总结
- 【2021-3-29】机器阅读理解综述(一)
- 【2021-3-14】机器阅读理解(Machine Reading Comprehension,MRC)是一种利用算法使计算机理解文章语义并回答相关问题的技术。学者 C. Snow 在 2002 年的一篇论文中定义阅读理解是“通过交互从书面文字中提取与构造文章语义的过程”。而机器阅读理解的目标是利用人工智能技术,使计算机具有和人类一样理解文章的能力。
- 机器阅读理解任务样例

- 大部分机器阅读理解任务采用问答式测评:设计与文章内容相关的自然语言式问题,让模型理解问题并根据文章作答。
- 在阅读理解这件事上,AI已甩人类几条街?
- 机器在阅读理解的评分上超过人类,也许是NLP发展历程上的一次重大突破,意味着机器在“指标”上对人类的胜利,机器也确实可以在限定场景下有超过人类的表现。但这终究是一场“指标性”胜利,想要做到能理解会思考,机器还有“万里长征路”要走。
- 斯坦福陈丹琦博士论文-156页PDF讲解【神经网络阅读理解】
- 【2021-1-14】美团智能问答技术探索与实践
- 近年来基于深度神经网络的机器阅读理解 ( Machine Reading Comprehension,MRC ) 技术得到了快速的发展,逐渐成为问答和对话系统中的关键技术。MRC模型以问题和文档为输入,通过阅读文档内容预测问题的答案。
- 根据需要预测的答案形式不同,阅读理解任务可以分为
- 填空式 ( Cloze-style )
- 多项选择式 ( Multi-choice )
- 片段提取式 ( Span-extraction )
- 自由文本 ( Free-form )
- 在实际问答系统中最常使用的是片段提取式阅读理解 ( MRC ),该任务需要从文档中提取连续的一段文字作为答案。
- 最具影响力的片段提取式MRC公开数据集有SQuAD和MSMARCO等,这些数据集的出现促进了MRC模型的发展。
- 在模型方面,深度神经网络结构被较早的应用到了机器阅读理解任务中,并采用基于边界预测(boundary-based prediction)方式解决片段提取式阅读理解任务。这些模型采用多层循环神经网络+注意力机制的结构获得问题和文档中每个词的上下文向量表示,在输出层预测答案片段的起始位置和终止位置。近年来预训练语言模型如BERT,RoBERTa和XLNet等在众多NLP任务上取得突破性进展,尤其是在阅读理解任务上。这些工作在编码阶段采用Transformer结构获得问题和文档向量表示,在输出层同样采用边界预测方式预测答案在文档中的位置。目前在单文档阅读理解任务SQuAD上,深度神经网络模型的预测EM/F1指标已经超越了人类标注者的水平,说明了模型在答案预测上的有效性。
- Document QA借助机器阅读理解 ( MRC ) 技术,从非结构化文档中抽取片段回答用户问题。在问答场景中,当用户输入问题后,问答系统首先采用信息检索方式从商户详情或诸多UGC评论中查找到相关文档,再利用MRC模型从文档中摘取能够确切回答问题的一段文本。美团和大众点评上商户的简介攻略、UGC评论均有专业内容运营团队,可以产生内容优质、高可信度的答案,应用机器阅读理解技术直接从文档中提取答案,不需要人工维护意图类目,可以在不同业务领域灵活迁移,人工维护成本小。
- 机器阅读理解模型
- 深度神经网络结构较早的应用到机器阅读理解任务,代表性的包括Bi-DAF、R-NET、QANet、BERT等。这些模型均采用多层循环神经网络或Transformer加注意力机制等方式来解决问题和文档的上下文向量表示,最后通过边界预测来获取答案片段的起始和结束位置。我们选择表现最好的BERT模型进行相应任务的建模,将问题和文档作为输入,预测在文档中的起始位置和结束位置,将最大可能的起始位置和结束位置之间的片段抽取出来,作为答案。
- 文档问答系统的答案预测流程包含三个步骤:
- (1) 文档检索与选择 ( Retriever ):根据Query关键字检索景点等商户下的相关详情和UGC评论,根据相关性排序,筛选出相关的评论用于提取候选答案;
- (2) 候选答案提取 ( Reader ):利用MRC模型在每个相关评论上提取一段文字作为候选答案,同时判断当前评论是否有答案,预测有答案和无答案的概率;
- (3) 答案排序 ( Ranker ):根据候选答案的预测得分排序。这样能够同时处理多篇相关评论,比较并选择最优答案,同时根据无答案概率和阈值判断是否拒绝回答,避免无答案时错误回答。
- 模型框架首先建模成Multi-Task架构,所有领域数据训练出一个共享参数,解决新领域与冷启动的问题,同时不同的领域,也会得到各自领域的参数,提升各自领域效果。除此之外,也发现只计算用户的Query和问答对里问题的相似度,是不太够的。答案往往也能帮助我们更好的去理解问题。上图中”还营业吗现在”的问题,语义上”正常营业吗?”比”关门了吗?”更相关,但从答案”肺炎期间闭园不营业”和”没去过”中很容易辨识出第一条答案更相关。因此建模时我们将答案也考虑进去,采用Multi-Field框架。最终我们的模型为Multi-Field Multi-Task RoBERTa模型。
- 主流的KBQA解决方案包括基于查询图方法 ( Semantic Parser )、基于搜索排序方法 ( Information Retrieval )。
- 查询图方案核心思路就是将自然语言问题经过一些语义分析方式转化成中间的语义表示 ( Logical Forms ),然后再将其转化为可以在 KG 中执行的描述性语言 ( 如 SPARQL 语言 ) 在图谱中查询,这种方式优势就是可解释强,符合知识图谱的显示推理过程。
- 搜索排序方案首先会确定用户Query中的实体提及词 ( Entity Mention ),然后链接到 KG 中的主题实体 ( Topic Entity ),并将与Topic Entity相关的子图 ( Subgraph ) 提取出来作为候选答案集合,通过对Query以及Subgraph进行向量表示并映射到同一向量空间,通过两者相似度排序得到答案。这类方法更偏向于端到端的解决问题,但在扩展性和可解释性上不如查询图方案。在美团场景里我们采用以Semantic Parser方法为主的解决方案。
简介
机器阅读理解(MachineReading Comprehension, MRC)任务主要是指让机器根据给定的文本回答与文本相关的问题,以此来衡量机器对自然语言的理解能力。这一任务的缘起可以追溯到 20 世纪 70 年代,但是受限于小规模数据集和基于规则的传统方法,机器阅读理解系统在当时并不能满足实际应用的需求。
这种局面在 2015 年发生了转变,主要归功于以下两点:
- 1)基于深度学习的机器阅读理解模型(神经机器阅读理解)的提出,这类模型更擅长于挖掘文本的上下文语义信息,与传统模型相比效果提升显著;
-
2)一系列大规模机器阅读理解数据集的公布,如 CNN & Daily Mail、SQuAD、MS MARCO等,这些数据集使得训练深度神经模型成为可能,也可以很好的测试模型效果。神经机器阅读理解在近几年逐渐受到越来越多的关注,成为了学术界和工业界的研究热点。
- 机器阅读理解包括 4 种比较常见的任务:完形填空,多项选择,片段抽取,自由作答。
完形填空:在文章中隐藏一些单词,然后预测被隐藏的单词。多项选择:给定一个问题、一段背景文字和一些候选答案,让模型判断哪些是正确答案。片段抽取:给定一个问题、一段背景文字,从文本中抽取出一些单词,作为答案。自由作答:给定一个问题、一段背景文字,生成单词序列作为答案。
- 多项选择和完形填空属于客观类答案,测评时可以将模型答案直接与正确答案比较,并以准确率作为评测标准,易于计算。
- A Gentle Introduction to Text Summarization in Machine Learning
文本摘要
文本摘要综述
【2020-9-5】文本摘要综述
- ACL 2020论文:Extractive Summarization as Text Matching,文本摘要新框架,抽取式摘要“轻松”取得SOTA,打破原有的解决抽取式摘要的思路,这里提出了一个全新的范式:将抽取式摘要任务转化为一个语义匹配的问题。代码MatchSum,eight Tesla-V100-16G GPUs to train our model, the training time is about 30 hours
- Text Summarization on WikiHow,第一名代码
1). 生成式
- 4-1. Seq2seq 模型
- 4-2. Seq2seq 模型+注意力机制
- 4-3. Transformer 模型
- 4-4. GPT 摘要生成
- 4-5. Bert-seq2seq
2). 抽取式
分类
阅读理解技术方案分类:
- (1)提取式 Extraction-based summarization
- (2)生成式 Abstraction-based summarization
- (3)组合 ——综合以上两种方法
- the pointer-generator network that gets the best of both worlds by combining both extraction(pointing) and abstraction(generating)

