总结
- 【2021-4-15】近几年工业界/学术界有关多任务学习的研究和成功实践层出不穷:比如推荐系统里的谷歌的MMOE,SNR,MOSE,Youtube排序模型,阿里的ESSM,腾讯最新的PLE;NLP里微软的MT-DNN,以及最近hotpotQA榜单上的IRRR模型。
- 【2021-4-3】一文”看透”多任务学习
- 现有的多标签 Survey 基本在 2014 年之前,主要有以下几篇:
- Tsoumakas 的《Multi-label classification: An overview》(2007)
- 周志华老师的《A review on multi-label learning algorithms》(2013)
- 一篇比较小众的,Gibaja 《Multi‐label learning: a review of the state of the art and ongoing research》2014
- 【2020-12-13】多标签学习最新综述, 武大刘威威老师、南理工沈肖波老师和 UTS Ivor W. Tsang 老师合作的 2020 年多标签最新的 Survey:The Emerging Trends of Multi-Label Learning,之前的综述较少,还旧
- 这篇文章主要内容有六大部分:
- Extreme Multi-Label Classification
- XML面临的问题
- 标签空间、特征空间都可能非常巨大
- 可能存在较多的 Missing Label
- 标签存在长尾分布,绝大部分标签仅仅有少量样本关联。
- 常见解法三类,分别为:Embedding Methods、Tree-Based Methods、One-vs-All Methods。
- XML面临的问题
- Multi-Label with Limited Supervision
- 相比于传统学习问题,对多标签数据的标注十分困难,更大的标签空间带来的是更高的标注成本。随着我们面对的问题越来越复杂,样本维度、数据量、标签维度都会影响标注的成本。因此,近年多标签的另一个趋势是开始关注如何在有限的监督下构建更好的学习模型。本文将这些相关的领域主要分为三类:
- MLC with Missing Labels(MLML):多标签问题中,标签很可能是缺失的。例如,对 XML 问题来说,标注者根本不可能遍历所有的标签,因此标注者通常只会给出一个子集,而不是给出所有的监督信息。文献中解决该问题的技术主要有基于图的方法、基于标签空间(或 Latent 标签空间)Low-Rank 的方法、基于概率图模型的方法。
- Semi-Supervised MLC:MLML 考虑的是标签维度的难度,但是我们知道从深度学习需要更多的数据,在样本量上,多标签学习有着和传统 AI 相同的困难。半监督 MLC 的研究开展较早,主要技术和 MLML 也相对接近
- Partial Multi-Label Learning (PML):PML 是近年来多标签最新的方向,它考虑的是一类 “难以标注的问题”。原因是目标本身就难以识别,或标注人员不专业导致。PML 选择的是让标注者提供所有可能的标签,当然加了一个较强的假设:所有的标签都应该被包含在候选标签集中
- 现有的 PML 方法划分为 Two-Stage Disambiguation 和 End-to-End 方法
- 相比于传统学习问题,对多标签数据的标注十分困难,更大的标签空间带来的是更高的标注成本。随着我们面对的问题越来越复杂,样本维度、数据量、标签维度都会影响标注的成本。因此,近年多标签的另一个趋势是开始关注如何在有限的监督下构建更好的学习模型。本文将这些相关的领域主要分为三类:
- Deep Multi-Label Classification
- 多标签深度学习的模型还没有十分统一的框架,当前对 Deep MLC 的探索主要分为以下一些类别:
- Deep Embedding Methods:早期的 Embedding 方法通常使用线性投影,将 PCA、Compressed Sensing 等方法引入多标签学习问题。一个很自然的问题是,线性投影真的能够很好地挖掘标签之间的相关关系吗?
- Deep Learning for Challenging MLC:深度神经网络强大的拟合能力使我们能够有效地处理更多更困难的工作。因此近年的趋势是在 CV、NLP 和 ML 几大 Community,基本都会有不同的关注点,引入 DNN 解决 MLC 的问题,并根据各自的问题发展出自己的一条线。
- 总结一下,现在的 Deep MLC 呈现不同领域关注点和解决的问题不同的趋势:
- 从架构上看,基于 Embedding、CNN-RNN、CNN-GNN 的三种架构受到较多的关注。
- 从任务上,在 XML、弱监督、零样本的问题上,DNN 大展拳脚。
- 从技术上,Attention、Transformer、GNN 在 MLC 上的应用可能会越来越多。
- 多标签深度学习的模型还没有十分统一的框架,当前对 Deep MLC 的探索主要分为以下一些类别:
- Online Multi-Label Classification
- 传统的全数据学习的方式已经很难满足现实需求。因此,Online Multi-Label Learning 可能是一个十分重要,也更艰巨的问题。当前 Off-line 的 MLC 模型一般假设所有数据都能够提前获得,然而在很多应用中,或者对大规模的数据,很难直接进行全量数据的使用。一个朴素的想法自然是使用 Online 模型,也就是训练数据序列地到达,并且仅出现一次。
- 面对这样的数据,如何有效地挖掘多标签相关性呢?本篇 Survey 介绍了一些已有的在线多标签学习的方法,如 OUC[18]、CS-DPP[19]等。
- Statistical Multi-Label Learning
- 多标签学习的许多统计性质并没有得到很好的理解。近年 NIPS、ICML 的许多文章都有探索多标签的相关性质。一些值得一提的工作例如,缺失标签下的低秩分类器的泛化误差分析 [21]、多标签代理损失的相合性质[22]、稀疏多标签学习的 Oracle 性质[23] 等等。
- New Applications
- 以上方法依然是由任务驱动的
- Extreme Multi-Label Classification
【2021-4-15】多任务学习的所有资料,包括:代表性学者主页、论文、综述、最新文集和开源代码。github
Personal Page
- Massimiliano Pontil - UCL
- Yu Zhang (张宇) - HKUST
- Tong Zhang (张潼)- Tencent AI Lab
- Fuzhen Zhuang (庄福振)
- Lei Han’s Homepage
- Pattern Recognition & Neural Computing Group - NUAA
- Fei Sha University of Southern California
- Dr Xiaojun Chang – Faculty of Information Technology – Monash University
- Yu-Gang Jiang Prof.
