servers= ['localhost:9092'])
consumer.subscribe(topics= ['my_topic', 'topic_1'])
# (2)或 正则匹配topic
consumer = KafkaConsumer(group_id= 'group2', bootstrap_servers= ['localhost:9092'], value_deserializer=lambda m: json.loads(m.decode('ascii')))
consumer.subscribe(pattern= '^my.*')
for msg in consumer:
print(msg)
Zookeeper
Zookeeper 是一个成熟的分布式协调服务,它可以为分布式服务提供分布式配置服、同步服务和命名注册等能力.。对于任何分布式系统,都需要一种协调任务的方法。Kafka 是使用 ZooKeeper 而构建的分布式系统。但是也有一些其他技术(例如 Elasticsearch 和 MongoDB)具有其自己的内置任务协调机制。
Kafka 将 Broker、Topic 和 Partition 的元数据信息存储在 Zookeeper 上。通过在 Zookeeper 上建立相应的数据节点,并监听节点的变化,Kafka 使用 Zookeeper 完成以下功能:
- Kafka Controller 的 Leader 选举
- Kafka 集群成员管理
- Topic 配置管理
- 分区副本管理
Lindorm 云原生多模数据库
Lindorm是一款适用于任何规模、多种模型的云原生数据库服务,支持海量数据的低成本存储处理和弹性按需付费,提供宽表、时序、搜索、文件等多种数据模型,兼容HBase、Cassandra、Phoenix、OpenTSDB、Solr、SQL等多种开源标准接口,是为阿里巴巴核心业务提供关键支撑的数据库之一。
Lindorm创新性地使用存储计算分离、多模共享融合的云原生架构,以适应云计算时代资源解耦和弹性伸缩的诉求。其中云原生存储引擎LindormStore为统一的存储底座,向上构建各个垂直专用的多模引擎,包括宽表引擎、时序引擎、搜索引擎、文件引擎。在多模引擎之上,Lindorm既提供统一的SQL访问,支持跨模型的联合查询,又提供多个开源标准接口(HBase/Phoenix/Cassandra、OpenTSDB、Solr、HDFS),满足存量业务无缝迁移的需求。最后,统一的数据Stream总线负责引擎之间的数据流转和数据变更的实时捕获,以实现数据迁移、实时订阅、数湖转存、数仓回流、单元化多活、备份恢复等能力。
- Lindorm团队最初都是做阿里内部HBase的,他们基于HBase做了一系列优化,解决了HBase的一系列问题,并以此为基点,慢慢研发出自己的多模引擎,试图一统存储分析技术,凭一己之力,实现MySQL、HBase、时序数据库等等的完整功能。Lindorm支持类SQL和类HBase两种访问方式,分别对标MySQL和HBase,作为其的升级替代品。
Lindorm 与 MySQL 对比
- 第一个优点,我称之为存储伸缩性。MySQL的数据表,容量是有界的,而号称支持单表百万亿行规模、千万级并发、百PB级数据存储的Lindorm,你基本上可以认为它的数据是无界的,其存储伸缩性轻易地支持数据表的水平扩展。
- 第二个优点,是可以免除分库分表的困扰。还记不记得MySQL我们怎么去应对海量数据?我们会去做分库分表,我们会对业务做垂直分表,从而不能使用数据宽表的便利;更复杂的,我们还需要去做水平分表,按照特定的分片算法去对同一张数据表做横向切分。数据库领域很多高深晦涩的问题,都是分库分表引入的,比如分布式事务问题、横向扩容问题、跨库join问题、跨表结果集合并问题、历史库清理问题等。
Lindorm与HBase对比
