数据挖掘方向知识点、经验总结
总结
- 待定
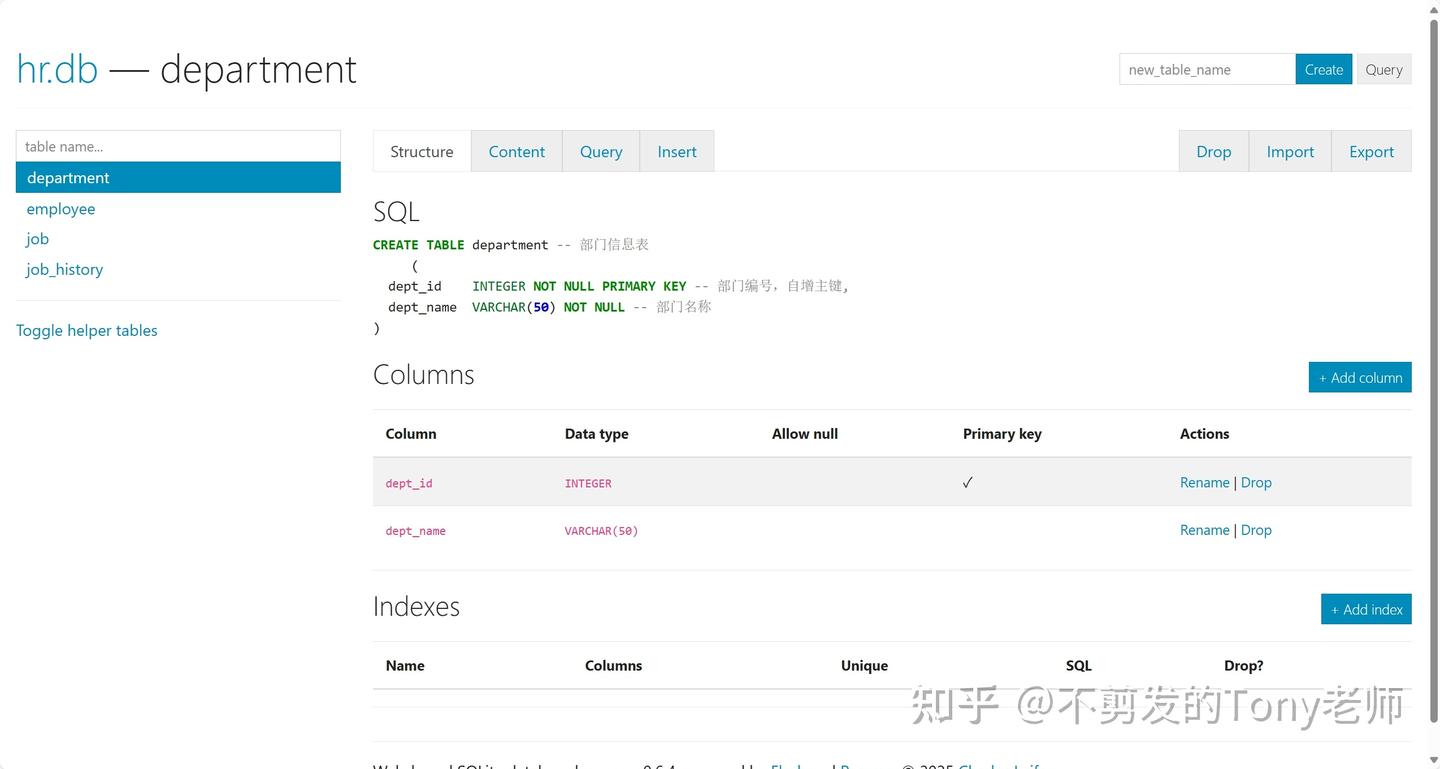
数据库介绍
数据仓库
实时数仓(Realtime Data Warehouse)分层介绍
- ODS: 原始数据,日志和业务数据。可通过Kafka进行收集。
- DWD: 根据数据对象为单位进行分流,比如订单、页面访问等等。可存储在Kafka中。
- DIM: 维度数据。可存储在HBase中。
- DWM: 对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据。
- DWS: 根据某个主题将多个事实数据轻度聚合,形成主题宽表。 可存储在Doris、ClickHouse、Elasticsearch中。
- ADS: 把Doris/ClickHouse中的数据根据可视化需进行筛选聚合。 一般不存储,进行MPP计算。
类型
(1)关系型数据库,是指采用了关系模型来组织数据的数据库。关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。银行系统会大量的用关系数据库.比如大家经常用的MySQL就是典型的关系数据库.
优点:
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的SQL语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
(2)非关系数据库
关系数据库虽然很好,但是随着互联网大规模的爆发,弱点也越来越明显,比如事务的一致性,多表联查,高并发等等瓶颈很明显。
于是NoSQL一词横空出世,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。比如MongoDb就是典型的NoSQL型数据库(键值对大家想到了什么,对json格式).
数据结构
【2023-5-12】数据库常用数据结构
| Types | Illustration | Use Case | Note 备注 |
|---|---|---|---|
| Skiplist | In-memory | Redis使用 | |
| Hash index | In-memory | 最常用内存索引方案 | |
| SSTable | Disk-based | 不变数据结构,很少单独使用 | |
| LSM tree | Memory+Disk | 高写入吞吐,磁盘压缩影响性能 | |
| B-Tree | Disk-based | 最流行数据库索引实现 | |
| Inverted index | Search document | 文档搜索引擎,如 lucene | |
| Suffix tree | Search string | 字符查找,如前缀匹配 | |
| R-tree | Search multi-dimention shape | 最近邻 |
关系型数据库 SQL
主流的数据库有Oracle,MySQL,Mongodb,Redis,SQLite,SQL Server等等
注:关系型数据库其实不擅长处理关系型数据
ACID
关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,有如下四个特性:
- 1、
A(Atomicity) 原子性- 原子性很容易理解,事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
- 比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
- 2、
C(Consistency) 一致性- 一致性也比较容易理解,数据库要一直处于一致状态,事务的运行不会改变数据库原本的一致性约束。
- 例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
- 3、
I(Isolation) 独立性- 独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
- 比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
- 4、
D(Durability) 持久性- 持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
SQL
什么是 SQL
【2021-12-14】史上最全SQL基础知识总结(理论+举例)
SQL(Structured Query Language)==是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server 等。SQL 标准(ANSI/ISO)有:
- SQL-92:1992 年发布的 SQL 语言标准;
- SQL:1999:1999 年发布的 SQL 语言标签;
- SQL:2003:2003 年发布的 SQL 语言标签; 这些标准就与 JDK 的版本一样,在新的版本中总要有一些语法的变化。不同时期的数据库对不同标准做了实现。
虽然 SQL 可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如 MySQL 中的 LIMIT 语句就是 MySQL 独有的方言,其它数据库都不支持!当然,Oracle 或 SQL Server 都有自己的方言。
语法注意:
- SQL 语句可以单行或多行书写,以分号结尾;
- 可以用空格和缩进来来增强语句的可读性;
- 关键字不区别大小写,建议使用大写;
SQL执行顺序
文字:
- FROM/JOIN/ON
- WHERE
- GROUP BY
- HAVING
- SELECT(窗口函数即在此步骤执行)
- ORDER BY
- LIMIT
从这个顺序中我们可以发现,所有的查询语句都是从 FROM 开始执行的。在实际执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。 接下来,我们详细的介绍下每个步骤的具体执行过程。
(9) SELECT (10) DISTINCT column,
(6) AGG_FUNC(column or expression),..
(1) FROM left_table
(3) JOIN right_table
(2) ON tablename.column = other tablename.column
(4) WHERE constraint expression
(5) GROUP BY column
(7) WITH CUBE ROLLUP
(8) HAVING constraint_expression
(11) ORDER BY column ASC \| DESC
(12) LIMIT count OFFSET count;
1 FROM执行笛卡尔积
- FROM 才是 SQL 语句执行的第一步,并非 SELECT 。对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1,获取不同数据源的数据集。
- FROM子句执行顺序为从后往前、从右到左,FROM 子句中写在最后的表(基础表 driving table)将被最先处理,即最后的表为驱动表,当FROM 子句中包含多个表的情况下,我们需要选择数据最少的表作为基础表。
2 ON 应用ON过滤器
- 对虚拟表VT1 应用ON筛选器,ON 中的逻辑表达式将应用到虚拟表 VT1中的各个行,筛选出满足ON 逻辑表达式的行,生成虚拟表 VT2 。
3 JOIN 添加外部行
- 如果指定了OUTER JOIN保留表中未找到匹配的行将作为外部行添加到虚拟表 VT2,生成虚拟表 VT3。保留表如下:
- LEFT OUTER JOIN把左表记为保留表
- RIGHT OUTER JOIN把右表记为保留表
- FULL OUTER JOIN把左右表都作为保留表
- 在虚拟表 VT2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予NULL值,最后生成虚拟表 VT3。
- 如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1~3,直到处理完所有的表为止。
4 WHERE 应用WEHRE过滤器
- 对虚拟表 VT3应用WHERE筛选器。根据指定的条件对数据进行筛选,并把满足的数据插入虚拟表 VT4。
- 由于数据还没有分组,因此现在还不能在WHERE过滤器中使用聚合函数对分组统计的过滤。
- 同时,由于还没有进行列的选取操作,因此在SELECT中使用列的别名也是不被允许的。
5 GROUP BY 分组
- 按GROUP BY子句中的列/列表将虚拟表 VT4中的行唯一的值组合成为一组,生成虚拟表VT5。如果应用了GROUP BY,那么后面的所有步骤都只能得到的虚拟表VT5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。
- 同时,从这一步开始,后面的语句中都可以使用SELECT中的别名。
6 AGG_FUNC计算聚合函数
- 计算 max 等聚合函数。SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。常用的 Aggregate 函数包涵以下几种:
- AVG:返回平均值
- COUNT:返回行数
- FIRST:返回第一个记录的值
- LAST:返回最后一个记录的值
- MAX: 返回最大值
- MIN:返回最小值
- SUM: 返回总和
7 WITH 应用ROLLUP或CUBE
- 对虚拟表 VT5应用ROLLUP或CUBE选项,生成虚拟表 VT6。
CUBE 和 ROLLUP 区别如下:
- CUBE 生成的结果数据集显示了所选列中值的所有组合的聚合。
- ROLLUP 生成的结果数据集显示了所选列中值的某一层次结构的聚合。
8 HAVING 应用HAVING过滤器
- 对虚拟表VT6应用HAVING筛选器。根据指定的条件对数据进行筛选,并把满足的数据插入虚拟表VT7。
- HAVING 语句在SQL中的主要作用与WHERE语句作用是相同的,但是HAVING是过滤聚合值,在 SQL 中增加 HAVING 子句原因就是,WHERE 关键字无法与聚合函数一起使用,HAVING子句主要和GROUP BY子句配合使用。
9 SELECT 选出指定列
- 将虚拟表 VT7中的在SELECT中出现的列筛选出来,并对字段进行处理,计算SELECT子句中的表达式,产生虚拟表 VT8。
10 DISTINCT 行去重
- 将重复的行从虚拟表 VT8中移除,产生虚拟表 VT9。DISTINCT用来删除重复行,只保留唯一的。
11 ORDER BY 排列
- 将虚拟表 VT9中的行按ORDER BY 子句中的列/列表排序,生成游标 VC10 ,注意不是虚拟表。因此使用 ORDER BY 子句查询不能应用于表达式。同时,ORDER BY子句的执行顺序为从左到右排序,是非常消耗资源的。
12 LIMIT/OFFSET 指定返回行
- 从VC10的开始处选择指定数量行,生成虚拟表 VT11,并返回调用者。
数据类型
MySQL 与 Java、C 一样,也有数据类型MySQL 中数据类型主要应用在列上。
常用类型:
- int:整型
- double:浮点型,例如 double(5,2)表示最多 5 位,其中必须有 2 位小数,即最大值为 999.99;
- decimal:泛型型,在表单线方面使用该类型,因为不会出现精度缺失问题;
- char:固定长度字符串类型;(当输入的字符不够长度时会补空格)
- varchar:固定长度字符串类型;
- text:字符串类型;
- blob:字节类型;
- date:日期类型,格式为:yyyy-MM-dd;
- time:时间类型,格式为:hh:mm:ss
- timestamp:时间戳类型;
| 类 型 | 大 小 | 描 述 |
|---|---|---|
| CAHR(Length) | Length字节 | 定长字段,长度为0~255个字符 |
| VARCHAR(Length) | String长度+1字节或String长度+2字节 | 变长字段,长度为0~65 |
| TINYTEXT | String长度+1字节 | 字符串,最大长度为255个字符 |
| TEXT | String长度+2字节 | 字符串,最大长度为65 |
| MEDIUMINT | String长度+3字节 | 字符串,最大长度为16 |
| LONGTEXT | String长度+4字节 | 字符串,最大长度为4 |
| TINYINT(Length) | 1字节 | 范围:-128~127,或者0~255(无符号) |
| SMALLINT(Length) | 2字节 | 范围:-32 |
| MEDIUMINT(Length) | 3字节 | 范围:-8 |
| INT(Length) | 4字节 | 范围:-2 |
| BIGINT(Length) | 8字节 | 范围:-9 |
| FLOAT(Length, | Decimals) | 4字节 |
| DOUBLE(Length, | Decimals) | 8字节 |
| DECIMAL(Length, | Decimals) | Length+1字节或Length+2字节 |
| DATE | 3字节 | 采用YYYY-MM-DD格式 |
| DATETIME | 8字节 | 采用YYYY-MM-DD |
| TIMESTAMP | 4字节 | 采用YYYYMMDDHHMMSS格式;可接受的范围终止于2037年 |
| TIME | 3字节 | 采用HH:MM:SS格式 |
| ENUM | 1或2字节 | Enumeration(枚举)的简写,这意味着每一列都可以具有多个可能的值之一 |
| SET | 1、2、3、4或8字节 | 与ENUM一样,只不过每一列都可以具有多个可能的值 |
执行sql
-- 从.sql文件引入SQL语句
SOURCE my.sql;
SQL 分类
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)
DDL 数据定义语言
-- 基本操作
-- 查看所有数据库
show databases;
use mydb1; -- 切换到 mydb1 数据库;
-- 创建数据库
CREATE DATABASE mydb1; -- 如果mydb1存在,就报错
CREATE DATABASE IF NOT EXISTSmydb1; -- 不报错
-- 删除数据库
DROP DATABASE mydb1; -- 删除名为 mydb1 的数据库。如果不存在会报错。
DROP DATABASE IF EXISTS mydb1; -- 就算 mydb1不存在,也不会报错。
-- 修改数据库编码
ALTER DATABASE mydb1 CHARACTER SET utf8; -- 修改数据库 mydb1 的编码为 utf8。
-- 注意,在 MySQL 中所有的 UTF-8 编码都不能使用中间的“-”,即 UTF-8 要书写为 UTF8。
-- 创建表
CREATE TABLE stu(
sid CHAR(6),
sname VARCHAR(20),
age INT,
gender VARCHAR(10)
);
DESC stu; -- 查看表的结构
DROP TABLE stu; -- 删除表
-- 修改表
ALTER TABLE stu ADD (classname varchar(100)); -- 添加列:给 stu 表添加 classname 列
ALTER TABLE stu MODIFY gender CHAR(2); -- 修改列的数据类型:修改 stu 表的 gender 列类型为 CHAR(2)
ALTER TABLE stu change gender sex CHAR(2); -- 修改列名:修改 stu 表的 gender 列名为 sex
ALTER TABLE stu DROP classname; -- 删除列:删除 stu 表的 classname 列
ALTER TABLE stu RENAME TO student; -- 修改表名称:修改 stu 表名称为 student
-- 建索引
create table IF NOT EXISTS `query_info`(
`id` VARCHAR(255) primary key COMMENT '问题ID',
`content` varchar(1024) COMMENT '问题内容',
`category` INT COMMENT '问题种类',
`create_ucid` BIGINT COMMENT '创建人id',
`update_ucid` BIGINT COMMENT '更新人id',
`status` INT COMMENT '问题状态',
`work_group` INT COMMENT '权限ID',
`created_at` int COMMENT '创建时间',
`update_at` int COMMENT '更新时间',
`delete_at` int COMMENT '删除时间',
INDEX(`id`),
INDEX(`content`),
INDEX(`work_group`)
) COMMENT='存储问题title相关基础信息' ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 【2021-12-29】执行通过
CREATE TABLE IF NOT EXISTS `kb_question_info`(
`question_id` BIGINT(20) PRIMARY KEY AUTO_INCREMENT COMMENT '问题id(唯一)',
`question_name` VARCHAR(255) COMMENT '问题名称(驻场生产的默认都是相似问)',
`question_type` INT(5) COMMENT '类型:0(未知)、1标准问、2相似问',
`question_range` INT(5) COMMENT '问题使用范围:0(未知)、1(通用问题)、2(个性化问题,适用个别楼盘)',
`std_question_id` INT(10) COMMENT '标准问id',
`question_weight` DOUBLE(4,2) COMMENT '标准问id',
`operate_ucid ` INT(10) COMMENT '操作人ucid ',
`created_time` TIMESTAMP COMMENT '创建时间', -- 样例:'2021-12-31 18:39:45'
`update_time` TIMESTAMP COMMENT '更新时间',
`is_valid` INT(5) COMMENT '是否有效(0无效、1有效)'
) COMMENT='知识点-问题表' DEFAULT CHARSET=utf8;
-- 外键
CREATE TABLE country(
country_id smallint unsigned not null auto_increment,
country varchar(50) not null,
last_update timestamp not null default current_timestamp on update current_timestamp,
primary key(country_id)
)engine=INNODB default charset=utf8;
CREATE TABLE `city` (
`city_id` smallint(5) unsigned NOT NULL auto_increment,
`city` varchar(50) NOT NULL,
`country_id` smallint(5) unsigned NOT NULL,
`last_update` timestamp NOT NULL default CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP,
PRIMARY KEY (`city_id`),
KEY `idx_fk_country_id` (`country_id`),
CONSTRAINT `fk_city_country` FOREIGN KEY (`country_id`) REFERENCES `country` (`country_id`) on delete restrict ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
birth TIMESTAMP,
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
partition BY RANGE (store_id) (
partition p0 VALUES LESS THAN (10000),
partition p1 VALUES LESS THAN (50000),
partition p2 VALUES LESS THAN (100000),
partition p3 VALUES LESS THAN (150000),
Partition p4 VALUES LESS THAN MAXVALUE
);
外键
外键的作用
- 保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。 使两张表形成关联,外键只能引用外表中的列的值!