- Zhuoliang Kang Ph.D student, Computer Science, USC
- Shiliang Sun’s Home Page
- Dr. Timothy Hospedales
- ML^2 @ UCF
- Elisa Ricci
- Gjorgji Strezoski
- Machine Learning with Interdependent and Non-identically Distributed Data
- SFU Machine Learning Reading Group
Package and Toolbox
- MALSAR: Multi-task learning via Structural Regularization
- Multi-Task Learning: Theory, Algorithms, and Applications
- SparseMTL Toolbox
- Bayesian multi-task learning based parametric trajectory model
- Probabilistic Machine Learning
- HMTL: Hierarchical Multi-Task Learning
- Matlab MultiClass MultiTask Learning (MCMTL) toolbox
- Multi Task Learning Package for Matlab
- Multi-task_Survival_Analysis
Papers
- Multitask Learning
- A Survey on Multi-Task Learning
- An overview of multi-task learning
- A brief review on multi-task learning
- Online Multitask Learning
- Online multitask relative similarity learning
- New Directions in Transfer and Multi-Task: Learning Across Domains and Tasks
Multitask Learning Areas
多任务建模方式
- 多任务关系学习
- 多任务特征学习
- 多任务特征与关系学习
- 聚类多任务学习
- 多任务聚类
- 联邦多任务学习
- 模型保护多任务学习
多任务学习方法
凸优化 Convex Optimization
- EE364a: Convex Optimization I Professor Stephen Boyd, Stanford University
- EE227BT: Convex Optimization — Fall 2013
- CRAN - Package ADMM
多任务学习介绍
Stein 悖论是探索多任务学习(MTL)(Caruana,1997)的早期动机。很多东西看起来表面上是不相关的,但其实它们会服从一个潜在的相似的模式,这就是多任务学习在统计学上的基础。
多任务学习是一种学习范式,其中来自多任务的数据被用来获得优于独立学习每个任务的性能。即便是真实世界中看似无关的任务也因数据共享的过程而存在一定的依赖性或者相关性。
1.Introduction
这一节主要介绍一些基础知识和背景,包括多什么是任务学习和多任务学习的挑战。
概念区别(multi-class/multi-label等)
- 【2020-12-16】几种概念区别(参考:Multi-class, Multi-label 以及 Multi-task 问题)
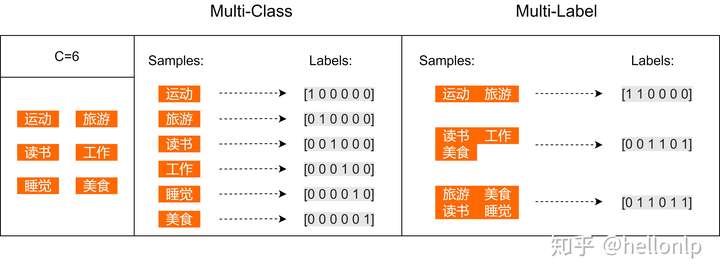
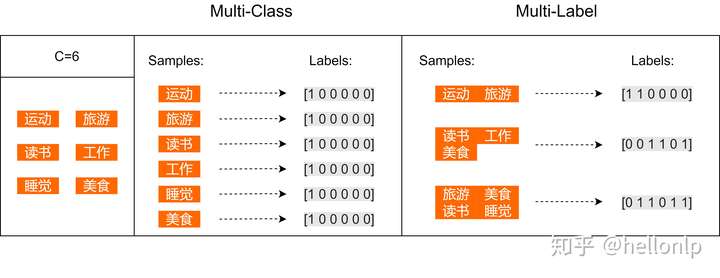
- Multiclass classification 就是多分类问题,比如年龄预测中把人分为小孩,年轻人,青年人和老年人这四个类别。Multiclass classification 与 binary classification相对应,性别预测只有男、女两个值,就属于后者。
- Multilabel classification 是多标签分类,比如一个新闻稿A可以与{政治,体育,自然}有关,就可以打上这三个标签。而新闻稿B可能只与其中的{体育,自然}相关,就只能打上这两个标签。
- Multioutput-multiclass classification 和 multi-task classification 指的是同一个东西。仍然举前边的新闻稿的例子,定义一个三个元素的向量,该向量第1、2和3个元素分别对应是否(分别取值1或0)与政治、体育和自然相关。那么新闻稿A可以表示为[1,1,1],而新闻稿B可以表示为[0,1,1],这就可以看成是multi-task classification 问题了。 从这个例子也可以看出,Multilabel classification 是一种特殊的multi-task classification 问题。之所以说它特殊,是因为一般情况下,向量的元素可能会取多于两个值,比如同时要求预测年龄和性别,其中年龄有四个取值,而性别有两个取值。
- 多标签文本分类介绍,以及对比训练
-
- 参考:模型汇总-14 多任务学习-Multitask Learning概述
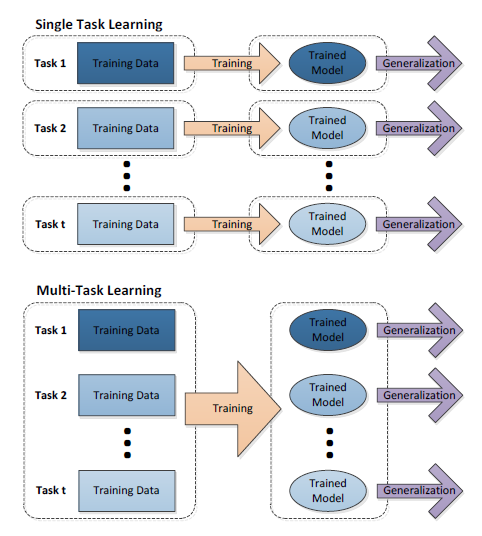
- 单任务学习 VS 多任务学习
- 单任务学习:一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
- 现在大多数机器学习任务都是单任务学习。对于复杂的问题,也可以分解为简单且相互独立的子问题来单独解决,然后再合并结果,得到最初复杂问题的结果。
- 看似合理,其实是不正确的,因为现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。
- 多任务学习:把多个相关(related)的任务放在一起学习,同时学习多个任务。
- 多任务学习就是为了解决这个问题而诞生的。把多个相关(related)的任务(task)放在一起学习
- 多个任务之间共享一些因素,它们可以在学习过程中,共享它们所学到的信息,这是单任务学习所具备的。相关联的多任务学习比单任务学习能去的更好的泛化(generalization)效果。
- 对比
- 单任务学习时,各个任务之间的模型空间(Trained Model)是相互独立的。
- 多任务学习时,多个任务之间的模型空间(Trained Model)是共享的
- 单任务学习:一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
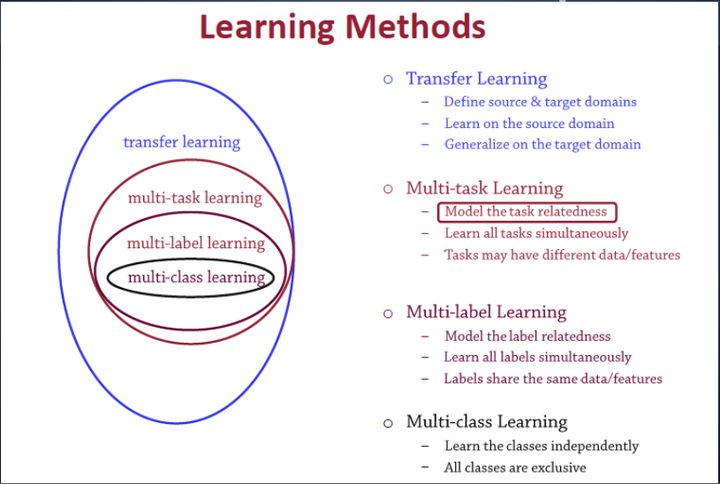
- 多任务学习(Multitask learning)是迁移学习算法的一种,迁移学习之前介绍过。定义一个一个源领域source domain和一个目标领域(target domain),在source domain学习,并把学习到的知识迁移到target domain,提升target domain的学习效果(performance)。
- 多标签学习(Multilabel learning)是多任务学习中的一种,建模多个label之间的相关性,同时对多个label进行建模,多个类别之间共享相同的数据/特征。
- 多类别学习(Multiclass learning)是多标签学习任务中的一种,对多个相互独立的类别(classes)进行建模。这几个学习之间的关系如图5所示:

1.1 MTL
什么是多任务学习?