- 阅读理解进阶三部曲——关键知识、模型性能提升、产品化落地
- 【2021-3-19】国防科技大学团队2019年在arXiv上发布了预印版综述文章 Neural Machine Reading Comprehension: Methods and Trends。神经机器阅读理解最新综述:方法和趋势


SQuAD 2.0[67]是一个具有代表性的MRC数据集,问题是无法回答。基于2016年发布的前一个版本,《SQuAD 2.0》有超过5万个由群众工人创造的无法回答的问题。
- 按照构建难易程度(Construction)、对自然语言理解的测试水平(Understanding)、答案灵活程度(Flexibility)、评价难易程度(Evaluation)和实际应用贴合程度(Application)等五个维度出发,对四类常见的机器阅读理解任务进行比较,依据每个任务在不同维度上的表现,得分最低 1 分、最高 4 分

任务构造数据集是否容易不是越简单,分数越高。
- construction 构造:这个维度度量为任务构造数据集是否容易。越简单,分数越高。
- Understanding: 这个维度评估任务在多大程度上可以测试机器的理解能力。如果一项任务需要更多的理解和推理,分数就会更高。
- Flexibility: 答案表单的灵活性可以度量任务的质量。当答案更灵活时,flflexibility分数更高。
- Evaluation: 评估是MRC任务的必要组成部分。一项任务是否容易评估也决定了它的质量。在这种情况下,易于评价的任务得分较高。
- Application:应用:一个好的任务应该是接近实际应用的。因此,如果一个任务可以很容易地应用到现实世界中,那么这个维度的分数就很高.
总结:
- 完形填空任务的数据集易于构建,可以用准确率指标进行评价。但是由于这一任务的答案限定为原文中的一个词或实体,所以并不能很好的测试机器对自然语言的理解能力且与实际应用相距较远。
- 多项选择任务由于提供了候选答案,答案的形式相较于完形填空而言更为灵活,构建数据集可以直接利用现有的语言测试中的多项选择题目,所以较为容易。由于该任务要求从备选答案中选出正确答案,模型的搜索空间相对较小,对自然语言理解的测试较为局限,提供备选答案与实际应用场景不太相符。
- 片段抽取任务是一个适中的选择,数据集相对容易构建,模型效果也可以使用精确匹配和 F1 分数进行衡量,答案限定为原文中的子片段,相较于多项选择有了更大的搜索空间,也在一定程度上能测试机器对自然语言的理解能力,但是和实际应用仍有一定差距。
- 自由作答任务答案形式非常灵活,能很好的测试对自然语言的理解,与现实应用最为贴近,但是这类任务的数据集构造相对困难,如何有效的评价模型效果有待进行更为深入的研究。
机器阅读理解综述:2019—Neural Machine Reading Comprehension_Methods and Trends
评估方法 Evaluation Metrics
- 主流方法
- Accuracy:完形填空、多项选择
- F1:
- ROUGE-L
- BLEU
完形填空 Cloze Test
给定上下文 ,一个词或实体
被移除,完形填空任务要求模型使用正确的词或实体进行填空,最大化条件概率
。
- 数据集:CNN & Daily Mail 、CBT、LAMBADA、Who-did-What、CLOTH、CliCR

多项选择 Multiple Choice
给定上下文 ,问题
,候选答案列表
,多项选择任务要求模型从A中选择正确的答案
,最大化条件概率
。与完形填空任务的区别就是答案不再局限于单词或实体,并且候选答案列表是必须要提供的。
- 数据集:MCTest、RACE

片段抽取 Span Extraction
尽管完形填空和多项选择一定程度上可以机器阅读理解的能力,但是这两个任务有一定的局限性。
- 首先,单词或实体可能不足以回答问题,需要完整的句子进行回答;
- 其次,在很多情形是没有候选答案的。所以片段抽取任务应运而生。
给定上下文 和问题
,其中
,片段抽取任务要求模型从C中抽取连续的子序列
作为正确答案,最大化条件概率
。
- 数据集:SQuAD、NewsQA、TriviaQA、DuoRC

自由作答 Free Answering
对于答案局限于一段上下文是不现实的,为了回答问题,机器需要在多个上下文中进行推理并总结答案。自由回答任务是四个任务中最复杂的,也更适合现实的应用场景。
给定上下文C和问题Q,在自由回答任务中正确答案可能不是C中的一个子序列, 或
,自由回答任务需要预测正确答案a,并且最大化条件概率
。
- 数据集:bAbI、MS MARCO 、SearchQA、NarrativeQA、DuReader

