总结
- 【2020-8-6】联邦学习Python实践:Federated Learning Demo in Python using Socket Programming
- 【2021-1-8】字节跳动在联邦学习领域的探索及实践,联邦学习在广告投放和金融等场景中的应用模式、算法研究、软件系统及实践经验
- 【2020-4-10】联邦学习:Tensorflow中的逐步实现
- 【2021-6-17】AI新算法群体学习(Swarm Learning,以下简称SL)登Nature封面!解决医疗数据隐私问题,超越联邦学习?比联邦学习更安全,SL可保障医疗数据共享. 联邦学习方法(Federated Learning)解决了其中的一些问题。数据保存在数据所有者本地,保密性问题得到解决,但参数设置仍要中央协调员协调。此外,这种星型架构降低了容错能力。更好的选择是采取完全去中心化的人工智能解决方案,即SL来克服已有方案的不足,适应医学领域固有的分散式数据结构以及数据隐私和安全法规的要求。
- SL具有以下优势:
- (1)将大量医疗数据保存至数据所有者本地;
- (2)不需要交换原始数据,从而减少数据流量;
- (3)提供高级别的数据安全保障;
- (4)能够保证网络中成员的安全、透明和公平加入,不再需要中央托管员;
- (5)允许参数合并,实现所有成员权力均等;
- (6)可以保护机器学习模型免受攻击。
- 论文题目为《用于去中心化且保密临床数据分析的Swarm Learning机器学习技术 Swarm Learning for decentralized and confidential clinical machine learning 》,于5月26日发表在Nature上
- SL具有以下优势:
联邦学习介绍
常规机器学习的问题
- “集中式”模型训练
- 设备(pc/phone)→服务器→API/gRPC
- 问题
- 无法保证用户隐私保护——数据被服务器收集
- 那以保证低时延——实时服务
大数据时代的机器学习困境
- 小数据
- 数据和特征是模型和算法的上确界
- 高质量、有标准的数据往往是小数据
- 数据孤岛
- 中国的数据主要掌握在政府、运营商、互联网企业等三大“数据岛屿群”中,岛屿群间相互割裂,彼此孤立,甚至在岛屿群内部,或某一特定岛屿(企业)中,数据也并不是一个可方便流通的整体,而呈各自分散的“岛中岛”状态。
- 安全隐私
- 5月6日,脱口秀演员王越池(艺名“池子”)在微博发布长文指责中信银行上海虹口支行在未经其本人授权的情况下,向与其有经济纠纷的笑果文化泄露其个人账户交易明细,再次引发人们对于自身信息安全的热议
- 央视:别把用户信息扔出池子!
隐私保护立法
- 国际
- 2018年6月13日,英国Dixons Carphone (跨国电信公司)宣布调查“大量客户数据被非法访问”事件。黑客“试图在Currys PC World和Dixons旅行商店的一个处理系统中破坏客户590万张卡和120万张包含非财务数据的记录,如姓名、地址或电子邮件地址……”这是英国有史以来最大的数据泄露事件
- 1998年英国数据保护法
- 2018年,欧盟一般数据保护条例(GDPR)生效
- 2019年1月22日,法国监管机构对Google开出了首笔GDPR罚款,金额达5000万欧元(约5700万美元)
- GDPR其中一条:可以用来大数据分析,提升用户体验,但不能用于别的场景,如训练对话系统等
- 国内
什么是联邦学习
- 2017 年 Google 发表 Federated Learning
- Blaise:
- 能否用一个大型分布式神经网络模型训练框架,让用户数据不出本地(在自己的设备中进行训练)的同时也能获得相同的服务体验?