- 多任务学习(Multitask learning)定义:
- 基于共享表示(shared representation),把多个相关的任务放在一起学习的一种机器学习方法。
- 多任务学习(Multitask Learning)是一种推导迁移学习方法,主任务(main tasks)使用相关任务(related tasks)的训练信号(training signal)所拥有的领域相关信息(domain-specific information),做为一直推导偏差(inductive bias)来提升主任务(main tasks)泛化效果(generalization performance)的一种机器学习方法。
- 多任务学习涉及多个相关的任务同时并行学习,梯度同时反向传播,多个任务通过底层的共享表示(shared representation)来互相帮助学习,提升泛化效果。
- 简单来说:多任务学习把多个相关的任务放在一起学习(注意,一定要是相关的任务,后面会给出相关任务(related tasks)的定义,以及他们共享了那些信息),学习过程(training)中通过一个在浅层的共享(shared representation)表示来互相分享、互相补充学习到的领域相关的信息(domain information),互相促进学习,提升泛化的效果。
- 相关(related)的具体定义很难,但我们可以知道的是,在多任务学习中,related tasks可以提升main task的学习效果,基于这点得到相关的定义:
- Related(Main Task,Related tasks,LearningAlg)= 1
-
LearningAlg(Main Task Related tasks)> LearningAlg(Main Task) (1)
- LearningAlg表示多任务学习采用的算法,公式(1):第一个公式表示,把Related tasks与main tasks放在一起学习,效果更好;第二个公式表示,基于related tasks,采用LearningAlg算法的多任务学习Main task,要比单学习main task的条件概率概率更大。特别注意,相同的学习任务,基于不同学习算法,得到相关的结果不一样:
- Related(Main Task,Related tasks,LearningAlg1)不等于 Related(Main Task,Related tasks,LearningAlg2)
- 多任务学习并行学习时,有5个相关因素可以帮助提升多任务学习的效果。
- (1)、数据放大(data amplification)。相关任务在学习过程中产生的额外有用的信息可以有效方法数据/样本(data)的大小/效果。主要有三种数据放大类型:统计数据放大(statistical data amplification)、采样数据放大(sampling data amplification),块数据放大(blocking data - amplification)。
- (2)、Eavesdropping(窃听)。假设
- (3)、属性选择(attribute selection)
- (4)、表示偏移(representation bias)
- (5)、预防过拟合(overfitting prevention)
所有这些关系(relationships)都可以帮助提升学习效果(improve learning performance)
共享表示shared representation:
- 共享表示的目的是为了提高泛化(improving generalization),图2中给出了多任务学习最简单的共享方式,多个任务在浅层共享参数。MTL中共享表示有两种方式:
- (1)、基于参数的共享(Parameter based):比如基于神经网络的MTL,高斯处理过程。
- (2)、基于约束的共享(regularization based):比如均值,联合特征(Joint feature)学习(创建一个常见的特征集合)。
- 基于特征的共享MTL(联合特征学习,Joint feature learning),通过创建一个常见的特征集合来实现多个任务之间基于特征(features)的shared representation
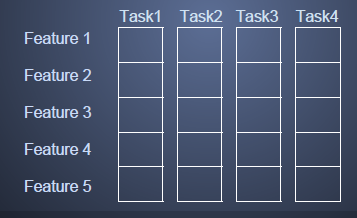
- 基于特征共享的MTL输入输出关系如图4所示,其中采用L1正则来保证稀疏性
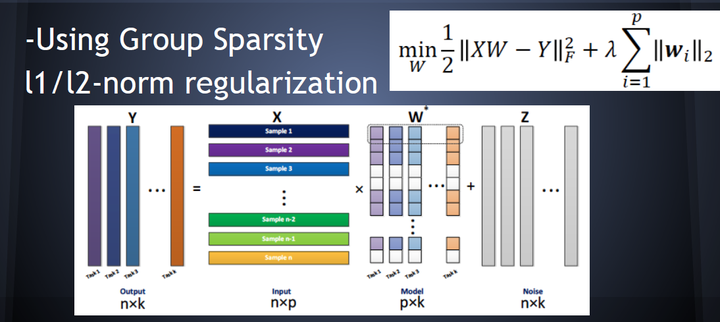
- 其他MTL
- 均值约束 MTL:基于均值来约束所有的task
- 参数共享的高斯处理MTL
- 低秩约束MTL
- 交替结构优化MTL等等
为什么把多个相关的任务放在一起学习,可以提高学习的效果?关于这个问题,有很多解释。这里列出其中一部分,以图2中由单隐含层神经网络表示的单任务和多任务学习对比为例。
- (1)、多人相关任务放在一起学习,有相关的部分,但也有不相关的部分。当学习一个任务(Main task)时,与该任务不相关的部分,在学习过程中相当于是噪声,因此,引入噪声可以提高学习的泛化(generalization)效果。
- (2)、单任务学习时,梯度的反向传播倾向于陷入局部极小值。多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值。
- (3)、添加的任务可以改变权值更新的动态特性,可能使网络更适合多任务学习。比如,多任务并行学习,提升了浅层共享层(shared representation)的学习速率,可能,较大的学习速率提升了学习效果。
- (4)、多个任务在浅层共享表示,可能削弱了网络的能力,降低网络过拟合,提升了泛化效果。
还有很多潜在的解释,为什么多任务并行学习可以提升学习效果(performance)。多任务学习有效,是因为它是建立在多个相关的,具有共享表示(shared representation)的任务基础之上的,因此,需要定义一下,什么样的任务之间是相关的。
机器学习解释:
多任务学习通过提供某种先验假设(inductive knowledge)来提升模型效果,这种先验假设通过增加辅助任务(具体表现为增加一个loss)来提供,相比于L1正则更方便(L1正则的先验假设是:模型参数更少更好)。