框架 General Architecture
- 早期的阅读理解模型大多基于检索技术,即根据问题在文章中进行搜索,找到相关的语句作为答案。但是,信息检索主要依赖关键词匹配,而在很多情况下,单纯依靠问题和文章片段的文字匹配找到的答案与问题并不相关。
- 随着深度学习的发展,机器阅读理解进入了神经网络时代。相关技术的进步给模型的效率和质量都带来了很大的提升。机器阅读理解模型的准确率不断提高,在一些数据集上已经达到或超过了人类的平均水平。
- 基于深度学习的机器阅读理解模型虽然构造各异,但是经过多年的实践和探索,逐渐形成了稳定的框架结构。
- 机器阅读理解模型的输入为文章和问题。
- 首先对这两部分进行数字化编码,变成可以被计算机处理的信息单元。
- 编码层:编码过程中,模型需要保留原有语句在文章中的语义。每个单词、短语和句子的编码必须建立在理解上下文的基础上。
- 交互层:由于文章和问题之间存在相关性,模型需要建立文章和问题之间的联系。如问题中出现关键词“河流”,而文章中出现关键词“长江”,虽然两个词不完全一样,但是其语义编码接近。阅读理解模型将文章和问题的语义结合在一起进行考量,进一步加深模型对于两者各自的理解。
- 输出层:模型建立起文章和问题之间的语义联系,就可以预测问题的答案。完成预测功能的模块称为输出层。由于机器阅读理解任务的答案有多种类型,因此输出层的具体形式需要和任务的答案类型相关联。此外,输出层需要确定模型优化时的评估函数和损失函数。
- 机器阅读理解模型的一般架构。机器阅读理解模型的总体架构,输出层以区间式答案为例
- 可以看出,编码层用于对文章和问题分别进行底层处理,将文本转化成为数字编码。交互层可以让模型聚焦文章和问题的语义联系,借助于文章的语义分析加深对问题的理解,同时也借助于问题的语义分析加深对文章的理解。输出层根据语义分析结果和答案的类型生成模型的答案输出。
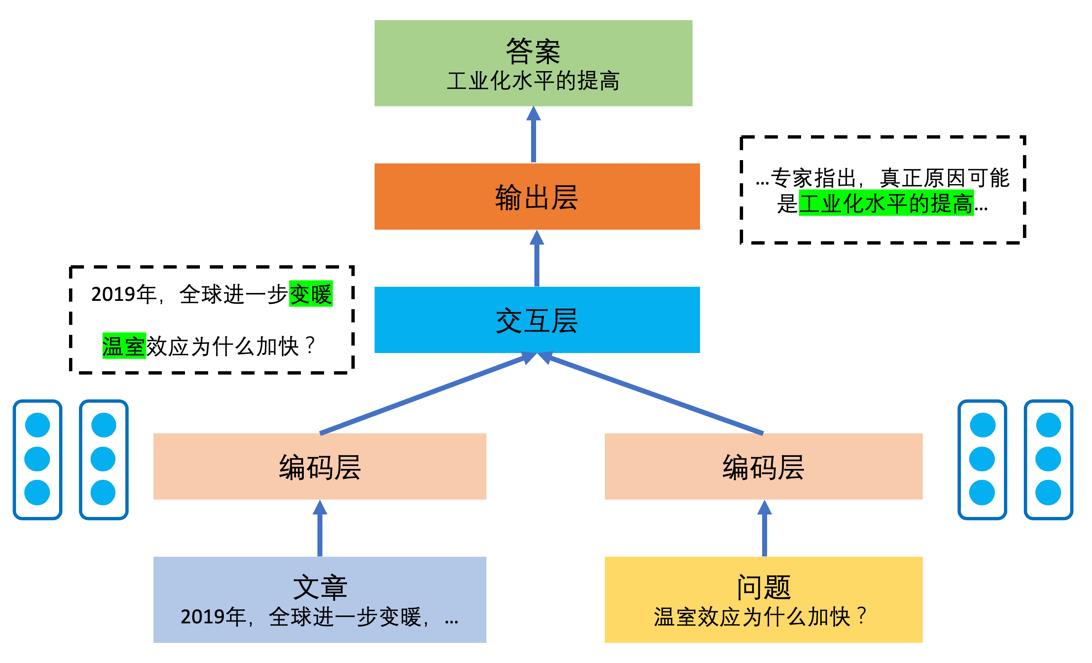
【2021-3-29】机器阅读理解综述(一),(二),(三)
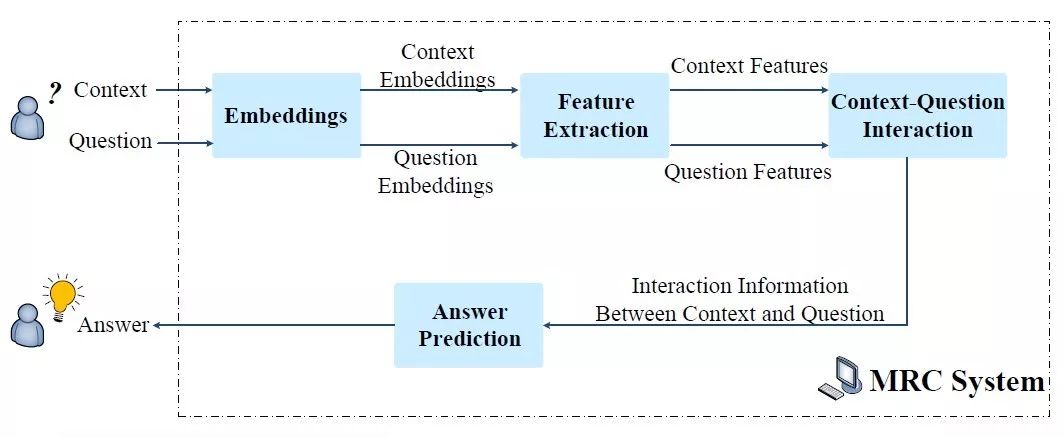
典型的MRC系统以上下文和问题为输入,然后输入答案,系统包含四个关键模块:Embeddings, Feature Extraction, Context-Question Interaction,Answer Prediction。
- Embeddings:将单词映射为对应的词向量,可能还会加上POS、NER、question category等信息;
- Feature Extraction:抽取question和context的上下文信息,可以通过CNN、RNN等模型结构;
- Context-Question Interaction:context和question之间的相关性在预测答案中起着重要作用。有了这些信息,机器就能够找出context中哪些部分对回答question更为重要。为了实现该目标,在该模块中广泛使用attention机制,单向或双向,以强调与query相关的context的部分。为了充分提取它们的相关性,context和question之间的相互作用有时会执行多跳,这模拟了人类理解的重读过程。