- 可以!上传权重,而不是数据
- 人会在睡觉的时候通过做梦来更新自己的大脑认知系统;
- 同样设备终端的系统也可以通过闲置时进行模型训练和更新。
- 设备端联邦学习
- 用户本地训练,加密上传训练模型(权重),服务器端会综合成千上万的用户模型后再反馈给用户模型改进方案

联邦学习原理
【2021-5-17】终于有人把联邦学习讲明白了
联邦学习是一种带有隐私保护、安全加密技术的分布式机器学习框架,旨在让分散的各参与方在满足不向其他参与者披露隐私数据的前提下,协作进行机器学习的模型训练。
经典联邦学习框架的训练过程可以简单概括为以下步骤:
- 协调方建立基本模型,并将模型的基本结构与参数告知各参与方;
- 各参与方利用本地数据进行模型训练,并将结果返回给协调方;
- 协调方汇总各参与方的模型,构建更精准的全局模型,以整体提升模型性能和效果。
联邦学习框架包含多方面的技术,比如传统机器学习的模型训练技术、协调方参数整合的算法技术、协调方与参与方高效传输的通信技术、隐私保护的加密技术等。此外,在联邦学习框架中还存在激励机制,数据持有方均可参与,收益具有普遍性。
Google首先将联邦学习运用在Gboard(Google键盘)上,联合用户终端设备,利用用户的本地数据训练本地模型,再将训练过程中的模型参数聚合与分发,最终实现精准预测下一词的目标。
除了分散的本地用户,联邦学习的参与者还可以是多家面临数据孤岛困境的企业,它们拥有独立的数据库但不能相互分享。联邦学习通过在训练过程中设计加密式参数传递代替原有的远程数据传输,保证了各方数据的安全与隐私,同时满足了已出台的法律法规对数据安全的要求。
联邦?
- 一种国家政体几个成员国(如共和国或邦、州等)联合组成统一国家
- 联邦同成员国间的权限划分由联邦宪法规定。
- 各成员国按联邦宪法规定,设自己的立法机关和行政机关,制定自己的宪法和法律,在自己辖区内行使职权。
- 如:美国、加拿大、澳大利亚、英国、俄罗斯、巴基斯坦等
- 邦联:多个国家结盟,邦联包含联邦
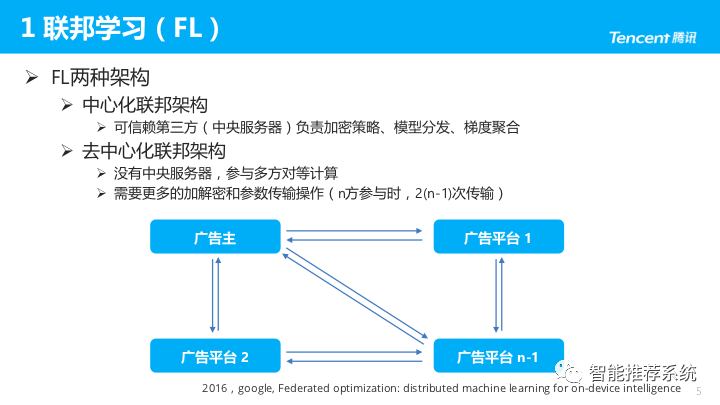
联邦学习的架构思想
联邦学习的架构分为两种,一种是中心化联邦(客户端/服务器)架构,一种是去中心化联邦(对等计算)架构。
- 针对联合多方用户的联邦学习场景,一般采用的是客户端/服务器架构,企业作为服务器,起着协调全局模型的作用;
- 而针对联合多家面临数据孤岛困境的企业进行模型训练的场景,一般可以采用对等架构,因为难以从多家企业中选出进行协调的服务器方。
在客户端/服务器架构中,各参与方须与中央服务器合作完成联合训练,如图2-1所示。当参与方不少于两个时,启动联邦学习过程。
联邦学习基本过程
- 要点
- 上传非对称加密的权重到服务器,云端算法聚合,更新模型并下发
- 设备端联邦学习过程
- 设备端下载当前版本的模型;
- 通过学习本地数据来改进模型;
- 把对模型的改进,概括成一个比较小的更新;
- 该更新被加密发送到云端;
- 与其他用户的更新即时整合,作为对共享模型的改进。
- 关键环节
- 根据用户使用情况,每台手机在本地对模型进行个性化改进;
- 形成一个整体的模型修改方案;
- 应用于共享的模型。该过程会不断循环。
同态加密
- 同态性源自抽象代数(近世代数),群、环、域、理想、四元数
- 同态加密是其中一个应用
- 原理
- 加密算法可以隔着加密层去进行运算,完成任意算法的运算
- 类似线性代数里的加法+数乘运算

联邦学习分类
总结
- 联邦学习具有以下特点:
- 在联邦学习的框架下,各参与者地位对等,能够实现公平合作;