- HBase的优点:读写性能优秀,支持批量导入,无需分库分表,存储计算分离,成本低,弹性好。 随着时代的发展HBase的缺点也体现出来了:
- Row Key设计复杂,无数据类型缺乏约束。只能基于主键查询,不能很好支持复杂业务场景
- 读写毛刺影响业务使用体感
- 客户端逻辑过重,CPU承载高,客户端需要直连ZK,Meta表获取路由信息,出现BUG难以排查
- 主备集群切换无法保证一致性,备集群只接受复制流量,资源严重浪费
HBase的这些缺点,导致了我们很少在真正的线上服务中使用HBase,即使它有着听上去天花乱坠的强大性能。而HBase的升级版本Lindorm破解了这一切。
数据的游戏:冰与火
- 【2013-7-31】陈皓(左耳朵耗子)

我对数据挖掘和机器学习是新手,从去年7月份在Amazon才开始接触,而且还是因为工作需要被动接触的,以前都没有接触过,做的是需求预测机器学习相关的。后来,到了淘宝后,自己凭兴趣主动地做了几个月的和用户地址相关数据挖掘上的工作,有一些浅薄的心得。下面这篇文章主要是我做为一个新人仅从事数据方面技术不到10个月的一些心得,也许对你有用,也许很傻,不管怎么样,欢迎指教和讨论。
另外,注明一下,这篇文章的标题模仿了一个美剧《权力的游戏:冰与火之歌》。在数据的世界里,我们看到了很多很牛,很强大也很有趣的案例。但是,数据就像一个王座一样,像征着一种权力和征服,但登上去的路途一样令人胆颤。
数据挖掘中的三种角色
在Amazon里从事机器学习的工作时,我注意到了Amazon玩数据的三种角色。
- Data Analyzer:数据分析员。这类人的人主要是分析数据的,从数据中找到一些规则,并且为了数据模型的找不同场景的Training Data。另外,这些人也是把一些脏数据洗干净的的人。
- Research Scientist:研究科学家。这种角色主要是根据不同的需求来建立数据模型的。他们把自己戏称为不近人间烟火的奇异性物种,就像《生活大爆炸》里的 那个Sheldon一样。这些人基本上玩的是数据上的科学
- Software Developer :软件开发工程师。主要是把 Scientist 建立的数据模型给实现出来,交给Data Analyzer去玩。这些人通常更懂的各种机器学习的算法。
我相信其它公司的做数据挖掘或是机器学习的也就这三种工作,或者说这三种人,对于我来说,
- 最有技术含量的是 Scientist,因为数据建模和抽取最有意义的向量,以及选取不同的方法都是这类人来决定的。这类人,我觉得在国内是找不到的。
- 最苦逼,也最累,但也最重要的是Data Analyzer,他们的活也是这三个角色中最最最重要的(注意:我用了三个最)。因为,无论你的模型你的算法再怎么牛,在一堆烂数据上也只能干出一堆垃圾的活来。正所谓:Garbage In, Garbage Out !但是这个活是最脏最累的活,也是让人最容易退缩的活。
- 最没技术含量的是Software Developer。现在国内很多玩数据的都以为算法最重要,并且,很多技术人员都在研究机器学习的算法。错了,最重要的是上面两个人,一个是苦逼地洗数据的Data Analyzer,另一个是真正懂得数据建模的Scientist!而像什么K-Means,K Nearest Neighbor,或是别的什么贝叶斯、回归、决策树、随机森林等这些玩法,都很成熟了,而且又不是人工智能,说白了,这些算法在机器学习和数据挖掘中,似乎就像Quick Sort之类的算法在软件设计中基本没什么技术含量。当然,我不是说算法不重要,我只想说这些算法在整个数据处理中是最不重要的。
数据的质量
- 目前所流行的Buzz Word——
大数据是相当误导人的。在我眼中,数据不分大小,只分好坏。 - 在处理数据的过程中,我第一个感受最大的就是数据质量。下面我分几个案例来说明:
案例一:数据的标准