- Answer Prediction:基于上述模块获得的信息输出最终答案。因为MRC任务根据答案形式分为了很多种,所以该模块与不同任务相关。对于完形填空,该模块输出context中的一个单词或一个实体;对于多项选择,该模块从候选答案中选择正确答案。
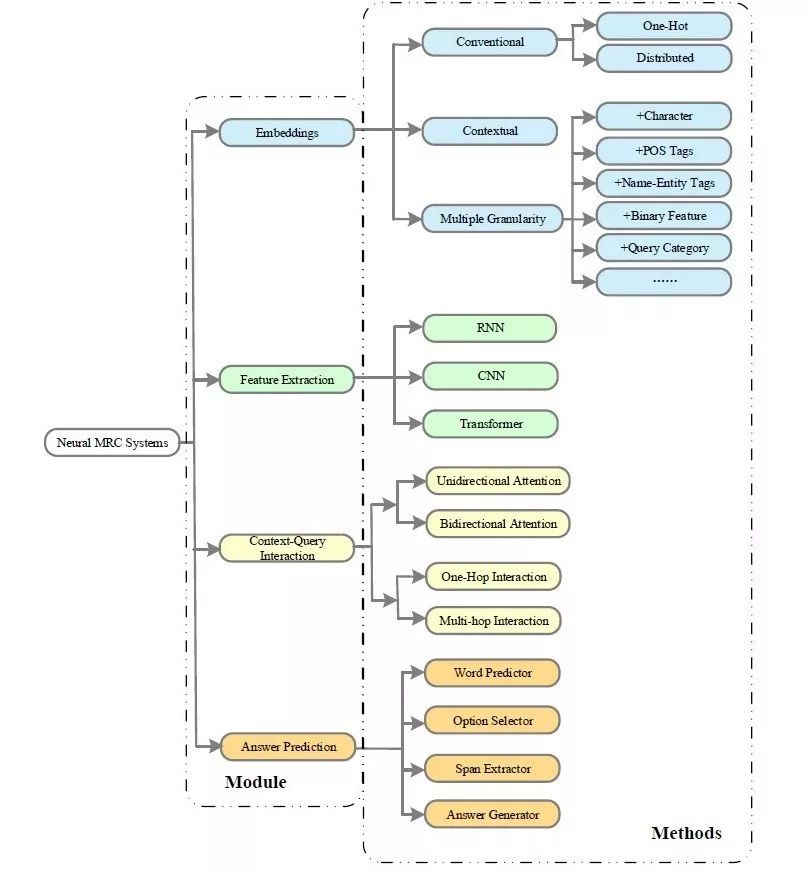
方法 Methods
有各种各样的方法应用到MRC系统中,如下图所示,接下来会一一介绍。
Embeddings
Embeddings模块将单词转换为对应的向量表示。如何充分编码context和question是本模块中的关键任务。在目前的MRC模型中,词表示方法可以分为传统的词表示和预训练上下文表示。为了编码更丰富的语义信息,MRC系统在原来的词级别表示的基础上,还会融合字向量、POS、NER、词频、问题类别等信息。
(1) 传统表示方法 Conventional Word Representation
- One-Hot:向量长度为词表大小,只有单词的位置为1,其它全0,这种表示方法无法表示两个单词之间的关系;
- Distributed Word Representation:将单词编码为连续的低维向量,如word2vec、glove;
(2) 预训练表示方法 Pre-Trained Contextualized Word Representation
尽管分布式词表示可以在编码低维空间中编码单词,并且反映了不同单词之间的相关性,但是它们不能有效地挖掘上下文信息。具体来说,就是词的分布式表示在不同上下文中都是一个常量。为了解决这个问题,研究学者提出了上下文的词表示,在大规模数据集预训练,直接当做传统的词表示来使用或者在特定任务finetune。
- CoVE:利用大规模语料训练Seq2Seq模型,将Encoder的输出拿出来作为CoVE。
- ELMo:在大规模文本语料预训练双向语言模型,特征抽取模块为LSTM。
- GPT:采用单向的Transformer在大规模语料上预训练;
- BERT:采用双向的Transformer在大规模语料上预训练,目标任务为masked language model (MLM)和next sentence prediction(NSP)。
(3) 多粒度表示 Multiple Granularity
- Character Embeddings
- Part-of-Speech Tags
- Name-Entity Tags
- Binary Feature of Exact Match (EM):如果context中的一个单词在query中存在,那么值为1,否则为0;
- Query-Category
Feature Extraction
- Recurrent Neural Networks:LSTM、GRU