mysql外键设置方式/在创建索引时,可指定在delete/update父表时,对子表进行的相应操作,包括: restrict, cascade, set null 和 no action ,set default.
- restrict, no action:
- 立即检查外键约束,如果子表有匹配记录,父表关联记录不能执行 delete/update 操作;
- cascade:
- 父表delete /update时,子表对应记录随之 delete/update ;
- set null:
- 父表在delete /update时,子表对应字段被set null,此时留意子表外键不能设置为not null ;
- set default:
- 父表有delete/update时,子表将外键设置成一个默认的值,但是 innodb不能识别,实际mysql5.5之后默认的存储引擎都是innodb,所以不推荐设置该外键方式。如果你的环境mysql是5.5之前,默认存储引擎是myisam,则可以考虑。
- 选择set null ,setdefault,cascade 时要谨慎,可能因为错误操作导致数据丢失。
索引

为最经常查询和最经常排序的数据列建立索引,大幅提升查询速度;MySQL里同一个数据表里的索引总数限制为16个
最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时很糟糕。好在CS的发展提供了很多更优秀的查找算法,如二分查找(binary search)、二叉树查找(binary tree search)等
- 每种查找算法都只能应用于特定数据结构之上
- 二分查找要求被检索数据有序, 而二叉树查找只能应用于二叉查找树,但数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织)
- 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,以某种方式引用(指向)数据,这样就可以实现高级查找算法,这种ADT就是索引

大部分数据库系统及文件系统都采用 B Tree 或其变种B+Tree作为索引结构
- 优点
- 索引大大减小了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机IO变成顺序IO
- 索引对于InnoDB(对索引支持行级锁)非常重要,因为它可以让查询锁更少的元组。在MySQL5.1和更新的版本中,InnoDB可以在服务器端过滤掉行后就释放锁,但在早期的MySQL版本中,InnoDB直到事务提交时才会解锁。对不需要的元组的加锁,会增加锁的开销,降低并发性。 InnoDB仅对需要访问的元组加锁,而索引能够减少InnoDB访问的元组数。但是只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。一旦索引不允许InnoDB那样做(即索引达不到过滤的目的),MySQL服务器只能对InnoDB返回的数据进行WHERE操作,此时,已经无法避免对那些元组加锁了。如果查询不能使用索引,MySQL会进行全表扫描,并锁住每一个元组,不管是否真正需要。
- 关于InnoDB、索引和锁:InnoDB在二级索引上使用共享锁(读锁),但访问主键索引需要排他锁(写锁)
- 缺点
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效;
数据库默认建立的索引是给唯一键建立的
- 主键索引(唯一且非空)
- 唯一索引(唯一可为空)
- 普通索引(普通字段的索引)
- 全文索引(一般是varchar,char,text类型建立的,但很少用)
- 组合索引(多个字的建立的索引)
CREATE TABLE tb_stu_info
(
id INT NOT NULL,
name CHAR(45) DEFAULT NULL,
dept_id INT DEFAULT NULL,
age INT DEFAULT NULL,
height INT DEFAULT NULL,
INDEX(height) -- 创建普通索引
-- UNIQUE INDEX(height) -- 创建唯一索引
);
-- ENGINE=InnoDB DEFAULT CHARSET=gb2312
- 聚簇索引(InnoDB):col1主键索引
- 二级索引(MyISAM):按照插入的顺序在磁盘上存储数据,MyISAM不支持聚簇索引
DML 数据操作语言
注意:
- 【2021-12-24】where条件中数值与类型一致,如果是字符串类型,务必设置加字符串符号,否则报错!
- where a = ‘2’ # 不是 where a = 2
- 1292 - Truncated incorrect DOUBLE value: ‘NULL’
- update 大量数据批量更新
- MySql中4种批量更新的方法
- ① replace into
- replace into 操作本质是对重复的记录先delete 后insert,如果更新的字段不全会将缺失的字段置为缺省值,用这个要悠着点否则不小心清空大量数据可不是闹着玩的。
- ② insert into …on duplicate key update批量更新
- insert into 则是只update重复记录,不会改变其它字段。
- ③ 创建临时表,先更新临时表,然后从临时表中update
- ④ mysql 自带的语句构建批量更新:set x= case id when … then … when … then … end where …
- ① replace into
-- 插入数据
INSERT INTO stu(sid, sname,age,gender) VALUES('s_1001', 'zhangSan', 23, 'male');
INSERT INTO stu(sid, sname) VALUES('s_1001', 'zhangSan');
INSERT INTO stu VALUES('s_1002', 'liSi', 32, 'female'); -- 另一种插入方法:未指定列名,按顺序依次插入
INSERT INTO stu(sid, sname) VALUES('s_1001', 'zhangSan'),('s_102', 'lisi'),('s_1003', 'wangwu'); -- 一次插入多条
-- 批量导出
SELECT * INTO OUTFILE 'data.txt' FIELDS TERMINATED BY ',' FROM table2; -- 数据读取并写入本地文件data.txt
-- 批量插入数据集
-- LOAD DATA INFILE语句从一个文本文件中以很高的速度读入一个表中
LOAD DATA INFILE 'data.txt' INTO TABLE table2 FIELDS TERMINATED BY ','; -- 从文件读数据,写入数据库
-- mysqldump工具 shell环境
-- mysqldump -u root -p -q -e -t webgps4 dn_location2 > dn_location2.sql -- 导出数据,sql文件形式
-- mysqldump -u root -p -q -e -t --single-transaction webgps4 dn_location2 > dn_location2.sql -- sql文件形式
-- source dn_location2.sql -- 执行sql
-- 修改数据
UPDATE stu SET sname='zhangSanSan', age='32', gender='female' WHERE sid's_1001';
UPDATE stu SET sname='liSi', age='20' WHERE age>50 AND gender='male';
UPDATE stu SET sname='wangWu', age='30' WHERE age>60 OR gender='female';
UPDATE stu SET gender='female' WHERE gender IS NULL
UPDATE stu SET age=age+1 WHERE sname='zhaoLiu';
-- 批量修改多个字段
UPDATE mytable SET myfield = 'value' WHERE other_field = 'other_value'; -- 一条数据的某个字段
UPDATE mytable SET myfield = 'value' WHERE other_field in ('other_values'); -- 多条数据的某个字段
-- mysql并没有提供直接的方法来实现批量更新多个字段(多次执行update命令,性能差),但是可以用点小技巧来实现
UPDATE mytable
SET myfield =
CASE id
WHEN 1 THEN 'value'
WHEN 2 THEN 'value'
WHEN 3 THEN 'value'
END
WHERE id IN (1,2,3)
-- 更新一个值
UPDATE categories
SET display_order = CASE id
WHEN 1 THEN 3
WHEN 2 THEN 4
WHEN 3 THEN 5
END
WHERE id IN (1,2,3)
-- 更新多个值
UPDATE categories
SET display_order = CASE id
WHEN 1 THEN 3
WHEN 2 THEN 4
WHEN 3 THEN 5
END,
title = CASE id
WHEN 1 THEN 'New Title 1'
WHEN 2 THEN 'New Title 2'
WHEN 3 THEN 'New Title 3'
END
WHERE id IN (1,2,3)
-- 其它方法:① replace
replace into test_tbl (id,dr) values (1,'2'),(2,'3'),...(x,'y');
-- 或者使用 ②insert
insert into test_tbl (id,dr) values (1,'2'),(2,'3'),...(x,'y') on duplicate key update dr=values(dr);
-- ③ 创建临时表,先更新临时表,然后从临时表中update
create temporary table tmp(id int(4) primary key,dr varchar(50));
insert into tmp values (0,'gone'), (1,'xx'),...(m,'yy');
update test_tbl, tmp set test_tbl.dr=tmp.dr where test_tbl.id=tmp.id;
-- 注意:这种方法需要用户有temporary 表的create 权限。
-- 多表多个字段
-- 不使用select情况
UPDATE OldData o, NewData n
SET o.name = n.name, o.address = n.address
where n.nid=234 and o.id=123;
-- 使用select情况
UPDATE OldData o, (select name, address from NewData where id = 123) n
SET o.name = n.name, o.address = n.address
where n.nid=234;
-- 删除数据
DELETE FROM stu WHERE sid='s_1001';
DELETE FROM stu WHERE sname='chenQi' OR age > 30;
DELETE FROM stu;
TRUNCATE TABLE stu; -- 另一种删除方法
-- DELETE的效率没有 TRUNCATE 高!
-- TRUNCATE 其实属性 DDL 语句,因为它是先 DROP TABLE,再 CREATE TABLE。而TRUNCATE删除的记录是无法回滚的,但DELETE删除的记录是可以回滚的(回滚是事务的知识!)
DCL 数据控制语言
-- 创建用户
CREATE USER ‘user1’@localhost IDENTIFIED BY ‘123’;
CREATE USER ‘user2’@'%' IDENTIFIED BY ‘123’;
-- 给用户授权
GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON mydb1.* TO user1@localhost;
GRANT ALL ON mydb1.* TO user2@localhost;
-- 撤销授权
REVOKE CREATE,ALTER,DROP ON mydb1.* FROM user1@localhost;
-- 查看用户权限
SHOW GRANTS FOR user1@localhost;
-- 删除用户
DROP USER ‘user1’@localhost;
-- 修改用户密码
use mysql;
alter user '用户名'@localhost identified by '新密码';
DQL 数据查询语言
数据库执行 DQL 语句不会对数据进行改变,而是让数据库发送结果集给客户端。
语法:
- select 列名 —-> 要查询的列名称
- from 表名 —-> 要查询的表名称
- where 条件 —-> 行条件
- 条件查询:
- =、!=、<>、<、<=、>、>=;
- BETWEEN…AND;
- IN(set);
- IS NULL;
- AND;
- OR;
- NOT;
- 模糊查询:
- SELECT 字段 FROM 表 WHERE 某字段 Like 条件,其中关于条件,SQL 提供了两种匹配模式:
- % :表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
- _: 表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字 符长度语句。
- SELECT 字段 FROM 表 WHERE 某字段 Like 条件,其中关于条件,SQL 提供了两种匹配模式:
- 条件查询:
- group by 分组列 —-> 对结果分组
- having 分组条件 —-> 分组后的行条件
- order by 排序列 —-> 对结果分组
- limit 起始行, 行数 —-> 结果限定
-- 数据准备
CREATE TABLE stu (
sid CHAR(6),
sname VARCHAR(50),
age INT,
gender VARCHAR(50)
);
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);
CREATE TABLE emp(
empno INT,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
) ;
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
CREATE TABLE dept(
deptno INT,
dname varchar(14),
loc varchar(13)
);
INSERT INTO dept values(10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept values(20, 'RESEARCH', 'DALLAS');
INSERT INTO dept values(30, 'SALES', 'CHICAGO');
INSERT INTO dept values(40, 'OPERATIONS',
-- 查询
SELECT * FROM stu;
SELECT sid, sname, age FROM stu;
-- 条件查询
-- 查询性别为女,并且年龄小于 50 的记录
SELECT * FROM stu WHERE gender='female' AND age<50;
-- 查询学号为 S_1001,或者姓名为 liSi 的记录
SELECT * FROM stu WHERE sid ='S_1001' OR sname='liSi';
-- 查询学号为 S_1001,S_1002,S_1003 的记录
SELECT * FROM stu WHERE sid IN ('S_1001','S_1002','S_1003')
-- 查询学号不是 S_1001,S_1002,S_1003 的记录
SELECT * FROM stu WHERE sid NOT IN ('S_1001','S_1002','S_1003');
-- 【2021-12-27】子查询, 类似左连接
SELECT * FROM stu WHERE sid IN ( SELECT sid FROM stu WHERE gender='female' AND age<50 )
SELECT a.*, b.* FROM stu a join (SELECT sid FROM stu WHERE gender='female' AND age<50)b on (a.sid=b.sid)
-- 查询年龄为 null 的记录
SELECT * FROM stu WHERE age IS NULL;
-- 查询年龄在 20 到 40 之间的学生记录
SELECT * FROM stu WHERE age>=20 AND age<=40;
SELECT * FROM stu WHERE age BETWEEN 20 AND 40;
-- 查询性别非男的学生记录
SELECT * FROM stu WHERE gender != 'male';
SELECT * FROM stu WHERE gender <> 'male';
SELECT * FROM stu WHERE NOT gender = 'male';
-- 查询姓名不为 null 的学生记录
SELECT * FROM stu WHERE NOT sname IS NULL;
SELECT * FROM stu WHERE sname IS NOT NULL;
-- 模糊查询
-- 配合like使用的占位符:
-- _:单个任意字符 -> .