MTL(Multi-Task Learning)有很多形式:联合学习(joint learning)、自主学习(learning to learn)和带有辅助任务的学习(learning with auxiliary task)等都可以指 MTL。一般来说,优化多个损失函数就等同于进行多任务学习(与单任务学习相反)。
本篇文章,包括之前的 ESMM 都是属于带有辅助任务的多任务学习。
MTL 的目标在于通过利用包含在相关任务训练信号中特定领域的信息来提高泛化能力。
那么,什么是相关任务呢?我们有以下几个不严谨的解释:
- 使用相同特征做判断的任务;
- 任务的分类边界接近;
- 预测同个个体属性的不同方面比预测不同个体属性的不同方面更相关;
- 共同训练时能够提供帮助并不一定相关,因为加入噪声有时也可以增加泛化能力。
任务是否相似不是非0即1的。越相似的任务收益越大。但即使相关性不佳的任务也会有所收益。
1.1.1 Common form
MLT 主要有两种形式,一种是基于参数的共享,另一种是基于约束的共享。
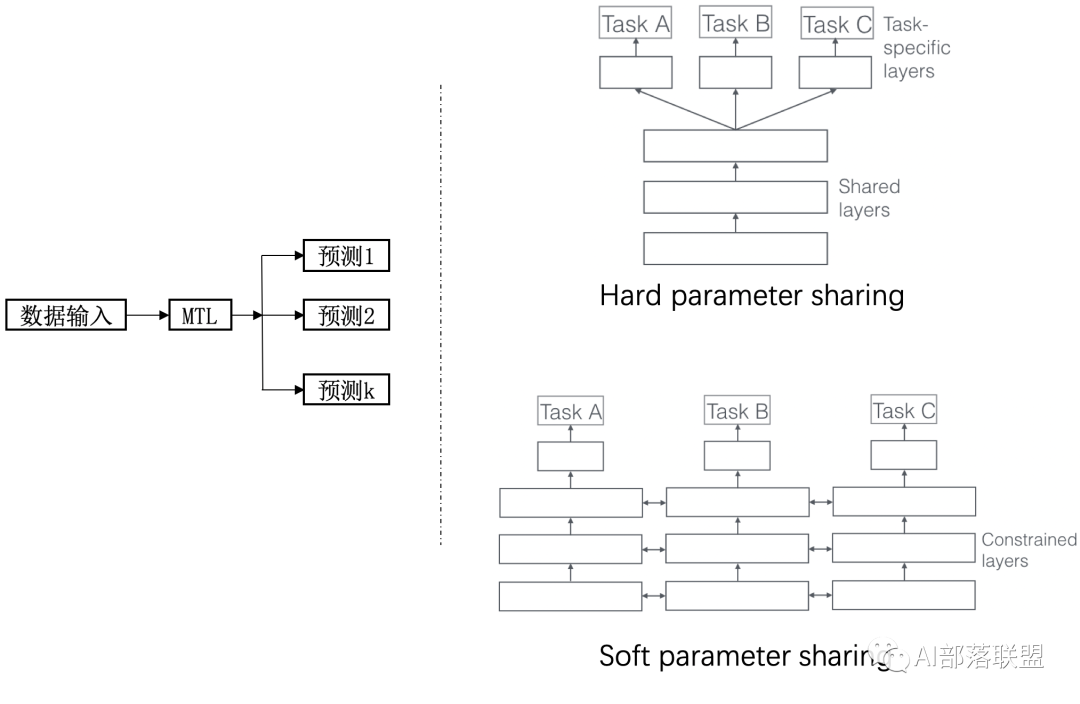
Hard 参数共享
参数共享的形式在基于神经网络的 MLT 中非常常见,其在所有任务中共享隐藏层并同时保留几个特定任务的输出层。这种方式有助于降低过拟合风险,因为同时学习的任务越多,模型找到一个含有所有任务的表征就越困难,从而过拟合某个特定任务的可能性就越小。ESMM 就属于这种类型的 MLT。
即便是2021年,hard parameter sharing依旧是很好用的baseline系统。
Soft 参数共享
每个任务都有自己的参数和模型,最后通过对不同任务的参数之间的差异施加约束。比如可以使用L2进行正则, 迹范数(trace norm)等。
现代研究重点倾向的方法:soft parameter sharing
- 底层共享一部分参数,自己还有独特的一部分参数不共享;顶层有自己的参数。底层共享的、不共享的参数如何融合到一起送到顶层,也就是研究人员们关注的重点啦。这里可以放上咱们经典的MMOE模型结构(图3),大家也就一目了然了。和最左边(a)的hard sharing相比,(b)和(c)都是先对Expert0-2(每个expert理解为一个隐层神经网络就可以了)进行加权求和之后再送入Tower A和B(还是一个隐层神经网络),通过Gate(还是一个隐藏层)来决定到底加权是多少。
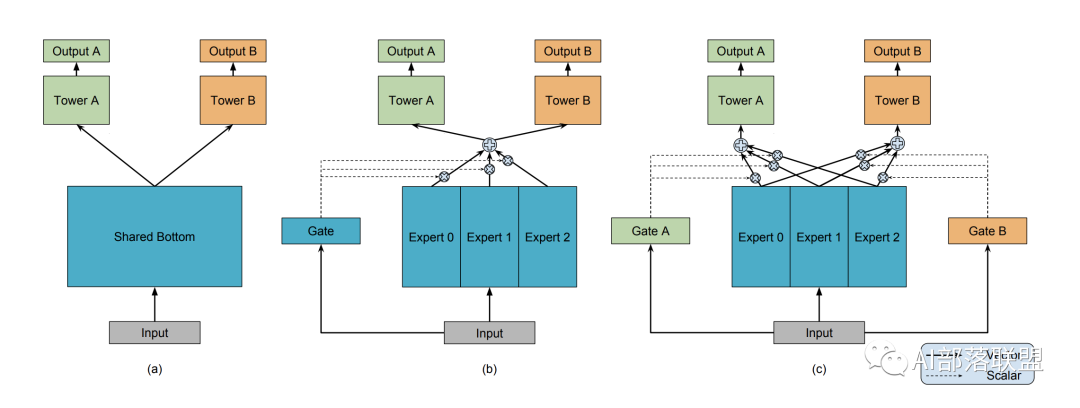
1.1.2 Why MTL work
那么,为什么 MLT 有效呢?主要有以下几点原因:
- 多任务一起学习时,会互相增加噪声,从而提高模型的泛化能力;
- 多任务相关作用,逃离局部最优解;
- 多任务共同作用模型的更新,增加错误反馈;
- 降低了过拟合的风险;
- 类似 ESMM,解决了样本偏差和数据稀疏问题,未来也可以用来解决冷启动问题。
1.2 Challenge in MTL
在多任务学习中,假设有这样两个相似的任务:猫分类和狗分类。他们通常会有比较接近的底层特征,比如皮毛、颜色等等。如下图所示:
多任务的学习的本质在于共享表示层,并使得任务之间相互影响:
如果我们现在有一个与猫分类和狗分类相关性不是太高的任务,如汽车分类:
那么我们在用多任务学习时,由于底层表示诧异很大,所以共享表示层的效果也就没有那么明显,而且更有可能会出现冲突或者噪声:
作者给出相关性不同的数据集上多任务的表现,其也阐述了,相关性越低,多任务学习的效果越差:
其实,在实际过程中,如何去识别不同任务之间的相关性也是非常难的:
工程实现
ESMM模型
- 【2022-5-18】多任务学习模型ESMM原理与实现
- 【2021-4-1】多任务学习(MTL)在转化率预估上的应用
SIGIR’2018 的论文《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》
- 基于 Multi-Task Learning (MTL) 的思路,提出一种名为ESMM的CVR预估模型,有效解决了真实场景中CVR预估面临的数据稀疏以及样本选择偏差这两个关键问题。后续还会陆续介绍MMoE,PLE,DBMTL等多任务学习模型。
- 工业中使用的推荐算法已不只局限在单目标(ctr)任务上,还需要关注后续的转换链路,如是否评论、收藏、加购、购买、观看时长等目标。
CVR预估面临两个关键问题:
- 样本选择偏差:Sample Selection Bias (SSB)
- 转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。
- 即训练数据与实际要预测的数据来自不同分布,这个偏差对模型的泛化能力构成了很大挑战,导致模型上线后,线上业务效果往往一般。
- 数据稀疏 Data Sparsity (DS)
CVR预估任务的使用的训练数据(即点击样本)远小于CTR预估训练使用的曝光样本。仅使用数量较小的样本进行训练,会导致深度模型拟合困难。- 一些策略可以缓解这两个问题,例如从曝光集中对unclicked样本抽样做负例缓解SSB,对转化样本过采样缓解DS等。但无论哪种方法,都没有从实质上解决上面任一个问题。
- 由于 点击 => 转化,本身是两个强相关的连续行为,作者希望在模型结构中显示考虑这种“行为链关系”,从而可以在整个空间上进行训练及预测。这涉及到CTR与CVR两个任务,因此使用
多任务学习(MTL)是一个自然的选择,论文的关键亮点正在于“如何搭建”这个MTL。
首先需要重点区分下,CVR预估任务与CTCVR预估任务。
CVR=转化数/点击数。是预测“假设item被点击,那么它被转化”的概率。CVR预估任务,与CTR没有绝对的关系。一个item的ctr高,cvr不一定同样会高,如标题党文章的浏览时长往往较低。这也是不能直接使用全部样本训练CVR模型的原因,因为无法确定那些曝光未点击的样本,假设他们被点击了,是否会被转化。如果直接使用0作为它们的label,会很大程度上误导CVR模型的学习。-
CTCVR=转换数/曝光数。是预测“item被点击,然后被转化”的概率。 - ESMM:完整空间多任务模型(Entire Space Multi-Task Model),是阿里2018年提出的模型思想,是一个hard参数共享的MTL模型。主要为了解决传统CVR建模过程中样本选择偏差(sample selection bias, SSB)和数据稀疏(data sparsity,DS)问题。