- Convolution Neural Networks
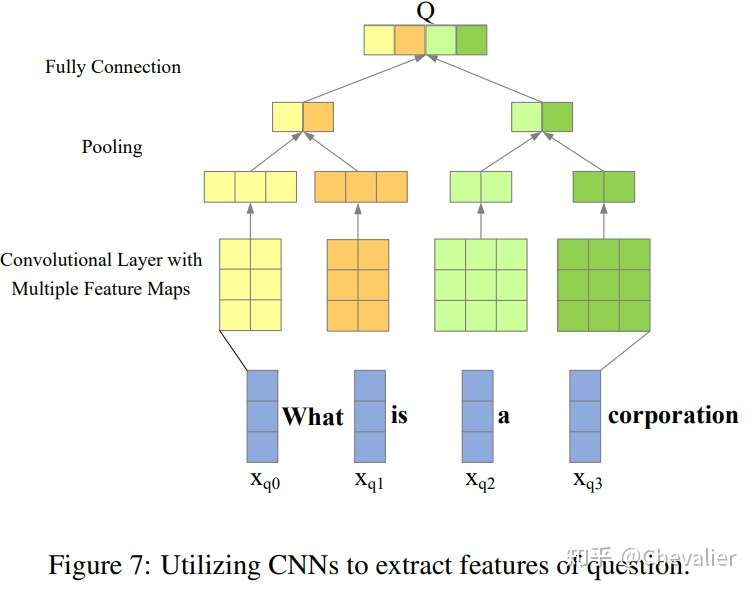
- Transformer
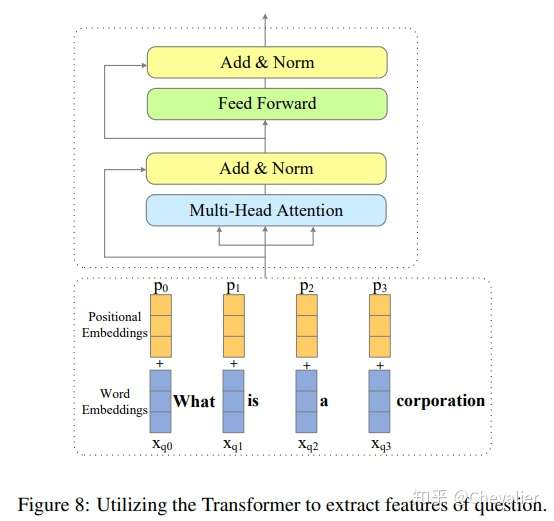
Context-Question Interaction
通过提取context和question之间的相关性,模型能够找到答案预测的证据。根据模型是如何抽取相关性的方式,目前的工作可以分为两类,一跳交互和多条交互。无论哪种交互方式,在MRC模型中,attention机制在强调context哪部分信息在回答问题方面更重要发挥着关键作用。在机器阅读理解中,attention机制可以分为无向和双向的。
(1a) Unidirectional Attention
单向的attention主要是根据问题关注context中最相关的部分。如果context中的单词与问题更相似,那么该单词更可能是答案。通过计算公式 得到context中的单词与question的相似度,其中
是context中的单词的embedding,Q是question的句子表示,最后通过softmax进行权重归一化,如下公式所示。
其中 的计算方式有很多种,如下所示。
单向的attention可以关注context中最重要的词来回答问题,但是该方法无法关注对答案预测也至关重要的question的词。因此,单向的attention不足以抽取context和query之间的交互信息。
(1b) Bidirectional Attention
同时计算query-to-context attention和context-to-query attention。