- 数据保留在本地,避免数据泄露,满足用户隐私保护和数据安全的需求;
- 能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长;
- 建模效果与传统深度学习算法建模效果相差不大;
- 联邦学习是一个「闭环」的学习机制,模型效果取决于数据提供方的贡献。
联邦学习与分布式机器学习比较
精度上界:联邦学习不像优化其他具体的排序、召回模型,更像是在数据安全限制下,去推动整个建模。所以,理论上把共享数据下分布式机器学习(Distributed Machine Learning,DML)的结果作为上限。
虽然有人把联邦学习作为一种分布式机器学习的特殊情况,但是与一般的DML相比,联邦学习仍存在如下区别:
- 存在数据不共享的限制;
- 各server节点对worker节点控制弱;
- 通讯频率和成本较高。
【2021-10-27】联邦学习属于分布式学习,但正如背景中所介绍的,它有具体适用的场景,与典型的分布式学习有明显的区别。表2全面地总结了典型分布式以及联邦学习间的不同之处。概括而言,与典型的分布式优化问题相比,联邦优化问题有以下几个关键特性:
- 设备通常由大量的移动设备组成,每一个设备上的数据量相对较小,而设备数相对较多。
- 设备间的数据通常是非独立同分布、且不平衡的。
- 设备有通信限制:移动设备可能存在频繁掉线、速度缓慢、费用昂贵等问题。
- 更注重隐私,不允许原始数据在设备间互相传输。 其中,隐私问题和通信效率被视为是需要优先考虑的问题。联邦学习这些独有的特性,对其理论研究和算法改进都带来巨大的挑战。
架构
- 中心化联邦架构:早期发展包括 Google、微众银行,皆是此类架构。由可信赖的第三方(中央服务器)负责加密策略、模型分发、梯度聚合等。
- 去中心化联邦架构:但有时双方合作,找不到可信赖的第三方,各方需参与对等计算。此架构需要更多的加解密和参数传输操作,比如:n方参与时,需进行2(n-1)次传输。这里可以认为加解密算法实际上扮演了第三方的角色。
分类
- 横向联邦学习:样本的联合,适用于特征重叠多,用户重叠少时的场景。比如:两个业务相似的公司,用户正交多但画像相似,可进行横向联邦学习,更像是一种数据变形的分布式机器学习。
- 纵向联邦学习:特征的联合,适用于用户重叠多,特征重叠少时的场景。比如:广告主与广告平台,希望结合两方的特征进行训练。
- 联邦迁移学习:参与者间的特征和样本重叠都很少时,可以考虑使用,但难度较高。
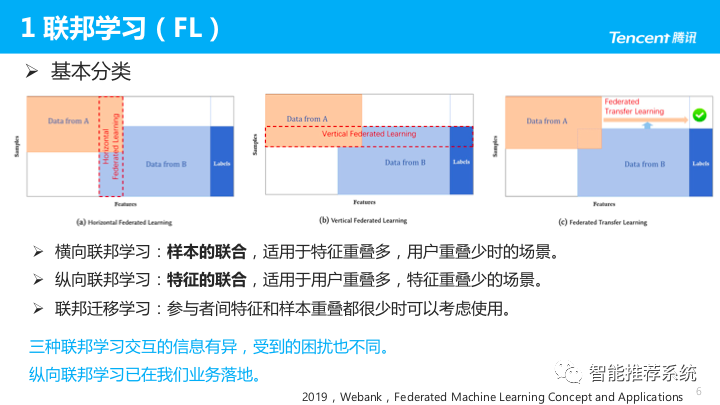
三种联邦学习交互的信息有异,受到的困扰也不同;
- 比如:横向联邦学习时,各参与方数据异构,因此数据非独立同分布,也是联邦学习的研究热点。
- 目前纵向联邦学习已在我们业务中落地,也在探索联邦迁移学习、横向纵向的结合。
横向联邦学习
- 横向联邦学习是每行过来都可以看作一个用户的数据。按照用户来分,可以看作一、二、三个手机,它叫横向学习。还有一个原因是它们的纵向都是特征,比如手机型号、手机使用时间、电池以及人的位置等,这些都是特征。他们的特征都是一样的,样本都是不一样的,这是横向联邦学习。

- 主要做法是首先把信用评级得到,然后在加密状态下做聚合,这种聚合里面不是简单的加,而是很复杂的加,然后把征信模型再分发下来。
纵向联邦学习
- 大家的Feature不一样,一个机构红色、一个机构蓝色,大家可以想象两个医院,一个病人在红色医院做一些检测,在蓝色的医院做另外一些检测,当我们知道这两个医院有同样一群病人,他们不愿意直接交换数据的情况下,有没有办法联合建模?