在Amazon里,所有的商品都有一个唯一的ID,叫ASIN——Amazon Single Identify Number,这个ID是用来标识商品的唯一性的(来自于条形码)。也就是说,无论是你把商品描述成什么样,只要ASIN一样,这就是完完全全一模一样的商品。
这样,就不像淘宝一样,当你搜索一个iPhone,会出现一堆各种各样的iPhone,有的叫“超值iPhone”,有的叫“苹果iPhone”,有的叫“智能手机iPhone”,有的叫“iPhone 白色/黑色”……,这些同一个商品不同的描述是商家为了吸引用户。但是带来的问题有两点:
- 1)用户体验不好。以商品为中心的业务模型,对于消费者来说,体验明显好于以商家为中心的业务模型。
- 2)只要你不能正确读懂(识别)数据,你后面的什么算法,什么模型统统没用。
所以,只要你玩数据,你就会发现,如果数据的标准没有建立起来,干什么都没用。数据标准是数据质量的第一道关卡,没这个玩意,你就什么也别玩了。所谓数据的标准,为数据做唯一标识只是其中最最基础的一步,数据的标准还单单只是这个,更重要的是把数据的标准抽象成数学向量,没有数学向量,后面也无法挖掘。
所以,你会看到,洗数据的大量的工作就是在把杂乱无章的数据归并聚合,这就是在建立数据标准。这里面绝对少不了人肉的工作。无非就是:
- 聪明的人在数据产生之前就定义好标准,并在数据产生之时就在干数据清洗的工作。
- 一般的人是在数据产生并大量堆积之后,才来干这个事。
另外,说一下Amazon的ASIN,这个事从十多年前就开始了,我在Amazon的内网里看到的资料并没有说为什么搞了个这样一个ID,我倒觉得这并不是因为Amazon因为玩数据发现必需建议个商品ID,也许因为Amazon的业务模型就是设计成以“商品为中心”的。今天,这个ASIN依然有很多很多的问题,ASIN一样不能完全保证商品就是一样的,ASIN不一样也不代表商品不一样,不过90%以上的商品是保证的。Amazon有专门的团队Category Team,里面有很多业务人员天天都在拼命地在对ASIN的数据进行更正。
案例二:数据的准确
用户地址是我从事过数据分析的另一个事情。我还记得当时看到那数以亿计的用户地址的数据的那种兴奋。但是随后我就兴奋不起来了。因为地址是用户自己填写的,这里面有很多的坑,都不是很容易做的。
第一个是假/错地址,因为有的商家作弊或是用户做测试。所以地址是错的,
- 比如,直接就输入“该地址不存在”,“13243234asdfasdi”之类的。这类的地址是可以被我的程序识别出来的。
- 还有很难被我的程序所识别出来的。比如:“宇宙路地球小区”之类的。但这类地址可以被人识别出来。
- 还有连人都识别不出来的,比如:“北京市东四环中路23号南航大厦5楼540室”,这个地址根本不存在。
第二个是真地址,但是因为用户写的不标准,所以很难处理,比如:
- 缩写:“建国门外大街” 和 “建外大街”,“中国工商银行”和“工行”……
- 错别字:“潮阳门”,“通慧河”……
- 颠倒:“东四环中路朝阳公园” 和 “朝阳公园 (靠东四环)” ……
- 别名:有的人写的是开发商的小区名“东恒国际”,有的则是写行政的地名“八里庄东里”……
这样的例子多得不能再多了。可见数据如果不准确,会增加你处理的难度。有个比喻非常好,玩数据的就像是在挖金矿一样,如果含金量高,那么,挖掘的难度就小,也就容易出效果,如果含金量低,那么挖掘的难度就大,效果就差。
上面,我给了两个案例,旨在说明——
- 1)数据没有大小之分,只有含金量大的数据和垃圾量大的数据之分。
- 2)数据清洗是一件多么重要的工作,这也是一件人肉工作量很大的工作。
所以,这个工作最好是在数据产生的时候就一点一滴的完成。
有一个观点:
- 如果数据准确度在60%的时候,你干出来的事,一定会被用户骂!
- 如果数据准确度在80%左右,那么用户会说,还不错!