- 样本选择偏差:用户在广告上的行为属于顺序行为模式impression -> click -> conversion,传统CVR建模训练时是在click的用户集合中选择正负样本,模型最终是对整个impression的用户空间进行CVR预估,由于click用户集合和impression用户集合存在差异(如下图),引起样本选择偏差。
- ESMM算法引入两个辅助任务学习任务,分别拟合pCTR和pCTCVR,都是从整个样本空间选择样本,来同时消除上面提到的两个问题。
- ESMM模型的优化
在ESMM模型的基础上,我们做了以下两点优化:
- a. 优化网络embedding层,使其可以处理用户不定长行为特征
- 用户历史行为属于不定长行为,比如曾经点击过的ID列表,一般我们对这种行为引入网络中的时候,会将不定长进行截断成统一长度(比如:平均长度)的定长行为,方便网络使用。很多用户行为没有达到平均长度,则会在后面统一补0,这会导致用户embedding结果里面包含很多并未去过的节点0的信息。这里我们提出一种聚合-分发的特征处理方式,使得网络的特征embedding层可以处理不定长的特征。
- 由于单个特征节点的embedding结果是和用户无关的,比如:用户A点击k,用户B也点击了k,最终embedding得到的k结果是唯一的,对A和B两个用户访问的k都是一样的。基于该前提,我们采用聚合-分发的处理思想。将min-batch的所有用户的不定长行为聚合拼接成一维的长矩阵,并记录下各个用户行为的索引,在embedding完成之后,根据索引将各个用户的实际行为进行还原,并降维成固定长度,输入到dense层使用。
- b. 由于训练正负样本差异比较大,模型引入Focal Loss,使训练过程更加关注数量较少的正样本
代码实现
- 【2022-5-18】多任务学习模型ESMM原理与实现
基于EasyRec推荐算法框架,我们实现了ESMM算法,具体实现可移步至github:EasyRec-ESMM。 EasyRec
EasyRec介绍:
- EasyRec是阿里云计算平台机器学习PAI团队开源的大规模分布式推荐算法框架,EasyRec 正如其名字一样,简单易用,集成了诸多优秀前沿的推荐系统论文思想,并且有在实际工业落地中取得优良效果的特征工程方法,集成训练、评估、部署,与阿里云产品无缝衔接,可以借助 EasyRec 在短时间内搭建起一套前沿的推荐系统。作为阿里云的拳头产品,现已稳定服务于数百个企业客户。
Google 多任务学习框架 MMoE
基于神经网络的多任务学习已经过成功应用内许多现实应用中,比如说之前我们介绍的阿里巴巴基于多任务联合学习的 ESMM 算法,其利用多任务学习解决了 CVR 中样本选择偏差和样本稀疏这两大问题,并在实际应用场景中取得了不错的成绩。
多任务学习的目的在于用一个模型来同时学习多个目标和任务,但常用的任务模型的预测质量通常对任务之间的关系很敏感(数据分布不同,ESMM 解决的也是这个问题),因此,google 提出多门混合专家算法(Multi-gate Mixture-of-Experts,以下简称 MMoE)旨在学习如何从数据中权衡任务目标(task-specific objectives)和任务之间(inter-task relationships)的关系。所有任务之间共享混合专家结构(MoE)的子模型来适应多任务学习,同时还拥有可训练的门控网路(Gating Network)以优化每一个任务。
MMoE 算法在任务相关性较低时能够具有更好的性能,同时也可以提高模型的可训练性。作者也将 MMoE 应用于真实场景中,包括二分类和推荐系统,并取得了不错的成绩。
作者提出了 MMoE 框架,旨在构建一个兼容性更强的多任务学习框架。
2.MMoE
本节我们详细介绍下 MMoE 框架。
2.1 Shared-Bottom model
先简单结下 shared-bottom 模型,ESMM 模型就是基于 shared-bottom 的多任务模型。这篇文章把该框架作为多任务模型的 baseline,其结构如下图所示:
给出公式定义:
其中,f 为表征函数, 为第 k 个子网络(tower 网络)。
2.2 One-gate MoE Layer
而 One-gate MoE layer 则是将隐藏层划分为三个专家(expert)子网,同时接入一个 Gate 网络将各个子网的输出和输入信息进行组合,并将得到的结果进行相加。
公式如下:
其中, 为第 i 个专家子网的输出;, 为第 i 个 logit 输出,表示专家子网 的权重,其由 gate 网络计算得出。
MoE 的主要目标是实现条件计算,对于每个数据而言,只有部分网络是活跃的,该模型可以通过限制输入的门控网络来选择专家网络的子集。
2.3 Multi-gate MoE model
MoE 能够实现不同数据多样化使用共享层,但针对不同任务而言,其使用的共享层是一致的。这种情况下,如果任务相关性较低,则会导致模型性能下降。
所以,作者在 MoE 的基础上提出了 MMoE 模型,为每个任务都设置了一个 Gate 网路,旨在使得不同任务和不同数据可以多样化的使用共享层,其模型结构如下:
给出公式定义:
这种情况下,每个 Gate 网络都可以根据不同任务来选择专家网络的子集,所以即使两个任务并不是十分相关,那么经过 Gate 后也可以得到不同的权重系数,此时,MMoE 可以充分利用部分 expert 网络的信息,近似于单个任务;而如果两个任务相关性高,那么 Gate 的权重分布相差会不大,会类似于一般的多任务学习。
3.Experiment
简单看下实验。
首先是不同 MLT 模型对在不同相关性任务下的参数分布,其可以反应模型的鲁棒性。可以看到 MMeE 模型性能还是比较稳定的。
第一组数据集的表现:
第二组数据集的表现:
大型推荐系统的表现:
Gate 网络在两个任务的不同分布:
4.Conclusion
总结:作者提出了一种新颖的多任务学习方法——MMoE,其通过多个 Gate 网络来自适应学习不同数据在不同任务下的与专家子网的权重关系系数,从而在相关性较低的多任务学习中取得不错的成绩。
共享网络节省了大量计算资源,且 Gate 网络参数较少,所以 MMoE 模型很大程度上也保持了计算优势
谷歌SNR模型
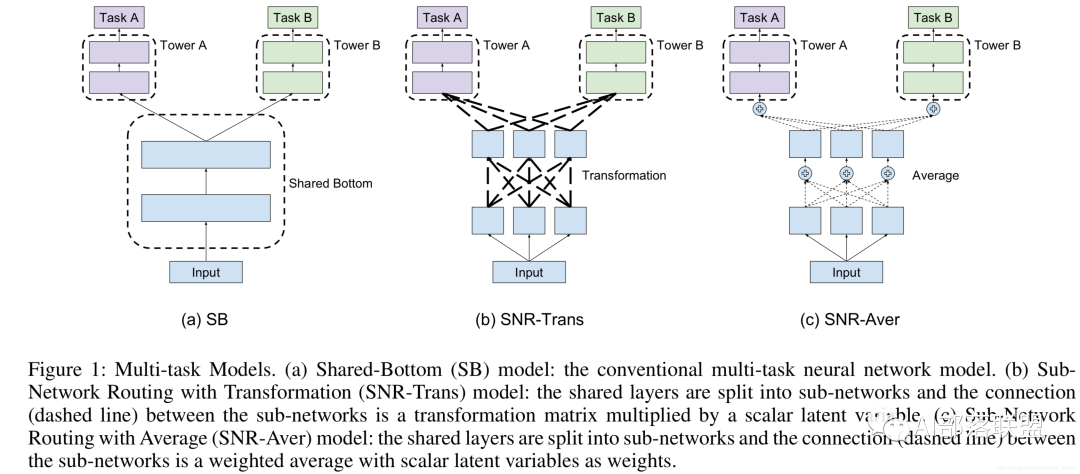
实践
- 【2020-12-16】多标签文本分类 ALBERT+TextCNN-附代码