- 它们中间有一个部门墙,我们可以在两边各自建一个深度学习模型,建模的时候关键的一步是梯度下降,梯度下降我们需要知道几个参数,上一轮参数、Loss(gradients)来搭配下一个模型的weight参数。

- 这个过程中我们需要得到全部模型的参数级,这时候需要进行交换,交换的时候可以通过同态加密的算法,也可以通过secure multiparty computation,这里面有一系列的算法,两边交换加密参数,对方进行更新,再次交换参数,一直到系统覆盖。
联邦迁移学习
- 它们在特征上一样,或者在特征上不一样,但是他们的用户有些是有交集的,当用户和特征没有交集时,我们退一步想,我们可以把他们所在的空间进行降维或者升维,把他们带到另外的空间去。
- 在另外的空间可以发现他们的子空间是有交互的,这些子空间的交互就可以进行迁移学习。虽然他们没有直接的特征和用户的重合,我们还是可以找到共性进行迁移学习。

- 总的来说,联邦学习的这种思想,事实上并不仅仅适用于设备用户数据的隐私保护和模型更新。
-
我们将设备用户抽象来看,视作数据的拥有者,可以是手机持有者,也可以是公司、医院、银行等;而服务器或云端视作模型共享综合平台。
- 联邦学习最重要的就是保护数据的可用而不可见,也就是数据的隐私保护,其研究有如下方面:
- 一是基于差分隐私的数据保护;
- 二是基于秘密共享的加密计算方法;
- 三是基于同态加密的加密计算方法。
联邦学习算法
目前最流行的联邦学习方法,是由McMahan et al, 2017提出的Federated Averaging(也称parallel SGD/local SGD)方法(及其变体)。具体而言,机器学习中经典的SGD算法为:每次使用一个样本来计算梯度并进行参数更新。扩展到多台机器的版本,即为:
- 每个Client在每次通信中使用一个样本来计算梯度并局部更新参数,将参数传给Server。Server汇总平均后更新模型参数再返回给Clients。这样的效率对于通信受限的联邦学习框架是难以承受的。
- 因此,为了提高通信效率,Federated Averaging考虑每个Client首先在本地多次通过SGD更新模型,再将更新后的模型参数传给Server进行汇总平均。
应用
风控
- 在众多金融业务环节中,饱受数据隐私和孤岛效应困扰的信贷风控,无疑是实现联邦学习落地的最佳场景之一。
- 微众银行联邦学习团队指出,基于联邦学习的信贷风控解决方案,能够“在建模过程中,双方交换梯度值,类似于方向向量的概念,交换的是中间变量,不是原始数据。同时对这个中间变量还进行了同态加密,所以数据并不会出库,保证数据源和应用方的数据安全。”
- 联邦学习所采用的局部数据收集和最小化原则,将降低传统中心化机器学习方法带来的一些系统性隐私风险和成本,这样的效果也正契合了信贷风控的提升方向。
- 多维度联邦数据建模,风控模型效果约可提升12%,相关企业机构有效节约了信贷审核成本,整体成本预计下降5%-10%,并因数据样本量的提升和丰富,风控能力进一步增强。

医疗
- 医疗健康数据领域长期存在“信息孤岛”问题,不同地区甚至不同医院间的医疗数据没有互联,也没有统一的标准。与此同时,数据安全问题也存在着巨大挑战。
- 腾讯天衍实验室公开宣布,其联合微众银行研发的医疗联邦学习,在脑卒中预测的应用上,准确率在相关数据集中高达80%。

安防
- 微众银行AI部门副总经理陈天健透露,“在‘联邦视觉系统’项目中,通过联邦学习技术,整体模型的性能提升了15%,且模型效果无损失,极大地提升了建模效率。”

工程实现
FL架构的基本形式包括一个位于中心的管理员或服务器,负责协调训练活动。客户端主要是边缘设备,可以达到数百万。这些设备在每次训练迭代中至少与服务器通信两次。首先,它们各自从服务器接收当前全局模型的权重,在各自的本地数据上对其进行训练,以生成更新后的参数,然后将这些参数上传到服务器进行汇总。这种通信循环一直持续到达到预先设定的epochs数或准确度条件为止。在联邦平均算法中,汇总仅仅意味着平均操作。
数据集
(1)数据集
- EMNIST数据集: 原始数据由671,585个数字图像和大小写英文字符(62个类)组成。联邦学习的版本将数据集拆分到3,400个不平衡Clients,每个Clients上的数字/字符为同一人所写,由于每个人都有独特的写作风格,因此数据是非同分布的。
- Stackoverflow数据集: 该数据集由Stack Overflow的问答组成,并带有时间戳、分数等元数据。训练数据集包含342,477多个用户和135,818,730个例子。其中的时间戳信息有助于模拟传入数据的模式。下载地址
- Shakespeare数据集: 该数据是从The Complete Works of William Shakespeare获得的语言建模数据集。由715个字符组成,其连续行是Client数据集中的示例。训练集样本量为16,068,测试集为2,356。
TensorFlow实现