- 只有数据准确度到了90%的时候,用户才会觉得真牛B。
- 但是从数据准确度从80%到90%要付出的成本要比60% 到 80%的付出大得多得多**。
- 大多数据的数据挖掘团队都会止步于70%这个地方。
- 因为,再往后,这就是一件相当累的活。
数据的业务场景
我不知道有多少数据挖掘团队真正意识到了业务场景和数据挖掘的重要关系?我们需要知道,根本不可能做出能够满足所有业务的数据挖掘和分析模型。
推荐音乐视频,和电子商务中的推荐商品的场景完全不一样。电商中,只要你买了一个东西没有退货,那么,有很大的概率我可以相信你是喜欢这个东西的,然后,对于音乐和视频,你完全不能通过用户听了这首歌或是看了这个视频就武断地觉得用户是喜欢这首歌和这个视频的,所以,我们可以看到,推荐算法在不同的业务场景下的实现难度也完全不一样。
说到推荐算法,你是不是和我一样,有时候会对推荐有一种感觉——推荐就是一种按不同维度的排序的算法。我个人以为,就提一下推荐这个东西在某些业务场景下是比较Tricky的,比如,推荐有两种(不是按用户关系和按物品关系这两种),
- 一种是
共性化推荐,结果就是推荐了流行的东西,这也许是好的,但这也许会是用户已知的东西,比如,到了北京,我想找个饭馆,你总是给我推荐烤鸭,我想去个地方,你总是给我推荐天安门故宫天坛(因为大多数人来北京就是吃烤鸭,就是去天安门的),这些我不都知道了嘛,还要你来推荐?另外,共性化的东西通常是可以被水军刷的。 - 另一种是一种是
个性化推荐,这个需要分析用户的个体喜好,好的就是总是给我我喜欢的,不好的就是也许我的口味会随我的年龄和环境所改变,而且,总是推荐符合用户口味的,不能帮用户发掘新鲜点。比如,我喜欢吃辣的,你总是给我推荐川菜和湘菜,时间长了我也会觉得烦的。
推荐有时并不是民主投票,而是专业用户或资深玩家的建议;推荐有时并不是推荐流行的,而是推荐新鲜而我不知道的。你可以看到,不同的业务场景,不同的产品形态下的玩法可能完全不一样,
另外,就算是对于同一个电子商务来说,书、手机 和服装的业务形态完全不一样。我之前在Amazon做Demand Forecasting(用户需求预测)——通过历史数据来预测用户未来的需求。
- 对于书、手机、家电这些东西,在Amazon里叫Hard Line的产品,你可以认为是“标品”(但也不一定),预测是比较准的,甚至可以预测到相关的产品属性的需求。
- 但是地于服装这样的叫Soft Line的产品,Amazon干了十多年都没有办法预测得很好,因为这类东西受到的干扰因素太多了,比如:用户的对颜色款式的喜好,穿上去合不合身,爱人朋友喜不喜欢…… 这类的东西太容易变了,买得人多了反而会卖不好,所以根本没法预测好,更别Stock/Vender Manager 提出来的“预测某品牌的某种颜色的衣服或鞋子”。
对于需求的预测,我发现,长期在这个行业中打拼的人的预测是最准的,什么机器学习都是浮云。机器学习只有在你要面对的是成千上万种不同商品和品类的时候才会有意义。
数据挖掘不是人工智能,而且差得还太远。不要觉得数据挖掘什么事都能干,找到一个合适的业务场景和产品形态,比什么都重要。
数据的分析结果
我看到很多的玩大数据的,基本上干的是数据统计的事,从多个不同的维度来统计数据的表现。最简单最常见的统计就是像网站统计这样的事。比如:PV是多少,UV是多少,来路是哪里,浏览器、操作系统、地理、搜索引擎的分布,等等,等等。
唠叨一句,千万不要以为,你一天有十几个T的日志就是数据了,也不要以为你会用Hadoop/MapReduce分析一下日志,这就是数据挖掘了,说得难听一点,你在做的只不过是一个统计的工作。那几个T的Raw Data,基本上来说没什么意义,只能叫日志,连数据都算不上,只有你统计出来的这些数据才是有点意义的,才能叫数据。
当一个用户在面对着自己网店的数据的时候,比如:每千人有5个人下单,有65%的访客是男的,18-24岁的人群有30%,等等。甚至你给出了,你打败了40%同类型商家的这样的数据。作为一个商户,面对这些数据时,大多数人的表现是完全不知道自己能干什么?是把网站改得更男性一点,还是让年轻人更喜欢一点?完全不知道所措。
只要你去看一看,你会发现,好些好些的数据分析出来的结果,看上去似乎不错,但是其实完全不知道下一步该干什么?