(2) One-Hop Interaction & Multi-Hop Interaction
One-Hop Interaction可能无法全面理解相互question-context信息,与此相反,Multi-Hop Interaction可以记住之前的context和question信息,能够深度提取相关性并聚合答案预测的证据。
Answer Prediction
该模块与任务高度相关,之前我们将MRC分为四类,分别是完形填空、多项选择、片段抽取、自由回答,那么对应的答案预测方法也有四种,分别是word predictor,option selector,span extractor,answer generator。
(1) Word Predictor
完形填空要求模型预测单词或实体进行填空,该单词或实体来自给定的context。这方面的工作有Attentive Reader、Attention Sum Reader
(2) Option Selector
对于多项选择任务,模型从候选答案列表中选择一个正确答案。很普遍的做法是衡量attentive context representations和候选答案表示之间的相似度,选择相似度最高的作为预测答案。
(3) Span Extractor
片段抽取任务是完形填空任务的扩展,要求模型从context中抽取一个子串,而不是一个单词。目前的工作有Sequence Model、Boundary Model。
(4) Answer Generator
自由回答任务中答案不再局限于context中的一个片段,而是需要根据context和question合成答案。目前的工作有S-Net。
Other Tricks
- (1) Reinforcement Learning
- (2) Answer Ranker
- (3) Sentence Selector
实际上,如果给MRC模型一个很长的文档,那么理解全部上下文来回答问题是很费时的。但是,事先找到问题中最相关的句子是加速后续训练过程的一种可能方法。有研究学者提出了sentence selector来选择回答问题需要的最小句子集合。
新趋势 New Trends
考虑到目前方法的局限性,MRC出现了新的任务,比如,knowledge-based MRC, MRC with unanswerable questions, multi-passage MRC,conversational question answering。
知识融合 Knowledge-Based Machine Reading Comprehension
- 当有些问题不能根据给定文本进行回答时,人们会利用常识或积累的背景知识进行作答,而在机器阅读理解任务中却没有很好的利用外部知识,这是机器阅读理解和人类阅读理解存在的差距之一。
- 为了引入额外的外部知识,一些学者提出了基于知识的机器阅读理解任务,与之前所介绍的任务不同,这一任务的输入除了文章和问题,还有从外部知识库中抽取的知识,以此来提高机器进行答案预测的准确率。
- 代表性的基于知识的机器阅读理解数据集有 MC [25],其中的文本关于人类的一些日常活动,有些问题仅根据给定文本不能作答,需要一定的常识。例如回答“用什么来挖洞”(What was used to dig the hole?)这一问题,依据常识我们知道一般是用“铲子”(a shovel)而不是用“手”(bare hands)。
有时只根据context是无法回答问题的,需要借助外部知识。因此,基于外部知识的MRC应运而生。KBMRC和MRC的不同主要在输入部分,MRC的输入是context和question,而KBMRC的输入是context、question、knowledge。

目前KBMRC的主要挑战在于:
- Relevant External Knowledge Retrieval: 相关外部知识的检索(如何从知识库中找到“用铲子挖洞”这一常识)
- External Knowledge Integration: 外部知识的融合(知识库中结构化的知识如何与非结构化的文本进行融合)
含无答案问题 Unanswerable Questions
机器阅读理解任务有一个潜在的假设,即在给定文章中一定存在正确答案,但这与实际应用不符,由于给定文章中所含的知识有限,一些问题仅根据原文可能并不能做出回答,这就出现了带有不能回答问题的机器阅读理解任务。在这一任务中,首先机器要判断问题仅根据给定文章能否进行作答,如若不能,将其标记为不能回答,并停止作答;反之,则给出答案。
SQuAD2.0 是带有不能回答问题的机器阅读理解任务的代表数据集。在下面的例子中,问题是“1937 年条约的名字”(What was the name of the 1937 treaty?),但是原文中虽然提到了 1937 年的条约,但是没有给出它的名字,仅根据原文内容不能对问题进行作答,1940 年条约的名字还会对回答问题造成误导。