【2020-4-10】联邦学习:Tensorflow中的逐步实现
Tensorflow中从头开始构建一个FL,并在Kaggle的MNIST数据集上对其进行训练。
- 使用MNIST数据集的jpeg版本。它由42000个数字图像组成,每个类保存在单独的文件夹中。我将使用一下Python代码片段将数据加载到内存中,并保留10%的数据,以便稍后测试经过训练的全局模型。
import numpy as np
import random
import cv2
import os
from imutils import paths
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.metrics import accuracy_score
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras import backend as K
from fl_mnist_implementation_tutorial_utils import *
# 加载数据
# 从磁盘读取每个图像作为灰度,然后将其flattened
def load(paths, verbose=-1):
'''expects images for each class in seperate dir, e.g all digits in 0 class in the directory named 0 '''
data = list()
labels = list() # loop over the input images
for (i, imgpath) in enumerate(paths): # load the image and extract the class labels
im_gray = cv2.imread(imgpath, cv2.IMREAD_GRAYSCALE) #9
image = np.array(im_gray).flatten()
label = imgpath.split(os.path.sep)[-2] # scale the image to [0, 1] and add to list
# 将图像缩放到[0,1],以减弱像素亮度变化的影响
data.append(image/255) #13
labels.append(label) # show an update every `verbose` images
if verbose > 0 and i > 0 and (i + 1) % verbose == 0:
print("[INFO] processed {}/{}".format(i + 1, len(paths))) # return a tuple of the data and labels
return data, labels
# load函数来获得图像列表(现在是numpy数组)和标签列表
# 数据集划分
# declear path to your mnist data folder
img_path = '/path/to/your/training/dataset'#get the path list using the path object
image_paths = list(paths.list_images(img_path))#apply our function
# 获得图像列表(现在是numpy数组)和标签列表
image_list, label_list = load(image_paths, verbose=10000)#binarize the labels
# 用来自sklearn的LabelBinarizer对象对标签进行one-hot编码,适配交叉熵损失函数
lb = LabelBinarizer()
label_list = lb.fit_transform(label_list)#split data into training and test set
# 数据拆分成比例为9:1的train/test
X_train, X_test, y_train, y_test = train_test_split(image_list, label_list, test_size=0.1, random_state=42)
联邦成员(客户端)
- 在FL的实际实现中,每个联邦成员将独立拥有自己的数据。请记住,FL的目标是将模型传递到数据。
- 将训练集分成10个碎片,每个客户一个
def create_clients(image_list, label_list, num_clients=10, initial='clients'):
''' return: a dictionary with keys clients' names and value as data shards - tuple of images and label lists.