所以,我觉得,数据分析的结果并不仅仅只是把数据呈现出来,而更应该关注的是通过这些数据后面可以干什么?如果看了数据分析的结果后并不知道可以干什么,那么这个数据分析是失败的。
总结
综上所述,下面是我觉得数据挖掘或机器学习最重要的东西:
- 1)数据的质量。分为数据的标准和数据的准确。数据中的杂音要尽量地排除掉。为了数据的质量,大量人肉的工作少不了。
- 2)数据的业务场景。我们不可能做所有场景下的来,所以,业务场景和产品形态很重要,我个人感觉业务场景越窄越好。
- 3)数据的分析结果,要让人能看得懂,知道接下来要干什么,而不是为了数据而数据。
搞数据挖掘的人很多,但成功的案例却不多(相比起大量的尝试来说),就目前而言,我似乎觉得目前的数据挖掘的技术是一种过渡技术,还在摸索阶段。
另外,好些数据挖掘的团队搞得业务不业务,技术不技术的,为其中的技术人员感到惋惜……
不好意思,我只给出了问题,没有建议,这也说明数据分析中有很多的机会……
最后,还要提的一个是“数据中的个人隐私问题”,这似乎就像那些有悖伦理的黑魔法一样,你要成功就得把自己变得黑暗。是的,数据就像一个王座一样,像征着一种权力和征服,但登上去的路途一样令人胆颤。
数据挖掘
数据挖掘工具
【2018-6-15】数据挖掘软件:weka适用于EDA探索性数据分析,Orange数据挖掘和机器学习软件
服务质量评价
- 【2021-1-28】服务质量模型
评分卡
KANO模型(卡诺)
- KANO模型分析法是授野纪昭基于KANO模型对顾客需求的细分原理,开发的一套结构型问卷和分析方法。KANO模型是一个典型的定性分析模型,KANO模型分析法并一般不直接用来测量用户的满意程度,主要用于识别用户对新功能的接受度,帮助企业了解不同层次的用户需求,找出顾客和企业的接触点,识别使顾客满意的至关重要的因素。
- KANO模型的属性分类
- 在卡诺模型中,将产品功能/需求和服务的特性分为五种属性:必备属性、期望属性、魅力属性、无差异属性、反向属性。
- (1)魅力属性:用户意想不到的,如果不提供此需求,用户满意度不会降低,但当提供此需求,用户满意度会有很大提升;
- (2)期望属性:当提供此需求,用户满意度会提升,当不提供此需求,用户满意度会降低;
- (3)必备属性:当优化此需求,用户满意度不会提升,当不提供此需求,用户满意度会大幅降低;
- (4)无差异属性:无论提供或不提供此需求,用户满意度都不会有改变,用户根本不在意;
- (5)反向属性:用户根本都没有此需求,提供后用户满意度反而会下降

- KANO模型实际操作流程
- 1.设计问卷调查表并实施有效的问卷调查
- KANO问卷中每个属性特性都由正向和负向两个问题构成,分别测量用户在面对具备或不具备某项功能所做出的反应。问卷中的问题答案一般采用五级选项,按照:喜欢、理应如此、无所谓、勉强接受、我不喜欢,进行评定。
- 2.收集数据并清洗
- 3.将调查结果的功能属性进行分类,建立原型;
- (1)KANO模型区分产品需求的操作方法介绍:原始数据处理阶段,需要注意是每个功能各个样本量针对正反两题确立属性。