TensorFlow实现多任务学习
- Tensorflow多任务学习总结,faster rcnn是检测和分类的多任务学习
- 英文原文
单任务网络框架

- 代码
# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Create Placeholders For X And Y (for feeding in data)
X = tf.placeholder("float",[10, 10],name="X") # Our input is 10x10
Y = tf.placeholder("float", [10, 1],name="Y") # Our output is 10x1
# Create a Trainable Variable, "W", our weights for the linear transformation
initial_W = np.zeros((10,1))
W = tf.Variable(initial_W, name="W", dtype="float32")
# Define Your Loss Function
Loss = tf.pow(tf.add(Y,-tf.matmul(X,W)),2,name="Loss")
with tf.Session() as sess: # set up the session
sess.run(tf.initialize_all_variables())
Model_Loss = sess.run(
Loss, # the first argument is the name of the Tensorflow variabl you want to return
{ # the second argument is the data for the placeholders
X: np.random.rand(10,10),
Y: np.random.rand(10).reshape(-1,1)
})
print(Model_Loss)
交替训练
- 多任务的一个特点是单个tensor输入(X),多个输出(Y_1,Y_2…)。因此在定义占位符时要定义多个输出。同样也需要有多个损失函数用于分别计算每个任务的损失。
- 选择训练需要在每个loss后面接一个优化器,这样就意味着每一次的优化只针对于当前任务,也就是说另一个任务是完全不管的
- 在训练上有些疑惑,feed数据上面是否要同时把两个标签的数据都输入呢?需要,那么就意味着另一任务还是会进行正向传播运算的。

# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10], name="X")
Y1 = tf.placeholder("float", [10, 20], name="Y1")
Y2 = tf.placeholder("float", [10, 20], name="Y2")
# Define the weights for the layers
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights, name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights, name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights, name="share_Y2", dtype="float32")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
# optimisers
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
for iters in range(10):
if np.random.rand() < 0.5:
_, Y1_loss = session.run([Y1_op, Y1_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y1_loss)
else:
_, Y2_loss = session.run([Y2_op, Y2_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y2_loss)
联合训练

- 代码
# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10], name="X")
Y1 = tf.placeholder("float", [10, 20], name="Y1")
Y2 = tf.placeholder("float", [10, 20], name="Y2")
# Define the weights for the layers
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights, name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights, name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights, name="share_Y2", dtype="float32")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
Joint_Loss = Y1_Loss + Y2_Loss
# optimisers
Optimiser = tf.train.AdamOptimizer().minimize(Joint_Loss)
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)
# Joint Training
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
_, Joint_Loss = session.run([Optimiser, Joint_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Joint_Loss)
交替训练还是联合训练?