args:
image_list: a list of numpy arrays of training images
label_list:a list of binarized labels for each image
num_client: number of fedrated members (clients)
initials: the clients'name prefix, e.g, clients_1
'''
#create a list of client names
# 用前缀字符串创建了一个客户端名称列表
client_names = ['{}_{}'.format(initial, i+1) for i in range(num_clients)] #13
#randomize the data
# 将数据和标签压缩,将所得的元组列表随机化并分片为所需数量的客户端(num_clients)
data = list(zip(image_list, label_list))
random.shuffle(data) #shard data and place at each client
size = len(data)//num_clients
shards = [data[i:i + size] for i in range(0, size*num_clients, size)] #number of clients must equal number of shards
assert(len(shards) == len(client_names))
# 返回了一个字典,其中包含作为键的每个客户端名称和作为值的它们的数据共享
return {client_names[i] : shards[i] for i in range(len(client_names))} #26
#create clients
clients = create_clients(X_train, y_train, num_clients=10, initial='client')
批处理客户端和测试数据
- 接下来是将每个客户端数据处理为tensorflow数据集并进行批处理。为了简化这个步骤并避免重复,将这个过程封装到一个名为batch_data的小函数中。
def batch_data(data_shard, bs=32):
'''Takes in a clients data shard and create a tfds object off it
args: shard: a data, label constituting a client's data shard
bs:batch size
return: tfds object
'''
#seperate shard into data and labels lists
data, label = zip(*data_shard) #9
dataset = tf.data.Dataset.from_tensor_slices((list(data), list(label)))
return dataset.shuffle(len(label)).batch(bs)
# 每个客户端数据集都是以create_clients中的数据/标签元组列表的形式出现的。
#process and batch the training data for each client
clients_batched = dict()
for (client_name, data) in clients.items():
clients_batched[client_name] = batch_data(data) #process and batch the test set
test_batched = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(len(y_test))
创建模式
# 2层MLP作为分类任务的模型
class SimpleMLP:
@staticmethod
def build(shape, classes):
model = Sequential()
model.add(Dense(200, input_shape=(shape,)))
model.add(Activation("relu"))
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
# 优化器、损失函数和度量
# SGD是默认优化器。损失函数为categorical_crossentropy,度量为accuracy。
lr = 0.01
comms_round = 100 # 全局epochs(aggregations)数量
loss='categorical_crossentropy'
metrics = ['accuracy']
optimizer = SGD(lr=lr, decay=lr / comms_round, momentum=0.9)
模型汇总(加权平均)
- 数据是水平分区的,因此将简单地进行组件级参数平均,并根据每个参与客户端贡献的数据点的比例进行加权。
- 这是用的联邦平均方程
- 右侧根据单个客户端持有的每个数据点上记录的损失值来估计权重参数。
- 左侧缩放了客户的参数并对结果求和
封装成三个函数
- (1)weight_scalling_factor 计算客户的本地训练数据在所有客户持有的总体训练数据中所占的比例。
- 首先,我们估计客户的批次大小,然后使用它来计算自己的数据点数量。
- 然后,我们获得了第6行上的总体全局训练数据大小。
- 最后,我们在第9行以分数的形式计算了比例因子。这当然不可能是实际应用程序中的方法。任何客户都不能访问合并的训练数据。在这种情况下,在每个本地训练步骤之后用新参数更新服务器时,每个客户机都应该指出它们所持有的数据点的数量。
- (2)scale_model_weights根据(1)中计算的比例因子的值来缩放每个局部模型的权重
- (3)sum_scaled_weights将所有客户的比例权重加在一起
def weight_scalling_factor(clients_trn_data, client_name):
client_names = list(clients_trn_data.keys()) #get the bs
bs = list(clients_trn_data[client_name])[0][0].shape[0] #first calculate the total training data points across clinets
global_count = sum([tf.data.experimental.cardinality(clients_trn_data[client_name]).numpy()
for client_name in client_names])*bs # get the total number of data points held by a client
local_count = tf.data.experimental.cardinality(clients_trn_data[client_name]).numpy()*bs
return local_count/global_count
def scale_model_weights(weight, scalar):
'''function for scaling a models weights'''
weight_final = []
steps = len(weight)
for i in range(steps):
weight_final.append(scalar * weight[i])
return weight_final
def sum_scaled_weights(scaled_weight_list):
'''Return the sum of the listed scaled weights. The is equivalent to scaled avg of the weights'''
avg_grad = list() #get the average grad accross all client gradients
for grad_list_tuple in zip(*scaled_weight_list):