-- %:多个任意字符 -> .*
-- 查询姓名由 5 个字母构成的学生记录
SELECT * FROM stu WHERE sname LIKE '_ _ _ _ _';
-- 查询姓名由 5 个字母构成,并且第 5 个字母为“i”的学生记录
SELECT * FROM stu WHERE sname LIKE '_ _ _ _i';
-- 查询姓名以“z”开头的学生记录
SELECT * FROM stu WHERE sname LIKE 'z%'; -- 其中“%”匹配 0~n 个任何字母。
-- 查询姓名中第 2 个字母为“i”的学生记录
SELECT * FROM stu WHERE sname LIKE '_i%';
-- 查询姓名中包含“a”字母的学生记录
SELECT * FROM stu WHERE sname LIKE '%a%';
-- 字段控制查询
-- 去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如 emp 表中 sal 字段就存在相同的记录。当只查询 emp 表的 sal 字段时,那么会出现重复记录,那么想去除重复记录,需要使用 DISTINCT:
SELECT DISTINCT sal FROM emp;
-- 查看雇员的月薪与佣金之和
-- 因为 sal 和 comm 两列的类型都是数值类型,所以可以做加运算。如果 sal 或 comm 中有一个字段不是数值类型,那么会出错。
SELECT *, sal+comm FROM emp;
-- comm 列有很多记录的值为 NULL,因为任何东西与 NULL 相加结果还是 NULL,所以结算结果可能会出现 NULL。下面使用了把 NULL 转换成数值 0 的函数 IFNULL:
SELECT *, sal+IFNULL(comm,0) FROM emp;
-- 给列名添加别名,在上面查询中出现列名为 sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为 total:
SELECT *, sal+IFNULL(comm,0) AS total FROM emp;
-- 给列起别名时,是可以省略 AS 关键字的:
SELECT *, sal+IFNULL(comm,0) total FROM emp;
-- 排序
-- 查询所有学生记录,按年龄升序排序
SELECT * FROM stu ORDER BY sage ASC;
SELECT * FROM stu ORDER BY sage;
-- 查询所有学生记录,按年龄降序排序
SELECT * FROM stu ORDER BY age DESC;
-- 查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
SELECT * FROM emp ORDER BY sal DESC ,empno ASC;
-- 聚合函数
-- 聚合函数是用来做纵向运算的函数:
-- COUNT():统计指定列不为 NULL 的记录行数;
-- MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
-- MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
-- SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为 0;
-- AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为 0;
-- 时间转字符串
select date_format(now(), ‘%Y-%m-%d %H:%i:%s’); -- 结果:2018-05-02 20:24:10
-- 时间转时间戳
select unix_timestamp(now()); -- 结果:1525263383
-- 字符串转时间
select str_to_date(‘2018-05-02’, ‘%Y-%m-%d %H’); -- 结果:2018-05-02 00:00:00
-- 字符串转时间戳
select unix_timestamp(‘2018-05-02’); -- 结果:1525263383
-- 时间戳转时间
select from_unixtime(1525263383); -- 结果:2018-05-02 20:16:23
-- 时间戳转字符串
select from_unixtime(1525263383, ‘%Y-%m’); -- 结果:2018-05
-- 查询 emp 表中记录数:
SELECT COUNT(*) AS cnt FROM emp;
-- 查询 emp 表中有佣金的人数:
SELECT COUNT(comm) cnt FROM emp; -- 注意,因为 count()函数中给出的是 comm 列,那么只统计 comm 列非 NULL 的行数。
-- 查询 emp 表中月薪大于 2500 的人数:
SELECT COUNT(*) FROM emp WHERE sal > 2500;
-- 统计月薪与佣金之和大于 2500 元的人数:
SELECT COUNT(*) AS cnt FROM emp WHERE sal+IFNULL(comm,0) > 2500;
-- 查询有佣金的人数,以及有领导的人数:
SELECT COUNT(comm), COUNT(mgr) FROM emp;
-- 查询所有雇员月薪和:
SELECT SUM(sal) FROM emp;
-- 查询所有雇员月薪和,以及所有雇员佣金和:
SELECT SUM(sal), SUM(comm) FROM emp;
-- 查询所有雇员月薪+佣金和:
SELECT SUM(sal+IFNULL(comm,0)) FROM emp;
-- 统计所有员工平均工资:
SELECT SUM(sal), COUNT(sal) FROM emp;
SELECT AVG(sal) FROM emp;
-- 查询最高工资和最低工资:
SELECT MAX(sal), MIN(sal) FROM emp;
-- 分组查询
-- 当需要分组查询时需要使用 GROUP BY子句,例如查询每个部门的工资和,这说明要使用部分来分组。
-- 查询每个部门的部门编号和每个部门的工资和:
SELECT deptno, SUM(sal) FROM emp GROUP BY deptno;
-- 查询每个部门的部门编号以及每个部门的人数
SELECT deptno,COUNT(*) FROM emp GROUP BY deptno;
-- 查询每个部门的部门编号以及每个部门工资大于 1500 的人数:
SELECT deptno ,COUNT(*) FROM emp WHERE sal>1500 GROUP BY deptno;
-- HAVING 子句
-- 查询工资总和大于 9000 的部门编号以及工资和:
SELECT deptno, SUM(sal) FROM emp GROUP BY deptno HAVING SUM(sal) > 9000;
-- 注意,WHERE 是对分组前记录的条件,如果某行记录没有满足 WHERE 子句的条件,那么这行记录不会参加分组;而 HAVING 是对分组后数据的约束。
-- LIMIT:用来限定查询结果的起始行,以及总行数。
-- 查询 5 行记录,起始行从 0 开始
SELECT * FROM emp LIMIT 0, 5; -- 注意,起始行从 0 开始,即第一行开始!
-- 查询 10 行记录,起始行从 3 开始
SELECT * FROM emp LIMIT 3, 10;
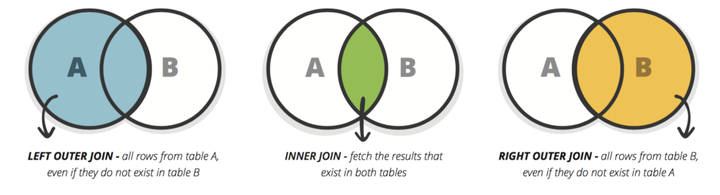
-- 多表连接查询: 表连接分为内连接和外连接。
select staff.name,deptname from staff,deptno where staff.name=deptno.name; -- 内连接
-- 外连接分为左连接和右连接
-- 左连接:包含左边表中所有的记录,右边表中没有匹配的记录显示为 NULL。
-- 右连接:包含右边表中所有的记录,左边表中没有匹配的记录显示为 NULL。
select staff.name,deptname from staff left join deptno onstaff.name=deptno.name;
select staff.name,deptname from staff full outer join deptno onstaff.name=deptno.name; -- 全外链接
-- 视图:视图(view)是虚拟的SQL表。它包含行和列,和一般的SQL表格很类似。视图总是显示数据库中的最新数据。
CREATE VIEW my_view AS SELECT * FROM course WHERE credits=3;
DROP VIEW my_view;
三种join类型:
非关系型数据库 NoSQL
NoSQL简介
NoSQL = Not Only SQL(不仅仅是SQL)
- Not Only Structured Query Language
分析:
- 关系型数据库:列+行,同一个表下数据的结构一样。
- 非关系型数据库:数据存储没有固定格式,并且可以进行横向扩展。
NoSQL 泛指非关系型数据库,随着web2.0互联网的诞生,传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区,暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是发展最快的。
Nosql 特点
- 方便扩展(数据之间没有关系,很好扩展!)
- 大数据量高性能(Redis一秒可以写8万次,读11万次,NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高!)
- 数据类型是多样型的!(不需要事先设计数据库,随取随用)
传统 RDBMS 和 NoSQL
传统的 RDBMS(关系型数据库)
- 结构化组织
- SQL
- 数据和关系都存在单独的表中 row col
- 操作,数据定义语言
- 严格的一致性
- 基础的事务
Nosql
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库(社交关系)
- 最终一致性
- CAP定理和BASE
- 高性能,高可用,高扩展
大数据时代的3V :主要是描述问题的
- 海量Velume
- 多样Variety
- 实时Velocity
大数据时代的3高 : 主要是对程序的要求
- 高并发
- 高可扩
- 高性能 真正在公司中的实践:NoSQL + RDBMS 一起使用才是最强的
NoSQL 分类
Nosql 四大分类
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 |
|---|---|---|---|---|
| 键值对(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 |
Redis

Redis 资讯
smallchat
【2023-11-15】 Redis创始人开源最小聊天服务器 SmallChat ,C语言实现,仅200行代码
cd smallchat
# 编译
# gcc smallchat.c -o smallchat && ./smallchat
make
# 启动服务, 默认端口 SERVER_PORT 7711
./smallchat-server
# 启动客户端连接
/nick # 设置昵称
./smallchat-client 127.0.0.1 7711
Redis简介
Redis(Remote Dictionary Server ),即远程字典服务。
- 是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
- 与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统。和 Memcache 类似,但很大程度补偿了Memcache的不足,它支持存储的value类型相对更多,包括string、list、set、zset和hash。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作。在此基础上,Redis支持各种不同方式的排序。
常见的内存型数据库,除 Redis 之外,还有 Oracle Berkeley DB(甲骨文旗下的一款产品)、SQlite(轻量级内存数据库)、Memcache(键值型分布式缓存数据库)、Altibase(基于内存的高性能数据库)。
与其他内存型数据库相比,Redis 具有以下特点:
- Redis 不仅可以将数据完全保存在内存中,还可以通过磁盘实现数据的持久存储;
- Redis 支持丰富的数据类型,包括 string、list、set、zset、hash 等多种数据类型,因此它也被称为“数据结构服务器”;
- Redis 支持主从同步,即 master-slave 主从复制模式。数据可以从主服务器向任意数量的从服务器上同步,有效地保证数据的安全性;
- Redis 支持多种编程语言,包括 C、C++、Python、Java、PHP、Ruby、Lua 等语言。
与 SQL 型数据库截然不同,Redis 没有提供新建数据库的操作,因为它自带了 16 (0—15)个数据库(默认使用 0 库)。在同一个库中,key 是唯一存在的、不允许重复的,它就像一把“密钥”,只能打开一把“锁”。键值存储的本质就是使用 key 来标识 value,当想要检索 value 时,必须使用与 value 相对应的 key 进行查找。
Redis 数据库没有“表”的概念,它通过不同的数据类型来实现存储数据的需求,不同的数据类型能够适应不同的应用场景,从而满足开发者的需求。
Redis 的优势进行了简单总结:
- 性能极高:Redis 基于内存实现数据存储,它的读取速度是 110000次/s,写速度是 81000次/s;
- 多用途工具: Redis 有很多的用途,比如可以用作缓存、消息队列、搭建 Redis 集群等;
- 命令提示功能:Redis 客户端拥有强大的命令提示功能,使用起来非常的方便,降低了学习门槛;
- 可移植性:Redis 使用用标准 C语言编写的,能够在大多数操作系统上运行,比如 Linux,Mac,Solaris 等。
Redis与其他数据库对比
| 名称 | 类型 | 数据存储选项 | 附加功能 |
|---|---|---|---|
| Redis | 基于内存存储的键值非关系型数据库 | 字符串、列表、散列、有序集合、无序集合 | 发布与订阅、主从复制、持久化存储等 |
| Memcached | 基于内存存储的键值缓存型数据库 | 键值之间的映射 | 为提升性能构建了多线程服务器 |
| MySQL | 基于磁盘的关系型数据库 | 每个数据库可以包含多个表,每个表可以包含多条记录;支持第三方扩展。 | 支持 ACID 性质、主从复制和主主复制 |
| MongoDB | 基于磁盘存储的非关系文档型数据库 | 每个数据库可以包含多个集合,每个集合可以插入多个文档 | 支持聚合操作、主从复制、分片和空间索引 |
Redis 不适合存储较大的文件或者二进制数据,否则会出现错误,Redis 适合存储较小的文本信息。理论上 Redis 的每个 key、value 的大小不超过 512 MB。
安装
linux中安装:Linux 安装 Redis
wget http://download.redis.io/redis-stable.tar.gz
tar xzf redis-6.0.8.tar.gz
cd redis-6.0.8
make
# 启动服务
cd src
./redis-server # 默认配置
./redis-server ../redis.conf # 指定配置
# 客户端连接
redis-cli
redis-cli -h host -p port -a password
# redis> set foo bar
# OK
# redis> get foo
# "bar"
Mac 安装 Redis
brew install redis
redis-server # 启用前台 redis 服务
brew services start redis # 后台服务
brew services info redis # 检测状态
brew services stop redis # 停止服务
# 客户端连接
redis-cli
redis-cli --raw # UTF8 中文显示 解决中文乱码
lpush demos redis-macOS-demo # 设置值
rpop demos # "redis-macOS-demo"
python 连接 Redis
- redis-py 使用 connection pool 来管理对一个 redis server 的所有连接,避免每次建立、释放连接的开销。
import redis # 导入redis 模块
#r = redis.StrictRedis(host='localhost', port=6379, db=0)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 连接池
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True) # 连接池
r = redis.Redis(connection_pool=pool)
# 设置值
r.set('name', 'runoob') # 设置 name 对应的值
print(r['name'])
print(r.get('name')) # 取出键 name 对应的值