- 什么时候交替训练好? 不同数据集
- Alternate training is a good idea when you have two different datasets for each of the different tasks (for example, translating from English to French and English to German). By designing a network in this way, you can improve the performance of each of your individual tasks without having to find more task-specific training data.
- 当对每个不同的任务有两个不同的数据集(例如,从英语翻译成法语,英语翻译成德语)时,交替训练是一个好主意。通过以这种方式设计网络,可以提高每个任务的性能,而无需找到更多任务特定的训练数据。
这里的例子很好理解,但是“数据集”指的应该不是输入数据X。我认为应该是指输出的结果Y_1、Y_2关联不大。
- 什么时候联合训练好?相同数据集
- 交替训练容易对某一类产生偏向,当对于相同数据集,产生不同属性的输出时,保持任务的独立性,使用联合训练较好。
MNIST与Fashion MNIST实践
- 参考:TensorFlow使用记录 (十四): Multi-task to MNIST + Fashion MNIST
- 数据集:MNIST、Fashion_MNIST
- 这两个数据集下载下来是压缩文件格式的,为了方便后面使用,先用一下代码转一下

- 转换
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ================================================================
# @Time : 2019/10/25 10:50
# @Author : YangTao
# @Site :
# @File : process.py
# @IDE: PyCharm Community Edition
# ================================================================
import os
# MNIST
MNIST = '../../MNIST_data'
def convert(imgf, labelf, outf, n):
f = open(imgf, "rb")
o = open(outf, "w")
l = open(labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(n):
image = [ord(l.read(1))]
for j in range(28*28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image)+"\n")
f.close()
o.close()
l.close()
convert(os.path.join(MNIST, "train-images-idx3-ubyte"), os.path.join(MNIST, "train-labels-idx1-ubyte"), os.path.join(MNIST, "mnist_train.csv"), 60000)
convert(os.path.join(MNIST, "t10k-images-idx3-ubyte"), os.path.join(MNIST, "t10k-labels-idx1-ubyte"), os.path.join(MNIST, "mnist_test.csv"), 10000)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ================================================================
# @Time : 2019/10/25 13:50
# @Author : YangTao
# @Site :
# @File : dataset.py
# @IDE: PyCharm Community Edition
# ================================================================
import os
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
F_class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
class MNISTplusFashion(object):
data_dirM = './MNIST'
data_dirF = './F_MNIST'
def __init__(self, phase, batch_size=10):
self.num_classes = 10
self.train_input_size_h = 28
self.train_input_size_w = 28
self.batch_size = batch_size
if phase == 'train':
self.dataM = open(os.path.join(self.data_dirM, 'mnist_train.csv'), 'r').read().split('\n')[:-1]
self.flagM = np.zeros(shape=(len(self.dataM)), dtype=np.int)
self.dataF = open(os.path.join(self.data_dirF, 'fashion_mnist_train.csv'), 'r').read().split('\n')[:-1]
self.flagF = np.ones(shape=(len(self.dataF)), dtype=np.int)
elif phase == 'val':
self.dataM = open(os.path.join(self.data_dirM, 'mnist_test.csv'), 'r').read().split('\n')[:-1]
self.flagM = np.zeros(shape=(len(self.dataM)), dtype=np.int)
self.dataF = open(os.path.join(self.data_dirF, 'fashion_mnist_test.csv'), 'r').read().split('\n')[:-1]
self.flagF = np.ones(shape=(len(self.dataF)), dtype=np.int)
self.dataM = [d.split(',') for d in self.dataM]
self.dataF = [d.split(',') for d in self.dataF]
data = self.dataM + self.dataF
flag = np.concatenate([self.flagM ,self.flagF],axis=0)
self.num_samples = len(flag) # dataset size
self.num_batchs = int(np.ceil(self.num_samples / self.batch_size)) # 向上取整
self.batch_count = 0 # batch index
# np.random.seed(1)
random_idx = np.random.permutation(self.num_samples)
self.data = []
for index in random_idx:
self.data.append(data[index] + [flag[index]])
def __iter__(self):
return self
def __next__(self):
with tf.device('/cpu:0'):
batch_image = np.zeros((self.batch_size, self.train_input_size_h, self.train_input_size_w, 1))
batch_label = np.zeros((self.batch_size, self.num_classes))
batch_tag = np.zeros((self.batch_size, 1))
num = 0 # sample in one batch's index
if self.batch_count < self.num_batchs:
while num < self.batch_size:
index = self.batch_count * self.batch_size + num
if index >= self.num_samples: # 从头开始
index -= self.num_samples
batch_image[num, :, :, :] = np.array(
self.data[index][1:-1]).reshape(
self.train_input_size_h, self.train_input_size_w,1
).astype(np.float32) / 255.0
# ======================
# smooth onehot label
onehot = np.zeros(self.num_classes, dtype=np.float)
onehot[int(self.data[index][0])] = 1.0
uniform_distribution = np.full(self.num_classes, 1.0 / self.num_classes)
deta = 0.01
smooth_onehot = onehot * (1 - deta) + deta * uniform_distribution
# ======================
batch_label[num, :] = smooth_onehot # self.data[index][0]
batch_tag[num] = self.data[index][-1]
num += 1
self.batch_count += 1
return batch_image, batch_label, batch_tag
else:
self.batch_count = 0
np.random.shuffle(self.data)
raise StopIteration
def __len__(self):
return self.num_batchs
def show_batch(img_batch):
grid_image = img_batch[0,:,:,0]
for idx, img in enumerate(img_batch):
if idx == 0:
continue
grid_image = np.hstack((grid_image, img[:,:,0]))
plt.imshow(grid_image)
plt.title('Batch from dataloader')
if __name__ == "__main__":
val_data = MNISTplusFashion(phase='val', batch_size=10)
for idx in range(val_data.num_batchs):
batch_image, batch_label, batch_tag = val_data.__next__()
print("sample %d," % idx, batch_image.shape, batch_label.shape, batch_tag.shape)
plt.figure()
show_batch(batch_image)
plt.axis('off')
plt.ioff()
plt.show()
- 代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ================================================================
# @Time : 2019/10/25 15:30
# @Author : YangTao
# @Site :
# @File : dataset.py
# @IDE: PyCharm Community Edition
# ================================================================
import tensorflow as tf
from tqdm import tqdm
import numpy as np
from matplotlib import pyplot as plt