layer_mean = tf.math.reduce_sum(grad_list_tuple, axis=0)
avg_grad.append(layer_mean)
return avg_grad
def test_model(X_test, Y_test, model, comm_round):
cce = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
#logits = model.predict(X_test, batch_size=100)
logits = model.predict(X_test) loss = cce(Y_test, logits)
acc = accuracy_score(tf.argmax(logits, axis=1), tf.argmax(Y_test, axis=1))
print('comm_round: {} | global_acc: {:.3%} | global_loss: {}'.format(comm_round, acc, loss))
return acc, loss
联邦模型训练
- 训练逻辑有两个主循环,外循环用于全局迭代,内循环用于迭代每个客户端的本地训练。
- 首先构建全局模型,输入形状为(784),数字类为10。然后我进入了外循环。首先获得全局模型的初始化权值。第15行和第16行随机化了客户端字典顺序。然后开始遍历客户端。
- 对于每个客户端,我初始化一个新的模型对象,编译它,并将它的初始化权重设置为全局模型的当前参数。然后对局部模型(客户端)进行一个epoch的训练。在训练之后,新的权重将被缩放并附加到scaled_local_weight_list中。
- 回到第41行的外循环,我获取了所有缩放后的局部训练权重的总和,并将全局模型更新为这个新的汇总。这样就结束了完整的全局训练epoch。按照前面声明的comms_round参数的规定,我运行了100个全局训练循环。
- 最后在第48行,我使用预留的测试集,在每一轮通信结束后,对训练好的全局模型进行测试
#initialize global models
mlp_global = SimpleMLP()
global_model = smlp_global.build(784, 10) #commence global training loop
for comm_round in range(comms_round): # get the global model's weights - will serve as the initial weights for all local models
global_weights = global_model.get_weights() #initial list to collect local model weights after scalling
scaled_local_weight_list = list() #randomize client data - using keys
client_names= list(clients_batched.keys()) #15
random.shuffle(client_names) #loop through each client and create new local model
for client in client_names:
smlp_local = SimpleMLP()
local_model = smlp_local.build(784, 10)
local_model.compile(loss=loss,optimizer=optimizer,metrics=metrics) #set local model weight to the weight of the global model
local_model.set_weights(global_weights) #fit local model with client's data
local_model.fit(clients_batched[client], epochs=1, verbose=0) #scale the model weights and add to list
scaling_factor = weight_scalling_factor(clients_batched, client)
scaled_weights = scale_model_weights(local_model.get_weights(), scaling_factor) scaled_local_weight_list.append(scaled_weights) #clear session to free memory after each communication round
K.clear_session() #to get the average over all the local model, we simply take the sum of the scaled weights
average_weights = sum_scaled_weights(scaled_local_weight_list) #41
#update global model
global_model.set_weights(average_weights) #test global model and print out metrics after each communications round
for(X_test, Y_test) in test_batched:
global_acc, global_loss = test_model(X_test, Y_test, global_model, comm_round) #48
def test_model(X_test, Y_test, model, comm_round):
cce = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
#logits = model.predict(X_test, batch_size=100)
logits = model.predict(X_test)
loss = cce(Y_test, logits)
acc = accuracy_score(tf.argmax(logits, axis=1), tf.argmax(Y_test, axis=1))
print('comm_round: {} | global_acc: {:.3%} | global_loss: {}'.format(comm_round, acc, loss))
return acc, loss
结果
- 测试结果有10个客户端,每个客户端运行1个本地epoch,并进行100次全局通信
FL模型测试结果很好,经过100轮通信后,测试准确率达到了96.5%。但它与在相同数据集上训练的标准SGD模型相比如何呢?我将在联邦训练数据上训练一个模型(而不是像在FL中那样训练10个模型)。为此,我将使用分区之前的预处理训练数据来训练完全相同的2层MLP模型。
Google TFF 框架
- TensorFlow Federated: TensorFlow框架,专门针对研究用例,提供大规模模拟功能来控制抽样。支持在模拟环境中加载分散数据集,每个Client的ID对应于TensorFlow数据集对象。
- 【2021-3-14】联邦学习:Tensorflow中的逐步实现
- FL架构的基本形式包括一个位于中心的管理员或服务器,负责协调训练活动。客户端主要是边缘设备,可以达到数百万的数量。这些设备在每次训练迭代中至少与服务器通信两次。首先,它们各自从服务器接收当前全局模型的权重,在各自的本地数据上对其进行训练,以生成更新后的参数,然后将这些参数上传到服务器进行汇总。这种通信循环一直持续到达到预先设定的epochs数或准确度条件为止。在联邦平均算法中,汇总仅仅意味着平均操作。
- 在Tensorflow中从头开始构建一个FL,并在Kaggle的MNIST数据集上对其进行训练 来源:The TFF Authors. TensorFlow Federated, 2019. URL:https://www.tensorflow.org/federated.