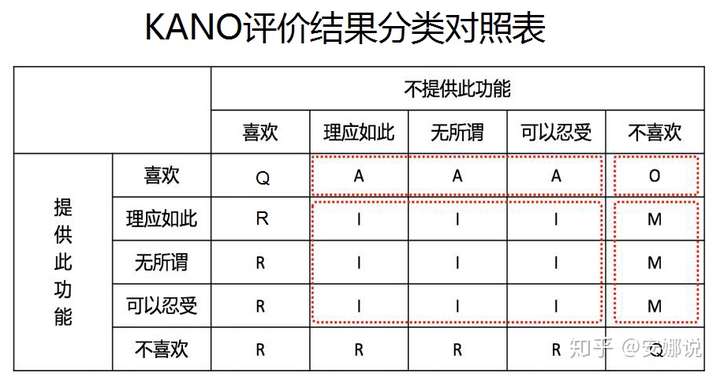
- A:魅力属性;O:期望属性;M:必备属性;I:无差异属性;R:反向属性;Q:可疑结果
- (3)根据better-worse系数值,将散点图划分为四个象限,以确立需求优先级。

- 1.设计问卷调查表并实施有效的问卷调查
- 参考资料
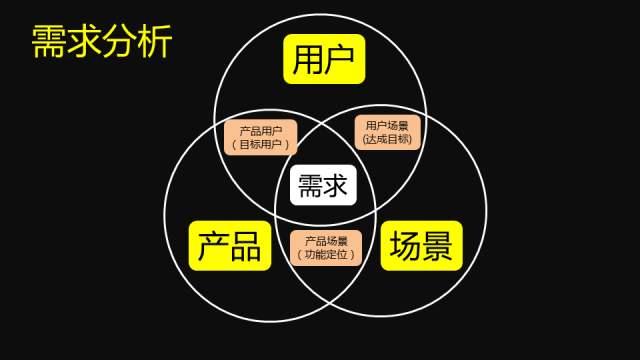
SERVQUAL模型(SERVQUAL Model)
- SERVQUAL理论是20世纪80年代末由美国市场营销学家帕拉休拉曼(A.Parasuraman)、来特汉毛尔(Zeithaml)和白瑞(Berry)依据全面质量管理(Total Quality Management,TQM)理论在服务行业中提出的一种新的服务质量评价体系,其理论核心是“服务质量差距模型”,即:服务质量取决于用户所感知的服务水平与用户所期望的服务水平之间的差别程度(因此又称为“期望-感知”模型),用户的期望是开展优质服务的先决条件,提供优质服务的关键就是要超过用户的期望值。
- 模型为: Servqual 分数 = 实际感受分数 - 期望分数。
- SERVQUAL将服务质量分为五个层面:有形设施(Tangibles)、可靠性(Reliability)、响应性 (Responsiveness)、保障性(Assurance)、情感投入(Empathy),每一层面又被细分为若干个问题,通过调查问卷的方式,让用户对每个问题的期望值、实际感受值及最低可接受值进行评分。并由其确立相关的22 个具体因素来说明它。然后通过问卷调查、顾客打分和综合计算得出服务质量的分数,
- 五个尺度,SERVQUAL模型衡量服务质量的五个尺度为;有形资产、可靠性、响应速度、信任和移情作用。
- 有形性:有形的设施、设备、人员和沟通材料的外表;如:设备完好率、工作人员的精神面貌、以及用以提供服务的其他工具和设备的完好情况。
- 可靠性:可靠地、准确地履行服务承诺的能力;如:企业提供服务的及时性和其承诺的履行情况。
- 响应性:帮助顾客并迅速提供服务的愿望;
- 保证性:员工所具有的知识、礼节以及表达出自信与可信的能力;
- 移情性:设身处地地为顾客着想和对顾客给予特别的关注
- Servqual Model: Five Key Service Dimensions, Servqual Gaps & Reasons
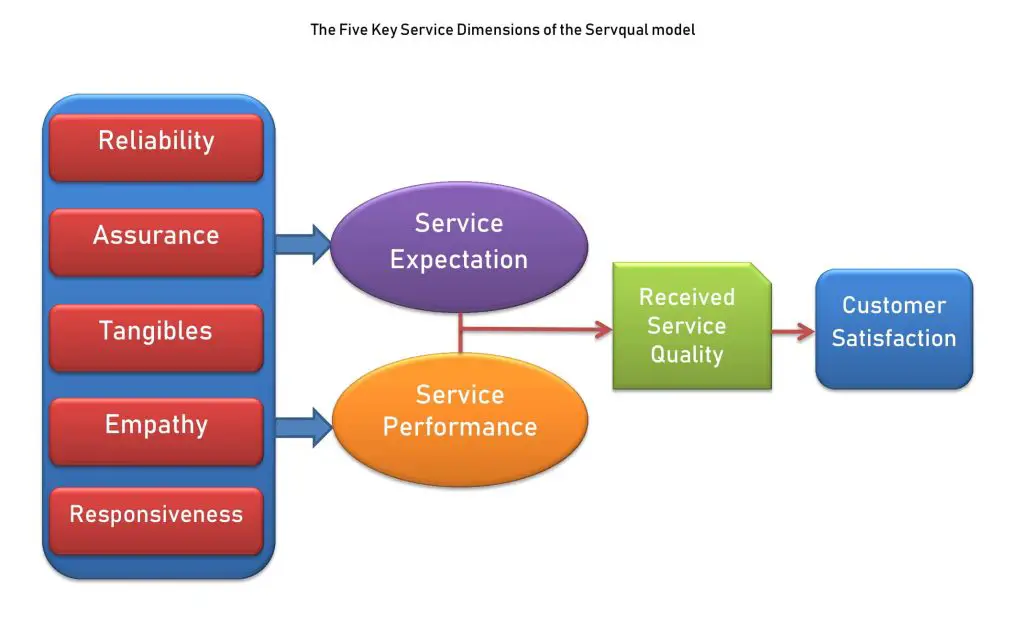
NPS 净推荐值
【2021-9-7】
- 净推荐值NPS(Net Promoter Score)
- 用户体验指数NPS(净推荐值)的定义和应用
净推荐(Net Promoter)是Fred Reichheld(2003)针对企业良性收益与真实增长所提出的用户忠诚度概念。
- 请用户回答“您在多大程度上愿意向您的朋友(亲人、同事……)推荐XX公司/产品?”(0-10分,10分表示非常愿意,0分表示非常不愿意)

- 根据用户的推荐意愿,将用户分为三类:
推荐者、被动者、贬损者,推荐者与贬损者是对企业实际的产品口碑有影响的用户,这两部分用户在用户总数中所占百分比之差,就是净推荐值(Net Promoter Score,NPS)。
根据愿意推荐的程度让客户在0-10之间来打分,然后你根据得分情况来建立客户忠诚度的3个范畴:
推荐者(Promoter,得分在9-10之间):是具有狂热忠诚度的人,他们会继续购买并引见给其他人。被动者(Passives,得分在7-8之间):总体满意但并不狂热,将会考虑其他竞争对手的产品。批评者(Detractors,得分在0-6之间):使用并不满意或者对你的公司没有忠诚度。
净推荐值是等于推荐者所占的百分比减去批评者所占的百分比,计算公式:
净推荐值(NPS) = (推荐者数/总样本数)×100%-(贬损者数/总样本数)×100%
NPS计算公式的逻辑是推荐者会继续购买并且推荐给其他人来加速你的成长,而批评者则能破坏你的名声,并让你在负面的口碑中阻止成长。
NPS的得分值在50%以上被认为是不错的。如果NPS的得分值在70-80%之间则证明你们公司拥有一批高忠诚度的好客户。调查显示大部分公司的NPS值还是在5-10%之间徘徊。
NPS的存在是一个衡量标尺,但没有绝对的高低之分,不同的行业有着不同的标准,比如下图统计出来各个行业的NPS平均值水平中所示,银行业的NPS值跨度从-18%到77%,行业平均值23%,如果高于23%就算比较优秀,而汽车经销行业的NPS值就很稳定,平均分数也很低,那么用衡量银行业的 23%来衡量汽车销售业,就非常不客观了。
积分体系
贝壳分
【2020-6-5】贝壳找房升级经纪人贝壳分信用体系 买房租房迎来“按分找人”时代
贝壳分
- 2018年11月,贝壳找房CEO彭永东正式发布“
贝壳分”——这是房产经纪行业首个基于经纪人真实行为数据和综合服务能力,以大数据算法对经纪人的服务能力与信用度进行综合评价的模型,一经推出便广受行业关注,也成为很多用户买房、租房时挑选经纪人的标准。 - 2020年,
贝壳分迎来全面升级,从学历参考、专业考试成绩、合作伙伴评价以及用户评价等角度进行了针对性调整,让经纪人贝壳分指标更加公平公正。“更高贝壳分,服务更称心”,未来,用户可以通过贝壳分,以及依托贝壳分所评选出的“星光经纪人”、“客户推荐前10%”、“圈内口碑前10%”等标签,更加准确的找到专业、高服务质量经纪人。
随着贝壳找房进驻110多个城市,连接经纪人数接近40万,贝壳分正在成为经纪行业首个真正衡量经纪人服务能力与水平的信用标准。
贝壳分有五大维度,是一个综合评价经纪人服务水平的体系。高分经纪人代表着高水平、高素质、高能力, 不仅更受同行合作者欢迎,也更受用户喜爱。相信不远的将来,贝壳分一定会成为经纪人与用户之间的非常核心的“硬通货”。
- 贝壳分拥有基础素质(内力)
- 服务质量评价(信誉)
- 行业影响力(声望)
- 平台合作度(侠义)
- 平台生态贡献(活力)
这五个维度,通过大数据模型算法基于经纪人在平台的真实行为数据得出,并保持实时更新。贝壳也将根据经纪人在各维度的表现,给予多项权益和资源,鼓励经纪人不断提高自己的贝壳分,更好地服务用户。