from dataset import MNISTplusFashion, show_batch
print(tf.__version__)
# 1. create data
trainset = MNISTplusFashion(phase='train', batch_size=100)
testset = MNISTplusFashion(phase='val', batch_size=20000)
with tf.variable_scope('Input'):
tf_x = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28, 1], name='x')
tf_y = tf.placeholder(dtype=tf.float32, shape=[None, 10], name='y')
tf_flag = tf.placeholder(dtype=tf.float32, shape=[None, 1], name='flag')
is_training = tf.placeholder(dtype=tf.bool, shape=None)
global_step = tf.Variable(1.0, dtype=tf.float64, trainable=False, name='global_step')
idxM = tf.where(tf.equal(tf_flag, 0))[:,0]
idxF = tf.where(tf.equal(tf_flag, 1))[:,0]
tf_yM = tf.gather(tf_y, idxM)
tf_yF= tf.gather(tf_y, idxF)
# 2. define Network
with tf.variable_scope('Net'):
# conv1 = tf.layers.conv2d(inputs=tf_x, filters=96, kernel_size=3,
# strides=1, padding='same', activation=tf.nn.relu) # 96x28x28
# conv2 = tf.layers.conv2d(inputs=conv1, filters=96, kernel_size=3,
# strides=1, padding='same', activation=tf.nn.relu) # 96x28x28
# conv3 = tf.layers.conv2d(inputs=conv2, filters=96, kernel_size=3,
# strides=2, padding='same', activation=tf.nn.relu) # 96x14x14
# conv4 = tf.layers.conv2d(inputs=conv3, filters=192, kernel_size=3,
# strides=1, padding='same', activation=tf.nn.relu) # 192x14x14
# conv5 = tf.layers.conv2d(inputs=conv4, filters=192, kernel_size=3,
# strides=1, padding='same', activation=tf.nn.relu) # 192x14x14
# conv6 = tf.layers.conv2d(inputs=conv5, filters=192, kernel_size=3,
# strides=2, padding='same', activation=tf.nn.relu) # 192x7x7
# conv7 = tf.layers.conv2d(inputs=conv6, filters=192, kernel_size=3,
# strides=1, activation=tf.nn.relu) # 192x5x5
# conv8 = tf.layers.conv2d(inputs=conv7, filters=192, kernel_size=1,
# strides=1, activation=tf.nn.relu) # 192x5x5
# classifier = tf.layers.conv2d(inputs=conv8, filters=10, kernel_size=1,
# strides=1, activation=tf.nn.relu) # 10x5x5
# predict = tf.layers.average_pooling2d(inputs=classifier, pool_size=5, strides=1)
# predict = tf.reshape(predict, [-1, 1])
# ======================
conv1 = tf.layers.conv2d(inputs=tf_x, filters=32, kernel_size=5,
strides=1, padding='same', activation=tf.nn.relu) # 32x28x28
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=2, strides=2) # 32x14x14
conv2 = tf.layers.conv2d(pool1, 64, 3, 1, 'same', activation=tf.nn.relu) # 64x14x14
pool2 = tf.layers.max_pooling2d(conv2, 2, 2) # 64x7x7
pool2_flat = tf.reshape(pool2, [-1, 7*7*64])
pool2_flatM = tf.gather(pool2_flat, idxM)
pool2_flatF = tf.gather(pool2_flat, idxF)
with tf.variable_scope('MNIST'):
fc1M = tf.layers.dense(pool2_flatM, 1024, tf.nn.relu)
fc1M = tf.layers.dropout(fc1M, rate=0.5, training=is_training)
fc2M = tf.layers.dense(fc1M, 512, tf.nn.relu)
fc2M = tf.layers.dropout(fc2M, rate=0.5, training=is_training)
predictM = tf.layers.dense(fc2M, 10)
with tf.variable_scope('F_MNIST'):
fc1F = tf.layers.dense(pool2_flatF, 1024, tf.nn.relu)
fc1F = tf.layers.dropout(fc1F, rate=0.5, training=is_training)
fc2F = tf.layers.dense(fc1F, 521, tf.nn.relu)
fc2F = tf.layers.dropout(fc2F, rate=0.5, training=is_training)
predictF = tf.layers.dense(fc2F, 10)
# 3. define loss & accuracy
with tf.name_scope('loss'):
lossM = tf.losses.softmax_cross_entropy(onehot_labels=tf_yM, logits=predictM, label_smoothing=0.01)
tf.summary.scalar('lossM', lossM)
lossF = tf.losses.softmax_cross_entropy(onehot_labels=tf_yF, logits=predictF, label_smoothing=0.01)
tf.summary.scalar('lossF', lossF)
loss = lossM + lossF
tf.summary.scalar('loss', loss)
with tf.name_scope('accuracy'):
# tf.metrics.accuracy() 返回 累计[上次的平均accuracy, 这次的平均accuracy]
accuracyM = tf.metrics.accuracy(labels=tf.argmax(tf_yM, axis=1), predictions=tf.argmax(predictM, axis=1))[1]
tf.summary.scalar('accuracyM', accuracyM)
accuracyF = tf.metrics.accuracy(labels=tf.argmax(tf_yF, axis=1), predictions=tf.argmax(predictF, axis=1))[1]
tf.summary.scalar('accuracyF', accuracyF)
# 4. define optimizer
with tf.name_scope('train'):
optimizer_op = tf.train.AdamOptimizer(1e-4).minimize(loss, global_step=global_step)
# 5. initialize
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
# 6.train
saver = tf.train.Saver()
save_path = './cnn_mnist.ckpt'
# Set sess configuration
# ============================== config GPU
sess_config = tf.ConfigProto(allow_soft_placement=True)
# sess_config.gpu_options.per_process_gpu_memory_fraction = 0.95
sess_config.gpu_options.allow_growth = True
sess_config.gpu_options.allocator_type = 'BFC'
# ==============================
with tf.Session(config=sess_config) as sess:
sess.run(init_op)
# =================
merge_op = tf.summary.merge_all()
train_writer = tf.summary.FileWriter('logs/train', sess.graph)
test_writer = tf.summary.FileWriter('logs/test', sess.graph)
# tensorboard --logdir=logs --host=127.0.0.1
# =================
for epoch in range(20):
pbar = tqdm(trainset)
train_epoch_loss = []
for train_data in pbar:
_, ls, train_output, global_step_val = sess.run([optimizer_op, loss, merge_op, global_step],
feed_dict={tf_x: train_data[0], tf_y: train_data[1],
tf_flag: train_data[2], is_training: True})
train_writer.add_summary(train_output, global_step=global_step_val)
pbar.set_description(("train loss:{:.4f}").format(ls))
for test_data in testset:
acc_testM, acc_testF, test_ouput = sess.run([accuracyM, accuracyF, merge_op],
feed_dict={tf_x: test_data[0], tf_y: test_data[1],
tf_flag: test_data[2], is_training: False})
print('epoch: ', epoch, ' | test accuracyM: {:.3f}, test accuracyF: {:.3f}'.format(acc_testM, acc_testF))
sess.run(tf.local_variables_initializer()) # 不加上这句的话 accuracy 就是个累积平均值了
test_writer.add_summary(test_ouput, global_step=global_step_val)
saver.save(sess, save_path)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