print(type(r.get('name'))) # 查看类型
执行完 make 命令后,redis-6.0.8 目录下会出现编译后的 redis 服务程序 redis-server,还有用于测试的客户端程序 redis-cli,两个程序位于安装目录 src 目录下
- 配置 Redis 为后台服务 将配置文件中的 daemonize no 改成 daemonize yes,配置 redis 为后台启动。
- Redis 设置访问密码 在配置文件中找到 requirepass,去掉前面的注释,并修改后面的密码。
常用配置文件例子 redis.conf
#默认端口6379
port 6379
#绑定ip,如果是内网可以直接绑定 127.0.0.1, 或者忽略, 0.0.0.0是外网
bind 0.0.0.0
#守护进程启动
daemonize yes
#超时
timeout 300
loglevel notice
#分区
databases 16
save 900 1
save 300 10
save 60 10000
rdbcompression yes
#存储文件
dbfilename dump.rdb
#密码 abcd123
requirepass abcd123
数据类型
Redis 支持 5 中数据类型:string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)。
Redis 为了存储不同类型的数据,提供了五种常用数据类型:
string(字符串): 一个K/V值- string 是 redis 最基本的数据类型。一个 key 对应一个 value,就像map。
- 二进制安全(binary safe)特性(string可以包含任何数据),长度是已知的,不由任何其他终止字符决定的,一个字符串类型的值最多能够存储 512 MB 的内容
hash(哈希散列): 一堆K/V值集合- 由字符串类型的 field 和 value 组成的映射表;一个 Hash 中最多包含 2^32-1 个键值对。
- Redis hash 是一个键值对(key - value)集合, string 类型的 key 和 value 的映射表,hash 特别适合用于存储对象
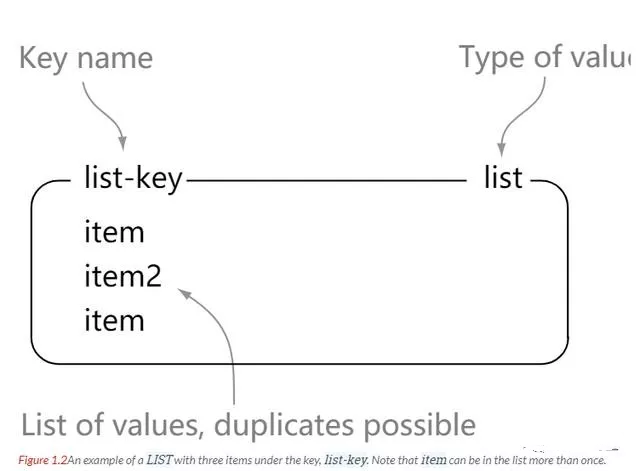
list(列表): 一系列K/V列表,可以用来实现消息队列- Redis 列表是简单的字符串列表,按照插入顺序排序,可以重复
- List 中的元素是字符串类型,其中的元素按照插入顺序进行排列,允许重复插入,最多可插入的元素个数为 2^32 -1 个(大约40亿个),可以添加一个元素到列表的头部(左边)或者尾部(右边)。
set(集合):- 字符串类型元素构成的无序集合。Redis 中集合是通过哈希映射表实现的,所以添加/删除/查找元素,时间复杂度都为 O(1)。
- 集合成员具有唯一性,所以重复插入元素不会成功,集合的同样可容纳 2^32 -1 个元素
zset(sorted set:有序集合):有序集合,集合中的元素唯一,而且每个元素还会关联一个 double 类型的分数,该分数允许重复。Redis 正是通过这个分数来为集合中的成员排序。
list图解:更多图解见原文:学 Redis ,至少要看看这篇
除了上述五种类型之外,Redis 还支持 HyperLogLog 类型,以及 Redis 5.0 提供的 Stream 类型。
Redis 允许为 key 设置一个过期时间(使用 EXPIRE 等命令),也就是“到点自动删除”,这在实际业务中是非常有用的,一是它可以避免使用频率不高的 key 长期存在,从而占用内存资源;二是控制缓存的失效时间。
# ------ string ---------
set test 123 # 设置一个值
type test # 查看key类型,string
mset x 34 y 22 # 一次设置多个值
get test # 查询某个key
# 查询多个key
mget x y
del x # 删除key
# ------ hash ---------
# 设置散列key:user1
HMSET user1 username xiaoming password 123456 website www.biancheng.net
hgetall user1 # 获取散列值
hdel user1 password # 删除其中的一个键值对
# ------ list ---------
# list
LPUSH z Java
LPUSH z C
LPUSH z B
LPUSH z A
lpop z B # 弹出最后一个元素
LRANGE z 1 # 查看第2个元素
LRANGE z 0 6 # 查看 前6个元素
LRANGE z 0 -1 # 查看所有元素
# ------ set ---------
# set
SADD s JAVA # 插入元素
SADD s HTML
SMEMBERS s # 查看集合元素
sismember s HTML # 判断元素是否存在
srem s HTML
# 有序集合
zadd t 0 Python
zadd t 1 java
zadd t 1 php
ZSCORE t Redis # 查看元素分数值
zrange biancheng 0 4 # 查看所有成员
zrem t java
# ---------
expire test 2 # 设置test过期时间(s)
exist test # key是否存在
dump test # 序列化
keys te* # 寻找匹配的key
RANDOMKEY # 随机返回一个key
rename test new # 重命名
move test 2 # key移动到指定库
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
Redis GEO 操作方法有:
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
发布订阅
一般不用 Redis 做消息发布订阅。
- Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
- Redis 客户端可以订阅任意数量的频道。
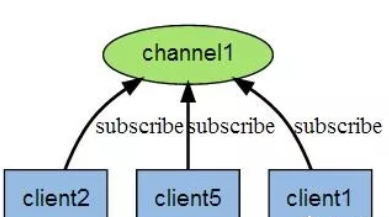
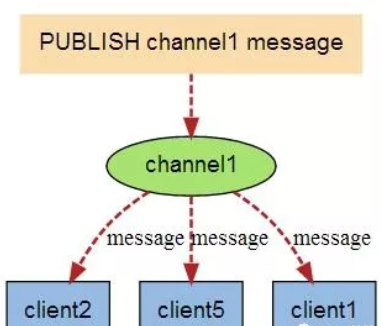
# 发布订阅
SUBsCRIBE redisChat # 创建订阅频道 redisChat
# 重新开启redis客户端
PUBLISH redisChat "send message"
PUBLISH redisChat "hello world"
# 订阅者收到消息,三行为一次消息
# 1) "message"
# 2) "redisChat"
# 3) "send message"
# 1) "message"
# 2) "redisChat"
# 3) "hello world"
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余命令依然被执行。也就是说 Redis 事务不保证原子性。
- 在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。 一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令
MULTI # 开始事物
SET book-name "Mastering C++ in 21 days"
GET book-name
SADD tag "C++" "Programming" "Mastering Series"
SMEMBERS tag
EXEC # 执行以上事物
# 1) OK
# 2) "Mastering C++ in 21 days"
# 3) (integer) 3
# 4) 1) "Mastering Series"
# 2) "C++"
# 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
redis 事务的相关命令:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | DISCARD | 取消事务,放弃执行事务块内的所有命令。 |
| 2 | EXEC | 执行所有事务块内的命令。 |
| 3 | MULTI | 标记一个事务块的开始。 |
| 4 | UNWATCH | 取消 WATCH 命令对所有 key 的监视。 |
| 5 | WATCH key [key …] | 监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。 |
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
- 将某个时间点的所有数据都存放到硬盘上。
- 可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。
- 如果系统发生故障,将会丢失最后一次创建快照之后的数据。
- 如果数据量大,保存快照的时间会很长。
AOF 持久化
- 将写命令添加到 AOF 文件(append only file)末尾。
- 使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。
redis集群架构
几种模式
- 主从模式:读写分离,主机只用来写,从机用来读,主机定期往从机同步全量数据
- 哨兵模式
| 模式 | 思想 | 优点 | 缺点 |
|---|---|---|---|
| 主从模式 | 读写分离,主机只用来写,从机用来读,主机定期往从机同步全量数据 | 读写分离大大减轻redis读写压力,主从模式同时提供多个备份 | 主机无自动容错和恢复,单主机性能受限,数据同步不及时、卡顿,主机宕机时,需要人工停服干预,把另一台从机变主机 |
| 哨兵模式 | 通过哨兵监控获取主机工作状态,一旦故障就自动将从机提升为主机,哨兵存储节点地址 | 无人人工干预;多个哨兵相互监视,保证稳定性 |
主从模式
软件架构中,主从模式(Master-Slave)是使用较多的一种架构。主(Master)和从(Slave)分别部署在不同的服务器上,当主节点服务器写入数据时,同时也会将数据同步至从节点服务器,通常情况下,主节点负责写入数据,而从节点负责读取数据。
- 图
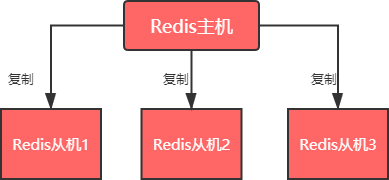
- Redis 主机会一直将自己的数据复制给 Redis 从机,从而实现主从同步。在这个过程中,只有 master 主机可执行写命令,其他 salve 从机只能只能执行读命令,这种读写分离的模式可以大大减轻 Redis 主机的数据读取压力,从而提高了Redis 的效率,并同时提供了多个数据备份。 主从模式是搭建 Redis Cluster 集群最简单的一种方式。
主从模式并不完美,它也存在许多不足之处,下面做了简单地总结:
- 1) Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
- 2) 如果主机宕机前有一部分数据未能及时同步到从机,即使切换主机后也会造成数据不一致的问题,从而降低了系统的可用性。
- 3) 因为只有一个主节点,所以其写入能力和存储能力都受到一定程度地限制。
- 4) 在进行数据全量同步时,若同步的数据量较大可能会造卡顿的现象。
哨兵模式
- Redis 主从模式不具备自动恢复的功能,所以当主服务器(master)宕机后,需要手动把一台从服务器(slave)切换为主服务器。在这个过程中,不仅需要人为干预,而且还会造成一段时间内服务器处于不可用状态,同时数据安全性也得不到保障,因此主从模式的可用性较低,不适用于线上生产环境。
- Redis Sentinel 哨兵模式(官方推荐),弥补了主从模式的不足。Sentinel 通过监控的方式获取主机的工作状态是否正常,当主机发生故障时, Sentinel 会自动进行 Failover(即故障转移),并将其监控的从机提升主服务器(master),从而保证了系统的高可用性。
哨兵模式是一种特殊的模式,Redis 为其提供了专属的哨兵命令,它是一个独立的进程,能够独立运行。下面使用 Sentinel 搭建 Redis 集群,基本结构图如下所示:
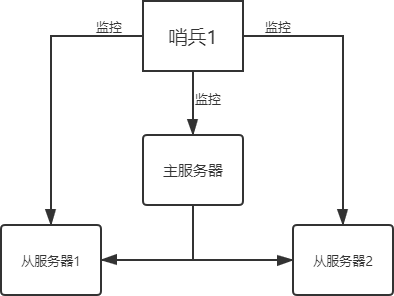 哨兵主要有两个重要作用:
哨兵主要有两个重要作用:- 第一:哨兵节点会以每秒一次的频率对每个 Redis 节点发送PING命令,并通过 Redis 节点的回复来判断其运行状态。
- 第二:当哨兵监测到主服务器发生故障时,会自动在从节点中选择一台将机器,并其提升为主服务器,然后使用 PubSub 发布订阅模式,通知其他的从节点,修改配置文件,跟随新的主服务器。 Redis Sentinel 是集群的高可用的保障,为避免 Sentinel 发生意外,一般是由 3~5 个节点组成
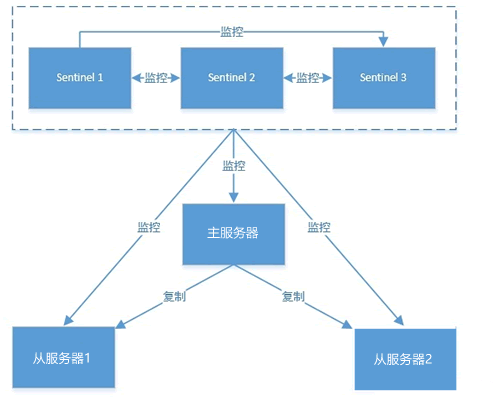
- Sentinel 负责监控主从节点的“健康”状态。当主节点挂掉时,自动选择一个最优的从节点切换为主节点。客户端来连接 Redis 集群时,会首先连接 Sentinel,通过 Sentinel 来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 Sentinel 要地址,Sentinel 会将最新的主节点地址告诉客户端。因此应用程序无需重启即可自动完成主从节点切换。
多个哨兵之间也存在互相监控,这就形成了多哨兵模式,现在对该模式的工作过程进行讲解,介绍如下:
- 1) 主观下线
- 主观下线,适用于主服务器和从服务器。如果在规定的时间内(配置参数:down-after-milliseconds),Sentinel 节点没有收到目标服务器的有效回复,则判定该服务器为“主观下线”。比如 Sentinel1 向主服务发送了PING命令,在规定时间内没收到主服务器PONG回复,则 Sentinel1 判定主服务器为“主观下线”。
- 2) 客观下线
- 客观下线,只适用于主服务器。 Sentinel1 发现主服务器出现了故障,它会通过相应的命令,询问其它 Sentinel 节点对主服务器的状态判断。如果超过半数以上的 Sentinel 节点认为主服务器 down 掉,则 Sentinel1 节点判定主服务为“客观下线”。
- 3) 投票选举
- 投票选举,所有 Sentinel 节点会通过投票机制,按照谁发现谁去处理的原则,选举 Sentinel1 为领头节点去做 Failover(故障转移)操作。Sentinel1 节点则按照一定的规则在所有从节点中选择一个最优的作为主服务器,然后通过发布订功能通知其余的从节点(slave)更改配置文件,跟随新上任的主服务器(master)。至此就完成了主从切换的操作。
消息队列 Stream (redis 5)
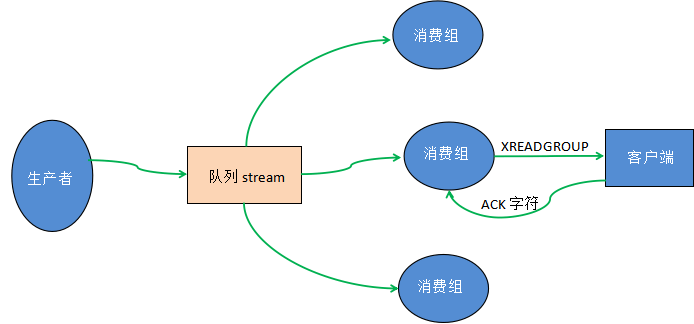
Stream 实际上是一个具有消息发布/订阅功能的组件,也就常说的消息队列。其实这种类似于 broker/consumer(生产者/消费者)的数据结构很常见,比如 RabbitMQ 消息中间件、Celery 消息中间件,以及 Kafka 分布式消息系统等,而 Redis Stream 正是借鉴了 Kafaka 系统。
Stream 除了拥有很高的性能和内存利用率外, 最大的特点就是提供了消息的持久化存储,以及主从复制功能,从而解决了网络断开、Redis 宕机情况下,消息丢失的问题,即便是重启 Redis,存储的内容也会存在。
Stream 消息队列主要由四部分组成,分别是:消息本身、生产者、消费者和消费组
- 一个 Stream 队列可以拥有多个消费组,每个消费组中又包含了多个消费者,组内消费者之间存在竞争关系。当某个消费者消费了一条消息时,同组消费者,都不会再次消费这条消息。被消费的消息 ID 会被放入等待处理的 Pending_ids 中。每消费完一条信息,消费组的游标就会向前移动一位,组内消费者就继续去争抢下消息。
Redis Stream 消息队列结构
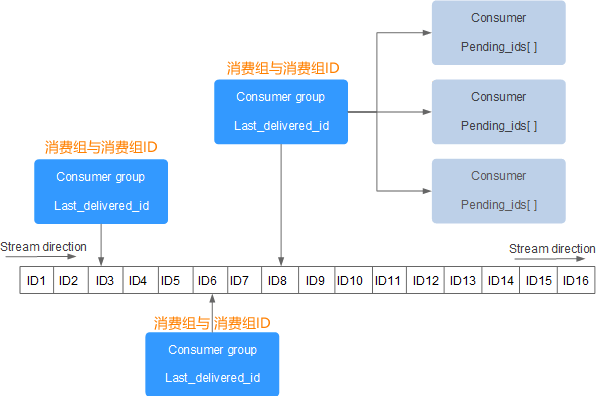
简单解释:
- Stream direction:表示数据流,它是一个消息链,将所有的消息都串起来,每个消息都有一个唯一标识 ID 和对应的消息内容(Message content)。
- Consumer Group :表示消费组,拥有唯一的组名,使用 XGROUP CREATE 命令创建。一个 Stream 消息链上可以有多个消费组,一个消费组内拥有多个消费者,每一个消费者也有一个唯一的 ID 标识。
- last_delivered_id :表示消费组游标,每个消费组都会有一个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id - 往前移动。
- pending_ids :Redis 官方称为 PEL,表示消费者的状态变量,它记录了当前已经被客户端读取的消息 ID,但是这些消息没有被 ACK(确认字符)。如果客户端没有 ACK,那么这个变量中的消息 ID 会越来越多,一旦被某个消息被 ACK,它就开始减少。
创建消息
- Redis Stream通过XGROUP CREATE指令创建消费组(Consumer Group),在创建时,需要传递起始消息的 ID 用来初始化 last_delivered_id 变量。
消费消息
- Redis Stream 通过XREADGROUP命令使消费组消费信息,它和XREAD命令一样,都可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的 PLE(正在处理的消息)结构里,客户端处理完毕后使用 XACK 命令通知 Redis 服务器,本条消息已经处理完毕,该消息的 ID 就会从 PEL 中移除。