- PySyft: PyTorch框架,使用PyTorch中的联邦学习。适用于考虑隐私保护的机器学习,采用差分隐私和多方计算(MPC)将私人数据与模型训练分离。
- 开源FL工具包FATE
腾讯联邦学习
参考:
工程特色
腾讯联邦学习平台PowerFL除了易部署、兼容性好等机器学习平台基本要求,还有以下五个工程特色:
- 学习架构:使用去中心化联邦架构,不依赖第三方;
- 加密算法:实现并改进了各种常见的同态加密、对称和非对称加密算法;
- 分布式计算:基于 Spark on Angel 的分布式机器学习框架;
- 跨网络通信:利用 Pulsar 对跨网通信优化,增强稳定性,提供多方跨网络传输接口;
- 可信赖执行环境:TEE(SGX等)的探索和支持。
算法特色
针对算法侧也做了许多优化:
- 密文运算重写:基于 C++ GMP 重写密文运算库;
- 协议改进:支持 Pailler 和腾讯自研的同态对称加密协议 RIAC,均比开源 FATE 的 gmpy-Paillier 快 10-20 倍;
- 数据求交优化:分别就双方和多方优化,特别是多方侧进行了理论上的改造(改进的 FNP 协议);
- GPU支持:密文运算部分可用GPU并行;
- 模型扩展支持:支持模型灵活扩展,可使用Tensorflow、Pytorch开发DNN模型嵌入。
联邦学习框架
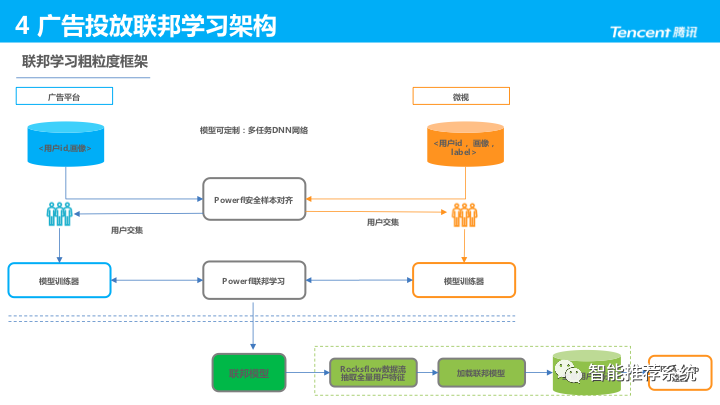
联邦学习粗粒度框架:
- 微视侧提供用户ID、画像、Label,广告平台侧提供用户ID、画像;
- 安全样本对齐(Private Set Intersection,PSI)得到用户交集,开始联邦学习协作训练;
- 模型评估后,双方合作抽取全量用户特征导出,并对全量用户打分;
- 最后将结果返回 RTA-DMP。
资料
- 2019年全球架构师峰会
- 【InfoQ】陈天健:基于联邦学习新技术连接数据孤岛
- 2019-12, 54页PPT全解联邦学习中的同态运算与密文传输
- 联邦学习诞生1000天的真实现状
- 联邦学习tensorflow工具包
- 书籍:杨强的《联邦学习》
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