- 比如,“星光经纪人”荣誉称号需要经纪人的贝壳分排名整体靠前;
- 而“客户推荐前10%”的荣誉,只有这位经纪人服务过的用户,对其服务的评价达到该城市前10%的才能获得,代表着用户的充分认可;
- 同样,“圈内口碑前10%”的称号,需要该经纪人在与其他人的合作互评中得分达到所在城市前10%。
- 此外,还有“业务精英”、“行业新星”等,这些称号都将展示在贝壳APP的经纪人的个人页面上,以及其所在的房源推荐经纪人列表页面上,并用鲜明标识出来,让用户“一眼就看到”——毫无疑问,用户会更倾向于选择拥有多项荣誉标签的经纪人提供服务。
贝壳分指标升级2.0版本,也是围绕这五大维度,根据经纪人、用户反馈意见,在学历参考、专业考试成绩、合作伙伴评价以及用户对经纪人的评价等维度做了调整升级,让贝壳分体系更加公平公正的同时,也给用户选择优质服务提供更准确的参考价值,推动“按分找人”新时代到来!
贝壳分的背后,凝聚着贝壳一整套产品、机制与规则,这也是贝壳能推出这样一套经纪人信用体系的基础。
- 比如在基础素质指标上,学历高是个加分项,那么很多专科学历的经纪人会选择进修本科学业;贝壳举办的房产经纪人专业考试“搏学大考”成绩也是基础素质加分项,大家就会格外重视考试成绩——这项考试覆盖了房产政策、交易流程、财务、贷款等各个专业领域,间接上就让大家越来越专业。
- 比如在合作评价指标,考核的是一个经纪人在与其他经纪人合作时候,对方的评价。这就促进经纪人多与人合作,打破以前的恶性竞争,提升用户买房、卖房的效率和体验。而在这背后,是贝壳平台构建的ACN经纪人合作网络——大家共享房源,通过合作为用户买房、卖房,最后根据贡献度来分佣。
- 平台生态贡献维度上,则有贝壳打造的A+经纪人作业系统,除了日常的房源、客源管理,它会根据经纪人自己的情况,以任务的方式指导和提升经纪人的日常学习、工作,堪称不断提升经纪人个人能力和服务水平的重要渠道。
随着贝壳分权益越来越多、“按分找人”的现象越来越明显,贝壳分将成为驱动经纪人不断提升自己专业知识和服务水平的一个指导体系,更是长期追求的目标。
对经纪人来说,如何提高贝壳分?
- 知乎:拉新,A级VR带看,A级带看,学历完善,证件完善(如协理,经纪)带看,成交,维护动作,经济学院学习。码上有客的转发
- 只有不断提升自己的专业能力、服务质量以及日常点点滴滴的贡献,这就形成了 “自我提升和积累优质服务动作 —— 贝壳分提高 —— 被用户选择的机会增加 —— 为更多用户提供更好服务 —— 促进更多用户选择” 的正循环链条。
贝壳分口碑
【2022-11-19】脉脉 不是贝壳找房的合作流程不够复杂,而是不够精准。 在这里,讨论这个是没用的。这事要改,需要更改贝壳分的体制……
- 现在贝壳找房平台的流量分配的核心,其中之一是贝壳分,最近还有维护分。
- 贝壳分7-8个维度,就很失效,需要全面围绕合作效能制定流量配置规则。(建议有心者,参考TOC约束理论)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}