常用命令
| 命令 | 说明 |
|---|---|
| XADD | 添加消息到末尾。 |
| XTRIM | 对 |
| XDEL | 删除指定的消息。 |
| XLEN | 获取流包含的元素数量,即消息长度。 |
| XRANGE | 获取消息列表,会自动过滤已经删除的消息。 |
| XREVRANGE | 反向获取消息列表,ID |
| XREAD | 以阻塞或非阻塞方式获取消息列表。 |
| XGROUP | CREATE |
| XREADGROUP | GROUP |
| XACK | 将消息标记为”已处理”。 |
| XGROUP | SETID |
| XGROUP | DELCONSUMER |
| XGROUP | DESTROY |
| XPENDING | 显示待处理消息的相关信息。 |
| XCLAIM | 转移消息的归属权。 |
| XINFO | 查看 |
| XINFO | GROUPS |
| XINFO | STREAM |
| XINFO | CONSUMERS |
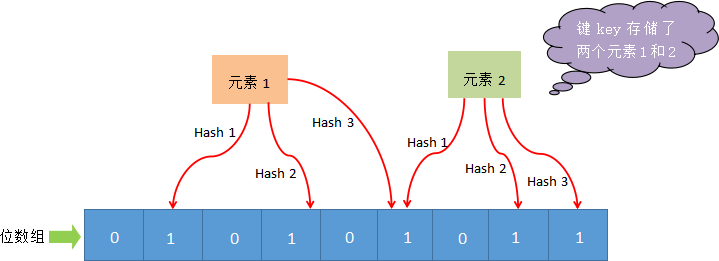
布隆过滤器(redis 4)
布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。
布隆过滤器使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。
工作流:
布隆过滤器(Bloom Filter)是 Redis 4.0 版本提供的新功能,它被作为插件加载到 Redis 服务器中,给 Redis 提供强大的去重功能。
相比于 Set 集合的去重功能而言,布隆过滤器在空间上能节省 90% 以上,但是它的不足之处是去重率大约在 99% 左右,也就是说有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。俗话说“鱼与熊掌不可兼得”,如果想要节省空间,就需要牺牲 1% 的误判率,而且这种误判率,在处理海量数据时,几乎可以忽略。
常用命令
| 命令 | 说明 |
|---|---|
| bf.add | 只能添加元素到布隆过滤器。 |
| bf.exists | 判断某个元素是否在于布隆过滤器中。 |
| bf.madd | 同时添加多个元素到布隆过滤器。 |
| bf.mexists | 同时判断多个元素是否存在于布隆过滤器中。 |
| bf.reserve | 以自定义的方式设置布隆过滤器参数值,共有 |
import redis
size=10000
r = redis.Redis()
count = 0
for i in range(size):
#添加元素,key为userid,值为user0...user9999
r.execute_command("bf.add", "userid", "user%d" % i)
#判断元素是否存在,此处切记 i+1
res = r.execute_command("bf.exists", "userid", "user%d" % (i + 1))
if res == 1:
print(i)
count += 1
#求误判率,round()中的5表示保留的小数点位数
print("size: {} ,error rate:{}%".format(size, round(count / size * 100, 5)))
分布式锁
在分布式系统中,当不同进程或线程一起访问共享资源时,会造成资源争抢,如果不加以控制的话,就会引发程序错乱。此时使用分布式锁能够非常有效的解决这个问题,它采用了一种互斥机制来防止线程或进程间相互干扰,从而保证了数据的一致性。
分布式锁并非是 Redis 独有,比如 MySQL 关系型数据库,以及 Zookeeper 分布式服务应用,它们都实现分布式锁,只不过 Redis 是基于缓存实现的。
Redis分布式锁有很对应用场景,举个简单的例子,比如春运时,您需要在 12306 上抢购回家火车票,但 Redis 数据库中只剩一张票了,此时有多个用户来预订购买,那么这张票会被谁抢走呢?Redis 服务器又是如何处理这种情景的呢?在这个过程中就需要使用分布式锁。
Redis 分布式锁主要有以下特点:
- 第一:互斥性是分布式锁的重要特点,在任意时刻,只有一个线程能够持有锁;
- 第二:锁的超时时间,一个线程在持锁期间挂掉了而没主动释放锁,此时通过超时时间来保证该线程在超时后可以释放锁,这样其他线程才可以继续获取锁;
- 第三:加锁和解锁必须是由同一个线程来设置;
- 第四:Redis 是缓存型数据库,拥有很高的性能,因此加锁和释放锁开销较小,并且能够很轻易地实现分布式锁。
缓存问题
在实际的业务场景中,Redis 一般和其他数据库搭配使用,用来减轻后端数据库的压力,比如和关系型数据库 MySQL 配合使用。
- Redis 会把 MySQL 中经常被查询的数据缓存起来,比如热点数据,这样当用户来访问的时候,就不需要到 MySQL 中去查询了,而是直接获取 Redis 中的缓存数据,从而降低了后端数据库的读取压力。如果说用户查询的数据 Redis 没有,此时用户的查询请求就会转到 MySQL 数据库,当 MySQL 将数据返回给客户端时,同时会将数据缓存到 Redis 中,这样用户再次读取时,就可以直接从 Redis 中获取数据。
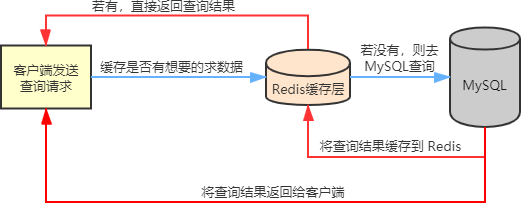
用 Redis 作为缓存数据库的过程中,有时会遇到一些棘手问题,比如常见缓存穿透(大量不存在key)、缓存击穿(key过期)和缓存雪崩(key同时过期)等问题
- (1)缓存穿透:当用户查询某个数据时,Redis 中不存在该数据,也就是缓存没有命中,此时查询请求就会转向持久层数据库 MySQL,结果发现 MySQL 中也不存在该数据,MySQL 只能返回一个空对象,代表此次查询失败。如果这种类请求非常多,或者用户利用这种请求进行恶意攻击,就会给 MySQL 数据库造成很大压力,甚至于崩溃,这种现象就叫缓存穿透。解决方法:
- ① 缓存空对象:当 MySQL 返回空对象时, Redis 将该对象缓存起来,同时为其设置一个过期时间
- ② 布隆过滤器:布隆过滤器判定不存在的数据,那么该数据一定不存在。首先将用户可能会访问的热点数据存储在布隆过滤器中(也称缓存预热),当有一个用户请求到来时会先经过布隆过滤器,如果请求的数据,布隆过滤器中不存在,那么该请求将直接被拒绝,否则将继续执行查询。相较于第一种方法,用布隆过滤器方法更为高效、实用
- (2)缓存击穿:用户查询的数据缓存中不存在,但是后端数据库却存在,这种现象原因是一般是由缓存中 key 过期导致的。比如一个热点数据 key,它无时无刻都在接受大量的并发访问,如果某一时刻这个 key 突然失效了,就致使大量的并发请求进入后端数据库,导致其压力瞬间增大。这种现象被称为缓存击穿。解决方法:
- ① 改变过期时间:设置热点数据永不过期。
- ② 分布式锁:上锁、解锁
- (3)缓存雪崩:缓存中大批量的 key 同时过期,而此时数据访问量又非常大,从而导致后端数据库压力突然暴增,甚至会挂掉,这种现象被称为缓存雪崩。它和缓存击穿不同,缓存击穿是在并发量特别大时,某一个热点 key 突然过期,而缓存雪崩则是大量的 key 同时过期,因此它们根本不是一个量级。解决方案
- 缓存雪崩和缓存击穿有相似之处,所以也可以采用热点数据永不过期的方法,来减少大批量的 key 同时过期。再者就是为 key 设置随机过期时间,避免 key 集中过期。
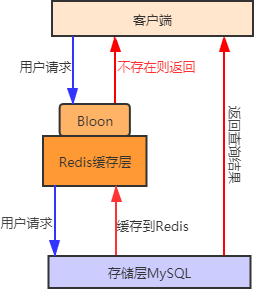
redis可视化
- (1)命令行工具
- iredis, 利用iredis,用|将redis通过pipe用shell的其他工具,比如jq/fx/rg/sort/uniq/cut/sed/awk等处理。还能自动补全,高亮显示,功能很多。
- (2)桌面软件
- Redis Desktop Manager 使用率最广的可视化工具。存在时间很久。经过了数次迭代。跨平台支持。以前是免费的,现在为收费工具。试用可以有半个月的时间。
- key的显示可以支持按冒号分割的键名空间,除了基本的五大数据类型之外,还支持redis 5.0新出的Stream数据类型。在value的显示方面。支持多达9种的数据显示方式。
- medis, 界面符合个人审美。布局简洁。跨平台支持,关键是免费。
- 颜值挺高,功能符合日常使用要求。对key有颜色鲜明的图标标识。在key的搜索上挺方便的,可以模糊搜索出匹配的key,渐进式的scan,无明显卡顿。在搜索的体验上还是比较出色的。
- 缺点是不支持key的命名空间展示,不支持redis 5.0的stream数据类型,命令行比较单一,不支持自动匹配和提示。支持的value的展现方式也只有3种
- RedisPlus: 一款开源的免费桌面客户端软件。
- Another Redis Desktop Manager:一款比较稳定简洁的redis UI工具 。
- Redis Desktop Manager 使用率最广的可视化工具。存在时间很久。经过了数次迭代。跨平台支持。以前是免费的,现在为收费工具。试用可以有半个月的时间。
- (3)Web软件
- Redis Insight: redis labs出的一款监控分析级别的redis可视化工具。这款软件是web版的。redis labs创立于2011年,公司致力于为Redis、Memcached等流行的NoSQL开源数据库提供云托管服务, 专门致力于redis云的一家专业公司。除了可以连接企业私有的redis服务,也可以连接他们的redis云。
- 基于浏览器的管理界面检查Redis数据,监视运行状况并执行运行时服务器配置,以进行Redis部署

探索您的Redis数据并与之交互 使用基于Web的CLI扫描和查看您的Redis密钥并执行CRUD操作。
官网地址:https://redislabs.com/redisinsight/
Python使用redis
安装:pip install redis
redis 模块采用了两种连接模式:直接模式和连接池模式
- 连接池模式:redis 模块使用 connection pool(连接池)来管理 redis server 的所有连接,每个 Redis 实例都会维护一个属于自己的连接池,这样做的目的是为了减少每次连接或断开的性能消耗。
- 连接池的作用:当有新的客户端请求连接时,只需要去连接池获取一个连接即可,实际上就是把一个连接共享给多个客户端使用,这样就节省了每次连接所耗费的时间。
import redis
# 本地连接,创建数据库连接对象
# db 表示当前选择的库,其参数值可以是 0-15;如果设置连接数据库的密码,那么就需要使用 password 进行验证,否则可以省略。
# ----- 直接连接 ------
r = redis.Redis(host='127.0.0.1', port=6379, db=0, password='123456')
# ----- 连接池 -------
#创建连接池并连接到redis,并设置最大连接数量;
conn_pool = redis.ConnectionPool(host='127.0.0.1',port=6379,max_connections=10)
# 第一个客户端访问
re_pool = redis.Redis(connection_pool=conn_pool)
# 第二个客户端访问
re_pool2 = redis.Redis(connection_pool=conn_pool)
# ----- 字符串 ------
# 设置数值s
r.set(k, v, ex=604800) # 有效期一周
# 或者单独设置有效期
r.expire(str(project_id), 172800) # 过期时长7
# 读取数值
print(r.get(k))
print(json.dumps(json.loads(r.get(k)), ensure_ascii=False))
# 批量读取数值
print(r.keys('*'))
key_list = r.keys('*')
#转换为字符串
for key in key_list:
print(key.decode())
#查看key类型
print(r.type('webname'))
# 返回值: 0 或者 1
print(r.exists('username'))
# 删除key
r.delete('webname')
if "age" in key_list:
print("删除失败")
else:
print("删除成功")
# ----- 列表 ------
r.lpush('database','sql','mysql','redis')
r.linsert('database','before','mysql',',mongodb')
print(r.llen('database'))
print(r.lrange('database',0,-1))
print(r.rpop('database'))
#保留指定区间内元素,返回True
print(r.ltrim('database',0,1))
while True:
# 如果列表中为空时,则返回None
result = r.brpop('database',1)
if result:
print(result)
else:
break
r.delete('database')
# ------- 散列 ------
# 1、更新一条数据的value,若不存在时,则新建这条数据
hset(key, field, value)
# 2、读取数据的指定字段属性,返回值为字符串类型
hget(key, field)
# 3、批量更新字段属性,参数mapping为字典类型
hmset(key, mapping)
# 4、批量读取数据的字段属性
hmget(key, fields)
# 5、获取这条数据的所有属性字段和对应的值,返回值为字典类型
hgetall(key)
# 6、获取这条数据的所有属性字段,返回值为列表类型
hkeys(key)
# 7、删除这条数据的指定字段
hdel(key, field)
# 设置一条数据
r.hset('user1','name','www.baidu.com')
# 更新数据
r.hset('user1','name','www.biancheng.net')
# 获取数据
print(r.hget('user1','name'))
# 一次性设置多个field和value
user_dict = {
'password':'123',
'gender':'M',
'height':'175cm'
}
r.hmset('user1',user_dict)
# 获取所有数据,字典类型
print(r.hgetall('user1'))
# 获取所有fields字段和所有values值
print(r.hkeys('user1'))
print(r.hvals('user1'))
# ---- 集合 -----
#1、给name对应的集合中添加元素
sadd(name,values)
r.sadd("set_name","tom")
r.sadd("set_name","tom","jim")
#2、获取name对应的集合的所有成员
smembers(name)
r.smembers('set_name')
#3、获取name对应的集合中的元素个数
scard(name)
r.scard("set_name")
#4、检查value是否是name对应的集合内的元素,返回值为True或False
sismember(name, value)
r.sismember('set_name','tom')
#5、随机删除并返回指定集合的一个元素
spop(name)
member = r.spop('set_name')
#6、删除集合中的某个元素
srem(name, value)
r.srem("set_name", "tom")
#7、获取多个name对应集合的交集
sinter(keys, *args)
r.sadd("set_name","a","b")
r.sadd("set_name1","b","c")
r.sadd("set_name2","b","c","d")
print(r.sinter("set_name","set_name1","set_name2"))
#输出:{b'b'}
#8、获取多个name对应的集合的并集
sunion(keys, *args)
r.sunion("set_name","set_name1","set_name2")
MongoDB
MongoDB 是一个文档型数据库,以类似 JSON 的文档形式存储数据。
MongoDB 设计理念:大数据量、高性能和灵活性需求。
MongoDB 使用集合(Collections)来组织文档(Documents),每个文档都是由键值对组成的。
数据库(Database):存储数据的容器,类似于关系型数据库中的数据库。集合(Collection):数据库中的一个集合,类似于关系型数据库中的表。文档(Document):集合中的一个数据记录,类似于关系型数据库中的行(row),以 BSON 格式存储。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成,文档类似于 JSON 对象,字段值可以包含其他文档,数组及文档数组:
云数据库
【2022-4-7】数据库技术新版图 - Serverless 数据库
数据库的发展已走过近四十年,作为基础软件之一,数据库称得上是一个“古老”的领域。而随着新技术的涌现,这个传统的领域也正不断焕发出新的生机。如果说云时代的到来推动了数据库的变革,那么,与 Serverless 的结合,则再次为数据库的发展添了把火。
- Serverless 数据库会成为未来的趋势吗?