关于不可回答的问题,相比传统的MRC,在该新任务上又有新的挑战:
- Unanswerable Question Detection:不能回答问题的判别(判断“1937 年条约的名字是什么”这个问题能否根据文章内容进行作答)
- Plausible Answer Discrimination:干扰答案的识别(避免被 1940 年条约名字这一干扰答案误导)
多文档 Multi-Passage Machine Reading Comprehension
机器阅读理解任务中,文章是预先定义的,再根据文章提出问题,这与实际应用不符。人们在进行问答时,通常先提出一个问题,再利用相关的可用资源获取回答问题所需的线索。
为了让机器阅读理解任务与实际应用更为贴合,一些研究者提出了多文档机器阅读理解任务,不再仅仅给定一篇文章,而是要求机器根据多篇文章对问题进行作答。这一任务可以应用到基于大规模非结构化文本的开放域问答场景中。多文档机器阅读理解的代表数据集有 MS MARCO [3]、TriviaQA [13]、SearchQA [16]、DuReader [18] 和 QUASAR [27]。
在MRC任务中,相关的段落是预定义好的,这与人类的问答流程矛盾。因为人们通常先提出一个问题,然后再去找所有相关的段落,最后在这些段落中找答案。因此研究学者提出了multi-passage machine reading comprehension,相关数据集有MS MARCO、TriviaQA、SearchQA、Dureader、QUASAR。

多文档机器阅读理解的挑战有:
- Massive Document Corpus:相关文档的检索(如何从多篇文档中检索到与回答问题相关的文档)
- Noisy Document Retrieval:噪声文档的干扰(一些文档中可能存在标记答案,但是这些答案与问题可能存在答非所问的情况)
- No Answer:检索得到的文档中没有答案
- Multiple Answers:可能存在多个答案(例如问“美国总统是谁”,特朗普和奥巴马都是可能的答案,但是哪一个是正确答案还需要结合语境进行推断)
- Evidence Aggregation:需要对多条线索进行聚合(回答问题的线索可能出现在多篇文档中,需要对其进行总结归纳才能得出正确答案)。
对话式 Conversational Question Answering
机器阅读理解任务中所提出的问题一般是相互独立的,而人们往往通过一系列相关的问题来获取知识。当给定一篇文章时,提问者先提出一个问题,回答者给出答案,之后提问者再在回答的基础上提出另一个相关的问题,多轮问答对话可以看作是上述过程迭代进行多次。为了模拟上述过程,出现了对话式阅读理解,将对话引入了机器阅读理解中。
对话式阅读理解的代表性数据集有 CoQA、QuAC等。下图展示了 CQA 中的一个对话问答的例子。对于给定的文章,进行了五段相互关联的对话,不仅问题之间存在联系,后续的问题可能与之前的答案也有联系,如问题 4 和问题 5 都是针对问题 3 的答案 visitors 进行的提问。
MRC系统理解了给定段落的语义后回答问题,问题之间是相互独立的。然而,人们获取知识的最自然方式是通过一系列相互关联的问答过程。比如,给定一个问答,A提问题,B回复答案,然后A根据答案继续提问题。这个方式有点类似多轮对话。