- 又该如何让 Serverless 数据库从概念走向落地? 亚马逊云科技 Tech Talk 特别邀请资深数据库专家马丽丽带来分享《 Serverless 数据库为应用开发带来的变革》。
为什么要 云数据库?
从自建数据库到迁移上云,云数据库帮助企业和开发者省掉了很大一部分精力。开发者不再需要进行数据库的安装或备份工作
云数据库选型
数据库的选型难题却并未得到很好的解决。尽管云上数据库能够提供一些监控信息,但在多数场景下,工作负载是不均衡的,波峰和波谷往往差异极大,那么在这样的情况下该如何进行数据库选型呢?一般来说,有以下几个方式:
- 第一,为了避免数据库成为瓶颈,开发者可以按照波峰的方式进行部署。但工作负载不是始终都处于波峰,如果统一按照波峰位置部署数据库,就会带来资源浪费,提升成本。
- 第二,开发者可考虑按照波峰波谷的工作负载,配置一个平均值。这样成本的确有所节约,但问题是,一旦工作负载达到波峰,数据库将成为瓶颈,严重影响终端用户的体验。
- 第三,也是开发者现阶段最为常用的方式,即对不同指标进行监控,设置预警,比如设置当监测到 CPU 利用率到达 80% 的时候,系统发送告警信息,然后由开发或运维人员手动对数据库容量进行调整。尽管这样的方式的确可行,但却会耗费大量的时间成本。
从以上 3 种方式可以看出,在预算有限的情况下,依赖持续的监控和手动对数据库容量进行调整是非常困难的。是否有一种方式能够解决数据库这方面的痛点?Serverless 数据库正是这样一种切实有效的解决方案。
为什么要用 Serverless 数据库
Serverless 数据库可按需求自动缩放配置,根据应用程序的需求自动扩展容量,并内置高可用和容错能力,采用 Serverless 数据库开发者将无需考虑选型问题,只需要关注如何设计数据库模式,怎样查询数据,及如何进行相应的优化即可。
Serverless 数据库应用场景
Serverless 数据库数据库的应用场景概括为以下四种。
- 开发多租户的 SaaS 应用
- 支撑企业中同时发展的多个应用程序
- 简化分库分表的数据库容量选择
- 实现全栈 Serverless 应用架构
Serverless 数据库从概念到落地
2004 年,由于亚马逊的电商网站面临数据库扩展性的挑战,Serverless 数据库的探索之旅便已经启程。
- 当年,亚马逊内部自研了名为 Dynamo 的分布式键值存储,以解决数据库扩展性方面的挑战。
- 在进行一系列内部实践后,亚马逊于 2012 年正式对外推出可商用的 Amazon DynamoDB,DynamoDB 在发布之初就被定义为 Serverless 架构。而当初发表的论文《Dynamo: Amazon’s Highly Available Key-value Store》也凭借着对 NoSQL 的启发与深远影响,在操作系统领域顶级学术会议 SOSP2017 上,获得了 Hall of Fame Award 终身成就奖。
- 如今,DynamoDB 已发展整整十年,并在众多领域都有着非常广泛的应用。
- 与此同时,在 NoSQL 领域,亚马逊云科技也不断在 Serverless 数据库方面进行着探索,形成了完善的 Serverless 数据库服务体系。
工程实践
Python数据库操作
没有Python DB API之前,接口程序混乱。Python分别于数据库(MySQL/Oracle/SQLServer)交互
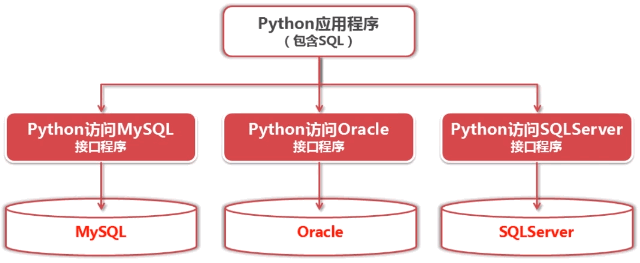 当应用程序想切换不同的的数据库时,由于程序接口的混乱所带来的代价是非常大的。为此,Python 官方规范访问数据库的接口,防止在使用不同数据库时造成的问题。这个官方规范的接口叫做 Python DB API 。该接口的说明文档
当应用程序想切换不同的的数据库时,由于程序接口的混乱所带来的代价是非常大的。为此,Python 官方规范访问数据库的接口,防止在使用不同数据库时造成的问题。这个官方规范的接口叫做 Python DB API 。该接口的说明文档 Python DB API包含的内容. API中主要的模块如下
Python DB API包含的内容. API中主要的模块如下- (1)Connection
- 参数信息:db_connection = pymysql.connect(host=’127.0.0.1’, user=’xxxx’, password=’xxxx’, database=’python2test’, charset=’utf8’)
- 支持的方法:cursor(), commit(), rollback(), close()
- (2)Cursor: 游标对象:用于执行查询和获取结果
- 执行SQL将结果从数据库获取到客户端的过程
- 支持的方法:execute(), fetchone(), fetchmany(), fetchall(), rowcount(), close()
- 执行SQL将结果从数据库获取到客户端的过程
- (3)Exceptions 各模块的作用:
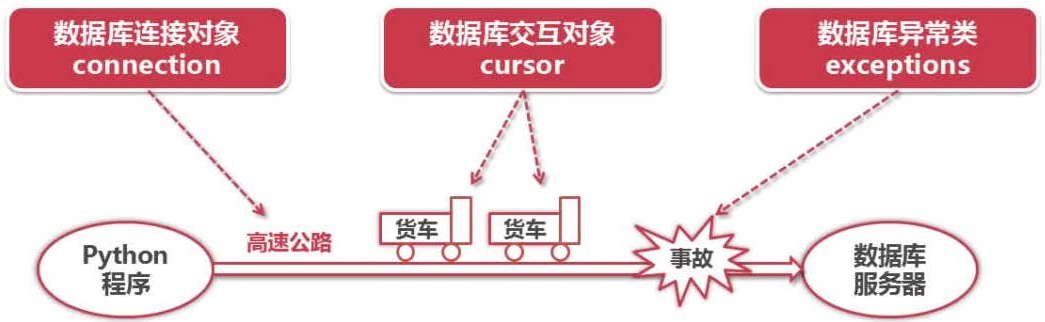 Python DB API访问数据库流程:
Python DB API访问数据库流程: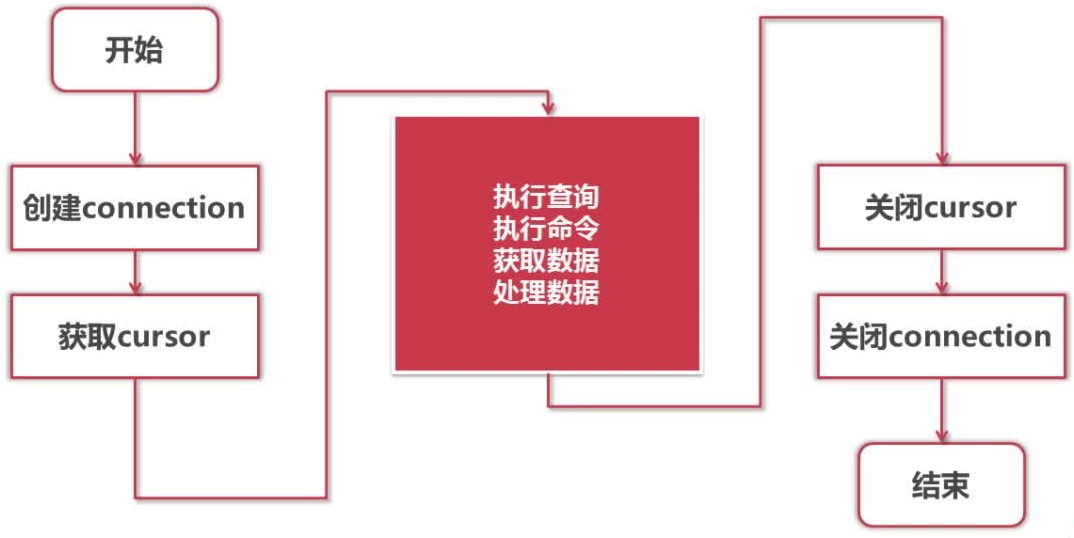


Python DB-API使用流程也非常简单:
- a).引入 API 模块
- b).获取与数据库的连接
- c).执行相关的语句进行查询,搜索和存储过程
- d).关闭数据库连接
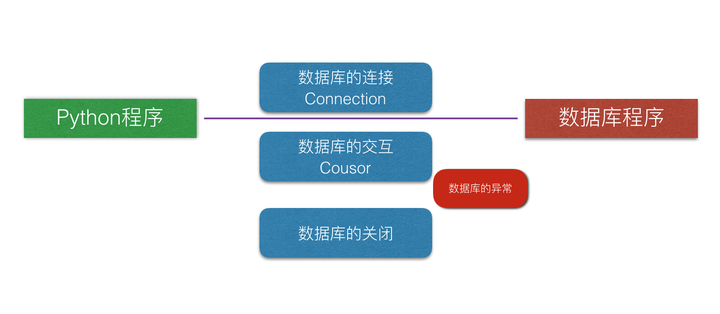
pymysql 和 MySQLdb(仅python2)
- pymysql 是在 Python3.x 和 2.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb。
- pymysql 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。下面便以 pymysql 为例,对于其他数据库同样的有着 pysql、pymongo 等等。
- pymysql 下载地址
- 安装:pip install pymysql
SQLite —— Python内置
SQLite 是一种用C写的小巧的嵌入式数据库,它的数据库就是一个文件。
SQLite 不需要一个单独的服务器进程或操作的系统,不需要配置,这意味着不需要安装或管理,所有的维护都来自于SQLite 软件本身。
可视化工具
SQLite-Web:
- github sqlite-web
SQLite-Web 提供功能:
- 添加或删除表、列和索引:你可以通过 Web 界面轻松地添加或删除表、列和索引。
- 导入和导出数据:支持将数据导出为 JSON 或 CSV 格式,也可以从 JSON 或 CSV 文件中导入数据。
- 浏览表数据:你可以查看表中的所有数据,并对数据进行排序。
- 执行 SQL 查询:在查询选项卡中,你可以对表执行任意 SQL 查询,查询结果可以导出为 JSON 或 CSV。
安装使用
列选项:
- -p, –port:指定端口,默认值为 8080。
- -H, –host:指定主机,默认值为 127.0.0.1。
- -d, –debug:启用调试模式,默认值为 false。
- -x, –no-browser:启动时不打开 Web 浏览器。
- -P, –password:提示输入密码以访问 SQLite-Web。
- -r, –read-only:以只读模式打开数据库。
- -u, –url-prefix:指定应用程序的 URL 前缀。
pip install sqlite-web
# 安装完成后,启动 SQLite-Web:
sqlite_web /path/to/your-database.db # 单个数据库文件
sqlite_web /path/to/db1.db /path/to/db2.db /path/to/db3.db # 多个数据库文件
# 高性能 wsgi 服务,要求安装 gevent
sqlite_wsgi /path/to/db.db
sqlite_wsgi -p 8000 -H '0.0.0.0' /path/to/db1.db /path/to/db2.db
# 启动模版
sqlite_web [options] /path/to/database-file.db
默认情况下,SQLite-Web 在 http://127.0.0.1:8080 启动 Web 服务器。
可以通过浏览器访问这个地址来管理 SQLite 数据库。
命令行
sqlite3工具是 SQLite 库的基于终端的前端,可以交互地评估查询并以多种格式显示结果。 它也可以在脚本中使用。
完整的 SQLite 数据库存储在单个跨平台磁盘文件中,.sqlite_history文件记录历史命令
- 【2022-3-4】sqlite教程
sqlite3 # 本地环境(空)
sqlite3 test.db # 指定本地数据库 test.db,如果test不存在,就自动创建
sqlite3 test.db "SELECT * FROM Cars;" # shell环境下直接执行sql语句
sqlite3 -version # 显示版本
# 进入sqlite终端环境
.help # sqlite3工具的元命令之一; 它列出了所有元命令。
.exit # 退出sqlite3会话。或 Ctrl + D组合键
.quit # 退出sqlite3会话。
.shell clear # 清除当前屏幕内容
.prompt # 更改sqlite3的提示符
.prompt "> " ". " # 提示符从>改成.
# Ctrl + L清除屏幕
# Ctrl + U清除当前行。
.databases # 显示附加的数据库。
.tables # 列出了可用的表。
.tables # 显示表
.schema # 显示所有表的结构,建表sql语句
.schema backend_chinacities # 显示某表的建表sql语句
# CREATE TABLE IF NOT EXISTS "backend_chinacities" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "city_name" varchar(255) NOT NULL, "city_code" integer NOT NULL, "create_time" datetime NOT NULL);
# 直接执行sql命令
# 默认情况下,输出模式为line,分隔符为|。
select * from demo; # sql语句一定以;结尾
DROP TABLE Cars; # 删除表
ALTER TABLE Names RENAME TO NamesOfFriends; # 修改表
# ------ 输出格式 --------
.separator : # 设置分隔符:
.mode column # 列模式
.headers on # 显示表头
.width 15 18 # 调整列宽,第一列15个字符,第二列18个字符
.show # 列出了各种设置。 其中包括输出模式,列表模式中使用的分隔符以及标题是否打开。
.nullvalue NULL # 控制显示值 NULL
# ------ 数据导出 -------
.dump Cars # 输出表Cars表建表语句及数据到终端,即创建Cars表所需的 SQL
.output cars2.sql # 将建表语句输出到文件(cars2.sql)
.dump Cars
.read cars.sql # 从文件加载表及数据
可视化管理
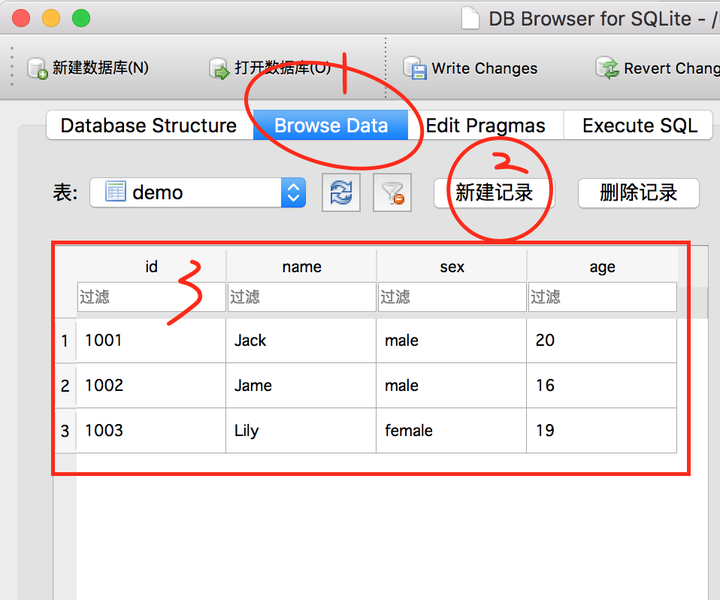
参考, DB Browser for SQLite
免费可视化工具
| 工具名 | 介绍 | 下载 | 备注 |
|---|---|---|---|
| sqliteStudio | 开源,支持多平台 | 下载 | |
| DB Browser | 开源,支持多平台 | 下载 | |
| SQLPro | 开源,只支持mac OS | ||
| Sqlite Expert | 有开原版,支持 Windows | ||
| Sqliteviz | 免费开源,web版 | 无需安装 | |
| SQLite Viewer | 免费开源,web版 | 无需安装 | 页面相对美观些 |
| SQLite Viewer Web App | 免费开源,web版 | 无需安装 | 简洁,但页面简陋 |
| SQLite Viewer Chrome 插件 | 免费,web版 | 浏览器安装 | 不好用 |
【2026-4-22】 Sqliteviz 是免费开源、离线优先的数据可视化工具,用于对 SQLite 数据库和 CSV、JSON 等文件进行可视化分析。
Sqliteviz 无需安装,直接通过浏览器即可访问:sqliteviz
代码
import sqlite3
# 创建与数据库的连接
# - 数据库文件的格式是test.db,如果该数据库文件不存在,那么它会被自动创建。
# - 返回一个Connection对象
conn = sqlite3.connect('test.db') # 文件形式的数据库
conn = sqlite3.connect(':memory:') # 内存中创建数据库
#创建一个游标 cursor
cur = conn.cursor()
# 建表的sql语句
sql_text_1 = '''CREATE TABLE scores
(姓名 TEXT,
班级 TEXT,
性别 TEXT,
语文 NUMBER,
数学 NUMBER,
英语 NUMBER);'''
# 执行sql语句
cur.execute(sql_text_1)
# 插入单条数据
sql_text_2 = "INSERT INTO scores VALUES('A', '一班', '男', 96, 94, 98)"
cur.execute(sql_text_2)
# 插入多条数据
data = [('B', '一班', '女', 78, 87, 85),
('C', '一班', '男', 98, 84, 90),
]
cur.executemany('INSERT INTO scores VALUES (?,?,?,?,?,?)', data)
# 连接完数据库并不会自动提交,所以需要手动 commit 你的改动conn.commit()
# 查询数学成绩大于90分的学生
sql_text_3 = "SELECT * FROM scores WHERE 数学>90"
cur.execute(sql_text_3)
# 获取查询结果
cur.fetchall() # .fetchone()方法(获取第一条)
# 提交改动的方法:对数据库做改动后(比如建表、插数等),都需要手动提交改动,否则无法将数据保存到数据库。
conn.commit()
# 使用完数据库之后,需要关闭游标和连接
cur.close() # 关闭游标
conn.close() # 关闭连接
MySQL
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用fetchall() 方法获取多条数据。
- fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
- fetchall(): 接收全部的返回结果行.
- rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数。
事务机制可以确保数据一致性。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability)。持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
Python DB API 2.0 的事务提供了两个方法 commit 或 rollback。Python数据库编程中,当游标建立之时,就自动开始了一个隐形的数据库事务。
- commit()方法游标的所有更新操作
- rollback()方法回滚当前游标的所有操作。 每一个方法都开始了一个新的事务。
安装
Windows
【2025-1-4】win10 64 安装 MySQL
- 下载地址 mysql
Linux
# 检查是否安装mysql
rpm -qa | grep mysql
# 删除已有mysql
rpm -e --nodeps mysql-libs-5.1.73-5.el6_6.x86_64
# 检查mysql用户组和用户是否存在,如果没有,则创建
cat /etc/group | grep mysql
cat /etc/passwd |grep mysql
groupadd mysql
useradd -r -g mysql mysql
# 下载
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz
# 解压
tar xzvf mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz
# 移动
mv mysql-5.7.24-linux-glibc2.12-x86_64 /usr/local/mysql
# 创建data目录
mkdir /usr/local/mysql/data
# 修改权限
chown -R mysql:mysql /usr/local/mysql
chmod -R 755 /usr/local/mysql
# 编译安装并初始化mysql,务必记住初始化输出日志末尾的密码(数据库管理员临时密码)
cd /usr/local/mysql/bin
./mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data --basedir=/usr/local/mysql
# 安装位置
whereis mysql
# 启动
/usr/local/mysql/support-files/mysql.server start
# 连接
mysql -u root -p
shell下执行SQL
# ① sql代码写入shell脚本
# execute sql stat
mysql -uroot -p123456 -e "
tee /tmp/temp.log
drop database if exists tempdb;
create database tempdb;
use tempdb
create table if not exists tb_tmp(id smallint,val varchar(20));
insert into tb_tmp values (1,'jack'),(2,'robin'),(3,'mark');
select * from tb_tmp;
notee
quit"
sh exec_shell.sh # 包含sql语句
# ② 文件执行
mysql -uroot -p123456 -e "source /root/temp.sql"
# ③ 使用管道
mysql -uroot -p123456 < /root/temp.sql
# ④ shell脚本中MYsql提示符
mysql -uroot -p123456 <<EOF
source /root/temp.sql;
select current_date();
delete from tempdb.tb_tmp where id=3;
select * from tempdb.tb_tmp where id=2;
EOF
exit;
# ⑤ 变量方式
echo "select count(*) from tempdb.tb_tmp" | mysql -uroot -p123456 -s
# 【2021-12-29】实践
# mac本地连接:苹果logo → 系统偏好 → 左下角mysql图标;
# 用workbench连接数据库
mysql -h 127.0.0.1 -P 3306 -u root -pwangqiwen
# 【2022-2-24】ip登录授权,如授权给机器(10.29.0.195)
Grant all privileges on *.*to'root'@'10.29.0.195' identified by 't3lQNhwYBu'with grant option;
flush privileges;
# 测试机连接
host='m11607.mars.testcom'
port=11607
user='root'
password='*****'
#database='bwbd_test_database'
database='newhouse_database'
charset='utf8'
# 注意:-p后面密码字段必须紧贴-p参数,否则失败!
mysql -h $host -P $port -u $user -p$password -D $database -e "use newhouse_database; show tables;desc kb_answer_info"
mysql -h "$host" -P "$port" -u "$user" -p"$password" -D "$database" -e "use newhouse_database; show tables;desc kb_answer_info"
# 从sql文件执行
mysql -h"$host" -P"$port" -u"$user" -p"$password" -D"$database" < newhouse/create_kb.sql
#mysql -h"$host" -P"$port" -u"$user" -p"$password" -D"$database" -e "source create_kb.sql"
# 备份数据库
mysqldump -uroot -p123456 CS -B >csdata.sql
python代码
# -*- coding: utf-8 -*-
import pymysql
# ------ 连接 ------
db = pymysql.connect(
host='127.0.0.1',
user='XXXX',
password='XXXX',
database='python2test',
charset='utf8'
)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# -------- 创建 --------
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
# 使用预处理语句创建表
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)"""
cursor.execute(sql)
# -------- 插入 ---------
# SQL 插入语句
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
cursor.execute(sql) # 执行sql语句
db.commit() # 提交到数据库执行
print("插入成功!")
except:
# 如果发生错误则回滚
db.rollback()
print("插入失败!")
# --------- 更新 -----------
# SQL 更新语句
sql = "UPDATE EMPLOYEE SET INCOME = INCOME * 1.2 WHERE SEX = '%c'" % ('M')
try:
cursor.execute(sql) # 执行SQL语句
db.commit() # 提交到数据库执行
except:
db.rollback() # 发生错误时回滚
# ----------- 查询 ----------
# SQL 查询语句
sql = "SELECT * FROM EMPLOYEE WHERE INCOME > '%d'" % (1000)
try:
cursor.execute(sql) # 执行SQL语句
results = cursor.fetchall() # 获取所有记录列表
print("FIRST_NAME\tLAST_NAME\tAGE\tSEX\tINCOME |")
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# 打印结果
print("%s\t\t\t%s\t\t\t%d\t%s\t%d" %(fname, lname, age, sex, income))
except:
print("Error: unable to fetch data")
# ----------- 删除 -----------
# SQL 删除语句
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
cursor.execute(sql) # 执行SQL语句
db.commit() # 提交修改
except:
db.rollback() # 发生错误时回滚
# ---------- 关闭 ----------
db.close()
MySQL主从库
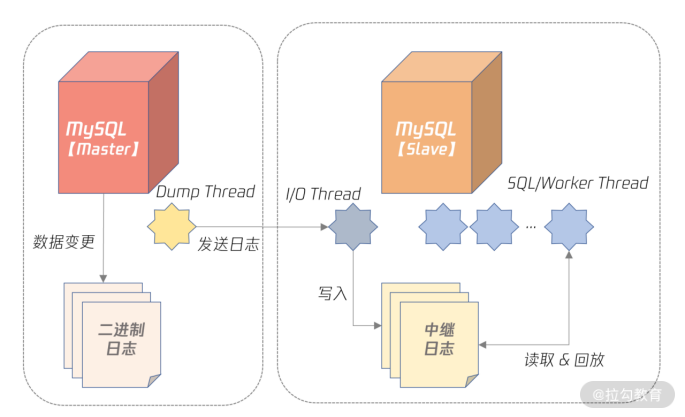
【2022-1-3】Mysql 复制架构
数据库复制的其实就是数据的同步,Mysql数据库基于binary log日志进行数据增量同步,binary log 日志记录了所有对Mysql数据库的修改操作。
- 查看:show binlog_events in ‘binlog.000001’或者:mysqlbinlog -vv ‘binlog.000001’
如下图所展示:
- Master 服务器将数据变更产生的二进制日志通过Dump线程发送给Slave服务器。
- slave服务器的I/O线程负责接收日志数据,保存为中继日志。
- slave服务器的worker线程负责执行中继日志,完成在slave服务器回放Master的日志。
操作步骤:
- 创建复制的账号,赋权。
- 从Master服务器上通过mysqldump工具拷贝全量数据。
- 通过命令change master to 搭建复制关系。
- 通过命令show slave status 观察复制状态。
建议配置:
- gtid_mode = on
- enforce_gtid_consistency = 1
- binlog_gtid_simple_recovery = 1
- relay_log_recovery = ON
- master_info_repository = TABLE
- relay_log_info_repository = TABLE 可以保证无论是Master还是Slave宕机恢复后,数据一致。
Mysql复制分类:
- 异步复制,Master和Slave 相互不依赖,性能最好,用在数据不太重要,容易丢失,比如日志监控场景。
- 多源复制,多个Master复制到一台Slave上,便于做统计。
- 延迟复制,Slave延迟回放收到的二进制日志,防止Master上误操作被同步到Slave上:
- 半同步复制: Master在事务提交的过程中,至少N个Slave已经接收到了二进制日志,确保Master宕机时候,至少N台Slave的数据是完整的,用于核心业务场景。 CHANGE MASTER TO master_delay = 3600
日志
Mysql 三大日志的作用:binlog、undolog、redolog。
何时写入?