相关数据集:CoQA、QuAC

对话式阅读理解(CQA)存在的挑战有:
- Conversational History:对话历史信息的利用(后续的问答过程与之前的问题、答案紧密相关,如何有效利用之前的对话信息);
- Coreference Resolution:指代消解(理解问题 2,必须知道其中的 she 指的是 Jessica)。
Open Issues
- Incorporation of External Knowledge 外部知识的引入
- 常识和背景知识作为人类智慧的一部分常常用于人类阅读理解过程中,虽然基于知识的机器阅读理解任务在引入外部知识方面有一定的尝试,但是仍存在不足。
- 一方面,存储在知识库中的结构化知识的形式和非结构化的文章、问题存在差异,如何将两者有效的进行融合仍值得研究;
- 另一方面,基于知识的机器阅读理解任务表现高度依赖于知识库的构建,但是知识库的构建往往是费时费力的,而且存储在其中的知识是稀疏的,如果不能在知识库中直接找到相关的外部知识,可能还需要对其进行进一步的推理。
- Robustness of MRC Systems:机器阅读理解系统的鲁棒性
- 正如 Jia & Liang指出的,现有的基于抽取的机器阅读理解模型对于存在误导的对抗性样本表现非常脆弱。如果原文中存在干扰句,机器阅读理解模型的效果将大打折扣,这也在一定程度上表明现有的模型并不是真正的理解自然语言,机器阅读理解模型的鲁棒性仍待进一步的提升。
- Limitation of Given Context:限定文章带来的局限性
- 机器阅读理解任务要求机器根据给定的原文回答相关问题,但是在实际应用中,人们往往是先提出问题,之后再利用可用的资源对问题进行回答。多文档机器阅读理解任务的提出在一定程度上打破了预先定义文章的局限,但是相关文档的检索精度制约了多文档机器阅读理解模型在答案预测时的表现。信息检索和机器阅读理解需要在未来进行更为深度的融合。
- Lack of Inference Ability:推理能力的缺乏
- 现有的机器阅读理解模型大多基于问题和文章的语义匹配来给出答案,这就导致模型缺乏推理能力。例如,给定原文“机上五人地面两人丧命”,要求回答问题“几人丧命”时,机器很难给出正确答案“7 人”。如何赋予机器推理能力将是推动机器阅读理解领域发展的关键问题。
经典模型
- 阅读理解的经典 Model,主要包括:
- Allen AI 提出的
BIDAF - 微软提出的
R-NET - Google 提出的
QANet - 最近刷榜的
GPT&BERT: Google 于 2018 年提出的双向编码器模型 BERT. 在 SQuAD 2.0 竞赛中,排名前 20 名的模型全部基于 BERT;CoQA 竞赛中,前 10 名模型全部基于 BERT。并且这两个竞赛中模型的最好表现已经超越人类水平。
- Allen AI 提出的
- 代表模型有:双向注意力流(BiDAF),使用门机制的 R-net、融合网络(FusionNet)等。
应用
- 典型应用场景如下:
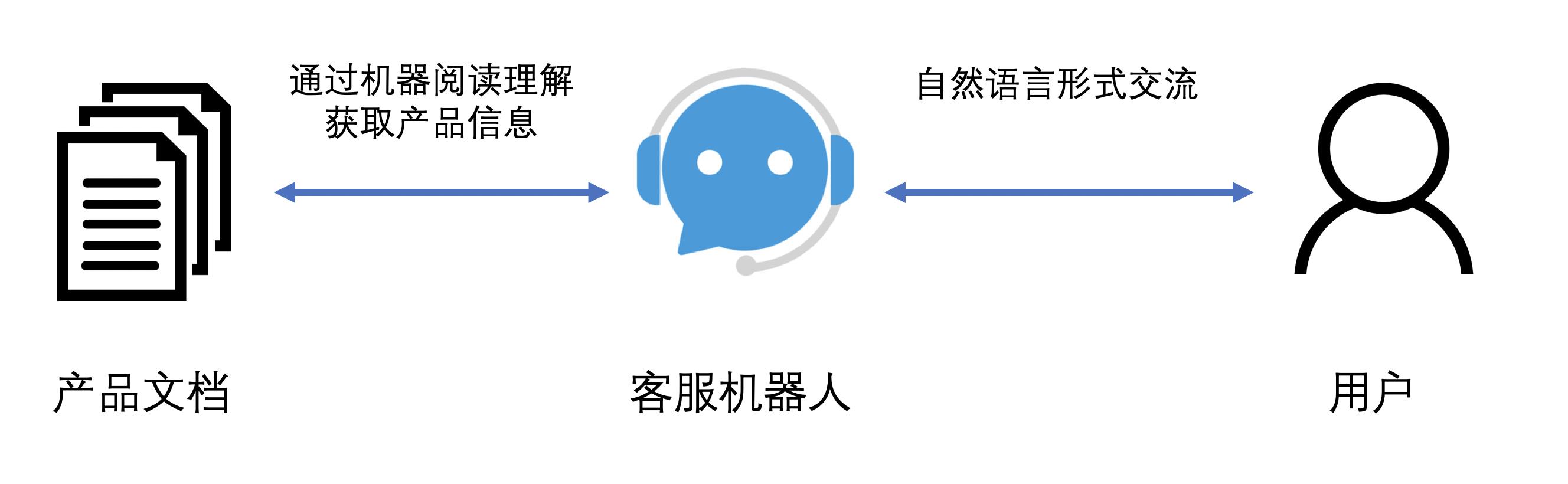
- 客服机器人是一种基于自然语言处理的拟人式服务,通过文字或语音与用户进行多轮交流,获取相关信息并提供解答。机器阅读理解可以帮助客服系统根据用户提供的信息在产品文档中快速找到解决方案,如图 3 所示。
- 智能法律用于自动处理和应用各种错综复杂的法律法规实现对案例的自动审判,这正可以利用机器阅读理解在处理和分析大规模文档方面的速度优势。
- 智能教育利用计算机辅助人类的学习过程。机器阅读理解在这个领域的典型应用是作文自动批阅。自动作文批阅模型可以作为学生写作时的助手,理解作文语义,自动修改语法错误,个性化总结易错知识点。这些技术与当前流行的在线教育结合,很有可能在不久的将来对教育行业产生颠覆性的影响。
- 客服机器人是一种基于自然语言处理的拟人式服务,通过文字或语音与用户进行多轮交流,获取相关信息并提供解答。机器阅读理解可以帮助客服系统根据用户提供的信息在产品文档中快速找到解决方案,如图 3 所示。
- 展望
- 机器阅读理解研究仍面临如知识与推理能力、可解释性、缺乏训练数据等挑战,但也有很大的应用空间。基于机器阅读理解高速处理大量文本的特点,这项技术最容易在劳动密集型文本处理行业落地。
- 参考:机器阅读理解是什么?有哪些应用?终于有人讲明白了
Demo
百度新闻摘要
【2023-5-24】百度新闻摘要接口
huggingface QA
【2022-10-18】huggingface(抱抱脸 ![]() )支持快速部署模型demo
)支持快速部署模型demo
- Question Answering models can retrieve the answer to a question from a given text, which is useful for searching for an answer in a document. Some question answering models can generate answers without context!
Task Variants
There are different QA variants based on the inputs and outputs:
- 抽取式QA Extractive QA: The model extracts the answer from a context. The context here could be a provided text, a table or even HTML! This is usually solved with BERT-like models.
- 生成式QA Open Generative QA: The model generates free text directly based on the context. You can learn more about the Text Generation task in its page.
- 纯生成式QA Closed Generative QA: In this case, no context is provided. The answer is completely generated by a model.
TLDR This
- 【2022-12-29】TLDR This helps you summarize any piece of text into concise, easy to digest content so you can free yourself from information overload.
Bert-MRC
文本摘要生成
代码实战
- 《机器阅读理解:算法与实践》书籍配套代码
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