| 日志类型 | 说明 | 作用 | 写入时机 |
|---|---|---|---|
binlog |
二进制日志 | binlog主要用于记录数据库的更改操作,包括INSERT、UPDATE、DELETE等数据修改语句。它是用于数据复制和恢复的重要组成部分,用于保持数据的一致性。 | binlog在事务提交时被写入。这意味着当事务成功提交后,相关更改会被记录到binlog中 |
undolog |
回滚日志 | undo log用于支持数据库事务的回滚操作。它保存了之前的数据版本,以便在事务回滚或其他读一致性操作时使用 | |
redolog |
重做日志 | redo log用于数据库的崩溃恢复和持久性保证。它记录了数据库引擎对数据页的物理更改,以便在数据库崩溃后能够重放这些更改,确保数据的完整性。 | redo log在事务进行数据修改时被写入,并在事务提交时被刷新到持久存储(通常是磁盘)。这确保了即使数据库在崩溃前还没有将数据写入磁盘,redo log中的信息也足以还原数据。 |
区别:
- 1、binlog 数据复制和恢复,记录了逻辑更改。
- 2、undolog 支持事务的回滚和读一致性,记录了逻辑更改的逆操作。
- 3、redolog 物理崩溃恢复,记录了数据页的物理更改。
数据库管理系统
CRUD
CRUD:
- 创建 – 在数据库的表中创建或添加新条目。
- 检索 – 以列表的形式(列表视图)读取,检索,搜索或查看现有条目,或详细检索特定的条目(详细视图)
- 更新 – 更新或编辑数据库表中的现有条目
- 删除 – 删除,停用或删除数据库表中的现有条目

SQL可视化工具
Web可视化
从名字就可以看出来,这是一个Chrome浏览器的扩展插件,跟简单地安装其他Chrome插件没有区别,由日本程序员Yoichiro Tanaka开发维护。界面清爽,可以满足对数据库的基本操作——增删改查。对于一些偶尔想去数据库里面查一下数据的用户,例如QA,运营,或者甚至会点SQL的小老板来说,这款工具是一个不错的选择。
OmniDB算是一款比较知名的Web端数据库管理程序了。基于Python Django开发。支持MySQL / MariaDB、PostgreSQL和Oracle,其他知名数据库产品例如IBM DB2、Microsoft SQL Server、SQLite的支持正在开发中,这些产品的数据库用户可以再期待一下。OmniDB应该说更像一个console控制台,除了满足最基本的“增删改查”之外,还支持数据库服务器的维护和监控,是一款开发和运维都友好的数据库Web工具。
phpMyAdmin应该是最流行的基于经典Apache + PHP的MySQL数据库Web客户端了。因为历史悠久而且用户众多,所以也可以说是最成熟的产品了。
GUI 可视化
【2022-11-13】常用的数据库管理工具:Navicat、Datagrip、Dbeaver。
- Navicat,包括界面功能以及运行速度。但要说强大
- Datagrip这个后来者更厉害。可好用归好用,每年几百块的费用,还是有点扛不住。
- 最后还是使用Dbeaver,Windows、Mac、Linux几台机子上用的都是它。虽然功能和使用便利性没有Navicat好,功能没有Datagrip强大。但人家免费
各家的数据库管理软件的特性。最好用的 10 款 MySQL 管理工具测评概览
- MySQL Workbench - 免费、官方、有付费软件才有的重型功能
- Sequel Pro - 免费、小巧、轻量级、Mac Only
- Beekeeper Studio - 免费、小巧、跨平台、多数据库支持
- HeidiSQL - 免费 Win Linux only 功能丰富直给 有中文版
- DBeaver - 免费 小巧、跨平台、功能大合集式,多数据库 有中文版
- phpMyadmin - 免费、跨平台在线版、简单直接,上手快
- 卡拉云 - 免费、无需安装 跨平台 多数据库支持 灵活搭建 定制开发 新一代
- Navicat - 付费、跨平台、稳定、重型功能、有中文版
- dbForge Studio - 付费 Win only 稳定 产品逻辑扎实
- SQLyog - 付费 Win Only 付费中的精巧版 中文版

| 工具 | 费用 | 平台 | 中文 | 特点 |
|---|---|---|---|---|
| MySQL Workbench | 免费 | 多平台客户端 | ? | 官方,有付费软件才有的重型功能 |
| Sequel Pro | 免费 | Mac | ? | 小巧、轻量级,停止维护 |
| Beekeeper Studio | 免费 | 跨平台客户端 | ? | 多数据库支持 |
| HeidiSQL | 免费 | Win/Linux | 中文 | 功能丰富 |
| DBeaver | 免费 | 跨平台 | 中文 | 功能大合集式,多数据库 |
| phpMyadmin | 免费 | 跨平台Web | ? | 简单直接,上手快 php语言,依赖LAMP架构 |
| 卡拉云 | 免费 | 跨平台 | 多数据库,免安装 | |
| Navicat | 付费 | 跨平台 | 中文 | 稳定、重型功能 |
| dbForge Studio | 付费 | win | 中文 | 稳定 产品逻辑扎实 |
| SQLyog | 付费 | win | 中文 | |
| WebcatEE | 免费 | 跨平台Web | 支持 | java版的 web 数据库管理和运维软件 支持多种数据库,包含了SQL审核,SQL执行,SQL查询,线上发布等功能 WebcatEE 同时支持 Redis, MongoDB 等主流 NoSQL 数据库且功能强大易用 |
MySQL Workbench - 官方、免费、功能全
-

-
安装:官方网站,centos下载链接
生成 UML 图
MySQL Workbench 生成UML的步骤示例:
- 从MySQL官方网站 下载并安装 MySQL Workbench。
- 打开 MySQL Workbench, 并连接到相应的MySQL数据库。
- 在顶部菜单中选择“Database”->“Reverse Engineer”。
- 输入数据库连接信息并点击“Next”。
- 选择要包括在UML图中的表,并点击“Next”。
- MySQL Workbench将自动生成基于所选表的UML图。
【2025-1-4】win10本地实测有效
- 提前安装 mysql community server
Beekeeper Studio - 免费、小巧、跨平台、多数据库支持
Beekeeper Studio不仅免费开源,跨平台(WIndows、Mac、Linux)而且还支持多种数据库管理:MySQL、MariaDB、Postgres、SQLite、SQL Server、Amazon Redshift、CockroachDB 等多种数据库接入。
- 持多种数据格式导出。
 Beekeeper 太灵活了,如果仅是日常维护查询,强烈推荐。Sequel Pro 和 Beekeeper 都没有复杂功能,比如数据迁移、数据自动备份、ER 自动同步等,但也正因为他们没有这些大型功能,才能如此轻巧,秒开秒用。
Beekeeper 太灵活了,如果仅是日常维护查询,强烈推荐。Sequel Pro 和 Beekeeper 都没有复杂功能,比如数据迁移、数据自动备份、ER 自动同步等,但也正因为他们没有这些大型功能,才能如此轻巧,秒开秒用。
HeidiSQL - 免费 Win Linux only
HeidiSQL的界面太 2000年了,绿色版(无需安装版)的免费软件的调调,把所有的功能都摊在界面上,直给的感觉。它有一个很大的状态栏,把所有 SQL 运行过程全都展现在这里面,你或它自动帮你执行的所有动作,都是如此的直接。
 HeidiSQL 用起来很像 dbForge 和 SQLyog 的无产品经理版,一切都是如此的程序员。
HeidiSQL 用起来很像 dbForge 和 SQLyog 的无产品经理版,一切都是如此的程序员。
HeidiSQL 相对于 Beekeeper 和 Sequel Pro 来说功能要多一些,HeidiSQL 更像是一个 MySQL 管理工具,而 Beekeeper 和 Sequel Pro 更像是轻巧的简单维护工具。
还有一个大家挺关心的,介绍道这里终于出现了支持中文的 MySQL 管理软件,如果你对中文很在意,可以试试 HeidiSQL 和接下来我要介绍的 DBeaver
DBeaver - 免费 小巧、跨平台、多数据库
DBeaver比 HeidiSQL 更程序员(这家公司一定把产品经理都干掉了),把所有能装进来的功能全装进来了,有点像 Win 相对于 Mac 的使用体验,功能都有,就是糙。
 DBeaver 在国内占有率相对于国外使用者比例来说要多,猜想可能是因为免费、中文版、全功能又跨平台。虽然不精,但什么功能 DBeaver 都占上了。
DBeaver 在国内占有率相对于国外使用者比例来说要多,猜想可能是因为免费、中文版、全功能又跨平台。虽然不精,但什么功能 DBeaver 都占上了。 DBeaver 支持各类知名或不知名的数据库接入,能想到的都在这个上面。我自己对 DBeaver 的使用体验来说,在执行大型查询的过程中,没办法终止,要不一直等着,要不只能杀进度了。
DBeaver 支持各类知名或不知名的数据库接入,能想到的都在这个上面。我自己对 DBeaver 的使用体验来说,在执行大型查询的过程中,没办法终止,要不一直等着,要不只能杀进度了。
phpMyadmin 跨平台在线版 MySQL 管理工具
phpMyadmin使用全宇宙最好用的 PHP 语言开发,这也决定了它可以部署在你的服务器上,在任何设备上都可以直接通过浏览器访问 phpMyadmin 来对你的 MySQL 数据库进行维护。

phpMyadmin 真正的跨平台,支持中文,操作逻辑迭代了无数代,上手及其容易。
# 安装php、phpmyadmin
sudo yum install php.x86_64 phpMyAdmin.noarch
Adminer
Adminer(以前称为phpMinAdmin)是一个基于PHP的免费开源数据库管理工具。上传单个PHP文件,将浏览器指向它,然后登录。
- 下载:wget https://github.com/vrana/adminer/releases/download/v4.8.1/adminer-4.8.1.php
- 复制到 /var/www/html 目录
- 访问:https://your-website.com/adminer-4.8.1.php 即可
与phpMyAdmin仅支持管理MySQL和MariaDB数据库不同,Adminer还支持管理其他数据库,如PostgreSQL、SQLite、MS SQL、Oracle、SimpleDB、Elasticsearch、MongoDB和Firebird。它还提供43种语言版本。
Adminer提供易于使用的界面,更好地支持许多MySQL功能,更卓越的性能和更高的安全性。
Adminer登录页面
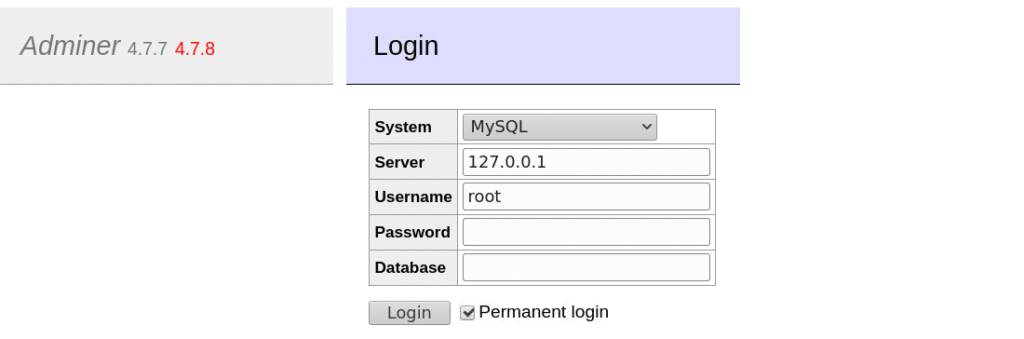 MySQL数据库服务器,默认用户名是root,默认密码是空字符串。
MySQL数据库服务器,默认用户名是root,默认密码是空字符串。
参考:
Python Web管理系统
Django 通过 ORM 实现表的CRUD
- 使用Python Web框架Django连接和操作MySQL数据库学生信息管理系统(SMS),主要包含对学生信息增删改查功能,旨在快速入门Python Web,文章结尾有整个项目的源码地址。

github上示例:
- 入门级:Django_CRUD_Student
- 带UI的Web数据库管理系统: Web Database Management
- 带UI,工作机会发布系统,支持新增、修改、删除:django_hrjobapp
- 音乐分享管理:Django-Music-Web-App
Java版Web管理系统
WebcatEE —— 功能强、可用
WebcatEE 是java版的 web 数据库管理和运维软件,支持多种数据库,包含了SQL审核,SQL执行,SQL查询,线上发布等功能。
- WebcatEE 同时支持 Redis, MongoDB 等主流 NoSQL 数据库且功能强大易用。
- WebcatEE 是一个免费软件,您可以在完全遵守最终用户许可协议的基础上,将本软件应用于非商业和商业用途,而不必支付软件版权授权费用。
- 在线演示
- 下载地址
- 在线文档

个人demo
- 百度云下载地址,提取码:xruq
- 支持功能
- 多标签页执行SQL
- 查看数据库与表列表
- 复制表名
- 查看表结构
- 登录登出
交互示例
 登录 登录 |
 执行SQL 执行SQL |
 查看表结构 查看表结构 |
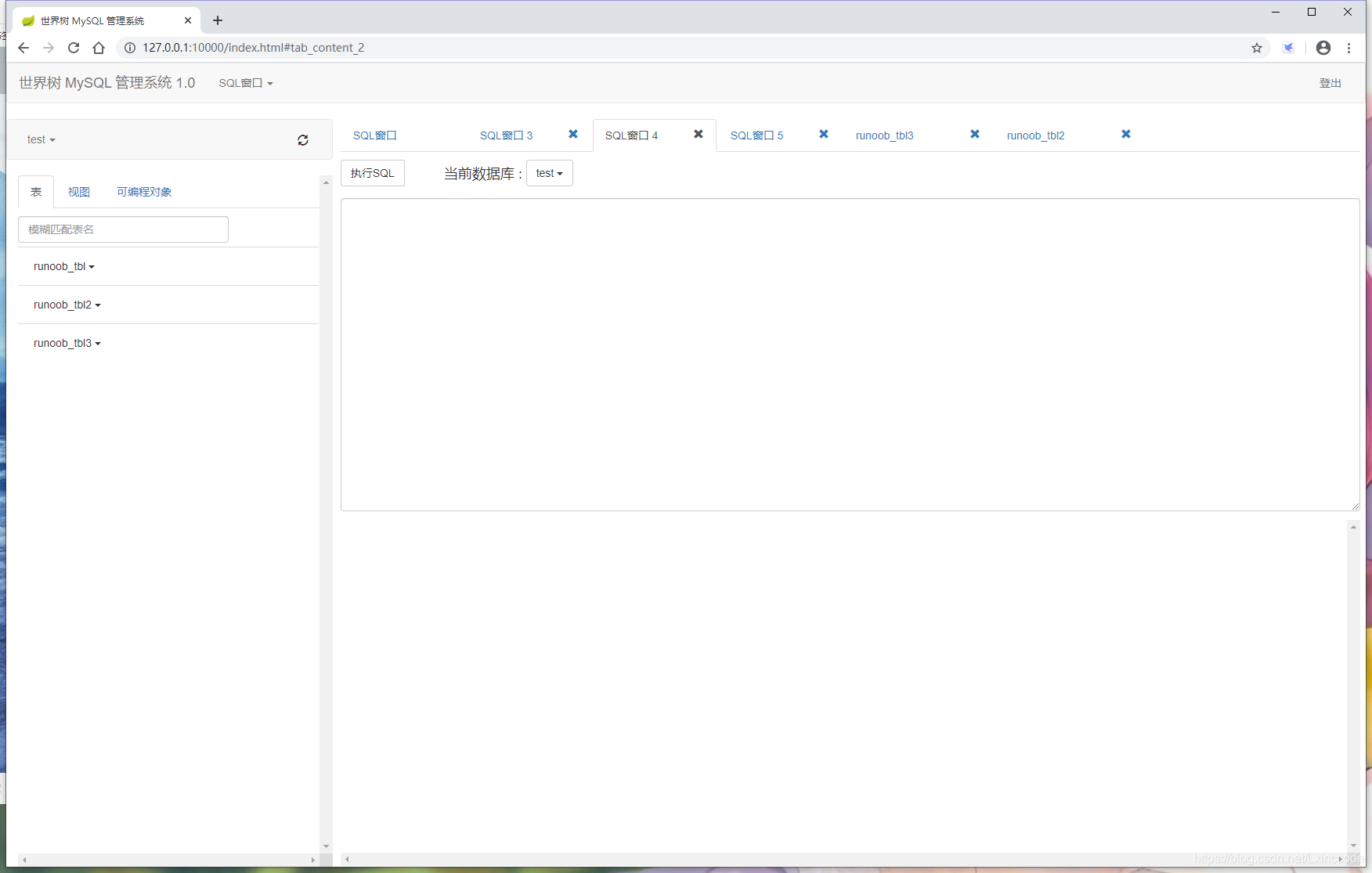 多标签页 多标签页 |
go语言版
【2022-3-5】go语言快速crud开发框架,一行代码不用敲
项目介绍
- 快速crud开发框架,甚至于一行代码不用敲
- 自动根据数据库表结构自动生成crud代码
- 低代码开发框架
- 至少减少百分90%工作量
- 可快速把现有系统转成GfEasy版本
- 后端使用GoFrame开发;后台前端使用 cool-admin-vue
- 后台使用自适应布局,手机、PC完美使用
安装
GoLand编辑器
#克隆仓库——后端
git clone https://gitee.com/jasonlaw1015/GfEasy.git
# 配置本地环境
# 。。。。
#格式化代码
gofmt ./
#安装更新相关依赖
go mod tidy
# 运行或者你点击GoLang IDE编辑器;
# 运行安装过程完成后,运行以下命令启动服务。您可以在浏览器中预览网站 [http://localhost:8000](http://localhost:8000)
go run main.go
# 前端仓库
git clone https://gitee.com/jasonlaw1015/GfEasyAdmin.git
#GfEasyAdmin目录下,运行下面命令安装依赖
yarn
#或者
npm i
- 打开mysql=》创建gf-easy库=》 运行db/gf-easy.sql;创建表结构和初始化数据
- 配置mysql、Redis
- 打开文件 /config/config.toml
- 安装gf开发工具
- 生成接口文档
- gf swagger –pack
- 交叉编译
- 运行已下命令,生成linux环境可执行文件
- gf build main.go -n my-app -v 1.0 -a amd64 -s linux -p ./
- 生成bin文件
- gf build 会生成所有平台的可执行文件
- 后台前端Vue
- 启动服务
- 运行以下命令启动服务。yarn dev,或,npm run dev
- 可以在浏览器中预览网站 http://localhost:8000
效果
- 拥有基于角色的权限控制模型RBAC
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
